
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Hybrid Deep Learning Approach Using Vision Transformer and U-Net for Flood Segmentation
1 Department of Institute of Information Science and Technology, Jeju National University, Jeju-si, 63243, Republic of Korea
2 Department of Computer Engineering, Jeju National University, Jeju, 63243, Republic of Korea
3 Department of Computer Engineering, Major of Electronic Engineering, Jeju National University, Food Tech Center (FTC), Jeju National University, Jeju, 63243, Republic of Korea
* Corresponding Author: Yung-Cheol Byun. Email:
Computers, Materials & Continua 2026, 86(2), 1-19. https://doi.org/10.32604/cmc.2025.069374
Received 21 June 2025; Accepted 27 August 2025; Issue published 09 December 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Recent advances in deep learning have significantly improved flood detection and segmentation from aerial and satellite imagery. However, conventional convolutional neural networks (CNNs) often struggle in complex flood scenarios involving reflections, occlusions, or indistinct boundaries due to limited contextual modeling. To address these challenges, we propose a hybrid flood segmentation framework that integrates a Vision Transformer (ViT) encoder with a U-Net decoder, enhanced by a novel Flood-Aware Refinement Block (FARB). The FARB module improves boundary delineation and suppresses noise by combining residual smoothing with spatial-channel attention mechanisms. We evaluate our model on a UAV-acquired flood imagery dataset, demonstrating that the proposed ViT-UNet+FARB architecture outperforms existing CNN and Transformer-based models in terms of accuracy and mean Intersection over Union (mIoU). Detailed ablation studies further validate the contribution of each component, confirming that the FARB design significantly enhances segmentation quality. To its better performance and computational efficiency, the proposed framework is well-suited for flood monitoring and disaster response applications, particularly in resource-constrained environments.Keywords
The increasing frequency and severity of floods driven by climate change demand advanced, accessible, and efficient flood detection solutions. Recent progress in deep learning, particularly with convolutional neural networks (CNNs) and Vision Transformers (ViTs), has significantly enhanced flood segmentation using aerial and satellite imagery. However, current methods face notable limitations. CNN-based models, such as U-Net variants, excel at capturing local spatial details but struggle to model global context, resulting in inaccurate delineation of complex flood boundaries in regions with water reflections, shadows, or low-contrast edges [1,2]. Furthermore, many existing approaches lack domain-specific post-processing to address flood-specific artifacts, such as noisy textures or ambiguous boundaries, which are prevalent in high-resolution aerial imagery [3,4]. These limitations hinder real-time deployment in disaster management, particularly in resource-constrained settings like developing countries, where affordable and robust flood notification systems are scarce.
These systems can enhance the effectiveness of crisis response and resilience to floods, which have experienced a relatively high incidence in recent years [5]. Timely flood detection and monitoring are essential for minimizing these effects and implementing preventive measures to protect the affected population and mitigate financial losses. Despite the challenges and noise present in various image types, such as those from fixed surveillance cameras, drones, crowdsourced observations, and social media streams, automated image analysis techniques have rapidly evolved into flexible and robust tools for information extraction [6]. Here, we introduce a tailored post-processing refinement block that further improves segmentation boundaries, which is detailed in the Methods.
This study builds upon the established ViT-UNet hybrid backbone and centers its core contribution on the design and integration of the Flood-Aware Refinement Block (FARB), a novel post-processing module for improving flood boundary delineation. The key contributions of this work are as follows:
• Proposed a hybrid ViT-UNet framework that performs pixel-wise flood segmentation, integrating a novel Flood-Aware Refinement Block (FARB) that enhances boundary delineation through spatial-channel attention and residual refinement.
• To introduce a domain-specific flood-aware refinement block, a post-processing module that enhances segmentation quality by refining boundaries affected by reflections, shadows, and noisy textures. It integrates residual smoothing with spatial-channel attention to improve segmentation of complex flood contours.
• We develop a comprehensive and efficient training pipeline, incorporating a targeted data augmentation strategy that simulates diverse environmental conditions. This ensures model robustness and generalization to unseen flood scenarios.
Based on the literature, we selected widely adopted architectures for segmentation tasks, including U-Net variants and Swin Transformer, as strong CNN and transformer baselines. These models have been used extensively in both general and flood-specific segmentation studies.
The selection of U-Net variants (e.g., U-Net Conv2D, U-Net Residual, U-Net Attention Gate) was motivated by their established success in medical image segmentation—where precise boundary delineation is crucial—and their frequent adaptation to remote sensing applications, including flood mapping. Swin Transformer was included due to its strong performance in vision tasks, specifically its ability to model global spatial dependencies, which is critical for complex flood imagery. While other state-of-the-art architectures such as DeepLabv3+ and SegFormer were considered, they were excluded due to higher computational demands or limited suitability for UAV-based flood datasets at the target resolution (512
Vision Transformers (ViTs) have emerged as powerful architectures for image segmentation due to their ability to capture long-range dependencies and global contextual information. Recent studies have applied ViTs to flood detection tasks, demonstrating their potential in diverse imaging scenarios. We enhanced a Vision Transformer model for binary flood classification by transferring knowledge across multispectral imagery, and we reached CNN-based models for disaster management [7,8]. SemT-Former detects real floods in high-risk regions [9]. The latest methods leverage UAV images with probabilistic optimization for flood mapping [10]. FWSARNet leverages deformable convolutions rather than self-attention to better detect the boundaries in SAR imagery [11]. This presents Vision Transformer-based models with differential attention to improve flood mapping in SAR and camera images. Federated learning transformers for rain and flood classification in urban areas [12]. While previous models such as Swin Transformer and DeepSARFlood lack a mechanism to refine segmented boundaries in flood-prone urban environments, we address this persistent limitation by introducing a domain-specific post-processing innovation. Recent advances demonstrate the effectiveness of combining Transformer-based encoders with CNN-based decoders for semantic segmentation, and our work adopts this established hybrid backbone [13,14]. We extend it with the Flood-Aware Refinement Block (FARB), specifically designed to correct boundary-level artifacts—such as water reflections, terrain occlusions, or low-contrast flood areas—that remain problematic in earlier designs.
Selective feature reinforcement and adaptive token extraction have proven effective for highlighting flood-affected areas and improving the delineation of water borders, debris, and infrastructure damage. Following this line, our work integrates Vision Transformer (ViT) with UNet-based segmentation, drawing inspiration from hybrid transformer-CNN strategies like AtTransUNet [8,15], to strike a balance between fine-grained spatial segmentation and global contextual understanding.
In urban flood detection, visual transformers combined with hydrometeorological forecasting systems have shown strong performance in real-time rain and flood classification, supporting early warning and post-disaster assessment efforts. Additionally, incorporating attention gates into UNet architectures improves focus on critical features, significantly enhancing flood area segmentation for disaster management and response [16]. The adoption of deep learning, convolutional neural network (CNN) has enhanced flood detection precision. Models like Multi-Scale Deeplab, UNet, and Feature Pyramid Networks (FPN) segment flood-affected areas by leveraging neural network architectures [17,18].
To tackle challenges in SAR image processing and the lack of labeled data, a near real-time flood detection method for the Yangtze River Basin, was presented. In examining the performance of CNN models, a FCN-8, SegNet, UNet, and DeepResUNet, on 16 flood cases, it was found that UNet and DeepResUNet had the best pixelwise accuracy compared to traditional thresholding [19]. Existing solutions have included connected vision systems and deep learning pipelines to improve flood detection by leveraging various, real-time data sources like social media, traffic cameras and river feeds to enrich their training datasets [20,21].
Deep learning models, such as UNet, SegNet, and FCN32, have achieved high accuracy in flood zone delineation using aerial and satellite images while improved performance is observed in the case of UNet and DeepResUNet for SAR image analysis [19]. High-level architectures involve transformer encoders and geophysical information as well as U-Net frameworks for generating flood inundation maps, without forgetting EfficientNet-B7 encoders and multi-scale averaging, facilitating better performance on varying areas [22,23]. In addition, a CNN-based approach for classification of flood water depth as knee-high, waist-high, and dangerously high was also developed, where a strong real-time classification performance was obtained by using deep architectures, such as VGG16, ResNet, and Inception, with ResNet-50 architecture offering the best results. Their system, along with being connected to a mobile application, gleans the feasible application of deep learning for real-time disaster coping [24–27].
Recent research has explored hybrid architectures have been proposed to improve computational efficiency and segment quality. WVResU-Net Another recent method for flood mapping using the Sentinel-1 SAR source, which combines Vision Multi-Layer Perceptrons and a ResU-Net to cope with the computational complexity and to enhance the features extraction ResU-Net. DeepLabv3+ and ASPP have achieved good results on post-disaster elastic research of UAV images [28]. LSTM-SegNet-MSA and ES-DeepLab, attention-based schemes, improve flood risk estimation by integrating spatial and temporal information. U-Net is the classic model in medical image processing and ViT is widely used to process global contextual information, which are all important in flood segmentation [29].
Building on these advancements, our proposed study integrates Vision Transformer (ViT) with UNet-based segmentation models to exploit their complementary strengths. By focusing on multi-temporal analysis and post-processing refinement, we aim to deliver more precise flood delineation, advancing the state of the art in flood detection research.
This research presents a hybrid deep learning approach that integrates Vision Transformers (ViT) and U-Net to achieve high-precision flood segmentation. The methodological pipeline consists of dataset acquisition, pre-processing, feature extraction, segmentation, post-processing, and evaluation, shown in the Fig. 1. This workflow is designed to ensure accuracy, computational efficiency, and real-world applicability.
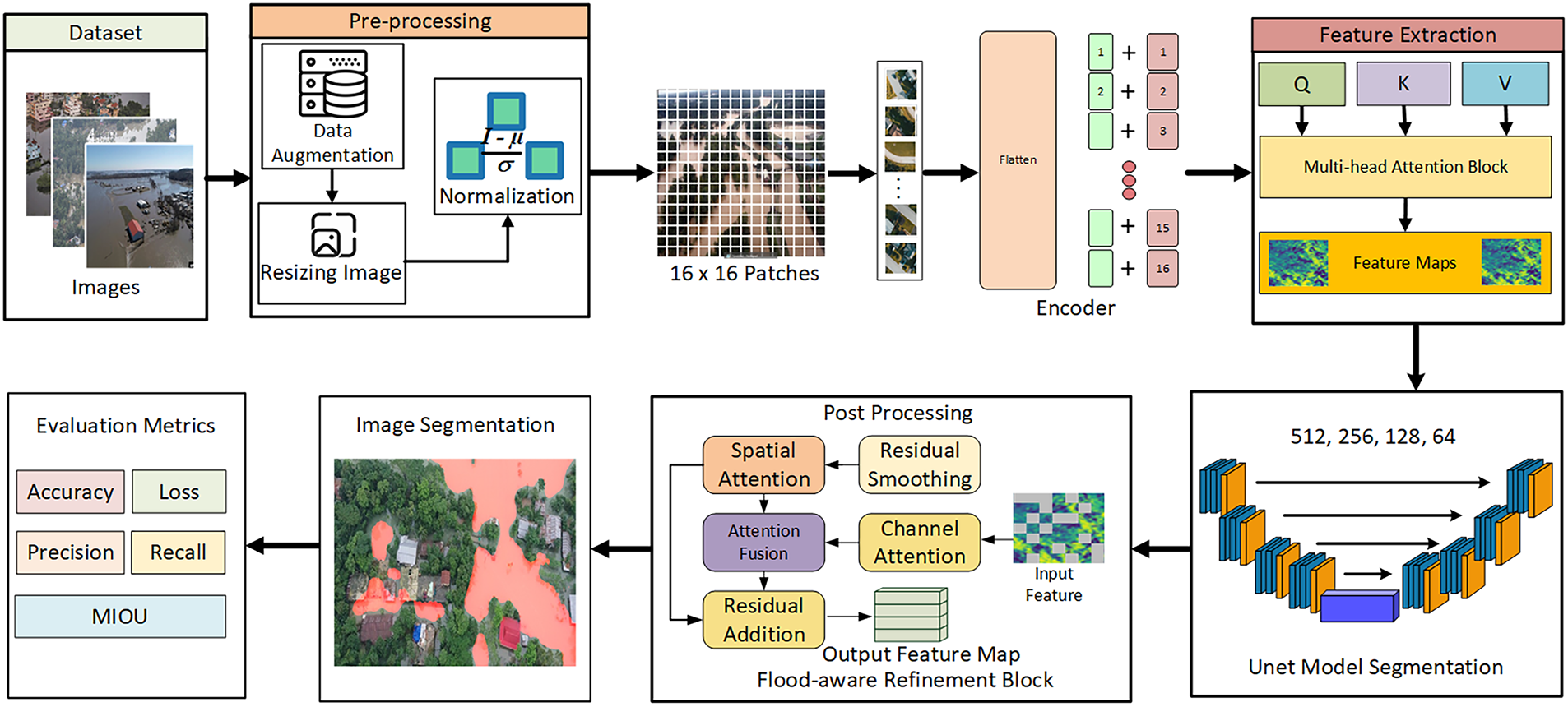
Figure 1: Workflow of the proposed model. This diagram illustrates the end-to-end pipeline, including pre-processing, Vision Transformer encoding, U-Net decoding, post-processing with the Flood-Aware Refinement Block, and output evaluation
Flood-specific datasets were developed by processing fine-resolution imagery obtained through autonomous aerial systems. This dataset comprised 290 original images, which were expanded to 1160 images through data augmentation, as shown in Fig. 2. Augmentation procedures included controlled brightness adjustment (

Figure 2: Sample original and augmented flood images. The left panel shows the original UAV-acquired images, while the right panel displays augmented images generated using brightness adjustment, contrast shift, flipping, and salt-and-pepper noise to simulate diverse environmental conditions
Prior to model training, a comprehensive series of pre-processing steps was applied to all images to ensure high-quality input for the segmentation models. First, each image was resized to a standard resolution of 512
For processing through the Vision Transformer encoder, images were divided into 16
The images were normalized, resized and converted to YCbCr color space before embedding into the ViT Encoder using patch-wise embedding. The uniform resolution matches the ViT and U-Net segmentation model for computational efficiency. The dataset is separated into three subsets for learning, tuning, and evaluation. These pre-processing steps prepare data for the ViT-UNet model to delineate flood-affected regions, ensuring reliable segmentation results as shown in Eq. (1). Additionally, batch normalization was applied during training to stabilize learning and improve convergence.
Here I,
During normalization, images are divided into 16
3.3 ViT-UNet with Flood-Aware Refinement
Shown in Fig. 3, the ViT-UNet architecture starts by leveraging a Vision Transformer backbone to extract both global and local contextual features from input imagery. This is followed by a U-Net decoder, which reconstructs segmentation masks through a four-stage upsampling strategy. Each upsampling stage applies a transposed convolution succeeded by a 3
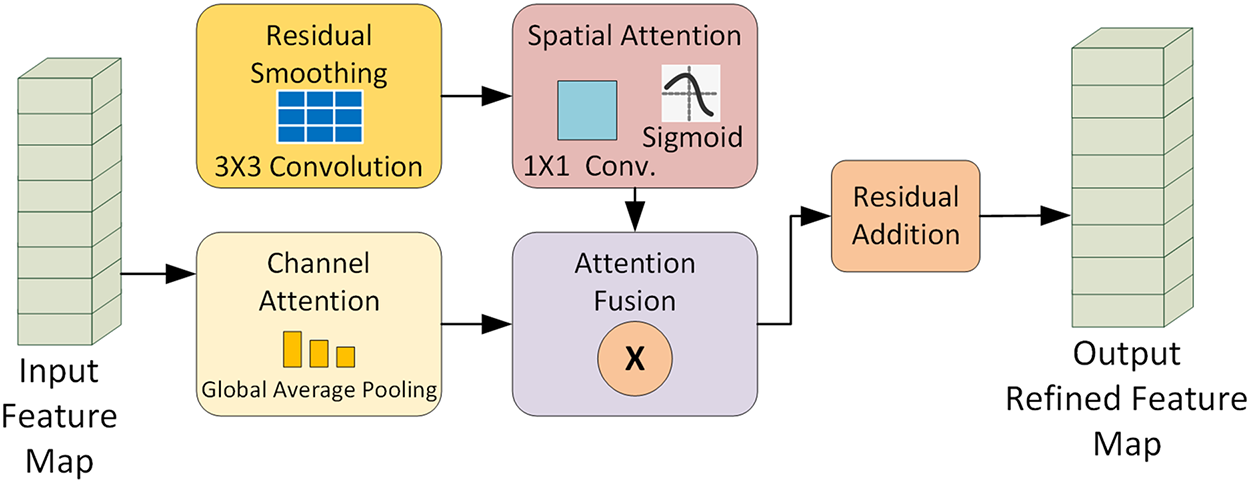
Figure 3: The input feature map from the U-Net decoder is processed in three parallel pathways, residual smoothing via a 3
To address the persistent challenges of complex flood boundaries, such as reflections and blurred edges the final feature map produced by the decoder is processed by the proposed Flood-Aware Refinement Block (FARB). This specialized module integrates residual smoothing with spatial and channel attention to enhance boundary delineation and suppress noise. The network outputs a binary, pixel-wise segmentation mask, in which each pixel is classified as either flooded or non-flooded, enabling fine-grained flood extent delineation.
To address the ambiguity of flood boundaries in aerial imagery, we propose a flood-aware refinement block (FARB), a learnable module integrating residual refinement for preserving essential spatial features, spatial-channel attention for highlighting flood regions and suppressing noise, and a convolution-based smoothing layer to ensure boundary continuity. This yields sharper and more reliable flood masks.
Unlike standard smoothing operations, we propose a refinement block that combines spatial-channel attention and a residual learning path. The residual connection preserves essential spatial features by combining smoothed inputs while filtering out irrelevant regions, improving accuracy. This process can be mathematically formalized, as shown in Eq. (6).
Let X be the input feature map:
where
where GAP is global average pooling, FC1 reduces channels to
The decoder output is further refined by the proposed Flood-Aware Refinement Block (FARB). A detailed, step-by-step schematic of the FARB architecture, including all operations and their mathematical formulations, is provided in Table 1 and Eqs. (2) to (6). As illustrated in Fig. 3, FARB integrates residual smoothing, spatial attention, and channel attention with fusion and residual addition, sharpening segmentation boundaries and suppressing irrelevant noise. Complete hyperparameter details are provided to ensure full reproducibility. The complete architecture of the Flood-Aware Refinement Block (FARB) is summarized in which lists each operation, its function, and the resulting output shape. This table provides a clear step-by-step view of how residual smoothing, spatial attention, and channel attention are integrated and fused, ultimately producing the refined feature map used by the segmentation head.

The post-processing block also contributes to real-time prediction capability, enabling accurate and actionable outputs in resource-constrained flood response environment.
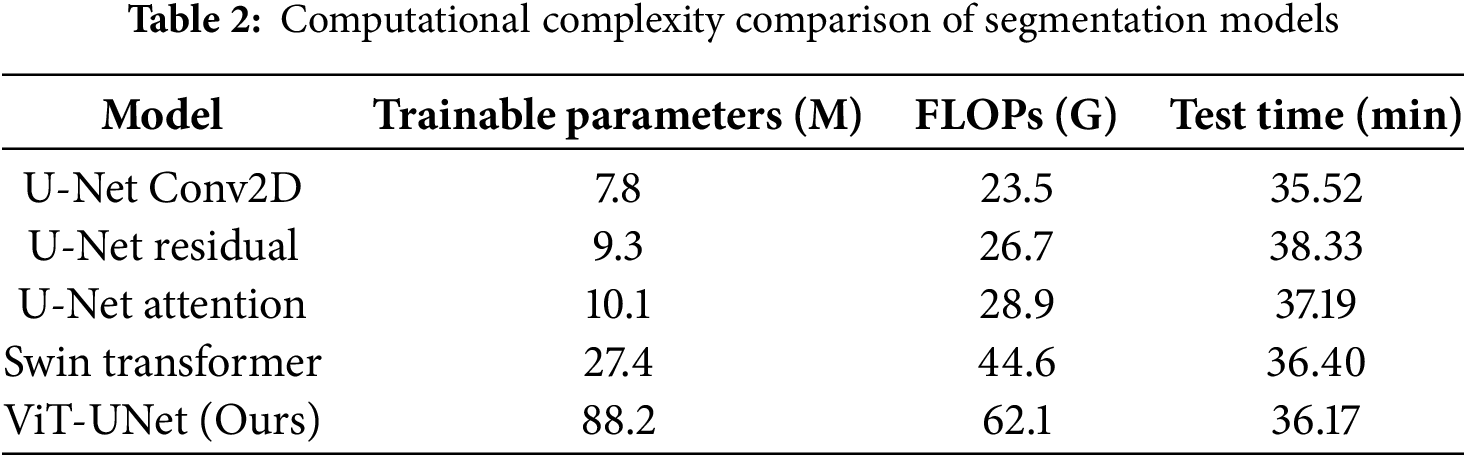
Computational Complexity Analysis
The Vision Transformer encoder introduces
We also report model complexity in terms of trainable parameters and FLOP ViT-UNet+FARB has 45.2 M parameters and 34.8 GFLOPs per 512
As shown in Table 2, our method achieves a favorable trade-off between accuracy and computational cost, being more efficient than Swin Transformer and significantly outperforming traditional U-Net models.
To address the challenges of accurately segmenting ambiguous flood boundaries, we propose a Flood-Aware Refinement Block (FARB) as a learnable post-processing stage. This block integrates residual fine-tuning, spatial-channel attention, and convolutional smoothing to enhance mask predictions. The residual pathway preserves essential spatial features by learning an additive correction over the smoothed input, effectively reducing noise while maintaining edge sharpness. The spatial-channel attention mechanism emphasizes flood-relevant regions and suppresses background interference, allowing precise delineation of water extents. The convolution-based relative smoothing and attention module ensures boundary continuity and smooth transitions. These combined operations significantly sharpen the raw segmentation outputs while adding negligible computational overhead.
The model was trained using a low learning rate of 0.00001 to prevent oscillations in the loss function and ensure stable convergence. A batch size of 8 was used to balance GPU memory constraints with gradient accuracy. Training was conducted over 50 epochs, with validation loss stabilizing around epoch 45. To prevent overfitting on the small dataset, a dropout rate of 0.5 was applied, encouraging robust feature learning. The Adam optimizer was selected for its ability to dynamically adapt learning rates across parameters, proving more effective than SGD for our hybrid architecture. Furthermore, a smoothing module was incorporated to refine edge clarity and align the predicted features with the marginal distributions of flood and non-flood regions, thereby reducing noise and weak artifacts. Learnable parameters
4.1 Training Configuration and Evaluation Metrics
To assess the segmentation performance of the proposed ViT-UNet with Flood-Aware Refinement Block (FARB), a comprehensive set of metrics was employed, accounting for the class imbalance inherent in flood datasets where non-flooded areas often dominate. The primary focus is on metrics that provide a balanced evaluation of segmentation quality. Mean Intersection over Union (mIoU) serves as a key indicator, measuring the overlap between predicted and ground truth segmentation masks across both flooded and non-flooded classes. Precision and recall are included to evaluate positive predictions and coverage, respectively, while the Dice Score (also known as F1-Score) is introduced as a critical metric, balancing precision and recall to better reflect performance on imbalanced datasets. Accuracy, while reported, is de-emphasized due to its potential to mislead in the presence of class imbalance, as a model predicting the majority (non-flooded) class could achieve high scores without effective segmentation.
4.2 Comparative Analysis with Other Models
The proposed ViT-UNet was benchmarked against recent state-of-the-art segmentation models, including U-Net variants and the Swin Transformer. Our model achieved the highest performance with an mIoU of 0.8640 and test accuracy of 93.09%, demonstrating a significant improvement over conventional CNN-based approaches. This can be attributed to the hybrid architecture, which leverages the ViT encoder for global context modeling and the U-Net decoder for precise spatial recovery.
All baseline models U-Net variants and Swin Transformer were retrained and evaluated using our UAV dataset with identical data splits, augmentation strategies, and preprocessing steps to ensure fair comparison. Our proposed ViT-UNet leverages the complementary strengths of Vision Transformers for global context modeling and U-Net decoders for fine spatial recovery. This combination, along with the Flood-Aware Refinement Block (FARB), enables superior boundary delineation and noise suppression in complex flood scenarios, as supported by both quantitative and visual results.
While other state-of-the-art segmentation architectures such as DeepLabv3+ and SegFormer offer strong performance in general-purpose vision tasks, they were not included in this study due to their significantly higher computational demands when applied to 512
While the total training duration for 50 epochs was approximately 1.29 h on an NVIDIA RTX 4080 GPU, this was achievable due to the relatively small dataset size (1160 images) and the moderate input resolution (512
where N denotes the total sample size across all groups,
To assess whether the observed performance differences were statistically significant, we conducted a Kruskal-Wallis H-test using mIoU scores from all models under identical data splits. The test yielded a statistically significant result (p = 0.0003), indicating meaningful performance differences. Pairwise comparisons confirmed that the proposed ViT-UNet significantly outperformed both U-Net (p = 0.0032) and Swin Transformer (p = 0.0081), while the full three-way test also highlighted the contribution of FARB (p = 0.0017), as shown in Table 3.

To ensure a fair and consistent comparison, we re-implemented and trained all baseline models, including U-Net Conv2D, Residual U-Net, Attention U-Net, Multi-Residual U-Net, and Swin Transformer, on our augmented UAV dataset using the same experimental settings. These models were selected based on their frequent usage in recent flood segmentation and general semantic segmentation literature. Table 4 presents the implementation of various segmentation models with data augmentation. Results show that data augmentation increases accuracy, recall and precision across models. Classification error rates dropped significantly for models with poor coverage of the original dataset. UNet variants and Transformer architectures showed improved feature extraction and segmentation with augmented data. The Swin Transformer outperformed other approaches, demonstrating improvements in class imbalance as found previously and highlighting needs in data methodology and mining techniques. This confirms augmentation’s importance for segmentation accuracy and model robustness.
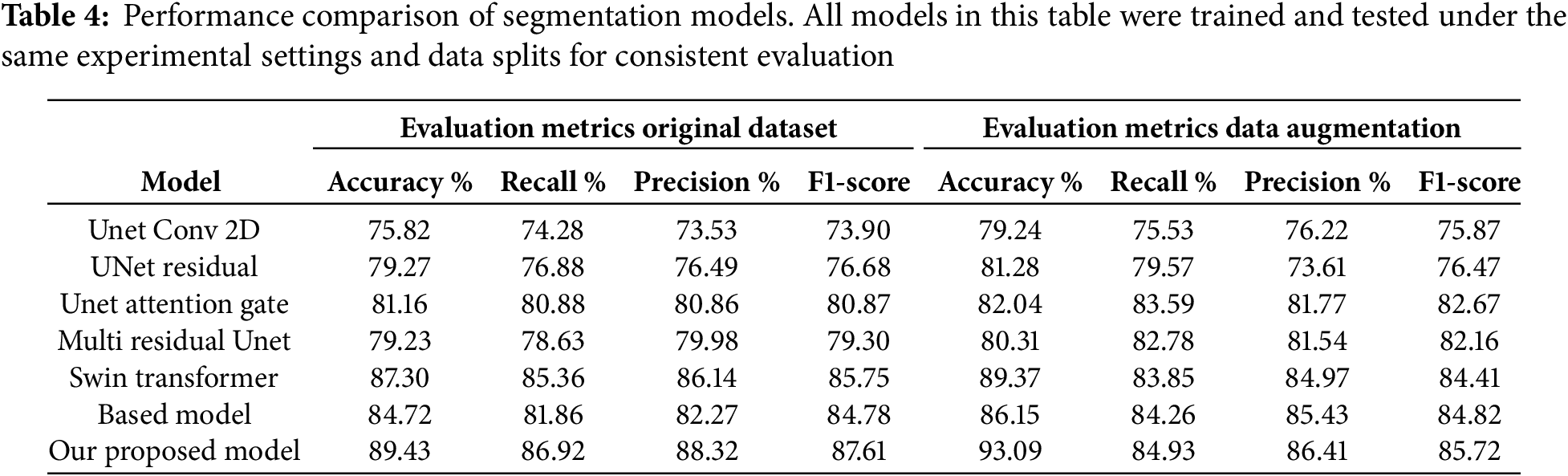
Table 5 presents a comparative summary of segmentation performance and computational cost. Traditional CNN models like U-Net Conv2D achieved faster training (01:03 h) but yielded lower mIoU (0.6952), while Swin Transformer demonstrated better context modeling (mIoU = 0.7962) but still struggled with boundary delineation, especially in reflective or ambiguous regions.
The total training time for 50 epochs was approximately 1.29 h on an NVIDIA RTX 4080 GPU. This efficiency stems from the input resolution of 512
The multi-residual U-Net, despite improved architecture, required 4.06 h for training and 38.64 min for testing, while yielding an mIoU of only 0.7247—indicating diminishing returns with added complexity. Our model’s architecture, which integrates the ViT’s long-range contextual modeling with the U-Net’s fine-grained spatial recovery, results in a superior segmentation framework suitable for real-time or near-real-time flood monitoring applications. We compare flood segmentation effects from various models including UNet-based architectures, Swin Transformer and our proposed ViT-UNet model, as shown in Fig. 4. The ViT-UNet model yields the highest MIoU of 0.8640, indicating best segmentation performance. UNet Convolutional 2D and ResNet architectures show lower MIoU scores and misclassify larger areas along complex flood boundaries. The Swin Transformer performs competitively due to self-attention mechanisms, though inferior to our proposed model. These results confirm the ViT-UNet hybrid approach better captures local and global flood features and improves segmentation compared to ViT and UNet. The model achieved strong metrics, reaching of 0.1448 and 0.1906 in training and validation loss, demonstrating good generalization.

Figure 4: Visual comparison of segmentation results for the proposed ViT-UNet and various baseline models. The first and second rows highlight successful predictions with accurate flood boundary delineation. The third row illustrates failure or challenging cases, such as scenes with heavy reflections or complex textures, where the models perform suboptimally. Ground truth masks are included for each row to support visual comparison. This figure demonstrates both the strengths and limitations of the models across diverse flood
As shown in Table 6, several recent models have reported strong flood segmentation performance on similar public datasets. For example, the Graph Attention Convolutional U-Net achieved an accuracy of 91% and mIoU of 0.7600, while our proposed ViT-UNet attained a higher accuracy of 93.09% and mIoU of 0.8640. Unlike [33], which focuses on graph-based spatial modeling, our approach explicitly combines global attention from Vision Transformers with the spatial precision of U-Net and further enhances boundary detection using the refinement block. Moreover, compared to [10], which used a color-space segmentation approach with 87.4% accuracy, and [32], which used SegNet with 89.46% accuracy, our model consistently outperformed both in all metrics. These comparisons confirm that our method not only exceeds recent SOTA results in segmentation accuracy but also provides a tailored architecture for flood-specific challenges, validated using a publicly available benchmark.
In Fig. 5, specifically includes challenging and failure cases (bottom row), such as strong reflections or complex terrain, where all models, including our proposed ViT-UNet, demonstrate degraded boundary segmentation. Common failure patterns include missed small flood patches and confusion with urban surfaces or debris. These highlight the need for further data enrichment and targeted attention mechanisms.

Figure 5: Qualitative comparison of segmentation accuracy on external flood images using a baseline model and the proposed ViT-UNet. Panel (a) shows original aerial flood imagery; panel (b) displays predictions from the baseline model with notable misclassifications (highlighted in red circles); and panel (c) shows results from the proposed model, which more accurately captures flood extents, particularly in ambiguous regions, demonstrating superior generalization to unseen flood scenarios
The flooded areas are also presented on the segmented regions. Column (b) both the baseline and our model fail to segment regions with intense surface reflections (Image 2), while debris occlusion causes false positives in Image 3, while column (c) is our proposed method. For example in Image 1 the baseline is missing the water shown by the red circle, but ours is able to detect the water. The baseline does not recognize water bodies in the red-circled locations in Image 2, while our method successfully detects them. In Image 3, the baseline predicts water, while ours establishes water from non-water correctly. These outcomes show the improvement of our ViT-UNet model in capturing flood boundaries.
We present a case study comparing segmentation outputs between the baseline models and our proposed ViT-UNet+FARB using test images. The top panel highlights successful cases where the proposed model captures flood boundaries more accurately and with better visual clarity. The bottom panel showcases difficult scenes with water reflections, debris, and occlusions where baseline models tend to fail, either missing flood regions or producing blurred boundaries. These visual comparisons demonstrate that the ViT-UNet+FARB model provides more consistent and refined segmentation across a variety of challenging conditions.
The ViT encoder uses multi-head self-attention (MHSA) to extract global context. The encoder consists of 12 attention layers, a configuration chosen based on extensive experimentation to balance performance and computational efficiency. A comparative analysis of different configurations (6, 8, and 12 attention layers) was conducted, and 12 layers provided the best trade-off between accuracy and training stability. The decision to use 12 layers was based on empirical results, as shown in Table 7, where this configuration demonstrated the highest accuracy of segmentation and Mean Intersection over Union (MIoU). This structure allows the model to effectively capture long-range dependences in flood imagery while maintaining feasible training times.
Flood segmentation in imagery acquired by unmanned aerial vehicles (UAVs) or satellites remains a persistent challenge due to factors such as blurred boundaries, water reflections, low contrast, and debris-induced noise. Conventional convolutional neural network (CNN) models, including various U-Net architectures, exhibit strong capabilities in spatial detail recovery; however, they often lack the capacity to capture global context. Conversely, transformer-based approaches, such as Swin Transformer, are effective in modeling global dependencies but generally fall short in achieving precise spatial delineation, particularly around complex flood contours.
The proposed hybrid ViT-UNet architecture effectively addresses these limitations by integrating the long-range attention mechanisms inherent in Vision Transformers with the hierarchical spatial reconstruction abilities of U-Net decoders. A core innovation of this model is the Flood-Aware Refinement Block (FARB), a post-processing module designed to improve boundary clarity through the use of residual smoothing and spatial-channel attention mechanisms.
Ablation studies and comparative analyses substantiate that the FARB module markedly enhances segmentation outcomes, especially in scenarios where traditional models struggle. As detailed in Tables 5 and 8, incorporating FARB leads to significant improvements in mean Intersection over Union (mIoU) and boundary consistency, as demonstrated both quantitatively and through visual analysis, as shown in Fig. 4.
Unlike many prior models that demand substantial computational resources or fail to provide pixel-level refinement, the proposed approach achieves an optimal balance between segmentation accuracy and computational efficiency. This balance is particularly advantageous for operational flood monitoring in resource-constrained environments, where deployment on UAVs and local servers is more practical than reliance on high-performance computing infrastructure.
Comparative evaluations against state-of-the-art methods, including Swin Transformer and U-Net Attention Gate, demonstrate that ViT-UNet consistently delivers superior segmentation structure and enhanced resistance to noise. Qualitative assessments further reveal that ViT-UNet produces sharper boundaries and more accurately detects flood-affected regions, particularly in ambiguous areas characterized by shadows or intense reflectance.
Despite strong benchmark performance, some limitations persist, the detection of small, fragmented water patches or scenarios involving considerable debris. These challenges, discussed in Fig. 5, underscore the need for broader environmental datasets and the development of targeted augmentation strategies to further enhance model robustness.
We performed an ablation study to assess the contribution of key architectural components in our model, as shown in Table 8. The baseline U-Net decoder achieved an accuracy of 81.24% and a mean Intersection over Union (mIoU) of 0.7247. Incorporating the Vision Transformer (ViT) encoder alone improved the performance to 85.45% accuracy and 0.8140 mIoU. Further enhancement using the Flood-Aware Refinement Block (FARB) as a learnable post-processing module significantly boosted the accuracy to 93.09% and mIoU to 0.8640. This reflects a 7.64% absolute improvement in accuracy and a 5.00% increase in mIoU over the ViT-only configuration, highlighting the effectiveness of our proposed architectural design in improving segmentation precision.
The model was trained using a low learning rate of 0.00001 to prevent oscillations in the loss function and ensure stable convergence. A batch size of 8 was used to balance GPU memory constraints with gradient accuracy. Training was conducted over 50 epochs, with validation loss stabilizing around epoch 45. To prevent overfitting on the small dataset, a dropout rate of 0.5 was applied, encouraging robust feature learning. The Adam optimizer was selected for its ability to dynamically adapt learning rates across parameters, proving more effective than SGD for our hybrid architecture. Furthermore, a smoothing module was incorporated to refine edge clarity and align the predicted features with the marginal distributions of flood and non-flood regions, thereby reducing noise and weak artifacts. Learnable parameters
Hyperparameter Justification: The learning rate of 0.00001 was determined through empirical testing, where higher rates led to unstable convergence due to the complex feature distributions in flood imagery, while lower rates ensured gradual optimization of the ViT-UNet hybrid model. The batch size of 8 was chosen to balance computational efficiency with gradient stability, as larger batch sizes 16 exceeded GPU memory limits, and smaller sizes 4 increased training time without significant performance gains. The dropout rate of 0.5 was selected based on common practices in deep learning literature for segmentation tasks, as it effectively mitigated overfitting on the augmented dataset of 1160 images, validated through cross-validation experiments showing improved generalization compared to lower rates of 0.3.
A principal limitation of this study is the reliance on a single UAV-acquired dataset, which, even after augmentation, may not capture the full spectrum of flood events encountered in different regions, under varying imaging conditions, or across diverse sensor types such as SAR or multispectral satellites. As a result, the generalizability of the model to new domains remains to be established.
In addition to segmentation quality, our model is designed for real-time processing, with optimized training and inference times. The competitive advantage of our approach lies in this balance between high accuracy and computational efficiency, making it suitable for deployment in real-world flood detection systems with limited computational resources.
Our study shows a hybrid ViT-UNet segmentation model specifically designed for better flood detection using aerial imagery. By integrating a Vision Transformer encoder with a U-Net decoder and a specialized post-processing module, our approach enhances the delineation of flood boundaries. The extensive evaluation indicates that our suggested model performs a test accuracy of 93.09% and an mIoU of 0.8640, outperforming state-of-the-art models such as Swin Transformer, DeepSARFlood, and various U-Net variants in both accuracy and computational efficiency. Although we utilize a ViT-UNet hybrid backbone, our core contribution is the design and integration of the Flood-Aware Refinement Block (FARB), which is tailored to enhance segmentation quality in flood-prone environments. Overall, this framework offers substantial practical value for flood response and disaster management, particularly in disaster-prone or resource-limited regions utilizing UAV or satellite data. The enhanced ablation study also confirms the importance of each internal component of the FARB module, showing that combining residual refinement with spatial and channel attention yields the best segmentation performance.
For future work, we will enhance model generalization by incorporating a broader range of flood types, environmental dynamics, and geographic regions. Architectural improvements, such as relative positional encoding and adaptive token extraction, will be explored to further refine spatial understanding in complex flood environments. We also aim to support real-time flood tracking through temporal analysis and predictive modeling, optimize deployment for edge devices, and integrate multi-modal data sources from aerial imagery, ground sensors, and social platforms for a comprehensive flood detection solution.
Recognizing that our current validation is limited to a single UAV dataset, future work will rigorously evaluate the model on additional benchmarks such as FloodNet, Sen1Floods11, and SAR/satellite datasets to assess robustness across different sensors, geographic contexts (urban and rural), and environmental conditions.
Moreover, error cases, especially those involving reflections and occlusions, highlight limitations in training data diversity and model expressiveness. Addressing these will require additional data collection, targeted augmentation strategies, and improved attention mechanisms designed for challenging flood boundaries.
Acknowledgement: Not applicable.
Funding Statement: This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2024-00405278). This research was also partially supported by the Jeju Industry-University Convergence District Project for Promoting Industry-Campus Cooperation, funded by the Ministry of Trade, Industry and Energy (MOTIE, Korea) [Project Name: Jeju Industry-University Convergence District Project for Promoting Industry-Campus Cooperation/Project Number: P0029950].
Author Contributions: The authors confirm contribution to the paper as follows: writing, visualization, methodology, formal analysis, conceptualization: Cyreneo Dofitas Jr; conceptualization, validation, review: Yong-Woon Kim; supervision, software, project administration, investigation, funding acquisition, resources: Yung-Cheol Byun. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The dataset used in this study is publicly available at: https://www.kaggle.com/datasets/faizalkarim/flood-area-segmentation (accessed on 26 August 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Bahrami B, Arbabkhah H. Enhanced flood detection through precise water segmentation using advanced deep learning models. J Civil Eng Res. 2024;6(1):1–8. doi:10.61186/jcer.6.1.1. [Google Scholar] [CrossRef]
2. Song W, Guan M, Yu D. SwinFlood: a hybrid CNN-swin transformer model for rapid spatiotemporal flood simulation. J Hydrol. 2025;660(16):133280. doi:10.1016/j.jhydrol.2025.133280. [Google Scholar] [CrossRef]
3. Fernandes FEJr, Nonato LG, Ueyama J. A river flooding detection system based on deep learning and computer vision. Multimed Tools Appl. 2022;81(28):40231–51. doi:10.1007/s11042-022-12813-3. [Google Scholar] [CrossRef]
4. Zhang Y, Crawford P. Automated extraction of visible floodwater in dense urban areas from RGB aerial photos. Remote Sens. 2020;12(14):2198. doi:10.3390/rs12142198. [Google Scholar] [CrossRef]
5. Vineeth V, Neeba E. Flood detection using deep learning. In: 2021 International Conference on Advances in Computing and Communications (ICACC); 2021 Oct 21–23; Kochi, India. p. 1–5. [Google Scholar]
6. Zaffaroni M, Rossi C. Water segmentation with deep learning models for flood detection and monitoring. In: Proceedings of the 17th ISCRAM Conference; 2020 May 24–27; Blacksburg, VA, USA. p. 66–74. [Google Scholar]
7. Chamatidis I, Istrati D, Lagaros ND. Vision transformer for flood detection using satellite images from Sentinel-1 and Sentinel-2. Water. 2024;16(12):1670. doi:10.3390/w16121670. [Google Scholar] [CrossRef]
8. Debnath A, Kim YW, Byun YC. LightSTATE: a generalized framework for real-time human activity detection using edge-based video processing and vision language models. IEEE Access. 2025;13(14):97609–27. doi:10.1109/access.2025.3574659. [Google Scholar] [CrossRef]
9. Saleh T, Holail S, Xiao X, Xia GS. High-precision flood detection and mapping via multi-temporal SAR change analysis with semantic token-based transformer. Int J Appl Earth Obs Geoinf. 2024;131(1):103991. doi:10.1016/j.jag.2024.103991. [Google Scholar] [CrossRef]
10. Simantiris G, Panagiotakis C. Unsupervised color-based flood segmentation in UAV imagery. Remote Sens. 2024;16(12):2126. doi:10.3390/rs16122126. [Google Scholar] [CrossRef]
11. Yu H, Wang R, Li P, Zhang P. Flood detection in polarimetric SAR data using deformable convolutional vision model. Water. 2023;15(24):4202. doi:10.3390/w15244202. [Google Scholar] [CrossRef]
12. Le QC, Le MQ, Tran MK, Le NQ, Tran MT. FL-Former: flood level estimation with vision transformer for images from cameras in urban areas. In: International Conference on Multimedia Modeling. Cham, Switzerland: Springer; 2023. p. 447–59. [Google Scholar]
13. Sharma NK, Saharia M. DeepSARFlood: rapid and Automated SAR-based flood inundation mapping using vision transformer-based deep ensembles with uncertainty estimates. Sci Remote Sens. 2025;11:100203. doi:10.1016/j.srs.2025.100203. [Google Scholar] [CrossRef]
14. Nazir K, Byun YC. AETUnet: enhancing retinal segmentation with parameter-efficient unet architecture and lightweight attention mechanism. IEEE Access. 2025;13(3):33471–84. doi:10.1109/access.2025.3539372. [Google Scholar] [CrossRef]
15. Li X, Pang S, Zhang R, Zhu J, Fu X, Tian Y, et al. Attransunet: an enhanced hybrid transformer architecture for ultrasound and histopathology image segmentation. Comput Biol Med. 2023;152(2):106365. doi:10.1016/j.compbiomed.2022.106365. [Google Scholar] [PubMed] [CrossRef]
16. Madake J, Mali R, Shahapure A, More P, Bhatlawande S. FloodDetectionNet: U-Net attention based flooded area segmentation. In: International Conference on Innovations and Advances in Cognitive Systems. Cham, Switzerland: Springer; 2024. p. 319–33. [Google Scholar]
17. Wu H, Song H, Huang J, Zhong H, Zhan R, Teng X, et al. Flood detection in dual-polarization SAR images based on multi-scale deeplab model. Remote Sens. 2022;14(20):5181. doi:10.3390/rs14205181. [Google Scholar] [CrossRef]
18. Islam MS, Sun X, Wang Z, Cheng I. FAPNET: feature fusion with adaptive patch for flood-water detection and monitoring. Sensors. 2022;22(21):8245. doi:10.3390/s22218245. [Google Scholar] [PubMed] [CrossRef]
19. Wu X, Zhang Z, Xiong S, Zhang W, Tang J, Li Z, et al. A near-real-time flood detection method based on deep learning and SAR images. Remote Sens. 2023;15(8):2046. doi:10.3390/rs15082046. [Google Scholar] [CrossRef]
20. Pally R, Samadi S. Application of image processing and convolutional neural networks for flood image classification and semantic segmentation. Environ Model Softw. 2022;148:105285. [Google Scholar]
21. Waqar M, Kim YW, Byun YC. A Stacking ensemble framework leveraging synthetic data for accurate and stable crop yield forecasting. IEEE Access. 2025;13(1):136909–26. doi:10.1109/access.2025.3591802. [Google Scholar] [CrossRef]
22. Yin Z, Leon AS. Riverine flood hazard map prediction by neural networks. HydroResearch. 2025;8(16):139–51. doi:10.1016/j.hydres.2024.10.003. [Google Scholar] [CrossRef]
23. Mesvari M, Shah-Hosseini R. Flood detection based on UNet++ segmentation method using Sentinel-1 satellite imagery. Earth Observ Geomat Eng. 2023;7(1):1–7. [Google Scholar]
24. Gandhi J, Gawde S, Ghorai A, Dholay S. Flood water depth classification using convolutional neural networks. In: 2021 International Conference on Emerging Smart Computing and Informatics (ESCI); 2021 Mar 5–7; Pune, India. p. 284–9. [Google Scholar]
25. Hidayat MT, Adiba F, Yahya M, Andayani DD, Kaswar AB. Enhanced flood detection on highways: a comparative study of MobileNet and VGG16 CNN models based on CCTV images. In: 2024 4th International Conference of Science and Information Technology in Smart Administration (ICSINTESA); 2024 Jul 12–13; Balikpapan, Indonesia. p. 125–30. [Google Scholar]
26. Du W, Qian M, He S, Xu L, Zhang X, Huang M, et al. An improved ResNet method for urban flooding water depth estimation from social media images. Measurement. 2025;242(2022):116114. doi:10.1016/j.measurement.2024.116114. [Google Scholar] [CrossRef]
27. Lin H, Luo J, Zhou C, Tao Z. Research on model material selection based on inception similarity in impact analysis of flood overtopping on tailings dam. Environ Earth Sci. 2023;82(11):276. doi:10.1007/s12665-023-10965-5. [Google Scholar] [CrossRef]
28. Wan J, Xue F, Shen Y, Song H, Shi P, Qin Y, et al. Automatic segmentation of urban flood extent in video image with DSS-YOLOv8n. J Hydrol. 2025;655(128545):132974. doi:10.1016/j.jhydrol.2025.132974. [Google Scholar] [CrossRef]
29. Situ Z, Zhong Q, Zhang J, Teng S, Ge X, Zhou Q, et al. Attention-based deep learning framework for urban flood damage and risk assessment with improved flood prediction and land use segmentation. Int J Disaster Risk Reduct. 2025;116(2):105165. doi:10.1016/j.ijdrr.2024.105165. [Google Scholar] [CrossRef]
30. Khan SD, Basalamah S. Multi-scale and context-aware framework for flood segmentation in post-disaster high resolution aerial images. Remote Sens. 2023;15(8):2208. doi:10.3390/rs15082208. [Google Scholar] [CrossRef]
31. Ashikuzzaman M, Emran MA, Rahul MKA, Ornab SA, Rahman M, Abedin S. Flood area detection and segmentation using satellite image in Bangladesh by U-Net: a deep learning approach. In: 2025 International Conference on Electrical, Computer and Communication Engineering (ECCE); 2025 Feb 13–15; Chittagong, Bangladesh. p. 1–6. [Google Scholar]
32. Sunil P, Sinha S, Roy R. SegNet-ATT: cross-channel and spatial attention-enhanced U-Net for semantic segmentation of flood affected areas. In: International Conference on Pattern Recognition. Cham, Switzerland: Springer; 2024. p. 287–300. [Google Scholar]
33. Danish MU, Buwaneswaran M, Fonseka T, Grolinger K. Graph attention convolutional U-NET: a semantic segmentation model for identifying flooded areas. In: IECON 2024-50th Annual Conference of the IEEE Industrial Electronics Society; 2024 Nov 3–6; Chicago, IL, USA. p. 1–6. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools