
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A Materials Discovery Method Considering the Trade-Off Phenomenon in Machine Learning Prediction Capabilities between Interpolation and Extrapolation: Case Study on Multi-Objective Mg-Zn-Al Alloy Design
1 School of Materials Science and Chemical Engineering, Harbin University of Science and Technology, Harbin, China
2 Key Laboratory of Engineering Dielectric and Applications (Ministry of Education), School of Electrical and Electronic Engineering, Harbin University of Science and Technology, Harbin, China
* Corresponding Author: Shu Li. Email:
(This article belongs to the Special Issue: Machine Learning Methods in Materials Science)
Computers, Materials & Continua 2026, 87(2), 14 https://doi.org/10.32604/cmc.2026.075830
Received 09 November 2025; Accepted 23 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The exploration of high-performance materials presents a fundamental challenge in materials science, particularly in predicting properties for materials beyond the known range of target property values (extrapolation). This study formally investigated the interpolation-extrapolation trade-off phenomenon in the prediction capabilities of machine learning (ML) models. A new ML scheme was proposed, featuring a newly developed ML model and forward cross-validation-based hyperparameter optimization, which demonstrated superior extrapolation prediction across multiple materials datasets. Based on this ML scheme, multi-objective optimization was performed to systematically identify lightweight Mg-Zn-Al alloys with both high bulk modulus and high Debye temperature. Subsequently, the designed alloys were validated through density functional theory calculations. Furthermore, a three-category classification strategy was summarized through the dual-driven approach combining domain knowledge and data, emphasizing their synergistic potential for materials discovery. The practical framework developed in this study provides a novel research perspective for exploring high-performance materials.Keywords
Supplementary Material
Supplementary Material FileThe discovery of advanced materials with extreme physical/chemical properties surpassing conventional counterparts remains a persistent and fundamental challenge in materials science. Some typical examples are the search for materials with high mechanical properties (e.g., high-entropy alloys (HEAs) [1]), high piezoelectric performance (e.g., scandium-alloyed aluminum nitride), and higher superconducting critical temperatures (e.g., trilayer nickelate [2]). Considering the immense scale of the material space, both experimental approaches and theoretical calculations encounter inherent limitations [3]. Data science solutions address this by learning the relationship between material features and target properties from existing material datasets, enabling efficient prediction of unknown materials [4]. There are two scenarios: interpolation and extrapolation. As depicted in Fig. 1a, unknown material data with target properties lying within the range of known data are classified as interpolation data, whereas those outside this range are categorized as extrapolation data. Large-scale materials screening generally encompasses both scenarios, where extrapolation plays a relatively more critical and challenging role, as the most promising candidates often fall beyond the boundaries of existing data.
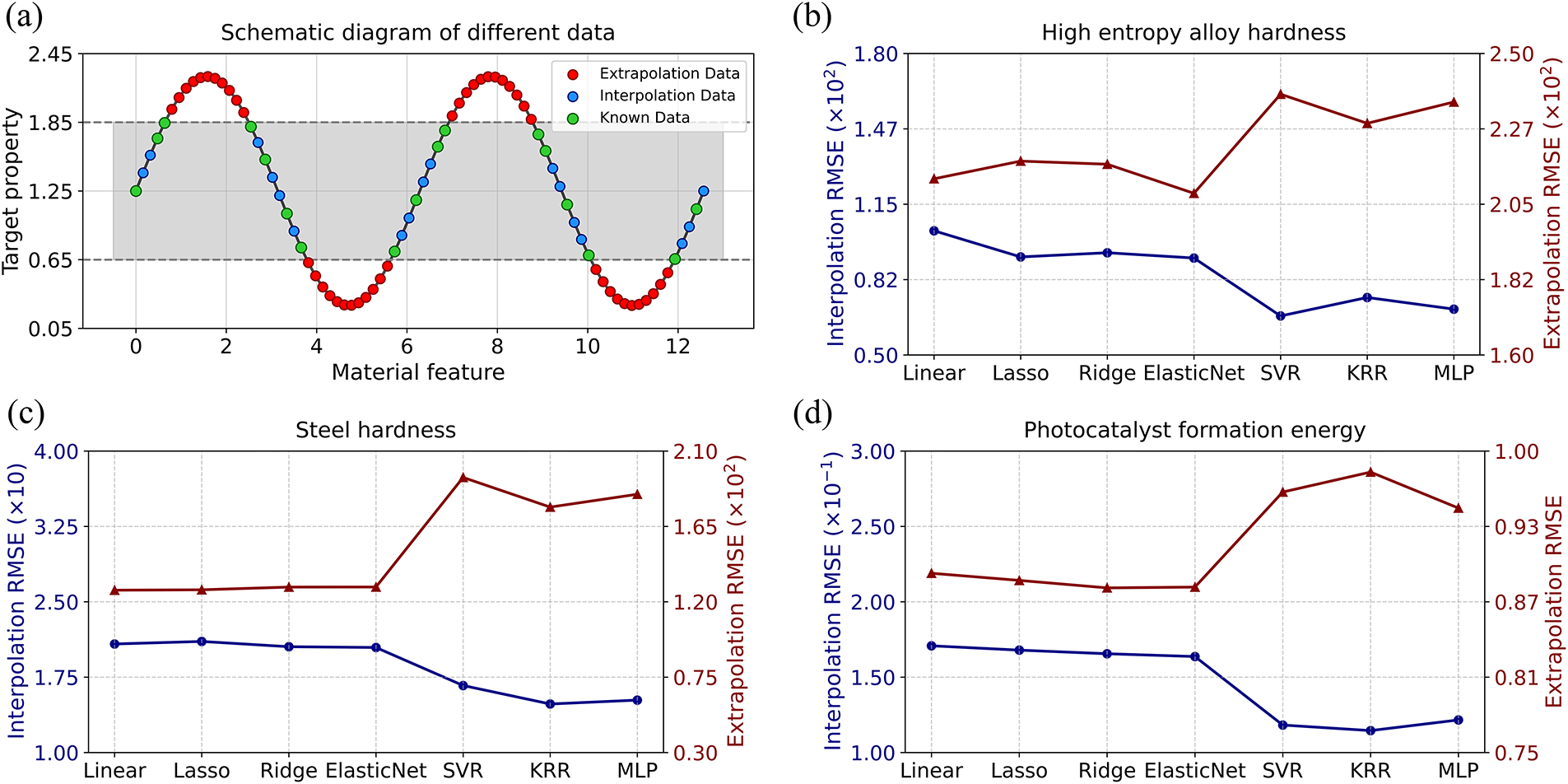
Figure 1: Illustration of the relationship between interpolation and extrapolation. (a) Schematic diagram of different types of data. (b–d) The prediction errors of interpolation and extrapolation for different ML models on different materials datasets.
Previous research on discovering high-performance materials using machine learning (ML) has predominantly centered on developing models with robust interpolation capabilities, usually assessed via random splitting or cross-validation of existing datasets [5]. However, these models may not be the most appropriate for extrapolation tasks, and extrapolation should be studied specifically. While these models have successfully identified some high-performance materials, it should be acknowledged that substantial portions of the search space, particularly those with extreme properties, remain under-explored.
ML aims to uncover the underlying laws of nature, whether through interpolation or extrapolation [5]. However, achieving such an ideal model remains impractical in reality due to constraints such as data scarcity and complexity [5]. Extensive experience and empirical insights reveal a trade-off phenomenon between the prediction capabilities of interpolation and extrapolation in ML-driven large-scale material prediction. Authors collected diverse materials datasets and performed comprehensive computations using various ML algorithms (related details are provided in the Supplementary Materials and Section 3.1). As shown in Fig. 1b–d, the interpolation and extrapolation prediction errors for each ML model reveal a distinct trade-off phenomenon across multiple datasets. Specifically, a model that demonstrates exceptional performance in interpolation tasks frequently shows limitations in extrapolation tasks, and the converse is also true. There is no single model that is optimal for both tasks simultaneously. Therefore, interpolation and extrapolation scenarios should be treated separately when exploring unknown materials by ML models.
Mg-Zn-Al alloys and their binary systems have emerged as highly promising materials due to their low density, high specific strength, and excellent castability, making them potential for automotive, aerospace, and energy-saving applications [6]. These alloys have the potential to address key limitations of other similar and common alloy systems, making them strong candidates for advanced material researches. For instance, while 7xxx series Al-Zn-Mg-(Cu) alloys achieve exceptional yield strength, they suffer from poor formability and corrosion resistance [7]. Conversely, 5xxx series Al-Mg-(Mn) alloys offer high ductility and corrosion resistance but exhibit lower strength [8]. Some studies on Mg-Zn-Al alloys or their binary systems have investigated microstructural evolution, corrosion behavior, mechanical properties, and other characteristics, demonstrating excellent results [9]. For example, Joung Sik Suh et al. developed a machine learning-assisted approach integrating microstructure, texture, and aging parameters to predict the mechanical properties of Mg-Zn-Al alloys [9]. However, a critical yet underexplored research direction is the design of novel Mg-Zn-Al alloys that simultaneously enhance elastic modulus and Debye temperature (
This work formally proposes, for the first time, the trade-off phenomenon between interpolation and extrapolation prediction capabilities for ML models. It not only identifies a prevalent misconception in previous research, but also provides a novel theoretical perspective. Building upon this theoretical premise, the study aims to develop a scheme for searching materials with extreme properties, with an emphasis on enhancing the extrapolation prediction capability of the ML model. Therefore, in the present work a concise and effective model has been developed by integrating linear regression, polynomial regression, and random forest, with hyperparameter optimization using forward cross-validation. The proposed method was thoroughly validated on various materials datasets. This work explored this new framework in ML-guided design strategies for Mg-Zn-Al alloys and even their binary systems, highlighting their potential to achieve an optimal exploration between low density, high bulk modulus, and elevated Debye temperature for next-generation structural applications. Finally, the study also explored a promising dual approach that integrates both knowledge-driven and data-driven methodologies.
2.1 The Interpolation-Extrapolation Trade-Off in ML Predictions
How universal is the interpolation-extrapolation (IE) trade-off phenomenon for ML prediction capabilities? The current state of ML-driven materials exploration is characterized by limited training data (either in quantity or quality) and complex feature-target relationships. This is precisely the condition and scope that make the IE trade-off prominent. When training data becomes more abundant and high-quality, it enables the model to achieve better generalization and greater universality for more unknown data. When feature-target property relationships are simpler and more clearly reflect nature’s underlying laws, ML models can learn them more easily, both in interpolation and extrapolation. In such scenarios, the IE trade-off may either diminish or completely vanish, and the opposite holds true as well. In addition, some extreme cases such as abnormal model training and too small prediction space should also be excluded from the universality of IE trade-off. Note that due to variations in real-world data and models, the IE trade-off reflects general trends rather than absolute rules.
Why does this IE trade-off phenomenon exist? As shown in Fig. 2a, an ideal model is one that predicts perfectly but is practically unattainable [4]. In practice, empirical risk minimization on the training data may not generalize to the true data distribution, especially when the training data suffers from inadequate quantity or quality [4]. Consequently, the trained ML model tends to perform well on data that closely matches the training data distribution (in either feature or label space). These data practically amounts to interpolation data. Conversely, the trained model performs less effectively on out-of-distribution data, which frequently constitutes extrapolation data. Furthermore, given the complex correlations between feature-target properties, interpolation and extrapolation may operate as distinct regimes under certain conditions. For instance, in hardness exploration of solid-solution alloys, Body-Centered Cubic (BCC) phases are typically harder than FCC phases. Consequently, BCC phases prevail in extrapolation data, while Face-Centered Cubic (FCC) phases dominate interpolation and training data. The distinct feature-hardness correlations between BCC and FCC critically affect model predictions in interpolation and extrapolation data. As shown in Fig. 2b, if the model extensively learns the distribution information within the training data, its interpolation capability will be enhanced. However, certain information may be redundant and potentially detrimental to extrapolation predictions. By comparing Fig. 2b,c, it is further indicated that the complexity of ML model are positively correlated with its learning capability. Consequently, a more complex and powerful model is also more prone to encountering this issue, while simpler models are less likely to experience such problems.
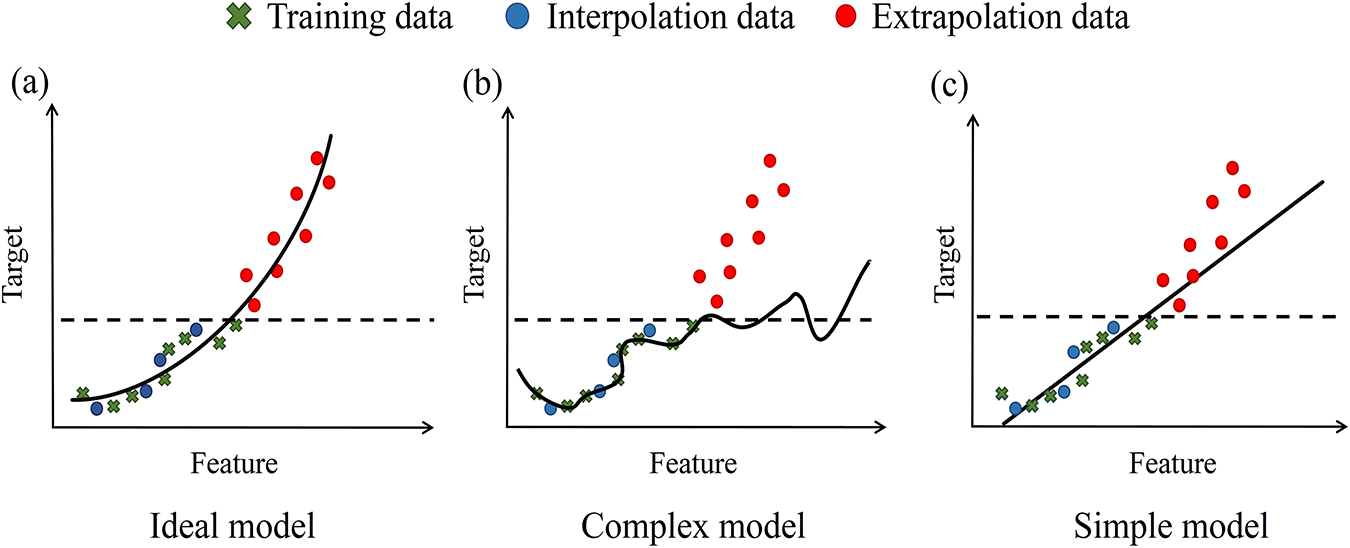
Figure 2: Schematic diagram on comparison of predictive performance with different ML model types.
In addition, some works have described the interpolation-extrapolation relationship in various intuitive and fragmented ways. Several studies have suggested that the optimal models for interpolation and extrapolation may not be the same [10,11]. Some studies have also indicated that nonlinear models typically outperform in interpolation prediction, while linear models often superior in extrapolation prediction [12,13]. A widely accepted empirical principle suggests that considering ML model simplicity, rather than excessive pursuit of interpolation accuracy, enhances generalization performance [14]. According to Occam’s Razor, among different hypotheses explaining the same phenomenon, the one with the fewest and simplest assumptions should be prioritized. Thus, they totally support the IE trade-off phenomenon proposed in this work. Based on this principles, to increase extrapolation capability the relatively simple model should be taken into account in ML modeling on given training data.
2.2 The Extrapolation Random Forest Regression Model
As shown in Fig. 3, a regression model named Extrapolation Random Forest (ERF) is proposed, which integrates the strengths of linear regression, polynomial regression, and random forest, thereby enabling more precise extrapolation predictions. For comparative purposes and to facilitate the description, commonly used Random Forest (RF) model is introduced firstly. In common RF regression model, firstly, multiple subsets are generated by randomly sampling with replacement (each matching the training set size) from the training set. Secondly, for each subset, a random feature subset is selected to construct a regression tree through recursive partitioning, where split thresholds are determined by minimizing the variance of the target variable. The split thresholds commonly selected from midpoints between samples. Partition-generated regions are known as nodes. The tree output is the mean of training samples within the last region (leaf node) where the predicting instance is located. Finally, the RF prediction is the average value of all tree outputs.
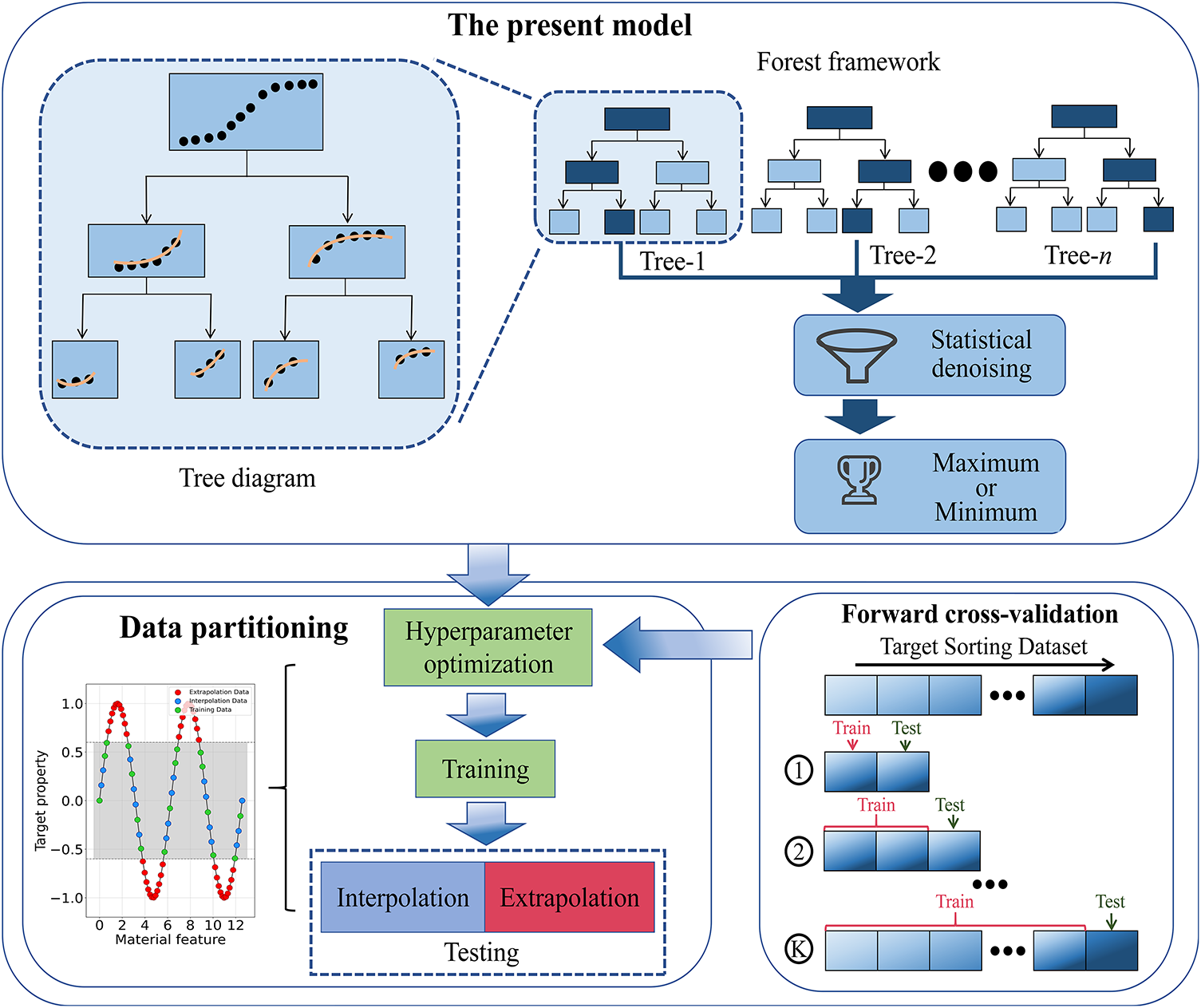
Figure 3: The construction of the present model.
As for the ERF, piecewise regression is introduced in tree construction, statistical denoising is introduced in the ensemble strategy, and extreme value theory is introduced in final prediction selection. As shown in Fig. 3, during the construction of a tree model, a specific regression model type is first determined (linear, quadratic (second-order), or cubic (third-order) polynomial regression models). Subsequently, each node within this tree is adopted to train a corresponding regression model using its allocated data subset. The possible segmentation nodes in trees are selected probabilistically instead of being fixed at the midpoint between sample, and this approach introduces randomness in threshold selection, enabling smoother prediction curves even in data-sparse regions. The final split thresholds are determined by regression model error minimization. The output of each tree corresponds to its leaf node’s regression model output. To further enhance performance and mitigate the risk of overfitting, an ensemble strategy is utilized by integrating multiple trees into a forest. Firstly, the output values from all individual trees are collecting in the ensemble, then statistical denoising and extreme value theory are introduced, the quartile-based denoising operation is adopted to filter out the outliers, and finally selecting the maximum or minimum (depending on the requirement) from the remaining refined predictions as the final result. This model retains the simplicity and strong extrapolation capabilities of linear models while enhancing the focus and stability of their training process.
The polynomial regression implementation procedure can be systematically described as follows. The polynomial regression model could be seen as a framework that performs linear regression after polynomial expansion of the original features. However, this feature expansion process typically induces combinatorial growth in feature space dimensionality, creating two principal challenges, the resulting increase in model complexity substantially degrades extrapolation performance, and the expanded computational requirements significantly impair operational efficiency. To address these challenges, a post-expansion feature selection mechanism based on F-test significance is adopted. By screening the subset of features (with a randomly determined size) based on the highest statistical significance, this approach not only preserves the model’s extrapolation prediction performance but also markedly enhances computational efficiency. The numbers of trees based on linear or quadratic (second-order) or cubic (third-order) regression model are hyperparameters. The proposed framework introduces key innovations for extrapolation prediction, with some details informed by prior research, such as some hyperparameter setting [15].
The evaluation criterion for hyperparameter optimization adopts forward cross-validation [16]. The training data is sorted by values of the target property and partitioned into n folds (the sorting direction depends on the requirement). The ML model is subsequently trained on the first k folds to predict the (k + 1)-th fold, with k ranging from 1 to (n − 1). The final metric value is the weighted average of all folds, scaled by their respective k values. This approach identifies hyperparameters more suitable for extrapolation rather than interpolation, particularly under limited training data constraints. Related details about the hyperparameter optimizations are provided in the Supplementary Materials.
As described in the previous content, generally speaking, more complex models tend to perform better at interpolation, while simpler models are often better at extrapolation. This is a general tendency, not an absolute rule. It is important to emphasize that the design of ERF-including its piecewise regressors, probabilistic splitting, and extreme-value ensemble-is specifically aimed at capturing underlying data trends and ensuring stability in extrapolation regions. Consequently, while ERF demonstrates strong extrapolation performance, its interpolation accuracy may not match that of models specifically optimized for in-distribution prediction, such as kernel ridge regression. This performance difference directly reflects the IE trade-off outlined in Section 2.1 and aligns with the core objective of this work: to develop a model specialized for materials discovery beyond known property boundaries.
3.1 The Performance Evaluation of the Present Model
Several material datasets were systematically prepared for the performance evaluation of the proposed model, including high entropy alloys hardness (583 data) [17,18], steel hardness (1373 data) [19], and photocatalyst formation energy (3099 data) [20]. In order to simulate the conditions of real-world material space exploration tasks, a new data partitioning approach was designed for training and evaluating the model. Each dataset was sorted by values of the target property. Half of the data with the most desirable target property were assigned as the extrapolation data, and the remaining data were alternately allocated to training and interpolation data. This data partitioning strategy aims to realistically emulate materials exploration conditions while mitigating stochastic effects. In addition, commonly used ML models were employed for model comparison and categorized into two groups: simple models (linear, lasso, ridge, ElasticNet) and complex models (support vector regression (SVR), kernel ridge regression (KRR), multilayer perceptron (MLP) neural network). A standard random forest inherently lacks extrapolation capability, as its predictions are confined to local averages of the training targets within partitioned regions. This makes it fundamentally an interpolation model, unsuitable as a comparison model in our extrapolation-focused study. The improved genetic algorithm (GA), as presented in our prior study [21], was utilized for feature selection in each model. The improved GA is designed to find the global optimal feature subset more accurately, quickly and robustly. Details are provided in the Supplementary Materials.
The discussion of the comparative results across various models is presented based on the four metrics. (1) classification accuracy: the proportion of predicted values that fall below the threshold (the maximum target property value in the training set) for the total interpolation set (interpolation accuracy), or above this threshold for the total extrapolation set (extrapolation accuracy). (2) prediction error: the root mean square errors (RMSE) for interpolation and extrapolation sets. (3) top-n accuracy: the proportion of genuinely top-n materials among the top-n candidates predicted by the model within the extrapolation data. (4) top-n fitness: the Jensen-Shannon Divergence (JS Divergence) between the true and predicted target property distributions of the top-n candidates. Lower JS Divergence values suggest a stronger alignment between the predicted and actual optimal target value distributions, thereby reflecting both the precision of ranking and the degree of value range correspondence. The results presented in Fig. 1 for these seven common ML models were obtained by the hyperparameter optimization based on the conventional cross-validation. The results for these seven common ML models—as discussed in the following analysis—show that all exhibit smaller extrapolation errors with either of two hyperparameter optimization methods: standard cross-validation or forward cross-validation. The results of the present model, along with the average effects across each model group, are shown in Table 1 and Fig. 4. The detailed results are provided in the Supplementary Materials.

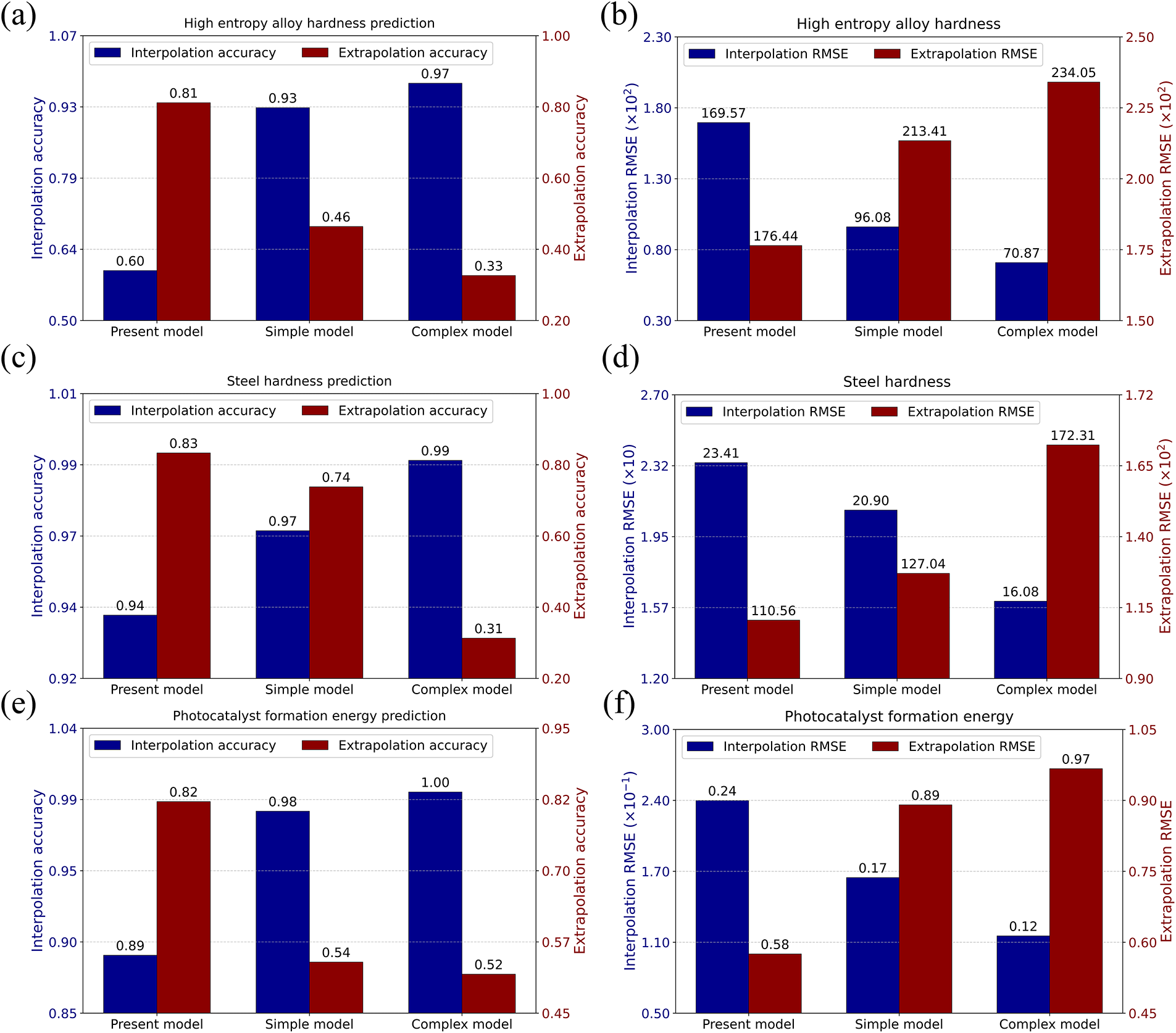
Figure 4: The prediction performance of different models. Classification accuracy values and prediction error values for interpolation and extrapolation across different models and materials datasets.
It can be observed from Fig. 4 that for classification accuracy and prediction error in any material datasets, there is a distinct IE trade-off phenomenon, where simple models perform better in extrapolation but worse in interpolation compared to complex models. The present model exhibits superior extrapolation capabilities but the poorest interpolation performance, not only compared to the average effects for simple models and complex models, but also to any individual model from seven ML models. As shown in Table 1, for the top-n accuracy and top-n fitness, there is still an IE trade off phenomenon, and no other model surpasses the present model across these two metrics simultaneously. Even for ERF predictions that are incorrectly ranked in top-n data, their actual target values remain relatively high. In addition, a scheme can be implemented to achieve superior prediction performance in both interpolation and extrapolation. Specifically, unknown data can be categorized as either interpolation or extrapolation based on model predictions. Subsequently, conventional models can be employed for interpolation prediction, while the proposed model is utilized for extrapolation prediction. The choice of classification and interpolation models depends on the specific problem.
Parity plots visualizing the predicted vs. true values for the present model across all datasets are provided in Fig. S3 (Supplementary Materials). These plots corroborate the numerical findings, showing that while interpolation predictions exhibit expected scatter due to the IE trade-off, extrapolation predictions maintain a functionally useful rank-order correlation and successfully identify high-value candidates outside the training label range.
3.2 The Multi-Objective Optimization of Mg-Zn-Al Alloy
The current model was utilized to design lightweight Mg-Zn-Al alloys with high bulk modulus and high Debye temperature, thereby addressing the pressing need for “lightweight-high stiffness-thermal stability” synergistic properties in aerospace and electronic applications. The process of alloy design is shown in Fig. 5a, firstly, the 2295 Mg-Zn-Al configurations with varying composition ratios were generated by the Universal Structure Predictor: Evolutionary Xtallography (USPEX) method. This method enables efficient global optimization and metastable structure exploration, and it avoids local minima traps while maintaining diversity on alloy composition and structure [22]. Secondly, 200 samples were selected as training samples. Density functional theory (DFT) calculations were conducted to determine target properties B and
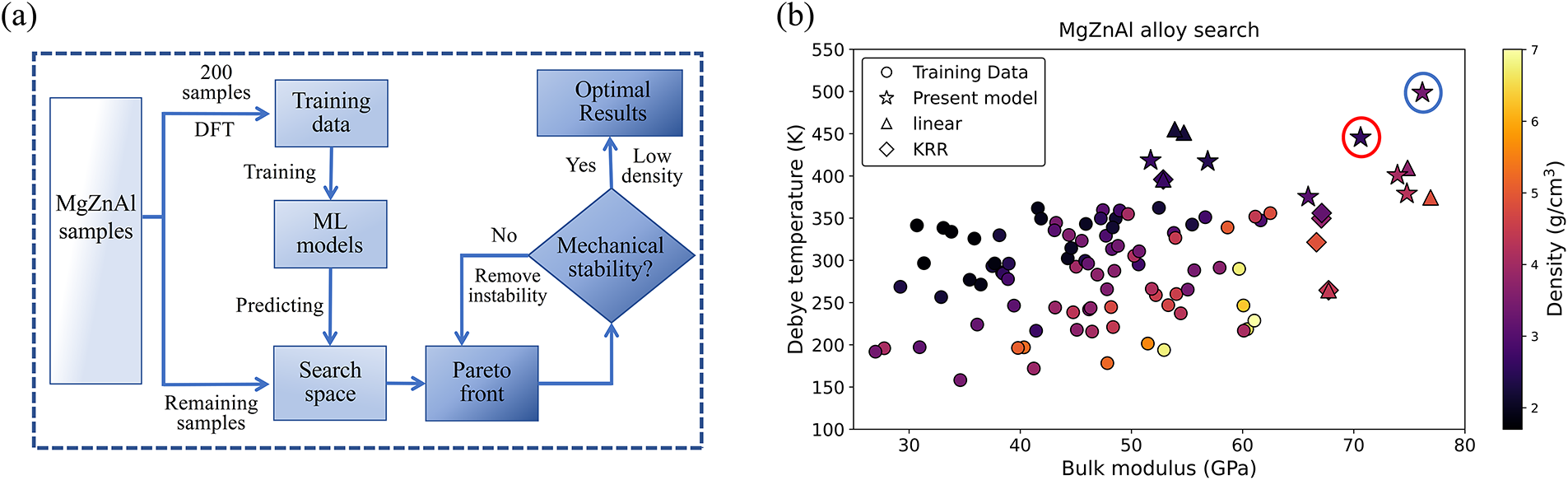
Figure 5: The multi-objective optimization of Mg-Zn-Al alloy. (a) The workflow of the multi-objective optimization process of Mg-Zn-Al alloy. (b) The properties of training samples (mechanically stable) and designed alloys by different models (with property breakthroughs).
The material features contain both elemental and structural descriptors. Building upon prior research [24,25], the elemental composition data were quantified using the Magpie descriptor [26], which incorporates fundamental atomic properties including nuclear charge, molar mass, Pauling electronegativity, valence electron count, and crystallographic space group classifications across different atomic layers. For structural characterization, the Smooth Overlap of Atomic Positions (SOAP) descriptor is employed [27], which mathematically represents local atomic environments through a spectral decomposition of the Gaussian-smoothed atomic density distribution using orthogonal basis functions derived from spherical harmonics and radial basis function expansions.
Taking the present model, linear regression (as a simple model), and KRR (as a complex model) as search models, the properties of the finally designed alloy samples, as well as those of the training samples, are shown in Fig. 5b. The present model clearly outperforms the linear model, which in turn surpasses KRR. The alloy in the blue circle (alloy-1) exhibits high B and high, with increases of 20.08% and 35.33% respectively, compared to the corresponding maximum values in the training data, while maintaining an acceptable density of 3.39 g/cm3, which is slightly below the average value of the training set. In contrast, the alloy in the red circle (alloy-2) shows increases of 11.32% and 20.91%, and an obviously lower density of 2.58 g/cm3. Their corresponding DFT-calculated properties and the model-predicted values are listed in Table 2. Details of calculation and designed alloys are provided in the Supplementary Materials.

This paper presents a discussion on the potential dual-driven approach for further enhancing the ML extrapolation capability. As depicted in Fig. 6, both data-driven and knowledge-driven approaches can yield satisfactory outcomes provided that the available data or domain-specific knowledge (e.g., materials science) is sufficiently comprehensive. However, the scarcity of data and knowledge gives rise to significant challenges, such as the IE trade-off. To address this, one potential approach is to explore innovative model architectures, as illustrated in this study, while another valuable strategy involves integrating existing domain knowledge into ML models, and this is regarded as dual-driven approach [28]. It can closely approximate the ideal model (Fig. 2a) by capturing the underlying principles, thereby enabling accurate predictions in both interpolation and extrapolation while mitigating or entirely avoiding the IE trade-off phenomenon [29]. Some designs are specially optimized for extrapolation. This method has been extensively investigated across multiple disciplines, but the current practices exhibit significant variability, and the existing literature outlines intricate and complex classification systems [28]. Here, by focusing on the ML workflow in materials design, a universally applicable and clearly understandable three-category classification framework is proposed. Data Embedding: Filtering or supplementing existing datasets based on domain knowledge and theoretical calculations [30]. Feature Embedding: Performing feature engineering guided by domain knowledge to capture critical factors for material property [31]. Model Embedding: Directly integrating rules and conditions into model training, such as the well-known Physics-Informed Neural Networks (PINNs) [32]. To visually represent the hierarchy of these integration strategies, Fig. 6 introduces a third axis perpendicular to the knowledge–data plane, which denotes the “depth of fusion or embedding” in dual-driven modeling. The column representing the dual-driven paradigm is thus stratified along this axis into the three levels described above: from the bottom (data embedding) to the top (model embedding), indicating progressively tighter coupling between domain knowledge and data-driven models. The majority of studies and reviews have limited their scope to the third category, while the first two have received little attention as dual-driven approach. The dual-driven approach demonstrates significant advantages but remains exploratory and demands substantial domain expertise.
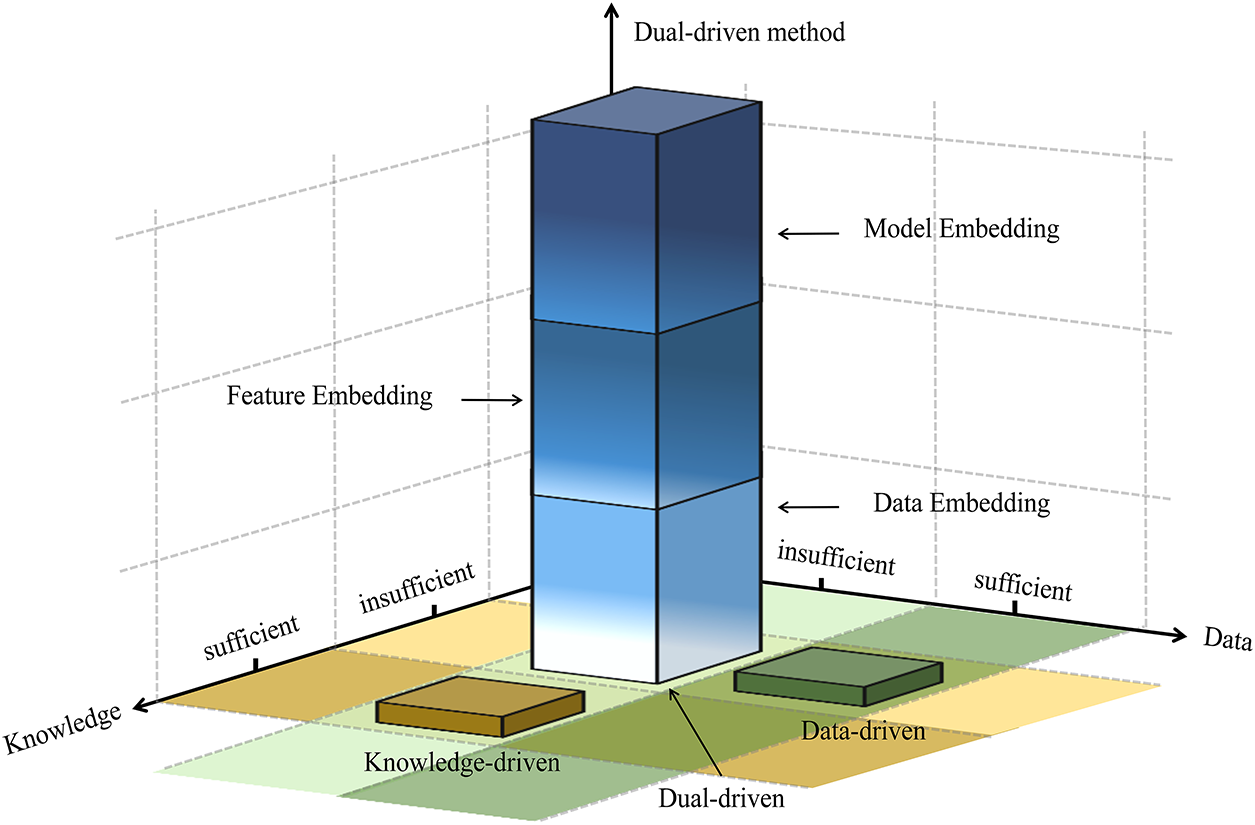
Figure 6: Classification of modeling approaches based on domain knowledge and data sufficiency, clearly distinguishing between knowledge-driven, data-driven, and dual-driven paradigms while incorporating hierarchical dual-driven methodologies.
Additionally, significant progress has recently been made in extrapolation-oriented neural network architectures, such as a physics-informed hybrid machine learning [33], a physics-inspired hybrid method [34], physics-constrained deep learning framework, physics-informed Extrapolation-Driven Neural Networks [35]. These works enhance model extrapolation performance by embedding physical laws into the network structure and can be regarded as typical examples of the “model embedding” category within the dual-driven framework proposed in this paper. Although such hybrid models often require in-depth customization for specific physical problems, and their systematic comparison extends beyond the scope of this work, their development direction is highly consistent with the dual-driven framework advocated here. This further validates the potential of integrating domain knowledge with data to improve extrapolation prediction capability. Future research can build upon the ERF model and the interpolation–extrapolation trade-off analysis presented in this work to further explore the systematic application of knowledge-embedded models in materials discovery.
4.2 The Discussion between IE Trade-Off and Bias-Variance Trade-Off
The IE trade-off introduced in this study shares conceptual connections with the classical bias-variance trade-off yet is fundamentally distinct in its scope and implications. While both frameworks address generalization challenges under limited data, the bias-variance trade-off concerns the balance between underfitting and overfitting within a fixed data distribution. In contrast, the IE trade-off explicitly examines the tension between model performance inside and outside the training data distribution, particularly when predicting beyond the range of observed target values. This distinction is critical in scientific domains such as materials discovery, where the primary objective often involves extrapolating to novel, extreme regions of the property space. Rather than merely extending the bias-variance paradigm, our work establishes the IE trade-off as an independent analytical dimension for out-of-distribution generalization. Accordingly, we develop tailored modeling and validation strategies (including Extrapolation-Robust Forests and forward cross-validation) to address this specific challenge, providing a coherent theoretical and methodological foundation for reliable machine learning in exploratory science.
4.3 The Generalizability of the Method
The interpolation-extrapolation trade-off framework proposed in this study has been systematically validated under data-limited conditions. While the Mg-Zn-Al alloy case presented in Section 3.2 employs a relatively small training set (200 samples), such a scale is representative in DFT-driven materials design. The structural diversity and coverage of the compositional space ensured by evolutionary sampling (USPEX) provide a reliable foundation for extrapolation. The successful identification of candidate materials beyond the training range (e.g., Alloy-1 and Alloy-2) demonstrates the robustness of the method in data-scarce scenarios.
To substantiate the generalizability of the framework, systematic validation was conducted across three distinct material systems: high-entropy alloy hardness (compositional and processing descriptors), steel hardness (compositional and heat-treatment descriptors), and photocatalyst formation energy (electronic-structure descriptors). The ERF model consistently outperformed baseline methods such as standard random forests in extrapolation tasks, confirming the broad applicability of the approach across different material systems and property types.
When extending the framework to new systems, the following aspects should be considered:
Data Quality Requirements: The training set should adequately reflect the underlying trends in feature-property relationships. For data with significant noise or uneven distribution, the dual-driven approach described in Section 4.1 is recommended, which incorporates domain knowledge through feature engineering or data augmentation.
Handling High-Dimensional Descriptors: In cases of extremely high descriptor dimensionality (>500 dimensions), pre-screening based on physicochemical prior knowledge is advisable to enhance computational efficiency.
Limits of Extrapolation Mechanisms: In regions where physical mechanisms undergo abrupt changes (e.g., phase boundaries), purely data-driven extrapolation faces inherent limitations. Integrating physically constrained models or employing physics-informed neural networks can serve as viable extensions.
Validation Strategies: The framework significantly reduces the number of candidates requiring first-principles validation. In experimental studies, an iterative experimental design guided by model uncertainty is recommended to improve validation efficiency.
4.4 Model Comparison with Other Work
It should be noted that research on extrapolation prediction is not entirely novel. Early Quantitative structure property/activity relationship (QSPAR) studies introduced “perimeter-oriented” validation set selection methods aimed at improving model performance in extrapolation within chemical space [36]. Building upon this foundation, our work further systematically enhances extrapolation capability from multiple dimensions including model architecture, hyperparameter optimization, and evaluation strategy, and is the first to explicitly reveal the “interpolation-extrapolation trade-off phenomenon” within the multidimensional feature space of materials. Future research could incorporate more extrapolation-specialized architectures for comparison to further validate the competitiveness of the proposed framework.
In this work, focusing on the field of ML-based high-performance material exploration, this study formally proposes the IE trade-off phenomenon based on extensive experimental investigations and rigorous statistical analysis, highlighting its universality and underlying causes. It identifies a prevailing misconception and provides new research perspectives. Furthermore, a ML scheme that integrates forward cross-validation-based hyperparameter optimization with the ERF model has been developed. Compared with seven conventional ML models, ranging from simple to complex architectures, the present model demonstrates superior extrapolation performance across multiple materials datasets. In the multi-objective optimization of lightweight Mg-Zn-Al alloys with high bulk modulus and high Debye temperature, two candidates were successfully designed based on the proposed scheme. Finally, three types of the dual-driven approach have been systematically summarized, and the advantages of this approach for ML-based material exploration are further highlighted. In this work, the developed practical framework provides a novel research perspective for exploring high-performance materials.
Acknowledgement: Not applicable.
Funding Statement: This work is supported by National Natural Science Foundation of China (No. 51671075 and 51971086) and Natural Science Foundation of Heilongjiang Province of China (No. LH2022E081).
Author Contributions: Shuai Li: data curation; formal analysis; investigation; methodology; software; validation; visualization; writing—original draft; writing—review & editing. Dongrong Liu: data curation; formal analysis; investigation; validation. Shu Li: conceptualization; project administration; supervision; methodology; writing—review & editing. Minghua Chen: investigation; methodology; resources; software. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data and code supporting this work can be accessed at https://github.com/Tujingrenshi/A-materials-discovery-method-considering-the-trade-off-phenomenon-in-machine-learning-prediction.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
Supplementary Materials: The supplementary material is available online at https://www.techscience.com/doi/10.32604/cmc.2026.075830/s1.
References
1. Niu MC, Qiu S, Yu Q, Li W, Zhang SZ, Guo JM, et al. Achieving excellent elevated-temperature mechanical properties in dual-phase high-entropy alloys via nanoscale co-precipitation and heterostructure engineering. Acta Mater. 2025;284:120634. doi:10.1016/j.actamat.2024.120634. [Google Scholar] [CrossRef]
2. Zhu Y, Peng D, Zhang E, Pan B, Chen X, Chen L, et al. Superconductivity in pressurized trilayer La4Ni3O10-δ single crystals. Nature. 2024;631(8021):531–6. doi:10.1038/s41586-024-07553-3. [Google Scholar] [PubMed] [CrossRef]
3. Mao X, Wang L, Xu Y, Wang P, Li Y, Zhao J. Computational high-throughput screening of alloy nanoclusters for electrocatalytic hydrogen evolution. npj Comput Mater. 2021;7(1):46. doi:10.1038/s41524-021-00514-8. [Google Scholar] [CrossRef]
4. Xu P, Ji X, Li M, Lu W. Small data machine learning in materials science. npj Comput Mater. 2023;9(1):42. doi:10.1038/s41524-023-01000-z. [Google Scholar] [CrossRef]
5. Li S, Yang J, Li S, Liu DR, Zhang MY. Phase classification of high entropy alloys with composition, common physical, elemental-property descriptors and periodic table representation. Trans Nonferrous Met Soc China. 2025;35(6):1855–74. doi:10.1016/S1003-6326(25)66787-2. [Google Scholar] [CrossRef]
6. Nishimura K, Matsuda K, Lee S, Nunomura N, Shimano T, Bendo A, et al. Abnormally enhanced diamagnetism in Al-Zn-Mg alloys. J Alloys Compd. 2019;774:405–9. doi:10.1016/j.jallcom.2018.10.037. [Google Scholar] [CrossRef]
7. Li Y, Zheng X, Liu Y, Kong Y, Zeng S, Wang B, et al. Design of ultrahigh strength Al-Zn-Mg-Cu alloys through a hybrid approach of high-throughput precipitation simulation and decisive experiment. J Mater Sci Technol. 2024;195:234–47. doi:10.1016/j.jmst.2023.12.072. [Google Scholar] [CrossRef]
8. Qin J, Li Z, Ma MY, Yi DQ, Wang B. Diversity of intergranular corrosion and stress corrosion cracking for 5083 Al alloy with different grain sizes. Trans Nonferrous Met Soc China. 2022;32(3):765–77. doi:10.1016/S1003-6326(22)65831-X. [Google Scholar] [CrossRef]
9. Suh JS, Suh BC, Lee SE, Bae JH, Moon BG. Quantitative analysis of mechanical properties associated with aging treatment and microstructure in Mg-Al-Zn alloys through machine learning. J Mater Sci Technol. 2022;107:52–63. doi:10.1016/j.jmst.2021.07.045. [Google Scholar] [CrossRef]
10. Na GS, Jang S, Chang H. Nonlinearity encoding to improve extrapolation capabilities for unobserved physical states. Phys Chem Chem Phys. 2022;24(3):1300–4. doi:10.1039/d1cp04450h. [Google Scholar] [PubMed] [CrossRef]
11. Xiong Z, Cui Y, Liu Z, Zhao Y, Hu M, Hu J. Evaluating explorative prediction power of machine learning algorithms for materials discovery using k-fold forward cross-validation. Comput Mater Sci. 2020;171:109203. doi:10.1016/j.commatsci.2019.109203. [Google Scholar] [CrossRef]
12. von Korff M, Sander T. Limits of prediction for machine learning in drug discovery. Front Pharmacol. 2022;13:832120. doi:10.3389/fphar.2022.832120. [Google Scholar] [PubMed] [CrossRef]
13. Hsieh WW. Improving predictions by nonlinear regression models from outlying input data. J Environ Inform. 2023;41:75–87. doi:10.3808/jei.202300493. [Google Scholar] [CrossRef]
14. Ren W, Zhang YF, Wang WL, Ding SJ, Li N. Prediction and design of high hardness high entropy alloy through machine learning. Mater Des. 2023;235:112454. doi:10.1016/j.matdes.2023.112454. [Google Scholar] [CrossRef]
15. Numata K, Tanaka K. Stochastic threshold model trees: a tree-based ensemble method for dealing with extrapolation. arXiv:2009.09171. 2020. [Google Scholar]
16. Yong W, Zhang H, Fu H, Zhu Y, He J, Xie J. Improving prediction accuracy of high-performance materials via modified machine learning strategy. Comput Mater Sci. 2022;204:111181. doi:10.1016/j.commatsci.2021.111181. [Google Scholar] [CrossRef]
17. Li S, Li S, Liu D, Yang J, Zhang M. Hardness prediction of high entropy alloys with periodic table representation of composition, processing, structure and physical parameters. J Alloys Compd. 2023;967:171735. doi:10.1016/j.jallcom.2023.171735. [Google Scholar] [CrossRef]
18. Yang Z, Li S, Li S, Yang J, Liu D. A two-step data augmentation method based on generative adversarial network for hardness prediction of high entropy alloy. Comput Mater Sci. 2023;220:112064. doi:10.1016/j.commatsci.2023.112064. [Google Scholar] [CrossRef]
19. Murdoch HA, Field DM, Szajewski BA, McClenny LD, Garza A, Rinderspacher BC, et al. Tempered hardness optimization of martensitic alloy steels. Integr Mater Manuf Innov. 2023;12(4):301–20. doi:10.1007/s40192-023-00311-9. [Google Scholar] [CrossRef]
20. Kumar R, Singh AK. Chemical hardness-driven interpretable machine learning approach for rapid search of photocatalysts. npj Comput Mater. 2021;7(1):197. doi:10.1038/s41524-021-00669-4. [Google Scholar] [CrossRef]
21. Li S, Li S, Liu D, Zou R, Yang Z. Hardness prediction of high entropy alloys with machine learning and material descriptors selection by improved genetic algorithm. Comput Mater Sci. 2022;205:111185. doi:10.1016/j.commatsci.2022.111185. [Google Scholar] [CrossRef]
22. Glass CW, Oganov AR, Hansen N. USPEX—Evolutionary crystal structure prediction. Comput Phys Commun. 2006;175(11–12):713–20. doi:10.1016/j.cpc.2006.07.020. [Google Scholar] [CrossRef]
23. Hafner J. Ab-initio simulations of materials using VASP: density-functional theory and beyond. J Comput Chem. 2008;29(13):2044–78. doi:10.1002/jcc.21057. [Google Scholar] [PubMed] [CrossRef]
24. Chen D, Li S, Tao T, Li S, Liu D, Liu X, et al. A machine learning framework for predicting physical properties in configuration space of gate alloys. Mater Today Commun. 2023;37:107526. doi:10.1016/j.mtcomm.2023.107526. [Google Scholar] [CrossRef]
25. Tao T, Li S, Chen D, Li S, Liu D, Liu X, et al. Structural descriptors evaluation for MoTa mechanical properties prediction with machine learning. Model Simul Mater Sci Eng. 2024;32(2):025004. doi:10.1088/1361-651X/ad1cd1. [Google Scholar] [CrossRef]
26. Ward L, Agrawal A, Choudhary A, Wolverton C. A general-purpose machine learning framework for predicting properties of inorganic materials. npj Comput Mater. 2016;2(1):16028. doi:10.1038/npjcompumats.2016.28. [Google Scholar] [CrossRef]
27. Bartók AP, Kondor R, Csányi G. On representing chemical environments. Phys Rev B. 2013;87(18):184115. doi:10.1103/physrevb.87.184115. [Google Scholar] [CrossRef]
28. Karniadakis GE, Kevrekidis IG, Lu L, Perdikaris P, Wang S, Yang L. Physics-informed machine learning. Nat Rev Phys. 2021;3(6):422–40. doi:10.1038/s42254-021-00314-5. [Google Scholar] [CrossRef]
29. Ouyang W, Ouyang W, Tian X, Liu SW, Wang J, Chan SL. Nonlinear analysis of glass panes under complex lateral pressures through physics informed neural networks. Eng Struct. 2025;334:120262. doi:10.1016/j.engstruct.2025.120262. [Google Scholar] [CrossRef]
30. Wang X, Li S, Liu F. Modeling for free dendrite growth based on physically-informed machine learning method. Scr Mater. 2024;242:115918. doi:10.1016/j.scriptamat.2023.115918. [Google Scholar] [CrossRef]
31. Jiang X, Jia B, Zhang G, Zhang C, Wang X, Zhang R, et al. A strategy combining machine learning and multiscale calculation to predict tensile strength for pearlitic steel wires with industrial data. Scr Mater. 2020;186:272–7. doi:10.1016/j.scriptamat.2020.03.064. [Google Scholar] [CrossRef]
32. Raissi M, Perdikaris P, Karniadakis GE. Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J Comput Phys. 2019;378:686–707. doi:10.1016/j.jcp.2018.10.045. [Google Scholar] [CrossRef]
33. Wu H, Gui M, Wu D. Physics-Informed hybrid machine learning for critical heat flux prediction: a comparative analysis of modeling approaches. Nucl Eng Des. 2025;445:114434. doi:10.1016/j.nucengdes.2025.114434. [Google Scholar] [CrossRef]
34. Hou M, Gong S, Zuo Y, Liu Y. Physics-inspired hybrid method for the conducting target’s RCS extrapolation in the frequency domain. IEEE Anntenas Wirel Propag Lett. 2023;22(4):699–703. doi:10.1109/LAWP.2022.3222798. [Google Scholar] [CrossRef]
35. Wang Y, Yao Y, Gao Z. An extrapolation-driven network architecture for physics-informed deep learning. Neural Netw. 2025;183:106998. doi:10.1016/j.neunet.2024.106998. [Google Scholar] [PubMed] [CrossRef]
36. Szántai-Kis C, Kövesdi I, Kéri G, Orfi L. Validation subset selections for extrapolation oriented QSPAR models. Mol Divers. 2003;7(1):37–43. doi:10.1023/b:modi.0000006538.99122.00. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools