
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
LLE-Fuse: Lightweight Infrared and Visible Light Image Fusion Based on Low-Light Image Enhancement
Faculty of Information Engineering, Xinjiang Institute of Technology, Aksu, 843100, China
* Corresponding Author: Shuping Zhang. Email:
Computers, Materials & Continua 2025, 82(3), 4069-4091. https://doi.org/10.32604/cmc.2025.059931
Received 20 October 2024; Accepted 16 December 2024; Issue published 06 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Infrared and visible light image fusion technology integrates feature information from two different modalities into a fused image to obtain more comprehensive information. However, in low-light scenarios, the illumination degradation of visible light images makes it difficult for existing fusion methods to extract texture detail information from the scene. At this time, relying solely on the target saliency information provided by infrared images is far from sufficient. To address this challenge, this paper proposes a lightweight infrared and visible light image fusion method based on low-light enhancement, named LLE-Fuse. The method is based on the improvement of the MobileOne Block, using the Edge-MobileOne Block embedded with the Sobel operator to perform feature extraction and downsampling on the source images. The intermediate features at different scales obtained are then fused by a cross-modal attention fusion module. In addition, the Contrast Limited Adaptive Histogram Equalization (CLAHE) algorithm is used for image enhancement of both infrared and visible light images, guiding the network model to learn low-light enhancement capabilities through enhancement loss. Upon completion of network training, the Edge-MobileOne Block is optimized into a direct connection structure similar to MobileNetV1 through structural reparameterization, effectively reducing computational resource consumption. Finally, after extensive experimental comparisons, our method achieved improvements of 4.6%, 40.5%, 156.9%, 9.2%, and 98.6% in the evaluation metrics Standard Deviation (SD), Visual Information Fidelity (VIF), Entropy (EN), and Spatial Frequency (SF), respectively, compared to the best results of the compared algorithms, while only being 1.5 ms/it slower in computation speed than the fastest method.Keywords
The distinct working principles of various imaging modalities lead to unique characteristics in the scenes they capture [1]. Visible light images capture light reflected from objects, offering rich texture and structural details, alongside an intuitive visual experience. However, their reliance on ambient lighting makes them vulnerable to environmental factors, such as smoke, which can compromise image quality and usability. In contrast, infrared images are generated by detecting thermal radiation emitted by objects, enabling consistent image quality across different conditions, independent of external light sources. Despite their advantages, infrared images often exhibit lower resolution and a lack of intricate background textures, limiting their effectiveness in some applications. By merging infrared and visible light images, it is possible to harness the complementary strengths of both modalities, resulting in a fused image that combines information from each source [2]. This integrated image not only retains rich scene details but also enhances target recognition and clarity. Consequently, such fusion significantly improves the comprehensiveness and accuracy of visual information, thereby increasing the practical value of the images.
Fig. 1 provides an example of a low-light scenario. In Fig. 1a, the visible and infrared images captured under low illumination are presented. The result shown in Fig. 1b stems from a contemporary image fusion technique, which, when confronted with inadequate lighting, leads to substantial degradation in the visible light image, thus lacking sufficient detail for effective fusion. Although Fig. 1c displays the results after enhancing the low-light image with the advanced Zero-DCE (Zero-Reference Deep Curve Estimation) enhancement algorithm [3] prior to fusion, it still falls short of producing a visually satisfying outcome. In contrast, Fig. 1e illustrates the result from the proposed algorithm, which significantly enhances visual quality. Additionally, Fig. 1d,f demonstrates the performance of the YOLOv5s (You Only Look Once) detection algorithm [4] in Fig. 1c,e, respectively, revealing that the proposed method achieves superior pedestrian identification. An effective image fusion approach should not only aim for aesthetic quality but also ensure the preservation of essential information from the source images while highlighting critical targets. This balance is vital for facilitating higher-level visual tasks, such as target detection. By catering to the needs of both human and machine perception, image fusion technology can greatly expand its utility across various practical applications, including pedestrian re-identification [5], target detection [6], and semantic segmentation [7].

Figure 1: Fusion and target detection results in the LLVIP’s (Visible-infrared paired dataset for low-light vision) low-light scenario #010042 using ICAFusion (Iterative cross-attention guided feature fusion) and the method proposed in this paper
Recently, the integration of deep learning into image fusion has significantly transformed the field, moving away from conventional techniques like multi-scale transformation [8], subspace transformation [9], sparse representation [10], and saliency analysis [11]. These new methods typically offer superior visual outcomes. Deep learning-based fusion approaches can be classified into four primary categories: autoencoder (AE)-based, convolutional neural network (CNN)-based, generative adversarial network (GAN)-based, and unified architecture-based techniques. In the initial phase of combining deep learning with image fusion, AE-based methods relied on pre-trained encoders and decoders for extracting features and reconstructing images, applying specific strategies for fusing these features. On the other hand, CNN-based approaches execute feature extraction, fusion, and reconstruction in a seamless end-to-end process, leveraging carefully designed network architectures and customized loss functions to produce unique fusion effects. Furthermore, GAN-based methods enhance CNN techniques by adding a generative adversarial component, where the generator and discriminator engage in adversarial training, allowing the fusion outputs to approximate the source images’ probability distribution in an unsupervised context.
While current deep learning-based fusion techniques are capable of effectively merging the complementary information from infrared and visible light images, several challenges remain unresolved. One key issue is that many existing methods operate on the premise that texture details primarily originate from visible light images, while salient features are sourced from infrared images. This assumption is valid under typical lighting conditions; however, in low-light or nighttime environments, the absence of sufficient illumination leads to significant degradation in visible light image quality, often obscuring crucial texture details. Consequently, these fusion methods struggle to retrieve necessary texture information, which ultimately compromises the quality of the fused output. One approach to mitigate this issue is to apply advanced low-light enhancement algorithms to improve the quality of visible light images before fusing them with infrared data. However, such enhancements can create compatibility challenges, as illustrated in Fig. 1c, where the low-light enhancement algorithm modifies the color distribution of light sources, potentially exacerbating the problem. Furthermore, using stacked network models that are tailored for different tasks may hinder the practical application and advancement of image fusion techniques. Thus, there remains a significant need to focus on designing lightweight network architectures that can address these concerns more effectively.
To address the shortcomings of current image fusion algorithms, we present a novel lightweight network for fusing infrared and visible light images, termed LLE-Fuse, specifically designed for low-light enhancement. The proposed method features a dual-branch architecture that separately extracts features from infrared and visible light images while performing downsampling at various levels. These multi-scale features are then combined through a cross-modal attention fusion module. The fused information is subsequently used to reconstruct the final image via an upsampling network. In addition, the CLAHE algorithm is employed to enhance both infrared and visible light images. The network is trained to improve its capabilities in enhancing and fusing images under low-light conditions by utilizing a combination of enhancement loss and correlation loss. To further enhance the network’s representational power while keeping it lightweight, an Edge-MobileOne Block is introduced based on structural re-parameterization, functioning as both the encoder and decoder. This design aims to boost fusion performance without incurring additional computational costs during inference. The primary contributions of this paper are summarized as follows:
• This paper proposes a lightweight infrared and visible light image fusion framework based on low-light enhancement (LLE-Fuse), which can rapidly enhance the visual perception of low-light scenes, generating fused images with high contrast and clear textures.
• This paper introduces an enhancement loss designed to guide the network model to learn the intensity distribution and edge gradients of CLAHE-enhanced results, thereby enabling the model to end-to-end generate fused images with low-light enhancement effects. This effect does not incur additional computational costs during the testing phase.
• This paper designs the Edge-MobileOne Block (EMB) as the encoder and decoder of the network model, significantly improving fusion performance without increasing the computational burden during the inference phase. Additionally, this paper designs a Cross-Modality Attention Fusion Module (CMAM) that effectively integrates information from heterogeneous image modalities.
The remainder of this paper is organized as follows. In Section 2, we provide a brief overview of the related work in image fusion and low-light enhancement. Section 3 delves into a detailed exposition of the proposed LLE-Fuse, including its specific modules. Section 4 presents an extensive experimental comparison demonstrating the superior performance of our method in comparison to other approaches, followed by a summary in Section 5.
2.1 Deep Learning-Based Fusion Methods
Methods based on autoencoder (AE) leverage a pre-trained encoder and decoder to facilitate feature extraction and image reconstruction. These methods utilize custom-designed fusion rules tailored to the specific attributes of the source images, ensuring the effective completion of the fusion process. A notable example of an AE-based fusion method is DenseFuse [12], which incorporates DenseNet [13] as its backbone and employs addition and l1-Norm as its fusion strategies. To further enhance the feature extraction capabilities of the autoencoder architecture, Li et al. [14] introduced NestFuse. This approach features a nested connection encoder and a spatial channel attention fusion module, allowing the network to capture finer detail features more effectively. Additionally, Li et al. [15] developed RFN-Nest, which utilizes residual fusion networks along with detail preservation and feature enhancement loss functions to ensure that rich texture details are maintained in the fusion outputs. Recognizing the interpretability challenges associated with fusion strategies, Xu et al. [16] proposed a learnable fusion rule designed to assess the significance of each pixel concerning classification outcomes, thereby enhancing the interpretability of the fusion network. Furthermore, the MUFusion method introduced by Cheng et al. [17] addresses the severe degradation issues encountered during training by implementing an adaptive loss function that combines content loss with memory loss.
Methods for fusing infrared and visible light images that are based on convolutional neural networks (CNNs) utilize intricate loss functions and sophisticated network architectures to facilitate feature extraction, integration, and reconstruction. For instance, STDFusionNet [18] incorporates saliency target masks to enhance the fusion process, which helps in better preserving essential features from the images. RXDNFuse [19] merges the structural benefits of ResNet (Residual Network) [20] and DenseNet [13], enabling more comprehensive multi-scale feature extraction for effective image fusion. Li et al. [21] implemented a meta-learning strategy, allowing a single CNN model to perform image fusion across various resolutions, significantly improving the model’s adaptability. Additionally, Tang et al. [22] proposed a novel semantic loss function aimed at enhancing the suitability of fused images for high-level visual tasks. In subsequent work, Tang et al. [23] revisited the integration of image fusion models with those designed for high-level visual tasks to further enhance fusion performance. Therefore, evaluating image fusion should encompass not only the visual quality and performance metrics of the results but also consider the requirements of machine vision for future high-level tasks.
Given their ability to estimate probability distributions in unsupervised learning, generative adversarial networks (GANs) have emerged as promising tools for various applications, including image fusion. FusionGAN [24] was the pioneering model to leverage GAN technology for this purpose, establishing a generative adversarial framework that enhances the textural representation of the fused images. However, relying solely on this adversarial approach can result in imbalances between the modalities in the fusion output. To tackle this issue, Ma et al. [25] introduced a dual discriminator conditional generative adversarial network (DDcGAN), which integrates both infrared and visible light images into the adversarial training process, thereby achieving a more balanced fusion outcome. Expanding on the DDcGAN concept, AttentionFGAN [26] incorporated a multi-scale attention mechanism designed to better retain foreground target information from infrared images while preserving background details from visible light images. Although training models with dual discriminators present certain complexities, Ma et al. [27] further advanced the field by proposing a GAN framework that employs multi-class constraints to effectively balance the information derived from both infrared and visible light images. Despite these advancements in visual quality, many of these methods do not fully account for how the fusion results impact subsequent high-level visual tasks. To address this gap, Liu et al. [28] developed a model that merges fusion with detection, employing a dual-layer optimization strategy. This paper aims to achieve optimal fusion results by meticulously designing a range of network architectures and loss functions, enabling CNN-based methods to implement image fusion with low-light enhancement effects.
2.2 Low-Light Scenarios-Based Fusion Methods
In scenarios where lighting conditions are inadequate, visible light images frequently undergo significant degradation during nighttime, complicating the task for current fusion methods to extract detailed texture information effectively. This often results in low-quality fused images. Research specifically addressing low-light image fusion within the image fusion domain remains sparse. For example, PIAFusion [29] acknowledges lighting conditions but relies on a simplified model that fails to adjust effectively to complex lighting environments. To counteract the detrimental effects of low light, Liu et al. [30] incorporated a visual enhancement module following the fusion network, enhancing the representation of image information. Additionally, Tang et al. [31] developed the first architecture dedicated to scene illumination fusion, which integrates low-light enhancement with dual-modality fusion to yield more informative fused images, thereby enhancing performance in subsequent visual tasks. Furthermore, Chang et al. [32] proposed an image decomposition network aimed at correcting the illumination component of the fused image, leading to improved fusion quality.
Additionally, the aforementioned fusion methods tailored for low-light scenarios primarily achieve image fusion by connecting two distinct network pipelines, each designed for different tasks. However, this type of solution often employs complex network models and loss functions to constrain the final fusion outcome, potentially leading to increased computational demands. This could limit the practical application of image fusion in real-world scenarios.
2.3 Lightweight-Based Fusion Methods
Currently, research on lightweight fusion model-based studies primarily focuses on designing network models that reduce model parameters and convolutional dimension channels. IFCNN [33] achieves feature extraction and image reconstruction with only two convolutional layers in both the encoder and decoder, adjusting fusion rules based on the type of source images to implement a unified network for various fusion tasks. PMGI [34] extracts information through gradient and intensity ratio preservation, reusing, and fusing features extracted from each convolutional layer. SDNet [35] addresses fusion tasks by reconstructing the generated fusion image into the squeezed network structure of the source images, forcing the fusion image to contain more information from the source images. SeAFusion [23] performs feature extraction through gradient residual dense blocks and guides the training of the fusion network using semantic segmentation task losses. FLFuse [36] completes the generation of fusion images in a lightweight and rapid manner through a weight-sharing encoder and feature exchange training strategy. However, these methods, in pursuit of lightweight design, set the network channel dimensions to be relatively shallow and employ simple fusion strategies, which fail to fully extract and fuse image features, resulting in poor performance in visual effects and performance metrics. Secondly, these overly simplistic network structures are not conducive to the training of deep learning networks, but overly complex networks are difficult to lightweight, requiring an effective method to balance the two. Structural re-parameterization technology, represented by RepVGG [37], is a new method characterized by high performance during the training phase and fast speed during the inference phase, achieving good results in multiple advanced visual tasks. However, directly using structural re-parameterization blocks designed for advanced visual tasks brings little improvement to the fusion task of infrared and visible light images. Therefore, targeted structural re-parameterization modules need to be designed for the fusion task to rapidly extract feature information from the source images.
To tackle those challenges, this paper explicitly adopts the principle of lightweight models in network design, employing simpler and more effective approaches to accomplish the task of low-light image fusion.
In low-light conditions, visible light images often suffer from illumination degradation, leading to challenges for existing fusion algorithms in effectively extracting background texture details. Simply relying on infrared images to compensate for this loss proves inadequate. Consequently, the critical challenge in fusing infrared and visible light images at night lies in efficiently utilizing the information from the source images to guide the fusion network toward producing higher-quality results. One straightforward yet effective approach to address this issue is through histogram equalization. In this context, the present study employs Contrast Limited Adaptive Histogram Equalization (CLAHE) [38] for enhancing both infrared and visible light images. The network model is directed by the loss function to produce fusion images with similar characteristics, enabling it to learn low-light enhancement capabilities without adding to the inference workload.
This section aims to clarify the function of CLAHE in enhancing infrared and visible light images by showcasing visual results related to image intensity and edge details. In particular, for a registered pair of low-light infrared and visible light images, the maximum intensity and gradient outcomes derived during the computation of intensity loss and gradient loss can be expressed as follows:
In the equation,
Most fusion algorithms are designed based on the assumption that visible images contain a wealth of background texture details and that they have prominent target information. This assumption holds true in most imaging environments with sufficient lighting. However, in low-light scenarios, visible images suffer from severe degradation and are unable to provide effective texture detail information. Consequently, models trained under such conditions are inevitably incapable of generating high-quality fusion images.
To better utilize the information obscured in low-light scene images, enhancing visible light images with low-light enhancement techniques is a widely adopted strategy. Among these, Contrast Limited Adaptive Histogram Equalization (CLAHE) stands out as a straightforward yet highly effective method for low-light enhancement. It significantly boosts image contrast and improves overall visual quality. Following the enhancement of both infrared and visible light images using CLAHE, the next step involves calculating the maximum intensity and maximum gradient results, which can be expressed as follows:
Fig. 2 provides an example of a typical low-light scenario, illustrating the comparison of intensity and gradient before and after processing infrared and visible light images with CLAHE.

Figure 2: Intensity and gradient comparison of infrared and visible light images before and after CLAHE processing
Fig. 2 illustrates that both Fig. 2c,d exhibit superior visual quality compared to Fig. 2a,b. This indicates that the CLAHE method effectively enhances both infrared and visible light images in low-light conditions, significantly enriching the texture detail of the scene. Consequently, this study will utilize the images in Fig. 2k,l as pseudo-labels for the fusion network. By assessing the intensity distribution and edge gradients between the fusion image and the pseudo-label via an enhancement loss, the network can acquire low-light enhancement capabilities akin to those of the CLAHE method. This process enables the network to not only integrate information from both infrared and visible light images but also to better tackle fusion challenges in low-light scenarios. Furthermore, this method of guiding network training with a loss function ensures that the fusion network achieves low-light enhancement effects without incurring additional computational costs.
To improve the network model’s representational capability while adhering to lightweight requirements, the LLE-Fuse framework is illustrated in Fig. 3. This framework effectively and efficiently carries out the image fusion task in a streamlined manner.
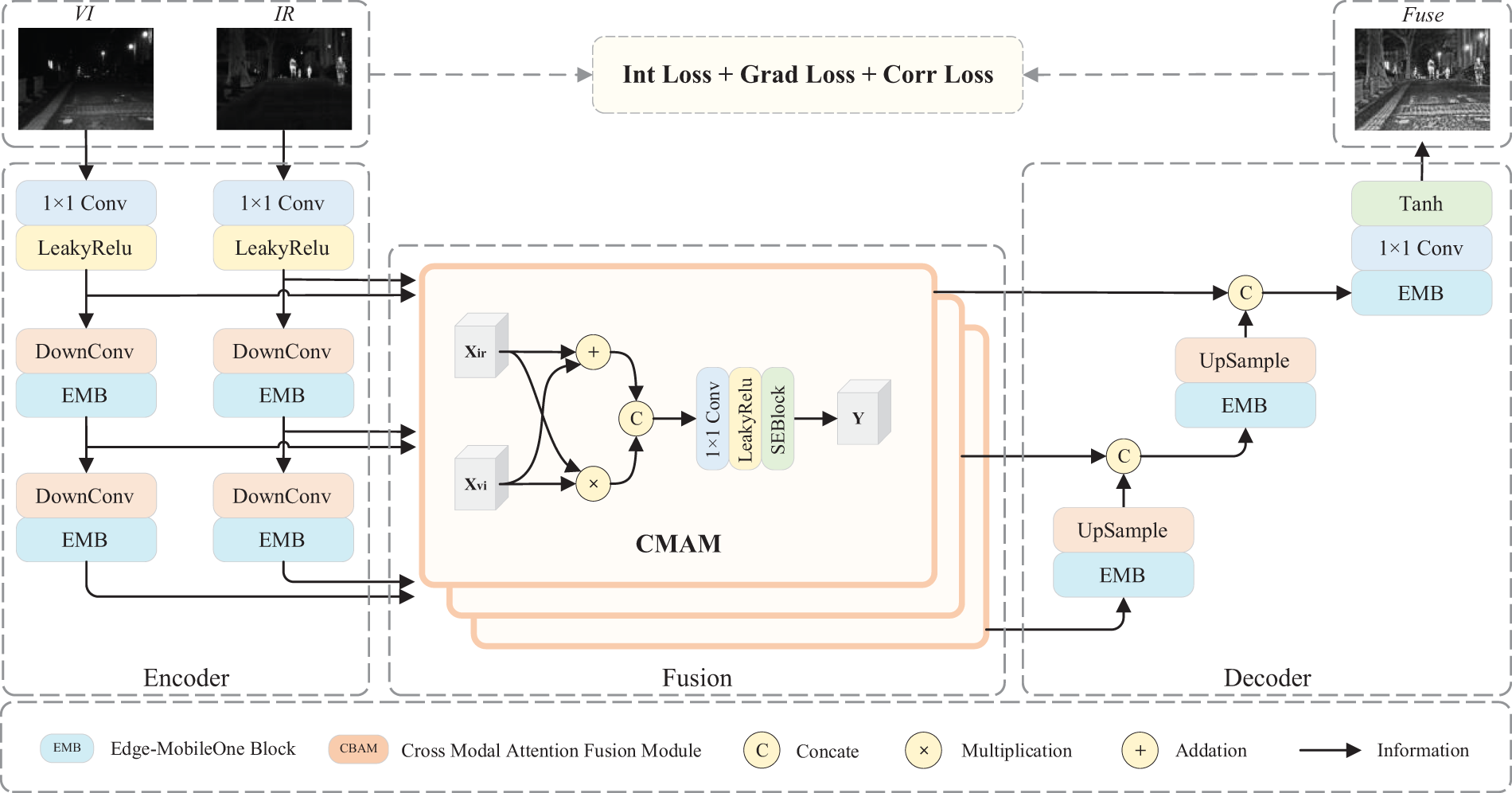
Figure 3: The overall network framework of LLE-Fuse comprises the Edge-MobileOne Block (EMB) and the Cross-Modal Attention Fusion Module (CMAM)
During the training process, the network receives infrared and visible light images through separate branches for feature extraction. The initial step involves a 1 × 1 convolution to capture shallow features, which are then processed in the Edge-MobileOne Block (EMB) for deeper extraction of texture and salient features. Throughout this extraction phase, the Cross-Modal Attention Module (CMAM) effectively integrates feature information from multiple stages, combining both common and distinct features while minimizing computational demands. Next, a decoder performs upsampling to merge features of varying scales, facilitating image reconstruction. Subsequently, CLAHE is applied to enhance both infrared and visible light images in low-light conditions, supporting the training of the fusion network through the loss function. Upon completing the training phase, structural re-parameterization optimizes the entire network, preparing it for the inference stage.
The model proposed in this paper is composed of multiple Edge-MobileOne Blocks (EMB), which are improved based on the MobileOne Block [39]. The specific structure of this module is shown in Fig. 4.
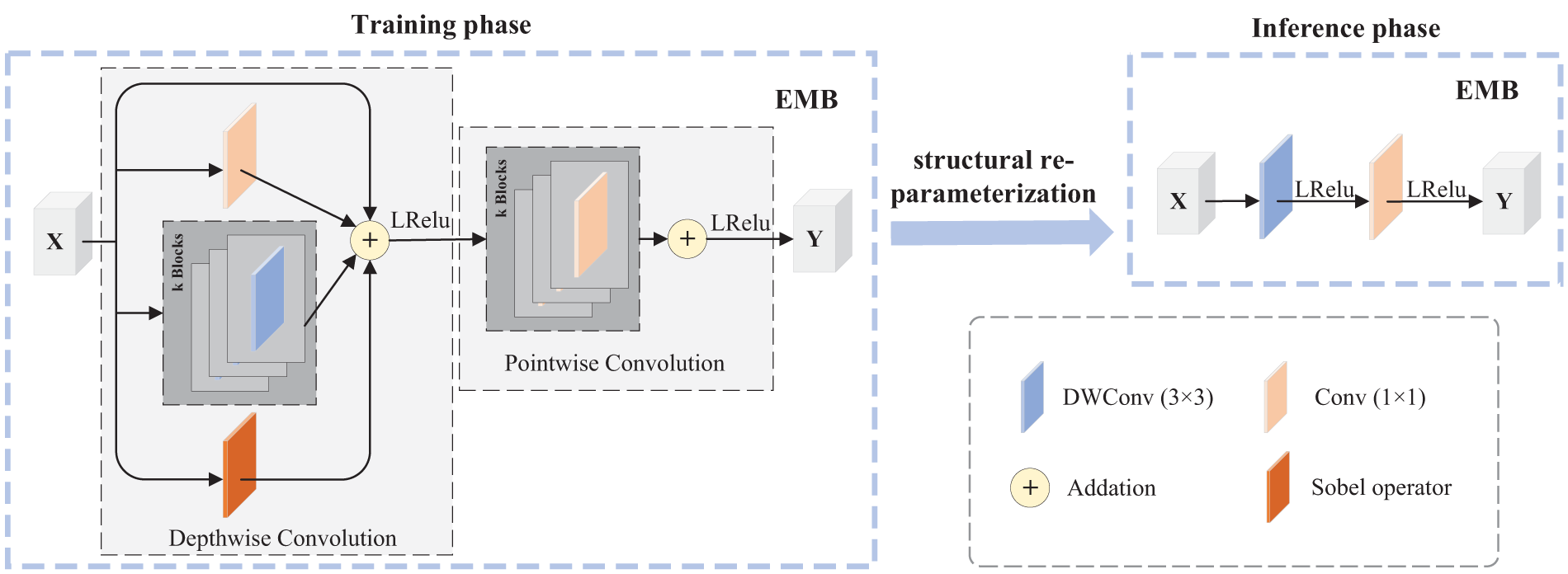
Figure 4: The network structure of the Edge-MobileOne Block (EMB)
In low-light scenarios, the feature network should fully extract the texture information and salient targets from infrared images to compensate for the severe degradation of visible light images. Therefore, the network should extract features at different levels, but a multi-scale feature extraction network would increase the computational load. To this end, a multi-scale network structure, MobileOne Block, is introduced in the network to enrich the representational capacity of the network model during the training phase. To further reduce computational resource consumption, deep convolutional parts and point convolutions are included. Similarly, in low-light conditions, the background texture details of visible light images are lost, making the extraction of texture particularly important during the feature extraction phase. Therefore, in EMB, we replace the original structure with the Sobel operator, which enhances the expression of texture details and strengthens the network’s ability to represent texture during the feature extraction phase. Concurrently, structural re-parameterization technology simplifies the multi-branch network in the training phase into a direct connection network during the inference phase, enriching the network model’s representational capacity without increasing additional computational resource consumption in the inference phase.
Specifically, the EMB is primarily composed of a depthwise convolution section and a pointwise convolution section, with each section further expanded into k sub-branches, thereby implicitly enhancing the network’s representational capacity. Through multiple experiments, k = 4 has been selected as the parameter for the EMB. This process can be formulated as follows:
where,
Strengthening image edge textures often effectively facilitates the progress of fusion tasks, but convolutional layers trained by the network also find it challenging to extract edge information parameters, necessitating the introduction of prior knowledge parameters capable of extracting edge information. Inspired by Chen et al. [40], an additional Sobel operator branch was incorporated into the depthwise convolution branch of the EMB to enhance the module’s edge detection capabilities. It should be noted that the computation of this Sobel operator is consistent with that of DWConv (Depthwise Convolution). Therefore, the modified EMB, like the MobileOne Block, can be optimized into the network structure of MobileNetV1 through structural re-parameterization technology. Such an operation can further reduce the computational resource consumption of the model during the inference phase, and the performance improvement brought by the added Sobel branch is cost-free. After the equivalent transformation through structural re-parameterization technology, the processing procedure of the EMB is formulated as follows:
3.2.3 Cross-Modal Attention Fusion Module
The fusion layer in our approach incorporates the Cross-Modal Attention Fusion Module (CMAM), with its specific structure depicted in Fig. 3. The encoder of the fusion network extracts intermediate feature information at various scales from both infrared and visible light images. Given that these features originate from different modalities, they each emphasize distinct aspects of the scene while containing both complementary and shared information. The primary objective of the fusion module is to effectively integrate this complementary data from the distinct modalities, along with the shared information. A critical challenge lies in leveraging the unique complementary information found in one modality to effectively merge these two sets of features. For thermal targets illuminated adequately, it is essential to enhance both sets of feature information during the fusion process. However, applying methods that address complementary information similarly may risk diminishing one of the feature sets.
To effectively tackle the challenge of fusing information from diverse modalities, our approach utilizes element-wise addition to capture the complementary information present in the images from different sources. Simultaneously, element-wise multiplication is applied to extract the shared information between these modalities. The mathematical representations for both operations are as follows:
where,
Using the Channel and Modality Attention Module (CMAM), the extracted common and complementary features are combined to create a feature vector, which is subsequently processed through a 1 × 1 convolutional layer for channel feature compression. Following this, the Channel Attention Module (SEBlock) [41] directs the network’s attention toward the relevant regions, thereby improving the contrast of the identified targets. This procedure can be illustrated as follows:
where,
In the design of fusion networks based on convolutional neural networks, the selection and design of the loss function have a crucial impact on the network’s performance. The loss function not only guides the weight updates during the network training process but also directly affects the feature representations learned by the network and the final output results. This paper employs an enhanced loss function
where,
The enhanced loss aims to instruct the network model in effectively learning low-light enhancement while preserving high contrast and intricate texture details. To achieve this, the model must consider both the intensity distribution and edge gradient of the fused images. This enhanced loss is composed of intensity loss and gradient loss, represented by the following formulas:
where,
In order to enhance the model’s ability to learn low-light enhancement effects, this study utilizes CLAHE to elevate the quality of both infrared and visible light images. This approach not only boosts the local contrast but also significantly minimizes noise, producing processed images with improved visual appeal, enhanced texture details, and more uniform contrast. Therefore, CLAHE will be employed to enhance both the visible light and infrared images, aiming to optimize the brightness and edge features of the fused images for superior quality in image fusion.
The intensity loss plays a crucial role in regulating the overall brightness of the fused image. To enhance the low-light effects in the fused output, this study substitutes the original infrared and visible light images with their enhanced counterparts in the common intensity loss calculation. By doing so, the maximum intensity is computed to inform the training process of the fusion network. The formula used to calculate the intensity loss is presented below:
where,
To enrich the edge texture details of the fused image, the edge gradient of the fused image should be directed towards the maximum edge gradient of the enhanced infrared and visible light images. The formula for the edge gradient loss is as follows:
where,
Furthermore, to better preserve the information of the source images, this paper also introduces a regularization term to strengthen the correlation between the fused image and the source images. The formula is as follows:
where, this paper uses
This section outlines the experimental framework for training the network, covering aspects such as the dataset, experimental protocols, comparative algorithms, and evaluation criteria. Subsequently, both comparative fusion experiments and generalization tests are conducted to showcase the advantages of the proposed method. An efficiency comparison is then presented to highlight the lightweight characteristics of the approach. Finally, an ablation study is conducted to assess the effectiveness of the proposed techniques.
To assess the effectiveness and generalizability of our method, comparative experiments were performed using three publicly available datasets: LLVIP [42], TNO [43], MSRS [29] and M3FD [28]. For the training phase, the LLVIP dataset, which comprises registered pairs of infrared and visible light images, was utilized. For ease of training, the image pairs from the LLVIP dataset were cropped to a resolution of 224 pixels by 224 pixels, resulting in twenty thousand pairs of images, and the CLAHE algorithm was applied to enhance the low-light conditions of these cropped images. In addition to the comparative experiments conducted on the LLVIP dataset, generalization tests were carried out using the TNO, MSRS and M3FD datasets to further validate the performance of the proposed approach.
The method proposed in this paper is an end-to-end model, with the network optimizer being AdamW, epoch = 100, learning rate = 1 × 10−3. The loss function parameters are denoted by
To further validate the superiority of the algorithm presented in this paper, LLE-Fuse was compared with 12 mainstream fusion methods, including one traditional method GTF [44], one AE-based method (DenseFuse [12]), six CNN-based methods (IFCNN [33], PMGI [34], SDNet [35], STDFusionNet [18], FLFuse [36], and U2Fusion [45]), and four GAN-based methods (FusionGAN [24], GANMcC [27], UMF-CMGR [46], and ICAFusion [47]). The performance of the algorithm in this paper was primarily measured against mainstream fusion methods through both visual results and evaluation metrics.
Since fusing infrared and visible light images lacks a reference image, relying on a single evaluation metric is inadequate to demonstrate the quality of the fusion results. Thus, this paper incorporates five widely recognized image quality metrics: Standard Deviation (SD), Visual Information Fidelity (VIF), Average Gradient (AG), Entropy (EN), and Spatial Frequency (SF). Each metric offers a distinct perspective on the fusion outcomes. SD evaluates the overall contrast and distribution of the fused image. VIF measures the amount of information retained between the fused and source images by considering natural scene statistics and human visual perception. AG and SF assess image clarity through gradient and frequency analysis, respectively, while EN quantifies the informational content of the fused image. All these metrics are positively correlated; higher values indicate superior image quality. By employing these comprehensive evaluation metrics, the performance of various fusion algorithms can be assessed and compared more objectively.
The performance of image fusion in nighttime settings is vital for this task. Consequently, the LLVIP dataset, designed specifically for urban street scenes at night, was chosen for comparative analysis. Fig. 5 illustrates the visual results obtained from the proposed method alongside ten other algorithms using the LLVIP dataset. In these figures, background texture details are highlighted with green frames, while infrared salient targets are outlined in red. To enhance clarity, some images framed in solid lines have been enlarged for better detail visibility.

Figure 5: The comparative results of the algorithm proposed in this paper and 12 mainstream algorithms on the LLVIP dataset #210149
The comparative results are depicted in Fig. 5. Upon examining the background details within the enlarged green frames, it can be observed that the edge details within the green frames are nearly indiscernible in GTF, FusionGAN, and FLFuse; PMGI does render the edges visible, but the contrast between the edges and the background is low, making them easily overlooked. The remaining methods are capable of identifying the edges in the background, but they are clearly outperformed by the clarity of our method. Focusing on the enlarged red frames, only FusionGAN, PMGI, and our method have preserved the high contrast of the infrared source images, while other methods have diminished the infrared targets to varying degrees. Overall, the fused images generated by our method are the clearest, and our method is able to extract the most information from both the background and infrared targets, thus offering a significant advantage over other methods.
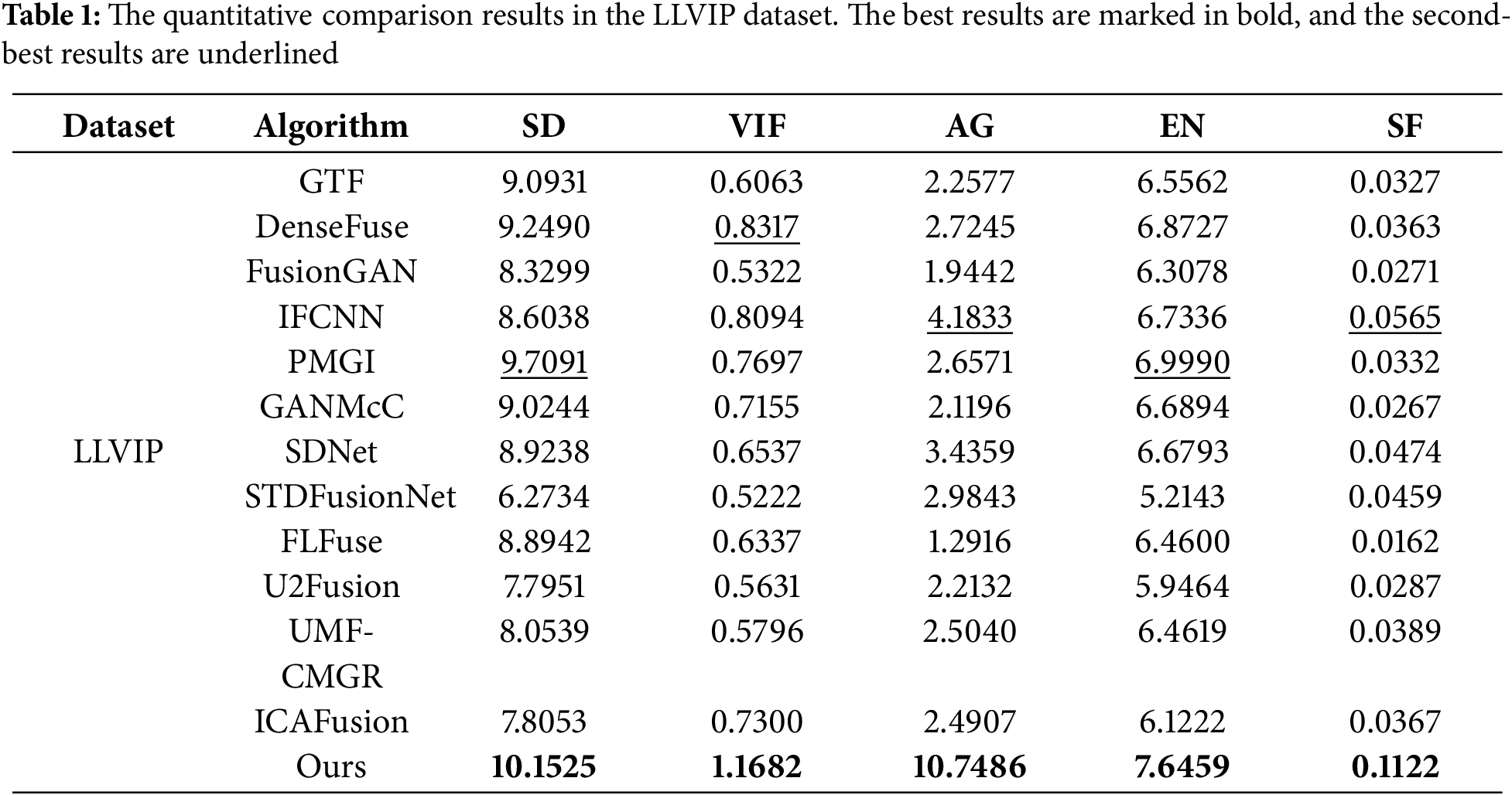
Table 1 presents the quantitative comparison results of our method with 12 mainstream fusion methods on the LLVIP dataset. The data in Table 1 demonstrate that our method has a significant advantage across all evaluation metrics. Specifically, our method outperformed the second-best PMGI by 4 percentage points in SD, indicating that the images generated by our method have higher contrast. In terms of VIF, our method improved by 40 percentage points compared to the best-performing DenseFuse, suggesting that the fusion results are more natural and aligned with the human visual system. Regarding the gradient assessment metric, our method showed a 156 percentage point increase compared to the top-performing IFCNN, which fully illustrates that the fusion results have extracted more gradient information. In addition, the improvements in EN and SF are also substantial, indicating that our method has a significant advantage in both visual effects and metric performance.
4.3 Generalization Comparative Experiments
The generalization capability of deep learning methods is also indicative of model performance. Therefore, in addition to comparative experiments on the LLVIP dataset, this paper also conducted experiments on the TNO, MSRS, and M3FD datasets. It is noteworthy that our method was trained on the LLVIP dataset and tested on the TNO, MSRS, and M3FD datasets.
The TNO dataset is the most classic collection of infrared and visible light images. The visual results of the comparative algorithms and our method are shown in Fig. 6. From the visual results in Fig. 6, it can be observed that the fusion results of FusionGAN, GANMcC, and UMF-CMGR are relatively blurry, with a loss of scene details; DenseFuse, PMGI, SDNet, STDFusionNet, and U2Fusion retain more background details, but the scenes are still limited by the illumination degradation of visible light images, resulting in low contrast; while IFCNN, CUFD, and ICAFusion do provide better scene contrast, they still fail to offer a more visually pleasing experience. In contrast, our method demonstrates surprisingly effective results in the TNO dataset, not only providing rich background texture details and salient thermal targets but also maintaining high contrast and illuminating the entire scene.


Figure 6: The comparative results of the algorithm proposed in this paper and 12 mainstream algorithms on the TNO dataset #Kaptein_1123
The quantitative comparison results of different methods on the TNO dataset are presented in Table 2. The data from Table 2 indicate that our method underperforms only in the VIF metric on the TNO dataset, but demonstrates significant advantages in several other evaluation metrics, an outcome attributed to the low-light enhancement capabilities of our method. Specifically, the improvements in AG and SF, which assess gradient information, are substantial, with increases of 160 and 139 percentage points, respectively. This suggests that the EMB module and enhancement loss of our method play a crucial role in extracting texture details. Furthermore, the improvements in SD and EN, with increases of 7 and 2 percentage points compared to the best-performing methods, indicate a certain advantage in the comprehensiveness of image information extraction.

The MSRS dataset includes some low-light scenes with insufficient illumination. This paper has selected a typical example, and the visual results of different algorithms are shown in Fig. 7. Our method is capable of providing brighter scenes with prominent targets and fully exploring the background information hidden in the darkness. From the enlarged green frames, it can be seen that, aside from PMGI and our method, other methods almost fail to reveal the background details hidden in the dark. Overall, while existing mainstream fusion methods maintain the information of the source images to varying degrees, only our method provides rich texture information while maintaining the prominence of infrared targets.

Figure 7: The comparative results of the algorithm proposed in this paper and 12 mainstream algorithms on the MSRS dataset #01023N
Table 3 compares LLE-Fuse’s performance with other methods on the MSRS dataset across five metrics, showing LLE-Fuse’s superiority in all. Its SD score reflects high contrast in fused images, while its VIF score indicates good alignment with human visual perception. LLE-Fuse’s EN score also indicates rich information capture. Its AG and SF scores demonstrate effective texture preservation. Collectively, these results validate LLE-Fuse’s efficacy on the MSRS dataset.

In addition to the TNO and MSRS datasets, the M3FD dataset encompasses scenes with insufficient lighting, characteristic of low-light conditions. This paper presents a typical example, with the visual results from various algorithms depicted in Fig. 8.

Figure 8: The comparative results of the algorithm proposed in this paper and 12 mainstream algorithms on the M3FD dataset #00621
Upon examining the enlarged green frames, it is evident that methods such as GTF, FusionGAN, PMGI, SDNet, and FLFuse conceal background details, rendering certain background elements nearly indistinguishable in the darkness. From the enlarged red frames, it is apparent that DenseFuse, GANMcC, IFCNN, U2Fusion, and UMF-CMGR all exhibit varying degrees of attenuation in the prominence of infrared targets. Beyond this, ICAFusion demonstrates certain advantages in preserving background textures, but overall, our method significantly outperforms other approaches in depicting scene elements like “cars” and “buildings”.
The quantitative comparison results on the M3FD dataset are presented in Table 4. According to the results in Table 4, our LLE-Fuse demonstrates a distinct advantage across all five evaluation metrics. The top ranking in the SD metric indicates that our method can produce fusion images with high contrast. The leading position in the VIF metric suggests that the fusion results align well with the human visual perception system. The first place in the EN metric indicates that our method can encompass rich information. The top rankings in both the AG and SF metrics indicate that our method can effectively preserve texture information from the source images in terms of gradient and frequency. In summary, the results from both qualitative and quantitative analyses substantiate the generalizability of LLE-Fuse.

4.4 Efficiency Comparative Experiment
This paper conducted a runtime test on 50 images of the LLVIP dataset with a resolution of 1280 × 1024 to further evaluate the operational efficiency of the proposed algorithm compared to mainstream fusion algorithms. The average comparison results of the runtime are shown in the Table 5.

As the table indicates, although the average runtime of the algorithm proposed in this paper is slightly worse than that of FLFuse, the smaller standard deviation suggests that the method is more stable. Moreover, the fusion performance of the proposed method is significantly better than that of FLFuse, making this minor difference acceptable. The algorithm presented in this paper is based on the concept of structural re-parametrization and is equivalently optimized into a MobileNetV1 [48] structure during the inference phase, which can greatly reduce the fusion time.
Additionally, this paper compared the runtime, forward propagation memory requirements, number of parameters, weight size, and per-pixel cumulative deviation of the fusion results before and after structural re-parametrization on the LLVIP dataset. The comparison results of the model parameters are shown in Table 6. According to the data in Table 6, it can be seen that the method proposed in this paper can effectively reduce the computational resource consumption of the network through structural re-parametrization techniques while maintaining the same fusion effect.

To further validate the effectiveness of the various modules designed in our approach, ablation studies were conducted in this section. Experiment 1 represents our method, Experiment 2 replaces the CLAHE-enhanced images in the enhancement loss with the original source images, Experiment 3 removes the Cross-Modality Attention Module (CMAM) from the setup of Experiment 2, and Experiment 4 further removes the Edge-MobileOne Block (EMB) from the configuration of Experiment 3. The qualitative and quantitative results of the experiments are depicted in Fig. 9 and Table 7, respectively.

Figure 9: The ablation experimental results of the algorithm proposed in this paper on the LLVIP dataset

The enhancement loss guides the network in generating fused images with low-light enhancement effects. Consequently, compared to the results of our method (Experiment 1), as shown in Fig. 9c, the scenes in the results of Experiment 2 are noticeably darker, with relatively fewer texture details. Secondly, as depicted in Fig. 9d, when the Cross-Modality Attention Module (CMAM) is removed from the basis of Experiment 2, the saliency of the fusion results is diminished. Lastly, Fig. 9e illustrates that when the Edge-MobileOne Block (EMB) is removed from the basis of Experiment 3, the fusion network fails to effectively extract target information from the infrared image, leaning the overall scene more towards the visible light image modality.
Additionally, the evaluation metrics in Table 7 show varying degrees of decline in Experiments 2–4, further demonstrating the effectiveness of each module. In summary, both qualitative and quantitative results indicate that each module plays a promotional role in the overall network.
This study introduced a novel lightweight infrared and visible light image fusion network, termed LLE-Fuse, specifically designed to address the challenges of image fusion under low-light conditions. The network employed a dual-branch architecture with Edge-MobileOne Blocks embedded with the Sobel operator for feature extraction and utilized a Cross-Modality Attention Fusion Module to integrate information from heterogeneous sources. Furthermore, this research incorporated pseudo-labels from CLAHE low-light enhancement and correlation loss into the enhanced loss function to guide the network in learning enhancement fusion capabilities in low-light scenarios. The experimental results confirmed that LLE-Fuse was capable of generating fused images with high contrast and clear textures under both low-light and normal lighting conditions while maintaining the lightweight nature of the network. This provided an effective solution for enhancing the performance and model lightweight of deep learning-based image fusion technology in low-light environments.
Despite the significant advancements achieved by the LLE-Fuse proposed in this study in the realm of low-light image fusion, certain limitations were noted. Specifically, the method was primarily tailored to address image fusion issues under low-illumination conditions, and it may exhibit overexposure phenomena under normal lighting conditions, leading to suboptimal fusion outcomes in brighter scenes. Additionally, if images of low-light scenes with noise are enhanced using the CLAHE method, it can amplify the image noise, thereby affecting the fusion results. This is also an issue that needs further consideration. To address this issue, future research endeavors will focus on refining the algorithm. Potential solutions include the design of network architectures capable of adapting to the varying light source distributions under both low-illumination and normal lighting conditions, thereby enabling adaptive image fusion across different lighting scenarios. Consequently, we plan to further develop an illumination classification module in the future to enhance the network’s adaptability and robustness to complex environments, thereby achieving superior image fusion results under a broad range of lighting conditions.
Acknowledgement: We are grateful to our families and friends for their unwavering understanding and encouragement.
Funding Statement: This research was Sponsored by Xinjiang Uygur Autonomous Region Tianshan Talent Programme Project (2023TCLJ02) and Natural Science Foundation of Xinjiang Uygur Autonomous Region (2022D01C349).
Author Contributions: Conceptualization, Song Qian, Guzailinuer Yiming; methodology, Yan Xue; software, Song Qian, Ping Li; validation, Song Qian, Junfei Yang; visualization, Song Qian; supervision, Shuping Zhang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest:: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhang H, Xu H, Tian X, Jiang J, Ma J. Image fusion meets deep learning: a survey and perspective. Inf Fusion. 2021;76:323–36. doi:10.1016/j.inffus.2021.06.008. [Google Scholar] [CrossRef]
2. Zhang X. Benchmarking and comparing multi-exposure image fusion algorithms. Inf Fusion. 2021;74:111–31. doi:10.1016/j.inffus.2021.02.005. [Google Scholar] [CrossRef]
3. Guo C, Li C, Guo J, Loy C, Hou J, Kwong S, et al. Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020; Seattle, WA, USA. p. 1780–9. doi:10.1109/CVPR42600.2020.00185. [Google Scholar] [CrossRef]
4. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR); 2016; Las Vegas, NV, USA. p. 27–30. doi:10.1109/CVPR.2016.91. [Google Scholar] [CrossRef]
5. Guan D, Cao Y, Yang J, Cao Y, Yang M. Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection. Inf Fusion. 2019;50:148–57. doi:10.1016/j.inffus.2018.11.017. [Google Scholar] [CrossRef]
6. Jiang C, Ren H, Yang H, Huo H, Zhu P, Yao Z, et al. M2FNet: multi-modal fusion network for object detection from visible and thermal infrared images. Int J Appl Earth Obs Geoinf. 2024;130:103918. doi:10.1016/j.jag.2024.103918. [Google Scholar] [CrossRef]
7. Zhang Q, Zhao S, Luo Y, Zhang D, Huang N, Han J. ABMDRNet: adaptive-weighted bi-directional modality difference reduction network for RGB-T semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021; Nashville, TN, USA. p. 2633–42. doi:10.1109/CVPR46437.2021.00266. [Google Scholar] [CrossRef]
8. Panda MK, Subudhi BN, Veerakumar T, Jakhetiya V. Integration of bi-dimensional empirical mode decomposition with two streams deep learning network for infrared and visible image fusion. In: Proceedings of 2022 30th European Signal Processing Conference (EUSIPCO); 2022; Belgrade, Serbia. p. 493–7. doi:10.23919/EUSIPCO55093.2022.9909631. [Google Scholar] [CrossRef]
9. Fu Z, Wang X, Xu J, Zhou N, Zhao Y. Infrared and visible images fusion based on RPCA and NSCT. Infrared Phys Technol. 2016;77:114–23. doi:10.1016/j.infrared.2016.05.012. [Google Scholar] [CrossRef]
10. Li H, Wu XJ, Kittler J. MDLatLRR: a novel decomposition method for infrared and visible image fusion. IEEE Trans Image Process. 2020;29:4733–46. doi:10.1109/TIP.2020.2975984. [Google Scholar] [PubMed] [CrossRef]
11. Panda MK, Parida P, Rout DK. A weight induced contrast map for infrared and visible image fusion. Comput Electr Eng. 2024;117:109256. doi:10.1016/j.compeleceng.2024.109256. [Google Scholar] [CrossRef]
12. Li H, Wu XJ. DenseFuse: a fusion approach to infrared and visible images. IEEE Trans Image Process. 2018;28(5):2614–23. doi:10.1109/TIP.2018.2887342. [Google Scholar] [PubMed] [CrossRef]
13. Huang G, Liu Z, Van Der Maaten L, Weinberger KQ. Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017; Honolulu, HI, USA. p. 4700–8. doi:10.1109/CVPR.2017.243. [Google Scholar] [CrossRef]
14. Li H, Wu XJ, Durrani T. NestFuse: an infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans Instrum Meas. 2020;69(12):9645–56. doi:10.1109/TIM.2020.3005230. [Google Scholar] [CrossRef]
15. Li H, Wu XJ, Kittler J. RFN-Nest: an end-to-end residual fusion network for infrared and visible images. Inf Fusion. 2021;73:72–86. doi:10.1016/j.inffus.2021.02.023. [Google Scholar] [CrossRef]
16. Xu H, Zhang H, Ma J. Classification saliency-based rule for visible and infrared image fusion. IEEE Trans Comput Imaging. 2021;7:824–36. doi:10.1109/TCI.2021.3100986. [Google Scholar] [CrossRef]
17. Cheng C, Xu T, Wu XJ. MUFusion: a general unsupervised image fusion network based on memory unit. Inf Fusion. 2023;92:80–92. doi:10.1016/j.inffus.2022.11.010. [Google Scholar] [CrossRef]
18. Ma J, Tang L, Xu M. STDFusionNet: an infrared and visible image fusion network based on salient target detection. IEEE Trans Instrum Meas. 2021;70:1–13. doi:10.1109/TIM.2021.3075747. [Google Scholar] [CrossRef]
19. Long Y, Jia H, Zhong Y, Jiang Y, Jia Y. RXDNFuse: an aggregated residual dense network for infrared and visible image fusion. Inf Fusion. 2021;69:128–41. doi:10.1016/j.inffus.2020.11.009. [Google Scholar] [CrossRef]
20. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2016; Las Vegas, NV, USA. p. 770–8. doi:10.1007/s11042-017-4440-4. [Google Scholar] [CrossRef]
21. Li H, Cen Y, Liu Y, Chen X. Different input resolutions and arbitrary output resolution: a meta learning-based deep framework for infrared and visible image fusion. IEEE Trans Image Process. 2021;30:4070–83. doi:10.1109/TIP.2021.3069339. [Google Scholar] [PubMed] [CrossRef]
22. Tang L, Yuan J, Ma J. Image fusion in the loop of high-level vision tasks: a semantic-aware real-time infrared and visible image fusion network. Inf Fusion. 2022;82:28–42. doi:10.1016/j.inffus.2021.12.004. [Google Scholar] [CrossRef]
23. Tang L, Zhang H, Xu H, Ma J. Rethinking the necessity of image fusion in high-level vision tasks: a practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity. Inf Fusion. 2023;99:101870. doi:10.1016/j.inffus.2023.101870. [Google Scholar] [CrossRef]
24. Ma J, Yu W, Liang P, Li C, Jiang J. FusionGAN: a generative adversarial network for infrared and visible image fusion. Inf Fusion. 2019;48:11–26. doi:10.1016/j.inffus.2018.09.004. [Google Scholar] [CrossRef]
25. Ma J, Xu H, Jiang J, Mei X, Zhang X. DDcGAN: a dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans Image Process. 2020;29:4980–95. doi:10.1109/TIP.2020.2977573. [Google Scholar] [PubMed] [CrossRef]
26. Li J, Huo H, Li C, Wang R, Feng Q. AttentionFGAN: infrared and visible image fusion using attention-based generative adversarial networks. IEEE Trans Multimed. 2020;23:1383–96. doi:10.1109/TMM.2020.2997127. [Google Scholar] [CrossRef]
27. Ma J, Zhang H, Shao Z, Liang P, Xu H. GANMcC: a generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans Instrum Meas. 2020;70:1–14. doi:10.1109/TIM.2020.3038013. [Google Scholar] [CrossRef]
28. Liu J, Fan X, Huang Z, Wu G, Liu R, Zhong W, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022; New Orleans, LA, USA. p. 5802–11. doi:10.1109/CVPR52688.2022.00571. [Google Scholar] [CrossRef]
29. Tang L, Yuan J, Zhang H, Jiang X, Ma J. PIAFusion: a progressive infrared and visible image fusion network based on illumination aware. Inf Fusion. 2022;83:79–92. doi:10.1016/j.inffus.2022.03.007. [Google Scholar] [CrossRef]
30. Liu B, Wei J, Su S, Tong X. Research on task-driven dual-light image fusion and enhancement method under low illumination. 2022 7th International Conference on Image, Vision and Computing (ICIVC); 2022; Xi'an, China. p. 523–30. doi:10.1109/ICIVC55077.2022.9886778. [Google Scholar] [CrossRef]
31. Tang L, Xiang X, Zhang H, Gong M, Ma J. DIVFusion: darkness-free infrared and visible image fusion. Inf Fusion. 2023;91:477–93. doi:10.1016/j.inffus.2022.10.034. [Google Scholar] [CrossRef]
32. Chang R, Zhao S, Rao Y, Yang Y. LVIF-Net: learning synchronous visible and infrared image fusion and enhancement under low-light conditions. Infrared Phys Technol. 2024;2024:105270. doi:10.1016/j.infrared.2024.105270. [Google Scholar] [CrossRef]
33. Zhang Y, Liu Y, Sun P, Yan H, Zhao X, Zhang L. IFCNN: a general image fusion framework based on convolutional neural network. Inf Fusion. 2020;54:99–118. doi:10.1016/j.inffus.2019.07.011. [Google Scholar] [CrossRef]
34. Zhang H, Xu H, Xiao Y, Guo X, Jia J. Rethinking the image fusion: a fast unified image fusion network based on proportional maintenance of gradient and intensity. Proc AAAI Conf Artif Intell. 2020;34(7):12797–804. doi:10.1609/aaai.v34i07.6975. [Google Scholar] [CrossRef]
35. Zhang H, Ma J. SDNet: a versatile squeeze-and-decomposition network for real-time image fusion. Int J Comput Vis. 2021;129:2761–85. doi:10.1007/s11263-021-01501-8. [Google Scholar] [CrossRef]
36. Xue W, Wang A, Zhao L. FLFuse-Net: a fast and lightweight infrared and visible image fusion network via feature flow and edge compensation for salient information. Infrared Phys Technol. 2022;127:104383. doi:10.1016/j.infrared.2022.104383. [Google Scholar] [CrossRef]
37. Ding X, Zhang X, Ma N, Han J, Ding G, Sun J. RepVGG: making VGG-style convnets great again. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021; Nashville, TN, USA. p. 13733–42. doi:10.1109/CVPR46437.2021.01352. [Google Scholar] [CrossRef]
38. Reza AM. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J VLSI Signal Process Syst Signal, Image Video Technol. 2004;38:35–44. doi:10.1023/B.0000028532.53893.82. [Google Scholar] [CrossRef]
39. Vasu PK, Gabriel J, Zhu J, Tuzel O, Ranjan A. MobileOne: an improved one millisecond mobile backbone. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023. p. 7907–17. doi:10.1109/CVPR52729.2023.00764. [Google Scholar] [CrossRef]
40. Chen Z, Fan H, Ma M, Shao D. FECFusion: infrared and visible image fusion network based on fast edge convolution. Math Biosci Eng. 2023;20(9):16060–82. doi:10.3934/mbe.2023717. [Google Scholar] [PubMed] [CrossRef]
41. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2018. p. 7132–41. doi:10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
42. Jia X, Zhu C, Li M, Tang W, Zhou W. LLVIP: a visible-infrared paired dataset for low-light vision. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2018; Montreal, BC, Canada. 7132–7141. doi:10.1109/ICCVW54120.2021.00389. [Google Scholar] [CrossRef]
43. Toet A. The TNO multiband image data collection. Proc Data Brief. 2017;15:249–51. [Google Scholar]
44. Ma J, Chen C, Li C, Huang J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf Fusion. 2016;31:100–9. doi:10.1016/j.inffus.2016.02.001. [Google Scholar] [CrossRef]
45. Xu H, Ma J, Jiang J, Guo X, Ling H. U2Fusion: a unified unsupervised image fusion network. IEEE Trans Pattern Anal Mach Intell. 2022;44(1):502–18. doi:10.1109/TPAMI.2020.3012548. [Google Scholar] [PubMed] [CrossRef]
46. Wang D, Liu J, Fan X, Liu R. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration. arXiv:2205.11876. 2022. [Google Scholar]
47. Wang Z, Shao W, Chen Y, Xu J, Zhang X. Infrared and visible image fusion via interactive compensatory attention adversarial learning. IEEE Trans Multimed. 2022;25:7800–13. doi:10.1109/TMM.2022.3228685. [Google Scholar] [CrossRef]
48. Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, et al. MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861. 2017. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools