
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Pathfinder: Deep Reinforcement Learning-Based Scheduling for Multi-Robot Systems in Smart Factories with Mass Customization
1 College of Computer and Data Science, Fuzhou University, Fuzhou, 350108, China
2 Department of Computer Science and Engineering, University of South Florida, Tampa, FL 33620, USA
* Corresponding Author: Qian Weng. Email:
Computers, Materials & Continua 2025, 84(2), 3371-3391. https://doi.org/10.32604/cmc.2025.065153
Received 05 March 2025; Accepted 15 May 2025; Issue published 03 July 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The rapid advancement of Industry 4.0 has revolutionized manufacturing, shifting production from centralized control to decentralized, intelligent systems. Smart factories are now expected to achieve high adaptability and resource efficiency, particularly in mass customization scenarios where production schedules must accommodate dynamic and personalized demands. To address the challenges of dynamic task allocation, uncertainty, and real-time decision-making, this paper proposes Pathfinder, a deep reinforcement learning-based scheduling framework. Pathfinder models scheduling data through three key matrices: execution time (the time required for a job to complete), completion time (the actual time at which a job is finished), and efficiency (the performance of executing a single job). By leveraging neural networks, Pathfinder extracts essential features from these matrices, enabling intelligent decision-making in dynamic production environments. Unlike traditional approaches with fixed scheduling rules, Pathfinder dynamically selects from ten diverse scheduling rules, optimizing decisions based on real-time environmental conditions. To further enhance scheduling efficiency, a specialized reward function is designed to support dynamic task allocation and real-time adjustments. This function helps Pathfinder continuously refine its scheduling strategy, improving machine utilization and minimizing job completion times. Through reinforcement learning, Pathfinder adapts to evolving production demands, ensuring robust performance in real-world applications. Experimental results demonstrate that Pathfinder outperforms traditional scheduling approaches, offering improved coordination and efficiency in smart factories. By integrating deep reinforcement learning, adaptable scheduling strategies, and an innovative reward function, Pathfinder provides an effective solution to the growing challenges of multi-robot job scheduling in mass customization environments.Keywords
As the Fourth Industrial Revolution progresses and Industry 4.0 evolves, artificial intelligence (AI) emerges as a pivotal force in diverse sectors [1]. The advent and progression of robotics technology have enabled the replacement of numerous conventional manual tasks, showcasing broad potential across various domains. Robots find applications from factory production to healthcare, and from logistics to household services, indicating their extensive future potential [2]. For instance, industrial robots significantly enhance efficiency and quality on automated assembly lines [3], while medical robots achieve precision in surgeries and diagnostics [4]. Additionally, smart home robots offer essential daily services. These advancements not only improve productivity but also ensure precision and reliability in complex tasks, gaining extensive recognition and significant interest from both academia and industry.
In contemporary society, smart factories epitomize the essence of Industry 4.0. These facilities incorporate cutting-edge technologies like Cyber-Physical Systems (CPS) [5], the Internet of Things (IoT) [6], big data [7], multi-robot systems [8], and virtual reality [9], enabling automation, digitization, and intelligence in manufacturing processes [10]. Distinguished from traditional manufacturing setups, smart factories offer enhanced flexibility and efficiency. They support real-time monitoring, predictive maintenance, and autonomous process optimization. These capabilities not only boost production efficiency and reduce operational costs but also allow swift adaptation to market changes, securing a competitive advantage for businesses [11].
In the realm of smart factories, industrial robots are indispensable, enhancing production and material transport efficiencies significantly. These include robotic arms and autonomous mobile robots, which not only reduce labor costs but also redirect human resources towards activities of higher value [12]. Extensive research within both academia and industry has yielded innovative solutions for intelligent production. These encompass areas such as production scheduling [13], resource allocation [14], logistics, storage [15], and emergency management [16].
Traditional industrial production processes are rigid, with flexibility constrained by the limited number of dedicated production lines. In contrast, dynamic customized production in smart factories demands production lines capable of handling mixed and multi-batch dynamic tasks [17]. The shift towards intelligent manufacturing emphasizes reconfigurable, multi-use dynamic production that can adapt in real-time to produce various products by leveraging AI, robotics, sensors, and information communication technology. However, this approach presents scheduling challenges, including time-varying machine structures, varying processing speeds of parallel machines, and dynamic job arrivals.
In traditional industrial production scheduling, practitioners typically rely on manually selecting one or more fixed scheduling rules based on past experience [18], requiring significant expertise. However, with the increasing complexity and flexibility demanded by customized production and unexpected events, the efficiency and robustness of scheduling cannot always be assured. Moreover, existing scheduling methods often prioritize local optimization, lacking a global perspective, which results in reduced production efficiency and resource utilization.
To address these challenges, Pathfinder, a scheduling approach, was developed by integrating deep learning and reinforcement learning, enabling autonomous adaptation and optimization of scheduling strategies in real-time production environments. Pathfinder efficiently manages uncertainties and dynamic fluctuations, achieving global optimization to maximize production efficiency. Experimental results demonstrate Pathfinder’s superior performance on various classic scheduling datasets, offering insights and methodologies for advancing smart factory operations.
The main contributions include:
• A specialized reward function is designed to support dynamic task allocation and real-time adjustments, creating a novel multi-robot job scheduling model tailored for smart factories. This approach improves production efficiency and optimizes robot coordination.
• An adaptable approach was adopted by selecting ten diverse scheduling rules instead of fixed actions. These rules enhance decision-making flexibility, with the optimal rule dynamically chosen based on environmental conditions. This strategy addresses the challenge of reflecting changes in custom production scheduling, allowing the model to adapt to dynamic scenarios and maintain optimal performance.
• A method called Pathfinder is proposed for decision-making in custom production job scheduling. It transforms scheduling data into matrices of execution time, completion time, and efficiency. By utilizing neural networks to extract features, Pathfinder optimizes machine utilization and minimizes job completion times, adapting to dynamic production demands and ensuring robust performance in real-world applications.
The paper is structured as follows: Section 2 reviews related work and motivation. Section 3 defines the problem and models. Section 4outlines the approach, followed by implementation in Section 5. Section 6 presents experimental validation, and Section 7 concludes with key contributions.
In this chapter, we present previous researchs on relevant issues and the challenges they have faced. Additionally, we elucidate the motivation behind proposing this algorithm.
Scheduling theory faces significant challenges in task allocation and sequencing within complex systems, particularly in multi-stage scheduling where genetic algorithms and ant colony optimization enhance efficiency [19]. These systems, characterized by their NP-complete or NP-hard nature, necessitate heuristic algorithms for practical solutions.
The evolution of smart factories has introduced complexities that require managing diverse production tasks [20]. Innovations in this domain include Wang et al.’s adaptive scheduling using edge computing [21] and Sharif et al.’s optimized resource allocation in health monitoring [22].
Edge computing’s pivotal role in intelligent manufacturing supports real-time applications such as augmented reality [23] and resource-efficient scheduling algorithms like the Whale Optimization algorithm [24].
In collaborative robotics, efficient task allocation and multi-robot cooperation strategies are explored by Baroudi et al., Dutta et al., and Wei et al. [25–27]. Quantum reinforcement learning for enhanced control is also being investigated in smart factories [28].
Deep reinforcement learning (DRL) has been applied to dynamic scheduling, with models like Zhang et al.’s DeepMAG integrating multi-agent systems for better decision-making [29]. Similar strategies were explored by Han et al. and Zhou et al. to enhance production in smart factories [30,31]. Ma et al. introduced a reliability-aware DRL approach for DNN tasks in mobile-edge computing [32]. Zhang et al. developed a multi-agent manufacturing system using an improved contract network protocol and PPO-trained AI scheduler, showing strong performance under disruptions [33]. Liu et al. proposed a hierarchical, distributed architecture for dynamic job-shop scheduling using a Double Deep Q-Network with tailored state-action spaces and reward shaping for efficient learning [34]. Alexopoulos et al. designed a DRL framework where an agent selects dispatching rules, improving scheduling and makespan in a bicycle production case [35]. Gui et al. employed a composite action framework with a DDPG-trained policy network for job-shop scheduling, outperforming traditional rules and DQN-based methods [36]. Li et al. applied DRL with PPO and a recurrent neural network to parallel machine scheduling with family setup constraints, achieving strong generalization and superior performance over heuristics [37].
Traditional fixed production lines with multiple robots face challenges in adapting to the flexibility needed for customized manufacturing. Existing methods lack the ability to reconfigure multi-robot tasks or adjust to dynamic schedules, limiting flexible production management.
Maximizing net profit requires considering resource consumption, robot types, energy use, and load balancing. Use of robot resources, including completion time and utilization rate, is vital.
We propose a reinforcement learning-based approach to optimize multi-robot task configurations in complex environments, enhanced by deep learning for high-dimensional data processing. This improves accuracy, efficiency, and flexibility through universal scheduling rules. Immediate rewards are tied to scheduling efficiency and utilization rates for precise goal evaluation.
By modeling the scheduling problem as a Markov decision process and applying a Deep Q Network, our method enables intelligent, collaborative, and adaptive robot scheduling in smart factories, ensuring robust performance under dynamic conditions.
3 Problem Description and Formulation
In this chapter, we introduce the problem and provide a formal description of it. Then, we proceed to establish the corresponding mathematical model.
Reinforcement learning is used to learn action-selection strategies by modeling the scheduling problem as a Markov Decision Process (MDP). An MDP assumes that future states and rewards depend solely on the current state and action, not on past states. Thus, the problem must be framed accordingly. A standard MDP is defined by a quintuple:
In this paper, the state space
The transition probability
The immediate reward function
Training begins by estimating the action-value function
Then, update the action value function by updating the Q-values. The update formula for Q-values is as follows:
here,
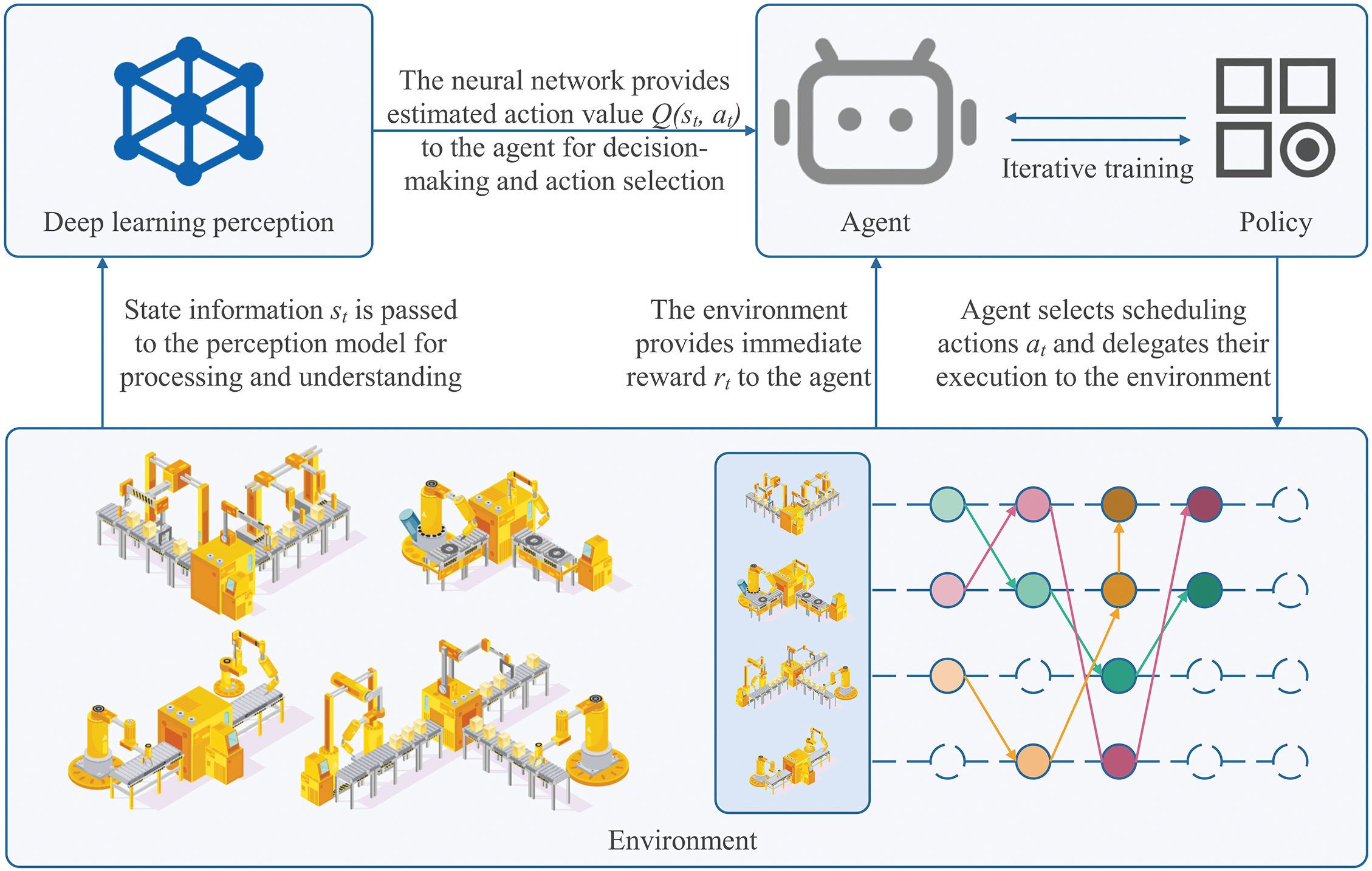
Figure 1: Deep reinforcement learning scheduling model
In this scheduling problem, we have a manufacturing system with a set of orders
For robots to be effective in completing orders, a description is shown as follows:
Input: Set of orders
Output: Completion time of orders
Objective: Maximize
In a smart factory, the job scheduling phase is critical to ensure that the manufacturing resources of each robot are fully utilized. This utilization is primarily reflected in the production duration (makespan) and the average machine utilization (
where
Eq. (6) provides the formula for average machine utilization
where M is the number of robots and
When
This objective is subject to the following constraints:
1. Job Assignment Constraint: Each job is assigned to at most one robot:
where
2. Job Sequence Constraint: Jobs must be completed in the specified order:
3. Completion Time Constraint: The completion time of each job must not exceed the maximum completion time of its associated job sequence:
4. Robot Occupancy Constraint: At any given time, a robot can only be assigned to one job:
where
5. Robot Availability Constraint: A robot can only execute a job if it is available at the given time:
where
6. Task-Robot Feasibility Constraint: A specific job
These conditions collectively define the optimization problem. The goal is to find the optimal assignment of jobs to robots, minimizing the makespan, and ensuring compliance with the specified constraints.
3.4 Table of Mathematical Notations
For improved readability, this paper presents notations and meanings in the Table 1.

This chapter offers a thorough overview of the structure of Pathfinder and its complete algorithmic process. Fig. 2 illustrates the overall framework of Pathfinder. Each string of small circles represents an order, where each circle represents a job. The same color indicates that the jobs are executed by the same robot, and the sequence is specified by the arrows. It mainly consists of the following stages.
• Stage I: Initialization.
–Step 1: Establish simulation environment.
– Step 2: Develop Neural Network.
– Step 3: Implement experience replay pool.
•Stage II: Extracting Experience for NN Training.
– Step 4: Sample experience data.
– Step 5: Train the network.
•Stage III: Training RL Model for Decisions.
– Step 6: Interact with virtual environment.
– Step 7: Update network parameters.
– Step 8: Store the state sequence (
Stage IV: Iterative Training and Online Scheduling.
– Step 9: Repeat training process.
– Step 10: Enable online job scheduling.
Figure 2: The structure and algorithm flow of Pathfinder
Pathfinder is introduced in Algorithm 1 in detail.

In this chapter, we will delve into the details of each stage in sequential order.
5.1 Establishment of Network Structure and Experience Replay Pool
In the stage 1, our primary focus was on constructing the neural network framework and establishing the experience replay pool. Within this subsection, we’ll delineate the comprehensive structure of both the network and the experience replay pool.
Our scheduling decision model employs a network (Fig. 3) that processes a 3D input matrix of execution time, completion time, and efficiency. The convolutional layer uses square kernels without pooling to preserve feature integrity. We maximize filters in the first layer and reduce them in later layers, keeping the stride fixed at 1. The final convolutional output is flattened and passed to fully connected layers.
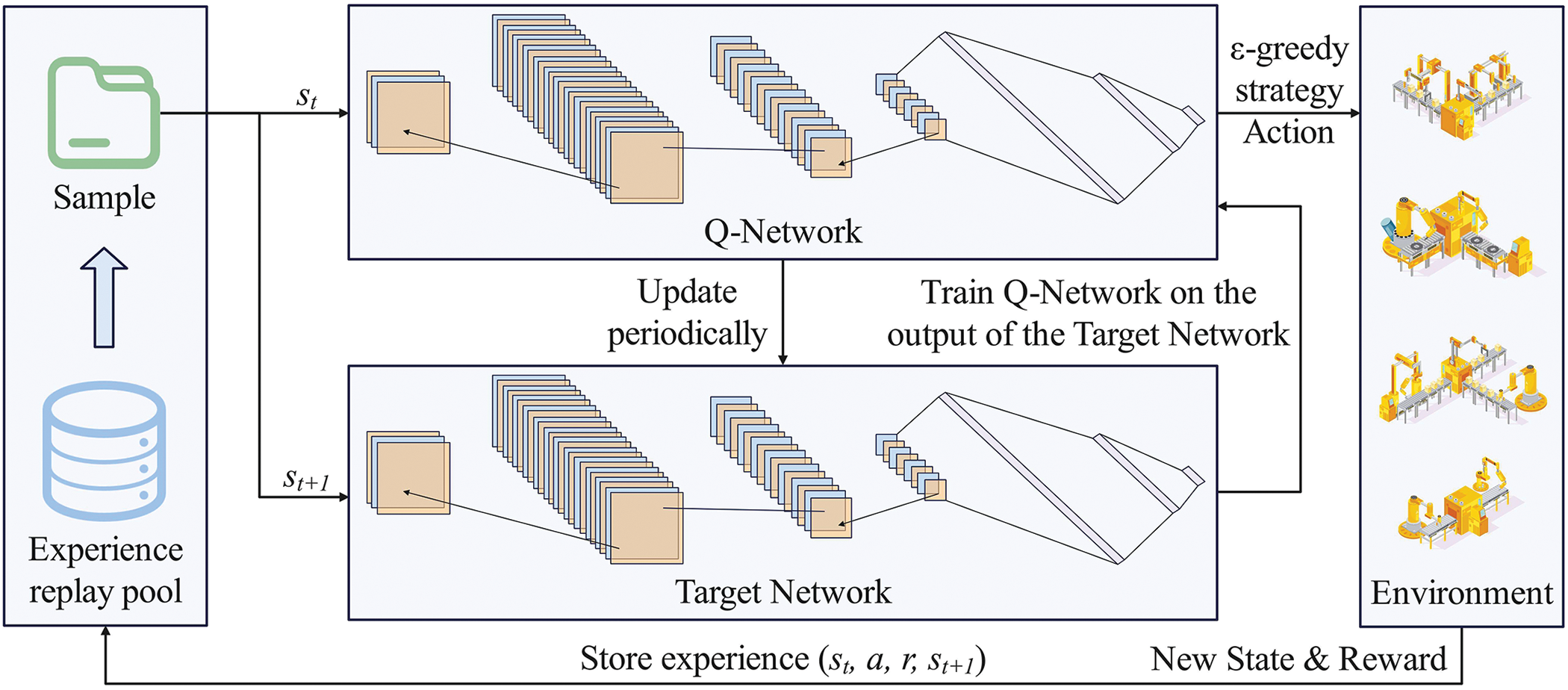
Figure 3: The structure of the Pathfinder scheduling decision model
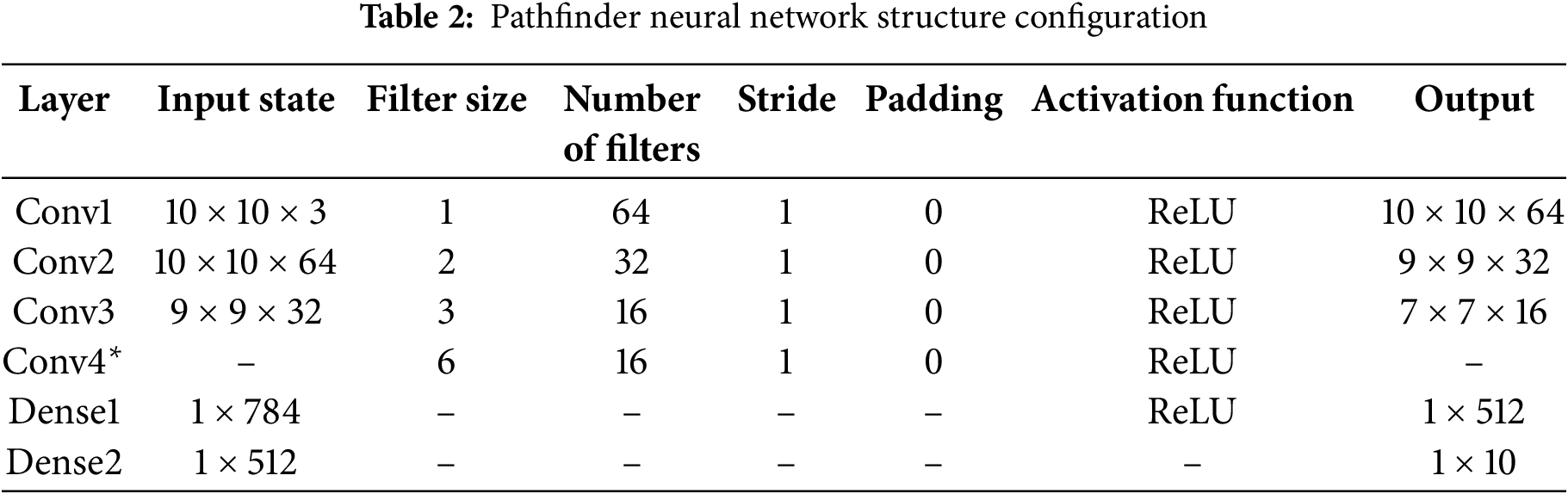
As detailed in Table 2, the network is configured for a 10
Our Q-network’s loss function, central to training, is defined as:
Here,
With the target Q network, the loss function incorporates target Q-values alongside current Q-values, promoting more stable and effective training:
where
Pathfinder employs an experience replay pool to improve learning efficiency and stability by reusing past experiences, enhancing sample efficiency and reducing update correlation. Unlike traditional online learning, which updates parameters using only current samples, experience replay enables random sampling from historical data.
This broadens state-action mapping and improves real-time scheduling decisions. As a result, training becomes more efficient, with demonstrated gains in performance and stability.
In stage 2, scheduling data from the experience replay pool is used to train the network. This section explains the state representation in the data.
To address dynamic job scheduling, a three-channel input overlays matrices for machines, job attributes, and scheduling efficiency. For example, in the ft06 dataset (Fig. 4), rows represent orders and column pairs denote jobs–odd columns indicate assigned machines, even columns show execution times. The total number of columns is based on the maximum jobs per order. In the red box example, job 1 of order 1 runs on robot 2 with an execution time of 1.

Figure 4: Illustration of the ft06 dataset matrix
The state is formally defined as a tuple of three time-dependent matrices:
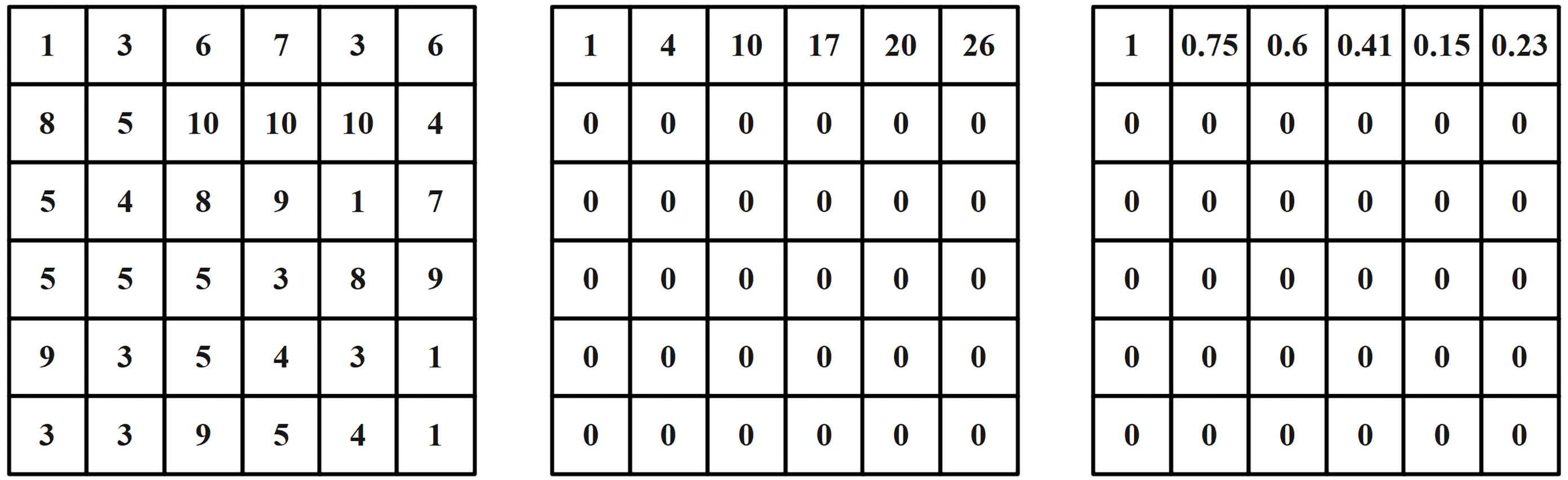
Figure 5: Schedule state matrix for ft06
5.3 Reinforcement Learning Scheduling Algorithm
In stage 3, environmental data is collected to train the reinforcement learning model, guiding algorithm updates and decision-making. This section defines the action space, decision implementation, and reward function.
In customized production, scheduling is more complex than in games with clear legal actions due to job dependencies and dynamic production demands. A job may follow different scheduling paths over time, making fixed action outputs insufficient to capture real-world variability.
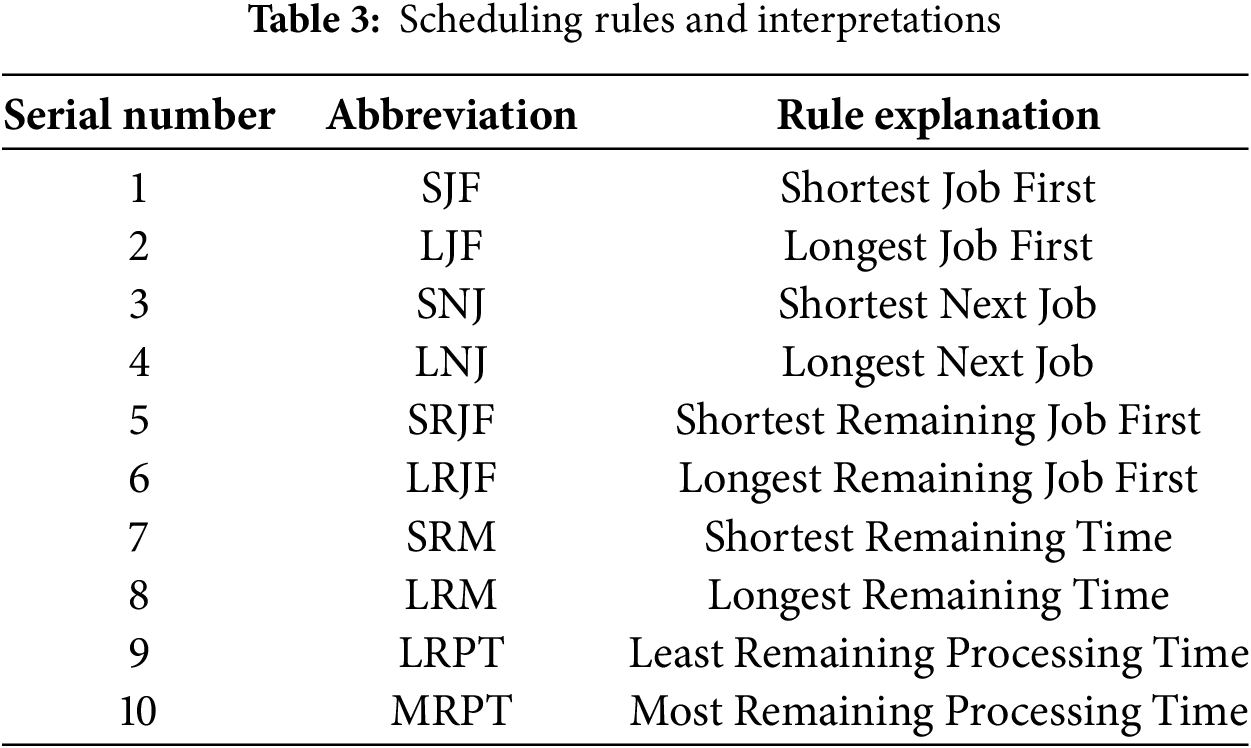
To address this, we adopt general scheduling rules instead of specific actions, improving adaptability to changing conditions. Ten commonly used rules are summarized in Table 3.
In our framework, an action is taken after each job completion, where the agent selects the next scheduling rule.
We use the
here,
To improve efficiency on large-scale scheduling data, we introduce the cur_policy strategy: when
As training progresses, Q-value estimates are continually updated. Unlike traditional Q-learning, deep reinforcement learning approximates Q-values via neural networks. The updated Q-value is computed as follows:
here,
The learning effectiveness of intelligent agents is directly impacted by the design of rewards. A well-crafted reward function plays a crucial role in ensuring the algorithm’s learning performance.
This paper examines the immediate reward
here,
here,
To evaluate the overall workload performance, the total reward over a scheduling horizon T is computed as:
where R represents the cumulative reward, which reflects the scheduling efficiency over the entire workload execution. This formulation ensures that the agent optimizes scheduling decisions across different job workloads rather than at individual time steps.
6 Experiment Results and Analysis
This chapter will evaluate the performance of the proposed job scheduling decision model by simulating both static and dynamic job scheduling environments. We will use classic scheduling data from the OR-library as a benchmark. Details regarding the specific test data, scale, and sources are presented in Table 4 below.

6.1 Algorithm Parameter Settings
This section outlines parameter settings used in model training. Key parameters for decision iteration, neural network hyperparameters, and reinforcement learning updates are listed in Table 5. We set 1000 training episodes, a replay pool size of 60000, and a batch size of 256. The target network updates every 200 steps, using the Adam optimizer with a learning rate of 0.0001.
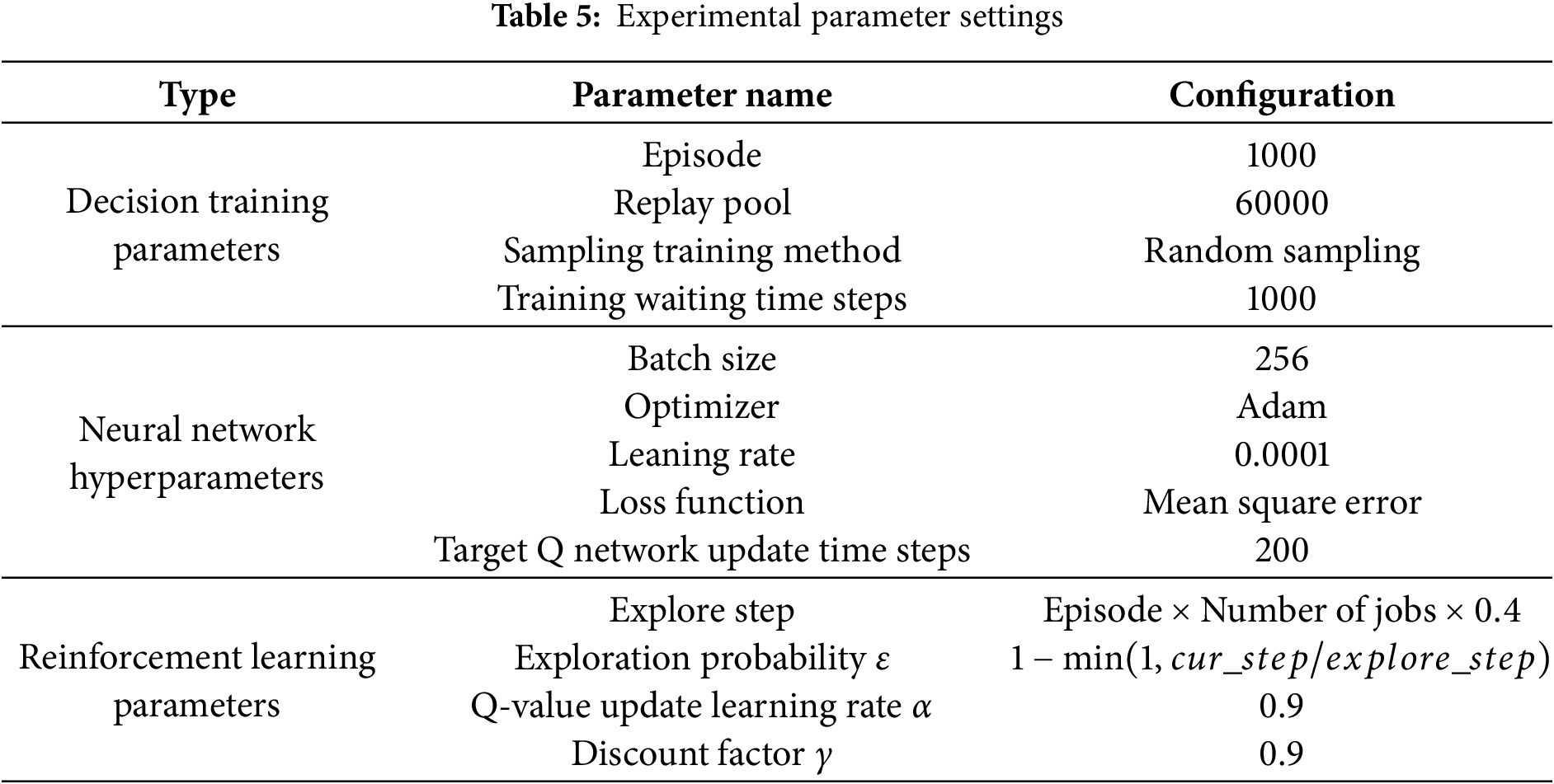
Exploration spans 40% of training, with
6.2 Model Convergence Analysis
This section evaluates the convergence of the decision model using the maximum scheduling completion time (makespan) as a criterion, with the benchmark abz5 chosen for testing. Results will be analyzed under different settings, including various batch data sizes, sampling training methods, exploration patterns, and numbers of scheduling rules.
To evaluate convergence without labeled data, makespan is used as a proxy loss. Over 1000 training rounds, average performance per 20-round period is reported.
Fig. 6a shows that larger batch sizes (e.g., batch256) enhance convergence speed and stability, especially under the cur_policy strategy. Fig. 6b indicates cur_policy accelerates convergence with more stable outcomes, while
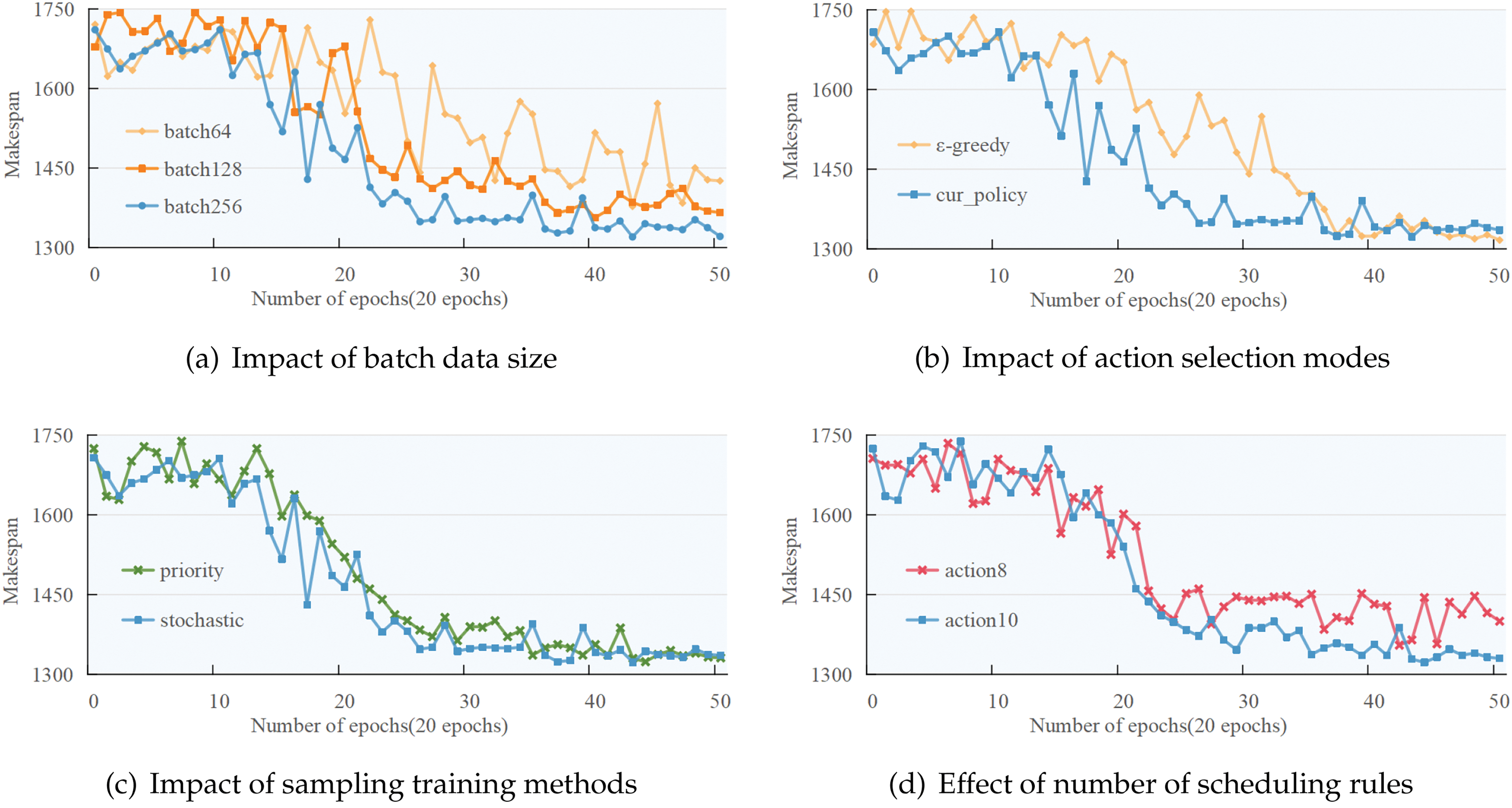
Figure 6: Convergence analysis plot under different parameter conditions
6.3 Experimental Results Comparative Analysis
Section 5 defines the model’s output as the scheduling rule best suited to the current situation. This section compares each scheduling rule’s performance. Table 6 presents results on small-scale benchmarks (6
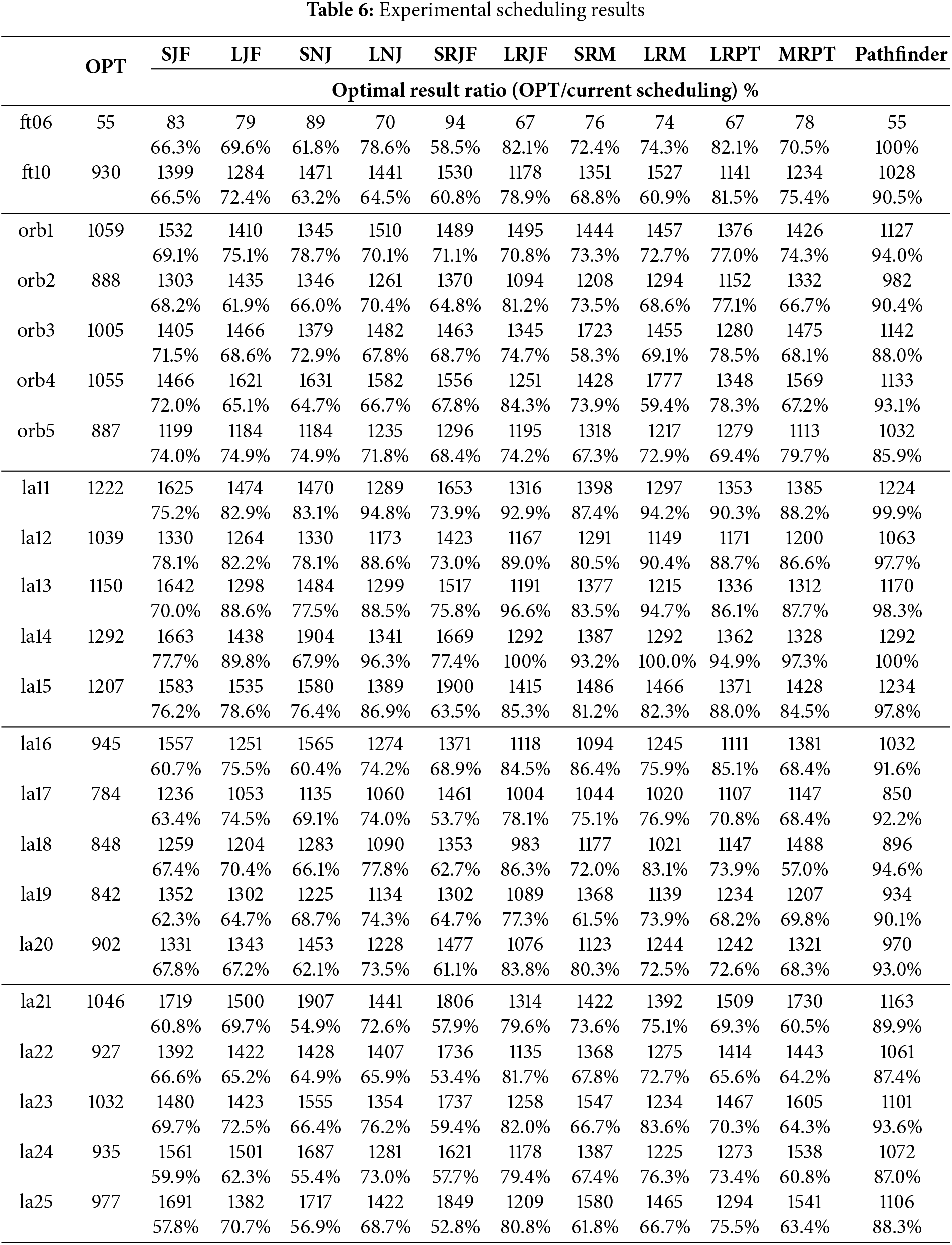
Table 7 shows the best performance of individual scheduling rules across benchmarks. LRJF consistently ranks highest, followed by LRPT, while others perform well only in specific cases. Our proposed method outperforms all single rules in terms of maximum completion time on small to medium-scale benchmarks. A paired t-test confirms it achieves at least 90% of optimal performance (p = 0.013), indicating statistical significance. Fig. 7 shows Pathfinder’s robot utilization closely matches OPT and significantly exceeds the Best Rule, confirming its overall effectiveness.
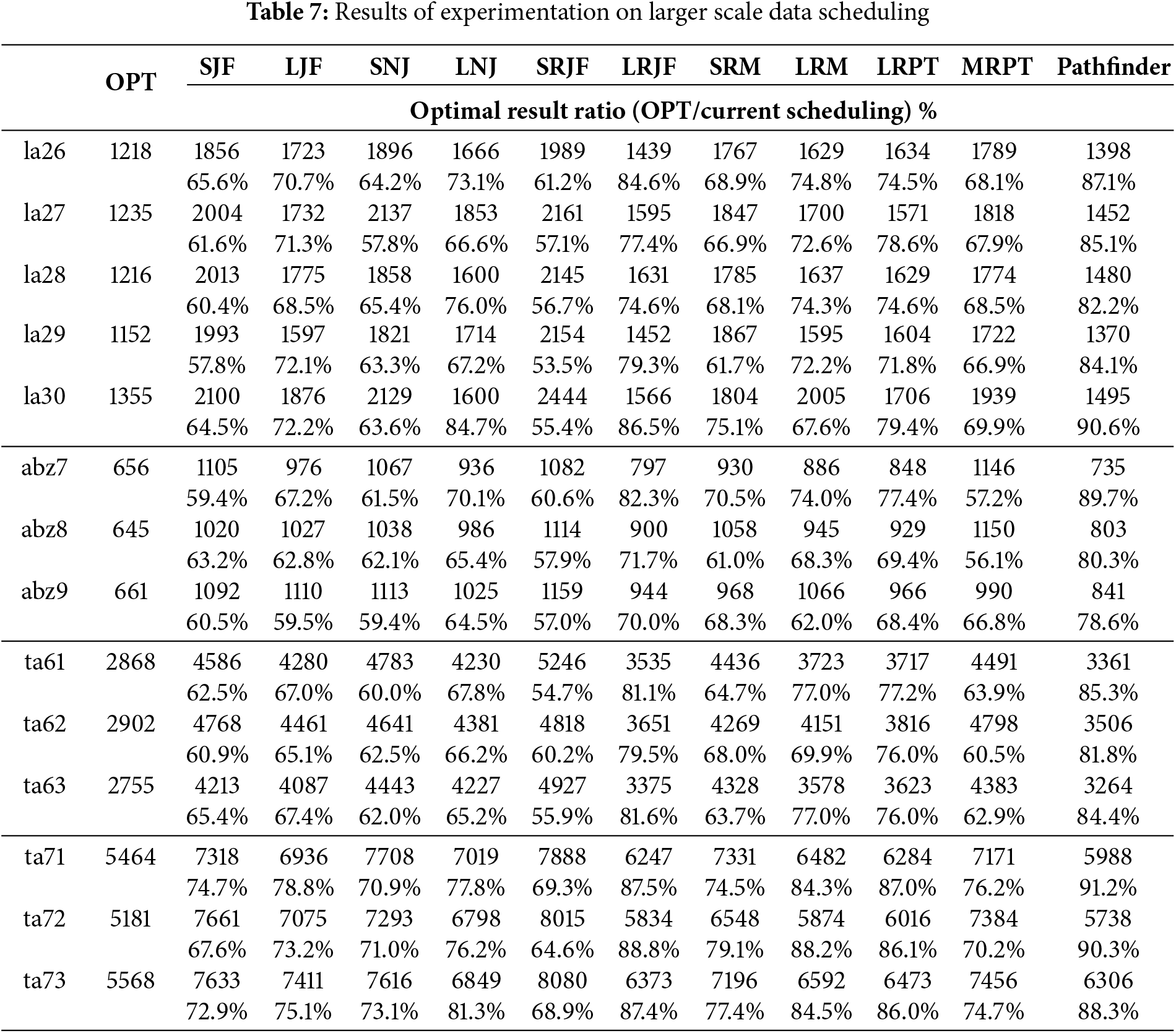
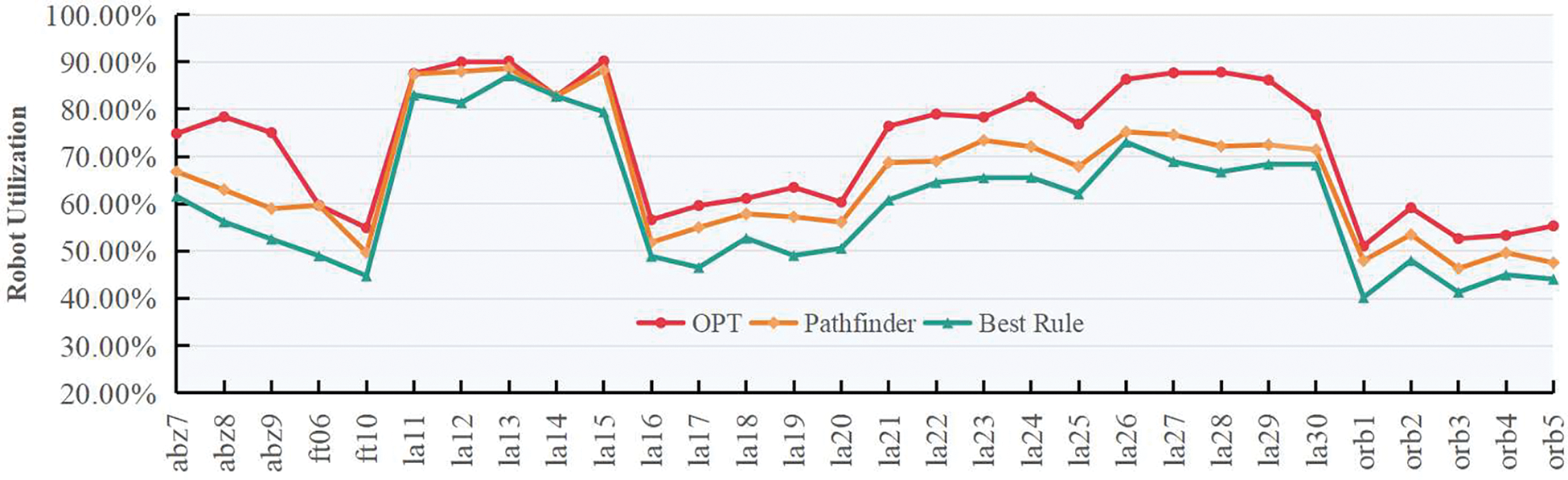
Figure 7: Comparison of utilization among OPT, Best Single Rule and Pathfinder
The model’s performance on larger-scale datasets (Table 7) shows a slight decline compared to smaller-scale results (Table 6), especially in benchmarks like abz8-9, la28, and ta62. This is likely due to increased scenario complexity, suggesting the need for more diverse scheduling rules, as single rules often yield only 60%–70% of the optimal.
A t-test confirms Pathfinder achieves at least 83% of optimal performance (p = 0.032), indicating statistical significance. Fig. 8 compares Pathfinder, Q-learning, and Actor-Critic methods. Pathfinder demonstrates strong performance and stability across scales, consistently approaching optimal solutions more closely than other methods.

Figure 8: Comparison of scheduling performance among various algorithms
Comparison of the maximum completion time ratios shows that Pathfinder, QL, and AC algorithms outperform single optimal rules, following similar trends due to the shared set of ten scheduling rules. Among them, the Actor-Critic algorithm converges fastest but may sacrifice exploration diversity, leading to performance gaps compared to Pathfinder and QL.
QL calculates rewards based on changes in machine utilization and stores Q-values in a table. While effective at small scales, its scalability is limited due to exponential growth in state space, restricting its application to 15 × 10 scheduling. Pathfinder and AC, using neural approximators, avoid this issue.
In conclusion, Pathfinder’s rule-based scheduling achieves superior performance over single rules. However, scheduling quality still depends on rule effectiveness, especially at larger scales. Expanding the rule set may further enhance performance.
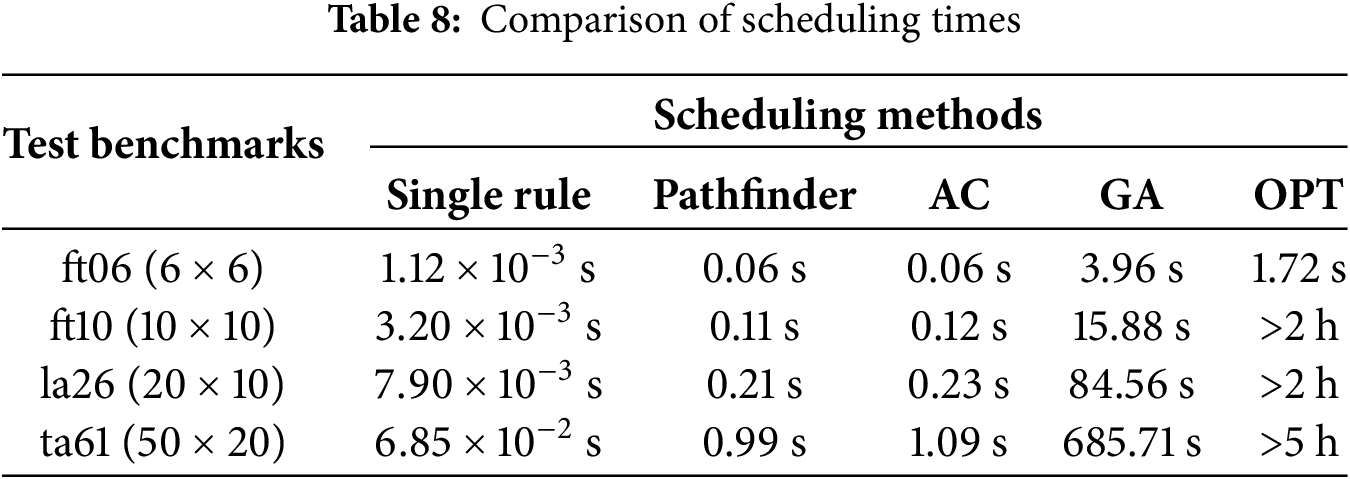
6.4 Decision Time and Robustness
Single scheduling rules exhibit the fastest completion results across all test benchmarks, completing about 20–50 times faster than the Pathfinder algorithm. Both the Pathfinder and AC algorithms demonstrate similar execution times in all benchmarks listed in Table 8. Even when facing scheduling data of size 50
Real-world scheduling faces uncertainties such as processing time fluctuations and machine failures. Traditional methods like mathematical programming and metaheuristics must re-execute under such changes, incurring extra time costs. In contrast, deep reinforcement learning can adapt to stochastic environments and respond quickly.
We test the trained Pathfinder model on datasets of varying scales with random job and machine seeds. Some job execution times fluctuate by up to 10% to simulate real-world variability. Results, averaged over 100 random datasets, are compared with the AC algorithm and the best single scheduling rule. As shown in Fig. 9, Pathfinder consistently delivers optimal performance across all scales.

Figure 9: Experimental results of random scheduling of data
Dynamic customized production introduces complex scheduling challenges. We model it as a multi-stage decision process and propose a deep reinforcement learning approach adaptable to diverse settings. The model achieves over 90% efficiency on small-scale tasks and maintains at least 85% on larger ones, outperforming traditional methods in both speed and adaptability.
Acknowledgement: We would like to thank the College of Computer and Data Science, Fuzhou University, for their technical support and assistance during the research process.
Funding Statement: This work is supported by National Natural Science Foundation of China under Grant No. 62372110, Fujian Provincial Natural Science of Foundation under Grants 2023J02008, 2024H0009.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Chenxi Lyu; methodology, Chen Dong; software, Qiancheng Xiong; validation, Yuzhong Chen; formal analysis, Qian Weng; data curation, Qiancheng Xiong; writing—original draft preparation, Chenxi Lyu; writing—review and editing, Chenxi Lyu; visualization, Zhenyi Chen; funding acquisition, Yuzhong Chen. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available within the article.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest regarding the present study.
References
1. Jan Z, Ahamed F, Mayer W, Patel N, Grossmann G, Stumptner M, et al. Artificial intelligence for industry 4.0: systematic review of applications, challenges, and opportunities. Expert Syst Appl. 2023;216(9):119456. doi:10.1016/j.eswa.2022.119456. [Google Scholar] [CrossRef]
2. Mia MR, Shuford J. Exploring the synergy of artificial intelligence and robotics in Industry 4.0 applications. J Artif Intell General Sci. 2024;1(1):17–20. [Google Scholar]
3. Daneshmand M, Noroozi F, Corneanu C, Mafakheri F, Fiorini P. Industry 4.0 and prospects of circular economy: a survey of robotic assembly and disassembly. Int J Adv Manufact Techno. 2023;124(9):2973–3000. doi:10.1007/s00170-021-08389-1. [Google Scholar] [CrossRef]
4. Yip M, Salcudean S, Goldberg K, Althoefer K, Menciassi A, Opfermann JD, et al. Artificial intelligence meets medical robotics. Science. 2023;381(6654):141–6. doi:10.1126/science.adj3312. [Google Scholar] [PubMed] [CrossRef]
5. Ryalat M, ElMoaqet H, AlFaouri M. Design of a smart factory based on cyber-physical systems and Internet of Things towards Industry 4.0. Appl Sci. 2023;13(4):2156. doi:10.3390/app13042156. [Google Scholar] [CrossRef]
6. Soori M, Arezoo B, Dastres R. Internet of things for smart factories in Industry 4.0, a review. Int Things Cyber-Phys Syst. 2023;3:192–204. doi:10.1016/j.iotcps.2023.04.006. [Google Scholar] [CrossRef]
7. Yu W, Liu Y, Dillon T, Rahayu W, Mostafa F. An integrated framework for health state monitoring in a smart factory employing IoT and big data techniques. IEEE Int Things J. 2021;9(3):2443–54. doi:10.1109/jiot.2021.3096637. [Google Scholar] [CrossRef]
8. Kalempa VC, Piardi L, Limeira M, de Oliveira AS. Multi-robot task scheduling for consensus-based fault-resilient intelligent behavior in smart factories. Machines. 2023;11(4):431. doi:10.3390/machines11040431. [Google Scholar] [CrossRef]
9. Alpala LO, Quiroga-Parra DJ, Torres JC, Peluffo-Ordóñez DH. Smart factory using virtual reality and online multi-user: towards a metaverse for experimental frameworks. Appl Sci. 2022;12(12):6258. doi:10.3390/app12126258. [Google Scholar] [CrossRef]
10. Büchi G, Cugno M, Castagnoli R. Smart factory performance and Industry 4.0. Technol Forecast Soc Change. 2020;150(3):119790. doi:10.1016/j.techfore.2019.119790. [Google Scholar] [CrossRef]
11. Osterrieder P, Budde L, Friedli T. The smart factory as a key construct of Industry 4.0: a systematic literature review. Int J Prod Econ. 2020;221(4):107476. doi:10.1016/j.ijpe.2019.08.011. [Google Scholar] [CrossRef]
12. Arents J, Greitans M. Smart industrial robot control trends, challenges and opportunities within manufacturing. Appl Sci. 2022;12(2):937. doi:10.3390/app12020937. [Google Scholar] [CrossRef]
13. Lei J, Hui J, Chang F, Dassari S, Ding K. Reinforcement learning-based dynamic production-logistics-integrated tasks allocation in smart factories. Inte J Product Res. 2023;61(13):4419–36. doi:10.1080/00207543.2022.2142314. [Google Scholar] [CrossRef]
14. Hussain RF, Salehi MA. Resource allocation of industry 4.0 micro-service applications across serverless fog federation. Future Generat Comput Syst. 2024;154(2):479–90. doi:10.1016/j.future.2024.01.017. [Google Scholar] [CrossRef]
15. Flores-García E, Jeong Y, Liu S, Wiktorsson M, Wang L. Enabling industrial internet of things-based digital servitization in smart production logistics. Int J Product Res. 2023;61(12):3884–909. doi:10.1080/00207543.2022.2081099. [Google Scholar] [CrossRef]
16. Tricomi G, Scaffidi C, Merlino G, Longo F, Puliafito A, Distefano S. A resilient fire protection system for software-defined factories. IEEE Int Things J. 2021;10(4):3151–64. doi:10.1109/jiot.2021.3127387. [Google Scholar] [CrossRef]
17. Shi Z, Xie Y, Xue W, Chen Y, Fu L, Xu X. Smart factory in Industry 4.0. Syst Res Behav Sci. 2020;37(4):607–17. doi:10.1002/sres.2704. [Google Scholar] [CrossRef]
18. Baker KR, Trietsch D. Principles of sequencing and scheduling. Hoboken, NJ, USA: John Wiley & Sons; 2013. [Google Scholar]
19. Cebi C, Atac E, Sahingoz OK. Job shop scheduling problem and solution algorithms: a review. In: 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT); 2020 Jul 1–3. Kharagpur, India: IEEE; 2020. p. 1–7. [Google Scholar]
20. Marzia S, AlejandroVital-Soto, Azab A. Automated process planning and dynamic scheduling for smart manufacturing: a systematic literature review. Manufact Letters. 2023;35:861–72. doi:10.1016/j.mfglet.2023.07.013. [Google Scholar] [CrossRef]
21. Wang J, Liu Y, Ren S, Wang C, Ma S. Edge computing-based real-time scheduling for digital twin flexible job shop with variable time window. Robot Comput Integr Manuf. 2023;79:102435. doi:10.1016/j.rcim.2022.102435. [Google Scholar] [CrossRef]
22. Sharif Z, Tang Jung L, Ayaz M, Yahya M, Pitafi S. Priority-based task scheduling and resource allocation in edge computing for health monitoring system. J King Saud Univ-Comput Inform Sci. 2023;35(2):544–59. doi:10.1016/j.jksuci.2023.01.001. [Google Scholar] [CrossRef]
23. Um J, Gezer V, Wagner A, Ruskowski M. Edge computing in smart production. In: Advances in Service and Industrial Robotics: Proceedings of the 28th International Conference on Robotics in Alpe-Adria-Danube Region (RAAD 2019) 28. Cham, Switzerland: Springer; 2020. p. 144–52. [Google Scholar]
24. Mangalampalli S, Karri GR, Kose U. Multi objective trust aware task scheduling algorithm in cloud computing using whale optimization. J King Saud Univ-Comput Inform Sci. 2023;35(2):791–809. doi:10.1016/j.jksuci.2023.01.016. [Google Scholar] [CrossRef]
25. Baroudi U, Alshaboti M, Koubaa A, Trigui S. Dynamic multi-objective auction-based (DYMO-auction) task allocation. Appl Sci. 2020;10(9):3264. doi:10.3390/app10093264. [Google Scholar] [CrossRef]
26. Dutta A, Czarnecki E, Ufimtsev V, Asaithambi A. Correlation clustering-based multi-robot task allocation: a tale of two graphs. ACM SIGAPP Appl Comput Rev. 2020;19(4):5–16. doi:10.1145/3381307.3381308. [Google Scholar] [CrossRef]
27. Wei C, Ji Z, Cai B. Particle swarm optimization for cooperative multi-robot task allocation: a multi-objective approach. IEEE Robot Automa Letters. 2020;5(2):2530–7. doi:10.1109/lra.2020.2972894. [Google Scholar] [CrossRef]
28. Yun WJ, Kim JP, Jung S, Kim JH, Kim J. Quantum multi-agent actor-critic neural networks for internet-connected multi-robot coordination in smart factory management. IEEE Internet Things J. 2023;10(11):9942–52. doi:10.1109/jiot.2023.3234911. [Google Scholar] [CrossRef]
29. Zhang JD, He Z, Chan WH, Chow CY. DeepMAG: deep reinforcement learning with multi-agent graphs for flexible job shop scheduling. Knowl Based Syst. 2023;259(5):110083. doi:10.1016/j.knosys.2022.110083. [Google Scholar] [CrossRef]
30. Han BA, Yang JJ. Research on adaptive job shop scheduling problems based on dueling double DQN. IEEE Access. 2020;8:186474–95. doi:10.1109/access.2020.3029868. [Google Scholar] [CrossRef]
31. Zhou T, Tang D, Zhu H, Zhang Z. Multi-agent reinforcement learning for online scheduling in smart factories. Robot Comput Integr Manuf. 2021;72(2):102202. doi:10.1016/j.rcim.2021.102202. [Google Scholar] [CrossRef]
32. Ma H, Li R, Zhang X, Zhou Z, Chen X. Reliability-aware online scheduling for DNN inference tasks in mobile edge computing. IEEE Internet Things J. 2023;10(13):11453–64. doi:10.1109/jiot.2023.3243266. [Google Scholar] [CrossRef]
33. Zhang Y, Zhu H, Tang D, Zhou T, Gui Y. Dynamic job shop scheduling based on deep reinforcement learning for multi-agent manufacturing systems. Robot Comput Integr Manuf. 2022;78(3):102412. doi:10.1016/j.rcim.2022.102412. [Google Scholar] [CrossRef]
34. Liu R, Piplani R, Toro C. Deep reinforcement learning for dynamic scheduling of a flexible job shop. Int J Product Res. 2022;60(13):4049–69. doi:10.1080/00207543.2022.2058432. [Google Scholar] [CrossRef]
35. Alexopoulos K, Mavrothalassitis P, Bakopoulos E, Nikolakis N, Mourtzis D. Deep reinforcement learning for selection of dispatch rules for scheduling of production systems. Appl Sci. 2024;15(1):232. doi:10.3390/app15010232. [Google Scholar] [CrossRef]
36. Gui Y, Tang D, Zhu H, Zhang Y, Zhang Z. Dynamic scheduling for flexible job shop using a deep reinforcement learning approach. Comput Indust Eng. 2023;180:109255. doi:10.1016/j.cie.2023.109255. [Google Scholar] [CrossRef]
37. Li F, Lang S, Hong B, Reggelin T. A two-stage RNN-based deep reinforcement learning approach for solving the parallel machine scheduling problem with due dates and family setups. J Intell Manufact. 2024;35(3):1107–40. doi:10.1007/s10845-023-02094-4. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools