
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MSD-YOLO: A Multi-Scale and Detail-Enhancement Network for Traffic Sign Detection
College of Big Data Information Engineering, Guizhou University, Guiyang, China
* Corresponding Author: Damin Zhang. Email:
(This article belongs to the Special Issue: Advances in Object Detection and Recognition)
Computers, Materials & Continua 2026, 87(3), 93 https://doi.org/10.32604/cmc.2026.076433
Received 20 November 2025; Accepted 26 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Traffic sign detection is a critical task in autonomous driving environmental perception. However, models often suffer from degraded detection performance in complex real-world scenarios due to variable target scales, blurred fine-grained features, and complex background interference. This paper proposes an improved YOLOv8n detection model, MSD-YOLO, to address these challenges. First, a Multi-scale Detail Enhancement Module (MDEM) is designed, which achieves targeted enhancement of edge features through high-frequency residual modulation and multi-scale cooperative attention. Second, an enhanced feature pyramid network termed SG-FPN is constructed. It introduces soft nearest neighbor interpolation (SNI) for semantic-spatial aligned feature fusion and employs enhanced lightweight convolution (GSConvE) to improve feature representation. Additionally, the Wise-ShapeIoU optimization loss function is adopted, integrating shape-aware geometric constraints and a dynamic sample weighting strategy to enhance the localization accuracy for traffic signs of different scales and shapes. Experiments on the TT100K dataset show that our method effectively improves detection performance, with mAP@0.5 and mAP@0.5:0.95 increasing by 3.1% and 2.7%, respectively, compared to the baseline YOLOv8n. Moreover, cross-dataset evaluations on CCTSDB and GTSDB show that the model exhibits good generalization capability and robustness. The experimental results indicate that the proposed method can enhance detection accuracy while maintaining efficient real-time inference, offering an effective solution for traffic sign detection in complex scenarios.Keywords
With the rapid advancement of artificial intelligence technology and the continuous growth in vehicle ownership, Intelligent Transportation Systems (ITS) and autonomous driving technology have become key drivers for enhancing road safety and traffic efficiency [1]. As a core component in this field, Traffic Sign Detection (TSD) technology aims to accurately locate and identify various traffic signs in real-time within road scenes. This capability provides critical environmental perception for autonomous driving decision-making, Advanced Driver Assistance Systems (ADAS), and intelligent traffic management. A robust TSD system effectively identifies critical traffic regulations such as speed limits, prohibitions, and instructions, serving as a vital safeguard for intelligent vehicles’ safe and reliable operation [2]. However, traffic signs in real-world driving environments often appear as small targets with weak features due to their distant locations. They are susceptible to complex lighting conditions, adverse weather, and background interference, significantly increasing detection difficulty [3]. Meanwhile, the limited computational resources of in-vehicle platforms impose stringent demands on model efficiency and real-time performance. Therefore, developing a traffic sign detection algorithm that balances high accuracy, strong robustness, and efficient inference holds significant practical importance.
Early traffic sign detection primarily relied on traditional image processing methods, typically involving manually designed feature extraction techniques. Color-based approaches utilized distinctive color distributions (e.g., red prohibition signs) for region segmentation, while shape-based methods identified geometric shapes through edge detection and contour analysis [4]. Additionally, researchers integrated feature descriptors like Histogram of Oriented Gradients (HOG) and Scale-Invariant Feature Transform (SIFT) with traditional machine learning classifiers such as Support Vector Machines (SVM) to construct detection systems [5]. However, these conventional approaches relied heavily on manually designed features and exhibited poor robustness to lighting variations, weather conditions, and occlusions. Consequently, they are often ill-suited for complex and dynamic real-world road environments. In recent years, deep learning-based object detection algorithms have emerged as the mainstream solution for traffic sign detection due to their powerful feature learning capabilities. Based on differences in detection workflows, these algorithms primarily fall into two categories: two-stage and single-stage. Two-stage detection algorithms (e.g., R-CNN [6], Faster R-CNN [7]) follow a “candidate region generation” followed by a “classification and regression” workflow. However, their complex architecture and high computational cost make them unsuitable for real-time detection requirements. In contrast, single-stage detection algorithms (e.g., YOLO [8], SSD [9] series) integrate object localization and classification into a single network to directly predict object category and location. Their streamlined architecture and rapid inference speed make them well-suited for in-vehicle environments with strict real-time requirements. However, their detection accuracy for small traffic signs in complex scenes traditionally has room for improvement.
Considering the dual requirements of real-time processing and high accuracy for traffic sign detection, this paper selects YOLOv8n as the benchmark model for research, which has an excellent balance between inference speed and detection performance. Although YOLOv8 has shown robust performance in general object detection, recent studies have shown that structural optimization for specific tasks can significantly improve its performance in specialized fields. Traffic signs exhibit significant scale diversity and are defined by strict geometric shapes (such as triangles and circles). In deep convolutional networks, the high-frequency edge information that defines these shapes is often smoothed out, leading to localization errors. Most current improvements focus on introducing independent attention modules or multi-scale fusion structures. However, they often fail to fundamentally address the misalignment between high-level semantic features and low-level spatial details during fusion. This limitation leads to missed detections of small targets and inaccurate edge localization. Therefore, constructing a system framework that can achieve collaborative optimization of feature alignment, detail preservation, and geometric perception is crucial for improving traffic sign detection performance in complex scenarios. Based on this, this paper proposes an improved YOLOv8n detection model, MSD-YOLO. Its core idea is to achieve balanced expression and accurate localization from local details to global semantics through a hierarchical feature alignment and enhancement mechanism.
The main contributions are as follows:
• A Multi-Scale Detail Enhancement Module (MDEM) is proposed, which integrates high-frequency residual enhancement with multi-scale feature extraction to effectively strengthen the perception of detailed information, such as edges and contours in traffic signs. This design mitigates the feature smoothing issue in deep networks.
• An enhanced feature pyramid network, SG-FPN, is designed. By introducing soft nearest neighbor interpolation (SNI) and the lightweight convolution (GSConvE), a feature fusion mechanism better adapted to the scale diversity of traffic signs is constructed. This enhances the transmission of semantic information while effectively preserving texture details critical for detection.
• The Wise-ShapeIoU loss function is adopted to optimize bounding box regression. This loss combines the geometric constraints of Shape-IoU with the dynamic sample weighting mechanism of Wise-IoU, significantly improving the localization accuracy and regression convergence speed for traffic signs of varying shapes and scales.
In recent years, deep learning has driven significant progress in traffic sign detection. This section reviews related literature across four key dimensions: multi-scale feature fusion, attention mechanisms, lightweight network design, and loss function optimization.
Regarding multi-scale feature fusion, recognizing traffic signs of varying sizes, particularly small distant targets, remains a core challenge. Early research focused on optimizing network structures to mitigate feature loss during transmission. For instance, Wang et al. [10] proposed AF-FPN, which reduces information loss via an adaptive attention module, while Zhang et al. [11] integrated BiFPN into YOLOv8 to facilitate cross-scale connections specifically for small-object detection. Subsequent studies introduced specialized modules to enrich feature representation; Liu et al. [12] utilized a text feature-guided network (TFG-Net) to extract auxiliary textual cues, and Sun et al. [13] developed MDSF-YOLO, employing multi-scale sequence fusion to capture temporal-spatial contexts. Zhu et al. [14] proposed an FCN-guided traffic sign proposal framework that improves the EdgeBox object proposal method and combines it with a fully convolutional network to generate more discriminative candidate regions, enhancing the speed and accuracy of the detection system. Other innovative approaches include simulating human visual mechanisms to handle [15] and combining Mamba architectures with YOLO to improve generalization across diverse environments [16].
In terms of attention mechanisms, these techniques are widely adopted to suppress background interference and enhance discriminative features. Chen and Luo [17] proposed VisioSignNet, which improves small-scale recognition via synergistic local-global interactions, while Shen et al. [18] designed a group multi-scale attention pyramid to effectively aggregate features across different resolutions. Recent works have tailored attention for specific challenges: Li et al. [19] combined dynamic snake convolution with attention to handle adverse weather conditions, and Deng et al. [20] embedded a heterogeneous attention mechanism into YOLOv8 to enhance the focus on key features reducing false and missed detections in complex traffic scenarios. Furthermore, Chu et al. [21] proposed a model featuring a multi-branch lightweight detection head. It utilizes self-attention to enhance inter-feature correlations, ensuring real-time performance while improving accuracy. Additionally, Yang and Tong [22] demonstrated that visual multi-scale attention significantly boosts the detection accuracy of tiny traffic signs.
For lightweight network design, balancing high detection accuracy with real-time performance is critical for in-vehicle applications constrained by computing resources. Sun et al. [23] proposed the LLTH-YOLOv5 framework, which employs a lightweight low-light enhancement network and a GhostDarkNet53 backbone network to improve real-time performance while maintaining accuracy. Zhang et al. [24] replaced the original feature extraction module with a C3Ghost module. This modification significantly accelerates inference speed without compromising detection accuracy. Similarly, Zhang et al. [25] focused on long-distance traffic sign detection, constructing a lightweight model based on DETR and designing a small-object detection module to enhance the detection performance of tiny signs. Lai et al. [26] adjusted the downsampling structure and introduced a new feature extraction module, achieving a good balance between accuracy and speed in complex scenarios. Qiu et al. [27] incorporated Transformer technology into a novel feature extraction module. This approach improves feature capability while reducing parameter count. Wang et al. [28] combined attention scale sequence fusion with a P2 detection layer and designed a lightweight convolution module, effectively reducing the model size.
Finally, concerning loss function optimization, the bounding box regression loss is pivotal for convergence speed and localization accuracy. Beyond standard metrics, adaptive frameworks have been developed to handle environmental variations, such as the intelligent illumination enhancement strategy proposed by Choudhary and Dey [29]. Saxena et al. [30] adopted an improved PANet structure and a generalized intersection over union loss to enhance the detection accuracy of the model. Kamal et al. [31] proposed the SegU-Net segmentation network, which innovatively transforms traffic sign detection into an image segmentation problem. By leveraging the advantages of SegNet and U-Net and combining them with a Tversky loss function, the model demonstrated excellent generalization capability across multiple datasets. However, standard loss functions often struggle with low-quality samples in complex road scenarios, highlighting the need for dynamic optimization strategies that can adaptively weight sample contributions based on their quality.
These studies have advanced traffic sign detection technology from various perspectives, providing a crucial foundation for this paper. The TT100K dataset has become a widely adopted benchmark in this field due to its large scale and rich scene diversity. However, existing methods still face challenge of balancing accuracy and speed when detecting multi-scale small objects in complex traffic scenes. Building upon the aforementioned achievements, this study addresses the severe category imbalance issue inherent in the TT100K dataset by selecting 45 frequently occurring sign categories and adopting a 7:2:1 data split. Through systematic optimization of the YOLOv8n model, we aim to further improve detection accuracy for small-scale traffic signs in complex scenes while maintaining real-time performance.
In this section, we first introduce the overall architecture of the improved model, MSD-YOLO. Subsequently, we elaborate on the three core improvement modules: the C2f-MDEM module for enhancing detail feature extraction, the SG-FPN module for optimizing multi-scale feature fusion, and the Wise-ShapeIoU loss function for improving localization accuracy.
3.1 Overall Network Architecture
This paper proposes an improved YOLOv8n model for traffic sign detection. As shown in Fig. 1, its overall structure primarily consists of three components: the backbone network, the neck (feature fusion network), and the detection head. Unlike previous methods that rely on stacking attention or multi-scale modules, we emphasize semantic-spatial alignment between feature layers. This strategy addresses feature spatial misalignment in deep networks while enhancing fine-grained edge capture and geometric regression. In the Backbone network, a Multi-scale Detail Enhancement Module (MDEM) is designed to construct the C2f-MDEM structure, effectively enhancing the feature extraction capability for traffic sign edges and contours. In the feature fusion section, an enhanced feature pyramid network named SG-FPN is designed. This network employs soft nearest neighbor interpolation in the top-down path to achieve adaptive feature fusion and integrates an enhanced GSConv module in the bottom-up path to improve feature representation capability. In the detection head, the Wise-ShapeIoU loss function is adopted, which optimizes bounding box regression by combining geometric constraints and a dynamic sample weighting mechanism. This design enables the model to better adapt to the scale variability and structural regularity of traffic signs while maintaining lightweight characteristics, thereby significantly improving its performance in traffic sign detection tasks.
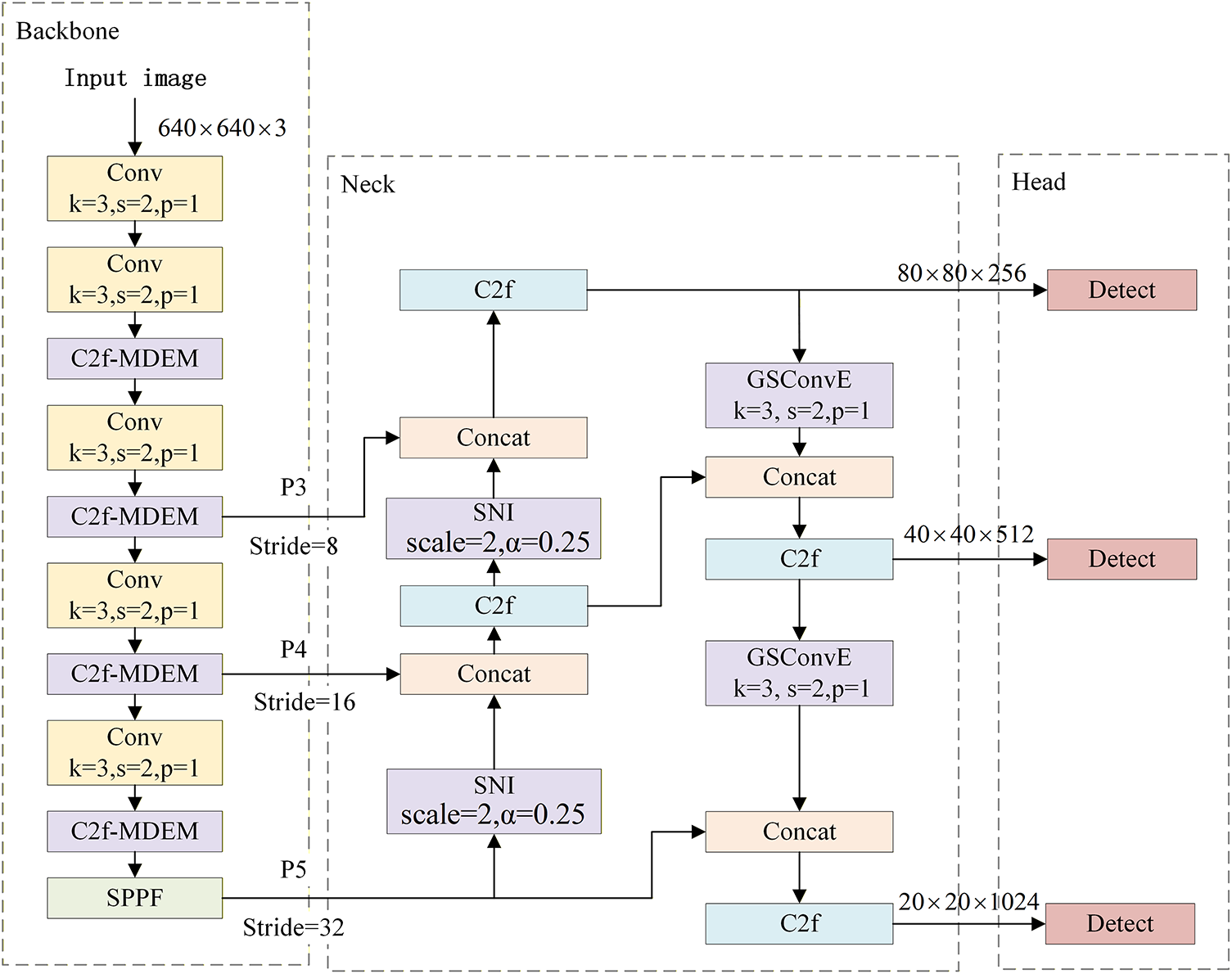
Figure 1: MSD-YOLO network structure.
In traffic sign detection, significant information loss occurs during downsampling, especially affecting high-frequency components (such as edges and contours) that are crucial for identifying small targets. Standard residual blocks in YOLOv8 primarily focus on semantic abstraction but often overlook these fine-grained structural details. Usman et al. [32] proved that integrated multi-scale attention can significantly enhance feature representation in saliency detection tasks. Inspired by this hierarchical processing strategy, this paper designs a Multi-scale Detail Enhancement Module (MDEM) to systematically capture and refine local details at different scales. Its structure is shown in Fig. 2. This module enhances and filters key detail features through hierarchical multi-scale pooling, high-frequency residual modulation and spatial-channel collaborative attention mechanism.
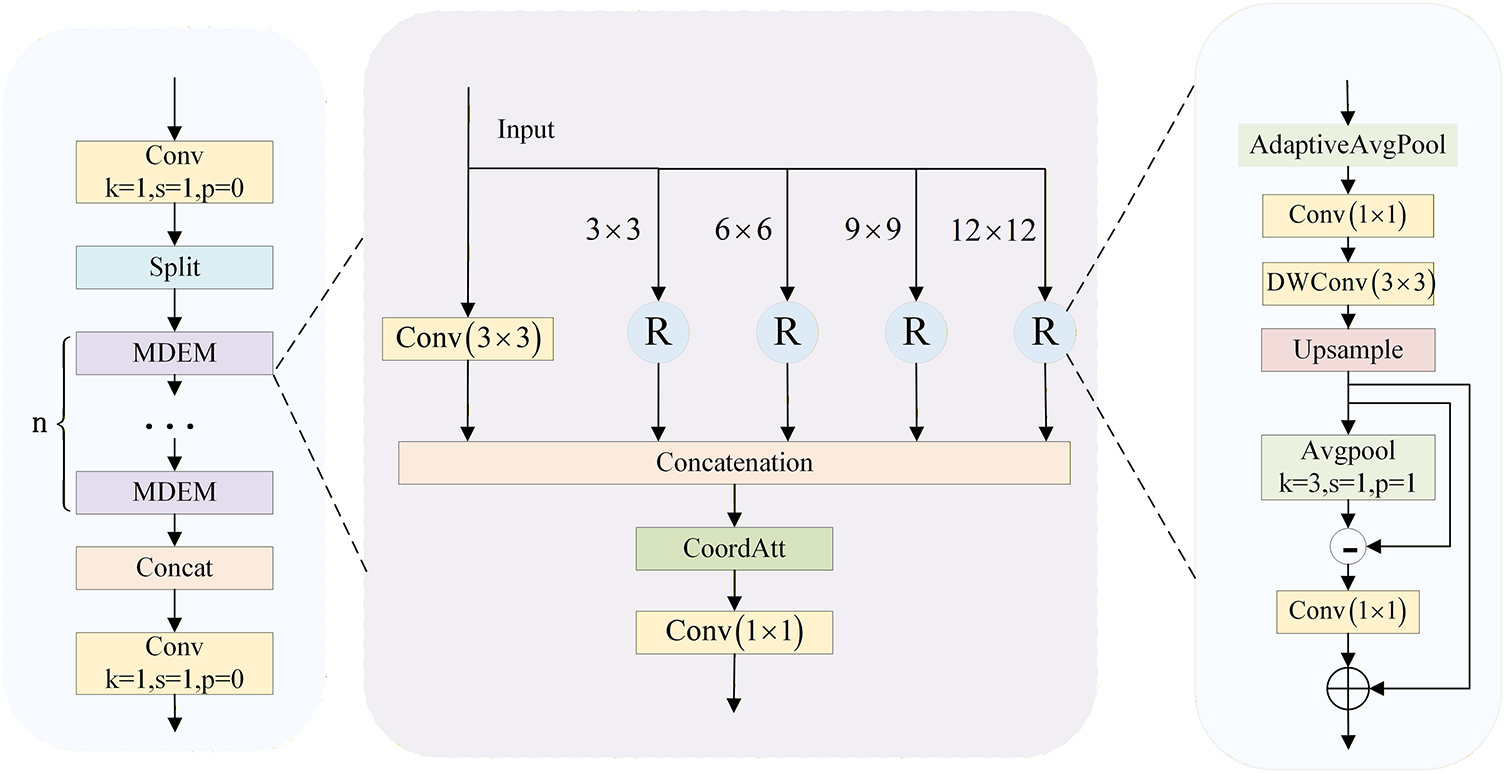
Figure 2: C2f-MDEM module.
Given an input feature map
where
Recognizing that traffic sign identification relies heavily on geometric contours, it is necessary to perform adaptive sharpening on the aforementioned multi-scale features. First, the feature
where
To integrate the enhanced multi-scale features while retaining precise positional information, the module concatenates the local transform of the original feature,
In terms of feature refinement, the attention mechanism is crucial for suppressing background redundancy and capturing optimal discriminative features [33]. For the concatenated feature

This attention-guided fusion strategy dynamically calibrates the contributions of each channel and spatial position, ensuring that features most sensitive to the geometric shapes of traffic signs are preserved and emphasized. Through this coherent pipeline of multi-scale feature capture, detail enhancement, and attention-guided fusion, the module significantly enhances the model’s perception of edge and detail features in traffic signs.
In object detection tasks within Intelligent Transportation Systems (ITS), traffic signs exhibit significant scale diversity and are often subject to uncertain environmental conditions, such as illumination variations, weather changes, and motion blur. In such scenarios, while the traditional Path Aggregation Network (PANet) structure enhances feature propagation through bidirectional paths, its feature fusion mechanism remains open to optimization. Specifically, nearest-neighbor interpolation in the top-down pathway often causes misalignment between spatial and semantic information. This issue significantly compromises detection accuracy, particularly for small signs. Concurrently, the standard strided convolution downsampling in the bottom-up pathway may result in the loss of fine-grained spatial information. Simple feature concatenation is insufficient to mitigate such interference, making effective feature fusion crucial for achieving robust detection. Related research [35] has introduced a bilateral feature fusion strategy to address robustness issues in such unpredictable environments. Building upon this premise, this study proposes an enhanced architecture termed SG-FPN (Soft-GSConvE Feature Pyramid Network), as illustrated in Fig. 3. By considering the scale distribution of traffic signs, this architecture improves the feature fusion mechanism to achieve robust fusion of multi-scale features and mitigate background interference in complex traffic scenarios.
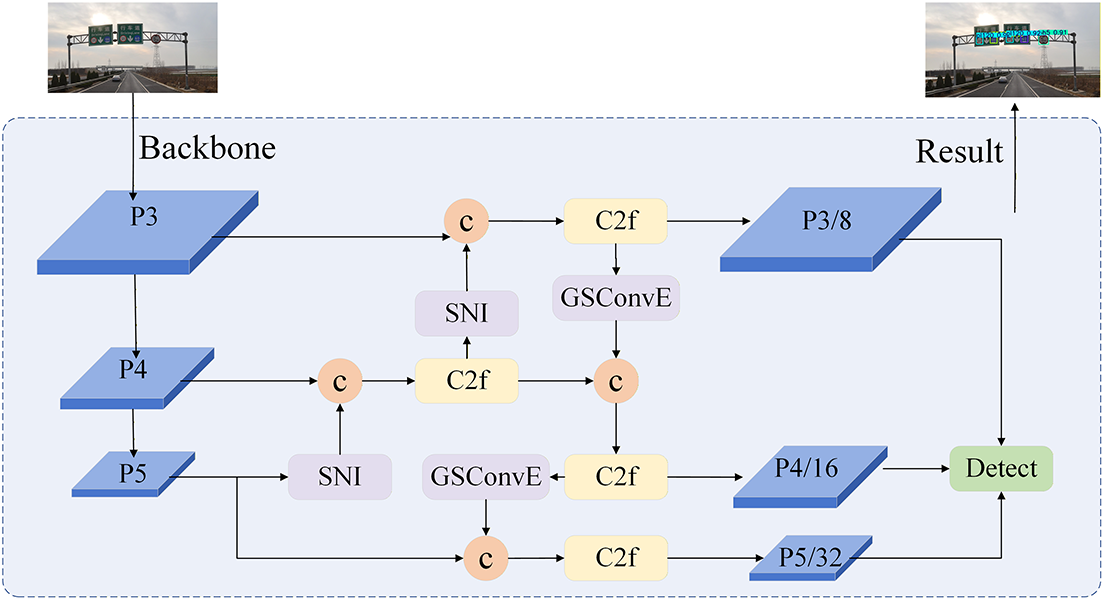
Figure 3: SG-FPN module.
In the top-down feature fusion path, a Soft Nearest Neighbor Interpolation (SNI) module is adopted to replace traditional upsampling operations. The SNI module introduces a soft weighting factor correlated with the resolution scaling ratio, enabling adaptive adjustment of the influence of high-level features on low-level features. Specifically, given a high-level feature map
where
In the bottom-up feature propagation path, the GSConvE module [36] is integrated. GSConvE is an optimized integration of standard depthwise separable convolution and conventional convolution, with its structure illustrated in Fig. 4. Through its carefully designed parallel branch architecture, the module enhances the feature representation capability of the model while maintaining low computational complexity. For traffic sign detection, where different categories of signs possess unique texture characteristics, GSConvE better preserves these discriminative features during 2× downsampling, thanks to its enhanced convolutional branch structure. Particularly when processing traffic scenes with complex backgrounds, this module effectively strengthens the feature response of the signs themselves while suppressing background interference, thereby improving the robustness of the model in real-road environments.
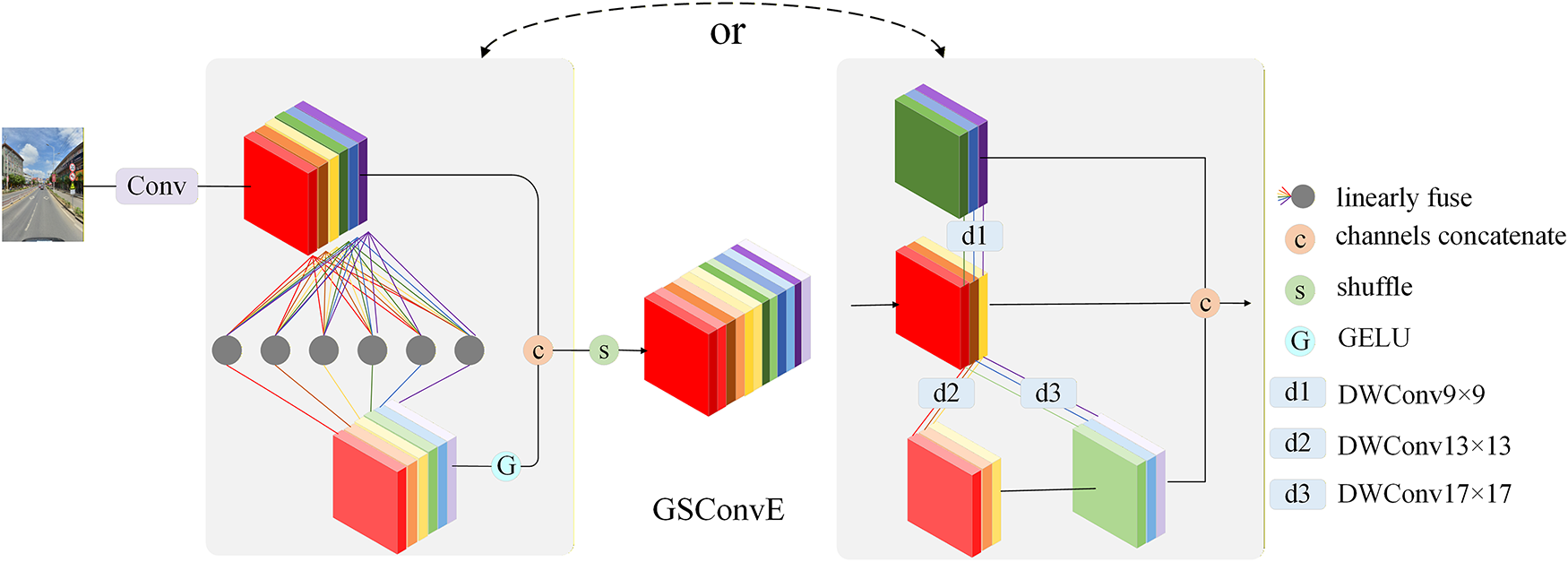
Figure 4: Illustration of GSConvE.
3.4 Wise-ShapeIoU Loss Function
The bounding box regression loss function is critical in determining the localization accuracy of traffic sign detection. YOLOv8 adopts the CIoU [37] loss by default. This loss improves upon the traditional IoU loss by incorporating penalties for center point distance and aspect ratio. However, its aspect ratio penalty only considers the relative difference in aspect ratios, failing to model the geometric characteristics of the target itself fully. Moreover, it applies a uniform optimization strategy to all samples, making it difficult to effectively handle low-quality samples (e.g., distant small signs or partially occluded signs) commonly present in road scenes. This limitation restricts the localization accuracy of the model in complex road environments. To address this, this paper proposes the Wise-ShapeIoU loss function, which combines a shape-adaptive mechanism and a dynamic sample weighting strategy to enhance model performance in traffic sign detection tasks. The core of this method integrates the geometric constraints of Shape-IoU [38] and the dynamic focusing mechanism of Wise-IoUv3 [39].
The Shape-IoU loss function constructs a fine-grained loss calculation method by analyzing the inherent shape characteristics of the target. Its core lies in introducing directional weight coefficients to differentiate regression accuracy requirements in different directions. First, to distinguish regression accuracy requirements in different directions, we calculate the horizontal (
where
Subsequently, these weights are utilized to compute the shape-aware center point distance loss and the dimensions (width-height) loss:
where
Although Shape-IoU enhances the detection potential for regular targets like traffic signs through detailed shape modeling, it treats all samples uniformly during training, similar to CIoU. When the dataset contains a large number of low-quality or outlier samples, these samples can generate large and unstable gradients, which hinders model convergence and limiting its performance potential.
To address the issue of imbalanced sample quality in real-road scenarios, this paper further introduces the dynamic non-monotonic focusing mechanism from Wise-IoUv3, constructing the Wise-ShapeIoU loss function:
where the non-monotonic focusing coefficient
In this formulation,
4 Experimental Results and Analysis
The detection model was developed and evaluated using the PyTorch 2.5.0 deep learning framework, leveraging the parallel computing capability of an NVIDIA GeForce RTX 4060 GPU for model training and inference. The software development environment was built on Python 3.10.16 with CUDA version 12.6. The Stochastic Gradient Descent (SGD) algorithm was employed for model optimization, with an initial learning rate of 0.01, a momentum factor of 0.937, and a weight decay coefficient set to 0.0005. A linear learning rate decay strategy was adopted (with a final learning rate factor of 0.01), and a warm-up period of 3 epochs was implemented (with warm-up momentum of 0.8). To enhance the model’s adaptability to complex traffic scenarios, a Mosaic data augmentation strategy with a probability of 1.0 was introduced during training. By randomly stitching, scaling, and applying color transformations to multiple training images, sample diversity was effectively enhanced. The model was trained for 300 epochs, with the batch size fixed at 16 and the input resolution set to 640 × 640. All experiments maintained identical hyperparameter configurations and data preprocessing procedures to ensure the fairness and reproducibility of the results.
This study employs the Tsinghua-Tencent 100K (TT100K) [40] traffic sign dataset for experiments. This dataset contains 100,000 high-resolution (2048 × 2048 pixels) real-road scene images, covering complex conditions such as varying lighting and weather, and includes 128 typical types of traffic signs, such as speed limits, no-parking signs, and warning signs. Each image is annotated with detailed category labels, as shown in Fig. 5. To address the issue of class imbalance in the original dataset and focus on the traffic sign categories of primary interest in this study, the dataset was filtered and restructured. A subset of 9738 images was constructed by selecting the 45 most frequently occurring traffic sign categories. To ensure effective model training and objective performance evaluation, the dataset was split into training (6793 images), validation (1949 images), and test (996 images) sets in a 7:2:1 ratio. These sets were used for model training, parameter tuning, and final performance evaluation, respectively.
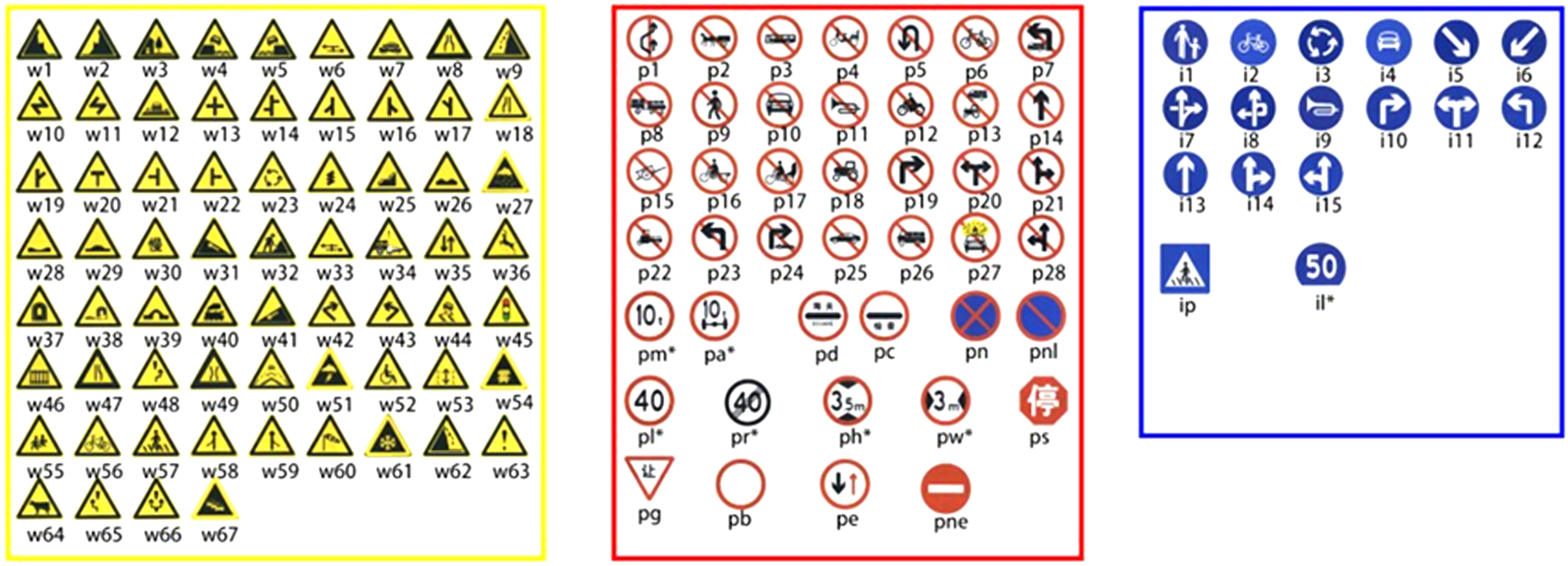
Figure 5: Traffic sign categories in TT100K dataset.
To further validate the generalization capability and robustness of the model in traffic sign detection, this study introduces two internationally recognized public benchmark datasets for evaluation: the CSUST Chinese Traffic Sign Detection Benchmark (CCTSDB) [41] and the German Traffic Sign Detection Benchmark (GTSDB) [42]. The CCTSDB dataset, constructed by the research team from Changsha University of Science and Technology, comprises 17,856 real-world traffic scene images covering diverse complex environments such as sunny days, rain, snow, fog, and nighttime. It is divided into 16,356 training images and 1500 test images, with annotations spanning three major sign categories: prohibitory, mandatory, and warning. The GTSDB dataset, a classic benchmark in traffic sign detection, contains 900 German road images with a resolution of 1360 × 800 pixels. This dataset consists of 600 training images and 300 test images categorized into four classes: prohibitory, danger, mandatory, and others.
To comprehensively evaluate the performance of the improved model, an evaluation framework was established across three dimensions: detection accuracy, model complexity, and inference speed. For detection accuracy, Precision (P), Recall (R), and mean Average Precision (mAP) were adopted as the core metrics. Their respective calculation formulas are as follows:
where
Model complexity is measured by the number of parameters and floating-point operations (FLOPs), reflecting the model’s storage requirements and computational load, respectively. Inference speed is evaluated using frames per second (FPS), calculated as:
where
4.4.1 Comparison of Attention Mechanisms
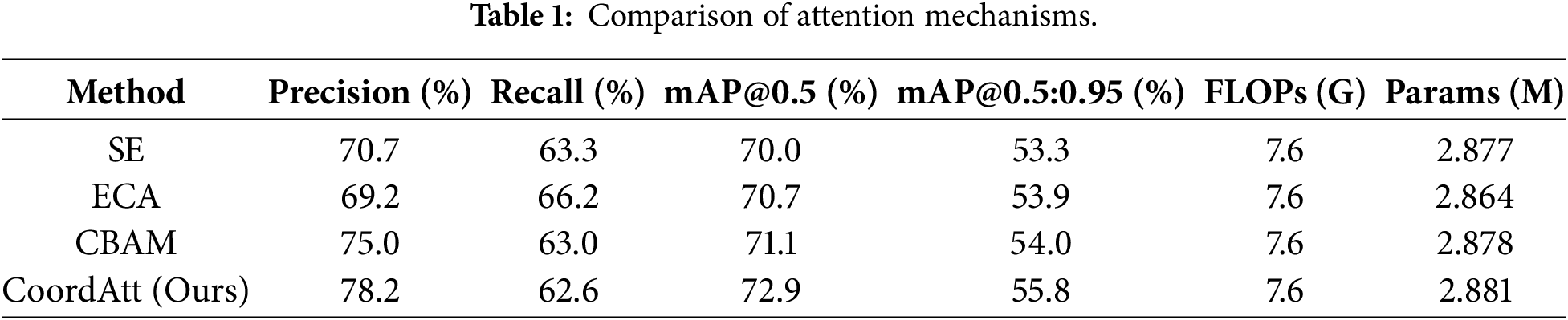
To validate the advantage of selecting CoordAtt in the C2f-MDEM module, comparative experiments were conducted with SE [43], ECA [44], and CBAM [45]. As shown in Table 1, under the identical C2f-MDEM framework and training configuration, CoordAtt achieved 72.9% in the comprehensive performance metric mAP@0.5, significantly outperforming other mechanisms. This result confirms the superiority of CoordAtt in the proposed multi-scale detail enhancement architecture. Its core advantage lies in its unique decomposed coordinate encoding design: by independently capturing long-range dependencies along the horizontal and vertical directions, it generates attention maps that simultaneously incorporate channel information and precise positional awareness. This direction-sensitive spatial-channel joint modeling capability highly aligns with the task characteristics of traffic signs, which typically have regular geometric shapes (e.g., circles, triangles) and strong positional priors. Consequently, the model can more accurately enhance edge contours and suppress background interference. In contrast, SE and ECA only model channel relationships, offering limited perception of spatial structure. Although CBAM combines channel and spatial attention, its spatial branch employs standard convolutions, making it less efficient than CoordAtt in modeling directional long-range dependencies.
4.4.2 Comparison of Loss Functions
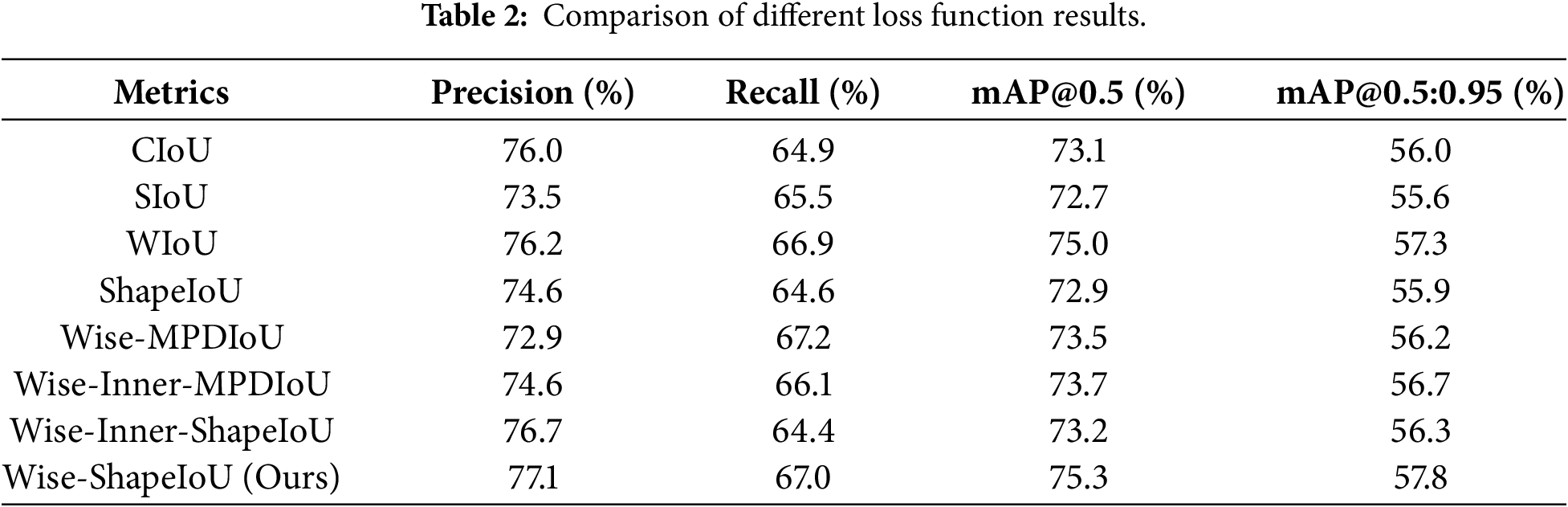
To thoroughly validate the effectiveness of the proposed loss function improvement strategy, this study conducted comprehensive comparisons between Wise-ShapeIoU and CIoU, SIoU, WIoU, ShapeIoU, as well as other mainstream composite loss functions. The experimental results presented in Table 2 demonstrate that Wise-ShapeIoU exhibits significant advantages across all key metrics. In terms of precision, it achieved 77.1%, outperforming CIoU and WIoU by 1.1 and 0.9 percentage points, respectively. This reflects its stronger capability in distinguishing positive samples and controlling false detections. The recall rate also reached an excellent level of 67.0%, second only to Wise-MPDIoU, indicating that it maintains high precision without sacrificing detection capability. More importantly, for the comprehensive performance metrics mAP@0.5 and mAP@0.5:0.95, Wise-ShapeIoU ranked first with scores of 75.3% and 57.8%, respectively, significantly surpassing all other loss functions. This fully demonstrates its optimal detection stability and generalization ability across different IoU thresholds. By integrating shape-aware characteristics with an adaptive weighting mechanism, Wise-ShapeIoU effectively addresses the insufficient geometric constraints of traditional loss functions in complex scenarios, achieving the best balance between precision and recall. Ultimately, it significantly enhances the overall detection performance of the model, validating the effectiveness and advancement of the proposed improvements.
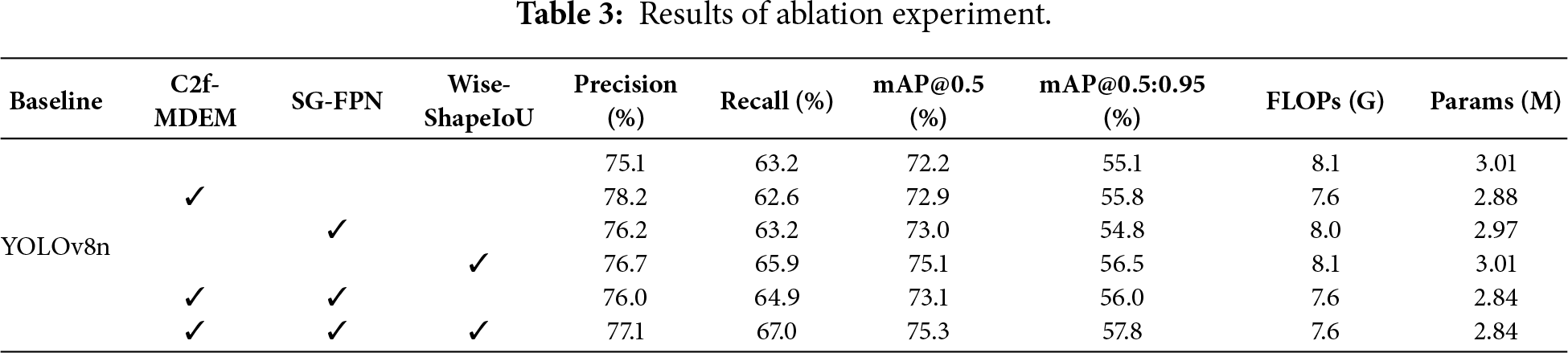
To systematically evaluate the effectiveness of each improvement module, this paper conducts ablation experiments on three core modules, with the results presented in Table 3. All experiments are performed under the same experimental settings, with YOLOv8n as the baseline. When the C2f-MDEM module is introduced individually, FLOPs decrease to 7.6 G and the parameter count reduces to 2.88M. Meanwhile, Precision improves to 78.2% and mAP@0.5 rises to 72.9%. This indicates that the module effectively enhances feature representation while significantly reducing the model’s computational complexity. With the addition of the SG-FPN module, the parameter count further decreases to 2.84M, mAP@0.5 reaches 73.1%, and mAP@0.5:0.95 reaches 56.0%. These results validate its effectiveness in improving multi-scale feature fusion through soft nearest-neighbor interpolation and GSConvE. The introduction of the Wise-ShapeIoU loss function brings the most significant performance improvements: mAP@0.5 increases by 3.1% to 75.3%, mAP@0.5:0.95 increases by 2.7% to 57.8%, and recall reaches 67.0%. This demonstrates that the loss function significantly optimizes bounding box regression without adding computational burden. The continuous performance improvements observed with the gradual introduction of each module visually highlight their complementary roles within the detection system. In summary, each improvement module contributed stable performance gains while maintaining nearly unchanged computational complexity. When all three modules were combined, the model achieved optimal levels across all key metrics. This fully demonstrates the effectiveness of the proposed scheme and provides a reliable technical pathway for real-time detection in complex scenarios.
To systematically evaluate the model’s efficiency in practical deployment, this paper further examines the impact of each key module on inference speed (FPS) and resource consumption, with the results presented in Table 4. Among these, the optimization of the Wise-ShapeIoU loss function operates during the training phase to improve regression accuracy and does not alter the model’s inference structure; therefore, it has no impact on deployment efficiency. Although the proposed C2f-MDEM module introduces multi-scale processing that increases per-frame computation time, the final model (MSD-YOLO) still maintains a real-time inference speed of 282 FPS. Meanwhile, the model size and GPU memory usage remain comparable to the baseline. This demonstrates that while achieving significant improvements in detection accuracy, the proposed method maintains good real-time performance at a controllable computational cost, providing a feasible solution for real-time traffic sign detection in complex scenarios.
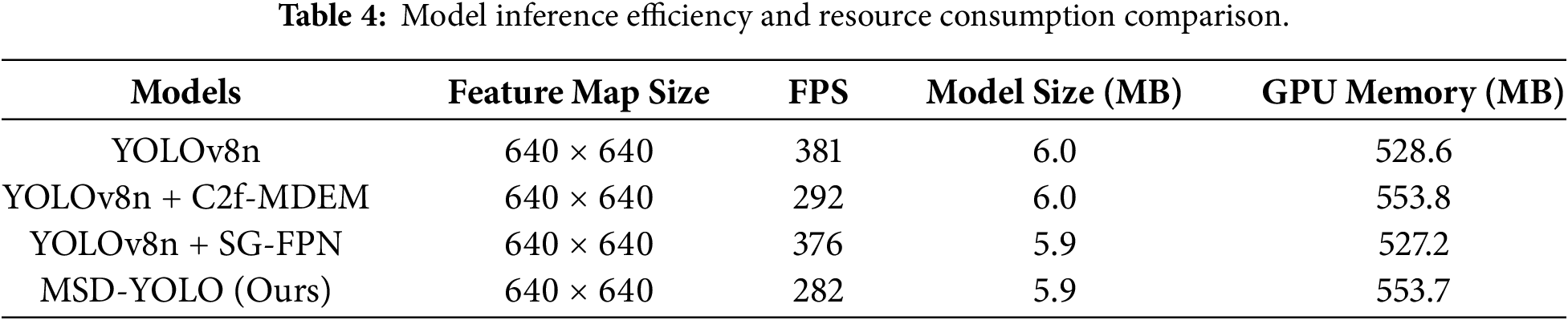
4.4.4 Comparison with Mainstream Algorithms
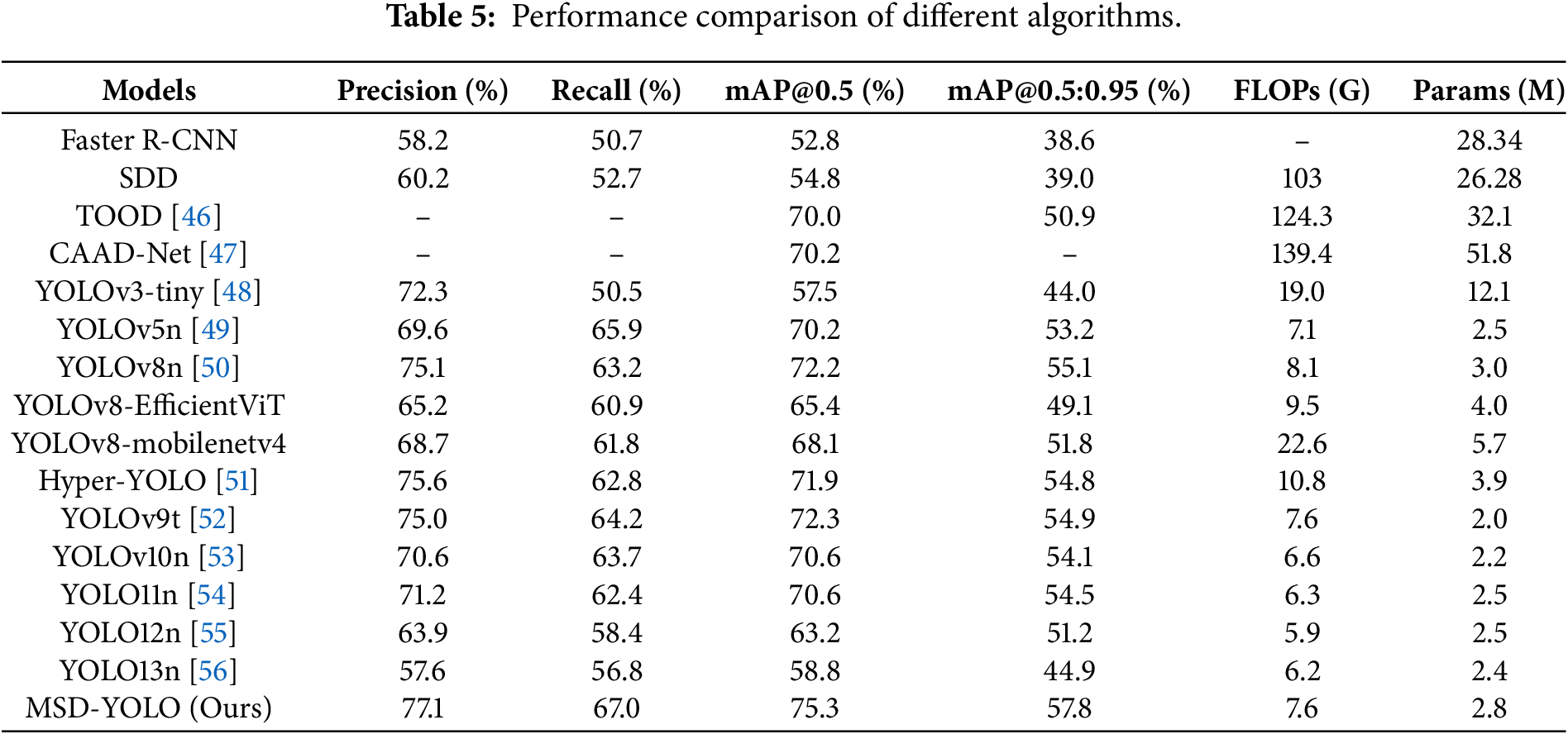
To validate the performance advantages of the MSD-YOLO model in traffic sign detection tasks, this study conducted comprehensive comparative experiments with several mainstream and state-of-the-art object detection models, covering different versions of the YOLO series and other representative algorithms. All compared models were trained and evaluated on our TT100K subset under the same experimental settings to ensure a fair comparison. As shown in Table 5, under the same experimental conditions, MSD-YOLO demonstrated optimal performance across multiple key metrics. In terms of detection accuracy, MSD-YOLO achieved a precision of 77.1% and a recall of 67.0%, with mAP@0.5 and mAP@0.5:0.95 of 75.3% and 57.8%, respectively. Compared to the baseline model YOLOv8n, these represent improvements of 2.0%, 3.8%, 3.1%, and 2.7%, respectively. In terms of model efficiency, MSD-YOLO requires only 2.8M parameters and 7.6 GFLOPs of computational load, achieving a level of lightweight design comparable to YOLOv8n (3.0M, 8.1 GFLOPs). It far surpasses models with higher parameter counts, such as YOLOv3-tiny (12.1M), and those with greater computational demands, such as YOLOv8-MobileNetV4 (22.6 GFLOPs). Compared to contemporary lightweight models, MSD-YOLO maintains similar complexity while achieving significantly higher mAP@0.5 than YOLOv10n (70.6%) and YOLOv12n (63.2%). When compared to YOLOv9t and Hyper-YOLO, MSD-YOLO still outperforms them by 3.0 and 3.4 percentage points, respectively, without introducing significant computational overhead. Additionally, this study compares MSD-YOLO with recently proposed detectors such as TOOD, CAAD-Net, and the YOLO10–13 series. MSD-YOLO demonstrates superior performance across all metrics, further validating the advanced capabilities and generalizability of the proposed multi-scale detail enhancement method. In summary, MSD-YOLO achieves an excellent balance among accuracy, lightweight design, and efficiency, fully demonstrating its effectiveness and practicality in traffic sign detection tasks.
We have plotted the composite precision-recall curves for MSD-YOLO and several classical methods across all categories, as illustrated in Fig. 6. The P-R curve of MSD-YOLO is situated consistently to the upper right of the baseline models, encompassing a larger area under the curve. Specifically, at the same recall level, MSD-YOLO achieves higher precision; conversely, at the same precision level, it yields a higher recall. These results indicate that the improvement strategies proposed in this study effectively enhance the model’s ability to balance precision and recall, thereby achieving superior overall detection performance.
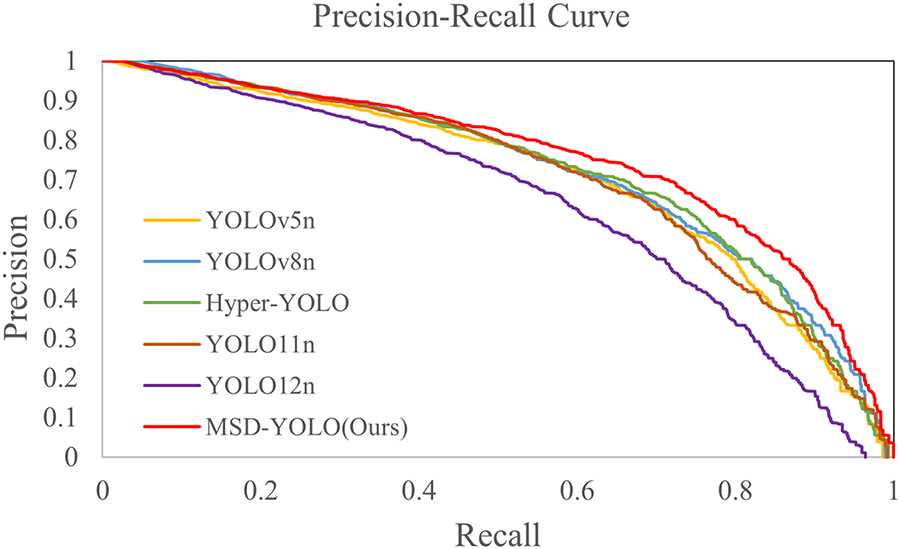
Figure 6: Overall precision-recall performance comparison.
In Fig. 7, we further illustrate the trade-off between detection accuracy and computational efficiency across different algorithms, providing an intuitive reference for comprehensive model performance evaluation. MSD-YOLO demonstrates excellent performance in the parameter-accuracy balance, occupying the upper-right corner of the Pareto frontier, indicating its ability to achieve optimal detection accuracy while maintaining a compact model size. In contrast, YOLOv3-tiny, despite its larger parameter count (12.1M), shows significantly inferior detection accuracy (57.5% mAP@0.5), reflecting the architectural limitations of early lightweight models. From a computational efficiency perspective, MSD-YOLO achieves 75.3% mAP@0.5 with only 7.6G FLOPs, significantly outperforming other models in the same computational range.
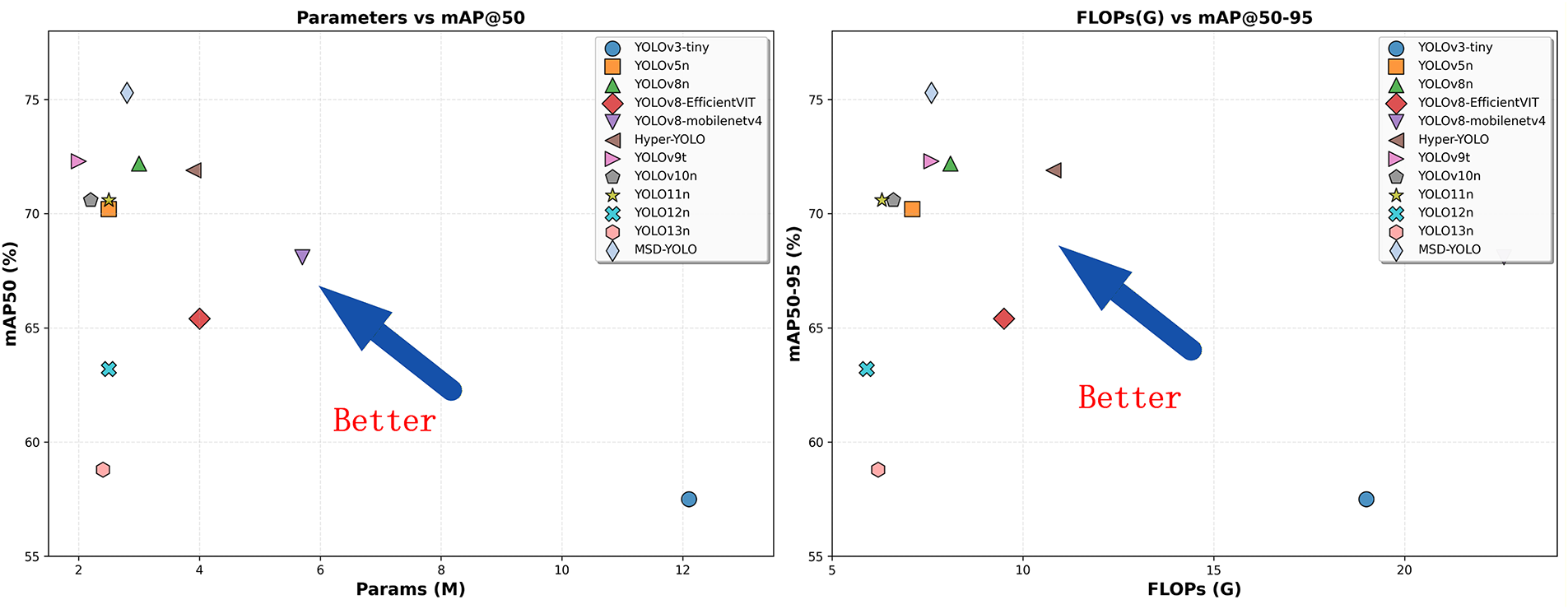
Figure 7: Comprehensive comparison of lightweight object detection models in terms of accuracy and efficiency.
To systematically evaluate the effectiveness of the proposed improved model in traffic sign detection tasks, Fig. 8 presents a comparison of detection results between the baseline and improved models in typical scenarios. In the first set of images (b), the baseline model YOLOv8n exhibits noticeable missed detections, failing to identify several critical traffic signs. In contrast, the proposed MSD-YOLO model benefits from the C2f-MDEM module’s effective preservation of multi-scale high-frequency details. It not only effectively mitigates missed detections but also significantly enhances the confidence scores of the detected targets. In the second set of images (b), the baseline model misclassifies a red object in the upper-right corner of the image as category “pne,” indicating a tendency toward false positives. This reveals the baseline model’s lack of sufficient geometric discrimination when facing complex background interference with similar color features. Conversely, the improved model successfully eliminates this false detection while notably improving detection accuracy for other correctly identified categories, demonstrating the effectiveness of the Wise-ShapeIoU loss function in enhancing shape awareness and suppressing background clutter. The third set of images further validates the comprehensive performance advantages of the proposed method. The improved model demonstrates significantly higher detection accuracy across all categories, with confidence scores for multiple targets exceeding 90%. These visual results fully demonstrate that the proposed model, incorporating the multi-scale detail enhancement module, the SG-FPN feature fusion mechanism, and the Wise-ShapeIoU loss function, exhibits stronger feature discrimination capability and robustness in complex traffic scenarios. It effectively identifies and corrects potential missed detections and false positives at a fundamental level, achieving comprehensive improvement in detection performance.

Figure 8: Comparison of detection results before and after model improvement.
To conduct an in-depth analysis of the effectiveness of the model improvements, this study employs Grad-CAM [57] to visualize the regions of interest focused on by the model. Fig. 9 presents a comparison of the heatmaps generated by the baseline and improved models, and we masked the heatmaps to retain only the regions within the detection bounding boxes. Comparative analysis reveals that in traffic sign detection, the heatmap of the YOLOv8n model exhibits relatively diffuse activation patterns. It often neglects the crucial edge information that defines the shape of traffic signs, resulting in feature responses that fail to precisely align with the geometric contours of the targets. This indicates that the baseline model loses significant high-frequency details during deep feature extraction, making it difficult to perceive the precise boundaries of the targets. In contrast, the heatmap of the MSD-YOLO model demonstrates significant contour sensitivity. Its high-response regions not only cover the main body of the target but are also distributed closely along the edges of the traffic signs. This distribution clearly delineates the target’s geometric shapes, such as circular or triangular boundaries. This high sensitivity to edges and contours proves that the proposed Multi-Scale Detail Enhancement Module (C2f-MDEM) successfully recovers the high-frequency detail information that is typically lost during downsampling. Coupled with the SG-FPN structure, the model is able to leverage distinct geometric features to resist interference from complex backgrounds. This lays a solid feature foundation for improved detection performance. The heatmap visualization results validate the effectiveness of the proposed improvements from the perspective of geometric perception and detail preservation, demonstrating that MSD-YOLO possesses superior feature perception capabilities in complex traffic scenarios.

Figure 9: Comparison of heatmaps before and after model improvement.
4.4.6 Generalization Capability Assessment
To verify the cross-dataset generalization capability and robustness of the proposed MSD-YOLO model, a comparative analysis was conducted with the baseline model YOLOv8n on two internationally recognized public benchmark datasets: CCTSDB and GTSDB. As shown in Table 6, MSD-YOLO demonstrates outstanding generalization performance and robustness. On the CCTSDB dataset, the improved model achieves an overall mAP@0.5 of 80.7%, representing a 2.3% improvement over the baseline YOLOv8n. Notably, the recall rates for prohibitory and mandatory signs increase significantly to 80.8% and 70.4%, respectively, indicating that the model effectively mitigates the problem of missed detections caused by appearance variations in cross-domain scenarios. On the GTSDB dataset, while maintaining high precision (98.7%), the improved model achieves an overall mAP@0.5 of 92.1%. The stricter localization metric mAP@0.5:0.95 reaches 74.7%, surpassing the baseline’s 72.6%. This demonstrates the model’s superior cross-domain adaptability for geometric bounding box localization. In summary, the results indicate that MSD-YOLO possesses excellent cross-domain generalization capability, maintaining outstanding detection performance on public datasets with varying sign designs and road environments that were not part of its training. This highlights its strong adaptability and reliability as a practical traffic sign detection model.
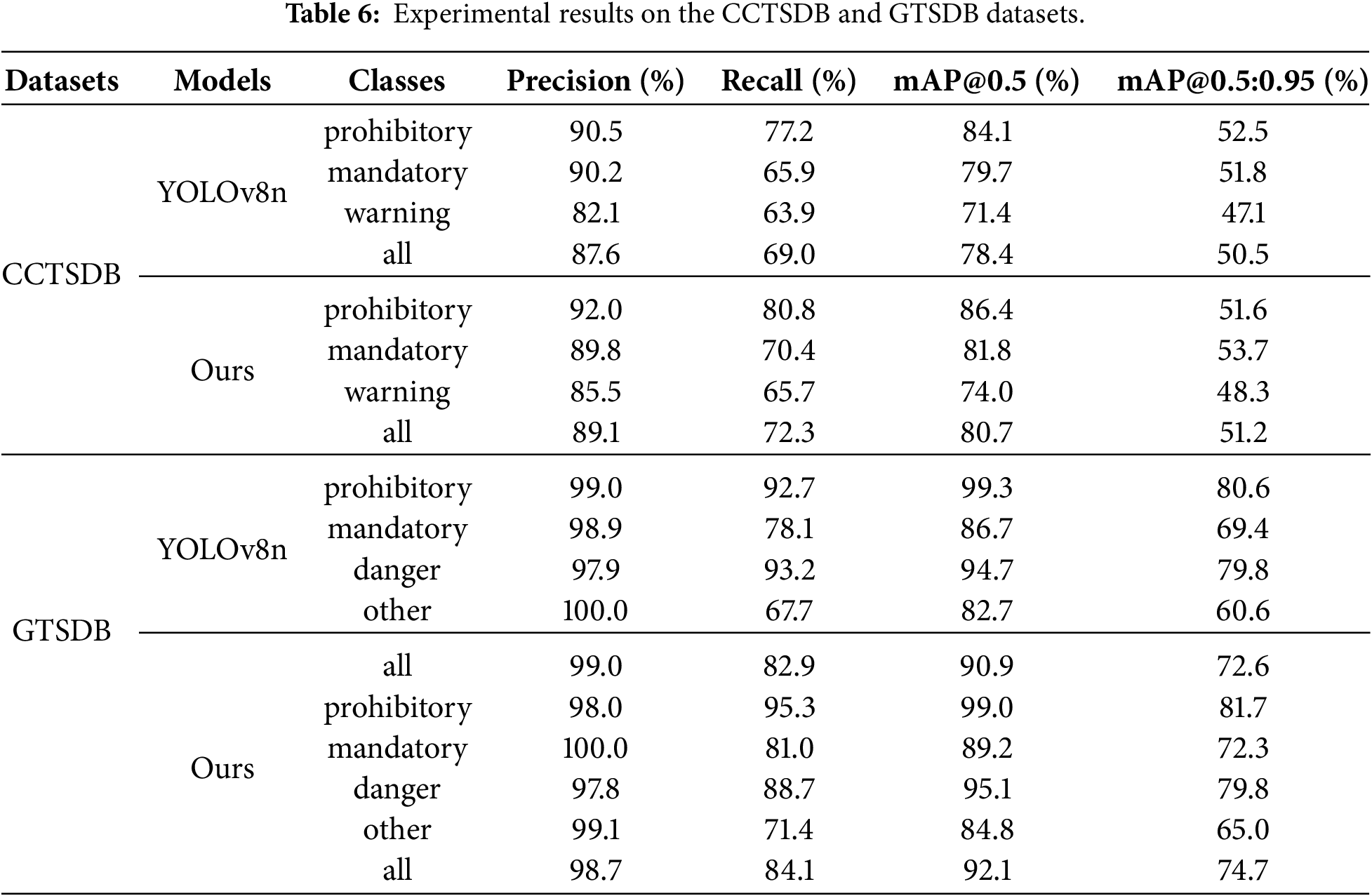
As shown in Fig. 10, a normalized confusion matrix obtained from testing the model on the CCTSDB dataset was further plotted. The matrix clearly shows occasional confusion between signs with different indicative contents. Compared to the baseline YOLOv8n, MSD-YOLO exhibits overall higher values on the diagonal of the matrix (i.e., the correct classification ratio for each category) and generally lower confusion values off the diagonal. This indicates that MSD-YOLO possesses superior class discrimination ability, enabling more accurate differentiation of traffic signs with different functions.
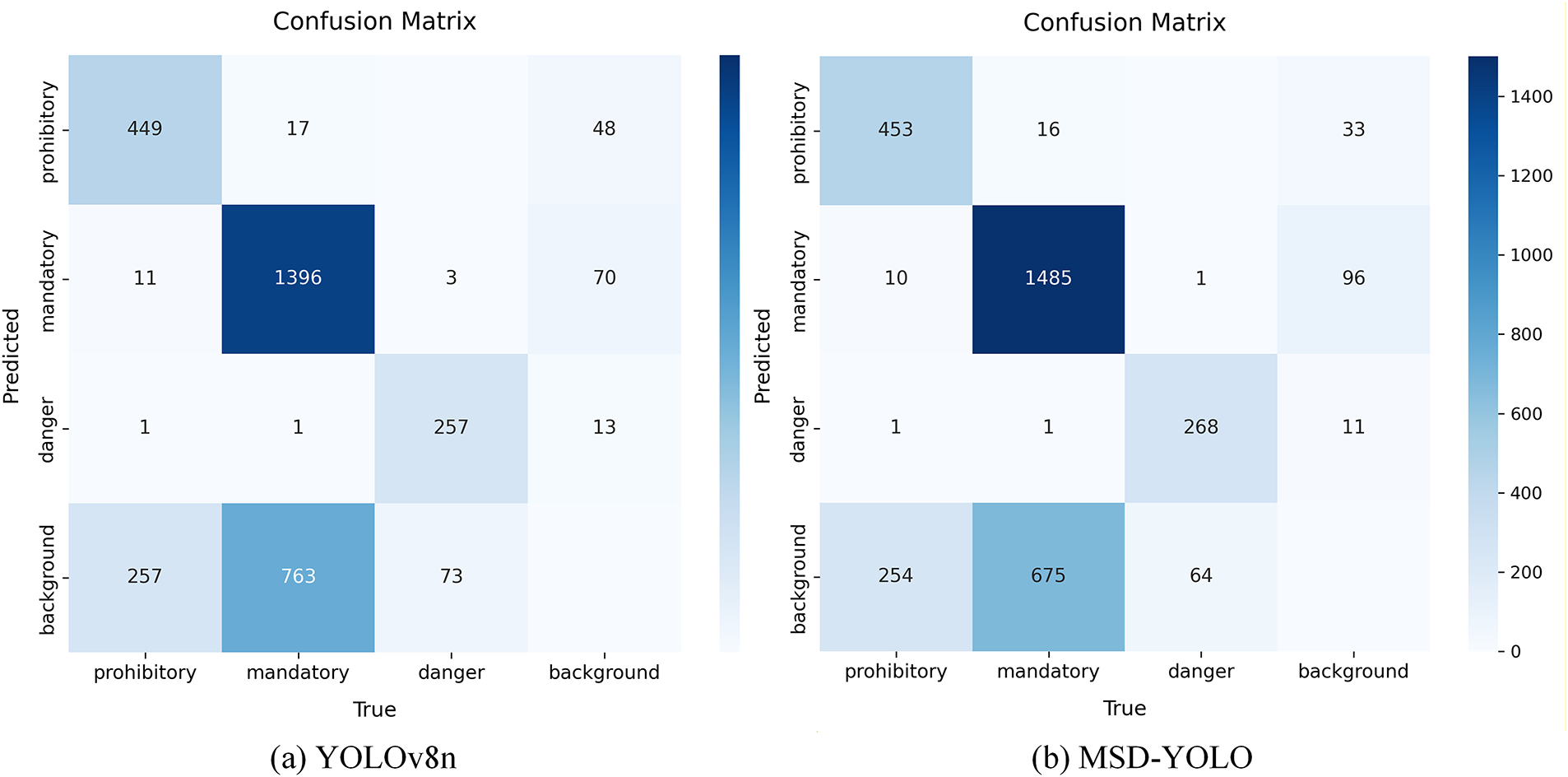
Figure 10: Confusion matrix comparing YOLOv8n and MSD-YOLO on the CCTSDB dataset.
To further validate the robustness of MSD-YOLO in real-world complex scenarios, we selected challenging and representative cases from the CCTSDB dataset for visual analysis and qualitative comparison, including low-light nighttime conditions, low-visibility foggy conditions, and low-contrast snowy conditions. The detection results of MSD-YOLO compared to the baseline model YOLOv8n in these scenarios are shown in Fig. 11. In nighttime scenes, MSD-YOLO more effectively distinguishes traffic signs from interference sources such as vehicle taillights, significantly reducing false detections. Under foggy and snowy conditions, the model overcomes image blurring and reduced contrast through enhanced feature fusion and detail preservation mechanisms. This leads to higher detection recall and more accurate bounding box localization. These results demonstrate that the multi-scale detail enhancement and feature alignment design adopted by MSD-YOLO effectively enhances the model’s stability and reliability in complex real-world environments, providing strong support for its practical deployment in autonomous driving systems.

Figure 11: Visualization of detection results under challenging weather conditions. The watermark “360记录仪” (meaning “360 Recorder”) appears in the images as they are part of the original public dataset and have been retained to maintain data authenticity.
This paper proposes a hierarchical feature enhancement model named MSD-YOLO for traffic sign detection. Addressing the structural characteristics of traffic signs, a coordinated design is implemented across three aspects: feature extraction, multi-scale fusion, and loss optimization. The proposed C2f-MDEM module achieves targeted enhancement of details through high-frequency residuals and attention mechanisms, significantly improving the model’s perception of edge features of traffic signs. The SG-FPN module promotes cross-scale feature alignment through soft interpolation fusion and enhances feature representation capability by incorporating enhanced lightweight convolution. The Wise-ShapeIoU loss introduces shape awareness and dynamic sample weighting, effectively improving bounding box localization accuracy and regression efficiency. Experimental results show that, while satisfying real-time requirements, the improved model achieves significant enhancements across multiple key metrics compared to the baseline model: mAP@0.5 increases by 3.1%, mAP@0.5:0.95 improves by 2.7%, and recall increases by 3.8%. These improvements effectively strengthen detection robustness in complex scenarios. Furthermore, the model demonstrates excellent generalization capability and stability in cross-dataset evaluations on CCTSDB and GTSDB, providing a reliable solution for traffic sign detection in complex traffic environments. Future research will further explore advanced model compression techniques, such as knowledge distillation and neural network pruning, to continuously optimize the model’s computational efficiency and memory footprint while maintaining detection performance. This will promote the practical application of the algorithm on edge computing devices.
Acknowledgement: Not applicable.
Funding Statement: This work is sponsored by the National Natural Science Foundation of China (NO. 62166006, NO. 52168011).
Author Contributions: Mingfang Li: Conceptualization, Methodology, Software, Validation, Formal analysis, Writing—original draft preparation. Damin Zhang: Validation, Resources. Qing He: Resources, Formal analysis. Chenglong Zhou: Writing—review and editing. Mingrong Li: Writing—review and editing. Xiaobo Zhou: Writing—review and editing. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets used and analysed during the current study are available from the corresponding author [Damin Zhang] on reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Chen L, Li Y, Huang C, Li B, Xing Y, Tian D, et al. Milestones in autonomous driving and intelligent vehicles: survey of surveys. IEEE Trans Intell Veh. 2023;8(2):1046–56. doi:10.1109/TIV.2022.3223131. [Google Scholar] [CrossRef]
2. Yang Y, Luo H, Xu H, Wu F. Towards real-time traffic sign detection and classification. IEEE Trans Intell Transp Syst. 2016;17(7):2022–31. doi:10.1109/TITS.2015.2482461. [Google Scholar] [CrossRef]
3. Temel D, Chen MH, AlRegib G. Traffic sign detection under challenging conditions: a deeper look into performance variations and spectral characteristics. IEEE Trans Intell Transp Syst. 2020;21(9):3663–73. doi:10.1109/TITS.2019.2931429. [Google Scholar] [CrossRef]
4. Maldonado-Bascon S, Lafuente-Arroyo S, Gil-Jimenez P, Gomez-Moreno H, Lopez-Ferreras F. Road-sign detection and recognition based on support vector machines. IEEE Trans Intell Transp Syst. 2007;8(2):264–78. doi:10.1109/TITS.2007.895311. [Google Scholar] [CrossRef]
5. Laganière R. OpenCV computer vision application programming cookbook second edition. Birmingham, UK: Packt Publishing Ltd.; 2014. [Google Scholar]
6. Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition; 2014 Jun 23–28; Columbus, OH, USA, p. 580–7. doi:10.1109/CVPR.2014.81. [Google Scholar] [CrossRef]
7. Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–49. doi:10.1109/TPAMI.2016.2577031. [Google Scholar] [PubMed] [CrossRef]
8. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA, p. 779–88. doi:10.1109/CVPR.2016.91. [Google Scholar] [CrossRef]
9. Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, et al. SSD: single shot MultiBox detector. In: Computer vision—ECCV 2016. Cham, Switzerland: Springer International Publishing; 2016. p. 21–37. doi:10.1007/978-3-319-46448-0_2. [Google Scholar] [CrossRef]
10. Wang J, Chen Y, Dong Z, Gao M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput Appl. 2023;35(10):7853–65. doi:10.1007/s00521-022-08077-5. [Google Scholar] [CrossRef]
11. Zhang H, Liang M, Wang Y. YOLO-BS: a traffic sign detection algorithm based on YOLOv8. Sci Rep. 2025;15(1):7558. doi:10.1038/s41598-025-88184-0. [Google Scholar] [PubMed] [CrossRef]
12. Liu X, Chu R, Liu B. TFG-net: a text feature-guided network for small traffic sign detection. IEEE Trans Neural Netw Learn Syst. 2025;36(7):13579–92. doi:10.1109/TNNLS.2024.3454063. [Google Scholar] [PubMed] [CrossRef]
13. Sun Y, Zhang C, Li X, Jing X, Kong H, Wang QG. MDSF-YOLO: advancing object detection with a multiscale dilated sequence fusion network. IEEE Trans Neural Netw Learn Syst. 2025;PP(99):1–12. doi:10.1109/TNNLS.2025.3617122. [Google Scholar] [PubMed] [CrossRef]
14. Zhu Y, Zhang C, Zhou D, Wang X, Bai X, Liu W. Traffic sign detection and recognition using fully convolutional network guided proposals. Neurocomputing. 2016;214(3):758–66. doi:10.1016/j.neucom.2016.07.009. [Google Scholar] [CrossRef]
15. Liu Z, Qi M, Shen C, Fang Y, Zhao X. Cascade saccade machine learning network with hierarchical classes for traffic sign detection. Sustain Cities Soc. 2021;67:102700. doi:10.1016/j.scs.2020.102700. [Google Scholar] [CrossRef]
16. Zhao R, Tang SH, Shen J, Bin Supeni EE, Rahim SA. Enhancing autonomous driving safety: a robust traffic sign detection and recognition model TSD-YOLO. Signal Process. 2024;225(1):109619. doi:10.1016/j.sigpro.2024.109619. [Google Scholar] [CrossRef]
17. Chen Y, Luo H. VisioSignNet: a dual-interactive neural network for enhanced traffic sign detection. Expert Syst Appl. 2024;255:124688. doi:10.1016/j.eswa.2024.124688. [Google Scholar] [CrossRef]
18. Shen L, You L, Peng B, Zhang C. Group multi-scale attention pyramid network for traffic sign detection. Neurocomputing. 2021;452(6):1–14. doi:10.1016/j.neucom.2021.04.083. [Google Scholar] [CrossRef]
19. Li J, Deng Q, Gao W, Yang B, Jia L, Zhou J, et al. DSF-YOLO for robust multiscale traffic sign detection under adverse weather conditions. Sci Rep. 2025;15(1):24550. doi:10.1038/s41598-025-02877-0. [Google Scholar] [PubMed] [CrossRef]
20. Deng Y, Huang L, Gan X, Lu Y, Shi S. A heterogeneous attention YOLO model for traffic sign detection. J Supercomput. 2025;81(6):765. doi:10.1007/s11227-025-07256-0. [Google Scholar] [CrossRef]
21. Chu J, Zhang C, Yan M, Zhang H, Ge T. TRD-YOLO: a real-time, high-performance small traffic sign detection algorithm. Sensors. 2023;23(8):3871. doi:10.3390/s23083871. [Google Scholar] [PubMed] [CrossRef]
22. Yang T, Tong C. Real-time detection network for tiny traffic sign using multi-scale attention module. Sci China Technol Sci. 2022;65(2):396–406. doi:10.1007/s11431-021-1950-9. [Google Scholar] [CrossRef]
23. Sun X, Liu K, Chen L, Cai Y, Wang H. LLTH-YOLOv5: a real-time traffic sign detection algorithm for low-light scenes. Automot Innov. 2024;7(1):121–37. doi:10.1007/s42154-023-00249-w. [Google Scholar] [CrossRef]
24. Zhang S, Che S, Liu Z, Zhang X. A real-time and lightweight traffic sign detection method based on ghost-YOLO. Multimed Tools Appl. 2023;82(17):26063–87. doi:10.1007/s11042-023-14342-z. [Google Scholar] [CrossRef]
25. Zhang L, Yang K, Han Y, Li J, Wei W, Tan H, et al. TSD-DETR: a lightweight real-time detection transformer of traffic sign detection for long-range perception of autonomous driving. Eng Appl Artif Intell. 2025;139(3):109536. doi:10.1016/j.engappai.2024.109536. [Google Scholar] [CrossRef]
26. Lai H, Chen L, Liu W, Yan Z, Ye S. STC-YOLO: small object detection network for traffic signs in complex environments. Sensors. 2023;23(11):5307. doi:10.3390/s23115307. [Google Scholar] [PubMed] [CrossRef]
27. Qiu J, Zhang W, Xu S, Zhou H. DP-YOLO: a lightweight traffic sign detection model for small object detection. Digit Signal Process. 2025;165(1):105311. doi:10.1016/j.dsp.2025.105311. [Google Scholar] [CrossRef]
28. Wang G, Jin P, Qi Z, Li X. Traffic sign detection method based on improved YOLOv8. Sci Rep. 2025;15(1):19385. doi:10.1038/s41598-025-03792-0. [Google Scholar] [PubMed] [CrossRef]
29. Choudhary P, Dey S. FAIERDet: fuzzy-based adaptive image enhancement for real-time traffic sign detection and recognition under varying light conditions. Expert Syst Appl. 2026;295(11):128795. doi:10.1016/j.eswa.2025.128795. [Google Scholar] [CrossRef]
30. Saxena S, Dey S, Shah M, Gupta S. Traffic sign detection in unconstrained environment using improved YOLOv4. Expert Syst Appl. 2024;238(2):121836. doi:10.1016/j.eswa.2023.121836. [Google Scholar] [CrossRef]
31. Kamal U, Tonmoy TI, Das S, Hasan MK. Automatic traffic sign detection and recognition using SegU-net and a modified tversky loss function with L1-constraint. IEEE Trans Intell Transp Syst. 2020;21(4):1467–79. doi:10.1109/TITS.2019.2911727. [Google Scholar] [CrossRef]
32. Usman MT, Khan H, Rida I, Koo J. Lightweight transformer-driven multi-scale trapezoidal attention network for saliency detection. Eng Appl Artif Intell. 2025;155:110917. doi:10.1016/j.engappai.2025.110917. [Google Scholar] [CrossRef]
33. Khan H, Ullah Khan S, Ullah W, Wook Baik S. Optimal features driven hybrid attention network for effective video summarization. Eng Appl Artif Intell. 2025;158(6):111211. doi:10.1016/j.engappai.2025.111211. [Google Scholar] [CrossRef]
34. Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 13708–17. doi:10.1109/cvpr46437.2021.01350. [Google Scholar] [CrossRef]
35. Khan H, Usman MT, Koo J. Bilateral feature fusion with hexagonal attention for robust saliency detection under uncertain environments. Inf Fusion. 2025;121(7):103165. doi:10.1016/j.inffus.2025.103165. [Google Scholar] [CrossRef]
36. Li H. Rethinking features-fused-pyramid-neck for object detection. In: Computer vision—ECCV 2024. Cham, Switzerland: Springer Nature; 2024. p. 74–90. doi:10.1007/978-3-031-72855-6_5. [Google Scholar] [CrossRef]
37. Zheng Z, Wang P, Liu W, Li J, Ye R, Ren D. Distance-IoU loss: faster and better learning for bounding box regression. Proc AAAI Conf Artif Intell. 2020;34(7):12993–3000. doi:10.1609/aaai.v34i07.6999. [Google Scholar] [CrossRef]
38. Zhang H, Zhang S. Shape-IoU: more accurate metric considering bounding box shape and scale. arXiv:2312.17663. 2023. [Google Scholar]
39. Tong Z, Chen Y, Xu Z, Yu R. Wise-IoU: bounding box regression loss with dynamic focusing mechanism. arXiv:2301.10051. 2023. [Google Scholar]
40. Zhu Z, Liang D, Zhang S, Huang X, Li B, Hu S. Traffic-sign detection and classification in the wild. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27–30; Las Vegas, NV, USA, p. 2110–8. doi:10.1109/CVPR.2016.232. [Google Scholar] [CrossRef]
41. Zhang J, Zou X, Kuang L-D, Wang J, Sherratt RS, Yu X. CCTSDB 2021: a more comprehensive traffic sign detection benchmark. Hum Centric Comput Inf Sci. 2022;12:1–18. [Google Scholar]
42. Houben S, Stallkamp J, Salmen J, Schlipsing M, Igel C. Detection of traffic signs in real-world images: the German traffic sign detection benchmark. In: Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN); 2013 Aug 4–9; Dallas, TX, USA, p. 1–8. doi:10.1109/IJCNN.2013.6706807. [Google Scholar] [CrossRef]
43. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA, p. 7132–41. doi:10.1109/cvpr.2018.00745. [Google Scholar] [CrossRef]
44. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: efficient channel attention for deep convolutional neural networks. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2020 Jun 13–19; Seattle, WA, USA. p. 11531–9. doi:10.1109/cvpr42600.2020.01155. [Google Scholar] [CrossRef]
45. Woo S, Park J, Lee JY, Kweon IS. CBAM: convolutional block attention module. In: Computer vision—ECCV 2018. Cham, Switzerland: Springer International Publishing; 2018. p. 3–19. doi:10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
46. Feng C, Zhong Y, Gao Y, Scott MR, Huang W. TOOD: task-aligned one-stage object detection. In: Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 10–17; Montreal, QC, Canada, p. 3490–9. doi:10.1109/ICCV48922.2021.00349. [Google Scholar] [CrossRef]
47. Wang G, Zhou K, Wang L, Wang L. Context-aware and attention-driven weighted fusion traffic sign detection network. IEEE Access. 2023;11:42104–12. doi:10.1109/ACCESS.2023.3264214. [Google Scholar] [CrossRef]
48. Redmon J, Farhadi A. YOLOv3: an incremental improvement. arXiv:1804.02767. 2018. [Google Scholar]
49. Jocher G. Ultralytics YOLOv5 [Internet]. 2020 [cited 2025 Nov 10]. Available from: https://github.com/ultralytics/yolov5. [Google Scholar]
50. Jocher G, Chaurasia A, Qiu J. Ultralytics [Internet]. 2023 [cited 2025 Nov 10]. Available from: https://github.com/ultralytics/ultralytics. [Google Scholar]
51. Feng Y, Huang J, Du S, Ying S, Yong JH, Li Y, et al. Hyper-YOLO: when visual object detection meets hypergraph computation. IEEE Trans Pattern Anal Mach Intell. 2025;47(4):2388–401. doi:10.1109/TPAMI.2024.3524377. [Google Scholar] [PubMed] [CrossRef]
52. Wang CY, Yeh IH, Mark Liao HY. YOLOv9: learning what you want to learn using programmable gradient information. In: Computer vision—ECCV 2024. Cham, Switzerland: Springer Nature; 2024. p. 1–21. doi:10.1007/978-3-031-72751-1_1. [Google Scholar] [CrossRef]
53. Chen H, Chen K, Ding G, Han J, Lin Z, Liu L, et al. YOLOv10: real-time end-to-end object detection. In: Proceedings of the Advances in Neural Information Processing Systems 37; 2024 Dec 10–15; Vancouver, BC, Canada. p. 107984–8011. doi:10.52202/079017-3429. [Google Scholar] [CrossRef]
54. Khanam R, Hussain M. YOLOv11: an overview of the key architectural enhancements. arXiv:2410.17725. 2024. [Google Scholar]
55. Tian Y, Ye Q, Doermann D. YOLOv12: attention-centric real-time object detectors. arXiv:2502.12524. 2025. [Google Scholar]
56. Lei M, Li S, Wu Y, Hu H, Zhou Y, Zheng X, et al. YOLOv13: real-time object detection with hypergraph-enhanced adaptive visual perception. arXiv:2506.17733. 2025. [Google Scholar]
57. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: visual explanations from deep networks via gradient-based localization. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV); 2017 Oct 22–29; Venice, Italy. p. 618–26. doi:10.1109/ICCV.2017.74. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools