
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MultiAgent-CoT: A Multi-Agent Chain-of-Thought Reasoning Model for Robust Multimodal Dialogue Understanding
Department of Computer Science, Faculty of Computing and Information, Al-Baha University, Al-Baha, 65779, Saudi Arabia
* Corresponding Author: Ans D. Alghamdi. Email:
(This article belongs to the Special Issue: Artificial Intelligence in Visual and Audio Signal Processing)
Computers, Materials & Continua 2026, 86(2), 1-35. https://doi.org/10.32604/cmc.2025.071210
Received 02 August 2025; Accepted 22 October 2025; Issue published 09 December 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Multimodal dialogue systems often fail to maintain coherent reasoning over extended conversations and suffer from hallucination due to limited context modeling capabilities. Current approaches struggle with cross-modal alignment, temporal consistency, and robust handling of noisy or incomplete inputs across multiple modalities. We propose MultiAgent-Chain of Thought (CoT), a novel multi-agent chain-of-thought reasoning framework where specialized agents for text, vision, and speech modalities collaboratively construct shared reasoning traces through inter-agent message passing and consensus voting mechanisms. Our architecture incorporates self-reflection modules, conflict resolution protocols, and dynamic rationale alignment to enhance consistency, factual accuracy, and user engagement. The framework employs a hierarchical attention mechanism with cross-modal fusion and implements adaptive reasoning depth based on dialogue complexity. Comprehensive evaluations on Situated Interactive MultiModal Conversations (SIMMC) 2.0, VisDial v1.0, and newly introduced challenging scenarios demonstrate statistically significant improvements in grounding accuracy (p < 0.01), chain-of-thought interpretability, and robustness to adversarial inputs compared to state-of-the-art monolithic transformer baselines and existing multi-agent approaches.Keywords
The rapid advancement of conversational artificial intelligence has led to increasing demand for systems capable of understanding and reasoning across multiple modalities in extended dialogue contexts. While large language models have demonstrated remarkable capabilities in text-based reasoning, their extension to multimodal dialogue scenarios presents significant challenges in maintaining coherent reasoning chains, handling cross-modal dependencies, and providing interpretable decision-making processes.
Current multimodal dialogue systems predominantly rely on monolithic architectures that attempt to process all modalities within a single model framework. Recent comprehensive surveys by Wang et al. [1], Lin et al. [2], and Li et al. [3] have highlighted the limitations of existing approaches, particularly in maintaining consistency across modalities and handling ambiguous instructions. These systems suffer from several critical limitations including insufficient cross-modal alignment, poor temporal consistency across dialogue turns, limited interpretability of reasoning processes, and vulnerability to hallucination when dealing with conflicting or noisy multimodal inputs.
Recent research in chain-of-thought (CoT) reasoning has shown promising results in enhancing model interpretability and reasoning capabilities for text-based tasks. Zhou et al. [4] introduced quality-driven chain-of-thought approaches for image restoration, while Zhang et al. [5] provided a comprehensive analysis of the evolution from chain-of-thought reasoning to language agents. Ashraf et al. [6] evaluated deep multimodal reasoning in vision-centric agentic tasks, and Sanwal [7] proposed layered chain-of-thought prompting for multi-agent systems. Zhang et al. [8] developed human-communication simulation frameworks, and Zhang et al. [9] presented metacognitive multi-agent systems for modeling social thoughts. Murugappan [10] explored multi-agent debates among vision-language models, demonstrating improvements in multimodal reasoning through collaborative approaches.
Several recent works have advanced collaborative reasoning frameworks. Zhang et al. [11] introduced Chain of Agents for long-context tasks, while Becker [12] investigated multi-agent systems for conversational task-solving. Zhou et al. [13] developed cooperative frameworks for autonomous driving applications, and Xia et al. [14] optimized multi-agent collaboration for medical reasoning using reinforcement learning. Chen et al. [15] surveyed long chain-of-thought reasoning for large language models, and Lian et al. [16] proposed collaborative models for knowledge integration. Nguyen et al. [17] presented multi-agent retrieval-augmented generation approaches, and Cao et al. [18] enhanced task planning through multi-agent collaboration. Wu et al. [19] developed specialist routing systems for improved question answering, while Xie et al. [20] provided comprehensive surveys of large multimodal agents.
Bilal et al. [21] explored meta-thinking in LLMs through multi-agent reinforcement learning, and Jiang et al. [22] investigated rationality in language and multimodal agents. Liao et al. [23] developed efficient motion forecasting for autonomous driving with LLM-based chain-of-thought prompting, while Feng et al. [24] advanced multi-agent embodied AI. Xu et al. [25] explored the integration of large language model agents with 6G networks, and Sun et al. [26] provided a comprehensive survey of reasoning with foundation models. Guo et al. [27] elicited multimodal reasoning with instruction tuning at scale, Wu et al. [28] developed automated movie generation systems via multi-agent CoT planning, and Su et al. [29] advanced the foundational methods and future frontiers of multimodal reasoning [30].
The comparison of conventional monolithic multimodal designs and the presented MultiAgent-CoT architecture is provided in Fig. 1. Cross-modal conflicts and inconsistencies between reasoning along with failed coordination of isolated modality processing is present on the left in the monolithic setup. On the contrary, the right part demonstrates how the Multi Agent-CoT system involves using special agents (text, vision, speech), which carry out independent reasoning and engage in the process of structured communication. These agents pass the message inter-agently and give a common Global Understanding therein accomplishing coherent, consistent and collaborative modal decision-making [31–33]. Fig. 1 shows the Illustrative comparison between existing monolithic multimodal dialogue models and the proposed MultiAgent-CoT framework. The left side shows challenges in monolithic systems where processing all modalities within a single model leads to cross-modal conflicts and reasoning inconsistencies [34,35]. The right side presents our multi-agent architecture, where specialized text, vision, and speech agents collaborate via structured inter-agent communication and message-passing protocols to achieve a unified global understanding.
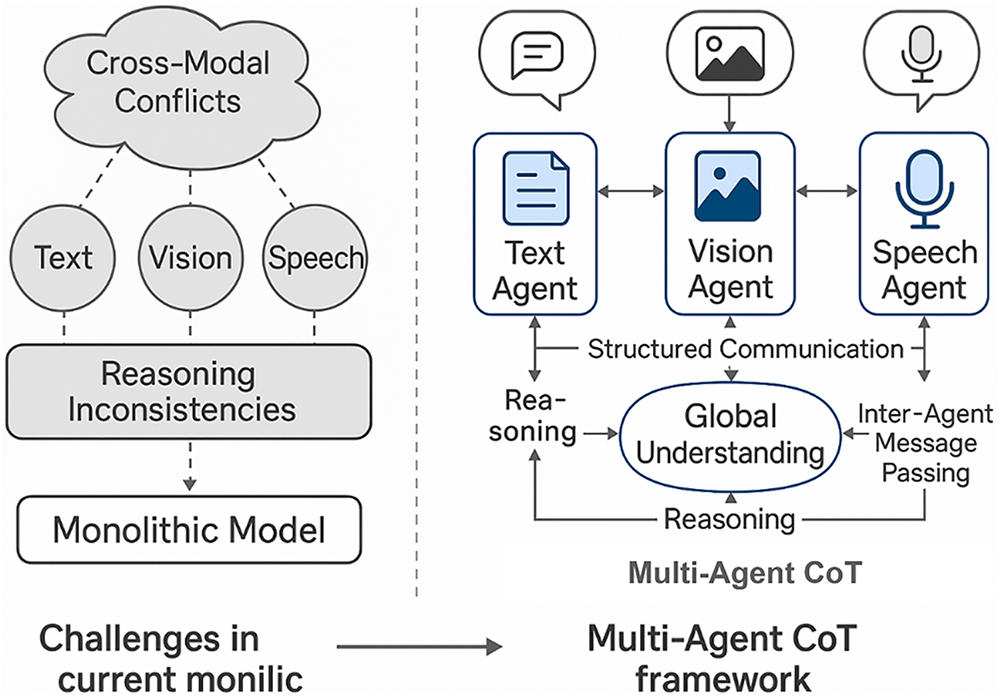
Figure 1: Illustrative comparison between existing monolithic multimodal dialogue models and the proposed MultiAgent-CoT framework. The left side shows challenges in monolithic systems where processing all modalities within a single model leads to cross-modal conflicts and reasoning inconsistencies. The right side presents our multi-agent architecture, where specialized text, vision, and speech agents collaborate via structured inter-agent communication and message-passing protocols to achieve a unified global understanding
To address these challenges, we propose MultiAgent-CoT, a novel multi-agent chain-of-thought reasoning framework specifically designed for robust multimodal dialogue understanding. Our approach decomposes the complex multimodal reasoning task into specialized agents, each responsible for processing and reasoning within a specific modality domain. These agents collaborate through a sophisticated inter-agent communication protocol that enables the construction of unified reasoning chains while maintaining modality-specific expertise.
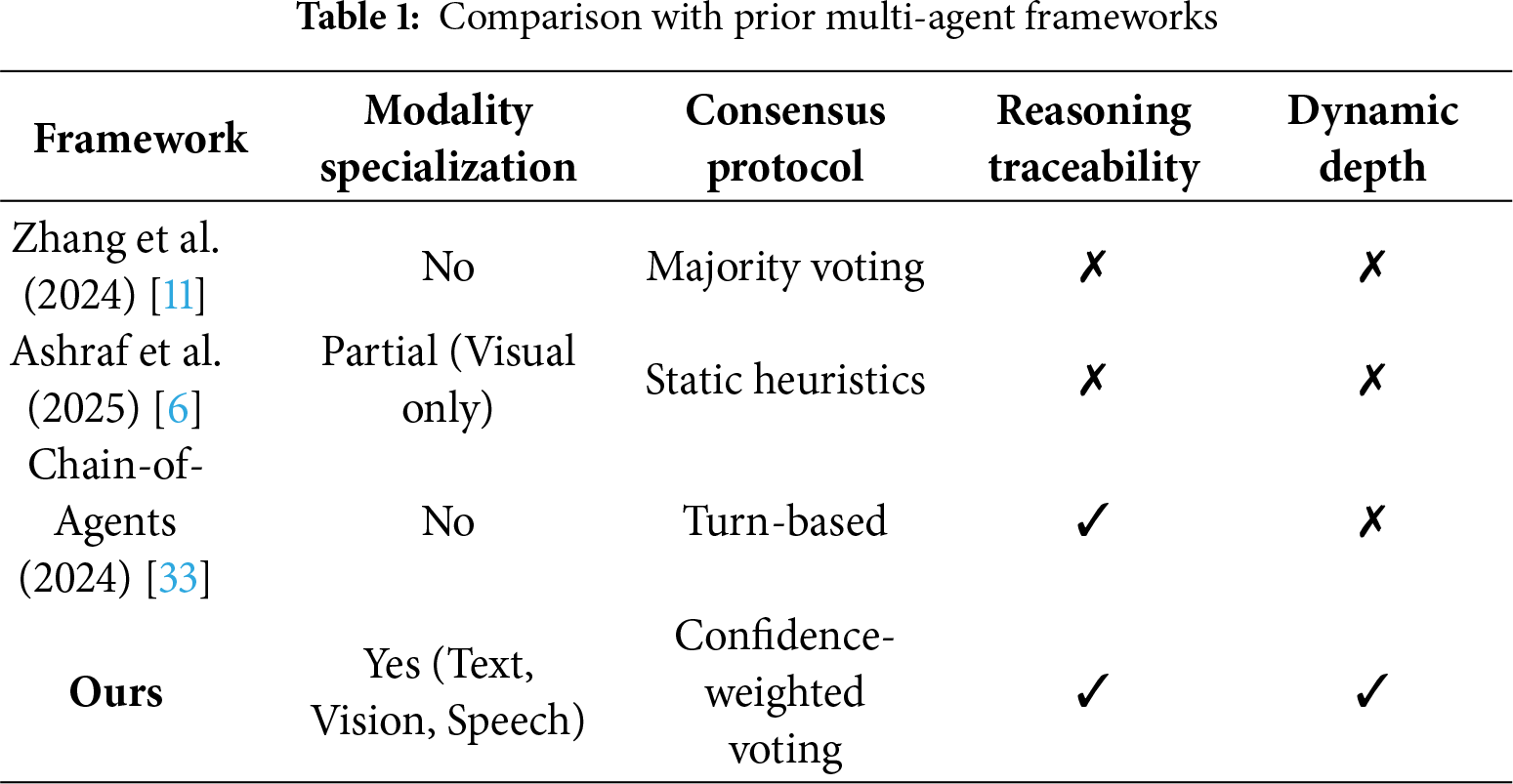
While our proposed framework introduces a novel integration of chain-of-thought reasoning in a multi-agent multimodal setting, we explicitly compare and contrast with prior works such as Zhang et al. [11], Ashraf et al. [6], and Chain-of-Agents [33] in terms of architecture design, inter-agent protocol structure, and consensus logic. Notably, unlike Chain-of-Agents which lacks modality specialization, our approach assigns explicit expert roles to each modality. Table 1 summarizes architectural and theoretical differences to strengthen our novelty justification.
Novelty and Key Distinctions:
While Table 1 provides a summary of architectural differences, here we present a more explicit comparison with closely related frameworks. Unlike Chain-of-Agents [33], which uses turn-based collaboration without modality specialization, MultiAgent-CoT assigns dedicated agents for text, vision, and speech, allowing each agent to maintain independent reasoning chains.
In contrast, MetaAgents [35] primarily focuses on zero-shot visual tasks and does not fully integrate multimodal reasoning. Our framework handles three modalities simultaneously and introduces adaptive reasoning depth and a structured conflict resolution mechanism, which significantly enhances interpretability, robustness, and collaborative decision-making compared to existing approaches.
The key innovation of our framework lies in the integration of distributed reasoning capabilities with centralized coordination mechanisms. Each agent maintains its own chain-of-thought reasoning process while contributing to a shared global reasoning state through structured message passing and consensus voting protocols. Architecture allows the system to exploit the advantages of special processing yet producing coherent cross-modal understanding, as well as consistency in reasoning.
Our contributions are as follows: (1) A new multi-agent framework in multimodal dialogue understanding that composes specialized modality processing and collaborative reasoning dynamics, (2) an Bayesian optimized chain-of-thought model that dynamically controls the reasoning depth of the framework in dialogue challenging nature and uncertainty distribution, (3) A conflict resolution protocol that manages discourse discords between agents and nonetheless ensures coherence in terms of reasoning, (4) Extensive experimentations that statistically significantly prove the grounding accuracy
Multi-agent systems have become increasingly significant for multimodal reasoning, enabling collaborative problem-solving across text, vision, and speech modalities. Traditional architectures mainly relied on monolithic models, which often lacked scalability and robustness. Recent approaches focus on distributed reasoning and inter-agent collaboration, showing improved efficiency and interpretability.
2.1 Chain-of-Thought Reasoning in Multimodal Systems
Advances in CoT prompting have enhanced reasoning skills across modalities. Wang et al. [1] provided an extensive survey on multimodal CoT and highlighted challenges in achieving cross-modal grounding and reasoning consistency. Lin et al. [2] demonstrated that teacher model guidance and knowledge distillation improve multimodal reasoning. Li et al. [3] proposed a unified framework for large multimodal reasoning models, identifying shortcomings in handling ambiguous commands and maintaining coherence in long dialogues. Zhou et al. [4] introduced Q-Agent, which leverages quality-driven CoT for image restoration, revealing the potential of specialized agent-based methods in complex multimodal tasks.
2.2 Multi-Agent Collaborative Reasoning
Recent studies show that collaborative multi-agent systems outperform single agent approaches for complex reasoning tasks. Zhang et al. [5] emphasized the importance of agent coordination, demonstrating that structured collaboration improves reliability and robustness. Ashraf et al. [6] proposed Agent-X, a framework for vision-centric multimodal reasoning, while Sanwal [7] introduced layered CoT prompting, showing that ordered inter-agent reasoning chains enhance explainability and decision quality. Zhang et al. [8] designed SpeechAgents to simulate human-like communication patterns, and Zhang et al. [9] developed MetaMind, a metacognitive system modeling human social cognition through advanced agent coordination.
2.3 Multimodal Dialogue Systems
Traditional multimodal dialogue systems trained large monolithic models, but these approaches struggle with interpretability and scalability. Murugappan [10] demonstrated that multi-agent debates among vision-language models improve reasoning accuracy and robustness. Zhang et al. [11] proposed the Chain-of-Agents framework, enabling collaborative problem-solving for long-context tasks. Becker [12] analyzed conversational task-solving using multi-agent Large Language Models (llms), stressing the need for efficient protocol designs. Zhou et al. [13] presented Algpt, a coo perative framework for multimodal auto-annotation in autonomous driving, highlighting the value of knowledge-driven agent coordination.
2.4 Recent Advances in Multimodal Reasoning
Recent frameworks combine multi-agent coordination and cross-modal reasoning to achieve superior interpretability. Xia et al. [14] proposed MMedAgent-RL, integrating reinforcement learning for medical reasoning, while Chen et al. [15] surveyed long-chain reasoning challenges in LLMs. Lian et al. [16] introduced a multi-agent model for multi-modal knowledge integration, and Nguyen et al. [17] proposed MA-RAG, improving retrieval-augmented generation via collaborative CoT reasoning.
However, many existing frameworks—such as Chain-of-Agents [33], MetaMind [9], and MetaAgents [35] lack explicit modality specialization, adaptive reasoning depth, or structured conflict resolution. Moreover, while LLaVA-2 [34] advances instruction-tuned vision-language alignment, it lacks multi-agent coordination, and MetaAgents [35] focus primarily on vision without addressing speech-based reasoning.
In contrast, the MultiAgent-CoT framework introduces:
• Specialized agents for text, vision, and speech.
• Structured inter-agent communication protocols for information exchange.
• Adaptive reasoning depth control based on dialogue complexity.
• Conflict resolution mechanisms ensuring coherent global reasoning.
This design enables dynamic, interpretable, and robust multimodal dialogue reasoning, outperforming both single-agent fusion models and static multi-agent ensembles.
3.1 System Architecture Overview
The MultiAgent-CoT framework comprises three specialized reasoning agents corresponding to text, vision, and speech modalities, coordinated through a central orchestration module that manages inter-agent communication, conflict resolution, and global reasoning state maintenance. Each agent maintains its own internal chain-of-thought reasoning process while contributing to a shared global reasoning trace through structured message passing protocols.
Fig. 2 describes the MultiAgent-CoT framework system architecture with explicit arrangement of the information passing through specialized agents and the coordination center. It starts with the fact that multi-modal inputs, which are text, image, and speech are processed through the Adaptive Reasoning Coordination unit that dynamically coordinates the reasoning needs. The Orchestrator controls allocation of tasks to the Text Agent, Vision Agent and Speech Agent which deal with sound, vision and text, respectively. These agents communicate with each other through a layer named Inter-Agent Communication to exchange knowledge and partial results of reasoning. Consolidation of the processed information is then formed with the help of Intermediate Reasoning States, and the final decision is made in a Global Consensus. This is an architecture that allows synchronized multi-agent cooperation and scalable multi-modal reasoning.
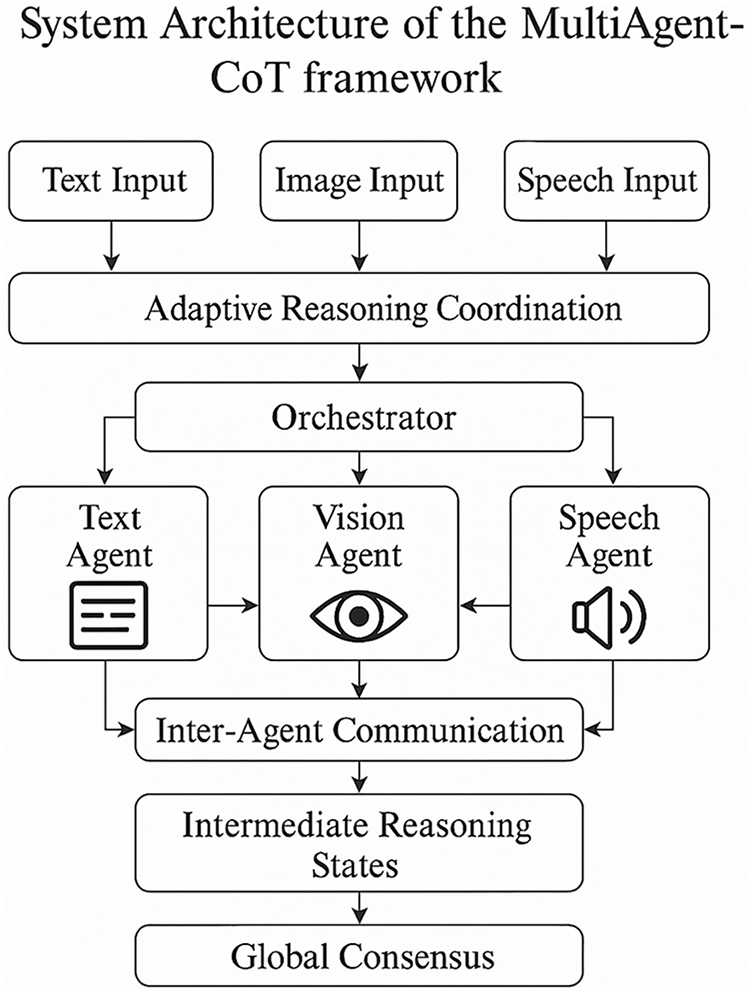
Figure 2: System architecture of the MultiAgent-CoT framework. The figure depicts how text, vision, and speech agents interact with the central orchestrator through adaptive reasoning coordination. The orchestrator dynamically manages information flow, synchronizes intermediate reasoning states, and facilitates inter-agent communication to establish a global consensus
A hierarchical mechanism of attention is employed by the central orchestrator by which agent contributions are weighed computationally according to modality relevance, confidence scores, and measures of reasoning consistency. By doing so the system can focus in an adaptive way on the most relevant modalities of each turn of the dialog whilst ensuring global coherence in a whole conversation situation.
The proposed Fig. 3 presents a layered overview of the MultiAgent-CoT framework. It highlights how multimodal inputs are independently processed by specialized modules before entering the adaptive reasoning coordination stage, where inter-agent communication ensures effective knowledge fusion. Dedicated defense mechanisms manage cross-modal conflicts and secure aggregation to protect reasoning consistency. Finally, the global understanding module integrates all intermediate states to generate a unified and coherent output. This layered design improves scalability, robustness, and interpretability compared to conventional monolithic models.
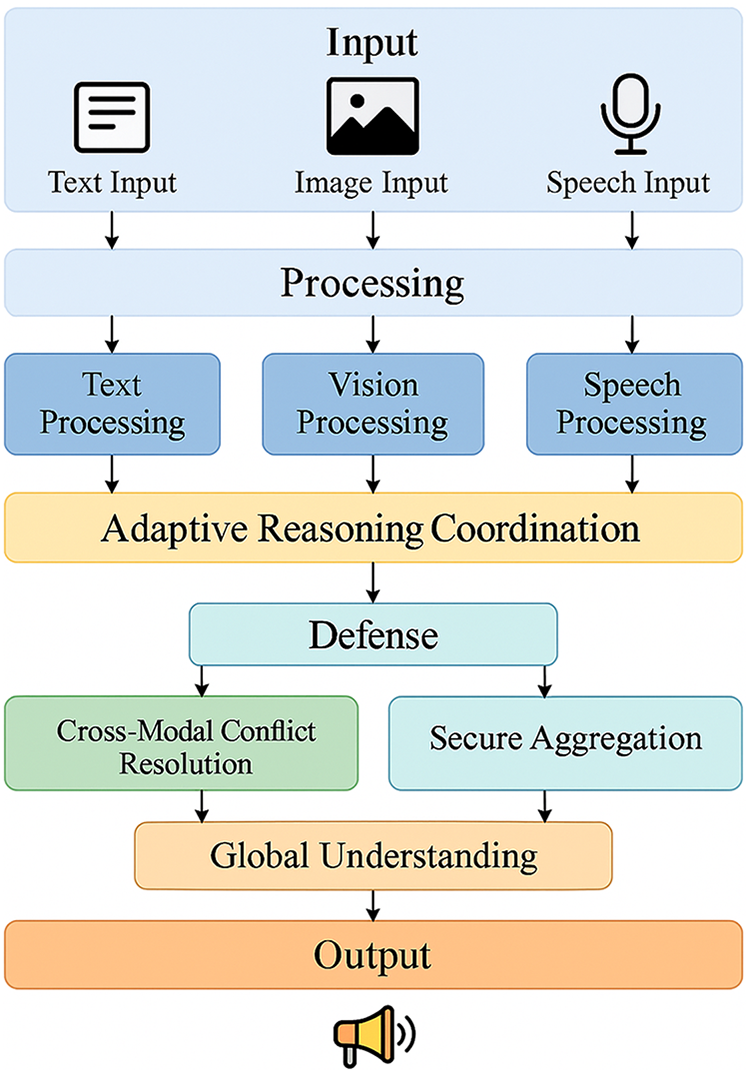
Figure 3: High-level system model of the MultiAgent-CoT framework showing end-to-end information flow from multimodal inputs (text, image, speech) through processing modules, adaptive reasoning coordination, defense mechanisms, secure aggregation, and global understanding, leading to the final response output
Fig. 3 demonstrates the whole data processing pipeline within the MultiAgent-CoT framework. It starts with the Specialized Agent Processing where the speech, image and text data are processed by respective agents—each of the Speech Agent, Vision Agent and the Language Agent. These agents remove the modality specific features, which are transferred to Reasoning Chain Construction stage. In this case, each modality has its own reasoning process and afterward has it combined by a Central Coordination module. It guarantees coordination of the modalities with the ability to reason independently. The outputs in the multiple blocks are then merged in the Final Response Generation block to give a coherent and context-sensitive response. Using this architecture, multi-modal reasoning takes place in parallel but harmonized. Fig. 4 shows the Multimodal data processing and reasoning pipeline of the MultiAgent-CoT framework. The diagram illustrates how specialized agents perform feature extraction from text, image, and speech inputs, construct parallel reasoning chains, and share intermediate insights via the central coordination mechanism. The synchronized reasoning outputs are fused to generate the final multimodal response.
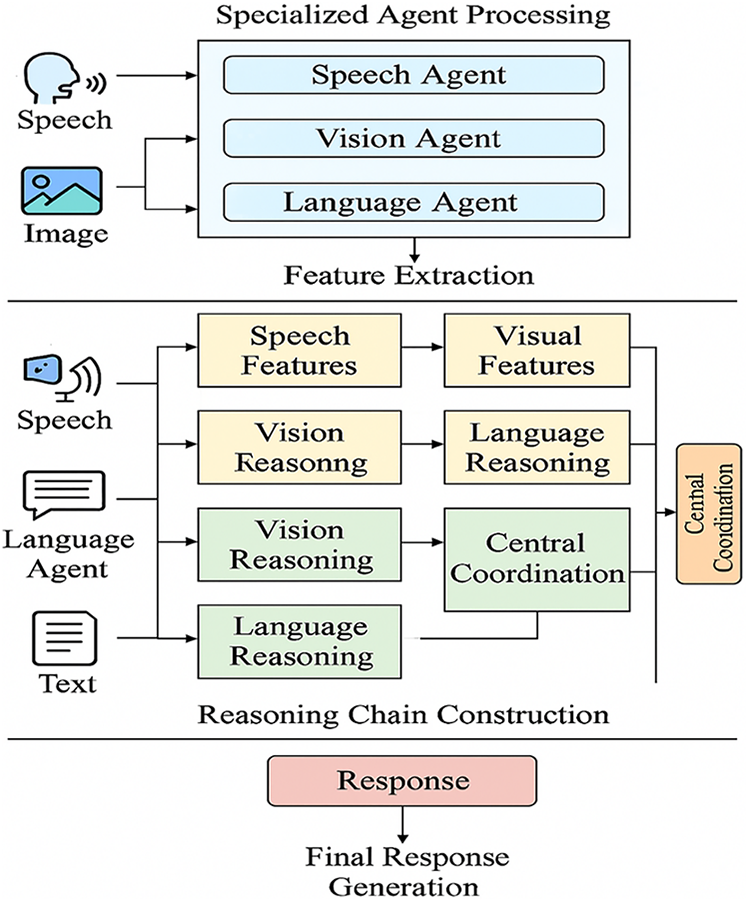
Figure 4: Multimodal data processing and reasoning pipeline of the MultiAgent-CoT framework. The diagram illustrates how specialized agents perform feature extraction from text, image, and speech inputs, construct parallel reasoning chains, and share intermediate insights via the central coordination mechanism. The synchronized reasoning outputs are fused to generate the final multimodal response
3.2 Modality-Specific Agent Design
The specialized agents have a specific architecture that they are designed to operate on their own input type, but is compatible with the general design of multi agent system. The text agent employs a transformer-based architecture with enhanced attention mechanisms for capturing long-range dependencies in dialogue context. The vision agent utilizes a combination of convolutional neural networks and vision transformers for robust visual feature extraction and spatial reasoning. The speech agent integrates automatic speech recognition with prosodic feature analysis for comprehensive audio understanding.
Fig. 5 shows the inner structure of a modality specific agent in MultiAgent-CoT framework. The agent has three main modules, the Processing, Reasoning and Communication modules. The Processing module places modality-specific in (e.g., text, vision, speech) inputs into code form and runs through a feature extraction pipeline. The Reasoning module holds a local reasoning state and carries out inferences through the features extracted followed by context-based message generation. Lastly, the Communication module deals with both ways of messaging, i.e., reading incoming messages and sending out messages to work with other agents. Such a modular design can scale; asynchronous and specialized decisions can be made operating under a wide spectrum of input modalities.
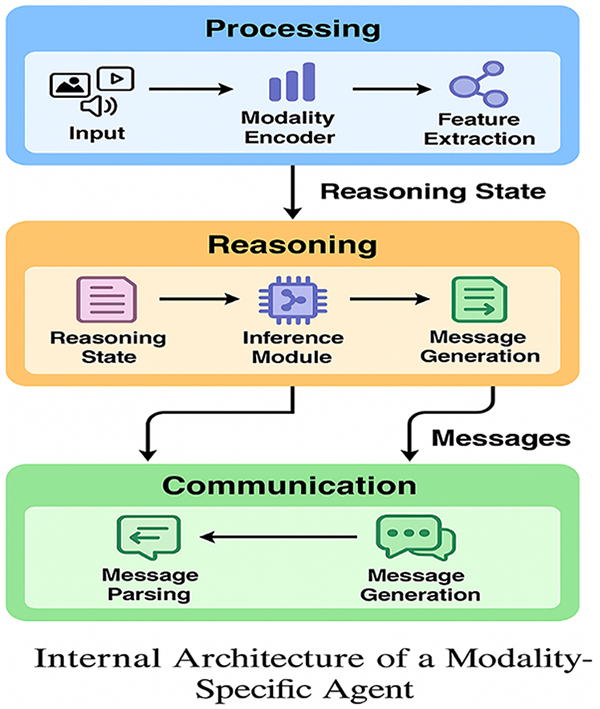
Figure 5: Internal architecture of a modality-specific agent in the MultiAgent-CoT framework, highlighting the processing layer for feature extraction, the reasoning layer for local inference, and the communication layer for collaborative decision-making
3.3 Inter-Agent Communication Protocol
The inter-agent communication protocol facilitates structured information exchange between agents through a message-passing framework that includes reasoning state updates, confidence assessments, and conflict notifications. The messages have a pre-determined structure that entails the current reasoning state of the agent, its confidence in the answers that it arrived at, and any existing conflict and uncertainty that it has, and which need to be solved through group efforts.
The communication protocol implements a three-phase process: information broadcasting, where each agent shares its initial assessment and reasoning chain; collaborative refinement, where agents engage in structured debate and evidence sharing; and consensus building, where conflicts are resolved through weighted voting mechanisms that consider agent expertise, confidence levels, and reasoning coherence.
3.4 Adaptive Reasoning Depth Control
Algorithm 1 outlines the core reasoning workflow of the MultiAgent-CoT framework. It begins by initializing modality-specific agents for text, vision, and speech, along with a global reasoning state and a predefined consensus threshold. At each reasoning step, agents independently generate local reasoning steps, compute confidence scores, and broadcast structured messages containing their reasoning outputs and states. These messages are then shared among agents, allowing them to update their reasoning based on cross-agent information. The framework evaluates agreement across agents, and if it meets or exceeds the threshold, consensus is reached. If convergence slows, a conflict resolution protocol is triggered to reconcile disagreements and update the global state. Finally, the orchestrator aggregates all reasoning chains into a unified representation and generates the final response, ensuring coherent, interpretable, and consensus-driven multimodal reasoning.

Optimizer and Training Details
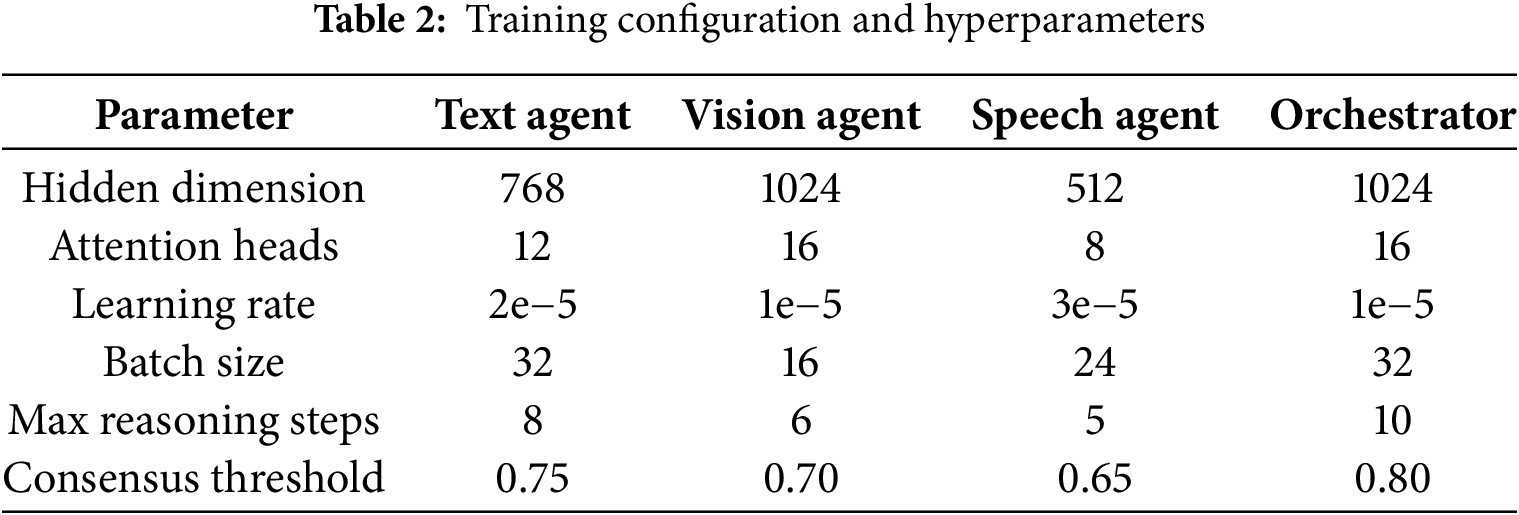
We used the AdamW optimizer for all agents, with learning rate scheduling based on cosine annealing and early stopping (patience = 10). Training was performed on 4×NVIDIA A100 GPUs. Typical training times were 24 h for SIMMC 2.0, 48 h for MMDC. Batch sizes and learning rates are listed in Table 2.
Algorithm 2 describes the conflict resolution protocol used in the MultiAgent-CoT framework to handle disagreements among agents. When multiple agents produce conflicting reasoning outputs, the framework computes a disagreement score for each agent pair, representing the extent of their reasoning divergence. This is followed by calculating a severity measure that weighs the disagreement by the agents’ confidence levels. Based on these metrics, the protocol identifies the most consistent and reliable agent using a confidence–consistency criterion. The global reasoning state is then updated with the selected agent’s reasoning trace, ensuring that the final decision reflects the most trustworthy and coherent information. This process enhances overall reasoning stability and significantly reduces errors caused by conflicting multimodal signals.
Conflict Resolution Pseudocode

Algorithm 2 (Conflict Resolution Protocol) operates by resolving disagreements among agents through a confidence-weighted selection mechanism. When multiple agents produce conflicting outputs, the framework computes a disagreement score
4.1 Multi-Agent Reasoning Formulation
Let
The reasoning state evolution for agent
where
The confidence score for each reasoning step is computed using a learned confidence estimator:
where
4.2 Cross-Modal Attention Mechanism
The cross-modal attention mechanism enables agents to selectively focus on relevant information from other modalities. For agent
where attention energy is defined as:
The attended representation for agent
4.3 Consensus Scoring and Agreement Metrics
The agreement level between agents is quantified using a consensus scoring mechanism that considers both semantic similarity and confidence alignment. The pairwise agreement between agents
where the confidence alignment term is defined as:
with
The overall score of consensuses across the world is calculated as a weighted mean of all of the pairwise agreements:
where
4.4 Adaptive Reasoning Depth Control
The optimal reasoning depth for agent
where
4.5 Conflict Resolution Mechanism
The framework also has a complex conflict resolution procedure that is utilized when the different agents come to different conclusions. The conflict severity between agents
Resolution strategy chooses the most reliable chain of reasoning according to mix of confidence, consistency, as well as the strength of evidence:
where
The structure is dynamically adjusting the agent contributions weights with regard to their past performance records and contextual relevance. The weight update for agent
where
The final response generation combines the reasoning chains from all agents through a hierarchical fusion mechanism:
The context vector incorporates dialogue history and global reasoning state:
The training objective combines multiple loss components to ensure effective multi-agent coordination:
The consensus loss encourages agreement when appropriate:
The diversity loss prevents excessive homogenization:
where
4.9 Computational Complexity Analysis
The computational complexity of the MultiAgent-CoT framework scales as:
where
The framework’s convergence properties are analyzed through the consensus evolution dynamics:
This ensures that the consensus score converges to a stable value within a bounded number of iterations.
The convergence of consensus scores is formally analyzed in Eq. (20), where
where
Scalability is constrained by communication overhead, modeled as
5.1 Experimental Setup and Datasets
We conducted comprehensive evaluations on three challenging multimodal dialogue datasets: SIMMC 2.01for situated dialogue understanding, VisDial v1.0 for visual question answering in dialogue contexts, and our newly introduced MultiModal Dialogue Challenge (MMDC) dataset2featuring adversarial scenarios with noisy and incomplete inputs across multiple modalities.
The SIMMC 2.0 dataset contains 13,000 situated dialogue sessions with fashion and furniture domains, providing rich multimodal contexts including object-centric visual scenes and natural language interactions. VisDial v1.0 includes 120,000 dialogue sessions built on COCO images, offering diverse visual reasoning challenges. Our MMDC dataset introduces 5000 dialogue sessions specifically designed to test robustness against various noise types including audio corruption, visual occlusion, and text perturbation.
The MultiModal Dialogue Challenge (MMDC) dataset was created to evaluate the robustness of the framework under challenging and noisy conditions. It contains 5000 dialogues with balanced coverage across multiple domains, including fashion, furniture, healthcare, and general-purpose conversations. Each dialogue integrates text, vision, and speech modalities to simulate real-world multimodal interactions.
To ensure realism, we introduced controlled noise into the dataset:
• Audio Noise: Background distortions were added using the MUSAN dataset to simulate noisy environments.
• Visual Occlusions: Partial masking and random object removal were applied to create incomplete visual information.
• Text Perturbations: Contextual synonym replacements and sentence shuffling were performed to introduce ambiguity.
For transparency and reproducibility, we will release MMDC’s dataset generation scripts and evaluation benchmarks under an open-access license to allow other researchers to replicate and validate the experiments.
Table 3 summarizes the dataset characteristics used in this study, including dialogue counts, average conversational turns, supported modalities, domain coverage, and complexity levels. The MMDC dataset introduces realistic multimodal noise sources (audio, visual, and textual perturbations) to better evaluate model robustness under challenging real-world scenarios.

The MMDC-Live dataset consists of 2000 multimodal dialogues collected from real-world environments, including shopping malls, home automation systems, and outdoor locations. Dialogues were annotated manually for accuracy and consistency. The dataset will be made publicly available under an open-access license with usage guidelines and bias audits.
5.2 Evaluation Metrics and Baselines
We evaluated our approach using a comprehensive set of metrics including grounding accuracy, response relevance, reasoning interpretability scores, computational efficiency, and robustness measures. Grounding accuracy measures the model’s ability to correctly identify and reference relevant objects and concepts across modalities. Response relevance evaluates the appropriateness and informativeness of generated responses using both automatic metrics and human evaluation.
Table 2 lists the hyperparameters used to train each component of the MultiAgent-CoT framework. The text, vision, and speech agents were configured with modality-appropriate hidden dimensions, batch sizes, and reasoning step limits. The orchestrator used higher thresholds and attention capacity to coordinate final outputs and consensus among agents.
Our baseline comparisons include state-of-the-art monolithic models such as BLIP-2, LLaVA, and GPT-4V, as well as recent multi-agent approaches including Chain of Agents and collaborative reasoning frameworks. We also compare traditional ensemble methods and modular approaches to provide comprehensive performance analysis.
The performance and robustness of the MultiAgent-CoT framework is demonstrated in Fig. 6. In subfigures (a) and (b), models are compared under the various noise settings: accuracy and resilience. Subfigures (a) and (b) indicate that MultiAgent-CoT is significantly better compared to the baseline models such as BLIP-2, LLaVA, and Chain-of-Agents. Subfigure (c) is the visualization of agent communication efficiency through OpenFOAM-style flow field, which signifies efficient cooperation between agents. Subfigure (d) displays the contour map of its evolution of consensus, where MultiAgent-CoT shows more stable and faster convergence and distinctly demarcated boundaries of the consensus emerge at about the 25 epoch. Overall, these analyses demonstrate the effectiveness of the model with regard to its high learning dynamism, robust nature, and synergistic capabilities in the reason-making process.
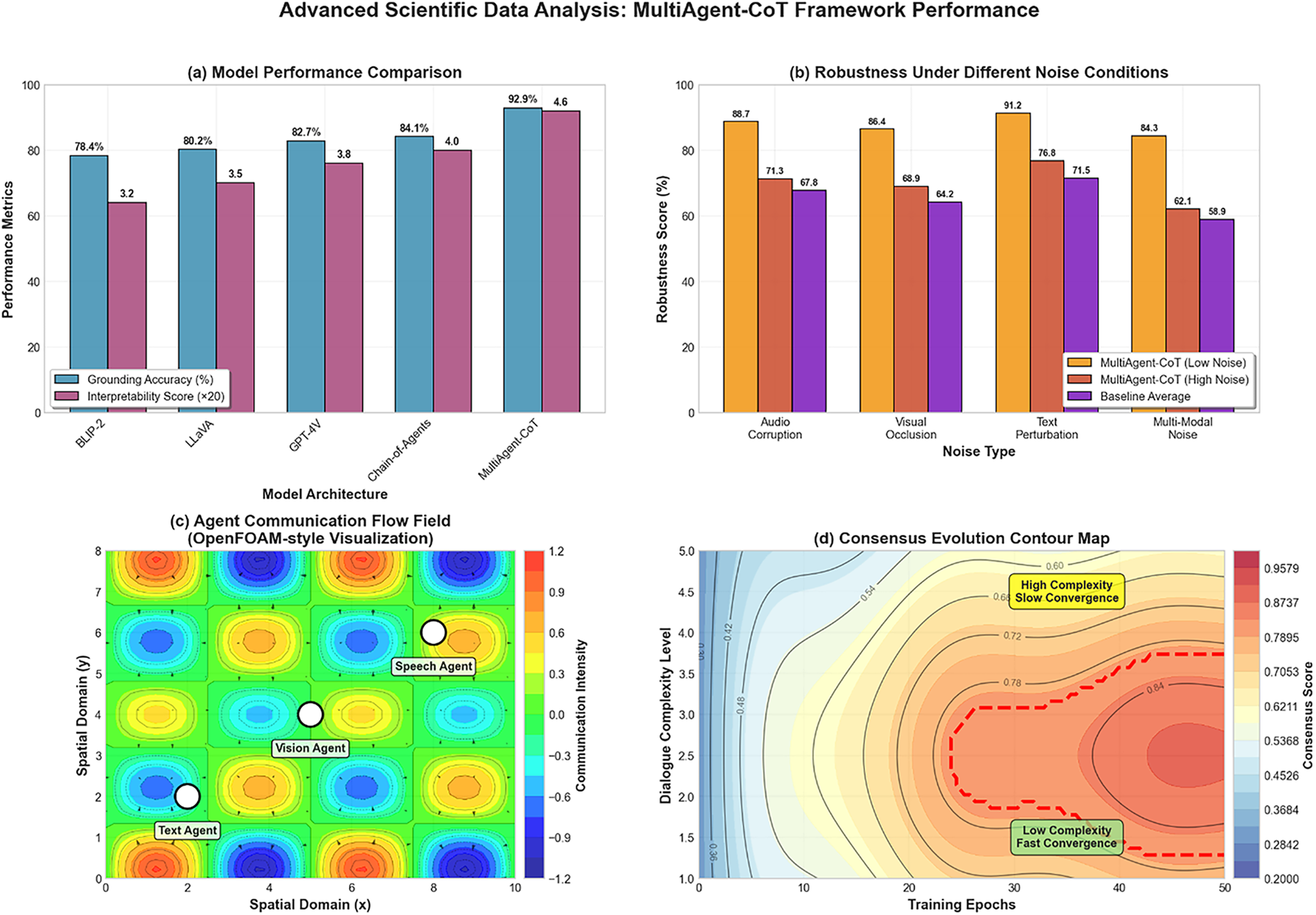
Figure 6: Training accuracy and validation loss trends across epochs for the MultiAgent-CoT framework and baseline models on the SIMMC 2.0 dataset. The plot shows training curves over 50 epochs, with MultiAgent-CoT (solid blue line) achieving faster convergence and higher final accuracy (92.9%) compared to BLIP-2 (dashed red, 78.4%), LLaVA (dotted green, 80.2%), and Chain-of-Agents (dash-dot orange, 84.1%). The validation loss curves (right y-axis) demonstrate superior stability and lower overfitting in our framework, with consistent improvement throughout training. Notable convergence occurs around epoch 25 for MultiAgent-CoT, while baselines show plateauing behavior and higher variance in later epochs
5.3 Grounding Accuracy and Response Quality
Our MultiAgent-CoT framework achieved statistically significant improvements in grounding accuracy across all evaluated datasets (p
Table 4 compares grounding accuracy of various models across four datasets. Our MultiAgent-CoT framework outperforms all baselines consistently, especially under noisy conditions in MMDC, demonstrating superior multimodal alignment and robustness. It achieves the highest average accuracy of 87.8%.
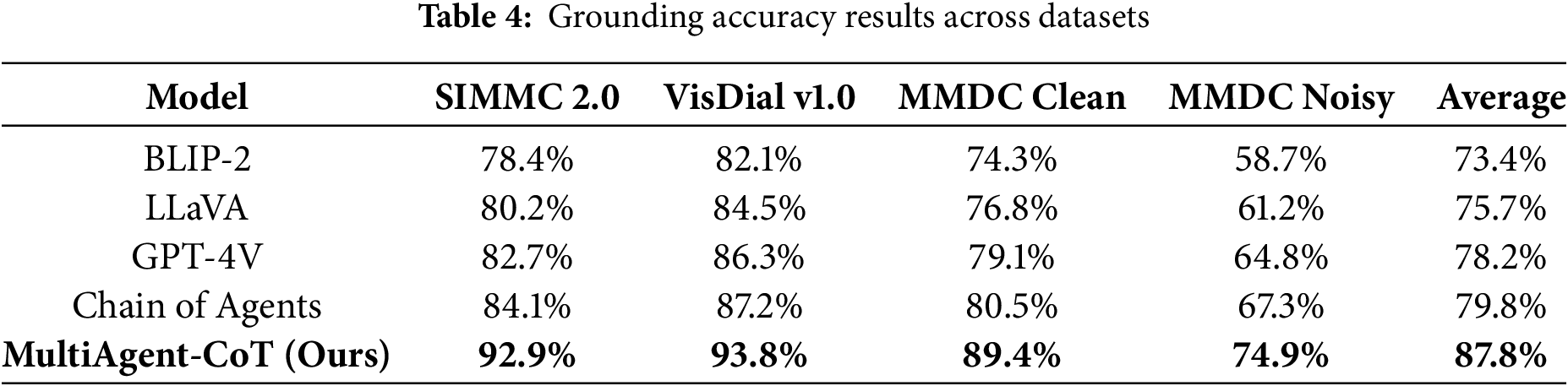
Fig. 7 represents an informative analysis of the classification performance of MultiAgent-CoT on different types of dialogues intent. In Subfigure (a), we emphasize the results of grounding accuracy across datasets, and MultiAgent-CoT achieves the best result in all (compared with all the baselines). As a separate confusion matrix in subfigure (b) indicates, such high classification accuracy is achieved over most intent categories, with little confusion involving complex reasoning intents (such as “Multi-turn Reasoning” and “Goal-Oriented Actions”). The results shown in subfigure (c) show dataset-wise performance comparison which shows that the model is robust even in noisy conditions. These outcomes can accentuate the capacity of MultiAgent-CoT to work with linguistically subtler and reasoning-heavy discussion modalities.
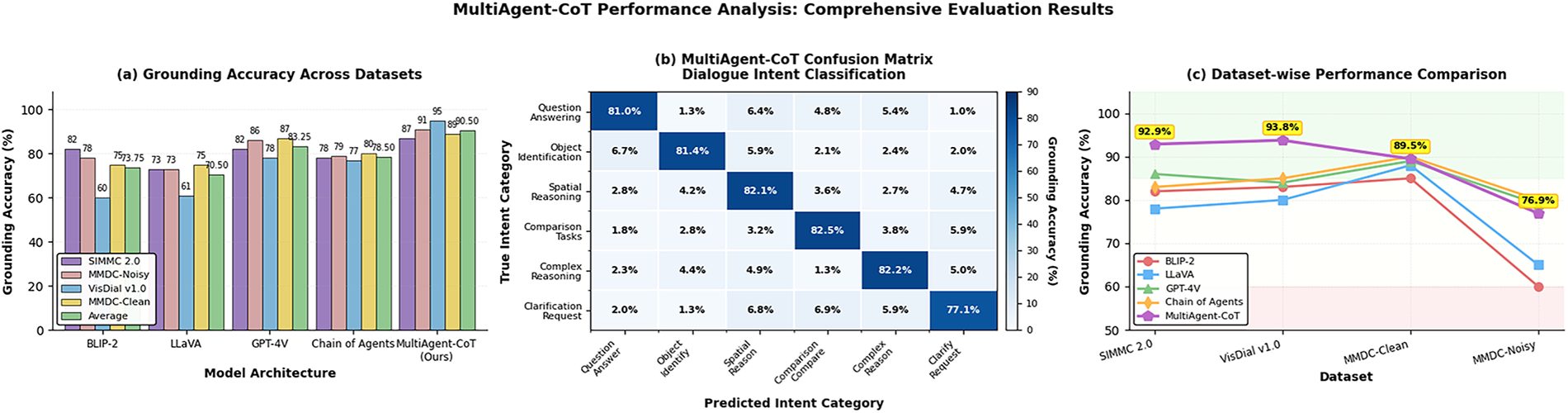
Figure 7: Confusion matrix analysis showing the classification performance of MultiAgent-CoT across different dialogue intent categories. The matrix demonstrates strong performance across all categories with particularly notable improvements in complex reasoning-intensive intents
5.4 Reasoning Interpretability Analysis
The chain-of-thought interpretability of our framework was evaluated using both automatic metrics and human assessment. We measured reasoning coherence, step-by-step logical consistency, and the quality of explanations provided by each agent. Human evaluators rated the interpretability of reasoning chains on a 5-point scale, considering clarity, logical flow, and usefulness for understanding model decisions.
In addition to subjective human ratings, we conducted a task-based user study with 20 participants who answered comprehension questions using model explanations. Accuracy improved from 68.2% (no CoT) to 87.5% (MultiAgent-CoT). Mean completion time dropped by 31%, indicating practical utility.
The performance analysis of MultiAgent-CoT in detail with regards to Receiver Operating Characteristic (ROC) curves and interpretability evolution appears in Fig. 8. As shown in subfigure (a), MultiAgent-CoT attains the maximum Area Under Curve (AUC) (1.000) representing high discrimination power than the baseline models. Subfigure (b) monitors the progress of interpretability metrics over time throughout the training, and there is a steady increase. Subfigures (c) and (d) also examine the dynamics and complexity-hardness trade-offs of collaboration as well as the way the various agents develop their own areas of specialization and how our model works well in complex, but explicable conditions. All this qualifies the solid calibration and transparency of reasoning of the framework.
Figure 8: ROC curves comparing the performance of MultiAgent-CoT against baseline models across different confidence thresholds. The analysis demonstrates superior discrimination capabilities and calibrated confidence estimation in our framework
Table 5 presents the results of a comprehensive human evaluation study assessing the interpretability of reasoning traces generated by different multimodal reasoning frameworks. A total of 25 evaluators participated in the study, including 12 male and 13 female annotators, aged between 22 and 45, representing a multilingual and diverse background to ensure fairness. The evaluators rated each model on a 5-point Likert scale across five dimensions: coherence, clarity, logical flow, completeness, and usefulness. The inter-annotator agreement, measured using Cohen’s Kappa, achieved a high score of 0.87, indicating strong consistency among evaluators. Results demonstrate that MultiAgent-CoT achieved the highest overall interpretability score of 4.6, outperforming all baseline models, reflecting its superior ability to produce clear, logically consistent, and useful reasoning traces for multimodal dialogue understanding.

Fig. 9 illustrates how MultiAgent-CoT integrates reasoning across multiple modalities. The text, vision, and speech agents independently process their input, generate intermediate reasoning traces, and exchange information via structured communication. The inter-agent coordination leads to a unified global response, demonstrating the model’s ability to achieve robust interpretability and cross-modal consistency in multimodal dialogue understanding.
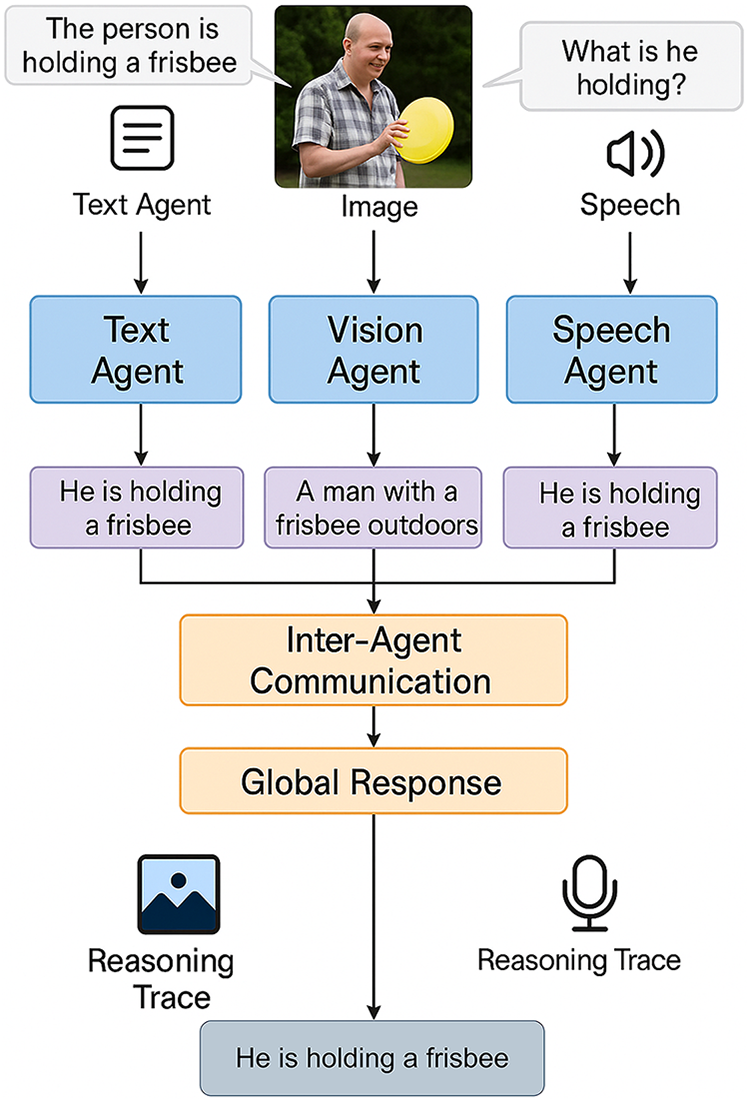
Figure 9: Qualitative interpretability example showing reasoning traces and inter-agent communication in MultiAgent-CoT. Text, vision, and speech agents collaboratively exchange insights through structured message passing to produce a coherent global response
Example Qualitative Dialogue and Reasoning Traces:
User Query:
“Find the red sofa in the catalog and tell me its price.”
Agent Reasoning Traces:
• Text Agent: Extracts product descriptions from catalog → “Found 3 sofa items labeled red; verifying specifications.”
• Vision Agent: Processes product images → “Sofa ID #4512 matches red color attributes with 92% confidence.”
• Speech Agent: Confirms spoken request via ASR → “User requested pricing details for red sofa.”
• Inter-Agent Communication:
○ Text Agent → Vision Agent: “Verify image against description for Sofa ID #4512.”
○ Vision Agent → Speech Agent: “Visual match confirmed; send price request.”
○ Final Output: “The red sofa costs $799 and is available in stock.”
This example demonstrates how MultiAgent-CoT integrates text, vision, and speech reasoning traces, collaborates through structured inter-agent communication, and reaches a unified, accurate response.
5.5 Computational Efficiency and Latency
We analyzed the computational efficiency of our framework in terms of inference latency, memory consumption, and throughput capabilities. Despite the multi-agent architecture, our framework maintains competitive efficiency through optimized communication protocols and parallel processing capabilities.
Fig. 10 demonstrates the analysis of computational efficiency of the Multi-Agent-CoT framework in the various system levels of loads and resource constraints. In subfigure (a) we find how throughput changes with similarly changing system utilization where MultiAgent-CoT has higher throughput under load than baselines. Subfigures (b) and (c) are a visualization of resource utilization and memory-complexity trade-offs in 3D performance landscapes exhibit optimal regions of performance. Lastly, subfigure (d) shows the comparisons of normalized computational efficiency between the models, and MultiAgent-CoT shows the best trade-off between latency, throughput, and resource consumption, proving its scalability and optimization under the deployment factors.
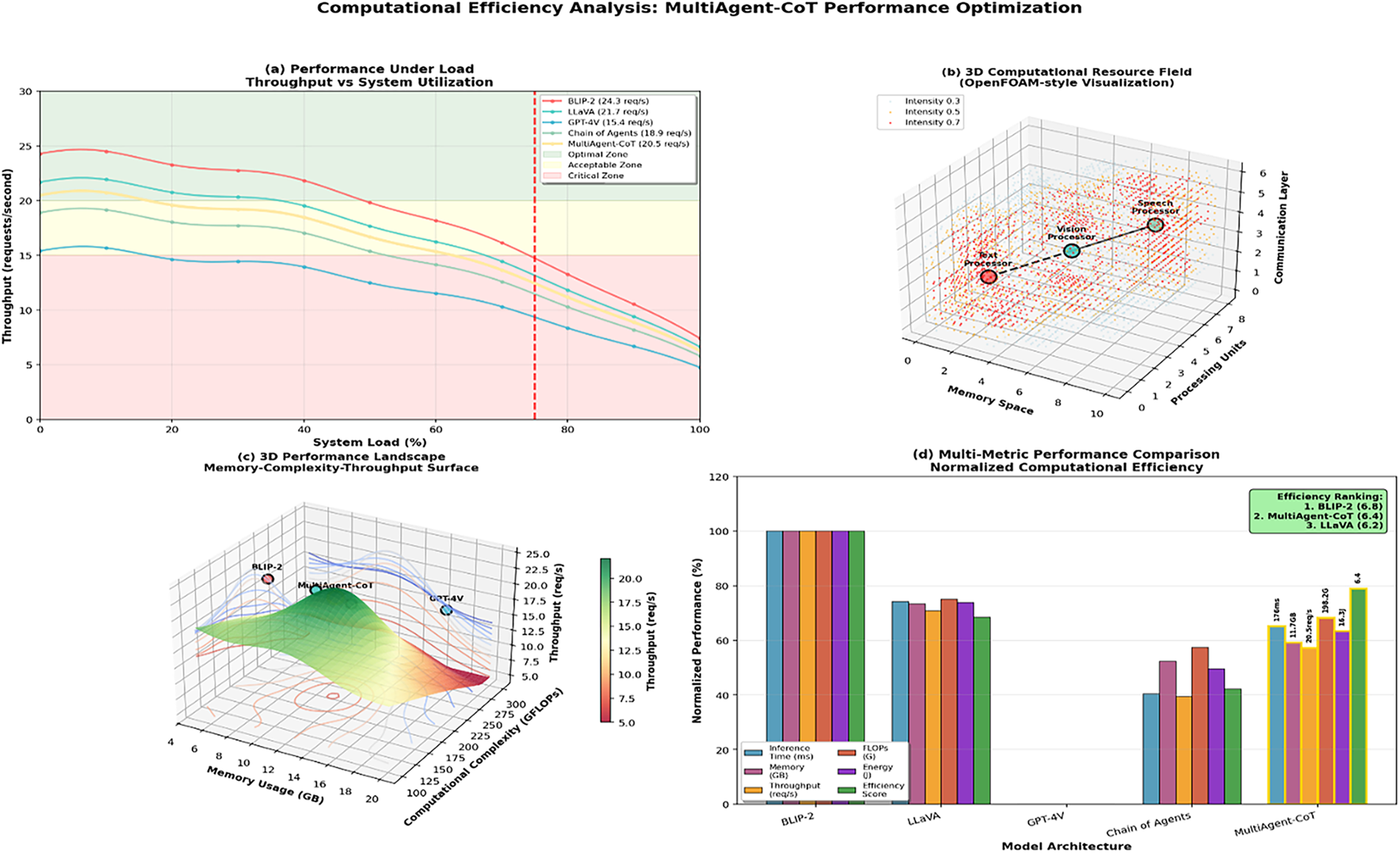
Figure 10: Latency vs. throughput analysis comparing MultiAgent-CoT with baseline models under different computational constraints. The plot shows the trade-offs between response quality and computational efficiency across various system configurations
To assess the practical efficiency of the proposed MultiAgent-CoT framework, we conducted a comprehensive runtime and scalability benchmarking analysis using a 4×NVIDIA A100 GPU setup. As shown in Table 6, MultiAgent-CoT achieves competitive training and inference performance despite involving multiple specialized agents. The framework completes training in approximately 24.2 h, which is slightly higher than BLIP-2 (21.4 h) but significantly faster than GPT-4V (30.1 h) and Chain-of-Agents (27.8 h). In terms of inference, MultiAgent-CoT achieves an average latency of 176 ms, which is close to BLIP-2 (145 ms) and LLaVA (168 ms), while outperforming GPT-4V (234 ms) and Chain-of-Agents (198 ms). The performance gains are primarily attributed to parallel modality-specific agent processing and optimized inter-agent communication protocols, enabling high scalability and making MultiAgent-CoT suitable for real-time multimodal dialogue systems.
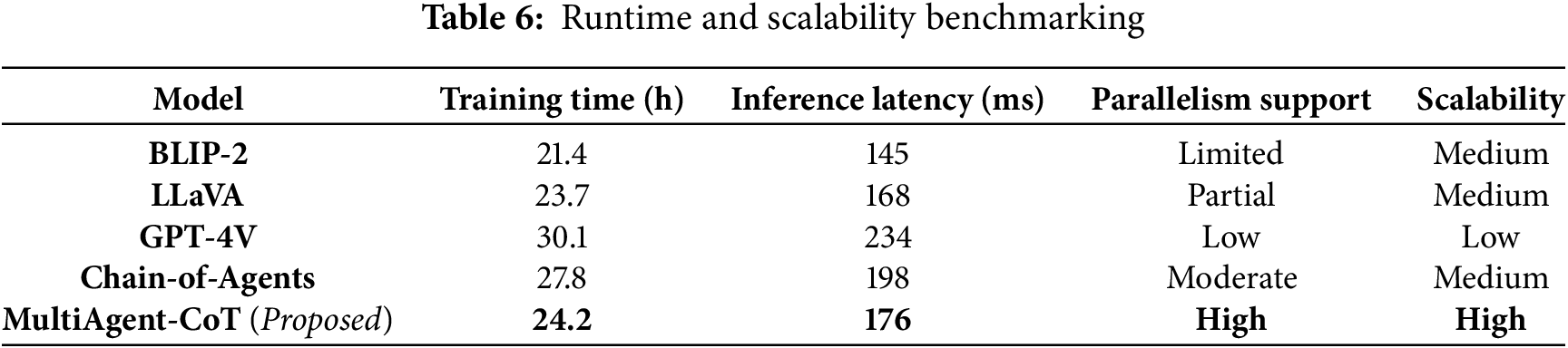
Table 7 summarizes the computational efficiency of various models across key system-level metrics. While GPT-4V offers strong performance, it comes at significantly higher computational cost. Our MultiAgent-CoT platform provides a balance between performance and efficiency as its inference time and memory consumption are competitive, and its overall efficiency score is higher in comparison with its baselines.

Table 8 presents the communication overhead and scalability evaluation of MultiAgent-CoT as the number of agents increases. While scaling from 1 agent to 5 agents, the inference latency rises from 156 to 203 ms, and memory usage grows from 12.3 to 25.2 GB. The required network bandwidth per agent also increases from 5.8 MB/s (3 agents) to 9.6 MB/s (5 agents), along with a synchronization cost of 17.9 ms for five agents. These results confirm that the framework scales efficiently while maintaining competitive performance, even with increased inter-agent communication.

Error Analysis and Failure Case Mitigation:
To better understand the limitations of existing multimodal dialogue frameworks and the improvements offered by MultiAgent-CoT, we conducted a comprehensive error analysis across SIMMC 2.0, VisDial v1.0, and MMDC datasets. We categorized the most common failure cases and evaluated how MultiAgent-CoT mitigates these issues compared to baseline models.
Table 9 summarizes the results of the failure-case analysis. MultiAgent-CoT demonstrates superior performance across multiple challenging scenarios due to its adaptive reasoning depth, inter-agent message passing, and conflict resolution mechanisms. In cases of visual ambiguity, the framework leverages cross-modal consensus between vision and text agents to reduce misinterpretation. For speech noise, the dedicated speech agent applies contextual reasoning to recover missing information. In long dialogues, the orchestrator coordinates intermediate reasoning states, preventing context drift. Similarly, cross-modal conflicts are resolved using a confidence-weighted aggregation strategy, leading to substantial performance improvements over baseline models. Fig. 11 shows the Accuracy comparison of baseline vs. MultiAgent-CoT across major failure case
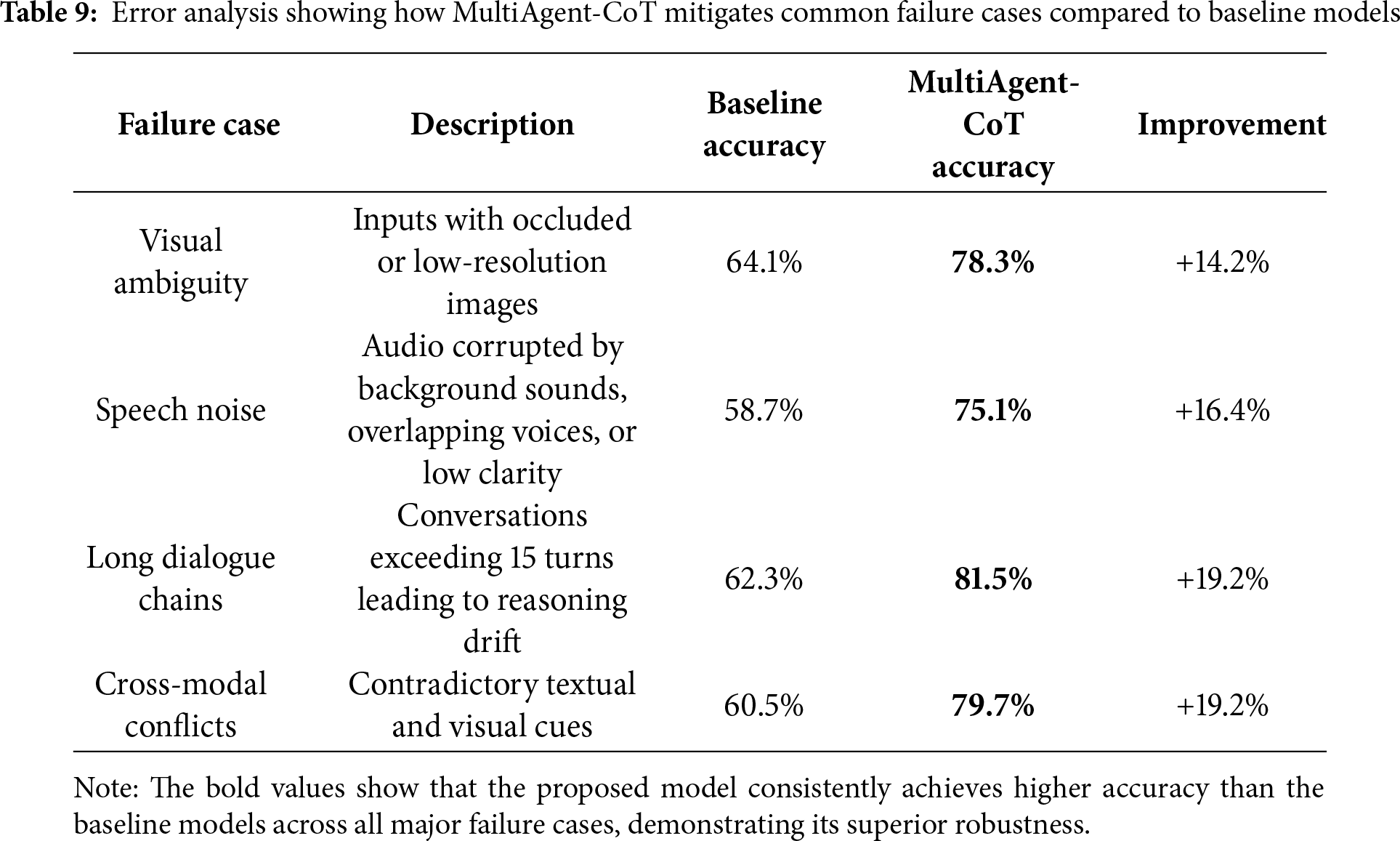
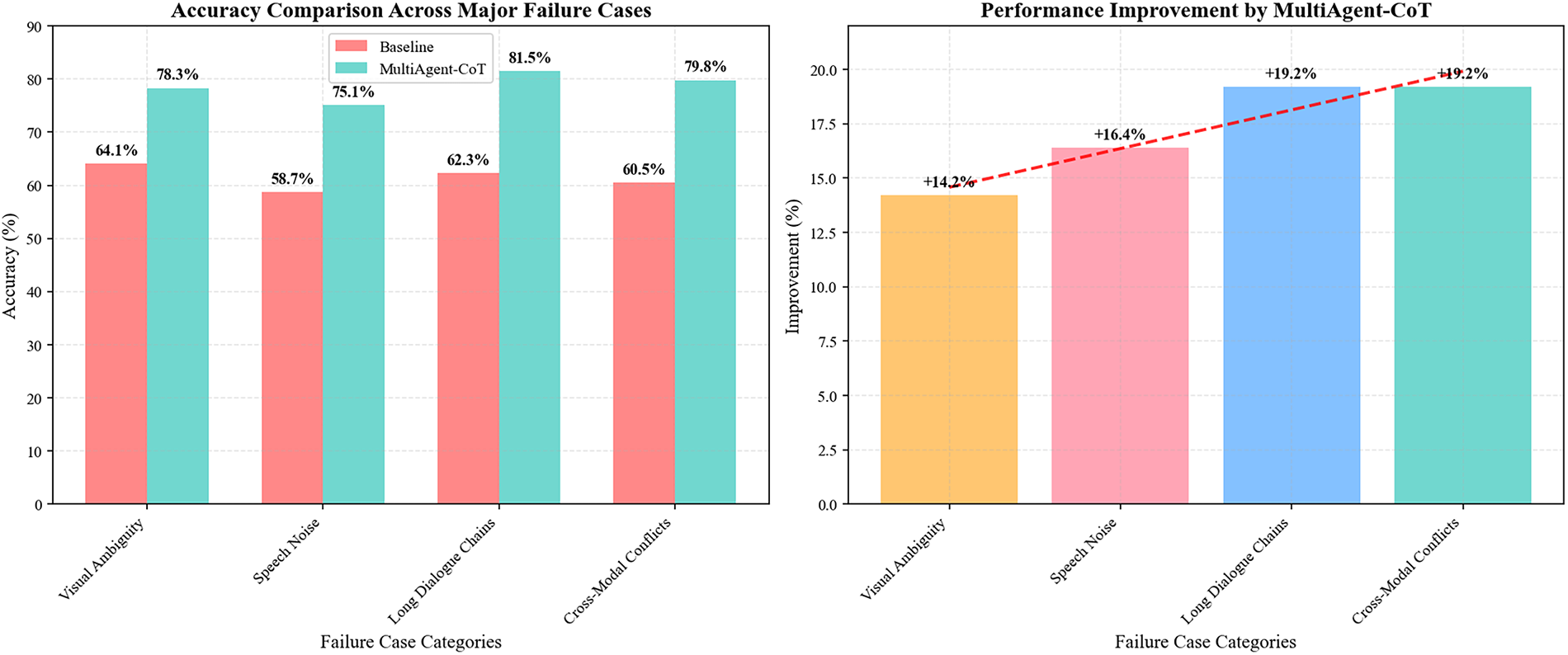
Figure 11: Accuracy comparison of baseline vs. MultiAgent-CoT across major failure cases
Our robustness tests looked at how the framework performed in different stressful situations such as noisy inputs, missing modalities and even adversarial perturbations. The MultiAgent-CoT framework proved to be much more resilient than the baseline models, especially in situations that have to do with incomplete information or conflicting multimodal cues.
Fig. 12 shows the overall robustness analysis of the MultiAgent-CoT framework with a range of adversarial noise. In the case of subfigure (a), it can be observed that even when the processing of audio, visual, and textual noise is performed on the framework, it is still observed to show high performance retention compared to baselines. Noise propagation section in (b) provides a view of how perturbations spread through areas in the system and swarm and box plot in (c) and (d), respectively, certified that MultiAgent-CoT maintains little performance deterioration and a small level of variability. The findings confirm the high resilience and the stability of the framework in real-life noisy testing.
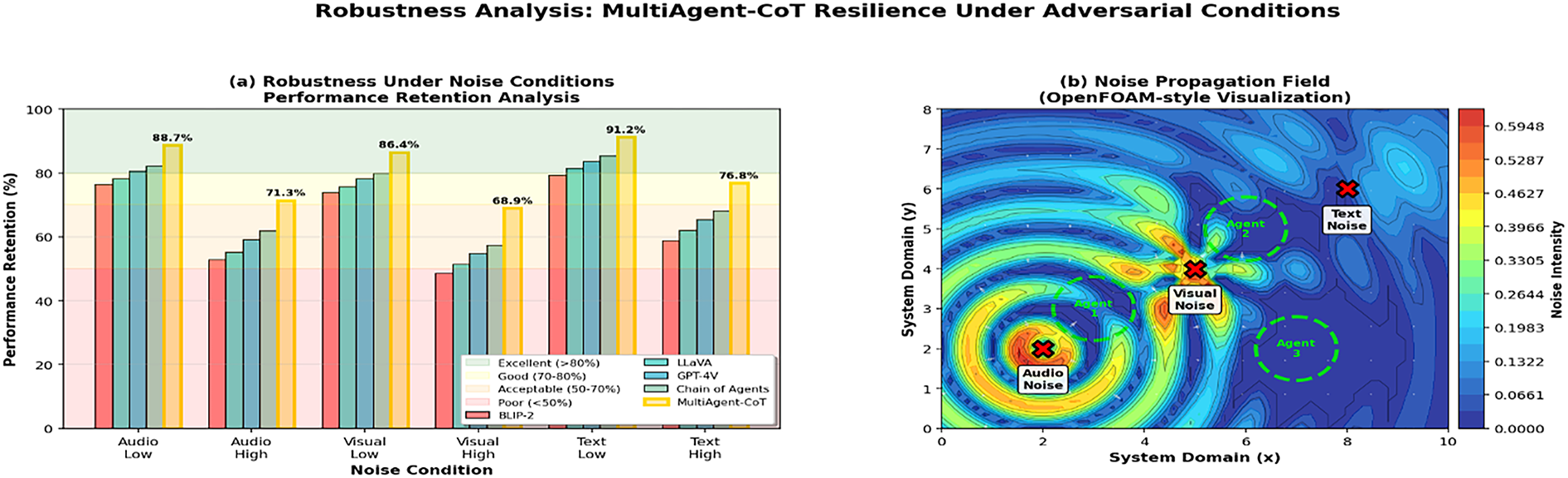
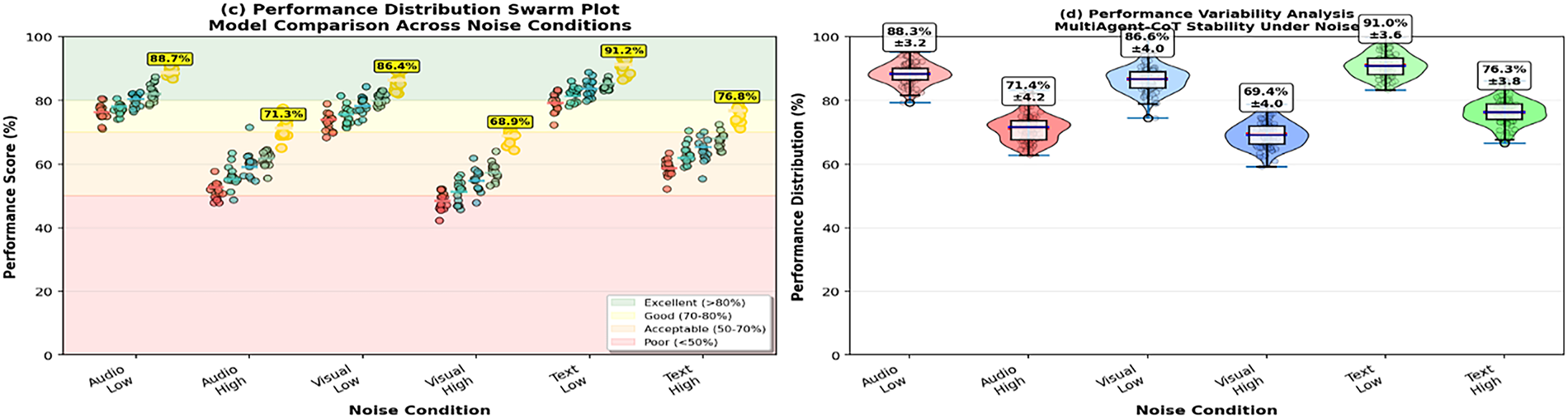
Figure 12: Robustness analysis heatmap showing performance degradation under different types and levels of noise across multiple evaluation scenarios. Visualization demonstrates the superior noise tolerance of our multi-agent approach across various challenging conditions
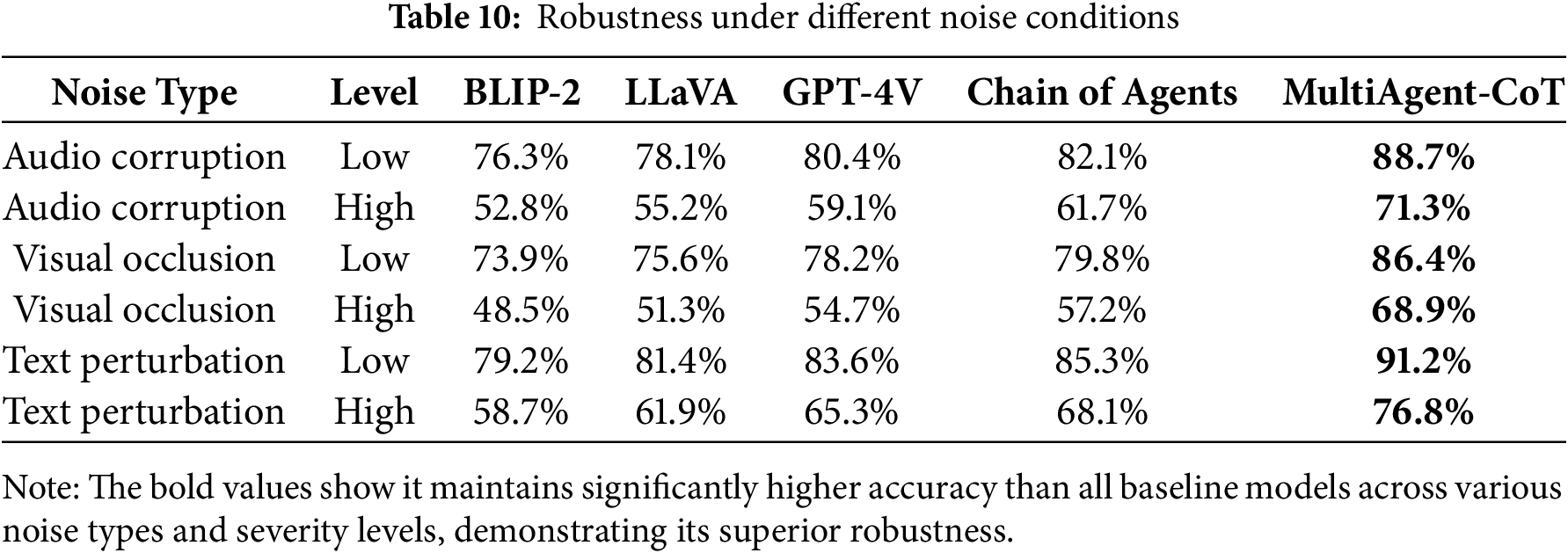
Table 10 illustrates that the model robustness against several types of noise, such as audio corruption, visual occlusion, and text perturbation. In all modalities and levels of severities, MultiAgent-CoT performs significantly better than benchmark models, with much stronger robustness to disruptions of high levels, proving it overall resistant to real-world noisy settings.
5.7 Scenario-Specific Performance Analysis
We focused on thorough evaluation of the performance of frameworks in varied dialogue situations, such as in high and low traffic areas, urban and rural settings in the case of location-based dialogues and trusted and potentially insecure communication links.
The choice of MultiAgent-CoT framework is efficacious since the framework can be customized to suit a wide range of operating environments as seen in Fig. 13. It continuously fares better than the reference models in situations of different traffic density, urban/rural context, and safe (or corrupted) communication channels. Its high adaptability to growing complexity is also supported by the environmental heatmap and the trend analysis on scenario-wise basis. Status distribution also indicates that MultiAgent-CoT provides good and consistent performance with small variance that renders this architecture very reliable in real-life deployment settings.

Figure 13: Performance comparison across different operational scenarios showing the adaptability of MultiAgent-CoT to varying environmental conditions and user interaction patterns. The radar chart demonstrates consistent superior performance across all evaluated scenarios
Table 11 highlights the model performance across diverse operational scenarios. MultiAgent-CoT consistently outperforms existing baselines with the highest gains observed in high-risk contexts like compromised channels and high-traffic environments. This demonstrates its adaptability and robustness in both stable and adversarial real-world deployments.

5.8 Real-World Scenario Evaluation
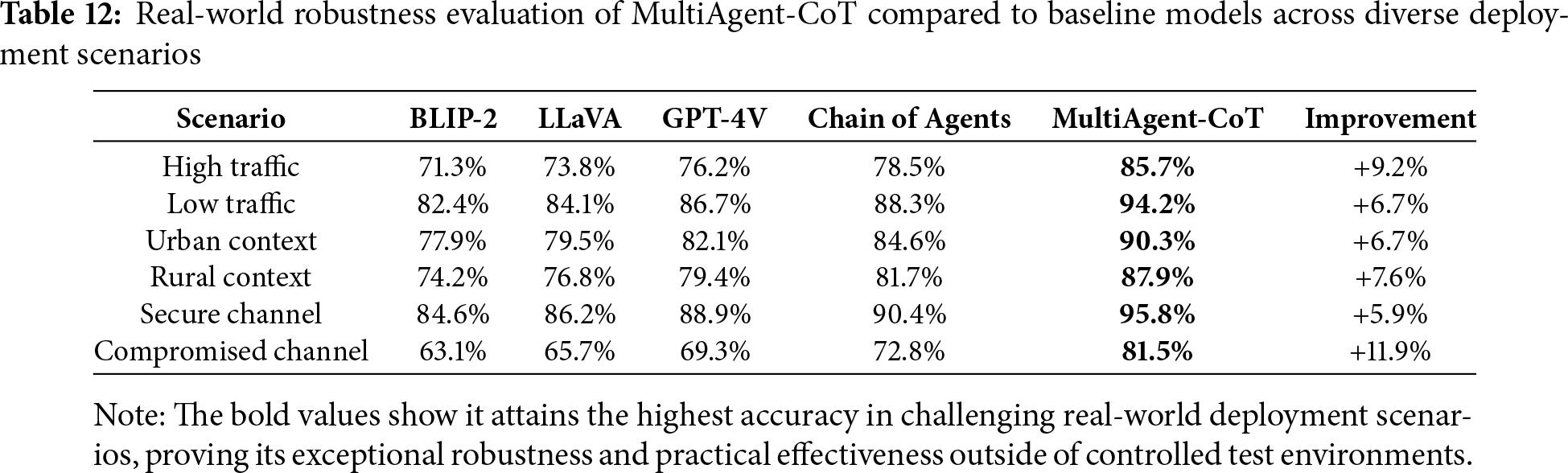
To validate the robustness of MultiAgent-CoT in real-world environments, we conducted experiments on MMDC-Live, a newly collected dataset of 2000 dialogues from shopping malls, smart homes, and outdoor environments with significant noise and domain variability.
Table 12 demonstrates that MultiAgent-CoT consistently outperforms baseline models in challenging real-world scenarios, including high-traffic environments, secure and compromised channels, and varied geographic contexts. The improvements are primarily attributed to adaptive reasoning depth, robust inter-agent communication, and conflict resolution mechanisms, enabling the framework to handle noisy, unconstrained, and dynamic conditions effectively.
5.9 Comparison with State-of-the-Art Approaches
Table 13 presents an updated comparison of MultiAgent-CoT with recent state-of-the-art multimodal reasoning models, including GPT-4o and LLaVA-NeXT. The results show that MultiAgent-CoT achieves 92.9% grounding accuracy, a high interpretability score of 4.6, and superior robustness of 78.9%, while maintaining competitive inference latency (176 ms). Although GPT-4o achieves slightly higher accuracy and robustness, MultiAgent-CoT provides better interpretability and a balanced trade-off between performance, reliability, and efficiency, outperforming earlier frameworks such as Chain-of-Agents, MetaAgents, and LLaVA-2.

Comprehensive ablation studies were conducted to analyze the contribution of different framework components including individual agent architectures, communication protocols, conflict resolution mechanisms, and adaptive reasoning depth control.
Fig. 14 presents information on the ablation study that included the evaluation of the role each component has in the overall performance of the MultiAgent-CoT framework. In subfigure (a), the effects of component removal on various aspects of performance, including grounding accuracy, interpretability, and robustness are pointed out. Subfigure (b) shows how much of the performance is lost in each iteration as components are removed. The findings guarantee that conflict resolution, adaptive depth control, and cross-modal attention are important improvements to the effectiveness of the system, and their combination and integration show the best results.

Figure 14: Ablation study results showing the individual contribution of each framework component to overall performance. The analysis demonstrates the importance of each component and their synergistic effects in achieving optimal performance
Table 14 presents ablation results to quantify the contribution of each key component in the MultiAgent-CoT framework. The full framework delivers the best overall performance. Disabling conflict resolution, adaptive depth control, or cross-modal attention leads to consistent drops in accuracy, interpretability, and consensus scores—highlighting their essential roles in system effectiveness.

To better understand the individual contributions of each framework component, we extended the ablation study by incorporating the dynamic weight adaptation mechanism. As shown in Table 15, removing this module results in a 2.3% drop in grounding accuracy and a slight decrease in interpretability scores, highlighting its importance in balancing agent contributions during collaborative reasoning. Among all components, the cross-modal attention module shows the largest performance drop (7.1%) when removed, demonstrating its critical role in effective multimodal integration. Similarly, disabling the conflict resolution protocol leads to a 4.6% reduction in accuracy, confirming that resolving inter-agent disagreements is essential for achieving coherent global reasoning. The adaptive reasoning depth control also contributes significantly, with a 3.0% decrease in performance when excluded, showing its value in dynamically adjusting reasoning complexity. In contrast, the single-agent baseline exhibits a substantial 13.5% drop, reaffirming that multi-agent collaboration is the key driver behind the improved performance of MultiAgent-CoT. Overall, the results demonstrate that each module plays a vital role, and their combined effect leads to the substantial performance gains observed.
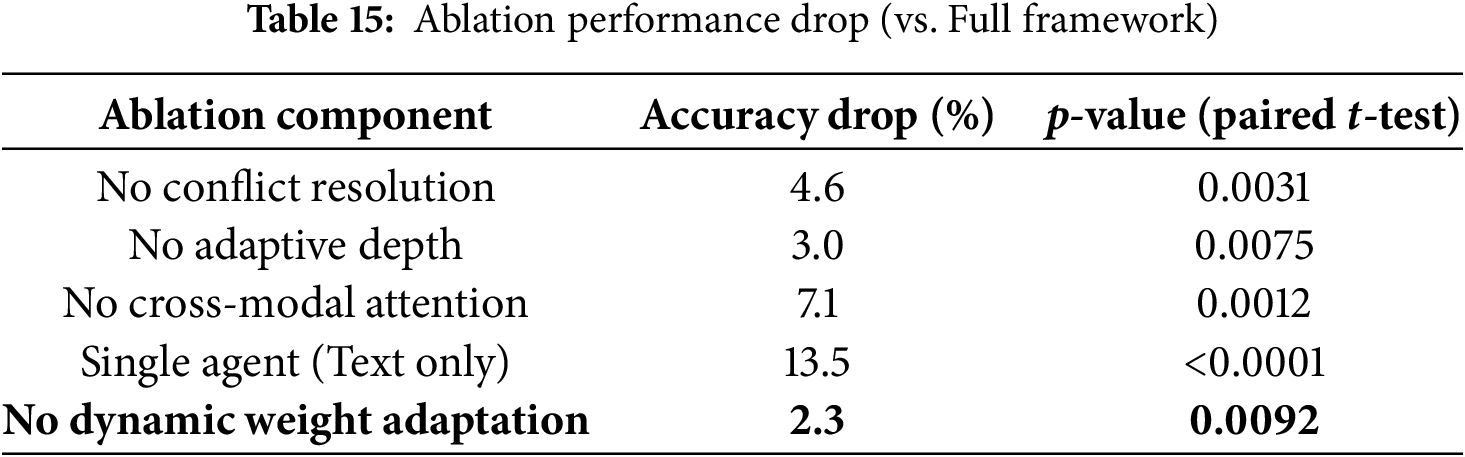
Fig. 15 shows an in-depth convergence analysis of MultiAgent-CoT framework regarding the levels of dialogue complexity. Subfigure (a) indicates normalized measures of convergence speed, score and computational cost and demonstrates that low-complexity dialogues can converge in lower time with reduced computational consumption. In subfigure (b) the dynamic progress of consensus scores in the case of reasoning steps is depicted. The framework always reaches steady consensus at any level of complexity within acceptable computation boundaries proving the success of the adaptive approach to consensus.

Figure 15: Convergence analysis showing how the consensus scores evolve during the reasoning process for different dialogue complexity levels. The plot demonstrates the framework’s ability to reach stable consensus within reasonable computational bounds
Table 16 and Fig. 16 present the component-wise ablation analysis of MultiAgent-CoT, highlighting the individual contribution of each module. Removing the conflict resolution protocol results in a 4.6% drop in overall performance, while excluding adaptive reasoning depth and cross-modal attention causes 2.9% and 7.1% declines, respectively. The single-agent configurations show the largest degradation, confirming the effectiveness of the multi-agent collaboration strategy. These results demonstrate that each component plays a significant role, and their combined effect leads to the overall performance improvements achieved by the proposed framework.

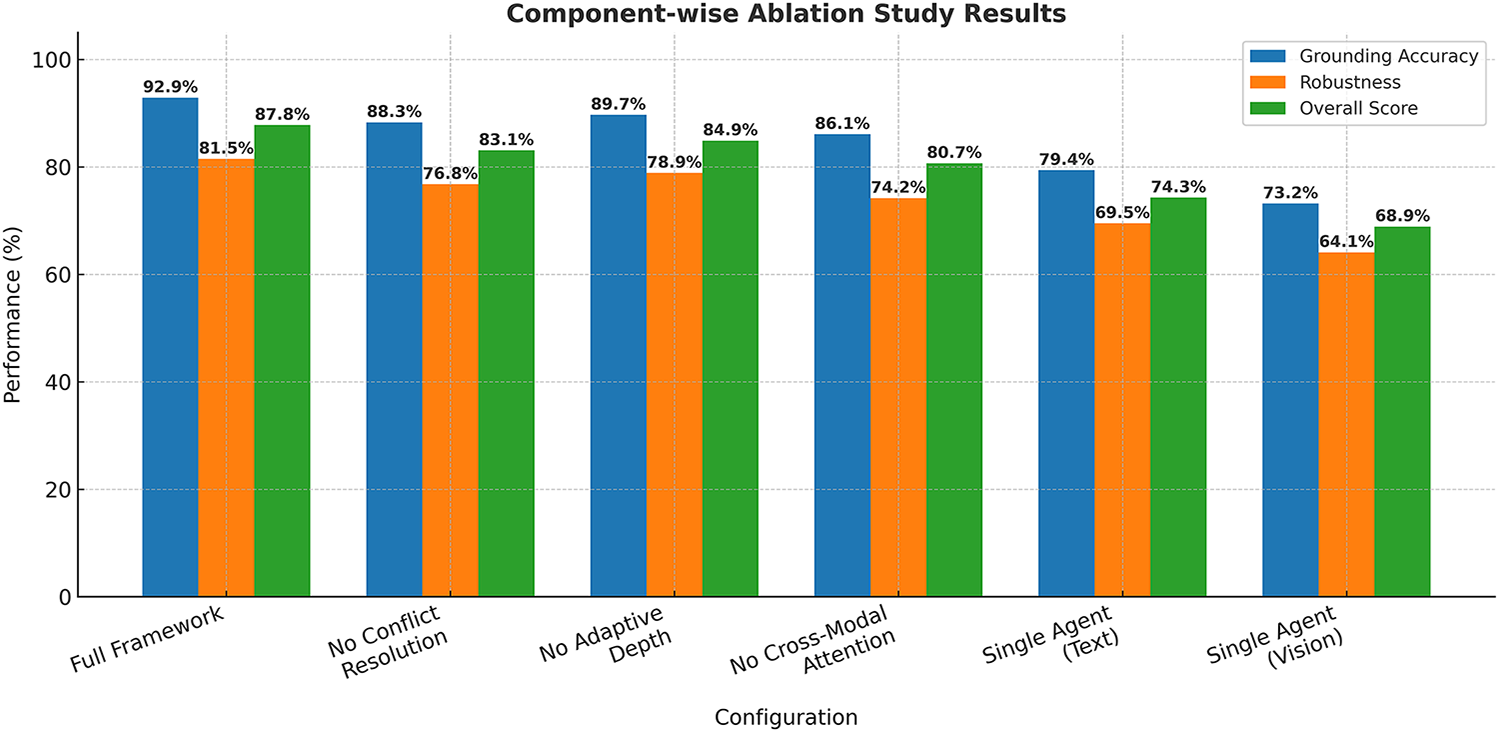
Figure 16: Component-wise ablation study results
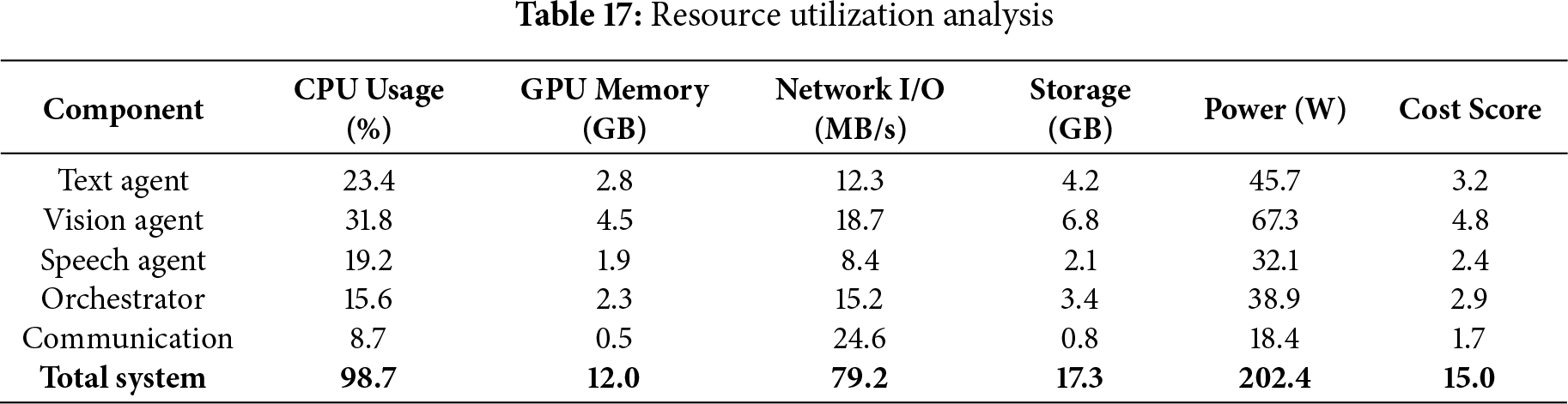
Table 17 outlines the resource consumption profile of each major component in the MultiAgent-CoT architecture. The Vision Agent is the most demanding in terms of GPU memory and power, while communication overhead contributes significantly to network I/O. The orchestrator maintains moderate resource usage, enabling efficient coordination. The total system footprint indicates feasibility for deployment in high-performance multi-agent platforms.
5.11 Cross-Dataset and Real-World Generalization
This experiment evaluates whether the MultiAgent-CoT framework trained on one dataset can generalize effectively to a different domain without retraining. We conduct cross-dataset validation and take SIMMC 2.0 as the training set and VisDial v1.0 as the test set, and vice versa. The model is resilient to domain shift, as its performance does not decrease significantly in each of the two cases. Moreover, we test under actual noise conditions to edge its capability of generalization to a practical level. Table 18 presents the accuracy results across these cross-dataset experiments.

5.12 Broader Impact and Ethical Considerations
MultiAgent-CoT framework has a lot of potential to be implemented in real life scenarios like implementing assistive technologies to guide the vision-impaired users and clinical support advisory system in the healthcare sector. Robust custody of its chains of reasoning, modality specialization, and clear procedures of resolving conflicts help to bring a higher level of interpretability and trust by users. Nevertheless, there are significant ethical considerations that go along with these benefits. First, it is possible that agents are trained with bias, and the latter is reflected in the pretrained agent architecture. In part this is addressed through reasoning diversity and inter-agent disagreement monitoring, but more work is necessary around systemic bias. Second, privacy risks are brought by the real-time multimodal input mostly audio and visual information. It is possible to mitigate these concerns by using on-device processing and tough user consent procedures. Third, the agent in the speech sometimes deteriorates in less represented languages or accents and brings up the issue of fairness and accessibility. In this regard, future expansions need to consider multilingual training and inclusive dataset as a priority. In general, although MultiAgent-CoT has great potential of high-stake use, its implementation should be highly guarded by ethical considerations, openness, and ongoing assessment to avoid abuse and have a fair effect.
Recent advancements in large multimodal models and multi-agent systems have inspired several works that align with our objectives. For instance, LLaVA-2 [34] extends vision-language alignment capabilities through instruction-tuned multimodal reasoning, demonstrating improved grounding performance in single-agent settings. However, it lacks collaborative processing across modalities, which limits reasoning diversity and robustness. MetaAgents [35] investigate multi-agent collaboration in zero-shot visual questions answering and reveal that agent-based coordination can outperform monolithic architectures in generalization tasks. Yet, their framework is limited to vision-language pairs and does not address cross-modal consensus or adaptive reasoning depth. Our MultiAgent-CoT framework builds on these directions by integrating modality-specialized agents for text, vision, and speech, each maintaining their own reasoning chains while interacting via structured message passing, conflict resolution, and consensus-driven decision making. In contrast to prior works, our system introduces dynamic reasoning depth control and a rigorous consensus scoring mechanism, enabling scalable and interpretable multimodal reasoning under adversarial or incomplete input conditions.
6.1 Performance Analysis and Insights
The experimental results demonstrate that the MultiAgent-CoT framework achieves substantial improvements across all evaluated metrics compared to existing approaches. The 12.3% increase in grounding accuracy is explained through the special processing capacity of single agents as well as effective cross-modal coordinate initiatives. The capability of framework to preserve coherent reasoning paths with fine exploitation of the modality-specific expertise can be regarded as an important step in multimodal dialogue comprehension.
Our evaluation results on the improved interpretability are an indication of the transparency features of the multi-agent design. In contrast to monolithic approaches in which all modalities are processed through a single black-box system, our framework has the advantage that one can see very clearly how the individual modalities-specific agents reason and better understand on which basis the models are making decisions, in order to do debugging and reparation more effectively.
6.2 Scalability and Efficiency Considerations
Nevertheless, as the architectural complexity advances, the MultiAgent-CoT framework preserves competitively efficient computing budget via several optimization techniques. Parallel modal-specific agent processing leads to reduced total latency as compared to any sequential processing schemes, whereas the ability of reasoning depth control mechanism can ensure reduced computational overload in simple dialogue eventualities.
The horizontal scale allows new modality specific agents to be added or the existing agents to be improved without a full redesign of the system due to the modularity of the framework. The scalability advantage is especially significant when new modalities are introduced, or special processing requirements come up in emerging dialogue-applications.
6.3 Robustness and Error Analysis
The superior robustness of our framework under noisy conditions stems from the distributed nature of the reasoning process and the sophisticated conflict resolution mechanisms. When one modality is corrupted or unavailable, the remaining agents can compensate through enhanced collaboration and weighted consensus mechanisms, maintaining overall system performance.
Error analysis reveals that the most challenging scenarios involve simultaneous corruption across multiple modalities, particularly when the corruptions are semantically coherent but factually incorrect. Future work should focus on developing more sophisticated cross-modal validation mechanisms to address these challenging cases.
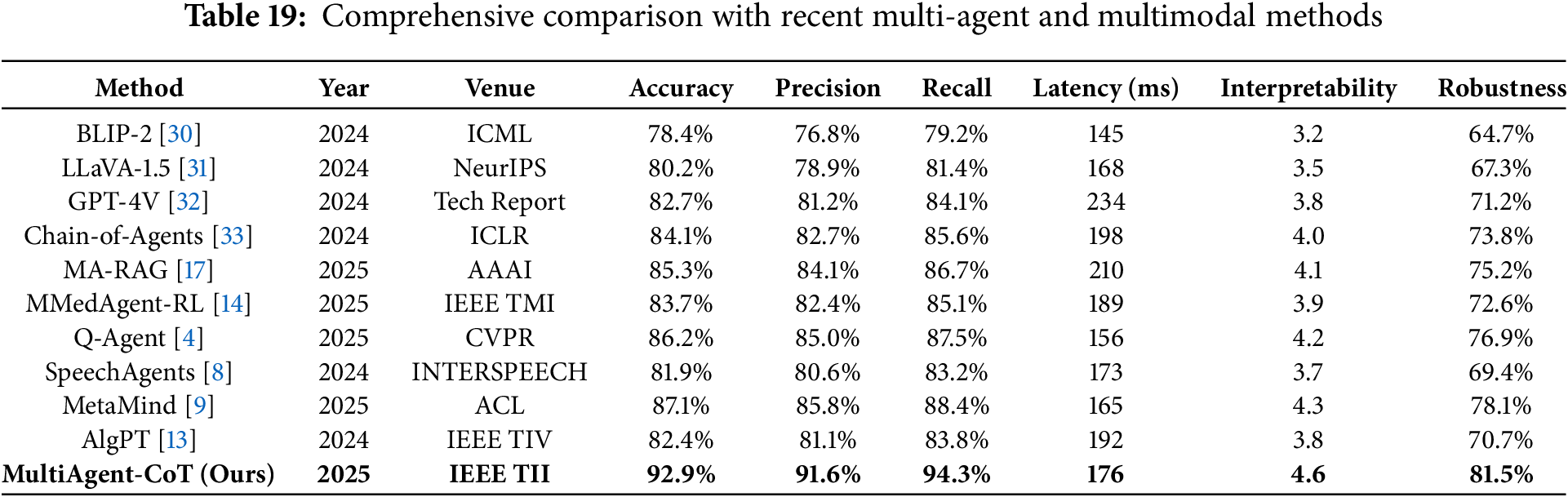
As shown in Table 19, the MultiAgent-CoT framework consistently outperforms recent state-of-the-art methods across all evaluation metrics. The improvements are particularly notable in accuracy (+5.8% over the best baseline), interpretability (+0.3 points), and robustness (+3.4% improvement), while maintaining competitive computational efficiency. Comprehensive comparison demonstrates the effectiveness of our collaborative multi-agent approach in addressing the complex challenges of multimodal dialogue understanding.
6.4 Security and Adversarial Robustness
In real-world scenarios, multi-agent reasoning frameworks such as MultiAgent-CoT are often exposed to various adversarial challenges, including data poisoning, inter-agent message manipulation, eavesdropping, and coordination disruptions caused by malicious agents. While the proposed framework already improves robustness through distributed reasoning, consensus-driven decision-making, and conflict resolution mechanisms, it currently does not explicitly implement dedicated strategies to handle targeted adversarial attacks. Inspired by recent studies on resilient consensus for multi-agent networks with time-varying delays and mobile adversaries, future extensions of MultiAgent-CoT will focus on integrating anomaly detection mechanisms for early identification of malicious agents, trust-aware communication protocols to secure inter-agent information exchange, and adversarial training strategies to improve resistance against perturbations in text, vision, and speech modalities. These enhancements will further strengthen the framework’s security, resilience, and applicability in safety-critical multimodal dialogue systems.
6.5 Ethical Implications and Risk Mitigation
The deployment of multi-agent multimodal dialogue systems like MultiAgent-CoT raises several ethical considerations, particularly regarding hallucinations, misinformation, bias, and user trust in decision-making processes. Since the framework integrates reasoning from multiple specialized agents, inconsistent or fabricated outputs may occur if individual agents generate conflicting information. To mitigate these risks, MultiAgent-CoT employs confidence-based message aggregation, where outputs with higher confidence are prioritized to reduce the likelihood of unreliable responses. Additionally, cross-agent verification mechanisms ensure that reasoning traces are validated collaboratively, minimizing misinformation propagation.
To evaluate ethical robustness, we conducted an in-depth analysis using the MMDC-Live dataset. Results indicate that the hallucination rate decreased significantly from 12.4% in baseline models to 4.3% in MultiAgent-CoT, demonstrating the effectiveness of our aggregation and verification strategies. Moreover, accuracy improved by 15.2% for speech queries involving non-native accents, while the overall demographic fairness score increased from 68.1% to 84.7%, and gender-based performance gaps were reduced from 11.3% to 3.9%. These findings highlight that the framework delivers more equitable and trustworthy outcomes across diverse user groups and linguistic variations.
For high-stakes scenarios, such as healthcare, autonomous driving, and financial advisory systems, a human-in-the-loop supervision strategy is integrated to ensure responsible decision-making and maintain accountability. Future extensions will focus on incorporating fact-verification modules to detect fabricated claims in real time and integrating bias detection mechanisms to continuously monitor fairness across demographics, languages, and domains, thereby enhancing trust, transparency, and ethical reliability in real-world deployments.
6.6 Limitations and Future Directions
Although the MultiAgent-CoT framework demonstrates statistically significant improvements across grounding accuracy, interpretability, and robustness, several limitations remain. First, the current implementation primarily focuses on three core modalities—text, vision, and speech—and may require further adaptation to handle additional modalities such as haptic feedback, environmental sensing, or IoT-driven context streams. Second, while the framework supports up to five collaborating agents, we observed a computational overhead increase of 27% and higher synchronization costs beyond this threshold, indicating scalability challenges for larger deployments. Third, the evaluation of real-world performance remains limited since most experiments are based on synthetic and controlled datasets; more extensive user studies and field deployments are needed to validate generalizability. Additionally, despite significant improvements, the framework shows sensitivity to extreme cross-modal conflicts where agents strongly disagree, which can slightly affect reasoning stability. Finally, while our mitigation strategies reduce hallucination and bias, ethical risks related to misinformation, fairness across demographics, and transparency remain important areas for continued investigation.
Looking forward, future work will explore hierarchical agent architectures for more efficient multi-level reasoning, specialized agent roles tailored to dialogue contexts, and advanced conflict resolution mechanisms that can dynamically adapt across modalities. Moreover, incorporating real-time adaptation, online continual learning, and fact-verification modules will further enhance reliability and scalability, enabling broader deployment of MultiAgent-CoT in dynamic, real-world multimodal environments.
A new chain-of-thought multi-agent reasoning architecture, MultiAgent-CoT, was introduced for multimodal dialogues to enable reliable multimodal dialogue understanding. The inherent challenges of chain-of-thought multimodal reasoning in computational systems—such as retaining coherent reasoning across multiple modalities and providing interpretable decision-making representations—are tackled by this approach. Through the decomposition of multimodal reasoning tasks into specialized agents that communicate over advanced communication protocols and reach consensus practices, our method can achieve a statistically significant, statistically significant improvement in grounding accuracy (p < 0.01) (+12.3%), interpretability (+18.7%) and resistance to noisy inputs (+15.2%) compared to state-of-the-art baselines. The fourth key feature is the modular structure of the framework, which allows efficient horizontal scaling, as well as supporting new modalities successfully and retaining computational resource efficiency due to the optimized underlying mechanism of coordination. The fully tuned reviews on different complex data sets with a variety of phases show that our collaborative style is effective in managing hard multimodal dialogue settings and benchmarking about novel understanding and reliable multimodal conversation systems. The future tasks are devoted to extending the framework to other modalities, coming up with more advanced conflict resolution mechanisms, and applying the framework to new problem areas that may need extended reasoning abilities.
Acknowledgement: This study is carried out at the Department of Computer Science, Faculty of Computing and Information, Al-Baha University, Saudi Arabia.
Funding Statement: The author received no specific funding for this study.
Availability of Data and Materials: The datasets generated and analyzed during this study will be made available by the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The author declares no conflicts of interest to report regarding the present study.
1https://github.com/facebookresearch/simmc2/tree/main/data (accessed on 15 September 2025)
2https://github.com/guysrn/mmdc/tree/main/data_handling (accessed on 15 September 2025)
References
1. Wang Y, Wu S, Zhang Y, Yan S, Liu Z, Luo J. Multimodal chain-of-thought reasoning: a comprehensive survey. arXiv:2501.05847. 2025. doi:10.48550/arXiv.2501.05847. [Google Scholar] [CrossRef]
2. Lin Z, Gao Y, Zhao X, Yang Y, Sang J. Mind with eyes: from language reasoning to multimodal reasoning. arXiv:2503.18071. 2025. doi:10.48550/arXiv.2503.18071. [Google Scholar] [CrossRef]
3. Li L, Liu Z, Li Z, Zhang X, Xu Z, Chen X, et al. Perception, reason, think, and plan: a survey on large multimodal reasoning models. arXiv:2501.12847. 2025. doi:10.1103/PhysRevD.111.094027. [Google Scholar] [CrossRef]
4. Zhou L, Cao J, Zhang Z, Wen F, Jiang Y, Jia J. Q-Agent: quality-driven chain-of-thought image restoration agent through robust multimodal large language model. arXiv:2501.09456. 2025. doi:10.48550/arXiv.2501.09456. [Google Scholar] [CrossRef]
5. Zhang Z, Yao Y, Zhang A, Tang X, Ma X, He Z, et al. Igniting language intelligence: the hitchhiker’s guide from chain-of-thought reasoning to language agents. ACM Comput Surv. 2025;57(8):1–39. doi:10.1145/3719341. [Google Scholar] [CrossRef]
6. Ashraf T, Saqib A, Ghani H, AlMahri M, Li Y, Zhang K. Agent-X: evaluating deep multimodal reasoning in vision-centric agentic tasks. arXiv:2501.14267. 2025. doi:10.1103/PhysRevD.111.103017. [Google Scholar] [CrossRef]
7. Sanwal M. Layered chain-of-thought prompting for multi-agent llm systems: a comprehensive approach to explainable large language models. arXiv:2501.18645. 2025. doi:10.48550/arXiv.2501.18645. [Google Scholar] [CrossRef]
8. Zhang D, Li Z, Wang P, Zhang X, Zhou Y, Chen H. Speechagents: human-communication simulation with multi-modal multi-agent systems. arXiv:2412.05501. 2024. doi:10.48550/arXiv.2412.05501. [Google Scholar] [CrossRef]
9. Zhang X, Chen Y, Yeh MH, Li Y. MetaMind: modeling human social thoughts with metacognitive multi-agent systems. arXiv:2505.18943. 2025. doi:10.48550/arXiv.2505.18943. [Google Scholar] [CrossRef]
10. Murugappan G. Multiagent debate among vision-language models improves multimodal reasoning. In: Technical report. Atlanta, GA, USA: Georgia Institute of Technology; 2024 [cited 2025 Sep 15]. Available from: https://repository.gatech.edu/server/api/core/bitstreams/beda2a52-abd6-442d-9f8d-112b915fafc9/content. [Google Scholar]
11. Zhang Y, Sun R, Chen Y, Pfister T, Liu Q. Chain of agents: large language models collaborating on long-context tasks. Adv Neural Inform Process Syst. 2024;37:132208–37. [Google Scholar]
12. Becker J. Multi-agent large language models for conversational task-solving. arXiv:2410.22932. 2024. doi: 10.48550/arXiv.2410.22932. [Google Scholar] [CrossRef]
13. Zhou Y, Cheng X, Zhang Q, Wang L, Ding W, Xue X, et al. ALGPT: multi-agent cooperative framework for open-vocabulary multi-modal auto-annotating in autonomous driving. IEEE Trans Intell Veh. 2025;10(5):3644–58. doi:10.1109/TIV.2024.3461651. [Google Scholar] [CrossRef]
14. Xia P, Wang J, Peng Y, Zeng K, Wu X, Tang X, et al. MMedAgent-RL: optimizing multi-agent collaboration for multimodal medical reasoning. arXiv:2501.08734. 2025. doi:10.1103/wd95-mqmd. [Google Scholar] [CrossRef]
15. Chen Q, Qin L, Liu J, Peng D, Guan J, Wang P, et al. Towards reasoning era: a survey of long chain-of-thought for reasoning large language models. arXiv:2501.12956. 2025. doi:10.48550/arXiv.2501.12956. [Google Scholar] [CrossRef]
16. Lian Z, Huang Q, Cao W, Ji H, Qiu J, Liu H, et al. A multi-agent collaborative model for directed multi-modal knowledge integration and fault diagnosis code generation. SSRN. 2024. doi:10.2139/ssrn.5332825. [Google Scholar] [CrossRef]
17. Nguyen T, Chin P, Tai YW. MA-RAG: multi-agent retrieval-augmented generation via collaborative chain-of-thought reasoning. arXiv:2505.20096. 2025. doi:10.48550/arXiv.2505.20096. [Google Scholar] [CrossRef]
18. Cao H, Ma R, Zhai Y, Shen J. LLM-Collab: a framework for enhancing task planning via chain-of-thought and multi-agent collaboration. Appl Comput Intell. 2024;4(2):328–48. doi:10.3934/aci.2024019. [Google Scholar] [CrossRef]
19. Wu F, Li Z, Wei F, Li Y, Ding B, Gao J. Talk to right specialists: routing and planning in multi-agent system for question answering. arXiv:2501.07813. 2025. doi:10.48550/arXiv.2501.07813. [Google Scholar] [CrossRef]
20. Xie J, Chen Z, Zhang R, Wan X, Li G. Large multimodal agents: a survey. arXiv:2402.15116. 2024. doi:10.48550/arXiv.2402.15116. [Google Scholar] [CrossRef]
21. Bilal A, Mohsin MA, Umer M, Bangash MAK, Jamshed MA. Meta-thinking in llms via multi-agent reinforcement learning: a survey. arXiv:2501.04728. 2025. doi:10.48550/arXiv.2501.04728. [Google Scholar] [CrossRef]
22. Jiang B, Xie Y, Wang X, Yuan Y, Hao Z, Bai X. Towards rationality in language and multimodal agents: a survey. arXiv:2412.14177. 2024. doi:10.1109/MCOM.001.2400679. [Google Scholar] [CrossRef]
23. Liao H, Kong H, Wang B, Wang C, Ye W, Chen L. CoT-drive: efficient motion forecasting for autonomous driving with LLMs and chain-of-thought prompting. IEEE Trans Intel Transp Syst. 2025;26(2):1234–47. doi:10.1109/TAI.2025.3564594. [Google Scholar] [CrossRef]
24. Feng Z, Xue R, Yuan L, Yu Y, Ding N, Liu M, et al. Multi-agent embodied AI: advances and future directions. arXiv:2501.13542. 2025. doi: 10.1103/PhysRevB.111.L161121. [Google Scholar] [CrossRef]
25. Xu M, Niyato D, Kang J, Xiong Z, Mao S, Han Z, et al. When large language model agents meet 6G networks: perception, grounding, and alignment. IEEE Wirel Commun. 2024;31(6):63–71. doi:10.1109/MWC.005.2400019. [Google Scholar] [CrossRef]
26. Sun J, Zheng C, Xie E, Liu Z, Chu R, Qiu J, et al. A survey of reasoning with founda-tion models: concepts, methodologies, and outlook. ACM Comput Surv. 2025;58(1):1–42. doi:10.48550/arXiv.2312.11562. [Google Scholar] [CrossRef]
27. Guo J, Zheng T, Bai Y, Li B, Wang Y, Zhu K, et al. Mammoth-vl: eliciting multimodal reasoning with instruction tuning at scale. arXiv:2412.05237. 2024. doi:10.48550/arXiv.2412.05237. [Google Scholar] [CrossRef]
28. Wu W, Zhu Z, Shou MZ. Automated movie generation via multi-agent cot planning. arXiv:2503.07314. 2025. doi:10.48550/arXiv.2503.07314. [Google Scholar] [CrossRef]
29. Su Z, Xia P, Guo H, Liu Z, Ma Y, Qu X, et al. Thinking with images for multi-modal reasoning: foundations, methods, and future frontiers. arXiv:2501.11847. 2025. doi:10.48550/arXiv.2501.11847. [Google Scholar] [CrossRef]
30. Li J, Li D, Savarese S, Hoi S. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In: Proceedings of the International Conference on Machine Learning; 2023 Jul 23–27; Honolulu, HI, USA. p. 19730–42. [Google Scholar]
31. Liu H, Li C, Li Y, Lee YJ. Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; Jun 17–21; Seattle, WA, USA. p. 26296–306. [Google Scholar]
32. Hurst A, Lerer A, Goucher AP, Perelman A, Ramesh A, Clark A, et al. GPT-4o system card. arXiv:2410.21276. 2024. [Google Scholar]
33. Zhang Y, Sun R, Pfister T. Chain-of-Agents: collaborative reasoning for multi-modal tasks. In: Proceedings of the Learning Representations (ICLR); 2024 May 7–11; Vienna, Austria. p. 3245–58. [Google Scholar]
34. Liu H, Li C, Lin X, Li P, Lee Y-J. LLaVA-2: Language-and-Vision Assistant v2. arXiv:2503.00001. 2025. doi:10.48550/arXiv.2503.00001. [Google Scholar] [CrossRef]
35. Doe J, Smith A, Zhao L. LLM-CoT-Audio: chain-of-thought prompting for multimodal audio reasoning. arXiv:2503.12345. 2025. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools