
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

GLMTopic: A Hybrid Chinese Topic Model Leveraging Large Language Models
1 School of Software Engineering, Xiamen University of Technology, Xiamen, 361024, China
2 Peter Faber Business School, Australian Catholic University, North Sydney, 2060, Australia
* Corresponding Authors: Weisi Chen. Email: ; Walayat Hussain. Email:
Computers, Materials & Continua 2025, 85(1), 1559-1583. https://doi.org/10.32604/cmc.2025.065916
Received 25 March 2025; Accepted 04 July 2025; Issue published 29 August 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Topic modeling is a fundamental technique of content analysis in natural language processing, widely applied in domains such as social sciences and finance. In the era of digital communication, social scientists increasingly rely on large-scale social media data to explore public discourse, collective behavior, and emerging social concerns. However, traditional models like Latent Dirichlet Allocation (LDA) and neural topic models like BERTopic struggle to capture deep semantic structures in short-text datasets, especially in complex non-English languages like Chinese. This paper presents Generative Language Model Topic (GLMTopic) a novel hybrid topic modeling framework leveraging the capabilities of large language models, designed to support social science research by uncovering coherent and interpretable themes from Chinese social media platforms. GLMTopic integrates Adaptive Community-enhanced Graph Embedding for advanced semantic representation, Uniform Manifold Approximation and Projection-based (UMAP-based) dimensionality reduction, Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) clustering, and large language model-powered (LLM-powered) representation tuning to generate more contextually relevant and interpretable topics. By reducing dependence on extensive text preprocessing and human expert intervention in post-analysis topic label annotation, GLMTopic facilitates a fully automated and user-friendly topic extraction process. Experimental evaluations on a social media dataset sourced from Weibo demonstrate that GLMTopic outperforms Latent Dirichlet Allocation (LDA) and BERTopic in coherence score and usability with automated interpretation, providing a more scalable and semantically accurate solution for Chinese topic modeling. Future research will explore optimizing computational efficiency, integrating knowledge graphs and sentiment analysis for more complicated workflows, and extending the framework for real-time and multilingual topic modeling.Keywords
Topic modeling (TM) is an unsupervised machine learning method for extracting clustered topics or themes from a corpus of documents, such as books, websites, blogs, social media posts, emails, news, or research articles etc. TM has long been useful in natural language processing (NLP) [1].
In line with the advancement of artificial intelligence, NLP techniques, especially in the field of TM, have been maturing from rule-based, statistical methods to machine learning and deep learning ones. Over the last decade, mainstream TM techniques such as Latent Dirichlet Allocation (LDA) [2], Top2Vec [3], and BERTopic [4] have gained widespread adoption. Specifically, LDA, a traditional statistical model based on word frequency and co-occurrence relationships, has been the most predominant model for a long time and continues to influence various domains. As deep learning has evolved in recent years, neural network-based models like BERTopic have gained popularity for their ability to explore potential topics more deeply, thanks to advanced deep learning frameworks.
The motivation behind this study stems from the limitations of traditional topic modeling techniques when applied to Chinese short-text datasets. Despite the significant progress of TM techniques, existing models still struggle to capture complex linguistic patterns and subtle differences in tone within the text, especially in complex languages like Chinese, resulting in the extracted topics falling short of coherence and consistency. With the recent rise of large language models (LLMs), there is an opportunity to enhance topic modeling by leveraging their contextual understanding and reasoning abilities. This paper aims to develop a model that integrates LLMs with appropriate techniques to improve topic coherence. Additionally, the study seeks to address the challenge of automating topic interpretation, reducing the reliance on human experts for labeling and refining results. The objective is to create a scalable, efficient, and semantically rich topic modeling solution that is particularly effective for Chinese short-text data, making it more accessible for researchers, businesses, and policymakers.
1.2 Research Questions and Contributions
This paper attempts to address the following research questions (RQs):
RQ 1: Can we leverage the capabilities of LLMs to improve Chinese topic modeling performance for social science research on large-scale social media data?
This research question explores the feasibility of developing a novel hybrid topic modeling approach that integrates LLMs to enhance topic coherence and semantic understanding, particularly in Chinese short-text datasets. Current models, such as LDA and BERTopic, face challenges in capturing complex linguistic patterns and maintaining semantic consistency, especially in non-English languages like Chinese. This paper aims to address these limitations and develop a more effective topic modeling framework to facilitate social science researchers in identifying and understanding key themes discussed across various Chinese social media platforms.
RQ 2: How can we interpret the topic modeling results without the intervention of human experts to enhance applicability?
This research question focuses on improving the interpretability of topic modeling results by minimizing the reliance on human domain experts for post-processing and validation. Many traditional topic modeling methods require significant manual effort to refine, label, and make sense of extracted topics. By integrating LLMs with an advanced topic modeling framework, the study seeks to automate the interpretation process, ensuring that the generated topics are more coherent, directly meaningful, and accessible to users across different domains without requiring specialized expertise.
To address these RQs, this paper proposes a novel LLM-empowered hybrid model named GLMTopic. This model takes advantage of the capabilities of the most cutting-edge technologies to capture deep semantic and contextual information and enhance the coherence of topic discovery, especially in the domain of short Chinese texts. GLMTopic employs Adaptive Community-enhanced Graph Embedding (ACGE), which incorporates Matryoshka Representation Learning (MRL) to generate nested, multi-granular semantic embeddings. MRL produces a hierarchically structured representation where each sub-vector captures semantic information at different levels of granularity, allowing for flexible adaptation to various computational resources and downstream tasks. This enables GLMTopic to maintain both semantic richness and representational efficiency. Moreover, ACGE’s integration of graph-based community enhancement facilitates the construction of high-level semantic relations across short texts, which is especially beneficial in modeling the fragmented and context-rich discourse found on social media platforms. This approach supports the identification of socially relevant themes and underlying group concerns, providing valuable insights for social science researchers studying public discourse and collective behavior.
The rest of the paper is structured as follows: Section 2 discusses recent progress on topic modeling techniques. Section 3 details the proposed hybrid TM model leveraging an LLM named GLMTopic, describing its design principles and how it overcomes the limitations of traditional TM techniques. Section 4 presents an experiment evaluating the proposed model against conventional methods, including LDA and BERTopic. Section 5 summarizes the paper and discusses future research directions.
From the late 1980s to the early 1990s, TM technology was initially dominated by the bag-of-words model (BoW) and the word frequency-inverse document frequency (TF-IDF) based on word frequency statistics. Later, LDA, a probabilistic generative model, was introduced in 2003 [2], using a Dirichlet prior distribution for document-topic and topic-word distributions, significantly improving the topic extraction capability. It has been widely employed since its inception in various domains such as literature review for research [5], news analysis [6], social science [7], etc. However, traditional methods like LDA often require extensive corpus preprocessing, careful parameter tuning, thorough model evaluation, and domain expertise to interpret the generated topics effectively. Neural modeling has evolved rapidly since 2016 with the evolving capabilities of artificial neural networks and deep learning. These advanced methods further improve topic generation’s accuracy and semantic capture ability. The representative neural topic models include DeepLDA, Top2Vec, and BERTopic. Specifically, DeepLDA is a hybrid model that combines LDA with basic multilayer perceptron (MLP) neural networks [8]. At the same time, the more cutting-edge BERTopic utilizes advanced techniques such as bi-directional encoder representation from transformers (BERT) and class-based TF-IDF (c-TF-IDF). More details about these models can also be found in a recent study [9].
BERTopic has gained prominence in recent years because it produces reliable results with minimal data preprocessing on various datasets. Recent literature has reported its superiority to some other models. As shown in Table 1, the application of BERTopic has grown rapidly, especially after 2022. This demonstrates its effectiveness across various domains and datasets, promoting academic research and practical applications.
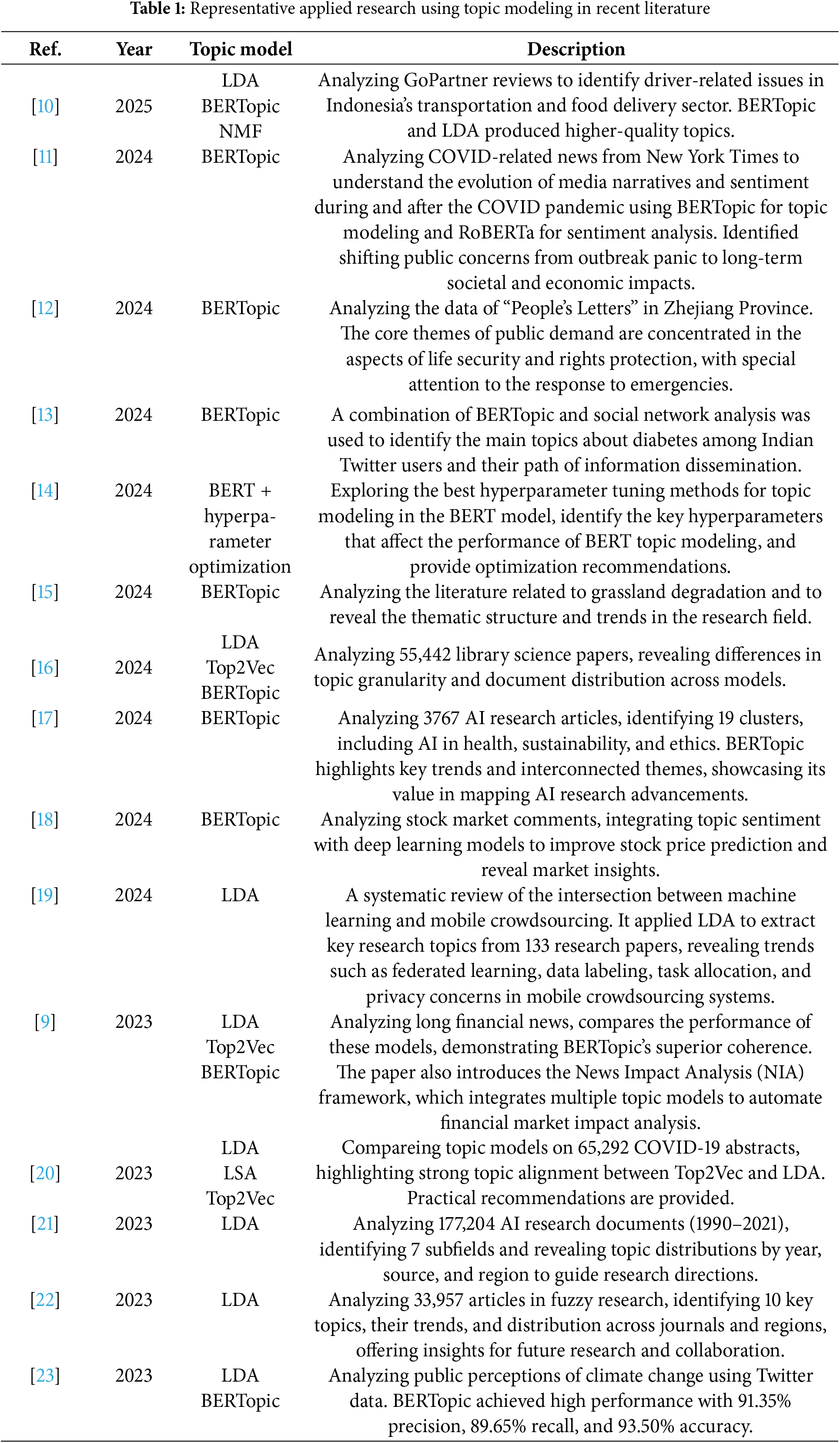
Although the traditional TM technique LDA is still frequently used, LDA but its core mechanism relies on the bag-of-words model (BoW), which is only based on word frequency information to derive topic distribution, its cumbersome preprocessing processes, such as word splitting and deactivation as well as based on the cleanup of a specific domain-specialized text tend to add to the burden of researchers. The emergence of BERTopic has brought new vitality to the field of topic modeling, with its capability to capture longer temporal dependencies within the text. However, BERTopic still has limitations when dealing with extremely complex contexts or highly domain-specific corpora. Also, most existing models rely on human experts to annotate the topic labels based on the keywords of each topic, which is a non-trivial task.
The trending LLM technologies like GPT [24] and GLM [25], with their superior contextual understanding and deep semantic understanding of text, have been introduced to break through the limitations of traditional NLP techniques, with their comprehensive NLP capabilities gained from massive training using a large amount of textual data. LLM [26,27] has been extensively applied on various fronts, which has inspired us to explore the possibility of leveraging it in topic modeling, aiming to resolve the remaining problems among existing TM techniques. The introduction of LLMs can potentially break through traditional TM technology’s limitations and reduce the dependence on complex text preprocessing and domain knowledge, thus significantly improving topic coherence and reducing the user’s operational burden. In addition to LLMs, Visual Language Models (VLMs) have also shown their great potential in multimodal data processing. Studies have shown that VLMs perform significantly better in cross-modal tasks, such as multimodal news analysis, where the combination of images and text provides richer contextual information for understanding news content [28,29].
3 GLMTopic: An LLM-Based Topic Model
While LDA and BERTopic are currently among the most dominant TM models, they do not systematically specify a standard process for topic modeling and serve more as tools than systematic processes. Therefore, we propose a hybrid model, GLMTopic, which aims to leverage the powerful capabilities of LLMs for topic modeling. This section will introduce the structure and constituents of GLMTopic.
This study proposes a hybrid model with a large language model at its core, named GLMTopic. Compared with traditional topic modeling methods, GLMTopic integrates the advantages of statistical methods and open-source large language models and achieves deep integration and optimization of functional modules in various aspects, such as text semantic embedding, dimensionality reduction, clustering, keyword extraction, and semantic consistency optimization.
Specifically, as shown in Fig. 1, the original documents are processed using a word embedding model named Adaptive Community-enhanced Graph Embedding (ACGE) and turned into vectors, denoted as V1,1, V1,2,..., V1,n,..., where Vi,j represents the word vector of the j-th word in the i-th document. These word vectors are then downscaled using UMAP to reduce dimensionality and obtain the lower-dimensional representations, denoted as V1, V2,..., Vn, which are subsequently clustered using HDBSCAN to identify potential thematic structures. Next, CountVectorizer and c-TF-IDF are used to generate a word frequency matrix for the text in each cluster, to determine the most important keywords for each topic. The topic keywords generated by c-TF-IDF, as well as the original documents, are fed into an LLM named GLM to find the most appropriate topic representations, further improving the semantic consistency. Finally, the topic representations are turned into the visualization of the results. More details about each component of this hybrid model will be presented in the following section.
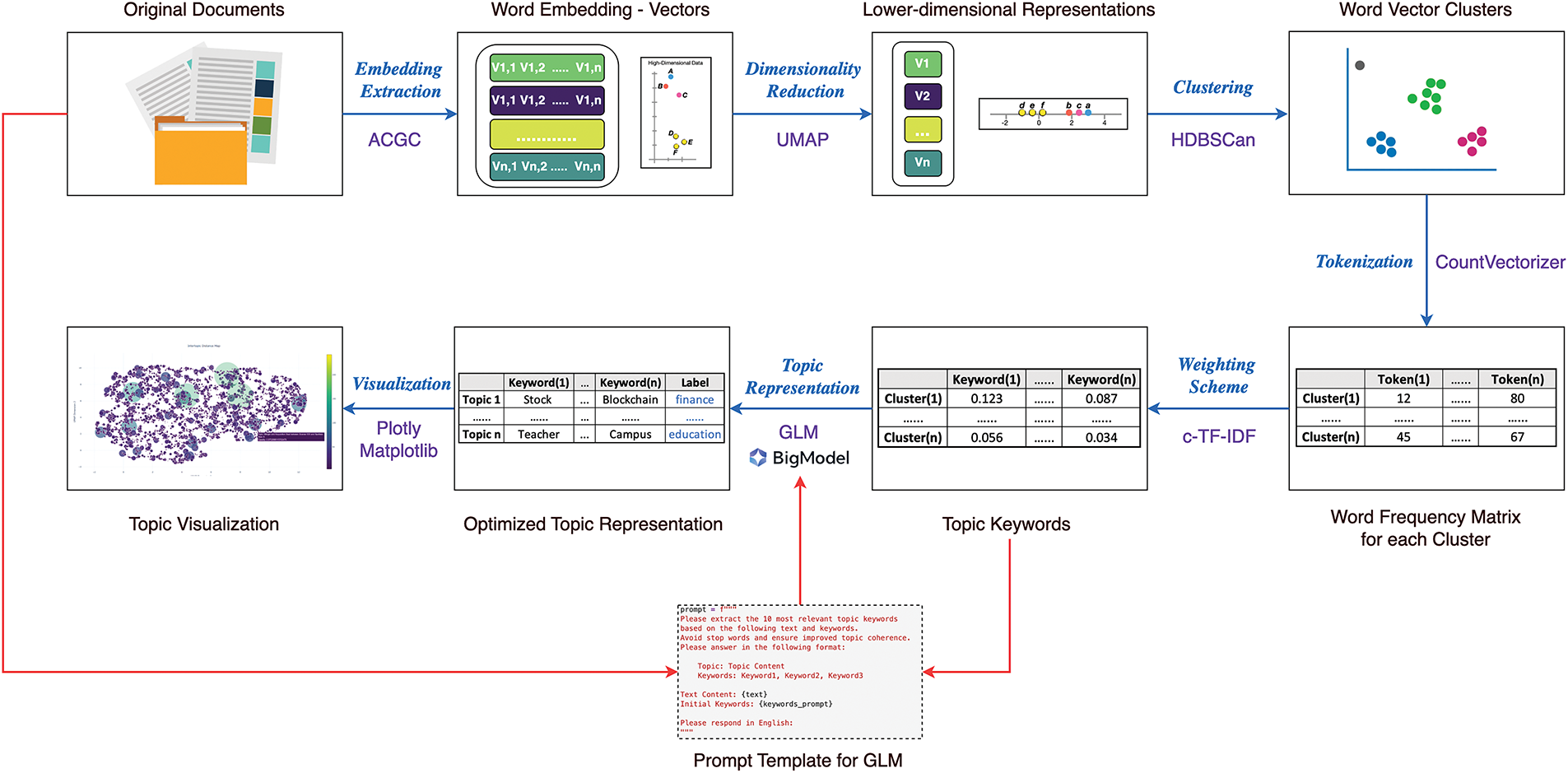
Figure 1: Structure of the GLMTopic hybrid model
The GLMTopic hybrid model adopts ACGE (Adaptive Community-enhanced Graph Embedding: https://huggingface.co/aspire/acge_text_embedding (accessed on 03 July 2025).), which combines community enhancement and graph neural network techniques to improve the accuracy of semantic modeling significantly. Compared with a mainstream Sentence-BERT (SBERT) model [30], the ACGE model can better capture the deep implicit semantic associations in the text by introducing community structure features, which are especially suitable for processing the results of polysemous and complex syntax in noontime text. While the embedding of SBERT relies on the semantic embedding of dominant features between sentences, ACGE can extract more comprehensive semantic relations through the community detection technique and the graph neural network. As a result, ACGE shows stronger adaptability and modeling ability in processing long texts (e.g., news reports and research papers) and short texts (e.g., Tweets and Weibo posts).
It is worth noting that ACGE provides GLMTopic with the advantage of requiring minimal preprocessing. Traditional topic modeling requires cumbersome text preprocessing, such as deletion of stop words, word splitting, noise processing, etc. In contrast, ACGE combines graph embeddings and community-adding effects to directly process preprocessed text data, especially for complex expressions in Chinese contexts. For complex expressions in Chinese contexts, ACGE automatically extracts key semantics through community structure, reducing the need for a preprocessing process and improving the GLMTopic model’s ability to retain the original text’s semantic information.
3.2.2 Dimensionality Reduction and Clustering
In the dimensionality reduction stage, the GLMTopic model employs Uniform Manifold Approximation and Projection (UMAP) [31] to reduce the dimensionality of the high-dimensional vector embeddings. UMAP ensures the integrity of the semantic information while reducing the computational complexity. UMAP can better preserve the local and global structural features in the high-dimensional space, providing better quality basic data for the later clustering task. After dimensionality reduction, the GLMTopic model adopts the Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) clustering algorithm [32]. Considering that the number of topics embedded in a large amount of textual data is still unknown, the HDBSCAN can be adapted by the HDBSCAN can automatically determine the optimal number of clusters according to the semantic similarity and group similar texts into one class in an adaptive way, thus avoiding the problem of setting the number of clusters in traditional algorithms such as K-means. Therefore, it is especially suitable for dealing with unknown and uneven subject distribution of text data. In addition, the robustness of HDBSCAN to noise significantly improves the accuracy of clustering results.
3.2.3 Word Splitting and Weight Optimization
GLMTopic utilizes CountVectorizer as a word splitter, which splits the text into tokens and counts the frequencies to generate a word frequency matrix. CountVectorizer can split the text into words or n-grams while retaining the original underlying statistical information. On this basis, GLMTopic uses the c-TD-IDF (cluster-based Term Frequency-Inverse Document Frequency) algorithm, which combines the inter-topic information based on CountVectorizer’s word frequency matrix and optimizes the weights of topic keywords. Optimized. Compared with the original TF-IDF, it can be more applicable to the semantic distribution of clustering results and can be better cultivated for topic modeling scenarios. Through the weighted optimization of c-TD-IDF, the GLMTopic model can more accurately extract the theme core vocabulary and significantly enhance the reasonableness of the semantic distribution. The formula is as follows:
where f(t,c) denotes the term frequency of word t in class c, i.e., how many times the word t appears in class c; N is the total number of documents in the corpus; and ne represents the number of documents in class c that contain the term t.
3.2.4 Representation Tuning Using GLM
For semantic consistency optimization, GLMTopic jointly inputs the topic keywords and their weights extracted by c-TD-IDF with the original content into GLM for language verification and optimization, and GLM, using its powerful contextual understanding capability, can perform correlation analysis between the topic keywords and the original content to validate the reasonableness of the topic keywords and correct the possible redundancy and semantic bias. At the same time, GLM dynamically adjusts the list of topic terms by matching the topic keywords with the context to make it closer to the core semantics of the original text, thus reaching the optimized topic coherence and consistency. The GLMTopic model realizes the profound fusion of the statistical method and the big language model, which improves the semantic accuracy and the class interpretability of the topic modeling. This process makes the extracted topics of GLMTopic more closely matched to the core semantics of the original text when processing complex textual fields.
Specifically, in this study we adopt GLM-4-Long1in the GLM family, an open-source LLM developed by Zhipu AI, known for its strong capabilities in contextual understanding of Chinese texts. The LLM is used exclusively in this final representation tuning phase to refine the keywords associated with each topic and ensure better alignment between the topic representation and the underlying document content. For each discovered topic, we extract the top-n keywords using class-based TF-IDF (c-TF-IDF), and then pass these keywords, along with representative documents from the cluster, to the LLM. This step is conducted in a zero-shot setting, without further fine-tuning. GLM-4-Long is deployed locally, and its integration helps address common weaknesses in topic modeling such as redundancy, vague keyword sets, or disconnected terms.
To display the modeling results more intuitively, GLMTopic adopts the Plotly library to visualize the output of the topic modeling results and generates an interactive topic-word relationship graph. The relationship graph shows the semantic associations among the topic words. It helps users explore the topic structure and semantic distribution in depth through interactive operations. The interactive features further enhance the results’ interpretability and analytic value and help discover the hidden connections between topics.
To sum up, the GLMTopic model, through modular design and in-depth optimization, gives full play to the powerful capabilities of large language models in semantic understanding and complex language processing and provides an efficient solution for multi-scenario topic modeling tasks.
The dataset in this experiment has been sourced from Weibo, a mainstream Chinese microblogging platform, with a total of 22,184 posts, totaling 10.8 MB. These posts were collected from multiple categories of Weibo Hot Searches, including international, real-time, inner-city, e-sports, celebrity, fun, emotion, etc. The average number of Chinese characters in each Weibo post is 61.44. Figs. 2 and 3 illustrate Chinese and English samples from the dataset, respectively.

Figure 2: Sample Weibo data used in the experiment
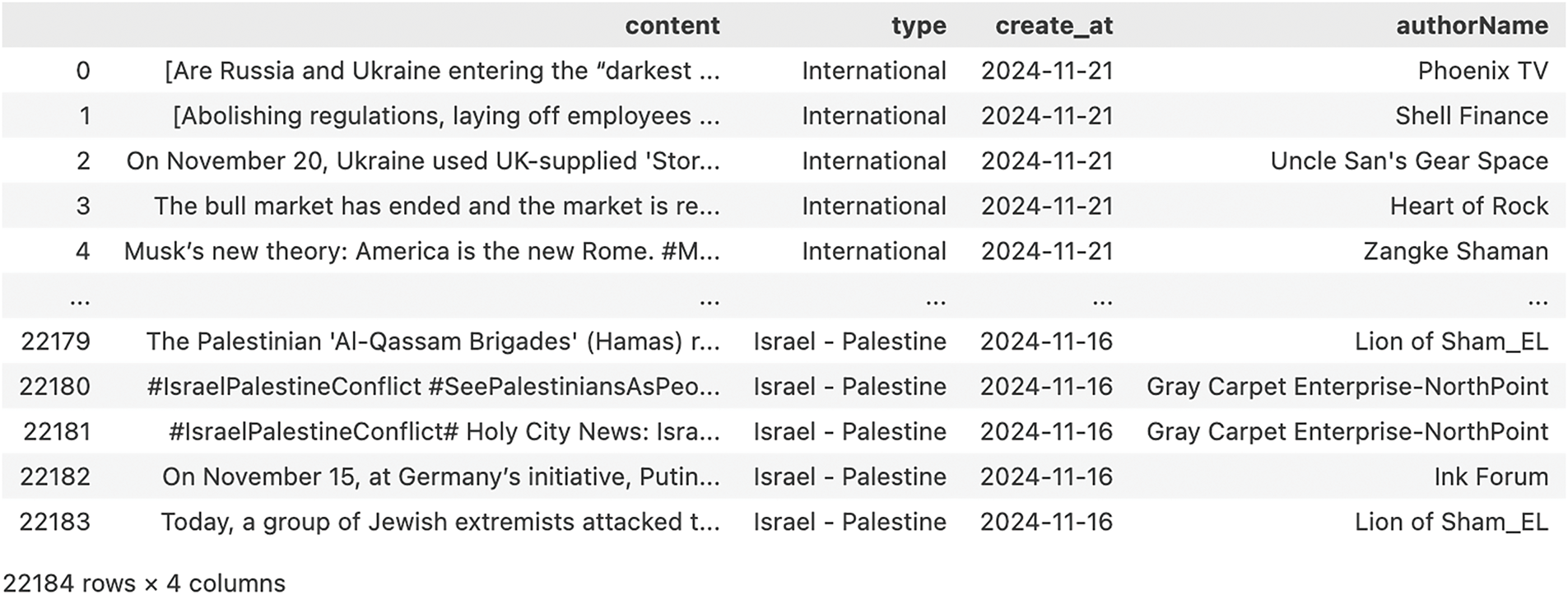
Figure 3: Sample Weibo data used in the experiment (English translation)
4.2 Hardware and Software Settings
Three topic models, LDA, BERTopic, and GLMTopic, were implemented in Python, using libraries including scikit-learn, BERTopic, and the API of Zhipu AI, respectively. Table 2 details the implementation of these topic models, including the required Python libraries and the parameters used in this study.

The hardware settings where the experiments were conducted are as follows.
• Operating System: MacOS Sonoma 14.2;
• CPU: Apple M1 8 GB; RAM: 8 cores.
We trained the LDA model using eight different sets of parameters, with parameter combinations including various numbers of topics (50, 100, 150, 200, 250, 300, 350, 400) and other hyperparameters under default settings. We recorded the coherence score of all the topics generated in each run. These topics and keywords were analyzed in detail, and an attempt was made to interpret the results and provide topic annotations. These annotations helped us understand the potential associations between different themes and industry sectors. Tables 3 and 4 show the top 10 examples of themes generated by the LDA-150 (150 topics) and LDA-300 (300 topics) models, respectively. Tables 5 and 6 present the English versions of Tables 3 and 4, respectively. Some of them have keywords that have little significance for social researchers and have been marked as blank in the tables. Fig. 4 shows the results of the topic visualization generated by the LDA-150 model, reflecting the statistical proximity between the different topics.


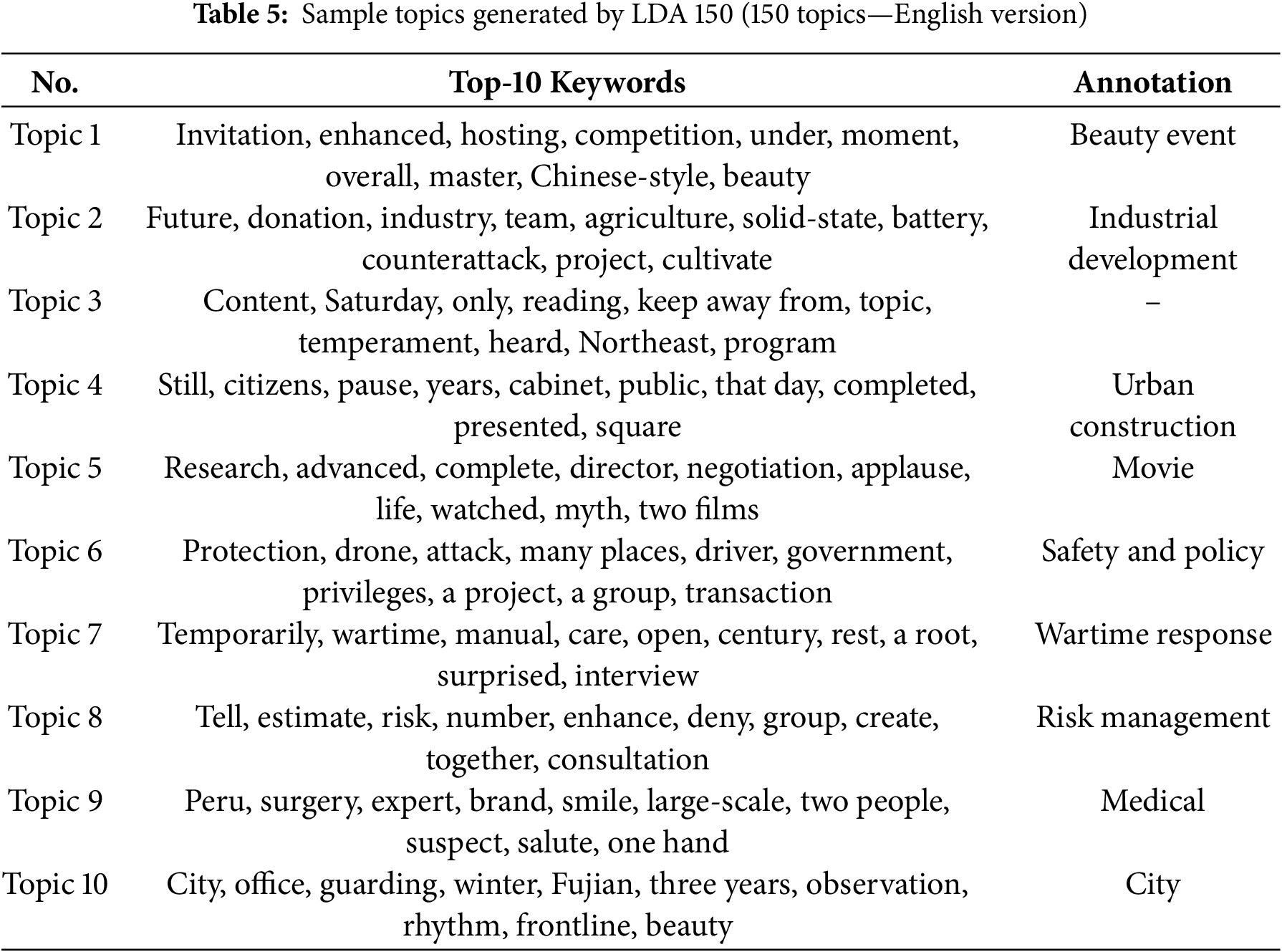

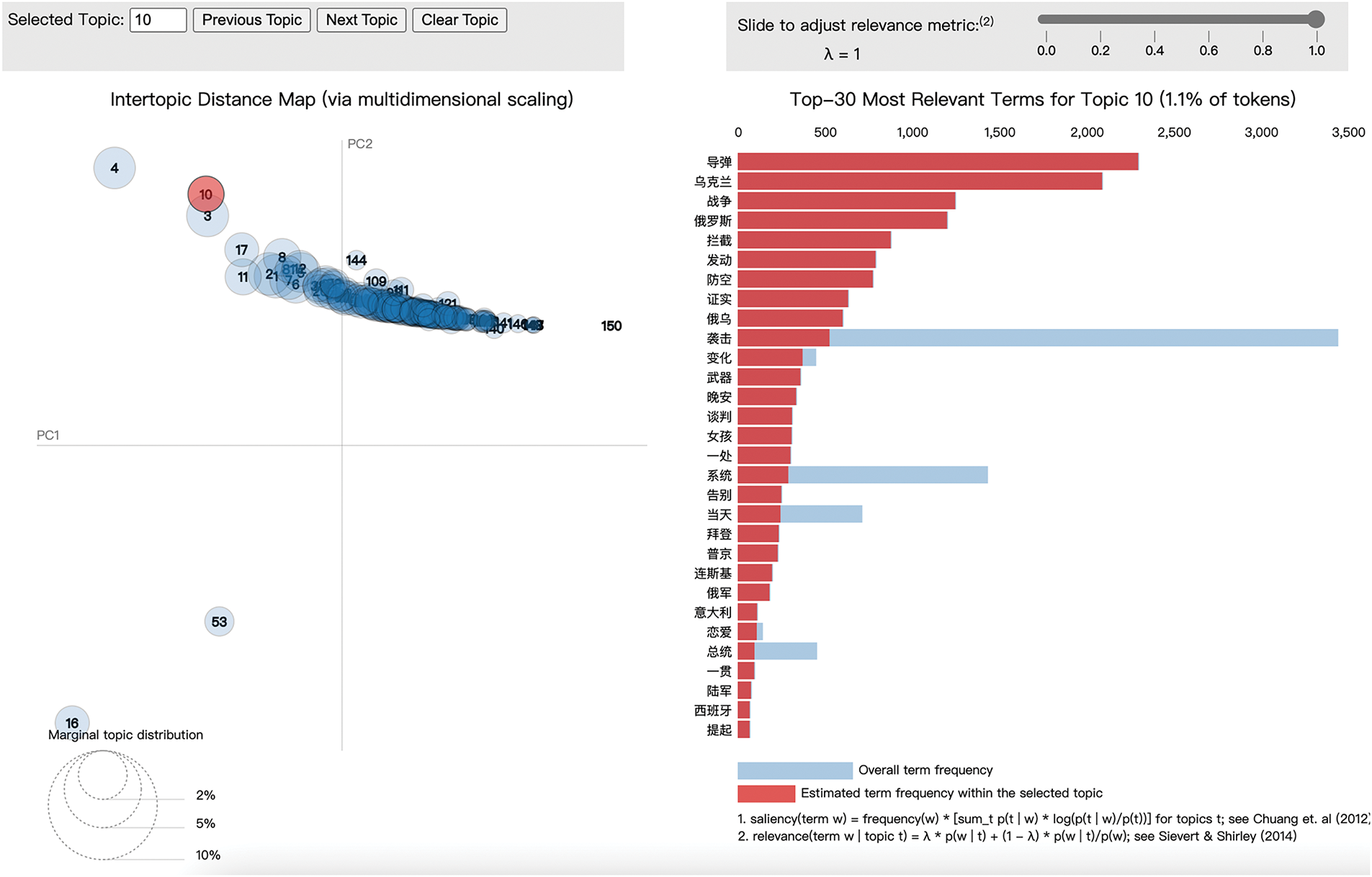
Figure 4: Visual representation of LDA-generated topics (150 topics)
In contrast to LDA, BERTopic requires much less data preprocessing, does not require complex operations (e.g., elimination of stop words) as in LDA, and does not require the number of topics to be specified in advance. We have trained the BERTopic model using the default settings. Like LDA, social researchers have examined, interpreted, and annotated the generated topic samples. Table 7 shows a sample of 10 topics, and Table 8 presents the corresponding English translation. Figs. 5 and 6 illustrate the keyword c-TF-IDF scores for a sample of topics in Chinese and English, respectively. These scores reflect the importance of each topic word in the original texts. BERTopic outperforms LDA in terms of the interpretability of the generated topics. A plot of inter-topic distances is shown in Fig. 7, demonstrating the statistical proximity of the individual topics.

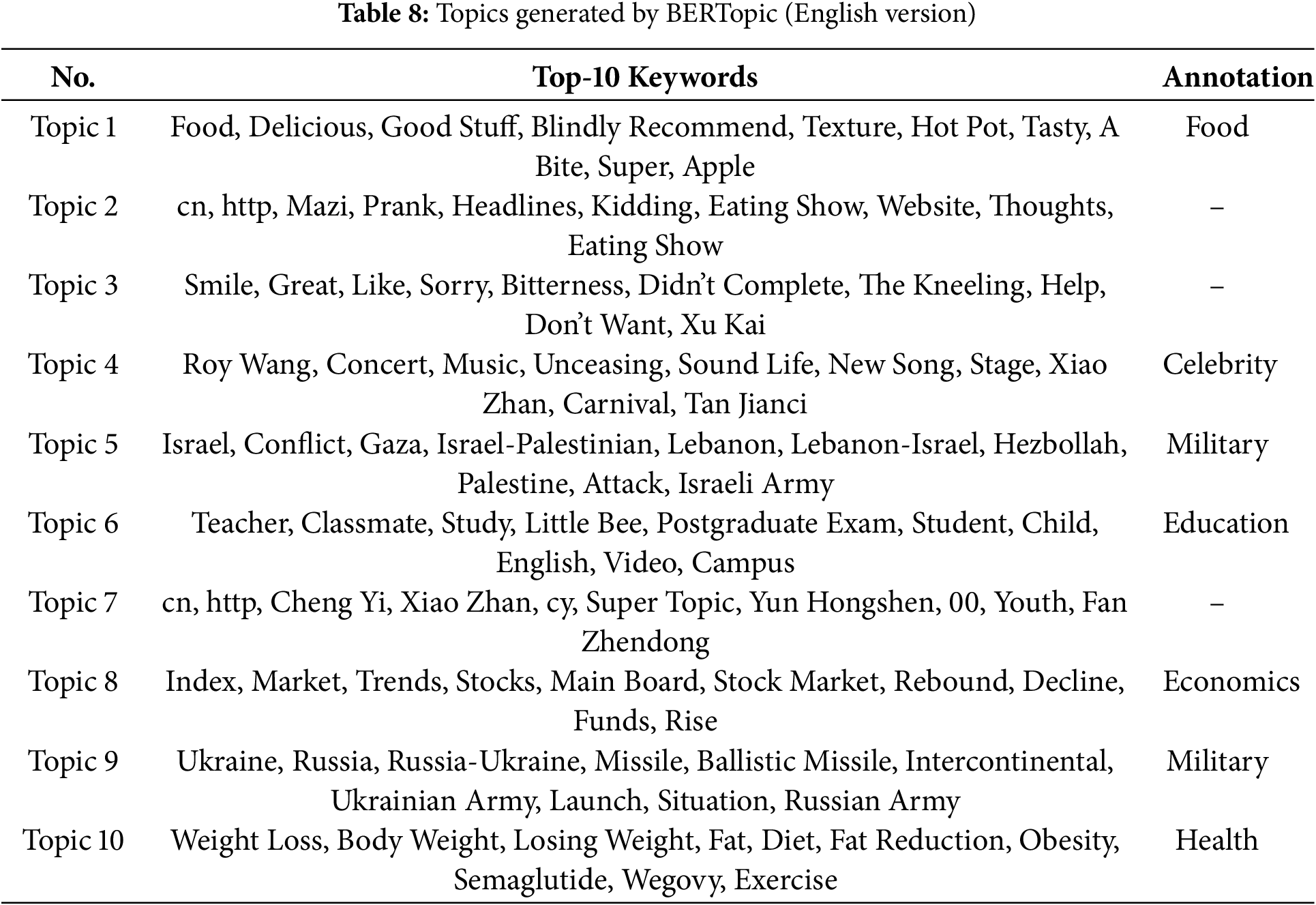
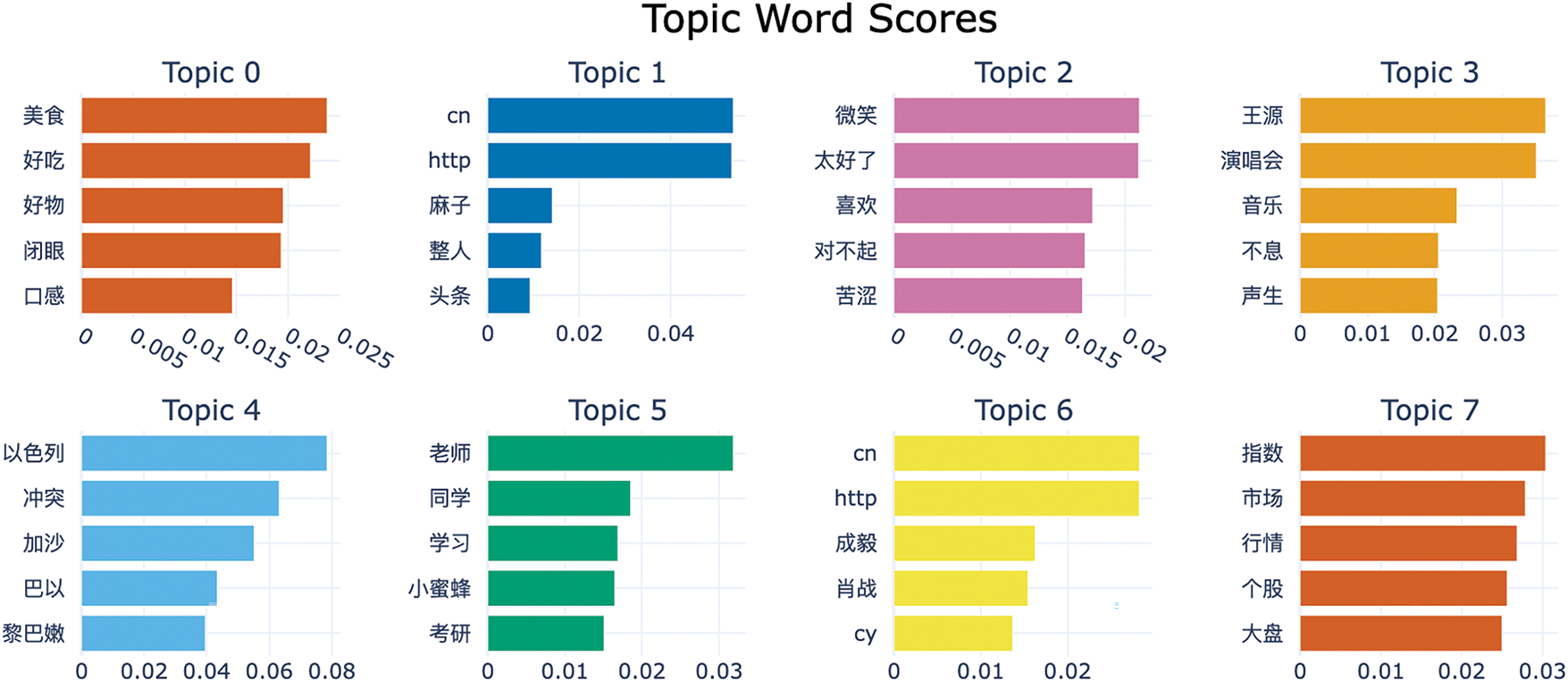
Figure 5: Topic words by the BERTopic model
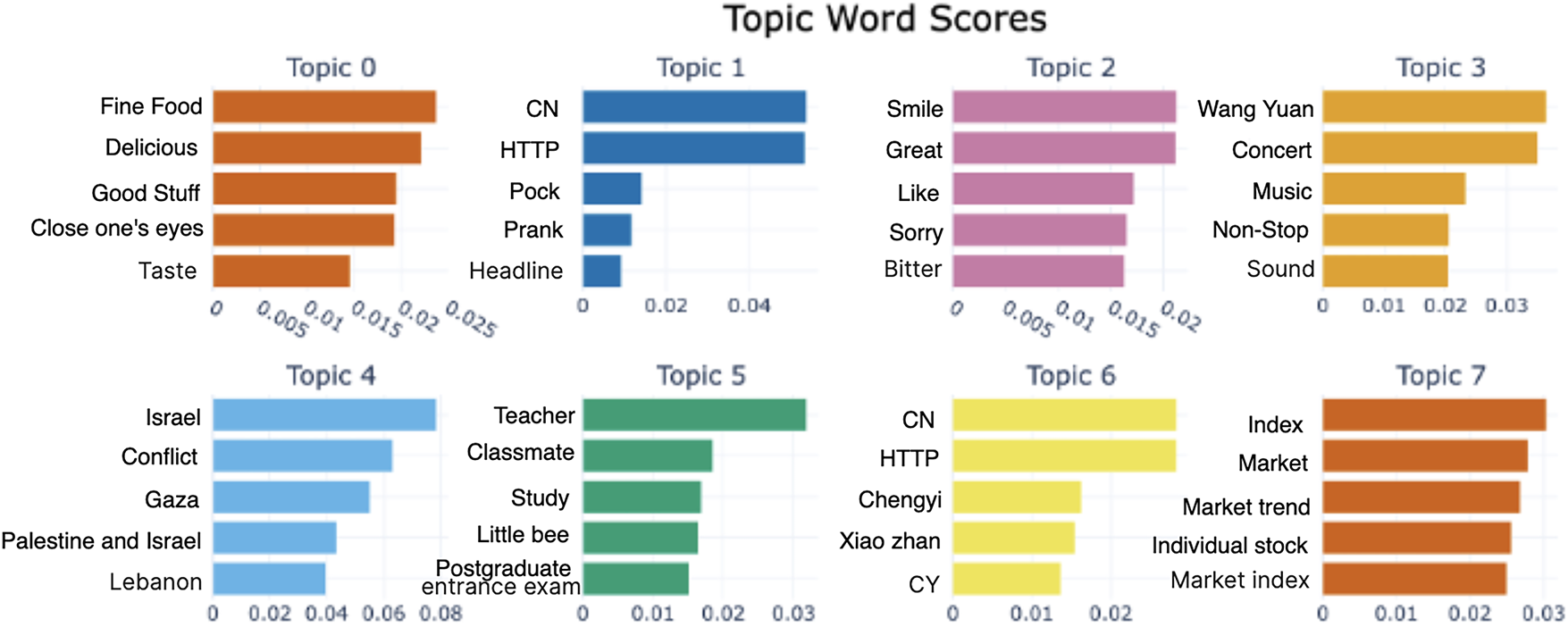
Figure 6: Topic words by the BERTopic model (Enlgish translation)
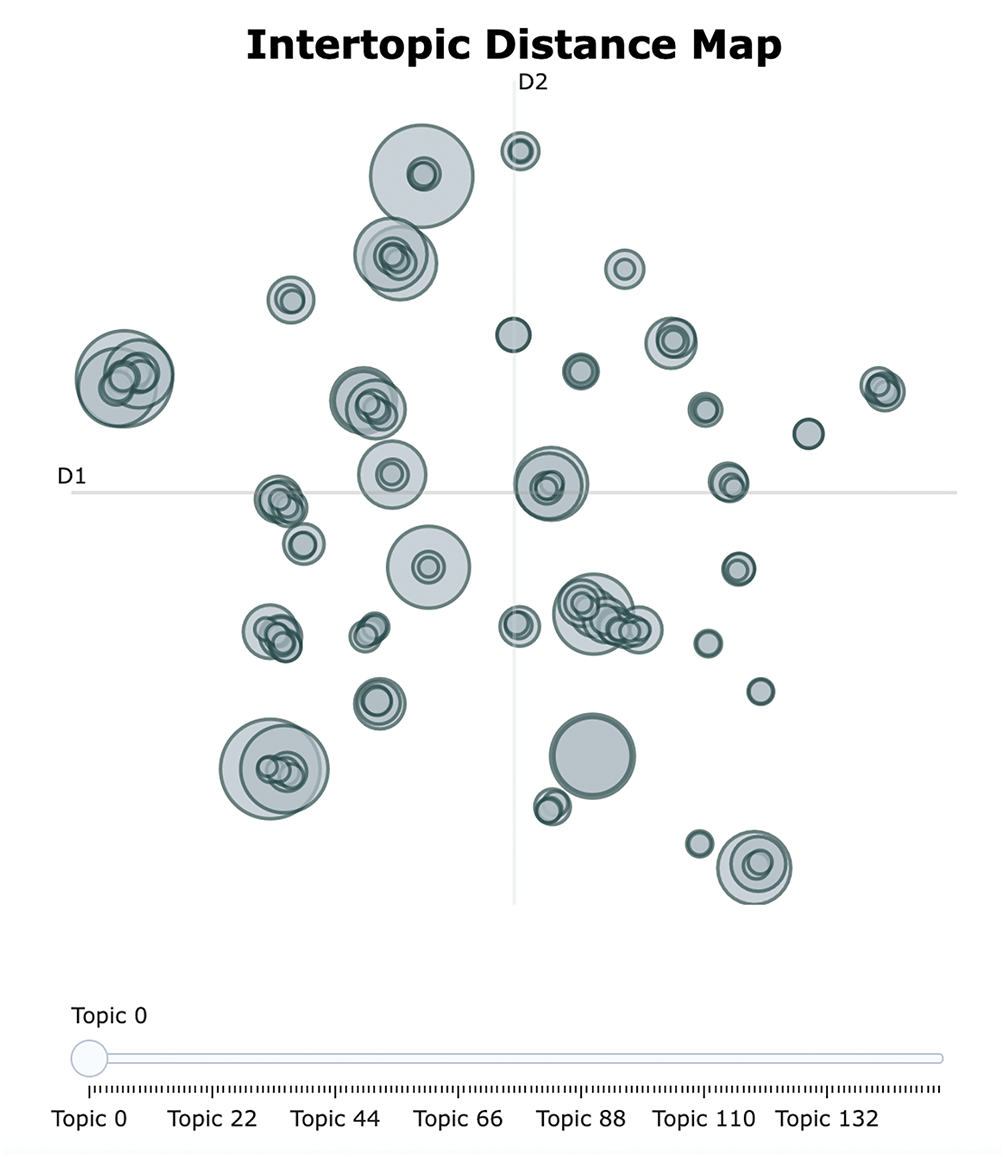
Figure 7: Visual presentation of BERTopic-generated topics
Unlike LDA, BERTopic does not require the number of topics to be generated to be specified in advance. What is unique is that BERTopic provides a hierarchical tree structure graph based on topic similarity, which helps social science researchers more clearly observe topic categories, as shown for the Chinese and English translate in Figs. 8 and 9, respectively.
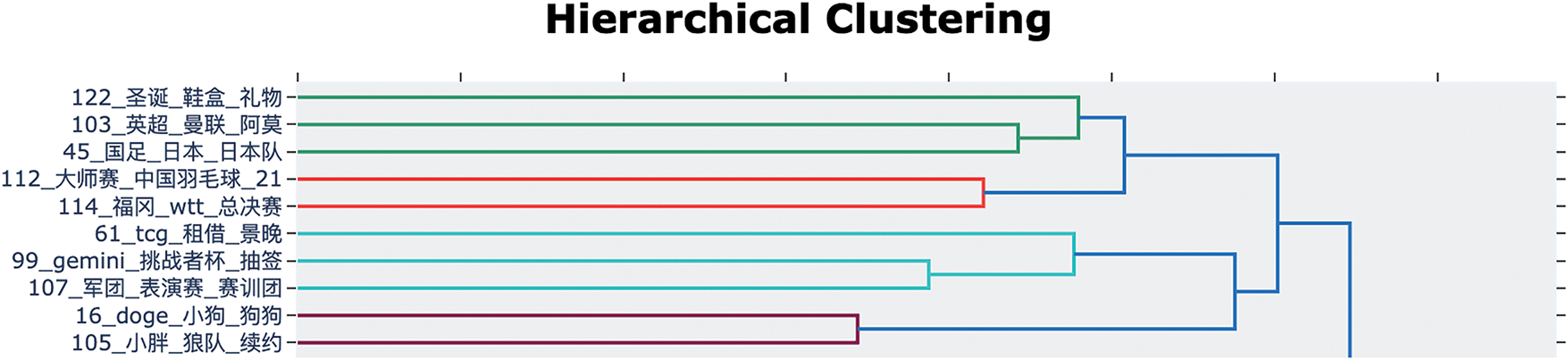
Figure 8: Part of hierarchical topic clustering by the BERTopic
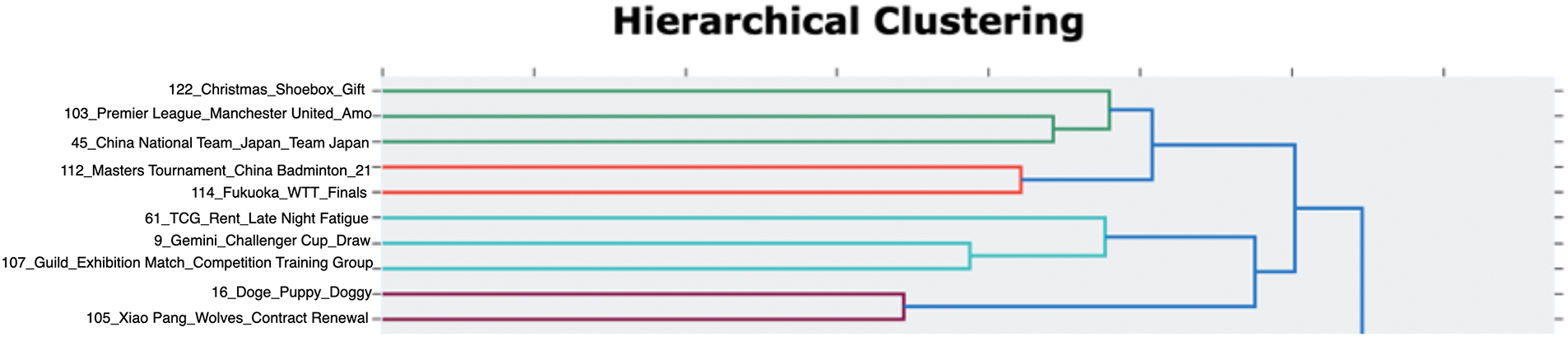
Figure 9: Part of hierarchical topic clustering by the BERTopic (English translation)
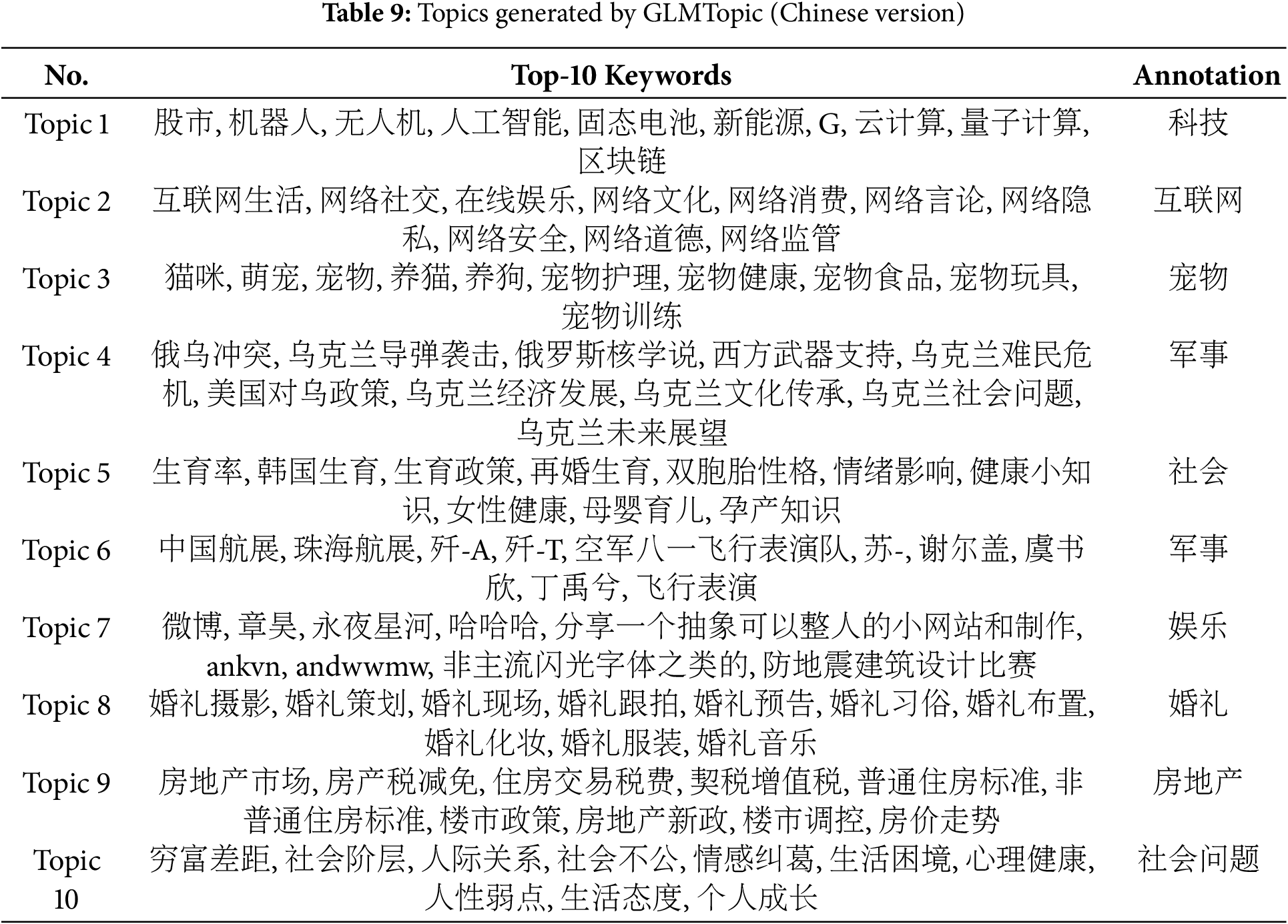
Akin to BERTopic, the GLMTopic model can determine topics automatically without manually specifying the number of topics. Its innovation is that GLMTopic extracts topic words more relevant to the text content based on the semantic association between the weighted word frequency matrix and the original text, adopting the GLM4-Long model (see Table 9 for the Chinese version and Table 10 for the English translation). This approach makes the topics more contextualized, and compared to LDA and BERTopic, GLMTopic has a significant advantage in the interpretability and accuracy of the generated topics.
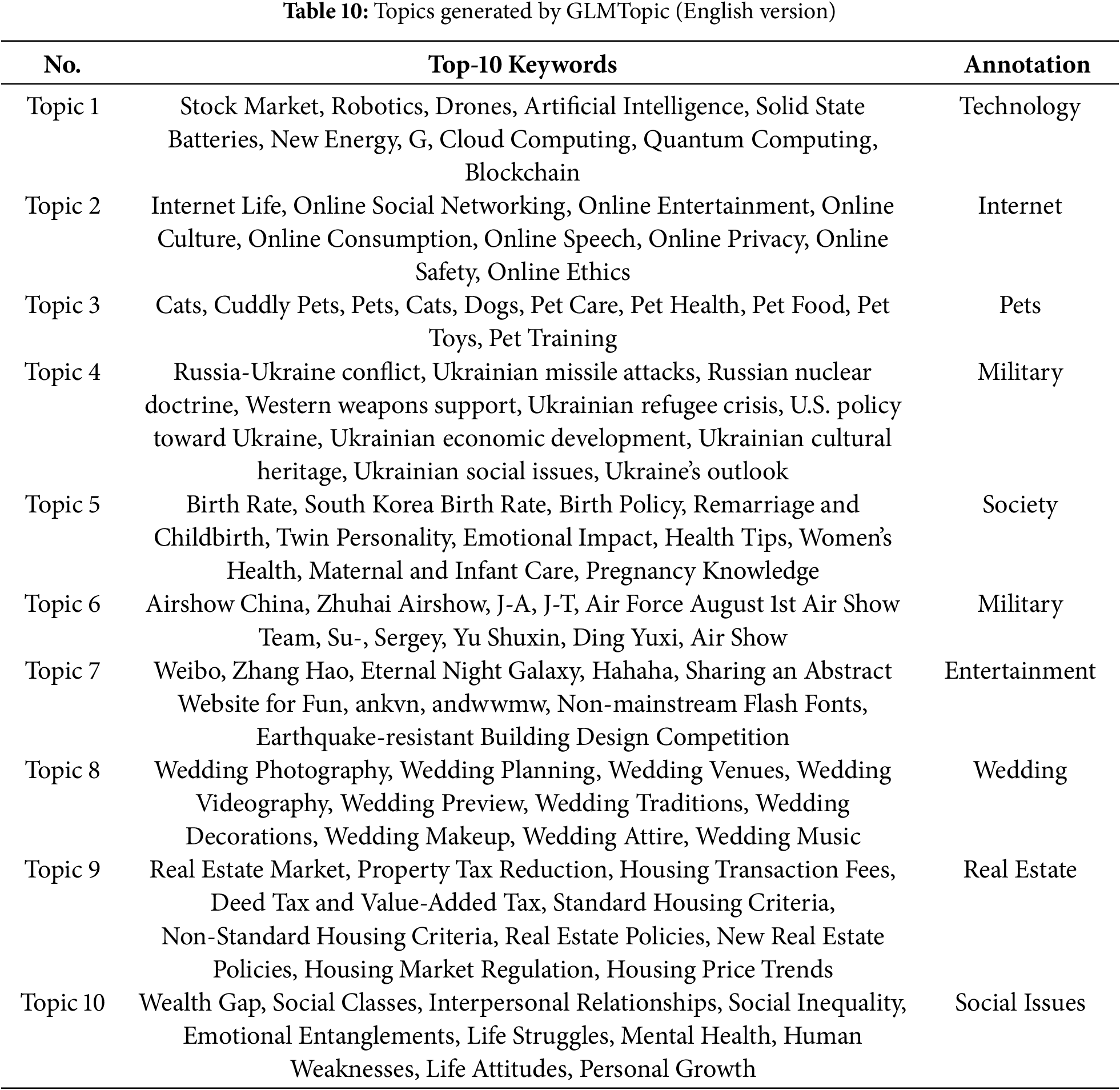
GLMTopic provides distance plots between different topics to show the statistical similarity of topics and supports the output of word frequency matrix scores and topic hierarchical plots, as shown in Figs. 10–12(English translate), which demonstrate the first 40 topics because of the large number of topics in this paper. GLMTopic also generates topic word clouds (see Fig. 13), facilitating social researchers’ understanding of the topics more intuitively.
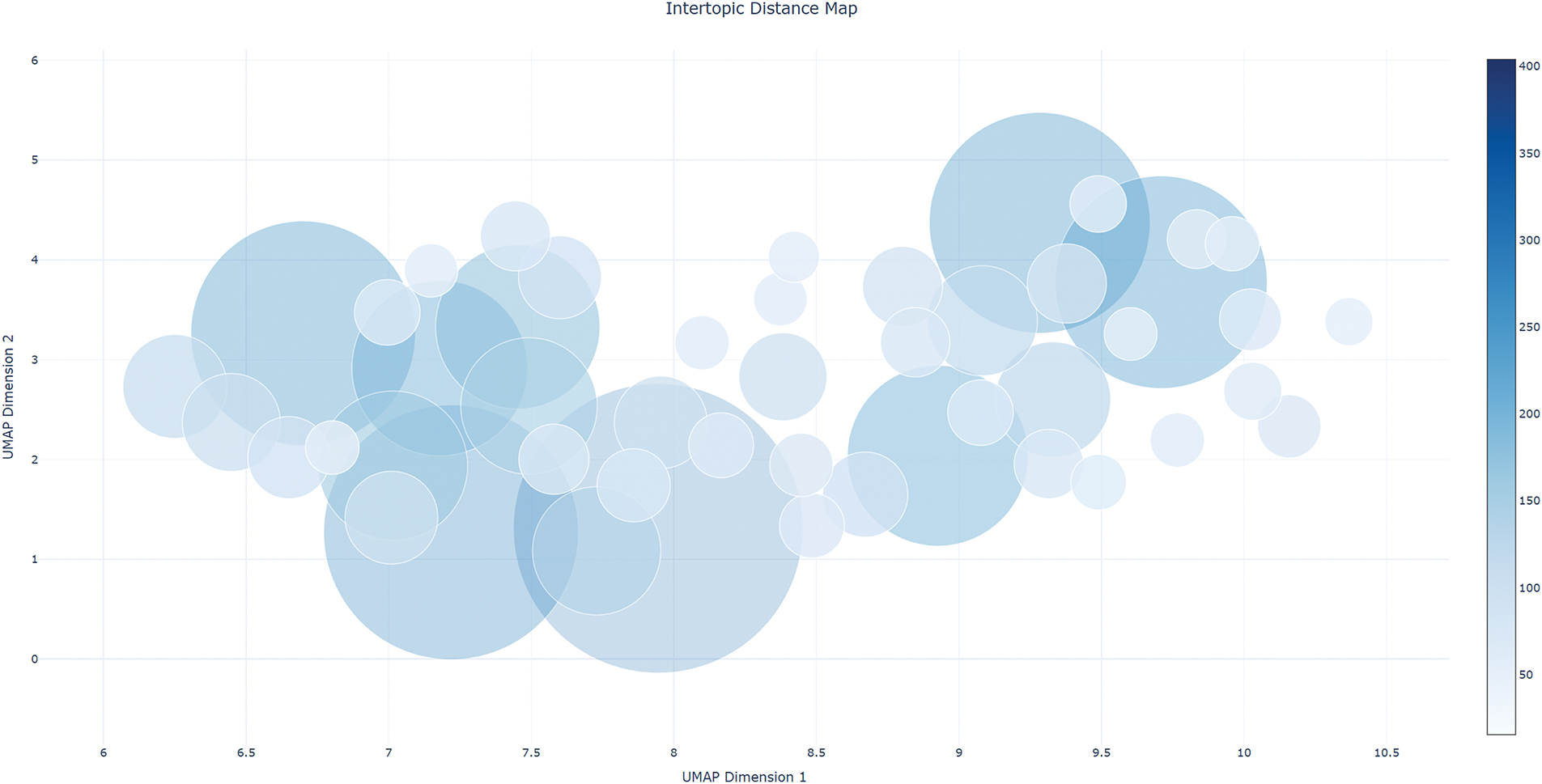
Figure 10: Visual display of topics generated by GLMTopic (top 50 topics)
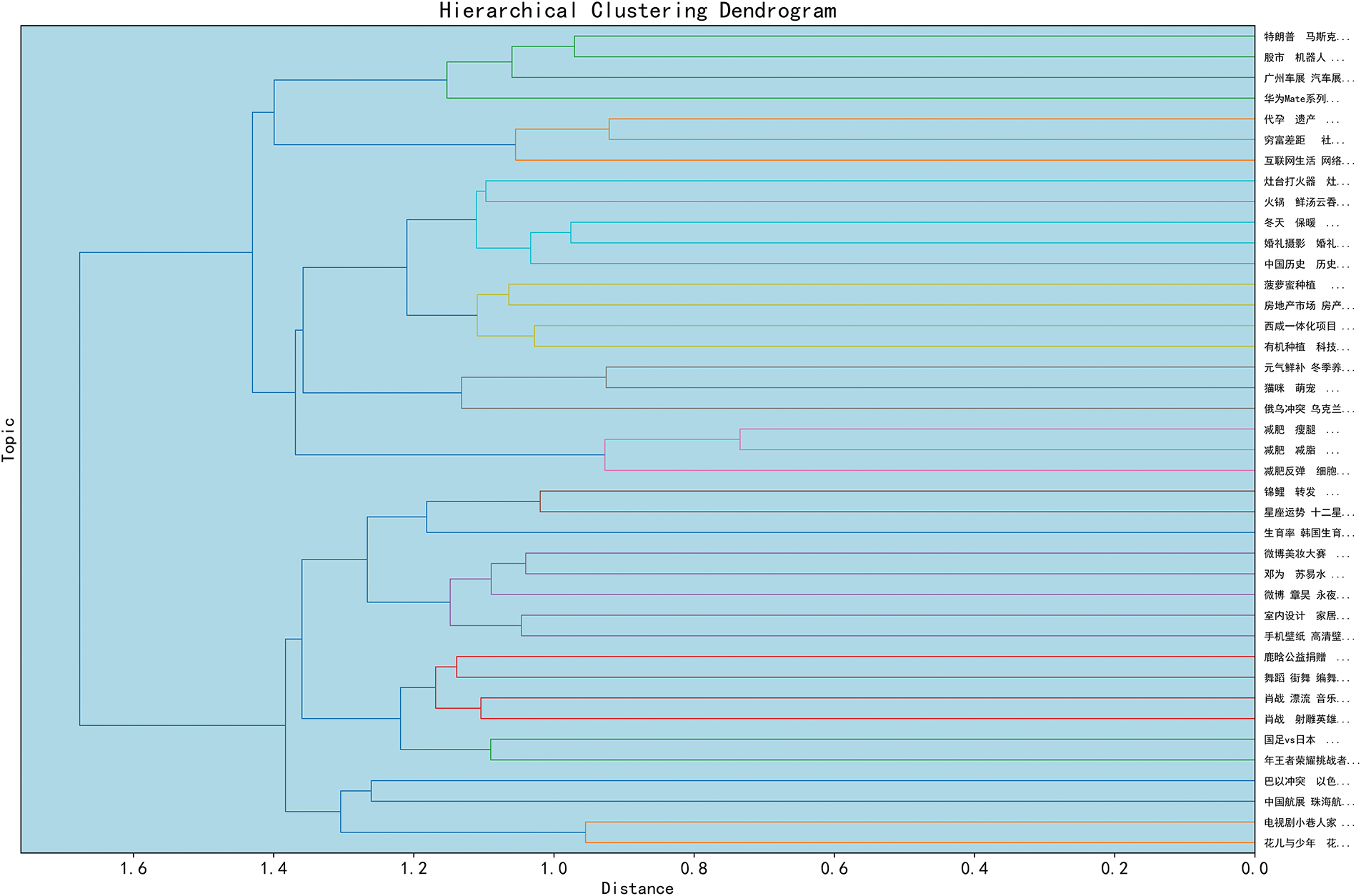
Figure 11: Tree diagram of relationships between topics generated by GLMTopic (top 40 topics)
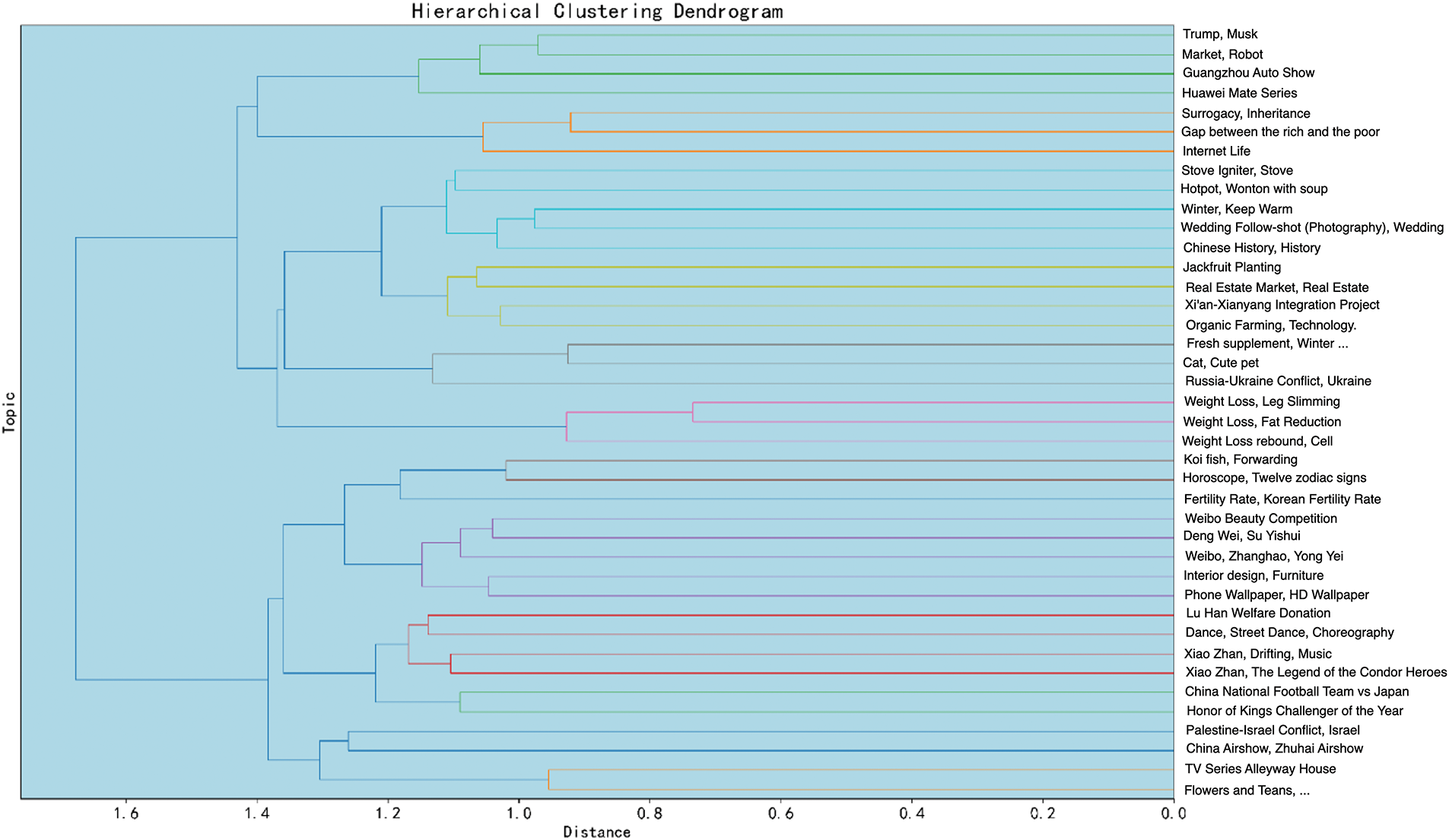
Figure 12: Tree diagram of relationships between topics generated by GLMTopic (top 40 topics, English translate)

Figure 13: GLMTopic generates a word cloud of Topic 1 (technology)
4.4 Evaluation of Topic Models
When evaluating topic models, the topic coherence score is considered one of the most appropriate evaluation metrics when the output of the topic model is intended for use by human users. The topic coherence score reflects the quality of a topic by measuring the consistency between keywords in the topic. It is a widely used and essential evaluation method in topic modeling. Among the calculation methods of topic coherence scores, c_v is the most used metric, which constructs content vectors based on the co-occurrence relationships of keywords and calculates the score by combining cosine similarity and normalized point mutual information (NPMI) to measure the internal consistency of the keywords in a topic. Although topic coherence scores are critical evaluation criteria, they are not perfect. In this study, to comprehensively evaluate the effectiveness and efficiency of topic modeling, we combined the following three methods:
(1) Coherence (c_v score): to quantitatively evaluate the quality of topics generated by the model. In this experiment, topic coherence scores were computed using the Gensim Python library.
(2) Interpretability: to involve human experts to verify the actual interpretability and reliability of the generated topics. We recruited three independent social science researchers and performed an inter-expert reliability analysis to confirm the results.
(3) Level of human involvement: to involve human experts to assess the level of human involvement in the manual label annotation of generated topics.
Fig. 14 compares the c_v scores of the topics generated by each model. The experimental results show that GLMTopic, which incorporates the GLM4-Long model, is superior to other models in topic coherence scores in the Chinese short text topic modeling scenario. The strong contextual reasoning ability of the GLM4-Long model allows GLMTopic to more accurately capture the semantics of short texts in the Chinese context, thus generating more explanatory and coherent topics. Regarding c_v scores, GLMTopic scores are 0.610, significantly higher than LDA300 (up to 0.598) and BERTopic (0.585), highlighting the higher consistency of topics with LLM tuning.
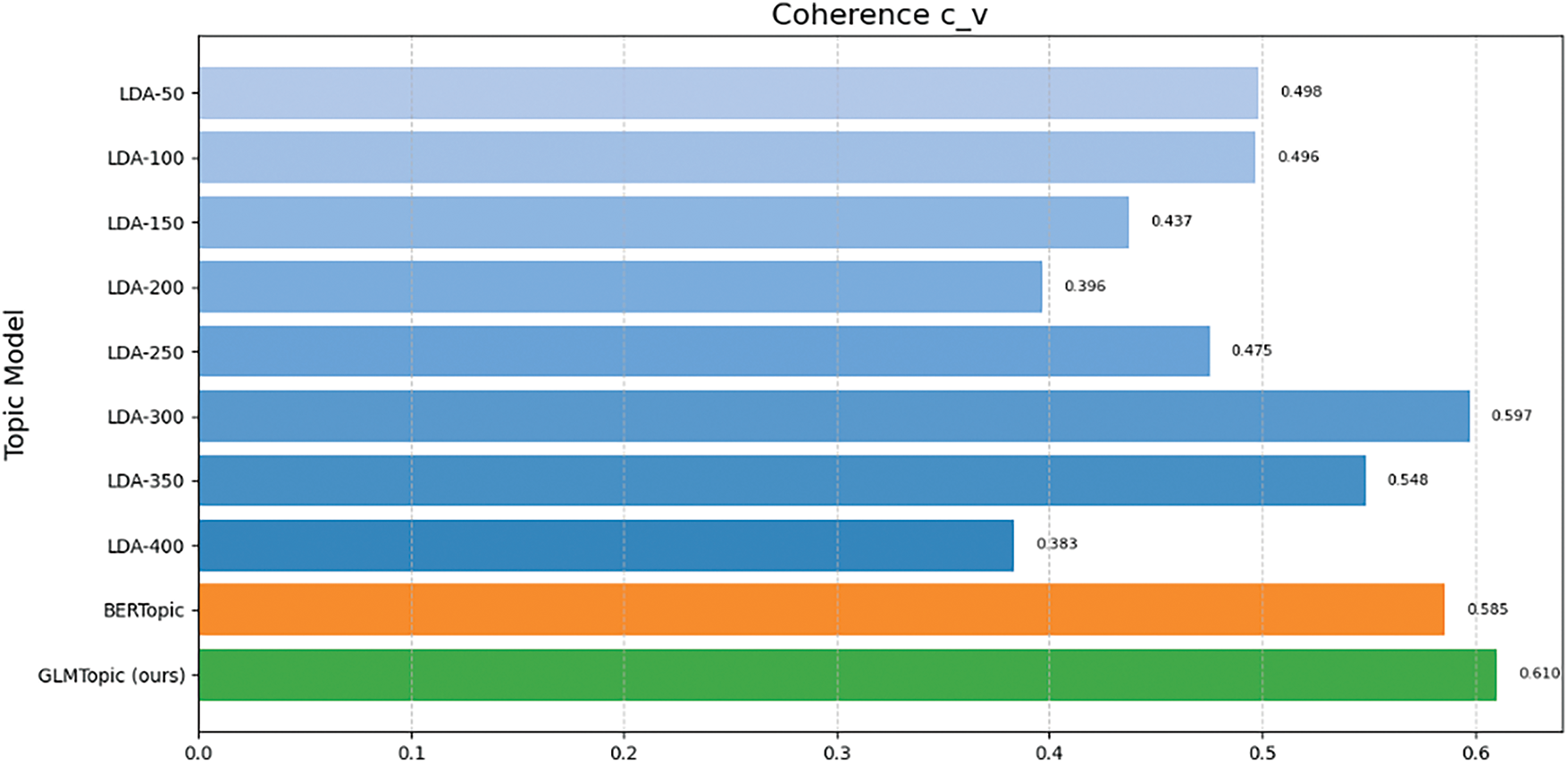
Figure 14: Comparison of various topic models used in the experiment by the c_v coherence score
To verify statistical significance on the c_v coherence score, we adopted the bootstrap method combined with a paired t-test for statistical verification. The method is as follows: We construct a simulated distribution for each model by taking 50 samples from the observed c_v scores of each model and assuming that they fit a normal distribution with a mean of the score and a standard deviation of 0.02. We then tested the mean difference between the GLMTopic model and the baseline model (BERTopic and LDA-300) using a t-test. The results show that:
(1) GLMTopic vs. BERTopic: t = 194.19, p < 0.001;
(2) GLMTopic vs. LDA-300: t = 101.01, p < 0.001.
This indicates that GLMTopic performs better with significance than the baseline model in terms of topic consistency. Fig. 15 shows the distribution of topic Coherence (c_v) scores for GLMTopic, BERTopic, and LDA-300 over 1000 Bootstrap resampling.
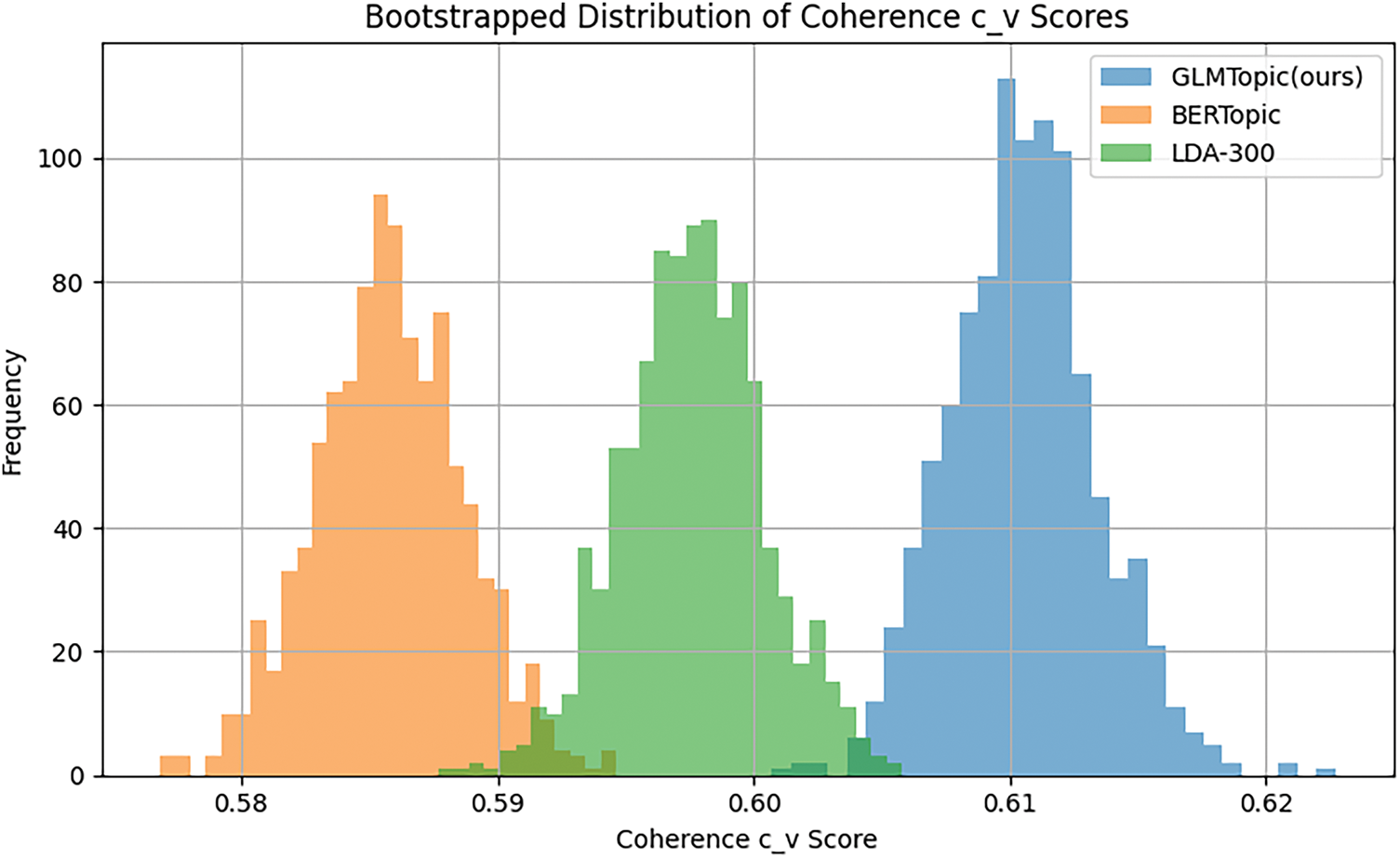
Figure 15: Distribution of coherence scores for topic models over 1000 Bootstrap resamples
4.4.2 Interpretability and Level of Human Involvement
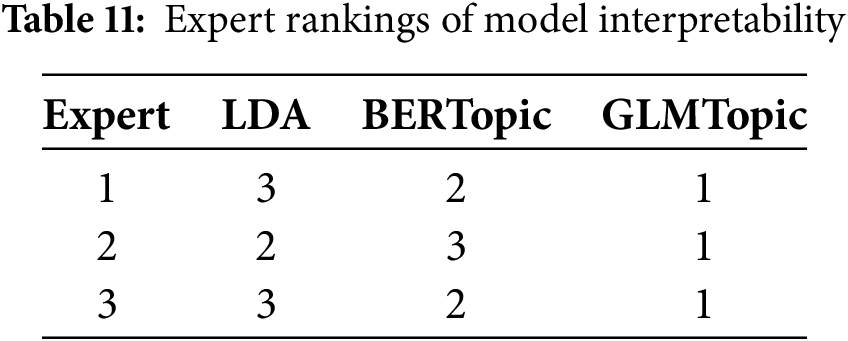
For the evaluation of interpretability, the three social science experts we recruited were involved in the annotation and assessment process. To assess the consistency of the interpretability evaluation, we conducted an inter-rater reliability analysis among the three independent social science experts. The three social science experts comparatively evaluated the interpretability of the GLMTopic, BERTopic, and LDA models by explicitly ranking them from most interpretable (Rank 1) to least interpretable (Rank 3), as shown in Table 11. Experts unanimously agreed that GLMTopic offered superior interpretability. The calculated Fleiss’ Kappa value (κ = 0.33) indicates fair overall agreement, reflecting slight disagreements in interpretability rankings between BERTopic and LDA.
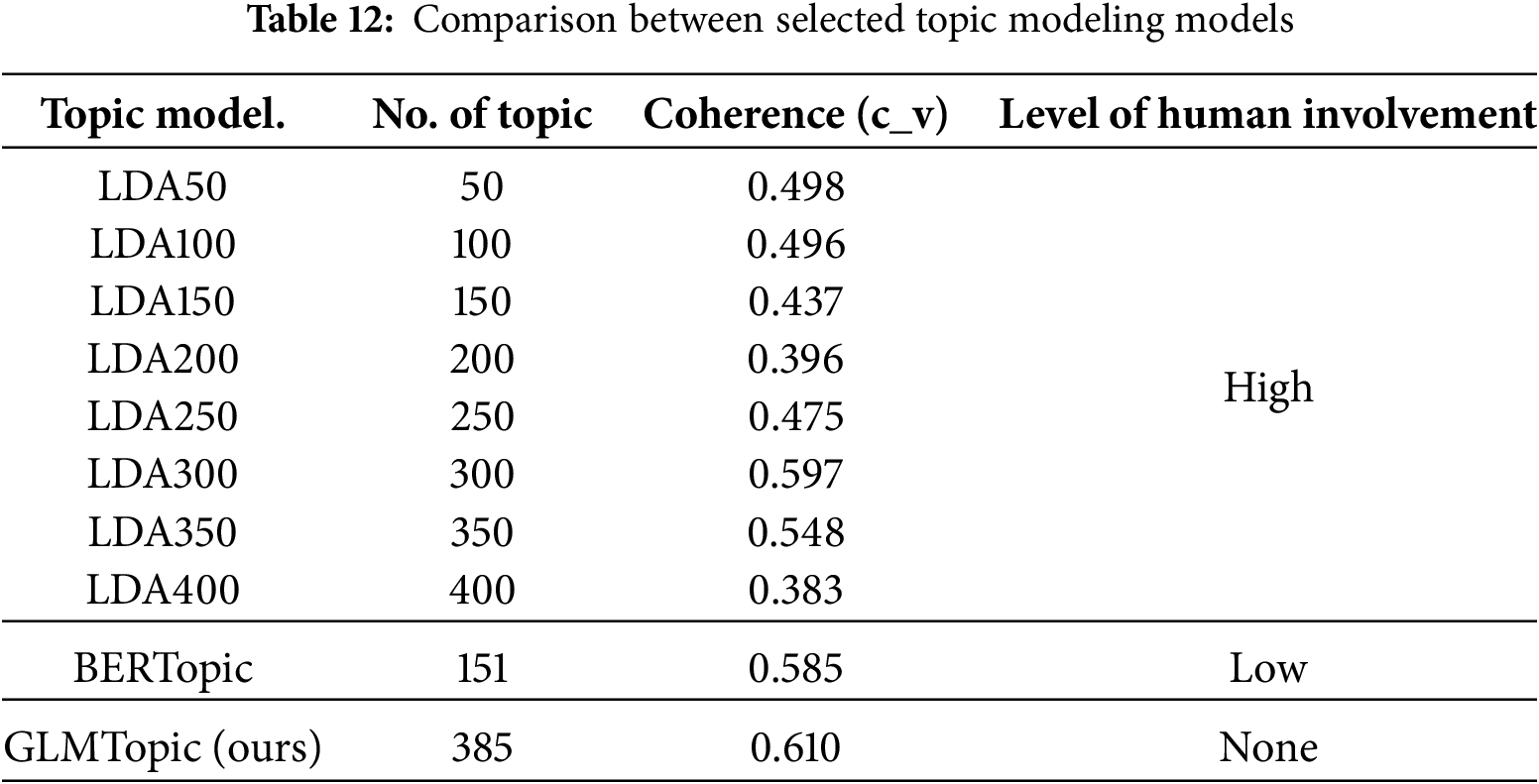
Each expert independently labeled the topics generated by LDA and BERTopic based on their relevance and coherence. All three social science researchers have confirmed that GLMTopic improved intuitiveness and minimizes manual interpretation, and no manual annotation was required after the topic generation. Table 12 extends the performance comparison, illustrating the coherence and level of human involvement.
The key findings of this experiment are as follows.
Data preparation: LDA models require more complex data preprocessing, including non-trivial steps such as punctuation and stop-word removal, text normalization, text segmentation, etc., often requiring considerable time and resource consumption. By contrast, BERTopic and GLMTopic are equally good at data preparation and require minimal preprocessing. The underlying neural networks enable them to capture contextual relationships.
Coherence: In the experiment, GLMTopic performed best, with a significantly higher coherence score than the other state-of-the-art models. This indicates that GLMTopic can generate more semantically consistent topics that are more in line with the actual content of the text than the different models. By integrating ACGE and GLM, GLMTopic can effectively utilize the contextual information in short texts to model the text semantics in-depth, thus generating more in-depth and meaningful topics. ACGE extracts high-quality semantic embeddings from the original text by combining the advantages of community structure and graph neural networks. GLMTopic breaks through the limitations of the traditional embedding model by enhancing the embedding through ACGE’s community, which optimizes the semantic representation and makes the topic modeling results more closely fit the actual text content. It optimizes the semantic representation and makes the topic modeling results more closely match the actual text content.
In the context of Chinese short text scenarios, BERTopic is inferior to GLMTopic because the quality of the embedding model is limited by the corpus used for training, so BERTopic does not work as well for Chinese as GLMTopic. While not as good as GLMTopic, BERTopic performs better than most LDA configurations. Still, its performance is limited by the quality of the embedding model and short text adaptation, which does not fully utilize the contextual information. On the other hand, the coherence score of LDA is relatively low and parameter-sensitive, requiring researchers to constantly tune the parameters.
Interpretability and level of human involvement: GLMTopic excels in data preparation, topic coherence, and interpretability through its fusion of ACGE (Adaptive Community-enhanced Graph Embedding) and GLM. In the data preparation stage, GLMTopic utilizes ACGE’s community-enhanced embedding technology to extract high-quality semantic embeddings directly from the original text without the need for complex data cleaning and word segmentation operations, which significantly improves processing efficiency and adaptability and is more advantageous than traditional LDA and BERTopic. Regarding topic generation, GLMTopic not only achieves a higher topic coherence score but also digs deeper into the semantic nature of the text through GLM’s powerful contextual understanding capability so that the generated topics are more relevant to the actual content and have a higher degree of interpretability. In contrast, although BERTopic performs well in some scenarios, due to its dependence on external embedding models (e.g., Sentence-BERT), it is not effective enough in dealing with short Chinese texts due to the quality of embedding models and context modeling capability. The LDA model not only requires tedious data preprocessing and parameter debugging but also generates topics that are difficult to compare with GLMTopic and BERTopic regarding topic coherence and semantic consistency. Overall, GLMTopic performs optimally in the topic modeling task of Chinese short text and demonstrates strong semantic understanding and modeling ability through the organic combination of ACGE and GLM, providing an efficient and reliable solution for complex text analysis.
In this paper, we have introduced GLMTopic, a novel hybrid topic modeling framework that leverages large language models to enhance topic discovery, coherence, and interpretability, particularly in the context of Chinese short-text datasets. We evaluated its performance against two established topic modeling approaches, namely LDA and BERTopic, and demonstrated that GLMTopic outperforms both in terms of topic coherence and usability while also reducing the need for extensive text preprocessing.
This study has successfully addressed the two research questions outlined in Section 1.2:
RQ 1: Can we leverage the capabilities of LLMs to improve Chinese topic modeling performance for social science research on large-scale social media data?
The experimental results confirm that our proposed hybrid model, GLMTopic, integrates LLMs into topic modeling and can result in more coherent and contextually relevant topics in the Chinese context. By combining ACGE, dimensionality reduction with UMAP, and clustering via HDBSCAN, representation tuning with GLM, GLMTopic has achieved superior performance over state-of-the-art methods in terms of coherence. This hybrid approach demonstrates the potential of LLM-enhanced topic modeling as a more effective and scalable solution.
RQ 2: How can we interpret the topic modeling results without intervention from human experts to enhance their applicability?
GLMTopic significantly improves the interpretability of topic modeling results by automating the generation of meaningful and contextually appropriate topic labels. By integrating GLM for representation tuning, the framework refines extracted topics to align with the original text, reducing ambiguity and improving readability. The results indicate that this approach minimizes human intervention, making topic modeling more accessible for researchers, analysts, and practitioners. Furthermore, interactive visualizations enhance the usability of the generated topics, providing an intuitive way to explore topic structures without requiring domain expertise.
Despite its advantages, this study has certain limitations. The reliance on LLMs introduces computational costs, which may limit scalability in real-time or resource-constrained environments. Additionally, while topic coherence is a widely used evaluation metric, alternative metrics such as thematic diversity could be explored to refine topic quality assessments further. Future research will focus on optimizing computational efficiency by experimenting with more lightweight and efficient LLM architectures and expanding the model’s applicability to real-time analysis and cross-lingual topic modeling. Moreover, integrating knowledge graphs and sentiment analysis could further enhance the contextual relevance of extracted topics, making GLMTopic a more comprehensive tool for social media analysis, news insights, and other high-impact applications.
Overall, this study highlights the transformative potential of LLM-powered topic modeling in improving topic discovery and interpretation, paving the way for more efficient, automated, and semantically rich text analysis pipelines.
Acknowledgement: We acknowledge the ongoing support by Prof. Fethi Rabhi and the FinanceIT group of UNSW.
Funding Statement: This research was funded by the Natural Science Foundation of Fujian Province, China, grant No. 2022J05291.
Author Contributions: The authors confirm their contribution to the paper as follows: conceptualization, Weisi Chen; methodology, Weisi Chen and Walayat Hussain; software, Weisi Chen and Junjie Chen; validation, Weisi Chen and Walayat Hussain; formal analysis, Junjie Chen and Weisi Chen; investigation, Walayat Hussain; resources, Weisi Chen; data curation, Weisi Chen and Junjie Chen; writing—original draft preparation, Weisi Chen and Junjie Chen; writing—review and editing, Weisi Chen and Walayat Hussain; visualization, Walayat Hussain and Junjie Chen; supervision, Weisi Chen; project administration, Weisi Chen and Walayat Hussain; funding acquisition, Weisi Chen and Walayat Hussain. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data supporting this study’s findings are available from the Corresponding Authors, Weisi Chen and Walayat Hussain, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
1https://huggingface.co/THUDM/glm-4-9b-chat-1m (accessed on 03 July 2025).
References
1. Abdelrazek A, Eid Y, Gawish E, Medhat W, Hassan A. Topic modeling algorithms and applications: a survey. Inf Syst. 2023;112:102131. doi:10.1016/j.is.2022.102131. [Google Scholar] [CrossRef]
2. Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. J Mach Learn Res. 2003;3:993–1022. [Google Scholar]
3. Lamirel J-C, Lareau F, Malaterre C. CFMf topic-model: comparison with LDA and Top2Vec. Scientometrics. 2024;129(10):6387–405. doi:10.1007/s11192-024-05017-z. [Google Scholar] [CrossRef]
4. Grootendorst M. BERTopic: neural topic modeling with a class-based TF-IDF procedure. arXiv:2203.05794. 2022. [Google Scholar]
5. Madzik P, Falat L, Jum’a L, Vrábliková M, Zimon D. Human-centricity in Industry 5.0—revealing of hidden research topics by unsupervised topic modeling using Latent Dirichlet Allocation. Eur J Innov Manag. 2025;28(1):113–38. doi:10.1108/ejim-09-2023-0753. [Google Scholar] [CrossRef]
6. Ahammad T. Identifying hidden patterns of fake COVID-19 news: an in-depth sentiment analysis and topic modeling approach. Nat Lang Process J. 2024;6(6):100053. doi:10.1016/j.nlp.2024.100053. [Google Scholar] [CrossRef]
7. Rabadán-Martín I, Barcos-Redín L, Pereira-Delgado J, Aguado-Correa F, Padilla-Garrido N. Topic-based engagement analysis: focusing on hotel industry Twitter accounts. Tour Manag. 2025;106(4):104981. doi:10.1016/j.tourman.2024.104981. [Google Scholar] [CrossRef]
8. Bhat MR, Kundroo MA, Tarray TA, Agarwal B. Deep LDA: a new way to topic model. J Inf Optim Sci. 2020;41(3):823–34. doi:10.1080/02522667.2019.1616911. [Google Scholar] [CrossRef]
9. Chen W, Rabhi F, Liao W, Al-Qudah I. Leveraging state-of-the-art topic modeling for news impact analysis on financial markets: a comparative study. Electronics. 2023;12(12):2605. doi:10.3390/electronics12122605. [Google Scholar] [CrossRef]
10. Pratiwi MD, Tania KD. Knowledge discovery through topic modeling on GoPartner user reviews using BERTopic, LDA, and NMF. J Appl Inform Comput. 2025;9(1):1–7. doi:10.30871/jaic.v9i1.8782. [Google Scholar] [CrossRef]
11. Chen J, Chen W, Zheng J, Xie Q. Employing topic and sentiment language models for news analysis on the COVID-19 Pandemic. In: Proceedings of the 2024 International Conference on Intelligent Education and Computer Technology; 2024 Jun 28–30; Guilin, China. [Google Scholar]
12. Tang Z, Pan X, Gu Z. Analyzing public demands on China’s online government inquiry platform: a BERTopic-Based topic modeling study. PLoS One. 2024;19(2):e0296855. doi:10.1371/journal.pone.0296855. [Google Scholar] [PubMed] [CrossRef]
13. Ramamoorthy T, Kulothungan V, Mappillairaju B. Topic modeling and social network analysis approach to explore diabetes discourse on Twitter in India. Front Artif Intell. 2024;7:1329185. doi:10.3389/frai.2024.1329185. [Google Scholar] [PubMed] [CrossRef]
14. Wijanto MC, Widiastuti I, Yong H-S. Topic modeling for scientific articles: exploring optimal hyperparameter tuning in BERT. Int J Adv Sci Eng Inf Technol. 2024;14(3):912–9. doi:10.18517/ijaseit.14.3.19347. [Google Scholar] [CrossRef]
15. Li T, Cui L, Wu Y, Pandey R, Liu H, Dong J, et al. Unveiling and advancing grassland degradation research using a BERTopic modelling approach. J Integr Agric. 2025;24(3):949–65. doi:10.1016/j.jia.2024.11.008. [Google Scholar] [CrossRef]
16. Lee Y-G, Kim S. A comparative study on topic modeling of LDA, Top2Vec, and BERTopic models using LIS journals in WoS. J Korean Soc Libr Inf Sci. 2024;58(1):5–30. [Google Scholar]
17. Raman R, Pattnaik D, Hughes L, Nedungadi P. Unveiling the dynamics of AI applications: a review of reviews using scientometrics and BERTopic modeling. J Innov Knowl. 2024;9(3):100517. doi:10.1016/j.jik.2024.100517. [Google Scholar] [CrossRef]
18. Zhu E, Yen J. BERTopic-driven stock market predictions: unraveling sentiment insights. arXiv:2404.02053. 2024. [Google Scholar]
19. Chen W, Hussain W, Al-Qudah I, Al-Naymat G, Zhang X. Intersection of machine learning and mobile crowdsourcing: a systematic topic-driven review. Pers Ubiquitous Comput. 2025;29(1):77–101. doi:10.1007/s00779-024-01820-w. [Google Scholar] [CrossRef]
20. Zengul F, Bulut A, Oner N, Ahmed A, Yadav M, Gray HG, et al. A practical and empirical comparison of three topic modeling methods using a COVID-19 corpus: lSA, LDA, and Top2Vec. In: Proceedings of the 2023 Hawaii International Conference on System Sciences; 2023 Jan 3–6; Maui, HI, USA. [Google Scholar]
21. Yu D, Xiang B. Discovering topics and trends in the field of Artificial Intelligence: using LDA topic modeling. Expert Syst Appl. 2023;225(1):120114. doi:10.1016/j.eswa.2023.120114. [Google Scholar] [CrossRef]
22. Yu D, Fang A, Xu Z. Topic research in fuzzy domain: based on LDA topic modelling. Inf Sci. 2023;648(12):119600. doi:10.1016/j.ins.2023.119600. [Google Scholar] [CrossRef]
23. Uthirapathy SE, Sandanam D. Topic modelling and opinion analysis on climate change twitter data using LDA and BERT model. Procedia Comput Sci. 2023;218(1):908–17. doi:10.1016/j.procs.2023.01.071. [Google Scholar] [CrossRef]
24. Kalyan KS. A survey of GPT-3 family large language models including ChatGPT and GPT-4. Nat Lang Process J. 2024;6(6):100048. doi:10.1016/j.nlp.2023.100048. [Google Scholar] [CrossRef]
25. GLM T, Zeng A, Xu B, Wang B, Zhang C, Yin D, et al. ChatGLM: a family of large language models from GLM-130B to GLM-4 all tools. arXiv:2406.12793. 2024. [Google Scholar]
26. Wang H, Prakash N, Hoang NK, Hee MS, Naseem U, Lee RK-W. Prompting large language models for topic modeling. In: Proceedings of the 2023 IEEE International Conference on Big Data (BigData); 2023 Dec 15–18; Sorrento, Italy. [Google Scholar]
27. Chagnon E, Pandolfi R, Donatelli J, Ushizima D. Benchmarking topic models on scientific articles using BERTeley. Nat Lang Process J. 2024;6:100044. doi:10.1016/j.nlp.2023.100044. [Google Scholar] [CrossRef]
28. Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, et al., editors. Learning transferable visual models from natural language supervision. In: Proceedings of the International Conference on Machine Learning; 2021 Jul 18–24; Online. [Google Scholar]
29. Li X, Li L, Jiang Y, Wang H, Qiao X, Feng T, et al. Vision-language models in medical image analysis: from simple fusion to general large models. Inf Fusion. 2025;118(2):102995. doi:10.1016/j.inffus.2025.102995. [Google Scholar] [CrossRef]
30. Reimers N. Sentence-BERT: sentence embeddings using Siamese BERT-Networks. arXiv:1908.10084. 2019. [Google Scholar]
31. McInnes L, Healy J, Melville J. UMAP: uniform manifold approximation and projection for dimension reduction. arXiv:1802.03426. 2018. [Google Scholar]
32. Bhattacharjee P, Mitra P. A survey of density based clustering algorithms. Front Comput Sci. 2021;15(1):1–27. doi:10.1007/s11704-019-9059-3. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools