
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Modified 2 Satisfiability Reverse Analysis Method via Logical Permutation Operator
1 School of Mathematical Sciences, Universiti Sains Malaysia, Minden, Penang, 11800, Malaysia
2 School of Distance Education, Universiti Sains Malaysia, Minden, Penang, 11800, Malaysia
3 Faculty of Computing and Informatics, Universiti Malaysia Sabah, Jalan UMS, Kota Kinabalu, 88450, Sabah, Malaysia
4 School of Pharmaceutical Sciences, Universiti Sains Malaysia, Minden, Penang, 11800, Malaysia
* Corresponding Author: Aslina Baharum. Email:
Computers, Materials & Continua 2023, 74(2), 2853-2870. https://doi.org/10.32604/cmc.2023.032654
Received 25 May 2022; Accepted 12 July 2022; Issue published 31 October 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The effectiveness of the logic mining approach is strongly correlated to the quality of the induced logical representation that represent the behaviour of the data. Specifically, the optimum induced logical representation indicates the capability of the logic mining approach in generalizing the real datasets of different variants and dimensions. The main issues with the logic extracted by the standard logic mining techniques are lack of interpretability and the weakness in terms of the structural and arrangement of the 2 Satisfiability logic causing lower accuracy. To address the issues, the logical permutation serves as an alternative mechanism that can enhance the probability of the 2 Satisfiability logical rule becoming true by utilizing the definitive finite arrangement of attributes. This work aims to examine and analyze the significant effect of logical permutation on the performance of data extraction ability of the logic mining approach incorporated with the recurrent discrete Hopfield Neural Network. Based on the theory, the effect of permutation and associate memories in recurrent Hopfield Neural Network will potentially improve the accuracy of the existing logic mining approach. To validate the impact of the logical permutation on the retrieval phase of the logic mining model, the proposed work is experimentally tested on a different class of the benchmark real datasets ranging from the multivariate and time-series datasets. The experimental results show the significant improvement in the proposed logical permutation-based logic mining according to the domains such as compatibility, accuracy, and competitiveness as opposed to the plethora of standard 2 Satisfiability Reverse Analysis methods.Keywords
Artificial Neural Network (ANN) is a subset of Artificial Intelligence that was inspired by artificial neurons. The primary aim of the ANN is to create black box model that can offer alternative explanation among the data. Using this explanation, one can use the output produced from ANN to solve various optimization problem. The main problem with conventional ANN is the lack of symbolic reasoning to govern the modelling of neurons. Reference [1] proposed logical rule in ANN by assigning each neuron to the variable of the logic. This leads to the introduction of Wan Abdullah method to find the optimal synaptic by comparing the cost function with the final energy function. Reference [2] proposed another variant of logic namely 2 Satisfiability (2SAT) in single layered ANN namely Discrete Hopfield Neural Network (DHNN). The proposed 2SAT was reported to obtain high global minima ratio if we optimize the learning phase of the DHNN. The discovery of this hybrid network inspires other study to implement 2SAT in ANN. Recently, [3] integrates 2SAT in Radial Basis Function Neural Network (RBFNN) by calculating the various parameters that leads to optimal output weight. The proposed work confirms the capability of the 2SAT in representing the modeling of the ANN. In another development, [4] proposed mutation DHNN by implementing estimated distribution algorithm (EDA) during retrieval phase of DHNN. This shows that the interpretation of the 2SAT logical rule in DHNN can be further optimized using optimization algorithm. The implementation of 2SAT in various network inspires the emergence of other useful logic such as [5–9] in doing DHNN. Various type of logical rule creates optimal modelling of DHNN that has wide range of behavior. Despite having various type of logical rule in this field, the exploration of different connectives among clauses is limited.
The most popular application of the logical rule in DHNN is logic mining. Reference [10] proposed the first logic mining namely Reverse Analysis (RA) method by implementing Horn Satisfiability in DHNN. The proposed logic mining managed to extract the logical relationship among the student datasets. One of the main issues of the proposed logic mining is the lack of focus of the obtained induced logic. In this context, more robust logic mining is required to extract single most optimal induced logic. Reference [11] proposed 2 Satisfiability Reverse Analysis Method (2SATRA) by introducing specific learning phase and retrieval phase that creates the most optimal induced logic. The proposed 2SATRA extracts the best induced logic for league of legends. The proposed logic mining was extended to various application such as Palm oil pricing [12,13] and football [14]. After the introduction of 2SATRA in the field of logic mining, [15] proposed the energy-based logic mining namely E2SATRA by considering only global neuron state during retrieval phase of DHNN. In this context, the proposed E2SATRA capitalize the dynamics of the Lyapunov energy function to arrive at the optimal final neuron state. Note that, the final global neuron state ensures the induced logic produced by E2SATRA is interpretable. One of the main issues with the conventional 2SATRA is the possible overfitting issue due to ineffective connection of attribute during pre-processing phase. In other word, the attribute might possess the optimal connection with other variable in 2SAT clause, but the other possible connection was disregarded. The optimal logical rule will be less flexible and fail to emphasize the appropriate non-contributing attributes of a particular data set.
In this paper, the modified 2SATRA integrated with permutation operator will enhance the capability of selecting the most optimal induced logic by considering other combination of variable in 2SAT logic. The proposed modified 2SATRA will extract the optimal logical rule for various real-life datasets. Therefore, Thus, the correct synaptic weight during learning phase will determine the capability of the logic mining model and the accuracy of the induced logic generated during testing phase. This work focused on the impact of the logical permutation mechanism in Hopfield Neural Network (HNN) towards the performance of 2SATRA in the tasks data mining and extraction. The contribution of this paper is as follows:
(a) To formulate 2 Satisfiability that incorporates permutation operators which consider various combination of variable in a clause.
(b) To implement permutation 2 Satisfiability in Discrete Hopfield Neural Network by minimizing the cost function during learning phase that leads to optimal final neuron state.
(c) To embed the proposed hybrid Discrete Hopfield Neural Network into logic mining where more diversified induced logic has been proposed.
(d) To evaluate the performance of the proposed permutation logic mining in doing real life datasets with other state of the art logic mining.
The organization of this paper is as follows. Section 2 encloses a bit of brief introduction of 2 Satisfiability logical representation including the conventional formulations and examples. Section 3 focuses on the formulations of logical permutation on 2 Satisfiability Based Reverse Analysis methods. Thus, Section 4 explains the experimental setup including benchmark dataset, performance metrics, baseline method and experimental design. Then, the results and discussions are covered briefly in Section 5. Definitively, the concluding remarks are included in the final section of this paper.
2 Satisfiability in Discrete Hopfield Neural Network
Satisfiability (SAT) is a class of problem of finding the feasible interpretation that satisfies a particular Boolean Formula based on the logical rule. Based on the literature in [16], SAT is recognized to be a variant of NP-complete problem and incorporated to generalize a plethora of constraint satisfaction problems. Thus, the breakthrough of SAT research contributes to the development of the systematic variant of SAT logical representation, for instance, the 2 Satisfiability (2SAT). Theoretically, the fundamental 2SAT logical representation composes of the following structural features [4]:
(a) Given a set of specified x variables,
(b) A set of logical literals comprising either the positive variable or the negation of variable in terms of
(c) Given a set of y definite clauses,
Based on the feature in (a) until (c), the precise definition of
whereby
Then, by governing the Eqs. (1) and (2) respectively, an illustration of
whereby the logical clauses in Eq. (3) are divided into 3 clauses such as
Specifically, the fundamental classification of DHNN with i-th activation is shown as follows
where
3 Permutation in 2 Satisfiability Based Reverse Analysis Method
Logic mining is a paradigm that used logical rule to simplify the information of the data set. Based on the inspiration of a study by [11], they have successfully utilized logic mining by implemented reverse analysis method in inducing all possible logical rules that generalize the behavior of the data set. However, the main task in assessing the behavior of the data set with the pre-defined goal is the extraction of correct
Given a set of data,

For instance, if the given dataset reads
Based on the Eq. (5), the possible permutation for
In this context, the
where
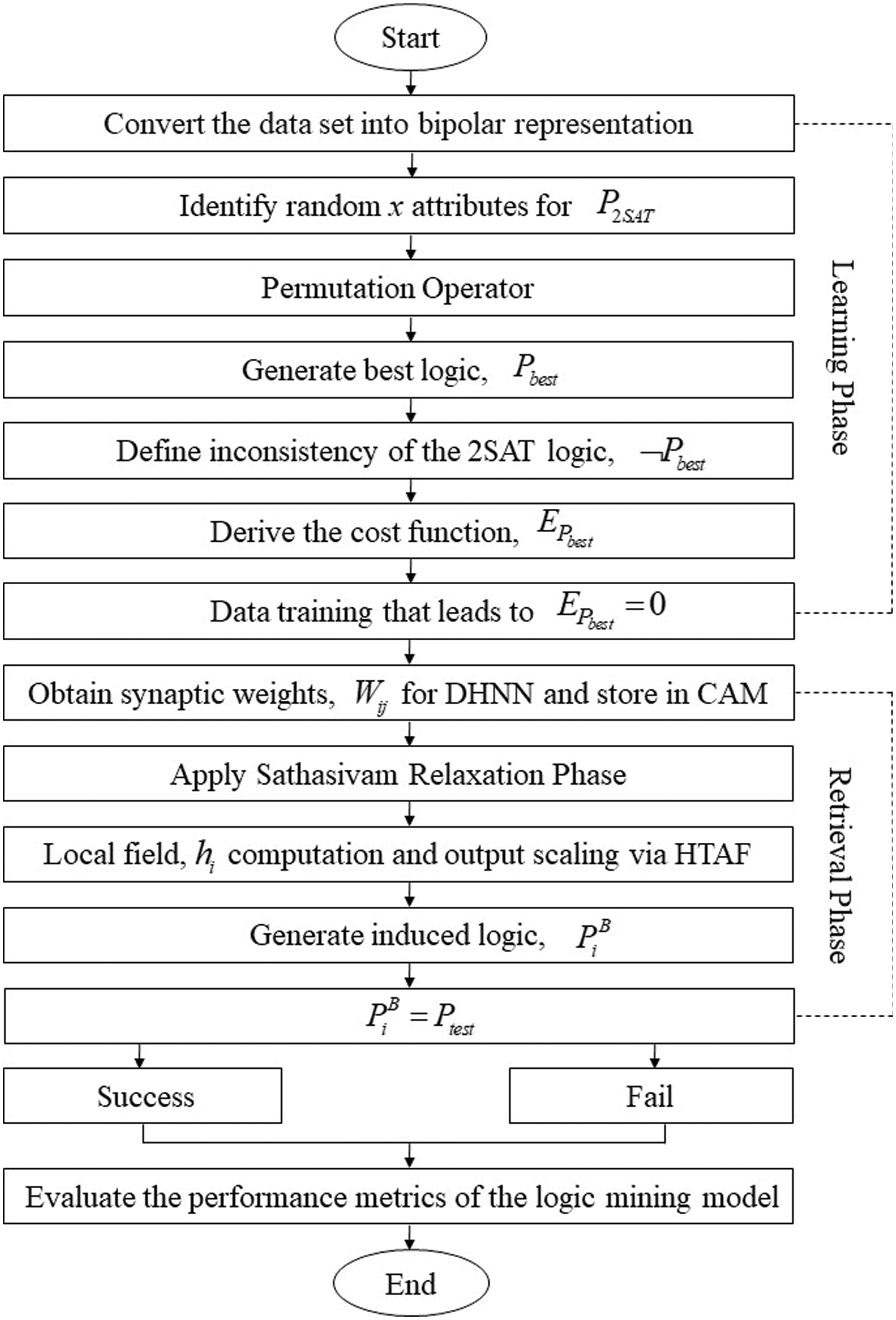
Figure 1: The execution of the proposed P2SATRA
Based on Fig. 1 and Algorithm 1, P2SATRA starts by identifying random logic

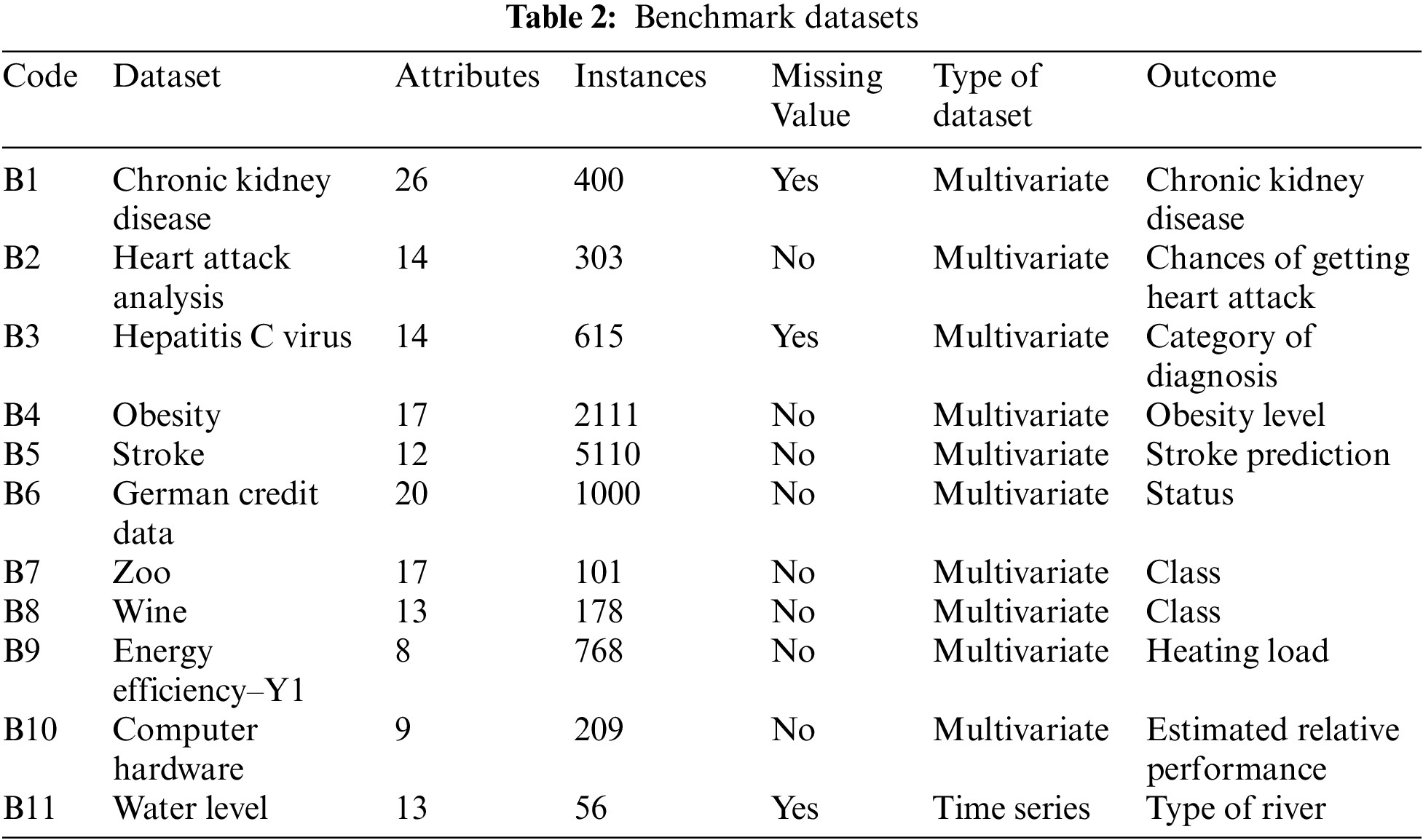
In this paper, the impact of logical permutation in attaining the optimum induced logic is examined. Thus, the first 10 publicly available datasets from repository (B1-B10) are acquired from the open source UCI repository databases via https://archive.ics.uci.edu/ml/datasets.php. Moreover, 1 real life dataset (B11) is taken from Department of Irrigation and Drainage, Malaysia. Tab. 2 encloses the lists of datasets being used in this experiment. Based on the analysis from several previous works, this study utilizes the standard train-test split method, via 60% set as a learning data and the remaining 40% as a testing data [17]. The data will be converted into bipolar representation (1 and −1) using k mean clustering as proposed by [18]. The conversion will be applied in both learning and retrieval phase. To guarantee reproducibility of the result, the implementation code of our proposed P2SATRA with the datasets can be retrieved from https://bit.ly/3nyUdm8.
As the primary impetus of this work is to evaluate the quality of the induced logical representation generated by P2SATRA, we restrict the baseline methods comparison to the standard method only with the capability in attaining the induced logic from the real datasets. Tabs. 3–6 show the list of important parameters for various logic mining approaches. The core concern of combining more attributes is the possible increment of the learning error as the results of non-effective learning phase of HNN [19]. Hence, the Hyperbolic activation function is applied to squash the final state of the neurons because of the capability and the behaviour of the functions such as the continuous, smooth, and non-linearity of the activation function. In retrieval phase of the logic mining method, the neuron initialization is set to be random in order to lessen the potential biasness of the network.




4.3 Performance Evaluation Metrics
Various performance evaluations such as the sensitivity, precision analysis, F-Score and Matthews Correlation Coefficient (MCC) are employed to analyze and assess the overall capability and the significant effect of logical permutation in P2SATRA. The performance of the P2SATRA is calculated based on the confusion matrix. Specifically,
Therefore, precision is employed to gauge the algorithm’s or model’s predictive capability. The computation and formulation for Precision
Accuracy
F-Score is a substantial indicator that indicates the maximum probability of optimal result, clearly demonstrating the capability of the computational model. Moreover, F-Score is depicted as the harmonic mean of the two-performance metrics, which are the precision and sensitivity analysis.
In addition, Matthews Correlation Coefficient
All simulations will be implemented and executed by employing the Dev C++ Version 5.11 software due to the versatility of the programming language and the user-friendly interface of the compiler. Hence, the simulations will be implemented in C++ language by using computer with Intel Core i7 2.5 GHz processor, 8GB RAM and Windows 8.1. Following that, the threshold CPU time for each execution was set 24 h and any possible outputs that go beyond the threshold time were omitted entirely from the analysis. The overall experiments were executed by using the similar device to prevent possible bad sector in the memory during the simulations.
This study created the 2SATRA integrated with HNN-2SAT to simulate and analyze the effect of logical permutation, forming P2SATRA. The composition of attributes will be randomly permuted as opposed to the previous 2SATRA models [11,12]. In this work, the comparison of our proposed P2SATRA will be examined with the conventional logic mining models such as RA, 2SATRA and E2SATRA methods.
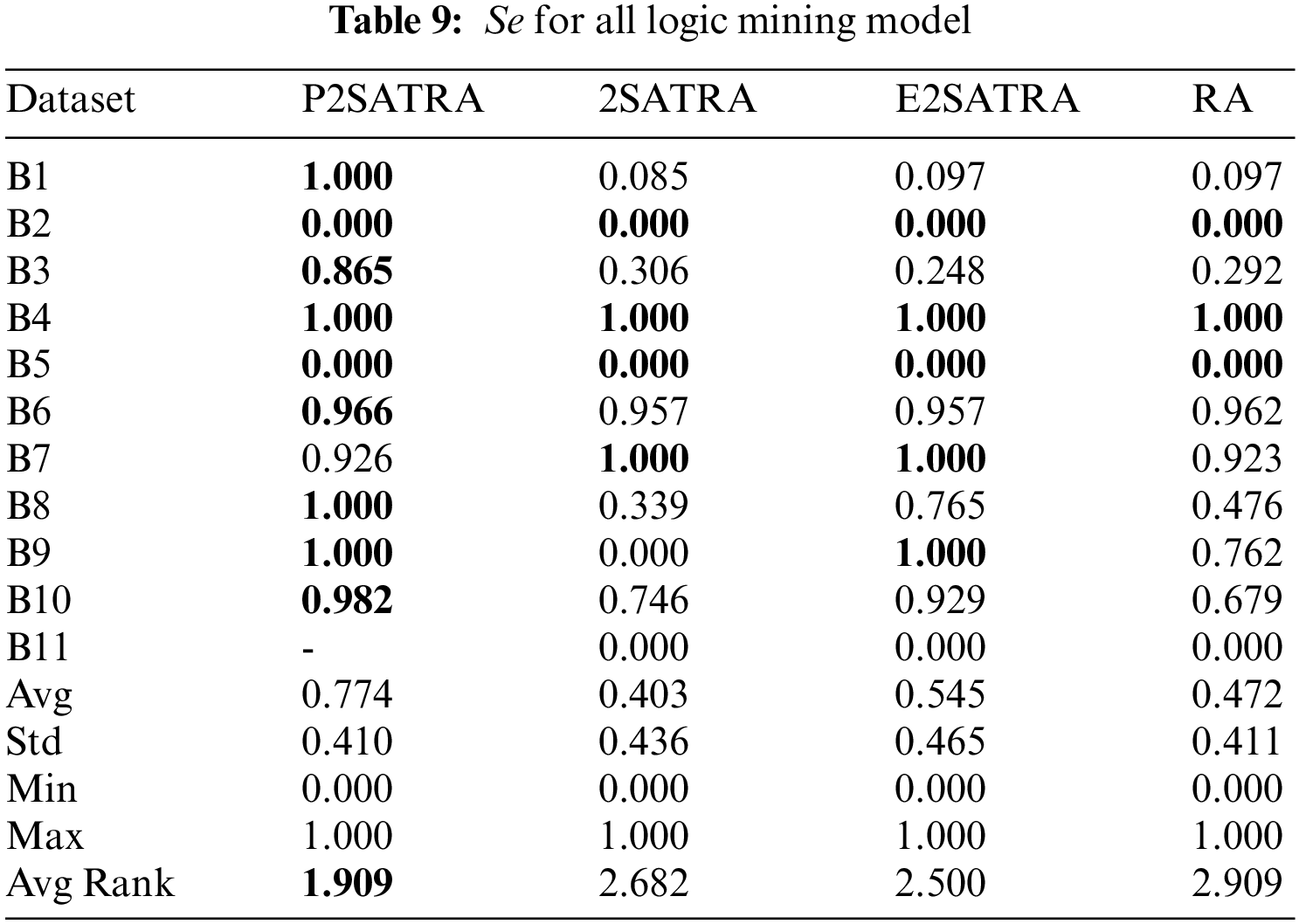
The results of Acc, Pr, Se, F-Score and MCC for four variants of logic mining apporaches can be viewed in Tab. 7 until Tabs. 8 and 11. Then, Tab. 12 encloses the induced logic of obtained for 11 real datasets. According to the results, there are several successful dominances and strength points for P2SATRA which are enclosed based on the analysis of the different performance metrics. Based on
(a) For
(b) For result of
(c) As well to
(d) According to the average rank for all the data sets in terms of
(e) The further analysis via Friedman test rank has been performed for all 11 datasets with





In this work, a new alternative approach of attaining the optimal induced logic entrenched in any of multivariate or time-series datasets by introducing the logical permutations in 2SATRA has been successfully developed. The enhancements can be seen clearly in the substantial accuracy improvement of the proposed model as opposed to the existing approach, indicating the success in the generalization of the datasets. In this study, we have exploited the multi-connection between the attribute arrangements in generating the
Acknowledgement: The authors would like to thank all AIRDG members and those who gave generously of their time, ideas and hospitality in the preparation of this manuscript.
Funding Statement: This research was supported by Universiti Sains Malaysia for Short Term Grant with Grant Number 304/PMATHS/6315390.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. W. A. T. W. Abdullah, “Logic programming on a neural network’,” International Journal of Intelligent Systems, vol. 7, no. 6, pp. 513–519, 1992. [Google Scholar]
2. M. S. M. Kasihmuddin, M. A. Mansor and S. Sathasivam, “Hybrid genetic algorithm in the hopfield network for logic satisfiability problem,” Pertanika Journal of Science & Technology, vol. 25, no. 1, pp. 227–243, 2017. [Google Scholar]
3. S. Alzaeemi, M. A. Mansor, M. S. M. Kasihmuddin, S. Sathasivam and M. Mamat, “Radial basis function neural network for 2 satisfiability programming,” Indonesian Journal of Electrical Engineering and Computer Science, vol. 18, no. 1, pp. 459–469, 2020. [Google Scholar]
4. M. S. M. Kasihmuddin, M. A. Mansor, M. F. M. Basir and S. Sathasivam, “Discrete mutation hopfield neural network in propositional satisfiability,” Mathematics, vol. 7, no. 11, pp. 1133, 2019. [Google Scholar]
5. S. A. Karim, N. E. Zamri, A. Alway, M. S. M. Kasihmuddin, A. I. M. Ismail et al., “Random satisfiability: A higher-order logical approach in discrete hopfield neural network,” IEEE Access, vol. 9, pp. 50831–50845, 2021. [Google Scholar]
6. A. Alway, N. E. Zamri, S. A. Karim, M. A. Mansor, M. S. M. Kasihmuddin et al., “Major 2 satisfiability logic in discrete hopfield neural network,” International Journal of Computer Mathematics, vol. 99, no. 5, pp. 924–948, 2022. [Google Scholar]
7. S. S. M. Sidik, N. E. Zamri, M. S. M. Kasihmuddin, H. A. Wahab, Y. Guo et al., “Non-systematic weighted satisfiability in discrete hopfield neural network using binary artificial bee colony optimization,” Mathematics, vol. 10, no. 7, pp. 1129, 2022. [Google Scholar]
8. Y. Guo, M. S. M. Kasihmuddin, Y. Gao, M. A. Mansor, H. A. Wahab et al., “YRAN2SAT: A novel flexible random satisfiability logical rule in discrete hopfield neural network,” Advances in Engineering Software, vol. 171, pp. 103169, 2022. [Google Scholar]
9. Y. Gao, Y. Guo, N. A. Romli, M. S. M. Kasihmuddin, W. Chen et al., “GRAN3SAT: Creating flexible higher-order logic satisfiability in the discrete hopfield neural network,” Mathematics, vol. 10, no. 11, pp. 1899, 2022. [Google Scholar]
10. S. Sathasivam and W. A. T. W. Abdullah, “Logic mining in neural network: Reverse analysis method,” Computing, vol. 91, no. 2, pp. 119–133, 2011. [Google Scholar]
11. L. C. Kho, M. S. M. Kasihmuddin, M. A. Mansor and S. Sathasivam, “Logic mining in league of legends,” Pertanika Journal of Science & Technology, vol. 28, no. 1, pp. 211–255, 2020. [Google Scholar]
12. A. Alway, N. E. Zamri, M. S. M. Kasihmuddin, M. A. Mansor and S. Sathasivam, “Palm oil trend analysis via logic mining with discrete hopfield neural network,” Pertanika Journal of Science & Technology, vol. 28, no. 3, pp. 967–981, 2020. [Google Scholar]
13. S. A. S. Alzaeemi and S. Sathasivam, “Examining the forecasting movement of palm oil price using RBFNN-2SATRA metaheuristic algorithms for logic mining,” IEEE Access, vol. 9, pp. 22542–22557, 2021. [Google Scholar]
14. L. C. Kho, M. S. M. Kasihmuddin, M. A. Mansor and S. Sathasivam, “Logic mining in football matches,” Indones. J. Electr. Eng. Comput. Sci, vol. 17, pp. 1074–1083, 2020. [Google Scholar]
15. S. Z. M. Jamaludin, M. S. M. Kasihmuddin, A. I. M. Ismail, M. A. Mansor and M. F. M. Basir, “Energy based logic mining analysis with hopfield neural network for recruitment evaluation,” Entropy, vol. 23, no. 1, pp. 40, 2020. [Google Scholar]
16. S. A. Cook, “The complexity of theorem-proving procedures,” in Proc. Third Annual ACM Symp. on Theory of Computing-STOC ‘71, New York, NY, USA, pp. 151–158, 1971. [Google Scholar]
17. K. Jha and S. Saha, “Incorporation of multimodal multiobjective optimization in designing a filter based feature selection technique,” Applied Soft Computing, vol. 98, pp. 106823, 2021. [Google Scholar]
18. N. E. Zamri, M. A. Mansor, M. S. M. Kasihmuddin, A. Alway, S. Z. M. Jamaludin et al., “Amazon employees resources access data extraction via clonal selection algorithm and logic mining approach,” Entropy, vol. 22, no. 6, pp. 596, 2020. [Google Scholar]
19. D. L. Lee, “Pattern sequence recognition using a time-varying hopfield network,” IEEE Transactions on Neural Networks, vol. 13, no. 2, pp. 330–342, 2002. [Google Scholar]
20. M. S. M. Kasihmuddin, M. A. Mansor and S. Sathasivam, “Discrete hopfield neural network in restricted maximum k-satisfiability logic programming,” Sains Malaysiana, vol. 47, no. 6, pp. 1327–1335, 2018. [Google Scholar]
21. H. Sun and R. Grishman, “Lexicalized dependency paths based supervised learning for relation extraction,” Computer Systems Science and Engineering, vol. 43, no. 3, pp. 861–870, 2022. [Google Scholar]
22. H. Sun and R. Grishman, “Employing lexicalized dependency paths for active learning of relation extraction,” Intelligent Automation & Soft Computing, vol. 34, no. 3, pp. 1415–1423, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools