
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CAPGen: An MLLM-Based Framework Integrated with Iterative Optimization Mechanism for Cultural Artifacts Poster Generation
School of Design, Hunan University, Changsha, 410082, China
* Corresponding Author: Fang Liu. Email:
Computers, Materials & Continua 2026, 86(1), 1-17. https://doi.org/10.32604/cmc.2025.068225
Received 23 May 2025; Accepted 22 July 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Due to the digital transformation tendency among cultural institutions and the substantial influence of the social media platform, the demands of visual communication keep increasing for promoting traditional cultural artifacts online. As an effective medium, posters serve to attract public attention and facilitate broader engagement with cultural artifacts. However, existing poster generation methods mainly rely on fixed templates and manual design, which limits their scalability and adaptability to the diverse visual and semantic features of the artifacts. Therefore, we propose CAPGen, an automated aesthetic Cultural Artifacts Poster Generation framework built on a Multimodal Large Language Model (MLLM) with integrated iterative optimization. During our research, we collaborated with designers to define principles of graphic design for cultural artifact posters, to guide the MLLM in generating layout parameters. Later, we generated these parameters into posters. Finally, we refined the posters using an MLLM integrated with a multi-round iterative optimization mechanism. Qualitative results show that CAPGen consistently outperforms baseline methods in both visual quality and aesthetic performance. Furthermore, ablation studies indicate that the prompt, iterative optimization mechanism, and design principles significantly enhance the effectiveness of poster generation.Keywords
Due to advancements in digitization [1,2], high-resolution imaging techniques for various categories of cultural artifacts, including bronzes, paintings, calligraphy, and ceramics, the development of multidimensional metadata systems [3], and the construction of knowledge graphs [3], cultural institutions have been able to accumulate a substantial amount of image resources and metadata related to cultural artifacts. In this context, effectively conveying high-quality images of cultural artifacts and their associated structured metadata to the public has become a central focus of research.
Social media platforms have become essential channels for cultural institutions to foster communication [4,5], as their formats of visual, lightweight, and shareable, such as posters, have gained widespread adoption. However, current poster generation practices in the cultural heritage domain rely primarily on manual creation by professional designers, which limits scalability and production efficiency. Meanwhile, it cannot support museum visitors in creating and sharing posters on the aesthetics of cultural relics. Therefore, an efficient and automated solution is needed to enable more people to create visually appealing posters of cultural relics for sharing and broadcasting.
Existing studies have explored the automatic generation of cultural artifact posters based on aesthetic matching principles combined with predefined poster templates. For example, Zhang et al. proposed a method that retrieves appropriate templates from a poster library based on user-captured images of cultural artifacts [6], thereby generating corresponding posters. However, this approach is heavily reliant on templates, leaving room for improvement in both generalizability and aesthetic quality. Moreover, the design of such templates still demands significant manual effort from professional designers, and the template-based generation method restricts users from customizing the textual elements displayed on the poster. Yang et al. introduced Posterllava [7], a method that integrates unsupervised learning with instruction-following fine-tuning, enabling automatic poster generation based on user-defined design intent and input visual elements. Although this method allows for customized poster generation in specific contexts, it relies heavily on explicit user-provided design instructions to generate a single poster, requiring users to articulate a clear and often expert-level design intent. This dependency significantly limits its applicability, as such professional input is unrealistic for general users. Our work is mainly aimed at non-experts without design experience, such as in the social sharing scenarios of tourists visiting museums.
Due to the diverse forms and profound cultural semantics of cultural artifacts, accurately perceiving their multidimensional visual features and integrating them with cultural meanings presents a significant challenge. In addition, although there have been efforts toward large-scale AI-driven poster generation, these approaches often lack well-defined and generalizable aesthetic principles, resulting in a heavy reliance on the professional expertise of designers for direction. Consequently, it is particularly challenging to adaptively generate aesthetic posters that align with the visual characteristics and information display requirements of different cultural artifacts.
To address these challenges, we developed CAPGen, an automated aesthetic poster generation framework based on a multimodal large language model (MLLM). CAPGen is capable of automatically generating aesthetically appealing posters by leveraging the visual characteristics of cultural artifacts and utilizing both artifact images and structured metadata, as illustrated in Fig. 1. CAPGen consists of three stages:
a. Parameterized Poster Design Stage constructs prompts based on design principles extracted from collaboration with professional designers, integrates them into an MLLM, and generates structured poster design parameters;
b. Poster Rendering Stage renders posters based on the generated structured parameters;
c. Iterative Optimization Stage evaluates the poster image and its structured parameters using an MLLM guided by designer-defined aesthetic evaluation criteria. The model conducts multi-round reviewing and modification. Iterative optimization continues until all evaluation dimensions meet the predefined thresholds, at which point the final poster is generated.

Figure 1: Automatically generated cultural artifact posters by CAPGen
Overall, the contributions of this paper are as follows:
1. Collaborated with professional designers to identify three design principles for cultural artifact posters: Visual hierarchy, Focal Point, and Rhythm;
2. Based on these principles, we designed prompts and developed an MLLM-based automated framework for aesthetic poster generation of cultural artifacts, thereby supporting cross-modal semantic understanding as well as the generation of structured poster design parameters, all without requiring additional model training or fine-tuning;
3. Formulated optimization criteria grounded in designer feedback on generated posters, introduced a closed-loop aesthetic review mechanism, and fully leveraged the reasoning capabilities of MLLMs to achieve iterative optimization and automatic poster refinement.
The remainder of this paper is organized as follows: Section 2 reviews related work; Section 3 presents the CAPGen framework and methodological design; Section 4 reports experimental results; and Section 5 concludes the study and outlines directions for future work.
2.1 Digital Dissemination of Cultural Artifacts
In recent years, with the accelerating transformation of digitization in the cultural and museum scenario, the digital dissemination of cultural artifacts has emerged as a new trend in the research and presentation of cultural heritage. Many museums and studies have established comprehensive cultural artifact databases, such as the CArt15K dataset [8] for ceramics with fine-grained factor annotations and the MeArt multimodal dataset [9] containing over 8000 annotated ancient ceramic images for metaphor-aware captioning, providing a solid foundation for the re-dissemination of these artifacts. Current studies highlight the increasingly critical role of digital technologies in the preservation and communication of cultural heritage [10]. These technologies effectively overcome temporal and spatial limitations, significantly bridging the gap between the public and cultural artifacts, thus improving the efficiency of cultural heritage dissemination and increasing user engagement [11].
In the field of digital humanities, scholars are actively exploring ways to strengthen the visual expression of cultural memory through image-text narratives and visual language reconstruction [12]. Some existing studies have attempted to improve exhibition experiences through techniques such as image enhancement and text extraction. However, much of the existing research focuses primarily on content presentation and lacks methods for the automated generation of cultural artifact posters in social contexts—an essential step toward meeting the public’s demand for social sharing.
2.2 Applications of MLLMs in Visual Content Creation
In recent years, Large Language Models (LLMs) have demonstrated significant potential in layout generation, particularly through the use of structured formats such as XML or JSON to represent graphic design parameters. This enables progress in tasks such as zero-shot composition [13], text-to-layout generation [14], and layout code synthesis [15,16]. Although LLMs have proven highly effective in understanding and generating textual content, many of these studies overlook the importance of visual features, which are crucial in real-world design processes, or rely on transforming visual modality inputs into textual representations before feeding them into the model.
MLLMs overcome this limitation by integrating additional modalities, such as vision and audio [7]. For example, MM-REACT proposed a system paradigm that combines ChatGPT with a visual expert library to enable multimodal reasoning and action-taking [17]. In addition, Nair et al. explore the integration of Computational Creativity theory into MLLMs to enhance the ability to solve creative problems in visual tasks [18]. Their work demonstrates the potential of MLLMs in design-oriented applications such as image substitution and task reframing, highlighting the emerging role of MLLMs in the domain of creative visual generation.
2.3 Multi-Round Iterative Optimization Mechanisms
With the advancement of AIGC and multimodal generative models, the automation of visual content creation has significantly improved, leading to growing interest in incorporating iterative optimization mechanisms to optimize generation quality. In tasks such as image generation and text-image layout, iterative optimization processes have been shown to enhance both aesthetic consistency and semantic accuracy of the outputs.
TextMatch, for instance, employs a scoring strategy supported by Large Language Models (LLMs) and Visual Question Answering (VQA) models to evaluate the semantic alignment between prompts and generated images [19]. IterComp aggregates perceptual synthesis preferences from multiple models and adopts an iterative feedback learning approach to enhance generative outcomes [20]. Other research has introduced rule-based automatic feedback loops—for example, Skywork R1V2 coordinates reward-model guidance with rule-based strategies to address the longstanding challenge of balancing complex reasoning abilities with broad generalization [21].
In design tasks such as poster creation, strong aesthetic control is critical. However, existing automated methods often rely on handcrafted aesthetic metrics (e.g., contrast, whitespace balance, alignment) or subjective human evaluation, both of which suffer from limited scalability and consistency [22]. In contrast, leveraging the visual-text understanding and structural perception capabilities of MLLMs, combined with rule-based prompt design to guide structured feedback and multi-round iterative optimization, offers a promising direction for both research and practical applications. VASCAR [23] proposes a visually self-correcting layout generation method that leverages Large Vision-Language Models for iterative optimization. By incorporating visual feedback on the generated layout, the model progressively improves the design to better align with aesthetic standards. However, VASCAR is fundamentally designed for the layout arrangement of textual and auxiliary elements on pre-existing poster visuals, without handling the parameter design of the main visual object. While we draw inspiration from its multi-round iterative optimization mechanism, it is not applicable to our end-to-end poster generation task, which requires full-layout creation based solely on artifact images and metadata.
CAPGen is a prompt-driven framework for the automatic generation of posters, as shown in Fig. 2. It consists of three stages: 1) the Parameterized Poster Design Stage, 2) the Poster Rendering Stage and 3) the Iterative Optimization Stage. Given an artifact image and its metadata (e.g. title, description, date and location), MLLM_design creates posters based on the artifacts’ characteristics and generates structured layout parameters during the Parameterized Poster Design Stage. The layout is then processed by a rendering module during the Poster Rendering Stage to generate a high-resolution poster image. The poster image, along with its layout parameters, is subsequently fed back into MLLM_optimization for evaluation during the Iterative Optimization Stage. The process of this stage continues until all dimensions meet the defined threshold, at which point the final layout is rendered to generate the completed poster. Both MLLM_design and MLLM_optimization were implemented using ChatGPT-4o (OpenAI, 2024), accessed via API. No custom model training or fine-tuning was performed, all functionality was achieved through prompt engineering.

Figure 2: An illustration of CAPGen’s framework
3.2 Parameterized Poster Design Stage
In collaboration with professional designers, we identified three key principles for the design of cultural artifact posters: Visual Hierarchy [24], Focal Point [24], and Rhythm [25]. These principles are essential for good design practice and are particularly important for ensuring visual flow, balance and readability in poster design. Firstly, Visual Hierarchy helps the audience clearly understand the importance of design elements by adjusting their size, position, color, and value to effectively guide the viewers’ attention. Secondly, Focal Point ensures that there is a most prominent and attention-grabbing area within the poster design, which is usually where the main character, artifact, or information is located. Thirdly, Rhythm creates a sense of visual flow through the repetition, spacing, and arrangement of elements, adding the sense of order or dynamism to the poster design.
Based on the constraints defined by the three design principles, we created a prompt to guide the generation of parameters for poster creation. The prompt includes strategies for margin settings, color selection, layout configuration, background and main image design, and textual elements, each expressed as structured parameters. Each strategy corresponds to one or two design principles. For clarity, we list only the most relevant principle for each strategy, as shown in Table 1.
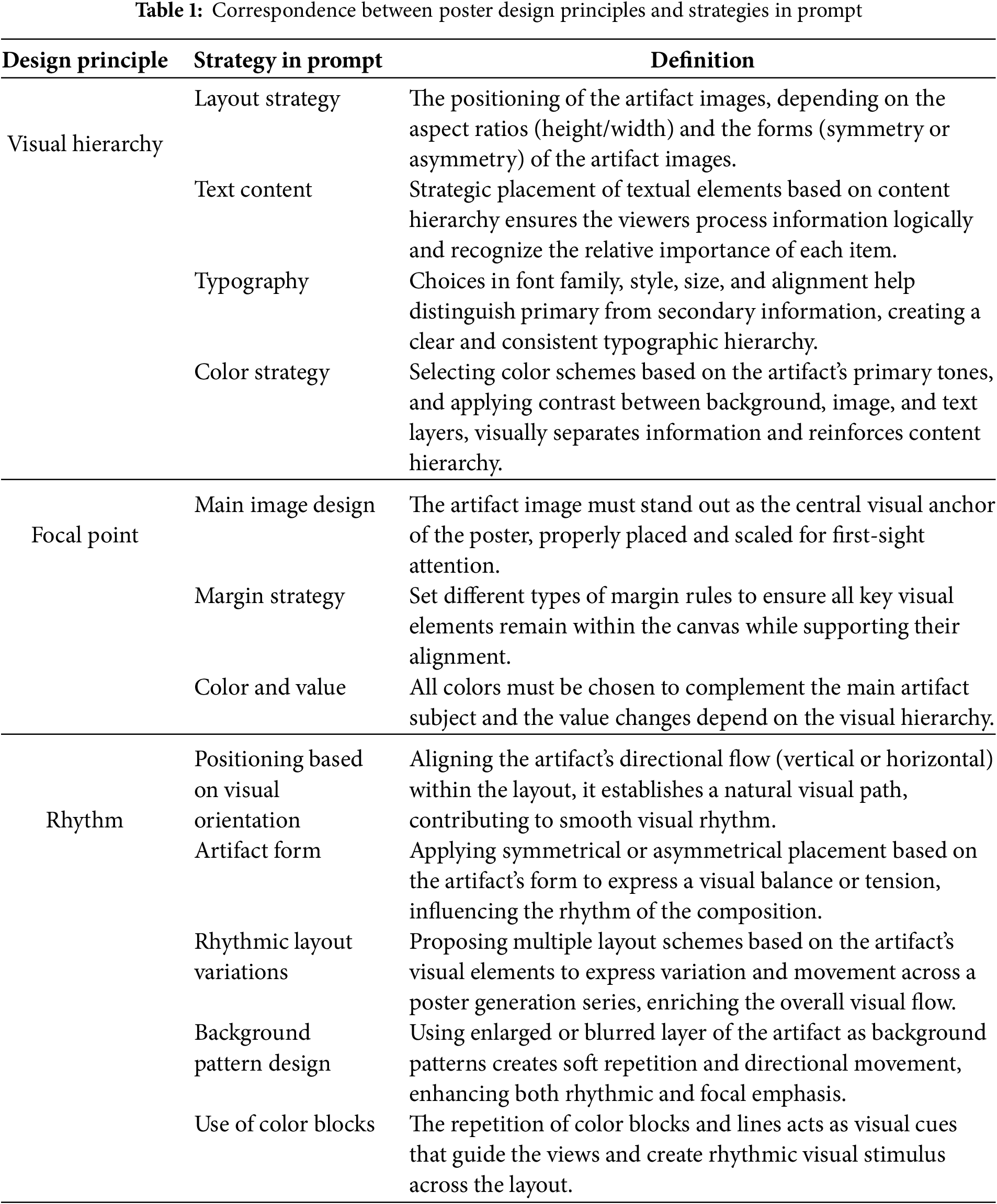
We integrate the prompt into the MLLM to form the MLLM_design. The input includes the cultural artifact image along with its structured metadata (such as title, description, date, location, signature, etc.). Based on this input, MLLM_design generates a set of structured layout parameters, which are output in JSON format. A representative example of poster parameters in JSON format is presented on Fig. A1 in Appendix A. These parameters are detailed to define the spatial positions, sizes, fonts, colors, and margin settings of each component in the poster. The output covers the main artifact image, textual information, optional background patterns, color blocks, and the overall color scheme.
To visualize layout parameters, the framework implements an automated poster rendering module based on the Python Pillow (PIL) image library. This module accurately parses each element specified in the JSON file and renders graphics, text, and auxiliary layers onto the canvas according to the defined layout logic, ultimately generating a high-quality poster image with a resolution of 760
3.4 Iterative Optimization Stage
Since the MLLM_design in the first stage only generates poster parameters and lacks access to visual information of the poster, it’s useful to provide the poster image to MLLM for visual-based analysis and optimization. We collaborated with professional graphic designers to analyze multiple sets of generated posters. Based on common issues identified in the posters, seven key dimensions were selected for iterative optimization: 1) semantic alignment harmony, 2) spatial distribution balance, 3) overlap, 4) vertical margin consistency, 5) text and typography readability, 6) background pattern logic, and 7) color harmony. We designed a second-stage prompt to guide further optimization and constructed MLLM_optimization. This prompt requires only the poster image and its structured parameters as input, enabling the MLLM to perform optimization based on direct visual features. The seven dimensions are scored on a scale of 1 to 10, with 8 considered the threshold for acceptance. Based on this framework, we implemented a multi-round iterative optimization mechanism. After each round, MLLM_optimization provides modification suggestions for dimensions scoring below 8 and modifies poster parameters accordingly and re-rendered the poster for next round. This feedback–correction cycle continues until all dimensions reach a score of 8 or above. All dimensions are treated as strict constraints, requiring the model to repeatedly inspect and correct deficiencies during each round of review. This ensures that the final poster clearly communicates the intended information and aligns with aesthetic expectations.
To evaluate the effectiveness of CAPGen, we conducted a multi-dimensional qualitative experiment and two ablation studies. The qualitative experiment comprehensively assessed the visual quality and aesthetic performance of the generated posters, while the ablation studies analyzed the impact of three key components within CAPGen: the prompt, the iterative optimization mechanism, and the three design principles. The current version of CAPGen was tested using GPT-4o accessed via OpenAI’s API and all local orchestration and rendering were conducted on a consumer-grade desktop computer equipped with an Intel Core i5-10400F CPU (2.90 GHz), 16 GB RAM and an NVIDIA GeForce GTX 1650 GPU. Under 100 tests, the initial layout generation and rendering take around 14.39 s on average, while each optimization and re-generation round adds about 20.30 s. Typically, the process completes within 1–2 optimization iterations.
This experiment draws on the qualitative evaluation methods used in the works of Bai et al. [26] and Zhang et al. [6] to assess the effectiveness of CAPGen in poster generation. First, we selected eight cultural artifact images from the official websites of museums, both domestic and international. The details about the eight artifacts are summarized in Table A1 in Appendix B. Subsequently, posters were generated using two methods: (i) CrePoster, and (ii) CAPGen as shown in Fig. 3. We recruited 47 participants: 20 without design backgrounds and 27 designers. They evaluated the posters generated by CAPGen and the baseline based on aesthetics.

Figure 3: Comparison of posters generated by CrePoster and CAPGen
Based on the evaluation frameworks of Bai et al. [26], and Zhang et al. [6], we introduced four additional aesthetic criteria to comprehensively assess the posters. Each criteria was rated on a 7-point Likert scale, ranging from 1 (very poor) to 7 (excellent):
a. Design Principle: Utilized to assess if a poster adheres to design principles, encompassing four aspects: 1) the relevance of visual elements and text content to theme and audience; 2) the poster’s ability to capture and sustain the audience’s interest; 3) the readability of textual content; 4) the logical coherence and rational integration of visual and textual elements.
b. Color Matching: The overall color harmony of the poster.
c. Visual Balance: The balance between the visual elements and textual content in a poster.
d. Overall Aesthetic: The artistic effect produced by the combination of factors, including visual appearance, design elements, and composition.
Table 2 shows that the posters generated by CAPGen significantly outperform those produced by the baseline method CrePoster across all evaluation criteria (Cronbach’s
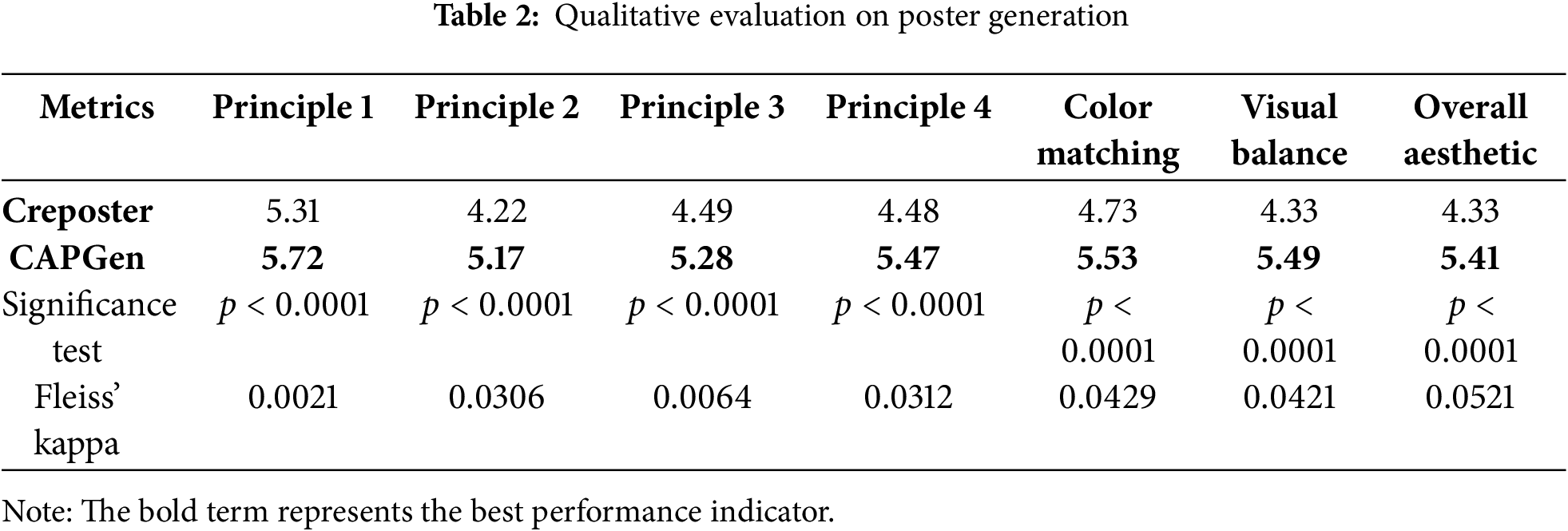
The greatest improvement was observed in visual balance, with an increase in score of 1.16 (from 4.33 to 5.49). These results clearly show that posters created using CAPGen, which adapts to the specific features of cultural artifacts while adhering to design principles, consistently outperform those produced by CrePoster using fixed templates across multiple aesthetic dimensions.
To validate the effectiveness of the poster design principles and the multi-round iterative optimization mechanism, we conducted two comprehensive ablation studies. Participants from the original qualitative experiment were invited to take part in these studies. Given the subjectivity inherent in aesthetic evaluation, participants were divided into two groups based on their design background: non-designers and designers. Considering the diversity of aesthetic preferences and evaluation standards, participants might hold differing opinions when assessing the same work. Therefore, we adopted 2 evaluation dimensions: 1) Best Poster: each participant selects only one poster, and 2) Aesthetically Acceptable Posters: participants may select one or more posters that meet their aesthetic standards.
We denote the proportion of posters meeting aesthetic quality standards as
To evaluate the impact of multi-round iterative optimization and prompt design on CAPGen, we used CAPGen to generate cultural artifact posters under four different conditions for each ablation study, as illustrated in Fig. 4.
Figure 4: Comparison of posters generated by CAPGen under different conditions
As shown in Table 3, posters generated under Condition 3 (single round with prompt) received significantly higher scores than those under Condition 1 (single round without prompt) across all evaluation metrics:
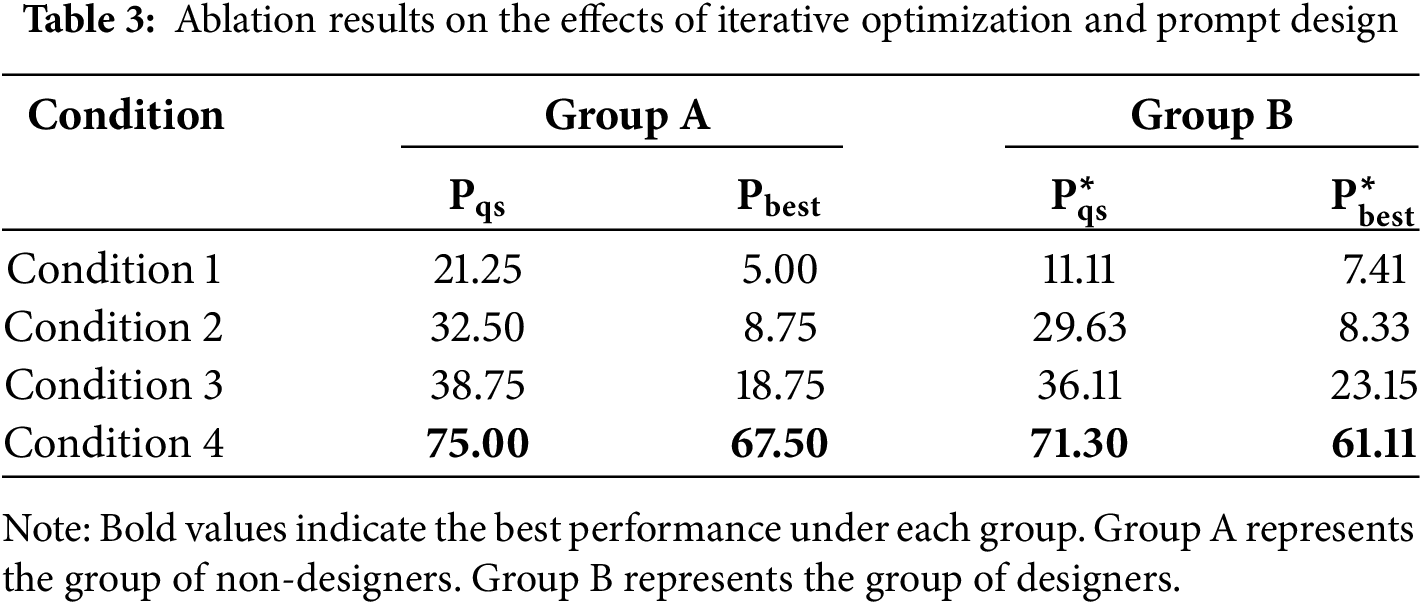
These results collectively confirm that both prompt design and multi-round optimization mechanism significantly enhance the quality of poster generation, and their combined use leads to the best performance. Interestingly, many participants noted that although the posters generated under condition 1 (single round without prompt) appeared logically structured, they were monotonous and tended to use nearly the same layout for different cultural artifacts posters.
To evaluate the impact of the three design principles embedded in the prompt on poster generation, we conducted an ablation study with 4 experimental conditions as shown in Fig. 5: (i) posters generated without visual hierarchy, (ii) posters generated without a focal point, (iii) posters generated without rhythm, and (iv) posters generated with all three design principles included.


Figure 5: Comparison of posters generated by CAPGen under different conditions: (1) posters generated without visual hierarchy, (2) posters generated without focal point, (3) posters generated without rhythm, and (4) posters generated with all three design principles included
The experimental results are shown in Table 4. The findings indicate that Condition 4, which retains all design principles, received the highest scores across all evaluation metrics:
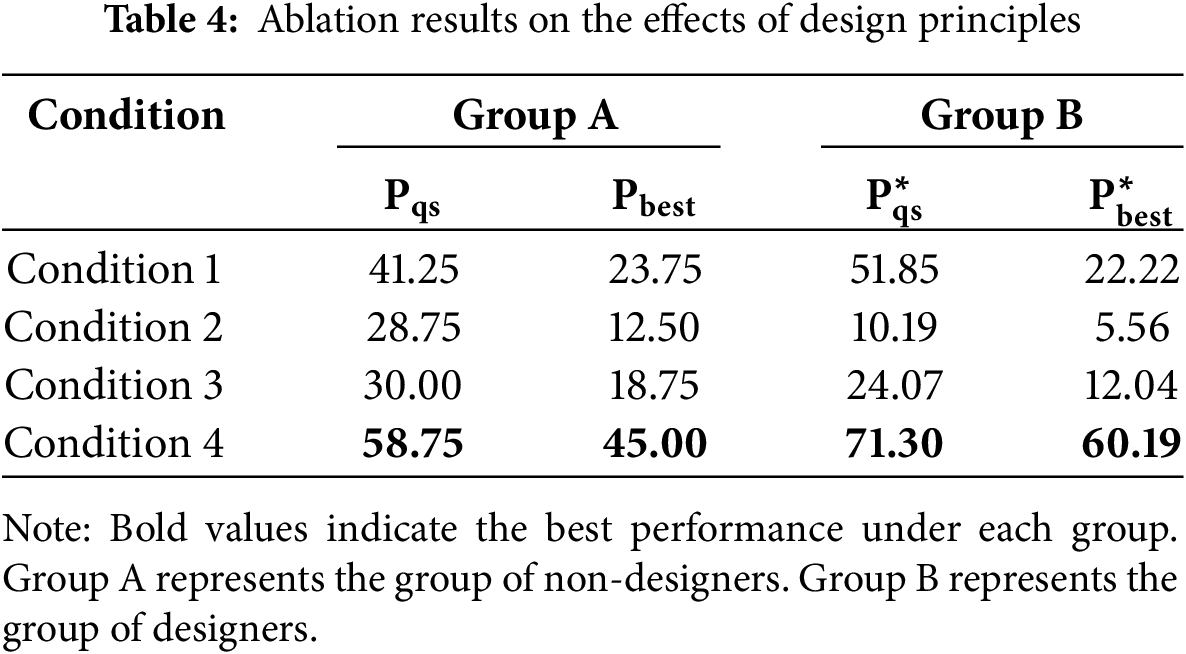
These results underscore the importance of design principles in poster generation, particularly those related to visual hierarchy, focal point, and rhythm, when using the CAPGen framework. Interestingly, Condition 1, which excludes visual hierarchy, received the second-highest scores, suggesting that the absence of visual hierarchy has a relatively smaller impact on the overall visual quality compared to the omission of the other two principles. This is because, although visual hierarchy affects the overall structure, it can be partially compensated for by strong focal points and a rhythmic poster design, making its absence less harmful to the visual quality of posters.
Existing template-based poster generation methods lack the flexibility to accommodate the varied visual forms and structural characteristics of cultural artifacts, and require substantial manual effort to design and maintain templates. Text-to-image generation models risk altering the visual integrity of artifacts, making them unsuitable for cultural heritage contexts. We also conducted a pilot experiment by prompting MLLM with pre-designed layout templates to guide the poster design process. In the absence of clear design guidance, the model tended to follow the template structure rigidly. This behavior appears to stem from language model’s inherent tendency to make minimal edits [28], which reflects a form of “lazy generation” and leads to outputs that closely mirror the input content. As a result, the generated posters became highly repetitive and failed to adapt effectively to the unique visual and semantic features of different cultural artifacts. To address these limitations, we propose a novel framework for automated aesthetic poster generation of cultural artifacts. It combines prompt-based integration of design principles with iterative optimization, without requiring model training or fine-tuning. It enables automatic poster generation based on the specific features of cultural artifacts, without the need for human intervention, making it well-suited for public to create and share artifact posters on social media, thereby enhancing cultural dissemination. Experimental results demonstrate significant improvements in visual quality and user preference compared to template-based methods.
Due to the current use of relatively basic graphic design principles and the inherent uncertainty in MLLM generation, a small number of generated posters do not meet the desired aesthetic standard, as illustrated in Fig. A2 in Appendix C. This issue arises from two main factors. Firstly, some artifact images do not fully capture the artifact’s form, such as the Plain Gauze Robe in Fig. A2. The design principles currently learnt by CAPGen cannot yet support the partial display of artifacts based on incomplete images as a designer would. This leads to a slight sense of disconnection in the generated posters. Secondly, some artifact images include multiple related pieces, such as the mask set on the right of Fig. A2, which consists of different components. In such cases, CAPGen is currently unable to decompose the artifact set and rearrange its elements for layout. This means that the poster design is constrained by the arrangement of elements in the original artifact image.
In future work, we plan to explore more refined and domain-specific design principles to further enhance the professionalism and reliability of CAPGen’s outputs. Moreover, when cultural artifacts lack annotations, additional algorithms are required to bridge the gap and enable poster generation. Future work could explore how to quickly and accurately generate annotations based on the characteristics of artifacts, such as patterns and shapes, to enrich the metadata. Furthermore, considering the effectiveness of retrieval-augmented generation (RAG) in enhancing MLLM capabilities, incorporating a poster design element library to enrich poster content is a promising direction. This could enable more stylized outputs suitable for high-quality exhibition use. By leveraging the visual perception capabilities of MLLMs, CAPGen can be adapted to domains such as advertising and educational materials through adjustments to design principles, and extended to other design tasks traditionally reliant on manual labor. Additionally, the design principles incorporated in CAPGen are derived from a select group of experienced designers. Mitigating potential design biases in MLLM outputs is also an important consideration for future refinement of these principles.
Acknowledgement: This research is supported by the National Museum of China, the Hunan Museum, and the Changsha Museum.
Funding Statement: This work is supported by the National Key Research and Development Program of China (2023YFF0906502) and the Postgraduate Research and Innovation Project of Hunan Province under Grant (CX20240473).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Qianqian Hu and Fang Liu; methodology, Qianqian Hu and Chuhan Li; validation, Qianqian Hu and Mohan Zhang; visulization, Chuhan Li; investigation, Qianqian Hu and Chuhan Li; data curation, Qianqian Hu; writing—original draft preparation, Qianqian Hu and Chuhan Li; writing—review and editing, Mohan Zhang and Fang Liu; funding acquisition, Fang Liu and Mohan Zhang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, Fang Liu, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
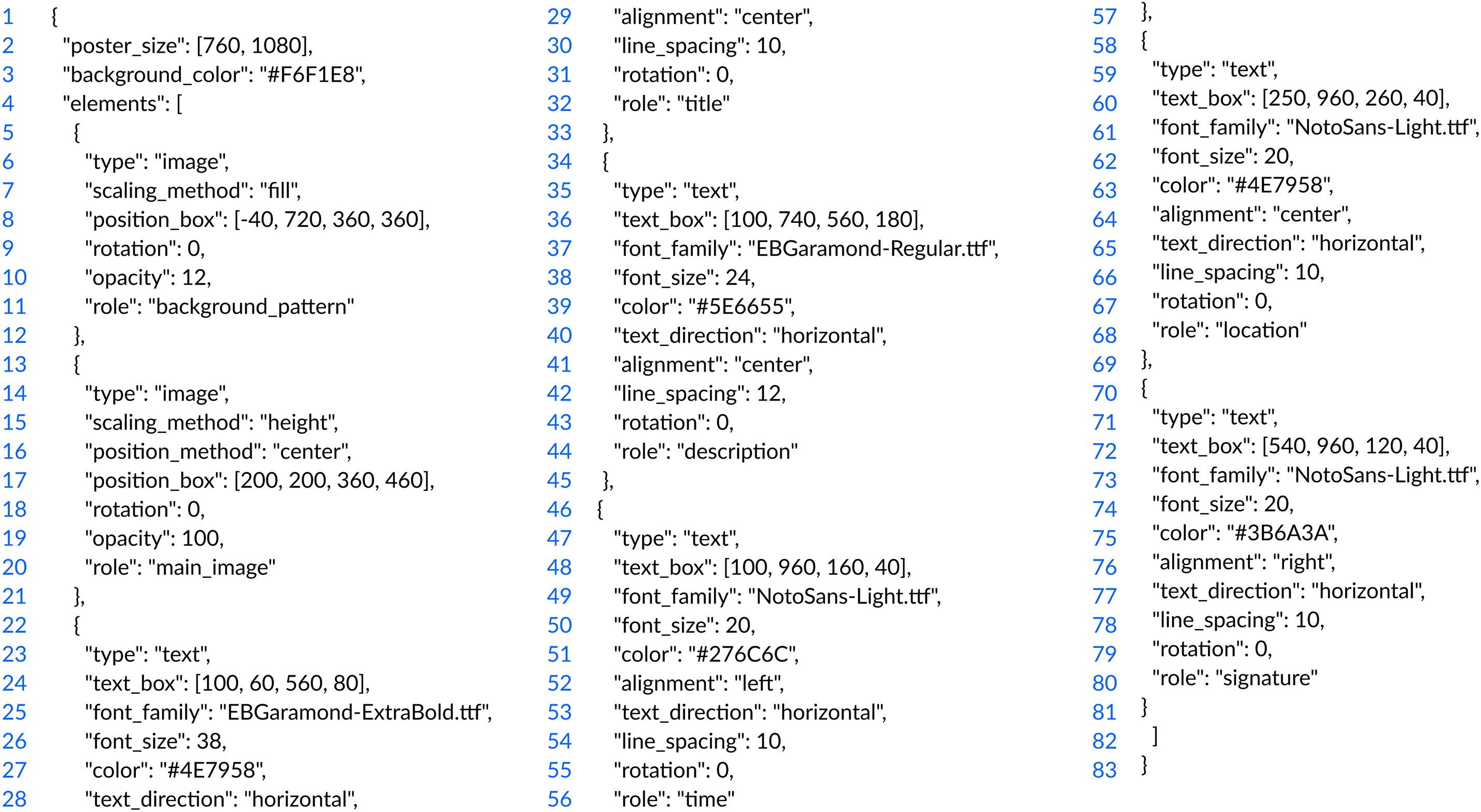
Figure A1: Example of JSON-formatted poster design parameters generated by CAPGen
We conducted testing and evaluation using artifact images from six museums, including the National Museum of China, the National Palace Museum in Taipei, the Metropolitan Museum of Art and so on. For the qualitative experiment, eight representative artifact posters were selected for evaluation. In qualitative experiment, we selected eight cultural artifact images from the official websites of museums, both domestic and international. For each artifact, we extracted part of its official description from the museum website to serve as the description field, and combined it with the artifact’s name, source museum, current date, and a simulated signature to form the metadata.


Figure A2: Representative failure cases generated by CAPGen
References
1. Abduraheem K, Sheri J. Significance of digitization of the cultural heritage: in the context of museums, archives, and libraries. In: Handbook of research on the role of libraries, archives, and museums in achieving civic engagement and social justice in smart cities. Hershey, PA, USA: IGI Global; 2022. p. 252–63. doi:10.4018/978-1-7998-8363-0.ch013. [Google Scholar] [CrossRef]
2. Jiang L, Li J, Wider W, Tanucan JCM, Lobo J, Fauzi MA, et al. A bibliometric insight into immersive technologies for cultural heritage preservation. npj Heritage Sci. 2025;13(1):126. doi:10.1038/s40494-025-01704-z. [Google Scholar] [CrossRef]
3. Mitchell ET. Metadata developments in libraries and other cultural heritage institutions. Libr Technol Rep. 2013;49(5):5–10. [Google Scholar]
4. Liang X, Lu Y, Martin J. A review of the role of social media for the cultural heritage sustainability. Sustainability. 2021;13(3):1055. doi:10.3390/su13031055. [Google Scholar] [CrossRef]
5. Gonzalez R. Keep the conversation going: how museums use social media to engage the public [Internet]. The Museum Scholar. 2017 [cited 2025 May 18]. Available from: https://articles.themuseumscholar.org/2017/02/06/vol1no1gonzalez/. [Google Scholar]
6. Zhang M, Liu F, Li B, Liu Z, Ma W, Ran C. Leveraging multi-level features for cultural relic poster generation via attention-based framework. Expert Syst Appl. 2024;245(C):123136. doi:10.1016/j.eswa.2024.123136. [Google Scholar] [CrossRef]
7. Yang T, Luo Y, Qi Z, Wu Y, Shan Y, Chen CW. Posterllava: constructing a unified multi-modal layout generator with LLM. arXiv:2406.02884. 2024. [Google Scholar]
8. Zheng B, Liu F, Zhang M, Zhou T, Cui S, Ye Y, et al. Image captioning for cultural artworks: a case study on ceramics. Multimed Syst. 2023;29(6):3223–43. doi:10.1007/s00530-023-01178-8. [Google Scholar] [CrossRef]
9. Liu F, Zhang M, Zheng B, Cui S, Ma W, Liu Z, et al. Feature fusion via multi-target learning for ancient artwork captioning. Inf Fusion. 2023;97(11):101811. doi:10.1016/j.inffus.2023.101811. [Google Scholar] [CrossRef]
10. Siliutina I, Tytar O, Barbash M, Petrenko N, Yepyk L. Cultural preservation and digital heritage: challenges and opportunities. Amazon Investig. 2024;13(75):262–73. doi:10.34069/AI/2024.75.03.22. [Google Scholar] [CrossRef]
11. Yang ZQ, Xu R, Zhang JM. Digital museum visualization digital system based on big data technology. In: Meiselwitz G, Moallem A, editors. HCI International 2022: Proceedings of the 24th International Conference on Human-Computer Interaction. Cham, Switzerland: Springer; 2022. p. 442–55. doi:10.1007/978-3-031-06047-2_33. [Google Scholar] [CrossRef]
12. Liem J, Kusnick J, Beck S, Windhager F, Mayr E. A workflow approach to visualization-based storytelling with cultural heritage data. In: Alexander E, Benito-Santos A, Forbes A, Heimerl F, Lamqaddam H, Zhang Y, editors. Proceedings of the 2023 IEEE 8th Workshop on Visualization for the Digital Humanities (VIS4DH). New York, NY, USA: IEEE; 2023. p. 13–7. doi:10.1109/vis4dh60378.2023.00008. [Google Scholar] [CrossRef]
13. Lin J, Guo J, Sun S, Yang Z, Lou J, Zhang D. Layoutprompter: awaken the design ability of large language models. Adv Neural Inf Process Syst. 2023;36:43852–79. [Google Scholar]
14. Li W, Duan M, An D, Shao Y. Large language models understand layout. arXiv: 2407.05750. 2024. [Google Scholar]
15. Tang Z, Wu C, Li J, Duan N. Layoutnuwa: revealing the hidden layout expertise of large language models. arXiv:2309.09506. 2023. [Google Scholar]
16. Tang H, Zhao S, Luo J, Su Y, Yang J. LayoutKAG: enhancing layout generation in large language models through knowledge-augmented generation. In: Proceedings of the 2024 3rd International Conference on Artificial Intelligence, Human-Computer Interaction and Robotics (AIHCIR); 2024 Nov 15–17; Hong Kong, China. p. 292–9. [Google Scholar]
17. Yang Z, Li L, Wang J, Lin K, Azarnasab E, Ahmed F, et al. MM-ReAct: prompting ChatGPT for multimodal reasoning and action. arXiv:2303.11381. 2023. [Google Scholar]
18. Nair L, Gizzi E, Sinapov J. Creative problem solving in large language and vision models—what would it take? arXiv:2405.01453. 2024. [Google Scholar]
19. Luo Y, Cheng M, Ouyang J, Tao X, Liu Q. TextMatch: enhancing image-text consistency through multimodal optimization. arXiv:2412.18185. 2024. [Google Scholar]
20. Zhang X, Yang L, Li G, Cai Y, Xie J, Tang Y, et al. IterComp: iterative composition-aware feedback learning from model gallery for text-to-image generation. arXiv:2410.07171. 2024. [Google Scholar]
21. Wang P, Wei Y, Peng Y, Wang X, Qiu W, Shen W, et al. Skywork R1V2: multimodal hybrid reinforcement learning for reasoning. arXiv:2504.16656. 2025. [Google Scholar]
22. Zhang J, Miao Y, Yu J. A comprehensive survey on computational aesthetic evaluation of visual art images: metrics and challenges. IEEE Access. 2021;9:77164–87. doi:10.1109/ACCESS.2021.3083075. [Google Scholar] [CrossRef]
23. Zhang J, Yoshihashi R, Kitada S, Osanai A, Nakashima Y. Vascar: content-aware layout generation via visual-aware self-correction. arXiv:2412.04237. 2024. [Google Scholar]
24. White AW. The elements of graphic design: space, unity, page architecture, and type. New York, NY, USA: Skyhorse Publishing, Inc.; 2011. [Google Scholar]
25. Lupton E, Phillips JC. Graphic design: the new basics. (second edition, revised and expanded). San Francisco, CA, USA: Chronicle Books; 2015. [Google Scholar]
26. Bai Z, Nakashima Y, Garcia N. Explain me the painting: multi-topic knowledgeable art description generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 11–17; Online. p. 5422–32. [Google Scholar]
27. Zhou M, Xu C, Ma Y, Ge T, Jiang Y, Xu W. Composition-aware graphic layout GAN for visual-textual presentation designs. arXiv:2205.00303. 2022. [Google Scholar]
28. Zhao Z, Wallace E, Feng S, Klein D, Singh S. Calibrate before use: improving few-shot performance of language models. In: Meila M, Zhang T, editors. Proceedings of the 38th International Conference on Machine Learning: Proceedings of Machine Learning Research. Westminster, UK: PMLR; 2021. p. 12697–706. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools