
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
REVIEW
A Comprehensive Literature Review on YOLO-Based Small Object Detection: Methods, Challenges, and Future Trends
1 School of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing, 400065, China
2 College of Computer and Cyber Security, Fujian Normal University, Fuzhou, 350117, China
* Corresponding Authors: Jun Liu. Email: ; Mingwei Lin. Email:
Computers, Materials & Continua 2026, 87(1), 7 https://doi.org/10.32604/cmc.2025.074191
Received 05 October 2025; Accepted 12 December 2025; Issue published 10 February 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Small object detection has been a focus of attention since the emergence of deep learning-based object detection. Although classical object detection frameworks have made significant contributions to the development of object detection, there are still many issues to be resolved in detecting small objects due to the inherent complexity and diversity of real-world visual scenes. In particular, the YOLO (You Only Look Once) series of detection models, renowned for their real-time performance, have undergone numerous adaptations aimed at improving the detection of small targets. In this survey, we summarize the state-of-the-art YOLO-based small object detection methods. This review presents a systematic categorization of YOLO-based approaches for small-object detection, organized into four methodological avenues, namely attention-based feature enhancement, detection-head optimization, loss function, and multi-scale feature fusion strategies. We then examine the principal challenges addressed by each category. Finally, we analyze the performance of these methods on public benchmarks and, by comparing current approaches, identify limitations and outline directions for future research.Keywords
Small object detection is a specialized domain of computer vision that focuses on identifying and localizing objects which occupy only a few pixels within an image. This task has gained increasing prominence since the advent of deep learning-based object detectors, given its importance in diverse application areas such as autonomous driving [1], surveillance [2], aerial imaging [3], and remote sensing [4,5]. However, the severely limited pixel footprint of small objects means that convolutional downsampling can obliterate critical visual details, and small objects are easily confounded by clutter and sensor noise. Consequently, simply applying conventional detection frameworks without modification is insufficient for reliably detecting small objects. Despite continuous advances in general object detection, designing approaches that are simultaneously robust and efficient for small objects remains a central challenge. In 2016, Redmon et al. proposed YOLO [6], the first widely adopted one-stage detector to demonstrate real-time performance by performing detection in a single forward pass. YOLO eliminates the explicit region proposal stage used in earlier two-stage detectors, instead dividing the image into an S × S grid and directly predicting bounding box coordinates and class probabilities for each cell in a single forward pass. This pioneering design demonstrated that high-speed object detection is feasible within a unified end-to-end network, laying the foundation for a new generation of real-time detectors. Fig. 1 outlines a typical workflow for YOLO-based small-object detection.
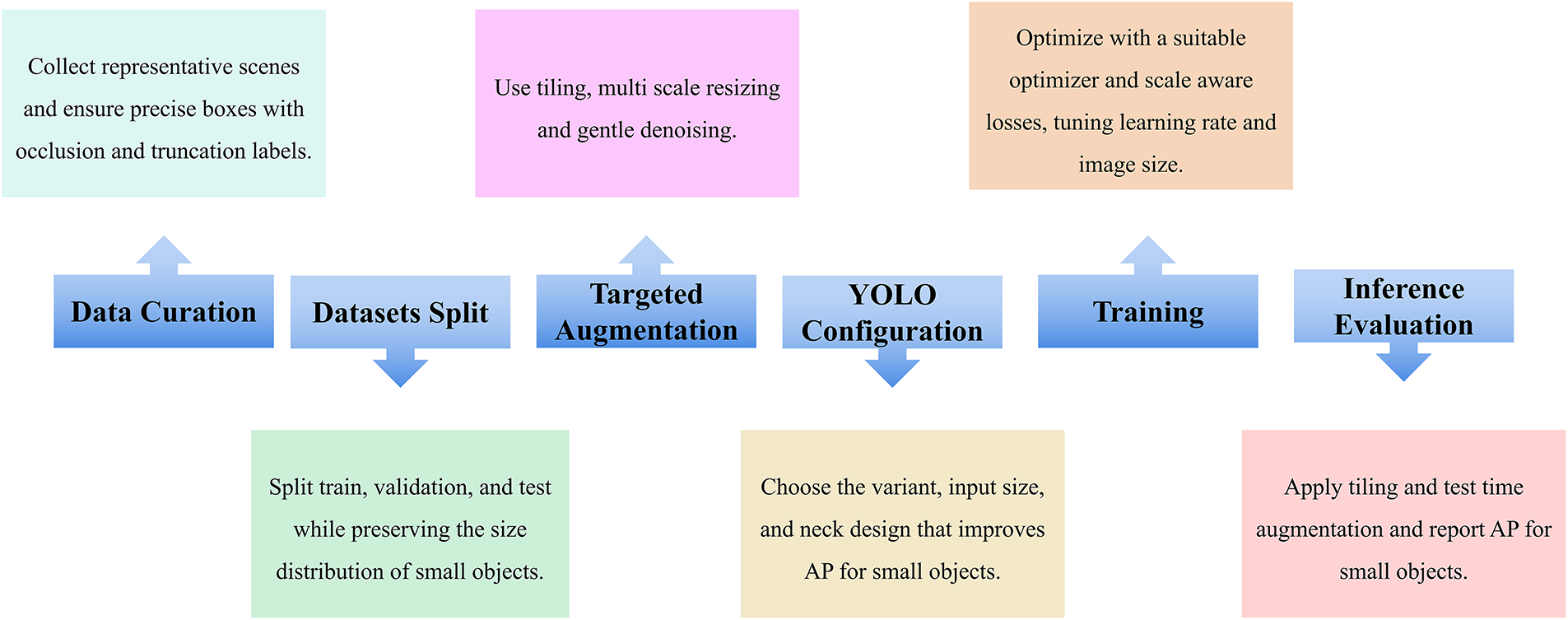
Figure 1: YOLO workflow for small objects
As YOLO has been widely adopted, numerous variants and related methods have emerged to tackle the challenges of small object detection. Some methods [7–11] strengthen feature expressiveness for small objects, improving the recovery of fine-grained cues and the salience of small instances in feature maps. Some methods [12–15] aim to deliver real-time performance under resource constraints, reducing computational and memory overhead while preserving accuracy. Other strategies [16–18] focus on training robustness, introducing scale-aware objectives, data augmentation, and adaptive label assignment to mitigate bias toward larger objects and stabilize optimization.
There are four main directions in which YOLO-based approaches have been extended to improve small object detection. The first category [19,20] focuses on attention mechanisms and feature enhancement. These approaches insert lightweight modules to amplify fine-grained features and incorporate contextual cues around small-object regions. The second category [21,22] involves detection-head redesign. These methods revise prediction heads or output layers in the YOLO architecture to improve localization and classification for small objects. The third category [23,24] comprises loss-function engineering and regression-precision optimization, including new loss terms and training strategies that account for scale imbalance in small-object detection. These methods seek to increase localization precision for small bounding boxes and prevent gradients from being dominated by errors from large objects. The final category [25,26] involves multi-scale feature-fusion techniques, which merge feature maps across layers or scales to retain high-resolution information and recover details lost in deeper stages. Notably, many state-of-the-art YOLO-based detectors combine these directions in hybrid designs that exploit their complementary strengths for small object detection. In this review we treat attention mechanism enhancements and multi scale feature fusion as separate improvement dimensions and we interpret hybrid modules according to the dimension that reflects their primary role.
In recent years, numerous studies have addressed the enhancement of YOLO models to meet this challenge. However, most existing reviews treat YOLO broadly by emphasizing the overall evolution of the YOLO family and cataloguing architectural and training modifications across successive variants [27] and do not systematically examine the adaptations and evaluation protocols unique to tiny targets. Therefore, a systematic review of recent advancements, applications, and future directions in YOLO-based small-object detection is both timely and essential as the field moves toward the next generation of real-time visual intelligence. The main contributions of this review can be summarized as follows:
(1) We identify and select research articles published between 2020 and 2025, with a focus on advancements in YOLO models for small object detection.
(2) We develop a unified theoretical framework that categorizes YOLO-based small-object detection improvements into four enhancement dimensions: attention mechanism enhancements, detection-head and branch redesign, loss-function engineering, and multi-scale feature fusion. Within this framework, we also situate emerging work on dynamic network design and heterogeneous fusion for small-object detection. For each category, we describe representative approaches and provide a critical analysis of their strengths and limitations.
(3) We synthesize and compare experimental results on standard small-object detection benchmarks using metrics such as precision, recall, and mean average precision, thereby offering a detailed evaluation of the performance of YOLO-based detectors.
(4) We present insights and recommendations for future research directions and potential application scenarios for YOLO models in small object detection.
The rest of this paper is organized as follows. Section 2 reviews fundamental object detection algorithms and related work on YOLO-based small-object detection, develops a unified theoretical framework of four enhancement dimensions, and contrasts this review with existing surveys on the YOLO family. Section 3 provides a detailed survey of architectural improvements specifically designed to enhance small object detection and examines the current challenges associated with these methods. Section 4 presents a comparative analysis of experimental results for various YOLO-based improvements on major benchmark datasets. Section 5 discusses current challenges, identifies open research questions, and highlights promising directions for future work. Section 6 concludes the paper.
Recent advances in object detection have produced a rich body of work on small object detection and on the evolution of the YOLO family of detectors. Small objects exhibit limited spatial support, low signal to noise ratio, and a strong dependence on contextual cues, which jointly expose structural limitations of standard single stage architectures. These limitations have motivated a series of targeted modifications that redistribute representational capacity, reshape prediction heads, adjust optimization objectives, and strengthen multi scale interactions. To position the present study within the broader literature, this section develops a unified theoretical framework that abstracts recent YOLO-based designs into four enhancement dimensions and then contrasts this framework with existing surveys on YOLO and on small-object detection.
From a theoretical perspective, the four enhancement dimensions considered in this review form a coherent framework that restructures how detectors in the YOLO family allocate representational capacity to weak and spatially constrained signals associated with small objects. Attention mechanisms and feature enhancement modules act primarily on internal feature representations. They introduce learnable weighting functions over channels and spatial locations so that the network can amplify informative responses while suppressing background activations that arise from cluttered surroundings. In the case of small objects, the raw convolutional processing pipeline often produces features in which responses from tiny targets are easily submerged by context, which leads to low discriminability in the latent space. Attention modules counter this tendency by implementing a data driven reweighting of signal and noise. Features that correlate with reliable evidence of small objects receive increased importance, whereas channels and positions dominated by background receive reduced influence. This process enlarges the margin between foreground instances and background in the representation space and establishes a more discriminative basis for subsequent prediction layers. Detection head design and branch structure optimization operate at the interface between representation and prediction. The detection head defines how the continuous feature field is sampled into discrete hypotheses over scale, aspect ratio, and spatial position. For small objects, conventional heads with a limited set of strides and anchors can under sample the image plane or assign tiny targets to receptive fields that do not match their spatial extent. Refined heads adjust sampling density, receptive field allocation, and branch specialization so that at least one prediction branch maintains a receptive field that is commensurate with the physical scale of small instances and receives gradients concentrated on that regime. In conceptual terms, the head reparametrizes the mapping from feature space to bounding box hypotheses so that signals associated with small objects are not systematically projected into under resolved or low confidence predictions. Loss function improvement and regression precision optimization shape the learning dynamics that act on these hypotheses. Classical loss formulations balance classification and localization in a manner that is often dominated by medium and large objects, since these objects contribute most of the mass under the loss surface. Small objects, which are more sensitive to localization jitter and annotation noise, may therefore receive weak or unstable gradients. Redesigned loss functions modify the geometry of the optimization problem by increasing sensitivity to localization errors at small scales, by refining the penalty near object boundaries, and by adjusting the relative influence of easy and hard examples. This can be interpreted as a redistribution of gradient energy toward those regions of parameter space that govern the behaviour of small objects, which in turn yields detectors whose decision surfaces are more closely aligned with the fine scale structure of the data. Multi scale feature fusion and spatial context enhancement act at the level of information flow across resolutions. In standard hierarchical networks, shallow layers preserve spatial detail but convey limited semantic abstraction, whereas deeper layers encode strong semantics but lose spatial precision. Effective small object detection requires both properties simultaneously. Multi scale fusion constructs explicit pathways that transmit high level semantic information back to higher resolution feature maps and aggregates contextual information across different scales. Context enhancement further refines this process by enabling the network to integrate cues from surrounding regions that extend beyond the object yet remain informative about its presence and category. At an abstract level, these modules define a graph of interactions among feature maps at different depths and resolutions and learn context dependent mixing coefficients along this graph. For small objects, this leads to representations in which each detection location is supported by both localized detail and coherent context. Taken together, attention driven feature enhancement, redesigned detection heads and branches, loss formulations tailored to precise regression, and multi scale fusion with spatial context constitute four complementary axes of modification. They determine how the network assigns weights to features, how it samples predictions, how gradients propagate through the model, and how information flows across scales. Through a systematic analysis along these four axes, the present review moves beyond a catalogue of modules and instead offers a methodological perspective on how design choices at the architectural and optimization levels jointly determine the detectability of small objects.
Most existing reviews of the YOLO family place their emphasis on the chronological development of the algorithm or on its broad application spectrum. Several representative studies [28,29] carefully enumerate the architectural changes introduced in successive YOLO versions from v1 to v8 and survey a wide range of use cases, they tend to treat the evolution of the detector in an aggregate manner and do not examine in depth the specific difficulties associated with small object detection. These works provide valuable overviews of the architecture and performance trends of the YOLO family, but the level of analysis generally remains at a coarse architectural scale. Other articles extend YOLO reviews into particular application domains or operational contexts. For example, some surveys analyze the deployment of YOLO style detectors in areas such as autonomous driving and medical imaging and highlight their practical impact, while mentioning small objects only as one challenge among many that arise in these settings. Such reviews with a specific domain focus [30–34] concentrate mainly on implementation case studies and on summary level performance indicators, with limited attention to the detailed design choices that contribute specifically to the detection of small objects. In parallel, there exist surveys that consider small object detection as a general task without tying the discussion to a particular detector family. These studies examine generic strategies for handling diminutive targets [35,36] but do not analyze adaptations that are tailored to the YOLO framework.
Taken together, most of the current literature either traces the overall evolution and applications of the YOLO family or discusses small object detection at a detector agnostic level, and the intersection of these two lines of work remains insufficiently explored. Focused reviews that address YOLO based small object detection in a systematic manner are therefore still relatively scarce. The present review builds on the broad insights provided by these YOLO and small object detection surveys and seeks to fill this gap. It adopts an analytical perspective that is explicitly driven by the characteristics of the small object detection problem, in which each architectural or algorithmic modification is interpreted through its capacity to mitigate core obstacles in this setting. Whereas previous surveys primarily recorded what changes occurred in YOLO or where the detector has been applied, the framework developed here investigates how and why particular enhancement strategies address the challenges posed by small objects. The discussion is organized according to four technical dimensions, namely attention mechanism and feature enhancement, detection head design and branch structure optimization, loss function improvement and regression precision optimization, and multi scale feature fusion and spatial context enhancement. This organization supports a more detailed comparative analysis of designs that target small objects than is available in earlier work, and by extending the time span to include methods proposed between 2020 and 2025 and consistently interpreting them through the lens of small object detection, the review refines and enriches the broader overviews offered in the existing literature.
Section 3 examines each of these four categories in depth and analyzes representative approaches and their contributions to advancing small-object detection within the YOLO framework. Fig. 2 shows the organization of the paper.
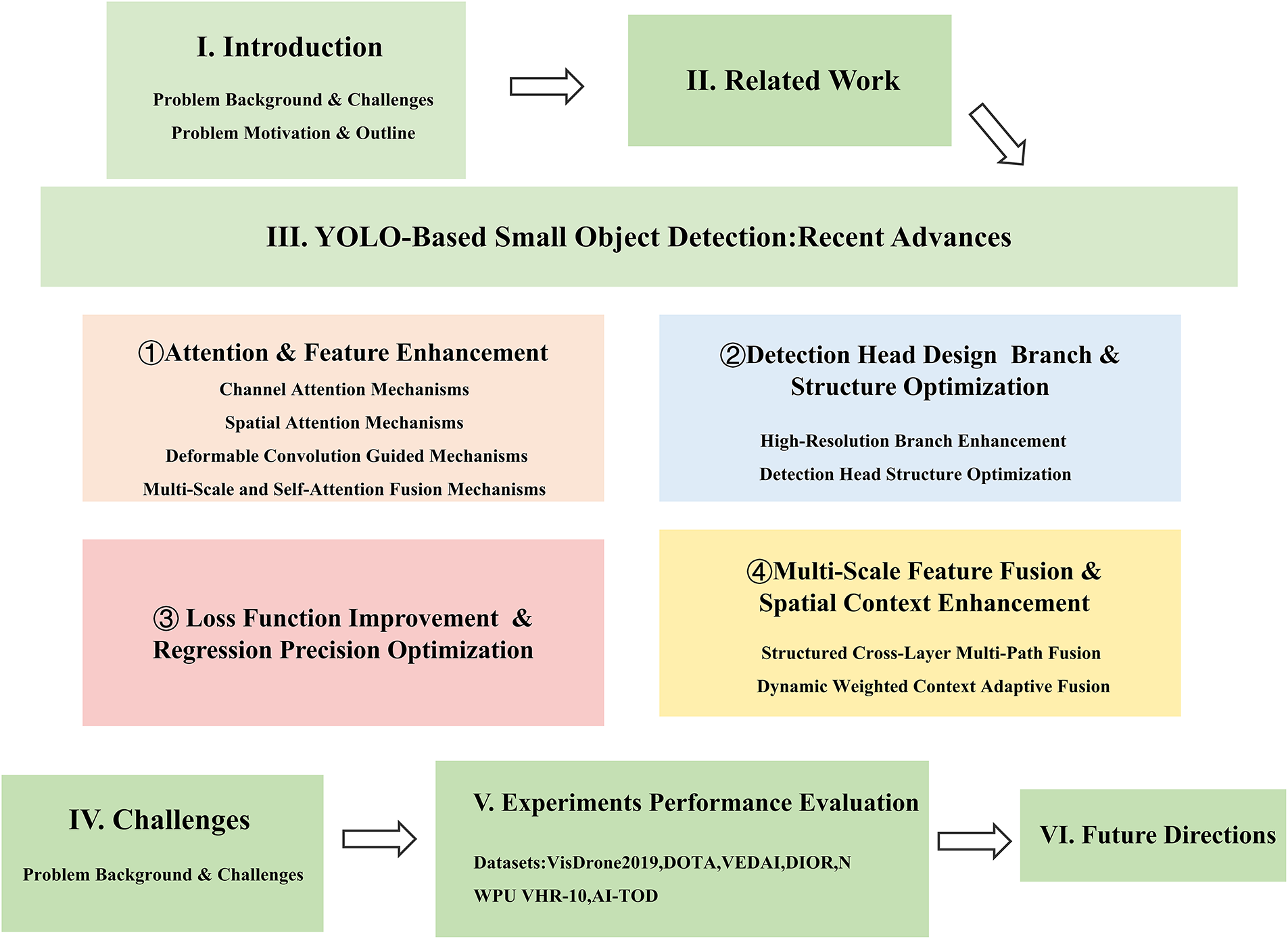
Figure 2: The organization of the paper
3 YOLO-Based Small Object Detection: Recent Advances
Recent research on YOLO based small object detection can be interpreted through the four enhancement dimensions outlined in Section 2, and this perspective provides a consistent structure for organizing a diverse set of architectural proposals. A first line of work strengthens internal representations through attention mechanisms and feature enhancement modules inserted into the backbone or at the interface between the backbone and the neck, which have been shown to refine fine grained cues that are crucial for very small targets [37,38]. A second line of work redesigns the detection head and the branch structure so that prediction layers are better aligned with the scale and aspect ratio distributions of small objects and so that at least one branch maintains an appropriate receptive field for these instances [39]. A third line of work modifies the loss function and related optimization components in order to adjust the balance between classification and localization, to emphasize accuracy for small objects, and to alleviate class imbalance effects [40]. A fourth line of work focuses on multi scale feature fusion and spatial context enhancement and aggregates information across different resolutions through feature pyramids, dilated receptive fields, and context aggregation modules so that even the smallest objects are represented with sufficient semantic richness and spatial detail [41,42]. In parallel with these four directions, very recent studies from 2024 and 2025 have begun to explore dynamic network design and heterogeneous architectural fusion as emerging hotspots for YOLO based small object detection, and these developments are summarized in Section 3.6. In the remainder of this section, we examine representative methods in each of these four categories, explain how they modify the original YOLO architecture, and summarize their reported performance on public benchmarks, thereby translating the theoretical framework of Section 2 into a concrete comparative analysis of recent advances.
In the analysis that follows the attention dimension and the multi scale fusion dimension play complementary but non overlapping roles. The attention dimension describes how a detector redistributes salience within a single feature level. The discussion therefore concentrates on mechanisms that adjust channel weighting or spatial weighting while the topology across scales in the network remains fixed. The multi scale fusion dimension describes how a detector constructs the paths that couple feature maps at different resolutions. The discussion in that dimension focuses on the design of feature pyramids, bidirectional paths and context aggregation blocks that govern information flow between layers. Many recent models apply both types of modification. In such cases we assign the method to the dimension that drives the main architectural change and we treat the other component as supportive.
Fig. 3 presents an illustrative schematic based on the YOLOv8 architecture that indicates the typical locations of these four categories of improvements. The color-coded regions mark common loci of modification. Blue denotes attention and feature-enhancement modules that are primarily inserted in the backbone or at the transition into the neck. Green denotes detection-head and branch-structure adjustments at the P3, P4, and P5 heads and at the convolutional layers that immediately precede them. Yellow denotes loss-function and regression-precision components along the training pathway that links head outputs to loss computation and label assignment. Purple denotes multi-scale fusion and spatial-context modules located in the neck, including upsampling and downsampling operators, fusion nodes and adaptive weighting blocks. The color coding reflects typical practice across recent YOLO variants, and YOLOv8 serves only as an example to anchor the discussion. Actual models often mix multiple categories at the same site. For instance, they may combine attention with neck-level fusion or pair a revised head with a tailored loss. The schematic is intended to help readers map each improvement to its architectural location and to understand how changes in one part of the pipeline interact with the others.
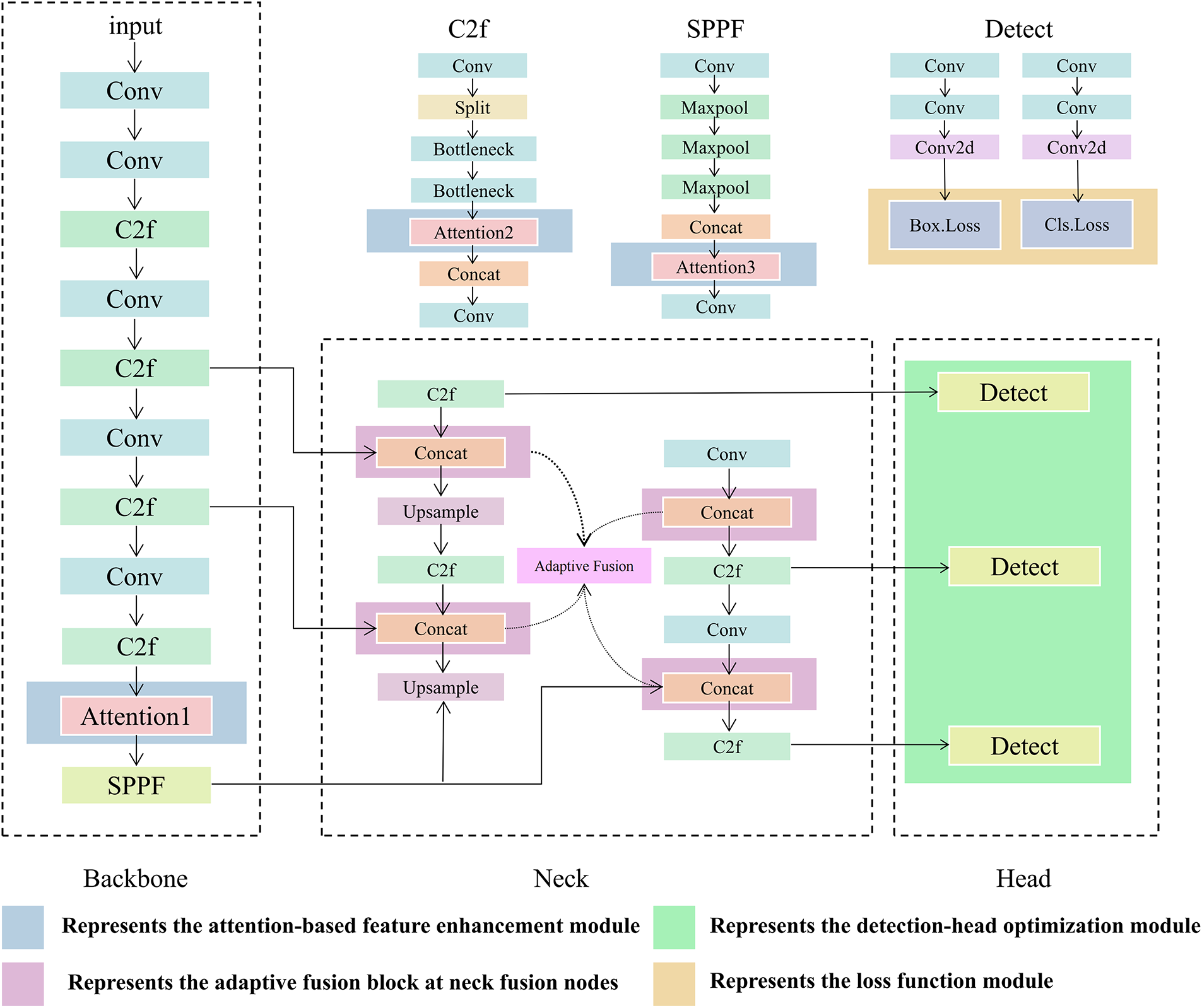
Figure 3: Schematic of YOLOv8 highlighting typical loci of four improvement categories
3.1 Attention Mechanism and Feature Enhancement
This subsection introduces attention mechanisms and their role in feature enhancement for small-object detection. Attention modules dynamically highlight informative features or spatial regions, effectively guiding the network to focus on the parts of the image most relevant to small objects. Broadly, attention in YOLO-based small object detectors can be categorized into four groups: (a) channel attention, which reweights feature maps across the channel dimension; (b) spatial attention, which emphasizes particular locations in feature maps; (c) combined or deformable attention mechanisms that capture complex feature dependencies; and (d) hybrid feature enhancement modules that integrate attention with other operations. Each type addresses different aspects of feature representation, and collectively they improve the network’s ability to represent and discriminate small objects under challenging conditions. Although attention and multi-scale fusion are discussed in separate subsections for clarity, the two approaches frequently co-occur within the same module, particularly in the neck, where attention gates or reweights cross-scale information flows. Throughout this subsection we interpret hybrid modules through the lens of attention. The narrative highlights how learned weighting functions reshape feature salience for small objects. The contribution of any embedded multi scale fusion operators is summarized only when it is necessary to understand how attention acts on aggregated features. A detailed comparison of the fusion operators themselves is presented in Section 3.4.
3.1.1 Channel Attention Mechanisms
Channel attention mechanisms selectively recalibrate channel-wise feature responses. These modules function by highlighting informative channels and suppressing redundant or noisy activations, which enables the network to focus on features relevant to small objects and mitigates the dilution of subtle details during the forward pass. Typical channel attention mechanisms include coordinate attention (CA) [43], efficient channel attention (ECA) [44], and squeeze-and-excitation (SE) [45], which enhance or suppress different channels by learning the importance of each feature channel. For instance, SE blocks adaptively reweight channel features based on the global context. Liu et al. introduced the Channel Weighting Module (CWM), which combined an SE block with a 1 × 1 convolution and improved mAP50 by 2.3% on VEDAI. Further refinements focused on making channel recalibration more efficient and lightweight.
In several representative designs, channel attention is not applied in isolation but is coupled with multi scale fusion so that reweighting acts on aggregated cross scale information. Wu et al. [46] fused multi scale features through parallel depthwise and pointwise convolutions followed by SE attention and obtained a 0.6% improvement in mAP. He et al. [47] extended this idea in FOS YOLO with two lightweight modules. ADEM separates features into depthwise and standard convolutional paths before SE based recalibration. LERM applies grouped depthwise convolutions with channel shuffle and a simplified SE structure. Together these modules increase mAP50 by 1.8 percentage points and reduce the parameter count by more than twenty percent. Wang et al. [48] proposed the CPMAEM module in SCAS Net, which uses multi branch depthwise convolutions and sequential channel spatial attention to strengthen multi scale cues. These designs show attention operating within cross scale pipelines. Their core operators perform explicit aggregation across scales, so their fusion behaviour belongs to the multi scale fusion dimension, while this subsection focuses on the attention effect. Readers can find the operator-level analysis in Section 3.4.
Coordinate Attention (CA) mechanisms were also adopted in YOLO-based detectors to embed spatial context into channel attention. By performing separate global pooling along the horizontal and vertical directions, CA encodes positional information into the channel-wise weights, which enables the network to localize small and elongated objects more accurately. This approach was incorporated into various architectures, such as GhostNet and CSP modules. Xie et al. [13] inserted a CA module at the output of each CSP stage to embed long range dependencies along both width and height and reweight channels accordingly, which allowed the model to focus on precise target locations, achieving an mAP of 88.74% on DOTA. Likewise, coordinate attention was used in cross-scale feature connections to adaptively highlight fine-grained targets, such as tiny ships in aerial imagery, and it markedly improved the detection of densely distributed objects [49].
RCA introduced a residual reweighting structure and employed mixed pooling, which strengthened the representation of small and dense objects [50]. Xu et al. [51] developed the Lightweight CSP Attention (LCA) block in MFFCI-YOLOv8, combining depthwise separable convolutions with a SimAM module that introduces no additional parameters for channel reweighting, which resulted in a 1.4% increase in mAP on VisDrone2019. Beyond explicit attention, alternative approaches use channel selection to achieve similar effects. Zhu and Miao [52] proposed the Selective Feature Enhancement Block in SCNet, which ranked channels by their globally pooled L1 norms, processed high- and low-contribution channels differently, and then fused them, attaining an mAP of 96.1% on NWPU VHR-10 and 71.9% on DIOR.
Beyond these mainstream channel-attention schemes, recent studies extended the mechanism to broader and more complex contexts. Hou et al. [53] introduced the C2f-GE module, which combined local feature extraction with global-context heatmaps to enhance channel attention. Transformer-inspired approaches also emerged. For instance, Li et al. [54] presented the Multi-Channel Trans-Attention (MCTA) module, which employed multi-head self-attention to learn inter-channel dependencies and to refine subtle features. Ding and Du [55] further validated this trend in an industrial logo inspection system. They replaced the early C2f blocks in the YOLOv8 backbone with contextual Transformer layers and equipped the detection head with a coordinate-aware CoordSaEBlock that fuses positional encoding with channel attention. This hybrid design produced more discriminative features for fine-grained cigarette-package logos and improved classification accuracy while maintaining real-time throughput on a large-scale production inspection line.
3.1.2 Spatial Attention Mechanisms
Spatial attention mechanisms in YOLO-based detectors focus on where the network should concentrate its attention, emphasizing important regions and contextual cues in the feature maps. For small-object detection, spatial attention is vital for isolating tiny targets from cluttered backgrounds and capturing the surrounding context that might indicate an object’s presence. A key direction in recent research on YOLO-based small-object detection involves leveraging transformer-based spatial attention to explicitly model long-range dependencies. For instance, Zhang et al. [7] introduced a Deformable Attention Transformer after the SPPF layer. The module used learnable reference points to direct sparse self-attention toward salient regions. They further proposed a Spatial Channel Attention Module that modulated spatial and channel information jointly. This combination improved spatial relationship modeling and yielded a 1.7% increase in mAP on the USOD dataset. Similarly, Zhao et al. [56] embedded a Swin Transformer block within the C2f module of the YOLOv8n backbone and increased mAP50 by 1.5%.
Building on these advances, some designs parallelized convolutional and transformer-based paths to capture local details and global dependencies more effectively. YOLO Ant exemplifies this hybrid approach. Its backbone uses depthwise separable convolutions with large kernels to obtain multi scale local representations. Its neck adds an attention module inspired by MobileViT that runs in parallel to the main convolutional stream. This design preserves fine details and global spatial dependencies with high computational efficiency, which makes the model suitable for small object recognition in resource constrained settings [57].
A common theme underlying these spatial-attention designs is the preservation of fine-grained location information for small objects while simultaneously leveraging broader contextual cues. To this end, several methods encoded explicit coordinate information or employed multi-scale pooling operations. Nan et al. [58] introduced coordinate attention by applying one-dimensional global pooling along the height and width axes, generating spatially aware attention maps that guided the network to focus on critical regions while retaining positional details. Similarly, Li et al. [59] proposed the Spatial Information Enhancement (SIE) module, which incorporated coordinate-convolution layers into both the backbone and neck. By pooling along spatial axes and concatenating these features, SIE augmented feature maps with explicit location cues and resulted in a 0.3% increase in mAP for UAV detection tasks.
Beyond coordinate based methods, other models adapt the receptive field in the spatial domain to capture context at multiple scales. Peng et al. [60] developed the Receptive Field Attention module, which modifies dilation rates or kernel sizes according to input features and highlights spatial patterns of small objects. Integrating RFA Conv led to a 2% improvement in mAP on VisDrone2019. Jiang et al. [61] proposed the RA3-DWA module for DSFPAP-Net. It applies a sequence of depthwise convolutions with different dilation rates to accumulate context across scales. A subsequent SimAM driven spatial channel attention mechanism recalibrates features at all detection heads and strengthens the representation of small objects. Zhu et al. [62] developed the Spatial Depthwise Atrous block for YOLOv5 on drone imagery. It fuses depthwise separable convolutions with multi branch dilated paths and then applies channel and spatial attention. This design recalibrates features and significantly boosts small object detection even without explicit positional encodings.
3.1.3 Deformable Convolution Guided Mechanisms
Deformable convolution essentially acts as an attention mechanism by using adaptive sampling and learning offset vectors to shift sampling locations toward more informative regions. In the context of YOLO detectors, this flexibility allows the network to focus on the exact shapes and positions of small objects, improving feature alignment and reducing background confusion.
Several studies successfully integrated deformable convolutional layers into the YOLO backbone or neck to harness these advantages. Chen et al. [63] systematically replaced all standard C2f convolutional units in both the backbone and neck of YOLOv8n with DCNv2 deformable convolutions, granting the network the flexibility to capture local geometric deformations. This modification led to a 2.6% improvement in mAP50, reflecting an enhanced ability to track object contours and keypoints in challenging scenarios. Peng et al. [64], in their MLSA-YOLO framework, introduced the DCN_C2f module by substituting a single 3 × 3 convolution in the C2f bottleneck with a DCNv3 layer. This adjustment allowed the receptive field to deform adaptively in response to object distribution, retaining more fine-grained information for small targets at low resolutions and leading to a 0.4% increase in mAP.
Beyond straightforward replacement strategies, other works coupled deformable convolutions with explicit attention mechanisms for further gains. Xu et al. [65] proposed ESOD-YOLO, featuring the SPPELAN module in the neck, which combined parallel DCNv3 convolutions with a Mixed Local Channel Attention (MLCA) mechanism. In this design, the deformable convolution provided adaptive sampling for geometric and multi-scale information, while MLCA assigned attention weights by jointly considering local feature patterns and global channel context. The addition of SPPELAN to SCCFF resulted in a 0.2% mAP improvement.
Furthermore, some studies integrated deformable convolution into feature fusion modules to better preserve small-object details. Shi et al. [66] designed the Deformable Convolution Guided Feature Learning (DCGFL) module for the backbone, utilizing a DCNv2 layer to dynamically adjust the sampling grid for multi-scale and shape-adaptive representations. This was followed by a channel-attention block to recalibrate feature responses, facilitating robust multi-scale information integration. In the neck, deformable convolution-guided fusion blocks (DCGFF) were employed to align and merge high-resolution shallow features with deep semantic information, ensuring that fine details were retained during fusion. Incorporation of the DCGFL module elevated mAP50 on the VisDrone2021 dataset to 57.6%.
3.1.4 Multi-Scale and Self-Attention Fusion Mechanisms
In YOLO-based small object detection, multi-scale feature fusion enriches representations by innovatively combining multi-scale convolutional processing with various attention mechanisms. This approach preserves fine-grained details while incorporating higher-level context, expanding the receptive field and integrating contextual cues without compromising the discriminability of small-object features.
Within the attention family, several representative designs deploy attention at fusion sites, where it gates or reweights cross scale features. Wang et al. [67] advanced the CSA module by using parallel convolutions and global pooling for multi context aggregation, followed by self-attention and residual fusion, and obtained a 0.6% improvement in performance. Zeng et al. [8] introduced the SCA block, which combined global pooling with SimAM based selection to guide spatial attention during feature fusion and achieved a 0.9% improvement on VisDrone2020. Zheng et al. [68] proposed the MSFAM module, which aggregated multi scale pyramid features and projected them into a joint space for channel and spatial reweighting, resulting in an mAP of 69.3% on VEDAI. Bai et al. [69] d designed a weight adaptive spatial attention mechanism that generated separate spatial maps for semantic and detailed features and balanced their contributions, reaching mAP50 of 87.2% on NWPU VHR-10 and 88.2% on DIOR. Wang et al. [14] proposed DyHead for improved YOLOv8, which unified scale, spatial and task attention within a dynamic head and produced a 1.5% increase in mAP. Liao et al. [70] further advanced this direction with the MS CET block, which coupled parallel dilated convolutions for multi scale context with multi head self-attention and boosted mAP by 1.7%. Collectively, these techniques show a fusion driven strategy in which attention is interwoven with multi scale aggregation and strengthens the granularity and contextual richness of small object representations.
One set of approaches focused on multi branch convolutional modules that gather multi scale information and can be fused or simplified for efficiency. Niu and Yan [71] integrated a Diversified Basic Block into the YOLOv8 backbone. During training, it uses parallel convolutional branches with varied kernel sizes to learn richer features. At inference, these branches are folded into a single convolution to retain multi path expressiveness. In another work, Jiang et al. [72] proposed MSFEM, a multi scale feature extraction module composed of four parallel branches with different kernel sizes, including 1 × 1 and 5 × 5 convolutions, pointwise convolutions and a residual connection. Other designs drew on mixture-of-experts ideas. Chen et al. [73] proposed MPMS for Para-YOLO, where three parallel dynamic-convolution branches of varying sizes operated on different channel proportions and were adaptively fused by a lightweight router, yielding a 1.6% gain in mAP. Liu et al. [74] diversified context extraction in SOD-YOLOv8n with the MFFM module, which divided feature channels into four groups processed by distinct branches and shuffling, achieving mAP50 of 54.62% on VEDAI.
Another prominent direction is the development of hybrid attention mechanisms that combine channel and spatial attention within a unified framework. The Convolutional Block Attention Module (CBAM) [64] exemplifies this approach, simultaneously applying both channel and spatial attention to refine feature maps. Tang et al. [75] enhanced YOLOv5 by appending a CBAM block at the end of the backbone, significantly boosting both channel and spatial representations. Building upon this, MSCA-CBAM [76] replaced global pooling in CBAM with a two-dimensional discrete cosine transform, enriching the frequency components during channel excitation and achieving mAP50 of 73.98% on DIOR and 97.50% on RSOD. Beyond CBAM, advanced hybrid attention mechanisms such as the Global Attention Module (GAM) proposed by Xie et al. [77] sequentially applied channel and spatial attention while preserving cross-dimensional dependencies, yielding an mAP50 of 37.6% on VisDrone2019.
A clear trend is the integration of transformer-based or self-attention modules, which are incorporated either alongside CNN backbones or as standalone pipelines, in order to further strengthen local and global context modeling. In TA-YOLO, Li et al. [54] implemented the MCSTA module, using multi-head channel self-attention to globally reweight channels before applying multi-head spatial self-attention to model positional dependencies, with their coordinated output merged via residuals for a substantial 6.2% increase in mAP50. Bai and Li [78] addressed similar challenges in industrial instrumentation by integrating a Swin-Transformer backbone with Focus and depthwise-separable convolutions and by adopting an SPPCSPC block followed by a C3STR neck to strengthen multi-scale feature interaction. This architecture substantially improved the detectability of small pointers and scale markings under complex backgrounds, while still delivering real-time inference on an industrial pointer meter dataset. Ge et al. [79] investigated lightweight UAV-based infrared detection by constructing an S2GM backbone from ShuffleNetV2 blocks with stride 2 and C2f Ghost modules. The design coupled this backbone with an AGFC attention block and a SENet-style multi-feature fusion neck. Together, these components reduced parameters and floating-point operations relative to the YOLOv8n baseline and improved detection accuracy for small infrared targets on the HIT-UAV dataset. The model still satisfied real-time requirements on embedded UAV platforms.
Altogether, these advances reflect a clear shift toward increasingly unified and adaptive multi-scale fusion frameworks in YOLO-based small object detectors. By systematically integrating convolutional, attention-based, and transformer-driven mechanisms, these models achieve a more balanced capture of fine-grained local features and global semantic context. This synergy not only enhances detection accuracy for small objects across challenging datasets but also sets a promising direction for future architectural innovation in the field.
3.1.5 Challenges and Limitations of Attention Mechanisms
Attention mechanisms and feature enhancement modules face intrinsic theoretical limitations when they are applied to small object detection because the underlying feature statistics differ fundamentally from those of medium or large targets. In convolutional backbones the activations corresponding to a very small object are distributed over only a few receptive fields and exhibit low energy relative to the global feature map, which leads to an extremely low signal to noise ratio in both channel and spatial dimensions. Standard attention modules estimate importance weights from these activations through global aggregation or similarity measures and implicitly assume that salient structures dominate the feature distribution. For tiny objects this assumption is violated, since the informative response of the object is often statistically indistinguishable from background fluctuations, and the attention module therefore tends to assign high weights to textured clutter, shadows, or neighboring large instances rather than to the true small target. From the perspective of optimization this misallocation of attention degrades gradient propagation, because the network repeatedly reinforces background dominated channels while the weak gradients associated with small objects are suppressed, which in turn further reduces the separability of their features in the latent space and can ultimately drive the model toward a solution in which small objects are systematically ignored. Moreover, many attention designs are scale agnostic and operate on a single feature map without explicit constraints on spatial extent, so they lack a mechanism to distinguish between a genuine tiny object and a fragment of a larger structure that occupies a similar image region. These theoretical issues indicate that direct insertion of generic attention modules is insufficient for small object detection and must be complemented by designs that are explicitly sensitive to scale and context. Shahapurkar et al. [80] evaluated fine tuned YOLO detectors on the SIRST-UAVB infrared benchmark. Even after extensive tuning, performance remained strong for UAV targets but weak for small birds in cluttered low contrast scenes. This gap illustrates the persistent difficulty of infrared small target detection and the limited suitability of generic YOLO backbones in such regimes. One promising direction is to couple attention with multi scale feature fusion so that the weighting functions are conditioned jointly on local features with fine spatial granularity and on more stable coarse semantic context, which can provide a prior about the plausible location and extent of small objects. This interaction between attention and multi scale feature aggregation is examined in detail in Section 3.4 of this review. Another possible avenue is to introduce additional supervision or regularization for attention maps, for example by aligning them with spatially subsampled ground truth masks or by penalizing overly diffuse responses, so that the learned weighting patterns concentrate more reliably around true target regions. It is also beneficial to design attention modules whose parameterization is constrained by geometric priors such as expected object size ranges or aspect ratios, which can prevent the mechanism from focusing almost exclusively on dominant large scale structures. In summary, the principal challenge for attention driven feature enhancement in small object detection arises from the mismatch between the statistical assumptions of standard attention formulations and the weak, sparse, and easily confounded signals produced by tiny targets, and effective solutions require mechanisms that are explicitly scale sensitive, guided by contextual information, and supported by stronger supervisory signals.
3.2 Detection Head Design and Branch Structure Optimization
For small-object detection, many studies have shown that modifying the YOLO head or adding extra prediction branches can markedly improve the capture of fine details. Broadly, improvements in this category fall into two groups: (1) High-Resolution Branch Enhancement, which adds or preserves finer-scale feature maps for prediction, and (2) Detection Head Structure Optimization, which redesigns the head to better localize small objects. The former mainly addresses the resolution of features used to detect small objects, while the latter involves changes like anchor-free heads, decoupled heads, or specialized layers to handle small-object geometry. By dividing improvements into these two categories, we can see a progression from simply increasing feature resolution for predictions to more fundamental redesigns of the head for small-object accuracy.
3.2.1 High-Resolution Branch Enhancement
A common enhancement in YOLO-based small object detection is adding an extra high-resolution prediction head at an earlier backbone stage to capture fine-grained features. Many studies introduced additional prediction heads at finer spatial scales. By tapping into shallow backbone outputs, these branches effectively preserve subtle textures and edges essential for accurate localization and classification of micro-scale targets, while incurring minimal computational cost. This approach was broadly validated across UAV surveillance, logistics, airport sensing, and underwater detection tasks. It consistently reduced missed detections and improved accuracy [81–84].
Tang et al. [85] implemented this strategy in YOLO-RSFM by appending a shallow P2 head directly to the earliest backbone feature map, without deep feature fusion, thereby concentrating on high-resolution texture and boundary cues. This modification led to a 1.3% increase in mAP. In a similar vein, Qi et al. [86] proposed SD-YOLO, which introduced a Low-Level Detection Head (LLDH) operating on early-stage feature maps, enabling the detection of minute aerial targets that are otherwise lost in deeper layers, with an mAP of 41.2 on VisDrone2019.
Recent studies have further strengthened high-resolution branches through adaptive fusion strategies. Representative examples include MIS-YOLOv8 and the approach of Ning et al. [9,87], which integrate high-resolution predictions with context-aware fusion mechanisms. These approaches are analyzed in more detail in Section 3.6 on dynamic context adaptive fusion.
In parallel with additional high-resolution branches, several works enhance feature fidelity through input or intermediate super resolution techniques. Zhang et al. [88] improved YOLOv5 by removing the Focus module and adding a lightweight encoder decoder super resolution branch during training to reconstruct high resolution features from low resolution inputs. This SuperYOLO design achieved an mAP of 64.4 on the VEDAI validation set. Liu et al. [89] extended this idea with a super resolution perceptual branch between the backbone and the neck. The branch uses residual blocks and up convolutions with a perceptual loss that aligns features to high resolution image patches during training. This scheme yields a 7.4 percentage point gain in mAP.
3.2.2 Detection Head Structure Optimization
Effective small object detection with YOLO architectures increasingly relies on specialized detection head redesigns that address the unique challenges posed by tiny, dense, or variably oriented targets. Recent research has converged on three primary directions: lightweight design and anchor strategy optimization, attention-driven adaptive heads, and architectures focused on task decoupling, spatial alignment, and rotation awareness. These improvements collectively enhance the detection head’s ability to extract, represent, and localize small objects in diverse scenarios.
Reducing the computational footprint of detection heads while maintaining robust representation is crucial for real-time and edge applications. Wu et al. [46,50] tackled the challenge of anchor generation by replacing traditional k-means clustering with a Differential Evolution (DE) algorithm. This approach iteratively refined anchor box dimensions to better match the scale distribution of small objects, yielding a substantial improvement in detection for remote sensing imagery and achieving 63.7% mAP on NWPU VHR-10. Parallel efforts in head design sought to unify and streamline head architecture. Wu et al. [46] introduced CRL-YOLO, which employed a single set of convolutional layers shared between classification and regression, regulated by Group Normalization and a learnable scale factor. This configuration achieved efficient parameter usage and facilitated deployment in resource-constrained environments. Liu et al. [90] developed EdgeYOLO, in which the Lite Decoupled Head eliminated redundant 3 × 3 convolutions and employed structural reparameterization to merge implicit feature learning layers, significantly compressing the head while sustaining effective feature extraction. EdgeYOLO also adopted an anchor-free detection paradigm inspired by FCOS, shifting to per-pixel prediction and discarding anchor-based post-processing, which simplified inference and proved advantageous in scenes with densely clustered small objects. On the MS COCO 2017 dataset, the Lite Decoupled Head enabled EdgeYOLO to achieve 50.6% mAP50. For industrial settings, Yuan et al. [91] presented YOLO-HMC, which pruned unnecessary layers from the YOLOv5 head and adaptively tuned the channel configuration for PCB defect detection, leading to a 3.5% increase in mAP.
To address the limited visibility and ambiguous features of small or densely packed objects, several models injected advanced attention mechanisms directly into the detection head. Peng et al. [60] proposed LGFF-YOLO, in which the Lightweight Detection Head (LDyHead) integrated sequential scale-sensitive, spatial-adaptive, and task-specific attention modules, dynamically modulating feature importance at each stage. The use of a computationally efficient FasterConv module further accelerated inference, and the replacement of the standard head with LDyHead resulted in a 2.1% improvement in mAP50.
This trend toward fine-grained attention is also evident in domain-specific applications. Hu et al. [92] introduced MOA-YOLO, enhancing each detection head with a Multi-head Latent Attention (MLA) module, which enabled the network to better distinguish small fish from background noise, leading to a 6.4% increase in mAP. For X-ray imagery, Cheng et al. [93] developed X-YOLO with an improved Dynamic Head that is aware of task, scale, and spatial information. The architecture adaptively reweighted features for classification and localization across different scales, supporting more accurate detection of small and cluttered targets. Liu et al. [94] investigated conveyor belt safety monitoring and proposed the YOLO-EV2 detector. The model coupled an EfficientNetV2 backbone with a scale-sensitive detection head. The head explicitly enhanced responses to small longitudinal tearing patterns along belt edges under heavy interference. On a coal mine conveyor belt tear dataset, YOLO-EV2 achieved higher mean average precision and frame rate than recent YOLO baselines. These attention-driven modifications enable detection heads to more effectively capture subtle and localized information required for challenging small object scenarios.
A third strand of head optimization targets the decoupling of tasks, explicit spatial alignment, and handling of oriented objects, thereby refining the head’s specialization for small target localization. Mo et al. [95] presented SGT-YOLO, which removed the higher-level (P4/P5) heads to simplify the architecture and introduced a Task-Specific Context Decoupling head. This decoupling enabled more focused feature learning for tiny defects, achieving a 0.4% improvement in mAP50. Building on the theme of task specialization, Jiao et al. [96] developed YOLO-DTAD, embedding a dedicated feature extractor within a decoupled head and employing dynamic loss weighting to strengthen the synergy between classification and localization streams. This architecture led to a 4.1% accuracy improvement. Addressing the alignment of spatial predictions, Zhuang et al. [97] introduced YOLO-KED, which utilized a Dynamic Alignment and Rotated Head (DARH) to coordinate the confidence and localization for each object and to support rotation-aware bounding boxes, achieving a 1.3% improvement in mAP0.5:0.95. For scenes involving arbitrary object orientation, Xie et al. [13] developed CSPPartial-YOLO, which featured a rotational prediction head comprising three parallel branches to estimate location, category, and rotation angle. The training strategy combined Varifocal Loss, ProbIoU Loss, and Distributed Focal Loss to address class imbalance, regression accuracy, and angle prediction stability, respectively. Their approach achieved 89.75% mAP on DOTA.
Collectively, these structural innovations significantly improve the adaptability and robustness of YOLO detection heads for small object scenarios. By integrating lightweight designs, advanced attention mechanisms, and specialized modules for challenging spatial contexts, recent methods have enabled YOLO-based detectors to more effectively localize and recognize small targets across diverse and complex applications.
3.2.3 Challenges of Detection Head and Branch Structure Optimization
Challenges in detection head design and branch structure optimization for small object detection arise from the central role that these components play in mapping continuous feature fields to discrete prediction hypotheses. In single stage detectors such as the YOLO family, each detection head defines a particular sampling of the multi scale feature hierarchy into bounding box and class predictions, and the introduction of additional heads or branches for small objects fundamentally alters this sampling geometry. When an extra prediction head is attached to a feature map with finer spatial stride, the number of candidate boxes increases sharply and many of these candidates occupy highly overlapping receptive fields. From a statistical viewpoint this causes a substantial rise in correlated outputs whose underlying features are almost identical, which increases the probability of false positives unless the allocation of responsibilities across heads is carefully constrained. In principle a head that is intended for small objects should respond only to targets within a particular range of scales, yet in practice the receptive fields of different heads overlap across scale and aspect ratio. As a result, the same object may be explainable by multiple heads, which creates ambiguity in label assignment during training and in confidence allocation during inference. This ambiguity has a direct impact on the optimization landscape. The multi head loss is a sum of coupled terms whose gradients compete for shared backbone parameters. If training targets are not assigned in a scale consistent manner, gradients from different heads may point in conflicting directions in parameter space, which slows convergence and can lead to solutions in which one head dominates while another remains under trained. Small object branches are particularly vulnerable to this phenomenon because they often operate on shallower features with weaker semantics and thus receive noisy supervision. At the same time, each additional head introduces new parameters and increases the dimensionality of the hypothesis space. This enlarges the search space that the optimizer must explore and can cause the model to overfit to spurious correlations in the small object regime. Computationally, extra heads and branches also increase the cost of dense prediction, which runs counter to the real time constraints that originally motivated the YOLO framework and may make some small object oriented designs impractical for deployment on resource limited platforms. These challenges suggest that effective detection head optimization requires more than simply adding fine scale branches. Promising directions include scale aware assignment strategies that enforce a clear partition of object sizes across heads, regularization schemes or knowledge distillation that stabilize gradients in multi head training, and dynamic gating mechanisms that activate only the branches that are informative for a given input distribution. In theoretical terms the goal is to design a prediction layer that increases the sensitivity of the network to small objects while maintaining a well conditioned optimization problem and preserving the global balance between recall, precision, and efficiency that defines high quality single stage detection.
3.3 Loss Function Improvement and Regression Precision Optimization
3.3.1 Recent Advances in Loss Functions for Small Object Detection
Recent studies in YOLO-based small object detection have focused on designing loss functions that incorporate scale-aware weighting, geometry-aware metrics, and adaptive task balancing to address the disproportionate influence of large objects and improve localization precision for small targets. Small objects occupy few pixels, so localization errors can be relatively large and heavily penalized by standard loss functions. Moreover, traditional loss functions like CIoU or DIoU assign equal importance to errors in both large and small bounding boxes, often causing the optimization to be influenced primarily by large-object samples. To address this, researchers have proposed a variety of improved loss functions and bounding-box regression strategies aimed at improving small-object accuracy.
A common theme in recent research is to make the localization loss more sensitive to small errors and to the presence of small targets. One direct approach is to reweight IoU-based losses so that small objects contribute more to the overall loss. For example, Xie et al. [77] proposed the WIoUv3 loss in KL-YOLO, which introduced a dynamic, non-monotonic weighting mechanism to adaptively adjust gradient gains for targets of different sizes. The core formula of WIoUv3 is as follows:
where
Similarly, to balance scale differences, Niu and Yan [71] integrated the Wise-IoU loss into their YOLOv8-based model, which increased the loss for bounding boxes on small objects and decreased it for large ones. Building on this, Wu et al. [50] proposed the Adaptive Weighted IoU, which further adjusted the regression focus to regular-sized anchors, preventing the loss from being dominated by extremely large or small instances. Replacing CIoU with AW-IoU in YOLOv5s achieved 64% mAP on NWPU VHR-10. In a related development, Sun et al. [98] introduced the Adaptive Focal Powerful IoU loss in SOD-YOLOv10. The Adaptive Focal Powerful IoU (FP-IoU) employed adaptive penalty and gradient modulation to assign higher costs to small errors, particularly for small bounding boxes, which in turn discouraged unnecessary enlargement of anchor boxes and accelerated convergence. It achieved 92.81% mAP on RSOD. These reweighting schemes share the goal of ensuring that the regression loss does not treat all errors equally and instead places greater emphasis on small-object bounding boxes that would otherwise be underrepresented.
Beyond weighting schemes, other loss function improvements incorporate additional geometric factors or alternative distance measures to further benefit small-object detection. Several studies proposed modified IoU or distance-based losses that capture object alignment and spatial relationships more effectively. Jiang et al. [16] introduced the Complete IoU with Normalized Wasserstein Distance for small manufacturing defect detection. The method augmented standard IoU with a normalized Wasserstein distance term that measured the displacement between box centers relative to their sizes, which provided a richer gradient signal for optimizing alignment. With CI-NWD, mAP50 increased by 0.4%.
In scenarios with oriented or elongated small objects, incorporating angle and shape information can further enhance localization. Hou et al. [53] proposed the α-SIoU loss in αS-YOLO, which extended the classic SIoU by introducing an adaptive angular control coefficient. This enabled the loss function to dynamically adjust convergence speeds in different directions according to the angular difference between the predicted and ground-truth boxes, facilitating precise localization for small and rotated objects. The α-SIoU loss is formulated as:
where
For general object detection, other approaches refined IoU formulations to improve bounding box regression for small targets. Gu et al. [26] replaced standard CIoU with Efficient IoU in an infrared small target detector. EIoU provided a more balanced treatment of width, height, and center distance, achieving an mAP of 87.5% on the FLIR dataset. Additionally, Mahaveerakannan et al. [99] proposed Shape_IOU, adding a shape-aware component to the IoU computation and enabling more accurate localization of objects with nonstandard measurements or irregular forms, especially small targets that occupy only a few pixels. By emphasizing geometric overlap and shape conformity between predicted and ground-truth boxes, Shape IOU improved detection robustness in challenging small-object scenarios. Du et al. [100] addressed industrial surface defect inspection with the MGF-YOLO detector. The method employed a multi-scale gated fusion neck and adopted a Focaler intersection over union regression loss. The loss suppressed gradients from well localized boxes and amplified gradients from poorly localized predictions. This formulation increased localization sensitivity around tiny steel surface defects and yielded higher mean average precision and recall than a vanilla YOLOv5s baseline.
Some loss functions incorporate scale-adaptive terms to enhance the localization sensitivity for small objects, thereby reducing the dominance of large-object errors in YOLO-based training. Li et al. [18] proposed the Adaptive Scale-Enhanced CIoU loss as part of YOLO-DFA, which modulated the penalty on aspect ratio and scale according to the size of each target, effectively amplifying errors on small objects relative to larger ones. This approach led to a 1.7% improvement in mAP50. Ni et al. [17] adopted a related strategy by introducing an adaptive Focal-EIoU loss in their Tri-Decoupling++ detector. This loss applied focal-like scaling to the components of the EIoU formulation, guiding regression gradients toward more challenging examples, especially small or irregularly shaped targets. With this design, the method achieved 94.4% mAP50 on NWPU VHR-10. In parallel, Wu et al. [50] improved the post-processing of densely packed small objects by integrating SCYLLA-IoU into a soft-NMS scheme. S-IoU used an IoU-based continuous suppression mechanism that retained multiple nearby detections more effectively. The incorporation of S-IoU resulted in a 0.9% improvement in mAP50. Although S-IoU primarily impacts NMS rather than the training loss, it reflects the broader trend of IoU-based innovations designed to better handle crowded small-object scenarios.
There are also hybrid loss strategies that integrate classification and localization terms to further benefit small-object training. For instance, some methods dynamically increase the weight of the classification loss for small objects, ensuring that the network learns to distinguish their subtle features. Jiao et al. [96] adopted dynamic task weighting in YOLO-DTAD, a scheme that prevented the classification of numerous large objects from overwhelming the localization of smaller targets. This loss optimization approach led to a 1.5% mAP improvement. In addition to loss function modifications, enhancements in label assignment and sample selection also contribute to improved small-object detection. Zhou et al. [12] in AD-YOLO introduced a dual-label assignment strategy, where small objects were assigned to multiple prediction scales during training. This multi-scale supervision allowed the loss to be computed from various levels, providing the network with additional opportunities to capture small object features. When combined with ECSA attention and a dedicated small-object detection layer, this strategy achieved a 4.4% mAP improvement.
In summary, ongoing advances in loss function design for small object detection have produced a diverse set of strategies that include reweighting schemes, geometry-aware and scale-aware formulations, as well as dynamic task balancing. These approaches aim to more precisely address the challenges posed by targets that are small, densely distributed, or irregularly shaped. By explicitly amplifying localization and classification signals associated with small objects, and by refining both regression and sample assignment processes, these methods collectively provide a more balanced and effective optimization landscape. As a result, modern YOLO-based detectors are increasingly able to achieve robust performance on small object benchmarks, even in complex and crowded environments.
3.3.2 Challenges and Limitations of Loss Function Improvements
Loss function improvement and regression precision optimization for small object detection face fundamental challenges that stem from the way gradients are distributed over highly imbalanced and heterogeneous data. Standard formulations of classification and localization loss tend to be dominated by medium and large objects, which contribute strong and relatively stable signals, while the weak and noisy responses of small objects induce gradients of much smaller magnitude. The gradient field becomes highly sensitive to hyperparameters that control how much emphasis is placed on rare small objects relative to abundant easy negatives and larger targets. If the weighting is too aggressive, the loss can overfocus on a small subset of difficult instances, which leads to underfitting of more common object sizes and makes training unstable. If the weighting is too conservative, the contribution of small objects remains negligible and the modification fails to change the effective learning dynamics. Even when hyperparameters are tuned carefully, there remains a structural limitation: loss reweighting operates on the outputs of the network and cannot create information that is not present in the underlying features, so it cannot fully overcome the intrinsic scarcity and low signal to noise ratio of small object representations. A further difficulty arises from the design of refined localization losses. Precise overlap based objectives and fine grained boundary terms provide more informative supervision for small boxes whose location error must be measured in a few pixels, yet they often require expensive geometric computations and numerical stabilization, which increases training time and may hinder deployment in large scale or real time regimes. These considerations suggest that loss function improvements for small object detection should be coupled with complementary mechanisms that enhance feature quality and sampling, and that the design of new objectives should emphasize robustness to hyperparameter variation, computational parsimony, and a balanced treatment of different object scales. Practical strategies include adaptive weighting schemes that are learned from data rather than fixed by hand, curriculum style training that gradually increases the influence of small objects as the backbone stabilizes, and multi task formulations in which auxiliary signals such as centerness or boundary uncertainty help to regularize the optimization of fine scale regression.
3.4 Multi-Scale Feature Fusion and Spatial Context Enhancement
Multi-scale feature fusion has improved through redesigned cross-layer connections and adaptive mechanisms, thereby better integrating fine-grained details with high-level semantics for spatial context modeling. Advances in this area generally fall into two complementary strategies: Structured Cross-Layer Multi-Path Fusion and Dynamic Weighted Context-Adaptive Fusion. The former approach introduces architectural modules that explicitly connect and combine feature maps across scales, ensuring the effective utilization of fine-grained details from shallow layers alongside the rich semantics from deeper layers. The latter employs adaptive mechanisms to adjust the fusion process based on contextual cues, enabling the network to dynamically focus on features most relevant to small objects. Together, these architectural and adaptive advances have significantly enriched the multi-scale representations that are vital for precise small object detection. Although many multi-scale fusion methods incorporate attention modules to adaptively refine feature aggregation, we treat fusion and spatial context enhancement as a distinct category in this section for clarity. In this survey, the multi-scale fusion dimension refers to the architectural design that specifies which feature maps interact and at which spatial resolutions. The analysis below focuses on the layout of cross-layer links, the choice of upsampling and downsampling operators, and the rules used to combine features across different depths. Complementary attention-centric perspectives are discussed in Section 3.1.
3.4.1 Structured Cross-Layer Multi-Path Fusion
Enhancing the feature pyramid has long been a foundational approach for small-object improvement. In this context, a variety of multi-branch modules have emerged to extract and merge features at diverse receptive fields, thereby providing a richer representational basis for small object detection. Niu and Yan [71] integrated a Diversified Basic Block into the YOLOv8 backbone. DBB leveraged parallel convolutional branches of different kernel sizes during training and fused them into a single equivalent convolution for inference, enabling the model to learn multi-path representations. Building on this concept, Jiang et al. [72] designed the MSFEM module, in which parallel convolutions were followed by concatenation and compression, capturing both fine and coarse features.
Efforts to enhance channel diversity and context adaptation have led to more sophisticated multi-branch fusions. Chen et al. [73] proposed the MPMS module for Para-YOLO, which grouped convolution branches by channel and employed a learnable router for expert-like multi-scale aggregation, leading to a 1.6% improvement in mAP50. This trend toward parallel, context-aware processing is mirrored by the CSA module of Wang et al. [67], which combined convolution and pooling pathways and then applied self-attention to refine context aggregation, increasing mAP50 on VisDrone2019 by 0.6%. In a complementary fashion, Liu et al. [74] exploited group convolution and channel shuffling in MFFM, which enhanced representational flexibility and achieved 54.62% mAP on VEDAI.
Several structured fusion modules integrate attention or adaptive sampling directly into the merging process. Wu et al. [101] adopted a decomposition strategy in BHFM, splitting large kernels into cascades of smaller convolutions integrated with attention mechanisms, thereby enabling broader contextual capture while constraining parameter growth. This design achieved a 3.4% mAP improvement. The utility of multi-scale kernel integration is particularly notable in vehicle detection. Methods for aligning and fusing features at different resolutions have also advanced, as illustrated by Shi et al. [66], who used deformable-convolution fusion blocks that adaptively sampled and integrated multi-resolution features and improved mAP50 by 0.6% on UAV. By embedding either explicit attention or deformable sampling within the fusion pathway, these approaches enhance the ability of the model to integrate broad context while preserving the fine detail required for reliable small-object detection.
To address the need for capturing wider spatial context without excessive computation, the use of large or dilated kernels within fusion branches has also been explored. Zhang et al. [102] employed a Multiscale Large-Kernel Module to target vehicles of varying sizes, achieving 90.3% mAP on USOD. The architectural philosophy behind these advances was further reflected in the Multiscale Dilated Separable Fusion block of Gu et al. [26], where depthwise kernels and multi-scale decomposition replaced standard convolutions, achieving 81.4% mAP on FLIR.
Beyond within-layer diversification, the effective propagation of information across different network depths has emerged as a critical concern. A variety of redesigned necks and cross-layer fusion mechanisms have sought to strengthen both semantic abstraction and the preservation of low-level detail, especially for objects at the limits of resolution. Wang et al. [14] provided an instructive example by employing a BiFPN-based neck in YOLOv8-QSD, leveraging iterative top-down and bottom-up blending with learnable weights. This configuration achieved a 1.5% mAP50 improvement for challenging distant traffic sign detection.
The principles underpinning bidirectional fusion are further demonstrated in the BPNet architecture proposed by Zan et al. [103], which enhanced the traditional FPN by augmenting cross-scale connections. This approach proved especially effective for fine-grained object detection in real-world surveillance, as reflected in state-of-the-art empirical results. Meanwhile, the benefit of dense connectivity is evident in the Layer-by-Layer Dense Residual Module designed by Ni et al. [17]. Through the establishment of direct semantic pathways between deep and shallow layers, Tri-Decoupling++Net achieved 68.3% mAP on DOTA and 93.6% mAP on NWPU VHR-10.
The exploration of optimal fusion strategies continued in the work of Wang et al. [25], who demonstrated that replacing the PANet module with a conventional FPN could enhance feature resolution, with mAP50 rising from 73.2% to 77.9% in multimodal small-object scenarios. The fusion of enhanced low-level textures with high-level abstractions, as achieved by the FF module in MSFE-YOLO from Qi et al. [10], further exemplified the integration of spatial detail and semantic richness, leading to a 2% improvement in mAP50. At the backbone level, the integration of shallow, detail-rich features with higher-level abstractions has also proven effective for maintaining small-object cues throughout the network. In the work of Zeng et al. [8], such a fusion strategy achieved 47.4% mAP on the VisDrone2020 test set. Tang et al. [104] addressed infrared small target detection by augmenting a YOLO-style backbone with an edge feature enhancement module that strengthened local gradient responses around tiny targets. An infrared relational enhancement module further aggregated multi-scale contextual information within a long-range receptive field. This multi-level fusion increased the detection probability of extremely small and low-contrast targets in infrared scenes and maintained a practical false-alarm rate.
3.4.2 Dynamic Weighted Context Adaptive Fusion
Dynamic Weighted Context-Adaptive Fusion can be understood as a coupling between multi-scale aggregation and attention-based selection. In modern YOLO pipelines, the fusion stage learns spatially and channel-wise varying weights that gate cross-scale flows, often via explicit attention or implicit attention proxies. Readers seeking attention mechanisms per se can refer to Section 3.1. This subsection examines how multi-scale aggregation is coupled with attention-based selection to preserve fine detail, inject global semantics, and suppress background clutter for small-object detection. A representative example is the Adaptive Spatial Feature Fusion module proposed by Sun et al. [9] in MIS-YOLOv8, where spatially varying weights are learned for each location in the feature map. This enabled the model to dynamically determine the optimal contributions of high-resolution (P2) and deeper semantic (P3, P4) features at every spatial point, leading to a 6.2% improvement in mAP50. This context-sensitive fusion ensures that the details essential for small object detection are preserved without being overwhelmed by irrelevant information.
Extending this paradigm, Ning et al. [87] developed a parallel P2–P3–P4 detection head architecture in which each head operates on relatively shallow feature maps. The P2 branch incorporates a spatial self-attention mechanism that helps capture long range dependencies and spatial relationships that are critical for distinguishing tiny targets in complex backgrounds. Removing redundant downsampling further preserves discriminative cues and leads to a 2.4% improvement in mAP50. Wang et al. [105] introduced an Adaptive Feature Fusion module within a super resolution aided YOLO framework. The network learns to integrate multi scale features from different layers according to the contextual demands of aerial scenes and surpasses rigid concatenation. The use of AFF yields an 11.11% improvement in mAP and shows the benefit of adaptive fusion in small object scenarios. Together these methods reveal a trend in which dynamic context aware fusion mechanisms improve the extraction of fine-grained information and enhance the reliability of small object detection.
Another tool for adaptive fusion is the use of explicit attention during feature aggregation. Sun et al. [98] introduced an Attention Gated Feature Pyramid Network in SOD-YOLOv10, where a gating mechanism driven by aggregated attention modulates the fusion of hierarchical features across scales. This enables the network to focus on essential features of small objects while suppressing background noise and leads to a 2.28% improvement in mAP50 on RSOD. Building upon this, Wang et al. [25] developed the Multi Scale Iterative Aggregation module, which repeatedly refines the integration of high level semantic features and low level spatial details through attention based fusion and improves sensitivity to small objects in complex backgrounds.
In addition to spatial and cross-scale adaptivity, the integration of both local and global contextual cues has proven valuable. Wu et al. [106] designed LGC-YOLO with the Gradient Optimized Spatial Information Interaction module and Edge-Semantic Fusion, enabling adaptive coordination between local and global context. This flexible interaction allowed the model to effectively adapt to varied scene compositions, achieving 89.5% mAP on NWPU VHR-10. Similarly, Gu et al. [19] employed a Global–Local Enhanced Attention mechanism in GLFE-YOLOX, combining global and local context modeling in both backbone and neck layers, leading to a 3% improvement in mAP50 on DIOR.
Focusing on the neck region, adaptation within modules that merge spatial or channel information has also proven effective. Kang et al. [20] extended the ELAN module of YOLOv7 to a weighted version in which learned weights control feature propagation and filter out less informative channels. This selectivity improves precision in blood cell detection, a domain with many tiny targets. Zhang et al. [102] introduced a Directional Global Context module in LGA YOLO. It combines global spatial cues with directional channel attention to suppress noise such as shadows and to highlight critical vehicle features and yields a 3% improvement in mAP50 on DIOR. Sun et al. [107] focused on missile borne infrared surveillance and proposed the CDT YOLO algorithm. The method combines a YOLO based detector with a temporal tracking module that uses multi frame context and cross scale aggregation to maintain trajectories of tiny moving targets under severe noise and platform motion. Joint optimization of multi scale detection features and the temporal association branch yields more robust tracking of distant infrared small objects than a static framewise YOLOv8 baseline.
Several works have further demonstrated that adaptive attention can be successfully tailored for specialized domains. In the case of MOA-YOLO, Hu et al. [92] embedded multi-head latent attention within the feature pyramid to enable robust discrimination of small fish against water glare, while Cheng et al. [93] focused on scale-aware attention for effective fusion in X-ray image detection. These designs underline how domain-specific adaptation of feature fusion and attention can drive detection gains for unique object types or imaging conditions.
In summary, fusion is most effective when it incorporates attention. Content-adaptive weighting through spatial and channel gating and through deformable sampling preserves fine-grained cues from shallow maps while selectively incorporating high-level context from deeper scales. This delineation between attention and fusion is a deliberate choice in our taxonomy, and readers can connect the mechanism level view in Section 3.1 with the operator level designs reviewed here.
3.4.3 Challenges of Multi-Scale Fusion and Context Enhancement
Multi scale feature fusion and spatial context enhancement introduce challenges that are rooted in the fundamental interaction between signals of different resolutions, receptive fields, and semantic strengths. When feature maps from distinct depths are combined, the network constructs a joint representation in which high resolution maps carry fine spatial detail and background texture, while low resolution maps encode abstract semantic information dominated by larger structures. If this integration is not carefully normalized and calibrated, strong responses associated with large objects or clutter can dominate the fused representation and suppress the already weak evidence produced by truly small targets. In theoretical terms, the fusion operation defines a mixing of feature subspaces with very different signal to noise properties, and without scale aware weighting the energy of the representation concentrates on patterns that occupy many pixels, which reduces the probability that the optimization process will align parameters with the sparse gradients generated by small objects. A further difficulty arises from geometric misalignment. Different layers correspond to different receptive fields and sampling grids, so naive upsampling and addition can create aliasing and spatial shifts. The fused features may no longer correspond precisely to object locations, which is particularly harmful for small objects whose extent is measured in a few cells. Even subtle misregistration can blur boundaries and degrade localization accuracy because the decision function is learned on features that are not perfectly anchored to the underlying image content. Context enhancement adds another layer of complexity. Enlarging the receptive field through context modules is intended to provide priors about typical object relationships and the overall scene layout. However, in many scenes the background contains repeated patterns or structures that closely resemble small objects. If the network relies too heavily on these contextual correlations, it may attend to regions that satisfy the context pattern while failing to place precise boundaries around the actual target or even predicting objects where none exist. These issues suggest that multi scale fusion and context integration for small objects require mechanisms that explicitly control the relative contribution of each scale, enforce geometric alignment, and regulate the influence of context. Potential strategies include the use of scale specific normalization that adjusts feature magnitudes before fusion, learnable gating functions that modulate information flow from each resolution according to local uncertainty, and alignment modules that estimate continuous offsets so that upsampled deep features match shallow spatial grids. In addition, context modules can be constrained to operate in a way that complements, rather than replaces, evidence from local appearance, for instance by using uncertainty guided weighting that reduces the impact of context when the local signal is ambiguous. Only when fusion, alignment, and context are jointly designed with these principles can multi scale architectures fully exploit their theoretical advantages for small object detection without amplifying noise or scale interference.
3.5 Common Challenges in Small Object Detection Improvements
Across YOLO based models that target small object detection, several overarching challenges arise from fundamental constraints in computation, data, and evaluation, and these limitations persist even when different architectural strategies are applied. A first difficulty concerns the systematic increase in computational and memory cost that accompanies most targeted improvements. Each additional attention module, detection branch, specialized loss component, or fusion pathway enlarges the parameter space and the number of intermediate activations. From a theoretical perspective, this broadens the hypothesis class that the model can represent but also increases the complexity of the function being learned and the number of operations required for inference. On resource constrained platforms, the resulting tension between expressive power and real time operation becomes acute, and even modest gains in small object accuracy may require hardware budgets that contradict the original design philosophy of the YOLO family.
A second pervasive issue is overfitting in the regime of scarce and weak small object signals. In many datasets, small objects occupy only a tiny portion of the image and appear less frequently than medium or large instances. The associated feature vectors lie near the noise floor of the representation and form a minority in the empirical distribution. When a detector is heavily tuned toward these cases, the learning process can latch onto incidental textures or dataset specific artifacts that happen to correlate with the small labels in the training set. Mitigation requires stronger forms of regularization, robust data augmentation that alters both appearance and geometry, and preferably additional data sources that increase coverage of small object conditions. A third structural challenge is persistent class and scale imbalance. The data distribution is typically long tailed with respect to both semantic labels and object sizes, so gradients are dominated by abundant medium and large instances. Reweighting schemes, modified sampling policies, and curriculum style schedules can partially redistribute gradient mass toward rare small objects, yet none of these techniques can fully compensate for the intrinsic scarcity of informative events. As a result, the optimization dynamics remain biased toward regimes where features are strong and stable, and the decision surface continues to favor larger and easier targets. A fourth difficulty lies in the evaluation protocols used to judge progress. Aggregate metrics such as mean average precision pool performance over a wide range of sizes and intersection over union thresholds, which can conceal systematic failures on very small objects. Moreover, a detector may show an apparent improvement at a commonly used threshold while still exhibiting poor localization accuracy at stricter overlaps or in low visibility conditions. This induces a form of evaluation bias in which models are selected for deployment based on metrics that do not fully reflect their behaviour on the smallest and most fragile targets. Fig. 4 highlights these key challenges and their interactions within YOLO-based small-object detectors.
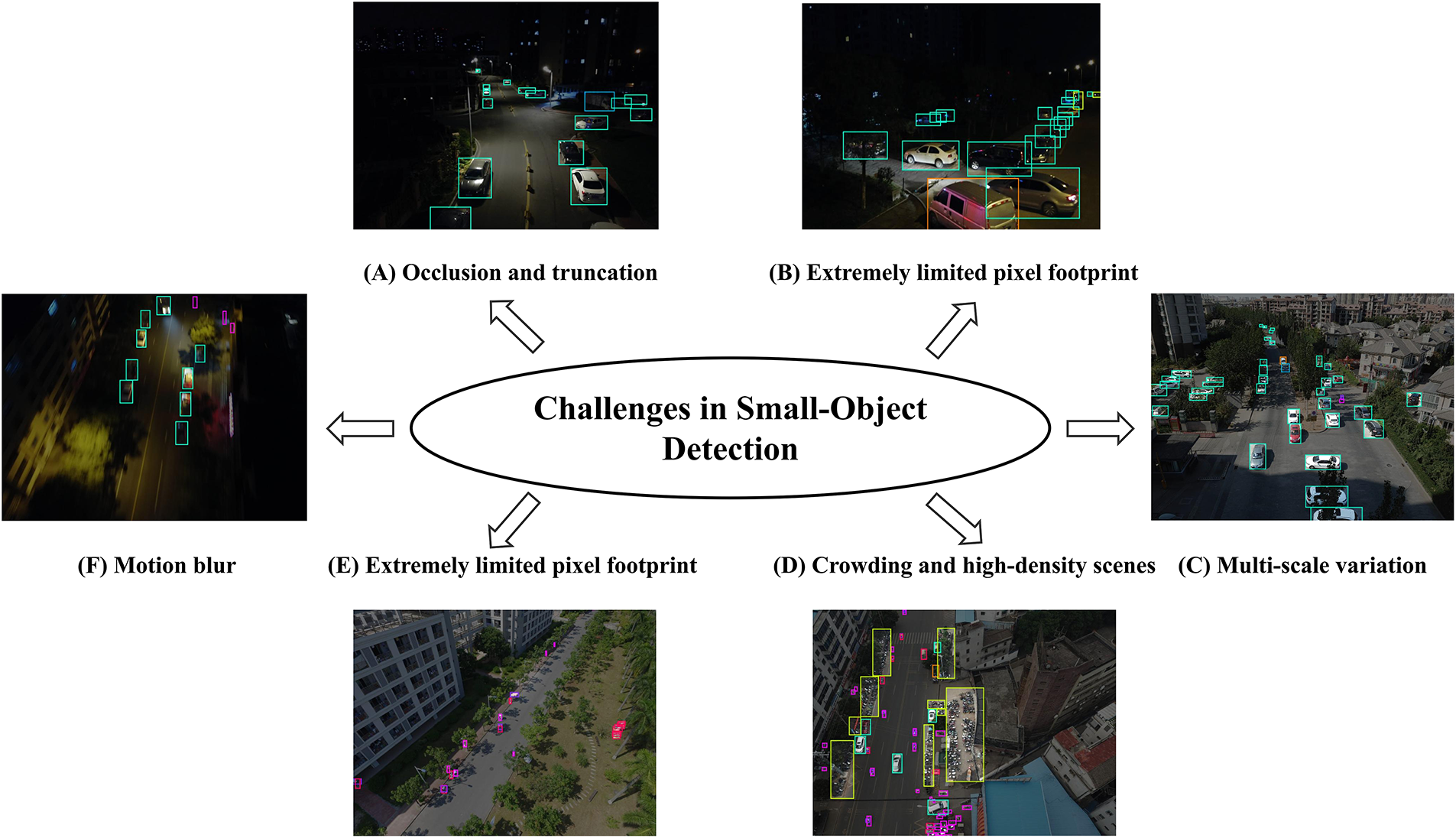
Figure 4: Challenges in Small-Object Detection. (A) Occlusion and truncation; (B) Extremely limited pixel footprint; (C) Multi-scale variation; (D) Crowding and high-density scenes; (E) Extremely limited pixel footprint; (F) Motion blur
Addressing these common challenges calls for a more integrated design philosophy in which architectural modifications are coupled with principled complexity control, small sample aware training strategies, and size sensitive evaluation criteria. Potential directions include the use of structurally regularized modules that add discriminative power without uncontrolled growth in capacity, joint optimization schemes that explicitly balance gradients across scales, and benchmark protocols that report size specific metrics and error decompositions. Only by confronting these cross cutting issues at both the theoretical and practical levels can future YOLO based detectors move beyond incremental improvements and achieve robust and efficient performance on small objects in real world scenarios.
3.6 Dynamic Network Design and Heterogeneous Fusion for Small Object Detection
Recent progress in small object detection has moved beyond manually designed backbones and fixed feature pyramids toward dynamic network design and heterogeneous architectural fusion. Instead of relying solely on hand-crafted YOLO variants, current research increasingly exploits Neural Architecture Search (NAS) to adapt depth, width, and connectivity to data characteristics, and combines convolutional detectors with transformer or spiking neural modules to balance accuracy, efficiency, and energy consumption. This section reviews two representative directions. Section 3.6.1 discusses NAS-driven design of YOLO-style detectors with an emphasis on small-object scenarios, including the state-of-the-art YOLO-DKR architecture. Section 3.6.2 analyzes heterogeneous fusion strategies that combine YOLO with Vision Transformer (ViT) or spiking neural networks (SNNs), highlighting both their advantages and their limitations for small target detection under realistic deployment constraints.
3.6.1 Neural Architecture Search for YOLO-Based Small Object Detection
Neural Architecture Search provides a way to discover detector designs that are tuned to the statistics of small objects rather than to generic object distributions. In the YOLO family, NAS controllers select backbone depth, neck width and fusion connectivity from a predefined search space. The resulting architectures can concentrate representational capacity on the scales where tiny targets appear while respecting latency and memory constraints that are typical in aerial and embedded deployments. For scenes that combine dense small instances with strict real time requirements, this automatic design process is often more effective than manual trial and error. Recent studies illustrate the promise of this approach through the use of YOLO NAS baselines in small object settings. YOLO NAS has been adopted in military surveillance of distant camouflaged targets [108], in traffic monitoring of far range vehicles [109], and in agricultural inspection of fine-grained disease spots on rice leaves [110]. In each case the searched architecture maintains real time throughput while recovering tiny and low contrast objects that challenge hand designed YOLO variants. However, these works typically reuse a single generic architecture and fine tune it for each task instead of performing a new architecture search that is explicitly guided by small object characteristics.
Methodological advances in NAS are now beginning to address this gap. Differentiable architecture search equipped with dual attention over feature channels and architecture parameters stabilizes training on deep detection backbones and allows the search to emphasize operations that benefit small object features [111]. Progressive partial channel connections with channel attention control memory usage during search and reduce the discrepancy between search networks and evaluation networks [112]. Multi objective search frameworks incorporate accuracy and resource costs into a joint objective [113], which is particularly important for airborne or embedded small object detectors that must satisfy strict limits on model size and latency.
Building on these developments, Xue et al. [114] introduced YOLO-DKR, a differentiable NAS framework that tailors YOLO-style architectures to small-object detection. The method adopts a DARTS-based continuous relaxation and applies a kernel reusing mechanism that consolidates multiple candidate convolutions into a single fused operation on each supernet edge, which substantially reduces memory usage and accelerates the search while preserving detection accuracy on large backbones. The architecture search jointly optimizes deep semantic layers and multi-scale fusion paths so that both are aligned with the characteristics of small objects. During retraining, lightweight coordinate attention modules are incorporated to reinforce fine-grained feature extraction. Experiments on PASCAL VOC and MS COCO show that YOLO-DKR and its tiny variant achieve higher overall and small-object detection accuracy than strong YOLO and NAS-based baselines.
Taken together, these developments show that NAS is no longer only a generic tool for model discovery but has begun to serve as a dedicated mechanism for shaping YOLO-style architectures to the specific demands of small-object detection. By enabling dynamic control over depth, width and cross-scale connectivity under explicit resource constraints, NAS-driven designs offer a principled way to balance accuracy and efficiency for tiny targets. As NAS techniques continue to mature and become more tightly integrated with task-aware objectives, dynamic network design for small-object detection is likely to remain a central research focus and a promising avenue for future advances in YOLO-based detectors.
3.6.2 Heterogeneous Architecture Fusion of Visual Transformer and YOLO for Small Target Detection
Heterogeneous fusion between convolutional YOLO detectors and Vision Transformer modules has emerged as a targeted strategy for small target detection. Transformer backbones can capture long range dependencies and localize very small key points with higher precision than purely convolutional baselines, which makes them suitable for fine grained spatial structures [115]. Transformer based detectors that integrate encoder decoder style attention with cross scale interaction modules achieve higher average precision on tiny objects in complex unmanned aerial vehicle scenes while preserving competitive inference efficiency [116]. These findings motivate the insertion of Transformer-style self-attention into YOLO-based dense prediction pipelines so that fragile small-object cues are supported by rich global context.
Current YOLO and Vision Transformer hybrids explore three main fusion patterns that are all relevant to small objects. In pipeline style designs, YOLO first generates coarse regions of interest that cover potential tiny targets and a transformer module performs refined recognition on cropped patches. This strengthens semantic discrimination of very small structures without altering the YOLO backbone [117]. In architecture level hybrids, transformer blocks are embedded into the YOLO backbone or detection head. Multi head self-attention enriches feature maps with long range contextual dependencies and yields more informative attention maps for distant or partially occluded targets [118]. In enhancement driven fusion, transformer modules are inserted into generative or enhancement networks that preprocess thermal or low light imagery before detection. Global context modeling increases contrast, suppresses background noise and amplifies weak cues associated with small objects, which leads to consistent gains for several YOLO variants on low visibility targets [119]. These patterns show that transformer components can be positioned at the recognition stage, inside the detection architecture or in the enhancement front end to provide global support for tiny targets in YOLO style detectors.
Given the stringent energy budget of battery-powered UAVs, spiking neural networks (SNNs) offer considerable potential for low-power onboard small-object detection. SNNs have recently gained attention in UAV perception because their event-driven computation and sparse spike activity can markedly reduce energy consumption compared with conventional ANN detectors. Shen et al. [120] proposed a directly trained SNN detector for infrared HIT-UAV imagery that achieves 87.33% mAP50 while reducing the estimated per-image energy from 179.40 mJ for YOLOv8m to 17.96 mJ, approximately one tenth of the baseline. Hou et al. [121] extended this line of work to RGB VisDrone2019 vehicle detection and combined a spike-based SPDS down-sampling block with an SNN BiFPN neck. Their model attains 73.98% mAP50 while consuming only 17.14% of the energy required by a residual ANN detector with a comparable architecture, corresponding to an 82.86% reduction. As summarized in Table 1, these results indicate that carefully designed SNN architectures can deliver competitive UAV small-object detection performance under a substantially reduced energy budget.
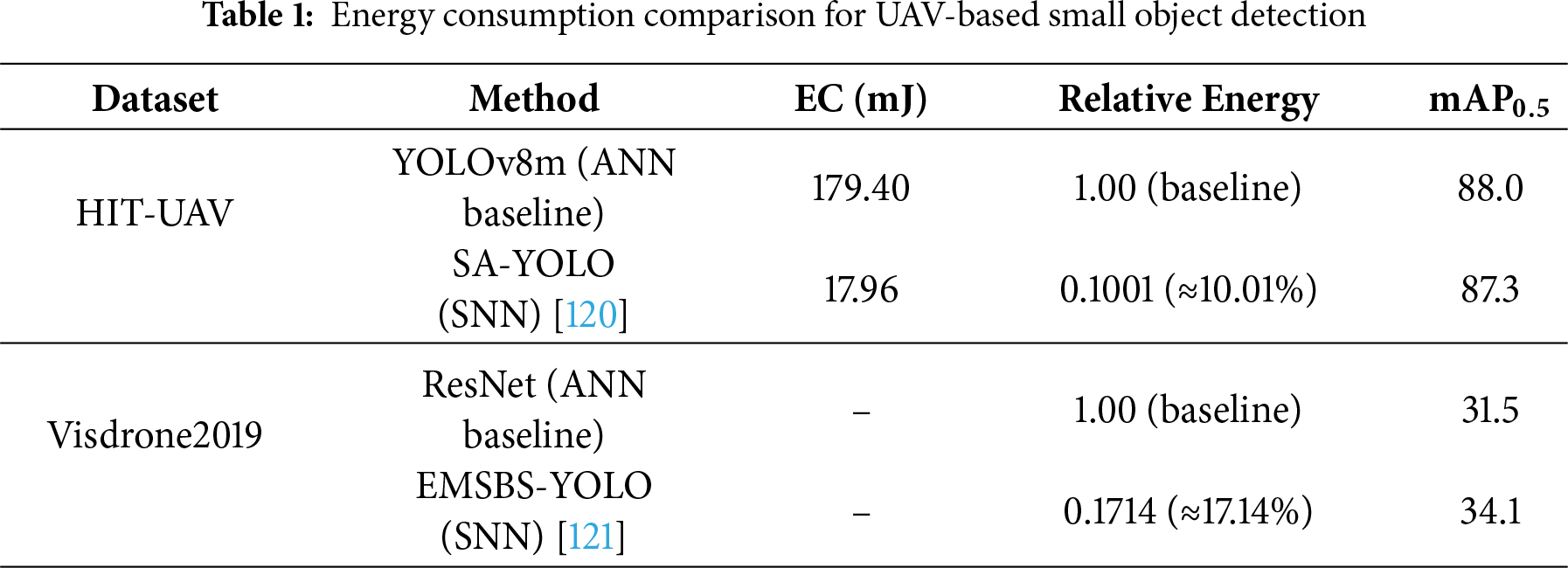
Despite these gains, existing fusion strategies that combine YOLO detectors with transformer modules or spiking components still exhibit limitations for small target detection. Transformer based hybrids often insert additional attention blocks or enhancement subnetworks on top of the YOLO backbone, which increases architectural complexity, memory consumption and inference latency. This makes deployment on platforms with strict resource and energy budgets more difficult. Many transformer modules are tuned to a particular dataset, so their benefits may degrade when the scale distribution, background clutter or illumination conditions of small objects differ from those seen during training. Fusions that incorporate spiking neural networks face additional challenges. Training pipelines remain immature and discrete time step simulation is required in most implementations. Spiking dynamics are also sensitive to algorithmic hyperparameters. These factors complicate stable optimization and efficient inference on general purpose hardware. Overall, YOLO based detectors enhanced with transformer or spiking modules offer clear potential for stronger global context modeling and lower energy usage in small object detection. However, advances in lightweight attention design, task robust fusion schemes and coordinated hardware and algorithm design are still required before heterogeneous fusion can be widely adopted as a standard solution for small target detection.
4 Experimental Setup and Performance Evaluation
4.1 Benchmark Datasets for Small Object Detection
In this review, we focus on seven benchmark datasets that are widely used for the evaluation of small object detection. These datasets are VisDrone2019, AI-TOD, DOTA, NWPU VHR-10, VEDAI, DIOR and UAVDT. For the purpose of this survey, a small object is defined as an instance whose projected size in the image is smaller than 10 by 10 pixels. These benchmarks contain large numbers of instances that satisfy this criterion. They also report quantitative indicators of dataset difficulty. The published statistics include size distributions, instance density, spatial resolution and details of the annotation protocol. Images in these datasets typically contain extremely small targets embedded in cluttered backgrounds. Many scenes exhibit high object density, strong occlusion and arbitrary target orientation. The seven datasets cover a wide range of imaging platforms and application scenarios. They span low altitude unmanned aerial vehicle video in urban traffic as well as high altitude satellite and aerial imagery. As a result, evaluation outcomes are not restricted to a single domain. Each dataset is associated with established evaluation protocols and widely reported baselines. Their size distributions include substantial proportions of tiny instances that meet the small object definition introduced above. They are therefore particularly suitable for assessing the performance of YOLO based detectors on small objects. Quantitative characteristics of each dataset and its small object statistics are summarized in Table 2.

In reviewing experimental results from the literature, we adopt a set of well-established evaluation metrics to synthesize and compare performance, focusing on those most pertinent to small object detection. We report Precision (P), Recall (R), Average Precision (AP), and inference speed (measured in Frames Per Second) as the primary criteria. Together, they provide a consistent basis for cross-paper comparison by capturing both effectiveness and efficiency under shared reporting conventions across studies. These metrics were selected because they collectively capture both the accuracy and efficiency of detection methods, which is crucial for a comprehensive analysis of small object detection systems.
Precision (P) and Recall (R) are fundamental to evaluating detectors and are particularly important for tiny objects. Detection outcomes are summarized as true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). Precision quantifies the proportion of predicted detections that correspond to real objects, which reflects the system’s ability to avoid false alarms. Recall measures the proportion of ground-truth objects that are successfully detected. Achieving high recall is especially challenging for small objects because weak signals and occlusion are common, so recall serves as a key indicator in this setting. Both metrics depend on the decision threshold and together describe the trade-off between selectivity and completeness. Formally,
Both metrics are threshold-dependent and jointly characterize the detector’s trade-off between selectivity and completeness.
Average Precision (AP) summarizes the relationship between precision and recall for a given class by computing the area under the curve of precision vs. recall. In practice, AP is obtained from precision values evaluated across recall levels from 0 to 1. Mean Average Precision (mAP) extends AP across categories by averaging the per-class AP values. The formulas for AP and mAP are given as follows:
where
Accuracy alone is not sufficient in many small object applications because deployment often takes place under strict computational and hardware constraints. To reflect the trade off between accuracy and model complexity in a more device independent way, each table now reports the number of parameters in millions and the floating point operations per image. The Params (M) and GFLOPs columns make it possible to interpret performance gains together with changes in model size and computational cost rather than from accuracy metrics alone. Precision, Recall, AP and mAP describe detection quality. Params (M) and GFLOPs provide a proxy for architectural efficiency. Throughout our study we follow standard metric definitions in the existing literature in order to preserve comparability as far as possible.
All numerical values are taken directly from the cited sources unless explicitly noted, and any necessary adjustments are clearly documented in the corresponding figure or table captions.
4.3 Comparative Performance of YOLO-Based Small Object Detection Methods
We compile results from recent literature to evaluate how different modifications influence performance on small-object benchmarks. Every numerical entry was curated directly from the primary source and checked against the exact location of reporting in the article body, the figure captions, and the official supplementary materials. For each method we recorded the dataset split, the input resolution, the definition of each metric, and the available efficiency indicators such as parameter count and floating-point operations. Metric names and significant figures follow the original sources so that every value can be traced without ambiguity. When a study reported repeated runs with a reported mean and variation, we adopted the authors’ aggregate and recorded the mean as the principal figure. Cells are left blank when a source does not report a metric. No imputation or re-estimation was performed.
For each method, we list the original model identifier and the evaluation metrics as reported in the primary source, so that readers can trace back the exact experimental setting. The availability and maintenance status of these assets vary across studies and may change over time, so we refer readers to the primary sources cited in the “Model” column, where authors describe their experimental settings and, when available, disclose official repositories, configuration files or model zoos.
Fig. 5 presents a bar chart comparing the mean increase in detection performance achieved by four categories of YOLO-based enhancements on the VisDrone dataset. The vertical axis measures the average mAP50 gain over the baseline YOLO model, while the horizontal axis lists the categories of improvement: attention mechanisms, detection head modifications, loss function changes, and multi-scale feature fusion.
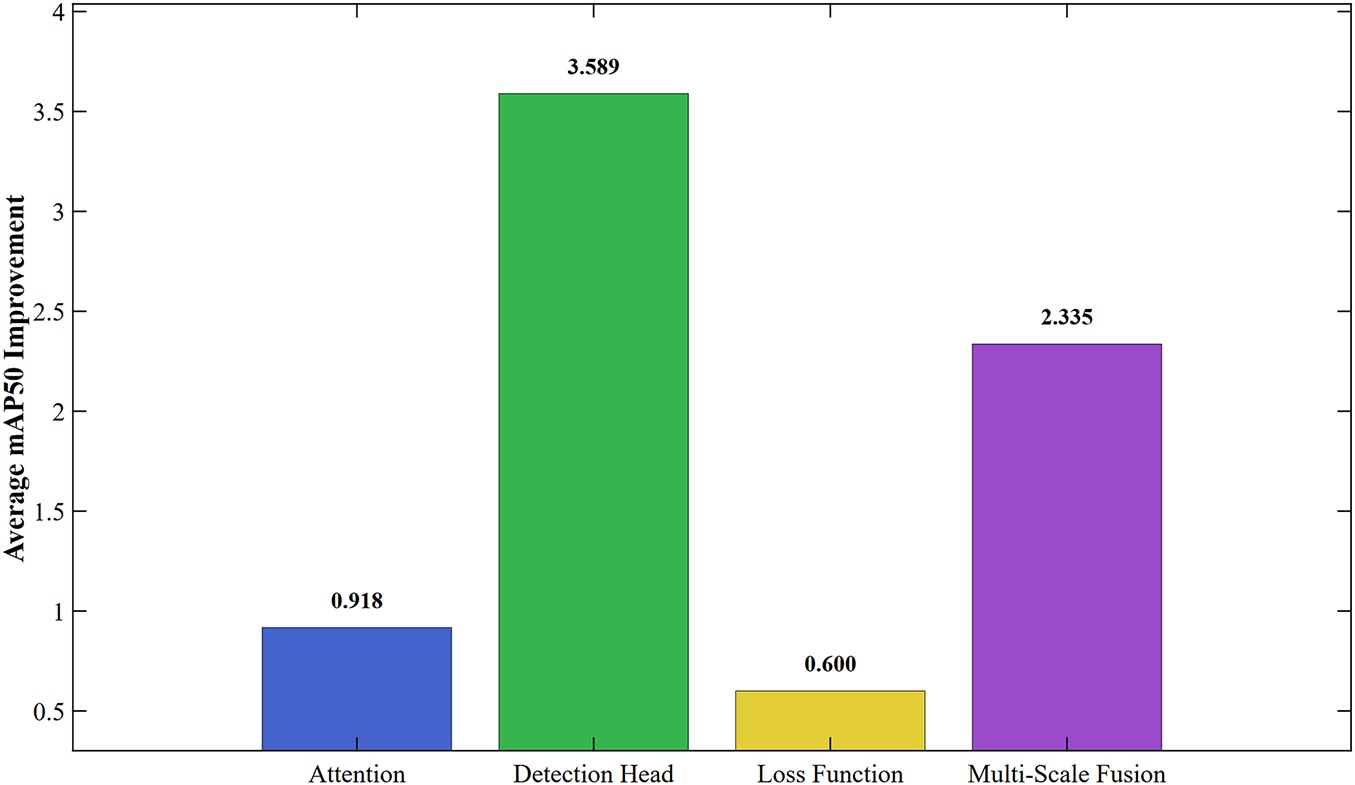
Figure 5: Average mAP50 improvement by enhancement category on VisDrone
Fig. 6 depicts the performance trade-offs of various YOLO-based small-object detectors on the VisDrone dataset using two complementary scatter plots. Fig. 6a plots each model’s precision vs. recall, with a series of concave iso-F1 curves for F1 scores of 0.4, 0.5, 0.6, and 0.7 overlaid to indicate the balance between these two metrics. Fig. 6b charts each model’s mAP50 against its recall and includes a dashed least-squares trend line; the coefficient of determination is approximately 0.65, which highlights the general relationship between recall and overall accuracy. In both panels, individual points represent different YOLO-SOD variants, and the color encodes the improvement type, where blue denotes attention-based models, green denotes detection-head modifications, yellow denotes loss-function adjustments, and purple denotes multi-scale fusion approaches; the marker shape indicates whether the model incorporates a single enhancement module or a combination of multiple improvements. The left plot shows clear trade-offs between precision and recall, as many methods cluster along an F1 band between 0.5 and 0.6, with some emphasizing higher recall at the expense of precision and appearing toward the lower right below the F1 equals 0.5 curve, whereas others achieve high precision while missing many targets and appear in the upper-left region. Only a few models approach the top-right corner near the F1 equals 0.7 contour, which indicates a superior balance of high precision and high recall. The right plot shows that models with higher recall generally attain higher mAP50 scores and that most points follow an upward trend, although noticeable variability remains around the trend line.
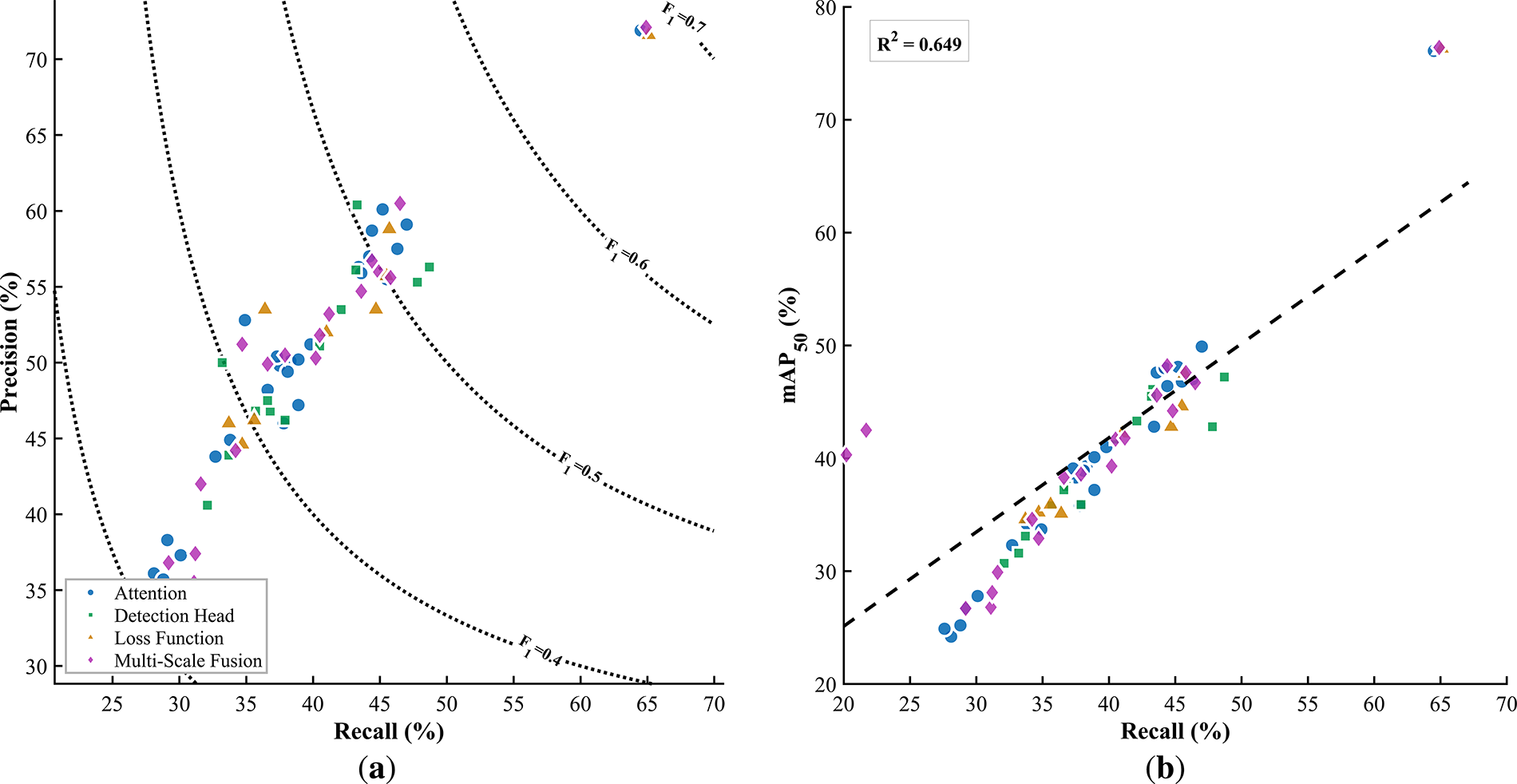
Figure 6: Precision, recall and mAP50 statistics of YOLO based small object detectors on the VisDrone dataset (a) Precision vs. Recall with Iso-F1 Contours on VisDrone; (b) mAP50 vs. Recall on VisDrone with Least-Squares Trend
For the single-module summaries in Tables 2–5 we extracted results from ablation or component-wise studies that isolate one category of modification on the VisDrone2019 benchmark. Each entry explicitly states the baseline model as reported by the source and reproduces the baseline score in the column labeled Original. This pairing allows readers to interpret the gain within the same training protocol and architectural context rather than across heterogeneous baselines. The performance numbers that follow the “Original” column are quoted from the corresponding ablation setting in the source so that the delta with respect to the paired baseline reflects only the stated modification.
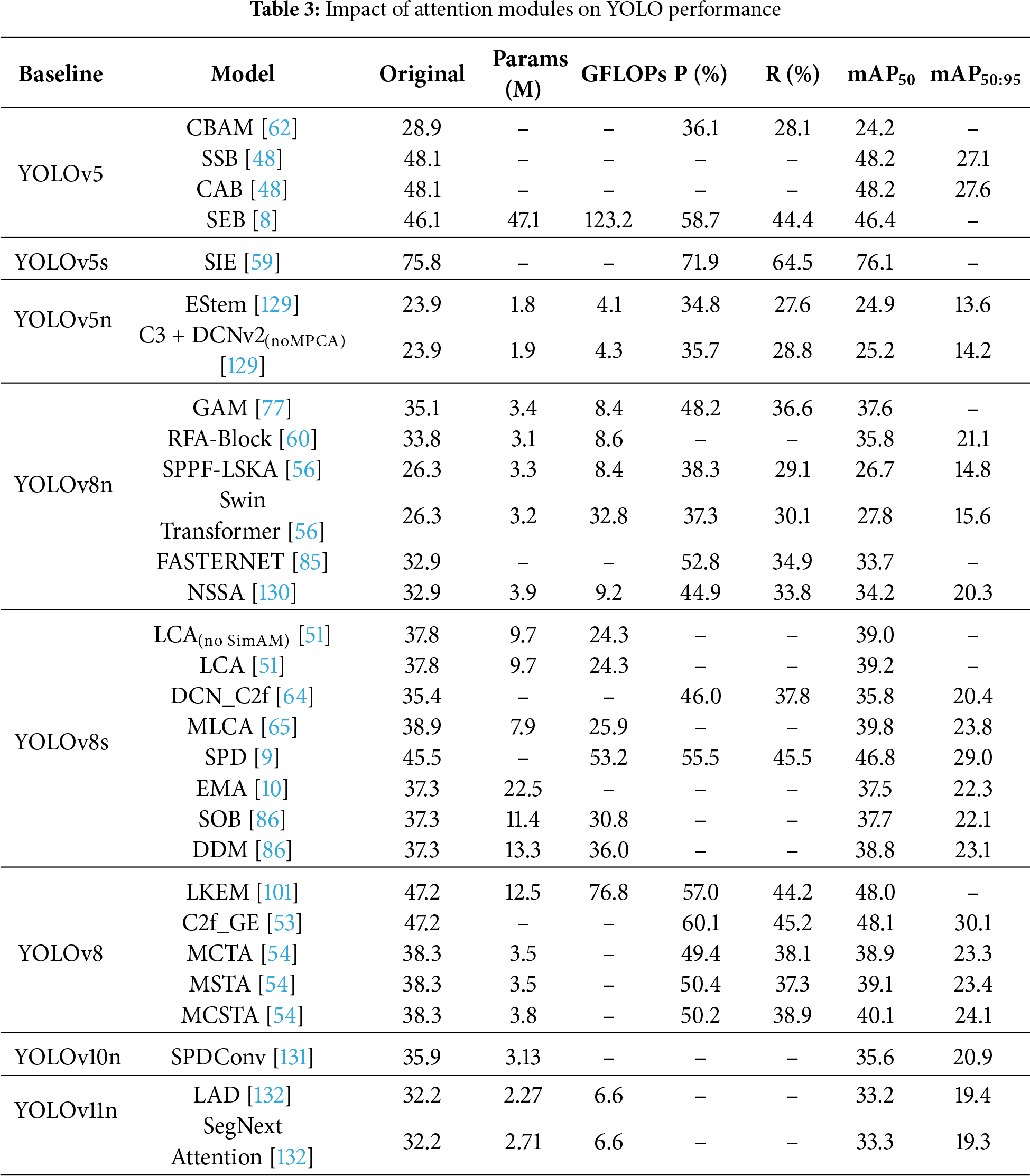
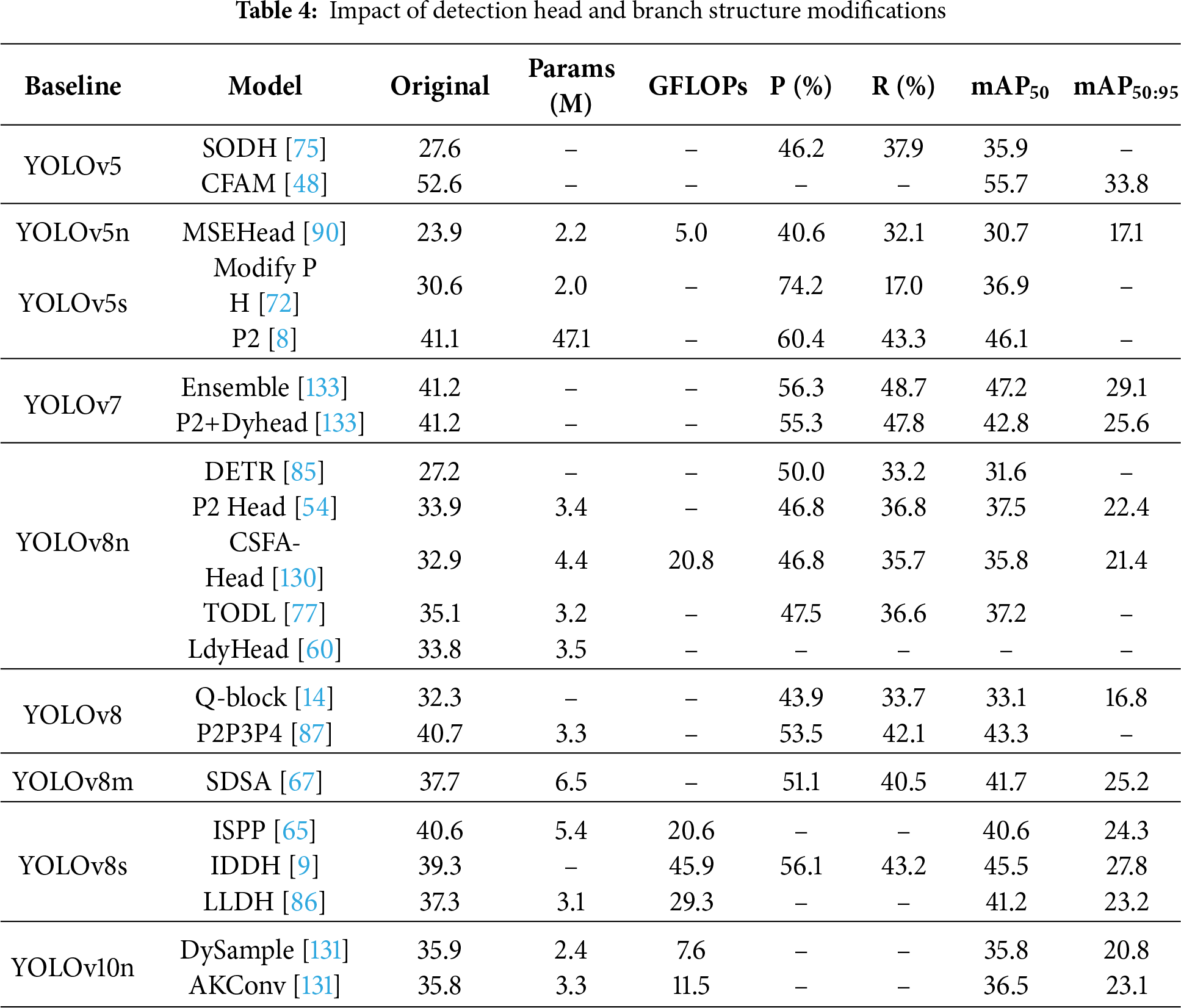
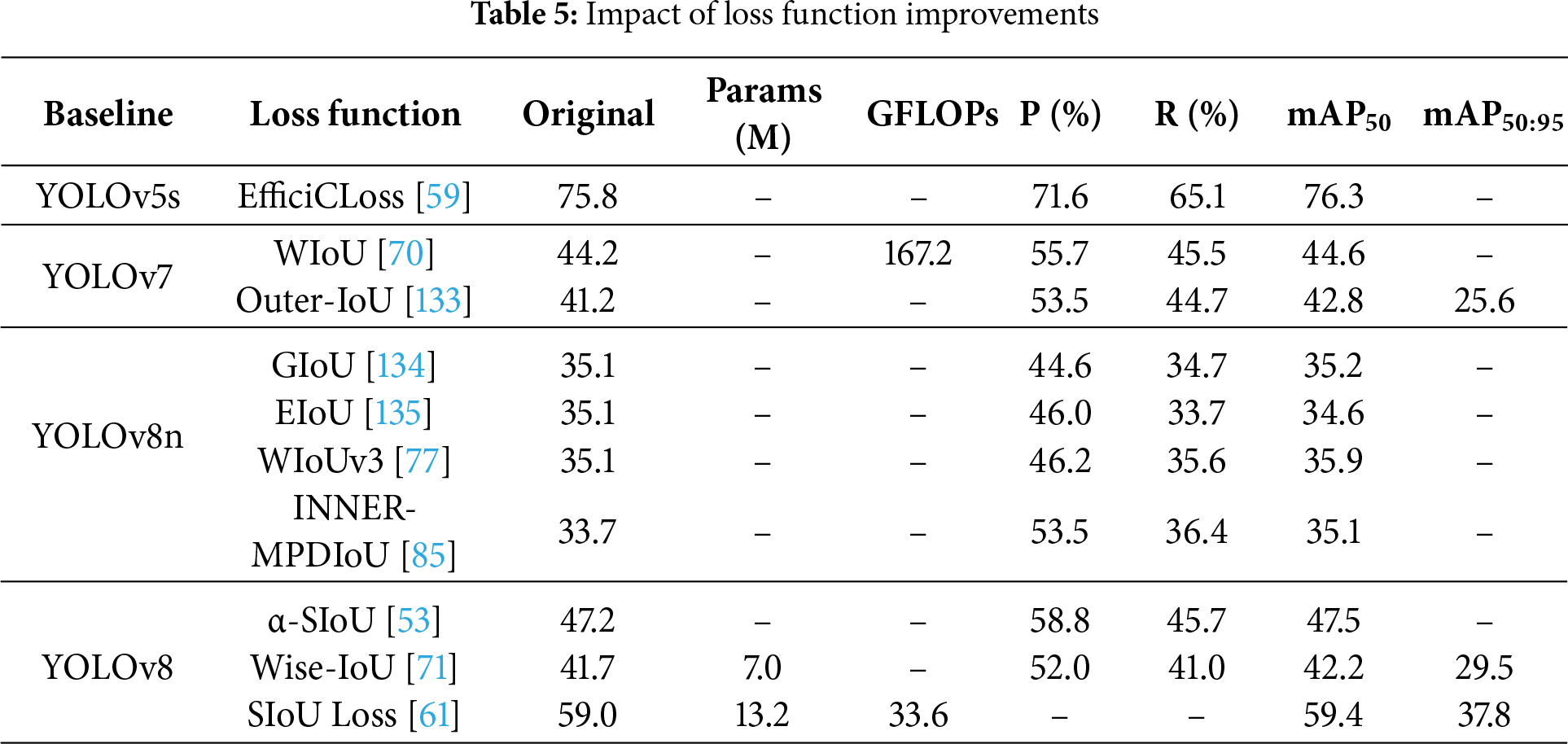
Table 3 summarizes methods that implement attention-based feature enhancement on top of a YOLO baseline. Table 4 covers detection head and branch structure optimizations. These entries typically involve models that add an extra detection layer or reconfigure the head specifically for small objects. Table 5 focuses on loss function refinements, listing results from studies that introduced improved loss terms to better train YOLO for small object accuracy. Similarly, Table 6 presents methods emphasizing multi-scale feature fusion and context enhancement, where the primary modification is the integration of feature pyramid networks, context modules, or other multi-scale strategies.
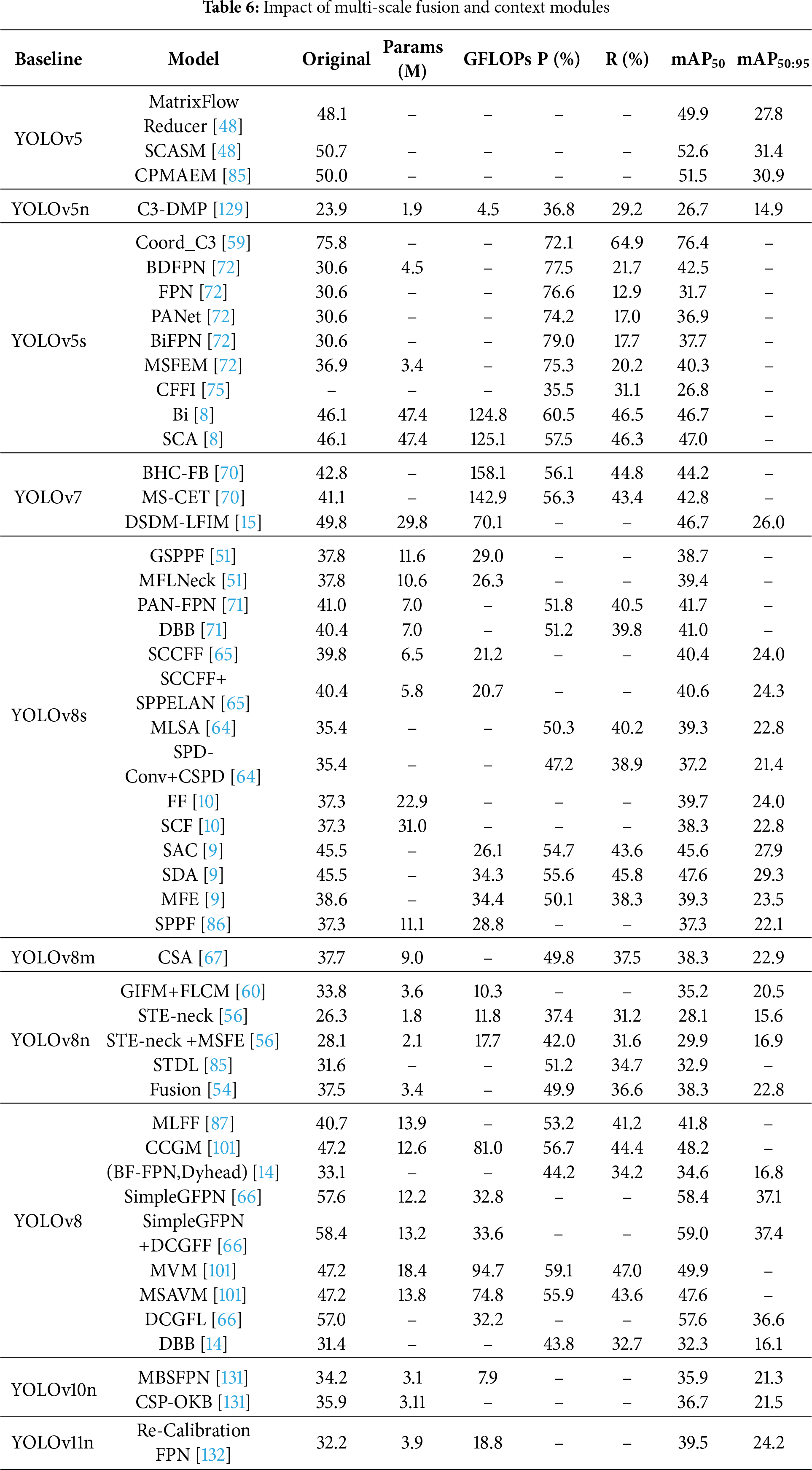
We present attention mechanisms and multi-scale fusion as distinct categories in order to differentiate structural design from weighting strategy. Multi-scale fusion defines the architectural skeleton that connects and aggregates information across resolutions through explicit cross-scale operators, whereas attention allocates weights to channels and spatial locations along those established paths. Accordingly, Table 2 reports only attention methods, defined as modules that modulate feature salience within a single representation without constructing explicit cross-scale links. Table 5 reports multi-scale fusion and context methods, defined as designs that perform aggregation or alignment across resolutions via explicit cross-scale operations. In contemporary YOLO research, multi-scale fusion methods almost always incorporate attention to adapt weights or to guide alignment across scales; therefore, entries in Table 5 should be interpreted as attention-augmented fusion by default. This delineation enforces precise classification criteria, supports mechanism-level comparison in Table 2 and operator-level comparison in Table 5, and removes ambiguity in the treatment of hybrid modules.
In each table we report the indicators that are standard in the cited works, including precision–recall based measures and computational measures, for representative detectors drawn from recent studies. All entries are transcribed from the original sources, and the original nomenclature and formatting are retained to preserve fidelity. When authors evaluated models on official test servers or on clearly specified validation partitions, we used those values to provide a stable basis for comparison. The ordering of methods within a table does not imply a ranking. The layout is designed to support clear side by side reading.
The following seven tables present a comparative summary of complete model results, with one table corresponding to each dataset. We aggregate state-of-the-art detectors evaluated on VisDrone, DOTA, UAVDT, VEDAI, NWPU VHR-10, AI-TOD, and DIOR so that readers can inspect model behavior under a consistent set of dataset-specific conditions and metrics. Table 7 reports experimental results of YOLO models for small-object detection on VisDrone, Table 8 reports results on DOTA, Table 9 reports results on UAVDT, Table 10 reports results on VEDAI, Table 11 reports results on NWPU VHR-10, Table 12 reports results on AI-TOD, and Table 13 reports results on DIOR.
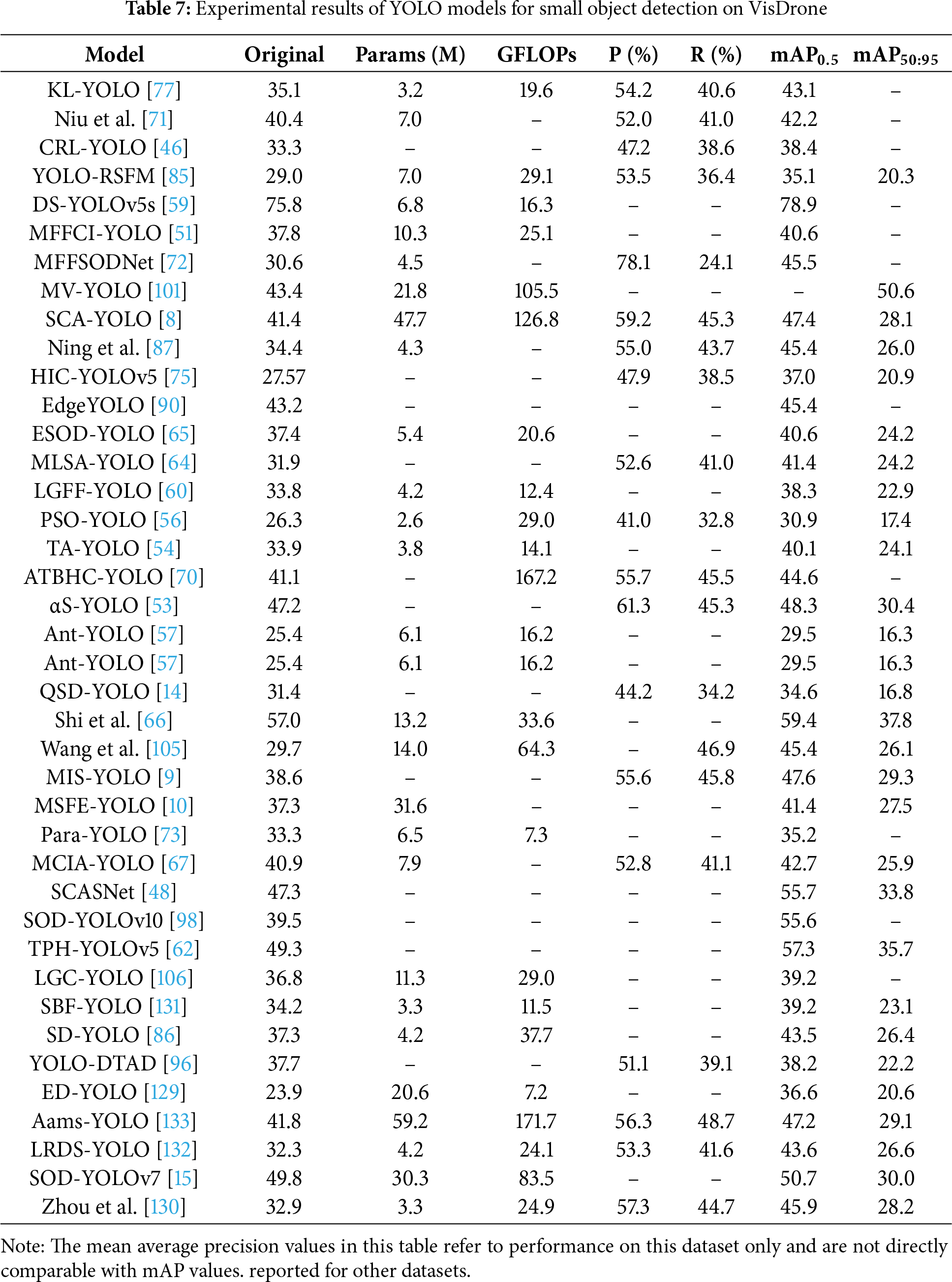
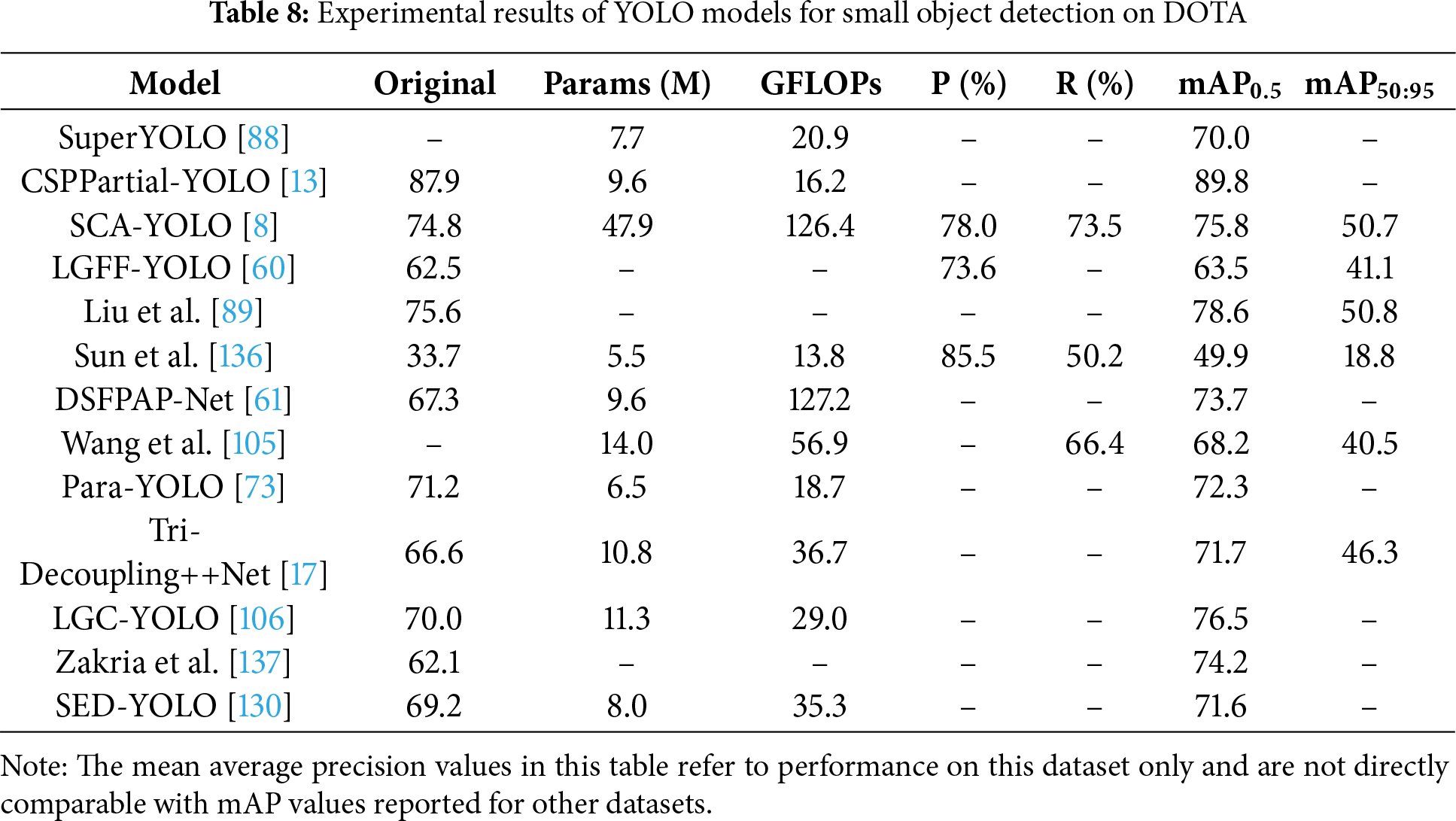
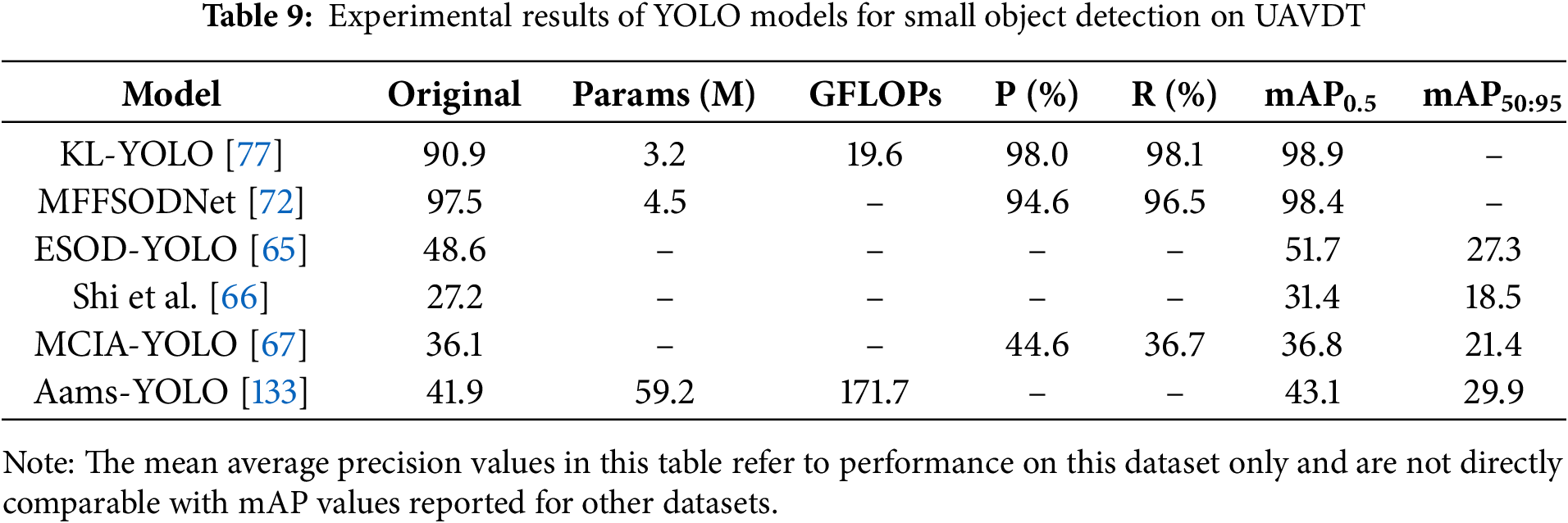
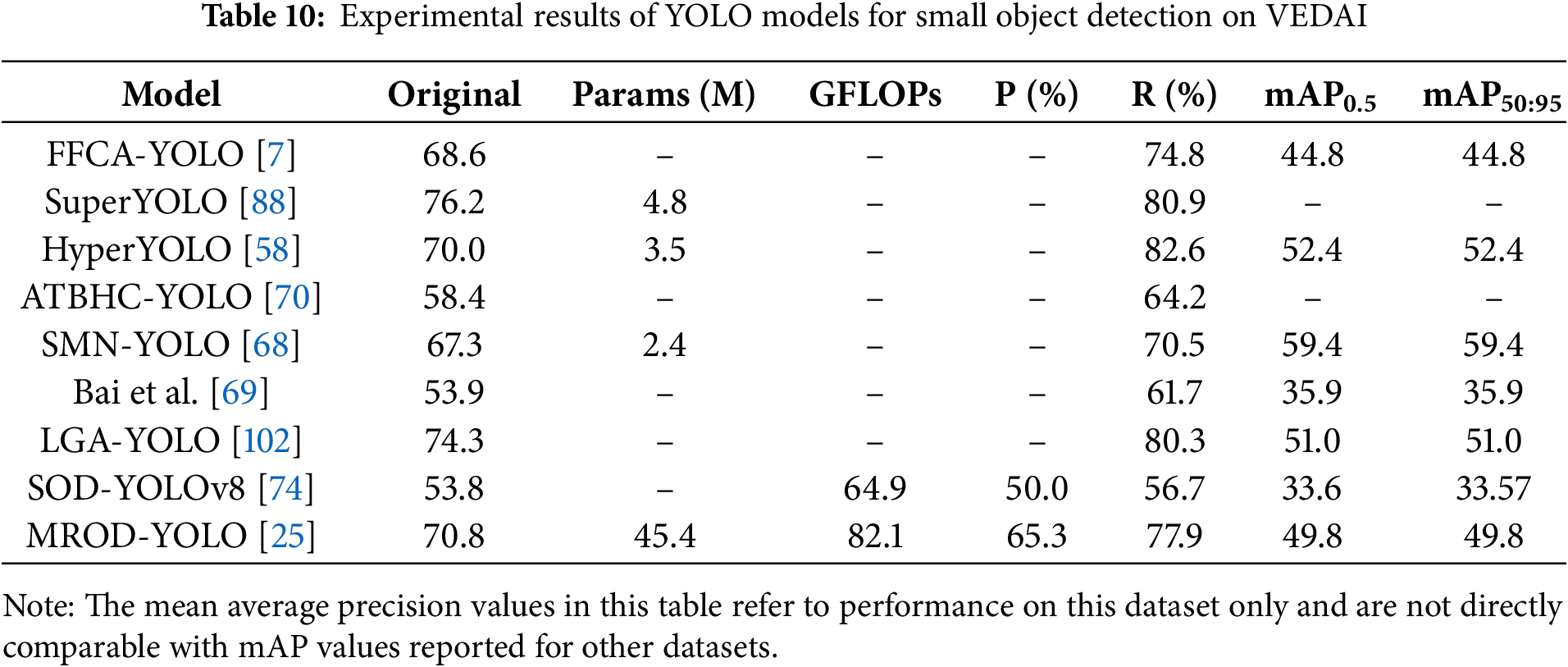
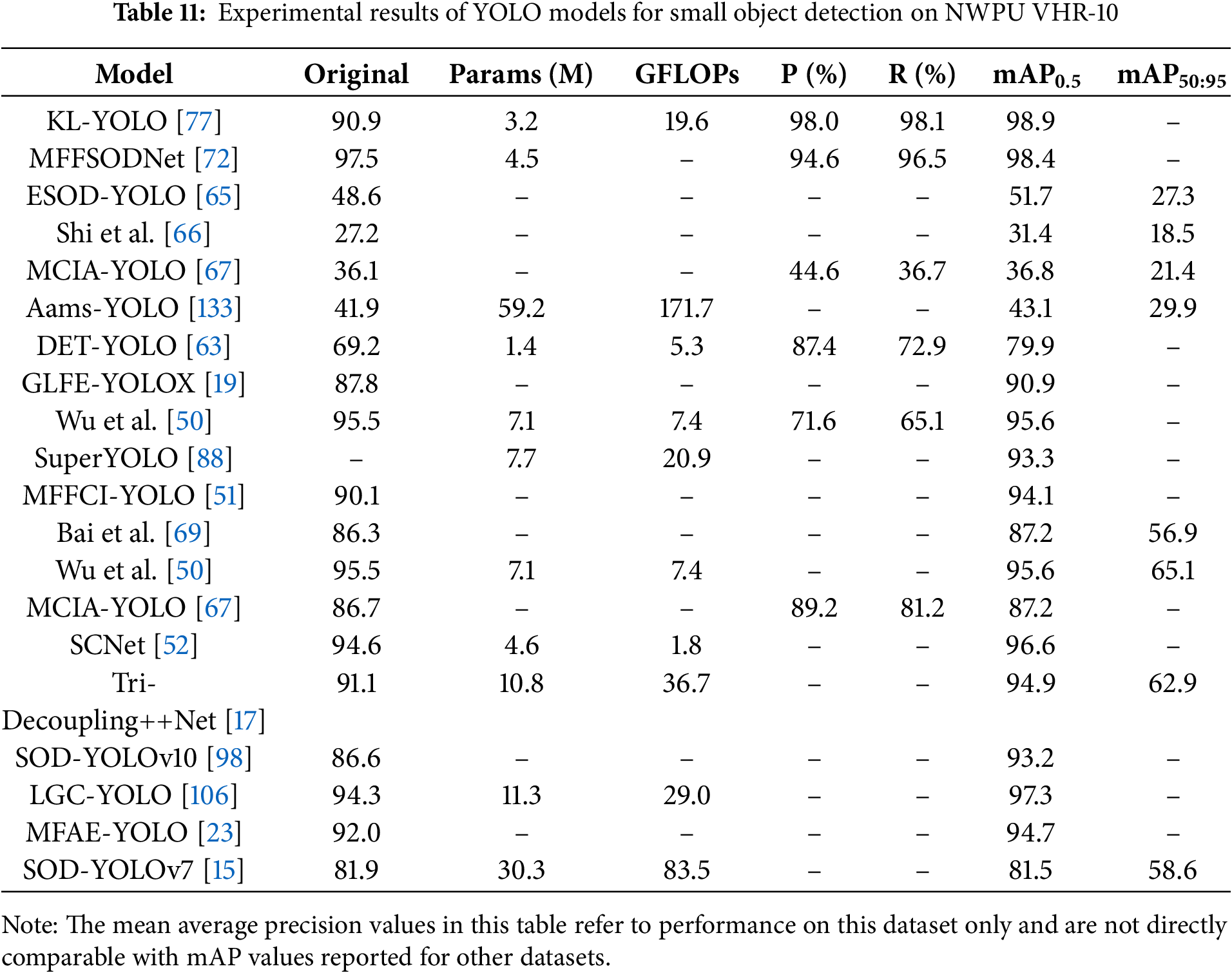
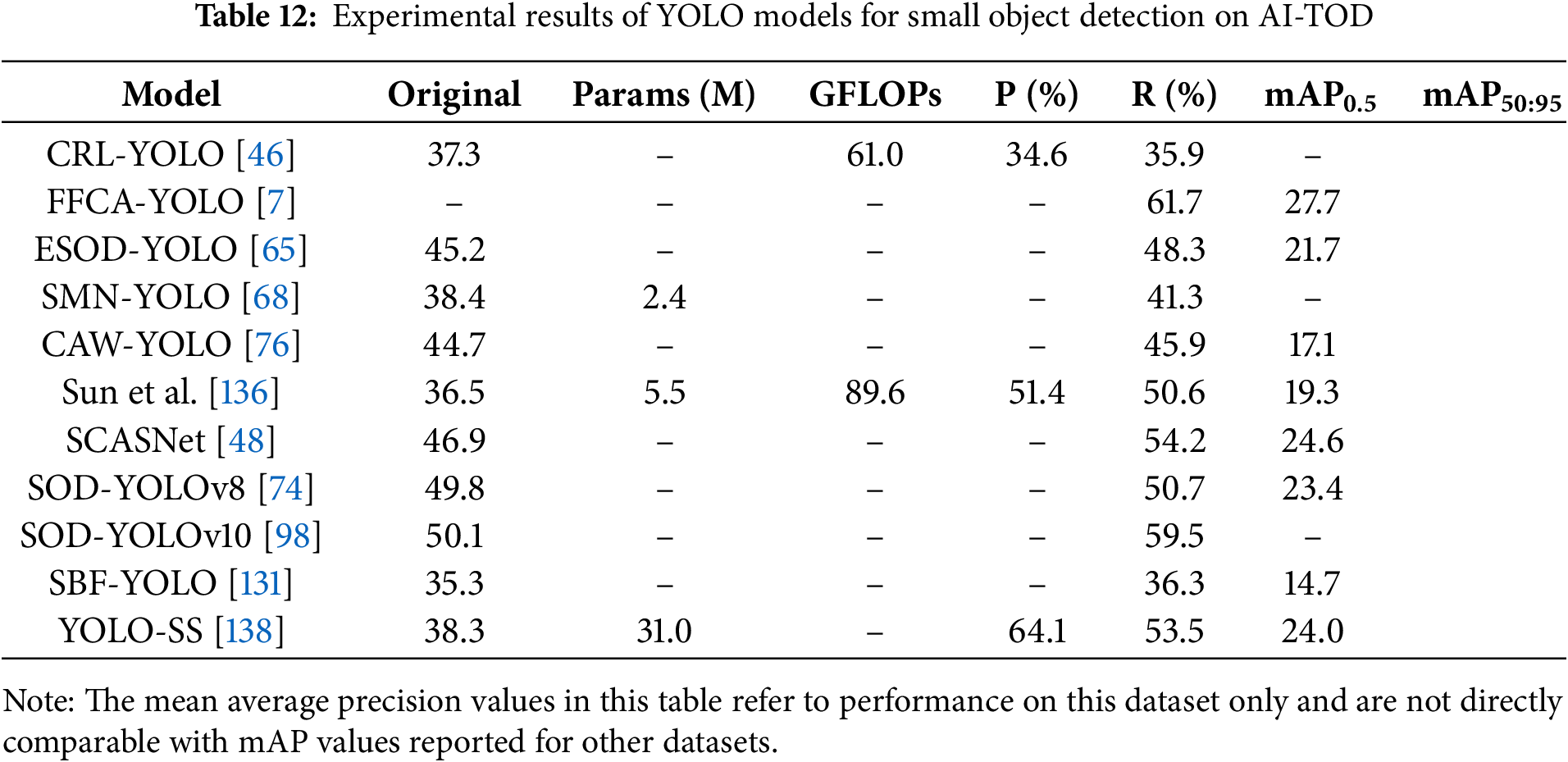
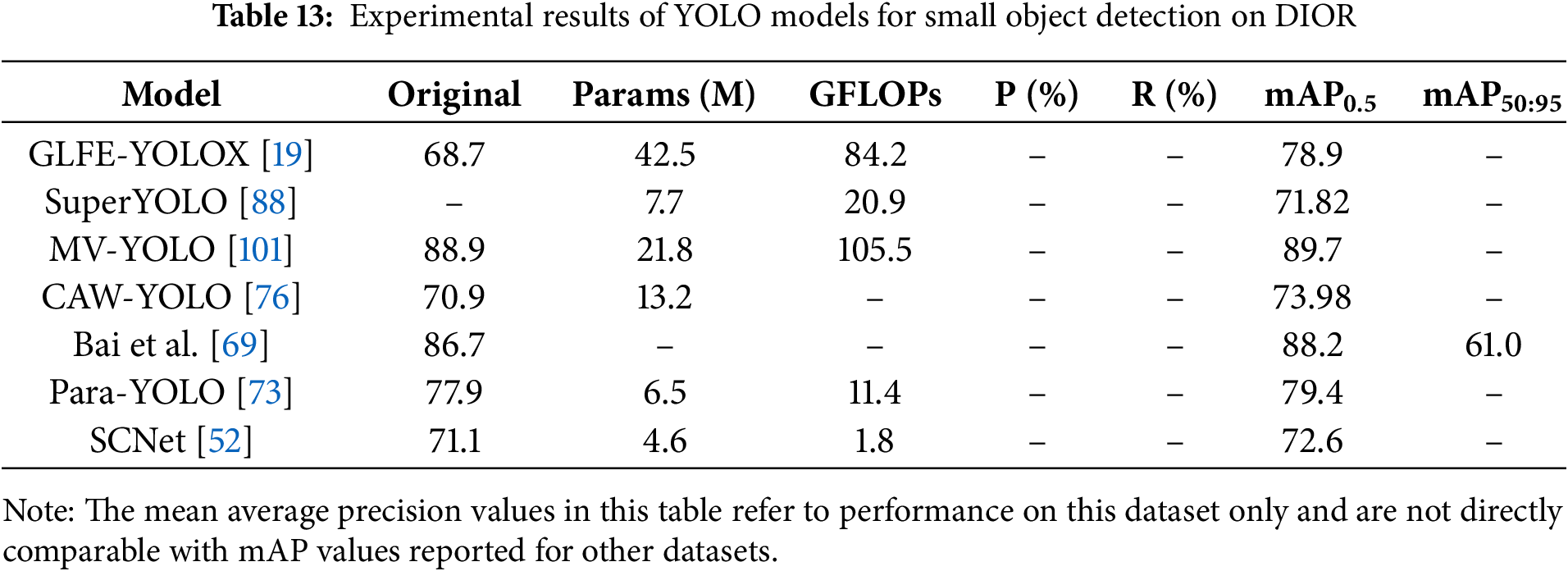
Each dataset represents a distinct application context or imaging source and introduces characteristic challenges for small object detection such as high target density or strong background clutter. Because target scale distribution, object density, viewpoint range and annotation protocol differ across benchmarks, the overall difficulty of each dataset is also different. Mean average precision values reported in different tables cannot therefore be compared directly across datasets. They should be interpreted only within the corresponding benchmark. In each table an “Original” column reports the baseline performance of the detector before any small object oriented modification is applied. Improvements are interpreted as gains over this baseline within the same dataset rather than as comparisons of absolute scores between datasets.
All numerical results in Tables 7–13 are taken directly from published studies so that the comparisons reflect the performance reported in the original papers and avoid inconsistencies that may arise from reimplementation. For each entry we cite the source in the table or in the accompanying discussion, and we align the evaluation metrics so that the contrasts are genuinely like for like. By analyzing these tables it is possible to outline the current landscape of YOLO based small object detection and to observe trade offs, for example between models that prioritize peak precision and models that emphasize recall for small objects, with many of these differences linked to specific architectural and training choices described in the original works. The tables are structured to isolate the effect of individual improvement strategies on a shared benchmark and to assess the overall behaviour of advanced detectors across multiple benchmarks. Each enhanced model is paired with its reported baseline under a common evaluation protocol and consistent metric calibration, which enables like for like comparisons that quantify the incremental contribution of attention mechanisms, detection head redesigns, loss formulations and multi scale fusion while helping to limit confounding from dataset or protocol shifts. At the same time, the tables extend the view across datasets with different object scales, scene densities and imaging conditions so that the robustness of each method can be examined under varied scenarios. Taken together, these summaries provide a consolidated reference that highlights recurring design patterns and supports meaningful cross paper comparison of YOLO based small object detectors.
Fig. 7 summarizes how the magnitude of mAP50 gains depends on dataset characteristics rather than the method alone. VisDrone shows a wide and right-skewed distribution because its imagery contains very small targets, dense layouts, frequent occlusion, and strong illumination changes, which create large headroom for attention and fusion modules that recover fine detail. AI-TOD exhibits the largest spread because it concentrates extremely tiny instances in complex backgrounds, so improvements are substantial when designs strengthen cross-scale aggregation or deformable sampling yet can be modest when only lightweight recalibration is added. UAVDT yields compact distributions with high medians because scenes contain traffic targets with relatively consistent scale and motion cues, which produce strong baselines and leave less room for additional gains. DIOR produces narrow improvements because objects are often larger within 800 by 800 crops and class diversity dilutes the effect of detectors specialized for tiny objects. VEDAI centers around mid-range gains because it focuses on vehicles with limited category variation while still presenting occlusion and rotation that benefit from context modeling. NWPU VHR-10 shows moderate variance because very-high-resolution imagery preserves detail but the dataset is smaller, which constrains robust learning and limits the stability of gains. DOTA displays heterogeneous improvements because arbitrary orientations and multi-scale clutter increase reliance on alignment quality, so methods that couple fusion with orientation-aware attention achieve larger benefits than those that only reweight features. Collectively, the distributions indicate that larger gains arise when a dataset concentrates tiny, dense, and cluttered instances that amplify the value of explicit cross-scale aggregation, alignment, and content-adaptive weighting, whereas datasets with larger objects, simpler scenes, or stronger baselines show smaller yet consistent improvements.
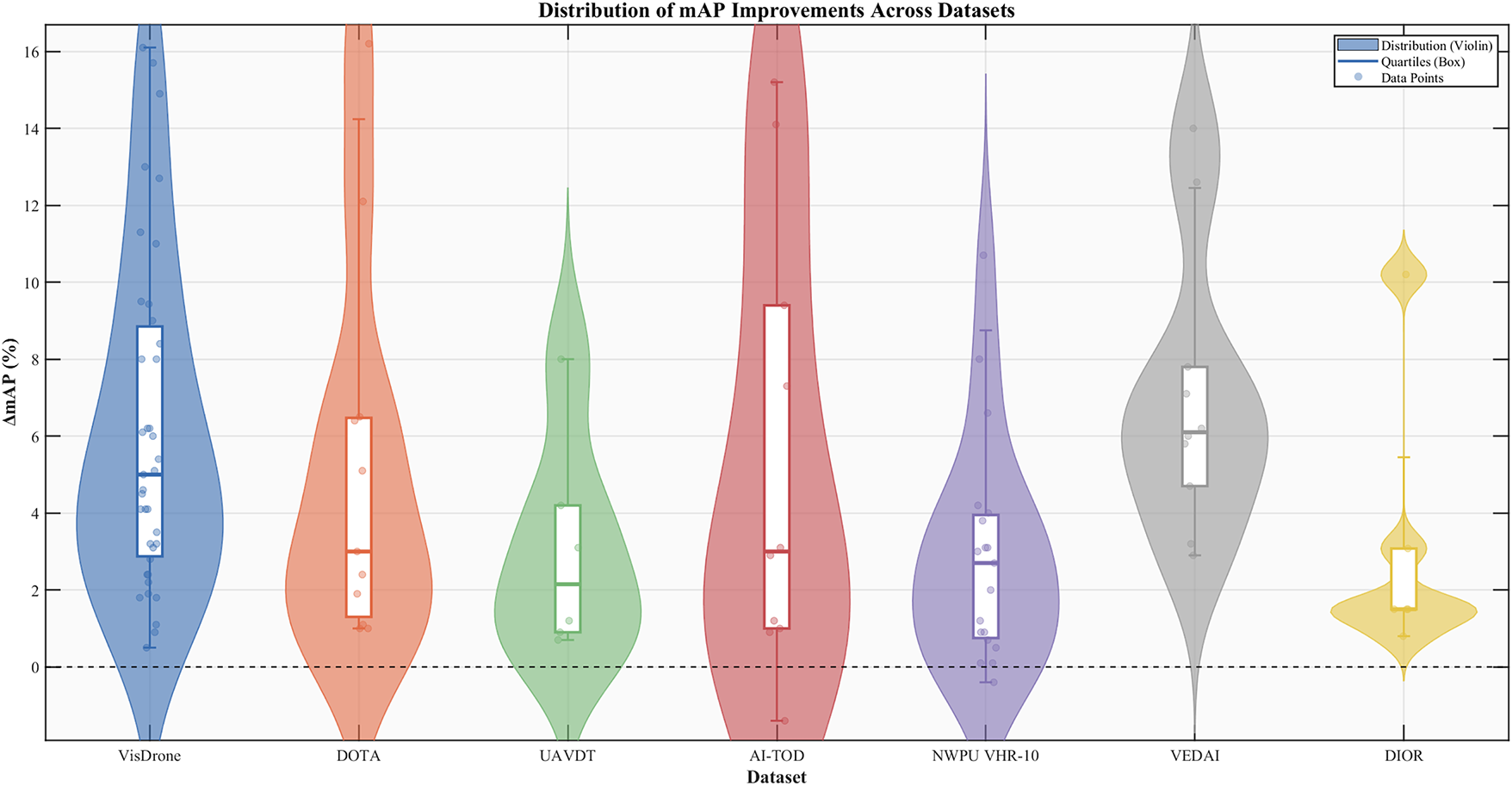
Figure 7: Distribution of mAP50 improvements across datasets
Our comparative tables are structured to isolate the effect of individual improvement strategies on a shared benchmark and to assess the holistic performance of advanced detectors across multiple benchmarks. By pairing each enhanced model with its reported baseline under a common evaluation protocol and metric calibration, the entries enable like-for-like contrasts that quantify the incremental contribution of attention mechanisms, detection-head redesigns, loss formulations, and multi-scale fusion while minimizing confounding from dataset or protocol shifts. The same compilation then extends the view to diverse datasets, allowing performance to be examined under differing object scales, scene densities, and imaging conditions so that generalizability can be appraised rather than inferred.
In summary, the comparative tables are structured to first isolate the effect of individual improvement strategies on a common benchmark, and then to examine the holistic performance of advanced detectors across multiple benchmarks. This two-level comparison strategy allows us to discuss both the micro-level impact of specific techniques and the macro-level effectiveness of entire models in varied small object detection scenarios. Through this academically rigorous synthesis of published results, our literature re-view provides a clear landscape of which YOLO-based improvements have the most promise and under what conditions, guiding future research towards the most fruitful directions.
Although YOLO based small object detection has progressed rapidly, several research directions remain central for future work. The synthesis in the previous sections highlights five themes that are likely to shape the next generation of detectors. These themes are cross domain generalization, dynamic and task aware architecture, lightweight design and model compression, multimodal fusion, and temporal reasoning in crowded scenes. Each theme reflects a specific constraint in real applications and points to methodological advances that go beyond incremental tuning of existing models. The following subsections outline these directions and discuss their implications for YOLO based small object detection.
5.1 Cross Domain Generalization for Small Object Detection
Cross domain generalization is a fundamental challenge for YOLO based small object detection. Detectors trained on a particular dataset or sensor modality often suffer a marked drop in accuracy when deployed in new cities or under different weather and illumination conditions. The effect is especially severe for small objects because their visual signatures are weak and can be masked by changes in background statistics or imaging noise. Future research needs to move beyond dataset specific optimization and develop representations that remain stable when the deployment domain differs from the training domain.
One line of work is domain invariant feature learning. Adversarial objectives can constrain intermediate features so that a domain classifier fails to infer the source dataset while the detector preserves discriminative power for target categories. Another line is meta learning for rapid adaptation. Training episodes can simulate domain shifts and encourage the detector to learn update rules that rely on a small amount of new data. Test time adaptation provides a complementary path. In this setting the detector updates batch statistics or selected parameters on unlabeled deployment data and gradually aligns its internal representation to the target domain. For small object detection it is also important to identify which layers should be adapted, since excessive changes in early filters may amplify background noise while insufficient adaptation in deeper layers can leave tiny targets poorly separated from clutter. Moreover, domain adaptation methods need to account for the long tailed distributions of scale and class frequency in small object benchmarks so that rare small instances are not overshadowed by more common medium sized objects. A coherent research agenda will integrate these strategies within the YOLO framework and will evaluate them on benchmarks that include explicit cross domain splits for small object scenarios.
5.2 Dynamic and Task-Aware Architectures
Most current YOLO based detectors adopt a fixed backbone depth, neck width, and fusion pattern for all inputs. Real scenes contain large regions with little structure and small regions with heavy clutter and dense tiny targets. A static architecture tends to allocate similar computation to both types of regions and may still fail to capture the subtle cues needed for small object discrimination. Dynamic and task aware architectures aim to adjust their effective capacity in response to the spatial, scale, and temporal structure of each input so that computation is concentrated on informative regions.
Future research can explore neural architecture search, conditional computation, and routing mechanisms that allow the network to vary its paths based on content. Cross scale connections can be activated only when the image contains many small objects. Uniform regions such as sky or road can be processed by lighter sub networks that require fewer operations. Architectures that combine local convolutional features with global context from attention style modules have particular promise. They can exploit fine texture. At the same time, they model extended contextual dependencies across the image, which helps resolve ambiguity between small targets and clutter. Dynamic design should also extend to video. Detectors for video streams can reuse features across frames and activate computationally expensive branches only when motion patterns or occlusions make the scene more complex. In crowded scenes dynamic heads can adjust receptive fields and anchor layouts according to estimated object density so that overlapping small objects remain separable. Continued work along these lines can yield YOLO based detectors that maintain high recall for small objects while adapting their computational structure to the demands of each scene.
5.3 Lightweight Design and Model Compression for Deployment
Practical deployment of small object detectors frequently occurs on edge platforms. Typical examples include unmanned aerial vehicles, embedded cameras in intelligent transportation systems, and mobile robotic platforms. These environments impose strict limits on computation, memory, and energy, yet they often require real time detection of numerous small targets in complex backgrounds. A central research objective is to sustain high detection performance for small objects while satisfying stringent constraints on computation, memory and energy.
Model compression provides a structured framework for this objective. Knowledge distillation [139] transfers behaviour from a high capacity teacher into a compact student network that preserves the detailed representations needed for small object detection [140]. Quantization reduces memory footprint and arithmetic cost by using low precision weights and activations. Structured pruning removes redundant channels or blocks and keeps the overall geometry of the backbone and detection heads. When compression techniques are co designed with architectures that emphasize high resolution features and enriched neck structures, the result can be streamlined YOLO variants that approach the accuracy of larger models while satisfying the constraints of embedded hardware. A promising direction is joint optimization of architecture and compression. Instead of compressing an existing model, future methods can search directly for backbones, necks, and heads that remain robust under strong pruning or low precision quantization. Training objectives can include explicit constraints on latency, memory, and power. Such pipelines would yield lightweight small object detectors that are tailored to specific devices and operating conditions.
5.4 Multimodal Fusion for Robust Small Object Perception
Single modality input often proves insufficient for reliable small object detection in adverse environments. In many real systems it is possible to acquire complementary data streams such as visible light imagery, infrared images, radar signals or depth maps. Each modality captures different physical properties of the scene and different aspects of small targets and background clutter. Visible images offer rich texture and colour cues but degrade under low illumination and weather degradation. Infrared imagery highlights thermal contrast but may blur fine structural details. Radar and depth sensors encode geometric and range information but provide limited spatial resolution. For small objects, whose footprint in each modality is already small, these strengths and weaknesses are magnified. Future research needs to exploit the complementary nature of these signals so that YOLO based detectors remain robust when a single modality becomes unreliable.
Multimodal fusion for small object detection should therefore focus on architectures that align and combine heterogeneous modalities at appropriate stages of the detection pipeline. Early fusion can merge registered raw inputs or shallow features so that small structures that are visible in only one modality become recoverable in the fused representation. Fusion at intermediate feature levels can integrate modality specific feature maps through attention or gating mechanisms that learn which channels and spatial locations carry reliable information for tiny targets. Late fusion at the detection head can aggregate modality specific predictions into unified bounding boxes and confidence scores while exploiting differences in error patterns across sensors. A key technical challenge is the calibration of geometric and photometric misalignment between modalities, especially when small objects occupy only a few pixels and even minor registration errors lead to inconsistent features. Robust training strategies are also required so that the detector degrades gracefully when one modality is noisy or unavailable. Continued progress in these aspects of multimodal fusion will be essential for improving the reliability of YOLO based small object detectors in real world applications.
5.5 Temporal Reasoning and Crowded Scenes
Crowded scenes with many overlapping small objects remain one of the most demanding settings for YOLO based detectors. Typical examples include dense traffic at urban intersections, formations of aircraft or birds, and large crowds observed by surveillance systems. In such scenes small instances often occlude one another and share very similar appearance. Conventional detection heads and non-maximum suppression can then produce both missed detections and duplicated bounding boxes. Spatial cues alone are frequently insufficient to resolve these ambiguities.
Future research should strengthen the interplay between spatial suppression mechanisms and temporal reasoning. Recent advances in non-maximum suppression, including discretization based and pooling-based strategies [141], show that suppression can be formulated as a stable and parallelizable operator. Extending these ideas to small object detection requires algorithms that remain reliable when many highly overlapping hypotheses occupy a compact region. At the same time multi object tracking across frames can provide motion trajectories and temporal consistency signals that help separate instances that are indistinguishable on a single frame. Integrating such sequence level information into YOLO style pipelines will require new training paradigms. Possible directions include joint optimization of detection and tracking losses and curriculum designs that expose the network to scenes with increasing levels of crowding and occlusion. Progress along this path would yield small object detectors that maintain consistent identities over time and provide reliable counts in dense scenes, which are critical capabilities for safety monitoring and large scale environmental observation.
Taken together, the research directions outlined in Sections 5.1–5.5 are closely interconnected. Cross domain generalization must account for variation in both scene distribution and sensor configuration. Dynamic and task aware architectures provide mechanisms that allocate computation adaptively in multimodal and temporally structured environments. Lightweight design constrains the space of feasible models and becomes critical when the detector processes multiple input streams or incorporates temporal modules. Multimodal fusion and temporal reasoning supply complementary forms of context that support reliable detection when small objects are occluded, poorly illuminated or heavily cluttered. Future work that treats these themes jointly rather than in isolation is likely to produce YOLO based small object detectors that are both accurate and deployable in realistic applications.
Achieving accurate and efficient recognition of small objects in cluttered environments has long remained a central goal for the vision community, highlighting the need for systematic improvements to YOLO-based detectors. This article presents the first comprehensive survey of YOLO-based small-object detection. We review progress across key application domains, including autonomous driving, surveillance, aerial imaging, and remote sensing, and we synthesize the literature into four principal avenues for improving small-object performance within the YOLO framework, namely attention-based feature enhancement, detection-head and branch-structure optimization, loss-function design with regression-precision optimization, and multi-scale feature fusion with spatial-context modeling. For each avenue we delineate the limitations and practical challenges that remain. We conclude by identifying outstanding open problems and outlining promising research directions intended to guide future work and to catalyze further advances in this rapidly evolving field.
Acknowledgement: The authors would like to thank all contributors and institutions that supported this research.
Funding Statement: This work was supported in part by the by Chongqing Research Program of Basic Research and Frontier Technology under Grant CSTB2025NSCQ-GPX1309.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Hui Yu and Jun Liu; methodology, Hui Yu; validation, Hui Yu, Jun Liu and Mingwei Lin; formal analysis, Mingwei Lin; resources, Mingwei Lin; writing—original draft preparation, Hui Yu; writing—review and editing, Jun Liu; supervision, Jun Liu; funding acquisition, Mingwei Lin. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Li MJ, Liu XY, Chen S, Yang L, Du QY, Han ZQ, et al. MST-YOLO: small object detection model for autonomous driving. Sensors. 2024;24(22):7347. doi:10.3390/s24227347. [Google Scholar] [PubMed] [CrossRef]
2. Hua CJ, Luo K, Wu YD, Shi R. YOLO-ABD: a multi-scale detection model for pedestrian anomaly behavior detection. Symmetry. 2024;16(8):1003. doi:10.3390/sym16081003. [Google Scholar] [CrossRef]
3. Tsai Y-S, Sit Y-H. Aerial object tracking with attention mechanisms: accurate motion path estimation under moving camera perspectives. Comput Model Eng Sci. 2025;143(3):3065–90. doi:10.32604/cmc.2025.066368. [Google Scholar] [CrossRef]
4. Peng J, He H, Zhang D. YOLOv8s-DroneNet: small object detection algorithm based on feature selection and ISIoU. Comput Mater Contin. 2025;84(3):5047–61. doi:10.32604/cmc.2025.066368. [Google Scholar] [CrossRef]
5. Tang X, Ruan C, Li X, Li B, Fu C. MSC-YOLO: improved YOLOv7 based on multi-scale spatial context for small object detection in UAV-view. Comput Mater Contin. 2024;79(1):983–1003. doi:10.32604/cmc.2024.047541. [Google Scholar] [CrossRef]
6. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 779–88. doi:10.1109/CVPR.2016.91. [Google Scholar] [CrossRef]
7. Zhang Y, Ye M, Zhu G, Liu Y, Guo P, Yan J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans Geosci Remote Sens. 2024;62:1–15. doi:10.1109/TGRS.2024.3363057. [Google Scholar] [CrossRef]
8. Zeng S, Yang W, Jiao Y, Geng L, Chen X. SCA-YOLO: a new small object detection model for UAV images. Vis Comput. 2024;40(3):1787–803. doi:10.1007/s00371-023-02886-y. [Google Scholar] [CrossRef]
9. Tao S, Shengqi Y, Haiying L, Jason G, Lixia D, Lida L. MIS-YOLOv8: an improved algorithm for detecting small objects in UAV aerial photography based on YOLOv8. IEEE Trans Instrum Meas. 2025;74(9):1. doi:10.1109/TIM.2025.3551917. [Google Scholar] [CrossRef]
10. Qi S, Song X, Shang T, Hu X, Han K. MSFE-YOLO: an improved YOLOv8 network for object detection on drone view. IEEE Geosci Remote Sens Lett. 2024;21:1–5. doi:10.1109/LGRS.2024.3432536. [Google Scholar] [CrossRef]
11. Bhanbhro H, Hooi Y-K, Zakaria M-N-B, Kusakunniran W, Amur Z-H. MCBAN: a small object detection multi-convolutional block attention network. Comput Mater Contin. 2024;81(11):2243–59. doi:10.32604/cmc.2024.052138. [Google Scholar] [CrossRef]
12. Zhou W, Cai C, Li C, Xu H, Shi H. AD-YOLO: a real-time YOLO network with swin transformer and attention mechanism for airport scene detection. IEEE Trans Instrum Meas. 2024;73:3472805. doi:10.1109/TIM.2024.3472805. [Google Scholar] [CrossRef]
13. Xie S, Zhou M, Wang C, Huang S. CSPPartial-YOLO: a lightweight YOLO-based method for typical objects detection in remote sensing images. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17(1):388–99. doi:10.1109/JSTARS.2023.3329235. [Google Scholar] [CrossRef]
14. Wang H, Liu C, Cai Y, Chen L, Li Y. YOLOv8-QSD: an improved small object detection algorithm for autonomous vehicles based on YOLOv8. IEEE Trans Instrum Meas. 2024;73:1–16. doi:10.1109/TIM.2024.3379090. [Google Scholar] [CrossRef]
15. Xiao Y, Di N. SOD-YOLO: a lightweight small object detection framework. Sci Rep. 2024;14(1):25624. doi:10.1038/s41598-024-77513-4. [Google Scholar] [PubMed] [CrossRef]
16. Jiang F, Ye W, Lu P, Zhang S, Wu Z, Zhu H. CNCR-YOLO: a comprehensive optimization strategy for small-target defect detection in injection-molded parts. IEEE Sens J. 2024;21(21):24. doi:10.1109/JSEN.2024.3454311. [Google Scholar] [CrossRef]
17. Ni L, Pan X, Wang X, Bao D, Zhang J, Shi J. Small-object detection model for optical remote sensing images based on Tri-Decoupling++ Head. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17:12256–73. doi:10.1109/JSTARS.2024.3417702. [Google Scholar] [CrossRef]
18. Li K, Zhong X, Han Y. A high-performance small target defect detection method for PCB boards based on a novel YOLO-DFA algorithm. IEEE Trans Instrum Meas. 2025;74:1–12. doi:10.1109/TIM.2025.3551584. [Google Scholar] [CrossRef]
19. Gu Q, Huang H, Han Z, Fan Q, Li Y. GLFE-YOLOX: global and local feature enhanced YOLOX for remote sensing images. IEEE Trans Instrum Meas. 2024;73:1–12. doi:10.1109/TIM.2024.3387499. [Google Scholar] [CrossRef]
20. Kang M, Ting C-M, Ting FF, Phan RC-W. CST-YOLO: a novel method for blood cell detection based on improved YOLOv7 and CNN-swin transformer. In: Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP); 2024 Oct 27–30; Abu Dhabi, United Arab Emirates. p. 3024–9. doi:10.1109/ICIP51287.2024.10647618. [Google Scholar] [CrossRef]
21. Luo X, Luo S, Chen M, Zhao G, He C, Wu H. MBFormer-YOLO: multibranch adaptive spatial feature detection network for small infrared object detection. IEEE Sens J. 2024;24(12):19517–30. doi:10.1109/JSEN.2024.3394956. [Google Scholar] [CrossRef]
22. Zhou W, Cai C, Srigrarom S, Wang P, Cui Z, Li C. ADH-YOLO: a small object detection based on improved YOLOv8 for airport scene images in hazy weather. J Supercomput. 2025;81(3):1–20. doi:10.1007/s11227-025-06999-0. [Google Scholar] [CrossRef]
23. Liu Y, Cheng X, Xu N, Wang L, Wang X, Zhong X. MFAE-YOLO: multifeature attention-enhanced network for remote sensing images object detection. IEEE Trans Geosci Remote Sens. 2025;63:1–14. doi:10.1109/TGRS.2025.3583467. [Google Scholar] [CrossRef]
24. Zhuo X, Tian J. YOLO-Pole: a deep learning framework for precise pole localization in aerial orthophotos. IEEE Trans Geosci Remote Sens. 2025;22:1–5. doi:10.1109/LGRS.2025.3566546. [Google Scholar] [CrossRef]
25. Wang S, Yang X, Lu R, Zhang D, Xie W, Su S, et al. MROD-YOLO: multimodal joint representation for small object detection in remote sensing imagery via multi-scale iterative aggregation. IEEE Trans Geosci Remote Sens. 2025;63:1–14. doi:10.1109/TGRS.2025.3590447. [Google Scholar] [CrossRef]
26. Gu Y, Guo Y, Xie W, Wu Z, Dong S, Xie G, et al. MDSF: a plug-and-play block for boosting infrared small target detection in YOLO-based networks. IEEE Trans Geosci Remote Sens. 2025;63:1–14. doi:10.1109/TGRS.2025.3566889. [Google Scholar] [CrossRef]
27. Vijayakumar A, Vairavasundaram S. YOLO-based object detection models: a review and its applications. Multimed Tools Appl. 2024;83(35):83535–74. doi:10.1007/s11042-024-18872-y. [Google Scholar] [CrossRef]
28. Badgujar CM, Poulose A, Gan H. Agricultural object detection with You Only Look Once (YOLO) algorithm: a bibliometric and systematic literature review. Comput Electron Agric. 2024;223:18. doi:10.1016/j.compag.2024.109090. [Google Scholar] [CrossRef]
29. Ayachi R, Said Y, Afif M, Alshammari A, Hleili M, Abdelali AB. Assessing YOLO models for real-time object detection in urban environments for advanced driver-assistance systems (ADAS). Alexandria Eng J. 2025;123(1):530–49. doi:10.1016/j.aej.2025.03.077. [Google Scholar] [CrossRef]
30. Lv X, Chen T, Song C, Yang C, Ping T. Application of YOLO algorithm for intelligent transportation systems: a survey and new perspectives. Int J Distrib Sens Netw. 2025;2025(1):2859040. doi:10.1155/dsn/2859040. [Google Scholar] [CrossRef]
31. Kamalesh KS, Ramalingam K, Pazhanivelan P, Jagadeeswaran R, Prabu P. YOLO deep learning algorithm for object detection in agriculture: a review. J Agric Eng Res. 2024;55(4):1641. doi:10.4081/jae.2024.1641. [Google Scholar] [CrossRef]
32. Sirisha U, Praveen SP, Srinivasu PN, Barsocchi P, Bhoi AK. Statistical analysis of design aspects of various YOLO-based deep learning models for object detection. Int J Comput Intell Syst. 2023;16(1):1–29. doi:10.1007/s44196-023-00302-w. [Google Scholar] [CrossRef]
33. Cai Z, Zhou K, Liao Z. A systematic review of YOLO-based object detection in medical imaging: advances, challenges, and future directions. Comput Mater Contin. 2025;85(2):2255–303. doi:10.32604/cmc.2025.067994. [Google Scholar] [CrossRef]
34. Gheorghe C, Duguleana M, Boboc R, Postelnicu C. Analyzing real-time object detection with YOLO algorithm in automotive applications: a review. Comput Model Eng Sci. 2024;141(3):43. doi:10.32604/cmes.2024.054735. [Google Scholar] [CrossRef]
35. Diwan T, Anirudh G, Tembhurne JV. Object detection using YOLO: challenges, architectural successors, datasets and applications. Multimed Tools Appl. 2023;82(6):9243–75. doi:10.1007/s11042-022-13644-y. [Google Scholar] [PubMed] [CrossRef]
36. Liu Y, Sun P, Wergeles N, Shang Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst Appl. 2021;172(4):114602. doi:10.1016/j.eswa.2021.114602. [Google Scholar] [CrossRef]
37. Li A, Song X, Sun S, Zhang Z, Cai T, Song H. YOLO-SA: an efficient object detection model based on self-attention mechanism. In: Proceedings of the 7th Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) International Joint Conference on Web and Big Data; 2024 Aug 31–Sep 2; Wuhan, China. p. 1–15. doi:10.1007/978-981-97-2421-5_1. [Google Scholar] [CrossRef]
38. Nimma D, Al-Omari O, Pradhan R, Ulmas Z, Krishna R, El-Ebiary TYAB, et al. Object detection in real-time video surveillance using attention based transformer-YOLOv8 model. Alexandria Eng J. 2025;118:482–95. doi:10.1016/j.aej.2025.01.032. [Google Scholar] [CrossRef]
39. Chen J, Er MJ. Dynamic YOLO for small underwater object detection. Artif Intell Rev. 2024;57(7):165. doi:10.1007/s10462-024-10788-1. [Google Scholar] [CrossRef]
40. Ji S-J, Ling Q-H, Han F. An improved algorithm for small object detection based on YOLO v4 and multi-scale contextual information. Comput Electr Eng. 2023;105(1):108490. doi:10.1016/j.compeleceng.2022.108490. [Google Scholar] [CrossRef]
41. Peng S, Fan X, Tian S, Yu L. PS-YOLO: a small object detector based on efficient convolution and multi-scale feature fusion. Multimedia Syst. 2024;30(5):1–16. doi:10.1007/s00530-024-01447-0. [Google Scholar] [CrossRef]
42. Li J, Yu C, Wei W, Li J, Huang K, Hussian A, et al. A multi-scale feature fusion network focusing on small objects in UAV-View. Cogn Comput. 2025;17(2):1–17. doi:10.1007/s12559-025-10445-x. [Google Scholar] [CrossRef]
43. Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 19–25; Nashville, TN, USA. p. 13713–22. doi:10.1109/CVPR46437.2021.01350. [Google Scholar] [CrossRef]
44. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: efficient channel attention for deep convolutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 11534–42. doi:10.1109/CVPR42600.2020.01155. [Google Scholar] [CrossRef]
45. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2018 Jun 18–23; Salt Lake City, UT, USA. p. 7132–41. doi:10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
46. Wu D, Yang W, Li J, Du K, Li L, Yang Z. CRL-YOLO: a comprehensive recalibration and lightweight detection model for UAV power line inspections. IEEE Trans Instrum Meas. 2025;74:1–21. doi:10.1109/TIM.2025.3562980. [Google Scholar] [CrossRef]
47. He S, Yu W, Tang T, Wang S, Li C, Xu E. FOS-YOLO: multiscale context aggregation with attention-driven modulation for efficient target detection in complex environments. IEEE Trans Instrum Meas. 2025;74:1–13. doi:10.1109/TIM.2025.3552465. [Google Scholar] [CrossRef]
48. Wang Z, Dong X-M, Xu Y. SCASNet: spatial context-aware selection network for small object detection in aerial imagery. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18:9351–67. doi:10.1109/JSTARS.2025.3555627. [Google Scholar] [CrossRef]
49. Liu S, Bu X, Xu M, Sheng H, Zeng Z, Yasir M. Svsdet: a fine-grained recognition method for ship target using satellite video. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17(5):4726–42. doi:10.1109/JSTARS.2024.3359252. [Google Scholar] [CrossRef]
50. Wu Q, Wu Y, Li Y, Huang W. Improved YOLOv5s with coordinate attention for small and dense object detection from optical remote sensing images. IEEE J Sel Top Appl Earth Obs Remote Sens. 2023;17(4):2543–56. doi:10.1109/jstars.2023.3341628. [Google Scholar] [CrossRef]
51. Xu S, Song L, Yin J, Chen Q, Zhan T, Huang W. MFFCI-YOLOv8: a lightweight remote sensing object detection network based on multiscale features fusion and context information. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17:19743–55. doi:10.1109/JSTARS.2024.3474689. [Google Scholar] [CrossRef]
52. Zhu S, Miao M. SCNet: a lightweight and efficient object detection network for remote sensing. IEEE Trans Geosci Remote Sens. 2024;21:1–5. doi:10.1109/LGRS.2023.3344937. [Google Scholar] [CrossRef]
53. Hou W, Wu H, Wu D, Shen Y, Liu Z, Zhang L, et al. Small object detection method for UAV remote sensing images based on αS-YOLO. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18:8984–94. doi:10.1109/JSTARS.2025.3539873. [Google Scholar] [CrossRef]
54. Li M, Chen Y, Zhang T, Huang W. TA-YOLO: a lightweight small object detection model based on multi-dimensional trans-attention module for remote sensing images. Complex Intell Syst. 2024;10(4):5459–73. doi:10.1007/s40747-024-01448-6. [Google Scholar] [CrossRef]
55. Ding H, Du S. CCSA-YOLO: enhanced YOLOv8 for industrial cigarette package classification with contextual transformer and coordinate channel attention. In: Proceedings of the 2025 IEEE 6th International Conference on Pattern Recognition and Machine Learning (PRML); 2025 Jun 13–16; Chongqing, China. p. 218–25. doi:10.1109/PRML66062.2025.11160295. [Google Scholar] [CrossRef]
56. Zhao Z, Liu X, He P. PSO-YOLO: a contextual feature enhancement method for small object detection in UAV aerial images. Earth Sci Inform. 2025;18(2):1–19. doi:10.1007/s12145-025-01780-6. [Google Scholar] [CrossRef]
57. Tang X, Chen X, Cheng J, Wu J, Fan R, Zhang C, et al. YOLO-Ant: a lightweight detector via depthwise separable convolutional and large kernel design for antenna interference source detection. IEEE Trans Instrum Meas. 2024;73:1–18. doi:10.1109/TIM.2024.3379397. [Google Scholar] [CrossRef]
58. Nan G, Zhao Y, Fu L, Ye Q. Object detection by channel and spatial exchange for multimodal remote sensing imagery. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17:8581–93. doi:10.1109/JSTARS.2024.3388013. [Google Scholar] [CrossRef]
59. Li C, Zhou S, Yu H, Guo T, Guo Y, Gao J. An efficient method for detecting dense and small objects in UAV images. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17:6601–15. doi:10.1109/JSTARS.2024.3373231. [Google Scholar] [CrossRef]
60. Peng H, Xie H, Liu H, Guan X. LGFF-YOLO: small object detection method of UAV images based on efficient local-global feature fusion. J Real-Time Image Proc. 2024;21(5):167. doi:10.1007/s11554-024-01550-5. [Google Scholar] [CrossRef]
61. Jiang L, Li Y, Bai T. DSFPAP-Net: deeper and stronger feature path aggregation pyramid network for object detection in remote sensing images. IEEE Trans Geosci Remote Sens. 2024;21:1–5. doi:10.1109/LGRS.2024.3398727. [Google Scholar] [CrossRef]
62. Zhu X, Lyu S, Wang X, Zhao Q. TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In: Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 11–17; Montreal, QC, Canada. p. 2778–88. doi:10.1109/ICCVW54120.2021.00312. [Google Scholar] [CrossRef]
63. Chen X, Jiang H, Zheng H, Yang J, Liang R, Xiang D, et al. Det-yolo: an innovative high-performance model for detecting military aircraft in remote sensing images. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17:17753–71. doi:10.1109/JSTARS.2024.3462745. [Google Scholar] [CrossRef]
64. Peng J, Lv K, Wang G, Xiao W, Ran T, Yuan L. MLSA-YOLO: a multi-level feature fusion and scale-adaptive framework for small object detection. J Supercomput. 2025;81(4):528. doi:10.1007/s11227-025-06961-0. [Google Scholar] [CrossRef]
65. Xu X, Li Q, Pan J, Lu X, Wei H, Sun M, et al. ESOD-YOLO: an enhanced efficient small object detection framework for aerial images. Computing. 2025;107(2):54. doi:10.1007/s00607-024-01398-4. [Google Scholar] [CrossRef]
66. Shi Y, Wang C, Xu S, Yuan M-D, Liu F, Zhang L. deformable convolution-guided multiscale feature learning and fusion for UAV object detection. IEEE Trans Geosci Remote Sens. 2024;21:1–5. doi:10.1109/LGRS.2024.3362890. [Google Scholar] [CrossRef]
67. Wang J, Ma M, Hang P, Mei S, Zhang L, Wang H. Remote sensing small object detection based on multi-contextual information aggregation. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;1–13. doi:10.1109/jstars.2025.3543189. [Google Scholar] [CrossRef]
68. Zheng X, Bi J, Li K, Zhang G, Jiang P. SMN-YOLO: lightweight YOLOv8-based model for small object detection in remote sensing images. IEEE Trans Geosci Remote Sens. 2025;22:1–5. doi:10.1109/LGRS.2025.3546034. [Google Scholar] [CrossRef]
69. Bai R, Song G, Wang Q. YOLORemote: advancing remote sensing object detection by integrating YOLOv8 with the CE-WA-CS feature fusion approach. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18(12):9546–65. doi:10.1109/JSTARS.2025.3543951. [Google Scholar] [CrossRef]
70. Liao D, Zhang J, Tao Y, Jin X. ATBHC-YOLO: aggregate transformer and bidirectional hybrid convolution for small object detection. Complex Intell Syst. 2025;11(1):38. doi:10.1007/s40747-024-01652-4. [Google Scholar] [CrossRef]
71. Niu K, Yan Y. A small-object-detection model based on improved yolov8 for uav aerial images. In: Proceedings of the 2023 2nd International Conference on Artificial Intelligence and Intelligent Information Processing (AIIIP); 2023 Oct 27–29; Hangzhou, China. p. 57–60. doi:10.1109/aiiip61647.2023.00016. [Google Scholar] [CrossRef]
72. Jiang L, Yuan B, Du J, Chen B, Xie H, Tian J, et al. MFFSODNet: multiscale feature fusion small object detection network for UAV aerial images. IEEE Trans Instrum Meas. 2024;73:1–14. doi:10.1109/TIM.2024.3381272. [Google Scholar] [CrossRef]
73. Chen H, Cao Q, Wang Y, Wang S, Fu H, Chen Z, et al. Para-YOLO: an efficient high-parameter low-computation algorithm based on YOLO11n for remote sensing object detection. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18:14630–43. doi:10.1109/JSTARS.2025.3576221. [Google Scholar] [CrossRef]
74. Liu Y, Ye Q, Sun L, Wu Z. SOD-YOLOv8n: small object detection in remote sensing images based on YOLOv8n. IEEE Geosci Remote Sens Lett. 2025;22:6008405. doi:10.1109/LGRS.2025.3567362. [Google Scholar] [CrossRef]
75. Tang S, Zhang S, Fang Y. HIC-YOLOv5: improved YOLOv5 for small object detection. In: Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA); 2024 May 13–17; Yokohama, Japan. p. 6614–9. doi:10.1109/ICRA57147.2024.10610273. [Google Scholar] [CrossRef]
76. Shi W, Zhang S, Zhang S. CAW-YOLO: cross-layer fusion and weighted receptive field-based YOLO for small object detection in remote sensing. Comput Mater Contin. 2024;139(3):3209–31. doi:10.32604/cmes.2023.044863. [Google Scholar] [CrossRef]
77. Xie J, Yuan B, Guo C, Li H, Wang F, Chu P, et al. KL-YOLO: a lightweight adaptive global feature enhancement network for small object detection in low-altitude remote sensing imagery. IEEE Trans Instrum Meas. 2025;74:1–13. doi:10.1109/TIM.2025.3576957. [Google Scholar] [CrossRef]
78. Bai J, Li M. small target detection algorithm for industrial pointer meters based on swin transformer. In: Proceedings of the 2025 6th International Conference on Computer Engineering and Application (ICCEA); 2025 Apr 25–27; Hangzhou, China. p. 185–8. doi:10.1109/ICCEA65460.2025.11103162. [Google Scholar] [CrossRef]
79. Ge P, Wan M, Qian W, Xu Y, Kong X, Gu G, et al. SGA-YOLO: a lightweight real-time object detection network for UAV infrared images. IEEE Trans Intell Transp Syst. 2025;26(12):22432–46. doi:10.1109/TITS.2025.3616525. [Google Scholar] [CrossRef]
80. Shahapurkar S, Angadi P, Kumari C, Uppar P, Akkasaligar PT. Challenges in infrared small-target detection: a benchmark of YOLO models on UAV and bird infrared imagery. In: Proceedings of the 2025 10th International Conference on Signal Processing and Communication (ICSC); 2025 Feb 20–22; Noida, India. p. 315–20. doi:10.1109/ICSC64553.2025.10968859. [Google Scholar] [CrossRef]
81. Zhou W, Cai C, Srigrarom S, Xu H, Liu R, Li C. SAD-YOLO: a small object detector for airport optical sensors based on improved YOLOv8. IEEE Sens J. 2025;25(11):20513–22. doi:10.1109/JSEN.2025.3557999. [Google Scholar] [CrossRef]
82. Wang Y. MBO-YOLO: an enhanced YOLOv8n-based algorithm for detecting marine benthic organisms. In: Proceedings of the 2025 5th International Conference on Artificial Intelligence and Industrial Technology Applications (AIITA); 2025 Mar 28–30; Xi’an, China. p. 854–60. doi:10.1109/AIITA65135.2025.11047694. [Google Scholar] [CrossRef]
83. Luo B. Integrating multiple attention mechanism fusion based YOLO logistics sorting and detection model. In: Proceedings of the 2025 8th International Conference on Advanced Algorithms and Control Engineering (ICAACE); 2025 Mar 21–23; Shanghai, China. p. 1196–201. doi:10.1109/ICAACE65325.2025.11019546. [Google Scholar] [CrossRef]
84. Kim J-H, Kim N, Won CS. High-speed drone detection based on yolo-v8. In: Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2023 Jun 4–10; Rhodes Island, Greece; 2023. p. 1–2. doi:10.1109/ICASSP49357.2023.10095516. [Google Scholar] [CrossRef]
85. Tang P, Ding Z, Lv M, Jiang M, Xu W. YOLO-RSFM: an efficient road small object detection method. IET Image Proc. 2024;18(13):4263–74. doi:10.1049/ipr2.13247. [Google Scholar] [CrossRef]
86. Qi S, Sun Y, Song X, Li J, Shang T, Yu L. SD-YOLO: a robust and efficient object detector for aerial image detection. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18:20563–74. doi:10.1109/JSTARS.2025.3591493. [Google Scholar] [CrossRef]
87. Ning T, Wu W, Zhang J. Small object detection based on YOLOv8 in UAV perspective. Pattern Anal Applic. 2024;27(3):103. doi:10.1007/s10044-024-01323-7. [Google Scholar] [CrossRef]
88. Zhang J, Lei J, Xie W, Fang Z, Li Y, Du Q. SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans Geosci Remote Sens. 2023;61:1–15. doi:10.1109/TGRS.2023.3258666. [Google Scholar] [CrossRef]
89. Liu J, Zhang J, Ni Y, Chi W, Qi Z. Small-object detection in remote sensing images with super resolution perception. IEEE J Sel Top Appl Earth Obs Remote Sens. 2024;17(000):15751–34. doi:10.1109/JSTARS.2024.3452707. [Google Scholar] [CrossRef]
90. Liu S, Zha J, Sun J, Li Z, Wang G. EdgeYOLO: an edge-real-time object detector. In: Proceedings of the 2023 42nd Chinese Control Conference (CCC); 2023 Jul 24–26; Tianjin, China. p. 7507–12. doi:10.23919/CCC58697.2023.10239786. [Google Scholar] [CrossRef]
91. Yuan M, Zhou Y, Ren X, Zhi H, Zhang J, Chen H. YOLO-HMC: an improved method for PCB surface defect detection. IEEE Trans Instrum Meas. 2024;73(12):1–11. doi:10.1109/TIM.2024.3351241. [Google Scholar] [CrossRef]
92. Hu Z, Chen Q. MOA-YOLO: an accurate, real-time and lightweight YOLOv10-based algorithm for deep-sea fish detection. IEEE Sens J. 2025;25(13):23933–47. doi:10.1109/JSEN.2025.3574723. [Google Scholar] [CrossRef]
93. Cheng Q, Lan T, Cai Z, Li J. X-YOLO: an efficient detection network of dangerous objects in X-ray baggage images. IEEE Signal Process Lett. 2024;31:2270–4. doi:10.1109/LSP.2024.3451311. [Google Scholar] [CrossRef]
94. Liu W, Tao Q, Pei H. Yolo-EV2: an industrial mining conveyor belt tear detection model based on improved Yolov5 algorithm for efficient backbone networks. In: Proceedings of the 2024 International Conference on Cyber-Physical Social Intelligence (ICCSI); 2024 Nov 8–12; Doha, Qatar. p. 1–5. doi:10.1109/ICCSI62669.2024.10799491. [Google Scholar] [CrossRef]
95. Mo C, Hu Z, Wang J, Xiao X. SGT-YOLO: a lightweight method for pcb defect detection. IEEE Trans Instrum Meas. 2025;74:1–11. doi:10.1109/TIM.2025.3563011. [Google Scholar] [CrossRef]
96. Jiao R, Liu J, Li K, Qiao R, Liu Y, Zhang W. YOLO-DTAD: dynamic task alignment detection model for multi-category power defects image. IEEE Trans Instrum Meas. 2025;74:1–14. doi:10.1109/TIM.2025.3541692. [Google Scholar] [CrossRef]
97. Zhuang Z, Liu P, Xu D, Cheng J. YOLO-KED: a novel framework for rotated object detection in complex environments. In: Proceedings of the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2025 Apr 6–11; Hyderabad, India. p. 1–5. doi:10.1109/ICASSP49660.2025.10888504. [Google Scholar] [CrossRef]
98. Sun H, Yao G, Zhu S, Zhang L, Xu H, Kong J. SOD-YOLOv10: small object detection in remote sensing images based on YOLOv10. IEEE Trans Geosci Remote Sens. 2025;22:1–5. doi:10.1109/LGRS.2025.3534786. [Google Scholar] [CrossRef]
99. Mahaveerakannan R, Anitha C, Balamanigandan R, Saraswathi S. Enhanced public security: modified YOLO network for unattended object detection in dynamic environments. In: Proceedings of the 2025 Global Conference in Emerging Technology (GINOTECH); 2025 May 9–11; Pune, India. p. 1–8. doi:10.1109/GINOTECH63460.2025.11076621. [Google Scholar] [CrossRef]
100. Du A, Lan R, Wang X, Long Z. MGF-YOLO: a lightweight industrial inspection algorithm for small defects on steel surfaces. In: Proceedings of the 2024 4th International Conference on Electronic Information Engineering and Computer Science (EIECS); 2024 Sep 27–29; Yanji, China. p. 173–8. doi:10.1109/EIECS63941.2024.10800534. [Google Scholar] [CrossRef]
101. Wu S, Lu X, Guo C, Guo H. MV-YOLO: an efficient small object detection framework based on mamba. IEEE Trans Geosci Remote Sens. 2025;63:1–14. doi:10.1109/TGRS.2025.3584955. [Google Scholar] [CrossRef]
102. Zhang Y, Wang W, Ye M, Yan J, Yang R. LGA-YOLO for vehicle detection in remote sensing images. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18(24):5317–30. doi:10.1109/JSTARS.2025.3535090. [Google Scholar] [CrossRef]
103. Zan J, Fang Y, Liu Q, Khairuddin U, Li Y, Sun K. MKD-YOLO: multi-scale and knowledge-distilling YOLO for efficient PPE compliance detection. In: Proceedings of the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); 2025 Apr 6–11; Hyderabad, India. p. 1–5. doi:10.1109/ICASSP49660.2025.10889626. [Google Scholar] [CrossRef]
104. Tang Y, Xu T, Qin H, Li J. IRSTD-YOLO: an improved YOLO framework for infrared small target detection. IEEE Trans Geosci Remote Sens. 2025;22:1–5. doi:10.1109/LGRS.2025.3562096. [Google Scholar] [CrossRef]
105. Wang D, Gao Z, Fang J, Li Y, Xu Z. Improving uav aerial imagery detection method via super-resolution synergy. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18:3959–72. doi:10.1109/JSTARS.2024.3525148. [Google Scholar] [CrossRef]
106. Wu Q, Li Y, Yin J, You X. LGC-YOLO: local-global feature extraction and coordination network with contextual interaction for remote sensing object detection. IEEE J Sel Top Appl Earth Obs Remote Sens. 2025;18:15376–93. doi:10.1109/JSTARS.2025.3575239. [Google Scholar] [CrossRef]
107. Sun S, Mo B, He Y, Zhao J, Li D. CDT-YOLO: a long-term detection and tracking algorithm for infrared moving small objects in missile-borne platforms. In: Proceedings of the 2024 39th Youth Academic Annual Conference of Chinese Association of Automation (YAC); 2024 Jun 7–9; Dalian, China. p. 904–11. doi:10.1109/YAC63405.2024.10598470. [Google Scholar] [CrossRef]
108. Atik I. Deep learning in military object detection: an example of the YOLO-NAS model. In: Proceedings of the 2024 8th International Symposium on Innovative Approaches in Smart Technologies (ISAS); 2024 Dec 6–7; İstanbul, Turkey. p. 1–7. doi:10.1109/ISAS64331.2024.10845459. [Google Scholar] [CrossRef]
109. Abinaya A, Sumathi S. Moving vehicles counting and detection using deep neural networks based YOLO-NAS algorithm. In: Proceedings of the 2025 International Conference on Innovative Trends in Information Technology (ICITIIT); 2025 Feb 21–22; Kottayam, India. p. 1–6. doi:10.1109/ICITIIT64777.2025.11040692. [Google Scholar] [CrossRef]
110. Jose P, Rekha S, Ponkavin B, Hemkiran S, Sheeja R, PV G. Automated vision-based system for real-time detection and classification of rice diseases using YOLO-NAS. In: Proceedings of the 2025 2nd International Conference on Trends in Engineering Systems and Technologies (ICTEST); 2025 Jul 16–18; Ernakulam, India. p. 1–6. doi:10.1109/ICTEST64710.2025.11042353. [Google Scholar] [CrossRef]
111. Xue Y, Han X, Wang Z. Self-adaptive weight based on dual-attention for differentiable neural architecture search. IEEE Trans Industr Inform. 2024;20(4):6394–403. doi:10.1109/TII.2023.3348843. [Google Scholar] [CrossRef]
112. Xue Y, Lu C, Neri F, Qin J. Improved differentiable architecture search with multi-stage progressive partial channel connections. IEEE Trans Emerg Top Comput Intell. 2024;8(1):32–43. doi:10.1109/TETCI.2023.3301395. [Google Scholar] [CrossRef]
113. Xue Y, Chen C, Słowik A. Neural architecture search based on a multi-objective evolutionary algorithm with probability stack. IEEE Trans Evol Comput. 2023;27(4):778–86. doi:10.1109/TEVC.2023.3252612. [Google Scholar] [CrossRef]
114. Xue Y, Yao C, Wahib M, Gabbouj M. YOLO-DKR: differentiable architecture search based on kernel reusing for object detection. Inf Sci. 2025;713(15):122180. doi:10.1016/j.ins.2025.122180. [Google Scholar] [CrossRef]
115. Kumar V, Pratihar DK. Vision transformer-based pose estimation for automated gait analysis in ankle-foot prosthetic design. In: Proceedings of the 2024 2nd International Conference on Advancement in Computation & Computer Technologies (InCACCT); 2024 May 2–3; Gharuan, India. p. 641–5. doi:10.1109/InCACCT61598.2024.10551002. [Google Scholar] [CrossRef]
116. Ma S, Zhang Y, Peng L, Sun C, Ding L, Zhu Y. OWRT-DETR: a novel real-time transformer network for small object detection in open water search and rescue from UAV aerial imagery. IEEE Trans Geosci Remote Sens. 2025;63:1–13. doi:10.1109/TGRS.2025.3560928. [Google Scholar] [CrossRef]
117. Jayaprada S, Reddy MHV, Reddy KMV, Prakash M, Chowdary KV. A hybrid approach combining YOLO and visual image transformers for automated mark digitization of exam scripts. In: Proceedings of the 2025 International Conference on Electronics, Computing, Communication and Control Technology (ICECCC); 2025 May 1–2; Bengaluru, India. p. 1–7. doi:10.1109/ICECCC65144.2025.11063807. [Google Scholar] [CrossRef]
118. Katangure RR, Meenakshi G, Rao S, Reddy K, Konkala VR, Veerapu G, et al. Hybrid YOLOv8-ViT framework for real-time intelligent wildlife monitoring system with XAI insights. In: Proceedings of the 2025 International Conference on Sensors and Related Networks (SENNET) Special Focus on Digital Healthcare; 2025 Jul 24–27; Vellore, India. p. 1–6. doi:10.1109/SENNET64220.2025.11135988. [Google Scholar] [CrossRef]
119. Wu R, Huang W, Xu X. AE-YOLO: asymptotic enhancement for low-light object detection. In: Proceedings of the 2024 17th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI); 2024 Oct 26–28; Shanghai, China. p. 1–6. doi:10.1109/CISP-BMEI64163.2024.10906253. [Google Scholar] [CrossRef]
120. Shen Y, Liu H, Zha K, Liu X, Ding Y. SA-YOLO: spike-driven attention for energy-efficient UAV-based small object detection. IEEE Internet Things J. 2025;12(21):44851–66. doi:10.1109/JIOT.2025.3596434. [Google Scholar] [CrossRef]
121. Hou J, Chen W, Yang G, Cong L, Qi X. EMSBS-YOLO: a vehicle detection model based on spiking neural networks. In: Proceedings of the 2024 8th Asian Conference on Artificial Intelligence Technology (ACAIT); 2024 Nov 8–10; Fuzhou, China. p. 745–9. doi:10.1109/ACAIT63902.2024.11022103. [Google Scholar] [CrossRef]
122. Du D, Zhu P, Wen L, Bian X, Lin H, Hu Q, et al. VisDrone-DET2019: the vision meets drone object detection in image challenge results. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW); 2019 Oct 27–28; Seoul, Republic of Korea. p. 213–26. doi:10.1109/ICCVW.2019.00030. [Google Scholar] [CrossRef]
123. Wang J, Yang W, Guo H, Zhang R, Xia G-S. Tiny object detection in aerial images. In: Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR); 2021 Jan 10–15; Milan, Italy. p. 3791–8. doi:10.1109/ICPR48806.2021.9413340. [Google Scholar] [CrossRef]
124. Xia G-S, Bai X, Ding J, Zhu Z, Belongie S, Luo J, et al. DOTA: a large-scale dataset for object detection in aerial images. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2018 Jun 18–23; Salt Lake City, UT, USA. p. 3974–83. doi:10.1109/CVPR.2018.00418. [Google Scholar] [CrossRef]
125. Cheng G, Han J, Zhou P, Guo L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. J Photogramm Remote Sens. 2014;98:119–32. doi:10.1016/j.isprsjprs.2014.10.002. [Google Scholar] [CrossRef]
126. Razakarivony S, Jurie F. Vehicle detection in aerial imagery: a small target detection benchmark. J Vis Commun Image Represent. 2016;34(10):187–203. doi:10.1016/j.jvcir.2015.11.002. [Google Scholar] [CrossRef]
127. Li K, Wan G, Cheng G, Meng L, Han J. Object detection in optical remote sensing images: a survey and a new benchmark. J Photogramm Remote Sens. 2020;159:296–307. doi:10.1016/j.isprsjprs.2019.11.023. [Google Scholar] [CrossRef]
128. Yu H, Li G, Zhang W, Huang Q, Du D, Tian Q, et al. The unmanned aerial vehicle benchmark: object detection, tracking and baseline. Int J Comput Vis. 2020;128(5):1141–59. doi:10.1007/s11263-019-01266-1. [Google Scholar] [CrossRef]
129. Li W, Xiao L, Yao S, Hou C, Wen Z, Ren D. ED-YOLO: an object detection algorithm for drone imagery focusing on edge information and small object features. Multimed Syst. 2025;31(3):1–15. doi:10.1007/s00530-025-01783-9. [Google Scholar] [CrossRef]
130. Zhou S, Zhou H, Qian L. A multi-scale small object detection algorithm SMA-YOLO for UAV remote sensing images. Sci Rep. 2025;15(1):9255. doi:10.1038/s41598-025-92344-7. [Google Scholar] [PubMed] [CrossRef]
131. Fu H, Yang Z, Peng Y. SBF-YOLO: a small object detection network for aerial scene. In: Proceedings of the 2025 28th International Conference on Computer Supported Cooperative Work in Design (CSCWD); 2025 May 5–7; Compiegne, France. p. 2360–5. doi:10.1109/CSCWD64889.2025.11033385. [Google Scholar] [CrossRef]
132. Han Y, Wang C, Luo H, Wang H, Chen Z, Xia Y, et al. LRDS-YOLO enhances small object detection in UAV aerial images with a lightweight and efficient design. Sci Rep. 2025;15(1):22627. doi:10.1038/s41598-025-07021-6. [Google Scholar] [PubMed] [CrossRef]
133. Liu Y, Zhang J, Liu S, Xu L, Wang Y. Aams-yolo: a small object detection method for UAV capture scenes based on YOLOv7. Cluster Comput. 2025;28(5):1–14. doi:10.1007/s10586-024-04972-9. [Google Scholar] [CrossRef]
134. Rezatofighi H, Tsoi N, Gwak J, Sadeghian A, Reid I, Savarese S. Generalized intersection over union: a metric and a loss for bounding box regression. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 658–66. doi:10.1109/CVPR.2019.00075. [Google Scholar] [CrossRef]
135. Zhang Y, Ren W, Zhang Z, Jia Z, Wang L, Focal TT. Focal and efficient IOU loss for accurate bounding box regression. Neuro Comput. 2022;42(9):146–57. doi:10.1016/j.neucom.2022.07.042. [Google Scholar] [CrossRef]
136. Sun H-R, Shi B-J, Hu Y-L. A lightweight YOLO-based model in small object detection for UAV optical sensors. IEEE Sens J. 2025;25(10):17585–99. doi:10.1109/JSEN.2025.3553871. [Google Scholar] [CrossRef]
137. Zakria Z, Deng J, Kumar R, Khokhar MS, Cai J, Kumar J. Multiscale and direction target detecting in remote sensing images via modified YOLO-v4. IEEE J Sel Top Appl Earth Obs Remote Sens. 2022;15(8):1039–48. doi:10.1109/JSTARS.2022.3140776. [Google Scholar] [CrossRef]
138. Tang Q, Su C, Tian Y, Zhao S, Yang K, Hao W, et al. YOLO-SS: optimizing YOLO for enhanced small object detection in remote sensing imagery. J Supercomput. 2025;81(1):303. doi:10.1007/s11227-024-06765-8. [Google Scholar] [CrossRef]
139. Wang L, Yoon K-J. Knowledge distillation and student-teacher learning for visual intelligence: a review and new outlooks. IEEE Trans Pattern Anal Mach Intell. 2022;44(6):3048–68. doi:10.1109/TPAMI.2021.3055564. [Google Scholar] [PubMed] [CrossRef]
140. Chen Y, Lin M, He Z, Polat K, Alhudhaif A, Alenezi F. Consistency- and dependence-guided knowledge distillation for object detection in remote sensing images. Expert Syst Appl. 2023;229(16):120519. doi:10.1016/j.eswa.2023.120519. [Google Scholar] [CrossRef]
141. Zhang T, Chen C, Liu Y, Geng X, Aly MMS, Lin J. PSRR-MaxpoolNMS++: fast non-maximum suppression with discretization and pooling. IEEE Trans Pattern Anal Mach Intell. 2025;47(2):978–93. doi:10.1109/TPAMI.2024.3485898. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools