
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Fairness-Aware Task Offloading Based on Location Prediction in Collaborative Edge Networks
1 School of Mechanical Engineering, Dalian University of Technology, Dalian, 116024, China
2 TBEA Xinjiang Cable Research Institute, TBEA Xinjiang Cable Co., Ltd., Xinjiang, 831100, China
* Corresponding Author: Yanjun Shi. Email:
Computers, Materials & Continua 2026, 87(2), 53 https://doi.org/10.32604/cmc.2026.075202
Received 27 October 2025; Accepted 31 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
With the widespread deployment of assembly robots in smart manufacturing, efficiently offloading tasks and allocating resources in highly dynamic industrial environments has become a critical challenge for Mobile Edge Computing (MEC). To address this challenge, this paper constructs a cloud-edge-end collaborative MEC system that enables assembly robots to offload complex workflow tasks via multiple paths (horizontal, vertical, and hybrid collaboration). To mitigate uncertainties arising from mobility, the location prediction module is employed. This enables proactive channel-quality estimation, providing forward-looking insights for offloading decisions. Furthermore, we propose a fairness-aware joint optimization framework. Utilizing an improved Multi-Agent Deep Reinforcement Learning (MADRL) algorithm whose reward function incorporates total system cost, positional reliability, and timeout penalties, the framework aims to balance resource distribution among assembly robots while maximizing system utility. Simulation results demonstrate that the proposed framework outperforms traditional offloading strategies. By integrating predictive mobility management with fairness-aware optimization, the framework offers a robust solution for dynamic industrial MEC environments.Graphic Abstract
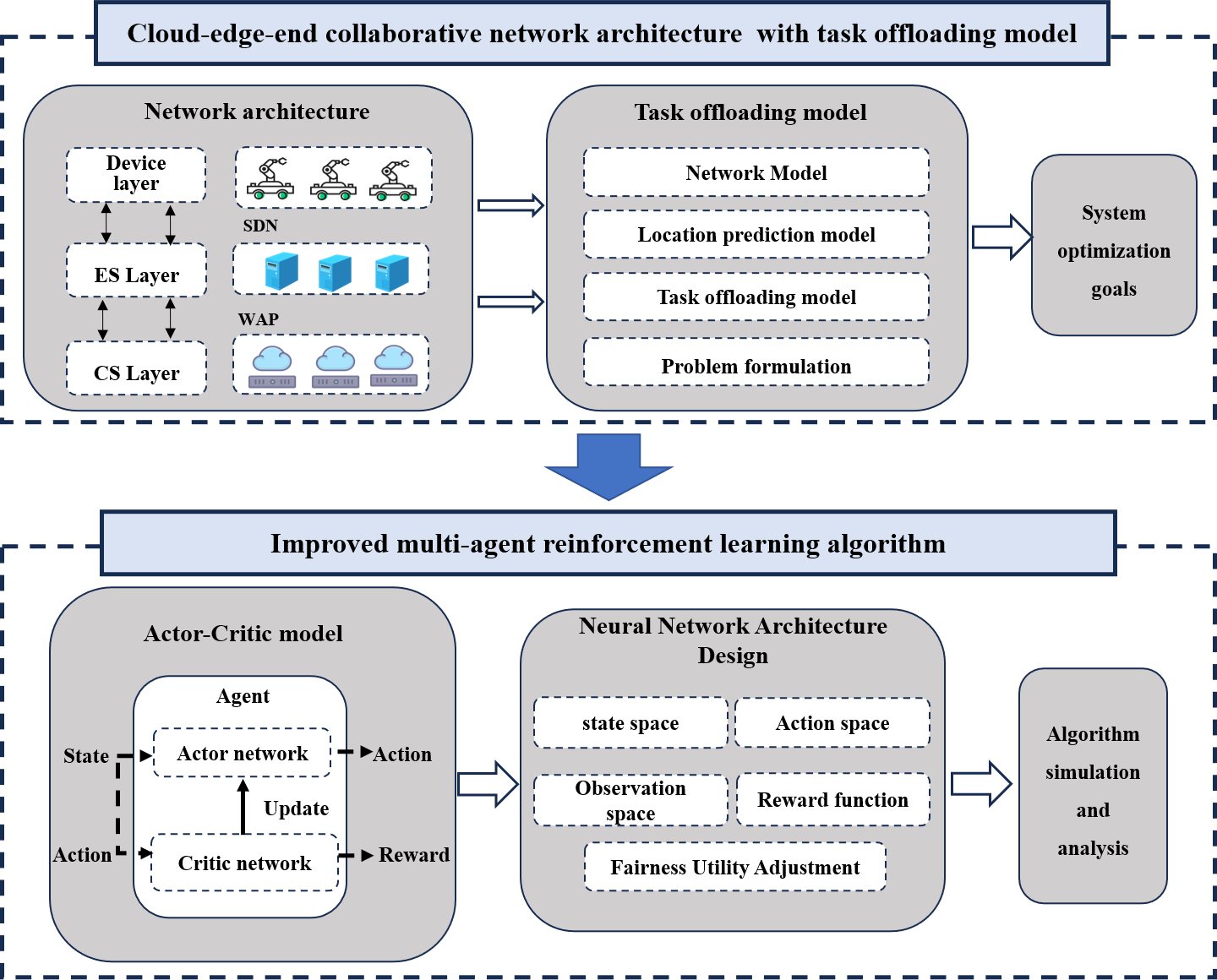
Keywords
Smart manufacturing, serving as a core element of Industry 4.0, is fundamentally reshaping traditional production paradigms [1,2]. Within this context, assembly robots are playing an increasingly critical role in smart factories. As illustrated in Fig. 1, these assembly robots must execute various workflow tasks with stringent latency constraints during operation, including real-time path planning and obstacle detection [3]. The substantial computational demands of these applications create a fundamental discrepancy with the robots’ limited inherent processing capacity. Mobile Edge Computing (MEC) technology offers a viable solution to this challenge by offloading computation-intensive tasks to servers located at the network edge for processing. However, the dynamic uncertainty introduced by robot mobility has become a critical bottleneck hindering the deeper application of MEC in smart manufacturing [4]. The movement of robots causes spatiotemporal fluctuations in the state of the wireless channel between them and edge servers. This dynamic characteristic renders traditional optimization models based on static assumptions inadequate, thereby seriously compromising the stability of the task offloading process and the quality of service [5,6].
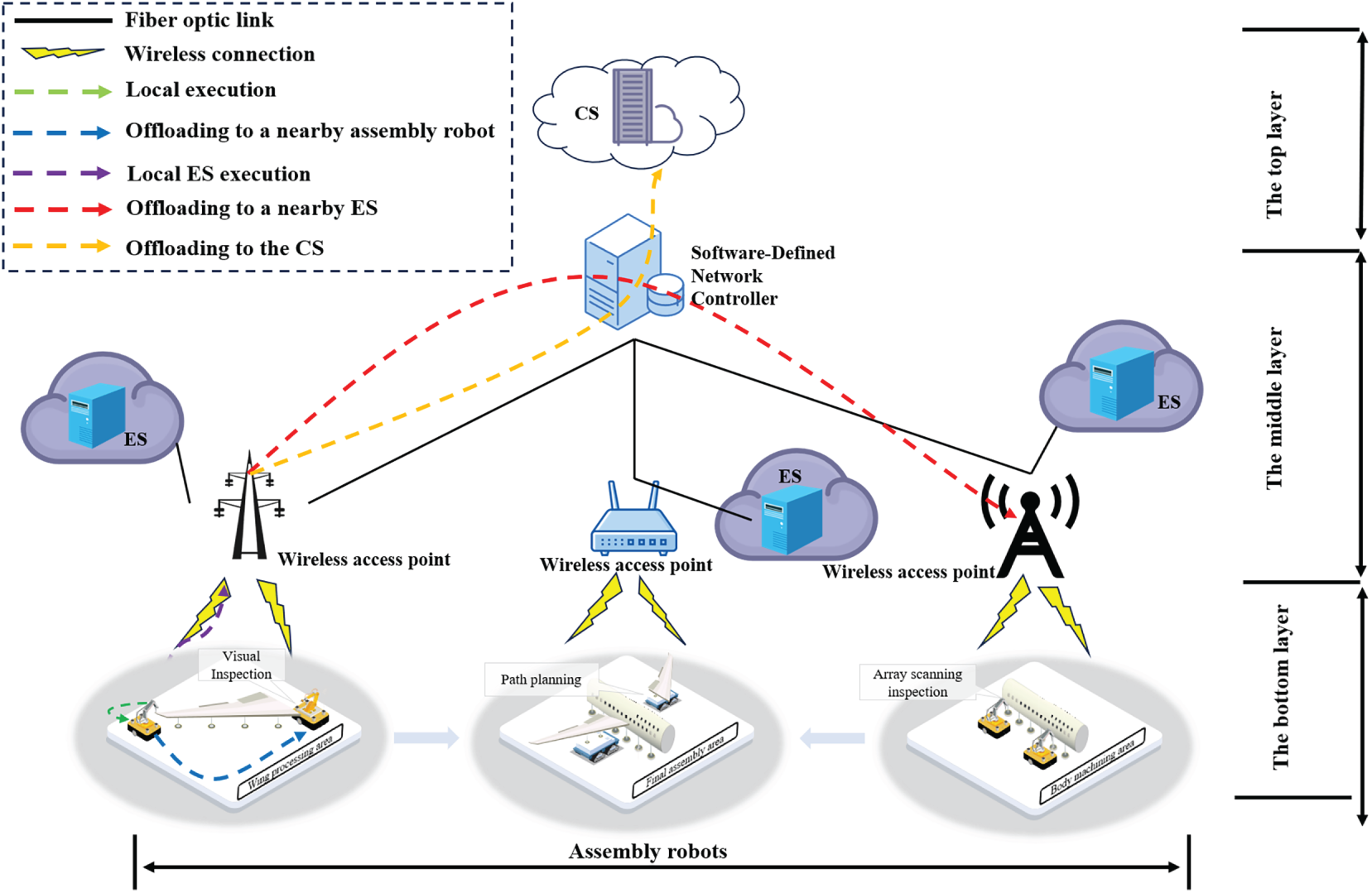
Figure 1: A three-layer collaborative mobile edge computing network
Conventional research on workflow task offloading predominantly assumes stationary robots or fixed mobility patterns [7–10], focusing mainly on dependency parsing and resource allocation in static environments. These approaches typically employ heuristic rules or meta-heuristic algorithms to seek optimal offloading decisions. However, in scenarios with rapidly moving robots, decisions based on instantaneous Channel State Information (CSI) degrade rapidly due to fast channel aging, leading to task timeouts or transmission interruptions. In contrast, prediction-based offloading strategies can cope with dynamic environments. By forecasting the future trajectory of robots [11], the trend of channel quality variation can be inferred, thereby enabling more proactive offloading decisions. Unlike passive reactive scheduling, predictive scheduling incorporates the temporal dimension, offering a new perspective for guaranteeing end-to-end latency of workflow tasks in mobility scenarios.
Nevertheless, existing prediction-based offloading frameworks still face severe challenges. Firstly, most studies simplify workflow tasks into independent sets [12–16], neglecting the complex Directed Acyclic Graph (DAG) [17] dependency structures prevalent in smart manufacturing. Data transfer and temporal constraints across subtasks significantly increase the complexity of joint optimization. Secondly, existing predictive algorithms primarily focus on optimizing a single performance metric [18–20], while insufficiently considering the fairness of resource allocation in multi-user scenarios [6,21,22]. In resource-constrained edge environments, the absence of fairness constraints may allow robots with high prediction accuracy to monopolize channel resources, leading to task starvation for others and, consequently, a collapse in the overall service equity of the system. Furthermore, the heterogeneity and coordination of computing resources across the cloud, edge, and robot levels have not been adequately modeled, lacking a cross-layer global optimisation perspective.
To address these issues systematically, this paper proposes a collaborative computing offloading and resource allocation framework for smart manufacturing that considers robot mobility. The main contributions of this paper are as follows:
• We construct a dynamic system model based on Collaborative Mobile Edge Computing (CoMEC) [23]. Comprehensively considering the time-varying channel characteristics caused by robot mobility, the complex DAG dependency structure of workflow tasks, and the heterogeneity of computing resources across three levels, accurate system latency and energy consumption cost models are established.
• We design a robot location-prediction module based on an Extended Kalman Filter (EKF) that accurately predicts short-term movement trajectories. This enables the generation of proactive channel-quality estimates, transforming the dynamic optimization problem into approximately a deterministic one and significantly enhancing the robustness of offloading decisions.
• We propose a collaborative task offloading framework, Gated Recurrent Unit(GRU)-enhanced multi-agent proximal policy optimization (RMAPPO), that integrates location prediction, fair utility, and GRU to provide an end-to-end solution for the complex problem of offloading dynamic DAG workflows in aircraft assembly.
The remainder of this paper is organized as follows: Section 2 reviews related work; Section 3 details the system model and problem formulation; Section 4 presents the improved algorithm; Section 5 discusses experimental results; and Section 6 concludes the paper.
In this section, we provide a detailed overview and classification of current offloading strategies in industrial environments, grouping them by device fairness, task dependency, and device mobility. We explore the details of these strategies and analyze their inherent limitations.
In the field of device fairness research, Du et al. [24] tackled the computation offloading challenge in fog/cloud hybrid systems by simultaneously optimizing offloading decisions and allocating computing resources, transmission power, and radio bandwidth to achieve device fairness while adhering to maximum allowable delay constraints. The offloading decisions were formulated using semi-definite relaxation and randomization techniques, whereas resource allocation was determined through fractional programming and Lagrangian dual decomposition. In a follow-up study, Li et al. [25] introduced a multi-agent energy-saving scheme that integrates trajectory planning and computation offloading, focusing on energy efficiency and device fairness. They used a multi-agent deep reinforcement learning (MADRL) algorithm to learn trajectory-control decisions autonomously, enabling the system to adapt to fluctuating user demands while preserving device fairness.
In the field of task dependency research, Cui et al. [26] developed a novel fine-grained offloading scheduling method for workflow tasks, using DAGs to define the subtask scheduling sequence and formulating computation offloading as a multi-objective optimization problem to minimize energy consumption and task latency. Following this, Pang et al. [27] proposed a deep reinforcement learning (DRL)-based method for task scheduling to ensure the real-time and efficient execution of tasks. They used DAGs to represent task dependencies and introduced penalties for task execution delays, applying the double deep Q-Network (DDQN) algorithm [28] to tackle the task offloading problem.
In the field of device mobility research, several studies have explored the significant impact of robot mobility on task offloading, particularly in scenarios where robots dynamically change their state, including direction and velocity. To address the challenges posed by robots with stochastic mobility, Chen et al. [29] integrated vehicular mobility characteristics and characterized inter-vehicle connectivity in terms of the maximum task-processing capabilities. This approach allows tasks to identify and select the most efficient offloading pathways through these established relationships. Subsequently, recognizing the complexity of using task processing capabilities to describe robot interactions, Liu et al. [30] proposed a time-based embedded link connectivity model to more intuitively capture the dynamics of robot connections. Furthermore, to address the complexities of robots with time-varying trajectories that require processing extensive, diverse datasets, Zhao et al. [31] developed a robot mobility detection algorithm. This algorithm identifies the communication intervals between robots and edge servers, thereby avoiding imprudent offloading decisions by reducing the dimensionality of the role space.
In the field of MADRL research, Ref. [25] demonstrated its potential for long-term performance optimization in dynamic environments. However, multi-agent DDQN often struggles with non-stationarity. Currently, multi-agent deep deterministic policy gradient (MADDPG) [23] and MAPPO [32] are two advanced MADRL algorithms developed to tackle the above challenge. This study also selects these two as primary comparative baselines. The former employs a centralized training and distributed execution framework, optimizing policies through information sharing via the Critic network. The latter extends multi-agent collaboration upon the PPO framework, offering superior training stability. This characteristic makes it more suitable for communication-sensitive industrial environments.
In summary, existing research still lacks a general MADRL solution that can deeply integrate the above constraints. To address this, this paper innovatively proposes a joint optimization framework that tackles mobility uncertainty through an EKF-based position prediction module and coordinates workflow offloading and fairness via the RMAPPO algorithm, ultimately minimizing system costs while ensuring fairness.
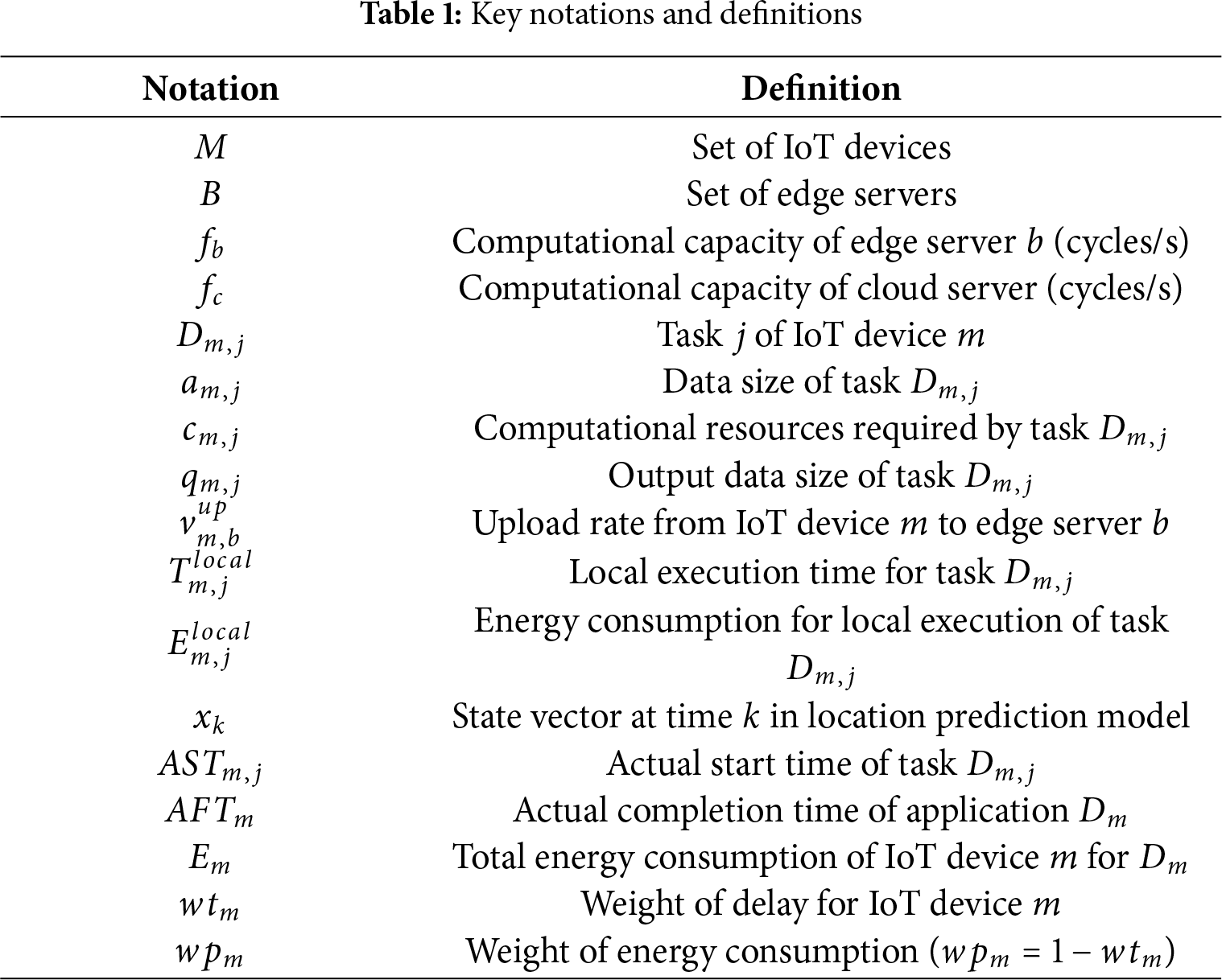
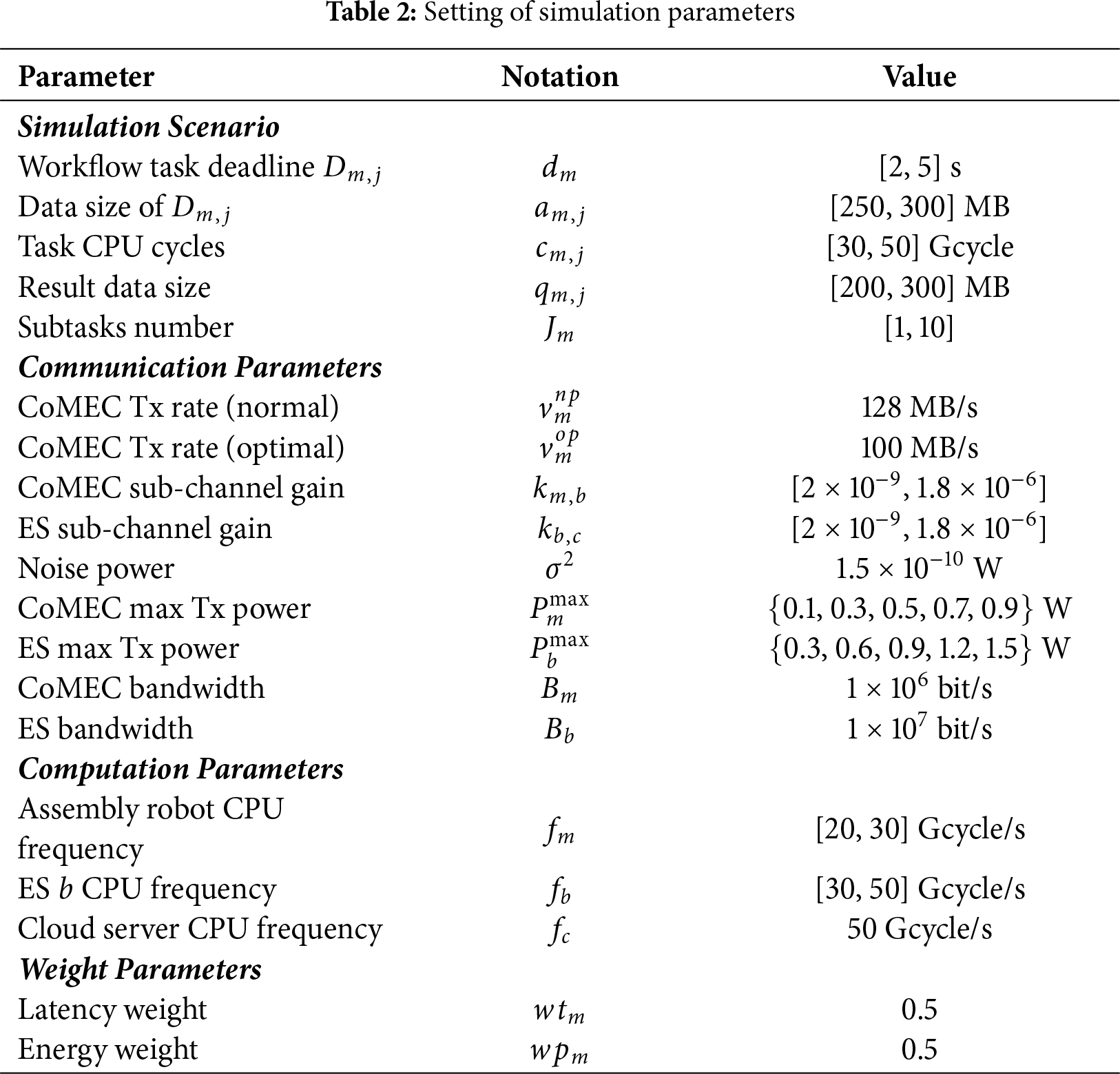
We investigated a three-layer CoMEC network for aircraft assembly environments, as shown in Fig. 1. Assembly robots execute workflow tasks with strict timing requirements, such as assembly and inspection. The robots’ mobility primarily involves linear movement along predefined trajectories and point-to-point navigation. The network topology is deployed according to the following physical scenario: the bottom layer consists of assembly robots, the middle layer comprises edge servers (ESs), and the top layer comprises a cloud server (CS) with powerful computational capabilities. Communication between robots and between robots and edge servers occurs via wireless channels. This network architecture ensures flexible, collaborative offloading of computational tasks locally, at the edge, or in the cloud. The main formula symbols defined in this paper are shown in Table 1.
To support efficient task offloading, the system employs Orthogonal Frequency-Division Multiple Access (OFDMA)-based device-to-device and device-to-infrastructure communication [19]. This study assumes orthogonality between subchannels and does not currently consider inter-cell interference. Assuming each assembly robot occupies a single sub-channel, the upload signal-to-noise ratio (SNR) between assembly robot
where
where
where
In the CoMEC network, the mobility of assembly robots introduces dynamic uncertainties that may lead to communication interruptions or performance degradation during task offloading. To address this issue, an EKF-based position prediction model is introduced [11]. Unlike conventional approaches that primarily rely on predicted positions for basic, static offloading selection, our work integrates mobility uncertainty into a joint optimization framework with system utility and device fairness as the ultimate objectives. As shown in Fig. 2, the workflow primarily consists of the following three phases:
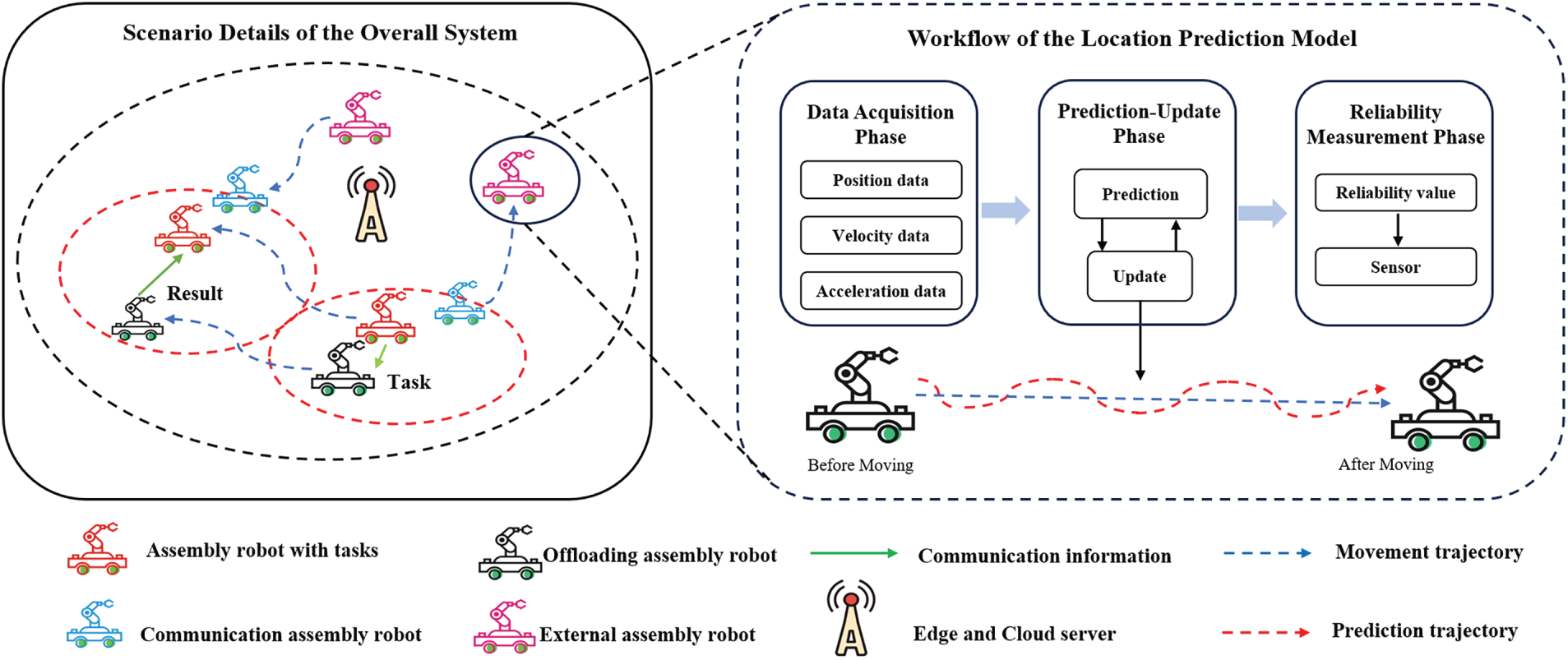
Figure 2: Overview of the location prediction model
(A) Data Acquisition Phase: Assembly robots collect real-time position
(B) Prediction-Update Phase: This phase integrates real-time observation data in (A) to estimate its future trajectory. The prediction step uses the state transition that follows a nonlinear function:
The error covariance matrix is projected forward by:
where
The update step refines the predicted state to obtain a posteriori estimate, which balances the trust between the prediction and the observation, and is computed as:
where
(C) Reliability Measurement Phase: When an assembly robot
where
This metric quantifies the probability of communication link stability during task execution. As a key input to the RMAPPO algorithm’s reward function,
Each assembly robot
where
(1) Local execution: The task
where
where
(2) Offloading to a nearby assembly robot: The task
where
The computation delay of task
where
(3) Local ES execution: The transmission delay for task
The transmission energy consumption of the assembly robot
The computation delay is:
The energy consumption for computation at the local ES
where
(4) Offloading to a nearby ES: Task
The transmission energy consumption is:
The computation latency of task
The energy consumption for computation at collaborative ES
where
(5) Offloading to the CS: Task
The transmission energy consumption is:
The computation latency of the task on CS
The energy consumption for computation at CS
where
The actual completion time of the task:
where
where
where
Furthermore, since the volume of result data is small, the transmission time for task execution results can be neglected. The actual execution completion time of workflow task
where
To complete the workflow task
This paper assumes that there are currently M assembly robots requesting workflow tasks. The study focuses on the task offloading strategy for the workflow tasks of these M assembly robots. Each DAG consists of
where
where
In this section, we first establish a Markov Decision Process (MDP) for the traditional problem, using a linear combination of system cost and location reliability metrics as the objective. Then, we refine the model by incorporating the average of past rewards to ensure user fairness.
To optimize the fair utility, we first formulate the traditional problem.
(1) State
where
where
(2) Action
where 0 represents local execution,
(3) Reward
A penalty will be imposed if the workflow task is not completed before the deadline. This penalty mechanism incentivizes the decision center to schedule tasks and resources more effectively to complete workflow tasks as quickly as possible.
In addition to stationary ESs and CS, each assembly robot may have its own movement direction and speed. Therefore, during task offloading, these assembly robots may continue to move and transition between them, thereby increasing the time required to return the task’s computational results.
The location reliability
The reward function is represented as:
where
4.2 Fairness Optimization Mechanism
Our optimization goal is to maximize fairness utility. The historical rewards of each assembly robot influence decision-making [33,34]. Therefore, we adjust the rewards based on the statistics of past rewards. We incorporate the
First, we use
Due to the adjustment of rewards, the relative state function
where
In DRL, we often use neural networks with parameter
4.3 Multi-Agent Collaborative Decision Framework
This section describes how the RMAPPO algorithm enhances the MAPPO architecture by integrating GRU layers into its Actor and Critic networks [32]. Fig. 3 illustrates that for mini-batch training, each agent
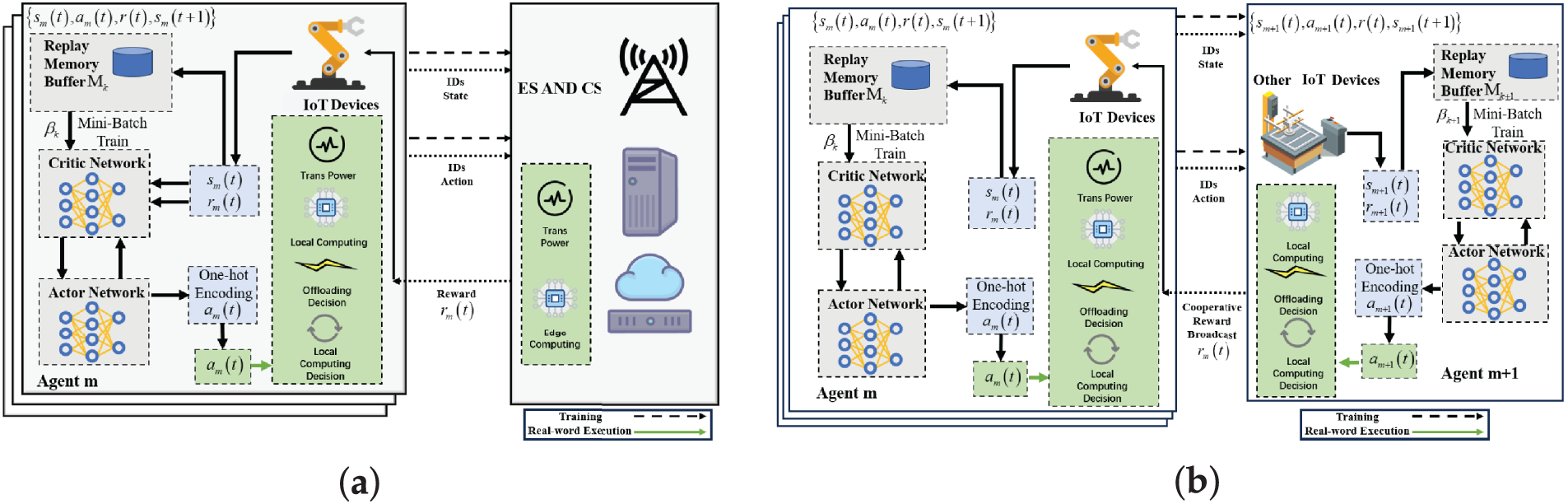
Figure 3: Framework diagram of the RMAPPO algorithm: (a) Offloading workflow tasks to edge or cloud servers; (b) Offloading workflow tasks to other assembly robots
Fig. 4 shows the network architectures for the Actor and Critic of the RMAPPO algorithm, in which GRUs offer significant advantages due to their ability to capture temporal dependencies in sequential decision-making. The continuous motion trajectories of robots or the dynamic evolution of task queues exhibit strong temporal correlations. Leveraging their gating mechanisms, GRUs effectively preserve critical information, enabling agents to make task offloading decisions not only based on the current state but also by integrating relevant historical data.
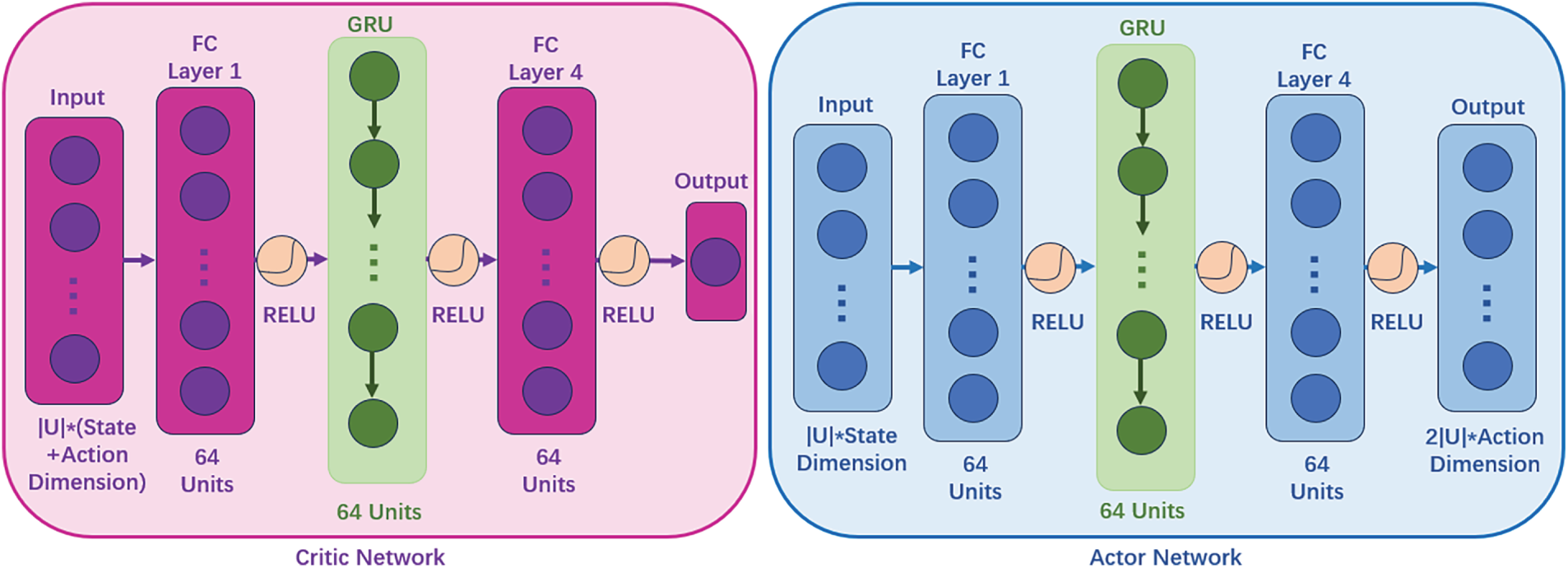
Figure 4: Actor and Critic network structure of the RMAPPO algorithm
Update and reset gates are used by GRUs in which the update gate
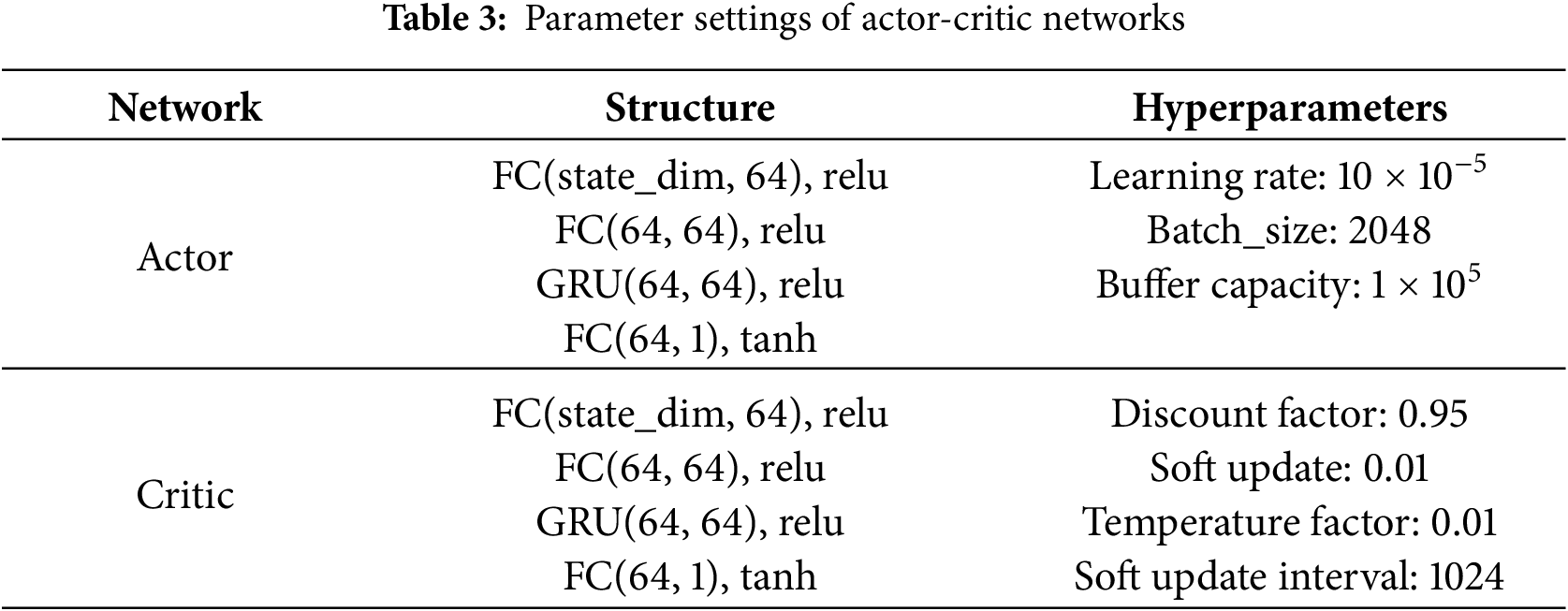
There are three steps in the RMAPPO pseudocode (Algorithm 1). Initialization (Lines 1–4) establishes an experience buffer M, configures hyperparameters (learning rate, clipping ratio, etc.), and sets Actor/Critic parameters (

This section conducts a complexity analysis of the RMAPPO algorithm. From an algorithmic perspective, the computational complexity of an agent mainly stems from the Actor network’s generation of offloading strategies and the Critic network’s evaluation and adjustment of these policies. Specifically, the Actor uses a deep neural network to encode the state of the CoMEC environment and outputs corresponding actions, i.e., offloading strategies. This process involves extensive matrix operations and computations of activation functions, which constitute the algorithm’s primary computational burden. In contrast, the Critic module operates at a lower frequency (typically once per batch) and has relatively low computational complexity, and is not the main source of the agent’s complexity.
For the Multilayer Perceptron (MLP) layer, the time complexity of the matrix multiplication in the fully connected layer is
In the RNN layer, the main operations include sequence data processing and regularization, with a time complexity of
This section evaluates RMAPPO’s performance in a 400 m
5.1 RMAPPO Algorithm’s Learning Efficiency Results
This section assesses the convergence and learning efficiency of the RMAPPO algorithm under unfair conditions. As training episodes progress, Fig. 5a agents’ average rewards increase; Fig. 5b latency gradually drops; and Fig. 5c energy consumption rises. All indicators show convergent trends after 400 episodes, demonstrating RMAPPO’s efficacy in multi-agent policy learning. Fig. 6 shows convergence across learning rates (
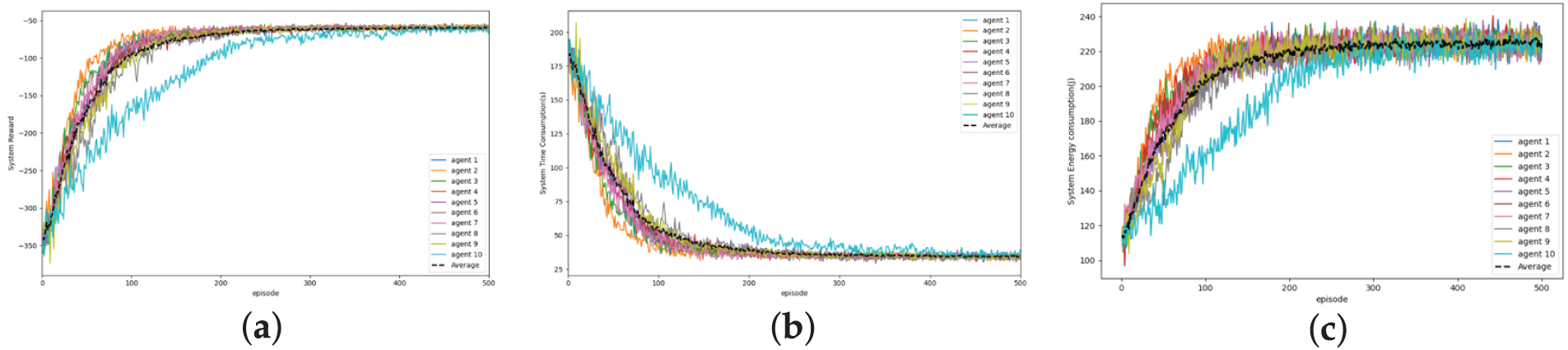
Figure 5: Convergence curves of all agents under the RMAPPO algorithm: (a) System reward; (b) Application processing latency; (c) System energy consumption
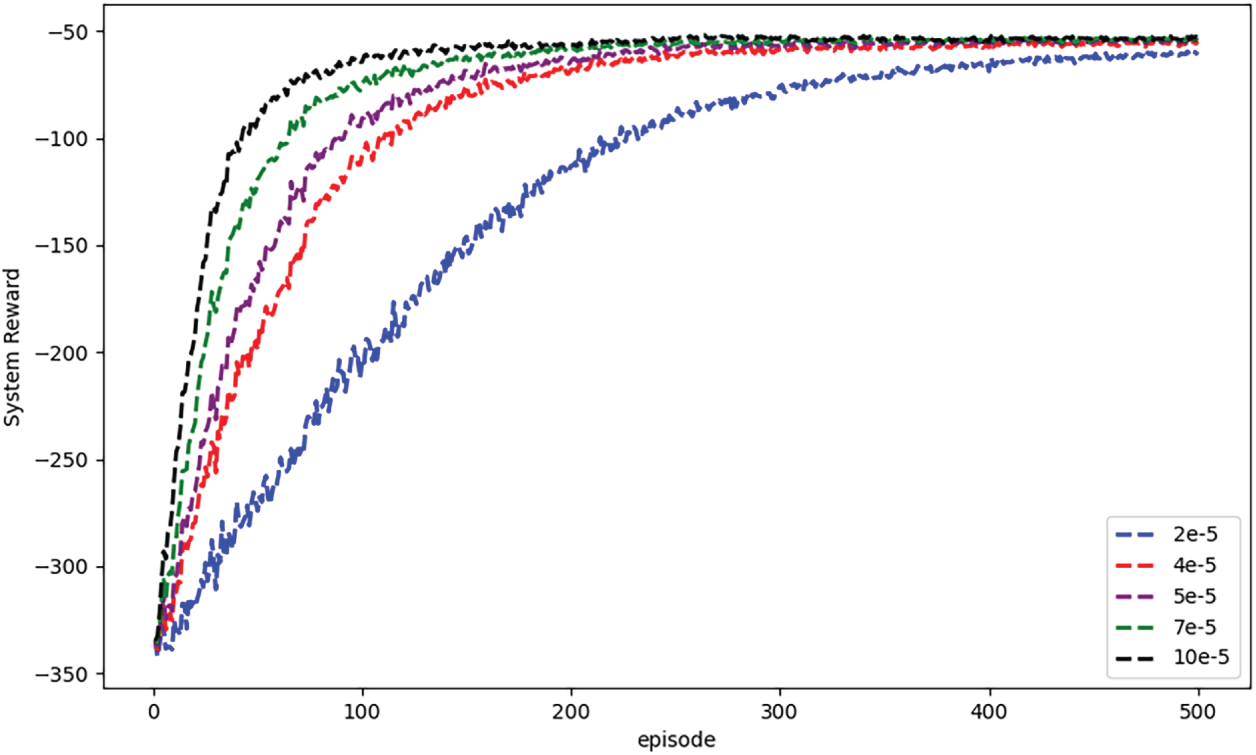
Figure 6: Convergence curves of all agents under different learning rates
5.2 Performance Comparison of Different Algorithms
Fig. 7 shows that under fairness scenarios, the RMAPPO algorithm consistently outperforms the MAPPO and MADDPG algorithms in terms of system reward, processing delay, and energy consumption. Compared with the two benchmark algorithms, RMAPPO reduces workflow task processing delay by 8.15% and 3.54%, respectively. After 500 training iterations, the system reward achieved by RMAPPO is 5.75% higher than that of MAPPO and 9.48% higher than that of MADDPG. Its energy consumption is reduced by 2.86% compared to MAPPO and by 4.02% compared to MADDPG. Analyzing the system reward and delay results, the significant increase in reward indicates that RMAPPO can effectively reduce task timeout rates, thereby indirectly demonstrating its higher task completion rate. Analyzing the energy consumption and delay results, RMAPPO significantly reduces task processing delay while controlling total energy consumption, indirectly reflecting its superior resource utilization. Additionally, the RMAPPO algorithm exhibits minimal performance degradation under load variations, suggesting it may possess adaptability to network fluctuations—including cloud latency—as its integrated location prediction module proactively estimates channel quality, partially offsetting latency uncertainties.
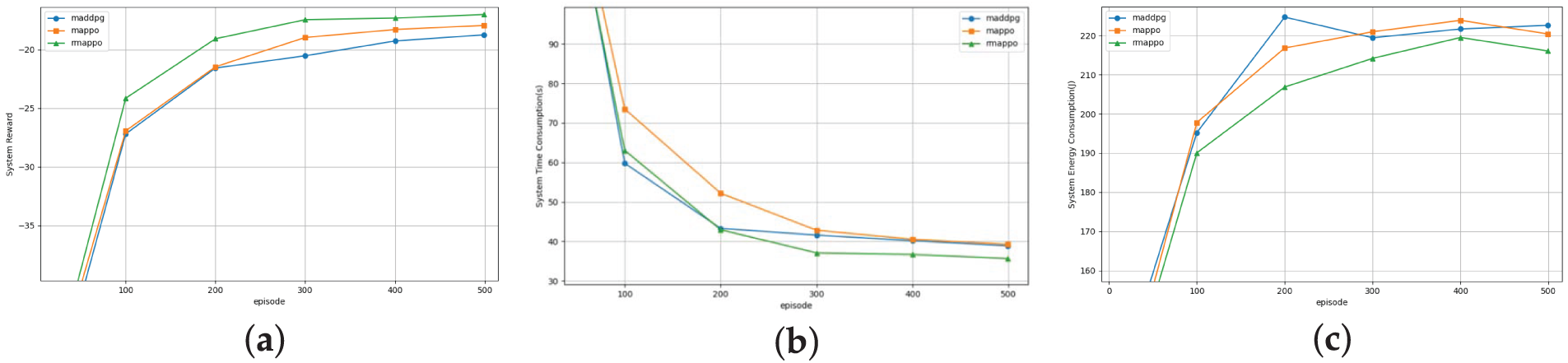
Figure 7: System performance comparison under different algorithms: (a) System reward; (b) System latency consumption; (c) System energy consumption
5.3 Performance under Different Problem Sizes
This study uses different problem sizes (i.e., rising agent numbers) to assess RMAPPO’s scalability in terms of workflow task processing delay and energy consumption. Two offloading benchmarks are compared: All-to-Edge (ATE), in which processes are offloaded straight to an ES, and All-to-Local (ALT), in which jobs are processed locally within the time window. In contrast to static techniques, this analysis demonstrates RMAPPO’s flexibility in responding to task complexity.
As computational task size increases, Fig. 8 compares the system-average rewards of RMAPPO, ATL (local task processing), and ATE (offloading all tasks to ESs). Agent-server placement and resource competition affect ATE’s performance, reducing offloading efficiency, whereas ATL passively queues work locally. The results, averaged across 9 trials with 95% confidence intervals, show that RMAPPO is more stable and offers higher rewards than static strategies, which struggle with changing environmental conditions. As the number of agents increases, Fig. 8 assesses the RMAPPO algorithm combined with ATL and ATE modes in terms of system-average rewards. According to the results, RMAPPO routinely outperforms the other two options in terms of incentives, demonstrating its promising scalability due to its temporal processing capabilities. However, the centralized Critic may encounter bottlenecks in ultra-large-scale scenarios, which represents a direction for future research.
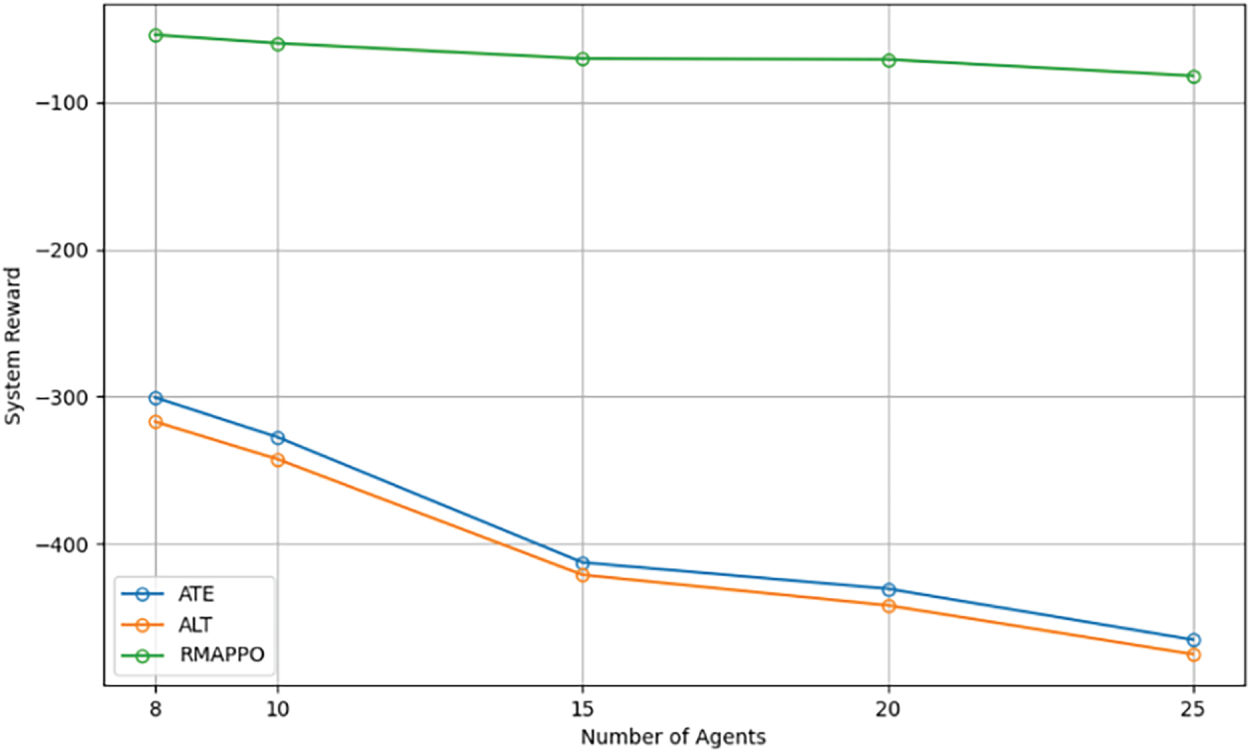
Figure 8: Comparison of rewards between RMAPPO algorithm and different offloading modes
5.4 Ablation Study on Module Contributions
To evaluate the impact of
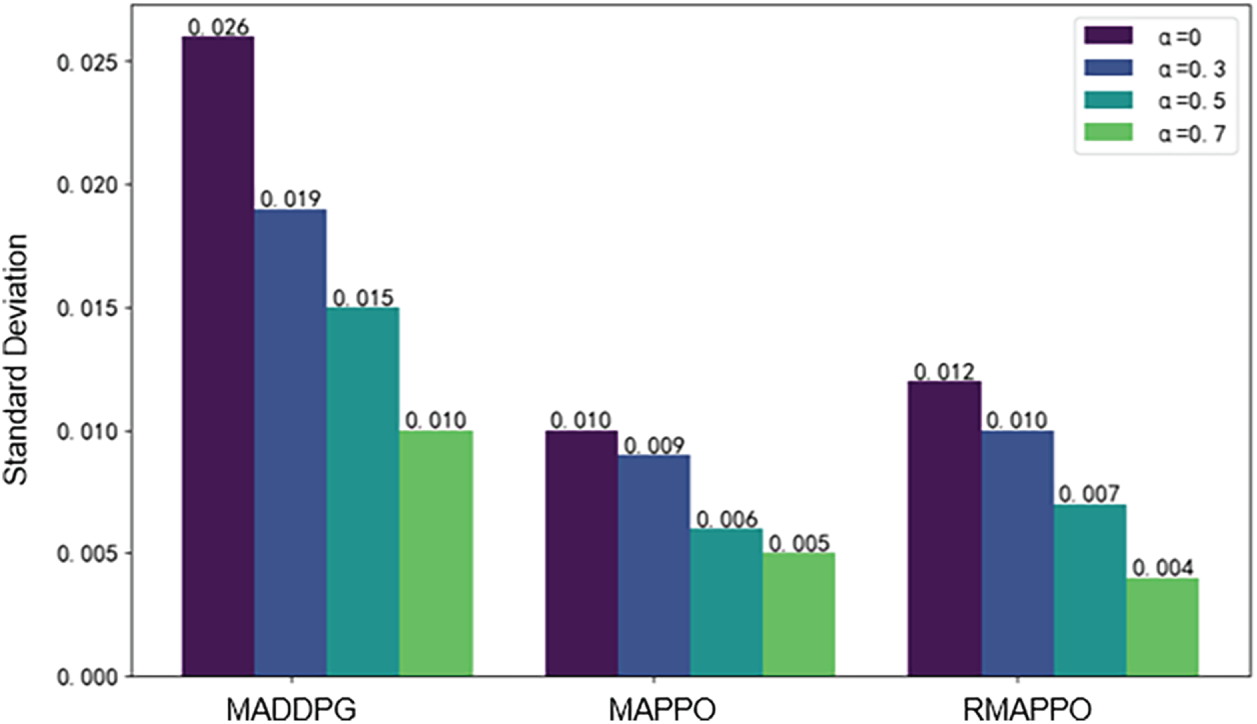
Figure 9: Impact of
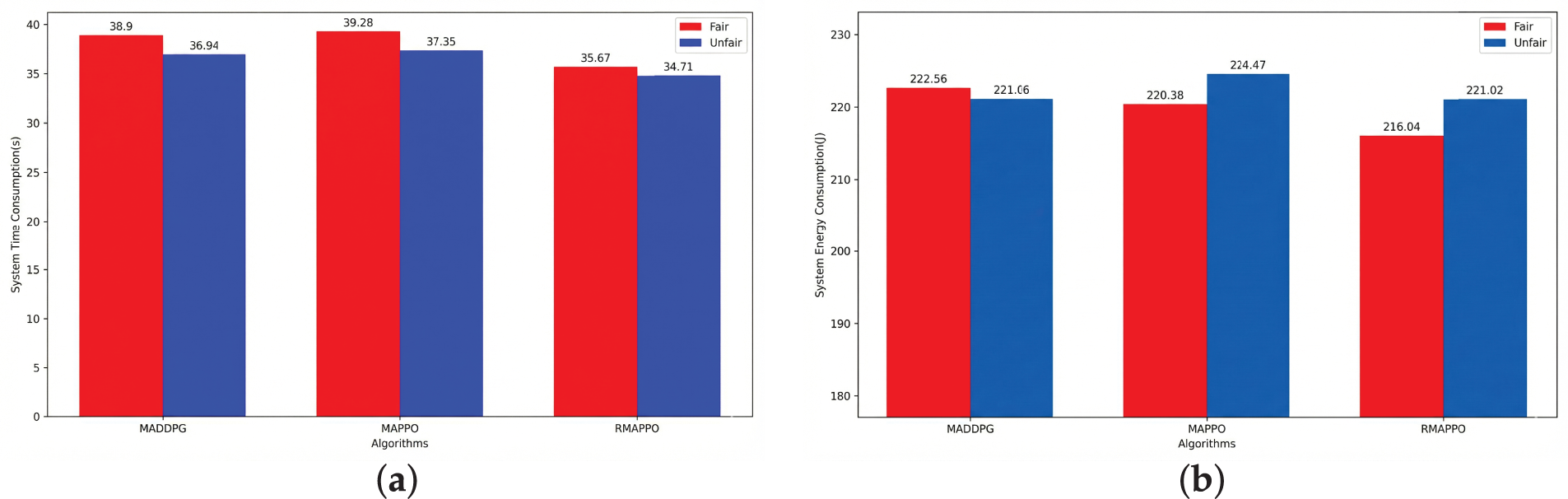
Figure 10: Comparison of system costs before and after introducing fairness in different algorithms: (a) System latency comparison; (b) System energy consumption comparison
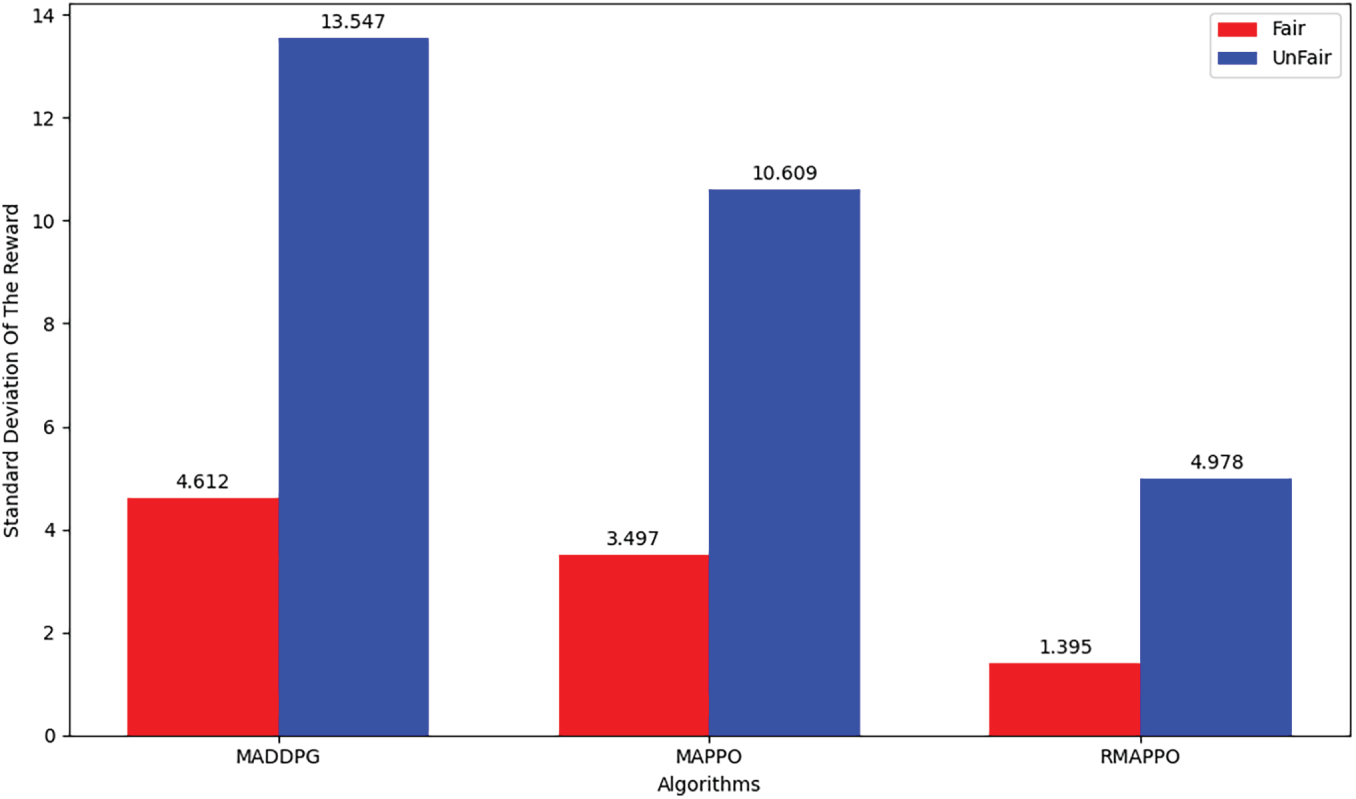
Figure 11: Comparison of the standard deviation of rewards before and after introducing fairness for different algorithms
The core contribution of this paper is to address the challenge of collaborative optimization for prediction, offloading, and fairness in dynamic industrial edge environments. First, a CoMEC system model is constructed that explicitly accounts for robot mobility, the complex dependency structures of workflow tasks, and heterogeneous computing resources. Second, the EKF-based module is designed to transform robot mobility uncertainty into prior knowledge for optimization, enabling a shift from reactive response to predictive scheduling. Third, an RMAPPO is also developed to achieve synergistic optimization of overall system utility and fairness in complex dynamic environments. Simulation experiments demonstrate that compared to baseline algorithms such as MAPPO and MADDPG, the proposed RMAPPO framework exhibits significant advantages across multiple key performance metrics, including system utility, task processing delay, and energy consumption. Future work will focus on the following areas: First, extending the communication model to more complex interference environments and investigating MADRL strategies for joint power and channel allocation; Second, exploring prediction models and robust distributed training mechanisms to enhance algorithm performance under non-ideal conditions such as sensor anomalies. Third, apply this framework to broader industrial scenarios to validate its universality and scalability.
Acknowledgement: We sincerely thank the Netlink Collaborative Manufacturing Laboratory team for their technical support.
Funding Statement: This work was partly supported by the National Key R&D Program of China under Grant Nos. 2024YFD2400200 and 2024YFD2400204. This work was supported in part by the Science and Technology Development Program for the Two Zones under Grant No. 2023LQ02004.
Author Contributions: Xiaocong Wang and Peng Zhao: Data collection, initial draft preparation, analysis and interpretation of results; Xiaocong Wang, Jiajian Li and Yanjun Shi: Research conception and design, review; Xiaocong Wang: Final manuscript formatting; Yanjun Shi and Hui Lian: Supervision; Yanjun Shi and Hui Lian: Funding acquisition. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data available on request from the authors.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhang T, Wang N, Yang Y, Wang Z. A generalised system for multi-mobile robot cooperation in smart manu-facturing. Robot Comput Integr Manuf. 2026;98:103139. doi:10.1016/j.rcim.2025.103139. [Google Scholar] [CrossRef]
2. Li X, Jing T, Yu FR, Zhu M, Wang H, Liu Z. Double-layer blockchain and MEC deployment enabled secure and efficient entity interaction framework for the industrial IoT. IEEE Internet Things J. 2025;12(17):35048–64. doi:10.1109/jiot.2025.3549428. [Google Scholar] [CrossRef]
3. Qiu T, Chi J, Zhou X, Ning Z, Atiquzzaman M, Wu DO. Edge computing in industrial Internet of Things: archi-tecture, advances and challenges. IEEE Commun Surv Tutor. 2020;22(4):2462–88. doi:10.1109/comst.2020.3009103. [Google Scholar] [CrossRef]
4. Shi J, Du J, Shen Y, Wang J, Yuan J, Han Z. DRL-based V2V computation offloading for blockchain-enabled ve-hicular networks. IEEE Trans Mobile Comput. 2022;22(7):3882–97. doi:10.1109/tmc.2022.3153346. [Google Scholar] [CrossRef]
5. Wang C, Liang C, Yu FR, Chen Q, Tang L. Computation offloading and resource allocation in wireless cellular networks with mobile edge computing. IEEE Trans Wireless Commun. 2017;16(8):4924–38. doi:10.1109/twc.2017.2703901. [Google Scholar] [CrossRef]
6. You C, Huang K, Chae H, Kim BH. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans Wirel Commun. 2016;16(3):1397–411. doi:10.1109/twc.2016.2633522. [Google Scholar] [CrossRef]
7. Chen C, Li H, Li H, Fu R, Liu Y, Wan S. Efficiency and fairness oriented dynamic task offloading in Internet of vehicles. IEEE Trans Green Commun Netw. 2022;6(3):1481–93. doi:10.1109/tgcn.2022.3167643. [Google Scholar] [CrossRef]
8. Yang H, Wei Z, Feng Z, Chen X, Li Y, Zhang P. Intelligent computation offloading for MEC-based cooperative vehicle infrastructure system: a deep reinforcement learning approach. IEEE Trans Veh Technol. 2022;71(7):7665–79. doi:10.1109/tvt.2022.3171817. [Google Scholar] [CrossRef]
9. Zhang Z, Zeng F. Efficient task allocation for computation offloading in vehicular edge computing. IEEE Internet Things J. 2022;10(6):5595–606. doi:10.1109/jiot.2022.3222408. [Google Scholar] [CrossRef]
10. Xue J, Hu Q, An Y, Wang L. Joint task offloading and resource allocation in vehicle-assisted multi-access edge computing. Comput Commun. 2021;177:77–85. doi:10.1016/j.comcom.2021.06.014. [Google Scholar] [CrossRef]
11. Zhang Z, Chen Z, Shen Y, Dong X, Xi N. A dynamic task offloading scheme based on location forecasting for mobile intelligent vehicles. IEEE Trans Veh Technol. 2024;73(6):7532–46. doi:10.1109/tvt.2024.3351224. [Google Scholar] [CrossRef]
12. Dai Y, Zhang K, Maharjan S, Zhang Y. Deep reinforcement learning for stochastic computation offloading in digital twin networks. IEEE Trans Ind Inf. 2020;17(7):4968–77. doi:10.1109/tii.2020.3016320. [Google Scholar] [CrossRef]
13. Dai X, Xiao Z, Jiang H, Alazab M, Lui JCS, Dustdar S, et al. Task co-offloading for D2D-assisted mobile edge computing in industrial Internet of Things. IEEE Trans Ind Inf. 2022;19(1):480–90. doi:10.1109/tii.2022.3158974. [Google Scholar] [CrossRef]
14. Jiang C, Cheng X, Gao H, Zhou X, Wan J. Toward computation offloading in edge computing: a survey. IEEE Access. 2019;7:131543–58. doi:10.1109/access.2019.2938660. [Google Scholar] [CrossRef]
15. Guo F, Yu FR, Zhang H, Ji H, Liu M, Leung VCM. Adaptive resource allocation in future wireless networks with blockchain and mobile edge computing. IEEE Trans Wirel Commun. 2019;19(3):1689–703. doi:10.1109/twc.2019.2956519. [Google Scholar] [CrossRef]
16. Yuan H, Zhou M. Profit-maximized collaborative computation offloading and resource allocation in distrib-uted cloud and edge computing systems. IEEE Trans Automat Sci Eng. 2020;18(3):1277–87. doi:10.1109/tase.2020.3000946. [Google Scholar] [CrossRef]
17. Jang J, Klabjan D, Liu H, Patel NS, Li X, Ananthanarayanan B, et al. Learning multiple coordinated agents un-der directed acyclic graph constraints. Expert Syst Appl. 2025;283(7):127744. doi:10.1016/j.eswa.2025.127744. [Google Scholar] [CrossRef]
18. Huang F, Wang W, Liu Q, Fan W, Guo J, Jia W, et al. DRMQ: dynamic resource management for enhanced QoS in collaborative edge-edge industrial environments. IEEE Trans Serv Comput. 2025;18(2):743–57. doi:10.1109/tsc.2025.3539201. [Google Scholar] [CrossRef]
19. Gao R, Zhang W, Mao W, Tan J, Zhang J, Huang H, et al. Method towards collaborative cloud and edge compu-ting via RBC for joint communication and computation resource allocation. J Ind Inf Integr. 2025;44:100776. doi:10.1016/j.jii.2025.100776. [Google Scholar] [CrossRef]
20. Li Y, Zhang X, Lei B, Zhao Q, Wei M, Qu Z, et al. Incentive-driven task offloading and collaborative computing in device-assisted MEC networks. IEEE Internet Things J. 2024;12(8):9978–95. doi:10.1109/jiot.2024.3508693. [Google Scholar] [CrossRef]
21. Luo Q, Hu S, Li C, Li G, Shi W. Resource scheduling in edge computing: a survey. IEEE Commun Surv Tutor. 2021;23(4):2131–65. doi:10.1109/comst.2021.3106401. [Google Scholar] [CrossRef]
22. Qin M, Cheng N, Jing Z, Yang T, Xu W, Yang Q, et al. Service-oriented energy-latency tradeoff for IoT task par-tial offloading in MEC-enhanced multi-RAT networks. IEEE Internet Things J. 2020;8(3):1896–907. doi:10.1109/jiot.2020.3015970. [Google Scholar] [CrossRef]
23. Zhang F, Han G, Liu L, Zhang Y, Peng Y, Li C. Cooperative partial task offloading and resource allocation for IIoT based on decentralized multiagent deep reinforcement learning. IEEE Internet Things J. 2023;11(3):5526–44. doi:10.1109/jiot.2023.3306803. [Google Scholar] [CrossRef]
24. Du J, Zhao L, Feng J, Chu X. Computation offloading and resource allocation in mixed fog/cloud computing systems with Min-max fairness guarantee. IEEE Trans Commun. 2017;66(4):1594–608. doi:10.1109/tcomm.2017.2787700. [Google Scholar] [CrossRef]
25. Li X, Du X, Zhao N, Wang X. Computing over the sky: joint UAV trajectory and task offloading scheme based on optimization-embedding multi-agent deep reinforcement learning. IEEE Trans Commun. 2023;72(3):1355–69. doi:10.1109/tcomm.2023.3331029. [Google Scholar] [CrossRef]
26. Cui YY, Zhang DG, Zhang T, Zhang J, Piao M. A novel offloading scheduling method for mobile application in mobile edge computing. Wirel Netw. 2022;28(6):2345–63. doi:10.1007/s11276-022-02966-2. [Google Scholar] [CrossRef]
27. Pang S, Hou L, Gui H, He X, Wang T, Zhao Y. Multi-mobile vehicles task offloading for vehicle-edge-cloud collaboration: a dependency-aware and deep reinforcement learning approach. Comput Commun. 2023;213:359–71. doi:10.1016/j.comcom.2023.11.013. [Google Scholar] [CrossRef]
28. Tang H, Wu H, Qu G, Li R. Double deep Q-network based dynamic framing offloading in vehicular edge computing. IEEE Trans Netw Sci Eng. 2022;10(3):1297–310. doi:10.1109/tnse.2022.3172794. [Google Scholar] [CrossRef]
29. Chen C, Zeng Y, Li H, Liu Y, Wan S. A multihop task offloading decision model in MEC-enabled Internet of vehicles. IEEE Internet Things J. 2022;10(4):3215–30. doi:10.1109/jiot.2022.3143529. [Google Scholar] [CrossRef]
30. Liu L, Zhao M, Yu M, Ahmad Jan M, Lan D, Taherkordi A. Mobility-aware multi-hop task offloading for au-tonomous driving in vehicular edge computing and net-works. IEEE Trans Intell Transp Syst. 2022;24:2169–82. doi:10.1109/tits.2022.3142566. [Google Scholar] [CrossRef]
31. Zhao L, Zhang E, Wan S, Hawbani A, Al-Dubai AY, Min G, et al. MESON: a mobility-aware dependent task of-floading scheme for urban vehicular edge computing. IEEE Trans Mobile Comput. 2023;23(5):4259–72. doi:10.1109/tmc.2023.3289611. [Google Scholar] [CrossRef]
32. Chung J, Fayyad J, Tamizi MG, Najjaran H. The effectiveness of state representation model in multi-agent proximal policy optimization for multi-agent path finding. In: Proceedings of the 2024 IEEE/RSJ Interna-tional Conference on Intelligent Robots and Systems (IROS); 2024 Oct 14–18; Abu Dhabi, United Arab Emirates. p. 9947–52. doi:10.1109/iros58592.2024.10802643. [Google Scholar] [CrossRef]
33. Wu H, Lyu X, Tian H. Online optimization of wireless powered mobile-edge computing for heterogeneous industrial Internet of Things. IEEE Internet Things J. 2019;6(6):9880–92. doi:10.1109/jiot.2019.2932995. [Google Scholar] [CrossRef]
34. Deng D, Wu X, Zhang T, Tang X, Du H, Kang J, et al. FedASA: a personalized federated learning with adaptive model aggregation for heterogeneous mobile edge computing. IEEE Trans Mobile Comput. 2024;23(12):14787–802. doi:10.1109/tmc.2024.3446271. [Google Scholar] [CrossRef]
35. Puterman ML. Markov decision processes. Handb Oper Res Manag Sci. 1990;2:331–434. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools