
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

AI-Driven Resource and Communication-Aware Virtual Machine Placement Using Multi-Objective Swarm Optimization for Enhanced Efficiency in Cloud-Based Smart Manufacturing
1 Department of Computer Science & Engineering, Koneru Lakshmaiah Education Foundation, Guntur, 522302, India
2 Department of Computer Engineering, College of Computer and Information Sciences, King Saud University, Riyadh, 11543, Saudi Arabia
3 Department of AI and Software, Gachon University, Seongnam-Si, 13120, Republic of Korea
4 Department of Electronics and Communication Engineering, SRM University, Amaravati, 522502, India
* Corresponding Author: Muhammad Shahid Anwar. Email:
(This article belongs to the Special Issue: Applications of Artificial Intelligence in Smart Manufacturing)
Computers, Materials & Continua 2024, 81(3), 4743-4756. https://doi.org/10.32604/cmc.2024.058266
Received 08 September 2024; Accepted 22 November 2024; Issue published 19 December 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Cloud computing has emerged as a vital platform for processing resource-intensive workloads in smart manufacturing environments, enabling scalable and flexible access to remote data centers over the internet. In these environments, Virtual Machines (VMs) are employed to manage workloads, with their optimal placement on Physical Machines (PMs) being crucial for maximizing resource utilization. However, achieving high resource utilization in cloud data centers remains a challenge due to multiple conflicting objectives, particularly in scenarios involving inter-VM communication dependencies, which are common in smart manufacturing applications. This manuscript presents an AI-driven approach utilizing a modified Multi-Objective Particle Swarm Optimization (MOPSO) algorithm, enhanced with improved mutation and crossover operators, to efficiently place VMs. This approach aims to minimize the impact on networking devices during inter-VM communication while enhancing resource utilization. The proposed algorithm is benchmarked against other multi-objective algorithms, such as Multi-Objective Evolutionary Algorithm with Decomposition (MOEA/D), demonstrating its superiority in optimizing resource allocation in cloud-based environments for smart manufacturing.Keywords
Glossary/Nomenclature/Abbreviations
| VM | Virtual Machine |
| PM | Physical Machine |
| MOPSO | Multi-Objective Particle Swarm Optimization |
| VMP | Virtual Machine Placement |
Cloud computing is the most widely used computing platform of the decade offering prefabricated service to organizations. Many organizations are adopting cloud models to improve the availability of their business to people around the world. The organization does not need to establish a data center in every region. Because of the cloud properties like on-demand (use only when you need), elasticity (can increase or decrease the resource with easy steps), and pay-as-you-go model. Many organizations are taking an active part in shifting their workload to cloud-based data centers. In recent years many services have been given to consumers as off-the-rack offerings. For example, Amazon Web Service (AWS) provides a service recognition service that has an inbuilt algorithm to perform facial recognition with greater accuracy. The user needs to use their Application Programming Interface (API) and send a request to the service without worrying about the type of algorithm used at the backend. The service will help in identifying similar faces, annotation, or identifying text in images with a JavaScript Object Notation (JSON) reply. The cloud has its footprint on delivering effective computational power to numerous business use cases.
Cloud computing services models are majorly classified into IaaS (Infrastructure-as-a-Service), PaaS (Platform-as-a-Service), and SaaS (Software-as-a-Service). In this manuscript, we are concerned about the Infrastructure as a Service (IaaS) cloud which offers the highest amount of customization compared to PaaS and SaaS [1]. In the IaaS cloud, the user has the freedom to bundle their virtual server, by installing their operating system, configuring the amount of Random Access Memory (RAM) and Central Processing Unit (CPU) needed for running the application, and also the application runtime preference. The terms virtual server or virtual machine are interchangeably used and referring the same entity in IaaS cloud. Virtual machines are space-sharing entities destined to execute in the physical machine or servers. The servers’ resources like CPU and RAM are utilized by the virtual machine until its lifecycle. When the virtual machines are terminated the server resources are utilized by another virtual machine. The power consumed by the datacenters is directly proportional to the number of virtual machines hosted in the datacenter and the communication between them VMs. It is estimated that a typical datacenter consumes electricity equivalent to 25,000 households. A report published in [2] states that a data center consumes 73 billion kWh, which is estimated to be 2% of the total energy consumption of the United States. This increase in power utilization is due to inefficiently managed datacenter resources. The increase in electricity utilization contributed highly to the emission of greenhouse gases leading to global warming. In [3], it is estimated that around 45% of the electricity is consumed by the server, 30% of the electricity datacenter is consumed by the networking devices, and the remaining 25% of the electricity is consumed by Heating, ventilation, and air conditioning (HVAC) system. Considering the above situation, our research is focused on reducing server resource wastage and inter-VM communication. Reducing the two also reduces the energy consumed by the HVAC systems.
Cloud providers need efficient algorithms to place the virtual machine as close as possible to a physical machine. This is equivalent to the bin packing problem. The bin is comparable to a Physical machine and VMs are equivalent to the number of items. The stated problem is a non-deterministic polynomial-time hard (NP-Hard) problem and it is proved in the literature. Apart from this VM placement, considering the inter-VM communication increases the complexity of the problem. Even though we placed the VMs as compact as possible the inter-VM communication increases (usually measured in terabytes) it is considered an inferior solution. This problem is equivalent to a muti-dimensional bin packing algorithm. Deterministic algorithms are inefficient in solving NP-Hard problems because deterministic algorithms intend to check every solution possibility (Brute Force) in the large solution space. To solve an NP-Hard problem, we employ bio-inspired algorithms that use guided random components to effectively exploit the large search space. These algorithms are non-deterministic and use heuristics to improve the existing solution even further during each iteration.
In this manuscript, we propose a modified Multi-Objective Genetic Algorithm (MOGA) to place the virtual machine improving data center resource utilization and reducing the inter-VM communication that in turn reduces the operating burden on networking equipment. The highlights of the research article are mentioned below:
1. A modified Multi-Objective Genetic Algorithm (MOGA) for Virtual Machine for Virtual Machine Placement is proposed. Optimal resource utilization and inter-VM communication are addressed using the proposed algorithm.
2. A novel mutation and crossover operator is proposed to improve the efficiency of the algorithm.
3. A fat tree topology-based communication model is adopted for the calculation of total data transfer between the VMs in the data center.
4. Resource utilization and inter-VM communication are modeled as minimization problems. The performance metrics resource wastage and inter-VM communication is compared with MOPSO and Space More Efficient Algorithms (SPEA).
The rest of the paper is organized as follows: Section 2 (Literature Survey) outlines the state of art technologies used for building an energy-efficient data center. Section 3 (Problem Formulation) presents the mathematical modeling of server resource utilization and Inter VM communication as a multi-objective minimization problem. Section 4 (Methodology) presents the modified Particle Swarm Optimization (PSO) algorithm to optimize the above-stated objectives. Section 5 presents Experimental Setup and Results with comparison and performance graphs.
In this section, we present the state of algorithms/methodologies discussed in recent years. In recent years cloud providers and scientists have been very much focused on reducing the carbon footprint to build green data centers. Datacenter energy consumption is an active research field for many cloud providers and scientists. All the stakeholders are working to achieve better utilization of the data center by refining the existing solutions and practices. Building an energy-efficient data center not only depends on proposing effective algorithms but also on building energy-efficient hardware [4] (DVFS) and using renewable/green energy sources (solar, wind, hydro energy). Without loss of generality, our research work focuses on building an algorithm to effectively utilize data center resources.
The deterministic algorithm presented in [5] is a greater fit for the problem with a smaller search space. The advantage of using such an algorithm provides us with an exact solution. If the search space increases this algorithm takes exponential time to find the solution. In real-time, working with smaller search spaces is very occasional. Also, these deterministic algorithms fail to work in multi-objective space where two or more objective functions need to be optimized simultaneously. The algorithm employed for bin packing greedy algorithms such as Least Fill First Bin Packing [6], Most Fill First Bin Packing [7] and Next Fit Bin Packing [8] can also be used for VM placement problems. Greedy algorithms are also deterministic algorithms and better than exact algorithms but while exploring the search space the solution falls into local minima. Greedy algorithms cannot be parallelized to execute in multiple machines for faster solution finding. The next class of algorithms is a meta-heuristic algorithm. The algorithms are designed to imitate the behaviors of animals birds or insects.
Genetic algorithms are made to imitate the evolutionary process of human beings. Genes of two parents are exposed to the process of crossover and mutation to produce a new offspring. The new offspring is evaluated using the objective function. If the offspring is a better-performing individual, then the solution is considered else the crossover of the mutation is performed again to produce a better-performing individual. Genetic algorithms are mostly widely applied for permutation-based NP-Hard problems including traveling salesperson problems, bin packing problems, flow shop scheduling problems, and even VM placement problems. In [9], the authors proposed a multi-objective fuzzy-induced genetic algorithm to optimize resource utilization and power consumption in cloud data centers. The proposed algorithm was compared with various bin-packing algorithms to show its superiority. In [10], the authors proposed a genetic algorithm and it is implemented in the real-time cloud data center at the Office of the Merchant Marine and Ports of Tunisia (OMMP). The real-time implementation shows a reduction in resource wastage and leads to a profitable business. The authors used uniform crossover and uniform mutation to generate a new offspring. In [11], the authors proposed an improved genetic algorithm to optimize the availability and energy consumption of a data center. A problem-specific selection operator, crossover, and mutation operator are proposed in the manuscript. In [12], the authors proposed a hybrid algorithm where a part of the optimization is carried out by a genetic algorithm and the remaining is carried out by a best-fit bin packing-based algorithm to reduce power utilization and resource wastage. The proposed algorithm is also used to compare well-known instances of the Travelling Salesman Problem (TSP) and Flow shop scheduling problems. Variation of genetic algorithm for solving Virtual Machine Placement (VMP) in a multi-objective perspective is presented in [13]. In [14], the authors proposed a multi-objective variation of the genetic algorithm with decomposition to optimize three objectives simultaneously. Permutation-based partially mapped crossover and multi-point mutation are used because of the larger gene structure (100 and 200 VMs). Apart from the genetic algorithm, other algorithms such as ant colony optimization, firefly algorithm [15], bat algorithm, and particle swarm algorithm [16] are majorly used in VMP. The above state algorithm works well for discrete optimization problems. Unlike genetic algorithms (natively permutation-based), the challenge in adopting these algorithms lies in implementing effective discretization methodologies. The author proposed an order-filling method to discretize the continuous values used along with the bat algorithm. The bat algorithm was initially proposed as a single objective algorithm. The author used the working methodology and proposed a multi-objective version of the bat algorithm.
A multi-objective virtual machine (VM) placement algorithm based on evolutionary methods with decomposition has been proposed [17]. Their approach aims to address multiple conflicting objectives, including resource utilization and communication overhead, through efficient VM placement strategies in cloud data centers. In another study, authors in [18] presented a VM placement algorithm based on a Multi-Objective Evolutionary Algorithm with Decomposition (MOEA/D), aimed at optimizing placement in distributed cloud environments. Their work demonstrated significant improvements in balancing resource allocation, reducing energy consumption, and enhancing cloud infrastructure efficiency. The authors also discuss interoperability issues in cloud computing, which is a key concern in multi-cloud and hybrid-cloud environments [18]. Their study laid the groundwork for addressing system compatibility challenges and improving resource integration across different cloud platforms. A foundational algorithm in this domain was proposed by [10], inspiring many modern swarm-based methods for VM placement. PSO has been widely adopted due to its simplicity and effectiveness in solving multi-dimensional optimization problems.
Finally, a power-aware, performance-guaranteed VM placement algorithm is presented in [11], offering a hybrid solution that combines energy efficiency with performance constraints. Their work provided a comprehensive framework for optimizing energy usage in cloud environments without compromising performance, making it relevant for power-sensitive applications.
As discussed earlier, VM placement is equivalent to the bin packing problem. The set of virtual machine requests from the cloud consumer must be spawned in the available physical machine without wasting server resources. The VM demands are specified in terms of CPU and RAM. In our research work, we do not consider the storage requirement because it is provided by the centralized storage arrays connected using Storage Area Network (SAN) fabric. VM can execute in any of the Polynomial Machines (PM) in the data center, and the storage can be routed to the PM using the SAN network. Since we do not know the type of physical machine each cloud provider is installed in the data center, to generically represent the utilization in our research article we use a percentage of utilization. For example, consider a physical machine has 10 CPU cores and 20 GB of RAM which is equivalent to 100% of the resources being free in PM, the VM request needs 2 core CPU (20%) and 4 GB RAM (20%). The VM is allocated to the PM as a result 20% CPU is utilized and 20% of the RAM is utilized. The remaining 80% of CPU and RAM can be allocated to some other VMs or it is considered as resource wastage
The total available resource of physical machine
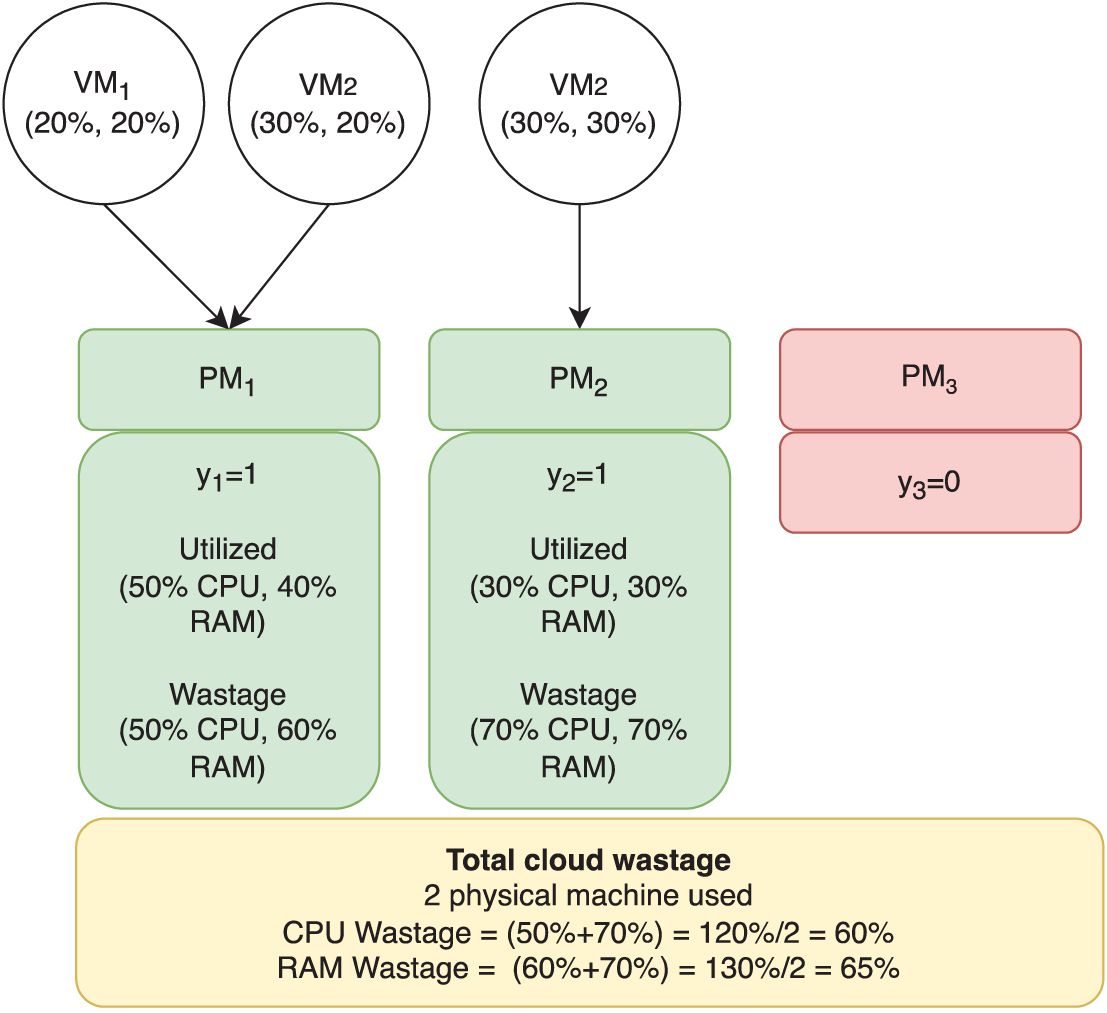
Figure 1: Resource wastage calculation—illustration
In the above illustration, three VMs are considered. The first two virtual machines are placed in
The next objective formulation is concerned with the inter VM communication. A cloud consumer may deploy multiple virtual machine in a cloud datacenter. Each of these VMs need to communicate with each other to complete a given task. When the VMs are placed in different PMs the communication from one VM should pass thorough a set networking devices to reach the destination. This in turns compromises the Quality of Service (QoS) for the VMs executing in cloud. At the same time, the networking devices are heavily utilized, and the power consumption will also increases. It is estimated in [3] that 30% of electricity is consumed by the networking devices due to misplacement of VMs. It is desired to place inter communicating VMs in single physical machine to reduce the impact on networking devices. For our research work we considered the datacenter follows fat tree topology as shown in the Fig. 2. The physical machines are denotes with the numbering
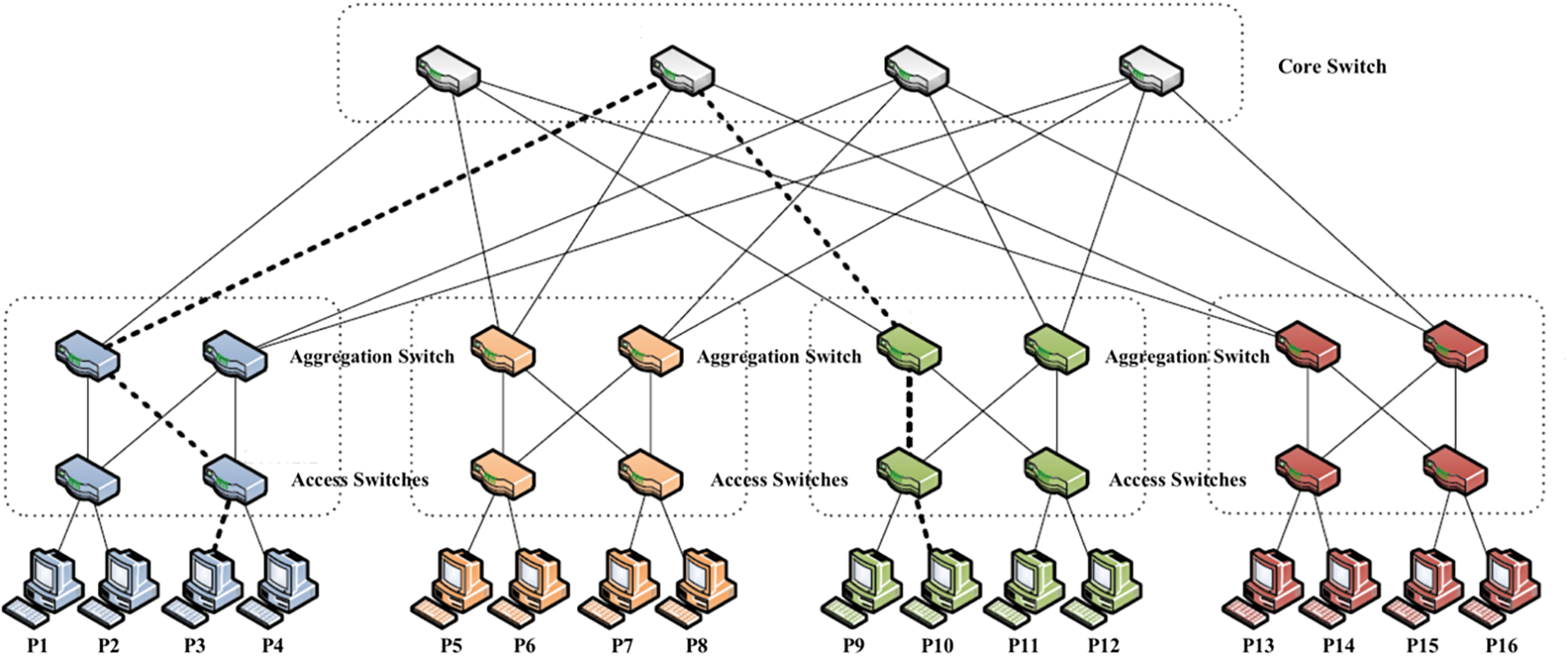
Figure 2: Flat tree topology
The data transfer from source to destination has four special cases mentioned in the Table 1. The case

For example, if
If 500 MB of data need to transferred between 2 VMs say
For the entire datacenter, the data transfer volume can be calculated using the below equation (minimization Objective function).
Both the objectives namely resource wastage and inter-VM communication are discussed in this section with a neat illustration. The problem we have here is conflicting objectives. The minimization of resource wastage objective may hurt inter-VM communication objectives. This kind of problem cannot be solved using traditional bin packing or deterministic algorithms. In the upcoming section, we discuss a multi-objective optimization and the algorithm.
4 Multi-Objective Optimization
The multi-objective optimization problem required specialized concepts to process and identify optimal values. In comparison with the single objective optimization problem, the fitness function produces only one value to be minimized, i.e., scalar quantity. But, in multi-objective optimization for a given problem instance, it is evaluated by more than one fitness function to produce a vector. For example, for two objective optimizations the output produced by the fitness function contains two values
Consider the input instance of the permutation problem is
The comparison of solution is a major issue in multi-objective optimization problems. For example, in multi-objective optimization the outputs are vector quantity. Consider two outputs of bi-objective optimization problem in the decision space as
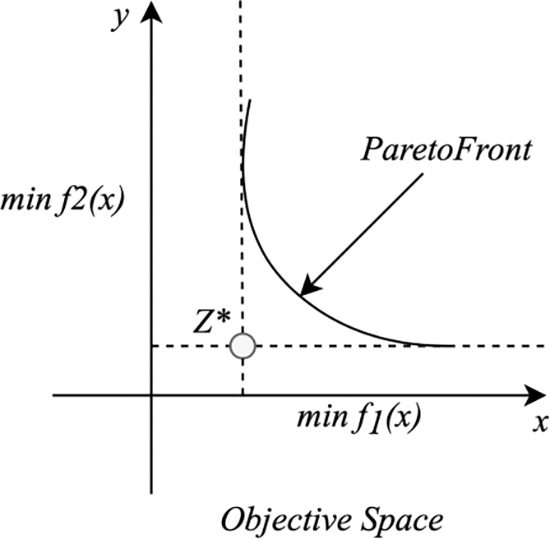
Figure 3: Illustration of pareto optimal front for bi-objective minimization problem
In this section, we cover the modified multi-objective version of the Particle Swarm Optimization algorithm (PSO). Initially, the particle swarm optimization algorithm was proposed to solve single objective continuous optimization problems. Throughout the literature, there are many variations of PSO algorithms that exist for multi-objective continuous optimization problems. As a part of our research, we have a discrete version of the multi-objective PSO algorithm with improved exploration methodology.
The PSO algorithm is a swarm-based heuristic algorithm that can be observed in many of the creatures like flocks of birds searching for food. PSO methodology concentrates on specific to gain collective intelligence. Each permuted virtual machine sequence is called a particle. Each of the particles has two components called personal best and current fitness value. For the whole population of the particle, there exists only one global best. Initially, each particle is evaluated using the objective function to get its fitness values. During the first iteration, both the personal best and current fitness value of the particle remain the same. The global best is the best-performing particle in the entire population. From the next iteration onwards, each of the particles will shift its position to find the optimal solution guided by the global best and the personal best value. The importance given to the global best and personal best is controlled by the parameters
The current position of the particle is denoted with

The first term
6 Experimental Setup and Results
The concepts described above were executed in MATLAB version R2022a in a computer system with the specification of an Intel core i3 processor with 16 GB of RAM running Windows operating system. The dataset needed to carry out the experimentation was statistically generated using the generating VM algorithm mentioned. Using this algorithm 200 virtual machines are generated by changing the reference probability values to
The inter-VM communication matrix is generated randomly, and the same dataset is used for running all the experiments and multiple independent runs. The VMs along the rows denote the source and the VM along the columns denotes the destination. A matrix is created of size 200 ∗ 200 and the values inside denote data volume. All the data volumes are represented in MBs and round off to the nearest 10’s (11 MB is rounded to 10 MB).
The proposed algorithm MOPSO is compared with MOEA/D in Table 2 which shows the superiority of finding the minimal Pareto front solution. Also, the plots in Fig. 4 show that MOPSO explores the search space more effectively compared to MOEA/D. The solutions represented in red are the non-dominated solutions. Since it is a discrete optimization problem the curve is discontinuous. The plots in Fig. 4a,b represent the results obtained for the strong negative dataset and Fig. 4c,d represent the results obtained for the strong positive dataset. Fig. 4a,c are the results of the MOPSO algorithm and Fig. 4b,d are the results of the MOEA/D algorithm.
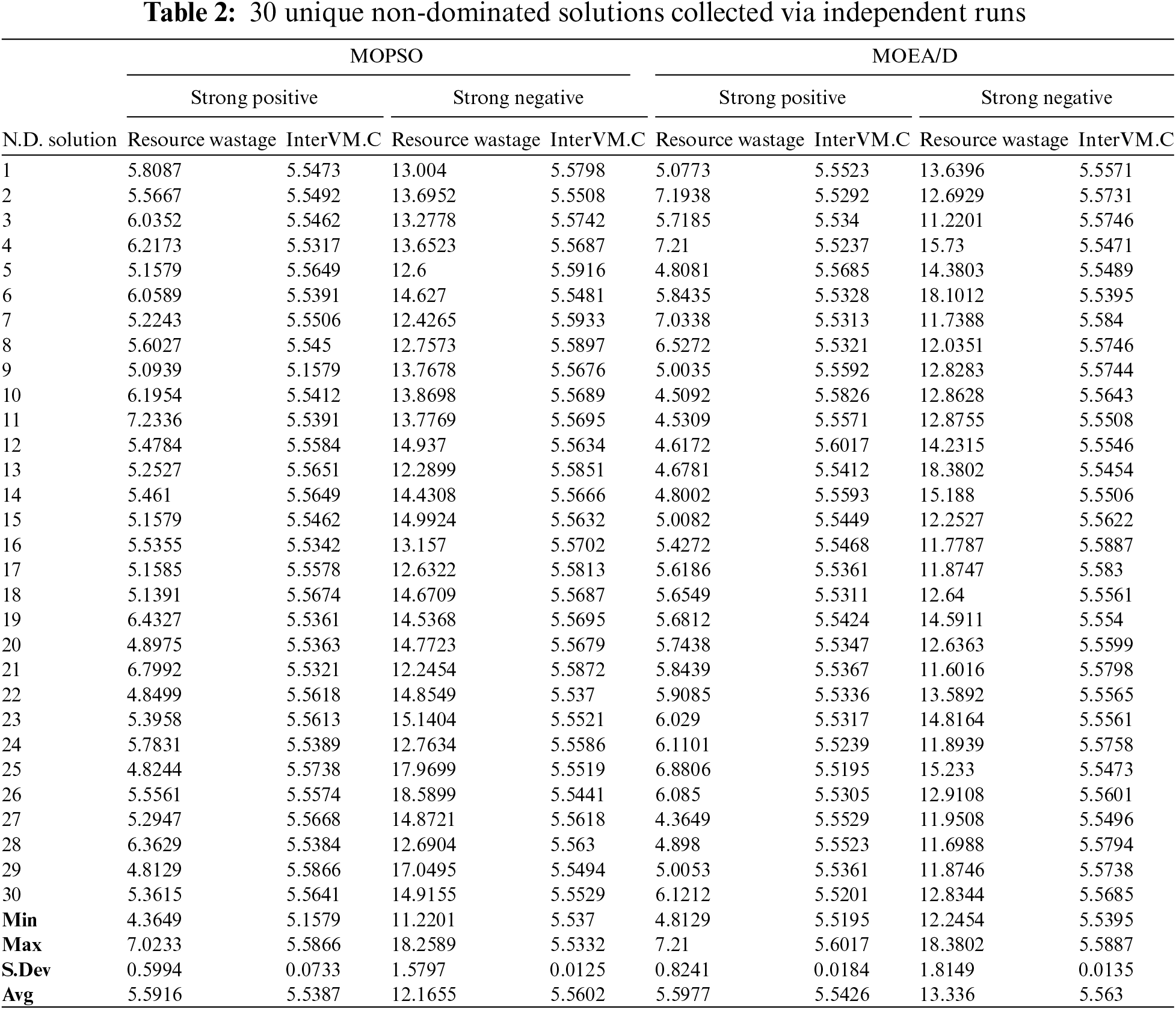
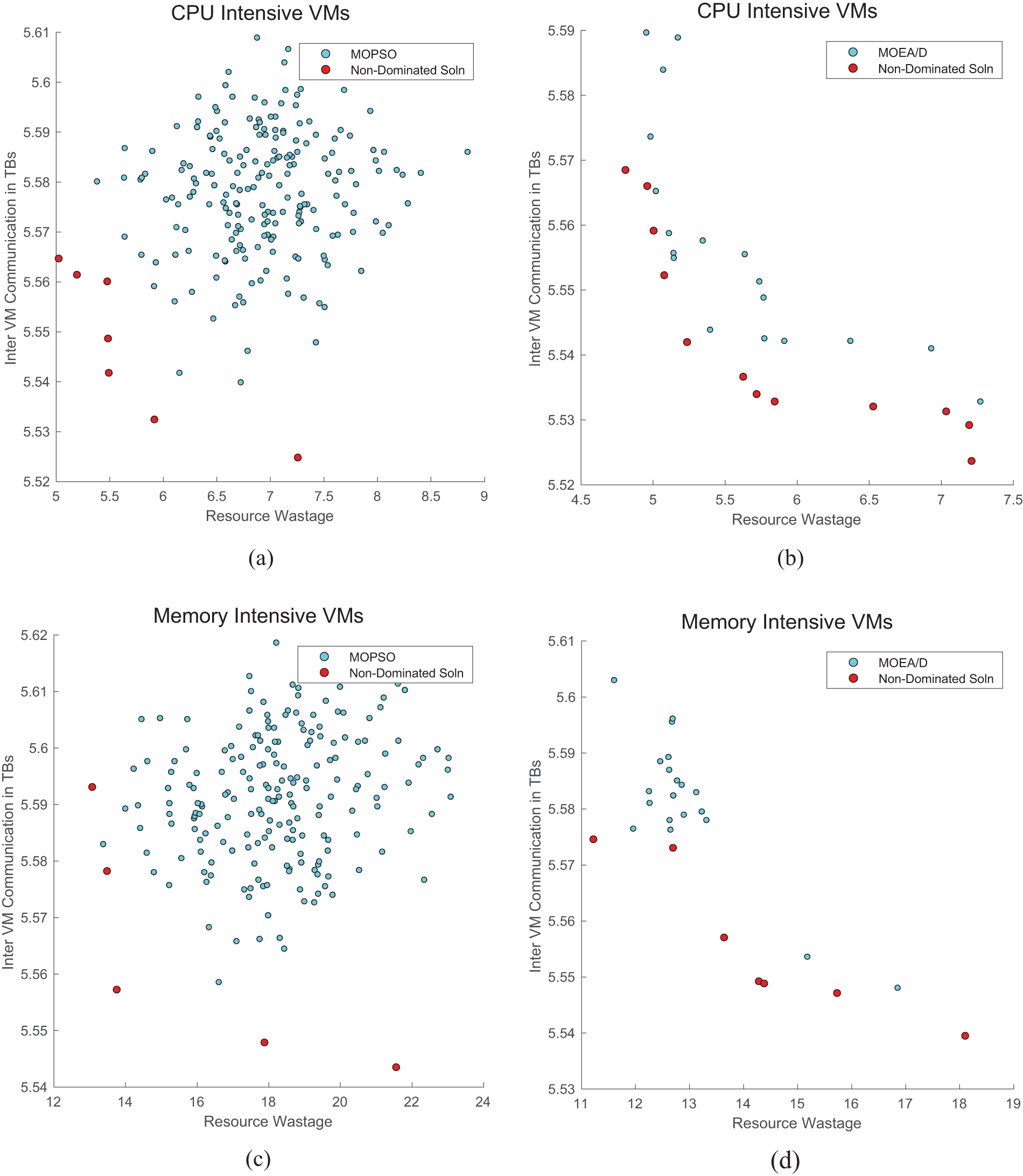
Figure 4: MOPSO vs. MOEA/D in solution exploration to attain global minima
Minimizing the impact on networking devices during inter-VM communication leads to reduced latency, improved throughput, better resource utilization, and decreased packet loss, all of which enhance overall system performance. This optimization is essential for maintaining the efficiency and reliability of cloud environments, especially in scenarios where real-time data exchange and high performance are critical.
This paper addresses the multi-objective version of virtual machine placement considering resource wastage and inter-VM communication as a minimization objective. The problem is designed for flat tree topology with 200 VM are scheduled to be placed in the physical machines. The mathematical model for the problem is illustrated with an example. The NP-Hard problem is effectively tackled by the proposed MOPSO algorithm, which performs considerably better than the MOEA/D algorithm. The algorithm is designed based on the concept of particle swarm optimization and adopted to address multi-objective problems. The experimental results show that the proposed algorithm explores the search space more effectively and can able to find more unique Pareto optimal solutions. In the future, we like to consider various networking architectures measuring the networking impact with the occurrence of VM migration.
Future work will involve refining the experimental setup by incorporating detailed performance metrics such as energy consumption and runtime analysis, as well as comparing with a broader range of multi-objective optimization techniques. Additionally, statistical validation will be used to demonstrate the significance of the results, ensuring a robust and scalable solution for cloud data center optimization.
Acknowledgement: None.
Funding Statement: This Research is funded by Researchers Supporting Project Number (RSPD2025R947), King Saud University, Riyadh, Saudi Arabia.
Author Contributions: The authors confirm their contribution to the paper as follows: Praveena Nuthakki: Investigation, writing—original draft, conceptualization, software. Pavan Kumar T.: Conceptualization, supervising, writing original draft, formal analysis. Musaed Alhussein: Conceptualization, methodology. Mahammad Shahid Anwar: Formal analysis, supervising, writing—review and editing. Khursheed Aurangzeb: Methodology, design, editing, writing—review and editing. Leenendra Chowdary Gunnam: Writing, original drafting, software. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data used to support the findings of this study are available from the corresponding author upon request.
Ethics Approval: This article does not contain any studies with human participant and animals performed by author.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. F. Alharbi, Y. -C. Tian, M. Tang, W. -Z. Zhang, C. Peng and M. Fei, “An ant colony system for energy-efficient dynamic virtual machine placement in data centers,” Expert. Syst. Appl., vol. 120, pp. 228–238, 2019. doi: 10.1016/j.eswa.2018.11.029. [Google Scholar] [CrossRef]
2. A. Shehabi et al., “United states data center energy usage report,” 2016. Accessed: May 15, 2022. [Online]. Available: https://escholarship.org/content/qt84p772fc/qt84p772fc.pdf [Google Scholar]
3. A. Greenberg et al., “VL2: A scalable and flexible data center network,” ACM SIGCOMM Comput. Commun. Rev., vol. 4, pp. 51–62, 2009. doi: 10.1145/1592568.1592576. [Google Scholar] [CrossRef]
4. J. Krzywda, A. Ali-Eldin, T. E. Carlson, P. O. Östberg, and E. Elmroth, “Power-performance tradeoffs in data center servers: DVFS, CPU pinning, horizontal, and vertical scaling,” Future Gener. Comput. Syst., vol. 81, pp. 114–128, 2018. doi: 10.1016/j.future.2017.10.044. [Google Scholar] [CrossRef]
5. J. W. Lin, C. H. Chen, and C. Y. Lin, “Integrating QoS awareness with virtualization in cloud computing systems for delay-sensitive applications,” Future Gener. Comput. Syst., vol. 37, pp. 478–487, 2014. doi: 10.1016/j.future.2013.12.034. [Google Scholar] [CrossRef]
6. K. Fleszar and K. S. Hindi, “New heuristics for one-dimensional bin-packing,” Comput. Oper. Res., vol. 29, no. 7, pp. 821–839, 2002. doi: 10.1016/S0305-0548(00)00082-4. [Google Scholar] [CrossRef]
7. J. Sgall, “Online bin packing: Old algorithms and new results,” in Language, Life, Limits, A. Beckmann, E. Csuhaj-Varjú, and K. Meer, Eds. Cham: Springer, Jun. 2014, vol. 8493. doi: 10.1007/978-3-319-08019-2_38. [Google Scholar] [CrossRef]
8. M. Labbé, G. Laporte, and S. Martello, “An exact algorithm for the dual binpacking problem,” Oper. Res. Lett., vol. 17, no. 1, pp. 9–18, 1995. doi: 10.1016/0167-6377(94)00060-J. [Google Scholar] [CrossRef]
9. J. Xu and J. A. Fortes, “Multi-objective virtual machine placement in virtualized data center environments,” in IEEE/ACM Int. Conf. Green Comput. Commun. Int. Conf. Cyber Phys. Soc. Comput., Hangzhou, China, IEEE, Dec. 2010, pp. 179–188. [Google Scholar]
10. M. Riahi and S. Krichen, “A multi-objective decision support framework for virtual machine placement in cloud data centers: A real case study,” J. Supercomput., vol. 74, no. 7, pp. 2984–3015, 2018. doi: 10.1007/s11227-018-2348-z. [Google Scholar] [CrossRef]
11. J. Lu, W. Zhao, H. Zhu, J. Li, Z. Cheng and G. Xiao, “Optimal machine placement based on improved genetic algorithm in cloud computing,” J. Supercomput., vol. 78, no. 3, pp. 3448–3476, 2022. doi: 10.1007/s11227-021-03953-8. [Google Scholar] [CrossRef]
12. A. S. Abohamama and E. Hamouda, “A hybrid energy-aware virtual machine placement algorithm for cloud environments,” Expert. Syst. Appl., vol. 150, 2020, Art. no. 113306. doi: 10.1016/j.eswa.2020.113306. [Google Scholar] [CrossRef]
13. J. Peake, M. Amos, N. Costen, G. Masala, and H. Lloyd, “PACO-VMP: Parallel ant colony optimization for virtual machine placement,” Future Gener. Comput. Syst., vol. 129, pp. 174–186, 2022. doi: 10.1016/j.future.2021.11.019. [Google Scholar] [CrossRef]
14. K. Balaji, P. S. Kiran, and M. S. Kumar, “Resource aware virtual machine placement in IaaS cloud using bio-inspired firefly algorithm,” J. Green Eng., vol. 10, pp. 9315–9327, 2020. [Google Scholar]
15. S. Parida, B. Pati, S. C. Nayak, and C. R. Panigrahi, “eMRA: An efficient multi-optimization based resource allocation technique for infrastructure cloud,” J. Ambient Intell. Humaniz. Comput., vol. 14, no. 10, pp. 1–19, 2022. [Google Scholar]
16. A. Gopu and V. Neelanarayanan, “Multiobjective virtual machine placement using evolutionary algorithm with decomposition,” in Proc. 6th Int. Conf. Big Data Cloud Comput. Chall., Singapore, Springer, 2020, pp. 149–162. [Google Scholar]
17. A. Gopu and N. Venkataraman, “Optimal VM placement in distributed cloud environment using MOEA/D,” Soft Comput., vol. 23, no. 21, pp. 11277–11296, 2019. doi: 10.1007/s00500-018-03686-6. [Google Scholar] [CrossRef]
18. R. K. Chaudhary, R. Kumar, K. Aurangzeb, J. Bedi, M. S. Anwar and A. Choi, “Enhancing clustered federated learning using artificial bee colony optimization algorithm for consumer IoT devices,” IEEE Trans. Consum. Electron., 2024. doi: 10.1109/TCE.2024.3478349. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools