
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
CAMSNet: Few-Shot Semantic Segmentation via Class Activation Map and Self-Cross Attention Block
1 School of Computer Science, Zhengzhou University of Aeronautics, Zhengzhou, 450046, China
2 National Key Laboratory of Air-Based Information Perception and Fusion, China Airborne Missile Academy, Luoyang, 471000, China
* Corresponding Authors: Xuyang Zhuang. Email: ; Xiaoyan Shao. Email:
(This article belongs to the Special Issue: Novel Methods for Image Classification, Object Detection, and Segmentation)
Computers, Materials & Continua 2025, 82(3), 5363-5386. https://doi.org/10.32604/cmc.2025.059709
Received 15 October 2024; Accepted 30 December 2024; Issue published 06 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The key to the success of few-shot semantic segmentation (FSS) depends on the efficient use of limited annotated support set to accurately segment novel classes in the query set. Due to the few samples in the support set, FSS faces challenges such as intra-class differences, background (BG) mismatches between query and support sets, and ambiguous segmentation between the foreground (FG) and BG in the query set. To address these issues, The paper propose a multi-module network called CAMSNet, which includes four modules: the General Information Module (GIM), the Class Activation Map Aggregation (CAMA) module, the Self-Cross Attention (SCA) Block, and the Feature Fusion Module (FFM). In CAMSNet, The GIM employs an improved triplet loss, which concatenates word embedding vectors and support prototypes as anchors, and uses local support features of FG and BG as positive and negative samples to help solve the problem of intra-class differences. Then for the first time, the Class Activation Map (CAM) from the Weakly Supervised Semantic Segmentation (WSSS) is applied to FSS within the CAMA module. This method replaces the traditional use of cosine similarity to locate query information. Subsequently, the SCA Block processes the support and query features aggregated by the CAMA module, significantly enhancing the understanding of input information, leading to more accurate predictions and effectively addressing BG mismatch and ambiguous FG-BG segmentation. Finally, The FFM combines general class information with the enhanced query information to achieve accurate segmentation of the query image. Extensive Experiments on and demonstrate that the CAMSNet yields superior performance and set a state-of-the-art.Keywords
Deep learning has rapidly advanced [1], resulting in significant improvements in semantic segmentation techniques [2]. However, accurate segmentation heavily relies on annotated data, necessitating extensive pixel-level labeling to achieve generalization. To mitigate this data dependency, semi-supervised and WSSS methods have been proposed. Despite their benefits, these methods struggle to generalize to novel class. Addressing the challenge of predicting numerous novel classes using limited base general class information has become a critical issue in the field of deep learning. Since Sanban et al. introduced the task of FSS, it has quickly become a prominent research area [3]. Currently, metric-based meta-learning strategies are the dominant approaches in this field [4]. These methods generally consist of two stages: meta-training, where feature representations of known classes are learned, and meta-testing, which enables fast inference and segmentation of unseen classes. However, these approaches still encounter substantial challenges, particularly in handling intra-class differences and BG mismatch.
Intra-class differences refer to instances within the same category that are difficult for the model to distinguish due to variations in appearance or form. For example, as shown in Fig. 1, both the oriole and white dove are “birds,” or the cow and cat, viewed from different perspectives, exhibit significant visual differences despite belonging to the same category. The existing methods have made improvements by adopting various strategies to address this issue. Reference [5] used an L2L similarity metric to measure the similarity between aligned local features in the embedding space. By learning a distinct metric for each category [6], the model can more effectively differentiate between samples within the same class. By minimizing cross-entropy loss and maximizing mutual information [7], the model can better handle query set uncertainty, reducing intra-class differences. However, these methods still face some challenges, especially when dealing with targets that exhibit significant intra-class differences, where their effectiveness is limited. This paper proposes the GIM that concatenates embedding vectors of dataset category words with support prototypes as anchor. It introduces the Local Feature Generator (LFG) to sample local support features as positive and negative pairs, calculating triplet loss to minimize the distance between positive samples and maximize the distance between negative ones. The General Information Genertor (GIG) produces embedding vectors for category words, aiding in the extraction of general feature information and addressing the challenge of intra-class differences in FSS.

Figure 1: Intra-class differences. (a) The object has the same semantic label but belongs to different categories. (b) The same object appearing differently from various perspectives is referred to as perspective distortion
BG mismatch occurs when the similarity between the BG in the query image and the FG features in the support set is excessively high, causing the query BG to incorrectly match the support FG, which ultimately affects the model’s segmentation accuracy. As shown in Fig. 2, the excessive similarity between the query BG (e.g., grassland) and the supported FG leads to an incorrect match. To alleviate this issue, existing studies have proposed various strategies. By fine-tuning the parameters in the Prototype Adaptive Module (PAM) module [8], the basic segmentation model can quickly adapt to new categories, thereby mitigating the impact of BG mismatch. Reference [9] proposed a novel NTRENet to effectively mine and eliminate BG and distracting object (DO) regions from the query images. Reference [10] introduced the FS-PCS, which calibrates the correlation of BG classes through the Basic Prototype Calibration (BPC) module. However, these methods still face certain limitations, especially in complex BG or when there is a high similarity between the FG and BG, which significantly constrains the performance of existing FSS methods. To address these challenges, the paper proposes an enhanced SCA Block, which enables the model to better distinguish between FG and BG features. This module helps the model to more effectively process input information, improve prediction accuracy, and resolve issues related to BG mismatch and unclear segmentation between FG and BG.
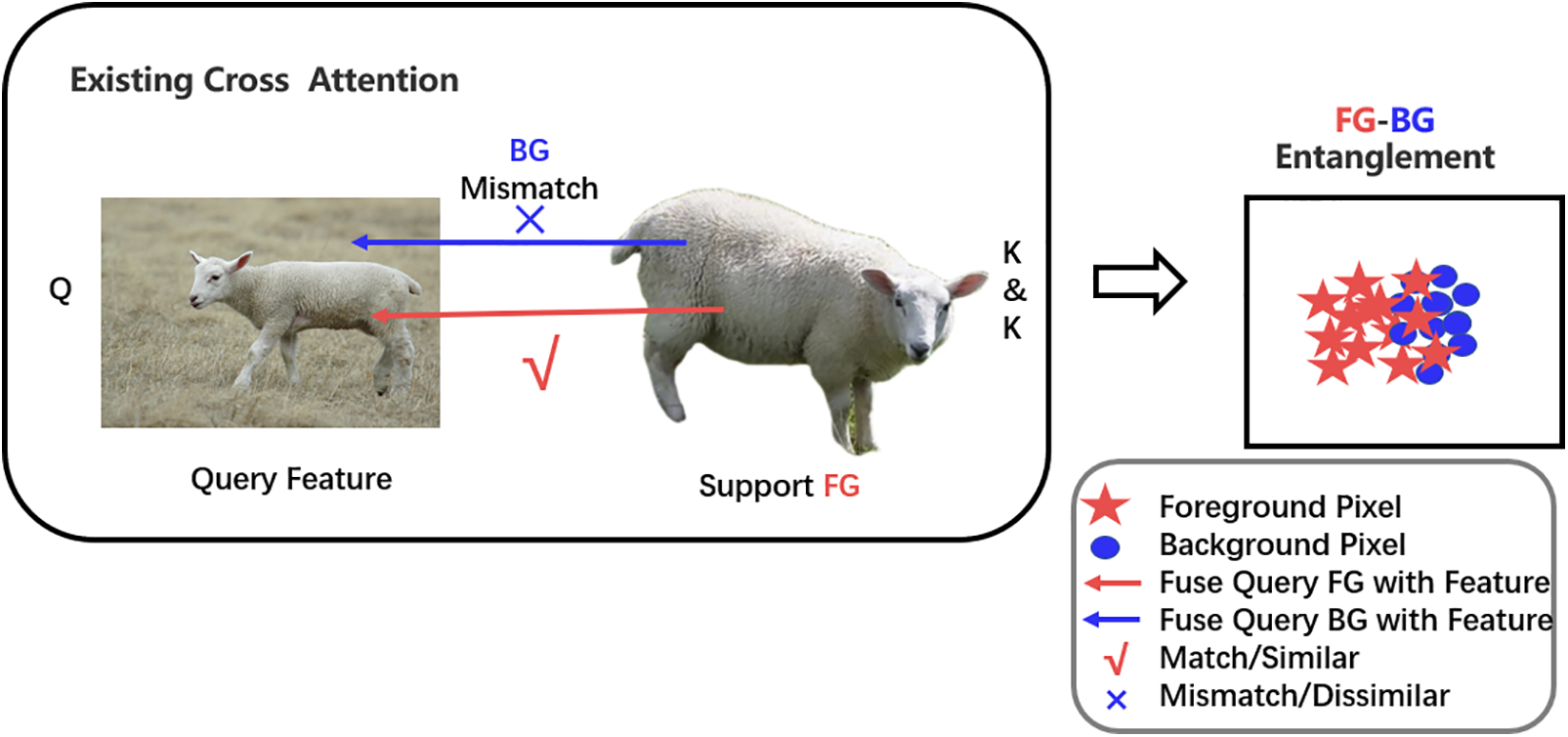
Figure 2: BG mismatch and ambiguous segmentation of BG and FG. The query FG matches correctly with the support FG, but the query BG incorrectly matches with the support FG
This paper proposes CAMSNet for accurate few-shot semantic segmentation. The model consists of the GIM, the CAMA module, the SCA Block, and the FFM. This method demonstrated superior performance on the
• The paper proposes four modules, GIM, CAMA, SCA, and FFM, to achieve more accurate FSS, with a performance improvement of 1.9% compared to state-of-the-art models.
• The paper propose a GIM that incorporates word embedding vectors and triplet loss to better extract general class information and address intra-class differences.
• For the first time, the CAM from the WSSS domain has been applied to FSS. This enhances the model’s ability to locate query set images and improves overall performance.
• The introduction of an improved SCA Block effectively learns support and query features, models global image information, and captures long-distance dependencies between different regions. This approach addresses the issues of BG mismatch and ambiguous FG and BG segmentation.
Through these methods, the CAMSNet model excels in FSS tasks by effectively addressing challenges such as intra-class differences, BG mismatch, and ambiguous FG and BG segmentation. This contribution not only resolves current issues in FSS but also introduces innovative ideas and methodologies for future research in this field.
The structure of this paper is as follows: Section 2 reviews the key technologies and developments in semantic segmentation, FSS, category activation maps, cross-attention mechanisms and feature fusion. Section 3 provides an overview of the paper’s overall framework, highlighting the key modules and technologies. Section 4 presents a detailed analysis of the experimental setup and results. Finally, Section 5 summarizes the proposed methods, discusses potential future developments, and identifies areas for further improvement in the model.
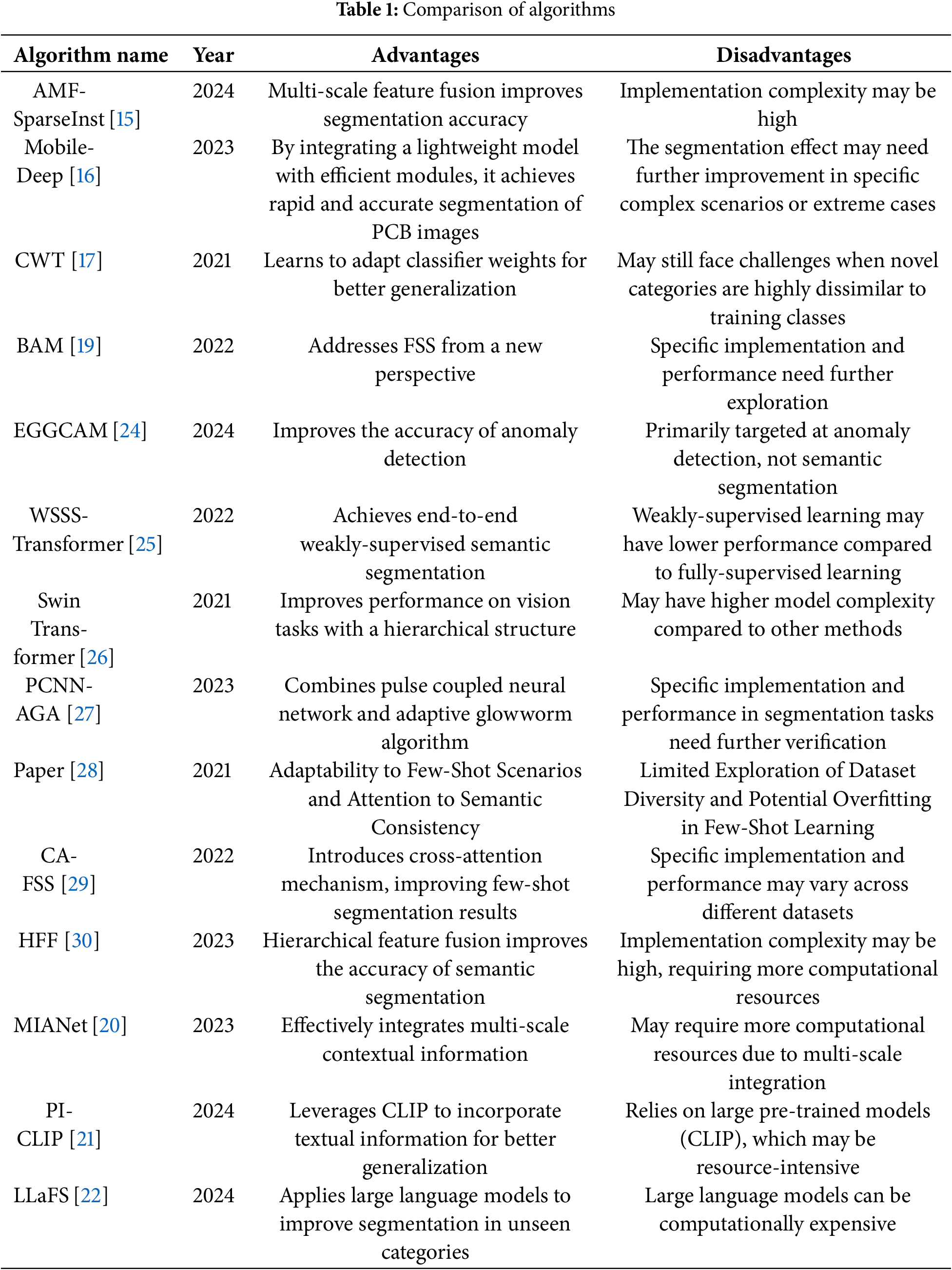
Semantic Segmentation. Semantic segmentation [12] is a fundamental computer vision task that aims to assign a specific category to each pixel in an image. Since the proposal of FCN [13], semantic segmentation has made significant progress and is widely used in fields such as medical image recognition, autonomous driving, and geological exploration [14]. AMF-SparseInst [15] is a real-time instance segmentation model that effectively emphasizes key features of small objects within complex backgrounds. It captures multi-scale contextual information and enhances the effectiveness of semantic fusion features using a pyramid pooling module (SimAM-ASPP) combined with depthwise separable convolution and a 3D attention mechanism (SimAM). The model also incorporates a Lite-BiFPN module and a feature enhancement module for further refinement. Mobile-Deep [16] built upon the DeepLabv3+ framework, utilizes MobileNetv2 to reduce parameters. It addresses sample imbalance by combining Focal Loss and Dice Loss, introduces the Efficient Atrous Spatial Pyramid Pooling (E-ASPP) module and Roberts operator to enhance accuracy, and leverages multi-scale feature fusion to improve model performance, thereby achieving rapid and accurate segmentation of Printed Circuit Boards (PCB) images. However, traditional semantic segmentation networks are incapable of handling novel categories. During training, pixel-level annotation of large-scale data is required, resulting in high labor costs and computational expenses, which hinder practical applications. Table 1 summarizes the advantages and disadvantages of each algorithm.
Few-Shot Semantic Segmentation. The key to FSS is to use limited labeled samples of known categories to segment images of unseen categories. Categorized by the availability of supervisory information, it falls into unsupervised (no additional info) and supervised learning (with additional info). CWT [17] addresses the distribution mismatch problem of pre-trained models through a two-stage training method. RePRI [18] improves supervision by applying an enhanced cross-entropy loss on top of traditional semantic segmentation training. BAM [19] combines a base learner and a meta-learner to separately handle segmentation tasks for base classes and novel categories. MIANet [20] improves model performance by interactively integrating information from different scales, utilizing multi-level contextual information. PI-CLIP [21] leverages CLIP to introduce textual information, enhancing the model’s generalization ability in the case of unseen categories and limited labeled samples. LLaFS [22] applies large language models to FSS, imporving the model’s performance in segmenting unseen categories and complex scenes. However, most of these methods focus on improvements in model architecture and training strategies, with relatively less attention given to the application of attention mechanisms in FSS. In this paper, we propose an effective SCA Block to address key issues in FSS. By introducing the self-cross attention mechanism, SCA Block can more effectively capture contextual information in the image, thereby improving the model’s generalization ability and segmentation accuracy.
Class Activation Map. Reference [23] introduced a gradient-independent class activation mapping method called Score-CAM.This method calculates linear weights by using the model’s global confidence score for the feature map. In [24], an integrated system is proposed, consisting of two modules: classification and segmentation. Multiple network architectures are independently trained to handle various anomalies, and their components are then combined. The final structure includes two branches: one for anomaly classification and the other for anomaly segmentation. To prevent information loss during deep Convolutional Neural Network (CNN) training on high-resolution images, guided GradCAM (GCAM) adjustment patch neural networks are employed for anomaly localization. The Layer-wise Relevance Propagation (LRP) mechanism provides a deeper explanation for class activation maps [25], further enhancing the understanding of the model’s internal reasoning process. However, these methods still suffer from inaccurate localization. The paper propose the CAMA module, which convolves high-level feature maps with the weights of the classification layer to calculate the activation map for each category. This is the first time that CAM, used in weakly supervised semantic segmentation, is applied to FSS to help precisely locate information in the query set.
Cross-Attention Mechanism. CNN excel at capturing local features in images due to their local convolution operations but struggle to effectively model global information and long-range dependencies between different regions. This is a significant drawback in FSS tasks. Recent works [26,31,32] have shown that Transformer [33] architectures can achieve outstanding results in computer vision tasks. Specifically, Swin Transformer (ST) [26] can compute efficient self-attention within small windows to reduce computational burden and achieve good segmentation results. In [27], an image segmentation algorithm is proposed that combines Pulse Coupled Neural Network (PCNN) and the adaptive firefly algorithm. This approach retains the advantages of the glowworm algorithm while introducing adaptive movement step size and overall optimal value as adjustment factors, enhancing the ability to find the global optimal solution. However, the aforementioned methods face challenges with invalid and misaligned patches. Based on this, the paper proposes an improved SCA mechanism for FSS tasks, which better captures the overall semantic information of images and helps understand the global context, demonstrating superior performance.
Feature Fusion. Feature fusion has become a key technique for improving the performance of FSS models, aiming to effectively combine features from different layers or sources to enhance the model’s representational power. Reference [28] proposed a method that fuses multi-level features from the network to integrate global context and local details, helping the model capture finer-grained information. Reference [29] implemented feature fusion between the support and query sets using a cross-attention module, enabling the model to dynamically adapt to different target instances, which effectively improved segmentation accuracy in few-shot learning scenarios. Reference [30] introduced a hierarchical feature fusion method that combines features from different layers to preserve both global and local information, thereby enhancing feature representation capability. In this paper, we adopt the FFM structure as the feature fusion module, which combines general class information and query features through layer-wise convolution operations and skip connections, resulting in more accurate feature fusion. This design helps the model better capture key features in few-shot segmentation tasks and effectively improves segmentation accuracy.
The objective of FSS is to leverage k-shot annotated support setS to predict the segmentation of novel classes in the query setQ. The training set
The training set
where
For support set S is defined as
The main process of FSS network involves feeding the support-query image pairs
The CAMSNet network consists of four modules: the General Information Module (GIM), the Class Activation Map Aggregation (CAMA) module, the Self-Cross Attention Block (SCA Block), and the Feature Fusion Module (FFM). The network architecture is shown in Fig. 3.
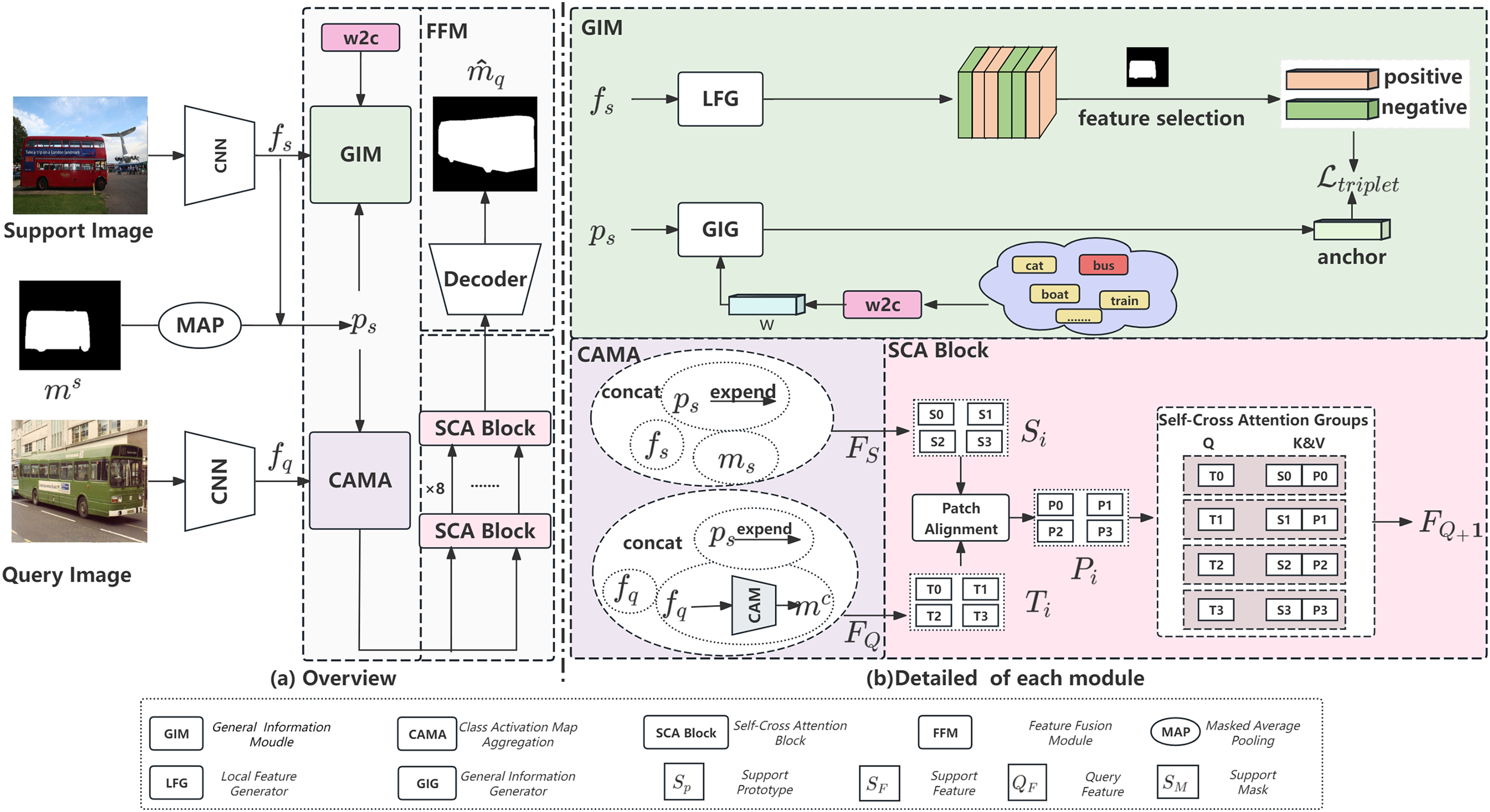
Figure 3: Overall architecture of (a) CAMSNet and (b) detailed of each module. The CAMSNet network consists of four modules: the General Information Module (GIM), the Class Activation Map Aggregation (CAMA) module, the Self-Cross Attention Block (SCA Block), and the Feature Fusion Module (FFM)
First, the task is to use a pre-trained backbone network, ResNet50, to extract support features
3.3 General Information Module
In the field of FSS, a key challenge is the inherent category differences within target objects. Existing methods [34] typically rely on aligning the query image with support samples by matching local image features. While these methods are effective in some cases, they often perform poorly when there are significant visual differences between the query and support images, as shown in Fig. 1. To address these limitations, the GIM is proposed. The goal of GIM is to generate a more powerful, category-based representation by integrating local region features with global semantic information, thereby improving segmentation performance. This method includes LFG and GIG, which are designed to comprehensively capture fine-grained spatial features and high-level semantic context. The specific algorithm flow is shown in Algorithm 1.

The LFG focuses on capturing features from specific regions in the support image. The support features
where
where
The goal of GIG is to capture the overall semantic information of the target category. By utilizing semantic embeddings associated with category labels, it achieves a semantic representation of the category. The semantic label embedding is generated using a pre-trained word embedding model, converting the category label into a high-dimensional vector representation
where
To ensure that the features generated by LFG and GIG remain semantically consistent, a triplet loss is introduced to compare the generated category prototype
To extract FG features, the features in the FG region where the mask is 1 are considered as
where
The BG samples
where
The GIM integrates local feature extraction with global semantic context information. By using the LFG and the GIG modules, region-specific and category-level features are generated and aligned through triplet loss. This approach demonstrates stronger robustness when handling intra-class variations, significantly improving segmentation accuracy even with a limited number of labeled support images.
3.4 Class Activation Map Aggregation
The CAMA module can further address the intra-class differences of FG in the support set and query set, and accurately locate the targets. This module introduces the CAM from WSSS into few-shot semantic segmentation task for the first time. By using CAM to aggregate query information, it achieves accurate localization of query information, compensating for the inability of few-shot data to cover all semantic concepts and helping to address intra-class differences. The algorithm implementation process is shown in Algorithm 2.

CNN are good at extracting local low-level features but fail to capture more global and semantic features. In contrast, Vision Transformer (ViT) can effectively model long-range dependencies between different regions, thus obtaining richer and more discriminative feature representations. In few-shot learning, where sample data is scarce, introducing ViT based on the self-attention mechanism to extract query features can capture the correlations between samples, thereby better generalizing to new categories.
CAMA first flattens the query features
The output X of ViT block is obtained by concatenating the outputs of each attention head
For the extracted feature map

Figure 4: Calculation process of class activation maps. Each class contributes its required attention parts
During the generation of the class activation map
CAMA aggregates support features
3.5 Self-Cross Attention Block
The SCA Block combines the strengths of Self-Attention and Cross-Attention, specifically tailored to tackle the challenges posed by BG mismatch and ambiguous FG-BG. This module comprises two essential components: Patch Alignment (PA) and Self-Cross Attention (SCA), both aimed at reinforcing the relationship between query and support features in the context of BG discrepancies and FG-BG ambiguities. The algorithm implementation process is shown in Algorithm 3.

The PA aims to mitigate the issues of ineffective support patches and misaligned support patches by aligning each query patch with the support patches. The specific process is as follows: Firstly, the prototype representations of the query patches and support patches are calculated through Patch Average Pooling (PAP). The prototype of each patch only contains foreground information, ensuring that the focus is on the foreground part while ignoring the background. Then, the cosine similarity is used to compute the similarity between the query patch prototypes and support patch prototypes. This similarity measure quantifies the degree of matching between the FG features.
where
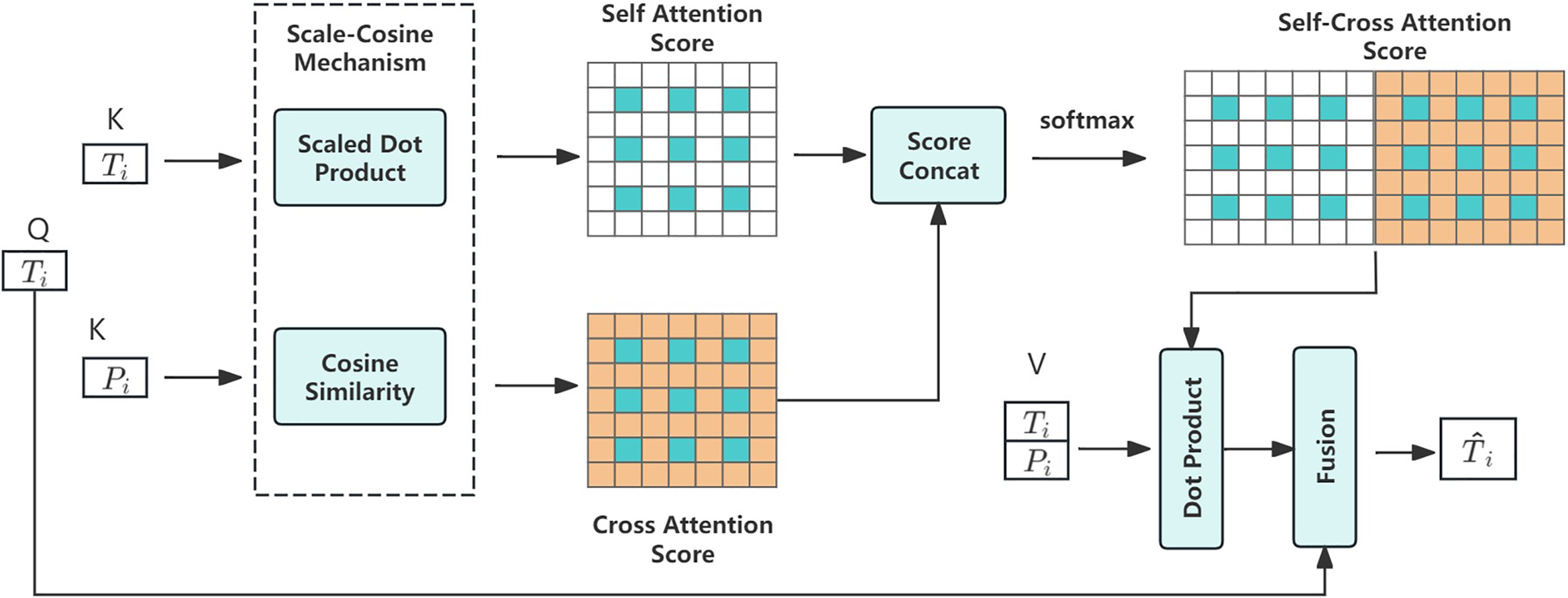
Figure 5: Details of self-cross attention (SCA). Query patch calculates self and cross attention scores with itself and the aligned support patch
The query patches are fused through self-attention and cross-attention. The query patches serve as Q, interacting with the K & V of the support patches to compute attention scores. Self-Attention calculates the relationship between the query patches Q and the query patches K & V using Scaled Dot Product. Cross-Attention computes the relationship between the query patches Q and the aligned support patches K & V using cosine similarity.
To prevent self-attention from overly focusing on the query foreground and ignoring support features, a Scaled Cosine (SC) mechanism is designed. By using Scaled Dot Product to calculate the attention within the query patches themselves and cosine similarity to compute the attention between query patches and aligned support patches, the model is encouraged to better integrate information from the support FG.
The scores are represented as
The attention scores are normalized through a softmax operation, resulting in weighted fused features between the query patches and the support patches.
where
A aggregates the query patches
where FFN stands for Feed-Forward Network. The enhanced query patches are fed into the next SCA Block. Through eight iterative layers of SCA Blocks, the SCA module continuously enhances the similarity and difference between query and support features, thereby improving the feature representation capability in few-shot segmentation tasks. The output of the last SCA Block is then fed into the Feature Fusion Module (FFM) for segmentation.
As shown in the Fig. 6, the SCA module effectively addresses the issues of BG mismatch and ambiguou FG-BG segmentation in FSS by combining PA and SCA. By precisely aligning the query patches with the support patches and enhancing the information interaction between features using self-attention and cross-attention mechanisms, the SCA module significantly boosts the performance of few-shot segmentation tasks. Especially when dealing with complex scenes, it can better capture the similarities and differences between support and query features.
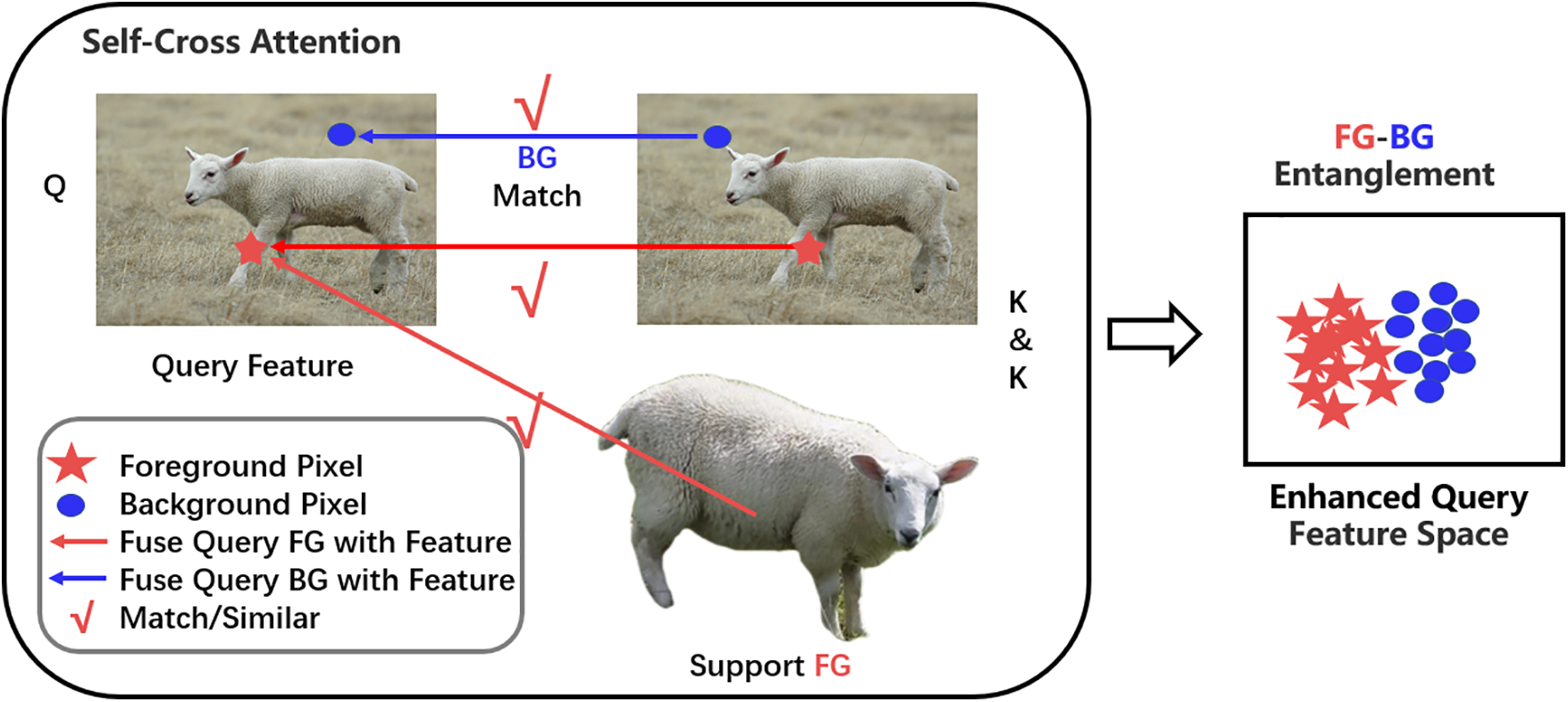
Figure 6: Our proposed self-cross attention. The BG of the query and support sets correctly matches, and the segmentation of the FG and BG in the query set is effective
To aggregate general class information

3.7 Prediction and Training Loss
The loss during the training process consists of segmentation loss and triplet loss. The segmentation loss includes intermediate prediction loss
The core idea of the triplet loss is to learn an embedding space by comparing triplets (anchor, positive, negative) such that similar samples are closer together and dissimilar samples are further apart. The general class information
Datasets. Experiments are conducted on two commonly used few-shot segmentation datasets,
Data Preprocessing and Splitting. The images are uniformly resized to
Data Augmentation. During the training process, data augmentation strategies such as random cropping and random rotation are employed. Random cropping involves randomly selecting a
Evaluation. The current few-shot segmentation algorithms are mostly evaluated using Foreground-Background Intersection over Union (FB-IoU) and mean Intersection over Union (mIoU). The mIoU is calculated by computing the IoU for each class and then averaging over the total number of classes. The formula for Intersection over Union is as follows:
where TP, FP and FN represent true positives, false positives, and false negatives, respectively. Assuming there are classes, the calculation formulas for FB-IoU and mIoU are:
When calculating FB-IoU, only FG and BG classes are considered, so
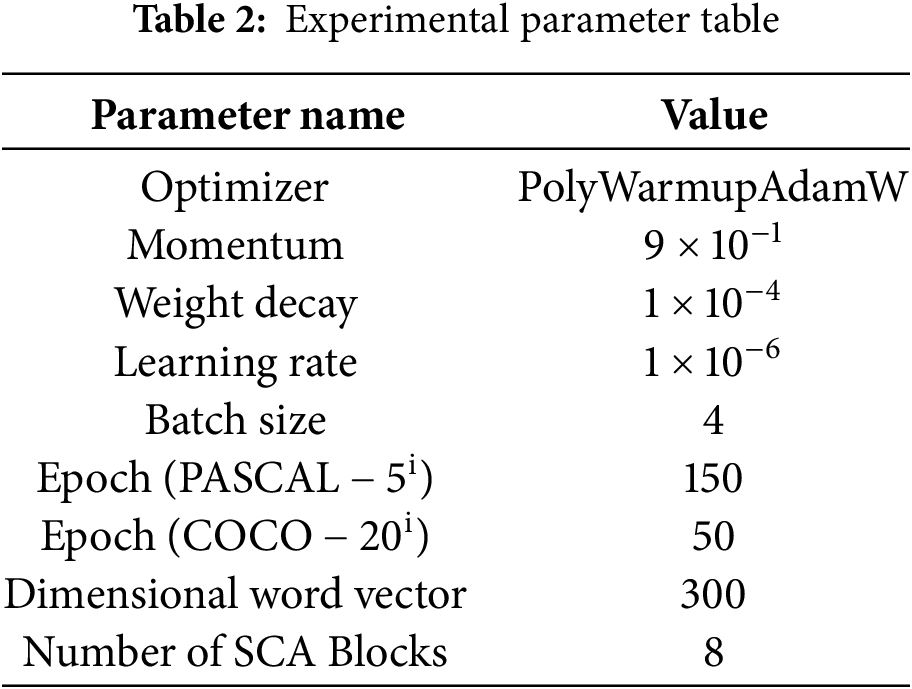
Implementation Details. The PolyWarmupAdamW optimizer is used to optimize the model separately, with an initial learning rate set to 6e-5. During training, the batch size is fixed at 4 to ensure a consistent number of samples processed in each training iteration. In terms of training epochs, the model is trained for 200 epochs on the PASCAL-5i dataset and 50 epochs on the COCO-20i dataset to fully train and test the model’s performance on different datasets. To optimize the model’s segmentation performance, the Dice loss is used as the loss function. Eight SCCA modules are designed, with each module’s window size set to 8 (as specified in the ablation experiments). For category embeddings, the Word2Vec model trained on Google News data is used, and the generated 300-dimensional word vectors are employed to represent categories. In the K-shot learning setting, when k > 1, the features of multiple support images are averaged to enhance the model’s ability to recognize minority classes.
The hyperparameter settings in Table 2 were optimized using a variety of strategies. First, the optimizer incorporates a combination of polynomial learning rate decay and the Warmup strategy to ensure stability during the early stages of training. The momentum and batch size settings were based on references [29] and [35], to meet the task requirements and hardware limitations. The number of training epochs was determined by the size and complexity of the datasets. For the smaller PASCAL-5i dataset, more epochs were required to fully optimize model performance. In contrast, for the larger and more complex COCO-20i dataset, fewer epochs were sufficient to achieve satisfactory results. The number and window size of SCCA modules were determined through extensive experimentation, achieving a practical trade-off between computational cost and performance. For category embeddings, 300-dimensional word vectors generated by Word2Vec were adopted as the default setting, providing a good balance between semantic representation capability and computational efficiency.
4.2 Comparision with State-of-the-Arts
An extensive ablation study was conducted on the dataset in the 1-shot setting to verify the effectiveness of the proposed key modules. The experiments in this section were performed on the dataset using ResNet50 as the backbone network.
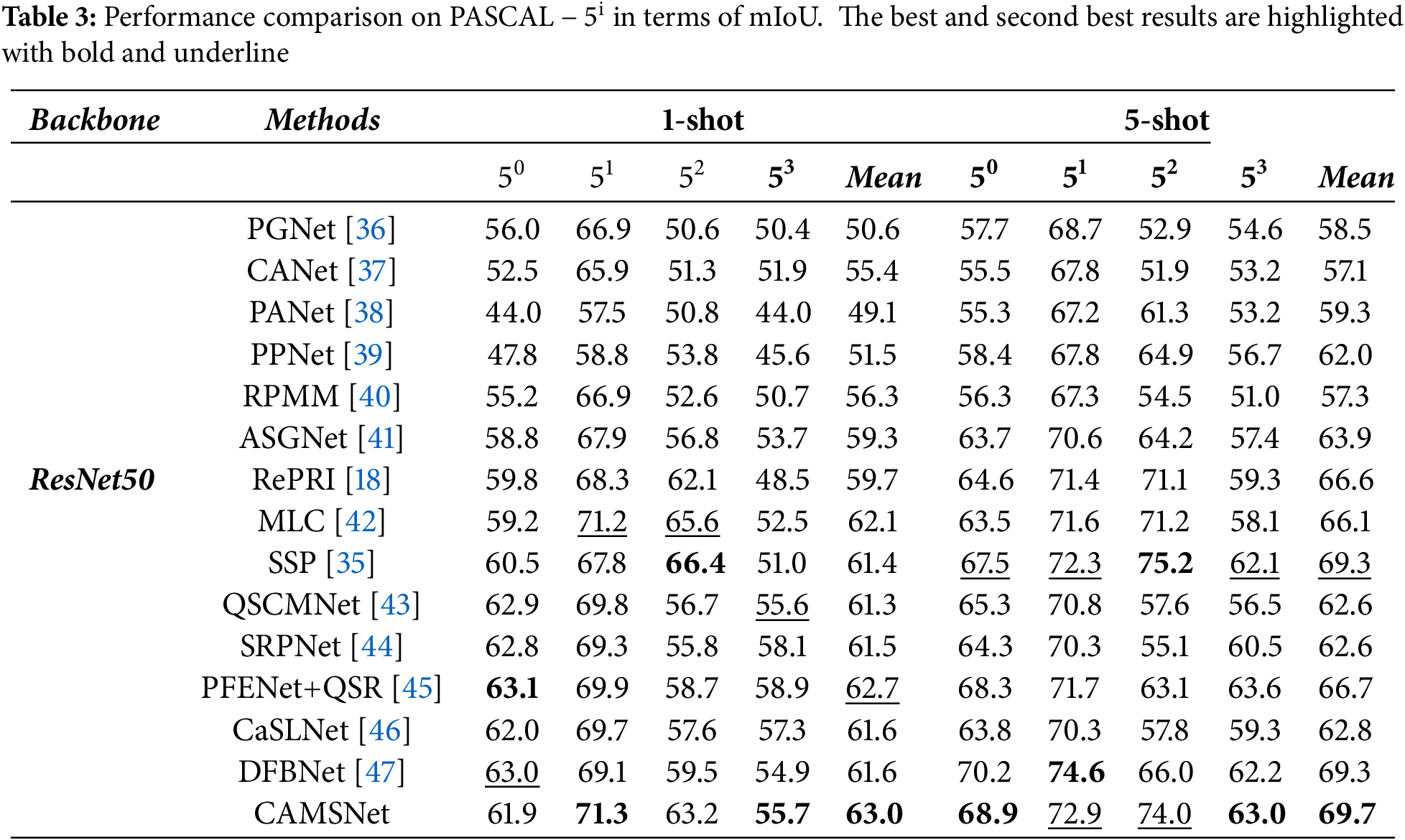
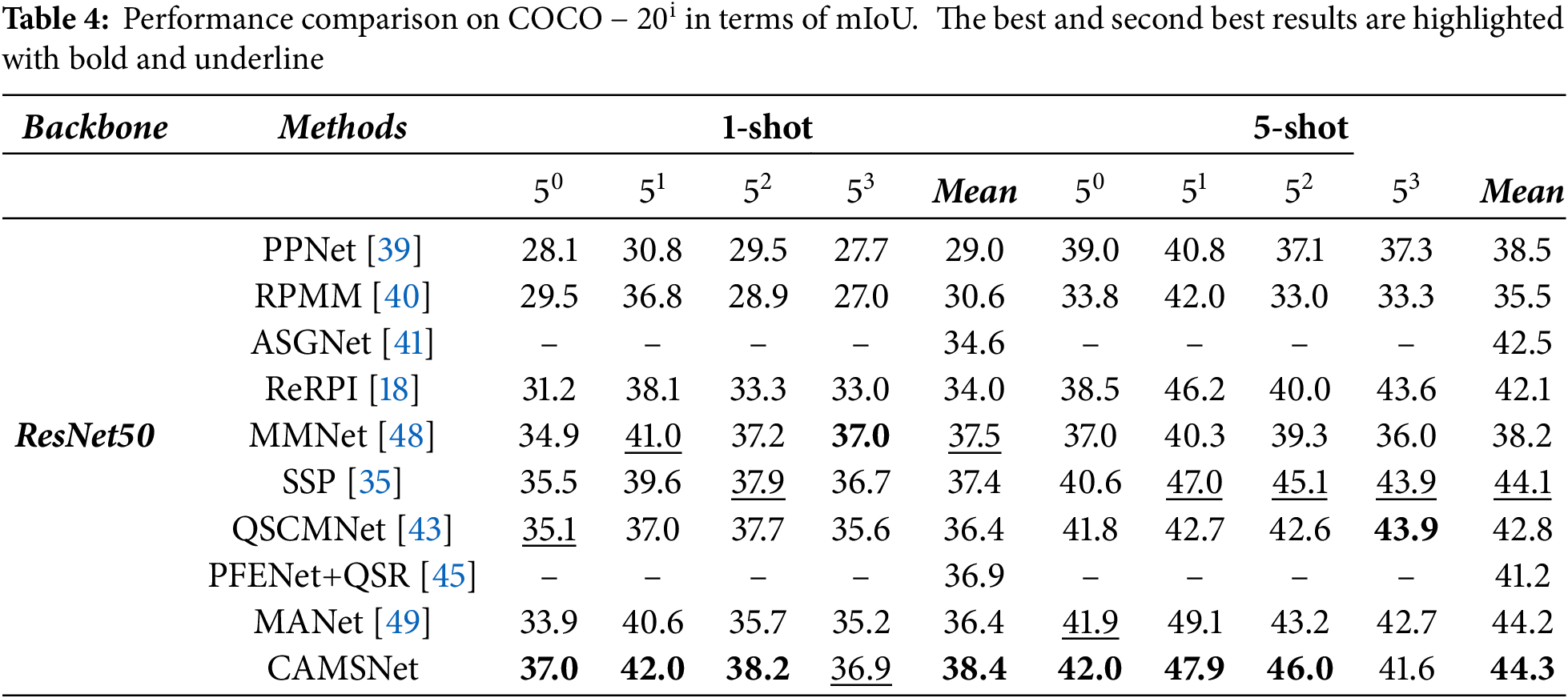
Table 5 illustrates the impact of each component on the model. The three proposed components resulted in an mIoU of 62.5%. Using only the GIM, the mIoU reached 54.7%. With only the CAMA module, the mIoU improved by 3.8% over the former. Using both the GIM and SCA modules resulted in a 6.1% improvement in mIoU compared to using only the GIM. This is because the GIM generates general information, while the SCA module better separates the FG and BG. When all three modules were used together, the mIoU increased by 1.7% compared to using only the GIM and SCA modules. This is because the CAMA module can precisely locate the target, thereby improving accurate segmentation.
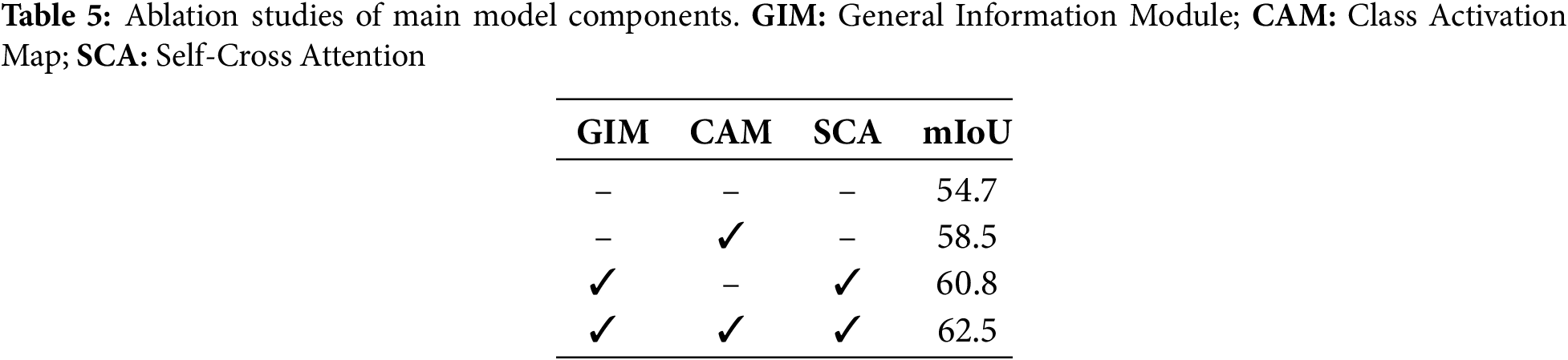
Table 6 shows the impact of different scale CAMs and ViT on the model. Using a single scale CAM resulted in an mIoU of 58.4%. When using multiple scales, the mIoU reached 58.6%. With the addition of ViT and using multiple scales CAM, the mIoU increased to 60.9%. When ViT was added with a single scale CAM, the mIoU reached 62.5%. This is because ViT can capture global features, providing the network with strong global modeling capabilities. However, combining ViT with multiple scale CAMs can lead to overfitting, so using a single scale CAM improved the model’s segmentation ability.

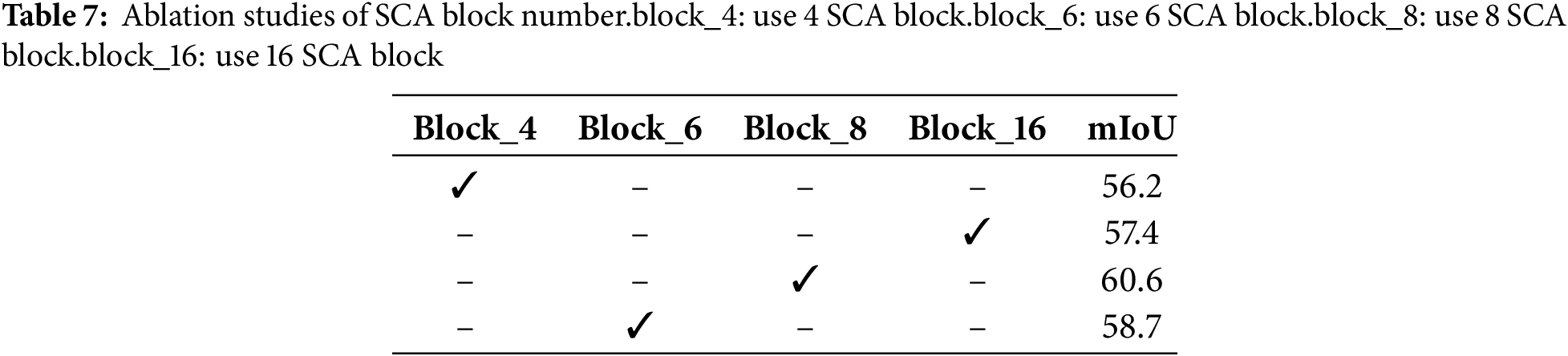
Table 7 demonstrates the impact of the number of SCA Blocks on model performance. When using fewer blocks, the model struggles to capture sufficiently complex features, resulting in lower accuracy and IoU values. As the number of blocks increases, the model’s performance improves, but it still does not reach the optimal level. Eight SCA Blocks represent the optimal configuration, balancing feature extraction and computational efficiency for the best performance. While increasing the number of blocks may further enhance the model’s complexity, setting it to 16 blocks may lead to excessive computational burden and performance degradation, potentially causing overfitting.
To verify the efficiency of ViT in generating CAMs, we conducted a t-test to compare CAMs generated by CNN and ViT. Fig. 7 displays the changes in mIoU. CNNs exhibit a slower initial improvement rate and subsequently plateau, whereas ViTs demonstrate faster growth and surpass CNNs in performance. This result confirms significant differences in mIoU between the two, favoring ViT’s overall superior performance. Therefore, ViT is more suitable for CAM generation due to its faster training speed and higher accuracy.
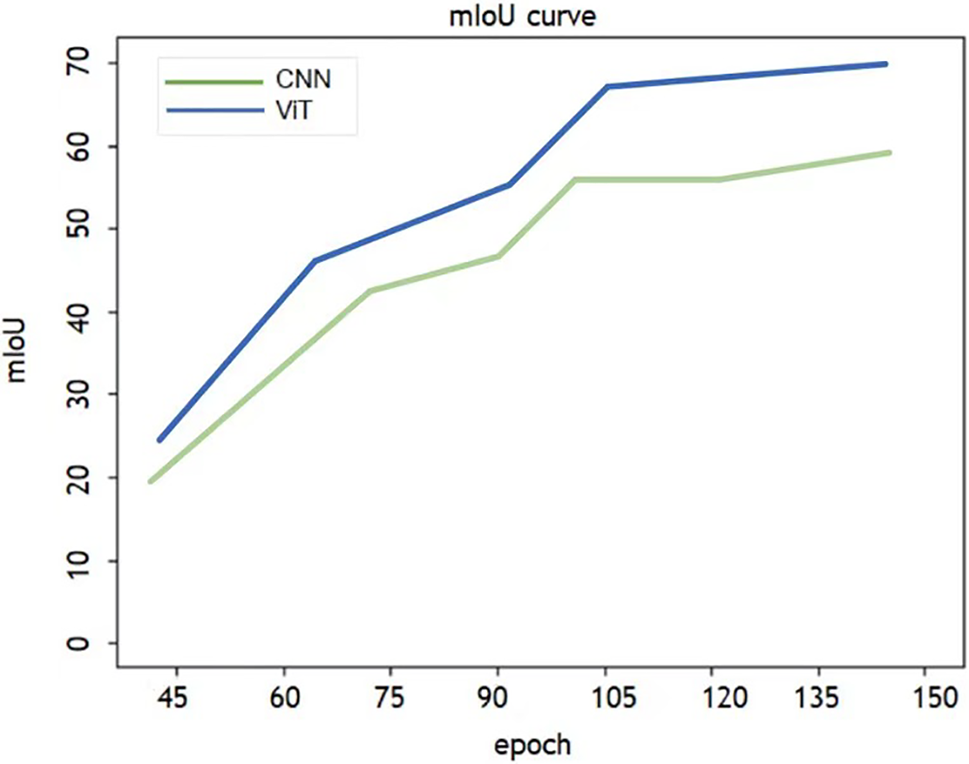
Figure 7: Comparison of the MIoU curves between the models generating CAMs via CNN and ViT
Fig. 8 presents the visualization results of the proposed CAMSNet in the 1-shot setting. The figure demonstrates accurate segmentation for various categories, including sheep, airplane, bird, cat, and bicycle. It shows that even with significant intra-class differences between query samples and the support set (columns 3 and 4), CAMSNet can successfully segment the target objects, highlighting its effectiveness. Additionally, CAMSNet effectively mitigates issues of BG mismatch and ambiguous separation between FG and BG (column 1).

Figure 8: Qualitative results of CAMSNet and baseline on
Fig. 9 illustrates the segmentation effects of different modules. It shows the incremental improvements to the network made by the GIM, CAMA, and SCA Blocks. Specifically, GIM enhances the ability to handle intra-class variance, the addition of CAMA helps in locating the query target, and SCA addresses BG mismatch and ambiguous separation between FG and BG. These results clearly demonstrate the crucial role each component plays in improving overall segmentation performance.

Figure 9: Segmentation effects of different modules
The paper propose a network called CAMSNet, which is composed of four main components: GIM, CAMA, SCA Block, and FFM, designed for FSS. The GIM generates general class information, helping to address intra-class differences. The CAMA utilizes CAM to create pseudo-masks for precise localization, deviating from the traditional use of cosine similarity for pseudo-mask generation. The SCA employs an improved self-cross attention to resolve issues of BG mismatch and ambiguous FG-BG segmentation. The FFM aggregates the general class information from the GIM and the enhanced query information from the SCA to facilitate precise segmentation. Extensive experiments on the dataset
Acknowledgement: We sincerely thank the National Natural Science Foundation of China, the Research Programs of Henan Provincial Science and Technology Department, the Chongqing Natural Science Foundation Committee, the Henan Provincial Key Research and Development Projects, the Aviation Science Foundation Committee, and the Henan Center for Outstanding Overseas Scientists for their financial support.
Funding Statement: The study has been supported by funding from the following sources: National Natural Science Foundation of China (U1904119); Research Programs of Henan Science and Technology Department (232102210033; 232102210054); Chongqing Natural Science Foundation (CSTB2023NSCQ-MSX0070); Henan Province Key Research and Development Project (231111212000); Aviation Science Foundation (20230001055002); supported by Henan Center for Outstanding Overseas Scientists (GZS2022011).
Author Contributions: The authors confirm contribution to the paper as follows: Jingjing Yan: Designed algorithms for research, wrote the paper. Xuyang Zhuang: Revised the manuscript, supervised the project. Xuezhuan Zhao: Research methodology, set the progress schedule. Xiaoyan Shao: Provided algorithmic support. Jiaqi Han: Revised the manuscript. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Li G, Wang X, Li Y, Li Z. Adaptive clustering object detection method for UAV images under long-tailed distributions. Inform Technol Cont. 2023;52(4):1025–44. doi:10.5755/j01.itc.52.4.33460. [Google Scholar] [CrossRef]
2. Zhou T, Wang W, Konukoglu E, Van Gool L. Rethinking semantic segmentation: a prototype view. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 2582–93. [Google Scholar]
3. Shaban A, Bansal S, Liu Z, Essa I, Boots B. One-shot learning for semantic segmentation. arXiv:170903410. 2017. [Google Scholar]
4. Catalano N, Matteucci M. Few shot semantic segmentation: a review of methodologies and open challenges. arXiv:230405832. 2023. [Google Scholar]
5. Zha Z, Tang H, Sun Y, Tang J. Boosting few-shot fine-grained recognition with background suppression and foreground alignment. IEEE Transact Circ Syst Video Technol. 2023;33(8):3947–61. doi:10.1109/TCSVT.2023.3236636. [Google Scholar] [CrossRef]
6. Liu G, Zhao L, Li W, Guo D, Fang X. Class-wise metric scaling for improved few-shot classification. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2021. p. 586–95. [Google Scholar]
7. Boudiaf M, Ziko I, Rony J, Dolz J, Piantanida P, Ben Ayed I. Information maximization for few-shot learning. Adv Neural Inform Process Syst. 2020;33:2445–57. [Google Scholar]
8. Wang J, Li J, Chen C, Zhang Y, Shen H, Zhang T. Adaptive FSS: a novel few-shot segmentation framework via prototype enhancement. Proc AAAI Conf Artif Intell. 2024;38:5463–71. [Google Scholar]
9. Liu Y, Liu N, Cao Q, Yao X, Han J, Shao L. Learning non-target knowledge for few-shot semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 11573–82. [Google Scholar]
10. An Z, Sun G, Liu Y, Liu F, Wu Z, Wang D, et al. Rethinking few-shot 3D point cloud semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3996–4006. [Google Scholar]
11. Nguyen K, Todorovic S. Feature weighting and boosting for few-shot segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2019. p. 622–31. [Google Scholar]
12. Thisanke H, Deshan C, Chamith K, Seneviratne S, Vidanaarachchi R, Herath D. Semantic segmentation using vision transformers: a survey. Eng Appl Artif Intell. 2023;126:106669. doi:10.1016/j.engappai.2023.106669. [Google Scholar] [CrossRef]
13. Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2015. p. 3431–40. [Google Scholar]
14. Tian Z, Zhao H, Shu M, Yang Z, Li R, Jia J. Prior guided feature enrichment network for few-shot segmentation. IEEE Transact Pattern Anal Mach Intell. 2020;44(2):1050–65. doi:10.1109/TPAMI.2020.3013717. [Google Scholar] [PubMed] [CrossRef]
15. Chen Y, Wan L, Li S, Liao L. AMF-SparseInst: attention-guided multi-scale feature fusion network based on sparseInst. Inform Technol Control. 2024;53(3):675–94. doi:10.5755/j01.itc.53.3.35588. [Google Scholar] [CrossRef]
16. Liu L, Ke C, Lin H. Mobile-deep based PCB image segmentation algorithm research. Comput Mater Contin. 2023;77(2):2443–61. doi:10.32604/cmc.2023.042582. [Google Scholar] [CrossRef]
17. Lu Z, He S, Zhu X, Zhang L, Song YZ, Xiang T. Simpler is better: few-shot semantic segmentation with classifier weight transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2021. p. 8741–50. [Google Scholar]
18. Boudiaf M, Kervadec H, Masud ZI, Piantanida P, Ben Ayed I, Dolz J. Few-shot segmentation without meta-learning: a good transductive inference is all you need?. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 13979–88. [Google Scholar]
19. Lang C, Cheng G, Tu B, Han J. Learning what not to segment: a new perspective on few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 8057–67. [Google Scholar]
20. Yang Y, Chen Q, Feng Y, Huang T. MIANet: aggregating unbiased instance and general information for few-shot semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023. p. 7131–40. [Google Scholar]
21. Wang J, Zhang B, Pang J, Chen H, Liu W. Rethinking prior information generation with CLIP for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3941–51. [Google Scholar]
22. Zhu L, Chen T, Ji D, Ye J, Liu J. LLaFS: when large language models meet few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3065–75. [Google Scholar]
23. Wang H, Wang Z, Du M, Yang F, Zhang Z, Ding S, et al. Score-CAM: score-weighted visual explanations for convolutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR); 2020. p. 24–5. [Google Scholar]
24. Rajkumar R, Shanthi D, Manivannan K. Efficient guided grad-CAM tuned patch neural network for accurate anomaly detection in full images. Inform Technol Control. 2024;53(2):355–71. doi:10.5755/j01.itc.53.2.34525. [Google Scholar] [CrossRef]
25. Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Interpreting deep neural networks with layer-wise relevance propagation. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV); 2020. p. 147–56. [Google Scholar]
26. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2021. p. 10012–22. [Google Scholar]
27. Zhu J, Ma Y, Huang J, Wang L. Image segmentation combining pulse coupled neural network and adaptive glowworm algorithm. Inform Technol Control. 2023;52(2):487–99. doi:10.5755/j01.itc.52.2.33415. [Google Scholar] [CrossRef]
28. Xie X, Chen X, Zhang W, Xu Y. Feature fusion for few-shot semantic segmentation. IEEE Transact Pattern Anal Mach Intell. 2021;43(7):1607–17. [Google Scholar]
29. Wang H, Liu Y, Li Z. Cross-attention for few-shot segmentation. IEEE Transact Image Process. 2022;31:1121–32. [Google Scholar]
30. Zhang Y, Wei L, Luo W. Hierarchical feature fusion for semantic segmentation. Comput Vis Image Underst. 2023;195:103432. [Google Scholar]
31. Ru L, Zhan Y, Yu B, Du B. Learning affinity from attention: end-to-end weakly-supervised semantic segmentation with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 16846–55. [Google Scholar]
32. Zhang G, Kang G, Yang Y, Wei Y. Few-shot segmentation via cycle-consistent transformer. Adv Neural Inform Process Syst. 2021;34:21984–96. [Google Scholar]
33. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16x16 words: transformers for image recognition at scale. arXiv:201011929. 2020. [Google Scholar]
34. Zhang B, Xiao J, Qin T. Self-guided and cross-guided learning for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 8312–21. [Google Scholar]
35. Fan Q, Pei W, Tai YW, Tang CK. Self-support few-shot semantic segmentation. In: European Conference on Computer Vision; 2022; Cham: Springer Nature Switzerland. p. 701–19. [Google Scholar]
36. Zhang C, Lin G, Liu F, Guo J, Wu Q, Yao R. Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2019. p. 9587–95. [Google Scholar]
37. Zhang C, Lin G, Liu F, Yao R, Shen C. Canet: class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019. p. 5217–26. [Google Scholar]
38. Wang K, Liew JH, Zou Y, Zhou D, Feng J. Panet: few-shot image semantic segmentation with prototype alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2019. p. 9197–206. [Google Scholar]
39. Liu Y, Zhang X, Zhang S, He X. Part-aware prototype network for few-shot semantic segmentation. In: Computer Vision–ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK: Springer; p. 142–58. [Google Scholar]
40. Yang B, Liu C, Li B, Jiao J, Ye Q. Prototype mixture models for few-shot semantic segmentation. In: Computer Vision–ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK: Springer; p. 763–78. [Google Scholar]
41. Li G, Jampani V, Sevilla-Lara L, Sun D, Kim J, Kim J. Adaptive prototype learning and allocation for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 8334–43. [Google Scholar]
42. Yang L, Zhuo W, Qi L, Shi Y, Gao Y. Mining latent classes for few-shot segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2021. p. 8721–30. [Google Scholar]
43. Shao J, Gong B, Chen JY. Query-support semantic correlation mining for few-shot segmentation. Eng Appl Artif Intell: Int J Intell Real-Time Automat. 2023;126:106797. doi:10.1016/j.engappai.2023.106797. [Google Scholar] [CrossRef]
44. Ding H, Zhang H, Jiang X. Self-regularized prototypical network for few-shot semantic segmentation. Pattern Recognit. 2023;133(9):109018. doi:10.1016/j.patcog.2022.109018. [Google Scholar] [CrossRef]
45. Guan H, Spratling M. Query semantic reconstruction for background in few-shot segmentation. Visual Comput. 2024;40(2):799–810. doi:10.1007/s00371-023-02817-x. [Google Scholar] [CrossRef]
46. Sun H, Zhang Z, Huang L, Jiang B, Luo B. Category-aware siamese learning network for few-shot segmentation. Cognit Comput. 2024;16(3):924–35. doi:10.1007/s12559-024-10273-5. [Google Scholar] [CrossRef]
47. Jiang C, Zhou Y, Liu Z, Feng C, Li W, Yang J. Learning discriminative foreground-and-background features for few-shot segmentation. Multimed Tools Appl. 2024;83(18):55999–6019. doi:10.1007/s11042-023-17708-5. [Google Scholar] [CrossRef]
48. Wu Z, Shi X, Lin G, Cai J. Learning meta-class memory for few-shot semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2021. p. 517–26. [Google Scholar]
49. Ao W, Zheng S, Meng Y, Yang Y. Few-shot semantic segmentation via mask aggregation. Neural Process Lett. 2024;56(2):56. doi:10.1007/s11063-024-11511-5. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools