
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Image Enhancement Combined with LLM Collaboration for Low-Contrast Image Character Recognition
1 School of Intelligent Manufacturing and Control Engineering, Shanghai Polytechnic University, Shanghai, 201209, China
2 School of Electrical Engineering and Telecommunications, UNSW Sydney, Sydney, NSW 2052, Australia
* Corresponding Author: Xuan Jiang. Email:
Computers, Materials & Continua 2025, 85(3), 4849-4867. https://doi.org/10.32604/cmc.2025.067919
Received 16 May 2025; Accepted 21 July 2025; Issue published 23 October 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The effectiveness of industrial character recognition on cast steel is often compromised by factors such as corrosion, surface defects, and low contrast, which hinder the extraction of reliable visual information. The problem is further compounded by the scarcity of large-scale annotated datasets and complex noise patterns in real-world factory environments. This makes conventional OCR techniques and standard deep learning models unreliable. To address these limitations, this study proposes a unified framework that integrates adaptive image preprocessing with collaborative reasoning among LLMs. A Biorthogonal 4.4 (bior4.4) wavelet transform is adaptively tuned using DE to enhance character edge clarity, suppress background noise, and retain morphological structure, thereby improving input quality for subsequent recognition. A structured three-round debate mechanism is further introduced within a multi-agent architecture, employing GPT-4o and Gemini-2.0-flash as role-specialized agents to perform complementary inference and achieve consensus. The proposed system is evaluated on a proprietary dataset of 48 high-resolution images collected under diverse industrial conditions. Experimental results show that the combination of DE-based enhancement and multi-agent collaboration consistently outperforms traditional baselines and ablated models, achieving an F1-score of 94.93% and an LCS accuracy of 93.30%. These results demonstrate the effectiveness of integrating signal processing with multi-agent LLM reasoning to achieve robust and interpretable OCR in visually complex and data-scarce industrial environments.Keywords
Accurate recognition of alphanumeric markings on cast steel surfaces is crucial for tracking quality in industrial production. It serves as a critical foundation for quality assurance, supply chain transparency, and intelligent process automation [1,2]. Metal castings, which are extensively used in the automotive, aerospace, and heavy equipment sectors, are commonly inscribed with identification codes through stamping or casting techniques [3]. However, these surface markings are frequently degraded by prolonged environmental exposure and harsh operating conditions [4]. Common degradation factors include low contrast, uneven illumination, surface corrosion, partial occlusion, and morphological distortion of characters [5]. These conditions substantially hinder the effectiveness of traditional Optical Character Recognition (OCR) methods, particularly in scenarios where robustness to noise, deformation, and surface variability is required [6–8].
Conventional OCR systems are typically designed for clean, high-contrast, and planar text. As a result, their applicability in visually degraded industrial contexts is significantly limited [6]. Deep learning-based methods, especially those employing Convolutional Neural Networks (CNNs), have demonstrated improved resilience in complex visual environments [8,9]. However, their reliance on large-scale annotated datasets and limited interpretability restricts their deployment in real-world manufacturing settings, where data scarcity and highly variable visual conditions pose significant challenges [4,7].
The recent development of multimodal Large Language Models (LLMs), such as GPT-4o and Gemini-2.0-flash, presents new opportunities for integrating high-level semantic reasoning with visual understanding [10]. These models exhibit strong capabilities in interpreting incomplete, ambiguous, or noisy visual inputs, making them potentially well-suited for character recognition tasks under industrial degradation [7,11]. Nevertheless, single-model frameworks often exhibit internal bias and insufficient visual grounding, thereby limiting robustness with deteriorated images due to the absence of complementary reasoning and validation mechanisms [12]. As a result, they tend to make rigid, unverified decisions when faced with ambiguous or incomplete inputs, leading to unstable performance in complex industrial scenarios [4].
Given the limitations of conventional OCR techniques and single-model inference frameworks, particularly their lack of adaptability, interpretability, and resilience under severe visual degradation, this study proposes a robust and interpretable character recognition framework specifically designed for cast steel surfaces affected by corrosion, occlusion, and structural noise [6,13]. The method integrates signal-level enhancement with structured collaborative reasoning among heterogeneous LLMs [7]. In the image enhancement module, a bior4.4 wavelet transform is configured using a global optimization strategy based on Differential Evolution (DE), thereby improving the clarity of character boundaries while reducing background interference [14,15]. In the reasoning module, a multi-agent architecture on the AutoGen platform uses two specialized LLMs: GPT-4o for logical inference and pattern recognition, and Gemini-2.0-flash for fine-grained visual analysis [16]. These agents follow a three-stage debate process of independent recognition, mutual verification, and consensus formation [17]. To further enhance recognition accuracy and disambiguation capability, domain-specific constraints such as character sets, structural templates, and heuristic rules are incorporated into the system prompts [4].
Accordingly, this work explores whether combining optimized visual enhancement techniques with structured multi-agent inference can effectively address the limitations of existing approaches, with the goal of improving character recognition accuracy, robustness, and interpretability in complex industrial environments where annotated data are scarce and surface conditions are highly variable [4,7,17].
The main contributions of this study are summarized as follows:
• An integrated recognition framework is proposed that combines wavelet-based visual enhancement with multi-agent LLM inference to address the challenges of low-quality inputs and ambiguous recognition scenarios in industrial OCR applications.
• A Differential Evolution-based optimization approach is employed to configure the bior4.4 wavelet transform, facilitating enhanced edge clarity and structural preservation in degraded casting images.
• A structured three-stage reasoning protocol is developed to enable complementary analysis and consensus formation between heterogeneous LLM agents, helping to reduce individual model limitations and enhance inference reliability.
• The proposed method is evaluated on a real-world industrial casting dataset, with experimental results indicating improved performance compared to conventional OCR baselines and component variants.
The remainder of this paper is organized as follows: Section 2 reviews related literature; Section 3 details the proposed methodology; Section 4 presents the experimental setup and evaluation protocols; Section 5 discusses the results; and Section 6 concludes the paper and outlines future directions.
Character recognition in industrial settings, particularly on cast steel surfaces, remains a persistent challenge due to a combination of environmental degradation, surface irregularities, and low-contrast visual conditions [18]. These factors severely impair the legibility of alphanumeric markings that are essential for component traceability, quality control, and automated inspection across manufacturing pipelines [7]. Current OCR research is limited by the absence of specialized datasets for industrial applications. Existing datasets (ICDAR, COCO-Text) focus on clean text, while no public dataset addresses character recognition on corroded metal surfaces in real manufacturing environments. Traditional OCR systems, originally developed for clean and high-contrast textual data, are inherently limited in their ability to cope with corrosion, occlusion, illumination inconsistency, and morphological deformation of characters encountered in real-world production environments [6].
To overcome these challenges, various deep learning-based methods have been introduced, notably Convolutional Recurrent Neural Networks (CRNNs) and attention-guided Scene Text Recognition (STR) architectures [18,19]. These approaches have demonstrated greater robustness in visually complex scenarios by leveraging large-scale supervised training on domain-specific datasets [4]. However, their reliance on extensive annotations and tight coupling with domain distribution renders them less effective in industrial settings, where annotated data are often scarce, expensive to obtain, or unavailable due to production constraints and privacy considerations [7,16].
Recently, the emergence of LLMs, such as GPT-4o and Gemini-2.0-flash, has expanded the capabilities of visual-semantic reasoning systems [10]. These models exhibit strong generalization ability through pretraining, enabling few-shot and even zero-shot inference without requiring task-specific fine-tuning. Their integration of language-guided vision processing opens up opportunities for handling ambiguous, occluded, or degraded visual inputs in a more human-like interpretative manner [20]. However, individual LLMs may exhibit bias, rigid priors, and limited sensitivity to fine-grained visual variations, particularly under challenging conditions such as corroded metal surfaces [4].
To address the inherent limitations of single-model inference, Multi-Agent Systems (MAS) have emerged as a promising paradigm that enables distributed, collaborative decision-making [12]. In such systems, individual LLMs are instantiated as autonomous agents with specialized reasoning capabilities [17]. Through structured interaction protocols, agents mutually verify outputs and resolve inconsistencies. Collaborative agentic Artificial Intelligence (AI) approaches enhance stability and performance in multi-modal tasks [21].
Despite significant progress in reasoning frameworks, the overall accuracy of industrial OCR systems remains fundamentally constrained by the quality of input imagery, particularly under conditions characterized by corrosion, uneven illumination, and structural degradation [7]. In this context, image preprocessing continues to serve as a critical foundation for ensuring reliable downstream recognition [4]. Conventional enhancement techniques, including histogram equalization and contrast-limited adaptive histogram equalization (CLAHE), offer limited spatial adaptability and frequently fail to recover localized features on textured metal surfaces. Morphological operations, such as dilation and erosion, are sensitive to structural parameters and may result in over-smoothing when applied to corroded surfaces with irregular geometries [22]. In a similar manner, median filtering is an effective method of reducing noise, but it has been observed to result in a degradation of character edge sharpness. Conversely, wavelet transform methods employing biorthogonal wavelets offer a superior approach to spatial-frequency decomposition, facilitating targeted enhancement of character boundaries while preserving morphological integrity [14]. These properties make wavelet methods especially well-suited for industrial scenarios involving low contrast and complex surface textures [5]. To further improve adaptability across diverse imaging conditions, global optimization techniques such as Differential Evolution (DE) have been integrated to automatically tune the parameters of the wavelet transform [15,23]. This optimization facilitates an effective balance between edge enhancement, noise suppression, and structure preservation, thereby enhancing the robustness of the preprocessing pipeline for industrial OCR applications [6].
Taken together, these advances highlight a need for integrated solutions that address both the perceptual and reasoning limitations of current systems [16]. From an industrial perspective, improving OCR reliability and accuracy under adverse conditions is critical for ensuring traceability, reducing inspection costs, and enabling automation in casting production lines [24]. This study is motivated by the observation that neither image enhancement alone nor LLM-based reasoning in isolation is sufficient to meet the performance demands of such environments [7]. Therefore, we propose a novel framework that incorporates adaptive signal-level enhancement and structured multi-agent inference to address the challenges of industrial OCR in data-scarce and visually degraded settings [12].
To effectively address the significant challenges posed by low image quality and information ambiguity inherent in industrial casting character recognition, this research introduces an innovative recognition system built upon two primary pillars: (1) an adaptive image preprocessing technique a parameter-optimized bior4.4 wavelet transform to enhance character details while suppressing interference, and (2) a collaborative multi-agent LLM debate mechanism implemented on the AutoGen platform to accurately interpret enhanced images (Fig. 1).
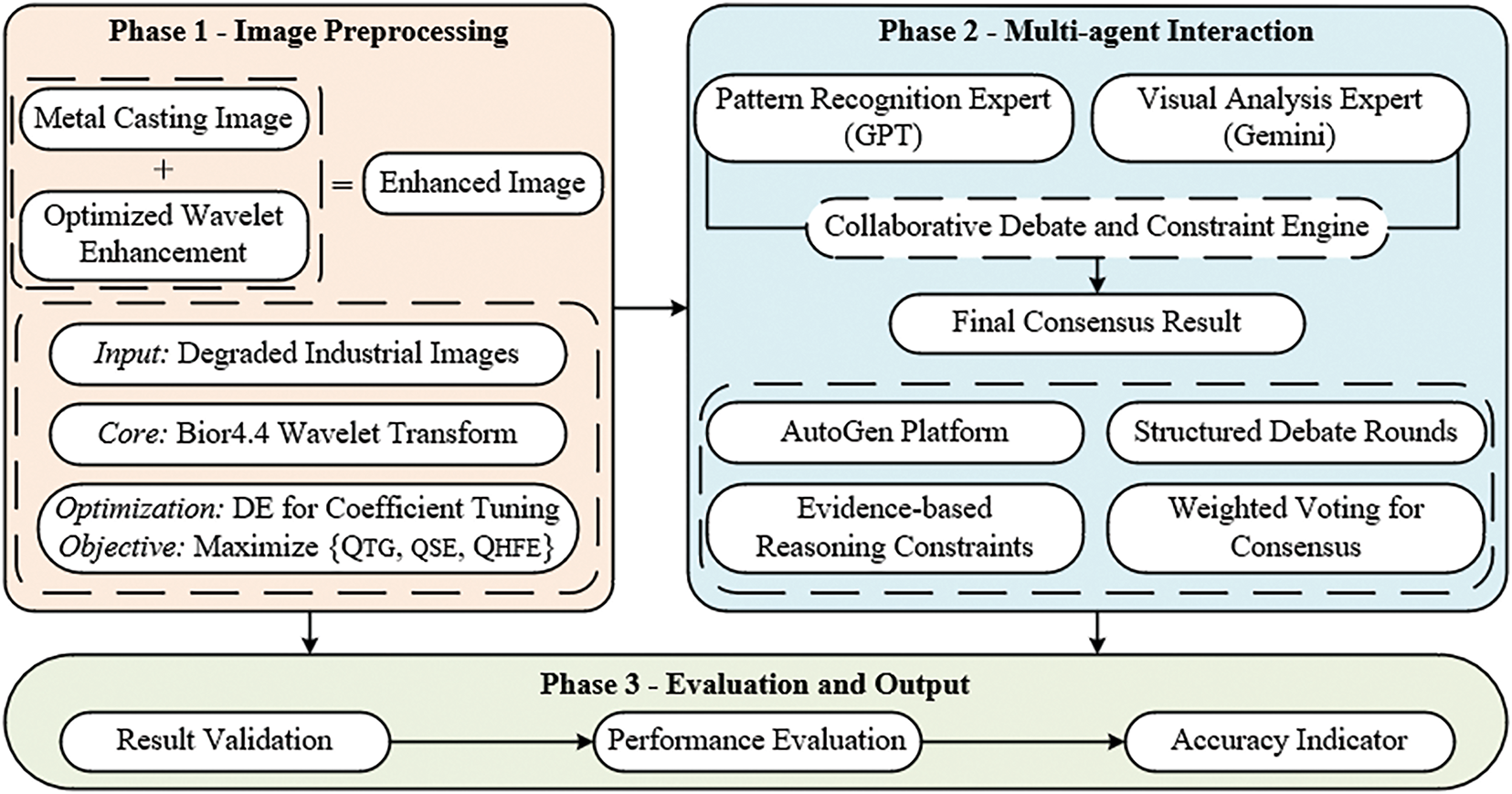
Figure 1: Main framework of character recognition
As illustrated in Fig. 1, the proposed framework consists of three main phases: image preprocessing, multi-agent interaction, and output evaluation. The first phase enhances character visibility using a parameter-optimized wavelet transform. In the second phase, two specialized LLM agents collaborate through a structured debate protocol to refine recognition. Finally, consensus outputs are verified and evaluated using accuracy metrics.
3.1 Image Preprocessing: Optimized Wavelet Transform
Character images captured from industrial castings often suffer from severe degradation, posing substantial challenges for downstream recognition—particularly for LLMs that rely on discernible visual patterns. To address this issue, the bior4.4 wavelet transform is employed as the foundation of the preprocessing module. The bior4.4 wavelet is selected due to its advantageous properties, including symmetry and linear phase response, which are essential for preserving character morphology and geometric fidelity during enhancement operations. Its four vanishing moments allow effective handling of edge discontinuities, thereby improving character boundary clarity. A single-level decomposition (Level 1) is adopted to capture the spatial frequency components most relevant to casting text while minimizing computational overhead and avoiding artifact amplification.
To further optimize enhancement performance, the DE algorithm is applied—a robust metaheuristic designed for nonlinear global optimization. DE iteratively evolves a population of candidate solutions through mutation, crossover, and selection operations. In this setting, the optimization targets a composite objective function that balances three critical image quality metrics:
• Edge Sharpness (
• Information Richness (
• Noise Suppression (
The objective
where denotes the normalized relative change in each quality metric after enhancement compared to the original image. The weights
The optimization procedure of DE is summarized in Algorithm 1.

The full optimization pipeline is illustrated in Fig. 2. A 2D grayscale image undergoes Level-1 bior4.4 wavelet decomposition, yielding approximation and detail coefficients. The DE algorithm then optimizes the enhancement weights by maximizing a composite objective function involving edge sharpness, entropy, and high-frequency suppression. These optimized coefficients are applied via inverse wavelet reconstruction to produce the final enhanced image, which is forwarded to the recognition module.
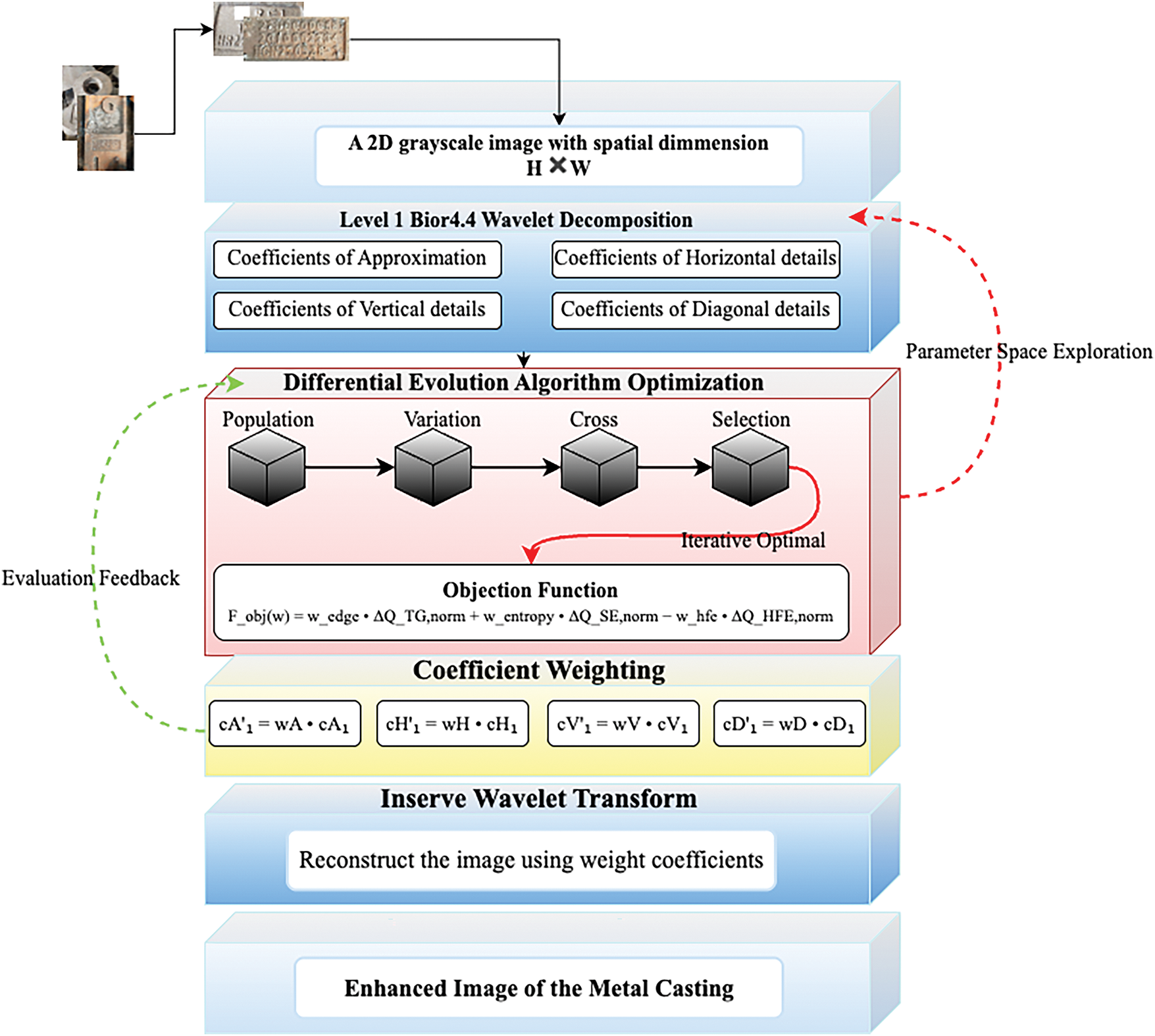
Figure 2: Schematic of the differential evolution-based bior4.4 wavelet enhancement process
3.2 Multi-Agent LLM Co-Recognition System
3.2.1 Agent Role Specialization and Framework Design
To overcome the perceptual limitations and inherent biases of single-model large language systems, a multi-agent collaborative recognition framework is proposed, leveraging the AutoGen platform to support structured agent coordination and inference. This design is inspired by dual-system theories of cognition, which emphasize the integration of fast perceptual and slow deliberative reasoning processes. Within this framework, two specialized LLM agents are assigned complementary roles:
• GPT-4o serves as the Pattern Recognition and Logical Reasoning Expert, focusing on the logical structure of alphanumeric sequences and layout coherence.
• Gemini-2.0-flash operates as the Visual Detail Analysis Expert, specializing in fine-grained visual inspection and character morphology interpretation.
3.2.2 Three-Round Debate Protocol
As illustrated in Fig. 3, the two agents engage in a structured three-round debate protocol designed to systematically refine recognition accuracy. The process consists of:
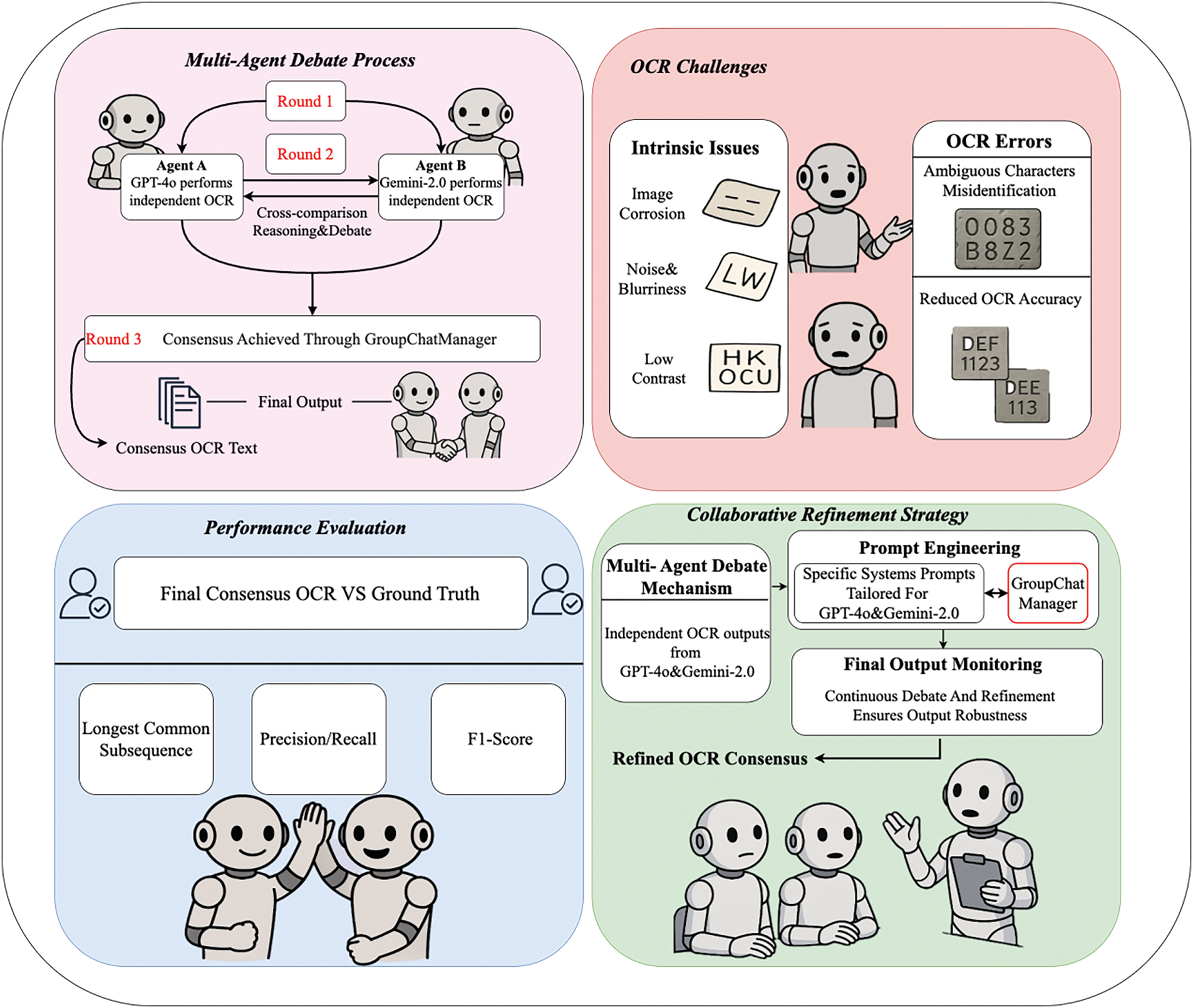
Figure 3: Overview of the multi-agent LLM debate-based OCR refinement strategy
• Independent Inference: Each agent performs standalone recognition based on the enhanced input image.
• Cross-Agent Comparison and Justification: Agents exchange their results, identify inconsistencies, and present evidence-based reasoning for their outputs.
• Final Consensus Generation: The GroupChatManager component synthesizes the debate outcome and resolves disagreements, producing a unified, high-confidence prediction.
As shown in Fig. 3, the proposed multi-agent strategy addresses the inherent perceptual limitations of single-model systems through a structured debate framework. GPT-4o and Gemini-2.0-flash act as role-specialized agents—one emphasizing logical reasoning, the other focusing on fine-grained visual analysis. Their interaction is guided by carefully engineered prompts and consists of three coordinated stages: independent inference, mutual critique, and final consensus formation via the GroupChatManager. The refined output is then evaluated using comprehensive metrics including Longest Common Subsequence (LCS), character-level precision/recall, and F1-score.
This collaborative framework enables complementary reasoning and mutual error correction between heterogeneous agents, which is particularly beneficial in the presence of ambiguity, low contrast, or character occlusion. The structured debate protocol allows each agent to contribute from its area of specialization—either logical sequence analysis or visual detail interpretation—thereby improving robustness in degraded image scenarios.
3.2.3 Detailed Implementation and Conflict Resolution
• Detailed Role Implementation: GPT-4o functions as the Pattern Recognition Expert, analyzing character sequences for logical consistency, validating against industrial coding standards (e.g., date formats, part numbering conventions), and identifying structural patterns in multi-line layouts. Gemini-2.0 operates as the Visual Detail Analyst, examining character morphology, distinguishing visually similar characters (e.g., ‘0’ vs. ‘O’, ‘1’ vs. ‘I’), and analyzing spatial relationships between characters.
• Conflict Resolution Mechanism: When agents disagree, the GroupChatManager employs a structured resolution process. Each agent provides specific reasoning for their interpretation, and the system prioritizes results with stronger supporting evidence. In cases of equal evidence strength, GPT-4o’s result is selected due to its superior pattern recognition capabilities in industrial contexts.
The complete multi-agent debate protocol is formalized in Algorithm 2:
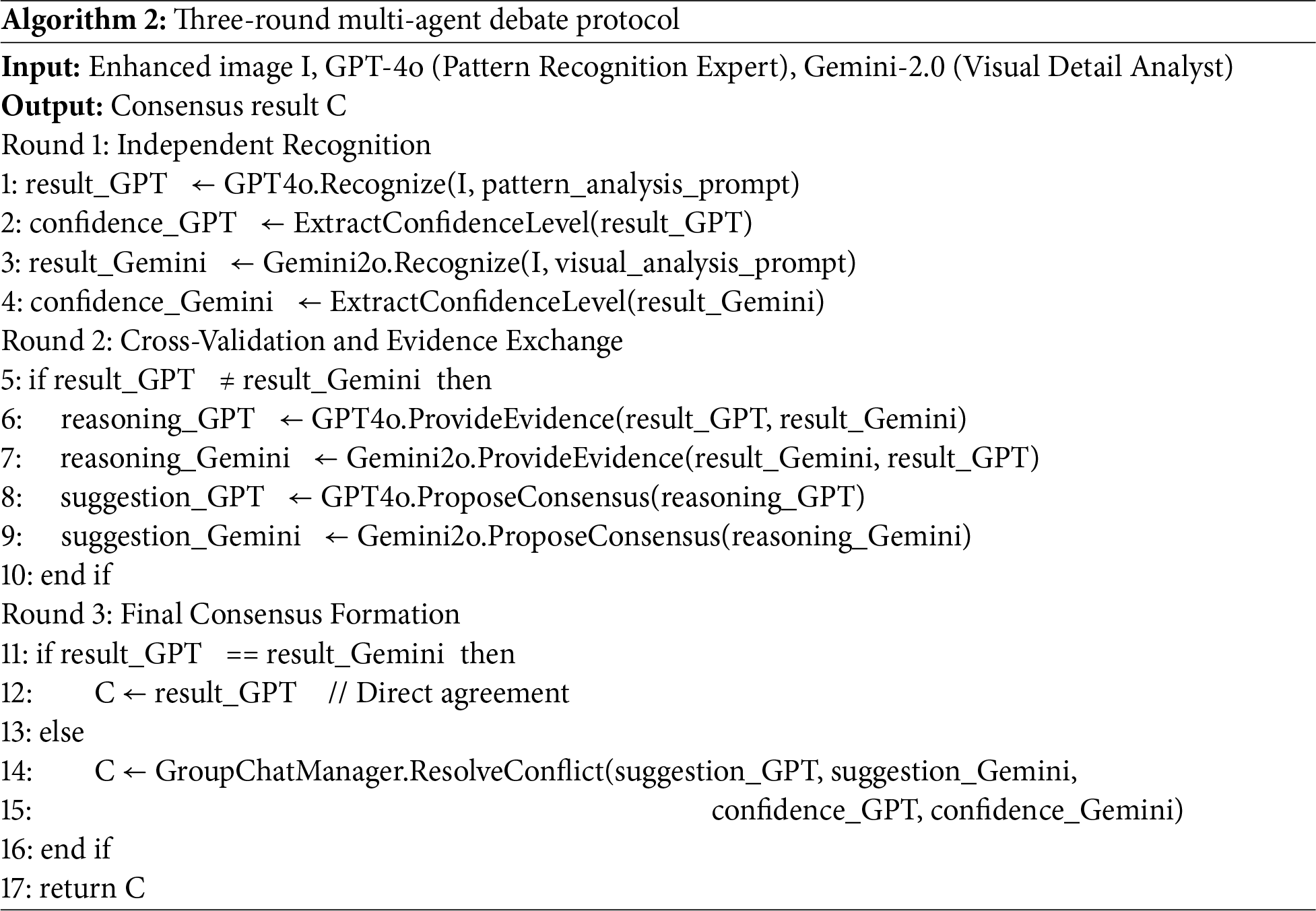
3.2.4 Domain-Specific Constraints and Prompt Engineering
Additionally, domain-specific constraints such as character sets, layout interpretation rules, and disambiguation heuristics are embedded into each agent’s operational logic through carefully crafted prompts. These constraints ensure that the recognition output remains consistent, domain-appropriate, and structurally interpretable.
As illustrated in Fig. 4, each agent is initialized with a role-specific system prompt that encodes its core responsibilities and domain knowledge. GPT-4o functions as the pattern recognition expert, guided by prompts that emphasize logical structure, layout awareness, and character-level reasoning. In contrast, Gemini-2.0 is positioned as the visual detail analyst, with prompts that highlight sensitivity to spatial features and morphological clarity.

Figure 4: Role-specific prompt design for structured multi-agent collaboration
The integration of role-specific prompt engineering with structured debate not only enhances the transparency and reproducibility of the recognition pipeline, but also strengthens its ability to resolve conflicting interpretations. By clearly defining task responsibilities and interaction rules, the system effectively combines symbolic reasoning with visual analysis to achieve high-confidence predictions under noisy and low-information conditions.
Dataset: To evaluate the proposed framework under realistic industrial conditions, a private dataset was constructed comprising 48 high-resolution images of cast or stamped alphanumeric characters on steel components. The images were obtained from real-world production settings using handheld cameras under diverse environmental conditions, including variable illumination, corrosion severity, surface roughness, and character layout complexity. This dataset captures degradation patterns commonly encountered in manufacturing environments, providing a representative testbed for industrial OCR evaluation. Representative samples are shown in Fig. 5, illustrating visual variability in character morphology, background interference, and surface irregularities.

Figure 5: Examples from the self-collected industrial casting character dataset
Dataset Representativeness: The dataset contains 48 images, each representing distinct degradation scenarios encountered in industrial environments. The diversity of corrosion patterns, surface textures, and character orientations provides comprehensive coverage of technical challenges that the proposed method addresses. No public dataset exists for character recognition on corroded metal surfaces in industrial environments. This work presents the first specialized benchmark for this domain, establishing a foundation for future research in industrial OCR applications.
4.2 Implementation Details and System Configuration
This section outlines the core implementation details of the proposed framework, focusing on the parameterization of the wavelet-based image enhancement module and the configuration of the multi-agent recognition system.
4.2.1 Wavelet Enhancement Parameters
Bior4.4 wavelet transform is adopted due to its symmetric structure and linear phase response, both of which are critical for preserving character edge morphology during enhancement. A single-level (Level-1) wavelet decomposition is employed to strike a balance between spatial detail extraction and computational efficiency.
The enhancement process amplifies both approximation and detail coefficients through a set of multiplicative weights. Specifically, the enhancement strategy is formulated as a parameter optimization problem, where the optimal coefficient values are selected to maximize a composite objective function—as defined in Eq. (1)—that integrates edge sharpness, information richness, and noise suppression.
To solve this optimization problem, DE algorithm is employed using the DE/rand/1/bin strategy. The optimizer is configured with a population size of 20, a mutation factor of 0.8, a crossover rate of 0.9, and a maximum of 50 generations. These settings are widely recognized as robust defaults for global optimization in continuous search spaces.
The weights parameters in Eq. (1), specifically
It is worth noting that the optimizer tolerates a moderate increase in high-frequency energy when it arises from deliberate edge sharpening. This phenomenon is particularly important in our scenario, as sharper character boundaries significantly improve recognition accuracy by large language models. For ablation and baseline comparison, a fixed-parameter configuration of [4.5, [3.2, 3.2, 0.3]] is also includes, which reflects a manually tuned but non-optimized setting.
4.2.2 Multi-Agent System Configuration
All recognition tasks were executed using GPT-4o and Gemini-2.0-flash as autonomous agents within the AutoGen platform. Each agent was initialized with a role-specific system prompt, as illustrated in Fig. 4, which encodes layout interpretation rules, character sets, and visual disambiguation heuristics (e.g., distinguishing ‘0’ from ‘O’). These prompts were designed to support a structured three-round debate protocol—comprising independent inference, mutual justification, and consensus generation—as described in Section 3.2.
To ensure consistency and reproducibility, all experiments were performed through deterministic Application Programming Interface (API) calls, and model outputs were formatted in standardized JavaScript Object Notation (JSON) structures to facilitate automated comparison and evaluation across methods.
4.3 Evaluation Metrics and Accuracy Criteria
To assess the effectiveness of the proposed character recognition framework under realistic industrial conditions—characterized by noisy backgrounds, occlusions, and frequent character distortions—a set of robust and fine-grained evaluation metrics is adopted. These metrics are widely used in state-of-the-art OCR and scene text recognition benchmarks, allowing for a comprehensive analysis of both high-level recognition accuracy and detailed error patterns.
Prior to evaluation, all predicted outputs (P_proc) and ground truth sequences (A_proc) are standardized by converting to lowercase, removing punctuation and whitespace, and normalizing visually similar characters (e.g., ‘0’ and ‘o’ treated equivalently). This preprocessing step ensures fair and consistent comparisons across all configurations.
• LCS-based Character Accuracy (LCS Accuracy): This metric is based on the Longest Common Subsequence (LCS) between the predicted and ground truth character sequences. It quantifies the proportion of correctly ordered characters while being tolerant to insertions and deletions—making it particularly suited for degraded visual inputs. It provides a robust measure of sequence-level structural similarity under distortion.
• Character-level Precision (P), Recall (R), and F1-Score (F1):
These metrics are computed based on edit-distance alignment between predicted and actual sequences. Precision evaluates the proportion of correctly predicted characters among all predicted characters; Recall measures the proportion of ground truth characters that are correctly retrieved; F1-Score provides the harmonic mean of precision and recall, offering a balanced assessment. Here, true positives (TP) represent correctly predicted characters, while false positives (FP) and false negatives (FN) account for character-level insertions, deletions, and substitutions.
Together, these metrics capture both the holistic sequence accuracy (via LCS) and token-level precision and coverage (via F1), offering a thorough evaluation of model robustness and reliability in noisy, real-world industrial OCR settings.
4.4 Baseline Comparison and Ablation Study
To thoroughly validate the effectiveness of the proposed system, a series of baseline and ablation experiments is conducted to isolate and analyze the contribution of each core module: the wavelet-based visual enhancement and the multi-agent structured collaboration mechanism.
The experiments are divided into two major phases: (1) evaluating visual enhancement strategies using image quality metrics, and (2) comparing system variants under different enhancement and agent configurations. Tables 1 and 2 summarize the results and configurations, respectively.


Evaluation of Enhancement Strategies To assess the effectiveness of the proposed enhancement module, wavelet-based enhancement is compared with several conventional preprocessing techniques, including binary thresholding, morphological operators (dilation, erosion, opening, closing), and median filtering. Each method is evaluated based on three metrics:
• Tenengrad: edge sharpness, reflecting boundary visibility.
• Shannon Entropy: structural information richness.
• High-Frequency Energy (HFE): noise content.
As shown in Table 1, binary thresholding achieves extremely high Tenengrad values (0.10647) but fails to preserve information (entropy = 0.83) and introduces severe high-frequency noise (HFE = 0.02056). Morphological operations and median filtering moderately suppress noise but degrade structural detail. In contrast, the wavelet-based approach achieves a superior balance across all metrics, preserving rich information (entropy = 6.24) while maintaining edge clarity (Tenengrad = 0.00556) and minimizing noise (HFE = 0.00052). These results empirically justify the use of wavelet enhancement in downstream recognition tasks.
Multi-Agent Collaboration and System Ablation To evaluate the contribution of multi-agent reasoning and collaborative refinement, a total of 12 system variants are defined across four categories. Their configurations are summarized in Table 2.
• Traditional OCR Baseline: Tesseract, a rule-based OCR method.
• Deep Learning OCR Baseline: EasyOCR, a CNN-based method.
• Transformer-Based OCR Baseline: TrOCR, a Vision Transformer method.
• Single-Agent Baselines: Org_GPT and Org_Gemini, which apply GPT-4o or Gemini-2.0 to the original images without any enhancement or collaborative reasoning.
• Naive Dual-Agent Fusion: Org_Dou_Agents, Seg_Dou_Agents, and Seg_Dou_Agents_Wav, where both agents independently infer without structured interaction, and their outputs are combined via simple fusion.
• Single-Agent with Enhancement: Seg_GPT_Wav and Seg_Gemini_Wav, which apply the wavelet-enhanced images to each LLM individually.
• Full Multi-Agent Debate Variants:
• Seg_Dou_Deb_Con: using segmented inputs without enhancement.
• Seg_Dou_Wav_Deb_Con: combining segmentation with wavelet enhancement.
• Seg_Dou_DE_Wav_Deb_Con: integrating DE-optimized wavelet preprocessing and full multi-agent debate.
Each configuration isolates the impact of one or more modules. By comparing progressive variants, the relative benefits of visual enhancement, model diversity, and structured reasoning are quantified.
This section presents a detailed evaluation of the proposed framework from two perspectives: the impact of DE-optimized wavelet enhancement on image quality, and the effectiveness of multi-agent collaborative reasoning in improving recognition accuracy.
DE-Based Wavelet Optimization The DE-optimized wavelet enhancement module demonstrates consistent improvements across all three evaluation metrics, confirming its effectiveness in balancing clarity, structure, and noise suppression. Fig. 6 shows that, compared to the original image and default wavelet settings, the DE-enhanced images exhibit:
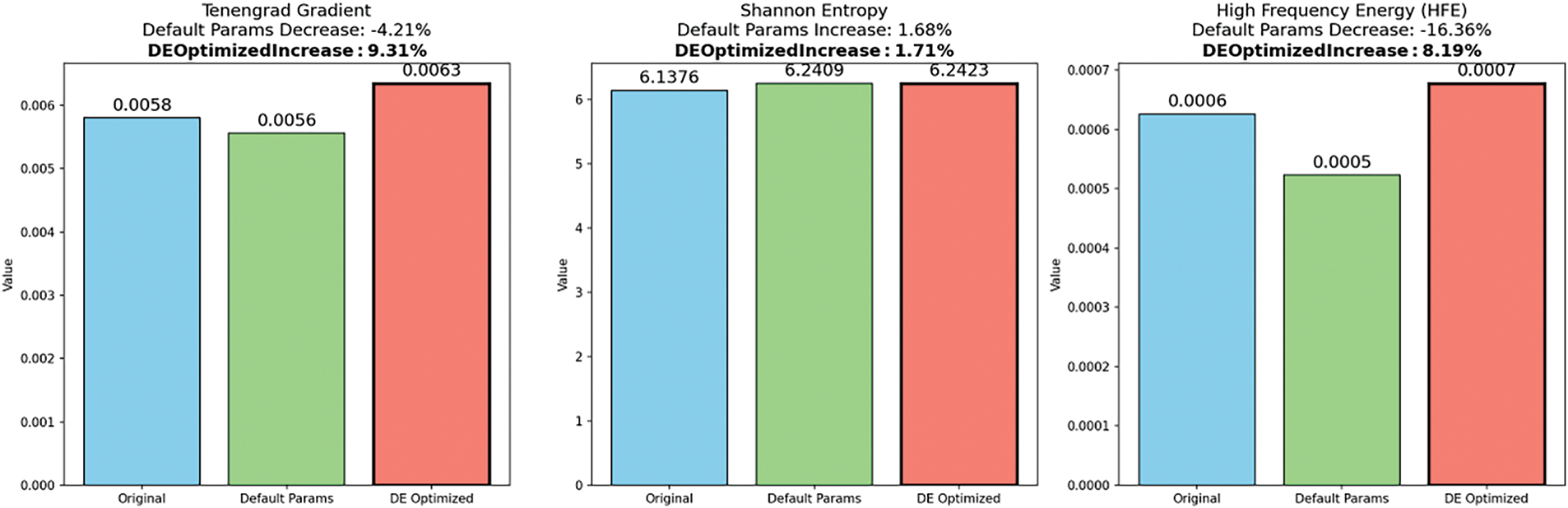
Figure 6: Evaluation of image quality metrics for OCR-oriented enhancement
• A +9.31% improvement in Tenengrad gradient, indicating sharper edge transitions;
• A +1.71% increase in Shannon entropy, suggesting richer structural information;
• A controlled +8.19% rise in HFE, which, although higher, reflects intentional stroke enhancement rather than background noise amplification.
These trends highlight the deliberate trade-off embedded in the multi-objective function (see Eq. (1)). Specifically, the DE algorithm selectively favors coefficient combinations that slightly tolerate high-frequency energy in exchange for significantly improved edge definition—critical for downstream OCR accuracy on embossed or corroded industrial characters.
This behavior reflects a goal-aware optimization strategy:
• Tenengrad is prioritized because sharper edges enhance character separability, especially under weak lighting, blur, or metal oxidation.
• Entropy gains indicate that DE not only sharpens boundaries but also preserves internal textures—crucial for distinguishing similarly shaped characters (e.g., ‘B’ vs. ‘8’).
• HFE increase is constrained: rather than noise amplification, it captures signal-rich high-frequency regions introduced by controlled sharpening.
Importantly, the optimization does not overfit one metric at the expense of others. While binary thresholding maximizes Tenengrad, it collapses entropy and inflates noise. In contrast, the DE-enhanced setting ensures that edge enhancement is aligned with recognition fidelity—a principle rarely achieved by manual parameter tuning.
Together, these findings empirically justify the integration of DE into the wavelet pipeline, showing that evolutionary search outperforms static or hand-tuned methods in task-specific image enhancement for real-world OCR applications.
Multi-Agent Collaborative Reasoning To evaluate the role of collaborative reasoning in complex visual environments, the performance of various system variants is compared in Table 3. These results reveal not only quantitative superiority of the proposed method, but also provide insight into how structured interaction enhances the robustness and accuracy of recognition.

Traditional OCR Methods Demonstrate Significant Limitations on Industrial Datasets. The baseline comparison reveals substantial performance gaps between conventional OCR approaches and specialized methods. Tesseract achieves only 12.10% F1-score, while modern deep learning approaches EasyOCR and TrOCR reach 47.31% and 38.13%, respectively. These results underscore the inadequacy of existing OCR technologies for severely degraded industrial surfaces, validating the necessity for domain-specific solutions that can handle extreme visual corruption and low-contrast conditions.
Dual-agent setups outperform single models by leveraging complementary strengths. Without interaction, Org_Dou_Agents already improves F1 to 85.19%, compared to Org_GPT (76.63%) and Org_Gemini (83.79%). This gain comes from combining GPT-4o’s layout-aware logic with Gemini’s visual detail recognition, offering robustness through redundancy. However, this improvement stalls in Seg_Dou_Agents_Wav (F1: 89.66%), which barely surpasses Seg_GPT_Wav (89.91%), showing that uncoordinated fusion fails to resolve model disagreement effectively.
Structured reasoning enables agents to resolve ambiguity and converge on high-confidence predictions.With the debate protocol, Seg_Dou_Wav_Deb_Con reaches 94.93% F1, improving both precision and recall. This jump is not just from adding more models, but from explicitly comparing results, justifying decisions, and generating consensus. The system filters false positives and aligns conflicting interpretations, turning model diversity into coherent output.
DE-enhanced collaboration improves global structure but slightly reduces token precision. Seg_Dou_DE_Wav_Deb_Con achieves the best LCS Accuracy (93.30%) but a slightly lower F1 (93.91%) than its non-DE counterpart. This trade-off reflects a shift: DE sharpening improves character boundary clarity and aids sequence alignment, but may increase segmentation errors in fine details. The result favors layout integrity over individual symbol fidelity, which is preferable for tasks prioritizing full-string recognition.
Overall, the experimental results demonstrate that both DE-based enhancement and structured agent collaboration independently contribute to performance gains, but their integration yields the highest accuracy and robustness. These findings validate the effectiveness of the proposed framework under real-world recognition challenges.
While the proposed framework shows promising results in character recognition under industrial degradation, yet several research avenues remain unexplored. These include methodological extensions and practical considerations to enhance applicability and sustain long-term system improvements.
Adaptive objective weighting. The current DE optimization uses fixed weights for enhancement objectives, limiting adaptability to varying surface conditions or degradation levels. Future work could develop adaptive weighting mechanisms that dynamically adjust parameters based on image characteristics or recognition feedback, using self-supervised learning or reinforcement-guided adaptation to improve system flexibility and robustness across diverse applications.
Domain-specific multimodal adaptation. Large language models exhibit robust multimodal generalization, yet their performance can be enhanced through task-specific knowledge integration. Fine-tuning on industry-relevant datasets, such as annotated casting images, inspection logs, or layout templates, could improve capture of domain-specific semantics and structural patterns, enhancing alignment between visual inputs and interpretive reasoning.
Expansion of collaborative agent architecture. The current framework uses two specialized agents for visual perception and logical inference. Incorporating additional agents for tasks like error correction, spatial layout analysis, or multilingual interpretation could enhance reasoning capacity. This modular expansion may broaden applicability to complex industrial documentation and cross-lingual recognition tasks.
Leveraging LLM-driven frameworks for generalized visual reasoning. Integrating large language models into structured multi-agent systems enables advanced visual reasoning. Beyond character recognition, LLMs can serve as a general-purpose reasoning layer, abstracting and contextualizing complex visual data. Future research could investigate their potential to enhance explainability, human-aligned decision-making, and cross-task transferability in diverse industrial vision applications.
In this work, a novel character recognition framework tailored for industrial casting surfaces is proposed, addressing challenges such as severe corrosion, low contrast, and irregular text morphology. The framework integrates two core innovations: (1) a DE-optimized wavelet enhancement module that adaptively balances edge sharpening, noise suppression, and structural detail preservation; and (2) a constrained three-round multi-agent debate mechanism that enables robust OCR consensus through coordinated reasoning between GPT-4o and Gemini-2.0-flash.
Extensive experiments on a private industrial dataset demonstrate that the proposed DE-based enhancement significantly improves both visual clarity and objective quality metrics compared to conventional preprocessing methods. Furthermore, the multi-agent collaboration protocol yields substantial performance gains, with the full system achieving 94.93% F1-score and 93.30% LCS Accuracy—surpassing all baseline and ablation models.
Importantly, this study highlights the practical viability of LLM-based OCR solutions in real-world industrial environments. Compared to traditional deep-learning-based OCR approaches, LLMs—when guided by structured prompts and supported by effective preprocessing—offer high flexibility, rapid inference, and strong generalization, without the need for retraining. These properties make the proposed framework particularly suitable for real-time, low-data manufacturing scenarios such as steel production lines.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization: Qin Qin and Xuan Jiang; methodology: Qin Qin, Xuan Jiang and Jinhua Jiang; software: Qin Qin, Xuan Jiang and Jinhua Jiang; validation: Qin Qin and Xuan Jiang; formal analysis: Qin Qin and Xuan Jiang; investigation: Qin Qin and Xuan Jiang; resources, Qin Qin and Xuan Jiang; writing—original draft preparation, Qin Qin and Xuan Jiang; writing—review and editing, Dongfang Zhao, Zimei Tu and Zhiwei Shen; visualization: Jinhua Jiang and Dongfang Zhao; supervision: Zimei Tu and Zhiwei Shen. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, [Xuan Jiang], upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Giganto S, Martínez-Pellitero S, Cuesta E, Meana VM, Barreiro J. Analysis of modern optical inspection systems for parts manufactured by selective laser melting. Sensors. 2020;20(11):3202. doi:10.3390/s20113202. [Google Scholar] [PubMed] [CrossRef]
2. Kusiak A. Smart manufacturing. Int J Prod Res. 2018;56(1–2):508–17. doi:10.1080/00207543.2017.1351644. [Google Scholar] [CrossRef]
3. Mikell PG. Fundamentals of modern manufacturing: materials, processes, and systems: fundamentals of modern manufacturing: materials, processes, and systems. Hoboken, NJ, USA: John Wiley & Sons; 2010. [Google Scholar]
4. Long SB, He X, Yao C. Scene text detection and recognition: the deep learning era. Int J Comput Vis. 2021;129(1):161–84. doi:10.1007/s11263-020-01369-0. [Google Scholar] [CrossRef]
5. Yin XC, Yin X, Huang K, Hao HW. Robust text detection in natural scene images. IEEE Trans Pattern Anal Mach Intell. 2014;36(5):970–83. doi:10.1109/TPAMI.2013.182. [Google Scholar] [PubMed] [CrossRef]
6. Ye Q, Doermann D. Text detection and recognition in imagery: a survey. IEEE Trans Pattern Anal Mach Intell. 2015;37(7):1480–500. doi:10.1109/TPAMI.2014.2366765. [Google Scholar] [PubMed] [CrossRef]
7. Tang Q, Lee Y, Jung H. The industrial application of artificial intelligence-based optical character recognition in modern manufacturing innovations. Sustainability. 2024;16(5):2161. doi:10.3390/su16052161. [Google Scholar] [CrossRef]
8. Sharma N, Jain V, Mishra A. An analysis of convolutional neural networks for image classification. Procedia Comput Sci. 2018;132:377–84. doi:10.1016/j.procs.2018.05.198. [Google Scholar] [CrossRef]
9. LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–44. doi:10.1038/nature14539. [Google Scholar] [PubMed] [CrossRef]
10. Hackl V, Müller AE, Granitzer M, Sailer M. Is GPT-4 A reliable rater? Evaluating consistency in GPT-4’s text ratings. Front Educ. 2023;8. doi:10.3389/feduc.2023.1272229. [Google Scholar] [CrossRef]
11. Yin S, Fu C, Zhao S, Li K, Sun X, Xu T, et al. A survey on multimodal large language models. Natl Sci Rev. 2024;11(12):nwae403. doi:10.1093/nsr/nwae403. [Google Scholar] [PubMed] [CrossRef]
12. Jose S, Nguyen KTP, Medjaher K, Zemouri R, Lévesque M, Tahan A. Advancing multimodal diagnostics: integrating industrial textual data and domain knowledge with large language models. Expert Syst Appl. 2024;255:13. doi:10.1016/j.eswa.2024.124603. [Google Scholar] [CrossRef]
13. Poudel U, Regmi AM, Stamenkovic Z, Raja SP. Applicability of OCR engines for text recognition in vehicle number plates, receipts and handwriting. J Circuits Syst Comput. 2023;32(18):2350321. doi:10.1142/s0218126623503218. [Google Scholar] [CrossRef]
14. Mallat SG. A wavelet tour of signal processing: a wavelet tour of signal processing. 3rd ed. Burlington, MA, USA: Elsevier; 2010. [Google Scholar]
15. Opara KR, Arabas J. Differential evolution: a survey of theoretical analyses. Swarm Evol Comput. 2019;44:546–58. doi:10.1016/j.swevo.2018.06.010. [Google Scholar] [CrossRef]
16. Chen X, Yi HH, You MK, Liu WZ, Wang L, Li HR, et al. Enhancing diagnostic capability with multi-agents conversational large language models. npj Digit Med. 2025;8(1):159. doi:10.1038/s41746-025-01550-0. [Google Scholar] [PubMed] [CrossRef]
17. Mann SP, Earp BD, Moller N, Vynn S, Savulescu J. AUTOGEN: a personalized large language model for academic enhancement-ethics and proof of principle. Am J Bioeth. 2023;23(10):28–41. doi:10.1080/15265161.2023.2233356. [Google Scholar] [PubMed] [CrossRef]
18. Shi BG, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans Pattern Anal Mach Intell. 2017;39(11):2298–304. doi:10.1109/tpami.2016.2646371. [Google Scholar] [PubMed] [CrossRef]
19. Baek J, Kim G, Lee J, Park S, Han D, Yun S, et al. What is wrong with scene text recognition model comparisons? Dataset and model analysis, seoul, the Republic of Korea. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, the Republic of Korea. [Google Scholar]
20. Gan Z, Li L, Li C, Wang L, Liu Z, Gao J. Vision-language pre-training: basics, recent advances, and future trends. Found Trends Comput Graph Vis. 2022;14(3–4):163–352. doi:10.1561/0600000105. [Google Scholar] [CrossRef]
21. Hosseini S, Seilani H. The role of agentic AI in shaping a smart future: a systematic review. Array. 2025;26:100399. doi:10.1016/j.array.2025.100399. [Google Scholar] [CrossRef]
22. Lo WY, Puchalski SM. Digital image processing. Vet Radiol Ultrasound. 2008;49(1):S42–7. doi:10.1111/j.1740-8261.2007.00333.x. [Google Scholar] [PubMed] [CrossRef]
23. Wu GH, Shen X, Li HF, Chen HK, Lin AP, Suganthan PN. Ensemble of differential evolution variants. Inf Sci. 2018;423:172–86. doi:10.1016/j.ins.2017.09.053. [Google Scholar] [CrossRef]
24. Monteiro G, Camelo L, Aquino G, Fernandes RD, Gomes R, Printes A, et al. A comprehensive framework for industrial sticker information recognition using advanced OCR and object detection techniques. Appl Sci. 2023;13(12):7320. doi:10.3390/app13127320. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools