
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Weighted Multi-Layer Analytics Based Model for Emoji Recommendation
1 Faculty of Computers and Information Technology, Future University in Egypt, Cairo, 11835, Egypt
2 Alkamil College of Science and Arts, University of Jeddah, Jeddah, 21959, Saudi Arabia
* Corresponding Author: Amira M. Idrees. Email:
Computers, Materials & Continua 2024, 78(1), 1115-1133. https://doi.org/10.32604/cmc.2023.046457
Received 01 October 2023; Accepted 14 November 2023; Issue published 30 January 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The developed system for eye and face detection using Convolutional Neural Networks (CNN) models, followed by eye classification and voice-based assistance, has shown promising potential in enhancing accessibility for individuals with visual impairments. The modular approach implemented in this research allows for a seamless flow of information and assistance between the different components of the system. This research significantly contributes to the field of accessibility technology by integrating computer vision, natural language processing, and voice technologies. By leveraging these advancements, the developed system offers a practical and efficient solution for assisting blind individuals. The modular design ensures flexibility, scalability, and ease of integration with existing assistive technologies. However, it is important to acknowledge that further research and improvements are necessary to enhance the system’s accuracy and usability. Fine-tuning the CNN models and expanding the training dataset can improve eye and face detection as well as eye classification capabilities. Additionally, incorporating real-time responses through sophisticated natural language understanding techniques and expanding the knowledge base of ChatGPT can enhance the system’s ability to provide comprehensive and accurate responses. Overall, this research paves the way for the development of more advanced and robust systems for assisting visually impaired individuals. By leveraging cutting-edge technologies and integrating them into a modular framework, this research contributes to creating a more inclusive and accessible society for individuals with visual impairments. Future work can focus on refining the system, addressing its limitations, and conducting user studies to evaluate its effectiveness and impact in real-world scenarios.Keywords
Different research tackled the subject of using Emoji, stating that about five billion social network users interact daily. Users of all types use Emoji, whether their gender, age, or culture are different. This fact raised the flag for the vital usage of social networks. People find it easy to communicate through social networks by text and Emoji that support this communication by transforming the user’s emotions into a visual representation. In addition, Emoji are currently used in social networks and other sources such as the Oxford Dictionary. Historically speaking, the Japanese initiated the idea of Emoji in the nineties. The word “Emoji” is a concatenation of the letter “e,” which means a picture in the Japanese language, and the word “Moji,” which indicates the “letter” word in the Japanese language. In the twenties, Emoji have been engaged in other platforms such as WhatsApp. Then, more usage of Emoji opened the consideration of these Emoji in different applications, networks, and websites. Statistically, the researchers have demonstrated that over ninety percent of online users use Emoji in their interactions through feedback, chatting, messages, emails, or others. According to reference [1], the Emoji set currently includes more than three thousand Emoji; the highest usage rates are for the faces, hearts, and hands.
The simplicity and preference of using emotional expressions are the main key motivations for users. Using Emoji provides the ability to express feelings. It is a fact that using them changes a person’s emotional status. Establishing suitable Emoji not only provides easier individual processing to the speech but also supports the weak possibility of expressing one’s emotion through words and even provides stronger understanding. Using Emoji could be extended to more professional usage. For example, passengers’ notifications to the bus driver could be pronounced through Emoji in the reflecting screen as a replacement for voice communication or direct interaction. Prior research [2] confirmed that Emoji provides more subtle semantical meaning in messages compared to text. Moreover, another study [3] demonstrated that Emoji could be ranked to be the first in successful social communication. On a broader perspective, different research highlighted that Emoji represent a vital method not only on a social level but also in business domains. Emoji could be considered as a tool to monitor customers' social network activity and track their preferences, especially with the large amount of Emoji continuously growing in the digital era. However, analyzing Emoji is a sophisticated task that requires more accurate and high-performance techniques than text, as they lack both phonetic and direct interpretation.
Therefore, it is vital to mention that Emoji sets are continuously extending over time by creating more Emoji for different situations. Using Emoji has passed the reason of amusement; it has become one of the main methods to express the words meaning. Emoji users could provide their whole speech with Emoji if possible. Users have different reasons for using Emoji, which are a significant part of their expressions. Using Emoji has drawn the attention of the visual conversation vitality. It now could replace speech virtually. It shows most of the emotions with different methods and even indicates the level of emotion, such as glad, happy, and delighted. With the continuous extension, this set could initiate the plan to officially use Emoji for users’ conversations. The Emoji set has an unbelievable method to embed a personality in the conversation and invade more engagement and interference with the words. Moreover, it could provide more discussion in less time and effort with a brief representation compared to words. One Emoji may replace a complete phrase. A simple example is that the Emoji of happiness may replace the sentence “I love you.” Emoji also break the ice in any conversation by moving the conversation to the comfort zone, making it more delightful to use Emoji instead of words [4].
The Emoji list includes a large number of members and is still growing [5]. The users’ diversity could be one of the obstacles to understanding expressions using Emoji. It is vital to highlight that the selection of individuals for the Emoji representing their meaning may be ambiguous. Prior research highlighted that users may use the same Emoji while they may need to express different meanings. This situation results in misunderstandings between participants. On the other hand, although the prior researchers who focused on predicting Emoji applied different techniques, their research depended on a large set of training data and embedding prior resources to the applied model, such as lexicons. These resources require extensive preparation effort in addition to continuous revision as they represent the static part of the mode. With the fact that the Emoji set is continuously growing, these needs have become a serious obstacle in the prediction task. Moreover, prior research adopted the approaches of contextual analysis as well as sentimental analysis with no consideration for the words’ interrelationships. It is a fact that the exact words could represent different meanings when embedded in different contexts. This situation highlighted the need to respect the text context while respecting the terms in the surrounding environment.
The vital step is correctly selecting the Emoji to express the required word(s). The importance of using Emoji in daily life with the enormous number of Emoji make it difficult to select the most expressive one. This situation raised the trigger for the Emoji recommendation task vitality. Recommending the right Emoji for a specific text or emotion expressed in a timely manner could be currently considered a vital research point. Emoji recommendations have many benefits. For users, it helps to better represent their intentions and emotions in a timely manner with concrete meaning. It supports users to understand the emotions of each other rather than using words. It supports better and faster analysis of the users’ reviews for business. It could also support businesses to predict the customers’ requirements efficiently. Emoji recommendations have different challenges. One of these challenges is the different statement interpretations by different people. While a phrase could reveal a positive interpretation to one user, it could reveal a negative interpretation to the other. On the other hand, a phrase may indicate meaning while it is intended as humor, while its meaning is different if it is embedded in a more formal conversation. Moreover, a shortened phrase could reveal an incorrect meaning.
Accordingly, engaging text analysis techniques could positively contribute to the recommendation task. Text analysis reveals a concrete understanding of the text under examination, while machine learning algorithms could contribute to identifying the correct Emoji class. Moreover, the Emoji recommendations could be released by exploring the whole words’ relationship in a phrase. Different text analytics techniques are introduced, such as word similarity, word associations and correlations, (Term Frequency-Inverse Document Frequency) TF-IDF, and others [6,7]. Each has its possible successful contribution according to the required text analytics task. Different machine learning algorithms contributed to the classification task, such as neural networks, long short-term memory, and others, targeting more elaboration for the recommendations [8]. However, this research triggers the challenge that the text analysis with a novel text representation method could reveal to the successful recommendation task.
This paper proposes a novel model for text analysis. It depends on the words’ meaning relationship and the surrounding environment of the representative phrase, which is also expressed by words. The paper adopts the assumption that the words have sibling relationships, such as any other objects. The assumption is extended that these siblings usually live in the same environment characteristics, making identifying these siblings more efficient. The following sections will illustrate a more detailed description of the proposed model.
Converting expressions into Emoji modality and vice versa leads to intelligent textual speech systems optimization not only on a social basis but also in business. Therefore, this research aims to propose and develop a novel method to accomplish the following goals, which highlights the novelty of the proposed model:
• Automatic categorization of the Emoji into a defined class with a unified meaning for the users. This unification ensures ambiguity elimination and highlights the ability for a unified language for all users despite their diversity.
• Labeling emotions with no requirements for prior resources such as lexicons. The current research supports the continuous increase in the Emoji set and provides a novel approach for the continued enrichment of a self-built lexicon during the testing phase. The self-based lexicon is built during reasoning while continuously enriched during the reasoning process.
• The proposed model embeds a novel semantic approach, which was not considered in the prior research. The current study applies text analysis not only to the contextual meaning but also explores the text semantic relationship, which is highlighted by the fact of the siblings’ relationships. The current research adopts the positive contribution of embedding the object-oriented relationships into text and considers the words as possible siblings according to their surrounding environment.
• The research extends the explored semantics by weighing the explored siblings’ relationship as well as detecting its granularity. This consideration not only provides possible Emoji representing the textual context, but it also provides higher accuracy in the prediction task by minimizing the predicted set to the minimum, which significantly reduces the representation ambiguity.
The related work that demonstrates the research contribution is discussed in Section 2, Section 3 discusses the proposed model in detail, Section 4 presents the experiment and the findings, and finally, Section 5 presents the research conclusion and future work.
The direction of extracting valuable knowledge from text has been the focus of many researchers [9–11]. The research [12] highlighted that cultural knowledge could be extracted from text represented in the users’ comments. The research in reference [10] applied a fuzzy approach for sentiment analysis to the consumers’ reviews, targeting for exploring the set of recommended products based on the consumers’ opinions based on their emotional expressions. Another research [11] also highlighted the valuable knowledge that reside in the consumers’ reviews. It proposed a model for ranking the products’ features through the reviews’ sentimental analysis, ranking the products’ features through this analysis, and relating the ranked features with the consumers’ location. These research papers successfully tackled the immense valuable knowledge that could be extracted through the different consumer sources, which is a leading step to considering these sources with more details.
On the other hand, many researchers have tackled the Emoji semantics understanding using different models. A skip-gram model was introduced by reference [12] with training data equal to one hundred million tweets. The research confirmed the positive contribution of the gram models in identifying similarities and clustering tasks. This similarity direction has been followed by other researchers, such as in reference [13], which was similar to identifying the Emoji with the support of the neural embedding model. The authors of reference [14] have proposed another enhancement of the neural embedding model to include the Emoji’ descriptions with the target of labeling these Emoji. The research generated over five hundred Emoji using the applied model. Other researchers have applied machine learning algorithms, such as the long short-term memory model for the Emoji prediction, such as in reference [15]. According to the presented results, the model outperformed the direction of bag-of-words and skip-gram models. The long short-term memory model has also been introduced in other research, such as in reference [16]. While reference [17] applied neural networks on unbalanced data with satisfying results [18], the performance was not higher than the support vector machine model. Labeling textual data was applied by reference [19], whose results also showed the model outperformance over the long short-term memory model. The idea of labeling Emoji has also been released in reference [20] using a neural network algorithm that identified the word level and sentence level representations for Emoji prediction. Additionally, reference [18] has also proved the contribution of the support vector machine algorithm with the n-gram approach to identify the required features for Emoji classification.
More researchers have tackled Emoji classification using different models. The research in reference [21] highlighted the contribution of Emoji to personality prediction through sentence-level base analysis using word embedding techniques. The study utilized a large set of training data to be able to apply the required analysis. Another research highlighted the relationship between Emoji and personal characteristics [5] using mining techniques. The study utilized the frequency approach in relating Emoji with the context; then, the usage percentage was the main pillar in determining Emoji with their related context. Moreover, the research in reference [22] applied sentimental analysis using a deep memory learning approach over the users’ microblogs targeting to extract blog information through Emoji and text analysis. The research applied textual analysis using syntactic parsers and sentimental lexicons while utilizing training data for the sentimental classification task. Although the researchers have reached satisfying results, the current research tackles a vital unexplored aspect of Emoji recommendations, the need to spare the effort of gathering exhaustive resources, the processing cost for the machine learning models, and others. Moreover, the current research discriminates the relation between the Emoji and the context through the weighting approach. It explores the level of trustiness in this relationship through the detected weight and granularity.
The main contribution of this study is building a text-to-Emoji mapping lexicon. The study applies text analytics methods with an N-gram-based approach to detect the equivalent terms for the Emoji. The study not only proposes a single term for Emoji mapping, it extends the mapping scheme to two directions, granularity and multiplication. Moreover, the study also proposes an incremental enrichment phase in the proposed model for continuously enriching the generated lexicon. The proposed model is illustrated in Fig. 1, while the following summarizes the study contributions, and the details are discussed in the following sections.
1. The study does not utilize any preprocessing sources such as lexicons.
2. The study applies the Tf-Idf measure to extract Uni-gram keywords from the text.
3. Detecting the Emoji granularity weight is performed by detecting the bi-gram and tri-gram keywords relationship. It is the relationship between each two keywords. This relationship will be confirmed to provide more accurate results in the recommendation process.
4. Detecting the Emoji multiplication weight is performed by extracting the strong multiplication keywords using a collaborative weighting approach.
5. Building an Emoji lexicon is another target for this study. The study also targets a continuous enrichment for the targeted lexicon using the generated mapped terms to the Emoji relationship.
6. The study recommends the suitable Emoji based on the given text phrase by extending the recommendation to two directions. The Emoji multiplication, the count replication of the same Emoji, and the granularity.
7. The proposed model is generic and could be applied to any social network data.
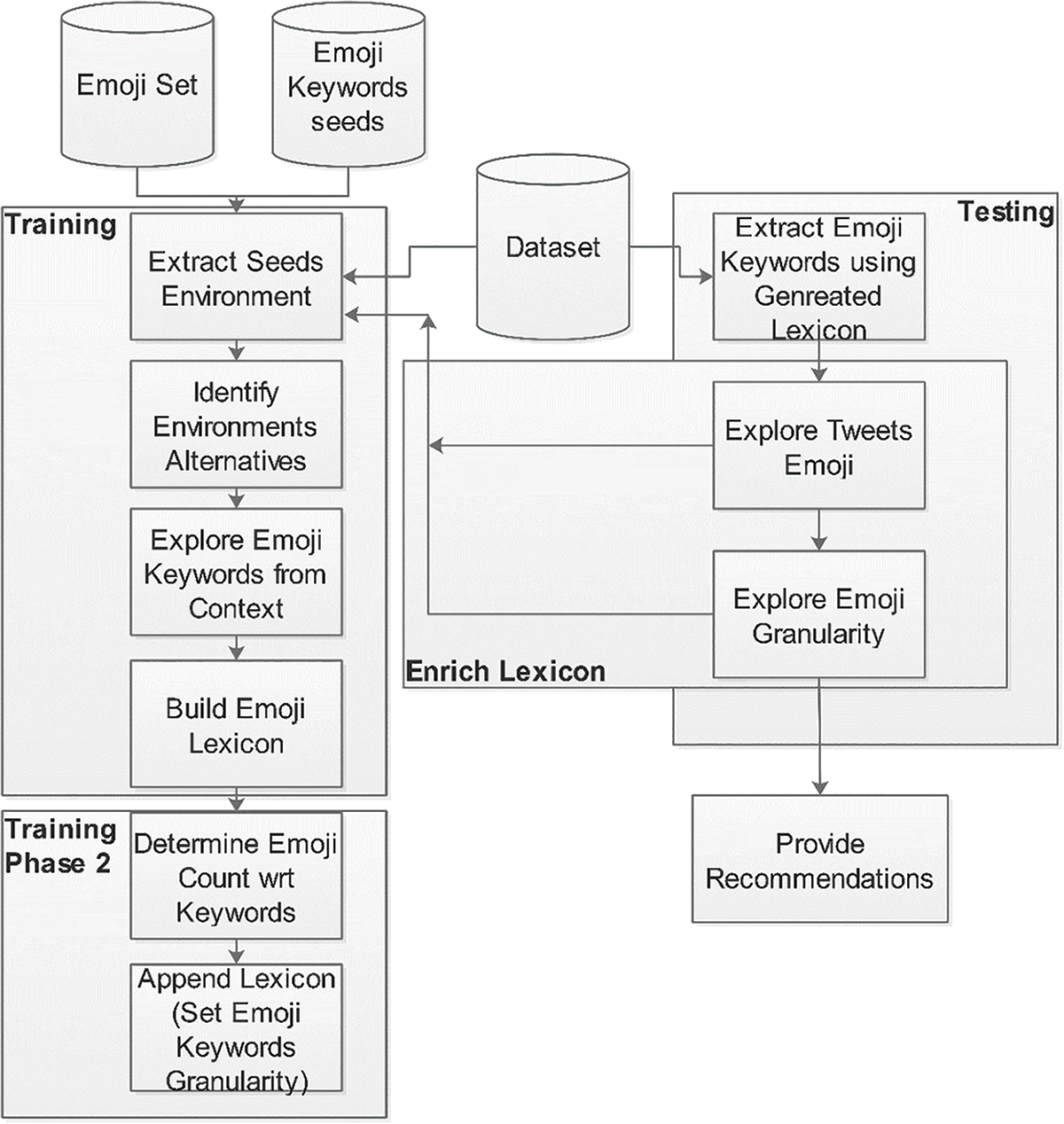
Figure 1: An illustration of the main proposed model stages
3.1 A Concise Pseudo Code (General Steps) of the Proposed Model

3.2 Description of the Proposed Model
The Dataset is formally described as:
Each ‘Rz’ element in the dataset is an organized set of tokens. It is described as:
The training dataset is a subset of the dataset, which is described as:
The testing dataset is a subset of the dataset, which is described as:
The Emoji set is described as:
Each Emoji has a dataset that contains its representative keywords. This dataset is extracted by the proposed model from the training dataset with the support of one seed keyword, “Keyi1”.
The Emoji ‘i’ keyword set is described as:
The single token preceding Keyim in Rz representing the single prefix of Keyim in Rz is defined as:
The double tokens preceding Keyim in Rz representing the double prefix of Keyim in Rz is defined as:
The single token following Keyim in Rz representing the single postfix of Keyim in Rz is defined as:
The double tokens following Keyim in Rz representing the double postfix of Keyim in Rz is defined as:
The environment set of Keyi1 “ENV (Keyi1)” is the union of all four sets
The environment pairs of the key term Keyi1 is a vector of any two elements that are members in ENV (Keyif). This vector represents the prefix and postfix that are used to extract the new sibling key terms.
The environment pairs set of a key term Keyi1 is described as:
The environment of an emoji “emojii” is the union of all ENVPair sets of all key terms associated with the emoji “emoji”
The set of all key terms of all Emoji is described as a set of vectors. Each vector represents the Emoji and its associated key terms. The set of all key terms of all Emoji is described as:
The set of all multiplication keys is described as:
The set of all keys of emojii that are extracted from a record t in the testing dataset is described as:
The extracted set of multiplication key terms from the testing set TY as an association with and emoji “emojii” is described as:
The count set of multiplication key terms from the testing set TY as an association with the count of emoji “emojii” with respect to the multiplication key term “multiw” and the record “Rt” in TY is described as:
where x is the count of emoji “emojii” ∈ Emoji in the record Rt ∈ TY associated with the multiplication key term multiw that having a count y
The average count of the emoji “emojii” associated with the average count of the multiplication key term “multiw” is described as a vector:
The complete average count of the emoji “emojii” associated with the average count of all the multiplication key terms is described as:
The complete average count of all the Emoji associated with the average count of all the multiplication key terms is described as:
3.3 The Emoji Recommendation Algorithm
3.3.1 Training Phase: Build Text–Multiple Emoji Lexicon
The training set is described as:

Lexicon Enrichment Module Steps

Build Emoji Multiplication Set Module Steps

3.3.2 Testing Phase: Recommend Emoji–Emoji Multiplication Phase


4 Experimental Study for the Proposed Emoji Recommendation Model
The study applied the proposed model in two individual experiments to confirm the applicability of the recommendation process. The two datasets are retrieved from the Kaggle website [23]. The first dataset includes about 850 thousand tweets. The second dataset includes over eighteen million tweets. Both datasets are minimized according to a set of criteria, which is described in the following sub-sections. One common eliminating criterion is that the two experiments are restricted to two hundred Emoji, including face, heart, and hand Emoji. A file including Emoji, their ID, and a description is used to identify the Emoji dataset. The authors gathered the initial multiplication keywords, including one hundred keywords. The first experiment focuses on the recommendation task. Experts evaluated the results, while the second experiment is extended by applying a classification step as an automated method to confirm the recommendation task results. As the proposed model relies on building its own sources during the training phase with continuous enrichment during the testing phase, it could be highlighted that the model builds a domain-oriented source. However, the study argues that the model applies to any domain and could provide reliable recommendations in various fields. Therefore, the two experiments are conducted over two different datasets with no restrictions on the tweets domain to prove the research argument.
The experiment utilized a dataset from the Kaggle website [23]. The dataset was gathered from Twitter using Python [24]. The data was collected with each Emoji having its file with the tweets, including the Emoji.
The dataset includes eight hundred and fifty thousand tweets divided into forty-three files. The tweets may consist of more than one Emoji. Therefore, a tweet may exist in more than one file. Therefore, a preprocessing step is applied to remove redundancies. A tweet that all of its Emoji are members of the Emoji dataset is included in the experiment. However, the tweets that some (even one) of its Emoji are not members of the Emoji dataset are eliminated. The reason for this elimination is to avoid a conflict in the Emoji keywords, as some of the keywords could belong to the unconsidered Emoji. After the elimination process, the complete set of tweets contributing to the experiment was about three hundred thousand tweets. The experiment utilized 90% of the tweets’ dataset for the training phase and 10% for the testing phase. The training dataset included 90% of the tweets of each Emoji file. Then, a preprocessing step is applied to combine all the tweets in a unified file by eliminating redundancies and combining the Emoji for each tweet. The same process is applied to the testing dataset to prepare it for the validation step. Then, all Emoji are disabled from the tweets to be used in the testing phase. The five-fold approach was followed, and the results accuracy measures (precision, recall, F1-measure, F2-measure) were calculated after revising the results with experts in the linguistics department. The results of the accuracy measure are summarized at the end of this subsection. A sample of the tweets’ dataset is illustrated in Table 1.

4.1.1 Training Phase: Build Text–Multiple Emoji Lexicon
The associated keywords for each Emoji are extracted. In the first iteration, an average of forty keywords are extracted for each Emoji, with a total of 7532 Emoji key terms. Table 2 illustrates a sample of the statistics for Emoji keywords.

The lexicon enrichment module is applied, and the results are revealed in three iterations until the stopping criteria are invoked. After the three iterations, the Emoji keywords set has been extended to include a total of 9820 Emoji key terms. The next module calculates the Emoji keywords multiplication average by following the proposed steps. Each multiple key is associated with each Emoji with a different multiplication. Following the sample in Tables 2 and 3 illustrates a sample for the association results.
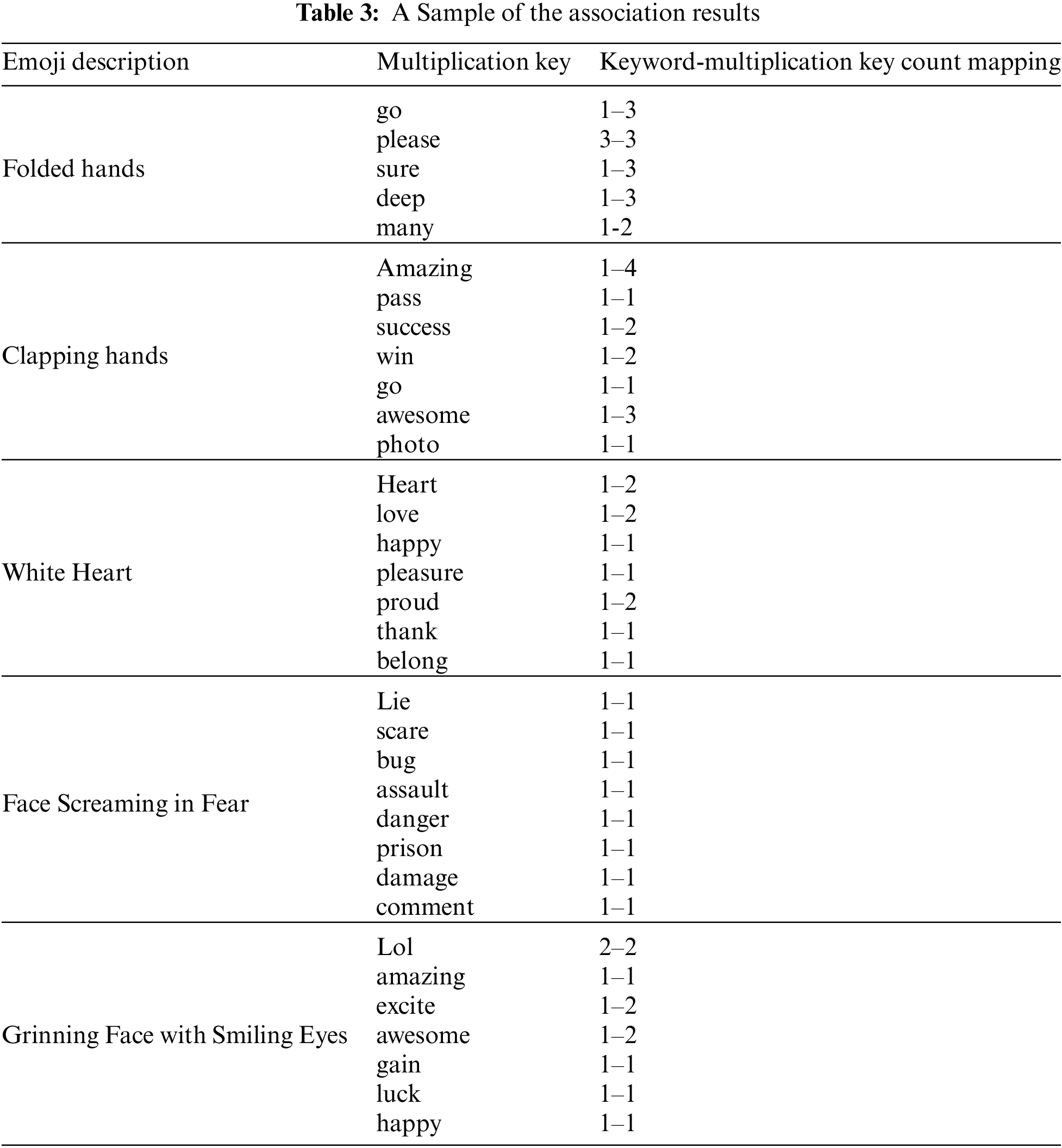
Moreover, Table 4 demonstrates statistics for the extracted environment and keywords siblings. Following the three-fold evaluation, results have been evaluated by determining precision, recall, F1_measure, and F2_measure (see Table 5). An example of the extracted uni-gram prefix is “high(ly|est|er)?” with an associated uni-gram postfix “(un)?talent(ed|ing)?” which had a recall equal to 95% and a precision equal to 94%.

4.1.2 Testing Phase: Recommend Emoji-Emoji Multiplication Phase
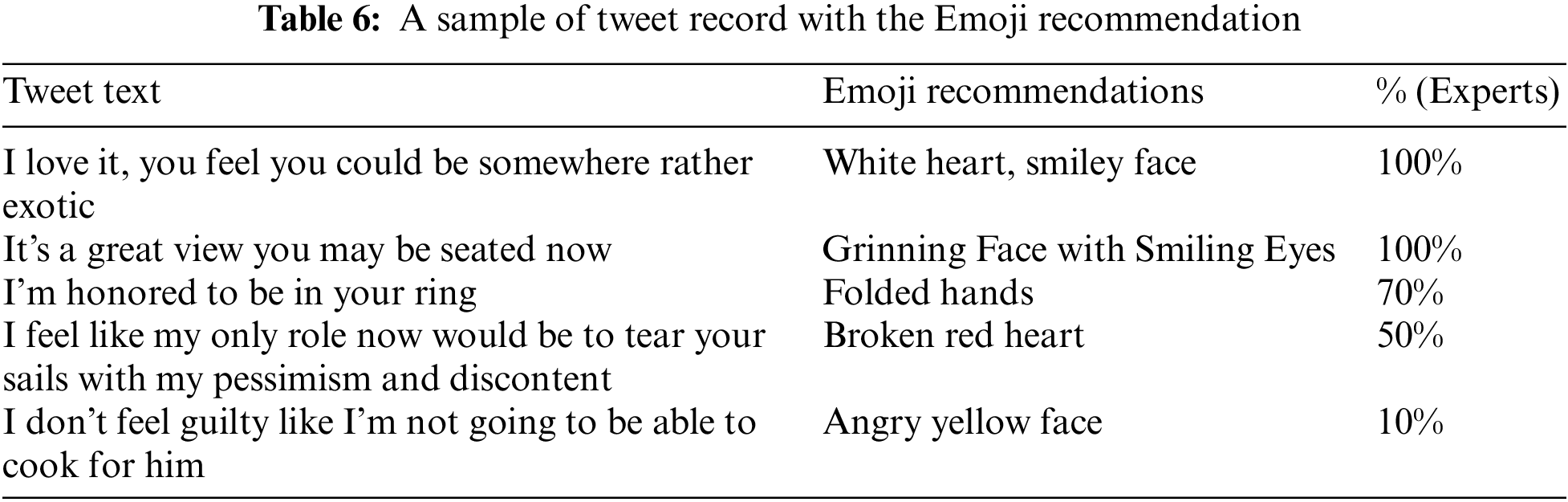
It is worth highlighting that the keywords may belong to more than one Emoji. This case results in the recommendation of more than one Emoji for a single keyword. However, it could be recommended with different multiplication according to the applied multiplication module steps. As the keywords-Emoji relationship did not consider the keyword count, the recommendation results of Emoji are not ordered. However, the count of the Emoji will be inferred by following the Recommend Emoji Multiplication module steps. The contribution of this phase is the fact that the Emoji list will be minimized to the recommended Emoji that are suitable according to the extracted keywords. Table 6 illustrates a sample of the Emoji recommendation based on the tweet record.
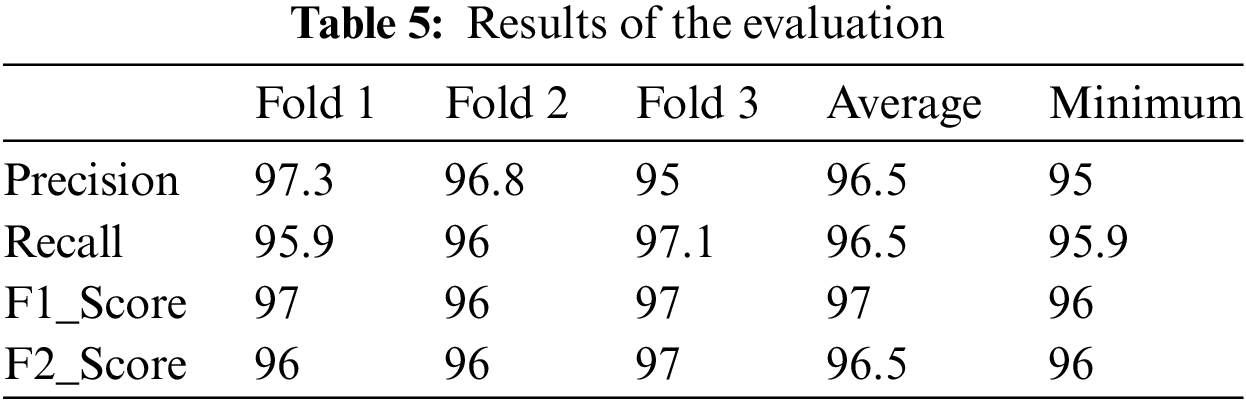
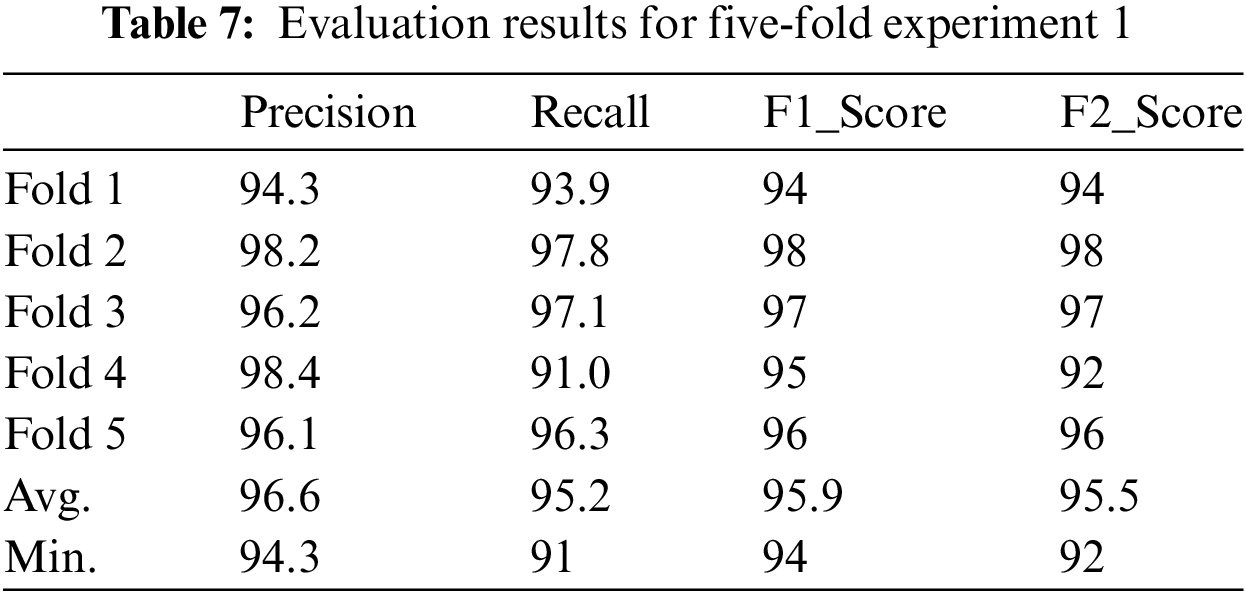
Following the five-fold approach, five experiments are performed from the start. Each experiment applied the whole model, and the evaluation measures were calculated. Table 7 illustrates a summary of the results of the five experiments while the average and minimum for each measure are calculated for more results illustration. The results demonstrate that the minimum evaluation measure is the recall in the fourth fold. However, this minimum is acceptable as it exceeded 90%. This minimum value could result in the training data bias toward certain Emoji subsets, revealing inaccurate keyword retrieval. This situation was different for other folds. On the other hand, increasing the folds may reveal more accurate results.
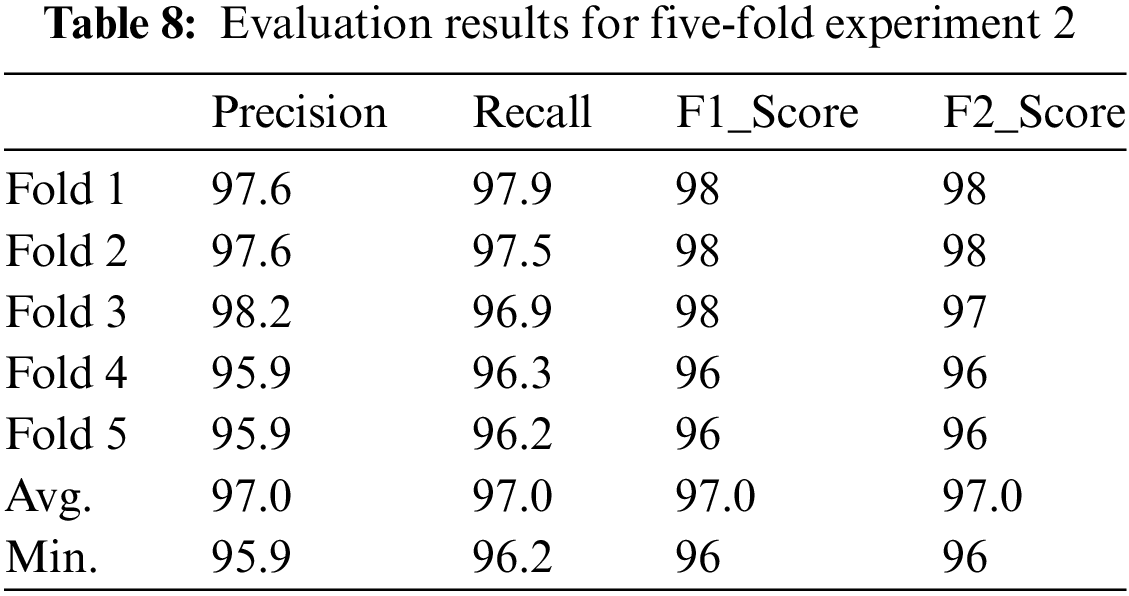
This experiment uses a dataset from the Kaggle website as a benchmark dataset [23]. The team members of the ArchiveTeam collected it as part of the TwitterStream project [25]. After collecting the dataset, the team filtered the tweets to include only the tweets written in the English language, with a confirmation that each tweet in the refined dataset included at least one Emoji. The team also preprocessed the tweets. All symbols, characters, URLs, etc., are eliminated in the tweets’ contents to include only English letters and Emoji. The original dataset included over eighteen million tweets, which could move the research to apply more complex algorithms to be able to deal with this big amount of data. Therefore, the experiment was applied to a subset of the original dataset with the intention of more research direction to include the complete dataset and more promising contributions. The elimination process was organized to maintain as much data as possible. The first criterion is eliminating the tweets that included Emoji outside the research scope (200 Emoji, including face, hearts, and hands Emoji). For each Emoji, a set of two thousand tweets is considered. The tweet that included more than one Emoji in the Emoji dataset is counted for both Emoji. This step eliminated the dataset to only two hundred thousand and fifty-five tweets. The same steps in the first experiment were applied. The final evaluation results are demonstrated in Table 8, following the five-fold experiment to avoid repeating the previous discussion. The results confirmed the proposed model’s applicability to map the tweets’ text into the suitable Emoji set. These results are promising for further investigation in the same direction and vice versa.
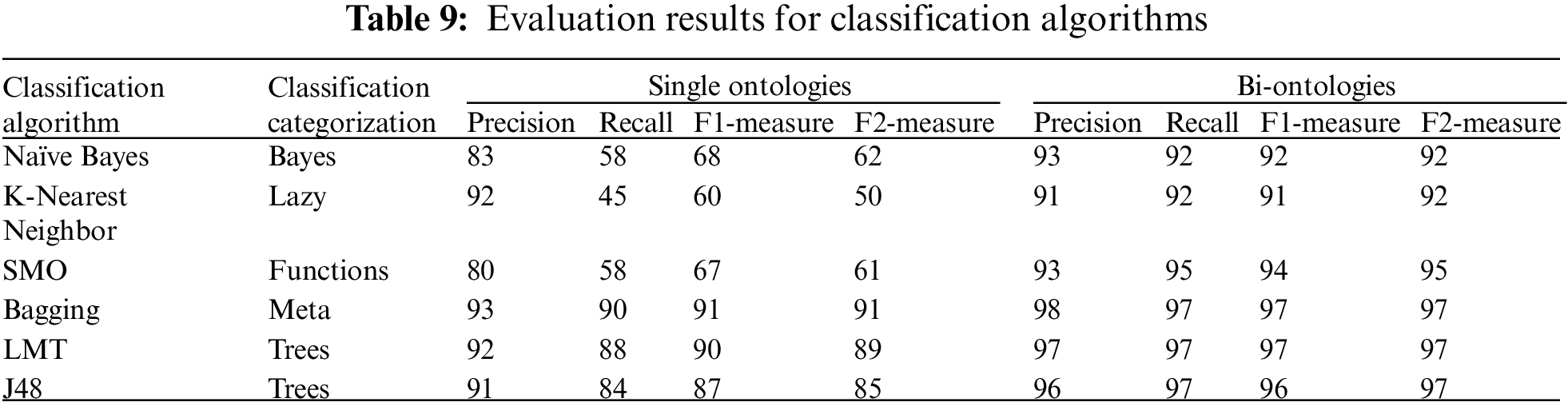
Moreover, an inverse experiment has been conducted to confirm the proposed model further. A dataset was prepared to include the Emoji keyword of each tweet with a label of the recommended Emoji. In case the recommendation includes more than one Emoji, then the record is repeated, and the labels are separated for each record. Six classification algorithms are applied. They are selected from different classification categorizations to cover all types. Table 9 illustrates the classification evaluation results, revealing the proposed model’s applicability for the keyword selection. As shown in Table 9, the Bagging algorithm revealed the highest evaluation for the bi-gram keywords.
It is worth highlighting that the performance of the classification algorithms is stable compared with prior research under consideration by the authors, which reveals the success of the extraction process. By the stable results, the study is considered one of the steps in a series of research aimed to be performed by the authors.
Comparing the results with other research in the literature, the research in reference [22] applied a set of experiments and reached a maximum F1-score equal to 87%, while the research [26] reached 73% and the research in reference [21] reached 70%. On the other hand, the study in reference [11] applied the extraction task but for the products’ features with a maximum precision equal to 95%. By demonstrating these results, it confirms the advancement of the proposed model in the recommendation task. Moreover, although the proposed model is domain-oriented as the task of self-enrichment is applied through the provided dataset, applying two experiments confirms the applicability of the proposed approach in different domains and different datasets’ nature. In both experiments, the results have shown an advancement of the proposed approaches over the literature.
The study proposed a novel model for Emoji recommendations based on text analytics and machine learning algorithms. The proposed model released the recommendation process from the exhaustive resources. One of the challenging phases is building an Emoji keywords lexicon through the extraction phase with an enrichment approach. The study was based on the siblings near similarity concept. As nature proved that siblings most probably have the same features, the study applied this concept to textual data and extracted the Emoji keywords. The n-gram approach helped extract the keywords to three levels; however, it is applicable to investigate more n-gram levels’ applicability. Moreover, the study applied the proposed model to a limited set of Emojis due to the availability. However, the authors believe that the proposed model suits a larger set. Two experiments proved the applicability of the proposed model. Each experiment has a set of tweets that include Emojis. The results of the experiments have been evaluated, which revealed a success of an average of 96% for the recommendation task and 97% for the classification task. The contributions of the paper are listed as follows:
• Automatic categorization of the Emoji into a defined class with a unified meaning for the users. This standardization eliminates ambiguity and underscores the capacity for a unified language accessible to all users, regardless of their diversity.
• Labeling emotions with no requirements for prior resources such as lexicons. The latest research backs the ongoing expansion of the Emoji set and introduces a new method for continuously enhancing a custom lexicon during the testing phase. The self-based lexicon is built during reasoning while continuously enriched during the reasoning process.
• The proposed model embeds a novel subject-oriented semantic approach that applies text analysis not only to the contextual meaning but also explores the text’s semantic relationship, which is highlighted by the fact of the siblings’ relationships. The current research adopts the positive contribution of embedding the object-oriented relationships into text and considers the words as possible siblings according to their surrounding environment.
• The research extends the explored semantics by weighing the explored siblings’ relationship as well as detecting its granularity. This consideration not only provides possible Emoji representing the textual context, but it also provides higher accuracy in the prediction task by minimizing the predicted set to the minimum. It significantly reduces the representation ambiguity.
The limitations of the current research were its dependency on the language. The proposed model could be employed across various languages. However, the entire process needs to be recalibrated to construct the dynamically generated lexicon in the specific target language. Another limitation is that the approach depends on self-extraction to the Emoji keys. Therefore, the accuracy of the recommendation task has a direct relationship with the size of the context. A third limitation is that the proposed model is subjective and related directly to the applied field, so the generated lexicon could be characterized as domain-oriented. Finally, the researchers applied the proposed approach to subsets of data regardless of more hardware requirements to process big data.
The future research of the study could have different directions. One direction is to apply the proposed model to other datasets with different natures, such as feedback and other social network data. Another direction is to investigate tri-gram and more of the text boundaries. A third direction investigates applying the proposed model to different languages and larger datasets while providing suitable hardware requirements.
Acknowledgement: Not applicable.
Funding Statement: The authors received no funding for this study.
Author Contributions: The authors confirm their contribution to the paper as follows: data collection, study conception and design, analysis and interpretation of results, draft manuscript preparation, and revising manuscript: A. M. Idrees and A. L. M. Al-Solami. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available on the Kaggle website [24].
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. Ranjan and P. Yadav, “Emoji prediction using LSTM and Naive Bayes,” in TENCON 2021-2021 IEEE Region 10 Conference (TENCON), Auckland, New Zealand, pp. 284–288, 2021. [Google Scholar]
2. S. Khandekar, J. Higg, Y. Bian, C. W. Ryu, J. O. T. Iii et al., “Opico: A study of emoji-first communication in a mobile social app,” in WWW'19: Companion Proc. of the 2019 World Wide Web Conf., San Francisco, USA, 2019. [Google Scholar]
3. M. Sadiq, Shahida, “Learning Pakistani culture through the namaz emoji,” in 2019 2nd Int. Conf. on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 2019. [Google Scholar]
4. P. Chandra, M. T. Ahammed, S. Ghosh, R. Hasan Emon, M. Billah et al., “Contextual emotion detection in text using Deep Learning and Big Data,” in Proc. of 2022 Second Int. Conf. on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, IEEE, pp. 1–5, 2022. [Google Scholar]
5. W. Li, Y. Chen, T. Hu and J. Luo, “Mining the relationship between Emoji usage patterns and personality,” in Proc. of the Twelfth Int. AAAI Conf. on Web and Social Media (ICWSM 2018), Palo Alto, California, USA, pp. 648–651, 2018. [Google Scholar]
6. A. Al Mazroi, A. E. Khedr and A. M. Idrees, “A proposed customer relationship framework based on information retrieval for effective firms’ competitiveness,” Expert Systems with Applications, vol. 176, pp. 1–14, 2021. [Google Scholar]
7. A. M. Idrees, A. E. Khedr and A. A. Almazroi, “Utilizing data mining techniques for attributes’ intra-relationship detection in a higher collaborative environment,” International Journal of Human-Computer Interaction, pp. 1–13, 2022. [Google Scholar]
8. F. Yasser, S. AbdelMawgoud and A. M. Idrees, “News’ credibility detection on social media using machine learning algorithms,” Future Computing & Informatics Journal, vol. 8, no. 1, pp. 21–31, 2023. [Google Scholar]
9. T. P. Nguyen, S. Razniewski, A. Varde and G. Weikum, “Extracting cultural commonsense knowledge at scale,” in WWW'23: Proc. of the ACM Web Conf., Austin, TX, USA, pp. 1907–1917, 2023. [Google Scholar]
10. Z. Zhang, J. Guo, H. Zhang, L. Zhou and M. Wang, “Product selection based on sentiment analysis of online reviews: An intuitionistic fuzzy TODIM method,” Complex & Intelligent Systems, vol. 8, no. 4, pp. 3349–3362, 2022. [Google Scholar]
11. L. Zhou, L. Tang and Z. Zhang, “Extracting and ranking product features in consumer reviews based on evidence theory,” Journal of Ambient Intelligence and Humanized Computing, vol. 14, pp. 9973–9983, 2023. [Google Scholar]
12. F. Barbieri, L. Espinosa-Anke and H. Saggion, “Revealing patterns of Twitter emoji usage in Barcelona and Madrid,” in Proc. of 19th Int. Conf. of the Catalan Association for Artificial Intelligence, Barcelona, Catalonia, Spain, pp. 239–244, 2016. [Google Scholar]
13. H. Pohl, C. Domin and M. Rohs, “Beyond just text: Semantic Emoji similarity modeling to support expressive communication,” ACM Transactions on Computer-Human Interaction, vol. 24, no. 1, pp. 1–42, 2017. [Google Scholar]
14. S. Wijeratne, L. Balasuriya, A. Sheth and D. Doran, “A semantics-based measure of emoji similarity,” in Proc. of the Int. Conf. on Web Intelligence, Leipzig, Germany, pp. 646–653, 2017. [Google Scholar]
15. F. Barbieri, M. Ballesteros and H. Saggion, “Are emoji predictable?,” in Proc. of the 15th Conf. of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, vol. 2, pp. 105–111, 2017. [Google Scholar]
16. B. Felbo, A. Mislove, A. Søgaard, I. Rahwan and S. Lehmann, “Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm,” in Proc. of the 2017 Conf. on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, pp. 1615–1625, 2017. [Google Scholar]
17. F. Barbieri, L. Espinosa-Anke, J. Camacho-Collados, S. Schockaert and H. Saggion, “Interpretable emoji prediction via label-wise attention LSTMs,” in Proc. of the 2018 Conf. on Empirical Methods in Natural Language Processing, Brussels, Belgium, pp. 4766–4771, 2018. [Google Scholar]
18. Ç. Çöltekin and T. Rama, “Tübingen-oslo at SemEval-2018 task 2: SVMs perform better than RNNs in emoji prediction,” in Proc. of the 12th Int. Workshop on Semantic Evaluation, New Orleans, Louisiana, USA, pp. 34–38, 2018. [Google Scholar]
19. G. Guibon, M. Ochs and P. Bellot, “Emoji recommendation in private instant messages,” in SAC’8: Proc. of the 33rd Annual ACM Symp. on Applied Computing, Pau, France, pp. 1821–1823, 2018. [Google Scholar]
20. C. Wu, F. Wu, S. Wu, Y. Huang and X. Xie, “Tweet emoji prediction using hierarchical model with attention,” in UbiComp'18: Proc. of the 2018 ACM Int. Joint Conf. and 2018 Int. Symp. on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, pp. 1337–1344, 2018. [Google Scholar]
21. L. Zhou, Z. Zhang, L. Zhao and P. Yang, “Attention-based BiLSTM models for personality recognition from user-generated content,” Information Sciences, vol. 596, pp. 460–471, 2022. [Google Scholar]
22. L. Zhou, Z. Zhang, L. Zhao and P. Yang, “Microblog sentiment analysis based on deep memory network with structural attention,” Complex & Intelligent Systems, vol. 9, pp. 3071–3083, 2023. [Google Scholar]
23. E. Wang and D. Qin, “Kaggle Website,” 2023. [Online]. Available: https://www.kaggle.com/datasets/ericwang1011/tweets-with-emoji (accessed on 22/06/2023) [Google Scholar]
24. M. Thoma, “The WiLI benchmark dataset for written,” arXiv:1801.07779v1, 2018. [Google Scholar]
25. D. Larionov, “Archive team: The Twitter stream grab,” [Online]. Available: https://archive.org/details/twitterstream (accessed on 22/05/2023) [Google Scholar]
26. Z. Ahanin and M. A. Ismail, “A multi-label emoji classification method using balanced pointwise mutual information-based feature selection,” Computer Speech & Language, vol. 73, pp. 1–20, 2022. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools