
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CAFE-GAN: CLIP-Projected GAN with Attention-Aware Generation and Multi-Scale Discrimination
1 School of Communication and Information Engineering, Xi’an University of Posts and Telecomunications, Xi’an, 710121, China
2 Test Center, National University of Defense Technology, Xi’an, 710106, China
* Corresponding Author: Yijun Zhang. Email:
Computers, Materials & Continua 2026, 86(1), 1-19. https://doi.org/10.32604/cmc.2025.069482
Received 24 June 2025; Accepted 04 September 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Over the past decade, large-scale pre-trained autoregressive and diffusion models rejuvenated the field of text-guided image generation. However, these models require enormous datasets and parameters, and their multi-step generation processes are often inefficient and difficult to control. To address these challenges, we propose CAFE-GAN, a CLIP-Projected GAN with Attention-Aware Generation and Multi-Scale Discrimination, which incorporates a pre-trained CLIP model along with several key architectural innovations. First, we embed a coordinate attention mechanism into the generator to capture long-range dependencies and enhance feature representation. Second, we introduce a trainable linear projection layer after the CLIP text encoder, which aligns textual embeddings with the generator’s semantic space. Third, we design a multi-scale discriminator that leverages pre-trained visual features and integrates a feature regularization strategy, thereby improving training stability and discrimination performance. Experiments on the CUB and COCO datasets demonstrate that CAFE-GAN outperforms existing text-to-image generation methods, achieving lower Fréchet Inception Distance (FID) scores and generating images with superior visual quality and semantic fidelity, with FID scores of 9.84 and 5.62 on the CUB and COCO datasets, respectively, surpassing current state-of-the-art text-to-image models by varying degrees. These findings offer valuable insights for future research on efficient, controllable text-to-image synthesis.Keywords
Due to its involvement in cross-modal domains, particularly text-to-image conversion, ensuring semantic consistency between synthesized images and the provided text, both globally and locally, is a challenging issue [1,2]. Over the last decade or so, text-to-image generation emerged as a major research topics, driving advancements in multimodal learning and vision–language reasoning [2,3]. Recently, autoregressive and diffusion models, powerful methods for generating high-quality, complex-scene images, have been introduced into the text-guided field of image synthesis [4,5]. These models leverage extensive training with large-scale parameter models and massive datasets. Notably, models such as DALL-E 2 [6] and Stable Diffusion [7] have demonstrated impressive capabilities. However, such models also come with significant drawbacks. They require vast training data, enormous model sizes, and substantial computational resources (often involving specialized hardware), which greatly limits their accessibility. Moreover, their multi-step iterative generation is computationally inefficient and offers limited control over fine-grained details in the output [8].
In contrast, Generative Adversarial Networks (GANs) can produce images with a single forward pass and operate in a smooth latent space, enabling more efficient and controllable generation. However, GAN training is notoriously unstable, often leading to degraded image quality or limited diversity, especially for complex scenes. Unlike autoregressive and diffusion models, StackGAN++ [9] utilizes multiple generators and discriminators to improve image resolution. While this technique enhances image quality, it exacerbates training instability. Furthermore, many GAN-based methods struggle to fully fuse textual information into the image synthesis process, which can undermine the realism of generated images. For example, AttnGAN [10] uses attention mechanisms to amplify local textual influence on image subregions, improving image quality but still underutilizing textual inputs. Effectively leveraging textual information remains a critical issue in text-to-image generation. Furthermore, incorporating a multi-scale discriminator together with suitable regularization can further stabilise GAN training and enhance feature extraction, yet this strategy has so far received little attention in text-to-image generation.
To properly handle the above issues of both large-scale models and classical GANs, we propose an enhanced framework named CLIP-Projected GAN with Attention-Aware Generation and Multi-Scale Discrimination (CAFE-GAN). This model integrates a pre-trained CLIP architecture [11] to support cross-modal representation learning. It also incorporates several architectural improvements to enhance semantic alignment and stabilize adversarial training. Specifically, CAFE-GAN introduces: (1) a coordinate attention module in the generator to enrich feature encoding by capturing both spatial and channel-wise dependencies; (2) a trainable linear projection layer after the CLIP text encoder to better align text features with the image generation space; and (3) a multi-scale discriminator built upon pre-trained visual features, enhanced with a feature regularization strategy to mitigate overfitting and stabilize training. The key contributions of this paper are summarized as follows:
• We design an attention-aware fusion generator that effectively integrates input textual information and visual features. The coordinate attention mechanism allows the generator to capture cross-channel and spatial dependencies, significantly improving generation fidelity.
• We propose a CLIP-based, single-stage text-to-image generation pipeline by inserting a trainable linear projection after the CLIP text encoder. This adaptation bridges the semantic gap between natural language and visual content, resulting in better semantic alignment.
• We develop a multi-scale discriminator that utilizes pre-trained visual representations and incorporates feature regularization. This design enables the discriminator to robustly evaluate image realism across multiple scales, improving both stability and diversity of the generated results.
2.1 GAN-Based Text-to-Image Generation Techniques
Since the emergence of Generative Adversarial Networks (GANs), related tasks have garnered increasing attention from researchers, with generating high-quality images guided by text becoming a prominent topic across numerous real-world applications [12–14]. The work of Reed et al. [15] firstly applied GANs to text-guided field of image synthesis. However, this model was only capable of generating low-resolution (64 × 64) images, which lacked vividness and fine-grained details, thus limiting its applicability in practical scenarios.
To address the resolution limitations, models such as StackGAN++ [9] and AttnGAN [10] introduced stacked architectures to progressively refine clarity of images. While this approach has achieved good results, the entanglement introduced among stacked generators increased model complexity and training instability, and the overall realism of generated images still left room for improvement.
In an effort to simplify architectures, Tao et al. [16] developed a single-stage backbone structure, demonstrating that reducing structural complexity can enhance GAN performance. Building upon DF-GAN, Ye et al. [17] introduced the Recurrent Affine Transformation (RAT) mechanism, which effectively improve the training efficiency. Yang et al. [2] proposed a multi-head attention module and a word-level discriminator to improve semantic consistency.
More recently, advances in feature-guided generation and contrastive learning have further improved the controllability and semantic alignment of GAN-based models. For instance, StyleGAN-T [18] incorporated transformer modules into StyleGAN to better align visual attributes with text.
2.2 Large-Scale Models in Text-Guided Image Generation
Remarkable achievements have been made in generating images from diverse textual descriptions, driven by advances in diffusion models, autoregressive transformers, and large-scale language encoders [19,20]. DALL-E [19] and CogView [20] are representative autoregressive approaches that utilize VQ-VAE [21] or VQGAN [22] to discretize images into visual tokens, enabling high-quality image synthesis from text.
To address the slow generation speed inherent in autoregressive models, diffusion-based approaches have been extensively explored. The Latent Diffusion Model (LDM) [7] performs denoising in a low-dimensional latent space to reduce computational costs. However, despite this optimization, LDMs still require substantial computation, which limits their applicability in real-time scenarios.
Compared with GANs, diffusion models are less effective in capturing fine-grained visual details. Moreover, the progressive denoising process in diffusion models typically requires hundreds of inference steps, making them significantly slower than GANs in image generation speed.
In addition to traditional GAN-based and diffusion-based approaches, recent models such as Muse [4], and Sora [23] have demonstrated impressive capabilities in high-quality text-to-image synthesis. However, these models are often computationally expensive and require large-scale datasets and resources, making lightweight and controllable models like CAFE-GAN more suitable for practical and real-time applications. In parallel, the field of style transfer has also evolved significantly, offering insights for enhancing visual fidelity and personalization. Method such as StyTr2 [24] uses transformer-based modules or meta-learning strategies to rapidly adapt style representations, which can be potentially extended to boost text-guided generative quality.
In our work, we adopt an efficient single-stage GAN paradigm similar to DF-GAN [16], and focus on introducing novel modules to more fully leverage textual information, thereby enhancing semantic alignment between text and generated images and improving the fidelity of the results.
As illustrated in Fig. 1, the proposed generator adopts a dual-modal conditional input architecture, jointly driven by noise-guided diversity generation and text-driven semantic control. The input text description is first encoded into a global text feature vector using a pre-trained CLIP text encoder [8]. We then pass this text feature through a learned linear projection layer that maps it into the semantic space of the generative network, ensuring the text information is in a compatible representation. The projected text feature, together with a randomly sampled noise vector z, is fed into the generator to produce the output image.
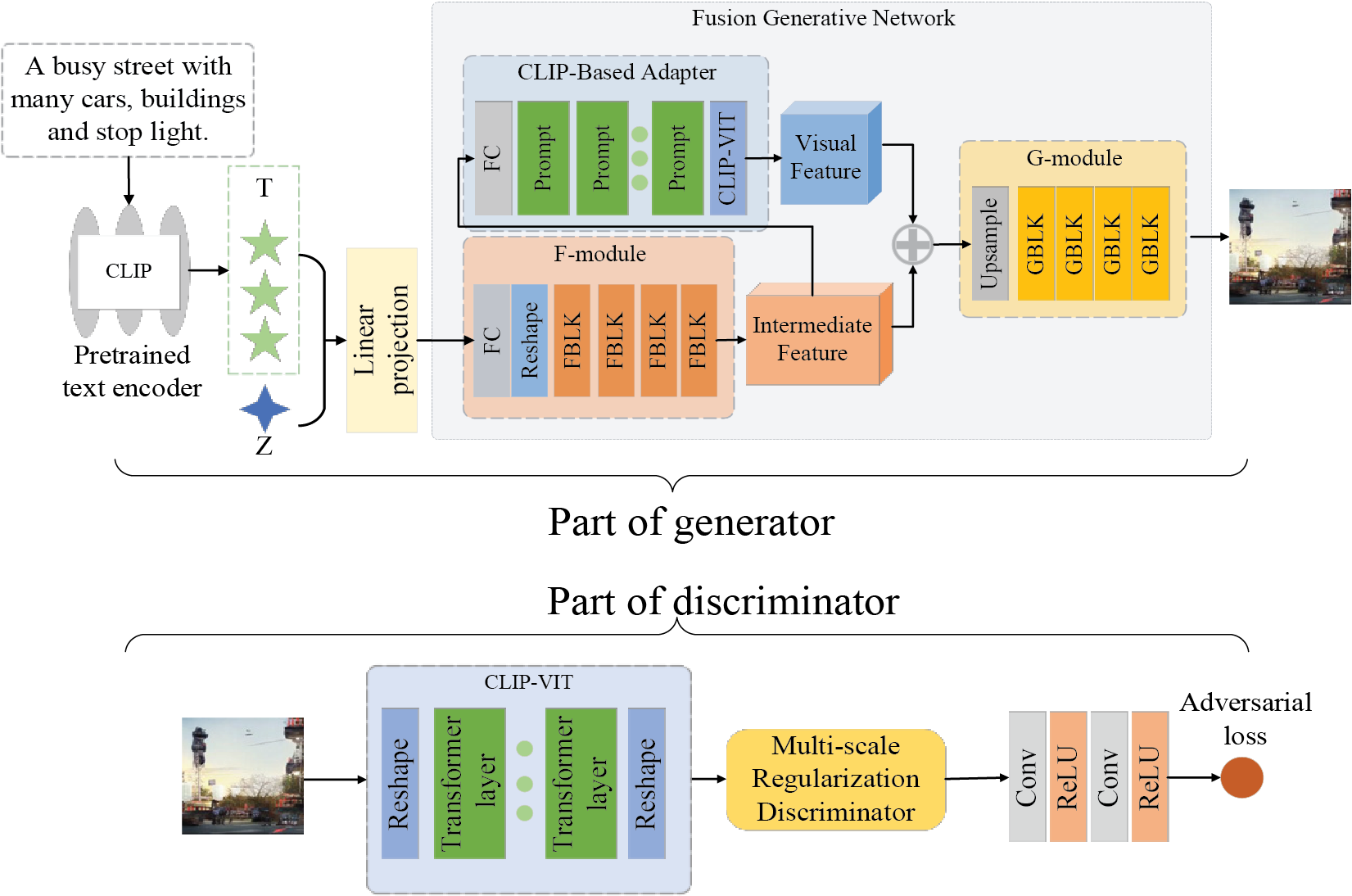
Figure 1: The overall framework of the generator and discriminator. The generator fuses CLIP text features and noise via an adapter and F-module, then decodes through the G-module. The discriminator uses CLIP-ViT and a multi-scale module to compute adversarial loss
On the discriminator side, we leverage a pre-trained visual feature extractor to analyze the generated image at multiple scales. The discriminator is designed to assess image realism from both global and local perspectives, effectively operating at different spatial scales to examine the output. Additionally, we incorporate a feature regularization technique during discriminator training to stabilize the adversarial process and prevent the discriminator from overfitting or becoming overly sensitive to minor artifacts.
3.2 CLIP-Based Single-Stage Generator
In this subsection, we provide a detailed description of the generator, which primarily consists of a CLIP-based text encoder, a fusion module (F-module), a CLIP-based visual adapter, and a generation module (G-module).
3.2.1 Fusion Generative Network
The Fusion Generative Network is responsible for deeply integrating textual and visual information before the final image is synthesized, and it is composed of a fusion module, a CLIP-based visual feature adapter, and the subsequent generation module. In the fusion module, the projected text feature is concatenated with the noise vector and passed through a fully connected layer to produce an initial fused feature representation. This fused feature is then iteratively refined by a series of Fusion Blocks (FBLKs), each of which includes a convolutional layer and a fusion sub-layer that progressively injects textual information into the visual feature stream. Through a series of image processing operations, the model ultimately produces high-quality images.
To address the issue of insufficient semantic alignment between text and visual features, this work designs a fusion module that progressively injects textual guidance into the visual representation. As illustrated in Fig. 2a, the fusion module consists of a fully connected (FC) layer followed by four FBLK blocks. The initial features still contain substantial noise and irrelevant information, which can negatively affect the quality of the subsequently generated images if not properly handled. To address this, we apply a series of FBLK blocks to gradually introduce textual information into the image feature generation process, thereby enabling deep semantic fusion between the two modalities.
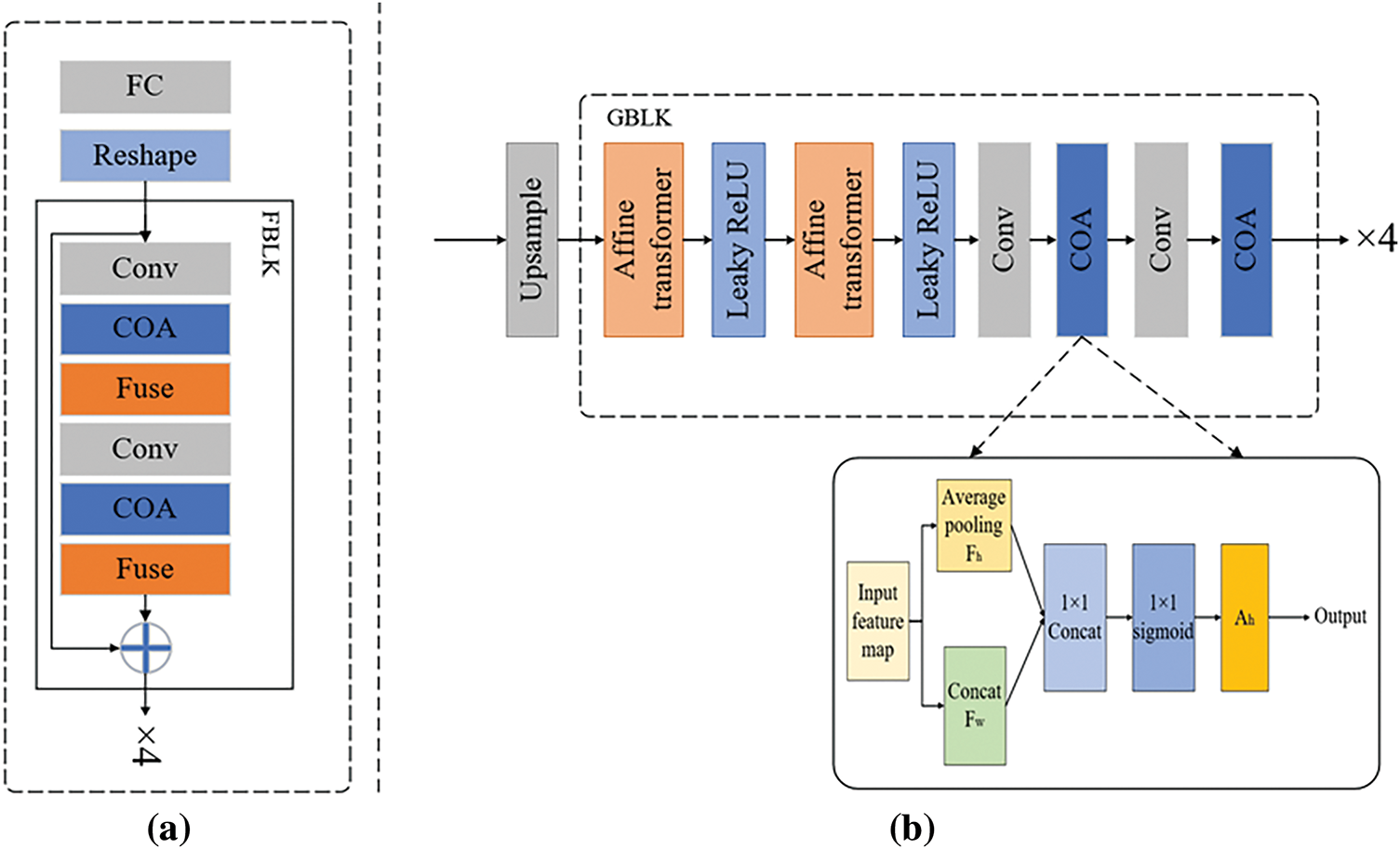
Figure 2: (a) The structure of the F-module, which integrates CLIP-projected features through convolution and COA-based fusion blocks. (b) The architecture of the G-module, where affine transformer blocks and COA guide progressive generation, with spatial attention applied to enhance detail
Each FBLK is composed of a convolutional layer (Conv), a coordinate attention block (COA), and a fusion layer (Fuse). Coordinate attention jointly encodes the channel relationships and spatial positional information of features, allowing the model to highlight important image regions relevant to the text condition. By doing so, this attention mechanism improves the efficacy of cross-modal feature fusion, ensuring that critical information described by the text is preserved in the feature maps and contributes to finer image details. Through the sequential application of multiple FBLK blocks, the global sentence vector and the noise vector are progressively transformed into intermediate image features enriched with textual semantics. These features are then processed by the CLIP-based visual transformer to obtain semantically fused visual features, which are subsequently passed to the generation module.
To address the challenge of limited capacity in traditional fusion networks to model complex conditions, this work proposes a generation module that expands the conditional representation space through affine transformations and non-linear activations. As shown in Fig. 2b, we integrate a Leaky ReLU layer between two affine transformations to introduce non-linearity into the fusion process, thereby expanding the conditional representation space. The intermediate features generated by the fusion module and the visual features extracted by the CLIP-based visual transformer are first input into an upsampling layer for initial spatial enlargement. To convert the image features into high-quality images, a series of GBLKs are applied.
Each GBLK consists of the affine transformation layer, the Leaky ReLU activation layer, and the coordinate attention block. Following the affine transformation and Leaky ReLU layers, the coordinate attention modules are applied for two-stage feature refinement. The coordinate attention mechanism is designed to encode both channel dependencies and precise positional information, enabling the network to highlight spatially-relevant regions conditioned on text. Given an input feature map
X (c, i, j) denotes the value at channel
These two context descriptors capture long-range dependencies along the spatial dimensions, facilitating fine-grained attention modeling in the subsequent layers. Then the context descriptors
here,
where
where
This formulation allows the model to focus on task-relevant spatial regions while maintaining global contextual consistency, which is especially beneficial for text-to-image generation tasks that require fine-grained semantic alignment.
3.3 Multi-Scale Regularization Discriminator
To tackle the instability of adversarial training and the over-sensitivity of discriminators to minor artifacts, this work designs a multi-scale discriminator with a feature regularization strategy. As shown in Fig. 3, our discriminator is designed to robustly distinguish real images from generated ones by analyzing features at multiple scales. We build the discriminator’s feature extraction backbone on a pre-trained vision model; specifically, we employ the pre-trained CLIP visual transformer (ViT-B/32 architecture) to obtain a rich representation of the input image [8]. The input image is partitioned into 32 × 32 patches before being processed. Inspired by ViT block structures, we extract multi-scale features from the outputs of Block 1, 4, and 7, corresponding to shallow, middle, and deep levels of visual representation. These features are directly accessed without additional downsampling. The discriminator leverages these different levels of features to judge the realism of the image, ensuring that it evaluates both the global structure of the image and the local details.
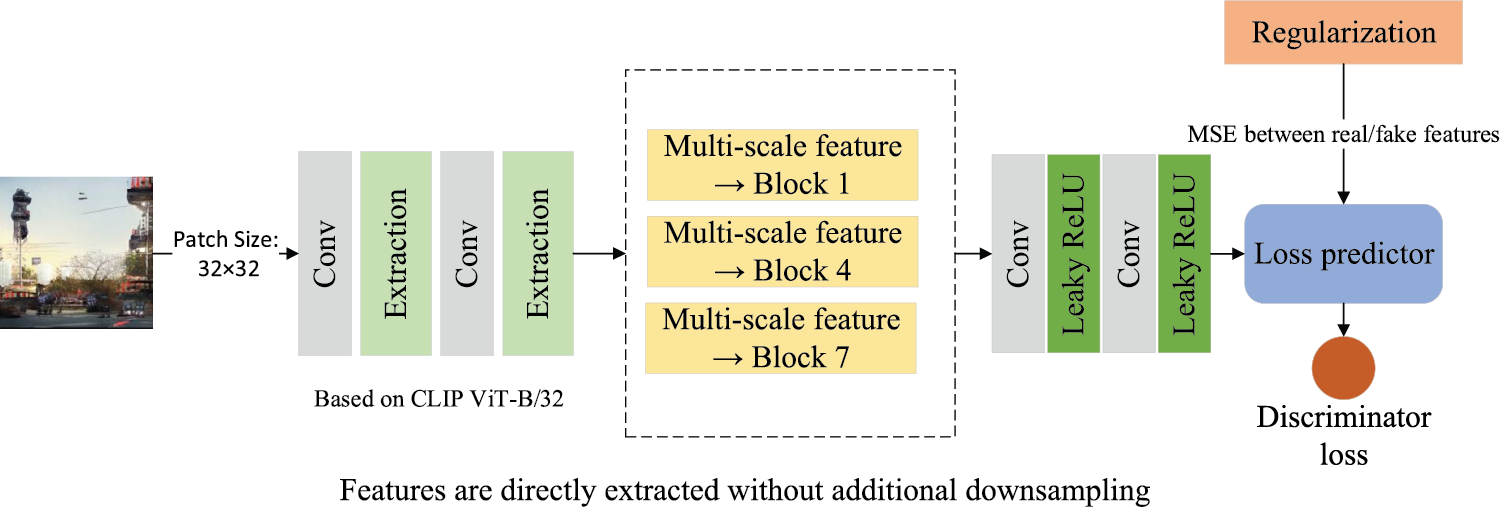
Figure 3: The architecture of the multi-scale discriminator. It extracts features at multiple resolutions and predicts adversarial loss via a regularized loss prediction module
On top of these multi-scale features, we add an adversarial loss predictor which outputs a score indicating whether the image is real or fake. To further improve the reliability of the discriminator, we introduce a feature regularization strategy during training: we encourage the discriminator’s feature representations for real and generated images to not diverge drastically. This regularization helps prevent the discriminator from relying too heavily on minute differences to make its decision, thereby mitigating instability in training. Overall, the multi-scale discriminator with feature regularization provides more stable gradient signals to the generator and more effectively differentiates subtle differences between real and synthesized images, resulting in more realistic outputs.
To explicitly define the feature regularization strategy, we introduce a regularization term that penalizes the divergence between the multi-scale features of real and generated images. Formally, let
This term encourages the discriminator to learn more generalizable and structure-aware features by reducing over-reliance on subtle noise artifacts. It is jointly optimized with the adversarial loss:
where
To effectively address the challenges of semantic misalignment, weak spatial correspondence, and instability during adversarial training, our objective design integrates three innovations in a synergistic manner. First, the coordinate attention mechanism embedded in the generator enhances spatially-aware feature fusion, allowing the model to better align important regions in the generated images with the semantic cues in the text. Second, the CLIP-based semantic projection layer maps textual information into a compatible visual latent space, enabling more accurate and controllable generation. Third, the multi-scale discriminator with feature regularization evaluates both global and local realism while stabilizing training through regularized feature alignment. Collectively, these components ensure that the objectives not only improve image fidelity but also maintain semantic consistency and training robustness.
The discriminator provides feedback to the generator, allowing the quality of generated images to be continuously improved. As image quality increases, the generator’s performance is further enhanced, which in turn drives the discriminator to become more accurate in distinguishing real from synthesized images. This positive feedback loop ultimately enables the generator to produce high-quality images that are semantically aligned with the input text. The objectives for the discriminator and generator can be formulated as follows:
Discriminator Objective:
Generator Objective:
where z denotes the noise vector sampled from a Gaussian distribution, e represents the global sentence embedding, G is the generator, D is the discriminator, C refers to the CLIP-based visual transformer, S denotes the cosine similarity between CLIP-encoded visual and textual features,
3.5 Architectural Comparison with GALIP
To clearly differentiate our proposed CAFE-GAN from the related CLIP-based model GALIP [8], we briefly summarize the key architectural innovations. First, while both models utilize CLIP encoders, CAFE-GAN introduces a trainable semantic projection layer that maps textual embeddings into the generator’s semantic space, which improves modality alignment compared to the direct usage of CLIP text features in GALIP. Second, our Fusion Blocks (FBLKs) incorporate a coordinate attention mechanism, allowing the generator to focus on spatially important regions in accordance with textual cues—a design not present in GALIP. Third, in contrast to GALIP’s single-scale discriminator, CAFE-GAN deploys a multi-scale discriminator enhanced with feature-level regularization, which improves training stability and fine-grained discrimination. These combined improvements enable CAFE-GAN to generate more semantically accurate and visually realistic images with fewer resources, as supported by our experimental results.
To verify the effectiveness of CAFE-GAN and its core components, we design experiments to evaluate its performance in terms of semantic alignment, visual quality, and training stability. In this section, we first introduce the datasets, evaluation metrics, and implementation details. We then assess the CAFE-GAN model through both quantitative and qualitative experiments, comparing it with several existing state-of-the-art models. Finally, we perform some ablation studies on individual components in our design.
We evaluate our proposed model on two challenging datasets: CUB bird [25] and COCO [26]. The CUB bird dataset contains 8855 training images from 150 bird species and 2933 test images from 50 species, with each image accompanied by 10 textual descriptions. Due to the wide variety of bird morphologies represented in CUB, this dataset has become popular in the image generation community as it meets the diverse experimental needs of researchers. The COCO dataset includes 80,000 training images and 40,000 test images. Each image in the dataset is annotated with five different textual descriptions. COCO images often depict multiple objects in various complex real-world scenes.
Currently, Fréchet Inception Distance (FID) [27] and R-precision [10] are two widely used and recognized metrics for evaluating the performance of generated images. In addition, the CLIPSIM (CS) metric [28], which leverages the CLIP encoder to assess the semantic consistency between text and image pairs, has become increasingly popular in various text-to-image training pipelines. Therefore, we adopt FID, CLIPSIM, and R-precision for assessing our model’s performance. FID measures the difference between generated and real images. It calculates the Fréchet distance between feature distributions of synthesized and real images in the feature space. A lower FID score indicates higher visual realism of the generated images. In contrast, a higher CLIPSIM score indicates stronger semantic alignment between the content of a generated image and its textual description. R-precision evaluates how well the generated image matches its corresponding text description. Higher R-precision values indicate better consistency between visual and textual content.
All experiments are conducted using a PyTorch-based framework on a single NVIDIA RTX 4090 GPU. We adopt the ViT-B/32 [15] architecture as the CLIP model backbone. The model is optimized using the Adam optimizer [29] with hyperparameters set to β1 = 0.0 and β2 = 0.9. These values follow the setting used in the GALIP model [8], as they have been empirically validated to enhance the stability of adversarial training and accelerate convergence in text-to-image generation tasks. Following the Two Time-Scale Update Rule (TTUR) [27], the learning rate is set to 0.0001 for the generator and 0.0004 for the discriminator. Our model is trained for 1500 epochs on both the CUB and COCO datasets.
To evaluate the performance of our CAFE-GAN, we compare it with several state-of-the-art methods. Representative GAN-based models include StackGAN++ [9], AttnGAN [10], DR-GAN [30], DF-GAN [16], DAE-GAN [31], LAFITE [32], GALIP [8], RAT-GAN [17], and DMF-GAN [2]. As shown in Table 1, our proposed CAFE-GAN demonstrates significant performance advantages over these advanced GAN-based models on both the CUB and COCO datasets. For example, compared with LAFITE [32], our model improves the FID score from 14.58 to 9.84, and the CLIPSIM (CS) score from 0.3125 to 0.3286 on the CUB dataset. On the COCO dataset, FID is improved from 8.21 to 5.62, and CS increases from 0.3325 to 0.3418.

Moreover, our model exhibits competitive performance when compared to several large-scale text-to-image generation models, including DALL·E [18], DALL·E 2 [6], CogView [19], CogView2 [20], Parti [33], VQ-Diffusion [34], GLIDE [35], Imagen [5], and LDM [7]. Detailed results can be found in Table 2. These large models typically require massive GPU resources and weeks of pretraining, whereas our model is significantly more resource-efficient and well-suited for environments with limited computational capabilities. To further validate the computational efficiency of our method, we compare the inference time with several representative diffusion models and GAN baselines. As reported in Table 2, our model achieves faster generation speed (90 ms/image) compared to diffusion-based methods like Imagen and GLIDE, while maintaining a competitive FID score.

Extensive quantitative evaluations demonstrate that CAFE-GAN is capable of generating high-quality and diverse image samples, both for objects with rich fine-grained attributes and complex scenes involving multiple entities. In summary, CAFE-GAN achieves more effective high-quality image generation compared to existing models.
We further conduct a qualitative comparison between our model and several representative methods, including LAFITE [32], VQ-Diffusion [34], GALIP [8], and RAT-GAN [17]. As shown in Fig. 4, our model generates images maintaining better semantic consistency with the input text descriptions.

Figure 4: Example images synthesized from test set text descriptions of the CUB dataset using LAFITE [32], VQ-Diffusion [34], GALIP [8], RAT-GAN [17], and our proposed CAFE-GAN
For instance, in Column 1, given the input text “This bird is white with brown and has a very short beak”, our model generates an image with a more realistic appearance, whereas the images generated by other models exhibit various visual artifacts or inconsistencies. Across multiple columns, the superiority of our model’s performance becomes apparent. In Column 3, both LAFITE [32] and VQ-Diffusion [34] produce birds with blurred shapes and overly simplistic backgrounds. In Column 4, RAT-GAN [17] synthesizes an incompletely shaped bird. Additionally, in Column 5, GALIP generates a bird with an unnatural and distorted appearance.
Qualitative results on the COCO dataset are shown in Fig. 5, where our model produces images that are more photorealistic and semantically accurate. In Column 1, the image generated by RAT-GAN [17] does not visually correspond to the semantics provided by the input text. In Columns 2 and 3, GALIP [8] fails to clearly and completely generate the objects specified in the descriptions. In Columns 4 and 5, while both VQ-Diffusion [34] and LAFITE [32] produce semantically relevant images, our model yields superior visual quality, with correctly shaped objects and clearly rendered fine-grained details.

Figure 5: Example images synthesized from test set text descriptions of the COCO dataset using LAFITE [32], VQ-Diffusion [34], GALIP [8], RAT-GAN [17], and our proposed CAFE-GAN
To provide a more comprehensive evaluation of our model’s performance, we further include typical failure cases in Fig. 6. These examples illustrate two main limitations of our current CAFE-GAN. When the input text contains rare species names (e.g., “wren-like beak” or “hooded merganser”) or uncommon objects, the model struggles to retrieve accurate visual priors and often generates semantically mismatched images. For text prompts involving multiple entities with relative spatial layouts (e.g., “a man on a motorcycle next to a yellow van”), the generator fails to correctly capture and organize spatial relationships, leading to blurry or chaotic compositions. We believe these limitations stem from the single-stage GAN architecture’s limited ability to model hierarchical spatial dependencies and the lack of fine-grained grounding of uncommon textual tokens. In future work, we plan to incorporate spatial layout modules or scene-graph guidance to better handle complex composition, as well as vocabulary enhancement strategies to address rare textual descriptions.

Figure 6: Failure cases generated by CAFE-GAN on the CUB and COCO datasets. These examples highlight typical limitations of our model in handling rare object descriptions (top row: birds) and complex spatial relationships (bottom row: multi-object COCO scenes)
To verify the effectiveness of each component in the CAFE-GAN, we conduct a series of ablation experiments on the COCO test set:
Baseline—A single-stage text-to-image GAN [16] is used as the baseline.
Baseline + Fusion Module (F-Module)—The fusion module is added to the baseline.
Baseline + Generation Module (G-Module)—The generation module is added to the baseline.
Baseline + Fusion Module + Generation Module—Combines the baseline with the complete fusion generative network.
Baseline + Multi-scale Discriminator Module (MS-D)—Adds the multi-scale discriminator module to the baseline.
Baseline + Fusion Module + Multi-scale Discriminator Module—Combines the fusion module and multi-scale discriminator with the baseline.
Baseline + Generation Module + Multi-scale Discriminator Module—Combines the generation module and multi-scale discriminator with the baseline.
Full Model—All components are integrated into the baseline.
As shown in Table 3, adding either the fusion module or the generation module to the baseline improves both FID and CLIPSIM (CS) scores. Further improvement is observed when both modules are integrated together, demonstrating that the proposed fusion generative network can effectively utilize the input textual information to produce high-quality images. Additionally, when the multi-scale discriminator is introduced independently, overall performance is also enhanced, indicating its benefit in improving semantic alignment between images and text. Finally, the full model, which combines both the fusion generative network and the multi-scale discriminator, achieves the best performance. And the ablation results on the COCO dataset are shown in Fig. 7. In summary, the ablation study confirms that each component contributes significantly to improving the image generation quality of the CAFE-GAN model. All quantitative results in Table 3 are averaged over 3 independent runs with different random seeds. We report mean and standard deviation (±) to account for the inherent stochasticity in GAN training.


Figure 7: Images synthesized by Baseline, w/F-Module, w/G-Module, w/MS-D, and full model on the COCO test set
To evaluate the effectiveness of our proposed trainable semantic projection layer in improving text-image alignment, we conducted a comparative experiment between Frozen CLIP and Projected CLIP. In the Frozen CLIP setting, the pre-trained CLIP model is used as a fixed text encoder without gradient updates. In contrast, Projected CLIP adds a trainable linear projection layer on top of the frozen CLIP embeddings, allowing task-specific adaptation.
As shown in Table 4, on both the CUB and COCO datasets, Projected CLIP consistently outperforms Frozen CLIP in terms of FID, R-precision, and CLIPSIM. The improvements are especially pronounced in CLIPSIM, indicating better semantic correspondence between the generated images and the input text. This suggests that while CLIP is a strong cross-modal encoder, its semantic space is not directly optimized for text-to-image synthesis. Introducing a lightweight semantic projection layer allows CAFE-GAN to more effectively exploit CLIP representations, yielding improved semantic fidelity and controllability in generation.

5.4 Human Perceptual Evaluation
To better assess the perceptual quality and alignment of generated images beyond FID and CLIPSIM, we conduct both a Human Perceptual (H.P.) Study and LPIPS metric evaluation. Specifically, we randomly select 100 samples from the CUB and COCO test sets. For the human study, we invited 30 participants to compare results from our model and two baselines (GALIP, VQ-Diffusion) using a forced-choice protocol. Each participant was shown pairs of images with the corresponding text prompt and asked to select the image that better matched the description. In addition, we compute the Learned Perceptual Image Patch Similarity (LPIPS) [36] score using a pre-trained AlexNet to measure perceptual distances between generated images and ground-truth samples. A lower LPIPS indicates higher perceptual similarity. The results, summarized in Table 5, show that our model achieves significantly higher human preference and lower LPIPS scores, suggesting better alignment with human perception and stronger fidelity.

In this paper, we propose a novel CLIP-Projected GAN with Attention-Aware Generation and Multi-Scale Discrimination (CAFE-GAN). CAFE-GAN incorporates a coordinate attention mechanism to enhance feature fusion in the generator, adds a semantic projection layer for text embeddings to bridge the cross-modal semantic gap, and employs a multi-scale discriminator with feature regularization to improve training stability and discrimination power. Extensive experimental results and ablation studies confirm that our CAFE-GAN significantly outperforms existing state-of-the-art models on the two traditional datasets. Without requiring extremely large models or computational resources, CAFE-GAN achieves high-fidelity image synthesis and effectively addresses some of the challenges faced by previous GAN-based and diffusion-based models. We believe that the ideas and approach presented in this paper open up new avenues for efficient and controllable text-to-image generation, and we hope it will inspire further exploration and innovation in this field.
Although our method achieves excellent performance and strong metrics on two mainstream datasets, there remains a gap when compared to some of the current large-scale generative models. For future work, we plan to integrate CAFE-GAN with even larger pre-trained models or diffusion model frameworks to further enhance its image generation capabilities.
Acknowledgement: Not applicable. Use of AI Tools: No generative AI systems were used to create or analyze data, figures, or results. AI-assisted language tools (e.g., ChatGPT) were used only for English polishing. All scientific content was conceived, validated, and approved by the authors.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Conceptualization: Xuanhong Wang; Methodology, Software, Validation, Writing—Original Draft, Writing—Review & Editing, Visualization: Hongyu Guo; Investigation, Formal Analysis: Jiazhen Li; Data Curation: Xian Wang; Resources: Mingchen Wang; Supervision, Project Administration: Yijun Zhang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data for this study is derived from open-source datasets.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Agnese J, Herrera J, Tao H, Zhu X. A survey and taxonomy of adversarial neural networks for text-to-image synthesis. WIREs Data Min Knowl. 2020;10(4):e1345. doi:10.1002/widm.1345. [Google Scholar] [CrossRef]
2. Yang B, Xiang X, Kong W, Zhang J, Peng Y. DMF-GAN: deep multimodal fusion generative adversarial networks for text-to-image synthesis. IEEE Trans Multimed. 2024;26:6956–67. doi:10.1109/TMM.2024.3358086. [Google Scholar] [CrossRef]
3. Gou Y, Wu Q, Li M, Gong B, Han M, Segattngan: Text to image generation with segmentation attention. arXiv:2005.12444. 2020. doi: 10.48550/arxiv.2005.12444. [Google Scholar] [CrossRef]
4. Chang H, Zhang H, Barber J, Maschinot AJ, Lezama J, Jiang L, et al. Text-to-image generation via masked generative transformers. arXiv:2301.00704. 2023. [Google Scholar]
5. Saharia C, Chan W, Saxena S, Li L, Whang J, Denton EL, et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv Neural Inform Process Syst. 2022;35:36479–94. doi:10.5555/3600270.3602913. [Google Scholar] [CrossRef]
6. Ramesh A, Dhariwal P, Nichol A, Chu C, Chen M. Hierarchical text-conditional image generation with clip latents. arXiv:2204.06125. 2022. [Google Scholar]
7. Rombach R, Blattmann A, Lorenz D, Esser P, Ommer B. High-resolution image synthesis with latent diffusion models. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA: IEEE; 2022. p. 10674–85. doi:10.1109/CVPR52688.2022.01042. [Google Scholar] [CrossRef]
8. Tao M, Bao BK, Tang H, Xu C. GALIP: generative adversarial CLIPs for text-to-image synthesis. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada: IEEE; 2023. p. 14214–23. doi:10.1109/CVPR52729.2023.01366. [Google Scholar] [CrossRef]
9. Zhang H, Xu T, Li H, Zhang S, Wang X, Huang X, et al. StackGAN: realistic image synthesis with stacked generative adversarial networks. IEEE Trans Pattern Anal Mach Intell. 2019;41(8):1947–62. doi:10.1109/TPAMI.2018.2856256. [Google Scholar] [PubMed] [CrossRef]
10. Xu T, Zhang P, Huang Q, Zhang H, Gan Z, Huang X, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA: IEEE; 2018. p. 1316–24. doi:10.1109/CVPR.2018.00143. [Google Scholar] [CrossRef]
11. Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the International Conference on Machine Learning; 2021 Jul 18–24; online. p. 8748–63. [Google Scholar]
12. Xue A. End-to-end Chinese landscape painting creation using generative adversarial networks. In: 2021 IEEE Winter Conference on Applications of Computer Vision (WACV); 2021 Jan 3–8; Waikoloa, HI, USA. IEEE; 2021. p. 3862–70. doi:10.1109/wacv48630.2021.00391. [Google Scholar] [CrossRef]
13. Xia W, Yang Y, Xue JH, Wu B. TediGAN: text-guided diverse face image generation and manipulation. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA: IEEE; 2021. p. 2256–65. doi:10.1109/cvpr46437.2021.00229. [Google Scholar] [CrossRef]
14. Kocasarı U, Dirik A, Tiftikci M, Yanardag P. StyleMC: multi-channel based fast text-guided image generation and manipulation. In: 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2022 Jan 3–8; Waikoloa, HI, USA. IEEE; 2022. p. 3441–50. doi:10.1109/WACV51458.2022.00350. [Google Scholar] [CrossRef]
15. Reed S, Akata Z, Yan X, Logeswaran L, Schiele B, Lee H. Generative adversarial text to image synthesis. In: International Conference on Machine Learning; 2016 Jun 19–24; New York, NY, USA. p. 1060–9. [Google Scholar]
16. Tao M, Tang H, Wu F, Jing XY, Bao BK, Xu C. Df-gan: a simple and effective baseline for text-to-image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 19–24; New Orleans, LA, USA. p. 16515–25. doi:10.48550/arXiv.2008.05865. [Google Scholar] [CrossRef]
17. Ye S, Wang H, Tan M, Liu F. Recurrent affine transformation for text-to-image synthesis. IEEE Trans Multimed. 2023;26(14):462–73. doi:10.1109/TMM.2023.3266607. [Google Scholar] [CrossRef]
18. Sauer A, Karras T, Laine S, Geiger A, Aila T. Stylegan-t: unlocking the power of gans for fast large-scale text-to-image synthesis. In: International Conference on Machine Learning; 2023 Jul 3; Honolulu, HI, USA. p. 30105–18. doi:10.48550/arXiv.2303.11540. [Google Scholar] [CrossRef]
19. Ramesh A, Pavlov M, Goh G, Gray S, Voss C, Radford A, et al. Zero-shot text-to-image generation. In: International Conference on Machine Learning; 2021 Jul 18–24; Vienna, Austria. p. 8821–31. doi:10.48550/arXiv.2102.12092. [Google Scholar] [CrossRef]
20. Ding M, Yang Z, Hong W, Zheng W, Zhou C, Yin D, et al. Mastering text-to-image generation via transformers. Adv Neural Inform Process Syst. 2021;34:19822–35. doi:10.48550/arXiv.2105.13290. [Google Scholar] [CrossRef]
21. Ding M, Zheng W, Hong W, Tang J. Cogview2: faster and better text-to-image generation via hierarchical transformers. Adv Neural Inform Process Syst. 2022;35:16890–902. doi:10.48550/arXiv.2204.14217. [Google Scholar] [CrossRef]
22. Van Den Oord A, Vinyals O, Kavukcuoglu K. Neural discrete representation learning. In: NeurIPS 2017: Advances in Neural Information Processing Systems 30; 2017 Dec 4–9; Long Beach, CA, USA. [Google Scholar]
23. OpenAI. Sora: generative video model by OpenAI. [cited 2025 Sep 1]. Available from: https://openai.com/sora. [Google Scholar]
24. Deng Y, Tang F, Dong W, Ma C, Pan X, Wang L, et al. StyTr2: image style transfer with transformers. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. IEEE; 2022. p. 11316–26. doi:10.1109/CVPR52688.2022.01104. [Google Scholar] [CrossRef]
25. Wah C, Branson S, Welinder P, Perona P, Belongie S. The Caltech-UCSD Birds-200-2011 Dataset [Internet]. Pasadena, CA, USA: California Institute of Technology; 2011. [cited 2025 Sep 1]. Available from: https://www.vision.caltech.edu/datasets/cub_200_2011/. [Google Scholar]
26. Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: common objects in context. In: Computer Vision—ECCV 2014. Cham, Switzerland: Springer International Publishing; 2014. p. 740–55. doi:10.1007/978-3-319-10602-1_48. [Google Scholar] [CrossRef]
27. Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In: Advances in Neural Information Processing Systems 30 (NIPS 2017); 2017 Dec 4–9; Long Beach, CA, USA. doi:10.48550/arXiv.1706.08500. [Google Scholar] [CrossRef]
28. Wu C, Liang J, Ji L, Yang F, Fang Y, Jiang D, et al. NÜWA: visual synthesis pre-training for neural visual world creation. In: Computer Vision—ECCV 2022. Cham, Switzerland: Springer Nature Switzerland; 2022. p. 720–36. doi:10.1007/978-3-031-19787-1_41. [Google Scholar] [CrossRef]
29. Kingma DP, Ba J. Adam: a method for stochastic optimization. arXiv:1412.6980. 2014. [Google Scholar]
30. Tan H, Liu X, Yin B, Li X. DR-GAN: distribution regularization for text-to-image generation. IEEE Trans Neural Netw Learn Syst. 2023;34(12):10309–23. doi:10.1109/TNNLS.2022.3165573. [Google Scholar] [PubMed] [CrossRef]
31. Ruan S, Zhang Y, Zhang K, Fan Y, Tang F, Liu Q, et al. DAE-GAN: dynamic aspect-aware GAN for text-to-image synthesis. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada: IEEE; 2021. p. 13940–9. doi:10.1109/ICCV48922.2021.01370. [Google Scholar] [CrossRef]
32. Zhou Y, Zhang R, Chen C, Li C, Tensmeyer C, Yu T, et al. Towards language-free training for text-to-image generation. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA: IEEE; 2022. p. 17886–96. doi:10.1109/CVPR52688.2022.01738. [Google Scholar] [CrossRef]
33. Yu J, Xu Y, Koh JY, Luong T, Baid G, Wang Z, et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv:2206.10789. 2022. [Google Scholar]
34. Gu S, Chen D, Bao J, Wen F, Zhang B, Chen D, et al. Vector quantized diffusion model for text-to-image synthesis. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA: IEEE; 2022. p. 10686–96. doi:10.1109/CVPR52688.2022.01043. [Google Scholar] [CrossRef]
35. Nichol A, Dhariwal P, Ramesh A, Shyam P, Mishkin P, McGrew B, et al. Glide: towards photorealistic image generation and editing with text-guided diffusion models. arXiv:2112.10741. 2021. [Google Scholar]
36. Zhang R, Isola P, Efros AA, Shechtman E, Wang O. The unreasonable effectiveness of deep features as a perceptual metric. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA: IEEE; 2018. p. 586–95. doi:10.1109/CVPR.2018.00068. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools