
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Delving into End-to-End Dual-View Prohibited Item Detection for Security Inspection System
College of Information Science and Engineering, Northeastern University, Shenyang, 110819, China
* Corresponding Author: Dongyue Chen. Email:
(This article belongs to the Special Issue: Advancements in Pattern Recognition through Machine Learning: Bridging Innovation and Application)
Computers, Materials & Continua 2025, 85(2), 2873-2891. https://doi.org/10.32604/cmc.2025.067460
Received 04 May 2025; Accepted 11 August 2025; Issue published 23 September 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In real-world scenarios, dual-view X-ray machines have outnumbered single-view X-ray machines due to their ability to provide comprehensive internal information about the baggage, which is important for identifying prohibited items that are not visible in one view due to rotation or overlap. However, existing work still focuses mainly on single-view, and the limited dual-view based work only performs simple information fusion at the feature or decision level and lacks effective utilization of the complementary information hidden in dual view. To this end, this paper proposes an end-to-end dual-view prohibited item detection method, the core of which is an adaptive material-aware coordinate-aligned attention module (MACA) and an adaptive adjustment strategy (AAS). Specifically, we observe that in X-ray images, the material information of an object can be represented by color and texture features, and remains consistent across views, even under complex backgrounds. Therefore, our MACA first integrates the material information of the prohibited items in each view and then smoothly transfers these clear material clues along the shared axis to the corresponding locations in the other view to enhance the feature representation of the blurred prohibited items in the other view. In addition, AAS can autonomously adjust the importance of the two views during feature learning to make joint optimization more stable and effective. Experiments on the DvXray dataset demonstrate that the proposed MACA and AAS can be plug-and-played into various detectors, such as Faster Region-based Convolutional Neural Network (Faster R-CNN) and Fully Convolutional One-Stage Object Detector (FCOS), and bring consistent performance gains. The entire framework performs favorably against state-of-the-art methods, especially on small-sized prohibited items, highlighting its potential application in reality.Keywords
X-ray based security inspection has played a crucial role as a cost-effective measure in protecting public spaces from terrorist attacks. Among these, dual-view X-ray machines have been widely used in real-world scenarios in recent years due to their ability to provide complementary and diverse information about baggage. However, current automatic security inspection using computer vision technology still predominantly operates within single-view [1–4]. For example, Akcay et al. [5] applied a transfer learning technique so that a conventional detector is first trained on adequate natural images, and then can be further fine-tuned for the data-constrained domain of X-ray images. Miao et al. [6] proposed a hierarchical refinement strategy, where high-level semantic features at the highest level are directly supervised by the ground-truth, and feature maps at the remaining levels are guided by the higher-level features to remove the irrelevant information. Based on this, Ma et al. [7] introduced a dense de-overlap module that leverages high-level information as a guiding signal to purify irrelevant channel responses in the mid-level features through reverse connections. Additionally, since edges and colors can effectively reflect object characteristics in X-ray baggage images, Wei et al. [8] proposed a plug-and-play module called de-occlusion attention module, which utilized different appearance information of threat items to generate the attention map, thereby enhancing prediction results. Zhao et al. [9] designed a label-aware mechanism to overcome the object overlapping issue, which can adaptively adjust the corresponding feature channels based on the interaction with pseudo-labels. Shao et al. [10] separated foreground and background through reconstruction and then used the reconstructed foreground as an attention map to enrich the feature representation of obscured prohibited items. Hassan et al. [11] iteratively selected contour-based feature information from different orientations to detect heavily occluded objects. Wang et al. [12] designed a dense attention module that employs spatial and channel attention mechanisms to extract discriminative features, which proves highly effective in locating concealed prohibited items in cluttered objects. Tao et al. [13] proposed the lateral inhibition module, which adaptively filters noise through bidirectional cross-layer information flow and utilizes boundary information to suppress the influence of neighboring regions on the target area. Ma et al. [14] developed a global context-aware multi-scale feature aggregation strategy that accounts for the specific characteristics of features from multi-scale layers to improve the detection of overlapping prohibited items. Furthermore, Jia et al. [15] drew ideology from feature decoupling and proposed a foreground-background specific feature learning framework for accurate single-view prohibited item detection. Cheng et al. [16] introduced an X-YOLO, which combines feature fusion and attention mechanisms on YOLOv5 to achieve a trade-off between speed and accuracy. Bhowmik et al. [17] evaluated synthetic X-ray image generation for CNN training, comparing real and synthetic data performance in prohibited item detection. Nevertheless, directly adopting single-view prohibited item detection methods through result fusion for dual-view X-ray images is not advisable. This is because X-ray images differ from natural images [18], the objects within them often appear semi-transparent, causing the feature representation of prohibited items to be overshadowed by those non-interest safe objects. If images from two views are independently fed into single-view detectors and their results are directly fused, it implies that the model makes predictions based on a coupled latent space, leading to consequential performance degradation.
In recent years, several researchers have turned their attention to dual-view X-ray images [19,20]. For instance, Liang et al. [21] introduced an OR-gate based fusion strategy to integrate detection results from multiple viewpoints, demonstrating the performance benefits of multi-view analysis. Wang et al. [22] pioneered the application of 3D CNN for volumetric threat detection in CT baggage screening. Ma et al. [23] proposed a hierarchical cross refinement strategy that extends information interaction to the feature space. Building upon this, Hong et al. [24] delved deeper in terms of refinement target, way, and function. These findings underscore the significance of information interaction at feature-level stage, although their focus remains on prohibited item classification tasks. Tao et al. [25] introduced a dual-view prohibited item detection framework, however, it directly treats the side view as auxiliary information and does not fully exploit the potential complementary information hidden in the orthogonal viewpoints. In this paper, we delve into the characteristics of dual-view X-ray images, where objects overlapped in one view are spread out in the other, allowing the two views to serve as mutual guidance signals to disentangle feature coupling in the latent space. Based on this observation, we propose an adaptive material-aware coordinate-aligned attention module (MACA) and an adaptive adjustment strategy that can be seamlessly integrated into the most popular detectors to form an end-to-end high-accuracy dual-view prohibited item detection framework.
The contributions of this work are summarized as follows:
• In dual-view X-ray baggage images, the shape and size of objects can vary significantly in different viewpoints, while the material attributes (reflected in color and texture) remain independent of the viewpoint. Therefore, we propose a MACA that propagates clear material clues along the shared axis to the corresponding positions in the other view, thereby precisely enhancing the feature discriminability of prohibited items in coupled states. In MACA, we further introduce an adaptive coefficient to make interaction process smoother and smarter. It controls whether and how much information is transferred based on the confidence score of the presence of prohibited items in the current view.
• Inspired by the cosine annealing algorithm, we propose an adaptive adjustment strategy that allows a gradual transition from overlook view dominance to balanced dual-view utilization during the training process. This makes joint optimization more effective and stable.
• We verify our method on the DvXray dataset and compare it with different baselines, including various basic detectors, prohibited item detection methods, and commonly used feature integration mechanisms. The results demonstrate the superiority and universality of our proposed framework.
The attention mechanism aims to enhance the network’s ability to identify and locate significant features in an image, while suppressing irrelevant or less important regions, which can help models resist interference and improve detection accuracy. Since its introduction, it has led to significant advancements in the computer vision community. Early attention mechanisms were mainly channel attention or spatial attention. Specifically, considering that different channels contribute unequally to tasks, channel attention assigns varying weights to different channels, emphasizing those critical for recognizing specific objects. Spatial attention refers to the discovery of regions of interest in a task, which typically occupy only a small portion of the image. It then computes attention weights based on the similarity of pixels in contextual features. Recently, combining attention mechanisms across two dimensions can further boost model performance, commonly including CBAM [26], SimAM [27], and CA [28]. CBAM sequentially applied channel and spatial attention to enhance feature representation by emphasizing important channels and spatial regions. SimAM was a parameter-free 3D attention module that assigns weights based on neuron discriminability, leveraging neuroscience principles without adding learnable parameters. CA integrated positional information into channel attention by decomposing attention into horizontal and vertical directions, enabling precise location-aware feature refinement. However, unlike natural images, where each pixel typically belongs to a single category, X-ray baggage images contain superimposed information about both foreground and background objects at each pixel, leading to severe feature coupling. Consequently, the model struggles to accurately distinguish foreground features from background features in such coupled spaces without additional knowledge, significantly diminishing the effectiveness of classic attention mechanisms. To this end, we explore dual-view X-ray imaging properties, converting the clear material information in the other view into an attention map and transferring it to the current view to enhance the feature representation of prohibited items in complex backgrounds.
Multi-view learning (MVL) aims to learn a common feature space or shared patterns by effectively integrating multiple diverse features or data sources. This direction has long attracted significant attention in the machine learning and computer vision communities, yielding numerous promising algorithms. However, these algorithms are typically designed for general-purpose tasks such as cross-modal retrieval, 3D view object recognition, and multi-view clustering. Among them, Su et al. [29] proposed MVCNN, a pioneering framework for 3D shape recognition that aggregates multi-view 2D projections into a unified descriptor. By sharing convolutional weights across views and applying view-pooling to integrate discriminative features, MVCNN effectively captures 3D geometry while maintaining computational efficiency. Based on this, Feng et al. [30] proposed GVCNN, which hierarchically groups semantically similar views and assigns attention weights to each group. This can mitigate redundancy in multi-view data by emphasizing view clusters with high discriminative power, significantly improving fine-grained 3D object classification. Furthermore, Zhen et al. [31] developed a cross-modal retrieval framework that simultaneously optimizes the common representation space and the label space to enhance joint feature learning across modalities. Sun et al. [32] introduced an improved capsule network architecture for multi-view 3D object recognition tasks, which features a dynamic routing mechanism for efficient information flow between capsule layers. Federici et al. [33] proposed an information-theoretic approach that eliminates view-specific redundancies while preserving shared information across views, enabling more robust multi-view representation learning in an unsupervised manner. However, unlike generic MVL, the aim of our task is to mine specific patterns in dual-view images rather than learning a common feature space, and thus generic methods do not achieve satisfactory performance on our task, especially when X-ray baggage images also have some other unique challenges, such as object overlapping and complex backgrounds.
Due to the penetrative nature of X-rays and the orthogonal position of the X-ray sources, dual-view X-ray images exhibit three distinctive characteristics. First, the images mainly stand out in shape and material (reflected in color and texture) attribute of the objects, which is well preserved even under heavy overlaps. However, the shape information varies significantly across different viewpoints, such as the gun in the second example and pliers in the third example in Fig. 1, whereas material attributes remain viewpoint-invariant. Therefore, this paper employs material cues as guiding signals for information interaction. Second, objects that overlap within one viewpoint will separate or flatten in the other viewpoint, and the two views, namely the overlook view and the side view, have a shared axis. This allows us to transfer the aforementioned non-overlapping material cues along the shared axis to the corresponding positions in the other view, thereby avoiding the wastage of computational resources on irrelevant regions. Third, in dual-view X-ray baggage images, despite the theoretical equivalence of orthogonal views, the overlook view tends to reveal more features of the objects of interest since baggage is typically placed flat on the conveyor belt of X-ray security scanners. Therefore, during model training, the overlook view data should initially dominate the learning process, with its influence gradually balanced against the side view data as training progresses. This way can preserve the complementary advantages of dual-view inspection while accommodating the physical constraints of baggage presentation. Based on these three observations, we propose a MACA module and an AAS to enhance the performance of dual-view prohibited item detection through information interaction.

Figure 1: Examples of prohibited items from the DvXray dataset
In the object detection paradigm, whether one-stage or two-stage detectors, their pipeline typically comprises five components: feature extraction, feature fusion, label assignment, detection head, and loss function. In this paper, we set up a baseline model for the dual-view prohibited item detection task. Specifically, we employ two parallel detectors (e.g., Faster R-CNN [34] and FCOS [35]) to process each view independently, while sharing weights in the feature extraction component. To achieve more effective utilization of complementary information, we introduce an MACA in the feature extraction component and an AAS in the loss function component, respectively. The reason we act MACA on the feature extraction component is that feature extraction serves as the foundation of the entire pipeline, and its quality directly influences the overall performance of the detector. AAS is mainly used to ensure the effectiveness and stability of the whole training process and thus acts on the loss function component.
Note that when employing single-view prohibited item detection models, we process the two views sequentially by feeding them individually into the detection model to generate independent prediction results, without any intermediate interaction or parameter-sharing strategy. Compared to our proposed dual-view detection framework, this approach cannot process both views simultaneously, resulting in relatively slower inference speeds. A schematic comparison of different methods is presented in Fig. 2.

Figure 2: Comparison of dual-view prohibited item detection frameworks under different configurations
Formally, given a pair of X-ray images, where
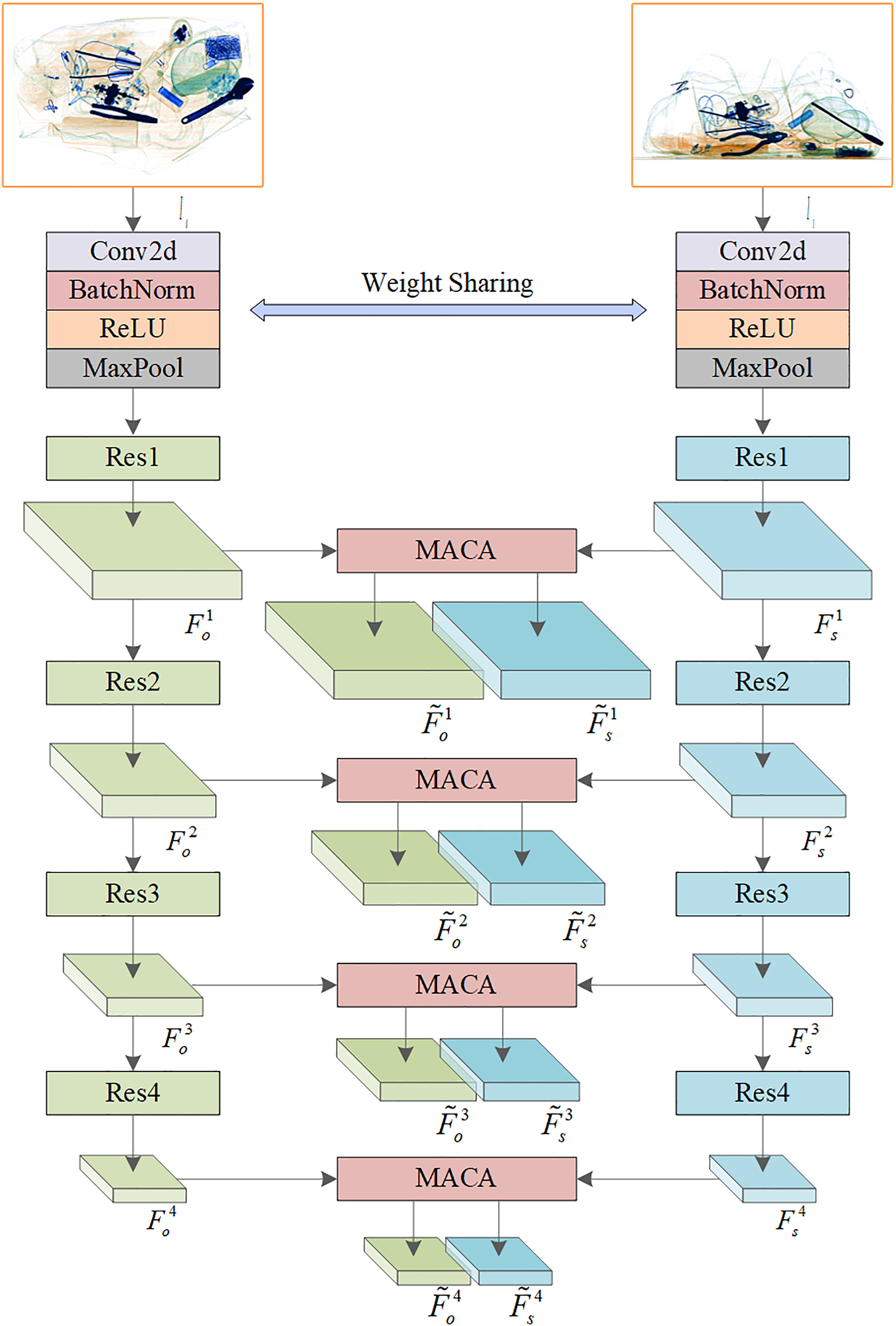
Figure 3: Implementation details of the MACA
3.3 Adaptive Material-Aware Coordinate-Aligned Attention Module
In X-ray baggage images, the material information of objects is primarily reflected in color and texture. It is well-known that each position in an image can represent color information alone, whereas texture information requires incorporating its surrounding context to be effectively expressed. Based on this, we aggregate regional information to represent these two characteristics.
Specifically, for each pair of
where
Subsequently, we employ the residual connection followed by a convolutional layer
Since we aggregate information from regions of varying sizes (different

Figure 4: The process of generating guidance signals. The right subscripts of the operation, such as
After that, we perform information interactions by cross-multiplying the guidance signals with the original features of the other view. To make this process smoother and more intelligent, we introduce two control coefficients,
where
As mentioned above, the entire end-to-end dual-view prohibited item detection framework is built upon existing detectors. Therefore, for the two detection branches, the standard loss functions of the base detectors can be directly adopted for training. As such, the joint optimization loss of the framework can be represented as:
where
and for FCOS,
where
This section provides comprehensive experiments to evaluate the performance of the proposed framework on dual-view prohibited item detection task. First, we detail the experimental settings, including hardware environment, datasets, and evaluation metrics. Second, we verify the general applicability of MACA and AAS across various basic detectors. Third, we compare with some state-of-the-art counterparts, including those working within single-view and dual-view. Fourth, we demonstrate that MACA outperforms other feature integration mechanisms to prove its effectiveness in dealing with X-ray baggage images. Finally, we carry on ablation experiments and provide visualizations to thoroughly evaluate the role of each component.
Configurations: The input images are rescaled to a resolution of 300
Note that, in order to avoid any impact on MACA, we intentionally abstain from employing data augmentation techniques that modify pixel values or artificially expand the dataset. This allows the model to better perceive the material properties of objects and the spatial alignment relationship between views.
Dataset: In this paper, we utilize the DvXray dataset to assess the performance of our proposed framework as it is currently the only publicly available large-scale dual-view prohibited item detection dataset that provides comprehensive ground-truth annotations for both views. This benchmark dataset comprises 5000 pairs, 10,000 X-ray images containing prohibited items. The categories of prohibited items cover gun, bat, dart, knife, pliers, wrench, lighter, battery, hammer, scissors, fireworks, saw blade, razor blade, screwdriver, and pressure vessel. To ensure a fair comparison with existing methods, we adhere to the original dataset partitioning scheme. The detailed category distribution of the DvXray dataset is summarized in Table 1.

Evaluation metrics: This paper adopt mean average precision (mAP) to independently assess each view. This metric represents the mean of Average Precision (AP) scores across all categories, where AP combines both precision and recall metrics. The evaluation involves four fundamental detection outcomes: True Positives (TP, correctly identified objects), False Positives (FP, background misclassified as objects), True Negatives (TN, correctly ignored background), and False Negatives (FN, missed objects).
The AP represents the mean precision value computed across all possible recall levels:
Then calculate the average across all categories to get mAP. Be more specific,
4.2 Integration with Different Detectors
Here, we employ four popular detectors to verify the generalizability of the proposed MACA and AAS, including two one-stage detectors, FCOS and ATSS [38], and two two-stage detectors, Faster R-CNN and Cascade R-CNN [39]. Note that for the basic detectors, they process the two views in a purely parallel manner without any cross-view information interaction. As observed in Table 2, the proposed framework achieves consistent performance improvements across all six metrics. For instance, when incorporated with Faster R-CNN, the performance is increased by 4.8% and 3.9% in
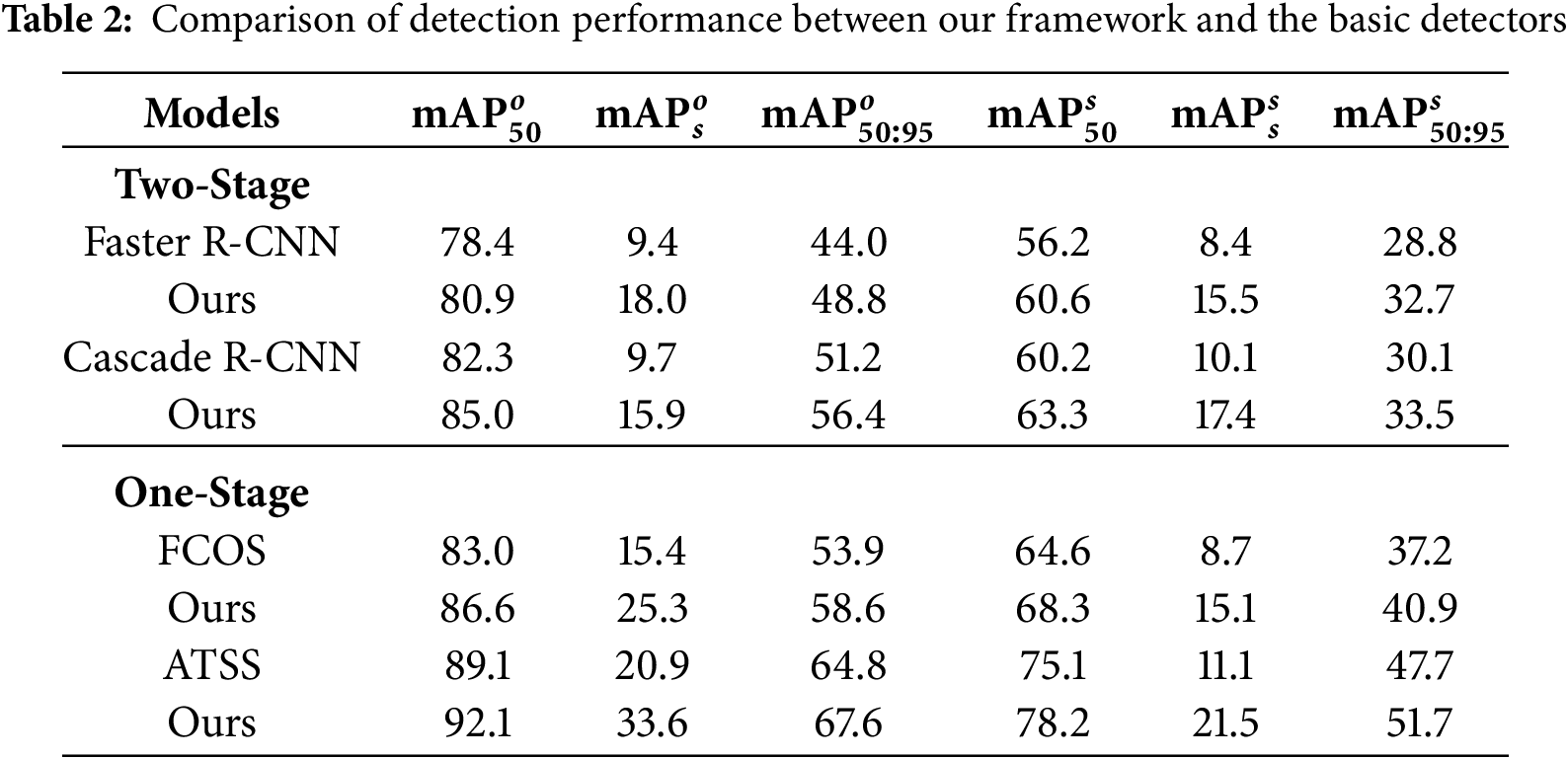

Figure 5: Visualizations of our dual-view prohibited item detection framework on challenging cases
4.3 Comparison with Current Prohibited Item Detectors
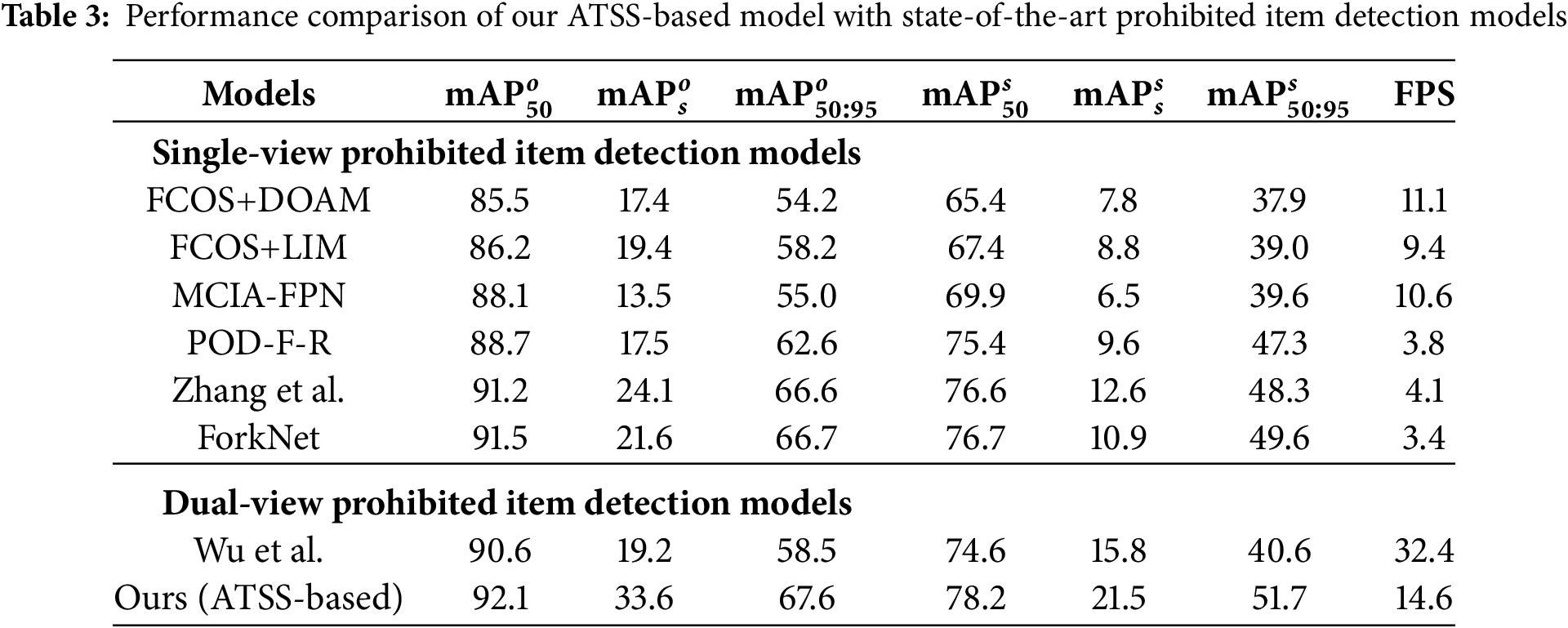
In this experiment, we compare our entire framework built based on ATSS with other prohibited item detection models to demonstrate the superiority of our method, including FCOS+DOAM, FCOS+LIM, MCIA-FPN [40], POD-F-R, Zhang et al. [41], ForkNet, and Wu et al. For those methods designed for single-view, we trained and tested them on the overlook view and side view individually using their standard configurations. As can be seen from Table 3, our model achieves the best performance across all six metrics, surpassing the second-best by 0.6%, 9.5%, 0.9%, 1.5%, 5.7%, and 2.1%, respectively. This impressive result highlights the significance of information interactions, especially given that competitors often rely on more complex operations. We also find that our detector can bring more performance gains in the side view compared to the overlook view, which we believe is due to the fact that objects in the side view are typically in a flat position and tend to loss their discriminative features, leading to false and missed detections. Our method, by targeting complementary information at the feature level, can substantially enhance the recognition performance of these objects. Additionally, single-view methods require processing the two views independently, whereas dual-view methods can simultaneously process both images, which is highly advantageous for practical applications.
4.4 Comparison with Different Feature Integration Mechanisms
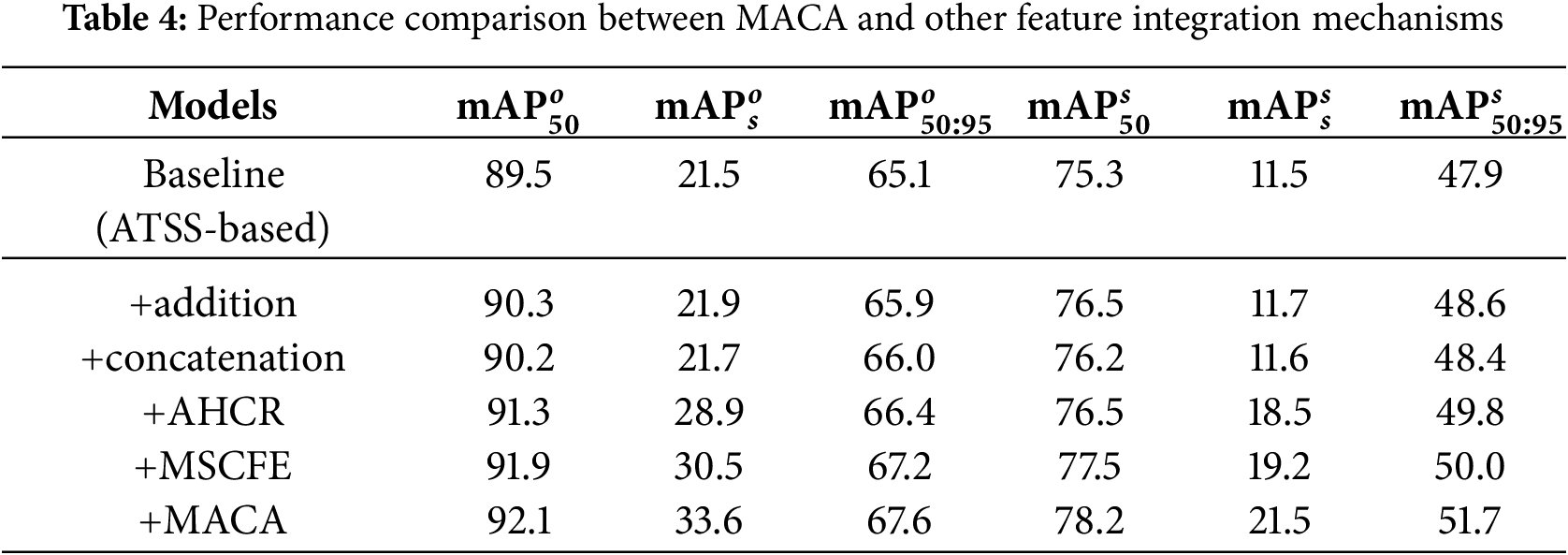
In this part, we compare our MACA with common operations such as addition, concatenation, and specially designed modules AHCR and MSCFE. From Table 4, it can be observed that MACA outperforms the state-of-the-art MSCFE in all six metrics, and exceeds the small-object metrics
In this subsection, we perform detailed ablation studies with visualizations to analyze the individual role of components MACA and AAS to the overall framework.
Analysis of adaptive material-aware coordinate-aligned attention module (MACA): The quantitative results are presented in Table 5, where MA and AII denote material awareness and adaptive information interaction, respectively. It can be observed that MA provides a clear performance boost to the model, demonstrating the advantage of MA in preserving material information of prohibited items, even under complex background overlaps. AII enables more accurate feature extraction and dynamic adjustment, avoiding performance degradation caused by over-guidance. The qualitative effects of MACA are visualized in Fig. 6. In X-ray baggage images, the discriminative features of prohibited items are often lost due to placement angles or background overlaps, causing general-purpose detectors (such as ATSS) to either scatter focus or fail to localize accurately, as illustrated by the knife in the first example and the lighter in the second example. After the MACA transfers non-overlapping complementary information to the other view, these missed and misclassified items are now correctly detected, significantly enhancing the reliability of the model.
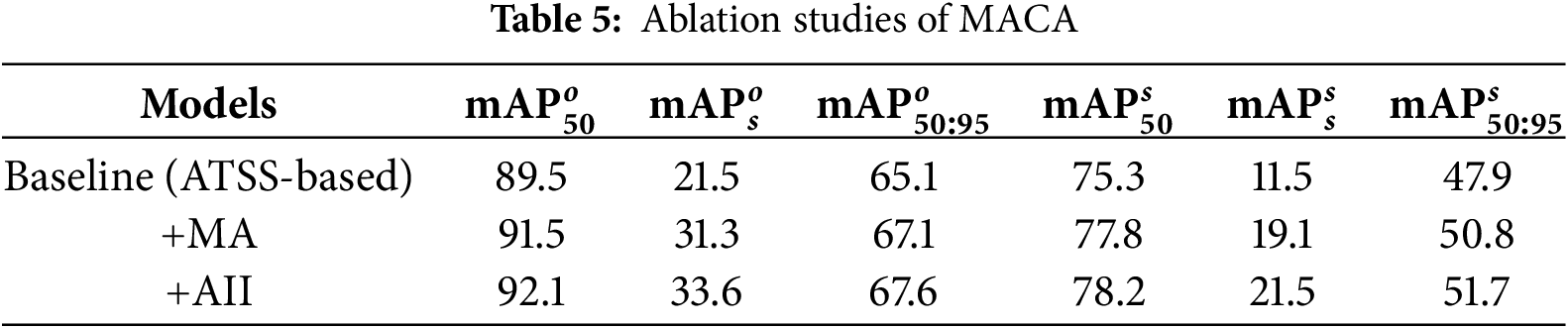


Figure 6: Visualizations with and without MACA
Here, we further analyze the model complexity with or without MACA in terms of parameters, GFLOPs, and FPS. As can be seen from Table 6, since we have reduced the channel dimension of multi-scale features before information interaction, MACA only brings trifling additions to the baseline, with specific increases by 8% and 11% on parameters and GFLOPs, respectively. From the FPS metric, we know that our proposed framework can serve the task of dual-view prohibited item detection in real time.
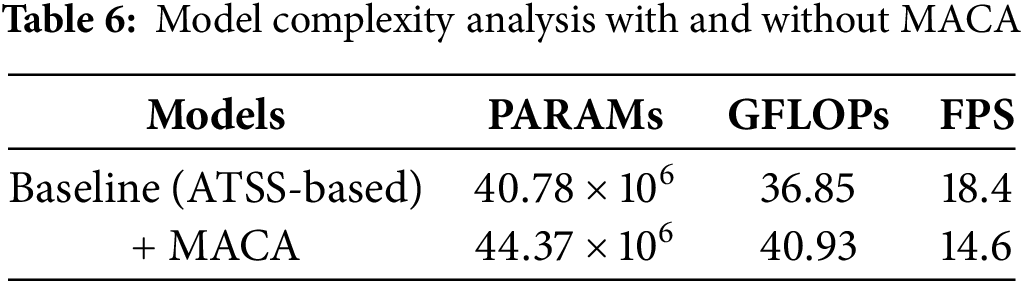
Furthermore, in order to verify the effect of different kernel sizes in our gated convolutional neural network on the performance of the model, we conduct comparative experiments using
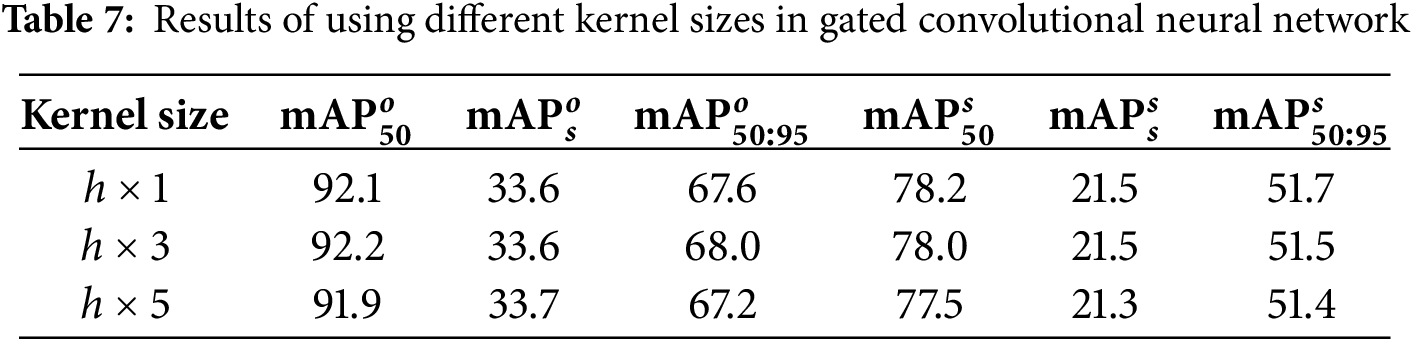
Analysis of adaptive adjustment strategy (AAS): Since our proposed dual-view prohibited item detection framework is built with dual-task loss


Figure 7: Traning loss comparison between Fixing and AAS strategies
In this section, we will discuss two unique characteristics of our dual-view prohibited item detection framework. First, we explore the impact of rationally integrating the potential complementary information of dual views at the feature level on the overall detection performance. Specifically, we focus on two key properties of material information salience and inter-view spatial alignment and propose a specially designed attention module MACA. As can be seen from Table 5 and Fig. 6, our MACA significantly improves the model’s performance in recognizing prohibited items that are difficult to notice in a single view due to angularity or occlusion. This enhancement helps apply the model in practice, which is due to the fact that human security personnel can easily recognize obvious prohibited items in the baggage, even without the help of computer-aided detection. For deliberately hidden prohibited items, it is difficult for security personnel to identify them in a short period of time, and this is where high-accuracy computer-aided detection algorithms are necessary. Second, the end-to-end dual-view prohibited item detection framework belongs to the multi-task paradigm, so how to balance view-specific importance during training is a key issue, in this paper, we simulate the screening habits of security personnel and propose a simple and effective solution. In the current work, we only use the view-invariant material information as a guidance signal, but not the view-dependent shape attributes. However, we strongly believe that there should be potential correspondences for the changing shape information as well, and it will be interesting to mine more view relationships to further improve the recognition accuracy of prohibited items. In addition, in real scenarios, the prohibited item is likely to be invisible in one view due to rotation or severe overlapping, in which case the information interaction may have side effects, and although our proposed adaptive control coefficients can alleviate this problem to a certain extent, we look forward for a more powerful model to deal with this kind of situation. We hope that our results will inspire researchers to think about this very important but unexplored task from the perspective of information interaction and joint optimization.
In this paper, we dig deeper into the image characteristics and viewpoint relationships of dual-view X-ray baggage images and contribute an end-to-end prohibited item detection framework. Its core is an adaptive material-aware coordinate-aligned attention module MACA and an adaptive adjustment strategy AAS to achieve efficient information interaction. MACA enhances the discriminability of prohibited items in complex backgrounds by complementarily transferring view-independent material cues to the other view, which can be plug-and-played into any existing detection framework and brings consistent performance improvement. AAS solves the problem of inefficient and unstable training during joint optimization. Experimental results prove the effectiveness and superiority of the proposed framework, especially on small-sized prohibited items, demonstrating its feasibility for real-world applications.
Acknowledgement: Not applicable.
Funding Statement: This research was supported by the Guangdong Basic and Applied Basic Research Foundation under Grant 2021B1515120064.
Author Contributions: Conceptualization, Zihan Jia and Bowen Ma; methodology, Zihan Jia and Bowen Ma; software, Zihan Jia; validation, Bowen Ma and Dongyue Chen; formal analysis, Bowen Ma and Dongyue Chen; investigation, Zihan Jia and Dongyue Chen; resources, Zihan Jia; data curation, Zihan Jia; writing—original draft preparation, Zihan Jia; writing—review and editing, Bowen Ma and Dongyue Chen; visualization, Zihan Jia and Dongyue Chen; supervision, Bowen Ma and Dongyue Chen; project administration Dongyue Chen; funding acquisition, Dongyue Chen. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in https://github.com/trapper163/MACA (accessed on 10 August 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
1 We omit the superscript i for brevity when the context is clear.
References
1. Wang H, Jia T, Ma B, Chen D, Deng S. Delving into cluttered prohibited item detection for security inspection system. IEEE Transact Indust Inform. 2024;20(10):11825–34. doi:10.1109/TII.2024.3413316. [Google Scholar] [CrossRef]
2. Yang F, Jiang R, Yan Y, Xue JH, Wang B, Wang H. Dual-mode learning for multi-dataset X-ray security image detection. IEEE Transact Inform Foren Secur. 2024;19:3510–24. doi:10.1109/TIFS.2024.3364368. [Google Scholar] [CrossRef]
3. Velayudhan D, Ahmed A, Hassan T, Gour N, Owais M, Bennamoun M, et al. Autonomous localization of X-ray baggage threats via weakly supervised learning. IEEE Transact Indust Inform. 2024;20(4):6563–72. doi:10.1109/TII.2023.3348838. [Google Scholar] [CrossRef]
4. Ma B, Jia T, Wu S. Automatic annotation approach for prohibited item in X-ray image based on PANet. In: 2020 10th Institute of Electrical and Electronics Engineers International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER); 2020 Oct 10–13; Xi’an, China. p. 130–3. doi:10.1109/CYBER50695.2020.9279111. [Google Scholar] [CrossRef]
5. Akcay S, Kundegorski ME, Willcocks CG, Breckon TP. Using deep convolutional neural network architectures for object classification and detection within X-ray baggage security imagery. IEEE Transact Inform Foren Secur. 2018;13(9):2203–15. doi:10.1109/TIFS.2018.2812196. [Google Scholar] [CrossRef]
6. Miao C, Xie L, Wan F, Su C, Liu H, Jiao J, et al. Sixray: a large-scale security inspection X-ray benchmark for prohibited item discovery in overlapping images. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA. p. 2119–28. doi:10.1109/CVPR.2019.00222. [Google Scholar] [CrossRef]
7. Ma B, Jia T, Su M, Jia X, Chen D, Zhang Y. Automated segmentation of prohibited items in X-ray baggage images using dense de-overlap attention snake. IEEE Transact Multim. 2022;25(2):4374–86. doi:10.1109/TMM.2022.3174339. [Google Scholar] [CrossRef]
8. Wei Y, Tao R, Wu Z, Ma Y, Zhang L, Liu X. Occluded prohibited items detection: an X-ray security inspection benchmark and de-occlusion attention module. In: Proceedings of the 28th ACM International Conference on Multimedia; 2020 Oct 12–16; Seattle, WA, USA. p. 138–46. doi:10.1145/3394171.3413828. [Google Scholar] [CrossRef]
9. Zhao C, Zhu L, Dou S, Deng W, Wang L. Detecting overlapped objects in X-ray security imagery by a label-aware mechanism. IEEE Transact Inform Foren Secu. 2022;17:998–1009. doi:10.1109/TIFS.2022.3154287. [Google Scholar] [CrossRef]
10. Shao F, Liu J, Wu P, Yang Z, Wu Z. Exploiting foreground and background separation for prohibited item detection in overlapping X-Ray images. Pattern Recognit. 2022;122(7):108261. doi:10.1016/j.patcog.2021.108261. [Google Scholar] [CrossRef]
11. Hassan T, Akcay S, Bennamoun M, Khan S, Werghi N. Cascaded structure tensor framework for robust identification of heavily occluded baggage items from X-ray scans. arXiv:2004.06780. 2020. [Google Scholar]
12. Wang B, Zhang L, Wen L, Liu X, Wu Y. Towards real-world prohibited item detection: a large-scale X-ray benchmark. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision; 2021 Oct 10–17; Montreal, QC, Canada. p. 5412–21. doi:10.1109/ICCV48922.2021.00536. [Google Scholar] [CrossRef]
13. Tao R, Wei Y, Jiang X, Li H, Qin H, Wang J, et al. Towards real-world X-ray security inspection: a high-quality benchmark and lateral inhibition module for prohibited items detection. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision; 2021 Oct 10–17; Montreal, QC, Canada. p. 10923–32. doi:10.1109/ICCV48922.2021.01074. [Google Scholar] [CrossRef]
14. Ma C, Zhuo L, Li J, Zhang Y, Zhang J. Occluded prohibited object detection in X-ray images with global context-aware multi-scale feature aggregation. Neurocomputing. 2023;519(6):1–16. doi:10.1016/j.neucom.2022.11.034. [Google Scholar] [CrossRef]
15. Jia T, Ma B, Wang H, Li M, Lin S, Chen D. Forknet: overlapping image disentanglement for accurate prohibited item detection. IEEE Trans Instrum Meas. 2024;73(11):4505312. doi:10.1109/TIM.2024.3394483. [Google Scholar] [CrossRef]
16. Cheng Q, Lan T, Cai Z, Li J. X-YOLO: an efficient detection network of dangerous objects in X-ray baggage images. IEEE Signal Process Lett. 2024;31:2270–4. doi:10.1109/LSP.2024.3451311. [Google Scholar] [CrossRef]
17. Bhowmik N, Wang Q, Gaus YFA, Szarek M, Breckon TP. The good, the bad and the ugly: evaluating convolutional neural networks for prohibited item detection using real and synthetically composited X-ray imagery. arXiv:1909.11508. 2019. doi:10.48550/arXiv.1909.11508. [Google Scholar] [CrossRef]
18. Isaac-Medina BK, Yucer S, Bhowmik N, Breckon TP. Seeing through the data: a statistical evaluation of prohibited item detection benchmark datasets for X-ray security screening. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2023 Jun 17–24; Vancouver, BC, Canada. p. 524–33. doi:10.1109/CVPRW59228.2023.00059. [Google Scholar] [CrossRef]
19. Isaac-Medina BK, Willcocks CG, Breckon TP. Multi-view object detection using epipolar constraints within cluttered x-ray security imagery. In: 2020 25th International Conference on Pattern Recognition (ICPR). New York, NY, USA: IEEE; 2021. p. 9889–96. doi:10.1109/ICPR48806.2021.9413007. [Google Scholar] [CrossRef]
20. Wu M, Yi F, Zhang H, Ouyang X, Yang J. Dualray: dual-view X-ray security inspection benchmark and fusion detection framework. In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Cham, Switzerland: Springer; 2022. p. 721–34. doi:10.1007/978-3-031-18916-6_57. [Google Scholar] [CrossRef]
21. Liang KJ, Heilmann G, Gregory C, Diallo SO, Carlson D, Spell GP, et al. Automatic threat recognition of prohibited items at aviation checkpoint with X-ray imaging: a deep learning approach. In: Anomaly detection and imaging with X-rays (ADIX) III. Vol. 10632. Bellingham, WA, USA: SPIE; 2018. 1063203 p. doi:10.1117/12.2309484. [Google Scholar] [CrossRef]
22. Wang Q, Bhowmik N, Breckon TP. On the evaluation of prohibited item classification and detection in volumetric 3d computed tomography baggage security screening imagery. In: 2020 International Joint Conference on Neural Networks (IJCNN); 2020 Jul 19–24; Glasgow, UK. p. 1–8. doi:10.1109/IJCNN48605.2020.9207389. [Google Scholar] [CrossRef]
23. Ma B, Jia T, Li M, Wu S, Wang H, Chen D. Toward dual-view X-ray baggage inspection: a large-scale benchmark and adaptive hierarchical cross refinement for prohibited item discovery. IEEE Transact Inform Foren Secur. 2024;19(11):3866–78. doi:10.1109/TIFS.2024.3372797. [Google Scholar] [CrossRef]
24. Hong S, Zhou Y, Xu W. A multi-scale feature fusion framework integrating frequency domain and cross-view attention for dual-view X-ray security inspections. arXiv:2502.01710. 2025. doi:10.48550/arXiv:2502.01710v2. [Google Scholar] [CrossRef]
25. Tao R, Wang H, Guo Y, Chen H, Zhang L, Liu X, et al. Dual-view X-ray detection: can AI detect prohibited items from dual-view X-ray images like humans? arXiv:2411.18082. 2024.doi:10.48550/arXiv:2411.18082. [Google Scholar] [CrossRef]
26. Woo S, Park J, Lee JY, Kweon IS. Cbam: convolutional block attention module. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Cham, Switzerland: Springer; 2018. p. 3–19. doi:10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
27. Yang L, Zhang RY, Li L, Xie X. Simam: a simple, parameter-free attention module for convolutional neural networks. In: International Conference on Machine Learning. London, UK: PMLR; 2021. p. 11863–74. [cited 2025 Aug 1]. Available from: https://proceedings.mlr.press/v139/yang21o.html. [Google Scholar]
28. Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021 Jun 20–25; Nashville, TN, USA. p. 13713–22. doi:10.1109/CVPR46437.2021.01350. [Google Scholar] [CrossRef]
29. Su H, Maji S, Kalogerakis E, Learned-Miller E. Multi-view convolutional neural networks for 3d shape recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision; 2015 Dec 7–13; Santiago, Chile. p. 945–53. doi:10.1109/ICCV.2015.114. [Google Scholar] [CrossRef]
30. Feng Y, Zhang Z, Zhao X, Ji R, Gao Y. Gvcnn: group-view convolutional neural networks for 3D shape recognition. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 264–72. doi:10.1109/CVPR.2018.00035. [Google Scholar] [CrossRef]
31. Zhen L, Hu P, Wang X, Peng D. Deep supervised cross-modal retrieval. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA. p. 10394–403. doi:10.1109/CVPR.2019.01064. [Google Scholar] [CrossRef]
32. Sun K, Zhang J, Liu J, Yu R, Song Z. DRCNN: dynamic routing convolutional neural network for multi-view 3D object recognition. IEEE Transact Image Process. 2020;30:868–77. doi:10.1109/TIP.2020.3039378. [Google Scholar] [PubMed] [CrossRef]
33. Federici M, Dutta A, Forré P, Kushman N, Akata Z. Learning robust representations via multi-view information bottleneck. arXiv:2002.07017. 2020. [Google Scholar]
34. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Transact Pattern Analy Mach Intell. 2016;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
35. Tian Z, Shen C, Chen H, He T. Fcos: fully convolutional one-stage object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision; 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 9627–36. doi:10.1109/ICCV.2019.00972. [Google Scholar] [CrossRef]
36. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition; 2016 Jun 27–30; Las Vegas, NV, USA. p. 770–8. doi:10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
37. Yu J, Lin Z, Yang J, Shen X, Lu X, Huang TS. Free-form image inpainting with gated convolution. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision; 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 4471–80. doi:10.1109/ICCV.2019.00457. [Google Scholar] [CrossRef]
38. Zhang S, Chi C, Yao Y, Lei Z, Li SZ. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 9759–68. doi:10.1109/CVPR42600.2020.00978. [Google Scholar] [CrossRef]
39. Cai Z, Vasconcelos N. Cascade R-CNN: delving into high quality object detection. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 6154–62. doi:10.1109/CVPR.2018.00644. [Google Scholar] [CrossRef]
40. Wang M, Du H, Mei W, Wang S, Yuan D. Material-aware Cross-channel Interaction Attention (MCIA) for occluded prohibited item detection. Visual Comput. 2023;39(7):2865–77. doi:10.1007/s00371-022-02498-y. [Google Scholar] [CrossRef]
41. Zhang L, Jiang L, Ji R, Fan H. Pidray: a large-scale X-ray benchmark for real-world prohibited item detection. Int J Comput Vis. 2023;131(12):3170–92. doi:10.1007/s11263-023-01855-1. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools