
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Leveraging Deep Learning for Precision-Aware Road Accident Detection
1 Chitkara University Institute of Engineering and Technology, Chitkara University, Rajpura, 140401, Punjab, India
2 Department of Networks and Communications Engineering, College of Computer Science and Information Systems, Najran University, Najran, 61441, Saudi Arabia
3 Department of Electrical Engineering, College of Engineering, King Faisal University, Al-Ahsa, 31982, Saudi Arabia
* Corresponding Author: Ashu Taneja. Email:
Computers, Materials & Continua 2025, 85(3), 4827-4848. https://doi.org/10.32604/cmc.2025.067901
Received 15 May 2025; Accepted 18 July 2025; Issue published 23 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Accident detection plays a critical role in improving traffic safety by enabling timely emergency response and reducing the impact of road incidents. The main challenge lies in achieving real-time, reliable and highly accurate detection across diverse Internet-of-vehicles (IoV) environments. To overcome this challenge, this paper leverages deep learning to automatically learn patterns from visual data to detect accidents with high accuracy. A visual classification model based on the ResNet-50 architecture is presented for distinguishing between accident and non-accident images. The model is trained and tested on a labeled dataset and achieves an overall accuracy of 91.84%, with a precision of 94%, recall of 90.38%, and an F1-score of 92.14%. Training behavior is observed over 100 epochs, where the model has shown rapid accuracy gains and loss reduction within the first 30 epochs, followed by gradual stabilization. Accuracy plateaues between 90−93%, and loss values remain consistent between 0.1 and 0.2 in later stages. To understand the effect of training strategy, the model is optimized using three different algorithms, namely, SGD, Adam, and Adadelta with all showing effective performance, though with varied convergence patterns. Further, to test its effectiveness, the proposed model is compared with existing models. In the end, the problems encountered in implementing the model in practical automotive settings and offered solutions are discussed. The results support the reliability of the approach and its suitability for real-time traffic safety applications.Keywords
The rapid development in artificial intelligence (AI) has revolutionized numerous industries with automotive systems among the most significantly transformed [1]. Intelligent transportation systems (ITS) improve general vehicle performance, traffic flow optimization, and safety enhancement by means of ML techniques. As connected and autonomous automobiles gain increasing acceptability, the integration of ML-based solutions has become absolutely vital for addressing problems such accident avoidance, real-time traffic management, and predictive maintenance [2]. The acceptance of ML in modern transportation has been accelerated by increasing availability of big-scale vehicle data coupled with advances in processing capacity.
Road safety is a primary concern given the rising frequency of traffic accidents, many of which result in fatalities or major injuries. Late reporting of accident occurrences can significantly impact the response time of emergency services in various situations [3]. As per the eyewitness testimonies or surveillance operators, traditional methods may not always be quick or reliable. This underlines the importance of a more automated and efficient strategy [4]. A smart accident detection system can help to reduce this gap by recognizing accidents as they happen, hence reducing emergency response delays and possibly saving lives. Incorporating such technology into car or road infrastructure helps authorities to respond faster and manage traffic more effectively, hence enhancing road safety for everyone.
AI is playing a transformative role in the automotive sector, making vehicles more intelligent, responsive, and capable of adapting to complex driving environments as illustrated in Fig. 1. In today’s smart vehicles, AI supports a wide range of features such as autonomous driving, where systems can interpret surroundings and make decisions without human input [5]. It also drives sophisticated safety technologies including adaptive cruise control, lane keeping, and collision avoidance. Beyond safety, AI helps to optimize traffic by examining road conditions and recommending effective routes. By learning driver preferences and automating in vehicle settings, it also improves user experience. Predictive maintenance systems and communication between vehicles and infrastructure help to further show how AI is enabling cars to run more safely and effectively. These advances are altering not only how cars operate but also how they interact with their environment and people daily.

Figure 1: Applications of AI in smart vehicles
Modern vehicle technologies mostly focus on ensuring road safety by real-time danger detection and accident avoidance [6]. Conventional approaches of traffic control and accident detection may depend on predetermined guidelines and sensor based systems, which can be constrained in accuracy and adaptability [7]. Analyzing large volumes of vehicle data has shown amazing promise for machine learning, especially deep learning models such as Convolutional Neural Networks (CNNs) [8] and Recurrent Neural Networks (RNNs) [9], therefore enabling accurate and rapid decision-making. To offer extremely exact and quick answers, these models combine real-time data from many sources including GPS systems, car sensors, and surveillance cameras.
Moreover, ML techniques help to provide intelligent traffic monitoring, autonomous navigation, and advanced driver-assistance systems (ADAS) [10]. CNN-based models for scene analysis and YOLO (You Only Look Once) for real-time object detection help vehicles to effectively identify pedestrians, other vehicles, and obstacles. The combination of ML with Internet of Things (IoT) technologies creates smart infrastructure that uses real-time traffic analytics to help to minimize congestion and maximize vehicle circulation [11]. ML-driven predictive maintenance models also help to minimize vehicle downtime by anticipating likely issues before they happen, hence improving fleet management and operational performance. Predictive analytics ensures preventive maintenance and reduces the likelihood of breakdowns by means of engine performance, tire pressure, and other essential vehicle criteria evaluation.
Key Contributions
The main challenge in automotive systems is ensuring the safety and reliability in complex real-time environments. With an eye towards accident detection, traffic management and predictive analytics, the performance of automotive systems can be enhanced. This paper presents a structured approach to accident detection using a deep learning model based on the ResNet-50 architecture. The key contributions of this work are as follows:
• A visual classification model is developed to distinguish accident scenes from non-accident situations using image data.
• The model is trained and evaluated across multiple optimization strategies, including SGD, Adam and Adadelta, to assess performance consistency.
• A detailed analysis of training and validation accuracy, as well as loss behavior is presented to understand the model’s learning process.
• Performance is measured using standard classification metrics which includes accuracy, precision, recall, F1-score, Dice-coefficient and Jaccard index and compared against traditional classifiers to establish effectiveness.
• Additional evaluation is performed using Mean Squared Error (MSE) to assess prediction reliability based on probability confidence.
• The practical considerations of deploying such a model in real-time traffic systems are discussed, including reliability and optimization trade-offs.
This study introduces a deep learning methodology for accident detection utilizing the ResNet-50 architecture. The suggested model employs image-based classification to enhance detection accuracy and generalization, in contrast to previous studies that predominantly utilized conventional machine learning techniques or rule-based systems. The model is trained on both accident and non-accident image data, and the performance is evaluated with the optimizers, namely, SGD, Adam and Adadelta. The results are compared with other methods in the recent literature to validate its effectiveness.
Paper Organization
The remainder of this paper is structured as follows. Section 2 reviews existing studies and approaches related to accident detection and related machine learning applications in smart vehicles. Section 3 describes the methodology used in developing the proposed ResNet-50-based model, along with details on data preparation, training settings, and optimization strategies. Section 4 presents the experimental results, including accuracy, loss behavior, confusion matrix analysis, MSE and optimizer comparison. Section 4 offers a discussion on model performance, learning patterns, and real-time application considerations. Finally, Section 8 summarizes the key findings and outlines potential directions for future work.
Numerous studies have applied machine learning and deep learning techniques for accident detection and severity prediction. While traditional models like decision trees and logistic regression offer interpretable outcomes, they often fall short in handling complex real-time data. Recent models leverage deep learning and ensemble methods for improved performance, yet many lack real-time capability and extensive sensor-based features. Some of these related studies are summarized in Table 1.

Several studies have explored the impact of machine learning on vehicular systems [21], particularly in accident detection [22], traffic management [23], and predictive maintenance [24]. Researchers have extensively utilized deep learning techniques to improve vehicle perception and decision-making. For instance, CNN-based models have been widely applied in real-time accident detection and classification, achieving high accuracy in analyzing dashcam footage, traffic surveillance videos, and sensor data [25]. Studies such as [26] have demonstrated how CNNs outperform traditional rule-based models in recognizing vehicular collisions. Machine learning continues to shape the future of transportation by supporting a wide range of intelligent applications.
Another key application is traffic flow management, where machine learning techniques have contributed to more efficient urban mobility. One area of focus has been adaptive traffic signal control. For instance, the approach developed by Chen et al. [27] uses a deep Q-network (DQN) to dynamically adjust traffic lights, reducing vehicle delays significantly. In parallel, researchers like Ahmed et al. [28] have used real-time and historical traffic data to predict congestion and recommend alternative routes. Incorporating graph-based models such as Graph Neural Networks (GNNs) has further enhanced prediction accuracy by capturing complex spatial and temporal relationships within road networks. The study by Tasabat and Aydin [29] demonstrated how LSTM models could improve engine failure forecasting, helping operators plan maintenance and reduce costs. Fleet management systems have adopted similar techniques to monitor vehicle health, detect performance anomalies, and optimize fuel efficiency, as noted by Usmani et al. [30]. More recently, unsupervised learning methods, including autoencoders and GANs, have been applied to anomaly detection, allowing the identification of irregularities in sensor data without requiring labeled examples.
Autonomous vehicle development has greatly benefited from the use of machine learning. Technologies such as sensor fusion, real-time object detection, and reinforcement learning enable vehicles to navigate dynamic environments with improved safety [31]. YOLO-based models and cooperative communication strategies, like V2X, have played important roles in enhancing decision-making on the road. For instance, the study by Li et al. [32] explored federated learning to train autonomous systems across distributed networks while preserving data privacy. Explainable AI (XAI) techniques are increasingly being explored to make ML-based vehicular decisions more transparent and interpretable [33].
Recent research has persistently investigated sophisticated learning architectures for accident detection and traffic safety applications. Chang et al. put out a deep learning for monitoring safety in railway traffic system utilising object detection and segmentation for early accident prediction and to increase detection performance [34]. Wang et al. utilized a data-driven deep learning model to forecast traffic collisions at intersections by analysing historical data and traffic volume [35]. Jaradat et al. used deep learning models to segment video streams using multimodal LLM and CNN to identify miss or crash incidents in real time [36]. These contributions underscore the increasing transition towards deep learning-based accident detection utilizing both static and dynamic visual data.
Recent initiatives have broadened accident detection beyond binary classification. Grigorev et al. [37] put forth a multi-task framework that not only finds accidents, but also divides the impacted road sections and uses traffic speed data to anticipate how long the interruption will last. Their model attained elevated detection accuracy and shown a substantial decrease in prediction error. The current study, on the other hand, only looks at visual classification based on single-frame photographs. Its goal is to create a smaller and more portable solution that works with camera-based systems in IoV situations with low resources.
Despite these advancements, challenges remain in the deployment of ML in vehicular systems. Issues such as data scarcity, model interpretability, and real-world adaptability need further exploration. Additionally, concerns regarding cyber security threats, adversarial attacks on ML models, and ethical dilemmas in autonomous decision-making require extensive research.
Even though a lot of research has been done on using both old and new machine learning methods to find accidents, there are still some big problems. Numerous current models depend on structured or sensor-based data instead of visual input [38], which restricts their use in image-centric settings like traffic cameras or vehicle-mounted systems. Furthermore, there is a scarcity of studies that do a direct comparison of various optimization procedures, which is crucial for comprehending model stability and convergence behavior. Another gap exists in the assessment of prediction confidence, where metrics such as Mean Squared Error (MSE) are frequently neglected, despite their utility in evaluating probability-based outputs. Moreover, although real-time detection is frequently cited as an objective, there has been insufficient research on the difficulties of reconciling performance with computational economy. These discoveries underscore the necessity for a vision-based, performance-evaluated model that incorporates both classification accuracy and training dynamics goals that are addressed in the present study.
This section presents the methodology offering a disciplined framework for applying machine learning methods to improve vehicle system performance. Data collection, pre processing, feature engineering, model selection, training, evaluation, and deployment constitute a few of the various phases in the process as shown in the operational flow presented in Fig. 2.
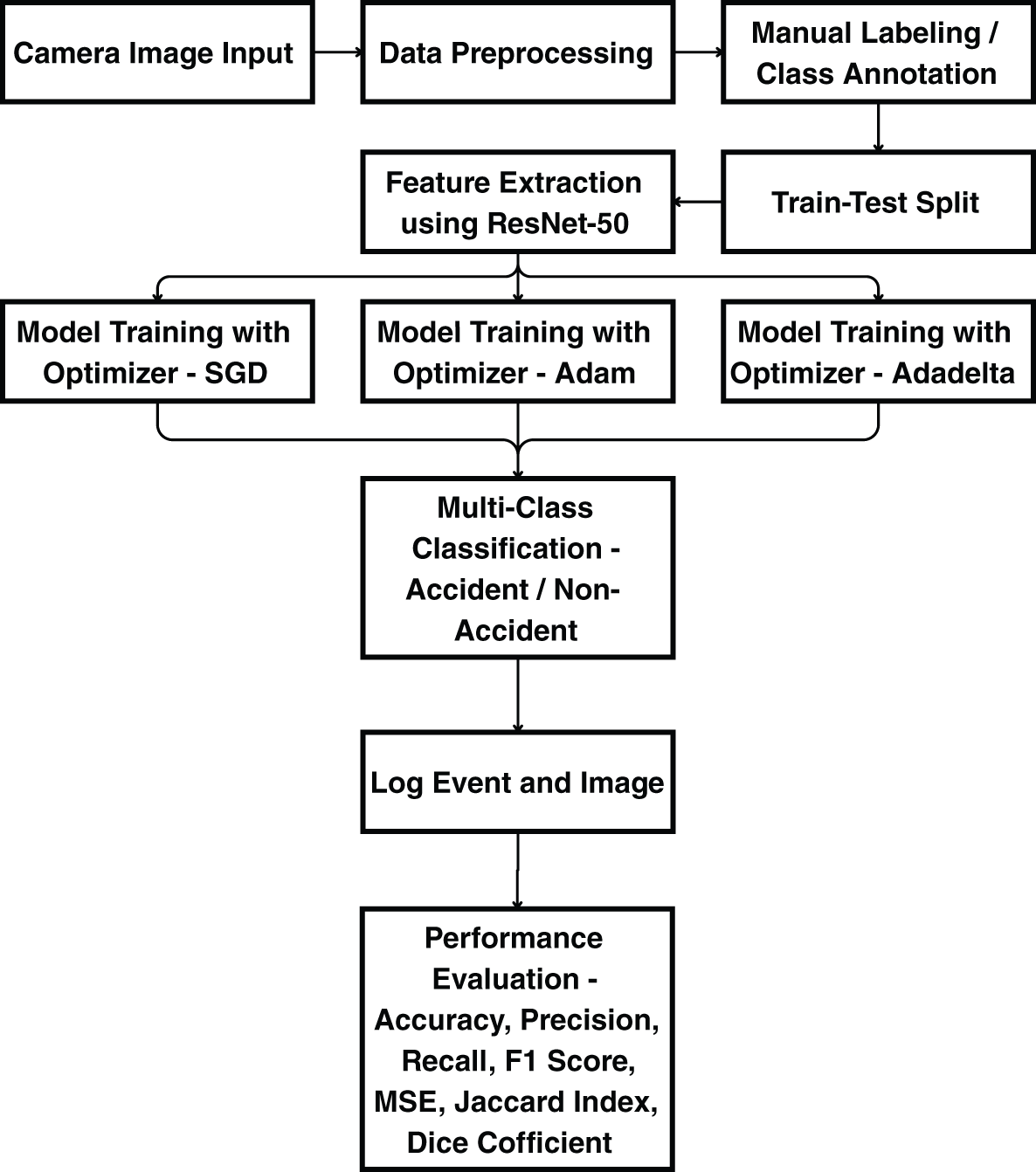
Figure 2: Flowchart of the proposed methodology
A key first step guaranteeing the availability of high-quality input data for training and testing machine learning models is data collection.
This study uses photos from both accident and non-accident sources taken from CCTV footage as shown in Fig. 3. Each of the three folders, training, testing, and validation sets has sub folders for photographs both accident and non-accident. The information comes from publicly accessible repositories and is tagged such that it supports supervised learning. This guarantees a varied presentation of actual accident situations and regular traffic conditions, therefore strengthening the dataset for training. The image dataset for this investigation is obtained using fixed-position CCTV cameras often employed in urban traffic monitoring systems. The cameras use a 2-megapixel CMOS sensor and can record at 30 frames per second with a resolution of 1920

Figure 3: Used dataset
3.1.2 Data Acquisition Techniques
Video surveillance systems provide data that are then converted into visual frames. The dataset exists in a structured directory style. The image_dataset_from_directory
Feature Engineering and Preprocessing
Preprocessing and feature engineering enhance model performance by improving the quality of raw data. By guaranteeing a clean, well-structured dataset suitable for machine learning algorithms, these tasks help to lower noise and increase accuracy.
Data cleaning identifies anomalies and improves the quality of the dataset. The dataset examines erroneous labeled samples, duplicate records, and defective photos. Any low-resolution or fuzzy photos are filtered out to avoid misclassification. Removing artifacts brought on by inadequate lighting or motion blur guarantees the integrity of the dataset, hence affecting model predictions. Automated scripts locate and delete such anomalies, hence guaranteeing a high-quality dataset.
Normalizing standardizes the pixel intensity levels across all photos. To keep consistency among training samples, every image is scaled to a 250
Techniques for data augmentation serve to artificially enlarge the dataset and enhance the generalizing capacity of the model. Methods of augmentation applied are:
• Flipping: Horizontal and vertical flips to increase dataset volatility.
• Rotation: Random rotations of up to 30 degrees to make the model robust to changes in orientation.
• Contrast Adjustments: By means of contrast improvement or decrease, one can simulate several lighting scenarios.
• Gaussian Noise: Adding random noise to boost model resilience to distortions.
• Random Cropping: Extracting smaller image parts allows the model to focus on different regions of interest.
• Brightness Changes: Altering brightness levels to reflect different times of the day. Changing brightness settings to simulate different times of the day. These developments help to prevent overfitting and ensure the model operates efficiently under many configurations.
Mostly, feature extraction decides how clear the model is and how well it performs. By means of its convolutional layers gathering fundamental picture patterns, the MobileNetV2 design is a feature extractor. Though the top layers of the model are fine-tuned for accident categorization, the lowest layers preserve generic image characteristics including borders and textures. If required, feature selection methods like Principal Component Analysis (PCA) are used to lower dimensionality while keeping pertinent information. Studying activation maps from several layers also helps one to identify which image areas most influence the decision-making process of the model.
3.2 Model Selection and Training
ResNet-50 architecture is a feature extractor in the deep learning-based suggested model for accident detection. This model’s main objective is to sort images into two groups: accidental and non-accidental. Through batch normalization and dropout layers, the general architecture is meant to effectively learn pertinent features while minimizing overfit as in Fig. 4.
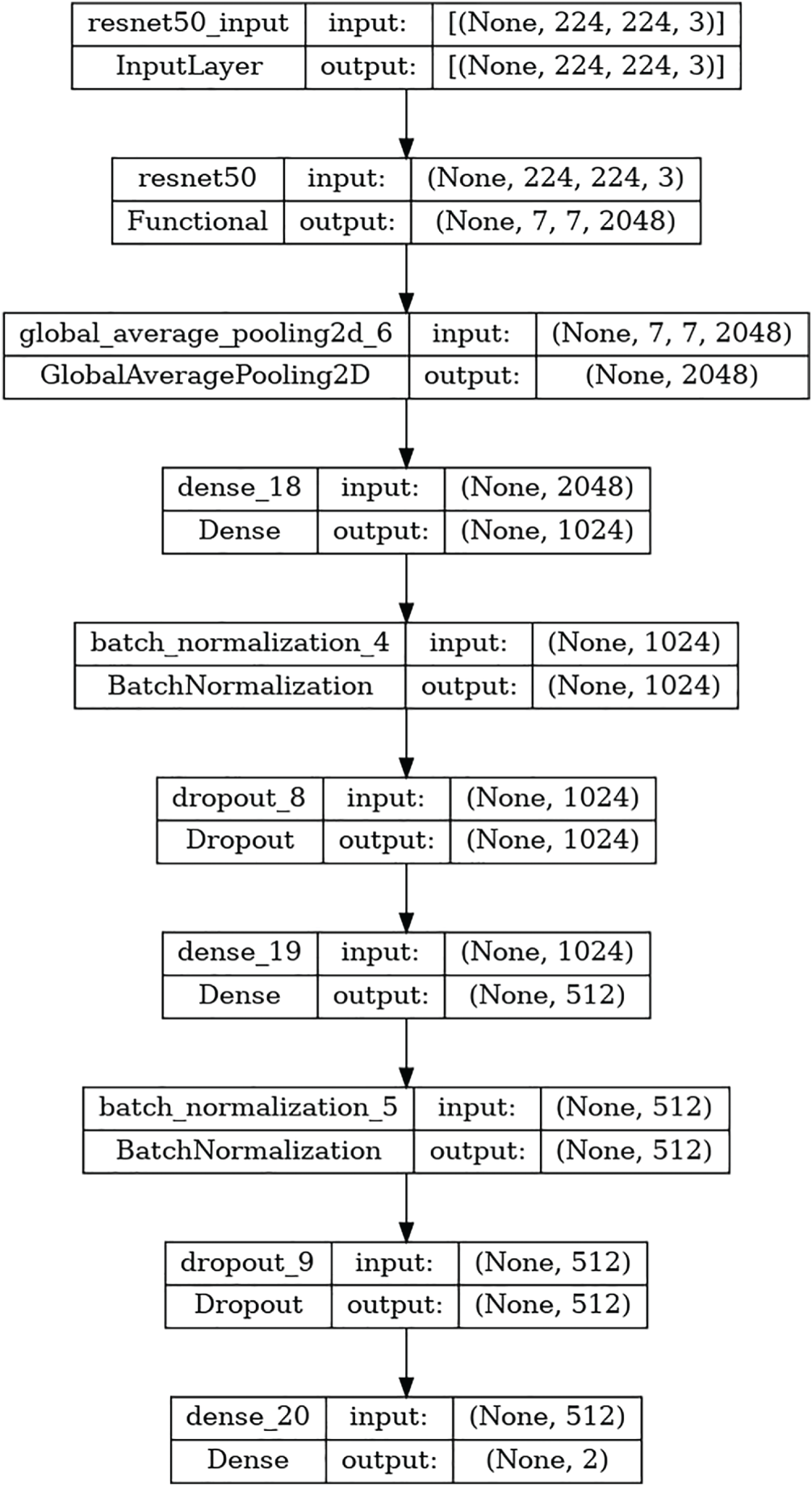
Figure 4: Resnet 50 model structure
The model consumes an input image of shape (224, 224, 3), matching a 224
3.2.2 Feature Extraction Using ResNet-50
The ResNet-50 architecture, a well-known deep convolutional neural network distinguished by its residual learning framework, forms the basis of the model as defined in Fig. 5.
Figure 5: Application of Resnet 50 to extract features
Reaching deep feature extraction without the issue of vanishing gradients, the ResNet-50 model accepts the input image and works it via several convolutional layers and residual blocks.
The generated feature map has a size of (7, 7, 2048) following through the ResNet-50 layers. Capturing important structural and contextual information, this feature map functions as a condensed form of the original image.
3.2.3 Process of Feature Extraction
To further reduce dimensionality while preserving key information, the extracted feature map is passed through a Global Average Pooling (GAP) layer.
This layer converts the (7, 7, 2048) feature map into a 2048-dimensional vector, summarizing important spatial and feature-based information.
Unlike traditional fully connected layers, the GAP layer helps reduce overfitting by minimizing the number of parameters while still retaining crucial information.
3.2.4 Fully Connected Layers (Dense Layers)
To refine the extracted features and prepare them for classification, the model incorporates a series of fully connected (Dense) layers, each followed by batch normalization and dropout to enhance performance and generalization.
First Dense Layer
• A fully connected (Dense) layer with 1024 units takes the 2048-dimensional feature vector as input.
• Batch Normalization is used to equalize activations, hence enhancing convergence speed and training stability.
• A Dropout layer is added to stop overfitting by randomly deactivating some neurons during training. Randomly deactivating certain neurons during training, a Dropout layer is added to stop overfitting.
Second Dense Layer
• To further hone the feature representation, another fully linked layer with 512 neurons is included.
• For improved regularization and stability, batch normalization and dropout are used as in the preceding layer. For improved regularization and stability, batch normalization and dropout are used much as in the prior layer.
The last classifying layer is made up of:
• A Dense layer with two neurons, one for each class: Accident and Non-Accident.
• A Softmax activation function is used to make probability scores for each class. This lets the model rate how likely its forecasts are to come true.
3.2.6 Model Regularization and Optimization
The following methods are included to guarantee model resilience and avoid overfitting:
• By normalizing intermediate activations, Batch Normalization helps to stabilize training, hence improving convergence and lowering sensitivity to weight initialization.
• Dropout Layers: By randomly deactivating neurons during training, these layers push the model to acquire more broad characteristics instead than memorizing particular patterns.
• ResNet-50 with transfer learning The model gains from prior knowledge obtained on big datasets by using pre-trained weights from ResNet-50, hence lowering the need of training data for efficient feature extraction.
Examining the model’s performance ensures reliability and robustness in practical settings.
Model’s accuracy, precision, recall, F1-score, loss values are used to gauge performance. The categorization report and the confusion matrix help to clarify even more how well the model functions. Examining false positives and false negatives increases the sensitivity of the model to accident identification.
3.3.2 Cross-Valuation Methodologies
K-fold cross-valuation not only prevents overfitting but also ensures generalizability. Training, validation, and testing subsets divide the dataset to assess performance on formerly unprocessed data. This approach ensures consistent performance across multiple data distributions and aids in identifying potential model problems.
To determine practical applicability, the trained model is assessed on unobserved frames of CCTV footage. The results are looked at to determine how well the model adapts under dynamic conditions. Measuring the latency and inference time guarantees that the model fits for real-time implementation in automotive systems.
The performance of the accident detection model based on accuracy/loss curves and the confusion matrix is thoroughly examined in this part. The assessment criteria—including accuracy, precision, recall, and F1-score—are also covered in depth.
4.1 Model Accuracy and Loss Analysis
The training and validation accuracy/loss graphs indicate the model’s learning behavior over time.
The accuracy plot shows a sharp increase in both training and validation accuracy within the initial 10 epochs. The training accuracy rapidly approaches 100%, while the validation accuracy stabilizes around 92%–93% after approximately 20 epochs as in Fig. 6. Key observations include:
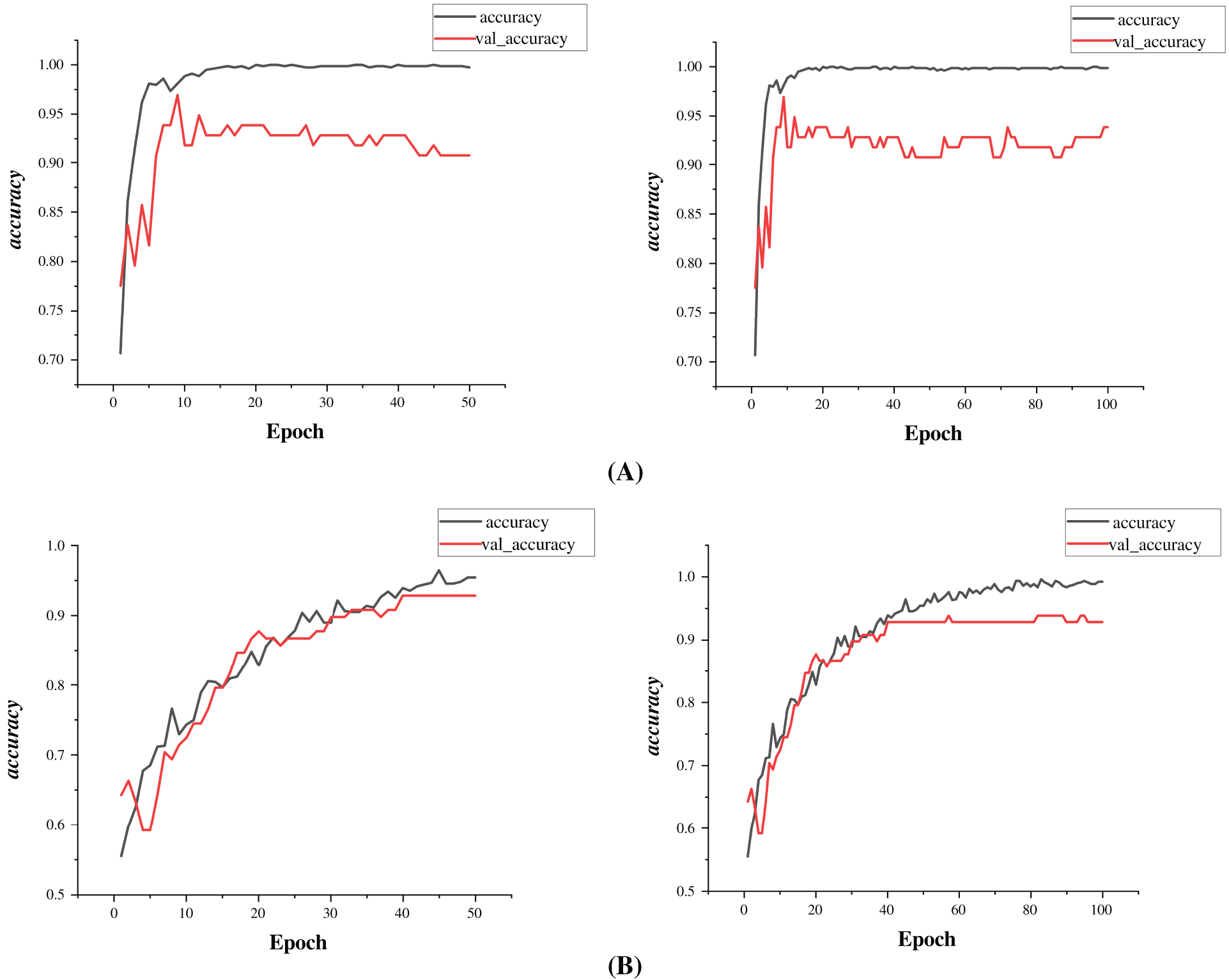
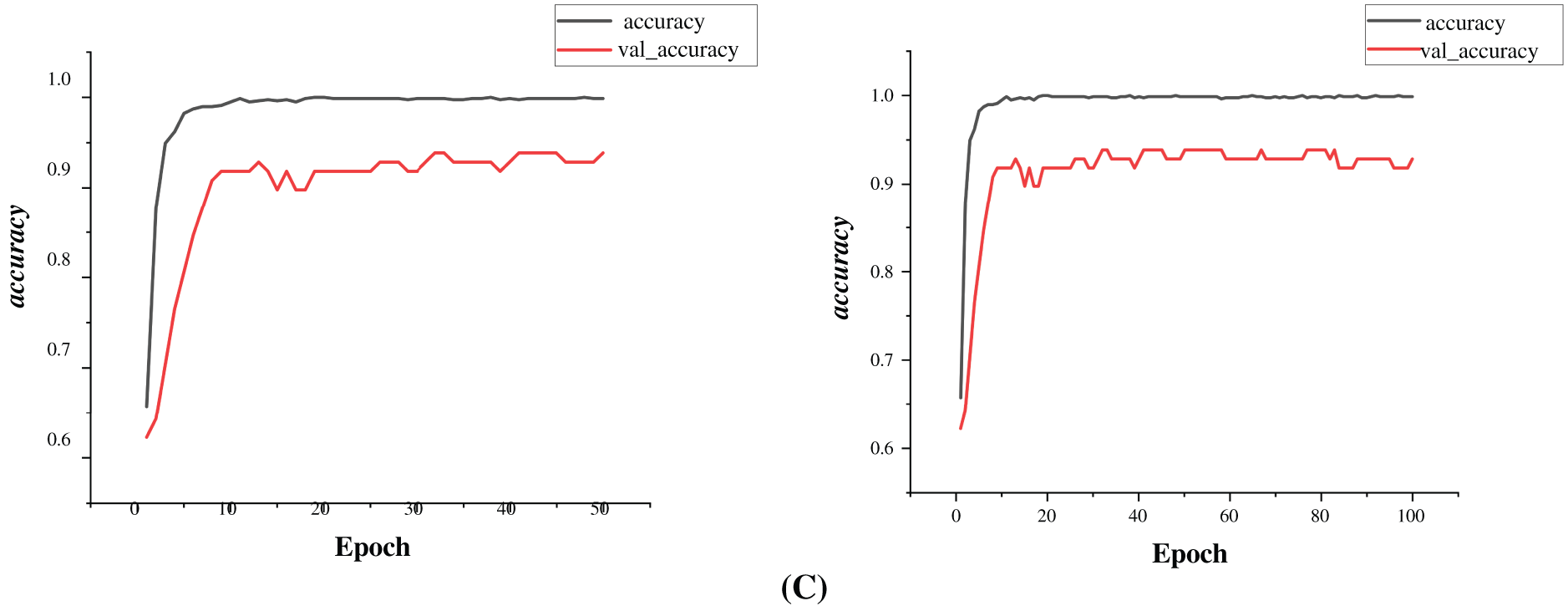
Figure 6: Plot of train and validation accuracy over 50 and 100 epochs using (A) Adam, (B) Adadelta and (C) SDG as optimizers
• The model learns quickly, as seen from the steep rise in accuracy.
• Validation accuracy follows training accuracy but diverges slightly after 20 epochs, suggesting the onset of overfitting.
• The final validation accuracy (92%–93%) suggests a well-trained model, though a small gap remains between training and validation accuracy.
The accuracy graph in Fig. 6 presents how the model’s performance developed over time for both training and validation sets. A clear upward trend is visible, particularly during the initial 30 epochs, where training accuracy increases steadily and surpasses 95%. Validation accuracy also improves alongside, gradually stabilizing between 90% and 93%. The model was trained using different optimizers, namely, SGD, Adam, and Adadelta to observe their influence. While all optimizers allowed the model to reach high accuracy, Adam showed quicker initial improvement, whereas SGD demonstrated stable, consistent learning over a longer duration. This suggests that the model was able to learn effectively under varied optimization settings, adapting well to the classification task.
Fig. 7 presents a side-by-side comparison of the model’s accuracy for two categories, non-accident and accident recorded across different training epochs. Each pair of bars represents the classification accuracy for both classes at a specific stage of the training process. It can be observed that the accuracy for non-accident cases starts high and remains relatively steady, while the accuracy for accident cases improves gradually over time. This pattern suggests that the model initially finds it easier to identify non-accident situations, while it requires more training to effectively recognize accident-related features. The visual comparison highlights the progression in performance and reflects how the model becomes more balanced in handling both classes as training advances.
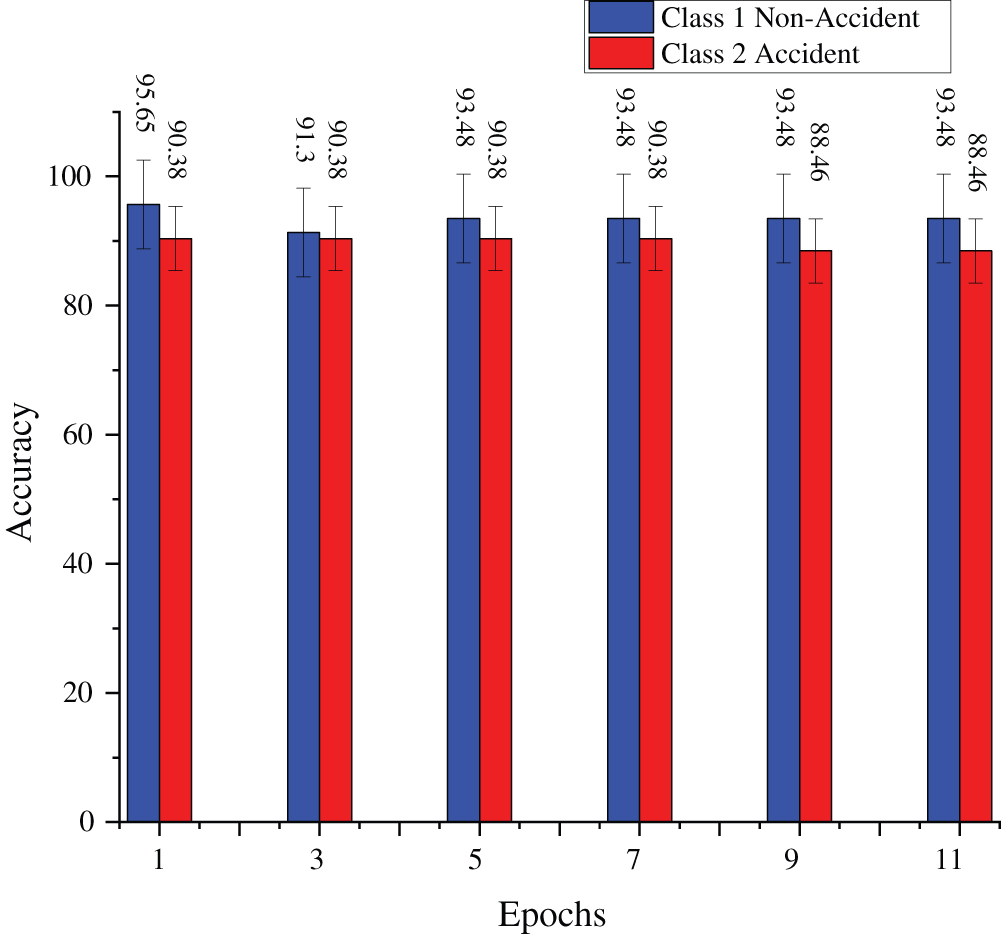
Figure 7: Comparison of classification accuracy for accident and non-accident categories across multiple training epochs
The loss plot in Fig. 8 provides crucial insights into the model’s optimization process:
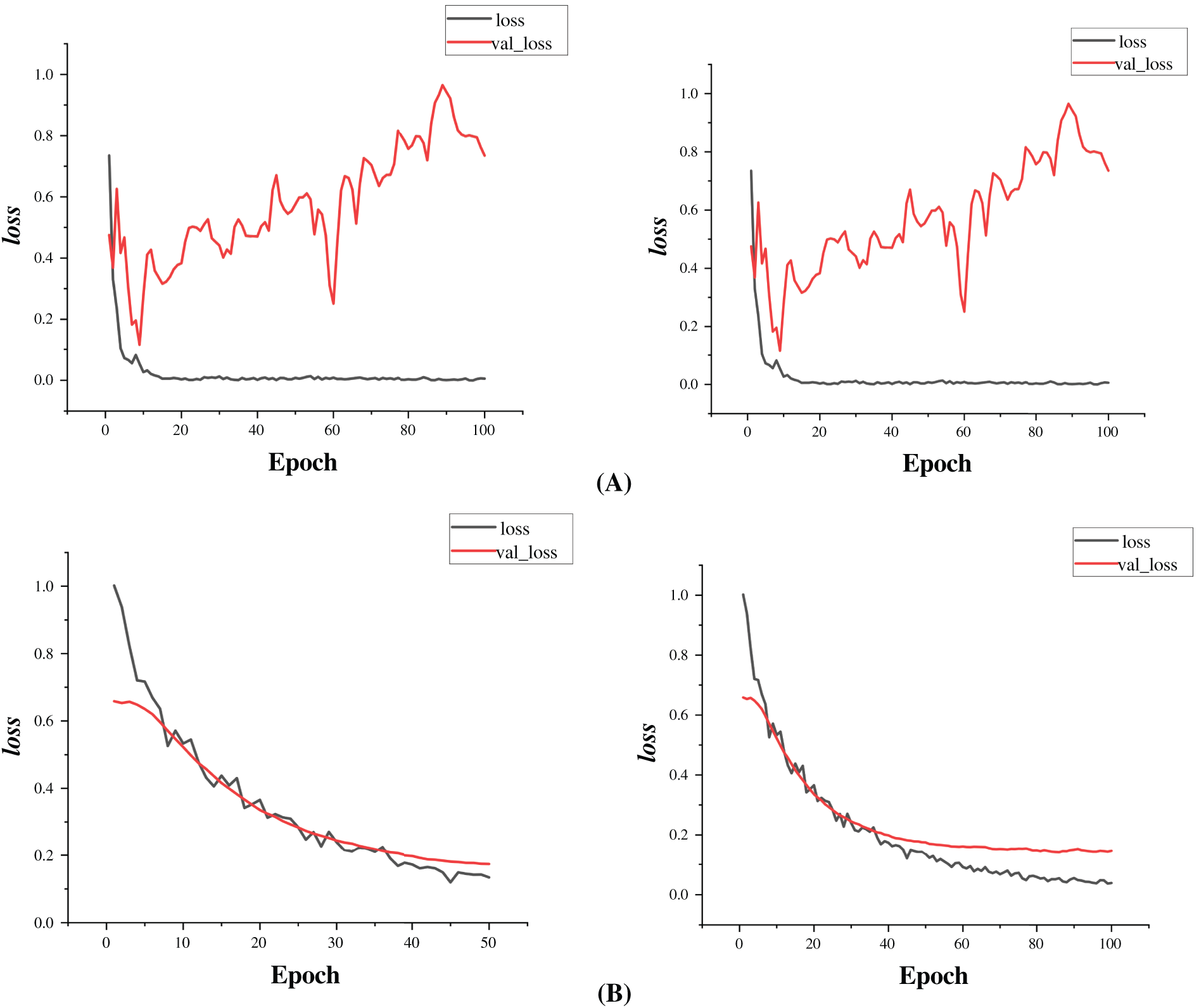
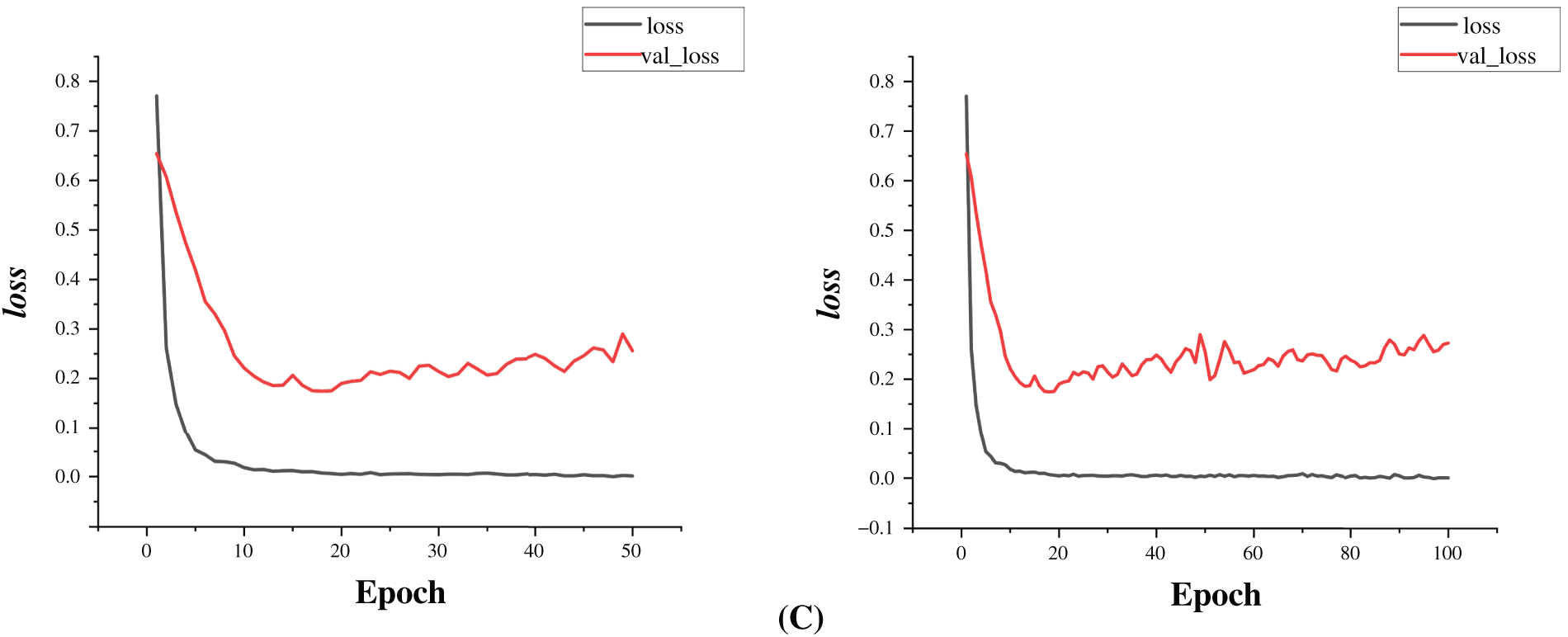
Figure 8: Plot of train and validation loss over 50 and 100 epochs by using (A) Adam, (B) Adadelta and (C) SDG as Optimizers
• Both training and validation loss decrease sharply within the first 10 epochs, indicating that the model is effectively learning patterns from the data.
• The training loss continues to decrease steadily, eventually nearing zero, which suggests that the model is memorizing training data.
• Validation loss reaches its minimum around 20 epochs and then begins to increase slightly, indicating the onset of overfitting.
• The widening gap between training and validation loss after 20 epochs suggests that while the model fits the training data extremely well, it struggles to generalize effectively to unseen data.
• The slight fluctuation in validation loss in later epochs suggests that the model may benefit from early stopping or additional regularization techniques such as dropout or weight decay to enhance generalization.
Fig. 8 shows the change in training and validation loss across the same training period. The training loss drops quickly during the early epochs, reflecting the model’s ability to fit the data effectively. After around epoch 30, the curve flattens, indicating that the model is nearing convergence. Validation loss follows a similar pattern and stabilizes between 0.1 and 0.2, showing that the model is learning generalizable features rather than overfitting. Each optimizer influenced the rate at which loss decreased. Adam reduced loss sharply early on, while SGD and Adadelta showed smoother, more gradual declines. The overall closeness of training and validation loss throughout the process supports that the model remained well-balanced during learning.
Applying strategies like dropout layers, batch normalization, or collecting a more diverse dataset could help mitigate overfitting and improve the model’s robustness.
The confusion matrix presents the classification results.
The following evaluation metrics were calculated from Fig. 9 using method from [39]:
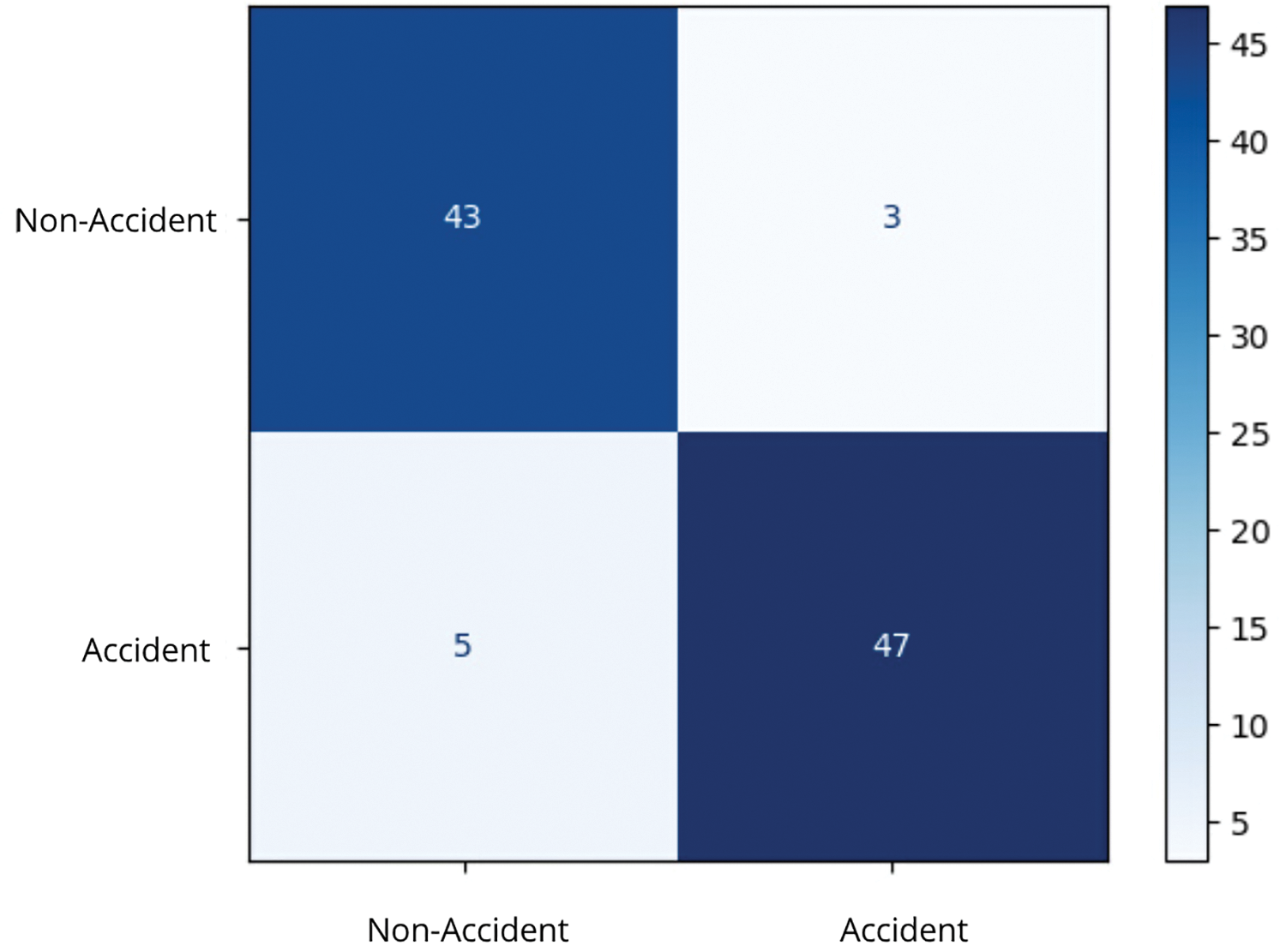
Figure 9: Confusion matrix
4.3 Mean Squared Error (MSE) Evaluation
To measure how closely the predicted values align with the actual class labels, the Mean Squared Error (MSE) was used as an additional evaluation metric. The formula for MSE is given by:
Here,
4.4 Optimizer Comparison on Other Parameters
A comparison was made between three different optimizers, SGD, Adam, and Adadelta in order to observe how each influences the model’s overall performance. As illustrated in Fig. 10, all three optimizers delivered competitive results, though slight variations were noted across key evaluation metrics. SGD, despite its simpler update rule, performed reliably and maintained high values for both precision and F1-score. This suggests that with appropriate parameter settings, SGD can serve as an effective option for training classification models, especially in tasks that require stable learning and efficient convergence.
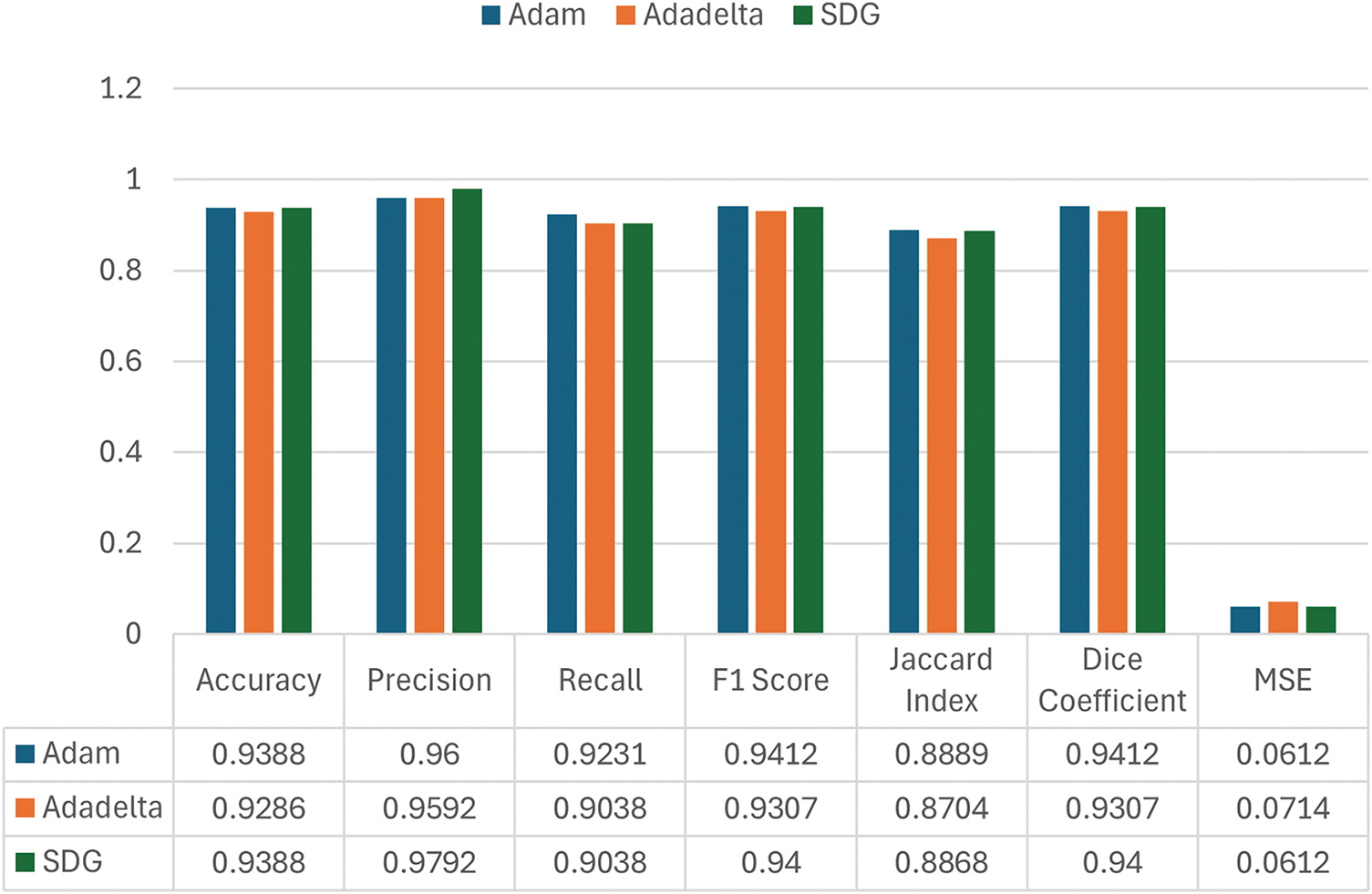
Figure 10: Study of confusion matrix parameters on different optimizers
All optimizers reached similar levels of accuracy (
4.5 Insights and Performance Summary
The results suggest that the accident detection model is highly effective. However, a few key issues require attention:
• Overfitting: The accuracy gap between training and validation suggests slight overfitting. Techniques such as dropout layers and early stopping could improve generalization.
• False Negatives: Five accident cases are incorrectly classified as non-accidents. This could have serious implications in real-world scenarios where emergency response is needed. Adjusting decision thresholds and using ensemble models can help mitigate this issue.
• False Positives: Three non-accident cases are incorrectly classified as accidents. While less critical than false negatives, excessive false alarms may lead to reduced trust in the system. Post-processing steps and additional contextual features can enhance decision-making.
• Future Improvements: Advanced deep learning models, such as CNNs or RNNs, and diverse datasets covering various driving conditions can improve model robustness. Real-time deployment strategies using edge computing or cloud services can further optimize accident detection.
4.6 Comparison with Existing Models
The referenced studies in Table 2 explore various machine learning models for accident detection. Traditional classifiers like the Multi-layer Perceptron (MLP) achieve the highest performance with an accuracy of 85.3%, followed by BayesNet at 80.6% and J48 Decision Tree at 78.6%. Other models such as Random Forest (75.5%), Logistic Regression (74.5%), Naive Bayes (73.1%), and AdaBoost (74.5%) demonstrate moderate accuracy, showing their potential but also limitations in capturing complex traffic or sensor patterns effectively.

In contrast, our proposed approach leverages the ResNet-50 architecture, a deep convolutional neural network known for its residual connections, which helps in learning deeper representations. This model significantly outperforms earlier methods by achieving an accuracy of 91.84%. Its superior performance can be attributed to its capacity to process visual and temporal data with greater precision, making it more suitable for real-world accident detection tasks that demand high reliability and detail-oriented classification.
CNNs have been widely utilised in traffic analytics, but they are still useful since they are very efficient, especially in situations where high-complexity models do not work. For this investigation ResNet-50 is chosen because it has a good balance between depth and cost, and it can learn from pre-trained weights. ResNet-50 works well on single-frame CCTV images, unlike models that need temporal sequences or multi-modal input (like transformer-based or multi-task frameworks). This makes it a good choice for deployments in limited or old infrastructure where video streams, sensor fusion, or a lot of temporal data are not available. The objective is not to surpass all contemporary models, but to offer a resilient, efficient, and reproducible benchmark that functions within the practical constraints of real-world roadside systems.
5 Advantages and Potential Benefits
The proposed strategy offers number of benefits over traditional methods for detecting accidents which are given as follows:
• The model does away with the requirement for complicated pre-processing or hand-crafted features by using image-based classification with a deep residual network (ResNet-50). This makes it easy to connect to traffic camera feeds or cameras inside cars.
• Using more than one optimizer during training lets the model adapt to diverse computing conditions, balancing speed and stability. The model also showed that it was quite accurate and could be used in many different situations, which are both important for making decisions in real time.
• Utilizing MSE for probability-based evaluation adds another level of dependability to measuring prediction confidence. These benefits make the method a good choice for use in smart transportation systems, especially in cases where quick, accurate, and automated accident detection is needed.
6 Problems Encountered and Solutions Offered
Implementing the trained model in practical automotive settings calls for careful evaluation of scalability, hardware compatibility, and inference speed.
Real-Time Inferential Learning
The last model guarantees fast decision-making in vehicle systems by being tuned for real-time inference. Edge devices have TensorFlow [40] Lite or ONNX [41] optimizations investigated for use. Model size is lowered using techniques including model quantization and pruning yet accuracy is preserved.
Computational Effectiveness
Computational efficiency of the model is investigated under several hardware setups including CPUs, GPUs, and embedded artificial intelligence accelerators such as NVIDIA Jetson. Performance criteria help to guarantee that the model can run effectively in conditions of limited resources.
Integration with Vehicles
The ML model is intended for IoT frameworks and smart traffic monitoring systems’ integration. Remote analytics and processing guaranteed by compatibility with cloud systems middle ware technologies and APIs help to enable flawless communication between the ML model and current vehicle systems.
Adaptability and Scalability
The feasibility of the model scale to bigger datasets and various traffic conditions is investigated. Measures of adaptation are taken to improve model resilience under different environmental settings. Considered are continuous learning systems that enable the model to evolve with new accident data availability.
Temporal Dynamics
The model can only process still images right now, which makes it hard to see how things changed before and after an accident. To recognize motion-based patterns or early warning indicators important for proactive detection, sequential learning models, like LSTM, GRU, or 3D CNNs, add time context which make both early accident prediction and decision-making more accurate.
Environmental Diversity
The dataset employed in this study is mostly made up of clear daylight settings, with very few examples of difficult weather situations like fog, rain, or night. The use of advanced augmentation techniques or domain adaption tactics help the model work in low light or bad visibility.
7 Limitations and Future Scope
The proposed model shows good classification performance but uses static images as input. It doesn’t use time information, which can be useful in the context of video sequences. The dataset utilized was small and not much varied, making it harder for the model to work in all real-world situations, especially when the weather or lighting is bad.
Future research can focus on enhancing the efficiency using lightweight network topologies or pruning methodologies. The system’s responsiveness can be improved for live video streams using sequential models like LSTM or 3D CNNs, Also, adding more road types and rare sorts of accidents to the dataset would make it more resilient and adaptable for a wider range of uses. Multi-task architectures [37], which combine detection, segmentation, and time prediction, can be investigated to make a more complete accident response pipeline. Thus, finding applicability in pragmatic accident detection systems.
To address the challenge of real-time and highly accurate accident detection in complex IoV environments, this paper investigates a deep learning approach for accident detection utilizing picture data and the ResNet-50 architecture. A set of classification metrics and training analysis is used to test the system. The key findings are listed below:
• The system is evaluated on a dataset of accident and non-accident photos which yielded an overall accuracy of 91.84%, with precision, recall, and F1-score values of 94%, 90.38%, and 92.14%, respectively. These findings imply that the model can separate the two categories with a great degree of dependability.
• Apart from classification measures, MSE is computed to assess the prediction confidence. An MSE score of 0.5 suggests that, on average, the expected probabilities are fairly near the actual class labels.
• The loss analysis is also carried out in which the loss values fell quickly at the beginning of training and stayed between 0.1 and 0.2, which meant that the model learnt well without overfitting.
• The performance comparison with different optimizers, namely, SGD, Adam, and Adadelta reveals how the learning speed and outcomes are affected by the choice of optimizer. While SGD keeps steady development throughout time, Adam exhibits quicker early improvement. Adadelta also works consistently with consistent accuracy and loss values.
In the end, the potential benefits, limitations, and implications of the model’s practical implementation are thoroughly discussed. The outcomes suggest its use in categorizing accidents from image data and the tests validate the need of training stability and optimization approach. Thus, finding applicability in real-time traffic monitoring systems.
Acknowledgement: Not applicable.
Funding Statement: The authors are thankful to the Deanship of Graduate Studies and Scientific Research at Najran University for funding this work under the Growth Funding Program grant code (NU/GP/SERC/13/358-6).
Author Contributions: Conceptualization, methodology: Kunal Thakur and Ashu Taneja; formal analysis: Kunal Thakur and Ashu Taneja; software, validation: Kunal Thakur, Ashu Taneja and Ali Alqahtani; writing—original draft: Kunal Thakur and Ashu Taneja; writing—review and editing, Kunal Thakur, Ashu Taneja, Ali Alqahtani and Nayef Alqahtani; data curation: Kunal Thakur, Ashu Taneja, Ali Alqahtani and Nayef Alqahtani. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The dataset is available at: https://www.kaggle.com/code/fahaddalwai/cnn-accident-detection-91-accuracy (accessed on 17 July 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Gyllenhammar M, Rodrigues de Campos G, Törngren M. The road to safe automated driving systems: a review of methods providing safety evidence. IEEE Trans Intell Transp Syst. 2025;26(4):4315–45. doi:10.1109/tits.2025.3532684. [Google Scholar] [CrossRef]
2. Cavus M, Dissanayake D, Bell M. Next generation of electric vehicles: ai-driven approaches for predictive maintenance and battery management. Energies. 2025;18(5):1041. doi:10.3390/en18051041. [Google Scholar] [CrossRef]
3. Liu T, Liu H, Yang B, Zhang Z. Ldcnet: limb direction cues-aware network for flexible hpe in industrial behavioral biometrics systems. IEEE Trans Ind Inform. 2024;20(6):8068–78. doi:10.1109/tii.2023.3266366. [Google Scholar] [CrossRef]
4. Khoshnevisan L, Liu X. A secure adaptive resilient neural network-based control of heterogeneous connected automated vehicles subject to cyber attacks. IEEE Trans Veh Technol. 2025;74(6):8734–44. doi:10.1109/tvt.2025.3537869. [Google Scholar] [CrossRef]
5. Liu H, Liu T, Zhang Z, Sangaiah AK, Yang B, Li Y. Arhpe: asymmetric relation-aware representation learning for head pose estimation in industrial human-computer interaction. IEEE Trans Ind Inform. 2022;18(10):7107–17. doi:10.1109/tii.2022.3143605. [Google Scholar] [CrossRef]
6. Liu C, Yang H, Zhu M, Wang F, Vaa T, Wang Y. Real-time multi-task environmental perception system for traffic safety empowered by edge artificial intelligence. IEEE Trans Intell Transp Syst. 2024;25(1):517–31. doi:10.1109/tits.2023.3309100. [Google Scholar] [CrossRef]
7. Ferrara A, Sacone S, Siri S. An overview of traffic control schemes for freeway systems. Free Traffic Model Control. 2018:193–234. doi:10.1007/978-3-319-75961-6_8. [Google Scholar] [CrossRef]
8. Li Z, Liu F, Yang W, Peng S, Zhou J. A survey of convolutional neural networks: analysis, applications, and prospects. IEEE Trans Neural Netw Learn Syst. 2021;33(12):6999–7019. doi:10.1109/tnnls.2021.3084827. [Google Scholar] [PubMed] [CrossRef]
9. Liu D, Yang LT, Zhao R, Deng X, Zhu C, Ruan Y. Multi-tree compact hierarchical tensor recurrent neural networks for intelligent transportation system edge devices. IEEE Trans Intell Transp Syst. 2024;25(8):8719–29. doi:10.1109/tits.2024.3364250. [Google Scholar] [CrossRef]
10. Möller DP, Haas RE, Möller DP, Haas RE. Advanced driver assistance systems and autonomous driving. In: Guide to Automotive Connectivity and Cybersecurity: Trends, Technologies, Innovations and Applications. Cham, Switzerland: Springer; 2019. p. 513–80. doi:10.1007/978-3-319-73512-2_11. [Google Scholar] [CrossRef]
11. Bian J, Al Arafat A, Xiong H, Li J, Li L, Chen H, et al. Machine learning in real-time internet of things (IoT) systems: a survey. IEEE Internet Things J. 2022;9(11):8364–86. doi:10.1109/jiot.2022.3161050. [Google Scholar] [CrossRef]
12. Hussain S, Muhammad LJ, Ishaq FS, Yakubu A, Mohammed IA. Performance evaluation of various data mining algorithms on road traffic accident dataset. In: Information and communication technology for intelligent systems. Singapore: Springer; 2019. doi:10.1007/978-981-13-1742-2_7. [Google Scholar] [CrossRef]
13. Al Mamlook RE, Kwayu K, Frefer A. Comparison of machine learning algorithms for predicting traffic accident severity. In: 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT); 2019 Apr 9–11; Amman, Jordan. p. 272–6. [Google Scholar]
14. Obasi IC, Benson C. Evaluating the effectiveness of machine learning techniques in forecasting the severity of traffic accidents. Heliyon. 2023;9(8):e18812. doi:10.1016/j.heliyon.2023.e18812. [Google Scholar] [PubMed] [CrossRef]
15. Adekunle A, Olisah S, Taiwo E, Oyetubo O, Tella E, Obunadike C. Predicting accident severity: an analysis of factors affecting accident severity using random forest model. Int J Cybern Inform (IJCI). 2023;12(6):107–21. [Google Scholar]
16. Parsa AB, Chauhan RS, Taghipour H, Derrible S, Mohammadian A. Applying deep learning to detect traffic accidents in real time using spatiotemporal sequential data. arXiv:1912.06991. 2019. [Google Scholar]
17. Cao J, Fang Z, Qu G, Sun H, Zhang D. An accurate traffic classification model based on support vector machines. Int J Netw Manag. 2017;27(1):e1962. [Google Scholar]
18. Sufian MA, Varadarajan J, Niu M. Enhancing prediction and analysis of uk road traffic accident severity using AI: integration of machine learning, econometric techniques, and time series forecasting in public health research. Heliyon. 2024;10(7):e28547. doi:10.1016/j.heliyon.2025.e42841. [Google Scholar] [PubMed] [CrossRef]
19. Rifat MAK, Kabir A, Huq A. An explainable machine learning approach to traffic accident fatality prediction. Procedia Comput Sci. 2024;246(2):1905–14. doi:10.1016/j.procs.2024.09.704. [Google Scholar] [CrossRef]
20. Rajkumar AR, Prabhakar S, Priyadharsini AM. Prediction of road accident severity using machine learning algorithm. Int J Adv Sci Technol. 2020;29(6):1234–45. [Google Scholar]
21. Tan K, Bremner D, Le Kernec J, Zhang L, Imran M. Machine learning in vehicular networking: an overview. Digit Commun Netw. 2022;8(1):18–24. doi:10.1016/j.dcan.2021.10.007. [Google Scholar] [CrossRef]
22. Alvi U, Khattak MAK, Shabir B, Malik AW, Muhammad SR. A comprehensive study on iot based accident detection systems for smart vehicles. IEEE Access. 2020;8:122480–97. doi:10.1109/access.2020.3006887. [Google Scholar] [CrossRef]
23. Modi Y, Teli R, Mehta A, Shah K, Shah M. A comprehensive review on intelligent traffic management using machine learning algorithms. Innov Infrastruct Solut. 2022;7(1):128. doi:10.1007/s41062-021-00718-3. [Google Scholar] [CrossRef]
24. Liu H, Zhang C, Deng Y, Xie B, Liu T, Li YF. Transifc: invariant cues-aware feature concentration learning for efficient fine-grained bird image classification. IEEE Trans Multimed. 2025;27:1677–90. doi:10.1109/tmm.2023.3238548. [Google Scholar] [CrossRef]
25. Taneja A, Rani S. Quantum-enabled intelligent resource control for reliable communication support in internet-of-vehicles. IEEE Trans Consum Electron. 2024;70(3):5545–52. doi:10.1109/tce.2024.3376701. [Google Scholar] [CrossRef]
26. Li P, Abdel-Aty M, Yuan J. Real-time crash risk prediction on arterials based on LSTM-CNN. Accid Anal Prev. 2020;135:105371. [Google Scholar] [PubMed]
27. Chen Y, Zhang H, Liu M, Ye M, Xie H, Pan Y. Traffic signal optimization control method based on adaptive weighted averaged double deep Q network. Appl Intell. 2023;53(15):18333–54. doi:10.1007/s10489-023-04469-9. [Google Scholar] [CrossRef]
28. Ahmed SF, Kuldeep SA, Rafa SJ, Fazal J, Hoque M, Liu G, et al. Enhancement of traffic forecasting through graph neural network-based information fusion techniques. Inf Fusion. 2024;110:102466. doi:10.1016/j.inffus.2024.102466. [Google Scholar] [CrossRef]
29. Tasabat SE, Aydin O. Using long-short term memory networks with genetic algorithm to predict engine condition. Gazi Univ J Sci. 2021;35(3):1200–10. [Google Scholar]
30. Usmani UA, Happonen A, Watada J. A review of unsupervised machine learning frameworks for anomaly detection in industrial applications. In: Intelligent computing; Cham, Switzerland: Springer; 2022. p. 158–89. doi:10.1007/978-3-031-10464-0_11. [Google Scholar] [CrossRef]
31. Andronie M, Lăzăroiu G, Iatagan M, Hurloiu I, Ștefănescu R, Dijmărescu A, et al. Big data management algorithms, deep learning-based object detection technologies, and geospatial simulation and sensor fusion tools in the internet of robotic things. ISPRS Int J Geo Inf. 2023;12(2):35. doi:10.3390/ijgi12020035. [Google Scholar] [CrossRef]
32. Li Y, Tao X, Zhang X, Liu J, Xu J. Privacy-preserved federated learning for autonomous driving. IEEE Trans Intell Transp Syst. 2021;23(7):8423–34. doi:10.1109/tits.2021.3081560. [Google Scholar] [CrossRef]
33. Wu Y, Li W, Zhang J, Tang B, Xiang J, Li S, et al. Driver’s hand-foot coordination and global-regional brain functional connectivity under fatigue: via graph theory and explainable artificial intelligence. IEEE Trans Intell Veh. 2024;9(2):3493–508. doi:10.1109/tiv.2023.3339673. [Google Scholar] [CrossRef]
34. Chang C-C, Huang K-H, Lau T-K, Huang C-F, Wang C-H. Using deep learning model integration to build a smart railway traffic safety monitoring system. Sci Rep. 2025;15(1):4224. doi:10.1038/s41598-025-88830-7. [Google Scholar] [PubMed] [CrossRef]
35. Wang M, Lee W-C, Liu N, Fu Q, Wan F, Yu G. A data-driven deep learning framework for prediction of traffic crashes at road intersections. Appl Sci. 2025;15(2):752. doi:10.3390/app15020752. [Google Scholar] [CrossRef]
36. Jaradat S, Elhenawy M, Ashqar HI, Paz A, Nayak R. Leveraging deep learning and multimodal large language models for near-miss detection using crowdsourced videos. IEEE Open J Comput Soc. 2025;6:223–35. doi:10.1109/ojcs.2025.3525560. [Google Scholar] [CrossRef]
37. Grigorev A, Mihăiţă A-S, Saleh K, Chen F. Automatic accident detection, segmentation and duration prediction using machine learning. IEEE Trans Intell Transp Syst. 2024;25(2):1547–68. doi:10.1109/tits.2023.3323636. [Google Scholar] [CrossRef]
38. Golmohammadi A, Hernando D, Van den bergh W, Hasheminejad N. Advanced data-driven fbg sensor-based pavement monitoring system using multi-sensor data fusion and an unsupervised learning approach. Measurement. 2025;242:115821. doi:10.1016/j.measurement.2024.115821. [Google Scholar] [CrossRef]
39. Wang S, Zhao Z-A, Chen Y, Mao Y-J, Cheung JC-W. Enhancing thyroid nodule detection in ultrasound images: a novel yolov8 architecture with a c2fa module and optimized loss functions. Technologies. 2025;13(1):28. doi:10.3390/technologies13010028. [Google Scholar] [CrossRef]
40. Toyib R, Mussa APA, Wijaya A, Sonita A. Indonesian sign system introduction application with tensorflow lite and firebase authentication. Jurnal Teknik Informatika Dan Sistem Informasi. 2025;11(1):31–48. doi:10.28932/jutisi.v11i1.9678. [Google Scholar] [CrossRef]
41. Wang Y, Zhao J. A unified and resource-aware framework for adaptive inference acceleration on edge and embedded platforms. Electronics. 2025;14(11):2188. doi:10.3390/electronics14112188. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools