
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
REVIEW

Applications of Machine Learning in Polymer Materials: Property Prediction, Material Design, and Systematic Processes
1 Key Laboratory of Engineering Dielectric and Applications (Ministry of Education), School of Electrical and Electronic Engineering, Harbin University of Science and Technology, Harbin, China
2 School of Materials Science and Chemical Engineering, Harbin University of Science and Technology, Harbin, China
* Corresponding Author: Shu Li. Email:
(This article belongs to the Special Issue: Machine Learning Methods in Materials Science)
Computers, Materials & Continua 2026, 87(3), 2 https://doi.org/10.32604/cmc.2026.076492
Received 21 November 2025; Accepted 27 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper reviews the research progress and application prospects of machine learning technologies in the field of polymer materials. Currently, machine learning methods are developing rapidly in polymer material research; although they have significantly accelerated material prediction and design, their complexity has also caused difficulties in understanding and application for researchers in traditional fields. In response to the above issues, this paper first analyzes the inherent challenges in the research and development of polymer materials, including structural complexity and the limitations of traditional trial-and-error methods. To address these problems, it focuses on introducing key basic technologies such as molecular descriptors and feature representation, data standardization and cleaning, and records a number of high-quality polymer databases. Subsequently, it elaborates on the key role of machine learning in polymer property prediction and material design, covering the specific applications of algorithms such as traditional machine learning, deep learning, and transfer learning; further, it deeply expounds on data-driven design strategies, such as reverse design, high-throughput virtual screening, and multi-objective optimization. The paper also systematically introduces the complete process of constructing high-reliability machine learning models and summarizes effective experimental verification, model evaluation, and optimization methods. Finally, it summarizes the current technical challenges in research, such as data quality and model generalization ability, and looks forward to future development trends including multi-scale modeling, physics—informed machine learning, standardized data sharing, and interpretable machine learning.Keywords
As an important branch of material research, polymer science is gradually shifting its research paradigm from traditional experiment-driven to data-driven. The vigorous development of machine learning technology provides strong support for this transformation. In recent years, this technology has made remarkable progress in the fields of polymer material discovery, property prediction, and process optimization, showing broad application prospects. However, how to help researchers in traditional fields understand and apply these rapidly evolving technologies has become a key challenge for promoting the successful transformation of the paradigm.
As basic materials in modern industry, polymer materials are widely used in key fields such as aerospace, biomedicine, new energy, and electronic information, thanks to their advantages of light weight, corrosion resistance, and strong designability. Their research focuses on the correlation between “structure-performance-application”, specifically covering core topics such as molecular chain structure regulation (e.g., repeating unit composition, sequence arrangement, branched/cross-linked topology), aggregated structure optimization (e.g., crystallinity, phase separation morphology), macro-performance control (e.g., mechanical strength, thermal stability, conductivity), and process adaptability design [1]. After decades of development, polymer science has formed a traditional research system centered on experimental synthesis, theoretical calculation (e.g., molecular dynamics simulation, density functional theory), and process optimization, laying a solid foundation for new material R&D [2].
Currently, although there are mature non-machine learning research methods in polymer materials science, these methods face insurmountable bottlenecks when dealing with complex problems. Traditional research mainly relies on chemical intuition and trial-and-error methods, which are not only inefficient but also make it difficult to fully grasp the complex structure-property relationships of polymer materials [1]. For example, in the research on sequence regulation and performance matching of multi-component copolymers, traditional experimental methods need to verify hundreds or thousands of combination schemes one by one, with a cycle often lasting months or even years. Although theoretical calculations can reveal micro-mechanisms, when facing the multi-scale structure of polymer chains (from atomic level to macro aggregated state) and massive chemical space (with more than 1018 potential polymer structures) [3], the calculation cost increases exponentially, failing to meet the demand for large-scale screening. In addition, traditional methods have low efficiency in data utilization and cannot effectively integrate hidden laws in multi-source heterogeneous data (such as experimental data, simulation data, and literature data), resulting in a lot of repetitive work and resource waste in the material R&D process.
In contrast, machine learning can break through the limitations of traditional methods with its excellent high-dimensional data processing capabilities and non-linear modeling capabilities. In data-scarce scenarios, through technologies such as transfer learning and data enhancement, machine learning can mine structure-property relationships from limited samples. Facing multi-objective optimization problems (such as balancing mechanical strength, thermal stability, and biocompatibility of materials), it can quickly locate Pareto optimal solutions, significantly shortening the R&D cycle. For example, in the design of polymer thermal conductive materials, traditional methods are difficult to balance molecular chain regularity and process feasibility, while machine learning models successfully predicted new structures with a 40% increase in thermal conductivity by integrating more than 1000 sets of experimental data, reducing the R&D cycle from 2 years to 3 months [4–6].
To address the limitations of traditional methods and promote the paradigm transformation of polymer science, this study focuses on exploring the application progress of machine learning technologies in polymer research, systematically sorts out their development context and research status, and refines efficient and practical methodologies and systematic processes, aiming to provide valuable references for polymer material researchers to enter this field.
The structure of this paper is shown in Fig. 1: Section 2 elaborates on data characterization and preprocessing methods for polymer materials, including molecular descriptor construction, data standardization processes, and enhancement technologies; Section 3 comprehensively analyzes the application of various machine learning algorithms in property prediction, covering multi-level technologies such as traditional methods, deep learning, and transfer learning; Section 4 focuses on exploring data-driven polymer design strategies, including innovative methods such as reverse design, high-throughput screening, and multi-objective optimization; Section 5 discusses key links of experimental verification and model optimization; Section 6 demonstrates practical application results through typical cases; finally, the current challenges are summarized and future directions are prospected. This review clearly presents the complete knowledge system and technical route of machine learning technology in polymer science, providing a reference for interdisciplinary innovation.
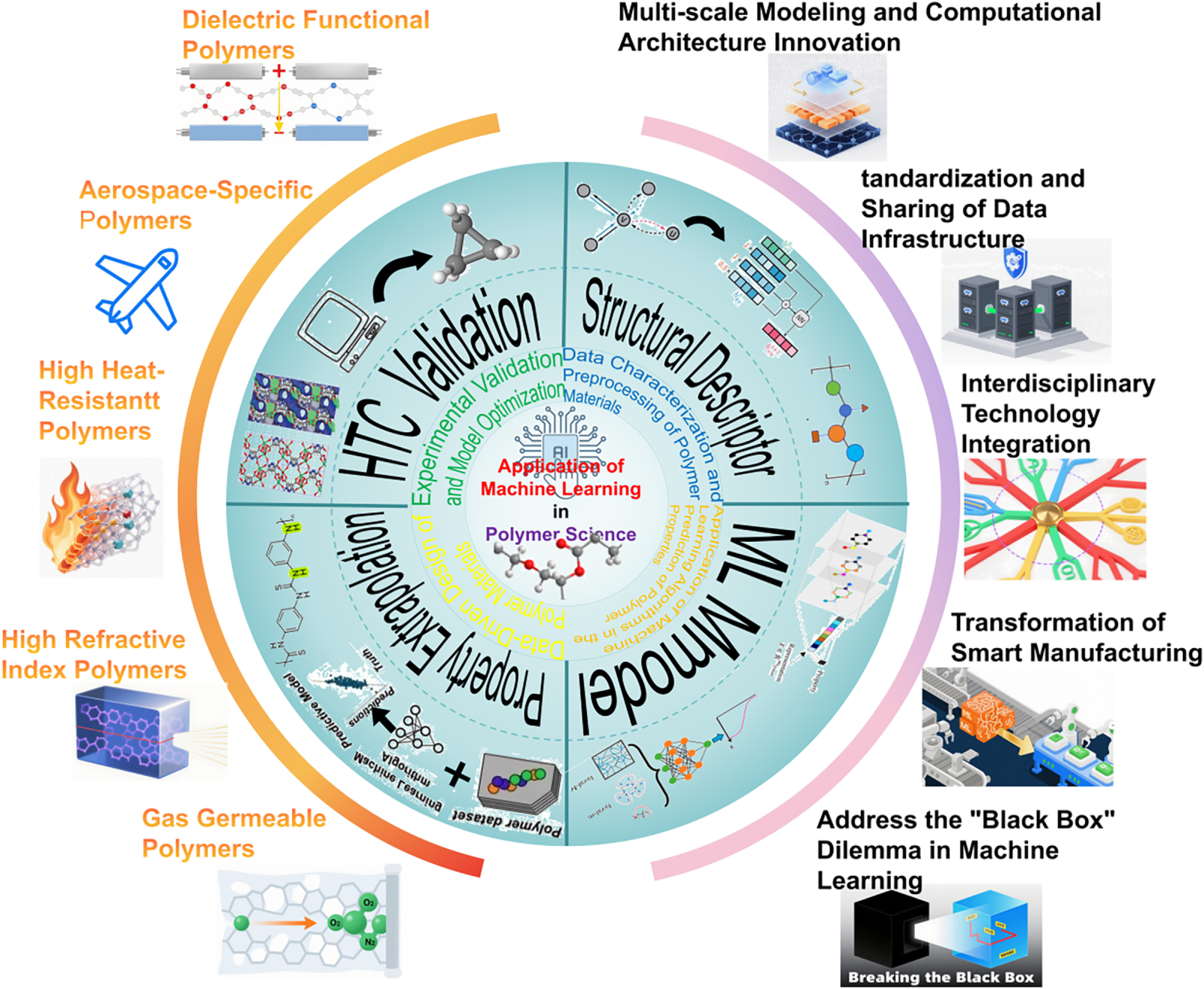
Figure 1: The framework includes four core modules: structural descriptors (converting polymer structures into computer-processable feature vectors, such as molecular fingerprints and multi-scale descriptors), machine learning models (algorithm systems including traditional machine learning, deep learning, and transfer learning), machine learning-driven property extrapolation (achieving accurate prediction of key properties such as thermal conductivity and mechanical strength), and high-throughput computation (generating massive data through molecular dynamics simulation and first-principles calculation to support model training). The left side of the framework shows existing typical application cases (e.g., polymer electrolyte design, biodegradable material optimization), and the right side lists current core challenges (e.g., uneven data quality, insufficient model generalization ability, lack of interpretability), intuitively presenting the complete logical chain of “data-model-application-challenge”.
1.1 Research Background and Significance
As a basic material in modern industry, polymer materials face long-term challenges in precise design and performance improvement due to their structural complexity and multi-functional requirements. Traditional research methods mainly rely on chemical intuition and trial-and-error methods, which are not only inefficient but also make it difficult to fully grasp the complex structure—property relationships of polymer materials [1]. With the arrival of the big data era, the combination of artificial intelligence and traditional scientific research has given birth to a new paradigm of “AI for Science”. As an important branch of artificial intelligence, machine learning has shown significant advantages in revealing the in-depth physical and chemical laws of polymer materials due to its excellent high-dimensional data processing ability [2].
The core challenge in the field of polymer science lies in the fact that the relationship between its huge and complex multi-scale structural characteristics and properties has not been fully mastered. Polymer materials are usually composed of a collection of one or more similar molecules rather than a single structure, which brings unique challenges to traditional chemical representation and machine learning methods [3]. For example, the low thermal conductivity of intrinsic polymers contradicts their wide application requirements in the fields of integrated circuit packaging and organic semiconductors. However, due to the complex synthesis process and high cost of polymers, the publicly available reliable polymer thermal conductivity data are very scarce, which seriously hinders the understanding of the mapping relationship between the micro-structure of polymers and thermal conductivity [4]. Machine learning technology provides a new possibility to solve this problem through its ability to extract useful relationships from limited data [5].
The application of machine learning in polymer science has multiple practical significances. In terms of material design, machine learning can efficiently handle the huge chemical and configuration space of polymers and accelerate the discovery process of new materials [6]. Through the machine learning—assisted inverse analysis method of polymer synthesis, the appropriate polymerization reaction conditions can be quickly and accurately predicted, thereby efficiently developing high-performance polymer materials [7]. In terms of property prediction, machine learning models can handle meaningful patterns in large-scale data that are difficult for humans to interpret, which is particularly useful for systems with complex interactions [8]. Especially when dealing with the complex structure—function relationships of polymer materials, machine learning can establish connections between the chemical composition and conformation of molecular chains, the aggregated structure, and macro-properties [8–10].
From the perspective of industrial application, the introduction of machine learning technology is reshaping the R & D paradigm of polymer materials. The traditional “trial-and-error” experiment has been replaced by the intelligent R & D model of “prediction–verification”, which not only changes the working mode of researchers but also redefines the performance boundaries of future energy equipment. In many industries such as aerospace, automobile manufacturing, energy development, and biomedicine, machine learning technology can quickly and accurately predict material properties, significantly shortening the R & D cycle and reducing costs [10]. For example, in the field of polymer composites, machine learning models can solve the thermal management problems that are difficult to handle with traditional development methods by analyzing a large amount of experimental data [11].
The particularity of polymer science also puts forward unique requirements for the application of machine learning. Since polymer materials are usually a collection of one or more similar molecules rather than a single structure, traditional chemical representation methods face challenges. At the same time, the scarcity of high-quality experimental data limits the effectiveness of supervised learning methods, especially in polymer property prediction tasks [12]. These challenges have prompted researchers to develop new methods, such as combining machine learning and high-throughput molecular dynamics simulation to predict material properties, and using transfer learning technology to solve the problem of data distribution differences [13].
As an important branch of material research, polymer science is gradually shifting its research paradigm from traditional experiment-driven to data-driven. The vigorous development of machine learning technology provides strong support for this transformation. In recent years, this technology has made remarkable progress in the fields of polymer material discovery, property prediction, and process optimization, showing broad application prospects [14]. However, how to help researchers in traditional fields understand and apply these rapidly evolving technologies has become a key challenge for promoting the successful transformation of the paradigm [15].
The core challenge in the field of polymer science lies in the fact that the relationship between its huge and complex multi-scale structural characteristics and properties has not been fully mastered [16]. Polymer materials are usually composed of a collection of one or more similar molecules rather than a single structure, which brings unique difficulties to traditional chemical characterization and research methods [17]. For example, the low thermal conductivity of intrinsic polymers contradicts their wide application requirements in fields such as integrated circuit packaging and organic semiconductors. However, due to the complex synthesis process and high cost of polymers, publicly available reliable thermal conductivity data are very scarce, which seriously hinders the understanding of the mapping relationship between polymer microstructure and thermal conductivity [18]. Machine learning, with its ability to extract useful correlations from limited data, offers a new possibility to address this core challenge—it can break through the limitations of traditional methods in handling multi-scale structures, massive chemical spaces, and complex structure-property relationships, serving as a powerful tool to solve key problems in polymer science [19,20].
In contrast, machine learning overcomes the bottlenecks of traditional methods through its superior high-dimensional data processing and non-linear modeling capabilities. It excels in data-scarce scenarios by leveraging transfer learning and data enhancement to mine structure-property relationships from limited samples, and efficiently navigates multi-objective optimization problems (e.g., balancing mechanical strength, thermal stability, and biocompatibility) to pinpoint Pareto optimal solutions [21]. A notable example is the design of polymer thermal conductive materials: while traditional methods struggle to reconcile molecular chain regularity with process feasibility, machine learning models integrated over 1000 sets of experimental data to predict novel structures with 40% enhanced thermal conductivity, cutting the R&D cycle from 2 years to 3 months [5–7].
To address the limitations of traditional methods, solve the core challenges of polymer science, and promote the paradigm transformation of the discipline, this study focuses on exploring the application progress of machine learning technologies in polymer research, systematically sorts out their development context and research status, and refines efficient and practical methodologies and systematic processes, aiming to provide valuable references for polymer material researchers to enter this field.
2 Data Characterization and Preprocessing of Polymer Materials
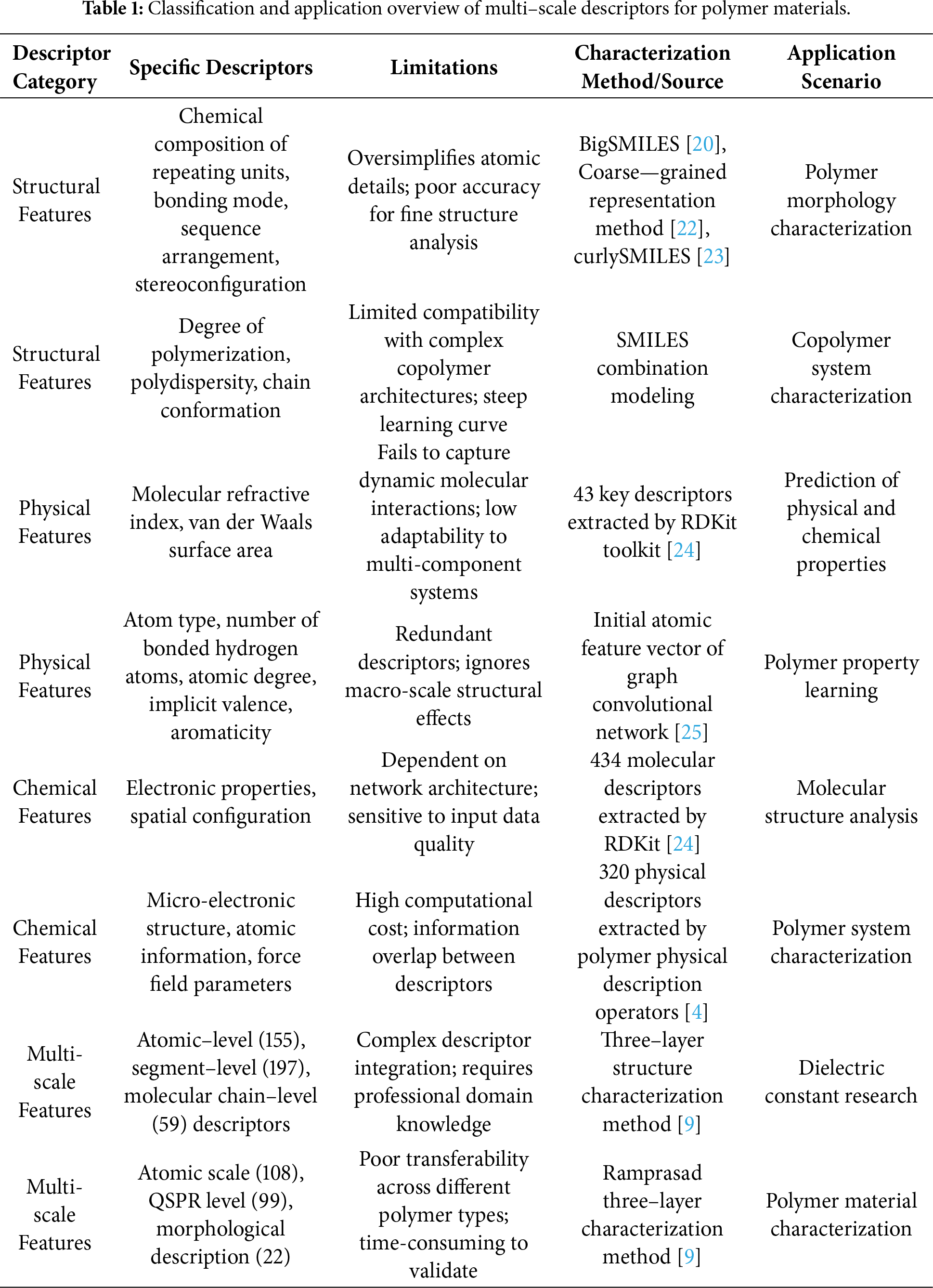
Data characterization and preprocessing of polymer materials are the fundamental pillars of machine learning applications, with data quality directly determining the reliability and generalization ability of subsequent models. This process focuses on extracting, standardizing, and enhancing data from multi-source channels (experimental measurements, computational simulations, literature mining) to construct structured datasets that meet the requirements of machine learning algorithms. The core challenge lies in addressing the data-specific issues caused by polymer materials’ complex molecular structures, variable physical and chemical properties, and non-linear structure-property relationships—including data scarcity, format inconsistency, and feature redundancy. As shown in Table 1, multi-scale descriptors covering structural, physical, chemical, and multi-dimensional features provide quantitative tools for capturing polymer characteristics, while standardized data processing and enhancement technologies further improve data utility, laying a solid foundation for accurate modeling.
2.1 Molecular Descriptors and Feature Representation
The core of polymer data characterization is converting complex chemical structures into quantifiable data features [26,27], with molecular descriptors serving as the bridge between polymer structures and machine learning models (as shown in Table 1). The diversity of polymer structures (composition, architecture, sequence) requires multi-dimensional descriptor systems to capture key information, and the selection and extraction of descriptors directly affect data quality and model performance [28].
As shown in Fig. 2, SMILES and its extended formats are core tools for encoding polymer structural data. Traditional SMILES syntax has limitations in describing complex polymer morphologies, leading to the development of extended encoding formats such as BigSMILES and curlySMILES. These formats enhance the expression ability of structural data, enabling accurate encoding of linear, branched, random, block, alternating, and grafted polymers. For example, BigSMILES extends the SMILES syntax to capture the repeating unit combination and branch structure information of polymers, improving the consistency and completeness of structural data for multi-repeating unit composites [29]. For copolymer systems, structural data encoding is achieved by combining SMILES of each repeating unit, supplemented by key parameter data such as degree of polymerization, polydispersity, and chain conformation to enrich the descriptor dimension [30].
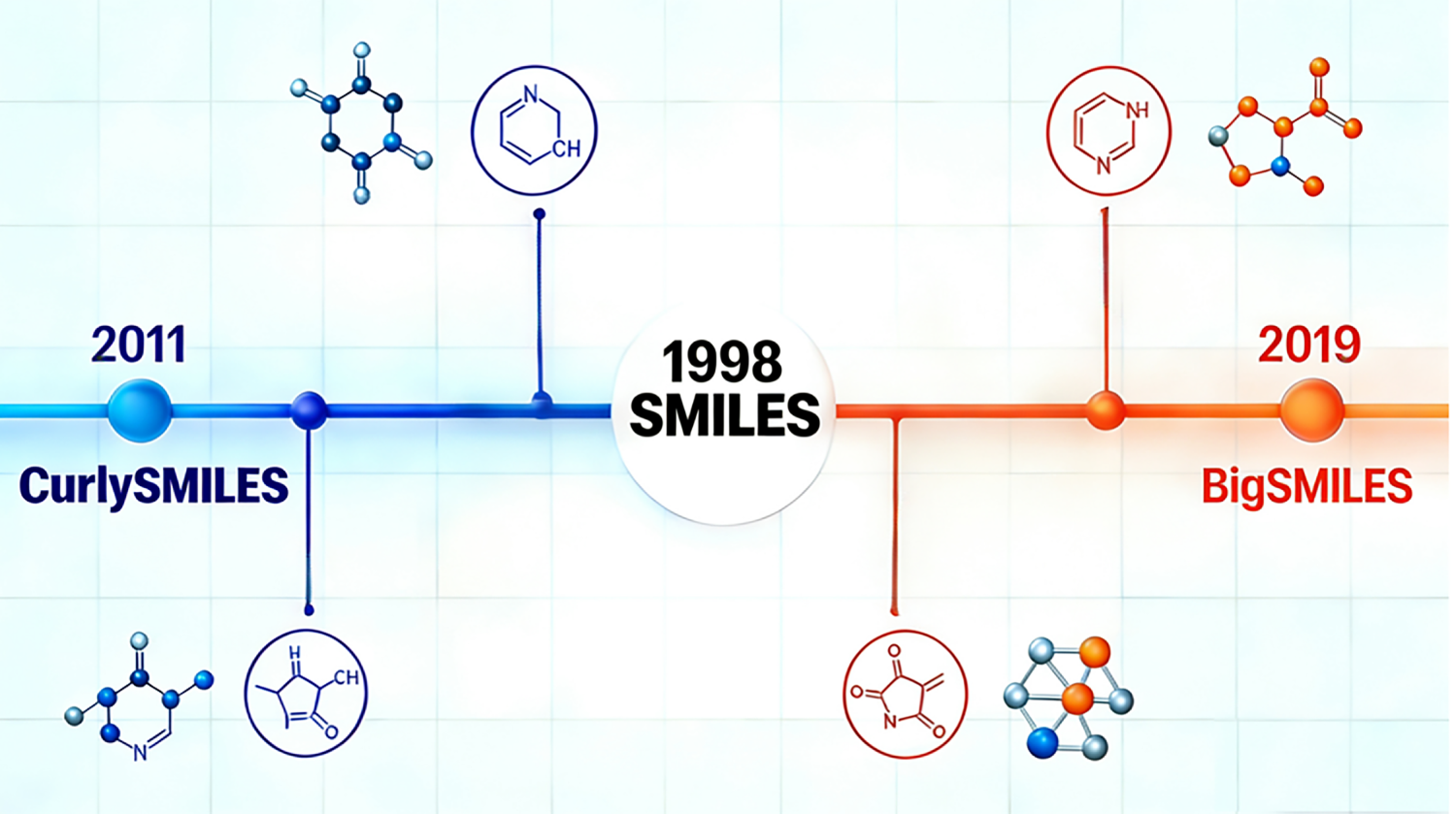
Figure 2: The figure shows a schematic diagram of the development process of SMILES (Simplified Molecular Input Line Entry System) and its extended forms (BigSMILES, CurlySMILES). From the proposal of traditional SMILES in 1988, to the subsequent development of extended representation methods such as BigSMILES (2019) and CurlySMILES (2011) 6 by researchers to solve its shortcomings in the characterization of complex polymer structures, these methods can more effectively characterize different polymer morphologies such as linear and branched, contributing to the accurate description of polymer structures.
Molecular fingerprint technology provides high-dimensional data representation for polymer structures. Morgan fingerprints characterize molecular substructure data by identifying all possible substructures, with the improved MFF format further incorporating substructure frequency data [31]. Extended Connectivity Fingerprints (ECFP) convert monomer chemical structure data into binary descriptor vectors, effectively capturing the distribution characteristics of key substructures in polymers [32]. In practical applications, the RDKit chemical information toolkit is used to extract descriptor data from SMILES-encoded structures: 434 initial descriptors covering electronic properties, spatial configuration, and physical and chemical properties are extracted, and 43 key descriptors (including molecular refractive index, van der Waals surface area) are retained after Pearson correlation coefficient analysis and redundancy removal, improving data efficiency [33].
As shown in Fig. 3, Graph representation methods enrich the structural data characterization dimension [34]. Graph Convolutional Networks (GCN) use atomic-level data (atom type, number of bonded hydrogen atoms, atomic degree, implicit valence, aromaticity) as initial feature vectors, and update node data through iterative learning to capture polymer structure-property relationships [35]. The graph-based molecular set representation combined with the Weighted Directed Message Passing Neural Network (wD-MPNN) architecture parameterizes the underlying molecular distribution data to capture the average graph structure features of repeating units [3]. For complex polymer systems, polymer physical description operators extract 320 physical descriptor data from monomer micro-electronic structure, atomic information, and force field parameters. Through statistical analysis and 100 rounds of random sequence feature screening, the data dimension is reduced to 20 optimized descriptors, balancing data richness and computational efficiency [4].
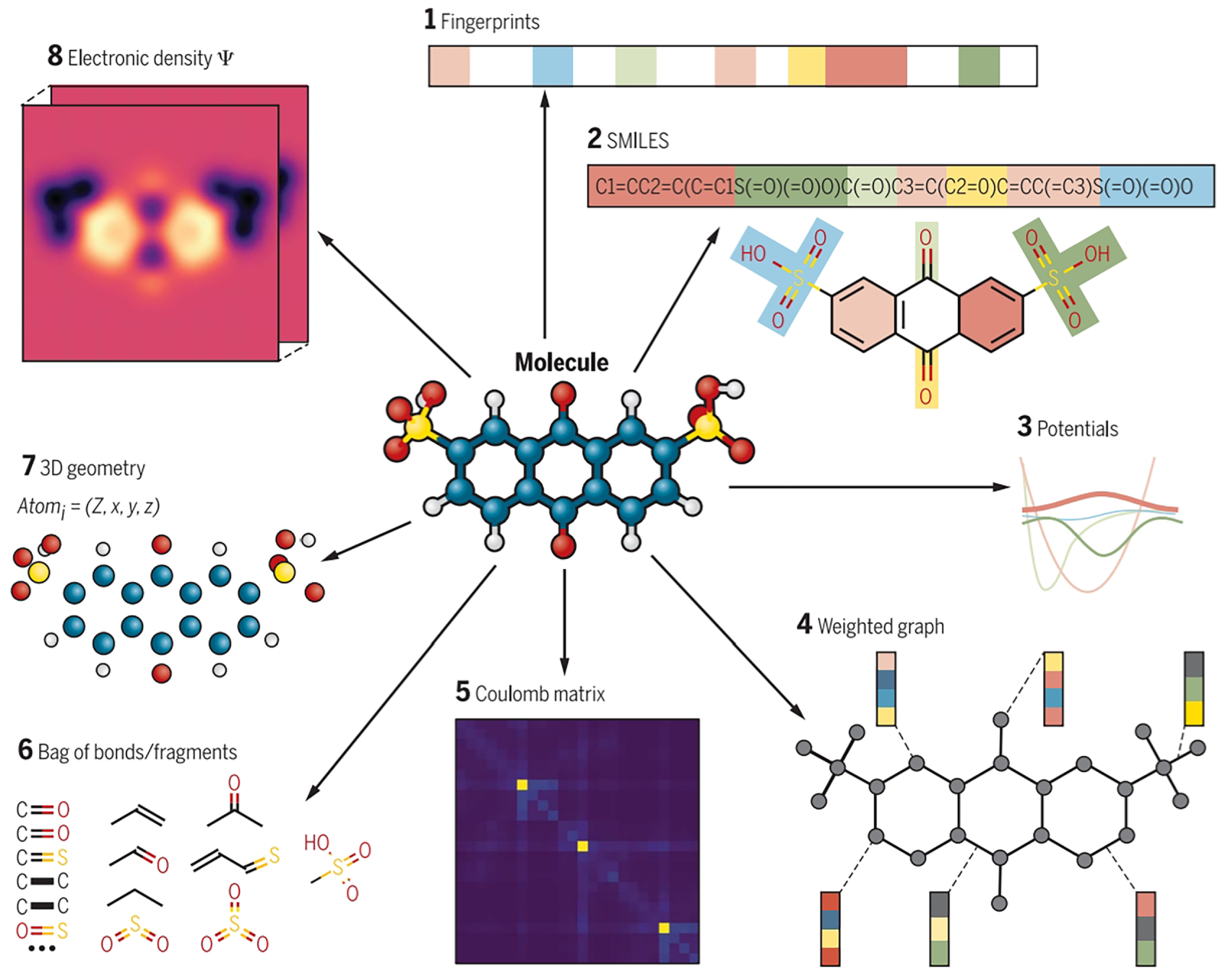
Figure 3: Different types of molecular representations for the same molecule [35]. (1) Fingerprint vector; (2) SMILES string; (3) Potential energy function; (4) Weighted graph of atoms and bonds; (5) Coulomb matrix; (6) Combination of bonds/fragments; (7) 3D geometry of atomic charges; (8) Electronic density.
Structural data has been divided into atomic-level (155 descriptors), segment-level (197 descriptors), and molecular chain-level (59 descriptors) to form a multi-scale data system [36]. A three-layer data characterization strategy has been adopted, consisting of atomic scale (108 descriptors, e.g., O1-C3-C4 segment data), QSPR level (99 descriptors, e.g., van der Waals surface area data), and morphological description level (22 descriptors, e.g., inter-ring topological distance data) [37].
2.2 Data Standardization and Cleaning
Data standardization and cleaning are key steps to eliminate data noise and ensure consistency, addressing issues such as compatibility problems and non-uniform standards in polymer data from different sources [20]. As shown in Fig. 4, high-quality data is the prerequisite for avoiding “garbage in, garbage out”, and standardized processing improves data comparability and usability [5]. Polymer characterization data often exists in the form of statistical indicators (molecular weight and its distribution, crystallinity), increasing the complexity of data processing [22].
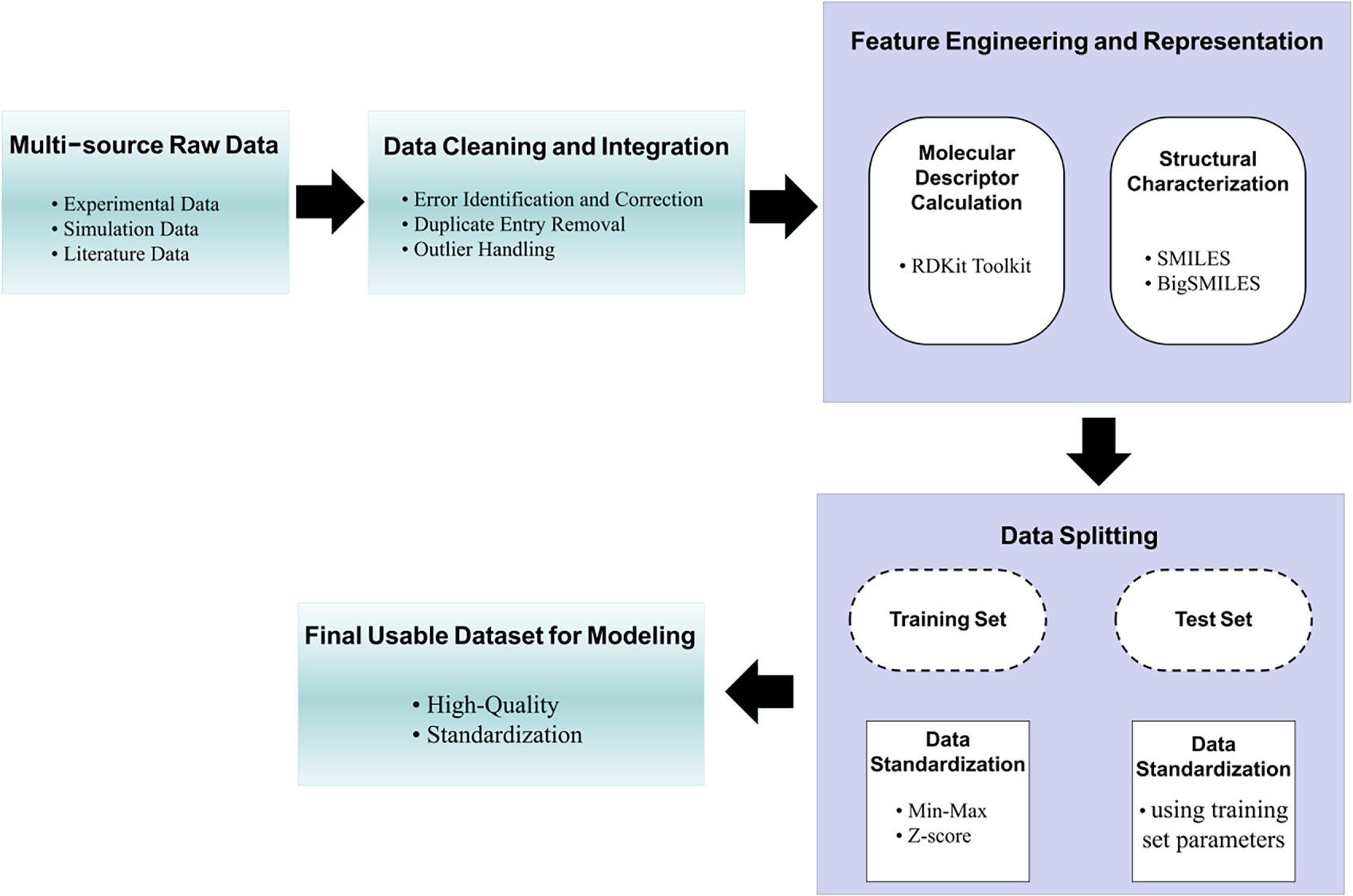
Figure 4: This diagram outlines the systematic preprocessing of polymer data for machine learning.
Data preprocessing focuses on three core tasks: error correction, duplicate removal, and outlier handling. Error correction involves verifying and correcting experimental data deviations and simulation data errors; duplicate removal eliminates redundant data entries from multi-source integration; outlier handling identifies and processes abnormal data points using methods such as z-score and boxplot analysis [38]. For numerical data, standardization (min-max scaling, z-score standardization) is performed to ensure consistent data range, while categorical data (polymer type, synthesis method) is converted into machine-readable formats via one-hot encoding or label encoding. Min-max scaling is widely used for its ability to maintain data distribution characteristics [39]. In model training, data is typically split into training and test sets at an 8:2 or 9:1 ratio, with separate standardization to avoid data leakage [34].
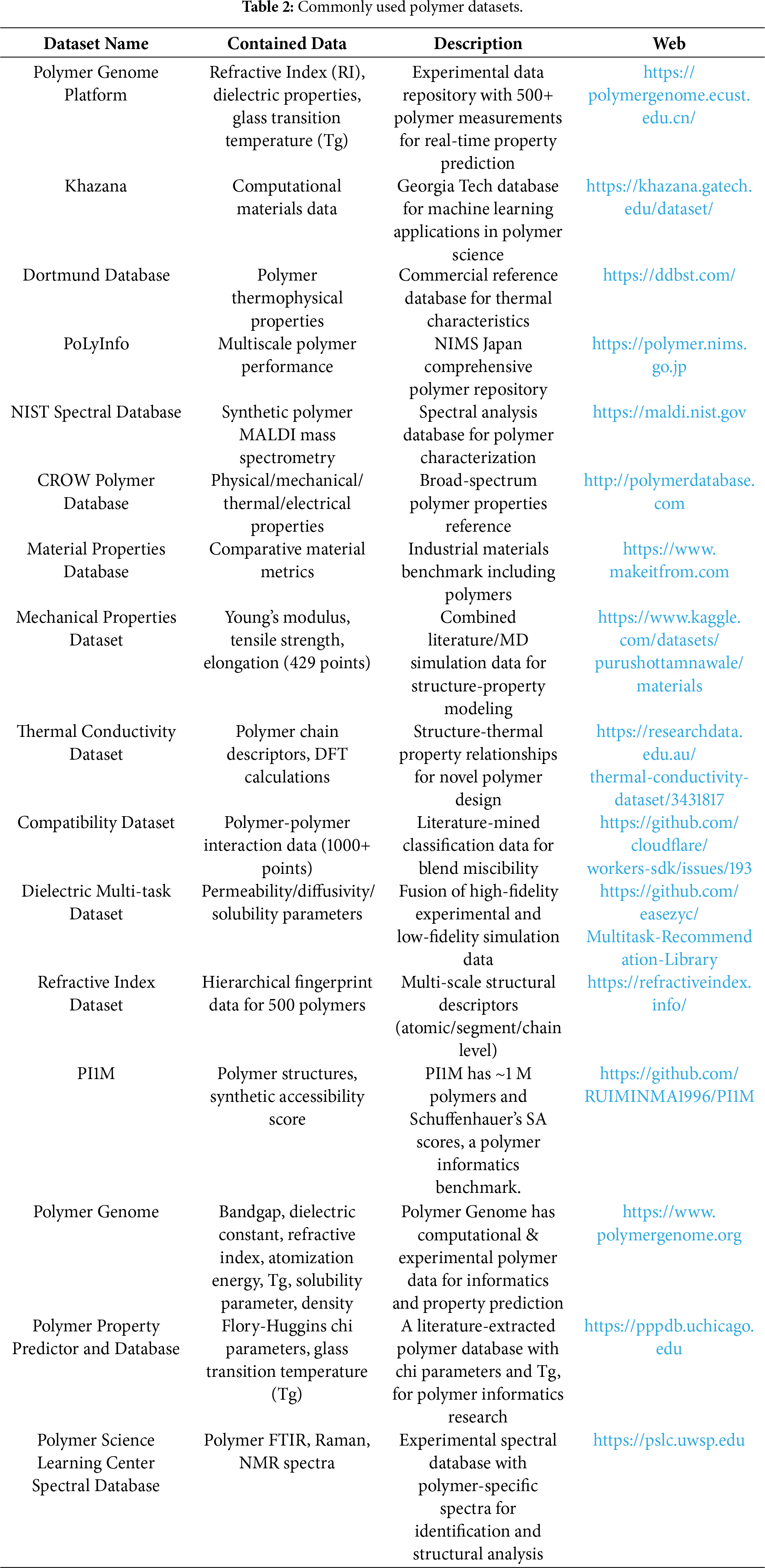
Data standardization relies on unified data systems and databases. To address data dispersion and non-standardization, the polymer research community has developed specialized database systems such as PoLyInfo and CRIPT [8]. The Polydat framework supports standardized integration of structural data and characterization parameters; BigSMILES format ensures consistent encoding of polymer repeating units and branch structure data [30]. The PoLyInfo database contains property data of ~100 polymers (glass transition temperature, melting point, density, thermal conductivity), which have undergone strict cleaning and standardization, improving model prediction accuracy [40]. Table 2 lists commonly used polymer datasets, covering various property data types and providing high-quality data resources for machine learning applications.
Data quality control also involves strict screening criteria. For example, polymer structures with glass transition temperature or melting point standard deviations exceeding 30 K are excluded to ensure data reliability [41]. The construction of datasets adhering to the FAIR principle (Findable, Accessible, Interoperable, Reusable) is emphasized, requiring systematic accumulation of experimental data or high-throughput data generation [13]. However, challenges remain, such as missing reaction parameters and incomplete characterization conditions in open-source data [42], which need to be addressed through data integration and supplementation.
2.3 Data Enhancement Technology
Data scarcity is a critical bottleneck restricting the performance of polymer machine learning models. Given the high cost and difficulty of polymer experimental data acquisition, data enhancement technologies are developed to expand dataset scale while maintaining data rationality and physical consistency, providing sufficient data support for model training.
Physical modeling-based data enhancement generates simulated data with physical significance. Liu et al. used the Fire Dynamics Simulator (FDS) to simulate cone calorimeter experiments, generating ignition time and peak heat release rate data consistent with physical laws, effectively expanding the training sample library [12]. This method avoids the limitations of experimental data acquisition and ensures the reliability of generated data through physical constraints.
Transfer learning and cross-dataset data reuse improve data utilization. In thermal conductivity prediction, researchers pre-trained 1000 neural network models using the PoLyInfo and QM9 databases, then fine-tuned them with limited target data, significantly improving prediction accuracy [36]. This approach leverages existing large-scale datasets to compensate for target data scarcity, enhancing model generalization.
Molecular fragment recombination enriches structural data diversity. The polyBERT model decomposes known polymer structures into fragments and recombines them to generate 100 million hypothetical PSMILES strings, expanding the polymer structure data space [37]. This chemical knowledge-guided data enhancement ensures the rationality of generated molecular structures while increasing data volume.
Resampling and generative model-based data expansion address small sample issues. Bootstrap resampling expands 180 experimental samples to 1500 samples, retaining the statistical characteristics of original data and solving the data scarcity problem in natural fiber-reinforced polymer composite research [14]. The graph grammar distillation framework decomposes amino acid structures into molecular graph grammar fragments, realizing accurate exploration of high-dimensional polymer space through recombination [19]. Generative recurrent neural networks in the PI1M database generate ~1 million theoretical polymer data [38], while large language models construct extended datasets covering four types of polymer property prediction tasks [39], significantly expanding data scale.
Multi-source data integration and active learning optimize data efficiency. Research teams integrate multi-source small molecule databases, generate massive hypothetical structures of 8 polymer types and 1 copolymer type via rule-based polymerization reactions, and construct structured datasets for thermal, mechanical, and gas permeation property prediction [40]. In high-cost data acquisition scenarios, active learning combined with Bayesian optimization selects the most informative samples for experimentation, maximizing data utility. High-throughput computing and experimental collaboration (molecular dynamics simulation + automated experiments) construct high-quality standardized datasets, providing systematic data solutions for polymer research [22].
3 Application of Machine Learning Algorithms in Polymer Property Prediction
In recent years, machine learning algorithms have driven a paradigm shift in polymer property prediction, with algorithm selection, optimization, and innovation directly determining the accuracy and efficiency of property prediction. The core goal is to establish the mapping relationship between polymer structural features and macro-properties through algorithmic modeling, addressing the limitations of traditional methods in handling high-dimensional, non-linear, and small-sample data. Current research focuses on three algorithmic directions: traditional machine learning algorithms for feature-engineered data modeling, deep learning algorithms for end-to-end automatic feature learning, and transfer/multi-task learning algorithms for data scarcity and multi-property correlation mining. As shown in Table 3, different algorithm categories have distinct advantages in model structure, computational efficiency, and applicable scenarios, providing diverse algorithmic tools for polymer property prediction (as shown in Table 3).
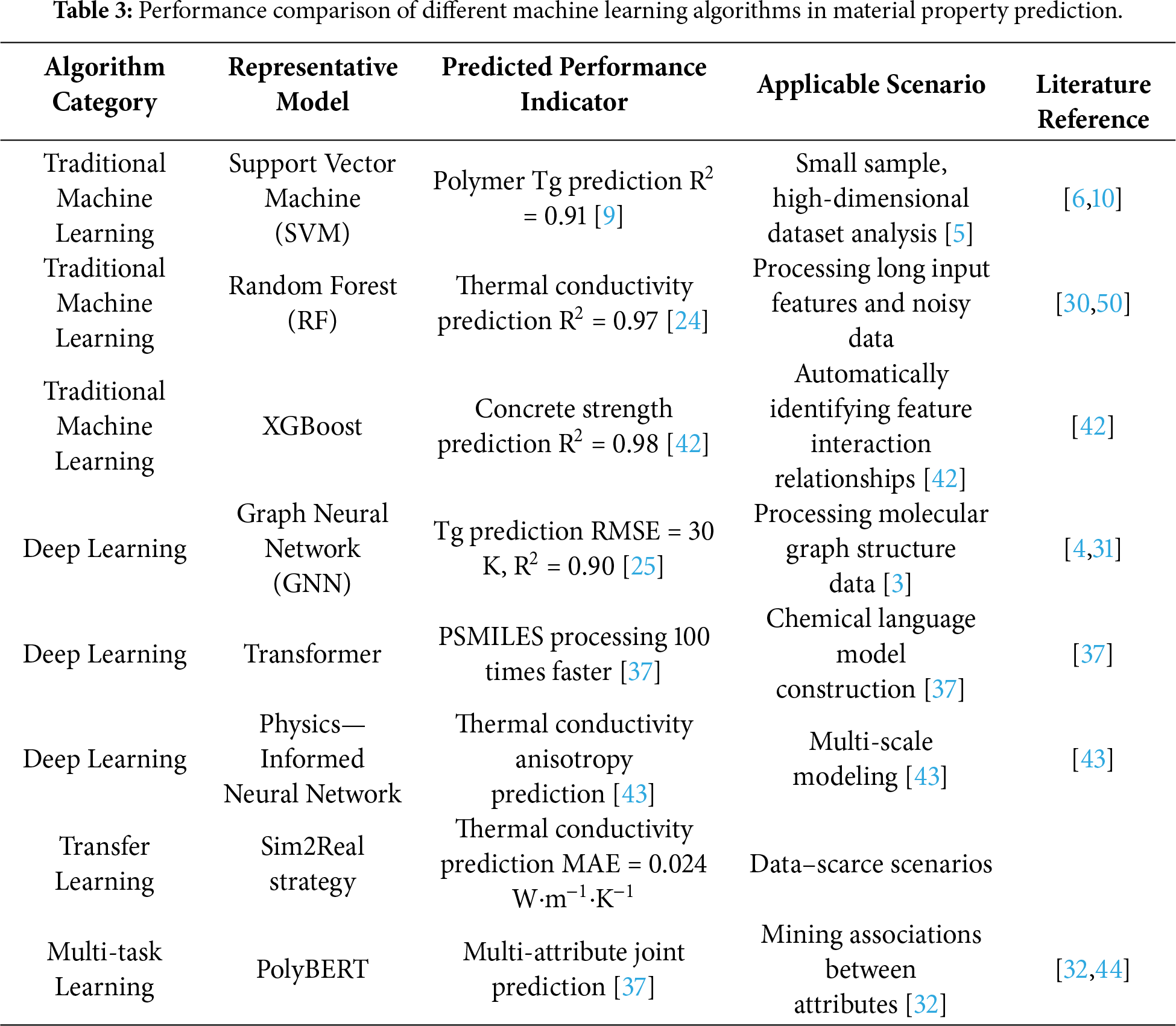
3.1 Traditional Machine Learning Methods
Traditional machine learning algorithms play a foundational role in polymer property prediction, relying on feature engineering to extract key structural information and establish mapping relationships with properties. These algorithms are characterized by clear principles, efficient computing, and strong adaptability to small-sample data, making them widely used in early polymer informatics research.
Support Vector Machine (SVM) excels in non-linear modeling and high-dimensional data analysis. By constructing an optimal hyperplane in the high-dimensional feature space, SVM realizes classification and regression tasks, with the Gaussian radial basis function (RBF) as the most commonly used kernel function for polymer property prediction [5]. In polymer glass transition temperature (Tg) and electrostrictive property prediction, SVM models achieve high prediction accuracy by optimizing kernel parameters (γ) and regularization parameters (C), balancing model complexity and generalization ability [5]. For transverse mechanical property prediction of Fiber-Reinforced Polymer (FRP) composites, SVM shows excellent cross-system generalization, adapting to different fiber types and manufacturing processes, with prediction accuracy significantly exceeding traditional theoretical analysis methods [40]. The algorithm’s structural risk minimization principle makes it particularly suitable for small-sample, high-dimensional polymer datasets.
Gradient Boosting Decision Tree (GBDT) excels at capturing complex correlations between multi-factor data through stepwise boosting. By iteratively optimizing weak learners and reducing prediction errors via residual correction, GBDT enhances model generalization, and has yielded prominent outcomes in polymer sequence regulation-reactivity ratio modeling [15]. Chen Mao’s research team constructed a copolymer structure prediction platform based on GBDT, establishing a quantitative correlation model between copolymer sequence distribution and monomer reactivity ratios in multi-component copolymerization. The algorithm can output precise reactivity ratio values using sparse experimental data and optimize monomer feeding strategies considering sequence uniformity, tapping into its strength in processing high-dimensional structured feature data [15]. In polymer thermal conductivity prediction, the RF model achieves a coefficient of determination (R2) of 0.97, comparable to the CatBoost model, and its feature importance ranking function can identify key structural descriptors affecting thermal conductivity [24].
Support Vector Regression (SVR) extends SVM to continuous value prediction. In polymer band gap prediction, Zhu et al. used SVR with Gaussian RBF kernel to achieve R2 = 0.91, outperforming traditional statistical methods such as partial least squares and multiple linear regression [9]. In electrostriction and Curie temperature prediction, SVR optimizes the trade-off between model complexity and training error, constructing reliable prediction models for complex polymer systems [41]. The algorithm’s strong generalization ability in small-sample scenarios makes it a core tool for polymer property regression tasks.
Extreme Gradient Boosting (XGBoost) enhances prediction accuracy through gradient boosting. In geopolymer concrete strength prediction, the XGBoost model achieves R2 = 0.98, significantly outperforming SVM (0.91) and MLP (0.88) [42]. The algorithm iteratively optimizes decision tree models to automatically capture complex interactions between polymer structural features and performance indicators, and is widely used in organic photovoltaic material efficiency prediction (Power Conversion Efficiency, PCE) [43]. XGBoost’s regularization mechanism (L1/L2) and missing value processing capabilities improve its robustness to noisy polymer data, making it suitable for multi-source data integration modeling.
Traditional machine learning algorithms also show unique advantages in polymer phase identification and self-assembly behavior prediction. SVM combined with polynomial kernel function successfully distinguishes different phases of two-dimensional spin models (ferromagnetic Ising model, etc.), learning mathematical expressions of physical discriminators (order parameters, Hamiltonian constraints) to understand polymer phase transition behavior [44]. RF realizes accurate classification of the new PISA (Polymerization-Induced Self-Assembly) system by analyzing key features such as monomer composition and polymerization conditions, demonstrating strong adaptability to complex polymer system classification tasks [35].
Deep learning algorithms drive revolutionary progress in polymer property prediction by enabling automatic feature learning and end-to-end modeling, addressing the limitations of traditional algorithms in handling complex structural data (molecular graphs, sequences). With their powerful non-linear fitting and high-dimensional data processing capabilities, deep learning models excel in capturing multi-scale structure-property relationships of polymers.
Graph Neural Networks (GNNs) specialize in processing molecular graph-structured data. As a representative of graph-based Message Passing Neural Network (MPNN) architecture, Chemprop realizes efficient modeling of small organic molecules and polymer repeating unit structures through a directed message passing mechanism [3]. Its improved version, wD-MPNN, enhances the modeling accuracy of polymer collective properties by optimizing message passing rules. The hybrid GCN-NN (Graph Convolutional Network + Neural Network Regression) model achieves Tg prediction with RMSE = 30 K and R2 = 0.9 [25], but shows relatively poor performance in elastic modulus (E) prediction, reflecting the sensitivity of GNN architecture to property-specific structural features. GNNs’ ability to directly model atomic-level interactions makes them ideal for polymer structure-property relationship mining.
Generative deep learning models enable polymer inverse design and structure generation. Variational Autoencoders (VAEs) integrate attribute estimation models into the latent space, realizing the innovative strategy of inferring molecular structures from performance targets [5]. Generative Adversarial Networks (GANs) generate copolymer structures with specific Young’s modulus by adversarial training between generator and discriminator, providing new tools for polymer structure design [31]. Notably, such generative paradigms have also been extended to biomimetic intelligent thermal management materials—where machine learning-driven discovery, combined with nature-inspired design, has yielded advanced materials for thermal regulation, further validating the versatility of generative models in functional polymer development. These generative models require large-scale training data to master chemical rules and SMILES syntax, and have achieved remarkable results in polymer antifouling material design—with the predicted and measured values showing R2 = 0.9869 [45]. Beyond polymer-specific tasks, machine learning approaches (e.g., for geopolymer concrete strength prediction) also demonstrate the transferability of data-driven modeling logic, where similar feature-learning and optimization principles support accurate property forecasting for related composite systems. The end-to-end learning mode of generative models overcomes the limitations of traditional descriptor-based methods in capturing complex polymer structures.
As shown in Fig. 5, Transformer architecture leads breakthroughs in polymer informatics. The polyBERT chemical language model, based on the DeBERTa architecture, converts PSMILES strings into numerical fingerprint representations through a multi-head self-attention mechanism, with a prediction speed two orders of magnitude faster than traditional manual design fingerprints [37]. The model deeply mines chemical patterns and sequence dependencies in PSMILES data, achieving efficient multi-property prediction. The MMPolymer framework adopts a multi-modal multi-task pre-training strategy, integrating CNNs (for spatial structure features) and RNNs (for sequence features), and fuses multi-source data through a multi-head attention mechanism to reveal deep correlations between polymer sequences and properties [46]. Transformers’ parallel computing capability and long-range dependency capture ability make them suitable for large-scale polymer data processing.
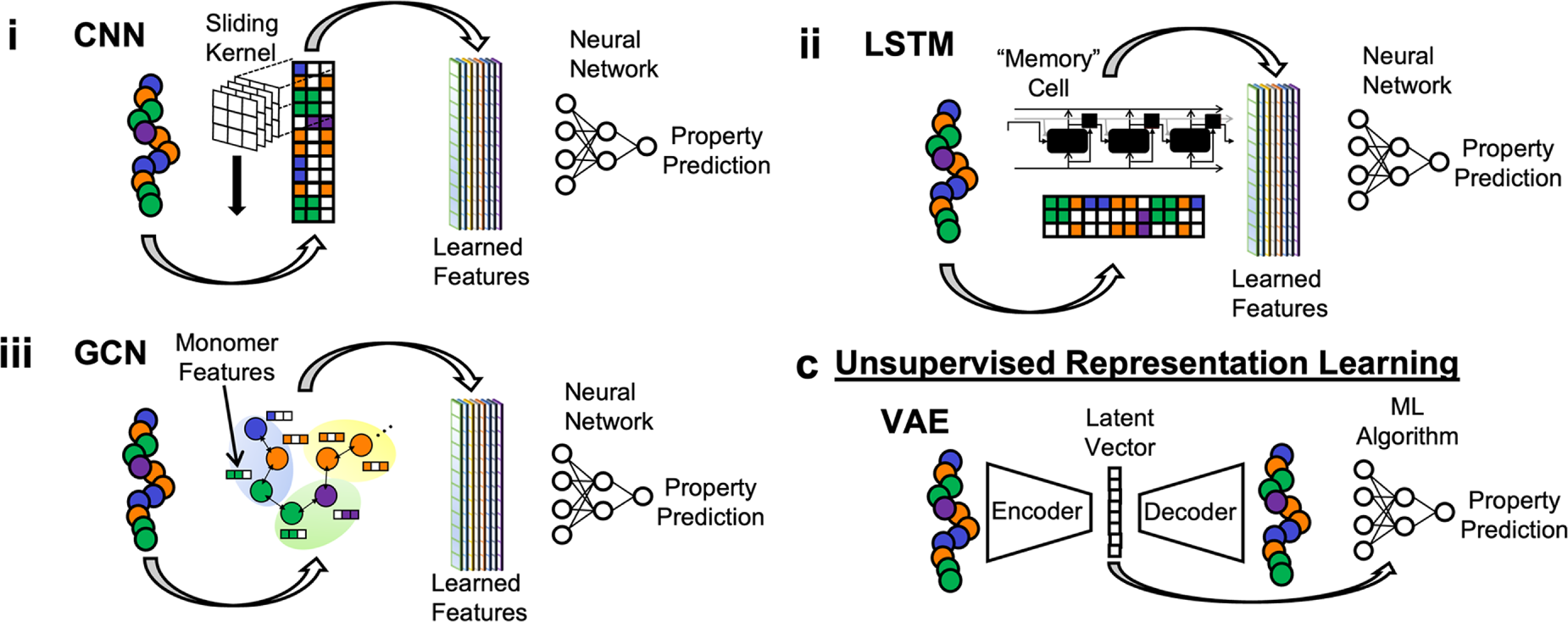
Figure 5: The figure shows a variety of machine learning methods in polymer materials. It shows a schematic diagram of the principles of CNN, LSTM, GCN, and VAE [5].
Recurrent Neural Networks (RNNs) and their variants excel in sequence data modeling. In processing text input data such as SMILES strings, RNNs and LSTMs (Long Short-Term Memory) effectively capture the sequence dependence of polymer chains, providing tools for understanding polymer structure-activity relationships [20]. Physics-Informed Neural Networks (PINNs) integrate physical laws into the neural network loss function, combining molecular dynamics simulation and experimental data to achieve breakthroughs in phase transition interface evolution and thermal conductivity anisotropy prediction [47]. PINNs enhance model interpretability and extrapolation ability by incorporating physical constraints, addressing the “black box” problem of traditional deep learning models and promoting multi-scale polymer modeling.
3.3 Transfer Learning and Multi-Task Learning
Transfer learning and multi-task learning address key challenges in polymer property prediction (data scarcity, multi-property correlation) through algorithmic innovation, expanding the application scope of machine learning in polymer science.
Transfer learning solves data scarcity via knowledge transfer. The Sim2Real strategy pre-trains models on large-scale simulation data to learn general polymer structure-property relationships, then fine-tunes with a small amount of experimental data to adapt to target tasks [18]. In polymer thermal conductivity prediction, the WU team constructed a pre-trained model using the PoLyInfo and QM9 databases, achieving MAE = 0.024 W·m−1·K−1 with only 28 experimental data points for fine-tuning—significantly outperforming models trained directly on small datasets [48]. In membrane electrode assembly research, transfer learning established a high-performance prediction model with only 12 samples, greatly reducing experimental costs [49]. Key technical points of transfer learning include domain adaptation (aligning data distributions between pre-training and target tasks) and transfer boundary control (avoiding negative transfer) [50]. For example, the Mossa team adjusted the 3D convolutional neural network architecture when transferring the surfactant classification model to the Nafion system, improving model adaptability to multi-scale disordered polymer materials [51].
Multi-task learning enhances model performance by mining inter-property correlations. By training multiple related property prediction tasks simultaneously, multi-task learning enables feature sharing between tasks, improving model generalization and prediction accuracy. The Ramprasad team found that joint training of glass transition temperature, melting temperature, and degradation temperature enables the neural network to capture intrinsic attribute correlations, enhancing prediction performance for each individual task [32]. The polyBERT chemical language model adopts a multi-task framework, mapping molecular fingerprints to multiple polymer properties and constructing an end-to-end informatics pipeline two orders of magnitude faster than traditional methods [37]. Research shows that encoding target attributes into feature inputs (e.g., one-hot vectors) is more effective than separate prediction, as it leverages inter-property physical correlations [49]. The effectiveness of multi-task learning depends on task relevance—tasks with physical correlations (e.g., different temperature-related properties) achieve better feature sharing [52].
The integration of transfer and multi-task learning further optimizes algorithm performance. The TransPolymer framework pre-trains on a large amount of unlabeled polymer data through Masked Language Modeling (MLM), laying a foundation for multi-task property prediction [50]. The MMPolymer model integrates 1D sequence and 3D structure data, adopts a multi-modal multi-task pre-training strategy, and aligns cross-modal features through contrastive learning to enhance model generalization [46]. The Yoshida team combined transfer learning and Bayesian optimization to establish a quantitative relationship between polymer structure and thermal conductivity, overcoming data volume limitations [52]. These hybrid algorithmic strategies provide systematic solutions for complex polymer property prediction tasks.
4 New Ideas for Data-Driven Polymer Material Design by Machine Learning
The introduction of current machine learning technology enables researchers to deeply analyze the complex correlation mechanism between polymer structures and properties, which has brought a revolutionary breakthrough to the traditional material R & D model. The field of materials science is experiencing a paradigm change driven by data, especially in the design of polymer materials. Compared with the trial-and-error method that relies on experience accumulation, modern data-driven methods establish a machine learning model with predictive functions by integrating multi-scale modeling data, high-throughput experimental data, and increasingly improved material databases. This innovative method shows significant advantages in practice: it not only greatly shortens the time cycle and funding investment for new material R & D but also, more importantly, reveals the in-depth structure—property relationship that is difficult to capture by traditional research methods. As shown in Table 3, the three types of methods, reverse design, high-throughput screening, and multi-objective optimization, show complementary value in solving the structure—property relationship problem in material genome engineering. They systematically compare the core technical methods, typical application cases, advantages, and disadvantages of the three intelligent design strategies for polymer materials, providing methodological guidance for the directional development of new functional polymers. It is worth noting that the application scope of this method has expanded from the optimization of a single performance index to more challenging research fields such as multi-objective collaborative design, providing strong technical support for the directional development of functional polymer materials (as shown in Table 4).
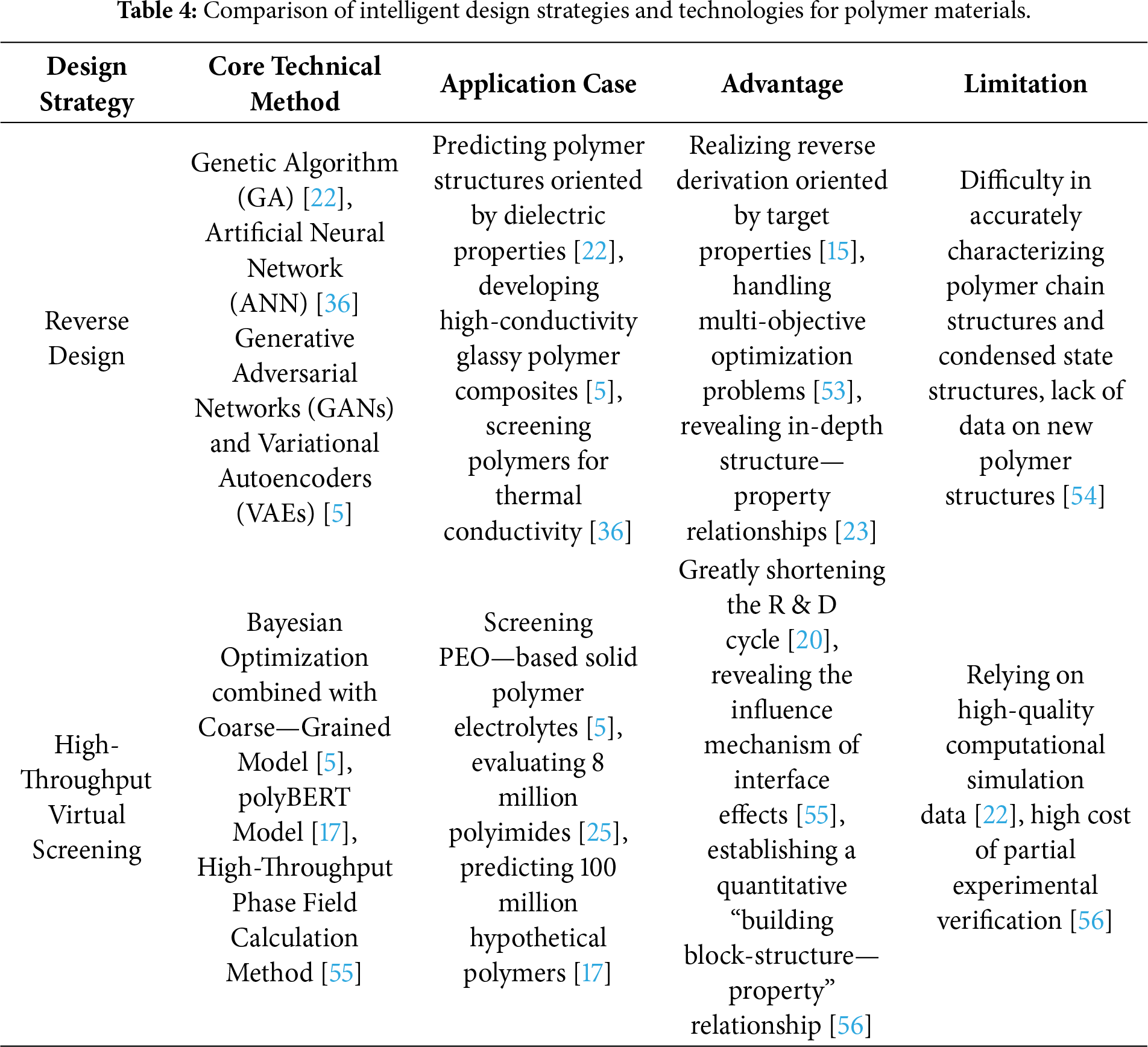
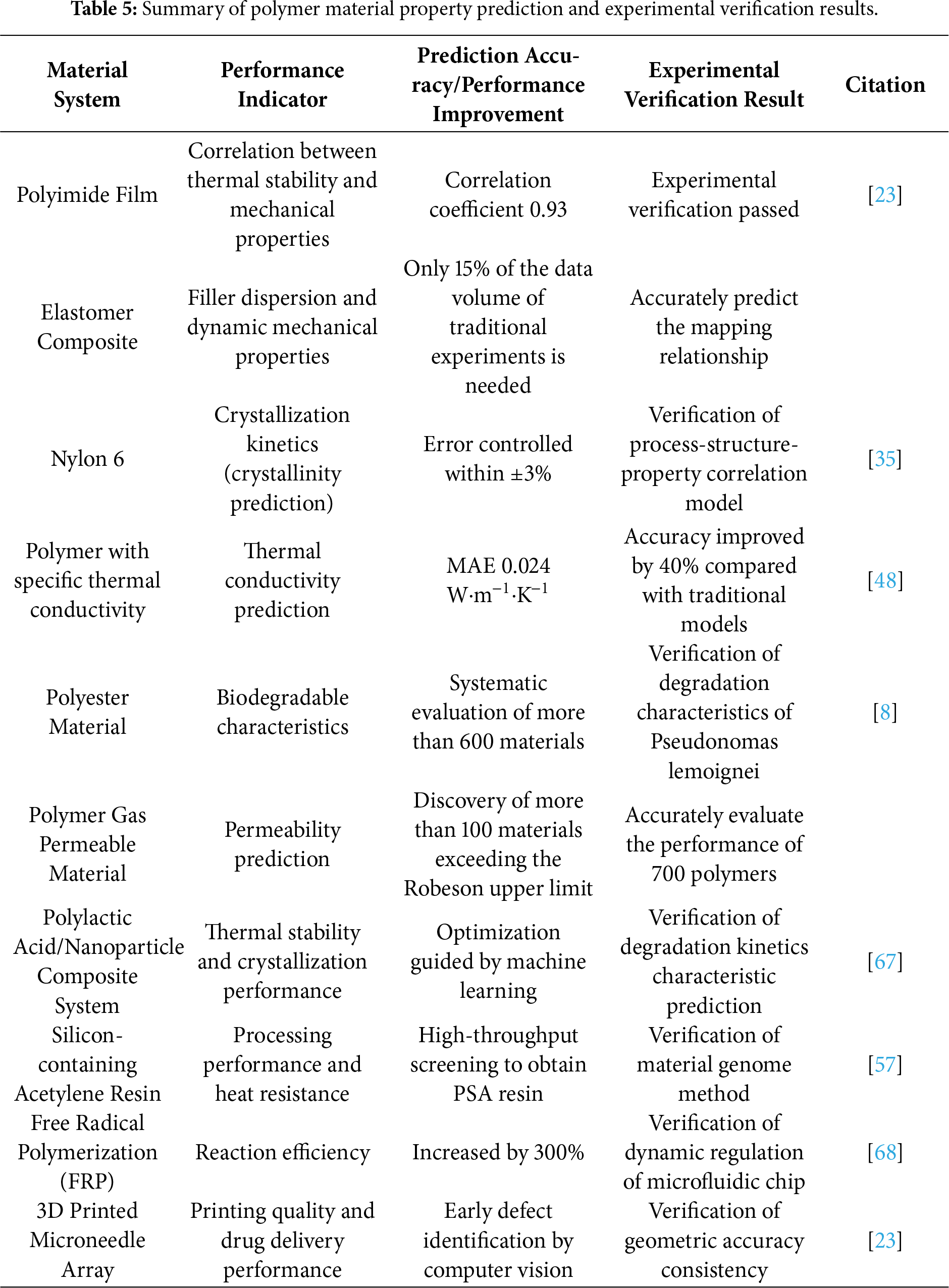
The reverse design strategy in the field of polymer material design is oriented by target properties and reversely infers the molecular structure that meets specific needs. Compared with the traditional forward design method, this strategy has outstanding performance in improving the efficiency of material R & D, and is especially good at handling multi-objective optimization problems. The machine learning—assisted polymerization inverse analysis platform, as a typical application, can infer the polymerization conditions in reverse according to the target molecular weight and molecular weight distribution, and is applicable to a variety of reactant structures including monomers and initiators [7]. As shown in Fig. 6, By establishing a quantitative relationship model between polymerization reaction conditions and experimental results, this method realizes the accurate mapping between the high-dimensional structure space and the experimental parameter space, providing a scientific basis for controlled synthesis.
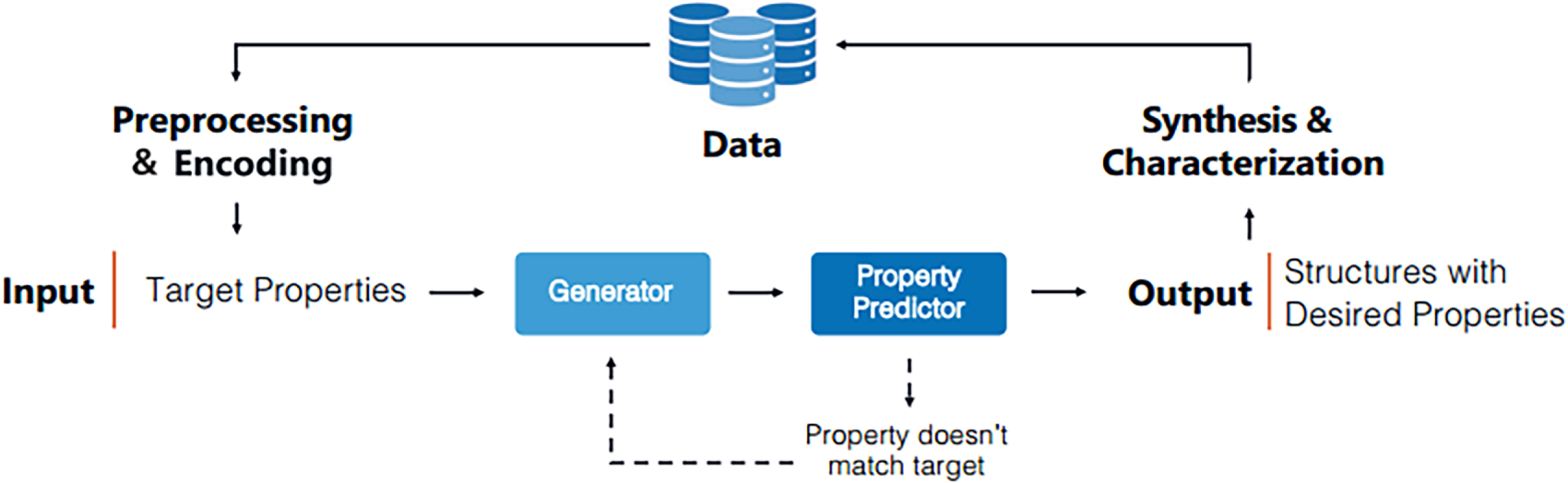
Figure 6: A general machine learning workflow for the inverse design of polymers begins by generating candidate structures (e.g., via a generator model). These structures are then fed into a property predictor. The algorithm iteratively refines the candidates by comparing the predicted properties with the targets until an optimal polymer structure is identified [20].
Black-box optimization algorithms such as Genetic Algorithm (GA) and Bayesian Optimization are key technologies for implementing reverse design. The Ramprasad research team successfully simulated and generated more than 200 kinds of polymers by linearly combining 7 kinds of polymer segments, and accurately predicted the polymer structure oriented by dielectric properties using the Genetic Algorithm [22]. Scholars such as Mannodi-Kanakkithodi combined machine learning prediction with Genetic Algorithm to develop new polymers with specific functions [53]. These research results confirm the effectiveness of the reverse design strategy in exploring the chemical structure space and reaction condition space, and can accurately recommend polymer structures and synthesis parameters that meet the target properties. The systematic polymer synthesis platform (SPP) developed by the PolyMao team further verifies the practicality of this method. Its machine learning—based inverse synthesis analysis technology can infer the synthesis instructions in reverse from the target molecular weight results [54].
The HELAO framework’s modular autonomous feedback-loop strategy enables reverse design in materials science by integrating automated synthesis, high-throughput characterization, and data-driven models to link structures with target properties, using real-time feedback and optimization (e.g., active learning) to refine the design space. It has supported narrowing optimal parameters from large candidate pools for functional materials, addressing “structure-property” complexity.
The application of deep learning technology in reverse design is becoming increasingly widespread, among which Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) have shown particularly outstanding performance. These models can learn the latent representation space of polymer materials and generate new candidate structures through interpolation or perturbation. A research team combined GANs and VAEs with Gaussian Process (GP) regression to successfully develop high-conductivity glassy polymer composites. The TransPolymer model developed by the Farimani team is based on the Transformer architecture and can parse the sequence structure and topological structure information implied in polymer SMILES strings, providing an innovative tool for the inverse design of high-performance polymer materials [5]. These deep learning methods adopt an end-to-end learning mode, which effectively overcomes the limitation that traditional descriptor methods are difficult to capture the complex structural features of polymers.
As shown in Fig. 7, although the reverse design strategy has made important breakthroughs, there are still many technical bottlenecks in practical applications. The complexity of polymer chain structures and condensed state structures makes it difficult to accurately characterize statistical parameters such as molecular weight distribution, sequence structure, and topological structure. In addition, the open access restrictions of existing polymer databases and the lack of data on new polymer structures also bring challenges to the construction of initial datasets for reverse design [55]. Future research needs to focus on the development of multi-objective collaborative optimization algorithms for materials and deepen the cross-integration of machine learning technology and polymer materials to meet the inverse design needs of complex systems such as ladder and cross-linked polymers [23].
Figure 7: (I) The SPP platform operates through a streamlined workflow: first, an ML model is built to correlate synthesis conditions with results (a–c); this model is then used in reverse to pinpoint the optimal conditions needed to achieve target polymer properties (c–e). (II) In practice, for PET-RAFT polymerization, the platform analyzes a dataset of substrate structures and molecular weights to provide specific instructions on feed ratio, light source, and reaction time. (III) The platform’s performance was validated by comparing multiple ML algorithms (Ridge, SVM, kNN, XGB, Neural Network, Random Forest), with their predictive accuracy assessed via RMSE and R2 metrics [37].
4.2 High-Throughput Virtual Screening
Machine learning—driven high-throughput virtual screening technology is reshaping the paradigm of polymer material R & D. By integrating computational simulation and data-driven methods, this technology has brought a revolutionary improvement in efficiency to material discovery. Its core lies in using first—principles calculations or molecular dynamics simulations to obtain the dynamic and thermodynamic properties of polymer three-dimensional structures, and converting complex molecular information into computable digital representations. This digital processing method provides a rich data foundation for the construction of machine learning models [22]. Taking PEO—based solid polymer electrolytes (SPEs) as an example, the research team innovatively adopted a strategy combining Bayesian optimization and coarse—grained models to successfully identify a material system with excellent lithium ion conductivity [5]. More notably, by establishing a quantitative relationship model between monomer structure and hygroscopicity, critical low thermal expansion rate, and tensile modulus, researchers can not only quickly screen target structures but also reveal the key structural features affecting performance through data mining [2].
High-throughput experimental technologies that complement virtual screening show a diversified development trend. From continuous flow systems to microreactor arrays, these parallel experimental platforms can efficiently generate verification data. When these experimental data are combined with active learning algorithms or Bayesian optimization frameworks, the predictive ability of the model can be significantly improved [20]. In the field of organic optoelectronic materials, high-throughput virtual screening shows unique advantages. Yang’s research team accurately located 10 new polymers with excellent mechanical properties by systematically evaluating 8 million hypothetical polyimides, and their prediction results were fully verified by molecular dynamics simulations [25]. A similar technical route has also made breakthrough progress in the research on CO2 separation performance of mixed matrix membranes (MOF-Polymers65). By systematically regulating the composition and structure parameters of polymers and MOFs, researchers have successfully designed new separation materials with high selectivity and adsorption capacity [56].
The latest progress in chemoinformatics has opened up a new way for high-throughput screening. The polyBERT model developed by the Kuenneth team has realized the multi-attribute prediction of 100 million hypothetical polymers. This deep learning method based on SMILES strings has greatly expanded the exploration range of polymer space [37]. By establishing a non-linear mapping relationship between molecular fingerprints and performance parameters, this model shows excellent accuracy in predicting the thermal conductivity of materials in the PLyInfo and PI1M databases. It is particularly worth noting that through high-precision molecular dynamics verification, the research team confirmed 107 high-performance materials with thermal conductivity exceeding 20 W·m−1·K−1 [4]. In the field of high-temperature resistant resins, researchers have established a dual—model evaluation system, which effectively solves the problem of collaborative optimization of processing performance and heat resistance of virtual polymer resins and provides a new idea for the rapid development of silicon—containing aryl acetylene resins [57].
The introduction of the material genome concept marks that high-throughput screening technology has entered a stage of systematic development. The polymer material genome platform constructed by the team of Professor Lin Jiaping from East China University of Science and Technology integrates the performance data of more than 30,000 kinds of polymers. By establishing a quantitative structure—activity relationship of “building blocks-structure-properties”, it realizes the intelligentization of material design [58]. In the research of dielectric composites, the innovative combination of high-throughput phase field calculation method and data-driven strategy establishes a prediction model of dielectric properties by introducing interface phase parameters. This multi-scale calculation method not only reveals the influence mechanism of interface effects on energy density but also provides theoretical guidance for the interface engineering design of nanocomposites [59].
4.3 Multi-Objective Optimization Design
The design of polymer materials usually involves the collaborative optimization of multiple performance indicators, and there are often complex mutually restrictive relationships between these indicators. The multi-objective optimization method provides a systematic way to solve this problem, and its key lies in identifying the Pareto optimal solution set—a set of solutions that cannot be further improved in all objective functions. Taking the design of polymer hybrid electrolytes as an example, the Ganesan research team used the weighting method to balance ion transport performance and mechanical properties. By systematically comparing the experimental results under different weight conditions, the optimal material formula was finally obtained [9]. Although this method is easy to operate, the determination of weight coefficients often depends on the subjective judgment of researchers, making it difficult to accurately reflect the intrinsic relationship between various performance indicators. In contrast, multi-objective genetic algorithms can directly explore the Pareto frontier. For example, the NSGA-II algorithm successfully achieved the dual goals of maximizing the number—average molecular weight and minimizing the polydispersity index in the optimization of epoxy resin polymerization process by introducing a fast non-dominated sorting and elite retention strategy [23].
The multi-objective Bayesian optimization technology developed in recent years has opened up a new path for polymer material design. The Wang research team innovatively improved the traditional single-objective acquisition function, proposed the EI matrix method, and successfully applied it to the design of the coarse—grained force field of polycaprolactone, optimizing two key performance indicators, elastic modulus and water diffusion coefficient, at the same time [1]. This method adopts an active learning strategy, which comprehensively considers the accuracy and uncertainty of prediction results in each iteration process, and realizes the dynamic balance between exploring new regions and utilizing known information. In the field of polymer nanoparticle synthesis, researchers have also developed a variety of advanced algorithms such as TS-EMO, RBFNN/RVEA, and EA-MOPSO for the systematic optimization of important parameters such as molecular weight distribution, particle size, and polydispersity index [60]. These methods not only significantly improve the optimization efficiency but also help researchers deeply understand the intrinsic correlation mechanism between different performance indicators by intuitively displaying the Pareto frontier.
The design of organic optoelectronic materials is a typical application scenario of multi-objective optimization technology. Researchers need to accurately regulate multiple structural parameters such as the ratio of electron donor to acceptor groups, material hydrophilicity and hydrophobicity, and conjugation length to achieve the best photoelectric conversion performance [45]. In the development of proton exchange membrane materials, the team of Li Yunqi from the Changchun Institute of Applied Chemistry, Chinese Academy of Sciences, established a prediction model including four targets: proton conductivity, methanol permeability, tensile modulus, and thermal stability. Through a multi-objective ranking algorithm, it successfully guided the molecular design of new hydrocarbon—based sulfonated copolymers [23]. These research results fully prove that the multi-objective optimization method can break through the limitations of traditional single-objective optimization and provide strong theoretical guidance and technical support for the development of polymer materials with comprehensive performance advantages.
The introduction of deep learning technology has brought new development opportunities for multi-objective optimization. The multi-task deep neural network model developed by the Ramprasad research team can accurately predict the glass transition temperature, melting temperature, and degradation temperature of copolymers at the same time, showing excellent prediction accuracy and generalization ability. The polyBERT model trained by Kuenneth et al. based on 100 million polymer SMILES strings has realized the efficient correlation between molecular structure features and multiple performance parameters, laying a solid technical foundation for large-scale multi-objective optimization research [22]. The breakthroughs of these cutting—edge technologies enable researchers to explore combination schemes with more excellent performance in a broader material design space and promote the development of polymer materials towards multi-functionalization and intelligentization.
5 Machine Learning Performance Validation and Evaluation Methods
As shown in Fig. 8, the practical value of machine learning models in polymer materials research must be confirmed through rigorous performance validation and scientific evaluation systems. This process not only objectively reflects the model’s predictive ability for unknown data but also identifies model shortcomings and guides iterative optimization, serving as a key link connecting theoretical modeling and practical applications. Focusing on the three cores of “validation methods—evaluation indicators—optimization strategies”, this section systematically elaborates on the performance validation logic, scientific evaluation standards, and efficient optimization paths of machine learning models in the field of polymer materials, providing methodological support for model reliability.
Figure 8: Closed-loop framework for ML-driven polymer research. The cycle integrates prediction, experimental verification, and model optimization to iteratively improve design outcomes.
5.1 Experimental Verification Methods
Experimental validation is the core means to test the credibility of model predictions. It requires designing targeted experiments, comparing the deviations between predicted values and measured values, and verifying the model’s applicability in real scenarios. Its core goal is to avoid models being “theoretical only” and ensure that prediction results have experimental repeatability and engineering practicality.
The reliability of the prediction results of machine learning models highly depends on rigorous experimental verification, which is particularly important in the research of polymer materials. The chemoinformatics—driven ML model developed by the Bradford team successfully predicted the ionic conductivity of SPEs, and its effectiveness was fully confirmed by experimental data [5]. Experimental verification usually adopts an iterative optimization strategy, and dynamically adjusts model parameters by analyzing the differences between predicted attributes and measured attributes. Taking the adaptive machine learning framework as an example, the Support Vector Regression (SVR) model combined with the Efficient Global Optimization (EGO) method can intelligently recommend the most potential candidate materials for experimental verification [41]. This closed-loop verification mechanism significantly improves the R & D efficiency. For example, in the development of additive manufacturing materials, only 120 samples need to be tested in parallel to complete 30 rounds of algorithm optimization [61].
The modern experimental verification system integrates a variety of advanced technical means. High-throughput experimental platforms have become important carriers for verifying ML predictions. The Ada automated laboratory developed by the MacLeod team realizes the fully autonomous operation from material design to characterization and optimizes the experimental scheme through continuous learning [8]. In the research of mixed matrix membranes, researchers verified the prediction accuracy of computational screening and machine learning models by systematically preparing MOF-Polymers samples with different ratios and testing their CO2 separation performance [56].
The data division strategy is crucial for model verification. In the research of polymer property prediction, two strategies of polymer type division and data point division are adopted, and five-fold cross—validation is used to effectively prevent overfitting. For small sample scenarios, ten-fold cross-validation shows good results. In the research of solution polymerized styrene—butadiene rubber performance prediction, a reliable prediction model was finally established through the segmentation verification of category—balanced datasets [62]. During the verification process, it is also necessary to quantitatively analyze the impact of uncertain factors such as measurement noise on the prediction performance [25].
In the machine learning-driven polymer design framework, experimental verification plays a dual role: it not only tests the algorithm’s predictive ability for unknown data but also provides new data for algorithm improvement [33]. The Kang Peng team synthesized eight new PI structures and conducted molecular dynamics simulations, confirming that the prediction error was controlled within 15%. Scientific experimental design is the key to ensuring the reliability of verification, such as using Latin Hypercube Sampling (LHS) for preliminary screening and then conducting iterative experiments based on the algorithm output [60]. This closed-loop verification mechanism can operate continuously until the preset standard is met or manual termination, ensuring the systematicness and completeness of the verification process.
5.2 Model Performance Evaluation
In the machine learning research of polymer materials, reliable model performance evaluation is crucial to the credibility of prediction results. For different prediction tasks and data characteristics, appropriate evaluation indicators need to be selected. For regression problems, indicators such as Root Mean Square Error (RMSE), Coefficient of Determination (R2), and Mean Absolute Error (MAE) are usually used. Taking the prediction of glass transition temperature as an example, the CNN model based on repeating units performed well on Data set_1, with R2 of the training set and test set reaching 0.84 and 0.82, respectively, while it was 0.65 on Data set_2 [24]. For classification tasks, indicators such as accuracy, precision, and recall are more concerned. For example, in the ferromagnetic Ising model, the SVM using the quadratic polynomial kernel function has a test set accuracy close to 100% for phase classification [44]. These indicators can not only measure the fitting effect of the model on known data but also effectively evaluate its generalization performance in processing unknown data.
The selection of evaluation methods has a decisive impact on the objectivity of performance determination. Although traditional Cross-Validation (CV) is widely used, it has certain limitations in the field of material discovery. The latest research shows that LOCO CV (Leave–One–Cluster–Out Cross–Validation) based on cluster segmentation can more accurately evaluate the extrapolation ability of the model between different material groups [52]. For datasets with a small sample size, ten-fold cross-validation shows good results. For example, in the research of solution polymerized styrene—butadiene rubber performance prediction, the Q2 of the model established through the segmentation verification of category—balanced data is as high as 0.9375 [45]. Facing the problem of data distribution deviation, the bootstrap method is a feasible solution, but attention should be paid to the estimation error that may be introduced by this method [5]. In addition, during the evaluation process, it is also necessary to consider uncertain factors such as measurement noise, and model the parameter uncertainty through multivariate probability density distribution to provide a probabilistic basis for molecular design decisions [63].
Combining model interpretation technology can deeply understand the feature contribution. Tools such as SHAP (SHapley Additive exPlanations) and PDP (Partial Dependence Plot) can reveal the key structure—property relationships. For example, the number of rotatable bonds and the minimum local charge have been proved to be the main factors affecting the Tg of polyimides. In the prediction of polymer conductivity, the feature importance analysis of the CatBoost model shows that the number of rotatable bonds, the number of hydrogen bond donors/acceptors, and the number of heavy atoms have a significant impact on the tensile strength [24]. This interpretability analysis not only verifies the reliability of the model but also provides directional guidance for material design. When the XGBoost algorithm predicts the performance of polymer composites, it decodes the decision mechanism through SHAP causal analysis, achieving a prediction accuracy of up to R2 = 0.95 [11].
A horizontal comparison of the performance of different models is an effective method to evaluate the advanced nature of the technology. The test results of TransPolymer on ten polymer performance prediction benchmarks show that it reduces the test RMSE by an average of 7.70% and increases R2 by 0.11, which is significantly better than the traditional ECFP method [50]. The polyBERT chemical language model achieves an R2 of 0.80 in 29 performance predictions, and its calculation speed is two orders of magnitude faster than that of manually designed fingerprints [37]. It is worth noting that the data division strategy will affect the evaluation results. The division of polymer types and data points will produce different effects. The former can better test the cross—material generalization ability of the model, while the latter focuses on the adaptability of data distribution [62]. In addition, computational efficiency is also an important consideration in performance evaluation [63]. The GC-GNN model maintains the prediction accuracy, but its transferability varies with the polymer structure, which reflects the limitation of the ideal Gaussian chain assumption [64].
5.3 Model Optimization Strategies
The key to machine learning research on polymer materials is to improve the prediction performance through model optimization. Bayesian Optimization (BO), as an efficient global optimization method, uses Gaussian process regression to estimate the performance distribution of untested formulations and selects the optimal candidate samples from them for verification [5]. Compared with random search, this method shows stronger exploration ability in the screening of amino acid random copolymers and successfully identifies copolymer structures with higher enzyme—like activity [22]. Genetic Algorithm simulates the natural selection mechanism and generates a new generation of candidate samples through “hybridization” and “mutation” operations, which has unique advantages in the optimization of polymer nanoparticle synthesis [60].
Hyperparameter tuning has a decisive impact on the prediction performance of the model. Grid search combined with five-fold cross-validation can systematically optimize key parameters such as GCN layer depth, width, learning rate, and L2 regularization weight [25]. In the research of predicting the conductivity of ionic polymers, GridSearchCV with fixed random state ensures the reproducibility of experiments and provides a reliable basis for the design of lithium-ion battery electrolytes [24]. In the optimization of large language models, the Hyperband method comprehensively tunes the neural network hyperparameters, and parameter–efficient fine–tuning technologies such as LoRA (Low—Rank Adaptation) significantly improve the performance of polymer property prediction [65]. In the SVM model, the reasonable setting of the regularization parameter γ can obtain a test set accuracy close to the optimal, while maintaining the physical correlation of the decision function [44].
The problem of data scarcity can be effectively solved through transfer learning and multi-task learning. The two-stage training strategy first uses physically modeled synthetic data for supervised pre-training to enable the model to master the basic physical properties of polymers; then, a small amount of real experimental data (45 samples) is used for fine-tuning, which significantly improves the prediction accuracy [12]. The polyBERT model realizes the accurate prediction of 29 polymer attributes through five-fold cross-validation and meta-learner integration [37]. The MMPolymer framework adopts a multi-modal multi-task pre-training paradigm, aligns the features of different modalities through contrastive learning, combines the multi-head attention mechanism for feature fusion, and enhances the modal aggregation effect through the dynamic weighted pooling layer, achieving the optimal performance in a number of polymer property prediction tasks [46].
Feature engineering and model structure adjustment are important dimensions of optimization strategies. The LASSO method combined with Recursive Feature Elimination (RFE) can effectively reduce the dimension and significantly improve the model efficiency [62]. In the prediction of polymer dielectric constant, the Maximum Relevance Minimum Redundancy (mRMR) method evaluates and ranks all descriptors to screen the optimal feature subset [9]. G-BigSMILES extends the expression ability of traditional BigSMILES, including key information such as molecular weight and molecular weight distribution, providing more abundant input features for the model [8]. In terms of model structure adjustment, the cosine annealing strategy for dynamically adjusting the learning rate performs well in polymer property prediction. Setting the peak learning rate to 5E6, the model can converge after 100 training rounds [39].
At present, the field of polymer material research has achieved a leapfrog development of machine learning technology from theory to engineering practice. Taking the Material Genome Initiative as an example, researchers have successfully predicted the correlation law between the thermal stability and mechanical properties of polyimide films by integrating high-throughput computing and deep learning algorithms, and the correlation coefficient verified by experiments has reached 0.93. In the development of elastomer composites, the Random Forest model can accurately predict the mapping relationship between filler dispersion and dynamic mechanical properties with only 15% of the data volume of traditional experiments. More notably, the cross-scale modeling method based on transfer learning has shown unique advantages in the research of nylon 6 crystallization kinetics, and the process-structure-property correlation model established by it controls the crystallization degree prediction error within ±3%. These research cases systematically summarize the typical applications of machine learning methods in the field of polymer material property prediction, covering the prediction accuracy improvement effects and experimental verification results of key performance indicators such as thermal stability, mechanical properties, and crystallization kinetics [66]. These breakthroughs not only confirm the reliability of machine learning in the multi-parameter optimization of polymers but also reveal the great potential of data-driven methods in solving complex non-linear problems in materials science, providing empirical evidence for the effectiveness of the material genome method in polymer design (as shown in Table 5).
6.1 High-Performance Polymer Design
Machine learning technology is profoundly changing the R & D paradigm of high-performance polymers. The inverse design method realizes the accurate prediction of the structure of polymers with specific thermal conductivity by establishing the performance-structure mapping relationship [23]. The prediction model constructed by WU et al. by combining transfer learning and Bayesian molecular design algorithm has outstanding performance, with an MAE of only 0.024 W·m−1·K−1, which is 40% more accurate than the traditional small-sample training model [48]. In the field of aerospace materials, the machine learning model trained based on multi-features such as molecular weight, chain structure, and cross-linking density has successfully guided the development of new polymer systems with both excellent mechanical strength and thermal stability.
The integration of Generative Adversarial Networks (GANs) with coarse-grained molecular dynamics (CGMD) has enabled breakthroughs in material design. For instance, researchers have utilized GANs to generate copolymer structures with targeted Young’s modulus, followed by efficient screening via CGMD simulations [5]. Beyond generative models, the TransPolymer model, developed by the Farimani team and based on the Transformer architecture, demonstrates excellent performance in property prediction by effectively capturing polymer sequence and topological features [22]. These data-driven approaches are proving highly effective in application-oriented research. In the field of dielectric materials, for example, machine learning models have accurately predicted the frequency-dependent dielectric behavior of 11,000 unknown polymers, successfully identifying five candidate materials for capacitors and microelectronics applications [62].
The collaborative optimization of Genetic Algorithm and machine learning has greatly improved the efficiency of material development. A study designed 132 new polymers through 100 generations of evolutionary iterations, six of which showed ideal characteristics [66]. The prediction model constructed by Barnett et al. not only accurately evaluated the gas permeability of 700 polymers but also discovered more than 100 excellent materials that exceed the Robeson upper limit. In the design of polyimides, Afzal’s team used 29 building blocks to efficiently screen 10,000 candidates from 660 million compounds, and finally obtained the target material with ultra-high refractive index [67].
Autonomous optimization systems have promoted the design of polymer blending systems to enter a new stage. The integrated robot platform, through high-throughput experiments combined with evolutionary algorithms, discovered random heteropolymer blends with performance exceeding that of single components and revealed the regulatory mechanism of molecular fragment interaction on protein thermal stability [68]. Research in the field of thermosetting resins shows that the material genome method combined with machine learning can efficiently design silicon-containing acetylene resins, and high-throughput screening can obtain PSA resins with both excellent processing performance and heat resistance [57]. South Korean scholars innovatively introduced product grade features to construct an XGBoost model, which significantly improved the prediction accuracy of key performance indicators of polymer composites and provided a reliable tool for industrial applications [11].
6.2 Optimization of Biodegradable Materials
Machine learning provides a new technical path for the research and development of biodegradable materials, and shows unique advantages especially in performance prediction and structural design. The deep neural network model developed by Bakar’s team realizes the accurate prediction of the density characteristics of degradable plastics through principal component analysis and a “coarse-to-fine” optimization strategy. This type of model has excellent non-linear fitting ability and can effectively capture the complex relationship between material structure and performance, showing good stability in the prediction of mechanical properties and degradation behavior. However, it is worth noting that neural networks are more sensitive to data scale. The prediction accuracy will decrease significantly under small sample conditions, and the model interpretability has inherent limitations [49]. In contrast, Support Vector Machines have more advantages in small sample scenarios. The Fransen research group successfully synthesized more than 600 kinds of polyester materials through high-throughput experimental technology combined with machine learning methods, and systematically evaluated their degradation characteristics on Pseudonomas lemoignei [8]. This method constructs a model based on statistical learning theory, which reduces the dependence on large-scale data sets but faces the challenge of computational efficiency when processing massive data.
The inverse design of biodegradable materials is benefiting from the breakthrough of machine learning technology. Researchers have adopted a large-scale screening strategy to generate candidate materials in the design space, and then used the trained prediction model to evaluate their degradation characteristics and mechanical properties [23]. This method has achieved significant results in the optimization combination of natural fibers and bio-based resins. For example, the composite materials of flax, hemp fibers and polylactic acid or polyhydroxyalkanoate recommended by the model have been verified by experiments to show excellent mechanical strength and controllable degradation characteristics under various environmental conditions [48]. Mathematical optimization methods transform material design into a problem of solving objective functions under constraints, and find the optimal solution through deterministic or random algorithms, which effectively alleviates the restriction of combinatorial complexity on design efficiency [23]. The application of transfer learning technology provides a solution to the problem of data scarcity. Studies have shown that pre-trained models have good adaptability in new material systems. For example, Mossa’s team successfully applied the convolutional neural network trained on the surfactant system to the perfluorosulfonic acid resin system [20].
At present, the research and development of biodegradable materials still faces key challenges such as accurate regulation of degradation time and optimization of biocompatibility. Through analyzing the correlation between chemical structure and degradation behavior, machine learning can predict the degradation kinetics characteristics under different environmental conditions [36]. In the research of polylactic acid (PLA)/BiFeO3 (BFO) nanoparticle composite system, BFO was evenly coated on the 3D printed PLA substrate by a simple dip-coating method. The composite system showed excellent piezoelectric photocatalytic degradation performance for Congo Red (CR) and Methylene Blue (MB) (the degradation rates reached 98.9% and 74.3%, respectively within 90 min). Moreover, with the help of regression models constructed by machine learning models such as Catboost and XGBoost (the R2 values of photocatalysis, piezoelectric catalysis and piezoelectric photocatalysis predictions are 0.93, 0.99 and 0.99, respectively), the application optimization of BFO catalyst was effectively guided, providing a powerful solution for wastewater purification [69]. However, it should be pointed out that the long test cycle of biodegradable materials and the non-uniform experimental standards restrict the construction of high-quality data sets [55]. Future research should focus on the development of multi-scale characterization methods and standardized test schemes to lay a more solid data foundation for the application of machine learning. By integrating automated experimental platforms and high-throughput computing technologies, it is expected to establish a more complete database of biodegradable materials and promote the in-depth development of data-driven design methods in this field [70,71].
6.3 Machine Learning Aiding Polymer Material Manufacturing
The field of polymer material manufacturing is experiencing profound changes brought about by machine learning technology, which is rapidly penetrating from laboratory research to industrial practice. The team of Nara Institute of Science and Technology in Japan has made a breakthrough in the research of styrene-methyl methacrylate copolymer system. The flow synthesis method they developed combined with machine learning modeling has significantly improved the mixing effect and heating efficiency [71]. This innovative method not only reduces the time and cost of traditional experiments but also, more importantly, establishes an accurate mathematical model, laying a technical foundation for the industrial production of complex polymer systems.
Exciting progress has been made in the field of real-time process control. As shown in Fig. 9, the integration of microfluidic chips and machine learning has achieved a qualitative leap in the regulation of monomer ratio in free radical polymerization (FRP). Studies have shown that this dynamic regulation system can increase the reaction efficiency by 300% [72]. The core of this technology lies in the synergy between online monitoring and machine learning models, which ensures that the reaction process is always in the best state by adjusting process parameters in real time. The injection molding process also benefits from machine learning technology. By in-depth analysis of historical production data, the model can accurately predict key parameters such as mold temperature and cooling rate, thereby effectively avoiding product defects. This predictive method improves product quality while significantly reducing production costs.
Figure 9: Data-driven development of polymer composite capacitors. (a–f) Model Development & Simulation: (a) Generative model schematic. (b,c) Validation of HOMO/LUMO predictions. (d,e) Benchmarking against DFT calculations. (f) Electron density simulations for different fillers. (g–i) Experimental Characterization: (g) Cross-sectional SEM/EDS of composite. (h) SEM/EDS of a self-healing point. (i) Photographs of final capacitor devices [72].
The process control of polymer manufacturing is undergoing revolutionary changes brought about by autonomous optimization systems. The newly developed self-driving laboratory platform integrates cloud computing and a variety of online analysis technologies to realize the multi-objective optimization of polymer nanoparticle synthesis [60]. The system can simultaneously optimize multiple performance indicators such as molecular weight distribution and particle size, and find the optimal process parameters through continuous iteration. The NSGA-II algorithm applied in the epoxy resin polymerization process is a successful case, which has achieved significant results in the optimization of number—average molecular weight and polydispersity index [2]. This kind of multi-objective optimization method provides a new idea for solving the balance problem of performance indicators commonly found in industrial production.
Although the application of machine learning in polymer manufacturing has broad prospects, it is still necessary to overcome challenges such as data quality and model generalization. The innovative application of the QLoRA framework provides a new idea for solving the problem of data scarcity. This technology can achieve 91.1% accuracy in processing parameter extraction with only 224 samples [73]. This small-sample learning technology is particularly suitable for scenarios where data acquisition is difficult in polymer manufacturing. Future research should focus on the development of more universal machine learning models and promote the in-depth integration of manufacturing equipment and intelligent algorithms to accelerate the transformation of polymer manufacturing towards comprehensive intelligence.
Although the application of machine learning in the field of polymer science has achieved remarkable results, this field still faces a series of technical problems to be solved (as shown in Table 6). As shown in Table 5, the uneven quality of data, insufficient generalization ability of models, and high demand for computing resources have become the main bottlenecks restricting the progress of research. This table systematically summarizes the main technical challenges and their solutions in the machine learning research of polymer materials, including the above-mentioned key issues, and lists the representative solutions and typical cases in the current field, providing methodological references for subsequent research. Especially when dealing with polymer systems with complex structures, the prediction accuracy and stability of existing models are often difficult to meet practical needs. To address these challenges, researchers need to seek breakthroughs from multiple dimensions: constructing a more universal algorithm system, improving the collection and characterization technology of experimental data, and strengthening collaborative innovation between different disciplines. It can be predicted that with the rapid development of high-performance computing technology and the continuous optimization of new algorithms, machine learning will play a more critical role in the field of polymer science, which can not only promote the innovative breakthrough of basic theories but also significantly accelerate the industrialization process of related technologies.
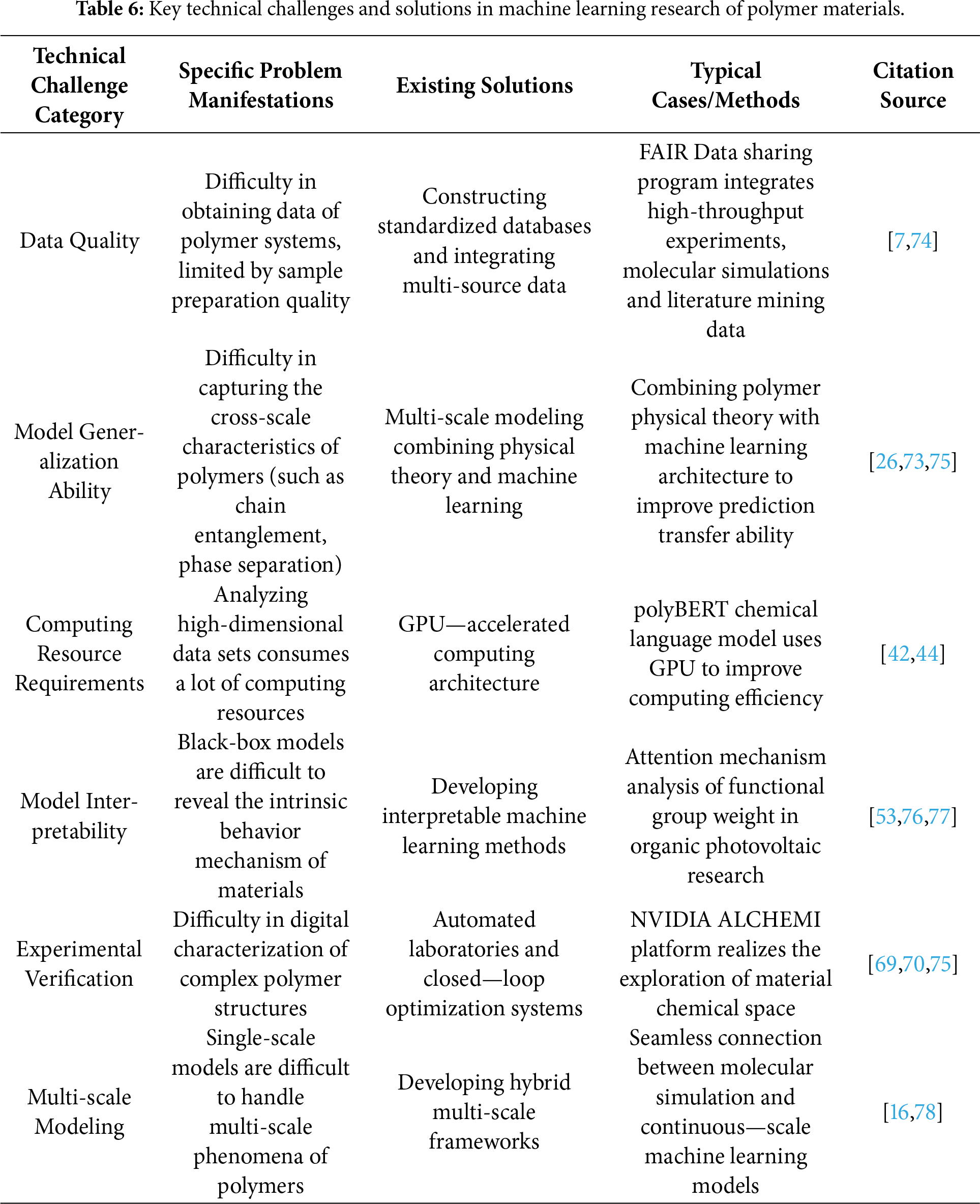
Although the introduction of machine learning methods in the field of polymer science has broad prospects, there are still several technical problems to be solved in practical applications. The most urgent problem at present is the difficulty in obtaining high-quality data. High costs and many practical restrictions have seriously restricted the training effect and performance of machine learning models [64]. Taking complex polymer systems as an example, insufficient data makes it difficult for models to accurately capture the cross-scale characteristics of materials, including key features such as random sequences of polymer chains and diversity of condensed state structures [22]. This problem is particularly prominent in the research of solid electrolytes. High-precision molecular simulation methods are difficult to carry out large-scale calculations, while conventional experimental characterization is limited by the quality of sample preparation and cannot effectively distinguish intrinsic ionic conductivity from other interfering factors [73].
The digital characterization of polymer structures also faces severe challenges. Most of the existing characterization methods are limited to the structure of repeating units and cannot fully reflect statistical characteristics such as molecular weight distribution, sequence structure, and topological structure [13]. This characterization defect makes it difficult for machine learning models to fully grasp the complex characteristics of polymer materials. For example, in the study of multi-component polyurethane elastomers, the prediction results of the model on hydrogen bonds on molecular chains are significantly discrete from the overall hydrogen bond distribution of the system, which fully reflects the amorphous characteristics of a single molecular chain in the polymer system. Another tricky problem is the lack of standardized formats for polymer characterization data. Existing data often mixes multiple variables such as molecular weight, processing history, and characterization protocols, which brings great difficulties to data mining and machine learning applications [59].
The lack of model interpretability also limits the in-depth development of machine learning in the polymer field. Traditional AI models generally have the problem of “black box”. Although they can produce prediction results, it is difficult to clarify their internal mechanisms [74]. This defect is particularly prominent in fields that need to understand the intrinsic behavior of materials. Taking the research of organic photovoltaic devices as an example, although machine learning methods can accurately model material properties, they often cannot explain which chemical properties play a key role in performance improvement. Another common challenge is the phenomenon of model overfitting, especially when there are many parameters, the model may perform well on the training set, but its prediction ability on new data decreases significantly [75].
Computing resource requirements and algorithm complexity constitute another obstacle. Training large neural networks or analyzing high-dimensional data sets from molecular simulations and spectroscopy consumes a lot of computing resources. When solving the optimal polymer design problem with multi-parameter uncertainty, traditional integration methods will bring a heavy computing burden, and new algorithms need to be developed to deal with this high-dimensional and parameter correlation problem [76]. In addition, existing models perform poorly in dealing with multi-scale phenomena, and the behavioral characteristics of polymer materials often span multiple orders of magnitude, from chain entanglement, phase separation to fracture and creep, but most machine learning tools can only play a role at a single length or time scale [77].
The field of polymer science is experiencing profound changes brought about by machine learning technology, and this change presents the significant characteristics of multi-dimensional and interdisciplinary integration. The data-driven research paradigm is reshaping the pattern of polymer material R & D, among which the combination of multi-scale modeling and physics—informed machine learning methods is particularly striking. The latest research shows that the organic integration of polymer physical theory and machine learning architecture can effectively improve the prediction transfer ability of the model under different conditions, providing a new idea for solving the long-standing problem of complex characterization of polymer systems [64]. The innovation of computing architecture is also worthy of attention. With the iterative upgrading of GPU technology, the computing efficiency of chemical language models such as polyBERT has been significantly improved, making polymer structure design based on molecular fingerprints possible. This full—process automation from prediction to design will completely subvert the traditional trial-and-error research model [37].
In terms of data infrastructure construction, the improvement of standardization and sharing mechanisms has become a consensus in the academic community. At present, polymer data generally faces the problems of chaotic format and uneven quality, and there is an urgent need to establish a unified and standardized data production and analysis process [18]. The advancement of global data sharing programs such as FAIR Data is building a more complete polymer database by integrating multi-source data such as high-throughput experiments, molecular simulations, and literature mining [6]. The continuous expansion of high-quality data sets has significantly improved the prediction accuracy of machine learning models for material performance parameters, especially in key indicators such as the power conversion efficiency of organic photovoltaic devices [45]. The construction of this data ecosystem cannot be separated from the full cooperation of industry, university, and research sectors, and it is necessary to jointly formulate practical data standards and sharing agreements.
The integration of interdisciplinary methods has given birth to the emerging research paradigm of automated laboratories. Cutting-edge research is committed to developing hybrid multi-scale frameworks that combine physical and chemical principles with machine learning algorithms to achieve seamless connection between molecular simulations and continuous—scale machine learning models [76]. The successful development of AI platforms such as NVIDIA ALCHEMI marks that the application of generative AI models in material chemical space exploration and candidate material recommendation has entered the practical stage [70]. The proposal of the concept of autonomous laboratories is more revolutionary. It organically integrates machine learning, robot technology, and cloud computing to build a closed-loop optimization system from material design to synthesis. This integrated innovation has greatly improved R & D efficiency [60].
The development of interpretable machine learning provides a new opportunity for theoretical breakthroughs in polymer science. To address the problem that current black-box models are difficult to reveal internal mechanisms, the academic community is committed to developing more interpretable machine learning methods to make the model decision—making process more transparent [77]. By introducing the knowledge of domain experts and constructing descriptors that can identify the key features of materials, it helps to deeply understand the essential connection between polymer structure and performance [78]. The attention mechanism analysis in the research of organic photovoltaic materials is a typical case. The study found that the model assigns higher weights to adjacent language fragments (usually belonging to the same functional group). This interpretable analysis provides a new perspective for revealing the structure—activity relationship of materials [79]. With the continuous improvement of interpretive tools, machine learning can not only predict material properties but also become an important tool for discovering new scientific laws [79].
The innovation of the education system has a fundamental supporting role in the development of polymer science. It has become an inevitable choice to integrate programming skills and machine learning knowledge into the chemistry curriculum system. This change aims to cultivate a new generation of polymer scientists with interdisciplinary capabilities [80,81]. The establishment of industry-university-research collaborative education mechanisms is also crucial. Cultivating compound talents through practical projects can effectively promote the practical application of machine learning technology in the polymer field. This transformation of talent training mode will fundamentally solve the practical dilemma that the threshold of computer majors is too high and synthetic chemists are difficult to apply machine learning tools [82]. It can be predicted that with the continuous deepening of these trends, the application of machine learning in polymer science will achieve a qualitative leap from auxiliary tools to leading paradigms, opening up unprecedented development paths for material innovation.
The field of polymer science is ushering in profound changes brought about by machine learning technology, and its application potential has penetrated into multiple dimensions such as material R & D, production and manufacturing, and environmental governance [83]. In the development of new materials, the ML-driven workflow is gradually realizing the full-chain automation from literature mining to material synthesis. This closed-loop system compresses the traditional R & D cycle to an unprecedented extent [84]. The design of polymer materials represented by solution polymerized styrene—butadiene rubber (SSBR) has shown the feasibility of machine learning replacing the traditional trial-and-error method, and its accurate prediction ability is expected to be extended to a wider range of material systems and performance indicators [85,86].
The deep integration of the Material Genome Initiative and machine learning is reshaping the methodology of polymer design. Inspired by the breakthrough results of AlphaFold2 in protein structure prediction, deep learning technology provides a new idea for solving the problem of polymer structure prediction. This model has important enlightenment significance for industries such as biopharmaceuticals [87]. Experimental studies have shown that data-driven methods can accurately regulate the morphological characteristics of single-chain nanoparticles (SCNPs), especially under the condition of low functionalization, providing a reliable verification platform for sequence—based design strategies [88–90]. In the field of mixed matrix membranes, machine learning—assisted high-throughput screening technology significantly improves the performance prediction efficiency of CO2 separation membranes by analyzing the synergistic effect between metal-organic frameworks (MOFs) and polymers [91].
The intelligent transformation of the intelligent manufacturing system cannot be separated from the support of machine learning technology. The development efficiency of materials dedicated to additive manufacturing has achieved a qualitative leap due to data-driven methods. This innovative model shows unique advantages in addressing material challenges in the fields of bioengineering and aerospace [92]. The newly developed autonomous laboratory platform has built an intelligent optimization system for polymer nano-synthesis by integrating cloud computing and online characterization technology, realizing the accurate production of “on-demand granulation” [93]. It is worth noting that the intelligent information extraction technology based on large language models has made a breakthrough in the optimization of injection molding processes. It can realize the high-precision extraction of processing parameters with only 224 samples, opening up a new way for the digital transformation of traditional manufacturing processes [94].
The development of environment—friendly materials is achieving leapfrog development with the help of machine learning. The performance optimization research of materials such as polyurethane elastomers reveals that the eigenvalue of system parameters has a more significant impact on material performance than the characteristics of a single molecular chain. This finding provides an important basis for the overall regulation of material components [95]. The discovery of ionene materials with Troger’s base structure marks a major progress in the field of sustainable energy materials. Their excellent conductivity provides an innovative idea for the design of a new generation of lithium-ion batteries [96]. Biomimetic intelligent thermal management materials, by simulating the biological thermal regulation mechanism and combining machine learning optimization strategies, show the unique value of dynamic regulation in fields such as wearable devices and building energy conservation [97].
The integration of interdisciplinary technologies continues to expand the application depth of machine learning in polymer science. The polyBERT chemical language model provides a universal solution for polymer space exploration with its high-throughput screening capability. Graph Neural Networks (GNNs) perform well in capturing the topological structure information of polymer chains, establishing a new paradigm for molecular ensemble modeling. With the iterative upgrading of professional computing platforms, AI proxy models such as Machine Learning Interatomic Potentials (MLIPs) will accelerate the process of material discovery, promote the paradigm shift of polymer science from experience—driven to data-driven, and finally realize the historic leap of material R & D from “trial-and-error game” to “precision navigation”.
Machine learning is revolutionizing polymer materials research through a data-driven paradigm, achieving full-chain penetration from basic data processing and algorithm modeling to material design and manufacturing optimization. Within the core technical system outlined in this paper, the basic segment involves constructing polymer molecular descriptors using BigSMILES and curlySMILES, screening key parameters with the RDKit toolkit, standardizing data via methods like Min-Max normalization, enhancing data through Bootstrap resampling and transfer learning, and laying a solid foundation with high-quality polymer databases such as PoLyInfo- which contains critical data for approximately 100 polymers. At the algorithm level, traditional machine learning (e.g., SVM achieving an R2 of 0.91 in polymer glass transition temperature (Tg) prediction, and Random Forest reaching an R2 of 0.97 in thermal conductivity prediction), deep learning (e.g., Graph Neural Networks (GNN) achieving an RMSE of approximately 30 K and an R2 of 0.9 in Tg prediction, and the polyBERT model increasing processing speed by two orders of magnitude), as well as transfer learning and multi-task learning (e.g., the Sim2Real strategy achieving a mean absolute error (MAE) of 0.024 W/mK in thermal conductivity prediction) each demonstrate their advantages, enabling accurate prediction of material properties. In terms of design strategies, reverse design, high-throughput screening, and multi-objective optimization have reshaped the R&D model. Typical cases show that machine learning can improve the accuracy of thermal conductivity prediction by 40%, optimize the degradation characteristics of over 600 types of polyesters, and increase polymerization reaction efficiency by 300%, significantly shortening R&D cycles and costs while revealing structure-property relationships that are difficult to capture using traditional methods. Current research faces challenges such as uneven data quality, insufficient model generalization, and poor interpretability. However, solutions like multi-scale modeling and physics-informed machine learning provide directions for addressing these issues. In the future, deeper interdisciplinary integration will drive polymer research from “trial-and-error exploration” to “precision navigation,” providing core support for material innovation in fields such as aerospace, biomedicine, and new energy.
Acknowledgement: Not applicable.
Funding Statement: This work is supported by National Natural Science Foundation of China (Nos. 51671075 and 51971086) and Natural Science Foundation of Heilongjiang Province of China (No. LH2022E081).
Author Contributions: Hongtao Guo: Data curation; Formal analysis; Investigation; Methodology; Software; Validation; Visualization; Writing—original draft; Writing—review&editing. Shuai Li: Data curation; Formal analysis; Investigation; Validation. Shu Li: Conceptualization; Project administration; Supervision; Methodology; Writing—review&editing. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: No new data were generated or analyzed in support of this study.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Cencer MM, Moore JS, Assary RS. Machine learning for polymeric materials: an introduction. Polym Int. 2021;71(5):537–42. doi:10.1002/pi.6345. [Google Scholar] [CrossRef]
2. Cao X, Zhang Y, Sun Z, Yin H, Feng Y. Machine learning in polymer science: a new lens for physical and chemical exploration. Prog Mater Sci. 2025;156:101544. doi:10.1016/j.pmatsci.2025.101544. [Google Scholar] [CrossRef]
3. Liang Z, Li Z, Zhou S, Sun Y, Yuan J, Zhang C. Machine-learning exploration of polymer compatibility. Cell Rep Phys Sci. 2022;3(6):100931. doi:10.1016/j.xcrp.2022.100931. [Google Scholar] [CrossRef]
4. Ju S, Shiga T, Feng L, Shiomi J. Revisiting PbTe to identify how thermal conductivity is really limited. Phys Rev B. 2018;97(18):184305. doi:10.1103/physrevb.97.184305. [Google Scholar] [CrossRef]
5. Wang K, Shi H, Li T, Zhao L, Zhai H, Korani D, et al. Computational and data-driven modelling of solid polymer electrolytes. Digit Discov. 2023;2(6):1660–82. doi:10.1039/d3dd00078h/v2/response1. [Google Scholar] [CrossRef]
6. Patra TK. Data-driven methods for accelerating polymer design. ACS Polym Au. 2021;2(1):8–26. doi:10.1021/acspolymersau.1c00035. [Google Scholar] [PubMed] [CrossRef]
7. Paradiso SP, Delaney KT, Fredrickson GH. Swarm intelligence platform for multiblock polymer inverse formulation design. ACS Macro Lett. 2016;5(8):972–6. doi:10.1021/acsmacrolett.6b00494. [Google Scholar] [PubMed] [CrossRef]
8. Struble DC, Lamb BG, Ma B. A prospective on machine learning challenges, progress, and potential in polymer science. MRS Commun. 2024;14(5):752–70. doi:10.1557/s43579-024-00587-8. [Google Scholar] [CrossRef]
9. Zhu L, Zhou J, Sun Z. Materials data toward machine learning: advances and challenges. J Phys Chem Lett. 2022;13(18):3965–77. doi:10.1021/acs.jpclett.2c00576. [Google Scholar] [PubMed] [CrossRef]
10. Tsai ML, Huang CW, Chang SW. Theory-inspired machine learning for stress-strain curve prediction of short fiber-reinforced composites with unseen design space. Extreme Mech Lett. 2023;65:102097. doi:10.1016/j.eml.2023.102097. [Google Scholar] [CrossRef]
11. Malashin IP, Martysyuk D, Nelyub V, Borodulin A, Gantimurov A, Tynchenko V. Deep learning for property prediction of natural fiber polymer composites. Sci Rep. 2025;15:27837. doi:10.1038/s41598-025-10841-1. [Google Scholar] [PubMed] [CrossRef]
12. Liu N, Jafarzadeh S, Lattimer BY, Ni S, Lua J, Yu Y. Harnessing large language models for data-scarce learning of polymer properties. Nat Comput Sci. 2025;5(3):245–54. doi:10.1038/s43588-025-00768-y. [Google Scholar] [PubMed] [CrossRef]
13. Doan Tran H, Kim C, Chen L, Chandrasekaran A, Batra R, Venkatram S, et al. Machine-learning predictions of polymer properties with Polymer Genome. J Appl Phys. 2020;128(17):171104. doi:10.1063/5.0023759. [Google Scholar] [CrossRef]
14. Gu Y, Lin P, Zhou C, Chen M. Machine learning-assisted systematical polymerization planning: case studies on reversible-deactivation radical polymerization. Sci China Chem. 2021;64(6):1039–46. doi:10.1007/s11426-020-9969-y. [Google Scholar] [CrossRef]
15. Zhang Z, Zhou C, Chen Y, Gu Y, Chen M. Copolymer sequence regulation enabled by reactivity ratio fingerprints via machine learning. Angew Chem Int Ed. 2025;64(50):e202513086. doi:10.1002/anie.202513086. [Google Scholar] [PubMed] [CrossRef]
16. Kuenneth C, Ramprasad R. polyBERT: a chemical language model to enable fully machine-driven ultrafast polymer informatics. Nat Commun. 2023;14:4099. doi:10.1038/s41467-023-39868-6. [Google Scholar] [PubMed] [CrossRef]
17. Jain A, Ong SP, Hautier G, Chen W, Richards WD, Dacek S, et al. Commentary: the Materials Project: a materials genome approach to accelerating materials innovation. APL Mater. 2013;1:011002. doi:10.1063/1.4812323. [Google Scholar] [CrossRef]
18. Meaurio E, Sanchez-Rexach E, Zuza E, Lejardi A, del Pilar Sanchez-Camargo A, Sarasua JR. Predicting miscibility in polymer blends using the Bagley plot: blends with poly(ethylene oxide). Polymer. 2017;113:295–309. doi:10.1016/j.polymer.2017.01.041. [Google Scholar] [CrossRef]
19. Li YQ, Jiang Y, Wang LQ, Li JF. Data and machine learning in polymer science. Chin J Polym Sci. 2023;41(9):1371–6. doi:10.1007/s10118-022-2868-0. [Google Scholar] [CrossRef]
20. McDonald SM, Augustine EK, Lanners Q, Rudin C, Brinson LC, Becker ML. Applied machine learning as a driver for polymeric biomaterials design. Nat Commun. 2023;14:4838. doi:10.1038/s41467-023-40459-8. [Google Scholar] [PubMed] [CrossRef]
21. Tristram F, Jung N, Hodapp P, Schröder RR, Wöll C, Bräse S. The impact of digitalized data management on materials systems workflows. Adv Funct Mater. 2024;34(20):2303615. doi:10.1002/adfm.202303615. [Google Scholar] [CrossRef]
22. Gao L, Lin J, Wang L, Du L. Machine learning-assisted design of advanced polymeric materials. Acc Mater Res. 2024;5(5):571–84. doi:10.1021/accountsmr.3c00288. [Google Scholar] [CrossRef]
23. Tao L, Varshney V, Li Y. Benchmarking machine learning models for polymer informatics: an example of glass transition temperature. J Chem Inf Model. 2021;61(11):5395–413. doi:10.1021/acs.jcim.1c01031. [Google Scholar] [PubMed] [CrossRef]
24. Piroozi G, Kammakakam I. Designing imidazolium-mediated polymer electrolytes for lithium-ion batteries using machine-learning approaches: an insight into ionene materials. Polymers. 2025;17(15):2148. doi:10.3390/polym17152148. [Google Scholar] [PubMed] [CrossRef]
25. Day EC, Chittari SS, Bogen MP, Knight AS. Navigating the expansive landscapes of soft materials: a user guide for high-throughput workflows. ACS Polym Au. 2023;3(6):406–27. doi:10.1021/acspolymersau.3c00025. [Google Scholar] [PubMed] [CrossRef]
26. Yue T, He J, Tao L, Li Y. High-throughput screening and prediction of high modulus of resilience polymers using explainable machine learning. J Chem Theory Comput. 2023;19(14):4641–53. doi:10.1021/acs.jctc.3c00131. [Google Scholar] [PubMed] [CrossRef]
27. Ge W, De Silva R, Fan Y, Sisson SA, Stenzel MH. Machine learning in polymer research. Adv Mater. 2025;37(11):2413695. doi:10.1002/adma.202413695. [Google Scholar] [PubMed] [CrossRef]
28. Park J, Shim Y, Lee F, Rammohan A, Goyal S, Shim M, et al. Prediction and interpretation of polymer properties using the graph convolutional network. ACS Polym Au. 2022;2(4):213–22. doi:10.1021/acspolymersau.1c00050. [Google Scholar] [PubMed] [CrossRef]
29. Dangayach R, Jeong N, Demirel E, Uzal N, Fung V, Chen Y. Machine learning-aided inverse design and discovery of novel polymeric materials for membrane separation. Environ Sci Technol. 2025;59(2):993–1012. doi:10.1021/acs.est.4c08298. [Google Scholar] [PubMed] [CrossRef]
30. Huang Y, Zhang J, Jiang ES, Oya Y, Saeki A, Kikugawa G, et al. Structure-property correlation study for organic photovoltaic polymer materials using data science approach. J Phys Chem C. 2020;124(24):12871–82. doi:10.1021/acs.jpcc.0c00517. [Google Scholar] [CrossRef]
31. Van den Hurk RS, Pirok BWJ, Bos TS. The role of artificial intelligence and machine learning in polymer characterization: emerging trends and perspectives. Chromatographia. 2025;88(5):357–63. doi:10.1007/s10337-025-04406-7. [Google Scholar] [PubMed] [CrossRef]
32. Wu S, Kondo Y, Kakimoto MA, Yang B, Yamada H, Kuwajima I, et al. Machine-learning-assisted discovery of polymers with high thermal conductivity using a molecular design algorithm. npj Comput Mater. 2019;5:66. doi:10.1038/s41524-019-0203-2. [Google Scholar] [CrossRef]
33. Martin TB, Audus DJ. Emerging trends in machine learning: a polymer perspective. ACS Polym Au. 2023;3(3):239–58. doi:10.1021/acspolymersau.2c00053. [Google Scholar] [PubMed] [CrossRef]
34. Kumar JN, Li Q, Jun Y. Challenges and opportunities of polymer design with machine learning and high throughput experimentation. MRS Commun. 2019;9(2):537–44. doi:10.1557/mrc.2019.54. [Google Scholar] [CrossRef]
35. Meftahi N, Klymenko M, Christofferson AJ, Bach U, Winkler DA, Russo SP. Machine learning property prediction for organic photovoltaic devices. npj Comput Mater. 2020;6:166. doi:10.1038/s41524-020-00429-w. [Google Scholar] [CrossRef]
36. Aoki Y, Wu S, Tsurimoto T, Hayashi Y, Minami S, Tadamichi O, et al. Multitask machine learning to predict polymer-solvent miscibility using flory-Huggins interaction parameters. Macromolecules. 2023;56(14):5446–56. doi:10.1021/acs.macromol.2c02600. [Google Scholar] [CrossRef]
37. Ferji K. Basic concepts and tools of artificial intelligence in polymer science. Polym Chem. 2025;16(21):2457–70. doi:10.1039/d5py00148j. [Google Scholar] [CrossRef]
38. Zhu MX, Song HG, Yu QC, Chen JM, Zhang HY. Machine-learning-driven discovery of polymers molecular structures with high thermal conductivity. Int J Heat Mass Transf. 2020;162:120381. doi:10.1016/j.ijheatmasstransfer.2020.120381. [Google Scholar] [CrossRef]
39. Zhao Y, Mulder RJ, Houshyar S, Le TC. A review on the application of molecular descriptors and machine learning in polymer design. Polym Chem. 2023;14(29):3325–46. doi:10.1039/d3py00395g. [Google Scholar] [CrossRef]
40. Qiu H, Liu L, Qiu X, Dai X, Ji X, Sun ZY. PolyNC: a natural and chemical language model for the prediction of unified polymer properties. Chem Sci. 2024;15(2):534–44. doi:10.1039/d3sc05079c. [Google Scholar] [PubMed] [CrossRef]
41. Yue T, He J, Li Y. Polyuniverse: generation of a large-scale polymer library using rule-based polymerization reactions for polymer informatics. Digit Discov. 2024;3(12):2465–78. doi:10.26434/chemrxiv-2024-7069c. [Google Scholar] [CrossRef]
42. Machello C, Aghabalaei Baghaei K, Bazli M, Hadigheh A, Rajabipour A, Arashpour M, et al. Tree-based machine learning approach to modelling tensile strength retention of fibre reinforced polymer composites exposed to elevated temperatures. Compos Part B Eng. 2023;270:111132. doi:10.1016/j.compositesb.2023.111132. [Google Scholar] [CrossRef]
43. Balachandran PV. Adaptive machine learning for efficient materials design. MRS Bull. 2020;45(7):579–86. doi:10.1557/mrs.2020.163. [Google Scholar] [CrossRef]
44. Han S, Kang Y, Park H, Yi J, Park G, Kim J. Multimodal transformer for property prediction in polymers. ACS Appl Mater Interfaces. 2024;16(13):16853–60. doi:10.1021/acsami.4c01207. [Google Scholar] [PubMed] [CrossRef]
45. Sun W, Zheng Y, Yang K, Zhang Q, Shah AA, Wu Z, et al. Machine learning-assisted molecular design and efficiency prediction for high-performance organic photovoltaic materials. Sci Adv. 2019;5(11):eaay4275. doi:10.1126/sciadv.aay4275. [Google Scholar] [PubMed] [CrossRef]
46. Zhang Y, Shen C, Xia K. Multi-Cover Persistence (MCP)-based machine learning for polymer property prediction. Brief Bioinform. 2024;25(6):bbae465. doi:10.1093/bib/bbae465. [Google Scholar] [PubMed] [CrossRef]
47. Sanchez-Lengeling B, Aspuru-Guzik A. Inverse molecular design using machine learning: generative models for matter engineering. Science. 2018;361(6400):360–5. doi:10.1126/science.aat2663. [Google Scholar] [PubMed] [CrossRef]
48. Lin C, Zhang H. Polymer biodegradation in aquatic environments: a machine learning model informed by meta-analysis of structure-biodegradation relationships. Environ Sci Technol. 2025;59(2):1253–63. doi:10.1021/acs.est.4c11282. [Google Scholar] [PubMed] [CrossRef]
49. Minami S, Hayashi Y, Wu S, Fukumizu K, Sugisawa H, Ishii M, et al. Scaling law of Sim2Real transfer learning in expanding computational materials databases for real-world predictions. npj Comput Mater. 2025;11:146. doi:10.1038/s41524-025-01606-5. [Google Scholar] [CrossRef]
50. Xu C, Wang Y, Barati Farimani A. TransPolymer: a Transformer-based language model for polymer property predictions. npj Comput Mater. 2023;9:64. doi:10.1038/s41524-023-01016-5. [Google Scholar] [CrossRef]
51. Pai SM, Shah KA, Sunder S, Albuquerque RQ, Brütting C, Ruckdäschel H. Machine learning applied to the design and optimization of polymeric materials: a review. Next Mater. 2025;7:100449. doi:10.1016/j.nxmate.2024.100449. [Google Scholar] [CrossRef]
52. Meredig B, Antono E, Church C, Hutchinson M, Ling J, Paradiso S, et al. Can machine learning identify the next high-temperature superconductor? Examining extrapolation performance for materials discovery. Mol Syst Des Eng. 2018;3(5):819–25. doi:10.1039/c8me00012c. [Google Scholar] [CrossRef]
53. Jackson NE, Webb MA, de Pablo JJ. Recent advances in machine learning towards multiscale soft materials design. Curr Opin Chem Eng. 2019;23:106–14. doi:10.1016/j.coche.2019.03.005. [Google Scholar] [CrossRef]
54. Patel RA, Webb MA. Data-driven design of polymer-based biomaterials: high-throughput simulation, experimentation, and machine learning. ACS Appl Bio Mater. 2023;7(2):510–27. doi:10.1021/acsabm.2c00962. [Google Scholar] [PubMed] [CrossRef]
55. Gao L, Wang L, Lin J, Du L. An intelligent manufacturing platform of polymers: polymeric material genome engineering. Engineering. 2023;27:31–6. doi:10.1016/j.eng.2023.01.018. [Google Scholar] [CrossRef]
56. Rahmanian F, Flowers J, Guevarra D, Richter M, Fichtner M, Donnely P, et al. Enabling modular autonomous feedback-loops in materials science through hierarchical experimental laboratory automation and orchestration. Adv Mater Inter. 2022;9(8):2101987. doi:10.1002/admi.202101987. [Google Scholar] [CrossRef]
57. Kim C, Chandrasekaran A, Huan TD, Das D, Ramprasad R. Polymer genome: a data-powered polymer informatics platform for property predictions. J Phys Chem C. 2018;122(31):17575–85. doi:10.1021/acs.jpcc.8b02913. [Google Scholar] [CrossRef]
58. Wan H, Fang Y, Hu M, Guo S, Sui Z, Huang X, et al. Interpretable machine-learning and big data mining to predict the CO2 separation in polymer-MOF mixed matrix membranes. Adv Sci. 2025;12(16):2405905. doi:10.1002/advs.202405905. [Google Scholar] [PubMed] [CrossRef]
59. Zhang S, Du S, Wang L, Lin J, Du L, Xu X, et al. Design of silicon-containing arylacetylene resins aided by machine learning enhanced materials genome approach. Chem Eng J. 2022;448:137643. doi:10.1016/j.cej.2022.137643. [Google Scholar] [CrossRef]
60. Shen ZH, Shen Y, Cheng XX, Liu HX, Chen LQ, Nan CW. High-throughput data-driven interface design of high-energy-density polymer nanocomposites. J Materiomics. 2020;6(3):573–81. doi:10.1016/j.jmat.2020.04.006. [Google Scholar] [CrossRef]
61. Knox ST, Wu KE, Islam N, O’Connell R, Pittaway PM, Chingono KE, et al. Self-driving laboratory platform for many-objective self-optimisation of polymer nanoparticle synthesis with cloud-integrated machine learning and orthogonal online analytics. Polym Chem. 2025;16(12):1355–64. doi:10.1039/d5py00123d. [Google Scholar] [CrossRef]
62. Bai X, Zhang X. Artificial intelligence-powered materials science. Nano Micro Lett. 2025;17(1):135. doi:10.1007/s40820-024-01634-8. [Google Scholar] [PubMed] [CrossRef]
63. Chen L, Kim C, Batra R, Lightstone JP, Wu C, Li Z, et al. Frequency-dependent dielectric constant prediction of polymers using machine learning. njp Comput Mater. 2020;6:61. doi:10.1038/s41524-020-0333-6. [Google Scholar] [CrossRef]
64. Tang H, Yue T, Li Y. Assessing uncertainty in machine learning for polymer property prediction: a benchmark study. J Chem Inf Model. 2025;65(13):6585–98. doi:10.1021/acs.jcim.5c00550. [Google Scholar] [PubMed] [CrossRef]
65. Jiang S, Webb MA. Physics-guided neural networks for transferable property prediction in architecturally diverse copolymers. Macromolecules. 2025;58(10):4971–84. doi:10.1021/acs.macromol.5c00720. [Google Scholar] [CrossRef]
66. Malashin I, Tynchenko V, Gantimurov A, Nelyub V, Borodulin A. Boosting-based machine learning applications in polymer science: a review. Polymers. 2025;17(4):499. doi:10.3390/polym17040499. [Google Scholar] [PubMed] [CrossRef]
67. Sattari K, Xie Y, Lin J. Data-driven algorithms for inverse design of polymers. Soft Matter. 2021;17(33):7607–22. doi:10.1039/d1sm00725d. [Google Scholar] [PubMed] [CrossRef]
68. Hassan AU, Güleryüz C, El Azab IH, Elnaggar AY, Mahmoud MHH. A graph neural network assisted reverse polymers engineering to design low bandgap benzothiophene polymers for light harvesting applications. Mater Chem Phys. 2025;339:130747. doi:10.1016/j.matchemphys.2025.130747. [Google Scholar] [CrossRef]
69. Kim C, Batra R, Chen L, Tran H, Ramprasad R. Polymer design using genetic algorithm and machine learning. Comput Mater Sci. 2021;186:110067. doi:10.1016/j.commatsci.2020.110067. [Google Scholar] [CrossRef]
70. Caramelli D, Granda JM, Mehr SHM, Cambié D, Henson AB, Cronin L. Discovering new chemistry with an autonomous robotic platform driven by a reactivity-seeking neural network. ACS Cent Sci. 2021;7(11):1821–30. doi:10.1021/acscentsci.1c00435. [Google Scholar] [PubMed] [CrossRef]
71. Madika B, Saha A, Kang C, Buyantogtokh B, Agar J, Voorhees P, et al. Artificial intelligence for materials discovery, development, and optimization. ACS Nano. 2025;19(30):27116–58. doi:10.1021/acsnano.5c04200. [Google Scholar] [PubMed] [CrossRef]
72. Yang M, Wan C, Zhou L, Li X, Pan J, Li H, et al. High-temperature polymer composite capacitors with high energy density designed via machine learning. Nat Energy. 2025;10(11):1323–33. doi:10.1038/s41560-025-01863-0. [Google Scholar] [CrossRef]
73. Tao L, Chen G, Li Y. Machine learning discovery of high-temperature polymers. Patterns. 2021;2(4):100225. doi:10.1016/j.patter.2021.100225. [Google Scholar] [PubMed] [CrossRef]
74. Meng Y, Lin Y, Zhang A. Prediction and explanation of properties in multicomponent polyurethane elastomers: integrating molecular dynamics and machine learning. Macromolecules. 2024;57(23):10912–25. doi:10.1021/acs.macromol.4c02559. [Google Scholar] [CrossRef]
75. Gormley AJ, Webb MA. Machine learning in combinatorial polymer chemistry. Nat Rev Mater. 2021;6(8):642–4. doi:10.1038/s41578-021-00282-3. [Google Scholar] [PubMed] [CrossRef]
76. Mysona JA, Nealey PF, de Pablo JJ. Machine learning models and dimensionality reduction for prediction of polymer properties. Macromolecules. 2024;57(5):1988–97. doi:10.1021/acs.macromol.3c02401. [Google Scholar] [CrossRef]
77. Jiang X, Fu H, Bai Y, Jiang L, Zhang H, Wang W, et al. Interpretable machine learning applications: a promising prospect of AI for materials. Adv Funct Mater. 2025;35(41):2507734. doi:10.1002/adfm.202507734. [Google Scholar] [CrossRef]
78. Wagner N, Rondinelli JM. Theory-guided machine learning in materials science. Front Mater. 2016;3:28. doi:10.3389/fmats.2016.00028. [Google Scholar] [CrossRef]
79. Fernandes C. Scientific machine learning for polymeric materials. Polymers. 2025;17(16):2222. doi:10.3390/polym17162222. [Google Scholar] [PubMed] [CrossRef]
80. Zhong X, Gallagher B, Liu S, Kailkhura B, Hiszpanski A, Han TY. Explainable machine learning in materials science. NPJ Comput Mater. 2022;8:204. doi:10.1038/s41524-022-00884-7. [Google Scholar] [CrossRef]
81. Mikulskis P, Alexander MR, Winkler DA. Toward interpretable machine learning models for materials discovery. Adv Intell Syst. 2019;1(8):1900045. doi:10.1002/aisy.201900045. [Google Scholar] [CrossRef]
82. Ma L, Li W, Yuan J, Zhu J, Wu Y, He H, et al. Recent advances in machine learning-assisted design and development of polymer materials. Macromol Rapid Commun. 2025;135:e00361. doi:10.1002/marc.202500361. [Google Scholar] [PubMed] [CrossRef]
83. Yue T, Tao L, Varshney V, Li Y. Benchmarking study of deep generative models for inverse polymer design. Digit Discov. 2025;4(4):910–26. doi:10.26434/chemrxiv-2024-gzq4r. [Google Scholar] [CrossRef]
84. Liu H, Zhang F, Chen J. Machine learning-assisted prediction of polymer degradation behavior. Environ Sci Technol. 2024;58(10):4215–24. doi:10.1021/acs.est.4c00123. [Google Scholar] [CrossRef]
85. Zhou R, Bao L, Bu W, Zhou F. Exploring high-performance viscosity index improver polymers via high-throughput molecular dynamics and explainable AI. npj Comput Mater. 2025;11:52. doi:10.1038/s41524-025-01539-z. [Google Scholar] [CrossRef]
86. Zhang X, Sheng Y, Liu X, Yang J, Goddard WA, Ye C, et al. Polymer-unit graph: advancing interpretability in graph neural network machine learning for organic polymer semiconductor materials. J Chem Theory Comput. 2024;20(7):2908–20. doi:10.1021/acs.jctc.3c01385. [Google Scholar] [PubMed] [CrossRef]
87. Parvez MA, Mehedi IM. High-accuracy polymer property detection via Pareto-optimized SMILES-based deep learning. Polymers. 2025;17(13):1801. doi:10.3390/polym17131801. [Google Scholar] [PubMed] [CrossRef]
88. Shen ZH, Liu HX, Shen Y, Hu JM, Chen LQ, Nan CW. Machine learning in energy storage materials. Interdiscip Mater. 2022;1(2):175–95. doi:10.1002/idm2.12020. [Google Scholar] [CrossRef]
89. Bai H, Chu P, Tsai JY, Wilson N, Qian X, Yan Q, et al. Graph neural network for Hamiltonian-based material property prediction. Neural Comput Appl. 2022;34(6):4625–32. doi:10.1007/s00521-021-06616-0. [Google Scholar] [CrossRef]
90. Wang Y, Lu L, Wang Z, Zhou G, Lu Y. Integrating graph convolutional network to BiLSTM for enhanced polymer knot identification. Macromolecules. 2024;57(16):7980–9. doi:10.1021/acs.macromol.4c00931. [Google Scholar] [CrossRef]
91. Zheng Y, Biswal AK, Guo Y, Thakolkaran P, Kokane Y, Varshney V, et al. Toward sustainable polymer design: a molecular dynamics-informed machine learning approach for vitrimers. Digit Discov. 2025;4(9):2559–69. doi:10.1039/d5dd00239g. [Google Scholar] [CrossRef]
92. Takahashi L, Kuwahara M, Takahashi K. AI and automation: democratizing automation and the evolution towards true AI-autonomous robotics. Chem Sci. 2025;16(35):15769–80. doi:10.1039/d5sc03183d. [Google Scholar] [PubMed] [CrossRef]
93. Barakat M, Reda H, Harmandaris V. A semi-continuum multiscale model of graphene-based polymer nanocomposites: mechanical characterization. Comput Mater Sci. 2025;257:113968. doi:10.1016/j.commatsci.2025.113968. [Google Scholar] [CrossRef]
94. Ricci E, Vergadou N. Integrating machine learning in the coarse-grained molecular simulation of polymers. J Phys Chem B. 2023;127(11):2302–22. doi:10.1021/acs.jpcb.2c06354. [Google Scholar] [PubMed] [CrossRef]
95. Wang R, Sing MK, Avery RK, Souza BS, Kim M, Olsen BD. Classical challenges in the physical chemistry of polymer networks and the design of new materials. Acc Chem Res. 2016;49(12):2786–95. doi:10.1021/acs.accounts.6b00454. [Google Scholar] [PubMed] [CrossRef]
96. Xu P, Chen H, Li M, Lu W. New opportunity: machine learning for polymer materials design and discovery. Adv Theory Simul. 2022;5(5):2100565. doi:10.1002/adts.202100565. [Google Scholar] [CrossRef]
97. Webb MA, Jackson NE, Gil PS, de Pablo JJ. Targeted sequence design within the coarse-grained polymer genome. Sci Adv. 2020;6(43):eabc6216. doi:10.1126/sciadv.abc6216. [Google Scholar] [PubMed] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools