
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CP-YOLO: A Multi-Scale Fusion Method for Electric Vehicle Charging Port Identification
1 Tianjin Key Laboratory for Advanced Mechatronic System Design and Intelligent Control, School of Mechanical Engineering, Tianjin University of Technology, Tianjin, China
2 National Demonstration Center for Experimental Mechanical and Electrical Engineering Education, Tianjin University of Technology, Tianjin, China
* Corresponding Author: Pengfei Ju. Email:
Computers, Materials & Continua 2026, 87(3), 92 https://doi.org/10.32604/cmc.2026.075309
Received 29 October 2025; Accepted 13 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
As the number of electric vehicles continues to rise, pressure on charging infrastructure grows increasingly intense. Mobile charging technology, with its flexibility and deployability, has emerged as an effective solution. Within this technology, charging robots or vehicles must autonomously locate and dock with charging ports. Consequently, precise and stable charging port recognition constitutes both a prerequisite and the core bottleneck for achieving automated operations in mobile charging systems. However, in practical scenarios, charging ports often prove difficult to detect reliably due to factors such as physical obstructions, variations in lighting, and long shooting distances. To address this, this paper proposes CP-YOLO, an improved YOLOv9-based detection model for electric vehicle charging ports. The method first incorporates Space-to-Depth Convolution (SPDConv) into the backbone network, reorganising spatial dimensions into channel dimensions to preserve fine-grained features, thereby providing high-fidelity detail for subsequent processing. Secondly, it constructs the C2f-MLKA module, which fuses multi-level features and enhances contextual modelling capabilities through large-kernel attention and gating mechanisms. Finally, introducing Spatially Adaptive Feature Modulation (SAFM) in the neck network enables multi-scale feature fusion and dynamic adjustment of feature weights in critical regions. This forms a progressive mechanism—detailed fidelity, enhanced contextual understanding, and spatial adaptability—to elevate the model’s recognition performance. Experimental results demonstrate that compared to the original YOLOv9 model, Mean Average Precision (mAP) improves by 3.8%, outperforming Faster Region-based Convolutional Neural Networks (R-CNN), EfficientDet and Real-Time Detection Transformer (RT-DETR) by 22.8%, 18.8% and 10%, respectively, and surpasses other YOLO variants by 12.6%, 8.0%, 3.8%, 5.5%, 7.3% and 9.4%, respectively. This effectively enhances detection accuracy for charging ports in complex environments, offering practical reference value for mobile charging technology applications.Keywords
With the accelerating global energy transition, the widespread adoption of electric vehicles has become a key pathway for energy-driven sustainable development [1,2]. Nonetheless, the delay in charge infrastructure has turned into a hindrance, limiting its effective development. Traditional stationary charging stations face constraints due to factors like on-site availability, electrical capacity, and the duration of construction, complicating the rapid increase in charging needs [3], particularly in high-demand holiday periods, isolated regions, and ancient cities, where the issues of limited charging capacities and extended waiting times are especially evident. Additionally, conventional manual charging poses risks, with incorrect functioning potentially harming the charging ports during actions like extracting the charging gun and docking them. Traditional charging stations are typically set up outside, where weather conditions can lead to harm, posing a threat of electric shock to synthetic charging systems. These charging stations, often stationary on the ground, lack the adaptability to fulfill charging requirements. Consequently, mobile charging technology emerged as a novel, supplementary energy solution, utilizing the “pile to find the car” model to reshape the charging service environment, thus playing a crucial role in resolving charging issues [4]. Although State Grid Corporation of China has piloted ‘emergency charging pods’ in certain motorway service areas as an attempt to enhance charging capacity within confined spaces, such facilities remain fundamentally fixed installations. They suffer from inherent limitations including insufficient flexibility and constrained user experience optimisation. While countries like the United States and Japan have undertaken research and demonstration projects in electric vehicle charging technology, their focus has predominantly centred on boosting charging power or single technical metrics. Systematic research remains insufficient in developing multi-scenario, intelligent, and mobile charging solutions designed to comprehensively enhance user comfort and integrate diverse service functions. Such solutions commonly suffer from limited functionality and low levels of intelligence and integration. A pivotal step in achieving mobile charging is the rapid, stable, and high-precision identification of electric vehicle charging ports. This serves as an absolute prerequisite for subsequent actions such as robotic arm servo docking, secure plug insertion removal, and electrical connection—its importance being self-evident.
In recent years, due to the rapid development of image processing and deep learning technology, mobile charging technology has also ushered in a new development opportunity [5], and the object detection technology can realize stable and acc-urate identification of charging ports. Traditional object detection methods can be broadly categorized into three types: One-stage object detectors method based on regression analysis, which mainly includes networks such as SSD [6], YOLO [7–11] series and Retina-Net [12]. The second is a two-stage object detection method based on candidate frames, mainly Faster R-CNN [13], Mask R-CNN [14], Cascade R-CNN [15] and other networks. Finally, there are Transformer based [16] object detection methods, mainly DETR, RT-DETR [17], UP-DETR [18] and other networks. One-stage object detection methods have relatively fast detection speeds and low memory consumption, but they can lead to information loss and ignore the association between the whole and the parts, reducing detection accuracy. The two-stage object detection method is more accurate in localization and has higher detection accuracy, but its training pace is sluggish, the use of resources is excessive, and it falls short for tasks involving real-time detection. Object detection techniques based on transformers excel in accuracy, yet they require more resources and exhibit slow convergence rates. In contrast, employing single-stage object detection algorithms such as the YOLO series, while maintaining relatively rapid detection speeds, would prove more suitable for real-time monitoring by mobile charging robots if detection accuracy were enhanced through refinement. When directly applied to charging port detection, these algorithms often struggle to effectively address core challenges such as loss of small target features, partial occlusion, varying light conditions, and differences in appearance across multiple types.
Early research into charging port recognition primarily relied on conventional image processing techniques, Quan et al. [19,20] proposed a method for electric vehicle charging port recognition, according to the charging port characteristics of the whole recognition process is divided into two parts, first based on the Hough circle and the Hough line algorithm to obtain the charging port recognition area, and then use the Canny operator to obtain the charging port area of the original image and gradient image information, and then fusion of the two types of information to get more effective contour information. The two kinds of information are fused to get more effective contour information, which effectively improves the recognition accuracy. Such methods prove effective in controlled environments, yet their reliance on manual feature design renders them insufficiently robust in complex real-world scenarios. Subsequently, end-to-end detection based on convolutional neural networks became the mainstream approach., a method using a combination of CBAM [21] and YOLOV7 [22]-tinp is proposed to obtain the feature information of the charging port, and then the CTMA is used to obtain the accurate feature location and label type, which realizes the recognition of the charging port in a variety of categories and scenarios, however, the performance of the CTMA template matching algorithm is highly dependent on the quality and completeness of the pre-stored templates. When the charging port is partially obscured or incomplete in the image, the algorithm cannot achieve effective matching, making it highly susceptible to false negatives. Zhu et al. [23] proposed a POI feature extraction method based on YOLOv4 [24] network, which utilizes the rectangular box position and size information to segment the original image to get the charging port position, and then uses ROI to extract to the charging port feature information, which effectively reduces the image processing time and improves the recognition accuracy, however, this approach fails to address the fundamental issue of detail loss in small targets caused by downsampling within YOLOv4’s deep network architecture. Consequently, the extracted features lack the fine-grained information required to distinguish between different charging port types. Li et al. [25] used the SIFT feature extraction algorithm to realize the construction of spatial scale and get the detailed features of the charging port area, and then used the FLANN matching algorithm to match with the pre-stored features of the charging ports to get the high-precision mapping set of the points, which is highly robust even under different lighting environments, and is able to realize accurate recognition. Mahaadevan et al. [26]. proposed a recognition method that can be applied to a variety of charging port types, improved the YOLOv5s network model by adding Swin transform [27] module and SimAM attention mechanism, which can get more global information and enhance the network’s ability of aggregation of features through context, and finally proved that by validating on the test set, it with higher average accuracy and real-time inference speed, which has a good future prospect, However, its design exhibits certain limitations in the specific context of mobile charging scenarios. The Swin Transformer demonstrates insufficient modelling of local details and channel features, while the generalised SimAM mechanism fails to adequately identify discriminative features for small targets such as charging ports. This points the way towards constructing a more efficient, task-specific model in this paper. Subsequently, Mahaadevan et al. [28] proposed an advanced system, AViTRoN (Advanced Visual Tracking, Routing and Navigation), based on the YOLOv8 deep learning model. Utilising data inputs from 3D depth sensors and infrared sensors, it achieves real-time charging port type recognition within the Robot Operating System (ROS) framework. This has effectively enhanced the system’s operational precision.
Based on the research into existing algorithms outlined above, this paper proposes a YOLOv9-based detection algorithm for electric vehicle charging ports—CP-YOLO. We abandon the approach of single-layer enhancements, instead systematically embedding targeted innovation modules at different critical stages of the detection framework: SPDConv preserves low-level details, C2f-MLKA enhances long-range contextual semantics for small targets, and SAFM achieves adaptive fusion of multi-scale occlusion features. This constructs a progressive processing approach spanning detail fidelity, semantic enhancement, and spatial optimisation. Experimental results demonstrate that the CP-YOLO model exhibits outstanding detection performance across diverse environments while effectively resolving the aforementioned challenges. The principal contributions of this paper are as follows:
(1) For the complex background to make the image quality degradation lead to charging port False Positive and False Negative and other problems, the SPDConv [29] is referenced in the backbone network, so that the input feature map, after the extraction of features by the backbone network, provides richer fine-grained information for the overall model, and improves the recognition rate of the charging port objective.
(2) A Spatially-adaptive Feature Modulation (SAFM) [30] is implemented in the neck network to tackle the issue of various types of charging ports, which are either hidden or impaired in the detection task’s field of view. This system undertakes channel segmentation, generates features across multiple scales, and adaptively aggregates the features of the charging ports. Subsequently, it dynamically modifies the weight of these features to selectively boost feature extraction in crucial areas, thereby elevating the accuracy of detection.
(3) To address the issues of weak semantic information, susceptibility to decay, and lack of contextual dependency in small targets, this paper introduces a novel C2f-MLKA module integrated into the backbone network [31]. This module integrates a large-core attention mechanism, multi-scale learning, and gated aggregation. By establishing long-range spatial dependencies, it enables the model to correlate charging ports with contextual information from their surrounding vehicle environments. This effectively enhances semantic representations of small-scale and ambiguous targets, improving localisation and classification accuracy in complex backgrounds.
The rest of this paper is structured as follows: Section 2 presents the main theoretical methods of the study; Section 3 describes the experiments and conclusions; and Section 4 presents the conclusions.
Our research has identified several challenges during the charging process of mobile charging robots for new energy vehicles, including reduced recognition accuracy due to complex environments, obstructed charging ports, and small target dimensions. Analysis of these issues indicates the necessity for preserving high-resolution detail features, adaptive spatial selection capabilities, and robust global contextual understanding. Consequently, we propose the task-driven CP-YOLO model, which integrates SPDConv, SAFM, and C2f MLKA for collaborative detection. This model systematically resolves the aforementioned challenges through a progressive mechanism: detail fidelity preservation, context understanding enhancement, and spatial adaptation. The YOLO network aids the supervision system by proposing Programmable Gradient Information based on its predecessor version and designing a new lightweight network architecture, the Generalized Efficient Layer Aggregation Network. This study selected YOLOv9 as the foundational framework, primarily due to its combination of cutting-edge innovation and practical utility. YOLOv9’s Programmable Gradient Information (PGI) mechanism effectively mitigates information loss within deep neural networks, proving crucial for charging port detection tasks demanding high detail retention. Compared to other real-time detection models, YOLOv9 achieves an optimal balance of accuracy and speed on standard benchmarks, providing an excellent foundation for this research. It demonstrates high recognition accuracy and strong robustness for charging port identification in complex environments. Therefore, this paper selects YOLOv9 network as the base model and proposes the improved CP-YOLO model, as shown in Fig. 1. Subsequent enhancements were applied to the initial model to address various issues: First, SPDConv is introduced to optimise each feature map, thereby retaining a large amount of fine-grained information and effectively improving the model’s image recognition accuracy in complex backgrounds. This makes it easier to identify charging port features in complex back grounds and effectively reduces false negatives and false positives. Secondly, SAFM is used to perform channel segmentation, multi-scale feature generation, and adaptive aggregation on the input features. Based on the complexity of the input content, the feature weights are dynamically adjusted to selectively enhance feature extraction in critical reg-ions. This provides an effective solution to issues such as multiple types of charging ports in the image, occlusion, or incomplete visibility in the field of view, which can lead to incorrect recognition or low recognition accuracy. Finally, through the constructed C2f-MLKA module, the target features are processed at a deeper level, taking into account both local and long-range information. Combining large kernel decomposition and multi-scale learning, adeendency based, multi-scale mechanism is established to obtain heterogeneous scale correlations and gate aggregation dynamic calibration, thereby obtaining long-range dependencies at different granularities and improving the model’s representation capabilities. This solves problems such as blurred charging port images and loss of detail due to small targets.
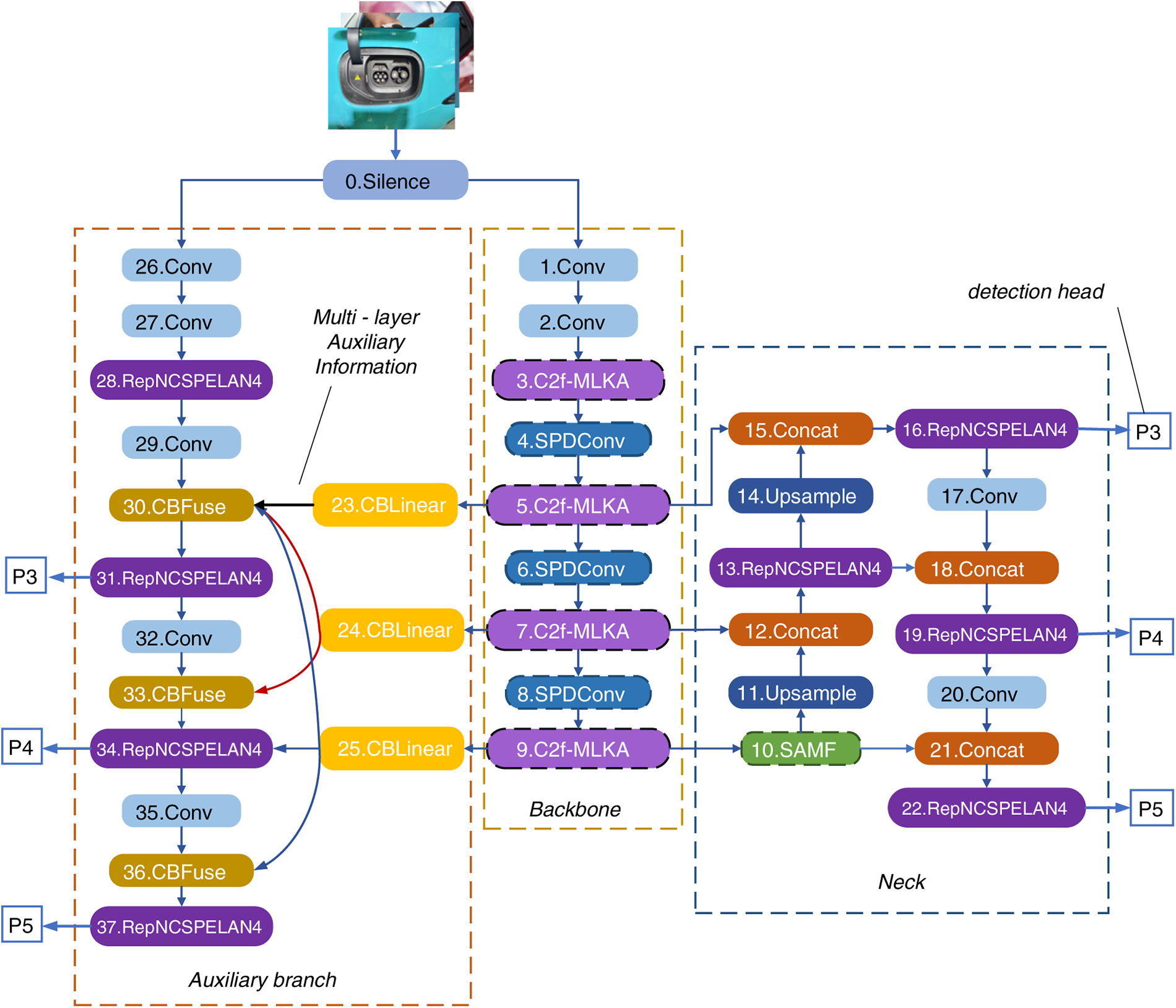
Figure 1: Overall structure of CP-YOLO.
2.1 Introduction of the SPDConv
The accuracy of charging port detection is highly dependent on the resolution of the input image. In practical mobile charging scenarios, environmental factors such as insufficient lighting and long shooting distances frequently result in degraded image quality. Low-resolution images further blur the already pixel-scarce features of charging ports, while complex vehicle backgrounds may be misclassified as targets due to texture interference. Furthermore, the stride-based convolutions and pooling operations relied upon by mainstream detectors like YOLOv9 inevitably result in the loss of fine-grained information during feature extraction, exacerbating the misclassification and omission of small targets. To address these issues, this paper introduces the SPDConv module, comprising a Spatial-to-Depth layer and a non-stride convolution layer. The unique advantage of this module lies in its ability to perform downsampling without information loss. Specifically, the SPD layer achieves lossless resolution reduction by compressing the spatial dimensions of feature maps and reorganising them along the channel dimension. Subsequently, the non-stride convolution layer performs standard convolution operations on the restructured features, effectively integrating information while suppressing potential redundancy introduced by the restructuring process. This design ensures critical details such as charging port edges and textures are fully preserved, providing high-fidelity feature representations for subsequent detection layers. It proves highly suitable for the reliable recognition of small-scale, detail-rich objects like charging ports within complex scenes.
The SPDConv module downsampling process is shown in Fig. 2.
where
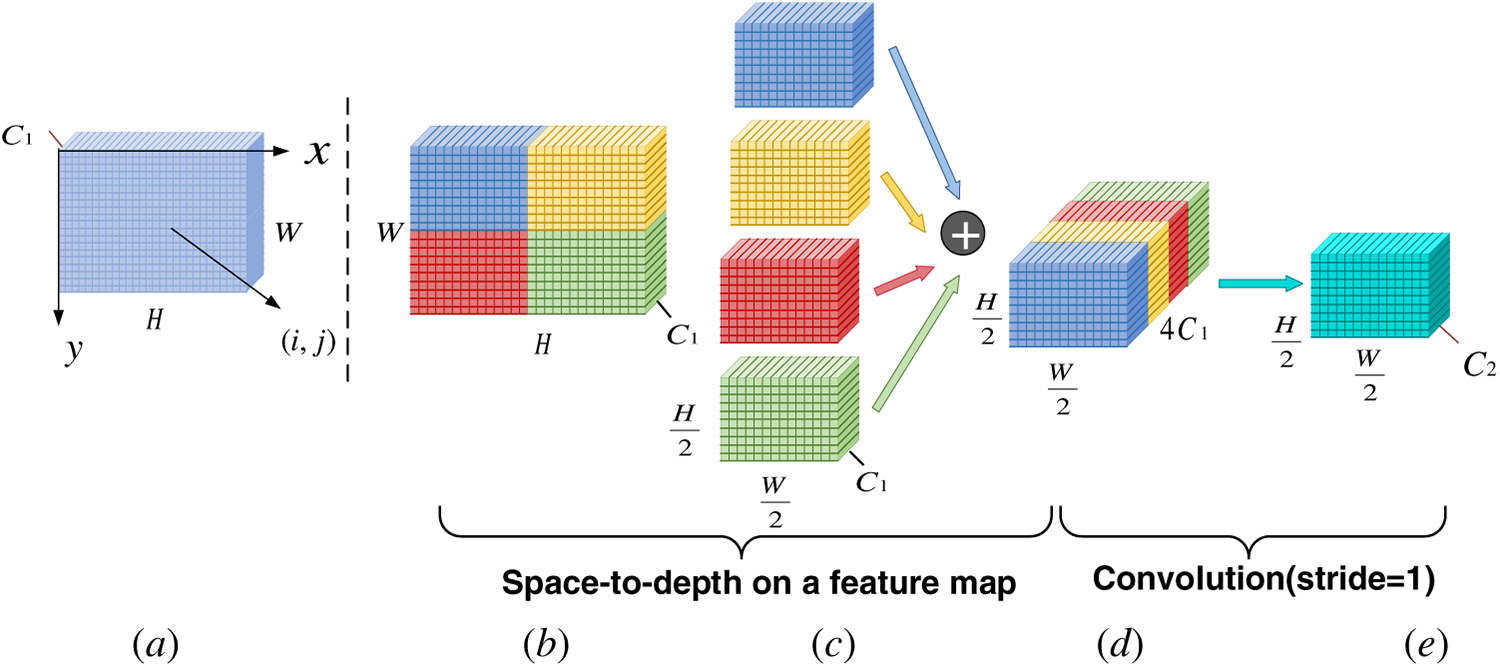
Figure 2: Schematic diagram of SPDConv module.
2.2 Spatially-Adaptive Feature Modulation
In the charging port detection task, charging port targets often exhibit multi-category appearance variations due to standard specifications. Moreover, in practical scenarios such as mobile charging, they are prone to occlusion or partial visibility, resulting in incomplete features that are difficult to recognise. As illustrated in Fig. 3, although the SPPELAN module employed by YOLOv9 can fuse multi-scale information, its reliance on multiple fixed-size max-pooling layers for feature extraction and cascaded fusion lacks adaptability to dynamic content. When confronted with charging ports exhibiting category variations, occlusions, or incompleteness, this static pooling and simple concatenation mechanism struggles to distinguish and enhance key features. Instead, it may compromise detection robustness due to information loss and interference from invalid features.
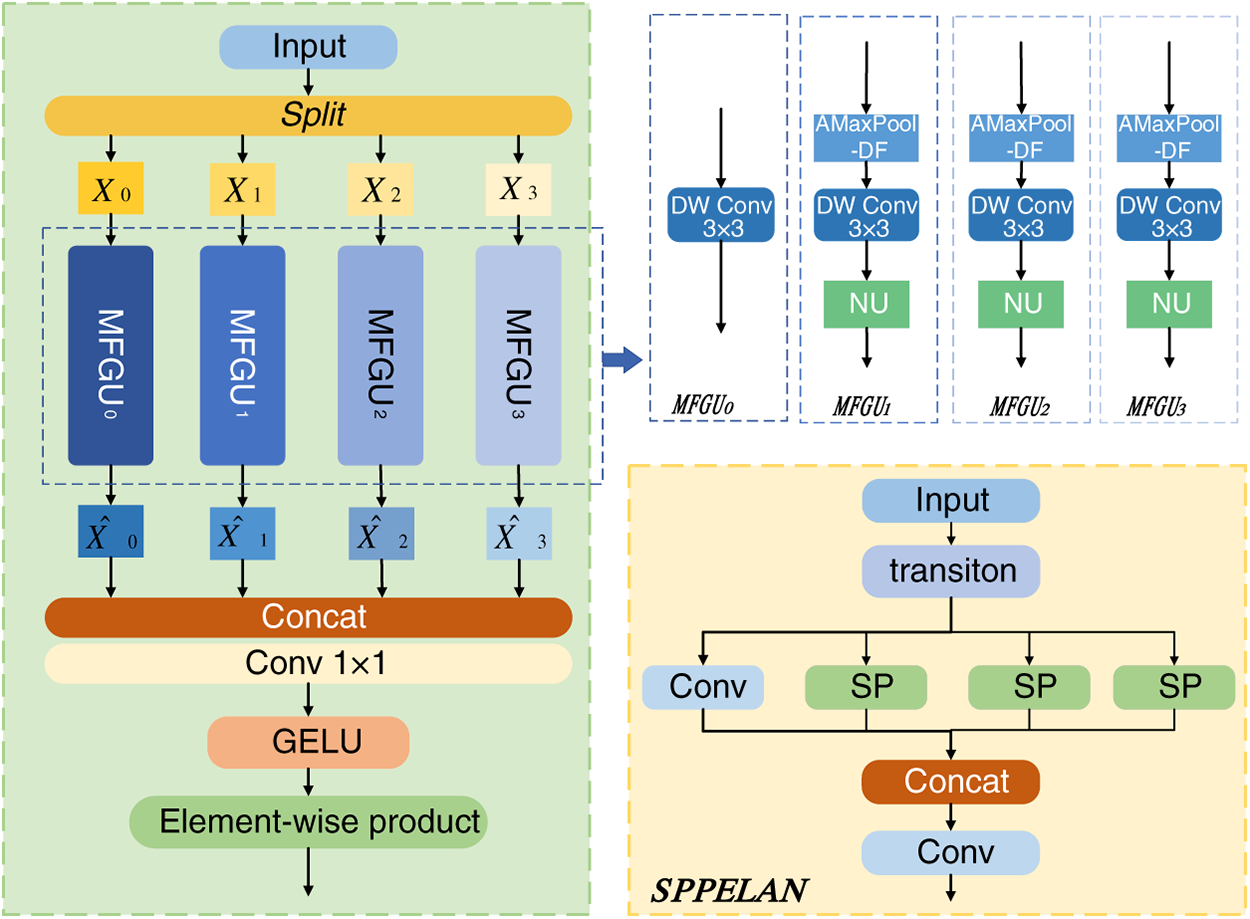
Figure 3: Schematic diagram of SAFM and SPPELAN structures.
To this end, this paper replaces the SPPELAN module in the neck region with a Spatially Adaptive Feature Modulation (SAFM) module. Through channel segmentation, multi-scale feature generation, and adaptive weight aggregation, SAFM dynamically adjusts the importance of positional and scale features based on the semantic content of the input features. Addressing category variations, local occlusions, and incomplete regions within charging port images, SAFM autonomously enhances key features while suppressing irrelevant background responses. Concurrently, it generates adaptive feature maps via the GELU activation function, achieving synergistic optimisation of local details and global context. This dynamic fusion mechanism significantly mitigates information loss caused by fixed pooling in SPPELAN, enhancing the model’s recognition capabilities for complex appearances and partially visible objects.
The input feature
Eq. (3) denotes that
Eq. (4) denotes that features of
where
After splicing these features of different scales in the channel dimension, they are aggregated by 1 × 1 convolution, then normalized by the Gaussian Error Linear Unit (GELU) activation function to obtain the attention map
where
2.3 Construction of the C2f-MLKA
In the task of detecting charging ports, the targets within images are often small in size, making them prone to semantic information decay. Existing detection methods typically rely on deep convolutional networks to extract features. However, while the RepNCSPELAN4 module employed by YOLOv9 achieves a favourable balance between speed, accuracy, and lightweight design, it struggles to adequately model the long-range dependencies of small targets, thereby limiting its semantic representation capabilities. To address this, this paper proposes a novel C2f-MLKA module to replace the RepNCSPELAN4 in the backbone network. Its core lies in cascading multiple BottleneckMLKA units, each integrating multi-scale large-kernel attention, and fusing multi-level features through dense residual connections. By enhancing local detail perception and global dependency modelling, the model’s ability to extract and preserve small objects and ambiguous features is significantly improved.
Furthermore, by applying adaptive weighting to multi-path features through a gated fusion strategy, the model enhances the coherence and discriminative power of global semantic representations while strengthening its ability to preserve local details. This design markedly improves the model’s ability to extract and retain features of small-scale charging ports under conditions such as blurring and occlusion. It complements the detailed information provided by the aforementioned SPDConv and the spatial adaptive mechanism of SAFM, collectively enhancing the model’s detection robustness in complex scenarios.
As shown in Fig. 4, in the RepNCSPELAN4, multiple RepNCSP layers are used after the convolutional layer to extract the target features, but the extracted features are not sufficient, which can easily lead to the gradual weakening of small target features. For this reason, C2f-MLKA improves the connection part of multiple BottleneckMLKA layers, through multiple BottleneckMLKA for deeper processing of target features, and to ensure that the features extracted by each BottleneckMLKA are effectively retained, C2f-MLKA introduces multiple residual connections to integrate multiple features, fully utilize multiple layers of target features, and enhance the target information transfer, and C2f-MLKA can acquire target information features, while taking into account both local and long distance information, by combining Large kernel attention and Multi-scale mechanism. By the large kernel of attention to establish the dependence, multiscale mechanism to obtain the heterogeneous scales of correlation, the dynamic calibration of the gated aggregation, in different granularity to obtain the long-distance dependence, to improve the model representation capability.
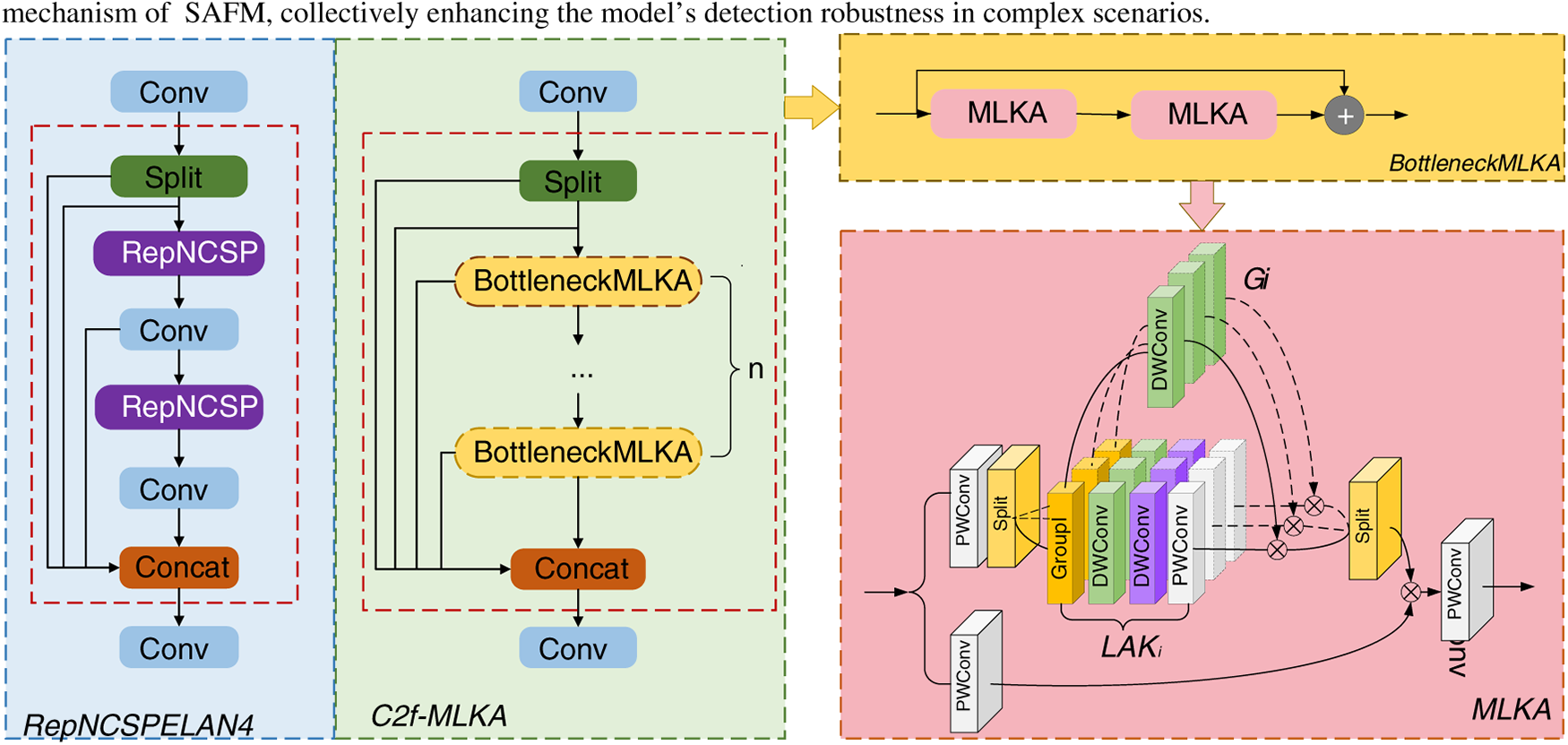
Figure 4: Schematic representation of RepNCSPELAN4 and C2f-MLKA structures. In BottleneckMLKA, features are extracted by two MLKA modules and residual joins are used to give better gradient propagation. The MLKA module structure is composed of three main parts: Large kernel attention (
The number of instances of different types of charging ports, type images and data enhancement effects in the dataset for this experiment are shown in Fig. 5. The dataset employed in this study’s experiments comprises a hybrid collection, with images sourced from both publicly available datasets and proprietary datasets. The ratio of publicly available to proprietary datasets is approximately 3:1. The publicly available dataset originates from the Charging port dataset within the Roboflow Universe community. Following consolidation, the total number of images across the entire dataset stands at 3984. Given the prevalence of noise and label inconsistencies within the Roboflow dataset, each image was meticulously examined to determine its suitability for experimental requirements.
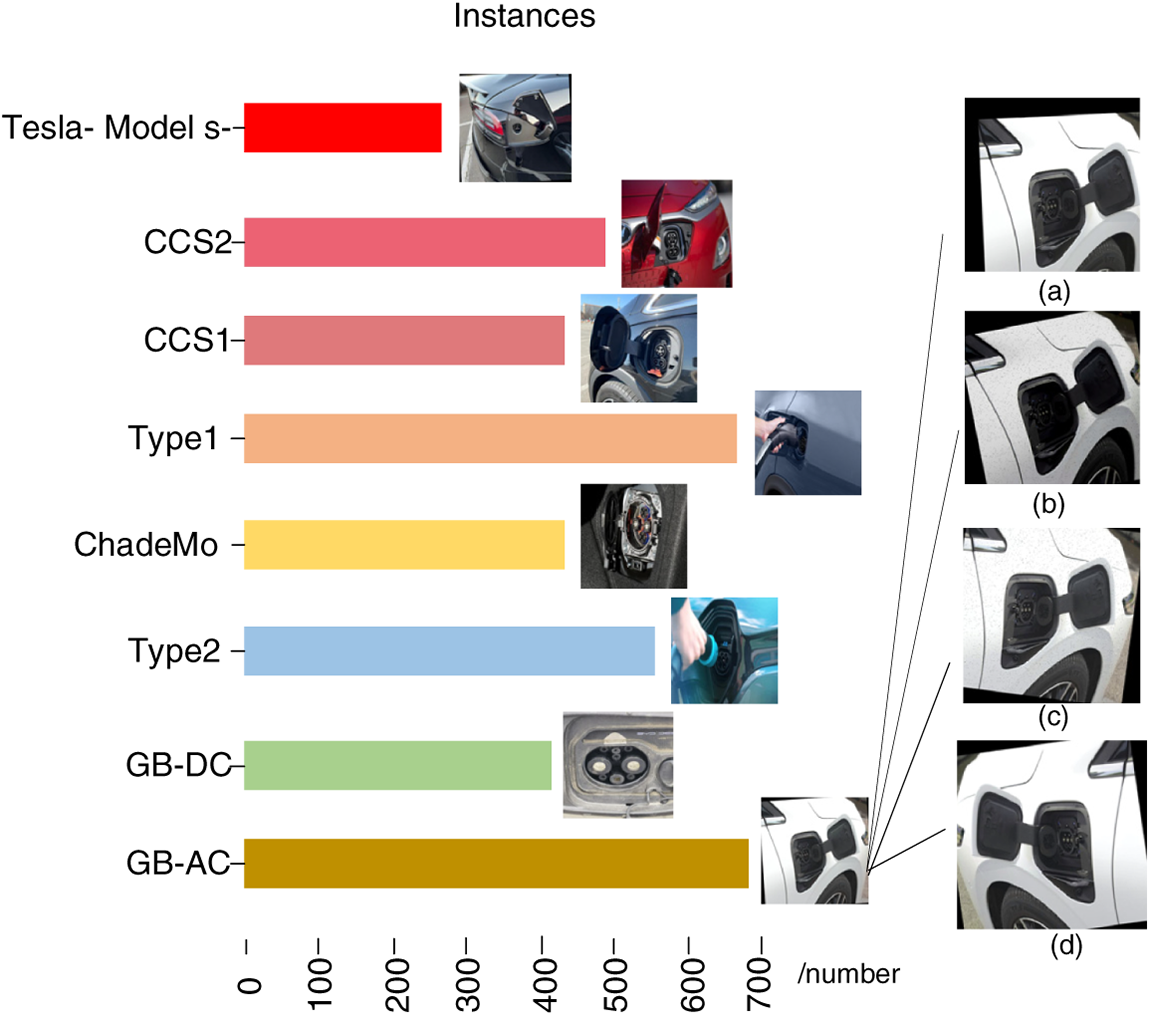
Figure 5: Schematic representation of the number, shape and data enhancement of each category of the training dataset. Where (a) is the image rotated and cropped, (b) is the image rotated, added noise and reduced brightness, (c) is the image rotated and added noise, and (d) is the image flipped and rotated.
The produced datasets were categorized into eight categories: the Tesla-Model S-, CCS2, CCS1, Type1, ChadeMo, Type2, GB-DC, GB-AC; Among them, Tesla-Model S-, CCS2, CCS1, Type1, ChadeMo, and Type2 are public datasets, from which images that meet the experimental requirements are selected, including different lighting and backgrounds, different types of charging ports, charging ports that are blocked and crippled in the image, charging ports that are small in size in the target and blurred in the image, etc., and normal charging scenarios are included as well, GB-DC and GB-AC are the datasets with manual shooting number meeting the requirements, as shown in Fig. 6 in order to avoid model overfitting and improve the robustness of the algorithm, data enhancement is performed on the dataset, including adjusting the brightness of the image, adding noise, rotating, cropping, flipping, etc. As there are very few original Tesla Model S images meeting the requirements, we have added more augmented images to this category to increase its proportion within the dataset, thereby striving to achieve a balanced distribution of data across all categories. Finally, using the LabelImg software, each image was relabelled with the charging port object as the annotated target. The dataset was then randomly partitioned into training, testing, and validation sets in an 8:1:1 ratio. All subsequent experiments employed this same dataset.


Figure 6: Partial dataset images. (a) GB-AC and GB-DC images under normal lighting conditions, (b) GB-AC and GB-DC images in dim lighting conditions, (c) ChadeMo and Type1 images in dim lighting conditions, (d) GB-AC and GB-DC images under strong light conditions, (e) GB-AC and GB-DC images with obstructed views, (f) GB-AC images with damaged charging ports and complete GB-DC images, (g) Type1 images with small targets, and (h) Type2 images with blurred targets.
3.2 Experimental Details and Evaluation Criteria
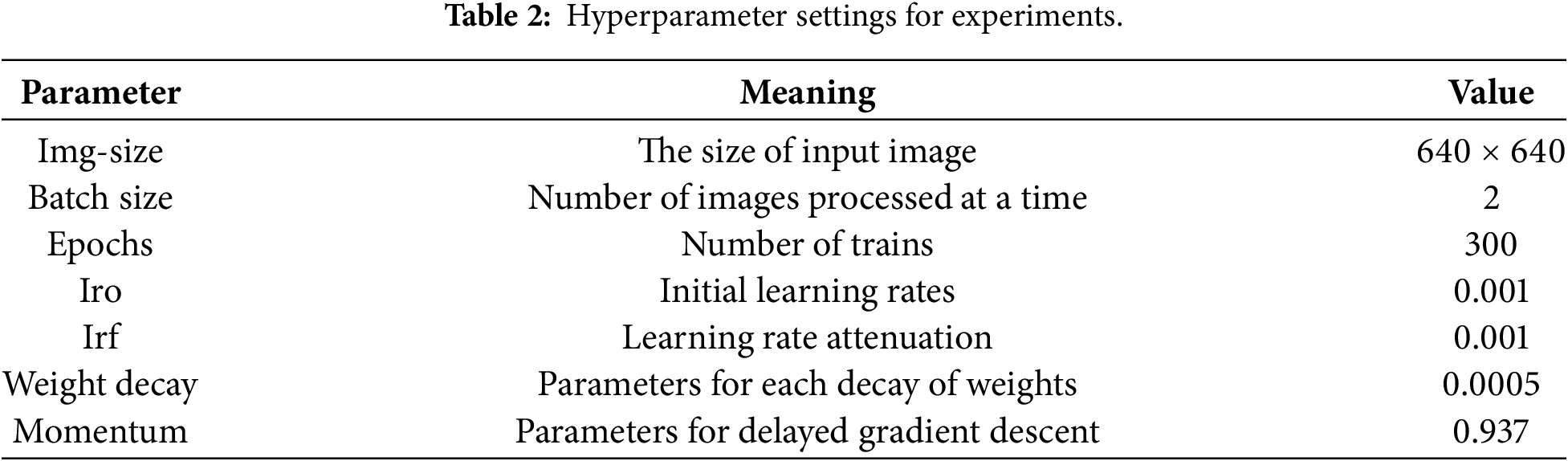
The experimental environment for this paper is shown in Table 1, and the hyperparameter are shown in Table 2. The selection of specific hyperparameters was determined through experimental analysis. This set of parameters maximises the model’s generalisation performance and precision ceiling for this task while ensuring stable training convergence. It provides a reliable training foundation for the efficacy of the CP-YOLO architecture and guarantees the reproducibility of the experiments.

In this experiment, the common evaluation criteria: precision, recall, GFLOPs and mean average precision(mAP) are chosen as the evaluation indexes. The GFLOPs are indicative of the model’s computational intricacy, serving as a metric for evaluating mobile deployment efficiency. The model’s accuracy in identifying charging ports is gauged by its precision, it is calculated using Eq. (7).
Recall rate is indicative of its comprehensive capability to detect these ports. A higher recall signifies a reduced rate of misdetections. It is calculated using Eq. (8).
Average Precision is a crucial performance metric for evaluating a model’s performance across various object categories in object detection tasks. It is calculated using Eq. (9).
The average precision value plays a crucial role in gauging the model’s performance, indicating its overall accuracy in recognizing various charging port categories and thoroughly evaluating the efficacy of multi-category object detection. Among them, the 0.5 metric is used to represent the mAP when the IoU is 0.5. its calculation formula is shown Eq. (10).
where
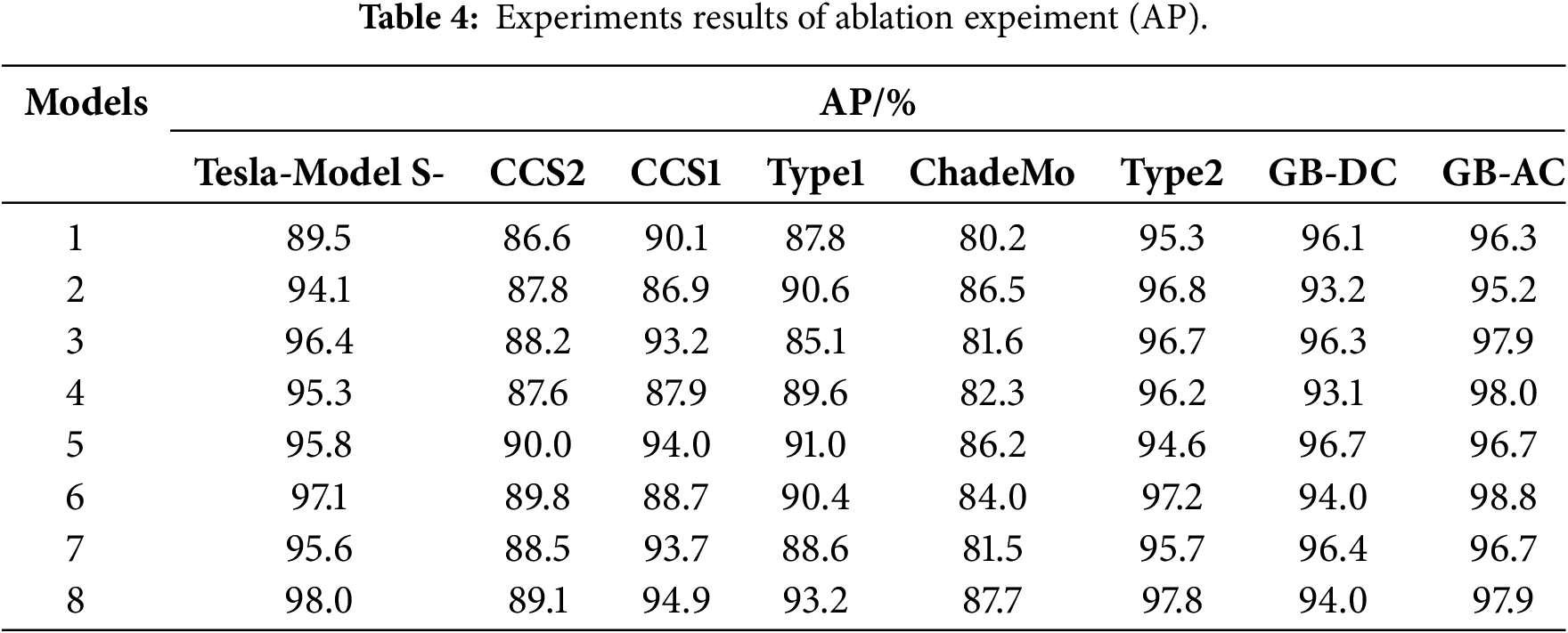
To further validate the effectiveness of the proposed method, we design an ablation study under consistent experimental parameters for a comparative analysis to demonstrate the role of the introduced module. The experimental results are shown in Tables 3 and 4. In the table we use “√” to indicate the use of this model and “–” to indicate its exclusion.
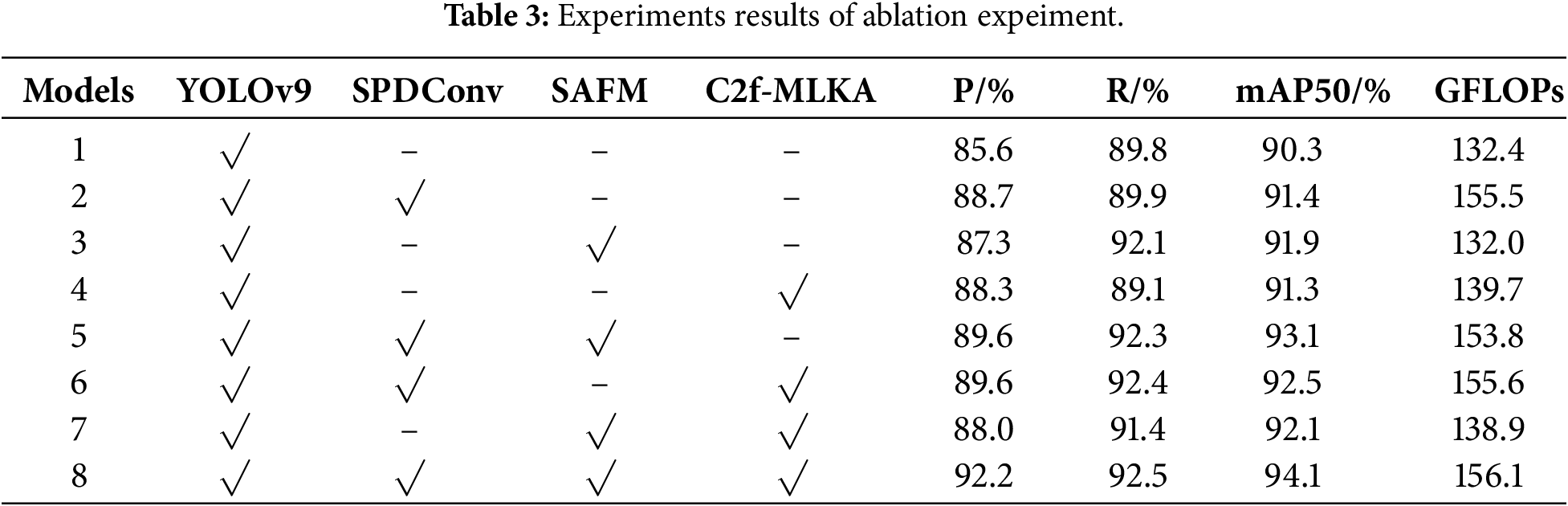
(1) Single-module performance analysis: Experimental data reveal a clear trend in how each module influences model performance. Model 2 achieves improvements of 3.1% and 1.1% in P and mAP, respectively, with notably enhanced accuracy for Tesla-Model S and ChadeMo categories. This demonstrates its distinct efficacy in handling low-resolution images and detail enhancement, though it also introduces some noise, resulting in a slight decline in accuracy for categories such as CCS2 and GB-DC. Model 3 achieved gains of 2.3% and 1.6% in R and mAP, respectively, demonstrating strong spatial adaptability for occluded and incomplete objects. Although accuracy slightly decreased in individual categories, the overall improvement was substantial. Model 4 primarily contributed to accuracy gains of 2.7% and mAP improvements of 1.0%, further enhancing contextual modelling capabilities. Collectively, each individual module enhances model performance from distinct perspectives, with SAFM demonstrating the most pronounced improvements in recall and overall detection stability.
(2) Multi-module combination performance analysis: Experimental results demonstrate that synergistic effects between modules are further accentuated. Model 5 exhibits consistent improvements in Precision, Recall, and mAP, indicating that SAFM effectively filters and utilises the detailed features provided by SPDConv while suppressing its noise. Model 6 achieves a 2.2% increase in mAP, particularly attaining peak accuracy in the GB-AC category, suggesting that combining detail preservation with context enhancement significantly improves recognition of complex objects. Model 7 achieves accuracy gains across all categories, demonstrating that robust detection performance can be attained through the fusion of strong semantic features with spatial adaptation. Ultimately, Model 8 outperforms the baseline YOLOv9 by 6.6%, 2.7%, and 3.8% in P, R, and mAP, respectively, with significant accuracy improvements across the vast majority of categories. This validates the effectiveness of the model’s progressive mechanism: detail fidelity → context enhancement → spatial adaptation. Minor declines occurred in certain categories where contextual aggregation rendered fine-grained noise difficult to filter accurately, as illustrated in Fig. 7: (a) presents the feature heatmap for Model 1, while (b) shows that for Model 2. The figure reveals that when processing GB-DC class samples, Model 2 incorporating SPDConv occasionally exhibits feature heatmap diffusion, particularly under dim lighting conditions. This suggests that the fine-grained noise retained by SPDConv may interfere with subsequent network judgements under extremely low signal-to-noise ratios. Finally, this paper conducted three rounds of independent random seed training for both CP-YOLO and YOLOv9 models, followed by statistical analysis. Experimental results demonstrate that CP-YOLO achieves mAP values of 94.1%, 94.1%, and 94.0%, while YOLOv9 achieves 90.3%, 90.0%, and 89.4%. CP-YOLO consistently outperforms YOLOv9 across all runs, confirming that the improvement is robust rather than attributable to random noise. In summary, CP-YOLO exhibits significant improvements in accuracy, recall, and mAP. This demonstrates its outstanding performance when addressing challenges such as varying lighting and backgrounds, different charging port types, occluded or partially visible charging ports, small charging port targets, and image blurring.
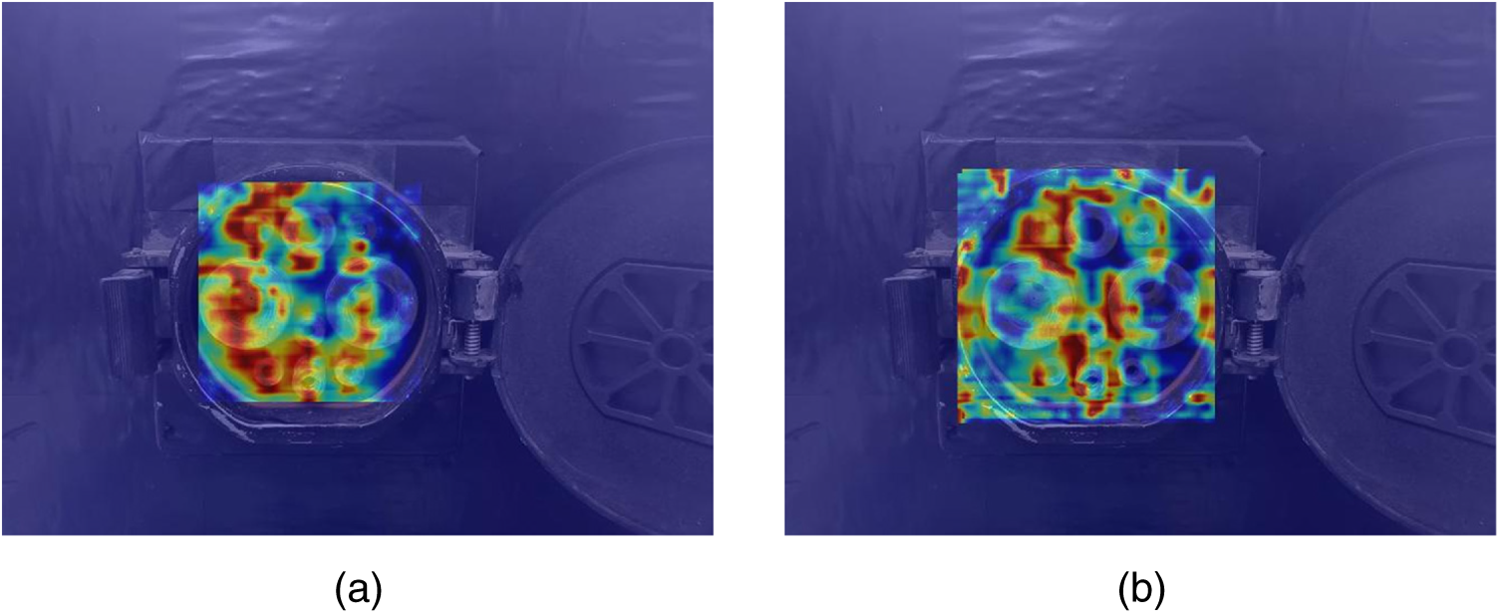
Figure 7: Heatmap comparison between Model 1 and Model 2.
Experimental results demonstrate that CP-YOLO achieves significant improvements in accuracy, recall, and mAP. This indicates its outstanding performance when addressing challenges such as varying lighting conditions and backgrounds, different charging port types, obstructed or partially visible charging ports, small charging port targets, and image blurring.
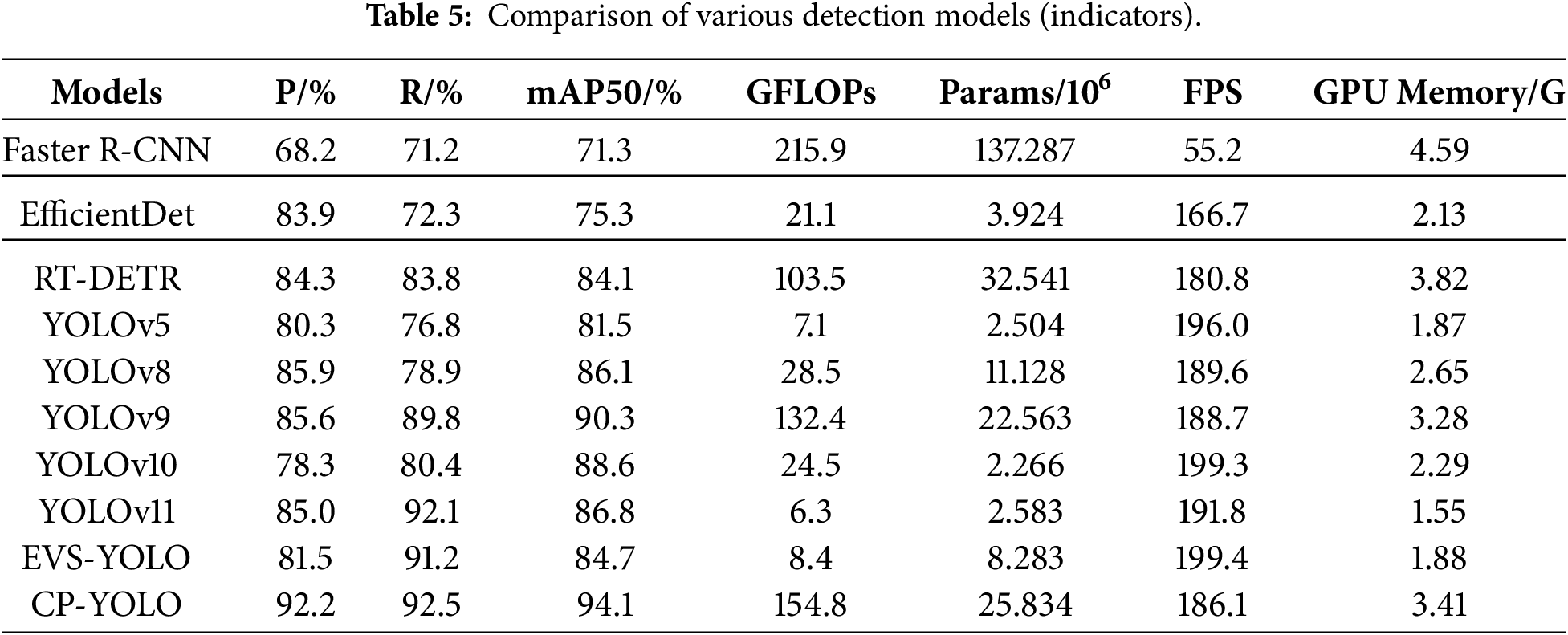
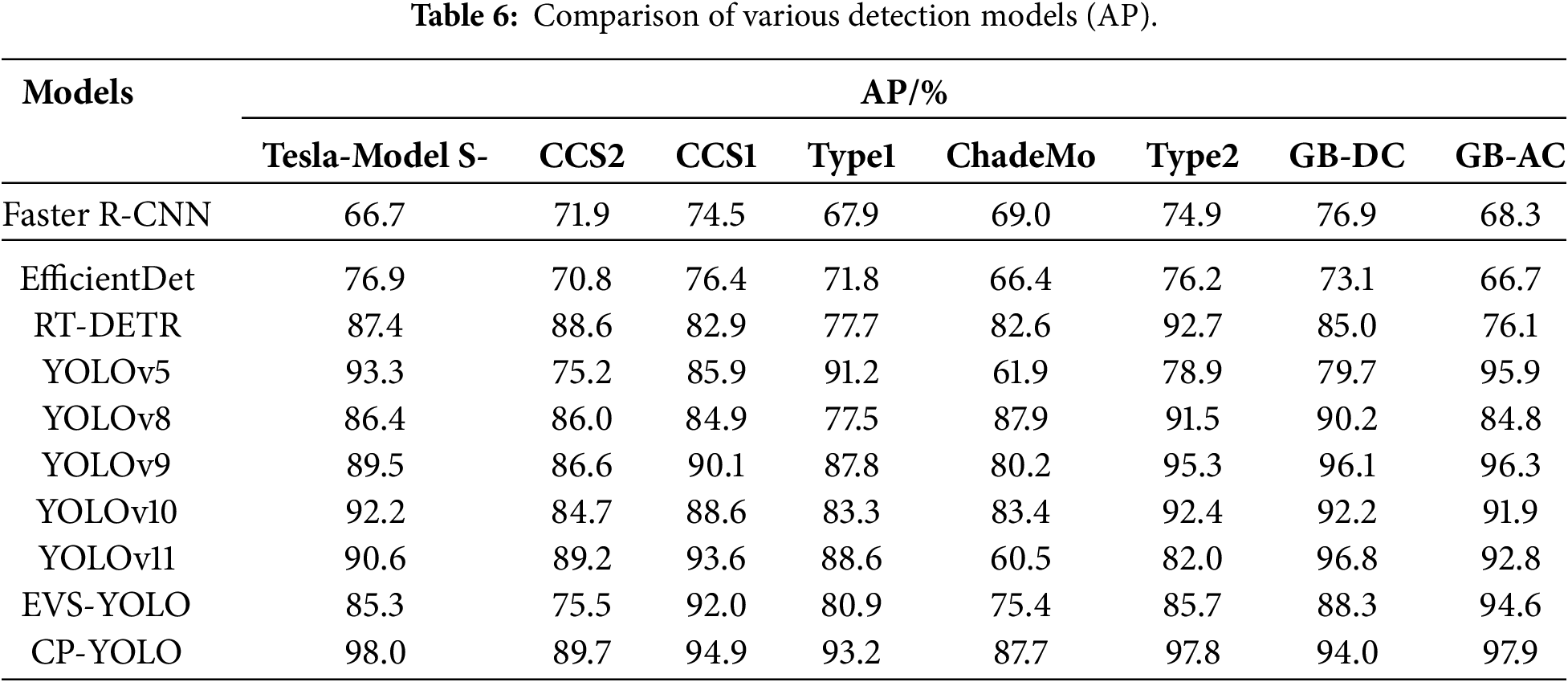
To further validate the recognition performance of the CP-YOLO algorithm, we selected comparisons with currently mainstream object detection algorithms—Faster R-CNN, EfficientDet, and RT-DETR—alongside the YOLO series comprising YOLOv5, YOLOv8, YOLOv9, YOLOv10, YOLOv11, and the EVS-YOLO proposed in [26]. These were subjected to comparative experiments on the test dataset. As shown in Table 3, the results indicate that CP-YOLO achieves accuracy improvements of 24%, 8.3%, and 7.9% compared to Faster R-CNN, EfficientDet, and RT-DETR, respectively, and outperformed other YOLO variants by 11.9%, 6.3%, 6.6%, 13.9%, 7.2%, and 10.7%, respectively, in terms of accuracy. This demonstrates that the CP-YOLO model achieves higher accuracy, resulting in fewer false detections during charging port recognition by mobile robots. This is crucial for enhancing operational efficiency in practical scenarios.
In terms of recall rate P, the model outperformed Faster R-CNN, EfficientDet and RT-DETR algorithms by 21.3%, 20.2% and 8.7%, respectively. Compared to other YOLO-based algorithms, it achieved improvements of 15.7%, 13.6%, 2.7%, 12.1%, 0.4%, and 1.3%, respectively. The higher recall rate indicates that the CP-YOLO model can detect nearly all charging port targets while minimising false positives and false negatives, representing a crucial metric in mobile charging technology.
Compared to Faster R-CNN, EfficientDet and RT-DETR, mAP improved by 22.8%, 18.8% and 10%, respectively. and compared to other YOLO variants, it achieved mAP improvements of 12.6%, 8.0%, 3.8%, 5.5%, 7.3%, and 9.4%, respectively. This demonstrates that the CP-YOLO model exhibits higher recognition accuracy across diverse charging port categories and complex environments, enabling mobile charging technology to adapt to varied real-world scenarios. Regarding average precision (AP) across eight charging port categories, the CP-YOLO model demonstrates significantly higher recognition accuracy than other models in all categories except GB-DC for YOLOv9. Overall, the CP-YOLO model achieves marked improvements in recognition precision for diverse charging port targets.
Additionally, as deployed on mobile charging robots, this paper evaluates practical application value through four engineering metrics: GFLOPs, parameters, frames per second (FPS), and GPU memory. As shown in Table 5. The CP-YOLO model achieves lower GFLOPs than Faster R-CNN, fewer parameters than both Faster R-CNN and RT-DETR, and higher FPS than Faster R-CNN, EfficientDet, and RT-DETR, while remaining comparable to other models. GPU Memory is lower than both Faster R-CNN and RT-DETR. However, as detection accuracy is the paramount consideration for deployment on mobile charging robots, and sufficient space exists to accommodate larger, high-performance hardware, optimisation strategies such as hardware acceleration and resolution adjustment can be implemented post-deployment. This enables the model to achieve both higher detection accuracy and excellent real-time detection speed, thereby demonstrating strong practical application value.
As shown in Fig. 8 the training trends also reveal that the CP-YOLO model demonstrates superior recognition accuracy compared to other models. Its training curve exhibits stability and faster convergence. Under three random seeds, its training trajectory and recognition accuracy show high consistency, indicating that the CP-YOLO model possesses excellent stability. In summary, the CP-YOLO model demonstrates a marked improvement in charging port recognition accuracy compared to other models when operating in complex environments characterised by port occlusion, blurred images, and small targets. As shown in Table 6. This enhancement stems from its progressive mechanism combining detail fidelity, context-aware understanding, and spatial adaptability. Furthermore, it exhibits excellent practical application performance, striking a favourable balance between accuracy and computational efficiency in real-time scenarios.
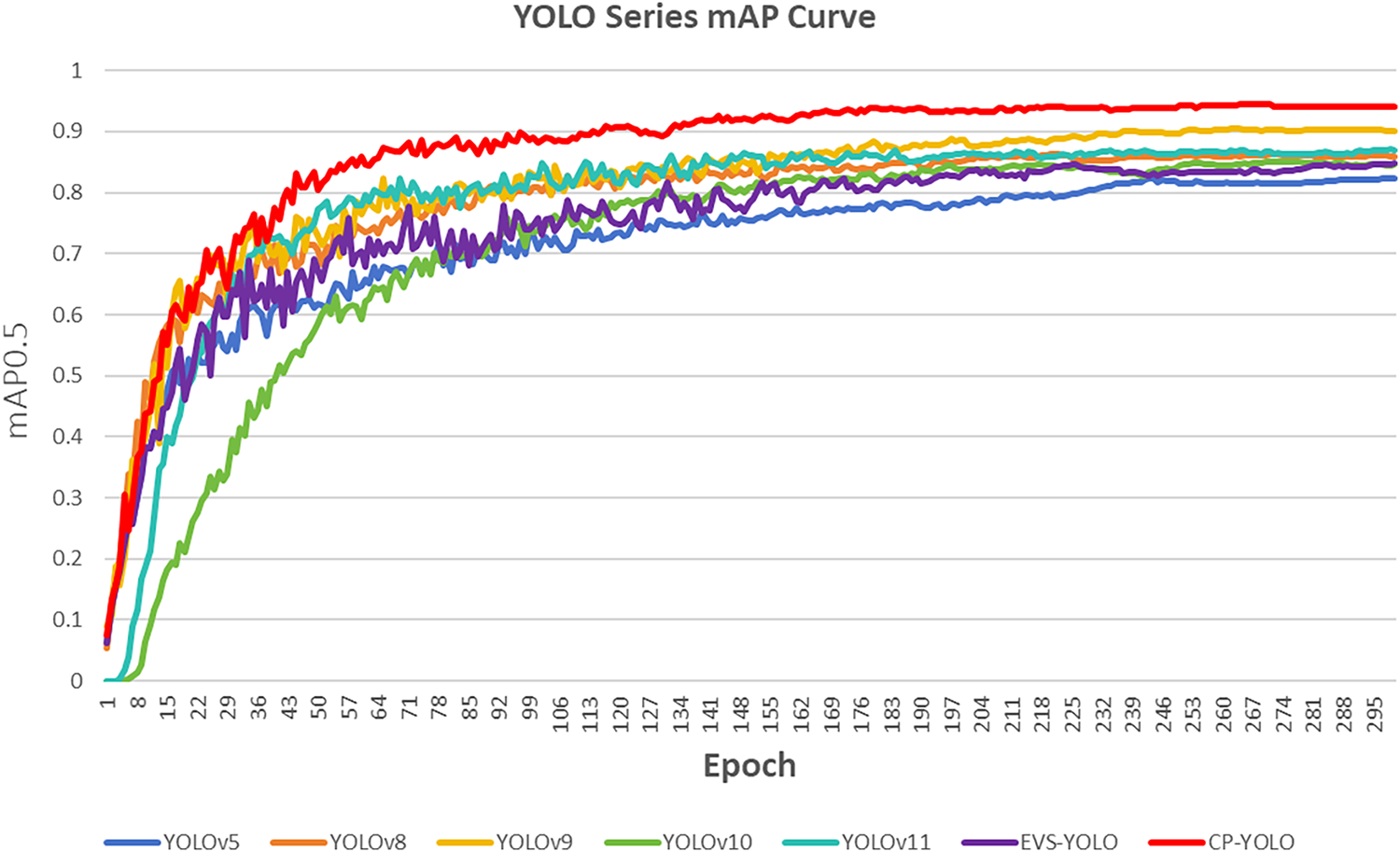
Figure 8: Comparison results with YOLO series algorithm.
Finally, the detection results of the CP-YOLO model were compared with those of other models. As shown in Fig. 9 The RT-DETR model and other YOLO series models with higher recognition accuracy were selected. The detection result images encompassed eight categories of charging ports, images of charging ports under varying lighting conditions, images of charging ports with occlusions or partial damage, and images of charging ports with small or blurred targets. The experimental results are shown in Fig. 10. whereas the RT-DETR and YOLOv8 models exhibited misdetections and missed detections. The YOLOv5, YOLOv10 and EVS-YOLO models produced multiple overlapping prediction boxes. The CP-YOLO model exhibited none of these issues, generating more precise prediction boxes with consistently higher and more stable confidence scores compared to other models. Taking the GB-AC category as an example, the YOLOv9 model achieved confidence scores of 0.92 and 0.75 under dim lighting (third image) and normal lighting conditions (fourth image), respectively, whereas the CP-YOLO model attained 0.95 and 0.83. The detection results demonstrate that the CP-YOLO model achieves high detection accuracy with low false positive and false negative rates across different charging port categories, diverse scenarios, and images featuring incomplete or small charging ports.

Figure 9: Detection results from different YOLO models.

Figure 10: Visualization feature maps for different improvement modules.
To evaluate the detection performance of the CP-YOLO model, this paper selected a subset of detection images and conducted experiments using Grad-CAM. As shown in Fig. 10 Grad-CAM attention heatmaps provide a highly intuitive visualisation of the regions of interest to the model, with colour intensity representing varying degrees of attention focus. As illustrated in the figure, The YOLOv9 model exhibited both missed detections (third image in the third row) and false detections (fourth image in the first row) in its results. In contrast, the CP-YOLO model correctly identified the objects and demonstrated higher attention to the correct detection regions. It also exhibited deeper colour intensity for smaller targets and the charging port area. These findings indicate that the CP-YOLO model possesses greater robustness and more precise localisation, with heightened attention directed towards correctly detected regions.
To address the challenge of charging port recognition for mobile charging robots in complex environments, this paper proposes a CP-YOLO network model specifically designed for charging port object detection. Building upon YOLOv9, this model incorporates targeted enhancements centred on the SPDConv module, SAFM module, and C2f-MLKA module. SPDConv and C2f-MLKA modules are introduced into the backbone network, while the Spatially Adaptive Feature Modulation (SAFM) module reconstructs the neck network. Through the collaborative detection of SPDConv, C2f MLKA, and SAFM collaborate to detect, implementing a progressive mechanism of detail fidelity-contextual understanding enhancement-spatial adaptation to address charging port recognition in complex environments.
Experimental results demonstrate that this model significantly enhances charging port recognition accuracy in complex scenarios. Compared to Faster R-CNN, EfficientDet, and RT-DETR, it achieves improvements of 22.8%, 18.8%, and 10%, respectively, in mAP. Against other YOLO variants, it surpasses their average precision by 12.6%, 8.0%, 3.8%, 5.5%, 7.3% and 9.4%. This detection accuracy improvement ensures the mobile charging robot responds exclusively to charging ports, providing a reliable technical foundation for subsequent robotic arm docking. It substantially reduces false trigger probabilities, safeguarding vehicle and equipment safety while enhancing the service quality of mobile charging technology. The proposed CP-YOLO model effectively addresses recognition challenges such as occluded and fragmented targets, complex backgrounds, small objects, and multi-class detection, while maintaining high recognition accuracy. This provides valuable reference for algorithmic architecture and engineering practice, enabling robust application of mobile charging robots or automated charging equipment in unstructured environments such as underground car parks, night-time roads, and congested parking areas.
This study proposes a viable solution for mobile robots to detect electric vehicle charging ports, with experiments demonstrating robust detection performance. However, comparative results indicate that the CP-YOLO model still exhibits issues, such as reduced accuracy for single charging port categories and underutilised model capabilities. Future research will focus on further optimising the CP-YOLO model. Firstly, we will systematically prune redundant channels or layers through structured pruning, thereby reducing model size, computational latency, and energy consumption while maintaining accuracy. This will enhance operational efficiency and real-time performance on mobile robot platforms. Concurrently, we shall construct a large-scale cross-domain dataset, gathering images of charging ports under varying weather conditions, lighting scenarios, and degrees of deterioration to enhance the model’s cross-scenario generalisation capabilities. By integrating online learning for system self-optimisation and enabling CP-YOLO to integrate with other detection architectures, we aim to empower it to effectively execute more complex mobile charging tasks.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, He Tian and Ziliang Zhu; methodology, He Tian and Ziliang Zhu; software, He Tian and Ziliang Zhu; validation, Ziliang Zhu, Jiangping Li and Ziyun Li; formal analysis, Ziliang Zhu and Baofeng Tang; investigation, Ziliang Zhu, Jiangping Li and Ziyun Li; resources, He Tian and Pengfei Ju; writing—original draft preparation, Ziliang Zhu; writing—review and editing, He Tian and Pengfei Ju; visualization, Ziliang Zhu, Jiangping Li and Ziyun Li; supervision, He Tian; project administration, He Tian; funding acquisition, He Tian. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: Due to the nature of this research, participants of this study did not agree for their data to be shared publicly, so supporting data is not available.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Ding Y, Chen F, Feng J, Cheng H. Competition and pricing strategy of electric vehicle charging services considering mobile charging. IEEE Access. 2024;12:88739–55. doi:10.1109/ACCESS.2024.3418996. [Google Scholar] [CrossRef]
2. Hu H, Zhao D, Zockaie A, Ghamami M. Growth patterns and factors of electric vehicle charging infrastructure for sustainable development. Sustain Cities Soc. 2025;126(12):106417. doi:10.1016/j.scs.2025.106417. [Google Scholar] [CrossRef]
3. Willey LC, Salmon JL. Infrastructure optimization of in-motion charging networks for electric vehicles using agent-based modeling. IEEE Trans Intell Veh. 2021;6(4):760–71. doi:10.1109/TIV.2021.3064549. [Google Scholar] [CrossRef]
4. Zhang J, Hou L, Zhang B, Yang X, Diao X, Jiang L, et al. Optimal operation of energy storage system in photovoltaic-storage charging station based on intelligent reinforcement learning. Energy Build. 2023;299(1):113570. doi:10.1016/j.enbuild.2023.113570. [Google Scholar] [CrossRef]
5. Liu L, Qi X, Xi Z, Wu J, Xu J. Charging-expense minimization through assignment rescheduling of movable charging stations in electric vehicle networks. IEEE Trans Intell Transp Syst. 2022;23(10):17212–23. doi:10.1109/TITS.2022.3154444. [Google Scholar] [CrossRef]
6. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: Single Shot MultiBox Detector. In: European conference on computer vision. Cham, Switzerland: Springer International Publishing; 2016. p. 21–37. doi:10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
7. Khanam R, Hussain M. What is YOLOv5: a deep look into the internal features of the popular object detector. arXiv:2407.20892. 2024. doi:10.48550/arXiv.2407.20892. [Google Scholar] [CrossRef]
8. Yaseen M. What is YOLOv8: an in-depth exploration of the internal features of the next-generation object detector. arXiv:2408.15857. 2024. doi:10.48550/arXiv.2408.15857. [Google Scholar] [CrossRef]
9. Wang CY, Yeh IH, Liao HM. YOLOv9: learning what you want to learn using programmable gradient information. arXiv:2402.13616. 2024. doi:10.48550/arXiv.2402.13616. [Google Scholar] [CrossRef]
10. Wang A, Chen H, Liu L, Chen K, Lin Z, Han J. YOLOv10: real-time end-to-end object detection. arXiv:2405.14458. 2024. doi:10.48550/arXiv.2405.14458. [Google Scholar] [CrossRef]
11. Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements. arXiv:2410.17725. 2024. doi:10.48550/arXiv.2410.17725. [Google Scholar] [CrossRef]
12. Lin TY, Goyal P, Girshick R, He K, Dollár P. Focal loss for dense object detection. arXiv:1708.02002. 2017. doi:10.48550/arXiv.1708.02002. [Google Scholar] [CrossRef]
13. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. arXiv:1506.01497. 2015. doi:10.48550/arXiv.1506.01497. [Google Scholar] [CrossRef]
14. He K, Gkioxari G, Dollár P, Girshick R. Mask R-CNN. arXiv:1703.06870. 2017. doi:10.48550/arXiv.1703.06870. [Google Scholar] [CrossRef]
15. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. arXiv:1706.03762. 2023. doi:10.48550/arXiv.1706.03762. [Google Scholar] [CrossRef]
16. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-end object detection with transformers. arXiv:2005.12872. 2020. doi:10.48550/arXiv.2005.12872. [Google Scholar] [CrossRef]
17. Wang S, Xia C, Lv F, Shi Y. RT-DETRv3: real-time end-to-end object detection with hierarchical dense positive supervision. arXiv:2409.08475. 2024. doi:10.48550/arXiv.2409.08475. [Google Scholar] [CrossRef]
18. Dai Z, Cai B, Lin Y, Chen J. UP-DETR: unsupervised pre-training for object detection with transformers. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 June 20–25; Nashville, TN, USA. p. 1601–10. doi:10.1109/cvpr46437.2021.00165. [Google Scholar] [CrossRef]
19. Quan P, Lou Y, Lin H, Liang Z, Di S. Research on fast identification and location of contour features of electric vehicle charging port in complex scenes. IEEE Access. 2022;10(4):26702–14. doi:10.1109/ACCESS.2021.3092210. [Google Scholar] [CrossRef]
20. Quan P, Lou YN, Lin H, Liang Z, Wei D, Di S. Research on identification and location of charging ports of multiple electric vehicles based on SFLDLC-CBAM-YOLOV7-tinp-CTMA. Electronics. 2023;12(8):1855. doi:10.3390/electronics12081855. [Google Scholar] [CrossRef]
21. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. arXiv:1807.06521. 2018. doi:10.48550/arXiv.1807.06521. [Google Scholar] [CrossRef]
22. Wang CY, Bochkovskiy A, Liao HM. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv:2207.02696. 2022. doi:10.48550/arXiv.2207.02696. [Google Scholar] [CrossRef]
23. Zhu H, Sun C, Zheng Q, Zhao Q. Deep learning based automatic charging identification and positioning method for electric vehicle. Comput Model Eng Sci. 2023;136(3):3265–83. doi:10.32604/cmes.2023.025777. [Google Scholar] [CrossRef]
24. Bochkovskiy A, Wang CY, Liao HM. YOLOv4: optimal speed and accuracy of object detection. arXiv:2004.10934. 2020. doi:10.48550/arXiv.2004.10934. [Google Scholar] [CrossRef]
25. Li T, Xia C, Yu M, Tang P, Wei W, Zhang D. Scale-invariant localization of electric vehicle charging port via semi-global matching of binocular images. Appl Sci. 2022;12(10):5247. doi:10.3390/app12105247. [Google Scholar] [CrossRef]
26. Mahaadevan VC, Narayanamoorthi R, Gono R, Moldrik P. Automatic identifier of socket for electrical vehicles using SWIN-transformer and SimAM attention mechanism-based EVS YOLO. IEEE Access. 2023;11(4):111238–54. doi:10.1109/ACCESS.2023.3321290. [Google Scholar] [CrossRef]
27. Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, et al. Swin transformer: hierarchical vision transformer using shifted windows. arXiv:2103.14030. 2021. doi:10.48550/arXiv.2103.14030. [Google Scholar] [CrossRef]
28. Mahaadevan VC, Narayanamoorthi R, Panda S, Dutta S, Dooly G. AViTRoN: advanced vision track routing and navigation for autonomous charging of electric vehicles. IEEE Access. 2024;12(S3):12402–23. doi:10.1109/ACCESS.2024.3355018. [Google Scholar] [CrossRef]
29. Sunkara R, Luo T. No more strided convolutions or pooling: a new CNN building block for low-resolution images and small objects. arXiv:2208.03641. 2022. doi:10.48550/arXiv.2208.03641. [Google Scholar] [CrossRef]
30. Sun L, Dong J, Tang J, Pan J. Spatially-adaptive feature modulation for efficient image super-resolution. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023 Oct 1–6; Paris, France. p. 13144–53. doi:10.1109/ICCV51070.2023.01213. [Google Scholar] [CrossRef]
31. Wang Y, Li Y, Wang G, Liu X. Multi-scale attention network for single image super-resolution. arXiv:2209.14145. 2022. doi:10.48550/arXiv.2209.14145. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools