
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Deep Learning Based Online Defect Detection Method for Automotive Sealing Rings
1 School of Intelligent Manufacturing and Control Engineering, Shanghai Polytechnic University, Shanghai, 201209, China
2 School of Electrical Engineering and Telecommunications, UNSW, Sydney, NSW 2052, Australia
* Corresponding Author: Qin Qin. Email:
Computers, Materials & Continua 2025, 83(2), 3211-3226. https://doi.org/10.32604/cmc.2025.059389
Received 06 October 2024; Accepted 24 February 2025; Issue published 16 April 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Manufacturers must identify and classify various defects in automotive sealing rings to ensure product quality. Deep learning algorithms show promise in this field, but challenges remain, especially in detecting small-scale defects under harsh industrial conditions with multimodal data. This paper proposes an enhanced version of You Only Look Once (YOLO)v8 for improved defect detection in automotive sealing rings. We introduce the Multi-scale Adaptive Feature Extraction (MAFE) module, which integrates Deformable Convolutional Network (DCN) and Space-to-Depth (SPD) operations. This module effectively captures long-range dependencies, enhances spatial aggregation, and minimizes information loss of small objects during feature extraction. Furthermore, we introduce the Blur-Aware Wasserstein Distance (BAWD) loss function, which improves regression accuracy and detection capabilities for small object anchor boxes, particularly in scenarios involving defocus blur. Additionally, we have constructed a high-quality dataset of automotive sealing ring defects, providing a valuable resource for evaluating defect detection methods. Experimental results demonstrate our method’s high performance, achieving 98.30% precision, 96.62% recall, and an inference speed of 20.3 ms.Keywords
In the context of automotive intelligence, enhancing vehicle safety has become a widespread societal demand [1–3]. The Electronic Control Unit (ECU) is a key component in modern vehicles. Its malfunction can lead to significant safety risks [4]. Given the critical role of automotive sealing rings in protecting the ECU from external damage, even minor defects can lead to serious issues, such as electrical short-circuits, corrosion, and system failures [5]. Detecting such defects is essential for maintaining product quality and meeting vehicle safety standards [6,7].
Common defects in automotive sealing rings, such as blowout, fracture, excess material, and burr, are critical issues that can undermine the functionality of the ECU. However, defect detection faces unique challenges due to the small size of the sealing rings (1.3 cm × 0.5 cm), compounded by harsh industrial conditions such as uneven lighting and defocus blur. Traditionally, defect detection in automotive sealing rings has relied heavily on manual inspection [8], limited by low accuracy and efficiency. To overcome these limitations, advanced automated detection technologies that integrate seamlessly into high-speed production lines are essential. The adoption of advanced technologies, such as deep learning-based systems, offers a promising solution by accurately identifying defects, thereby reducing waste and improving overall productivity in automotive manufacturing [9,10].
Given the complexity and varied nature of defects in automotive sealing rings, selecting an appropriate deep learning detection algorithm is crucial. Deep learning detection methods are classified into one-stage and two-stage approaches [11]. While two-stage algorithms achieve high accuracy, their slower inference speed limits real-time applications [12,13]. In contrast, one-stage algorithms provide faster inference and are more suitable for real-time industrial scenarios, although they often struggle with small-object localization [14,15]. For real-time automotive sealing ring defect detection, the YOLO algorithm is preferable [16].
Building on YOLOv8’s suitability for real-time detection, we propose an Enhanced YOLO. Our approach introduces the Multi-scale Adaptive Feature Extraction (MAFE) Module, which integrates deformable convolutional networks (DCN) and Space-to-Depth (SPD) to enhance feature extraction for small and irregular defects, minimizing spatial information loss. We also develop the Blur-Aware Wasserstein Distance (BAWD) loss function, which improves regression accuracy and detection capability for small object anchor boxes, particularly in scenarios with defocus blur.
We have constructed a high-quality dataset of automotive sealing ring defects. This dataset replicates real-world industrial conditions, providing a challenging benchmark for evaluating defect detection methods. Our experiments show significant improvements in defect detection using our Enhanced YOLOv8. Additionally, our model demonstrates robust performance on the COCO2017 dataset, validating its adaptability across diverse scenarios. The key contributions of this paper are outlined as follows:
(1) Introducing the MAFE module into YOLOv8. This module combines DCN for capturing long-range dependencies and adaptive spatial aggregation with SPD operations to reduce information loss during feature extraction, especially for small objects and low-resolution images.
(2) Developing the BAWD Loss to improve regression accuracy and detection capability for small object anchor boxes, especially in scenarios with defocus blur.
(3) Constructing a high-quality dataset of automotive sealing ring defects, providing a valuable resource for evaluating various defect detection methods. The dataset is available as an open-source resource at https://github.com/xika1234/automotive-seal-ring-dataset (accessed on 23 February 2025).
2.1 Industrial Defect Detection Algorithm
Current mainstream approaches for defect detection include RCNN-based frameworks, Transformer-based models, and YOLO-based methods, each with distinct strengths and limitations. RCNN-based frameworks [17], achieve robust feature extraction and high accuracy, particularly for complex defects [18]. For instance, Faster R-CNN has been enhanced with deformable convolution for small weld defects [19], while Cascade R-CNN has been applied to multiscale defect localization in wheel hubs [20]. However, their two-stage nature limits real-time applicability. Transformer-based models, such as DETR [21], Deformable DETR [22], and Dynamic DETR [23], leverage attention mechanisms for global context modeling and have been applied to defect detection tasks like aero-engine blades and roller bearings [24,25]. Despite their potential, Transformers often face high computational costs, making them less practical for time-sensitive applications [26]. YOLO-based methods, such as YOLOv5 and YOLOv7 [27], balance speed and accuracy but struggle with small, subtle defects under harsh industrial conditions like motion blur. To address these limitations, methods such as Feature Pyramid Networks (FPN) and attention-based mechanisms have been explored. FPN enhances multi-scale feature representation by integrating spatial and semantic information from different feature levels [28,29], while attention mechanisms recalibrate feature importance to improve detection precision [30]. However, these approaches often rely on rigid structures or static attention designs, limiting their adaptability to irregular defect shapes and complex industrial scenarios.
To address these challenges, our Enhanced YOLOv8 introduces the MAFE module and the BAWD loss function. MAFE combines SPD operations and DCN. SPD expands the receptive field by rearranging spatial information, improving the extraction of long-range dependencies critical for small-object detection. Meanwhile, DCN introduces adaptive sampling to focus on irregular object shapes, addressing the limitations of conventional pooling and attention mechanisms. BAWD further strengthens the model by incorporating blur-aware adjustments into bounding box regression, mitigating uncertainties from defocus blur and enhancing robustness. Together, these innovations enable superior accuracy and efficiency in detecting small defects under challenging industrial conditions.
2.2 Automotive Sealing Rings Defect Detection
Defect detection in automotive sealing rings has been a critical area of research in quality control. Li et al. proposed a defect detection method based on the K-means clustering approach and particle swarm optimization [31]. Their approach involves preprocessing seal images, utilizing the SURF algorithm for feature point extraction, and performing image segmentation. However, their method relies on traditional machine learning techniques, which may lack the adaptability and efficiency required for diverse defect types and high-volume production environments. Scholz et al. both explored 3D-based approaches for defect detection [8]. They developed an automated optical inspection system based on sheet-of-light laser measurement, integrating a 3D data acquisition unit for rapid full-surface scanning of parts. Nevertheless, these approaches do not specifically address the challenges of real-time detection or the processing of high-volume production data.
In contrast, the enhanced YOLOv8 model proposed in this paper has been specifically optimized to address the challenges in industrial environments. This method is not only capable of adapting to diverse defect types but also possesses real-time detection capabilities, effectively handling high-frequency data input.
In object detection, Intersection over Union (IoU) serves as a key metric for evaluating anchor box matching accuracy, with various enhancements proposed to improve its effectiveness [32]. Variants like GIoU [33], EIoU [34], and SIoU [35] have been introduced to address specific limitations, such as handling non-overlapping bounding boxes or incorporating geometric considerations for better localization accuracy. While these advancements have improved object detection in many scenarios, they remain less effective for precise localization of small objects, often leading to positional offset errors that compromise performance in such cases [36].
To optimize the YOLOv8 model, we introduced BAWD loss, built on the foundation of NWD Loss [37,38]. NWD Loss models bounding boxes as Gaussian distributions, enabling a smooth and continuous distance metric. However, defocus blur in industrial images compromises this modeling by making object edges less distinct, leading to inaccuracies in estimating Gaussian parameters. BAWD loss mitigates this issue by incorporating blur awareness, dynamically adjusting covariance matrices based on blur levels. This refinement ensures more robust localization of small objects under blurred conditions, improving detection accuracy in challenging industrial environments.
3.1 Automotive Sealing Ring Defect Detection Process
This paper presents a detection method composed of three parts, specifically designed for detecting surface defects in automotive sealing rings, as shown in Fig. 1.
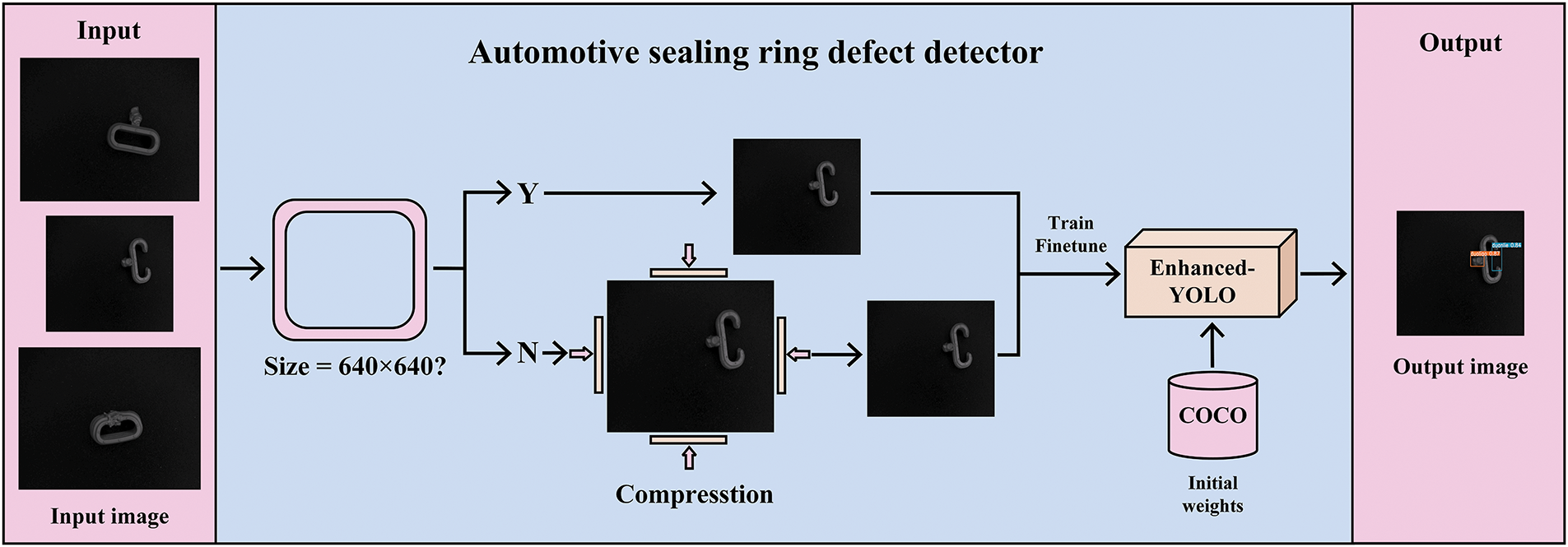
Figure 1: Automotive sealing ring defect detection process
(1) Input: This module inputs the captured image into the automotive sealing ring defect detector without any specific size constraints.
(2) Automotive Sealing Ring Defect Detector: Initially, images are checked for their sizes, and those not meeting the 640 × 640 pixel requirement are compressed. This physically enlarges the defects and reduces the negative sample information. The Enhanced YOLO network is then trained using COCO dataset weights.
(3) Output: The defects are detected in the obtained image using Enhanced YOLO network and the detection results are obtained.
This section proposes an improved model Enhanced YOLO based on the network structure of YOLOv8. The specific structure is shown in Fig. 2. This study introduces two major improvements to YOLOv8. Firstly, the MAFE module is incorporated into the network to establish long-range dependencies during feature extraction, offering stronger spatial aggregation capabilities compared to standard convolutional modules. Additionally, the MAFE module minimizes parameters while mitigating inherent limitations of stride and pooling operations. This enhancement improves the focus on low-resolution images and boosts the detection of small object defects. Secondly, the BAWD loss function is introduced, which measures the similarity of the bounding box’s Gaussian distribution, enabling more accurate regression of predicted boxes. This modification further strengthens small object detection and boosts overall precision.
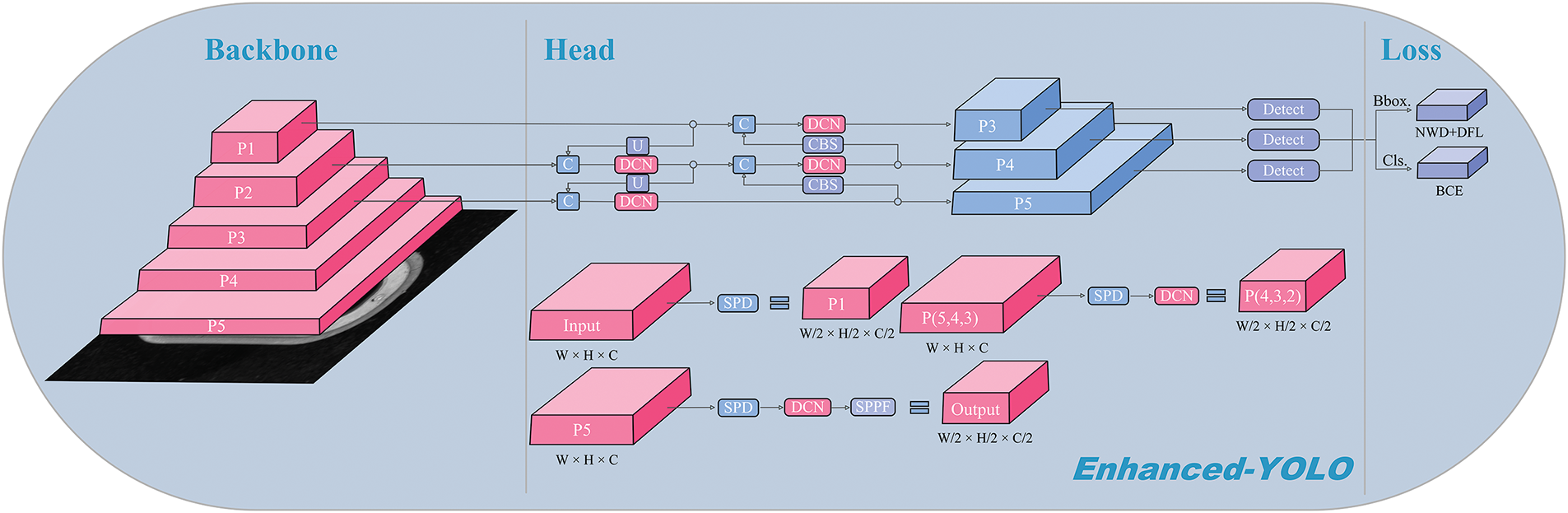
Figure 2: Enhanced YOLO network structure
The MAFE module combines SPD and DCN to enhance feature extraction specifically for small and irregular defects. SPD rearranges spatial information into channel dimensions, effectively expanding the receptive field and enhancing focus on fine-grained details. This is particularly advantageous for small defects such as burrs and fractures. Meanwhile, DCN introduces learnable spatial offsets, allowing convolutions to dynamically adapt to irregular defect shapes and deformations. This adaptation ensures critical spatial information is preserved, overcoming limitations of conventional pooling methods. These mechanisms collectively enable the model to capture long-range dependencies and provide robust feature representations under complex industrial conditions. The structure of the MAFE module is shown in Fig. 3.
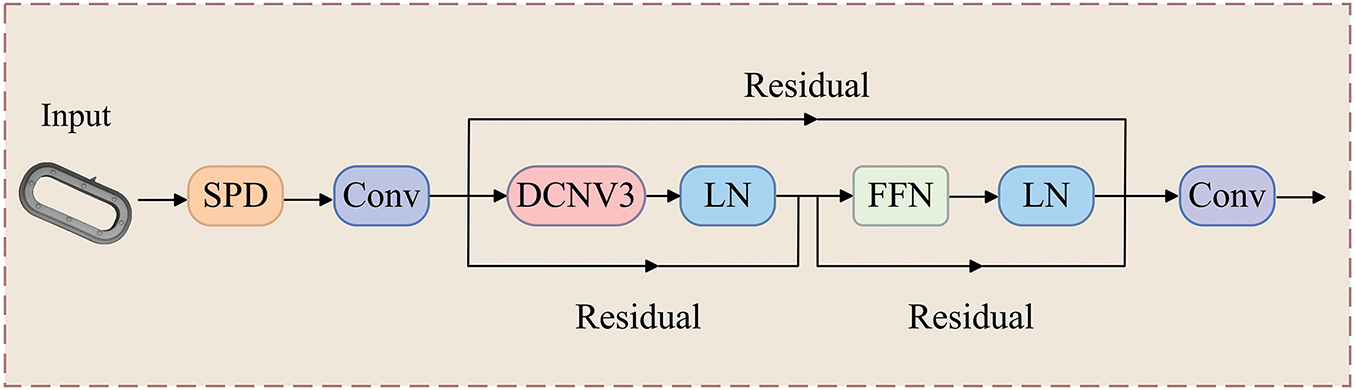
Figure 3: MAFE module
The SPD operation rearranges the spatial information of the input feature map into the channel dimension. Assuming the input feature map is
where
Specifically, first SPD converts the feature image
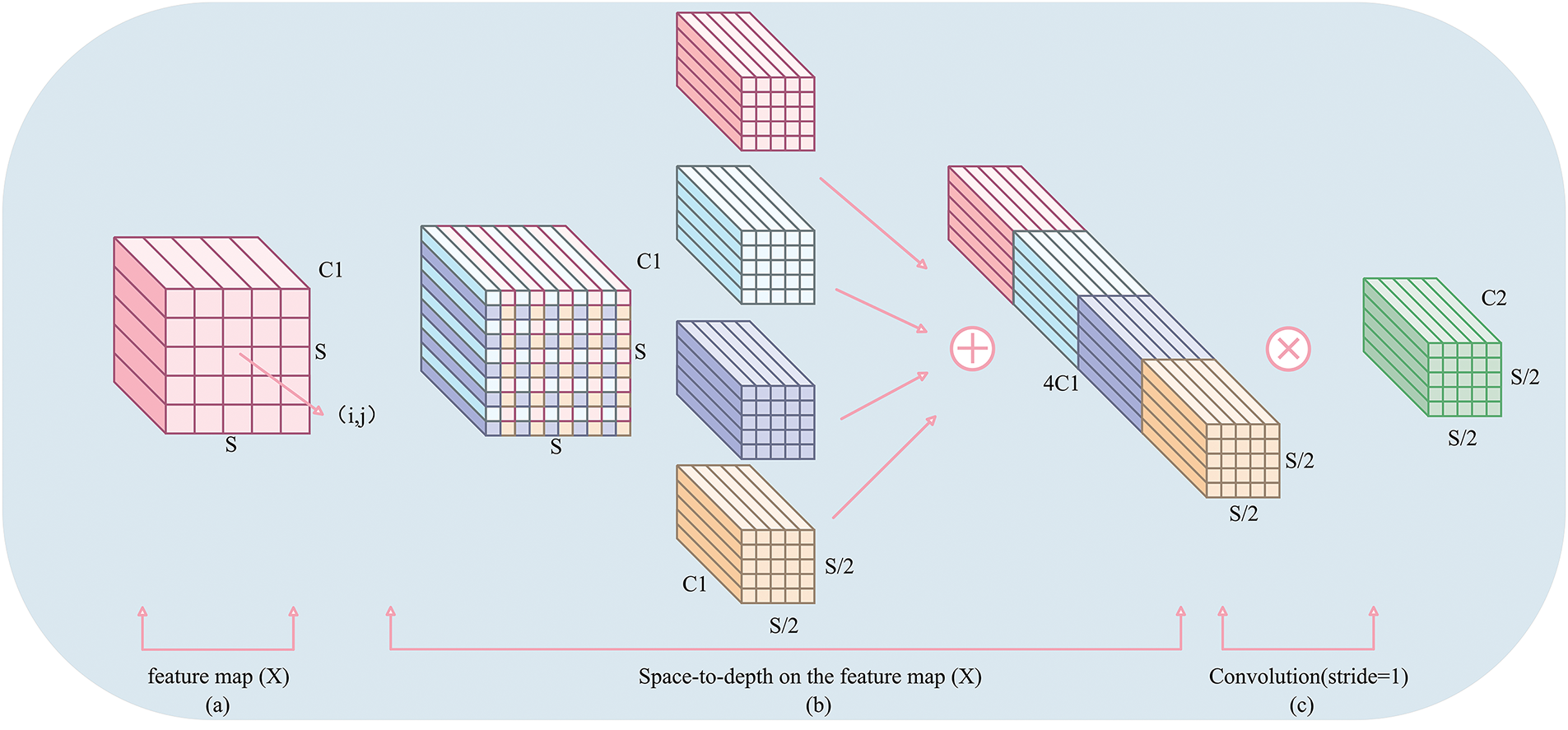
Figure 4: The process of SPD-Conv operation
The SPD operation compresses spatial information into the channel dimension, expanding the receptive field, which is particularly effective for extracting long-range dependencies and features of small targets.
DCN introduces learnable spatial offsets, making the sampling locations of convolution kernels more flexible. The conventional convolution is expressed as:
where
With the introduction of learnable offsets, DCN enables adaptive adjustment of convolution kernel sampling locations. The mathematical expression is:
By introducing grouped convolution, spatial feature aggregation across multiple groups is achieved. The corresponding formula is:
where
Finally, the feature map
BAWD loss addresses the challenges posed by defocus blur in high-speed production environments by refining the covariance matrices in Gaussian modeling. Specifically, it adjusts the Gaussian parameters dynamically to reflect varying levels of blur, mitigating edge ambiguities that often compromise small-object localization. This approach ensures robust and precise regression by smoothing the Wasserstein distance calculations between predicted and ground-truth boxes. The effectiveness of BAWD in handling blurred scenarios has been validated through experiments, showing significant improvements over conventional losses like CIoU and NWD in detecting small and subtle defects.
A rotating bounding box
where
The Gaussian distributions
where
The NWD loss is as follows:
Incorporating the blur-aware weight
Here,
The Enhanced YOLO object detection algorithm is validated on two datasets: 1) automotive sealing ring defect dataset constructed by us, and 2) the MS COCO2017 dataset. The performance on the automotive sealing ring dataset directly reflects the model’s capability in the specific task of automotive sealing ring defect detection. Meanwhile, its performance on the COCO dataset demonstrates the model’s generalization ability across diverse detection scenarios.
4.1.1 Automotive Sealing Ring Defect Dataset
This study manually constructed a dataset containing four common defects: blowout, fracture, excess material and burr. The defective automotive sealing rings are from a real-world project conducted by Shanghai Inspect Spring Automation Technology Company. This dataset was created to apply deep learning-based object detection models to automotive sealing ring defect detection. Purposefully, we set up harsh conditions in the dataset to ensure the images closely resemble actual industrial environments. This includes simulating situations such as uneven lighting, noise interference, and image blurring to enhance the robustness required of the algorithm. With such a dataset setup, this study aims to provide a challenging evaluation platform for testing and improving the performance of the sealing ring defect detection algorithm.
The automotive sealing ring defect dataset constructed by us consists of 4977 images, and the data acquisition equipment is shown in Fig. 5. The dataset includes four types of defects: blowout, fracture, excess material and burr. The quantity of each defect is shown in Fig. 6. To facilitate supervised learning, the dataset was split in an 8:1:1 ratio into a training set (4031 images), validation set (448 images), and test set (498 images).

Figure 5: The data acquisition system
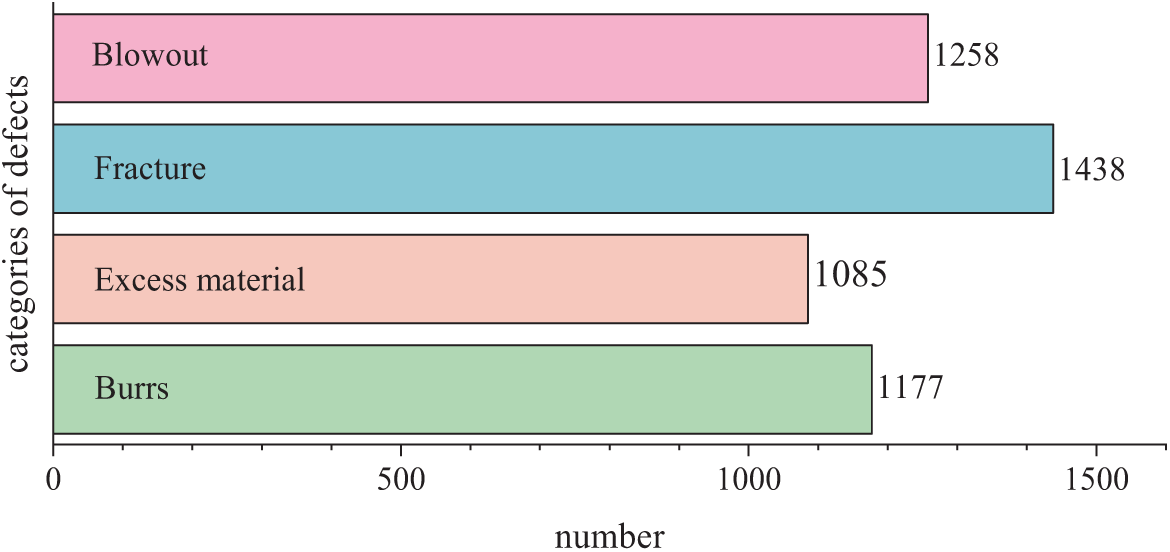
Figure 6: Sealing ring defect data distribution
The MS COCO2017 dataset, also called COCO2017, consists of 80 object categories, including humans, animals, vehicles, and household items. It is partitioned into 118,287 training images, 5000 validation images, and 40,670 test images, serving as a standard benchmark for evaluating object detection models and assessing their robustness.
The performance of the model will be evaluated by a variety of metrics such as Precision, Recall, mAP@0.5, mAP@0.5:0.95, Params and FLOPs.
Precision reflects the accuracy of the model in identifying positive samples, minimizing false positives. Recall represents the proportion of actual positives correctly predicted, with a high score indicating strong capability in detecting positive instances. The equations for Precision and Recall are as follows:
mAP@0.5 focuses on the average accuracy of the model’s predictions concerning the actual objects (Ground Truth) with a bounding box overlap of 0.5. This evaluation emphasizes the model’s performance at relatively high intersection and overlap ratio thresholds. In contrast, mAP@0.5:0.95, which covers multiple intersection and merging ratio thresholds ranging from 0.5 to 0.95, comprehensively assesses the model across different conditions. The AP and mAP formulas are given below:
where
Params denotes the model’s trainable parameters, indicating the size of the model. FLOPs (Floating Point Operations) quantify the computational cost of model inference or training. Higher FLOPs indicate increased resource requirements. The equations of Params and FLOPs can be expressed as:
where
4.3 Validation Results on the Automotive Sealing Ring Dataset
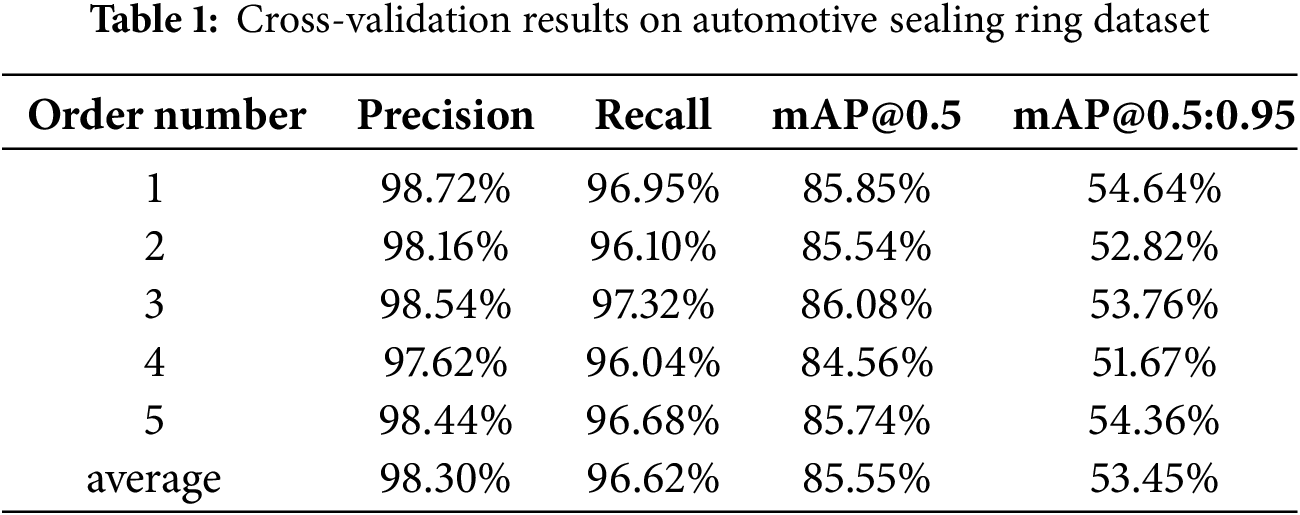
In order to avoid a single evaluation being affected by a specific data distribution, leading to unstable evaluation results, this study conducted five-fold cross-validation experiments on the automotive sealing ring dataset to more accurately assess the model’s generalization ability. The results are shown in Table 1. The improved model proposed in this paper achieves 98.30%, 96.62%, 85.55% and 53.45% in precision, recall, mAP@0.5 and mAP@0.5:0.95. It is worth noting that the fluctuation range of each metric is minimal in different cross-validation experiments, which validates that the automotive sealing ring dataset we constructed has an excellent and balanced data distribution.
4.3.2 Comparison with Other Methods
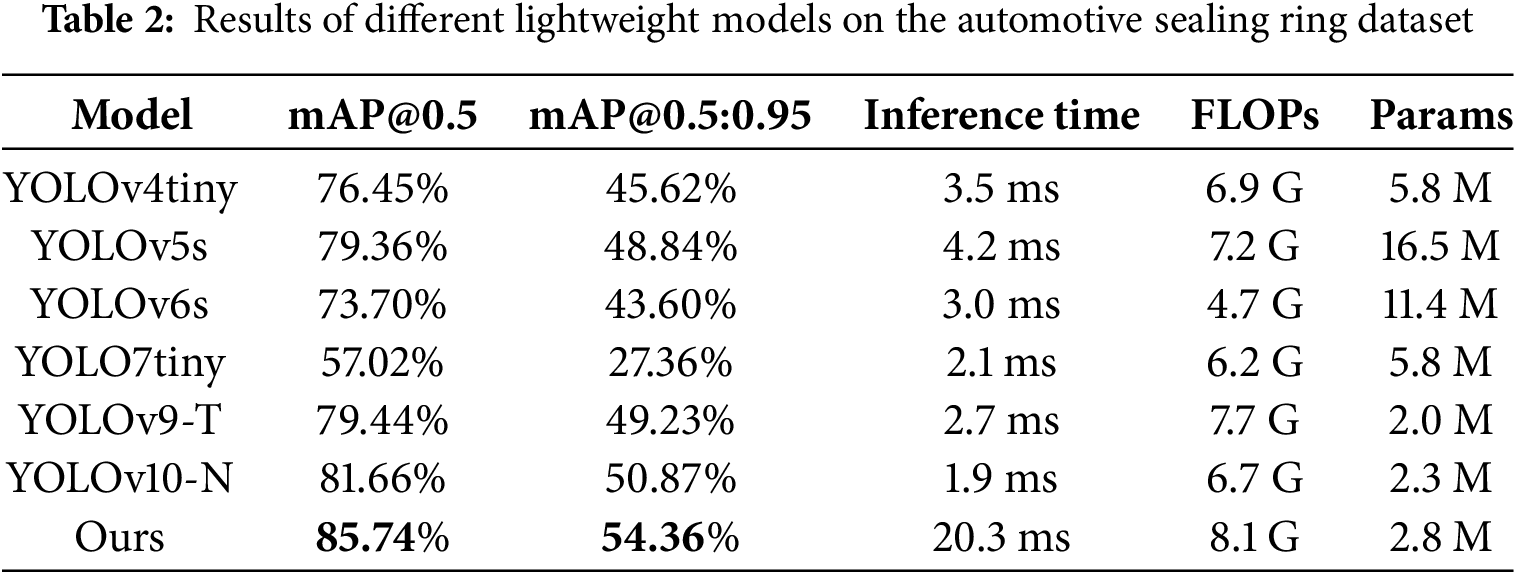
To assess the detection performance of the proposed model, we conducted a comparative analysis with other lightweight models on the automotive sealing ring dataset. The comparison results from the cross-validation experiment are shown in Table 2. While the Enhanced YOLO may not hold the edge in terms of inference speed and FLOPs, its performance in accuracy metrics stands out. Specifically, it achieves mAP@0.5 and mAP@0.5:0.95 scores of 85.73% and 54.36%, respectively, indicating superior performance levels. In addition, the parameters of proposed model are 2.8 M in total, lower than other existing methods. This makes it suitable for embedded devices and reduces hardware strain. This experiment offers a valuable benchmark for the industrial community when determining the optimal model for defect detection in automotive sealing rings.
4.4 Validation Results on COCO2017 Dataset
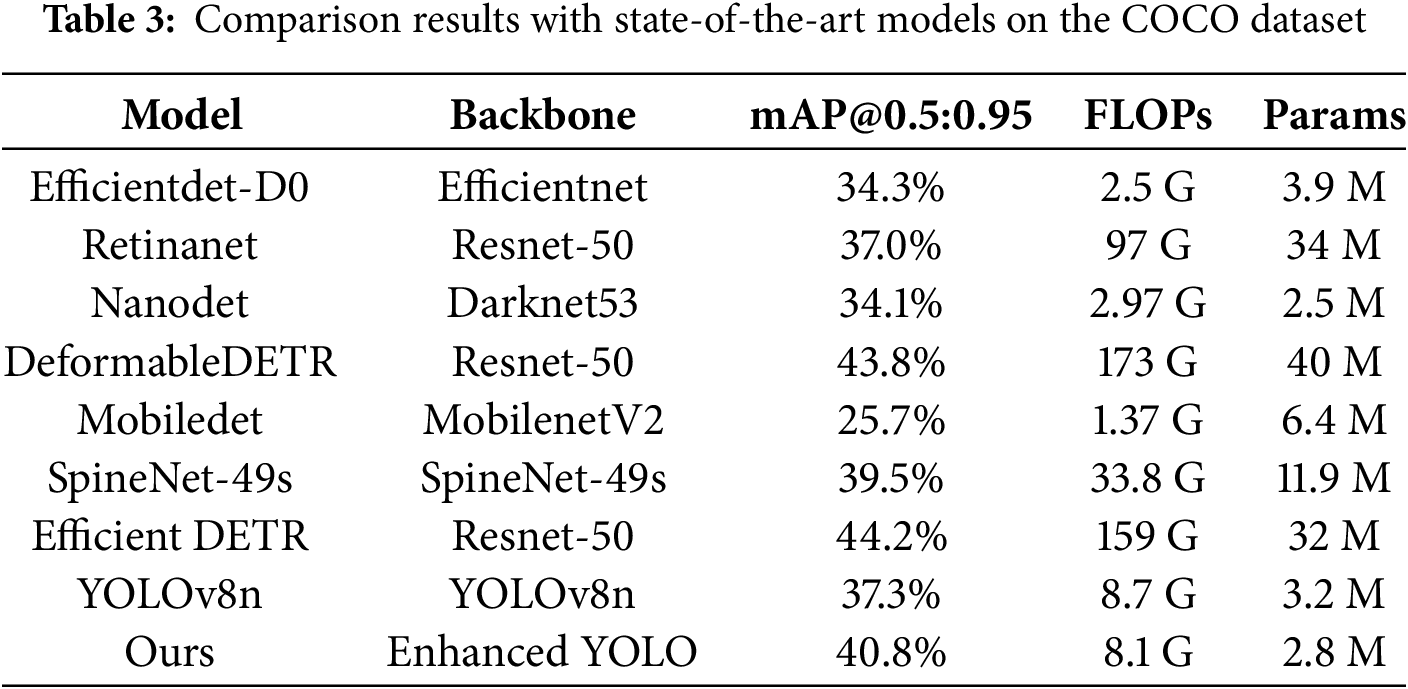
To assess our model’s robustness, we compared it with mainstream object detection models using the COCO dataset. Detailed numerical results are presented in the Table 3. As depicted in Table 3, although EfficientDet-D0, NanoDet, and MobileDet are comparable to our model in terms of the amount of parameter computation, the Enhanced YOLO outperforms in accuracy. Moreover, while SpineNet-49s achieves similar accuracy, and Deformable DETR and Efficient DETR perform slightly better than ours, it is noteworthy that our model retains a significant advantage in both parameter count and computational complexity. The outstanding performance on the COCO dataset demonstrates the robust generalization capability of the Enhanced YOLO across diverse scenarios.
To assess the effect of each enhancement, we performed a detailed ablation study. The visualization process of the model training is shown in Fig. 7. The specific results are shown in Table 4. For each enhancement strategy, respective control groups were set up to evaluate its impact on model performance. Specifically, “+DCN”, “+SPD”, “+BAWDLoss” and “Ours” represent the introduction of the DCN module, the introduction of the SPD module, adding the BAWD loss function, and our proposed model, respectively. As shown in Table 4, adding the DCN module, the SPD module, or changing the loss function each enhances performance metrics like Recall, mAP@0.5, and mAP@0.5:0.95. Moreover, introducing both modules consistently and substantially improved the model compared to the enhancements achieved by introducing a single module. The performance of the improvements with both modules also steadily improves compared to that of separate modules. Ultimately, when all three modules were simultaneously introduced, the model achieved optimal performance. In conclusion, the ablation study facilitated a precise understanding of the contribution of each enhancement. It also provided clarity on how individual and collective integrations of the strategies influenced the model’s performance, guiding future optimizations and decisions. The detection results and the heatmaps of the original model and the improved model are shown in Figs. 8 and 9, respectively.
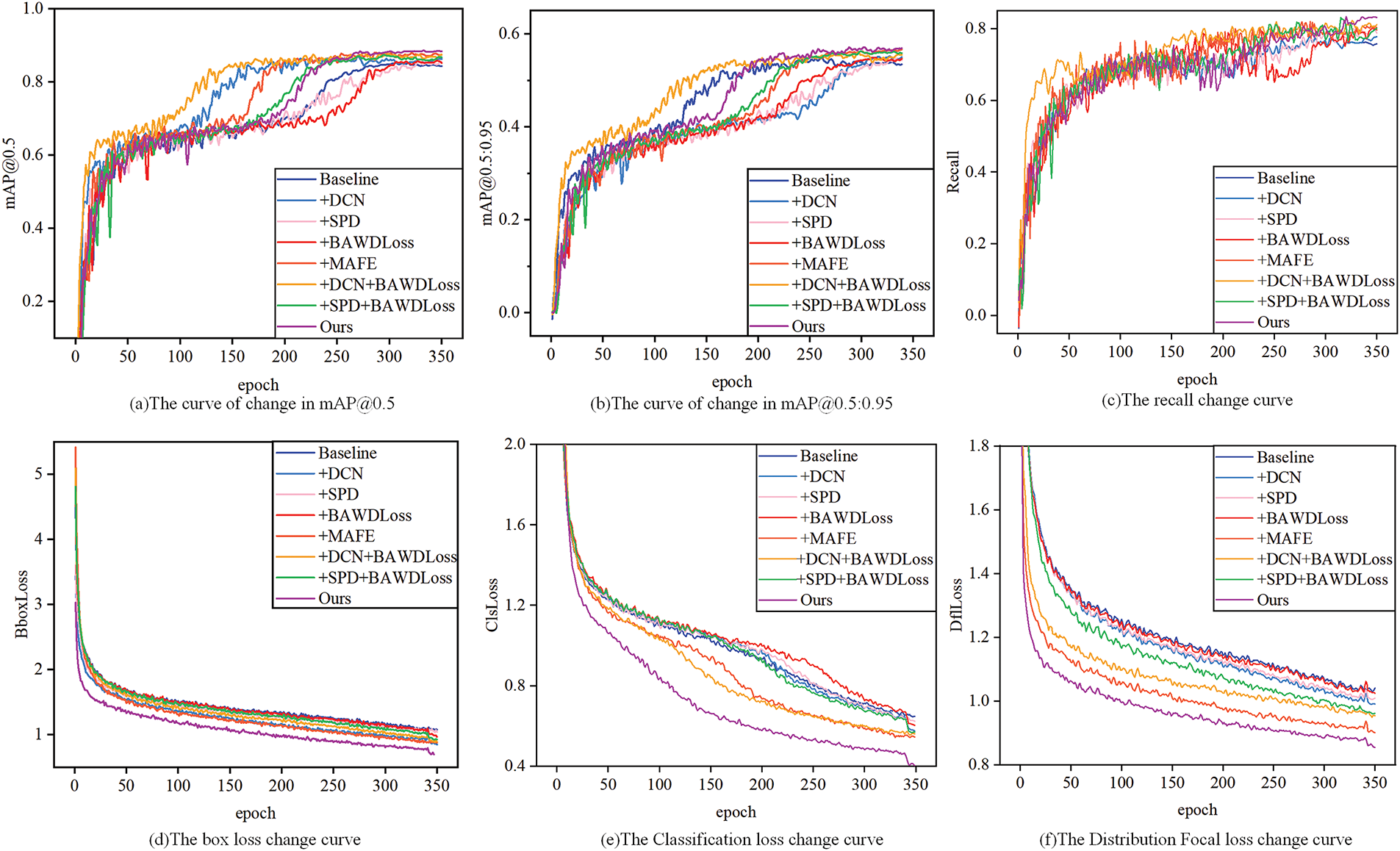
Figure 7: The model’s performance variations with different improvements on the automotive sealing ring dataset. Different curves highlight changes in metrics like mAP and recall over epochs, evaluating the impact of each enhancement

Figure 8: The detection results of the original model and the improved model
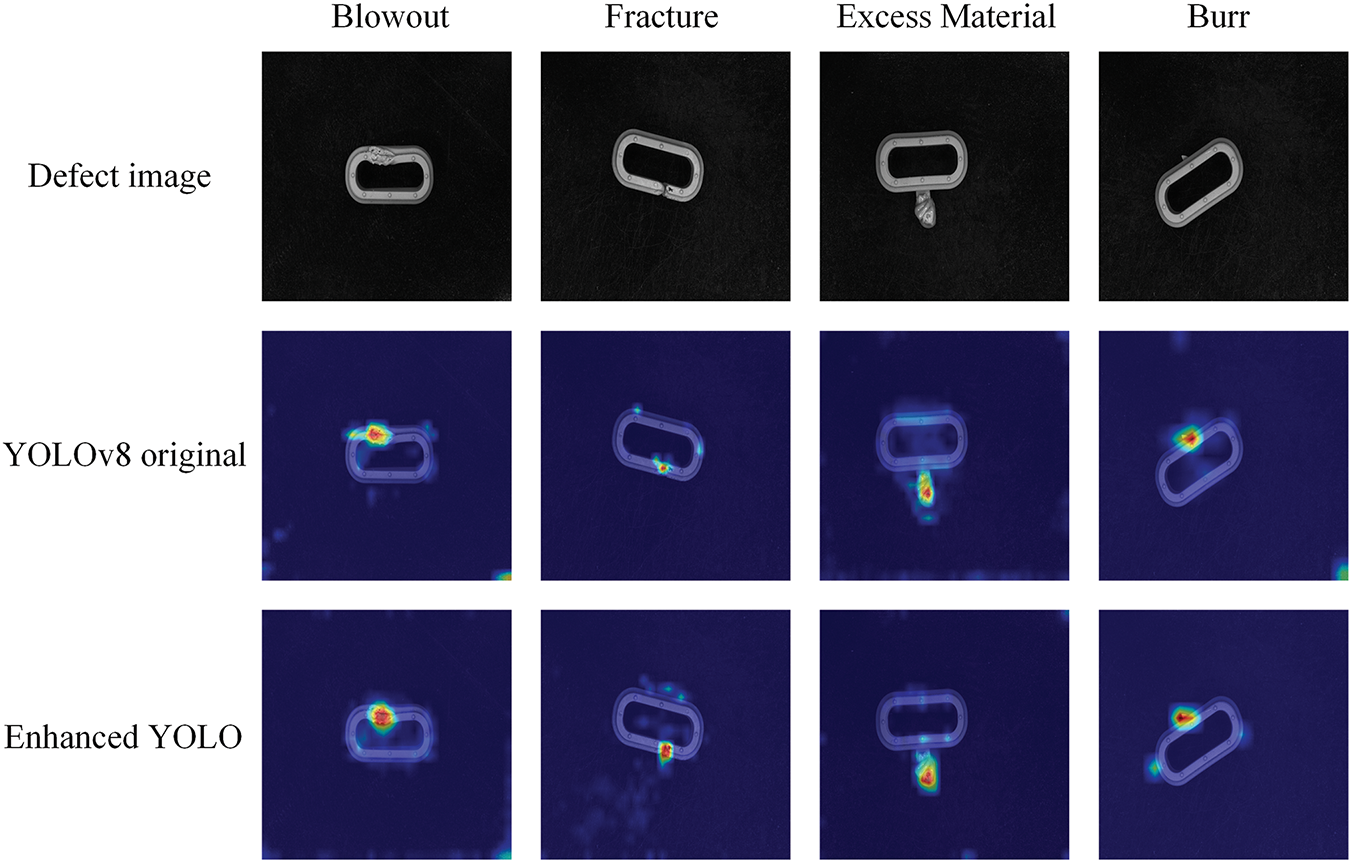
Figure 9: The heatmaps of the original model and the improved model
This paper proposes an improved model based on the state-of-the-art model YOLOv8 in order to solve the task of automotive sealing ring defect detection. The introduction of the MAFE module enhances the model’s ability to capture long-range dependencies and aggregate spatial features, significantly improving its robustness in detecting defects under complex industrial conditions. Additionally, the incorporation of the BAWD loss enhances the model’s precision in identifying small objects by more accurately modeling the bounding box similarity, especially in challenging scenarios with blurry or uncertain object boundaries. These improvements enable the model proposed in this paper to obtain significant performance enhancement while maintaining the characteristics of lightweight design and high-speed inference. It is worth mentioning that this paper achieves advanced accuracy performance on a specially constructed automotive sealing ring dataset. This approach significantly reduces the leakage and false detection rates, providing an excellent example for the field of automotive sealing ring defect detection and other rubber industrial products.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Jian Ge; data collection: Jian Ge, Yahui Zhang; analysis and interpretation of results: Jian Ge, Zimei Tu, Jinhua Jiang; draft manuscript preparation: Jian Ge, Qin Qin, Zhiwei Shen. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Due to the nature of this research, participants of this study did not agree for their data to be shared publicly, so supporting data is not available.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Muhammad K, Ullah A, Lloret J, Del Ser J, de Albuquerque VHC. Deep learning for safe autonomous driving: current challenges and future directions. IEEE Trans Intell Transp Syst. 2020;22(7):4316–36. doi:10.1109/TITS.2020.3032227. [Google Scholar] [CrossRef]
2. Wang Z, Zhan J, Duan C, Guan X, Lu P, Yang K. A review of vehicle detection techniques for intelligent vehicles. IEEE Trans Neural Netw Learn Syst. 2023;34(8):3811–31. doi:10.1109/TNNLS.2021.3128968. [Google Scholar] [PubMed] [CrossRef]
3. Chen S, Jin D, He H, Yang F, Yang J. Deep learning based online non-destructive defect detection for self piercing riveted joints in automotive body manufacturing. IEEE Trans Ind Inform. 2023;19(8):9134–44. doi:10.1109/TII.2022.3226246. [Google Scholar] [CrossRef]
4. Varol S, Odougherty P. A predictive analysis of electronic control unit system defects within automotive manufacturing. J Fail Anal Prev. 2022;22(3):918–25. doi:10.1007/s11668-022-01401-0. [Google Scholar] [CrossRef]
5. Türköz M, Evcen DC. Investigation on the sealing performance of polymers at ultra high pressures. Int Polym Process. 2022;37(5):549–58. doi:10.1515/ipp-2022-4226. [Google Scholar] [CrossRef]
6. Zhang Y, Wang Y, Jiang Z, Zheng L, Chen J, Lu J. Domain adaptation via transferable swin transformer for tire defect detection. Eng Appl Artif Intell. 2023;122(1):106109. doi:10.1016/j.engappai.2023.106109. [Google Scholar] [CrossRef]
7. Parlak IE, Emel E. Deep learning-based detection of aluminum casting defects and their types. Eng Appl Artif Intell. 2023;118(2):105636. doi:10.1016/j.engappai.2022.105636. [Google Scholar] [CrossRef]
8. Scholz O, Doerfler N, Seifert L, Zöller U. Fully-automatic surface inspection of O-ring seals. In: SAE technical paper; 2015. [Google Scholar]
9. Lu X, Jiang C, Ma Z, Li H, Liu Y. A simple and effective surface defect detection method of power line insulators for difficult small objects. Comput Mater Contin. 2024;79(1):373–90. doi:10.32604/cmc.2024.047469. [Google Scholar] [CrossRef]
10. Kim G-I, Yoo H, Cho H-J, Chung K. Defect detection model using time series data augmentation and transformation. Comput Mater Contin. 2024;78(2):1713–30. doi:10.32604/cmc.2023.046324. [Google Scholar] [CrossRef]
11. Jiang W, Li T, Zhang S, Chen W, Yang J. PCB defects target detection combining multi-scale and attention mechanism. Eng Appl Artif Intell. 2023;123(4968):106359. doi:10.1016/j.engappai.2023.106359. [Google Scholar] [CrossRef]
12. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Analy Mach Intell. 2016;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
13. He K, Gkioxari G, Dollár P, Girshick R. Mask R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision; 2017; Venice, Italy. p. 2980–8. [Google Scholar]
14. Redmon J. You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2016. [Google Scholar]
15. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, et al. Ssd: single shot multibox detector. In: Computer Vision-ECCV 2016: 14th European Conference; 2016 Oct 11–14; Amsterdam, The Netherlands: Springer. [Google Scholar]
16. Jiang P, Ergu D, Liu F, Cai Y, Ma B. A review of yolo algorithm developments. Procedia Comput Sci. 2022;199(11):1066–73. doi:10.1016/j.procs.2022.01.135. [Google Scholar] [CrossRef]
17. Cai Z, Vasconcelos N. Cascade R-CNN: delving into high quality object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018; Salt Lake City, UT, USA. p. 6154–62. [Google Scholar]
18. Revathy G, Kalaivani R. Fabric defect detection and classification via deep learning-based improved mask RCNN. Signal Image Video Process. 2024;18(3):2183–93. doi:10.1007/s11760-023-02884-6. [Google Scholar] [CrossRef]
19. Chen C, Wang S, Huang S. An improved faster RCNN-based weld ultrasonic atlas defect detection method. Meas Control. 2023;56(3–4):832–43. doi:10.1177/00202940221092030. [Google Scholar] [CrossRef]
20. Cheng S, Lu J, Yang M, Zhang S, Xu Y, Zhang D, et al. Wheel hub defect detection based on the DS-cascade RCNN. Measurement. 2023;206(1):112208. doi:10.1016/j.measurement.2022.112208. [Google Scholar] [CrossRef]
21. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. In: European Conference on Computer Vision; 2020; Cham: Springer. [Google Scholar]
22. Zhu X, Su W, Lu L, Li B, Wang X, Dai J. Deformable DETR: deformable transformers for end-to-end object detection; 2020. arXiv:201004159. 2020. [Google Scholar]
23. Dai X, Chen Y, Yang J, Zhang P, Yuan L, Zhang L. Dynamic DETR: end-to-end object detection with dynamic attention. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2021; Montreal, QC, Canada. p. 2968–77. [Google Scholar]
24. Zhou X, Ren Z, Zhang Y, Mi T, Zhou S, Jiang Z. A shunted-swin transformer for surface defect detection in roller bearings. Measurement. 2024;238(1):115283. doi:10.1016/j.measurement.2024.115283. [Google Scholar] [CrossRef]
25. Sun X, Song K, Wen X, Wang Y, Yan Y. SDD-DETR: surface defect detection for no-service aero-engine blades with detection transformer. IEEE Trans Autom Sci Eng. 2024;22:6984–97. doi:10.1109/TASE.2024.3457829. [Google Scholar] [CrossRef]
26. Zhang Q, Lai J, Zhu J, Xie X. Wavelet-guided promotion-suppression transformer for surface-defect detection. IEEE Trans Image Process. 2023;32:4517–28. doi:10.1109/TIP.2023.3293770. [Google Scholar] [PubMed] [CrossRef]
27. Wang C-Y, Bochkovskiy A, Liao H-YM. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023; Vancouver, BC, Canada. p. 7464–75. [Google Scholar]
28. Huang X, Zhu J, Huo Y. SSA-YOLO: an improved YOLO for hot-rolled strip steel surface defect detection. IEEE Trans Instrum Meas. 2024;73(10):5040017. doi:10.1109/TIM.2024.3488136. [Google Scholar] [CrossRef]
29. Li H, Wang C, Liu Y. YOLO-FDD: efficient defect detection network of aircraft skin fastener. Signal Image Video Process. 2024;18(4):3197–211. doi:10.1007/s11760-023-02983-4. [Google Scholar] [CrossRef]
30. Xiao D, Xie FT, Gao Y, Li ZN, Xie HF. A detection method of spangle defects on zinc-coated steel surfaces based on improved YOLO-v5. Int J Adv Manuf Technol. 2023;128(1–2):937–51. doi:10.1007/s00170-023-11963-4. [Google Scholar] [CrossRef]
31. Li X, Zhu J, Shi H, Cong Z. Surface defect detection of seals based on k-means clustering algorithm and particle swarm optimization. Sci Program. 2021;2021(1):3965247–12. doi:10.1155/2021/3965247. [Google Scholar] [CrossRef]
32. Yu J, Jiang Y, Wang Z, Cao Z, Huang T. UnitBox: an advanced object detection network. In: Proceedings of the 24th ACM International Conference on Multimedia; 2016. p. 516– 520. [Google Scholar]
33. Rezatofighi H, Tsoi N, Gwak J, Sadeghian A, Reid I, Savarese S. Generalized intersection over union: a metric and a loss for bounding box regression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019. p. 658–66. [Google Scholar]
34. Zhang Y-F, Ren W, Zhang Z, Jia Z, Wang L, Tan T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing. 2022;506(9):146–57. doi:10.1016/j.neucom.2022.07.042. [Google Scholar] [CrossRef]
35. Gevorgyan Z. SIoU loss: more powerful learning for bounding box regression. arXiv:2205.12740. 2022. [Google Scholar]
36. Zhao J, Zhu H. CBPH-Net: a small object detector for behavior recognition in classroom scenarios. IEEE Trans Instrum Meas. 2023;72:2521112. doi:10.1109/TIM.2023.3296124. [Google Scholar] [CrossRef]
37. Wang J, Xu C, Yang W, Yu L. A normalized gaussian wasserstein distance for tiny object detection. arXiv:2110.13389. 2021. [Google Scholar]
38. Li X, Wang W, Wu L, Chen S, Hu X, Li J, et al. Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection. Adv Neural Inf Process Syst. 2020;33:21002–12. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools