
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Securing Restricted Zones with a Novel Face Recognition Approach Using Face Feature Descriptors and Evidence Theory
1 Department of Computer Engineering, Faculty of Computers and Information Technology, University of Tabuk, Tabuk, Saudi Arabia
2 Laboratoire de Robotique Intelligente, Fiabilité Et Traitement du Signal Image (RIFTSI), ENSIT-Université de Tunis, Tunis, Tunisia
* Corresponding Author: Rafika Harrabi. Email:
Computers, Materials & Continua 2026, 87(2), 74 https://doi.org/10.32604/cmc.2026.072054
Received 18 August 2025; Accepted 29 September 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Securing restricted zones such as airports, research facilities, and military bases requires robust and reliable access control mechanisms to prevent unauthorized entry and safeguard critical assets. Face recognition has emerged as a key biometric approach for this purpose; however, existing systems are often sensitive to variations in illumination, occlusion, and pose, which degrade their performance in real-world conditions. To address these challenges, this paper proposes a novel hybrid face recognition method that integrates complementary feature descriptors such as Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (Modular-LBP) with Dempster–Shafer (DS) evidence theory for decision fusion. The proposed framework extracts global, structural, and local texture features, models them using Gaussian distributions to estimate belief factors, and fuses these belief factors through DS theory to explicitly handle uncertainty and conflict among descriptors. Experimental validation was performed on two widely used benchmark datasets, ORL and Cropped Yale B, achieving recognition rates exceeding 98%, which outperform traditional methods as well as recent deep learning-based approaches. Furthermore, the method demonstrated strong robustness under noisy conditions, maintaining accuracies above 96% with salt-and-pepper and Gaussian noise. These results highlight the effectiveness of the proposed integration strategy in enhancing accuracy, reliability, and resilience compared to single-descriptor and conventional fusion methods. Given its high performance and efficiency, the proposed method shows strong potential for deployment in real-world restricted-zone applications such as smart parking systems, secure facility access, and other high-security domains.Keywords
Authentication is the security function that involves providing and verifying proof of a person’s identity, the message sender, the software, the logical server, or the device. Various identification methods have been proposed for exchanging safety-related information [1]. Biometrics is considered one of the most relevant technologies for identifying and authenticating individuals based on unique biological characteristics, reliably and rapidly [2,3]. Biometric technologies are based on the principle that each person can be uniquely identified through one or more biological characteristics, such as fingerprints, hand morphology, retina and iris patterns, or signatures. Additionally, biometric authentication is the application of these technologies to verify a person’s identity as part of the user validation process for accessing a system.
Face recognition is the process of automatically identifying a human face from database images [4]. Recently, the development of biometric applications, such as face recognition, fingerprint recognition, and iris recognition [5], has become increasingly important in smart cities. In these settings, researchers have focused on developing robust and accurate algorithms to enhance the performance and reliability of these systems. Face recognition is one of the most important systems currently used in personal identification, verification and security applications [6]. In addition, it is used in identification of criminals, verification of credit cards [7] etc.
Several studies on face recognition systems have focused on identifying individual facial features, such as the eyes, nose, mouth, and the outline of the head. Furthermore, researchers have worked on defining the facial model by analyzing the location, size, and spatial relationships between these features [6,8].
There are many challenges in the face recognition process, with one of the most significant being the ability to account for all possible differences in appearance caused by changes in illumination, occlusions, and variations in facial features [4,9].
Despite significant progress, existing face recognition systems still face major challenges when deployed in high-security environments such as airports, military bases, or smart parking facilities. One critical issue is sensitivity to illumination variations, where changes in lighting conditions can significantly degrade recognition accuracy. Similarly, occlusions caused by masks, glasses, or hats frequently interfere with reliable identification, a problem that has become increasingly relevant in post-pandemic security scenarios. In addition, pose variations and facial expressions further complicate the recognition task, as many conventional algorithms lack robustness to such dynamic changes. Another limitation lies in the reliance on single-feature extraction techniques, which, while effective under controlled conditions, often fail when confronted with real-world noise, background clutter, and intra-class variability. Traditional systems often face challenges in maintaining a balance between accuracy and computational efficiency, which is critical for real-time operation in restricted zones where decisions must be made instantly. These challenges highlight the need for advanced recognition strategies that can fuse complementary features and handle uncertainty more effectively. To address these limitations, this work proposes a hybrid facial recognition approach that integrates Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (Modular-LBP), combined through Dempster-Shafer Evidence Theory. This integration enhances robustness by leveraging the strengths of multiple feature descriptors while effectively resolving uncertainty in the decision-making process, making the system highly suitable for securing restricted and sensitive environments.
Numerous techniques are widely used for facial feature extraction [10]. The most notable ones include Histogram of Oriented Gradients (HOG) [11,12], Independent Component Analysis (ICA) [11], Haar wavelets [11], Scale-Invariant Feature Transform (SIFT) [11–13], Eigenfaces [11,14], Gabor filters [11], Local Phase Quantization (LPQ) [11], Fourier transforms [11], Linear Discriminant Analysis (LDA) [11], and Local Binary Patterns (LBP) [11,15]. In addition, various classifier systems are used to recognize the identity of a person in a human face image. The most notable include Support Vector Machines (SVM), Hidden Markov Models (HMM), Nearest Neighbor Classifiers (NNC), Convolutional Neural Networks (CNNs) [16], and Bayesian Classifiers (BC) [15]. Among these, Deep Neural Networks (DNNs) represent the state-of-the-art in face recognition systems, generally outperforming other methods due to their exceptional learning capabilities [17].
In this context, Kardile [4] presented a Feed Forward Neural Network (FFNN) algorithm for facial recognition. The authors employed Principal Component Analysis (PCA) to reduce image dimensionality and used the Neural Network as the classification algorithm. The proposed recognition system was evaluated using 200 facial images from the Yale dataset. The results indicated that the system was fast and achieved an acceptance ratio of over 90%. In addition, Gupta [5] and Bhuiyan [18] utilized the Eigenfaces method for facial recognition. Their recognition process considered challenging details such as the background, eyes, beard, mustache, and glasses. First, the Eigenfaces for the specified face image were computed. Next, the Euclidean distances between these Eigenfaces and the previously stored Eigenfaces were calculated. Finally, the Eigenface with the smallest distance, which most closely resembled the target individual, was selected.
With the same objective, Chaabane et al. [13] proposed a face recognition system based on statistical features and an SVM classifier. The Yale dataset was used to evaluate the proposed recognition system, with
Narayana et al. [11] proposed a face recognition system utilizing Principal Component Analysis (PCA) as a feature extraction technique and Support Vector Machine (SVM) as the classification algorithm [17]. The system was evaluated using the ORL face database, which comprises 400 images of 40 individuals, exhibiting significant variation in facial expressions, composition, and details. The authors conducted a comparative analysis of three types of SVM classifiers: Linear SVM (LSVM), Polynomial SVM (PSVM), and Radial Basis Function SVM (RBFSVM). The experimental results revealed that the Polynomial SVM and Radial Basis Function SVM outperformed the Linear SVM on the ORL face dataset in terms of recognition accuracy. Additionally, the findings demonstrated that SVM-based classification surpassed the Eigenface approach when paired with a Multi-Layer Perceptron (MLP) classifier. This highlights the robustness and effectiveness of SVM classifiers, particularly when combined with PCA for feature extraction, in handling complex facial recognition tasks. Furthermore, Cui et al. [6] proposed a hybrid facial recognition system that integrates a Convolutional Neural Network (CNN) with a Logistic Regression Classifier (LRC). In this system, the CNN is employed to detect and extract features from facial images, while the LRC is used to classify the features learned by the CNN. The combination leverages the powerful feature extraction capabilities of CNNs and the simplicity and efficiency of LRC for classification. To train the CNN, the authors utilized the backpropagation algorithm with gradient descent optimization, which iteratively minimizes the loss function and updates the network weights to improve feature learning. This hybrid approach enhances recognition accuracy by combining the strengths of deep learning and traditional classification methods. Experimental results demonstrated the system’s robustness and effectiveness in handling diverse facial datasets.
In their work, Garg et al. [19] analyzed the performance of various facial recognition techniques. They employed Local Binary Patterns (LBP), Gabor Wavelets, and Histogram of Oriented Gradients (HOG) for feature extraction, while Principal Component Analysis (PCA) was used for feature selection and similarity matching between images. The similarity measurement was performed using different distance functions, including Cosine, Euclidean, Correlation, City Block, Spearman, and Minkowski. The experimental results indicated that the combination of Gabor Wavelets with PCA achieved better accuracy than LBP and HOG across both evaluated databases. In addition, ElDahshan et al. [20] proposed a facial emotion recognition system based on Deep Belief Networks (DBN) and Quantum Particle Swarm Optimization (QPSO). The system operates through several key stages. First, the input image undergoes preprocessing, where the Region of Interest (ROI) is cropped to isolate the desired facial region while discarding non-significant parts. Next, the ROI is divided into multiple blocks, and the integral image technique is applied to identify the most efficient (superior) blocks for feature representation. Following this, a down-sampling algorithm is employed to reduce the size of the new sub-image, enhancing system performance by minimizing computational complexity. Finally, the emotion class is identified using the trained DBN, which efficiently captures and processes the extracted features for accurate emotion classification.
In another study, El Dahshan et al. [21] also proposed a quantum face authentication method. This method consists of multiple phases, including detecting face boundaries, resizing the image, noise removal, feature extraction, matching, and decision-making. During the feature extraction phase, the method leverages Quantum Fast Wavelet Transform (QFWT) and Quantum Fourier Transform (QFT) to enhance the quality and robustness of the extracted features. These quantum-inspired techniques enable superior processing speed and accuracy, making the system highly effective for face authentication tasks. Both approaches demonstrate the innovative integration of quantum computing principles with advanced machine learning techniques, achieving robust performance in facial emotion recognition and face authentication. In addition, researchers have turned to ensemble and hybrid decision-making frameworks to further improve robustness in face recognition. In this context, Shah et al. [22] proposed an ensemble face recognition mechanism based on three-way decisions (E3FRM), which integrates PCA/FLD for feature extraction and employs a dual verification strategy to improve accuracy, recall, and F1-score, thereby enhancing trust and reliability in human–computer interaction systems. Similarly, Wani et al. [23] explored supervised deep learning approaches using Convolutional Neural Networks (CNNs) to address key challenges in face recognition, including variations in expression, illumination, and poses, demonstrating their effectiveness in improving recognition accuracy. Additionally, Al Rayes et al. [24] combined Local Binary Patterns (LBP) with transfer learning to enhance face recognition under low-light conditions, demonstrating that VGG16 achieved superior performance on the Extended Yale B dataset. These studies highlight the increasing trend toward multi-feature fusion and ensemble-based solutions, which are conceptually aligned with our proposed approach.
This paper presents a novel facial recognition method designed to verify the identities of individuals accessing smart parking facilities. The proposed system combines advanced facial feature descriptors with the Dempster-Shafer Evidence Theory to achieve accurate and reliable face verification. Specifically, three feature extraction methods such as Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (Modular-LBP) are employed to generate feature vectors corresponding to face images [25]. These feature vectors are fed into a Gaussian model to compute belief factors. The belief factors derived from the different feature sets are then fused using Dempster-Shafer Evidence Theory to calculate a merit value for each class. This integration enhances information quality by combining the complementary characteristics of the different feature sets, resulting in a robust and optimized facial recognition process.
The main contribution of this work lies in the integration of multiple feature extraction techniques with Dempster-Shafer Evidence Theory to enhance identity verification accuracy, making it highly applicable for real-world security and authentication scenarios. Specifically, the proposed approach combines complementary feature descriptors FG-2DFLD, G2DLDA, and Modular-LBP to capture both global and local discriminative facial characteristics, thereby improving robustness against variations in illumination, occlusion, and pose. To further strengthen decision-making, Dempster-Shafer Evidence Theory is employed to fuse belief factors from multiple feature sets, reducing ambiguity and improving classification reliability. Experimental validation conducted on benchmark datasets, including ORL and Cropped Yale B, demonstrates the superiority of the proposed method, achieving recognition rates exceeding 98% and outperforming state-of-the-art techniques. These results highlight the method’s strong potential for deployment in high-security applications such as smart parking facilities and restricted access zones, where fast, accurate, and reliable identity verification is crucial.
So, this recent work may be seen to be straightforwardly complementary to that of earlier studies [4,5,11,13,18,19] that rely on single feature extraction techniques, such as PCA, Eigenfaces, LBP, or Gabor Wavelets, or traditional fusion methods. While previous studies have demonstrated the effectiveness of individual feature extraction or classification approaches—such as the use of PCA with FFNN [4], Eigenfaces with Euclidean distance matching [5,18], SVM classifiers with statistical features [13], and Gabor Wavelet-based feature extraction combined with PCA [19]—they often face limitations in handling complex variations in facial appearances. In contrast, the proposed method offers a more robust and reliable multi-feature fusion strategy by integrating multiple complementary feature descriptors (FG-2DFLD, G2DLDA, and Modular-LBP) and combining their outputs through Dempster-Shafer Evidence Theory, leading to enhanced facial recognition performance under varying conditions.
The proposed approach demonstrates its potential in improving the accuracy and reliability of human face recognition, making it a suitable solution for securing access in military and other high-security environments. Unlike our earlier work, which primarily focused on statistical feature extraction with SVM classification, the present study introduces a hybrid framework that integrates FG-2DFLD, G2DLDA, and Modular-LBP to capture complementary global, structural, and local texture characteristics. A key novelty lies in the use of Dempster–Shafer evidence theory to fuse Gaussian-modeled belief factors from these descriptors, enabling explicit handling of uncertainty and conflict in the decision-making process. In addition, we extend the evaluation beyond standard accuracy metrics by analyzing robustness under noisy conditions, demonstrating the method’s resilience against salt-and-pepper and Gaussian disturbances. Finally, this study emphasizes the deployment of the proposed method in restricted-zone security applications such as smart parking systems, thereby highlighting its practical relevance and scalability for real-world authentication scenarios.
Section 2 introduces the proposed face recognition method. The experimental results are discussed in Section 3, and the conclusion is given in Section 4.
Face recognition is a technique used to identify or verify the identity of an individual by analyzing their facial features. Face recognition systems can identify individuals from photographs, videos, or in real-time scenarios. In recent years, the importance and relevance of face recognition have grown significantly due to its wide range of potential applications, including security, access control, surveillance, and user authentication.
However, facial recognition poses unique challenges, as human faces are highly dynamic and exhibit variations due to changes in pose, lighting, expressions, aging, and occlusions. To address these complexities and enhance robustness and recognition accuracy, researchers in pattern recognition, computer vision, and artificial intelligence have proposed various innovative approaches. There are three major approaches in the automatic recognition of faces by computer: global feature approach (face-based recognition), local feature approach (constituent-based recognition), and hybrid approaches.
In this work, we propose a novel facial recognition method specifically designed to verify the identities of individuals accessing smart parking facilities. The proposed system consists of two major components: feature extraction and face recognition. Employing optimal face feature descriptors in combination with evidence theory is identified as a highly effective approach.
The proposed method adopts a hybrid face recognition technique that integrates the outputs of face feature descriptors with evidence theory. Notably, the method is divided into two stages. In the first stage, the essential characteristics of the human face are extracted from each original image to construct detailed feature vectors. Specifically, three feature extraction methods such as Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (Modular-LBP) are employed to generate feature vectors corresponding to face images [25]. These feature vectors are then fed into a Gaussian model to compute belief factors. In the second stage, the belief factors obtained from the different feature sets are fused using evidence theory to calculate a merit value for each class.
This integration enhances the quality of the information by combining the complementary characteristics of the various feature sets, resulting in a robust and optimized facial recognition process. The main components of the proposed face recognition system are illustrated in the diagram shown in Fig. 1.
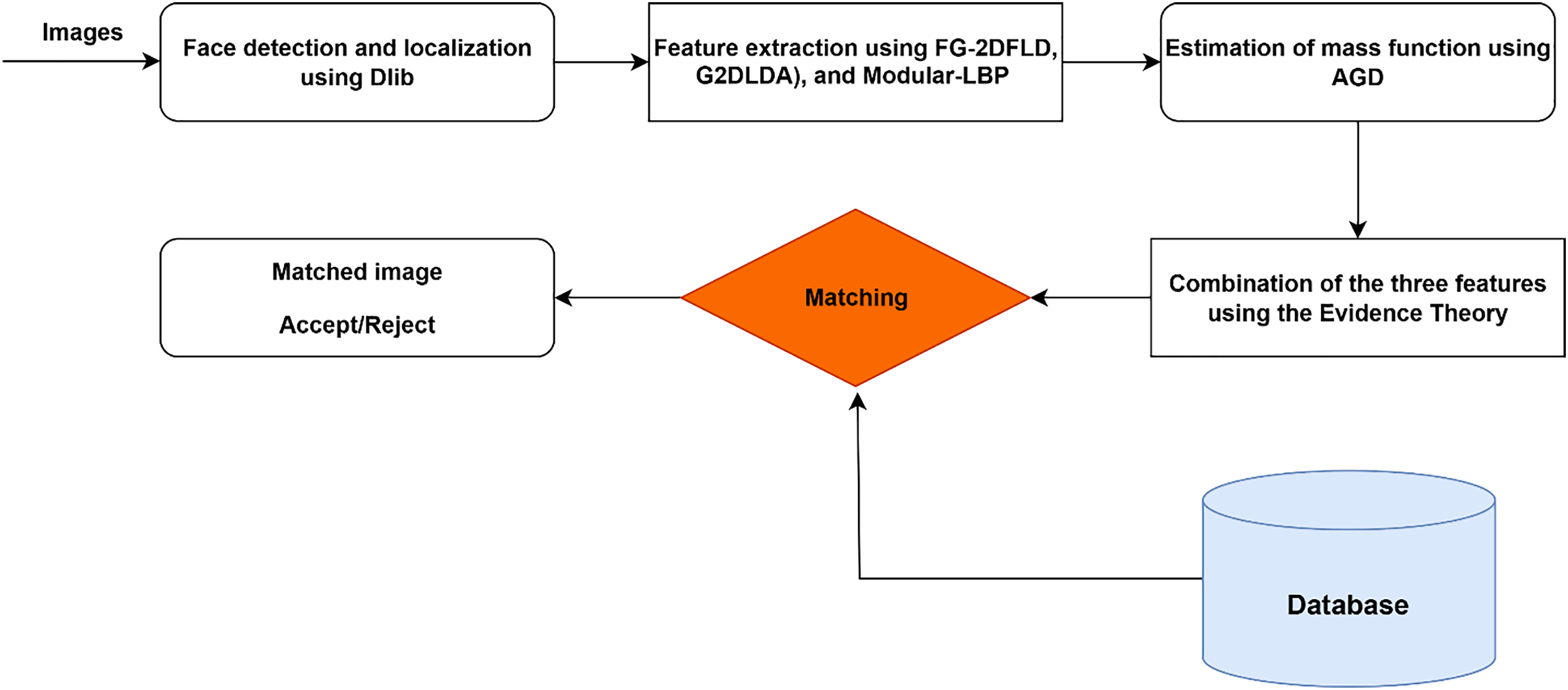
Figure 1: The flowchart of the face recognition method.
Feature extraction plays a decisive role in the success of any face recognition system, as it determines the quality and discriminability of the features available for classification. Traditional single-descriptor methods such as PCA, LBP, or Gabor filters have demonstrated good performance in controlled environments; however, they often fail under real-world conditions involving illumination changes, pose variations, partial occlusions, and noise. The motivation behind our approach is therefore to design a more resilient feature extraction strategy by combining complementary descriptors that capture global, structural, and local textural information simultaneously. This ensures that the weaknesses of one descriptor are compensated by the strengths of the others.
The feature extraction consists in extracting from the face the most discriminating and relevant characteristics, necessary and useful for its identification. To do this, three feature extraction methods—Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (Modular-LBP) are employed to generate feature vectors corresponding to face images [22]. The process of face encoding therefore consists of representing the signature of the face.
To achieve this, we integrate three advanced descriptors: FG-2DFLD, G2DLDA, and Modular-LBP selected based on their ability to address specific challenges in facial recognition. FG-2DFLD captures frequency–orientation information and enhances robustness to illumination variations through fuzzy weighting. G2DLDA directly processes image matrices in two dimensions, thereby preserving spatial relationships and solving the small sample size problem that often affects classical LDA. Modular-LBP, on the other hand, emphasizes fine-grained local texture analysis by partitioning the image into sub-blocks, improving resistance to occlusions and facial expression variations.
The selection of FG-2DFLD, G2DLDA, and Modular-LBP as feature extraction methods in this work is motivated by their complementary strengths in handling the inherent challenges of face recognition. FG-2DFLD integrates Gabor filters with fuzzy logic and Fisher Linear Discriminant analysis, enabling the extraction of robust frequency and orientation-based features while maintaining resilience to illumination variations and image noise. G2DLDA was chosen because it operates directly on two-dimensional image matrices, thereby preserving the spatial structure of facial images and enhancing class separability without suffering from the curse of dimensionality that affects traditional LDA. This makes it particularly effective when the number of training samples is limited. Modular-LBP, on the other hand, captures local textural features by dividing the image into smaller modules and extracting binary patterns from each, which enhances robustness against partial occlusion and local variations such as facial expressions. By combining these three descriptors, the proposed method benefits from both global discriminative features (FG-2DFLD), spatial structural preservation (G2DLDA), and localized textural details (Modular-LBP). This hybrid selection ensures improved robustness and accuracy under diverse real-world conditions, including changes in lighting, pose, and occlusion.
2.1.1 Fuzzy-Gabor 2D Fisher Linear Discriminant
The Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD) [25], is an advanced technique combining fuzzy logic, Gabor filters, and two-dimensional Fisher Linear Discriminant analysis to enhance feature extraction and classification for image-based recognition tasks.
A Gabor filter [11,25] is a linear filter with a sinusoidal wave modulated by a Gaussian envelope, which is defined as
where
A set of Gabor filters with different
where
Each Gabor response
Fuzzy logic is then integrated into the Gabor feature extraction process to enhance robustness, as proposed in [25]. Each Gabor feature
where
Each Gabor magnitude response [25,26] is multiplied by the fuzzy weight:
The Combination of features across all filters to form the final feature representation [25,26]:
where
After fuzzy-weighted Gabor responses
The resulting feature vector
2.1.2 Generalized 2D Linear Discriminant Analysis
Traditional Linear Discriminant Analysis (LDA) is widely used for dimensionality reduction and feature extraction. However, when applied to images, LDA requires reshaping 2D face images into 1D vectors, leading to high computational costs and poor performance due to the curse of dimensionality. To overcome these limitations, generalized 2D Linear Discriminant Analysis (G2DLDA) [22], directly operates on 2D images instead of converting them into 1D vectors. This approach improves feature extraction, enhances classification accuracy, and reduces computational complexity.
In the data preparation step, a set of grayscale face images of size
Then, the computing of
where,
The between-class scatter matrix is defined similarly, as shown in [25], where the mean image across classes is used for enhanced class separability. The Between-class scatter matrix (
where,
In the feature extraction and classification step, each new face image [25], is projected onto the discriminant subspace by computing:
where
where
Hence, G2DLDA offers several advantages for face recognition by working directly with 2D images, preserving their spatial structure and essential facial features. It reduces dimensionality by avoiding high-dimensional vector space, leading to improved computational efficiency. Additionally, it enhances discriminative power by maximizing class separability, ensuring optimal feature extraction for classification. Moreover, G2DLDA effectively addresses the Small Sample Size Problem (SSSP), making it suitable for face recognition databases with limited training samples.
2.1.3 Modular-Local Binary Patterns
Modular-LBP is an enhanced version of Local Binary Patterns (LBP) designed to capture both local and modular features from 2D images [25]. By dividing the image into smaller modules and extracting LBP features from each module independently, it achieves better robustness, discriminative power, and localized feature representation.
Let the input be a grayscale
Each module is denoted as
where
The histogram of LBP values for the module [25], is computed using:
where
The histogram
The concatenation of module histograms into a global Modular-LBP vector follows the formulation in [25]. The normalized histograms from all
The novelty of our feature extraction stage lies not only in the choice of descriptors but also in their integrated role within the proposed framework. Unlike conventional concatenation or dimensionality reduction methods (e.g., PCA), which may dilute discriminative information or ignore uncertainty, each feature set in our method is modeled statistically through Gaussian distributions to estimate belief factors. These belief factors are then interpreted as sources of evidence and fused using Dempster–Shafer theory in the classification stage. This principled approach allows the system to exploit complementary information while explicitly managing conflicts or ambiguities among descriptors. As a result, the proposed feature extraction design forms a hybrid and uncertainty-aware representation, leading to significantly improved recognition accuracy and robustness across noisy and unconstrained environments.
2.2 Classification Using Evidence Theory
The purpose of classification is to assign input images to specific classes accurately. The use of Dempster-Shafer (DS) evidence theory in image classification provides a powerful framework for integrating information from multiple sources while accounting for the uncertainty associated with each piece of evidence.
The choice of Dempster-Shafer (DS) Evidence Theory for feature fusion is motivated by its advantages over more conventional methods such as weighted averaging or principal component analysis (PCA). In weighted averaging, the fusion process requires predefined weights, which can be subjective and may not accurately capture the varying reliability of different features under changing conditions. PCA, while effective for dimensionality reduction, is primarily variance-driven and does not provide a mechanism to explicitly handle uncertainty or conflict among features. In contrast, DS theory offers a flexible mathematical framework that allows the assignment of belief values not only to individual classes but also to subsets of classes, making it particularly well suited to situations where the available evidence is incomplete or ambiguous. This property enables the system to effectively manage uncertainty, noise, and conflicting information, which are common in real-world face recognition scenarios involving illumination changes, occlusion, or pose variations. By fusing evidence from FG-2DFLD, G2DLDA, and Modular-LBP using DS theory, the proposed approach ensures more reliable and robust classification compared to traditional fusion strategies.
Unlike conventional fusion strategies such as weighted averaging or PCA-driven combination, the novelty of our approach lies in integrating FG-2DFLD, G2DLDA, and Modular-LBP through the Dempster–Shafer (DS) framework. Each descriptor contributes complementary information: FG-2DFLD enhances robustness against noise and illumination changes, G2DLDA preserves spatial discriminative structures while mitigating the small sample size problem, and Modular-LBP strengthens resilience to occlusion and local variations. By modeling belief factors with Gaussian distributions and then fusing them using DS theory, the system is able to explicitly handle uncertainty and conflict between feature sources, leading to a more reliable and optimized decision-making process.
Initially, features are extracted from the input images using Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (Modular-LBP). Each feature serves as a distinct source of information. In the DS framework, each feature is represented as a piece of evidence through a belief function. The belief function assigns degrees of belief to various hypotheses (classes, such as face identities), reflecting the evidence’s support for each class. The DS evidence theory then fuses the belief functions from all features. This fusion process integrates the information from different features while resolving conflicts and uncertainties, producing a combined belief function.
Finally, a classification decision is made based on the combined belief function. The image is assigned to one or more predefined classes depending on the accumulated evidence. This method not only ensures robust classification by leveraging complementary information from multiple features but also effectively handles uncertainties, improving overall classification accuracy.
The Dempster-Shafer Theory (DS) [26,27], often referred to as the theory of belief functions, is a robust mathematical framework designed to handle reasoning in situations involving uncertainty or incomplete knowledge. Unlike conventional probability theory, which assigns probabilities exclusively to individual events, DS theory provides a more versatile mechanism by allowing degrees of belief to be distributed across subsets of the possible outcomes. This feature enables DS theory to effectively capture and represent the ambiguity and partial information that often arise in real-world scenarios, making it a valuable tool for applications requiring nuanced uncertainty modeling.
In the present study, the frame of discernment
where:
To express a degree of confidence for each proposition A in
The idea of using the evidence theory for image classification is to fuse, one by one, the features extracted from the input image. Each feature is first analyzed and represented using a Gaussian distribution model [25], which captures its statistical characteristics and accounts for any associated uncertainties.
For the Gaussian model, the distribution parameters, such as mean (μ) and variance (σ2) were estimated directly from the training data of each class using Maximum Likelihood Estimation (MLE) [29], which ensures that the probability density function accurately reflects the statistical characteristics of the extracted features. This data-driven estimation avoids the need for manual tuning, as the parameters are optimized automatically during training. To validate this modeling choice, we analyzed the distribution of the feature vectors, and normality tests confirmed that they exhibit near-Gaussian behavior. This makes the Gaussian assumption suitable for belief factor estimation, providing both robustness and stability in the fusion process.
Based on these representations, corresponding mass functions are generated for the individual features. These mass functions are then combined iteratively using the Dempster-Shafer (DS) combination rule, which aggregates the evidence provided by each feature while managing conflicts and uncertainties effectively. This fusion process culminates in the generation of the final classification results, offering improved accuracy by leveraging the collective information from all features.
The masses associated with the simple hypotheses
where:
•
•
•
•
The mass function assigned to a double hypothesis, which arises when there is uncertainty between two potential clusters, is influenced by the mass functions of the individual hypotheses. In the framework of evidence theory, specifically Dempster-Shafer theory, the mass function for a double hypothesis is determined by combining the mass functions of the individual hypotheses, while also considering the uncertainty or conflict between them.
To elaborate, let us define two simple hypotheses
where:
Once the mass functions for the three attributes have been estimated, their combination can be carried out using Dempster’s rule of combination, also known as the orthogonal sum, which is a core concept of Dempster-Shafer theory. This rule facilitates the fusion of evidence originating from different sources, allowing for the computation of a final mass function or belief that incorporates all available information. The goal is to combine the individual mass functions in a manner that reflects the collective uncertainty and belief about the system under consideration.
When combining two mass functions,
where:
In Dempster-Shafer (DS) combination theory [30], the mass functions of the three attributes are integrated to produce a single, consolidated value that reflects the combined evidence. After calculating the orthogonal sum of the mass functions for the three attributes, the classification process involves selecting the most probable hypothesis
This decisional procedure ultimately identifies the best-fitting class based on the integrated data, offering an efficient method for classification in the presence of uncertainty. The evidence-theory-based fusion of heterogeneous descriptors represents the key innovative contribution of the proposed method, as it not only leverages the strengths of each feature set but also introduces a principled uncertainty-handling mechanism that significantly improves robustness compared to existing face recognition approaches.
Consequently, the steps of the proposed face recognition technique are outlined in Algorithm 1. This algorithm provides a systematic approach for extracting discriminative features from face images and classifying them using the evidence theory. Furthermore, the pseudocode for the proposed method is provided in Fig. 2, offering a detailed visualization of the process for better understanding and implementation. All experiments were conducted on a workstation equipped with an Intel Core i7-11700K CPU (3.6 GHz, 8 cores), 32 GB RAM, and an NVIDIA GeForce RTX 3060 GPU (12 GB) running Windows 11 (64-bit) with Python 3.9, NumPy, and OpenCV libraries. The average training time per dataset was approximately 14 min for the ORL dataset and 38 min for the Cropped Yale B dataset, including feature extraction, belief factor computation, and fusion. The testing phase was significantly faster, requiring less than 1 s per image on average. These results indicate that the proposed method is computationally efficient and suitable for real-time or near-real-time deployment in restricted zone applications such as smart parking systems.

Figure 2: The pseudo code of the proposed method.

The study implemented the proposed method for facial recognition to verify the identities of individuals accessing the smart parking system, as illustrated in Fig. 1. This method utilizes feature vectors derived from FG-2DFLD (Fisher-Gabor Two-Dimensional Fisher Linear Discriminant), G2DLDA (Gabor Two-Dimensional Linear Discriminant Analysis), and Modular-LBP (Local Binary Patterns) as inputs, producing classification information for each data point as output.
In this section, we first introduce the datasets and evaluation metrics used in the study. The performance of the proposed method is then assessed through a series of experiments, including quantitative comparisons, misclassification analysis, parameter analysis, computational complexity evaluation, and generalization tests.
To evaluate the proposed method, two face image datasets were utilized in this study: ORL dataset [31], and Yale-B Cropped Face [32].
In this study, the widely used ORL dataset was employed, which comprises images of 40 individuals, each represented by 10 different poses. To ensure compatibility with the proposed method, the dataset was converted to JPEG format, while maintaining the original image dimensions to preserve the integrity of the data. A detailed overview of the dataset is provided in Table 1. Additionally, Fig. 3 illustrates a sample of the dataset, displaying five individuals, each represented by their corresponding ten images.


Figure 3: Samples of ORL database.
Additionally, the Yale-B Cropped Face Database was used to evaluate the performance and robustness of the proposed method. The Yale-B Cropped Face Database comprises images of 38 individuals, with 65 unique images per person, amounting to a total of 2470 images. These images were captured under varying lighting conditions, including dark, medium, and bright settings. A sample of images from the Yale-B Cropped Face Database is presented in Fig. 4.

Figure 4: Samples of Yale-B cropped database.
The proposed model was rigorously evaluated to ensure its effectiveness and reliability. Comparative analyses with existing state-of-the-art models were also conducted to highlight the improvements introduced by the proposed method. These comparisons provided a clear demonstration of the model’s superiority in terms of accuracy, efficiency, and robustness.
Performance metrics such as accuracy, precision, and F1 score were analyzed to provide a comprehensive assessment [33,34]. Accuracy represents the proportion of correct predictions to the total number of samples. Precision is defined as the ratio of true positive samples to the total number of positive predictions. The F-score, which is the harmonic mean of precision and recall, was also calculated. The formulas for these metrics are provided below:
The accuracy is computed as the ratio of correctly classified instances to the total number of samples, as defined in standard performance evaluation metrics [33,34]:
This measure reflects the overall correctness of the recognition system [33].
The Precision measures the proportion of true positive predictions relative to the total positive predictions made by the model, indicating the model’s effectiveness in minimizing false positives [33].
Finally, F1-score [33,34], which is the harmonic mean of precision and recall, is defined as:
F1-score provides a balanced assessment by considering both false positives and false negatives, making it particularly valuable for imbalanced datasets [34].
where, TP (True Positive) refers to the number of positive samples correctly predicted. FP (False Positive) represents the number of negative samples incorrectly classified as positive. TN (True Negative) is the number of negative samples correctly identified. FN (False Negative) denotes the number of positive samples mistakenly classified as negative.
By analyzing these metrics, a comprehensive understanding of the proposed model’s performance and its effectiveness in accurately categorizing the data can be obtained.
3.3 Quantitative Comparison and Analysis
The diagram of the smart parking system is given in Fig. 5, incorporates the following components:
– Camera Module (e.g., USB Camera): To capture the face image.
– Microcontroller (e.g., Arduino): To process the image and interface with other components.
– Motor (for gate control): To open or close the gate based on facial recognition.
– Relay (for controlling the motor): To connect and control the motor.
– Power Supply: To power the system components.
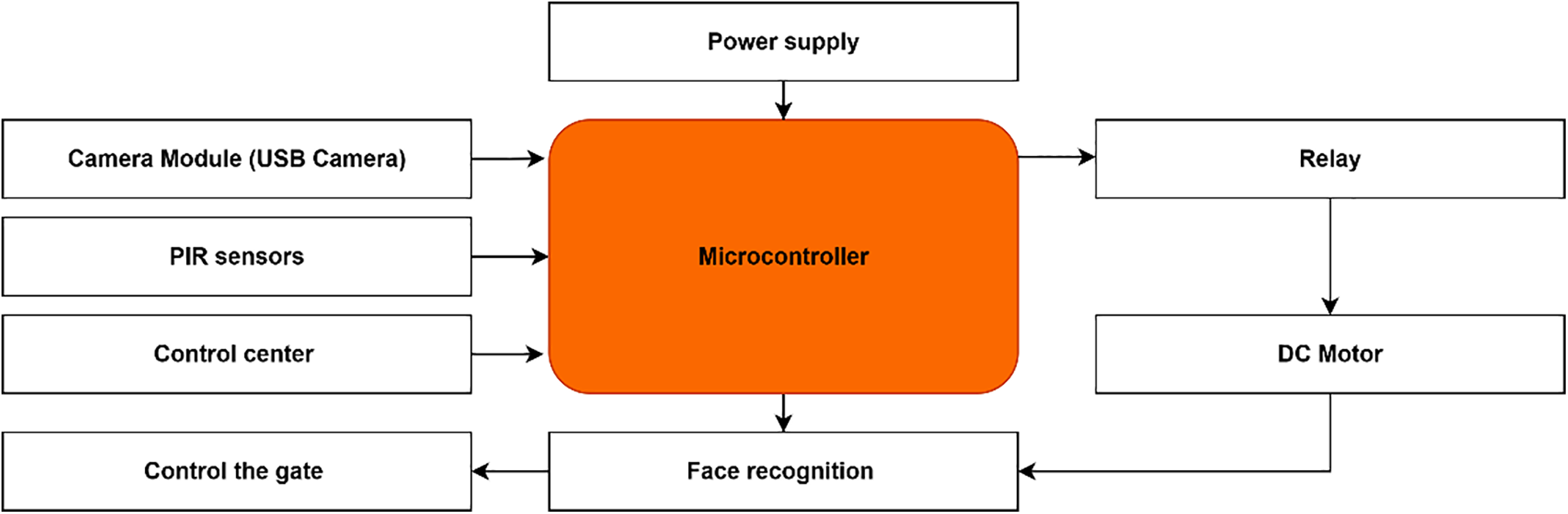
Figure 5: Block diagram of the smart parking system.
This schematic provides a comprehensive visualization of how the various components are interconnected within the electrical framework of the smart parking system.
The physical implementation of the smart parking system is depicted in Fig. 6, presenting the prototype of the smart parking.

Figure 6: The prototype of smart parking.
When a user arrives at the parking facility, a high-resolution camera captures their facial image in real-time. The captured image is then preprocessed to enhance quality and extract key facial features using advanced techniques such as FG-2DFLD (Fisher-Gabor Two-Dimensional Fisher Linear Discriminant), G2DLDA (Gabor Two-Dimensional Linear Discriminant Analysis), and Modular-LBP (Local Binary Patterns).
The extracted feature vectors are then analyzed through a Gaussian model, which assigns belief factors based on the likelihood of the features matching stored templates. The belief factors derived from different feature extraction methods are subsequently fused to compute a merit score for each class, representing the probability of a successful match. If the calculated merit score confirms a match with an authorized user profile, the system grants access by automatically opening the parking gate. Conversely, if no match is found, access is denied, ensuring that only authorized individuals can enter the facility. This robust process not only enhances security but also ensures a seamless and efficient authentication experience.
Fig. 7 illustrates a scenario where the system successfully detects and recognizes a known individual. Upon identifying the person, the system verifies their identity and automatically grants access by activating the gate mechanism, allowing entry. If the facial data of the detected individual does not match any entries in the system’s database, the monitoring system labels the person as “unknown”, as shown in Fig. 8a.

Figure 7: (a) Detection and recognition of an individual, (b) The activation of the gate mechanism.
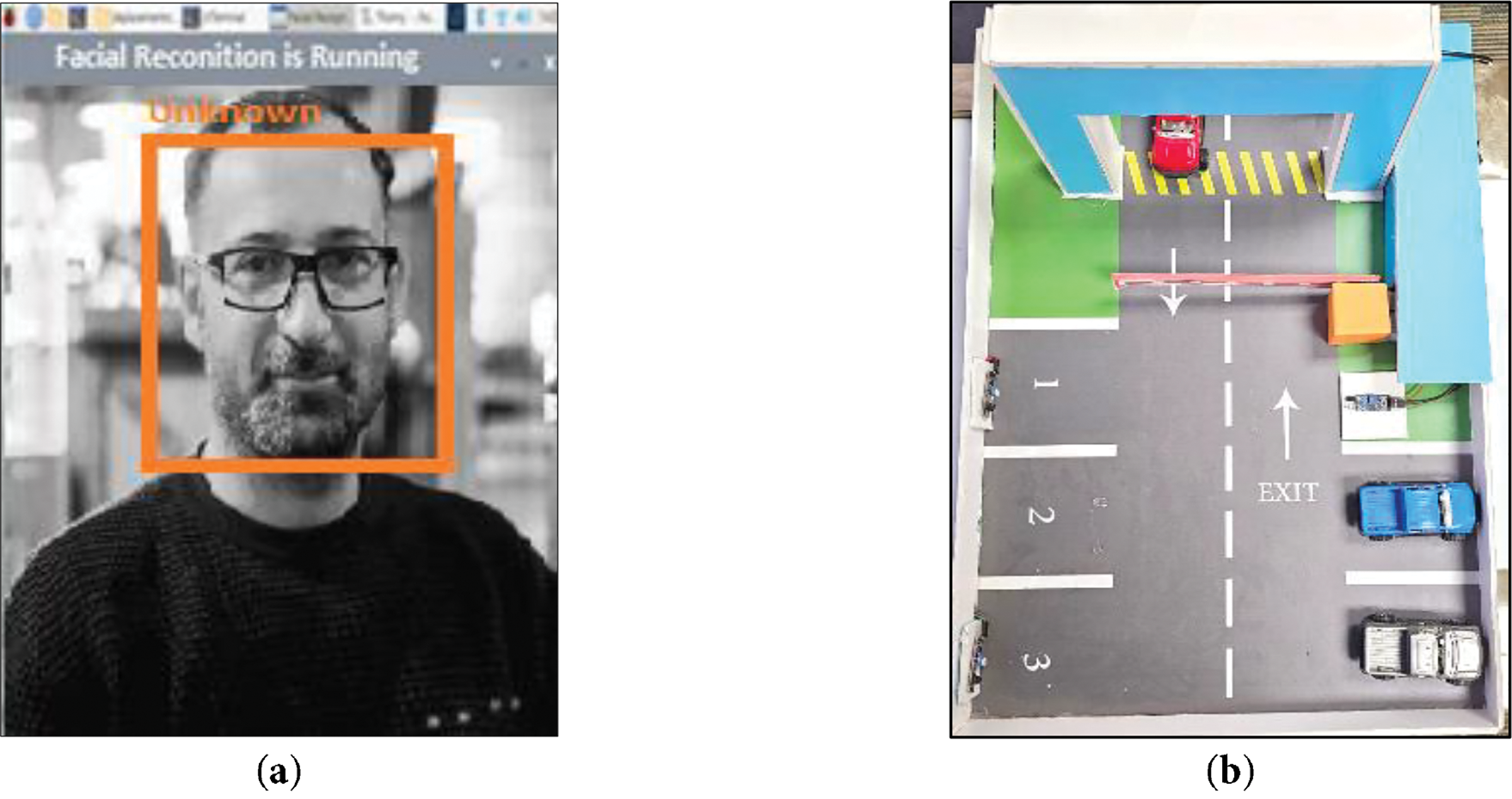
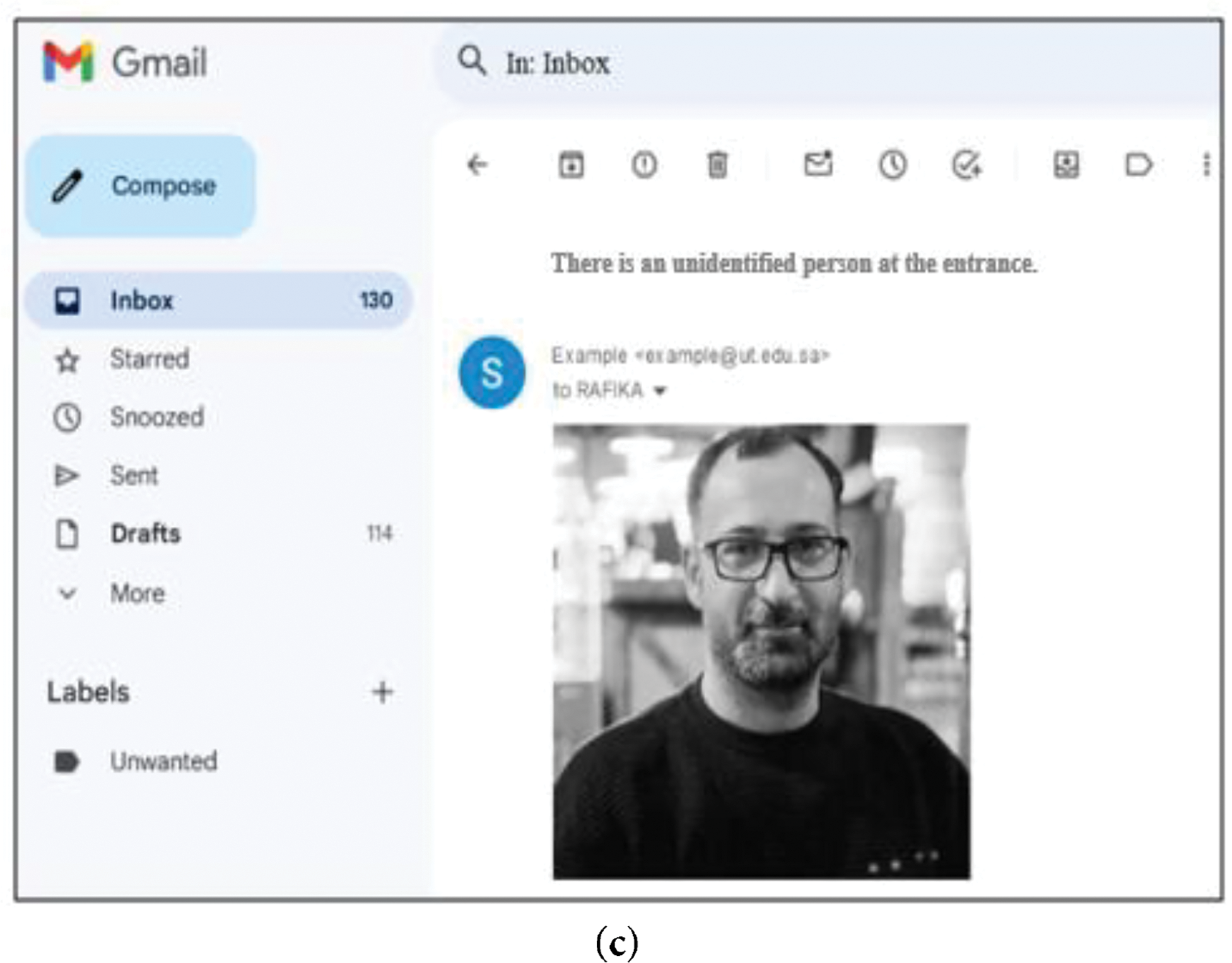
Figure 8: (a) An intruder detected by the system, (b) Gate mechanism status: deactivated, (c) Email containing the person’s photo sent when the system detects an unidentified person.
In the case of an unknown person, the gate mechanism remains deactivated to prevent unauthorized access, as illustrated in Fig. 8b. This ensures that only recognized individuals are granted entry, enhancing the security and reliability of the system.
At the same time, the system sent an email, which includes a captured image of the individual, to the control center, as illustrated in Fig. 8c. This process ensures timely awareness and enables an appropriate response to potential security concerns. We primarily compare our proposed method with commonly used methods on the ORL dataset [31], and Yale-B Cropped Face [32], along with an additional 1–6 methods specific to each dataset.
To evaluate the performance of the proposed face recognition method, we conducted a series of experiments using the two datasets. First, we compare the results of the proposed face recognition method with commonly used methods on ORL and Yale-B Cropped Face datasets, which include HOG features and SVM classifier method [27]; Face Recognition Using Gabor, PCA, and SVM with Illumination Normalization [35] and PCA and DCT Based Approach for Face Recognition [36].
Additionally, we compared the results obtained from our method with those of state-of-the-art face recognition methods, which were specifically applied to the ORL dataset. These included Face Recognition by Integrating Compressive Sensing, Curvelet Transform, and PCA [37], face recognition based on a CNN model [38], and Face Recognition Using Deep Learning Algorithms [39].
This comprehensive analysis provided a clear understanding of how our method performs relative to existing approaches. A detailed performance comparison is presented in Table 2, which comprehensively evaluates various face recognition methods based on key performance metrics: accuracy, precision, and F-score, using the ORL dataset. These metrics collectively assess each method’s effectiveness in correctly identifying faces, minimizing false positives, and achieving a balanced trade-off between precision and recall.
As shown in Table 2, the accuracy, precision, and F-score achieved by our proposed method on the ORL dataset exceed 98%. These results underscore the robustness and effectiveness of the proposed model, displaying consistently high performance across all key evaluation metrics. The performance of traditional methods, such as HOG features combined with an SVM classifier, shows limitations, with accuracy, precision, and F-score at 86.13%, 87.43%, and 86.88%, respectively. Similarly, the PCA and DCT based approach achieves slightly better results, with 89.13% accuracy, 89.67% precision, and 89.09% F-score. These methods, while foundational, struggle to effectively capture complex facial features, resulting in relatively lower performance.
Modern approaches demonstrate significant improvements. Face recognition using Gabor features, PCA, and SVM shows enhanced feature extraction capabilities, achieving 91.95% accuracy, 92.46% precision, and 91.99% F-score.
An even greater leap in performance is seen with the integration of compressive sensing, curvelet transform, and PCA, which records 93.44% accuracy, 94.53% precision, and 94.36% F-score. These advancements highlight the benefits of combining multiple feature extraction techniques. Deep learning-based methods emerge as top performers. A CNN-based face recognition model achieves 94.32% accuracy, 94.95% precision, and 94.83% F-score, highlighting its robust capability in feature extraction and classification.
Similarly, face recognition using general deep learning algorithms records slightly higher metrics, with 94.89% accuracy, 94.97% precision, and 95.12% F-score, underscoring the effectiveness of deep neural networks in handling complex datasets.
The proposed method surpasses all other approaches, achieving remarkable performance with 98.46% accuracy, 98.84% precision, and 98.36% F-score. This significant improvement highlights its robustness, high accuracy, and efficient classification capabilities. The integration of innovative techniques within the proposed model establishes a new benchmark, demonstrating its superiority over both traditional and modern face recognition methods.
In conclusion, while traditional methods provide a strong foundation, modern techniques like curvelet transforms, CNNs, and deep learning have significantly advanced the field. The proposed method exemplifies how leveraging cutting-edge algorithms can yield near-perfect recognition performance, making it a reliable choice for face recognition tasks, particularly in challenging datasets like ORL.
In addition to the three common methods, we also compared our approach to the recently proposed face recognition method presented by Xu and Cheng [40], and Al Rayes et al. [24]. This comparison is conducted on the Yale-B cropped database to evaluate the performance and robustness of our technique relative to state-of-the-art approaches.
Table 3 compares various face recognition methods on the Yale-B cropped database, highlighting their performance based on key evaluation metrics, including accuracy, precision, and F-score. The comparison results show that traditional methods, such as HOG features combined with an SVM classifier, achieve moderate performance, with an accuracy of 85.44%, precision of 86.56%, and an F-score of 85.82%.
While this approach lays the groundwork for feature-based face recognition, it is limited in its ability to handle variations in lighting, pose, and facial expressions, resulting in lower overall performance compared to modern techniques.
The PCA and DCT-based approach for face recognition slightly improves on the performance, recording 88.34% accuracy, 87.96% precision, and 87.59% F-score. By leveraging dimensionality reduction and feature extraction, this method offers better results than the HOG-SVM approach, but it still falls short when dealing with more complex face recognition challenges. Advanced methodologies demonstrate significant improvements. Face recognition using Gabor features, PCA, and SVM achieves 92.46% accuracy, 91.76% precision, and 90.64% F-score, reflecting the effectiveness of Gabor filters in capturing discriminative facial features. However, its performance is slightly lower than more sophisticated approaches, indicating the need for enhanced feature fusion and classification techniques.
The correlation coefficient and ensemble-augmented sparsity-based method delivers even better results, with 93.82% accuracy, 94.72% precision, and 94.56% F-score. This approach benefits from the integration of ensemble techniques, which improve robustness and handle variations in the dataset more effectively. Similarly, the method based on the integration of Local Binary Patterns (LBP) with transfer learning achieves impressive results, recording 94.66% accuracy, 94.82% precision, and 94.96% F-score, highlighting the advantages of combining texture-based features with deep learning-based transfer learning for improved recognition.
The integration of advanced feature extraction, robust classification techniques, and efficient processing enables the model to outperform all other methods. In conclusion, while traditional and intermediate methods provide foundational insights into face recognition, modern approaches leveraging ensemble techniques, transfer learning, and advanced feature extraction have significantly enhanced performance. The proposed method sets a new benchmark for face recognition on the Yale-B cropped dataset, demonstrating its robustness, accuracy, and generalization capabilities. Fig. 9 shows an example of face recognition result obtained by the proposed method.
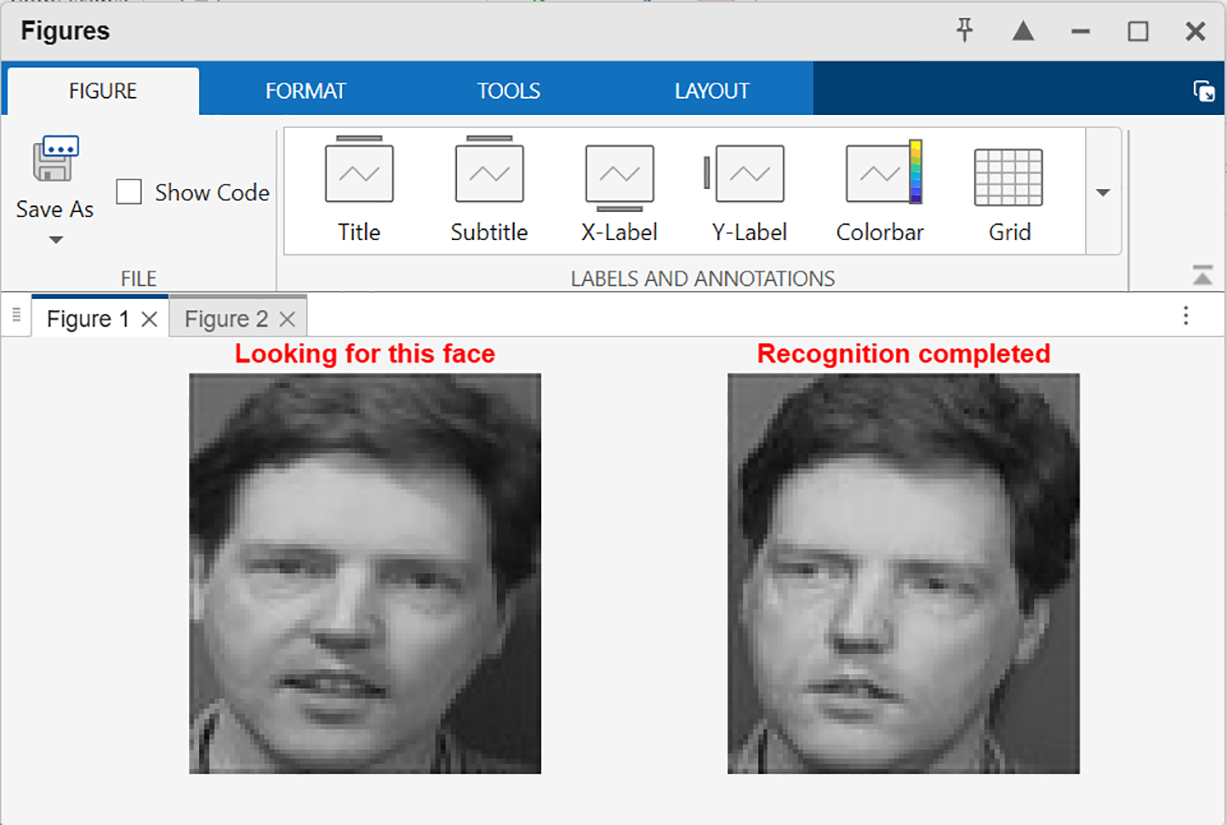
Figure 9: Example of Face recognition result.
The correlation coefficient and ensemble-augmented sparsity-based method delivers even better results, with 93.82% accuracy, 94.72% precision, and 94.56% F-score. This approach benefits from the integration of ensemble techniques, which improve robustness and handle variations in the dataset more effectively.
The proposed method achieves the highest performance, with an outstanding 98.34% accuracy, 98.42% precision, and 98.22% F-score. This demonstrates the superior capability of the proposed approach in effectively extracting and classifying facial features, even under challenging conditions.
To further demonstrate the robustness of the proposed method under noisy conditions, Fig. 10 presents examples from the ORL dataset corrupted with two types of noise: (a) salt-and-pepper noise with a density of

Figure 10: (a) Original image, (b) Original image disturbed with a “salt and pepper” noise, (c) Original image disturbed with a “Gaussian” noise.
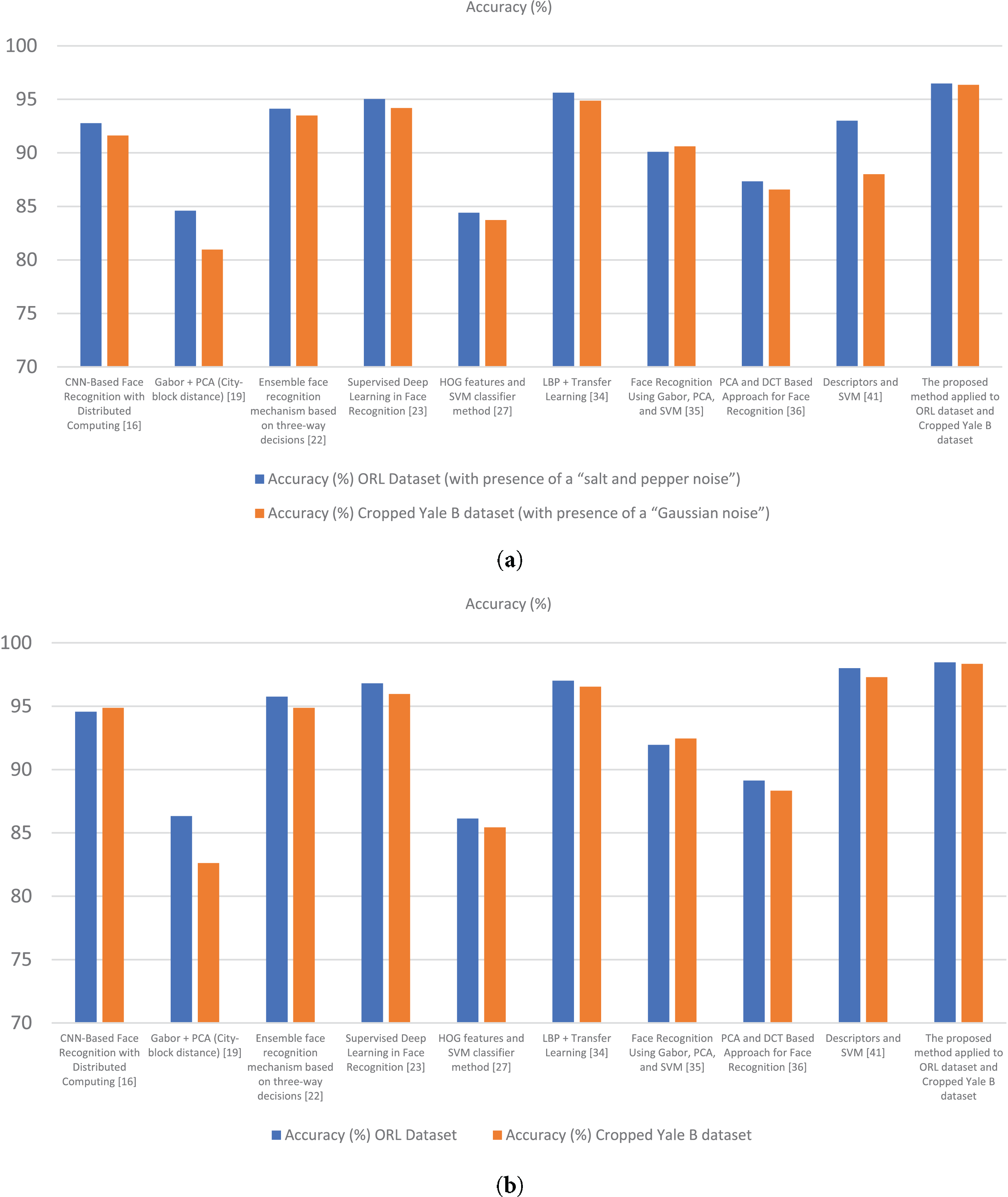
Figure 11: Accuracy comparison of face recognition methods for ORL and Cropped Yale B datasets, (a) Accuracy with noise (Salt & Pepper for ORL, Gaussian for Cropped Yale B) (b) Accuracy without noise [16,19,22,23,27,34–36,41].
As shown in Table 4 and Fig. 11, the proposed method achieved 96.49% accuracy on the ORL dataset with salt-and-pepper noise and 96.37% accuracy on the Cropped Yale B dataset with Gaussian noise, which are significantly higher than those obtained by competing methods. This confirms that the integration of complementary feature descriptors with Dempster–Shafer evidence theory provides strong resilience against common noise disturbances, ensuring reliable recognition performance even under degraded imaging conditions.
The presence of noise significantly affects the accuracy of face recognition methods. For the ORL dataset with “salt and pepper noise”, the HOG features and SVM classifier method achieves an accuracy of 84.40%, while for the Cropped Yale B dataset with “Gaussian noise”, its accuracy drops slightly to 83.73%.
Similarly, methods like Supervised Deep Learning in Face Recognition [23] and PCA and DCT-Based Approach [36] show a noticeable decline in performance under noisy conditions, with accuracies ranging from 84.51% to 95.03% on the ORL dataset and 86.57% to 94.20% on the Cropped Yale B dataset. This indicates that traditional and intermediate methods are moderately sensitive to noise, as they rely heavily on unaltered feature extraction.
The Gabor + PCA (City-block distance) [19] method also demonstrates reduced accuracy under noise, with 84.59% on the ORL dataset and 80.96% on the Cropped Yale B dataset. Despite leveraging Gabor filters, this approach struggles with noisy data, indicating the need for enhanced preprocessing techniques to handle such conditions. In contrast, the proposed method achieves outstanding accuracy under noise conditions, recording 96.49% on the ORL dataset and 96.37% on the Cropped Yale B dataset. This robustness highlights the effectiveness of its noise-resilient feature extraction and classification strategies. Under noise-free conditions, all methods show improved accuracy; however, significant performance gaps remain among them.
The HOG features combined with an SVM classifier [36] method achieves 86.13% accuracy on the ORL dataset and 85.44% on the Cropped Yale B dataset, indicating limited scalability in more complex datasets. Similarly, the PCA and DCT-Based Approach improves to 89.13% and 88.34% on the ORL and Cropped Yale B datasets, respectively, demonstrating a modest increase but still falling behind more advanced methods.
The Face Recognition Using Gabor, PCA, and SVM method [35] shows stronger results, with 91.95% accuracy on the ORL dataset and 92.46% on the Cropped Yale B dataset. This highlights the advantage of combining Gabor filters with PCA for feature extraction and SVM for classification. However, even this approach lags behind more sophisticated models.
The proposed method sets itself apart with the highest accuracy, achieving 98.46% on the ORL dataset and 98.34% on the Cropped Yale B dataset. Its ability to consistently outperform other methods, even in the absence of noise, underscores its superior design and feature-handling capabilities.
In addition to the models compared above, it is worth noting that ensemble-based approaches have recently shown promising results in face recognition tasks. For instance, Shah et al. [22] introduced an ensemble mechanism based on three-way decisions that demonstrated improved adaptability in uncertain recognition scenarios. Likewise, Al Rayes et al. [24] achieved robust performance under challenging lighting conditions by combining LBP with transfer learning. Although these methods provide valuable insights, our proposed approach outperforms them by integrating complementary handcrafted descriptors with the Dempster-Shafer Evidence Theory, thereby offering both high accuracy and strong resilience to uncertainty.
The proposed method demonstrates consistently superior performance across both datasets and under varying noise conditions. For the ORL dataset with salt-and-pepper noise, it achieves an accuracy of 96.49%, outperforming recent ensemble-based approaches [22] (94.12%) as well as deep learning-based methods [23,24] (95.03% and 95.62%, respectively). Similarly, on the Cropped Yale B dataset with Gaussian noise, the proposed method attains 96.37%, exceeding state-of-the-art techniques and highlighting its robustness to noisy environments. Under noise-free conditions, the method achieves 98.46% on the ORL dataset and 98.34% on the Cropped Yale B dataset, further demonstrating its high accuracy and reliability. By comparison, the LBP + Transfer Learning approach [24] achieves 97.02% and 96.54%, which, while strong, remains below the performance of the proposed method, indicating the clear advantage of integrating complementary feature descriptors with Dempster-Shafer Evidence Theory.
Recent approaches also show notable improvements over traditional methods. The ensemble three-way decision mechanism [22] significantly enhances performance by leveraging uncertainty-aware ensemble strategies, while supervised deep learning [23] and LBP + transfer learning [24] achieves competitive results, particularly in noise-free scenarios. However, their performance declines slightly under noisy conditions, whereas the proposed method maintains high accuracy and robustness. In contrast, classical methods such as HOG + SVM and PCA + DCT exhibit moderate performance and greater sensitivity to noise. Overall, combining handcrafted complementary features with Dempster-Shafer fusion, as implemented in the proposed approach, achieves the optimal balance of accuracy, precision, and resilience. These results establish a new benchmark for facial recognition in both controlled and noisy environments, demonstrating the method’s suitability for applications such as smart parking systems and other real-world security scenarios.
While traditional and intermediate methods provide foundational approaches for face recognition, their sensitivity to noise limits their practicality in real-world applications. Advanced methods like Gabor-PCA and deep learning offer improved accuracy but still exhibit some susceptibility to challenging conditions. The proposed method excels in both noisy and noise-free scenarios, setting a new benchmark for face recognition tasks. Its robustness and high accuracy make it a reliable solution for diverse and complex datasets.
While the experimental results demonstrate that the proposed method achieves superior recognition accuracy on benchmark datasets, certain limitations must be acknowledged. In real-world deployments, the system may encounter challenges such as variations in image quality, low-resolution inputs, motion blur, and uncontrolled environmental factors including illumination changes or weather conditions in outdoor settings. Additionally, since the approach relies on handcrafted feature extraction methods (FG-2DFLD, G2DLDA, and Modular-LBP), it may be less adaptive than deep learning-based models when handling very large-scale or highly heterogeneous datasets. These factors could affect overall robustness and scalability in practical applications. Nevertheless, the integration of Dempster-Shafer Evidence Theory provides resilience against uncertainty and partial information, which helps mitigate some of these drawbacks. Future work will focus on optimizing the method for real-time scenarios and exploring hybridization with deep learning techniques to enhance adaptability and scalability in more diverse operational environments.
This paper introduces a novel hybrid method for face recognition that combines feature vectors generated by Fuzzy-Gabor 2D Fisher Linear Discriminant (FG-2DFLD), Generalized 2D Linear Discriminant Analysis (G2DLDA), and Modular-Local Binary Patterns (LBP), integrated through the Dempster-Shafer (DS) evidence theory. Unlike conventional approaches that rely on a single descriptor, the proposed method leverages the complementary strengths of multiple feature extractors, using them as the foundation for classification within the DS framework.
Experimental results demonstrate the effectiveness of the proposed facial recognition method under both clean and noisy conditions, achieving accuracy rates of 98.46% on the ORL dataset and 98.34% on the Cropped Yale B dataset. These results highlight its robustness against challenges such as “salt and pepper noise” and “Gaussian noise”. The integration of FG-2DFLD, G2DLDA, and Modular-LBP with DS theory significantly enhances resilience to noise, preserves discriminative structures, and improves classification precision, outperforming traditional, intermediate, and even state-of-the-art approaches. Its scalability and reliability make it suitable for deployment in sensitive domains such as restricted areas, military facilities, and intelligent parking systems.
In addition to the technical contributions, it is important to recognize the ethical considerations associated with deploying facial recognition technology. Concerns such as privacy, potential misuse, data protection, and demographic bias have been widely discussed in recent literature. In this work, the proposed system is designed specifically for restricted-zone applications such as smart parking facilities or secure access points, where individuals’ consent and authorization are prerequisites for enrollment, thereby reducing risks of misuse. To further safeguard personal data, best practices such as secure storage, encryption of facial templates, and compliance with international privacy regulations should be followed in real-world deployments. It is also essential to evaluate recognition performance across diverse demographic groups to mitigate potential bias and ensure fairness. Finally, it should be noted that all experiments in this study were conducted using publicly available benchmark datasets, ensuring that no sensitive personal information was compromised during model development and testing.
Although the proposed method achieves superior results, it may still face challenges when dealing with low-resolution images, motion blur, and severe occlusions, particularly when multiple adverse factors occur simultaneously. In addition, scalability to very large and heterogeneous datasets may be limited due to the reliance on handcrafted descriptors. To address these issues, future research will focus on optimizing the method for real-time facial recognition systems to ensure low latency and high throughput, while also hybridizing it with deep learning techniques to improve robustness. Validation will be extended to larger and more diverse benchmark datasets such as LFW, FERET, and CASIA-WebFace, which include broader variations in age, facial expressions, demographics, and environmental conditions. This will enable a more comprehensive evaluation of the proposed approach under unconstrained and dynamic real-world scenarios.
Acknowledgement: The authors would like to express their sincere gratitude to the University of Tabuk for its continuous support and valuable resources that contributed to the successful completion of this work.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Rafika Harrabi and Slim Ben Chaabane have conceptualized the study, developed the methodology, performed the experiments, and wrote the initial draft of the manuscript. Hassene Seddik provided feedback to refine the approach, involved in the review and editing process and supervised the research work. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: Data is available from the corresponding author upon request.
Ethics Approval: Ethics approval and consent to participate were not applicable as this research did not involve human or animal participants.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Fallahi M, Arias-Cabarcos P, Strufe T. On the usability of next-generation authentication: a study on eye movement and brainwave-based mechanisms. In: Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems; 2024 May 11–16; Honolulu, HI, USA. p. 1–14. [Google Scholar]
2. Salagean GL, Leba M. Face recognition: a literature review. In: Proceedings of the 7th International Scientific Conference ITEMA Recent Advances in Information Technology, Tourism, Economics, Management and Agriculture; 2023 Oct 26; Varaždin, Croatia. p. 55–60. [Google Scholar]
3. Hamidi H. An approach to develop the smart health using Internet of Things and authentication based on biometric technology. Future Gener Comput Syst. 2019;91:434–49. doi:10.1016/j.future.2018.09.024. [Google Scholar] [CrossRef]
4. Kardile HA. Face recognition using PCA and eigen face approach. Int Res J Eng Technol. 2017;4(12):460–3. [Google Scholar]
5. Gupta P. Deep neural network for human face recognition. Int J Eng Manuf. 2018;8(1):63–71. doi:10.5815/ijem.2018.01.06. [Google Scholar] [CrossRef]
6. Cui WX, Zhan W, Yu JJ, Sun CF, Zhang YY. Face recognition via convolutional neural networks and Siamese neural networks. In: Proceedings of the International Conference on Intelligent Computing, Automation and Systems (ICICAS); 2019 Dec 6–8; Chongqing, China. p. 746–50. [Google Scholar]
7. Kortli Y, Jridi M, Falou AA, Atri M. Face recognition systems: a survey. Sensors. 2020;20(2):342–62. doi:10.3390/s20020342. [Google Scholar] [PubMed] [CrossRef]
8. Srivastava A, Mane S, Shah A, Shrivastava N, Thakare B. A survey of face detection algorithms. In: Proceedings of the 2017 International Conference on Inventive Systems and Control (ICISC); 2017 Jan 19–20; Coimbatore, India. p. 1–4. [Google Scholar]
9. Lenc L, Král P. Automatic face recognition system based on the SIFT features. Comput Electr Eng. 2015;46:256–72. doi:10.1016/j.compeleceng.2015.01.014. [Google Scholar] [CrossRef]
10. Shaukat A, Aziz M, Akram U. Facial expression recognition using multiple feature sets. In: Proceedings of the 2015 5th International Conference on IT Convergence and Security (ICITCS); 2015 Aug 24–27; Kuala Lumpur, Malaysia. p. 1–5. [Google Scholar]
11. Narayana KV, Manoj V, Swathi K. Enhanced face recognition based on PCA and SVM. Int J Comput Appl. 2015;117(2):40–2. doi:10.5120/20530-2871. [Google Scholar] [CrossRef]
12. Li XY, Lin ZX. Face recognition based on HOG and fast PCA algorithm. In: Proceedings of the Fourth Euro-China Conference on Intelligent Data Analysis and Applications; 2017 Oct 9–11; Málaga, Spain. p. 10–21. [Google Scholar]
13. Chaabane SB, Hijji M, Harrabi R, Seddik H. Face recognition based on statistical features and SVM classifier. Multimed Tools Appl. 2022;81(6):8767–84. doi:10.1007/s11042-021-11816-w. [Google Scholar] [CrossRef]
14. Jalaja V, Anjaneyulu GSGN. Face recognition by using eigen face method. Int J Sci Technol Res. 2020;9(3):1–6. [Google Scholar]
15. Pooja R. Face recognition using feed forward neural network. IOSR J Comput Eng. 2015;17(5):61–5. [Google Scholar]
16. Liu Y, Zhang L, Zhang D. Face recognition method based on convolutional neural network and distributed computing; 2025. [cited 2025 Jan 1]. Available from: https://www.degruyterbrill.com/document/doi/10.1515/jisys-2024-0121/html. [Google Scholar]
17. Panchal P, Mewada H. Robust illumination and pose invariant face recognition system using support vector machines. Int J Appl Eng Res. 2018;13(16):12689–701. doi:10.5772/8934. [Google Scholar] [CrossRef]
18. Bhuiyan MAA. Towards face recognition using eigenface. Int J Adv Comput Sci Appl. 2016;7(5):25–31. doi:10.14569/ijacsa.2016.070505. [Google Scholar] [CrossRef]
19. Garg S, Mittal S, Kumar P. Performance analysis of face recognition techniques for feature extraction. J Comput Theor Nanosci. 2019;16(9):3830–4. doi:10.1166/jctn.2019.8257. [Google Scholar] [CrossRef]
20. ElDahshan KA, Elsayed EK, Aboshoha A, Ebeid EA. Applying quantum algorithms for enhancing face authentication. Al Azhar Bull Sci. 2017;9:83–93. [Google Scholar]
21. El Dahshan KA, Elsayed EK, Aboshoha A, Ebeid EA. Recognition of facial emotions relying on deep belief networks and quantum particle swarm optimization. Int J Intell Eng Syst. 2020;13(4):90–101. doi:10.22266/ijies2020.0831.09. [Google Scholar] [CrossRef]
22. Shah A, Ali B, Habib M, Frnda J, Ullah I, Shahid Anwar M. An ensemble face recognition mechanism based on three-way decisions. J King Saud Univ Comput Inf Sci. 2023;35(4):196–208. doi:10.1016/j.jksuci.2023.03.016. [Google Scholar] [CrossRef]
23. Wani MA, Bhat FA, Afzal S, Khan AI. Supervised deep learning in face recognition. In: Advances in deep learning. Singapore: Springer Singapore; 2019. p. 95–110. doi:10.1007/978-981-13-6794-6_6. [Google Scholar] [CrossRef]
24. Al Rayes L, Haggag M, Alsmirat M. Leveraging local binary patterns with transfer learning for face recognition in low-light conditions. In: Proceedings of the 2024 International Conference on Multimedia Computing, Networking and Applications (MCNA); 2024 Sep 17–20; Valencia, Spain. p. 28–34. [Google Scholar]
25. Ghosh M, Dey A, Kahali S. A weighted fuzzy belief factor-based DS evidence theory of sensor data fusion method and its application to face recognition. Multimed Tools Appl. 2024;83(4):10637–59. doi:10.1007/s11042-023-16037-x. [Google Scholar] [CrossRef]
26. Zhang Y, Liu Y, Chao HC, Zhang Z, Zhang Z. Classification of incomplete data based on evidence theory and an extreme learning machine in wireless sensor networks. Sensors. 2018;18(4):1046. doi:10.3390/s18041046. [Google Scholar] [PubMed] [CrossRef]
27. Feng T, Ma H, Cheng X. Land-cover classification of high-resolution remote sensing image based on multi-classifier fusion and the improved Dempster-Shafer evidence theory. J Appl Remote Sens. 2021;15(1):014506. doi:10.1117/1.JRS.15.014506. [Google Scholar] [CrossRef]
28. Wang S, Tang Y. An improved approach for generation of a basic probability assignment in the evidence theory based on Gaussian distribution. Arab J Sci Eng. 2022;47(2):1595–607. doi:10.1007/s13369-021-06011-w. [Google Scholar] [CrossRef]
29. Kobayashi M, Nishiwaki Y, Shimizu Y, Takaoka N. Maximum likelihood estimation of mean functions for Gaussian processes under small noise asymptotics. arXiv:2507.05628. 2025. [Google Scholar]
30. Chen L, Zhang Z, Yang G, Zhou Q, Xia Y, Jiang C. Evidence-theory-based reliability analysis from the perspective of focal element classification using deep learning approach. J Mech Des. 2023;145(7):071702. doi:10.1115/1.4062271. [Google Scholar] [CrossRef]
31. Albakri IMR, Ahmad MI, Md Isa MN, Al-Dabagh MZN. Face recognition based on fusion feature extraction algorithms. In: Proceedings of the 2024 International Conference on Emerging Smart Computing and Informatics (ESCI); 2024 Mar 5–7; Pune, India. p. 1–5. [Google Scholar]
32. Alqudah A, Qazan S, Alquran H, Qasmieh I, Alqudah A. COVID-19 detection from X-ray images using different artificial intelligence hybrid models. Jordan J Electr Eng. 2020;6(2):168. doi:10.5455/jjee.204-1585312246. [Google Scholar] [CrossRef]
33. Alquran H, Alsalatie M, Mustafa WA, Al Abdi R, Ismail AR. Cervical net: a novel cervical cancer classification using feature fusion. Bioengineering. 2022;9(10):578. doi:10.3390/bioengineering9100578. [Google Scholar] [PubMed] [CrossRef]
34. Li M, Yu X, Ryu KH, Lee S, Theera-Umpon N. Face recognition technology development with Gabor, PCA and SVM methodology under illumination normalization condition. Clust Comput. 2018;21(1):1117–26. doi:10.1007/s10586-017-0806-7. [Google Scholar] [CrossRef]
35. Varyani M, Narware P, Banafar LS. PCA and DCT based approach for face recognition. J Trend Sci Res Dev. 2019;3(3):1286–90. doi:10.31142/ijtsrd23283. [Google Scholar] [CrossRef]
36. Biswas S. Performance improvement of face recognition method and application for the COVID-19 pandemic. Acta Polytech Hung. 2022;19(7):47–67. doi:10.12700/aph.19.7.2022.7.3. [Google Scholar] [CrossRef]
37. Kak SF, Mustafa FM, Varol A. Design and enhancement of a CNN model to augment the face recognition accuracy. In: Proceedings of the 2022 3rd International Informatics and Software Engineering Conference (IISEC); 2022 Dec 15–16; Ankara, Turkey. p. 1–5. [Google Scholar]
38. Atay M, Poudyel M. Evaluating impact of wearing masks in face recognition using deep learning algorithms. In: Proceedings of the 2023 International Conference on Machine Learning and Applications (ICMLA); 2023 Dec 15–17; Jacksonville, FL, USA. p. 1438–43. [Google Scholar]
39. Meena MK, Meena HK. Occluded face recognition using non-global features extraction and K-means clustering algorithm. In: Data science and applications. Singapore: Springer Nature Singapore; 2024. p. 257–68. doi:10.1007/978-981-99-7820-5_21. [Google Scholar] [CrossRef]
40. Xu Y, Cheng J. Face recognition algorithm based on correlation coefficient and ensemble-augmented sparsity. IEEE Access. 2020;8:183972–82. doi:10.1109/ACCESS.2020.3028905. [Google Scholar] [CrossRef]
41. Harrabi R. A hybrid face recognition method based on face feature descriptors and support vector machine classifier. Int J Image Process. 2022;16(1). doi:10.1109/ivcnz.2009.5378368. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools