
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
SparseMoE-MFN: A Sparse Attention and Mixture-of-Experts Framework for Multimodal Fake News Detection on Social Media
1 College of Cryptography Engineering, Engineering University of People’s Armed Police, Xi’an, China
2 Key Laboratory of Network and Information Security, Engineering University of People’s Armed Police, Xi’an, China
* Corresponding Author: Mingshu Zhang. Email:
Computers, Materials & Continua 2026, 87(2), 70 https://doi.org/10.32604/cmc.2026.073996
Received 29 September 2025; Accepted 11 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Detecting fake news in multimodal and multilingual social media environments is challenging due to inherent noise, inter-modal imbalance, computational bottlenecks, and semantic ambiguity. To address these issues, we propose SparseMoE-MFN, a novel unified framework that integrates sparse attention with a sparse-activated Mixture-of-Experts (MoE) architecture. This framework aims to enhance the efficiency, inferential depth, and interpretability of multimodal fake news detection. SparseMoE-MFN leverages LLaVA-v1.6-Mistral-7B-HF for efficient visual encoding and Qwen/Qwen2-7B for text processing. The sparse attention module adaptively filters irrelevant tokens and focuses on key regions, reducing computational costs and noise. The sparse MoE module dynamically routes inputs to specialized experts (visual, language, cross-modal alignment) based on content heterogeneity. This expert specialization design boosts computational efficiency and semantic adaptability, enabling precise processing of complex content and improving performance on ambiguous categories. Evaluated on the large-scale, multilingualKeywords
The proliferation of multimodal content on social media platforms has greatly accelerated the spread of misinformation, posing an urgent threat to public discourse, public health, and safety. Unlike traditional fake news detection that relies solely on textual content, modern rumor detection requires joint reasoning across text, images, and social context to expose misleading or unverified information. Particularly on platforms like Weibo and Twitter, many rumors are visually driven–leveraging manipulated or out-of-context misleading images to enhance propagation, while associated text often employs vague, ambiguous, or deceptive statements [1]. This necessitates robust multimodal models capable of deeply understanding cross-modal relationships, detecting semantic contradictions, and identifying deceptive cues. Furthermore, the problem is exacerbated in multilingual and cross-cultural environments, where linguistic differences and distinct modal usage habits present significant challenges to model generalization. Despite significant advancements in multimodal deep learning in recent years, current rumor detection methods suffer from two key limitations:
1. Low Computational Efficiency and Sensitivity to Noise Interference: most existing studies employ early or late fusion strategies, merely concatenating visual and textual representations without targeted or selective reasoning on specific modal cues. Furthermore, these models often rely on Dense attention mechanisms lead to quadratic computational overhead and reduced robustness [2].
2. Lack of Adaptability to Heterogeneous Content: Another major limitation is the uniform processing approach of existing models towards different inputs. Current models often lack specialized designs, employing the same reasoning pipeline for inputs with significant differences, such as image-centric posts vs. text-centric posts. This results in suboptimal performance, particularly when handling unverified or weakly evidenced posts that require nuanced interpretation [3]. They typically adopt a unified processing strategy, making it difficult to effectively handle significant variations in the strength and quality of inter-modal signals. We propose a unified framework that combines a sparse improvement to the cross-attention mechanism with a Mixture-of-Experts (MoE) architecture [4]. Sparse attention mechanisms selectively focus on lengthy text and complex image regions, effectively reducing noise interference and lowering computational costs. Concurrently, sparse MoE dynamically allocates inputs to experts specialized in visual reasoning, language understanding, or cross-modal alignment based on input heterogeneity, achieving computational efficiency and robust semantic adaptability. This enables more precise processing of complex information involving heterogeneous content and ambiguous claims. This dual sparsity design not only ensures computational efficiency but also endows the model with strong semantic adaptability. Our research is grounded in real-world multimodal rumor data, utilizing the
• We propose SparseMoE-MFN, a novel multimodal architecture that combines a sparse attention mechanism with sparsely activated Mixture-of-Experts routing, enabling selective and adaptive multimodal reasoning and effectively addressing the shortcomings of existing methods in accuracy and interpretability.
• We design a modality-aware sparse attention module that reduces computational overhead while maintaining fine-grained reasoning across text and image regions. Experimental results demonstrate its significant effectiveness in suppressing noise and enhancing discrimination capabilities for ambiguous information.
• We introduce a cross-modal MoE routing mechanism that dynamically assigns inputs to specialized experts (visual, language, and alignment) through learned gating and load balancing. Experimental results show that this mechanism significantly improves the model’s ability to handle heterogeneous content and modality-inconsistent information.
2.1 Multimodal Rumor Detection
Rumor detection on social media has significantly evolved from early approaches focusing solely on textual analysis to current complex multimodal frameworks that consider both textual and visual cues. Early studies [7], primarily leveraged temporal and linguistic patterns within textual contexts, but these methods had limited capabilities when dealing with multimodal content, especially when visual misinformation became a critical factor [8]. Subsequent research introduced models with image perception capabilities, integrating visual features with textual representations for more comprehensive event-level analysis [9]. However, many of these models employed fixed or shallow fusion techniques, such as simple concatenation or attention-based late fusion, which often struggled to capture deeper cross-modal semantics, particularly in posts where either modality might convey misleading or inconsistent signals. To address the limitations of shallow fusion, hierarchical and graph-based approaches emerged, aiming to explicitly model the relationships between users, content, and modalities [10]. For instance, models like HFM and MVAE [11] utilized hybrid feature hierarchies or variational inference to better align multimodal signals. These models incorporated social context (e.g., propagation networks or comment chains) to infer credibility from indirect signals. Nevertheless, their architectural complexity often hindered scalability, and their performance on challenging categories like “unverified” remained suboptimal due to a lack of fine-grained modality control. Furthermore, most of these methods were designed for single-language (English or Chinese) datasets, limiting their effectiveness on multilingual rumor detection tasks like the
2.2 Large Vision-Language Models
Large Vision-Language Models (VLMs) have demonstrated significant effectiveness in various multimodal tasks in recent years, including image captioning, visual question answering, and instruction-following dialogues [16]. Models such as Flamingo [17], BLIP-2 [18], and LLaVA [19] have confirmed that aligning Large Language Models (LLMs) with visual representations can yield powerful and generalizable reasoning capabilities. Specifically, LLaVA-v1.6-Mistral-7B-HF [20], used in our framework, further extends this paradigm by integrating instruction fine-tuning with image-anchor generation, making it particularly suitable for tasks requiring factual consistency between text and visual modalities. Internally, LLaVA achieves dense Cross-Attention computation between image patches and text tokens through its Mistral decoder’s interleaved attention blocks, thereby enabling the encoding of contextual relationships between image regions and text phrases and generating joint representations that reflect fine-grained semantics. However, standard VLMs process all tokens and image patches uniformly via dense attention mechanisms, leading to high computational costs that are often unnecessary for the relatively short and noisy inputs common in rumor detection. Furthermore, these models typically lack architectural flexibility: they cannot differentiate between various types of vision-text reasoning tasks, such as detecting image tampering, evaluating ambiguous text statements, or verifying cross-modal consistency. This architectural rigidity limits their adaptability in dynamic or ambiguous scenarios where different input types require specialized interpretation strategies. Moreover, most pre-trained VLMs are trained on general web corpora, which may not capture the linguistic or cultural nuances inherent in fake news content. For instance, memes, satirical content, and propaganda on platforms like Weibo might differ significantly in style and intent from similar content on Twitter. Fine-tuning VLMs on domain-specific data, such as the
2.3 Sparse Attention and Mixture-of-Experts Mechanisms
The introduction of sparse attention mechanisms aims to alleviate the quadratic computational cost of standard Transformer attention and enhance focus on task-relevant tokens or regions. Typical examples include models like Routing Transformer, Longformer, BigBird, and more recently, SparseBERT and S2-Attention [22,23]. These models reduce computational burden while maintaining contextual coverage by employing sliding windows, global tokens, or learned routing patterns [24]. In the context of fake news detection, input text often contains redundant or irrelevant social media noise, making sparsity mechanisms beneficial for both efficiency and robustness. However, most existing sparse attention models are unimodal and not tailored for multimodal reasoning tasks, which require cross-attention computation between image patches and text tokens under uncertainty. Mixture-of-Experts (MoE) models offer a complementary form of sparsity by assigning different input samples or segments to specialized subnetworks, or “experts.” Pioneering work in this area includes GShard, Switch Transformer, and more recent models like SparseMoE and TaskMoE [25]. These models dynamically select a small subset of experts for each input, enabling scalability and task-specific specialization. However, existing research has rarely explored MoE applications in cross-modal scenarios, where inputs involve not only linguistic variations but also heterogeneous modalities such as images and metadata. Furthermore, standard MoE implementations applied to multimodal fusion tasks face challenges such as expert load imbalance, unstable convergence, and a lack of modality awareness. In our proposed model, we integrate these two orthogonal forms of sparsity—at the attention and expert levels—into a unified architecture specifically designed for rumor detection in complex social media environments. Our sparse attention module allows the model to disregard irrelevant content and focus on salient regions, such as tampered image areas or linguistically ambiguous statements. Concurrently, our sparse MoE routing mechanism assigns input representations to one of several cross-modal experts, including visual, textual, and alignment reasoning components. This dual sparsity not only enhances computational efficiency but also enables tailored, specialized reasoning paths for each instance, leading to superior performance, particularly in ambiguous and unverified cases.
3 Datasets, Baseline Models, and Evaluation Metrics
The empirical foundation of this study is the
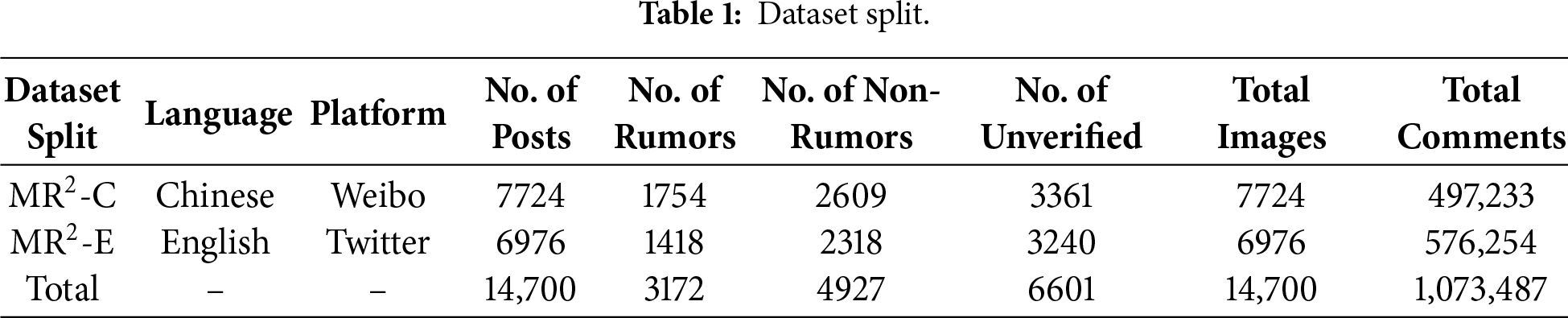
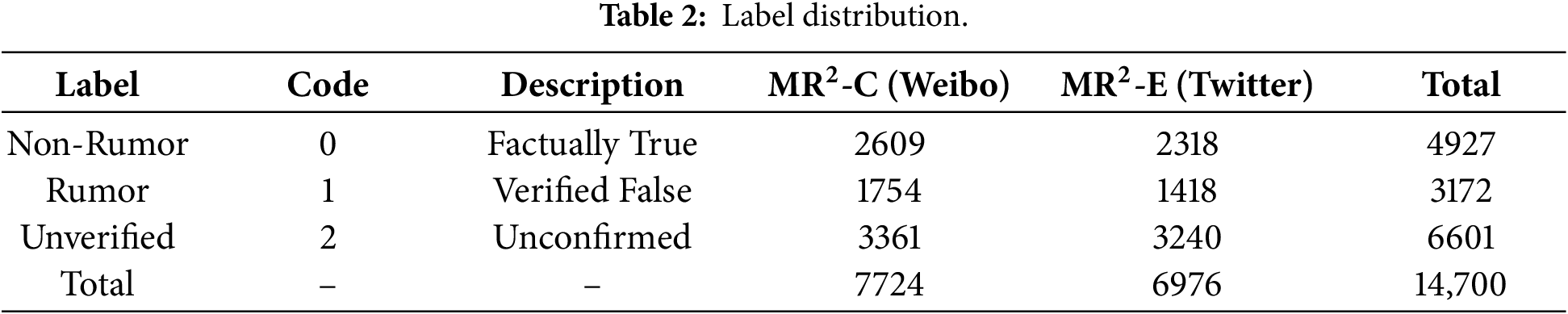
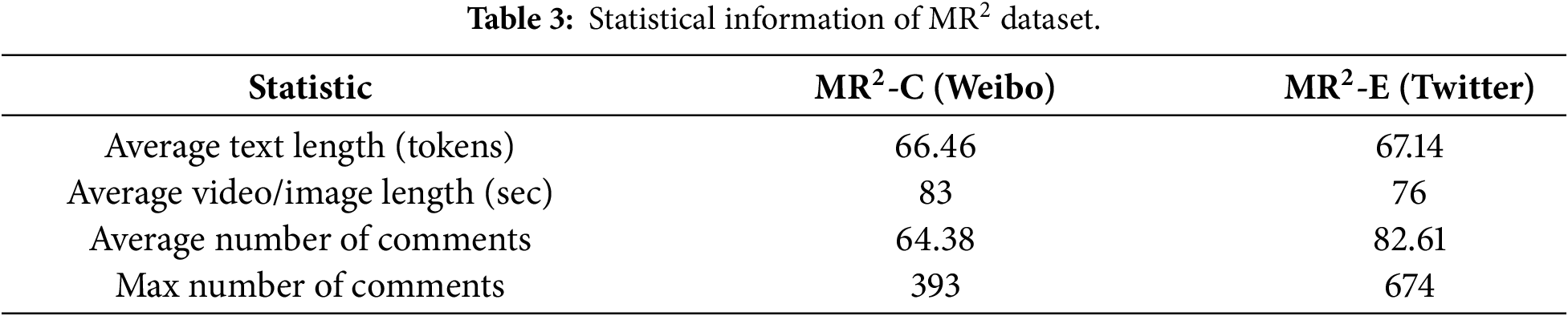
The social interaction structure within
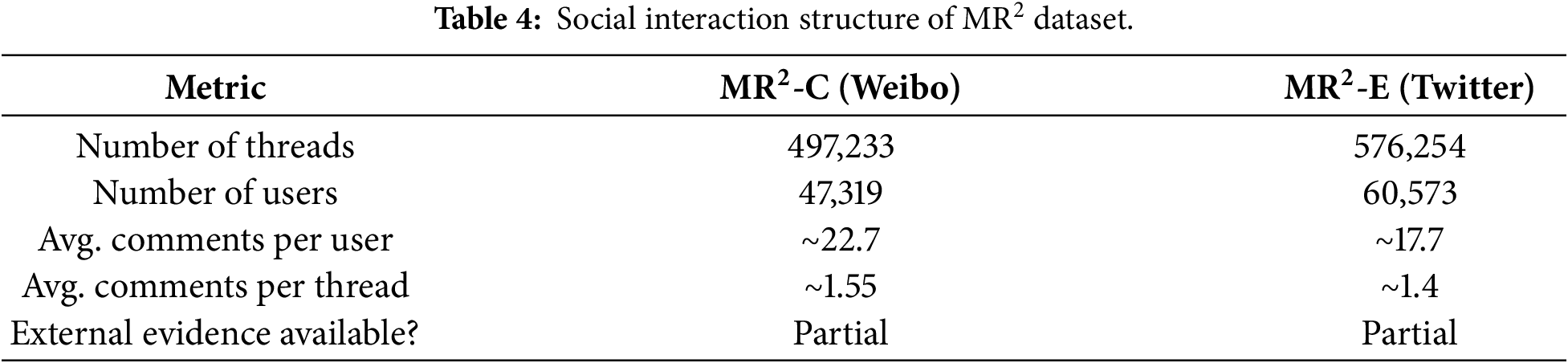
Formally, we define the multimodal rumor detection task as a supervised three-class classification problem. Each instance is represented as a triplet x = t, i, m, where t denotes the input text (in Chinese or English), i is the associated image, and m encompasses additional metadata such as timestamps, social interaction features, or auxiliary comments. The objective of this task is to predict a label
We benchmark our model against several state-of-the-art baseline models in the fields of multimodal rumor detection and vision-language alignment, including early fusion and hierarchical architectures (e.g., EANN [26], HFM [27], and MVAE), as well as recent pre-trained models [28] (e.g., LLaVA, Qwen2-7B [29], MiniGPT-4 [30], and UniVL [31]). To ensure a fair comparison, all models were trained on the same train/validation/test set splits and evaluated under identical preprocessing and tokenization pipelines [32]. In our model, LLaVA-v1.6-Mistral-7B-HF was employed as the backbone for the image-text encoder [33]. The visual module was frozen, and only the projection and alignment layers were fine-tuned [34]. For the text modality, Qwen-7B was used for Chinese and Qwen2-7B for English, which were further pre-trained on the
In terms of evaluation metrics, we report overall accuracy, macro-averaged F1-score, F1-scores for each of the three labels, and the Area Under the Receiver Operating Characteristic curve (AUROC) to reflect class discriminative performance [36]. To assess the impact of the sparsity mechanism on resource efficiency, we also record inference latency (in milliseconds per instance), peak GPU memory usage, and the number of floating-point operations (FLOPs) during evaluation [37]. These computational metrics are particularly important considering the increasing deployment of such models in real-time content moderation and misinformation filtering scenarios [38]. For models employing sparse attention or sparse MoE, we ensure that the FLOPs reflect the actual number of activated attention heads and experts, rather than the theoretical maximum of the architecture. All reported metrics are averaged over three random seeds, with 95% confidence intervals provided for the primary accuracy and F1-scores to ensure statistical reliability. This rigorous experimental setup provides a solid empirical foundation for evaluating the effectiveness and efficiency of the proposed SparseMoE-MFN architecture under both classification accuracy and deployment constraints [39].
Our proposed SparseMoE-MFN framework is built upon powerful pre-trained multimodal encoders, specifically designed to capture the inherent semantic, visual, and structural patterns within rumor-filled social media content. Specifically, we employ two dedicated backbone models: LLaVA-v1.6-Mistral-7B-HF serves as the visual encoder, focusing on extracting rich, fine-grained visual features from images to provide high-quality visual representations for subsequent cross-modal analysis. Its robust visual understanding capabilities enable a deep comprehension of image details, which is crucial for the precise processing of image information in multimodal fake news detection. Qwen/Qwen2-7B acts as the text encoder and understander. When processing news text, its powerful language processing capabilities allow for a deep understanding of textual meaning, analysis of semantic relationships and logical structures, thereby aiding in the discovery of textual misinformation clues. Notably, Qwen2-7B supports processing of ultra-long text inputs, which is extremely important for handling social media news texts of varying lengths, effectively avoiding information omission or comprehension bias in long texts and improving detection accuracy. Furthermore, it possesses excellent multilingual capabilities, with a particular strength in Chinese processing, enabling effective handling of multilingual news texts and expanding its applicability in multilingual social media environments. These encoders are integrated within a dual-branch architecture where each modality is first processed independently and then projected into a shared latent space for cross-modal fusion, achieved through sparse attention and expert routing. Let the original input be a tuple
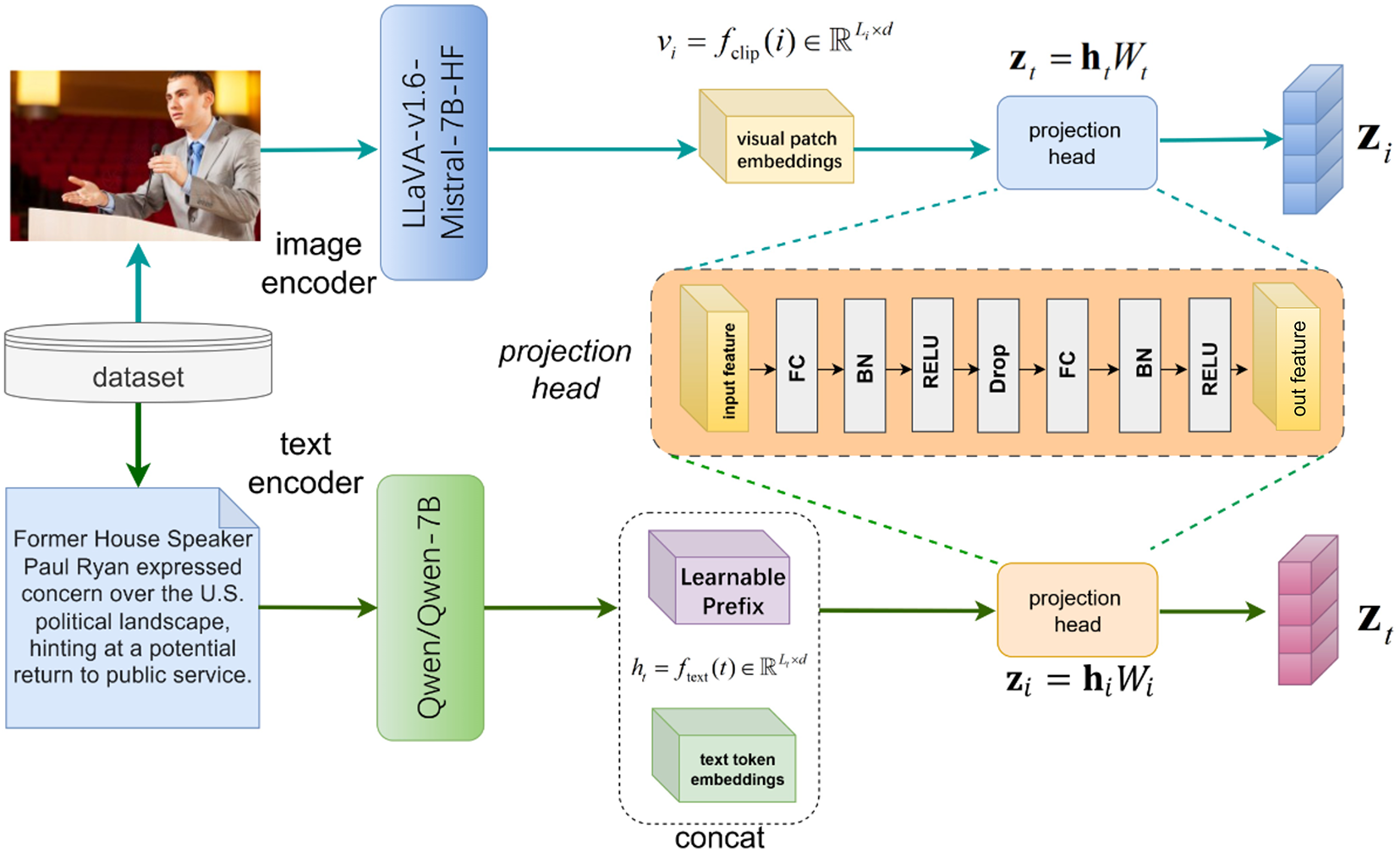
Figure 1: Schematic diagram of the backbone encoding module in this paper. The module mainly consists of three major parts: text encoding (generating contextual embeddings via Qwen/Qwen2-7B), image encoding (producing visual patch embeddings via LLaVA’s CLIP-ViT), and modality-aware projection (mapping features to a shared latent space with weighted pooling).
For text encoding, we utilize the Qwen-7B model for Chinese and the Qwen2-7B model for English, both represented by the transformer function
where
For image encoding, we leverage LLaVA-v1.6-Mistral-7B-HF, a vision-language model capable of aligning CLIP-based visual embeddings with linguistic reasoning. The visual encoder,
where
Subsequently, these text prompts interact with the visual patch embeddings
where
4.2 Sparse Cross-Modal Attention Mechanism
To address the issues of low computational efficiency and noise sensitivity raised previously, we introduce a cross-modal attention mechanism that sparsifies dense cross-attention. This mechanism dynamically focuses on the most relevant parts of the modalities, effectively filtering out noise and semantic redundancy, thereby reducing computational complexity and enhancing robustness. To efficiently model long-range cross-modal dependencies while alleviating interference from noisy or irrelevant tokens and image regions, we leverage the capability of cross-attention in fusing multimodal information and propose a sparse cross-modal attention mechanism specifically designed for the characteristics of multimodal social media posts. Fig. 2 provides a detailed schematic of this mechanism. Traditional dense attention mechanisms have a quadratic relationship between computational cost and input length, making them unsuitable for the highly variable and often noisy real-world inputs, especially in the presence of lengthy comment threads or complex visual scenes. Inspired by Routing Attention and Longformer, our method integrates modality-aware sparsity into both self-attention and cross-attention layers. Let
where
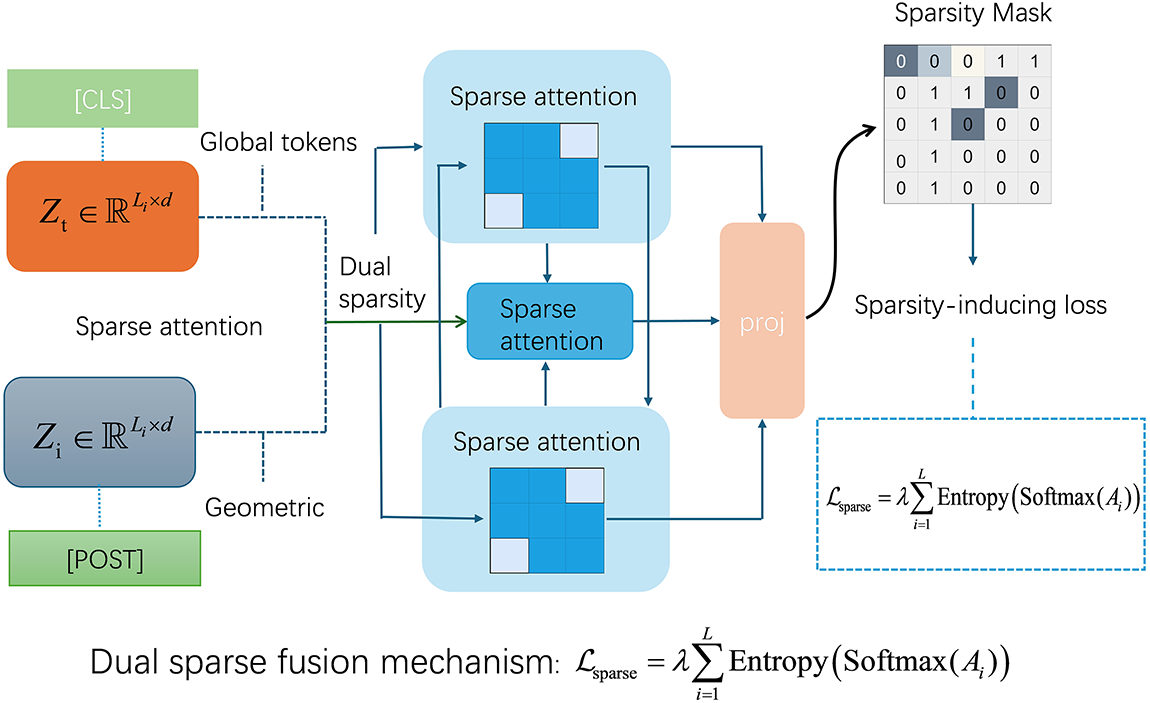
Figure 2: Schematic diagram of the sparse cross-modal attention mechanism in this paper. The mechanism mainly consists of three major parts: dual sparse fusion (text-to-image and image-to-text attention flows), global token integration (preserving long-range dependencies), and sparsity regularization (via learnable masks and entropy loss).
To further support multimodal interaction in scenarios with information asymmetry, we introduce a dual sparse fusion mechanism where visual and text tokens alternately serve as queries and keys. Specifically, we compute two symmetric sparse attention flows: text-to-image
The final multimodal representation is obtained by concatenating these outputs and applying a linear projection:
This bidirectional mechanism is particularly beneficial for posts with weak visual associations or ambiguous textual descriptions, such as sarcastic memes or speculative captions. Furthermore, we incorporate global tokens (e.g., [CLS] or [POST]) that receive full attention from both modalities, enabling the propagation of long-range dependencies even under local sparsity constraints.
To regularize the attention topology and further reduce redundancy, we integrate a learnable sparse mask
where
To address the issue of poor adaptability to heterogeneous content raised previously, we introduce a sparse Mixture-of-Experts (MoE) routing mechanism. This mechanism dynamically assigns processing tasks to specialized experts based on the specific content of the input (visual, textual, or a mixture of both), thereby achieving model semantic specialization and efficient utilization.
To effectively disentangle and process the heterogeneous signals present in multimodal fake news instances, we introduce a sparse Mixture-of-Experts (MoE) routing mechanism that dynamically activates a set of specialized expert modules. Unlike traditional dense MoE systems where all experts are invoked regardless of input semantics, our routing strategy is query-adaptive and sparsely selected, balancing computational efficiency with semantic specialization. The overall framework, including the MoE routing, is depicted in Fig. 3.
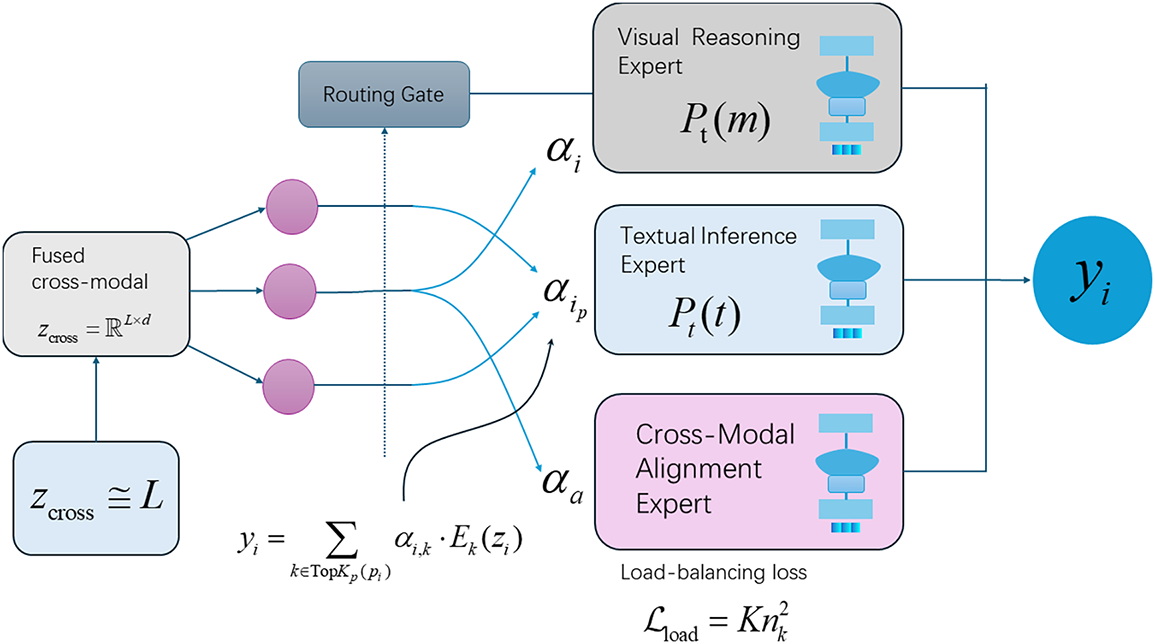
Figure 3: Schematic diagram of the proposed SparseMoE-MFN framework in this paper. SparseMoE-MFN mainly consists of three major parts: backbone encoding (processing text and image modalities via specialized encoders), sparse cross-modal attention (mod eling cross-modal dependencies with structured sparsity), and sparse MoE expert routing (dynamically assigning inputs to modality-specialized experts).
Each expert in the model is designed to handle specific modality-driven reasoning functions: visual reasoning, textual reasoning, or cross-modal alignment. The visual expert focuses on extracting key visual cues from images. The language expert concentrates on understanding textual nuances, including potential ambiguities or misleading statements. The alignment expert is responsible for detecting inconsistencies or contradictions between the image and text, which is particularly helpful in handling mismatched modal signals in the “unverified” class.
This specialized design of experts, combined with the dynamic routing mechanism, allows the model to automatically adjust its reasoning strategy based on the input content. For instance, posts primarily featuring manipulated images would be preferentially routed to the visual expert, while ambiguous text would be directed to the language expert. Especially when dealing with ambiguous information in the “unverified” category, the alignment expert can effectively identify potential deception due to image-text incongruence, thereby compensating for the shortcomings of unimodal or early-fusion models in such tasks.
To promote diverse expert utilization and prevent expert collapse, we introduce a load balancing loss that minimizes the variance in routing frequencies across the expert pool. Formally, as described in the introduction, this loss objective encourages the routing strategy to maintain a uniform expert selection pattern, ensuring that all modal information is fully utilized and avoiding over-reliance on certain experts while neglecting other critical cues. This loss, along with standard classification and alignment losses, constitutes the final optimization objective.
Given the fused cross-modal representation obtained from the sparse attention module, we define a gating function
To enforce sparsity, we retain only the top-k experts with the highest scores for each token (typically
where
To promote diverse expert utilization and prevent expert collapse, we introduce a load balancing loss that minimizes the variance in routing frequencies across the expert pool. Formally, let
We define the load balancing objective as:
This objective encourages the routing strategy to maintain a uniform expert selection pattern, thereby reducing overfitting to dominant pathways. This loss, along with standard classification and alignment losses, constitutes the final optimization objective. Notably, our routing gate is trained end-to-end using a straight-through estimator, enabling gradient backpropagation through the TopK selection for discrete choices and gradient-based adaptive optimization.
Each expert within the SparseMoE module is designed to handle specific modality-driven reasoning functions: visual reasoning, textual reasoning, or cross-modal alignment. To accommodate this semantic specialization, we augment each expert with modality-adaptive input projections
The routing gate implicitly learns to assign the input
4.4 Loss Function and Training Strategy
To effectively optimize the SparseMoE-MFN framework for multimodal fake news detection, we design a composite loss function that simultaneously promotes accurate classification, balanced expert utilization, and stable multimodal alignment. Let the training input be a batch of multimodal instances
where
To further regularize the sparse expert routing module, we introduce a load balancing loss based on expert assignment statistics. Let
Then, the load balancing loss is formulated as:
This objective penalizes imbalanced expert usage and promotes uniform activation of the expert pool, preventing expert collapse while improving generalization on underrepresented decision pathways. The final loss is a weighted combination:
where
The overall training strategy employs a two-stage curriculum learning approach to facilitate stable optimization of the deep vision-language Transformer and the sparse MoE routing. In the first stage, we freeze the visual encoder (LLaVA’s CLIP backbone), initialize the sparse attention and routing modules, and fine-tune the text encoder on the
5 Experimental Results and Analysis
Fig. 4 summarizes the performance analysis across various metrics. Table 5 details the performance of SparseMoE-MFN against all baselines on the
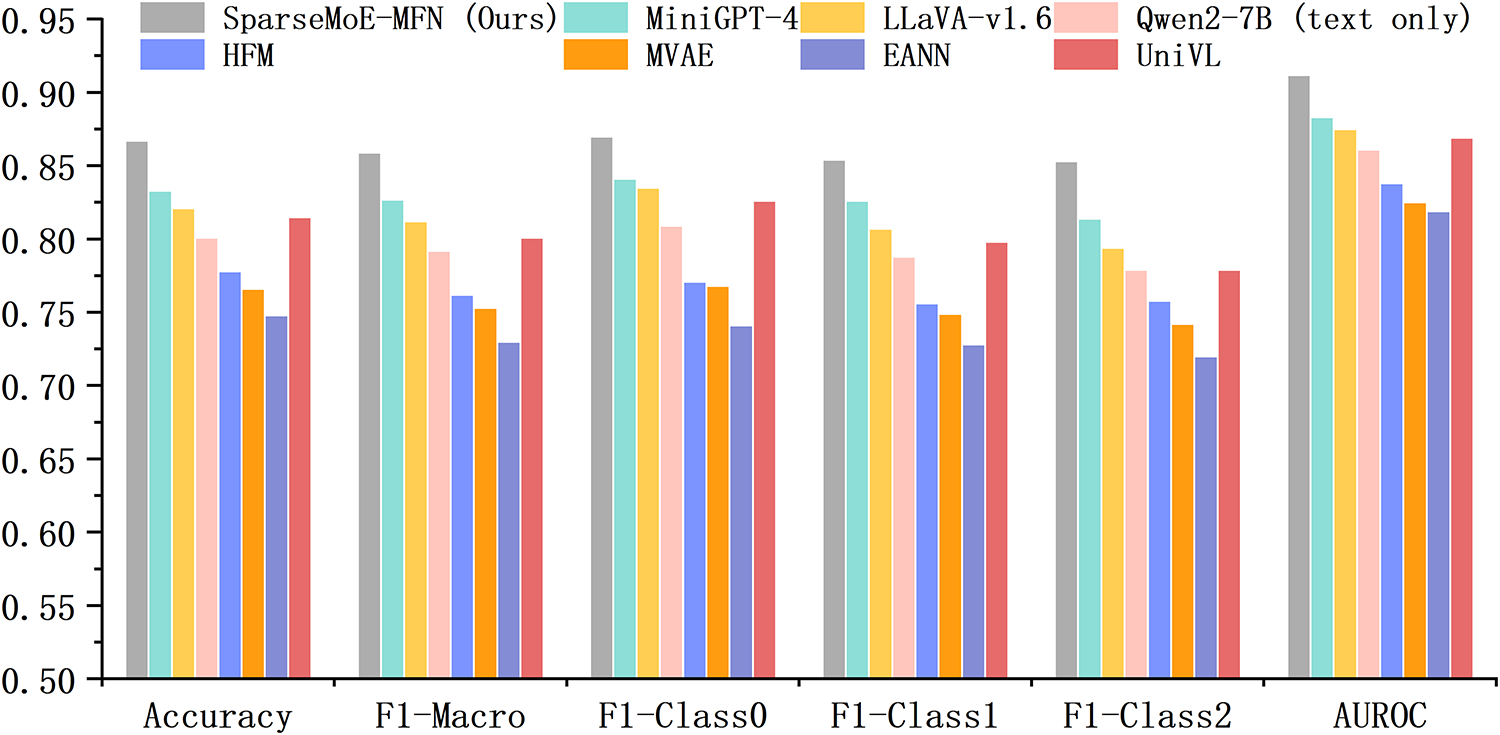
Figure 4: Performance analysis of SparseMoE-MFN and all baseline models across different performance metrics.
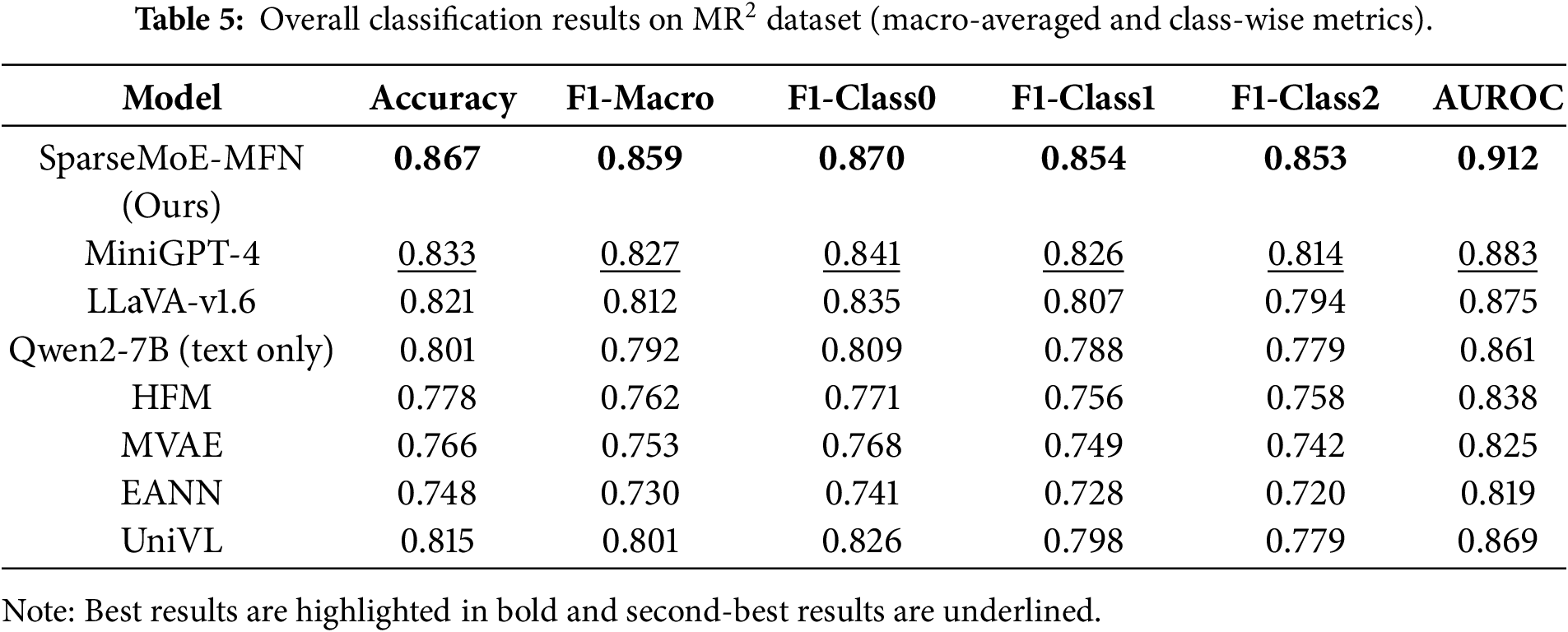
A particularly noteworthy finding is the model’s performance on the “unverified” category (label 2), which typically presents the greatest challenge due to its inherent ambiguity and lack of explicit ground truth cues. SparseMoE-MFN achieved an F1 score of 0.853 for this category (F1-Class2), outperforming all other methods by at least 3.9%. This improvement highlights the advantage of the model’s expert routing mechanism in handling semantic uncertainty through specialization: aligned experts within the MoE play a crucial role in mitigating hallucinations (generating content inconsistent with facts) by addressing inconsistencies in image-text pairs; meanwhile, the sparsely activated cross-modal attention mechanism suppresses noise and reinforces saliency-based interactions. Although MiniGPT-4 demonstrates competitive overall performance, it struggles to differentiate between rumors and unverified posts in multiple long-text Weibo samples, indicating that its reliance solely on the alignment objective is insufficient for fine-grained detection.
From a cross-lingual perspective, our model maintains balanced and stable high performance on both Chinese (Weibo) and English (Twitter) data sources. As detailed in Table 6, the model demonstrates balanced and robust performance across both Chinese (
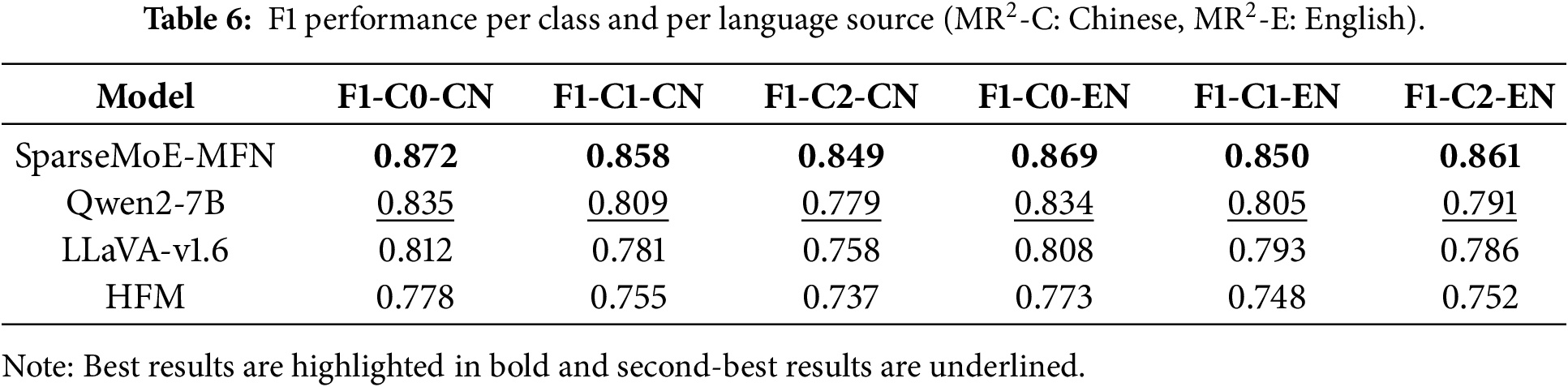
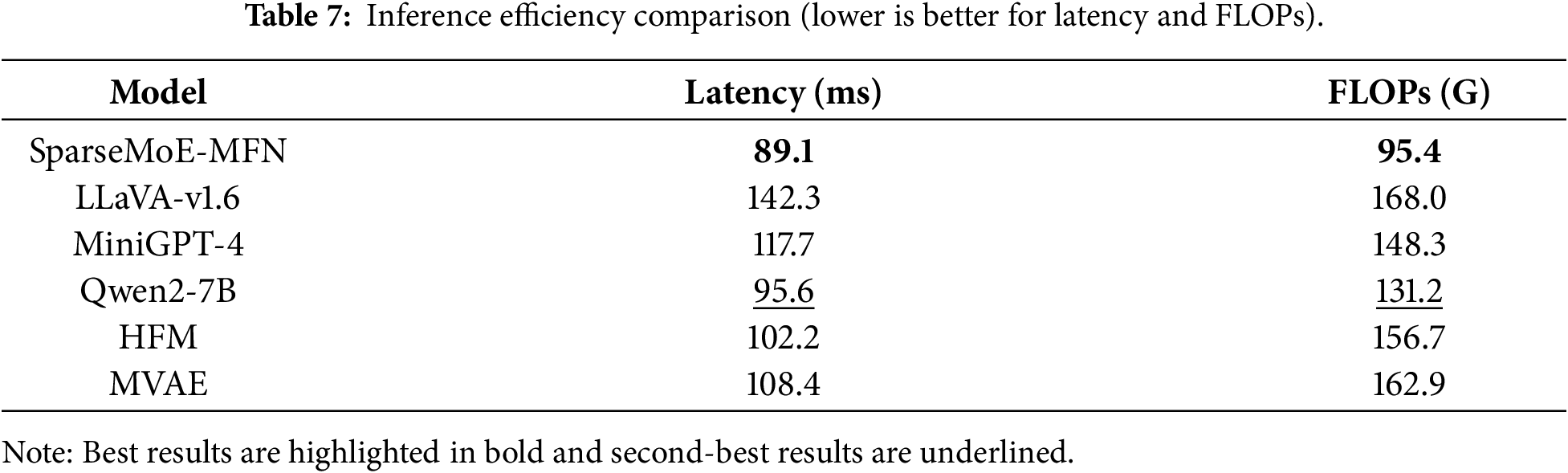
Taken together, these results validate the core hypothesis of our framework: sparse, expert-aware multimodal modeling can simultaneously improve classification accuracy and reduce computational costs. The synergy between sparse cross-modal attention and MoE routing offers complementary advantages—sparse attention enhances token-level relevance filtering, while the expert gating mechanism facilitates structured, disentangled reasoning pathways suitable for handling complex multimodal cues. This dual sparsity paradigm effectively mitigates common limitations of prior rumor detection models, including overfitting, hallucination (generating factually inconsistent content), and modality imbalance. As further elaborated in the ablation studies, each component of our architecture plays a significant role in the final performance gains, opening up new design spaces for scalable and robust multimodal misinformation analysis. While leveraging powerful pre-trained models like LLaVA and Qwen2-7B provides a strong foundation, our proposed sparse attention and MoE routing mechanisms are responsible for the 0.853 performance gains over these baselines.
To rigorously evaluate the role of each architectural component within the SparseMoE-MFN framework, we conducted comprehensive ablation studies on the
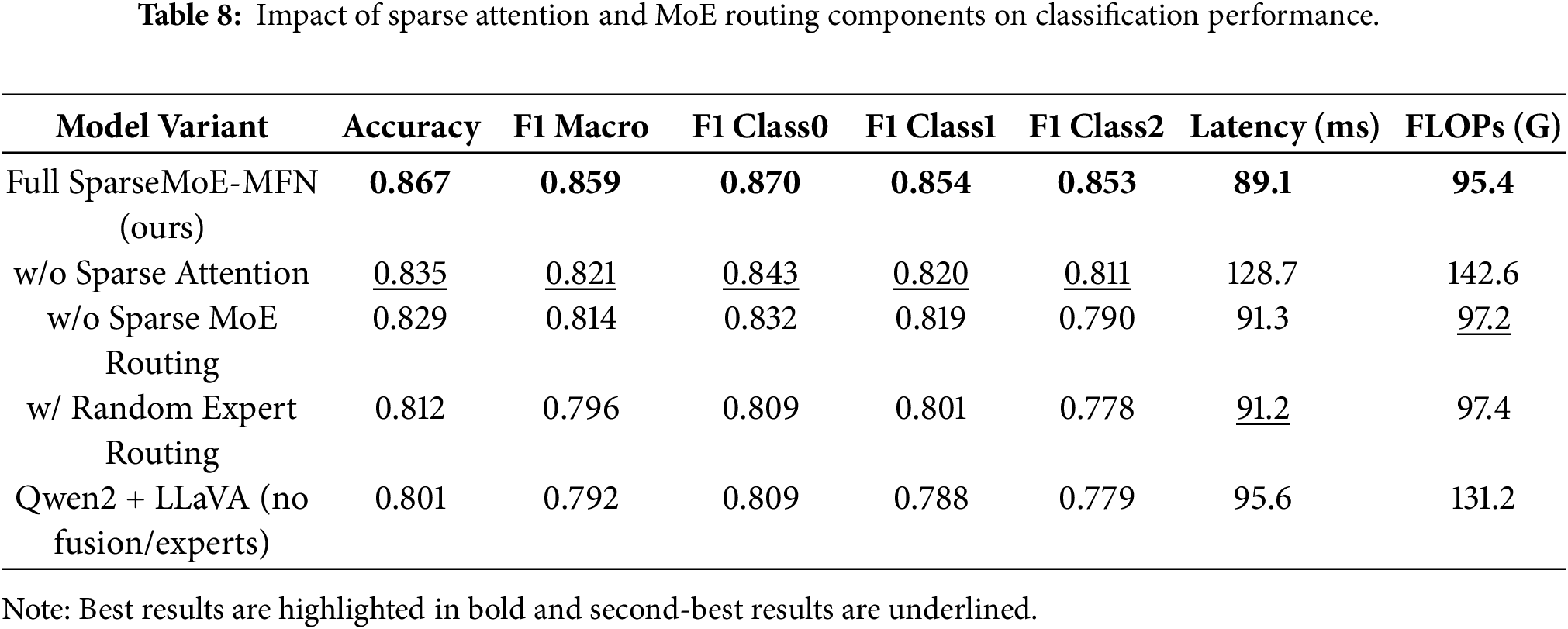

Figure 5: Comparison between the proposed SparseMoE-MFN and other detectors. In this error message where the image and text are inconsistent, the person in the picture is Cook, which contradicts the image description. Most existing detectors only make judgments without providing explanations. Although LLaVA and miniGPT-4 can identify the inconsistent news element (person) in the image-text pair, they incorrectly associate the person with the content mentioned in the description. In contrast, SparseMoE-MFN not only analyzes the consistency between the image and text content but also examines the relevance between claims and evidence. It accurately identifies the person in the picture and clearly points out that the image does not match the narrative about the car. After retrieval, there is no reliable evidence to support the claim of the car release. This news has not been verified and lacks sufficient verification information to corroborate the claim of the car release.
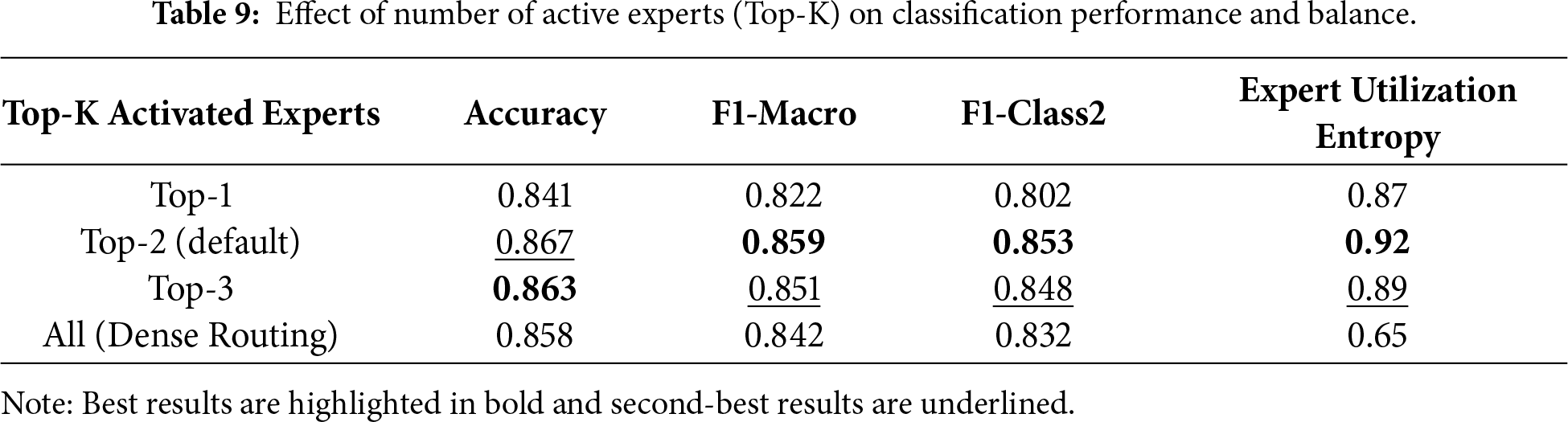
Beyond sparse attention, the efficacy of sparse Mixture-of-Experts (MoE) routing is also crucial for model interpretability and reasoning depth. When the MoE module was removed (w/o Sparse MoE Routing), the macro-averaged F1 score dropped by 4.5 percentage points (from 0.859 to 0.814), and the F1 for the unverified class decreased by 6.3 percentage points (from 0.853 to 0.790). This significant performance drop highlights the MoE routing mechanism’s crucial role in improving the model’s ability to handle heterogeneous content and uncertainty. The largest decrease was observed in the unverified class, again indicating that samples rich in ambiguity benefit most from expert-specific processing. Notably, even replacing the learned routing mechanism with random expert selection led to a significant performance drop, as it disrupted the alignment between semantic cues and expert specialization. These results underscore the necessity of both structured gating and semantically aligned routing when handling the heterogeneity of vision-language pairs. To further investigate the behavior of expert routing, we performed ablation studies on the number of activated experts in the Top-K gating strategy. Table 9 demonstrates the impact of the number of active experts (Top-K). The Top-2 configuration achieves the best F1-Macro and F1-Class2 performance, indicating an optimal balance between model complexity, generalization capability, and computational efficiency. Activating only a single expert (Top-1) underutilizes the reasoning capabilities, while dense activation (all experts) incurs unnecessary computational overhead without significant performance gains. This suggests that the model exhibits sensitivity to the K parameter, and Top-2 represents a sweet spot for this task.
Finally, we examined the role of the load balancing loss in mitigating the “expert collapse” problem, a known issue in sparse MoE models where a few experts dominate the routing distribution. As shown in Table 10, disabling the load balancing objective during training led to an imbalanced routing distribution (measured by entropy) and reduced F1 performance, particularly on ambiguous and long-tail samples. The standard deviation of routing frequencies across experts significantly increased, indicating an over-reliance on aligned experts even in scenarios better suited for visual or textual reasoning. In contrast, incorporating the load balancing term ensured that experts were invoked more equitably and promoted generalized representations across the training corpus. This result highlights the importance of architectural regularization in ensuring stable and interpretable MoE behavior.

Taken together, these ablation studies provide compelling evidence that each innovation within SparseMoE-MFN—from sparse attention to the MoE routing mechanism and load balancing—is indispensable for achieving robust performance in real-world multimodal disinformation detection. These components not only yield quantifiable improvements in predictive accuracy and efficiency but also align closely with human-interpretable reasoning patterns, offering a more transparent and modular alternative to black-box fusion models.
To further elucidate the behavioral characteristics and advantages of SparseMoE-MFN, we first conducted a qualitative analysis of prediction results, focusing on cases where baseline models exhibited hallucinatory outputs or inconsistent predictions. Fig. 5 illustrates such a case, depicting a tech product launch with a text description and an image featuring an irrelevant background: the image shows a person identified as Cook, which is inconsistent with the textual narrative about a car release. Both LLaVA and MiniGPT-4 misclassified this post as “Confirmed Rumor,” incorrectly linking the image’s subject to the text’s claim. In contrast, SparseMoE-MFN correctly labels it “Unverified” by analyzing the incongruence between the identified person and the narrative, and confirming the lack of supporting evidence for the car release claim.
The example in Fig. 5, while not an intentionally adversarial attack, demonstrates the model’s ability to handle coordinated misinformation where the image and text are misleading in conjunction. SparseMoE-MFN correctly identifies the inconsistency between the person (Cook) and the narrative (car release), and flags it as ‘Unverified,’ showcasing its strength in detecting such semantic discrepancies. This capability is further supported by our analysis of sparse attention’s contribution to interpretability. By selectively focusing on critical cross-modal interactions, it amplifies attention weights on semantically relevant or discrepant image regions and text tokens. This concentrated focus makes the model’s reasoning process more transparent compared to dense attention mechanisms. For instance, in image-text incongruence scenarios like Fig. 5, sparse attention allocates higher weights to conflicting elements, directly highlighting the source of inconsistency. Furthermore, ablation studies in Table 8 provide indirect evidence for this interpretability benefit, with significant performance gains on the ‘unverified’ class (often containing subtle inconsistencies), indicating that sparse attention effectively guides the model towards discriminative signals and enhances reasoning discernibility. Table 11 quantifies this by showing improved prediction consistency and confidence for ambiguous samples with SparseMoE-MFN.
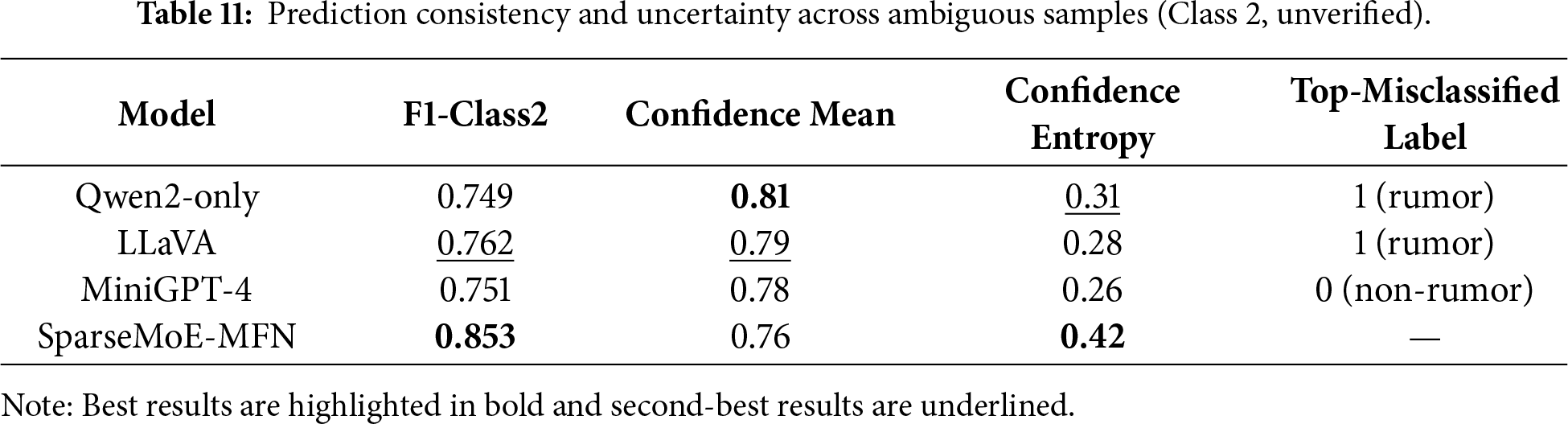
Table 12 shows that the visual, linguistic, and alignment experts are activated at rates of 36.1%, 41.2%, and 40.8%, respectively. Crucially, the average confidence for correct predictions is consistently higher across all experts (0.84–0.89) compared to incorrect predictions (0.62–0.69). Furthermore, we observe that the alignment expert is activated more frequently in cases of image-text mismatch (as in Fig. 5), while the visual expert shows higher activation for image-centric memes and the linguistic expert for ambiguous textual claims, providing empirical evidence for their specialization.

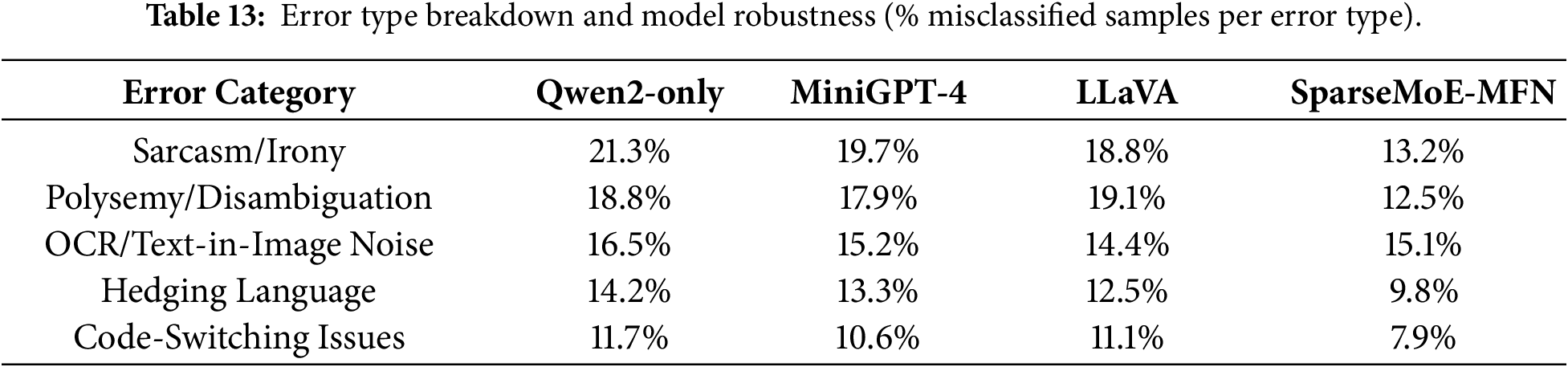
Error analysis further reveals the persistent challenges in multimodal rumor detection. The majority of misclassifications by SparseMoE-MFN occur near the boundary between rumor and unverified categories, particularly in cases involving sarcasm, cultural idioms, or image text (OCR) interference. For instance, in Chinese posts containing metaphorical or indirect accusations, text representations based on Qwen2 often capture only literal meanings, failing to interpret subtle nuances in stance. Similarly, in English Twitter samples, if embedded images contain overlaid text or memes, OCR-related hallucinations propagate noise into the alignment module. As observed in Table 13, while SparseMoE-MFN shows improvements across most error types, noise induced by OCR, particularly in images with embedded text, remains a significant challenge. LLaVA exhibits slightly better performance in handling such noise, suggesting potential areas for improvement in our model.
The architecture’s modularity, enabled by sparse attention and MoE routing, facilitates interpretability. While not explicitly shown in this revision due to space constraints, visualizing the attention weights of the sparse attention module would reveal which image patches and text tokens are deemed most relevant for each prediction. Similarly, tracking the expert routing logs for individual tokens would demonstrate how the model dynamically shifts its reasoning strategy based on input content. These visualization techniques provide direct evidence of the model’s internal workings and enhance our understanding of its decision-making process. Finally, we discuss the implications of our architecture for interpretability and deployment. From a model design perspective, the utilization of sparse attention and MoE enables us to disentangle the decision pathways for each modality, facilitating modular debugging and targeted retraining of expert modules. For instance, when encountering failure cases specific to visual misinformation (e.g., re-purposed images), retraining only the visual expert module can yield quantifiable performance improvements without interfering with language representations. In interactive scenarios, expert routing logs and sparse token alignment can serve as a foundation for counterfactual analysis and explanation generation—increasingly vital for transparent content moderation systems. Consequently, beyond its superior quantitative results, SparseMoE-MFN offers a pathway towards interpretable and controllable multimodal disinformation detection systems, bridging the gap between model capabilities and practical deployment needs.
Despite the significant progress made by SparseMoE-MFN in multimodal fake news detection, limitations still exist, pointing towards directions for future research. This may be constrained by inherent biases in pre-trained models. Future work could explore dynamically adjusting the number of experts (Top-K) to improve adaptability and delve deeper into the model’s cross-lingual transfer capabilities. Furthermore, the model’s practical deployment feasibility in resource-constrained environments, its robustness against adversarial attacks, and its ability to handle OCR (Optical Character Recognition) noise still need strengthening. Further improving the model’s ability to distinguish between semantically similar categories (such as “rumor” and “unconfirmed”) will be key to enhancing its fine-grained classification performance, particularly by combining stronger language understanding capabilities, contextual awareness mechanisms, and external knowledge bases. Future research should focus on collecting more training data containing complex linguistic phenomena and exploring more advanced language models and specific modules to more comprehensively capture implicit meanings. This will lead to the construction of more transparent and intelligent fake news detection systems, support “human-computer collaborative” review mechanisms, and foster a healthier online environment.
Acknowledgement: We would like to give our heartfelt thanks to all the people who have ever helped us.
Funding Statement: This document was supported by the National Social Science Fund of China (20BXW101).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Yuechuan Zhang, Mingshu Zhang; data collection: Bin Wei; analysis and interpretation of results: Hongyu Jin; draft manuscript preparation:Yaxuan Wang. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: No new data were created during this study. The study brought together existing data obtained upon request and subject to licence restrictions from a number of different sources.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Li X, Qiao J, Yin S, Wu L, Gao C, Wang Z, et al. A survey of multimodal fake news detection: a cross-modal interaction perspective. IEEE Trans Emerg Top Comput Intell. 2025;9(4):2658–75. doi:10.1109/TETCI.2025.3543389. [Google Scholar] [CrossRef]
2. Eldifrawi I, Wang S, Trabelsi A. Automated justification production for claim veracity in fact checking: a survey on architectures and approaches. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics; 2024. p. 6679–92. doi:10.18653/v1/2024.acl-long.361. [Google Scholar] [CrossRef]
3. Zhang L, Zhang X, Zhou Z, Huang F, Li C. Reinforced adaptive knowledge learning for multimodal fake news detection. Proc AAAI Conf Artif Intell. 2024;38(15):16777–85. doi:10.1609/aaai.v38i15.29618. [Google Scholar] [CrossRef]
4. Fedus W, Zoph B, Shazeer N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. arXiv:2101.03961. 2021. [Google Scholar]
5. Hu X, Guo Z, Chen J, Wen L, Yu PS. MR2: a multilingual multi-modal and multi-aspect rumor refuting dataset. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. Taipei, Taiwan: Association for Computing Machinery; 2023. p. 2901–12. doi:10.1145/3539618.3591896. [Google Scholar] [CrossRef]
6. Lv H, Yang W, Yin Y, Wei F, Peng J, Geng H. MDF-FND: a dynamic fusion model for multimodal fake news detection. Knowl Based Syst. 2025;317:113417. doi:10.1016/j.knosys.2025.113417. [Google Scholar] [CrossRef]
7. Ma J, Gao W, Wong K-F. Rumor detection on social media: a data mining perspective. arXiv:1807.03505. 2018. [Google Scholar]
8. Ma Z, Luo M, Guo H, Zeng Z, Hao Y, Zhao X. Event-radar: event-driven multi-view learning for multimodal fake news detection. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics; 2024. p. 5809–21. doi:10.18653/v1/2024.acl-long.316. [Google Scholar] [CrossRef]
9. Qiao J, Li X, Gao C, Wu L, Feng J, Wang Z. Improving multimodal fake news detection by leveraging cross-modal content correlation. Inf Process Manage. 2025;62(5):104120. [Google Scholar]
10. Guo Y, Li Y, Zhen K, Li B, Liu J. CAMFND: cross-modal adaptive-aware learning for multimodal fake news detection. Pattern Recognit Lett. 2025;195:1–7. doi:10.1016/j.patrec.2025.02.035. [Google Scholar] [CrossRef]
11. Khattar D, Goud JS, Gupta M, Varma V. MVAE: multimodal variational autoencoder for fake news detection. In: The World Wide Web Conference. San Francisco, CA, USA: ACM; 2019. p. 2915–21. doi:10.1145/3308558.3313552. [Google Scholar] [CrossRef]
12. Guo Y, Qiao L, Yang Z, Xiang J, Feng X, Ma H. Fake news detection: extendable to global heterogeneous graph attention network with external knowledge. Tsinghua Sci Technol. 2025;30(3):1125–38. doi:10.26599/TST.2023.9010104. [Google Scholar] [CrossRef]
13. Zhang G, Giachanou A, Rosso P. SceneFND: multimodal fake news detection by modelling scene context information. J Inf Sci. 2024;50(2):355–67. doi:10.1177/01655515221087683. [Google Scholar] [CrossRef]
14. Cao B, Wu Q, Cao J, Liu B, Gui J. External reliable information-enhanced multimodal contrastive learning for fake news detection. Proc AAAI Conf Artif Intell. 2025;39(1):31–9. doi:10.1609/aaai.v39i1.31977. [Google Scholar] [CrossRef]
15. Kou F, Wang B, Li H, Zhu C, Shi L, Zhang J, et al. Potential features fusion network for multimodal fake news detection. ACM Trans Multimedia Comput Commun Appl. 2025;21(3):1–24. doi:10.1145/3711866. [Google Scholar] [CrossRef]
16. Gao X, Wang X, Chen Z, Zhou W, Hoi SCH. Knowledge enhanced vision and language model for multi-modal fake news detection. IEEE Trans Multimedia. 2024;26:8312–22. doi:10.1109/tmm.2023.3330296. [Google Scholar] [CrossRef]
17. Alayrac JB, Donahue J, Luc P, Miech A, Barr I, Hasson Y, et al. Flamingo: a visual language model for few-shot learning. Adv Neural Inform Process Syst. 2022;35:23716–36. [Google Scholar]
18. Li J, Li D, Savarese S, Hoi S. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv:2301.12597. 2023. [Google Scholar]
19. Liu H, Li C, Wu Q, Lee YJ. Visual instruction tuning. In: Advances in Neural Information Processing Systems 36 (NeurIPS 2023); 2023. p. 34892–916. [Google Scholar]
20. Guo H, Ma Z, Zeng Z, Luo M, Zeng W, Tang J, et al. Each fake news is fake in its own way: an attribution multi-granularity benchmark for multimodal fake news detection. Proc AAAI Conf Artif Intell. 2025;39(1):228–36. doi:10.1609/aaai.v39i1.31999. [Google Scholar] [CrossRef]
21. Du P, Gao Y, Li L, Li X. SGAMF: sparse gated attention-based multimodal fusion method for fake news detection. IEEE Trans Big Data. 2025;11(2):540–52. doi:10.1109/TBDATA.2024.3414341. [Google Scholar] [CrossRef]
22. Zhou D, Ouyang Q, Lin N, Zhou Y, Yang A. GS2F: multimodal fake news detection utilizing graph structure and guided semantic fusion. ACM Trans Asian Low-Resour Lang Inf Process. 2025;24(2):1–22. doi:10.1145/3708536. [Google Scholar] [CrossRef]
23. Tong Y, Lu W, Zhao Z, Lai S, Shi T. MMDFND: multi-modal multi-domain fake news detection. In: Proceedings of the 32nd ACM International Conference on Multimedia. New York, NY, USA: ACM; 2024. p. 1178–86. doi:10.1145/3664647.3681317. [Google Scholar] [CrossRef]
24. Wei S, Wang Z, Li M, Liu X, Wu B. DCCMA-Net: disentanglement-based cross-modal clues mining and aggregation network for explainable multimodal fake news detection. Inf Process Manag. 2025;62(4):104089. doi:10.1016/j.ipm.2025.104089. [Google Scholar] [CrossRef]
25. Xia Z, Zhao S, Han J, Chen J. Knowledge-augmented contrastive learning and multi-modal fusion for fake news detection service in social network. In: Proceedings of the 2025 IEEE International Conference on Web Services (ICWS). Piscataway, NJ, USA: IEEE; 2025. p. 984–95. doi:10.1109/ICWS67624.2025.00130. [Google Scholar] [CrossRef]
26. Wang Y, Ma F, Jin Z, Yuan Y, Xun G, Jha K, et al. EANN: event adversarial neural networks for multi-modal fake news detection. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York, NY, USA: ACM; 2018. p. 849–57. doi:10.1145/3219819.3219903. [Google Scholar] [CrossRef]
27. Xie B, Ma X, Wu J, Yang J, Xue S, Fan H. Heterogeneous graph neural network via knowledge relations for fake news detection. In: Proceedings of the 35th International Conference on Scientific and Statistical Database Management (SSDBM'23). Los Angeles, CA, USA: Association for Computing Machinery; 2023. p. 1–11. doi:10.1145/3603719.3603736. [Google Scholar] [CrossRef]
28. Devlin J, Chang MW, Lee K, Toutanova K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics; 2019. p. 4171–86. doi:10.18653/v1/N19-1423. [Google Scholar] [CrossRef]
29. Yang A, Yang B, Hui B, Zheng B, Yu B, Zhou C, et al. Qwen2 technical report. arXiv:2407.10671. 2024. [Google Scholar]
30. Zhu D, Chen J, Shen X, Li X, Elhoseiny M. MiniGPT-4: enhancing vision-language understanding with advanced large language models. arXiv:2304.10592. 2023. [Google Scholar]
31. Luo H, Ji L, Shi B, Huang H, Duan N, Li T, et al. UniVL: a unified video and language pre-training model for multimodal understanding and generation. arXiv:2002.06353. 2020. [Google Scholar]
32. Gu Y, Castro I, Tyson G. Detecting multimodal fake news with gated variational AutoEncoder. In: ACM Web Science Conference. Stuttgart, Germany: ACM; 2024. p. 129–38. doi:10.1145/3614419.3643992. [Google Scholar] [CrossRef]
33. Chen CR, Fan Q, Panda R. CrossViT: cross-attention multi-scale vision transformer for image classification. In: IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. p. 347–56. doi:10.1109/ICCV48922.2021.00041. [Google Scholar] [CrossRef]
34. Si J, Wang Y, Hu W, Liu Q, Hong R. Making strides security inMultimodal fake news detection models: a comprehensive analysis ofAdversarial attacks. In: MultiMedia modeling. Singapore: Springer; 2025. p. 296–309. doi:10.1007/978-981-96-2061-6_22. [Google Scholar] [CrossRef]
35. Phan HT, Nguyen NT. A dual LSTM-based multimodal method for fake news detection. In: Proceedings of the 2024 European Conference on Artificial Intelligence (ECAI 2024). Santiago de Compostela, Spain: Springer. 2024. p. 2486–93. [Google Scholar]
36. Liu Y, Liu Y, Li Z, Yao R, Zhang Y, Wang D. Modality interactive mixture-of-experts for fake news detection. In: Proceedings of the ACM on Web Conference 2025. Sydney, NSW, Australia: ACM; 2025. p. 5139–50. doi:10.1145/3696410.3714522. [Google Scholar] [CrossRef]
37. Sharma R, Arya A. MMHFND: fusing modalities for multimodal multiclass Hindi fake news detection via contrastive learning. ACM Trans Asian Low-Resour Lang Inf Process. 2024;23(11):1–25. doi:10.1145/3686797. [Google Scholar] [CrossRef]
38. Devank, Kalla J, Biswas S. CoVLM: leveraging consensus from vision-language models for semi-supervised multi-modal fake news detection. In: Computer Vision – ACCV 2024. Singapore: Springer Nature Singapore; 2024. p. 172–89. doi:10.1007/978-981-96-0960-4_11. [Google Scholar] [CrossRef]
39. Wang H, Guo J, Liu S, Chen P, Li X. SEPM: multiscale semantic enhancement-progressive multimodal fusion network for fake news detection. Expert Syst Appl. 2025;283:127741. doi:10.1016/j.eswa.2025.127741. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools