
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Two-Stage Category-Guided Frequency Modulation for Few-Shot Semantic Segmentation
School of Computer Science, Fudan University, Shanghai, 200438, China
* Corresponding Author: Yiming Tang. Email:
Computers, Materials & Continua 2025, 83(2), 1707-1726. https://doi.org/10.32604/cmc.2025.062412
Received 18 December 2024; Accepted 18 February 2025; Issue published 16 April 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Semantic segmentation of novel object categories with limited labeled data remains a challenging problem in computer vision. Few-shot segmentation methods aim to address this problem by recognizing objects from specific target classes with a few provided examples. Previous approaches for few-shot semantic segmentation typically represent target classes using class prototypes. These prototypes are matched with the features of the query set to get segmentation results. However, class prototypes are usually obtained by applying global average pooling on masked support images. Global pooling discards much structural information, which may reduce the accuracy of model predictions. To address this issue, we propose a Category-Guided Frequency Modulation (CGFM) method. CGFM is designed to learn category-specific information in the frequency space and leverage it to provide a two-stage guidance for the segmentation process. First, to self-adaptively activate class-relevant frequency bands while suppressing irrelevant ones, we leverage the Dual-Perception Gaussian Band Pre-activation (DPGBP) module to generate Gaussian filters using class embedding vectors. Second, to further enhance category-relevant frequency components in activated bands, we design a Support-Guided Category Response Enhancement (SGCRE) module to effectively introduce support frequency components into the modulation of query frequency features. Experiments on the and datasets demonstrate the promising performance of our model. The code will be released at accessed on 17 February 2025.Keywords
Computer vision has made significant progress in the era of deep learning [1–3]. Semantic segmentation [4–6] is a fundamental task in computer vision. It assigns a label to every pixel in an image, which allows models to interpret the scene at a fine-grained level. However, training semantic segmentation models is typically resource-intensive and time-consuming, as they rely heavily on carefully annotated large-scale datasets. Additionally, these models struggle to maintain accurate predictions for objects belonging to categories unseen in the training set, limiting their applicability in real-world scenarios. Few-shot semantic segmentation aims to address these problems by providing a few examples (the support set) for each target class and attempting to identify objects from the same class in other images (the query set) based on these examples. To make sure that the trained model can be well generalized to unseen classes, classes (base classes) contained in the train set are designed to have no overlap with those (novel classes) in the test set. Few-shot segmentation has emerged as a promising paradigm across various fields [7–10] demonstrating its versatility and potential for solving real-world segmentation challenges with limited labeled data.
To successfully recognize the target objects in the query set, it is essential to extract effective target class representations from the limited support set examples. Most few-shot segmentation (FSS) methods [11–15] employ masked average pooling (MAP) to obtain the class representation. MAP utilizes target object masks provided by the support set to mask out all background regions and then applies global average pooling to the remaining object regions. The obtained feature vector is subsequently used as the prototype for the target class. Some approaches have attempted to increase the number of prototypes [16–19] using superpixels or clustering, but these methods often face optimization difficulties and high costs on computation, especially with multiple support samples. Besides, authors in [20–22] attempt to replace prototype comparison with point-wise comparsion approaches to identify target objects in the query set, but such methods need to consider each pixel in support samples and are vulnerable to noise interference. Consequently, following approaches [21,23] tend to integrate prototypes into the query and support features before point-wise comparison, which can effectively eliminates class-irrelevant noise. As a result, MAP remains widely used in both prototypical and point-wise FSS methods.
However, the global average pooling operation used in MAP may have some shortages. Study [24] finds that for image features, vectors obtained through global average pooling are equivalent to the first component of image frequency features, which means it discards other frequency components. As shown in Fig. 1, preserving only the first few components of the frequency features may lead to the loss of structure information and failure in perfectly reconstructing the target object. In FSS, this means a certain loss of class-level information and will ultimately affect the model’s prediction accuracy. To address this issue, we propose to preserve more frequency components and extract representative class-level features from them. Considering the inter-class variances between base and novel classes, as well as among the novel classes themselves, handling frequency-domain features without guidance may lead the model to directly apply knowledge learned from the training set to novel classes, resulting in poor generalization. Furthermore, the intra-class variances between the support and query set are also not negligible. Segmentation tasks are sensitive to the position information of objects in the input images. The position information in the support set contained in frequency features is quite different from that in the query set. Directly introducing support frequency features may disrupt the position information in the query set and cause severe performance reduction.

Figure 1: Comparison of features reconstructed using the first
To address the aforementioned problems, we propose a two-stage Category-Guided Frequency Modulation (CGFM) approach. In the first stage, we propose a Dual-Perception Gaussian Band Pre-activation (DPGBP) module to preactivate class-relevant frequency bands and minimize the impact of class-irrelevant signals in the frequency features. This operation is guided by a class embedding vector, initialized with class prototypes, and updated in Transformer blocks to percept and capture both class-level and instance-level information. The dual-perception mechanism makes our model self-adaptive to different target classes and samples. In the second stage, the Support-Guided Category Response Enhancement (SGCRE) module further enhances category-relevant frequency components by introducing support frequency features. In this module, the support and query frequency features are first decomposed into phase and amplitude features to separately process position and intensity information. By introducing position-irrelevant class information, our CGFM model can effectively strengthen the model’s response to frequency components most relevant to the target class and alleviate the impact of background noise.
In summary, our contributions can be summarized as follows:
• We propose the Dual-Perception Gaussian Band Pre-activation (DPGBP) module to perceive and capture category and instance information, and then leverage them to guide the activation of class-relevant regions.
• We design the Support-Guided Category Response Enhancement (SGCRE) module to further enhance class-relevant frequency components in query features by introducing the category information decomposed from the support frequency features.
• We evaluated our model on
2.1 Few-Shot Semantic Segmentation
Few-shot semantic segmentation was first proposed by OSLSM [11]. As pixel-wise annotations have been provided in the support set, authors in [25] proposed to extract categorical prototypes using masked average pooling (MAP), which masks out background pixels from support features and then makes a global average pooling on them. To get a robust prototype, study [16] leverages a graph attention network to extract more semantic information from unlabeled data, and [17–19,26] extract multiple prototypes for a single category, which are generated using the Expectation-Maximization algorithm, super-pixel segmentation, or self-guided mechanism. PFENet [13] proposed a simple but effective way to improve the model’s generalization ability, which constructs prior maps by calculating the cosine similarity between each support and query pixel pair and picking the maximum scores for query pixels. The prior map mechanism does not introduce extra training and largely improves the model’s generalization ability, which makes it widely used in the following FSS methods. CyCTR [23] fuses the prior map with corresponding support and query features, then it aggregates support features into query ones using cross-attention between support and query features. To filter out irrelevant pixel pairs between support and query images, it implements a cycle-consistent attention mechanism to suppress possible harmful support features. HDMNet [14] proposed a hierarchical transformer framework by distilling category information between multi-scale features.
The representation ability of class prototype may be restrained by the scarcity of samples for target classes. To address this issue, study [27] uses superpixel-based pseudo-labels to train a few-shot medical image segmentation model without manual annotations. Study [28] proposes a self-supervised tuning framework for few-shot segmentation, which dynamically adjusts the distribution of latent features across different episodes using a self-supervised inner-loop base learner. Study [29] designs another self-supervised meta-learning framework to create training pairs without manual annotations by leveraging unsupervised saliency estimation and image augmentations. Study [30] estimates target distributions through graph partitioning and Laplacian matrix eigenvectors. Then they adaptively predicts the query mask using the eigenvectors from the support images without the need for manual annotation.
Frequency learning has served as a classic tool in digital image processing [31,32] for a long time. Frequency-based methods have proven effective in improving the representation learning in various tasks. Authors in [33] proposed a fast and privacy-preserving framework to evaluate CNN models using Fourier Transform and fully homomorphic encryption to efficiently evaluate CNN models, and enable secure predictions without compromising model or input privacy. Authors in [34] propose to mix tokens in the frequency space by learning instance-adaptive masks for semantic filtering. They achieve remarkable improvements in lightweight neural networks for visual recognition. Study [35] jointly exploit global frequency information and local spatial dependencies to improve the quality of face super-resolution. Their method highlights the importance of phase information in the frequency domain for preserving facial structures, combining both frequency and spatial learning for superior performance. Authors in [36] introduce deep frequency filtering into domain generalization to suppress domain-specific features and enhance cross-domain transferability. Study [37] presents a novel transformer-based deep learning method for medical image denoising signals, addressing the limitations of existing techniques that often fail to handle complex noise patterns and generate artifacts.
For segmentation tasks, authors in [38] introduced a novel self-attention mechanism in the frequency domain that decouples high and low-frequency components. They significantly reduce computational complexity while achieving state-of-the-art segmentation performance with improved edge preservation and object consistency. Study [39] removes the decoder and uses an adaptive frequency filter to reduce complexity while preserving high-resolution semantics. However, these methods are fully supervised segmentation models trained on large datasets. These methods do not consider few-shot scenarios with significant class variances. They fail to include the inherent characteristics of each target class and sample in their features, which may lead to a lack of self-adaption to target classes.
Few-shot semantic segmentation aims to segment objects belonging to a specific class using only a few annotated examples. As defined in [11], a few-shot segmentation episode splits the data into two parts: the support set and the query set. Both sets contain images with objects from the same specific class. The support set provides a few example images
4.1 Dual-Perception Gaussian Band Pre-activation Module
Samples from the support set and query set, denoted as

Figure 2: Dual-perception gaussian band pre-activation module
The Dual-Perception Gaussian Band Pre-activation (DPGBP) module modulates frequency features using a series of Gaussian filters, which are generated by perciving category and instance information. We utilize a class embedding vector to capture the intrinsic class attributes and guide the filter generation. The class embedding vector is initialized using the class prototype. Specifically, we perform masked global average pooling (GAP) on the support set features to obtain the class prototype:
where
The updated class embeddings
G denotes the Gaussian filters constructed using
4.2 Support-Guided Category Response Enhancement Module
4.2.1 Decomposition of Frequency Features
As shown in Fig. 3,
where

Figure 3: Support-guided category response enhancement module
4.2.2 Category Response Enhancement
We introduce the frequency amplitude of the support set as the target class representation to enhance the class-relevant frequency components in the query set. To achieve this, we first reshape
Subsequently, we perform self-activation on the enhanced frequency features to further strengthen the class-relevant frequency components:
The query set features are finally reconstructed with enhanced amplitudes and phases:
4.3 Objective Function and k-shot Extension
The query features output by the SGCRE module are processed by the segmentation decoder to obtain the prediction result
where
All experiments in this section are based on the PASCAL-
For a fair comparison, we follow the preprocessing steps proposed in [13], which includes mirroring and random rotation within a range of -10 to 10 degrees during the training phase. The input images are obtained by cropping 473
To evaluate the performance of our model, we primarily use the mean intersection over union (mIoU) as the main evaluation metric, complemented by the foreground-background IoU (FB-IoU) for additional insights. The mIoU metric is defined as:
where C is the total number of classes in each fold, and
The FB-IoU metric is calculated as:
where
5.3 Comparison with Other FSS Methods
As shown in Table 1, CGFM demonstrates consistent and robust performance across the three backbones: VGG16, ResNet50, and ResNet101. Using the VGG16 backbone, CGFM achieves an average mIoU of 67.3% in the 1-shot setting and 71.0% in the 5-shot setting, showing substantial improvement compared to prior methods such as PFENet (58.0% and 59.0%, respectively). With the ResNet50 backbone, CGFM achieves an average mIoU of 70.0% in the 1-shot setting and 72.7% in the 5-shot setting, consistently outperforming other methods on both metrics. In ResNet101, CGFM achieves an average mIoU of 71.2% in the 1-shot setting and 73.9% in the 5-shot setting, demonstrating its ability to generalize across folds effectively. In addition to mIoU, CGFM achieves high FBIoU scores, with results of 75.5%, 78.5%, and 79.5% in the 1-shot setting and 78.3%, 80.1%, and 81.1% in the 5-shot setting for VGG16, ResNet50, and ResNet101, respectively. These results highlight the consistent performance of CGFM across various backbones and few-shot settings and demonstrate its ability to handle different scenarios effectively. Based on Table 2, CGFM shows strong performance in the
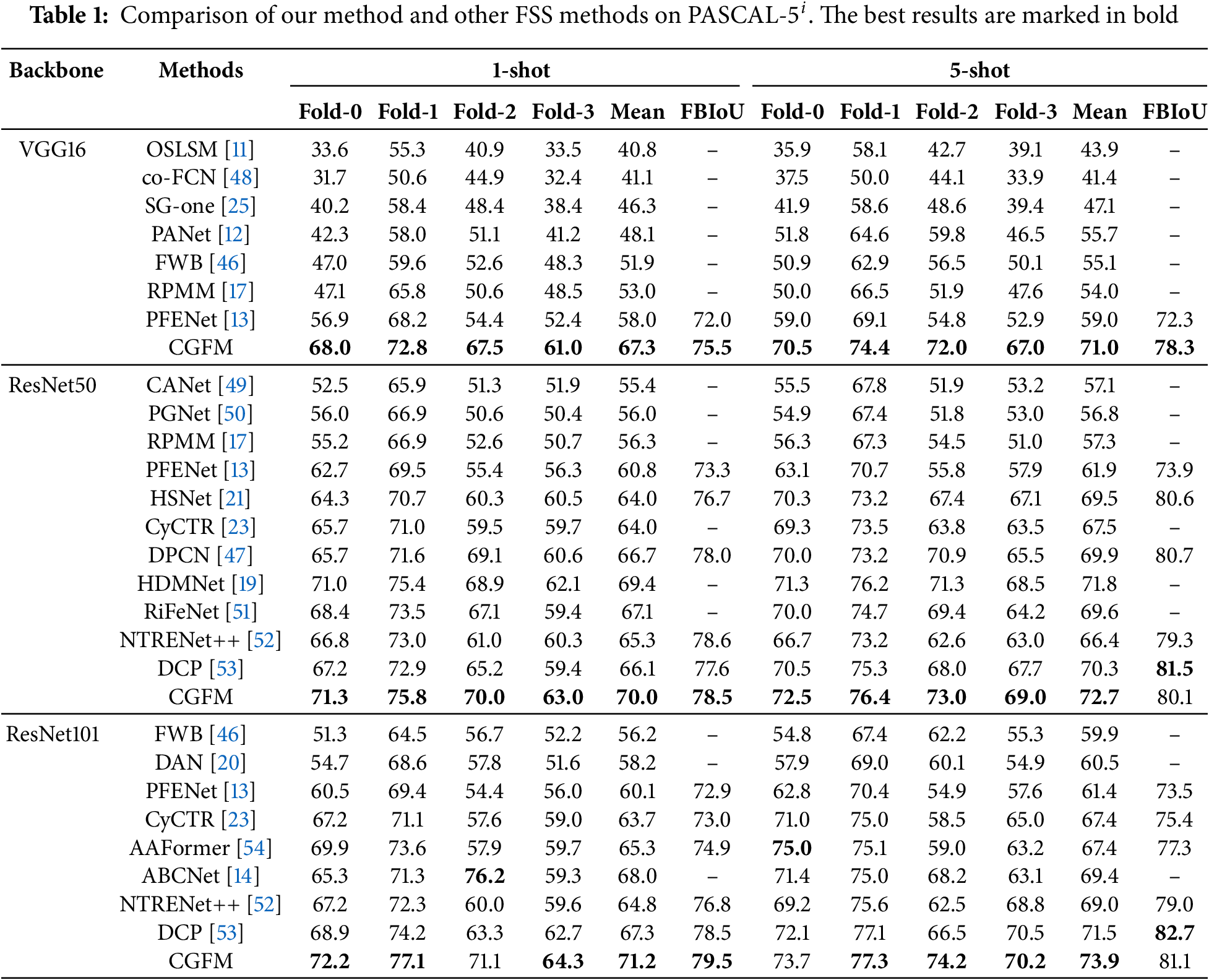
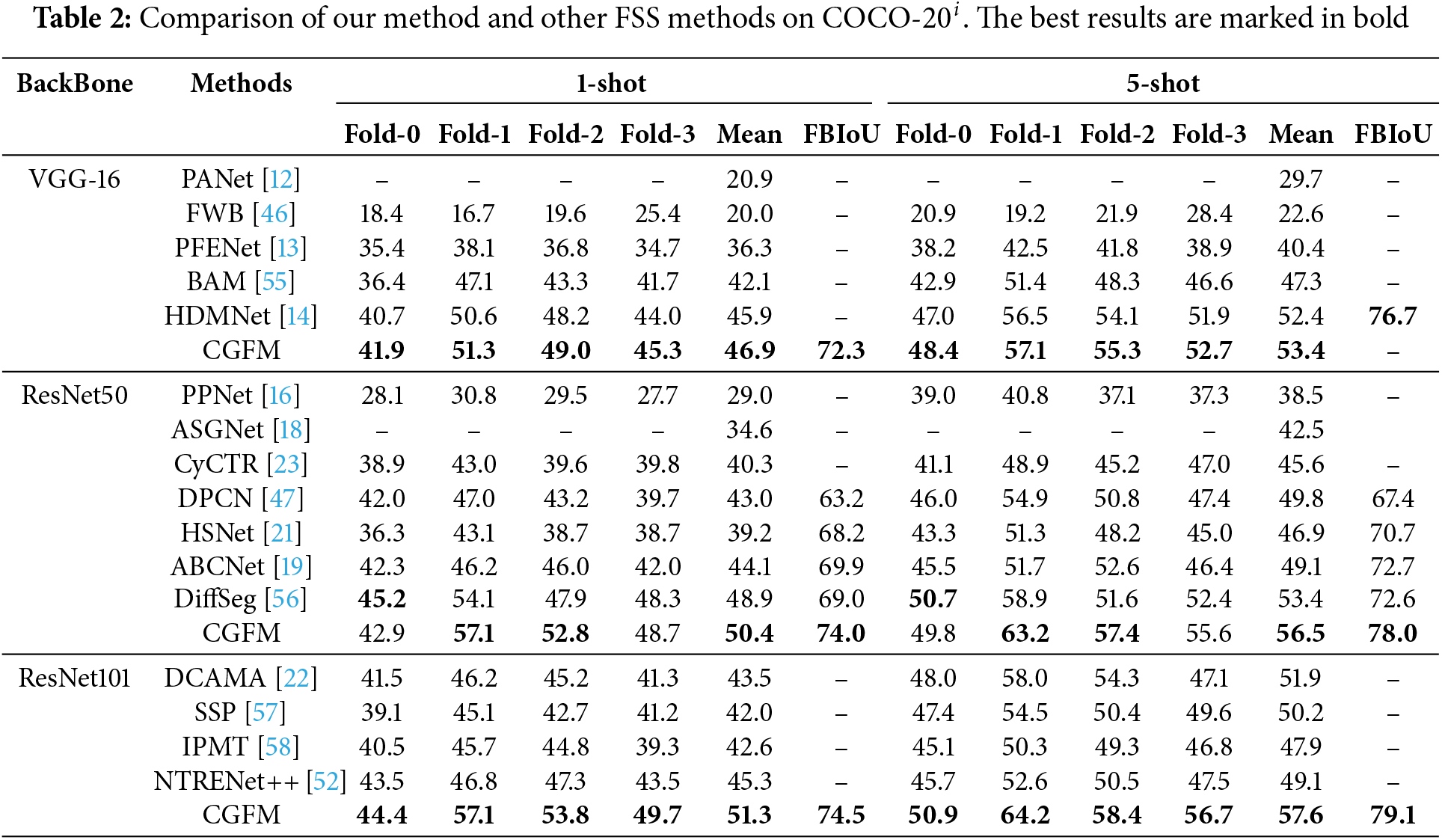
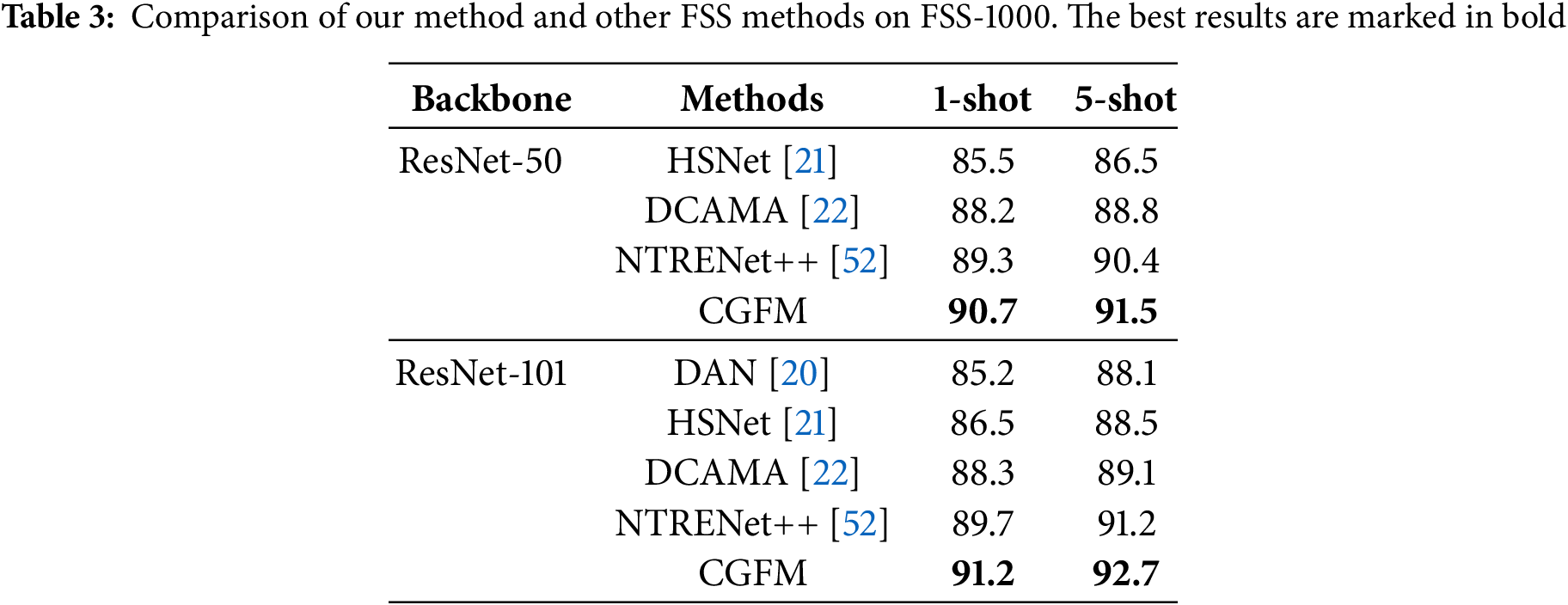
In summary, the experimental results demonstrate that CGFM performs well across various experimental settings and datasets. CGFM not only achieves promising results in average mIoU but also exhibits strong consistency across different folds, highlighting its potential as an effective few-shot segmentation method. Furthermore, CGFM’s performance on the challenging
We conducted ablation experiments on
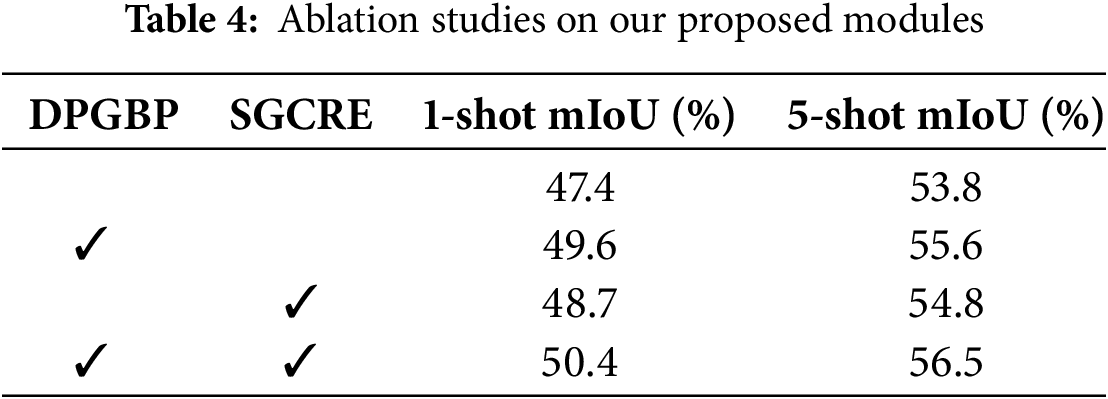

Figure 4: Comparison of CGFM model predictions with the baseline model
The third row in Fig. 5 illustrates the effect of the DBGBP module, where the support set annotations and query set ground-truths are highlighted in green in the first row. The remaining three rows display heat maps of the feature activations. The results indicate that, without frequency enhancement, the original feature maps struggle to focus on category-relevant areas and instead show high responses in background and edge regions. After applying the DBGBP module, the model begins to focus on the target objects, and its response to the target class is gradually improved, in contrast to the surrounding background objects.

Figure 5: Comparison of the model’s response to the target category
Table 5 explores the impact of using different class embedding strategies in DBGBP. When only a randomly initialized vector is used, as shown in the ‘RI’ column, the model’s performance decreases by approximately 1.7% compared to the original results, highlighting the importance of category information in the embedding vector. When randomly initialized vectors are updated alongside sample tokens in the Transformer blocks, as shown in the ‘RIU’ column, the model learns both class and instance information from the query and support features, resulting in a performance improvement of around 1.2%. The ‘PI’ column shows that using class prototypes to initialize the class embedding vector results in a 1% improvement over the randomly initialized vector. The best performance is achieved in the ‘PIU’ column, where the prototype-initialized vector is updated in the subsequent Transformer blocks, underscoring the importance of the dual-perception mechanism in DBGBP.

Fig. 6 demonstrates cases where the generated Gaussian kernels change according to different classes and instances. These results show that DBGBP can dynamically adjust the Gaussian kernel generation process based on the inherent characteristics of the target class and instance. This ability ensures the activation of the most relevant frequency bands for the current task.

Figure 6: Gaussian kernels generated under different classes and instances
The last row of Fig. 4 shows that, compared to the DBGBP, SGCRE further suppresses class-irrelevant background noise and effectively strengthens the model’s response to the target class in fine-grained structures. The two-stage CGFM method gradually directs the model’s focus toward the target objects, leading to a notable improvement in the model’s performance. We investigated the impact of different scaling coefficients

Figure 7: Comparison of model performance under different
In Fig. 8, we compare feature activations using different frequency fusion methods. The first and second columns present images from the support and query sets. The target classes are marked by highlighted green areas. The third column displays the query features enhanced directly with the undecomposed support frequency features, while the fourth column shows the query features enhanced by SGCRE, in which support frequency features are decomposed to remove the positional information in the phase spectrum. Experimental results reveal that incorporating raw support features without decomposition transfers spatial information from the support set to query features, adversely affecting model performance. As a comparison, when using decomposed support frequency features to enhance query features in SGCRE, the impact from support position information is largely alleviated and class-relevant information is successfully enhanced.

Figure 8: Comparison of query features enhanced using direct frequency fusion and SGCRE
5.7 Comparison of Results Using Different
We compared the model’s performance using different objective function weights


Figure 9:
5.8 Comparison of Computation Cost
In Table 7, we present a comprehensive performance comparison of various methods in terms of mIoU, the number of parameters and FLOPS. Compared with other non-transformer methods, CGFM achieves a higher mIoU of 50.4% with only 2.3 million parameters. Compared to transformer-based methods (CyCTR and HDMNet), CGFM achieves a comparatively FLOPS amount. The above results demonstrate that our method achieves promising results with few additional computation costs.

We propose a two-stage Category-Guided Frequency Modulation (CGFM) method for Few-Shot Segmentation (FSS). In the first stage, we leverage category embedding vector-guided Gaussian kernels to activate target class-related frequency band regions in the Dual-Perception Gaussian Band Pre-activation (DBGBP) module. This module leverages dynamically generated Gaussian filter kernels to activate class-relevant frequency bands. The kernels are derived from class embedding vectors to ensure robust generalization across various categories and instances. These embeddings are initialized using class prototypes and subsequently refined through transformer blocks by incorporating contextual information from both support and query sets. In the second stage, we further enhance the response to the target class through the Support-Guided Category Response Enhancement (SGCRE) module. SGCRE specifically strengthens class-related components in activated frequency bands and suppresses class-irrelevant background noise. To achieve this and alleviate the impact of the position information, SGCRE decomposes the frequency features from the support set and leverages the amplitude parts as the target class representation to enhance corresponding components on query features. Experiments show that our CGFM model achieves promising results, demonstrating the effectiveness of our approach.
CGFM alleviates the impact of structure information loss caused by class prototypes, but it still suffers from the inherent limitations of few-shot semantic segmentation. It enhances class-relevant information based on extracted example features, but there are only limited examples in the support set. This undermines the representational capability of the extracted class prototypes and further impacts the performance of the information enhancement module. Additionally, few-shot segmentation aims to reduce the annotation cost of the segmentation task. Although existing few-shot semantic segmentation settings have greatly reduced the number of annotated samples needed per class, the masks for the support and query sets used in training still require careful pixel-level annotation, which makes dataset production costly. In the future, on the one hand, we will work on improving feature extractors to obtain more representative example features, which may help to develop more effective frequency enhancement methods. On the other hand, we will resort to semi-supervised or self-supervised methods to further reduce the cost of training few-shot segmentation models and improve the efficiency in leveraging class information contained in provided samples.
Acknowledgement: Not applicable.
Funding Statement: None.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Yiming Tang; data collection: Yiming Tang; analysis and interpretation of results: Yiming Tang, Yanqiu Chen; draft manuscript preparation: Yiming Tang, Yanqiu Chen. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data available within the article.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhou B, Zhao H, Puig X, Fidler S, Barriuso A, Torralba A. Scene parsing through ADE20K dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017. p. 633–41. [Google Scholar]
2. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems 28 (NIPS 2015); 2015. p. 91–9. [Google Scholar]
3. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16 x 16 words: transformers for image recognition at scale. arXiv: 2010.11929. 2020. [Google Scholar]
4. Xie E, Wang W, Yu Z, Anandkumar A, Alvarez JM, Luo P. SegFormer: simple and efficient design for semantic segmentation with transformers. In: Advances in Neural Information Processing Systems 34 (NeurIPS 2021); 2021. Vol. 34, p. 12077–90. [Google Scholar]
5. Wang X, Zhang X, Cao Y, Wang W, Shen C, Huang T. SegGPT: towards segmenting everything in context. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2023. p. 1130–40. [Google Scholar]
6. Qureshi AM, Butt AH, Alazeb A, Mudawi NA, Alonazi M, Almujally NA, et al. Semantic segmentation and YOLO detector over aerial vehicle images. Comput Mater Contin. 2024;80(2):3315–32. doi:10.32604/cmc.2024.052582. [Google Scholar] [CrossRef]
7. Zhao N, Chua TS, Lee GH. Few-shot 3D point cloud semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021. p. 8873–82. [Google Scholar]
8. Saha O, Cheng Z, Maji S. Improving few-shot part segmentation using coarse supervision. In: European Conference on Computer Vision; 2022; Cham: Springer Nature Switzerland; p. 283–99. [Google Scholar]
9. Chen J, Li X, Zhang H, Cho Y, Hwang SH, Gao Z, et al. Adaptive dynamic inference for few-shot left atrium segmentation. Med Image Anal. 2024;98(1):103321. doi:10.1016/j.media.2024.103321. [Google Scholar] [PubMed] [CrossRef]
10. Li X, Chen J, Zhang H, Cho Y, Hwang SH, Gao Z, et al. Hierarchical relational inference for few-shot learning in 3D left atrial segmentation. IEEE Trans Emerg Top Comput Intell. 2024;8(5):3352–67. doi:10.1109/TETCI.2024.3377267. [Google Scholar] [CrossRef]
11. Shaban A, Bansal S, Liu Z, Essa I, Boots B. One-shot learning for semantic segmentation. arXiv:1709.03410. 2017. [Google Scholar]
12. Wang K, Liew JH, Zou Y, Zhou D, Feng J. PaNet: few-shot image semantic segmentation with prototype alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2019. p. 9197–206. [Google Scholar]
13. Tian Z, Zhao H, Shu M, Yang Z, Jia J. Prior guided feature enrichment network for few-shot segmentation. IEEE Trans Pattern Anal Mach Intell. 2020;44(2):1050–65. doi:10.1109/TPAMI.2020.3013717. [Google Scholar] [PubMed] [CrossRef]
14. Peng B, Tian Z, Wu X, Wang C, Liu S, Su J, et al. Hierarchical dense correlation distillation for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023. p. 23641–51. [Google Scholar]
15. Zhu L, Chen T, Yin J, See S, Liu J. Addressing background context bias in few-shot segmentation through iterative modulation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2024. p. 3370–9. [Google Scholar]
16. Liu Y, Zhang X, Zhang S, He X. Part-aware prototype network for few-shot semantic segmentation. In: Computer Vision—ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK: Springer International Publishing; 2020. p. 142–58. [Google Scholar]
17. Yang B, Liu C, Li B, Jiao J, Ye Q. Prototype mixture models for few-shot semantic segmentation. In: Computer Vision–ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK: Springer International Publishing; 2020. p. 763–78. [Google Scholar]
18. Li G, Jampani V, Sevilla-Lara L, Sun D, Kim J, Kim J. Adaptive prototype learning and allocation for few-shot segmentation. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA: IEEE; 2021. p. 8330–9. [Google Scholar]
19. Wang Y, Sun R, Zhang T. Rethinking the correlation in few-shot segmentation: a buoys view. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada: IEEE; 2023. p. 7183–92. [Google Scholar]
20. Wang H, Zhang X, Hu Y, Yang Y, Cao X, Zhen X. Few-shot semantic segmentation with democratic attention networks. In: Computer Vision–ECCV 2020: 16th European Conference; 2020 Aug 23–28; Glasgow, UK: Springer International Publishing; 2020. p. 730–46. [Google Scholar]
21. Min J, Kang D, Cho M. Hypercorrelation squeeze for few-shot segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2021. p. 6941–52. [Google Scholar]
22. Shi X, Wei D, Zhang Y, Lu D, Ning M, Chen J, et al. Dense cross-query-and-support attention weighted mask aggregation for few-shot segmentation. In: Computer Vision—ECCV 2022. Cham: Springer Nature Switzerland; 2022. p. 151–68. [Google Scholar]
23. Zhang G, Kang G, Yang Y, Wei Y. Few-shot segmentation via cycle-consistent transformer. Adv Neural Inform Process Syst. 2021;34:21984–96. [Google Scholar]
24. Qin Z, Zhang P, Wu F, Li X. FcaNet: frequency channel attention networks. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada: IEEE; 2021. p. 763–72. [Google Scholar]
25. Zhang X, Wei Y, Yang Y, Huang TS. SG-One: similarity guidance network for one-shot semantic segmentation. IEEE Trans Cybern. 2020;50(9):3855–65. doi:10.1109/TCYB.2020.2992433. [Google Scholar] [PubMed] [CrossRef]
26. Zhang B, Xiao J, Qin T. Self-guided and cross-guided learning for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021. p. 8312–21. [Google Scholar]
27. Ouyang C, Biffi C, Chen C, Kart T, Qiu H, Rueckert D. Self-supervision with superpixels: training few-shot medical image segmentation without annotation. In: Computer Vision—ECCV 2020. Cham: Springer International Publishing; 2020. p. 762–80. [Google Scholar]
28. Zhu K, Zhai W, Zha ZJ, Cao Y. Self-supervised tuning for few-shot segmentation. arXiv:2004.05538. 2020. [Google Scholar]
29. Amac MS, Sencan A, Baran B, Ikizler-Cinbis N, Cinbis RG. Masksplit: self-supervised meta-learning for few-shot semantic segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision; 2022. p. 1067–77. [Google Scholar]
30. Karimijafarbigloo S, Azad R, Merhof D. Self-supervised few-shot learning for semantic segmentation: an annotation-free approach. In: International Workshop on Predictive Intelligence In Medicine; 2023; Springer. p. 159–71. [Google Scholar]
31. Baxes GA. Digital image processing: principles and applications. John Wiley & Sons, Inc.; 1994. [Google Scholar]
32. Pitas I. Digital image processing algorithms and applications. Vol. 2. John Wiley & Sons, Inc.; 2000. p. 133–8. [Google Scholar]
33. Li S, Xue K, Zhu B, Ding C, Gao X, Wei D, et al. FALCON: a fourier transform based approach for fast and secure convolutional neural network predictions. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA: IEEE. p. 8702–11. [Google Scholar]
34. Yu H, Zheng N, Zhou M, Huang J, Xiao Z, Zhao F. Frequency and spatial dual guidance for image dehazing. In: Computer Vision—ECCV 2022. Cham: Springer Nature Switzerland; 2022. p. 181–98. [Google Scholar]
35. Wang C, Jiang J, Zhong Z, Liu X. Spatial-frequency mutual learning for face super-resolution. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada: IEEE; 2023. p. 22356–66. [Google Scholar]
36. Lin S, Zhang Z, Huang Z, Lu Y, Lan C, Chu P, et al. Deep frequency filtering for domain generalization. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada: IEEE; 2023. p. 11797–807. [Google Scholar]
37. Naqvi RA, Haider A, Kim HS, Jeong D, Lee SW. Transformative noise reduction: leveraging a transformer-based deep network for medical image denoising. Mathematics. 2024;12(15):2313. doi:10.3390/math12152313. [Google Scholar] [CrossRef]
38. Zhang F, Panahi A, Gao G. FsaNet: frequency self-attention for semantic segmentation. IEEE Trans Image Process. 2023;32:4757–72. doi:10.1109/TIP.2023.3305090. [Google Scholar] [PubMed] [CrossRef]
39. Dong B, Wang P, Wang F. Head-free lightweight semantic segmentation with linear transformer. Proc AAAI Conf Artif Intell. 2023;37(1):516–24. doi:10.1609/aaai.v37i1.25126. [Google Scholar] [CrossRef]
40. Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning; 2021; PMLR. p. 8748–63. [Google Scholar]
41. Gonzalez RC. Digital image processing. India: Pearson education; 2009. [Google Scholar]
42. Li X, Wei T, Chen YP, Tai YW, Tang CK. FSS-1000: a 1000-class dataset for few-shot segmentation. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA: IEEE; 2020. p. 2866–75. [Google Scholar]
43. Everingham M, Van Gool L, Williams CK, Winn J, Zisserman A. The pascal visual object classes (VOC) challenge. Int J Comput Vis. 2010;88(2):303–38. doi:10.1007/s11263-009-0275-4. [Google Scholar] [CrossRef]
44. Hariharan B, Arbeláez P, Girshick R, Malik J. Simultaneous detection and segmentation. In: Computer Vision—ECCV 2014. Cham: Springer International Publishing; 2014. p. 297–312. [Google Scholar]
45. Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft coco: common objects in context. In: Computer Vision—ECCV 2014. Cham: Springer International Publishing; 2014. p. 740–55. [Google Scholar]
46. Nguyen K, Todorovic S. Feature weighting and boosting for few-shot segmentation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea: IEEE. p. 622–31. [Google Scholar]
47. Liu J, Bao Y, Xie GS, Xiong H, Sonke JJ, Gavves E. Dynamic prototype convolution network for few-shot semantic segmentation. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA: IEEE; 2022. p. 11543–52. [Google Scholar]
48. Rakelly K, Shelhamer E, Darrell T, Efros A, Levine S. Conditional networks for few-shot semantic segmentation. In: International Conference on Learning Representations; 2018. [Google Scholar]
49. Zhang C, Lin G, Liu F, Yao R, Shen C. CaNet: class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA: IEEE; 2019. p. 5212–21. [Google Scholar]
50. Zhang C, Lin G, Liu F, Guo J, Wu Q, Yao R. Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea: IEEE; 2019. p. 9586–94. [Google Scholar]
51. Bao X, Qin J, Sun S, Wang X, Zheng Y. Relevant intrinsic feature enhancement network for few-shot semantic segmentation. Proc AAAI Conf Artif Intell. 2024;38(2):765–73. doi:10.1609/aaai.v38i2.27834. [Google Scholar] [CrossRef]
52. Liu Y, Liu N, Wu Y, Cholakkal H, Anwer RM, Yao X, et al. NTRENet++: unleashing the power of non-target knowledge for few-shot semantic segmentation. IEEE Trans Circuits Syst Video Technol. 2024. [Google Scholar]
53. Lang C, Cheng G, Tu B, Han J. Few-shot segmentation via divide-and-conquer proxies. Int J Comput Vis. 2024;132(1):261–83. doi:10.1007/s11263-023-01886-8. [Google Scholar] [CrossRef]
54. Wang Y, Sun R, Zhang Z, Zhang T. Adaptive agent transformer for few-shot segmentation. In: European Conference on Computer Vision; 2022; Springer. p. 36–52. [Google Scholar]
55. Lang C, Cheng G, Tu B, Han J. Learning what not to segment: a new perspective on few-shot segmentation. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA: IEEE; 2022. p. 8047–57. [Google Scholar]
56. Shi G, Zhu W, Wu Y, Zhao D, Zheng K, Lu T. Few-shot semantic segmentation via perceptual attention and spatial control. In: Proceedings of the 32nd ACM International Conference on Multimedia; 2024. p. 5374–83. [Google Scholar]
57. Fan Q, Pei W, Tai YW, Tang CK. Self-support few-shot semantic segmentation. In: European Conference on Computer Vision; 2022; Cham: Springer Nature Switzerland. p. 701–19. [Google Scholar]
58. Liu Y, Liu N, Yao X, Han J. Intermediate prototype mining transformer for few-shot semantic segmentation. Adv Neural Inform Process Syst. 2022;35:38020–31. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools