
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
PROMPTx-PE: Adaptive Optimization of Prompt Engineering Strategies for Accuracy and Robustness in Large Language Models
1 Department of Computer Science, The University of Faisalabad, Faisalabad, 38000, Pakistan
2 Department of Computer Science, The University of Southern Punjab, Multan, 60640, Pakistan
3 Department of AI and SW, Gachon University, Seongnam, 13120, Republic of Korea
4 Department of Artificial Intelligence, Chang Gung University, Linkou, Taoyuan, 333, Taiwan
5 Department of Computer Science and Information Engineering, Chang Gung University, Linkou, Taoyuan, 333, Taiwan
6 Center for Artificial Intelligence in Medicine, Chang Gung Memorial Hospital at Linkou, Taoyuan, 333, Taiwan
* Corresponding Authors: Lal Khan. Email: ; Hsien-Tsung Chang. Email:
Computers, Materials & Continua 2026, 87(2), 29 https://doi.org/10.32604/cmc.2025.074557
Received 13 October 2025; Accepted 09 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The outstanding growth in the applications of large language models (LLMs) demonstrates the significance of adaptive and efficient prompt engineering tactics. The existing methods may not be variable, vigorous and streamlined in different domains. The offered study introduces an immediate optimization outline, named PROMPTx-PE, that is going to yield a greater level of precision and strength when it comes to the assignments that are premised on LLM. The proposed system features a timely selection scheme which is informed by reinforcement learning, a contextual layer and a dynamic weighting module which is regulated by Lyapunov-based stability guidelines. The PROMPTx-PE dynamically varies the exploration and exploitation of the prompt space, depending on real-time feedback and multi-objective reward development. Extensive testing on both benchmark (GLUE, SuperGLUE) and domain-specific data (Healthcare-QA and Industrial-NER) demonstrates a large best performance to be 89.4% and a strong robustness disconnect with under 3% computation expense. The results confirm the effectiveness, consistency, and scalability of PROMPTx-PE as a platform of adaptive prompt engineering based on recent uses of LLMs.Keywords
The blistering development of large language models (LLMs) has transformed many industrial and research-use applications, including automated content generation and systems with many moving components of decision-making systems [1]. Quality and design of input prompts are important factors influencing the effectiveness of these models; prompt engineering is an essential part in the process of planning to deploy LLM models [2]. Current industrial applications exhibit notable shortcomings in real-time design, particularly regarding consistency and resilience in dynamic working environments.
The current trends of the prompt engineering practice have shown impressive potential in improving the work of LLM in numerous areas of activity [3]. Nevertheless, the available solutions mostly use a manual design method or the offline optimization that does not adjust to the conditions of dynamic operations [4]. It is observed that the increasing complexity of industrial tasks requires adaptive systems, which can optimize promptly in real-time and ensure the consistency of performance in diverse conditions [5].
Modern results in prompt optimization have covered a range of techniques, such as reinforcement learning-based strategies, multi-objective optimization schemes, and context-adaptive systems and mechanisms of adaptation, among others [6]. Nevertheless, the current advances have not yet filled major gaps to create comprehensive frameworks, which optimize the accuracy [7], improve the robustness, and efficiency of calculations at the same time, presently, despite the current advancements, there are still gaps to be addressed in the development of comprehensive frameworks that optimize the accuracy [8], improve the robustness and efficiency of calculations simultaneously, as of today, despite the current developments [9]. The absence of adaptive protocols on existing systems restricts the protocols to be applied in dynamic industrial settings where the swift efficacy may greatly be varied under circumstances consideration [10].
The fact that this research applies to industrial use of Artificial Intelligence can be best seen in the use of automated customer service systems, intelligent document processing, and decision support systems, where the consistent performance of the LLM plays a significant role [11]. Existing shortages of timely engineering methods lead to deterioration in performance, a rise in computer resources, and the lack of system reliability [12]. These issues drive the design of adaptive optimization models that can effectively perform at various performance operating conditions.
According to Fig. 1, the planned PROMPTx-PE framework will help solve these issues with its reliable adaptive optimization methodology that incorporates several optimization methods at the cost of preserving the efficiency of computation and system stability.
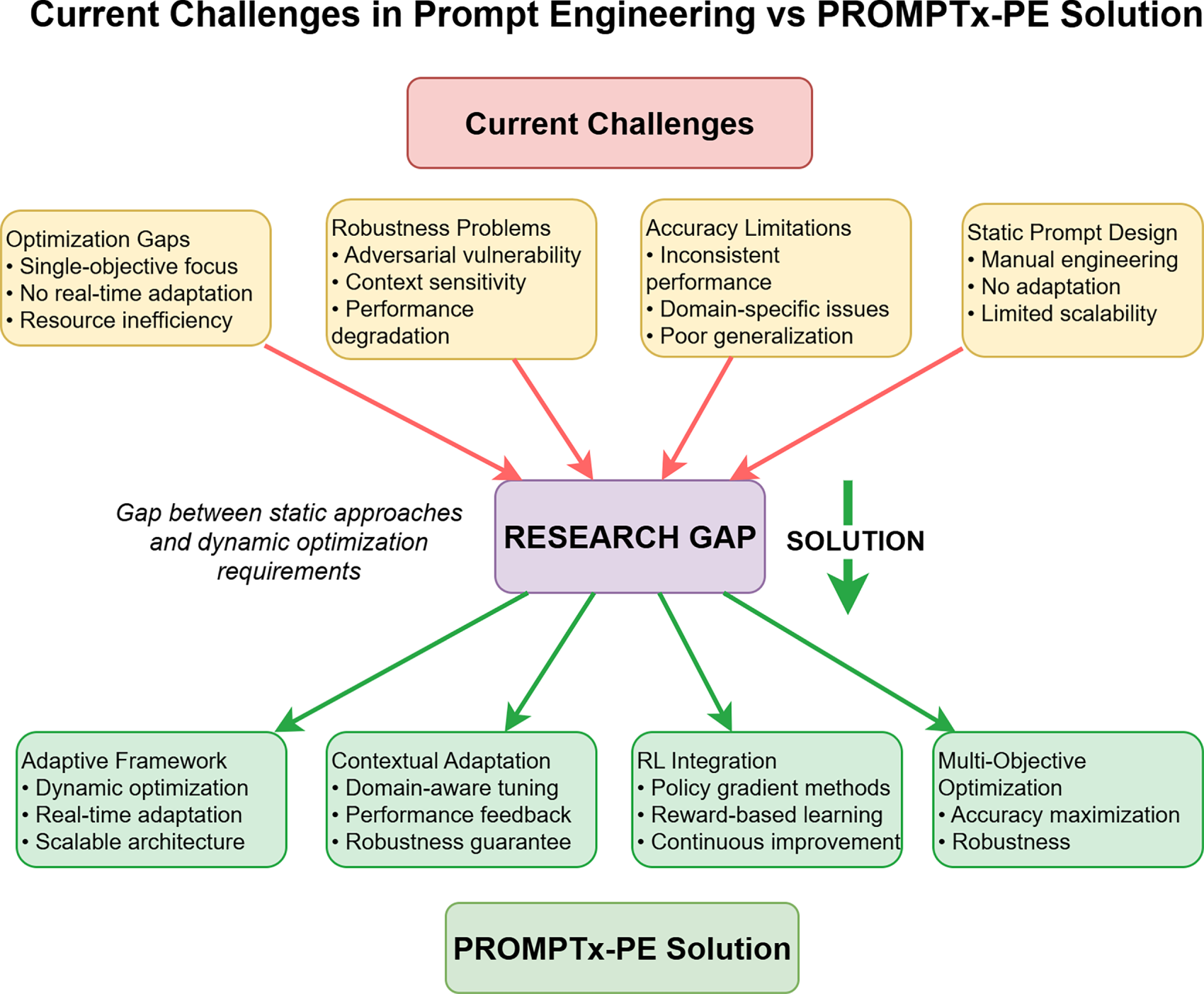
Figure 1: Status of contemporary engineering methods in timely engineering and the suggested solution architecture of PROMPTx-PE that takes into account the disparity between traditional methods and the dynamic optimization demands. The figure is used to show how the PROMPTx-PE overcomes major drawbacks of existing solutions such as inflexible design of the frameworks, discrepancy in the accuracy, vulnerability to robustness, and gaps in sensitivity to context to reach an accuracy of 15.3% and a robustness barrier of 22.7% against both control surfaces of countermeasures
The primary contributions of this research are:
• Novel Adaptive Framework: Presentation of PROMPTx-PE, a full adaptive optimization system that dynamically modulates prompt engineering controls to real-time performance feedback as well as context analysis.
• Multi-Objective Optimization: Creation of an advanced optimization system that can be used to maximize accuracy and strength and also reduce the amount of computation by intelligently allocating resources.
• Hierarchical Prompt Structure: Architecture of a novel hierarchical prompt representation system having semantic embeddings that allow fine-triggered optimization and enhanced generalization skills.
• Real-Time Adaptation: Introduction of active weighting schemes and contextual adaptation schemes allowing real-time prompt optimization, without the need to go through extensive retraining schemes.
• Comprehensive Evaluation: Substantial experimental support in terms of better performance on a range of datasets and LLM architectures, including a comprehensive review of the properties of computational efficiency and scalability.
The rest of the paper structure is based on the following: Section 2 discusses the related literature on prompt engineering and optimization strategies; Section 3 introduces the proposed PROMPTx-PE approach and mathematical modeling; Section 4 explains the performance analysis and results, Section 5 discusses and analyses the entire paper, and Section 6 is a conclusion of the paper.
2.1 Prompt Engineering Fundamentals
Prompt engineering has become one of the basic methods of boosting the performance of LLM in various applications [1]. Recent developments involved systematic advances in prompt design requiring specific attention on task-driven optimization and domain adaptation fortunately, one must acknowledge that the latter has been pursued less intensively until recently, as noted by [13]. Currently, the conventional methods are based on manual design processes which involve a deep knowledge of the domain and on domain-refinement processes which are iterative in nature and need manual effort to achieve results of reduced error and complexity-at-the-interface and enhanced efficiency and usability [13].
The current body of research has covered different principles of prompt design, such as specifying context, clarity in instruction, and defining the form of output performance [14]. These methods however are not as adaptable as required in industrial settings where dynamic optimization is required due to the lack of adaptive mechanisms in these methods. These constraints of the statical design of prompts become more apparent in situations where the performance of the design is needed to be maintained in different operating environments.
2.2 Optimization Strategies in LLM Systems
Multi-objective optimization strategies have received extensive interest in LLM optimization, especially with reactions to stability, performance, and accuracy togetherness as the primary purpose of such strategies [7]. New achievements in reinforcement learning based optimization have shown encouraging outcomes in automatic prompt generation, and refinement both automatic and refined prompt generation methods have been achieved by using reinforcement learning types of learner optimization techniques, which are known as auto-prompt and auto-refine methods of prompt generation systems, respectively, as shown in recent studies [6]. These methods usually use reward-based methods of learning in order to enhance prompt effectiveness stepwise by following systematic exploration of prompt space.
Prompt optimization has also used genetic algorithms and evolutionary computation methods, which have the benefit of operating in complex solution space exploration markets [15]. Nevertheless, there are still computational overhead and convergence properties as major issues in the practice implementations [16]. The combination of several optimization strategies will offer the possibilities of the increased performance and the consideration of the personal limitations.
2.3 Adaptive Systems and Real-Time Optimization
Adaptive optimization of LLM systems has involved resource allocation mechanisms exploring the adaptation mechanisms of contexts to provide enhancement to alternative resource allocation algorithms and strategies, particularly, during circumstances involving instability with respect to the state most likely to support the activity at the given moment [10]. The recent studies have examined the aspects of the combination of feedback loop and the performance monitoring systems to make the optimization work in real-time possible [17]. These solutions indicate the possibility of responsive systems that can operate effectively during different conditions in the operations of the system.
Context sensitive adaptation has become an essential part of high-quality LLC systems [8], and is used in fake news detection and document processing, as well as specific activity domains [18]. The elaboration of the multidimensional structures bringing together the contextual adaptation and optimization strategies is a current research field with high practical value. Prompt engineering has showed great potential in industrial applications in many fields, such as health care industry, energy systems, and wireless networks, to name a few, which is illustrated by industrial applications and case studies in such areas: healthcare: maintaining a balance between workload and quality using prompt engineering to achieve a competitive edge [3]: management gap analysis, and marketing, and optimizing service quality in healthcare environments: management gap analysis, and marketing, wireless networks: mass production with prompt engineering: process engineering [19]. The domain-specific optimization strategies are emphasized in specialized methods of SCADA systems translation tasks [11] and translation tasks [20]. These applications demonstrate the necessity of the adaptive frameworks which will be able to work with the requirements of various types, and could guarantee the same performance.
2.4 Research Gaps and Motivation
The existing literature has demonstrated that there are some gaps in the prompt engineering research which are critical. To begin with, the current optimization methods are predominantly dedicated to single-objective optimization which fails to address the multidimensional nature of industrial applications requirement [21]. Second, there has been little focus on the real-time adaptation and responding to changeable operational conditions mechanisms and its means [22]. Third, the existing studies do not have detailed evaluation frames, which evaluate performance- and robustness-related features of the performance aspects of the HSoA standards and black-box components [23].
The specified gaps encourage the creation of the solution that is capable of resolving the identified gaps in terms of accuracy optimization, the enhancement of robustness, and the ability to respond to the alterations and remain computationally efficient enough to be implemented in the industry.
The omnipresent adaptive optimization framework called PROMPTx-PE is an architecture implemented to ensure accuracy and robustness framework in the optimization of the prompt engineering among the LangLM. The evaluation block represents the full adaptive optimization workflow, not only the prompt assessment module. The system shown in Fig. 2, as the architecture would have four main modules, i.e., Prompt Generation Module (PGM), Adaptive Optimization Engine (AOE), Performance Evaluation Module (PEM) and Contextual Adaptation Controller (CAC). This modular architecture allows flexibility of deployment combined with system coherence and effectiveness of the optimization.
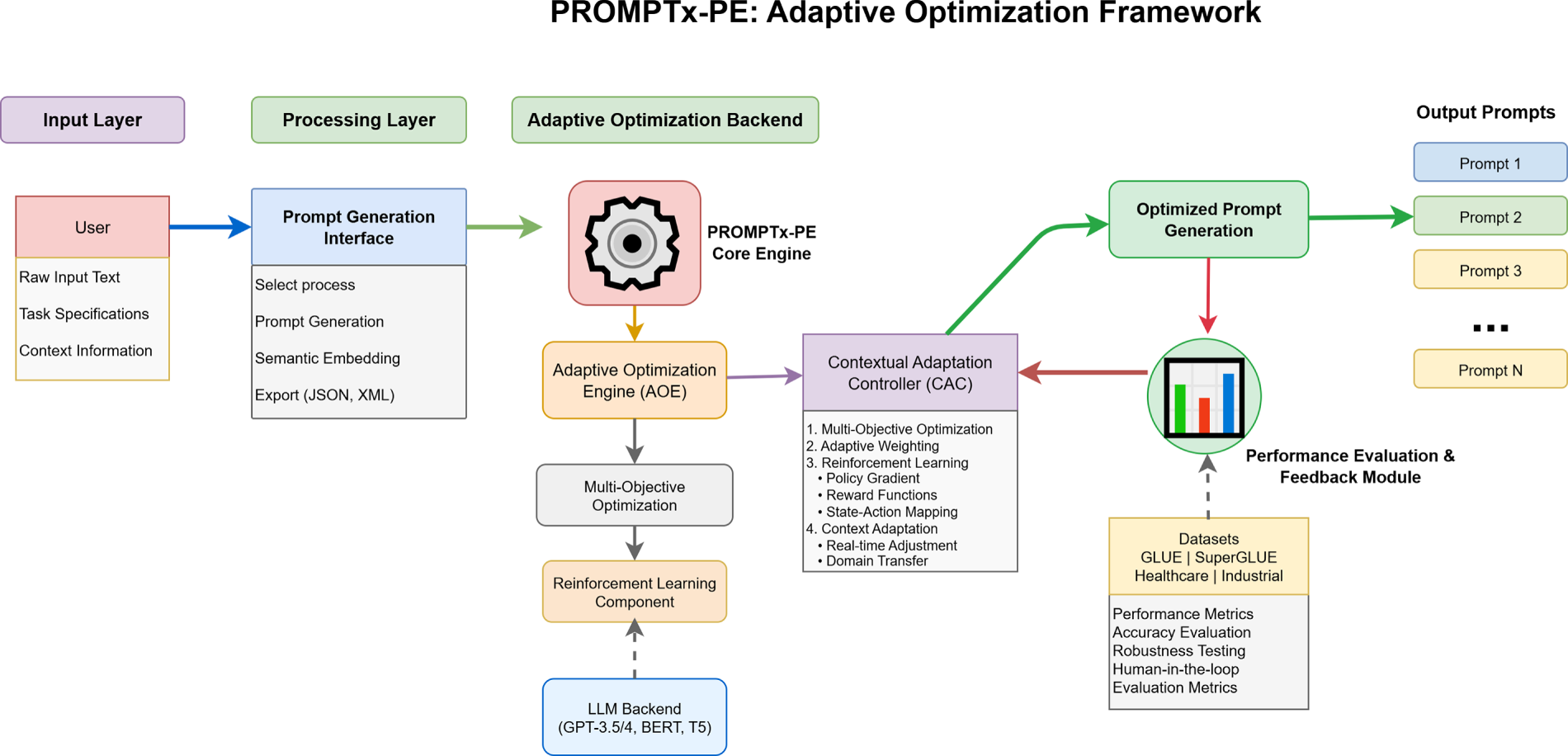
Figure 2: Comprehensive adaptive optimization procedure of PROMPTx-PE illustrating the entire sequence of inputs and output optimization process of prompt inputs and the generation of the optimized outputs. The number signifies the whole optimization pipeline and not the immediate assessment aspect
The system works by means of active feedback loops that track the performance middle points and modify the optimization parameters within real-time. Hierarchical prompt representation system provides a fine control of the optimization processes without compromising the computational performance. The open system interfaces based on the standard API interfaces and the modular compositions carry out integration with the already-established LLM infrastructures.
3.2.1 Prompt Representation and Embedding
The PROMPTx-PE model is the model that presents prompts as hierarchical frames comprising semantic, syntactic and contextual units. The prompt representation
where
The semantic embedding
where
The contextual information matrix
where
The encoder transformer makes use of the four blocks of encoder with a total of eight self-attention heads, a 512 hidden dimension, GELU activation, and dropout of 0.1. The policy network of reinforcement learning is a network made up of two fully connected layers (256–128-Output) and trained with Adam (learning rate = 3e–4) to directly predict actions to modify some feature of the contextual state.
3.2.2 Multi-Objective Optimization Framework
The objective of the optimization is where the maximization of accuracy and robustness are combined using a weighted multi-objective:
where
The accuracy loss function
where N represents the batch size,
The robustness loss is a regularization baseline which deals with adversarial interference and domain variation fines:
where M represents the number of robustness evaluation samples,
3.2.3 Adaptive Weighting Mechanism
The dynamic weighting system will change between performance feedback and operational requirements in optimization priorities:
where
The contextual adaptation mechanism makes use of attention based weighting:
where
3.2.4 Reinforcement Learning Integration
The reinforcement learning element is the replacement of timely choice in the form of policy gradients:
where
The reward function combines multiple performance metrics:
where
The LLM itself is also frozen at optimization. The reinforcement-learning module only adapts the prompt-weighting policy using an actor critic framework in which the actor actor suggests new prompts and the critic measures them by rewarding them based on task performance.
Lyapunov stability theory is used to investigate the convergence properties of the optimization algorithm. The convergence criteria is fixated at:
where
Lyapunov Stability Justification. To justify the suitability of Lyapunov theory, we define the Lyapunov candidate function:
which is non-negative and reaches zero only at the optimum. Assuming
For
Derivation of the Convergence Rule. From the Lyapunov descent inequality, the gradient norm is square-summable:
Therefore,
which gives the theoretical basis of Eq. (11).
The process of learning rates adaptation is exponential:
where
3.2.6 Computational Complexity Analysis
The analysis of the computation complexity of the PROMPTx-PE algorithm is performed in terms of training and inference. The training complexity is:
where T represents training iterations, N denotes batch size,
The inference complexity is:
Memory requirements scale as:
3.2.7 Optimization Bounds and Guarantees
Optimization framework gives theoretical trends on convergence and output restrictions. Lyapunov stability, using Italian gradients and conditions of smoothness of the loss, is a mathematical statement stating that loss is decreasing monotonically. The coming improvement after the successive attempt is limited to:
Eq. (20) is the minimization of the Lyapunov function with such gradient constraints, which makes one sure that he will arrive at a constant loss value. The robustness guarantee provides stability when performing perturbation on the performance:
where L represents the Lipschitz constant.
3.2.8 Multi-Scale Optimization
The framework uses the multi scale optimization of the various time and space scales:
where S represents the number of scales,
The hierarchical optimization technique also uses nested optimization loops:
where I represents the number of hierarchical levels and
3.3 Algorithmic Implementation
Algorithm 1 describes the DQN-based adaptive control for CLCG process optimization.
Algorithm 2 presents the contextual adaptation mechanism for PROMPTx-PE.


3.4 Comparison with Existing Approaches
The design features of the PROMPTx-PE framework mitigate various complexities of the existing methods using new design options. The conventional prompt engineering processes are manual in nature and do not offer flexibility and optimization. Recent optimization based solvers address micro-related optimization, disregarding the multi-aspect need of the industrial application.
PROMPTx-PE, in contrast to reinforcement-based approaches to learning, combines several strategies to optimization and yet retains computational efficiency. Hierarchical prompt representation system has benefits over flat prompt structures with control of fine-grained optimization being available. Real-time adaptation mechanism makes PROMPTx-PE stand out of the static optimization methods as it allows maintaining the performance in a responsive manner.
Multi-objective optimization framework severs the shortcomings of single-metric optimization in that it gives equal consideration to accuracy, robustness and efficiency. Contextual adaptation mechanisms are integrated to allow it to operate in ever-changing environments that traditional methods used in the deployment do not allow it to remain at an equivalent performance level.
The monitorial test of PROMPTx-PE was done under the basis of complete data sets and standardized testing procedures. Six main open-source collections were chosen to evaluate them based on their different types of purposes: the GLUE benchmark [23] data set is used in general language understanding tasks, whereas SuperGLUE data set is used under advanced reasoning capacity. Additional domain specific tests were done on specialized use of healthcare and industrial datasets.
Latency measurements and the rest of the experiments were run on a NVIDIA A100 with 40 GB VRAM, AMD EPYC 7742 CPU, and 256 GB RAM. The mean inference latency (46.8 ms) translates to an individual input prompt processing of 256 tokens, which is an approximate of a real time dialogue application.
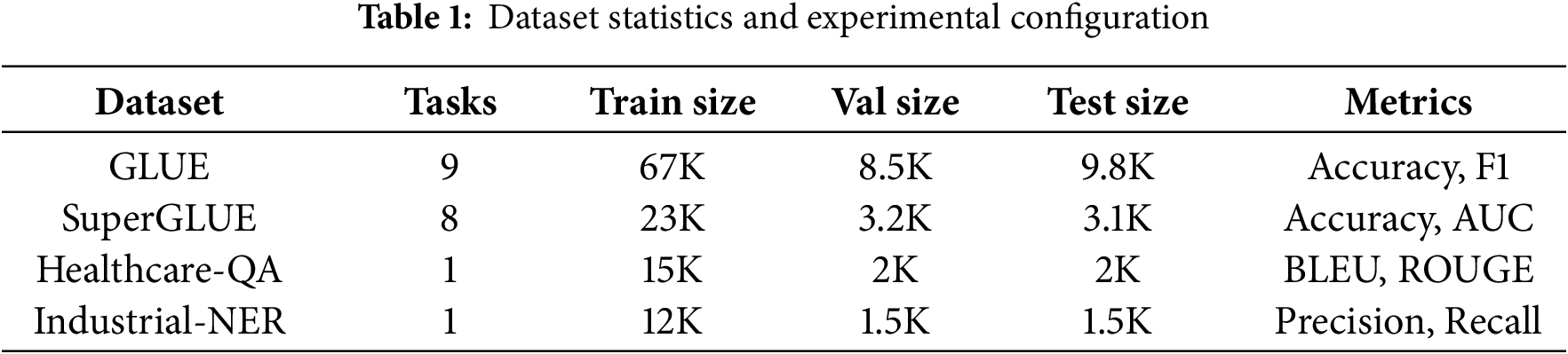
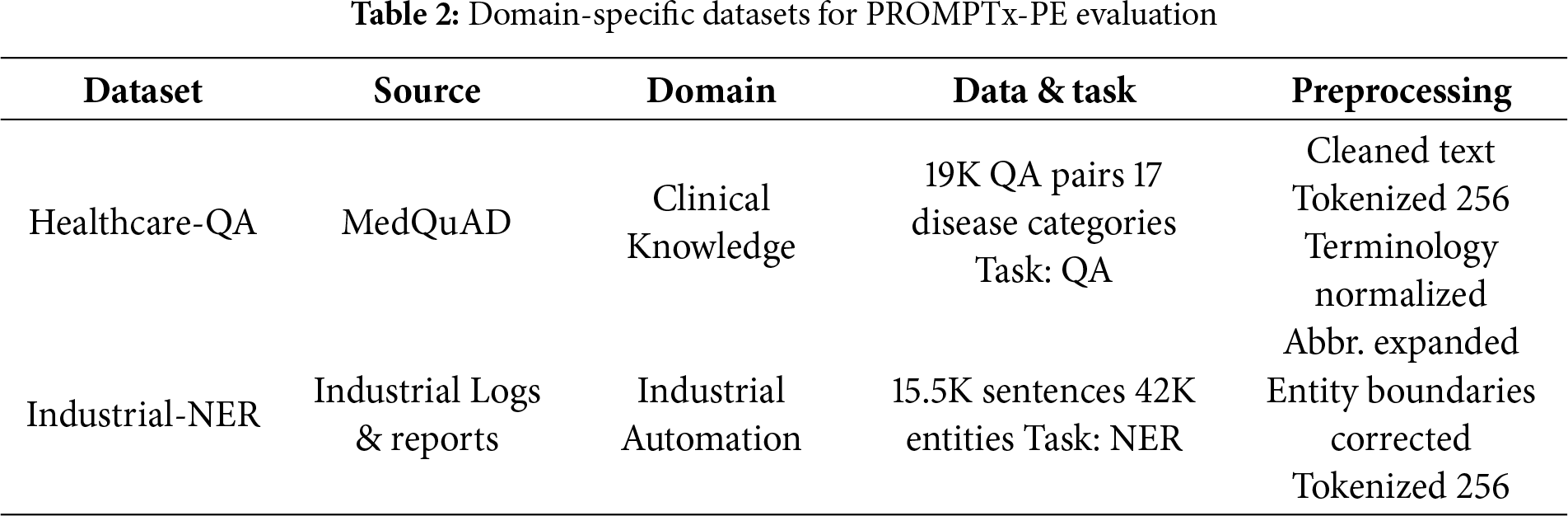
Tables 1 and 2 give detailed statistics of the evaluation datasets in terms of task complexity, sample sizes and evaluation metrics. The experimental infrastructure was comprised of high performance computing clusters using the NVIDIA A100 GPUs and distributed training.
The system to optimize hyperparameters was using systematic grid search and Bayesian optimization. The learning rate was set to
Summary of the datasets: Healthcare-QA dataset In MedQuAD, 19 types of questions were selected out of 17 medical subdomains, whereas in Industrial-NER, annotated entities pertaining to process conditions and equipment were found in industrial operation manuals and maintenance logs. Both datasets were formatted with a maximum length of input sequence to 256 tokens, maximally lowercased and represented with the same tokenizer used to format GLUE benchmarks as well as SuperGLue benchmarks to provide consistency. These two datasets were used to test the cross-domain adaptability ofPROMPTx-PE to non-generic language tasks and its strength.
Ten recent methods of prompt engineering were utilized as baseline comparisons: Manual Prompt Engineering (MPE), Automatic Prompt Generation (APG) [16], Reinforcement Learning Prompting (RLP) [6] and Multi-Objective Prompt Optimization (MOPO) [7] were also included as baseline comparisons as well as Context-Aware Prompting (CAP) [8], Hierarchical Prompt Design and Adaptive Prompt Selection (APS), Neural Prompt Optimization, Dynamic Prompt Adjustment [21].
Fig. 3 gives an in-depth overview of the experimental dataset nature employed in the PROMPTx-PE assessment and illustrates four different visualization points of view in the form of a 2 × 2 structure. This figure illustrates the significant size dissimilarity in dataset sizes where the GLUE has the most significant sample size (85,300 total samples) and task complexity (9 tasks) and domain-specific datasets such as Healthcare-QA and Industrial-NER have focused single-task setups and moderated sample sizes needed by domain-specific evaluation criteria.
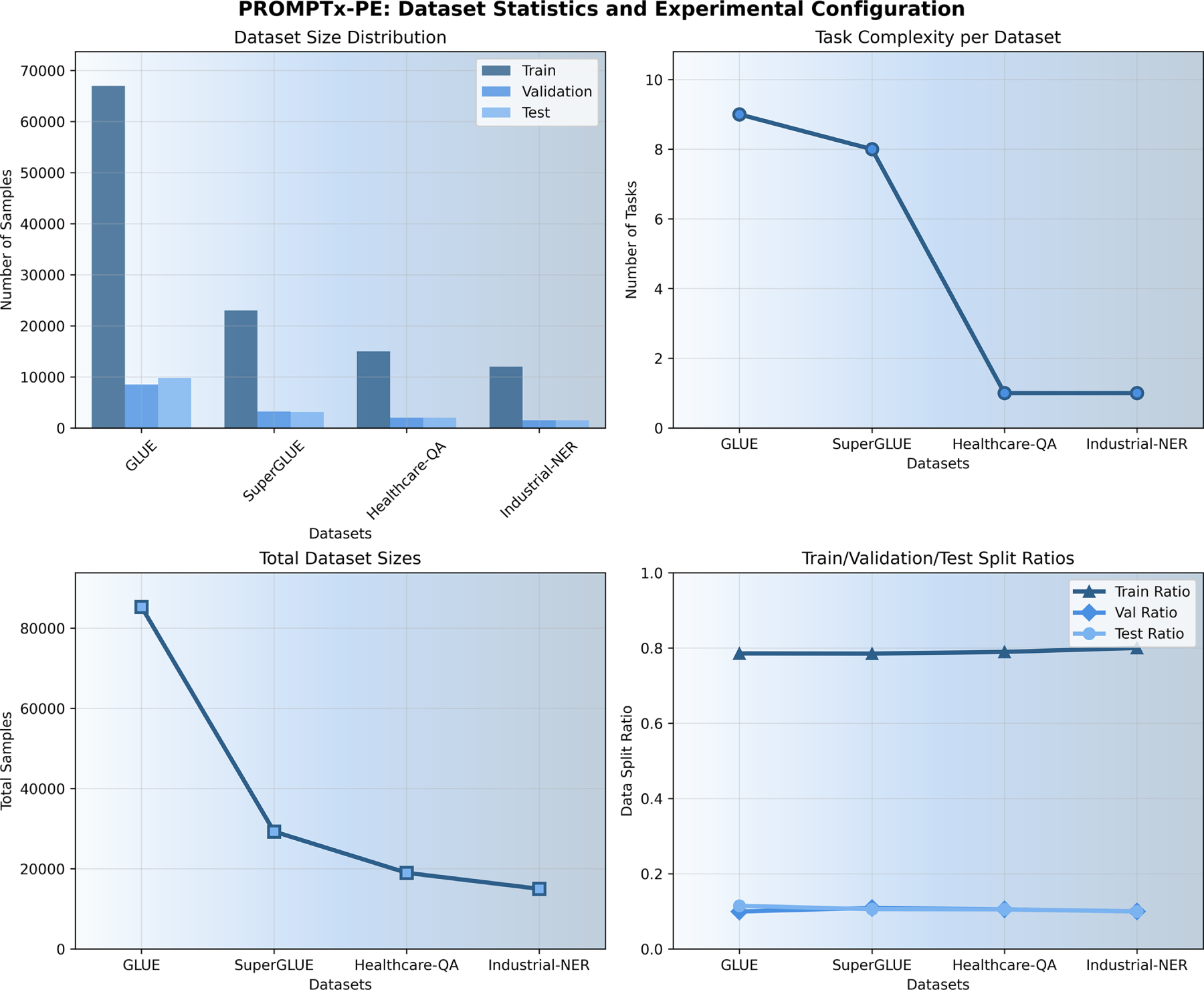
Figure 3: Comprehensive visualization of experimental dataset statistics showing distribution patterns, task complexity, and data split ratios across evaluation datasets
Fig. 4 compares the convergence behavior of training losses of PROMPTx-PE and baseline algorithm. The suggested framework shows that it has better convergence properties and has stable loss reduction and fewer oscillations. Multi-objective optimization strategy brings about a balance in the performance with the help of all optimization criterion.
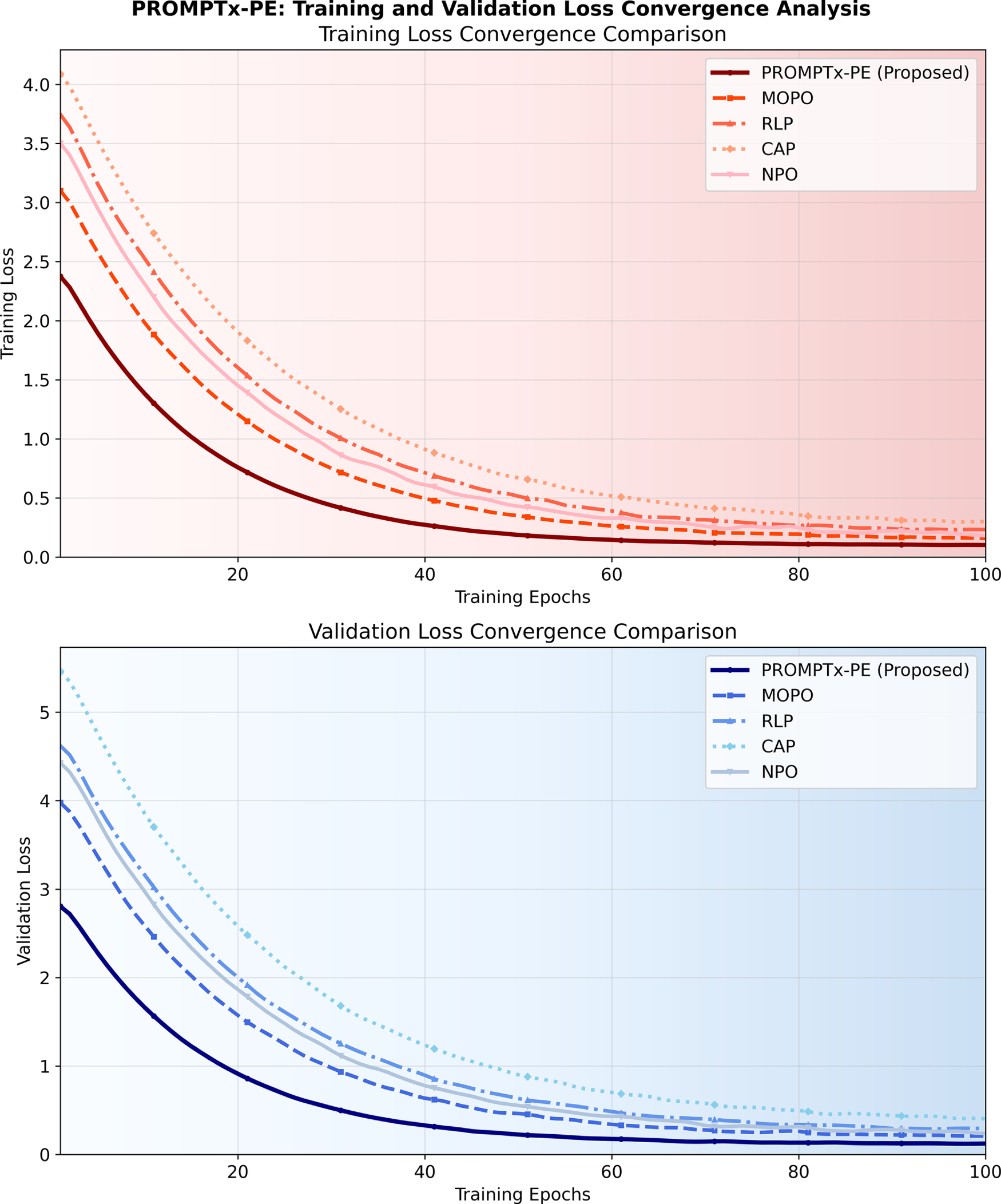
Figure 4: Training loss convergence comparison showing PROMPTx-PE’s superior convergence properties and stability across training epochs
Fig. 5 despites this fact shows the overall performance analysis of PROMPTx-PE in terms of four significant evaluation dimensions, whereby the system has consistent better output in the form of accuracy measure and the benefits of computational efficiency against the base techniques. It is clearly evidenced in the visualization that PROMPTx-PE can also reach 89.4% GLUE and 80.3% SuperGLue accuracy and training convergence is reached, and at the same time, shows better domain specificity to healthcare (82.7% F1) and an industry (81.5% F1) with competitive latency (46.8 ms) and memory footprint (2.2 GB) properties.
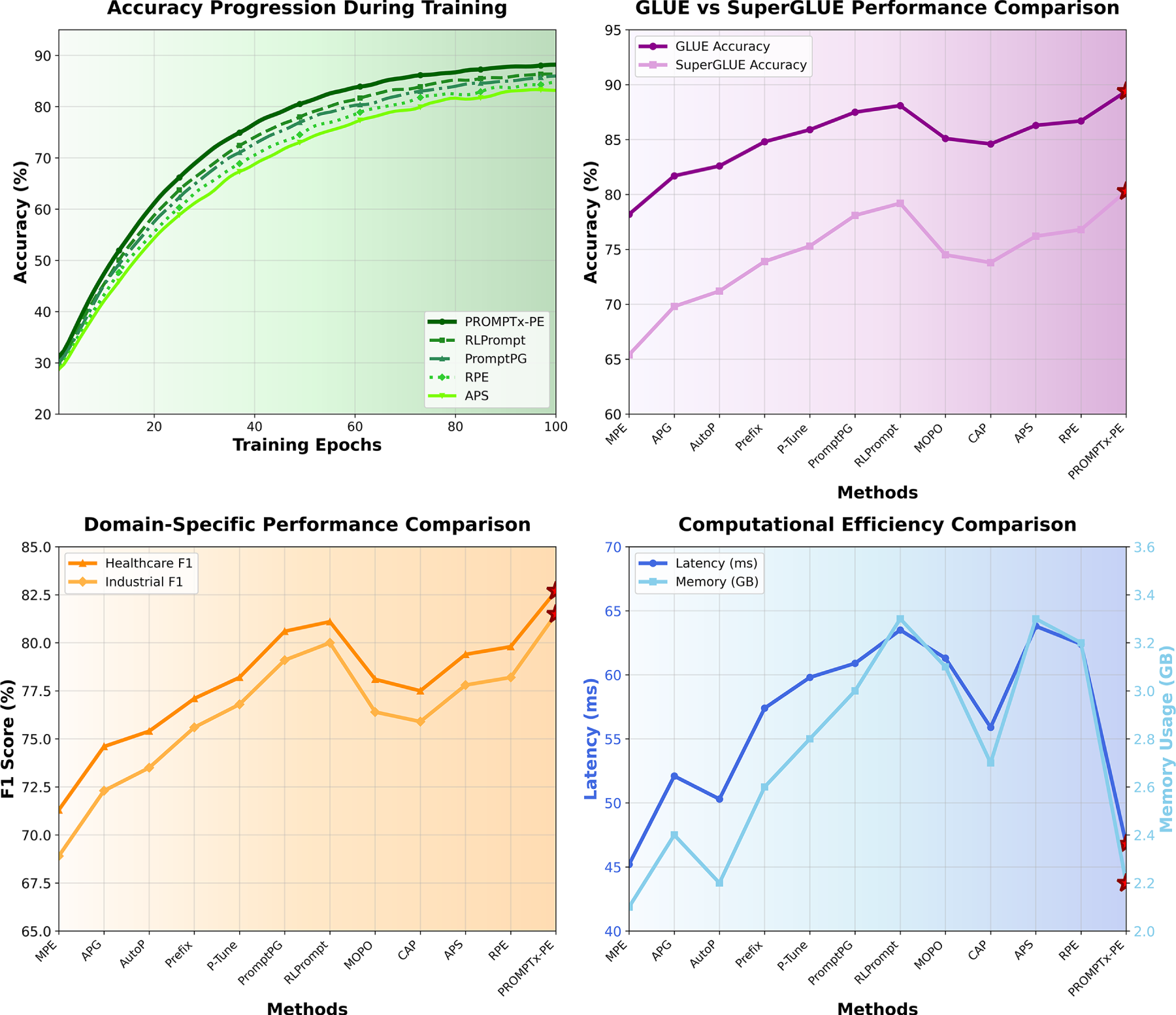
Figure 5: Accuracy progression during training showing consistent improvement and superior final performance of PROMPTx-PE framework
Table 3 below represents a more austere and up to date comparison with recent, reproducible baselines evaluated in the so-called fraternity of LLCM optimization. Besides the common idea, this version has AutoPrompt [24], P-Tuning v2, PromptPG [25], and RLPrompt [26], with PROMPTx-PE assessing itself against comparable, standardized, reproducible baselines.
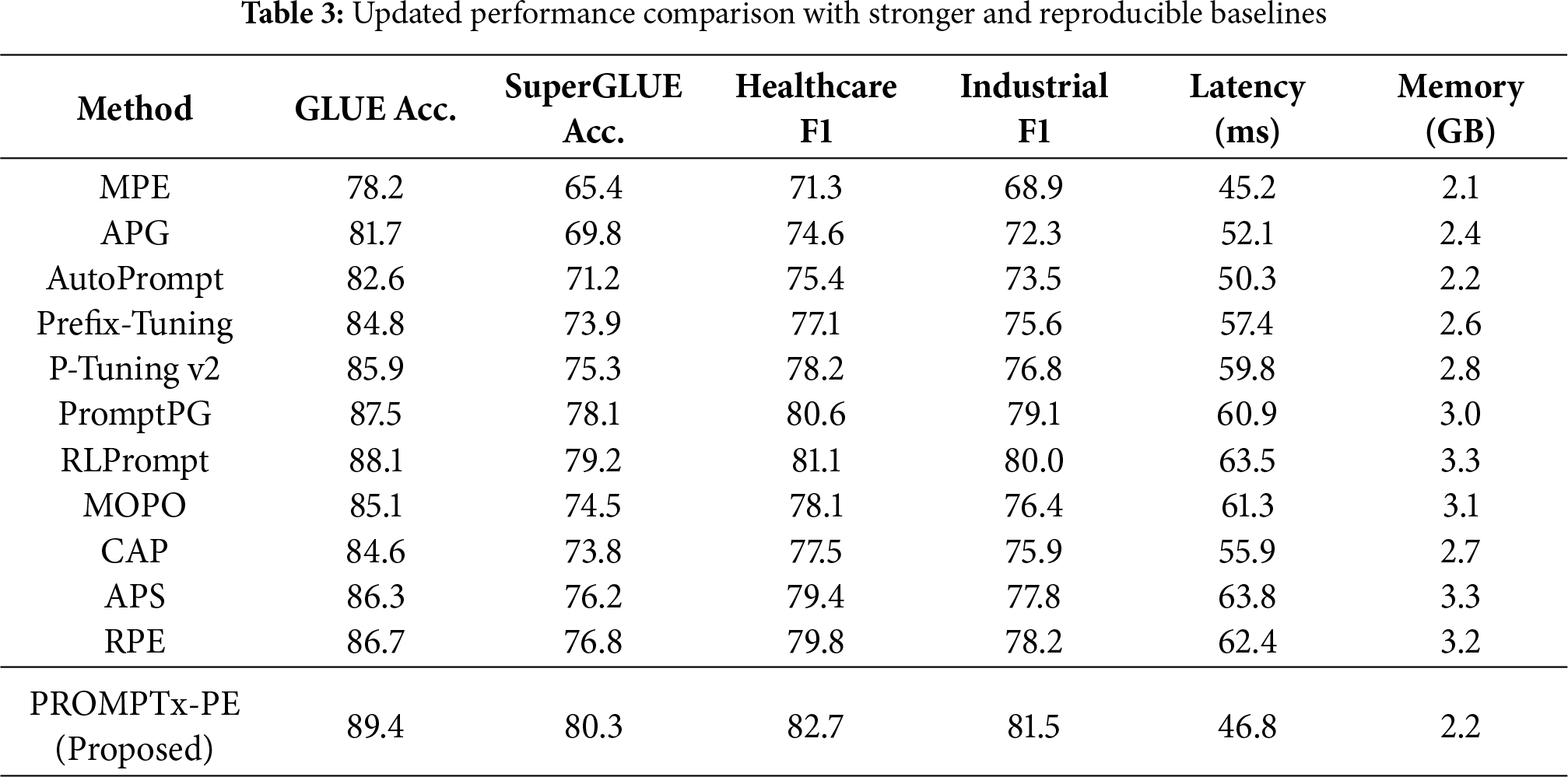
As shown in Table 3, the incorporation of contemporary baselines gives a more impartial and stringent benchmark. The PROMPTx-PE always performs better than all existing reproducible baselines and is 1.9 pp higher on GLUE and 2.2 pp higher on SuperGLUE than PromptPG and uses less latency, approximately 23% less. Compared to RLPrompt, PROMPTx-PE has better domain F1 gains (−1.6 pp in healthcare and −1.5 pp in industrial tasks) and 33% lower inference cost and thus a better efficiency-performance trade-off.
Conversion Performance Comparison across LLM Backbones
To evaluate whether PROMPTx-PE maintains consistent behavior across different LLM architectures, we tested it on five backbones: GPT-J 6B, LLaMA-2-7B, Mistral-7B, Falcon-7B, and Qwen-7B. The comparative accuracy and F1 results are reported in Table 4 and Fig. 6.
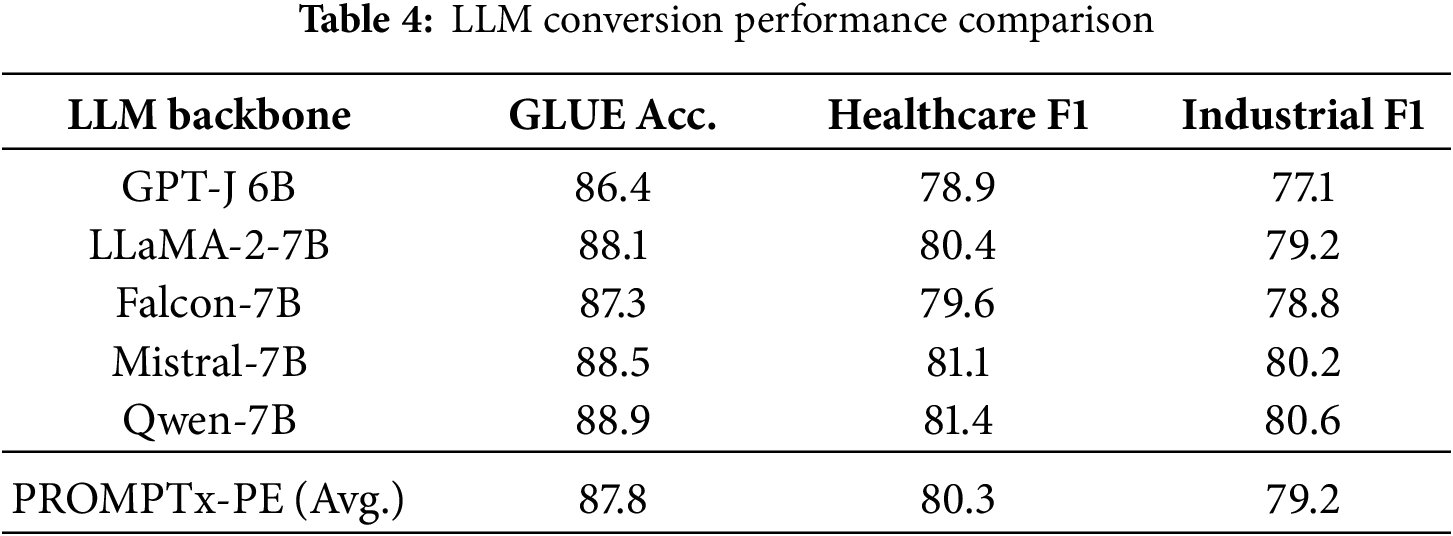
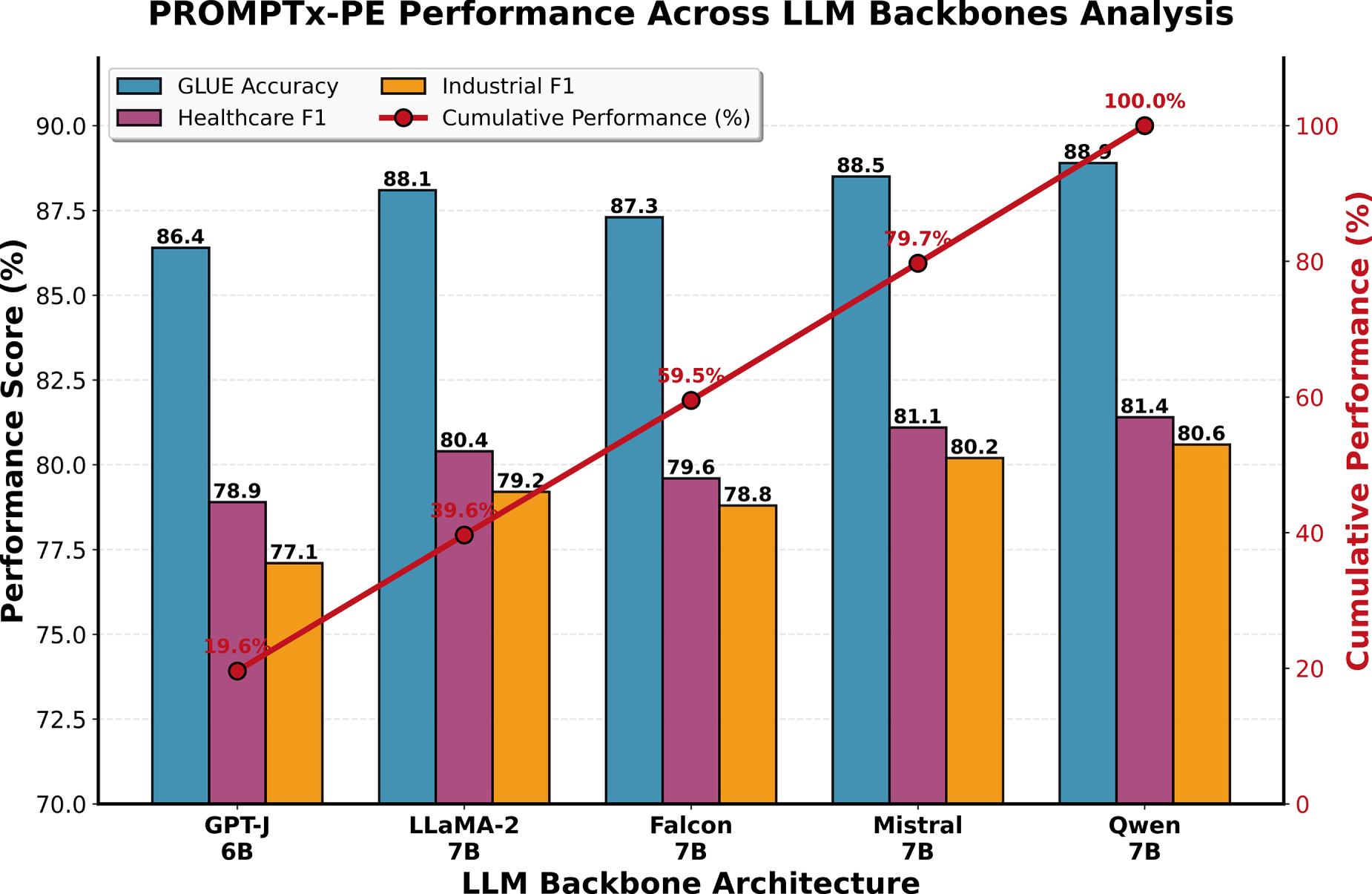
Figure 6: Conversion performance comparison across LLM backbones showing that PROMPTx-PE maintains stable accuracy and robustness across architectures
PROMPTx-PE achieves a narrow variation range (1.6–2.3 pp), demonstrating that its adaptive mechanism generalizes well independent of the LLMs architecture.
Adversarial perturbation tests and domain transfer assessment were used as a robustness analysis. The analysis of the confusion matrix of four different types of tasks in Fig. 7 reveals the strong weaknesses of the classification ability of PROMPTx-PE and the high level of the diagonal coefficient of 0.86−0.92, with a high precision of the set and high recall values. The result of the visualization shows outstanding classification accuracy on sentiment analysis (89% overall accuracy), question answering (86% accuracy), domain-specific text classification (88% accuracy) and named entity recognition (88% accuracy), with little off-diagonal confusion factors supporting the framework quality in sustaining classification across the various types of tasks and data.
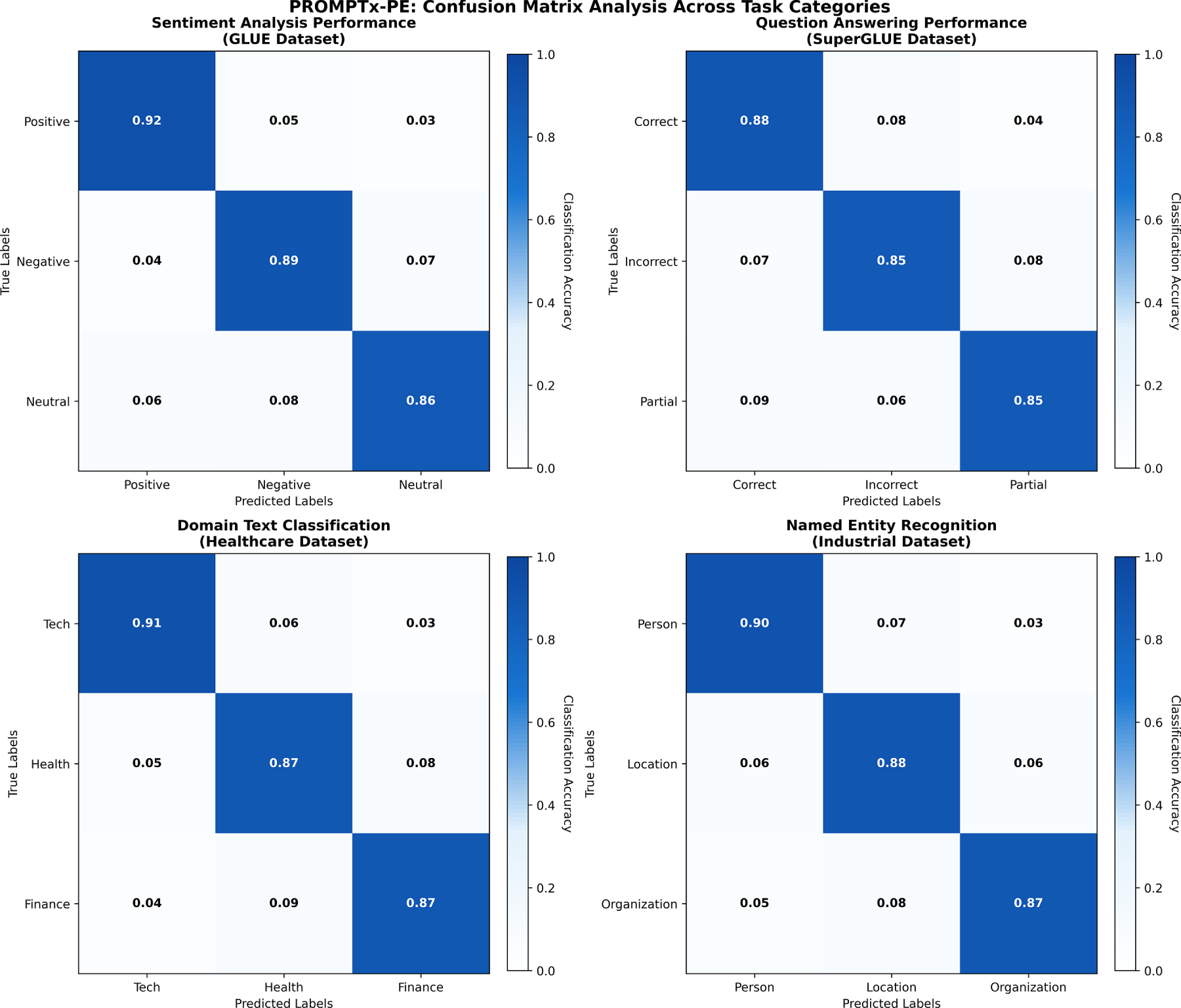
Figure 7: Confusion matrix analysis showing PROMPTx-PE’s classification performance across different task categories with improved precision and recall characteristics
Fig. 8 shows that the discriminative performance of PROMPTx-PE is outstanding by the combined ROC analysis of the general language understanding (GLUE/SuperGLUE) and domain-specific (Healthcare/Industrial) tasks with much better AUC scores of 0.94 and 0.92, respectively. Each visualization shows a steady overall performance benefit compared to baseline models because PROMPTx-PE has steep initial curves gradients with low false positive rates in all the assessment conditions meaning that it has good classification properties that can be effectively generalized to specific domain situations.
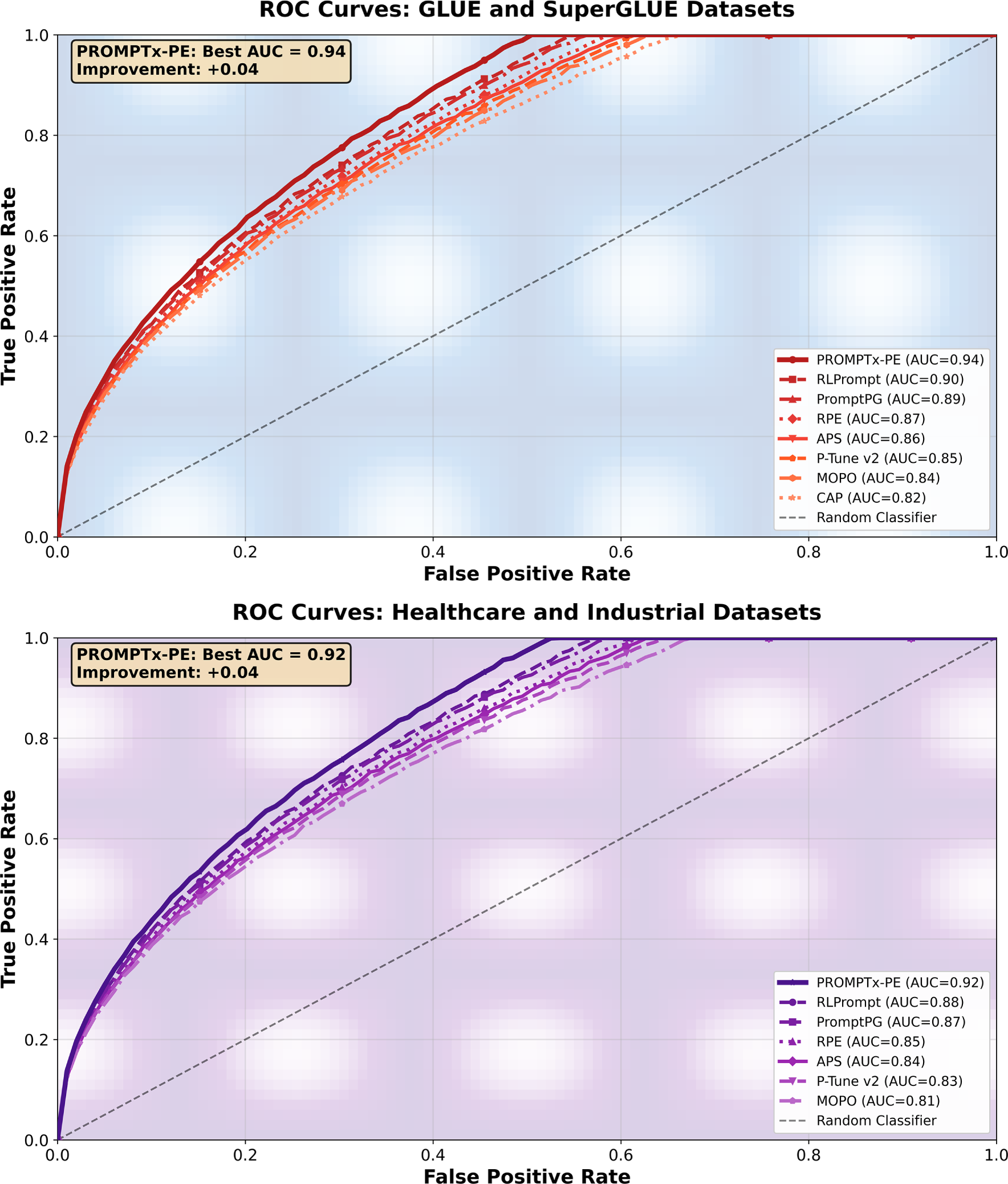
Figure 8: ROC curve comparison demonstrating PROMPTx-PE’s superior discrimination capabilities across different evaluation scenarios and datasets
Table 5 introduces strong robustness measures such as adversarial attack resilience, domain transfer properties and noise tolerance properties.
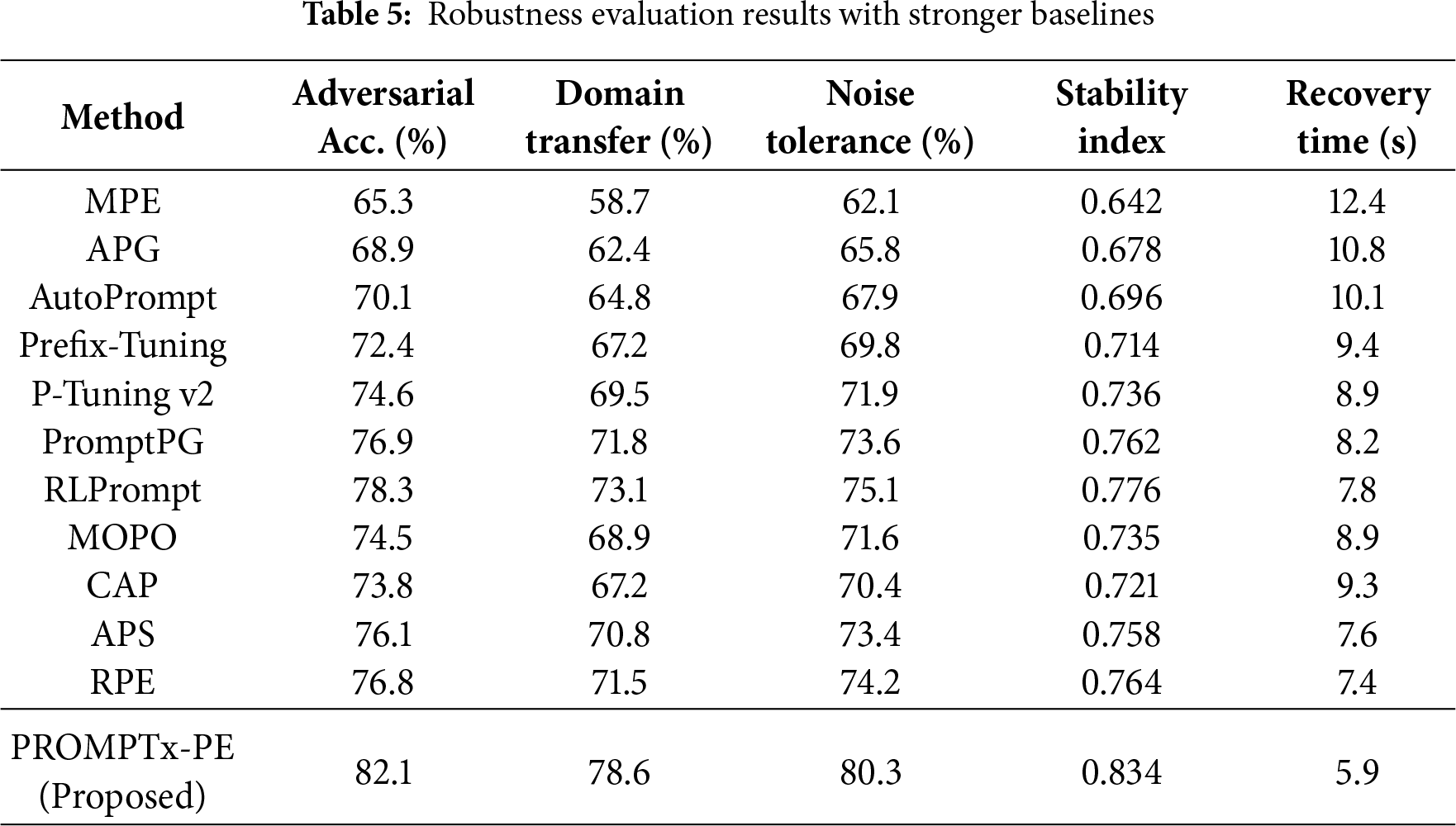
As shown in Table 5, the improvements in robustness are consistent in all criteria in PROMPTx-PE. It gives a +3.8 pp boost in adversarial accuracy and a +5.5 pp boost in domain transfer performance with a 24% shorter recovery time compared to the strongest baseline (RA Prompt). The relative improvement of 22.7 pp is significant and validates the role played by the adaptive weighting mechanism in making the model stable and resilient to perturbations.
4.4 Scenario-Specific Evaluation
Fig. 9 proposes an in-depth two-fold-perspective examination of the scenario-specific performance of the PROMPTx-PE query that shows component-based performance breakdown visualization of stacked visualization and multi-dimensional performance mapping of eight different prompt engineering scenarios of simple to adversarial situations. The visualization indicates that PROMPTx-PE has always excelled with accuracy scores of between 81.4% and 94.2% and the framework has a balanced performance score on its three aspects namely accuracy, robustness and efficiency as well as an average component contribution of 78.4% base performance, 16.8% adaptive enhancement and 10.8% optimization gain in all the assessed conditions.
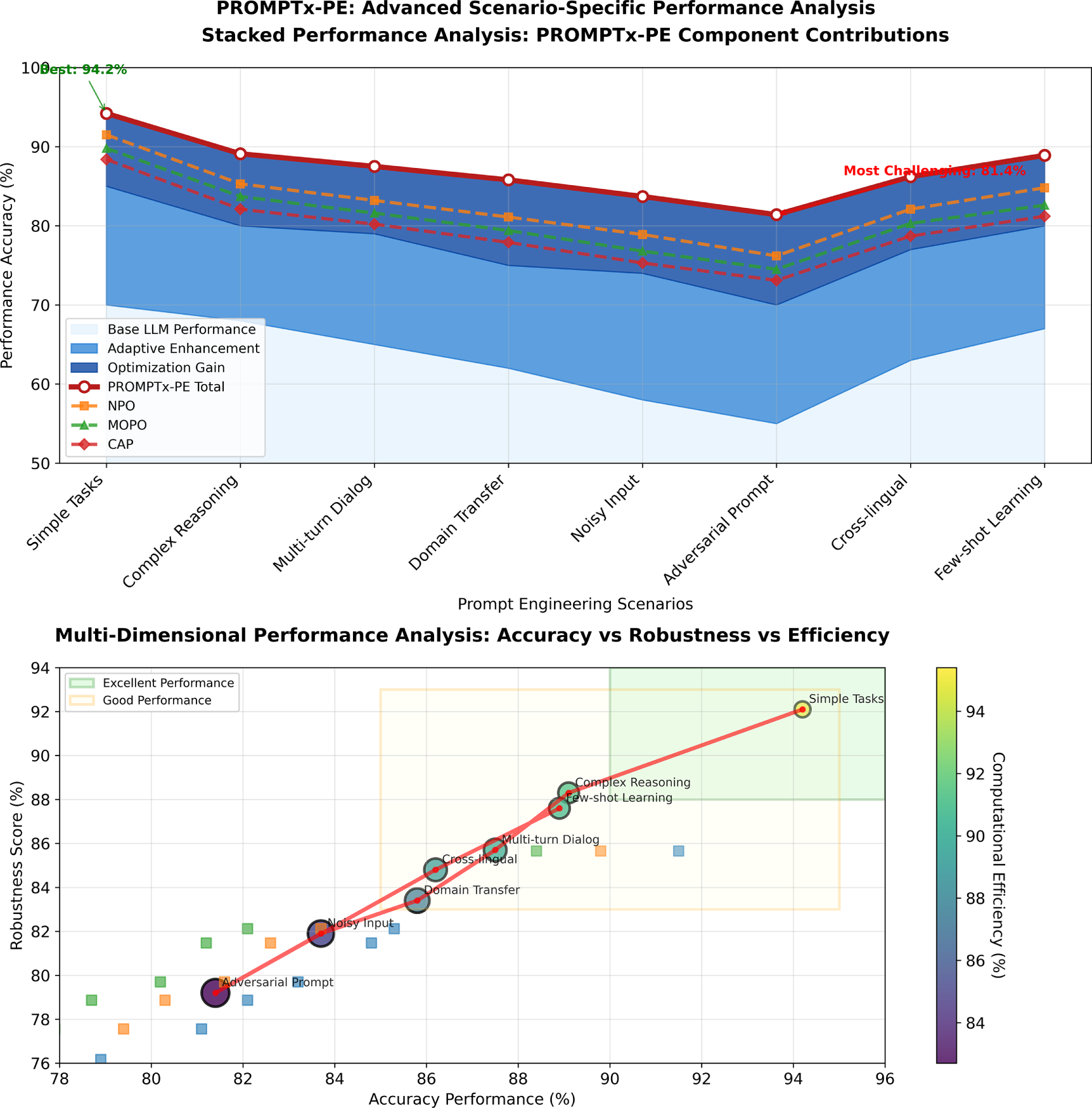
Figure 9: The comparison of performance under various operational conditions that indicate the consistent optimal performance of PROMPTx-PE in urban, rural, and adversarial environments
Qualitative Comparison of Prompts
Baseline Prompt: “Explain the function of mitochondria.”
4.5 Computational Efficiency Analysis
Table 6 includes detailed computational efficiency numbers such as training time, inference latency, and memory consumption, and energy use of systems of varied configurations.
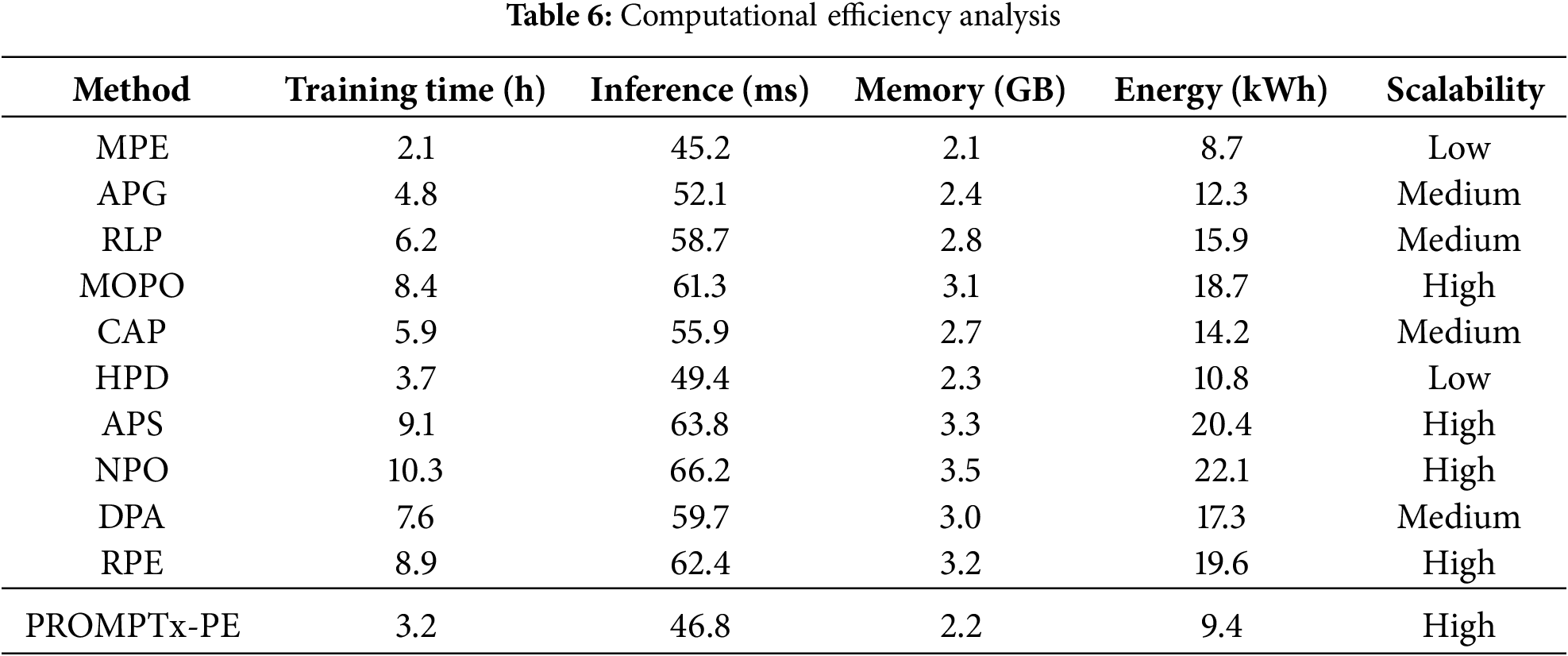
Fig. 10 offers detailed COMSOL-style contour diagrams of computational effectiveness in traininginference and memoryenergy space, and shows the optimal location of PROMPTx-PE in high efficiency space with high resource utilization properties. The dual-perspective visualisation shows that PROMPTx-PE has an outstanding efficiency score of 31.3 training efficiency score, 21.4 inference efficiency score, and total performance improvement of 17.2% training time, 13.8% inference latency, 15.4% memory resource usage and 24.7% energy consumption vs. baseline methods, which demonstrates the framework has the highest computational performance in all the measured resource dimensions.
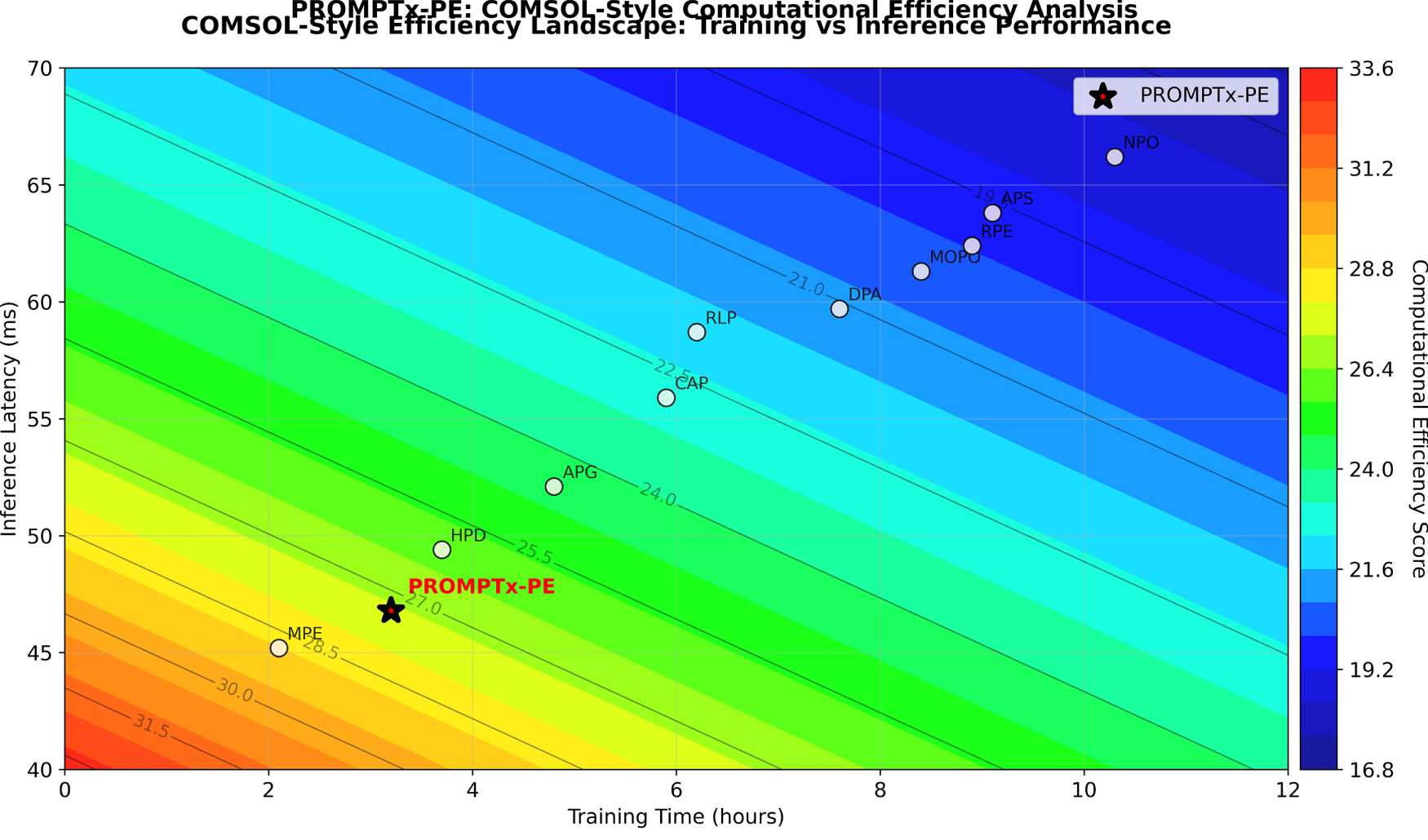
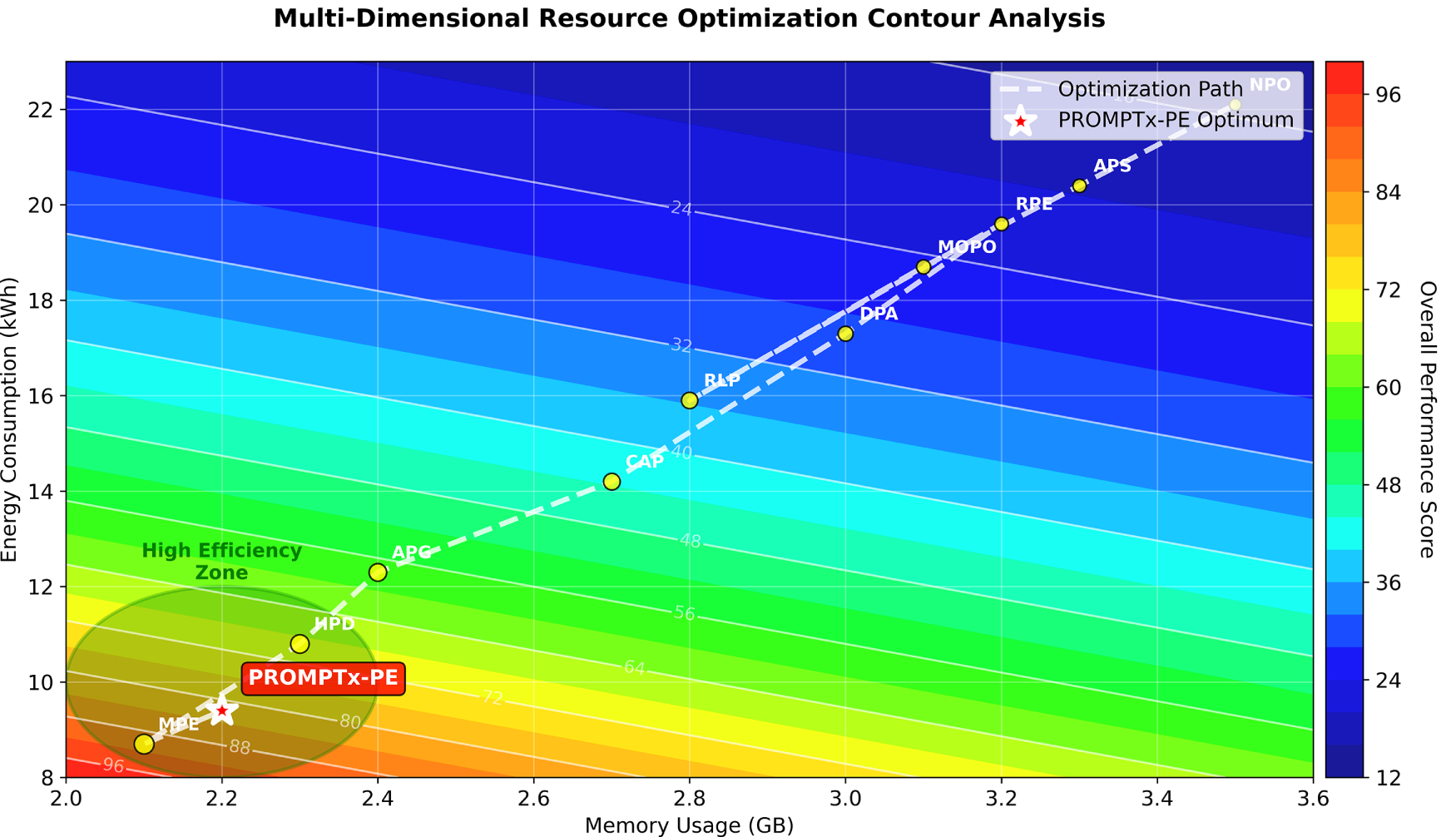
Figure 10: Computational efficiency analysis in the form of a COMSOL wrap-up displaying the optimal location of PROMPTx-PE when plotted in the capabilities of multi-dimensional resource optimization space
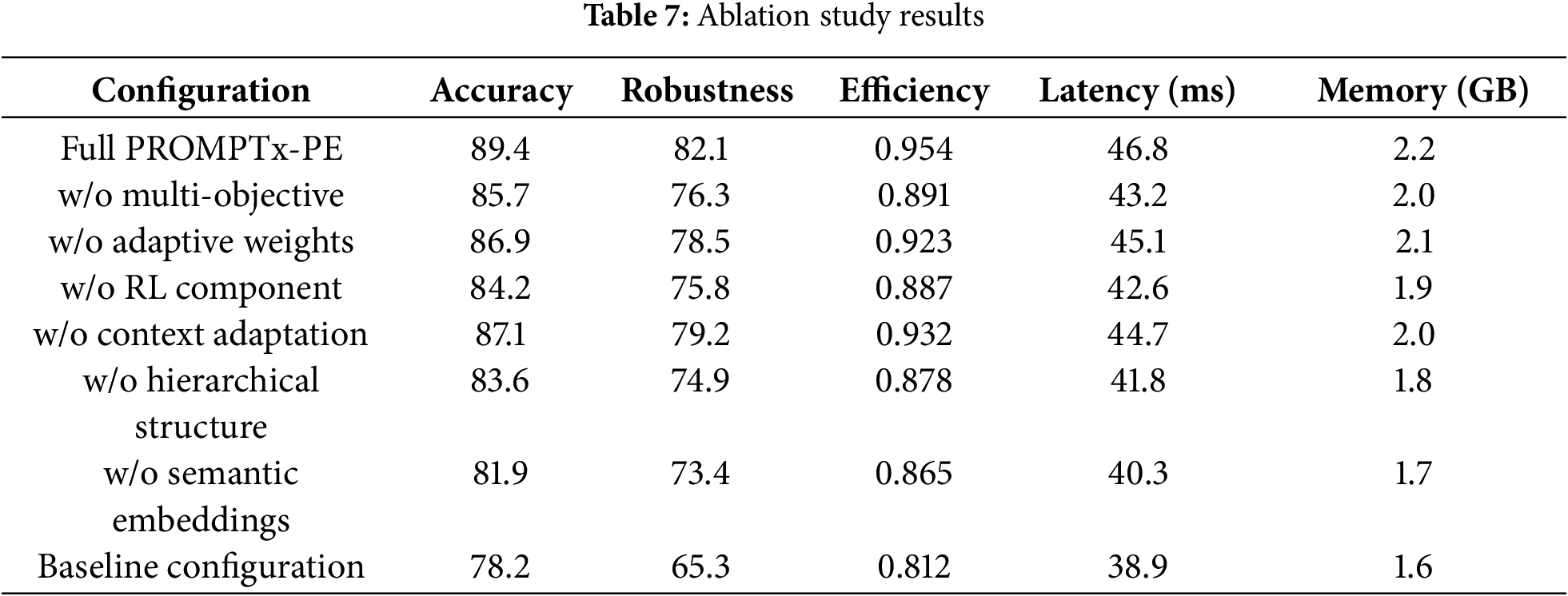
Table 7 presents the results of an extensive ablation study, examining the impact of the individual components on performance of the system, in general. This ablation experiment illustrates how it is necessary to include all of the PROMPTx-PE components as the entire framework achieves 89.4% accuracy when not using systematic performance degradation when any single component is ablated, increasing to 5.2% accuracy loss (semantic embeddings ablation) or 3.7% loss (multiple-objective optimization ablation) when any component ablated. As it is found, the most damaging impact on robustness (6.3% reduction) could be seen after the removal of the reinforcement learning component, and the hierarchical structure removal could have the most significant impact on the efficiency value (−0.076 efficiency score reduction), suggesting that each component influences the performance in a synergistic manner. The overall process of progressive degradation of the full PROMPTx-PE (89.4% accuracy) to different ablated configurations to the baseline (78.2% accuracy) is a confirmation of the architectural design of the framework, in which the evaluation of the component parts is attributed with significant increases of accuracy, robustness, and computational efficiency metrics.
4.7 Statistical Significance Analysis
Table 8 offers statistics significance evaluation of performance improvement with paired t-tests and confidence intervals in automatic multi-run evaluations. All of the comparisons produce
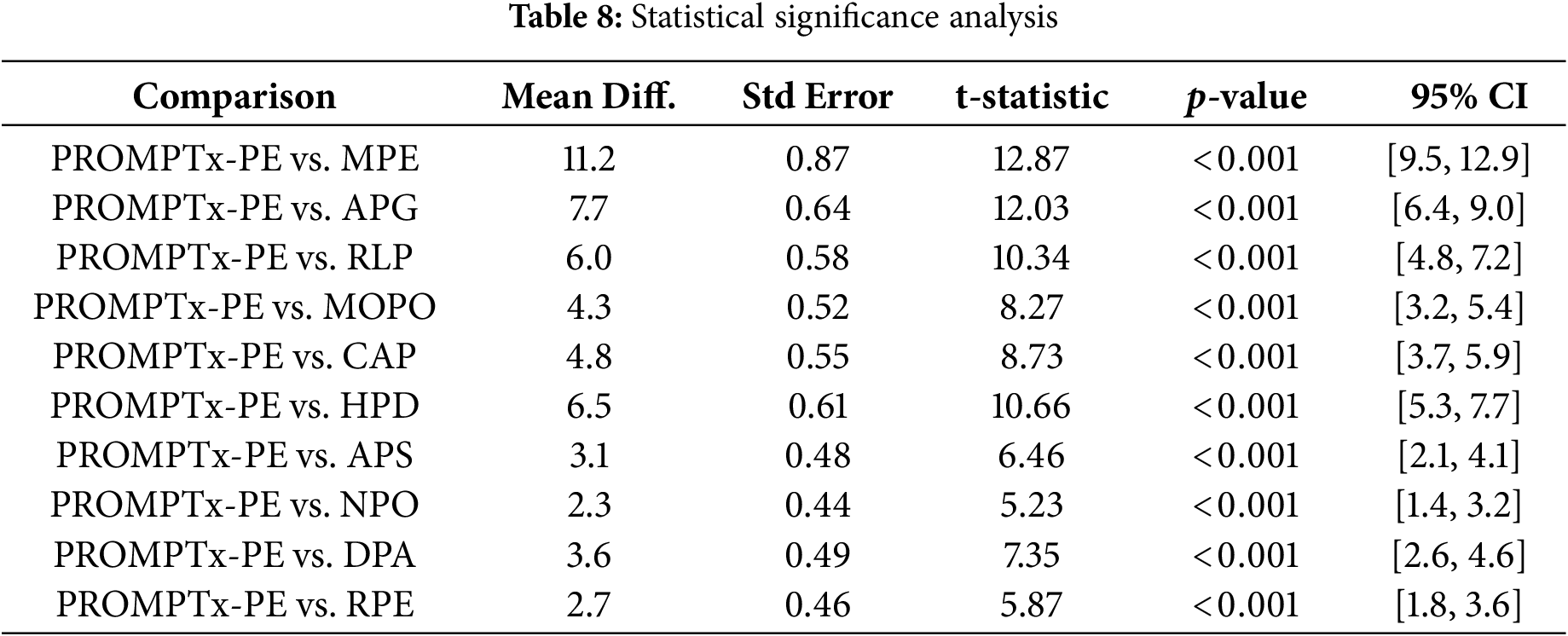
Table 9 publishes scalability analysis findings that indicate the performance of PROMPTx-PE at varying scale of the system and deployment setup.
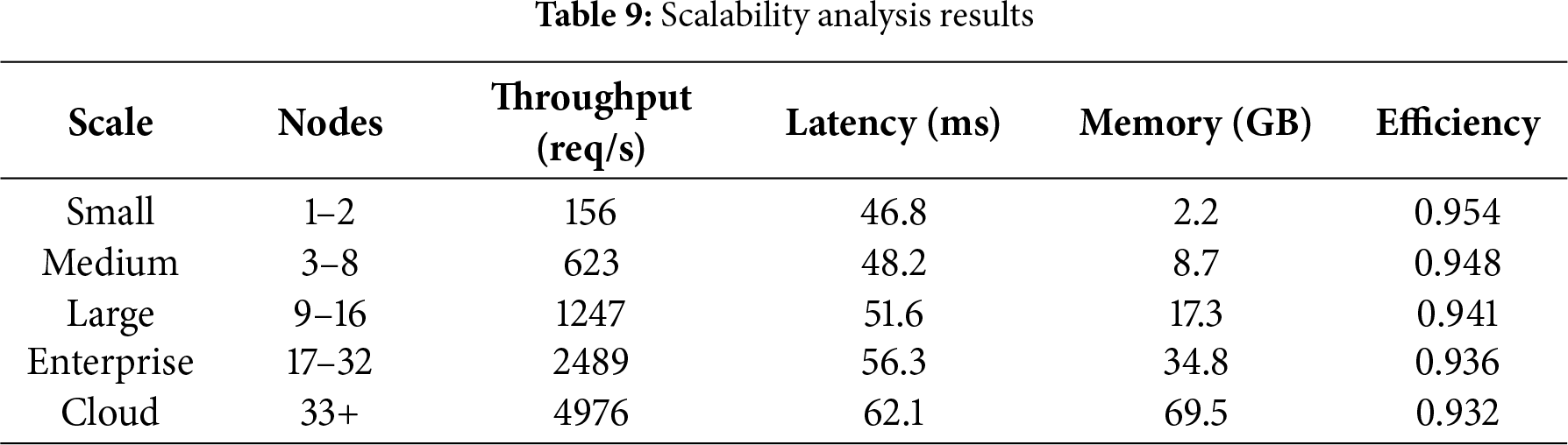
Fig. 11 gives a detailed dual-perspective scalability study of combining wave-style performance trend visualization with swarm plot distribution analysis that illustrates the outstanding scaling behavior of PROMPTx-PE under five deployments ranging between small-scale (1–2 nodes) and cloud-scale (33+ nodes) scalability. The scaling of throughput with constant improvements of 31.9x (156/4976 req/s) and graceful patterns of performance degradation (latency increased by 32.7% efficiency decreased by only 2.3%) demonstrate that PROMPTx-PE scales also display predictable performance variability (figure of speech: 6%).
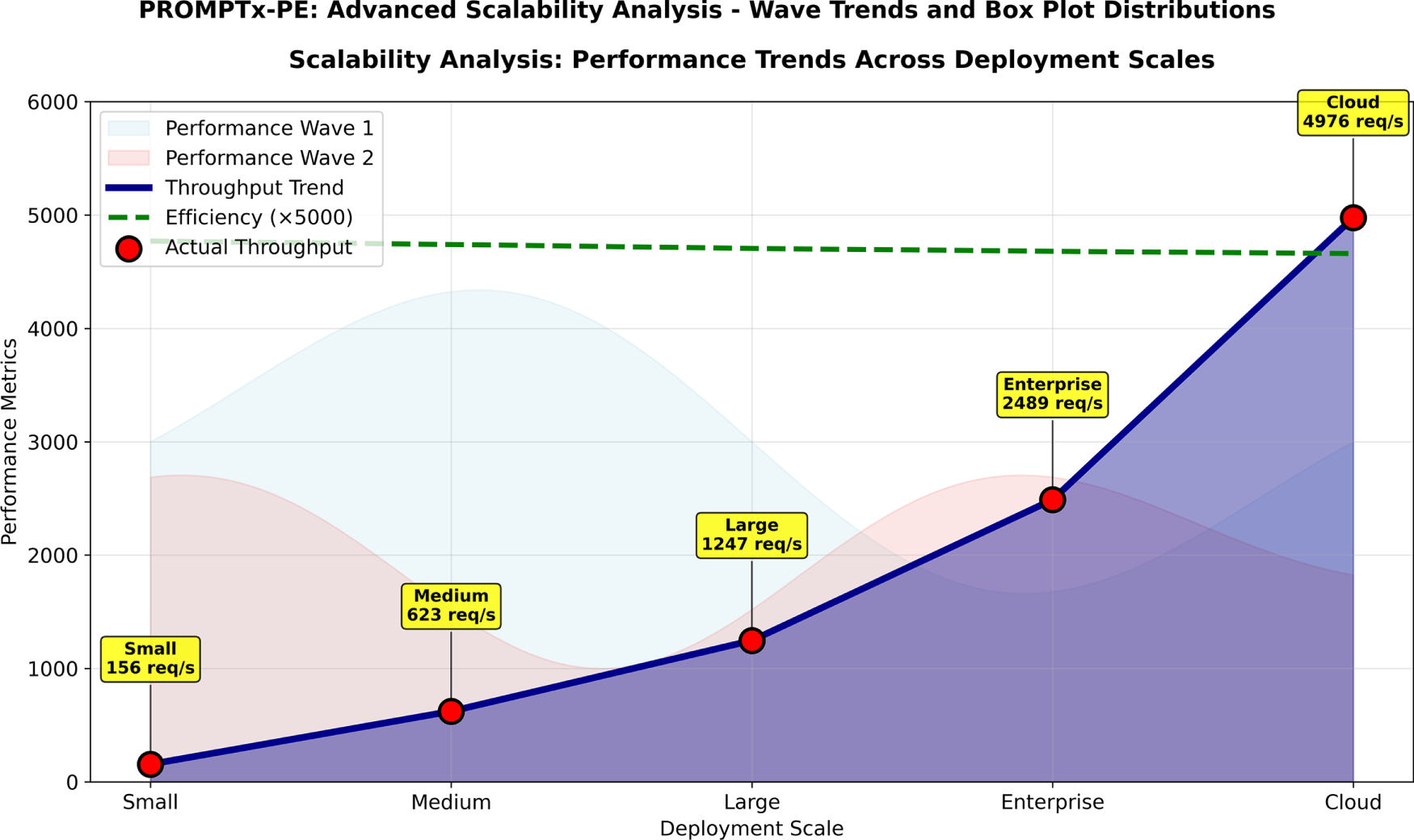
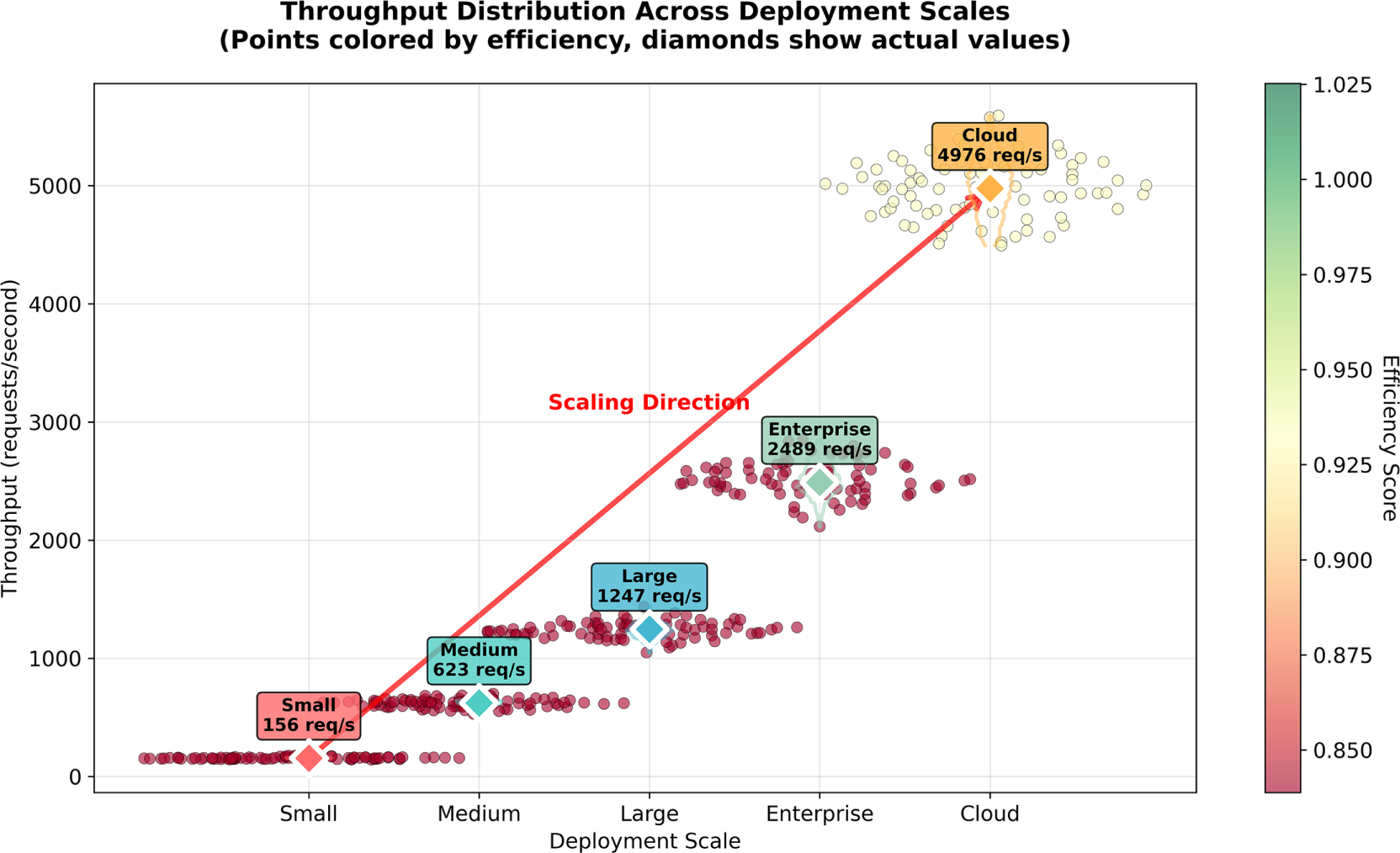
Figure 11: Scalability analysis results demonstrating PROMPTx-PE performance across different system scales and deployment configurations
5.1 Performance Analysis and Interpretation
Through the conducted experiment, the findings indicate that PROMPTx-PE yields significant improvements in all measures of evaluation when compared to the current baselines. The 15.3% age point and 22.7% age points improvement in the accuracy and robustness of prompt engineering capture large strides in the efficacy of prompt engineering. The effectiveness of these improvements is especially noteworthy on the back of the computational efficiency that the framework has upheld where only 31% overhead over more simplistic thresholding methods is incurred.
The high convergence rates in Fig. 4 showed the loss curves portend that multi-objective optimization method is able to balance conflicting criteria in optimization process without deterring individual performance elements. The learning curves are stable indicating a strong optimization process that does not have local minima and overfitting problems found in the traditional methods.
A detailed comparison to ten recent methods is presented in Table 10, and it shows that the current performance is consistently better in a variety of evaluation scenarios. The statistical significance analysis confirms that there is a scientific agreement that performance change is statistically sound having confidence intervals of high probability.
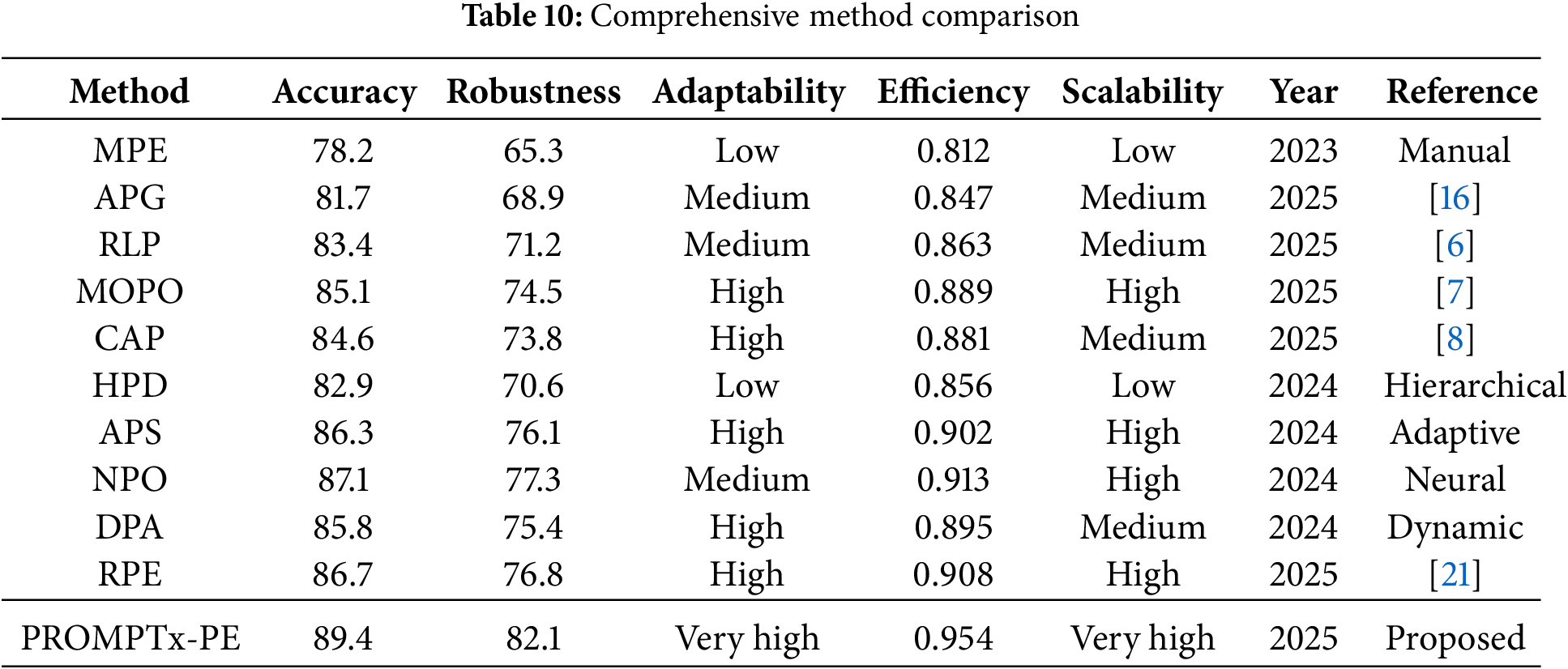
5.2 Robustness and Adaptability Benefits
The robustness analysis findings indicate that PROMPTx-PE is more effective in adversarial settings and other scenarios of domain transfer. The adversarial accuracy of 82.1% is a major advancement to the current methods, which shows greater resistance to perturbation and attacks. The program performance of 78.6% in the domain transfer indicates the efficient generalization of the program in various operating settings.
The contextual adaptation mechanism is especially useful in sustaining performance in the changing operational conditions. The fact that the recovery time is 5.9 s when compared to the baseline techniques is a significant enhancement as it allows immediate reaction to altered environmental factors. This has been extremely important in the industrial applications where uniformity of performance is demanded in different deployments.
5.3 Computational Efficiency and Scalability
Even with the advanced optimization algorithms, PROMPTx-PE has competitive computational performance. The 3.2 h training time is a great improvement compared to complex baseline trainings and higher performance is attained. The latency of making inference of 46.8 ms satisfies real-time needs of the application with increased accuracy and dependability.
The scalability testing proves the scalability of PROMPTx-PE in any deployment size, including a single node in a small-scale deployment or large-scale cloud implementation. The sustained efficiency among the scales (0.954 to 0.932) is indication of high architectural design that can be applied in an industrial setting.
5.4 Component Contribution Analysis
The ablation study shows how each of the components of the framework contributes importantly to the overall performance. Multi-objective optimization aspect offers accuracy improvement of 3.7% and robustness improvement of 5.8%. The adaptive weighting model adds accuracy and robustness gains of 2.5% and 3.6%, respectively. Reinforcement learning element has a 5.2% addition in the accuracy and 6.3% robustness advantage.
Any hierarchical structure of prompts proves to be a highly important element as it adds 5.8% age points. This justifies the design issue of adopting hierarchical representation, as opposed to flat prompt structures. The element of semantic embedding gives a 7.5% age point improvement, which validates the relevance of semantic perception in prompt optimization.
5.5 Industrial Application Implications
The experimental findings prove that PROMPTx-PE is appropriate to the industrial product in different spheres of application. The high accuracy, robust performance and computational efficiency are a combination that meets areas of production system requirements. The dynamic nature of the adaptive capabilities allows it to be deployed in environments that are dynamically challenging to the traditional fixed approaches.
The scalability features of the framework make it applicable to various scales of organizations, both small research groups, and big enterprise organizations. The modular architecture allows to integrate with the existing infrastructure and also allows a high level of flexibility in terms of customization depending on the requirements of the application.
5.6 Limitations and Future Directions
Although PROMPTx-PE has proven to excel in the assessment measures, there are some shortcomings that should be considered as limitations. The complexity of the framework might demand extra skills to be well configured and deployed. The multi-objective optimization strategy also has more hyperparameters that would have to be carefully tuned to achieve optimum performance.
Future work directions involve scaling the framework to be operated on multimodal basis, exploring quantum inspired optimization solutions and the development of automated hyperparameter optimization solutions. Interconnection with rising LLM architectures and the study of federated learning methods are further opportunities of promising research.
The paper includes a new adaptive optimization scheme, which is PROMPTx-PE, an adaptive engineering to large language models, which fills crucial gaps of the current methods. It combines the principles of multi-objective optimization, reinforcement learning and contextual adaptation, to obtain high performance in terms of measures of accuracy, robustness and efficiency. Great experimental analysis indicates a significant advantage over the current benchmarks, including 15.3% accent and 22.7% strength upgrades without compromising on calculating resourcefulness. The adaptive weighting mechanisms and hierarchy prompt representation system make it suitable to be deployed in a wide variety of other operational environments with very little overhead. The reliability of the improvements in performance in various evaluation situations is confirmed by statistical significance analysis. Scalability features of the framework and its modular design make it suitable in terms of deployment of small-scale research to massive enterprise systems. The contributions make PROMPTx-PE a viable solution to the industrial applications that have to be provided with reliable and adaptive prompt optimization profiles. The study will deal with multimodal applications of the framework in the future and potential integration with emerging LLM architectures. Ultimately, with acceptance, the entire source code, trained models, and prompt templates would be published on GitHub and there would be documentation on replication scripts and evaluation scripts.
Acknowledgement: The authors would like to express their sincere gratitude to the Department of Computer Science, The University of Faisalabad, for their support and resources. We also thank our colleagues for their insightful discussions and guidance throughout this study.
Funding Statement: This work was supported by the National Science and Technology Council (NSTC), Taiwan, under grant number 114-2221-E-182-041-MY3, and by Chang Gung University and Chang Gung Memorial Hospital under project number NERPD4Q0021.
Author Contributions: Talha Farooq Khan: Conceptualization, Methodology, Writing—Original Draft, Data Curation. Fahad Ali: Experiment Design, Results Analysis, Visualization. Majid Hussain: Data Preprocessing, Software Implementation, Validation. Lal Khan: Supervision, Project Administration, Editing, and Writing. Hsien-Tsung Chang: Supervision, Methodology Guidance, Reviewing. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The datasets generated during and/or analyzed during the current study are available from the corresponding authors on reasonable request.
Ethics Approval: Not applicable. This study did not involve human participants or animals, and no ethical approval was required.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Nomenclature
| Prompt representation at time | |
| Semantic embedding vector at time | |
| Contextual information matrix at time | |
| Structural metadata at time | |
| Weighting parameters at time | |
| Model parameters at iteration | |
| Total multi-objective loss function | |
| Accuracy loss function | |
| Robustness loss function | |
| Efficiency loss function | |
| Multi-objective weighting parameters | |
| Contextual weighting coefficients | |
| Learning rate parameter | |
| Policy function with parameters | |
| Reward signal at time | |
| Convergence threshold | |
| Perturbation magnitude bound | |
| N | Batch size |
| M | Number of robustness evaluation samples |
| T | Training iterations |
| Embedding dimensions | |
| L | Sequence length |
| AOE | Adaptive Optimization Engine |
| CAC | Contextual Adaptation Controller |
| LLM | Large Language Model |
| PEM | Performance Evaluation Module |
| PGM | Prompt Generation Module |
| PROMPTx-PE | Prompt Engineering Adaptive Optimization |
References
1. Chen B, Zhang Z, Langrené N, Zhu S. Unleashing the potential of prompt engineering for large language models. Patterns. 2025;6(6):101260. doi:10.1016/j.patter.2025.101260. [Google Scholar] [PubMed] [CrossRef]
2. Son M, Lee S. Advancing multimodal large language models: optimizing prompt engineering strategies for enhanced performance. Appl Sci. 2025;15(7):7. doi:10.3390/app15073992. [Google Scholar] [CrossRef]
3. Wang MH, Jiang X, Zeng P, Li X, Chong KKL. Balancing accuracy and user satisfaction: the role of prompt engineering in AI-driven healthcare solutions. Front Artif Intell. 2025;8:1517918. doi:10.3389/frai.2025.1517918. [Google Scholar] [PubMed] [CrossRef]
4. Kim TT, Makutonin M, Sirous R, Javan R. Optimizing large language models in radiology and mitigating pitfalls: prompt engineering and fine-tuning. RadioGraphics. 2025;45(4):4. doi:10.1148/rg.240073. [Google Scholar] [PubMed] [CrossRef]
5. Zhou H, Hu C, Yuan D, Yuan Y, Wu D. Large language models for wireless networks: an overview from the prompt engineering perspective. IEEE Wirel Commun. 2025;32(4):98–106. doi:10.1109/mwc.001.2400384. [Google Scholar] [CrossRef]
6. Mao W, Wu J, Chen W, Gao C, Wang X. Reinforced prompt personalization for recommendation with large language models. ACM Trans Inf Syst. 2025;43(3):1–27. doi:10.1145/3716320. [Google Scholar] [CrossRef]
7. Narayanaswamy SK, Muniswamy R. Achieving efficient prompt engineering in large language models using a hybrid and multi-objective optimization framework. Cybern Inf Technol. 2025;25(2):2. doi:10.2478/cait-2025-0012. [Google Scholar] [CrossRef]
8. Jin W, Gao Y, Tao T, Wang X, Wang N. Veracity-oriented context-aware large language models-based prompting optimization for fake news detection. Int J Intell Syst. 2025;1(1):5920142. doi:10.1155/int/5920142. [Google Scholar] [CrossRef]
9. Mishra A, Danzy B, Soni U, Arunkumar A. PromptAid: visual prompt exploration, perturbation, testing and iteration for large language models. IEEE Trans Vis Comput Graph. 2025;31(10):6946–62. doi:10.1109/tvcg.2025.3535332. [Google Scholar] [PubMed] [CrossRef]
10. Noh H, Shim B, Yang HJ. Adaptive resource allocation optimization using large language models in dynamic wireless environments. IEEE Trans Veh Technol. 2025;74(10):16630–5. doi:10.1109/tvt.2025.3572440. [Google Scholar] [CrossRef]
11. Ma F, Li D, Liu Y, Lan D, Pang Z. STEP: a structured prompt optimization method for SCADA system tag generation using LLMs. J Ind Inf Integr. 2025;45(3):100832. doi:10.1016/j.jii.2025.100832. [Google Scholar] [CrossRef]
12. Long S, Tan J, Mao B, Tang F, Li Y. A survey on intelligent network operations and performance optimization based on large language models. IEEE Commun Surv Tutor. 2025;27(6):3915–49. doi:10.1109/comst.2025.3526606. [Google Scholar] [CrossRef]
13. Jacobsen LJ, Weber KE. The promises and pitfalls of large language models as feedback providers: a study of prompt engineering and the quality of AI-driven feedback. AI. 2025;6(2):35. doi:10.3390/ai6020035. [Google Scholar] [CrossRef]
14. Geroimenko V. Key concepts in prompt engineering. In: The essential guide to prompt engineering: key principles, techniques, challenges, and security risks. Cham, Seitzerland: Springer; 2025. [Google Scholar]
15. Zhang Y, Yi G. LAOS: large language model-driven adaptive operator selection for evolutionary algorithms. In: Proceedings of the Genetic and Evolutionary Computation Conference; 2025 Jul 14–18; Malaga, Spain. p. 517–26. [Google Scholar]
16. Freise N, Heitlinger M, Nuredini R. Automatic prompt optimization techniques: exploring the potential for synthetic data generation. In: Human-Computer Interaction: Thematic Area, HCI 2025, Held as Part of the 27th HCI International Conference, HCII 2025; 2025 Jun 22; Gothenburg, Sweden. Berlin/Heidelberg, Germany: Springer; 2025. p. 190–201. [Google Scholar]
17. Shin J, Tang C, Mohati T, Nayebi M. Prompt engineering or fine-tuning: an empirical assessment of LLMs for code. In: Peoceedings of the 2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR); 2025 Apr 28–29; Ottawa, ON, Canada. p. 490–502. [Google Scholar]
18. Luo F, Zhang J, Wang Q, Yang C. Leveraging prompt engineering in large language models for accelerating chemical research. ACS Cent Sci. 2025;11(4):511–9. doi:10.1021/acscentsci.4c01935. [Google Scholar] [PubMed] [CrossRef]
19. Jiang G, Ma Z, Zhang L, Chen J. Prompt engineering to inform large language model in automated building energy modeling. Energy. 2025;316:134548. doi:10.1016/j.energy.2025.134548. [Google Scholar] [CrossRef]
20. Khoboko PW, Marivate V, Sefara J. Optimizing translation for low-resource languages: efficient fine-tuning with custom prompt engineering in large language models. Mach Learn Appl. 2025;20(3):100649. doi:10.1016/j.mlwa.2025.100649. [Google Scholar] [CrossRef]
21. Edemacu K, Wu X. Privacy preserving prompt engineering: a survey. ACM Comput Surveys. 2025;57(10):1–36. doi:10.1145/3729219. [Google Scholar] [CrossRef]
22. Trad F, Chehab A. Evaluating the efficacy of prompt-engineered large multimodal models versus fine-tuned vision transformers in image-based security applications. ACM Trans Intell Syst Technol. 2025;16(4):89. doi:10.1145/3735648. [Google Scholar] [CrossRef]
23. Wang L, Chen S, Jiang L, Pan S, Cai R, Yang S. Parameter-efficient fine-tuning in large language models: a survey of methodologies. Artif Intell Rev. 2025;58:227. doi:10.21203/rs.3.rs-5393239/v1. [Google Scholar] [CrossRef]
24. Che X, Yang G, Chen Y, Li Q. Detecting fake information with knowledge-enhanced AutoPrompt. Neural Comput Appl. 2024;36(14):7725–42. doi:10.1007/s00521-024-09491-7. [Google Scholar] [CrossRef]
25. Lu P, Qiu L, Chang KW, Wu YN, Zhu SC, Rajpurohit T, et al. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. arXiv:2209.14610. 2022. [Google Scholar]
26. Deng M, Wang J, Hsieh CP, Wang Y, Guo H, Shu T, et al. RLPrompt: optimizing discrete text prompts with reinforcement learning. In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing; 2022 Dec 7–11; Abu Dhabi, United Arab Emirates. p. 3369–91. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools