
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Abel-Net: Aggregate Bilateral Edge Localization Network for Multi-Task Binary Segmentation
1 School of Automation, Hangzhou Dianzi University, Hangzhou, 310018, China
2 Zhuoyue Honors College, Hangzhou Dianzi University, Hangzhou, 310018, China
3 School of Cyberspace, Hangzhou Dianzi University, Hangzhou, 310018, China
* Corresponding Author: Yixiu Liu. Email:
Computers, Materials & Continua 2026, 87(2), 40 https://doi.org/10.32604/cmc.2026.075593
Received 04 November 2025; Accepted 22 December 2025; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Binary segmentation tasks in computer vision exhibit diverse appearance distributions and complex boundary characteristics. To address the limited generalization and adaptability of existing models across heterogeneous tasks, we propose Abel-Net, an Aggregated Bilateral Edge Localization Network designed as a universal framework for multi-task binary segmentation. Abel-Net integrates global and local contextual cues to enhance feature learning and edge precision. Specifically, a multi-scale feature pyramid fusion strategy is implemented via an Aggregated Skip Connection (ASC) module to strengthen feature adaptability, while the Edge Dual Localization (EDL) mechanism performs coarse-to-fine refinement through edge-aware supervision. Additionally, Edge Attention (EA) and Edge Fusion Attention (EFA) modules prioritize edge-critical regions and facilitate accurate boundary alignment. Extensive experiments on nine diverse binary segmentation tasks demonstrate that Abel-Net performs comparably to or surpasses state-of-the-art task-specific networks, exhibiting strong adaptability to a wide range of visual perception challenges.Keywords
As a fundamental component of modern computer vision, image segmentation [1] provides the mathematical foundation for high-level visual perception [2] through pixel-wise classification and structural understanding. Among various segmentation paradigms, binary segmentation [3] plays a crucial role by simplifying complex visual interpretation tasks into foreground–background separation, thereby achieving an effective balance between accuracy and computational efficiency. This property has made binary segmentation a key technique not only in industrial inspection [4] but also in a wide range of vision-based applications such as medical imaging, remote sensing, and autonomous perception systems.
With the rapid development of deep learning (DL) and multimodal perception, visual understanding tasks are evolving toward increasingly diverse and complex environments. This trend has posed significant challenges for binary segmentation models in adapting to heterogeneous data domains and maintaining precise boundary localization. For instance, existing frameworks for camouflaged object detection (COD) often struggle to distinguish concealed targets from visually similar backgrounds, leading to suboptimal detection accuracy. Similarly, salient object detection (SOD) [5] remains challenging under conditions of multiple overlapping targets or strong background interference. In remote sensing image salient object detection (RSISOD), performance degradation frequently occurs due to complex environmental noise and multidirectional variations of targets.
In other specialized domains, such as optical imaging and medical analysis, similar challenges persist. Shadows often introduce pseudo-edge artifacts that hinder precise measurement, emphasizing the need for robust shadow detection algorithms [6]. Defocus blur detection remains an open problem where accurate delineation of blurred regions is difficult to achieve. Likewise, detecting transparent and specular materials introduces substantial complexity due to their reflective and refractive properties, which distort spatial and photometric information. In medical image segmentation, although notable progress has been made, more intelligent and fine-grained models are still required to accurately delineate anatomical structures and pathological regions. Collectively, these challenges highlight the limitations of existing binary segmentation frameworks and underscore the urgent demand for unified, generalizable, and edge-aware architectures to improve precision and cross-domain adaptability across diverse visual tasks.
Current research indicates that despite the remarkable progress of DL in specific segmentation tasks, existing methods generally suffer from inadequate cross-domain generalization capabilities. In this paper, we propose a universal network for multiple binary segmentation tasks, as illustrated in Fig. 1, which effectively handles a binary segmentation task set containing nine typical scenarios.
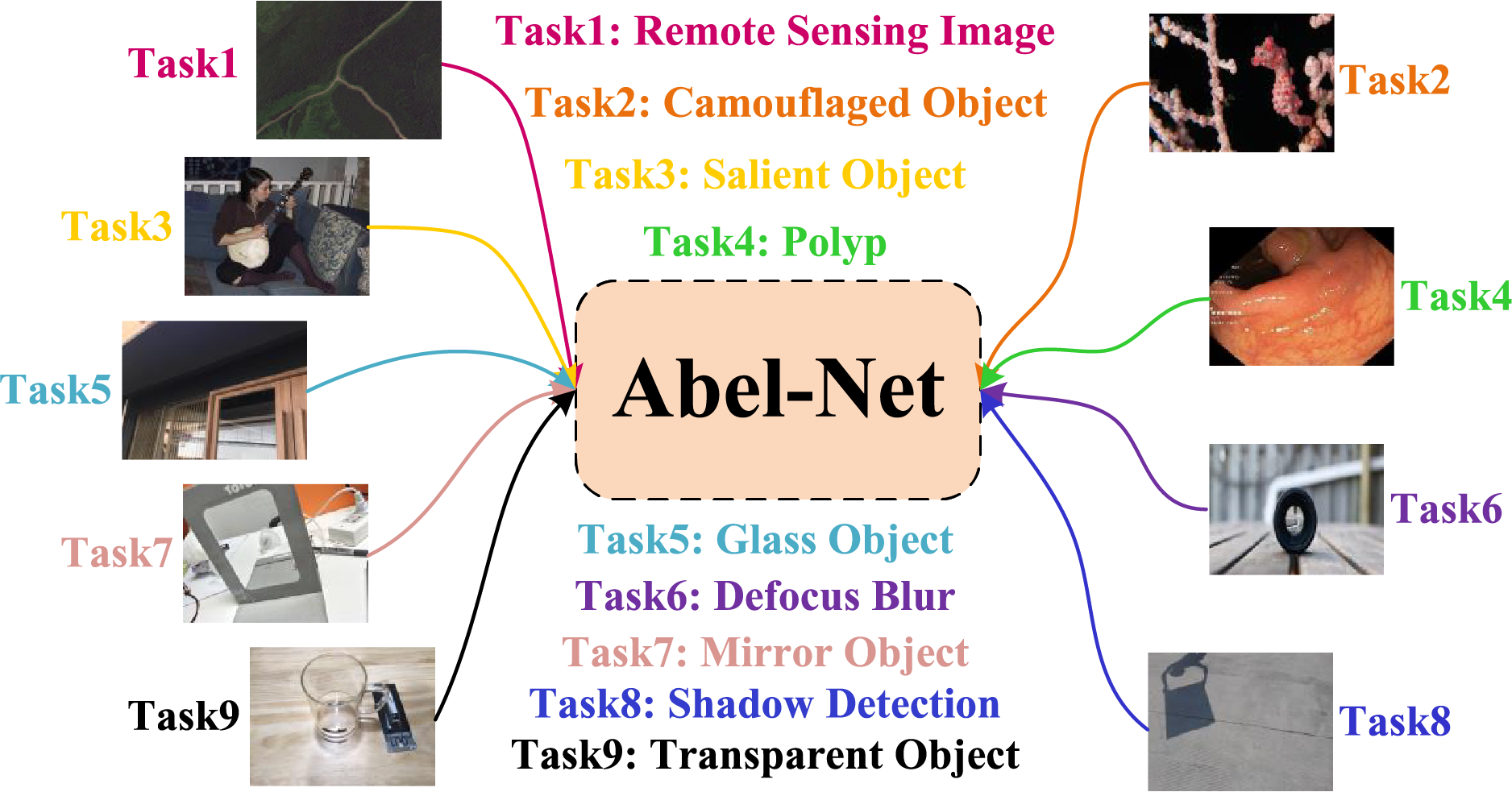
Figure 1: All binary segmentation tasks processed by Abel-Net in this paper
Firstly, following common practice, we adopt the U-Net [7] architecture as the baseline framework to leverage its feature pyramid structure, constructing aggregated skip connections. However, distinct from traditional encoder-decoder architectures like U-Net that directly concatenate shallow features through skip connections, our work introduces a multi-scale feature pyramid fusion strategy, which is materialized via the proposed Aggregated Skip Connection (ASC). This approach extracts multi-depth features through four convolutional layers with different parameters while dynamically aggregating features from the current decoder layer, upper decoder layers, and pyramid outputs. Compared with the DeepLab [8] series, which relies on dilated convolutions to expand receptive fields or multi-scale pooling in ASPP modules, our method enhances cross-domain feature representation robustness while reducing information loss through complementary inter-layer feature fusion.
Secondly, we design an Edge Dual Localization (EDL) module. Specifically,
Finally, we propose Edge Attention (EA) and Edge Fusion Attention (EFA) modules. Unlike traditional attention mechanisms that focus on channel or spatial-wise feature recalibration without explicit edge prior integration, our EA innovatively multiplies predicted edge maps with attention key-value matrices in an element-wise manner. The EFA module further achieves dynamic fusion between edge features and contextual semantics through edge-guided local attention focusing. Compared with self-attention in Transformers, EFA enhances the capability of capturing subtle edge structures while reducing computational complexity.
To validate the generalizability of our network, we conduct evaluations across 22 datasets covering mainstream tasks (salient and camouflaged object detection) and specialized applications (transparent, glass, and specular object detection). Experimental results demonstrate that our universal network outperforms most single-task methods in diverse binary segmentation scenarios.
The principal contributions of this work are summarized as follows:
• We propose an aggregated bilateral edge localization network (Abel-Net) that demonstrates effective performance across a wide range of binary segmentation tasks, addressing the common limitation of conventional binary segmentation networks’ lack of generalizability.
• We propose a multi-scale feature pyramid fusion strategy implemented via a novel ASC. This module aggregates features from different depths of the image, allowing the decoder to access richer feature representations.
• To achieve precise edge localization, we introduce the EDL module and EDL loss. The EDL module effectively enhances edge identification through dual localization, while the EDL loss ensures that the predicted edges progressively align with the ground truth edges.
• We embed the predicted edge information in the attention mechanism through our proposed EA and EFA modules, allowing the network to focus more on the edges of the image and achieve edge exposure.
• Extensive experiments on 22 datasets demonstrate the quantitative and qualitative superiority of our method over state-of-the-art approaches in nine binary segmentation tasks.
The remainder of this paper is organized as follows: Section 2 reviews related work in binary segmentation and multi-task learning. Section 3 details the proposed Abel-Net architecture, including the aggregated skip connection, edge dual localization, and attention mechanisms. Section 4 presents the experimental setup, quantitative and qualitative comparisons with state-of-the-art methods, and ablation studies. Finally, Section 5 concludes the paper, discussing the limitations and future scope of this work.
Recent research has explored a variety of binary segmentation tasks under a unified DL framework. Multi-task binary segmentation approaches, such as GateNet [9] and EVP [10], aim to share representations across multiple domains, balancing multi-level features and achieving efficient adaptation without architectural redesign. These studies inspired our overall design, motivating multi-scale feature fusion and lightweight attention mechanisms (EA, EFA) to improve generalization while maintaining model compactness.
Salient object detection (SOD) and its variants, including camouflaged object detection (COD), shadow detection, and transparent or glass object detection, all focus on segmenting visually challenging regions that differ from the background in distinct ways. Modern methods leverage feature aggregation modules and attention-based decoders to enhance localization accuracy. For instance, ICON [5] and EDN [11] improve feature refinement, while COD-related works such as DGNet [12] and HitNet [13] emphasize multi-scale feedback and texture-context decoupling.
Polyp segmentation and remote sensing salient object detection (RSISOD) extend binary segmentation to medical and aerial imagery domains, respectively. Polyp segmentation methods such as PraNet [14] and MSNet [15] focus on hierarchical multi-scale feature extraction, while RSISOD models like MCCNet [16] and SeaNet [17] address cross-sensor feature fusion and complex scene understanding through attention-based modules.
Finally, defocus blur detection [18,19] targets blurred region segmentation, where high variability in focal distances increases task difficulty. Recent methods integrate context- and edge-aware representations to enhance blur localization and image restoration performance.
In summary, while the aforementioned works have established strong baselines, clear distinctions exist between them and our proposed Abel-Net. First, compared to task-specific models like PraNet [14] or SINet [20], which are tailored to specific visual characteristics, Abel-Net is designed as a universal framework capable of generalizing across nine heterogeneous tasks without architectural redesign. Second, unlike existing multi-task approaches such as GateNet [9] and EVP [10] that primarily rely on implicit feature sharing or visual prompting, Abel-Net introduces an explicit Edge Dual Localization (EDL) mechanism. This allows for coarse-to-fine boundary refinement, directly addressing the challenge of edge ambiguity common in binary segmentation. Finally, distinct from standard multi-scale fusion methods used in general segmentation, our Aggregated Skip Connection (ASC) implements a specialized pyramid fusion strategy that preserves rich semantic details across depths, ensuring robust performance even in complex scenarios like transparent or shadow object detection.
In this section, we provide a detailed introduction to the aggregate bilateral edge localization network (Abel-Net), including ASC, EDL, EA, and EFA. As shown in Fig. 2, in the Abel-Net, we adopt the U-Net architecture to build the network because it provides a symmetric encoder–decoder structure with skip connections, which enables the direct transfer of spatially detailed features from the encoder to the decoder. Moreover, U-Net’s hierarchical feature fusion is highly compatible with multi-scale backbone networks such as the second version of the Pyramid Vision Transformer (PVTv2) [21], allowing semantic-rich deep features to be seamlessly integrated with high-resolution shallow features. Its modular design also facilitates the incorporation of advanced components, such as the ASC, EDL, and attention mechanisms, making it a flexible and robust foundation for multi-task binary segmentation. We utilize the PVTv2 as the encoder backbone because its pyramid structure enables efficient multi-scale feature extraction with progressively reduced resolution, which is crucial for handling objects of varying sizes across different tasks. Additionally, PVTv2 introduces a spatial-reduction attention mechanism, which reduces computational complexity while maintaining the ability to capture long-range dependencies, making it suitable for high-resolution inputs common in binary segmentation tasks. And we choose the Swin Transformer block [22] as the decoder backbone due to its shifted window attention mechanism, which balances local feature refinement and global context aggregation. This design not only allows the decoder to recover fine details such as object boundaries but also preserves semantic consistency across scales. Compared with traditional CNN-based decoders, Swin Transformer blocks offer superior adaptability to diverse binary segmentation scenarios by better modeling complex spatial relationships and reducing overfitting when generalizing to unseen tasks. In addition to enhancing deep features, the encoder also utilizes a feature pyramid network (FPN). The collaborative use of edge attention and edge fusion attention enables effective exposure of objects, and EDL serves as input to the decoder to improve the accuracy of edge localization.
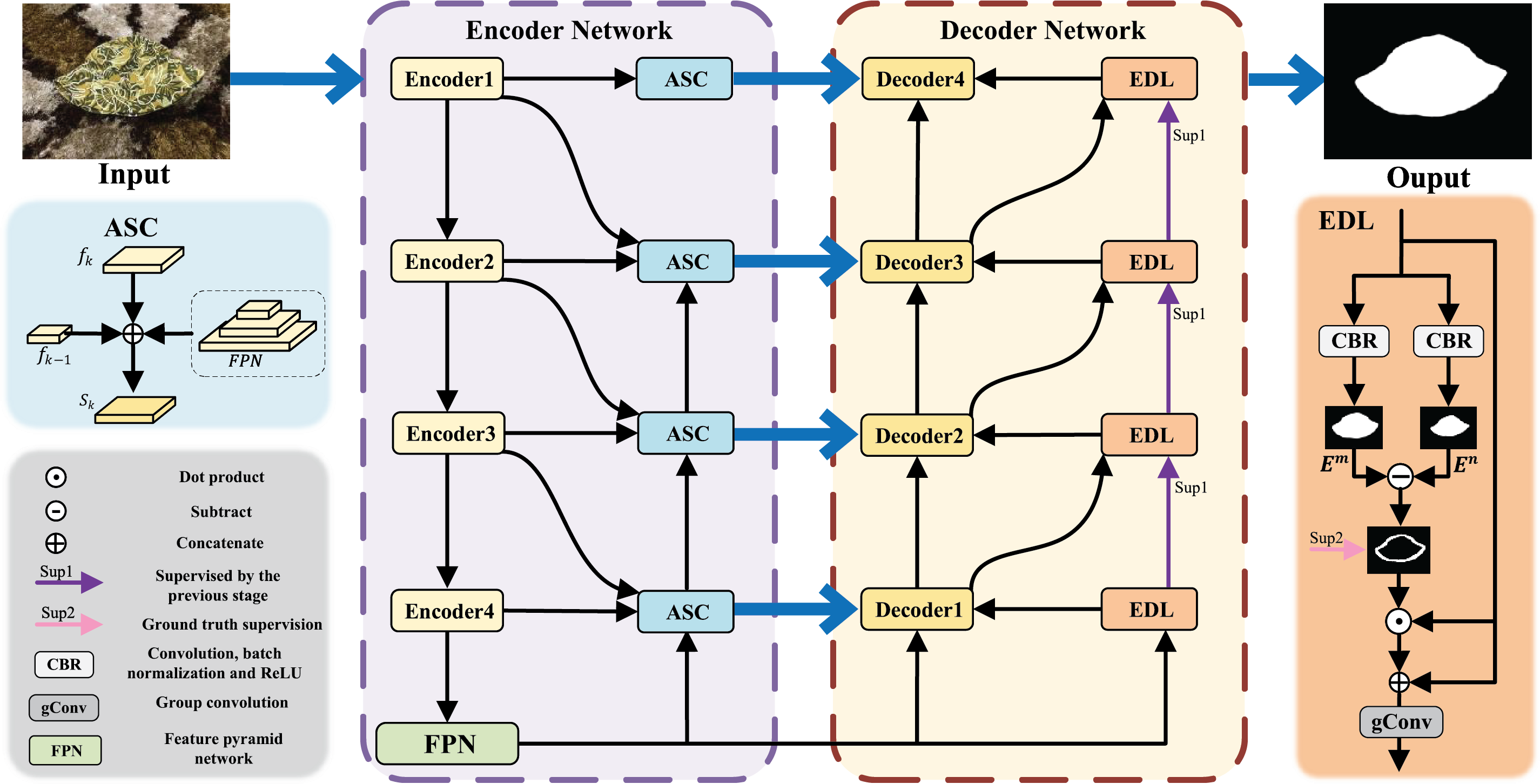
Figure 2: Overall architecture of the Abel-Net. The aggregation skip connection (ASC) aggregates features from multiple depths of the encoder and the FPN, and then delivers multi-scale contextual information to the decoder. The EDL module ensures that the predicted edges become more refined with each iteration
3.2 Aggregation Skip Connection
Aggregation skip connection based on AIMs and the Swin Transformer, combined with the integration of FPN, has significantly enhanced Abel-Net’s ability to perform segmentation tasks.
FPN incorporates multiple levels of detailed information, allowing the network to effectively handle features of varying depths. Furthermore, this cross-level feature fusion facilitates the extraction of richer and more semantically representative features, thereby improving the accuracy and robustness of object detection. Given that the backbone follows a 4-level encoder-decoder structure, the number of levels in this paper is also set to 4.
Assuming the current encoder output is
where
Here,
Finally, the output feature
It is challenging to accurately detect edges with a single localization. Therefore, we perform two convolutions to capture more edge information and obtain finer edges. The first convolution produces dilated image edges, and the second convolution yields eroded image edges. By subtracting the results, we effectively enhance the feature details and eliminate background noise, resulting in more precise edge detection.
In the EDL module,
where
where
The fine-grained edge mask generated by the EDL module is not only utilized for optimizing the edge branch but is also fused with the multi-scale features output by the ASC module during the decoding stage. Specifically, the edge mask serves as a guidance signal that, together with the cross-layer features from ASC, jointly contributes to the EA and EFA modules, thereby enhancing the decoder’s sensitivity to object boundaries. Throughout the multi-stage processing, the high-level semantics provided by ASC help suppress edge noise, while the fine-grained edges from EDL compensate for ASC’s limitations in capturing detailed structures. This complementary interaction between the two modules improves overall segmentation accuracy and enhances cross-task generalization capability.
To enhance the network’s attention to image edges and thereby improve edge recognition, we propose predicted edge attention based on the self-attention mechanism, which consists of edge attention (EA) and edge fusion attention (EFA). As shown in Fig. 3, EA takes the output
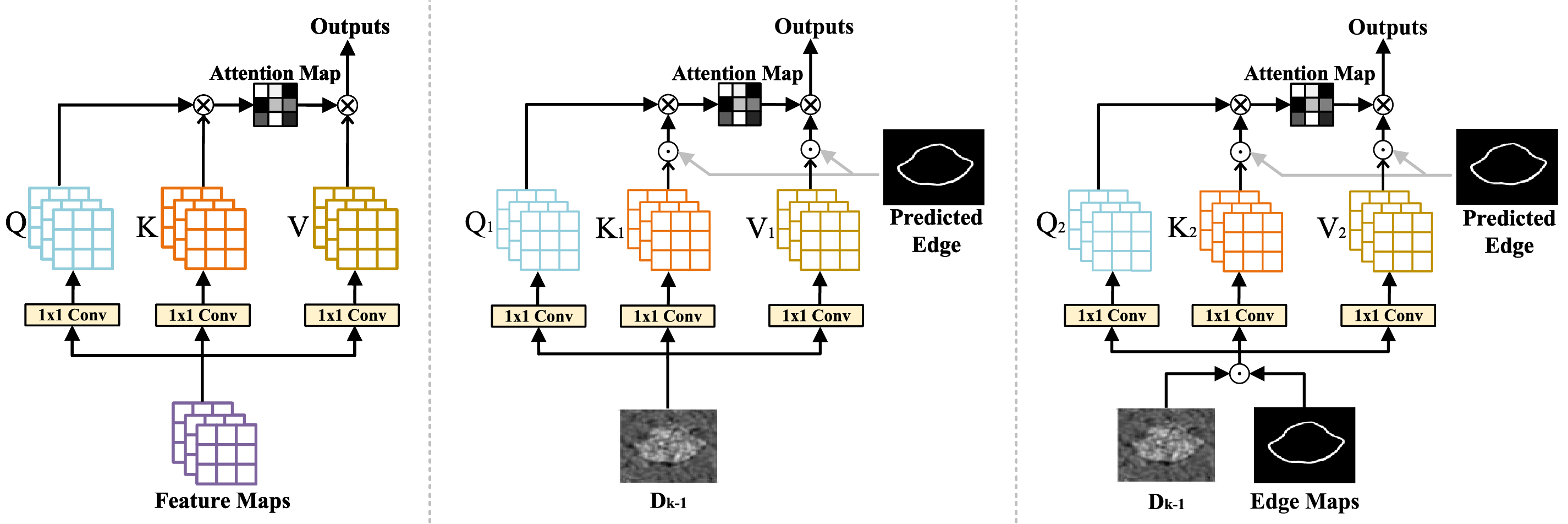
Figure 3: Comparison of our network’s attention modules with a traditional attention module. Left: traditional self-attention module. Middle: edge attention (EA). Right: edge fusion attention (EFA)
By element-wise multiplying the predicted edge
where
Finally, the attention weights can be represented as:
Unlike conventional self-attention modules that compute the attention weights purely within the feature space of the input, the proposed edge fusion attention introduces an explicit integration of predicted edge maps into the attention process. Specifically, EFA differs from standard self-attention in two key aspects:
(1) Cross-attention with explicit edge priors: Instead of computing the query, key, and value solely from the same feature representation, EFA employs the predicted edge map as an additional prior, ensuring that edge cues are explicitly embedded into the attention weights. This cross-modality design allows EFA to guide the network towards more edge-sensitive feature refinement.
(2) Enhanced edge localization: While conventional self-attention emphasizes global contextual dependencies, EFA emphasizes spatial alignment between decoder features and edge maps. This design leads to more accurate boundary localization, which is particularly beneficial for tasks such as camouflaged object detection, where edges are often weak and difficult to capture. Therefore, the distinctive role of EFA is to combine the advantages of self-attention with edge-aware priors, resulting in improved edge representation and sharper object boundaries.
Through EA and EFA, our network can effectively improve the accuracy of identifying the edges of camouflaged objects.
The loss function includes
where N represents the total number of pixels in the image,
The second part of the loss ensures that the edge probability map includes the ground truth edges, which we define as
where
where N represents the total number of pixels in the image.
where
where
4.1 Segmentation Tasks and Experimental Details
We evaluate our model on multiple datasets across nine different tasks. Specifically, for camouflaged object detection, we adopt CAMO, COD10K, and NC4K, which are widely used benchmarks covering diverse scenarios of camouflaged targets. For salient object detection, we employ OMRON, DUTS-TE, HKU-IS, PASCAL-S, and ECSSD, which provide large-scale and diverse images with complex backgrounds for robust evaluation. For defocus blur detection, we use CUHK and DUT, two standard datasets that cover typical defocus blur patterns. For remote sensing image salient object detection, we select EORSSD, a high-quality dataset capturing remote sensing scenarios. For transparent object detection, we adopt Transparent-easy and Transparent-hard, which represent different levels of difficulty in transparent object recognition. For glass object detection, we use GDD, the most widely adopted benchmark for this task. For mirror object detection, we use MSD, a challenging dataset containing mirror objects in complex environments. For polyp segmentation, we adopt CVC-300, CVC-ClinicDB, CVC-ColonDB, ETIS, and Kvasir, which together provide sufficient diversity in medical imaging conditions and polyp appearances. For shadow detection, we employ SBU and ISTD, two commonly used benchmarks with rich variations in shadow scale and intensity. These datasets are selected because they are widely recognized, diverse, and challenging benchmarks in their respective domains, ensuring both comprehensive evaluation and fair comparison with existing methods.
We use the PyTorch framework to implement our models on 2 Nvidia RTX 3090 GPUs for 100 epochs and the batch size is 20. The input resolutions of images are resized to 352
We mainly used five evaluation metrics to evaluate indicators: structure measure [25] (
4.3 Comparison with State-of-the-Art Methods
Tables 1–7 show the results of our method compared to other advanced methods on different datasets for nine different tasks, with the optimal method corresponding to each dataset marked in bold. We can see that in most tasks across the majority of datasets, our method can achieve good results. As shown in Figs. 4–6, we conduct a visual comparison with different state-of-the-art models. Through visual display, the superiority of our method can be more intuitively demonstrated: In nine different tasks, Abel-Net consistently achieves good results, indicating that our method has strong generalization capabilities.
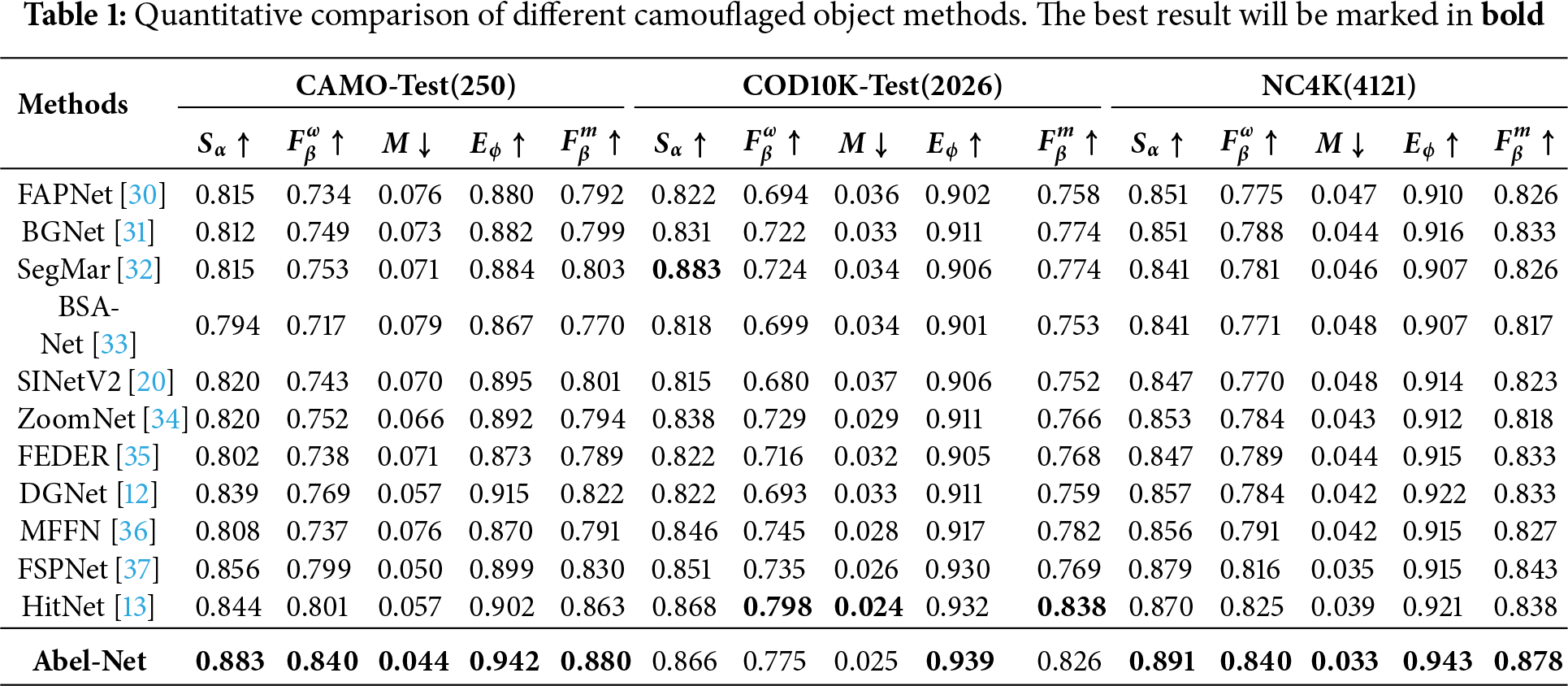
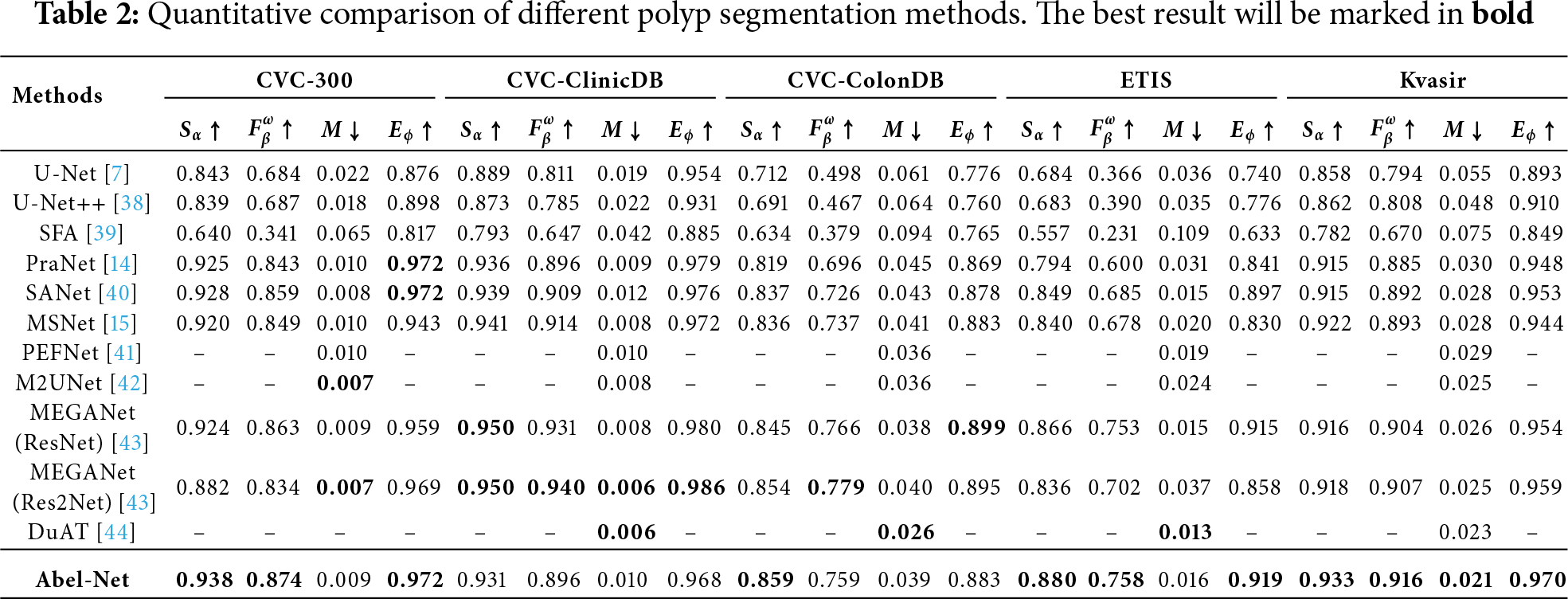
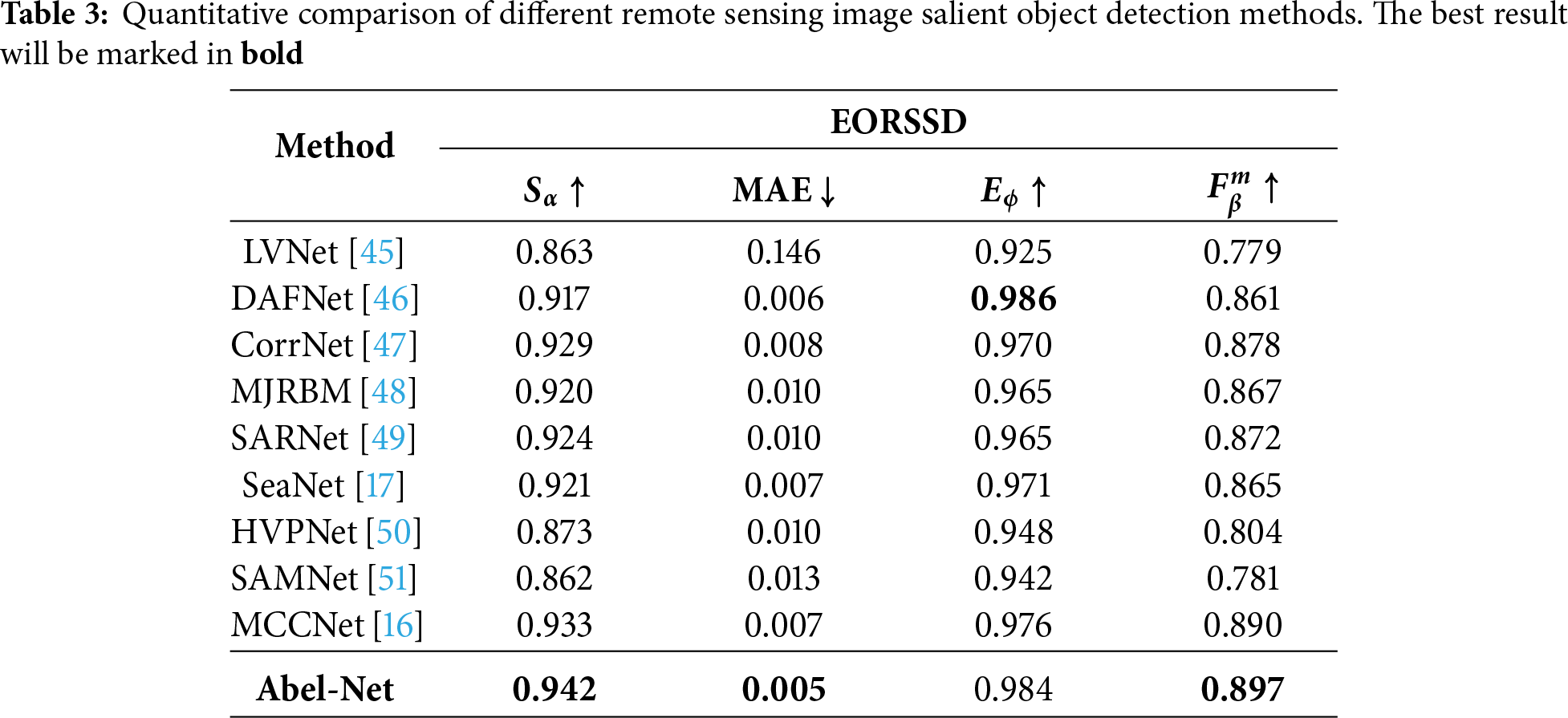
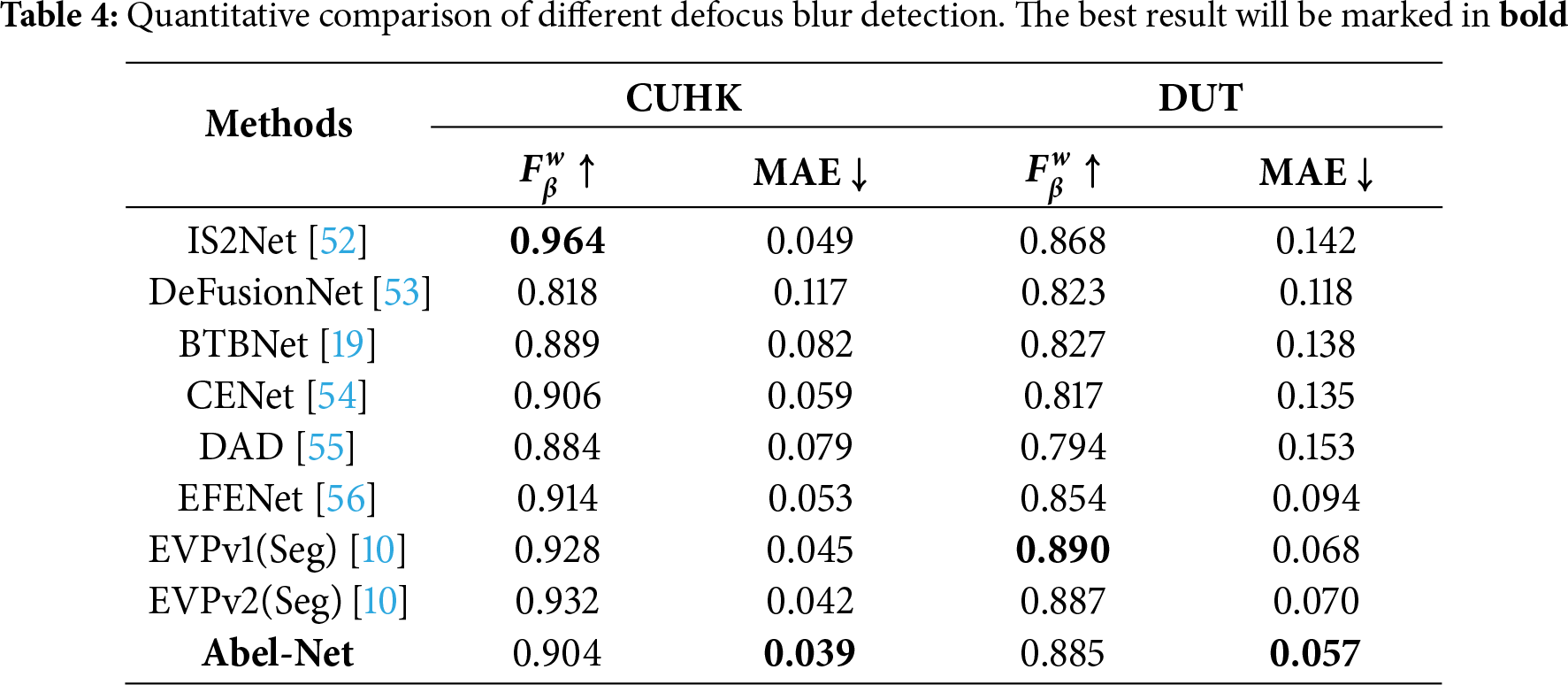
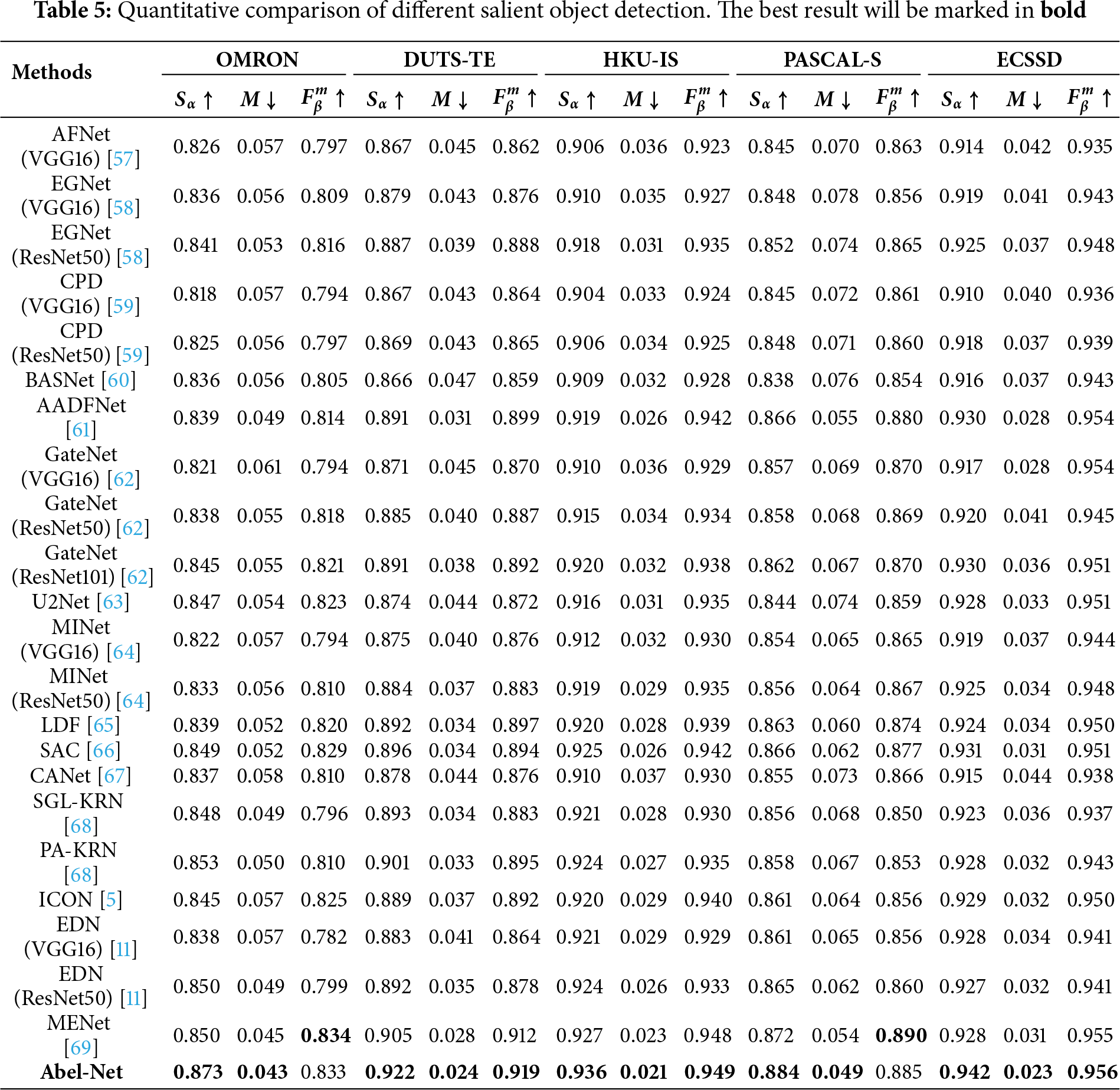
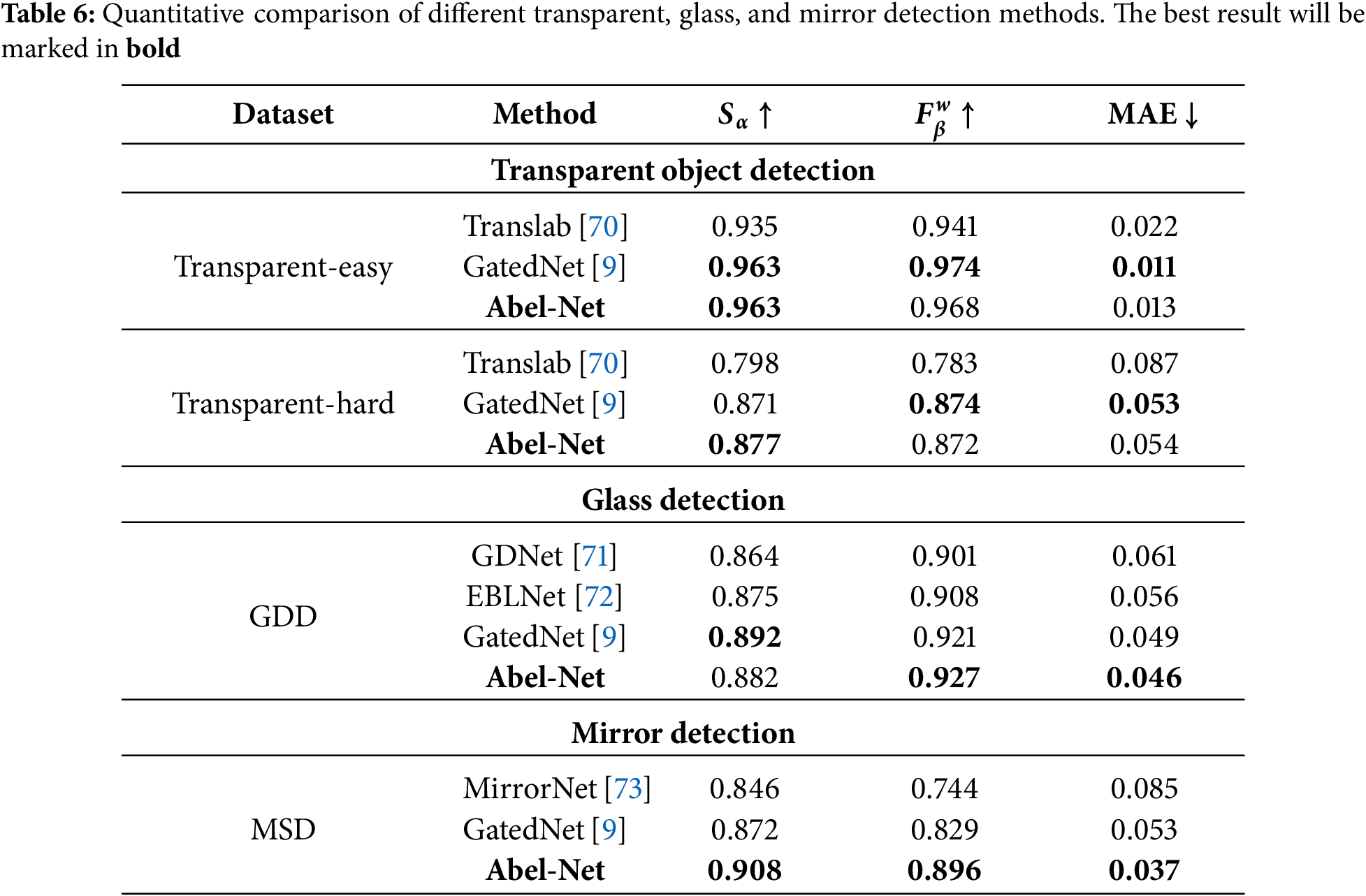
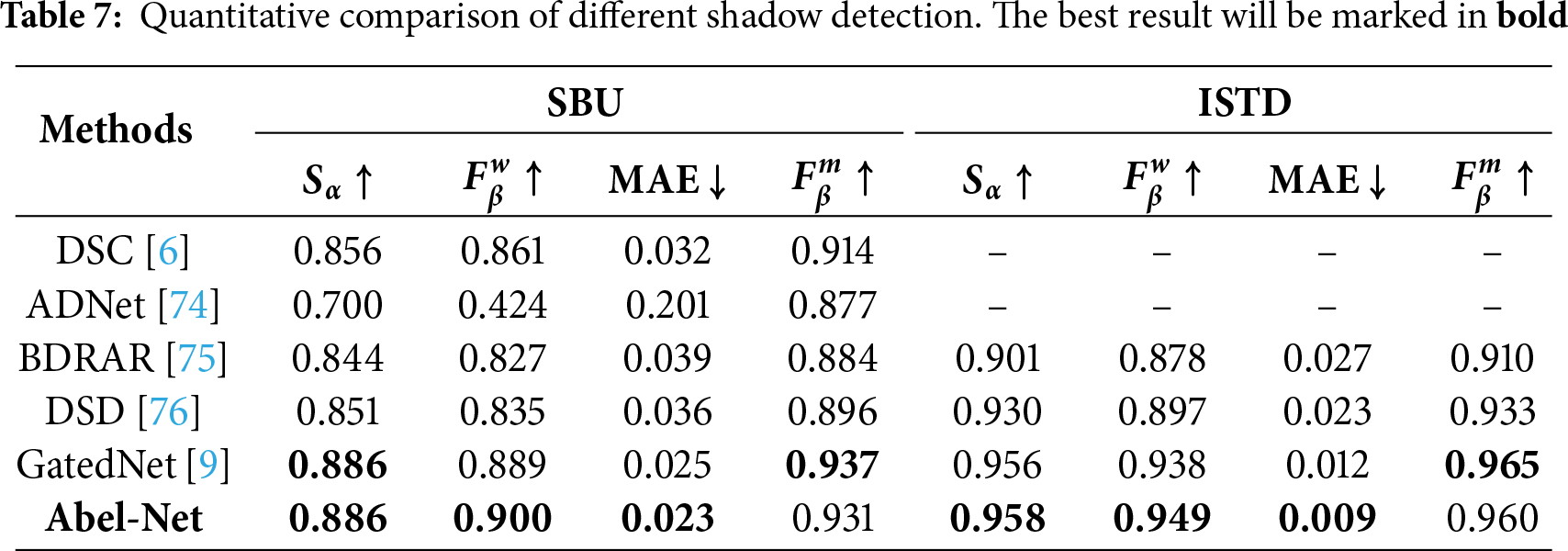

Figure 4: Comparison with other methods on some common datasets. (a) Spider [77] and GateNet [9] on DUTS dataset (top-left). (b) MTMT [78], SAM [79], and EVP [10] on ISTD dataset (top-middle). (c) DuAT [44], MEGA [43], and Spider [77] on Kvasir dataset (top-right). (d) AGNet [80], BSCGNet [81], CorrNet [47], MJRBM [48], SARNet [49], and SeaNet on EORSSD dataset (middle). (e) EVP [10], ICON [5], ZoomNet [34], JCOD [82], RankNet [83], and SINet [20] on CAMO dataset (bottom)

Figure 5: Our method can achieve good results on the defocus blur detection task. Here are the visualization results of our method and other advanced methods on the CUHK dataset: DBD [84], AENet [56], DFFNet [85], EFENet [56], EVP [10], IS2CNet [52]

Figure 6: Results of our method on mirror detection, transparent object detection, and glass detection. The top row represents the original images, the middle row represents the GT, and the bottom row represents our results
At the same time, Fig. 7 shows the PR curve of the results achieved by our method. The PR curve is a tool that is used to evaluate the performance of binary classification models. It helps analyze the classification performance of different models by plotting the relationship between precision and recall. From Fig. 7, we can further see the superiority of our method. Whether in popular classification tasks like camouflaged object detection and remote sensing image salient object detection, or the well-developed polyp segmentation task, our method performs well.
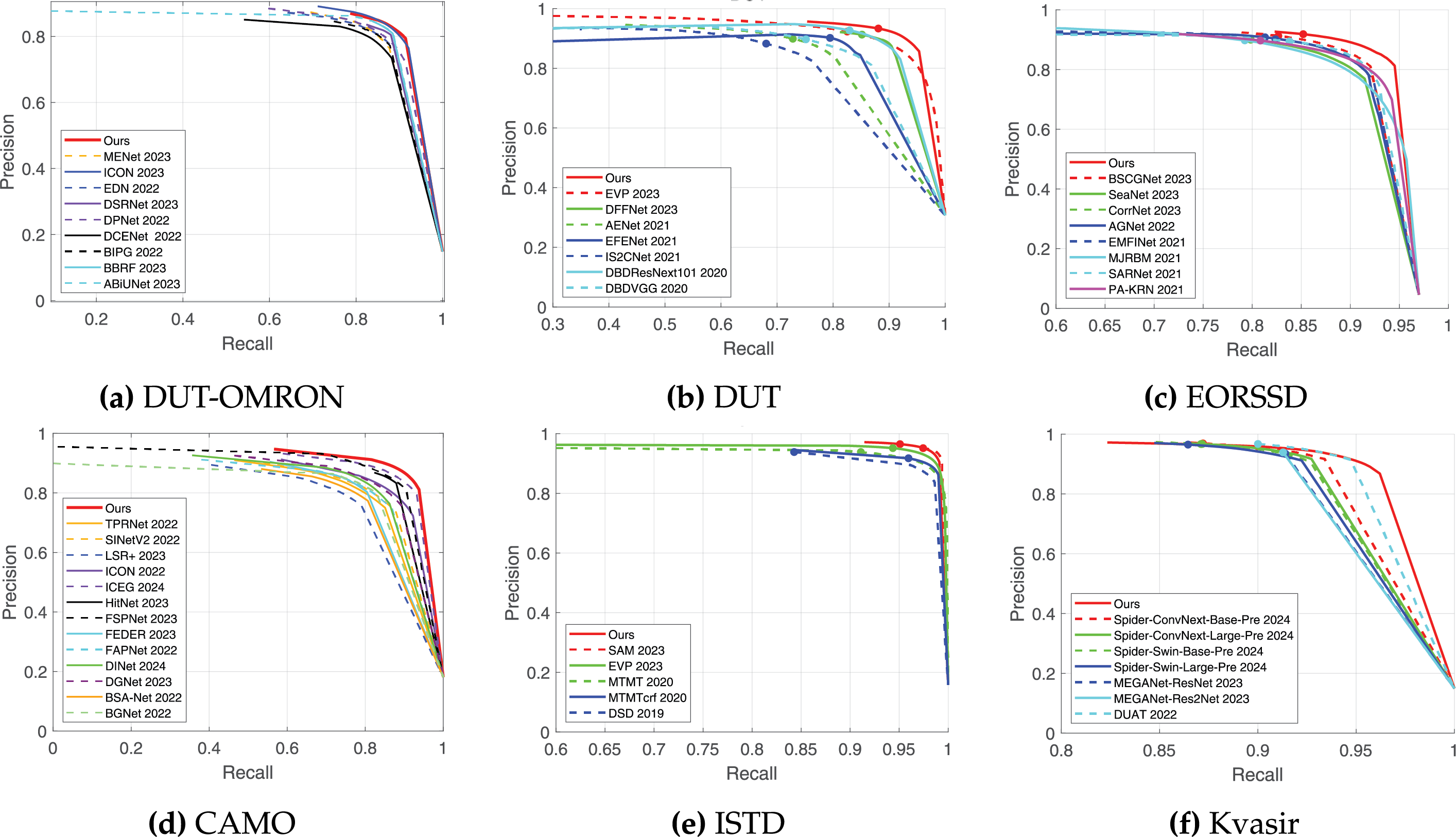
Figure 7: Comparison of our method’s PR curve with other methods on six different task datasets
Compared to most networks with multi-parameter fine-tuning, we introduce only a small number of adjustable parameters, yet our performance can surpass the best networks in the vast majority of tasks. It is worth noting that the substantial total parameter count (471.9 M) primarily originates from the PVTv2 backbone employed to ensure robust feature extraction, while the computational overhead introduced by our proposed modules (ASC, EDL, EA, EFA) remains marginal. As shown in Fig. 8, we performed multiple experiments with different
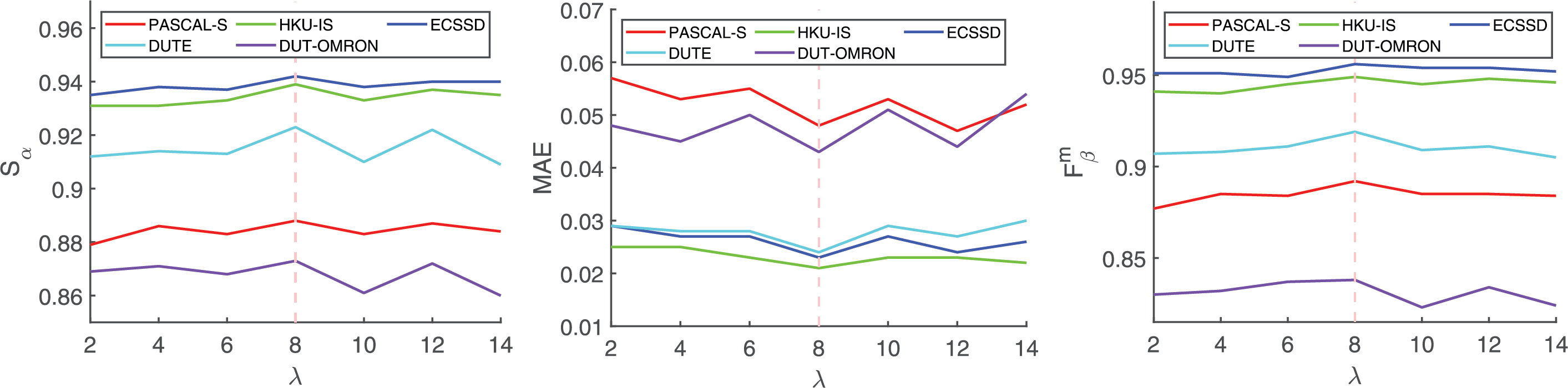
Figure 8: The impact of different parameters
To verify the impact of each module on the entire network, we conduct an ablation study on nine datasets corresponding to nine tasks using
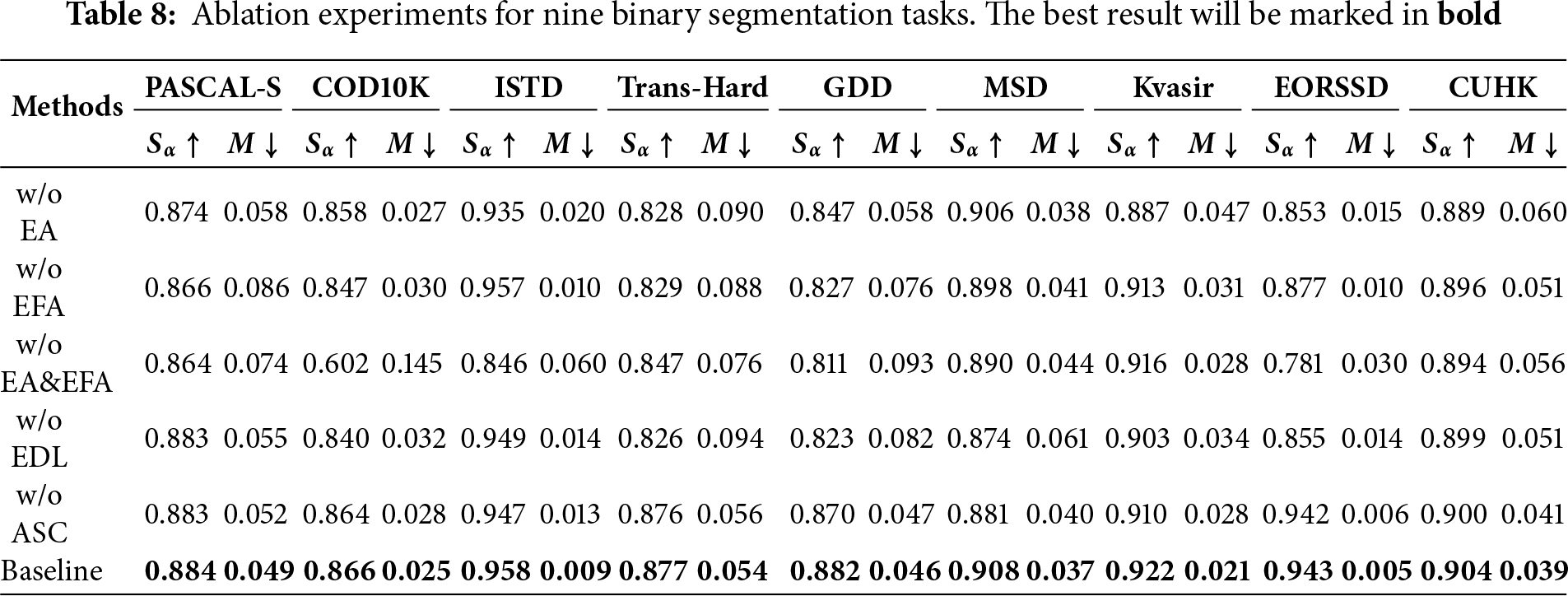
In this paper, we propose Abel-Net, a universal network designed for multi-task binary image segmentation. This network aggregates multi-level feature information through a feature pyramid module and explicitly optimizes boundary identification through a two-stage edge dual localization (EDL) strategy. By integrating the Aggregated Skip Connection (ASC) and edge-aware attention mechanisms (EA/EFA), Abel-Net effectively improves the accuracy of segmentation edges. Extensive experiments demonstrate that our network performs comparably to, and in many cases surpasses, state-of-the-art task-specific networks across nine diverse binary segmentation tasks. In summary, our method outperforms most networks designed specifically for these tasks in single-task scenarios and exhibits strong adaptability to a wide range of visual perception challenges.
5.2 Limitations and Future Scope
Despite the superior performance, we acknowledge certain limitations in the current framework. First, the introduction of the dual-branch EDL module and attention mechanisms introduces extra computational burden and memory requirements. As noted in our parameter analysis, the model operates at 4.24 FPS with 471.9 M parameters (largely due to the backbone), which restricts its deployment in real-time or resource-constrained applications. Second, while the network is designed as a universal framework, the optimal balance between edge and semantic features may vary across tasks with distinct boundary characteristics, potentially requiring task-specific fine-tuning of hyperparameters.
Future work will focus on two main directions: (1) Enhancing robustness and generalization to unseen complex scenarios where extremely fine edges are present; (2) Optimizing the architecture for better efficiency, potentially by exploring lightweight backbones or knowledge distillation techniques to make the model suitable for real-time applications. We hope this work will encourage further exploratory research in the field of general binary segmentation.
Acknowledgement: The authors would like to thank their colleagues and mentors for their helpful discussions and encouragement during the course of this research.
Funding Statement: This work is supported by the National Natural Science Foundation of China under Grant 62206083.
Author Contributions: The authors confirm their contribution to the paper as follows: Zhengyu Wu conceptualized the study, conducted the experiments, collected and analyzed the data, and contributed to the method development, model evaluation, performance comparison, and manuscript writing. Kejun Kang participated in the study conceptualization and experiment implementation, contributed to data collection and performance comparison. Yixiu Liu provided overall guidance and supervision throughout the research process, and contributed to the manuscript revision. Chenpu Li conducted some ablation experiment verification and paper polishing work. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data available on request from the authors.
Ethics Approval: The study did not include human or animal subjects.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Shu X, Zhang A, Xu Z, Zhu F, Hua W. Adaptive encoding and comprehensive attention decoding network for medical image segmentation. Appl Soft Comput. 2025;174:112990. doi:10.1016/j.asoc.2025.112990. [Google Scholar] [CrossRef]
2. Al-Sahaf H, Mesejo P, Bi Y, Zhang M. Evolutionary deep learning for computer vision and image processing. Appl Soft Comput. 2024;151:111159. doi:10.1016/j.asoc.2023.111159. [Google Scholar] [CrossRef]
3. Liu X, Li D. Binary segmentation based on visual attention consistency under background-change. Appl Soft Comput. 2022;121:108738. doi:10.1016/j.asoc.2022.108738. [Google Scholar] [CrossRef]
4. Liu CL, Chung CC. Anomaly detection and segmentation in industrial images using multi-scale reverse distillation. Appl Soft Comput. 2025;168:112502. doi:10.1016/j.asoc.2024.112502. [Google Scholar] [CrossRef]
5. Zhuge M, Fan DP, Liu N, Zhang D, Xu D, Shao L. Salient object detection via integrity learning. IEEE Trans Pattern Anal Mach Intell. 2023;45(3):3738–52. doi:10.1109/TPAMI.2022.3179526. [Google Scholar] [PubMed] [CrossRef]
6. Hu X, Zhu L, Fu CW, Qin J, Heng PA. Direction-aware spatial context features for shadow detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 7454–62. doi:10.1109/CVPR.2018.00778. [Google Scholar] [CrossRef]
7. Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015. Cham, Switzerland: Springer International Publishing; 2015. p. 234–41. doi:10.1007/978-3-319-24574-4_28. [Google Scholar] [CrossRef]
8. Ghosh S, Das N, Das I, Maulik U. Understanding deep learning techniques for image segmentation. ACM Comput Surv. 2020;52(4):1–35. doi:10.1145/3329784. [Google Scholar] [CrossRef]
9. Zhao X, Pang Y, Zhang L, Lu H, Zhang L. Towards diverse binary segmentation via a simple yet general gated network. Int J Comput Vis. 2024;132(10):4157–234. doi:10.1007/s11263-024-02058-y. [Google Scholar] [CrossRef]
10. Liu W, Shen X, Pun CM, Cun X. Explicit visual prompting for universal foreground segmentations. IEEE Trans Pattern Anal Mach Intell. 2025:1–16. doi:10.1109/tpami.2025.3619490. [Google Scholar] [PubMed] [CrossRef]
11. Wu YH, Liu Y, Zhang L, Cheng MM, Ren B. EDN: salient object detection via extremely-downsampled network. IEEE Trans Image Process. 2022;31:3125–36. doi:10.1109/TIP.2022.3164550. [Google Scholar] [PubMed] [CrossRef]
12. Ji GP, Fan DP, Chou YC, Dai D, Liniger A, Van Gool L. Deep gradient learning for efficient camouflaged object detection. Mach Intell Res. 2023;20(1):92–108. doi:10.1007/s11633-022-1365-9. [Google Scholar] [CrossRef]
13. Hu X, Wang S, Qin X, Dai H, Ren W, Luo D, et al. High-resolution iterative feedback network for camouflaged object detection. Proc AAAI Conf Artif Intell. 2023;37(1):881–9. doi:10.1609/aaai.v37i1.25167. [Google Scholar] [CrossRef]
14. Fan DP, Ji GP, Zhou T, Chen G, Fu H, Shen J, et al. PraNet: parallel reverse attention network for polyp segmentation. In: Medical image computing and computer assisted intervention–MICCAI 2020. Cham, Switzerland: Springer International Publishing; 2020. p. 263–73. doi:10.1007/978-3-030-59725-2_26. [Google Scholar] [CrossRef]
15. Zhao X, Zhang L, Lu H. Automatic polyp segmentation via multi-scale subtraction network. In: Medical image computing and computer assisted intervention–MICCAI 2021. Cham, Switzerland: Springer International Publishing; 2021. p. 120–30. doi:10.1007/978-3-030-87193-2_12. [Google Scholar] [CrossRef]
16. Li G, Liu Z, Lin W, Ling H. Multi-content complementation network for salient object detection in optical remote sensing images. IEEE Trans Geosci Remote Sens. 2022;60:5614513. doi:10.1109/TGRS.2021.3131221. [Google Scholar] [CrossRef]
17. Li G, Liu Z, Zhang X, Lin W. Lightweight salient object detection in optical remote-sensing images via semantic matching and edge alignment. IEEE Trans Geosci Remote Sens. 2023;61:5601111. doi:10.1109/TGRS.2023.3235717. [Google Scholar] [CrossRef]
18. Shi J, Xu L, Jia J. Discriminative blur detection features. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition; 2014 Jun 23–28; Columbus, OH, USA. p. 2965–72. doi:10.1109/CVPR.2014.379. [Google Scholar] [CrossRef]
19. Zhao W, Zhao F, Wang D, Lu H. Defocus blur detection via multi-stream bottom-top-bottom network. IEEE Trans Pattern Anal Mach Intell. 2020;42(8):1884–97. doi:10.1109/TPAMI.2019.2906588. [Google Scholar] [PubMed] [CrossRef]
20. Fan DP, Ji GP, Cheng MM, Shao L. Concealed object detection. IEEE Trans Pattern Anal Mach Intell. 2022;44(10):6024–42. doi:10.1109/TPAMI.2021.3085766. [Google Scholar] [PubMed] [CrossRef]
21. Wang W, Xie E, Li X, Fan DP, Song K, Liang D, et al. Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. p. 548–58. doi:10.1109/ICCV48922.2021.00061. [Google Scholar] [CrossRef]
22. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. p. 9992–10002. doi:10.1109/ICCV48922.2021.00986. [Google Scholar] [CrossRef]
23. Wei J, Wang S, Huang Q. F3Net: fusion, feedback and focus for salient object detection. Proc AAAI Conf Artif Intell. 2020;34(7):12321–8. doi:10.1609/aaai.v34i07.6916. [Google Scholar] [CrossRef]
24. Kingma DP, Ba J. Adam: a method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015; 2015 May 7–9; San Diego, CA, USA. p. 1–15. [Google Scholar]
25. Cheng MM, Fan DP. Structure-measure: a new way to evaluate foreground maps. Int J Comput Vis. 2021;129(9):2622–38. doi:10.1007/s11263-021-01490-8. [Google Scholar] [CrossRef]
26. Achanta R, Hemami S, Estrada F, Susstrunk S. Frequency-tuned salient region detection. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition; 2009 Jun 20–25; Miami, FL, USA. p. 1597–604. doi:10.1109/CVPR.2009.5206596. [Google Scholar] [CrossRef]
27. Margolin R, Zelnik-Manor L, Tal A. How to evaluate foreground maps. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition; 2014 Jun 23–28; Columbus, OH, USA. p. 248–55. doi:10.1109/CVPR.2014.39. [Google Scholar] [CrossRef]
28. Fan DP, Gong C, Cao Y, Ren B, Cheng MM, Borji A. Enhanced-alignment measure for binary foreground map evaluation. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence; 2018 Jul 13–19; Stockholm, Sweden. International Joint Conferences on Artificial Intelligence Organization; 2018. p. 698–704. doi:10.24963/ijcai.2018/97. [Google Scholar] [CrossRef]
29. Perazzi F, Krhenbhl P, Pritch Y, Hornung A. Saliency filters: contrast based filtering for salient region detection. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition; 2012 Jun 16–21; Providence, RI, USA. p. 733–40. doi:10.1109/CVPR.2012.6247743. [Google Scholar] [CrossRef]
30. Zhou T, Zhou Y, Gong C, Yang J, Zhang Y. Feature aggregation and propagation network for camouflaged object detection. IEEE Trans Image Process. 2022;31:7036–47. doi:10.1109/TIP.2022.3217695. [Google Scholar] [PubMed] [CrossRef]
31. Sun Y, Wang S, Chen C, Xiang TZ. Boundary-guided camouflaged object detection. In: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence; 2022 Jul 23–29; Vienna, Austria; 2022. p. 1335–41. doi:10.24963/ijcai.2022/186. [Google Scholar] [CrossRef]
32. Jia Q, Yao S, Liu Y, Fan X, Liu R, Luo Z. Segment, magnify and reiterate: detecting camouflaged objects the hard way. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. p. 4703–12. doi:10.1109/CVPR52688.2022.00467. [Google Scholar] [CrossRef]
33. Zhu H, Li P, Xie H, Yan X, Liang D, Chen D, et al. I can find you! Boundary-guided separated attention network for camouflaged object detection. Proc AAAI Conf Artif Intell. 2022;36(3):3608–16. doi:10.1609/aaai.v36i3.20273. [Google Scholar] [CrossRef]
34. Pang Y, Zhao X, Xiang TZ, Zhang L, Lu H. Zoom in and out: a mixed-scale triplet network for camouflaged object detection. In: Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. p. 2150–60. doi:10.1109/CVPR52688.2022.00220. [Google Scholar] [CrossRef]
35. He C, Li K, Zhang Y, Tang L, Zhang Y, Guo Z, et al. Camouflaged object detection with feature decomposition and edge reconstruction. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 22046–55. doi:10.1109/CVPR52729.2023.02111. [Google Scholar] [CrossRef]
36. Zheng D, Zheng X, Yang LT, Gao Y, Zhu C, Ruan Y. MFFN: multi-view feature fusion network for camouflaged object detection. In: Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2023 Jan 2–7; Waikoloa, HI, USA. p. 6221–31. doi:10.1109/WACV56688.2023.00617. [Google Scholar] [CrossRef]
37. Huang Z, Dai H, Xiang TZ, Wang S, Chen HX, Qin J, et al. Feature shrinkage pyramid for camouflaged object detection with transformers. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 5557–66. doi:10.1109/CVPR52729.2023.00538. [Google Scholar] [CrossRef]
38. Zhou Z, Siddiquee MMR, Tajbakhsh N, Liang J. UNet++: redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans Med Imaging. 2020;39(6):1856–67. doi:10.1109/TMI.2019.2959609. [Google Scholar] [PubMed] [CrossRef]
39. Fang Y, Chen C, Yuan Y, Tong KY. Selective feature aggregation network with area-boundary constraints for polyp segmentation. In: Medical image computing and computer assisted intervention–MICCAI 2019. Cham, Switzerland: Springer International Publishing; 2019. p. 302–10. doi:10.1007/978-3-030-32239-7_34. [Google Scholar] [CrossRef]
40. Wei J, Hu Y, Zhang R, Li Z, Zhou SK, Cui S. Shallow attention network for polyp segmentation. In: Medical image computing and computer assisted intervention–MICCAI 2021. Cham, Switzerland: Springer International Publishing; 2021. p. 699–708. doi:10.1007/978-3-030-87193-2_66. [Google Scholar] [CrossRef]
41. Nguyen-Mau TH, Trinh QH, Bui NT, Thi PV, Nguyen MV, Cao XN, et al. PEFNet: positional embedding feature for polyp segmentation. In: MultiMedia modeling. Cham, Switzerland: Springer Nature Switzerland; 2023. p. 240–51. doi:10.1007/978-3-031-27818-1_20. [Google Scholar] [CrossRef]
42. Trinh QH, Bui NT, Nguyen-Mau TH, Nguyen MV, Phan HM, Tran MT, et al. M2UNet: MetaFormer multi-scale upsampling network for polyp segmentation. In: Proceedings of the 2023 31st European Signal Processing Conference (EUSIPCO); 2023 Sep 4–8; Helsinki, Finland. p. 1115–9. [Google Scholar]
43. Bui NT, Hoang DH, Nguyen QT, Tran MT, Le N. MEGANet: multi-scale edge-guided attention network for weak boundary polyp segmentation. In: Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2024 Jan 3–8; Waikoloa, HI, USA. p. 7970–9. doi:10.1109/WACV57701.2024.00780. [Google Scholar] [CrossRef]
44. Ho NV, Nguyen T, Diep GH, Le N, Hua BS. Point-unet: a context-aware point-based neural network for volumetric segmentation. In: Medical image computing and computer assisted intervention–MICCAI 2021. Cham, Switzerland: Springer International Publishing; 2021. p. 644–55. doi:10.1007/978-3-030-87193-2_61. [Google Scholar] [CrossRef]
45. Li C, Cong R, Hou J, Zhang S, Qian Y, Kwong S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans Geosci Remote Sens. 2019;57(11):9156–66. doi:10.1109/TGRS.2019.2925070. [Google Scholar] [CrossRef]
46. Zhang Q, Cong R, Li C, Cheng MM, Fang Y, Cao X, et al. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans Image Process. 2021;30:1305–17. doi:10.1109/TIP.2020.3042084. [Google Scholar] [PubMed] [CrossRef]
47. Li G, Liu Z, Bai Z, Lin W, Ling H. Lightweight salient object detection in optical remote sensing images via feature correlation. IEEE Trans Geosci Remote Sens. 2022;60:5617712. doi:10.1109/TGRS.2022.3145483. [Google Scholar] [CrossRef]
48. Tu Z, Wang C, Li C, Fan M, Zhao H, Luo B. ORSI salient object detection via multiscale joint region and boundary model. IEEE Trans Geosci Remote Sens. 2022;60:5607913. doi:10.1109/TGRS.2021.3101359. [Google Scholar] [CrossRef]
49. Huang Z, Chen H, Liu B, Wang Z. Semantic-guided attention refinement network for salient object detection in optical remote sensing images. Remote Sens. 2021;13(11):2163. doi:10.3390/rs13112163. [Google Scholar] [CrossRef]
50. Liu Y, Gu YC, Zhang XY, Wang W, Cheng MM. Lightweight salient object detection via hierarchical visual perception learning. IEEE Trans Cybern. 2021;51(9):4439–49. doi:10.1109/TCYB.2020.3035613. [Google Scholar] [PubMed] [CrossRef]
51. Liu Y, Zhang XY, Bian JW, Zhang L, Cheng MM. SAMNet: stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans Image Process. 2021;30:3804–14. doi:10.1109/TIP.2021.3065239. [Google Scholar] [PubMed] [CrossRef]
52. Zhao F, Lu H, Zhao W, Yao L. Image-scale-symmetric cooperative network for defocus blur detection. IEEE Trans Circuits Syst Video Technol. 2022;32(5):2719–31. doi:10.1109/TCSVT.2021.3095347. [Google Scholar] [CrossRef]
53. Tang C, Zhu X, Liu X, Wang L, Zomaya A. DeFusionNET: defocus blur detection via recurrently fusing and refining multi-scale deep features. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 2695–704. doi:10.1109/CVPR.2019.00281. [Google Scholar] [CrossRef]
54. Zhao W, Zheng B, Lin Q, Lu H. Enhancing diversity of defocus blur detectors via cross-ensemble network. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 8897–905. doi:10.1109/CVPR.2019.00911. [Google Scholar] [CrossRef]
55. Zhao W, Shang C, Lu H. Self-generated defocus blur detection via dual adversarial discriminators. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 6929–38. doi:10.1109/cvpr46437.2021.00686. [Google Scholar] [CrossRef]
56. Zhao W, Hou X, He Y, Lu H. Defocus blur detection via boosting diversity of deep ensemble networks. IEEE Trans Image Process. 2021;30:5426–38. doi:10.1109/tip.2021.3084101. [Google Scholar] [PubMed] [CrossRef]
57. Feng M, Lu H, Ding E. Attentive feedback network for boundary-aware salient object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 1623–32. doi:10.1109/CVPR.2019.00172. [Google Scholar] [CrossRef]
58. Zhao J, Liu JJ, Fan DP, Cao Y, Yang J, Cheng MM. EGNet: edge guidance network for salient object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 8778–87. doi:10.1109/iccv.2019.00887. [Google Scholar] [CrossRef]
59. Wu Z, Su L, Huang Q. Cascaded partial decoder for fast and accurate salient object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 3902–11. doi:10.1109/CVPR.2019.00403. [Google Scholar] [CrossRef]
60. Qin X, Zhang Z, Huang C, Gao C, Dehghan M, Jagersand M. BASNet: boundary-aware salient object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 7471–81. doi:10.1109/CVPR.2019.00766. [Google Scholar] [CrossRef]
61. Zhu L, Chen J, Hu X, Fu CW, Xu X, Qin J, et al. Aggregating attentional dilated features for salient object detection. IEEE Trans Circuits Syst Video Technol. 2020;30(10):3358–71. doi:10.1109/TCSVT.2019.2941017. [Google Scholar] [CrossRef]
62. Zhao X, Pang Y, Zhang L, Lu H, Zhang L. Suppress and balance: a simple gated network for salient object detection. In: Computer vision-ECCV 2020. Cham, Switzerland: Springer International Publishing; 2020. p. 35–51. doi:10.1007/978-3-030-58536-5_3. [Google Scholar] [CrossRef]
63. Qin X, Zhang Z, Huang C, Dehghan M, Zaiane OR, Jagersand M. U2-Net: going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020;106:107404. doi:10.1016/j.patcog.2020.107404. [Google Scholar] [CrossRef]
64. Zhang L, Wu J, Wang T, Borji A, Wei G, Lu H. A multistage refinement network for salient object detection. IEEE Trans Image Process. 2020;29:3534–45. doi:10.1109/TIP.2019.2962688. [Google Scholar] [PubMed] [CrossRef]
65. Wei J, Wang S, Wu Z, Su C, Huang Q, Tian Q. Label decoupling framework for salient object detection. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 13022–31. doi:10.1109/cvpr42600.2020.01304. [Google Scholar] [CrossRef]
66. Hu X, Fu CW, Zhu L, Wang T, Heng PA. SAC-net: spatial attenuation context for salient object detection. IEEE Trans Circuits Syst Video Technol. 2021;31(3):1079–90. doi:10.1109/TCSVT.2020.2995220. [Google Scholar] [CrossRef]
67. Ren Q, Lu S, Zhang J, Hu R. Salient object detection by fusing local and global contexts. IEEE Trans Multimed. 2021;23:1442–53. doi:10.1109/TMM.2020.2997178. [Google Scholar] [CrossRef]
68. Xu B, Liang H, Liang R, Chen P. Locate globally, segment locally: a progressive architecture with knowledge review network for salient object detection. Proc AAAI Conf Artif Intell. 2021;35(4):3004–12. doi:10.1609/aaai.v35i4.16408. [Google Scholar] [CrossRef]
69. Wang Y, Wang R, Fan X, Wang T, He X. Pixels, regions, and objects: multiple enhancement for salient object detection. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 10031–40. doi:10.1109/CVPR52729.2023.00967. [Google Scholar] [CrossRef]
70. Xie E, Wang W, Wang W, Ding M, Shen C, Luo P. Segmenting transparent objects in the wild. In: Computer vision-ECCV 2020. Cham, Switzerland: Springer International Publishing; 2020. p. 696–711. doi:10.1007/978-3-030-58601-0_41. [Google Scholar] [CrossRef]
71. Mei H, Yang X, Wang Y, Liu Y, He S, Zhang Q, et al. Don’t hit me! Glass detection in real-world scenes. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 3684–93. doi:10.1109/cvpr42600.2020.00374. [Google Scholar] [CrossRef]
72. He H, Li X, Cheng G, Shi J, Tong Y, Meng G, et al. Enhanced boundary learning for glass-like object segmentation. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. p. 15839–48. doi:10.1109/ICCV48922.2021.01556. [Google Scholar] [CrossRef]
73. Yang X, Mei H, Xu K, Wei X, Yin B, Lau R. Where is my mirror? In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 8808–17. doi:10.1109/iccv.2019.00890. [Google Scholar] [CrossRef]
74. Le H, Vicente TFY, Nguyen V, Hoai M, Samaras D. A+D net: training a shadow detector with adversarial shadow attenuation. In: Computer vision-ECCV 2018. Cham, Switzerland: Springer International Publishing; 2018. p. 680–96. doi:10.1007/978-3-030-01216-8_41. [Google Scholar] [CrossRef]
75. Zhu L, Deng Z, Hu X, Fu CW, Xu X, Qin J, et al. Bidirectional feature pyramid network with recurrent attention residual modules for shadow detection. In: Computer vision-ECCV 2018. Cham, Switzerland: Springer International Publishing; 2018. p. 122–37. doi:10.1007/978-3-030-01231-1_8. [Google Scholar] [CrossRef]
76. Zheng Q, Qiao X, Cao Y, Lau RWH. Distraction-aware shadow detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2019 Jun 15–20; Long Beach, CA, USA. p. 5162–71. doi:10.1109/CVPR.2019.00531. [Google Scholar] [CrossRef]
77. Zhao X, Pang Y, Ji W, Sheng B, Zuo J, Zhang L, et al. Spider: a unified framework for context-dependent concept segmentation. arXiv:2405.01002. 2024. [Google Scholar]
78. Chen Z, Zhu L, Wan L, Wang S, Feng W, Heng PA. A multi-task mean teacher for semi-supervised shadow detection. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 5610–9. doi:10.1109/cvpr42600.2020.00565. [Google Scholar] [CrossRef]
79. Jie L, Zhang H. AdapterShadow: adapting segment anything model for shadow detection. arXiv:2311.08891. 2023. [Google Scholar]
80. Lin Y, Sun H, Liu N, Bian Y, Cen J, Zhou H. Attention guided network for salient object detection in optical remote sensing images. In: Artificial neural networks and machine learning-ICANN 2022. Cham, Switzerland: Springer International Publishing; 2022. p. 25–36. doi:10.1007/978-3-031-15919-0_3. [Google Scholar] [CrossRef]
81. Feng D, Chen H, Liu S, Liao Z, Shen X, Xie Y, et al. Boundary-semantic collaborative guidance network with dual-stream feedback mechanism for salient object detection in optical remote sensing imagery. IEEE Trans Geosci Remote Sens. 2023;61:4706317. doi:10.1109/TGRS.2023.3332282. [Google Scholar] [CrossRef]
82. Li A, Zhang J, Lv Y, Liu B, Zhang T, Dai Y. Uncertainty-aware joint salient object and camouflaged object detection. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 10066–76. doi:10.1109/CVPR46437.2021.00994. [Google Scholar] [CrossRef]
83. Lv Y, Zhang J, Dai Y, Li A, Liu B, Barnes N, et al. Simultaneously localize, segment and rank the camouflaged objects. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 11586–96. doi:10.1109/cvpr46437.2021.01142. [Google Scholar] [CrossRef]
84. Cun X, Pun CM. Defocus blur detection via depth distillation. In: Computer vision-ECCV 2020. Cham, Switzerland: Springer International Publishing; 2020. p. 747–63. doi:10.1007/978-3-030-58601-0_44. [Google Scholar] [CrossRef]
85. Jin Y, Qian M, Xiong J, Xue N, Xia GS. Depth and DOF cues make a better defocus blur detector. In: Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME); 2023 Jul 10–14; Brisbane, QLD, Australia. p. 882–7. doi:10.1109/ICME55011.2023.00156. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools