
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Lightweight Airborne Vision Abnormal Behavior Detection Algorithm Based on Dual-Path Feature Optimization
1 School of Information Engineering, Engineering University of PAP, Xi’an, 710086, China
2 Unit Command Department, Officers College of PAP, Chengdu, 610213, China
* Corresponding Author: Yueping Peng. Email:
(This article belongs to the Special Issue: Advances in Deep Learning and Neural Networks: Architectures, Applications, and Challenges)
Computers, Materials & Continua 2026, 86(2), 1-31. https://doi.org/10.32604/cmc.2025.071071
Received 30 July 2025; Accepted 12 September 2025; Issue published 09 December 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Aiming at the problem of imbalance between detection accuracy and algorithm model lightweight in UAV aerial image target detection algorithm, a lightweight multi-category abnormal behavior detection algorithm based on improved YOLOv11n is designed. By integrating multi-head grouped self-attention mechanism and Partial-Conv, a two-way feature grouping fusion module (DFPF) was designed, which carried out effective channel segmentation and fusion strategies to reduce redundant calculations and memory access. C3K2 module was improved, and then unstructured pruning and feature distillation technology were used. The algorithm model is lightweight, and the feature extraction ability for airborne visual abnormal behavior targets is strengthened, and the computational efficiency of the model is improved. Finally, we test the generalization of the baseline model and the improved model on the VisDrone2019 dataset. The results show that com-pared with the baseline model, the detection accuracy of the final improved model on the airborne visual abnormal behavior dataset is improved from 90.2% to 94.8%, and the model parameters are reduced by 50.9% to meet the detection requirements of high efficiency and high precision. The detection accuracy of the improved model on the Vis-Drone2019 public dataset is 1.3% higher than that of the baseline model, indicating the effectiveness of the improved method in this paper.Keywords
Mass security incidents pose a serious threat to social stability and people’s lives and property safety. Traditional manual monitoring methods have some drawbacks. Most of the surveillance cameras are limited in height and Angle, and in the face of a large area, there may be monitoring blind spots or fuzzy imaging of individual behavior, resulting in the inability to accurately identify abnormal behavior. Therefore, in order to effectively assist social security departments to deal with social mass security incidents, it is of great research value to accurately and quickly detect group abnormal behaviors [1].
With the rapid development of UAV technology, UAV has the characteristics of flexibility, low cost and easy deployment, and can quickly avoid obstacles to obtain a broad monitoring field of view. Therefore, UAV plays an important role in emergency rescue and disposal of social emergency security incidents. Object detection methods based on deep learning are widely used in aerial image detection tasks [2]. YOLO (you only look once) series algorithms first proposed the concept of one-stage detection, which has shorter detection time by eliminating the operation of generating pre-selected boxes in two-stage algorithms. It is usually used for real-time detection tasks [3]. The problems that need to be solved in aerial image detection tasks can be mainly summarized as the following three points:
• First, the UAV is a mobile platform in the air. Due to the continuous change of the airborne perspective, the abnormal human behavior has the complex situation of multi-scale characteristics of the target, and the abnormal behavior shows the characteristics of small target detection in some airborne perspectives.
• Second, the UAV aerial image detection task has high requirements for accuracy and real-time performance, and the model with a large number of parameters has large computational overhead. If lightweight processing is carried out, the detection accuracy will be reduced, and the detection accuracy and detection speed cannot be well balanced.
• Thirdly, due to the small amount of public data on abnormal behaviors of people under aerial vision, and the fact that most datasets only have one category, or the number of abnormal behavior categories is too small compared to normal categories, there exists a problem of long-tail distribution in abnormal behavior data.
Due to the good performance of YOLOv11n model in algorithm lightweight and detection accuracy, this paper chooses the YOLOv11n model to solve the imbalance between aerial image detection accuracy and proposes a lightweight airborne visual abnormal behavior detection algorithm. The main innovations are as follows:
1. A Dual-channel Feature Packet Fusion (DFPF) module is designed to enhance the multi-scale feature extraction ability of the model and improve the computational efficiency of the model by fusing the channel-level multi-head self-attention mechanism and Partial Conv.
2. The DFPF module proposed in this paper is effectively combined with the C3K2 module to form the C3K2-DFPF module, which improves the YOLOv11n model and improves the detection accuracy of the model.
3. The unstructured pruning and feature distillation techniques are used to lightweight the model and improve the detection ability of the model for multi-category abnormal behaviors of airborne vision.
2.1 Airborne Visual Object Detection
Since the UAV belongs to the aerial mobile platform, the distance and the airborne view Angle between the UAV and the target to be detected will also change during the maneuvering process, so the abnormal behavior target in the data set will show a multi-scale feature distribution. In some aerial images, the human behavior characteristics are small targets, usually containing only a small number of pixels. It is easy to lose important information, resulting in low accuracy of model detection [4]. At the same time, due to the complex background interference in aerial images, there may also be overlaps and occlusion between human actions, which further increases the difficulty of detection. In order to improve the adaptability and detection accuracy of the model for complex scenes. Zhang et al. [5] proposed a dual-temporal feature aggregation module (BFAM) by using hole group convolution and SimAM attention mechanism, so as to make the network focus on pixel-level features, extract features of different receptive fields, and perform feature fusion through channel splicing and down sampling to compensate for the loss of detail information in deep features. Dai et al. proposed the iterative attention feature fusion (iAFF) mechanism to solve the problem of fusion of different scales and semantic features [6]. The multi-scale channel attention mechanism was mainly used to fuse different features in the dual-branch structure model to enhance the detection ability of the model for objects of different scales. Therefore, in the object detection network, the design of the double-branch network structure can make the model focus on objects of different scales, respectively, and improve the accuracy of model detection by integrating the features of these branches, aggregating multi-scale features and combining high-level and low-level semantic information [7].
In addition to the two-branch feature extraction module network design introduced above, the Attention mechanism is also widely used to enhance the feature expression of the model. In order to efficiently deal with limited information resources, the model needs to be able to focus on specific parts in the target area. According to the implementation characteristics of Attention mechanism [8], it is usually divided into Channel Attention, Spatial Attention, Self-Attention and Dynamic Attention. Pan et al. proposed ACmix hybrid self-attention mechanism [9]. Firstly, it projected the input feature map through three 1 × 1 convolutions to generate intermediate features and then aggregated them according to the self-attention and convolution paradigms, respectively. Finally, the outputs of different feature maps are added together.
Since it is quite difficult thnbo deploy neural networks on embedded devices with limited storage space and computing resources, it is necessary to compress the amount of model calculation and parameters [10]. The reliable lightweight network structure design can effectively reduce the number of parameters of the model. There are too many redundant parameters in the neural network model from the convolutional layer to the fully connected layer. Pruning operation can remove the redundant part in the network structure to achieve the effect of lightweight model. However, the accuracy of model detection may de-crease after model pruning, especially in multi-category target detection, because different targets need different expression features. Therefore, part of the network model structure may affect the expression ability of the model after pruning [11]. In order to cope with the decline in detection accuracy after model pruning, model distillation is usually performed after pruning operation. Knowledge distillation is an effective method to further improve the accuracy of model checking [12], which can be divided into the following three types according to the use method: Response-based knowledge distillation (using the output of the teacher model or imitation of the final prediction), feature-based knowledge distillation (using the feature representation in the middle layer of the teacher model), and relation-based knowledge distillation (exploiting the relationship between different layers in-side the model or different data points). Each method aims to extract effective information from the large model and instill this information into the student model through a specific loss function. At present, distillation technology has not been widely used in the improvement of YOLO series algorithms, especially for airborne vision multi-category ab-normal behavior target detection [13]. Therefore, we choose to use distillation technology on the improved model after pruning, so as to realize the improvement of detection performance while reducing the weight of the model.
2.3 Airborne Vision Multi-Class Abnormal Behavior Dataset
There are few public datasets of abnormal crowd behavior in aerial images, and most of them have a single category, which does not have universality and generalization [14]. Therefore, in order to obtain abnormal behavior data with multiple categories and different feature region sizes, we use drones to shoot abnormal behavior videos according to different perspectives and heights and obtain single frame pictures by frame extraction [15]. It is divided into five abnormal behavior categories, which are “normal”, “fight”, “run”, “gather” and “fall”. Due to the small number of abnormal behavior categories in the dataset, we choose to expand the data of abnormal categories by data enhancement methods such as image flipping, center cropping, adding noise, changing brightness, and enhancing contrast or saturation, so as to weaken the problem of long tail distribution of data caused by less abnormal category data. The total number of the expanded data set is 8186, and then according to the ratio of 9:1, it is divided into training set and test set [16]. Fig. 1 shows the data of each category in the dataset. Fig. 2 shows the number of data sample categories after data augmentation, the relative size of sample boxes in the training set, the coordinate distribution of the center point of the data set, and the position information of the candidate boxes [17].

Figure 1: Part of the data of each anomaly category in the self-built data set. (a) Normal category; (b) The normal category of occlusion situation exists. (c) Fall category; (d) Cluster category; (e) Fight category; (f) Run category
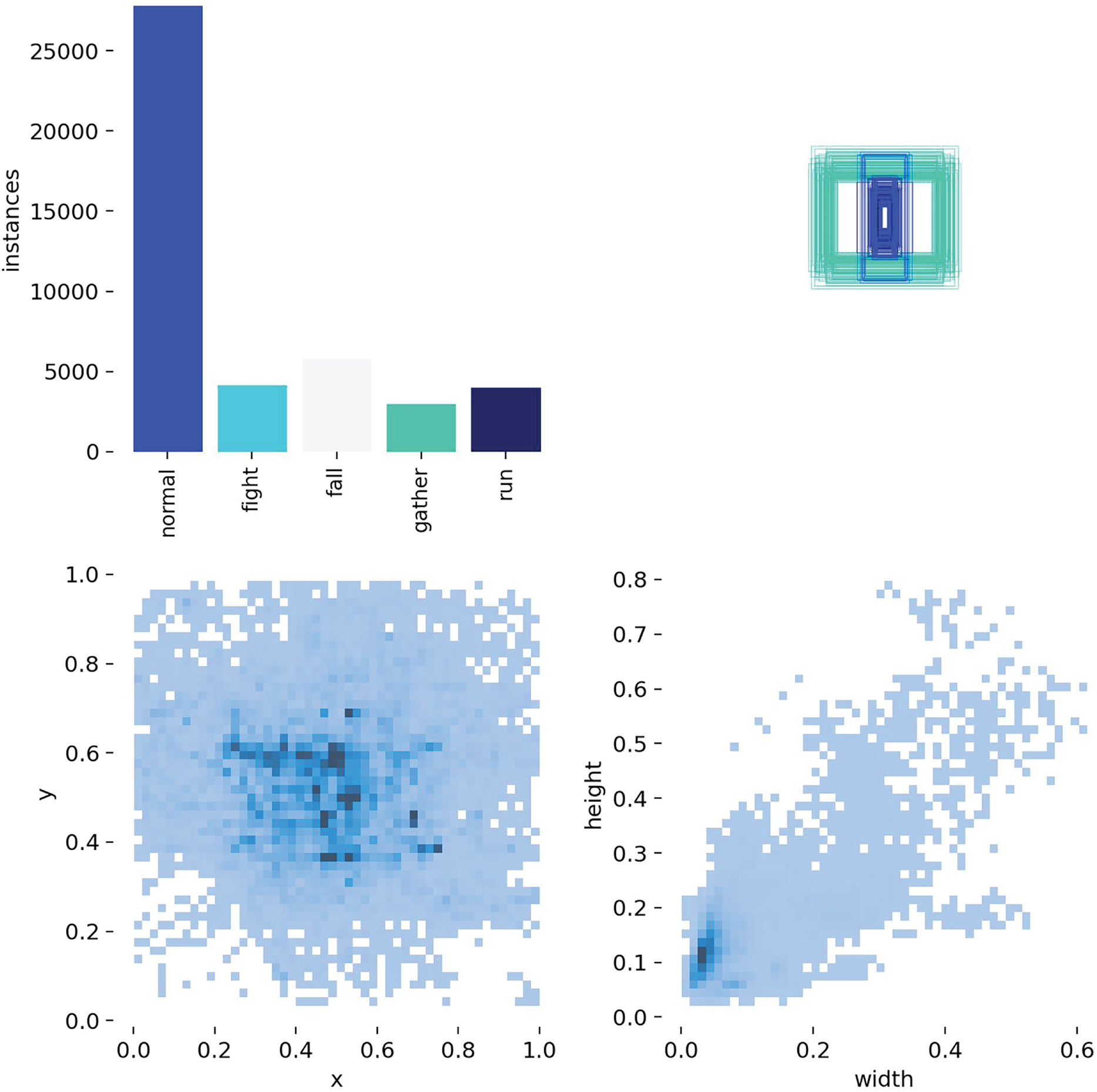
Figure 2: Normalized plot of each index of the dataset
2.4 VisDrone2019 Public Dataset
To illustrate the effectiveness of the improved algorithm in this paper for multi-category object detection tasks in aerial images, we chose to conduct a comparative experiment between the baseline model and the final improved model in this paper on the VisDrone2019 public dataset. The VisDrone2019 dataset was constructed and made public by Tianjin University, including various environmental backgrounds, target density distributions, lighting conditions, and weather conditions, etc. This paper selects a total of 10,209 aerial images for testing, including 6471 images in the training set, 548 images in the validation set, and 3190 images in the test set. The dataset consists of 10 categories, namely pedestrian, people, bicycle, car, van, truck, tricycle, awning-tricycle, bus, and motor. The number of sample categories in the public dataset, the relative dimensions of sample boxes in the training dataset, the distribution of center point coordinates in the dataset, and the position information of candidate boxes are shown in Fig. 3.
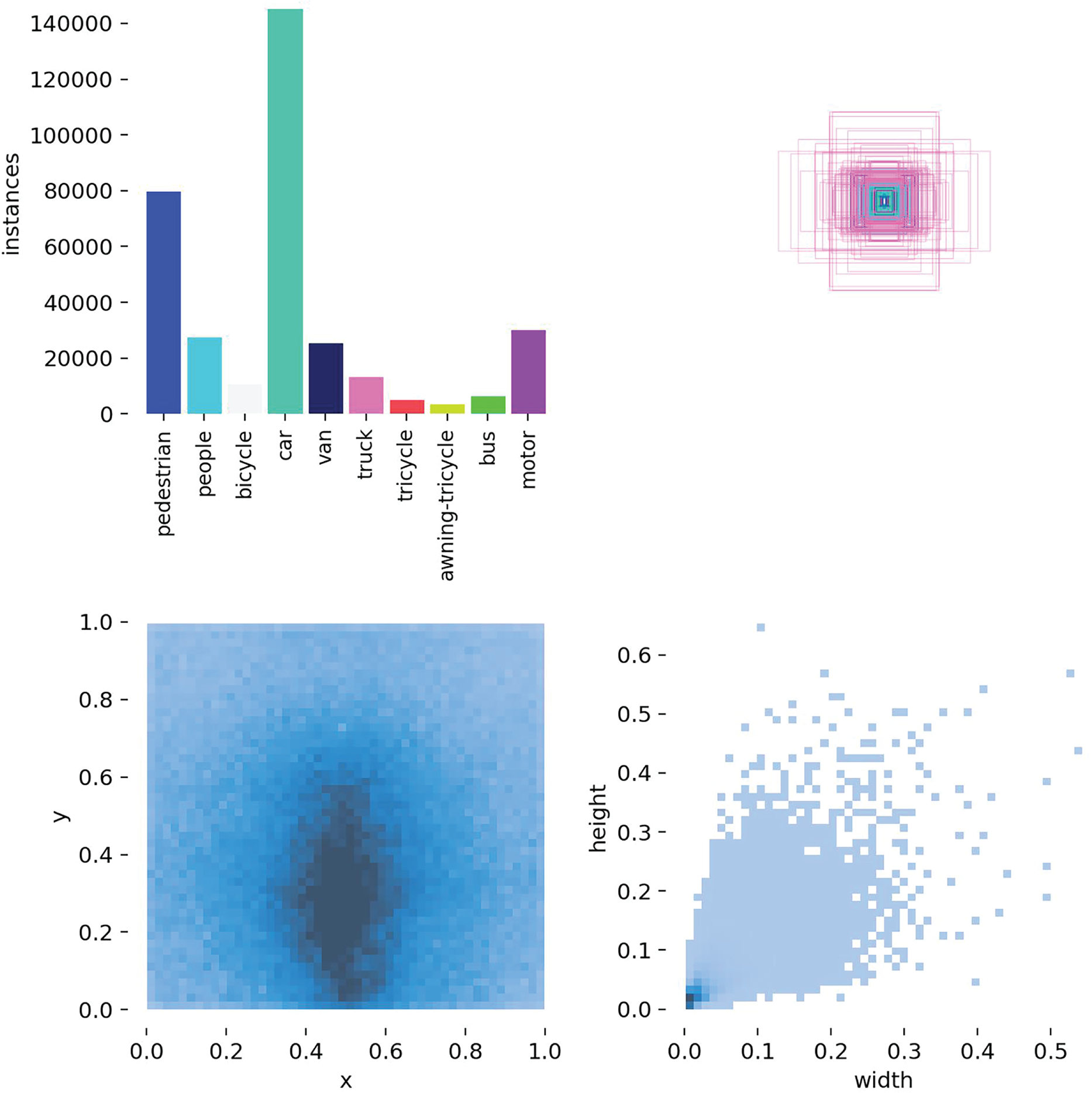
Figure 3: Normalized graph of the VisDrone2019 dataset
The C3K2 module in YOLOv11 model is designed based on the C3 module, mainly by introducing a multi-scale C3K module, where the K value is used to adjust the size of the variable convolution kernel, so as to change the size of the receptive field and capture a wider range of context information. At the same time, the Bottleneck structure is also used in the module to enhance the feature extraction ability, but in the test, it is found that the performance is not good for the complex airborne vision multi-category abnormal behavior detection task. This is because the multi-category detection in complex scenes requires more powerful feature representation ability, and there is no fixed paradigm for human abnormal behavior [18]. Different abnormal behaviors may be reflected in the same detection image at the same time, and there is mutual occlusion, which leads to the reduction or mixing of some abnormal behavior features, resulting in the model cannot accurately detect [19].
In order to extract the deep features of the network more effectively, this paper pro-poses the DFPF module, which has two inputs, x and skip. In the Bottleneck module of the YOLOv11 model, the output feature after the convolutional layer and batch normalization layer is set to x, and the input of the skip connection part is set to SKIP [20]. We use DFPF to reconstruct the Bottleneck structure in YOLOv11 model. C3K2 module usually contains two C3K modules, and C3K module is composed of two groups of Bottleneck modules, so we use the proposed DFPF module to fuse into the Bottleneck module. It forms the Bottle-neck-DFPF module and is applied in the C3K module to form the C3K-DFPF module and then merges into the original C3K2 module to form the C3K2-DFPF module finally. In the process of designing the experiment, although all C3K2 modules were replaced by the c3K2-DFPF module, the improved self-attention mechanism was not placed in all C3K2-DFPF modules [21]. This is because the self-attention mechanism is more suitable for global feature extraction in context information, and a large number of parameters that need to be calculated will be introduced in the feature propagation stage of the participating model. In the shallow stage of feature extraction of YOLOv11 model, the information in the feature map does not contain a lot of global information, and the context information is still less. Therefore, in order to keep the number of model parameters and computation within a reasonable interval of lightweight, we choose to use the improved self-attention mechanism in the DFPF module only in the output part of the model back-bone network, as well as the output part of the down-sampling and detection head, while the other parts of the network only use 1 × 1 × 1 spatial convolution to extract spatial features [22]. This does not introduce additional calculation parameters and can ensure that the improved self-attention mechanism can effectively play the extraction effect of global features for context information. Fig. 4 shows the structure diagram of the improved YOLOv11n model proposed in this paper. The original C3K2 structure diagram of the baseline model is shown in Fig. 5a, and the improved C3K2-DFPF module in this paper is shown in Fig. 5b.
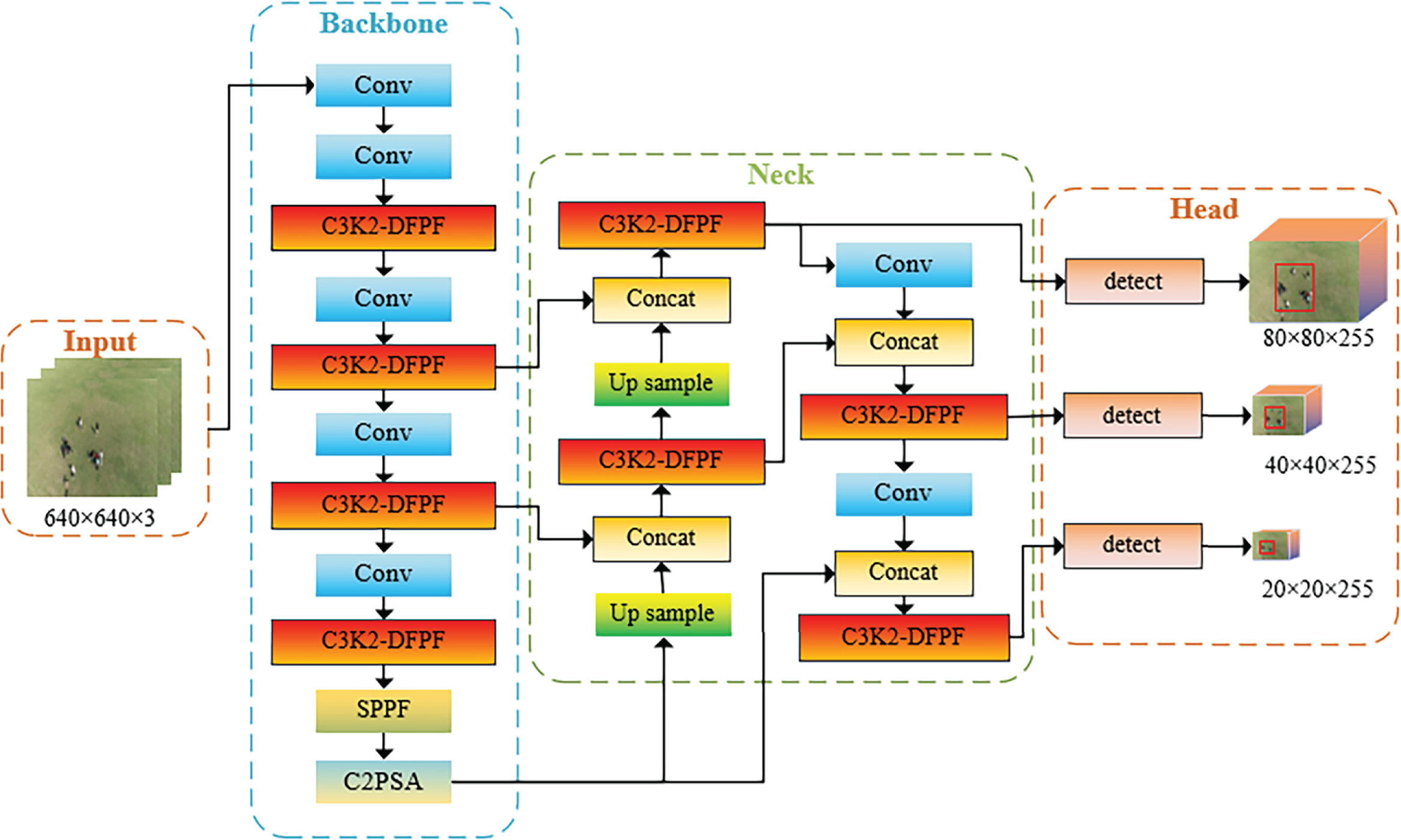
Figure 4: Improved YOLOv11n model structure diagram
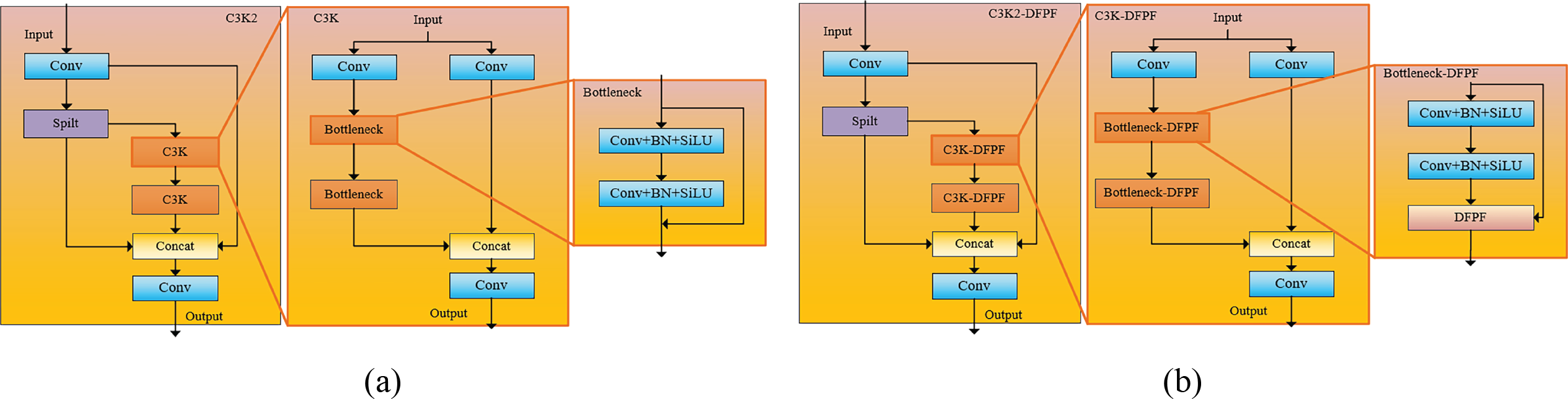
Figure 5: Comparison pictures of the C3K2 model before and after improvement. (a) C3K2; (b) C3K2-DFPF
3.1 Dual-Channel Feature Packet Fusion Module
In order to make full use of complex spatial information and channel information at different scales, improve the robustness of airborne visual abnormal behavior detection. We propose a Dual-channel feature packet fusion module (DFPF) to fuse multi-scale features based on global and spatial information in the feature extraction process. In the fusion process, the channel-level multi-head self-attention mechanism is used to retain important feature maps, and the Partial-Conv is used to improve the spatial information extraction mechanism to highlight important spatial regions, reduce the complexity of the model and improve the computational efficiency [23]. The DFPF model structure diagram is shown in Fig. 6.

Figure 6: DFPF module structure diagram
Firstly, the DFPF module uses two input feature maps x and skip layer, and the input features are denoted as
Due to the complex background and noise interference of aerial images, the Max pooling operation will take the maximum value of the pixels in the pooling area, which makes the backbone network more sensitive to the texture information in the feature map, so it can enhance the features of small target pixels. Average pooling can focus on the global average feature and has a smoothing effect on the background noise.
We choose to compress a part of the input feature maps through average pooling and Max pooling for global feature compression, and compress the feature maps of each channel to the size of 1 × 1 to capture the channel-level global information. This global information extraction ability enables the channel attention mechanism to understand the semantics of the feature map as a whole, rather than focusing on the local feature patterns. Then, Parietal-Conv is used to generate channel attention weights, and the fused features are weighed on the channel dimension to enhance the attention to the key channel features. At the same time, Sigmod function is used to ensure that the attention weights are in a reasonable range and avoid gradient explosion. In the last part of the channel feature extraction branch, the weight and the splicing feature are multiplied channel by channel, and the channel dimension is reduced by 1 × 1 convolution to halve the number of fused feature channels. The calculation process is shown in Eqs. (4) and (5).
The Spatial feature extraction branch uses an improved Multi-head spatial Grouping Self-attention (MSGS) mechanism, which will be explained in detail in Section 3.3. The spatial information of
After the spatial feature extraction branch and the channel feature extraction branch, the spatial attention weights and channel attention weights are obtained, respectively, and the weighted fusion is carried out. Finally, the processed feature map is output. The weighted fusion calculation process is shown in Eq. (13). Attention when weighting fusion
Then the feature map
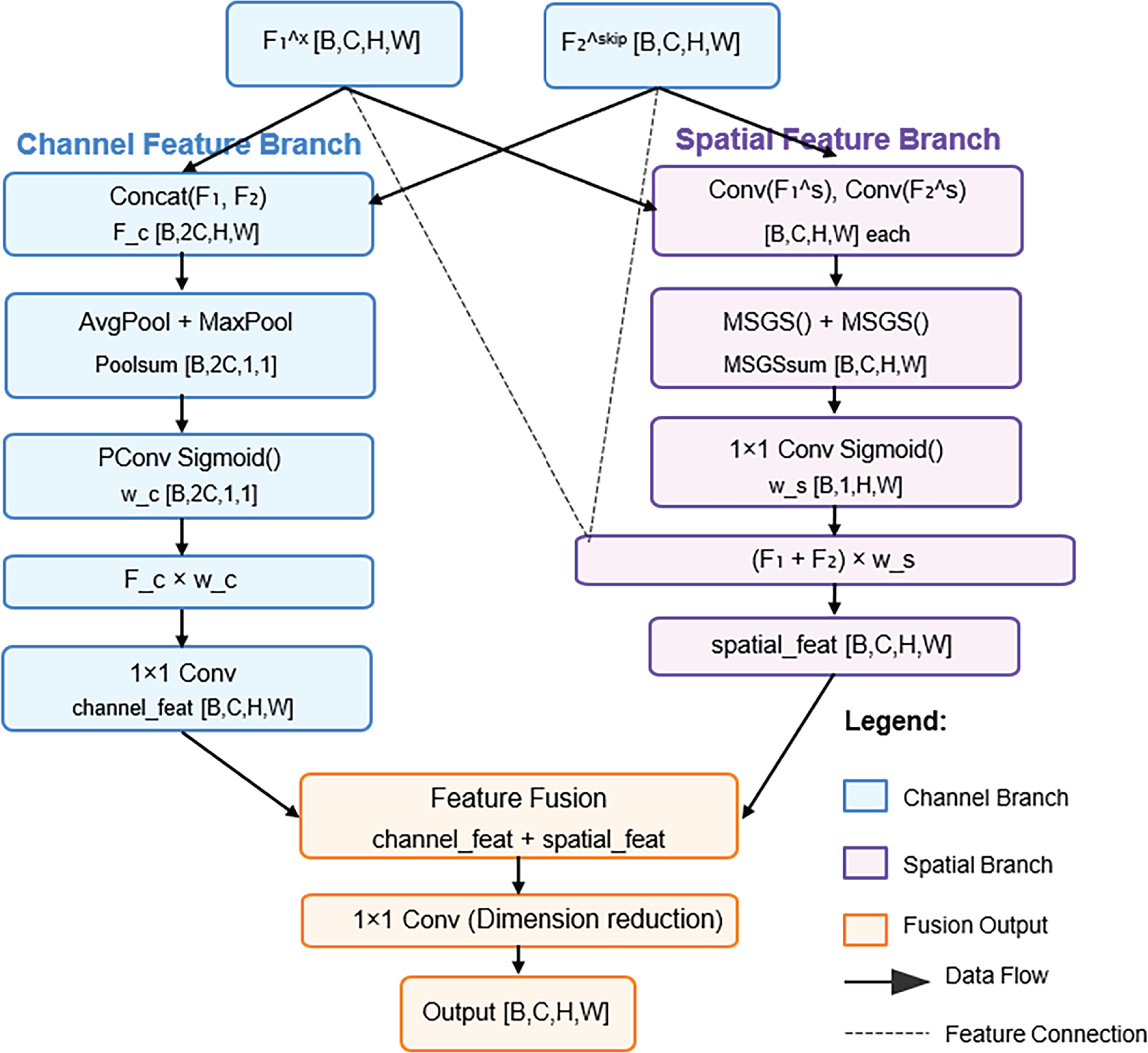
Figure 7: Flowchart of dual-channel feature packet fusion module
Partial-Convolution
The traditional Depth-wise separable Convolution is composed of a Depth-wise Convolution layer and a Pointwise Convolution layer. Firstly, the input channel features are convolved by 3 × 3 channels. Then a 1 × 1 pointwise convolution is used to combine the output of the channel, which can effectively reduce the number of parameters and computation. The depth-wise separable convolution operation is shown in Fig. 8 [25].

Figure 8: Depth-wise separable convolution operations
Although the FLOPs are reduced during the computation of DWConv, the frequent memory accesses cause the computation to be slower. Therefore, in order to reduce computational redundancy and memory access, and improve computational efficiency, this paper uses Partial-Convolution (hereinafter referred to as PConv) to replace the deep convolution in the model, to achieve the purpose of lightweight model to a certain extent. P-Conv is a convolution operation that optimizes computational efficiency by calculating part of the channels. Its core idea is to apply regular convolution only to part of the channels of the input feature map, leaving the rest unchanged, thereby reducing FLOPs (Floating Point Operations) while improving FLOPS (Floating Point Operations per Second).
Computation process Let the Input feature map be
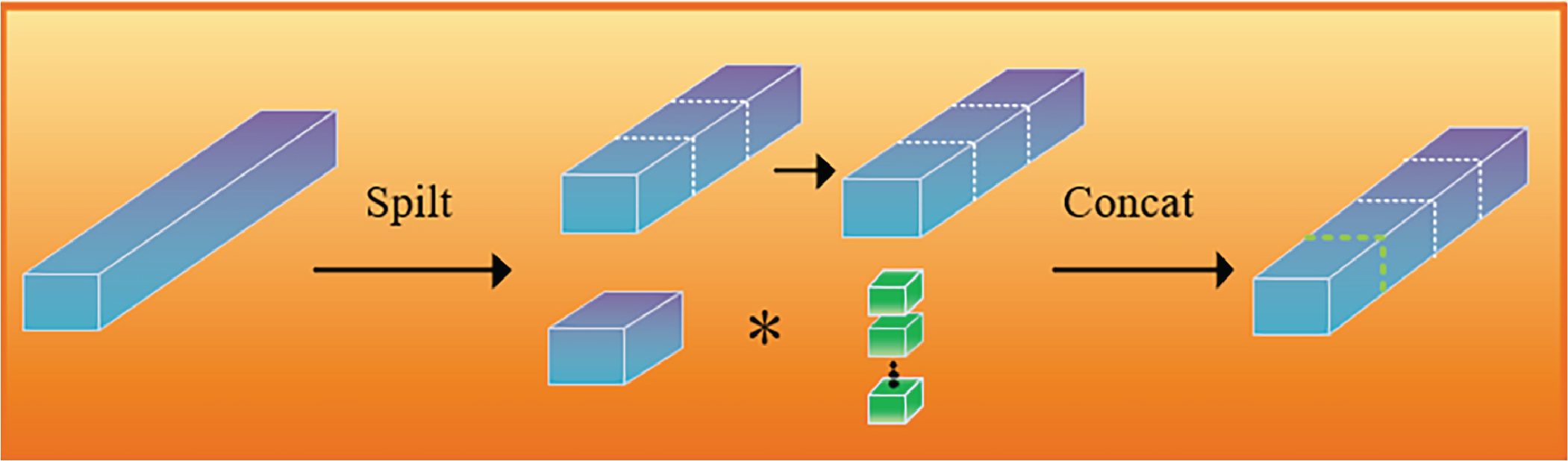
Figure 9: Schematic of the Partial-Convolution process
Compared with the conventional convolution, when
3.2 Multi-Head Spatial Grouping Self-Attention
The improved Multi-head Spatial Grouping Self-attention (MSGS) in this paper is a method that combines some convolution operations and the self-attention mechanism. The aim is to simultaneously utilize the local feature extraction capability of convolution operations and the global dependency modeling capability of self-attention mechanisms. By dividing the feature map into multiple groups of heads and conducting separate attention weight calculations for each group of heads. This enables the MSGS module to capture the dependency relationship between any two positions in the feature map, enhancing the model’s processing ability for complex scenarios.
First, a combined tensor of Query, Key and Value is generated using a common convolutional layer. Then, three sets of PConv are used to generate three corresponding feature maps of Q, K and V in the spatial dimension. Among them, PConv is to alleviate the situation of large computational load in the calculation process of the self-attention mechanism. In the forward propagation stage, the rearrange function needs to be used to transform the dimensions of the three tensors Q, K, and V, and determine the number of multi-head groups. The selection of the number of groups (head) directly affects the computational complexity of the model, its feature expression ability, the performance of model detection, and the memory usage during the detection process. When the number of groups is small, each group has more channels, resulting in higher computational complexity. This, in turn, leads to more thorough feature fusion and stronger feature expression ability. However, it may introduce excessive redundant information, causing overfitting. When the number of groups is large, the number of channels in each group is smaller, the computational complexity decreases, and this leads to an increase in feature independence. The feature expression ability may decline, but it can reduce redundant information and improve generalization ability. The initial shapes of the three tensors Q, K, and V are
Among them,
For each query
Finally, the rearrange function is used to reshape the shape of the attention output back to the original shape, and the attention output is projected through the 1 × 1 convolution layer to obtain the final output, whose tensor dimension is
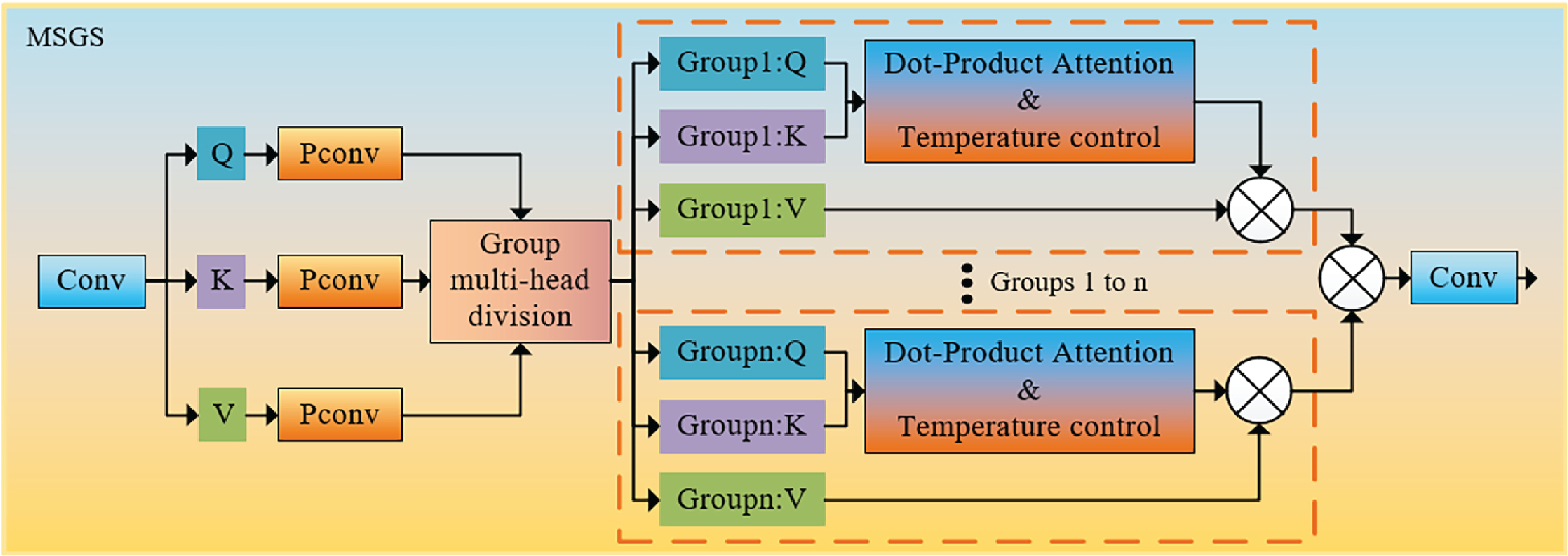
Figure 10: Group multi-head self-attention mechanism diagram
In this paper, Layer-adaptive sparsity for the magnitude-based pruning (Lamp) is used to prune the model. In the pruning process, the score of channel weight is needed to determine whether to remove a channel structure [29]. There is a weight in each connection. Lamp score is the square of weight, and the weight with smaller score is considered as redundant part, that is, the part to be pruned. Lamp is a kind of global pruning, and the design idea is as follows: In a neural network, the weights of a fully connected layer are represented as a two-dimensional matrix, where the rows and columns of the matrix represent the inputs and outputs, respectively, while the weights of a convolutional layer are represented as a four-dimensional matrix, usually
To ensure that the scale of the extracted feature map is consistent between the student model and the teacher model, we choose the YOLOv11x model as the teacher model to distill the improved model after pruning. In this paper, we use the Masked Generative Distillation (MGD) method, which achieves knowledge distillation through two key steps [31]. The first step is Feature Generation, that is, the teacher model generates high-quality feature maps as the learning target of the student model. By simulating the intermediate feature distribution of the teacher model, generative distillation enhances the generalization of the student model and reduces the risk of overfitting caused by insufficient training data. Secondly, the mask guidance is used to guide the student model to focus on the key area in the teacher feature map and avoid the interference of irrelevant background through the dynamic mask mechanism. The MGD distillation process is shown in Fig. 11.
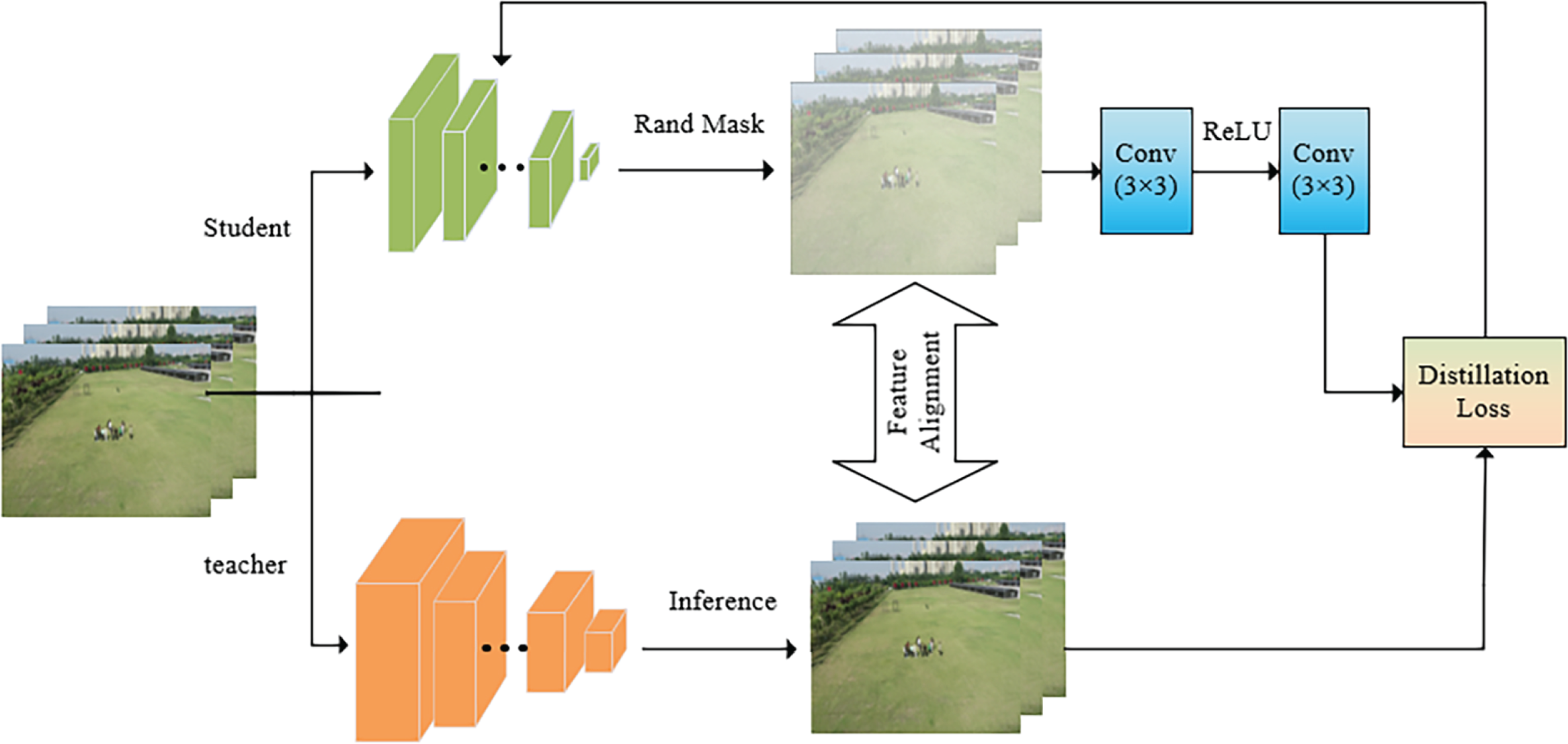
Figure 11: MGD distillation process
The teacher model and the student model respectively extract feature maps
where
Subsequently, the distillation loss
where
4 Experiment and Result Analysis
On the self-built UAV aerial multi-category abnormal behavior dataset, we carry out the application test on the abnormal behavior detection effect of aerial images, adopt a variety of commonly used evaluation indicators, and make horizontal comparisons with other mainstream object detectors to further verify the effectiveness of the algorithm de-signed in this paper. The experimental environment used in this paper is configured as: Windows 10, 64 bit; The CPU processor is Hygon C86 3250 with 64 GB running memory. The GPU was NVIDIA GeForce RTX 3090 (24 GB memory). In the experiment, the iteration batch size is set to 16, the total number of iterations is 100 epochs, the number of workers threads is 8, the initial learning rate is 0.01, the warm-up momentum is 0.8, the bias weight warm-up learning rate is 0.1, and the bounding box loss weight is 0.8. Bounding box loss weight: 7.5; Category loss weight: 0.5; Distributed focus loss weight: 1.5; pose loss weight: 12.0; Target loss weight: 1.0; label_smoothing: 0.0; HSV tone adjustment: 0.015; HSV saturation adjustment: 0.7; HSV brightness adjustment: 0.4; Rotation Angle: 0.0; Translation amplitude: 0.1.
4.1 Ablation Experiment of Feature Fusion Module
To ensure the lightweight of the model and the robustness of the detection effect, the partial convolution and multi-head self-attention mechanism used in this paper are improved for the dual-channel feature extraction module DFPF. In some of the convolutions, the number of different channel subsets is set to affect the effect of feature extraction. Therefore, in order to test the effect of partial convolution separately, we replace the two layers of ordinary convolution in the Bottleneck module with partial convolution, and decrement at equal intervals: Covering the gradient of “from preliminary lightweight to in-depth lightweight” to ensure the full coverage of the search space, five sets of hyperparameters of different channel subsets proportion of 1, 1/2, 1/3, 1/4, 1/5 are designed to verify the different detection effects of multiple types of abnormal behaviors of UAV aerial photography.
When some convolution parameters are set to 1, It means that all channel features have passed the convolution operation, and its effect is equivalent to ordinary convolution, which can represent the baseline YOLOv11n model used in this paper without any modification [33]. When the parameter is 1/3, it means that the input feature channels are evenly divided into three groups, one group is calculated by convolution, and the other two groups directly pass the output. When the parameter is 1/4, it means that the input feature channels are evenly divided into four groups, one group is calculated by convolution, and the other three groups are directly passed output. Represents that the input feature channels are equally divided into four groups, one of which is calculated by convolution, while the remaining three groups directly pass the output, when the parameter is 1/5. The detection result data is shown in Table 1. The detection accuracy is represented by mAP_50, and the line chart between the proportion of different channel subsets and the detection accuracy is shown in Fig. 12.
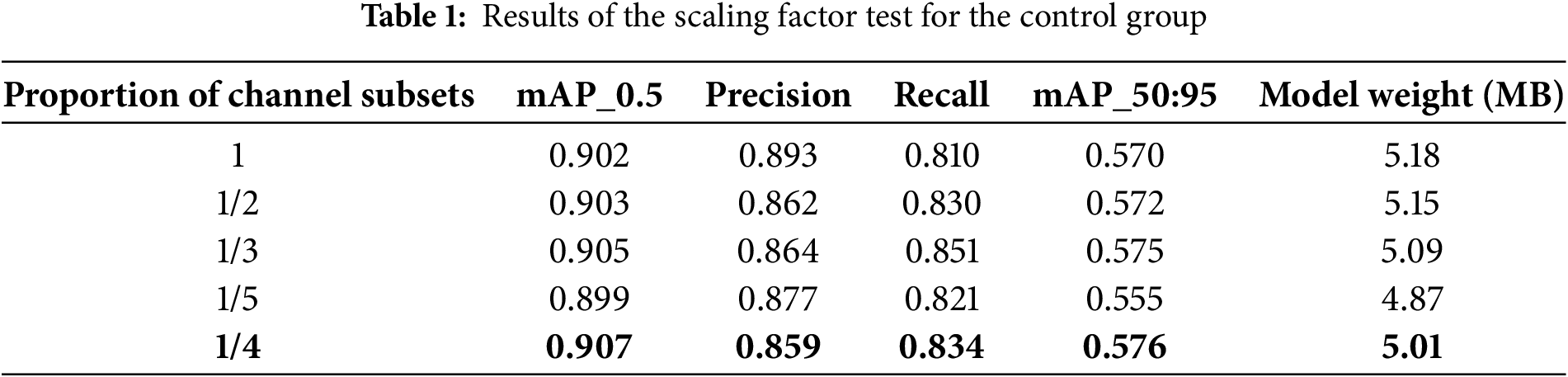
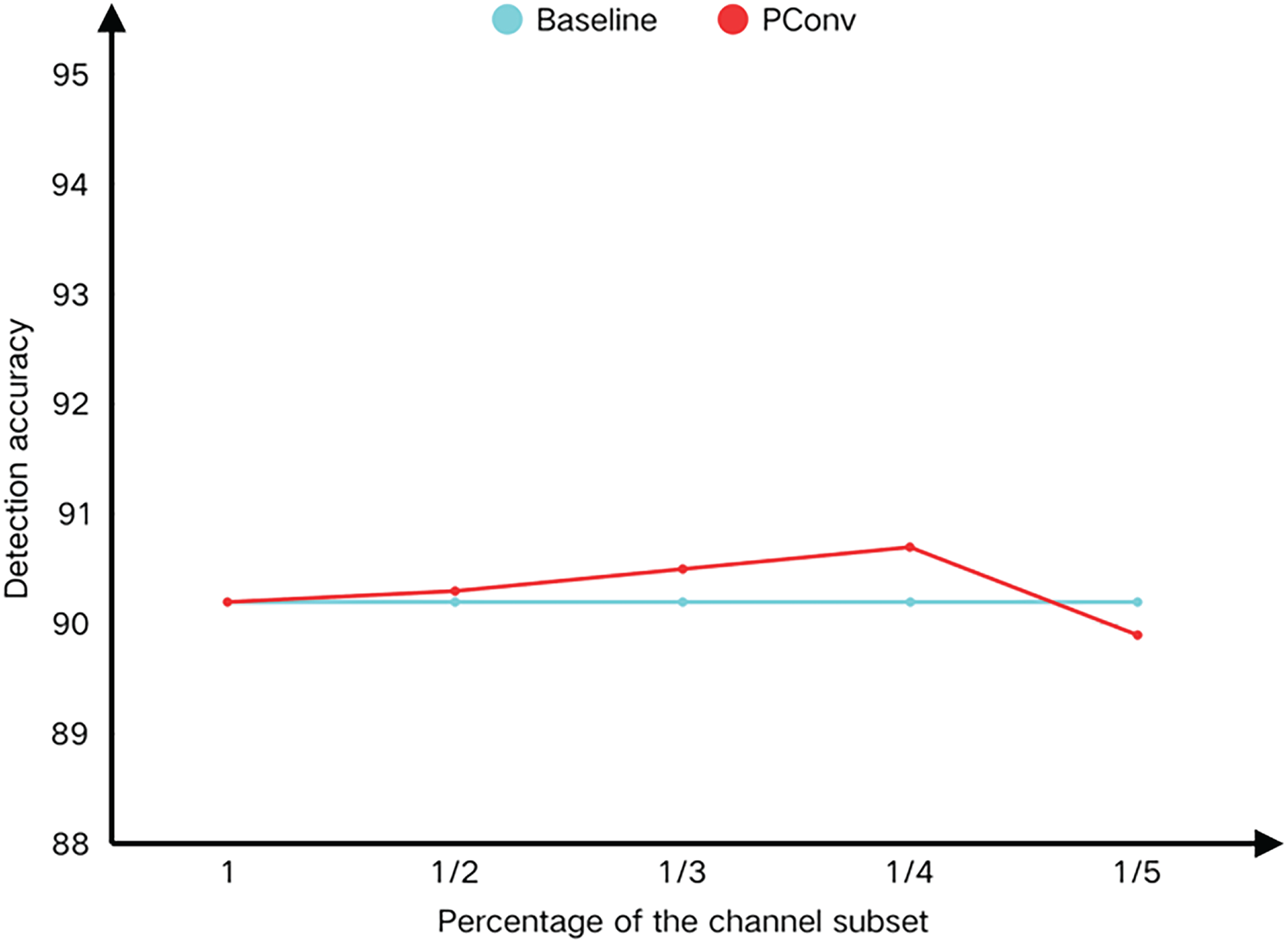
Figure 12: Scale factor test plot
According to the test results and test curve in the table, as the proportion of channel subset gradually decreases in the test process, the amount of calculation shows a downward trend. When the proportion of channel subset is 1/4, the detection accuracy reaches the highest. According to the data in the table, when the parameter of PConv channel subset proportion is 1/2 in the test process, it means that half of the channels are involved in the convolution operation, which has a certain lightweight effect compared with the baseline model, but does not achieve the best lightweight effect. For the aerial image crowd abnormal behavior detection task with few samples and many complex categories, many feature maps show a high degree of pattern similarity, which indicates that when the number of channels is large, there is a lot of repeated information between feature maps, as well as irrelevant information such as noise. Especially in shallow networks, redundant features will dilute key semantic information, so the detection accuracy is improved compared with the baseline model, but it does not achieve the expected effect. However, when part of the convolution parameters is set to 1/5, only 1/5 channels are used for convolution operation. Although the calculation amount will be further reduced, the model detection accuracy begins to decrease. We analyzed that if the proportion of channel subset is too small in the testing process, the model may not be able to learn enough feature information, resulting in insufficient feature expression ability, thus reducing the detection performance. Therefore, a smaller channel subset proportion parameter was not set. In order to realize the lightweight index of the construction module and obtain the generalization index for the abnormal behavior detection task of aerial images, this paper selects the channel subset of the hyperparameter of partial convolution to be 1/4 for subsequent experiments, which means that the input feature channels are evenly divided into four groups, one group is calculated by convolution, and the remaining three groups are directly transmitted to the output [34].
In the MSGS spatial grouping multi-head self-attention mechanism, the number of groups determines how many independent heads the input feature map is divided into, and each group is calculated independently in parallel. The selection of the number of groups directly affects the computational complexity of the model, the ability of feature expression, the performance of model checking and the memory occupation during the checking process. When the number of groups is small, the number of channels in each group is large, and the computational complexity is high, which leads to more full feature fusion and stronger feature expression ability, but too much redundant information may be introduced, resulting in overfitting. When the number of groups is large, the number of channels in each group is small, the computational complexity is reduced, and then the feature independence is enhanced, and the feature expression ability may decrease, but the redundant information can be reduced, and the generalization ability can be improved.
The number of channels (dim) of input features must be divisible by the number of groups so that each group can handle an equal number of channels, resulting in an even distribution of features. Therefore, in this paper, according to the number of groups from low to high, the number of groups is set as 2, 4 and 8 control groups, respectively, to determine the number of groups with the best detection effect for multi-category abnormal behavior of UAV aerial photography. To verify the influence of the number of groups on the experimental results, a test experiment is carried out. The test results are shown in Table 2.
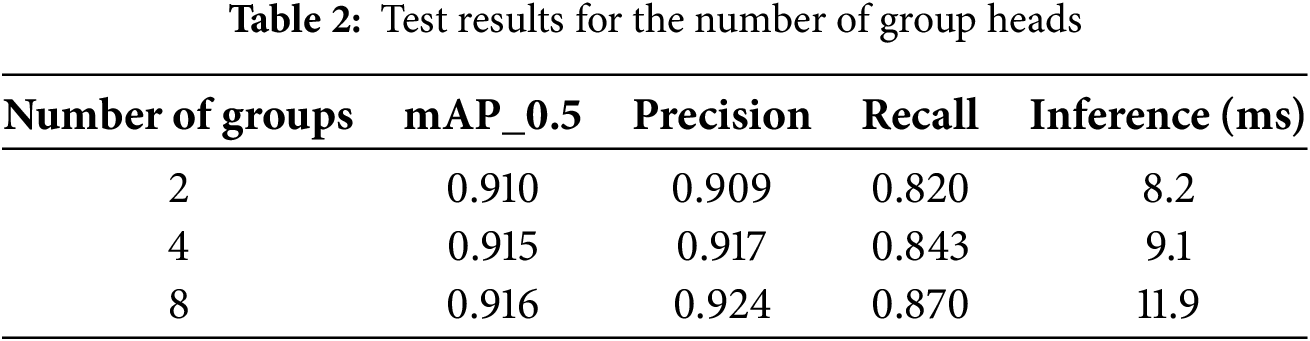
When the number of groups is 4, the detection accuracy and detection calculation time are better balanced. Especially when the number of groups is 8, although the detection accuracy is improved, too much calculation consumption is introduced. It conflicts with the experimental purpose of improving computational efficiency through light-weight algorithms. Therefore, this paper chooses the multi-head self-attention mechanism with a group number of 4 for subsequent experiments.
To verify the detection effect of the improved module proposed in this paper on the abnormal behavior data set of aerial images, ablation experiments are carried out on the improved points in the DFPF module, and the experimental results are shown in Table 3. The Baseline model is YOLOv11n model. Because this paper uses partial convolution and multi-head self-attention mechanism to improve the dual feature fusion mod-ule, the ablation experiment design for partial convolution and multi-head self-attention mechanism is carried out on the basis of the DFPF module, but in order to illustrate the robustness of a single module for detection effect, we also tested the effect of the MSGS module and the partial convolution module separately. We chose to place the MSGS module behind the convolutional layer of the Bottleneck module for testing, and we chose to use PConv to replace the ordinary convolution in the Bottleneck module for testing.
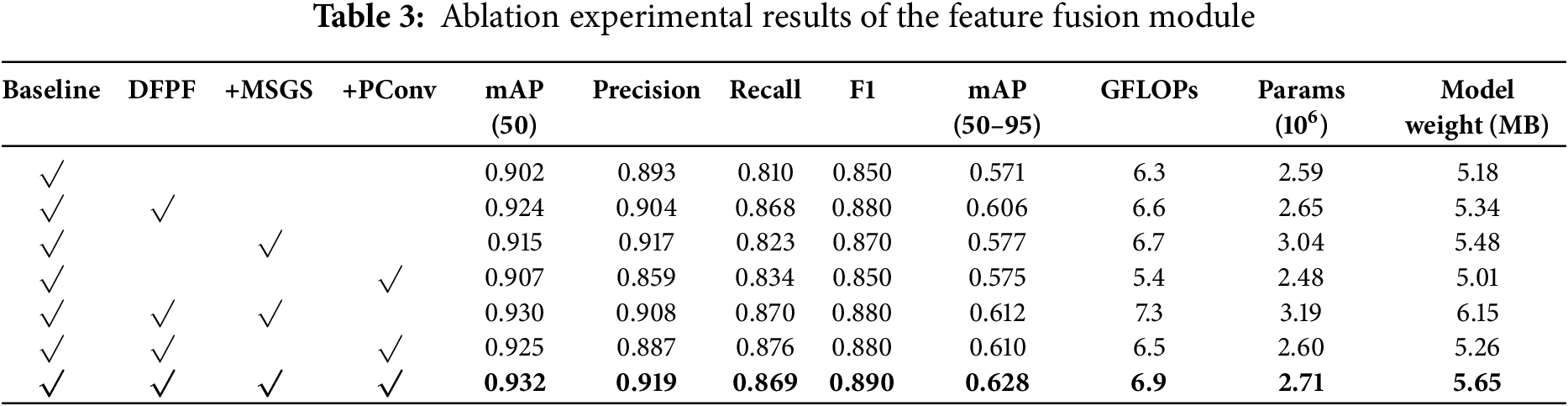
According to the experimental results in Table 3, compared with the baseline model, the detection accuracy of the network model after using the DFPF dual-channel branch feature fusion module proposed in this paper is improved by 3.0%, and the calculation amount and weight of the model are kept within the appropriate range, which lays a good foundation for subsequent pruning and distillation operations. Fig. 13 shows the model detection accuracy plots corresponding to seven groups of control experiments. It can be seen in the figure that the detection accuracy of five abnormal behavior categories in aerial images is significantly improved compared with the baseline model. Especially for the complex behavior category of fighting, the improvement effect of the improved module detection is the most obvious. According to the experimental data in Table 3, after adding the MSGS self-attention module to the C3k2 module in the YOLOv11n baseline model, the mAP_50 is increased by 0.13%, but the calculation amount will increase significantly. After adding the partial convolution module to the baseline model alone, the amount of calculation is significantly reduced, indicating that the lightweight effect of partial convolution is obvious, which can effectively reduce the number of partial parameters of the model and improve the reasoning efficiency of the model. Fig. 13 shows the values of mAP_50 and the detection accuracy of each category of abnormal behaviors for all control groups in the ablation experiment on the abnormal behavior data set in this paper [35]. Fig. 14 shows the iterative curve of the loss function of the improved algorithm in this paper. It can be seen from the figure that after 100 trainings, the detection accuracy of the algorithm model has hardly changed, indicating that the loss function has been fitted.

Figure 13: Results of ablation experiments in the control group

Figure 14: The iterative curve of the loss function of the improved algorithm
To further verify the detection effect of the DFPF module proposed in this paper for multi-category abnormal behavior in aerial images, this paper selected similar feature ex-traction modules proposed in recent years, which are the iAFF dual-branch iterative feature ex-traction module, the ACmix hybrid self-injection mechanism. And the commonly used Mo-bileNetV4 lightweight backbone network, the test results are shown in Table 4.
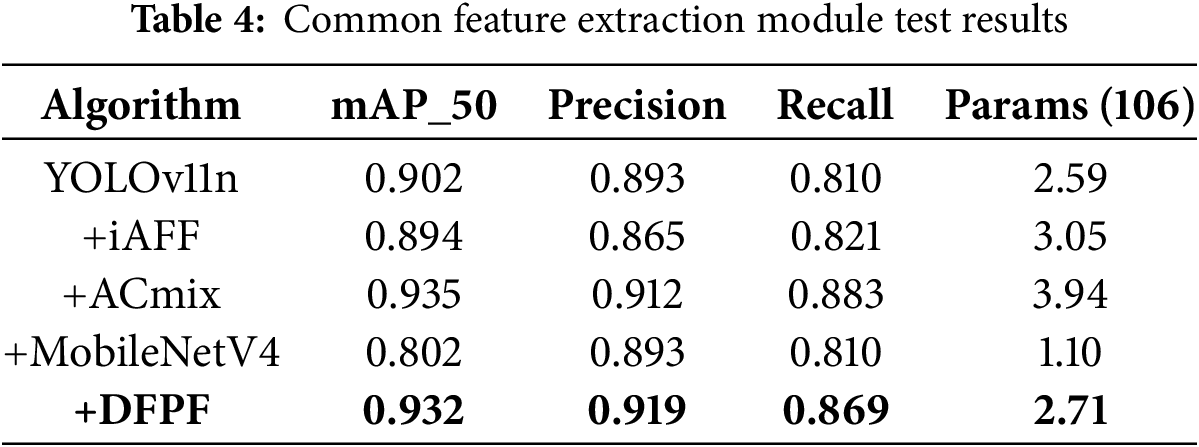
We added the iAFF module, ACmix self-attention mechanism and the DFPF module pro-posed in this paper to the C3K2 module of YOLOv11n model, respectively. In general, the DFPF module proposed in this paper achieves the expected effect of model detection, and its computational overhead and parameter amount are within a reasonable range. The design idea of iAFF module is related to the method of dual-channel feature extraction, which may cause the accuracy of abnormal behavior detection in aerial images to decrease due to the inconsistency between the design purpose and aerial image detection. At the same time, the ACmix hybrid self-attention mechanism has a significant effect on the improvement of detection accuracy, indicating that it can effectively extract context information.
However, compared with the DFPF module proposed in this paper, the detection accuracy of the ACmix self-attention module is only increased by 0.3%, and the number of parameters is significantly increased by 45.4%, which will lead to large computational overhead and is different from the lightweight design requirement of this paper. Then we added the latest lightweight MobileNetV4 network backbone to the baseline model, and its computational overhead and model parameters are significantly reduced, but the detection accuracy for multi-category aerial image object detection tasks is low and does not reach the high accuracy detection standard [36].
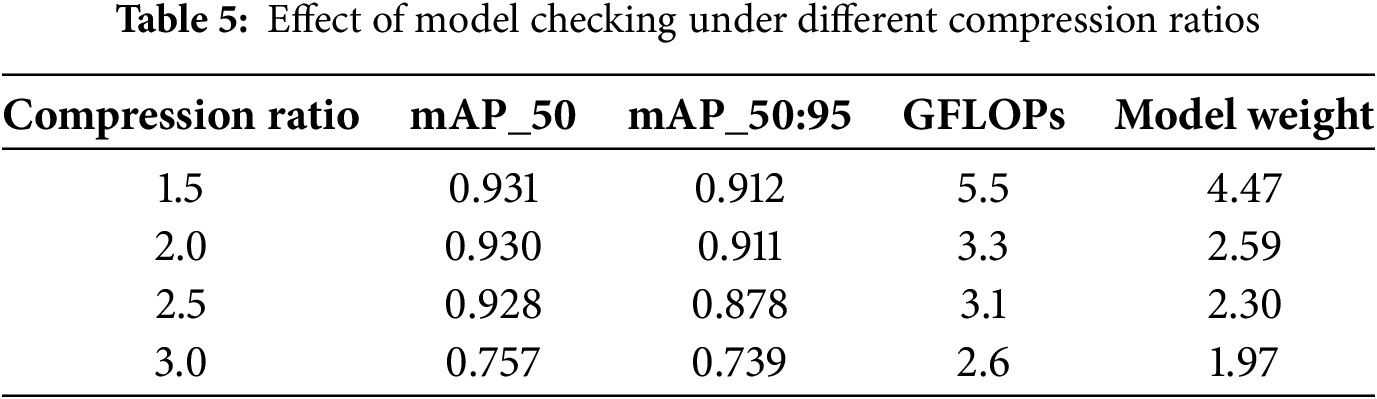
In the model LAMP pruning process, we choose the sparse learning rounds to be 100, aiming to make the model better adapt to the pruned structure and improve the robust-ness of model detection, while avoiding excessive sparse training leading to model over-fitting. During model pruning, it is found that with the increase of compression ratio, the loss of model accuracy also increases. Therefore, it is necessary to find a balance between pruning rate and model accuracy, to achieve lightweight model while maintaining high accuracy. Table 5 shows the effect of model checking under different compression ratios [37].
Since this paper adopts the global pruning method for the airborne visual multi-class object detection task, it is necessary to analyze the relationship between the global pruning rate and the detection accuracy of different object classes. Fig. 15 shows the detection accuracy results tested on the airborne visual abnormal behavior detection dataset under different pruning rates. The figure also shows the detection accuracy of different target categories in the dataset. The data in the figure corresponds to the detection accuracy under pruning rates of 1.5, 2.0, 2.5 and 3.0. As shown in the detection accuracy of each category in Fig. 15, with the gradual increase of the global pruning rate, some feature extraction channels with low weight proportion are reduced, and the model weight is gradually reduced, which means that the number of model parameters is also gradually reduced, but the detection accuracy is gradually reduced.
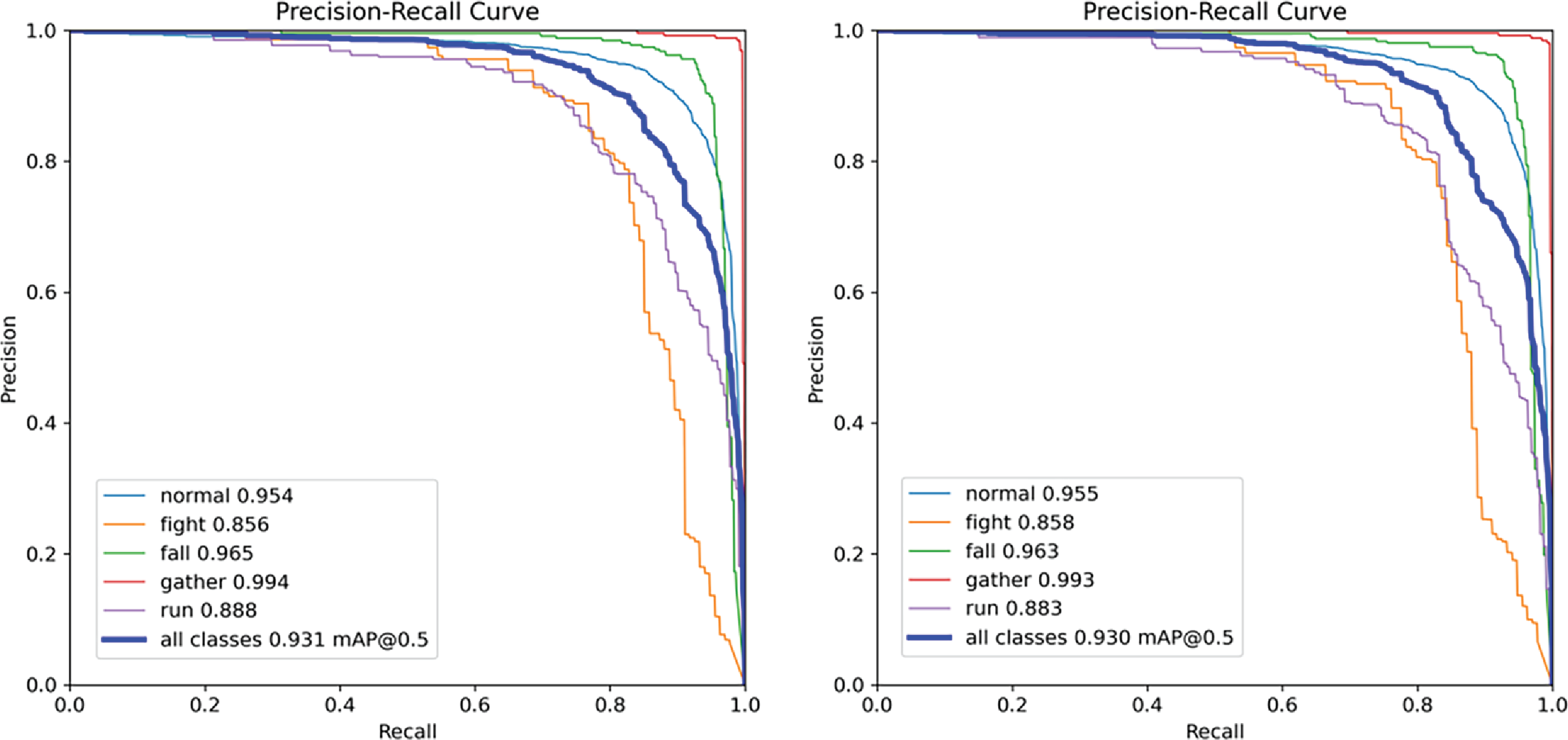
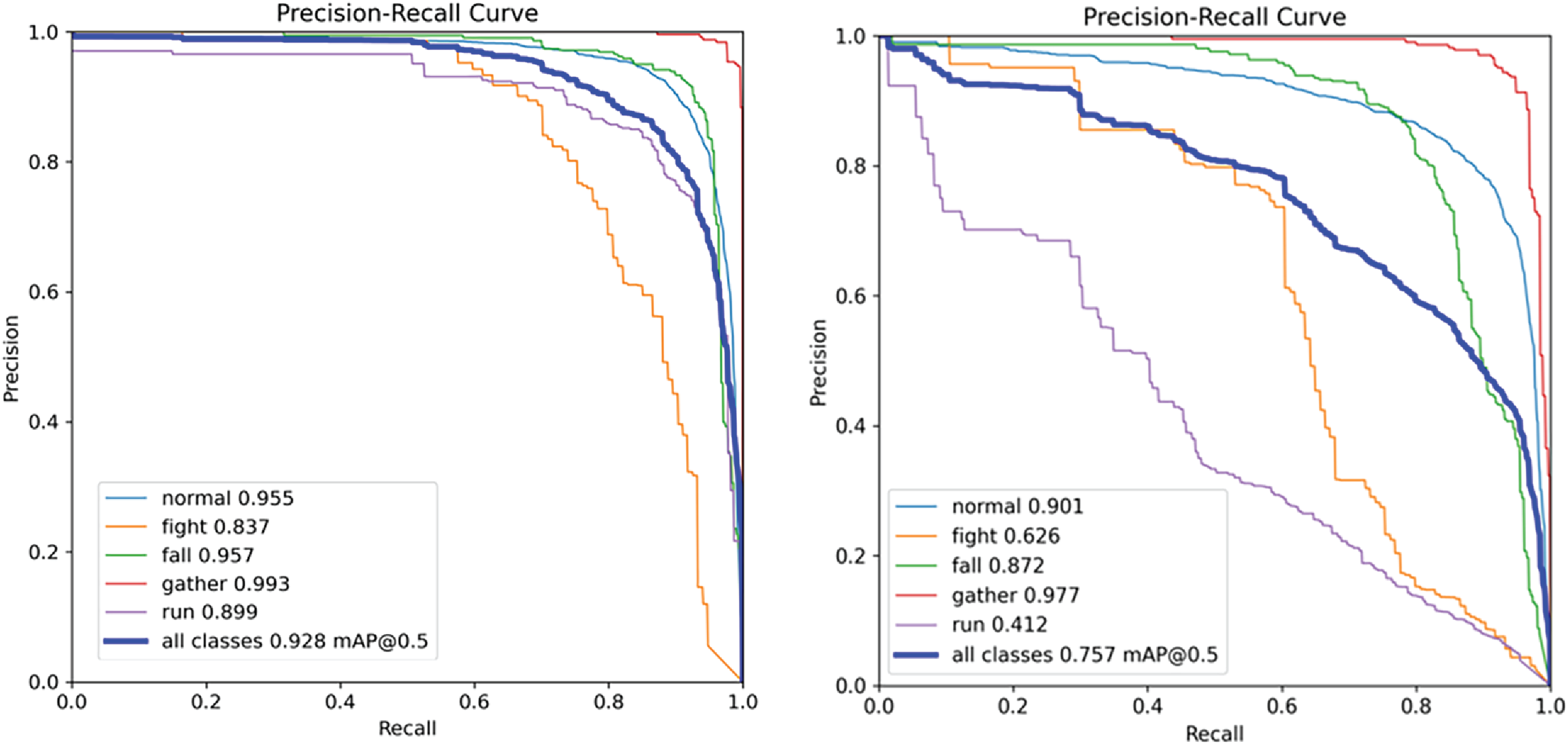
Figure 15: Plots of model detection accuracy for different pruning rates
There are five types of targets in the airborne visual abnormal behavior detection data set. Among them, the “gathering” category belongs to the larger target, which represents the group state, so the detection accuracy of this category changes less, and the model can still effectively recognize it under the condition of high pruning rate.
However, the “fighting” category, the “running” category, and the “falling” category belong to the complex single individual behavior category. With the increase of the global pruning rate, the detection accuracy of these categories decreased significantly, especially for the “running” category and the “fighting” category, the detection accuracy decreased from the highest 0.899 to 0.412 and from the highest 0.858 to 0626, respectively. It shows that with the increase of the global pruning rate, the number of channels used to extract such features is greatly reduced, resulting in a serious decline in the detection accuracy of the model for these complex single individual categories.
According to the test results in Table 5, when the compression ratio is less than 3, the impact of precision, recall and average precision is small, and the weight of the model is greatly reduced. Especially when the compression ratio is 2, the detection accuracy still remains high. When the compression ratio is 2.5, the detection accuracy is slightly lower than that of the control group with 2, and the reduction of the number of parameters and calculation of the model is small. When the compression ratio is 3, the recall rate and the average precision rate are greatly reduced, indicating that when the compression ratio is greater than 3, the pruning channel has affected the performance of the model. Since the model pruning operation is mainly to achieve the best effect of lightweight model and lay a good detection foundation for the next distillation operation, we choose the compression ratio with a good balance between detection effect and lightweight effect. That is, the pruning strategy with com-pression ratio 2 prunes the model.
Under the LAMP pruning strategy, the model contains multiple submodules, and each submodule contains multiple convolutional layers. The pruning operation performs targeted channel reduction inside these submodules, and the adaptive global pruning method retains more critical layer channels to maintain model performance, while more pruning is performed on non-critical layers. Fig. 16 shows the comparison of the number of channels in each convolutional layer of the network model before and after pruning, where the red bar graph represents the number of model parameters after pruning, the yellow bar graph part represents the number of network parameters in each layer of the baseline model, the horizontal axis represents the convolutional layers of each network model involved in the calculation, and the vertical axis represents the number of output channels of the convolution kernel of each layer. It can be clearly and intuitively seen from Fig. 16 that the number of channels after pruning (represented by red) is generally lower than that of the original model (represented by yellow), indicating that the pruning operation effectively reduces the number of parameters and computational complexity of the model. The value of the pruned channels at some positions becomes 0, which indicates that the corresponding channels are removed during the pruning process, that is, these channels are no longer involved in the operation in the pruned model. Among them, the network model is 0 without pruning at the beginning, because this part of the network layer belongs to the module improvement layer, and we carry out layer skipping operation, that is, no pruning operation is carried out on this part of the network layer. In the figure, the pruning operation plays a global role in the network layer of the model, especially in the middle part of the network layer, indicating that there is more redundancy to be re-moved in the channel processing. Some channels in the back-end layer of the network are not pruned, indicating that some channels contain highly abstract and complex semantic features, which play a key role in the extraction of the overall features and the output of the final results. From the overall point of view, pruning reduces the number of model parameters and makes the model more compact without losing too much performance by adjusting the channel values. It helps to reduce the risk of model overfitting and improve generalization ability.
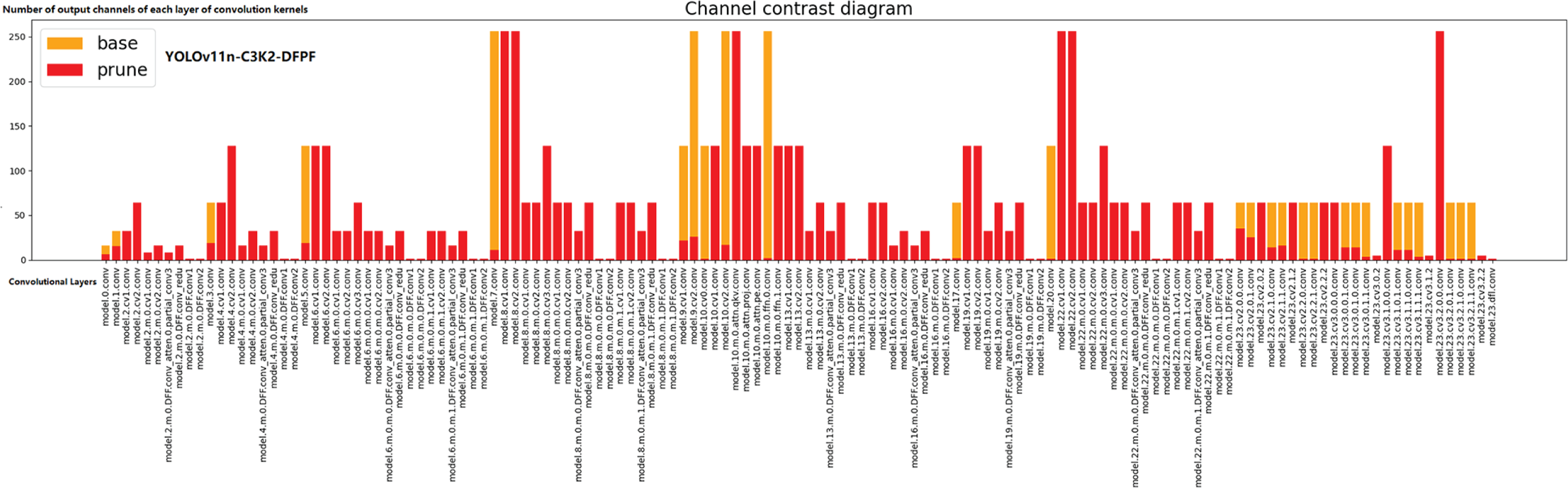
Figure 16: Pruning results of each channel of the model
4.3 Model Distillation Experiment
In the training process of YOLO model, the Neck part of the model is usually selected as the distillation layer, because the feature maps of these layers contain rich semantic in-formation and spatial information, and are the key layers for feature fusion and upsampling, which can better transfer the knowledge of the teacher model to the student model than other layers. In the UAV aerial image detection task, there is a characteristic of small target detection, and shallow features can usually capture high-resolution features, which is helpful to improve the detection effect of small targets. Therefore, the number of distillation layers is selected as [6,8,12,15,18,21] in this paper. This combination can cover features of different scales from shallow to deep layers, which is suitable for multi-scale object detection.
Multi-Granularity Distillation (MGD) In the experiment, we found that the weight coefficient of distillation has a great impact on the distillation effect. By adjusting the weight coefficient, the original loss function can be retained while the MGD loss has a certain impact on the model training. It is common to start with a small value. In this paper, we choose to set the weight coefficient of the control group as 0.0001, 0.001, 0.01 and 0.1 for testing. When the weight coefficient value gradually approaches 1, the MGD loss will gradually dominate the total training loss value, making the model pay more attention to the distillation loss. However, the above situation applies when the teacher model has strong expressive ability, and the student model needs to learn a lot of the characteristics of the teacher model to improve its performance. Or when the original loss function does not work well, we need to use distillation loss to improve the performance of the model. This helps to gradually introduce the distillation loss and guide the student model to learn the features of the teacher model without changing the original training direction.
Based on the student model (DFPF-YOLO) and teacher model (YOLOv11x), the influence of different distillation weight coefficients on knowledge distillation is explored. The experimental results for different distillation weights are shown in Table 6. It can be seen from Table 6 that when the distillation weight coefficient is 0.001 and 0.01, the distilled model has high accuracy and average accuracy of 94.6% and 94.8%, respectively. When λ = 0.0001 is too small: the distillation loss ratio is low, the student model is difficult to effectively learn the feature distribution of the teacher model (YOLOv11x), resulting in limited accuracy improvement (mAP_50 = 0.946). With different distillation weight coefficients, the precision rate and recall rate fluctuate up and down, indicating that different weight coefficients will cause the model to pay attention to different abnormal behavior characteristic information. In general, the mean average precision always tends to a higher level, indicating that the distilled model has a good performance in detecting abnormal behavior targets in aerial images. When the distillation weight is set to 0.1, the model accuracy decreases significantly. We analyze that when λ = 0.1 is too large: the proportion of distillation loss is too high, and the student model over mimics the teacher’s features, which may cover the task-specific features (such as small target details) learned by itself in the lightweight network, resulting in accuracy degradation.
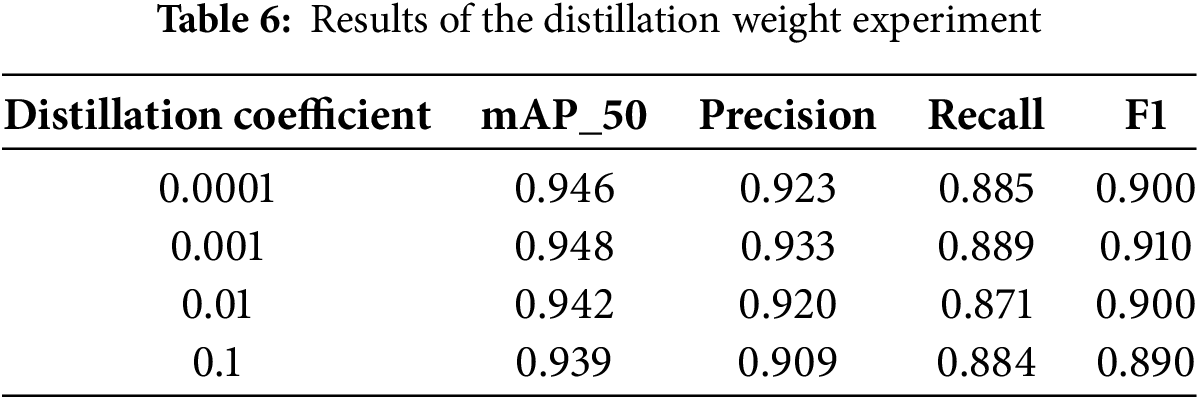
The core of adjusting sensitivity is that the value of λ needs to match the task’s demand weight for “teacher features” and “task features”. Airborne visual abnormal behavior detection task needs to balance multi-category small target features and global semantics (teacher features), and λ = 0.001 can just meet this balance.
4.4 Comparative Experiments on Multi-Category Abnormal Behavior Datasets
In order to further verify the detection effect of the algorithm designed in this paper for multi-category abnormal line targets in aerial images, a variety of evaluation indicators are adopted, and the detection effect of each abnormal behavior category is recorded. The widely used YOLOv5m algorithm, YOLOv9m algorithm, lightweight DEIM-DFINE-n algorithm and DEIM-DFINE-s algorithm, YOLOv11x algorithm as a teacher model, YOLOv11n baseline model and DFPF-YOLO algorithm were compared and tested. Among them, Table 7 shows the experimental results of the algorithm designed in this paper and the algorithms in the same category. According to the experimental results shown in Table 5, according to the test results, compared with the same type of YOLOv5m, YOLOv9m and the baseline model YOLOv11n, the detection accuracy of each category in abnormal behavior is significantly improved. Through model distillation operation, the detection accuracy of the algorithm proposed in this paper is similar to that of the YOLOv11x teacher model. It shows that the student model has effectively learned some layer features of the teacher model, but due to the large number of model parameters of YOLOv11x version, the detection delay is higher, and the detection time is longer when detecting the same image, but its detection time is the shortest. Among them, the DEIM-DFINE-N algorithm and DEIM-DFINE-S algorithm are the latest algorithms pro-posed under the end-to-end detection Transformer architecture. These two versions of the algorithm have lightweight characteristics. The detection accuracy of the DEIM algorithm is better, but it is not lightweight enough compared with the improved model in this paper. Especially for DEIM-DFINE-s algorithm, the improved algorithm in this paper is more lightweight when the accuracy gap is not large [38].
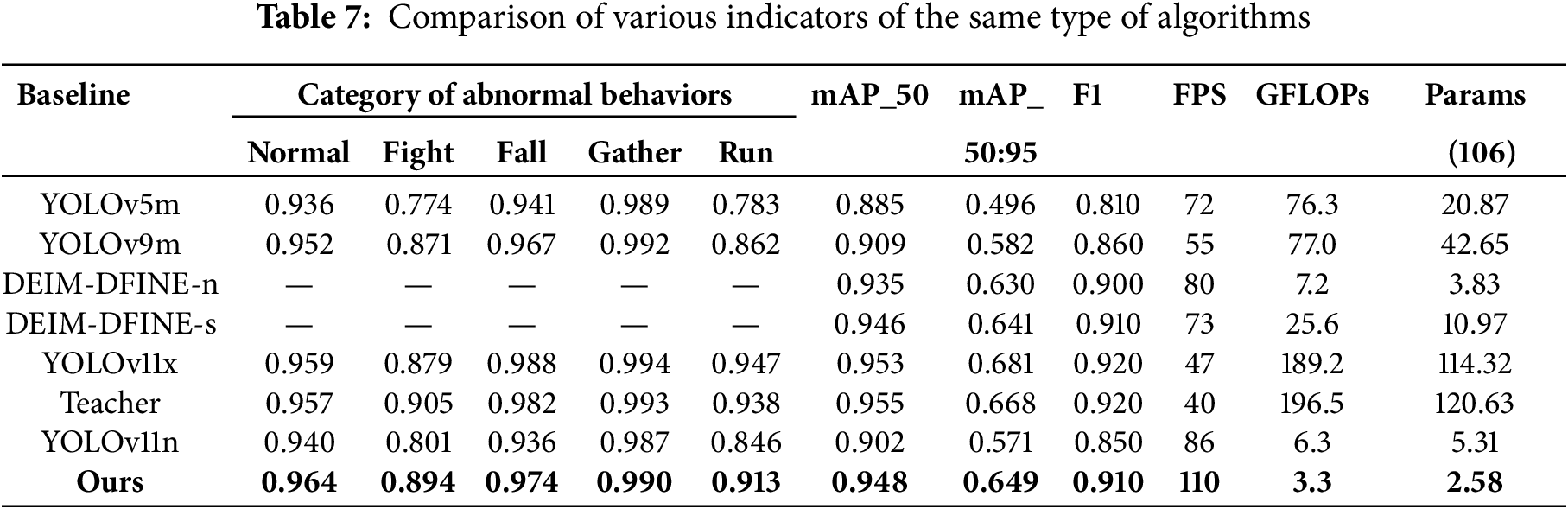
Fig. 17 shows the effect diagram of the algorithm designed in this paper on the data set of multi-category abnormal and normal behaviors. In order to verify the detection effect of the improved algorithm for multi-scale and multi-category abnormal behavior features, we selected images including all abnormal behavior categories for testing, and the five groups of images selected had abnormal behaviors at different distances and from different UAV viewpoints. According to the detection effect diagram and the experimental data in Table 7, it can be clearly seen that the test effect of the proposed algorithm has significantly improved the detection accuracy compared with the original baseline model, especially for the three more complex individual abnormal behavior feature categories of running, falling and fighting, the detection accuracy of the running abnormal category is improved from 0.846 to 0.913 from the baseline model. The fight category increased from 0.801 to 0.894, while the detection accuracy of the aggregation category changed little. This is because the aggregation category required the algorithm to focus more on the global detection of abnormal behavior, while the abnormal behavior categories such as falling, running and fighting mainly detected single or part of individual behavior targets in the image, which further verified the improved algorithm in this paper. The detection effect of small targets in aerial images is significantly improved. Table 7 shows the detection ac-curacy curve of all test results, which also contains the detection data of each abnormal behavior category. After testing, the FPS index of the improved model in this paper is 110, and the average detection time of each image on the RTX3090GPU is about 9.1 ms. Compared with the baseline model, the FPS index of the baseline model is 86, and the single image detection time of the baseline model is 11.6 ms, the detection efficiency is significantly improved.

Figure 17: Visualization of multi-category abnormal behavior detection in aerial images. (a) Original image; (b) Baseline model test result graph; (c) Improved model test result graph
Through the analysis of ablation experimental results, the detection performance of the improved method for small targets is greatly improved, and the average detection delay is also within an acceptable and reasonable range, which is in line with the design idea of the algorithm in this paper. Then we chose to use Layer-CAM to draw heat maps for visual display and analysis. The heat map comparison results are shown in Fig. 18, where the leftmost part is the original map, the middle part is the heat map of the baseline model, and the right part is the heat map of the improved algorithm presented in this paper. Since the target of abnormal crowd behavior is small in the image and the receptive field for detection is small, the head detection layer closer to the bottom is needed. Therefore, the connection layer of the head of the model is selected as the heat map output layer. To verify the effectiveness of this paper for the detection of small targets with abnormal behavior, abnormal behavior images from different aerial angles are specially selected for testing.

Figure 18: Visualization results of heat maps. (a) Original image; (b) Baseline model test result graph; (c) Improve the test result graph of the model
There are crowd features and scattered individual features in the heat map, which are used to verify the attention of the algorithm to the global characteristics of abnormal behavior and the abnormal individual behavior characteristics, respectively. In our study, we found that there are two main situations for target occlusion, one is the occlusion of the target caused by terrain features, and the other is the occlusion between the abnormal behavior target and the normal target caused by the target position and the aerial Angle. To this end, we selected a total of seven groups of heat maps for comparison. Through the first group of heat maps, it can be intuitively seen that when there is a category of “fall” in the crowd, the improved algorithm in this paper can focus on a relatively single individual abnormal behavior and cover all the targets compared with the baseline model. The improved algorithm in this paper can effectively cover all the crowd samples and pay attention to the overall characteristics of abnormal crowd behavior, while the baseline model only focuses on part of the areas, and there are some omissions.
Compared with the baseline model, the improved algorithm in this paper can focus on each single individual feature more accurately. Especially in the third and fourth group of controls, there is mutual occlusion within the crowd, and the proposed algorithm can effectively focus on the occluded abnormal behavior target. In the heat map comparison of the fifth and sixth groups, some of the behavior characteristics of the human body are occluded by trees. Compared with the baseline model, the proposed algorithm can pay attention to the abnormal behavior characteristics that are not occluded, which further verifies the effectiveness of the improved algorithm in detection accuracy and effect.
4.5 Comparative Experiments on VisDrone2019 Dataset
In order to further verify the detection effect of the algorithm designed in this paper for multi-category targets in aerial images, a variety of evaluation indicators are adopted, and the detection effect of each abnormal behavior category is recorded. The YOLOv11n baseline model and the DFPF-YOLO algorithm are compared on the VisDrone2019 public dataset. Among them, Table 8 shows the experimental results of the algorithm designed in this paper and the baseline model. According to the experimental results shown in Table 8, compared with the baseline model YOLOv11n, the proposed algorithm has significantly improved the accuracy of multi-category target detection under airborne vision. Fig. 19 shows the detection accuracy curves of the baseline model and the proposed improved model.


Figure 19: Detection accuracy on public datasets. (a) Baseline; (b) Improve the test result graph of the model
Table 8 shows the detection accuracy and average detection accuracy of each category of the baseline model and the improved algorithm in this paper on the VisDrone2019 dataset. According to the data in the table, the improved algorithm in this paper is better than the baseline model in the accuracy of 10 detection categories of VisDrone2019 dataset, and the final detection accuracy is 0.318. Especially, the detection effect of the three target categories of “pedestrian”, “motor” and “truck” is significantly improved. It shows the effectiveness of the improved method proposed for multi-category object detection tasks under airborne vision. Fig. 20 shows the detection effect of the baseline model and the improved algorithm in this paper for the test set. We select images containing many crowd characteristics and aerial images under complex scene occlusion for visual comparison of detection effect. There are four groups of comparison images, corresponding to the original test images from left to right. The detection renderings of the baseline model and the improved model in this paper. In the first set of comparison figures, the baseline model did not detect some crowd targets, which were highlighted by the yellow box. In the remaining three groups of comparison figures, the baseline model has missed detection and false detection problems of multi-category targets in complex scenes, and the detection accuracy of the baseline model in all control groups is lower than that of the improved model in this paper, which illustrates the robustness and generalization of the improved model for aerial image target detection [39].

Figure 20: Public dataset detection effect. (a) Original image; (b) Baseline model test result graph; (c) Improve the test result graph of the model
Aiming at the multi-category abnormal behavior detection task under airborne vision, this paper tests on the UAV aerial abnormal behavior dataset, selects and uses a variety of evaluation indicators for ablation experiments, and compares the effect of other similar algorithms horizontally. At the same time, to show the generalization of the improved algorithm for aerial image object detection, a comparative test is carried out on the VisDrone2019 public dataset. Experimental results show that the improved algorithm designed in this paper has significantly improved the detection of these categories, especially for the fight category, running category and fall category, which has obvious complex behavior small target detection effect, indicating the excellent and robustness of the algorithm designed in this paper for the complex abnormal behavior target detection performance of aerial images. Finally, through pruning and distillation operations, the improved algorithm achieved a balance between detection accuracy and detection speed in terms of model lightweight. In future work, to improve the detection effect at night and in more complex scenarios, we will mainly focus on expanding the dataset and conducting multimodal detection.
Acknowledgement: Not applicable.
Funding Statement: This work was supported by y the Applied Research Advancement Project in Engineering University of PAP (WYY202304); Research and Innovation Team Project in Engineering University of PAP (KYTD202306); Funding for postgraduate education and teaching.
Author Contributions: Methodology, Baixuan Han and Zecong Ye; Validation, Hexiang Hao and Xuekai Zhang; Formal analysis, Wei Tang and Wenchao.Kang; Writing—original draft, Baixuan Han; Writing review & editing, Qilong Li; Funding acquisition, Yueping Peng. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Nasir R, Jalil Z, Nasir M, Alsubait T, Ashraf M, Saleem S. An enhanced framework for real-time dense crowd abnormal behavior detection using YOLOv8. Artif Intell Rev. 2025;58(7):202. doi:10.1007/s10462-025-11206-w. [Google Scholar] [CrossRef]
2. Yang H, Wu J, Lu Y, Huang Y, Yang P, Qian Y. Lightweight detection and counting of maize tassels in UAV RGB images. Remote Sens. 2025;17(1):3. doi:10.3390/rs17010003. [Google Scholar] [CrossRef]
3. Yu W, Zhang J, Liu D, Xi Y, Wu Y. An effective and lightweight full-scale target detection network for UAV images based on deformable convolutions and multi-scale contextual feature optimization. Remote Sens. 2024;16(16):2944. doi:10.3390/rs16162944. [Google Scholar] [CrossRef]
4. Lu X, Li Q, Li J, Zhang L. Deep learning-based method for detection and feature quantification of microscopic cracks on the surface of concrete dams. Measurement. 2025;240(3):115587. doi:10.1016/j.measurement.2024.115587. [Google Scholar] [CrossRef]
5. Zhang Z, Bao L, Xiang S, Xie G, Gao R. B2CNet: a progressive change boundary-to-center refinement network for multitemporal remote sensing images change detection. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17:11322–38. doi:10.1109/JSTARS.2024.3409072. [Google Scholar] [CrossRef]
6. Dai Y, Gieseke F, Oehmcke S, Wu Y, Barnard K. Attentional feature fusion. In: 2021 IEEE Winter Conference on Applications of Computer Vision (WACV); 2021 Jan 3–8; Waikoloa, HI, USA. p. 3559–68. doi:10.1109/wacv48630.2021.00360. [Google Scholar] [CrossRef]
7. Ouyang D, He S, Zhang G, Luo M, Guo H, Zhan J, et al. Efficient multi-scale attention module with cross-spatial learning. In: ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2021 Jan 3–8; Greece, Rhodes Island; 2023. p. 1–5. doi:10.1109/ICASSP49357.2023.10096516. [Google Scholar] [CrossRef]
8. Lv H, Chen J, Pan T, Zhang T, Feng Y, Liu S. Attention mechanism in intelligent fault diagnosis of machinery: a review of technique and application. Measurement. 2022;199(2):111594. doi:10.1016/j.measurement.2022.111594. [Google Scholar] [CrossRef]
9. Pan X, Ge C, Lu R, Song S, Chen G, Huang Z, et al. On the integration of self-attention and convolution. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. p. 805–15. doi:10.1109/CVPR52688.2022.00089. [Google Scholar] [CrossRef]
10. Yuan J, Ma X, Zhang Z, Xu Q, Han G, Li S, et al. EFFC-Net: lightweight fully convolutional neural networks in remote sensing disaster images. Geo-Spat Inf Sci. 2025;28(1):212–23. doi:10.1080/10095020.2023.2183145. [Google Scholar] [CrossRef]
11. Wieczorek M, Siłka J, Woźniak M, Garg S, Hassan MM. Lightweight convolutional neural network model for human face detection in risk situations. IEEE Trans Ind Inform. 2022;18(7):4820–9. doi:10.1109/TII.2021.3129629. [Google Scholar] [CrossRef]
12. Dong X, Yan S, Duan C. A lightweight vehicles detection network model based on YOLOv5. Eng Appl Artif Intell. 2022;113(1):104914. doi:10.1016/j.engappai.2022.104914. [Google Scholar] [CrossRef]
13. Fan Q, Li Y, Deveci M, Zhong K, Kadry S. LUD-YOLO: a novel lightweight object detection network for unmanned aerial vehicle. Inf Sci. 2025;686:121366. doi:10.1016/j.ins.2024.121366. [Google Scholar] [CrossRef]
14. Liu Y, Fu Z, Zhan Y, Xia Y. MVTC: data and knowledge-based distributed multi-view information mixing network for traffic classification in Internet of unmanned agents. IEEE Internet Things J. 2025:1. doi:10.1109/JIOT.2025.3552666. [Google Scholar] [CrossRef]
15. Chriki A, Touati H, Snoussi H, Kamoun F. Deep learning and handcrafted features for one-class anomaly detection in UAV video. Multimed Tools Appl. 2021;80(2):2599–620. doi:10.1007/s11042-020-09774-w. [Google Scholar] [CrossRef]
16. Han B, Peng Y, Hao H, Kang W, Zhang X. Multi-class abnormal behavior detection algorithm based on YOLOv9. In: 2024 2nd International Conference on Algorithm, Image Processing and Machine Vision (AIPMV); 2024 Jul 12–14; Zhenjiang, China. p. 36–40. doi:10.1109/aipmv62663.2024.10692055. [Google Scholar] [CrossRef]
17. Yan J, Wang H, Yan M, Diao W, Sun X, Li H. IoU-adaptive deformable R-CNN: make full use of IoU for multi-class object detection in remote sensing imagery. Remote Sens. 2019;11(3):286. doi:10.3390/rs11030286. [Google Scholar] [CrossRef]
18. Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements. arXiv:2410.17725. 2024. [Google Scholar]
19. Al Rabbani Alif M. YOLOv11 for vehicle detection: advancements, performance, and applications in intelligent transportation systems. arXiv:2410.22898. 2024. [Google Scholar]
20. Yang J, Qiu P, Zhang Y, Marcus DS, Sotiras A. D-net: dynamic large kernel with dynamic feature fusion for volumetric medical image segmentation. arXiv:2403.10674. 2024. [Google Scholar]
21. Qian X, Zhang C, Chen L, Li K. Deep learning-based identification of maize leaf diseases is improved by an attention mechanism: self-attention. Front Plant Sci. 2022;13:864486. doi:10.3389/fpls.2022.864486. [Google Scholar] [PubMed] [CrossRef]
22. Zhang Z, Li B, Yan C, Furuichi K, Todo Y. Double attention: an optimization method for the self-attention mechanism based on human attention. Biomimetics. 2025;10(1):34. doi:10.3390/biomimetics10010034. [Google Scholar] [PubMed] [CrossRef]
23. Zhu J, Tan Y, Lin R, Miao J, Fan X, Zhu Y, et al. Efficient self-attention mechanism and structural distilling model for Alzheimer’s disease diagnosis. Comput Biol Med. 2022;147(1):105737. doi:10.1016/j.compbiomed.2022.105737. [Google Scholar] [PubMed] [CrossRef]
24. Lv Z, Zhao J. Resource-efficient artificial intelligence for battery capacity estimation using convolutional FlashAttention fusion networks. eTransportation. 2025;23(6553):100383. doi:10.1016/j.etran.2024.100383. [Google Scholar] [CrossRef]
25. Liu G, Dundar A, Shih KJ, Wang TC, Reda FA, Sapra K, et al. Partial convolution for padding, inpainting, and image synthesis. IEEE Trans Pattern Anal Mach Intell. 2022;4(2):1–15. doi:10.1109/tpami.2022.3209702. [Google Scholar] [PubMed] [CrossRef]
26. Liu G, Shih KJ, Wang TC, Reda FA, Sapra K, Yu Z, et al. Partial convolution based padding. arXiv:1811.11718. 2018. [Google Scholar]
27. Alamri F, Dutta A. Multi-head self-attention via vision transformer for zero-shot learning. arXiv:2108.00045. 2021. [Google Scholar]
28. Do NQ, Selamat A, Krejcar O, Fujita H. Detection of malicious URLs using temporal convolutional network and multi-head self-attention mechanism. Appl Soft Comput. 2025;169(6):112540. doi:10.1016/j.asoc.2024.112540. [Google Scholar] [CrossRef]
29. Jin L, Ding W, Han S, Wang J. A real-time edge inference method for insulator contamination detection with YOLOv11-ssL. IEEE Trans Instrum Meas. 2025;74:3534315. doi:10.1109/TIM.2025.3565254. [Google Scholar] [CrossRef]
30. Yuan Z, Wang S, Wang C, Zong Z, Zhang C, Su L, et al. Research on calf behavior recognition based on improved lightweight YOLOv8 in farming scenarios. Animals. 2025;15(6):898. doi:10.3390/ani15060898. [Google Scholar] [PubMed] [CrossRef]
31. Yang Z, Li Z, Shao M, Shi D, Yuan Z, Yuan C. Masked generative distillation. In: Computer Vision—ECCV 2022. Cham, Switzerland: Springer; 2022. p. 53–69. doi:10.1007/978-3-031-20083-0_4. [Google Scholar] [CrossRef]
32. Wang W, He X, Zhang Y, Guo L, Shen J, Li J, et al. CM-MaskSD: cross-modality masked self-distillation for referring image segmentation. IEEE Trans Multimed. 2024;26:6906–16. doi:10.1109/TMM.2024.3358085. [Google Scholar] [CrossRef]
33. Peng Z, Wu G, Luo B, Wang L. Multi-UAV cooperative pursuit strategy with limited visual field in urban airspace: a multi-agent reinforcement learning approach. IEEE/CAA J Autom Sin. 2025;12(7):1350–67. doi:10.1109/JAS.2024.124965. [Google Scholar] [CrossRef]
34. Li Z, Sui H, Luo C, Guo F. Morphological convolution and attention calibration network for hyperspectral and LiDAR data classification. IEEE J Sel Top Appl Earth Obs Remote Sens. 2023;16:5728–40. doi:10.1109/jstars.2023.3284655. [Google Scholar] [CrossRef]
35. Nagarani N, Venkatakrishnan P, Balaji N. Unmanned Aerial vehicle’s runway landing system with efficient target detection by using morphological fusion for military surveillance system. Comput Commun. 2020;151(1):463–72. doi:10.1016/j.comcom.2019.12.039. [Google Scholar] [CrossRef]
36. Rezaee K, Khosravi MR, Anari MS. Deep-transfer-learning-based abnormal behavior recognition using Internet of drones for crowded scenes. IEEE Internet Things Mag. 2022;5(2):41–4. doi:10.1109/IOTM.001.2100138. [Google Scholar] [CrossRef]
37. Ye Z, Peng Y, Liu W, Yin W, Hao H, Han B, et al. An efficient adjacent frame fusion mechanism for airborne visual object detection. Drones. 2024;8(4):144. doi:10.3390/drones8040144. [Google Scholar] [CrossRef]
38. Han BX, Peng YP, Hao HX, Ye ZC. DMU-YOLO: multi-class abnormal behavior detection algorithm based on air-borne vision. Comput Eng Appl. 2025;61(7):128–40. (In Chinese). doi:10.1109/aipmv62663.2024.10692055. [Google Scholar] [CrossRef]
39. Bakirci M. Enhancing vehicle detection in intelligent transportation systems via autonomous UAV platform and YOLOv8 integration. Appl Soft Comput. 2024;164(5):112015. doi:10.1016/j.asoc.2024.112015. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools