
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Multi-Agent Deep Reinforcement Learning-Based Task Offloading Method for 6G-Enabled Internet of Vehicles with Cloud-Edge-Device Collaboration
1 School of Computer Science and Engineering, Hunan University of Science and Technology, Xiangtan, China
2 School of Electronic Information Engineering, Changsha Institute of Technology, Changsha, China
* Corresponding Author: Qi Fu. Email:
Computers, Materials & Continua 2026, 87(3), 75 https://doi.org/10.32604/cmc.2026.074154
Received 03 October 2025; Accepted 06 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In the Internet of Vehicles (IoV) environment, the growing demand for computational resources from diverse vehicular applications often exceeds the capabilities of intelligent connected vehicles. Traditional approaches, which rely on one or more computational resources within the cloud-edge-device computing model, struggle to ensure overall service quality when handling high-density traffic flows and large-scale tasks. To address this issue, we propose a computational offloading scheme based on a cloud-edge-device collaborative 6G IoV edge computing model, namely, Multi-Agent Deep Reinforcement Learning-based and Server-weighted scoring Selection (MADRLSS), which aims to optimize dynamic offloading decisions and resource allocation. The scheme first designs an improved multi-agent proximal policy optimization (MAPPO) algorithm, decoupling centralized training from distributed execution for multiple terminal vehicle agents. Specifically, the centralized training of terminal vehicles is migrated to the high-performance edge layer, while lightweight decision-making networks are retained at the terminal vehicles to enable efficient and dynamic task offloading decisions. Additionally, a server-weighted scoring selection (SS) algorithm is proposed, which integrates two key metrics—short-term server load and geographical proximity—to select the optimal server and allocate communication resources. The proposed scheme improves the quality of experience (QoE) while balancing energy consumption. Simulation results demonstrate that the MADRLSS scheme significantly outperforms existing benchmark methods in terms of task offloading efficiency and stability, maintaining QoE consistently above 82% and effectively enhancing service quality in complex vehicular scenarios.Keywords
With the rapid advancement of wireless network communication technology, the Internet of Vehicles (IoV) has laid the foundation for Intelligent Transportation Systems (ITS). The core of IoV lies in establishing an integrated network connecting diverse entities—vehicles, roadside infrastructure, pedestrians, and cloud services—to effectively enhance road safety and improve traffic efficiency [1]. As a key component of ITS, Intelligent Connected Vehicles (ICVs) have gained enhanced computing, storage, sensing, and communication capabilities, enabling numerous new applications such as vehicle control, real-time route planning, traffic condition alerts, and voice recognition. However, the tasks generated by these applications often exhibit characteristics of high real-time requirements, low latency, and high computational intensity, placing significant strain on onboard computers. For instance, real-time safety decisions in ICVs rely on processing sensor data streams of higher than 8 Gbps [1], which exceeds the limited computational capacity of On-Board Units (OBUs). This directly impacts the operational efficiency of vehicle applications and user experience. To alleviate the issue of insufficient computational power in vehicles, computational offloading offers a viable solution. This approach involves transferring computational tasks to other computing nodes with sufficient resources—such as edge servers or cloud servers—for execution [2].
Early computational offloading approaches involved delegating computational tasks to centralized processing on remote cloud servers. While the cloud possesses the most powerful computational resources and storage capabilities, this approach incurs significant communication latency [3]. To reduce transmission latency, Vehicular Edge Computing (VEC) has emerged. VEC deploys servers near terminal vehicles, shifting computational tasks from the cloud to locations closer to the vehicles themselves. This approach meets the demand for low communication latency, though computational resources remain limited. Furthermore, idle ICVs serve as dynamic “edge” computing nodes. However, the high mobility of vehicles often results in unstable communication connections, potentially causing offloading failures. Existing solutions predominantly employ single-layer or dual-layer computing resources [4,5]. However, in highly dense real-world traffic environments, the computational offloading demands of different vehicle applications vary significantly. Therefore, designing a computational offloading scheme that coordinates multi-tier computing resources to meet the diverse offloading requirements of various vehicle applications represents a vital challenge.
Meanwhile, as the next generation of wireless networks, 6G is expected to deliver extremely high data rates (with peak rates up to 1 Tbps), support massive-scale and ultra-high-speed wireless access (i.e., sub-millisecond latency while connecting tens of billions of communication devices), and provide smarter, more sustainable, and seamless 3-D coverage [6]. Prathiba et al. demonstrated the robustness and reliability of 6G technology by deploying a hybrid algorithm that integrates multi-agent reinforcement learning with Maximum Entropy Inverse Reinforcement Learning (MaxEntIRL) within the sensor network of a 6G Autonomous Vehicle Network (AVN). This approach significantly enhances the efficiency and accuracy of detecting malicious and anomalous behaviors by reducing transmission latency [7]. The enhanced data transmission capabilities of 6G technology will create favorable conditions for cross-tier computing resource coordination, thereby improving the efficiency of offloading computational tasks in complex scenarios.
In recent years, research on computational offloading in VEC environments has proliferated. Traditional approaches typically employ heuristics [8], game theory [9], and Machine Learning (ML) [10] to explore computational offloading performance, yielding favorable results. However, both heuristic and game-theoretic algorithms require meticulously designed computational offloading and resource allocation schemes tailored to specific offloading scenarios, often necessitating extensive iterations to converge on optimal solutions. Traditional ML methods are constrained by the need for manually designed data features and feature extraction. These approaches lack scalability and flexibility when applied to large-scale, dynamic IoV environments. Offloading algorithms based on deep reinforcement learning are currently employed to overcome the limitations of traditional approaches. Deep Reinforcement Learning (DRL) is an artificial intelligence approach that integrates the perceptual capabilities of deep learning with the decision-making abilities of reinforcement learning. Through repeated interactions between an agent and its environment, where actions yield rewards or penalties, DRL learns strategies that maximize benefits [11]. Consequently, DRL methods can adapt to complex offloading scenarios.
However, in the distributed real-world environment of IoV, a single agent must acquire global environmental information to make decisions for all vehicle application tasks. This incurs significant communication overhead, impacting decision-making efficiency. As an augmentation to single-agent DRL, Multi-Agent Deep Reinforcement Learning (MADRL) provides an effective solution for distributed decision-making in dynamic and decentralized environments [12,13]. In the learning paradigms of MADRL algorithms, the centralized training and distributed execution (CTDE) paradigm is generally adopted as the mainstream approach [12]. The centralized training phase in existing approaches typically deploys agents on distributed devices. In real-world IoV distributed environments, it is impossible to gather information from all agents for centralized training. This approach also neglects the training overhead associated with deploying agents to terminal vehicles.
To address these challenges, we adopt a cloud-edge-device collaborative [3] 6G-enabled Internet of Vehicles edge computing system model, which has three layers: the vehicle layer, the edge layer, and the cloud layer. As illustrated in Fig. 1, ICVs reside in the first layer. These vehicles not only generate data but also possess computational resources provided by their OBUs. Vehicles with idle resources can handle tasks with low to moderate complexity, such as those generated by navigation applications. The second layer comprises Roadside Units (RSUs) equipped with servers and edge system. This edge layer is capable of processing tasks with low-latency requirements, such as those arising from risk assessment applications. The third layer consists of a remote cloud configured with server clusters, offering the most powerful computational resources and storage capacity. It supports computationally intensive tasks that are not highly latency-sensitive, such as those generated by infotainment applications. This collaborative architecture, which integrates computational resources across all three layers, is well-suited for high-density urban road traffic scenarios. Terminal vehicles generate various tasks during operation. Due to limited onboard computational resources or insufficient battery power, all computational tasks are fully offloaded via Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communications to idle vehicles, edge servers, or the remote cloud, thereby achieving balanced utilization of system resources. On this basis, this paper proposes a computational offloading solution named Multi-Agent Reinforcement Learning with Server Selection (MADRLSS). This framework integrates MADRL with CTDE, alongside Server weighted scoring-based Selection (SS). By jointly optimizing Quality of Experience (QoE) and the energy consumption of tasks, MADRLSS addresses the diverse requirements of vehicle application tasks while enhancing the success rate of task offloading. The significant contributions of this paper are as follows:
1. Optimizing the 6G IoV architecture enhances modular management by dividing the edge system into the edge management module and the agent management module. This architecture achieves distributed coordination of cloud-edge-device computing and storage resources through exploring task offloading methods suitable for 6G networks, significantly improving the system’s overall computational offloading performance.
2. To address real-time offload decisions for each task, we design an improved MADRL algorithm by decoupling CTDE. The paper models a fully cooperative multi-agent reinforcement learning problem, designing a joint optimization objective to maximize the balance between QoE and energy consumption for tasks. Each terminal vehicle is treated as an independently executing agent that collaborates with other terminal vehicle agents. The edge system centrally trains each agent, guided by the global joint optimization objective, to refine each agent’s offload strategy.
3. A flexible SS algorithm is proposed. By incorporating weighted scores of two critical factors in the offloading process—the short-term load and the geographical distance of servers—the algorithm determines the optimal server and communication resource allocation for task offloading.
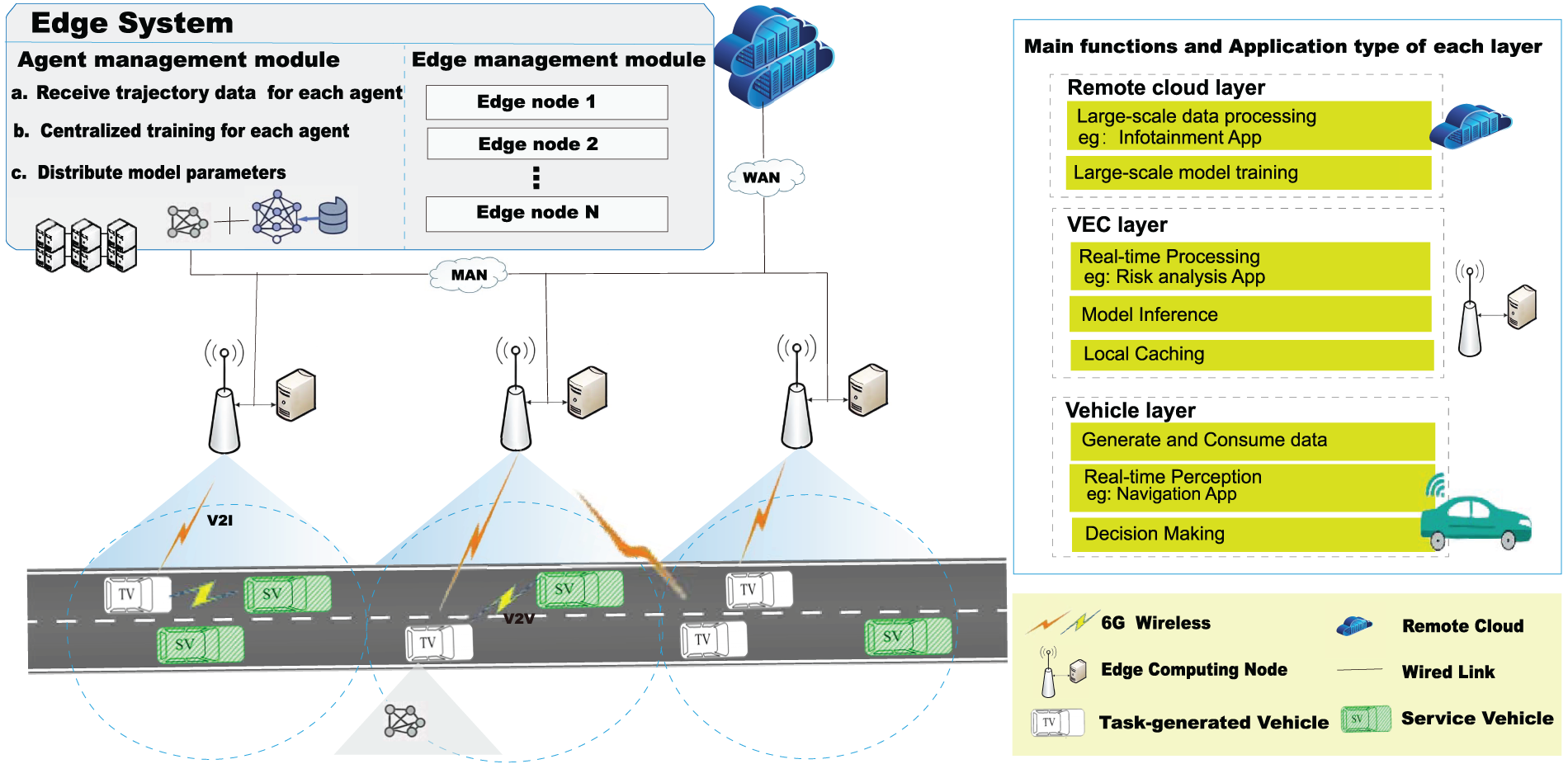
Figure 1: Task offloading system in the cloud-edge-device collaborative architecture for 6G IoV
The rest of this paper is ordered as follows. Section 2 introduces related work on task offloading in VEC. Section 3 describes the system model and issue formulation for computational task offloading. Section 4 designs the MADRLSS approach. In Section 5, experiments are reasonably designed, and the results are analyzed. Finally, Section 6 provides a conclusion.
In recent years, the task computation offloading problem in VEC environments has gradually emerged as a research hotspot attracting joint attention from both academia and industry.
2.1 Computational Offloading Architecture for IoV
The computing offloading architecture for IoV is becoming increasingly adaptable to diverse requirements as it continues to evolve.
Bitam et al. [14] designed a cloud computing model named VANET-Cloud for vehicular ad hoc networks (VANETs), which centrally processes task requirements (e.g., computational demands for safety and non-safety applications) through cloud servers. To address the high latency and inefficiency issues associated with cloud computing’s centralized task processing, Zhang et al. [15] proposed a collaborative fog architecture for IoV composed of a fog layer and an edge layer. This architecture enables computational resources to be located closer to the vehicles, thereby reducing latency. To minimize latency and enhance reliability in computational task completion for mobile devices, Lin et al. [13] proposed a two-tier edge architecture that integrates mobile vehicles—treated as mobile edge servers—and RSUs equipped with servers as fixed edge servers. By offloading computational tasks to either mobile or fixed edge servers, their approach aims to reduce latency and improve the quality of service for these tasks. Literature [16] proposes a three-tier collaborative computing architecture with cloud-edge-device coordination. Tasks are executed locally or offloaded to idle vehicles, edge servers, and cloud servers. By reducing energy consumption and task latency while improving task completion rates, this approach achieves 85% resource utilization.
2.2 Optimization Objective of Computational Offloading
Currently, research on computational offloading primarily focuses on optimization objectives such as minimizing task offloading latency, minimizing energy consumption, optimizing task dependencies, and improving application result quality [3,17].
Zhou et al. [18] proposed a computational offloading scheme with demand forecasting and Reinforcement Learning (RL), named CODR, which effectively decreases latency. In [19], an efficient task offloading based on traffic prediction in IoV-Enabled edge computing aims to resolve the computational load imbalance in edge servers resulting from irregular spatiotemporal traffic flow, thereby improving service response speed. In [20], battery-powered autonomous vehicles and edge devices consume significant amounts of energy during transmission and computation tasks. To reduce energy consumption costs, He and Li [21] proposed an offloading scheduling strategy with minimized power overhead for IoV based on Mobile Edge Computing (MEC). They designed a Simulated Annealing (SA) algorithm to solve the offloading optimization model. In [22], a method employing DRL and an edge computing architecture for vehicle task scheduling decisions is proposed to reduce computational completion delays and energy consumption in multi-task scheduling. Chen et al. [23] proposed a real-time, dependency-aware task offloading method (DODQ) based on Deep Q-Networks (DQN). By modeling task dependencies within vehicle applications as Directed Acyclic Graphs (DAGs), the DODQ enables real-time dynamic task scheduling to rapidly generate offloading plans within milliseconds. The trade-off among various optimization objectives in computation offloading is also a critical issue. Li et al. [24] identified a new trade-off between the Quality of Result (QoR) and service response time in MEC. By relaxing the requirement for the highest QoR, they managed to reduce both the service response time and application energy consumption.
2.3 Optimization Strategies of Computational Offloading
In the IoV environment, optimization strategies for computational offloading have undergone significant evolution.
The initial offloading strategies employed heuristic [8,25], game-theoretic [9], and contract-theoretic algorithms [26], tailored for vehicular networks. To address latency and quality-balanced task allocation in Vehicular Fog Computing (VFC), Zhu et al. utilized Mixed Integer Linear Programming (MILP) [27] to solve NP-hard problems. The approach achieved improved task allocation performance by balancing service latency and quality degradation. However, MILP relies on expert-designed heuristics, demanding specialized knowledge and limiting extensibility to non-binary integer variables. Meanwhile, traditional methods are prone to local optima, exhibit slow convergence, and often fail to attain global optimal solutions.
Subsequently, to adapt to the real-time, dynamic, and complex IoV environment, ML [10] and DRL [28] were introduced to address offloading decisions and resource allocation for vehicle computing tasks in cloud or edge environments. In [29], the researchers employed Dropout regularization and Double Deep Q-Network (DDQN) to mitigate the overestimation bias of DQN. They modeled communication and computational states using finite Markov chains to achieve resource allocation. However, this value-based DRL is well-suited for handling discrete action spaces but struggles with complex task offloading problems involving infinite states.
To extend Markov decision processes with infinite states and continuous action spaces, researchers have actively explored hybrid algorithms based on policy or policy-value functions. Zhou et al. [18] proposed a computational offloading method based on twin delayed deterministic policy gradient (TD3). The system’s intelligent center offloads vehicle application tasks to four distinct locations (local computation, edge servers on RSUs, edge servers on Base Station (BS), and idle vehicles within the same region) at varying proportions, thereby enhancing the overall performance of 6G IoV systems. Considering the partially observable characteristics of the distributed nature and environmental state in IoV networks, literature [30] designed an efficient algorithm based on Multi-Agent Deep Deterministic Policy Gradient (MADDPG). Each agent observes the local state of the environment to make computational offloading decisions, thereby alleviating the communication costs associated with a single centralized agent acquiring global information. This approach reduces the latency and energy consumption of computational offloading.
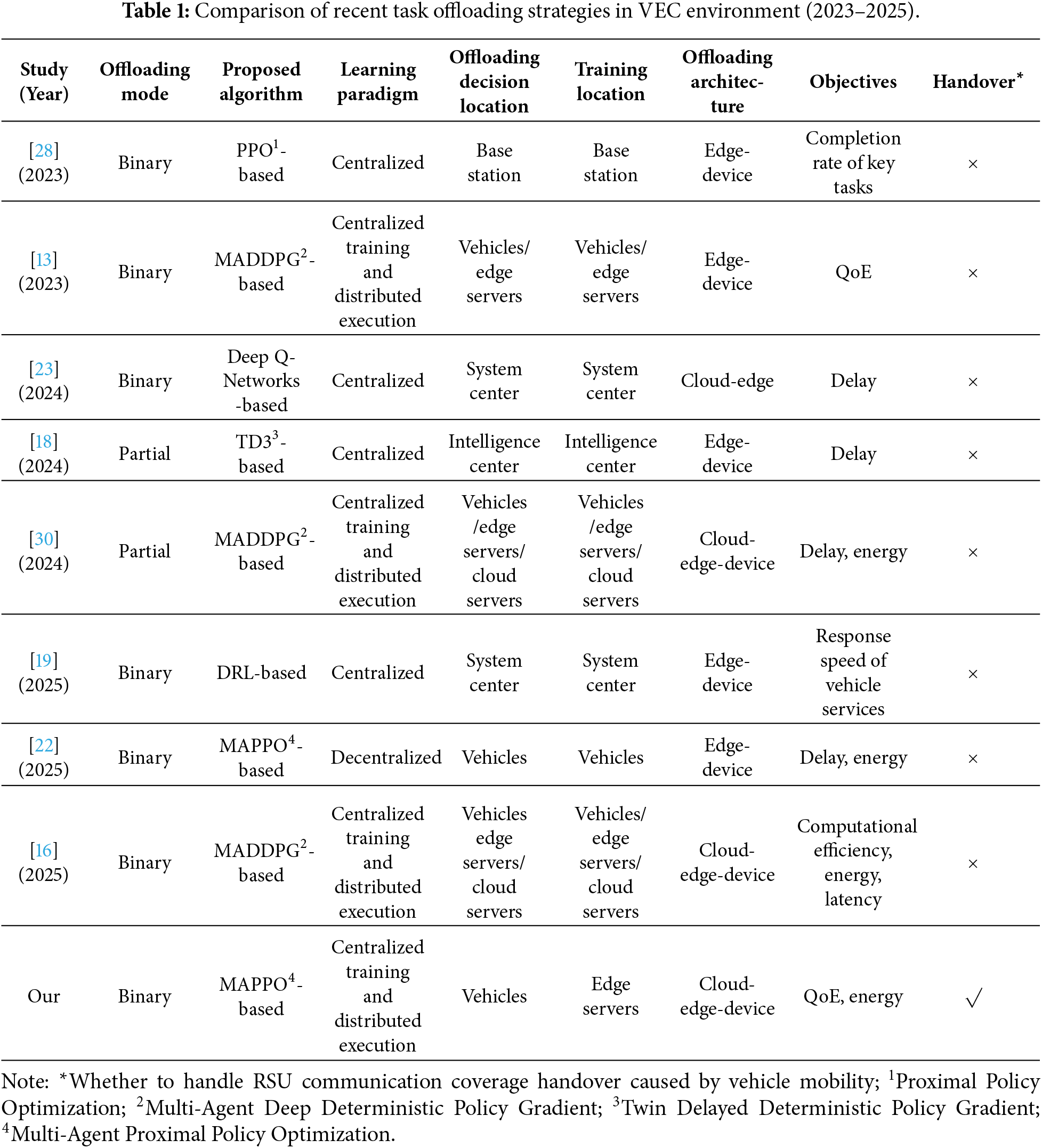
We briefly compared recent relevant studies in Table 1. It is found that although existing research has provided reasonable computation offloading strategies for in-vehicle application computing tasks under the VEC paradigm, the MADRL algorithm—which employs terminal vehicles as agents—still faces significantly increased computational burdens in high-density traffic and task scenarios. This primarily stems from existing methods that typically execute policies and conduct centralized training simultaneously on local vehicles, leading to resource constraints at the terminal level. To continuously optimize computation offloading strategies, this paper proposes a MADRL training approach distinct from existing solutions. We first enhance the modular management capabilities of the edge layer within the cloud-edge-device integrated computing model. Building upon this foundation, we investigate task offloading and resource allocation mechanisms, subsequently proposing a computational offloading method named MADRLSS. This approach decouples centralized training from distributed execution by migrating the data-driven training process of vehicle agents to edge servers, while vehicles solely execute policy actions. This design substantially reduces computational pressure on terminal vehicles, comprehensively optimizing the QoE of tasks and system energy consumption while significantly enhancing overall computational offloading efficiency in VEC environments.
3 System Model and Issue Statement
This section highlights the task offloading system within the cloud-edge-device collaborative architecture for 6G IoV, as shown in Fig. 1. It depicts the system modeling process, encompassing system model, mobility model, task model, communication model, computation model, and task utility model. The key symbols used in this paper and their descriptions are detailed in Table 2.

3.1 Cloud-Edge-Device Collaborative 6G VEC System Model
The system model described in this paper is made up of three layers: the remote cloud layer, the edge layer, and the vehicle layer. The system time is divided into multiple time slots, denoted
The remote cloud layer consists of a cluster equipped with multiple servers, offering abundant computing resources. The cluster is denoted as
The edge layer comprises N 6G edge computing nodes and an edge system, with each node consisting of an RSU and a single edge server connected via fiber optic links. The set of edge servers is represented as
The vehicle layer encompasses all ICVs on the road, comprising M task-generated vehicles (TVs) and O service vehicles (SVs) with idle resources. TVs locally execute computational tasks related to safety-critical applications, such as those generated by vehicle control and accident prevention systems. These types of tasks are not allowed to be offloaded. Computing tasks generated by other applications are fully offloaded to servers with abundant computing resources for processing. This paper discusses the scenario of complete task offloading. Each vehicle is represented as a seven-tuple, denoted as
When the TV enters the coverage area of the RSU signal, it observes local information and formulates its own offloading decision—that is, offloading tasks to cloud servers, edge servers, or SVs. Based on this offloading decision, the TV selects an appropriate target server and sends the requested task data to it. The target server executes the task and returns the computation results to the TV.
Based on the mobility models from references [4,28], we assume vehicles travel on conventional one-way dual-lane ordinary highways. The road represents the
where
The system includes three types of application tasks: navigation applications, risk assessment applications, and infotainment applications. Tasks of different application types exhibit significant differences in terms of data size, computational power requirements, and latency tolerance. This paper adopts the identifier variable
Assuming each TV generates one request task per time slot, the set of all request tasks within the system’s time slot
The IoV communication system primarily consists of two communication modes: V2V and V2I. The two parties establish a high-bandwidth communication connection via a 6G wireless channel. The OBUs equipped in vehicles utilize activated PC5 interfaces to enable V2V and V2R links, providing communication services between vehicles and between vehicles and RSUs, respectively [4,31]. Vehicles can detect nearby RSUs and other vehicles in real time through sidelink communication on PC5 [32]. RSUs and surrounding vehicles periodically broadcast collaborative perception information specified in the C-V2X standard—such as their geographic location, computational capabilities, and available communication resources—and transmit these data to perceiving vehicles at a 10 Hz frequency. This ensures a balance between timely discovery and network overhead. Given that edge computing nodes are fixed along roadside locations with proximity and a fixed network topology, fiber-optic networks connect these nodes to the metropolitan area network (MAN) [10]. This MAN connection enables edge computing nodes to share computational resources via task migration. To ensure continuity of computation offloading services, if a TV leaves the coverage area of the serving edge computing node before completing an offloaded task request, the computation results will be transmitted to the TV via other edge computing nodes using a multi-hop approach. The handover process between edge computing nodes will only fail if a TV leaves the coverage area of the serving edge computing node while sending or receiving data. The MAN connecting RSUs is linked to the wide area network (WAN) via fiber optic cables. Consequently, vehicles can connect to remote cloud servers through nearby RSUs [10].
In the communication system described in this paper, we employ frequency division multiple access (FDMA) technology to evenly distribute the server’s total channel bandwidth among all TVs [28,33]. It is assumed that communication interference between individual vehicles and between vehicles and edge computing nodes within a given road segment is negligible [28,34]. By Shannon’s theorem, the uplink transmission rate for V2V and V2I communications can be computed as:
where
In the IoV offloading system, the TV typically offloads requested tasks to other servers to alleviate its own computational limitations. To fully leverage the heterogeneous resources of the cloud-edge-end computing model and meet the computational demands of different task types, this paper categorizes task offloading into three modes. Since the data volume of task computation results is significantly smaller than the input data volume, the communication latency and energy consumption associated with the SV or the edge computing node returning data to the TV can be considered negligible. Assume that each server utilizes all of its computational resources when executing tasks. Latency and energy consumption are detailed as follows.
3.5.1 Offload to SV for Processing
The service time
where
The energy consumption
here,
3.5.2 Offload to Edge Server for Processing
The service time
where
here,
Corresponding to the service time, the energy consumption
where
3.5.3 Offload to Remote Cloud Server for Processing
Due to the high computational power of the servers deployed in the remote cloud, processing delay and processing energy consumption are negligible compared to transmission latency and energy consumption. Therefore, the service time
where
Similar to
where
Based on the above, the total service delay for the offloading
and the energy consumption is:
where
In IoV offloading systems, evaluating offloading benefits solely through the service time assessment system of successfully offloaded tasks is rather one-sided. For instance, if the offloading decision provides sufficient service time for a small fraction of successfully offloaded tasks while most offloading attempts fail, this does not demonstrate robust system performance. Therefore, we employ a QoE formula that simultaneously considers the service time and failure status of each task. The QoE formula is defined as follows:
here,
We aim to maximize the QoE for all tasks while minimizing energy consumption as much as possible. To accurately reflect the offloading utility of a task, we comprehensively consider both the task’s QoE and energy consumption as the total utility
where
Our objective is to enable vehicles to make effective offloading decisions for requested tasks based on current environmental conditions, thereby reducing task failure rates, minimizing service latency, and enhancing system performance. This is achieved through continuous training of decision-making network models under the assisted control of edge systems. Within the constraints of limited resources across all SVs, edge computing nodes, and remote clouds, to maximize the average total utility of all tasks. The optimization problem is defined as follows:
Constraint
When servers and vehicles in the IoV are integrated into the environment at once, particularly when the number of vehicles reaches a medium or large scale, or when there are a large number of servers, the state space and action space can become excessively high-dimensional, leading to a significant increase in neural network parameters. This may prolong training time and even make the network hard to train [4]. To address this issue, we decompose the MADRLSS scheme into two processes: task offloading decision and resource allocation, as shown in Fig. 2. First, a MADRL-based algorithm that decouples centralized training from distributed execution, MAPPO generates an offloading decision scheme for each request task, preliminarily determining its offloading destination. Next, the TV selects the optimal server as the target server using the SS algorithm based on the decision scheme and allocates appropriate channel bandwidth to the request task. Upon acquiring these resources, the request task is immediately offloaded by the TV to the physical target server. Assign a virtual machine to execute the request task based on the sequence of virtual machines of the physical target server. Repeat the two processes until the system reaches its final state
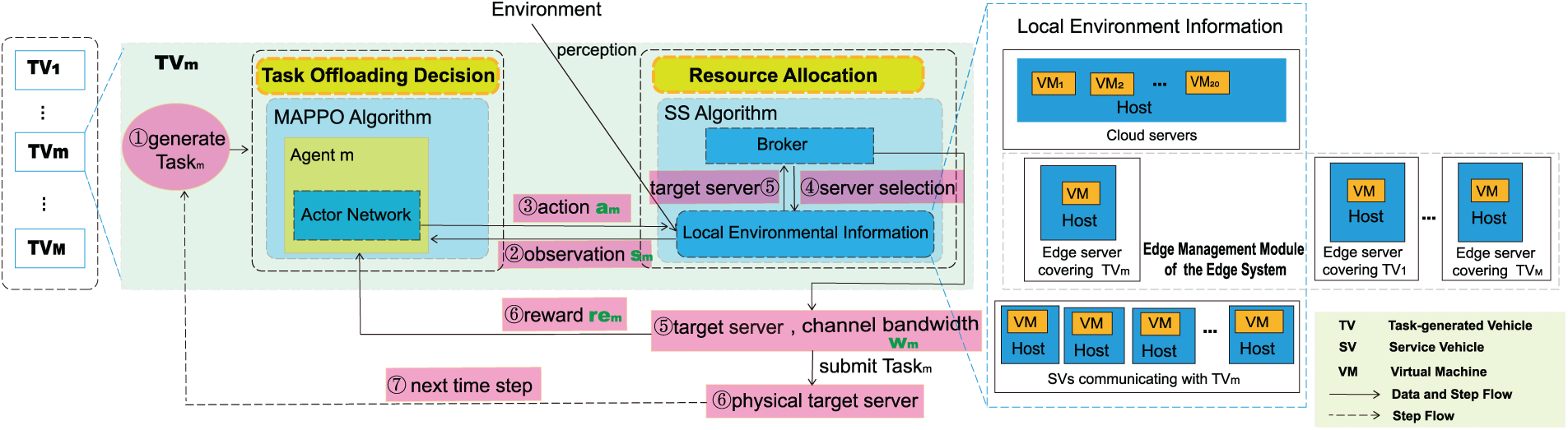
Figure 2: Task offloading full workflow for the MADRLSS scheme
4.1 Task Offloading Decision Based on MAPPO Algorithm with Decoupling Centralized Training from Distributed Execution
The task offloading process in the VEC environment exhibits Markovian properties and can be abstracted as a Markov decision process (MDP). In this paper, task offloading decisions are formulated as cooperative multi-agent reinforcement learning (MARL). Each TV is treated as an agent that continuously interacts with the environment, attempting actions and receiving rewards or penalties. Agents can collaboratively learn offloading strategies from others to achieve optimal task offloading decisions. First, we model the task offloading decision using a Markov game, which can be viewed as an extension of MDP to multi-agent settings [36]. Next, we outline the MADRL algorithm—MAPPO [37]—which offers stability advantages for finding optimal offloading decisions across multiple agents.
Task offloading decisions are modeled as a Markov game using the tuple
Local State Space
At time step
Global State Space
The global state of the system is the combination of the local state spaces of all agents at time step
Action Space
Each agent’s action space consists of the available offloading decision modes for the requested task (remote cloud server, edge server, and SVs).
where
Then, the action space of the entire system can be represented as:
Reward Function
The Agent
Therefore, the reward function for the
where
Since each agent is fully cooperative, at time step
To standardize the reward scale across different task types and prevent excessively large or small
The objective of the MARL algorithm is for each agent to find a policy
4.1.2 Analysis of the MAPPO Algorithm
MAPPO is a multi-agent reinforcement learning framework based on Proximal Policy Optimization (PPO) [39]. PPO is an Actor-Critic (AC) architecture reinforcement learning algorithm comprising two actor networks (
The MAPPO algorithm framework presented in this paper is illustrated in Fig. 3. All agents are homogeneous, and each agent can only observe local information when executing actions. We configure each agent with its own actor network, while all agents share a common critic network. To reduce learning pressure on individual agents, each agent
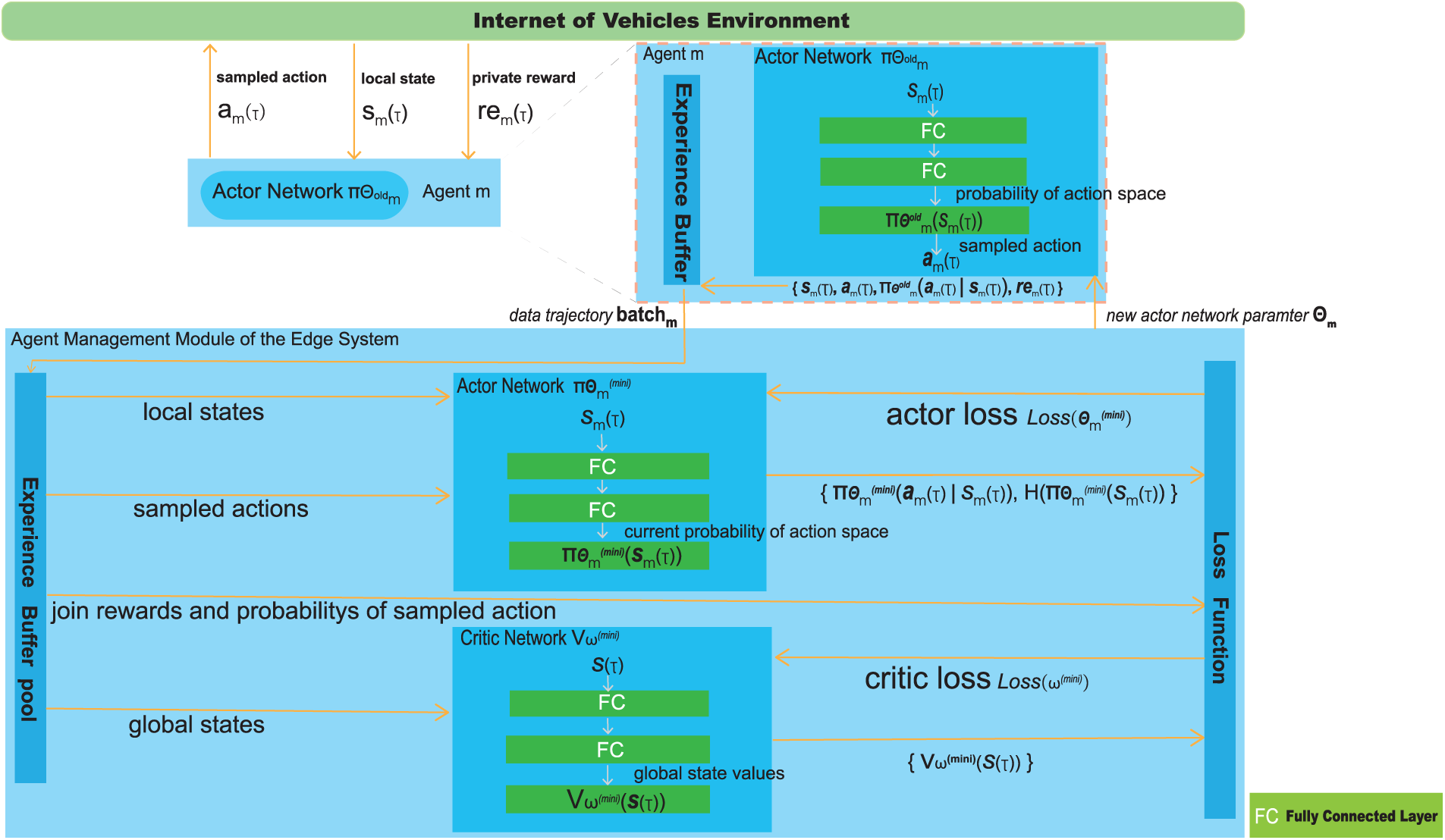
Figure 3: Framework of MAPPO.
During the MAPPO algorithm training, the agent management module of the edge system first forwards the initialized model parameters of the new actor network
here,
On the agent management module of the edge system, the data trajectory
then,
which
The generalized advantage estimation (GAE) method is employed to estimate the expected advantage function at each time step
where
To encourage exploration of actions of the actor
here, the function H refers to the entropy of the actor
The optimization objective of the critic network
where
After completing each batch update, the parameters of the new actor network
After the MAPPO algorithm training concluded, the fully trained new actor network

4.2 Resource Allocation Based on the SS Algorithm
After obtaining an offloading decision method, the task
4.2.1 Short-Term Load and Distance
There are two influencing factors involved in the SS algorithm: short-term load (STL) of a server and distance between the TV and a server (the SV or the edge server) calculated using Eq. (1) The STL of a server indicates the total number of tasks offloaded to the relevant server within a short period (e.g., the last 0.5 s). In this paper, task offloading decisions are made on a per-time-step basis. Within each time step, generated request tasks are immediately sent by the TV to the target server for execution based on the offloading decision. During this period, the server’s load state is considered instantaneously constant. Considering that the maximum expected service time for the in-vehicle application tasks involved in this paper is an integer multiple of 0.5 s, a single task can be completed in approximately 0.5 s at its fastest, thereby causing changes in server load. Therefore, this paper sets the server load update cycle to 0.5 s. Based on this update frequency, the STL value can be used to predict the future load state of the server [10]. It is denoted as
4.2.2 Weighted-Scoring Mechanism Based on the SS Algorithm
1) The request task
2) When task
where
3) When the request task
here,
Notably, when offloading the request task

This section will provide a detailed analysis of the time complexity of the algorithms involved.
The time complexity of the MAPPO algorithm requires distinguishing between the time complexity during training and after training completion. During training, the time complexity of the MAPPO algorithm primarily consists of the independent execution of the actor network
The time complexity of the SS algorithm primarily depends on the number of iterations over the set of edge servers
Therefore, the total time complexity for each vehicle agent in the MADRLSS method is the number of operations performed independently by each agent
This paper utilizes the EdgeCloudSim [41] experimental platform as the edge computing simulation software to emulate cloud-edge-device computing scenarios, enabling the modeling of computational and network resources as well as mobile vehicles. All algorithms are implemented using both JAVA and Python 3.10, along with PyTorch 2.5.1. All experiments are conducted on the same machine (13th Gen Intel(R) Core(TM) i5-13500H 2.60 GHz, 32 GB RAM, Windows 11 operating system).
The duration of each time slot
To verify the effectiveness of the presented task offloading scheme, MADRLSS, we picked the following three benchmark algorithms for comparison with the method proposed in this paper.
1. Multi-Agent Dueling Double Deep Q-Network (MAD3QN) and SS Algorithm-Based Offloading Method (MAD3QNSS): The MADRL algorithm MAD3QN [42] employs an epsilon-greedy strategy for discrete action exploration to obtain task offloading decisions. Resource allocation utilizes the SS algorithm presented in this paper.
2. Random and SS Algorithm-Based Offloading Method (RandomSS): Task offloading decisions are generated probabilistically using a random approach, where tasks are assigned with equal probability to execute on remote cloud servers, edge servers, or SV servers. Resource allocation employs the SS algorithm described in this paper.
3. MADRL and Default-Based Offloading Method (MADRLDefault): MADRLDefault employs the MAPPO algorithm described in this paper for task offloading decisions, with the system defaulting to selecting the target server instead of using the SS algorithm. That is, when the offloading decision method is set to remote cloud servers, it remains consistent with MADRLSS. When the offloading decision method is an edge server, tasks are only offloaded to edge servers within the communication coverage area of TV, without considering task migration. When tasks are offloaded to an SV server, the system randomly selects one SV to execute the task.
To completely analyze the performance of the proposed solution, we incorporate five key performance indicators into the comparative algorithm performance assessment: algorithm convergence, service time, task failure rate, energy consumption, and QoE.
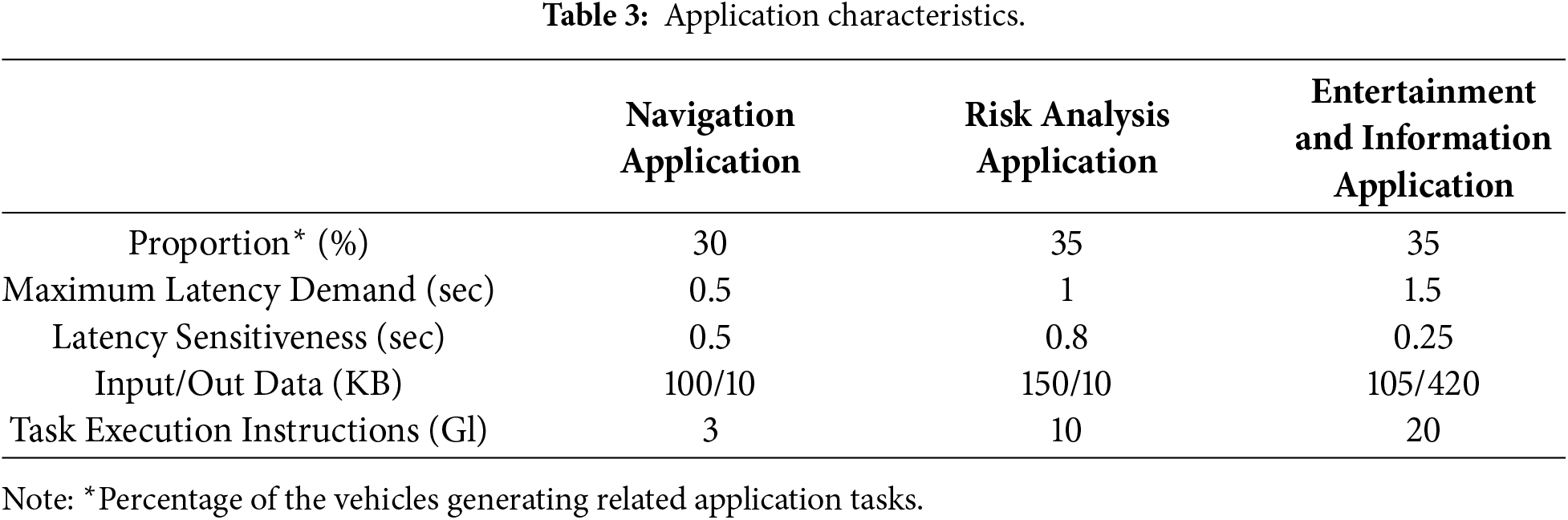
Fig. 4 illustrates the convergence performance of the task offloading schemes. The learning curves of MADRLSS, MAD3QNSS, and MADRLDefault during training are shown in (a), demonstrating convergent performance across the same number of tasks. The proposed MADRLSS exhibits poor reward performance within the first 50 episodes but enters a faster, smoother convergence phase with higher joint rewards after exceeding 50 episodes. In contrast, the MAD3QNSS learning curve initially increases, likely due to favorable state-action sequences encountered during multi-agent learning that temporarily yield higher rewards. However, the joint reward ceases to rise thereafter. MADRLDefault exhibits reward patterns similar to MADRLSS for the first 120 episodes, but the joint reward also stops increasing after 120 episodes. The primary reason is that the MAPPO algorithm employed in MADRLSS incorporates a pruning mechanism to limit the magnitude of policy updates. While ensuring the scale of policy updates, it introduces policy entropy to enhance exploration capabilities among agents, enabling cooperative learning of optimal offloading strategies. This also demonstrates that the SS algorithm in MADRLSS achieves higher rewards through rational resource allocation. Since RandomSS does not involve a reward function, its reward behavior was not analyzed.
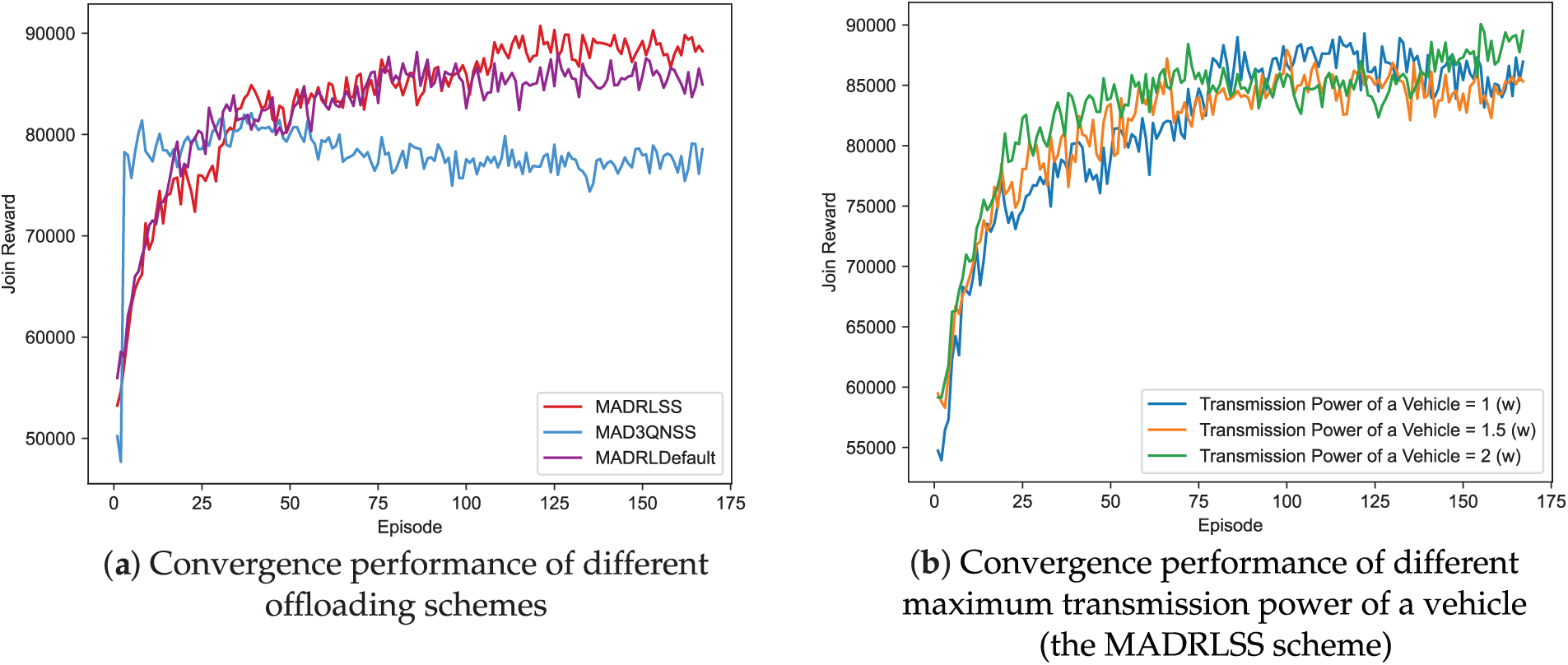
Figure 4: Comparison of convergence performance.
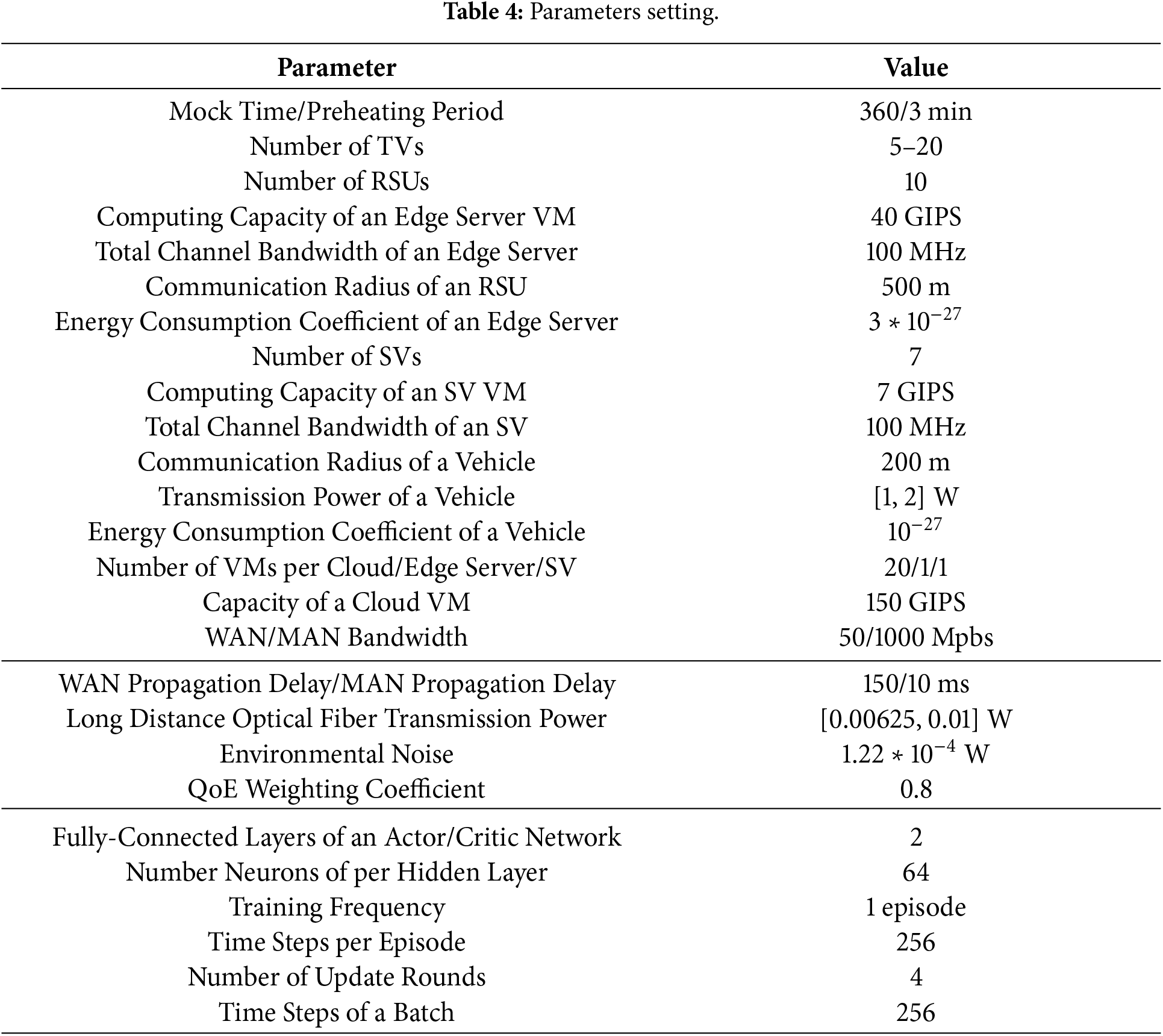
The impact of the proposed MADRLSS method on the joint reward at different maximum transmission powers of a vehicle is demonstrated in (b). As the maximum transmission power of a vehicle increases, the joint reward also increases. Additionally, under the condition of maximum transmission power of a vehicle, the proposed MADRLSS method exhibits lower reward volatility and more stable convergence. The primary reason is that increasing the maximum transmission power enables higher V2V and V2I transmission rates and shorter transmission times. This improves the service time and QoE for delay-sensitive tasks. Since QoE carries a higher weighting, the energy consumption increase resulting from the power boost is smaller than the corresponding QoE improvement. This enhances the stability of the agent’s collaborative learning optimization for offloading decision strategies.
5.3.2 Service Time and Task Failure Rate
Fig. 5 illustrates service time and the task failure rates of different offloading schemes.
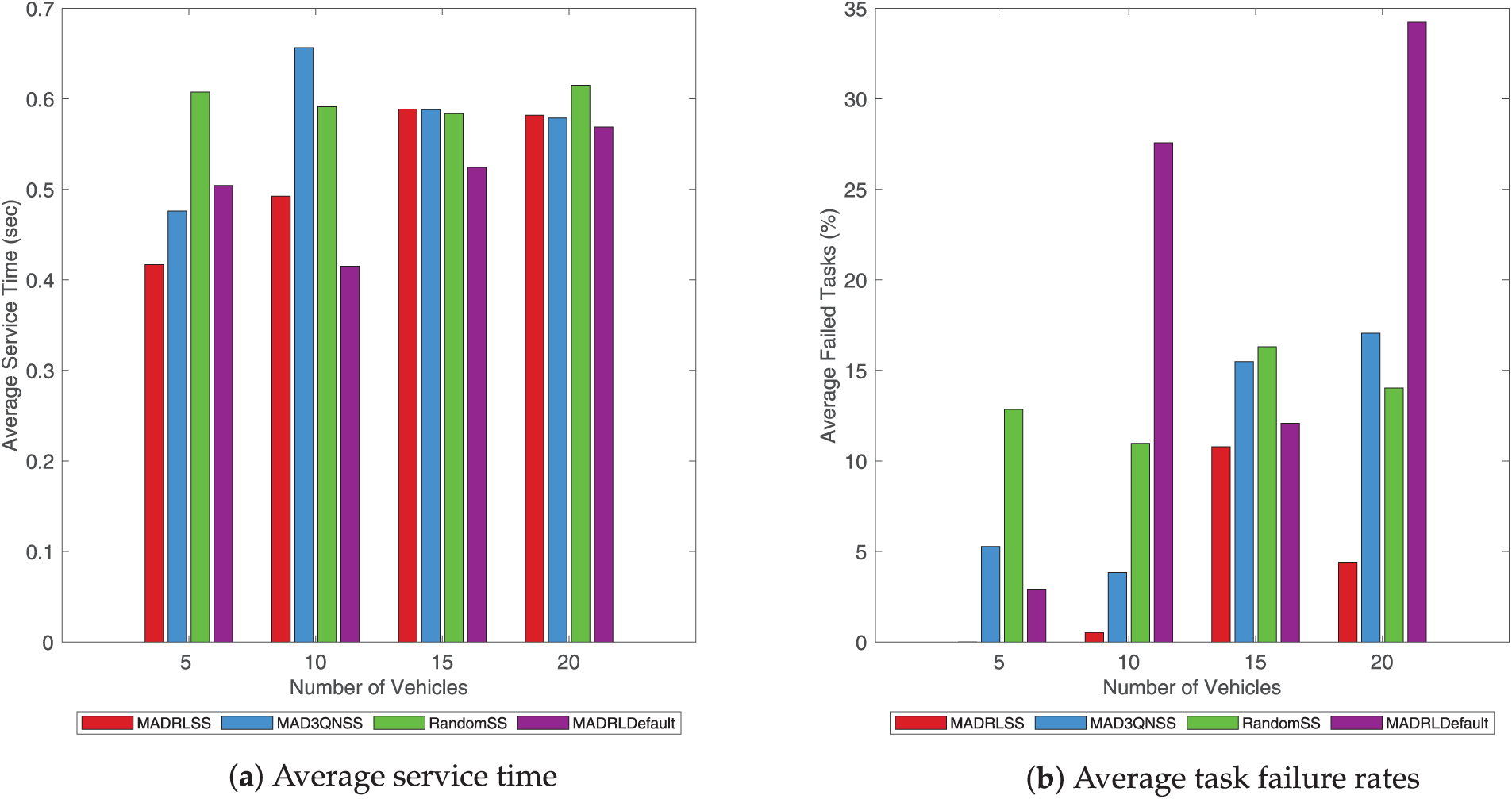
Figure 5: Comparison of average task failure rates and average service time of different offloading schemes.
Service time refers to the time from when a service task is requested to when it is successfully executed and returns. A comparison of the service time for different task offloading schemes with the same quantity of vehicles is demonstrated in (a). Along with the rising number of vehicles, the quantity of generated tasks also rises. Due to intensified resource competition and network congestion, the average service time of all offloading schemes increases. The average service time of MADRLSS is at a moderate level under the same quantity of vehicles. The average service time for MAD3QNSS and RandomSS is relatively high. MADRLDefault exhibits the lowest overall average service time, but it also has a high task failure rate. This indicates that only a small fraction of tasks are successfully executed. The primary reasons are the failure to migrate tasks to other edge servers with sufficient resources when the current edge server becomes locally overloaded during task offloading, coupled with a random selection of SVs. This demonstrates the effectiveness of the SS algorithm.
The relationship between the average number of failed tasks and the number of vehicles is shown in (b). As the number of task-generated vehicles increases, greater pressure is placed on the system’s various resources. Consequently, the average task failure rate rises for all schemes. The MADRLSS scheme proposed in this paper consistently maintains the lowest average task failure rate, remaining below 11%. The average task failure rate for MAD3QNSS and RandomSS is relatively high. MADRLDefault initially did not have the highest average task failure rate. However, as the number of vehicles increased, the average task failure rate suddenly surged, reaching its peak at 10 and 20 vehicles. The primary reason is that MADRLSS can synergistically utilize computational resources across cloud, edge, and idle vehicles to reduce task failure rates. Specifically, MADRLSS offloads most small-to-medium-sized request tasks to edge servers near TVs. When an edge server nears local overload, it migrates the request tasks to nearby alternative edge servers for execution. Large-scale, less time-sensitive requests are offloaded to cloud servers. Simple requests are offloaded when SVs with favorable conditions appear near the TV. This demonstrates MADRLSS’s robust capability to allocate computational resources reasonably even under resource-constrained and high-network-load conditions.
5.3.3 Energy Consumption and QoE
Fig. 6 illustrates the average energy consumption per task offloading and the average QoE per request task.
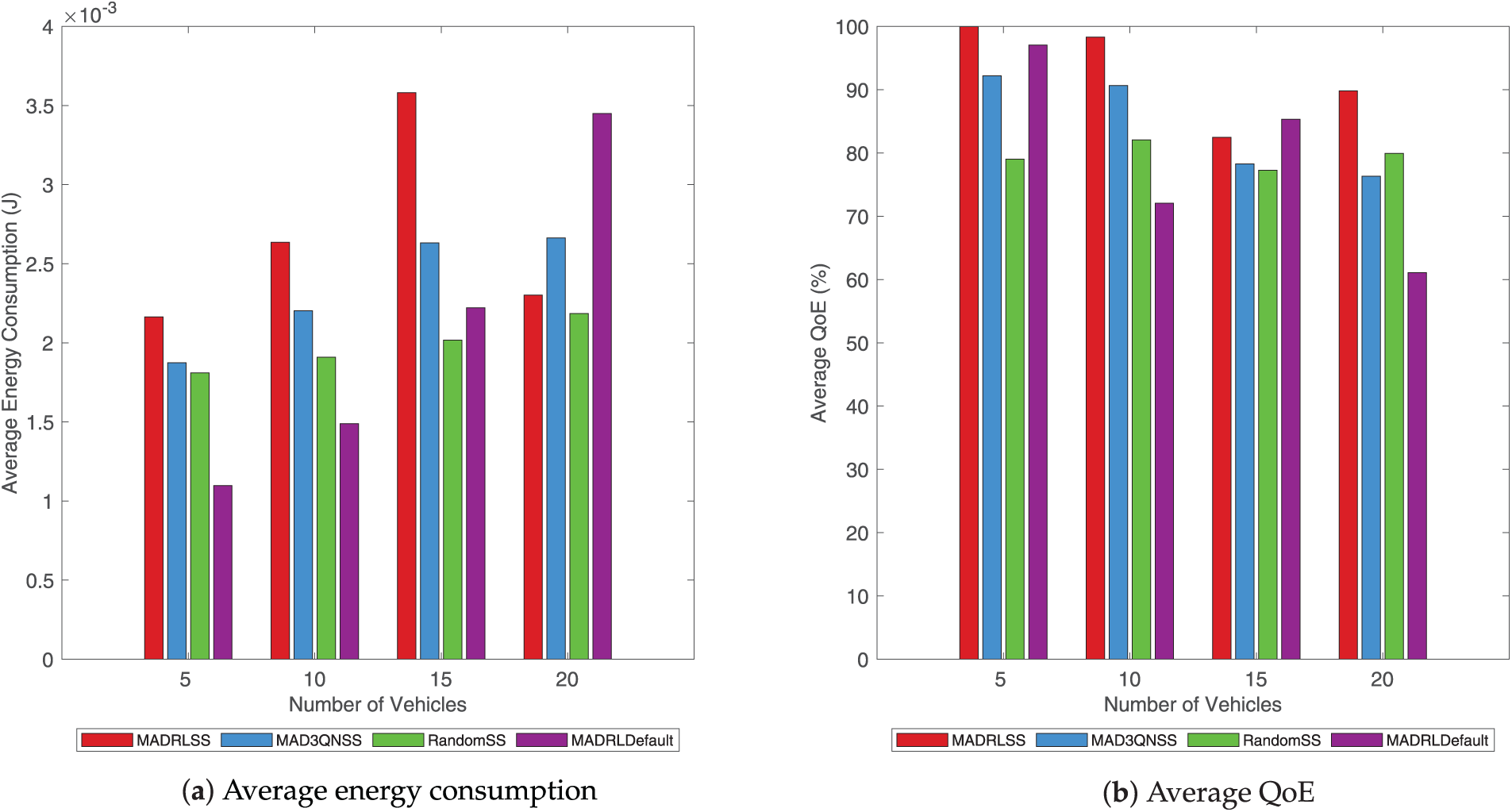
Figure 6: Comparison of average energy consumption and average QoE.
A comparison of the average energy consumption for different task offloading schemes with the same quantity of vehicles is demonstrated in (a). Along with the increase in the number of vehicles generated for tasks, the pressure on the system’s resources has grown accordingly. The average energy consumption of all offloading schemes increases. The proposed method, MADRLSS, exhibits relatively high overall average energy consumption, while MAD3QN and RandomSS demonstrate comparatively lower average energy consumption. MADRLDefault typically achieves the lowest average energy consumption in the early stages. However, when the number of vehicles reaches 20, it exhibits the highest average energy consumption, indicating task offloading instability.
The tendency of the average QoE of tasks to change with the quantity of vehicles is shown in (b). The increasing number of vehicles generated for tasks places greater strain on system resources, resulting in a continuous decline in the average QoE for all solutions. Under different vehicle densities, the MADRLSS scheme proposed in this paper achieves the highest average QoE overall compared to other schemes, consistently maintaining a level above 82%. When the number of vehicles is 5, the MADRLSS scheme can supply the highest QoE (100%). MAD3QNSS and RandomSS typically exhibit relatively low average QoE. Due to instability in the resource allocation process, MADRLDefault exhibits significant fluctuations in average QoE. Specifically, it achieves a higher average QoE when the number of vehicles is 5 or 15, but the average QoE is lowest for other vehicle counts.
Fig. 7 illustrates the average QoE comparison across different application types for various task offloading schemes under identical vehicle counts. In the navigation application (a) and the risk assessment application (b), the proposed MADRLSS method achieves the highest overall average QoE. In entertainment and information application (c), MADRLSS delivers the highest average QoE when vehicle counts are 5 and 10. Subsequently, MADRLSS’s average QoE was slightly lower than RandomSS and MADRLDefault, which incorporate random strategies, possibly due to encountering favorable conditions by chance. However, compared to the stable MAD3QNSS, MADRLSS consistently achieved the highest average QoE. Therefore, compared to the baseline methods, MADRLSS demonstrates optimal overall task offloading performance, ensuring the QoE for computational tasks across different application types.
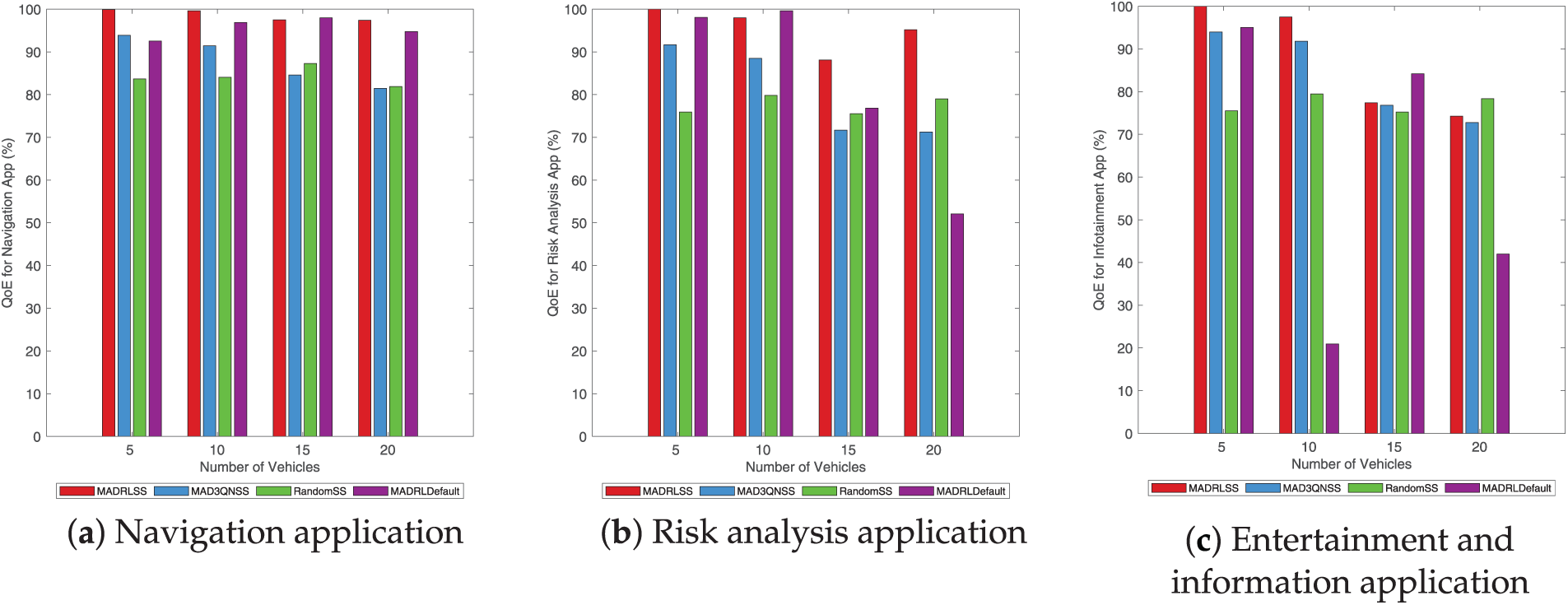
Figure 7: Comparison of average QoE of different application types.
Overall, while MADRLDefault achieves low energy consumption by avoiding frequent task transmission and processing, this comes at a high cost, such as higher task failure rates and lower, unstable QoE, severely impacting the overall performance of the IoV offloading system. In real-world IoV scenarios, the ability to guarantee task completion latency and service experience quality is often more critical than minimizing energy consumption. For instance, delays in processing critical tasks like navigation applications update or risk analysis applications may introduce safety hazards, potentially negating the benefits of reduced energy consumption. Furthermore, high task failure rates can result in the loss of critical tasks, undermining the emotional experience of vehicle users.
5.4 Experimental Summary and Implications
Experimental results demonstrate that the proposed MADRLSS scheme achieves superior performance across all evaluation metrics compared to existing benchmark approaches. Its advantages become particularly pronounced in scenarios with increased request task volumes, indicating not only its feasibility in small-scale environments but also its effective adaptation to complex scenarios involving high-density vehicles and large-scale tasks. This is primarily attributed to the CTDE architecture adopted in the method. This design transfers the computationally intensive model training process to edge systems, substantially reducing computational pressure on terminal vehicles. Consequently, it enables scaling to larger-scale distributed IoV environments. This characteristic positions MADRLSS as a robust task offloading solution with strong scalability, tailored for real-world complex scenarios.
This paper addresses the challenge of coordinating heterogeneous resources across cloud, edge, and terminal vehicles in high-density, large-scale task-based vehicle networking scenarios. By setting the optimization objective as maximizing the total utility of all tasks (i.e., the weighted sum of QoE and energy consumption of tasks), it proposes a MADRL method based on a centralized training and distributed execution decoupling architecture, termed MADRLSS, to achieve efficient task offloading and rational allocation of heterogeneous resources in distributed environments.
First, the MAPPO algorithm in the MADRLSS approach employs a Markov game to model the multi-vehicle, multi-server task offloading decision process. Through multi-agent collaborative learning, it shifts centralized evaluation and training to edge systems, enabling each agent to solve dynamic task offloading decisions in a lightweight manner. Then, considering edge server load balancing and unstable V2V communication connections, this paper designs the SS algorithm based on weighted server scoring. By incorporating two key factors—server load and distance between servers and TVs—it implements a weighted scoring mechanism, identifies the optimal target server, and achieves efficient communication resource allocation.
Experimental results indicate that at the same environmental conditions, the proposed MADRLSS scheme outperforms other baseline schemes. While it incurs a slight increase in energy consumption, it demonstrates significant advantages in most indicators, including algorithm convergence, service time, task failure rate, and QoE. This scheme coordinates multi-vehicle collaborative learning of respective offloading strategies through joint incentives, effectively integrating multi-level computational resources across cloud, edge, and terminal vehicles. Consequently, it significantly enhances the overall efficiency of task offloading and execution in IoV environments.
In future work, we will focus on task offloading in dynamic and open vehicle networking environments, extending existing algorithms to ensure their security and protect user privacy.
Acknowledgement: Not applicable.
Funding Statement: This work is supported in part by the Scientific Research Fund of Hunan Provincial Education Department (24A0337), and the Natural Science Foundation of Hunan Province (2025JJ50348).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, methodology, software, and writing, Fangxiang Hu; validation and formal analysis, Qi Fu and Jing Huang; supervision and project administration, Shiwen Zhang. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: Due to the nature of this research, participants of this study did not agree for their data to be shared publicly, so supporting data is not available.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Li C, Dong M, Fu Y, Richard Yu F, Cheng N. Integrated sensing, communication, and computation for IoV: challenges and opportunities. IEEE Commun Surv Tutor. 2026;2025(1):1. doi:10.1109/COMST.2025.3612388. [Google Scholar] [CrossRef]
2. Zhang S, Yi N, Ma Y. A survey of computation offloading with task types. IEEE Trans Intell Transp Syst. 2024;25(8):8313–33. doi:10.1109/TITS.2024.3410896. [Google Scholar] [CrossRef]
3. Liu J, Du Y, Yang K, Wu J, Wang Y, Hu X, et al. Edge-cloud collaborative computing on distributed intelligence and model optimization: a survey [Internet]. 2025 [cited 2025 Oct 3]. Available from: https://arxiv.org/abs/2505.01821. [Google Scholar]
4. Chen Q, Song X, Song T, Yang Y. Vehicular edge computing networks optimization via DRL-based communication resource allocation and load balancing. IEEE Trans Mob Comput. 2025;24(9):9222–37. doi:10.1109/TMC.2025.3559707. [Google Scholar] [CrossRef]
5. Ju T, Zhang W, Yang Y, Huo J. A second order decision-making dynamic offloading method for vehicle edge computing tasks. J Jilin Univ. 2025; 1–13. (In Chinese). doi:10.13229/j.cnki.jdxbgxb.20241283. [Google Scholar] [CrossRef]
6. Wang CX, You X, Gao X, Zhu X, Li Z, Zhang C, et al. On the road to 6G: visions, requirements, key technologies, and testbeds. IEEE Commun Surv Tutor. 2023;25(2):905–74. doi:10.1109/COMST.2023.3249835. [Google Scholar] [CrossRef]
7. Prathiba SB, Raja G, Anbalagan S, AK S, Gurumoorthy S, Dev K. A hybrid deep sensor anomaly detection for autonomous vehicles in 6G-V2X environment. IEEE Trans Netw Sci Eng. 2023;10(3):1246–55. doi:10.1109/TNSE.2022.3188304. [Google Scholar] [CrossRef]
8. Xu B, Deng T, Liu Y, Zhao Y,Xu J,QI J, et al. Optimization of cooperative offloading model with cost consideration in mobile edge computing. Soft Comput. 2023;27(12):8233–43. doi:10.1007/s00500-022-07733-1. [Google Scholar] [CrossRef]
9. Xia Y, Tian J, Zhang H, Yuan D. Joint task offloading and pricing strategy for multi-tier vehicular edge computing networks: a multi-leader multi-follower stackelberg game approach. IEEE Trans Cogn Commun Netw. 2026;12:1877–91. doi:10.1109/TCCN.2025.3600993. [Google Scholar] [CrossRef]
10. Sonmez C, Tunca C, Ozgovde A, Ersoy C. Machine learning-based workload orchestrator for vehicular edge computing. IEEE Trans Intell Transp Syst. 2021;22(4):2239–51. doi:10.1109/TITS.2020.3024233. [Google Scholar] [CrossRef]
11. Lei J, Liu H, Zhang J, Li S. Review of vehicular edge computing and task offloading based on deep reinforcement learning. Comput Syst Appl. 2025;34(11):1–19. (In Chinese). doi:10.15888/j.cnki.csa.010002. [Google Scholar] [CrossRef]
12. Mohamad A, Hady SH, Mahardhika Pratama ZC, Kowalczyk R. Multi-agent reinforcement learning for resources allocation optimization: a survey. Artif Intell Rev. 2025;58(11):354. doi:10.1007/s10462-025-11340-5. [Google Scholar] [CrossRef]
13. Lin J, Huang S, Zhang H, Yang X, Zhao P. A deep-reinforcement-learning-based computation offloading with mobile vehicles in vehicular edge computing. IEEE Internet Things J. 2023;10(17):15501–14. doi:10.1109/JIOT.2023.3264281. [Google Scholar] [CrossRef]
14. Bitam S, Mellouk A, Zeadally S. VANET-cloud: a generic cloud computing model for vehicular Ad Hoc networks. IEEE Wirel Commun. 2015;22(1):96–102. doi:10.1109/MWC.2015.7054724. [Google Scholar] [CrossRef]
15. Zhang W, Zhang Z, Chao HC. Cooperative fog computing for dealing with big data in the internet of vehicles: architecture and hierarchical resource management. IEEE Commun Mag. 2017;55(12):60–7. doi:10.1109/MCOM.2017.1700208. [Google Scholar] [CrossRef]
16. Zhang P, Wang E, Tan L, Kumar N, Wang J, Liu K. Enhancing task offloading in vehicular networks: a multi-agent cloud-edge-device framework. Veh Commun. 2025;53:100898. doi:10.1016/j.vehcom.2025.100898. [Google Scholar] [CrossRef]
17. Li ZY, Wang Q, Chen YF, Xie GQ, Li RF. A survey on task offloading research in vehicular edge computing. Chin J Comput. 2021;44(5):963–82. (In Chinese). doi:10.11897/SP.J.1016.2021.00963. [Google Scholar] [CrossRef]
18. Zhou X, Bilal M, Dou R, Rodrigues JJPC, Zhao Q, Dai J, et al. Edge computation offloading with content caching in 6G-Enabled IoV. IEEE Trans Intell Transp Syst. 2024;25(3):2733–47. doi:10.1109/TITS.2023.3239599. [Google Scholar] [CrossRef]
19. Xu XL, Yang W, Yang CY, Cheng Y, Qi LY, Xiang HL, et al. Efficient task offloading based on traffic prediction in IoV-enabled edge computing. Acta Electron Sin. 2025;53(2):329–43. (In Chinese). [Google Scholar]
20. Zhang Q, Wang Y, Zhang X, Liu L, Wu X, Shi W, et al. OpenVDAP: an open vehicular data analytics platform for CAVs. In: 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS); Piscataway, NJ, USA: IEEE; 2018. p. 1310–20. doi:10.1109/ICDCS.2018.00131. [Google Scholar] [CrossRef]
21. He B, Li T. An offloading scheduling strategy with minimized power overhead for internet of vehicles based on mobile edge computing. J Inf Process Syst. 2021;17(3):489–504. doi:10.3745/JIPS.01.0077. [Google Scholar] [CrossRef]
22. Li P, Xiao Z, Gao H, Wang X, Wang Y. Reinforcement learning based edge-end collaboration for multi-task scheduling in 6G enabled intelligent autonomous transport systems. IEEE Trans Intell Transp Syst. 2025;26(10):1–14. doi:10.1109/TITS.2024.3525356. [Google Scholar] [CrossRef]
23. Chen X, Hu S, Yu C, Chen Z, Min G. Real-time offloading for dependent and parallel tasks in cloud-edge environments using deep reinforcement learning. IEEE Trans Parallel Distrib Syst. 2024;35(3):391–404. doi:10.1109/TPDS.2023.3349177. [Google Scholar] [CrossRef]
24. Li Y, Chen Y, Lan T, Venkataramani G. MobiQoR: pushing the envelope of mobile edge computing via quality-of-result optimization. In: 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS); Piscataway, NJ, USA: IEEE; 2017. p. 1261–70. doi:10.1109/ICDCS.2017.54. [Google Scholar] [CrossRef]
25. Zhu C, Tao J, Pastor G, Xiao Y, Ji Y, Zhou Q, et al. Folo: latency and quality optimized task allocation in vehicular fog computing. IEEE Internet Things J. 2019;6(3):4150–61. doi:10.1109/JIOT.2018.2875520. [Google Scholar] [CrossRef]
26. Zhao N, Pei Y, Niyato D. Incentive mechanism for task offloading and resource cooperation in vehicular edge computing networks: a deep reinforcement learning-assisted contract approach. IEEE Internet Things J. 2024;11(24):41098–109. doi:10.1109/JIOT.2024.3457592. [Google Scholar] [CrossRef]
27. Zhu C, Pastor G, Xiao Y, Li Y, Ylae-Jaeaeski A. Fog following me: latency and quality balanced task allocation in vehicular fog computing. In: 2018 15th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON); Piscataway, NJ, USA: IEEE; 2018. p. 1–9. doi:10.1109/SAHCN.2018.8397129. [Google Scholar] [CrossRef]
28. Lv P, Xu W, Nie J, Yuan Y, Cai C, Chen Z, et al. Edge computing task offloading for environmental perception of autonomous vehicles in 6G networks. IEEE Trans Netw Sci Eng. 2023;10(3):1228–45. doi:10.1109/TNSE.2022.3211193. [Google Scholar] [CrossRef]
29. Ning Z, Dong P, Wang X, Rodrigues JJPC, Xia F. Deep reinforcement learning for vehicular edge computing: an intelligent offloading system. ACM Trans Intell Syst Technol. 2019;10(6):1–24. doi:10.1145/3317572. [Google Scholar] [CrossRef]
30. She H, Yan L, Guo Y. Efficient end-edge–cloud task offloading in 6G networks based on multiagent deep reinforcement learning. IEEE Internet Things J. 2024;11(11):20260–70. doi:10.1109/JIOT.2024.3372614. [Google Scholar] [CrossRef]
31. Annu, Rajalakshmi P. Towards 6G V2X sidelink: survey of resource allocation—mathematical formulations, challenges, and proposed solutions. IEEE Open J Veh Technol. 2024;5(22):344–83. doi:10.1109/OJVT.2024.3368240. [Google Scholar] [CrossRef]
32. Noor-A-Rahim M, Liu Z, Lee H, Khyam MO, He J, Pesch D, et al. 6G for vehicle-to-everything (V2X) communications: enabling technologies, challenges, and opportunities. Proc IEEE. 2022;110(6):712–34. doi:10.1109/JPROC.2022.3173031. [Google Scholar] [CrossRef]
33. Li H, Meng S, Sun J, Cai Z, Li Q, Zhang X. Multi-agent deep reinforcement learning based multi-task partial computation offloading in mobile edge computing. Future Gener Comput Syst. 2025;172:107861. doi:10.1016/j.future.2025.107861. [Google Scholar] [CrossRef]
34. Wang J, Lv T, Huang P, Mathiopoulos PT. Mobility-aware partial computation offloading in vehicular networks: a deep reinforcement learning based scheme. China Commun. 2020;17(10):31–49. doi:10.23919/JCC.2020.10.003. [Google Scholar] [CrossRef]
35. Yue K, Peng K, Lin Y, Zhao X, Xu X, Leung VCM. PORPRS: priority-aware task offloading in HAP-aided internet of vehicles via GRPO with dynamic residual shrinkage networks. Ad Hoc Netw. 2025;179:104004. doi:10.1016/j.adhoc.2025.104004. [Google Scholar] [CrossRef]
36. Liu Y, Wang W, Hu Y, Hao J, Chen X, Gao Y. Multi-agent game abstraction via graph attention neural network. Proc AAAI Conf Artif Intell. 2020;34(5):7211–8. doi:10.1609/aaai.v34i05.6211. [Google Scholar] [CrossRef]
37. Yu C, Velu A, Vinitsky E, Gao J, Wang Y, Bayen A, et al. The surprising effectiveness of PPO in cooperative multi-agent games. arXiv:2103.01955. 2022. doi:10.48550/arXiv.2103.01955. [Google Scholar] [CrossRef]
38. Engstrom L, Ilyas A, Santurkar S, Tsipras D, Janoos F, Rudolph L, et al. Implementation matters in deep policy gradients: a case study on PPO and TRPO.arXiv:2005.12729. 2020. [Google Scholar]
39. Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv:1707.06347. 2017. [Google Scholar]
40. Shuai K, Miao Y, Hwang K, Li Z. Transfer reinforcement learning for adaptive task offloading over distributed edge clouds. IEEE Trans Cloud Comput. 2023;11(2):2175–87. doi:10.1109/TCC.2022.3192560. [Google Scholar] [CrossRef]
41. Sonmez C. EdgeCloudSim. 2018 [cited 2025 Oct 3]. Available from: https://github.com/CagataySonmez/EdgeCloudSim/tree/master?tab=readme-ov-file. [Google Scholar]
42. Ji Y, Wang Y, Zhao H, Gui G, Gacanin H, Sari H, et al. Multi-agent reinforcement learning resources allocation method using dueling double deep Q-network in vehicular networks. IEEE Trans Veh Technol. 2023;72(10):13447–60. doi:10.1109/TVT.2023.3275546. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools