
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

EHDC-YOLO: Enhancing Object Detection for UAV Imagery via Multi-Scale Edge and Detail Capture
1 College of Intelligent Science and Engineering, Jinan University, 206 Qianshan Road, Xiangzhou District, Zhuhai, 519000, China
2 School of Mechanical-Electronic and Vehicle Engineering, Beijing University of Civil Engineering and Architecture, Beijing, 100044, China
* Corresponding Author: Jiangling Guo. Email:
Computers, Materials & Continua 2026, 86(1), 1-18. https://doi.org/10.32604/cmc.2025.069090
Received 14 June 2025; Accepted 05 September 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
With the rapid expansion of drone applications, accurate detection of objects in aerial imagery has become crucial for intelligent transportation, urban management, and emergency rescue missions. However, existing methods face numerous challenges in practical deployment, including scale variation handling, feature degradation, and complex backgrounds. To address these issues, we propose Edge-enhanced and Detail-Capturing You Only Look Once (EHDC-YOLO), a novel framework for object detection in Unmanned Aerial Vehicle (UAV) imagery. Based on the You Only Look Once version 11 nano (YOLOv11n) baseline, EHDC-YOLO systematically introduces several architectural enhancements: (1) a Multi-Scale Edge Enhancement (MSEE) module that leverages multi-scale pooling and edge information to enhance boundary feature extraction; (2) an Enhanced Feature Pyramid Network (EFPN) that integrates P2-level features with Cross Stage Partial (CSP) structures and OmniKernel convolutions for better fine-grained representation; and (3) Dynamic Head (DyHead) with multi-dimensional attention mechanisms for enhanced cross-scale modeling and perspective adaptability. Comprehensive experiments on the Vision meets Drones for Detection (VisDrone-DET) 2019 dataset demonstrate that EHDC-YOLO achieves significant improvements, increasing mean Average Precision (mAP)@0.5 from 33.2% to 46.1% (an absolute improvement of 12.9 percentage points) and mAP@0.5:0.95 from 19.5% to 28.0% (an absolute improvement of 8.5 percentage points) compared with the YOLOv11n baseline, while maintaining a reasonable parameter count (2.81 M vs the baseline’s 2.58 M). Further ablation studies confirm the effectiveness of each proposed component, while visualization results highlight EHDC-YOLO’s superior performance in detecting objects and handling occlusions in complex drone scenarios.Keywords
In recent years, the rapid development of computer vision has driven widespread interest and in-depth application of object detection technologies [1]. As a fundamental task in computer vision, object detection aims to accurately recognize and localize specific objects within images or videos. It plays a crucial role in human perception and decision-making assistance and finds broad applications in autonomous driving, surveillance systems, and aerial image analysis. Particularly with the rapid proliferation of unmanned aerial vehicles (UAVs), UAVs have been increasingly utilized in scenarios such as military and defense, public safety and emergency management, and transportation and logistics, owing to their high flexibility, ease of operation, and low cost [2,3]. However, UAV imagery presents multiple detection challenges: scale variations, dense distributions, occlusions, and environmental complexity. Additionally, the limited computational resources onboard UAV platforms make it difficult to balance detection accuracy and real-time performance, severely constraining the practical application of object detection models in UAV scenarios.
With the advancement of deep learning, especially Convolutional Neural Networks (CNNs), the object detection field has made significant breakthroughs. Mainstream detection methods can be broadly classified into two-stage and one-stage approaches [4]. Two-stage methods, such as the Region-based Convolutional Neural Network (R-CNN) series (R-CNN [5], Fast R-CNN [6], Faster R-CNN [7], etc.), first generate region proposals followed by classification and bounding box regression, achieving high accuracy but incurring high computational cost and slower inference. In contrast, one-stage methods like the YOLO series [8], Single Shot MultiBox Detector (SSD) [9], and RetinaNet [10] perform end-to-end prediction for object category and location, offering significantly faster inference and making them suitable for real-time applications.
To further improve object detection performance, researchers have mainly explored three aspects: the optimization of backbone networks, the enhancement of feature pyramid networks (FPNs), and the improvement of detection heads.
In the design of backbone networks, a primary challenge in object detection is the loss of detailed information and insufficient feature representation during the downsampling process. To address this, Jing et al. proposed a high-resolution branch structure [11], which enhances the retention of spatial details in the shallow network layers, effectively improving the extraction of object features. However, despite improving detail retention, traditional backbone structures, such as the widely used C3 module, still focus predominantly on general feature modeling and exhibit limitations in capturing multi-scale information and local edge details [12]. As a result, even though high-level features effectively model semantic information, crucial boundary and texture details in dense object or complex background scenarios may still be lost, significantly impacting the performance of the detection head.
Feature Pyramid Networks, which fuse features of different resolutions through top-down pathways and lateral connections, have been widely applied in multi-scale object detection tasks [13]. However, traditional FPNs still face challenges in object detection: shallow fine-grained information is underutilized, and detection typically relies only on P3 and higher layers, resulting in the loss of object information through downsampling. To address this issue, Khalili et al. [14] proposed incorporating P2-level shallow features. Although adding a P2 detection head increases computational and post-processing overhead, it helps mitigate object information loss. Beyond the underutilization of shallow features, traditional FPNs or Path Aggregation Feature Pyramid Networks (PAFPNs) often employ simple upsampling and element-wise addition for feature fusion, which fails to adequately account for semantic, spatial, and scale discrepancies across resolutions [15]. This coarse fusion leads to feature degradation in dense object or complex background scenarios, limiting detection performance. Zhou et al. [16] achieved partial improvements through shallow feature integration (e.g., P2) and enhanced fusion strategies like Bidirectional Feature Pyramid Network (BiFPN), but issues of network bloat and inference inefficiency still persist. Particularly for deployment on resource-constrained UAV platforms, balancing detection accuracy and inference speed remains a major challenge.
In the field of object detection, the design of detection heads is crucial to model performance, yet significant challenges remain. Traditional detection head structures exhibit notable limitations when processing objects with scale variations, complex backgrounds, and multi-scale targets. These structures typically employ fixed feature fusion strategies, lacking the adaptive modeling capabilities necessary for handling scale variations, viewpoint transformations, and multi-task requirements. Chen et al. [17] recognized this issue and proposed dynamic convolution techniques, enhancing model adaptability by applying attention mechanisms to convolution kernels. Although this approach made progress in improving detection head flexibility, traditional detection heads still struggle to effectively capture critical boundary and texture information, particularly when deep feature downsampling and detail loss occur, thereby affecting detection accuracy.
UAV detection systems face three core limitations: (1) Feature degradation during network downsampling reduces detection precision; (2) Conventional pyramidal structures underutilize shallow information and lack scale adaptability; (3) Standard detection heads provide insufficient adaptability for diverse viewing conditions and task requirements.
To effectively address these challenges, this paper aims to further improve object detection performance in UAV aerial imagery while maintaining a reasonable trade-off between detection accuracy and model complexity, even at the cost of a moderate increase in complexity. Based on the recently released lightweight detection framework YOLOv11n, our main contributions are as follows:
(1) A Multi-Scale Edge Enhancement (MSEE) module is proposed that leverages multi-scale pooling and group convolution strategies to enhance the network’s perception of objects at different scales. Additionally, an edge enhancement mechanism is introduced to significantly improve the resolution and localization accuracy of objects.
(2) We propose the Enhanced Feature Pyramid Network (EFPN), which improves feature fusion by incorporating P2-level features for finer spatial details, integrating CSP structure with OmniKernel convolution for better multi-scale representation, and employing dilated convolutions to expand receptive fields efficiently, thus balancing detection accuracy and computational cost.
(3) We introduce a multi-dimensional attention mechanism that fuses hierarchical, spatial, and task-specific attentions, which significantly improves the model’s adaptability and detection accuracy in complex backgrounds, multi-scale object sizes, and multi-view scenarios.
The remainder of this paper is organized as follows: Section 2 reviews related work in three key areas: feature extraction optimization, feature fusion optimization, and object detection optimization for UAV imagery. Section 3 presents the proposed EHDC-YOLO method, detailing the Multi-Scale Edge Enhancement (MSEE) module, Enhanced Feature Pyramid Network (EFPN), and Dynamic Head (DyHead) integration. Section 4 provides comprehensive experimental validation, including implementation details, dataset description, ablation studies, performance comparisons, and visualization results on the VisDrone-DET 2019 dataset. Finally, Section 5 concludes the paper with a summary of contributions and discusses future research directions.
This section provides a comprehensive review of related work in three key areas that are fundamental to our proposed approach. Section 2.1 discusses feature extraction optimization techniques that enhance the representation capability of convolutional neural networks. Section 2.2 examines feature fusion optimization methods that effectively combine multi-scale information. Section 2.3 reviews object detection optimization strategies specifically designed for multi-scale scenarios. These related works provide the theoretical foundation and motivation for our proposed EHDC-YOLO framework.
2.1 Feature Extraction Optimization
Feature extraction plays a central role in computer vision and image processing tasks, directly impacting the accuracy and robustness of object detection models. Especially in UAV aerial imagery, due to limited resolution and abundant semantic information, fine-grained features are easily lost during downsampling, leading to degraded detection performance. Therefore, designing efficient feature extraction methods that maximize the preservation of critical details has become a key to improving object detection performance [1]. Current research has mainly focused on two aspects: convolutional structure and residual structure optimization. On one hand, researchers have proposed dynamically adjusting the convolution kernel shape to adapt to different feature patterns [17], or leveraging attention mechanisms to dynamically modify the receptive field and enhance local detail extraction [18]. Other methods enhance channel feature modeling through efficient local cross-channel interaction, avoiding dimensionality reduction and reducing computational cost [19]. On the other hand, to enhance the expressive power of low-dimensional features, some works adopt inverted residual structures, expanding and compressing feature dimensions to better model objects [20], while others integrate multi-scale feature fusion mechanisms within a single residual block to improve fine-grained feature extraction [21].
Multi-Scale Approaches in Aerial Object Detection
Many existing methods enhance feature extraction capabilities through multi-scale approaches in aerial image object detection tasks. Recent advances in scale-aware detection have demonstrated significant improvements in handling objects of varying sizes in aerial imagery. These approaches focus on developing robust feature extraction mechanisms that can effectively capture both fine-grained details and global contextual information, which serves as the foundation for our proposed EHDC-YOLO framework.
2.2 Feature Fusion Optimization
In terms of feature fusion, multi-scale feature fusion techniques are widely used to improve the detection performance for objects of different sizes. The conventional Feature Pyramid Network (FPN) fuses features across different resolutions through top-down pathways and lateral connections, significantly enhancing object detection capabilities [22]. Building upon this, the Path Aggregation Network (PANet) introduces bottom-up feature propagation to make feature flow bidirectional and strengthen semantic information integration [23]. Furthermore, the BiFPN structure introduces learnable feature weights, dynamically adjusting the contribution of different feature levels during fusion to optimize the overall detection accuracy [24]. To further enhance scale adaptability, some studies adopt atrous convolutions with varying dilation rates to extract multi-scale features, effectively improving model robustness against scale variations and yielding better detection performance in complex scenes [25].
2.3 Object Detection Optimization
Multi-scale object detection remains a long-standing challenge in the object detection task, especially in high-resolution UAV imagery with vast backgrounds [26,27]. Since objects of different scales occupy varying pixel areas and are easily affected by complex backgrounds, traditional detectors often suffer from inconsistent performance across scales and inaccurate localization [22]. To address this, researchers have proposed several strategies. On one hand, the reinforcement of shallow fine-grained features during the feature extraction stage has been shown to improve the initial perception of objects; on the other hand, the introduction of shallow features (such as the P2 layer) into the feature fusion stage has been effective in mitigating the loss of object information during downsampling [28]. Additionally, methods incorporating atrous convolutions, multi-scale expansions, and feature enhancement modules further contribute to improved perception and localization precision for objects across different scales. In recent years, optimized frameworks specifically designed for UAV detection, such as TinyDet [29] have achieved notable improvements by enhancing local context modeling and fine-grained feature preservation.
EHDC-YOLO systematically addresses these limitations through coordinated enhancements. The Multi-Scale Edge Enhancement (MSEE) module tackles feature degradation, Enhanced Feature Pyramid Network (EFPN) optimizes shallow feature utilization, and Dynamic Head (DyHead) provides adaptive detection capabilities. This work proposes EHDC-YOLO (Edge-Enhance Detail-Capture YOLO), an enhanced detection framework based on YOLOv11n, specifically designed for UAV detection. EHDC-YOLO addresses challenges such as scale variations, feature degradation, and complex backgrounds through three major improvements. Fig. 1 presents the overall architecture of the baseline YOLOv11n. Fig. 2 illustrates the structure of the proposed EHDC-YOLO framework.
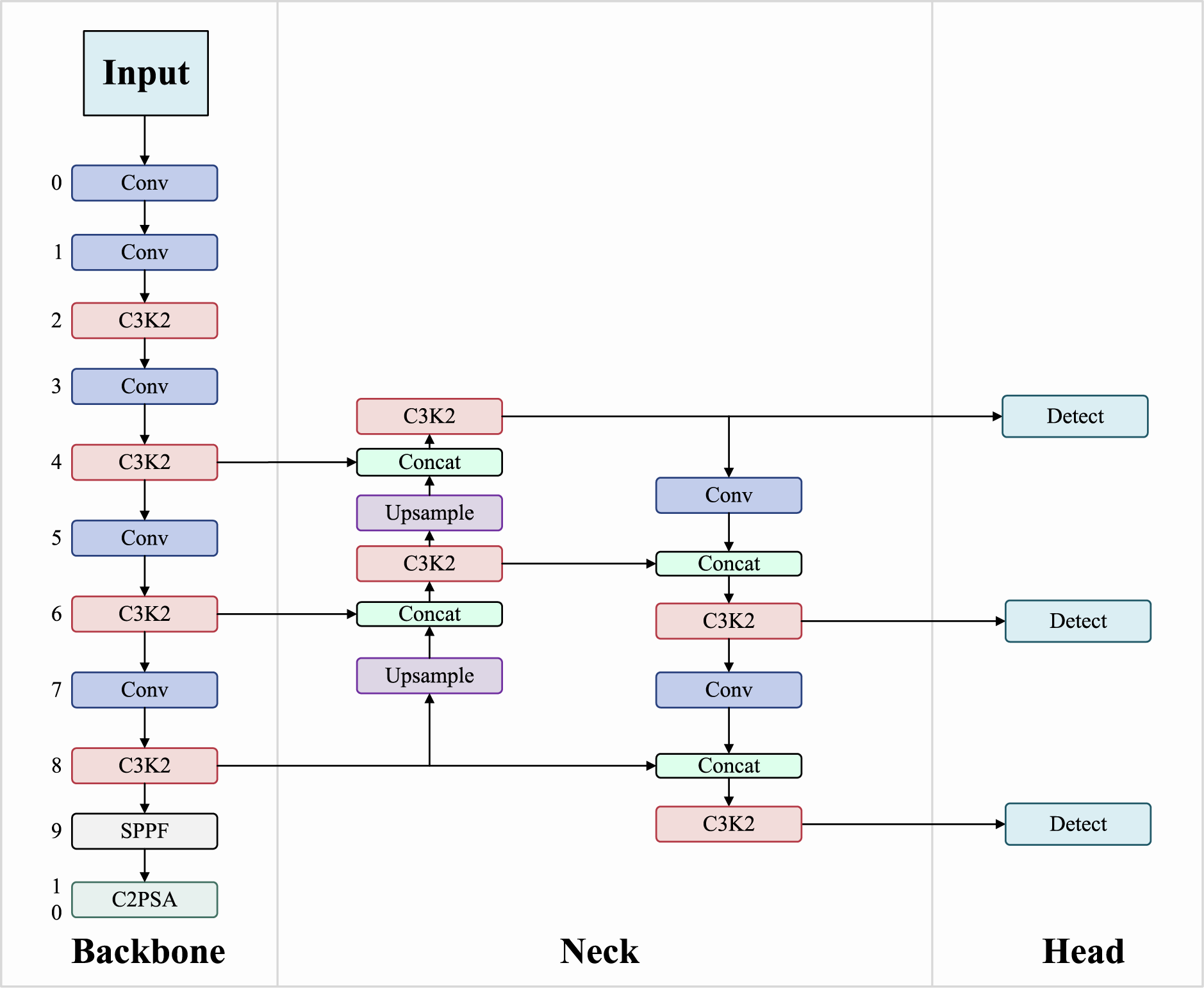
Figure 1: YOLOv11n baseline: C3K2 backbone, FPN neck, and standard detection head

Figure 2: EHDC-YOLO architecture: C3k2-MSEE backbone, EFPN neck, and DyHead detection head
3.1 Feature Pyramid Enhancement for Object Preservation
In UAV detection tasks, existing detection frameworks still face significant limitations in object detection performance due to scale variations, feature degradation during downsampling, and complex backgrounds.
To address these challenges, this paper proposes a series of structural enhancements based on the YOLOv11n baseline model, with the overall strategy consisting of the following aspects:
Systematic Hybrid Architecture: BiFPN and SOEP Integration. Our EFPN is not a simple module concatenation, but rather a systematic integration of complementary technologies: We adopt SOEP’s SPDConv and CSPOmniKernel modules and strategically integrate them into BiFPN’s bidirectional architecture, thereby creating enhanced information pathways. This combination achieves synergistic effects, specifically manifested as: (1) SPDConv’s detail preservation benefits from BiFPN’s rich propagation, (2) CSPOmniKernel’s multi-scale processing leverages bidirectional features, and (3) the overall architecture’s effectiveness exceeds the simple addition of individual components. Our hybrid approach achieves 46.1% mAP@0.5, significantly outperforming BIFPN-P2 (36.4%).
First, to mitigate the loss of object features caused by repeated downsampling in traditional feature pyramid networks (such as BiFPN), we optimize the original BiFPN structure by additionally introducing the P2 feature layer into the detection process. Additionally, we incorporate SPDConv (Space-to-Depth Convolution) for lossless downsampling, which preserves spatial information that would otherwise be lost in traditional convolution operations. By enabling both P2 and P3 layers to output detection results, the framework effectively preserves fine-grained shallow features and significantly enhances the representation capability for objects across different scales, thereby reducing the risk of missing targets during downsampling.
Second, to address the significant scale variations, fine-grained feature degradation, and spatial heterogeneity frequently encountered in UAV aerial images, we redesign the feature extraction module based on a combination of the Cross Stage Partial (CSP) structure and the OmniKernel module, as illustrated in Fig. 3 and the overall feature extraction process shown in Fig. 4.

Figure 3: Architecture of the OmniKernel structure within the CSP-OmniKernel module

Figure 4: Architecture of the CSP-OmniKernel-based multi-branch feature extraction module
Specifically, the redesigned feature extraction unit employs a multi-branch architecture, where three parallel branches—the global branch, large-scale branch, and local branch—are integrated. Each branch is designed to capture features at different receptive field scales, where the global branch focuses on broad contextual understanding to enhance object-background discrimination, the large-scale branch targets mid-sized structural information to support robust detection of medium-sized objects, and the local branch preserves fine-grained spatial details that are crucial for the accurate detection of objects at various scales.
The CSP mechanism is utilized to optimize information flow between branches while suppressing redundant feature representations, thus enhancing feature diversity and maintaining computational efficiency. Simultaneously, the OmniKernel design adaptively adjusts convolutional kernel sizes across branches, enabling the network to better model objects of varying scales and aspect ratios without substantial parameter overhead. The integration of CSPOmniKernel within our bidirectional feature pyramid creates multiple information pathways that enhance both scale adaptability and feature representation quality compared to traditional single-directional approaches.
By fusing the strengths of CSP and OmniKernel within a unified multi-branch framework, the proposed feature extraction module effectively overcomes the limitations of traditional single-scale processing methods, which often struggle to simultaneously handle large and small objects under complex UAV scenarios.
Overall, this enhancement significantly improves the network’s capability in scale-adaptive modeling, fine detail preservation, and robust semantic feature extraction, providing strong foundational support for the subsequent detection heads. The systematic integration of BiFPN’s bidirectional propagation with SOEP’s specialized modules creates a synergistic architecture that achieves superior performance while maintaining computational efficiency.
3.2 Detection Head: Integration of DyHead
In UAV detection tasks, significant challenges arise due to scale variations, viewpoint diversity, and multi-task demands. Variations in flight altitude and shooting angles result in a wide range of object sizes within aerial images, where distant objects are prone to missed detections while nearby large objects may introduce scale biases. Additionally, different viewpoints (such as top-down, oblique, side view) cause perspective distortion of target shapes, and occlusions in dense scenes further hinder detection accuracy. Moreover, different application scenarios—such as intelligent transportation, urban surveillance, and emergency rescue—require object detectors to handle various task demands, where traditional detection heads often lack sufficient generalization and adaptability.
To address these issues, the Dynamic Head (DyHead) structure is proposed [18], leveraging a Multi-Dimensional Attention Mechanism to comprehensively enhance detector robustness and cross-task adaptability. DyHead incorporates Level-Aware Attention to adaptively adjust feature importance across different scales, strengthening the feature representation of objects at various scales. Spatial-Aware Attention models the spatial feature distribution across different viewpoints, mitigating performance degradation caused by perspective variations and dense occlusions. Furthermore, Task-Aware Attention enables the detection head to dynamically adjust feature representations according to specific task requirements, improving performance across multiple application domains.
Therefore, in this work, DyHead is integrated into the YOLOv11n baseline as the detection head, leading to significant improvements in object detection accuracy, background robustness, and multi-scenario task generalization.
AI Tool Usage: The Claude AI language model (Anthropic) was used for language editing and formatting assistance only. All technical content, methodology, and analysis were developed entirely by the authors.
This section presents comprehensive experimental validation of the proposed EHDC-YOLO framework. Section 4.1 details the implementation settings and training configurations. Section 4.2 describes the VisDrone-DET 2019 dataset characteristics. Section 4.3 provides ablation studies to validate each proposed component. Section 4.4 compares overall performance with state-of-the-art methods. Section 4.5 presents fine-grained analysis across different object categories and scales. Section 4.6 visualizes detection performance through heatmaps to demonstrate the effectiveness of our approach.
Experiments used NVIDIA RTX 3090 GPU with YOLOv11n framework, 640
This study conducts experiments using the VisDrone-DET 2019 dataset [30], which was released by Northeastern University (NEU) and is specifically designed for object detection tasks from a UAV perspective. The dataset consists of 10,209 images with corresponding annotations, covering 10 object categories, including pedestrians, vehicles, and non-motorized vehicles. The image resolutions vary, typically ranging from
Fig. 5a shows the distribution of object categories in the training set, where cars, pedestrians, and people are the primary categories. There is a large variation in object sizes within the images, with objects of different scales being distributed throughout the dataset. According to the COCO dataset standard [31], we categorize the objects based on their area into three groups: small objects (area
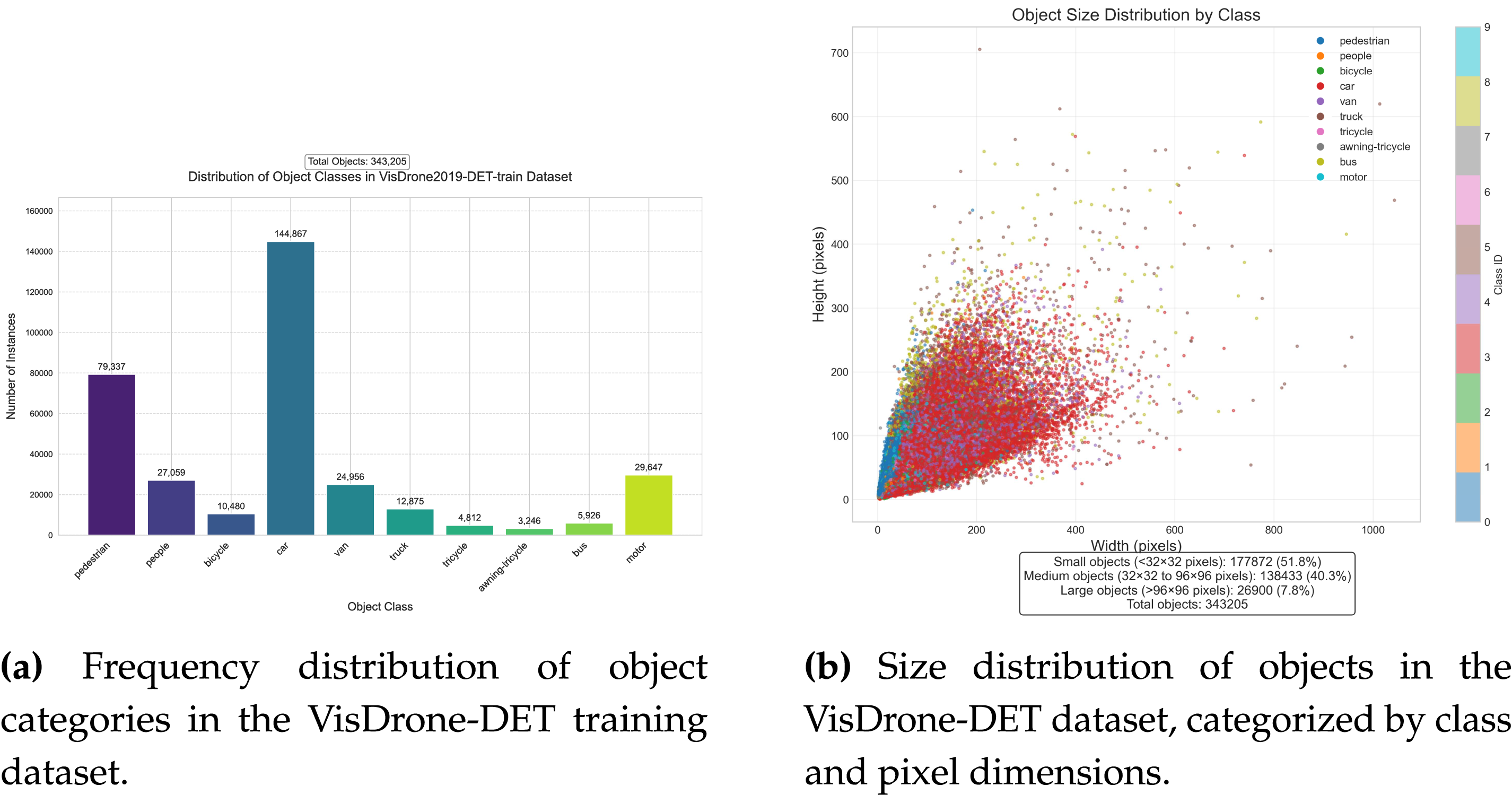
Figure 5: Quantitative analysis of object characteristics in the VisDrone-DET dataset
To visually demonstrate examples from the dataset, we provide several original images from the dataset, showing different object categories and complex background situations. Fig. 6a displays a typical object distribution image, where multiple objects are densely distributed across the scene. Fig. 6b depicts a scene where one object is partially occluded by another, with only part of the object visible, highlighting the occlusion between objects, which increases the challenge for detection algorithms in such complex background scenarios.

Figure 6: Examples of images from the VisDrone-DET dataset, highlighting various objects and partial occlusion
The dataset is split into a training set (6471 images), a validation set (548 images), and a test set (3189 images), following the official division. Each image is annotated with bounding box coordinates, class labels, and occlusion levels, allowing for a comprehensive evaluation of the algorithm’s performance in complex UAV scenarios.
4.3 Module Validation (Ablation Study)
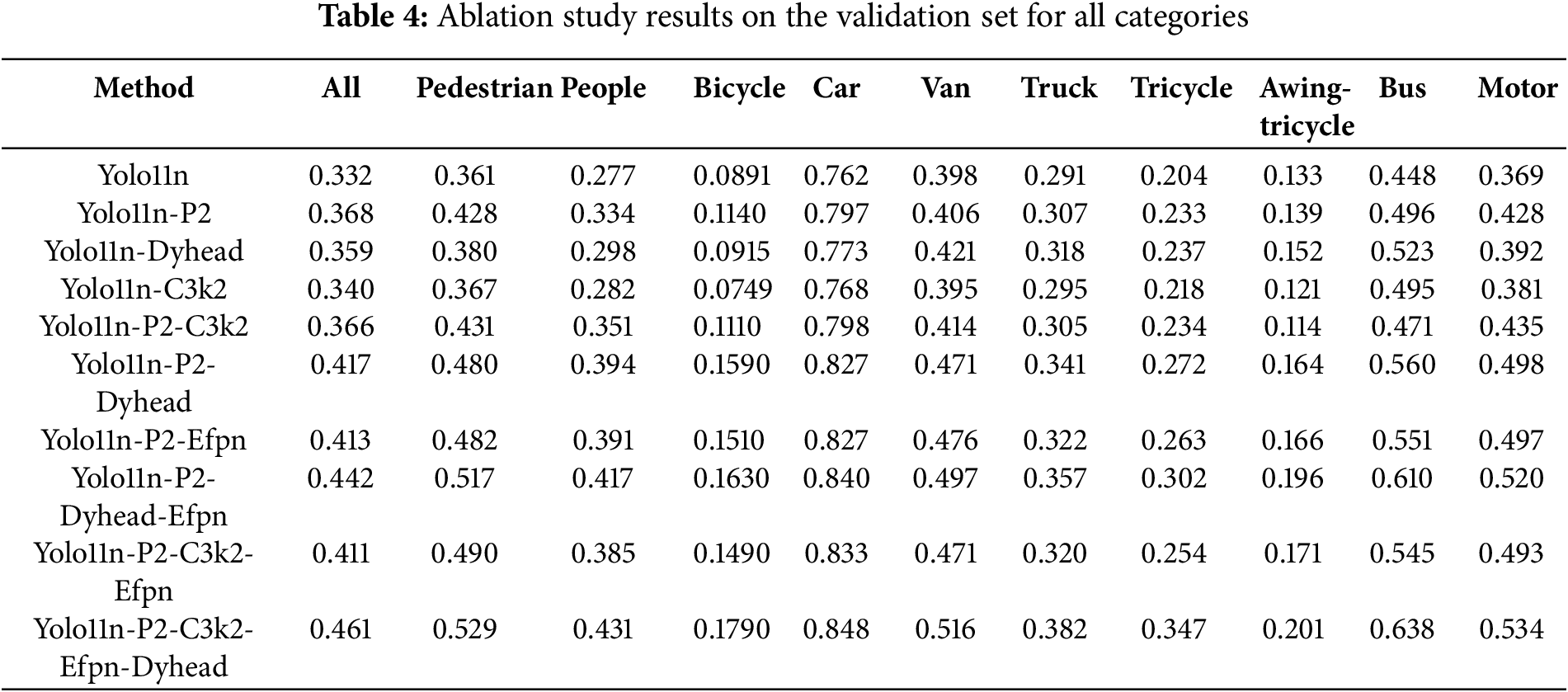
To verify the effectiveness of each proposed module—including the Multi-Scale Edge Enhancement (MSEE) module, the Enhanced Feature Pyramid Network (EFPN) structure, and the DyHead detection head—a comprehensive ablation study was conducted on the VisDrone-DET 2019 dataset. Different modules were progressively introduced, and changes in mAP@0.5, mAP@0.5:0.95, Floating Point Operations (FLOPs), and parameter counts were recorded on the validation set.
The ablation study results in Table 1 demonstrate the progressive improvement achieved by each proposed component. The introduction of P2-level features (YOLOv11n-P2) provides a significant boost of 3.5% in mAP@0.5, validating the importance of shallow feature preservation for small object detection. The MSEE module (YOLOv11n-C3k2Msee) contributes a modest 0.7% improvement, indicating its effectiveness in multi-scale feature extraction. The DyHead component shows substantial gains of 2.6% in mAP@0.5, demonstrating the value of adaptive attention mechanisms. The combination of all components achieves the best performance with 46.1% mAP@0.5, representing a 12.9% absolute improvement over the baseline while maintaining reasonable computational complexity.

In addition to the numerical results summarized in Table 1, the training curves for mAP@0.5 and mAP@0.5:0.95 over 300 epochs are plotted to further illustrate the performance evolution. As shown in Fig. 7a,b, EHDC-YOLO exhibits faster convergence and consistently higher detection accuracy compared to the baseline YOLOv11n.
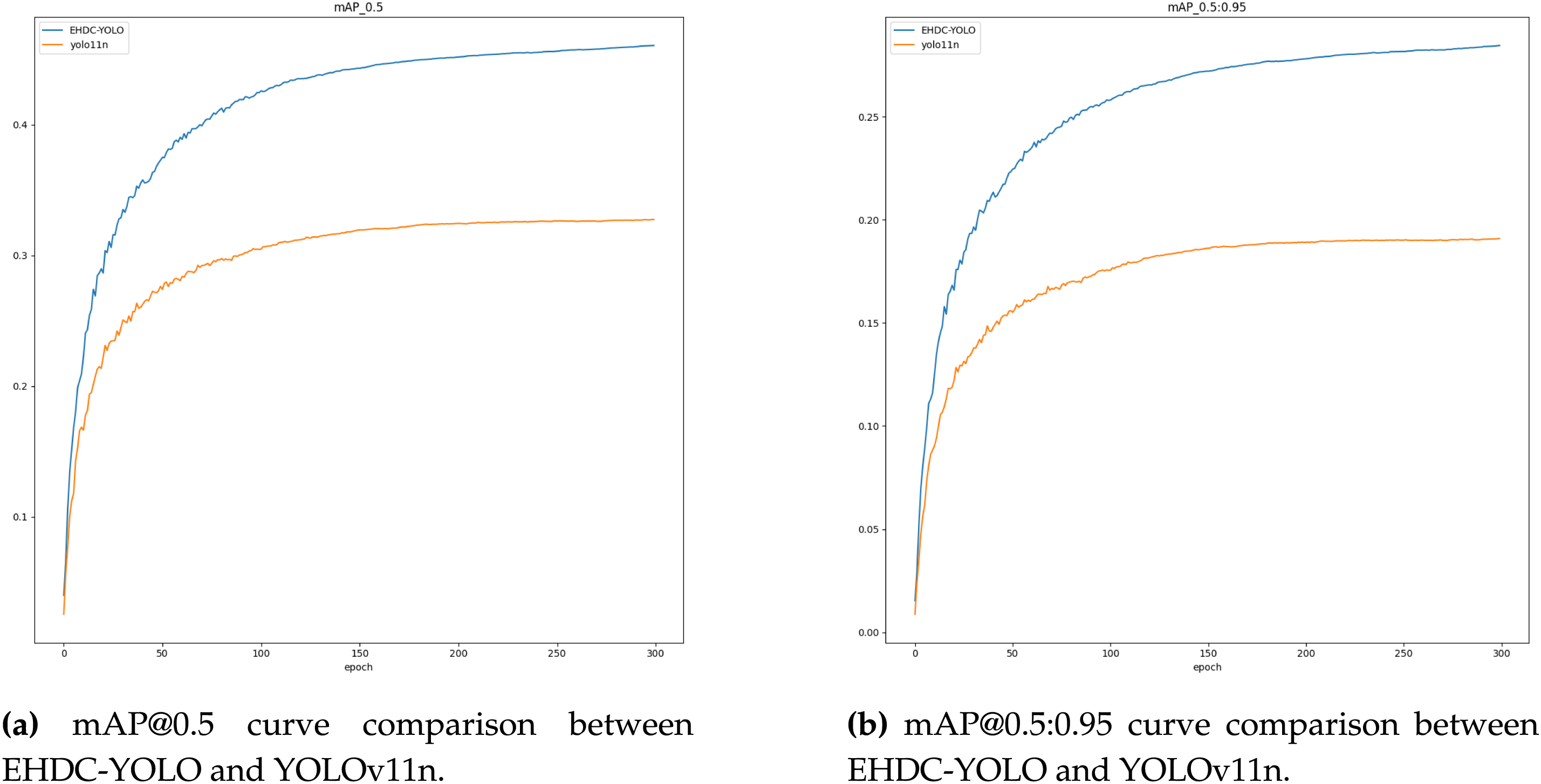
Figure 7: Training curve comparisons of EHDC-YOLO and YOLOv11n on the VisDrone-DET validation set
To provide visual evidence supporting the quantitative ablation results, we conduct detection performance visualization to demonstrate how each proposed module affects object detection capabilities. The following comparisons show detection heatmaps with and without each key component.
MSEE Module (C3K2) Detection Performance:
Fig. 8 shows the detection comparison with and without the C3K2-MSEE module. The enhanced model (right) demonstrates significantly better detection performance compared to the baseline (left).

Figure 8: Detection performance visualization comparing results with and without the MSEE module
Enhanced Feature Pyramid Network (EFPN) Detection Performance:
Fig. 9 shows the detection comparison with and without EFPN. The enhanced model (right) demonstrates significantly better detection performance compared to the baseline (left).

Figure 9: Detection performance visualization comparing standard FPN with Enhanced Feature Pyramid Network
Dynamic Head (DyHead) Detection Performance:
Fig. 10 shows the detection comparison with and without DyHead. The enhanced model (right) demonstrates significantly better detection performance compared to the baseline (left).

Figure 10: Detection performance visualization comparing standard detection head with Dynamic Head
4.4 Overall Performance Comparison
To further validate the effectiveness of the proposed method, EHDC-YOLO was compared with mainstream lightweight detectors, including YOLOv8n, YOLOv10n, and YOLOv11n. All models were trained and evaluated under the same hardware settings and training configurations to ensure fairness.
Table 2 demonstrates that EHDC-YOLO achieves competitive performance compared to state-of-the-art methods. While maintaining similar parameter counts to YOLOv11m (2.81 M vs. 20.0 M), our method achieves superior mAP@0.5:0.95 (28.0% vs. 27.0%). Compared to RT-DETR-R18, EHDC-YOLO achieves comparable mAP@0.5 (46.1% vs. 46.6%) but with higher mAP@0.5:0.95 (28.0% vs. 27.2%), indicating better localization accuracy. The FLOPs increase is justified by the significant accuracy improvements, particularly for the challenging UAV detection scenarios, EHDC-YOLO achieves higher mAP@0.5 and mAP@0.5:0.95 scores on both the VisDrone-DET 2019 validation and test sets compared to baseline models. In addition to improving detection accuracy, EHDC-YOLO effectively controls the increase in FLOPs and parameter counts, demonstrating a good balance between accuracy and inference efficiency. This makes it highly suitable for practical deployment, especially on resource-constrained UAV platforms.

As shown in Table 3, EHDC-YOLO demonstrates consistent performance improvements on the UAVDT dataset, achieving 35.3% mAP@0.5 compared to 32.9% for the YOLOv11n baseline. The results validate the generalization capability of our proposed framework across different UAV datasets. Notably, EHDC-YOLO outperforms YOLOv11m (35.3% vs. 34.1%), YOLOv12m (35.3% vs. 32.2%), and RT-DETR (35.3% vs. 33.1%) while maintaining significantly lower computational complexity than the larger models. The consistent improvements across both VisDrone-DET and UAVDT datasets demonstrate the robustness and transferability of our multi-scale edge enhancement and feature pyramid optimization strategies.

The cross-dataset evaluation confirms that our architectural enhancements are not dataset-specific but provide fundamental improvements for UAV detection tasks across diverse scenarios and environmental conditions.
4.5 Fine-Grained Ablation Analysis
For a more detailed evaluation, the performance of EHDC-YOLO was analyzed across different target categories (e.g., pedestrians, vehicles, tricycles) and various object scales (small, medium, large) within the VisDrone-DET validation set.
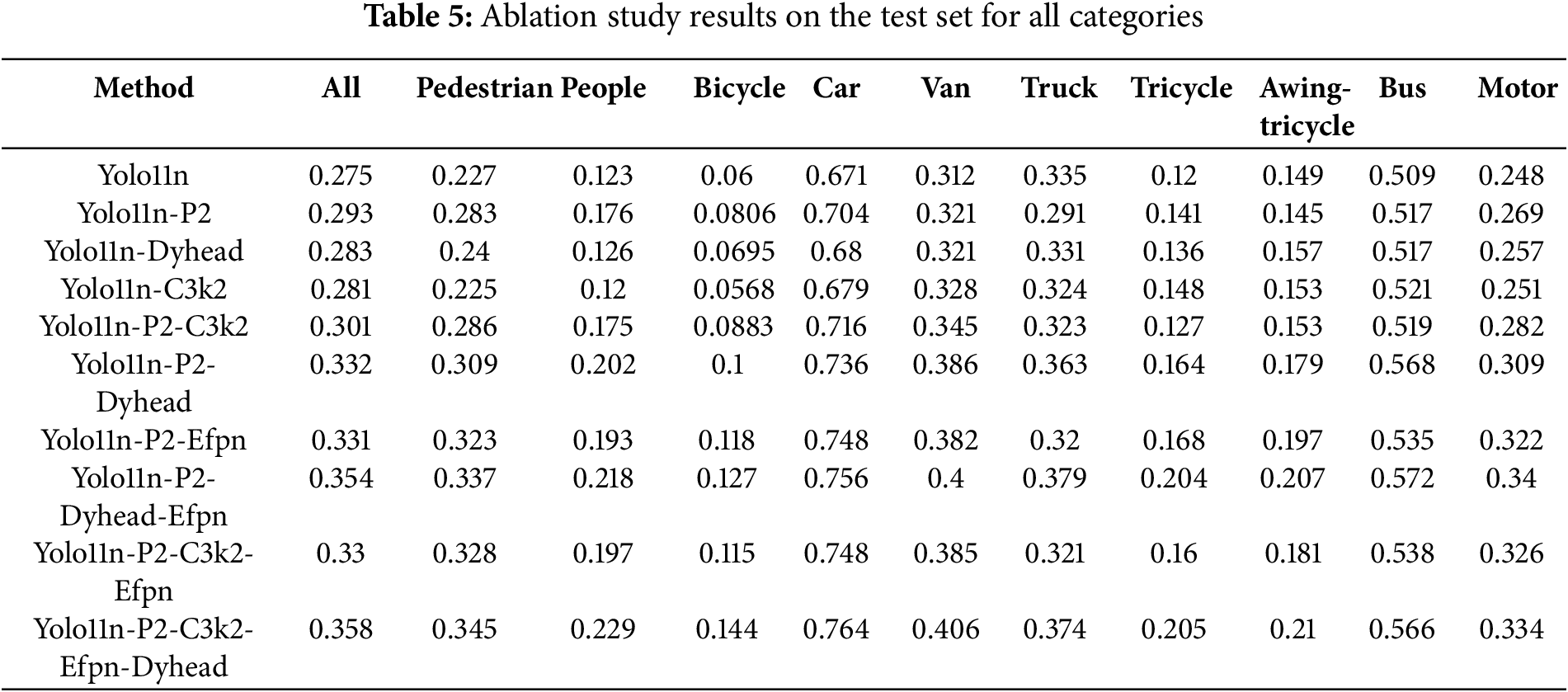
As presented in Tables 4 and 5, EHDC-YOLO shows consistent performance gains across different object categories compared to the baseline, confirming the effectiveness of the C3k2-MSEE and EFPN modules in multi-scale feature modeling. Furthermore, EHDC-YOLO demonstrates stronger robustness and more stable detection performance in densely populated, heavily occluded, and complex background scenarios. The category-wise analysis in Tables 4 and 5 reveals consistent improvements across all object classes. For small objects like pedestrians and people, EHDC-YOLO achieves substantial gains (pedestrian: 0.529 vs. 0.361, people: 0.431 vs. 0.277), validating the effectiveness of P2-level features and edge enhancement. For vehicles (car, van, truck), the improvements demonstrate robust performance in the most common UAV detection scenarios. The challenging categories like bicycle and tricycle show significant improvements (bicycle: 0.179 vs. 0.089, tricycle: 0.347 vs. 0.204), indicating enhanced capability for detecting small, elongated objects that are typically difficult in aerial imagery.
4.6 Detection Performance Heatmaps on the Test Set
This section presents the detection heatmap results based on the Yolo11n baseline network and the proposed EHDC-YOLO model on the test set, as shown in Figs. 11 and 12. In Fig. 11, it can be observed that even though only a small portion of the vehicle body is exposed in the upper left corner, the enhanced model is still able to successfully detect it. Similarly, in Fig. 12, objects represented by small dots are accurately detected, demonstrating a significant improvement in the model’s capability to recognize edge regions and fine details.

Figure 11: Visualization of edge enhancement: comparison among the original image, baseline YOLOv11n heatmap, and EHDC-YOLO enhanced heatmap

Figure 12: Visualization of fine-grained feature enhancement: comparisons among the original image, baseline YOLOv11n, and EHDC-YOLO results
4.7 Edge Deployment Feasibility Analysis
To address deployment concerns on UAV platforms, we provide performance analysis across different hardware configurations:
Based on RTX 3090 baseline performance (4–5 ms inference time), theoretical AI computing power comparison shows a 7
Current mainstream UAV computing platforms such as Jetson Orin NX (157 TOPS) can achieve 4–6 ms inference time, while Jetson Orin Nano (67 TOPS) provides 8–12 ms performance (83–125 FPS) with power consumption controlled within 25–40 W, supporting real-time application demands.
While our approach requires enhanced computational resources, EHDC-YOLO remains effectively deployable across various UAV computing platforms through appropriate hardware selection.
The experimental results demonstrate the superior performance of EHDC-YOLO across multiple metrics. On the VisDrone-DET 2019 dataset, our method achieves a mAP@0.5 of 46.1% and mAP@0.5:0.95 of 28.0%, representing absolute improvements of 12.9 and 8.5 percentage points respectively compared to the YOLOv11n baseline. The model maintains computational efficiency with 2.81 M parameters and 25.3 G FLOPs, demonstrating an effective balance between accuracy and complexity for UAV deployment scenarios.
This paper addresses the challenges of object detection in UAV aerial imagery, including severe scale variations, feature degradation, and complex backgrounds. We propose EHDC-YOLO, an enhanced detection framework based on YOLOv11n. The framework integrates a Multi-Scale Edge Enhancement (MSEE) module to boost perception of multi-scale targets and edge details, an Enhanced Feature Pyramid Network (EFPN) to strengthen shallow feature representation, and the DyHead detection head to improve model robustness and adaptability in complex multi-scale scenes.
Extensive experiments on the VisDrone-DET 2019 dataset demonstrate that EHDC-YOLO achieves an excellent balance between detection accuracy and inference efficiency, significantly outperforming the baseline YOLOv11n and several mainstream lightweight detectors. Ablation studies further confirm the effectiveness and complementarity of each proposed component.
However, some limitations remain. First, the overall model complexity increases compared to the original YOLOv11n, which may still pose challenges in extremely resource-constrained scenarios. Second, although improvements are achieved on the current dataset, the generalization ability under extreme occlusion, varying scales, and severe illumination changes needs further enhancement.
Future work will focus on the following aspects: (1) implementing comprehensive model compression strategies to reduce computational overhead while preserving detection accuracy, including: (a) knowledge distillation to transfer knowledge from the full EHDC-YOLO model to a more compact student network, (b) quantization techniques to reduce model precision from FP32 to INT8 or mixed-precision formats, and (c) neural architecture search (NAS) to automatically discover more efficient module configurations that maintain performance while reducing FLOPs; (2) incorporating multi-modal information, such as thermal or LiDAR data, to enhance robustness under complex environments.
Acknowledgement: We also appreciate the support from the laboratory members for their assistance in data collection and experiment validation. We acknowledge the use of Claude (Anthropic) for language editing and manuscript formatting assistance.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization: Zhiyong Deng and Jiangling Guo; Methodology: Zhiyong Deng; Software: Zhiyong Deng; Validation: Zhiyong Deng, Yanchen Ye, and Jiangling Guo; Formal Analysis: Zhiyong Deng; Investigation: Zhiyong Deng; Resources (Experimental Facilities): Zhiyong Deng, Jiangling Guo; Writing—Original Draft Preparation: Zhiyong Deng; Writing—Review & Editing: Zhiyong Deng, Yanchen Ye, and Jiangling Guo; Visualization: Zhiyong Deng; Supervision: Jiangling Guo; Project Administration: Jiangling Guo. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in the VisDrone repository at https://github.com/VisDrone/VisDrone-Dataset (accessed on 04 September 2025).
Ethics Approval: This study does not involve human or animal subjects, so ethical approval is not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Nikouei M, Baroutian B, Nabavi S, Taraghi F, Aghaei A, Sajedi A, et al. Small object detection: a comprehensive survey on challenges. Techn Real-World Appl. arXiv:2503.20516. 2025. [Google Scholar]
2. Yang C, Cao Y, Lu X. Towards better small object detection in UAV scenes: aggregating more object-oriented information. Pattern Recognit Lett. 2024;182(6):24–30. doi:10.1016/j.patrec.2024.04.002. [Google Scholar] [CrossRef]
3. Qu F, Li H, Wang P, Guo S, Wang L, Li X. Rice spike identification and number prediction in different periods based on UAV imagery and improved YOLOv8. Comput Mater Contin. 2025;84(2):3911–25. doi:10.32604/cmc.2025.063820. [Google Scholar] [CrossRef]
4. Wei W, Cheng Y, He J, Zhu X. A review of small object detection based on deep learning. Neural Comput Appl. 2024;36(12):6283–303. doi:10.1007/s00521-024-09422-6. [Google Scholar] [CrossRef]
5. Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition; 2014 Jun 23–28; Columbus, OH, USA. p. 580–87. [Google Scholar]
6. Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision; 2015 Dec 7–13; Santiago, Chile. p. 1440–48. [Google Scholar]
7. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2016;39(6):1137–49. doi:10.1109/tpami.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
8. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition; 2016 Jun 27–30; Las Vegas, NV, USA. p. 779–88. [Google Scholar]
9. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, et al. SSD: single shot multibox detector. In: European Conference on Computer Vision 2016; 2016 Oct 11–14; Amsterdam, The Netherlands. p. 21–37. [Google Scholar]
10. Lin T-Y, Goyal P, Girshick R, He K, Dollár P. Focal loss for dense object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision; 2017 Oct 22–29; Venice, Italy. p. 2980–8. [Google Scholar]
11. Jing X, Liu X, Liu B. Composite backbone small object detection based on context and multi-scale information with attention mechanism. Mathematics. 2024;12(5):622. doi:10.3390/math12050622. [Google Scholar] [CrossRef]
12. Zhang P, Zhu P, Sun Z, Ding J, Zhang J, Dong J, et al. Research on improved lightweight YOLOv5s for multi-scale ship target detection. Appl Sci. 2024;14(14):6075. doi:10.3390/app14146075. [Google Scholar] [CrossRef]
13. Deng C, Wang M, Liu L, Liu Y, Jiang Y. Extended feature pyramid network for small object detection. IEEE Trans Multimedia. 2021;24:1968–79. doi:10.1109/tmm.2021.3074273. [Google Scholar] [CrossRef]
14. Khalili B, Smyth AW. Sod-yolov8—enhancing yolov8 for small object detection in aerial imagery and traffic scenes. Sensors. 2024;24(19):6209. doi:10.3390/s24196209. [Google Scholar] [CrossRef]
15. Gong Y, Yu X, Ding Y, Peng X, Zhao J, Han Z. Effective fusion factor in FPN for tiny object detection. In: Proceedings of the 2021 IEEE/CVF Winter Conference on Applications of Computer Vision; 2021 Jan 5–9; Online. p. 1160–68. [Google Scholar]
16. Zhou J, Huang X, Qin Z, Yin G. Small object detection algorithm combining coordinate attention mechanism and P2-BiFPN structure. In: International Conference on Computer Engineering and Networks. Singapore: Springer Nature Singapore; 2023. p. 268–77. [Google Scholar]
17. Chen Y, Dai X, Liu M, Chen D, Yuan L, Liu Z. Dynamic convolution: attention over convolution kernels. In: Proceedings of the 2020 IEEE/CVF conference on computer vision and pattern recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 11030–39. [Google Scholar]
18. Dai X, Chen Y, Xiao B, Chen D, Liu M, Yuan L, et al. Dynamic head: unifying object detection heads with attentions. In: Proceedings of the 2021 IEEE/CVF Conference On Computer Vision And Pattern Recognition; 2021 Jun 20–25; Nashville, TN, USA. p. 7373–82. [Google Scholar]
19. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: efficient channel attention for deep convolutional neural networks. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. p. 11534–42. [Google Scholar]
20. Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC. Mobilenetv2: inverted residuals and linear bottlenecks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 4510–20. [Google Scholar]
21. Wang C, Zhong C. Adaptive feature pyramid networks for object detection. IEEE Access. 2021;9:107024–32. doi:10.1109/access.2021.3100369. [Google Scholar] [CrossRef]
22. Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition; 2017 Jul 21–26; Honolulu, HI, USA. p. 2117–25. [Google Scholar]
23. Liu S, Qi L, Qin H, Shi J, Jia J. Path aggregation network for instance segmentation. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 8759–68. [Google Scholar]
24. Tan M, Pang R, Le QV. Efficientdet: scalable and efficient object detection. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA p. 10781–90. [Google Scholar]
25. Li Y, Chen Y, Wang N, Zhang Z. Scale-aware trident networks for object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision; 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 6054–63. [Google Scholar]
26. Li J, Liang X, Shen S-M, Xu T, Feng J, Yan S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans Multimedia. 2017;20(4):985–96. doi:10.1109/tmm.2017.2759508. [Google Scholar] [CrossRef]
27. Singh B, Davis LS. An analysis of scale invariance in object detection snip. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 3578–87. [Google Scholar]
28. Ghiasi G, Lin TY, Le QV. NAS-FPN: learning scalable feature pyramid architecture for object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Visionand Pattern Recognition; Long Beach, CA, USA; 2019 Jun 15–20. p. 7036–45. [Google Scholar]
29. Chen S, Cheng T, Fang J, Zhang Q, Li Y, Liu W, et al. TinyDet: accurate small object detection in lightweight generic detectors. arXiv:2304.03428. 2023. [Google Scholar]
30. Zhu P, Wen L, Bian X, Ling H, Hu Q. Vision meets drones: past, present and future. IEEE Trans Pattern Anal Mach Intell. 2020;43(12):4142–64. [Google Scholar]
31. Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft coco: common objects in context. In: European Conference on Computer Vision; 2014 Sep 6–12; Zurich, Switzerland. p. 740–55. [Google Scholar]
32. Jocher G. YOLOv5 by Ultralytics [Internet]. 2020. [cited 2025 Apr 28]. Available from: https://github.com/ultralytics/yolov5. [Google Scholar]
33. Jocher G. Ultralytics. YOLOv8: SOTA object detection models [Internet]. 2023. [cited 2025 Apr 28]. Available from: https://github.com/ultralytics/ultralytics. [Google Scholar]
34. Wang A, Chen H, Liu L, Chen K, Lin Z, Han J, et al. Yolov10: real-time end-to-end object detection. Adv Neural Inf Process Syst. 2024;37:107984–8011. [Google Scholar]
35. Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements. arXiv:2410.17725. 2024. [Google Scholar]
36. Wang C, He W, Nie Y, Guo J, Liu C, Han K, et al. Gold-YOLO: efficient object detector via gather-and-distribute mechanism. In: Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS); 2023 Dec 10–16; New Orleans, LA, USA. p. 51094–112. [Google Scholar]
37. Zhang Z, Sun C, Lin Y, Shi J, Ding W. DAMO-YOLO: a report on real-time object detection design. arXiv:2211.15444. 2022. [Google Scholar]
38. Zhao Y, Lv W, Xu S, Wei J, Wang G, Dang Q, et al. DETRs beat YOLOs on real-time object detection. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2024 Jun 16–22; Seattle, WA, USA. p. 16965–74. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools