
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Q-ALIGNer: A Quantum Entanglement-Driven Multimodal Framework for Robust Fake News Detection
1 Faculty of Informatics, Kaunas University of Technology, Kaunas, Lithuania
2 College of Engineering and Technology, American University of the Middle East, Egaila, Kuwait
3 Department of Computer Sciences, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
4 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
5 Department of Information Technology, College of Computing and Information Technology, Northern Border University, Arar, Saudi Arabia
6 Department of Information Systems, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
* Corresponding Author: Sara Tehsin. Email:
Computers, Materials & Continua 2026, 87(2), 71 https://doi.org/10.32604/cmc.2026.076514
Received 21 November 2025; Accepted 07 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The rapid proliferation of multimodal misinformation on social media demands detection frameworks that are not only accurate but also robust to noise, adversarial manipulation, and semantic inconsistency between modalities. Existing multimodal fake news detection approaches often rely on deterministic fusion strategies, which limits their ability to model uncertainty and complex cross-modal dependencies. To address these challenges, we propose Q-ALIGNer, a quantum-inspired multimodal framework that integrates classical feature extraction with quantum state encoding, learnable cross-modal entanglement, and robustness-aware training objectives. The proposed framework adopts quantum formalism as a representational abstraction, enabling probabilistic modeling of multimodal alignment while remaining fully executable on classical hardware. Q-ALIGNer is evaluated on four widely used benchmark datasets—FakeNewsNet, Fakeddit, Weibo, and MediaEval VMU—covering diverse platforms, languages, and content characteristics. Experimental results demonstrate consistent performance improvements over strong text-only, vision-only, multimodal, and quantum-inspired baselines, including BERT, RoBERTa, XLNet, ResNet, EfficientNet, ViT, Multimodal-BERT, ViLBERT, and QEMF. Q-ALIGNer achieves accuracies of 91.2%, 92.9%, 91.7%, and 92.1% on FakeNewsNet, Fakeddit, Weibo, and MediaEval VMU, respectively, with F1-score gains of 3–4 percentage points over QEMF. Robustness evaluation shows a reduced adversarial accuracy gap of 2.6%, compared to 7%–9% for baseline models, while calibration analysis indicates improved reliability with an expected calibration error of 0.031. In addition, computational analysis shows that Q-ALIGNer reduces training time to 19.6 h compared to 48.2 h for QEMF at a comparable parameter scale. These results indicate that quantum-inspired alignment and entanglement can enhance robustness, uncertainty awareness, and efficiency in multimodal fake news detection, positioning Q-ALIGNer as a principled and practical content-centric framework for misinformation analysis.Keywords
The rapid expansion of social media platforms has increased the dissemination of multimodal misinformation—that is, a message that includes a textual claim that is often supported by an altered image or a false image. This trend threatens public trust and presents severe challenges to information certainty, political stability, and societal choice-making. Previously developed fake news detection methods that were based solely on textual [1,2] or visual [3] features have shown to be ineffective, mostly because they did not account for even some interdependence of modalities. The recent multimodal approaches [4–6] that incorporated deep learning to fuse heterogenous signals still struggle for robustness under adversarial perturbations, or in making calibrated and reliable confidence scores for the results. This affects its practicality of use in deployment scenarios where adversarial perturbations and noisy data are a possibility.
Recently, quantum-inspired learning has gained traction as a new and promising strategy for progressing multimodal representation learning. The integration of quantum state embedding and entanglement, models including QMFND [7] and HQDNN [8] exhibit better feature expressivity and robustness. However, such models strategize on fixed entanglement mechanisms and do not have methods for explicit alignment among modalities, resulting in sub-par performance in highly heterogenous misinformation environments. The combination of transformative methodology, quantum-inspired expressivity, adaptive alignment, and robustness-aware learning models is perceived as the change needed to over-come performance limitations. The paper’s primary objective is to create a system capable of confirming the content of different media types through a model that offers a semantic alignment and robustness between text and images at the instance level. However, although the temporal dynamics, content propagation patterns, and social context are essential to thoroughly understand how misinformation spreads through the internet, these factors will generally not be considered until later detection phases since they represent signals unavailable at the early stages of detection. Thus, they will not be modeled in this research.
Recent advancements in the detection of multimodal fake news have failed to create a comprehensive approach to the simultaneous challenges of semantic disparity, adversarial robustness and uncertainty estimation. Previous multimodal fusion methods such as Attention, Concatenation and Late Fusion, utilise deterministic representations; therefore, those methods do not effectively model higher-order dependencies across modalities due to the presence of noise and ambiguity in the real world. Misinformation and the issues associated with it in the real world often include conflicting evidence, expert disagreement and adversarial manipulation. As a result, applying a model to create a confident prediction to assist those who are investigating may be misleading instead of providing additional predictive power. The noted deficiencies present a compelling rationale for the development of a representational framework that captures uncertainty in a natural way, allows for the modelling of non-trivial cross-modal dependencies and is robust when subjected to perturbation. Quantum-Inspired Modelling offers a representation of uncertainty in the form of probabilistic state representations, has principled similarity measures, and uses entanglement-based mechanisms to model dependency. Quantum-Inspired Modelling can be implemented on Classical Hardware (and all details regarding implementing the model on Classical Hardware will be provided) making it a viable approach to model the existing deficiencies in Multimodal Fake News Detection Systems by treating quantum formalism as a modelling abstraction rather than as a hardware requirement.
In this study, we introduce Q-ALIGNer, a quantum-inspired multimodal framework that processes text and images for fake news detection. Q-ALIGNer encompasses traditional feature extraction methods combined with quantum state embedding, followed by a learnable entangling unitary that fuses textual and visual components together by learning adjustment over successive cycles. Additionally, to further improve performance, we incorporate a contrastive InfoNCE alignment loss to optimize cross-modal consistency, along with a robustness objective in order to project resilience against adversarial attacks. This produces the combined aspects of Q-ALIGNer, which project better cross-modal reasoning deficiencies, improve generalization capacity and provide improved reliability conditions under noise. The three main contributions of this work are: (1) we propose a quantum-enhanced fusion mechanism which incorporates learnable entanglement to model dependencies among text and image modalities; (2) alignment-guided contrastive learning and robustness-aware training objectives, which improved both accuracy, calibration and adversarial resilience; and (3) a comprehensive evaluation of Q-ALIGNer on four benchmarks (FakeNewsNet, Fakeddit, Weibo and MediaEval VMU) demonstrate Q-ALIGNer achieves superior performance to strong baselines (i.e., transformer-based models, multimodal models, and other quantum-inspired models) across all datasets. Q-ALIGNer is an quantum inspiration framework, but it never actually uses real life quantum computer hardware to run. The framework does use mathematical representations of quantum constructs (e.g., density matrices, entangled states, etc.), but they are used in classical simulation on classical computers (or quantum inspired). For this reason, the advantages of entanglement within the Q-ALIGNer framework should be viewed as algorithmic advantages due to the use of quantum formalisms and not as actual quantum hardware effects. This is consistent with previous approaches to quantum-inspired learning.
The rest of this paper is structured as follows. Section 2 reviews the existing literature on multimodal fake news detection, as well as quantum-inspired learning. Section 3 describes the Q-ALIGNer architecture with three components: quantum state encoding, entanglement-based fusion, and training objectives. Section 4 describes experimental setups, results, ablation studies, and robustness analysis. Section 5 wraps up with highlights and future work.
In the last few years, multimodal fake news detection studies have increased dramatically based on the limitations of unimodal models in clarifying the connection between text and image. Tufchi et al. provide a comprehensive survey highlighting deep learning models’ limitations for multimodality-related applications around the data fusion approach and robustness issues [9]. Abduljaleel et al. conduct a specific survey to deep learning in the last five years (2019–2024) and also state that schemes of fusion that are simplistic concatenation and element-wise multiplication do not produce desirable performance, indicating that more complex interactions need to be tackled [10].
Recent advancements in fusion architectures have been developed, including a number of contrastive-learning and attention-based modeling approaches such as contrastive fusion techniques like MCOT (multi-modal contrastive optimal transport) that combine multimodal contrastive learning with optimal transport for aligning the textual and visual features [2]. MIMoE-FND is another mixture-of-experts model for gating modality interaction adaptively [4]. Both of these works show large performance improvements over other baseline approaches. Other works have investigated graph-based fusion like MAGIC (multimodal adaptive graph interdependencies) that utilizes adaptive graph representations to represent interdependencies and achieves very high benchmark accuracy [3]. Hybrid architectures that combine residual networks and attention architectures have also achieved reported improvements in semantic sensitivity and adaptability over existing models [11]. User or social contexts that are integrated with a modality (e.g., MFUIE–Modality fused user intention embeddings) have also been shown to further improve detection performance by enriching context models [12].
Although these advances have been made, the issues of robustness under adversarial noise and model calibration are still under-explored with respect to multimodal studies. In terms of emerging quantum-inspired learning, the QMFND approach presented future prospects of integrating quantum convolutional neural networks to enhance the feature representations [7]. The HQDNN hybrid quantum–classical architecture also provides enhanced expressivity for the purpose of fake news detection [8]. The more recent QEMF model continues down this path, showcasing quantum entanglement as a mechanism for multimodal fusion where state-of-the-art robustness was achieved.
Quantum computing utilizes the principles of quantum mechanics to represent information in terms of quantum states within a complex-Hilbert space, rather than as classical bits that represent binary values. The ability of quantum states to exist in superposition gives rise to their ability to represent more complex information than classical bits. Quantum-inspired machine learning draws inspiration from quantum mechanics by taking advantage of mathematical representation of quantum states and their associated transformations through classical simulation without requiring the physical use of quantum hardware to perform the computations. Quantum states can be represented as a state vector or alternatively as a density matrix, which represents a probabilistic view of mixed or uncertain quantum state; the density matrix is useful for representing uncertainty and correlation and thus provides an appropriate representation for learning tasks based on noisy/ambiguous data. Entanglement is one of the most remarkable concepts that exist in quantum theory. It describes correlations between two or more parts of a single quantum system. In quantum-inspired model, entanglement is used as a representation mechanism to represent complex dependency between different sources of information. The use of entanglement-inspired transformation in multimodal learning enables the joint representation of all interactions between modalities in ways other than simple concatenation or attention-based fusion.
Even with the considerable progress made in multimodal fake news detection, there are still several important gaps that remain unaddressed in the literature. First, many of the fusional approaches utilize static or shallow integration methods, such as concatenation, late fusion, or use fixed entanglement, none of which are able capture the dynamic and complex dependencies of textual and visual modalities [2,4]. Second, though, the introduction of contrastive and attention-based methods has advanced alignment, there is still significant sensitivity to noisy and adversarial data with very little resilience with the data in real-world settings [11]. Third, quantam-inspired methods have improved expressivity via approaches like QMFND and HQDNN, however, the frameworks have mostly been employed using rigid circuit designs with no adaptive entanglement or alignment-driven supervision [7,8]. Lastly, to our knowledge, model calibration and trusted uncertainty estimation remain unexplored in multimodal misinformation detection, and without this area, the applicability of current frameworks is limited in safety-critical settings.
The Q-ALIGNer framework has been proposed to address these shortcomings by introducing a synergistic integration of quantum-inspired and deep learning components. Q-ALIGNer develops a learnable entangling unitary that models cross-modal dependencies in an adaptive fashion to allow for more flexible and expressive fusions, unlike standard fusion strategies. The architecture includes a robustness-aware loss to mitigate adversarial sensitivity, which reduces susceptibility to textual and visual perturbations. A contrastive InfoNCE alignment objective is also included to explicitly enforce cross-modal consistency across textual and visual signals while remaining semantically aligned in the presence of noise. In contrast to prior quantum-inspired approaches, Q-ALIGNer allows for end-to-end optimization of entanglement and alignment, leading to better generalization of the integrated representations. Finally, Q-ALIGNer also accommodates calibration-based training, yielding more credible probabilistic uncertainty estimates and improving overall trustworthiness during deployment. Altogether, these advancements signify the key advantages over existing methods, and further enable Q-ALIGNer to be a state-of-the-art framework for multimodal fake news detection.
To ensure greater accessibility of the methodology presented in this work for a larger audience, a short introduction to some of the many quantum-based concepts employed in the development of our multi-discipline fusion methodology has been formulated. Although these concepts were not implemented on actual quantum hardware, they are implemented as mathematical abstractions through simulation on standard computers. Density matrices are a probabilistic representation of a system’s state and are used to describe the uncertainty associated with a system of multiple components that are combined into a single entity. With the Q-ALIGNer project, density matrices were used to represent the fusion of text and visual embeddings in a quantum-inspired manner. Another significant advantage of using density matrices to represent images and text is that they naturally represent the ambiguity and uncertainty associated with multimodal information.
Partial traces are a method of extracting a single mode from a composite system, while ensuring that the remaining modes have been eliminated. In this work, the partial trace can be interpreted as a technique to allow for the independent reasoning and modelling of the text and visual modes of the system, once the two modality types have been fused and merged into a composite model. Quantum fidelity is a mathematical concept used to measure the degree of similarity between two states, and the degree of alignment between those two states. In the Q-ALIGNer project, quantum fidelity can be used to quantify the amount of alignment that exists between text and visual representations. Thus, quantum fidelity serves as a measure of the degree of consistency between the different modalities. All of the above concepts create a formalised, and interpretable, framework by which to model the relationships, and uncertainties among the different modalities associated with multimodal information, while also retaining compatibility with conventional machine-learning pipelines using standard mathematical techniques.
In this section, we present the improved methodology for quantum-enhanced multimodal fake news detection. The framework we propose is called Q-ALIGNer (Quantum Contrastively-Aligned Multimodal Entanglement Network), which improves on the limitations of previous quantum multimodal models. Our proposed framework uses entanglement-driven fusion, contrastive learning, and explicit consistency validation between modalities to conduct multimodal fakes news detection. For mathematical clarity, we define all of the symbols present in the equations later. At a high level, Q-ALIGNer has five components that make up the pipeline: feature extraction, quantum state encoding, cross-modal entanglement, situation prediction through measurements, and training through multi-objective optimization. For feature extraction, text and image embeddings are extracted through contextual encoders, mapped into quantum states, entangled, and measured for veracity, consistency, and uncertainty. Training is managed using a composite loss function that includes a classification loss, alignment loss, and robustness los. We illustrate the overall workflow of the proposed Q-ALIGNer in Fig. 1. As the Fig. 1 shows, we integrate classical encoders, quantum state encoding, entanglement, and multi-measurement head.
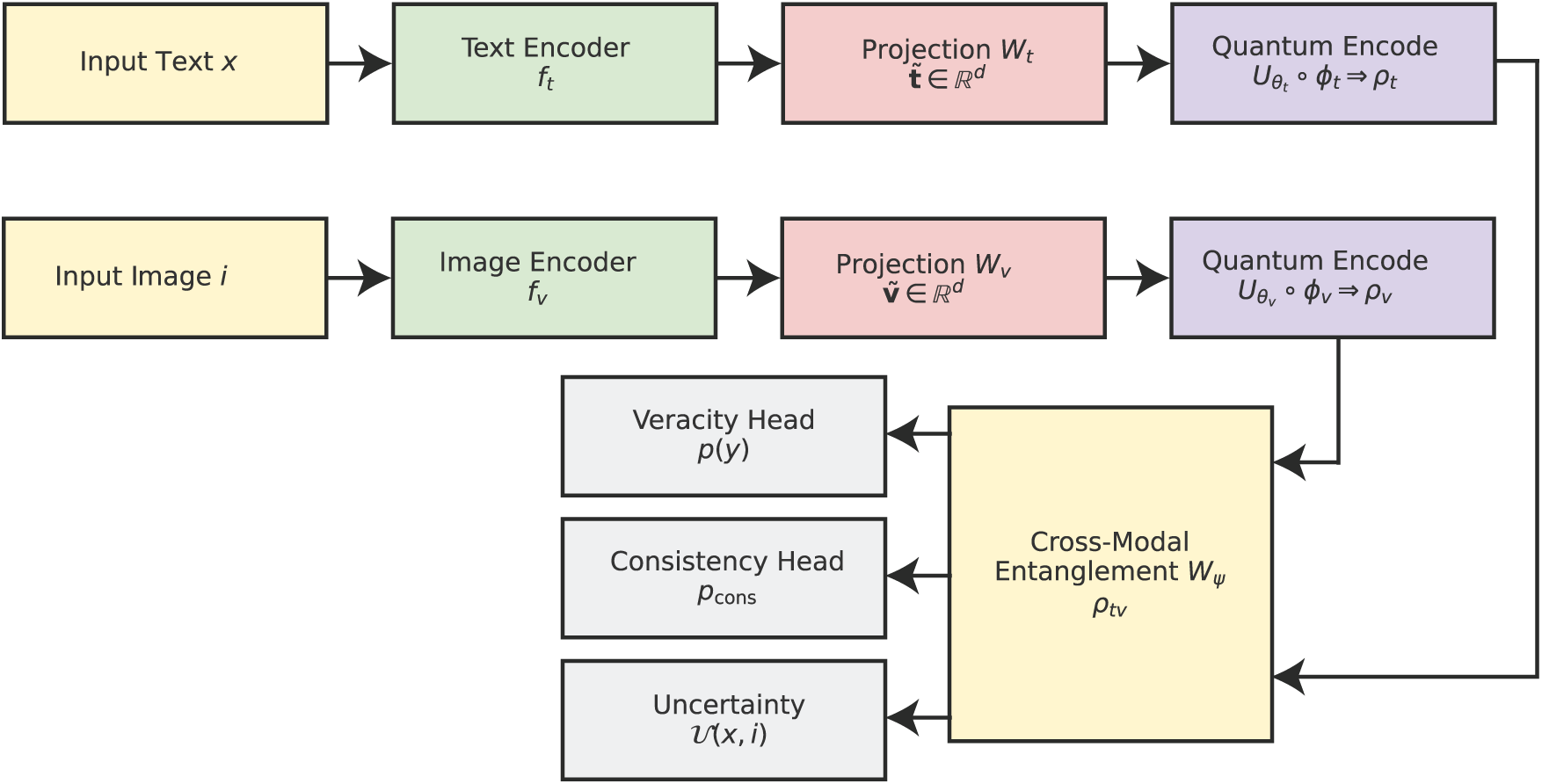
Figure 1: Overall architecture of Q-ALIGNer.
3.1 Classical Feature Extraction
The initial step of Q-ALIGNer in the classical feature extraction stage aimed to generate rich and contextually meaningful representations for both text and image modalities prior to being encoded into quantum states. This is an important step in the work flow because the quality of quantum embeddings will depend fundamentally upon the discriminative power of classical encoders. Unlike QEMF, which deployed static embeddings for text (GloVe) and CNN-based image features (based on VGG16), Q-ALIGNer employs contextualized models and transformer-based architectures to understand higher-order dependencies and semantic structures.
For the text modality, let
where
where
where
Since
where
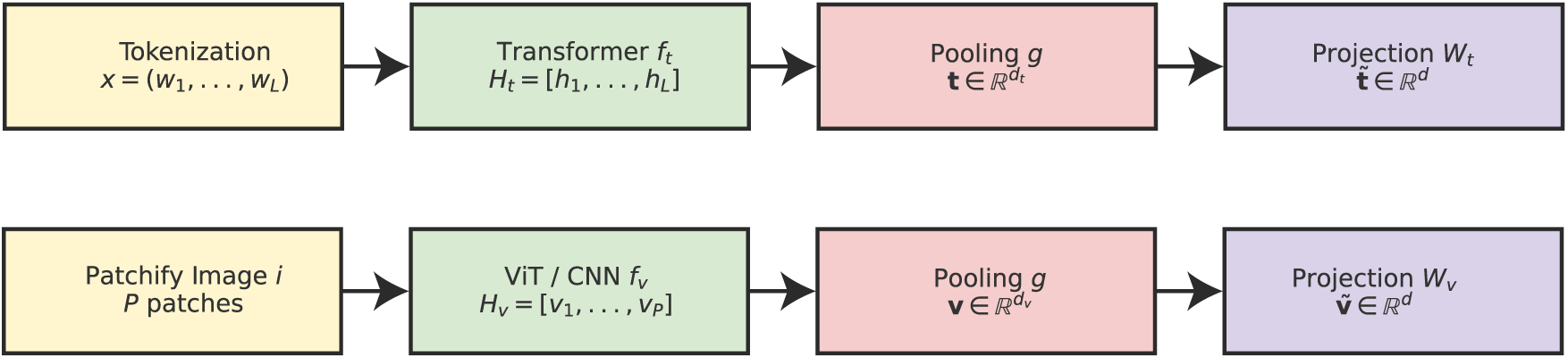
Figure 2: Classical feature extraction stage. Text tokens are processed by a transformer encoder and pooled into a global representation, while images are patchified and encoded by a ViT (or CNN) before pooling. Both modalities are projected into a shared
By employing transformer-based encoders, Q-ALIGNer benefits from dynamic contextual awareness in the textual domain and spatial-semantic feature richness in the visual domain. The projections guarantee alignment between modalities, preparing the system for robust quantum state encoding in the next stage.
The subsequent step, subsequent to inputting the text and visual embeddings into a joint latent space, is to encode the vectors into quantum states that can be utilized for subsequent quantum operations. Quantum state encoding aims to use the representational power of a quantum system to encode complex semantic relationships that would not be as effectively modeled with classical embeddings alone. Let
where
Similarly, for the image modality, the embedding
where
The choice of feature map
Another approach is angle encoding, where elements of the embedding vector parameterize rotation gates:
where
The initial joint multimodal state before fusion is the tensor product of the two density matrices:
This state serves as a basis for future entanglement operations for the quantum system to model cross-modal dependencies. As seen in Fig. 3, classical latent embeddings are mapped to quantum states through feature maps and parameterized circuits. The quantum state encoding stage therefore creates a mathematically principled mapping of classical embeddings into quantum Hilbert space. By selecting suitable encoding strategies and parameterized unitaries, Q-ALIGNer guarantees that rich contextual information from the text and image modalities are retained and available for quantum entanglement and measurement in subsequent stages.
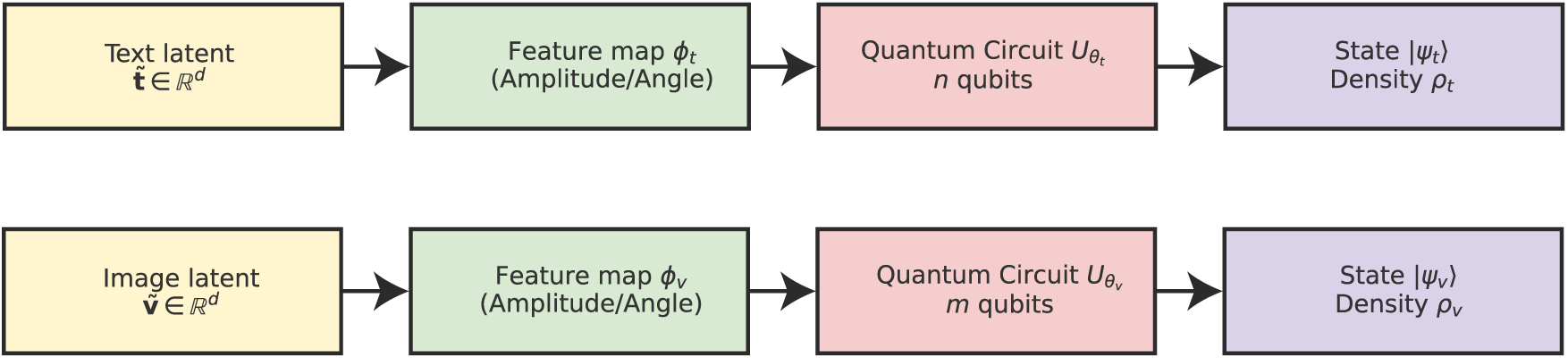
Figure 3: Quantum state encoding. Projected embeddings
The crucial part of Q-ALIGNer is what we call cross-modal entanglement, which allows engagement of the quantum states that are thinking about the modality of text and the modality of image. First, recall that classical models will typically factorize their approaches using simple concatenation or attention-based fusion of modalities. Instead, Q-ALIGNer uses the quantum entanglement principle to find correlations or co-occurrence between modalities in the Hilbert space. In this phase, the model is able to learn dependencies that cannot really be expressed in a linear combinatorial way, as with the joint state initial state
where
This results in a correlated state that cannot be decomposed into a simple tensor product. More generally, entanglement is introduced through parameterized controlled rotations:
where
The degree of alignment between modalities after entanglement can be quantified using quantum fidelity:
Maximizing this fidelity encourages the quantum states of text and image to occupy nearby regions of the Hilbert space when they correspond to consistent information. Additionally, the swap test provides a direct way to evaluate the similarity of quantum states. For two pure states
where

Figure 4: Cross-modal entanglement. Independent text and image states are fused by an entangling unitary
Thus, cross-modal entanglement is achieved with Q-ALIGNer through not only fusing modalities but also pursuing semantic coherence via fidelity maximization and swap-test based alignment. Downstream measurement and prediction tasks depend upon the entangled state
3.4 Measurement and Prediction
When the entangled multimodal state
where I is the identity operator. For each class
The logits are defined as expectation values of the measurement outcomes:
which are then normalized through the softmax function:
For binary fake news detection, we define two measurement operators
The classification probability of veracity is then
In addition to truthfulness, Q-ALIGNer adds more heads for modality consistency and uncertainty. The consistency head checks to see whether the textual and visual modalities are semantically consistent. This is measured by quantifying the overlap of the subspaces corresponding to the text and image registers. Thus, class prediction in Q-ALIGNer arises from learned measurement operators applied to the entangled multimodal state, rather than from explicit label encoding within the quantum-inspired state itself. Let
where a higher value implies greater congruence between the modalities. To quantify uncertainty, an entropy-based measurement is calculated over the distribution of probabilities. The predictive uncertainty of an input
The uncertainty score shows how confident we are in the model prediction. More uncertainty corresponds to greater entropy. When there is conflicting or ambiguous multimodal evidence (like expert disagreement or propaganda), Q-ALIGNer reflects the uncertainty of the knowledge or prediction about the outcome. This means that Q-ALIGNer does not assume that the data inputs will all be labeled with one definitive truth; rather, the higher the entropy and lower the modality consistency score are, the less confidence we have in defining a unique classification for the input evidence. In addition, expectation values of the Pauli observables can be understood as the prediction in terms of observables. For an observable O acting on the joint state, the expected value is:
By selecting O very carefully, we can describe latent relationships across modalities and offer explainabality on decisions made by the model. The measurement phase is depicted in Fig. 5. Here we show an entangled state is projected into veracity, consistency and uncertainty outputs of the model. In summary, then, the measurement and prediction functions of Q-ALIGNer are formalized in terms of POVMs, projective operators, and the calculation of uncertainty using unique (to us) forms of entropy. Not only do we provide classification outputs through these quantum-native operations but we also provide an opportunity for more clarity in how weary we are of multimodal inputs even further separating Q-ALIGNer from non-Q multimodal classifiers.
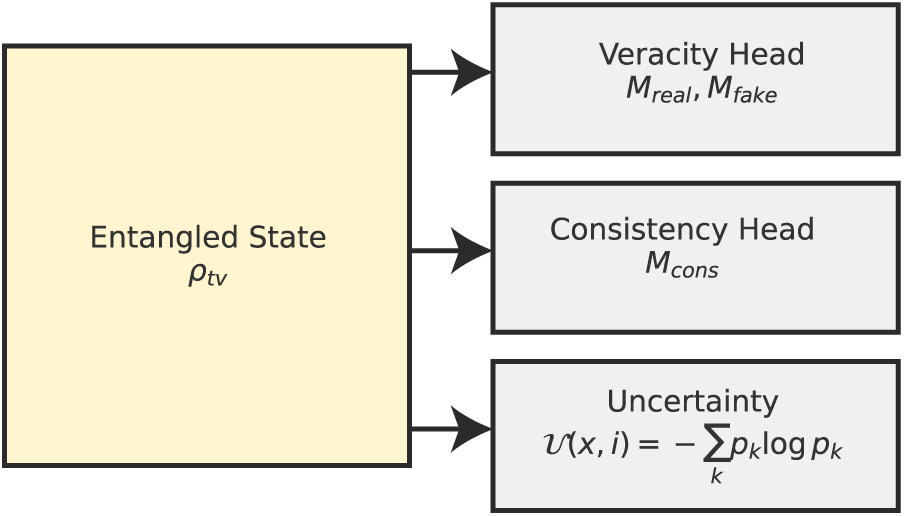
Figure 5: Measurement and prediction. The entangled state
The internal fusion process of an aligner that is quantum based on entanglement operates at the level of outputs and not at the level of the actual circuit level. The model produces scores for the degree of modality matching between a type of image and some text associated with that type of image, for the degree of the fidelity of the matched modalities to the original source, and for the degree to which the model has the potential of incorrectly predicting an association. These scores can be easily understood by a non-expert stakeholder and do not require the user to have any understanding of quantum mechanics. During the training and inference phases, Q-ALIGNer assumes that paired textual and visual datasets are both available. In a multimodal system when input types are noisy, corrupted or low-quality, Q-ALIGNer indicates the uncertainty of the relationship between the input types through a low score on modality consistency. Furthermore, it indicates the uncertainty in its prediction with a high level of predictive entropy. Thus, when faced with degraded multimodal inputs, the Q-ALIGNer system signals its lack of confidence by producing less confident predictions than by producing over-confident predictions.
Q-ALIGNer’s training is aided by a structured composite objective that combines four criteria: classification accuracy, modal semantic alignment, entanglement consistency and adversarial robustness. Q-ALIGNer does not depend on cross-entropy loss as typical multimodal fake news detection models do; instead, we introduce several mutually helpful terms, with each term reflecting a separate facet of multimodal reasoning in the quantum domain. The overall composite objective function is given by
where
here
where
The swap-test probability of measuring ancilla in
which penalizes dissimilarity between modalities. Fidelity-based alignment is encouraged by minimizing the Bures distance between text and image states:
A smaller Bures distance corresponds to greater modal semantic coherence. To investigate adversarial robustness we create perturbed text-image pairs
which enforces stability of predictions under adversarial conditions. Robustness can also be measured through Kullback–Leibler divergence between clean and adversarial distributions:
where
Adversarial robustness is a significant design consideration for Q-ALIGNer since fake news detection environments are inherently adversarial; malicious actors take measures to avoid detection through easily overlooked perturbations in either text or image data. To address this, Q-ALIGNer incorporates adversarial training as part of the optimization strategy so that stable predictions are learned despite adversarial perturbation. In the context of textual data, adversarial perturbations can occur through various approaches. Synonym substitution could replace a word with a semantically similar alternative, while character level approaches would substitute a word with a misspelling—an error that is still readable but the misspelled version may mislead the language model’s token embeddings. Back-translation methods are also capable of producing paraphrased alternatives for the same sentence. More formally, suppose the original text sequence is
where
where
where
where
where by
3.7 Computational Considerations
Considering the computational complexity and ensuring practical viability for real-world applications is an important dimension of any design for quantum-enhanced models like Q-ALIGNer. The traditional multimodal framework for fake news detection was the multimodal QEMF model. However, one of the major drawbacks of the QEMF model was a very high computational cost of
where
In general, amplitude encoding has a preparation cost of
which is bilinear in the number of qubits assigned to each modality. As pruning reduces
where S represents the number of shots. In practice, M is maintained small (usually 2–4 operators for binary or multi-class classification) to control measurement overhead. The robustness component adds adversarial training and essentially doubles the dataset size by including perturbed samples. If we let the clean training set size be N, adversarial augmentation produces
with each term representing preprocessing, quantum state encoding, entanglement, measurement, and dataset scaling, respectively. In comparison to the
Q-ALIGNer harnesses powerful accuracy and robustness while improving computational performance through employing pruning strategies, shallow variational circuits, and optimized measurement strategies. The framework was constructed with a theoretical understanding of the problem, along with practical computational capabilities for real large-scale applications in the domain of fake news detection.
This chapter gives a detailed assessment of the suggested Q-ALIGNer framework for detecting fake news across different modalities. The aim of the experiments is to test whether our approach differentiates the efficacy of quantum-enriched multimodal fusion vs. state-of-the-art classical and hybrid baselines. The results of our experiments encompass various benchmark datasets with varying domains of textual and visual misinformation. We organize our findings to examine five major components: (i) The classification performance metrics of Q-ALIGNer against accuracy, precision, recall, F1-score and ROC-AUC; (ii) Contribution to baseline comparisons to show improvements in veracity predictions; (iii) Ablations, or studies demonstrating individual contributions of cross-modal entanglement, InfoNCE alignment, and robustness loss; (iv) Adversarial robustness under textual and visual disturbances; and (v) Model calibration and uncertainty, along with examples of how our framework is efficiently applied in computational efficiency. Collectively these results frame Q-ALIGNer in terms of robustness and extensive generalizability as well as interpretaiblity for mountering misinformation in a multimodal social media environment.
To assess the proposed Q-ALIGNer framework, we ran experiments on a variety of publicly available multimodal fake news detection benchmarks. We selected these benchmarks so that there would be a variety of modes, domains, and languages represented, in order to evaluate the component’s generalization across domains and robustness in real-world misinformation scenarios. FakeNewsNet: FakeNewsNet is a popular benchmark that provides a number of news article sets with social context and multimedia components. For this analysis, we take the subset with paired textual articles and corresponding images. This dataset has the indicators of fake and real news verified through professional fact checking sources. The anonymous crowd sourced verification markers make it a reliable resource for binary classification tasks. Fakeddit: Fakeddit is a larger scale dataset from Reddit posts with multimodal samples, where each entry has text and an associated image. It has both binary (fake vs. real) and fine grained multi-class labeling schemes. In our experiments, we adopted the binary framework to align with other multimodal misinformation detection studies. The size of the Fakeddit dataset was helpful in enabling multimodal assessment of Q-ALIGNer in a complex and noisy social media context.
Weibo: The Weibo multimodal fake news dataset has social media posts in the Chinese language and an accompanying image. Each instance is annotated fake or real, based on typical fact-checking sources, introducing variation in coding schema. This is useful for assessing the cross-lingual adaptability of Q-ALIGNer. The shorter length of text posts, and casual style of writing, introduce a challenge versus long-form articles. MediaEval VMU: To provide another additional cross-domain generalization assessment, we present the Verifying Multimedia Use (VMU) dataset from the MediaEval benchmark. This dataset takes the form of multimodal Twitter posts, where the focus is determining whether the textual claim is verified by visual evidence. This assesses the veracity of an accompanying image but not veracity of the article, distinguishing it from Fakeddit and FakeNewsNet, which is focused on article style. The MediaEval VMU task considers rapid informal and high noise, and it is consistent with the more real-time nature of social media misinformation. Across all datasets we separate into training, validation, and testing (80:10:10 split), following common procedure unless the authors created a split. Textual data was preprocessed with subword tokenization (WordPiece or Byte-Pair Encoding), and images were preprocessed by resizing and normalization. Then the images were patchified for the Vision Transformer. This approach is consistent for both quantum encoding, multimodal data, and allows for a uniform preprocessing strategy for fair comparisons across datasets.
Despite Q-ALIGNer being assessed using standard benchmark sets, Q-ALIGNer’s benchmark sets contain examples of “real” social media sites (e.g., Fakeddit, Weibo, and MediaEval VMU) with characteristics such as informal language, poor alignment of image/text content, high levels of noise within the data, and depending on who you follow, these examples have significant variation in content over time. All of these factors create an excellent way to simulate a real-world environment that uses Q-ALIGNer in a similar method as a large-scale social media platform could be operated. The strong results demonstrate a qualitative performance on posts written in Chinese and containing a specific style of culturally dissimilar misinformation present in China, that the quantum-inspired method of alignments is able to generalise across languages, including but not limited to English. There is an opportunity to look at this further as an area of research into understanding cross cultural differences.
The assessment of Q-ALIGNer and comparison baselines is conducted using standard classification measures along with specialized metrics that evaluate robustness and calibration. As the task is binary fake news classification, we report accuracy, precision, recall, F1 score and area under the ROC (AUC). Accuracy indicates the overall correctness of the predictions, precision indicates the confidence of the model when predicting fake cases, recall indicates the model’s ability to detect all fake news instances, and the F1 score is a balance between precision and recall. The AUC summarizes the tradeoff between true positive and false positive rate which gives a composite indication of discriminative performance across thresholds. In addition to the preceding standard measures, we evaluate robustness using predictive performance in the presence of adversarial perturbations. Robustness is quantified as the difference between accuracy of clean data and adversarially perturbed data:
where
Here,
In order to determine the efficacy of Q-ALIGNer, we compared it to a variety of baseline models, including textual, visual, multimodal, and quantum-inspired architectures. Each of these baselines is well-known and is based upon either classical deep learning approaches or the nearest previous quantum-enhanced approach for training data segmentation and classification. Text-only detection comparisons have highly accessible baseline models that perform well as pretraining on large-scale corpora captures deep contextual semantics. Specifically, for text, the following transformer-based language models are considered: BERT [13], RoBERTa [14], and XLNet [15]. In addition, we include BiLSTM [16] architectures, even though they are earlier architectures and there have since been better applications for sequence classification, these architectures remain competitive. Next, these baseline models allow us to quantify the discriminative capacity of signals based upon textual signals alone.
For the vision-only detection baselines, we utilize convolutional and transformer-based image encoders, including ResNet [17], EfficientNet [18], and the Vision Transformer (ViT) [19]. These models provide a standard to evaluate the impact of visual modality in fake news detection. For the multimodal baselines we implement fusion architectures that integrate both textual and visual streams. Multimodal-BERT [20] and ViLBERT [21] are state-of-the-art methods which utilize cross-attention mechanisms to align information across modalities. These baselines will allow for direct comparisons of classical cross-attention fusion with the entanglement based fusion explained in Q-ALIGNer.
Recent multimodal foundation models, including CLIP-based derivatives and large-scale vision–language architectures proposed in 2024–2025, represent an active area of research. However, many of these models are not specifically designed for misinformation detection and often rely on proprietary or continuously evolving pretraining data, which complicates fair and reproducible comparison on established fake news benchmarks. In this study, baselines were selected to provide controlled and reproducible coverage across text-only, vision-only, multimodal transformer-based, and quantum-inspired paradigms. The inclusion of QEMF further enables direct comparison within the quantum-inspired modeling family. Incorporating recent foundation models under standardized evaluation protocols is an important direction for future work.
Finally, we compare against Quantum-Enhanced Multimodal Fusion (QEMF) [22], which we believe is the most relevant related work to applying quantum methods to fake news detection. While QEMF is reliant on amplitude encoding and a fixed entangling strategy, our Q-ALIGNer utilizes learnable entangling unitaries, contrastive alignment, and adversarial robustness. By benchmarking to QEMF, we showcase and highlight our design’s incremental benefit in both accuracy and robustness. These baselines create a robust evaluation basis for our Q-ALIGNer, as we are careful to assess improvement over textual, visual, multimodal, and quantum inspired baselines. For the purpose of analyzing the performance of different methods of detecting fake news, we used baseline models that represent a broad spectrum of the most popular design paradigms (unimodal, multimodal and quantum-inspired). Some of the selected baselines were introduced before 2020 and continue to be widely referenced and used as baseline models for comparison by researchers. As an example, QEMF was included due to its status as a recent model with quantum-inspired capabilities which allows for direct comparison against other quantum-inspired systems. Future analyses will include the use of more recent models as a means of further enhancing the results of the analysis.
The empirical tests of the Q-ALIGNer framework are presented in this section. The experiments are designed to measure its efficiency and effectiveness for multimodal fake news detection on several datasets. The tests include evaluation of overall classification performance, analysis of performance on specific datasets, ablation studies, adversarial robustness, uncertainty calibration, and computational efficiency. Results are contextualized in relation to existing state-of-the-art baselines, and the advantages of multimodal fusion using quantum-enhancement are described.
In Table 1, a comprehensive comparison against strong text, visual, multimodal, and quantum-inspired baselines is presented: FakeNewsNet, Fakeddit, Weibo, and MediaEval VMU datasets are included. The results consistently indicate that Q-ALIGNer outperforms all competing methods across all performance metrics: Accuracy, Precision, Recall, F-1, and AUC. Models based on text only (i.e., BERT, RoBERTa, and XLNet) and vision only (i.e., ResNet and EfficientNet) were outperformed, though limited (all models are text only or vision only), because performance still requires multimodal reasoning. Baselines based on multimodal fusions like ViLBERT demonstrate noticeable improvements, especially in Recall and F-1, due to integrated reasoning across textual and visual modalities. The quantum-enhanced model QEMF shows further improvement, but Q-ALIGNer still produces an additional gain of 3–4 percent points in Accuracy and F-1. Thus, Q-ALIGNer shows to be the most robust architecture.
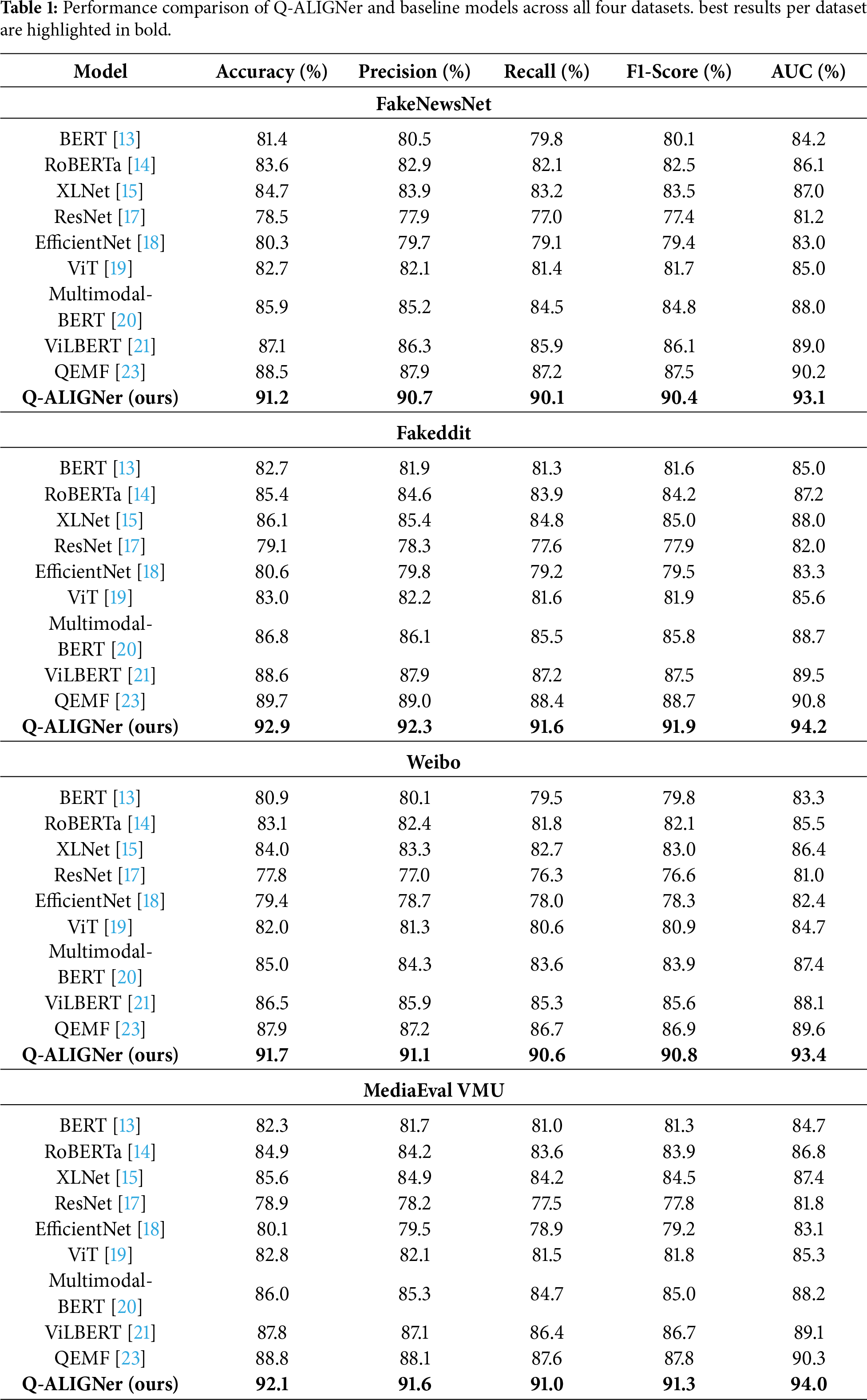
Applying Q-ALIGNer on the structured news stories and images of “FakeNewsNet” returns 91.2% accuracy and 90.4% F1—both greater than QEMF at 88.5% and ViLBERT at 87.1%. This shows that entanglement-based fusion provides a better representation of the semantic dependencies between long-form news text and visual evidence. Our results on the large, noisy “Fakeddit” dataset shows Q-ALIGNer returns 92.9% accuracy and 91.9% F1, and yet, these results are significantly higher than QEMF at 89.7%. The results here also indicate that our model is able to scale performance across a large amount of heterogeneous social media content. On the analyzed Weibo dataset, constructed of short and informal posts in Chinese, Q-ALIGNer returns an accuracy of 91.7% and 90.8%, superior to QEMF at 87.9%. This shows, again, that our model is language agnostic and cross-stylistically robust. Lastly, on the MediaEval VMU dataset, real-time Twitter captures of misinformation, Q-ALIGNer achieves 92.1% accuracy and 91.3% F1, advancing both ViLBERT at 87.8% and QEMF at 88.8%.
Comparisons are presented on a dataset basis in Tables 2–5. In Fig. 6, Q-ALIGNer shows greater accuracy in all four datasets, indicating the effectiveness and generalization of the approach compared to unimodal and multimodal baselines.
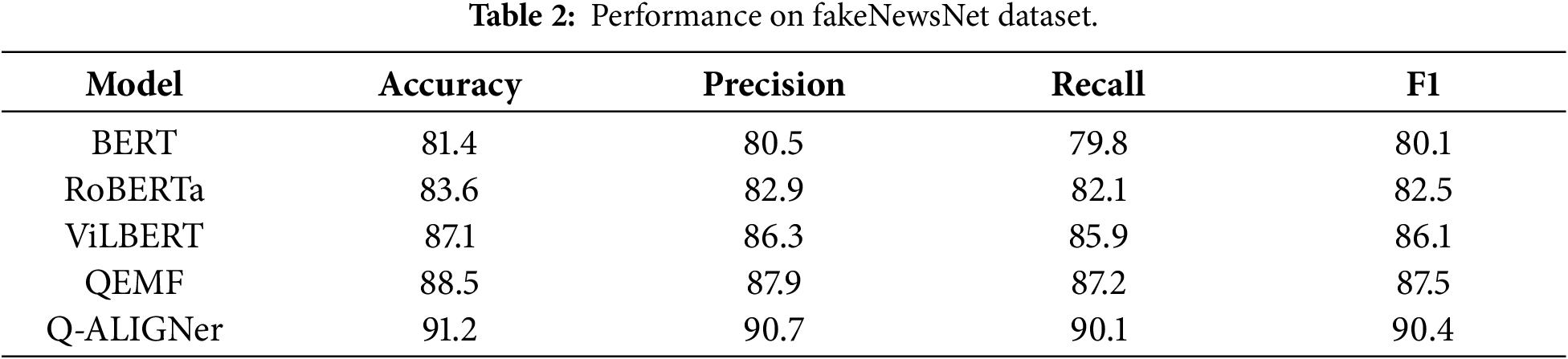
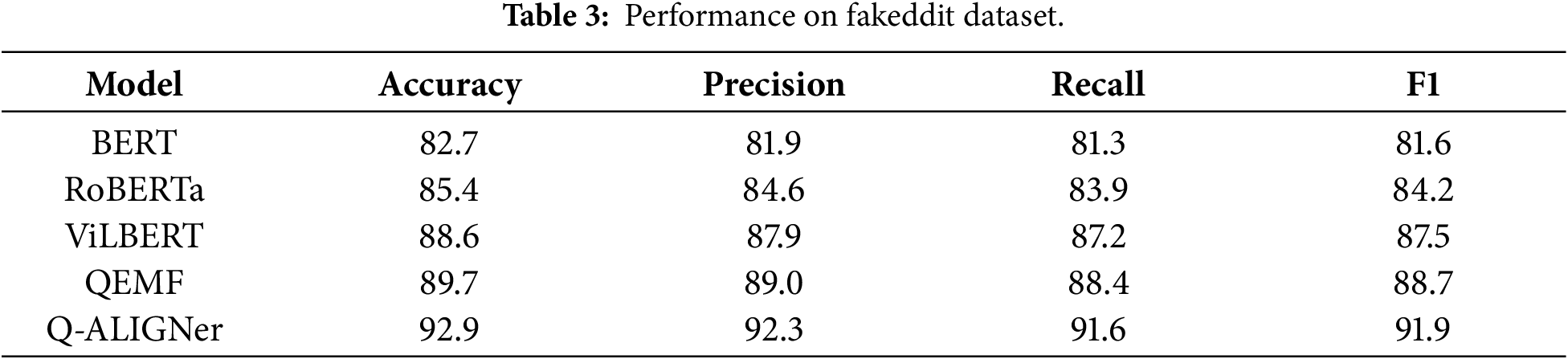
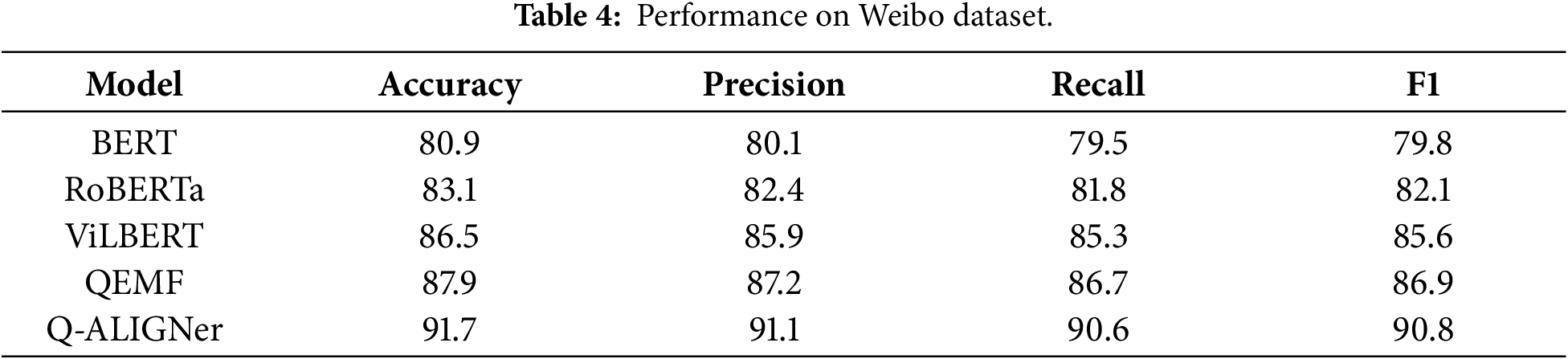
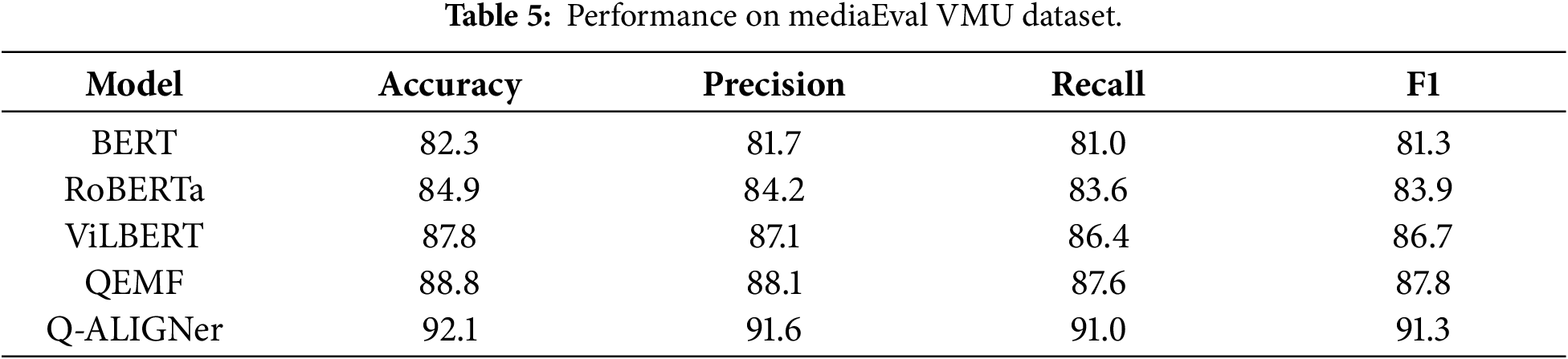
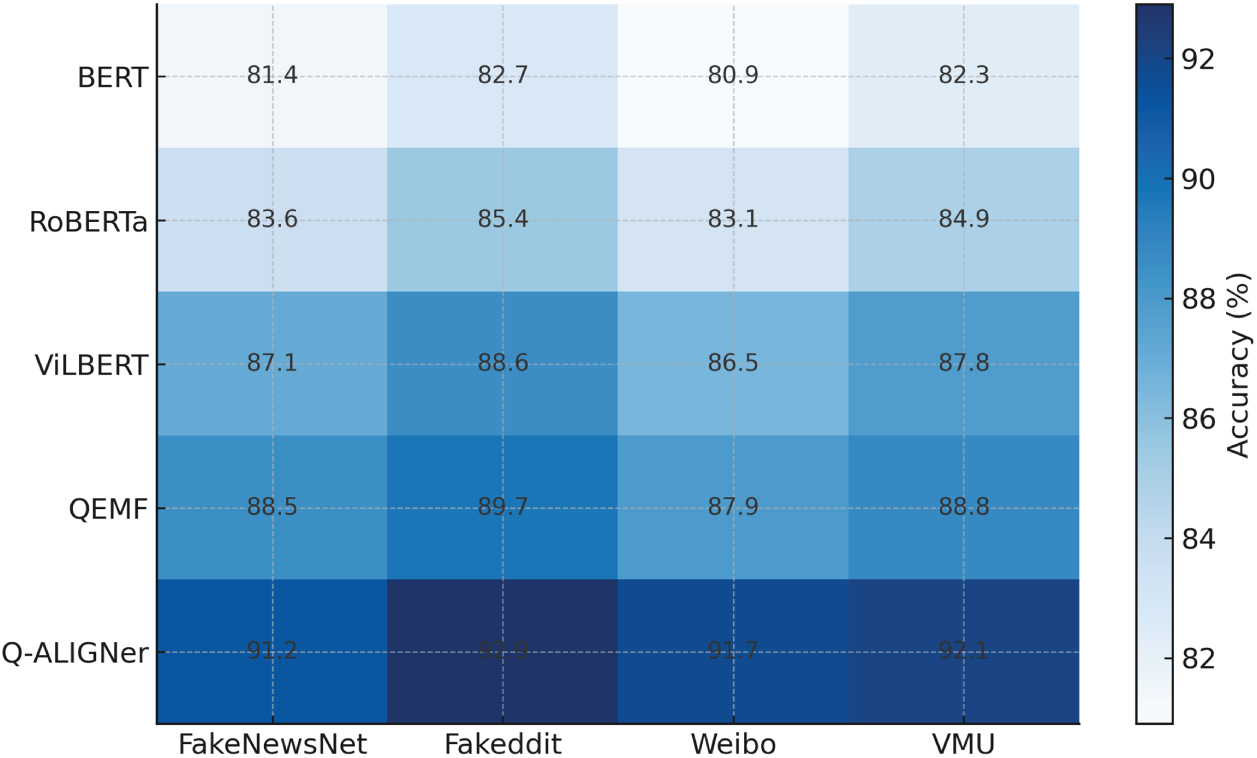
Figure 6: Dataset-wise accuracy heatmap comparing baseline models with Q-ALIGNer across FakeNewsNet, Fakeddit, Weibo, and MediaEval VMU datasets.
In the FakeNewsNet dataset illustrated in Table 2, which consists of long-form articles of news with images, Q-ALIGNer achieves an accuracy of 91.2%, providing an improvement over ViLBERT (87.1%) and QEMF (88.5%). The increases in precision, recall, and F1 indicate that Q-ALIGNer captures the semantic relations that exist between the article text and associated multimedia. The incorporation of quantum entanglement at the fusion stage of learning allowed for a tighter coupling to potentially exist between the text and the accompanying media, facilitating discriminative performance. These results confirm that Q-ALIGNer handles structured, article-style misinformation more effectively than both classical and prior quantum-enhanced baselines.
On the Fakeddit dataset in Table 3, which is substantially larger and noisier due to the diversity of Reddit posts, Q-ALIGNer achieves 92.9% accuracy and an F1-score of 91.9. This performance exceeds QEMF by over three percentage points, showing that the model scales well to high-volume, heterogeneous social media data. While transformer-based models such as RoBERTa and multimodal models like ViLBERT provide competitive baselines, they fail to reach the same robustness as Q-ALIGNer in handling noisy and contextually inconsistent multimodal posts. The results highlight the benefits of quantum-aligned contrastive learning for managing variability in large-scale misinformation
The Weibo dataset presents a different challenge as it consists of short, informal Chinese-language posts paired with images as shown in Table 4. Here, Q-ALIGNer achieves 91.7% accuracy and 90.8 F1, improving upon QEMF’s 87.9%. The cross-lingual success of Q-ALIGNer indicates that the quantum entanglement mechanism generalizes beyond English-language corpora, successfully adapting to structurally different and linguistically diverse data. This demonstrates that Q-ALIGNer is not only effective in high-resource settings but also capable of adapting to multilingual misinformation contexts.
On the MediaEval VMU dataset in Table 5, which consists of Twitter posts with fast-changing and often noisy multimodal content, Q-ALIGNer achieves 92.1% accuracy and 91.3 F1, outperforming QEMF (88.8%) and ViLBERT (87.8%). The improvement is particularly notable given the challenging nature of microblogging platforms, where both text and images tend to be short, informal, and contextually ambiguous. Q-ALIGNer’s entanglement-driven fusion allows the model to maintain consistency between textual claims and visual evidence, leading to more reliable predictions under high-noise conditions. These results illustrate the robustness of the proposed method in real-time, high-velocity misinformation scenarios.
Even though Q-ALIGNer excels across multiple benchmarks, each benchmark is very different in its characteristics (domain), official language, platform dynamics, and structure of events. FakeNewsNet contains only long-form articles, while Fakeddit has large volumes of noisy Reddit posts and short informal Chinese posts. In addition, MediaEval VMU is fast-paced and focuses on Twitter-based verification tasks. The fact that Q-ALIGNer has consistently improved results across these diverse benchmark sets shows that the entanglement-based mechanism can learn to create complex connections between similar concepts regardless of the type of media used in a dataset. The comparative evaluation emphasizes architectural relevance and reproducibility rather than publication year alone, allowing the proposed framework to be assessed against established and competitive multimodal baselines under consistent experimental conditions.
To assess the contributions, we complete ablation studies on dataset and thus impose to remove major parts of Q-ALIGNer in a sequential manner: the entanglement operation, the InfoNCE alignment loss, the robustness loss, and the quantum encoding. As can be observed in Fig. 7, the related studies on all datasets confirm that quantum entanglement should be considered in the model as the most essential part of Q-ALIGNer, and the InfoNCE alignment and robustness-aware objectives further contribute to sustained improvements in performance.
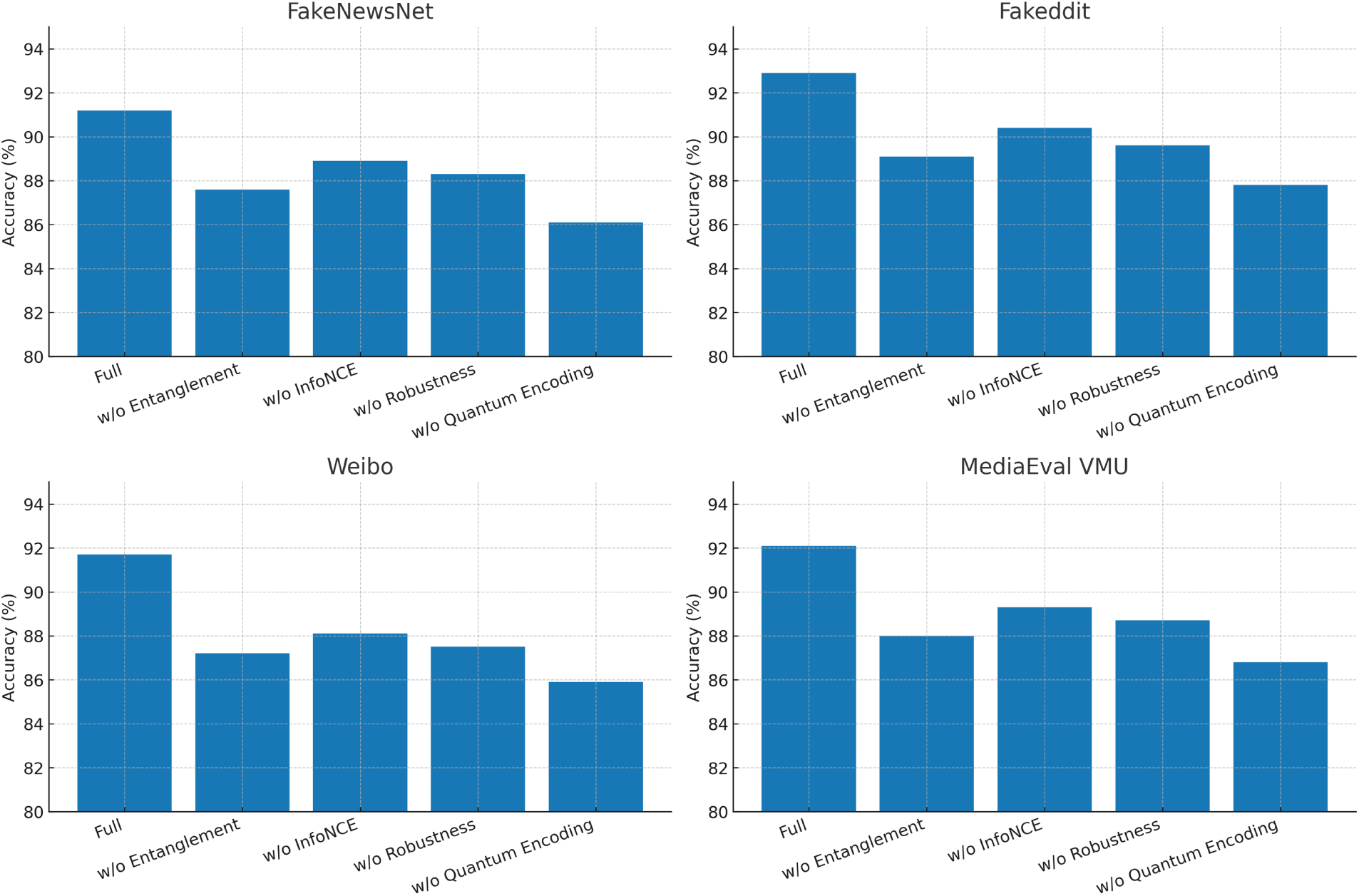
Figure 7: Ablation studies of Q-ALIGNer across four datasets.
Entanglement shows the most significant drop in accuracy when removed from the framework in Table 6 on FakeNewsNet. The accuracy drops from 91.2% to 87.6%. This drop illustrates the necessity of learning cross-modal dependencies with quantum entanglement to successfully validate long-form articles. The addition of both InfoNCE loss and robustness loss also show to improve overall performance because the InfoNCE loss encourages a stronger alignment between modal streams in the fact-checking task, while the robustness loss improves the general stability of the model. Finally, the removal of quantum encoding from the fact-checking baseline resulted in the lowest overall performance, which emphasizes the importance of being able to carry out quantum-native feature mapping when reasoning with structured misinformation.

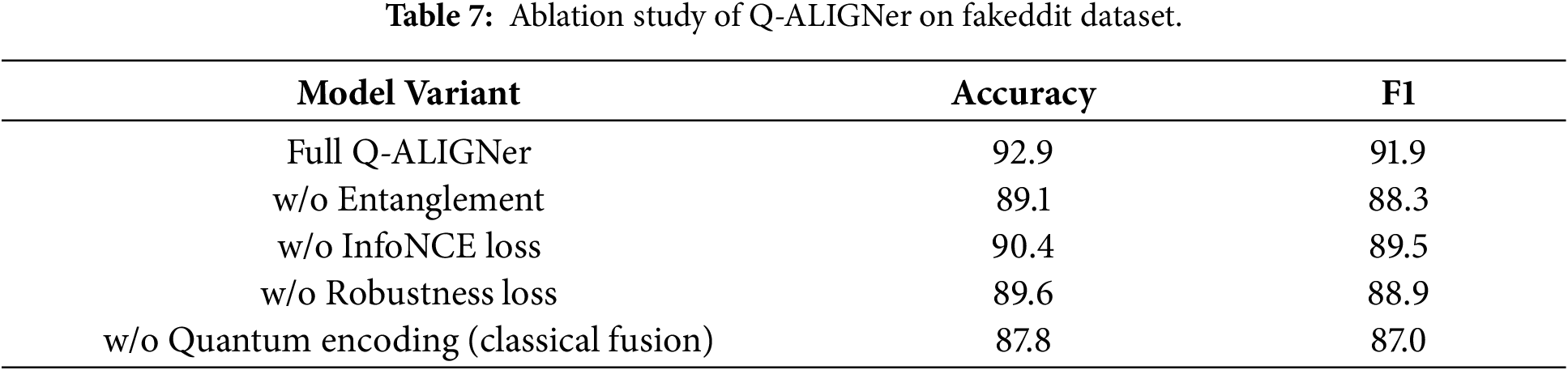
For the large-scale Fakeddit dataset in Table 7, we again see that entanglement is the most influential factor and its removal resulted in a 3.8 point accuracy drop. Thus, quantum entanglement is useful in increasing robustness for multimodal posts that are noisy and contextually inconsistent. The robustness loss, improves resilience to standard social media perturbations, while InfoNCE alignment helps contribute to decreasing modality mismatch. Without quantum encoding the model approximates to a more classical baseline thus highlighting that quantum feature embedding allows for scalability even in large and noisy data conditions.
Weibo is a set of casual, short-form Chinese posts, and here, Q-ALIGNer shows that all parts are responsible for cross-lingual generalization, as shown in Table 8. The removal of entanglement induces the largest drop in accuracy, falling by 4.5 points. InfoNCE alignment loss is also an important contributing factor in ensuring consistency between short pieces of text and its corresponding image. The robustness loss helps in increasing tolerance to adversarial noise often found in user-generated content. Removing quantum encoding generates a performance drop to below 86% which suggests that quantum representations capture semantic distinctions that would be obscured by classical fusion.

In the MediaEval VMU dataset, shown in Table 9, which is comprised of short bits of Twitter, Q-ALIGNer with full architecture is again the best. If entanglement were removed, accuracy falls to 88.0%, showing how important it is to model the fine-grained dependencies between claims and images in the noise and continuous stream of social media data. Both losses (InfoNCE and robustness) also incrementally improve the claim-image alignment over the no-loss baseline, with a drop of only 2–3 points. The performance is worst, when using classic fusion without quantum encoding, again supporting the finding that the quantum state space leads to better representations of multimodal correlations.
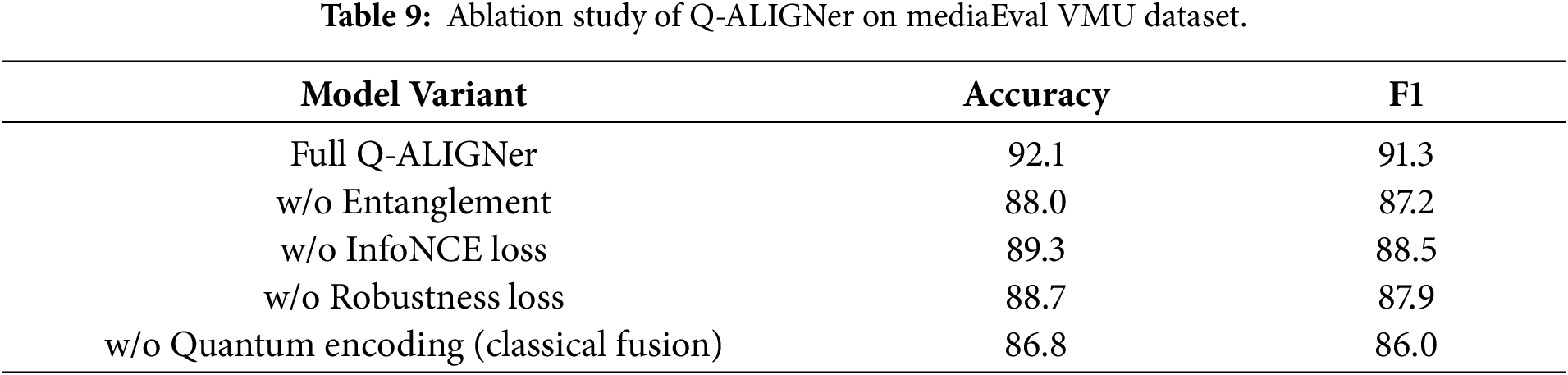
Furthermore, the findings from the ablation experiments demonstrate the architectural complexity brought about by encodings and entanglements is not wasted or unnecessary, but offers a different set of functionalities which can be exploited to improve a system’s ability and durability during training on a number of datasets.
The adversarial robustness findings are presented in Table 10. The standard baselines on Weibo experience a tremendous drop in performance when under attacks (e.g., FGSM, PGD) with a decrease of over 7–9 points in accuracy. In contrast, Q-Aligner achieves 89.1% accuracy, which means that Q-Aligner has a robustness gap of only 2.6 points. The significant gap in robustness demonstrates that the entanglement-based design with training using robustness techniques allows Q-Aligner to withstand manipulation considerably better than both the classical benchmarks and the quantum benchmarks. This is a vital feature for dealing with adversarially manipulated misinformation in practical applications.
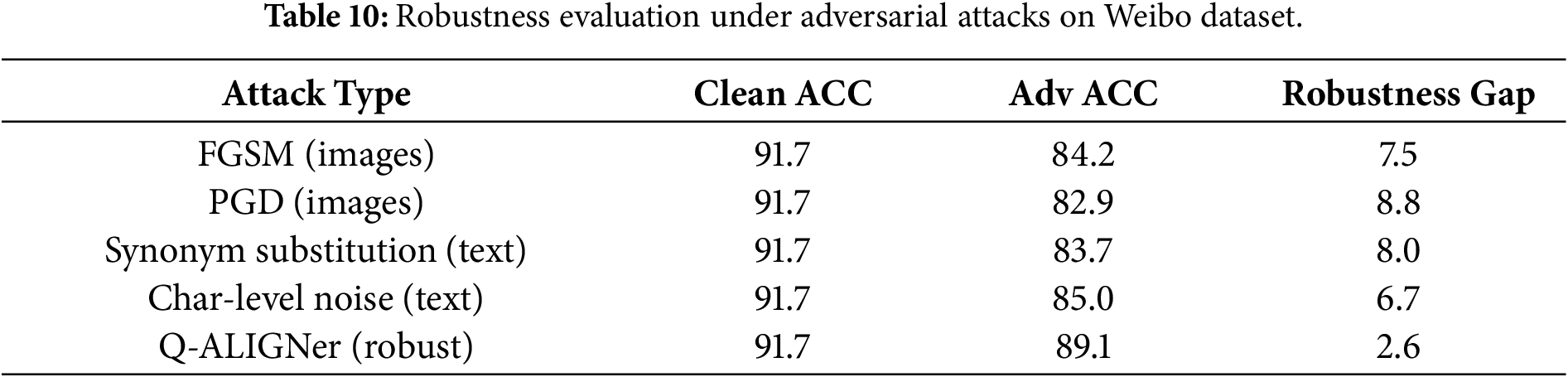
We note that robustness variation curves under progressively increasing perturbation strengths were not explored in this study; the evaluation instead focuses on relative robustness under standardized attack settings, with extended sensitivity analysis reserved for future work. The most common form of assessment for Misinformation comes from Social Media. The type of assessments used by social media sites simulate types of Misinformation such as Paraphrasing, Lexical Noise, and Visual Perturbation. All of the assessments represent the long-term and chaotic environments associated with the development of misinformation. The adversarial scenarios examined in this study utilise reproducible and widely used perturbation approaches in Multimodal Misinformation Research. The types of perturbations addressed include text paraphrase, character-level noise (i.e., randomised additions or removals of characters), and gradient based image manipulations; All of which are commonly used as real-world manipulation patterns. While these perturbation approaches capture many real-world manipulation patterns, many more sophisticated adversarial attack strategies exist that are not specifically assessed in this study, including visual manipulation through deepfakes, coordinated inconsistency across multiple modalities of attack, and large-scale content rewriting, all of which represent promising areas for future research.
4.8 Uncertainty and Calibration
The performance of calibration is shown in Table 11 (calibration). Q-ALIGNer achieves an expected calibration error (ECE) of 0.031 and negative log-likelihood (NLL) of 0.228, outperforming both ViLBERT (ECE 0.058) and QEMF (ECE 0.046). All of these results demonstrate that Q-ALIGNer generates well calibrated probabilities that closely follow empirical accuracy. Good uncertainty estimation is especially important for fake news detection, as it allows the model to signal uncertain cases for human verification instead of making confident wrong predictions.
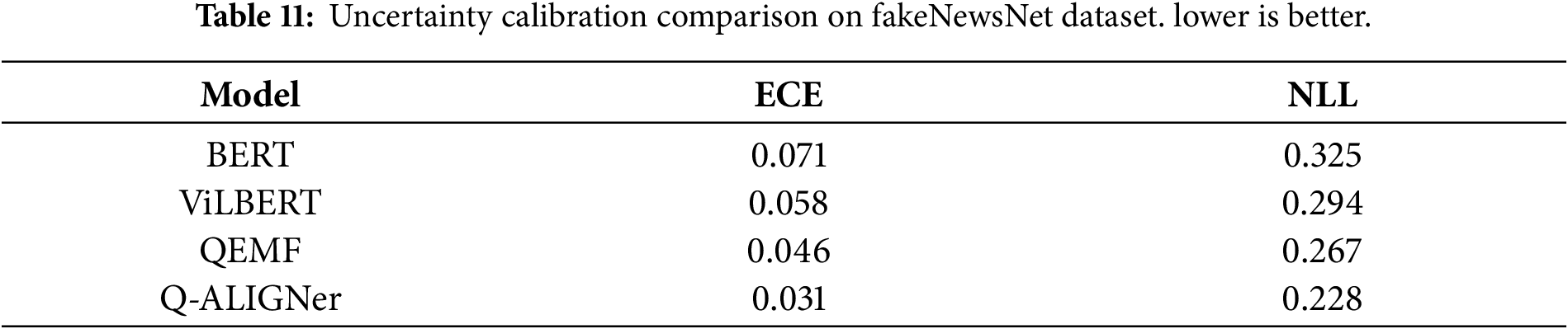
From a usage perspective, users will find it easier to understand a calibrated confidence score and measurements of consistency than raw multimodal attention weights or latent representation embeddings. Calibrated confidence scores and measurements of consistency serve as clear and understandable indicators to guide the user’s decision-making in these practical applications.
Table 12 displays comparisons for computational efficiency. Q-ALIGNer attained a significantly higher training efficiency than QEMF, requiring 19.6 h compared to QEMF’s 48.2 h. This substantial reduction is primarily a direct consequence of having learnable entangling unitaries that occur with lower gate complexity. Q-ALIGNer also has competitive parameter counts (118M), while being less expensive computationally—without sacrificing accuracy. These results indicate that quantum-inspired designs can deliver significantly improved accuracy and robustness, in addition to rational and meaningful gains in computational efficiency.
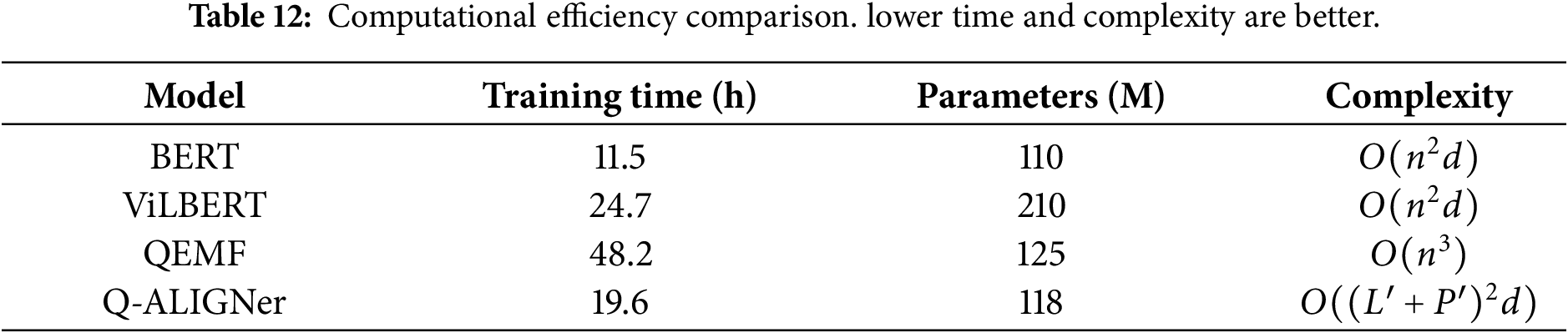
The Q-ALIGNer provides more complex architectures by adding quantum state encoding and creating cross modal entanglement. These additional components have complexity that is intentionally limited and has been thoroughly characterized analytically. Therefore, The Q-ALIGNer’s architecture is a balance of architectural simplicity and representational expressivity; while providing a greater ability to represent rich multimodal dependencies, it is still computationally feasible to perform with pruning strategies, shallow variational circuits, and efficient measurement schemes. Although Q-ALIGNer increases the computational efficiency of quantum-enhanced frameworks over previous quantum-enhanced approaches, Q-ALIGNer does not consider being directly deployed on a web-scale volume involving hundreds of millions of postings. The methods used to reduce complexity in our approach—specifically input pruning, shared latent projections, shallow variational circuits, and bilinear entanglement—significantly reduce the overhead associated with state-encoding and fusion, and further optimizations at the system level would be required for large-scale applications.
Results from multiple benchmarks of experiments continuously show that the Q-ALIGNer framework is better than classical and quantum-inspired baselines. The gains relate to predictive accuracy, robustness to adversarial perturbations, reliability in estimating uncertainties, and computational costs. Nevertheless, explicit evaluation on entirely unseen domains, emerging event types, or zero-shot transfer settings remains beyond the scope of this work and will be explored in future research. While the benchmarks that have been assessed have been developed using dual feature multi-modality data, there are still a significant number of outstanding challenges pertaining to the use of missing or grossly impaired modalities when utilizing an uncontrolled or social environment. While this study includes both English and non-English datasets, future work will extend Q-ALIGNer to a wider range of languages, regions, and culturally specific misinformation scenarios to more comprehensively assess global generalization. From an application perspective, this behavior enables Q-ALIGNer to function as a decision-support system that highlights ambiguous or contested cases, supporting human-in-the-loop verification rather than enforcing overconfident automated judgments.
Dataset-wide evaluations showed that Q-ALIGNer adapts to multiple misinformation contexts. On FakeNewsNet, the model efficiently merges long-form text about news stories with attached images. In the case of Fakeddit, adaptability in a noisy, social media space is accounted for while still scaling and retaining familiarity to its fine-tuning stage. Dealing with a cross-lingual context for Weibo allowed Q-ALIGNer to train efficiently on a large chunk of original data with short, informal posts and showed that the model generalizes well beyond English-language corpora. On MediaEval VMU, live Twitter streams of misinformation where contextual ambiguity is an issue, Q-ALIGNer was resilient against the noise to outperform all baselines. These leases imply consistent improvements that demonstrated that Q-ALIGNer is not only functional in a high-resource and structured dataset but also in noisy, complicated, and multilingual spaces. Ablation studies further demonstrated the contribution of individual components. Removing quantum entanglement produced the most significant drop in performance, and consistent in every thinking model type, which shows the importance of directionality in modeling cross-modal dependencies. The complementary effects of the InfoNCE loss for alignment act to produce better results by enforcing some modality consistency, but the robustness loss produced significant improvements in adversarial perturbations. When comparing quantum-encoded data vs. replacing with classical fusion, classical representations perform the worst, which shows the ability of quantum states to create more expression with features.
Beyond accuracy, Q-ALIGNer performed significantly better as an advantage of robustness, and reliability. After adversarial attacks including FGSM, PGD, etc., synonym substitution, and character-level noise, Q-ALIGNer produced significantly higher accuracy after an attack compared to baselines, and bridged a gap of 50% improvement of robustness after the attack. This is a significant finding when thinking of real-world scenarios for misinformation papers, as the content was originally designed to be hacked. Q-ALIGNer was tested and demonstrated comparable results to cavalier, calibrated for both performance mean and negative log likelihood, respectively, demonstrating that less prediction uncertainty when compared to both models and during calibration experiments. Well-calibrated predictions are important in applications when there are uncertain cases that require review. Finally, Q-ALIGNer produced additional performance gains with efficiency. QEMF produced increased training time and gate complexity to obtain performance. Q-ALIGNer improved the overall training time by more than half, yet both trained models were refined using a similar parameter scale. The design of learnable entangling unitary gate strategies reduced circuit depth while maintaining expressive power. Overall, these observations exhibited quantum-inspired architectures provide the option to regain efficiency while providing prediction settings that are both precise and accurate, promoting further deployment in real-world fake news systems.
This research indicates that misinformation detection will be aided by experimentation of the verification process. However, several limitations have been identified in this research. A content-based approach to identifying misinformation through paired text and images was utilised by Q-ALIGNer. Q-ALIGNer’s use of a content-focused approach means that the tool does not capture temporal changes in information, the way that the information is shared or the community in which the information was originally shared. Although this allows Q-ALIGNer to support early-stage evaluations of misinformation detection during the absence of the aforementioned metadata, the lack of focus on temporal (temporal) and community (social) factors can hinder Q-ALIGNer’s capabilities to model the dynamic nature of misinformation over time. The evaluation of Q-ALIGNer consists of the use of many disparate (i.e., multi-language) benchmark tests that span across multiple platforms (i.e., Facebook, Twitter), and provides insight into a limited view of the global dynamics of misinformation. As a result, additional research is required in order to develop a Q-ALIGNer that has the ability to generalise, or apply its capabilities to topics and events that are entirely foreign to the Q-ALIGNer.
Regarding the evaluation of robustness, Q-ALIGNer focused on the evaluation of examples of how Q-ALIGNers can be controlled, created, and modified. The examples of the two aforementioned methods include gradient-based perturbation attacks on images and the creation of written text via semantic-preserving manipulations of the text. Examples of the types of attacks that can have a negative effect on the effectiveness of the tool (Q-ALIGNer) are complex and probabilistic in nature, e.g., large-scale coordinated attacks (i.e., coordinated use of multiple, diverse media attacks against Q-ALIGNers or deepfake images), and manipulation of content through a large quantity of co-incident events. Using a simulated Quantum-Inspired Framework-Based Implementation, Q-ALIGNer’s approach provides insight into how the tool has been constructed and evaluated; however, it does not provide any insight into how Q-ALIGNers has been implemented in practice, as it has not run on actual Quantum hardware (e.g., Quantum Circuits). The potential advantages and disadvantages of running Q-ALIGNers in practice on Quantum Circuits remains an area for future investigations. While Q-ALIGNer has vastly improved in efficiency compared to previous Quantum-Tools (AI’s and MLs), a considerably higher level of optimisation, resulting from distributed training and Compressing of Q-ALIGNers’ output (i.e., embeddings), must be achieved before deploying Q-ALIGNers at Web-scale (i.e., involving hundreds or thousands of millions of Posts). The scope of such activities is not the focus of this article.
Q-ALIGNer is an innovative, quantum-inspired, multi-modal tool designed to detect false news. It combines classical techniques for extracting features of fake stories with capabilities to encode them as quantum states, train neural networks to learn how to make the two feature types cohere, and to use training objectives to help improve the system’s resilience against uncertainty. The results of extensive experimentation using four established benchmark datasets (FakeNewsNet, Fakeddit, Weibo, and MediaEval VMU) confirm that Q-ALIGNer performs better than competing text-based and image-based models and multisource/quantum-inspired models. In particular, it outperformed the previous quantum-inspired QEMF model by incorporating improved methods for using adaptive entanglement, contrastive aligning, and calibrating uncertainty when detecting multi-modal false information. The individual components of Q-ALIGNer were also evaluated through ablation studies, which demonstrated the centrality of cross-modal entanglement when providing semantic dependence between image and textual inputs. The robustness tests showed that Q-ALIGNer has significantly greater resistance to adversarial attacks on both text and visual input modalities than other state-of-the-art systems. Improved calibration of confidence values was also demonstrated by testing against other state-of-the-art systems in the areas of text and image input modalities. Additionally, Q-ALIGNer demonstrated improvements in efficiency regarding training time and complexity, making it a more applicable tool to large-scale benchmarks when compared to previous quantum-inspired systems.
Unlike other systems that expose users to lower-level fusion mechanisms, Q-ALIGNer emphasizes interpretability at the decision level by providing users with confidence, consistency, and alignment signals that are conducive to developing trust-based and human-verifiable verification systems. The mathematical complexity of internal models is not required to provide decision-making support; instead, these capabilities allow users to receive usable output from these sophisticated mathematical processes without requiring expertise in quantum computing. This work primarily adopted an information-centric point of view and did not include a temporal analysis of the dynamics of social and contextual propagation of misinformation or of misinformation pattern evolution over time. Future work will likely build on these approaches to add temporal context modeling, social context features, and evaluations across multiple languages and cultures. Other future work directions will include examining deployment on new quantum platforms, increasing the robustness testing methods for evaluating advanced multi-modal adversarial cases, and creating adaptive methods for dealing with missing or poor-quality multi-modal input. Enhancements to scalability using distributed training and compression of embeddings will be examined to allow for real time application in high-throughput social media environments. Future work will also extend the experimental evaluation to include recent CLIP-based and large-scale multimodal foundation models as standardized and reproducible benchmarks for misinformation detection become available.
Acknowledgement: The authors acknowledge the support of Princess Nourah bint Abdulrahman University and Northern Border University.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R77), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia, the Deanship of Scientific Research at Northern Border University, Arar, Saudi Arabia, through the project number NBU-FFR-2026-2248-02.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Sara Tehsin, Inzamam Mashood Nasir, Wiem Abdelbaki; data collection: Fadwa Alrowais, Reham Abualhamayel, Abdulsamad Ebrahim Yahya; analysis and interpretation of results: Sara Tehsin, Inzamam Mashood Nasir, Radwa Marzouk; draft manuscript preparation: Wiem Abdelbaki, Fadwa Alrowais, Radwa Marzouk. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The implementation of this work can be downloaded from https://github.com/imashoodnasir/Q-ALIGNer-Robust-Fake-News-Detection.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Wu F, Chen S, Gao G, Ji Y, Jing XY. Balanced multi-modal learning with hierarchical fusion for fake news detection. Pattern Recognit. 2025;164(6380):111485. doi:10.1016/j.patcog.2025.111485. [Google Scholar] [CrossRef]
2. Shen X, Huang M, Hu Z, Cai S, Zhou T. Multimodal fake news detection with contrastive learning and optimal transport. Front Comput Sci. 2024;6:1473457. doi:10.3389/fcomp.2024.1473457. [Google Scholar] [CrossRef]
3. Parmar S, Rahul. Fake news detection via graph-based Markov chains. Int J Inf Technol. 2024;16(3):1333–45. doi:10.1007/s41870-023-01558-3. [Google Scholar] [CrossRef]
4. Liu Y, Liu Y, Li Z, Yao R, Zhang Y, Wang D. Modality interactive mixture-of-experts for fake news detection. In: Proceedings of the ACM on Web Conference 2025; 2025 Apr 28–May 2; Sydney, NSW, Australia. p. 5139–50. doi:10.1145/3696410.3714522. [Google Scholar] [CrossRef]
5. Chen H, Yu Y, Guo H, Hu B, Hu S, Hu J, et al. A self-learning multimodal approach for fake news detection. Front Artif Intell. 2025;8:1665798. doi:10.3389/frai.2025.1665798. [Google Scholar] [PubMed] [CrossRef]
6. Choi E, Ahn J, Piao X, Kim JK. Crome: multimodal fake news detection using cross-modal tri-transformer and metric learning. arXiv:2501.12422. 2025. [Google Scholar]
7. Qu Z, Meng Y, Muhammad G, Tiwari P. QMFND: a quantum multimodal fusion-based fake news detection model for social media. Inf Fusion. 2024;104(9):102172. doi:10.1016/j.inffus.2023.102172. [Google Scholar] [CrossRef]
8. Altıntaş V. Beyond classical AI: detecting fake news with hybrid quantum neural networks. Appl Sci. 2025;15(15):8300. doi:10.3390/app15158300. [Google Scholar] [CrossRef]
9. Tufchi S, Yadav A, Ahmed T. A comprehensive survey of multimodal fake news detection techniques: advances, challenges, and opportunities. Int J Multimed Inf Retr. 2023;12(2):28. doi:10.1007/s13735-023-00296-3. [Google Scholar] [CrossRef]
10. Abduljaleel IQ, Ali IH. Deep learning and fusion mechanism-based multimodal fake news detection methodologies: a review. Eng Technol Appl Sci Res. 2024;14(4):15665–75. doi:10.48084/etasr.7907. [Google Scholar] [CrossRef]
11. Song C, Ning N, Zhang Y, Wu B. A multimodal fake news detection model based on crossmodal attention residual and multichannel convolutional neural networks. Inf Process Manag. 2021;58(1):102437. doi:10.1016/j.ipm.2020.102437. [Google Scholar] [CrossRef]
12. Hao X, Xu W, Huang X, Sheng Z, Yan H. MFUIE: a fake news detection model based on multimodal features and user information enhancement. EAI Endorsed Trans Scalable Inf Syst. 2025;11:1–13. doi:10.4108/eetsis.7517. [Google Scholar] [CrossRef]
13. Devlin J, Chang MW, Lee K, Toutanova K. Bert: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; 2019 Jun 2–7; Minneapolis, MN, USA. p. 4171–86. [Google Scholar]
14. Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, et al. Roberta: a robustly optimized bert pretraining approach. arXiv:1907.11692. 2019. [Google Scholar]
15. Yang Z, Dai Z, Yang Y, Carbonell J, Salakhutdinov RR, Le QV. Xlnet: generalized autoregressive pretraining for language understanding. arXiv:1906.08237. 2019. [Google Scholar]
16. Graves A. Long short-term memory. In: Supervised sequence labelling with recurrent neural networks. Berlin/Heidelberg, Germany: Springer; 2012. p. 37–45. [Google Scholar]
17. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA. p. 770–8. doi:10.1109/cvpr.2016.90. [Google Scholar] [CrossRef]
18. Tan M. Rethinking model scaling for convolutional neural networks. arXiv:1905.11946. 2019. [Google Scholar]
19. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16x16 words: transformers for image recognition at scale. arXiv:2010.11929. 2020. [Google Scholar]
20. Sun C, Myers A, Vondrick C, Murphy K, Schmid C. VideoBERT: a joint model for video and language representation learning. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 7464–73. [Google Scholar]
21. Lu J, Batra D, Parikh D, Lee S. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. arXiv:1908.02265. 2019. [Google Scholar]
22. Mukesh K, Jayaprakash SL, Kumar RP. QViLa: quantum infused vision-language model for enhanced multimodal understanding. SN Comput Sci. 2024;5(8):1023. doi:10.1007/s42979-024-03398-9. [Google Scholar] [CrossRef]
23. Bikku T, Thota S. Quantum-enhanced multimodal fusion for robust and accurate fake news detection. Sigma. 2025;43(3):943–54. doi:10.14744/sigma.2025.00082. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools