
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

BCAM-Net: A Bidirectional Cross-Attention Multimodal Network for IoT Spectrum Sensing under Generalized Gaussian Noise
1 Graduate School of Information Science and Electrical Engineering, Kyushu University, Fukuoka, Japan
2 Faculty of Information Science and Electrical Engineering, Kyushu University, Fukuoka, Japan
3 Electrical Engineering Department, Faculty of Engineering, Al-Azhar University, Cairo, Egypt
4 National Institute of Technology, Kagoshima College, Kagoshima, Japan
* Corresponding Authors: Yuzhou Han. Email: ; Osamu Muta. Email:
(This article belongs to the Special Issue: Advancements in Mobile Computing for the Internet of Things: Architectures, Applications, and Challenges)
Computers, Materials & Continua 2026, 87(2), 8 https://doi.org/10.32604/cmc.2026.076555
Received 22 November 2025; Accepted 20 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Spectrum sensing is an indispensable core part of cognitive radio dynamic spectrum access (DSA) and a key approach to alleviating spectrum scarcity in the Internet of Things (IoT). The key issue in practical IoT networks is robust sensing under the coexistence of low signal-to-noise ratios (SNRs) and non-Gaussian impulsive noise, where observations may be distorted differently across feature modalities, making conventional fusion unstable and degrading detection reliability. To address this challenge, the generalized Gaussian distribution (GGD) is adopted as the noise model, and a multimodal fusion framework termed BCAM-Net (bidirectional cross-attention multimodal network) is proposed. BCAM-Net adopts a parallel dual-branch architecture: a time-frequency branch that leverages the continuous wavelet transform (CWT) to extract time-frequency representations, and a temporal branch that learns long-range dependencies from raw signals. BCAM-Net utilizes a bidirectional cross-attention mechanism to achieve deep alignment and mutual calibration of temporal and time-frequency features, generating a fused representation that is highly robust to complex noise. Simulation results show that, under GGD noise with shape parameterKeywords
The rise of the information and digital era has opened unprecedented opportunities for wireless communications. As a key technology connecting the physical and digital worlds, the internet of things (IoT) is experiencing explosive growth [1]. This growth spans many critical domains, such as the industrial internet of things(IIoT) [2], smart grid [3], and vehicle-to-everything (V2X) systems [4], and drives demand for access by massive heterogeneous devices. With the concurrent access of a large number of devices, the finite wireless spectrum is under unprecedented pressure, since the available bands are limited while the number of accessing devices and their data demands continue to increase [5]. The traditional fixed spectrum allocation mechanism, which assigns specific bands exclusively and long-term to primary users (PUs), struggles to meet such dynamic and diverse access needs, resulting in low spectrum utilization and further intensifying spectrum scarcity [6].
To address spectrum scarcity, cognitive radio (CR) is regarded as a highly promising solution [7]. In IoT networks, CR allows secondary users (SUs)—such as wireless sensor nodes and industrial controllers in the IIoT, environmental monitoring devices and intelligent street-light systems in smart cities, and on-board units (OBUs) and roadside units (RSUs) in V2X systems—to dynamically access temporarily idle licensed bands that are not occupied by PUs, thereby improving spectrum utilization efficiency [8]. As the first critical step of CR, the accuracy of spectrum sensing directly affects the system’s understanding of spectrum occupancy and the rationality of subsequent decisions [9]. Efficient spectrum sensing enables SUs to accurately detect idle spectrum, avoid collisions with spectrum occupied by PUs and protect PU communication quality, while also optimizing communication performance and improving spectrum utilization. Therefore, spectrum sensing is fundamental to the efficient operation of CR systems, and the study of reliable and efficient spectrum sensing techniques is particularly important.
Traditional spectrum sensing techniques are mostly based on energy detection and correlation analysis, and are simple and easy to implement [10]. However, their adaptability to complex electromagnetic environments is limited, and they exhibit poor performance, especially under low signal-to-noise ratios (SNRs) and weak-signal conditions [11]. Meanwhile, traditional methods often model the disturbance as additive white Gaussian noise (AWGN), which is reasonable for thermal-noise-limited cellular or laboratory environments. In many practical IoT-oriented wireless scenarios, however, this assumption no longer holds: non-Gaussian noise (such as atmospheric noise and man-made electromagnetic interference) becomes dominant [12]. As shown in Fig. 1, such noise sources are widespread in typical IoT scenarios including the IIoT and V2X, for example industrial motors, vehicle ignition, and power-grid transients. This type of noise exhibits impulsive peaks and long tails and is one of the main sources of errors in wireless systems [13]; therefore, achieving highly robust spectrum sensing under non-Gaussian conditions is a key challenge in IIoT scenarios.
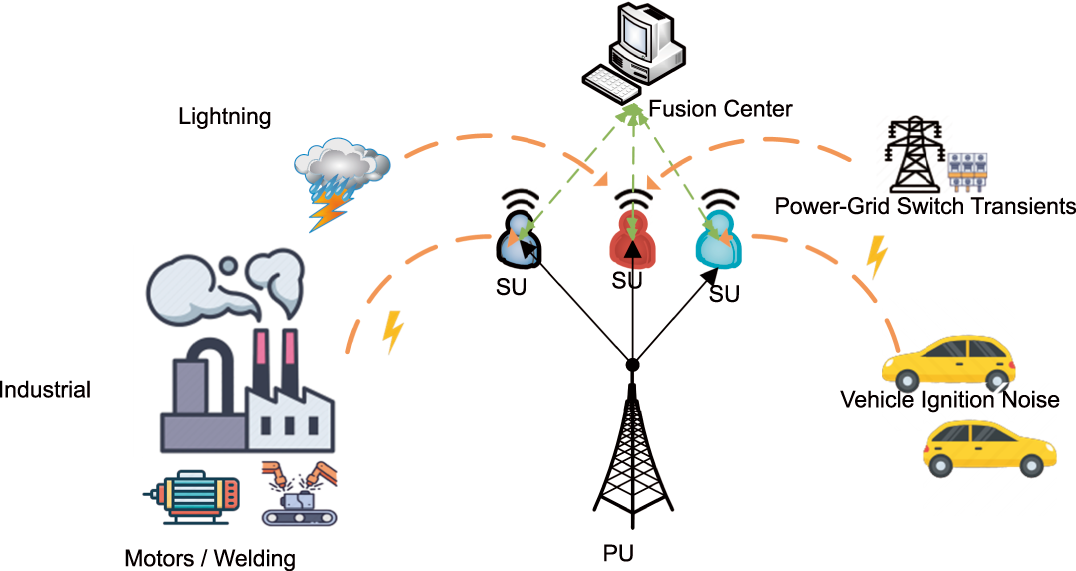
Figure 1: Non-Gaussian noise and cooperative spectrum sensing in IoT.
Since the essence of spectrum sensing is a binary classification problem that decides whether a signal is present [14], machine learning (ML) and deep learning (DL) offer new approaches to address the limitations of traditional methods under low SNR and non-Gaussian noise. With strong nonlinear modeling and data-driven feature extraction capabilities [15,16], ML/DL can reduce the strict reliance on prior signal information and instead learn subtle differences between signal and noise directly from the data.
Early studies mainly focused on traditional ML methods [17,18]. Saber et al. used the received signal energy as a feature, trained and tested artificial neural networks (ANNs) and support vector machine (SVM) classifiers to categorize received data as PU signal or noise, and concluded that SVM-based spectrum sensing was more accurate than ANN-based classification [19]. Varma and Mitra proposed a blind sensing model based on SVM, trained with two statistical features—smoothed correlation of reversed spectrum segments (SCRSS) and variance of multi-scale moving averages (VMMA)—which effectively detected spectrum signals at an SNR of
In recent years, DL with stronger end-to-end learning capabilities has been widely applied in wireless communications, providing new approaches to spectrum sensing [22,23]. Chen et al. proposed a spectrum sensing method based on the short-time Fourier transform (STFT) and a convolutional neural network (CNN) [24]. The method extracts time-frequency information using STFT and then performs classification with a CNN. To better capture the time-frequency characteristics of wireless signals, several studies employ the continuous wavelet transform (CWT) to convert IQ samples into time-frequency images as inputs to deep learning models. Zhen et al. addressed spectrum sensing of nonstationary signals under low SNRs by combining CWT with a residual network (ResNet) [25]. Their method first converts the signal into a time-frequency matrix via CWT and then feeds it into a ResNet classifier. The approach is fully data-driven and does not require prior information, and their results indicate that the Morlet wavelet yields the best detection performance among the tested options. Xu et al. transformed the IQ signals collected by secondary users into CWT-based time-frequency images and fed them into a Swin-Transformer for spectrum sensing [26]. Experimental results show that, compared with conventional CNN-based methods, this approach achieves significantly better detection performance at low SNRs, further confirming the effectiveness of CWT as a feature extractor for spectrum sensing. To improve spectrum utilization and minimize interference, Varma et al. employed CWT to transform the IQ signals of multiple wireless technologies into time-frequency images and, based on these representations, designed a lightweight CNN for signal identification [27]. Their method achieves over 90% classification accuracy, indirectly confirming the effectiveness of CWT for wireless signal feature extraction and providing valuable insights for spectrum sensing in complex coexistence environments. These CWT-based approaches demonstrate that time-frequency representations are highly informative for spectrum sensing. However, they typically treat the CWT image as a single modality and rarely explore explicit interactions with temporal features. Fang et al. proposed a CNN-Transformer hybrid model to address the inability of DL-based cooperative spectrum sensing (CSS) to extract correlations across different SUs [28]. The model exploits temporal correlations within each SU and features across SUs, and also considers imperfect reporting channels. Simulations show superior performance, with about a
Accordingly, to improve the stability and robustness of spectrum sensing in complex IoT scenarios under impulsive GGD noise, this paper proposes a bidirectional cross-attention multimodal network (BCAM-Net). The key idea of BCAM-Net lies in its bidirectional cross-attention fusion, which allows the model to adaptively cross-enhance temporal and time-frequency features under uncertain noise conditions. Compared with one-directional fusion, the bidirectional design mitigates the risk that modality-specific distortions in either stream dominate the fusion, thereby helping stabilize the fused representation even when one stream is heavily corrupted.
The main contributions are as follows:
• Construction of multimodal inputs for GGD noise and low SNR scenarios:
Time-frequency path: for each SU, the received complex IQ sequence is processed by continuous wavelet transform (CWT) to form an I/Q two-channel time-frequency tensor, which is stacked along the SU dimension to capture local time-frequency textures and global energy distribution. Unlike existing works, the aggregation of per-SU CWT features across the SU dimension explicitly exploits spatial diversity across SUs, improving robustness to impulsive and bursty GGD noise;
Temporal path: in the complex domain, cooperative averaging is performed over multiple SU signals to extract magnitude and phase sequences, which characterize the temporal evolution of the envelope and phase. This cooperative temporal representation suppresses SU-specific impulsive outliers, yielding a more stable temporal signature under heavy-tailed noise.
• Bidirectional cross-attention (BCA) module for cross-modal consistency correction, designed with two paths for spectrum sensing under non-Gaussian noise:
Temporal
Time-Frequency
• Simulation results verify the superiority and robustness of the proposed BCAM-Net. The results show that, in the low-SNR region, BCAM-Net achieves better detection performance than multiple baseline methods; for example, at SNR
The remainder of this paper is organized as follows. Section 2 describes the system model. Section 3 presents the multimodal spectrum sensing model for GGD noise. Section 4 provides the experiments and performance evaluation. Section 5 concludes the paper.
The multiuser cooperative spectrum sensing model considered in this study is illustrated in Fig. 2. Each SU independently samples the signal from the PU. The extracted data are then transmitted to the fusion center via a reporting channel, where a soft-fusion decision is performed; the final decision is subsequently fedback to the SUs.
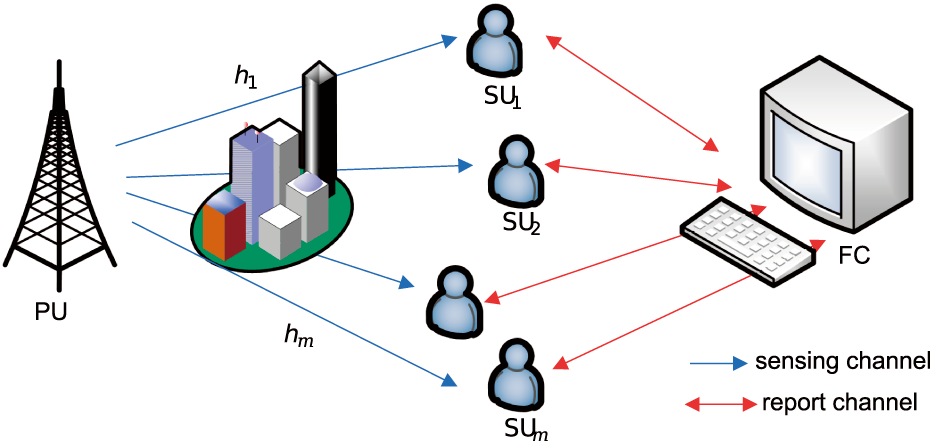
Figure 2: Cooperative spectrum sensing model.
The cooperative spectrum sensing model consists of a single-antenna Primary User (PU) and multiple Secondary Users (SUs). The SUs sense whether the PU is active. Under a binary hypothesis test, the signal received by the
where there are two hypotheses
The sensing performance of spectrum sensing algorithms is usually evaluated by the false-alarm probability
where
To more accurately characterize the impulsive non-Gaussian noise that SUs may encounter from sources such as industrial motors, electric welding and vehicle ignition systems, this paper adopts the Generalized Gaussian Distribution GGD to describe the statistics of the noise
where
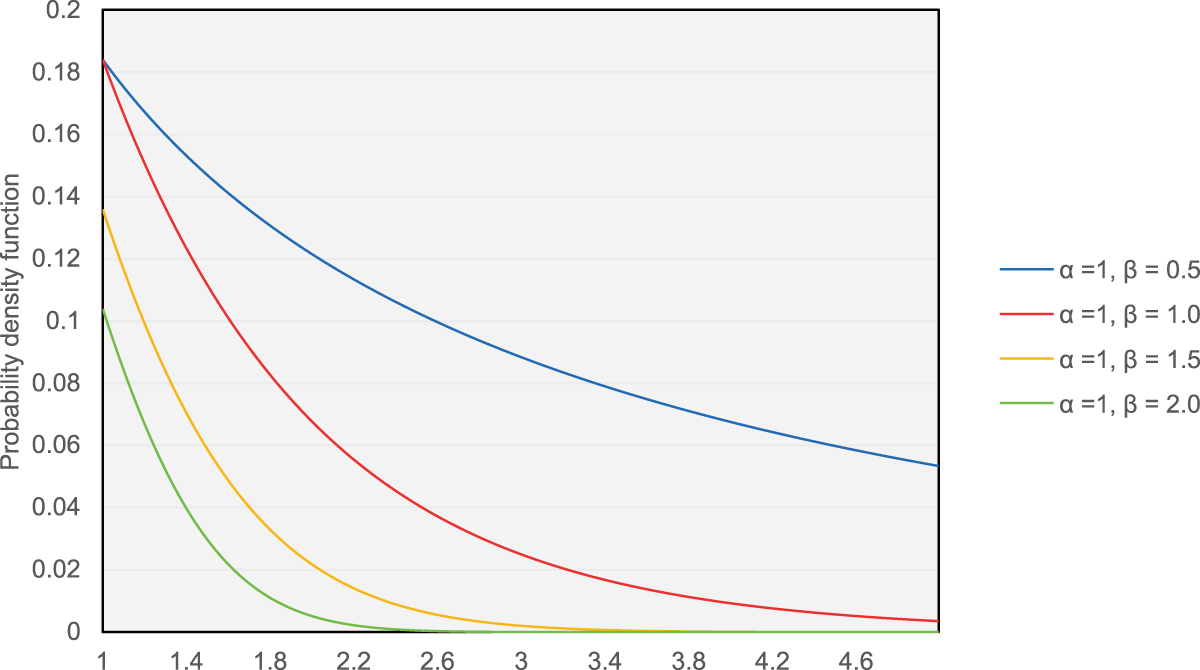
Figure 3: Probability density function of GGD distribution under different shape parameters.
In our simulations,
3 Multimodal Spectrum Sensing Model for GGD Noise
To achieve stable spectrum sensing in complex IoT scenarios, we propose a bidirectional cross-attention multimodal network (BCAM-Net) for spectrum sensing under GGD noise (see Fig. 4). The model exploits two complementary modalities: (i) time-frequency images of multiple SUs (obtained by applying CWT to the I/Q components) and (ii) magnitude-phase features of the cooperative IQ sequence. Feature representations are extracted by a time-frequency branch and a temporal branch, respectively. BCA is then introduced to guide the time-frequency branch with temporal information and to constrain the temporal representation with time-frequency information, enabling cross-modal complementarity and improved robustness when heavy-tailed noise coexists with weak signals. Finally, the model fuses three vectors—the original global time-frequency vector, the temporally guided time-frequency vector, and the temporal vector guided by time-frequency features—and outputs a binary decision.
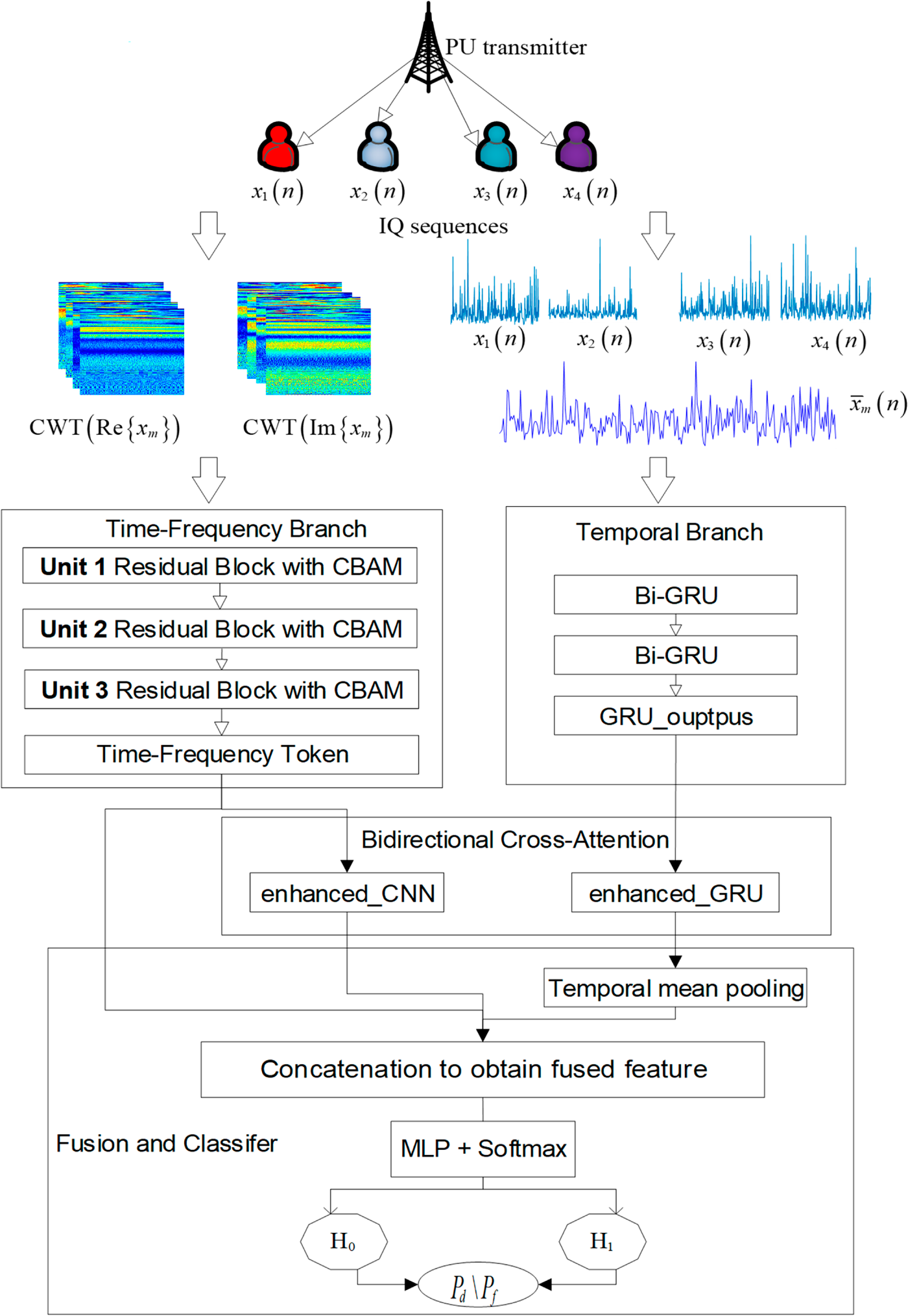
Figure 4: BCAM-Net model diagram.
3.1 Data and Input Construction
To preserve spatial diversity across SU receivers, the CWT is computed independently for the complex IQ sequence of the
where
Complex Morlet wavelet is adopted, owing to its favorable time-frequency localization and approximate analyticity, which preserves phase information while producing smooth time-frequency textures—properties particularly effective for discriminating signal from noise in spectrum-sensing tasks [25]. The complex Morlet analyzing wavelet is defined as
For the
For implementation, we compute the discrete CWT using the complex Morlet wavelet with sampling frequency
where
Stacking
where M is the number of SUs, the second dimension corresponds to the real and imaginary channels, and
For the temporal branch, cooperative IQ magnitude-phase features are employed to capture robust temporal statistics and phase dynamics. Complex observations from M SUs,
which serves as the complex-valued input sequence for the temporal branch. Each complex sample
where
To achieve stable spectrum sensing under GGD noise, the time-frequency branch takes as input the SU-stacked time-frequency tensor
where,
3.2.1 Residual Block with Convolutional Block Attention Module
The fusion unit of the residual block and the Convolutional Block Attention Module (CBAM) is illustrated in Fig. 5. The unit consists of convolution (Conv), batch normalization (BN), CBAM attention, residual addition and Rectified Linear Unit (ReLU). Convolution extracts locally correlated features within the time-frequency neighborhood; BN stabilizes feature statistics and accelerates convergence; CBAM re-calibrates features through channel-wise and spatial attention in sequence to highlight discriminative responses; residual addition provides a direct gradient pathway to alleviate degradation, and ReLU supplies nonlinearity. In the time-frequency branch, the residual block with CBAM is stacked three times (Unit
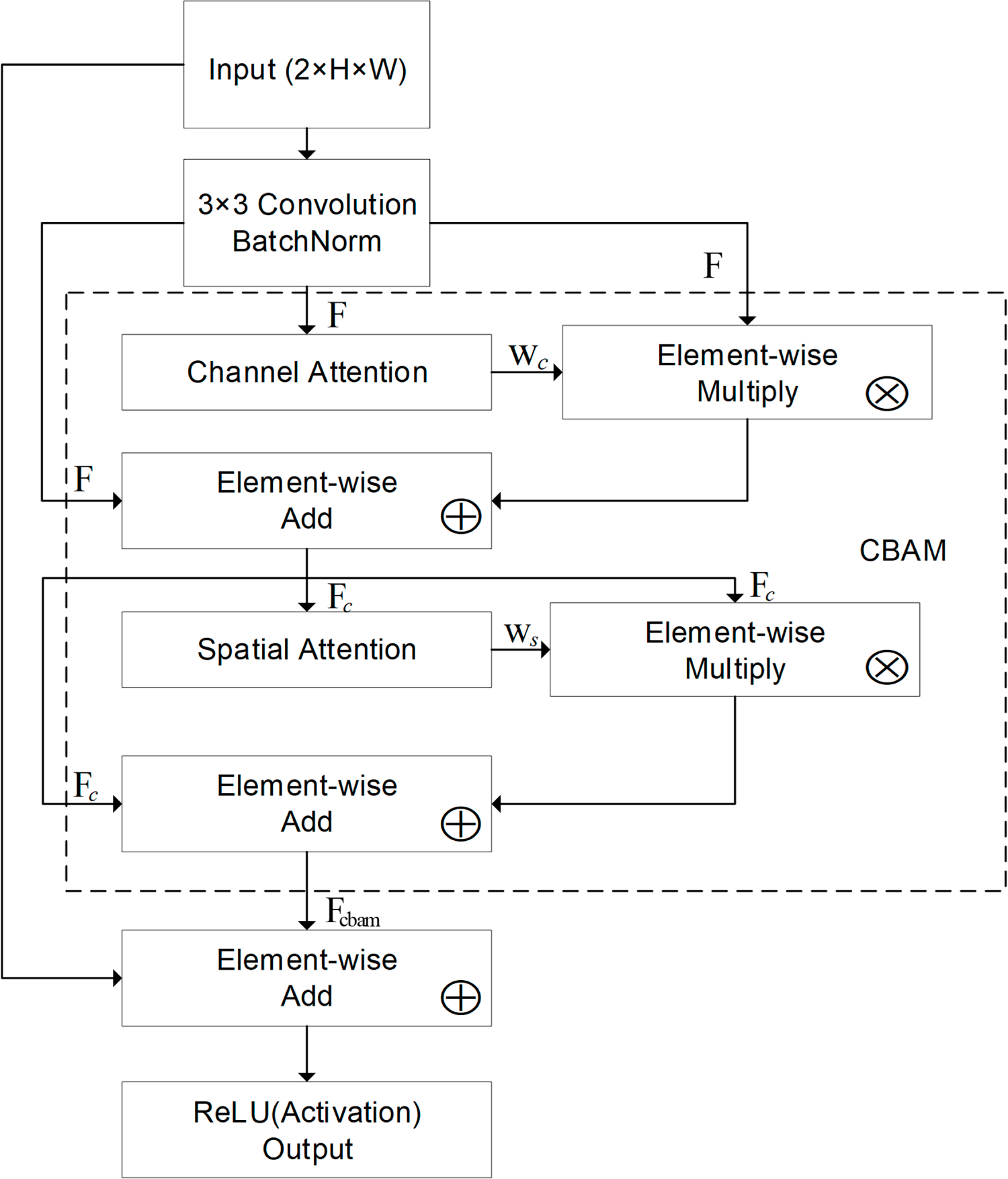
Figure 5: Schematic diagram of Residual Block with CBAM.
Let the block input be
The shortcut is identity when
Next, CBAM is applied to
• Channel attention. Global average pooling (GAP) and global max pooling (GMP) over spatial dimensions yield
Both descriptors are passed through shared
where
where
• Spatial attention. Channel-wise average and max of
which is passed through a
Residual-style spatial scaling:
Block output. The final output is obtained by residual addition with the shortcut followed by ReLU:
3.2.2 SU-Wise Global Pooling and Token Construction
To obtain stable time-frequency features while preserving SU diversity for bidirectional cross-attention, the time-frequency branch applies adaptive Global Average Pooling (GAP) to the third residual block output of each SU and keeps the SU-wise pooled vectors as tokens. Let the output of the third residual block for the
and its GAP vector be
Stacking the SU-wise vectors yields the time-frequency token set
which is fed into the BCA module.
3.3 Temporal Branch—Bidirectional GRU
In the presence of GGD noise, the temporal branch aims to enhance noise and signal separability at low SNR. It takes as input the cooperative mean IQ magnitude the complex-domain average across all SUs—to suppress sporadic outliers and to model the temporal evolution of the envelope and phase, thereby providing temporally grounded information of spectrum occupancy under low-SNR conditions.
A gated recurrent unit (GRU) is a recurrent neural architecture that controls information flow via an update gate and a reset gate, enabling selective retention of past context and suppression of spurious fluctuations [36]. For an input
where
In this work, two Bi-GRU layers are stacked (hidden size
This sequence supplies temporal information to the BCA attention module and, after attention, is mean-pooled over time to form the temporal summary used in the fusion head.
3.4 Bidirectional Cross-Attention (BCA) Module
Under GGD noise and low SNR, a single time-frequency representation can exhibit spurious peaks or textures, while a single temporal representation can suffer short-lived fluctuations. To achieve cross-modal complementarity and suppress noise interference in spectrum sensing, a BCA Attention module is introduced:
• Path1 (
• Path2 (
According to Sections 3.2 to 3.3, the outputs of the time-frequency branch and the temporal branch are denoted by
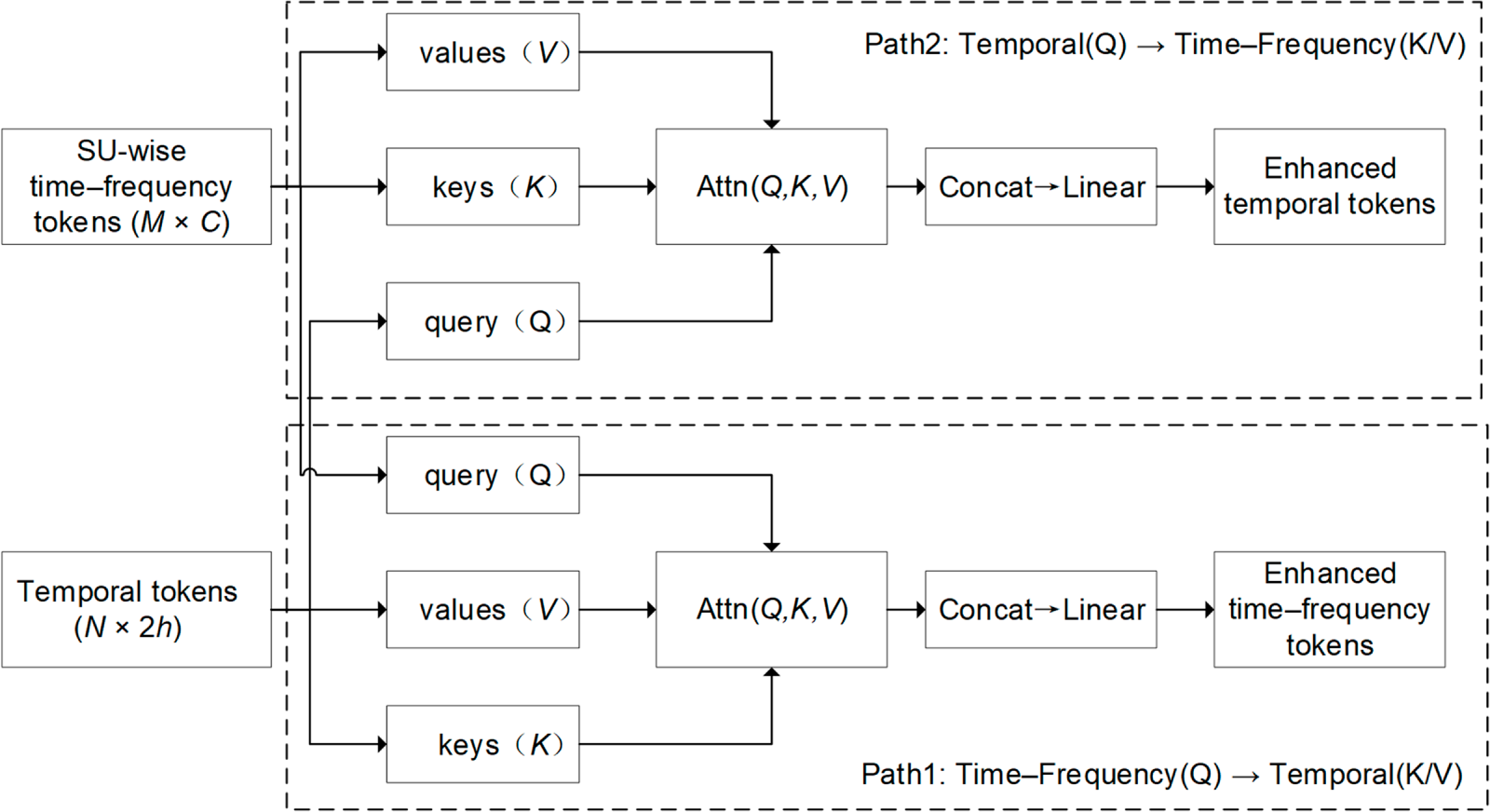
Figure 6: Schematic diagram of BCA module.
and the enhanced time-frequency tokens are
For Path2, the temporal sequence acts as the query and the time-frequency tokens provide the keys and values:
leading to an enhanced temporal representation
In both paths, attention is computed as
where
After multi-head aggregation and output projection, Path1 yields
To make the bidirectional cross-attention mechanism more intuitive, we visualize the cross-attention weight matrices for the two complementary paths, i.e., Te(Q)
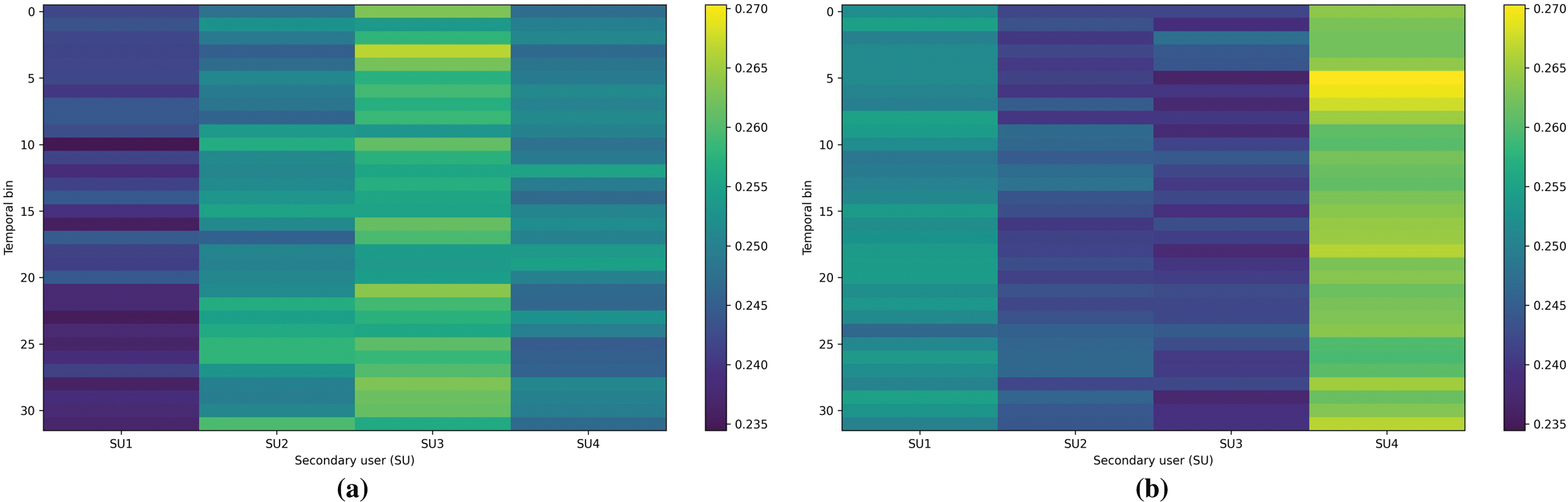
Figure 7: Visualization of the cross-attention weights in the Te(Q)
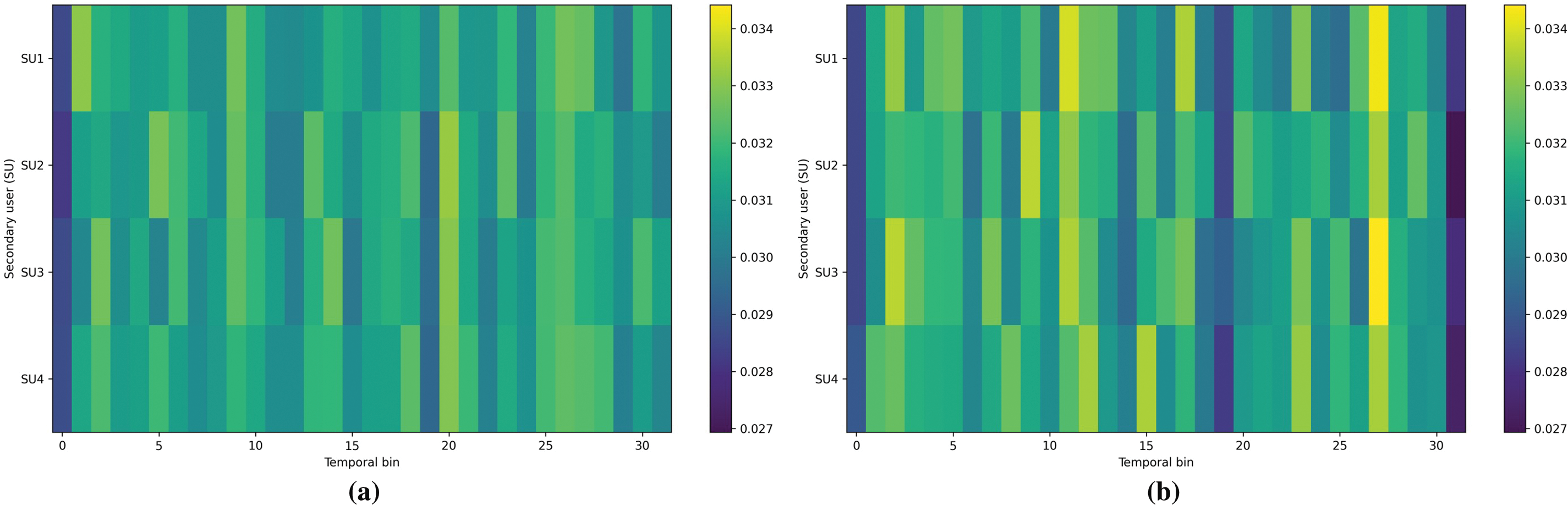
Figure 8: Visualization of the cross-attention weights in the TF(Q)
3.5 Feature Fusion and Classification
The BCA module outputs enhanced time-frequency tokens
where
Here,
Thus,
3.5.2 Normalization and Classifier
Given the fused vector
• Layer Normalization: feature-wise Layer Normalization (LN) is applied to
• Two-layer MLP with GELU and Dropout: the normalized vector passes through two linear mappings with a GELU nonlinearity:
where
• Probabilistic output for detection: posterior probabilities are obtained with Softmax:
3.6 Training and Online Detection
This paper adopts cross-entropy with label smoothing. Let
Standard optimization and regularization are used to ensure stable convergence.
3.6.2 Threshold Setting and Online Detection
The BCAM-Net output
1. Collect the scores of all training samples labeled
2. Sort these scores in descending order
3. Define the threshold as
4. Using the same
At test time, the fused vector is normalized as
An overview of the complete processing flow is provided in Fig. 9, and the spectrum sensing algorithm based on BCAM-Net is summarized in Table 1. For implementation details, BCAM-Net was trained using AdamW with a learning rate of 0.0008, a batch size of 64, and 40 training epochs.
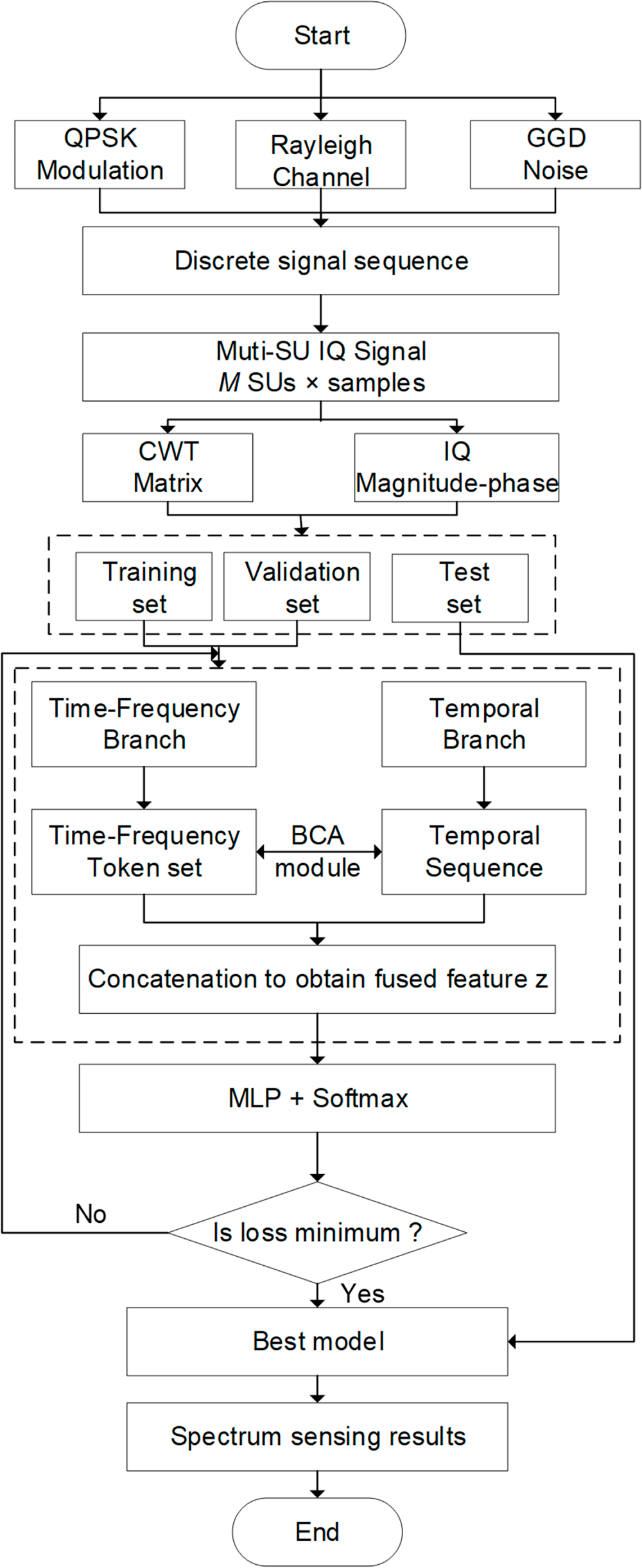
Figure 9: BCAM-Net Algorithm flowchart.

4 Experiments and Performance Evaluation
This section evaluates the proposed spectrum sensing method based on BCAM-Net. The simulation setup and data generation are first described. An ablation study then verifies the contributions of the dual-branch design and BCA attention fusion. Comparisons with representative deep-learning models and classical machine-learning baselines are presented, followed by a robustness study under varying GGD shape parameters. Performance on Real LoRa-Based Spectrum Sensing is then reported. Finally, model complexity is analyzed in terms of parameter count and inference latency.
4.1 Model Simulation Related Parameters
This section evaluates the spectrum sensing approach based on BCAM-Net under GGD noise. The cooperative system comprises one PU and four SUs. The PU employs Quadrature Phase Shift Keying (QPSK) with root-raised-cosine (RRC) pulse shaping, while SU observations are collected over a flat Rayleigh fading channel. Receiver noise in both the null hypothesis

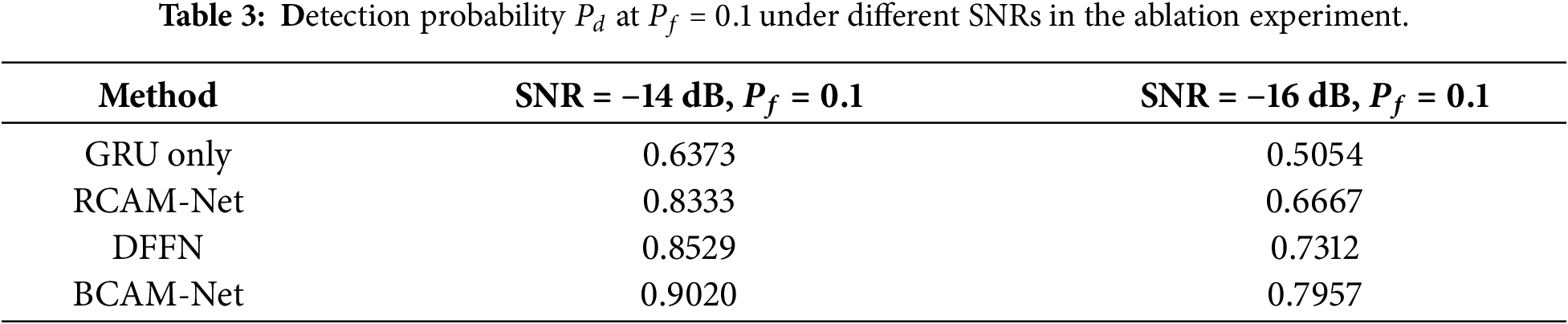
To verify the advantages of BCAM-Net over single-branch models and simple fusion models, ablation experiments were conducted using four comparable configurations: (a) GRU-only (temporal branch only); (b) RCAM-Net (CNN branch only with three residual-CBAM blocks); (c) DFFN (simple concatenation of Dual-branch output); and (d) BCAM-Net. All models are trained and evaluated under identical settings, and the detection probability
Ablation results in Fig. 10 show the detection probability
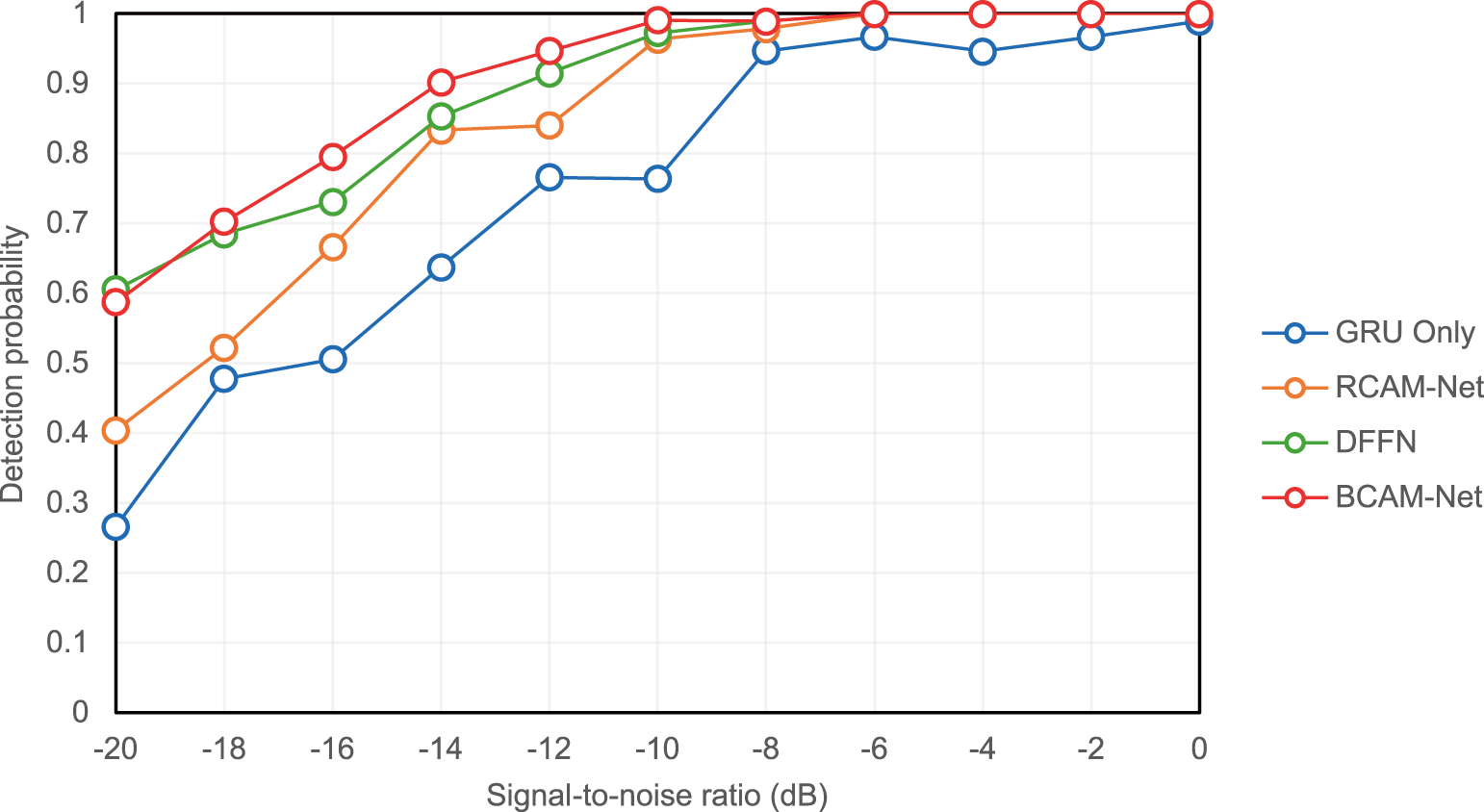
Figure 10: Detection probability under different SNRs in the ablation study at
Under the same experimental settings, the contribution of bidirectional interaction in the proposed BCA module is examined via two uni-directional variants, constructed by disabling one cross-attention path while keeping all other components unchanged. Uni-CA (Q = TF, KV = Te) uses the time-frequency tokens
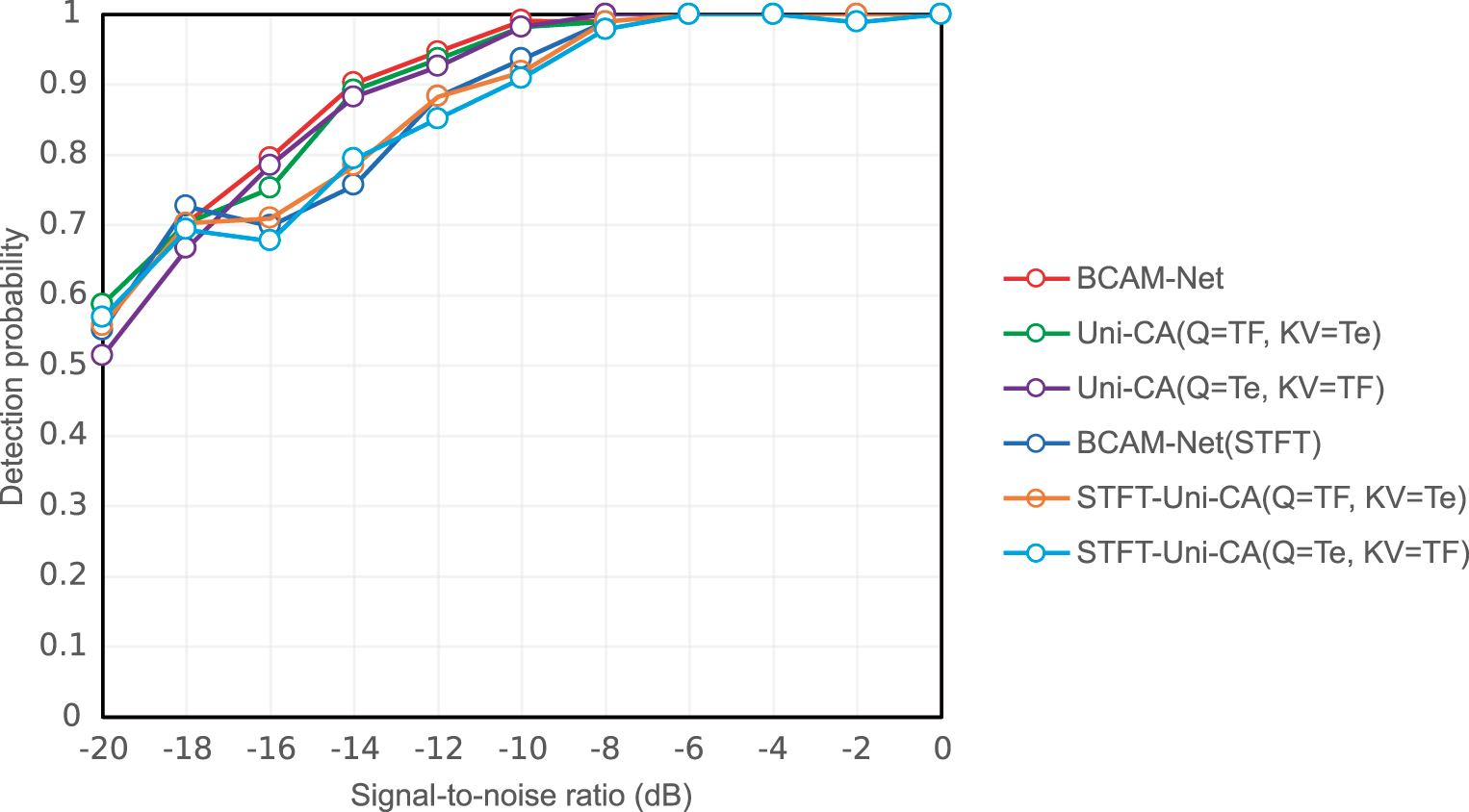
Figure 11: Detection probability under different SNRs for the BCA directionality ablation at
As shown in Fig. 11, BCAM-Net generally achieves higher
4.3 Performance Comparison with Other Models
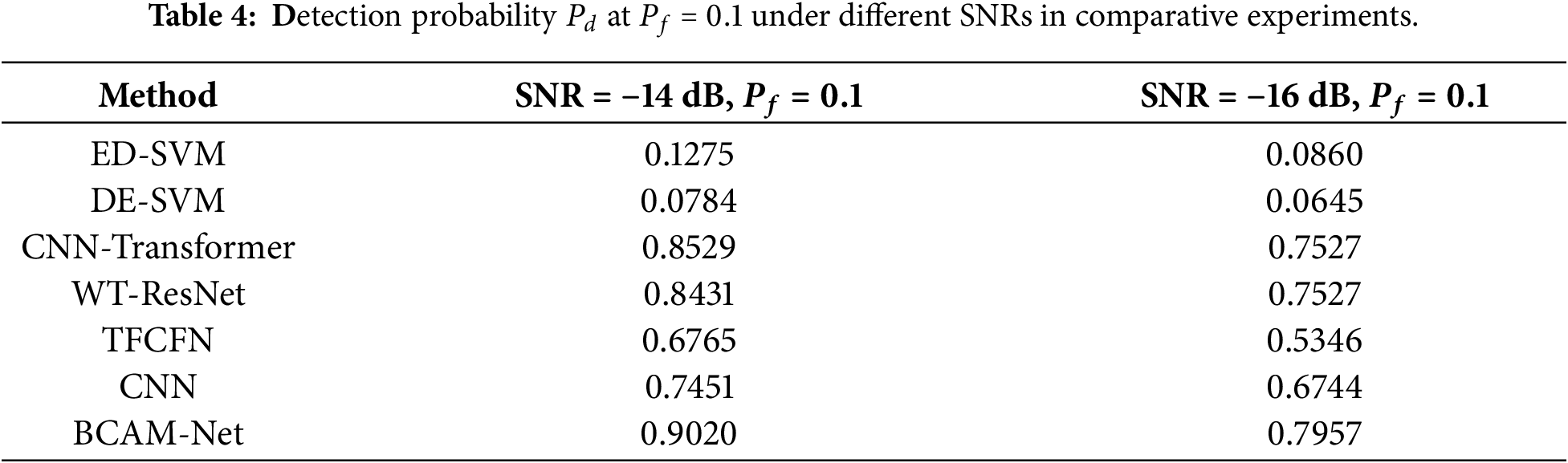
To further evaluate the model performance under identical data and training settings, BCAM-Net was compared with several representative methods. The deep learning models include CNN-Transformer [28], WT-ResNet [25], TFCFN [31], and CNN [24], whose architectural configurations were kept consistent with the original papers. The classical machine learning methods include ED-SVM [19] (an SVM using energy detection features) and DE-SVM [21] (an SVM using GGD differential entropy features).
At a fixed
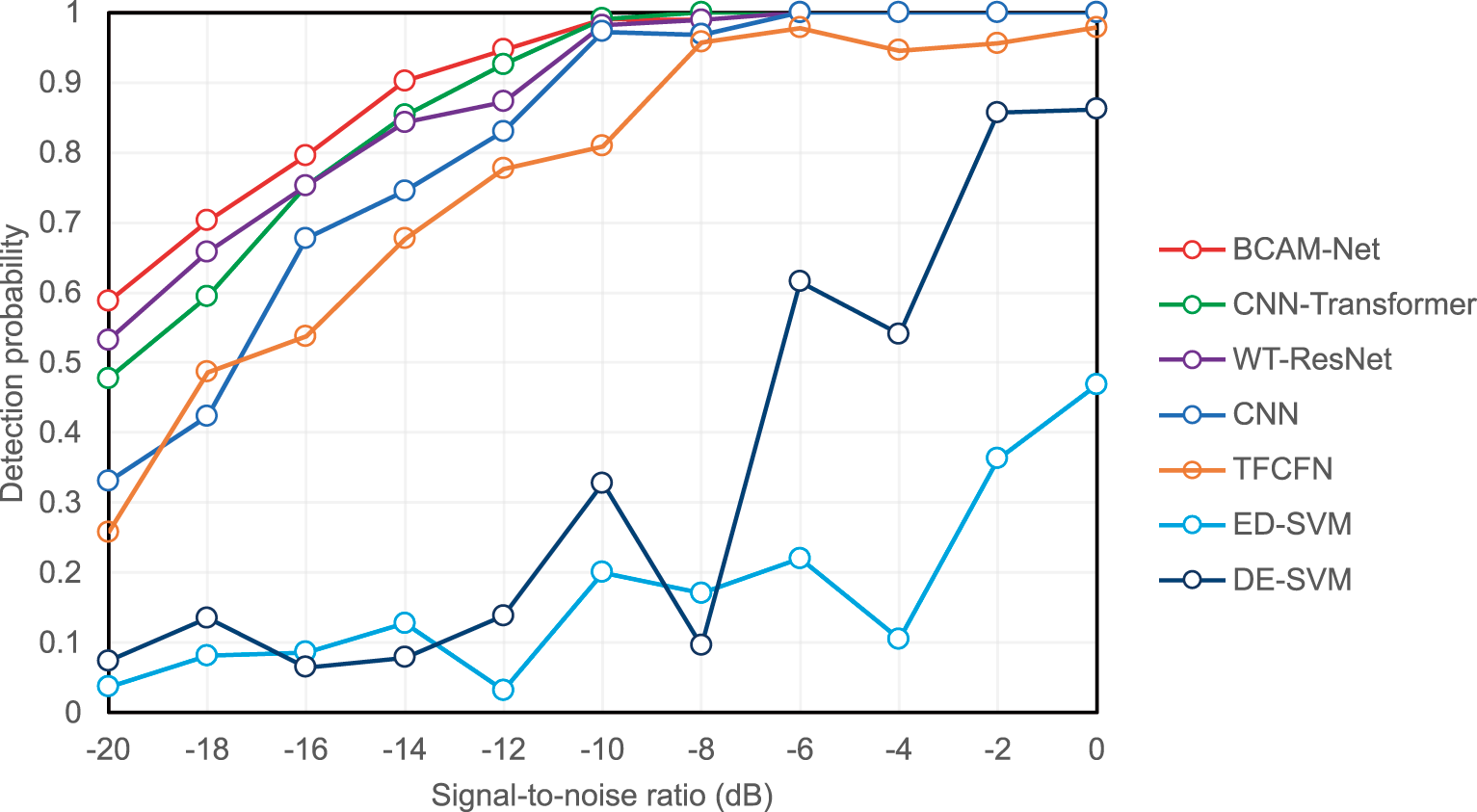
Figure 12: Detection performance comparison of different spectrum sensing models across SNRs at
4.4 GGD Noise Shape Parameter Robustness Test
To assess the stability of BCAM-Net under different levels of impulsive noise, for each
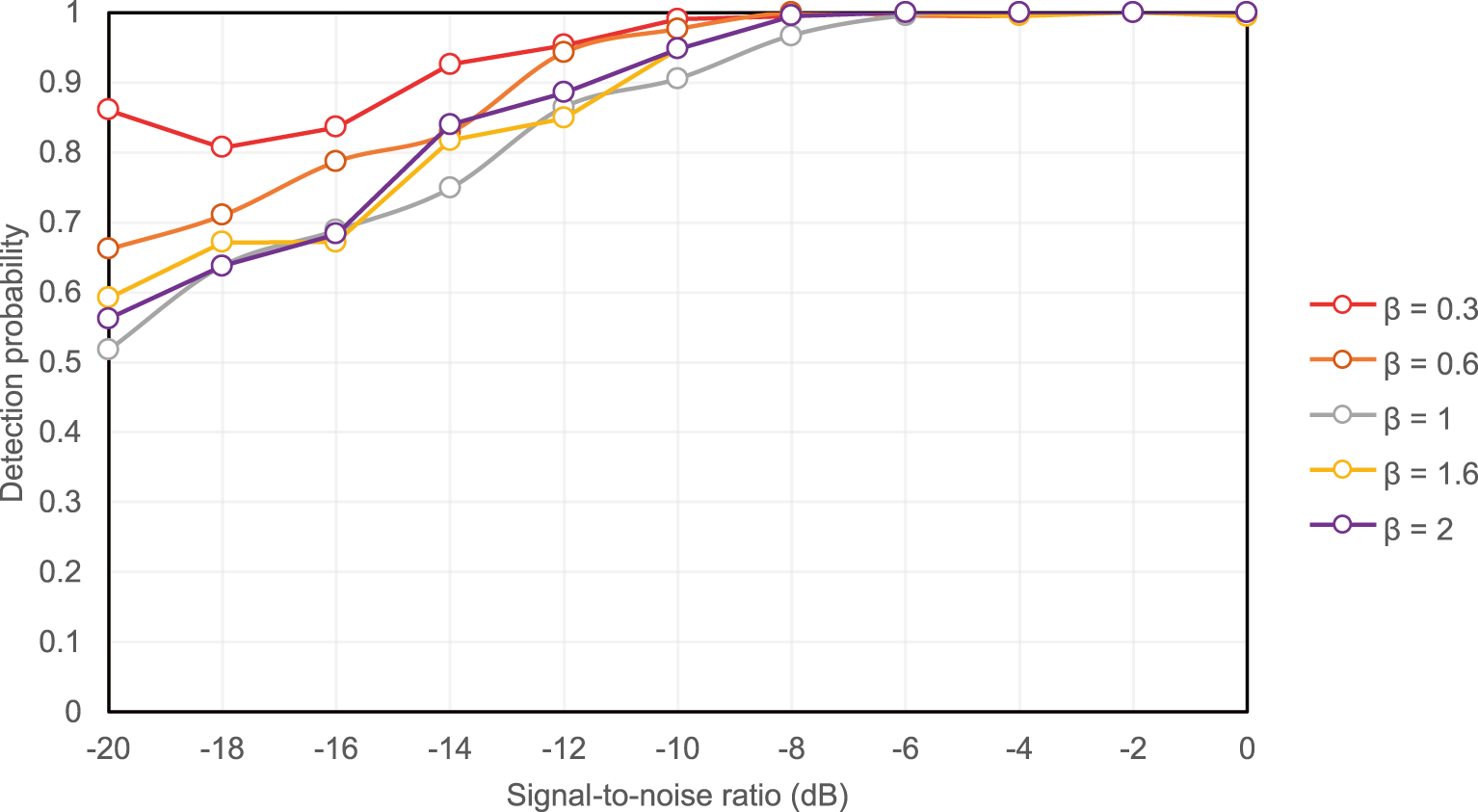
Figure 13: Detection performance of BCAM-Net across SNRs under different
Across all tested
Overall, the results indicate that the GGD shape parameter
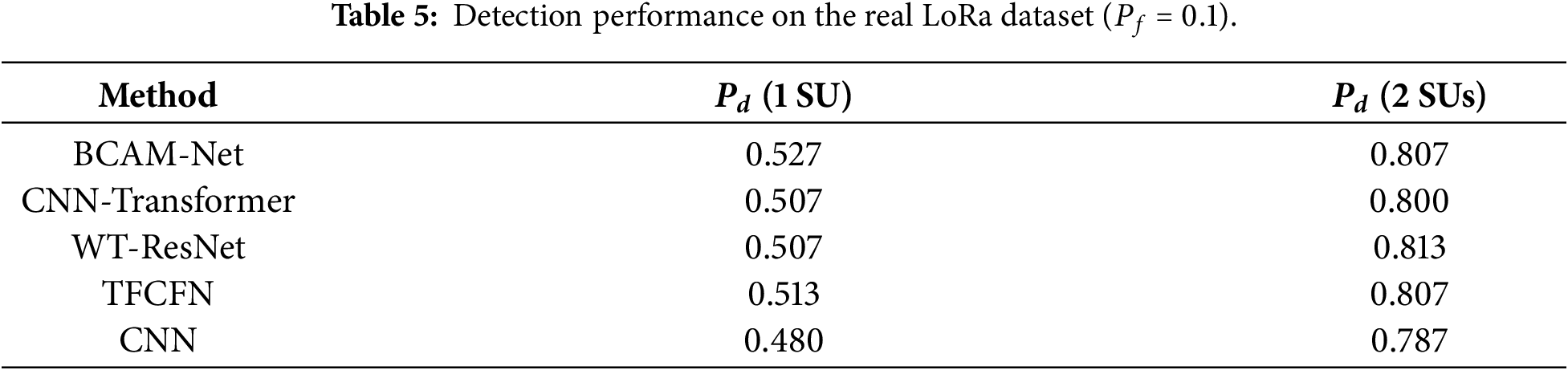
4.5 Performance on Real LoRa-Based Spectrum Sensing
To further verify the practical applicability of the proposed BCAM-Net, additional experiments were conducted on a publicly available real SDR dataset reported in [38], which contains over-the-air IQ recordings of uplink LoRa transmissions and background noise captured using an RTL-SDR. In this dataset, the LoRa signals are centered at 868.1 MHz with a 125 kHz bandwidth (SF7 and SF12, i.e., spreading factor 7 and 12) [38]. Since the dataset provides recordings collected under different receive-attenuation settings, two recordings with different attenuation levels were selected and treated as two SU observations to construct an approximate 2-SU cooperative sensing scenario. Note that this setting approximates heterogeneous SU sensing qualities using different attenuation levels rather than two synchronized receivers.
For each SU and each hypothesis, the baseband IQ samples were segmented into frames of 256 samples to form a binary detection dataset (hypothesis
Table 5 summarizes the detection performance on the real LoRa dataset at
This section analyzes model complexity in terms of parameter count (Params, in millions) and per-frame inference latency (ms/frame). All results were obtained under identical hardware and settings on an NVIDIA RTX 4090D (24 GB) GPU with an AMD EPYC 9754 host. As shown in Fig. 14, BCAM-Net has 0.12M parameters and 0.0313 ms/frame latency, offering low inference cost while remaining lightweight. CNN-Transformer [28] requires 0.92M parameters with 0.7601 ms/frame latency, both substantially higher than BCAM-Net. WT-ResNet [25] uses 0.14M parameters and attains the lowest latency (0.0115 ms/frame), whereas the two-layer CNN [24] has 0.11M parameters but a relatively high latency of 0.4412 ms/frame.
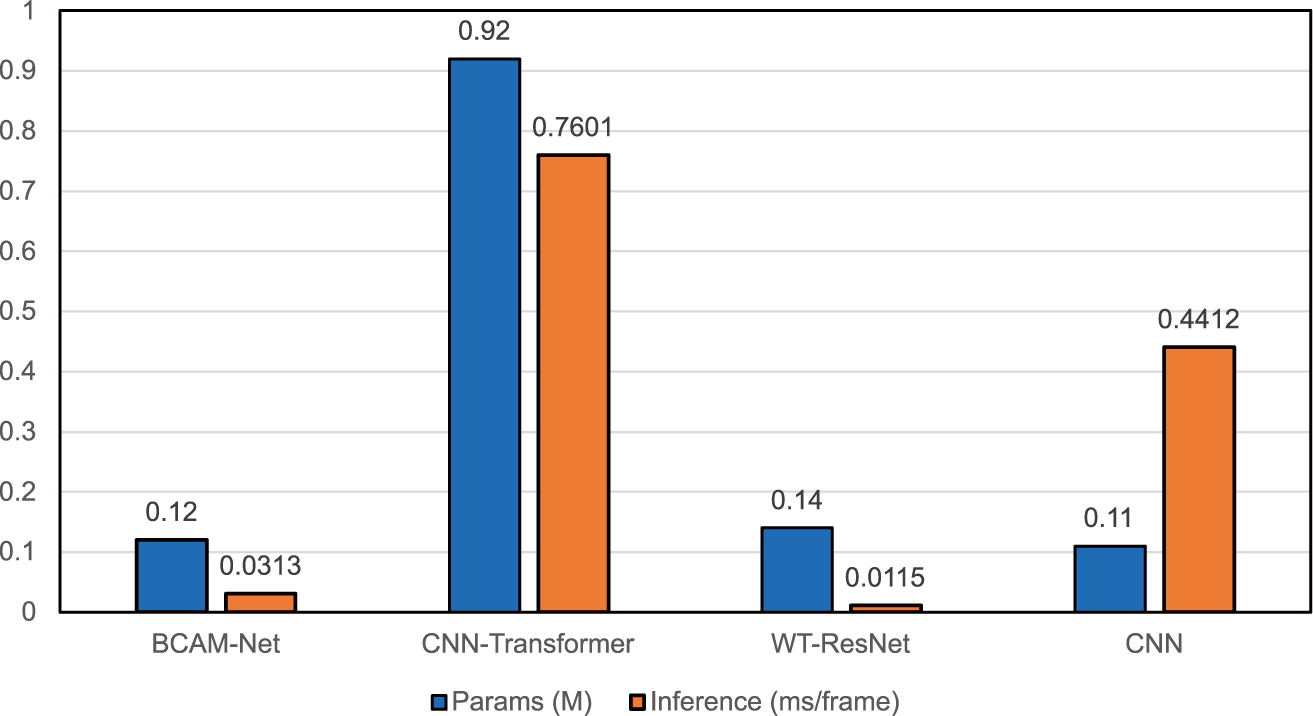
Figure 14: BCAM-Net complexity analysis comparison.
Based on the detection performance analysis above, BCAM-Net achieves a favorable balance between performance and efficiency under our unified GPU setting. Moreover, with 0.12M parameters, the model-weight storage is approximately 0.48 MB in FP32 (0.24 MB in FP16), which suggests potential suitability for memory-constrained edge deployment. Detailed on-device benchmarking of latency, energy consumption, and memory usage on representative edge platforms will be investigated in future work.
Nevertheless, practical deployments may involve additional challenges. In practical deployments, SUs may experience heterogeneous received SNRs, which can make cooperative fusion sensitive to unreliable observations. For controlled comparison, the current experiments assume identical SNR across SUs. Extending BCAM-Net to explicitly handle heterogeneous-SNR scenarios remains an important direction for future work.
This paper investigates spectrum sensing for IoT-oriented networks under GGD noise, where heavy-tailed disturbances can significantly degrade the reliability of conventional sensing pipelines. To address this challenge, BCAM-Net is proposed as a multimodal framework that jointly exploits time-frequency and temporal information. Specifically, BCAM-Net learns CWT-based time-frequency features through a time-frequency branch and learns magnitude-phase sequence features through a temporal branch; meanwhile, a BCA module is introduced to achieve explicit mutual calibration between the two modalities, thereby enhancing cross-modal feature fusion. In addition, BCAM-Net adopts a lightweight design, maintaining a low parameter count and low inference latency to improve practicality for real-world deployment scenarios.
Extensive experiments demonstrate that, at a fixed false-alarm probability
However, some limitations still exist. First, the performance still degrades in extremely low-SNR regimes, where both temporal and time-frequency cues become weak and attention reweighting may be less discriminative. Second, the evaluation assumes the same received SNR for all SUs, which may differ from practical networks where per-SU SNRs vary due to shadowing, fading, and hardware diversity. Third, the generalization capability to a broader range of modulation types and more complex signal environments has not been fully validated.
Future work will focus on improving detection performance in extremely low-SNR conditions, extending the evaluation to more realistic scenarios with heterogeneous SU sensing qualities, further validating the proposed method under broader signal settings and real-world SDR measurements, and benchmarking latency, energy consumption, and memory usage on representative edge platforms.
Acknowledgement: Not applicable.
Funding Statement: This research was supported in part by JSPS Grants-in-Aid for Scientific Research 25K07742 and 25K23457.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Yuzhou Han; data collection and dataset preparation: Yuzhou Han; analysis and interpretation of results: Yuzhou Han; draft manuscript preparation: Yuzhou Han. Osamu Muta, Ahmad Gendia, Zhuoran Li and Teruji Ide contributed through technical discussions and provided critical revisions and key suggestions on the initial draft that improved the manuscript. Ahmad Gendia also provided guidance on the experimental design and assisted with English grammar polishing. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data supporting the findings of this study are available from the corresponding author, Yuzhou Han, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Nguyen DC, Ding M, Pathirana PN, Seneviratne A, Li J, Niyato D, et al. 6G Internet of Things: a comprehensive survey. IEEE Internet Things J. 2022;9(1):359–83. doi:10.1109/JIOT.2021.3103320. [Google Scholar] [CrossRef]
2. Liu X, Jia M, Zhou M, Wang B, Durrani TS. Integrated cooperative spectrum sensing and access control for cognitive industrial Internet of Things. IEEE Internet Things J. 2023;10(3):1887–96. doi:10.1109/JIOT.2021.3137408. [Google Scholar] [CrossRef]
3. Wang J, Jiang W, Wang H, Huang Y, Chen R, Lin R. Multiband spectrum sensing and power allocation for a cognitive radio-enabled smart grid. Sensors. 2021;21(24):8384. doi:10.3390/s21248384. [Google Scholar] [PubMed] [CrossRef]
4. Rodríguez-Piñeiro J, Wei Z, Wang J, Gutiérrez CA, Correia LM. 6G-enabled vehicle-to-everything communications: current research trends and open challenges. IEEE Open J Veh Technol. 2025;6:2358–91. doi:10.1109/OJVT.2025.3599570. [Google Scholar] [CrossRef]
5. Parvini M, Zarif AH, Nouruzi A, Mokari N, Javan MR, Abbasi B, et al. Spectrum sharing schemes from 4G to 5G and beyond: protocol flow, regulation, ecosystem, and economics. IEEE Open J Commun Soc. 2023;4:464–517. doi:10.1109/OJCOMS.2023.3238569. [Google Scholar] [CrossRef]
6. Nasser A, Al Haj Hassan H, Abou Chaaya J, Mansour A, Yao K-C. Spectrum sensing for cognitive radio: recent advances and future challenge. Sensors. 2021;21(7):2408. doi:10.3390/s21072408. [Google Scholar] [PubMed] [CrossRef]
7. Liu X, Jia M. Intelligent spectrum resource allocation based on joint optimization in heterogeneous cognitive radio. IEEE Trans Emerg Top Comput Intell. 2020;4(1):5–12. doi:10.1109/TETCI.2018.2865630. [Google Scholar] [CrossRef]
8. Wasilewska M, Bogucka H, Poor HV. Secure federated learning for cognitive radio sensing. IEEE Commun Mag. 2023;61(3):68–73. doi:10.1109/MCOM.001.2200465. [Google Scholar] [CrossRef]
9. Ali A, Hamouda W. Advances on spectrum sensing for cognitive radio networks: theory and applications. IEEE Commun Surv Tutor. 2017;19(2):1277–304. doi:10.1109/COMST.2016.2631080. [Google Scholar] [CrossRef]
10. Gaiera B, Patel DK, Soni B, López-Benítez M. Performance evaluation of improved energy detection under signal and noise uncertainties in cognitive radio networks. In: 2019 IEEE International Conference on Signals and Systems (ICSigSys). Piscataway, NJ, USA: IEEE; 2019. p. 131–7. doi:10.1109/ICSIGSYS.2019.8811079. [Google Scholar] [CrossRef]
11. Arjoune Y, Kaabouch N. A comprehensive survey on spectrum sensing in cognitive radio networks: recent advances, new challenges, and future research directions. Sensors. 2019;19(1):126. doi:10.3390/s19010126. [Google Scholar] [PubMed] [CrossRef]
12. Yan X, Liu G, Wu H-C, Zhang G, Wang Q, Wu Y. Robust modulation classification over α-stable noise using graph-based fractional lower-order cyclic spectrum analysis. IEEE Trans Veh Technol. 2020;69(3):2836–49. doi:10.1109/TVT.2020.2965137. [Google Scholar] [CrossRef]
13. Mehrabian A, Sabbaghian M, Yanikomeroglu H. Spectrum sensing for symmetric α-stable noise model with convolutional neural networks. IEEE Trans Commun. 2021;69(8):5121–35. doi:10.1109/TCOMM.2021.3070892. [Google Scholar] [CrossRef]
14. Agrawal SK, Samant A, Yadav SK. Spectrum sensing in cognitive radio networks and metacognition for dynamic spectrum sharing between radar and communication system: a review. Phys Commun. 2022;52:101673. doi:10.1016/j.phycom.2022.101673. [Google Scholar] [CrossRef]
15. Salameh HB, Hussienat A. ML-driven feature-based spectrum sensing for NOMA signal detection in spectrum-agile IoT networks under fading channels. IEEE Sens J. 2025;25(13):25963–71. doi:10.1109/JSEN.2025.3569620. [Google Scholar] [CrossRef]
16. Zhang Y, Luo Z. A deep-learning-based method for spectrum sensing with multiple feature combination. Electronics. 2024;13(14):2705. doi:10.3390/electronics13142705. [Google Scholar] [CrossRef]
17. Janu D, Singh K, Kumar S. Machine learning for cooperative spectrum sensing and sharing: a survey. Trans Emerg Telecommun Technol. 2022;33(1):e4352. doi:10.1002/ett.4352. [Google Scholar] [CrossRef]
18. Wu Q, Ng BK, Lam C-T. Energy-efficient cooperative spectrum sensing using machine learning algorithm. Sensors. 2022;22(21):8230. doi:10.3390/s22218230. [Google Scholar] [PubMed] [CrossRef]
19. Saber M, El Rharras A, Saadane R, Aroussi HK, Wahbi M. Artificial neural networks, support vector machine and energy detection for spectrum sensing based on real signals. Int J Commun Netw Inf Secur. 2019;11(1):52–60. doi:10.17762/ijcnis.v11i1.3718. [Google Scholar] [CrossRef]
20. Varma AK, Mitra D. Statistical feature-based SVM wideband sensing. IEEE Commun Lett. 2020;24(3):581–4. doi:10.1109/LCOMM.2019.2959355. [Google Scholar] [CrossRef]
21. Saravanan P, Chandra SS, Upadhye A, Gurugopinath S. A supervised learning approach for differential entropy feature-based spectrum sensing. In: 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET). Piscataway, NJ, USA: IEEE; 2021. p. 395–9. doi:10.1109/WiSPNET51692.2021.9419447. [Google Scholar] [CrossRef]
22. Kumar A, Gaur N, Chakravarty S, Alsharif MH, Uthansakul P, Uthansakul M. Analysis of spectrum sensing using deep learning algorithms: CNNs and RNNs. Ain Shams Eng J. 2024;15(3):102505. doi:10.1016/j.asej.2023.102505. [Google Scholar] [CrossRef]
23. Wang L, Hu J, Zhang C, Jiang R, Chen Z. Deep learning models for spectrum prediction: a review. IEEE Sens J. 2024;24(18):28553–75. doi:10.1109/JSEN.2024.3416738. [Google Scholar] [CrossRef]
24. Chen Z, Xu Y-Q, Wang H, Guo D. Deep STFT-CNN for spectrum sensing in cognitive radio. IEEE Commun Lett. 2021;25(3):864–8. doi:10.1109/LCOMM.2020.3037273. [Google Scholar] [CrossRef]
25. Zhen P, Zhang B, Chen Z, Guo D, Ma W. Spectrum sensing method based on wavelet transform and residual network. IEEE Wirel Commun Lett. 2022;11(12):2517–21. doi:10.1109/LWC.2022.3207296. [Google Scholar] [CrossRef]
26. Xu L, Gao Z, Li Y, Gulliver TA. Cross-domain intelligent cooperative spectrum sensing algorithm based on Federated Learning and Swin-Transformer neural network. Eng Appl Artif Intell. 2025;157:111370. doi:10.1016/j.engappai.2025.111370. [Google Scholar] [CrossRef]
27. Varma DP, Yeduri SR, Yakkati RR, Boddu AB, Cenkeramaddi LR. Wireless technology identification using continuous wavelet transform and deep learning. IEEE Sens J. 2025;25(13):23284–91. doi:10.1109/JSEN.2024.3467681. [Google Scholar] [CrossRef]
28. Fang X, Jin M, Guo Q, Jiang T. CNN-transformer-based cooperative spectrum sensing in cognitive radio networks. IEEE Wirel Commun Lett. 2025;14(5):1576–80. doi:10.1109/LWC.2025.3550536. [Google Scholar] [CrossRef]
29. Gao Z, Li Y, Chen Z, Asif M, Xu L, Li X, et al. Intelligent spectrum sensing of consumer IoT based on GAN-GRU-YOLO. IEEE Trans Consum Electron. 2024;70(3):6140–8. doi:10.1109/TCE.2024.3418103. [Google Scholar] [CrossRef]
30. Zhang W, Wang Y, Chen X, Cai Z, Tian Z. Spectrum transformer: an attention-based wideband spectrum detector. IEEE Trans Wirel Commun. 2024;23(9):12343–53. doi:10.1109/TWC.2024.3391515. [Google Scholar] [CrossRef]
31. Xi H, Guo W, Yang Y, Yuan R, Ma H. Cross-attention mechanism-based spectrum sensing in generalized Gaussian noise. Sci Rep. 2024;14(1):23261. doi:10.1038/s41598-024-74341-4. [Google Scholar] [PubMed] [CrossRef]
32. Dao Y, Liang B, Hao L, Feng S, Wei S, Dai W, et al. Radio frequency interference identification using dual cross-attention and multi-scale feature fusing. Astron Comput. 2024;49:100881. doi:10.1016/j.ascom.2024.100881. [Google Scholar] [CrossRef]
33. Xing S, Wang Z, Zhao R, Guo X, Liu A, Liang W. Time-frequency-domain fusion cross-attention fault diagnosis method based on dynamic modeling of bearing rotor system. Appl Sci. 2025;15(14):7908. doi:10.3390/app15147908. [Google Scholar] [CrossRef]
34. Kockaya K, Develi I. Spectrum sensing in cognitive radio networks: threshold optimization and analysis. J Wirel Commun Netw. 2020;2020:255. doi:10.1186/s13638-020-01870-7. [Google Scholar] [CrossRef]
35. Gurugopinath S, Muralishankar R, Shankar HN. Differential entropy-driven spectrum sensing under generalized Gaussian noise. IEEE Commun Lett. 2016;20(7):1321–4. doi:10.1109/LCOMM.2016.2564968. [Google Scholar] [CrossRef]
36. Bai X, Xu J, Fang F, Wang X, Wang S. A multi-feature spectrum sensing algorithm based on GRU-AM. IEEE Wirel Commun Lett. 2025;14(7):2129–33. doi:10.1109/LWC.2025.3564053. [Google Scholar] [CrossRef]
37. Cai L, Cao K, Wu Y, Zhou Y. Spectrum sensing based on spectrogram-aware CNN for cognitive radio network. IEEE Wirel Commun Lett. 2022;11(10):2135–9. doi:10.1109/LWC.2022.3194735. [Google Scholar] [CrossRef]
38. Fontaine J, Shahid A, Elsas R, Seferagic A, Moerman I, de Poorter E. Multi-band sub-GHz technology recognition on NVIDIA’s Jetson Nano. In: 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall). Piscataway, NJ, USA: IEEE; 2020. p. 1–7. doi:10.1109/VTC2020-Fall49728.2020.9348566. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools