
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A Novel Hybrid Sine Cosine-Flower Pollination Algorithm for Optimized Feature Selection
1 Department of Mathematics, Lahore College For Women University (LCWU), Lahore, Pakistan
2 Department of Mathematics, Forman Christian College University (FCCU), Lahore, Pakistan
3 Faculty of Computer Information Systems, Higher Colleges of Technology, Abu Dhabi, United Arab Emirates
4 Department of Computer Engineering, College of Computer and Information Sciences, King Saud University, Riyadh, Saudi Arabia
* Corresponding Author: Shazia Javed. Email:
(This article belongs to the Special Issue: Advancing Feature Engineering for Knowledge Discovery and Explainable AI)
Computers, Materials & Continua 2026, 87(2), 82 https://doi.org/10.32604/cmc.2026.071977
Received 17 August 2025; Accepted 22 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Data serves as the foundation for training and testing machine learning and artificial intelligence models. The most fundamental part of data is its attributes or features. The feature set size changes from one dataset to another. Only the relevant features contribute meaningfully to classification accuracy. The presence of irrelevant features reduces the system’s effectiveness. Classification performance often deteriorates on high-dimensional datasets due to the large search space. Thus, one of the significant obstacles affecting the performance of the learning process in the majority of machine learning and data mining techniques is the dimensionality of the datasets. Feature selection (FS) is an effective preprocessing step in classification tasks. The aim of applying FS is to exclude redundant and unrelated features while retaining the most informative ones to optimize classification capability and compress computational complexity. In this paper, a novel hybrid binary metaheuristic algorithm, termed hSC-FPA, is proposed by hybridizing the Flower Pollination Algorithm (FPA) and the Sine Cosine Algorithm (SCA). Hybridization controls the exploration capacity of SCA and the exploitation behavior of FPA to maintain a balanced search process. SCA guides the global search in the early iterations, while FPA’s local pollination refines promising solutions in later stages. A binary conversion mechanism using a threshold function is implemented to handle the discrete nature of the feature selection problem. The functionality of the proposed hSC-FPA is authenticated on fourteen standard datasets from the UCI repository using the K-Nearest Neighbors (K-NN) classifier. Experimental results are benchmarked against the standalone SCA and FPA algorithms. The hSC-FPA consistently achieves higher classification accuracy, selects a more compact feature subset, and demonstrates superior convergence behavior. These findings support the stability and outperformance of the hybrid feature selection method presented.Keywords
With advances in technology, large amounts of data are generated regularly. This data is derived from real-world applications, such as text classification, spam detection, and medical and engineering fields. This massive amount of data contains a feature set of various sizes. Not all of these features are required for discovering and analyzing knowledge. Most of these features might be irrelevant or redundant to the problem. These unwanted features are not useful for handling classification problems. They decrease the computational simplicity and increase the classification error [1]. One of the significant preprocessing techniques is dimensionality reduction (DR). The purpose of DR is to reduce the number of features while meeting certain criteria and achieving superior performance. Feature Selection (FS) is one of the most substantial tools in DR. It is the process of choosing the most relevant and effective features to decrease classification error and manage the dimensionality of the data set by discarding unnecessary features [2].
There are four main stages of FS [3]. The first stage is the creation of a feature subset; the second stage is the assessment of the feature subset; the third stage is the establishment of termination criteria; and the fourth stage is validation. During the initial phase, various methods are employed to generate a feature subset using a search strategy. In the second stage, an objective function, also known as a fitness function and a classifier, is used to assess the quality of produced solutions. This procedure is repeated until the stopping criteria are reached. A wrapper-based technique is one of the FS approaches. It uses a specific classifier to find optimal or near-optimal solutions. The objective of FS (Feature Selection) is to find the optimum subset of features. It can be considered as a search procedure. Calculating
Nature-inspired algorithms have validated strong performance compared to classical optimization methods, mainly for nonlinear and complex real-world problems. According to the No Free Lunch (NFL) theorem [4], no single optimization algorithm can outperform all others for every problem. This motivates the ongoing development and compositing of efficacy from known procedures. Hybridizing functions allows the incorporation of complementary strengths from multiple algorithms to be better balanced between exploitation and exploration. The Flower Pollination Algorithm (FPA) [5] works fine for global optimization but can suffer from slow convergence due to a stochastic Lévy flight global search. The Sine Cosine Algorithm (SCA) [6] demonstrates durable exploration, but is limited in exploitation when calibrating into a local node search. Thus, combining the exploration capabilities of SCA and the exploitation of FPA can create a more balanced and efficient search procedure. The FPA component adds a layer to enhance local and global pollination dynamics. Together, these two phases sequentially coordinate to have the algorithm converge quickly. Thus, the design enables the proposed model to achieve higher classification accuracy while obtaining fewer but essential features across the multiple benchmark datasets. In FS, the datasets are typically high-dimensional, with idle features, and many complex interactions among features. These characteristics create difficulty for a single algorithm in achieving effective exploratory and efficient exploitative characteristics. Given these practical challenges, the developed hSC-FPA is inspired to find a balance created for a specific problem. The main contributions of this paper are as follows:
1. A new hybridized method, hSC-FPA, supported by the NFL nature of nature-inspired algorithms and tailored for FS problems, is proposed.
2. To avoid the long random jumps of Lévy flight, the global pollination in FPA is replaced by SCA for non-linear oscillations.
3. To merge the advantages of both SCA and FPA to accurately estimate the Pareto optimal solution by achieving an optimal trade-off between classification accuracy rate and feature reduction.
4. Classification performance is evaluated on 14 datasets and compared with existing methods to demonstrate effectiveness.
The rest of the paper is organized as follows: Section 2 presents a literature review of the hybridization of metaheuristic algorithms. Section 3 discusses the preliminaries. In Section 4, the methodology of the hybrid model is discussed in detail. Section 5 provides insights into the experimental setup. In Section 6, numerical experimentation and performance comparison of the hSC-FPA with other algorithms are presented. Finally, Section 7 concludes the paper and suggests some future directions.
Mafarja and Mirjalili [7] proposed a hybrid method, HBALO (Hybrid Binary Ant Lion Optimizer), integrating the Binary Ant Lion Optimizer with two incremental hill-climbing techniques, QuickReduct and CEBARKCC, to manage the complexity of FS. A novel hybrid FS algorithm called Mayfly-Harmony Search (MA-HS), combining the Mayfly Algorithm with Harmony Search to improve search space exploitation, was introduced by Bhattacharyya et al. [8]. Results showed the superior performance of MA-HS in selecting informative features and improving classification outcomes. Abualigah and Dulaimi [9] introduced the hybrid Sine Cosine Algorithm and Genetic Algorithm. The algorithm was tested on UCI (University of California, Irvine) datasets using metrics such as classification accuracy, fitness values, and the number of selected features. Mohammadzadeh and Gharehchopogh [10] proposed a hybrid firefly singed Sine Cosine Flower Pollination Algorithm called HWOAFPA. In this process, the Whale Optimization Algorithm was enhanced with opposition-based learning, and its final populations were used to initialize the flower pollination algorithm with improved convergence speed and accuracy. Sun et al. [11] presented a Feature Selection technique known as MetaSCA, which is based on Sine Cosine Algorithm (SCA), but enhances the original SCA by introducing features like the golden sine section coefficient and multi-level tuning factor. Abdelhamid et al. [12] introduced a new binary hybrid metaheuristic algorithm for FS called bSCWDTO, which combined the Sine Cosine Algorithm and Dipper Throated Optimization. Ragab [13] proposed a hybrid binary metaheuristic approach that integrated Particle Swarm Optimization and Firefly Algorithm. It was designed to optimize classification accuracy while minimizing the number of features for FS in machine learning classification problems. Hammouri et al. [14] proposed three improved binary versions of the White Shark Optimizer as a method for FS to address challenges with pre-mature convergence and local optima. The binary versions, Binary Distribution-based White Shark Optimizer (BDWSO), Binary Sine Cosine White Shark Optimizer (BSCWSO), and Binary Hybrid Sine Cosine White Shark Optimizer (BHSCWSO), introduced improvements for FS, including distribution-based updates, adaptive functions from sine-cosine algorithms, and hybrid acceleration strategies. Alkhonaini et al. [15] proposed HSCCOFS-DL, a hybrid deep learning-based method for threat recognition in IoT sensor networks. HSCCOFS-DL employed the Hybrid Sine-Cosine Chimp Optimization Algorithm to perform FS, used a symmetrical autoencoder to perform a classification task, and deployed the Sparrow Search Algorithm to tune the hyperparameters.
Kaur et al. [16] looked forward to applying an automated method to determine quality in Golden Delicious apples with an image processing and feature extraction method. Kaur was able to extract a total of 18,654 features from 1256 images and needed a technique for feature selection. For feature selection, Minimum Redundancy Maximum Relevance was used. Kumari et al. [17] addressed the shortcomings of conventional intrusion detection systems by presenting a hybrid model that successfully combined the Flower Pollination Algorithm, Cheetah Optimization Algorithm, and Artificial Neural Networks to increase accuracy and lower false alarms. Azeem et al. [18] presented a new combination of PSO-HHO to promote FS, advancing the strengths of both metaheuristics to eliminate unnecessary features while improving their classifier performance. A wrapper-based approach using K-Nearest Neighbors (K-NN) with Euclidean distance was employed to evaluate candidate solutions. Aly et al. [19] presented a hybrid metaheuristic algorithm HB-GWO (Hybrid Butterfly-Grey Wolf Optimizer), which combined the Butterfly Optimization Algorithm (BOA) and the Grey Wolf Optimizer (GWO) for effective feature selection in high-dimensional datasets. By using an adaptive switching mechanism to balance exploration and exploitation, HB-GWO achieves superior performance across benchmark datasets when evaluated with a Random Forest classifier. Experimental studies showed that HB-GWO obtained 96.8%, 80.6%, 89.5%, and 72.4% accuracy on breast cancer, colon cancer, and arrhythmia datasets, respectively.
Most existing hybrid metaheuristics emphasize convergence or exploration but overlook the balance between accuracy and feature reduction. To address these gaps, the proposed hSC-FPA enhances the balance between exploration and exploitation, confirming stable convergence and improved accuracy across various datasets.
This sections provides the FS problem design and a summary of the conventional Sine Cosine Algorithm (SCA) and Flower Pollination Algorithm (FPA).
3.1 Feature Selection (FS) Problem Formulation
Feature Selection (FS) aims to identify the most informative subset of features from a dataset of size
where
3.2 K-Nearest Neighbors (K-NN)
The K-Nearest Neighbors (K-NN) classifier is used as the evaluation model in the wrapper-based FS framework. Each sample is allocated to a class based on the majority vote among its
where
The suggested hybrid hSC-FPA for feature selection is presented here along with its three main steps: initialization, binary conversion, and hybrid optimization. In Algorithm 1, step-by-step instructions together with the underlying mathematics for the algorithm are presented.
Let
where
The feature selection problem is inherently binary, where each bit represents inclusion (1) or exclusion (0) of a feature. The continuous position
here,
4.3 Hybrid Sine Cosine-Flower Pollination Algorithm (hSC-FPA)
Let
If
where
If
where
The updated positions are binarized as:
Fitness is calculated using the predefined cost function:
and both local and global bests are updated if an improved solution is found.
The proposed FS process using the hybrid Sine Cosine-Flower Pollination Algorithm (hSC-FPA) is presented in Algorithm 1.

Fig. 1 describes the FS process. The dataset is typically preprocessed to handle outliers and missing values. Secondly, the selection of the best features is applied through an iterative procedure. Then, a subset of features is selected and assessed using specific conditions to determine whether to retain or eliminate them. The final output of this iterative procedure is the best feature subset, which can be evaluated using machine learning classifiers.
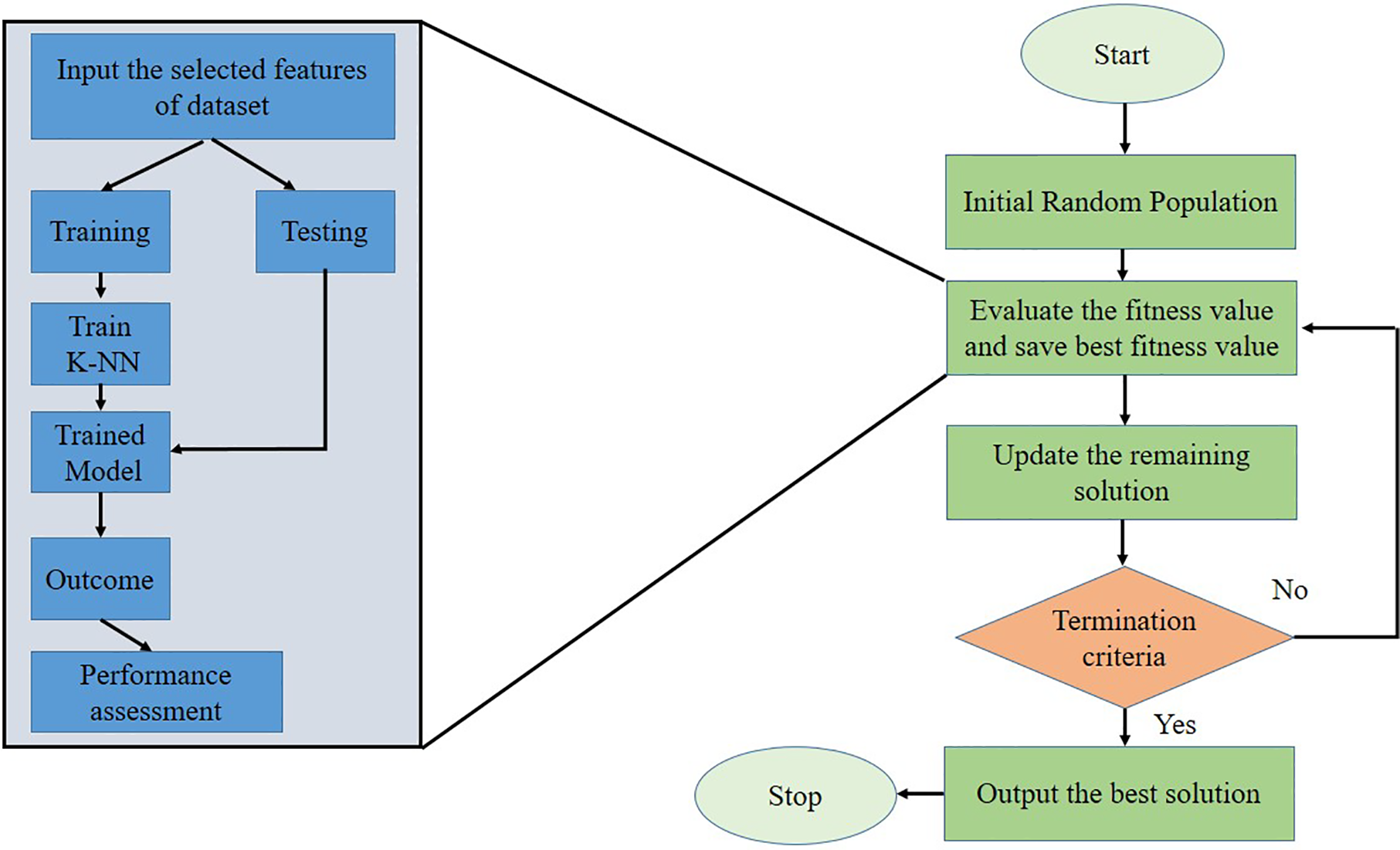
Figure 1: Feature selection procedure of the proposed hSC-FPA model.
4.3.1 Distinctive Features of hSC-FPA
To balance accuracy and search efficiency the suggested hSC-FPA blends the investigation strength of SCA with the exploitation capacity of the FPA. Using this hybrid strategy, SCA’s update rule is substituted for the global pollination stage in FPA to improve exploratory search and guard against premature convergence. The goal of the hybridization is to obtain an ideal cooperation between feature reduction and categorization accuracy. The previous hybrid sine cosine flower pollination algorithm [20] was mainly designed for continuous optimization and lacked a feature selection formulation. The suggested hSC-FPA introduces several key improvements for wrapper-based binary feature selection. The proposed methodology includes an explicit binary transfer function and threshold mechanism. The dynamic switching mechanism is based on probability and population updates. This adoptive control avoids premature convergence. The algorithm is practical for real-world data mining and biomedical tasks. Furthermore, the proposed procedure includes repeated runs and statistical tests, offering strong evidence of reliability and fairness.
4.3.2 Computational Complexity
The computational complexity of the proposed hSC-FPA is mainly determined by the number of search agents N, the problem dimension D (number of features), the maximum number of iterations T, and the cost of evaluating the fitness function. Each iteration per agent includes three chief operations: position update, binary conversion, and fitness evaluation through a wrapper-based K-NN classifier. While the update and binary conversion steps scale linearly with the number of features
Experiments were conducted on fourteen different datasets from various fields to measure the efficiency of the proposed algorithm. The selected datasets were sourced from the UCI repository [21]. Table 1 shows details about the datasets used, including the number of features, sample size, and characteristics.
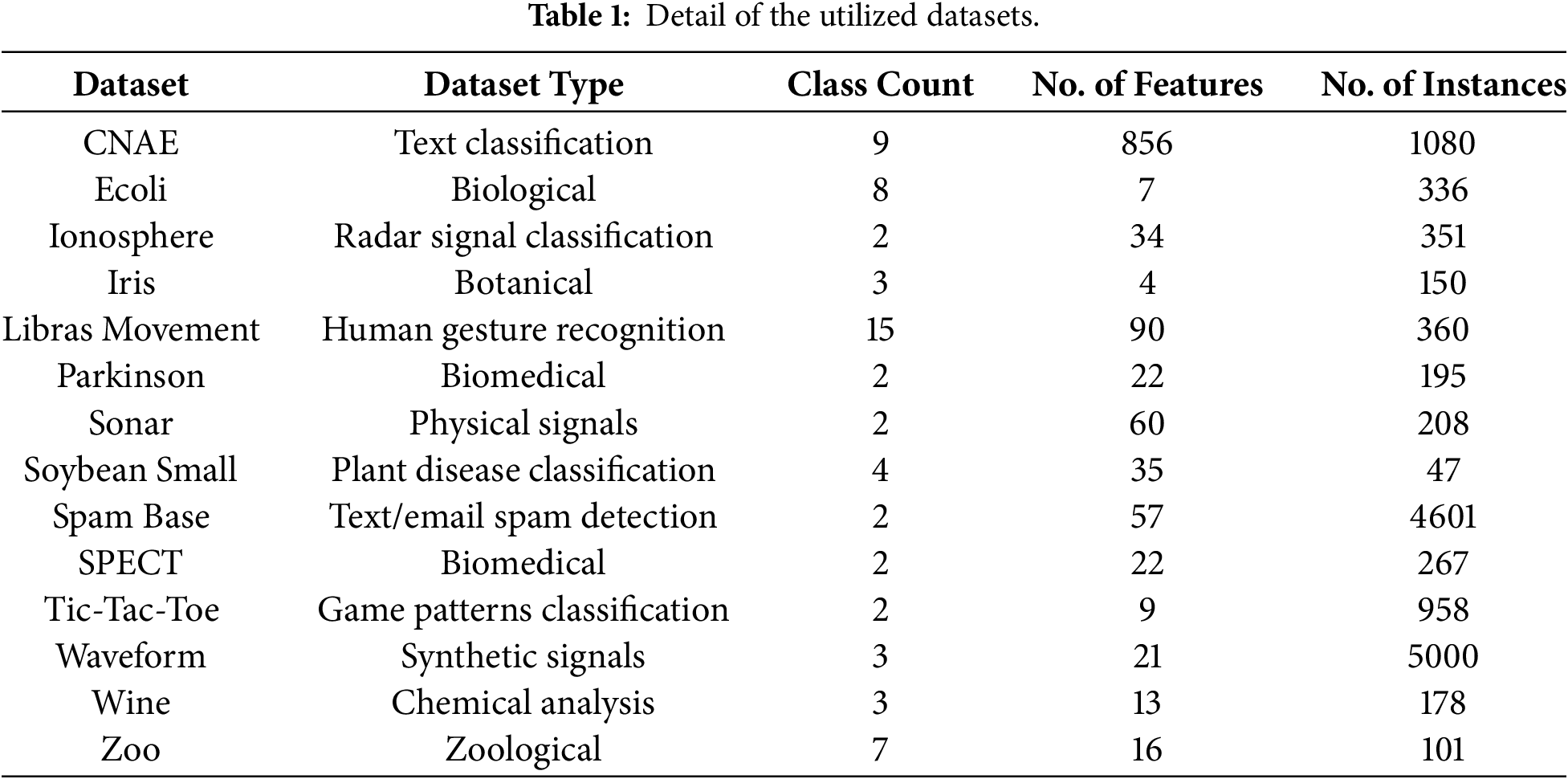
The experimental calculations were done on a Windows 10 Pro PC with an Intel Core i5 CPU running at 2.40 GHz and 8 GB of RAM. We used Python 3.9.12 to carry out the proposed method. To assess the effectiveness of the hSC-FPA approach, we used 14 datasets from the UCI Machine Learning Archive. The data preprocessing phase included cleaning and normalizing to maintain consistent input quality. We handled missing or inconsistent values appropriately. To ensure fair reproducibility, we applied a deterministic random seed based on the run number (np.random.seed(run)). This produced distinct but repeatable results across all experimental runs.
We divided the datasets into training and test subsets, each with the same random sizes. During the learning stage, the K-NN classifier was trained using the training subset. The capability of the resultant model was calculated using the testing subset. The experimental setup for hSC-FPA and the competing methodologies are offered in Table 2. The parameter values of P and

The attained results were examined based on the criteria given below. These benchmarks were engaged to examine the performance of the suggested FS method.
Let
Let
Let
The efficiency of the suggested hSC-FPA algorithm is evaluated using several measurement criteria, including average accuracy and average select size. Classical SCA and FPA are tested along with the proposed hSC-FPA. Furthermore, a comparative analysis was conducted with other hybrid models already proposed in the literature for FS. The proposed optimizer employs a hybrid approach to obtain the optimal solution, which involves maximizing accuracy while maintaining an optimal subset of features.
The following Table 3 presents the classification accuracies of FPA, SCA, and the proposed hybrid hSC-FPA across 14 benchmark datasets. In datasets such as CNAE, Ionosphere, Sonar, and Wine, the hybrid model surpasses FPA and SCA. This shows improved generality and FS capability. On data like Iris, Soybean Small, Ecoli, hSC-FPA performs competitively. The gains are especially pronounced in more complex datasets, such as Sonar and Tic-Tac-Toe, where hSC-FPA shows greater improvements.
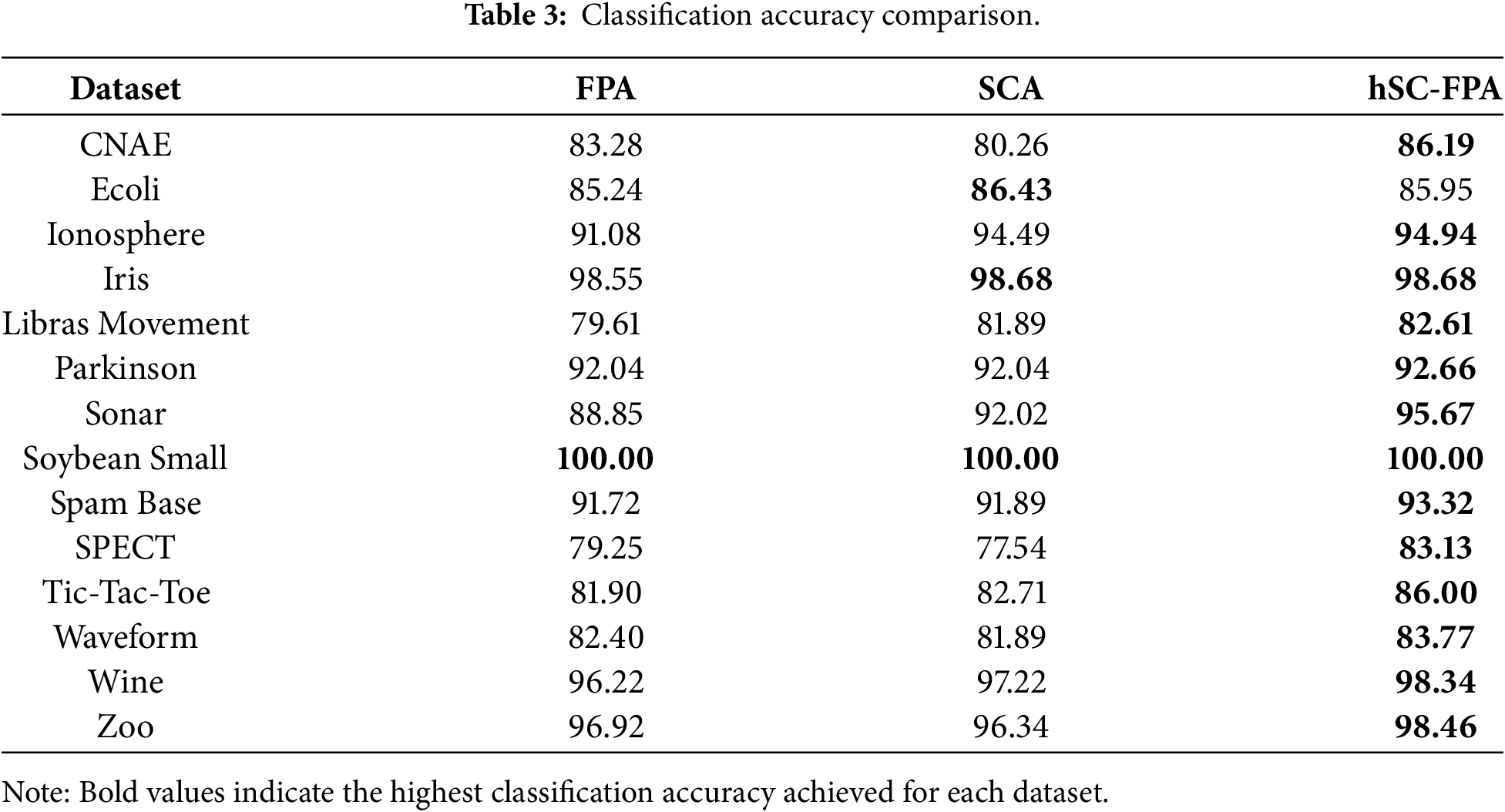
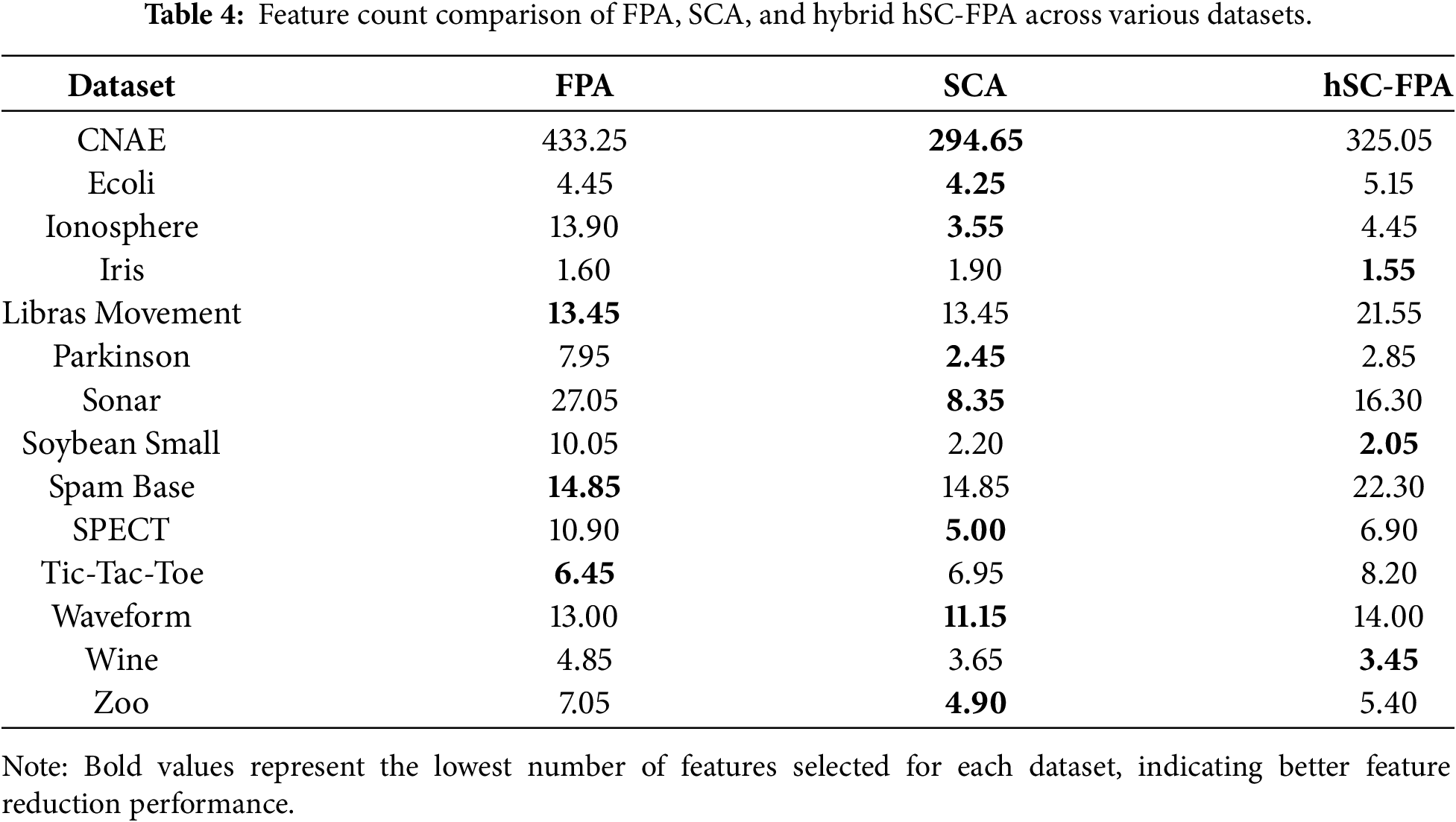
Table 4 compares the feature selection sizes from FPA, SCA, and the hybrid hSC-FPA across benchmark datasets. SCA usually generates the fewest features in most datasets. For datasets like Iris, Soybean Small, and Wine, hSC-FPA gives the least number of features. Although hSC-FPA does not always yield the smallest amount, it often avoids selecting too many features, especially in comparison to FPA. This indicates that the hybrid method is effective for both precision and for getting small, useful feature subsets. Thus, the goal of achieving a Pareto-optimal solution is met, as the proposed hSC-FPA reaches high classification accuracy while balancing accuracy and feature reduction effectively.
The Wilcoxon’s rank-sum test was performed at the 0.05 significance level to study the statistical difference between the proposed method and the alternative feature selection methods, FPA and SCA. When comparing the proposed algorithm’s output to other algorithms, this test can help reveal whether or not the results differ significantly. The proposed algorithm’s findings differ considerably from those of the compared methods when the
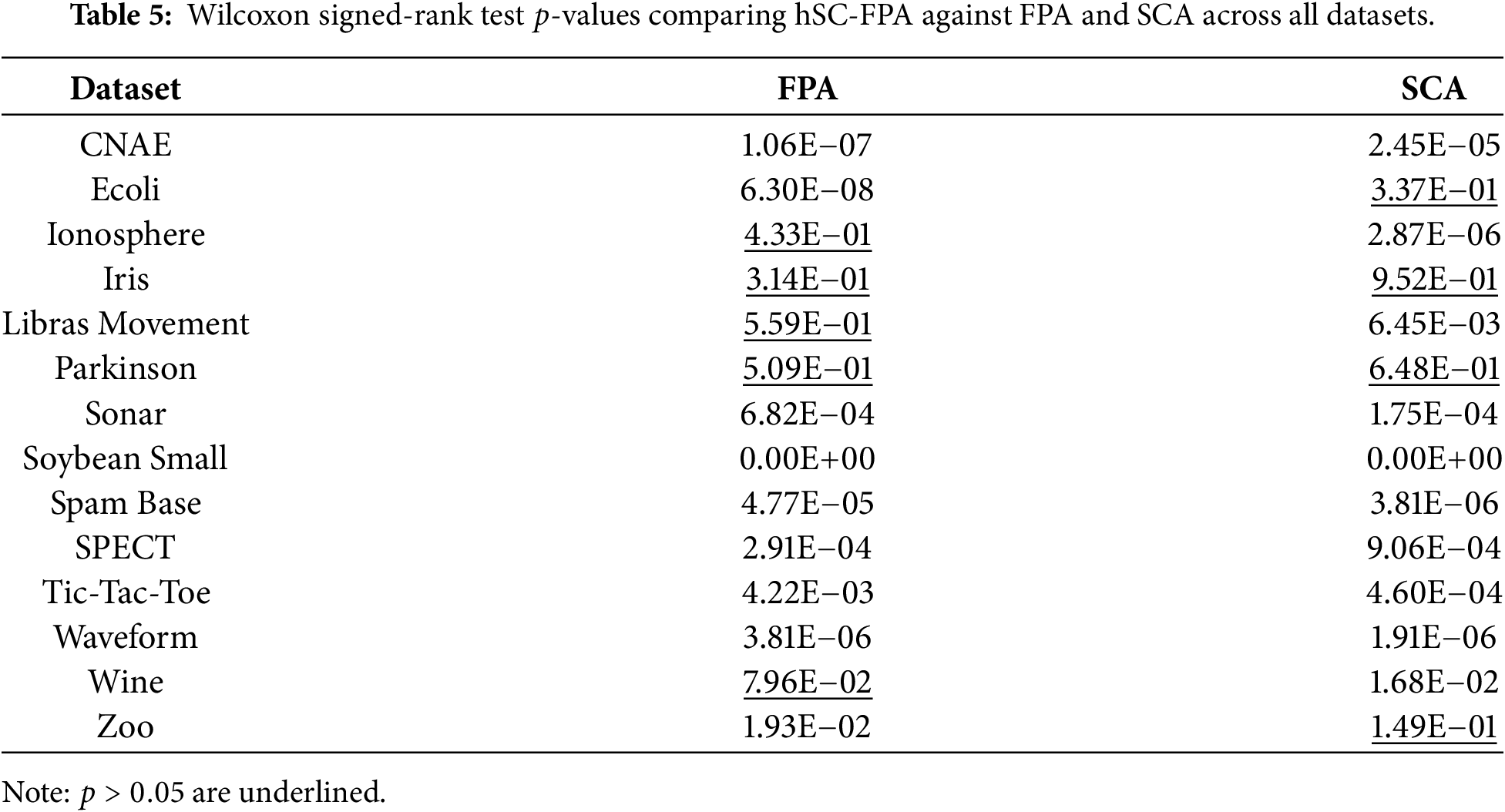
The variation in performance of the proposed hSC-FPA algorithm across datasets can be attributed to differences in dataset dimensionality and structure. For high-dimensional datasets such as CNAE and Spam Base, the hybridization mechanism supports effective navigation of a large and sparse feature space. This results in higher accuracy and a substantial reduction in irrelevant features. Conversely, for smaller or low-dimensional datasets such as Iris and Zoo, the search landscape is less complex, and therefore, the advantage of hybrid feature selection is less pronounced. As a result, the performance of hSC-FPA becomes comparable to that of other algorithms, since the reduced dimensionality requires less exploration effort and allows competing methods to achieve similar convergence and classification outcomes. This behavior aligns with the convergence patterns shown in Fig. 2, where high-dimensional datasets exhibit wider initial fluctuations due to exploration, while low-dimensional datasets converge rapidly with minimal variance across iterations.
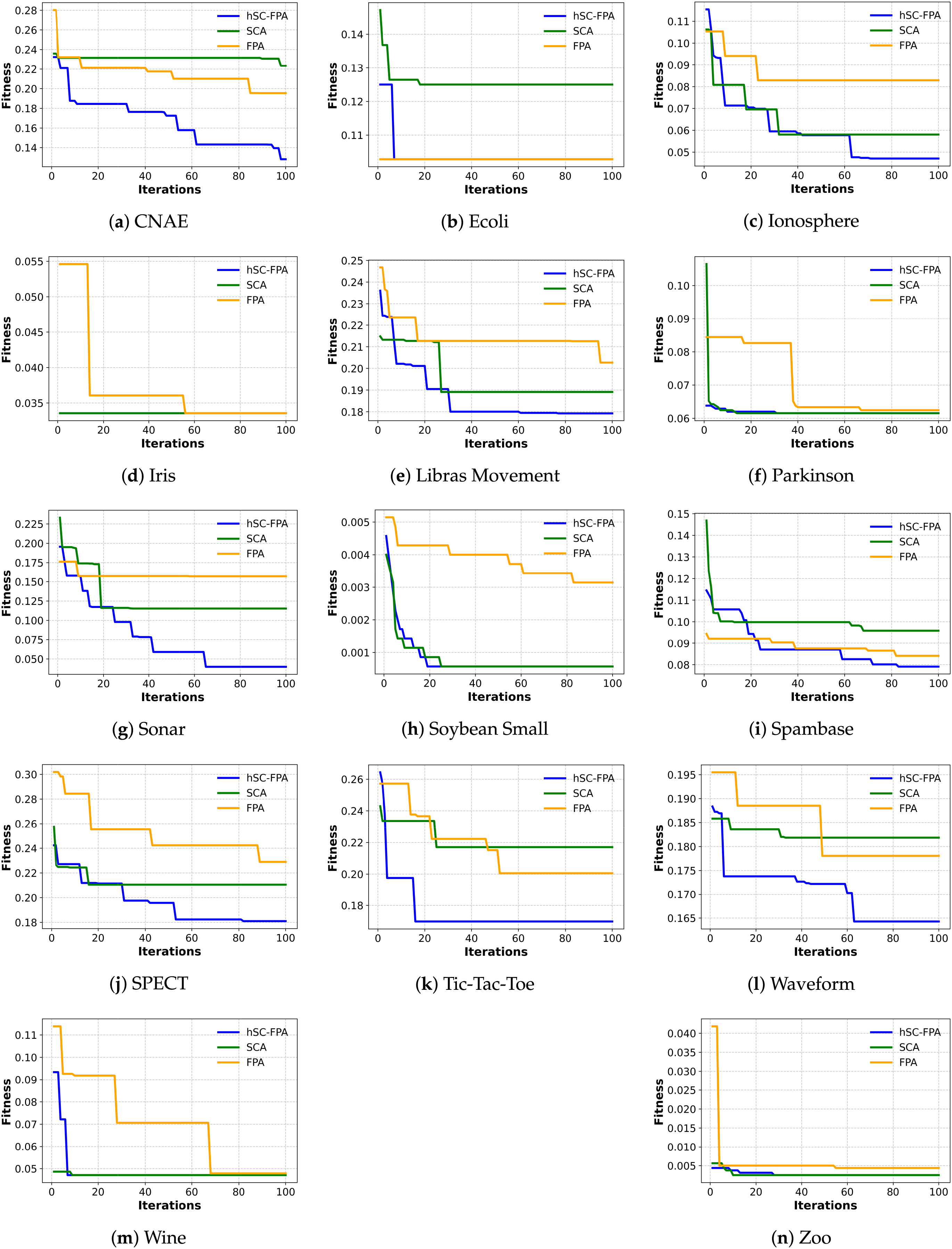
Figure 2: Convergence curves for the FPA, SCA, and hSC-FPA across various datasets. (a)–(n) correspond to individual benchmark datasets, respectively.
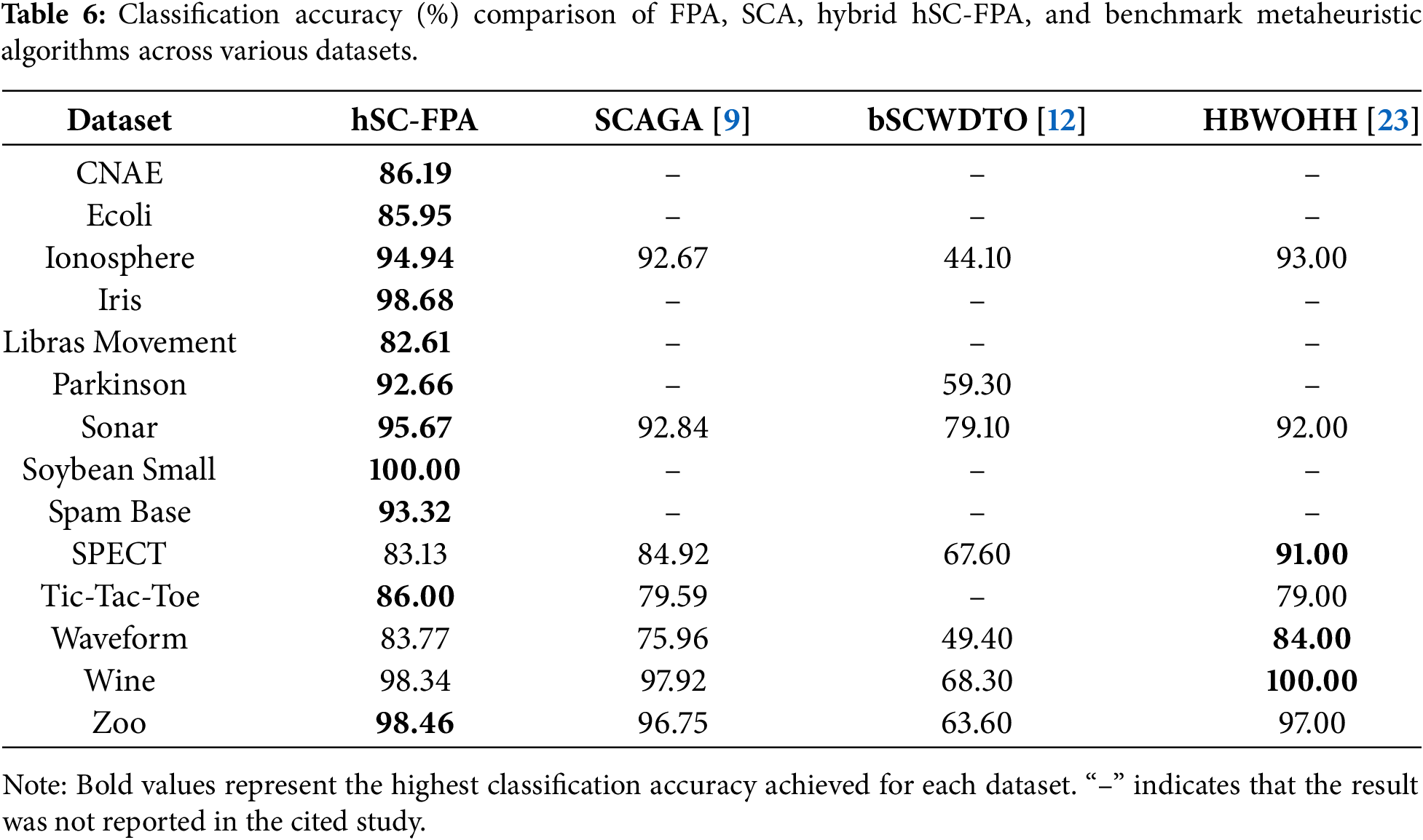
Table 6 provides a comparative evaluation of the proposed hSC-FPA algorithm relative to other existing hybrid optimization algorithms from the literature.
Implementing feature selection (FS) before the learning stage is crucial for improving classification performance. This approach simplifies the model. This work presents a hybrid method, hSC-FPA, which combines the exploration strengths of SCA with the exploitation abilities of FPA. We use the K-NN classifier for evaluation. In the proposed algorithm, SCA’s global search behavior boosts population diversity, while FPA ensures effective local refinement. The algorithm was tested on fourteen benchmark datasets to evaluate its accuracy and FS effectiveness. Its performance was compared with traditional FPA and SCA. Although the hSC-FPA shows good performance across various benchmark datasets, there are some limitations to consider. As a population-based metaheuristic algorithm, it can sometimes become stuck in local optima, particularly in high-dimensional or complex search spaces. Additionally, hybridizing SCA and FPA adds computational overhead when using single-algorithm strategies, especially with large datasets. Future research will aim to address these limitations by creating adaptive or parallel implementations of hSC-FPA to reduce computation time without losing accuracy. Since the algorithm’s main strength lies in balancing exploration and exploitation, future extensions could explore dynamic parameter control to further enhance this balance. Experiments demonstrated higher classification accuracy with compact feature subsets. As future directions, we suggest utilizing the proposed hybrid optimizer to address other real-world problems, including scheduling issues, engineering optimization problems, and molecular potential energy functions. The presented methodology can be applied to other popular classifiers, such as Artificial Neural Network (ANN), Random Forest, and Support Vector Machine (SVM), and examined to determine whether performance is stable or varies. Another potential future work is to hybridize the FPA with other machine learning and deep learning algorithms.
Acknowledgement: The authors would like to thank the Lahore College for Women University (LCWU), Lahore, Pakistan, for providing computational support and access to resources required for this research.
Funding Statement: This research is supported by a research grant from Lahore College for Women University (LCWU), Lahore, Pakistan.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Sumbul Azeem; methodology, Sumbul Azeem; software, Sumbul Azeem; validation, Sumbul Azeem, Shazia Javed, Farheen Ibraheem and Nazar Waheed; formal analysis, Sumbul Azeem, Farheen Ibraheem and Nazar Waheed; investigation, Sumbul Azeem and Nazar Waheed; resources, Shazia Javed; data curation, Sumbul Azeem; writing—original draft preparation, Sumbul Azeem; writing—review and editing, Sumbul Azeem, Uzma Bashir and Khursheed Aurangzeb; visualization, Uzma Bashir; supervision, Shazia Javed; critical review, Farheen Ibraheem and Khursheed Aurangzeb; project administration, Shazia Javed. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in UCI at [https://archive.ics.uci.edu/ml].
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Bala I, Karunarathne W, Mitchell L. Optimizing feature selection by enhancing particle swarm optimization with orthogonal initialization and crossover operator. Comput Mater Contin. 2025;84(1):727–44. doi:10.32604/cmc.2025.065706. [Google Scholar] [CrossRef]
2. Dokeroglu T, Deniz A, Kiziloz HE. A comprehensive survey on recent metaheuristics for feature selection. Neurocomputing. 2022;494(13):269–96. doi:10.1016/j.neucom.2022.04.083. [Google Scholar] [CrossRef]
3. Liu H, Motoda H. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans Knowl Data Eng. 2005;17(4):491–502. doi:10.1109/TKDE.2005.66. [Google Scholar] [CrossRef]
4. Wolpert DH, Macready WG. No free lunch theorems for optimization. IEEE Trans Evol Comput. 2002;1(1):67–82. doi:10.1109/4235.585893. [Google Scholar] [CrossRef]
5. Yang XS. Flower pollination algorithm for global optimization. In: International Conference on Unconventional Computing and Natural Computation. Berlin/Heidelberg, Germany: Springer; 2012. p. 240–49. doi:10.1007/978-3-642-32894-7_27. [Google Scholar] [CrossRef]
6. Mirjalili S. SCA: a sine cosine algorithm for solving optimization problems. Knowl-Based Syst. 2016;96(63):120–33. doi:10.1016/j.knosys.2015.12.022. [Google Scholar] [CrossRef]
7. Mafarja MM, Mirjalili S. Hybrid binary ant lion optimizer with rough set and approximate entropy reducts for feature selection. Soft Comput. 2019;23(15):6249–65. doi:10.1007/s00500-018-3282-y. [Google Scholar] [CrossRef]
8. Bhattacharyya T, Chatterjee B, Singh PK, Yoon JH, Geem ZW, Sarkar R. Mayfly in harmony: a new hybrid meta-heuristic feature selection algorithm. IEEE Access. 2020;8:195929–45. doi:10.1109/ACCESS.2020.3031718. [Google Scholar] [CrossRef]
9. Abualigah L, Dulaimi AJ. A novel feature selection method for data mining tasks using hybrid sine cosine algorithm and genetic algorithm. Clust Comput. 2021;24(3):2161–76. doi:10.1007/s10586-021-03254-y. [Google Scholar] [CrossRef]
10. Mohammadzadeh H, Gharehchopogh FS. A novel hybrid whale optimization algorithm with flower pollination algorithm for feature selection: case study email spam detection. Comput Intell. 2021;37(1):176–209. doi:10.1111/coin.12397. [Google Scholar] [CrossRef]
11. Sun L, Qin H, Przystupa K, Cui Y, Kochan O, Skowron M, et al. A hybrid feature selection framework using improved sine cosine algorithm with metaheuristic techniques. Energies. 2022;15(10):3485. doi:10.3390/en15103485. [Google Scholar] [CrossRef]
12. Abdelhamid AA, El-Kenawy EM, Ibrahim A, Eid MM, Khafaga DS, Alhussan AA, et al. Innovative feature selection method based on hybrid sine cosine and dipper throated optimization algorithms. IEEE Access. 2023;11:79750–76. doi:10.1109/ACCESS.2023.3298955. [Google Scholar] [CrossRef]
13. Ragab M. Hybrid firefly particle swarm optimisation algorithm for feature selection problems. Expert Syst. 2024;41(7):e13363. doi:10.1111/exsy.13363. [Google Scholar] [CrossRef]
14. Hammouri AI, Braik MS, Al-hiary HH, Abdeen RA. A binary hybrid sine cosine white shark optimizer for feature selection. Clust Comput. 2024;27(6):7825–67. doi:10.1007/s10586-024-04361-2. [Google Scholar] [CrossRef]
15. Alkhonaini MA, Al Mazroa A, Aljebreen M, Hassine SBH, Allafi R, Dutta AK, et al. Hybrid sine-cosine chimp optimization based feature selection with deep learning model for threat detection in IoT sensor networks. Alex Eng J. 2024;102(1):169–78. doi:10.1016/j.aej.2024.05.051. [Google Scholar] [CrossRef]
16. Kaur S, Sachan MK, Aggarwal AK. Classification of royal delicious apples using hybrid feature selection and feature weighting method based on SVM classifier. Scalable Comput Pract Exp. 2025;26(2):940–49. doi:10.12694/scpe.v26i2.3924. [Google Scholar] [CrossRef]
17. Kumari D, Pranav P, Sinha A, Dutta S. A novel approach to intrusion detection system using hybrid flower pollination and cheetah optimization algorithm. Sci Reports. 2025;15(1):13071. doi:10.1038/s41598-025-98296-2. [Google Scholar] [PubMed] [CrossRef]
18. Azeem S, Javed S, Naseer I, Ali O, Ghazal TM. A new hybrid PSO-HHO wrapper based optimization for feature selection. IEEE Access. 2025;13:87090–9. doi:10.1109/ACCESS.2025.3570901. [Google Scholar] [CrossRef]
19. Aly M, Alotaibi AS. Hybrid butterfly–grey wolf optimization (HB-GWOa novel metaheuristic approach for feature selection in high-dimensional data. Stat, Optim & Inform Comput. 2025;13(6):2575–600. doi:10.19139/soic-2310-5070-2617. [Google Scholar] [CrossRef]
20. Dao TK, Nguyen TT, Nguyen VT, Nguyen TD. A hybridized flower pollination algorithm and its application on microgrid operations planning. Appl Sci. 2022;12(13):6487. doi:10.3390/app12136487. [Google Scholar] [CrossRef]
21. Blake CL, Merz CJ. UCI repository of machine learning databases. 1998. [cited 2025 Jul 1]. Available from: https://archive.ics.uci.edu/ml. [Google Scholar]
22. Taghian S, Nadimi-Shahraki MH. Binary sine cosine algorithms for feature selection from medical data. arXiv:1911.07805. 2019. [Google Scholar]
23. Al-Wajih R, Abdulkadir SJ, Aziz N, Al-Tashi Q, Talpur N. Hybrid binary grey wolf with Harris hawks optimizer for feature selection. IEEE Access. 2021;9:31662–77. doi:10.1109/ACCESS.2021.3060096. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools