
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

TQU-GraspingObject: 3D Common Objects Detection, Recognition, and Localization on Point Cloud for Hand Grasping in Sharing Environments
1 Institute of Information Technology, Hanoi Pedagogical University 2, Phu Tho Province, Vietnam
2 University of Information Technology and Communication, Thai Nguyen University, Thai Nguyen Province, Vietnam
3 Information Technology Department, Tan Trao University, Tuyen Quang Province, Vietnam
* Corresponding Authors: Thi-Loan Nguyen. Email: ; Van-Hung Le. Email:
Computers, Materials & Continua 2026, 87(2), 72 https://doi.org/10.32604/cmc.2026.076732
Received 25 November 2025; Accepted 13 January 2026; Issue published 12 March 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
To support the process of grasping objects on a tabletop for the blind or robotic arm, it is necessary to address fundamental computer vision tasks, such as detecting, recognizing, and locating objects in space, and determining the position of the grasping information. These results can then be used to guide the visually impaired or to execute grasping tasks with a robotic arm. In this paper, we collected, annotated, and published the benchmark TQU-GraspingObject dataset for testing, validation, and evaluation of deep learning (DL) models for detecting, recognizing, and localizing grasping objects in 2D and 3D space, especially 3D point cloud data. Our dataset is collected in a shared room, with common everyday objects placed on the tabletop in jumbled positions by Intel RealSense D435 (IR-D435). This dataset includes more than 63k RGB-D pairs and related data such as normalized 3D object point cloud, 3D object point cloud segmented, coordinate system normalization matrix, 3D object point cloud normalized, and hand pose for grasping each object. At the same time, we also conducted experiments on four DL networks with the best performance: SSD-MobileNetV3, ResNet50-Transformer, ResNet101-Transformer, and YOLOv12. The results present that YOLOv12 has the most suitable results in detecting and recognizing objects in images. All data, annotations, toolkit, source code, point cloud data, and results are publicly available on our project website: https://github.com/HuaTThanhIT2327Tqu/datasetv2.Keywords
The task of learning-based object grasping by robot arms and blind people has been extensively studied. To do this, it is necessary to solve computer vision (CV) problems, such as detecting, recognizing, and locating objects. In particular, the emergence and strong development of DL have helped solve CV problems with many convincing results, but DL requires a very large amount of learning data and a large computational space [1] (calculations of DL models are often performed on high-configuration computers or GPUs). In the past five years, the problem of object grasping by robot arms and blind people has received great attention from the research community on CV and robotics.
In the process of building a grip support system, it is necessary to solve the basic problems of computer vision with a data-driven approach that offers the highest performance, including problems such as detecting, classifying [2], and locating [3], or like in 3D grasping [4]. Currently, there are many sensors for collecting environmental data such as ultrasonic sensors, LiDAR, stereo sensors, and RGB sensors, but the most cost-effective and informative sensor currently available and suitable is the RGB-D sensor, which was formerly Microsoft (MS) Kinect version (V)1, MS Kinect V2, and Xbox 360, and now IR-D435 sensor.
Research on object grasping using robotic arms often focuses on problems of detecting, recognizing, and determining grasping position [5]. Xie et al. [6] conduct comprehensive research on learning-based approaches to solve problems such as 3D object recognition, grasping configuration, and grasping pose for robot object grasping based on supervised learning, reinforcement learning, and unsupervised learning from 2015 to 2022. Jahanshahi and Zhu [7] conduct a survey study on the steps of grasp position detection, grasp planning, and grasp control implementation of a robot.
The problem of object grasping by robot arms and blind people still has many challenges, such as performing complex grasping operations like the human hand of a robot arm, or safe grasping for blind people. To solve these problems, the detection, recognition, and positioning of the grasped object must be performed accurately, and the problem of determining the position of the grasped object [8] is also very important to avoid dropping the object and ensure the safety of the blind, as illustrated in Fig. 1.
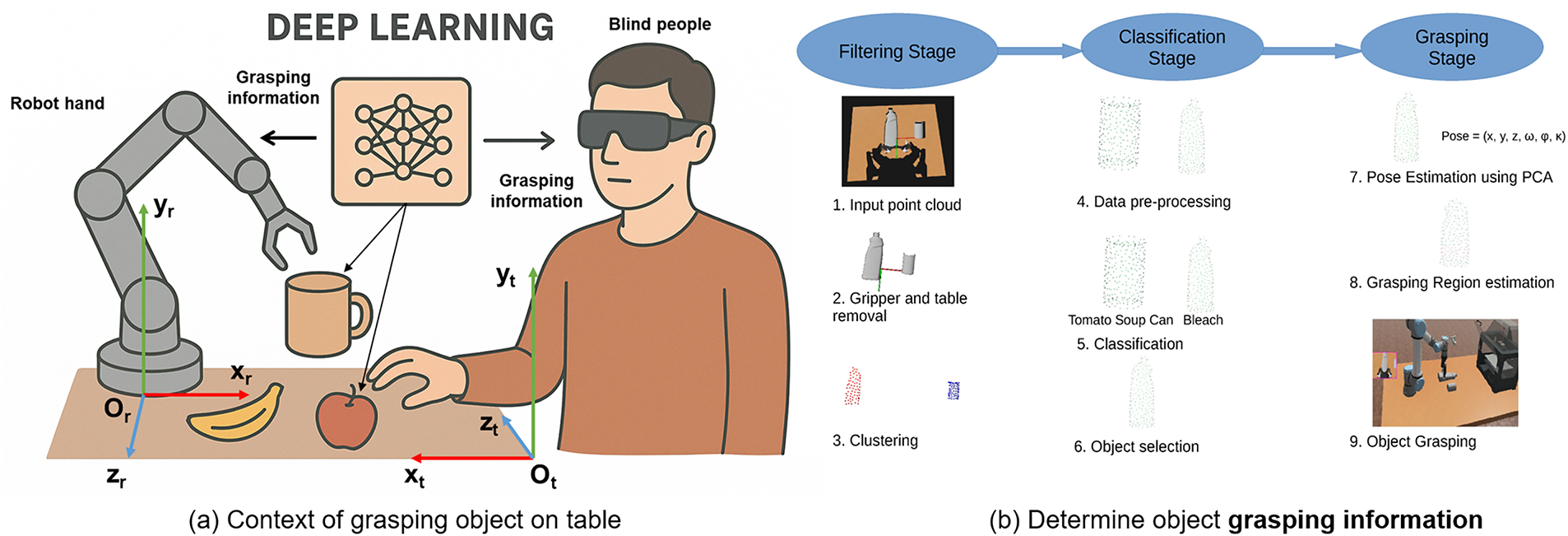
Figure 1: Illustration of the common object grasping operation on the table in a shared environment by a robot arm or a blind person. To perform the grasping operation, instructions on detecting, recognizing, and locating the object to be grasped are needed. Determining the position and posture of the hand for grasping. (a) is the context of grasping an object on the table, (b) is an illustration of the process of determining the position and posture of the object being grasped on the point cloud data.
The advent of digital translation has yielded compelling results in solving computer vision problems, but it also presents challenging requirements regarding the amount of data needed for modeling. The larger the data set, the more accurate the model. Therefore, to build models that perform well in solving component problems of a system assisting blind people or robotic arms in grasping objects on a tabletop, it is necessary to provide learning data that closely reflects the problem context. Thus, we publish the TQU-GraspingObject dataset, a benchmark dataset. This dataset provides learning data for DL models to solve problems such as detecting, recognizing, and locating 3D objects on a tabletop. This dataset was collected in a realistic context closely resembling the scenario where a visually impaired person or robotic arm would grasp common objects on a tabletop in a shared room environment. We used IR-D435 to collect RGB-D data and then construct a point cloud dataset. The TQU-GraspingObject dataset provides the original RGB-D image data, object box annotation, label annotation, coordinate system transformation matrix from the center of the camera to the tabletop, 3D object position annotation, 3D point cloud data, and hand pose for grasping. The process of collecting and constructing this dataset is shown in Fig. 2.
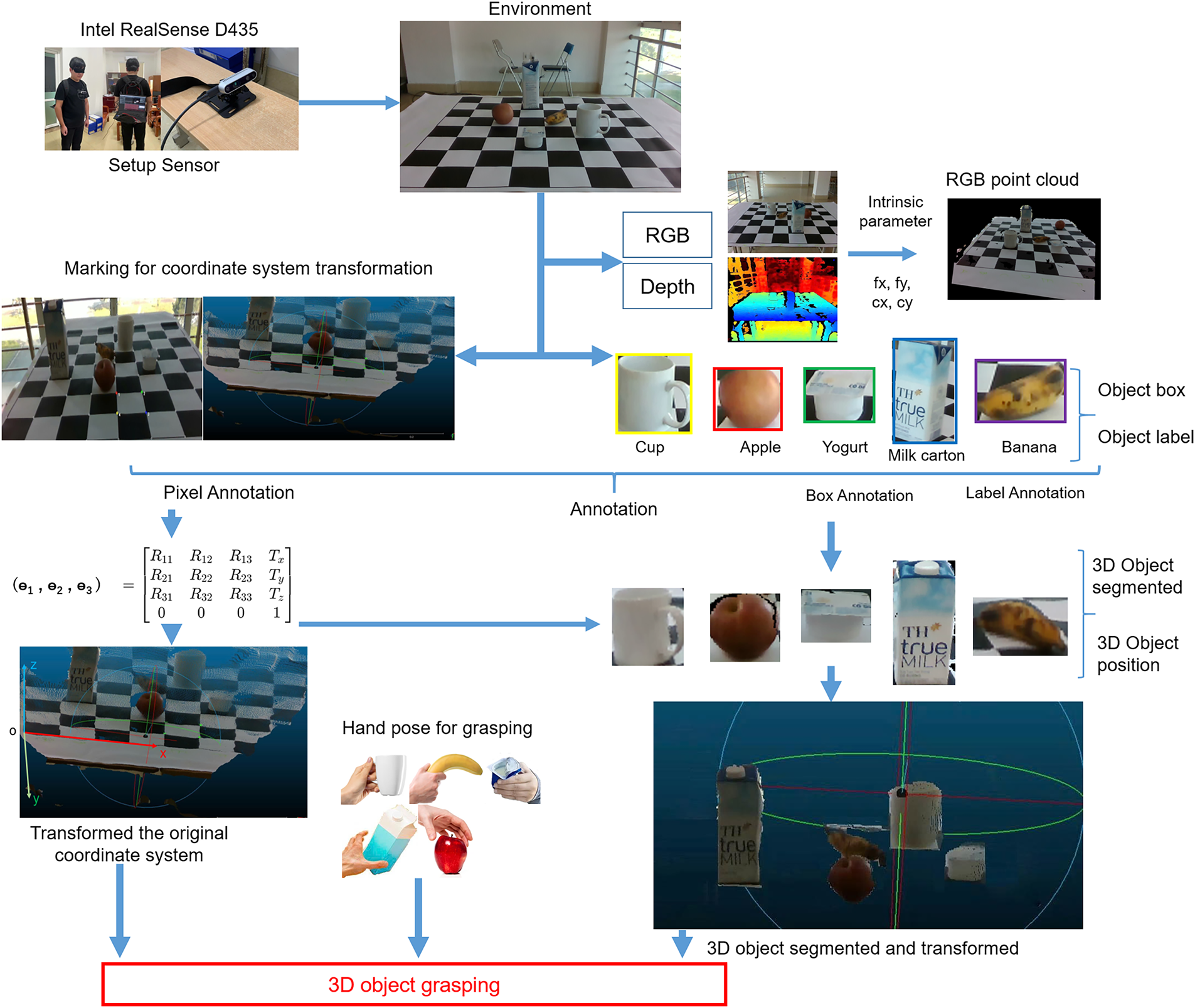
Figure 2: Describing the entire process of collecting, building, annotating, and publishing the benchmark TQU-GraspingObject dataset.
We also conduct experiments and evaluate the problem of detecting and recognizing objects on the tabletop, an initial step in the process of building a system to support the finding and grasping of common objects by robot arms or blind people in shared environments. Our experiments have implemented and compared using two high-performance DL models, CNN-based and transformer-based: SSD-MobileNetV3, ResNet50-Transformer, ResNet101-Transformer, and YOLOv12. At the same time, we also discussed and presented the challenges of 3D objects point cloud data.
The problem of grasping objects in the environment is researched and developed in two directions: supporting blind people in grasping objects and supporting robot arms that can grasp complex objects like human hands. To achieve grasping, it is necessary to solve some problems of CV, such as detection, recognition, and positioning, etc.
On using DL for solving CV problems for grasping objects, Huang et al. [8] proposed an improved method of U2Net as the backbone for pixel-based grasp pose detection and feature fusion. The improved network extracts and fuses the input image, and the grasp prediction layer detects the grasp pose on each pixel. The evaluation results image-wise and object-wise are 95.65% and 91.20%, and the processing time is 0.007 s/frame. The context for performing grasping is individual objects placed on a table, with the robotic arm fixed at a corner of the tabletop. Grasp pose is evaluated on a Cornell dataset, with the original data labeled on color images, and at any given time focuses only on one object on the tabletop, such as scissors or a flashlight. Li et al. [4] proposed a method consisting of three stages without the need for new learning: grasp pose prediction, which allows robots to pick up and transfer previously unseen objects. The method first identifies potential structures that can perform a hanging action by analyzing the hanging mechanics and geometric properties. Then, 6D poses are detected for a parallel gripper equipped with extension rods that, when closed, form loops to hook each possible hang structure. Finally, a quality assessment policy ranks the grasp candidates for each attempt. The grasp pose detection problem is performed on fully constructed object point cloud data or mesh data, where the grasping action only considers the object’s handle. The grasping action context only considers one object within an operation, and the object’s data is segmented and fully supplemented.
Regarding the robot’s object grasping, Song et al. [9] conducted a comprehensive review of recent research developments, focusing on learning-based approaches, from two perspectives: Grasp Generation (GG) and Grasp Execution (GE). Specifically, GG refers to the generation of appropriate grasp postures for the target object. GE refers to the execution of grasp postures by motion planning and motion control. Recent benchmark datasets and evaluation metrics are also introduced. Typical RGB-D databases are collected from manipulating five hand objects (FPHAB [10], HO3D [11], DexYCB [12], GRAB [13], H2O [14], …), where DDGData [15], HO3D, YCB-Affordance [16], ContactPose [17], and GRAB databases have hand poses annotated based on hand joints automatically; DexYCB and H2O are databases with hand poses manually labeled with two hands performing the manipulation; DVGG [18] and Oakink [19] are datasets using multi-modal and rich-annotated knowledge repositories; ARCTIC [20], AffordPose [21], Grasp’ D-1M [22], MultiDex [23], DexGraspNet [24], UniDexGrasp [25], DexGraspNet 2.0 [26], S2HGD [27], HIMO [28], and realDex [29] are datasets collected based on language-guided and human-like methods. These databases can be collected from the real environment or synthesized from data generation models. The creation of annotation data for the object pose for holding the object can be done using a MOCAP system or manually. Furthermore, this survey also presents methods for classifying groups of objects based on hand pose for object handling, or regression-based handling methods often applied to objects created from models, as well as generation-based methods, with input data being depth images or point clouds, and additional information on handling posture.
Zhao et al. [30] present the RSPFG-Net method for pixel-level object grasp detection based on the combination of MSRSPF and DeepLab v3. The average grasp detection result is 97.85% on Cornell, Jacquard, and NEU-MGD datasets. RSPFG-Net is capable of grasping the detection of multi-target objects with uncertain shape, pose, scale, and superposition. Object handling assistance is applied to the robotic arm, and the data is applied to RGB-D images; object pose annotation is performed on color images with various object types. Wu et al. [31] proposed a learning-free approach for an autonomous robotic system to grasp, transfer, and re-grasp previously unseen objects. The proposed framework consists of two main components: a novel grasp detector to predict grasp poses directly from the point cloud and a reachability-aware transfer planner to select exchange poses and grasp poses for two robots. The system, based on point cloud data of objects, recovers superquadrics after object optimization, applies pre-prepared grasp synthesis to objects corresponding to each object type, and then selects the best object pose for grasping.
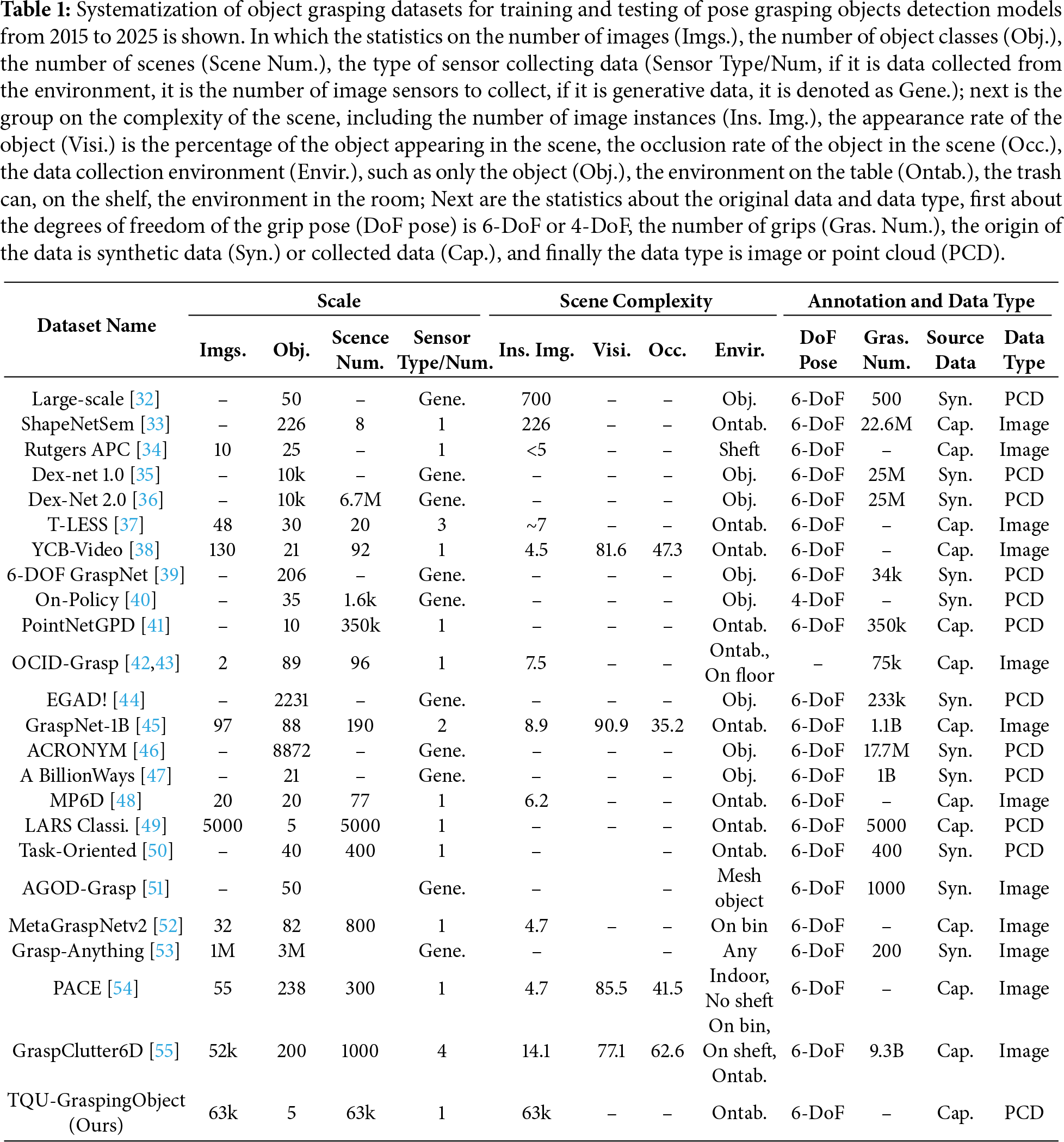
Regarding the datasets for object grasping, systematization of object grasping datasets for training and testing of pose grasping objects detection models from 2015 to 2025 is presented in Table 1. Most of the datasets are built for training and testing models of robot pose grasping detection. Many of them are synthetic datasets generated from 3D CAD software.
The environment in which we collected data was in a shared room at Tan Trao University (TQU). The data collection equipment was set up as follows: a laptop computer (MSI Modern 15 B12MO CPU-i5 1235U 16GB RAM GPU Intel Iris Xe Graphics) was mounted on a backpack worn by a mannequin with a blindfold (as shown in Fig. 3a), The data was collected by a 1.7 m tall male mannequin simulating a visually impaired person. A camera (IR-D435) was mounted on the man’s chest using a mount and connected to the laptop computer via USB. The computer was turned on and had IR-D435 Viewer software installed. The objects placed on the table (a cup, a yogurt, a banana, a milk carton, and an apple) are at a height of 0.8 m, the table surface dimensions are (0.8
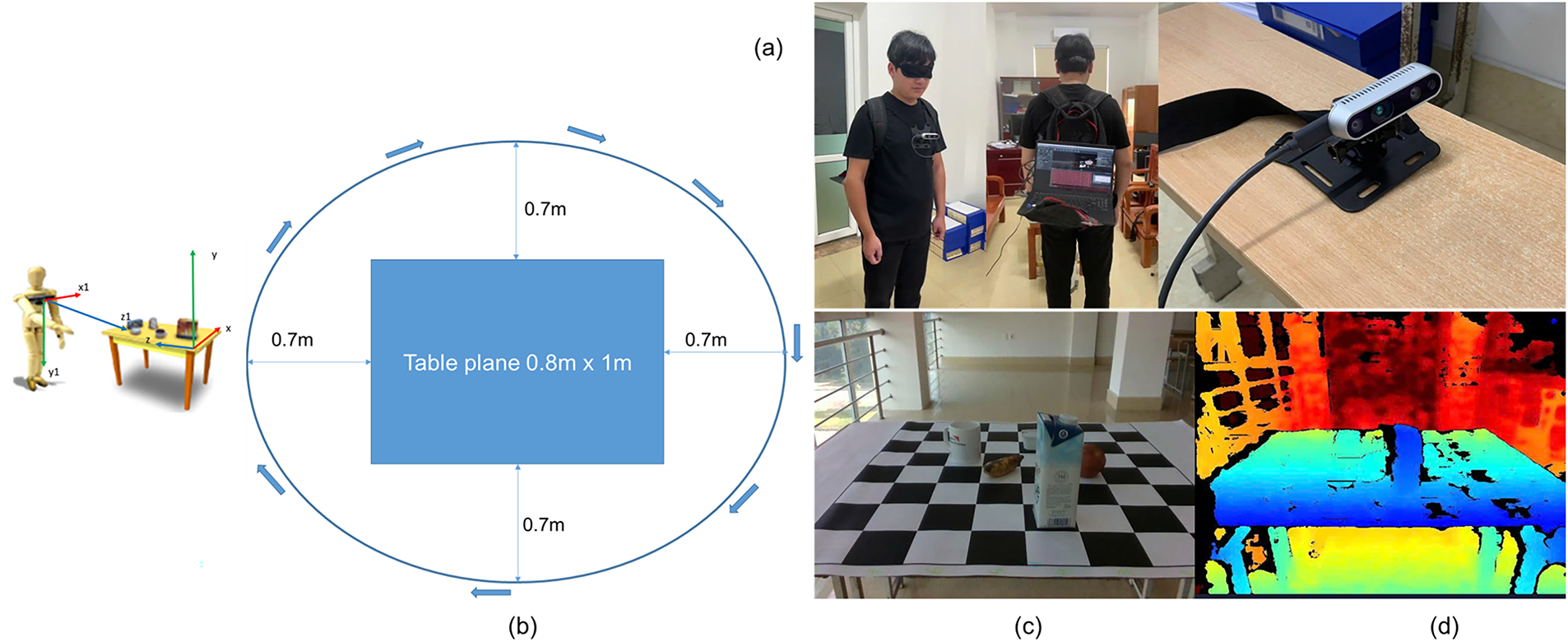
Figure 3: Illustration of device setup and settings for collecting data from the environment. (a) is the environment setup where the objects to be grasped by the blind person are placed on the table, (b) is the setup of the IR-D435 device mounted on the person’s chest and connected to a Laptop for data collection, (c) is an illustration of the RGB image collected from the environment, (d) is an illustration of the depth image collected from the corresponding environment along with the RGB image.
Objects are placed on the table in predetermined positions based on a checkerboard (for example, the apple is in square D7 on the chessboard). First, we plug the IR-D435 camera into the laptop and start the IR-D435 Viewer software, and adjust the parameters on it to start recording. Second, start recording with a simulated visually impaired person 360 degrees around the chessboard, each video will be recorded for about 3 min. Third, after finishing recording 1 video, we will start shuffling the objects on the chessboard and so on until the 10-th video. The data collected is 10 short videos, the video size is
The RGB and point cloud data of the scene captured from the environment, and RGB and point cloud data of objects on the tabletop are presented in Fig. 4.

Figure 4: Illustration the RGB and point cloud data of the scene captured from the environment, and the RGB and point cloud data of objects on the tabletop.
To perform object box annotation and object labeling using the labelImg software1, each object is represented by a rectangle (x1, y1, x2, y2) as shown in Fig. 5a.

Figure 5: Illustrating the process of creating object box annotations and marking points for constructing the coordinate system transformation matrix. (a) the process of box marking and labeling each object, and (b) highlighting important points on the RGB image, (c) presenting the coordinates of 4 marked points on the point cloud data.
To standardize the coordinate system on the tabletop, we built a toolkit in Python language to mark 4 points on the RGB image as shown in Fig. 5b, then these 4 points are converted to the corresponding point cloud data as shown in Fig. 5c. The points in Fig. 5b have coordinates on the chessboard respectively: 1 red point (40, 0, 20), 2 green points (50, 0, 20), 3 blue points (50, 0, 10), 4 yellow points (40, 0, 10) with the origin of the coordinates on the left corner of the chessboard and the
3.2.2 Original Coordinate System Transformation
To perform the transformation process, we need to transform the coordinate system from the center of IR-D435 to the coordinate system located on the tabletop in 3D space, as illustrated in Fig. 3b, with each frame/scene obtained from the image sensor, we need to find a rotation and translation matrix between these two positions. We combine the findings of the rotation matrix (R consists of 3 rows and 3 columns) and the translation matrix (T consists of 3 rows and 1 column) into a process, this process is called matrix transformation (including 4 rows and 4 columns). The rotation and translation matrices are represented in the 3D space [56] as Eq. (1) (left).
where
From the coordinates of the points in the table plane in the 3D-space, the number of points that need to be converted to the coordinate system includes
In particular, the rotation matrix and translation according to the
Let us assume that
where
The estimation of
3.3 RGB-D and 3D Point Cloud Object Benchmarks for Grasping
Fig. 2 illustrates the entire process of collecting, building, and publishing the TQU-GraspingObject dataset.
In which the data we publish includes RGB and depth image data, based on this pair of data, point cloud data is generated based on the camera’s internal parameter set according to the Formula (4).
where given a pixel coordinate
Based on the manual marking of the box of each object on the color image, we publish the object box annotation and label annotation in each frame. Based on the marked box of each object, we determine the point cloud data of each object/segmented data, as shown in Fig. 6.
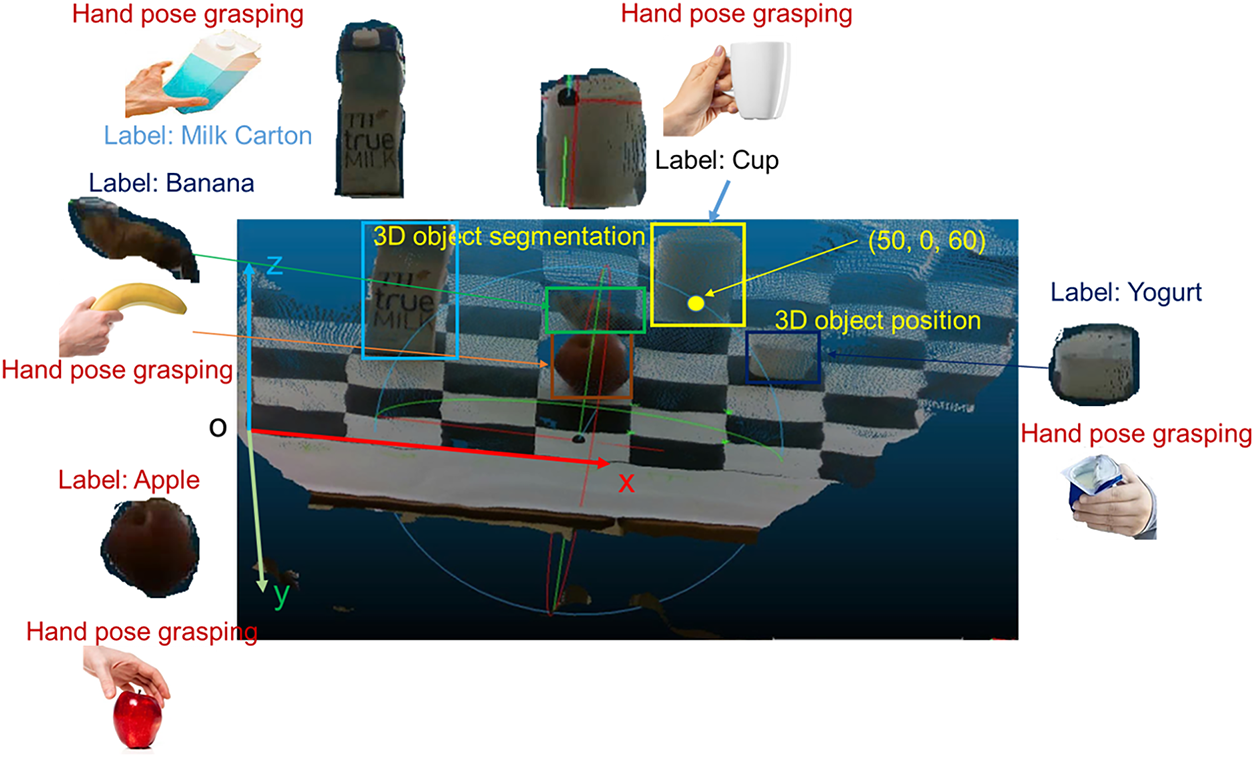
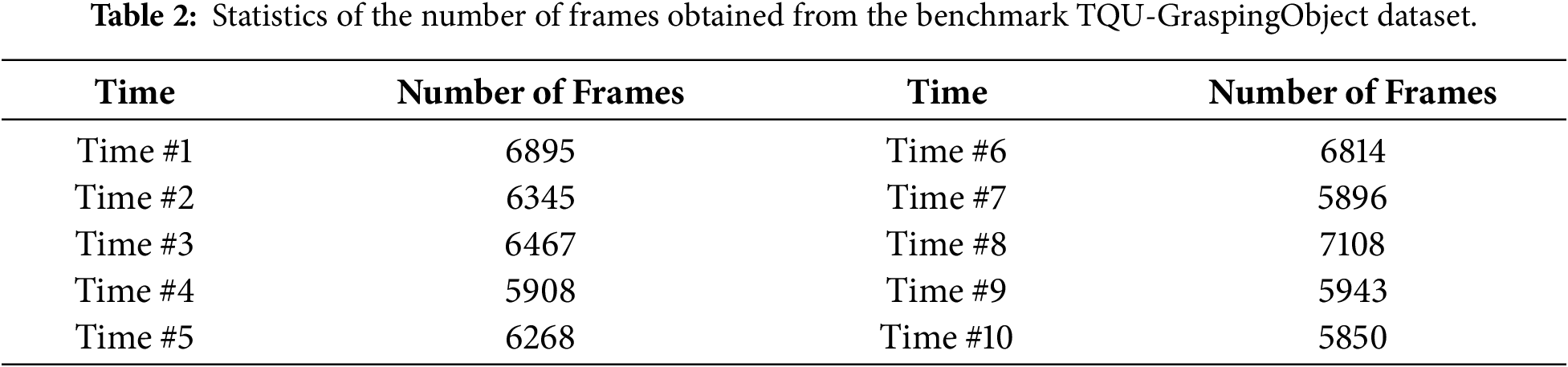
Figure 6: Illustrate segmented point cloud data, object labels, hand pose grasping, and 3D object position on the tabletop.
Based on the manual marking of 4 points on the table plane of the RGB image, we publish the data of 4 marked points, each point has coordinates
Based on the object box annotation, we use the Formula (4) to convert image data into point cloud data, and the matrix according to the Formula (3) (right) to move the coordinate system to the table, we publish the point cloud data of the objects, that is, 3D object segmented, 3D object position. The entire published data of the TQU-GraspingObject dataset is used for evaluating models, methods applying DL for detection, classification/recognition both in 2D space (classification/recognition on images) and 3D (classification/recognition on 3D point cloud data), building object grasping information for human hands based on information about location, size, shape, grasping position according to CV methods.
4 Object Detection and Recognition
To solve the problem of searching and grasping objects on the table for the visually impaired, especially in new environments with many changes, the problem of detecting and recognizing the objects to be searched and grasped is the first problem that needs to be solved. At the same time, this needs to be done quickly and accurately. Currently, with the strong development of DL, DL also brings impressive results to solve CV problems, such as detecting, recognizing, classifying, and segmenting objects. Therefore, in this article, we apply the two most effective approaches today to solving the problem of detecting and recognizing objects in CV, which are CNN-based and transformer-based.
4.1 DL Method for Object Detection and Recognition
In this paper, the data collected from the environment through the IR-D435 are RGB-D images. At the same time, detecting and recognizing objects on color images has the highest computational time cost and performance. Currently, CNN-based and transformer-based approaches are two approaches that give high results in detecting and recognizing objects on color images. In this paper, we apply four models for detecting and recognizing objects on RGB images, specifically as follows.
YOLO-Based: YOLOv12 [58] is a recent improvement of YOLO for object detection and recognition. The architecture of YOLOv11 is also divided into three modules: backbone, neck, and head. The backbone of YOLOv12 is designed to combine the advantages of ELAN into R-ELAN with an area attention mechanism, with ELAN blocks evolved from YOLOv7. R-ELAN is an improved feature pooling module based on ELAN, designed to solve optimization challenges, especially in larger-scale attention-focused models. R-ELAN introduces block-level residual connections with scale (similar to layer scale) and a redesigned feature pooling method, creating a bottleneck-like structure. R-ELAN is built to extract rich contextual features while keeping the computational cost low. Instead of using pure conv, YOLOv12 uses an optimized form of area-based attention (based on FlashAttention) to capture spatial interactions efficiently—allowing for modeling long/horizontal correlations between locations without too much speed loss. Eliminate location encoding for a cleaner and faster model. Adjust the MLP ratio (from the typical 4 to 1.2 or 2) to better balance the computation between attention and feed-forward layers. Reduce the depth of the stacked blocks for better optimization. Leverage convolutions (where appropriate) for computational efficiency. This is a key difference from previous pure CNN versions of YOLO. To expand the receptive field with low computational cost, paper/BREAKDOWN mentions using a large but separable convolution (depthwise + pointwise) with size
In Neck, YOLOv12 still uses the multi-scale feature fusion mechanism (like FPN/PAN, like previous YOLO versions), but adds attention to enrich and adjust the information flow between levels (improve fusion). Thereby keeping the advantage of detecting objects with many scales (small/medium/large objects) while increasing the representation.
In Head, YOLOv12 outputs bounding box/class prediction in one forward pass, like previous versions of YOLO. Head is designed to take advantage of the attention-enriched feature from the neck; YOLOv12 has many levels (e.g., YOLOv12-N, YOLOv12-S, …) to balance accuracy/speed.
SSD-MobileNet-Based: is a combination of SSD (Single Shot MultiBox Detector) [59] for object detection in images, and MobileNet for object recognition in images based on bounding boxes predicted by SSD.
SSD networks usually have backbones of VGG16 or ResNet, MobileNet… to extract initial features, with feature maps of decreasing resolution such as conv4_3, conv7, conv8_2, conv9_2, … SSD utilizes multiple feature layers with different sizes to detect objects at many sizes, with small sizes from high-resolution feature maps, with large sizes from low-resolution feature maps. At each cell of each feature map, SSD assigns a set of default boxes with different aspect ratios and scales. Each default box is used as a “reference frame” for the network to predict offsets (box regression) and classify (confidence). On each feature map, SSD uses small convolution filters (e.g.,
Currently, MobileNetV3 is the latest version, so we use MobileNetV3 for object recognition. MobileNetV3 [60] was developed to reduce the large number of parameters in previous DL models by using a mechanism called Depthwise Separable. With regular convolutional, suppose our input is a
CNN-Transformer-Based: In this paper, we employ a hybrid model that combines ResNet [61] and DETR [62], a powerful CNN backbone integrated into DETR (Detection Transformer), to create a modern object detection model that leverages both CNN and Transformers, as illustrated in Fig. 7.
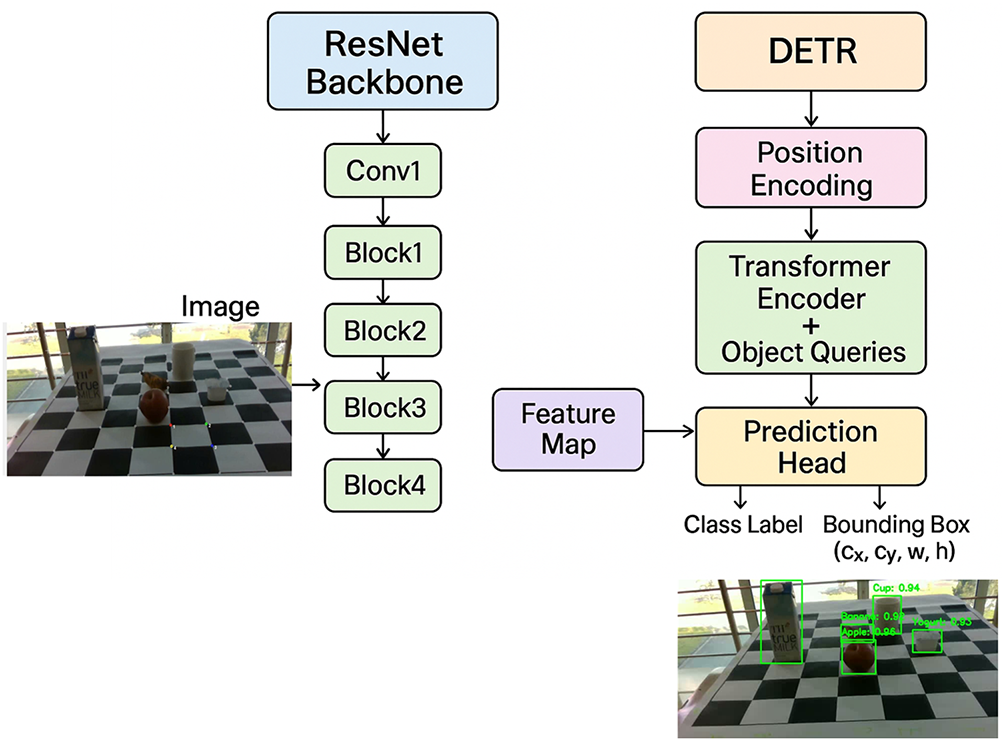
Figure 7: Illustration of the combined architecture of ResNet and DETR for object detection and recognition.
In which ResNet is used as the backbone to extract spatial features from images. The advantage is that it uses the Residual Connection mechanism (skip connection) with the objective function
The output of ResNet is a feature tensor of size [B, C,
In which DETR has no concept of the spatial position of the object, so it is necessary to add 2D position codes to the feature map extracted after ResNet, with the commonly used mechanism being sine–cosine positional encoding or learnable embeddings.
This helps queries learn to divide responsibilities among themselves (query 1 is apple, query 2 is cup, query 3 is cup) to avoid duplication in object detection. Next is the most important step of the Decoder is to perform cross-attention between queries and encoder output to predict different objects. With the Query mechanism is the person asking in the image, Where is my object? The Encoder output is the encoded image scene to provide information.
DETR usually has 6 decoder layers. In which the output of the previous layer is the input of the next layer, which makes the feature more and more “accurate” for each object. Finally, the output prediction, each query after the last decoder layer is passed through 2 branches of MLP, the first is the classification head: Predicting class label (object class or “no object”), and the second is the Bounding Box Head, which predicts bounding box (cx, cy, w, h). Where each query corresponds to an object prediction.
4.2 Experimental Design and Measurement
In this paper, to train the object detection and recognition model, we divide the TQU-GraspingObject dataset with two strategies as follows: first is to randomly divide according to the ratios % of the training/validation/testing data as follows: 50/25/25, 60/20/20, 70/15/15, 80/10/10, all ratios are divided randomly. The second is divided according to the K-Fold Cross-Validation strategy, with
Figure 8: Illustration of K-Fold Cross-Validation data splitting strategy, with
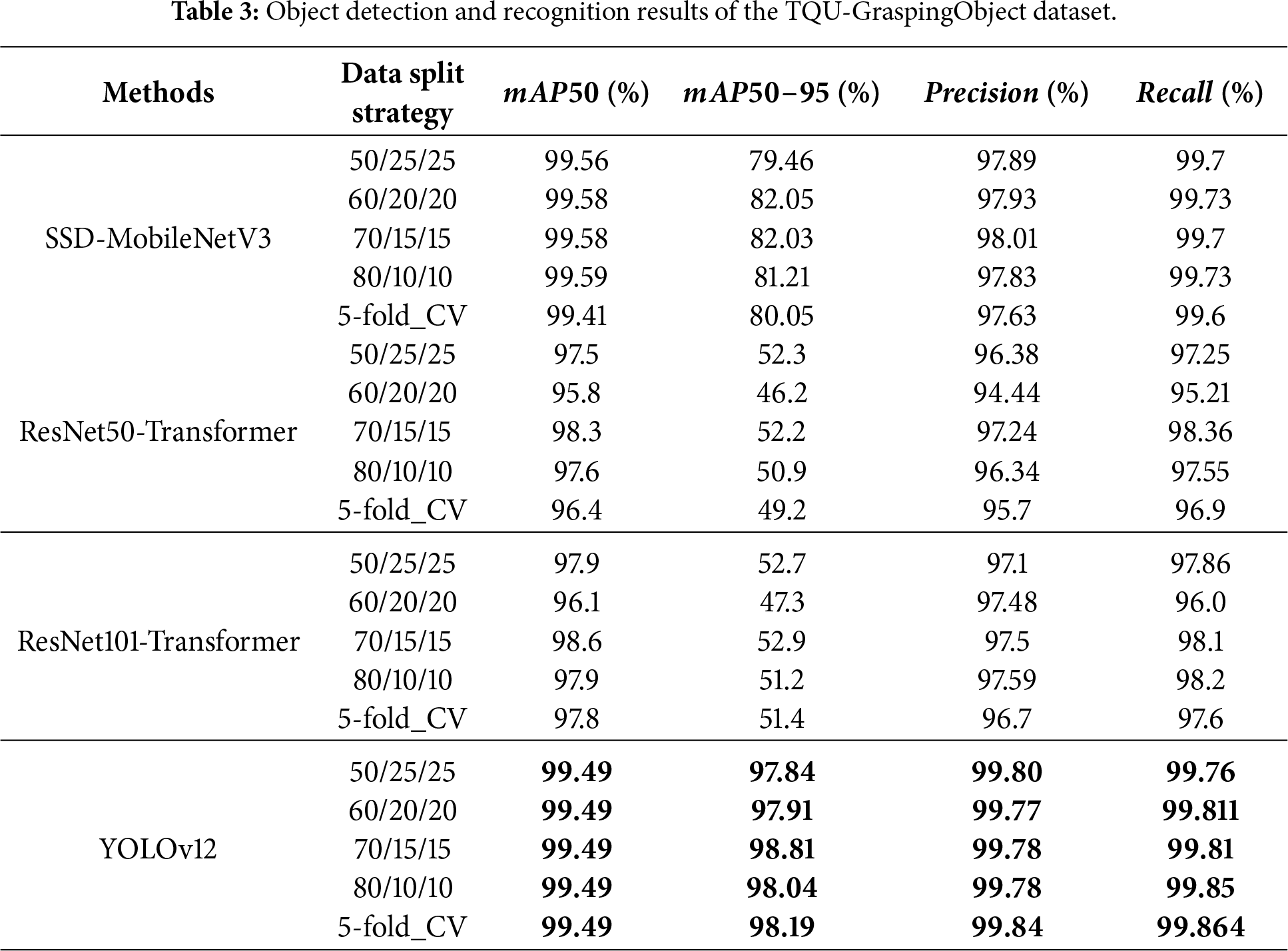
In this paper, we train and test object detection and recognition models on the tabletop with the methods and the source code we inherited uses: SSD-MobileNetV32, ResNet50-Transformer3, ResNet101-Transformer4, YOLOv125. In many variations of YOLOv12, we use YOLOv12n. Table 4 shows the parameter sets of the models in training, validation, and testing the object detection and recognition models.
In this paper, we evaluate the object detection and recognition results with metrics such as
In which, N is the number of classes,
mAP50:95 averaged across
4.3 Results, Discussions and Challenges
The results of object detection and recognition are shown in Table 3. The results in Table 3 show that YOLOv12 has the highest results; the results based on
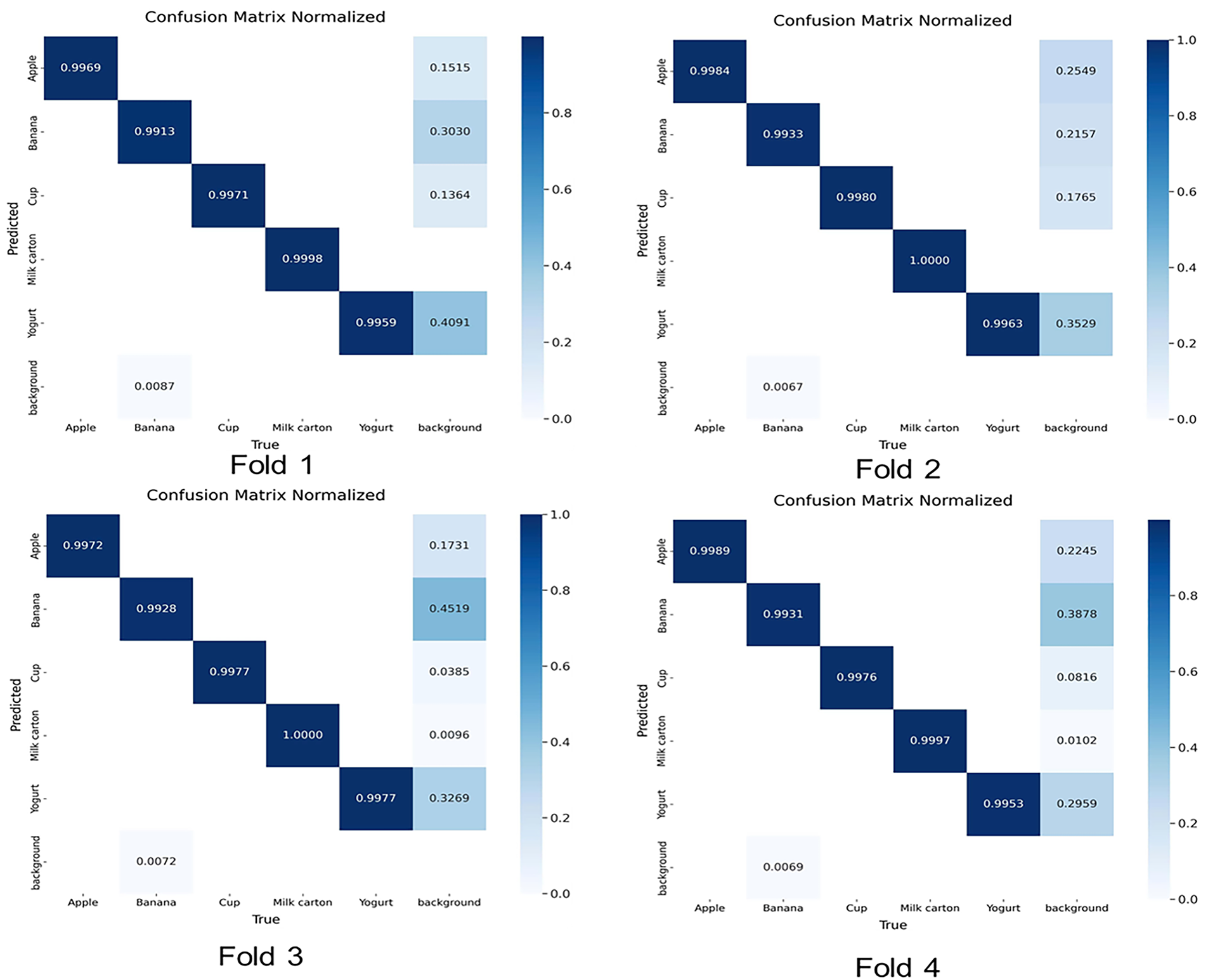
Figure 9: Confusion matrix of YOLOv12-based object detection and recognition model of Fold 1, Fold 2, Fold 3, and Fold 4 when evaluated on the measure Precision.
Fig. 10 illustrates the results of detecting and recognizing objects on the table with labels and confidence index of prediction based on YOLOv12; each object is bounded by a bounding box. The results of YOLOv12 show that the ratio of bounding box is very close to the size of the object, and the confidence index of prediction is very high.

Figure 10: Illustration of the results of object detection and recognition on a tabletop with labels and
Table 5 presents the processing time of object detection and recognition using the SSD-MobileNetV3, ResNet50-Transformer, ResNet101-Transformer, and YOLOv12 models on the TQU-GraspingObject dataset. Similar to the model parameter settings reported in Table 4, the results indicate that YOLOv12 achieves the fastest processing speed, reaching 42.82 frames/s. This performance is obtained when computations are conducted on a GPU with the configuration described in Section 4.2. In contrast, the ResNet101-Transformer model exhibits the lowest processing speed, at only 1.937 frames/s. Thus, based on the results presented in Tables 3 and 5, YOLOv12 demonstrates both the highest detection accuracy and the fastest computational speed. Furthermore, YOLOv12 is capable of operating on a CPU at a speed of 7.8 frames/s. Therefore, YOLOv12 is a suitable choice for developing a system to assist visually impaired individuals in grasping five objects placed on a table, which is the long-term objective of this research.

Although there are good results in detecting and recognizing objects on RGB images, there are still many challenges on the point cloud data of the objects. Fig. 11 shows the point cloud data of the object when rotated in four directions, the point cloud data of the objects is the surface of the objects, the point cloud data still has many points from other data areas (noisy data), to separate the data of the object, it is necessary to perform the point cloud segmentation process.
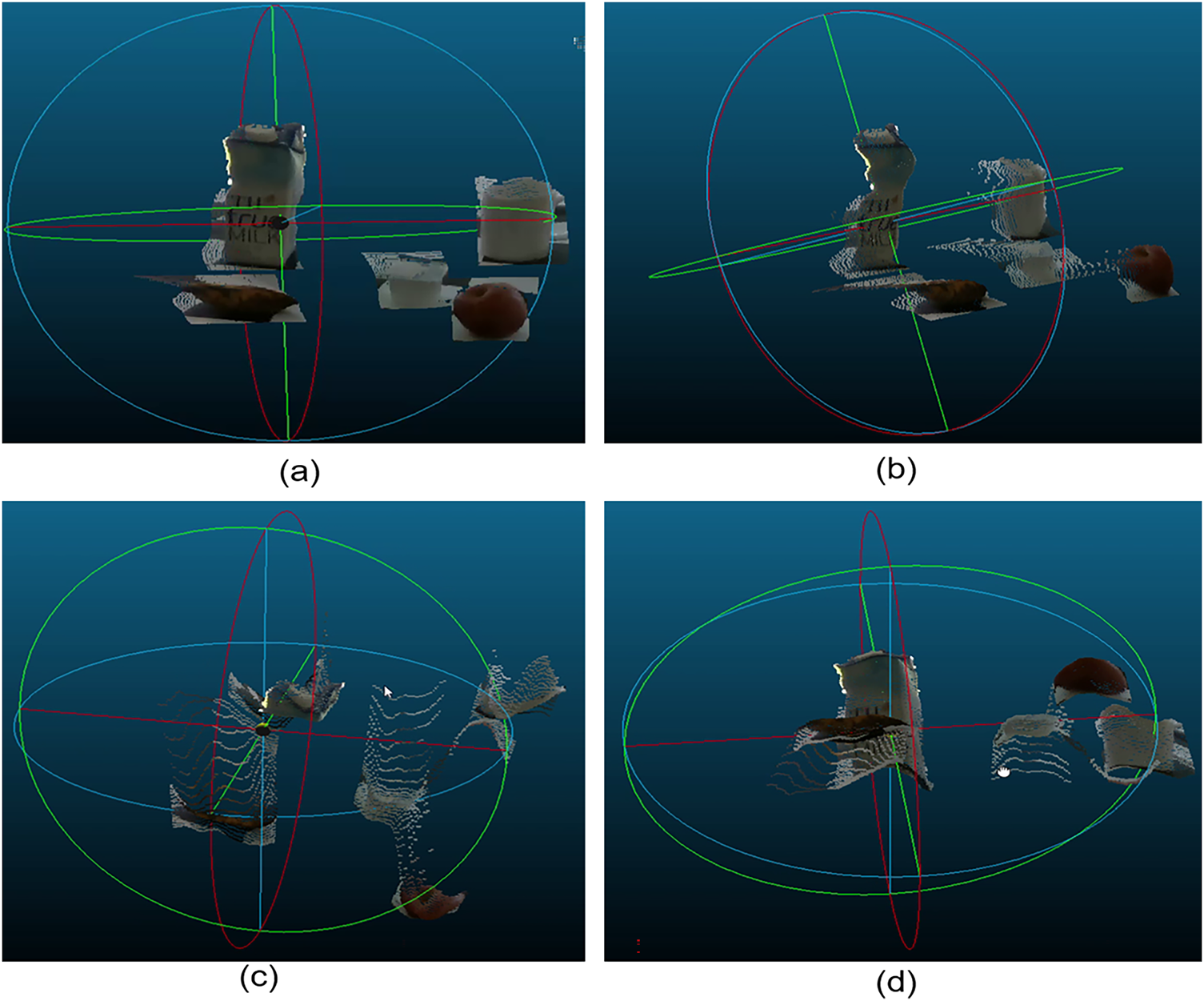
Figure 11: Illustration of rotating 3D point cloud data of objects on the tabletop in four directions. (a) is the color point cloud data from the image sensor’s viewing direction; the object’s surface accurately reflects the object’s color and shape. (b) is the color point cloud data from a viewing direction rotated to the right; only one corner of the object is visible, and the point cloud data is heavily influenced by the table surface. (c) is the color point cloud data from a top-down viewing direction; the point cloud data is only present on the front of the object, while the hidden parts are empty. (d) is the color point cloud data from a bottom-up viewing direction; the point cloud data is only present on the visible part of the object.
In the TQU-GraspingObject dataset benchmark, the image size is
5 Conclusions and Future Works
In this study, we introduce the benchmark TQU-GraspingObject dataset, including more than 63k RGB-D images, annotation object box, annotation label, coordinate system transformation matrix from camera to table, 3D annotation object position on the table, and hand types for grasping objects on the table. Data is collected in the indoor environment with common objects in the dining room, kitchen, such as an apple, a cup, a milk carton, a banana, and a yogurt. We also train and build a model to detect and recognize objects on the table, in which YOLOv12 is the most suitable method in the process of building a system to guide and assist in grasping objects. We believe that the published benchmark TQU-GraspingObject will be a good source of data for evaluating and testing machine learning and DL models for searching and grasping objects in real-life environments for blind people.
In the future, we will conduct research on applying the 3D CAD model to point cloud data of objects on the table to perform 3D object reconstruction [69] for 3D object detection, 3D object classification, and 3D object recognition [64]. We will also perform superquadric recovery of objects on the table and build grasp synthesis for objects to evaluate grasping objects [31]. Another new research direction is to add objects such as cups, yogurt, bananas, milk cartons, and apples to ShapeNet models for fine-tuning DL models for 3D object representation, 3D object reconstruction, and 3D object segmentation. Another important task for supporting object handling on the table is evaluating the accuracy of object positioning on the table after performing 3D object reconstruction, 3D object segmentation, 3D object recognition, and several methods for constructing object handling information on the tabletop.
However, in reality, data obtained from the environment using RGB-D sensors contains many errors and noise; therefore, point cloud data also contains many errors and noise, and sometimes data is lost. In particular, the real-world environment is subject to many disturbances and changes, making it difficult for trained models to adapt quickly to changes in the environment and objects. Therefore, for systems assisting the visually impaired and robots for object handling to function effectively, further research is needed to supplement learning data and more complex environments in the future.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: Study conception and design: Thi-Loan Nguyen, Huy-Nam Chu, The-Thanh Hua, Van-Hung Le; data collection: Huy-Nam Chu, The-Thanh Hua; analysis and interpretation of results: Trung-Nghia Phung; draft manuscript preparation: Thi-Loan Nguyen, Van-Hung Le; model optimization: Van-Hung Le; visual validation and perceptual metric analysis: Thi-Loan Nguyen; academic norm checking: Van-Hung Le. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, Van-Hung Le, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
1https://sourceforge.net/projects/labelimg.mirror/files/latest/download
2https://www.kaggle.com/code/joker2377/pytorch-mobilenetv3-ssd-practice (accessed 05 October 2025)
3https://github.com/sovit-123/vision_transformers (accessed 05 October 2025)
4https://github.com/sovit-123/vision_transformers (accessed 05 October 2025)
5https://github.com/sunsmarterjie/yolov12 (accessed 05 October 2025)
References
1. Avacharmal R, Pamulaparthyvenkata S, Pandiya DK, Krishna Prakash R, Ranjan P, Balakrishnan A, et al. Comprehensive investigation on deep learning models: applications, advantages, and challenges. In: 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT); 2024 Jun 24–28; Kamand, India. p. 1–6. doi:10.1109/ICCCNT61001.2024.10723970. [Google Scholar] [CrossRef]
2. Li Y. Learning to detect grasp affordances of 3D objects using deep convolutional neural networks [dissertation]. Groningen, The Netherlands: University of Groningen; 2019. [Google Scholar]
3. Zhou Z, Li L, Frsterling A, Durocher HJ, Mouridsen J, Zhang X. Learning-based object detection and localization for a mobile robot manipulator in SME production. Robot Comput Integr Manuf. 2022;73(11):102229. doi:10.1016/j.rcim.2021.102229. [Google Scholar] [CrossRef]
4. Li W, Su W, Chirikjian GS. Grasping by hanging: a learning-free grasping detection method for previously unseen objects. arXiv:2408.06734. 2024. [Google Scholar]
5. Bergamini L, Sposato M, Pellicciari M, Peruzzini M, Calderara S, Schmidt J. Deep learning-based method for vision-guided robotic grasping of unknown objects. Adv Eng Inform. 2020;44:101052. doi:10.1016/j.aei.2020.101052. [Google Scholar] [CrossRef]
6. Xie Z, Liang X, Roberto C. Learning-based robotic grasping: a review. Front Robot AI. 2023;10:1038658. doi:10.3389/frobt.2023.1038658. [Google Scholar] [PubMed] [CrossRef]
7. Jahanshahi H, Zhu ZH. Review of machine learning in robotic grasping control in space application. Acta Astronaut. 2024;220:37–61. doi:10.1016/j.actaastro.2024.04.012. [Google Scholar] [CrossRef]
8. Huang C, Pang Z, Xu J. Detection method of manipulator grasp pose based on RGB-D image. Neural Process Lett. 2024;56(4):211. doi:10.1007/s11063-024-11662-5. [Google Scholar] [CrossRef]
9. Song X, Li Y, Zhang Y, Liu Y, Jiang L. An overview of learning-based dexterous grasping: recent advances and future directions. Artif Intell Rev. 2025;58(10):300. doi:10.1007/s10462-025-11262-2. [Google Scholar] [CrossRef]
10. Garcia-Hernando G, Yuan S, Baek S, Kim TK. First-person hand action benchmark with RGB-D videos and 3D hand pose annotations. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA. p. 409–19. doi:10.1109/CVPR.2018.00050. [Google Scholar] [CrossRef]
11. Hampali S, Rad M, Oberweger M, Lepetit V. HOnnotate: a method for 3D annotation of hand and object poses. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 3193–203. doi:10.1109/cvpr42600.2020.00326. [Google Scholar] [CrossRef]
12. Chao YW, Yang W, Xiang Y, Molchanov P, Handa A, Tremblay J, et al. DexYCB: a benchmark for capturing hand grasping of objects. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 9040–9. doi:10.1109/cvpr46437.2021.00893. [Google Scholar] [CrossRef]
13. Taheri O, Ghorbani N, Black MJ, Tzionas D. GRAB: a dataset of whole-body human grasping of objects. arXiv:2008.11200. 2020. [Google Scholar]
14. Kwon T, Tekin B, Stühmer J, Bogo F, Pollefeys M. H2O: two hands manipulating objects for first person interaction recognition. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada. p. 10118–28. doi:10.1109/ICCV48922.2021.00998. [Google Scholar] [CrossRef]
15. Liu M, Pan Z, Xu K, Ganguly K, Manocha D. Deep differentiable grasp planner for high-DOF grippers. arXiv:2002.01530. 2020. [Google Scholar]
16. Corona E, Pumarola A, Alenya G, Moreno-Noguer F, Rogez G. GanHand: predicting human grasp affordances in multi-object scenes. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 5030–40. doi:10.1109/cvpr42600.2020.00508. [Google Scholar] [CrossRef]
17. Brahmbhatt S, Ham C, Kemp CC, Hays J. ContactDB: analyzing and predicting grasp contact via thermal imaging. arXiv:1904.06830. 2019. [Google Scholar]
18. Wei W, Li D, Wang P, Li Y, Li W, Luo Y, et al. DVGG: deep variational grasp generation for dextrous manipulation. arXiv:2211.11154. 2022. [Google Scholar]
19. Yang L, Li K, Zhan X, Wu F, Xu A, Liu L, et al. OakInk: a large-scale knowledge repository for understanding hand-object interaction. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18–24; New Orleans, LA, USA. p. 20921–30. doi:10.1109/CVPR52688.2022.02028. [Google Scholar] [CrossRef]
20. Fan Z, Taheri O, Tzionas D, Kocabas M, Kaufmann M, Black MJ, et al. ARCTIC: a dataset for dexterous bimanual hand-object manipulation. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 12943–54. doi:10.1109/CVPR52729.2023.01244. [Google Scholar] [CrossRef]
21. Jian J, Liu X, Li M, Hu R, Liu J. AffordPose: a large-scale dataset of hand-object interactions with affordance-driven hand pose. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023 Oct 1–6; Paris, France. p. 14667–78. doi:10.1109/ICCV51070.2023.01352. [Google Scholar] [CrossRef]
22. Turpin D, Zhong T, Zhang S, Zhu G, Heiden E, Macklin M, et al. Fast-Grasp’D: dexterous multi-finger grasp generation through differentiable simulation. In: 2023 IEEE International Conference on Robotics and Automation (ICRA); 2023 May 29–Jun 2; London, UK. p. 8082–9. doi:10.1109/icra48891.2023.10160314. [Google Scholar] [CrossRef]
23. Li P, Liu T, Li Y, Geng Y, Zhu Y, Yang Y, et al. GenDexGrasp: generalizable dexterous grasping. arXiv:2210.00722. 2022. [Google Scholar]
24. Wang R, Zhang J, Chen J, Xu Y, Li P, Liu T, et al. DexGraspNet: a large-scale robotic dexterous grasp dataset for general objects based on simulation. arXiv:2210.02697. 2022. [Google Scholar]
25. Xu Y, Wan W, Zhang J, Liu H, Shan Z, Shen H, et al. UniDexGrasp: universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. arXiv:2303.00938. 2023. [Google Scholar]
26. Wan W, Geng H, Liu Y, Shan Z, Yang Y, Yi L, et al. UniDexGrasp++: improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist-specialist learning. arXiv:2304.00464. 2023. [Google Scholar]
27. Wang YK, Xing C, Wei YL, Wu XM, Zheng WS. Single-view scene point cloud human grasp generation. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024 Jun 16–22; Seattle, WA, USA. p. 831–41. [Google Scholar]
28. Lv X, Xu L, Yan Y, Jin X, Xu C, Wu S, et al. HIMO: a new benchmark for full-body human interacting with multiple objects. arXiv:2407.12371. 2025. [Google Scholar]
29. Liu Y, Yang Y, Wang Y, Wu X, Wang J, Yao Y, et al. RealDex: towards human-like grasping for robotic dexterous hand. arXiv:2402.13853. 2024. [Google Scholar]
30. Zhao B, Chang L, Wu C, Liu Z. Robot multi-target high performance grasping detection based on random sub-path fusion. Sci Rep. 2025;15(1):8709. doi:10.1038/s41598-025-93490-8. [Google Scholar] [PubMed] [CrossRef]
31. Wu Y, Li W, Liu Z, Liu W, Chirikjian GS. Autonomous learning-free grasping and robot-to-robot handover of unknown objects. Auton Rob. 2025;49(3):18. doi:10.1007/s10514-025-10201-y. [Google Scholar] [CrossRef]
32. Kappler D, Bohg J, Schaal S. Leveraging big data for grasp planning. In: 2015 IEEE International Conference on Robotics and Automation (ICRA); 2015 May 26–30; Seattle, WA, USA. p. 4304–11. doi:10.1109/ICRA.2015.7139793. [Google Scholar] [CrossRef]
33. Savva M, Chang AX, Hanrahan P. Semantically-enriched 3D models for common-sense knowledge. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2015 Jun 7–12; Boston, MA, USA. p. 24–31. doi:10.1109/CVPRW.2015.7301289. [Google Scholar] [CrossRef]
34. Rennie C, Shome R, Bekris KE, de Souza AF. A dataset for improved RGBD-based object detection and pose estimation for warehouse pick-and-place. IEEE Robot Autom Lett. 2016;1(2):1179–85. doi:10.1109/LRA.2016.2532924. [Google Scholar] [CrossRef]
35. Mahler J, Pokorny FT, Hou B, Roderick M, Laskey M, Aubry M, et al. Dex-Net 1.0: a cloud-based network of 3D objects for robust grasp planning using a multi-armed bandit model with correlated rewards. In: 2016 IEEE International Conference on Robotics and Automation (ICRA); 2016 May 16–21; Stockholm, Sweden. p. 1957–64. doi:10.1109/ICRA.2016.7487342. [Google Scholar] [CrossRef]
36. Mahler J, Liang J, Niyaz S, Laskey M, Doan R, Liu X, et al. Dex-net 2.0: deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. In: Robotics: science and systems XIII. Cambridge, MA, USA: MIT Press; 2017. doi:10.15607/rss.2017.xiii.058. [Google Scholar] [CrossRef]
37. Hodan T, Haluza P, Obdrlek, Matas J, Lourakis M, Zabulis X. T-LESS: an RGB-D dataset for 6D pose estimation of texture-less objects. In: 2017 IEEE Winter Conference on Applications of Computer Vision (WACV); 2017 Mar 24–31; Santa Rosa, CA, USA. p. 880–8. doi:10.1109/WACV.2017.103. [Google Scholar] [CrossRef]
38. Xiang Y, Schmidt T, Narayanan V, Fox D. PoseCNN: a convolutional neural network for 6D object pose estimation in cluttered scenes. In: Robotics: science and systems XIV. Cambridge, MA, USA: MIT Press; 2018. doi:10.15607/rss.2018.xiv.019. [Google Scholar] [CrossRef]
39. Mousavian A, Eppner C, Fox D. 6-DOF GraspNet: variational grasp generation for object manipulation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 2901–10. doi:10.1109/iccv.2019.00299. [Google Scholar] [CrossRef]
40. Satish V, Mahler J, Goldberg K. On-policy dataset synthesis for learning robot grasping policies using fully convolutional deep networks. IEEE Robot Autom Lett. 2019;4(2):1357–64. doi:10.1109/LRA.2019.2895878. [Google Scholar] [CrossRef]
41. Liang H, Ma X, Li S, Gorner M, Tang S, Fang B, et al. PointNetGPD: detecting grasp configurations from point sets. In: 2019 International Conference on Robotics and Automation (ICRA); 2019 May 20–24; Montreal, QC, Canada. p. 3629–35. doi:10.1109/icra.2019.8794435. [Google Scholar] [CrossRef]
42. Suchi M, Patten T, Fischinger D, Vincze M. EasyLabel: a semi-automatic pixel-wise object annotation tool for creating robotic RGB-D datasets. In: 2019 International Conference on Robotics and Automation (ICRA); 2019 May 20–24; Montreal, QC, Canada. p. 6678–84. doi:10.1109/icra.2019.8793917. [Google Scholar] [CrossRef]
43. Ainetter S, Fraundorfer F. End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from RGB. In: 2021 IEEE International Conference on Robotics and Automation (ICRA); 2021 May 30–Jun 5; Xi’an, China. p. 13452–8. doi:10.1109/icra48506.2021.9561398. [Google Scholar] [CrossRef]
44. Morrison D, Corke P, Leitner J. EGAD! an evolved grasping analysis dataset for diversity and reproducibility in robotic manipulation. IEEE Robot Autom Lett. 2020;5(3):4368–75. doi:10.1109/LRA.2020.2992195. [Google Scholar] [CrossRef]
45. Fang HS, Wang C, Gou M, Lu C. GraspNet-1Billion: a large-scale benchmark for general object grasping. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 11441–50. doi:10.1109/cvpr42600.2020.01146. [Google Scholar] [CrossRef]
46. Eppner C, Mousavian A, Fox D. ACRONYM: a large-scale grasp dataset based on simulation. In: 2021 IEEE International Conference on Robotics and Automation (ICRA); 2021 May 30–Jun 5; Xi’an, China. p. 6222–7. doi:10.1109/icra48506.2021.9560844. [Google Scholar] [CrossRef]
47. Eppner C, Mousavian A, Fox D. A billion ways to grasp: an evaluation of grasp sampling schemes on a dense, physics-based grasp data set. In: Robotics research. Cham, Switzerland: Springer International Publishing; 2022. p. 890–905. doi:10.1007/978-3-030-95459-8_55. [Google Scholar] [CrossRef]
48. Chen L, Yang H, Wu C, Wu S. MP6D: an RGB-D dataset for metal parts’ 6D pose estimation. IEEE Robot Autom Lett. 2022;7(3):5912–9. doi:10.1109/LRA.2022.3154807. [Google Scholar] [CrossRef]
49. de Oliveira DM, Conceicao AGS. A fast 6DOF visual selective grasping system using point clouds. Machines. 2023;11(5):540. doi:10.3390/machines11050540. [Google Scholar] [CrossRef]
50. Patankar A, Phi K, Mahalingam D, Chakraborty N, Ramakrishnan I. Task-oriented grasping with point cloud representation of objects. In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Detroit, MI, USA: IEEE; 2023. p. 6853–60. doi:10.1109/IROS55552.2023.10342318. [Google Scholar] [CrossRef]
51. Andries M, Fleytoux Y, Ivaldi S, Mouret JB, Mouret JB. AGOD-grasp: an automatically generated object dataset for benchmarking and training robotic grasping algorithms [Internet]. 2023. [cited 2026 Jan 1]. Available from: https://inria.hal.science/hal-03983079/document. [Google Scholar]
52. Gilles M, Chen Y, Zeng EZ, Wu Y, Furmans K, Wong A, et al. MetaGraspNetV2: all-in-one dataset enabling fast and reliable robotic Bin picking via object relationship reasoning and dexterous grasping. IEEE Trans Autom Sci Eng. 2024;21(3):2302–20. doi:10.1109/TASE.2023.3328964. [Google Scholar] [CrossRef]
53. Vuong AD, Vu MN, Le H, Huang B, Binh HTT, Vo T, et al. Grasp-anything: large-scale grasp dataset from foundation models. In: 2024 IEEE International Conference on Robotics and Automation (ICRA); 2024 May 13–17; Yokohama, Japan. p. 14030–7. doi:10.1109/ICRA57147.2024.10611277. [Google Scholar] [CrossRef]
54. You Y, Xiong K, Yang Z, Huang Z, Zhou J, Shi R, et al. PACE: a large-scale dataset withpose annotations inCluttered environments. In: Computer vision–ECCV 2024. Cham, Switzerland: Springer; 2025. p. 473–89. doi:10.1007/978-3-031-72983-6_27. [Google Scholar] [CrossRef]
55. Back S, Lee J, Kim K, Rho H, Lee G, Kang R, et al. GraspClutter6D: a large-scale real-world dataset for robust perception and grasping in cluttered scenes. IEEE Robot Autom Lett. 2025;10(10):10498–505. doi:10.1109/LRA.2025.3601045. [Google Scholar] [CrossRef]
56. Geometric. Geometric transformations [Internet]. 2025 [cited 2025 Oct 4]. Available from: https://pages.mtu.edu/shene/COURSES/cs3621/NOTES/geometry/geo-tran.html. [Google Scholar]
57. Geeks forgeeks. Linear regression (Python Implementation) [Internet]. 2025 [cited 2025 Oct 4]. Available from: https://www.geeksforgeeks.org/machine-learning/linear-regression-python-implementation/. [Google Scholar]
58. Tian Y, Ye Q, Doermann D. YOLOv12: attention-centric real-time object detectors. arXiv:2502.12524. 2025. [Google Scholar]
59. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot MultiBox detector. In: Computer Vision–ECCV 2016. Cham, Switzerland: Springer; 2016. p. 21–37. doi:10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
60. Howard A, Sandler M, Chen B, Wang W, Chen LC, Tan M, et al. Searching for MobileNetV3. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. p. 1314–24. doi:10.1109/iccv.2019.00140. [Google Scholar] [CrossRef]
61. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. arXiv:1512.03385. 2015. [Google Scholar]
62. Rath SR. A repository for everything vision transformers [Internet]. 2025 [cited 2025 Oct 4]. Available from: https://github.com/sovit-123/vision_transformers. [Google Scholar]
63. Sarker S, Sarker P, Stone G, Gorman R, Tavakkoli A, Bebis G, et al. A comprehensive overview of deep learning techniques for 3D point cloud classification and semantic segmentation. Mach Vis Appl. 2024;35(4):67. doi:10.1007/s00138-024-01543-1. [Google Scholar] [CrossRef]
64. Zhao W, Yan Y, Yang C, Ye J, Yang X, Huang K. Divide and conquer: 3D point cloud instance segmentation with point-wise binarization. arXiv:2207.11209. 2023. [Google Scholar]
65. Kontogianni T, Celikkan E, Tang S, Schindler K. Interactive object segmentation in 3D point clouds. arXiv:2204.07183. 2023. [Google Scholar]
66. Shahraki M, Elamin A, El-Rabbany A. SAMNet++: a segment anything model for supervised 3D point cloud semantic segmentation. Remote Sens. 2025;17(7):1256. doi:10.3390/rs17071256. [Google Scholar] [CrossRef]
67. Sun Y, Zhang X, Miao Y. A review of point cloud segmentation for understanding 3D indoor scenes. Vis Intell. 2024;2(1):14. doi:10.1007/s44267-024-00046-x. [Google Scholar] [CrossRef]
68. Benallal H, Abdallah Saab N, Tairi H, Alfalou A, Riffi J. Advancements in semantic segmentation of 3D point clouds for scene understanding using deep learning. Technologies. 2025;13(8):322. doi:10.3390/technologies13080322. [Google Scholar] [CrossRef]
69. Liao Z, Waslander SL. Multi-view 3D object reconstruction and uncertainty modelling with neural shape prior. arXiv:2306.11739. 2023. [Google Scholar]
70. Bai Y, Wang S, Xu R, Tong Y, Xu C, Zhang Z. Segment any primitive: zero-shot 3D primitive segmentation from point cloud. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2025 Jun 11–12; Nashville, TN, USA. p. 5227–35. doi:10.1109/CVPRW67362.2025.00518. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools