
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Active Defense Method for Network Hopping Based on Dynamic Random Graph
1 School of Electronic Information, Wuhan University, Wuhan, China
2 State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan, China
3 Key Laboratory of Cyberspace Situation Awareness of Henan Province, Information Engineering University, Zhengzhou, China
* Corresponding Author: Zhu Fang. Email:
Computers, Materials & Continua 2026, 87(3), 49 https://doi.org/10.32604/cmc.2026.076043
Received 13 November 2025; Accepted 26 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In view of the problem that the IP address jump law is easy to predict in the current mobile target defense, this paper proposes a network address jump active defense method based on a dynamic random graph, designed to improve the unpredictability of IP address translation. Firstly, in order to make IP address transformation unpredictable in space and time, a random graph model is designed to generate a pseudo-random sequence of IP address randomization; these pseudo-random can meet the unpredictability of IP address translation in both space and time. Then, based on these pseudo-random sequences and IP address pool, a random map generation algorithm is proposed, which generates highly random IP address sequences through chaotic mapping (Logistic mapping) combined with encryption perturbation technology, meeting the requirements of resisting analysis attacks, while these transformed IP addresses are adapted to network target defense. And finally, this article uses buildMininet to build a cloud network trusted environment, by testing the spatial randomization and temporal randomization of the Random mapping model (CRM), the results show that the CRM model has a good effect on improving the local randomness. The test results of the ablation experiment further show that the CRM model can improve the local randomness while maintaining the global randomness.Keywords
With the development and iteration of digital technology, the functions of the Internet have been further expanded, gradually becoming a significant force in the production, daily life, and governance of human society. However, cyber attacks have occurred frequently in recent years. In February 2024, the “ESXiArgs” organization launched a blackmail attack targeting customers running the VMware ESXi virtual machine monitor, affecting over 3800 servers. In April 2024, Cactus ransomware attacked Aero Dynamic Machine, an American aerospace manufacturer, to steal 1.1 TB of data, including confidential drawings of SpaceX, Boeing, and other enterprises, directly threatening national security.
In the face of these network attacks, the current mainstream passive defense methods, such as firewalls, antivirus software, and intrusion detection systems, have significant shortcomings. For example, the essence of a firewall is a static rule-based defense system [1]; in the face of rapid iteration of attack means, it will cause the defense to lag [2]. Antivirus software relies on static file analysis and cannot detect fileless attacks in memory [3,4]. To address the shortcomings of these traditional defense methods, moving target defense (MTD) [5–7] emerged, increasing the difficulty and cost of attacks by dynamically changing system configurations, such as dynamic network topology, service virtualization, and protocol confusion [8,9]. IP address hopping, as one of its core technologies, can randomize or periodically change IP addresses, making it difficult for attackers to establish a persistent attack path [10].
Currently, the defense side enhances the unpredictability of IP address conversion to increase the cost of attacks, which can be achieved by dynamically adjusting the selection of IP addresses and the timing of hopping [11–13]. However, the IP hopping defense technology still faces the problem of identifying the IP address selected by the attacker to bypass the proxy server or SDN network hopping mechanism [14], as well as the challenge of predicting the current or next period’s IP address based on historical data analysis.
Based on the above problems, to increase the unpredictability of IP address transformation and prevent attackers from analyzing historical data to predict the IP address for the next period, this paper proposes a network jump defense method based on a dynamic random graph. The main contributions of this paper are as follows:
(1) Constructs a dynamic random graph model integrating chaotic systems and cryptographic techniques. This achieves dual unpredictability in both temporal and spatial dimensions through spatial randomization (IP address selection) and temporal randomization (hopping timing), addressing the predictability issues inherent in traditional fixed graphs.
(2) Introduces a Chaos-Randomization Model (CRM) combining chaotic (Logistic) and cryptographic (RC4) random mapping. This generates global random sequences through mapping while enhancing local randomness via cryptographic algorithms,resolving the issue of local non-uniformity in chaotic sequences. Concurrently proposes IP address conversion and anti-collision mechanisms to ensure algorithmic universality.
(3) Experiments show the new method produces nearly uniform IP address distributions. It proves resistant to analysis attacks, confirming its unpredictability. Tests also confirm high time-based randomness.
According to the different hopping strategies, IP hopping can be roughly divided into three types: random hopping, rule-based hopping, and intelligent adaptive hopping. This article discusses related work from these three main types.
The randomized hopping algorithm is the most basic and widely used type of algorithm in IP hopping technology, and its core idea is to generate unpredictable hopping address sequences using random number generators or pseudo-random functions. The main advantages of such algorithms are simple implementation, low overhead and the ability to provide a high hopping frequency. For exampleJafarian et al. used OpenFlow to develop an MTD architecture that transparently changes host IP addresses with high unpredictability and rate, while maintaining configuration integrity and minimizing overhead [15]. Heydari based on the shared key and timestamp, a hash chain is used to synchronously generate random IPv6 address suffixes to achieve end-to-end hopping [16]. Kong et al. used the time window adaptive adjustment (TWAA) algorithm to reduce the dependence on strict time synchronization, taking into account safety and efficiency [17]. Majid et al. tried to estimate the cost of path randomization in a message transmission system using IP hop randomization in the network, and obtained some experience with random hop cost strategies [18]. Random hopping is easy to implement and has good robustness in the face of different network attacks. However, random hopping lacks clear policy guidance, high-frequency hopping will increase network overhead, and random sequences with insufficient security are vulnerable to cracking and prediction attacks.
Rule-based hopping algorithminstead of being completely random, the hoppings are made according to a preset policy or rule, usually to achieve a specific security goal or to optimize resource utilization. For example, Liu et al. used the Multi-Homing feature of IPv6 nodes to hop between multiple address prefixes according to policies, provide “fast switching” and “over-retention” policies to ensure communication continuity [19]. Mei et al. used “pre-announcement” and “post-clear” mechanisms to reduce the communication interruption caused by the hopping of the subnet prefix and interface identifier at the same time according to the policy [20]. Han et al. proposed a random selection of addresses in the virtual address pool by weight in the SDN-controlled Internet of Things, rather than uniform random, to distinguish device status or address history [21]. Zhang et al. proposed a multi-constraint and multi-strategy hopping model with adaptive switching of hopping paths and intervals to deal with different attack scenarios [22]. The rule-based hopping algorithm can reduce the network overhead to some extent while ensuring security. However, the effectiveness is highly dependent on the designer’s pre-understanding of attack patterns, and the lack of adaptability in the face of new attacks or zero-day attacks. And the attacker can break the hopping law through long-term observation and pattern analysis.
An intelligent algorithmthe hopping strategy can be dynamically and adaptively adjusted according to network status, security threats or business requirements. For example, Gu et al. proposed a hopping strategy that provides differentiated hopping patterns and parameters in an SDN environment based on the identified types of communication services and their reliability requirements [23]. The Gao team used reinforcement learning to develop a complex deception defense mechanism called DSHopping (deception scene hopping), which intelligently converts the hopping probability by calculating the network overhead [24]. Shi et al. proposed an adaptive IP hopping method for moving target defense (MTD) using a one-dimensional convolutional neural network, which adaptively triggers the corresponding IP hopping strategy by detecting the type of attack [25]. Xu et al. proposed a lightweight convolutional neural network (CNN) detector composed of three convolution modules and a judgment module to sense scanning attacks, and the detection result is used to trigger IP hop points [26]. He et al. propose an intelligent hopping mechanism based on differential game methods, which can adaptively adjust the IP frequency hopping frequency to maximize defense benefits [27]. The intelligent algorithm can sense the type of attack and give a more efficient IP hopping strategy to maximize the hopping revenue. However, the training and inference process of deep neural networks requires considerable computing resources, which may be unaffordable on resource-constrained IoT devices, limiting their deployment range.
In summary, the current IP hopping in practical applications there is a large network and computing resource overhead, while the attacker can identify the proxy server or hopping mechanism to predict the hopping IP and other issues. In view of the above problems, this paper proposes a Dynamic random map IP hopping model based on chaotic sequence generation, and uses a logistic chaotic sequence to enhance the pseudo-random number generator (PRNG) the quality [28]. By designing the map generation algorithm and the enhanced perturbation algorithm, the high randomness and uniform distribution of the IP hopping sequence are realized, so that under the premise of small network resource overhead, make the hopping have a higher randomness, while improving the anti-analysis and anti-interference ability, effectively avoiding the attacker through continuous analysis to crack the hopping system, to avoid non-monotonic security, expands its deployment scope and application scenarios.
3 Random Map Model Based on Chaos and Encryption
This section builds a random graph model based on chaos and encryption, uses the random IP generation module as the basis for generating Dynamic random graphs, and optimizes the results through the chaotic sequence perturbation module, high entropy randomization of single-node IP addresses is realized from the spatial dimension, and a cross-period dynamic association mechanism is established from the time dimension to form a two-dimensional and space-time collaborative enhanced IP hopping defense system.
In view of the fact that the collaborative defense mechanism of the model in two dimensions of space-time is realized by specific technical paths respectively, the two sub-modules of the random IP generation module and the chaotic sequence disturbance module will be described in detail in the following, the design principles, key algorithms and synergy mechanisms of each sub-model are revealed to fully present the technical architecture and defense effectiveness improvement path of the random map model.
3.1 Random IP Generation Model Based on Chaotic Sequence
Chaos refers to the movement of uncertainty that occurs in a deterministic system, which is characterized by uncertainty, unrepeatability and unpredictability. Logistic mapping is a simple nonlinear differential equation, its characteristics reflect the chaos phenomenon, is a typical application in the chaotic system [29]. The chaotic sequence generated based on the Logistic map has the characteristics of long period, non-repetition and sensitivity to the initial value, and its most typical application is the one-dimensional chaotic map, the expression is as follows:
In getting the randomization results
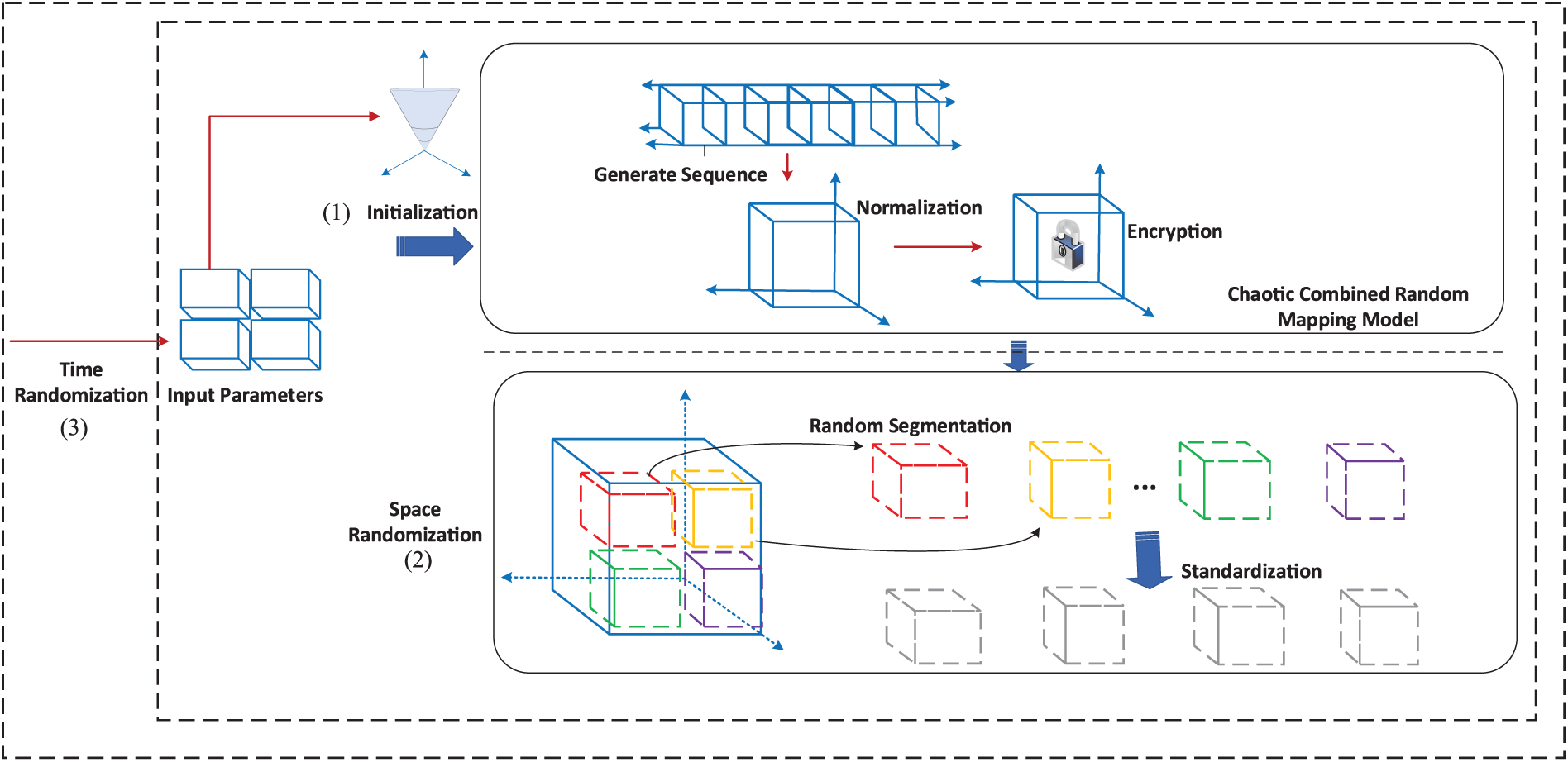
Figure 1: Schematic diagram of chaos combined with random mapping model.
The mapping process of chaotic sequence to IP address can be summarized into the following two parts:
(1) Normalization
Assumption
where
where
where
Among them,
(2) IP address translation
IP address translation is a random mapping method that combines Knuth Shuffle (Shuffle) and subspace, aiming to realize the conversion of normalized subspace to IP address. In IP address translation, starting from the last IP address in the IP address parameter pool, it is exchanged with the previous randomly selected IP address. Then, the corresponding IP address is selected from the shuffled IP address parameter pool according to the subspace as the converted IP address. Since this process is based on the subspace generated according to the model in this paper, the probability of each IP address in the pool being selected is the same, thus ensuring the equal probability of the resulting converted IP address. Knuth Shuffle (Shuffle) generated random permutation of π satisfies:
where
For the kth subspace
First generate a random integer
After that complete the base mapping process:
In the above process, although the possibility of IP address collision between subspace and Knuth Shuffle is very small, there is still the possibility of IP address collision in theory. Therefore, collision detection and processing are required in the process of IP address conversion:
where
From the above two processes, it has been possible to realize the function of generating random IP addresses from chaotic sequences, and make the generated random IP addresses uniform and legal, and will not be used by attackers. Known Intercept Results easily analyze other IP addresses with high unpredictability.
3.2 Dynamic Randomization Model on Perturbation Enhancement of Chaotic Sequence
The random map composed of the sequence of the above random IP and other network parameter changes has good randomness in general, but because the chaos algorithm and linear shift register have randomness in the small set range, and there may be a mapping degradation problem within an infinite set, and thus it may be difficult to meet the requirement that a random map whose length is theoretically Approximately Infinite should also be random, in order to ensure that the random IP generated by the chaotic sequence has better randomness and unpredictability in both space and time, the perturbation technique is introduced to process the chaotic sequence twice. Let the perturbation function be
Considering that RC4 can generate random disturbance to the local part of the sequence, RC4 is chosen as the disturbance function to generate the sequence with global and local uniformity. RC4 is an efficient stream encryption algorithm, the core of which is to generate a highly random byte stream through the dynamic parameter scheduling algorithm (KSA) and the pseudo-random generation algorithm (PRGA) [30] Which can effectively destroy the short-term correlation of chaotic sequences and prevent attackers from predicting subsequent IPs through local patterns. The specific disturbance process is as follows:
(1) We initialize the RC4 state vector(
(2) We generate the pseudo-random byte stream using the state vector(
(3) Sequence perturbation: the chaotic sequence and the pseudo-random flow are bit-by-bit different:
where ⊕ denotes a bitwise XOR operation, ensuring that the perturbed sequence
Chaotic sequence after perturbation
4 Chaos Combined with Random Map Model Random Map Generation Algorithm
Given according to the random map model (CRM) above
The flow of random map generation algorithm based on chaos combined with random mapping model is shown in Fig. 2.
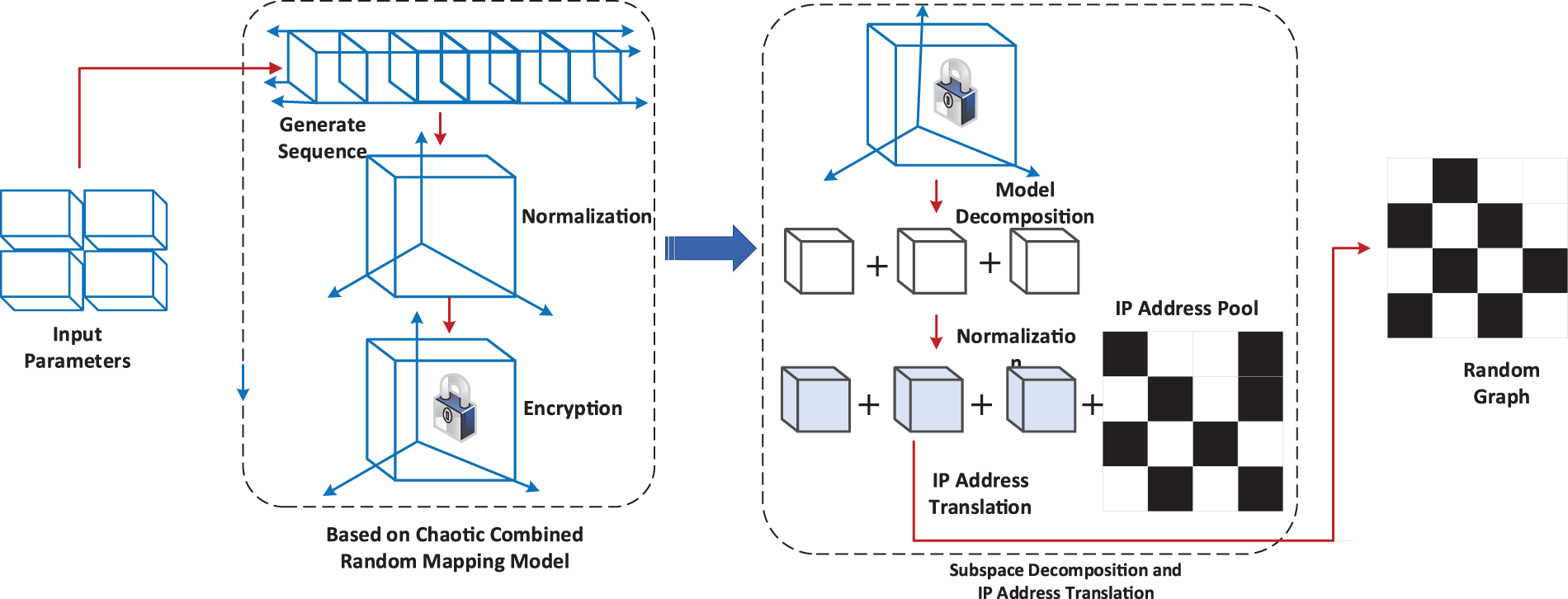
Figure 2: Flow chart of random map generation algorithm based on chaos combined with random mapping model.
As illustrated in Fig. 2, the chaos-random mapping model actively drives the random graph generation algorithm through three core steps: chaotic entropy generation with perturbation enhancement, subspace decomposition coupled with IP address mapping and collision resolution, and construction of the two-dimensional random graph.
First, the algorithm utilizes the Logistic map to generate the initial chaotic sequence and then applies RC4 perturbation to enhance local randomness. This dual mechanism effectively overcomes the potential local non-uniformity and degradation risks inherent in standalone chaotic systems, producing a hybrid entropy source that exhibits both global and local randomness.
Next, the algorithm normalizes the perturbed sequence, divides it into subspaces, and combines Knuth Shuffle to perform a uniform random permutation of the IP address pool. This ensures unbiased mapping from each subspace index to any IP in the pool. Simultaneously, an active collision detection and resolution mechanism enforces IP uniqueness: different nodes within the same period receive distinct addresses, and the same node across consecutive periods obtains different addresses.
Finally, the algorithm extends these steps to the spatiotemporal domain and constructs a random graph, where represents the number of hopping periods, denotes the number of nodes, and specifies the IP address assigned to the node in the
4.2 Random Mapping Algorithm Based on Logistic Chaos and RC4 Perturbation
Inheriting the Section 3.1 of the chaotic sequence generation mechanism, the use of Logistic mapping to generate the initial chaotic sequence, the specific generation process as shown in the Algorithm 1.

In Algorithm 1, by inputting the initial value
After obtaining the initial randomization results, further enhancement is required through disturbance processing using the RC4 disturbance algorithm, which includes the Key Scheduling Algorithm (KSA) and the Pseudo-Random Generation Algorithm (PRGA). First, a dynamic parameter

The random sequence with local and global randomness is obtained, which prevents the chaotic degradation of the Logistic chaotic sequence and further enhances the randomness of the chaotic sequence.
4.3 Knuth Shuffle and IP Address Anti-Collision Algorithm
In getting the randomization results
In The Algorithm 3, first enter the k-th subspace

In the process of IP address translation, there is theoretically the possibility of IP address collision. Therefore, this paper proposes an IP address anti-collision algorithm, if

In the Algorithm 4, the input includes the IP address of the k − 1
4.4 Random Map Generation Algorithm
In the generation of random maps, the models and methods described in the previous two sections are combined to form a random map generation algorithm based on chaos combined with random mapping model, as shown in Algorithm 5. This algorithm describes the process of random map generation.

In the Algorithm 5, the normalized subspace of the RCM model is obtained by the first 8 steps.
4.5 Performance Analysis of Algorithm
This section will analyze the two core dimensions of time complexity and security of the algorithm, aiming to systematically verify the feasibility and universality of the algorithm.
It is assumed that there are
Proposed under Section 4, this section performs a security analysis of the random graph generated by the algorithm to evaluate its ability to resist analytical attacks.
Assuming there are
When the attack time
Each moment represents the point at which the IP address pool may change. Second, define a state variable (
Poisson distribution, i.e.,
The above model takes into account the randomness of new IP addresses and IP address departures, and then introduces the
Attackers need to attack
The attacker is
Among them, the left part of the formula
From the above analysis, it can be seen that in the hopping period
Taking into account the hopping period
Assume that the address hopping device is provided. In given period
To quantitatively analyze the anti-interception ability of random maps, we introduce information entropy. This section uses information entropy to evaluate the resistance of IP addresses against interception and analysis. The information entropy
where
Assume that an addr-ss hopping device provides one IP address from a pool of n possible addresses. The probability of an attacker targeting any specific IP address is
Eq. (15) indicates that, from the perspective of information entropy, the difficulty for an attacker to infer the next IP address depends on three factors:
(1) The hopping period
(2) The time spent attacking a single IP address
(3) The total number of IP addresses nnn (a larger pool increases entropy).
When
Suppose an attacker intercepts a certain number
Proof: Assume that the set of IP addresses intercepted by the attacker is
Introducing the conditional entropy pair
Next to prove
Assumption
According to the definition of entropy:
where is a collection of IP addresses that are randomly generated in a known
Assumption
But this contradicts the nature in information theory, i.e.,
From the above analysis, it can be concluded that, suppose an attacker intercepts a certain number of IP addresses, it is also impossible to rely on known interception results to infer other IP addresses. This shows randomized algorithm in this paper randomly generated atlas with randomness and independence, they are not affected by the attacker’s known interception results, andhave the ability to resist analysis attacks.
5 Experimental Results and Analysis
In the simulation experiment, this paper uses
The data in the experiment mainly includes IP address database and data set, where the IP address database is qqzeng-ip database, the data set is NSL-KDD data set,
In the evaluation of spatial randomization and time randomization, the choice of Leap-forward type linear feedback register (LFSR), pseudo-random number generator (PRNG), Chaotic Sequence (CS), CS algorithm is compared with the randomization algorithm proposed in this paper.
This section uses three safety indicators to evaluate the effectiveness of the proposed method. These three indicators include: attack cost (
(1) Cost of attack (
where
(2) Attack returns (
where
(3) System availability (
where
5.3 Spatial Randomization Experiment
In the spatial randomization evaluation, the choice Kolmogorov-Smirow (K-S) the test Index evaluates the similarity of the random map generated by the map generation algorithm.
The K-S test is a non-parametric probability statistical test that tests whether the test sample and the reference sample come from the same probability distribution. The main parameters include K-S statistics, significance level,
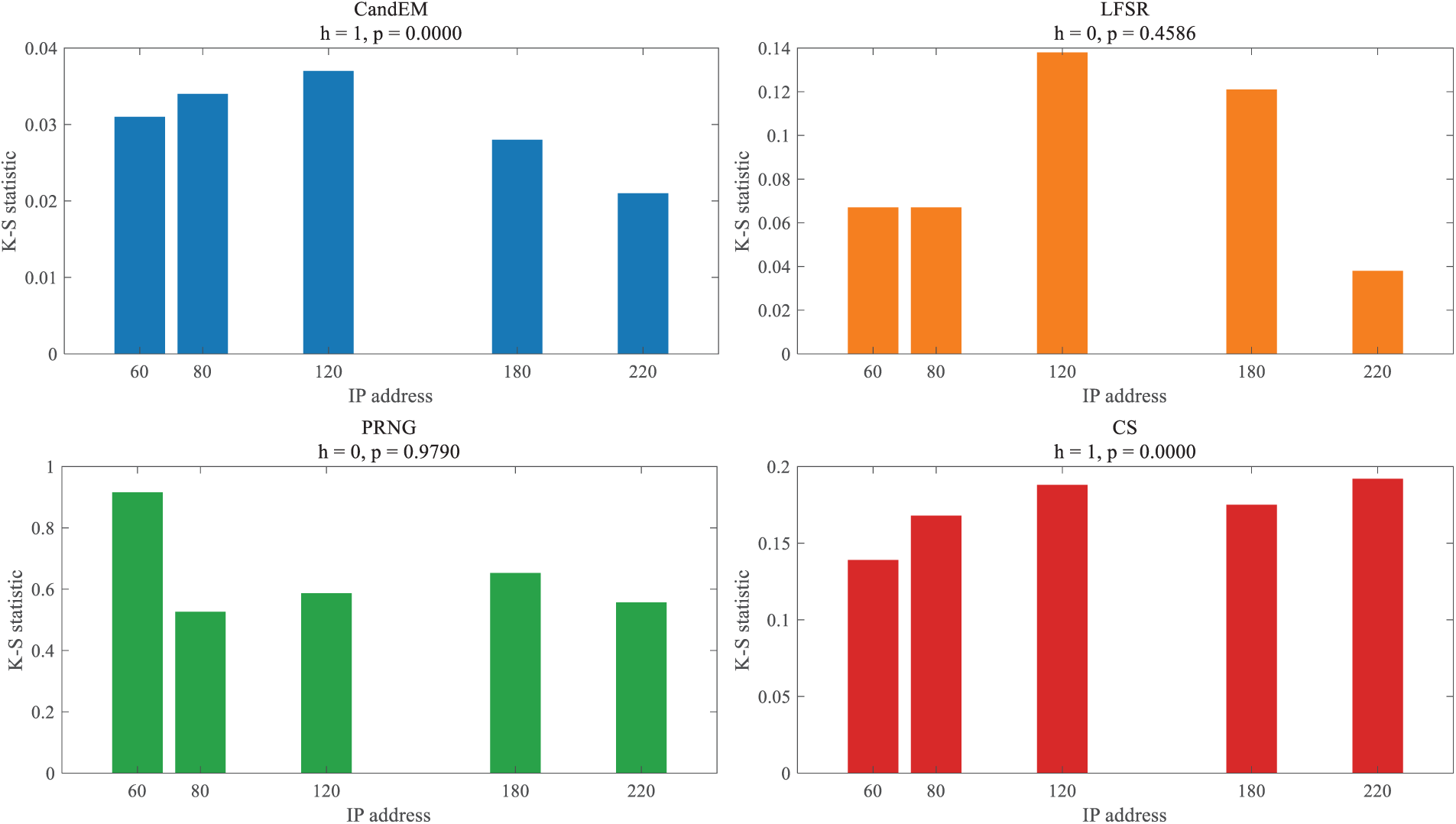
Figure 3: K-S comparison results.
As can be seen, when the graph 3 the h-value calculated by the four algorithms based on K-S statistics is 0, i.e., after supporting the Zero hypothesis, as the number of IP addresses in the test sample increases gradually from 60, 80, 120, 180 to 220, the value of the K-S statistic fluctuates slightly,
5.4 Time Randomized Experiment
The time randomization test is a non-parametric probability statistical test method used to analyze whether the probability distribution of sample occurrence in a time series is uniform. In the time randomization test, multiple sets of experiments were conducted on the similarity of IP addresses periodically generated by the Atlas generation algorithm through the K-S test, and the results are shown in Fig. 4.
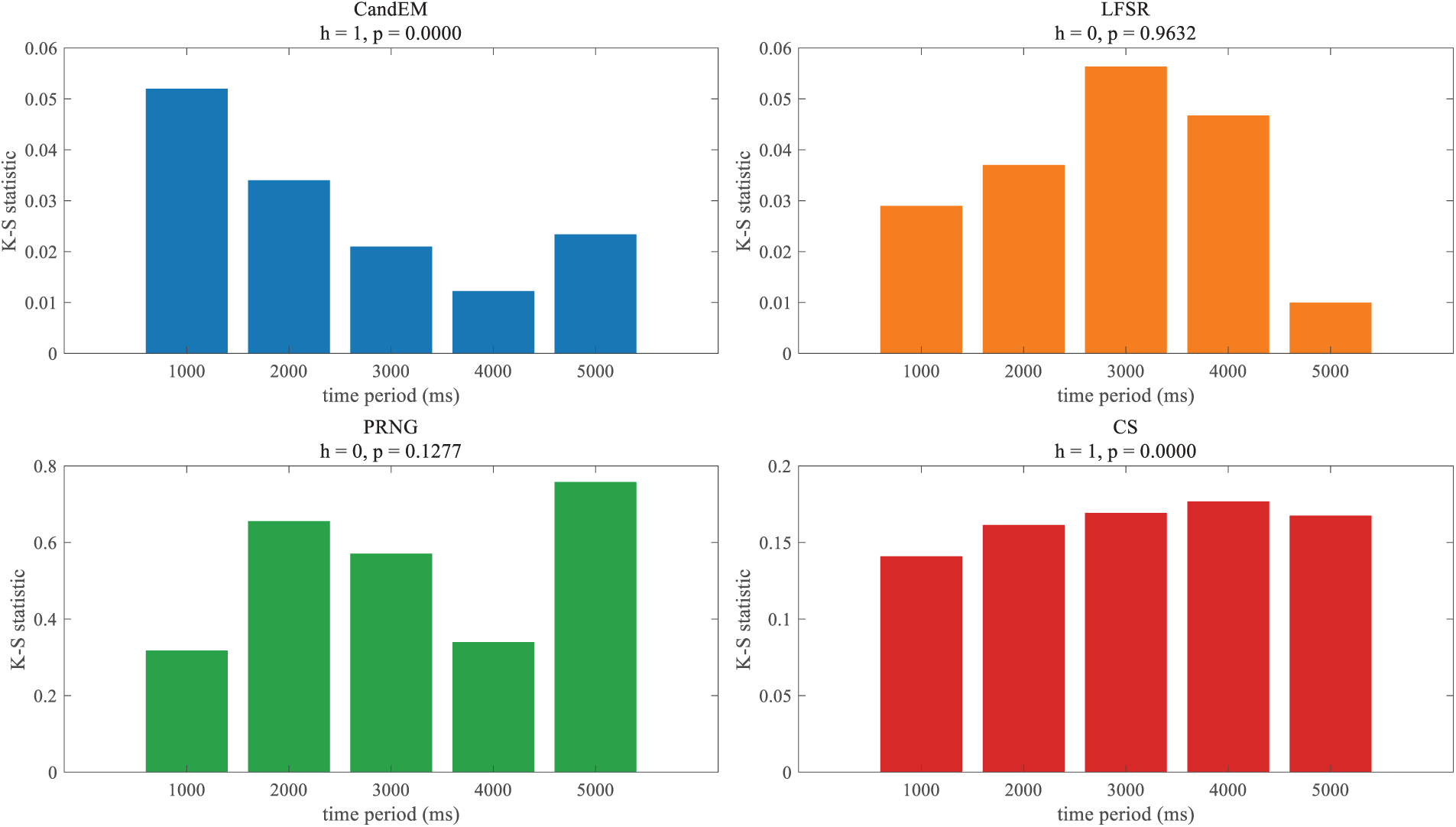
Figure 4: K-S statistics results.
Fig. 4 shows how several algorithms obtain the statistics of the K-S test. It can be seen that the
5.5 Anti-Analytical Attack Experiment
This section analyzes the security of the CRM model by four indicators:
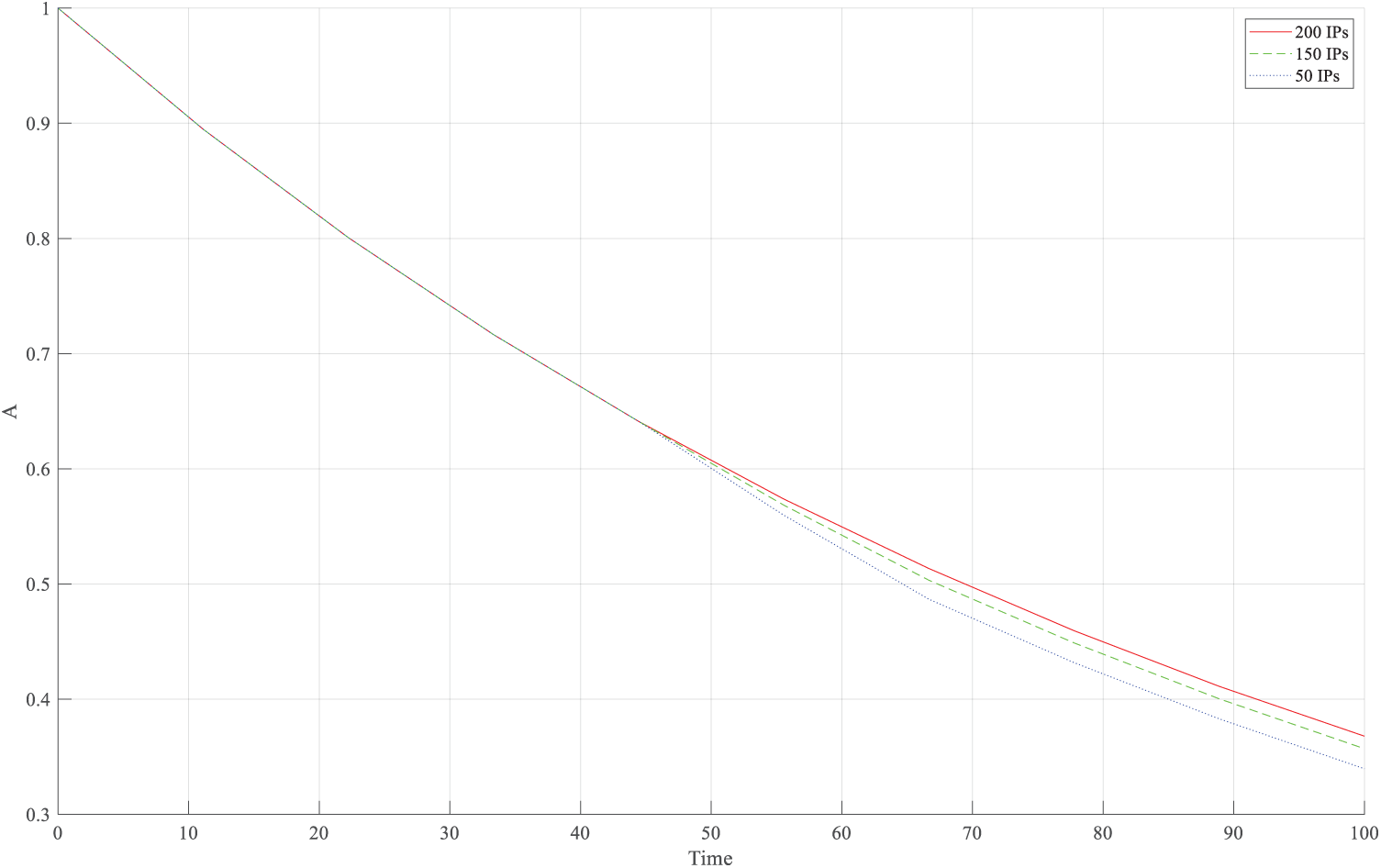
Figure 5: Availability indicators for random maps.
Fig. 6 shows the attack costs of the three metrics
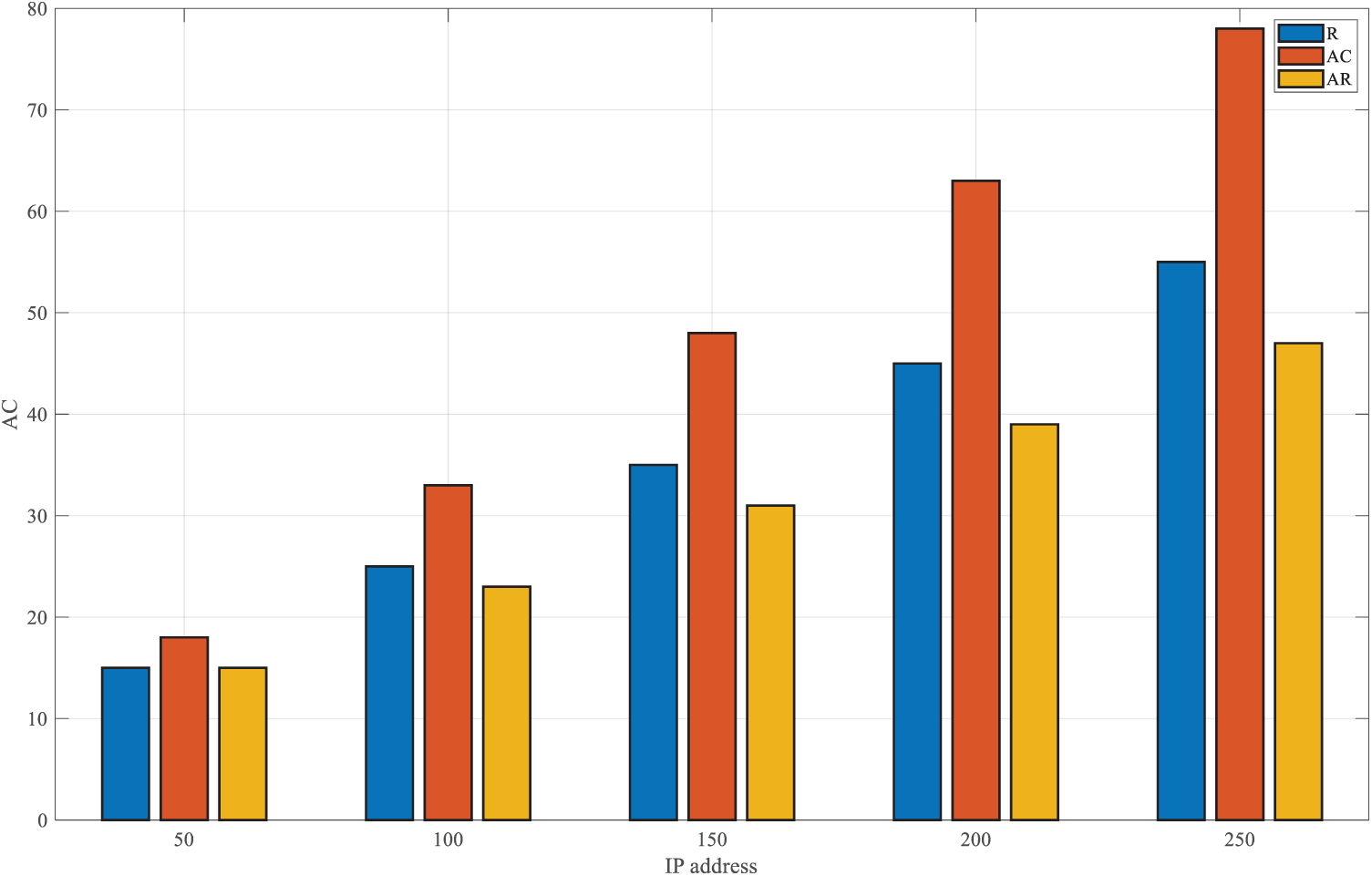
Figure 6: Attack costs of IP addresses.
Fig. 7 compares the defense success rate (
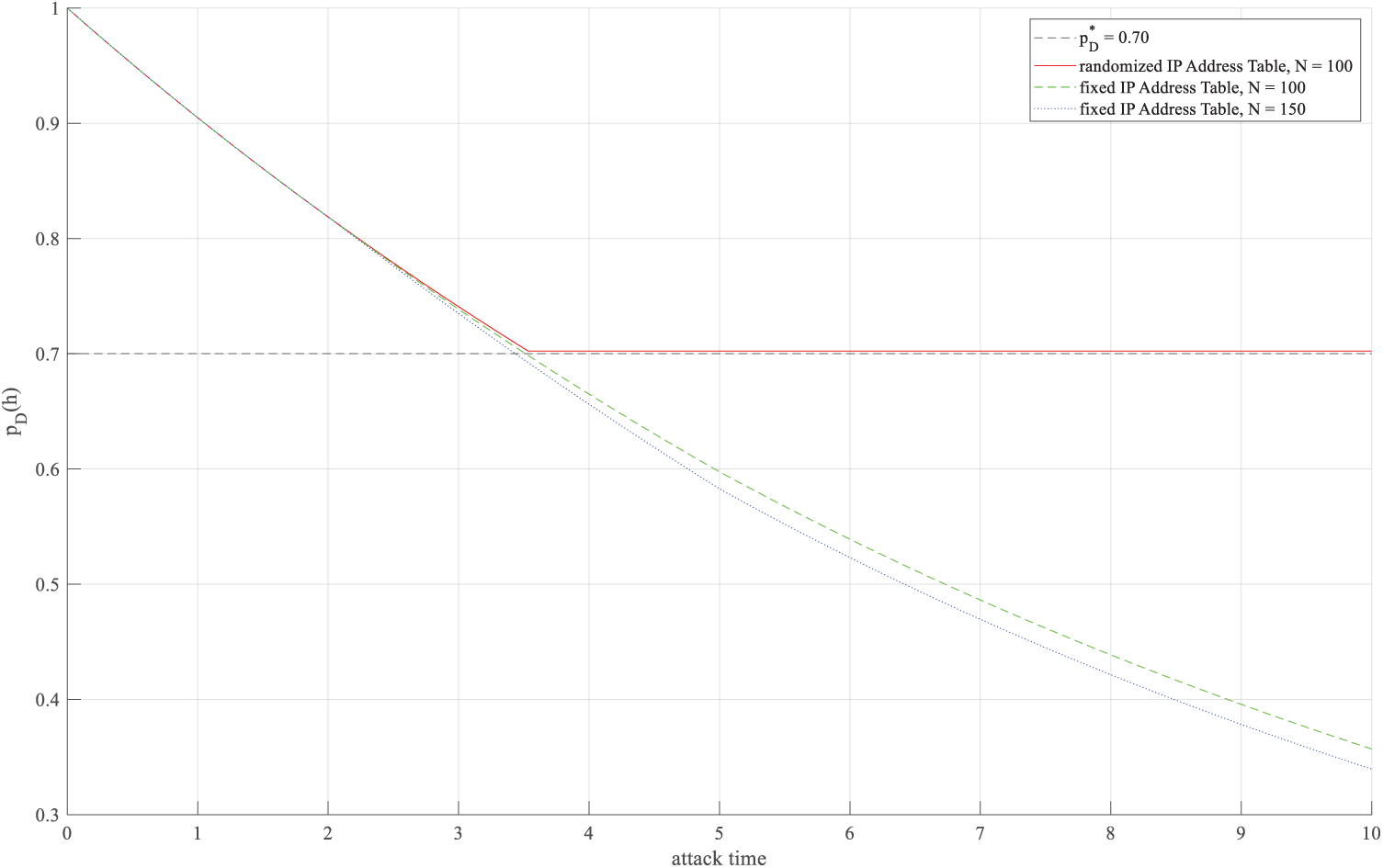
Figure 7: Defense success rate of random and fixed IP strategies over Attack Time.
For the problem that attackers can easily obtain the transformed IP address by analyzing and predicting the rules of IP address transformation in static IP hopping defense, this paper proposes a network hopping active defense method based on dynamic random graph. Firstly, a random graph model is designed to generate the normalized subspace, which lays the foundation for the spatial and temporal randomization of IP addresses. Secondly, based on subspace, a map randomization algorithm is used to achieve spatial and temporal randomization of IP addresses. In addition, the algorithm introduces a method to further disturb the IP address, and design an IP local anti-collision algorithm to prevent IP address collision. The experimental results show that this method is superior to several other test methods. By testing the spatial randomization and time randomization of the CRM model, the results indicate that the CRM model has a positive impact on enhancing the local randomness. The test results of the ablation experiment further demonstrate that the CRM model can enhance the local randomness while preserving global randomness.
Acknowledgement: We would like extend our appreciation to the colleagues and students from the School of Electronic Information at Wuhan University, the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, and the Key Laboratory of Cyberspace Situation Awareness of Henan Province for their valuable discussions and technical support during the course of this research. Special thanks are due to the experimental platform provided by Mininet, which facilitated the simulation and validation of our proposed model.
Funding Statement: This work was supported by the National Natural Science Foundation of China. Funding number: 41971407. The funding bodies had no role in the design of the study, data collection, analysis, interpretation of results, or the writing of the manuscript.
Author Contributions: Zhu Fang: Conceptualization, methodology, software, validation, formal analysis, investigation, data curation, writing—original draft. Zhengquan Xu: Supervision, conceptualization, methodology, resources, writing—review & editing, project administration, funding acquisition. Weizhen He: Software, validation, investigation, writing—review & editing. Bohao Xu: Methodology, software, validation, writing—review & editing. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets and materials generated during the current study are available from the corresponding author on reasonable request. The source code for the dynamic random graph-based IP hopping algorithm and the Mininet simulation environment can be accessed at http://192.168.62.56/data2/code. Any additional data or materials required to replicate the findings of this study are also available upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Liang J, Kim Y. Evolution of firewalls: toward securer network using next generation firewall. In: Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC); 2022 Jan 26–29; Las Vegas, NV, USA. p. 752–9. doi:10.1109/ccwc54503.2022.9720435. [Google Scholar] [CrossRef]
2. Wang Q, Chen J, Jiang Z, Guo R, Liu X, Zhang C, et al. Break the wall from bottom: automated discovery of protocol-level evasion vulnerabilities in web application firewalls. In: Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP); 2024 May 19–23; San Francisco, CA, USA. p. 185–202. doi:10.1109/sp54263.2024.00129. [Google Scholar] [CrossRef]
3. Sudhakar, Kumar S. An emerging threat Fileless malware: a survey and research challenges. Cybersecurity. 2020;3(1):1. doi:10.1186/s42400-019-0043-x. [Google Scholar] [CrossRef]
4. Sen S, Aydogan E, Aysan AI. Coevolution of mobile malware and anti-malware. IEEE Trans Inform Forensic Secur. 2018;13(10):2563–74. doi:10.1109/tifs.2018.2824250. [Google Scholar] [CrossRef]
5. Carvalho M, Ford R. Moving-target defenses for computer networks. IEEE Secur Privacy. 2014;12(2):73–6. doi:10.1109/msp.2014.30. [Google Scholar] [CrossRef]
6. Xu J, Guo P, Zhao M, Erbacher RF, Zhu M, Liu P. Comparing different moving target defense techqiques. In: Proceedings of the 1st ACM Workshop on Moving Target Defense; 2014 Nov 7; Scottsdale, AZ, USA. New York, NY, USA: ACM; 2014. p. 97–107. [Google Scholar]
7. Cai G, Wang B, Wang T, Luo Y, Cui X. Research and development of moving target defense technology. J Comput Res Dev. 2016;53(5):968–87. [Google Scholar]
8. Moghaddam T, Yang G, Thapa C, Camtepe S, Kim DD. MTD in plain sight: hiding network behavior in moving target defenses. In: Proceedings of the 2024 54th Annual IEEE/IFIP International Conference on Dependable Systems and Networks—Supplemental Volume (DSN-S); 2024 Jun 24–27; Brisbane, Australia. p. 50–2. doi:10.1109/dsn-s60304.2024.00022. [Google Scholar] [CrossRef]
9. Steinberger J, Kuhnert B, Dietz C, Ball L, Sperotto A, Baier H, et al. DDoS defense using MTD and SDN. In: Proceedings of the NOMS 2018—2018 IEEE/IFIP Network Operations and Management Symposium; 2018 Apr 23–27; Taipei, China. p. 1–9. doi:10.1109/noms.2018.8406221. [Google Scholar] [CrossRef]
10. Chang SY, Park Y, Ashok Babu BB. Fast IP hopping randomization to secure hop-by-hop access in SDN. IEEE Trans Netw Serv Manage. 2019;16(1):308–20. doi:10.1109/tnsm.2018.2889842. [Google Scholar] [CrossRef]
11. Krylov V, Kravtsov K. IP fast hopping protocol design. In: Proceedings of the 10th Central and Eastern European Software Engineering Conference in Russia; 2014 Oct 23–25; Moscow, Russia. p. 1–5. doi:10.1145/2687233.2687238. [Google Scholar] [CrossRef]
12. Wang P, Zhou M, Ding Z. A two-layer IP hopping-based moving target defense approach to enhancing the security of mobile ad-hoc networks. Sensors. 2021;21(7):2355. doi:10.3390/s21072355. [Google Scholar] [PubMed] [CrossRef]
13. Zhao Z, Liu F, Gong D, Chen L, Xiang F, Li Y. An SDN-based IP hopping communication scheme against scanning attack. In: Proceedings of the 2017 IEEE 9th International Conference on Communication Software and Networks (ICCSN); 2017 May 6–8; Guangzhou, China. p. 559–64. doi:10.1109/iccsn.2017.8230174. [Google Scholar] [CrossRef]
14. Zhang L, Wei Q, Tang XC, Fang J. SDN network active defense technology based on path and end address hopping. Comput Res Dev. 2017;54(12):2761–71. (In Chinese). doi:10.1109/fskd.2016.7603498. [Google Scholar] [CrossRef]
15. Jafarian HJ, Al-Shaer E, Duan Q. Openflow random host mutation. Charlotte, NC, USA: University of North Carolina at Charlotte; 2012. [Google Scholar]
16. Heydari V. Moving target defense for securing SCADA communications. IEEE Access. 2018;6:33329–43. doi:10.1109/access.2018.2844542. [Google Scholar] [CrossRef]
17. Kong Y, Zhang L, Wang Z. IPv6 address hopping active defense model based on sliding time window. Comput Appl. 2018;38(07):1936–73. (In Chinese). doi:10.11772/j.issn.1001-9081.2018010073. [Google Scholar] [CrossRef]
18. Ghaderi M, Jero S, Nita-Rotaru C, Safavi-Naini R. On randomization in MTD systems. In: Proceedings of the 9th ACM Workshop on Moving Target Defense; 2022 Nov 7; Los Angeles, CA, USA. p. 37–43. doi:10.1145/3560828.3564016. [Google Scholar] [CrossRef]
19. Liu H, Wang Z, Guo Y. An IPv6 active defense model based on multi-point jump. J Electron Inf Technol. 2012;34(07):1715–20. doi:10.3724/sp.j.1146.2011.01350. [Google Scholar] [CrossRef]
20. Mei Z, Wang Z, Wang Y, Zhang L. An IPv6 MTD model based on subnet hopping. Comput Appl Softw. 2016;33(12):301–24. (In Chinese). doi:10.3969/j.issn.1000-386x.2016.12.070. [Google Scholar] [CrossRef]
21. Han L, Song J, Sun S. Research on mobile target defense mechanism based on device address in SD-IoT. Inf Netw Secur. 2022;22(11):36–46. (In Chinese). [Google Scholar]
22. Zhang B, Li H, Zhang S, Sun J, Wei N, Xu W, et al. Multi-constraint and multi-policy path hopping active defense method based on SDN. Future Internet. 2024;16(4):143. doi:10.3390/fi16040143. [Google Scholar] [CrossRef]
23. Gu Y, Hu Y, Ding Y, Xie J. Random address hopping method based on traffic awareness. Comput Eng. 2018;44(10):28–41. (In Chinese). doi:10.19678/j.issn.1000-3428.0051042. [Google Scholar] [CrossRef]
24. Gao Y, Yang L, Zhu R, Yang F, Cao Y, Zhang L. Intelligent hopping mechanism for deception defense scenarios based on reinforcement learning. In: Proceedings of the 2024 IEEE 49th Conference on Local Computer Networks (LCN); 2024 Oct 8–10; Normandy, France. p. 1–8. doi:10.1109/lcn60385.2024.10639792. [Google Scholar] [CrossRef]
25. Shi F, Zhou Z, Yang W, Li S, Liu Q, Bao X. AHIP: an adaptive IP hopping method for moving target defense to thwart network attacks. In: Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD); 2023 May 24–26; Rio de Janeiro, Brazil. p. 1300–5. doi:10.1109/cscwd57460.2023.10152746. [Google Scholar] [CrossRef]
26. Xu X, Hu H, Liu Y, Zhang H, Chang D. An adaptive IP hopping approach for moving target defense using a light-weight CNN detector. Secur Commun Netw. 2021;2021:8848473. doi:10.1155/2021/8848473. [Google Scholar] [CrossRef]
27. He Y, Zhang M, Yang X, Sun QT, Luo J, Yu Y. The intelligent offense and defense mechanism of Internet of vehicles based on the differential game-IP hopping. IEEE Access. 2020;8:115217–27. doi:10.1109/access.2020.3004255. [Google Scholar] [CrossRef]
28. Kietzmann P, Schmidt TC, Wählisch M. A guideline on pseudorandom number generation (PRNG) in the IoT. ACM Comput Surv. 2022;54(6):1–38. doi:10.1145/3453159. [Google Scholar] [CrossRef]
29. Kanso A, Smaoui N. Logistic chaotic maps for binary numbers generations. Chaos Solitons Fractals. 2009;40(5):2557–68. doi:10.1016/j.chaos.2007.10.049. [Google Scholar] [CrossRef]
30. Jindal P, Singh B. RC4 encryption-a literature survey. Procedia Comput Sci. 2015;46:697–705. doi:10.1016/j.procs.2015.02.129. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools