
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
LWCNet: A Physics-Guided Multimodal Few-Shot Learning Framework for Intelligent Fault Diagnosis
1 College of Electrical and Electronic Engineering, Anhui Institute of Information Technology, Wuhu, China
2 College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing, China
3 College of Medical Imaging, Xuzhou Medical University, Xuzhou, China
* Corresponding Author: Xiangtong Du. Email:
Computers, Materials & Continua 2026, 87(2), 67 https://doi.org/10.32604/cmc.2026.074437
Received 11 October 2025; Accepted 04 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Deep learning-based methods have shown great potential in intelligent bearing fault diagnosis. However, most existing approaches suffer from the scarcity of labeled data, which often results in insufficient robustness under complex working conditions and a general lack of interpretability. To address these challenges, we propose a physics-informed multimodal fault diagnosis framework based on few-shot learning, which integrates a 2D time-frequency image encoder and a 1D vibration signal encoder. Specifically, we embed prior knowledge of multi-resolution analysis from signal processing into the model by designing a Laplace Wavelet Convolution (LWC) module, which enhances interpretability since wavelet coefficients naturally correspond to specific frequency and temporal structures. To further balance the guidance of physical priors with the flexibility of learnable representations, we introduce a parametric multi-kernel wavelet that employs channel-wise dynamic attention to adaptively select relevant wavelet bases, thereby improving the feature expressiveness. Moreover, we develop a Mahalanobis-Prototype Joint Metric, which constructs more accurate and distribution-consistent decision boundaries under few-shot conditions. Comprehensive experiments on the Case Western Reserve University (CWRU) and Paderborn University (PU) bearing datasets demonstrate the superior effectiveness, robustness, and interpretability of the proposed approach compared with state-of-the-art baselines.Keywords
With the rapid advancement of deep learning, an increasing number of data-driven methods have been applied to the manufacturing industry, particularly in critical sectors such as aerospace, wind power, and railway transportation. In these domains, mechanical systems often operate under harsh conditions, with the engine serving as a core component. The reliability of the engine is crucial to system safety, efficiency, and cost-effectiveness. Among its internal parts, bearings are highly susceptible to degradation, as they operate under extreme environments such as high temperature, noise, and heavy loads [1,2]. Consequently, accurate health monitoring of engine bearings has become a research priority for enabling predictive maintenance and preventing catastrophic failures.
Currently, intelligent fault diagnosis approaches for bearings can be broadly divided into machine learning-based methods and deep learning-based methods. Traditional machine learning methods, as early intelligent diagnostic approaches, mainly rely on handcrafted feature extraction followed by classifier-based diagnosis. Specifically, expert knowledge and signal processing techniques such as Fast Fourier Transform (FFT) and Short-Time Fourier Tranform (STFT) are employed to design discriminative time-domain and frequency-domain features. Subsequently, dimensionality reduction techniques such as PCA are applied to select effective feature representations, which are then fed into classifiers such as support vector machines [3,4], random forests [5,6], or k-nearest neighbors [7] for training and prediction.
In recent years, deep learning-based approaches—including convolutional neural networks (CNNs) [8–11], denoising autoencoders [12,13], deep belief networks (DBNs) [14,15], and recurrent neural networks (RNNs) [16] have emerged as mainstream methods for fault diagnosis. Their key advantage lies in performing end-to-end diagnosis by automatically learning hierarchical feature representations from large-scale data, thus avoiding complex and subjective manual feature engineering. These methods typically achieve higher diagnostic accuracy and better generalization than traditional approaches. However, these methods typically require large-scale labeled data for training and are sensitive to label noise. To overcome the challenge of data scarcity in fault diagnosis, researchers have proposed several strategies, including data augmentation (DA) [17–19], transfer learning (TL) [20–22], and few-shot learning (FSL) [23–25]. The core idea of DA is to generate new and diverse training samples from limited labeled data through transformations that preserve label semantics. This increases dataset scale and diversity, thereby improving model generalization and reducing overfitting. DA is simple to implement and requires no modification to the model structure, but it is domain-dependent and demands carefully designed augmentation strategies. The principle of TL is to transfer knowledge (e.g., model parameters or feature representations) learned in a source domain to a related target domain with limited data, under the assumption that transferable features exist across domains. Liu et al. [26] proposed a deep domain adaptation framework grounded in optimal transport theory, which demonstrated effectiveness in rotating machinery fault diagnosis by aligning feature distributions across domains. Building upon this, Yang et al. [27] developed a targeted transfer learning approach that leverages the distribution barycenter to optimize domain alignment, thereby improving diagnostic performance in machines. Li et al. [28] designed a gated recurrent generative transfer learning network, explicitly addressing challenges arising from data imbalance and varying operating conditions. To further mitigate domain-related issues, Ding et al. [29] introduced a deep imbalanced domain adaptation model for bearing fault diagnosis, focusing on alleviating the label shift problem in transfer learning. In addition, Li et al. [30] proposed a feature-based transfer learning strategy that minimizes cross-dataset discrepancies, offering a practical solution for cross-domain fault diagnosis tasks. Since the source domain usually contains abundant labels, TL can significantly reduce reliance on target-domain annotations. However, when the distribution gap between source and target domains is large (domain shift), naive transfer may cause negative transfer and degrade performance. Thus, domain discrepancy and source-domain dependency remain critical challenges. FSL, a branch of meta-learning, aims to teach models “how to learn”. By meta-training on a large number of tasks, the model can quickly adapt to new and unseen diagnostic tasks using only a few support samples. Fan et al. [31] developed a model-agnostic meta-learning (MAML) framework that exploits prior knowledge by optimizing initialization parameters, thereby enabling fault diagnosis under previously unseen operating conditions. In parallel, Liu et al. [25] introduced a semi-supervised meta-learning approach that incorporates a simplified graph convolutional network, allowing accurate node classification with only a limited number of training samples across variable working conditions. In addition to single-modal vibration-based models, recent studies have also explored multi-modal and multi-scale fusion schemes for mechanical fault diagnosis. For instance, a self-calibrated coordinate-attention multi-scale CNN (SC-MSCNN) [32] converts raw vibration signals into Markov transition field images and uses coordinate attention with multi-scale convolutions and skip connections to improve small-sample bearing diagnosis while reducing parameters and alleviating overfitting. In noisy Industrial IoT settings, a lightweight multi-modal fusion framework [33] combines multi-resolution decomposition and adaptive enhancement to transform 1D signals into multiple 2D representations, which are fused by a tri-branch attention network to achieve highly robust bearing diagnosis under low SNR with clear gains over state-of-the-art baselines. These works further demonstrate the effectiveness of multi-modal and multi-scale feature modeling for bearing fault diagnosis, but they are still designed for relatively data-rich regimes and do not explicitly target extreme few-shot scenarios with physics-guided, interpretable wavelet representations. Despite their success, data-driven methods still face the challenge of limited labeled data under complex operating conditions and often lack interpretability, which restricts their broader deployment in real-world scenarios.
To address the aforementioned challenges, we propose a physics-guided multimodal framework based on few-shot learning, termed LWCNet, designed to improve the accuracy, robustness, and interpretability of fault classification under limited-data scenarios. LWCNet incorporates a learnable parametric Laplace Wavelet Convolution (LWC) module to enhance both robustness and interpretability of the extracted features. First, the raw vibration signals are preprocessed to generate training samples consisting of both 1D temporal sequences and 2D time-frequency representations. Subsequently, the training data from the support set and query set are fed into a 1D temporal feature extractor and a 2D time-frequency feature extractor, respectively, to obtain discriminative feature embeddings. Specifically, in the 1D feature extractor, we introduce the Laplace Wavelet Convolution, where physically meaningful Laplace wavelet kernels replace traditional convolution kernels. This design ensures that the extracted features are inherently interpretable, as their responses explicitly correspond to specific frequency components and temporal positions. Moreover, to balance the guidance of physical priors with the adaptability of neural networks, we propose an Attention-Driven Multi-kernel Laplace Wavelet Convolution (AALWC) structure. In this design, each output channel is equipped with multiple parameterized wavelet kernels (with learnable scale and shift parameters), enabling the network to adaptively adjust the wavelet basis functions according to the data characteristics. Furthermore, a dynamic attention mechanism is incorporated to adaptively select and fuse the most relevant feature responses for each input sample, thereby significantly enhancing the representational capacity of the model. In the 2D time-frequency feature extractor, three convolutional kernels with different receptive field sizes are employed to perform multi-scale feature extraction. The extracted 1D temporal features are reshaped and concatenated with the 2D time-frequency features along the channel dimension for multimodal fusion. Additionally, to construct more accurate and robust decision boundaries under few-shot conditions, we propose a Mahalanobis-Prototype Joint Metric to model the correlation between support and query sets. This method not only computes the Euclidean distance between query samples and class prototypes but also incorporates the Mahalanobis distance to account for the intra-class covariance structure of the feature distributions.
By integrating physics-guided architectural design, parametric adaptive mechanisms, and a hybrid similarity metric, our method effectively addresses the core challenges of few-shot fault diagnosis, including poor interpretability of extracted features, insensitivity to weak fault signatures, and limited metric diversity. The proposed method is evaluated on benchmark bearing fault diagnosis datasets, and the experimental results demonstrate its superior effectiveness and robustness under complex operating conditions and few-shot scenarios. Our main contributions can be summarized as follows:
• We propose a novel few-shot fault diagnosis framework that jointly exploits 1D vibration signals and 2D time-frequency images. By embedding physical constraints into the learning process, the framework ensures both discriminability and consistency with domain knowledge, thus enhancing reliability under data-scarce conditions.
• We design an Interpretable Attention-Driven Adaptive Laplace Wavelet Convolution (AALWC) module that integrates multi-resolution wavelet analysis into deep networks. This not only improves feature discriminability but also enhances interpretability, as the learned coefficients correspond to explicit frequency–time patterns that align with physical principles.
• To reconcile physical priors with the flexibility of deep learning, we introduce a parametric multi-kernel wavelet model. By employing channel-wise dynamic attention, the model adaptively selects relevant wavelet bases, leading to more expressive and robust feature extraction across varying conditions.
• We develop a Mahalanobis–Prototype joint metric that combines prototype-based representation with Mahalanobis distance. This hybrid design captures intra-class variability and constructs more distribution-consistent decision boundaries, significantly improving classification accuracy in few-shot scenarios.
2.1 Fourier Transform and Short-Time Fourier Transform (STFT)
The Fourier Transform (FT) serves as a fundamental tool for analyzing stationary or quasi-stationary vibration signals characterized by stable harmonic structures, such as those induced by imbalance or misalignment. It produces a high-resolution global spectrum that facilitates accurate identification of characteristic frequencies and their associated sidebands. Mathematically, the discrete-time Fourier Transform (DTFT) is expressed as:
which yields a comprehensive description of the signal in the frequency domain. However, it does not provide any information about the temporal localization of spectral components. To overcome this limitation, the Short-Time Fourier Transform (STFT) introduces time–frequency localization by applying a sliding window to the signal. The STFT of x[n] with a sliding window g[n] is defined a:
where
The Wavelet Transform (WT) is a powerful tool for the analysis of non-stationary signals. Unlike the Fourier Transform (FT), which provides only global frequency information without temporal localization, the WT enables joint localization in both the time and frequency domains. Compared with the Short-Time Fourier Transform (STFT), which relies on a fixed window length, the WT employs short windows for high-frequency components and long windows for low-frequency components. This adaptive resolution makes it particularly suitable for analyzing non-stationary signals with abrupt changes, impulses, or modulations, such as bearing vibration signals. Unlike the FT, which utilizes global sinusoidal basis functions, the WT represents signals using a set of localized basis functions derived from a single mother wavelet function. The mother wavelet
where
In mechanical fault diagnosis, the WT is particularly effective due to its sensitivity to abrupt changes, transients, and impact components. Compared with traditional Fourier analysis, wavelet-based methods offer significant advantages for non-stationary and locally structured signals.
Typical examples of wavelets include the Morlet wavelet and the Laplace wavelet. The Morlet wavelet is defined as a complex exponential sinusoid modulated by a Gaussian envelope:
where
The Laplace wavelet, also known as the Mexican Hat or Ricker wavelet, is derived by applying the Laplacian operator (second derivative) to a Gaussian function. Its analytical form is given by:
which is highly sensitive to impulses, discontinuities, and transients. It is particularly effective for detecting impact-type features such as bearing faults and gear meshing defects. However, the selection of the mother wavelet and scale parameters is typically hand-crafted, which may be suboptimal under complex, data-rich, and highly variable operating conditions.
A typical one-dimensional convolutional neural network (1D CNN) generally consists of a 1D convolutional layer, a batch normalization (BN) layer, and an activation function layer. The BN layer normalizes the input features to stabilize and accelerate training, while the activation function introduces nonlinearity, thereby enhancing the network’s representation capability. The 1D convolutional layer performs convolution operations on the input sequence, which can be mathematically expressed as:
where
The overall pipeline of the proposed LWCNet is illustrated in Fig. 1, which consists of four major stages: data acquisition, data preprocessing, feature extraction via dual-branch encoders, and classification through a distribution-aware metric module.
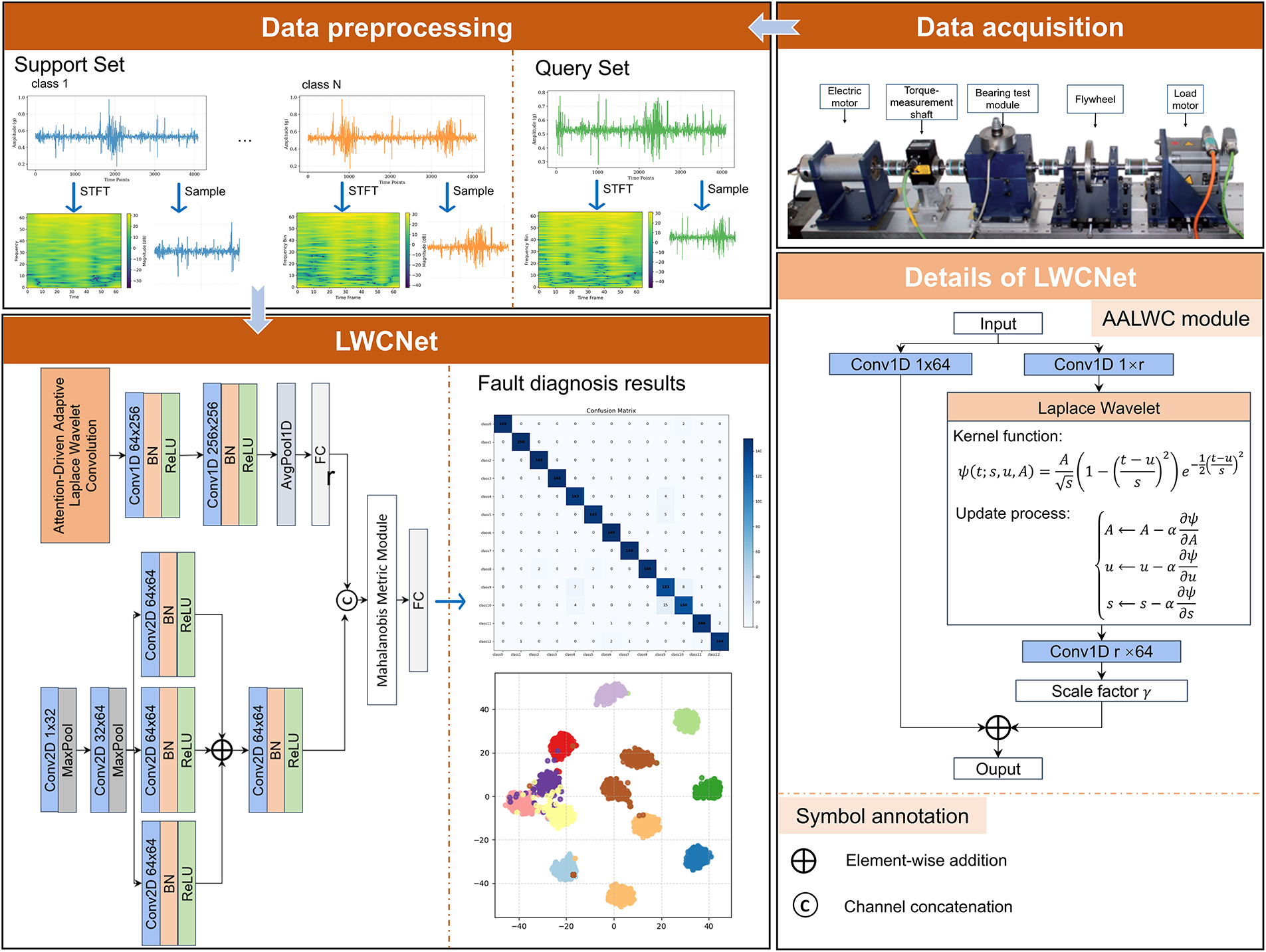
Figure 1: Overall architecture of the proposed LWCNet
Data Acquisition and Preprocessing. The vibration signals are collected from a rotating machinery test bench comprising an electric motor, torque shaft, bearing test module, flywheel, and load motor. The acquired raw signals are subsequently divided into the support set and query set, following the standard few-shot learning paradigm. Each vibration sample undergoes preprocessing to generate two complementary modalities: the 1D raw temporal signal, which preserves the oscillatory and transient structures in the time domain, and the 2D time–frequency spectrogram, obtained via Short-Time Fourier Transform (STFT), which encodes the localized spectral distribution.
Laplace Wavelet Convolution Net (LWCNet). The core of our framework is the proposed LWCNet, which is designed to jointly exploit temporal and time-frequency information through a dual-branch architecture. The processing pipeline can be summarized as follows: (1) Temporal Branch (1D Feature Extractor). The raw vibration signal
Mahalanobis-Prototype Joint Metric. To achieve robust classification under few-shot conditions, we introduce a Mahalanobis-Prototype Joint Metric. For each class, prototype vectors are computed as empirical means of support embeddings, while covariance matrices capture intra-class variability. The query features are then compared against class prototypes using both Euclidean distances and Mahalanobis distances, where the latter accounts for the covariance structure of feature distributions. These complementary similarity scores are fused via a lightweight classifier, yielding decision boundaries that closely approximate the Bayes optimal rule.
Fault Diagnosis and Interpretability. The final predictions are obtained through the joint metric module, and the diagnostic performance is visualized via confusion matrices and t-SNE feature distributions. Notably, the learned wavelet kernels provide interpretable insights into the spectral bands emphasized by the network, while the Mahalanobis–Prototype integration ensures distribution-aware robustness in small-sample regimes.
3.2 An Attention-Driven Adaptive Laplace Wavelet Convolution Module
We propose an Attention-Driven Adaptive Laplace Wavelet Convolution (AALWC) module, a dual-branch residual structure that incorporates both physics-informed priors and learnable adaptability. The AALWC is specifically designed to enhance the feature representation capability of deep neural networks when analyzing non-stationary and oscillatory signals. The module synergistically integrates three complementary components: (i) a learnable parametric Laplace wavelet kernel, which embeds multi-resolution prior knowledge; (ii) a dual-branch LoRA-inspired structure, which ensures parameter efficiency while maintaining representational richness; and (iii) an attention-based dynamic fusion mechanism, which adaptively selects the most informative features under varying signal conditions. This tripartite design effectively tackles the critical challenge of capturing multi-scale and transient signal characteristics in the presence of strong background noise, thereby ensuring robust and discriminative feature extraction. The AALWC module adopts a dual-branch architecture: the first branch employs a baseline 1D convolution, serving as a robust band-pass representation; the second branch incorporates a Laplace-of-Gaussian (LoG) wavelet enhanced with attention and LoRA mechanisms, where LoRA ensures parameter efficiency and the attention module enables conditional adaptivity. This design significantly strengthens the representation of impulsive and transient features. For an input
Here, A and B denote the low-rank adapters implemented by
where
We argue that not all wavelet kernels contribute equally to every input sample, and their relative importance should be adaptively determined according to the spectral characteristics of the input signal. To this end, we compute a set of attention weights
where
where
The attention-based fusion mechanism acts as a powerful non-linear gating function. It enables the network to emphasize the most relevant kernels (e.g., those tuned to fault-related frequencies) while suppressing irrelevant or noisy ones. This context-aware selection substantially enhances both the robustness and representational power of the extracted features. Finally, the extracted features are projected back to the higher-dimensional space via matrix B, scaled by the residual factor, and subsequently fused with the features extracted from the main convolutional branch.
3.3 Mahalanobis-Prototype Joint Metric
To achieve robust classification and construct more accurate, distribution-consistent decision boundaries under few-shot conditions, we integrate prototype-based representation with a Mahalanobis distance similarity metric. This approach effectively combines the “central tendency” of prototype learning with the “distributional shape” captured by the Mahalanobis metric, forming an advanced similarity measure. The design is motivated by the statistical optimality of the sample mean and covariance under Gaussian assumptions, which guarantees minimum estimation variance and strong discriminative power. Prototype Estimation. Given a support set
where
In practice, a low-rank approximation with shrinkage regularization is applied to enhance numerical stability under small-sample conditions. The inverse covariance
This formulation penalizes deviations more heavily along directions of low variance, thereby aligning the distance metric adaptively with the underlying feature distribution. Integration of Prototype and Mahalanobis Distance. In practice, the network computes both prototype-based similarity scores and Mahalanobis-based quadratic forms. These complementary representations are concatenated and processed by a lightweight classifier head:
where the convolutional layer learns to balance the contributions of Euclidean prototype similarity and covariance-aware Mahalanobis similarity. This hybrid strategy effectively combines the efficiency of prototype learning with the distribution-aware discriminability of the Mahalanobis distance, resulting in a classifier that closely approximates the Bayes optimal decision rule under Gaussian class-conditional models.
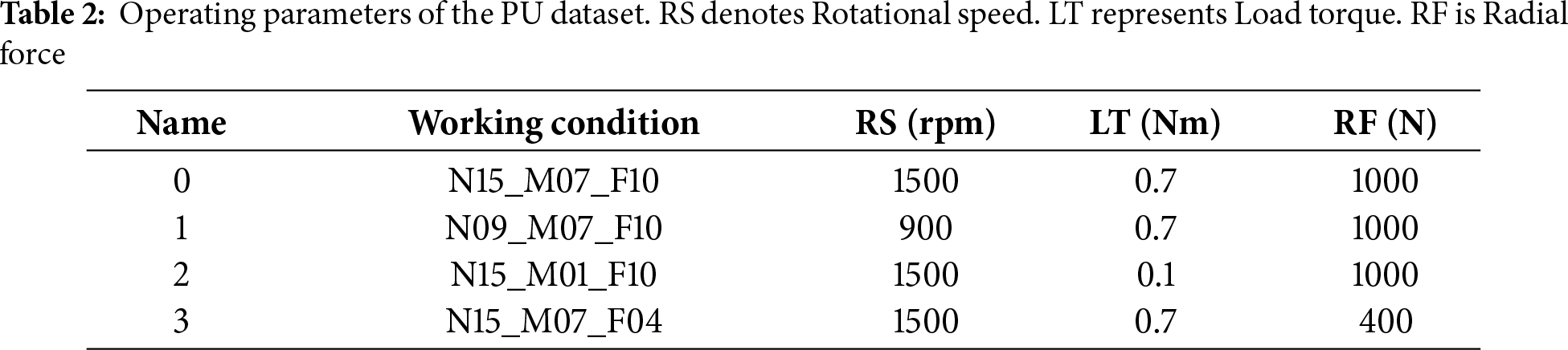
To rigorously evaluate the effectiveness and generalization of the proposed approach, we conduct experiments on two widely used bearing-fault benchmarks: CWRU and PU. These datasets are well established in the fault diagnosis community, owing to their diverse fault types, controlled test conditions, and high-quality vibration signals. Using these two complementary datasets enables a comprehensive performance assessment, ensuring that the proposed framework is validated on both controlled laboratory measurements (CWRU) and complex, mixed-condition scenarios (PU). CWRU dataset. The CWRU data were collected by the Bearing Data Center of Case Western Reserve University on a 2-hp Reliance motor test rig consisting of a drive motor, fan end, torque transducer/encoder, flywheel, and load motor (see Fig. 2). Faults were introduced into the inner race, outer race, and rolling element using electro-discharge machining (EDM) with diameters of 0.007, 0.014, and 0.021 inches. Vibration signals were measured by accelerometers at the drive end (DE) and fan end (FE) with sampling rates of 12 and 48 kHz (all FE data at 12 kHz). The dataset spans multiple loads (0, 1, 2, 3 hp) and fault locations, making it suitable for testing diagnostic algorithms across varied conditions. A detailed mapping of fault types, severities, and labels is given in Table 1. This dataset is particularly valuable for validating the robustness of diagnostic models under load variations and different fault severities. For a fair comparison with state-of-the-art (SOTA) methods, we adopt EnsembleNet [34] as the baseline and follow the same partitioning protocol across all datasets, while reproducing the performance of several representative SOTA approaches on this dataset.

Figure 2: Test rig of the CWRU dataset
For data preparation, each vibration sequence is first divided into two disjoint halves based on time: the first half is used exclusively for training, and the second half for testing. Both sets are segmented using a fixed-length window of 2048 consecutive points. To enhance the diversity of the training data while avoiding information leakage, a sliding window with stride 80 is applied within the training partition only, whereas non-overlapping segments are used for the test partition. This ensures strict temporal separation between training and testing samples, preventing overlapping windows from the same continuous signal from straddling both sets. To further assess robustness under varying data regimes, we fix the test set to 750 randomly selected non-overlapping samples and vary the training sample size from 30 to 19,800. The dataset covers multiple fault types across the inner race, outer race, and rolling element, ensuring consistent class complexity.
PU dataset. The Paderborn University (PU) dataset, released by the Chair of Mechatronics at the Heinz Nixdorf Institute (Germany), is designed to approximate realistic industrial operating conditions. It contains vibration and motor current signals from both healthy and faulty bearings, collected under laboratory as well as accelerated life test conditions. As illustrated in Fig. 3, the test bench comprises an electric motor, torque-measurement shaft, bearing module, flywheel, and load motor. Bearing faults were induced by three approaches: electrical discharge machining (EDM), manual damage, and natural degradation. Data acquisition was performed under three rotational speeds (900, 1500, 2700 rpm) and two radial loads (0.7, 1.4 kN), with a sampling rate of 64 kHz. By including both artificially induced and naturally developed faults, the PU dataset is particularly suitable for domain adaptation studies and cross-condition generalization in fault diagnosis. In total, the dataset provides 32 labels, each recorded under four different operating conditions (Table 2), ensuring diverse and challenging fault scenarios for thorough evaluation. Experiments on PU further validate the effectiveness and generalization of our method under complex operating environments. Compared to CWRU, PU presents more intricate fault patterns and diverse operating scenarios, thereby providing a more challenging benchmark. In this study, as summarized in Table 3, we select 13 fault labels: one healthy bearing, six artificially induced faults, and six naturally degraded faults. Following the same preparation strategy as for CWRU, we fix the test set to 750 randomly selected samples, while varying the number of training samples between 1040 and 19,800 across different settings. To further assess robustness and generalization, we also conduct experiments under single-condition and multi-condition scenarios, highlighting the proposed method’s superior performance in complex industrial environments.

Figure 3: Test rig of PU dataset
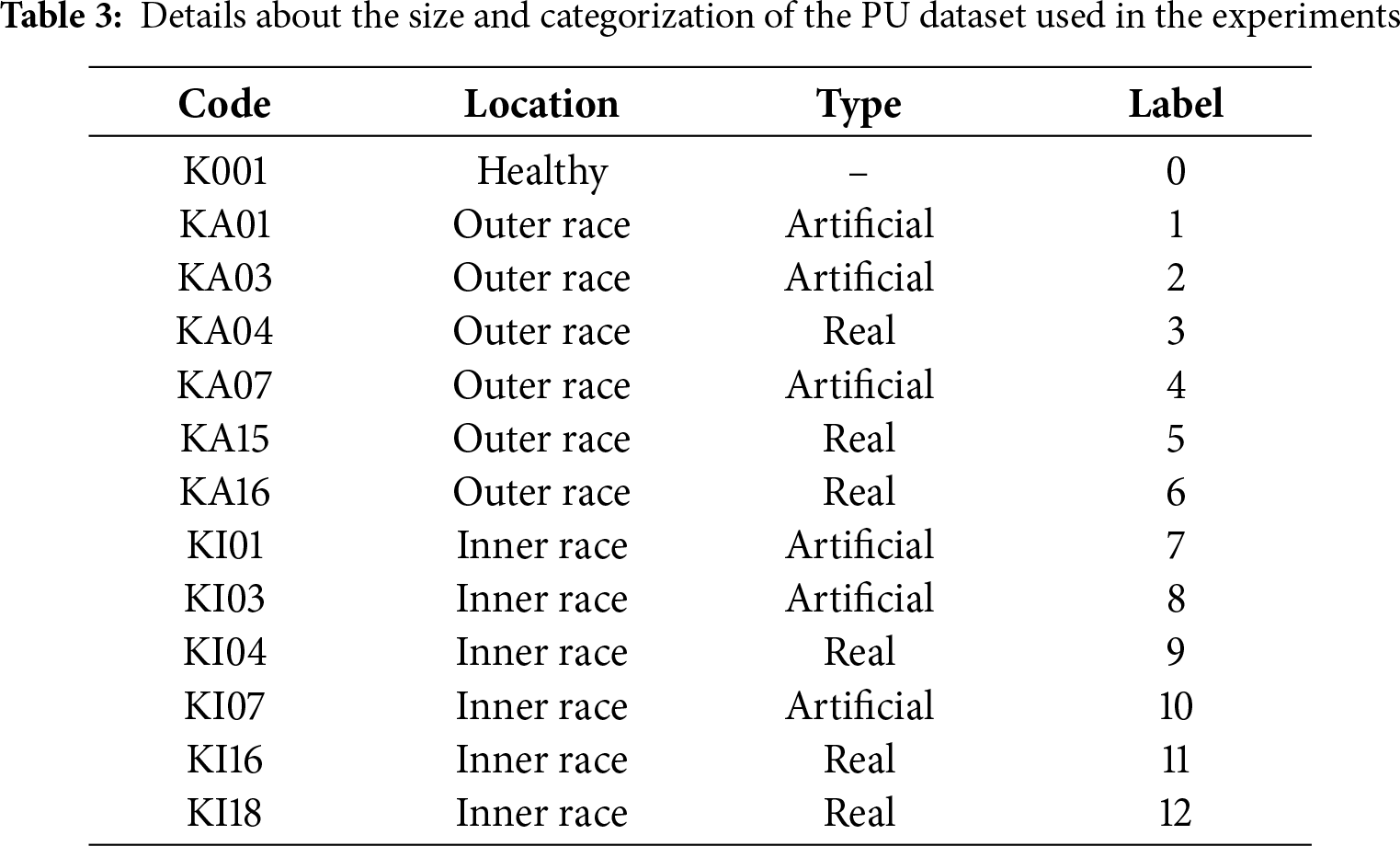
For all experiments, the vibration signals are segmented using a 2048-point window consistent with the data preparation described in Section 4.1. A non-overlapping sliding window is applied to the testing data to ensure strict temporal independence, while the training data are augmented using an overlapping sliding window with stride 80 within the training partition only. This segmentation strategy enriches the diversity of training samples without introducing temporal leakage between training and test sets, as segments from the same continuous bearing record are never split across the two subsets.
For a fair and consistent comparison, all baseline models (CovaMNet, MF-Net, and EnsembleNet) and our proposed method were trained under the same optimization and scheduling settings. Specifically, we employed the Adam optimizer with an initial learning rate of 0.001, a five-epoch warm-up phase, and a cosine annealing learning rate schedule to ensure smooth convergence. Each model was trained for 100 epochs using the same batch size of 32, input preprocessing pipeline, and without any data augmentation settings. To ensure fairness, no additional tuning was applied to individual baselines beyond reproducing their official configurations within the unified training framework. For our proposed model, a layer-specific learning rate adjustment was introduced in the Attention-Driven Adaptive Laplace Wavelet Convolution (AALWC) module. The learnable kernel parameters
Comparison Methods. To ensure a fair and comprehensive evaluation, we compare our method with a range of representative baselines, including classical metric-learning approaches such as ProtoNet [35] and Cosine Classifier [36], enhanced variants such as CovaMNet [37], and MF-Net [38], as well as more recent attention- and transformer-based architectures including QSFormer [39] and EnsembleNet [34]. These methods cover different modeling philosophies ranging from prototype-based learning to attention-augmented feature extractors and multi-branch fusion, thereby providing a solid benchmark for validating the effectiveness of our proposed approach.
Results on CWRU. Table 4 reports the results on the CWRU dataset under the 10-way
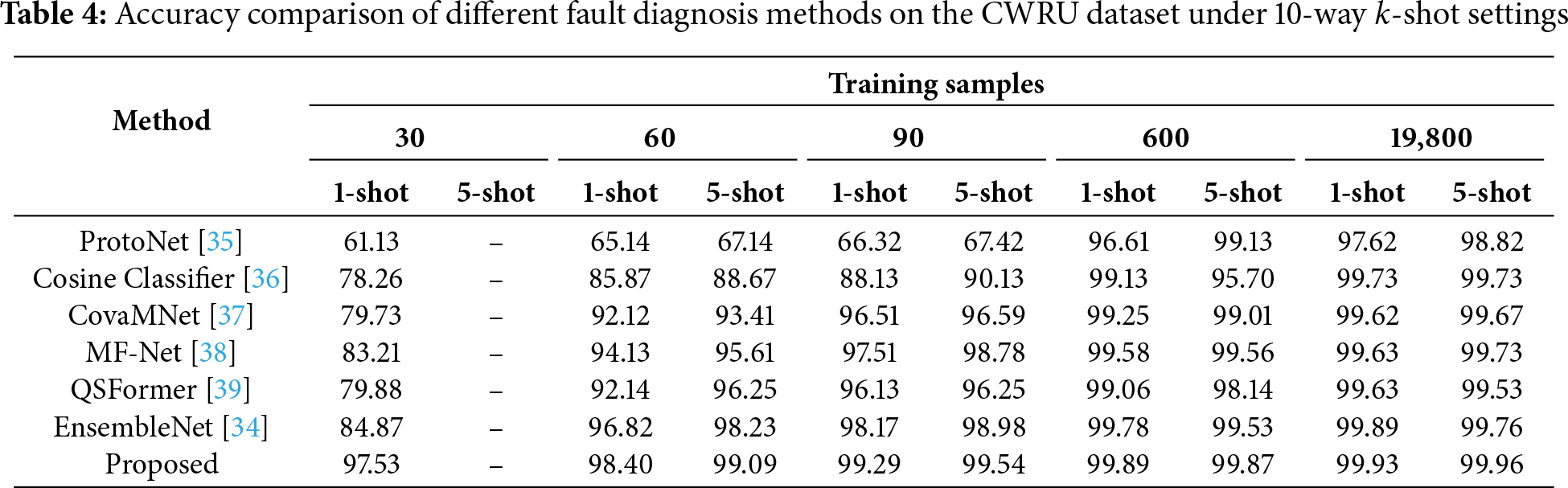
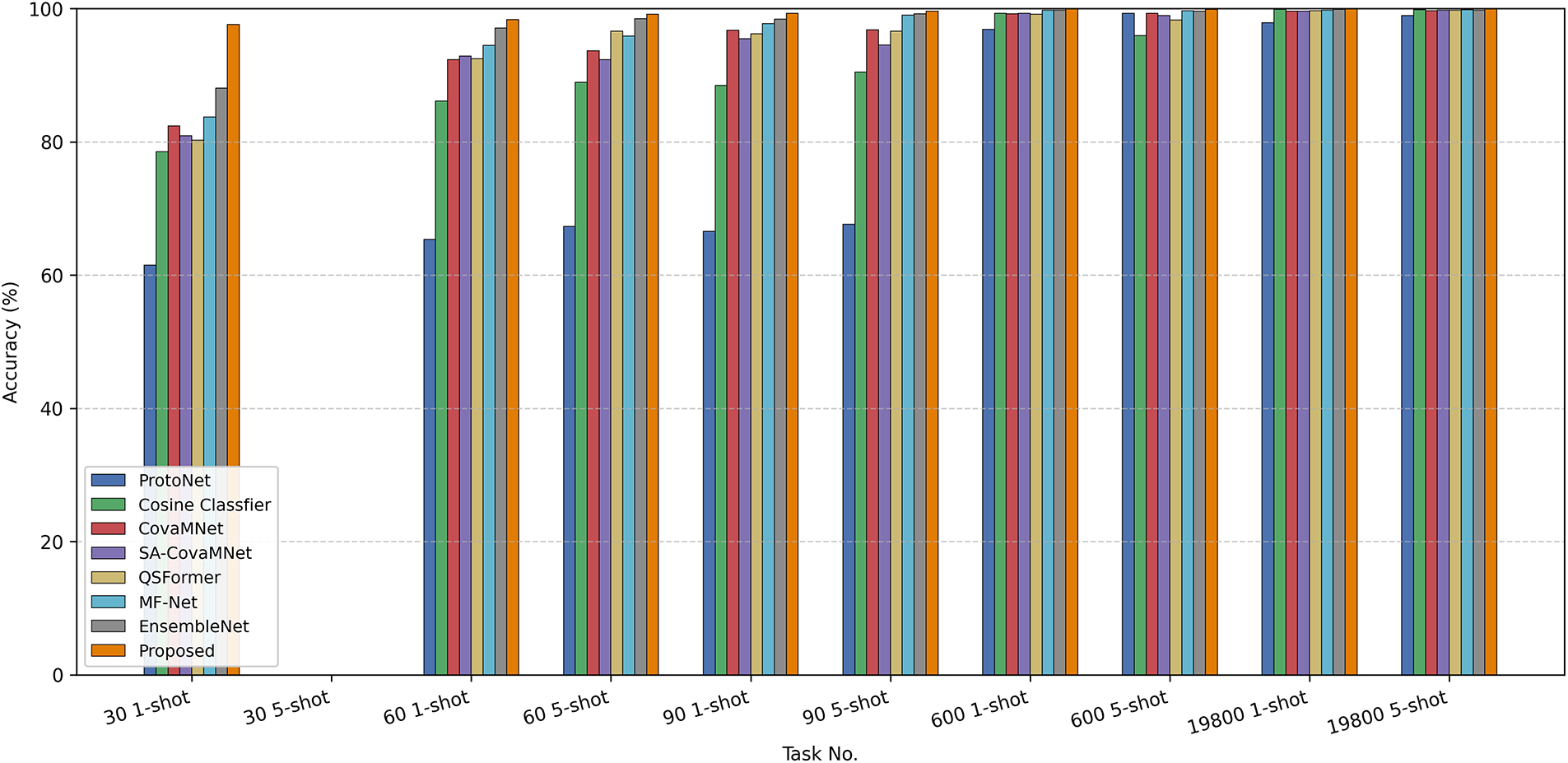
Figure 4: Comparison of testing accuracy among different few-shot learning methods on the CWRU dataset under 10-way k-shot fault diagnosis tasks with varying numbers of shots
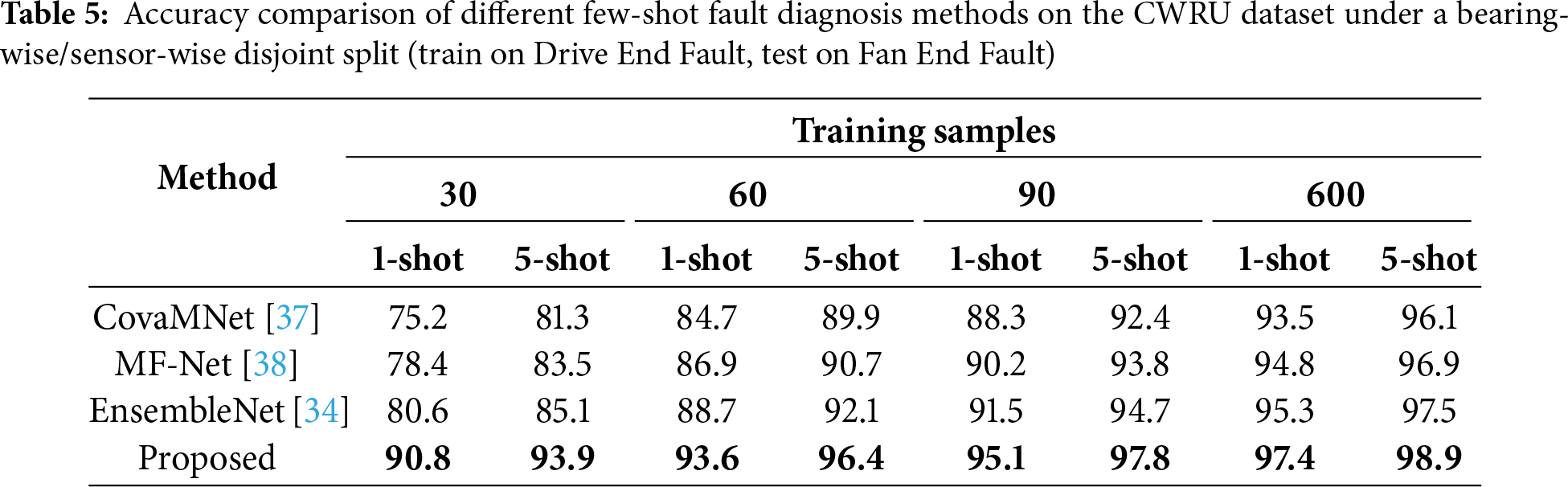
Results on PU (Condition 0). Table 6 summarizes the results on the PU dataset under Condition 0 with the 13-way
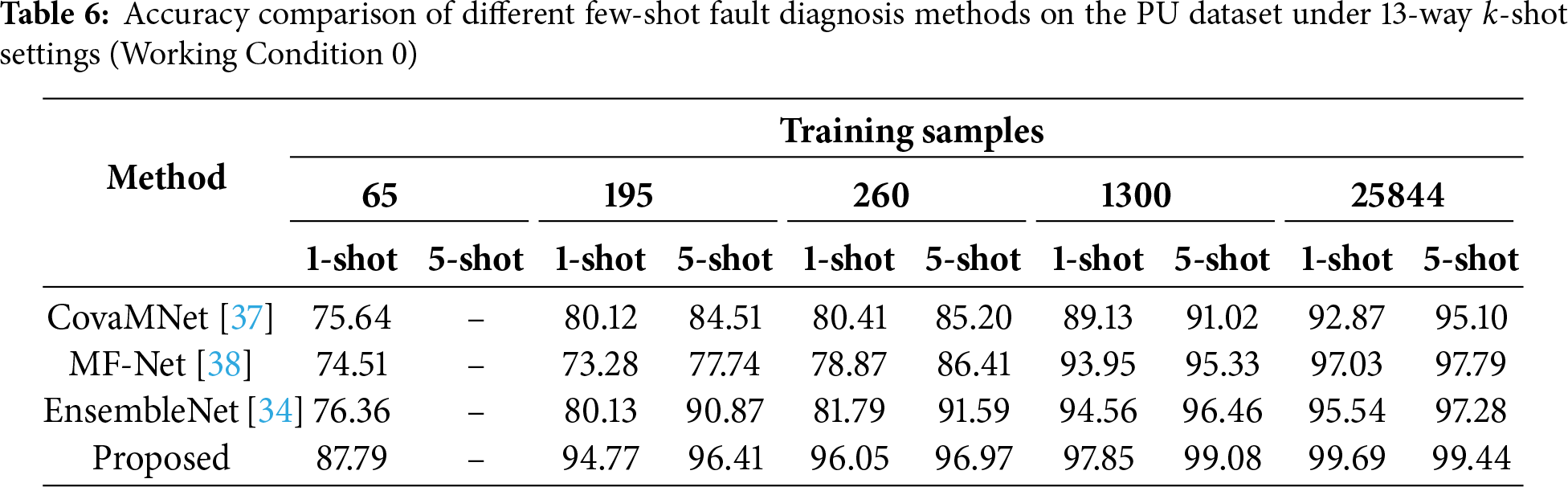
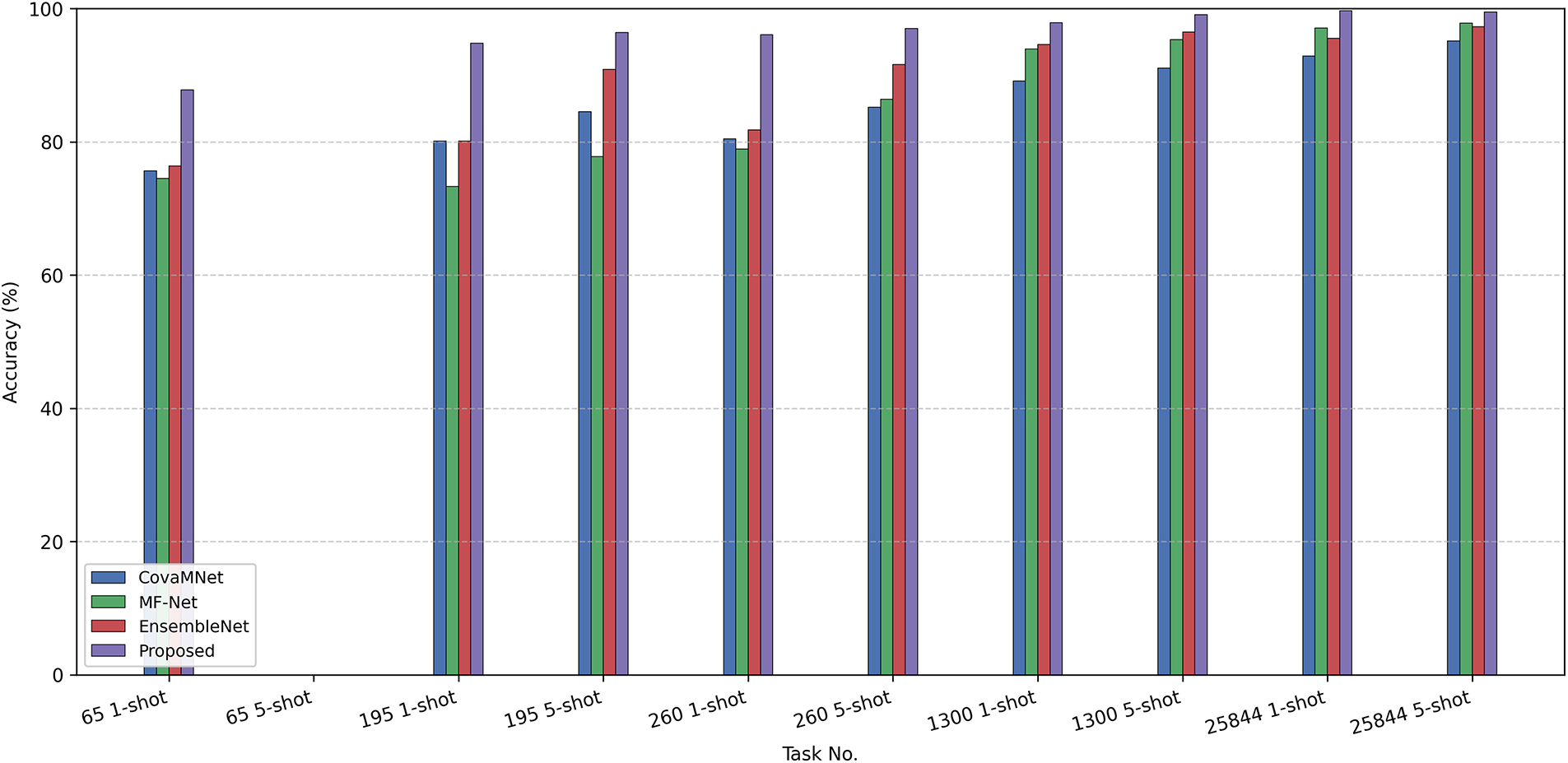
Figure 5: Comparison of testing accuracy among different few-shot learning methods on the PU dataset under 13-way k-shot fault diagnosis tasks
Results on PU (Multiple Conditions). To evaluate robustness under varying operating environments, Table 7 reports the average accuracy over four working conditions (0–3) under the 13-way, 5-shot setting. The average was computed by training on all four conditions combined and testing across all the conditions. However, to ensure the generalization capability of the proposed method across different working conditions, we further perform leave-condition-out evaluations: for example, training on conditions 0, 1, 2 and testing on condition 3. Our method achieves the best results across all training sample sizes, reaching 95.18% at 4160 samples compared to 87.20% for EnsembleNet and 83.44% for MF-Net. The relative improvements are especially significant in medium-scale regimes (260–1300), where our method improves accuracy by 7–10 percentage points over the strongest competitor. This demonstrates that the proposed framework not only excels in controlled scenarios but also generalizes effectively across diverse and complex working conditions. As presented in Fig. 6, we visualize the feature distributions using t-SNE. It can be observed that CovaMNet and MF-Net exhibit notable overlaps between different classes, while EnsembleNet improves the separation to some extent. In contrast, our proposed method produces more compact intra-class clusters and clearer inter-class boundaries. This indicates that the proposed approach can extract more discriminative and robust feature representations even under complex and variable operating conditions.
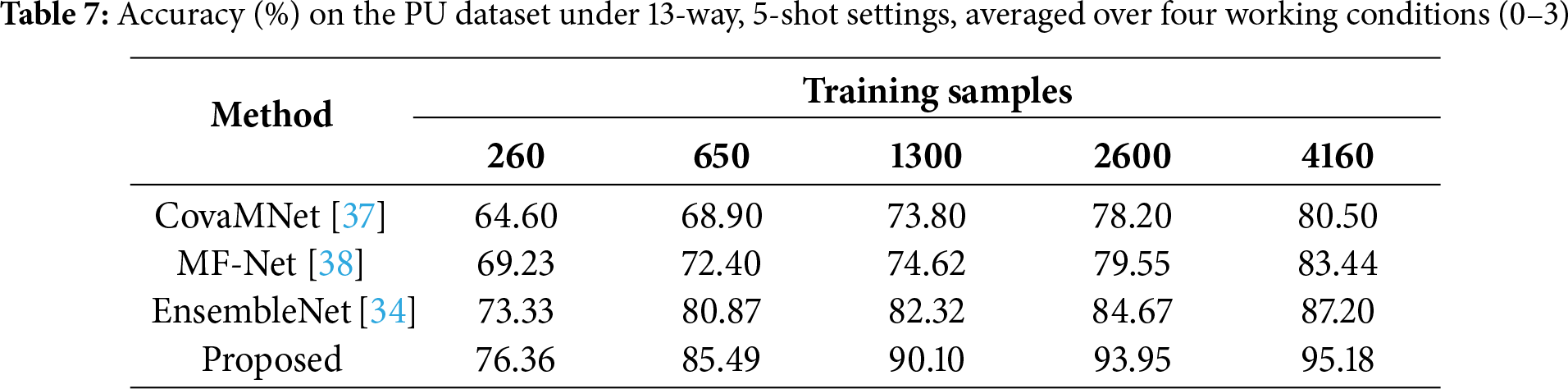
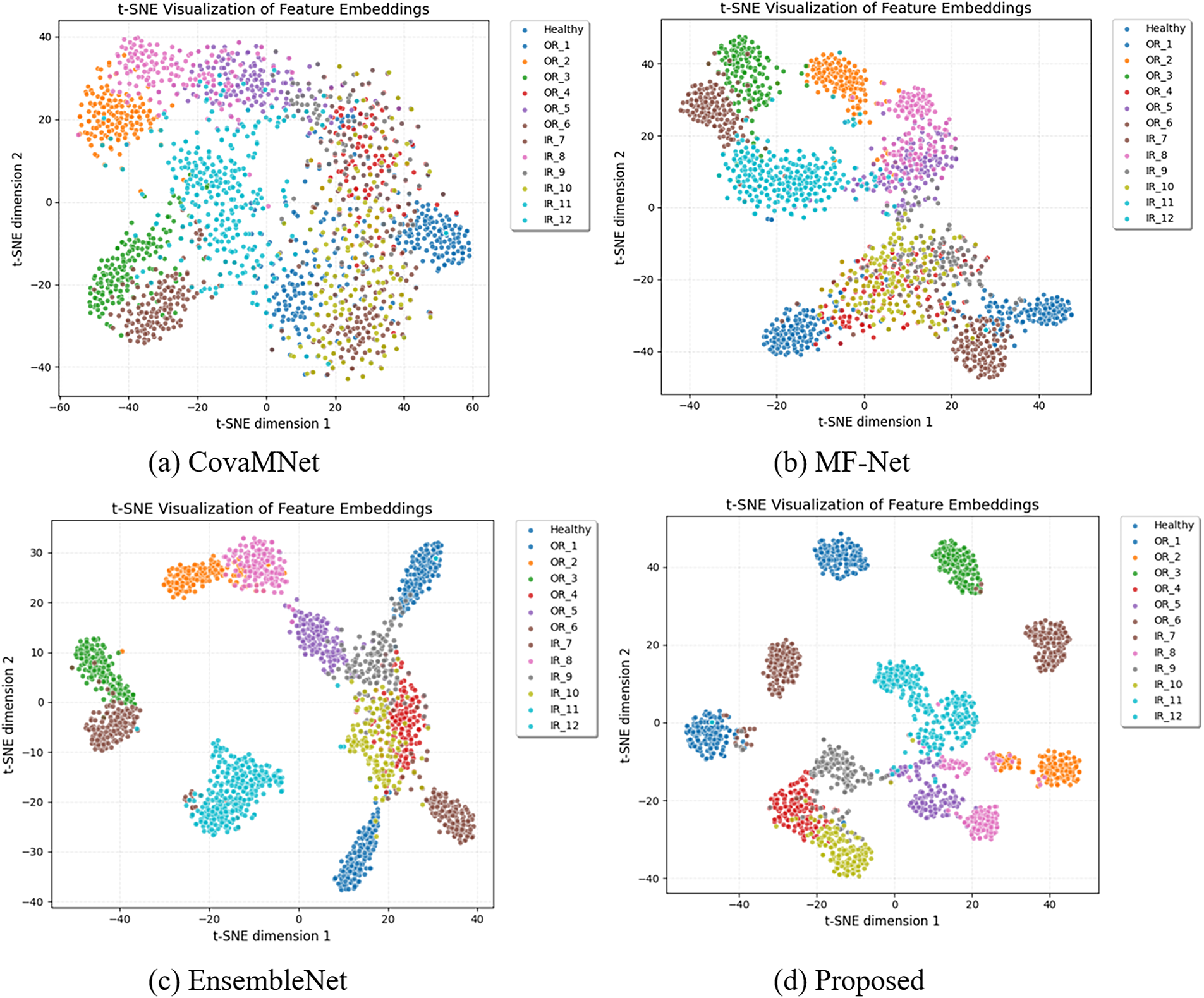
Figure 6: t-SNE visualization of feature embeddings under multiple working conditions on the PU dataset. Compared with baseline methods (a–c), the proposed method (d) achieves more compact intra-class clustering and clearer inter-class separation, highlighting its superior feature discriminability
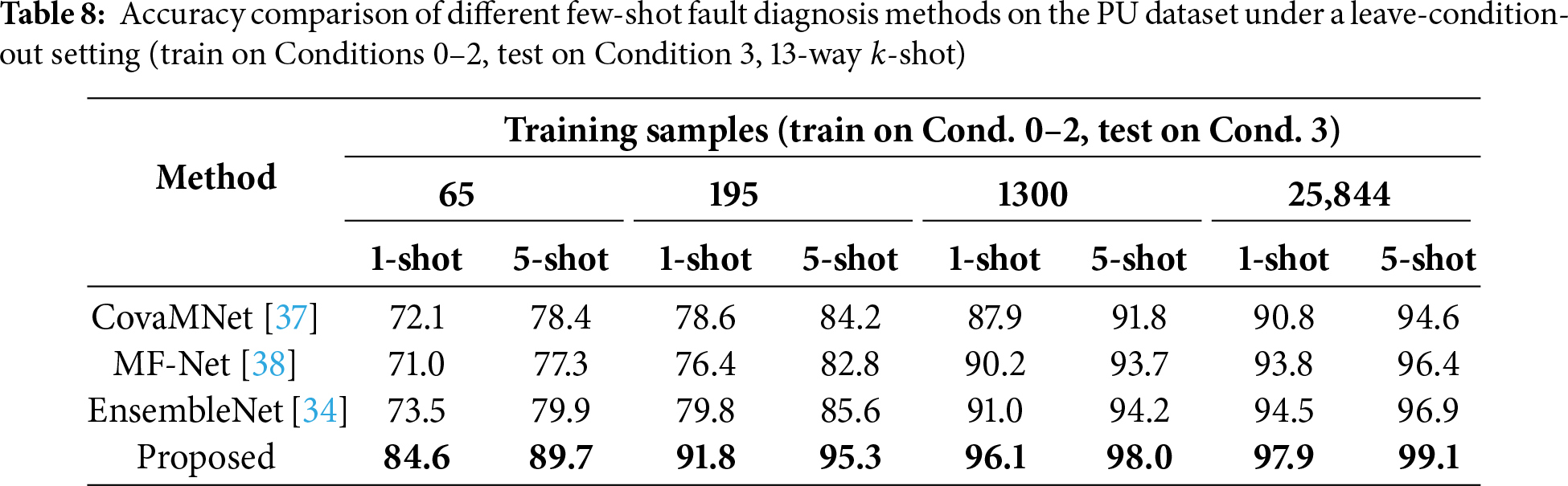
Results on PU (Leave-Condition-Out Evaluation). To further investigate generalization under unseen operating conditions, we additionally perform leave-condition-out experiments, following the reviewer’s suggestion. Specifically, the model is trained on Conditions 0, 1, and 2 and evaluated on the unseen Condition 3. Results are summarized in Table 8. This evaluation forms a much stricter distribution shift, as the model encounters a completely unseen load/speed condition at test time. Our proposed model achieves the highest accuracy across all sample sizes (65–25844). For instance, under the 65-sample 1-shot setting, our method reaches 84.6%, compared to 73.5% for EnsembleNet. The performance gap becomes even more pronounced in medium- and high-sample scenarios, highlighting the model’s strong resilience to operating-condition mismatch. These findings provide compelling evidence that the proposed method maintains robust discriminative ability even when deployed in previously unseen working conditions.
Interpretability Visualization Analysis. To further demonstrate the interpretability of the proposed learnable Laplace wavelet module, Fig. 7 provides a visualization of both the initial and the learned wavelet kernels. As shown in Fig. 7a, the randomly initialized kernel exhibits a wide time-domain envelope with no preference for any particular frequency component. After training, the kernels automatically adjust their scale parameters such that the time-domain shapes become narrower or wider depending on the target frequency. The frequency-domain responses presented in Fig. 7b reveal a clear alignment between the learned spectral peaks and the theoretical bearing fault characteristic frequencies. Specifically, the kernel associated with the BPFI fault converges to a dominant peak at approximately 161.7 Hz, while another kernel aligns with the BPFO frequency at approximately 107.36 Hz. This demonstrates that the learnable wavelet module not only differentiates between fault types but also emphasizes fault-relevant spectral bands that are physically consistent with the mechanical structure of the bearing. These observations validate the claim that the proposed method possesses inherent physical interpretability: the network adapts its wavelet parameters to selectively enhance characteristic fault frequencies, effectively bridging data-driven learning with domain-specific vibration knowledge.
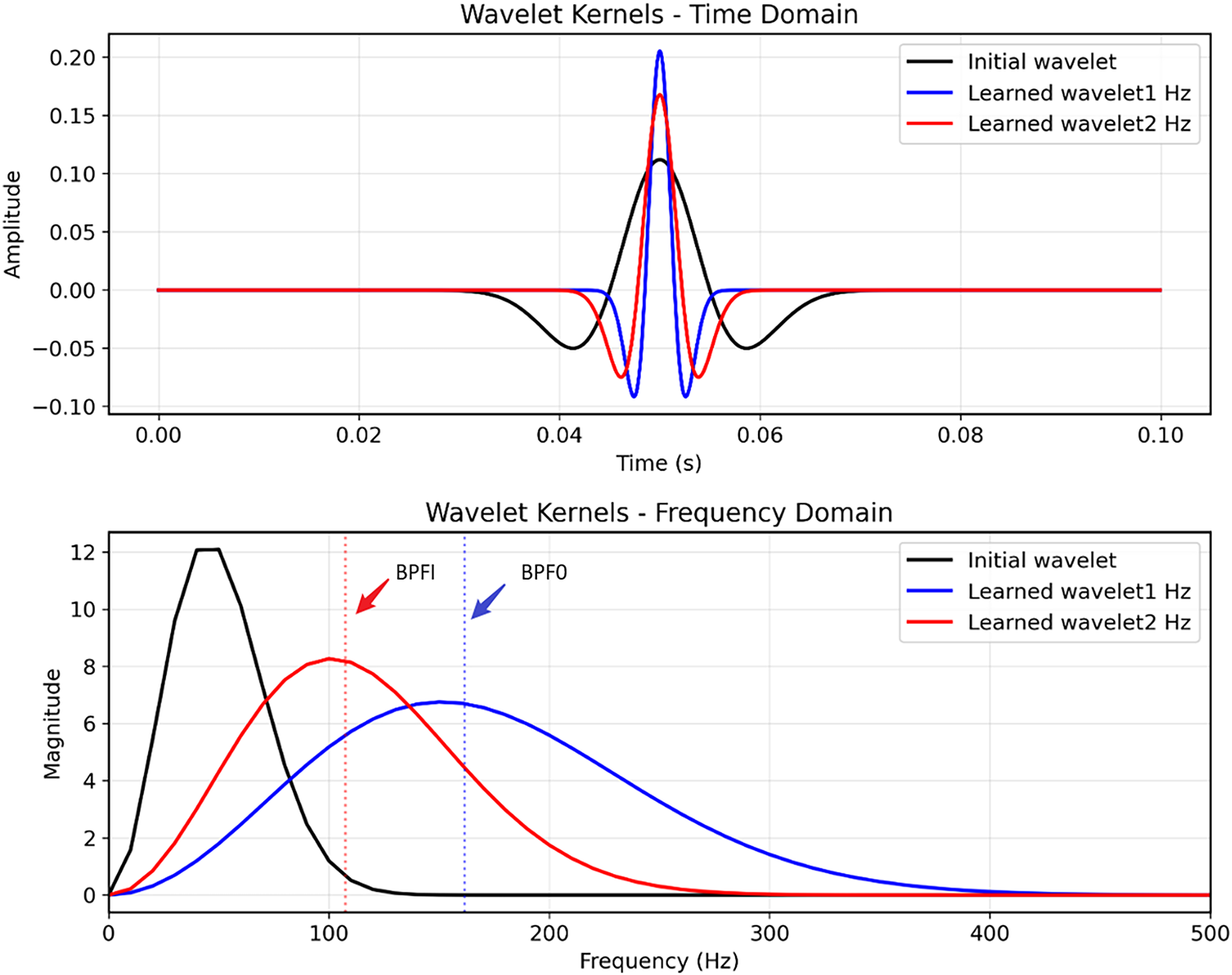
Figure 7: Visualization of the learnable Laplace wavelet kernels. (a) Time-domain kernels with random initialization (black) and learned kernels tuned to the theoretical inner-race (BPFI = 161.7 Hz, blue) and outer-race (BPFO = 107.36 Hz, red) characteristic frequencies. (b) Corresponding magnitude spectra, where the learned kernels exhibit clear peaks around BPFI and BPFO, indicating that the proposed module adaptively emphasizes fault-related frequency bands
Across both datasets and multiple working conditions, two clear trends emerge. First, the performance gains are particularly striking in the extreme few-shot regime, which aligns with the practical challenges of industrial applications where annotated data are scarce. Second, the superiority persists as the number of samples increases and as operating conditions vary, highlighting both scalability and robustness. We attribute these improvements to the synergy of (i) the physics-guided Laplace wavelet convolution, which extracts fine-grained spectral features, and (ii) the covariance-aware Mahalanobis metric, which enhances prototype discrimination by modeling intra-class variability. Together, these innovations enable the model to construct stable and generalizable representations under diverse settings. These strong results provide solid empirical evidence of the effectiveness of our framework and motivate a deeper analysis of its individual components via ablation studies in the following subsection.
We conduct ablation experiments on the PU dataset to validate the contribution of each component in the proposed framework, as summarized in Table 9 and visualized in Fig. 8. First, replacing the proposed AALWC module with a standard 1D convolution (E1 vs. E3) results in a significant performance drop, confirming the effectiveness of AALWC in feature extraction. Second, comparing E2–E4 verifies the benefit of the Mahalanobis–Prototype joint metric, which yields more accurate and consistent decision boundaries. Finally, experiments with varying numbers of wavelet kernels (E4–E7) show that moderate kernel numbers (e.g., 3 or 6) achieve optimal performance, while excessive kernel numbers (E7) lead to performance degradation. The t-SNE visualizations further validate these findings, demonstrating that the proposed configuration enables clearer clustering and better inter-class separability.
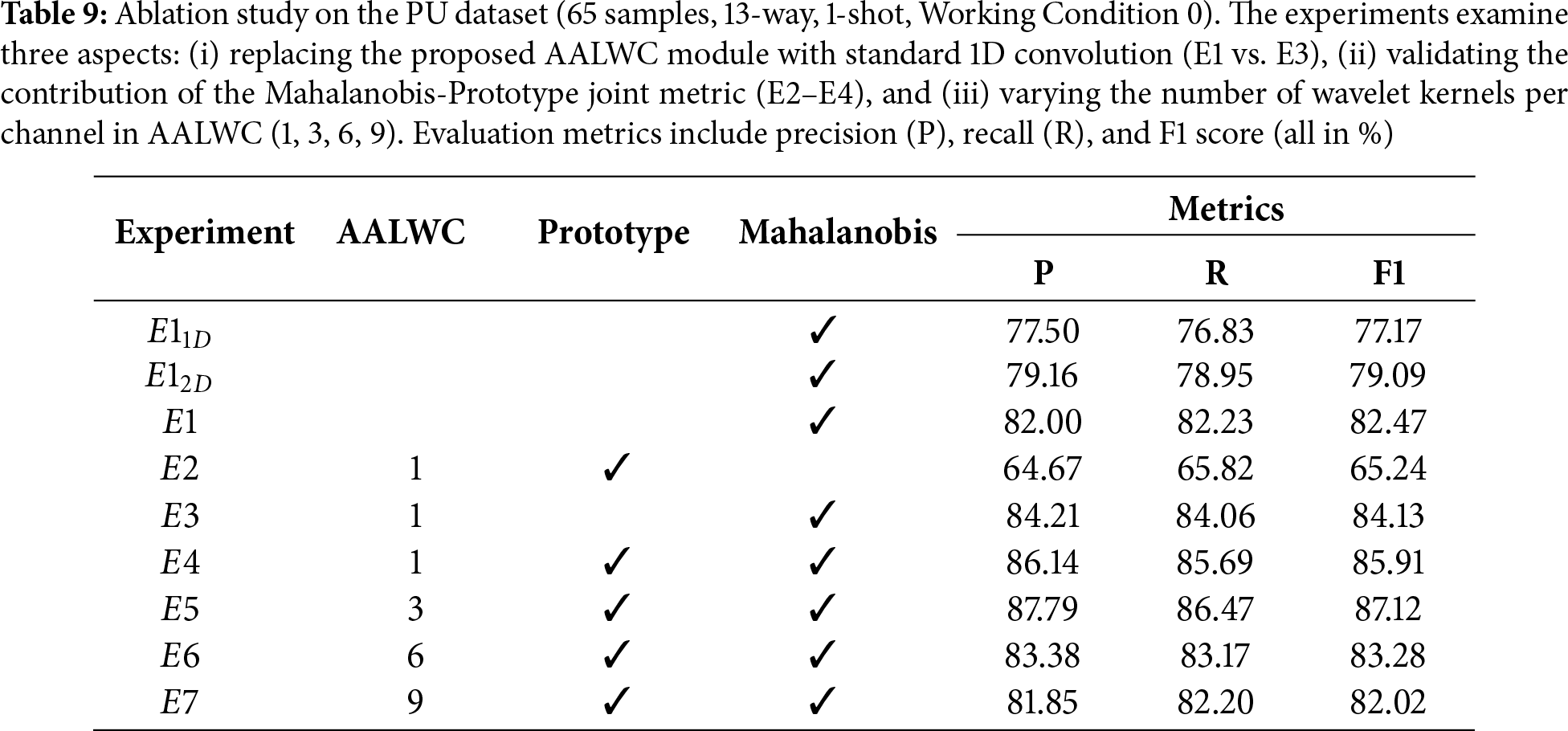
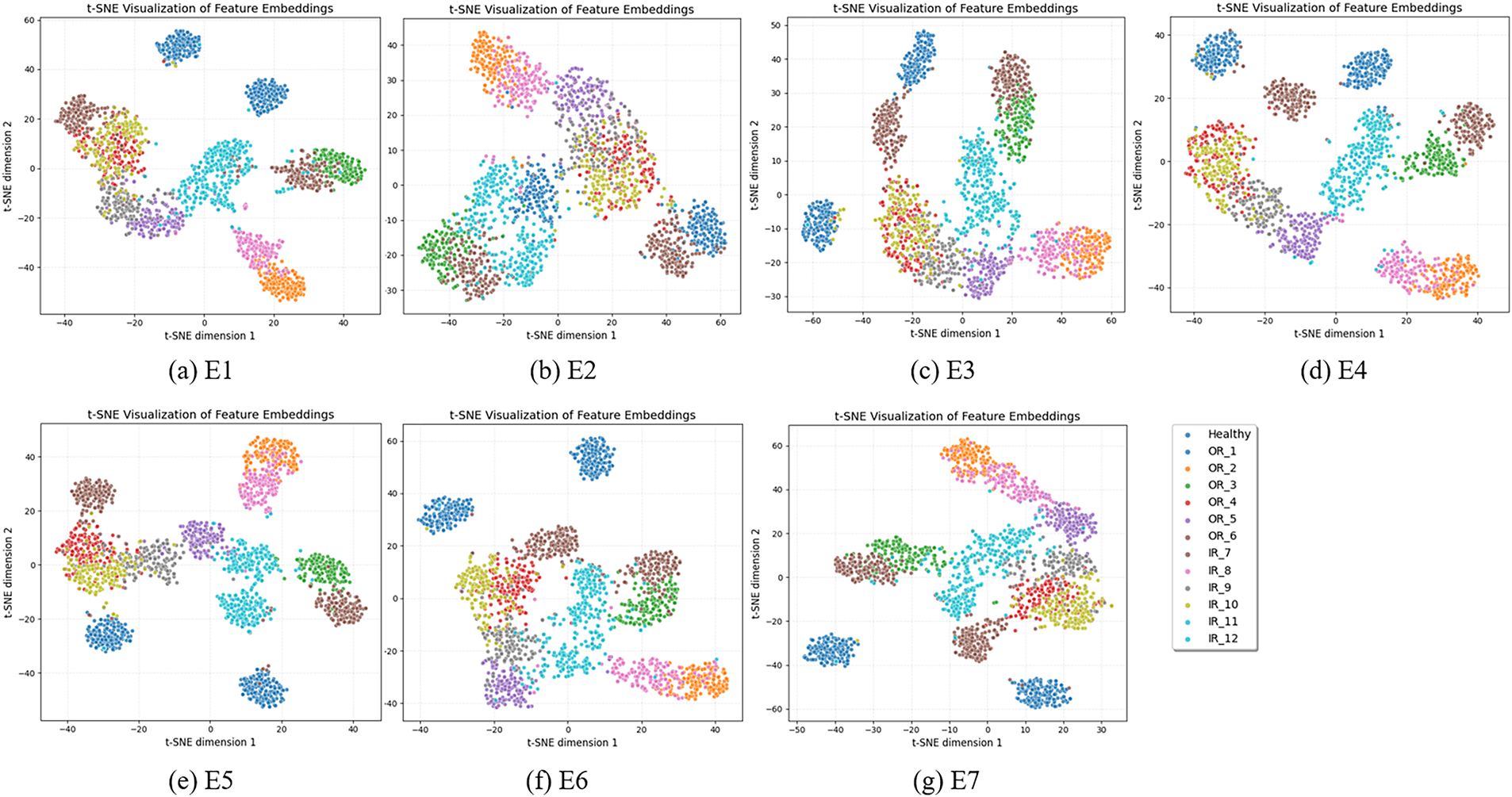
Figure 8: Ablation study on the PU dataset under 13-way 1-shot tasks. (Top) Quantitative results across different experimental settings (E1–E7). (Bottom) t-SNE visualizations of feature embeddings corresponding to each experiment, showing the impact of different components and wavelet kernel numbers on class separability
(i) Effect of AALWC vs. standard convolution. To quantify the gain brought by the proposed AALWC module, we compare E1 (standard 1D convolution + Mahalanobis) with E3 (AALWC + Mahalanobis). As shown in Table 9, introducing AALWC improves macro-F1 from 82.47% to 84.13%, together with consistent gains in precision and recall. This demonstrates that the AALWC is able to capture more discriminative and physically meaningful spectral patterns than conventional convolutions: the learnable Laplace wavelet kernels adapt their scales and centers to emphasize fault-related frequency bands, leading to tighter clusters and fewer misclassifications in the few-shot regime.
(ii) Contribution of the Mahalanobis-prototype joint metric. We next examine the effect of the proposed Mahalanobis-prototype joint metric. E2 (AALWC + prototype only) yields an F1 of 65.24%, which highlights the limitation of relying solely on prototype matching without modeling intra-class variability. Replacing the prototype metric with the Mahalanobis distance (E3: AALWC + Mahalanobis) raises F1 to 84.13%, a gain of nearly 19 percentage points. Further combining both metrics in E4 (AALWC + prototype + Mahalanobis) boosts F1 to 85.91%. These results indicate that the Mahalanobis component plays a crucial role in enhancing feature discrimination by explicitly encoding class-dependent covariance, while the prototype term provides a stable class center; their joint use yields more accurate and consistent decision boundaries than either metric alone.
(iii) Influence of kernel numbers in AALWC. We further vary the number of wavelet kernels per channel from 1 to 9 (E4–E7). The results show that using three kernels (E5) achieves the best overall performance, with an F1 of 86.49%, while increasing to six or nine kernels slightly decreases accuracy. This suggests that a moderate multi-kernel design provides sufficient frequency diversity without introducing excessive redundancy. When too many kernels are used, several of them tend to collapse into overlapping or highly correlated frequency bands, which effectively over-parameterizes the model under the few-shot regime and makes optimization more difficult. As a result, the additional capacity is not translated into useful discriminative features, but instead increases the risk of overfitting and noise amplification, whereas three kernels per channel strike a better balance between expressiveness and generalization.
(iv) Effect of 1D/2D modality fusion. To quantify the benefit of multi-modal fusion, we additionally evaluate two single-branch variants on the PU dataset:
Overall, these ablation studies clearly demonstrate that each component of our framework is indispensable: AALWC effectively captures discriminative spectral patterns, the Mahalanobis-prototype joint metric significantly enhances decision boundaries, and the multi-kernel design offers the best trade-off between feature diversity and generalization. The results provide strong empirical evidence that our architectural choices are both well-motivated and synergistic.
In this paper, we proposed a physics-guided multimodal few-shot learning framework that addresses the challenges of data scarcity, robustness, and interpretability in intelligent bearing diagnosis. Unlike most existing purely data-driven methods, our framework jointly leverages a 1D vibration encoder and a 2D time–frequency encoder to capture complementary temporal–spectral features. First, we designed an Attention-Driven Adaptive Laplace Wavelet Convolution (AALWC) module, which embeds prior knowledge from signal processing into the network, enabling the extraction of discriminative and physically interpretable features. By incorporating parametric multi-kernel wavelets with channel-wise attention, the model adaptively selects relevant bases and achieves a balance between physical priors and data-driven flexibility. Second, we introduced a Mahalanobis–Prototype Joint Metric, which explicitly models intra-class variability and constructs more consistent and accurate decision boundaries under few-shot conditions. Comprehensive experiments on the CWRU and PU datasets, covering both single-condition and multi-condition scenarios, demonstrate that the proposed approach consistently outperforms state-of-the-art baselines. The gains are particularly significant in extreme few-shot regimes and under complex operating conditions, highlighting the framework’s effectiveness, robustness, and interpretability. In future work, we plan to further enhance adaptability by developing dynamic wavelet kernel selection strategies, extend the framework to multi-sensor fusion and cross-domain adaptation, and explore its deployment in more diverse and highly dynamic industrial environments.
Acknowledgement: This work was supported by Youth Scientific Research Fund Project Plan of Anhui Institute of Information Technology.
Funding Statement: This research was funded by Yong Hu, grant number 23QNJJKJ010.
Author Contributions: The authors confirm contributions to the paper as follows: Conceptualization and methodology, Yong Hu, Weifan Xu; data curation and investigation, Yong Hu, Xiangtong Du; writing-original draft preparation, Yong Hu, Weifan Xu; writing-review and editing, Yong Hu, Weifan Xu, Xiangtong Du. All authors reviewd and approved the final version of the manuscript.
Availability of Data and Materials: Data available on request from the authors.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Lu N, Yin T. Transferable common feature space mining for fault diagnosis with imbalanced data. Mech Syst Signal Process. 2021;156:107645. doi:10.1016/j.ymssp.2021.107645. [Google Scholar] [CrossRef]
2. Huo J, Qi C, Li C, Wang N. Data augmentation fault diagnosis method based on residual mixed self-attention for rolling bearings under imbalanced samples. IEEE Trans Instrum Meas. 2023;72:1–14. doi:10.1109/tim.2023.3311062. [Google Scholar] [CrossRef]
3. Ding J, Wang Z, Yao L, Cai Y. Rolling bearing fault diagnosis based on gcmwpe and parameter optimization svm. China Mech Eng. 2021;32(2):147. [Google Scholar]
4. Rudsari FN, Razi-Kazemi AA, Shoorehdeli MA. Fault analysis of high-voltage circuit breakers based on coil current and contact travel waveforms through modified svm classifier. IEEE Trans Power Deliv. 2019;34(4):1608–18. doi:10.1109/tpwrd.2019.2915110. [Google Scholar] [CrossRef]
5. Yang Q, Liao Y. A novel mechanical fault diagnosis for high-voltage circuit breakers with zero-shot learning. Expert Syst Appl. 2024;245(8):123133. doi:10.1016/j.eswa.2023.123133. [Google Scholar] [CrossRef]
6. Ma S, Chen M, Wu J, Wang Y, Jia B, Jiang Y. High-voltage circuit breaker fault diagnosis using a hybrid feature transformation approach based on random forest and stacked autoencoder. IEEE Trans Ind Electron. 2018;66(12):9777–88. doi:10.1109/tie.2018.2879308. [Google Scholar] [CrossRef]
7. Zhao X, Jia M. Fault diagnosis of rolling bearing based on feature reduction with global-local margin fisher analysis. Neurocomputing. 2018;315:447–64. doi:10.1016/j.neucom.2018.07.038. [Google Scholar] [CrossRef]
8. Zhao K, Xiao J, Li C, Xu Z, Yue M. Fault diagnosis of rolling bearing using CNN and PCA fractal based feature extraction. Measurement. 2023;223:113754. doi:10.2139/ssrn.4400906. [Google Scholar] [CrossRef]
9. Ma J, Cai W, Shan Y, Xia Y, Zhang R. An integrated framework for bearing fault diagnosis: convolutional neural network model compression through knowledge distillation. IEEE Sens J. 2024;24(23):40083–95. doi:10.1109/jsen.2024.3481298. [Google Scholar] [CrossRef]
10. Li C, Xu J, Xing J. A frequency feature extraction method based on convolutional neural network for recognition of incipient fault. IEEE Sens J. 2023;24(1):564–72. doi:10.1109/jsen.2023.3334037. [Google Scholar] [CrossRef]
11. Han S, Sun S, Zhao Z, Luan Z, Niu P. Deep residual multiscale convolutional neural network with attention mechanism for bearing fault diagnosis under strong noise environment. IEEE Sens J. 2024;24(6):9073–81. doi:10.1109/jsen.2023.3345400. [Google Scholar] [CrossRef]
12. Chen L, Ma Y, Hu H, Khan US. An effective fault diagnosis approach for bearing using stacked de-noising auto-encoder with structure adaptive adjustment. Measurement. 2023;214:112774. doi:10.1016/j.measurement.2023.112774. [Google Scholar] [CrossRef]
13. Tian J, Jiang Y, Zhang J, Luo H, Yin S. A novel data augmentation approach to fault diagnosis with class-imbalance problem. Reliab Eng Syst Saf. 2024;243(4):109832. doi:10.1016/j.ress.2023.109832. [Google Scholar] [CrossRef]
14. Gao S, Xu L, Zhang Y, Pei Z. Rolling bearing fault diagnosis based on ssa optimized self-adaptive dbn. ISA Trans. 2022;128(1):485–502. doi:10.1016/j.isatra.2021.11.024. [Google Scholar] [PubMed] [CrossRef]
15. Zhao H, Yang X, Chen B, Chen H, Deng W. Bearing fault diagnosis using transfer learning and optimized deep belief network. Meas Sci Technol. 2022;33(6):065009. doi:10.1088/1361-6501/ac543a. [Google Scholar] [CrossRef]
16. An Z, Li S, Wang J, Jiang X. A novel bearing intelligent fault diagnosis framework under time-varying working conditions using recurrent neural network. ISA Trans. 2020;100:155–70. doi:10.1016/j.isatra.2019.11.010. [Google Scholar] [PubMed] [CrossRef]
17. Shi Y, Deng A, Deng M, Xu M, Liu Y, Ding X, et al. Domain augmentation generalization network for real-time fault diagnosis under unseen working conditions. Reliab Eng Syst Saf. 2023;235(4):109188. doi:10.1016/j.ress.2023.109188. [Google Scholar] [CrossRef]
18. Fan Z, Xu Q, Jiang C, Ding SX. Deep mixed domain generalization network for intelligent fault diagnosis under unseen conditions. IEEE Trans Ind Electron. 2023;71(1):965–74. doi:10.1109/tie.2023.3243293. [Google Scholar] [CrossRef]
19. Li Q, Chen L, Kong L, Wang D, Xia M, Shen C. Cross-domain augmentation diagnosis: an adversarial domain-augmented generalization method for fault diagnosis under unseen working conditions. Reliab Eng Syst Saf. 2023;234:109171. doi:10.1016/j.ress.2023.109171. [Google Scholar] [CrossRef]
20. Chen Z, Xia J, Li J, Chen J, Huang R, Jin G, et al. Generalized open-set domain adaptation in mechanical fault diagnosis using multiple metric weighting learning network. Adv Eng Inform. 2023;57(3):102033. doi:10.1016/j.aei.2023.102033. [Google Scholar] [CrossRef]
21. Li J, Huang R, Chen Z, He G, Gryllias KC, Li W. Deep continual transfer learning with dynamic weight aggregation for fault diagnosis of industrial streaming data under varying working conditions. Adv Eng Inform. 2023;55(10):101883. doi:10.1016/j.aei.2023.101883. [Google Scholar] [CrossRef]
22. Jiang F, Lin W, Wu Z, Zhang S, Chen Z, Li W. Fault diagnosis of gearbox driven by vibration response mechanism and enhanced unsupervised domain adaptation. Adv Eng Inform. 2024;61(11):102460. doi:10.1016/j.aei.2024.102460. [Google Scholar] [CrossRef]
23. Wang H, Li C, Ding P, Li S, Li T, Liu C, et al. A novel transformer-based few-shot learning method for intelligent fault diagnosis with noisy labels under varying working conditions. Reliab Eng Syst Saf. 2024;251:110400. doi:10.1016/j.ress.2024.110400. [Google Scholar] [CrossRef]
24. Li J, Yue K, Wu Z, Jiang F, Zhong Z, Zhang S, et al. Mtsnn: a few-shot fine-grained diagnosis framework for cross-machine fault diagnosis with heterogeneous fault categories. IEEE Trans Instrum Meas. 2025;74(6):1–11. doi:10.1109/tim.2025.3551907. [Google Scholar] [CrossRef]
25. Liu Z, Peng Z. Few-shot bearing fault diagnosis by semi-supervised meta-learning with graph convolutional neural network under variable working conditions. Measurement. 2025;240:115402. doi:10.1016/j.measurement.2024.115402. [Google Scholar] [CrossRef]
26. Liu Z-H, Jiang L-B, Wei H-L, Chen L, Li X-H. Optimal transport-based deep domain adaptation approach for fault diagnosis of rotating machine. IEEE Trans Instrum Meas. 2021;70:1–12. doi:10.1109/tim.2021.3050173. [Google Scholar] [CrossRef]
27. Yang B, Lei Y, Li X, Li N. Targeted transfer learning through distribution barycenter medium for intelligent fault diagnosis of machines with data decentralization. Expert Syst Appl. 2024;244:122997. doi:10.1016/j.eswa.2023.122997. [Google Scholar] [CrossRef]
28. Li Z, Ma J, Wu J, Wong PK, Wang X, Li X. A gated recurrent generative transfer learning network for fault diagnostics considering imbalanced data and variable working conditions. IEEE Trans Neural Netw Learn Syst. 2025;36(8):13782–93. doi:10.1109/tnnls.2024.3362687. [Google Scholar] [PubMed] [CrossRef]
29. Ding Y, Jia M, Zhuang J, Cao Y, Zhao X, Lee C-G. Deep imbalanced domain adaptation for transfer learning fault diagnosis of bearings under multiple working conditions. Reliab Eng Syst Saf. 2023;230:108890. doi:10.1016/j.ress.2022.108890. [Google Scholar] [CrossRef]
30. Li Y, Ren Y, Zheng H, Deng Z, Wang S. A novel cross-domain intelligent fault diagnosis method based on entropy features and transfer learning. IEEE Trans Instrum Meas. 2021;70:1–14. doi:10.1109/tim.2021.3122742. [Google Scholar] [CrossRef]
31. Fan C, Zhang Y, Ma H, Ma Z, Yu K, Zhao S, et al. A novel metric-based model with the ability of zero-shot learning for intelligent fault diagnosis. Eng Appl Artif Intell. 2024;129:107605. doi:10.1016/j.engappai.2023.107605. [Google Scholar] [CrossRef]
32. Xue L, Lei C, Jiao M, Shi J, Li J. Rolling bearing fault diagnosis method based on self-calibrated coordinate attention mechanism and multi-scale convolutional neural network under small samples. IEEE Sens J. 2023;23(9):10 206–14. doi:10.1109/jsen.2023.3260208. [Google Scholar] [CrossRef]
33. Liu J, Zhu J, Bai W, Zhang H, Wu L, Zhou T, et al. A multi-modal lightweight transformer for bearing fault diagnosis under high-noise industrial iot environments. IEEE Internet Things J. 2026;13(2):3552–67. doi:10.1109/jiot.2025.3634730. [Google Scholar] [CrossRef]
34. Vu M-H, Nguyen V-Q, Tran T-T, Pham V-T, Lo M-T. Few-shot bearing fault diagnosis via ensembling transformer-based model with mahalanobis distance metric learning from multiscale features. IEEE Trans Instrum Meas. 2024;73:1–18. doi:10.1109/tim.2024.3381270. [Google Scholar] [CrossRef]
35. Shen H, Zhao D, Wang L, Liu Q. Bearing fault diagnosis based on prototypical network. In: International Conference on Mechatronics Engineering and Artificial Intelligence (MEAI 2022); 2022 Nov 11–13; Changsha, China. 125960D p. [Google Scholar]
36. Yan S, Shao H, Long Z, Liu B. Incremental few-shot fault diagnosis with cosine-represent real-time evolved network of transmission systems. IEEE Trans Transp Electrif. 2025;11(4):9544–54. doi:10.1109/tte.2025.3563630. [Google Scholar] [CrossRef]
37. Li W, Xu J, Huo J, Wang L, Gao Y, Luo J. Distribution consistency based covariance metric networks for few-shot learning. Proc AAAI Conf Artif Intell. 2019;33(1):8642–9. doi:10.1609/aaai.v33i01.33018642. [Google Scholar] [CrossRef]
38. Vu M-H, Pham V-T. Mixerformer-covariance metric neural network: a new few-shot learning model for bearing fault diagnosis. In: 2023 12th International Conference on Control, Automation and Information Sciences (ICCAIS); 2023 Nov 27–29; Hanoi, Vietnam. p. 639–44. [Google Scholar]
39. Wang X, Wang X, Jiang B, Luo B. Few-shot learning meets transformer: unified query-support transformers for few-shot classification. IEEE Trans Circuits Syst Video Technol. 2023;33(12):7789–802. doi:10.1109/tcsvt.2023.3282777. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools