
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
3D Enhanced Residual CNN for Video Super-Resolution Network
1 School of Software, Northwestern Polytechnical University, Xi’an, 710072, China
2 Shenzhen Research Institute of Northwestern Polytechnical University, Northwestern Polytechnical University, Shenzhen, 518057, China
3 State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, 210023, China
4 School of Interdisciplinary Studies, Lingnan University, Hong Kong, 999077, China
5 Yangtze River Delta Research Institute, Northwestern Polytechnical University, Taicang, 215400, China
* Corresponding Author: Chunwei Tian. Email:
# These authors contributed equally to this work
(This article belongs to the Special Issue: Advancements in Pattern Recognition through Machine Learning: Bridging Innovation and Application)
Computers, Materials & Continua 2025, 85(2), 2837-2849. https://doi.org/10.32604/cmc.2025.069784
Received 30 June 2025; Accepted 15 August 2025; Issue published 23 September 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Deep convolutional neural networks (CNNs) have demonstrated remarkable performance in video super-resolution (VSR). However, the ability of most existing methods to recover fine details in complex scenes is often hindered by the loss of shallow texture information during feature extraction. To address this limitation, we propose a 3D Convolutional Enhanced Residual Video Super-Resolution Network (3D-ERVSNet). This network employs a forward and backward bidirectional propagation module (FBBPM) that aligns features across frames using explicit optical flow through lightweight SPyNet. By incorporating an enhanced residual structure (ERS) with skip connections, shallow and deep features are effectively integrated, enhancing texture restoration capabilities. Furthermore, 3D convolution module (3DCM) is applied after the backward propagation module to implicitly capture spatio-temporal dependencies. The architecture synergizes these components where FBBPM extracts aligned features, ERS fuses hierarchical representations, and 3DCM refines temporal coherence. Finally, a deep feature aggregation module (DFAM) fuses the processed features, and a pixel-upsampling module (PUM) reconstructs the high-resolution (HR) video frames. Comprehensive evaluations on REDS, Vid4, UDM10, and Vim4 benchmarks demonstrate well performance including 30.95 dB PSNR/0.8822 SSIM on REDS and 32.78 dB/0.8987 on Vim4. 3D-ERVSNet achieves significant gains over baselines while maintaining high efficiency with only 6.3M parameters and 77 ms/frame runtime (i.e., 20× faster than RBPN). The network’s effectiveness stems from its task-specific asymmetric design that balances explicit alignment and implicit fusion.Keywords
Super-resolution (SR) [1] constitutes a fundamental task in image processing and computer vision [2]. It is an inherently challenging problem due to the loss of both spatial and temporal information during image capture and transmission, rendering it ill-posed, particularly in complex scenes [3]. Unlike single image super-resolution (SISR) [4], video super-resolution (VSR) [5] leverages temporal information across adjacent frames, enabling the recovery of finer details and richer textures. Consequently, VSR techniques have found widespread application in domains such as video enhancement [6], autonomous driving [7], and security surveillance [8].
The advent of deep learning [9,10] has led to the widespread adoption of neural networks across various image tasks, such as denoising [11], super-resolution [12,13], watermark removal [14] and blind image quality assessment [15,16]. These advancements have significantly empowered convolutional neural networks (CNNs) for effective spatio-temporal feature extraction and modeling. Pioneering VSR works, such as SRCNN-based approaches [17,18], demonstrated the feasibility of deep learning for this task. Subsequent methods like ToFlow [19] improved frame alignment through trainable motion estimation. Furthermore, richer feature representations have been shown to yield significant improvements in super-resolution results [20]. Notable contributions include the Recurrent Back-Projection Network (RBPN) proposed by Haris et al. [21], which integrates multi-frame information with a single-frame SR path, and EDVR by Wang et al. [22], which incorporates deformable convolution and a spatio-temporal attention fusion module. More recent innovations explore dynamic adaptive filters for feature-level alignment [23] and the incorporation of fuzzy mechanisms to enhance reconstruction robustness [24]. Despite the notable progress made by deep learning based VSR models, significant challenges remain. Many CNN-based VSR models expand receptive fields using deeper layers, and this may lead to loss of fine details due to weakened shallow feature propagation. Moreover, existing models often rely solely on explicit alignment or insufficient temporal modeling, resulting in degraded performance in complex scenes.
Consequently, there is a need to design more efficient and streamlined network architectures that not only enhance shallow feature extraction but also enable more robust spatio-temporal feature acquisition and inter-frame relationship modeling through improved contextual understanding. To this end, we introduce a 3D Convolutional Enhanced Residual Video Super-Resolution Network (3D-ERVSNet). The core of our approach is a Forward and Backward Bidirectional Propagation Module (FBBPM), designed to extract and align features across video frame sequences. By incorporating an Enhanced Residual Structure (ERS) with skip connections, shallow and deep features are effectively combined, significantly enhancing the network’s ability to recover intricate image textures. The main contributions of this paper are summarized as follows:
1. We propose a novel video super-resolution network, termed 3D-ERVSNet, which employs an Enhanced Residual Structure (ERS) with multi-layer skip connections. This design facilitates improved texture restoration by effectively leveraging shallow feature information.
2. We introduce a Forward and Backward Bidirectional Propagation Module (FBBPM) for inter-frame alignment. The FBBPM incorporates an Optical Flow-guided Alignment Block (OFAB) to explicitly warp features using pre-computed optical flow. Furthermore, 3D convolutions are integrated to implicitly learn spatio-temporal relationships and enable adaptive alignment. This hybrid strategy effectively leverages both explicit and implicit mechanisms to exploit spatio-temporal information.
3. Extensive experiments demonstrate that the proposed 3D-ERVSNet achieves superior visual quality, particularly in restoring image edge and texture details, outperforming existing methods on benchmark datasets.
This section details the architecture of the proposed 3D-ERVSNet. As illustrated in Fig. 1, 3D-ERVSNet comprises four key modules: the Forward and Backward Bidirectional Propagation Module (FBBPM), the 3D Convolution Module (3DCM), the Deep Feature Aggregation Module (DFAM), and the Pixel-Upsampling Module (PUM). The FBBPM is specifically designed to extract features in parallel along both forward and backward temporal directions. It consists of three sub-modules: the Optical Flow Alignment Block (OFAB), the Feature Alignment Block (FAB), and the Enhanced Residual Structure (ERS). A 3D convolution layer is applied subsequent to the Backward Propagation Module (BPM). The DFAM then fuses the output features from the Forward Propagation Module (FPM) with those from the 3DCM. The fused result is subsequently fed into the PUM to generate the final high-resolution (HR) video frame.
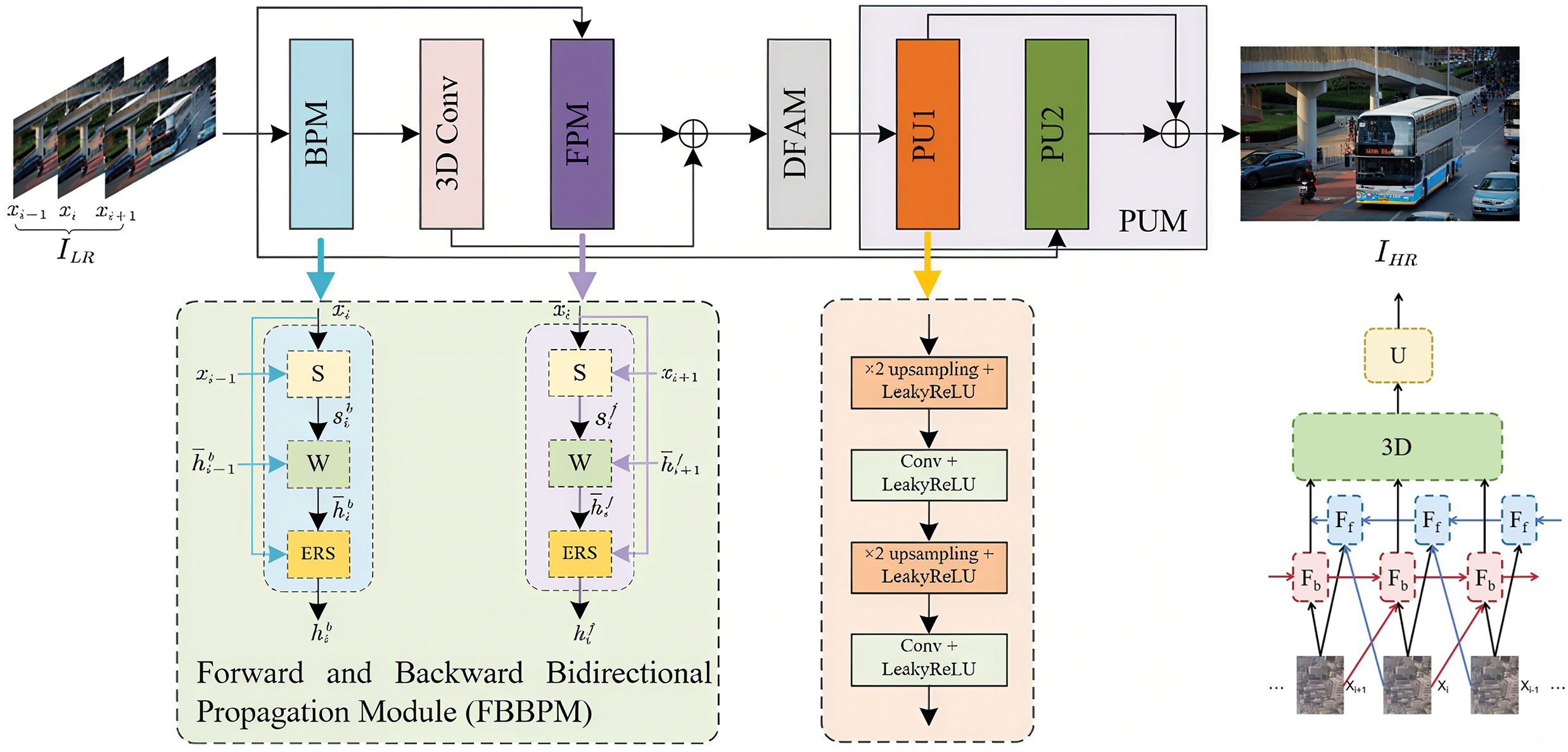
Figure 1: Overview of the proposed 3D-ERVSNet framework
2.2 Bidirectional Propagation Module
Recognizing the unique characteristic of the VSR task (i.e., the input comprises image sequences rather than individual frames as in SISR), it is essential to model both the spatial features within each frame and the temporal relationships between frames. Consequently, 3D-ERVSNet incorporates two parallel feature propagation pathways. As depicted in Fig. 1, the Forward Propagation Module (FPM,
where
2.2.1 Optical Flow Alignment Block (OFAB)
To achieve precise alignment between consecutive frames for enhanced texture reconstruction, we employ a pre-trained optical flow network. Among prominent candidates RAFT [25], PWC-Net [26], and SPyNet [27], SPyNet stands out as the most lightweight option, requiring only 1.2 million (1.2M) parameters compared to 5.3M for RAFT and 8.75M for PWC-Net. Furthermore, SPyNet exhibits a significantly smaller memory footprint (9.7 MB) than PWC-Net (41.1 MB). Notably, all three networks achieve inference times below 0.1 s. Based on this efficiency analysis, SPyNet is selected as our optical flow estimation network. Crucially, the parameters of SPyNet are frozen during the training of 3D-ERVSNet. This ensures consistent alignment performance across diverse scenes and reduces the overall model complexity. The optical flow computation is formally defined as:
where
2.2.2 Feature Alignment Block (FAB)
Within the FPM, the FAB utilizes the computed forward optical flow to warp the features from the preceding frame towards alignment with the current frame. Conversely, within the BPM, the FAB employs the backward optical flow to warp the features from the subsequent frame into alignment with the current frame. This alignment operation facilitates the fusion of relevant information from adjacent frames, contributing to enhanced sharpness and clarity in the processed frames. This process is expressed by:
where W denotes the feature alignment operation,
2.2.3 Enhanced Residual Structure (ERS)
Deep CNNs are susceptible to performance degradation stemming from the vanishing or exploding gradient problem. Residual learning, pioneered by He et al. [28], effectively mitigates this issue by incorporating skip connections that merge the output of a layer with the output of an earlier layer. Building upon this concept, we propose an Enhanced Residual Structure (ERS) incorporating multi-layer skip connections. This design facilitates the effective integration of both shallow and deep features, significantly strengthening the network’s capacity to recover intricate image textures. As depicted in Fig. 2, the ERS comprises an initial convolutional layer for channel adjustment, followed by a LeakyReLU activation function, and a series of stacked Enhanced Residual Blocks (ERBs). Each ERB contains three convolutional layers interspersed with two Gaussian Error Linear Unit (GELU) activation functions.

Figure 2: Schematic diagram of the Enhanced Residual Structure (ERS) and the Enhanced Residual Block (ERB)
Within the ERB, we adopt the GELU activation function in place of the conventional ReLU. Compared to standard residual blocks utilizing ReLU, GELU enhances neuron utilization efficiency, promotes smoother model convergence during training, and offers computational advantages.
2.3 3D Convolution Module (3DCM)
Motivated by the proven effectiveness of 3D convolutions for capturing spatio-temporal information in various computer vision tasks, such as face restoration using plug-and-play 3D facial priors [29], we incorporate a
where
2.4 Deep Feature Aggregation Module (DFAM)
To synthesize a more comprehensive feature representation, the DFAM aggregates the deep features generated by the preceding modules. The DFAM consists of a single
where
2.5 Pixel-Upsampling Module (PUM)
The Pixel-Upsampling Module (PUM) reconstructs the final high-resolution (HR) image from the aggregated deep features
where
3.1 Datasets and Evaluation Protocol
To ensure experimental fairness, the proposed 3D-ERVSNet model was trained on the REDS dataset [31]. Evaluation was conducted on three benchmark test sets: Vid4 [32], UDM10 [33], and Vim4 (comprising four sequences randomly selected from Vim90k [19]). The REDS dataset is partitioned into a training set (240 videos), a validation set (30 videos), and a test set (30 videos). The Vid4 test set contains four video sequences: ‘calendar’, ‘city’, ‘foliage’, and ‘walk’. The UDM10 dataset includes 10 video sequences, each consisting of 32 consecutive frames. The Vim4 dataset consists of 4 video sequences extracted from Vim90k, each containing 7 consecutive frames. Quantitative performance evaluation employs the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) metrics.
Following the training methodology of LapSRN [34], we employ the Charbonnier loss [35] to optimize the network parameters. This loss function measures the difference between the ground-truth high-resolution (HR) video frames and the predicted HR frames. For effective training, an input sequence length of 15 frames is utilized. Optimization is performed using the Adam optimizer with a cosine annealing learning rate schedule. The initial learning rates are configured as follows:
An ablation study is conducted to evaluate the individual contributions of the Enhanced Residual Structure (ERS) and the 3D Convolution Module (3DCM) within the proposed 3D-ERVSNet framework. Tables 1 and 2 present the quantitative results on the UDM10 and Vid4 (BD degradation) datasets, respectively.


The baseline model employs a standard residual structure, lacking both the ERS and 3DCM. As evidenced by Tables 1 and 2, integrating the ERS yields statistically significant improvements in both PSNR and SSIM metrics (e.g., approximately +1.40 dB PSNR on UDM10). This substantial gain underscores the critical role of the ERS in enhancing the feature extraction capability. The results suggest that the ERS successfully facilitates the extraction of richer features while effectively preserving vital shallow texture information present in the video frames. The subsequent integration of the 3DCM further enhances performance consistently across datasets (e.g., approximately +0.46 dB PSNR on Vid4). This improvement confirms the efficacy of the 3DCM in refining spatio-temporal details and implicitly capturing inter-frame dependencies. Consequently, the synergistic combination of both the ERS and 3DCM leads to the most accurate and detailed reconstruction performance.
Table 3 summarizes the quantitative comparison against other methods. The proposed 3D-ERVSNet demonstrates competitive or superior performance across all three benchmark datasets. Notably, it achieves the highest PSNR and SSIM values on the REDS (30.95 dB/0.8822) and Vim4 (32.78 dB/0.8987) datasets. On the challenging Vid4 benchmark with BD degradation, 3D-ERVSNet (27.02 dB/0.8224) also performs favorably compared to strong methods like RBPN (27.12 dB/0.8180) and EDVR-M (27.10 dB/0.8186), achieving comparable PSNR with a higher SSIM score.

Table 4 compares model complexity and inference speed. The proposed 3D-ERVSNet achieves an excellent balance, offering competitive performance (Table 3) with moderate parameter complexity (6.3M parameters, inclusive of the frozen SPyNet) and significantly faster inference time (77 ms per frame) compared to many methods like RBPN (1507 ms) and DUF (974 ms). This efficiency makes 3D-ERVSNet highly practical.

Visual comparisons further substantiate the effectiveness of 3D-ERVSNet. Fig. 3 illustrates that 3D-ERVSNet reconstructs finer texture details on the Vid4 dataset compared to other methods. In the zoomed upper-left region (marked area), our model reconstructs the structural texture of the mural with clear visibility, while competing methods fail to restore these patterns entirely. Similarly, Fig. 4 demonstrates superior sharpness and clarity in the marked region for results on the UDM10 dataset. Upon magnification, our result exhibits the closest resemblance to the HR ground truth in texture lines. Other methods either omit these lines or produce textures that significantly deviate from the HR reference. Fig. 5 highlights the realism achieved by 3D-ERVSNet on the Vim4 dataset, particularly evident in the accurate reconstruction of intricate elements like the door handle within the marked area. Vertical stripes on the truck are faithfully preserved without tilt (unlike the skewed outputs of other models). And our method avoids generating false patterns (e.g., MuCAN erroneously reconstructs the pickup truck’s door handle as a vertical line, while ours matches the GT structure). These qualitative observations align with the quantitative metrics, confirming that 3D-ERVSNet excels in recovering authentic spatial details and robustly modeling temporal information.

Figure 3: Visual comparison of ×4 super-resolution results on the Vid4 ‘city’ sequence. The proposed 3D-ERVSNet reconstructs sharper edges and more authentic textures (see marked region) compared to other methods. Ground Truth (GT) is shown for reference

Figure 4: Visual comparison of ×4 super-resolution results on the UDM10 dataset. 3D-ERVSNet produces results with enhanced sharpness and clarity in the marked region relative to competing approaches

Figure 5: Visual comparison of ×4 super-resolution results on the Vim4 dataset. The output of 3D-ERVSNet exhibits superior realism and detail, particularly noticeable in the reconstruction of complex structures like the door handle within the marked area
This paper presents 3D-ERVSNet, a novel and efficient network for video super-resolution. The core of our approach is a Forward and Backward Bidirectional Propagation Module (FBBPM), designed to achieve robust inter-frame feature alignment. The FBBPM incorporates an Enhanced Residual Structure (ERS) with multi-layer skip connections, enabling effective integration of shallow and deep features to enrich frame representations and enhance texture recovery. Furthermore, a 3D Convolution Module (3DCM) is strategically integrated following the backward propagation path to implicitly capture spatio-temporal dependencies and refine feature expression, effectively complementing the explicit alignment of the FBBPM. The resulting architecture achieves an advantageous balance between performance and efficiency. Despite its relatively streamlined design, 3D-ERVSNet demonstrates rapid convergence. Extensive quantitative and qualitative evaluations on multiple benchmark datasets (REDS, Vid4, UDM10, Vim4) confirm that 3D-ERVSNet achieves highly competitive performance in reconstructing high-resolution video frames with rich textures and fine details, while maintaining lower computational complexity and faster inference speed compared to many existing high-performance VSR models.
Acknowledgement: Not applicable.
Funding Statement: This project was supported in part by the Basic and Applied Basic Research Foundation of Guangdong Province [2025A1515011566]; in part by the State Key Laboratory for Novel Software Technology, Nanjing University [KFKT2024B08]; in part by Leading Talents in Gusu Innovation and Entrepreneurship [ZXL2023170]; and in part by the Basic Research Programs of Taicang 2024, [TC2024JC32].
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Weiqiang Xin and Xi Chen; methodology, Chunwei Tian and Zheng Wang; software, Weiqiang Xin, Xi Chen and Bing Li; validation, Zheng Wang and Bing Li; formal analysis, Yufeng Tang and Zheng Wang; visualization, Weiqiang Xin and Yufeng Tang; supervision, Chunwei Tian. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Open data available in https://github.com/xwq325/3D-ERVSNet (accessed on 30 June 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Tian C, Song M, Fan X, Zheng X, Zhang B, Zhang D. A tree-guided CNN for image super-resolution. IEEE Trans Consum Electron. 2025;71(2):1–10. doi:10.1109/TCE.2025.3572732. [Google Scholar] [CrossRef]
2. Lu M, Zhang P. Grouped spatio-temporal alignment network for video super-resolution. IEEE Signal Process Lett. 2022;29:2193–7. doi:10.1109/lsp.2022.3210874. [Google Scholar] [CrossRef]
3. Lu Y, Wang Z, Liu M, Wang H, Wang L. Learning spatial-temporal implicit neural representations for event-guided video super-resolution. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 1557–67. doi:10.1109/CVPR52729.2023.00156. [Google Scholar] [CrossRef]
4. Tian C, Yuan Y, Zhang S, Lin CW, Zuo W, Zhang D. Image super-resolution with an enhanced group convolutional neural network. Neural Netw. 2022;153(6):373–85. doi:10.1016/j.neunet.2022.06.009. [Google Scholar] [PubMed] [CrossRef]
5. Wang Y, Isobe T, Jia X, Tao X, Lu H, Tai YW. Compression-aware video super-resolution. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 2012–21. doi:10.1109/CVPR52729.2023.00200. [Google Scholar] [CrossRef]
6. Lv Z, Wu J, Xie S, Gander AJ. Video enhancement and super-resolution. In: Digital image enhancement and reconstruction. Amsterdam, The Netherlands: Elsevier; 2023. p. 1–28. doi:10.1016/b978-0-32-398370-9.00008-1. [Google Scholar] [CrossRef]
7. Haghighi H, Dianati M, Donzella V, Debattista K. Accelerating stereo image simulation for automotive applications using neural stereo super resolution. IEEE Trans Intell Transp Syst. 2023;24(11):12627–36. doi:10.1109/TITS.2023.3287912. [Google Scholar] [CrossRef]
8. Guo K, Zhang Z, Guo H, Ren S, Wang L, Zhou X, et al. Video super-resolution based on inter-frame information utilization for intelligent transportation. IEEE Trans Intell Transp Syst. 2023;24(11):13409–21. doi:10.1109/TITS.2023.3237708. [Google Scholar] [CrossRef]
9. Tian C, Zheng M, Li B, Zhang Y, Zhang S, Zhang D. Perceptive self-supervised learning network for noisy image watermark removal. IEEE Trans Circuits Syst Video Technol. 2024;34(8):7069–79. doi:10.1109/TCSVT.2024.3349678. [Google Scholar] [CrossRef]
10. Zhang S, Mao W, Wang Z. An efficient accelerator based on lightweight deformable 3D-CNN for video super-resolution. IEEE Trans Circuits Syst I Regul Pap. 2023;70(6):2384–97. doi:10.1109/TCSI.2023.3258446. [Google Scholar] [CrossRef]
11. Tian C, Zheng M, Lin CW, Li Z, Zhang D. Heterogeneous window transformer for image denoising. IEEE Trans Syst Man Cybern Syst. 2024;54(11):6621–32. doi:10.1109/TSMC.2024.3429345. [Google Scholar] [CrossRef]
12. Kim J, Lee JK, Lee KM. Deeply-recursive convolutional network for image super-resolution. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 1637–45. doi:10.1109/CVPR.2016.181. [Google Scholar] [CrossRef]
13. Kim J, Lee JK, Lee KM. Accurate image super-resolution using very deep convolutional networks. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 1646–54. doi:10.1109/CVPR.2016.182. [Google Scholar] [CrossRef]
14. Tian C, Zheng M, Jiao T, Zuo W, Zhang Y, Lin CW. A self-supervised CNN for image watermark removal. IEEE Trans Circuits Syst Video Technol. 2024;34(8):7566–76. doi:10.1109/TCSVT.2024.3375831. [Google Scholar] [CrossRef]
15. Wang Z, Ma K. Active fine-tuning from gMAD examples improves blind image quality assessment. IEEE Trans Pattern Anal Mach Intell. 2022;44(9):4577–90. doi:10.1109/TPAMI.2021.3071759. [Google Scholar] [PubMed] [CrossRef]
16. Wang Z, Wang H, Chen T, Wang Z, Ma K. Troubleshooting blind image quality models in the wild. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 16251–60. doi:10.1109/cvpr46437.2021.01599. [Google Scholar] [CrossRef]
17. Dong C, Loy CC, He K, Tang X. Learning a deep convolutional network for image super-resolution. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T, editors. Computer Vision—ECCV 2014; 2014 Sep 6–12. Zurich, Switzerland. Cham, Switzerland: Springer International Publishing; 2014. p. 184–99. doi:10.1007/978-3-319-10593-2_13. [Google Scholar] [CrossRef]
18. Kappeler A, Yoo S, Dai Q, Katsaggelos AK. Video super-resolution with convolutional neural networks. IEEE Trans Comput Imag. 2016;2(2):109–22. doi:10.1109/TCI.2016.2532323. [Google Scholar] [CrossRef]
19. Xue T, Chen B, Wu J, Wei D, Freeman WT. Video enhancement with task-oriented flow. Int J Comput Vis. 2019;127(8):1106–25. doi:10.1007/s11263-018-01144-2. [Google Scholar] [CrossRef]
20. Deng X. Enhancing image quality via style transfer for single image super-resolution. IEEE Signal Process Lett. 2018;25(4):571–5. doi:10.1109/LSP.2018.2805809. [Google Scholar] [CrossRef]
21. Haris M, Shakhnarovich G, Ukita N. Recurrent back-projection network for video super-resolution. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 3892–901. doi:10.1109/cvpr.2019.00402. [Google Scholar] [CrossRef]
22. Wang X, Chan KCK, Yu K, Dong C, Loy CC. EDVR: video restoration with enhanced deformable convolutional networks. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2019 Jun 16–17; Long Beach, CA, USA. p. 1954–63. doi:10.1109/cvprw.2019.00247. [Google Scholar] [CrossRef]
23. Zhou C, Chen C, Ding F, Zhang D. Video super-resolution with non-local alignment network. IET Image Process. 2021;15(8):1655–67. doi:10.1049/ipr2.12134. [Google Scholar] [CrossRef]
24. Ma L, Li N, Zhu P, Tang K, Khan A, Wang F, et al. A novel fuzzy neural network architecture search framework for defect recognition with uncertainties. IEEE Trans Fuzzy Syst. 2024;32(5):3274–85. doi:10.1109/TFUZZ.2024.3373792. [Google Scholar] [CrossRef]
25. Teed Z, Deng J. RAFT: recurrent all-pairs field transforms for optical flow. In: European Conference on Computer Vision; 2020 Aug 23–28; Glasgow, UK. Cham, Switzerland: Springer International Publishing; 2020. p. 402–19. doi:10.1007/978-3-030-58536-5_24. [Google Scholar] [CrossRef]
26. Sun D, Yang X, Liu MY, Kautz J. PWC-net: CNNs for optical flow using pyramid, warping, and cost volume. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 8934–43. doi:10.1109/CVPR.2018.00931. [Google Scholar] [CrossRef]
27. Ranjan A, Black MJ. Optical flow estimation using a spatial pyramid network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. p. 2720–9. doi:10.1109/CVPR.2017.291. [Google Scholar] [CrossRef]
28. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 770–8. doi:10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
29. Hu X, Ren W, Yang J, Cao X, Wipf D, Menze B, et al. Face restoration via plug-and-play 3D facial priors. IEEE Trans Pattern Anal Mach Intell. 2022;44(12):8910–26. doi:10.1109/TPAMI.2021.3123085. [Google Scholar] [PubMed] [CrossRef]
30. Ding X, Guo Y, Ding G, Han J. ACNet: strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 1911–20. doi:10.1109/iccv.2019.00200. [Google Scholar] [CrossRef]
31. Nah S, Baik S, Hong S, Moon G, Son S, Timofte R, et al. Challenge on video deblurring and super-resolution: dataset and study. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2019 Jun 16–17; Long Beach, CA, USA. p. 1996–2005. doi:10.1109/cvprw.2019.00251. [Google Scholar] [CrossRef]
32. Liu C, Sun D. On Bayesian adaptive video super resolution. IEEE Trans Pattern Anal Mach Intell. 2014;36(2):346–60. doi:10.1109/TPAMI.2013.127. [Google Scholar] [PubMed] [CrossRef]
33. Schultz RR, Meng L, Stevenson RL. Subpixel motion estimation for super-resolution image sequence enhancement. J Vis Commun Image Represent. 1998;9(1):38–50. doi:10.1006/jvci.1997.0370. [Google Scholar] [CrossRef]
34. Lai WS, Huang JB, Ahuja N, Yang MH. Deep Laplacian pyramid networks for fast and accurate super-resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. p. 5835–43. doi:10.1109/CVPR.2017.618. [Google Scholar] [CrossRef]
35. Lai WS, Huang JB, Ahuja N, Yang MH. Fast and accurate image super-resolution with deep Laplacian pyramid networks. IEEE Trans Pattern Anal Mach Intell. 2019;41(11):2599–613. doi:10.1109/TPAMI.2018.2865304. [Google Scholar] [PubMed] [CrossRef]
36. Li S, He F, Du B, Zhang L, Xu Y, Tao D. Fast spatio-temporal residual network for video super-resolution. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 10514–23. doi:10.1109/cvpr.2019.01077. [Google Scholar] [CrossRef]
37. Rifman SS. Digital rectification of ERTS multispectral imagery. In: NASA Goddard Space Flight Center Symposium on Significant Results Obtained from the ERTS-1; 1973 Mar 5–9; Greenbelt, MD, USA. [Google Scholar]
38. Jo Y, Oh SW, Kang J, Kim SJ. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 3224–32. doi:10.1109/CVPR.2018.00340. [Google Scholar] [CrossRef]
39. Yi P, Wang Z, Jiang K, Jiang J, Ma J. Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 3106–15. doi:10.1109/iccv.2019.00320. [Google Scholar] [CrossRef]
40. Li W, Tao X, Guo T, Qi L, Lu J, Jia J. MuCAN: multi-correspondence aggregation network for video super-resolution. In: Vedaldi A, Bischof H, Brox T, Frahm J-M, editors. Computer Vision—ECCV 2020; 2020 Aug 23–28; Glasgow, UK. Cham, Switzerland: Springer International Publishing; 2020. p. 335–51. doi:10.1007/978-3-030-58607-2_20. [Google Scholar] [CrossRef]
41. Xu G, Xu J, Li Z, Wang L, Sun X, Cheng MM. Temporal modulation network for controllable space-time video super-resolution. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 6384–93. doi:10.1109/cvpr46437.2021.00632. [Google Scholar] [CrossRef]
42. Wang H, Xiang X, Tian Y, Yang W, Liao Q. STDAN: deformable attention network for space-time video super-resolution. IEEE Trans Neural Netw Learn Syst. 2024;35(8):10606–16. doi:10.1109/TNNLS.2023.3243029. [Google Scholar] [PubMed] [CrossRef]
43. Zhu Q, Chen F, Zhu S, Liu Y, Zhou X, Xiong R, et al. DVSRNet: deep video super-resolution based on progressive deformable alignment and temporal-sparse enhancement. IEEE Trans Neural Netw Learn Syst. 2025;36(2):3258–72. doi:10.1109/tnnls.2023.3347450. [Google Scholar] [PubMed] [CrossRef]
44. Caballero J, Ledig C, Aitken A, Acosta A, Totz J, Wang Z, et al. Real-time video super-resolution with spatio-temporal networks and motion compensation. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017 Jul 21–26; Honolulu, HI, USA. p. 2848–57. doi:10.1109/CVPR.2017.304. [Google Scholar] [CrossRef]
45. Tao X, Gao H, Liao R, Wang J, Jia J. Detail-revealing deep video super-resolution. In: 2017 IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 4482–90. doi:10.1109/ICCV.2017.479. [Google Scholar] [CrossRef]
46. Sajjadi MSM, Vemulapalli R, Brown M. Frame-recurrent video super-resolution. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 6626–34. doi:10.1109/CVPR.2018.00693. [Google Scholar] [CrossRef]
47. Wang L, Guo Y, Lin Z, Deng X, An W. Learning for video super-resolution through HR optical flow estimation. In: Jawahar CV, Li H, Mori G, Schindler K, editors. Computer Vision—ACCV 2018; 2018 Dec 2–6; Perth, Australia. Cham, Switzerland: Springer International Publishing; 2019. p. 514–29. doi:10.1007/978-3-030-20887-5_32. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools