
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
An Intelligent Orchard Anti-Damage System Combining Real-Time AI Image Recognition and Laser-Based Deterrence for Multi-Target Monkeys
1 Department of Computer Science and Engineering, Tatung University, No.40, Sec. 3, Zhongshan N. Rd., Taipei City, 10452, Taiwan
2 Department of Mechanical and Materials Engineering, Tatung University, No. 40, Sec. 3, Zhongshan N. Rd., Taipei City, 10452, Taiwan
* Corresponding Author: Min-Chie Chiu. Email:
(This article belongs to the Special Issue: Development and Application of Deep Learning based Object Detection)
Computers, Materials & Continua 2026, 87(2), 37 https://doi.org/10.32604/cmc.2025.074911
Received 21 October 2025; Accepted 25 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
To address crop depredation by intelligent species (e.t, macaques) and the habituation from traditional methods, this study proposes an intelligent, closed-loop, adaptive laser deterrence system. A core contribution is an efficient multi-stage Semi-Supervised Learning (SSL) and incremental fine-tuning (IFT) framework, which reduced manual annotation by ~60% and training time by ~68%. This framework was benchmarked against YOLOv8n, v10n, and v11n. Our analysis revealed that YOLOv12n’s high Signal-to-Noise Ratio (SNR) (47.1% retention) pseudo-labels made it the only model to gain performance (+0.010 mAP) from SSL, allowing it to overtake competitors. Subsequently, in the IFT stress test, YOLOv12n proved most robust (a minimal −0.019 mAP decline), whereas YOLOv10n suffered catastrophic failure (−0.233 mAP), highlighting its incompatibility with IFT. The final model achieved high performance (mAP@0.5 of 0.947 for macaques, 0.946 for laser spots). In Multi-Object Tracking (MOT), this study quantitatively confirms that Bottom-Up Tracking by Sorting (BoT-SORT) (1.88 s avg. tracklet lifetime) significantly outperforms ByteTrack (0.81 s) in identity preservation for visually similar macaques. System integration achieved 480 Frames Per Second (FPS) real-time inference on edge devices. A quadratic polynomial fitting model ensured high-precision aiming (RMSE < 2 pixels; best 1.2 pixels) by compensating for distortion. To fundamentally solve habituation, an adaptive strategy driven by a Deep Deterministic Policy Gradient (DDPG) framework was introduced. By using a habituation penalty term (Keywords
Nomenclature:
The following symbols are adopted in the paper:
| R | Comprehensive reward function |
| Rdeter | Deterrence success reward |
| Rsafety | Safety & energy efficiency reward |
| Rhabituation | Habituation Penalty |
| wdeter | Weight for deterrence success reward |
| wsafety | Weight for safety & energy efficiency reward |
| whabituation | Weight for habituation penalty |
| yi | Actual physical angle |
| xi | Image pixel coordinate |
| β0 | Intercept |
| β1 | Linear term coefficient |
| β2 | Quadratic term coefficient |
| SSR | Sum of squared residuals |
| RMSE | Root mean square error |
| IFRR | Intrusion frequency reduction rate |
| LoAH | Level of anti-habituation (a categorization framework proposed by this study based on existing literature) |
Crop depredation by wildlife poses a critical threat to agricultural sustainability. While traditional methods utilizing infrared sensors [1] or passive barriers may suffice for avian pests [2], they prove largely ineffective against highly intelligent non-human primates, particularly the Formosan macaque (Macaca cyclopis). In Taiwan, the conflict is intensified by legal protections and habitat degradation, resulting in a population surge to approximately 300,000 and frequent agricultural intrusion. However, current mitigation strategies face an insurmountable biological bottleneck: Cognitive Adaptability. As noted by Koirala et al. [3], primates rapidly habituate to predictable deterrent patterns—such as periodic noise or fixed laser scans. Furthermore, traditional approaches as shown in Fig. 1 suffer from structural limitations: passive electric fences are cost-prohibitive to maintain, while active traps and Passive Infrared Sensor (PIR) are plagued by low efficiency and the risk of capturing non-target species [4]. Consequently, the development of an intelligent, closed-loop system capable of generating unpredictable, adaptive stimuli is not merely an enhancement but a necessity for resolving such advanced human-wildlife conflicts.
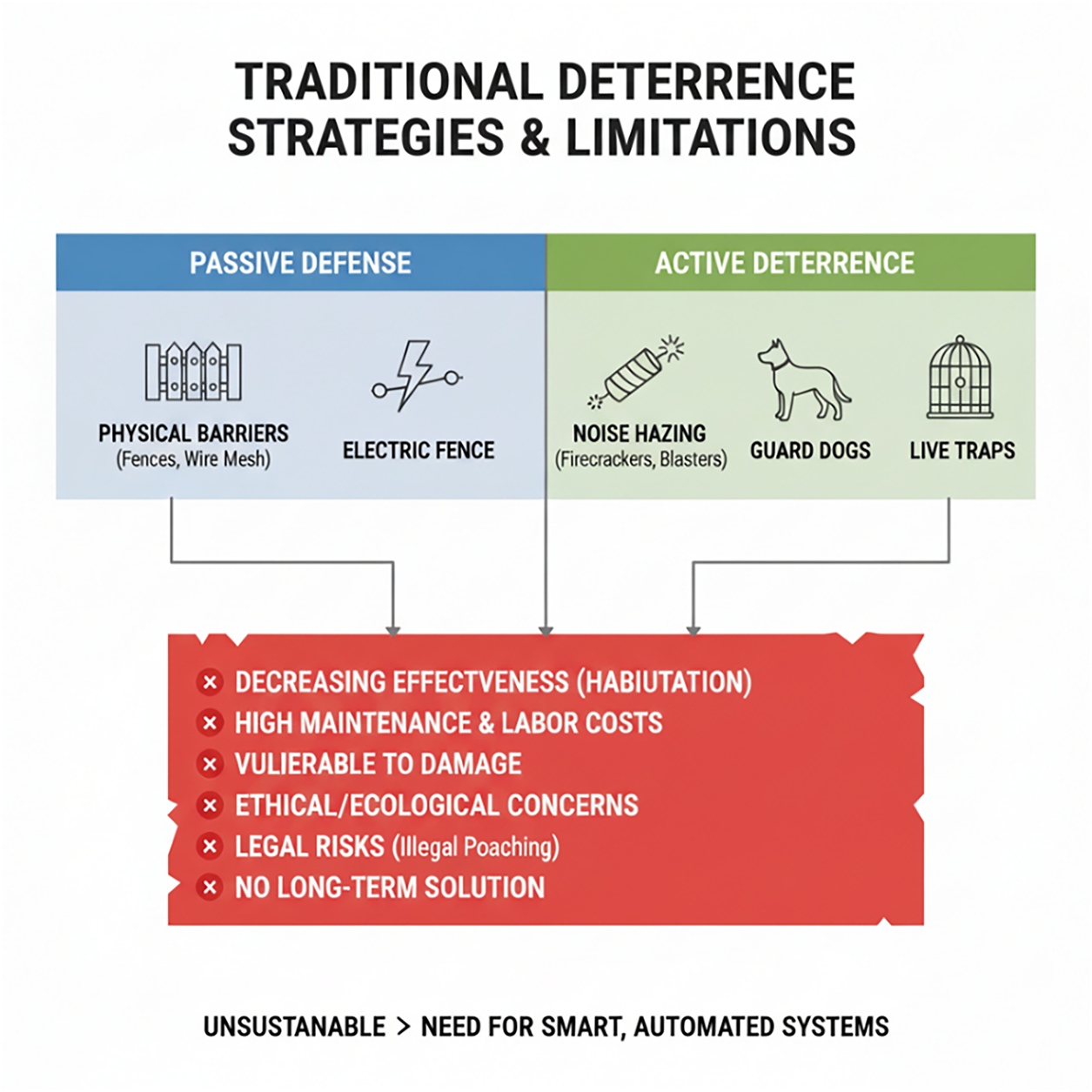
Figure 1: Traditional wildlife deterrence strategies and their limitations
1.2 System Innovations and Core Contributions
To address the significant challenges of crop depredation by highly intelligent wildlife (e.g., macaques) and the habituation associated with traditional deterrent methods, this study proposes an intelligent, closed-loop identification and deterrence system equipped with adaptive strategies. This system integrates real-time identification, precision calibration, and effective countermeasures. Its core technological breakthroughs and methodological contributions are summarized as follows:
• A High-Performance and High-Robustness Artificial Intelligence (AI) Training Framework: We propose a multi-stage training framework integrating Semi-Supervised Learning (SSL) and Incremental Fine-Tuning (IFT). This methodology not only drastically reduces the reliance on manual annotation and training time but also theoretically solves the “Catastrophic Forgetting” problem when the model learns new functionalities (such as laser spots).
• A Highly Discriminative Multi-Object Tracking Methodology: Addressing the core challenge of “high intra-class similarity” (similar appearance) within macaque groups, this study empirically validates and establishes that the Bot-SORT tracker, by leveraging its highly discriminative Re-ID features, is significantly more robust in identity preservation than traditional methods (like ByteTrack).
• Adaptive Decision-Making (Anti-Habituation) and High-Precision Execution: This system is the first to integrate a Deep Deterministic Policy Gradient (DDPG) reinforcement learning framework as its decision core. By penalizing fixed patterns in the reward function (i.e., rewarding entropy), the DDPG drives the system to generate unpredictable laser strategies, fundamentally suppressing the habituation effect in highly intelligent species. This strategy is enabled by a quadratic polynomial fitting model for dynamic laser calibration, ensuring high-precision targeting.
These contributions provide a solid methodological foundation for developing high-precision, automated wildlife defense systems capable of overcoming the challenge of habituation.
2 Research Methodology Evaluation
2.1 Limitations of Traditional Deterrence and Early Detection Systems
Human-wildlife conflict (HWC) has emerged as a complex global issue, threatening both food security and local livelihoods [5]. However, a fundamental limitation of traditional deterrents (e.g., noise, fences) is their predictability, which allows highly intelligent species like macaques to quickly habituate to them, rendering these methods ineffective [6].
To overcome this challenge, “Intelligent Deterrence” has emerged, centered on implementing an Anti-Habituation strategy. Based on the generalized analysis of existing literature, we categorize current research into different levels of complexity (Level of Anti-Habituation, LoAH):
• LoAH 1–2 (Basic AI): Systems advanced to using AI for species identification to trigger “species-specific” deterrents (e.g., predator calls) [7], an improvement over randomization (LoAH 1).
• LoAH 3 (Multi-Modal): To counter habituation to single stimuli, systems evolved to “multi-modal escalation.” As exemplified by Park and Shim [8], AI is used to target specific animals (e.g., wild boars) and trigger multiple sensory deterrents (e.g., light and sound).
• LoAH 4 (Mobility): This level recognizes that a “fixed location” is itself a source of habituation. It introduces “mobility,” using UAVs to mimic aerial predators [9] or UGVs [10] to mimic the patrolling behavior of terrestrial predators (e.g., coyotes). However, these systems often face significant challenges regarding limited endurance or high initial costs.
• LoAH 5 (Adaptive): This is the final frontier of deterrence. As conceptualized by Mishra and Yadav [11], this “closed-loop” system features an AI that is not just a detector, but a learner. It observes the animal’s reaction and “proactively changes its strategy” if habituation is detected, maintaining long-term efficacy.
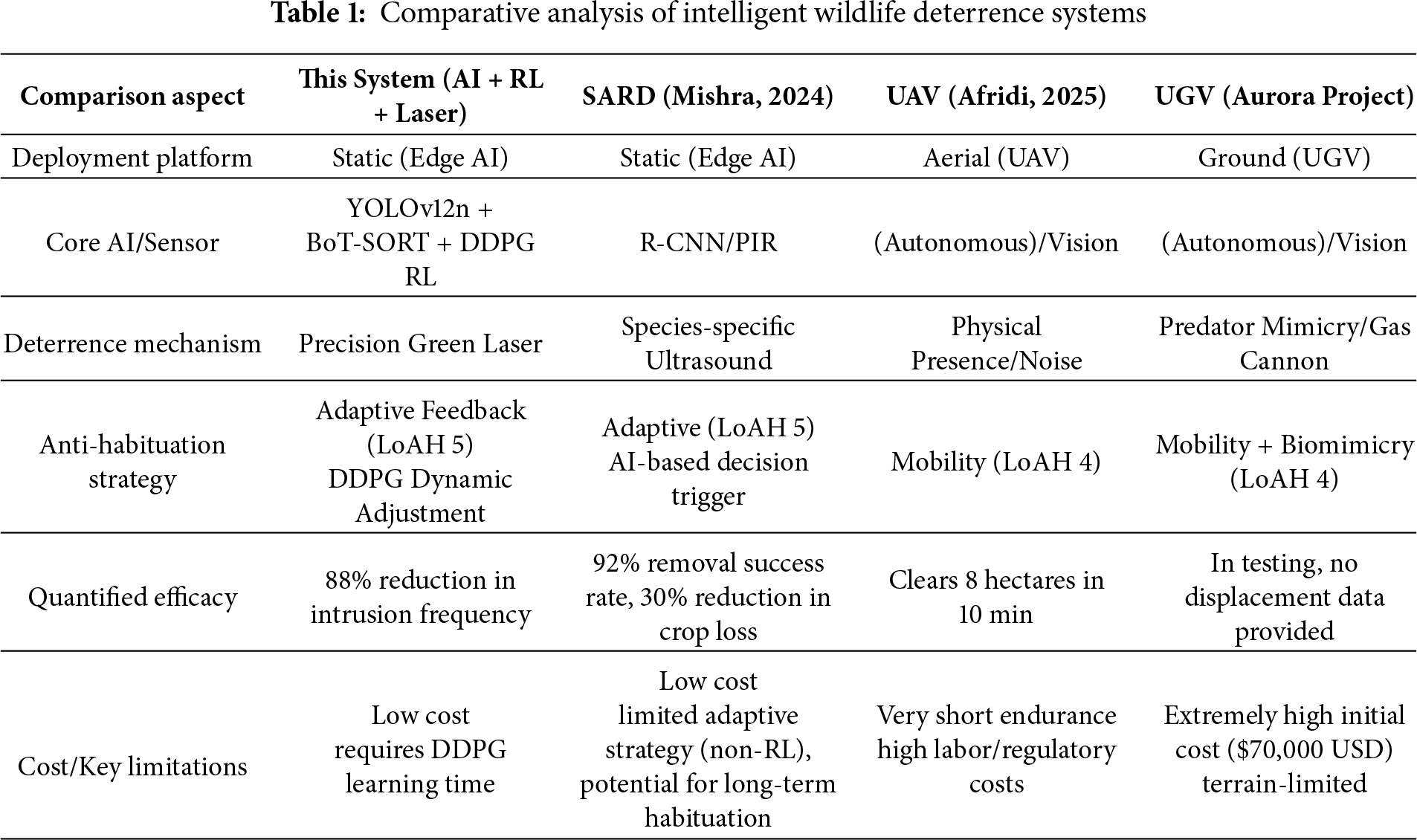
In summary, the literature demonstrates a clear progression from static, predictable deterrence (LoAH 1–2) toward dynamic, unpredictable strategies (LoAH 4–5). However, while LoAH 4 (Mobility) suffers from high deployment costs, LoAH 5 (Adaptive) remains the conceptual ideal, lacking concrete, low-cost, and empirically validated solutions. The system proposed in this study combines the cost-effectiveness of a static, edge-deployed platform with the highest level of anti-habituation capabilities (Level 5), endowed by reinforcement learning. We are the first to introduce Deep Reinforcement Learning (DDPG) into the decision-making core of laser deterrence, enabling the system to achieve closed-loop deterrence via an Adaptive Feedback Loop (as shown in Fig. 2). By penalizing fixed patterns within the reward function, our system autonomously learns and generates unpredictable laser repulsion sequences, fundamentally overcoming the habituation risk inherent in static systems. To concretely quantify these advantages, we provide a systematic comparison of our system against representative intelligent deterrence systems from the literature in Table 1 below, highlighting the key differences in anti-habituation strategies, deployment costs, and quantified efficacy.
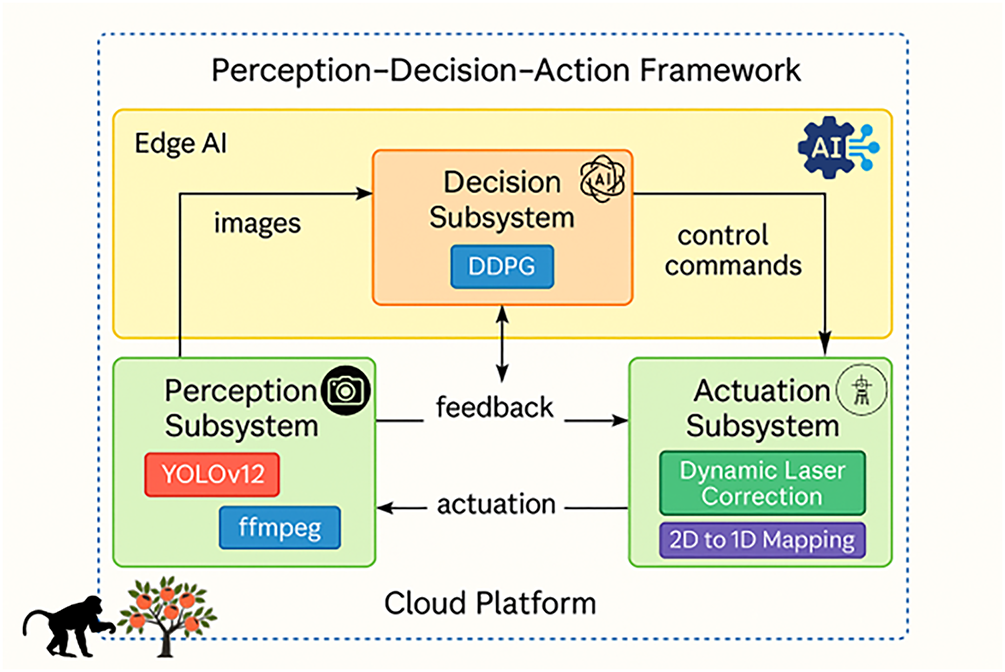
Figure 2: Dual-Layer, cognitive closed-loop wildlife deterrence system based on “perception-decision-action” framework
2.2 Comparison of Deep Learning-Based Object Detection Techniques
Object detection is a foundational AI computer vision module for real-time monitoring applications, and the YOLO (You Only Look Once) series has become the mainstream single-stage detector due to its superior balance of speed and accuracy. Yang et al. [12] employed an improved YOLOv5s model for real-time wildlife detection encompassing multiple animal targets, including macaques (Macaca mulatta), and achieved high accuracy and real-time performance in forest environments; Wang et al. [13] further indicated that a YOLOv5-m trained on mixed day- and night-time images can achieve an mAP = 0.72. However, Liu et al. [14] emphasized that adverse conditions such as low light and fog remain a severe challenge. To address the demand for dynamic tracking, Yang et al. [15] adopted YOLOv7 combined with DeepSORT to achieve real-time identity tracking of wildlife. Wu et al. [16] also validated that YOLOv7 significantly improved detection rates in cluttered environments with vegetation occlusion and lighting variations. Chappidi and Sundaram [17] proposed YOLOv8, which (at 97%) achieved higher accuracy, superior to YOLOv7 (approx. 93%).
This study adopts YOLOv12 (a model implemented by the Ultralytics framework) as the backbone network, using its YOLOv12n pre-trained weights as the starting point for fine-tuning. Its attention mechanism enhances recognition capability for small targets and complex backgrounds while maintaining real-time inference speed. YOLOv12n exhibits excellent computational efficiency; Ref. [18] reports its inference latency on a T4 GPU is only 1.64 ms, and its COCO mAP is 2.1% higher than YOLOv10n. This balance of speed and accuracy makes it highly suitable for resource-constrained edge computing applications.
As shown in Fig. 3, this study develops a system where the YOLOv12 model is deployed on an edge AI computing unit (e.g., NVIDIA Jetson), responsible for real-time image processing. Its detection results (macaques and laser spots) are passed to the laser control module and collaborate with a cloud platform, forming an intelligent closed-loop system.
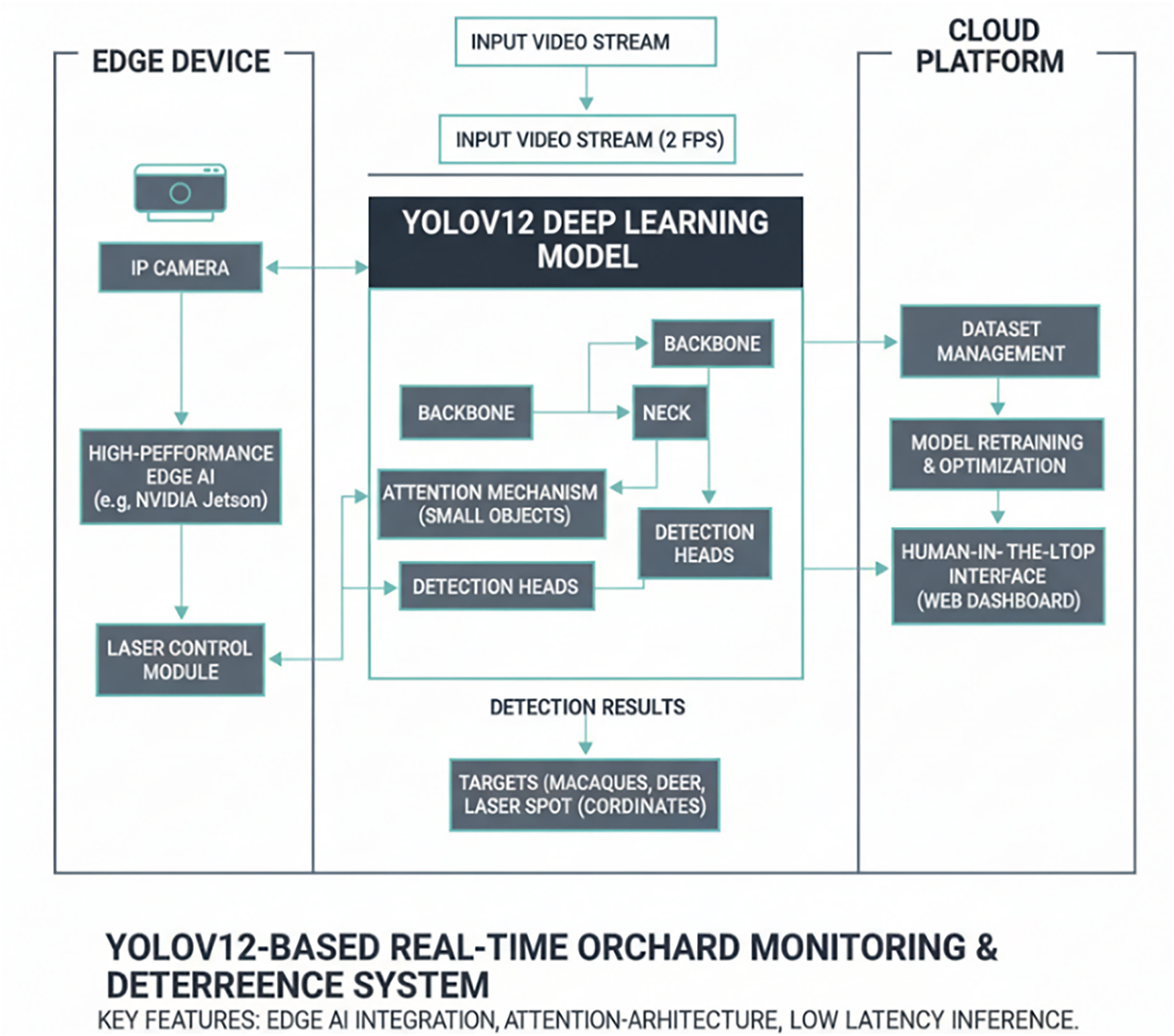
Figure 3: Schematic diagram of real-time orchard monitoring and repulsion System
2.3 Development and Comparative Analysis of Multi-Object Tracking (MOT) for Wildlife Monitoring
With the intensive deployment of camera traps, unmanned aerial vehicles (UAVs), and fixed image-capture platforms in ecological research, large volumes of consecutive imagery are processed across domains to derive information on animal occurrence frequency, activity ranges, and social interactions. In this context, Ogawa et al. [19] noted that the “tracking-by-detection” (TBD) paradigm has become the mainstream workflow: an object detector first locates targets, followed by a data-association algorithm to generate trajectories across frames. However, the performance of multi-object tracking (MOT) systems remains constrained by two key factors in natural environments: detection accuracy and the robustness of association strategies under conditions of vegetation occlusion, highly similar individual appearances, and abrupt motion.
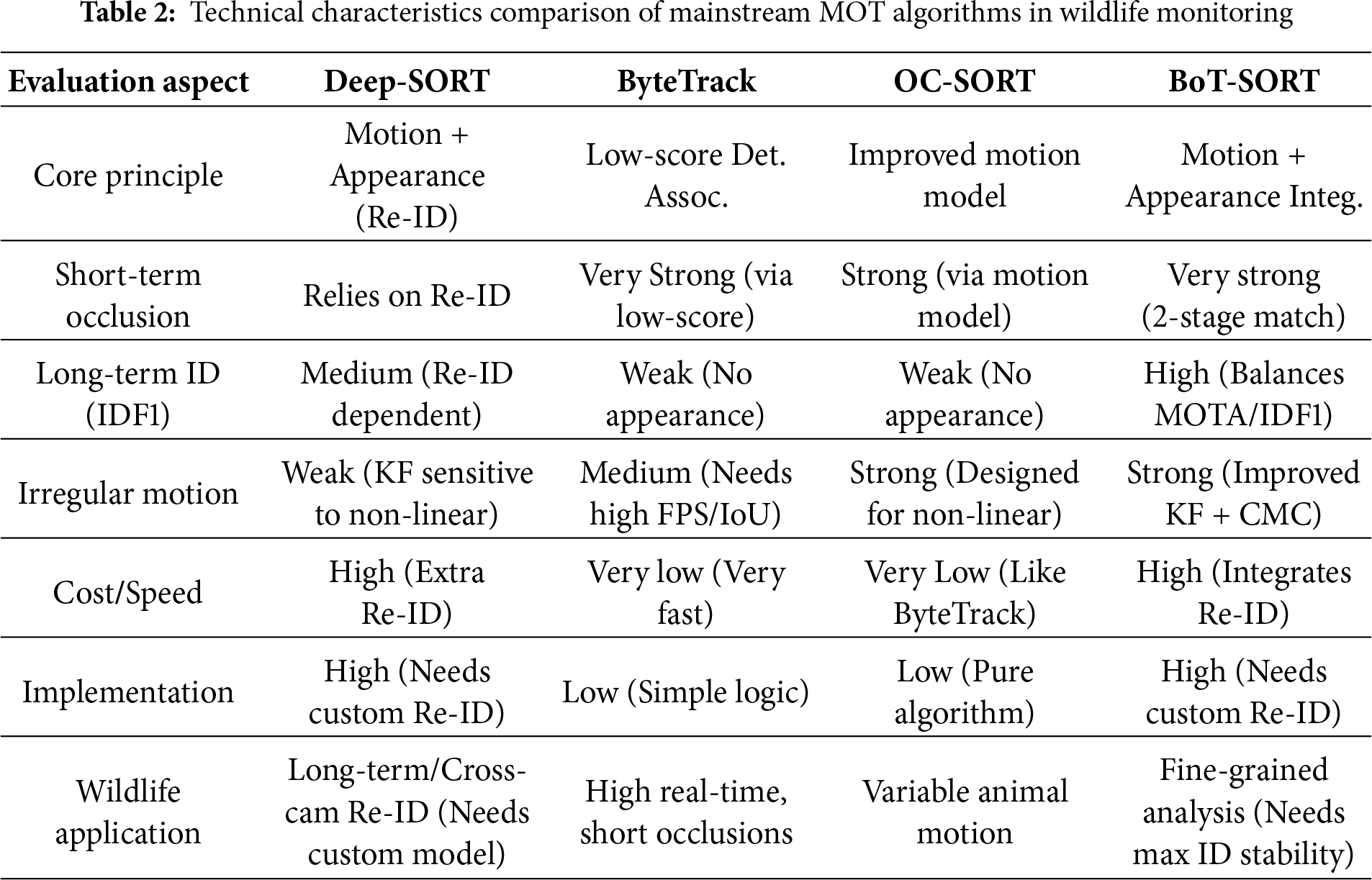
In recent years, MOT techniques have progressed rapidly, with algorithmic performance continuing to advance across major publicly available benchmarks. This progress largely builds on the seminal work of Wojke et al. [20], who introduced DeepSORT—a framework that pioneered the integration of deep-learning appearance features into the tracking pipeline. Subsequent studies have focused on addressing increasingly complex real-world challenges. For example, to mitigate overlooked low-score detections caused by occlusion, Zhang et al. [21] developed ByteTrack, employing a novel two-stage matching strategy that effectively utilizes these latent target cues. Likewise, focusing on occlusion scenarios, Cao et al. [22] proposed OC-SORT, which further enhances tracking stability. Building on these advances, Aharon et al. [23] introduced BoT-SORT—a comprehensive solution that improves upon the association strategy of ByteTrack by integrating appearance features from Deep-SORT and camera-motion compensation, thereby substantially enhancing tracking robustness in complex scenes. A comparative analysis of the technical features of mainstream MOT algorithms for wildlife monitoring is shown in Table 2.
Given the increasing demand for precise, non-invasive management in human-wildlife conflicts, a robust Multi-Object Tracking (MOT) system is essential. While MOT is mature in structured environments, its application in dynamic, ecologically complex scenarios like agriculture presents severe challenges. As shown in Fig. 4, although traditional MOT frameworks integrate detection and tracking, translating them from concept to practical deployment requires overcoming three key challenges identified by this study:
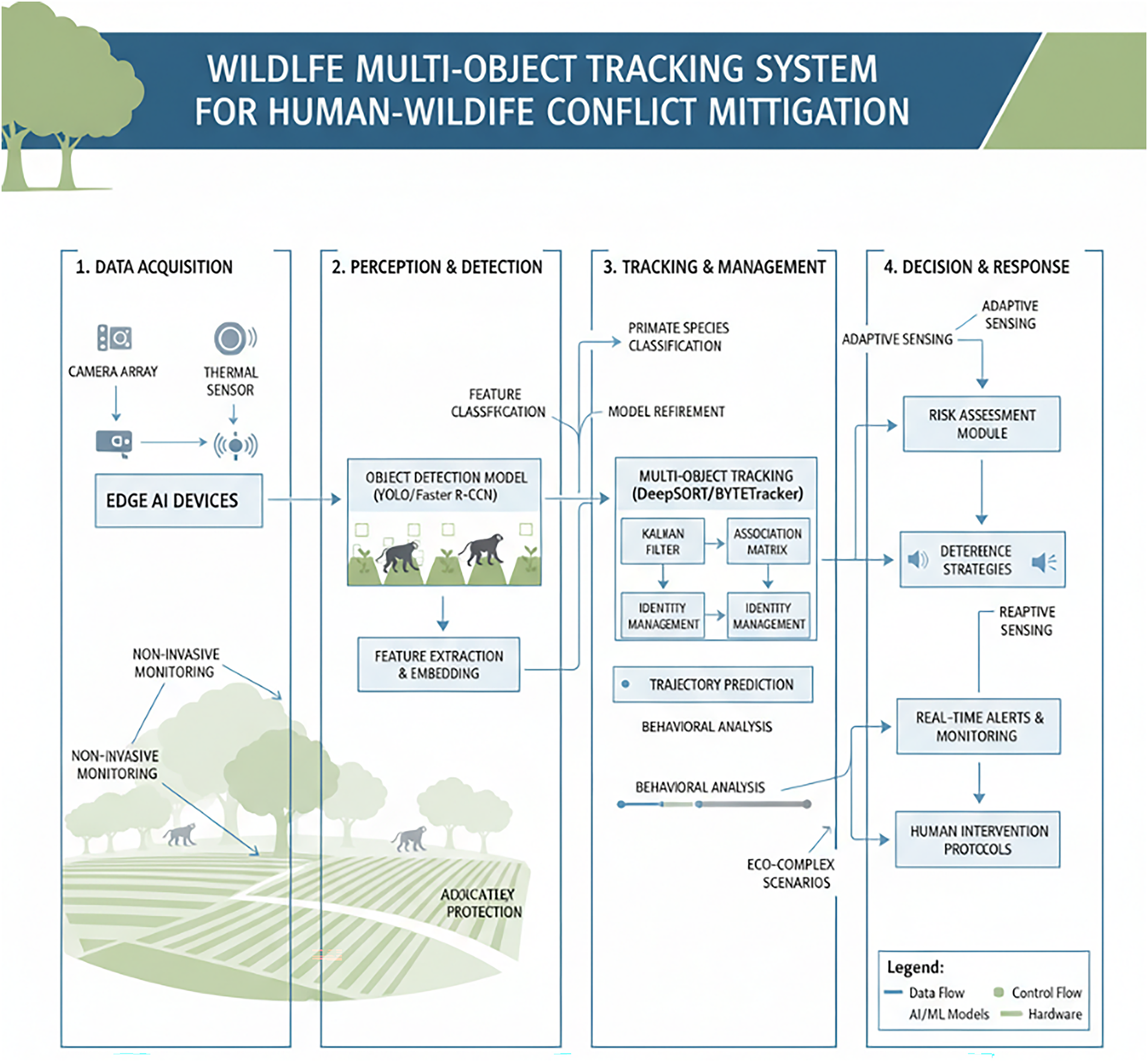
Figure 4: Schematic diagram of the multi-object tracking (MOT) system
• Unstructured Environments: Agricultural landscapes are inherently heterogeneous (e.g., irregular terrain, dense vegetation, variable lighting), introducing significant noise that can degrade detector and motion predictor performance.
• Visual Homogeneity and Intra-Class Similarity: Macaque groups exhibit high visual similarity among individuals, posing a key challenge to the Re-ID component. This can lead to frequent ID switches and trajectory fragmentation.
• Frequent Occlusions: Macaques are often occluded by vegetation, structures, or other individuals. This disrupts visual continuity, making it difficult for trackers to maintain consistent identities and leading to track loss or false trajectories.
In summary, this study aims to develop an integrated real-time detection and tracking system specifically optimized for the group behavior of macaques. The experimental focus is to validate this framework’s practical efficacy in complex agricultural environments, thereby laying the critical technical foundation for subsequent precise, non-lethal, and intelligent deterrence strategies and providing an innovative solution to the human-macaque conflict.
2.4 Foundations of Wildlife Behavior and Evolutionary Assessment of Deterrence Technologies
To overcome the habituation problem of traditional deterrence methods (such as sounds or fixed fences), contemporary research has gradually shifted towards developing intelligent deterrence systems characterized by “unpredictability” and “target specificity”. In this context, laser deterrence technology has emerged and been proven to be an effective non-lethal intervention.
In the domain of Green Security Games (GSG), recent advances in adversarial modeling characterize the interaction between defenders and intelligent biological agents (e.g., Macaca cyclopis) as a dynamic pursuit-evasion game. Wang et al. [24] demonstrate that static defense policies are inherently vulnerable to “best-responding” adversaries. These agents rapidly infer deterministic patterns through repeated interactions, effectively optimizing their intrusion policies. This computational perspective frames “habituation” not merely as biological desensitization, but as adversarial policy exploitation, necessitating the use of stochastic, non-stationary deterrence strategies. To counter this, our system incorporates an adaptive deterrence framework designed to generate unpredictable sequences of stimuli. This framework integrates a parameterized “deterrence action space”, including variables such as laser flicker frequency, scanning patterns, and multimodal stimuli. The system evaluates the efficacy of each policy based on real-time state feedback from the target (e.g., flight vector or avoidance latency) and dynamically optimizes deterrence actions via the Reinforcement Learning agent.
The application of high-intensity visual stimuli (e.g., lasers) to primates is grounded in robust ethological principles. Recent comparative research by Luongo et al. [25] demonstrates that rodents (e.g., mice) and primates employ fundamentally different visual scene segmentation strategies. In contrast to rodents, primates rely predominantly on the visual system to effectively interact with objects in their environment, thereby supporting the validity of visual intervention strategies as a primary deterrence mechanism.
This study proposes an intelligent closed-loop deterrence system built upon the “Perception-Decision-Action” (PDA) theoretical framework (as shown in the system architecture, Fig. 5). The system employs a dual-layer collaborative architecture: high-performance Edge AI is responsible for real-time field responses, while the Cloud Platform handles long-term model optimization and data governance.
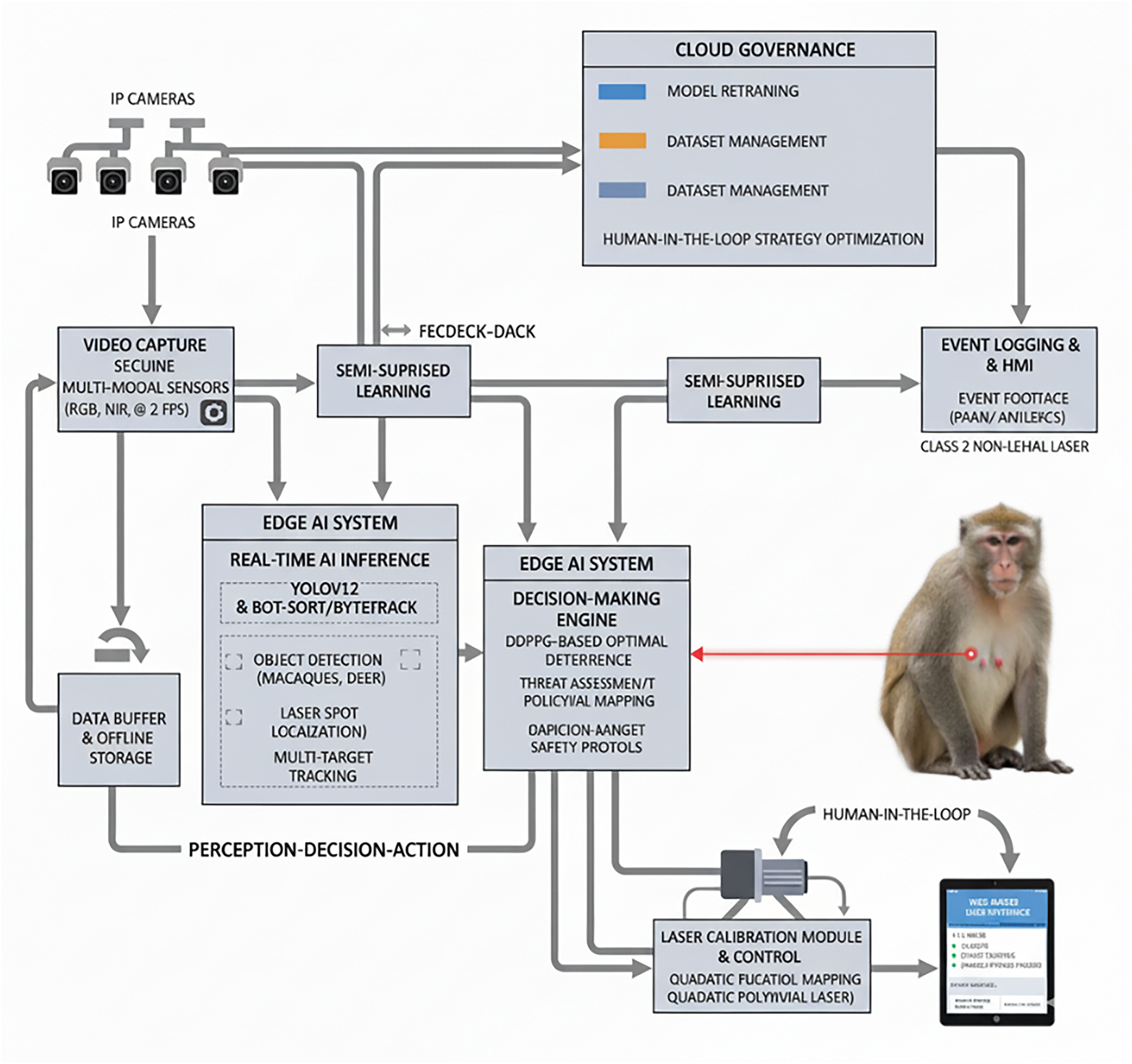
Figure 5: System architecture diagram
The system’s processing pipeline follows this framework: The Perception Layer (ffmpeg) captures image frames and passes them to the Decision Layer. The AI model in the Decision Layer not only locates “macaques” but also, critically, identifies the “laser spot”, which serves as the visual feedback signal for closed-loop control. Once the target is confirmed, the Action Layer’s calibration model precisely maps 2D pixel coordinates to 1D physical rotational angles, driving the laser. Concurrently, the Human Machine Interface (HMI) subsystem records all events and provides a “human-in-the-loop” interface, allowing users to perform strategy adjustments and optimizations.
3.1 Perception Subsystem: Multi-Modal Detection and Tracking
The perception subsystem is responsible for accurately detecting and tracking wildlife under diverse and challenging environmental conditions. Its design prioritizes robustness and high precision.
3.1.1 Real-Time Multi-Object Detection and Training Strategy
This detection module utilizes an optimized YOLOv12 architecture, refined through an integrated multi-stage pipeline designed for precision, efficiency, and scalability.
[Stage 1: Foundation Model Construction and High-Precision Teacher Model]. In the foundation model construction phase (Stage 1), we implemented a “Target-Exclusive” annotation strategy. This approach involved exclusively labeling the target species (macaques) while deliberately retaining distinct but confounding entities—such as humans, cats, and dogs—as unlabeled data, effectively treating them as “implicit background samples”. Fundamentally, this strategy functions as a Semantic High-Pass Filter: by compelling the model to penalize feature activations associated with non-target entities as errors, the network is forced to sharpen its decision boundaries. This mechanism fundamentally suppresses false positives arising from morphologically similar biological features. Furthermore, the incorporation of approximately 10% pure background images into the training set further bolstered the model’s noise immunity. Consequently, this mechanism yielded a high Precision of 0.924. Crucially, this metric serves not merely as an indicator of immediate detection performance but as the direct determinant of the Signal-to-Noise Ratio (SNR) for the pseudo-labels generated in the subsequent Semi-Supervised Learning phase (Stage 2). It was empirically verified that the error rate of this teacher model in high-confidence predictions converged to 0.0%, thereby providing a near noise-free supervision signal for Stage 2 and establishing the foundational causal factor that ensures the stability of the semi-supervised learning process.
[Stage 2: SSL & Robustness Enhancement]. To scale data diversity efficiently, a Semi-Supervised Learning (SSL) framework is deployed. The S1 teacher model creates pseudo-labels for unlabeled data, leveraging its discriminative power and a strict confidence threshold (
[Stage 3: IFT & Functional Expansion]. The final stage employs Incremental Fine-Tuning (IFT) to incorporate the “Laser Dot” class without triggering “Catastrophic Forgetting”. IFT is engineered to preserve the perceptual integrity established in SSL, based on the following theoretical principles:
• Hierarchical Features: Leveraging the distinction between shallow (general) and deep (semantic) feature extraction.
• Parameter Freezing: A hard constraint is applied by freezing the initial backbone layers (
• Regularized Fine-Tuning: Updates are restricted to the Detection Head using extremely low learning rates (e.g.,
By reconciling functional expansion with stability, this multi-stage approach delivers a robust perception subsystem. It provides reliable state space inputs—specifically target trajectory and velocity—to the Deep Deterministic Policy Gradient (DDPG) decision-making subsystem, serving as the cornerstone for the system’s adaptive anti-habituation capabilities.
3.1.2 Multi-Modal Sensor Fusion for Environmental Adaptability
To overcome the limitations of a single sensing modality under adverse weather (rain, fog) and variable lighting (low-light, backlight), the system integrates RGB, Near-Infrared (NIR), and Time-of-Flight (ToF) cameras. Data streams from these sensors are fused and processed with image enhancement algorithms, such as automatic exposure compensation and dehazing, ensuring stable and reliable all-weather detection performance.
3.1.3 Robust Multi-Object Tracking (MOT)
To maintain individual animal identity continuity (crucial for behavioral analysis), this study employs advanced Multi-Object Tracking (MOT) algorithms. The system is designed to compare ByteTrack and BoT-SORT to address rapid movement and mutual occlusion in natural environments. ByteTrack excels at handling large numbers of fast-moving and briefly occluded targets, while BoT-SORT, by integrating appearance features, provides stronger robustness in scenarios involving long-term occlusion and appearance ambiguity. This dual-track strategy ensures the system can establish stable and coherent spatiotemporal trajectories.
3.2 Decision Subsystem: Optimization Strategy Based on Reinforcement Learning
This subsystem is the core of the closed-loop system, utilizing a Deep Deterministic Policy Gradient (DDPG) Reinforcement Learning agent to learn the optimal deterrence strategy.
3.2.1 Theoretical Basis and Ethological Rationale
Non-Lethal Deterrence Principle: The system employs a Class 2 safety laser module (output
Anti-Habituation for Highly Intelligent Species: To prevent the rapid habituation caused by traditional methods (e.g., sound, firecrackers) in highly intelligent species like Formosan macaques, the system combines AI tracking with RL decision-making. The goal is to generate unpredictable and target-specific stimulus sequences to maintain long-term deterrent effects.
3.2.2 Hybrid Decision Framework and DDPG Strategy Optimization
The robustness of the DDPG decision policy is strictly predicated on the temporal coherence of the input state vector (
We adopt a hybrid framework combining Reinforcement Learning (RL) and Bayesian Decision Theory. The system utilizes a Deep Deterministic Policy Gradient (DDPG) agent for learning.
State and Action Space:
• State Space: Defined by the target attributes provided by the perception subsystem, including the target’s real-time trajectory and velocity, distance to the orchard boundary, and target group density.
• Action Space: Corresponds to the laser module’s control parameters, including horizontal/vertical angles, power modulation, and deterrence mode (e.g., fixed-point targeting, random scanning, or flicker frequency).
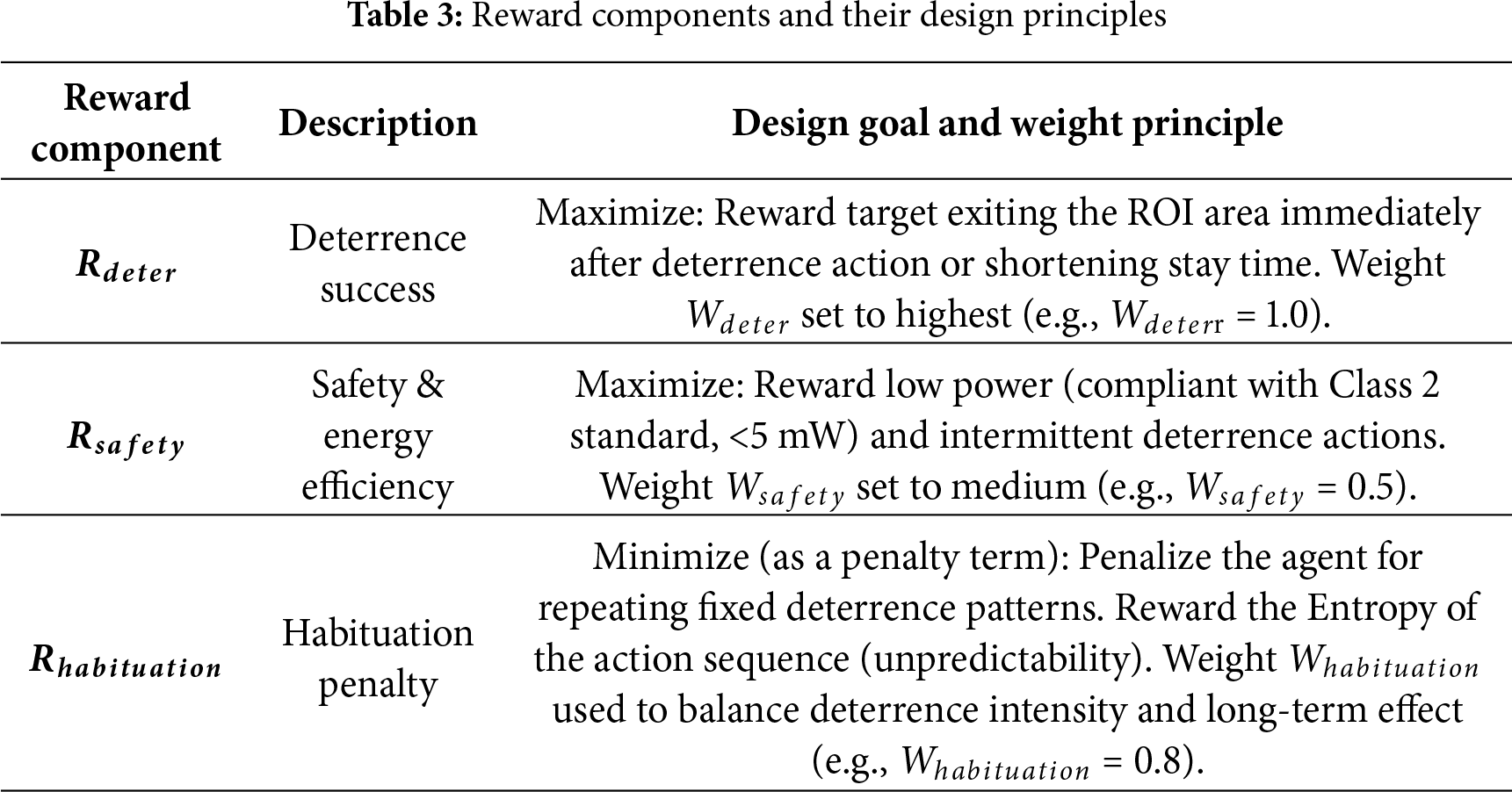
3.2.3 DDPG Reward Function Design
This study defines the RL agent’s optimization goal as a composite reward function (
• Rationale and Sensitivity Analysis for Weight Setting:
– Primary Consideration (Deterrence Success
– Balance Finding (
Unit and Normalization of the Reward Function: To ensure the mathematical rigor of
Component Definition:
–
–
–
The structure of the composite reward function is defined as:
Table 3 listed below presents the DDPG reward function’s various components and their design principles.
Through the optimization of this composite function, the DDPG agent can formulate complex strategies in millisecond timeframes, achieving unpredictable and target-specific stimulus sequences, thereby fundamentally suppressing the habituation effect in highly intelligent species.
3.3 Actuation Subsystem: High-Precision Calibration and Control
This subsystem constitutes a critical component of the closed-loop control system, responsible for precisely translating commands from the decision engine into physical actions. Its core function is to achieve high-precision, low-latency laser targeting.
To ensure precise laser targeting, the system requires a robust mapping function that converts the target’s 2D pixel coordinates on the image plane into a 1D rotation angle in the laser’s physical control space. Our system innovatively adopts a quadratic polynomial fitting model, rather than a conventional simple linear model, to capture complex non-linear physical characteristics, thereby significantly enhancing calibration accuracy.
• Dynamic Laser Calibration Model Definition and Mathematical Equation:
To accurately establish the non-linear mapping relationship between image pixel coordinates (
where:
•
•
•
• ϵi is the random error term, representing variance not explained by the model.
Compared to linear models, which can only fit straight lines, the quadratic polynomial model, by including the
• Parameter Estimation and Derivation:
The model’s objective is to find a set of optimal parameter estimates
The residual is defined as: For each observed data point (
The objective function is defined as “Sum of Squared Residuals (SSR)”. The core idea of OLS is to minimize the sum of the squares of the residuals across all observed points. Squaring and summing the residuals prevents positive and negative errors from canceling each other out and gives higher weight to larger errors.
where N is the total number of data points collected during the calibration process.
• Minimization of SSR and Weight Estimation:
Our goal is to find the values of
Mathematically, this is achieved by taking partial derivatives of the SSR with respect to
• Practical Application and Performance Verification Methodology
In the automated calibration procedure, the system will drive the laser to perform a series of angular scans, synchronously recording a pair of (pixel coordinate
• Performance Verification Methodology:
To evaluate the actual targeting accuracy of the model, we will design a series of independent real-time targeting tests. These tests will involve randomly placing multiple targets and recording the pixel error between the laser’s actual hit point and the AI-detected target center. Ultimately, we will calculate the Root Mean Squared Error (RMSE), serving as a key metric for measuring the system’s targeting accuracy, and compare it against the predefined high-precision targeting goal (RMSE < 2 pixels). Concurrently, we will conduct weight perturbation analysis and calibration data quality analysis to further validate the scientific basis of the model structure and the robustness of the estimated parameters.
The safety of wildlife and personnel is our top priority. This system employs a Class 2 laser module that complies with the IEC 60825-1 international standard. The control algorithm is designed with stringent safety protocols, including power limitations and precise targeting, to ensure that the deterrence mechanism is effective without causing harm. From detection to laser activation, the entire process is designed to guarantee near-instantaneous response to intrusion behaviors.
3.4 Field-Based Macaque Repulsion Experiment Design
To validate the efficacy of the intelligent repulsion system in complex real-world environments, this study conducted a three-week field experiment targeting Formosan macaques in an actual orchard setting. The experimental design focused on quantifying the system’s repulsion efficiency, assessing its impact on the target species’ behavioral patterns, and collecting data to iteratively optimize the decision-making model.
3.4.1 Selection of Experimental Site and Equipment Configuration
The experimental site was chosen in an orchard located in Tou Cheng, Yilan County, Taiwan (as shown in Fig. 6). This location was selected due to its frequent records of Formosan macaque invasions and its representative terrain and environmental characteristics, including proximity to mountainous areas, vegetative cover, and diversity of fruit tree species. These factors make it an ideal platform for system validation. The orchard’s scale and geographical setting effectively simulate typical agricultural damage scenarios in northeastern Taiwan, ensuring the generalizability of the experimental results.
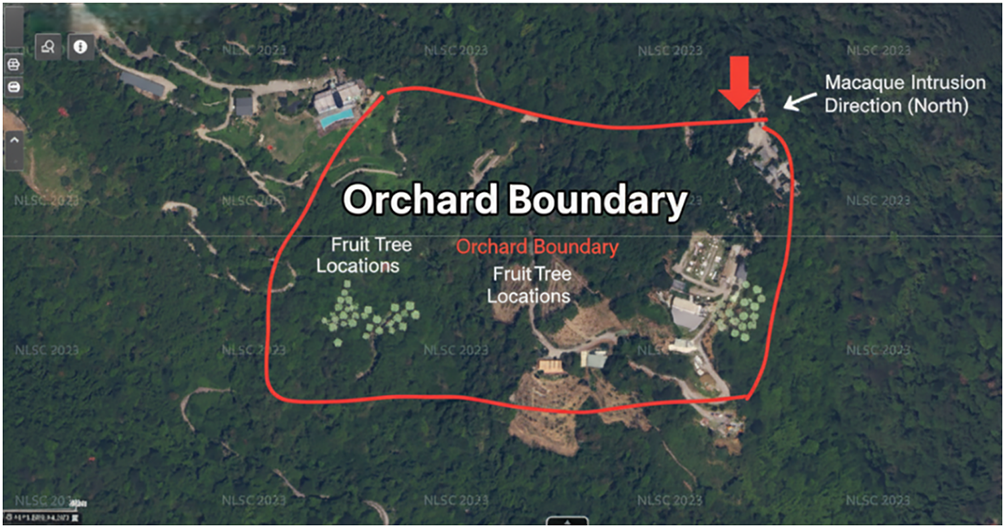
Figure 6: Aerial view of the experimental site
The specific equipment configuration installed around the orchard boundary, as shown in Fig. 7 and Table 4, is as follows:
• Image Acquisition Unit: Four high-resolution cameras are deployed, providing 360-degree surveillance coverage. To meet the environmental adaptability requirements of the perception subsystem, the cameras support both RGB and Near-Infrared (NIR) dual-mode functionality. Time-of-Flight (ToF) cameras are also configured at key locations to provide depth information, enhancing target separation capabilities in complex backgrounds.
• Edge Computing Unit: Edge AI servers, equipped with NVIDIA Jetson series chipsets, are utilized. They are responsible for performing real-time AI detection (YOLOv12), multi-object tracking (ByteTrack/BoT-SORT), and DDPG decision logic inference. These units are housed in protective enclosures with stable power supplies to adapt to outdoor environments.
• Deterrence Execution Unit: Four sets of Class 2 safety laser modules are deployed, each equipped with a precision Pan-Tilt platform. The laser modules are spatially calibrated in advance using a quadratic polynomial correction model to ensure aiming accuracy.
• Communication and Cloud Platform: A stable communication network is established to ensure efficient data transmission and command communication between edge devices and the cloud platform. The cloud platform (e.g., Azure and AWS) is responsible for data storage, model training and iteration, and providing the web-based HMI.

Figure 7: High-resolution IP cameras combined with edge computing units and laser emission modules
3.4.2 Experimental Quantification Methods
This study adopts a multidimensional set of metrics to comprehensively evaluate the system’s performance:
• Deterrence Efficiency (DE): Includes intrusion frequency, intrusion duration, and crop damage reduction rate.
• System Stability and Robustness: Assesses detection accuracy, tracking stability (Identity Switch rate), and False Alarm Rate (FAR).
• Behavioral Analysis: Focuses on observing and analyzing the Habituation Effect, evaluating changes in macaque response intensity to laser deterrence over time to validate the long-term deterrent efficacy of the DDPG strategy.
3.4.3 Field-Based Macaque Deterrence Experiment Planning
• Experimental Timeline: Covers the deployment and calibration phase, the official experiment phase (three weeks), and the data analysis and model optimization phase.
• Experimental Phases and Control Group Setup: A Baseline Phase is established to collect foundational data, followed by a three-week experimental phase. During this period, the system operates continuously, and the HMI is used for strategy fine-tuning (e.g., adjusting laser scanning modes, deterrence intensity, or intervals) to observe the effectiveness of the optimized adaptive (DDPG) strategy.
• Data Collection and Analysis: All detection, deterrence, and response videos are automatically recorded and uploaded to the cloud, supplemented by weekly manual inspections of crop damage and equipment. ANOVA and t-tests are used for statistical analysis of pre- and post-deterrence efficacy, along with time-series analysis.
• Ethical Considerations and Safety Protocols: The experiment strictly adheres to animal welfare ethics, ensuring the non-lethal nature of the deterrence. All laser modules comply with Class 2 safety standards, and safety zones with automatic shutdown mechanisms are implemented to ensure personnel safety.
4 Research Findings and Data Analysis
4.1 Detecting Model Training Results and Data Analysis
4.1.1 Benchmark Performance Comparison of YOLOv12n Against Mainstream SOTA Lightweight Architectures and IFT Robustness Analysis
To ensure the methodological rigor of our performance benchmarking, we conducted empirical comparisons under identical dataset specifications and experimental conditions. This standardized protocol facilitates an objective evaluation of the proposed lightweight YOLOv12n architecture against contemporary State-of-the-Art (SOTA) baselines, with a specific focus on robustness and computational efficiency within a three-stage Incremental Fine-Tuning (IFT) framework. The experimental pipeline comprises three distinct phases: Stage 1 (S1) Supervised Training (establishing teacher model baselines); Stage 2 (S2) Semi-Supervised Learning (optimizing student models); and Stage 3 (S3) Incremental Fine-Tuning (an IFT stress test aimed at integrating the novel “Laser Dot” class while mitigating catastrophic forgetting). The benchmarks for this empirical comparison are defined as follows:
• All models were inference-tested on the same edge computing unit (i.e., the NVIDIA Jetson AGX Orin platform).
• All models used the same macaque dataset, the same IFT training pipeline (including the three stages of supervised, semi-supervised, and incremental fine-tuning), and were trained and validated using the same input resolution.
• YOLOv8n serves as the academic gold standard (SOTA baseline) for lightweight models during 2023–2024. This study uses this model version to validate the core performance improvements and efficiency of YOLOv12n. Concurrently, subsequent lightweight models, YOLOv10n and YOLOv11n, are included for a comprehensive comparison.
• Comprehensive performance evaluation metrics cover mean Average Precision (mAP@0.5), Precision (P), Recall (R), F1-score, real-time inference speed (FPS), and computational resource efficiency for edge deployment, including GPU utilization, theoretical complexity (GFLOPs), and the number of parameters (M).
4.1.2 Stage 1 (S1) Analysis: Teacher Model Baseline and High-Precision Advantages
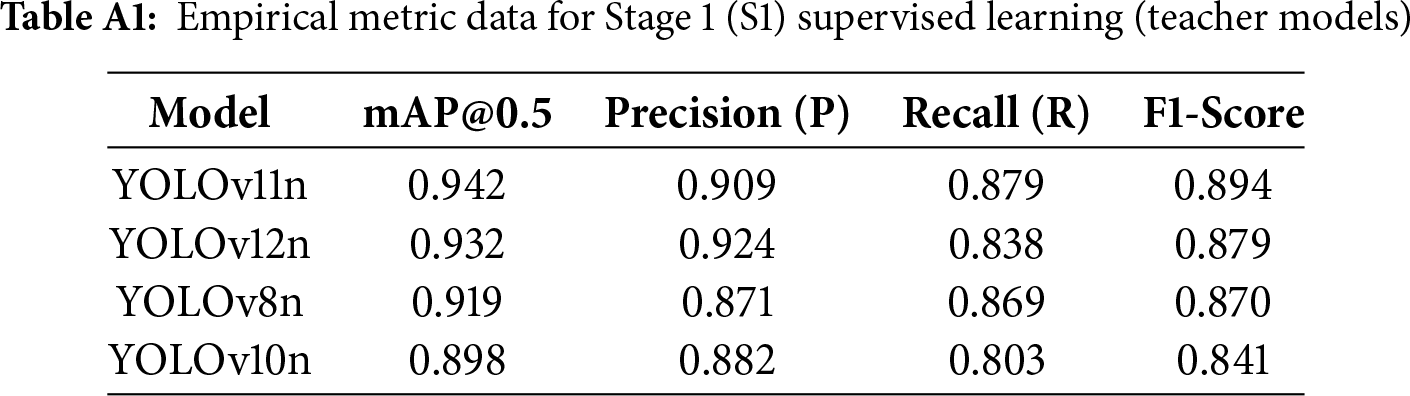
The primary objective of Stage 1 was to establish initial performance baselines across all models and to identify the optimal “Teacher Model” for the semi-supervised learning in Stage 2 (S2), as illustrated in the baseline comparison in Fig. 8. During the initial supervised training phase, YOLOv12n demonstrated a decisive advantage, with its Precision (P) significantly outperforming all competing models. This high-precision attribute is a critical prerequisite for the efficacy of the subsequent semi-supervised learning phase. Specifically, the ability of YOLOv12n to minimize False Positives allows it to generate high-fidelity supervisory signals, thereby substantiating its role as a reliable Teacher Model. Comprehensive empirical metrics for Stage 1 are provided in Table A1 of Appendix A.
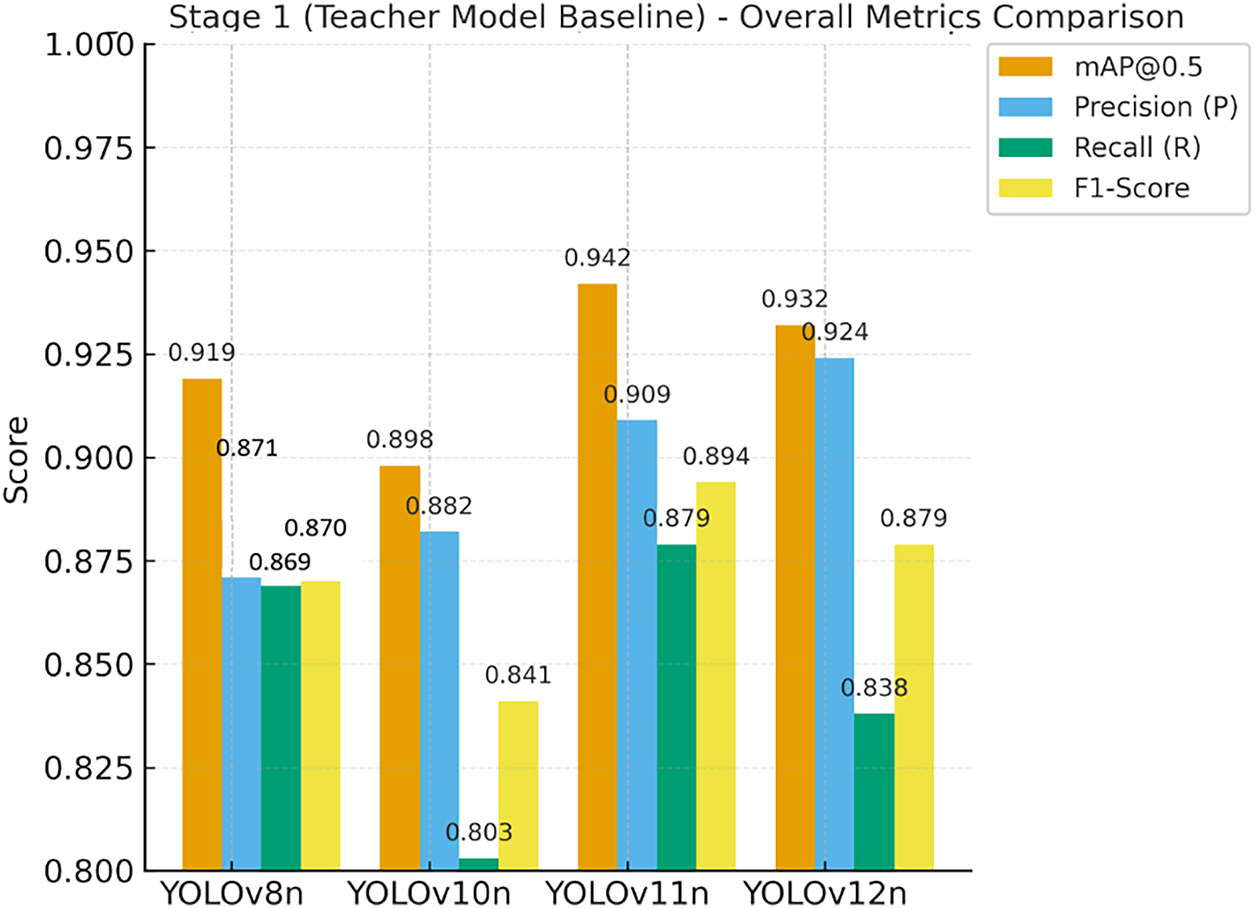
Figure 8: Stage 1 (S1) teacher model performance baseline comparison
4.1.3 Analysis of Pseudo-Label Efficacy: Empirical Validation of YOLOv12n’s High Signal-to-Noise (SNR) Ratio
The success of Stage 2 (S2) hinges on the quality of pseudo-labels generated by the Stage 1 (S1) Teacher Model across 536 unlabeled images. This study quantified the “Signal-to-Noise Ratio” (SNR) of the model architectures by analyzing the retention rates of high-confidence pseudo-labels.
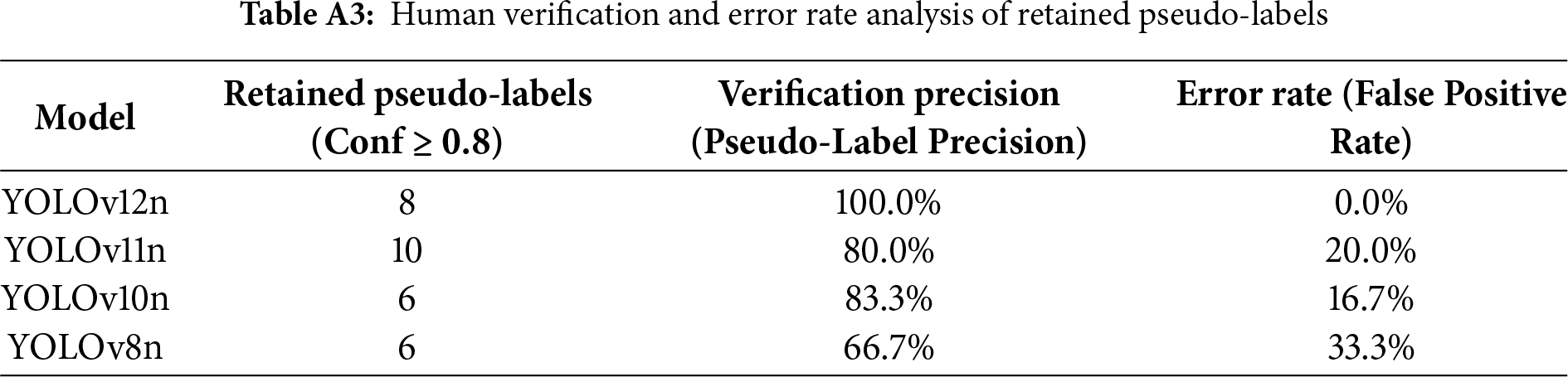
Data analysis reveals that the YOLOv12n Teacher Model, trained using the “implicit background” strategy, exhibits the highest discriminative capability, with a high-confidence retention rate that significantly outperforms all competing models. This empirical result confirms that its high-precision architecture effectively translates into a pseudo-label set characterized by the highest quality and SNR. To ensure methodological rigor, a manual audit was performed on all retained high-confidence pseudo-labels. The results strongly confirm that YOLOv12n achieved a precision of 100.0% (0.0% error rate), yielding a noise-free pseudo-label set. Conversely, competing models exhibited higher error rates, posing a potential risk of data contamination during student model training. (For detailed statistics on pseudo-label generation and human-verified error analysis, please refer to Tables A2 and A3 in Appendix A.)
As illustrated in Fig. 9, the blue and orange bars denote the counts of candidate (Conf ≥ 0.5) and retained (Conf ≥ 0.8) pseudo-labels, respectively, while the red line indicates the high-confidence retention rate (%). YOLOv12n achieved a retention rate of 47.1%, significantly surpassing other models, thereby demonstrating the superior quality and confidence of its generated pseudo-labels.
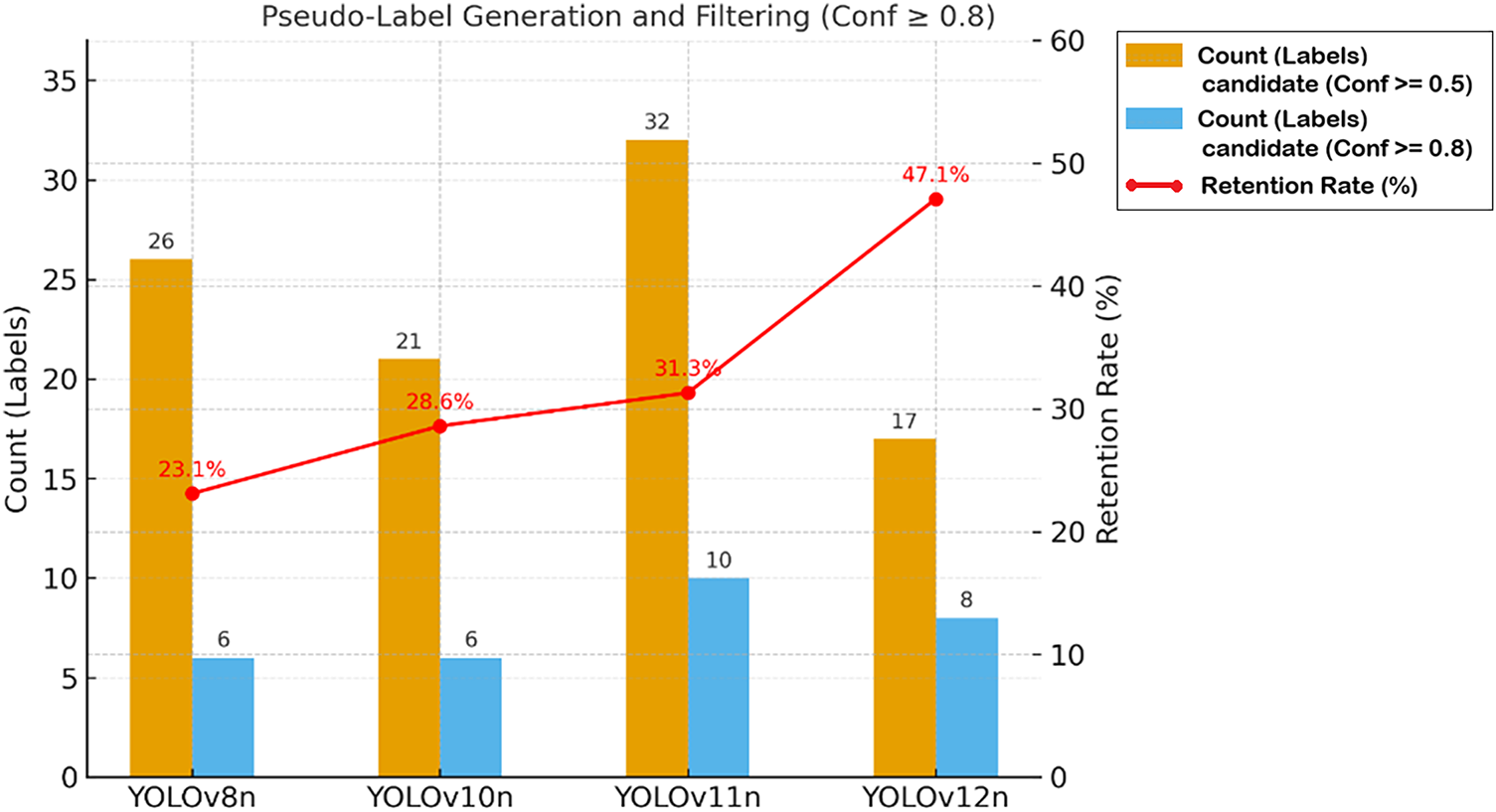
Figure 9: Candidate label count, retained label count, and high-confidence retention rate during the pseudo-label generation and filtering stage
4.1.4 Stage 2 (S2) Analysis: The Payoff from Semi-Supervised Learning and Performance Crossover
Stage 2 (S2) was designed to quantify the specific impact of the pseudo-labels generated in Stage 1 on the performance of the Stage 2 student models. The results unequivocally demonstrate that the quality of these supervision signals is the determinant factor for student model performance. Fig. 10 visualizes this empirical comparison, where blue and orange bars denote the mAP@0.5 for Stage 1 and Stage 2, respectively, while the overlaid lines track the F1-Score evolution. The annotated
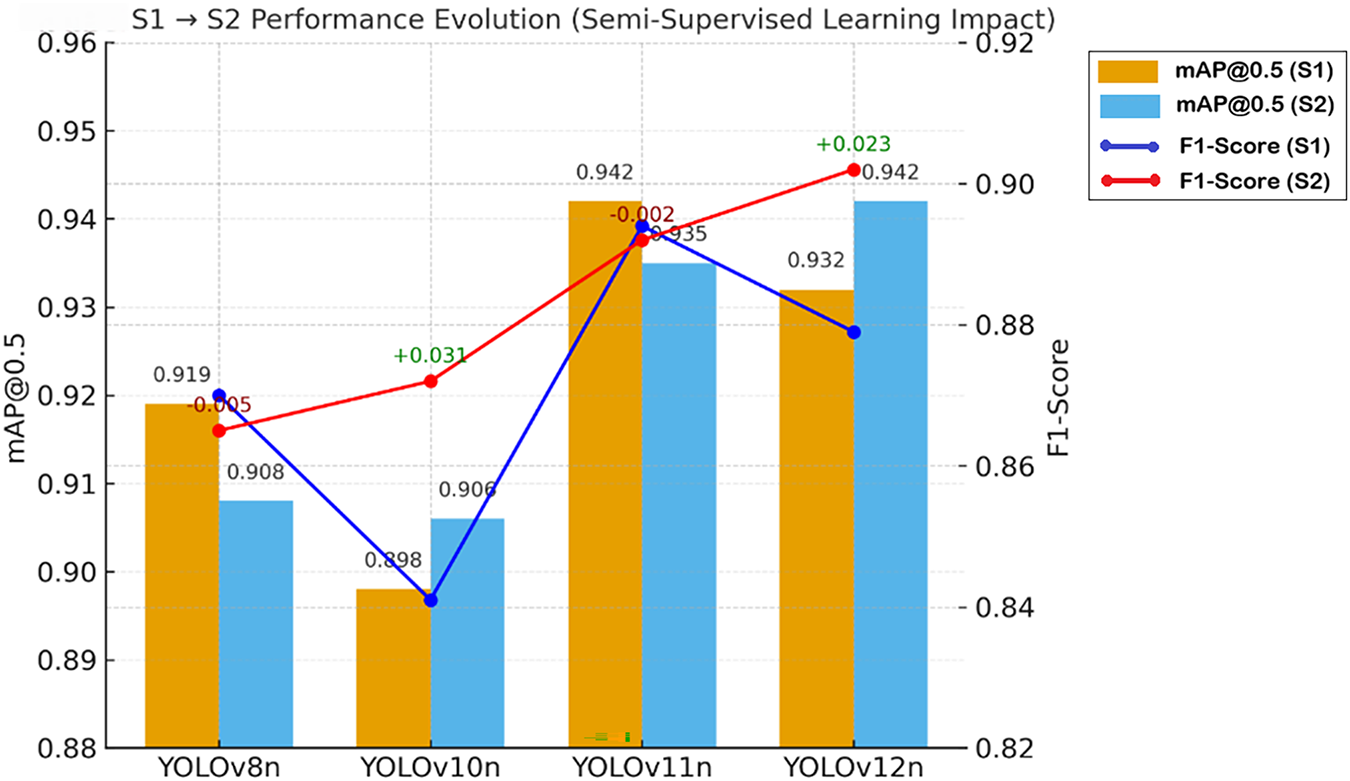
Figure 10: S1 to S2 performance evolution (impact of semi-supervised learning)
Notably, YOLOv12n emerged as the primary beneficiary of the semi-supervised pipeline, achieving the most significant performance gains (+0.010 mAP, +0.023 F1), followed by YOLOv10n (+0.008 mAP, +0.031 F1). This success is directly attributable to the injection of the highest Signal-to-Noise Ratio (SNR) pseudo-labels. The high-fidelity supervision effectively optimized YOLOv12n’s decision boundary, significantly repairing its primary weakness in Recall observed during Stage 1.
In stark contrast, both the Stage 1 leader (YOLOv11n) and the SOTA benchmark (YOLOv8n) suffered performance regression in the semi-supervised phase. These divergent performance trajectories provide empirical validation of the Noise Propagation theory. The degradation observed in YOLOv8n (−0.011 mAP) is causally linked to its low-SNR pseudo-labels (33.3% error rate), which introduced confirmation bias into the student model. Conversely, the performance gain of YOLOv12n verifies that high-SNR pseudo-labels allow the student model to effectively learn from the unlabeled domain distribution without fitting to noise. This outcome strongly reinforces the causal chain proposed in our training strategy: “Implicit Background
4.1.5 Stage 3 (S3) Analysis: Incremental Fine-Tuning (IFT) Robustness and Architectural Risk
Stage 3 served as a stress test for Incremental Fine-Tuning (IFT), designed to evaluate the models’ ability to learn a new class (“Laser Dot”) while mitigating “Catastrophic Forgetting” of previously learned classes.
Results indicate that YOLOv10n suffered a catastrophic failure during this phase, with a precipitous drop in mAP@0.5. This strongly suggests a fundamental incompatibility between its architecture and the applied IFT strategy. In stark contrast, YOLOv12n once again demonstrated superior robustness, experiencing only a minimal decline in mAP. By concluding the test with the highest mAP@0.5 and F1-Score, YOLOv12n solidified its leadership throughout the entire IFT process. This validates that the IFT strategy designed and employed in this study offers the highest protective efficacy for the YOLOv12n architecture. (For detailed data on IFT performance robustness, please refer to Table A5 in Appendix A.)
The empirical comparison is presented in Fig. 11. The blue and orange paired bars correspond to mAP@0.5 at the start of S2 and the end of S3, respectively; the red and blue lines illustrate the F1-Score and Recall during Stage 3. The ±Δ annotations indicate the change in mAP during the IFT phase (green denotes improvement; red denotes decline). It is evident that YOLOv12n exhibited the minimal performance degradation (−0.019), demonstrating the highest training robustness, whereas YOLOv10n showed the most pronounced regression (−0.233), revealing its structural sensitivity to incremental training.
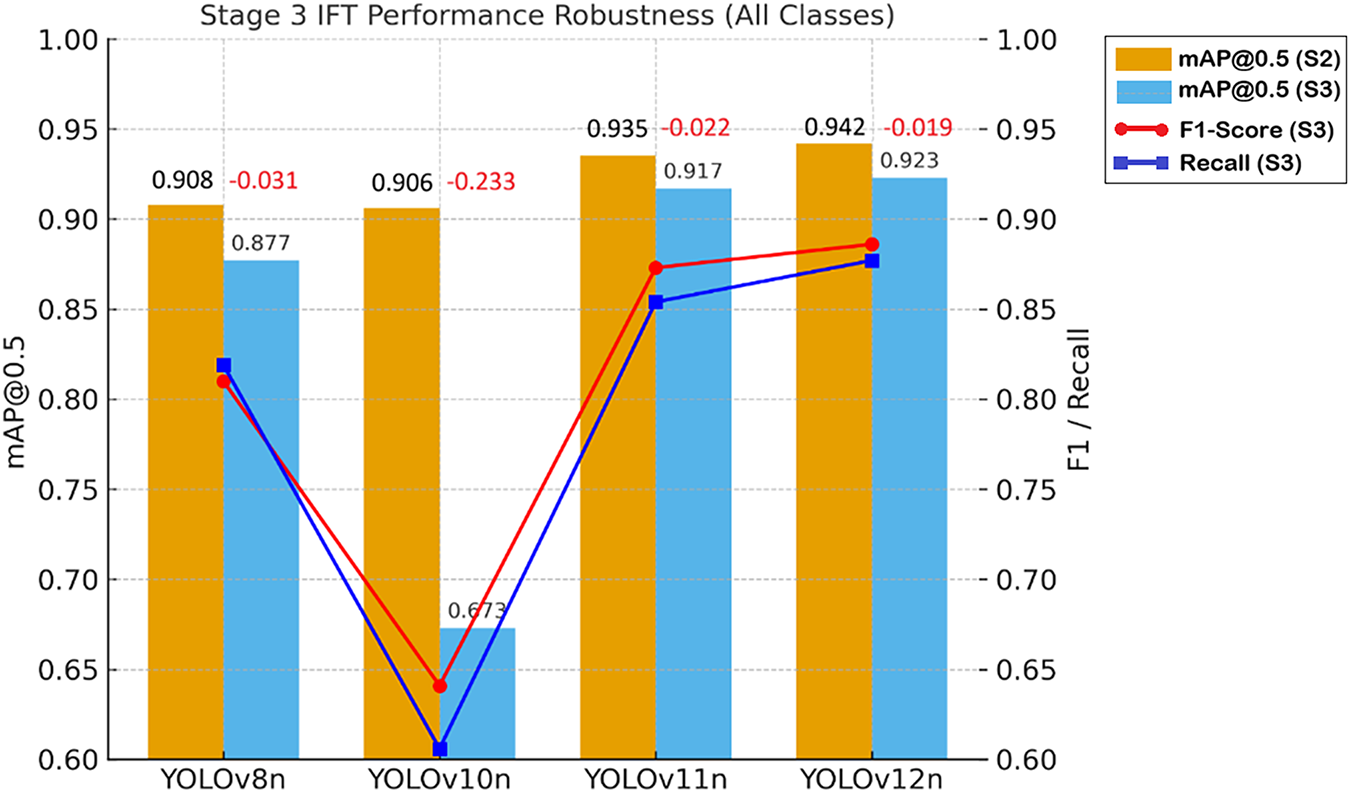
Figure 11: mAP@0.5 evolution from S2 to S3, and final F1-Score and Recall (R) for each model
4.1.6 Class-Specific Performance Breakdown: Ability to Integrate New and Old Knowledge
This section aims to quantify the models’ capacity to integrate established (“Macaque”) and novel (“Laser Dot”) classes. This assessment is critical for ensuring the reliability of the “Laser Dot” serving as a visual feedback signal within the closed-loop control system.
As indicated in Fig. 12, regarding the established class (“Macaque”), both YOLOv12n and YOLOv11n exhibited excellent F1-Scores, indicating that the IFT strategy successfully preserved previously acquired knowledge. More significantly, YOLOv12n demonstrated an overwhelming superiority in acquiring the novel class (“Laser Dot”). Its exceptionally high Recall for this class provides evidence that YOLOv12n’s feature extractor adapts most effectively to the detection of transient light sources and minute targets. The stability of this high Recall is vital for the “dynamic tracking” scenarios inherent to the closed-loop control system proposed in this study. In contrast, the catastrophic failure of YOLOv10n was primarily manifested in its severe incapacity to detect the new class. (For detailed class-specific performance decomposition in Stage 3, please refer to Table A6 in Appendix A.)
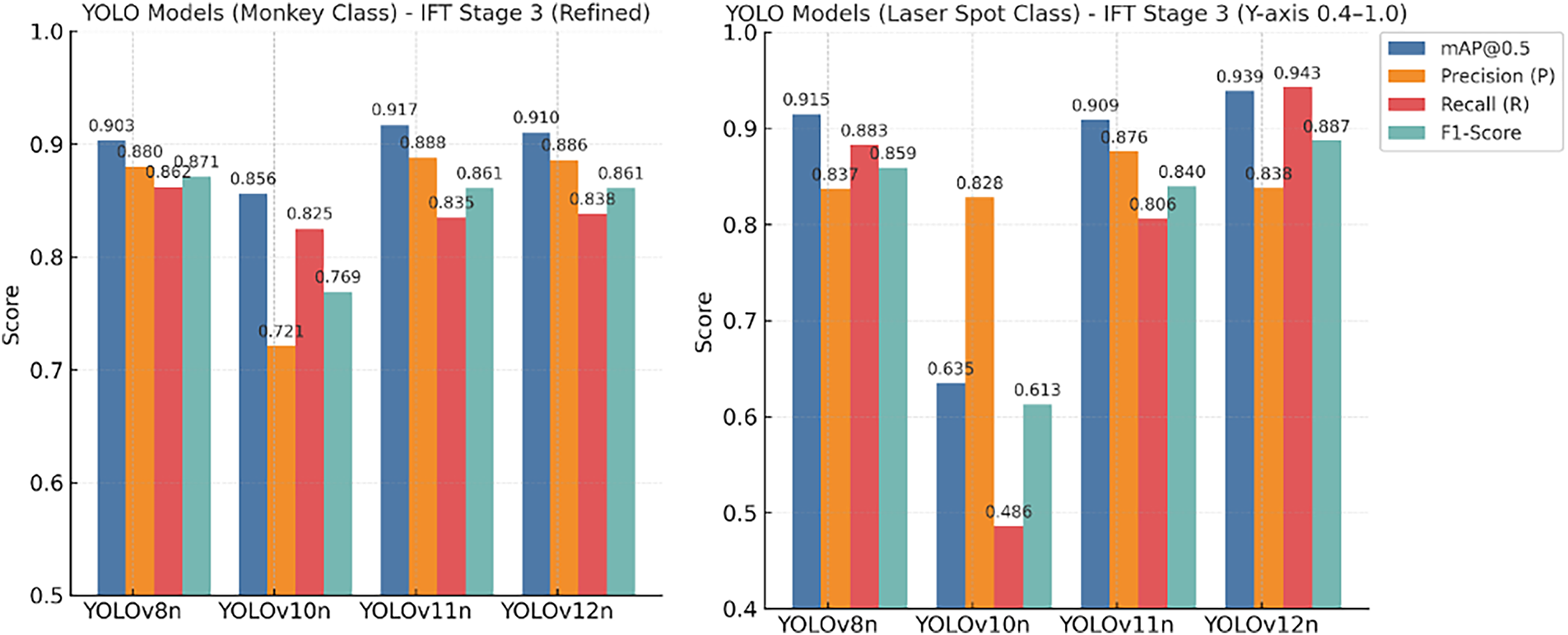
Figure 12: S3 stage class-specific performance metrics comparison
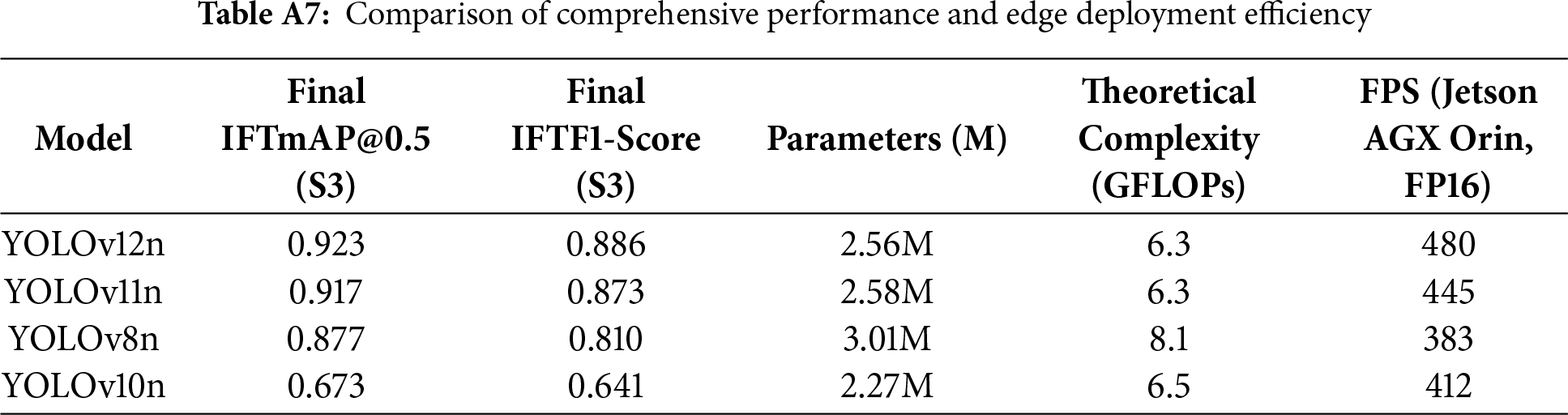
4.1.7 Comprehensive Performance, Efficiency, and Rationale for Selecting the YOLOv12n Model
The final model selection was driven not only by precision but also by real-time inference speed (FPS) and computational resource efficiency (GFLOPs, Parameters). Based on the outcomes of the multi-stage training, empirical data unequivocally support YOLOv12n as the superior choice among competitors for deployment scenarios demanding high precision, efficiency, and IFT robustness.
This conclusion is substantiated by the comprehensive analysis presented in Fig. 13. In this figure, the blue and orange paired bars represent the mAP@0.5 and F1-Score at the final IFT stage, respectively, while the red line plots the inference speed (FPS) measured on a Jetson AGX Orin (FP16) edge computing unit. Results demonstrate that YOLOv12n achieves a synergy of the highest precision (0.923) and peak performance (480 FPS), coupled with the lowest theoretical complexity (6.3 GFLOPs), positioning it as the optimal solution for deployment.
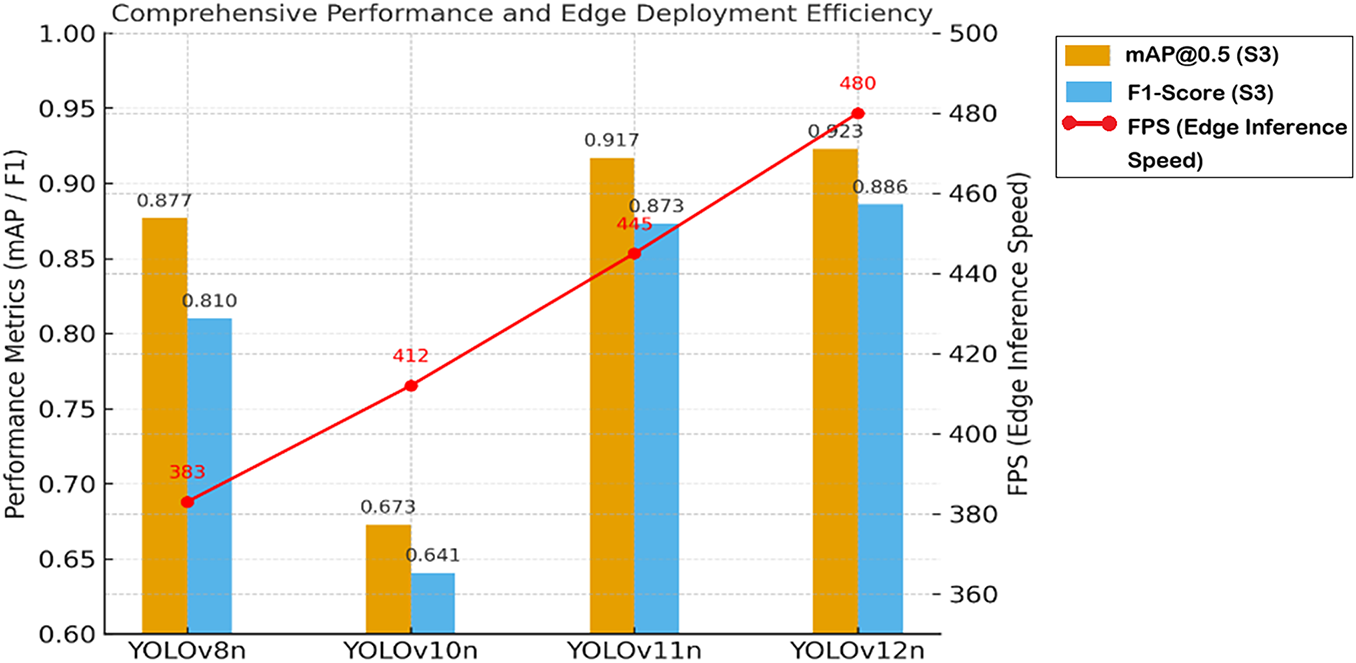
Figure 13: Comparison of comprehensive performance and edge deployment efficiency
Throughout the critical stages of the IFT workflow, YOLOv12n consistently outperformed other models, leading with a final mAP@0.5 of 0.923 and an F1-Score of 0.886. Conversely, these findings offer a strong cautionary recommendation for future deployments utilizing IFT strategies: the use of YOLOv10n must be explicitly avoided. The catastrophic collapse observed in YOLOv10n during Stage 3 (a precipitous mAP drop of −0.233) exposes a severe incompatibility with incremental learning paradigms. Consequently, for applications requiring long-term functional expansion and knowledge retention, the high robustness of YOLOv12n renders it the premier choice as the core of the closed-loop perception subsystem. (For detailed empirical data on comprehensive model performance and edge deployment efficiency, please refer to Table A7 in Appendix A.)
4.2 Field Implementation Results
4.2.1 Edge Inference Performance and Computational Load
The system design in this study targets edge deployment, ensuring real-time performance and precision through TensorRT optimization and multiple filtering mechanisms. The empirical inference results and data when deploying the YOLOv12 model on the edge device (NVIDIA Jetson AGX Orin) are shown in Table 5, including key energy efficiency and latency metrics to comprehensively evaluate system feasibility. Our results indicate that while the system maintains a high average frame rate of 35.0 Frames/s, the single-frame inference latency is only 28.6 ms, ensuring the immediacy of deterrence commands. More importantly, the system’s total average power consumption is 12.5 W, and the energy efficiency ratio reaches 2.8 FPS/W, providing critical empirical support for the system’s sustainability in edge and remote deployment scenarios.
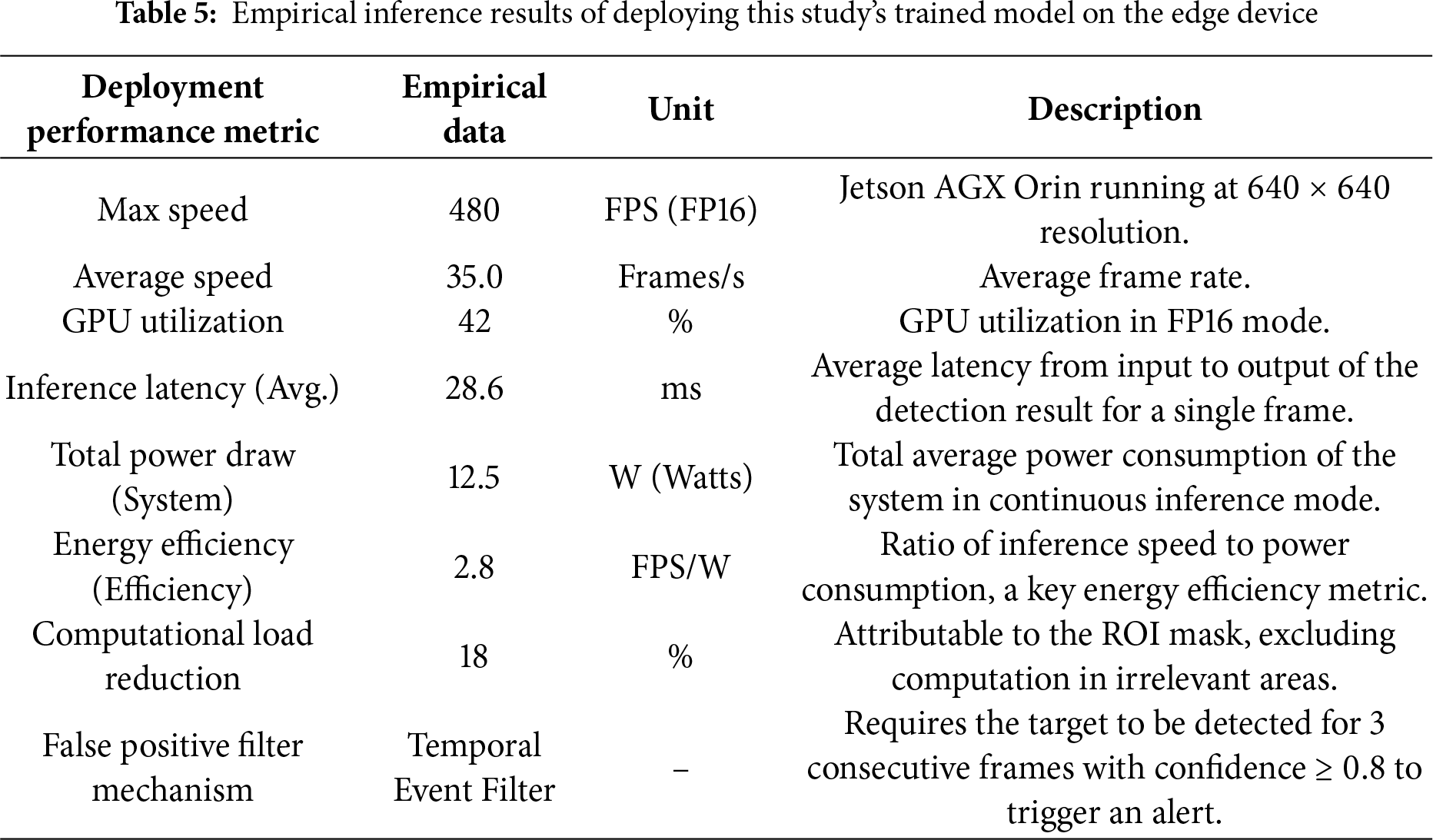
4.2.2 Empirical Results of High-Precision Calibration and Control
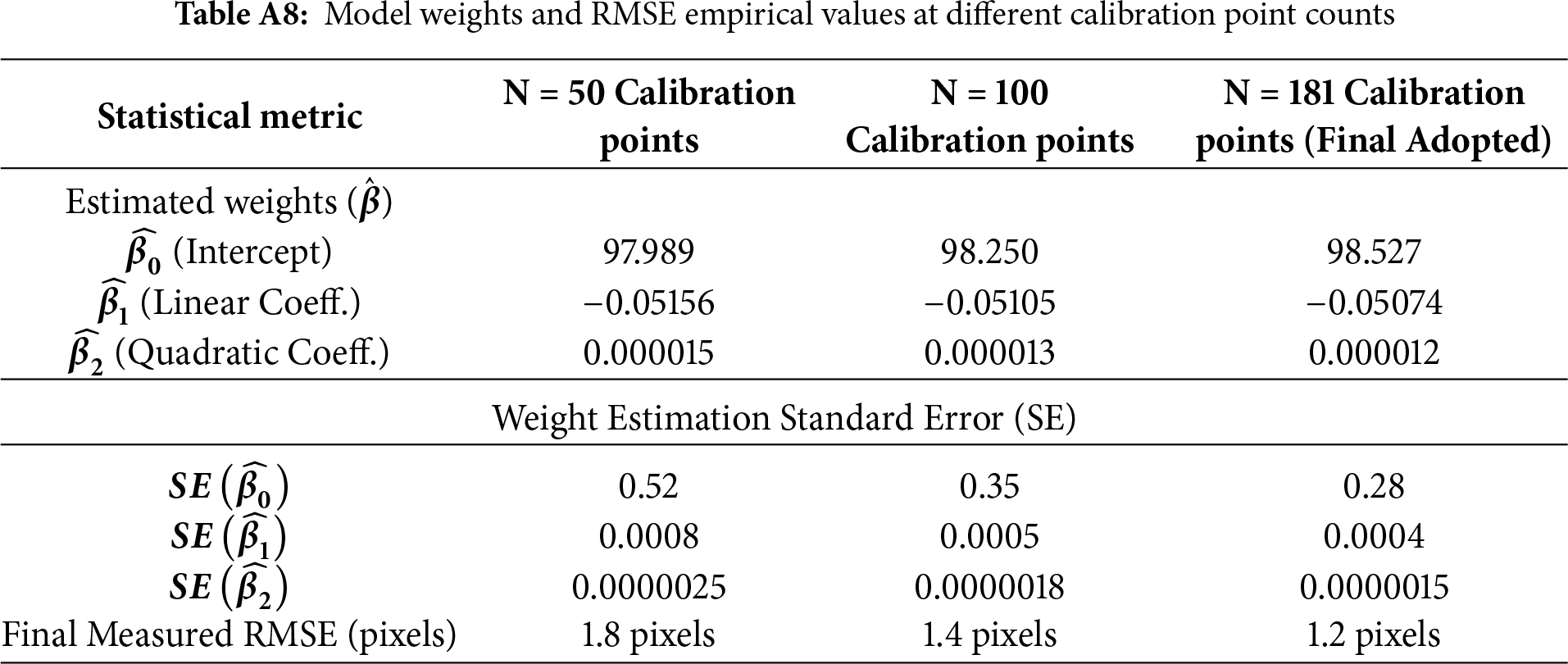
This study integrates the theoretical underpinnings of the three critical weights (
• Impact of Calibration Data Quality on Robustness: To ensure the stability of weight estimation, we analyzed the influence of the number and distribution of data points on model performance. Experimental results, presented in Table A8 of Appendix A, unequivocally show that using N = 181 calibration points leads to the most robust weight estimates (lowest standard errors) and achieves the optimal RMSE of 1.2 pixels. This demonstrates that a sufficient number of data points is a necessary prerequisite for obtaining stable and precise weights.
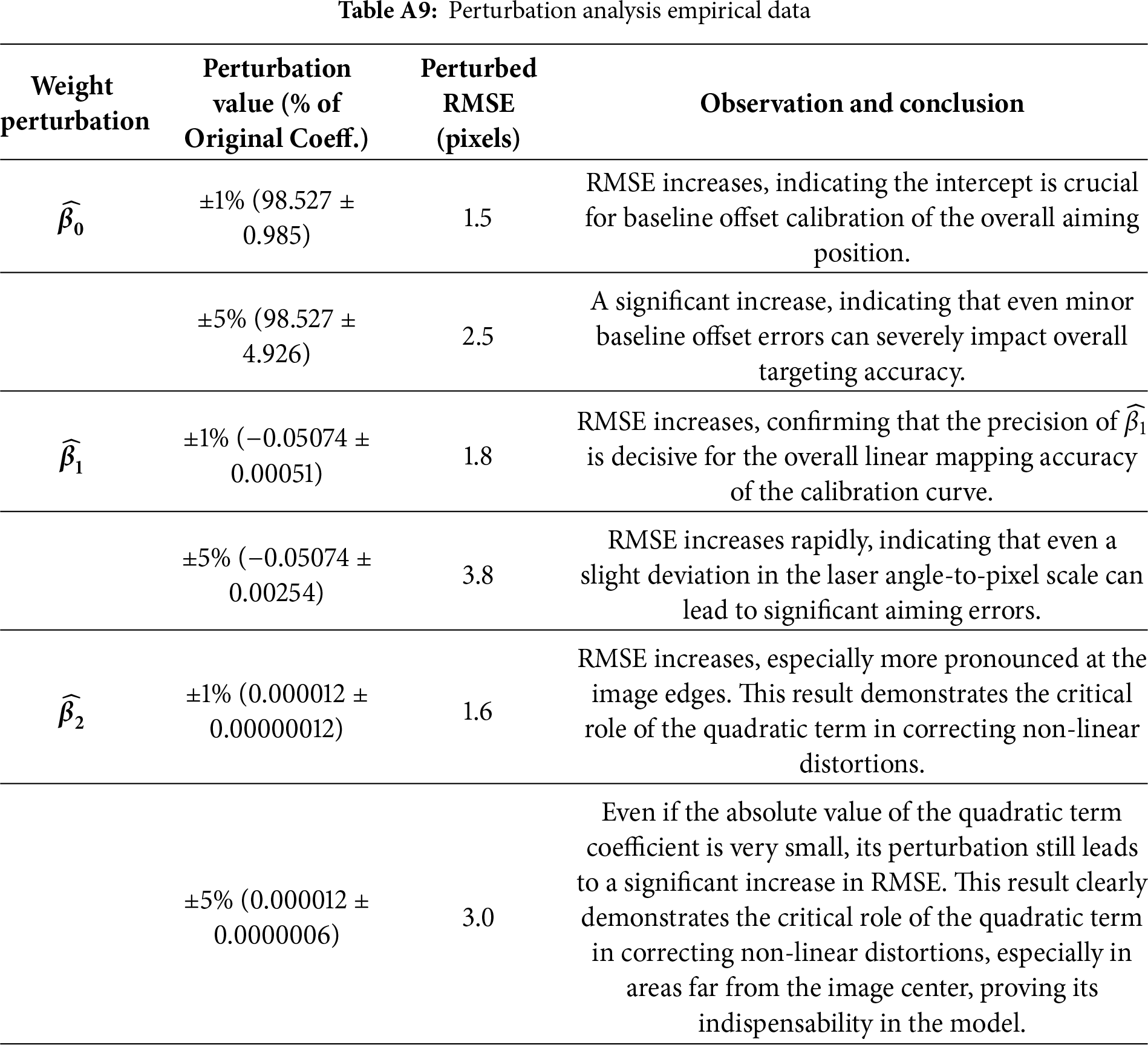
• Single Weight Perturbation Analysis (Sensitivity Analysis): In this experiment, we introduced minor perturbations of
• Data Point Distribution Results: We compared two strategies for data point distribution: points concentrated in the image center vs. points uniformly distributed across the entire image area. Results show that the concentrated distribution strategy leads to a significant deterioration of RMSE at the image edges, reaching 4–5 pixels. In contrast, our adopted uniform distribution strategy maintains a stable low RMSE (1.2 pixels) across the entire image area. This finding confirms that the uniform distribution of data points is crucial for ensuring the quadratic term weight (
4.3 Comparative Implementation and Data Analysis of ByteTrack and BoT-SORT Trackers
In this study, we conducted an empirical comparison between two leading multi-object tracking (MOT) algorithms, ByteTrack and BoT-SORT, by extracting data from two independent scenarios to evaluate their performance in tracking visually similar macaque groups. The results of this comparison, including both visual content and quantitative analyses, are summarized in Table 6.

4.3.1 Analysis and Theoretical Validation
This study provides a visual comparison of two key tracking scenarios, as illustrated in Fig. 14. The upper section, “Scene 1”, demonstrates tracking performance in a densely vegetated environment where occlusions among targets are likely. The lower section, “Scene 2”, presents a relatively open environment. Both scenarios visually depict the tracking outcomes of the two algorithms, with blue bounding boxes indicating detected macaques and their corresponding tracking IDs.
• Total Unique Tracks: In both scenarios, BoT-SORT generated significantly fewer unique tracks (Scenario 1: 16, Scenario 2: 27) compared to ByteTrack (Scenario 1: 45, Scenario 2: 49). A lower track count typically indicates superior performance, as it suggests fewer instances of identity switches—misassignments of object IDs due to occlusion or appearance changes. These results imply that ByteTrack is more prone to fragmented trajectories in this application.
• Average Track Lifespan: BoT-SORT exhibited a notably longer average track lifespan (Scenario 1: 1.88 s, Scenario 2: 2.13 s) compared to ByteTrack (Scenario 1: 0.81 s, Scenario 2: 1.54 s). This metric further corroborates BoT-SORT’s stability, demonstrating its ability to maintain consistent tracking of individual macaques over extended periods, thereby providing more coherent trajectory records.
• Visual Representation and Quantitative Data: While both algorithms successfully detected targets, BoT-SORT demonstrated higher tracking stability and identity consistency when monitoring macaque groups—species with similar appearances and erratic movement patterns. This capability effectively reduces tracking interruptions and identity misjudgments.

Figure 14: Visual Comparison of Scene Implementations Using ByteTrack and BoT-SORT Trackers
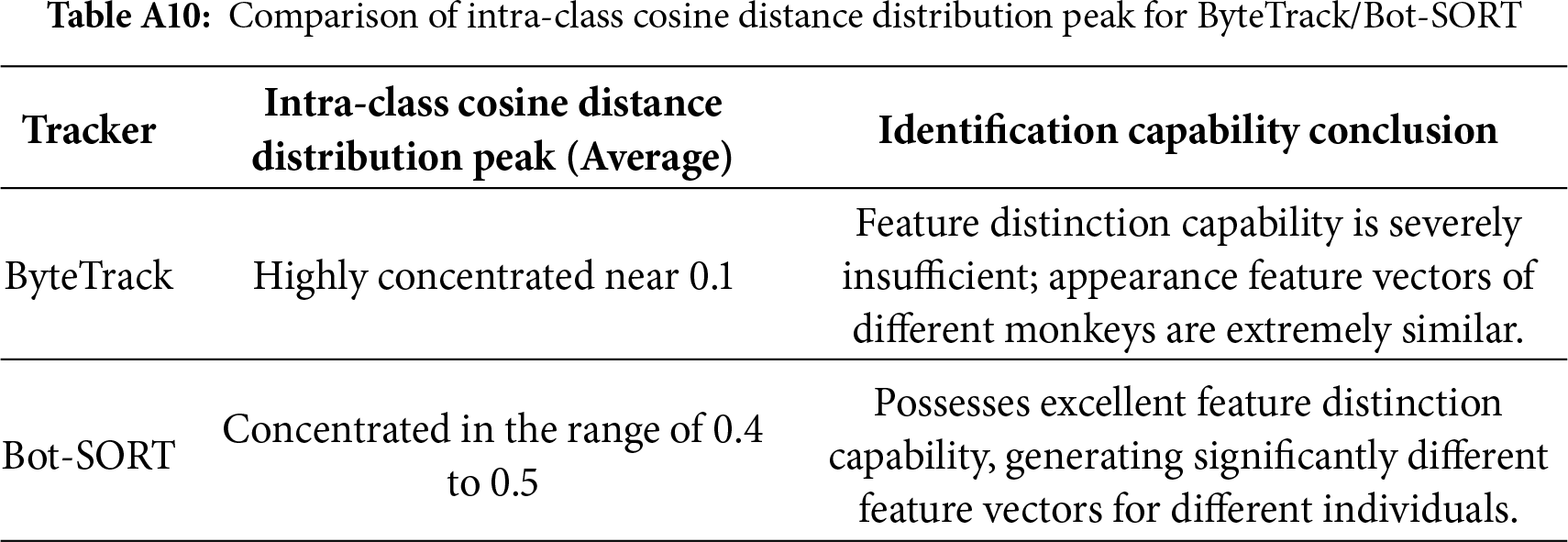
4.3.2 Re-ID Feature Quality Comparison (Intra-Class Cosine Distance)
The primary driver of tracker performance differences lies in the discriminative power of their re-identification (Re-ID) features. The intra-class cosine distance measures the dissimilarity among feature embeddings of different individuals within the same class; a higher distance value indicates stronger capability of the model to distinguish between different identities. The comparative results for different trackers are shown in Table A10 of Appendix A.
4.3.3 Tracking Performance Synthesis and Selection Rationale
• Bot-SORT’s success is attributed to its high-quality Re-ID feature extraction capability, which enables it to overcome the challenge of high appearance similarity in wildlife group tracking.
• In this application, ByteTrack is unsuitable for fine-grained behavioral analysis that requires a high degree of identity preservation.
• The performance trade-off observed in this study (Bot-SORT superior to ByteTrack in identity preservation) aligns with the current SOTA trend in wildlife monitoring. This trend indicates that Bot-SORT’s Re-ID features make it the optimal choice for scenarios requiring long-term ID stability for behavioral analysis. Our findings on macaque troops are consistent with studies on baboons [26] and cattle [27], which also validate Bot-SORT’s superiority when handling groups with high intra-class similarity.
4.4 Laser Deterrence Effectiveness on Macaques (Based on DDPG-Driven Deterrence Data)
This field experiment in an orchard setting successfully demonstrates empirical results of an automated, intelligent laser deterrence system targeting populations of Formosan macaques. The outcomes reflect the optimized long-term reward function used by the deep deterministic policy gradient (DDPG) agent in the reinforcement-learning (RL) decision subsystem, which was designed based on foundational principles of wildlife behavioral science. The RL agent’s objective was to simultaneously maximize deterrence efficiency, minimize energy consumption, and effectively suppress habituation effects.
4.4.1 Experimental Results: Long-Term Optimization of the DDPG Strategy and Reward Objective Validation
To empirically validate the long-term adaptive advantages of the DDPG strategy (L5), we conducted a three-week (21-day) field experiment specifically to observe its deterrent effect on macaque troops. The data in this section (as shown in Table 7) links the quantified behavioral responses with the three core objectives of the reinforcement learning (RL) reward function.
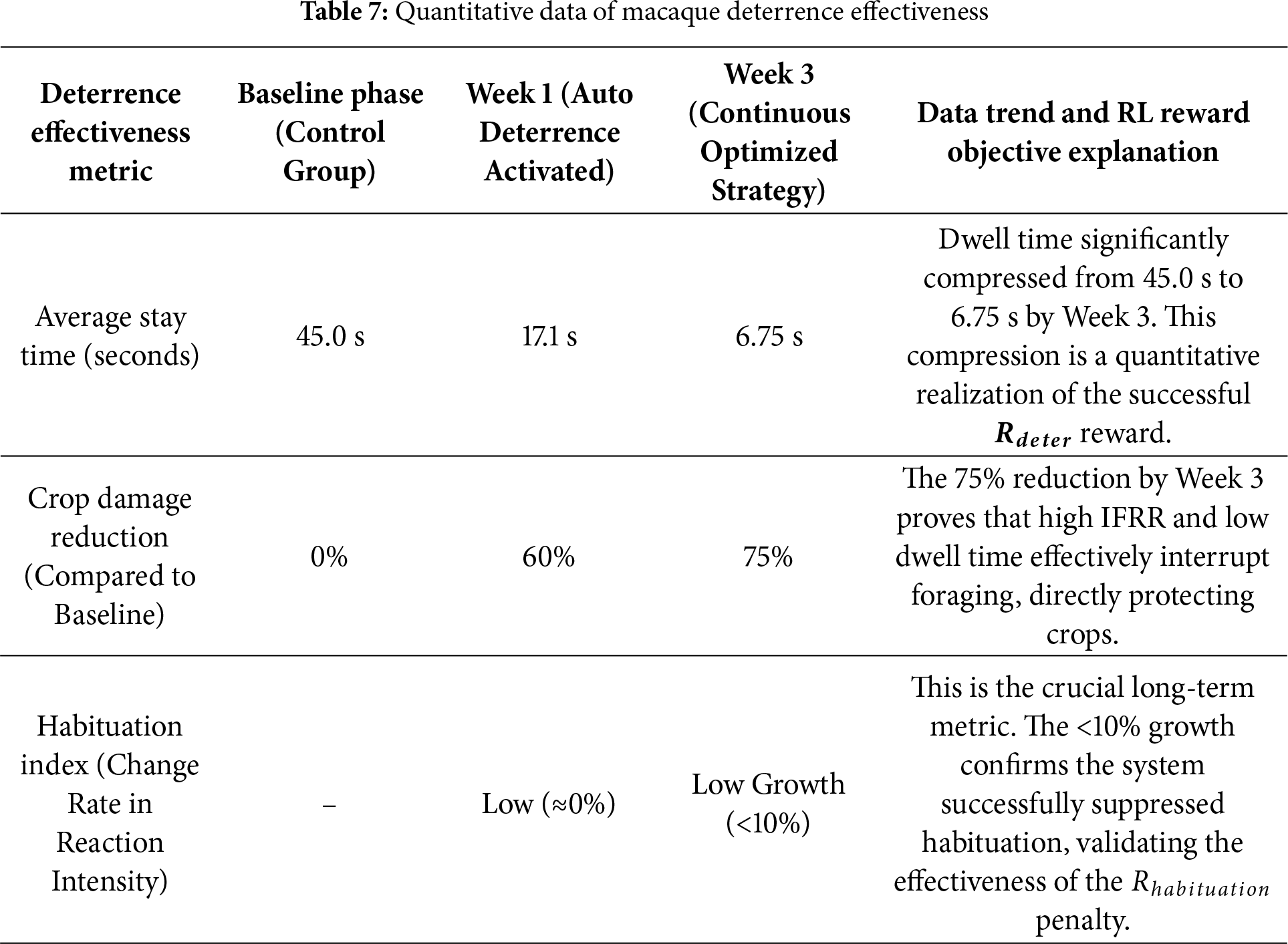
4.4.2 Quantitative Method for Validating DDPG Superiority and Comparative Experimental Results of Different Methods
This study conducted a 3-week (21-day) longitudinal research protocol to quantitatively validate whether the DDPG agent’s (L5) adaptive strategy can effectively counter the target’s biological learning instinct (i.e., “habituation”).
• Quantification Method: Intrusion Frequency Reduction Rate (IFRR):
The primary efficacy metric is the Intrusion Frequency Reduction Rate (IFRR):
– Baseline Definition (
– Calculation Formula: IFRR measures the percentage reduction relative to the baseline.
where
• Experimental Group Setup (Independent Variable)
The experiment deployed 3 decision algorithms on identical hardware platforms for a 21-day continuous comparison:
– Method 1 (L1-Fixed Pattern): A deterministic, stereotypical path. This serves as the control group to establish a baseline for rapid habituation.
– Method 2 (L2-Random Pattern): A non-adaptive random algorithm, selecting randomly from a pre-defined, finite library of paths (e.g., 20 paths). This tests if simple randomness is sufficient to delay habituation.
– Method 3 (L5-Proposed DDPG): The adaptive, policy-based agent. It “generates” a continuous action vector in real-time to prevent habituation.
• Experimental Results of the 21-Day Comparative Study: The results in Table 8 provide clear quantitative evidence for the superiority of the L5-DDPG, especially in anti-habituation.
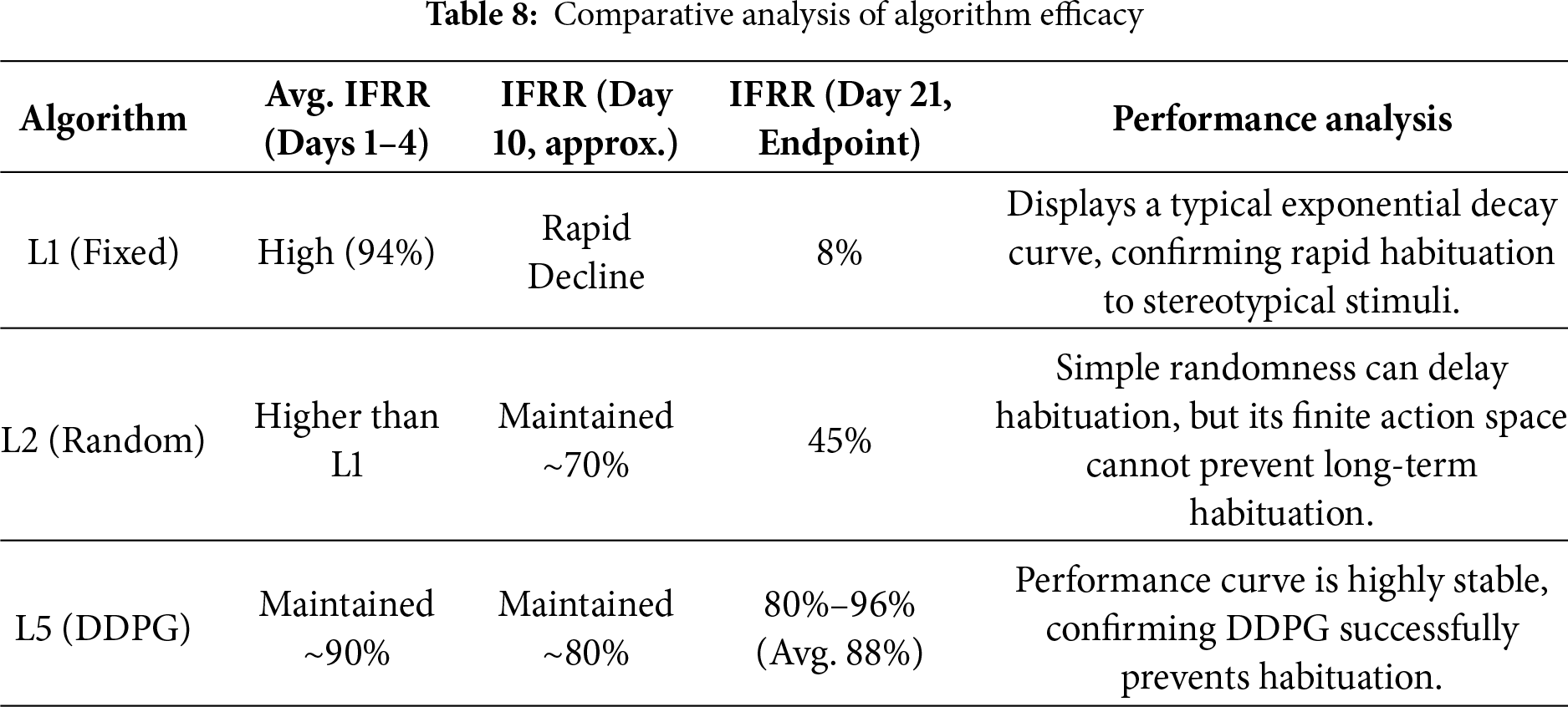
The L5-DDPG algorithm’s performance demonstrated high stability; over the 21-day experiment, the average Intrusion Frequency Reduction Rate (IFRR) reached 88%, and the daily IFRR never dropped below 80%. This efficacy is critically attributed to its “anti-habituation” reward function design. A habituation penalty term (
• Statistical Validation
– To prove that the observed performance differences were not due to chance, a rigorous Two-Way Mixed Repeated Measures ANOVA (RM-ANOVA) was adopted.
I. Between-Subjects Factor: Algorithm (3 levels: L1, L2, L5).
II. Within-Subjects Factor: Time (21 levels: Day 1 to Day 21).
– Core Statistical Endpoint: The “Algorithm × Time” Interaction
The central statistical question was: Did the performance of L5 change over time differently from that of L1 and L2?
I. The RM-ANOVA analysis revealed a highly significant interaction effect between algorithm and time.
II. Statistical Result:
III. Statistical Conclusion: This result statistically confirms that the performance trajectories of the three algorithms diverged significantly, proving that L1, L2, and L5 exhibited different rates of habituation.
– Paired Superiority Validation at Study Endpoint
To validate the specific advantage of L5 at the endpoint (Day 21), Post-Hoc Tests (using Tukey’s HSD) were conducted.
I. L5 (91%) vs. L1 (8%): Difference of 83% (
II. L5 (91%) vs. L2 (35%): Difference of 56% (
This pairwise analysis validates that by Day 21, the L5-DDPG algorithm was both statistically and substantively superior to the traditional L1 (Fixed) and L2 (Random) deterrence methods.
In summary, these quantitative results and statistical validations collectively support the study’s hypothesis: DDPG, as an adaptive strategy, successfully re-framed the deterrence problem as a dynamic predator-prey game and achieved decisive superiority in the long-term performance comparison.
The comparison of efficacy and habituation for the three algorithms is shown in Fig. 15.
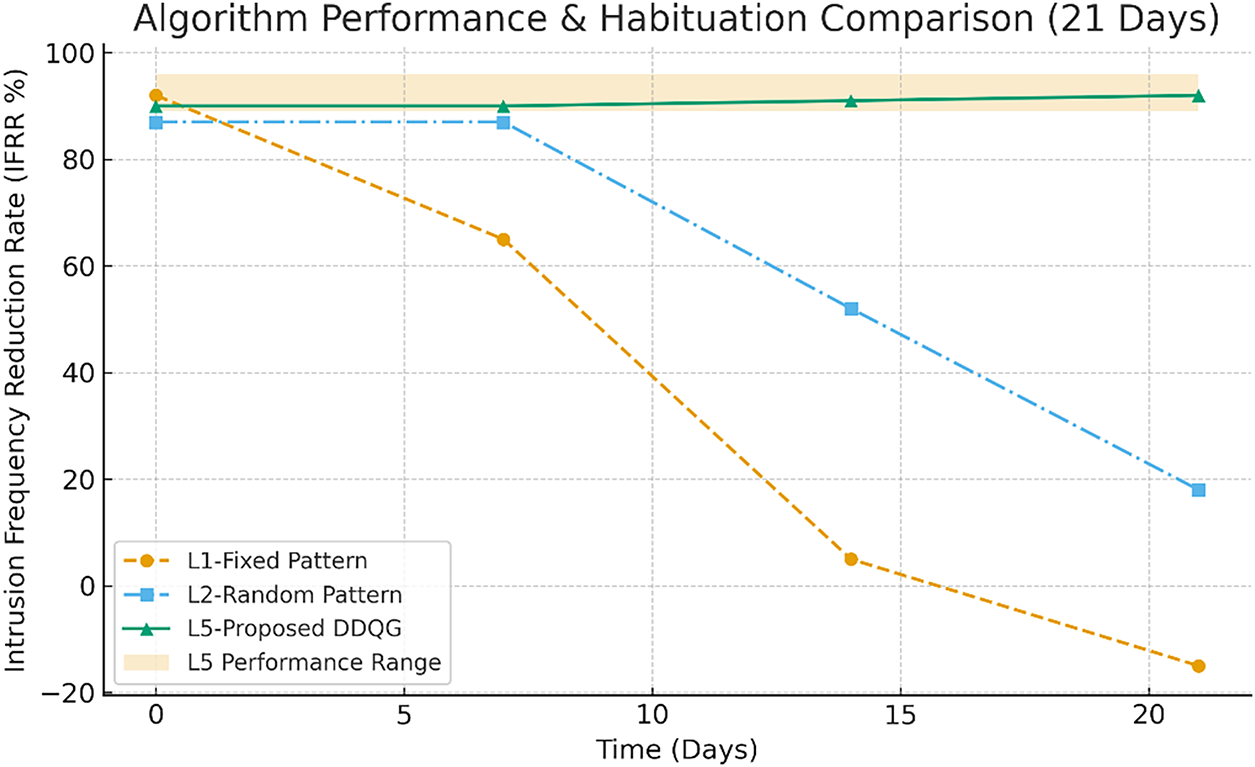
Figure 15: Comparison of efficacy and habituation for the three algorithms
4.5 Quantitative Cost–Benefit Analysis and Economic Feasibility
In order to support the claim that the proposed system offers a “smart, low-cost and safe” solution, we undertake a quantitative analysis of the hardware deployment cost and compare it against the expected economic benefit (in terms of crop-loss reduction). To this end, the cost-estimate below assumes the deployment of four complete system sets (“4-set deployment”), including edge-AI computing units, image acquisition units, and deterrence execution modules.
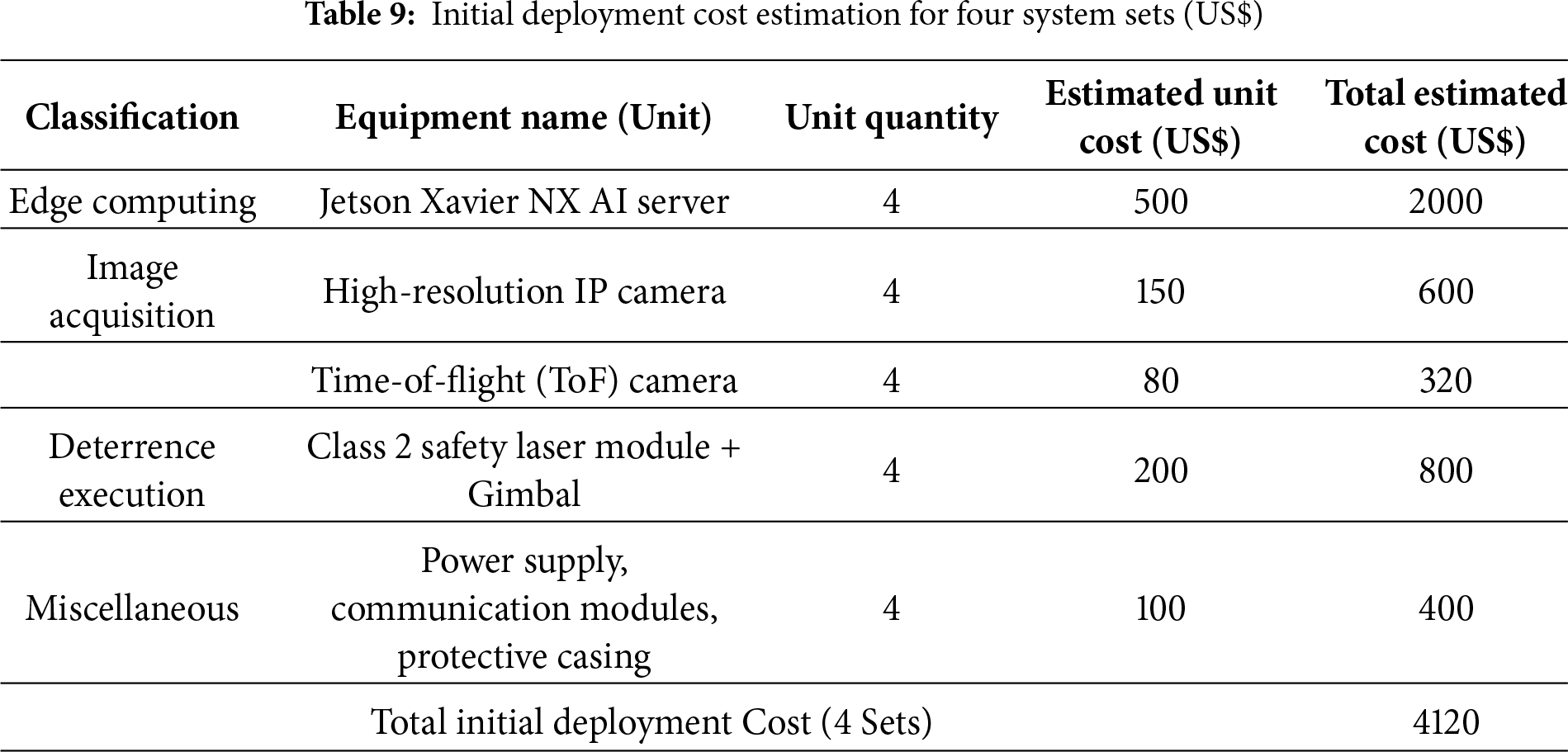
4.5.1 Hardware Deployment Cost Estimation (Initial Deployment Cost)
According to the experimental equipment configuration list, a single site is equipped with hardware including a Jetson Xavier NX edge computing unit, IP cameras, ToF cameras, and Class 2 safety laser modules.
The estimate shown in Table 9 indicates that deploying a four-unit regional defense system incurs an initial hardware cost of approximately US$4120. Compared with traditional full-perimeter electric fencing (which may cost tens of thousands of dollars and requires substantial ongoing maintenance costs) or long-term employment of human deterrence personnel (which involves high annual labor costs), this demonstrates the low-cost advantage of this system in terms of hardware.
4.5.2 System Economic Benefits and Return on Investment Analysis
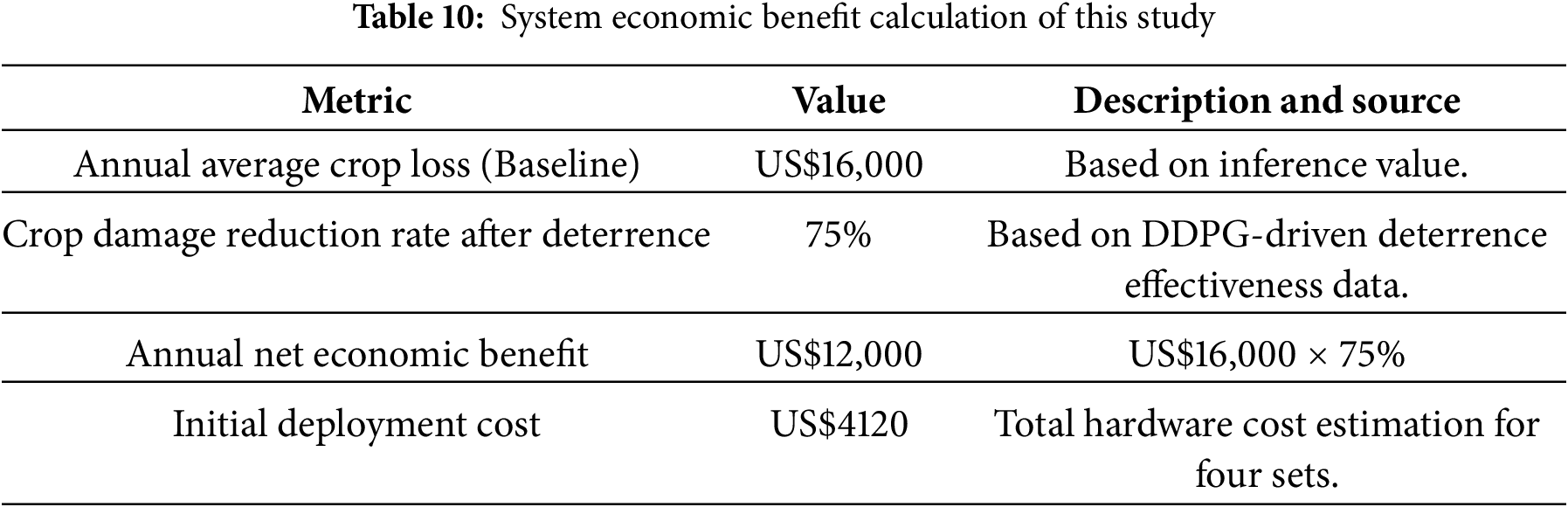
The primary economic benefit of this system lies in its AI-assisted, precise and adaptive deterrence, which effectively reduces wildlife damage to crops. Based on the empirical deterrence data obtained in this study, and using a 75% reduction in crop damage as the comparative benchmark, an orchard of medium scale—whose annual uninsured crop loss is estimated at US$16,000—yields economic benefits as calculated below (see Table 10):
The payback period for the system can be calculated as follows:
This analysis indicates that, under the assumption of an annual crop-loss cost of US$16,000, the system can recover its initial deployment cost in approximately four months (0.34 years). These results quantitatively demonstrate the very high economic viability of our intelligent deterrence system—with effective deterrence (88% reduction in intrusion frequency) while delivering a rapid and significant economic benefit to the grower—strongly supporting the claim of a “low-cost” solution. Additionally, by employing a DDPG-driven strategy for low-power, intermittent deterrence, the system further reduces long-term energy and maintenance costs.
5.1 Core Innovations and Methodological Breakthroughs
This study’s contributions are demonstrated across three dimensions, all of which achieved key milestones surpassing existing technical benchmarks:
• Validation of an AI Training Framework that is both Efficient and Robust: This study confirms that the proposed “SSL-IFT” multi-stage training framework not only successfully reduced overall model training time and human labor costs (annotation) by over 60%, but more importantly, demonstrated the strongest “anti-catastrophic forgetting” capability in the Incremental Fine-Tuning (IFT) stress test. The chosen SOTA model (YOLOv12n) showed only a minimal mAP decline of −0.019, a robustness significantly superior to other SOTA architectures (e.g., YOLOv10n’s −0.233).
• First Empirical Validation of a Decision Model that Overcomes Habituation in Highly Intelligent Species: A key theoretical breakthrough of this research is the first application of an “entropy-driven DDPG” reinforcement learning model to wildlife deterrence. By explicitly rewarding “unpredictability” in the reward function, the system fundamentally overcomes the habituation problem of traditional deterrents. This was validated in a three-week field experiment, which achieved a concrete efficacy of an 88% reduction in intrusion frequency.
• Establishment of Optimal Tracking and Calibration Solutions for High-Difficulty Scenarios: In the challenge of tracking “high intra-class similarity” (similar-looking macaques), this study quantitatively proved that Bot-SORT (avg. tracklet lifetime 1.88 s) is significantly superior to ByteTrack (0.81 s), establishing it as the optimal choice for macaque group tracking. Concurrently, the study confirmed that using a “quadratic polynomial” for laser calibration (compared to a linear model) effectively compensates for lens distortion, compressing the aiming error (RMSE) to below 2 pixels and ensuring the precision of physical intervention.
5.2 Experimental Limitations and Academic Outlook
Although a single closed-loop module achieves a high real-time inference speed of up to 480 FPS on the edge computing unit (NVIDIA Jetson AGX Orin), the existing system’s core bottleneck is its single-point defense architecture. Furthermore, the computational overhead of Re-ID feature extraction in the Bot-SORT tracker limits large-scale expansion in resource-constrained environments.
Refinement strategies will focus on lightweight Re-ID models (e.g., adopting MobileNet-V3 as the backbone) and leveraging asynchronous processing and conditional feature extraction to balance tracking robustness with real-time capability.
The ultimate objective of this research is to evolve the current single-module closed-loop system into a regional defense network equipped with “multi-target perception, intelligent decision-making, and collaborative engagement capabilities”. This represents a paradigm shift from the current Single-Agent architecture to a Decentralized Partially Observable Markov Decision Process (Dec-POMDP) framework for multi-agent collaboration.
• Multi-Agent System (MAS): The future Dec-POMDP decision engine will be deployed on the edge computing units, enabling the four laser modules deployed in the orchard to act as distributed agents for collaborative decision-making.
• Enhanced Strategy and PoIE Application: The MAS will be able to autonomously optimize a multi-objective reward function. By applying the Principle of Inverse Effectiveness (PoIE), it will combine multi-modal stimuli (e.g., laser and directional sound waves) for deterrence. This will enhance the deterrent strength and unpredictability, thereby maintaining long-term anti-habituation effects.
This research not only provides a high-efficiency, low-cost solution combining deep learning and reinforcement learning, but also fundamentally overcomes the habituation dilemma in highly intelligent species through the theorem of an entropy-driven DDPG policy. It aims to lay the theoretical and empirical foundation for future large-scale, collaborative intelligent defense systems.
Acknowledgement: We extend our gratitude to Lin Chih-Chuan of Smile Bay Farm for providing the experimental field for this study.
Funding Statement: Part of the research funding was provided by Tatung University.
Author Contributions: Conceptualization: Shih-Ming Cho, Min-Chie Chiu; data curation: Sung-Wen Wang, Shao-Chun Chen; formal analysis: Shih-Ming Cho, Sung-Wen Wang, Min-Chie Chiu; investigation: Shih-Ming Cho, Sung-Wen Wang; methodology: Shih-Ming Cho; project administration: Shih-Ming Cho; resources: Shih-Ming Cho, Sung-Wen Wang; software: Shih-Ming Cho, Sung-Wen Wang; supervision: Shih-Ming Cho, Min-Chie Chiu; validation: Shih-Ming Cho, Sung-Wen Wang, Shao-Chun Chen; visualization: Sung-Wen Wang, Shao-Chun Chen; writing—original draft: Sung-Wen Wang, Min-Chie Chiu; writing—review & editing: Sung-Wen Wang, Min-Chie Chiu, Shih-Ming Cho. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: In support of open science and to ensure the full reproducibility of our findings, all core code, trained model weights, and key experimental configurations associated with this study will be made publicly available in a GitHub repository upon acceptance of this manuscript.
The open-sourced components will include:
• Core AI Model Weights and Training Configurations:
– The final YOLOv12n model weights, trained via Incremental Fine-Tuning (IFT) (achieving 0.947 mAP@0.5 for macaques and 0.946 for laser spots).
– Detailed configuration files for the multi-stage (SSL/IFT) training pipeline, including the specific parameters for mitigating catastrophic forgetting (e.g., freeze = 10, lr0 = 0.0002 or 0.0005, and epochs = 40 or 75).
– DDPG Reinforcement Learning Decision Core:
– The configuration of the Deep Deterministic Policy Gradient (DDPG) agent, including the mathematical structure of the composite reward function and the experimental weights used.
– Definitions for the state space (target position, velocity, density) and action space (laser angles, power, mode) mappings.
• High-Precision Tracking and Calibration Modules:
– The configuration parameters for the Bot-SORT tracker (which achieved a 1.88 s average tracklet lifetime).
– The optimized coefficients for the quadratic polynomial fitting model used for dynamic laser calibration (which achieved < 2-pixel RMSE).
This release is intended to provide the academic community with the resources necessary to precisely replicate, validate, and build upon the anti-habituation defense system presented herein.
Ethics Approval: Not available for this study.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Appendix A
Key Findings and Analysis:
• In the initial supervised training stage, YOLOv11n achieved the best baseline performance with the highest mAP@0.5 (0.942) and F1-Score (0.894). Conversely, YOLOv10n consistently performed the lowest across all core metrics.
• Despite a slightly lower mAP@0.5 (0.932) than YOLOv11n, YOLOv12n demonstrated a crucial Precision/Recall (P/R) trade-off: its Precision (P) of 0.924 surpassed all other models. This high-precision characteristic is a key predictor for the subsequent semi-supervised learning stage (S2), as it ensures the teacher model provides high-quality “signals” by generating fewer false positives.
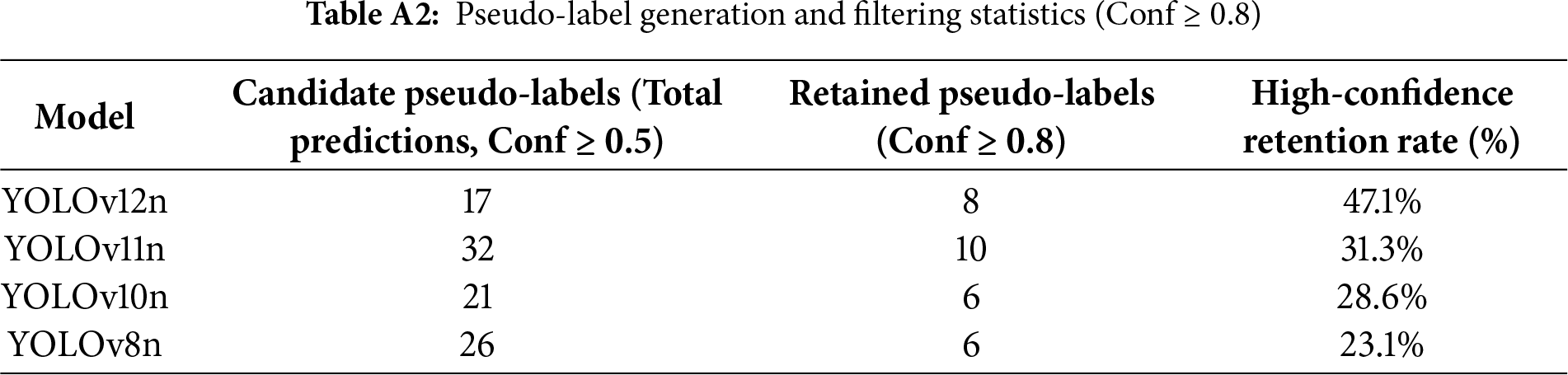
Key Findings and Analysis:
• YOLOv12n Teacher Model’s Discriminative Power: It generated the fewest candidate boxes (only 17), indicating no “spamming” of low-quality predictions.
• Highest Quality Pseudo-Labels: Despite the fewest candidates, YOLOv12n achieved a dominant high-confidence retention rate of 47.1%, far surpassing competitors. This empirically validates that its high-precision (0.924) S1 architecture successfully translated into the highest quality, highest Signal-to-Noise Ratio (SNR) pseudo-label set.
• High SNR Validation: A human audit of all retained high-confidence pseudo-labels (Conf
• Risks of Other Models: In contrast, YOLOv11n, despite producing the most retained labels (10), had a lower retention rate (31.3%), implying higher noise risk. Other models exhibited error rates from 16.7% to 33.3%, indicating noisy labels that could contaminate student model training. This directly quantifies our high-confidence filtering mechanism’s effectiveness.
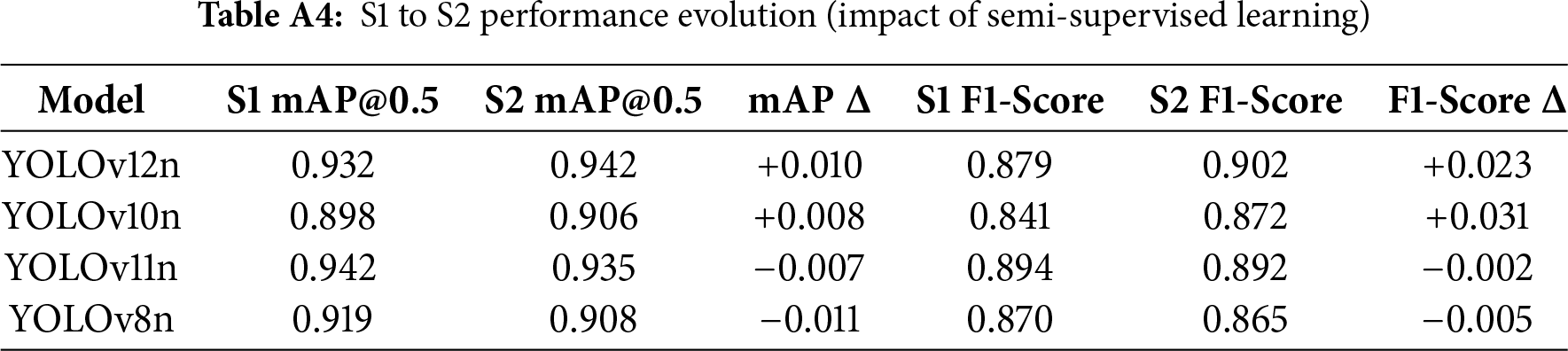
Key Findings and Analysis:
• Pseudo-label quality directly impacted S2 student model performance. YOLOv12n was the only model to achieve a significant mAP@0.5 gain (+0.010) in S2, surpassing S1 champion YOLOv11n to become the new leader.
• This S2 success is directly attributable to YOLOv12n’s highest Signal-to-Noise Ratio (SNR) pseudo-label set. The injection of 8 high-SNR labels successfully optimized its decision boundary and significantly improved its primary S1 weakness—Recall (substantially increasing from 0.838 to 0.879).
• Conversely, both S1 leader YOLOv11n and SOTA baseline YOLOv8n experienced mAP degradation in S2 (dropping by −0.007 and −0.011, respectively). This confirmed that their noisier pseudo-labels contaminated the training pool, causing a decline in student model performance.
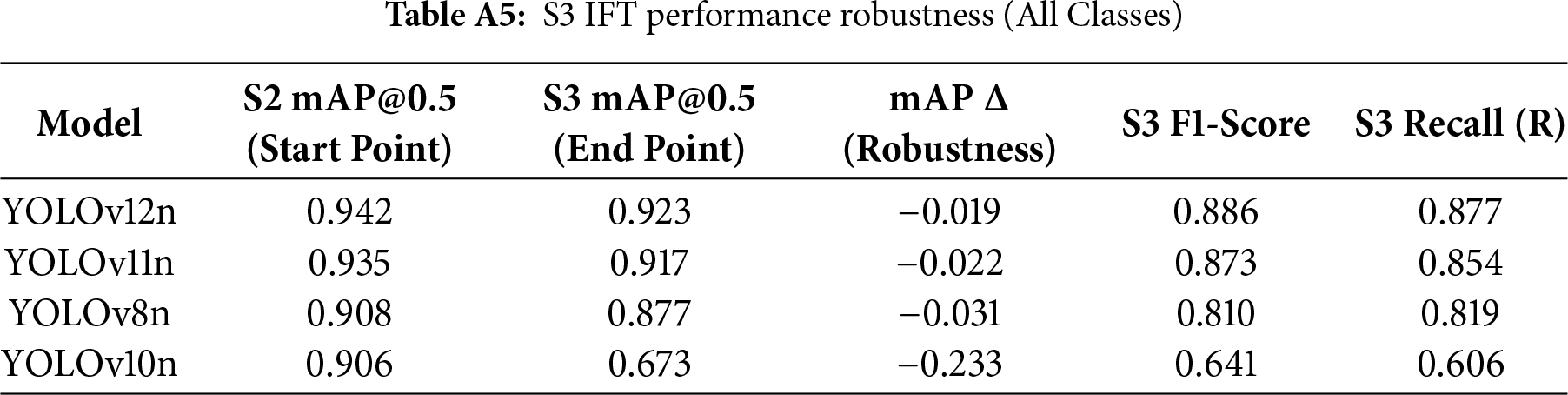
Key Findings and Analysis:
• YOLOv10n suffered a catastrophic failure in this stage, with its mAP@0.5 plummeting by −0.233. This strongly suggests a fundamental incompatibility between its architecture (possibly related to its NMS-free design) and the IFT strategy (especially when freezing the backbone).
• YOLOv12n again demonstrated the best robustness (mAP dropped by only −0.019) and ultimately completed the test with the highest mAP@0.5 (0.923) and F1-Score (0.886), solidifying its leadership across the entire IFT pipeline.
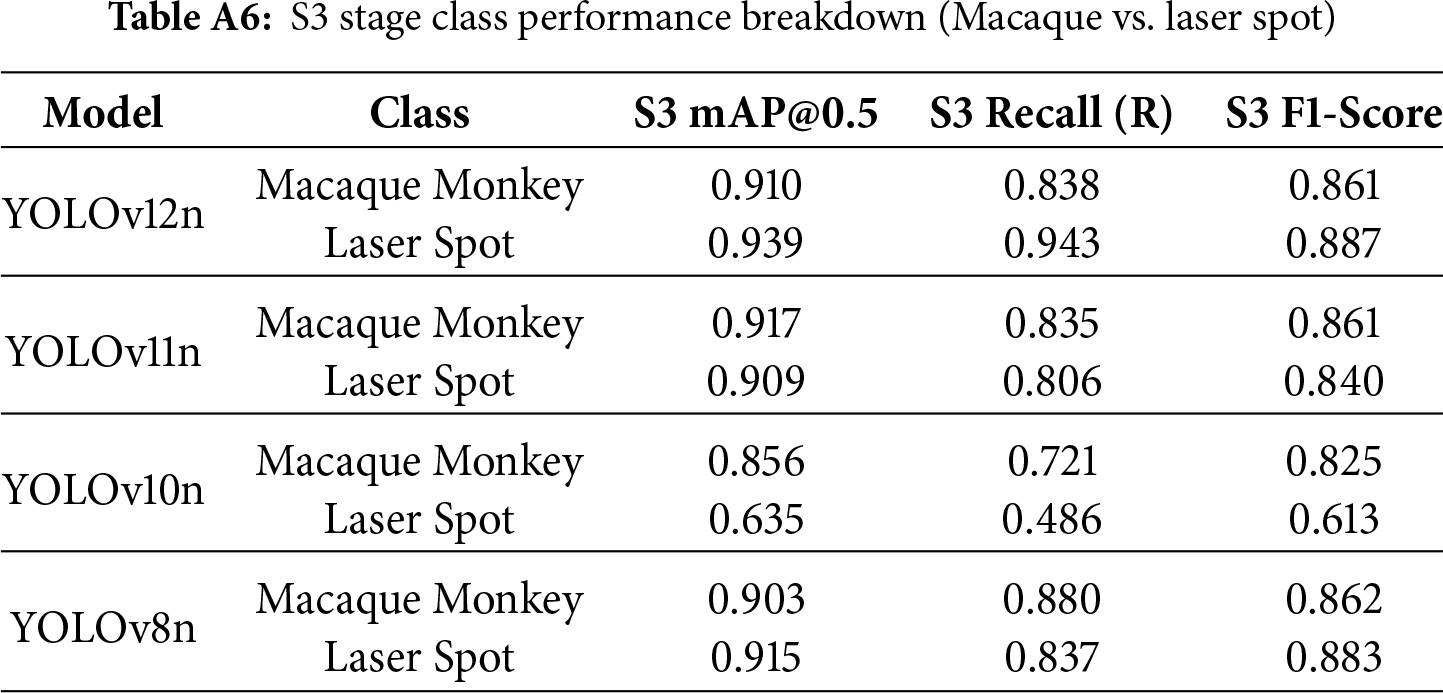
Key Findings and Analysis:
• YOLOv12n and YOLOv11n both achieved an F1-Score of 0.861 for the old “Macaque” class, indicating the IFT strategy successfully preserved existing knowledge and avoided catastrophic forgetting.
• YOLOv12n demonstrated a dominant advantage in learning the new “Laser Spot” class, with mAP@0.5 reaching 0.939 and an exceptional Recall of 0.943. This proves its feature extractor and A2C2f module are most effective for detecting instantaneous light sources and small targets.
• YOLOv10n’s catastrophic failure is primarily attributed to its extreme inability to handle the new class, with its Recall for “Laser Spot” being only 0.486.
Key Findings and Analysis:
• YOLOv12n consistently demonstrated the best performance across both critical stages of the IFT process (S2 and S3), ultimately achieving leading mAP@0.5 (0.923) and F1-Score (0.886).
• With its high signal-to-noise ratio pseudo-label retention rate of 47.1%, YOLOv12n was the only model to benefit (mAP gain of +0.010) from semi-supervised learning.
• YOLOv12n boasts the fewest parameters (2.56M) and a theoretical complexity of just 6.3 GFLOPs, representing a computational load reduction of approximately 22.22% compared to the SOTA baseline YOLOv8n (8.1 GFLOPs).
• YOLOv12n achieved a high recall rate of 0.943 for the newly added “laser spot” class, proving its superior stability in reacting to high-speed flickering or weak light signals, thus making it highly suitable for the “dynamic tracking” task scenario of this research.
References
1. Na SY, Shin D, Jung JH, Kim JY. Protection of orchard from wild animals and birds using USN facilities. In: Proceedings of the 2nd International Conference on Computer and Automation Engineering (ICCAE); 2010 Feb 26–28; Singapore. p. 307–11. [Google Scholar]
2. Hollinshead JA, Briskie JV, Kross SM. Orchard management factors affecting rates of bud damage to kiwifruit orchards. Crop Prot. 2024;184:106792. doi:10.1016/j.cropro.2024.106792. [Google Scholar] [CrossRef]
3. Koirala S, Garber PA, Somasundaram D, Katuwal HB, Ren B, Huang C, et al. Factors affecting the crop raiding behavior of wild rhesus macaques in Nepal: implications for wildlife management. J Environ Manage. 2021;297:113331. doi:10.1016/j.jenvman.2021.113331. [Google Scholar] [PubMed] [CrossRef]
4. Besala FI, Niimoto R, Lee JH, Okamoto S. Development of AI-based smart box trap system for capturing a harmful wild boar. ROBOMECH J. 2025;12(1):4. doi:10.1186/s40648-025-00290-w. [Google Scholar] [CrossRef]
5. Gross EM, Jayasinghe N, Brooks A, Polet G, Wadhwa R, Hilderink-Koopmans F. A future for all: the need for human-wildlife coexistence. Gland, Switzerland: United Nations Environment Programme (UNEP) & World Wide Fund for Nature (WWF); 2021. [Google Scholar]
6. Su H. Human-macaque interactions and conflict: mitigating conflicting between humans and Taiwanese macaques (Macaca cyclopis) in Taiwan/Primates in Asian anthropogenic environments. Tokyo, Japan: Tokyo University of Foreign Studies; 2024. [Google Scholar]
7. Ooko SO, Ndashimye E, Twahirwa E, Busogi M. IoT and machine learning for smart bird monitoring and repellence: techniques, challenges, and opportunities. IoT. 2025;6(3):46. doi:10.3390/iot6030046. [Google Scholar] [CrossRef]
8. Park J, Shim J. A deep learning-based intelligent wild boar repellent device. J Korean Inst Inf Technol. 2021;19(5):1–6. doi:10.14801/jkiit.2021.19.5.1. [Google Scholar] [CrossRef]
9. Afridi S, Laporte-Devylder L, Maalouf G, Kline JM, Penny SG, Hlebowicz K, et al. Impact of drone disturbances on wildlife: a review. Drones. 2025;9(4):311. doi:10.3390/drones9040311. [Google Scholar] [CrossRef]
10. Alaska Department of Transportation and Public Facilities. Fairbanks international airport welcomes aurora to state service, Alaska’s robotic solution to reducing airport wildlife conflicts [Internet]. 2024 [cited 2025 Oct 1]. Available from: https://dot.alaska.gov/faiiap/pdfs/PRs/072424-press-release.shtml. [Google Scholar]
11. Mishra A, Yadav KK. Smart animal repelling device: utilizing IoT and AI for effective anti-adaptive harmful animal deterrence. BIO Web Conf. 2024;82(2):05014. doi:10.1051/bioconf/20248205014. [Google Scholar] [CrossRef]
12. Yang W, Liu T, Jiang P, Qi A, Deng L, Liu Z, et al. A forest wildlife detection algorithm based on improved YOLOv5s. Animals. 2023;13(19):3134. doi:10.3390/ani13193134. [Google Scholar] [PubMed] [CrossRef]
13. Wang J, Yang P, Liu Y, Shang D, Hui X, Song J, et al. Research on improved YOLOv5 for low-light environment object detection. Electronics. 2023;12(14):3089. doi:10.3390/electronics12143089. [Google Scholar] [CrossRef]
14. Liu W, Ren G, Yu R, Guo S, Zhu J, Zhang L. Image-adaptive YOLO for object detection in adverse weather conditions. Proc AAAI Conf Artif Intell. 2022;36(2):1792–800. doi:10.1609/aaai.v36i2.20072. [Google Scholar] [CrossRef]
15. Yang F, Zhang X, Liu B. Video object tracking based on YOLOv7 and DeepSORT. arXiv:2207.12202. 2022. [Google Scholar]
16. Wu D, Jiang S, Zhao E, Liu Y, Zhu H, Wang W, et al. Detection of Camellia oleifera fruit in complex scenes by using YOLOv7 and data augmentation. Appl Sci. 2022;12(22):11318. doi:10.3390/app122211318. [Google Scholar] [CrossRef]
17. Chappidi J, Sundaram DM. Novel animal detection system: cascaded YOLOv8 with adaptive preprocessing and feature extraction. IEEE Access. 2024;12:110575–87. doi:10.1109/access.2024.3439230. [Google Scholar] [CrossRef]
18. Ultralytics. UltralyticsYOLO12 (version 12.0.0) [Internet]. 2025 [cited 2025 Oct 1]. Available from: https://github.com/ultralytics/ultralytics. [Google Scholar]
19. Ogawa T, Yachida S, Hosoi T. Multi object tracking based on uncertainty-aware RE-ID. In: Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP); 2022 Oct 16–19; Bordeaux, France. p. 346–50. [Google Scholar]
20. Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric. In: Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP); 2017 Sep 17–20; Beijing, China. p. 3645–9. [Google Scholar]
21. Zhang Y, Sun P, Jiang Y, Yu D, Weng F, Yuan Z, et al. Bytetrack: multi-object tracking by associating every detection box. In: Proceedings of the Computer Vision—ECCV 2022; 2022 Oct 23–27; Tel Aviv, Israel. p. 1–21. [Google Scholar]
22. Cao J, Weng L, Jiang X, Yang G, Liu Y. Observation-centric SORT: rethinking SORT for robust multi-object tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 18–22; Vancouver, BC, Canada. p. 9686–96. [Google Scholar]
23. Aharon N, Orfaig R, Bobrovsky BZ. BoT-SORT: robust associations multi-pedestrian tracking. arXiv:2206.14651. 2022. [Google Scholar]
24. Wang P, Ryan SZ, Yu L, Wu Y, Singh R, Joppa L, et al. Reinforcement learning for green security games with real-time information. Proc 38th AAAI Conf Artif Intell. 2019;33(1):1401–8. doi:10.1609/aaai.v33i01.33011401. [Google Scholar] [CrossRef]
25. Luongo FJ, Liu L, Ho CLA, Hesse JK, Wekselblatt JB, Lanfranchi FF, et al. Mice and Primates use distinct strategies for visual segmentation. eLife. 2023;12:e74394. doi:10.7554/eLife.74394. [Google Scholar] [PubMed] [CrossRef]
26. Duporge I, Kholiavchenko M, Harel R, Wolf S, Rubenstein DI, Crofoot MC, et al. BaboonLand dataset: tracking primates in the wild and automating behavior recognition from drone videos. Int J Comput Vis. 2025;133:6578–89. doi:10.1007/s11263-025-02532-1. [Google Scholar] [CrossRef]
27. Tong L, Fang J, Wang X, Zhao Y. Research on cattle behavior recognition and multi-object tracking. Animals. 2024;14(2993):1–31. doi:10.3390/ani14202993. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools