
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
An Improved Lightweight Safety Helmet Detection Algorithm for YOLOv8
1 Key Laboratory of Advanced Manufacturing and Automation Technology, Education Department of Guangxi Zhuang Autonomous Region, Guilin University of Technology, Guilin, 541004, China
2 Guangxi Key Laboratory of Special Engineering Equipment and Control, Guilin University of Aerospace Technology, Guilin, 541004, China
3 Guangxi Tianli Construction Engineering Co., Ltd., Guilin, 541001, China
4 School of Information Engineering, Nanning College of Technology, Guilin, 541004, China
* Corresponding Author: Cui Zhang. Email:
(This article belongs to the Special Issue: Computer Vision and Image Processing: Feature Selection, Image Enhancement and Recognition)
Computers, Materials & Continua 2025, 83(2), 2245-2265. https://doi.org/10.32604/cmc.2025.061519
Received 26 November 2024; Accepted 23 January 2025; Issue published 16 April 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Detecting individuals wearing safety helmets in complex environments faces several challenges. These factors include limited detection accuracy and frequent missed or false detections. Additionally, existing algorithms often have excessive parameter counts, complex network structures, and high computational demands. These challenges make it difficult to deploy such models efficiently on resource-constrained devices like embedded systems. Aiming at this problem, this research proposes an optimized and lightweight solution called FGP-YOLOv8, an improved version of YOLOv8n. The YOLOv8 backbone network is replaced with the FasterNet model to reduce parameters and computational demands while local convolution layers are added. This modification minimizes computational costs with only a minor impact on accuracy. A new GSTA (GSConv-Triplet Attention) module is introduced to enhance feature fusion and reduce computational complexity. This is achieved using attention weights generated from dimensional interactions within the feature map. Additionally, the ParNet-C2f module replaces the original C2f (CSP Bottleneck with 2 Convolutions) module, improving feature extraction for safety helmets of various shapes and sizes. The CIoU (Complete-IoU) is replaced with the WIoU (Wise-IoU) to boost performance further, enhancing detection accuracy and generalization capabilities. Experimental results validate the improvements. The proposed model reduces the parameter count by 19.9% and the computational load by 18.5%. At the same time, mAP (mean average precision) increases by 2.3%, and precision improves by 1.2%. These results demonstrate the model’s robust performance in detecting safety helmets across diverse environments.Keywords
Construction environments in sectors such as building sites, electrical operations, and resource exploration are inherently complex and present numerous safety hazards. Helmets, as essential protective gear, significantly reduce the risk of injury and are crucial for worker safety [1]. Consequently, monitoring helmet usage is a critical safety measure in these settings. Traditionally, helmet wear detection has relied on manual inspections, which are costly in terms of both human and time resources and are characterized by low efficiency and poor timeliness. As a result, object detection-based helmet wear detection has emerged as a critical method for enhancing safety management on construction sites [2].
In recent years, the ongoing advancement of object detection algorithms driven by deep learning has divided them into two groups, distinguished by the number of detection stages involved: object detection algorithms categorized as one-stage and two-stage [3]. Algorithms with two stages, like Fast R-CNN [4] and Faster R-CNN [5], start by generating candidate regions, selecting the positions of objects within these regions, and then further classifying and locating the objects to facilitate helmet wear detection. The Tiny Face model was improved by combining it with a CNN and adding supplementary modules [6]. This approach overcame the low accuracy issues commonly associated with traditional single deep learning models in detection tasks. Espinosa-Oviedo et al. [7] enhanced Faster R-CNN using the EspNet model. Li et al. [8] introduced the Faster R-CNN-LSTM approach, an enhancement of the Faster R-CNN framework, which improved mAP performance on the dataset. Sun et al. [9] developed a safety monitoring method for factories utilizing the Faster R-CNN algorithm, which builds a feature pyramid to integrate multi-scale features from the original network, improving the detection of small objects such as helmets and safety belts. Zhang et al. [10] introduced a helmet detection method for steel mill workshops using deep learning’s Faster R-CNN, enhancing detection accuracy and demonstrating good practicality and effectiveness.
Although these methods have enhanced model accuracy, their complex structures lead to high computational costs and substantial parameter sizes. Moreover, the detection scenarios, predominantly confined to single work environments, often exhibit poor real-time performance and do not adequately meet practical application requirements [11].
Safety helmet detection requires high real-time responsiveness. Single-stage object detection algorithms eliminate the need for a candidate region generation phase and accomplish object classification and location in a single step with only one detection iteration [12,13], thus offering faster detection speeds suitable for helmet wear detection. Notable examples of such algorithms include SSD and the YOLO series. Ku et al. [14] presented an enhanced helmet detection algorithm built on YOLOv4, effectively decreasing model complexity while boosting detection accuracy. Zhang et al. [15] proposed an SCM-YOLO, incorporating several optimization strategies into YOLOv4-tiny. These enhancements include integrating an SPP structure, a CBAM module, the Mish activation function, and K-Means++ clustering. The experimental results confirm the algorithm meets real-time processing and accuracy standards for safety helmet detection in challenging scenarios. Sadiq et al. [16] introduced a deep learning-driven safety helmet detection model that combines YOLOv5 with a fuzzy image enhancement module, leading to the development of the enhanced FD-YOLOv5 model. The FD-YOLOv5 outperforms YOLOv5 in complex surveillance videos, efficiently detecting helmets while demonstrating strong practicality and robustness in real-world construction environments. Shan et al. [17] introduced an enhanced YOLOv5 designed to improve detection accuracy for small, densely packed objects by incorporating weighted bidirectional feature pyramids. Yao et al. [18] proposed the AMCFF-YOLOv5s model, incorporating optimization strategies such as k-means++, BiFPN, and CBAM. This model improves the accuracy of miner status detection within cages and demonstrates strong robustness in complex environments, offering an efficient solution for coal mine safety monitoring. An et al. [19] presented an enhanced YOLOv5s model by optimizing anchor boxes, integrating attention mechanisms, adopting the SIoU, and integrating knowledge distillation techniques. Experimental findings show that the model delivers enhanced accuracy and better real-time performance. It performs exceptionally well in low-light and multi-distance conditions, and the model is highly effective for helmet detection. Song et al. [20] created an intelligent helmet detection system that combines the YOLOv5 detector with the DeepSort multi-object tracking algorithm. The system employs YOLOv5 to extract target bounding boxes and combines Kalman filtering with the Hungarian algorithm for trajectory prediction and tracking, enhancing detection accuracy in complex construction environments. Wang et al. [21] introduced a helmet recognition method built on a refined YOLOv7-tiny model, optimizing feature extraction efficiency and improving detection accuracy.
Notably, YOLOv8 incorporates a redesigned architecture and an optimized loss function, resulting in significantly faster training speeds and higher detection accuracy. These enhancements make YOLOv8 more efficient and effective for object detection tasks [22]. Lin et al. [23] the YOLOv8-SLIM-CA helmet recognition method was introduced, incorporating a coordinate attention mechanism, a streamlined neck design, and an additional layer for detecting small objects. These enhancements improve detection capabilities for small objects and complex backgrounds. The algorithm achieves real-time, efficient helmet detection performance, surpassing mainstream detection algorithms. Aboah et al. [24] introduced a helmet recognition model leveraging YOLOv8. This model utilizes a few-shot data sampling approach to reduce labeling efforts, enabling efficient video detection optimized for real-world real-time applications.
Although single-stage object detection algorithms have improved detection accuracy and speed, they face challenges, such as increased model parameters and computational costs when enhancing detection precision [25]. In practical application environments, using complex models can improve detection accuracy. However, due to factors such as network complexity, a large number of parameters, substantial physical memory requirements, and lengthy training times, these models are complex to deploy on embedded or edge devices, increasing deployment costs. Additionally, the traditional convolution process in complex models raises computational costs, wastes specific resources, and weakens the model’s real-time performance. In actual detection environments, complexities such as obstructions, lighting variations, and dense worker populations often result in missed and false detections, leading to suboptimal outcomes. Additionally, the considerable variation in helmet sizes and colors complicates accurate feature extraction by these algorithms. To overcome these challenges, this study introduces an optimized version of the YOLOv8n algorithm, FGP-YOLOv8, offering a lightweight solution for helmet wear detection.
This paper’s first section identifies helmet detection’s challenges in complex environments and reviews recent developments in neural network-based object detection techniques. The second section describes the architecture of the proposed FGP-YOLOv8 algorithm, followed by the third section, which focuses on its crucial improvement modules. The fourth section explains the experimental setup, including datasets and parameters, and presents detailed experiments to assess the effectiveness of the proposed improvements module. Finally, the fifth section concludes the study by highlighting its contributions, exploring practical applications of the model, and offering recommendations for future research.
The main contributions of this paper can be summarized as follows:
1. The FasterNet lightweight module, utilizing PConv as the primary operator, replaces the original backbone feature extraction network. This substantially decreases the model’s parameters and computational burden while maintaining detection accuracy at a comparable level, thus achieving efficient network lightweight.
2. The newly developed GSTA module reduces computational complexity while improving spatial and channel attention fusion. This improvement boosts the model’s target localization and feature expression capabilities, enhancing helmet wear detection performance.
3. A new ParNet-C2f module, based on structural reparameterization, employs a parallel network structure to broaden the feature map’s perceptual range. This improvement enhances the model’s ability to extract features and increases detection accuracy.
4. Implementing WIoU as the loss function balances penalties between high- and low-quality anchor boxes. It includes a dynamic non-monotonic focus mechanism that preserves feature information across various scales, accelerating convergence and boosting the model’s detection capabilities.
2 The Proposed FGP-YOLOv8 Algorithm
In 2023, Ultralytics introduced YOLOv8, a new model for object detection, instance segmentation, and image classification tasks [26]. Compared to the widely used YOLOv5, YOLOv8 has achieved broader adoption in object detection due to its superior detection accuracy and faster processing speeds [27]. YOLOv8 is categorized into five models based on model depth: n, s, l, m, x [28]. YOLOv8n features the smallest parameter size and the quickest detection speed, [29] making it the chosen baseline model for enhancements and structural redesigns in this study. The YOLOv8n model comprises three primary components: backbone, neck, and head networks [30]. Although YOLOv8n excels in detection speed, it exhibits areas that require further refinement. The simultaneous detection of helmets in scenes with multiple individuals poses challenges, particularly concerning the algorithm’s computational demands and parameter size, which render it less practical for deployment on construction sites [31]. In real-world applications, complex scenarios such as dense crowds, numerous small objects, and intricate backgrounds complicate feature extraction necessary for accurate helmet detection, often leading to false alarms and omissions [32].
To resolve the challenges of limited accuracy, as well as frequent missed and false detections faced by the YOLOv8n algorithm in helmet wear detection, and considering the necessity for model lightening, this paper develops the FGP-YOLOv8 algorithm based on the YOLOv8n model. We improved and optimized recent mainstream safety helmet detection models and, through comparative experiments, ultimately selected four modules to optimize the model. This algorithm is enhanced in four major areas to achieve superior detection performance and reduce computational costs.
Firstly, to address the excessive parameters and computational demands, this study substitutes YOLOv8n’s backbone network with a FasterNet model and incorporates Partial Convolution (PConv) into the backbone layers, substantially decreasing the model’s parameters and floating-point computations, thereby making it more lightweight. Secondly, the newly developed GSTA module is incorporated into the neck network, boosting the model’s target localization and feature representation abilities by leveraging three-dimensional attention weights in the feature maps, all while keeping the computational load unchanged. Thirdly, a novel ParNet-C2f module is designed to extract features from safety helmets of various colors and sizes more effectively. Lastly, the WIoU loss function is applied, utilizing a dynamic focusing mechanism to improve the precision of quality assessments between predicted and actual boxes, thereby accelerating model convergence and enhancing the network’s detection efficiency. These enhancements improve performance, reduce computational redundancy, and increase the algorithm’s efficiency. Fig. 1 presents a structural diagram illustrating the model’s architecture.
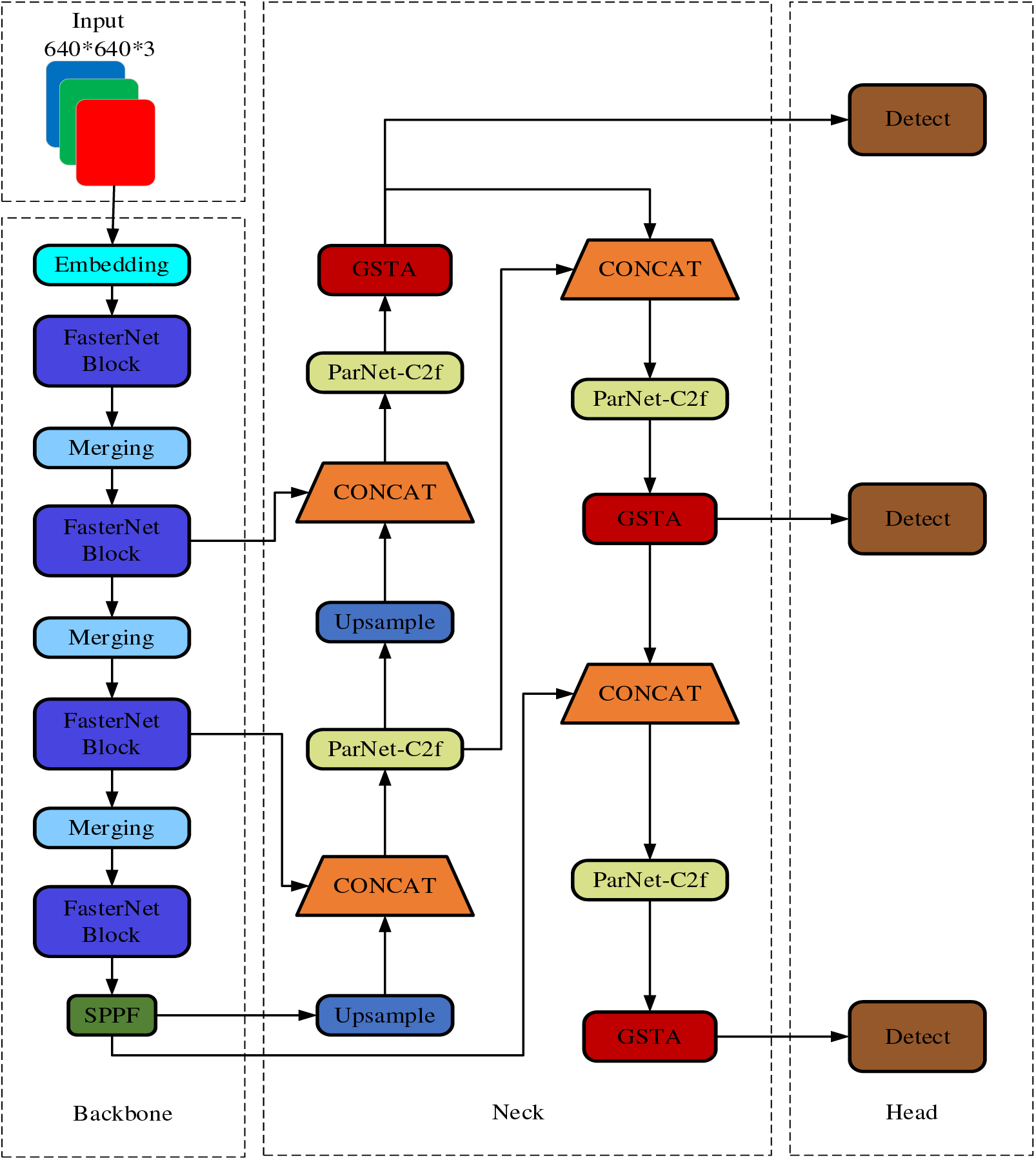
Figure 1: The network structure of FGP-YOLOv8
3.1 FasterNet Lightweight Module
In helmet-wearing detection tasks, the images often feature various colors, significant obstructions, and complicated settings. YOLOv8 employs the DarkNet-53 module as its backbone, which provides a deep network structure aiding in enhanced feature extraction but also accumulates numerous convolution operations, leading to feature redundancy. This results in a high parameter count and reduced detection speed, making it less ideal for deployment on portable devices. Introduced in 2023, FasterNet features a simpler architecture that achieves faster processing and greater accuracy across different devices. The FasterNet lightweight network is organized into four hierarchical stages [33], each stage beginning with either an embedding layer or a merging layer to facilitate spatial downsampling and channel expansion. Each stage incorporates a FasterNet Block, utilizing a 3 × 3 PConv as its primary operator, followed by two 1 × 1 Conv layers. Batch Normalization is strategically placed between the Conv layers, complemented by the ReLU to optimize inference speed and preserve feature diversity. The complete structure of FasterNet is depicted in Fig. 2.
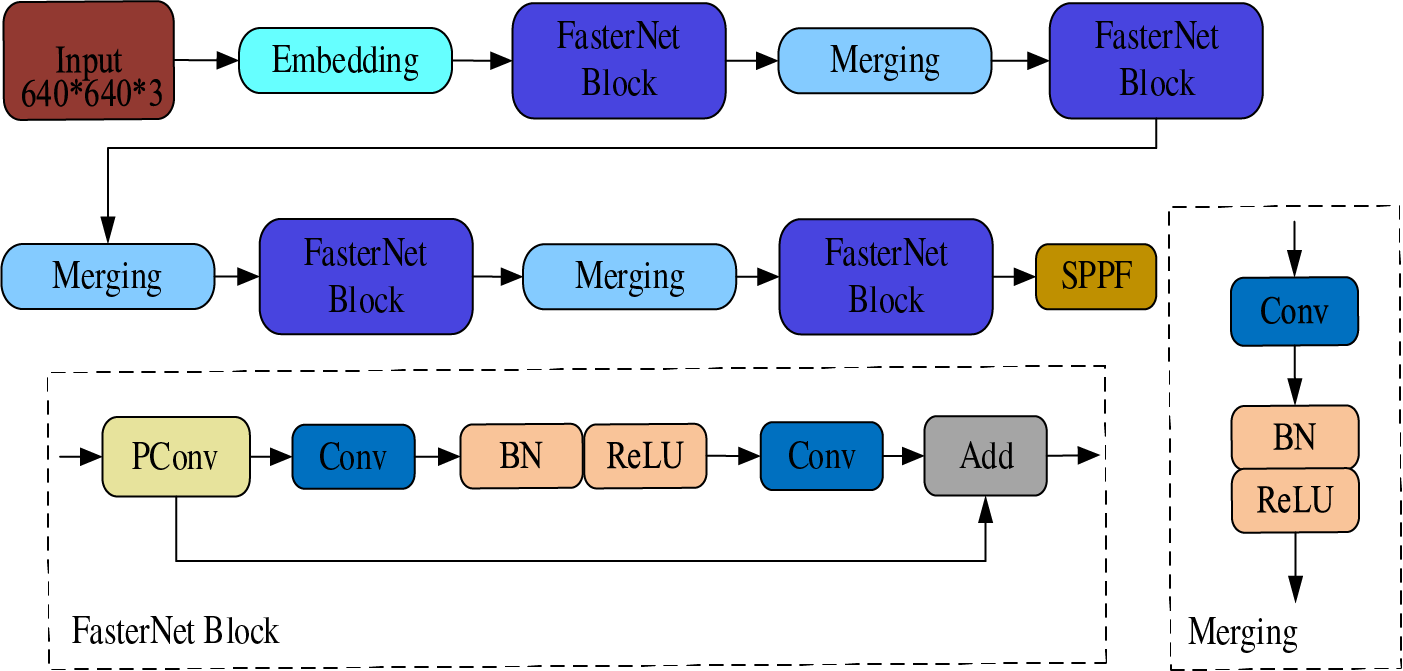
Figure 2: FasterNet network architecture diagram
The FasterNet network employs Partial Convolution (PConv) as its primary operator, improving algorithm accuracy while reducing FLOPs and memory usage. Fig. 3 illustrates the operational principle of PConv.

Figure 3: The operational principle of Conv and PConv
In Partial Convolution (PConv), the conventional convolution operation is selectively applied to particular input channels for spatial feature extraction, leaving the remaining channels unchanged. This approach facilitates sequential memory access by focusing on processing the feature map’s initial or final continuous channels. This technique efficiently captures spatial features while reducing computational and memory demands. The FLOPs involved in PConv are detailed in Eq. (1).
For regular convolution (Conv), the FLOPs related to the inputs
In the formula,
Integrating the FasterNet lightweight network has optimized the YOLOv8 backbone, markedly decreasing the algorithm’s computational demands and parameter count while improving detection speeds in diverse and complex environments.
Attention mechanisms have demonstrated significant effectiveness in artificial intelligence and are extensively employed in object detection tasks. Traditional attention mechanisms, which compute weights for individual channels, often overlook information integration across channel and spatial dimensions. The SE attention mechanism excels at adaptively learning the weights of each channel, thereby focusing on the critical channel information [34]. The CBAM adds spatial attention as a complement to channel attention, reference [35] yet it treats them as separate entities without considering their interaction. Distinctively, the Triplet Attention module utilizes three parallel branches to focus on different input dimensions, reference [36] effectively capturing spatial-channel interactions. This method fosters the development of interdependencies between channel and spatial locations, enhancing feature interpretation capabilities, albeit with increased computational and parameter demands.
This study combines GSConv with the traditional Triplet Attention module to mitigate the excessive increases in computational and parameter demands introduced by the Triplet Attention module. It also presents the newly developed GSTA module, as depicted in Fig. 4.

Figure 4: GSTA structure diagram
Recently introduced, GSConv represents a novel, lightweight convolution that combines standard convolution (SC), depth-wise separable convolution (DSConv), and shuffle mixed convolution [37]. Its implementation is illustrated in Fig. 5. GSConv operates at 60% to 70% of the computational cost of standard convolution while maintaining excellent accuracy.
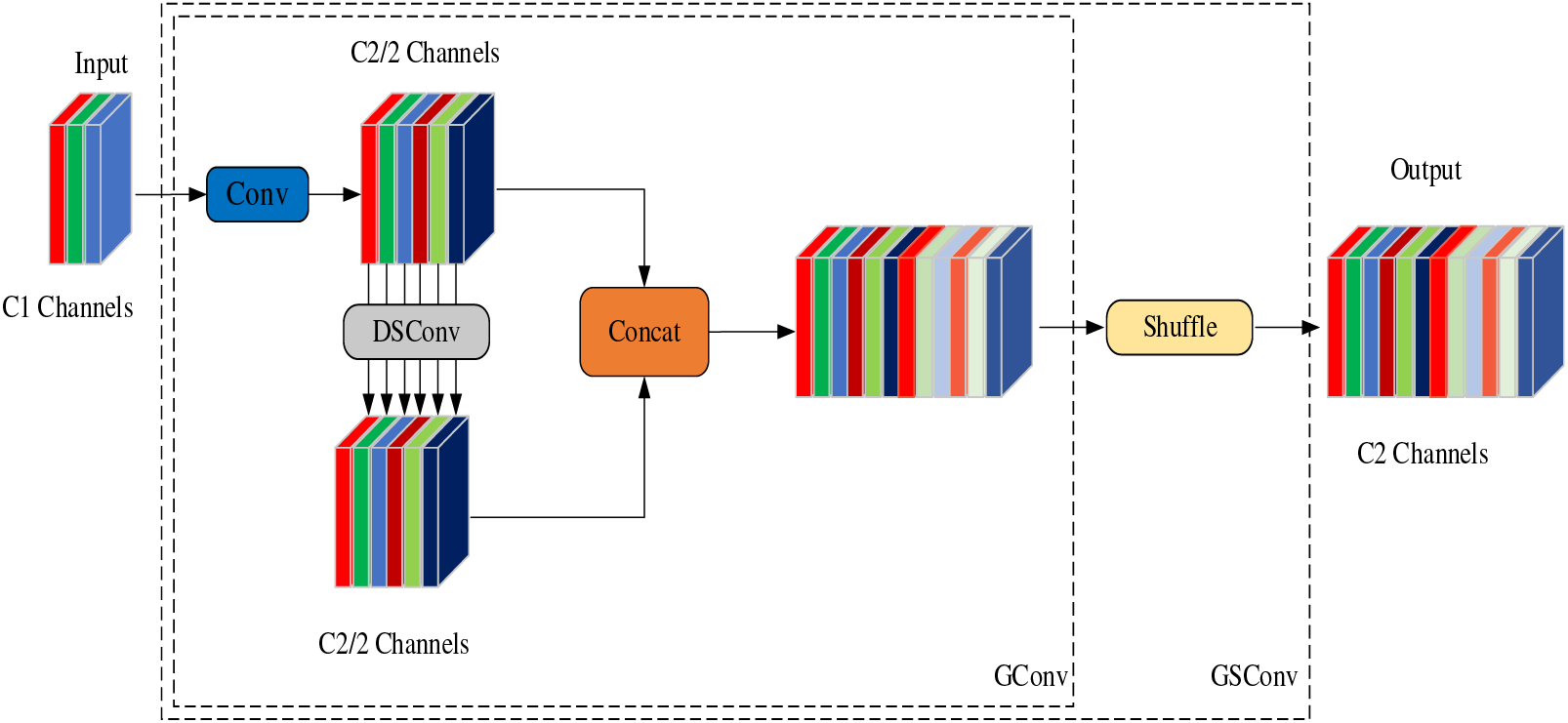
Figure 5: GSConv structure diagram
The GSTA module leverages three parallel branches to derive dependencies across the dimensions of the input tensor
In the Z-pool layer, average and maximum pooling is applied to the zero dimensions of the input, which are subsequently concatenated. This concatenation reduces the number of channels in this dimension to two, preserving the tensor’s rich representation while simplifying the computational process. The operation is detailed in the formula presented in Eq. (3).
Assuming the input
YOLOv8n network structure incorporates many C2f modules, which are crucial for feature extraction. Network performance quality directly relates to how well these C2f modules extract features. Detecting safety helmets, which vary widely in size and color and often appear against complex backgrounds with significant obstructions, poses a challenge for the current C2f modules to capture the boundary information of the objects accurately. This limitation hinders their ability to extract features from various helmets effectively.
Accordingly, this paper introduces the newly developed ParNet-C2f module, which replaces all Bottleneck modules within the existing C2f module with ParNet-Bottleneck modules. Fig. 6 illustrates the ParNet-C2f module design, which is based on the principles of the ParNet network.
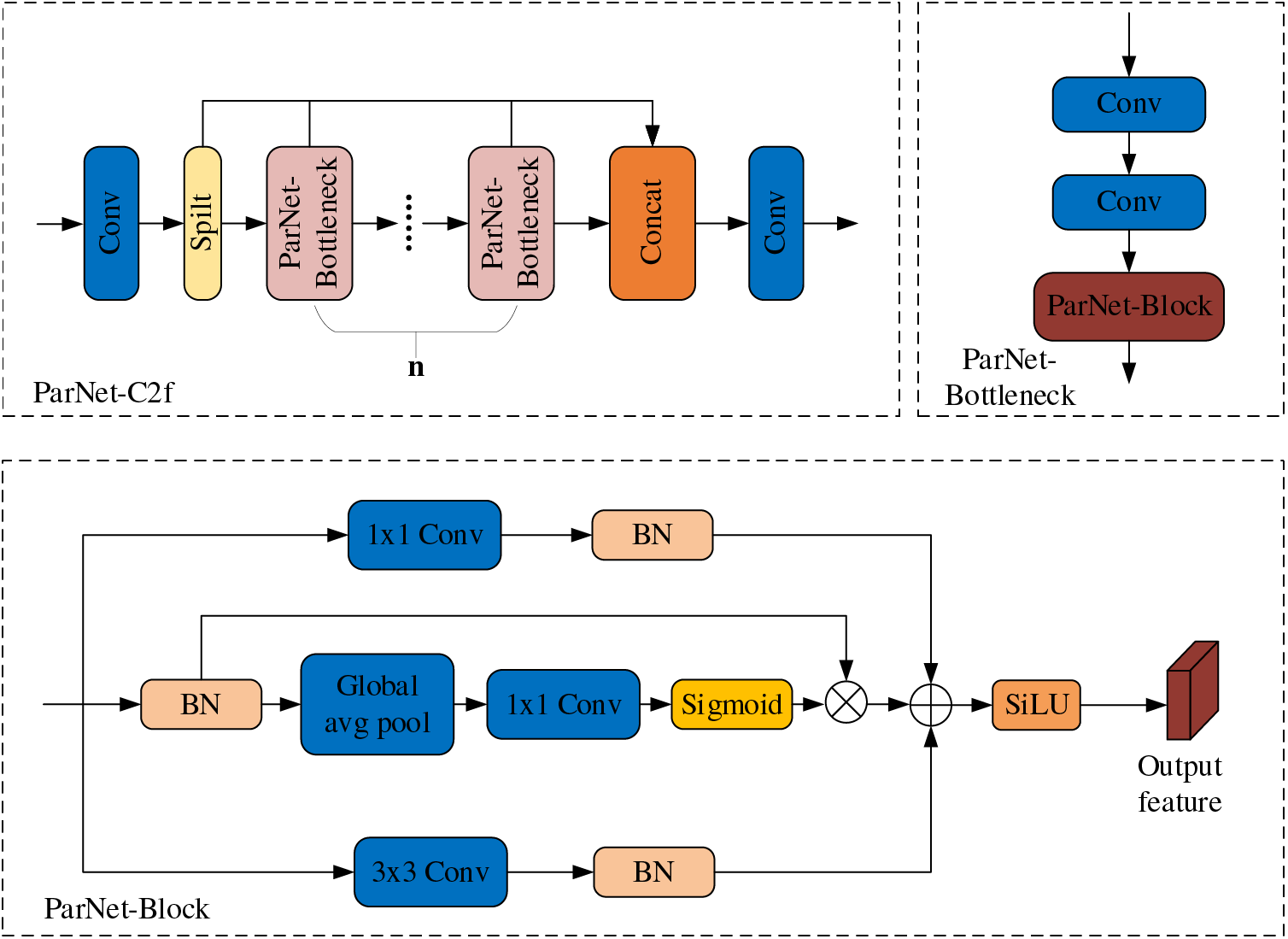
Figure 6: ParNet-C2f structure diagram
ParNet is based on structural reparameterization and employs a non-depth neural network design, offering performance benefits over deeper networks [38]. The ParNet-Block is the core component of ParNet that allows the neural network to focus on the most informative parts, enhancing its feature extraction capabilities. The ParNet-Block comprises three parallel branches: In the initial branch, input features go through a convolution layer to assign weights. The second branch utilizes a residual structure, where feature information, after passing through an average pooling layer, mitigates the convolution layer’s excessive sensitivity to position while preserving background information. Weights are adjusted via a convolution layer, processed through a Sigmoid activation function, and multiplied by the original feature map. The third branch extends the perceptual field of the feature map through another convolution layer. Ultimately, feature information from all three branches is combined in the output. The ParNet-Block utilizes multi-branch fusion to fine-tune the network’s focus on the image, expand the perceptual field, and bolster the backbone network’s feature extraction capabilities.
Based on the Intersection over Union (IoU), which evaluates the overlap between predicted and truth boxes, this metric is extensively utilized in object detection tasks. By default, YOLOv8n employs the CIoU loss function, which evaluates errors between model outputs and actual labels by considering the overlap area, the distance between the centers of the target and prediction boxes, and the angle to calculate localization losses accurately. This computation is detailed in Eq. (5). In this formula, IoU represents the overlapping area divided by the combined area of the predicted and truth boxes,
Given the limitations of traditional metrics, this paper adopts the WIoU. WIoU sets itself apart by evenly distributing penalties between high and low-quality boxes and employing a dynamic mechanism that maintains feature information across different scales, thus improving the model’s overall performance. WIoU implements a new dynamic non-monotonic focusing mechanism that uses the “outlier degree” rather than traditional IoU to evaluate the quality of anchor boxes, enhancing the distribution of gradient enhancements [39]. This approach reduces the dominance of high-quality anchor boxes. It mitigates the adverse gradients produced by low-quality anchor boxes, enabling the network to focus more effectively on average anchor boxes. This setup promotes the development of distance attention and leads to the formulation of WIoU-v1, as detailed in Eqs. (6)–(8).
4 Experiments and Results Analysis
In this experiment, a custom safety helmet-wearing detection dataset was employed. Images were sourced from surveillance video captures, on-site photography, and web scraping, with each image annotated using the LabelImg tool. The dataset comprises 8983 images from diverse, complex scenarios, including construction sites, aerial work, and offshore operations. It spans all times of day—morning, noon, and night, including 88,590 instances of wearing safety helmets (positive samples) and 13,926 cases of not wearing safety helmets (negative samples). It was partitioned into a training set of 6288 images, a validation set of 1797 images, and a test set of 898 images, adhering to a 7:2:1 ratio. Furthermore, we utilized Mosaic data augmentation to enhance the model’s generalization and robustness. This technique combines multiple images into a single training sample, increasing the diversity of the dataset and enabling the model to handle variations in object appearance and background better. This dataset includes three sample labels: Person, Head, and Helmet, each thoroughly described as shown in Table 1.

Network performance was assessed using several metrics, including Precision (P), Recall (R), mAP, parameters, model size, GFLOPs, and FPS. The methods for computing these metrics are outlined in Eqs. (9)–(11).
The formulas used for evaluating network performance,
4.3 Model Training Parameters and Results
The experiments outlined in this article took place on a PC that runs Win11, including an RTX 3060GPU, utilizing CUDA version 12.3. Simulations were performed using the Pytorch framework. The training parameters were set with an input image resolution of 640 × 640, employing an SGD optimizer to enhance the model across 300 training epochs. The batch size was established at 8, with an equivalent number of worker threads, and all other parameters were maintained at default settings. The results from training and evaluating the FGP-YOLOv8 model are displayed in Fig. 7.
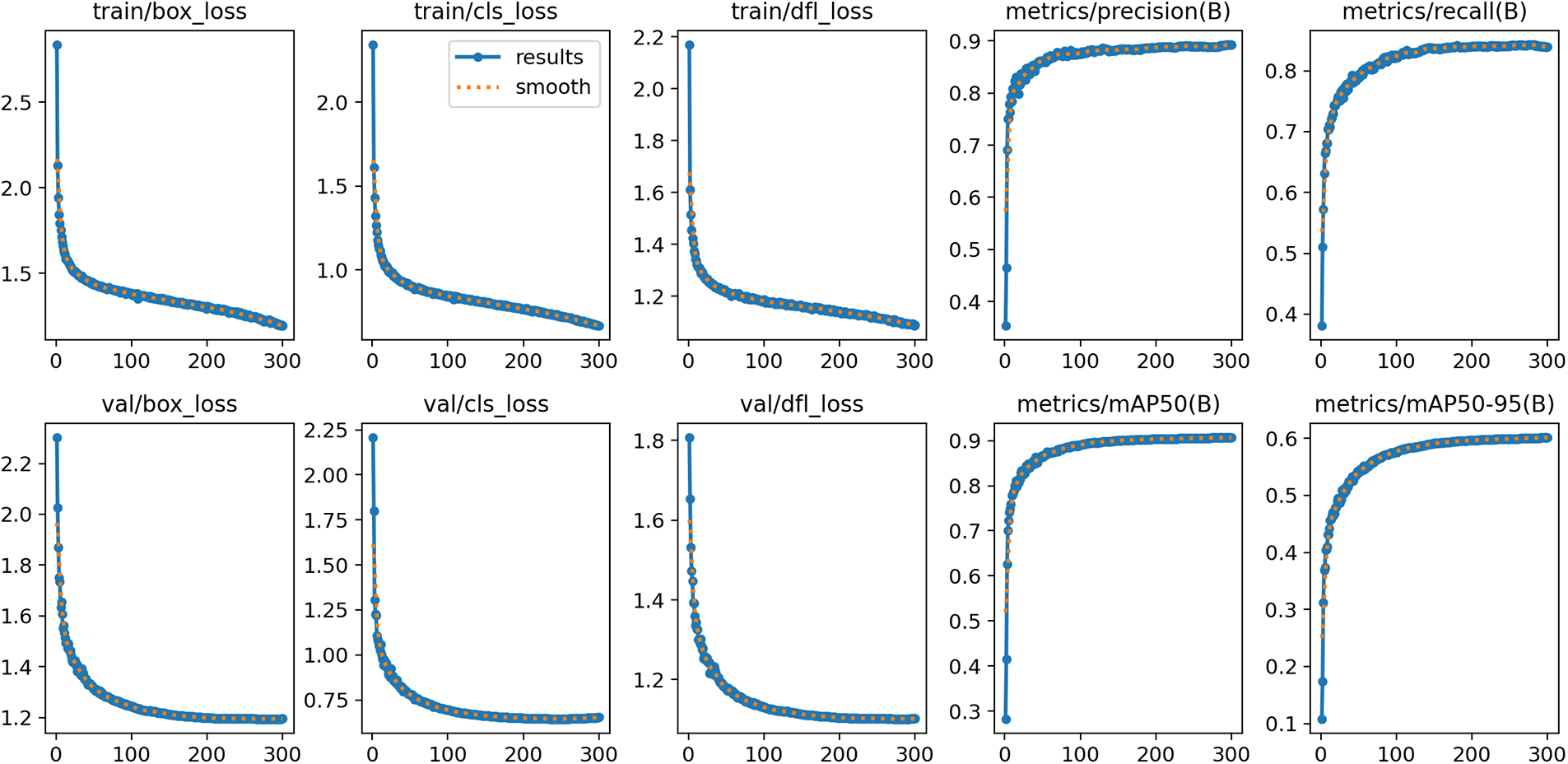
Figure 7: FGP-YOLOv8 model training evaluation results
The Precision-Recall (PR) curve is a widely recognized method for assessing model performance. The PR curve discussed in this study is depicted in Fig. 8.
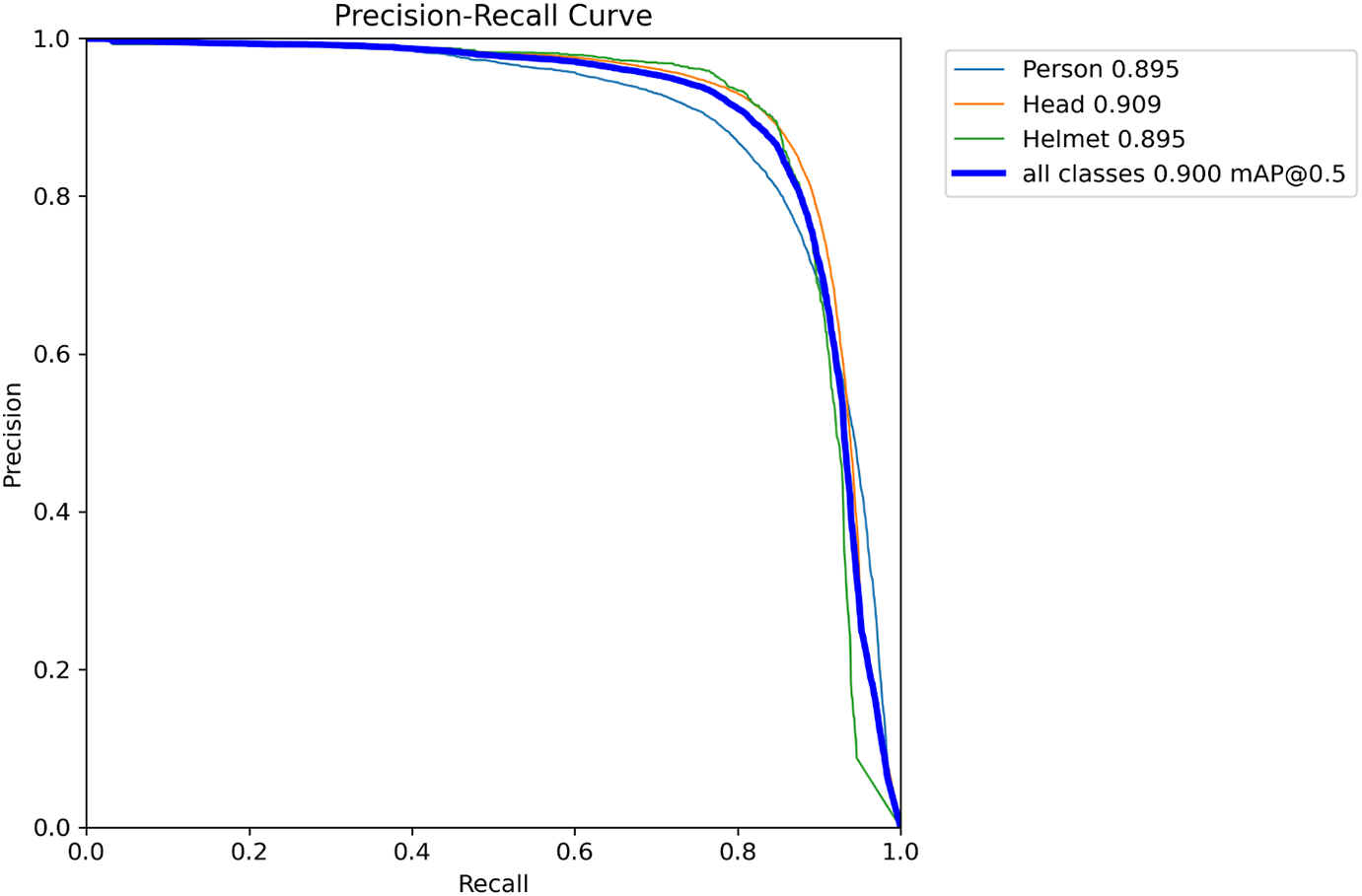
Figure 8: Precision-recall curve
The PR curve places Recall on the x-axis and Precision on the y-axis, visually depicting precision variations at various recall levels. An expanded area under the PR curve indicates an improved balance between precision and recall, indicating superior model performance.
To assess and study the effect of various enhancement modules on the algorithm’s detection capabilities, five sets of ablation experiments were carried out using different modules, with both training and testing carried out on a proprietary dataset. Using YOLOv8n as the foundational model, its backbone network was initially swapped for a FasterNet module, producing Model A. Subsequently, the GSTA module was incorporated into the neck network, yielding Model B. Next, integrating the ParNet-C2f module resulted in the development of Model C. Lastly, substituting the CIoU with the WIoU gave rise to Model D. The results of the experiments are shown in Table 2.
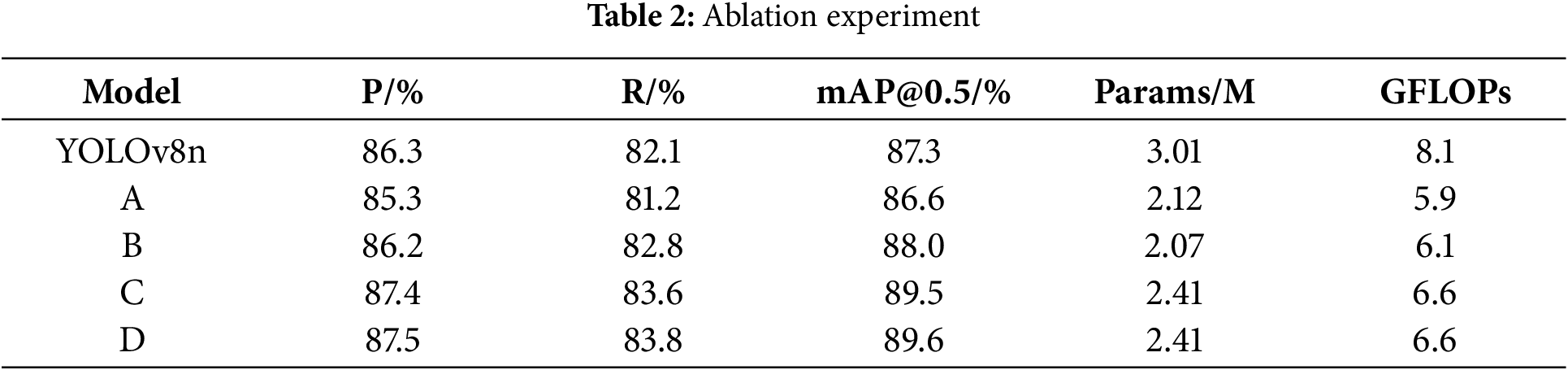
Based on the experimental findings, this study successfully validated five improvement methods, achieving the anticipated goals. The improved FGP-YOLOv8 algorithm showed a 2.3% rise in mAP@0.5, a 1.2% increase in precision, and a 1.7% enhancement in recall compared to the YOLOv8n. Furthermore, it achieved a 19.9% decrease in the number of parameters and an 18.5% decrease in computational load. The ablation studies proved the FGP-YOLOv8 algorithm’s superiority in detection accuracy and its lightweight architecture, affirming the viability of the proposed solutions for detecting safety helmet usage.
4.5.1 Comparative Experiment of Various Lightweight Networks
To assess the improved performance of the proposed lightweight backbone network, several mainstream lightweight models were benchmarked against FasterNet, using the YOLOv8n model as a baseline. The experimental data in Table 3 reveal that all models attained substantial decreases in parameters and computational load compared to YOLOv8n. Notably, ShuffleV2 exhibited a larger reduction in mAP@0.5. PP-LCNet and GhostNet demonstrated robust detection accuracy, though improvements are needed in detection speed. FasterNet markedly improved detection speed while maintaining high accuracy, with only minor reductions of 0.9% in recall and 0.7% in mAP@0.5. It also reduced the parameter and computational burdens by 29.6% and 27.2%, respectively, and enhanced FPS 2.7 times compared to the baseline model, demonstrating that the FasterNet lightweight model can effectively balance model lightness with accuracy while ensuring robust detection performance and real-time processing capabilities.

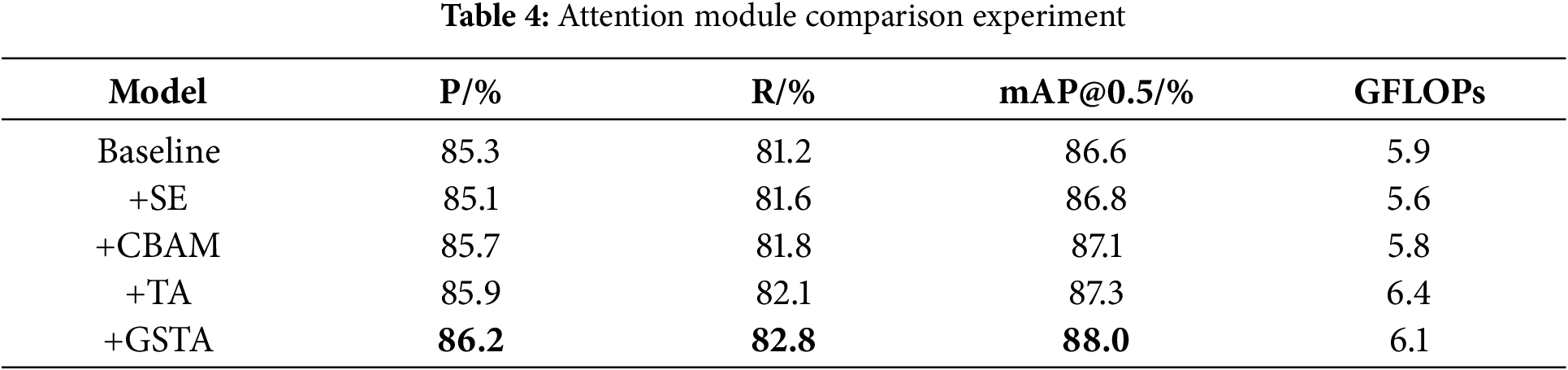
4.5.2 Comparative Experiment of Various Attention Modules
Using a model augmented with the FasterNet lightweight model as the baseline, this study explores the effects of different attention mechanisms incorporated into the neck network on training and performance, as illustrated in Table 4. Experimentally, the GSTA module in the neck network has been shown to vastly surpass classical attention modules in detection accuracy, achieving a mAP@0.5 of 88%. This enhancement led to increases of 0.9% in precision and 1.4% in recall while only causing a slight rise in computational load by 0.2 G. This demonstrates that the model’s detection ability was effectively enhanced with a minimal increase in computational demands. Furthermore, compared to traditional Triplet Attention (TA), the GSTA improved the mAP@0.5 by 0.7% and reduced the computational load by 0.3 G, verifying that the GSTA module enhances detection precision while reducing computational expenses, thus affirming its superiority.
4.5.3 Comparative Experiment of Various C2f Modules
To confirm the improved performance of the proposed ParNet-C2f module, this paper employs a model augmented with the FasterNet lightweight network and GSTA module as a foundation, conducting comparative experiments with a series of well-known C2f enhancement modules. The findings, shown in Table 5, indicate that incorporating the SCConv module led to a 1.5% reduction in mAP@0.5. In contrast, the NAM and CoT modules slightly improved mAP@0.5 by 0.2% and 0.3% but were accompanied by a significant decrease in FPS. In contrast, the ParNet-C2f module developed in this study increased mAP@0.5 by 1.5%, enhanced recall by 0.8%, and achieved an FPS of 103.4, surpassing alternative approaches. This indicates that the enhancements from the ParNet-C2f module effectively satisfy the requirements for real-time, high-precision detection of helmets.

4.5.4 Comparative Experiment of Various Loss Functions
To confirm the effectiveness of the proposed improvements to the loss function, experiments were conducted employing four loss functions-CIoU, SIoU (Scylla-IoU), EIoU (Efficient-IoU), and WIoU- for comparative analysis. As detailed in Table 6, the results demonstrate that only WIoU improved mAP@0.5 while maintaining stable parameters and computational effort among the four loss functions.

To evaluate the impact of the FGP-YOLOv8 algorithm modifications, comparative tests were carried out under uniform experimental settings compared with contemporary leading algorithms, including the Faster-RCNN, the SSD, and the YOLO series from YOLOv5 to YOLOv8, as well as other enhanced algorithms. Table 7 provides a detailed overview of the detection results for each algorithm.

According to the experimental outcomes, the FGP-YOLOv8 algorithm presented here achieved a mAP@0.5 of 89.6%, outperforming all other algorithms featured in the table. This algorithm shows a 7.4% improvement in mAP@0.5 over the two-stage Faster-RCNN, a 2.3% enhancement over the original YOLOv8n, and a 0.2% increase compared to YOLOv8s. It also recorded a 0.4% enhancement over YOLOv5-BEH and a 1.1% improvement relative to YOLOv8-SLIM-CA. While increases in accuracy generally lead to higher parameters and computational effort, the FGP-YOLOv8 maintains the lowest parameters and demands of computational, decreasing by 0.6 M and 1.5 G, respectively, compared to the YOLOv8n. Additionally, compared to YOLOv8s, it shows reductions of 8.71 M in parameters and 22.2 G in computational load. In terms of real-time performance, although the FPS of FGP-YOLOv8 is lower than that of the original YOLOv8n, it still reaches 102.7 frames, significantly faster than Faster-RCNN, YOLOv5n, YOLOv8s, and other algorithms, thus meeting the requirements for real-time detection. These results demonstrate that the FGP-YOLOv8 improves detection performance and preserves a lightweight profile, delivering precise detection results instantaneously and meeting real-time performance demands.
To comprehensively showcase the FGP-YOLOv8’s performance in safety helmet detection, the baseline YOLOv8n and recent improvements to YOLO series algorithms were selected for detection and comparison on the test set. The outcomes are depicted in Fig. 9, and the detection performances of the various algorithms are detailed in Table 8. Fig. 9 presents a series of images where the detection outcomes of YOLOv8n, YOLOv5-BEH, YOLOv8-SLIM-CA, and FGP-YOLOv8 are displayed sequentially from left to right.

Figure 9: Comparison chart of detection effects of various algorithms

The comparison in Fig. 9a reveals that the YOLOv8n algorithm underperforms in scenarios with dense targets, missing detections, and exhibiting low accuracy. In contrast, the FGP-YOLOv8 algorithm significantly enhances target detection and positioning for safety helmets, effectively improving miss rates and resolving accuracy issues. In the scenes with obstructed targets depicted in Fig. 9b, both YOLOv8n and YOLOv5-BEH algorithms experience missed detections. However, the enhanced algorithms successfully detect all targets and increase confidence levels. Fig. 9c illustrates that the YOLOv8n algorithm misses three targets due to background clutter on the left and upper right sides, with YOLOv5-BEH and YOLOv8-SLIM-CA also exhibiting misses and false positives. Conversely, the algorithm discussed in this paper successfully detects all mentioned targets. In Fig. 9d, the original algorithm misses half of the targets in the small target detection scene. YOLOv5-BEH encounters issues with misses and false positives, and although YOLOv8-SLIM-CA reduces false positives, it still misses targets. However, the algorithm introduced in this paper successfully detects every target. Fig. 9e presents a low-light detection scenario where the YOLOv8n algorithm significantly misses detections. YOLOv5-BEH and YOLOv8-SLIM-CA slightly improve but still suffer misses due to poor lighting. The FGP-YOLOv8 algorithm introduced in this document effectively detects all targets and enhances confidence under these challenging conditions.
The experimental outcomes clearly show that the algorithm described in this paper excels in detection performance while maintaining a lightweight architecture, making it well-suited for deployment on resource-limited devices.
Firstly, while FGP-YOLOv8 demonstrates excellent detection performance, the relatively small size of the training and testing dataset poses a limitation. This constraint may lead to missed or false detections when the model is applied to other detection scenarios or environments. To address this, further efforts are needed to collect more diverse images from various construction site environments to expand and enhance the dataset.
Additionally, the proposed FGP-YOLOv8 model achieves impressive parameter size and detection accuracy results. However, its detection speed is slightly lower compared to the original YOLOv8n. Future work will focus on optimizing the model structure to improve detection speed while maintaining its compact size and high accuracy.
In response to challenges such as high parameter volume, low accuracy, and inadequate real-time capabilities in safety helmet detection within complex environments, this article introduces the lightweight FGP-YOLOv8 algorithm, an enhancement of the original YOLOv8n. The algorithm’s key innovations include replacing the backbone network with a FasterNet lightweight network that primarily employs PConv, substantially decreasing the model’s parameters and computational requirements without compromising detection accuracy. Additionally, introducing the newly proposed GSTA module in the neck network enhances the interplay between spatial and channel attentions, further reducing the computational load and improving the model’s detection capacity. Subsequently, a novel ParNet-C2f module is introduced, incorporating a parallel network structure to broaden the perceptual field of the feature map, thus improving the model’s feature extraction efficiency. Finally, the WIoU loss function is employed to further enhance the model’s overall performance.
In conclusion, the improved model exhibits exceptional performance in detecting safety helmets in complex environments, minimizes computational costs, and fulfills the demands of real-time detection. However, there are still some shortcomings in the improvements proposed in this study. For instance, while we reduced the model size and achieved excellent detection accuracy, there is still room for improvement in detection speed. In the future, we will further optimize the model’s performance to achieve faster and more accurate detection. At the same time, we will continue to advance our research in deep learning, with a particular emphasis on lightweight module and small object detection. These two directions will also be key focuses of our future work.
Acknowledgement: The authors would like to express their gratitude for the valuable feedback and suggestions provided by all the anonymous reviewers and the editorial team.
Funding Statement: This research was funded by National Natural Science Foundation of China (61741303), the Foundation Project of Guangxi Key Laboratory of Spatial Information and Mapping (No. 21-238-21-16).
Author Contributions: Hao Ma: Conceptualization, Methodology, Writing—Original Draft, Investigation, Validation, Software. Lieping Zhang: Conceptualization, Methodology, Writing—Reviewing & Editing, Investigation. Jiancheng Huang: Analysis and Interpretation of Results. Cui Zhang: Writing—Review & Editing, Investigation. Xiaolin Gao: Visualization. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Cui Zhang, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Wei L, Liu P, Ren H, Xiao D. Research on helmet wearing detection method based on deep learning. Sci Rep. 2024;14(1):7010. doi:10.1038/s41598-024-57433-z. [Google Scholar] [CrossRef]
2. Zhou S, Peng Z, Zhang H, Hu Q, Lu H, Zhang Z. Helmet-YOLO: a new method for real-time, high-precision helmet wearing detection. IEEE Access. 2024. doi:10.1109/ACCESS.2024.3443146. [Google Scholar] [CrossRef]
3. Ahmed MIB, Saraireh L, Rahman A, Al-Qarawi S, Mhran A, Al-Jalaoud J, et al. Personal protective equipment detection: a deep-learning-based sustainable approach. Sustainability. 2023;15(18):13990. doi:10.3390/su151813990. [Google Scholar] [CrossRef]
4. Girshick R. Fast R-CNN. arXiv:1504.08083. 2015. [Google Scholar]
5. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
6. Fan Z, Peng C, Dai L, Cao F, Qi J, Hua W. A deep learning-based ensemble method for helmet-wearing detection. PeerJ Comput Sci. 2020;6(6):e311. doi:10.7717/peerj-cs.311. [Google Scholar] [PubMed] [CrossRef]
7. Espinosa Oviedo JE, Velastín SA, Branch Bedoya JW. EspiNet V2: a region based deep learning model for detecting motorcycles in urban scenarios. Dyna. 2019;86(211):317–26. doi:10.15446/dyna.v86n211.81639. [Google Scholar] [CrossRef]
8. Li X, Hao T, Li F, Zhao L, Wang Z. Faster R-CNN-LSTM construction site unsafe behavior recognition model. Appl Sci. 2023;13(19):10700. doi:10.3390/app131910700. [Google Scholar] [CrossRef]
9. Sun Z, Xuan Y, Fan L, Han R, Tu Y, Huang J, et al. Security monitoring strategy of distribution community operation site based on intelligent image processing method. Front Energy Res. 2022;10:931515. doi:10.3389/fenrg.2022.931515. [Google Scholar] [CrossRef]
10. Zhang W, Yang CF, Jiang F, Gao XZ, Zhang X. Safety helmet wearing detection based on image processing and deep learning. In: 2020 International Conference on Communications, Information System and Computer Engineering (CISCE); 2020 Jul 3–5; Kuala Lumpur, Malaysia. p. 343–7. doi:10.1109/cisce50729.2020.00076. [Google Scholar] [CrossRef]
11. Li J, Xie S, Zhou X, Zhang L, Li X. Real-time detection of coal mine safety helmet based on improved YOLOv8. J Real Time Image Process. 2024;22(1):26. doi:10.1007/s11554-024-01604-8. [Google Scholar] [CrossRef]
12. Li T, Li G. Road defect identification and location method based on an improved ML-YOLO algorithm. Sensors. 2024;24(21):6783. doi:10.3390/s24216783. [Google Scholar] [PubMed] [CrossRef]
13. Yu C, Liu Y, Zhang W, Zhang X, Zhang Y, Jiang X. Foreign objects identification of transmission line based on improved YOLOv7. IEEE Access. 2023;11:51997–2008. doi:10.1109/ACCESS.2023.3277954. [Google Scholar] [CrossRef]
14. Ku B, Kim K, Jeong J. Real-time ISR-YOLOv4 based small object detection for safe shop floor in smart factories. Electronics. 2022;11(15):2348. doi:10.3390/electronics11152348. [Google Scholar] [CrossRef]
15. Zhang B, Sun CF, Fang SQ, Zhao YH, Su S. Workshop safety helmet wearing detection model based on SCM-YOLO. Sensors. 2022;22(17):6702. doi:10.3390/s22176702. [Google Scholar] [CrossRef]
16. Sadiq M, Masood S, Pal O. FD-YOLOv5: a fuzzy image enhancement based robust object detection model for safety helmet detection. Int J Fuzzy Syst. 2022;24(5):2600–16. doi:10.1007/s40815-022-01267-2. [Google Scholar] [CrossRef]
17. Shan C, Liu H, Yu Y. Research on improved algorithm for helmet detection based on YOLOv5. Sci Rep. 2023;13(1):18056. doi:10.1038/s41598-023-45383-x. [Google Scholar] [PubMed] [CrossRef]
18. Yao W, Wang A, Nie Y, Lv Z, Nie S, Huang C, et al. Study on the recognition of coal miners’ unsafe behavior and status in the hoist cage based on machine vision. Sensors. 2023;23(21):8794. doi:10.3390/s23218794. [Google Scholar] [CrossRef]
19. An Q, Xu Y, Yu J, Tang M, Liu T, Xu F. Research on safety helmet detection algorithm based on improved YOLOv5s. Sensors. 2023;23(13):5824. doi:10.3390/s23135824. [Google Scholar] [PubMed] [CrossRef]
20. Song H, Zhang X, Song J, Zhao J. Detection and tracking of safety helmet based on DeepSort and YOLOv5. Multimed Tools Appl. 2023;82(7):10781–94. doi:10.1007/s11042-022-13305-0. [Google Scholar] [CrossRef]
21. Wang S, Wu P, Wu Q. Safety helmet detection based on improved YOLOv7-tiny with multiple feature enhancement. J Real Time Image Process. 2024;21(4):120. doi:10.1007/s11554-024-01501-0. [Google Scholar] [CrossRef]
22. Liu Y, Jiang X, Xu R, Cui Y, Yu C, Yang J, et al. A novel foreign object detection method in transmission lines based on improved YOLOv8n. Comput Mater Contin. 2024;79(1):1263–79. doi:10.32604/cmc.2024.048864. [Google Scholar] [CrossRef]
23. Lin B. Safety helmet detection based on improved YOLOv8. IEEE Access. 2024;12(3):28260–72. doi:10.1109/ACCESS.2024.3368161. [Google Scholar] [CrossRef]
24. Aboah A, Wang B, Bagci U, Adu-Gyamfi Y. Real-time multi-class helmet violation detection using few-shot data sampling technique and YOLOv8. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2023 Jun 17–24; Vancouver, BC, Canada: IEEE. p. 5350–8. doi:10.1109/CVPRW59228.2023.00564. [Google Scholar] [CrossRef]
25. Li Y, Xu H, Zhu X, Huang X, Li H. THDet: a lightweight and efficient traffic helmet object detector based on YOLOv8. Digit Signal Process. 2024;155(3):104765. doi:10.1016/j.dsp.2024.104765. [Google Scholar] [CrossRef]
26. Yu C, Lu Z. YOLO-VSI: an improved YOLOv8 model for detecting railway turnouts defects in complex environments. Comput Mater Contin. 2024;81(2):3261–80. doi:10.32604/cmc.2024.056413. [Google Scholar] [CrossRef]
27. Bakirci M. Enhancing vehicle detection in intelligent transportation systems via autonomous UAV platform and YOLOv8 integration. Appl Soft Comput. 2024;164(5):112015. doi:10.1016/j.asoc.2024.112015. [Google Scholar] [CrossRef]
28. Lin B. YOLOv8n-ASF-DH: an enhanced safety helmet detection method. IEEE Access. 2024;12(17):126313–28. doi:10.1109/ACCESS.2024.3435453. [Google Scholar] [CrossRef]
29. Shi C, Zhu D, Shen J, Zheng Y, Zhou C. GBSG-YOLOv8n: a model for enhanced personal protective equipment detection in industrial environments. Electronics. 2023;12(22):4628. doi:10.3390/electronics12224628. [Google Scholar] [CrossRef]
30. Hu L, Ren J. YOLO-LHD: an enhanced lightweight approach for helmet wearing detection in industrial environments. Front Built Environ. 2023;9:1288445. doi:10.3389/fbuil.2023.1288445. [Google Scholar] [CrossRef]
31. Yatheendra K, Hemalatha AN, Dhanasekhar Reddy A, Pavani K. Model for detecting safety helmet wearing using improved yolo-M. Int J Inform Technold Comput Eng. 2024;12(3):688–700. [Google Scholar]
32. Song X, Zhang T, Yi W. An improved YOLOv8 safety helmet wearing detection network. Sci Rep. 2024;14(1):17550. doi:10.1038/s41598-024-68446-z. [Google Scholar] [PubMed] [CrossRef]
33. Chen J, Kao SH, He H, Zhuo W, Wen S, Lee CH, et al. Run, don’t walk: chasing higher FLOPS for faster neural networks. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17-24; Vancouver, BC, Canada: IEEE. p. 12021–31. doi:10.1109/CVPR52729.2023.01157. [Google Scholar] [CrossRef]
34. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA: IEEE. p. 7132–41. doi:10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
35. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. In: Proceedings of the European Conference On Computer Vision (ECCV); 2018; Munich, Germany. p. 3–19. [Google Scholar]
36. Misra D, Nalamada T, Arasanipalai AU, Hou Q. Rotate to attend: convolutional triplet attention module. In: 2021 IEEE Winter Conference on Applications of Computer Vision (WACV); 2021; Waikoloa, HI, USA. p. 3138–47. doi:10.1109/WACV48630.2021.00318. [Google Scholar] [CrossRef]
37. Li H, Li J, Wei H, Liu Z, Zhan Z, Ren Q. Slim-neck by GSConv: a lightweight-design for real-time detector architectures. J Real Time Image Process. 2024;21(3):62. doi:10.1007/s11554-024-01436-6. [Google Scholar] [CrossRef]
38. Goyal A, Bochkovskiy A, Deng J, Koltun V. Non-deep networks. arXiv:2110.07641. 2021. [Google Scholar]
39. Tong Z, Chen Y, Xu Z, Yu R. Wise-IoU: bounding box regression loss with dynamic focusing mechanism. arXiv:2301.10051. 2023. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools