
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Local Adaptive Gradient Variance Attack for Deep Fake Fingerprint Detection
1 Engineering Research Center of Digital Forensics, Ministry of Education, Nanjing University of Information Science and Technology, Nanjing, 210044, China
2 School of Computer Science, Nanjing University of Information Science and Technology, Nanjing, 210044, China
3 Institute of Artificial Intelligence and Blockchain, Guangzhou University, Guangzhou, 510006, China
4 School of International Relations, National University of Defense Technology, Nanjing, 210039, China
5 Department of Electrical and Computer Engineering, University of Windsor, Windsor, N9B 3P4, Canada
* Corresponding Author: Xinting Li. Email:
Computers, Materials & Continua 2024, 78(1), 899-914. https://doi.org/10.32604/cmc.2023.045854
Received 09 September 2023; Accepted 20 November 2023; Issue published 30 January 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In recent years, deep learning has been the mainstream technology for fingerprint liveness detection (FLD) tasks because of its remarkable performance. However, recent studies have shown that these deep fake fingerprint detection (DFFD) models are not resistant to attacks by adversarial examples, which are generated by the introduction of subtle perturbations in the fingerprint image, allowing the model to make fake judgments. Most of the existing adversarial example generation methods are based on gradient optimization, which is easy to fall into local optimal, resulting in poor transferability of adversarial attacks. In addition, the perturbation added to the blank area of the fingerprint image is easily perceived by the human eye, leading to poor visual quality. In response to the above challenges, this paper proposes a novel adversarial attack method based on local adaptive gradient variance for DFFD. The ridge texture area within the fingerprint image has been identified and designated as the region for perturbation generation. Subsequently, the images are fed into the targeted white-box model, and the gradient direction is optimized to compute gradient variance. Additionally, an adaptive parameter search method is proposed using stochastic gradient ascent to explore the parameter values during adversarial example generation, aiming to maximize adversarial attack performance. Experimental results on two publicly available fingerprint datasets show that our method achieves higher attack transferability and robustness than existing methods, and the perturbation is harder to perceive.Keywords
Recently, biometric identification technologies such as fingerprint recognition [1], face recognition [2], and iris recognition [3], etc., have seen extensive deployment in a wide range of real-world applications. Fingerprint recognition, in particular, is favored due to its versatility, uniqueness and convenience. However recent studies have shown that these systems are vulnerable to fraudulent attacks involving fake fingerprints, the proposed fingerprint liveness detection technology can solve the above problems well, and its main task is to identify whether the fingerprint to be authenticated is from a human or a forged imitation.
In recent years, the iterative updating and development of deep learning technology has provided a whole new set of solutions for multiple types of tasks in the field of computer vision, such as image classification [4], object recognition [5], semantic segmentation [6], natural language processing [7]. These solutions have already been introduced to real-world scenarios, such as face recognition [8] and pedestrian detection [9], etc., and have obtained good feedback. Given the excellent performance of deep learning in image classification, it has also been applied to fingerprint liveness detection tasks. Notably, research on fingerprint liveness detection based on deep learning has garnered substantial attention from both academia and industry, showcasing remarkable achievements in deep fake fingerprint detection tasks [10], [11]. However, the latest research [12] has pointed out that in addition to the problem of spoofing attacks by forged fingerprints, DFFD models also face the problem of adversarial attacks. That is, by adding some fine perturbations to the fingerprint image, the constructed adversarial example enables the model to make false classifications with a high degree of confidence. The adversarial fingerprint is more destructive compared with the spoofing attack, and it is easier for the DFFD model to make wrong predictions. This poses a major threat to the integrity and security of the DFFD system. According to the level of knowledge, adversarial examples are generally divided into two categories: white-box attack entails crafting adversarial examples using knowledge of the target model’s internal structure and parameters. In contrast, a black-box attack is a method for generating adversarial examples without access to the internal architecture or parameters of the target model. Generally speaking, white-box attacks can design customized perturbations according to the structure and parameters of the model, and achieve a high success rate of attack, but poor transferability in the face of unknown models. In a real-world scenario, it is not realistic to discover and know the parameters and structure of the target model in advance. It is more based on the black box attack scenario, that is, the parameters and structure of the target model are not known in advance, so studying and improving the transferability between different models is more in line with the real scenario. In addition, adversarial attacks can be divided into targeted and untargeted attacks depending on whether the model is incorrectly classified into a particular category. There has been limited research in the realm of adversarial attacks on DFFD systems, despite the significant threats they pose. To deal with adversarial attacks and improve the security of fingerprint recognition systems, a novel adversarial example generation method based on local adaptive gradient variance is proposed in this paper. The main contributions of this paper are as follows:
• To enhance the visual quality of the adversarial fingerprint without affecting the original attack performance, Grad-CAM is used to visualize the attention area of the fingerprint image and as the additional area of the subsequent perturbation, which is difficult to perceive by human eyes.
• To improve the transferability in the gradient-based adversarial example generation method, this paper proposes a local adaptive gradient variance attack method, which realizes the gradient update direction controllable by computing gradient variance at each iteration.
• In this paper, an adaptive parameter search method is proposed to search the optimal hyper-parameters by using the stochastic gradient ascent method, thus reducing manual intervention and balancing the success rate of white-box attacks.
• In this paper, the performance evaluation is tested on two publicly available fingerprint datasets, LiveDet2019 [13] and LiveDet2017 [14]. Experimental results indicate that the proposed method can improve the transferability of adversarial examples between different DFFD models, and obtain good visual quality.
This paper is an extension of our previous conference paper [15]. Compared with the [15], this paper extends and improves it. The main differences are summarized as follows: (1) We have improved the introduction section, restated the research motivation, provided a more comprehensive introduction and solved the actual problems. (2) In Section 3, we constrain the region where perturbation is added, and discuss and analyze the feasibility. (3) In Section 4, we demonstrate that the proposed method can be combined with input transformations to improve the visual quality of adversarial examples via extensive experimentation and interpretation.
The rest of this paper is structured as follows: Section 2 presents a review of related work. In Section 3, we introduce the proposed method for generating adversarial examples. Section 4 provides the experimental results. Finally, the conclusion and future work are given.
Szegedy et al. [16] first disclosed the flaws in image classification tasks: although deep learning has achieved impressive performance in image classification, it faces a serious challenge, that is, adding some subtle perturbations to the original image can cause the model to make incorrect predictions, and the human visual system can hardly catch the anomaly. They also give a mathematical formula for the calculation of perturbation, expressed in ρ, which induces the model to give a wrong judgment:
In formulation (1),
To calculate the global optimal solution, Szegedy tried to transformed the adversarial attack into a convex optimization problem, and presented a L-BFGS method [17]. After that, more and more work has been proposed. Moosavi-Dezfooli et al. [18] designed an iterative method to calculate the minimum perturbation for input images and added perturbations to guide the output image toward the decision boundary of the classifier. Carlini et al. [19] presented a series of three attacks along with a novel loss function designed to deceive target networks via defensive distillation.
Concurrently, the research landscape has seen the emergence of various black-box attack techniques. Sarkar et al. [20] introduced the UPSET network, capable of generating adversarial examples with universal perturbations applied to original images, effectively causing the model to misclassify specific target classes. Bhagoji et al. [21] proposed a finite difference-based method (FD attack) rooted in finite difference principles, wherein pixel data is adjusted to estimate the gradient direction approximately, subsequently conducting iterative attacks based on this estimated gradient. Dong et al. [22] introduced momentum into the iterative adversarial example generation process. Su et al. [23] designed a single pixel attack using a differential evolution algorithm to explore extreme conditions by modifying a single pixel in an image to trick the classifier. Furthermore, Fei et al. [12] conducted pioneering research into the feasibility of adversarial examples within the context of DFFD networks. A series of improved and optimized adversarial example generation methods have been proposed, showing great potential in this field. In this paper, focusing on DFFD model, we focus on how to improve the mobility and visual quality of the detection model.
In this section, our primary focus is on presenting gradient-based attacks aimed at enhancing the transferability of adversarial attacks.
2.2.1 Fast Gradient Sign Method (FGSM)
To solve the nonlinear and vulnerability problems of the model, Goodfellow et al. [24] first proposed a FGSM, which realizes the generation of the adversarial example
here,
2.2.2 Iterative Fast Gradient Sign Method (I-FGSM)
In contrast to FGSM, which relies on a single iteration, Kurakin et al. proposed I-FGSM [25] conducts multiple iterations during adversarial example generation, employing a smaller step size
where
2.2.3 Momentum Iterative Fast Gradient Sign Method (MI-FGSM)
To enhance the update stability and avoid local maximum, MI-FGSM [22] is proposed to extend I-FGSM, that is, the momentum of previous iterations was included in gradient calculation to boost the transferability of adversarial examples, which is expressed as:
where
2.2.4 Nesterov Iterative Fast Gradient Sign Method (NI-FGSM)
NI-FGSM [26] introduces a Nesterov momentum, during the gradient update, predicts the gradient direction of the next iteration. NI-FGSM substitutes
2.2.5 Variance Tuning Momentum-Based Iterative Method (VMI-FGSM)
VMI-FGSM [27] calculates the gradient of the neighborhood data points during the update to optimize the gradient update direction in the next iteration. It can be expressed as:
where
2.2.6 Transformation Robust Attack (TRA)
TRA [12] stands as the pioneering adversarial attack method in the realm of DFFD, and it confirms the feasibility of adversarial attacks on DFFD.
This section introduces various input transformations to enhance the attack transferability.
2.3.1 Diverse Input Method (DIM)
DIM [28] implements stochastic alterations involving resizing and padding on input data using a fixed probability. Subsequently, the modified images are directed through the classifier to calculate gradients, thereby enhancing the potential for transferability.
2.3.2 Translation-Invariant Method (TIM)
TIM [29] employs a set of images to compute gradients, proving particularly effective, especially when confronting black-box models equipped with defensive mechanisms. To mitigate gradient calculations, Dong et al. introduce slight positional shifts to the images, followed by an approximation of gradient computation through convolving gradients from unaltered images with a kernel matrix.
2.3.3 Scale-Invariant Method (SIM)
SIM [26] introduces the concept of scale-invariant property and computes gradients across an array of images scaled by a factor of
It’s important to emphasize that different input transformation methods, namely DIM, TIM, and SIM, can be seamlessly incorporated into gradient-based attack methodologies, that is, the Composite Transformation Method (CTM) can improve mobility more effectively. In this study, the proposed method seeks to enhance the transferability of gradient-based attacks (e.g., MI-FGSM, VMI-FGSM). It can be synergistically employed alongside diverse input transformations to further bolster the transferability of the attack.
VMI-FGSM establishes gradient variance as the distinction between the average gradient in the vicinity neighborhood and the gradient from the previous iteration. We believe that simply combining the difference between the previous iteration and the current iteration gradient is not enough to solve the transferability problem of adversarial examples. Consequently, this paper designs a novel attack approach based on local adaptive gradient variance under lower perturbation levels, adversarial examples generated using our method demonstrate enhanced attack performance and increased transferability against unknown DFFD models. Fig. 1 provides visual insights into the effects of various attacks on both live and counterfeit fingerprints.
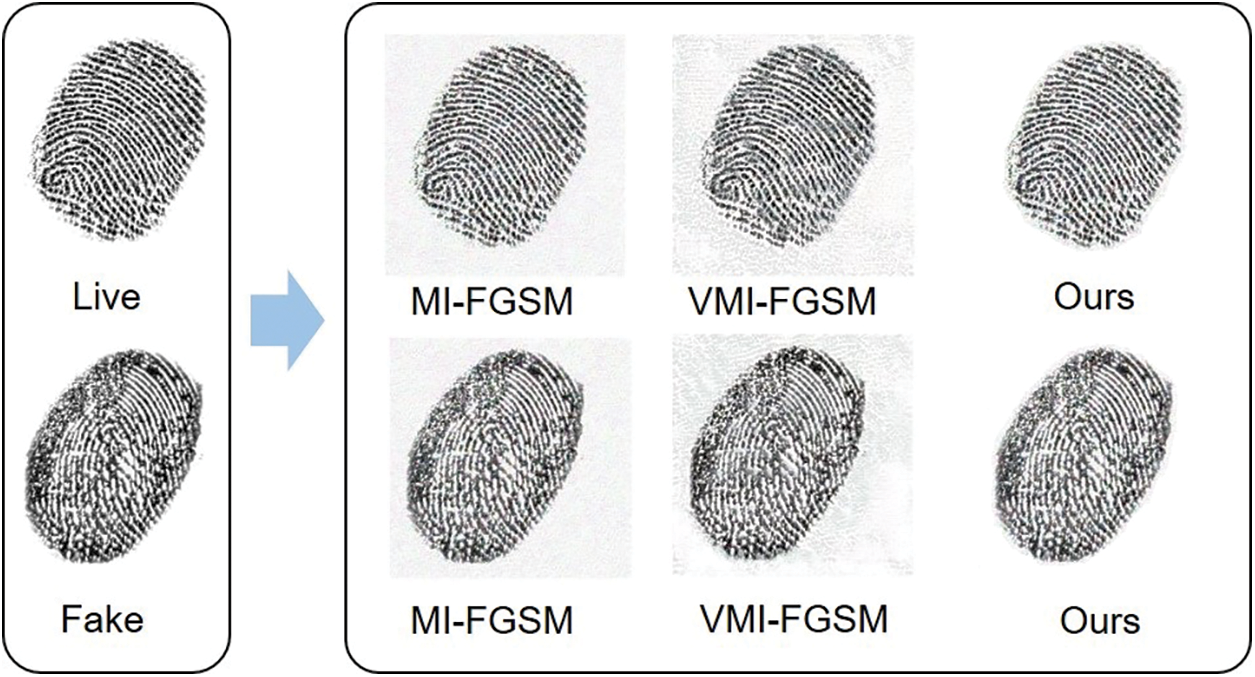
Figure 1: When the perturbation size of
3.1 Adversarial Fingerprint Area Location
The generation of adversarial examples involves adding subtle perturbations to the original image, typically constrained by specific norms like L0 or L∞. The requirement of these interference generation is that the human visual system cannot be observed without successfully attacking the task model. To delve into the underlying principles of adversarial fingerprints, we employ the Grad-CAM to highlight sensitive regions that influence DFFD classification.
As illustrated in Fig. 2, the layers of the VGG-16 model concentrate on discerning the texture of the original fingerprint within the image. When dealing with an adversarial fingerprint generated using the I-FGSM method, we observe that the introduced perturbations not only avoid diverting neural network attention to irrelevant areas but also focus on the fingerprint texture region. Consequently, our research uses YOLO-v5 [30] to restrict the addition of perturbations for adversarial fingerprints exclusively to the interior of the fingerprint texture region. This strategy not only improves the image quality without affecting the performance of the original task, but also makes the perturbations imperceptible to humans.
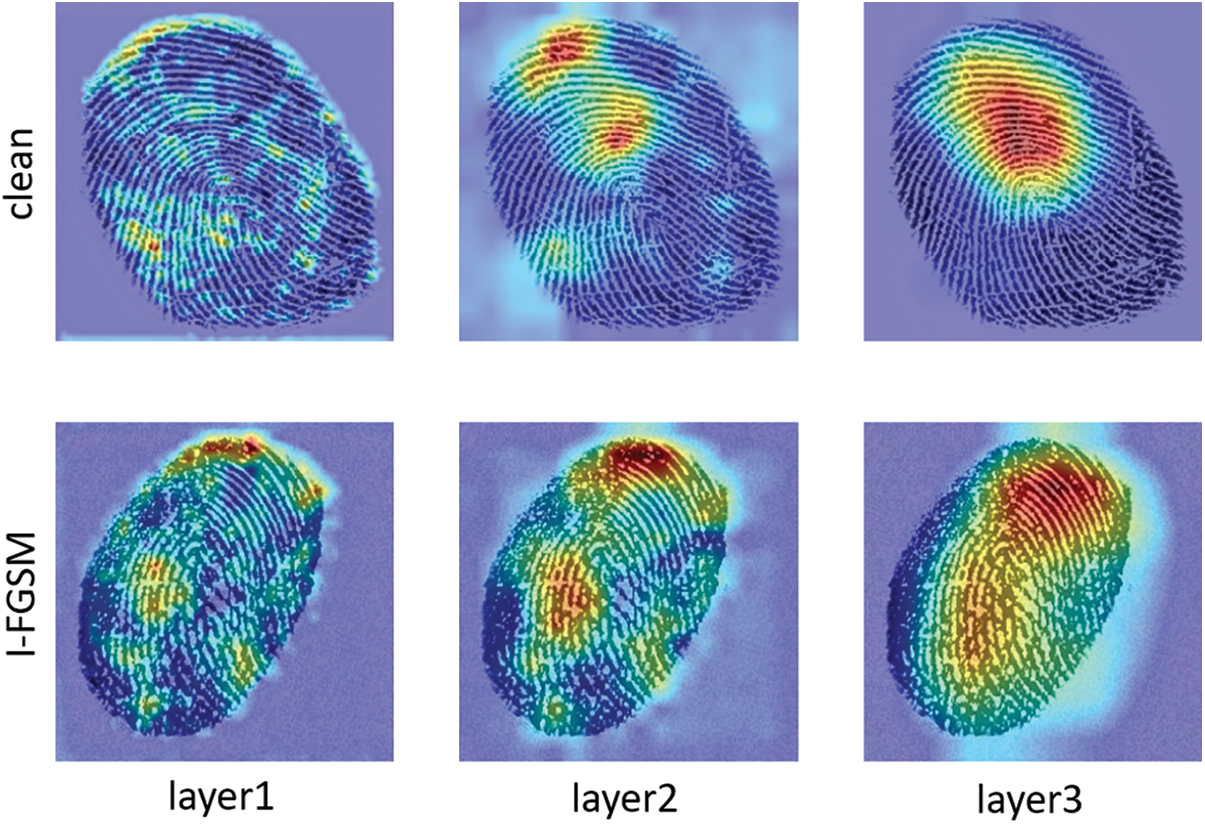
Figure 2: The Grad-CAM visualization of VGG-16 classifies a clean fingerprint image and an FGSM generated adversarial fingerprint, layer1 to layer3 represents the layer from shallow to deep

Given a clean image
We establish
Here,

3.3 Adaptive Parameter Selection
Optimizing the parameters in the above methods manually can be resource-intensive and susceptible to subjective biases. Hence, we have devised an adaptive parameter optimization method rooted in gradient descent. When provided with an adversarial example denoted as
Notably, our primary aim here is to increase the loss, effectively constituting a gradient ascent procedure. Given the need to generate corresponding adversarial examples in each iteration of the gradient update, we opt for a stochastic gradient ascent approach to manage computational costs. The parameter search process is concisely outlined in Algorithm 2.
In this section, a set of experiments is carried out using the LiveDet2019 and LiveDet2017 datasets to assess the effectiveness of the method. Initially, we delineate the specific experimental configurations and subsequently compare our success rate in performing attacks with other methods across various settings. It is important to emphasize that FLD constitutes a binary classification task. In the case of non-targeted attack on N categorized datasets, the model is tasked with classifying images into the remaining N-1 classes. In contrast, within the context of the binary classification task, images are categorized exclusively as either genuine or counterfeit. This inherent difference results in an appreciably lower success rate for binary classification attacks compared to their multi-class counterparts. Empirical findings also demonstrate that our method can enhance the transferability of adversarial attacks while improving visual effects compared to alternative methods.
In terms of data distribution and image quality, the dataset originates from the Liveness Detection Competitions of 2019 and 2017 (LiveDet2019 and LiveDet2017). These datasets consist of fingerprint images gathered by different sensors such as Digital Persona, Orcathus Sensors, and Green Bit. Each sensor's image collection comprises both genuine fingerprint images and counterfeit fingerprints crafted from a variety of materials such as Ecoflex, Latex and Gelatine.
Since the different quality of fingerprint images collected by different sensors, we have made the deliberate choice to exclusively utilize images gathered by the Digital Persona sensor for the dataset. Additionally, to maintain a balance in the quantities of counterfeit and live fingerprints, our dataset includes only counterfeit fingerprints derived from the initial three materials: Ecoflex, Gelatine, and Latex. This selection aims to ensure a more even distribution of features extracted during the training of our network model, thereby enhancing the model's classification accuracy. Every image in our dataset has undergone resizing to align with the input size required by our model, transforming the original 252 × 324 dimensions to 224 × 224. This meticulously curated dataset serves as the training data for our network model. In the context of testing adversarial attacks, 1000 images that can be reliably classified are selected to test the attack performance.
In this paper, the performance of adversarial examples is evaluated from two aspects: (1) Transferability, as the ability to deceive the black-box model is essential for effective adversarial attacks. (2) Image quality, that is, the size of the introduced perturbation, we use the Peak Signal-to-Noise Ratio (PSNR) value as the evaluation metric.
We have chosen gradient-based iterative adversarial attacks commonly employed in the field as our baseline, specifically, I-FGSM, MI-FGSM, and VMI-FGSM. It is worth noting that VMI-FGSM has been empirically demonstrated to exhibit superior transferability compared to other attack methods.
In the performance test, five classic networks, specifically, Inception-v3, Inception-v1, Inception-resnet-v2, VGG-16 and Mobilenet-v1, are selected to analyze the performance of different schemes. In addition, we combined two adversarial training models, namely Inception-v3adv, Inception-resnet-v2adv, to evaluate the robustness of adversarial attacks.
4.1.5 Hyper-Parameters Setting
In the experimental setup, we still use the relevant parameters in our previous work [15], where the magnitude of the perturbation is set to
First, the attack success rates of different network models I-FGSM, MI-FGSM, VMI-FGSM and ours are evaluated using LiveDet2019 and LiveDet2017 datasets at a fixed perturbation size, and the outcomes are summarized in Tables 1 and 2. The rows represent the attacked model, and adversarial examples are generated based on models in columns. Each neural network is trained using the designated dataset. Notably, the results in the table indicate that our proposed method consistently achieves a superior attack success rate when pitted against unknown models. Furthermore, it sustains its attack performance when confronted with the white-box model.
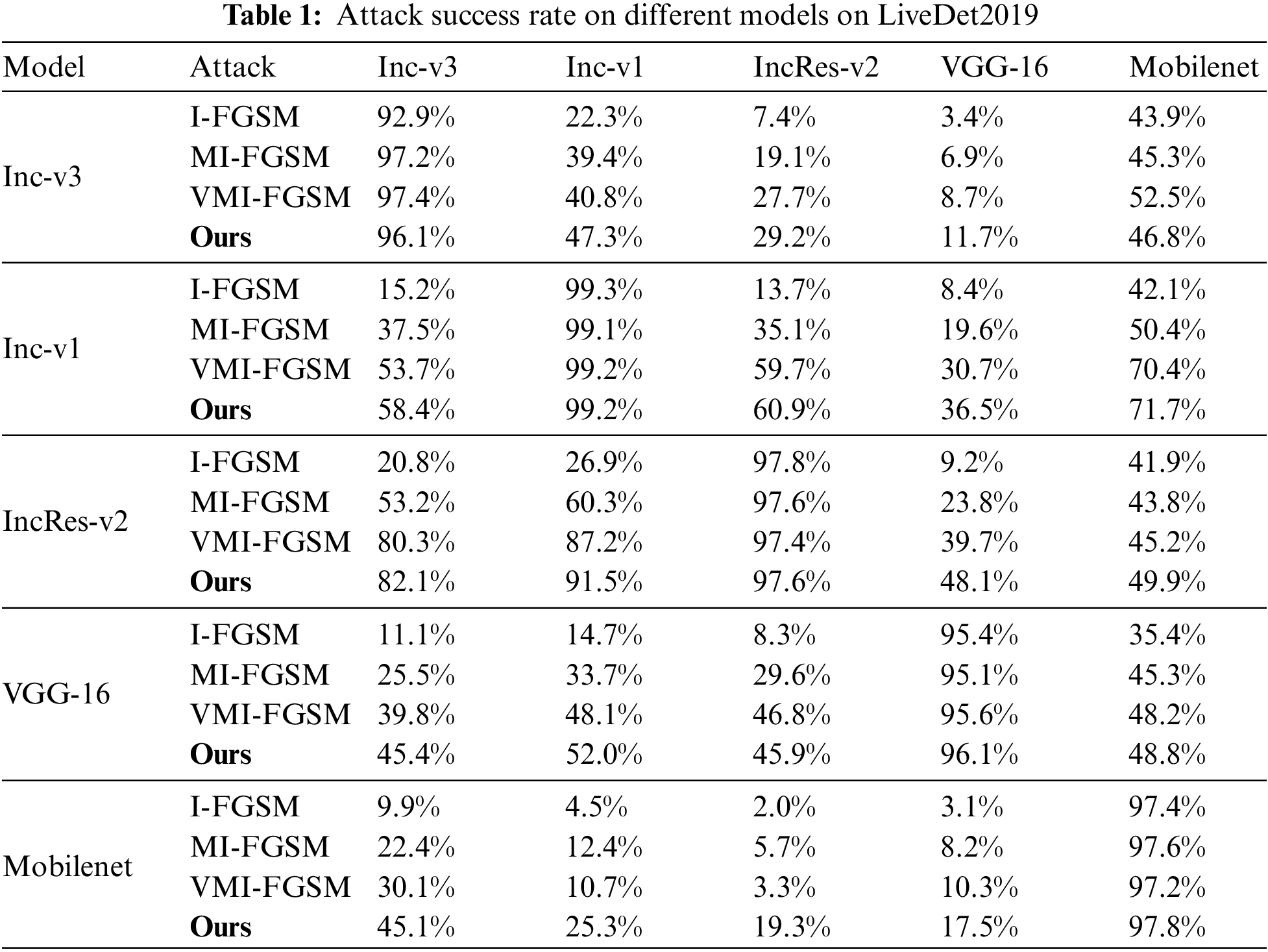
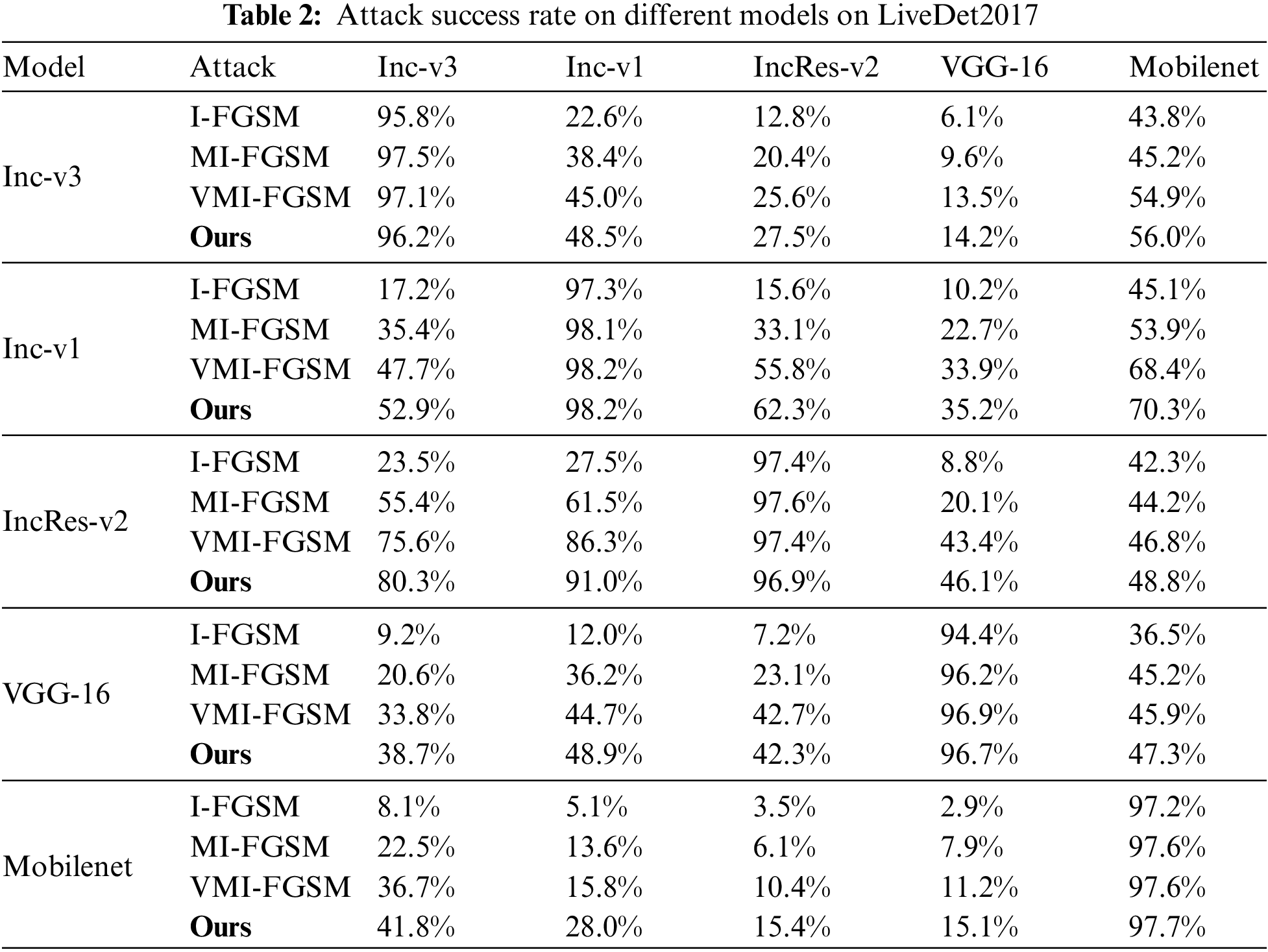
Taking Table 1 as an example, in the context of a white-box attack, the attack success rate of each method based on Inception-resnet-v2 exceeds 97%. For black-box attacks targeting Mobilenet and Inception-v1, our proposed method attains success rates of 91.5% and 49.9%, respectively. In comparison, VMI yields success rates of 87.2% and 45.2% for these models. It is also observed that when the architecture of the black-box model closely resembles that of the target model, the attack exhibits higher success rates. This underscores the robust transferability of our approach across a variety of models. When using the LiveDet2017 dataset, Table 2 presents similar results.
Additionally, we test the robustness of different methods by challenging three network models that have undergone adversarial training, as depicted in Table 3. The experimental findings demonstrate that our method exhibits greater robustness when faced with adversarially trained models.
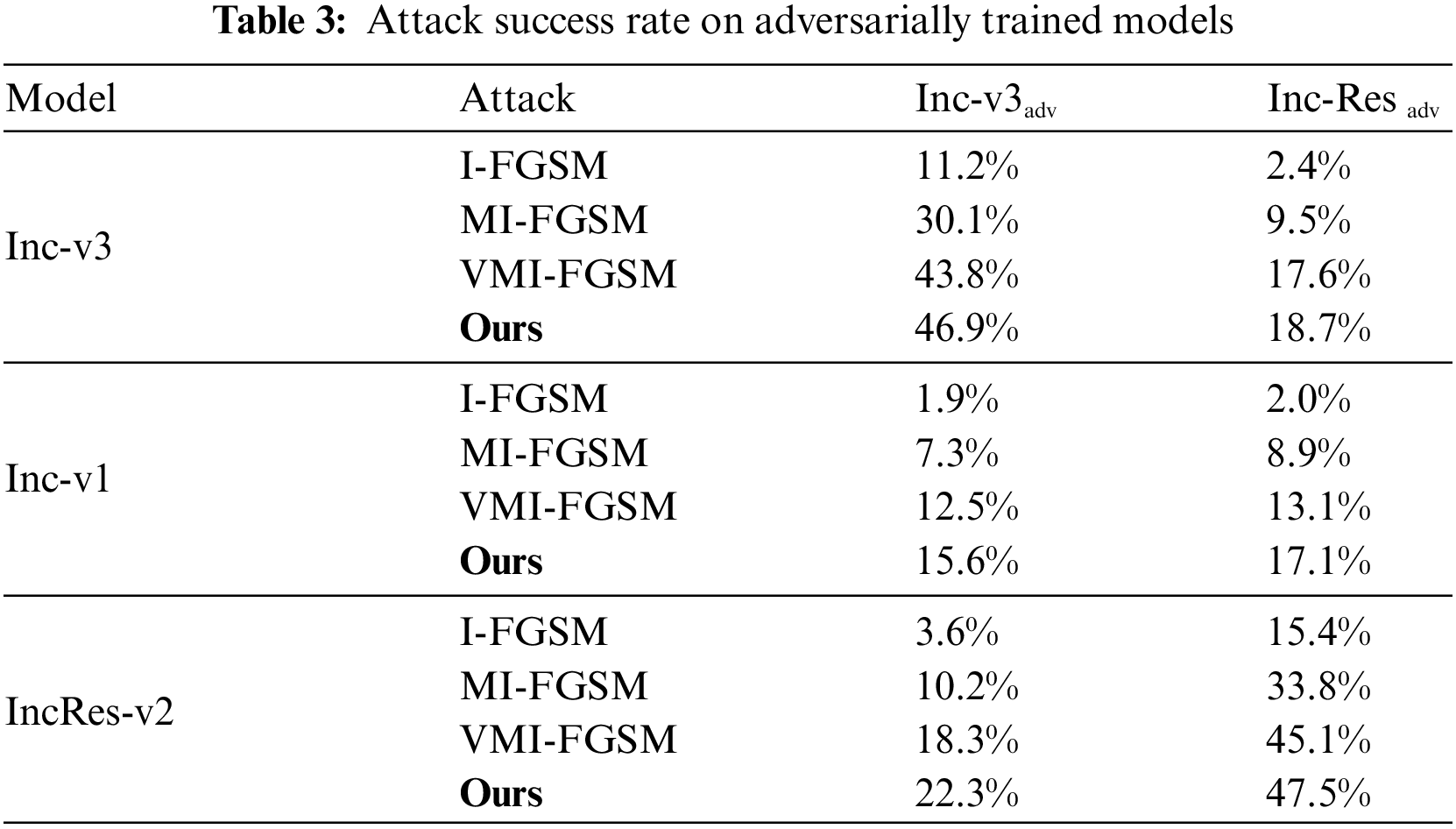
To further investigate the transferability of adversarial examples under varying levels of perturbation, we conducted experiments as presented in Table 4. Rows represent the attack methods employed, while columns denote the perturbation sizes set at 0.03, 0.06, 0.09, 0.12, and 0.16, respectively, with pixel values confined to [0, 1]. All attacks are conducted on Inception-v3, and the reported results represent the average black-box attack success rates, consistent with those detailed in Tables 1 and 2. In Fig. 3, we provide visualizations of a counterfeit fingerprint image and corresponding adversarial examples with different perturbation magnitudes. Due to the limitation of the perturbation region, the noise in the image is not obvious. As the perturbation increases, the black-box attack success rate will be higher. For instance, at ϵ = 0.16, the proposed method achieves a remarkable 35.1% success rate in attacks across various models, surpassing the performance of any other method.
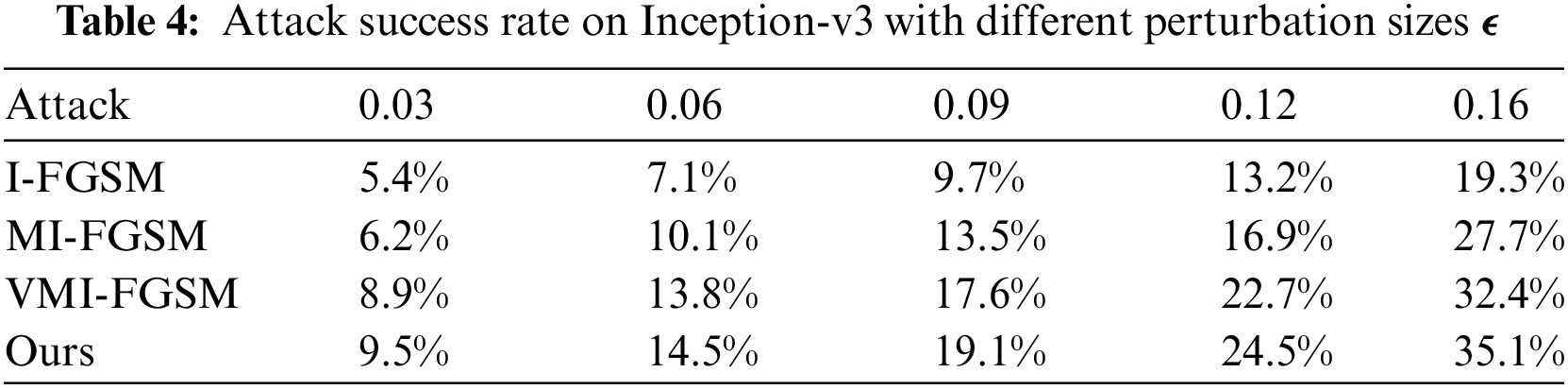

Figure 3: Adversarial examples generated by Ours with different
It is worth noting that although it may be difficult for human observers to detect alterations in the image with the increase of perturbation, the model is more vulnerable to deception because its feature perception is different from that of human beings.
4.2.2 Attack with Input Transformations
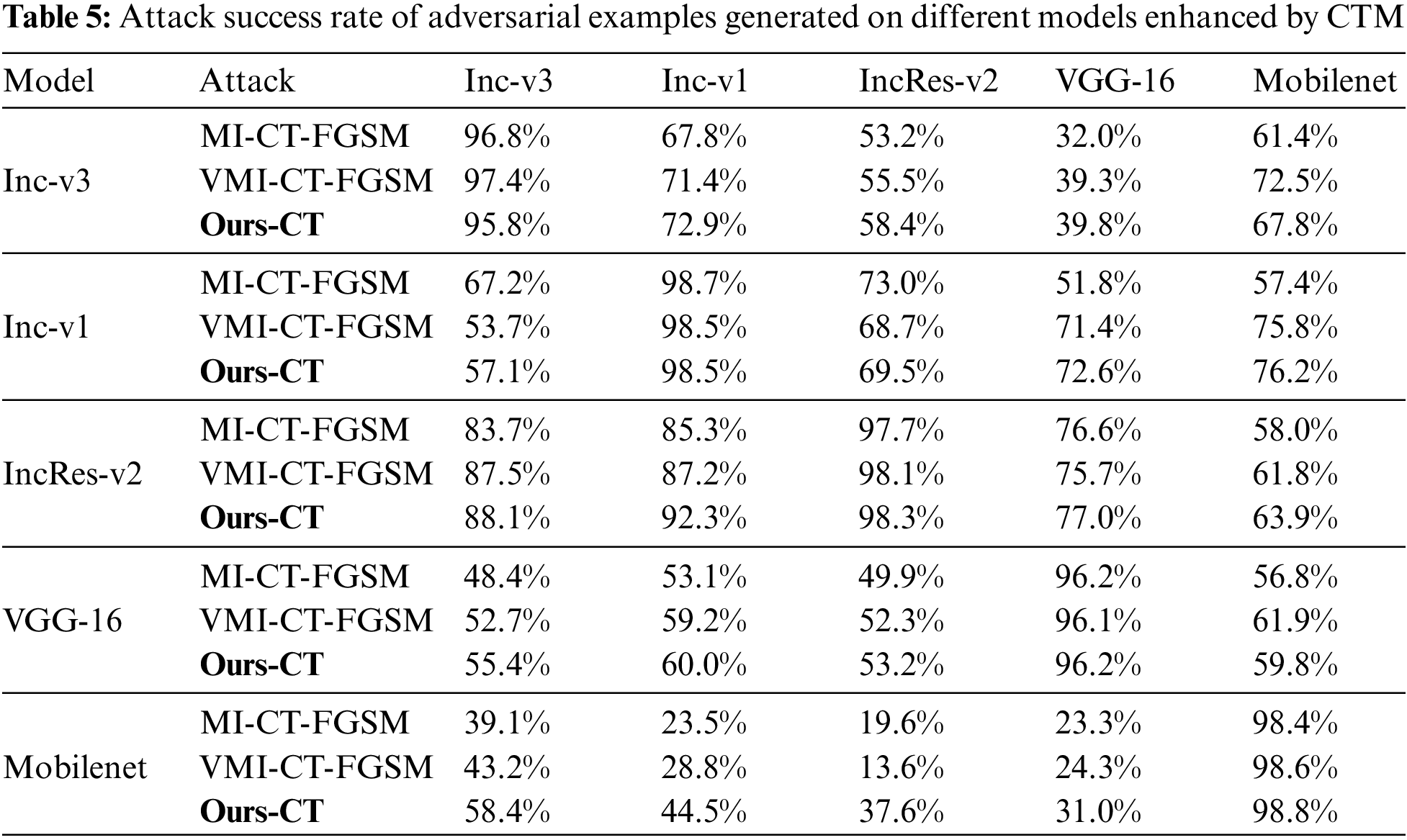
Input transformations, such as DIM, TIM, and SIM, can be seamlessly integrated with gradient-based adversarial attacks to significantly bolster transferability. In this paper, these input transformations have been incorporated into our method, resulting in a demonstrable enhancement of transferability. As detailed in Table 5, success rates exhibit further improvement across various models, with our proposed method consistently outperforming the baseline. These findings provide additional compelling evidence for the efficacy of our approach.
4.2.3 Quantitative Analysis of Visual Quality
Moreover, the PSNR metric has also been introduced to evaluate the quality of adversarial fingerprint images. As presented in Table 6, when compared to alternative attack methods, the adversarial fingerprints generated by our method exhibit a notably higher PSNR value, signifying superior visual quality. Again, the scheme proposed in this paper is effective.

FLD based on deep learning not only suffers from spoofing attacks of forged fingerprints, but also faces the deceptive attacks problem of adversarial fingerprints. The existing FLD research tasks lack the study of adversarial examples, and the transferability of adversarial attacks in the face of unknown network models is generally poor. To solve the above problems, we propose an adversarial attack method based on local adaptive gradient variance, which is designed to enhance the transferability of adversarial attacks and improve the visual quality, to further enhance the security of the fingerprint recognition system. Initially, we constrain the perturbation generation range and formulate gradient variance as the squared difference between the current gradient and the average gradient of the neighborhood during each iteration. Subsequently, during the generation of adversarial examples at each iteration, we optimize the current gradient direction based on the gradient variance from the previous iteration. To address the challenge of selecting appropriate parameters, this paper proposes an adaptive parameter search method that employs gradient ascent to identify the optimal solution.
Experimental results reveal that our proposed method can effectively enhance the transferability of adversarial attacks and further improve the visual quality while maintaining a high success rate for white-box attacks. These findings underscore the current vulnerabilities of DFFD systems, which struggle to withstand adversarial attacks. While black-box attacks have demonstrated feasibility, there remains room for improving their success rates, albeit at the cost of elevated computational complexity in generating adversarial examples. These challenges merit further exploration in future research, with an emphasis on developing more robust defenses against such attacks.
Acknowledgement: We are grateful to Nanjing University of Information Science and Technology for providing a research environment and computing equipment.
Funding Statement: This work is supported by the National Natural Science Foundation of China under Grant (62102189; 62122032; 61972205), the National Social Sciences Foundation of China under Grant 2022-SKJJ-C-082, the Natural Science Foundation of Jiangsu Province under Grant BK20200807, NUDT Scientific Research Program under Grant (JS21-4; ZK21-43), Guangdong Natural Science Funds for Distinguished Young Scholar under Grant 2023B1515020041.
Author Contributions: Study conception and design: C. Yuan, B. Cui; data collection: B. Cui; analysis and interpretation of results: C. Yuan, B. Cui; draft manuscript preparation: C. Yuan, B. Cui, Z. Zhou, X. Li and Q. M. J. Wu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All datasets and materials are publicly available.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. K. Karampidis, M. Rousouliotis, E. Linardos and E. Kavallieratou, “A comprehensive survey of fingerprint presentation attack detection,” Journal of Surveillance, Security and Safety, vol. 2, no. 4, pp. 117–161, 2021. [Google Scholar]
2. M. Wang and W. Deng, “Deep face recognition: A survey,” Neurocomputing, vol. 429, pp. 215–244, 2021. [Google Scholar]
3. J. Daugman, “How iris recognition works,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 14, no. 1, pp. 21–30, 2004. [Google Scholar]
4. L. Niu, A. Veeraraghavan and A. Sabharwal, “Webly supervised learning meets zero-shot learning: A hybrid approach for fine-grained classification,” in Proc. of CVPR, Salt Lake City, USA, pp. 7171–7180, 2018. [Google Scholar]
5. G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. R. Mohamed et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,” IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82–97, 2012. [Google Scholar]
6. J. Long, E. Shelhamer and T. Darrell, “Fully convolutional networks for semantic segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 4, pp. 640–651, 2015. [Google Scholar]
7. I. Sutskever, O. Vinyals and Q. V. Le, “Sequence to sequence learning with neural networks,” in Advances in Neural Information Processing Systems, vol. 27. pp. 3104–3112, 2014. [Google Scholar]
8. H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong et al., “CosFace: Large margin cosine loss for deep face recognition,” in Proc. of CVPR, Salt Lake City, USA, pp. 5265–5274, 2018. [Google Scholar]
9. Z. Zheng, X. Yang, Z. Yu, L. Zheng, Y. Yang et al., “Joint discriminative and generative learning for person re-identification,” in Proc. of CVPR, Long Beach, USA, pp. 2138–2147, 2019. [Google Scholar]
10. C. Yuan, X. Chen, P. Yu, R. Meng, W. Cheng et al., “Semi-supervised stacked autoencoder-based deep hierarchical semantic feature for real-time fingerprint liveness detection,” Journal of Real-Time Image Processing, vol. 17, no. 1, pp. 55–71, 2020. [Google Scholar]
11. W. E. N. Jian, Y. Zhou and H. Liu, “Densely connected convolutional network optimized by genetic algorithm for fingerprint liveness detection,” IEEE Access, vol. 9, pp. 2229–2243, 2020. [Google Scholar]
12. J. Fei, Z. Xia, P. Yu and F. Xiao, “Adversarial attacks on fingerprint liveness detection,” EURASIP Journal on Image and Video Processing, vol. 2020, no. 1, pp. 3104–3112, 2020. [Google Scholar]
13. G. Orrù, R. Casula, P. Tuveri, C. Bazzoni, G. Dessalvi et al., “Livdet in action-fingerprint liveness detection competition 2019,” in Proc. of ICB, Crete, Greece, pp. 1–6, 2019. [Google Scholar]
14. V. Mura, G. Orrù, R. Casula, A. Sibiriu, G. Loi et al., “LivDet 2017 fingerprint liveness detection competition 2017,” in Proc. of ICB, Gold Coast, Australia, pp. 297–302, 2018. [Google Scholar]
15. C. Yuan and B. Cui, “Adversarial attack with adaptive gradient variance for deep fake fingerprint detection,” in Proc. of MMSP, Shanghai, China, pp. 1–6, 2022. [Google Scholar]
16. C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan et al., “Intriguing properties of neural networks,” arXiv preprint arXiv: 1312.6199, 2014. [Google Scholar]
17. H. Tang and X. Qin, Practical Methods of Optimization, 1st ed., Dalian, China: Academic Press, Dalian University of Technology Press, pp. 138–149, 2004. [Google Scholar]
18. S. M. Moosavi-Dezfooli, A. Fawzi and P. Frossard, “DeepFool: A simple and accurate method to fool deep neural networks,” in Proc. of CVPR, Las Vegas, USA, pp. 2574–2582, 2016. [Google Scholar]
19. N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in Proc. of Symp. on Security and Privacy, San Jose, USA, pp. 39–57, 2017. [Google Scholar]
20. S. Sarkar, A. Bansal, U. Mahbub and R. Chellappa, “UPSET and ANGRI: Breaking high performance image classifiers,” arXiv preprint arXiv:1707.01159, 2017. [Google Scholar]
21. A. N. Bhagoji, W. He, B. Li and D. Song, “Practical black-box attacks on deep neural networks using efficient query mechanisms,” in Proc. of ECCV, Munich, Germany, pp. 3104–3112, 2018. [Google Scholar]
22. Y. Dong, F. Liao, T. Pang, H. Su, J. Zhu et al., “Boosting adversarial attacks with momentum,” in Proc. of CVPR, Salt Lake City, USA, pp. 9185–9193, 2018. [Google Scholar]
23. J. Su, D. V. Vargas and K. Sakurai, “One pixel attack for fooling deep neural networks,” IEEE Transactions on Evolutionary Computation, vol. 23, no. 5, pp. 828–841, 2019. [Google Scholar]
24. I. J. Goodfellow, J. Shlens and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014. [Google Scholar]
25. A. Kurakin, I. J. Goodfellow and S. Bengio, “Adversarial examples in the physical world,” in Proc. of Int. Conf. on Learning Representations Workshop, Toulon, France, pp. 1–15, 2017. [Google Scholar]
26. J. Lin, C. Song, K. He, L. Wang and J. E. Hopcroft, “Nesterov accelerated gradient and scale invariance for adversarial attacks,” in Proc. of ICLR, Addis Ababa, Ethiopia, 2020. [Google Scholar]
27. X. Wang and K. He, “Enhancing the transferability of adversarial attacks through variance tuning,” in Proc. of CVPR, Nashville, USA, pp. 1924–1933, 2021. [Google Scholar]
28. C. Xie, Z. Zhang, Y. Zhou, S. Bai, J. Wang et al., “Improving transferability of adversarial examples with input diversity,” in Proc. of CVPR, Long Beach, USA, pp. 2730–2739, 2019. [Google Scholar]
29. Y. Dong, T. Pang, H. Su and J. Zhu, “Evading defenses to transferable adversarial examples by translation-invariant attacks,” in Proc. of CVPR, Long Beach, USA, pp. 4312–4321, 2019. [Google Scholar]
30. W. Zhan, C. Sun, M. Wang, J. She, Y. Zhang et al., “An improved Yolov5 real-time detection method for small objects captured by UAV,” Soft Computing, vol. 26, pp. 361–373, 2022. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools