
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CRS-DQN: Non-Cooperative Dynamic Target Pursuit for Multi-Agent Systems with Communication Delay and Range Constraints
School of Mathematics and Statistics, Wuhan University of Technology, Wuhan, China
* Corresponding Author: Xi Fang. Email:
(This article belongs to the Special Issue: Cooperation and Autonomy in Multi-Agent Systems: Models, Algorithms, and Applications)
Computers, Materials & Continua 2026, 87(3), 89 https://doi.org/10.32604/cmc.2026.075607
Received 04 November 2025; Accepted 04 March 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper addresses the challenging problem of multi-agent dynamic target pursuit under stringent communication constraints (including delays and range limits), where the agile targets are non-cooperative and free from such limitations. To tackle this, we propose CRS-DQN, a novel Deep Q-Network algorithm designed for this scenario. CRS-DQN enables agents to learn effective pursuit strategies through deep reinforcement learning despite partial observability and constrained information sharing. Simulation experiments systematically evaluate the impact of key parameters. The results show that pursuit performance degrades monotonically with increased communication delay. In contrast, the communication radius exhibits a non-linear effect: performance peaks when the radius is within a specific range (approximately 1/10 to 1/5 of the environment size) and declines if the radius is too small or too large. Furthermore, an optimal balance exists between the communication radius and the delay threshold. This work demonstrates the feasibility of learning-based pursuit under strict communication constraints and provides insights into parameter tuning for robust multi-agent systems in adversarial, communication-degraded environments.Keywords
In recent years, with the rapid development of artificial intelligence technology, significant achievements have been made in the field of swarm intelligence. Many real-world scenarios, such as agriculture [1], autonomous driving [2], search and rescue [3], environmental exploration [4], and security patrolling [5], can be modeled as multi-agent systems. Among these, the pursuit-evasion problem of multi-agents is particularly crucial and has become a hot research topic.
The pursuit-evasion problem originates from the study of collective behavior [6]. The core of this problem is simulating and resolving the adversarial relationship between pursuers and evaders. It focuses on two main strategies: how pursuers can optimize their behavior to capture evaders quickly, and how evaders can distance themselves from pursuers to avoid capture. The process and outcome of the pursuit-evasion problem are determined by multiple factors, including the number of evaders, the cohesion and state of the pursuers, the efficiency of information acquisition [7], environmental settings, and the nature of cooperative or competitive relationships [8].
The multi-agent pursuit problem, serving as a general framework, possesses significant practical application value and has been extensively utilized across diverse scenarios, including environmental monitoring and surveillance [9], military confrontation, and biological behavior analysis [10]. Especially in search and rescue missions, when missing dynamic targets or individuals act as non-cooperative entities attempting to evade our agents, the pursuit-evasion problem plays a critical role [11].
However, a critical gap exists when transitioning these models to adversarial real-world operations. Their effectiveness is fundamentally limited by a reliance on stable communication, which is often unavailable. Despite significant progress in multi-agent pursuit, increasing task complexity under uncertain conditions poses new challenges [12]. Crucially, when systems face interference, communication-dependent models exhibit insufficient autonomy under constrained communication [13,14]. This is because constraints like latency and range limits directly degrade information quality, creating a challenging partially observable environment. This issue is severely compounded when the dynamic targets themselves are not bound by such constraints and employ non-cooperative strategies, amplifying randomness and complexity [8].
Existing research can be broadly categorized into two strands. The first focuses on coordinated pursuit under ideal communication, where agents share perfect global information to optimize capture [6,7]. The second addresses multi-agent learning under communication constraints, often by treating communication as a separate network-layer optimization problem [13,14]. While insightful, these approaches share two key limitations when applied to our target scenario: (i) they largely rely on the assumption of cooperative agents with aligned objectives, and (ii) they frequently model the evaders as passive or capability-inferior entities. Consequently, the intersecting challenge—where pursuers are non-cooperative, operate under strict and dynamic communication constraints, and must chase highly adaptive and unconstrained evaders—remains under-explored.
This paper directly targets this gap. We investigate the problem of non-cooperative dynamic target pursuit under simultaneous communication delay and range constraints. In our setting, pursuers have limited, delayed information about agile evaders who are free from such constraints and employ non-cooperative escape strategies. To address this, we propose CRS-DQN, a novel learning framework that integrates a task-aware dynamic action masking mechanism with deep reinforcement learning. This design allows pursuers to learn effective, decentralized policies that are inherently adaptive to the real-time quality of communication.
The core contribution of this study lies in the systematic establishment of a multi-agent dynamic pursuit model under communication constraints and, through empirical analysis, in-depth exploration of the mechanisms through which communication delays and distance affect the pursuit efficiency of multi-agent systems. The specific contributions are reflected in the following three aspects:
• The communication distance constraint, communication delay limit, and communication latency are comprehensively integrated into a new multi-agent pursuit model. This model establishes a more realistic benchmark for studying target pursuit under constrained information exchange.
• The proposed CRS-DQN algorithm strategically integrates deep reinforcement learning with a task-aware dynamic action masking mechanism. This design directly addresses the specified communication constraints, enabling agents to learn decentralized policies adapted to limited and delayed information.
• Through a systematic analysis of how communication constraints affect pursuit performance, this study provides concrete and actionable insights into the adaptability and practical efficiency of our approach in complex, non-cooperative scenarios.
This research aims to provide new theoretical insights and practical guidance for designing pursuit strategies in communication-constrained multi-agent systems, advancing the field of multi-agent dynamic target pursuit. The paper is organized as follows: Section 2 reviews related work, Section 3 builds the model, Section 4 introduces the algorithm, Section 5 presents simulation experiments and analysis, and Section 6 concludes the paper and outlines future work.
Multi-agent dynamic target pursuit involves agents capturing targets in complex environments. Cooperative strategies focus on collective action and global optimality, while non-cooperative ones emphasize individual actions and local optimality. The choice depends on the scenario.
2.1 Dynamic Target Cooperative Pursuit without Communication Constraint
The unconstrained dynamic target pursuit problem involves agents pursuing dynamic targets with unlimited communication capabilities. This allows for the exchange of information, such as positional data and target observations, facilitating information sharing and coordinated pursuit.
Unconstrained cooperative pursuit, a key area in dynamic target tracking, has attracted much research interest. It focuses on optimizing coordination and precise tracking among multiple agents with unimpeded, real-time information exchange. Han et al. [15] proposed a hierarchical decision-making method for target tracking in multi-agent systems through manned-unmanned collaboration, using a linear quadratic differential game model and an iterative solution strategy. Dong et al. [16] proposed a multi-target dynamic pursuit strategy that allocates agents via an improved K-means algorithm and an auction algorithm, with controllers based on the backstepping method. Chen et al. [17] proposed a multi-evader dynamic pursuit strategy that involves rational allocation of pursuers, target point assignment, and interactive reassignment during pursuit, integrating an improved AAPC algorithm, a tendering algorithm, and artificial potential field methods.
Some studies integrate graph-theoretic methods with other theories to optimize collaborative behavior. Pan and Yuan [18] proposed a circular relay pursuit strategy based on regional division, improving pursuit efficiency and reducing conflicts among pursuers. Wang et al. [19] employed a hybrid approach combining an Euler-Lagrange model with a distance-based rigid graph method, achieving dynamic formation tracking and target interception via adaptive control and Lyapunov stability theory.
When pursuing dynamic targets, heuristic algorithms are efficient. Yu et al. [20] proposed a bio-inspired tracking strategy based on the smooth transition of communication topology, inspired by wolf hunting. He et al. [21] simplified the pursuit problem in dynamic multi-target environments using fuzzy logic and heuristic optimization. Zhao et al. [22] introduced a bionic adaptive pure pursuit (A-PP) algorithm with quadratic polynomial adjustments. Other heuristic algorithms include the Simulated Annealing (SA) by Yan et al. [23], the Adaptive Robotic Bat Algorithm (ARBA) by Tang et al. [24], the Electric Eel Foraging Optimization (EEFO) by Zhao et al. [25], the Heuristic Experience Learning (HEL) algorithm by Jia et al. [26], and the Hippopotamus Optimization (HO) algorithm by Amiri et al. [27], among others.
Reinforcement learning enables agents to refine their strategies through trial and error. Cao and Xu [28] introduced a collaborative pursuit algorithm for autonomous underwater vehicles using dynamic trajectory prediction and deep reinforcement learning. Xia et al. [29] proposed a distributed multi-target pursuit algorithm for unmanned surface vehicles. Han et al. [30] enhanced the MATD3 algorithm with APF. Hua et al. [31] presented a collaborative hunting algorithm integrating Apollonius circle theory, game theory, and Q-learning. Qu et al. [32] examined the pursuit-evasion problem in multi-obstacle environments using a hybrid strategy of multi-agent deep reinforcement learning and imitation learning.
2.2 Cooperative Pursuit of Dynamic Targets under Limited Communication
In multi-agent dynamic target pursuit, constrained communication environments pose significant challenges to collaborative actions. Researchers have developed various innovative methods and strategies to mitigate these communication limitations, thereby improving agent performance during pursuit.
To tackle communication constraints, some scholars have used advanced math tools like Riccati equations. Du et al. [33] introduced an impulsive system model for controller design, ensuring network stability via the Riccati equation even with time delays. Du et al. [34] proposed a distributed controller for relay pursuit under input saturation and disturbances, achieving tracking consistency using an improved algebraic Riccati equation and low-gain techniques.
Leveraging graph theory, Lopez et al. [35] determined the Nash equilibrium using the Hamilton-Jacobi-Isaacs equation and applied a Minmax strategy for challenging scenarios, optimizing performance metrics and analyzing finite-time capture and asymptotic convergence. Yao et al. [36] addressed the consensus problem for nonlinear uncertain multi-agent systems with state constraints and input delays, proposing an adaptive control strategy based on RBFNN, Pade approximation, and backstepping techniques. Maity and Pourghorban [37] presented a decentralized feedback strategy that transforms the problem of multiple defenders capturing an intruder into a nonlinear consensus problem, achieving effective collaborative control through consensus algorithms based on agents’ velocities, sensing, and communication capabilities.
In communication-constrained scenarios, researchers innovate reinforcement learning algorithms to optimize collaborative pursuit strategies. De Souza et al. [38] proposed a multi-agent tracking algorithm based on Twin Delayed Deep Deterministic Policy Gradient (TD3), enabling non-communicating agents to make autonomous decisions based on shared experiences. Du et al. [39] addressed unauthorized drones in urban air traffic with a cooperative pursuit model based on multi-agent reinforcement learning, showing significant advantages in limited communication and high-speed drone scenarios.
Beyond this, notable advancements have been made in cooperative pursuit of non-cooperative dynamic targets. Sun and Dang [40] integrated deep neural networks with the Clohessy-Wiltshire equation for intent recognition of non-cooperative space targets. Xu et al. [41] proposed a novel control strategy based on the Bézier shape function for the pursuit-evasion game involving space and non-cooperative targets.
Beyond aerospace, Chen et al. [42] introduced a pursuit and encirclement strategy for mobile robots, achieving precise control in complex environments. Sun et al. [43] proposed a decentralized multi-agent framework and a fuzzy self-organizing cooperative co-evolutionary algorithm, decomposing multi-objective local problems into single-objective tracking tasks. Xue et al. [44] introduced a prescribed-time search algorithm for multi-agent pursuit-evasion games with second-order dynamics. Valianti et al. [45] developed a cooperative multi-agent jamming technology using reinforcement learning to disrupt rogue drones. Liao et al. [46] proposed an ETS-MAPPO algorithm combining spatio-temporal exploration with a global convolutional local ascending mechanism.
Consequently, a significant research gap persists at the intersection of non-cooperation, stringent communication constraints (delay and range), and highly dynamic targets. Specifically, there is a lack of frameworks that enable decentralized agents to learn effective pursuit strategies under partial observability induced by these constraints while competing against adaptive evaders. This work aims to bridge this gap by proposing a novel learning framework tailored for this challenging scenario.
This section details the environmental and communication models for the pursuit task, along with the reward functions for both intelligent agents and dynamic targets.
To clarify the core concept consistently used throughout this work, we formally define the “non-cooperative” nature of the pursuer agents. Non-cooperation specifically refers to the absence of explicit communication or negotiation protocols for action coordination during the decentralized execution phase. Each pursuer makes decisions independently based solely on its own local observations, without exchanging intentions, conducting joint planning, or negotiating task assignments with other pursuers.
Multi-agent dynamic target pursuit research often addresses communication constraints through optimized protocols and reduced latency. A common assumption is that evaders are less capable than pursuers, which may not reflect reality.
This study addresses the dynamic target pursuit problem with three key constraints: (1) limited communication radius; (2) communication delay radius; and (3) independent pursuit with communication lag. Dynamic targets operate without communication constraints, leading to unpredictable evasion behavior.
The setup simulates a complex scenario where a multi-agent system must pursue dynamic, non-cooperative targets to ensure security despite communication constraints. It investigates how multi-agents overcome these barriers to track and capture targets under extreme conditions, ensuring critical area security. This aims to determine the minimal communication requirements for successful pursuit.
The task environment is defined within a two-dimensional discrete space, with a size of
For the
In the formula,
For
In the expression,
The action spaces for the pursuer and the target are asymmetrically designed to reflect their differing roles and capabilities within the pursuit-evasion scenario. The pursuer is constrained to four cardinal directions (up, down, left, right), while the target is afforded the four cardinal directions along with diagonal movements. This design choice is primarily grounded in two key objectives: (1) to simulate the target’s superior agility and maneuverability, thereby constructing a more challenging and realistic pursuit scenario; and (2) to increase the diversity of the target’s escape paths and the unpredictability of its behavior, thus rigorously testing the robustness and adaptability of the pursuer’s learned strategy under conditions where the target holds an advantage.
Set the constraint radius
The diagram of the agent communication model is shown in Fig. 1:
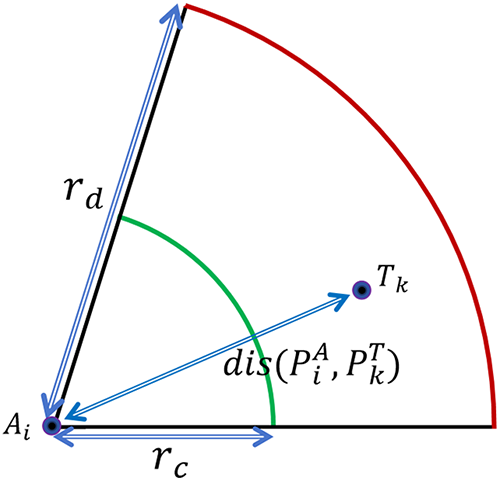
Figure 1: Agent communication model schematic.
Calculate the Euclidean distance between the ith agent and the kth target:
At time
When the dynamic target is within the communication delay radius
The settings simulate pursuing non-friendly targets in a multi-agent system with communication interference, threats, and harsh conditions. The simulation explores overcoming communication barriers to capture targets under extreme conditions, ensuring key area security. It aims to determine the minimal communication requirements for successful pursuit.
In reinforcement learning, a good reward function is key. It helps the agent get more rewards by interacting with the environment, encouraging good actions and discouraging bad ones. Designing it well shapes the agent’s strategy.
The reward function for the smart agent is divided into three parts: chase success reward, relative distance reward, and boundary constraint penalty.
The chase success reward is the incentive obtained when the smart agent successfully captures the dynamic target, denoted as
here,
The relative distance reward, denoted as
The mathematical formula for calculating the Euclidean distance
Calculate the mean Euclidean distance
When
From the equation, when
Boundary constraint penalty is the penalty that the intelligent agent will receive when it exceeds the boundaries of the task area, denoted as
Similar to the agent’s reward function, the dynamic target’s reward function is divided into three parts: escape failure penalty, relative distance reward, and boundary constraint penalty. Escape Failure Penalty is the penalty imposed on the dynamic target when it is captured by the agent, denoted as
here,
The relative distance reward, denoted as
For dynamic targets, they are not constrained by communication distance or communication delay. The Euclidean distance
To calculate the mean Euclidean distance
When
In the equation, when
The boundary constraint penalty, denoted as
In this section, an innovative dynamic target pursuit strategy based on the Deep Q-network (DQN) algorithm [47], designed for communication-restricted environments.
Compared to the state-action value function update formula
In the equation,
The mathematical expression for the target Q-value is:
For the sample size
In this formula,
The DQN algorithm aims to minimize the loss function, making the neural network’s predicted Q-values closely match the target Q-values.
Compute the gradient of the loss function with respect to the weight parameters
Through the above expression, the direction in the weight
In the equation,
The intelligent agent in this paper uses an improved Deep Q-Network (DQN) algorithm based on an experience replay pool to pursue dynamic targets. The process of the Deep Q-Network algorithm can be illustrated in Fig. 2:
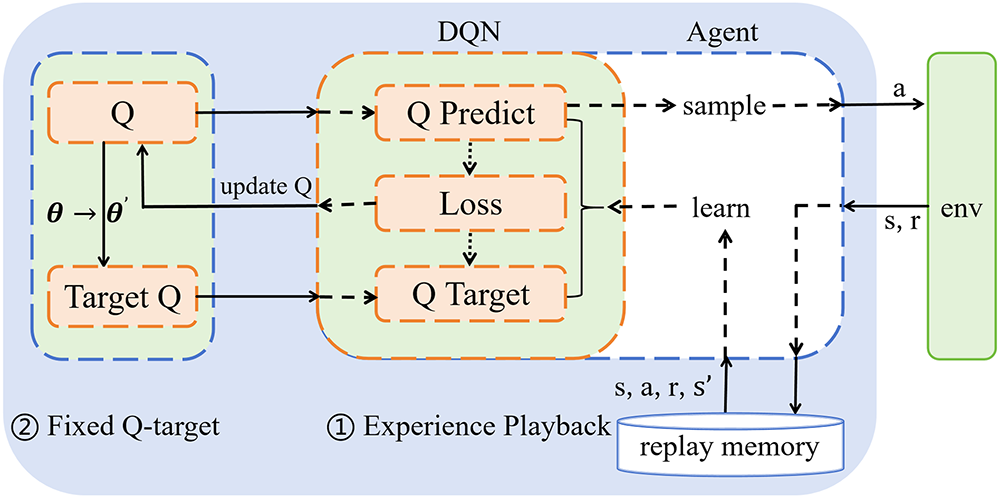
Figure 2: DQN algorithm flowchart.
This paper investigates the multi-agent pursuit problem in complex communication-constrained environments and examines the applicability of Deep Q-Networks (DQN) along with their experience replay mechanism in this scenario. It should be noted that although standard DQN inherently faces challenges such as partial observability and environmental non-stationarity when addressing such problems, overly complex multi-agent reinforcement learning architectures may obscure the analysis of the core influencing factor, namely communication constraints. Therefore, this research employs DQN as a structurally clear and stable baseline model to effectively isolate and thoroughly investigate the specific mechanisms through which communication limitations affect system performance.
To address the dynamic target pursuit problem under communication constraints, we further propose a novel learning strategy named the Communication-Constrained Reinforcement Search DQN (CRS-DQN). This algorithm constitutes a customized learning framework specifically designed for the aforementioned scenario, aiming to enhance the decision-making autonomy and pursuit efficiency of multi-agent systems in communication-constrained environments.
The core innovation of CRS-DQN lies in its rule-modulated action selection mechanism, which is seamlessly integrated into the standard DQN training framework. Specifically, during each step of the DQN training cycle—which includes experience sampling, Q-value prediction via the neural network, target value computation using the Bellman equation, and network updates through loss minimization—CRS-DQN dynamically adjusts the agent’s available action set based on real-time communication states. This integration ensures that the learning process is intrinsically guided by communication constraints, without disrupting the stability and convergence properties of the underlying DQN architecture.
Set the action selection strategy for multiple agents: (1) When the dynamic target is within the communication delay radius
For efficient pursuit, focus on one target at a time. In multi-target scenarios, rational selection enhances focus, improves success rates, and optimizes outcomes.
The intelligent agent selects the target
At the initial time of 0, at time
At time
The action selection strategy of the CRS-DQN algorithm is shown in Fig. 3:
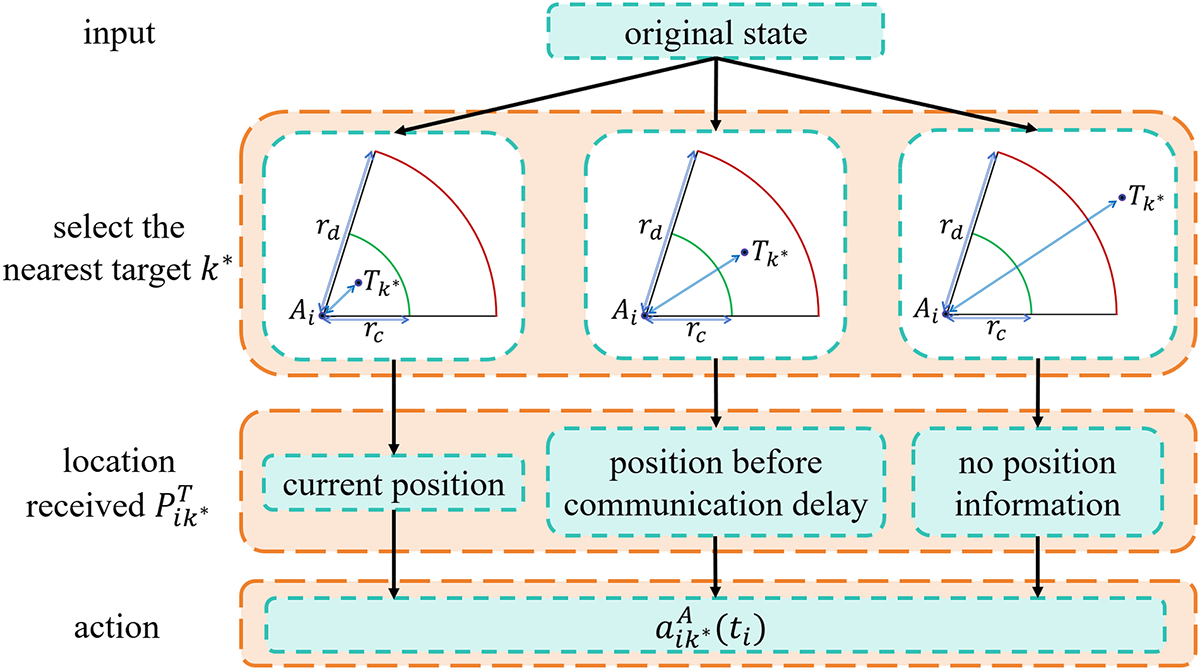
Figure 3: CRS-DQN algorithm action selection strategy.
The maximum Q-value for the next state is:
In the equation,
The mathematical formula for the target Q-value is:
For the sample size
CRS-DQN algorithm (agent) (Algorithm 1) pseudocode is as follows:

The dynamic target is not constrained by communication limitations. At time
At time
In this formula, except for the scenario where all agents are deceased, the target can always receive the position of the nearest agent.
Except when all agents are dead and the target chooses the hover action
The maximum Q-value for the next state is:
In the formula,
The mathematical expression for the target Q-value is:
In the training process, the sample size is NT, and the mathematical expression of the loss function is:
CRS-DQN algorithm (target) (Algorithm 2) pseudocode is as follows:

By combining a special action selection strategy under communication-limited conditions with the DQN framework, the CRS-DQN algorithm realizes efficient dynamic target pursuit by multiple agents in complex environments, providing an effective solution for multi-agent systems under communication-limited environments. The CRS-DQN algorithm’s technical route is shown in Fig. 4:
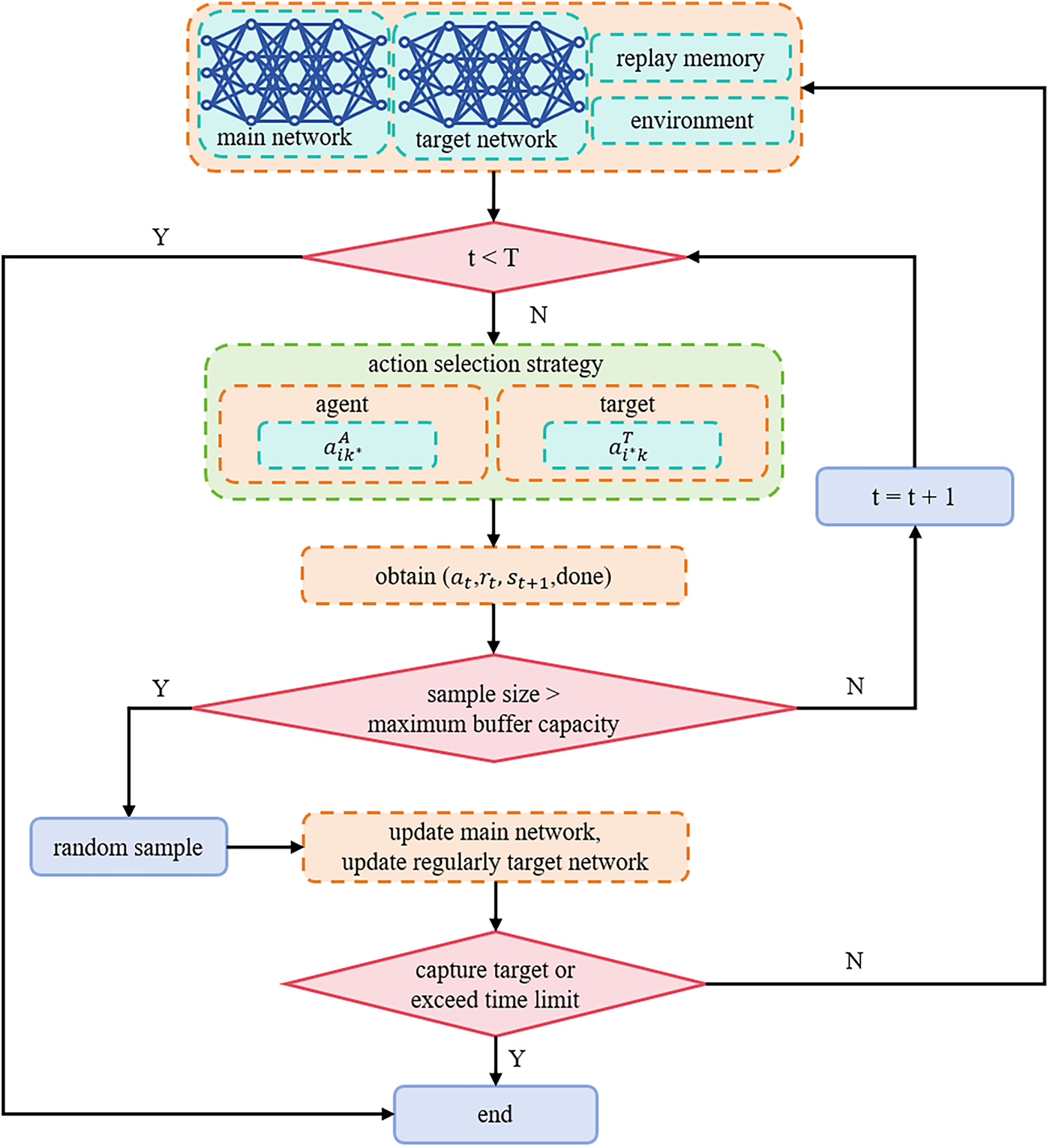
Figure 4: CRS-DQN algorithm flowchart.
The CRS-DQN algorithm in this paper addresses a POMDP, as it models the multi-agent pursuit problem under limited communication as an approximate POMDP under the Markov assumption. Due to communication delays and observation missing, each agent cannot obtain the complete global state, which essentially constitutes a partially observable Markov decision process. To adapt to the standard DQN algorithm, we adopt the following state approximation strategy: when an agent cannot receive target information, the target position components in its state vector are padded with the agent’s own current position; similarly, when a dynamic target cannot receive agent information, the agent position components in its state vector are padded with the target’s own current position. This approach not only ensures the completeness of state dimensions, but also implicitly encodes the “information missing” state as the “self-position” input.
In cases of information missing, both the agent and the dynamic target select the zero vector
5 Simulation Experiments and Analysis
In this section, simulation experiments are conducted using Python 3.8. The reward function is set up, and analyses of effectiveness, communication delay, communication radius size, and communication radius ratio are performed.
5.1 Experimental Environment Setup
In this section, the initial positions, initial parameters, performance evaluation criteria, and the value of
5.1.1 Initial Position Setting
To ensure randomness, initial agent and target positions are randomly generated within specific ranges, considering communication delay radius
Both scenarios utilize a unified randomization algorithm for initial position generation, ensuring fairness and reproducibility. This design mitigates the impact of initial positions on multi-agent system performance, offering valuable insights for practical applications.
5.1.2 Initial Parameters Setting
For the CRS-DQN algorithm proposed in this paper, to verify its performance in communication-constrained environments, it is first necessary to set parameters related to the communication-constrained environment and the algorithm. The experimental environment in this paper is set in a two-dimensional discrete space, which is finely divided into many small grids. The dynamic target pursuit task is conducted in a grid-based task scenario with a scale of 100 × 100.
In the grid-based task scenario, the agents and targets pursue or evade each other according to the grid. When an agent or target moves out of the scenario, it is considered that the agent or target has died. In each training or test trial, the initial positions of the agents and targets are randomly generated to ensure the randomness and diversity of the trials. The maximum number of iteration time steps for each trial is set to 150 steps, the number of training iteration trials is set to 1000 times, and the number of test iteration trials is set to 500 times.
After parameter setting and optimization, the learning rate
To control experimental variables, except for experiments specifically analyzing the communication delay variable, the communication delay variable
5.1.3 Performance Evaluation Criteria
To evaluate the performance of agents in pursuing dynamic targets, two core evaluation criteria are established: the success rate of agents in pursuing dynamic targets and the number of iterative time steps taken by agents to pursue dynamic targets.
The success rate, defined as the ratio of successful pursuits to total attempts (500 trials), reflects the agent’s adaptability and reliability in completing pursuit tasks under specified conditions. A high success rate indicates strong performance.
The average pursuit duration, measured in iterative time steps, reflects the agents’ efficiency. Calculated from the mean time steps across 500 trials (capped at 150 steps per iteration), a lower average indicates higher efficiency, assuming a high success rate.
5.1.4 Reward Function Settings
The reward function’s constant
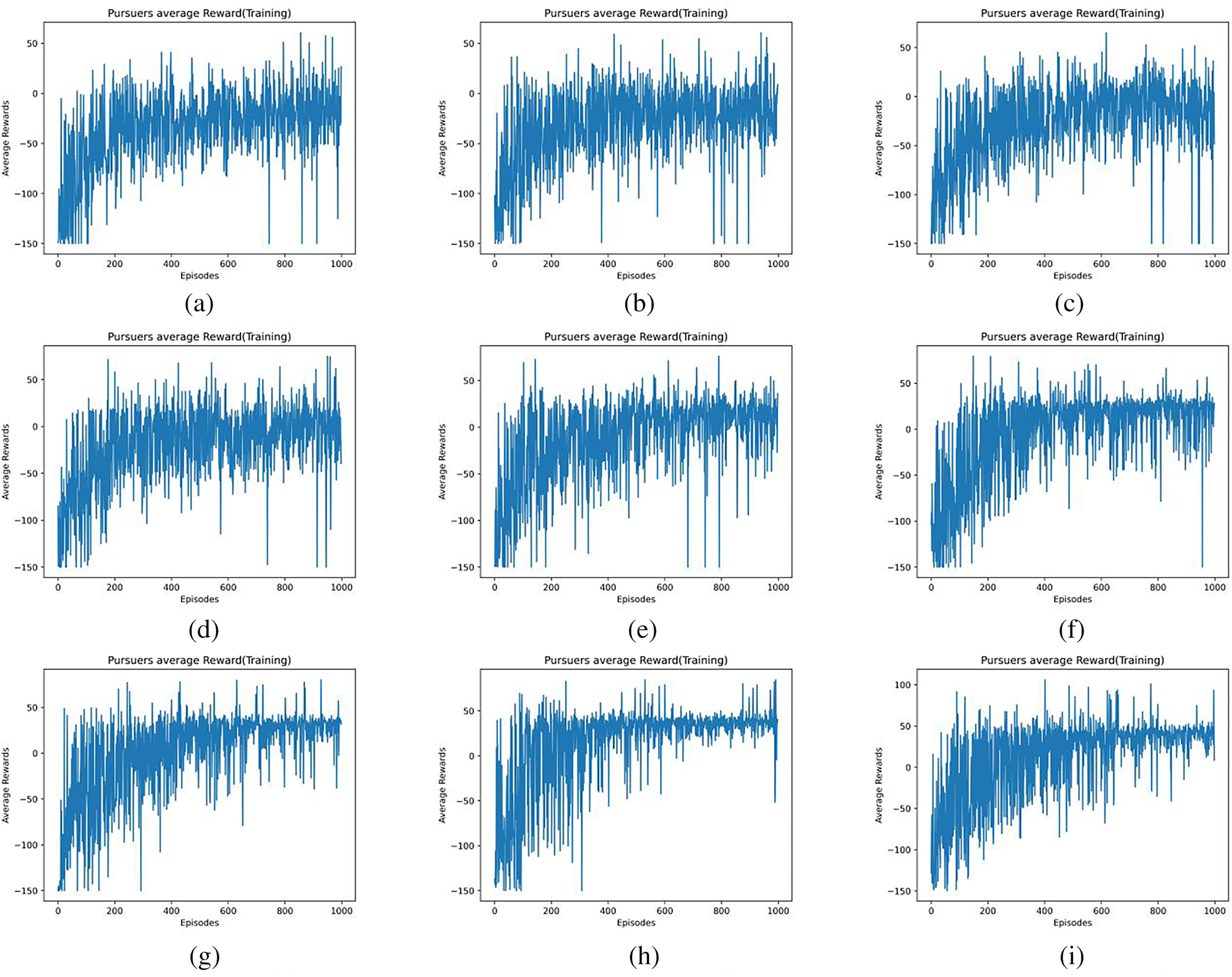
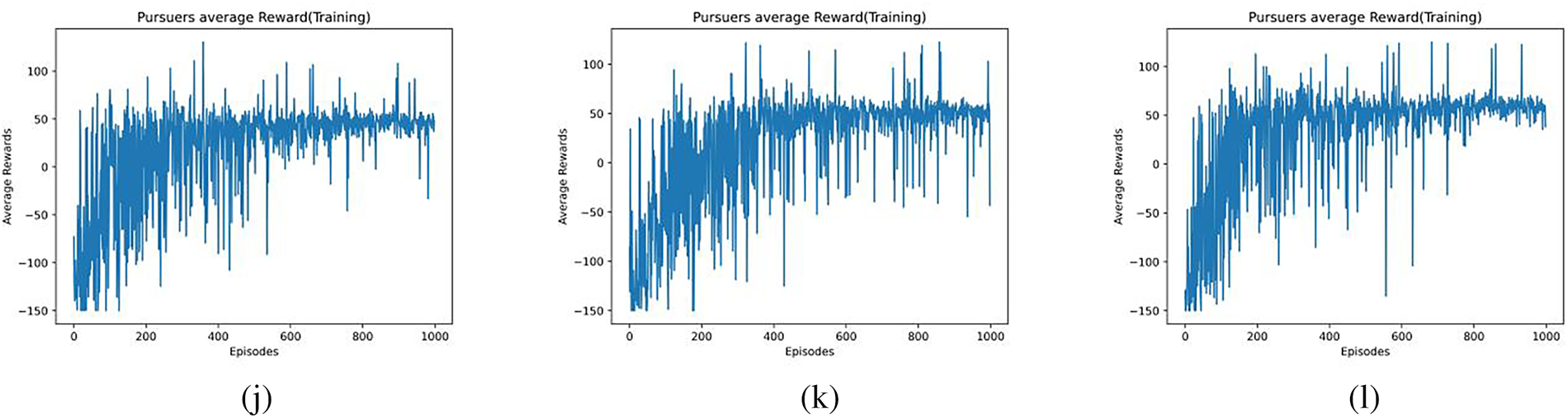
Figure 5: Average reward of agents with different
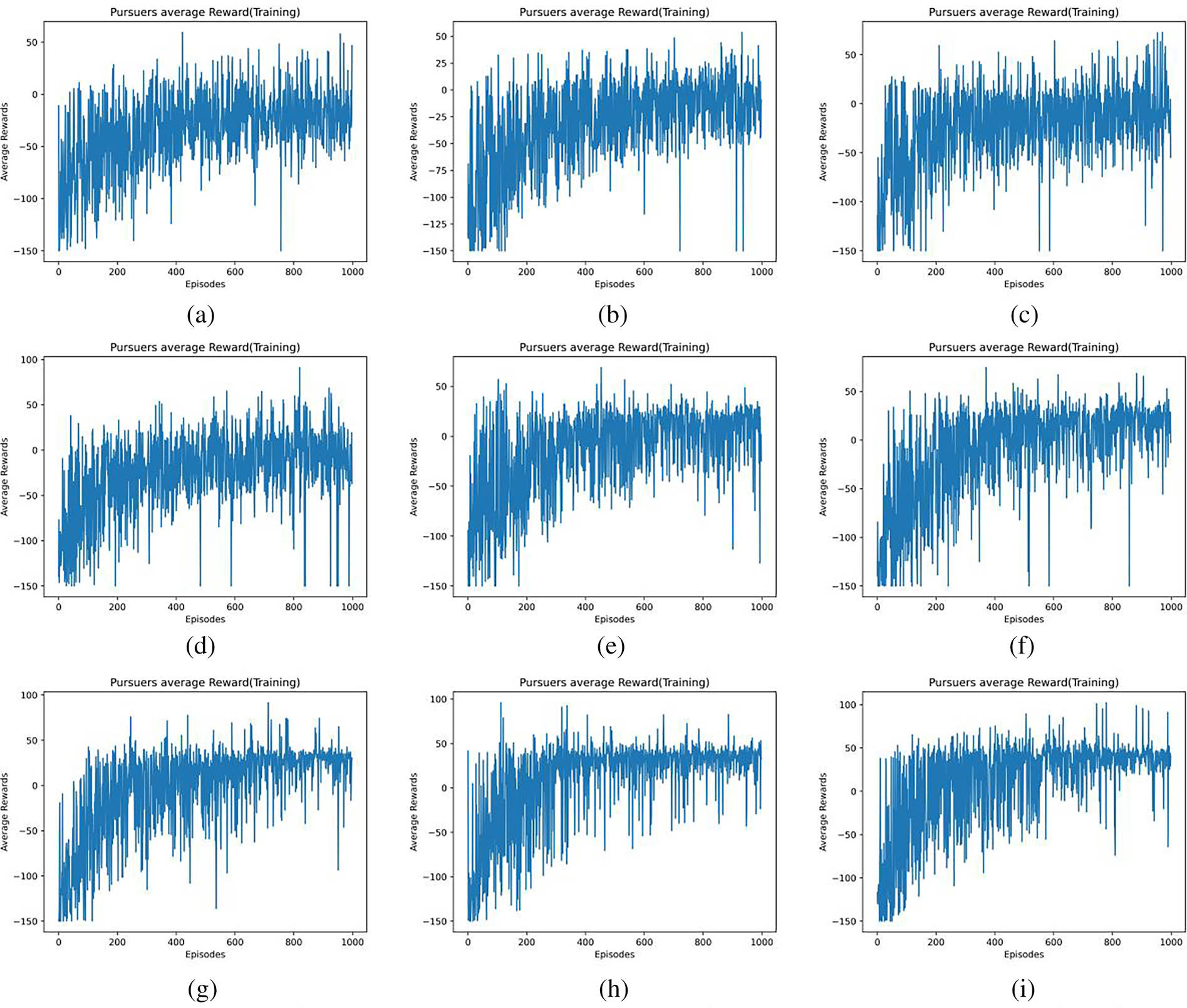
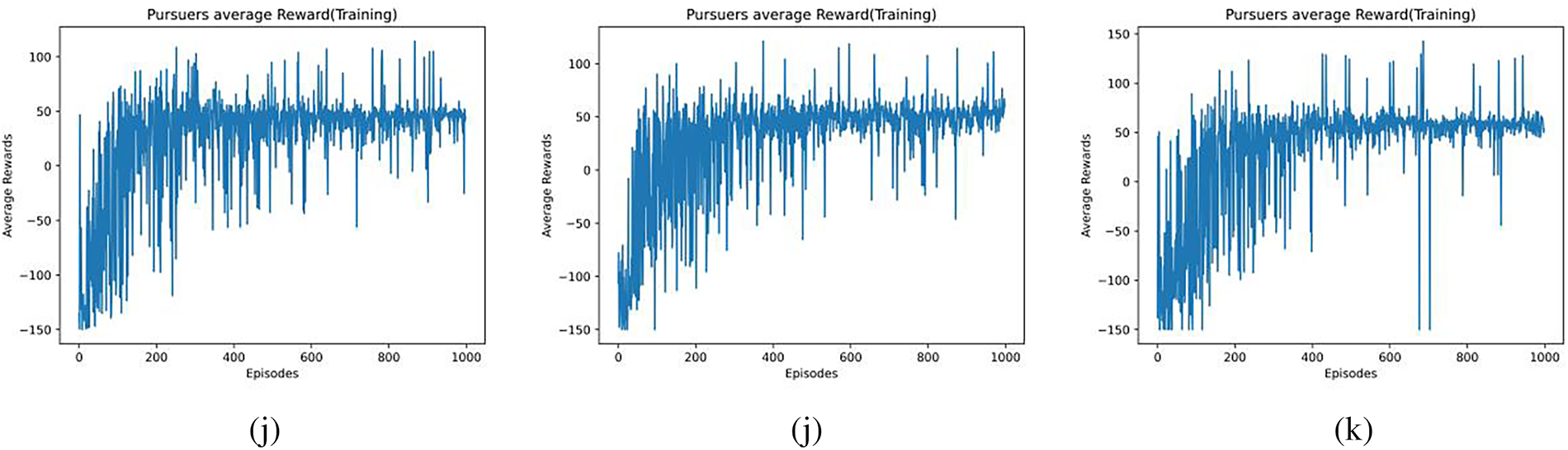
Figure 6: Average reward of agents with different
Figs. 5a–l and 6a–l show the average reward values for
The value of
The paper introduces CRS-DQN, a deep Q-network for dynamic target pursuit in communication-limited settings. It evaluates the algorithm in single-target and multi-target scenarios. In single-target, multiple agents pursue one target non-cooperatively. In multi-target, agents pursue two targets without cooperation.
Analyzing average reward data provides a performance comparison, validating CRS-DQN’s effectiveness in communication-constrained environments. The average reward represents the mean reward of agents (or targets).
Fig. 7a–d shows average rewards for agents pursuing a single dynamic target in different scenarios with varying numbers of agents. Initial positions are specified for Scenario 1 and Scenario 2. The communication delay radius
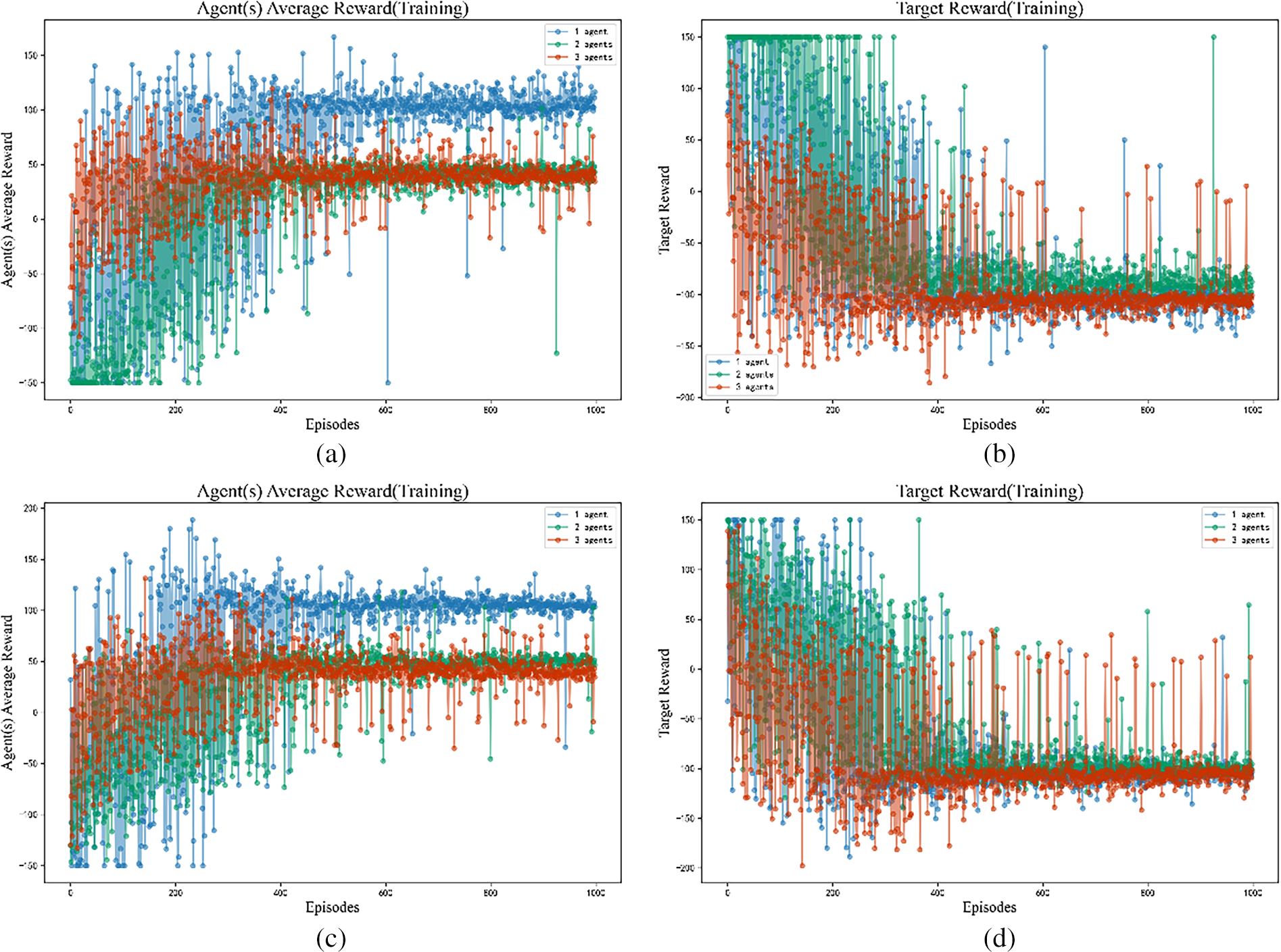
Figure 7: Average rewards for both the single-target chasing agent and the target: (a) Agent Average Reward (Scenario 1), (b) Target Reward (Scenario 1), (c) Agent Average Reward (Scenario 2), (d) Target Reward (Scenario 2).
In the single-target pursuit scenario, the agents’ average reward increased with the number of training iterations, while the average reward for the target decreased correspondingly. Around the 400th iteration, the average rewards for both sides entered and remained within a relatively stable range.
Fig. 8a–d illustrates the average rewards for both intelligent agents and two dynamic targets in multi-target pursuit scenarios, varying the number of intelligent agents. Initial positions are based on scenarios 1 and 2. The communication delay radius, denoted as
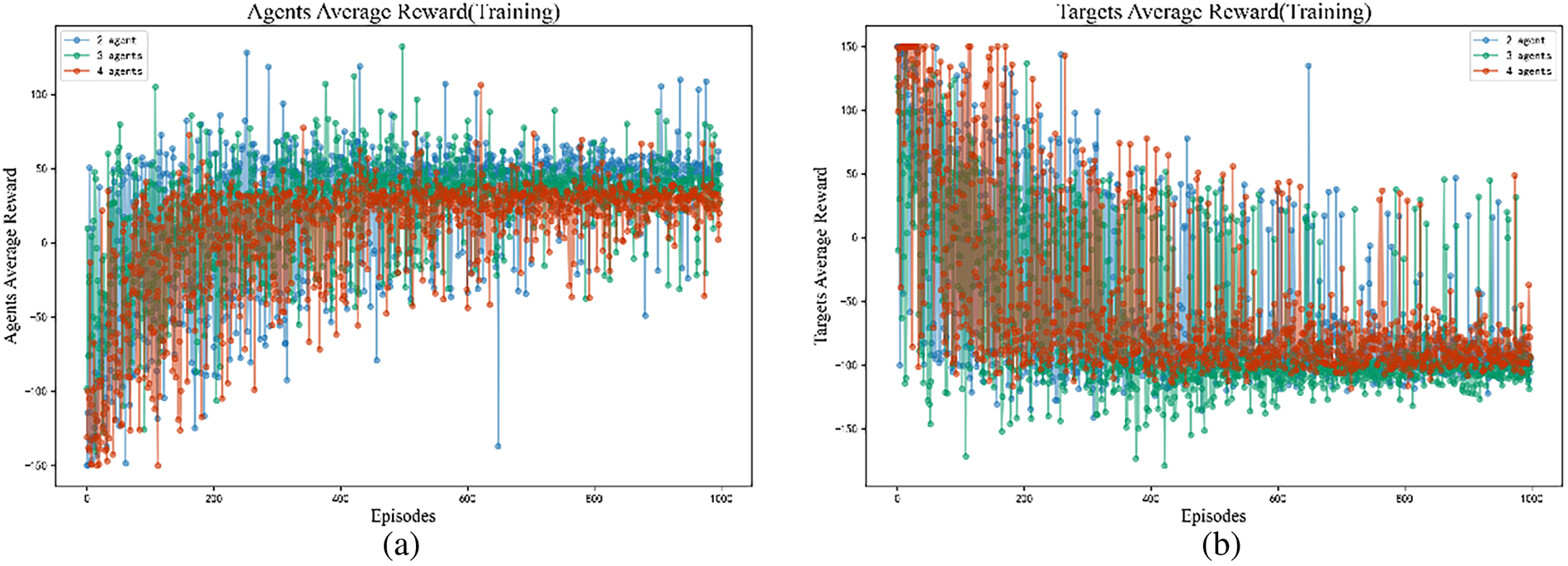
Figure 8: Average rewards for both the multi-target chasing agent and the target: (a) Agent Average Reward (Scenario 1), (b) Target Average Reward (Scenario 1), (c) Agent Average Reward (Scenario 2), (d) Target Average Reward (Scenario 2).
In the multi-target pursuit scenario, the average rewards for the agents and the targets also increased and decreased with training, respectively. However, the convergence of these reward curves was slower compared to the single-target case. The curves began to stabilize after approximately 600 iterations.
5.3 Communication Latency Variable Analysis
The acquisition of target location information by the agent is one of the key factors that determine the success of the pursuit task, measured by the communication latency variable
Fig. 9a–d displays the success rate and iterative time steps for 1, 2, and 3 agents pursuing a single dynamic target, under Scenario 1 and Scenario 2 initial positions, with communication latency ranging from 1 to 10:
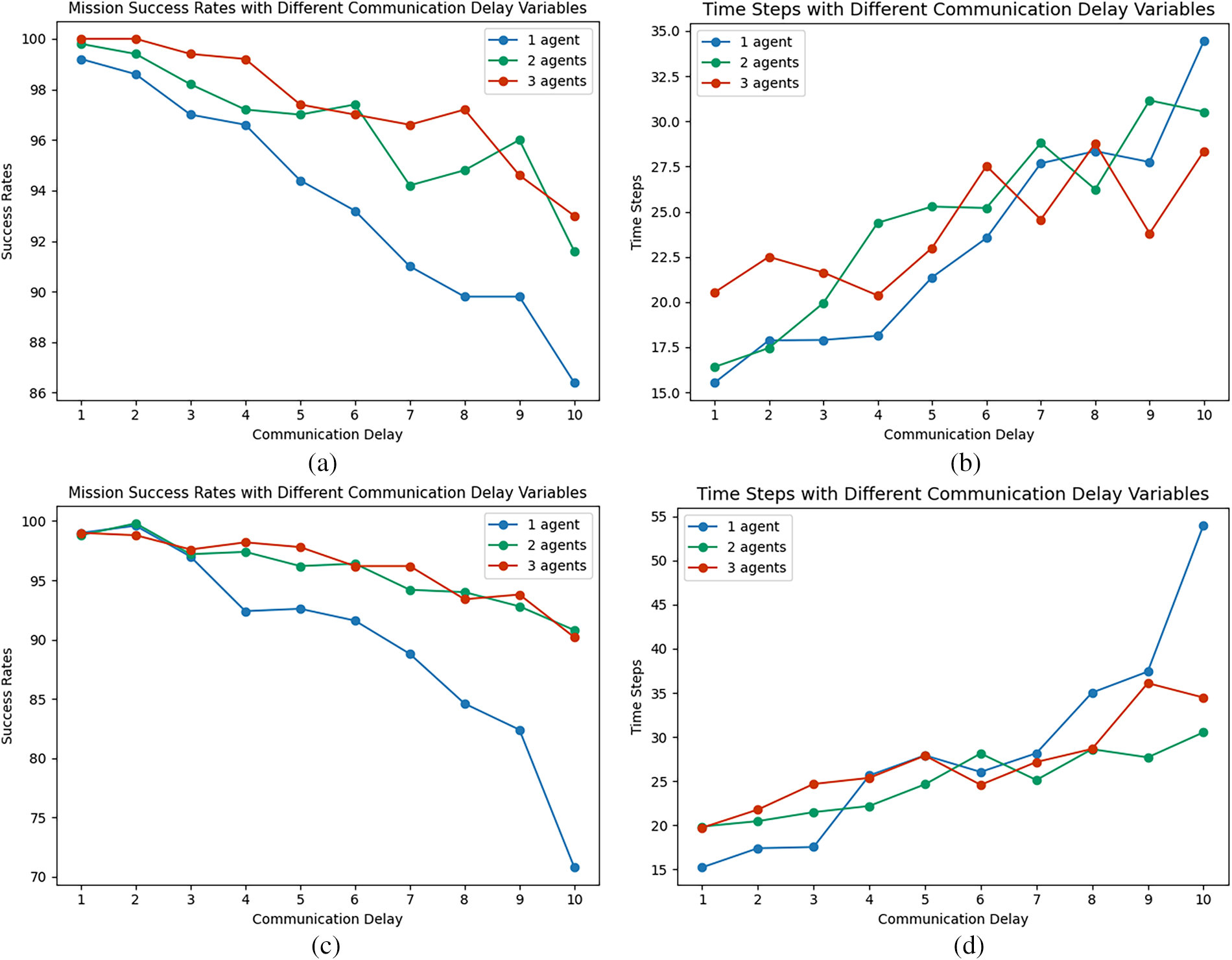
Figure 9: Single-target pursuit under different communication delay variables: (a) Success Rates (Scenario 1), (b) Iteration Time Steps (Scenario 1), (c) Success Rates (Scenario 2), (d) Iteration Time Steps (Scenario 2).
In the single-target pursuit scenario, as the communication latency
Fig. 10a–d shows the success rate and the number of iterative time steps for different numbers of agents pursuing two dynamic targets (multiple targets):
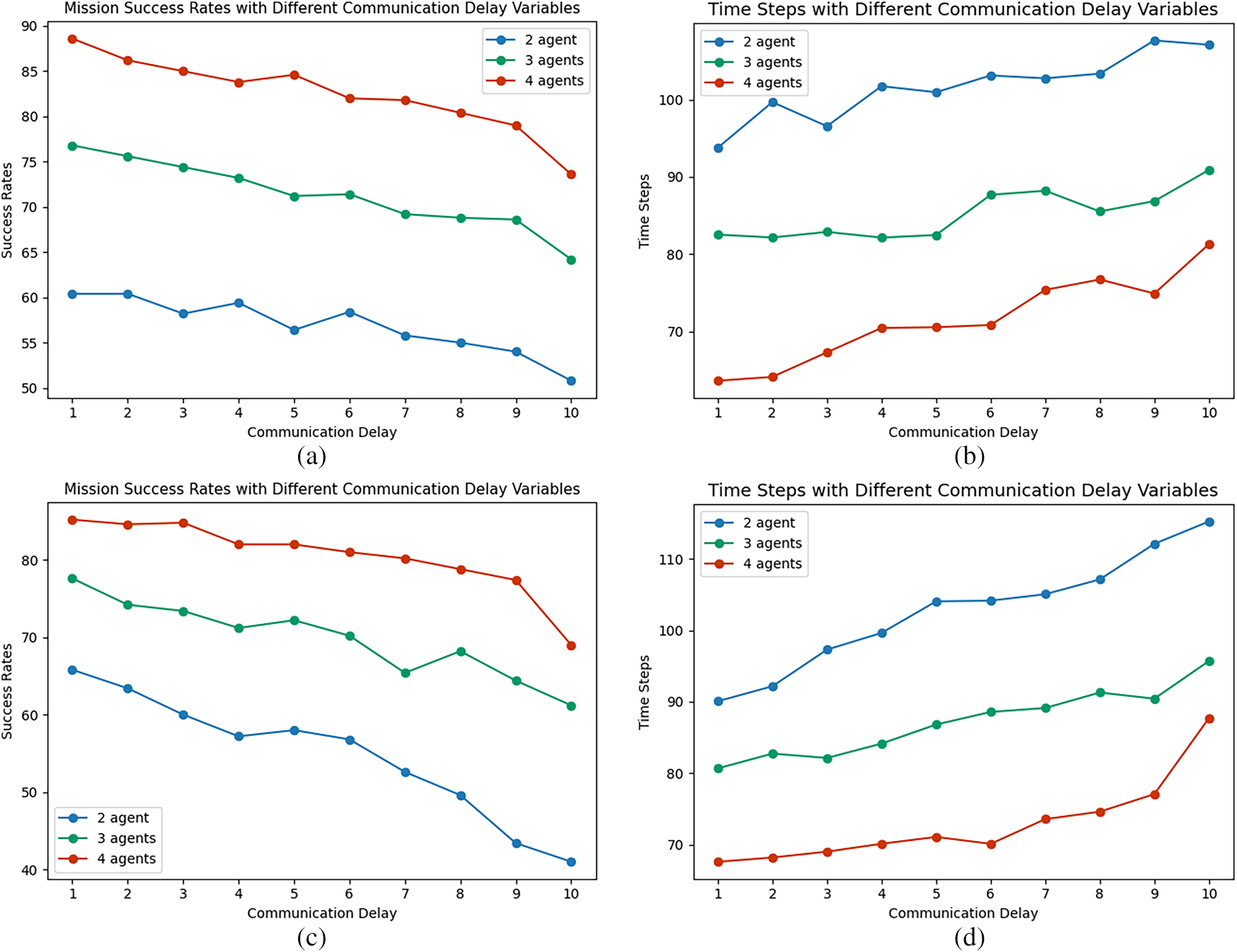
Figure 10: Multi-target pursuit under different communication delay variables: (a) Success Rates (Scenario 1), (b) Iteration Time Steps (Scenario 1), (c) Success Rates (Scenario 2), (d) Iteration Time Steps (Scenario 2).
In the dual-target pursuit scenario, increased communication latency
5.4 Communication Radius Size Analysis
Intelligent agents have the communication delay radius
Fig. 11a–d shows bar graphs comparing the success rate and iteration time steps for 2 and 3 agents pursuing a single dynamic target under various communication radii, with initial positions in Scenarios 1 and 2. The communication distance constraint radius is set to 10, 20, 30, 40, and 50, and the ratio of the communication delay radius
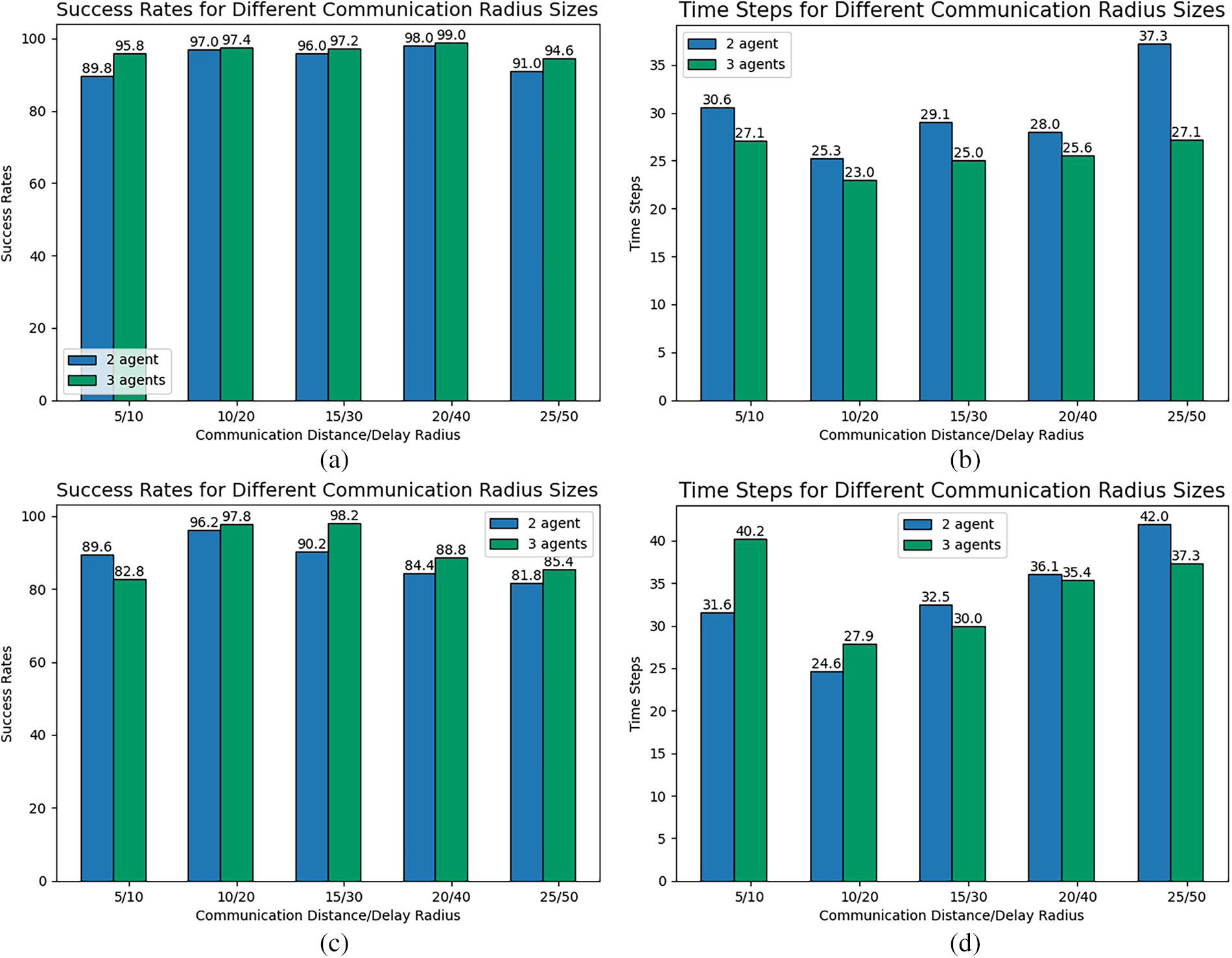
Figure 11: Single-target pursuit under different communication radius size: (a) Success Rates (Scenario 1), (b) Iteration Time Steps (Scenario 1), (c) Success Rates (Scenario 2), (d) Iteration Time Steps (Scenario 2).
The figure illustrates the impact of the communication delay radius
Fig. 12a–d shows bar graphs of the success rate and the number of iteration time steps for different numbers of agents pursuing two dynamic targets under different communication radius sizes:
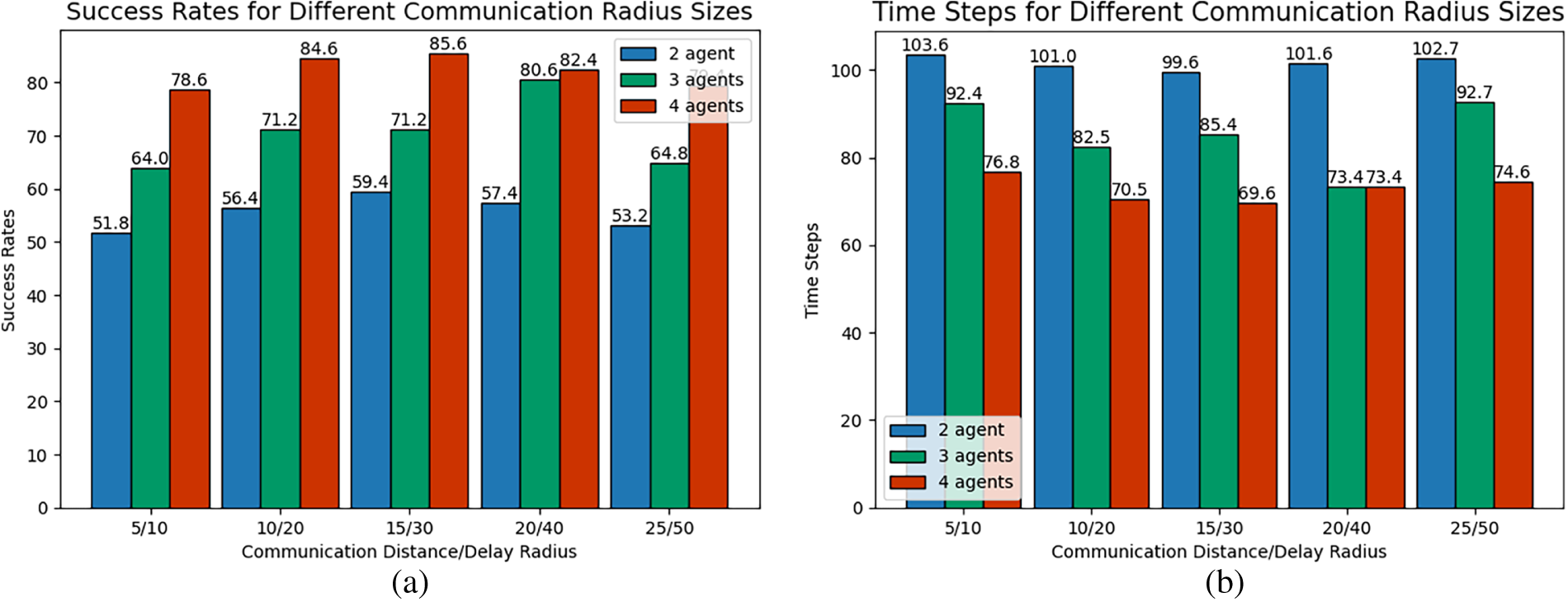
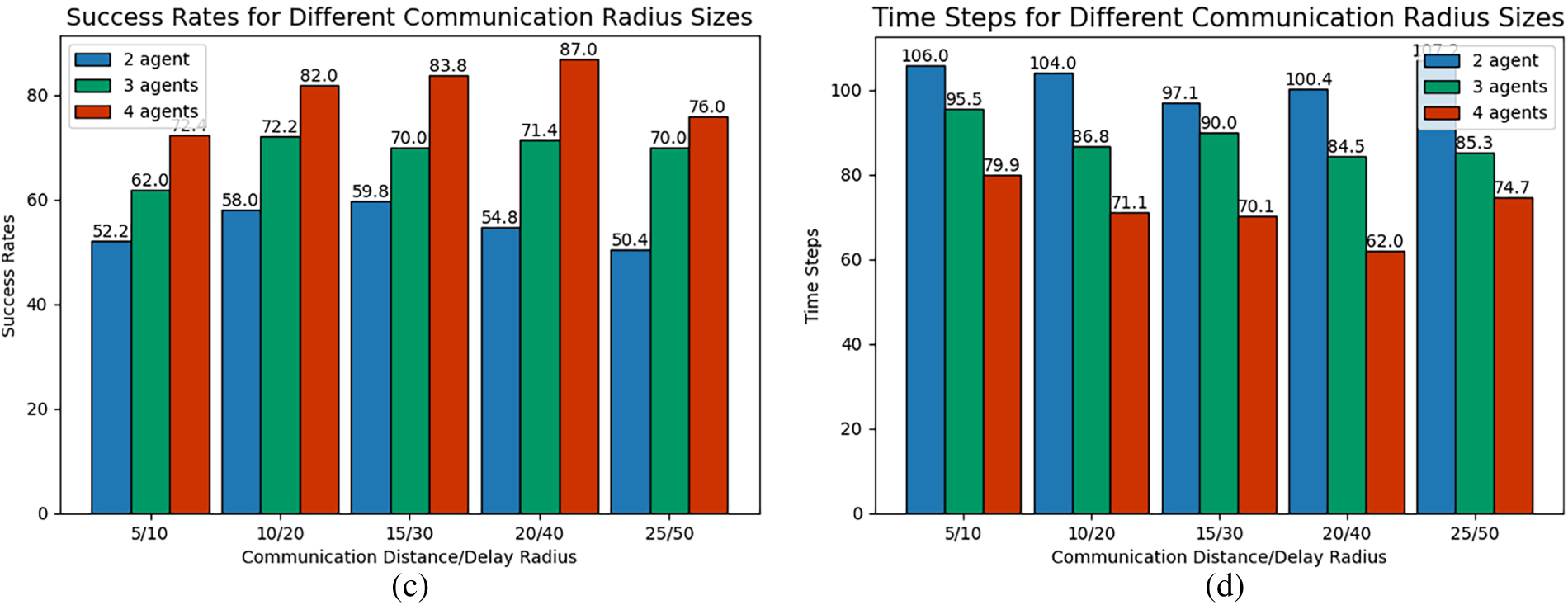
Figure 12: Multi-target pursuit under different communication radius size: (a) Success Rates (Scenario 1), (b) Iteration Time Steps (Scenario 1), (c) Success Rates (Scenario 2), (d) Iteration Time Steps (Scenario 2).
For multi-target pursuit, the success rate and the average iterative steps also exhibit a non-monotonic trend of initial improvement followed by degradation with increasing
5.5 Communication Radius Ratio Analysis
This section will explore the impact of different ratios between the communication delay radius
We analyze how varying communication sizes affect single and multiple target pursuit effectiveness. Using a communication distance constraint radius of
Fig. 13a–d shows success rate and iteration time step bar charts for 2 and 3 agents pursuing a single dynamic target under varying communication radius ratios, with initial positions in scenarios 1 and 2, with a fixed communication distance constraint radius of 30 and communication delay radius values of
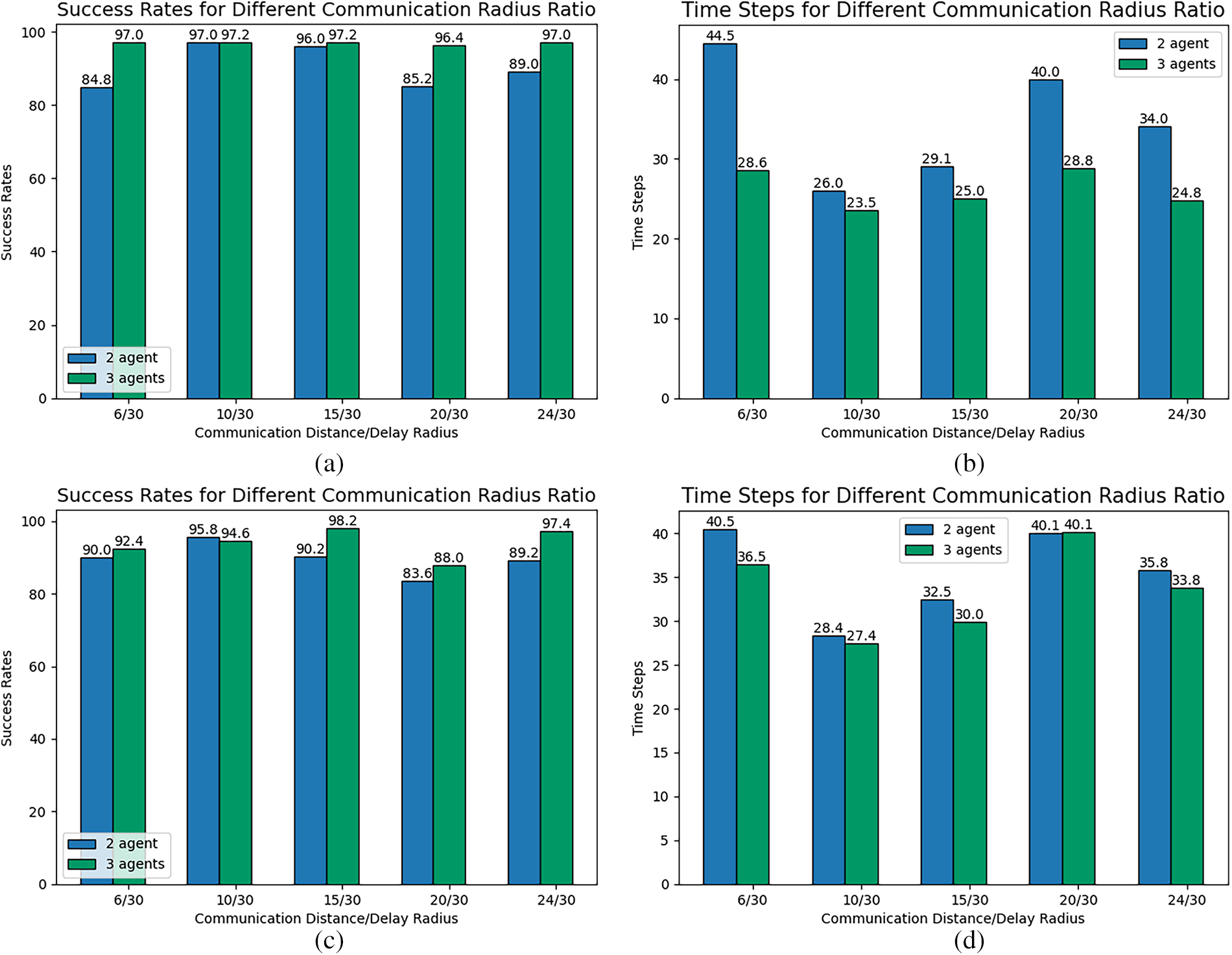
Figure 13: Single-target pursuit under different communication radius ratio: (a) Success Rates (Scenario 1), (b) Iteration Time Steps (Scenario 1), (c) Success Rates (Scenario 2), (d) Iteration Time Steps (Scenario 2).
In the single-target pursuit scenario, as the ratio
Fig. 14a–d illustrates the success rate and iteration time steps for 2, 3, and 4 agents pursuing two dynamic targets under varying communication radius ratios (
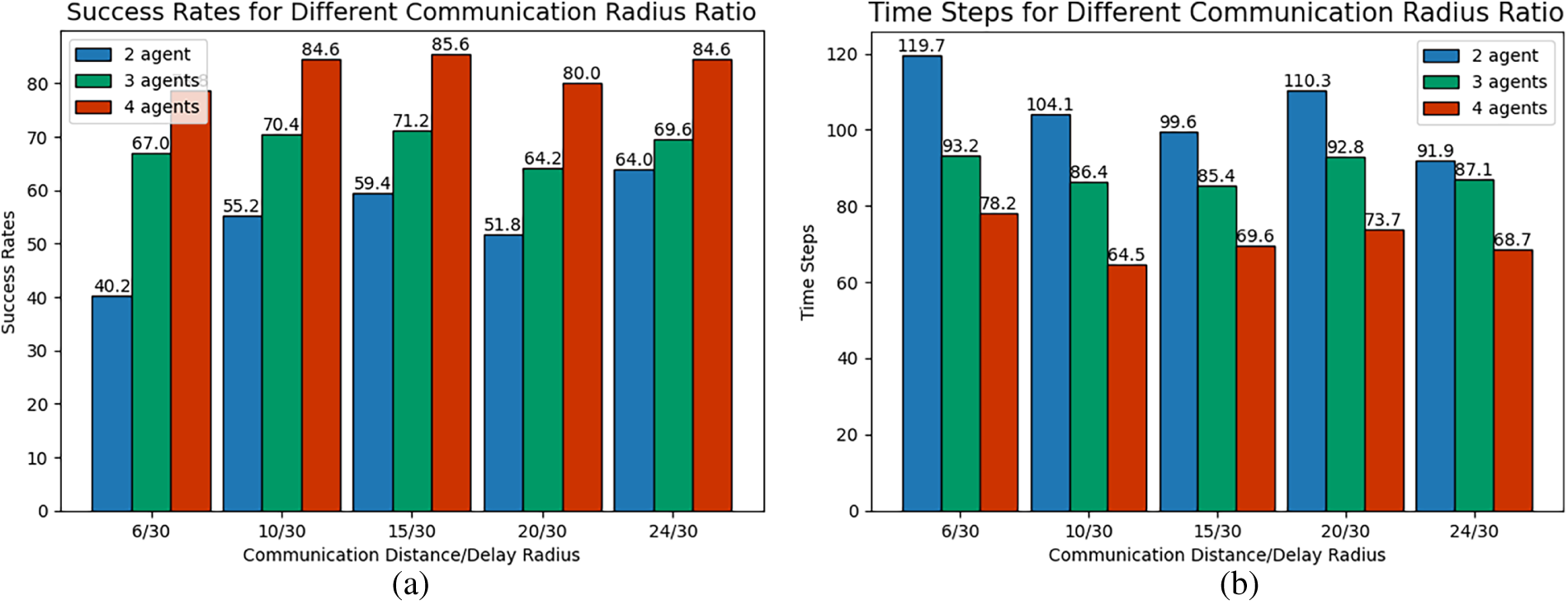
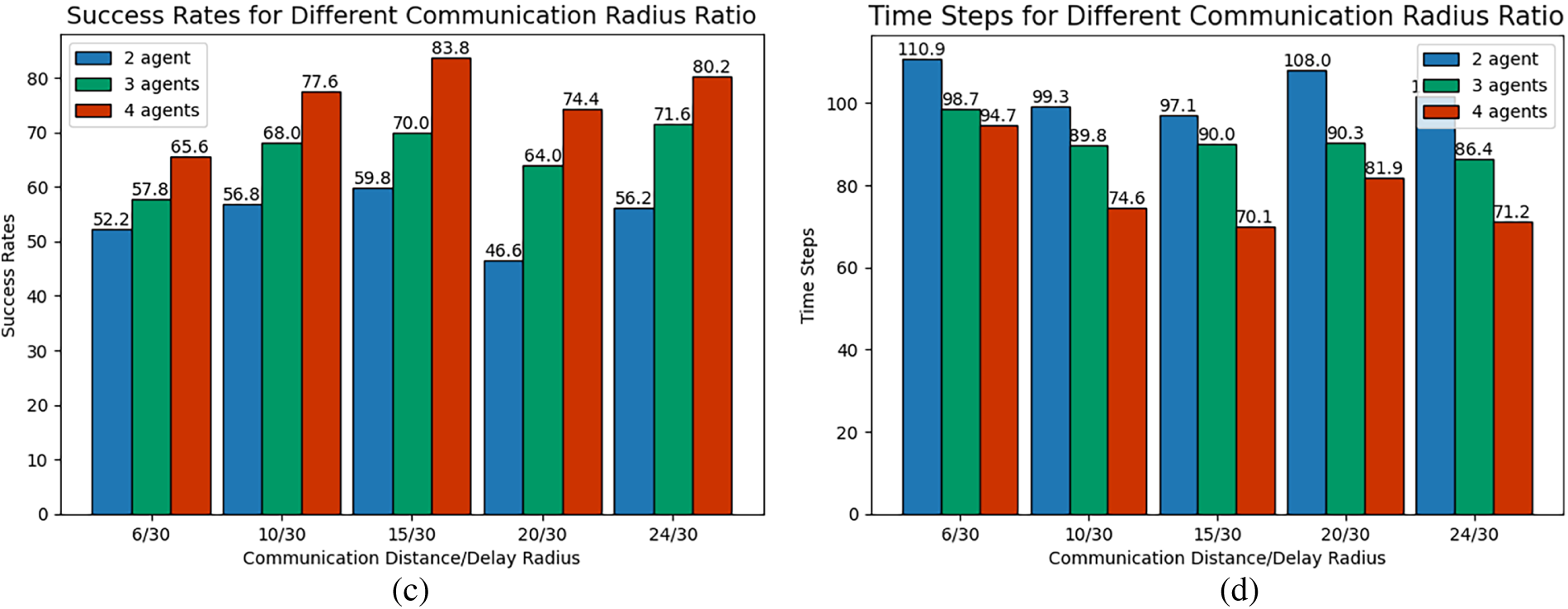
Figure 14: Multi-target pursuit under different communication radius ratio: (a) Success Rates (Scenario 1), (b) Iteration Time Steps (Scenario 1), (c) Success Rates (Scenario 2), (d) Iteration Time Steps (Scenario 2).
In the multi-target pursuit scenario, the success rate also demonstrates a three-phase variation of “increase, decrease, and then increase” with a growing
This study systematically evaluated the performance of the CRS-DQN algorithm for dynamic target pursuit under various communication constraints through a series of simulation experiments. The results revealed the complex effects of communication latency, communication radius size, and their ratio on pursuit efficacy. This section aims to provide an in-depth interpretation of the underlying logic of these findings, contextualize this work within related research, and clarify its theoretical contributions and practical implications.
5.6.1 The Impact Mechanism of Communication Constraints
The experimental results clearly indicate that communication latency has a significant negative impact on pursuit success rate (Section 5.3). Notably, increasing the number of agents can mitigate the negative impact of latency. This can be understood through information redundancy and cooperative observation: even if some information is outdated, observational data obtained by multiple agents from different positions can complement and cross-verify each other, thereby partially offsetting errors from a single information source and enhancing the system’s robustness.
Regarding the communication radius, the experiments observed a non-monotonic “peak” phenomenon: performance first improved and then deteriorated as the radius increased (Section 5.4). This reveals a critical trade-off in communication resource allocation. An excessively small radius leads to limited perception range for agents, resulting in an “information scarcity” state. Conversely, an overly large radius may cause “information overload” or network congestion. The latter not only increases the input dimensionality and computational burden on the agent’s decision-making model but may also introduce a large amount of irrelevant or interfering information, thereby degrading decision quality. Therefore, an optimal communication range exists that balances providing sufficient information and avoiding system overload.
5.6.2 Effectiveness and Innovativeness of the CRS-DQN Algorithm
The CRS-DQN algorithm demonstrated the ability to converge reward curves in both single-target and multi-target scenarios (Section 5.2), validating its fundamental learning capability under communication constraints. This design enables agents to dynamically adapt to different communication states: when information is limited, the algorithm relies on historical reinforcement learning experience for decision-making; when information is sufficient, it can leverage more precise cooperative information. Particularly in multi-target scenarios where the algorithm must simultaneously handle information flows and communication constraints for multiple targets, its convergence capability demonstrates considerable scalability.
5.6.3 Implications of Radius Ratio Optimization
The analysis of the radius ratio
This study investigated the challenging problem of dynamic target pursuit by non-cooperative agents under stringent communication constraints, namely simultaneous delay and range limitations. We proposed the CRS-DQN algorithm, whose core innovation is a task-aware dynamic action masking mechanism that seamlessly integrates real-time communication state into the DQN learning cycle. Simulation results quantified the impact of key parameters: pursuit performance degrades monotonically with increased delay, exhibits a non-linear relationship with communication range (with an optimal interval), and is sensitive to the balance between range and delay threshold.
6.1 Implications and Significance
Our findings offer concrete design principles for multi-agent systems operating in adversarial, communication-degraded environments. They demonstrate that simply maximizing communication range can be counterproductive; instead, there exists a critical trade-off between real-time information fidelity and decision-making autonomy. The CRS-DQN framework provides a viable paradigm for embedding domain-specific constraints (communication limits) as structured prior knowledge into general-purpose learning architectures, enhancing both sample efficiency and operational safety in partially observable settings.
This work has several inherent limitations that also define the scope of our contributions:
(1) Environmental Abstraction: The study is conducted in a 2D discrete grid world with a deterministic, range-based communication model. This simplifies the complexities of continuous 3D spaces and probabilistic wireless channels in real-world deployments.
(2) Algorithmic Focus: Our investigation centers on enhancing a value-based (DQN) framework. A systematic comparison with other multi-agent reinforcement learning paradigms (e.g., policy-gradient methods like MAPPO or MADDPG) under identical communication constraints remains for future work.
(3) Agent Homogeneity: We assume a homogeneous team of pursuer agents with identical capabilities and communication modules. The challenges and potential synergies in heterogeneous teams are not explored.
(4) Scenario Specificity: The current work focuses on obstacle-free environments. The dynamic impact of physical obstacles on both communication links and pursuit trajectories is not considered, which represents a significant area for further study.
Future research will extend this work along several axes guided by the above limitations: (1) exploring algorithm robustness under probabilistic channel models and in 3D continuous spaces; (2) conducting comparative studies between the core ideas of CRS-DQN and other MARL paradigms; (3) investigating pursuit strategies for heterogeneous multi-agent teams; (4) incorporating static and dynamic obstacles to study integrated perception-communication-pursuit challenges.
Acknowledgement: Not applicable.
Funding Statement: This work was supported by Equipment Pre-Research Ministry of Education Joint Fund [grant number 6141A02033703].
Author Contributions: Xin Yu: Conceptualization, Methodology, Software, Validation, Investigation, Writing—original draft. Xi Fang: Conceptualization, Supervision, Writing—review & editing. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: No data was used for the research described in the article.
Ethics Approval: Not applicable. This study did not involve any human or animal participants.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Shadkam E, Irannezhad E. A comprehensive review of simulation optimization methods in agricultural supply chains and transition towards an agent-based intelligent digital framework for agriculture 4.0. Eng Appl Artif Intell. 2025;143(29):109930. doi:10.1016/j.engappai.2024.109930. [Google Scholar] [CrossRef]
2. Ben Elallid B, Benamar N, Hafid AS, Rachidi T, Mrani N. A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving. J King Saud Univ Comput Inf Sci. 2022;34(9):7366–90. doi:10.1016/j.jksuci.2022.03.013. [Google Scholar] [CrossRef]
3. Cao X, Li M, Tao Y, Lu P. HMA-SAR: multi-agent search and rescue for unknown located dynamic targets in completely unknown environments. IEEE Robot Autom Lett. 2024;9(6):5567–74. doi:10.1109/LRA.2024.3396097. [Google Scholar] [CrossRef]
4. Gao M, Gao K, Ma Z, Tang W. Ensemble meta-heuristics and Q-learning for solving unmanned surface vessels scheduling problems. Swarm Evol Comput. 2023;82(2):101358. doi:10.1016/j.swevo.2023.101358. [Google Scholar] [CrossRef]
5. Guo H, Kang Q, Yau WY, Ang MH, Rus D. EM-patroller: entropy maximized multi-robot patrolling with steady state distribution approximation. IEEE Robot Autom Lett. 2023;8(9):5712–9. doi:10.1109/LRA.2023.3300245. [Google Scholar] [CrossRef]
6. Wang J, Li G, Liang L, Wang C, Deng F. Pursuit-evasion games of multiple cooperative pursuers and an evader: a biological-inspired perspective. Commun Nonlinear Sci Numer Simul. 2022;110:106386. doi:10.1016/j.cnsns.2022.106386. [Google Scholar] [CrossRef]
7. Yang B, Liu P, Feng J, Li S. Two-stage pursuit strategy for incomplete-information impulsive space pursuit-evasion mission using reinforcement learning. Aerospace. 2021;8(10):299. doi:10.3390/aerospace8100299. [Google Scholar] [CrossRef]
8. Majid AY, Saaybi S, Francois-Lavet V, Prasad RV, Verhoeven C. Deep reinforcement learning versus evolution strategies: a comparative survey. IEEE Trans Neural Netw Learning Syst. 2024;35(9):11939–57. doi:10.1109/tnnls.2023.3264540. [Google Scholar] [PubMed] [CrossRef]
9. Yu W, Liu C, Yue X. Reinforcement learning-based decision-making for spacecraft pursuit-evasion game in elliptical orbits. Control Eng Pract. 2024;153(7):106072. doi:10.1016/j.conengprac.2024.106072. [Google Scholar] [CrossRef]
10. Wang Y, Dong L, Sun C. Cooperative control for multi-player pursuit-evasion games with reinforcement learning. Neurocomputing. 2020;412(2):101–14. doi:10.1016/j.neucom.2020.06.031. [Google Scholar] [CrossRef]
11. Chung TH, Hollinger GA, Isler V. Search and pursuit-evasion in mobile robotics. Auton Rob. 2011;31(4):299–316. doi:10.1007/s10514-011-9241-4. [Google Scholar] [CrossRef]
12. Zhang L, Prorok A, Bhattacharya S. Pursuer assignment and control strategies in multi-agent pursuit-evasion under uncertainties. Front Robot AI. 2021;8:691637. doi:10.3389/frobt.2021.691637. [Google Scholar] [PubMed] [CrossRef]
13. Wang Z, Li J, Li J, Liu C. A decentralized decision-making algorithm of UAV swarm with information fusion strategy. Expert Syst Appl. 2024;237(3):121444. doi:10.1016/j.eswa.2023.121444. [Google Scholar] [CrossRef]
14. Zhu C, Dastani M, Wang S. A survey of multi-agent deep reinforcement learning with communication. Auton Agents Multi Agent Syst. 2024;38(1):4. doi:10.1007/s10458-023-09633-6. [Google Scholar] [CrossRef]
15. Han L, Song W, Yang T, Tian Z, Yu X, An X. Cooperative decisions of a multi-agent system for the target-pursuit problem in manned-unmanned environment. Electronics. 2023;12(17):3630. doi:10.3390/electronics12173630. [Google Scholar] [CrossRef]
16. Dong D, Zhu Y, Du Z, Yu D. Multi-target dynamic hunting strategy based on improved K-means and auction algorithm. Inf Sci. 2023;640(4):119072. doi:10.1016/j.ins.2023.119072. [Google Scholar] [CrossRef]
17. Chen M, Zhang X, Li G, Lai W, Yang C. Multi-evader dynamic pursuit strategy based on improved AAPC and auction algorithm amidst static and dynamic obstacles. Expert Syst Appl. 2025;266(6):126029. doi:10.1016/j.eswa.2024.126029. [Google Scholar] [CrossRef]
18. Pan T, Yuan Y. A region-based relay pursuit scheme for a pursuit-evasion game with a single evader and multiple pursuers. IEEE Trans Syst Man Cybern Syst. 2023;53(3):1958–69. doi:10.1109/TSMC.2022.3210022. [Google Scholar] [CrossRef]
19. Wang C, Sun Y, Ma X, Chen Q, Gao Q, Liu X. Multi-agent dynamic formation interception control based on rigid graph. Complex Intell Syst. 2024;10(4):5585–98. doi:10.1007/s40747-024-01467-3. [Google Scholar] [CrossRef]
20. Yu D, Long J, Philip Chen CL, Wang Z. Bionic tracking-containment control based on smooth transition in communication. Inf Sci. 2022;587(4):393–407. doi:10.1016/j.ins.2021.12.060. [Google Scholar] [CrossRef]
21. He S, Wang L, Liu M, Liu W, Wu Z. Dynamic multi-target self-organization hunting control of multi-agent systems. Appl Sci. 2024;14(9):3875. doi:10.3390/app14093875. [Google Scholar] [CrossRef]
22. Zhao S, Zhao G, He Y, Diao Z, He Z, Cui Y, et al. Biomimetic adaptive pure pursuit control for robot path tracking inspired by natural motion constraints. Biomimetics. 2024;9(1):41. doi:10.3390/biomimetics9010041. [Google Scholar] [PubMed] [CrossRef]
23. Yan F, Jiang J, Di K, Jiang Y, Hao Z. Multiagent pursuit-evasion problem with the pursuers moving at uncertain speeds. J Intell Rob Syst. 2019;95(1):119–35. doi:10.1007/s10846-018-0841-5. [Google Scholar] [CrossRef]
24. Tang H, Sun W, Yu H, Lin A, Xue M. A multirobot target searching method based on bat algorithm in unknown environments. Expert Syst Appl. 2020;141(2):112945. doi:10.1016/j.eswa.2019.112945. [Google Scholar] [CrossRef]
25. Zhao W, Wang L, Zhang Z, Fan H, Zhang J, Mirjalili S, et al. Electric eel foraging optimization: a new bio-inspired optimizer for engineering applications. Expert Syst Appl. 2024;238(1):122200. doi:10.1016/j.eswa.2023.122200. [Google Scholar] [CrossRef]
26. Jia Y, Zhang Y, Zhou C, Yang Y. HELOP: multi-target tracking based on heuristic empirical learning algorithm and occlusion processing. Displays. 2023;79:102488. doi:10.1016/j.displa.2023.102488. [Google Scholar] [CrossRef]
27. Amiri MH, Mehrabi Hashjin N, Montazeri M, Mirjalili S, Khodadadi N. Hippopotamus optimization algorithm: a novel nature-inspired optimization algorithm. Sci Rep. 2024;14(1):5032. doi:10.1038/s41598-024-54910-3. [Google Scholar] [PubMed] [CrossRef]
28. Cao X, Xu X. Hunting algorithm for multi-AUV based on dynamic prediction of target trajectory in 3D underwater environment. IEEE Access. 2020;8:138529–38. doi:10.1109/ACCESS.2020.3013032. [Google Scholar] [CrossRef]
29. Xia J, Luo Y, Liu Z, Zhang Y, Shi H, Liu Z. Cooperative multi-target hunting by unmanned surface vehicles based on multi-agent reinforcement learning. Def Technol. 2023;29:80–94. doi:10.1016/j.dt.2022.09.014. [Google Scholar] [CrossRef]
30. Han B, Shi L, Wang X, Zhuang L. Multi-agent multi-target pursuit with dynamic target allocation and actor network optimization. Electronics. 2023;12(22):4613. doi:10.3390/electronics12224613. [Google Scholar] [CrossRef]
31. Hua X, Liu J, Zhang J, Shi C. An Apollonius circle based game theory and Q-learning for cooperative hunting in unmanned aerial vehicle cluster. Comput Electr Eng. 2023;110:108876. doi:10.1016/j.compeleceng.2023.108876. [Google Scholar] [CrossRef]
32. Qu X, Gan W, Song D, Zhou L. Pursuit-evasion game strategy of USV based on deep reinforcement learning in complex multi-obstacle environment. Ocean Eng. 2023;273:114016. doi:10.1016/j.oceaneng.2023.114016. [Google Scholar] [CrossRef]
33. Du SL, Sun XM, Cao M, Wang W. Pursuing an evader through cooperative relaying in multi-agent surveillance networks. Automatica. 2017;83:155–61. doi:10.1016/j.automatica.2017.06.022. [Google Scholar] [CrossRef]
34. Du S, Zhu L, Han H, Qiao J. Cooperative relay pursuit with input saturation constraint and external disturbances. Int J Robust Nonlinear Control. 2022;32(18):9939–56. doi:10.1002/rnc.6353. [Google Scholar] [CrossRef]
35. Lopez VG, Lewis FL, Wan Y, Sanchez EN, Fan L. Solutions for multiagent pursuit-evasion games on communication graphs: finite-time capture and asymptotic behaviors. IEEE Trans Autom Control. 2020;65(5):1911–23. doi:10.1109/TAC.2019.2926554. [Google Scholar] [CrossRef]
36. Yao D, Dou C, Zhao N, Zhang T. Practical fixed-time adaptive consensus control for a class of multi-agent systems with full state constraints and input delay. Neurocomputing. 2021;446(1):156–64. doi:10.1016/j.neucom.2021.03.032. [Google Scholar] [CrossRef]
37. Maity D, Pourghorban A. Cooperative target defense under communication and sensing constraints. IEEE Control Syst Lett. 2024;8:3321–6. doi:10.1109/LCSYS.2024.3523843. [Google Scholar] [CrossRef]
38. de Souza C, Newbury R, Cosgun A, Castillo P, Vidolov B, Kuli D. Decentralized multi-agent pursuit using deep reinforcement learning. IEEE Robot Autom Lett. 2021;6(3):4552–9. doi:10.1109/lra.2021.3068952. [Google Scholar] [CrossRef]
39. Du W, Guo T, Chen J, Li B, Zhu G, Cao X. Cooperative pursuit of unauthorized UAVs in urban airspace via Multi-agent reinforcement learning. Transp Res Part C Emerg Technol. 2021;128(1):103122. doi:10.1016/j.trc.2021.103122. [Google Scholar] [CrossRef]
40. Sun Q, Dang Z. Deep neural network for non-cooperative space target intention recognition. Aerosp Sci Technol. 2023;142:108681. doi:10.1016/j.ast.2023.108681. [Google Scholar] [CrossRef]
41. Xu Y, Qi N, Li Z, Huo M, Fan Z. Research on proximity strategies for pursuit-evasion game with non-cooperative targets in space. Aerosp Sci Technol. 2025;158:109899. doi:10.1016/j.ast.2024.109899. [Google Scholar] [CrossRef]
42. Chen Y, Zhang Z, Wu Z, Wu Y, He B, Zhang H, et al. Multiple mobile robots planning framework for herding non-cooperative target. IEEE Trans Automat Sci Eng. 2024;21(4):7363–78. doi:10.1109/tase.2023.3341694. [Google Scholar] [CrossRef]
43. Sun L, Chang YC, Lyu C, Shi Y, Shi Y, Lin CT. Toward multi-target self-organizing pursuit in a partially observable Markov game. Inf Sci. 2023;648:119475. doi:10.1016/j.ins.2023.119475. [Google Scholar] [CrossRef]
44. Xue L, Ye J, Wu Y, Liu J, Wunsch DC. Prescribed-time Nash equilibrium seeking for pursuit-evasion game. IEEE/CAA J Autom Sinica. 2024;11(6):1518–20. doi:10.1109/jas.2023.124077. [Google Scholar] [CrossRef]
45. Valianti P, Malialis K, Kolios P, Ellinas G. Cooperative multi-agent jamming of multiple rogue drones using reinforcement learning. IEEE Trans Mob Comput. 2024;23(12):12345–59. doi:10.1109/TMC.2024.3409050. [Google Scholar] [CrossRef]
46. Liao G, Wang J, Yang D, Yang J. Multi-UAV escape target search: a multi-agent reinforcement learning method. Sensors. 2024;24(21):6859. doi:10.3390/s24216859. [Google Scholar] [PubMed] [CrossRef]
47. Shakya AK, Pillai G, Chakrabarty S. Reinforcement learning algorithms: a brief survey. Expert Syst Appl. 2023;231(7):120495. doi:10.1016/j.eswa.2023.120495. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools