
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

DAUNet: Unsupervised Neural Network Based on Dual Attention for Clock Synchronization in Multi-Agent Wireless Ad Hoc Networks
1 Institute of War, Academy of Military Science, Beijing, 100091, China
2 School of Graduate, Academy of Military Science, Beijing, 100091, China
* Corresponding Author: Xianzhou Dong. Email:
Computers, Materials & Continua 2026, 86(1), 1-23. https://doi.org/10.32604/cmc.2025.069513
Received 25 June 2025; Accepted 13 August 2025; Issue published 10 November 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Clock synchronization has important applications in multi-agent collaboration (such as drone light shows, intelligent transportation systems, and game AI), group decision-making, and emergency rescue operations. Synchronization method based on pulse-coupled oscillators (PCOs) provides an effective solution for clock synchronization in wireless networks. However, the existing clock synchronization algorithms in multi-agent ad hoc networks are difficult to meet the requirements of high precision and high stability of synchronization clock in group cooperation. Hence, this paper constructs a network model, named DAUNet (unsupervised neural network based on dual attention), to enhance clock synchronization accuracy in multi-agent wireless ad hoc networks. Specifically, we design an unsupervised distributed neural network framework as the backbone, building upon classical PCO-based synchronization methods. This framework resolves issues such as prolonged time synchronization message exchange between nodes, difficulties in centralized node coordination, and challenges in distributed training. Furthermore, we introduce a dual-attention mechanism as the core module of DAUNet. By integrating a Multi-Head Attention module and a Gated Attention module, the model significantly improves information extraction capabilities while reducing computational complexity, effectively mitigating synchronization inaccuracies and instability in multi-agent ad hoc networks. To evaluate the effectiveness of the proposed model, comparative experiments and ablation studies were conducted against classical methods and existing deep learning models. The research results show that, compared with the deep learning networks based on DASA and LSTM, DAUNet can reduce the mean normalized phase difference (NPD) by 1 to 2 orders of magnitude. Compared with the attention models based on additive attention and self-attention mechanisms, the performance of DAUNet has improved by more than ten times. This study demonstrates DAUNet’s potential in advancing multi-agent ad hoc networking technologies.Keywords
Clock synchronization, which provides a unified temporal reference for multi-agent collaboration to ensure consistent timestamps in node information interaction, remains one of the research hotspots in the field of multi-agent wireless communications [1,2]. However, challenges such as dynamic network topologies, communication delays, and complex environmental conditions have significantly complicated clock synchronization [3]. Developing a model that reduces algorithmic complexity while maintaining adaptability to various dynamic changes has become crucial for clock synchronization tasks in multi-agent wireless ad hoc networks [4].
In recent years, numerous scholars have investigated the issue of clock synchronization in wireless communication networks and proposed numerous solutions [5]. These solutions can be broadly categorized into two types: global synchronization and local synchronization. In global clock synchronization, all nodes synchronize with a global time reference to maintain high consistency across the entire network. A typical example is the use of satellite timing from the Global Navigation Satellite System (GNSS) to achieve time synchronization [6]. In local clock synchronization, nodes interact with neighboring nodes or within local subnetworks to coordinate their clock information. In consideration of the dynamic characteristics of multi-agent wireless ad-hoc networks, the distributed clock synchronization method within local synchronization approaches is typically employed. Distributed synchronization methods eschew predefined synchronization relationships between nodes [7]. Instead, nodes in the network achieve clock convergence through iterative exchanges of clock information with their neighbors. This approach features decentralization and self-adaptiveness, making it widely applicable in multi-agent wireless ad hoc networks [8].
For example, Jin et al. [1] proposed an adaptive dynamic topology-based time synchronization algorithm to compensate for time-varying clock parameter changes in UAV networks with dynamic topologies. Packet-based synchronization by coupling timestamp data exchanged between nodes is also a common methodology [9]. Protocols such as the Flooding Time Synchronization Protocol (FTSP) [10] and Network Time Protocol (NTP) [11] are extensively utilized. Algorithms like LT-Sync [12] employ timestamp mechanisms to solve clock synchronization parameters for synchronization. While these methods enhance clock synchronization performance in wireless ad hoc networks, they often simply merge information received from neighboring nodes without adequately addressing inherent delays in transmission that lead to outdated timestamp information or extraneous data interference [13].
With the continuous advancements in neural network research, deep learning has emerged as a solution to address challenges in multi-agent wireless ad hoc networks. Deep learning models can extract accurate features through large-scale dataset training, demonstrating greater robustness and superior generalization capabilities compared to traditional methods. For instance, Abakasanga et al. [14] proposed a clock synchronization method for wireless sensor networks using a backpropagation neural network algorithm. By adaptively adjusting weight and bias parameters, this approach mitigates the impacts of clock drift and other dynamic characteristics, thereby enhancing synchronization accuracy and interference resistance in communication networks. Zhang et al. [15] introduced a model-free reinforcement learning-based distributed synchronization algorithm that substantially reduces synchronization overhead vs. conventional methods. Additionally, researchers have designed distributed deep learning networks for signal classification in wireless communication systems to achieve precise time-frequency synchronization. These advancements underscore the substantial potential of deep learning in enhancing the performance of traditional wireless ad hoc network technologies [16].
The synchronization method based on pulse-coupled oscillators (PCOs) is an effective approach to addressing clock synchronization issues in multi-agent wireless networks [17]. This method primarily operates at the physical layer, where nodes in a multi-agent self-organizing network receive pulse signals from neighboring nodes and compute correction signals for local timing adjustments through a phase adjuster. By adaptively regulating the phase adjustment magnitude based on received signal power and calculated weighting values from neighboring nodes, it mitigates synchronization oscillations caused by topological fluctuations. Many scholars have conducted research on this method. Leng and Wu [18] studied the global clock synchronization problem in wireless sensor networks. By proposing a brand-new distributed algorithm, they reduced the computational cost and improved the accuracy of clock synchronization. Du and Wu [19] proposed a distributed algorithm based on belief propagation for jointly estimating clock deviations and offsets in wireless networks, which to some extent solved the distributed synchronization problem based on phase-locked loops. However, traditional PCO methods fail to achieve complete frequency and phase synchronization. When significant propagation delays and clock frequency discrepancies exist among nodes in the network, the performance of clock synchronization degrades substantially. Additionally, PCO methods typically rely on predefined parameters such as phase response curves and coupling strengths, requiring manual preconfiguration of different parameter sets for diverse network environments and application scenarios. This inflexibility increases the complexity of deployment and maintenance. Deep learning offers several key advantages in overcoming these challenges: The first one is complex nonlinear mapping. Deep neural networks can learn sophisticated nonlinear relationships between input features and optimal synchronization parameters, automatically accounting for propagation delays and clock differences. The second one is adaptive weight generation. Unlike fixed analytical rules, our proposed model dynamically generates appropriate weights through its dual-attention mechanism, enabling more accurate compensation for both propagation delays and clock period variations. A single attention mechanism cannot achieve this dual function. This is also demonstrated in the ablation experiments in Section 4.5. Due to the extremely high time sensitivity requirements in the clock synchronization of multi-agent wireless self-organizing networks, the model needs to converge quickly. Introducing a triple attention mechanism or adding more attention mechanisms would significantly increase computational complexity, require more computing power, and be difficult to deploy. Moreover, introducing more attention mechanisms has limited improvement on model performance. And another one is distributed learning capability. The unsupervised distributed training scheme allows each node to locally adapt its synchronization parameters based on actual network conditions, including specific propagation delays and clock characteristics in its vicinity. To address these challenges, we propose DAUNet, a deep learning-based network model that integrates a novel unsupervised distributed neural network framework into classical PCO-based synchronization methods. This framework serves as a backbone network, delivering higher precision and enhanced stability. The main contributions are summarized as follows:
1. We designed a novel network model named the Unsupervised Neural Network based on Dual Attention (DAUNet), which employs a distributed and unsupervised rapid training strategy. This model leverages parallel multi-layer perceptron (MLP) structures across nodes to dynamically generate weights for the PCO framework, thereby enabling efficient clock synchronization. This approach addresses critical limitations of conventional PCO methods, including high computational complexity, slow parameter learning in DNNs for wireless communication scenarios, and insufficient synchronization accuracy.
2. To achieve more effective feature weight allocation and reduce the computational complexity of the model, we introduce a Multi-Head Attention (MHA) module and a Gated Attention (GA) module. The dual attention architecture combines two different but complementary mechanisms. The MHA module captures the global synchronization patterns between nodes by analyzing the relationships in different representation subspaces (Section 3.3.1). The GA module achieves fine adjustments locally through dynamic feature filtering, suppressing noise while amplifying crucial temporal information (Section 3.3.2). The integration of these modules significantly enhances the model’s feature discriminability and information extraction capability.
3. By experiments, it is found that compared with conventional clock synchronization approaches and mainstream deep learning networks, higher clock synchronization accuracy and stability can be obtained by applying the proposed DAUNet method.
Clock models serve as a foundational dependency for achieving clock synchronization in multi-agent self-organizing networks. These models can be categorized into two types: analog clocks and discrete clocks. While analog clocks provide continuous-time representation with high theoretical precision, their implementation complexity often hinders practical operability in real-world systems. Consequently, existing studies predominantly adopt discrete clock models, which construct logical timelines by periodically sampling physical clocks. This approach balances synchronization accuracy with reduced algorithmic complexity. In distributed synchronization networks, each node employs a clock oscillator with its own inherent period, denoted as
Discrepancies in clock periods between nodes cause overlapping transmitted signals in both time and frequency domains, leading to information loss. In practical scenarios, prolonged operation induces gradual clock skew drift among nodes, as illustrated in Fig. 1. High-speed communication necessitates full clock synchronization, requiring simultaneous calibration of frequency and phase to a common time base. Nodes achieve this by exchanging timestamp information and dynamically adjusting local clock parameters, such as frequency compensation coefficients and phase offsets. Since the number of time slots required for synchronization is directly correlated with communication overhead, we propose a distributed deep learning approach to minimize broadcast frequency during clock synchronization, thereby significantly reducing communication costs.

Figure 1: Diagram of clock frequency synchronization with N = 3 and full clock synchronization
2.2 Distributed Pulse-Coupled Clock Synchronization
In pulse coupled synchronization, each node generates and broadcasts a unique synchronization signature sequence based on its local clock to identify itself. The signal transmission time of the sending node is determined by its local clock, and the receiving node can accurately identify the identity of different sending nodes and their corresponding signal reception time by screening the synchronization signatures of the received signal whose strength exceeds a preset threshold. Then, the local clock was dynamically adjusted by pulse-coupled phase-locked-loop (PLL).
Fig. 2 depicts a distributed pulse-coupled phase-locked loop. In a multi-agent system, state information can be exchanged between locally adjacent nodes. The PLL is a feedback loop consisting of a phase difference detector (PDD), a linear time invariant (LTI) filter with transfer function
where
where
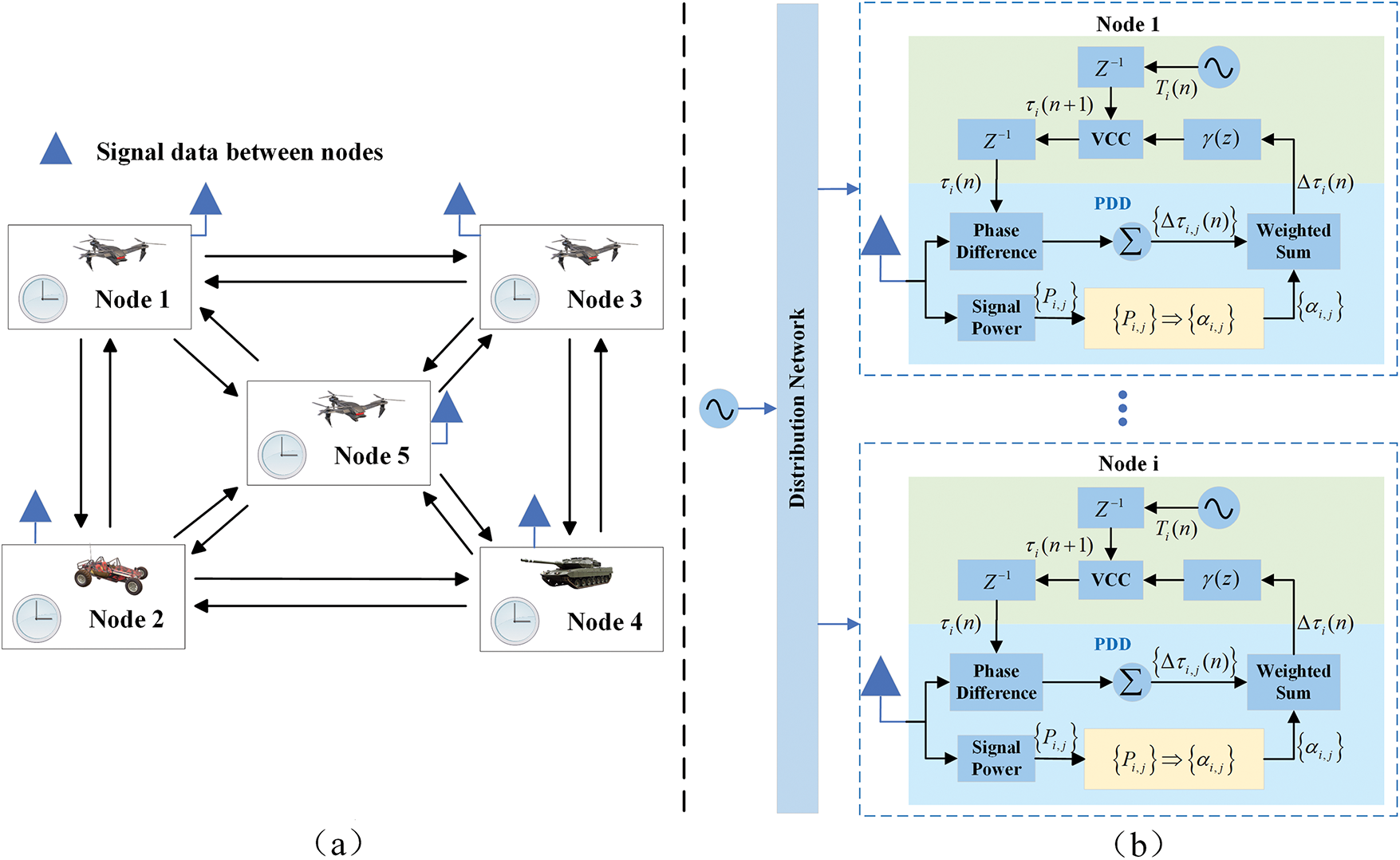
Figure 2: Example of distributed multi-agent pulse-coupled node topology deployment based on classical algorithms [17] (a) Sample topological deployment of N = 5 pulse-coupled nodes; (b) Structure of the synchronization algorithm based on the classic model
We refer to the distributed clock synchronization method based on the above weight allocation rules as the classical algorithm, which has been widely used in wireless network transmission. However, for multi-agent wireless ad hoc networks with propagation delay and different clock periods, the accuracy of clock synchronization is not enough.
In recent years, with the advancement of deep learning, it has also been applied to wireless ad hoc networks to address challenges such as traffic prediction, routing protocols, and anti-jamming protection [20]. As an empirical learning approach, deep learning enables intelligent agents to continuously update their weights based on historical data, allowing them to adapt to dynamic network topology changes. Traditional methods often rely on techniques like linear regression or double-edge detection to compensate for clock drift and errors. In contrast, deep learning leverages neural networks to autonomously learn error patterns, thereby reducing the need for manual intervention and complex parameter tuning. For instance, Zino et al. [21] proposed an online training scheme based on deep neural networks (DNNs) in HD-TDMA networks. By collecting and training DNNs with post-deployment data, they achieved high-precision clock synchronization, addressing both frequency and phase alignment issues. Similarly, Assylbek et al. [22] proposed a lightweight reinforcement learning method that dynamically adjusts the clock synchronization process in the Internet of Things by leveraging a set of states, actions, and rewards. These advancements highlight the significant potential of deep learning in enhancing clock synchronization for wireless ad hoc systems.
The attention mechanism boosts the model’s representational power and performance by learning the importance of different input data parts and dynamically attending to them [23]. In deep learning, the attention mechanism has been widely applied to various tasks, such as machine translation, text generation, speech recognition, and image processing. Among these, the multi-head attention mechanism enriches feature extraction by employing multiple attention heads to allocate attention across different dimensions of the input in parallel, thereby capturing more diverse features and contextual information. The gated attention mechanism further improves robustness by introducing learnable gating units to dynamically regulate attention weights or feature fusion processes, enhancing the model’s ability to prioritize critical information while suppressing noise. Within our distributed deep learning framework, we design MHA and GA modules. This integration strengthens the model’s information extraction capabilities, thereby improving clock synchronization precision in self-organizing networks.
Existing approaches for clock synchronization in multi-agent wireless ad hoc networks suffer from several critical limitations that our DAUNet architecture effectively addresses. Traditional PCO-based methods fail to achieve complete frequency and phase synchronization, where significant phase differences remain even after convergence [21]. These methods rely on manually configured parameters that lack adaptability to dynamic network conditions. Existing deep learning approaches like DASA [14] method and Zhang’s et al. [15] reinforcement learning framework demonstrate limited synchronization accuracy and fail to properly handle the temporal dependencies in clock signals. They lack attention mechanisms cannot effectively capture both global node relationships and local signal features simultaneously. Current attention-based solutions either focus solely on global patterns or local filtering, but not their optimal combination. To overcome these limitations, we propose DAUNet with some innovations. A dual-attention mechanism integrating both MHA and GA modules to simultaneously capture global node relationships and perform local signal refinement. An unsupervised distributed training framework that enables adaptive weight generation without centralized coordination. A lightweight MLP backbone that maintains low computational complexity while achieving superior synchronization accuracy. It also has robust performance in dynamic network topology. This comprehensive solution addresses the fundamental limitations of existing approaches while maintaining practical deployability in resource-constrained multi-agent systems.
In this section, we first elaborate on the multi-agent distributed clock synchronization problem in Section 3.1. Subsequently, Section 3.2 focuses on introducing the DAUNet network model proposed in this paper and explains how this model achieves local and independent training at each node of multi-agent systems in an unsupervised manner. Finally, Section 3.3 elaborates on the operational principles of the dual-attention mechanism module within the DAUNet network.
Consider a multi-agent ad hoc wireless network with
where

Figure 3: 16-nodes network with the distance
To demonstrate the shortcomings of the existing methods in a real environment, we use extended Simeone-Spagnolini-BarNess-Strogatz (ESSBS) algorithm [21] to simulate the clock phase variation of ad hoc network communication. In the experiment, we selected the experimental parameters from the research related to traditional algorithms as our basis. As shown in Fig. 4, we simulate the cases of first-order PLL

Figure 4: The modulus operation result of the clock time when the clock synchronization calculation reaches converged period
The examples above clearly demonstrate this research’s motivation and content: We design DAUNet, a deep learning network model based on multi-layer perceptrons and attention mechanisms, to achieve network-wide clock synchronization. The DAUNet network can be deployed independently in each node of the ad hoc network for distributed training. The dual attention mechanism improves the ability of the model to extract information, so as to generate the weight values required for the clock synchronization process more accurately. In the next section, we detail our proposed DAUNet-based clock synchronization algorithm.
Within the classical distributed PLL clock synchronization framework, we design the DAUNet network architecture. By transforming the input weight coefficients in the distributed framework into trainable discriminative models, the DAUNet architecture is utilized to learn dynamic weight generation rules. As shown in Fig. 5, DAUNet consists of three modules. The first module is a multilayer perceptron (MLP). As a classical feedforward neural network model, MLP exhibits unique advantages in complex pattern modeling and nonlinear relationship learning, particularly suited for scenarios such as multi-agent cooperative control and spatiotemporal data analysis.

Figure 5: DAUNet network architecture
As shown in Fig. 6, Each MLP module in the multi-agent nodes comprises fully connected layers with a total of six layers. Through extensive ablation studies in Section 4.5, we found that a six-layer network achieved the optimal balance between model complexity and synchronization performance. The 3-4 layer networks exhibited insufficient feature extraction capabilities, while deeper architectures showed diminishing returns with significantly increased computational overhead. Thus, an excessive number of layers is not beneficial. The 6-layer design, composed of alternating ReLU and LeakyReLU activation layers, effectively captured nonlinear relationships in node timing information while maintaining reasonable training efficiency. This configuration aligns with recent advances in distributed synchronization networks. Through multi-layer nonlinear activation, it balances nonlinear expressive capability and gradient stability. The ReLU layer enhances sparsity and accelerates training speed, better balancing complexity and computational load. The LeakyReLU layer retains the advantages of sparse activation and efficient computation, ensuring that all neurons maintain the ability to update gradients during training. The final Softmax layer ensures the output is a probability distribution, aligning with weight allocation requirements. The output
where

Figure 6: MLP module
Additionally, a dual-module parallel approach incorporating multi-head attention mechanisms and gated attention mechanisms is designed after the MLP module to alleviate the insufficient feature learning capability of the MLP. This mechanism enhances the model’s information extraction ability and improves the accuracy of clock synchronization. Specific design details of the attention mechanisms will be introduced in the next section. The weighted output
where
where
The structure of the loss function indicates that the gradient of the loss with respect to the weights can be computed through backpropagation over time. Additionally, the loss function can be locally calculated by each node in an unsupervised manner, facilitating unsupervised local training. We employ mini-batch stochastic gradient descent (MB-SGD) [25] to optimize the parameters of DAUNet, dividing the dataset into mini-batches. Each training epoch iterates through all mini-batches, computes the average loss per batch, and updates the parameters accordingly. The proposed method exhibits practical deployment characteristics, enabling generalization through multi-topology learning to address full-clock (frequency and phase) synchronization challenges in multi-agent self-organizing networks. The loss function in Eq. (9) reflects DAUNet’s distributed nature, where each node independently optimizes its synchronization parameters using only locally observable information. This design eliminates the need for centralized coordination or continuous global information exchange, making it particularly suitable for resource-constrained ad hoc networks. Meanwhile, in order to ensure that our network model achieves convergence during the training process, we will monitor the total loss of all nodes in each epoch during the experiment.
3.3 Dual Attention Mechanism Module
To address MLP’s information extraction limitations, DAUNet incorporates a dual-attention module comprising a multi-head attention (MHA) [26] and gated attention (GA) [27]. Within the dual-attention module, the features output by the MLP module in Section 3.2 are first processed through both MHA and GA to amplify the feature weights of critical information, directing the network to focus on locations with salient characteristics. The MHA captures underlying synchronization patterns among global nodes via multi-perspective feature extraction, while the GA enables local fine-grained signal filtering. This architecture enhances model robustness in dynamic networks. The proposed dual-channel attention mechanism not only optimizes the precision of weight allocation but also reduces redundant computations through sparsity constraints imposed by the gating mechanism. This ensures the system achieves high synchronization accuracy while maintaining enhanced real-time responsiveness.
3.3.1 Multi-Head Attention Module
The multi-head attention mechanism is an improvement of the self-attention mechanism. The multi-head attention mechanism can learn relevant information in different representation subspaces, and further improve the extraction ability of global context features [28]. The structure of the multi-head attention mechanism is shown in Fig. 7. One of the attention functions can be described as mapping a

Figure 7: Multi-head attention mechanism
Considering
where
where
Through the multi-head attention module, this paper can pay attention to the node relationships of different dimensions in multi-agents, and synthesize multi-angle information to generate more accurate weight values. At the same time, this module can adaptively capture the complex nonlinear relationship between nodes, and make more efficient use of effective information.
The gated attention module integrates gating and attention mechanisms to dynamically filter and enhance critical information in deep learning. To address the susceptibility of multi-head attention mechanisms to outliers, this paper adopts a dual-attention mechanism within the DAUNet network, with the internal structure of the gated attention module illustrated in Fig. 5. During distributed deep learning-based clock synchronization, challenges such as high computational overhead, noise sensitivity, and the absence of dynamic feature selection may arise. The proposed gated attention module mitigates these issues by dynamically modulating features or weights through gating units to suppress noise and amplify essential information, while also offering a more lightweight architecture with enhanced deployability.
The designed gated attention module in this paper consists of two parallel branches, where the gating and attention weights are fused through element-wise multiplication. The gating branch is primarily composed of a linear layer and activation functions, which can be expressed as:
where
where
where
To validate the effectiveness of the DAUNet model, this paper designed corresponding simulation studies to evaluate the performance of the proposed approach. Section 4.1 describes the data acquisition and training set generation. Section 4.2 introduces the evaluation metrics. Section 4.3 details the experimental simulation environment. Sections 4.4 and 4.5 present two types of experiments conducted on the dataset: comparative experiments and ablation studies, respectively.
4.1 Data Acquisition and Training Set Generation
According to the methodology outlined in [14], to achieve high-precision clock synchronization in multi-agent ad hoc networks, model training data must correspond to the actual parameters of network deployment, including practical clock frequency offsets, clock phases, propagation delays, and network topology. Therefore, during the data acquisition phase in this work, the process of each node collecting data through transmission and reception of synchronization signals is simulated. Specifically, each node receives synchronization pulse signals from other nodes via wireless physical-layer synchronization mechanisms, recording their arrival times and received power. Here, the received power is calculated via the two-ray propagation model. During the network initialization phase, all nodes asynchronously transmit multiple synchronization pulses, and each node collects the timestamps and power levels of all received pulses from others. These measurements are used to construct the local dataset
To enhance the model’s deployability and generalization capability across diverse network configurations, this work employs simulated data to generate over 1000 network topologies emulating real-world deployment scenarios. For each topology instance, we simulate nodes transmitting pulses and record data, including timing and power levels. All instance data are aggregated into a unified training set
The experimental evaluation metrics include the variation in clock update times and clock frequency changes across all nodes after the model achieves stable convergence. These metrics are used to validate the experimental results, with specific calculation methods referenced to the corresponding formulas in Section 3 (Method Design). In addition to these two metrics, to further compare the performance of different approaches and quantify phase synchronization accuracy in multi-agent ad hoc networks, the Normalized Phase Difference (
where
In addition, we also employ the mean period and standard deviation metrics. Here, the mean period reflects the consistency of frequency synchronization, while the standard deviation measures the stability of frequency synchronization.
The experiment uses Pytorch 1.8.1 deep learning framework, Windows 11 as the operating system, NVIDIA GeForce RTX4060Ti as the GPU with 16 GB memory, and Python 3.8 as the programming language. During training, the network model was optimized using the SGD optimizer with an initial learning rate of 0.4 and a momentum coefficient of 0.88 to accelerate the gradient descent process. Dynamic learning rate adjustment was applied to prevent oscillations caused by excessively large learning rates in later training stages. To mitigate memory overflow risks due to the limited memory of multi-agent systems, cache release optimization and gradient zeroing operations were incorporated during training. A batch size of 10 was adopted for the network, and since the training dataset contained 1000 topology instances, this resulted in 100 mini-batches. Considering the real-time requirements of clock synchronization, data flow size, and the importance of lightweight model design, the network was trained for 15 epochs, which sufficed to achieve convergence.
4.4 Analysis and Discussion of Comparison Experiments
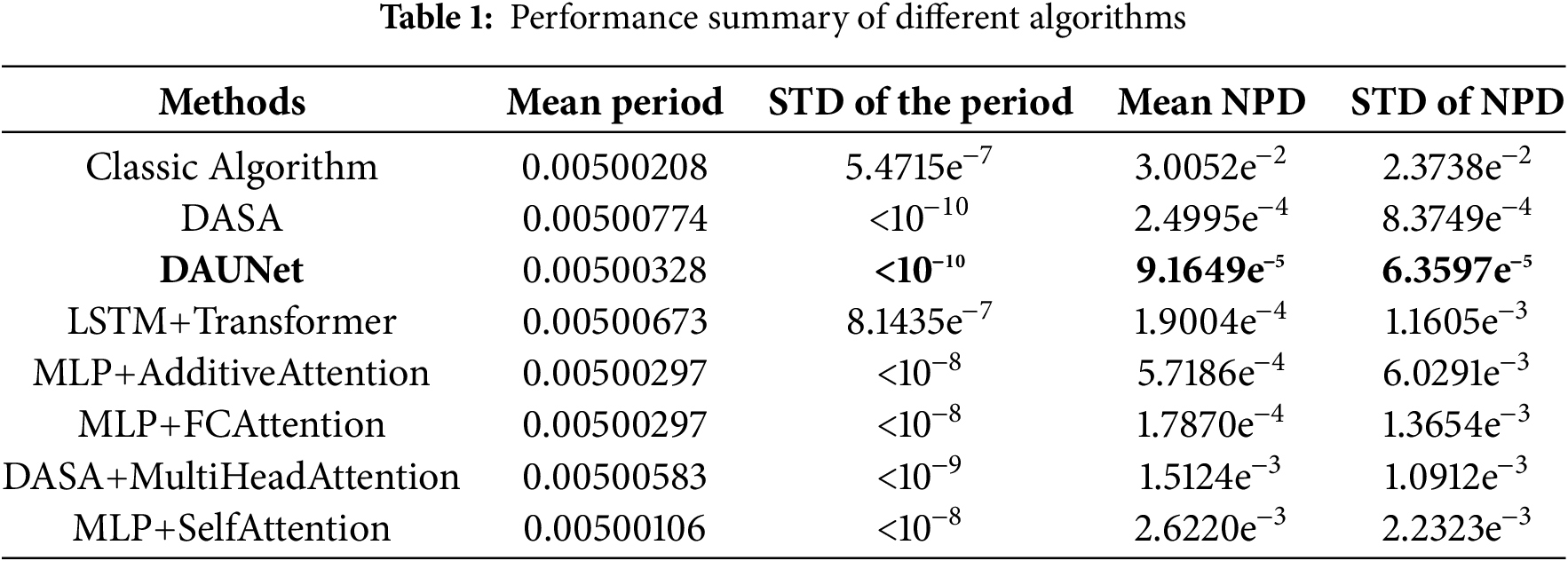
Based on the training dataset, DAUNet was compared with other deep learning models using different backbone networks, such as Transformer [29], LSTM [30], DASA [14], Additive-Attention [31], FC-Attention [32], and Self-Attention [33]. We repeated the experiments of these methods on the training set used in this paper and evaluated them using the metrics from Section 4.2. Partial experimental results are shown in Table 1. In Table 1, we compared the experimental results of different network algorithms in terms of mean period, period standard deviation, mean NPD, and NPD standard deviation. The results in Table 1 indicate that compared to classical algorithm-based methods, DAUNet reduces the period standard deviation by three orders of magnitude. Compared to deep learning networks based on DASA and LSTM, DAUNet reduces the mean NPD by 1-2 orders of magnitude. Compared to attention mechanisms based on Additive-Attention and Self-Attention, DAUNet improves the NPD accuracy by two orders of magnitude.
At the same time, we analyze the complexity of the model. For a 16-nodes network, DAUNet has 2.9 × 103 parameters. This number of parameters is several orders of magnitude less than that used by DNNS in typical deep learning tasks. It is slightly higher than the 2.5 × 103 parameter of the baseline DASA model, but it is an order of magnitude better in clock synchronization accuracy. In addition, compared with the LSTM+Transformer model with 4.5 × 103 parameters, DAUNet has significantly lighter performance and higher clock synchronization accuracy. Meanwhile, the FLOPs in this paper is about 3.2 × 103, while the baseline DASA is 3.5 × 103 FLOPs. The LSTM has about 4.1 × 103. The FLOPs of DAUnet is smaller than that of DASA, and the synchronization accuracy is higher. Therefore, compared to comparable models, DAUNet has low computational complexity, is feasible on real-time modern microcontrollers, and can support parallelization implemented by dedicated DNN hardware accelerators. Therefore, the DAUNet method proposed in this paper significantly enhances the accuracy of clock synchronization in multi-agent ad hoc networks.
Fig. 8 illustrates the variations in clock period over time for 16 nodes in a multi-agent ad hoc network. It can be observed from the figure that, compared to other methods, the DAUNet method enables all nodes to rapidly converge to a common mean period close to the nominal period. Although minor fluctuations exist, frequency synchronization is achieved overall, with the fluctuation amplitude being significantly smaller than the mean period, indicating relatively stable frequency synchronization.

Figure 8: The clock period results after the same time index for different algorithms
Fig. 9 shows the phase differences between nodes by comparing the modulo operation results of clock times. The results reveal that for classical algorithms, LSTM, and FC-Attention methods, the phases of each node do not fully align after stabilizing over time, achieving only frequency synchronization with significant phase differences. Conversely, the DAUNet method enables all nodes to rapidly converge to identical phase values, indicating full frequency and phase synchronization.

Figure 9: The results of taking the modulus of the clock time after the same time index when using different algorithms
Figs. 10 and 11 present the normalized phase difference (NPD) range and the final NPD distribution for different algorithms, respectively. The NPD range results in Fig. 10 show that as the time index advances, the NPD range of the DAUNet method has a smaller final convergence value and a smaller fluctuation range compared to the comparison algorithm, which means better clock synchronization. The results demonstrate that the NPD range of the DAUNet method converges to approximately 0.000228 over time. It achieves stability within 2000 clock index, showing significant improvement compared to other methods and indicating high algorithmic efficiency. Fig. 11 shows the NPD of 16 nodes under different algorithms. As can be seen from the statistical graph, compared with the comparison algorithm, the NPD gap between each node of DAUNet method is smaller, and the NPD value distribution of each node is more uniform. Moreover, the NPD distribution of all nodes in the DAUNet method has a smaller range, with a standard deviation of 6.3597e–5, proving high phase consistency among nodes after training.

Figure 10: The results of NPD range for different algorithms
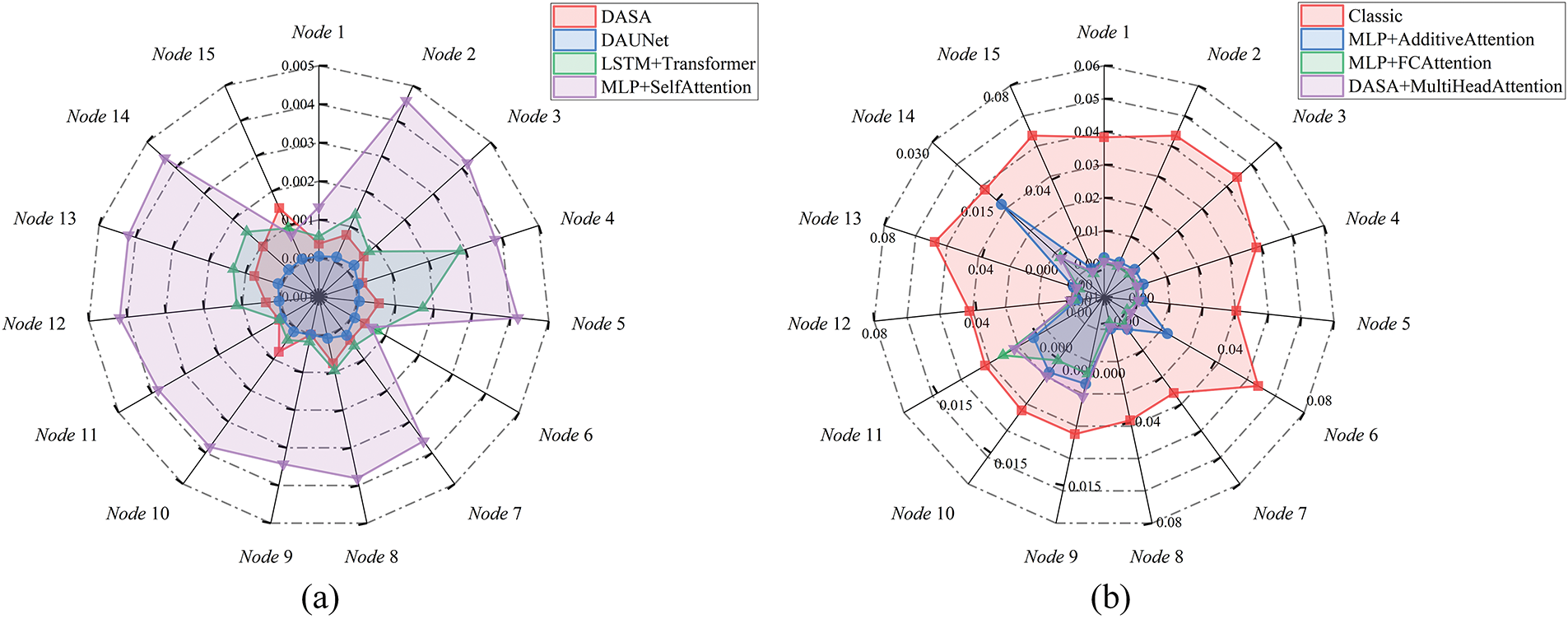
Figure 11: The results of final NPD under different algorithms for 16 nodes (a) The NPD results of DASA, DAUNet, LSTM+Transformer and MLP+SelfAttention algorithms; (b) The NPD results of Classic, MLP+AdditiveAttention, MLP+FCAttention and DASA+MultiHeadAttention algorithms
The comparative experiments demonstrate that the DAUNet network model achieves remarkable effectiveness in achieving full clock synchronization, including both phase and frequency, in multi-agent ad hoc networks. The efficacy of this model primarily stems from the proposed lightweight dual-attention mechanism framework. This framework combines a front-end MLP module to enhance the model’s information extraction capability while reducing computational complexity, thus enabling better deployment performance.
To further validate the effectiveness of each module in the DAUNet model, we conducted ablation experiments on the dataset, with results shown in Table 2.
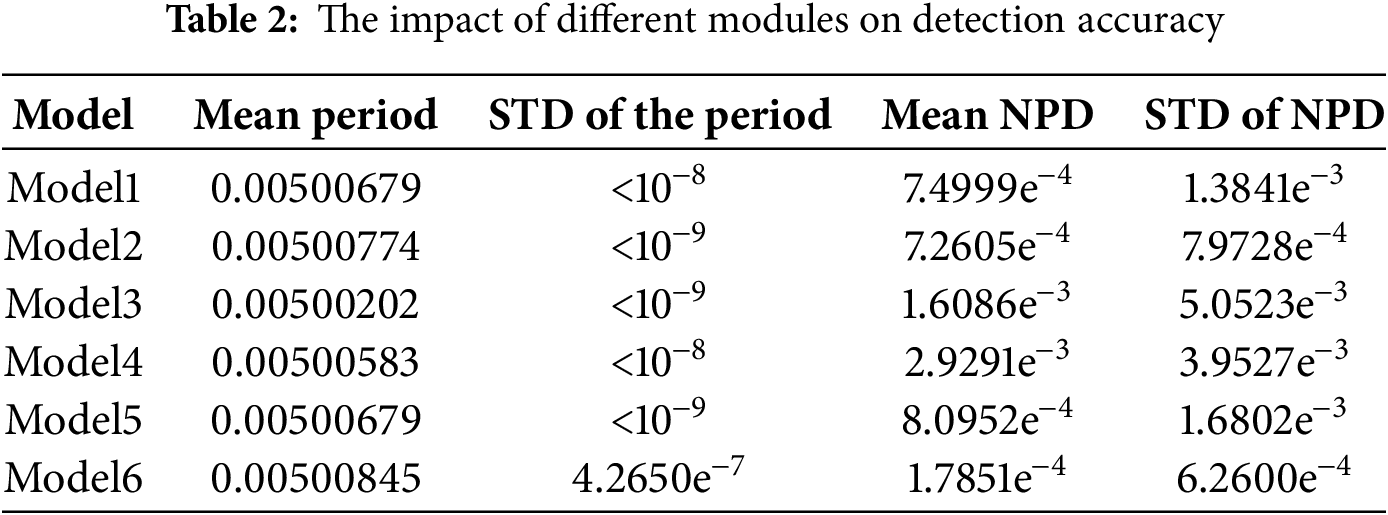
As illustrated in Fig. 12, Model 1 is a neural network model based on the MLP module. Model 2 introduces a multi-head attention mechanism on top of Model 1. As the multi-head attention mechanism captures node relationships across different dimensions and synthesizes multi-perspective information to generate more precise weight values, the NPD standard deviation is reduced by 42.4%. Model 3 introduces a gated attention mechanism based on Model 1. Since the gated attention mechanism dynamically adjusts features or weights to suppress noise and enhance key information, the period standard deviation is reduced by one order of magnitude compared to Model 1. To compare with the dual-attention mechanism in DAUNet, Model 4 adds an additive attention mechanism to Model 2, also employing a dual-attention mechanism for experimentation. The results indicate that compared to Model 4, the DAUNet model exhibits superior performance in both period standard deviation and NPD standard deviation, demonstrating better clock synchronization accuracy.

Figure 12: Deleting different branches in the DAUNet models
To further investigate the impact of different branches in each module on clock synchronization accuracy, ablation experiments were conducted on the three modules of Model 5 and Model 6 using the dataset. First, the MLP, multi-head attention mechanism, and gated attention mechanism were simultaneously integrated to form the complete DAUNet model. Then, based on this model, we sequentially removed key branches of the MLP module, followed by key branches of the multi-head attention mechanism and critical components of the gated attention mechanism.
The results in Table 2 demonstrate that after removing corresponding branches in each module of the DAUNet model, the model’s metrics did not improve; instead, some exhibited degradation, validating the effectiveness of the proposed model. The results reveal that operations on key components of the dual-attention mechanism most significantly impact clock synchronization accuracy. This is because sparsity constraints introduced through gating reduce redundant computation, enabling the system to maintain high synchronization accuracy while achieving stronger real-time responsiveness, which is essential for the DAUNet model.
To evaluate the robustness of the proposed model, we conducted multiple reset operations during clock synchronization experiments to simulate real-world extreme scenarios, including system reset, while monitoring clock frequency variations. As illustrated in Fig. 13, the clock frequency demonstrates rapid convergence to a stable value following repeated reset events, confirming the model’s strong robustness.

Figure 13: Convergence of clock frequencies after clock phase and frequency resets over time index for DAUNet
As a crucial field in multi-agent collaboration, clock synchronization research finds wide application in intelligent transportation, drone light shows, and emergency rescue. However, achieving perfect clock synchronization remains highly challenging due to propagation delays and node clock frequency variations, which exist in complex wireless ad hoc networks. Although numerous remarkable clock synchronization algorithms have emerged in recent years, most exhibit insufficient accuracy and high computational complexity. Therefore, this paper proposes an unsupervised deep learning approach based on a dual-attention mechanism for clock synchronization in multi-agent wireless ad hoc networks, abbreviated as DAUNet. This network learns from sample data through deep learning methods to generate the weight values required for clock synchronization calculations among nodes in multi-agent ad hoc networks. By fusing multi-head attention (MHA) and gated attention (GA) mechanisms, DAUNet constructs a distributed training framework that significantly enhances the accuracy and stability of clock synchronization under dynamic network environments. Numerical results demonstrate that DAUNet improves the accuracy of normalized phase difference by 1-2 orders of magnitude compared to conventional methods and mainstream deep learning approaches, achieving full frequency and phase synchronization. Moreover, the proposed method requires reduced training cycles and features low computational complexity, while incorporating a memory release strategy—attributes that better fulfill practical multi-agent application requirements. Despite the model’s clear advantages in computational complexity and synchronization accuracy over prevailing clock synchronization methods, its parameter scale remains relatively large when deployed on resource-constrained devices, with potential accuracy degradation. Therefore, future work will explore DAUNet’s adaptability in mobile edge computing scenarios and further downsize the model scale to accommodate extreme resource constraints without sacrificing performance. We plan to extend the application of DAUNet to larger-scale multi-agent clusters, such as those with hundreds or thousands of nodes. Due to the insufficiency of the existing data volume for such scenarios, it is necessary to expand the dataset to include various large-scale network topologies. Moreover, large-scale agent distributed training requires a higher-performance computing clusters. Therefore, we are deploying a high-performance computing cluster to handle the increased computational load during distributed training, while collecting more training datasets. Our laboratory is currently conducting preliminary experiments on larger networks, focusing on optimizing the dual-attention mechanism to achieve scalability while maintaining synchronization accuracy.
Acknowledgement: The authors would like to express their gratitude to all the researchers who contributed to enhancing the quality of the idea, concept, and the paper overall.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Haihao He, Xianzhou Dong; data collection: Shuangshuang Wang; analysis and interpretation of results: Haihao He, Chengzhang Zhu, Xiaotong Zhao; draft manuscript preparation: Haihao He, Xianzhou Dong, Chengzhang Zhu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Xianzhou Dong, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Jin X, An J, Du C, Pan G, Wang S, Niyato D. Frequency-offset information aided self time synchronization scheme for high-dynamic multi-UAV networks. IEEE Trans Wirel Commun. 2024;23(1):607–20. doi:10.1109/TWC.2023.3280536. [Google Scholar] [CrossRef]
2. Fan Z, Li X, Xu Y, Li Y, Yang T, Uhlig S. Work-in-progress: a novel clock synchronization system for large-scale clusters. In: 2022 IEEE Real-Time Systems Symposium (RTSS); 2022 Dec 5–8; Houston, TX, USA. IEEE; 2022. p. 519–22. doi:10.1109/RTSS55097.2022.00056. [Google Scholar] [CrossRef]
3. Dai W, Zhang R, Liu J. P-TimeSync: a precise time synchronization simulation with network propagation delays. In: 2024 IEEE World Forum on Public Safety Technology (WFPST); 2024 May 14–15; Herndon, VA, USA. IEEE; 2024. p. 13–8. [Google Scholar]
4. Gu X, Zheng C, Li Z, Zhou G, Zhou H, Zhao L. Cooperative localization for UAV systems from the perspective of physical clock synchronization. IEEE J Sel Areas Commun. 2024;42(1):21–33. doi:10.1109/JSAC.2023.3322797. [Google Scholar] [CrossRef]
5. Pla DA, Pellaco L, Dwivedi S, Händel P, Jaldén J. Clock synchronization over networks using sawtooth models. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2020 May 4–8; Barcelona, Spain. IEEE; 2020. p. 5945–9. doi:10.1109/ICASSP40776.2020.9054426. [Google Scholar] [CrossRef]
6. de Haag MU, Huschbeck S, Huff J. sUAS swarm navigation using inertial, range radios and partial GNSS. In: 2019 IEEE/AIAA 38th Digital Avionics Systems Conference (DASC); 2019 Sep 8–12; San Diego, CA, USA. IEEE; 2019. p. 1–10. doi:10.1109/dasc43569.2019.9081793. [Google Scholar] [CrossRef]
7. Lin N, Wu T, Zhao L, Hawbani A, Wan S, Guizani M. An energy effective RIS-assisted multi-UAV coverage scheme for fairness-aware ground terminals. IEEE Trans Green Commun Netw. 2025;9(1):164–76. doi:10.1109/TGCN.2024.3424980. [Google Scholar] [CrossRef]
8. Ben Amor S, Affes S, Bellili F, Vilaipornsawai U, Zhang L, Zhu P. Joint ML time and frequency synchronization for distributed MIMO-relay beamforming. In: 2019 IEEE Wireless Communications and Networking Conference (WCNC); 2019 Apr 15–18; Marrakesh, Morocco. IEEE; 2019. p. 1–8. doi:10.1109/wcnc.2019.8885457. [Google Scholar] [CrossRef]
9. Ha Y, Pak E, Park J, Kim T, Yoon JW. Clock offset estimation for systems with asymmetric packet delays. IEEE/ACM Trans Netw. 2023;31(4):1838–53. doi:10.1109/TNET.2022.3229407. [Google Scholar] [CrossRef]
10. Shi F, Tuo X, Yang SX, Lu J, Li H. Rapid-flooding time synchronization for large-scale wireless sensor networks. IEEE Trans Ind Inform. 2020;16(3):1581–90. doi:10.1109/TII.2019.2927292. [Google Scholar] [CrossRef]
11. Mills D, Martin J, Burbank J, Kasch W. Network time protocol version 4: protocol and algorithms specification. Internet Eng Task Force (IETF). 2010. doi:10.17487/RFC5905. [Google Scholar] [CrossRef]
12. Zhang C, Wu H. LT-sync: a lightweight time synchronization scheme for high-speed mobile underwater acoustic sensor networks. J Mar Sci Eng. 2025;13(3):528. doi:10.3390/jmse13030528. [Google Scholar] [CrossRef]
13. Huang Y, Zhang G, Kong M, He F. New timestamp mark-based energy efficient time synchronization method for wireless sensor networks. Int J Distrib Sens Netw. 2022;18(11):155013292211355. doi:10.1177/15501329221135516. [Google Scholar] [CrossRef]
14. Abakasanga E, Shlezinger N, Dabora R. Unsupervised deep-learning for distributed clock synchronization in wireless networks. IEEE Trans Veh Technol. 2023;72(9):12234–47. doi:10.1109/TVT.2023.3269381. [Google Scholar] [CrossRef]
15. Zhang H, Yan D, Zhang Y, Liu J, Yao M. Distributed synchronization based on model-free reinforcement learning in wireless ad hoc networks. Comput Netw. 2023;227:109670. doi:10.1016/j.comnet.2023.109670. [Google Scholar] [CrossRef]
16. Zhang Q, Guan Y, Li H, Xiong K, Song Z. Distributed deep learning-based signal classification for time-frequency synchronization in wireless networks. Comput Commun. 2023;201:37–47. doi:10.1016/j.comcom.2023.01.014. [Google Scholar] [CrossRef]
17. Simeone O, Spagnolini U, Bar-Ness Y, Strogatz SH. Distributed synchronization in wireless networks. IEEE Signal Process Mag. 2008;25(5):81–97. doi:10.1109/MSP.2008.926661. [Google Scholar] [CrossRef]
18. Leng M, Wu YC. Distributed clock synchronization for wireless sensor networks using belief propagation. IEEE Trans Signal Process. 2011;59(11):5404–14. doi:10.1109/TSP.2011.2162832. [Google Scholar] [CrossRef]
19. Du J, Wu YC. Distributed clock skew and offset estimation in wireless sensor networks: asynchronous algorithm and convergence analysis. IEEE Trans Wirel Commun. 2013;12(11):5908–17. doi:10.1109/TWC.2013.100213.130553. [Google Scholar] [CrossRef]
20. Akpınar M, Schmidt EG, Schmidt KW. Highly accurate clock synchronization with drift correction for the controller area network. IEEE Trans Parallel Distrib Syst. 2022;33(12):4071–82. doi:10.1109/TPDS.2022.3179316. [Google Scholar] [CrossRef]
21. Zino I, Dabora R, Poor HV. Model-based learning for network clock synchronization in half-duplex TDMA networks. In: ICC 2024-IEEE International Conference on Communications; 2024 Jun 9–13; Denver, CO, USA. IEEE; 2024. p. 1618–24. doi:10.1109/ICC51166.2024.10622797. [Google Scholar] [CrossRef]
22. Assylbek D, Nadirkhanova A, Zorbas D. Energy-efficient clock-synchronization in IoT using reinforcement learning. In: 2024 20th International Conference on Distributed Computing in Smart Systems and the Internet of Things (DCOSS-IoT); 2024 Apr 29–May 1; Abu Dhabi, United Arab Emirates. IEEE; 2024. p. 244–8. doi:10.1109/DCOSS-IoT61029.2024.00044. [Google Scholar] [CrossRef]
23. Yang Y, Tu S, Hashim Ali R, Alasmary H, Waqas M, Nouman Amjad M. Intrusion detection based on bidirectional long short-term memory with attention mechanism. Comput Mater Contin. 2023;74(1):801–15. doi:10.32604/cmc.2023.031907. [Google Scholar] [CrossRef]
24. Hulede IEL, Kwon HM. Distributed network time synchronization: social learning versus consensus. IEEE Trans Signal Inf Process Netw. 2021;7:660–75. doi:10.1109/TSIPN.2021.3119263. [Google Scholar] [CrossRef]
25. Qi H, Wang F, Wang H. Statistical analysis of fixed mini-batch gradient descent estimator. J Comput Graph Stat. 2023;32(4):1348–60. doi:10.1080/10618600.2023.2204130. [Google Scholar] [CrossRef]
26. Zou J, Mao Q, Xiao J, Liu S, Liang Y. Distributed learning-based channel estimation and feedback for RIS-aided wireless communications. IEEE Wirel Commun Lett. 2025;14(2):460–4. doi:10.1109/LWC.2024.3509612. [Google Scholar] [CrossRef]
27. Yechuri S, Vanambathina S. A subconvolutional U-Net with gated recurrent unit and efficient channel attention mechanism for real-time speech enhancement. Wirel Pers Commun. 2024;11:330. doi:10.1007/s11277-024-10874-1. [Google Scholar] [CrossRef]
28. Liang Z, Tao M, Xie J, Yang X, Wang L. A radio signal recognition approach based on complex-valued CNN and self-attention mechanism. IEEE Trans Cogn Commun Netw. 2022;8(3):1358–73. doi:10.1109/TCCN.2022.3179450. [Google Scholar] [CrossRef]
29. Wang S, Bi S, Zhang YA. Deep reinforcement learning with communication transformer for adaptive live streaming in wireless edge networks. IEEE J Sel Areas Commun. 2022;40(1):308–22. doi:10.1109/JSAC.2021.3126062. [Google Scholar] [CrossRef]
30. Hu X, Tian Y, Kho YH, Xiao B, Li Q, Yang Z, et al. Location prediction using Bayesian optimization LSTM for RIS-assisted wireless communications. IEEE Trans Veh Technol. 2024;73(10):15156–71. doi:10.1109/TVT.2024.3409739. [Google Scholar] [CrossRef]
31. Shaker A, Maaz M, Rasheed H, Khan S, Yang MH, Khan FS. SwiftFormer: efficient additive attention for transformer-based real-time mobile vision applications. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023 Oct 1–6; Paris, France. IEEE; 2023. p. 17379–90. doi:10.1109/ICCV51070.2023.01598. [Google Scholar] [CrossRef]
32. Qin Z, Zhang P, Wu F, Li X. FcaNet: frequency channel attention networks. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. IEEE; 2021. p. 763–72. doi:10.1109/ICCV48922.2021.00082. [Google Scholar] [CrossRef]
33. Li T, Yang Y, Lee J, Qin X, Huang J, He G. DCSaNet: dilated convolution and self-attention-based neural network for channel estimation in IRS-aided multi-user communication system. IEEE Wirel Commun Lett. 2023;12(7):1139–43. doi:10.1109/LWC.2023.3263836. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools