
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

M2ATNet: Multi-Scale Multi-Attention Denoising and Feature Fusion Transformer for Low-Light Image Enhancement
1 School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan, 232001, China
2 School of Mechatronics Engineering, Anhui University of Science and Technology, Huainan, 232001, China
* Corresponding Author: Zhongliang Wei. Email:
Computers, Materials & Continua 2026, 86(1), 1-20. https://doi.org/10.32604/cmc.2025.069335
Received 20 June 2025; Accepted 12 September 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Images taken in dim environments frequently exhibit issues like insufficient brightness, noise, color shifts, and loss of detail. These problems pose significant challenges to dark image enhancement tasks. Current approaches, while effective in global illumination modeling, often struggle to simultaneously suppress noise and preserve structural details, especially under heterogeneous lighting. Furthermore, misalignment between luminance and color channels introduces additional challenges to accurate enhancement. In response to the aforementioned difficulties, we introduce a single-stage framework, M2ATNet, using the multi-scale multi-attention and Transformer architecture. First, to address the problems of texture blurring and residual noise, we design a multi-scale multi-attention denoising module (MMAD), which is applied separately to the luminance and color channels to enhance the structural and texture modeling capabilities. Secondly, to solve the non-alignment problem of the luminance and color channels, we introduce the multi-channel feature fusion Transformer (CFFT) module, which effectively recovers the dark details and corrects the color shifts through cross-channel alignment and deep feature interaction. To guide the model to learn more stably and efficiently, we also fuse multiple types of loss functions to form a hybrid loss term. We extensively evaluate the proposed method on various standard datasets, including LOL-v1, LOL-v2, DICM, LIME, and NPE. Evaluation in terms of numerical metrics and visual quality demonstrate that M2ATNet consistently outperforms existing advanced approaches. Ablation studies further confirm the critical roles played by the MMAD and CFFT modules to detail preservation and visual fidelity under challenging illumination-deficient environments.Keywords
Low-light images frequently exhibit underexposure, chromatic distortions, amplified noise, and blurring of structural details. These degradations both compromise the visual fidelity of the images and hinder the performance of downstream operations, particularly in object detection [1–3], face localization [4], image segmentation [5], and applications such as underwater image enhancement [6] and underwater object recognition [7]. For instance, in surveillance videos recorded under poor lighting, facial features may appear blurred and object boundaries indistinct, significantly compromising the reliability of subsequent analyses like behavior recognition or identity tracking. In addition, the imaging process under such conditions often introduces non-uniform noise and unnatural color deviations, making it difficult to preserve the authenticity and semantic integrity of the scene.
To tackle these difficulties, numerous techniques for low-light image enhancement (LLIE) have been developed to improve visual clarity and information availability [8,9]. Traditional approaches, including histogram equalization and Retinex-based methods, enhance brightness and contrast by applying global or locally adaptive transformations. While effective in certain cases, they often result in noticeable color shifts and fail to recover valid content in regions that are severely underexposed or noise-corrupted.
Benefiting from deep learning breakthroughs, many neural network-based approaches have achieved notable progress in LLIE. Encoder-decoder architectures, in particular, show strong capability in modeling contextual illumination and color distributions. However, given the intrinsic constraints of localized receptive regions and repeated downsampling, these models tend to blur textures and omit fine-grained features. Furthermore, some methods overly adjust luminance and contrast, leading to perceptual inconsistency and color distortion [10,11]. Others lack the ability to effectively model spatial correlations, resulting in the degradation of edge and structure details [12,13].
Although recent methods have made progress in global illumination modeling, they often struggle to balance noise suppression and structural detail preservation under uneven lighting conditions. Moreover, the misalignment between luminance and chrominance channels further complicates the enhancement process. These challenges motivate us to design a more robust low-light image enhancement approach that addresses noise reduction, detail retention, and color consistency simultaneously.
This work introduces M2ATNet, a new approach for LLIE that achieves state-of-the-art (SOTA) performance over several standard datasets while maintaining computational efficiency. To address the coupling limitation of RGB, we employ the Horizontal/Vertical-Intensity (HVI) color space [14], an enhancement of HSV (Hue, Saturation, Value) that reconstructs the color distribution in polar coordinates and introduces a learnable luminance compression function. Compared to traditional color spaces such as HSV and YUV (Y: luminance, U: blue-difference chroma, V: red-difference chroma), which either suffer from hue discontinuity under low-light conditions or lack flexibility in luminance-chrominance separation, HVI offers a more adaptive decoupling mechanism. By representing color in polar coordinates and employing a learnable luminance compression function, HVI enables more accurate manipulation of luminance without distorting chrominance. This separation enables our model to enhance intensity and color information independently, thereby enhancing noise suppression, color correction, and visual realism. Specifically, we introduce a multi-scale multi-attention denoising (MMAD) module to capture spatial features at different receptive fields and suppress noise adaptively, and a multi-channel feature fusion Transformer (CFFT) module to align luminance and color representations through deep attention-guided interaction.
The main contributions of our research can be summarized as follows:
• A single-stage LLIE framework, M2ATNet, is proposed, which avoids the complexity of multi-stage training while achieving competitive performance.
• A MMAD module is designed to enable adaptive noise suppression and texture-aware feature extraction across multiple spatial scales.
• A CFFT module is developed to facilitate deep interaction between luminance and chrominance components, enhancing structural alignment and color fidelity.
• A hybrid loss function is constructed by integrating edge, color, and other complementary loss terms to provide comprehensive optimization guidance during training.
The structure of the remaining paper is outlined below: Section 2 discusses related work concerning LLIE. Section 3 delves into the details of our method and network architecture. Section 4 showcases the experimental design and presents the obtained results. Final conclusions and future prospects are discussed in Section 5.
Earlier traditional methods, widely used and including histogram equalization [15] and gamma correction [16], were employed for boosting visibility in poorly illuminated photographs. Nevertheless, these methods usually ignore the spatial non-uniformity of the light distribution in the image, which makes it difficult to adapt to local brightness variations, and can easily lead to noise amplification or overexposure in dark regions, while causing loss of details in the bright regions, thus degrading overall image quality and information.
2.1 Traditional Low-Light Image Enhancement Methods
Conventional approaches grounded in Retinex theory perform image decomposition by separating a light map and a reflectance map, with enhancement achieved by adjusting the light component. As an illustration, Guo et al. [17] constrain the smoothness of the illumination component by structural prior knowledge to avoid over-enhancement of texture regions, and multi-scale Retinex (MSR) [18] combines different scales of gaussian filtering to separate the low-frequency illumination from the high-frequency details. Du et al. [19] addressed the background blurring issue caused by the uniform noise assumption by introducing a patch-aware low-rank model combined with relative total variation constraints. However, such methods often assume that image noise is negligible, leading to noise amplification and local distortion after enhancement, and rely on a priori knowledge of manual design with high parameter sensitivity. Conventional approaches generally exhibit limited generalization ability and weak robustness, which limits their applications.
2.2 Deep Learning-Based Methods
Unlike traditional methods, deep learning approaches excel at feature learning and representation, making them highly effective for LLIE [20–22]. For example, Jiang et al. [23] presented EnlightenGAN, which employs generative adversarial networks (GANs) as the core architecture for LLIE without requiring paired training samples. Guo et al. [24] proposed Zero-DCE, which modeled LLIE as the problem of estimating mapping curves and designed a learning method without reference images, thus simplifying the training process. Liu et al. [25] proposed RUAS, which draws on Retinex theory to construct a Neural Architecture Search (NAS) framework that automatically mines efficient prior structures suitable for LLIE in a compact search space. Liu et al. [26] proposed a luminance-awareness based attentional and residual quantization codebook for luminance-aware networks, which solves the problem of not being able to fully utilize the auxiliary a priori knowledge provided by well-exposed images from the training set. These methods have achieved performance improvements but generally suffer from training instability, poor adaptability to extreme low-light conditions, high computational complexity, and increased model complexity. Further, convolutional neural networks (CNNs) have gradually become a mainstream modeling approach in LLIE applications by virtue of their multi-scale and hierarchical feature extraction capabilities, and are applied in various sub-tasks, including image decomposition, illumination estimation, and detail restoration. Methods such as RetinexNet [27] embed the Retinex decomposition into a two-branched CNNs for estimating the light illumination and reflectance, respectively, and similarly, the KinD [28] and its improved version KinD++ [29] use a combined decomposition and reconstruction strategy, and learn the mapping relationship and adjustment mechanism between the two through CNNs in the process, but the multi-stage training process is complex (requiring independent optimization of decomposition and denoising modules). Single-stage methods such as Wang et al. [30] directly predict the illumination map, which simplifies the process but does not explicitly model the noise distribution, resulting in significant noise after brightening. In addition, the local receptive field of CNNs restricts it from capturing long-distance dependencies, which is prone to detail breakage in texture-rich scenes (e.g., city streetscape, vegetation).
To address the restricted receptive field inherent in CNNs, Transformer-based methods have been proposed for their superior capability in modeling contextual relationships across distant positions. As an illustration, a Retinex and Transformer-based framework [31] that effectively addresses the visual quality loss due to inadequate illumination and the artifacts or noise introduced during the enhancement process, which traditional Retinex methods often neglect. Fan et al. [32] introduced an illumination-aware and structure-guided Transformer, which employs dynamic multi-domain self-attention and global maximum gradient search to enhance brightness recovery and high-frequency detail restoration in low-light images, tackling the challenge of capturing long-range dependencies and blurred details in existing methods. Lin et al. [33] developed a frequency-guided dual-collapse Transformer that alleviates issues of color shifts and texture loss. Nevertheless, these approaches still face struggle to fully eliminating artifacts, preserve local texture details, and mitigating color shifts. In recent years, hybrid approaches that combine CNNs with Transformers have become a research hotspot. Pei et al. [34] proposed FFTFormer, which integrates Fast Fourier Transform with a noise-aware mechanism to address the disruption of global feature representation caused by input noise in CNN-Transformer hybrid models, enabling denoising in both spatial and frequency domains. To restore images, Xu et al. [35] employed a Transformer tailored for noise robustness combined with CNNs featuring spatial adaptive processing. However, purely Transformer-based methods typically involve high computational costs and face challenges in recovering local details. Therefore, exploring efficient hybrid architectures and further optimizing Transformer applications in LLIE remains an active area of research.
An ideal LLIE model should effectively suppress degradation effects in low-light environments, maintain structural consistency, and adaptively adjust illumination. To fulfill this aim, we present M2ATNet, whose complete architecture is illustrated in Fig. 1. It adopts a dual-path approach to more effectively address noise suppression and illumination restoration. The first operation converts the input image into the HVI color space. This image is then decomposed into horizontal-vertical (HV) color channels and intensity (I) channel. Considering that the degraded low-light image contains minor noise present in the luminance part and the color shifts problem in the color channel, the structural and luminance guiding features from the I channel are introduced into the HV channels, and then the HV channels and the I channel are augmented by a MMAD with a U-shaped structure, respectively, in order to maintain the image structure while suppressing the noise. Afterwards, for light recovery adjustment, the I channel is enhanced by maxpooling downsampling, a multi-head self attention (MHSA), and upsampling. The enhanced HV channels and the I channel are integrated with dual-path features by the CFFT module to refine dark-area details while restoring the natural colors. Finally, the enhanced channels are combined into an HVI image that is transformed back to output an optimized RGB image.
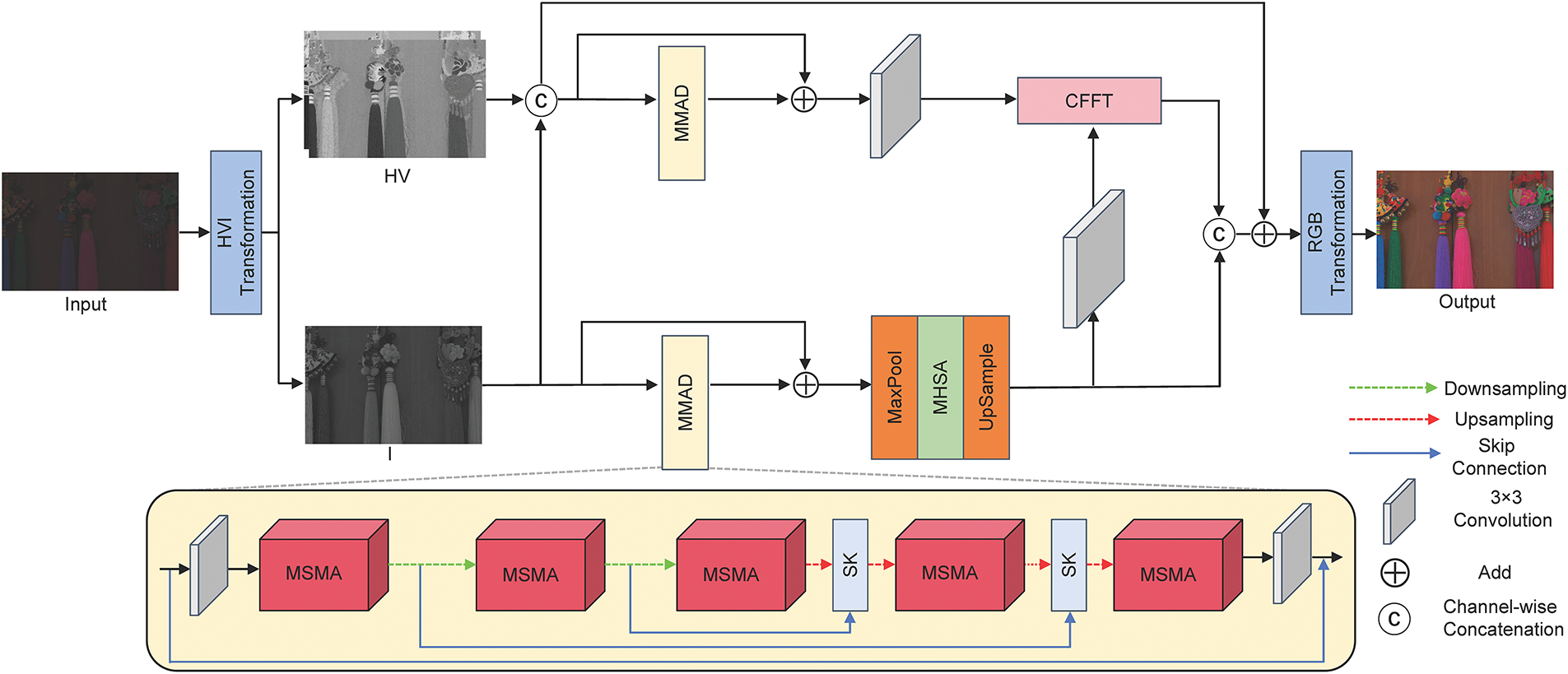
Figure 1: Schematic of M2ATNet, illustrating the dual-path design with HVI color space decomposition, multi-scale multi-attention (MMAD) denoising modules, multi-head self attention (MHSA) for illumination adjustment, and multi-channel feature fusion Transformer (CFFT)
3.1 Multi-Scale Multi-Attention Denoising Module (MMAD)
Considering that the U-Net architecture effectively preserves details through multi-scale feature extraction and skip connections, it can significantly enhance structural recovery during denoising. Therefore, the MMAD module is designed based on a U-Net-like architecture and contains downsampling, upsampling paths, multi-scale multi-attention (MSMA), and selective kernel (SK) mechanism [36]. The SK mechanism adaptively fuses multi-scale features from both the skip connections and the main branch, achieving the synergistic optimization of multilevel feature extraction and image denoising. To enhance local texture modeling, multiple skip connections also preserve detailed features within the module.
In Fig. 2, the MSMA module incorporates both multi-scale convolutional operations and multi-attention mechanisms. Specifically, the multi-scale convolutional branch initially applies convolution to adjust the channel depth, with a subsequent 5 × 5 convolution to extract fine-grained local features. To further capture rich contextual information across varying receptive fields, a set of depthwise separable convolutions using kernels sized 3 × 3, 5 × 5, and 7 × 7, each configured with a dilation rate of 3, are applied in parallel. This design facilitates the modeling of diverse spatial dependencies, thereby strengthening the capability to extract distinctive features. The specific steps in the operation are as follows:
where
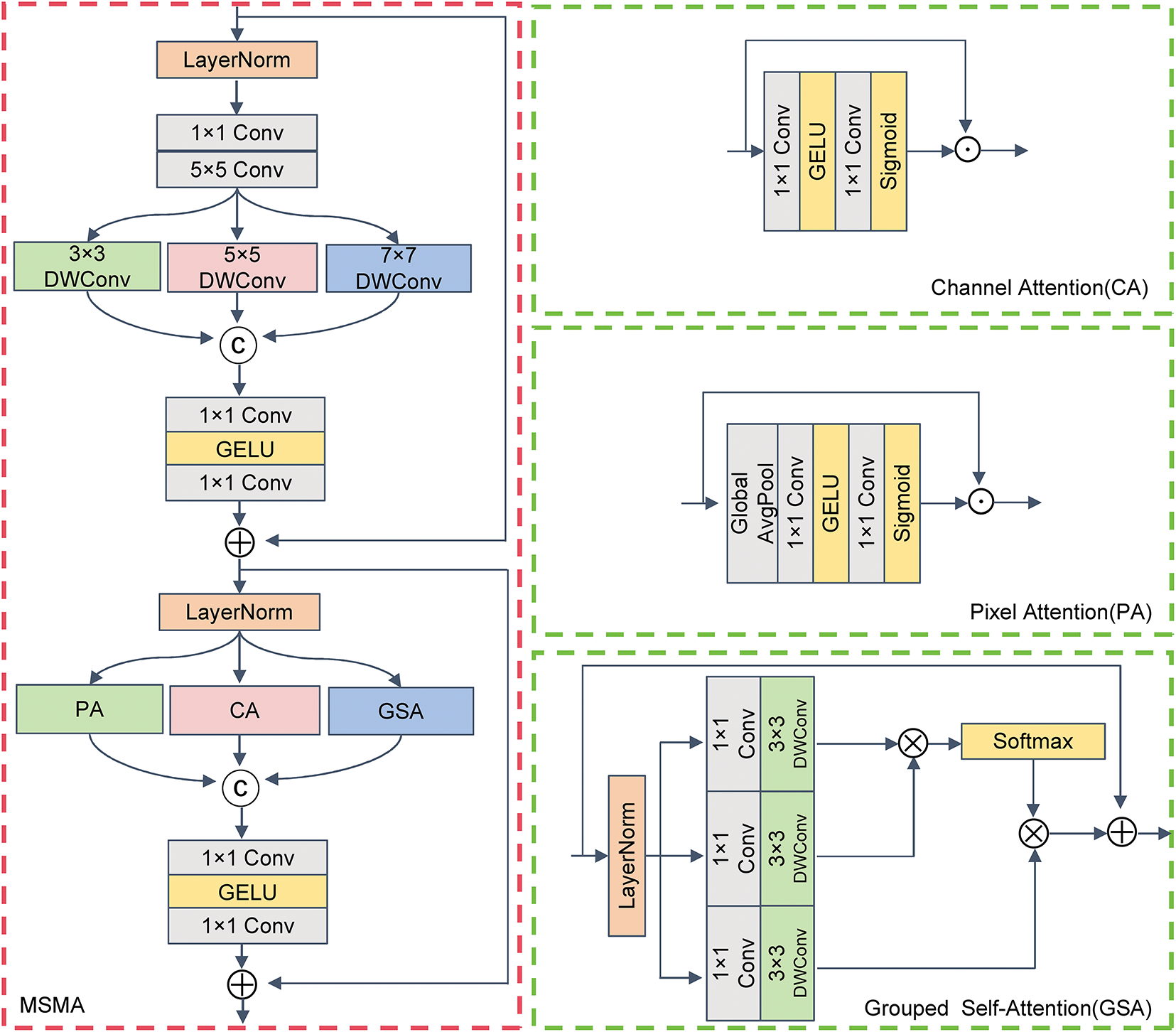
Figure 2: The structure of multi-scale multi-attention (MSMA) module, with the corresponding attention architecture shown on the right
To further address the limitations of convolution operations in modeling non-local information, the MSMA module incorporates three types of attention mechanisms: group self-attention (GSA) [37] for capturing long-range dependencies, channel attention (CA) to emphasize important feature channels, and pixel attention (PA) to enhance local detail perception. These local and global features are then fused through a multi-layer perceptron (MLP), which performs nonlinear transformation and integration. Additionally, residual connections are employed to preserve the original features, which in turn promote the capability to represent features and training stability. The detailed formulation is as follows:
where
3.2 Multi-Head Self Attention (MHSA)
As illustrated in Fig. 3, the MHSA module leverages multiple attention heads to learn diverse attention patterns in parallel, effectively capturing rich local and global dependencies among input features. The input feature map
where
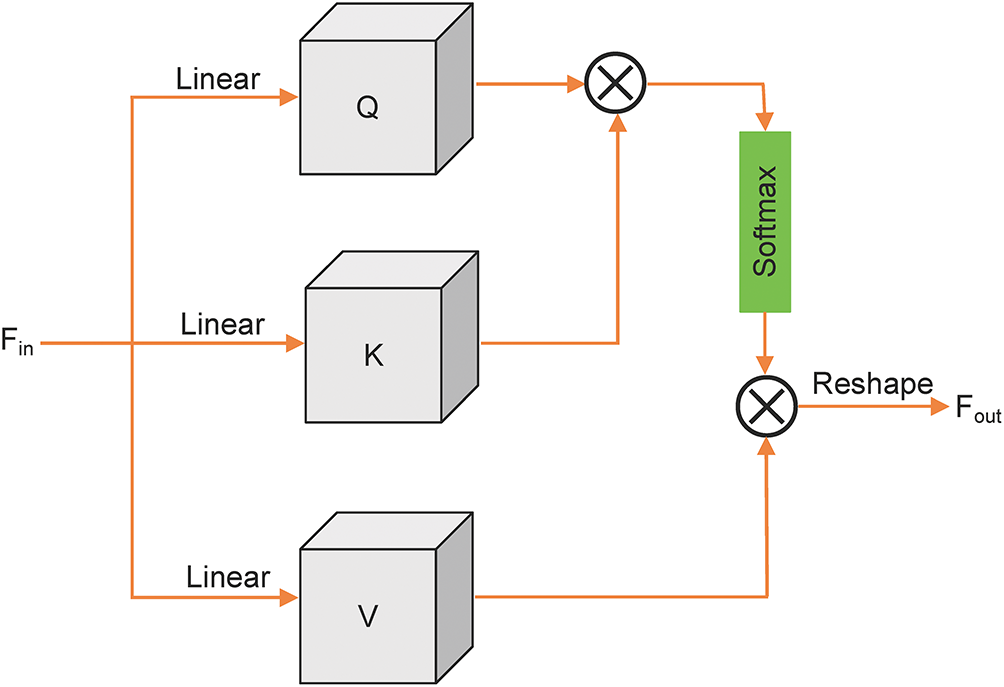
Figure 3: Details of multi-head self attention (MHSA). It achieves better luminance restoration by simultaneously capturing diverse luminance features and global dependencies in parallel
Finally, the attention outputs from all heads are merged and processed by a linear transformation aiming to restore the original input feature dimension using the concatenated features, producing the final output
3.3 Multi-Channel Feature Fusion Transformer (CFFT) Module
As shown in Fig. 4, the CFFT module aims to fuse color and intensity features effectively while reducing computational cost. First, initial features are extracted separately from the HV channels and the I channel using 3 × 3 convolutions. Given the global perceptual properties of both color and intensity, downsampling is performed to compress spatial dimensions, enables the subsequent MHSA module to effectively extract their respective global contextual features. Subsequently, the multi-head cross attention (MHCA) is employed to achieve illumination-guided fusion of color features: the HV features serve as the Query, while the I features act as Key and Value, enabling deep coupling between color and intensity information. The fused features are then further enhanced through nonlinear transformation, subsequently transformed to recover the initial spatial size. Finally, a residual connection adds the enhanced features to the initial color features to preserve more detailed information. The detailed formulation is as follows:
where
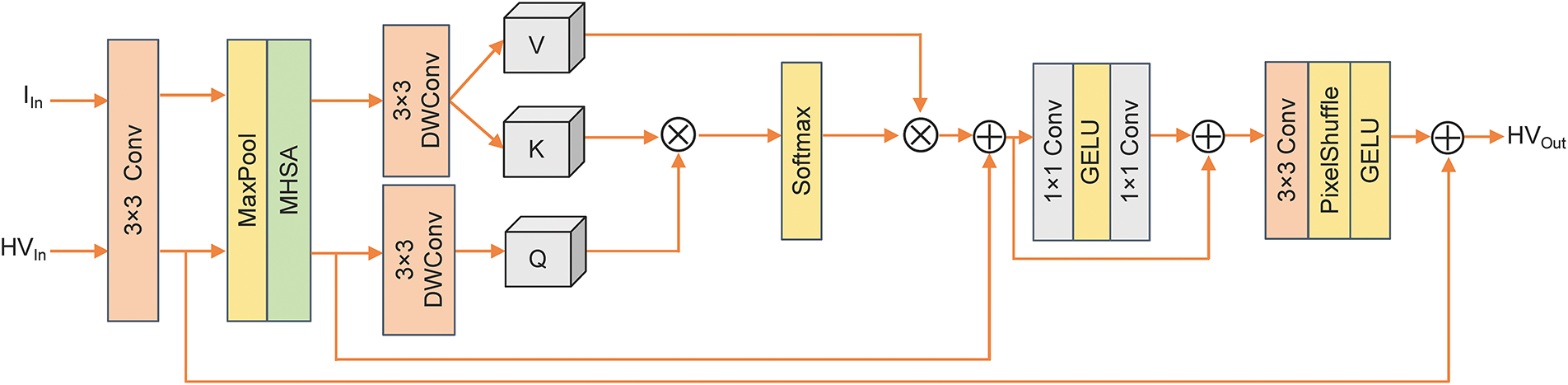
Figure 4: Details of multi-channel feature fusion Transformer (CFFT) module. It consists of five main components: downsampling, MHSA for global context extraction, MHCA as the internal structure for illumination-guided feature fusion, nonlinear transformation, and upsampling
Our methodology assigns critical importance to the loss function and its associated hyperparameters during the training phase. After extensive experimentation with multiple loss configurations, we ultimately developed a composite loss formulation specifically tailored for our optimization framework. Each loss function is specifically represented as follows:
Histogram loss
where
Color loss
where
Edge loss
where
A perceptual loss metric, denoted as
where
3.4.5 Structural Similarity Loss
Structural Similarity Loss
where
3.4.6 Mean Absolute Error Loss
A mean absolute error loss metric, denoted as
where
First, we define:
where
Therefore, the complete objective function may be mathematically expressed in the following manner:
where
To thoroughly assess the effectiveness and adaptability of our approach, we perform testing on datasets containing poorly illuminated images, including LOL-v1 [27], LOL-v2 [38], DICM [39], LIME [17] and NPE [40]. LOL-v2 consists of two distinct components, namely LOL-v2-real, which contains real-captured images, and LOL-v2-synthetic, which includes artificially generated samples.
• LOL-v1. This dataset contains 485 image pairs for training purposes along with 15 pairs designated for validation. Each pair includes a dark-scene input and its corresponding high-quality ground truth, with a resolution of 600 pixels × 400 pixels.
• LOL-v2-real. This dataset comprises 689 image pairs designated for training purposes, along with an additional 100 pairs reserved for validation, all captured under real low-light conditions. This dataset more accurately reflects the degradation characteristics of images in practical scenarios and is extensively utilized to assess the performance of LLIE approaches under practical settings.
• LOL-v2-synthetic. The dataset was created by generating dimly-lit images from RAW files, following illumination patterns typical of poor lighting environments. It comprises exactly 1000 matched sets of underexposed and properly exposed photographs, where 900 are allocated for model training while the remaining 100 serve as validation samples.
• DICM, LIME and NPE. The DICM collection comprises 64 distinct photographs, while the LIME repository holds 10 visual samples. Additionally, the NPE archive provides 8 separate image files. These benchmark datasets were acquired across diverse difficult scenarios including artificial illumination, external obstructions, harsh meteorological conditions, dusk periods, and nocturnal settings.
The diversity and scale of these datasets ensure a comprehensive and reliable evaluation of LLIE methods. All datasets, along with their respective train/validation splits, are used in accordance with the official specifications.
The neural architecture employs the Adam optimization technique, configured with momentum parameters
Comparison methods. We compare the proposed M2ATNet with several SOTA approaches, including RetinexNet (BMVC’18) [27], KinD (MM’19) [28], Zero-DCE (CVPR’20) [24], FIDE (CVPR’20) [12], Sparse (TIP’20) [38], MIRNet (ECCV’20) [42], EnlightenGAN (TIP’21) [23], RUAS (CVPR’21) [25], UFormer (CVPR’22) [11], Restormer (CVPR’22) [13], SNR-Net (CVPR’22) [35], LLFormer (AAAI’23) [10], Lightendiffusion (ECCV’24) [20], AGLLDIff (AAAI’25) [21], DPLUT (AAAI’25) [22] and CIDNet (CVPR’25) [14]. Experiments are performed over the LOL-v1 and LOL-v2 datasets. All baseline models are implemented using their code and pretrained models provided by the original researchers.
Quantitative comparison results. In Table 1, our approach is evaluated against multiple SOTA LLIE approaches from previous studies, where greater PSNR and SSIM scores reflect superior performance. Optimal outcomes appear in bold formatting, while the runner-up performance indicators receive underlining. Third-place achievements are distinguished through italicized presentation. Overall, our proposed method significantly outperforms the existing SOTA approaches, demonstrating strong competitiveness while maintaining a moderate level of computational cost.
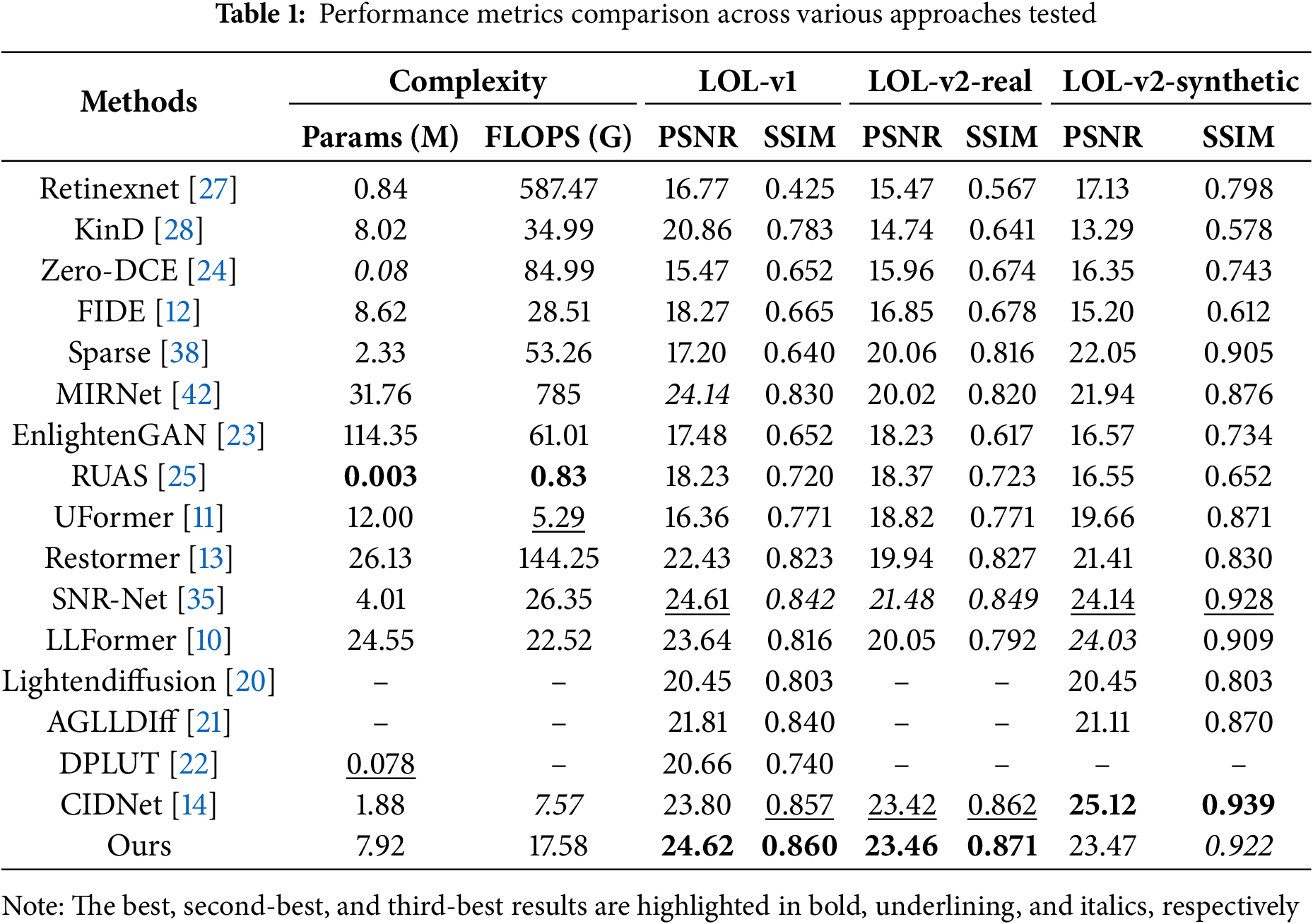
Compared to lightweight approaches like Zero-DCE [24] and RUAS [25], although these approaches have extremely low parameter counts (<0.1 M) and are computationally efficient (<1 G FLOPs), they are limited by simplified assumptions such as curve fitting or physical priors, making it difficult to adapt to complex lighting and noise environments. For example, Zero-DCE [24] achieves only 15.47 dB PSNR on LOL-v1, which is 9.15 dB lower than our method (24.62 dB), and its SSIM is 0.208 lower, indicating significant deficiencies in detail restoration. In contrast, our method introduces a multi-scale multi-attention mechanism that jointly models local and global features under different receptive fields, effectively enhancing adaptability to lighting and noise variations.
Compared with heavyweight models such as MIRNet [42] and Restormer [13], although their parameter counts (26 M–32 M) and computational costs (144 G FLOPs–785 G FLOPs) far exceed ours (7.92 M parameters, 17.58 G FLOPs), their generalization ability is limited. For example, Restormer’s [13] PSNR on LOL-v2-Real drops to 19.94 (a 2.49 dB decrease compared to LOL-v1), suggesting possible overfitting of its Transformer architecture to the training distribution. Our M2ATNet, however, achieves 23.46 dB on LOL-v2-real, benefiting from its dual-path enhancement and multi-channel fusion strategy, which significantly improves structural fidelity and detail recovery while maintaining model compactness.
Compared to the latest model CIDNet [14], although CIDNet [14] achieves 25.12 dB PSNR on LOL-v2-synthetic (better than our 23.47 dB), its performance on real-world scenes (LOL-v2-real) is slightly worse (23.42 dB vs. 23.46 dB), possibly due to its synthetic data-driven enhancement strategy being less adaptive to real noise. Meanwhile, SNR-Net [35]’s advantage on LOL-v1 (24.61 dB) does not carry over to LOL-v2, where it drops by 3.13 dB, reflecting limited generalization. In contrast, our method, combining multi-scale attention mechanisms with a Transformer architecture, achieves stable performance across different dataset subsets, demonstrating strong cross-domain generalization ability and robustness.
Qualitative comparison results on paired datasets. We provide a qualitative comparison involving our method with other prominent approaches using paired datasets in Figs. 5–7. From the visual results, methods like KinD [28] and SNR-Net [35] often exhibit color shift issues. This stems from their enhancement strategies relying on brightness channel transformation or Retinex decomposition, which fail to accurately model the color coupling under complex lighting conditions. Similarly, methods such as RUAS [25] and MIRNet [42] show some ability to restore details but still suffer from overexposure or underexposure in certain regions. This is due to their lack of effective global brightness modeling or contextual constraints, resulting in instability when handling high dynamic range areas, causing reduced contrast and detail loss.

Figure 5: Qualitative comparison results on the LOL-v1 dataset across different scenes

Figure 6: Qualitative comparison results on the LOL-v2-real dataset across different scenes

Figure 7: Qualitative comparison results on the LOL-v2-synthetic dataset across different scenes
In contrast, our method employs a multi-scale multi-attention mechanism that precisely focuses on jointly modeling local structures (e.g., textures, edges) and global illumination trends during the restoration process. This effectively enhances overall image contrast, restores true colors, and suppresses noise, yielding a more natural and harmonious subjective visual experience.
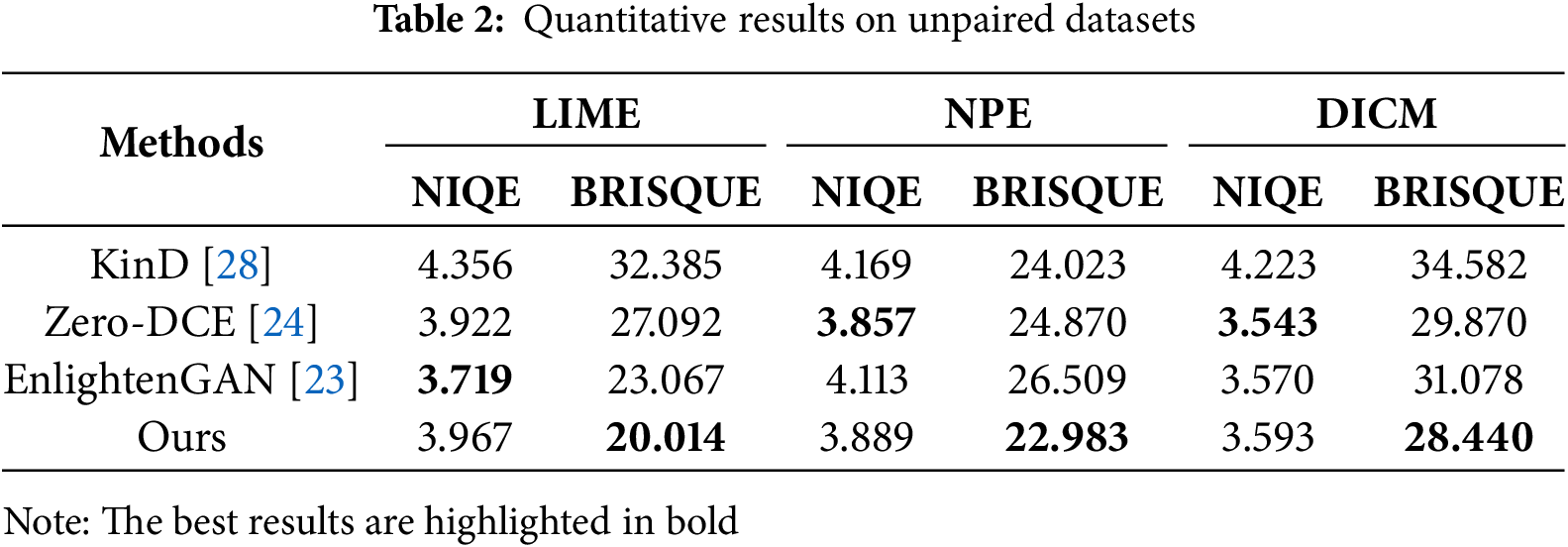
Qualitative comparison results on unpaired datasets. In the unpaired datasets shown in Fig. 8, such as DICM, LIME and NPE, we further observe that the proposed method still demonstrates significant advantages under supervision without ground truth (GT). The first row shows qualitative comparison results on LIME, the middle on DICM, and the bottom on NPE. For example, in indoor and architectural scenes, our approach is able to preserve fine-grained details such as wall textures and window frame structures. In contrast, Zero-DCE [24], which relies on local curve mapping without structural constraints, suffers from severe color shifts and artifacts. KinD [28] exhibits noticeable grayish artifacts in underexposed regions due to information loss during the separation of illumination and reflectance.

Figure 8: Qualitative comparison results on unpaired datasets
These observations provide additional evidence supporting the efficacy of our proposed CFFT and MSMA in LLIE. Specifically, CFFT is able to weight and fuse features according to their importance across different channels (e.g., luminance and color), thereby improving the complementary representation of structural and color information. Meanwhile, the attention mechanism empowers the model to better adapt to and deeply model local textures (such as wall details) and global illumination variations (such as large-scale light-shadow transitions). The synergy of these two components effectively prevents issues such as color shifts and residual artifacts, achieving more realistic and delicate visual restoration under complex lighting conditions.
Table 2 presents the quantitative comparison results on unpaired datasets. Lower NIQE and BRISQUE scores indicate better perceptual quality and naturalness. Although the fine detail and color enhancements introduced by our model may cause slight local contrast and color shifts—leading to minor deviations from natural image statistics and slightly affecting NIQE scores—our approach compensates for this by leveraging the CFFT module to adaptively fuse luminance and chrominance features. Additionally, the MSMA module effectively captures local textures and global illumination variations, resulting in enhanced detail preservation and superior perceptual realism, as reflected in our top performance on BRISQUE.
We performed multiple ablation studies employing the LOLv1 dataset, utilizing PSNR, SSIM, and LPIPS (Learned Perceptual Image Patch Similarity) as our assessment criteria, where better performance is shown by increased PSNR and SSIM, and better perceptual similarity is indicated by decreased LPIPS. To assess the contribution of the introduced components toward enhancing system efficacy, we designed ablation experiments for two key modules, MMAD and CFFT. The specific setup is as follows: MMAD module ablation: we deactivate this module on the I channel and the HV channel, respectively, and construct the following two variants: without (w/o) I-MMAD: the MMAD module is not applied to the I channel, and only the base enhancement process is retained for evaluating its contribution to the luminance structure restoration. W/o HV-MMAD: the MMAD module is not applied to the HV channel, to explore its effect on the noise suppression and structural coherence of the color channel. W/o CFFT-module: we remove the CFFT module and restore the RGB image by directly splicing and merging the enhancement results of the HV and I channels to test the fusion strategy on the final enhancement quality.
The empirical findings are presented in Table 3 below, where removing the MMAD module for either channel (w/o HV-MMAD or w/o I-MMAD) resulted in a significant degradation of the model in terms of PSNR and SSIM metrics. Especially in the image region where complex noise exists, the detail restoration ability is significantly weakened, with blurred structural boundaries as well as color shifts, indicating that the MMAD module plays a key role in multi-scale feature modeling with noise suppression guided by the attention mechanism. Further, when the CFFT module (w/o CFFT) is removed, the overall visual effect of the image is unnatural in color performance and the detail rendering ability in the dark region is reduced, indicating that the CFFT module supports fusing the dual-path enhancement information and facilitating the interaction between the color and luminance channels. Overall, the full model obtains the best outcomes across qualitative and quantitative measures on the LOLv1 dataset, indicating that the designed dual-path architecture and the synergistic design of the modules significantly enhance the quality of LLIE. Combined with the visualization comparison results in Fig. 9, it is noticeable that the complete model surpasses the ablation variants regarding dark texture restoration, color realism and structural information retention, further verifying the validity of the introduced dual-path structure and its key modules.
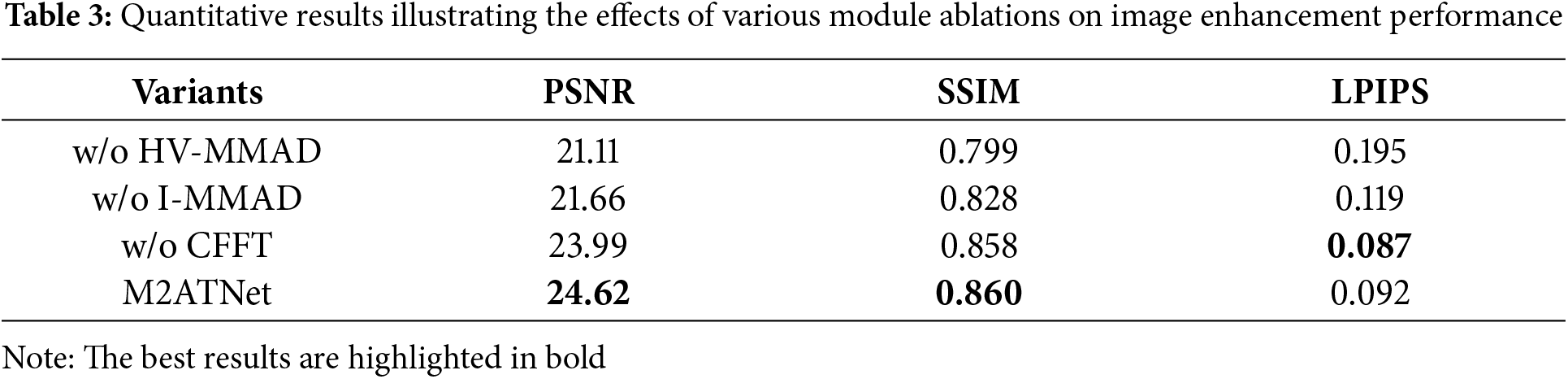

Figure 9: Qualitative comparison illustrating the influence of different module ablations on image enhancement performance
Fig. 10 presents a visual comparison of various low-light image enhancement methods under extreme low-light and complex degradation conditions, taking the real underground mining environment we collected as an example. The original input image is mostly shrouded in darkness, with severely lost details, prominent noise, and motion blur, making it challenging for traditional methods to produce satisfactory enhancement results. While Zero-DCE [24] improves brightness to some extent, it also introduces significant color distortion and amplified noise. KinD [28] achieves better illumination recovery and partial structural restoration; however, it still suffers from blurred textures and local artifacts. EnlightenGAN [23] further enhances overall brightness but tends to over-enhance certain regions and exhibits color fidelity issues. In contrast, our method demonstrates greater robustness in this extreme scenario by effectively boosting brightness, significantly suppressing noise, and restoring more structural details. The resulting image maintains more natural and balanced color tones.

Figure 10: Qualitative comparison results on a real underground mining scene
In addition to the qualitative analysis, as shown in Table 4, our method also outperforms existing representative approaches in terms of no-reference image quality assessment metrics. It achieves more favorable results under mainstream evaluation criteria such as NIQE and BRISQUE, further demonstrating the effectiveness and practical value of the proposed method in challenging low-light scenarios.

Although our method demonstrates robust performance in most cases, some limitations remain in specific regions. As observed in Fig. 10, certain areas of the enhanced image (e.g., the subject’s skin and the background wall) exhibit slight color temperature shifts or color distortions. Additionally, some high-brightness regions appear over-smoothed, leading to loss of fine details. Notably, visible noise persists in extreme scenarios—such as the dark area between the machine and the platform. While our model effectively improves noise suppression and detail restoration through its dual-path design and multi-scale attention mechanisms, challenges remain under extreme low-light conditions. In particular, regions with high noise intensity and severely sparse information require further enhancement in noise modeling and structural guidance. Future work will focus on integrating more refined perceptual loss functions and region-adaptive adjustment mechanisms to further improve performance.
As shown in Table 5, our proposed method achieves an average runtime of 0.265 s per image, which is significantly faster than most competing methods. Although it is slightly slower than the lightweight Zero-DCE (0.025 s), the latter often performs inadequately in complex scenarios such as structural preservation or color fidelity due to its simplified design. In contrast, our method strikes a better balance between enhancement performance and computational efficiency. Therefore, it is well-suited for near real-time applications where both visual quality and processing speed are required.

In this paper, a single-stage LLIE solution, M2ATNet, is proposed, which achieves excellent image enhancement without the need for a complex multi-stage training process. By introducing a dual-path structure based on HVI decomposition, the model is able to target enhancement to luminance and color channels separately, while achieving structure and illumination guidance between channels, effectively suppressing noise and repairing color shifts. We design a MMAD that can fully extract texture details at multiple levels, improve the detail restoration ability, and further strengthen the network’s contextual modeling ability by integrating multiple attention mechanisms. The CFFT, on the other hand, realizes the deep interaction between luminance and color channels to enhance the structure alignment and detail restoration in dark regions. In addition, we design and validate a hybrid loss function strategy that combines multiple dimensions of structural, perceptual and edge information to effectively optimize the training procedure and the final image quality. Quantitative and qualitative experimental results show that the proposed M2ATNet outperforms the current mainstream low-light image enhancement methods on multiple public datasets, demonstrating good generalization and robustness. In the future, we will further explore a more lightweight network design to further improve the computational efficiency and investigate the potential application of this model in target detection and other related vision tasks.
Acknowledgement: Thank all the people who contributed to this paper.
Funding Statement: This research was funded by the National Natural Science Foundation of China, grant numbers 52374156 and 62476005.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Zhongliang Wei, Jianlong An; data collection: Chang Su; analysis and interpretation of results: Zhongliang Wei, Jianlong An, Chang Su; draft manuscript preparation: Zhongliang Wei, Jianlong An, Chang Su. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in GitHub at https://github.com/CrazyAn-JL/M2ATNet (accessed on 11 September 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhao R, Li Y, Zhang Q, Zhao X. Bilateral decoupling complementarity learning network for camouflaged object detection. Knowl-Based Syst. 2025;314(9):113158. doi:10.1016/j.knosys.2025.113158. [Google Scholar] [CrossRef]
2. Wang W, Yin B, Li L, Li L, Liu H. A low light image enhancement method based on dehazing physical model. Comput Model Eng Sci. 2025;143(2):1595–616. doi:10.32604/cmes.2025.063595. [Google Scholar] [CrossRef]
3. Wang M, Li J, Zhang C. Low-light image enhancement by deep learning network for improved illumination map. Comput Vis Image Underst. 2023;232(4):103681. doi:10.1016/j.cviu.2023.103681. [Google Scholar] [CrossRef]
4. Jia C, Wu Z, Su C, Liu H, Xiao Y. Adversarial defense method to face forgery detection based on masked conditional diffusion model. Expert Syst Appl. 2025;287(3):128156. doi:10.1016/j.eswa.2025.128156. [Google Scholar] [CrossRef]
5. Huang W, Zhang L, Wang Z, Wang Y. GapMatch: bridging instance and model perturbations for enhanced semi-supervised medical image segmentation. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence; 2025 Feb 22–28; Vancouver, BC, Canada. Palo Alto, CA, USA: AAAI Press. p. 17458–66. doi:10.1609/aaai.v39i16.33919. [Google Scholar] [CrossRef]
6. Zhang W, Zhuang P, Sun H, Li G, Kwong S, Li C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans Image Process. 2022;31:3997–4010. doi:10.1109/TIP.2022.3177129. [Google Scholar] [PubMed] [CrossRef]
7. Zhang W, Zhou L, Zhuang P, Li G, Pan X, Zhao W, et al. Underwater image enhancement via weighted wavelet visual perception fusion. IEEE Trans Circuits Syst Video Technol. 2023;34(4):2469–83. doi:10.1109/TCSVT.2023.3299314. [Google Scholar] [CrossRef]
8. Huang Y, Liao X, Liang J, Quan Y, Shi B, Xu Y. Zero-shot low-light image enhancement via latent diffusion models. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence; 2025 Feb 22–28; Vancouver, BC, Canada. Palo Alto, CA, USA: AAAI Press; 2025. p. 3815–23. doi:10.1609/aaai.v39i4.32398. [Google Scholar] [CrossRef]
9. Sheng G, Hu G, Wang X, Chen W, Jiang J. Low-light image enhancement via clustering contrastive learning for visual recognition. Pattern Recognit. 2025;164(6):111554. doi:10.1016/j.patcog.2025.111554. [Google Scholar] [CrossRef]
10. Wang T, Zhang K, Shen T, Luo W, Stenger B, Lu T. Ultra-high-definition low-light image enhancement: a benchmark and transformer-based method. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence; 2023 Feb 7–14; Washington, DC, USA. Palo Alto, CA, USA: AAAI Press; 2023. p. 2654–62. doi:10.1609/aaai.v37i3.25364. [Google Scholar] [CrossRef]
11. Wang Z, Cun X, Bao J, Zhou W, Liu J, Li H. Uformer: a general u-shaped transformer for image restoration. In: Proceedings of the 35th IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 19–24; New Orleans, LA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2022. p. 17683–93. doi:10.1109/CVPR52688.2022.01716. [Google Scholar] [CrossRef]
12. Xu K, Yang X, Yin B, Lau R. Learning to restore low-light images via decomposition-and-enhancement. In: Proceedings of the 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2020. p. 2281–90. doi:10.1109/CVPR42600.2020.00235. [Google Scholar] [CrossRef]
13. Zamir S, Arora A, Khan S, Hayat M, Khan F, Yang M. Restormer: efficient transformer for high-resolution image restoration. In: Proceedings of the 35th IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 19–24; New Orleans, LA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2022. p. 5728–39. doi:10.1109/CVPR52688.2022.00564. [Google Scholar] [CrossRef]
14. Yan Q, Feng Y, Zhang C, Pang G, Shi K, Wu P, et al. HVI: a new color space for low-light image enhancement. In: Proceedings of the 38th Computer Vision and Pattern Recognition Conference; 2025 Jun 17–21; Seattle, WA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2025. p. 5678–87. doi:10.48550/arXiv.2502.20272. [Google Scholar] [CrossRef]
15. Zhou Z, Li K. Research on image enhancement algorithm based on histogram equalization. Electron Prod. 2025;33(4):75–8. (In Chinese). doi:10.16589/j.cnki.cn11-3571/tn.2025.04.004. [Google Scholar] [CrossRef]
16. Jing J, Gao Y, Zhao Z, Min B. A low-illumination image enhancement algorithm for coal mine based on reflection map enhancement. Mod Electron Technol. 2025;48(3):43–9. doi:10.16652/j.issn.1004-373x.2025.03.007 (In Chinese). [Google Scholar] [CrossRef]
17. Guo X, Li Y, Ling H. LIME: low-light image enhancement via illumination map estimation. IEEE Trans Image Process. 2016;26(2):982–93. doi:10.1109/TIP.2016.2639450. [Google Scholar] [PubMed] [CrossRef]
18. Mu Q, Ge X, Wang X, Li L, Li Z. An underground coal mine image enhancement method based on multi-scale gradient domain guided filtering. Ind Control Comput. 2024;50(6):79–88, 111. (In Chinese). doi:10.13272/j.issn.1671-251x.2023080126. [Google Scholar] [CrossRef]
19. Du S, Zhao M, Liu Y, You Z, Shi Z, Li J, et al. Low-light image enhancement and denoising via dual-constrained Retinex model. Appl Math Model. 2023;116(2):1–15. doi:10.1016/j.apm.2022.11.022. [Google Scholar] [CrossRef]
20. Jiang H, Luo A, Liu X, Han S, Liu S. Lightendiffusion: unsupervised low-light image enhancement with latent-Retinex diffusion models. In: Proceedings of the 24th European Conference on Computer Vision (ECCV); 2024 Sep 29–Oct 4; Milan, Italy. Cham, Switzerland: Springer Nature; 2024. p. 161–79. doi:10.1007/978-3-031-73195-2_10. [Google Scholar] [CrossRef]
21. Lin Y, Ye T, Chen S, Fu Z, Wang Y, Chai W, et al. AGLLDiff: guiding diffusion models towards unsupervised training-free real-world low-light image enhancement. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence; 2025 Feb 22–28; Vancouver, BC, Canada. Palo Alto, CA, USA: AAAI Press; 2025. p. 5307–15. doi:10.1609/aaai.v39i5.32564. [Google Scholar] [CrossRef]
22. Lin Y, Fu Z, Wen K, Ye T, Chen S, Meng G. DPLUT: unsupervised low-light image enhancement with lookup tables and diffusion priors. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence; 2025 Feb 22–28; Vancouver, BC, Canada. Palo Alto, CA, USA: AAAI Press; 2025. p. 5316–24. doi:10.1609/aaai.v39i5.32565. [Google Scholar] [CrossRef]
23. Jiang Y, Gong X, Liu D, Cheng Y, Fang C, Shen X, et al. EnlightenGAN: deep light enhancement without paired supervision. IEEE Trans Image Process. 2021;30:2340–9. doi:10.1109/TIP.2021.3051462. [Google Scholar] [PubMed] [CrossRef]
24. Guo C, Li C, Guo J, Loy C, Hou J, Kwong S, et al. Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 13–19; Seattle, WA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2020. p. 1780–89. doi:10.1109/CVPR42600.2020.00185. [Google Scholar] [CrossRef]
25. Liu R, Ma L, Zhang J, Fan X, Luo Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In: Proceedings of the 34th IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021 Jun 19–25; Virtual. Los Alamitos, CA, USA: IEEE/CVF; 2021. p. 10561–70. doi:10.48550/arXiv.2012.05609. [Google Scholar] [CrossRef]
26. Liu Y, Huang T, Dong W, Wu F, Li X, Shi G. Low-light image enhancement with multi-stage residue quantization and brightness-aware attention. In: Proceedings of the 23rd IEEE/CVF International Conference on Computer Vision; 2023 Oct 14–21; Paris, France. Los Alamitos, CA, USA: IEEE/CVF; 2023. p. 12140–49. doi:10.1109/ICCV51070.2023.01115. [Google Scholar] [CrossRef]
27. Wei C, Wang W, Yang W, Liu J. Deep Retinex decomposition for low-light enhancement. arXiv:1808.04560. 2018. doi:10.48550/arXiv.1808.04560. [Google Scholar] [CrossRef]
28. Zhang Y, Zhang J, Guo X. Kindling the darkness: a practical low-light image enhancer. In: Proceedings of the 27th ACM International Conference on Multimedia; 2019 Oct 21–25; Nice, France. New York, NY, USA: ACM; 2019. p. 1632–40. doi:10.1145/3343031.3350926. [Google Scholar] [CrossRef]
29. Zhang YH, Guo XJ, Ma JY, Liu W, Zhang J. Beyond brightening low-light images. Int J Comput Vis. 2021;129(4):1013–37. doi:10.1007/s11263-020-01407-x. [Google Scholar] [CrossRef]
30. Wang R, Zhang Q, Fu C, Shen X, Zheng W, Jia J. Underexposed photo enhancement using deep illumination estimation. In: Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 16–20; Long Beach, CA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2019. p. 6849–57. doi:10.1109/CVPR.2019.00701. [Google Scholar] [CrossRef]
31. Cai Y, Bian H, Lin J, Wang H, Timofte R, Zhang Y. RetinexFormer: one-stage Retinex-based transformer for low-light image enhancement. In: Proceedings of the 23rd IEEE/CVF International Conference on Computer Vision; 2023 Oct 14–21; Paris, France. Los Alamitos, CA, USA: IEEE/CVF; 2023. p. 12504–13. doi:10.1109/ICCV51070.2023.01149. [Google Scholar] [CrossRef]
32. Fan G, Yao Z, Gan M. Illumination-aware and structure-guided transformer for low-light image enhancement. Comput Vis Image Underst. 2025;252(2):104276. doi:10.1016/j.cviu.2024.104276. [Google Scholar] [CrossRef]
33. Lin J, Lai F, Lin S, Lin Z, Guo T. Frequency-guided dual-collapse Transformer for low-light image enhancement. Eng Appl Artif Intell. 2025;142(2):109906. doi:10.1016/j.engappai.2024.109906. [Google Scholar] [CrossRef]
34. Pei X, Huang Y, Su W, Zhu F, Liu Q. FFTFormer: a spatial-frequency noise aware CNN-Transformer for low light image enhancement. Knowl-Based Syst. 2025;314(4):113055. doi:10.1016/j.knosys.2025.113055. [Google Scholar] [CrossRef]
35. Xu X, Wang R, Fu CW, Jia J. SNR-aware low-light image enhancement. In: Proceedings of the 35th IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 19–24; New Orleans, LA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2022. p. 17714–24. doi:10.1109/CVPR52688.2022.01719. [Google Scholar] [CrossRef]
36. Li X, Wang W, Hu X, Yang J. Selective kernel networks. In: Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 16–20; Long Beach, CA, USA. Los Alamitos, CA, USA: IEEE/CVF; 2019. p. 510–19. [Google Scholar]
37. Li J, Zhang Z, Zuo W. Rethinking transformer-based blind-spot network for self-supervised image denoising. In: Proceedings of the 39th AAAI Conference on Artificial Intelligence; 2025 Feb 22–28; Vancouver, BC, Canada. Palo Alto, CA, USA: AAAI Press; 2025. p. 4788–96. doi:10.1609/aaai.v39i5.32506. [Google Scholar] [CrossRef]
38. Yang W, Wang W, Huang H, Wang S, Liu J. Sparse gradient regularized deep Retinex network for robust low-light image enhancement. IEEE Trans Image Process. 2021;30:2072–86. doi:10.1109/TIP.2021.3050850. [Google Scholar] [PubMed] [CrossRef]
39. Lee C, Lee C, Kim C. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans Image Process. 2013;22(12):5372–84. doi:10.1109/TIP.2013.2284059. [Google Scholar] [PubMed] [CrossRef]
40. Wang S, Zheng J, Hu HM, Li B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans Image Process. 2013;22(9):3538–48. doi:10.1109/TIP.2013.2261309. [Google Scholar] [PubMed] [CrossRef]
41. Mittal A, Soundararajan R, Bovik AC. Making a “completely blind” image quality analyzer. IEEE Signal Process Lett. 2012;20(3):209–12. doi:10.1109/LSP.2012.2227726. [Google Scholar] [CrossRef]
42. Zamir S, Arora A, Khan S, Hayat M, Khan F, Yang M, et al. Learning enriched features for real image restoration and enhancement. In: Proceedings of the 16th European Conference on Computer Vision (ECCV); 2020 Aug 23–28; Glasgow, UK. Cham, Switzerland: Springer; 2020. p. 626–43. doi:10.1007/978-3-030-58595-2_30. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools