
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Hybrid Mamba-Transformer Framework with Density-Based Clustering for Traffic Forecasting
School of Logistics Engineering, Shanghai Maritime University, Shanghai, China
* Corresponding Author: Zhenzhen Wang. Email:
(This article belongs to the Special Issue: Complex Network Approaches for Resilient and Efficient Urban Transportation Systems)
Computers, Materials & Continua 2026, 87(3), 62 https://doi.org/10.32604/cmc.2026.076562
Received 22 November 2025; Accepted 11 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In recent years, increasing urban mobility and complex traffic dynamics have intensified the need for accurate traffic flow forecasting in intelligent transportation systems. However, existing models often struggle to jointly capture short-term fluctuations and long-term temporal dependencies under noisy and heterogeneous traffic conditions. To address this challenge, this paper proposes a hybrid traffic flow forecasting framework that integrates Density-Based Spatial Clustering of Applications with Noise (DBSCAN), the Mamba state-space model, and the Transformer architecture. The framework first applies DBSCAN to multidimensional traffic features to enhance traffic state representation and reduce noise. The prediction module alternates between MambaBlocks, which capture local dynamics and high-frequency variations via state-space modeling, and TransformerBlocks, which employ a dynamic gating mechanism to efficiently model long-range dependencies using multi-query and linear attention. Experimental results demonstrate that the proposed model consistently outperforms baseline methods, including Decomposition-Linear (DLinear), Autoformer, and the standard Transformer, across 5-, 10-, 30-, and 60-min prediction horizons in terms of mean squared error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE). Ablation studies further verify the complementary contributions of DBSCAN preprocessing, Mamba-based short-term modeling, and Transformer-based global context learning. Overall, the proposed framework provides an effective and scalable solution for traffic flow forecasting in complex and dynamic environments.Keywords
With rapid urbanization and increasing motor vehicle ownership, traffic congestion and accidents have become global challenges that degrade traffic efficiency and quality of life. Merely expanding transportation supply is no longer sufficient to address these issues [1]. Traffic flow prediction is a core technology for urban intelligent traffic management and is crucial for optimizing resource allocation and alleviating traffic congestion [2]. Accurate forecasts support optimized signal control and traffic guidance, reducing delays and improving overall network efficiency [3]. Therefore, developing high-precision prediction models to cope with dynamic traffic demand has important practical value [4].
Traditional forecasting methods, such as autoregressive moving average (ARIMA) and seasonal ARIMA (SARIMA), can model linear traffic patterns but struggle to capture nonlinear spatiotemporal correlations in traffic flow data [5,6]. As traffic datasets expand, machine learning methods such as support vector machines (SVM) and random forests (RF) have been introduced to model more complex nonlinear relationships; however, their ability to represent long-term temporal dependencies and intricate spatiotemporal interactions remains limited [7]. In recent years, deep learning-based models, especially recurrent neural network (RNN) and their variants, long short-term memory network (LSTM) and gated recurrent unit (GRU), have achieved remarkable success in traffic flow forecasting by effectively capturing spatiotemporal correlations [8,9]. Nevertheless, RNN-based models suffer from information loss and vanishing gradients when modeling long-term dependencies. The Transformer model, with its attention-based architecture, addresses these issues by modeling global dependencies, thereby overcoming the limitations of RNNs [10].
To improve the efficiency of long-sequence traffic flow prediction, Linear Attention has been introduced into Transformer architectures to enhance scalability while preserving global temporal dependency modeling. By alleviating the quadratic complexity of standard self-attention, Linear Attention improves long-horizon efficiency. However, Transformer-based models remain less effective at capturing local short-term dynamics and high-frequency variations, and heavy reliance on attention mechanisms may cause feature oversmoothing and increased training cost, especially in fine-grained traffic scenarios. This observation aligns with traffic behavior studies showing that short-term responses and long-term traffic evolution are governed by distinct mechanisms under coupled influencing factors [11].
To address these limitations, this study proposes a hybrid forecasting framework that integrates dynamic attention, state-space modeling, and clustering-based preprocessing. A dynamic gated attention mechanism adaptively switches between multi-query and linear attention to balance modeling capacity and computational efficiency for long sequences. To enhance sensitivity to short-term fluctuations, Mamba—a selective State Space Model (SSM)—is incorporated to capture fine-grained temporal patterns and high-frequency variations. In addition, Density-Based Spatial Clustering of Applications with Noise (DBSCAN)-based preprocessing is applied to filter noise and aggregate traffic states, improving sample homogeneity and model robustness. By jointly combining these components, the proposed framework effectively integrates local dynamic modeling with global dependency learning, enabling robust and efficient traffic flow prediction under long-sequence and noisy conditions. The main contributions of this study include:
(1) Clustering-enhanced data representation: Enhances the model’s ability to identify complex traffic states and provides more discriminative input representations for subsequent prediction tasks.
(2) Alternating layer hybrid Mamba-Transformer architecture: Combines the sensitivity of the state-space model (Mamba) to local perturbations with the Transformer’s advantage in modeling long-range dependencies, improving adaptability to dynamic traffic patterns.
(3) Dynamic gated attention mechanism: Utilizes trainable gating functions to switch between multi-query and linear attention mechanisms, reducing computational costs and improving overall inference efficiency.
(4) Enhanced model regularization and representation: Uses Root Mean Square Layer Normalization (RMSNorm) to improve training stability, and combines residual connections with layer-wise normalization to accelerate convergence and improve generalization performance.
The remainder of this paper is organized as follows. Section 2 reviews related work; Section 3 describes the proposed model; Section 4 presents the experimental setup and results; and Sections 5 and 6 conclude the paper and discuss future research directions.
Recent traffic flow forecasting studies increasingly adopt deep learning models to capture complex temporal dependencies and heterogeneous traffic patterns, with attention mechanisms, state-space models, and clustering-based methods emerging as key research directions.
The Transformer model captures global dependencies in long-term traffic data through self-attention, enabling effective representation learning on large-scale datasets [12]. Li et al. [13] proposed a lightweight spatiotemporal Transformer that integrates dynamic spatiotemporal dependencies to improve efficiency and accuracy. Wei et al. [14] and He et al. [15] developed Transformer-based graph neural network models that enhance spatiotemporal prediction through different architectural designs. Huang et al. [16] introduced multi-granularity temporal embeddings to reduce temporal information loss. Luo et al. [17] employed a masked subsequence Transformer to learn long-term trends, short-term variations, and periodic patterns. Xiao and Long [18] applied Transformer variants for multi-source data fusion, while Qi and Fan [19] used Transformer-based models for spatiotemporal feature extraction, both improving prediction performance. Beyond traffic forecasting, MetaFormer-based architectures, a general Transformer-style modeling framework, have demonstrated strong representation capability in complex industrial perception tasks, highlighting the broad applicability of sequence modeling paradigms [20].
However, most Transformer-based research focuses on long-sequence prediction, lacks sensitivity to short-term fluctuations, and has difficulty accurately capturing instantaneous congestion or emergencies; recent studies have shown that the Mamba model has advantages in local feature extraction. Cheng et al. [21] combined Mamba with a graph neural network and a transfer learning framework, using pre-training, clustering, and knowledge querying for small-shot prediction. Tang et al. [22] combined Vision Mamba with LSTM and designed a recurrent unit, achieving higher prediction accuracy at lower computational cost.
Cluster analysis is crucial in traffic flow modeling. Recent traffic behavior studies further indicate that traffic systems exhibit strong heterogeneity across driving modes and environmental contexts, such as individual vs. platoon behaviors and scenario-dependent motion patterns, which motivates traffic-state partitioning prior to prediction [23,24]. Traditional methods such as K-means are susceptible to noise and shape restrictions, while Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is widely used due to its robustness and ability to identify clusters of arbitrary shapes. Shi et al. [25] applied DBSCAN to detect traffic flow patterns and solved the noise sensitivity problem. Zhang et al. [26] and Cesario et al. [27] used DBSCAN as the core and combined it with Dijkstra or parallel multi-density strategies to improve the accuracy and efficiency of accident clustering and hotspot detection in large-scale road networks. Tang et al. [28] incorporated spatial, temporal, and directional attributes into DBSCAN to extract urban travel patterns.
Currently, single models often struggle to capture complex traffic patterns, motivating the development of hybrid and multi-model strategies that combine complementary strengths to improve prediction accuracy. For example, CNN–LSTM and CNN–BiLSTM architectures, which combine convolutional neural networks (CNNs) for spatial feature extraction with long short-term memory (LSTM) or bidirectional LSTM (BiLSTM) networks for temporal dependency modeling, have shown improved performance in complex urban traffic networks [29,30]. Transformer-based models have also been integrated with graph neural networks (GNNs), graph convolutional networks (GCNs), and gated recurrent units (GRUs) to better capture complex spatiotemporal features and dynamic traffic conditions [31,32]. Bing et al. [33] combined Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN), Variational Mode Decomposition (VMD), convolutional neural networks (CNNs), and Transformers to reduce mean absolute percentage error (MAPE) in multi-step traffic prediction. Shao et al. [34] proposed an adaptive framework, namely LSC, based on attribute prediction and selective backpropagation, while Du et al. [35] developed a hybrid multimodal framework, HMDLF, integrating one-dimensional CNN (1D-CNN), GRU, and attention mechanisms for spatiotemporal modeling.
The proposed traffic flow prediction framework comprises two components: a DBSCAN clustering enhancement module and a Mamba–Transformer fusion prediction module (Fig. 1). DBSCAN clusters multidimensional traffic features—including standardized traffic flow, vehicle speed, numerical time features, and weekend/peak-hour indicators—and removes noise by adaptively determining neighborhood radius and minimum sample size via an optimized k-distance graph. The resulting cluster labels are appended as additional input features. The prediction stage employs a Mamba–Transformer network in which input data are embedded into a high-dimensional space and processed sequentially by a MambaBlock, a TransformerBlock, and a feedforward neural network, with LayerNorm and residual connections. The MambaBlock models local dynamics via state space representation, while the TransformerBlock captures global dependencies using multi-query and linear attention. Features are normalized with RMSNorm and linearly mapped to output traffic flow predictions. Model training uses mean squared error (MSE) loss and the Adam optimizer, with performance and generalization evaluated through and visualization.
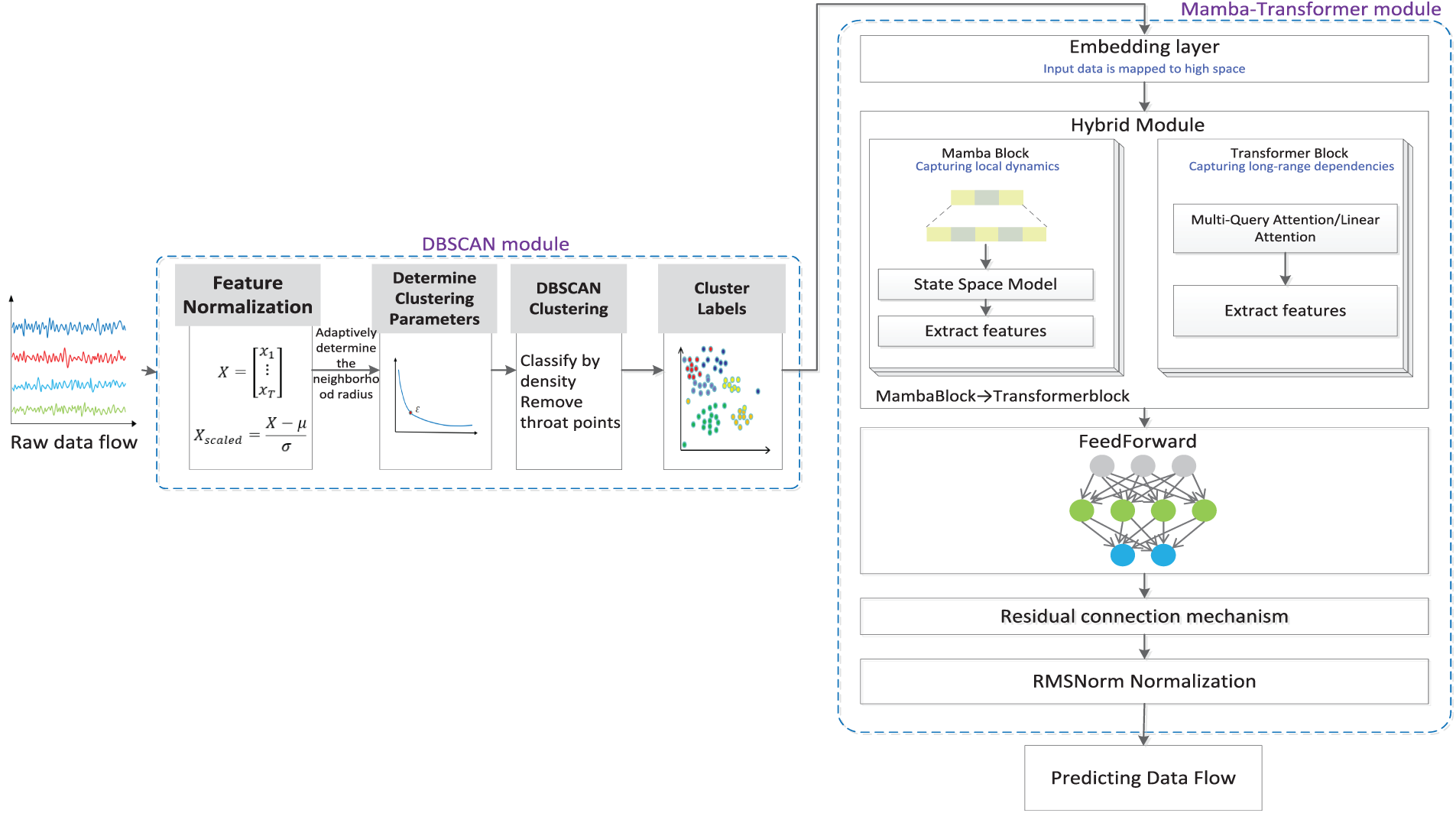
Figure 1: Overall architecture of the proposed traffic flow prediction framework.
Definition 1 (Traffic Flow Feature Data): In this study, traffic flow data are represented as a multidimensional time-series matrix, where T denotes the total length of the time series.
Each observation vector is defined as:
where
Definition 2 (Clustering-Enhanced Traffic Flow Feature Data): Building on flow volume, speed, and time, weekend and peak-hour indicators are added. DBSCAN then partitions the dataset into clusters, forming the enhanced traffic flow feature matrix.
Each observation vector is defined as:
where
Definition 3 (Traffic Flow Prediction Problem): Given the clustering-enhanced data from the past L consecutive time steps, predict the traffic flow for the next F consecutive time steps.
where f(.) denotes the prediction model to be trained, L is the historical observation window length, and F is the future prediction horizon. The objective is to minimize the error between predicted and actual values to improve prediction accuracy.
3.3 DBSCAN-Based Data Processing
In practical traffic monitoring systems, traffic data are frequently affected by sensor failures, missing or delayed records, and communication errors. In addition, traffic incidents, road maintenance, adverse weather, and sudden demand changes introduce deviations from normal traffic patterns. As a result, traffic flow data are inherently noisy and heterogeneous, motivating clustering-based preprocessing to enhance feature robustness. To better capture traffic state evolution, a density-based clustering module is applied to the basic features to partition typical traffic states and filter noise, providing stable input representations for the subsequent Mamba–Transformer prediction model. In this study, DBSCAN is performed offline, and the resulting cluster labels are treated as static traffic state features within each prediction window. The overall workflow is illustrated in Fig. 2 and Algorithm 1.
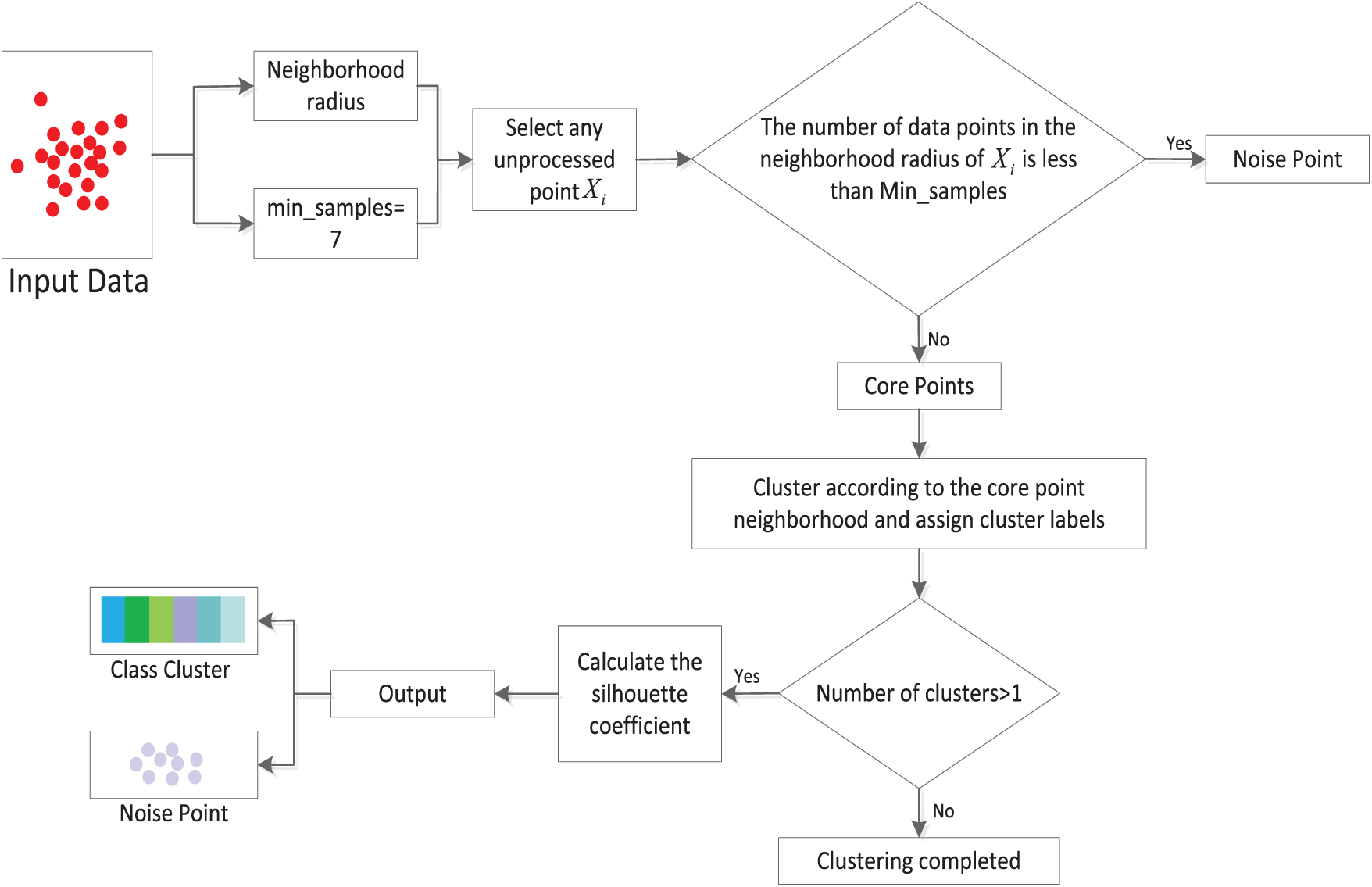
Figure 2: Workflow of the DBSCAN-based data processing module.
During preprocessing, two Boolean features—weekend status and peak-hour indicator—are extracted from the temporal field and combined with the original traffic flow, speed, and time features as inputs for clustering. Unlike conventional DBSCAN approaches that rely on fixed empirical parameters, this study employs an inflection-point detection method based on k-distance differential curves to adaptively determine the eps parameter, enhancing robustness to non-uniform density distributions in traffic data. Specifically, the Euclidean distance between each data point and its k-th nearest neighbor is calculated, sorted in descending order to form the k-distance sequence, and the optimal clustering radius is identified at the maximum difference point.

During clustering, standardized five-dimensional input features are processed by the DBSCAN algorithm, which, based on density partitioning principles, classifies sample points into core, border, or noise points. A data point
3.4 Mamba–Transformer Prediction
This study integrates the state-space–based MambaBlock with the attention-based TransformerBlock, alternately stacked to jointly model short-term disturbances and long-term dependencies in traffic flow. As shown in Fig. 3 and Algorithm 2, the DBSCAN-enhanced multidimensional time series is embedded into a high-dimensional space, processed through alternating MambaBlocks and TransformerBlocks, and output via a feedforward network with normalization and linear mapping. Each MambaTransformerBlock follows a “local–global–feedforward” sequence: the MambaBlock captures high-frequency fluctuations and sudden congestion, while the TransformerBlock, combining multi-query and linear attention, models long-range dependencies. The feedforward network then applies nonlinear transformation and dimensional mapping to generate final predictions.
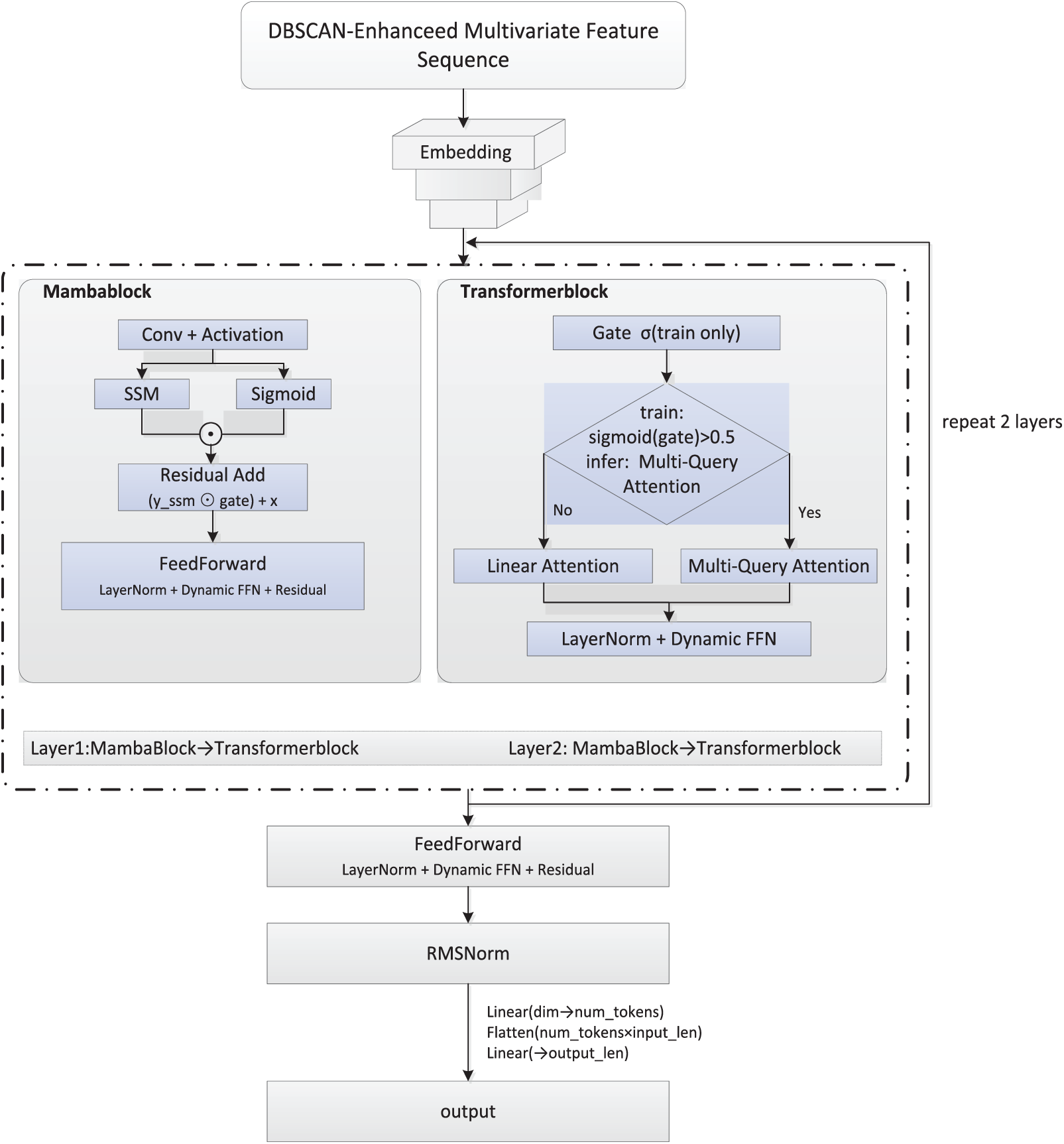
Figure 3: Mamba-transformer fusion prediction module flowchart.
MambaBlock is based on a state-space model, where
A, B, C, and D denote trainable linear transformations, and

The TransformerBlock models global dependencies across time steps using an attention-based architecture. When
The proposed model employs multi-query attention, which shares key–value representations across heads to improve parallelism and reduce GPU memory and computation compared with conventional multi-head attention. During training, a gating mechanism selects between multi-query and linear attention based on computational constraints, while multi-query attention is consistently used during inference to ensure prediction consistency. Queries and keys are independently scaled and normalized, reducing complexity from
The experimental data were obtained from the Performance Measurement System (PeMS) of the California Department of Transportation (Caltrans), covering a highway segment on Interstate I-980 in Oakland, California. Traffic data were aggregated at 5-min intervals over six months, including traffic flow (vehicles per 5 min) and speed (miles per hour). Temporal information was extracted from timestamps and encoded as auxiliary features, including hour of day, weekend indicator, and peak-hour indicator for morning and evening periods [36].
Before modeling, timestamps were converted into numerical temporal features, and weekend and peak-hour indicators were constructed. All numerical features were standardized to remove scale differences. A DBSCAN-based preprocessing step was further applied to enhance traffic state representation and reduce noise, as described in Section 3.3 The dataset was then split chronologically into training, validation, and testing sets with a ratio of 70%/10%/20%, ensuring no future information leakage.
Model performance was evaluated using Root Mean Square Error (RMSE), Mean Square Error (MSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE).
where
In DBSCAN, the critical parameter k defines the number of nearest neighbors used to estimate
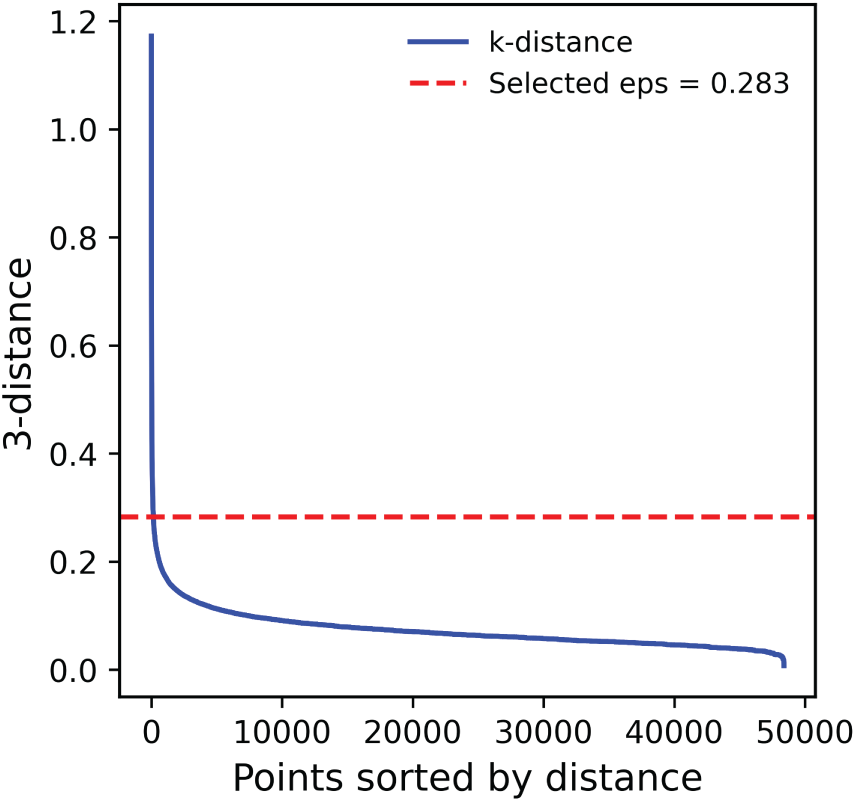
Figure 4: Improved k-distance curve (k = 3) used to estimate the DBSCAN clustering parameter eps.
The min_samples parameter in DBSCAN strongly affects clustering stability and accuracy. Three values (5, 7, 9) were evaluated (Table 1). With min_samples = 5, 12 clusters were formed, the silhouette coefficient was 0.343, and the noise ratio was 0.2%. Increasing to 7 reduced clusters to 10 and raised the silhouette coefficient to 0.376, with noise at 0.3%. At 9, clusters increased to 11, the silhouette coefficient dropped to 0.364, and noise remained 0.3%. Based on these quantitative comparisons, min_samples = 7 was selected as the final setting, as it provides the best trade-off between clustering stability, silhouette score, and noise ratio, and is adopted throughout the proposed framework.

DBSCAN clustering of traffic flow data, using k = 3, ε = 0.283, and min_samples = 7, produced 10 distinct traffic state clusters and several noise points. As shown in Table 2, clusters differed notably in data volume, average flow, and speed. Cluster 3 had the highest flow (321.33 Veh/5 min), representing weekday evening peak congestion. Cluster 0 had the lowest flow (121.45 Veh/5 min) with a mean occurrence of 3.46 h, reflecting nighttime and early morning free-flow. Clusters 4 and 9 showed moderate flow and high speeds (58.80 and 59.06 mph), typical of off-peak free-flow states.
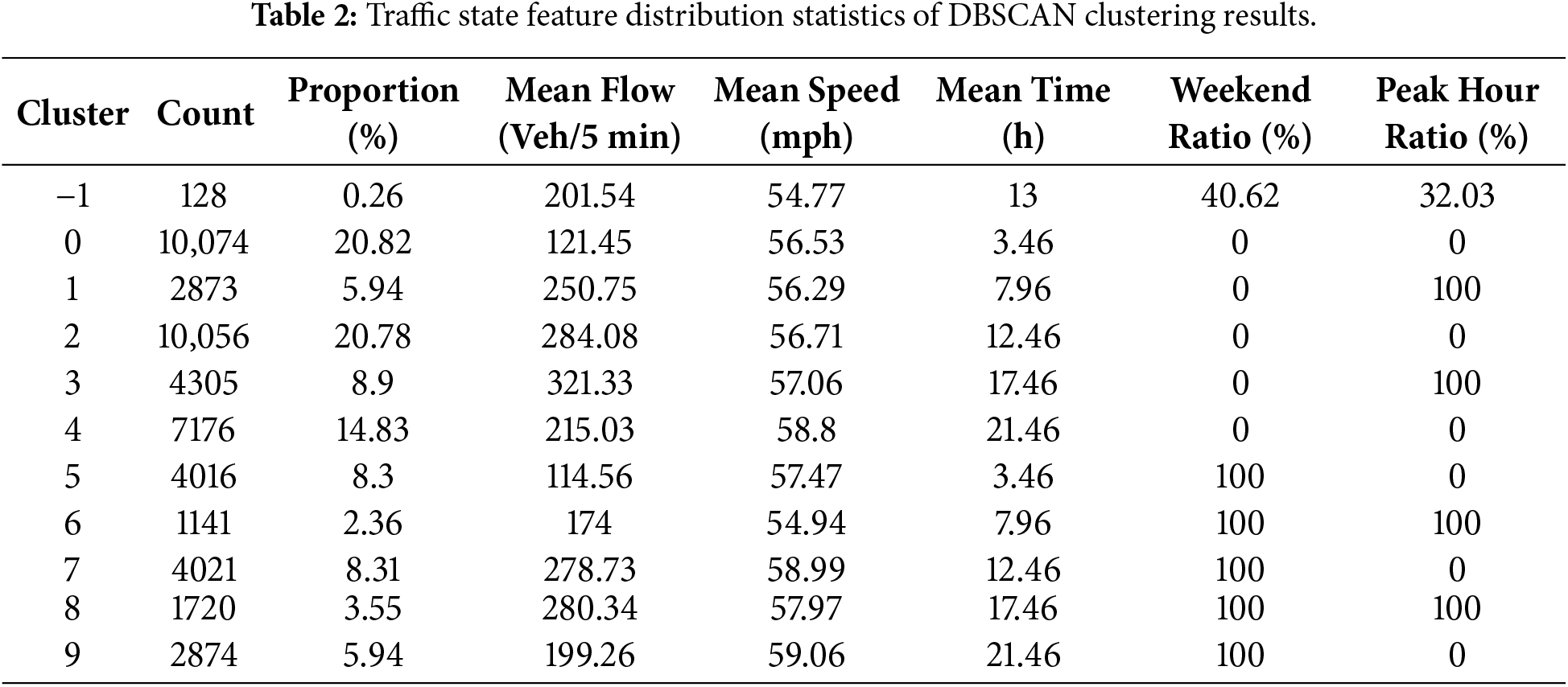
As shown in Fig. 5, the clustering results reveal clear intra-day and intra-week temporal patterns. On weekdays, commuting peaks around 7–9 a.m. and 17–19 p.m. are mainly associated with Clusters 1 and 3, which correspond to high-volume, low-speed traffic states. In contrast, weekend and holiday samples are predominantly distributed across Clusters 5–9 during non-peak periods, reflecting distinct travel behaviors. This distribution is consistent with the statistics in Table 2, where Clusters 1 and 3 occur almost exclusively during weekday peak hours, while Clusters 5–9 dominate non-weekday periods. The overall silhouette coefficient reaches 0.376, indicating reasonably compact clusters with acceptable inter-cluster separation. As illustrated in Fig. 6, Clusters 2, 3, 4, and 7 exhibit well-defined boundaries with silhouette values mainly in the 0.3–0.5 range. Although Cluster 0 contains more samples and shows slightly higher dispersion, its silhouette values remain predominantly positive, supporting the validity of the clustering results. Overall, these results confirm the robustness of DBSCAN for capturing representative traffic flow states and provide reliable state labels for subsequent Mamba–Transformer modeling.
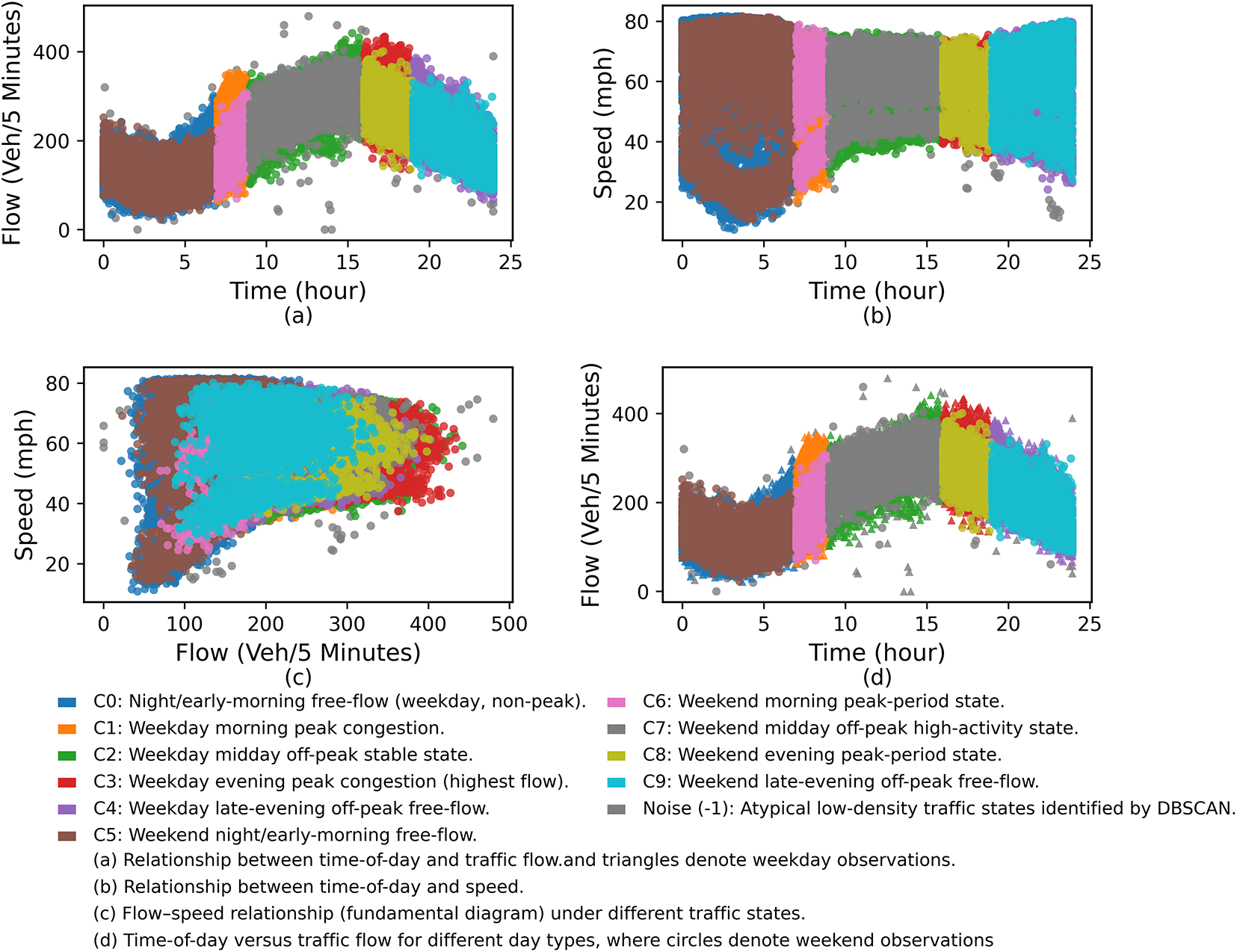
Figure 5: Traffic characteristics visualization of DBSCAN clustering results: time, flow, speed, and weekday-weekend comparison.
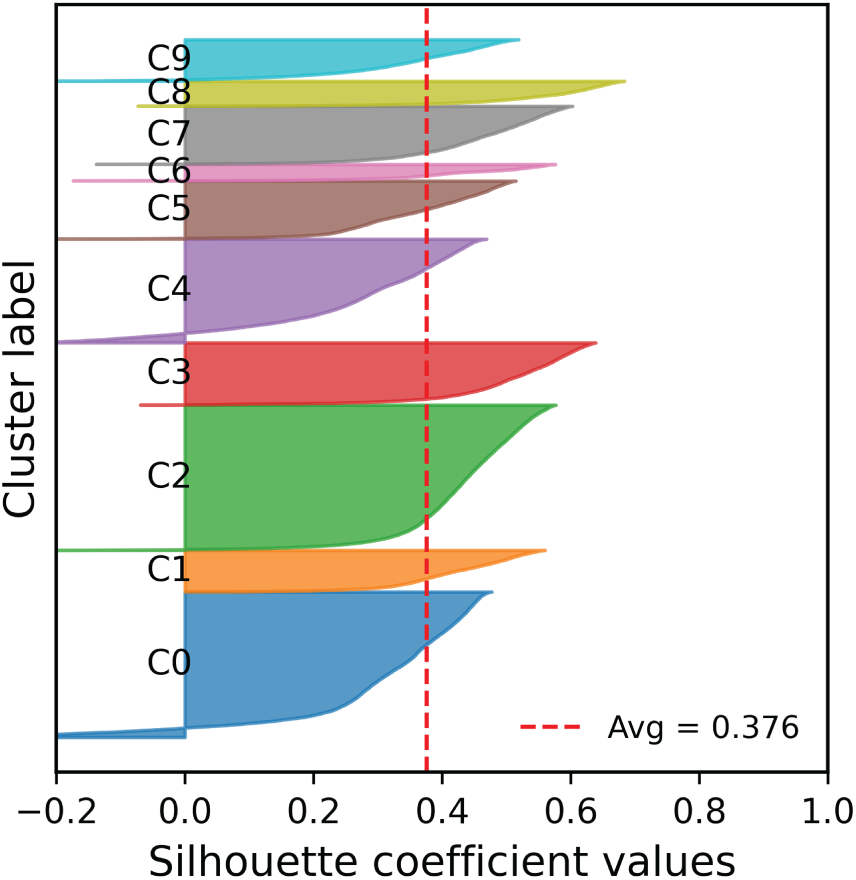
Figure 6: Silhouette coefficient distribution of DBSCAN clustering results.
To evaluate the DBSCAN-enhanced Mamba-Transformer model for traffic flow prediction, five baseline models were selected: DLinear, Autoformer, Crossformer, ETSformer, and Transformer. All models were tested under 5, 10, 30, and 60-min prediction horizons to assess performance across temporal scales.
(1) DLinear [37] decomposes input sequences into trend and seasonal components via moving averages, models each with linear layers, and sums the results.
(2) Autoformer [38] incorporates trend decomposition and auto-correlation attention to capture repeating patterns in extended sequences.
(3) Crossformer [39] applies dual-stage attention to temporal and variable dimensions, enhancing cross-scale sequence modeling through segmented fusion.
(4) ETSformer [40] integrates exponential smoothing and frequency-domain modeling with smoothing modules, Fourier transforms, and damping mechanisms.
(5) Transformer [41] is implemented with flow, speed, and temporal embeddings in a full encoder-decoder structure as a performance benchmark.
The DBSCAN-clustered traffic flow data were standardized using StandardScaler to normalize numerical features, while cluster labels were encoded with OneHotEncoder as categorical inputs. The input sequence length was set to 96 (8 h of historical data) to predict traffic volumes at 5-, 10-, 30-, and 60-min horizons. The input features consisted of traffic flow variables and one-hot encoded cluster labels. The model was trained using the Adam optimizer with a learning rate of 1e−4 and mean squared error (MSE) loss for 100 epochs with a batch size of 32. Key hyperparameters are summarized in Table 3. Training converged stably after 20 epochs (Fig. 7). A fixed learning rate was used without early stopping, and model parameters from the final epoch were adopted for evaluation.

Figure 7: Training loss curves for 5-, 10-, 30-, and 60-min traffic flow prediction horizons.
Table 4 compares the proposed Mamba-Transformer with five baseline models across four prediction horizons (5, 10, 30, and 60 min) using MSE, RMSE, MAE, and MAPE. Overall, Mamba-Transformer consistently achieves the lowest errors and exhibits the smallest performance degradation as the prediction horizon increases, indicating stable and robust predictive capability. In the 5-min forecast, Mamba-Transformer attains an MSE of 414.36 and a MAPE of 9.12%, substantially outperforming the weakest baseline, Autoformer (MSE = 808.55, MAPE = 15.29%). This advantage persists at the 10-min horizon, where Mamba-Transformer maintains low errors (MSE = 424.74, MAPE = 9.30%), while Autoformer degrades to an MSE of 955.67 and a MAPE of 16.63%. As the horizon extends to 30 and 60 min, the performance gap further widens: Mamba-Transformer remains stable (MAPE < 10%), whereas Autoformer deteriorates sharply, with MSE increasing from 1418.51 to 2332.37 and MAPE rising from 20.30% to 26.22%. These results demonstrate the superior robustness of the proposed model for both short-term and long-term traffic flow prediction.
Autoformer exhibits relatively weaker performance across all horizons in Table 4, primarily due to its emphasis on long-term trend decomposition and autocorrelation modeling. As the dataset focuses on short- to medium-term forecasting (5–60 min) with frequent high-frequency fluctuations, Autoformer tends to over-smooth short-term dynamics. The performance gap is attributed to model–data mismatch, not implementation factors.
To assess the reliability of these results, multiple runs with different random seeds were conducted under identical data splits, training procedures, and hyperparameters. As summarized in Table 5, the proposed Mamba–Transformer shows low variance across all horizons, with small standard deviations in both MSE and MAPE, confirming that the performance improvements are stable and reproducible.
Overall, Mamba-Transformer achieved MSE < 500 across all horizons, while most baselines exceeded 600 (and > 1000 beyond 30 min). Its MAPE remained stable at 9%–9.8%, whereas others generally exceeded 10%, with Autoformer reaching 26.22%. These results indicate that Mamba-Transformer delivers high accuracy and robustness in medium- to long-term traffic flow forecasting.
To further substantiate the robustness and accuracy observed in the quantitative results, Figs. 8–11 provide a horizon-wise qualitative comparison. In the 5-min prediction task (Figs. 8 and 9), the proposed Mamba–Transformer closely overlaps with the ground truth, exhibiting minimal phase shift and amplitude bias. In contrast, Crossformer and DLinear show smoothing effects that underestimate peaks and high-frequency variations, while Autoformer exhibits more pronounced lag and over-smoothing. When the prediction horizon extends to 60 min (Figs. 10 and 11), performance differences become more evident. The Mamba–Transformer remains closely aligned with the ground truth and preserves major fluctuation patterns, whereas Autoformer shows trend drift and amplitude distortion, and Crossformer, ETSformer, and DLinear exhibit increasing phase misalignment or peak underestimation. It should be noted that Figs. 9 and 11 present representative continuous segments of the test set rather than the entire evaluation period; therefore, localized deviations observed in some baseline models do not contradict their overall quantitative performance, which is averaged over the full test horizon.
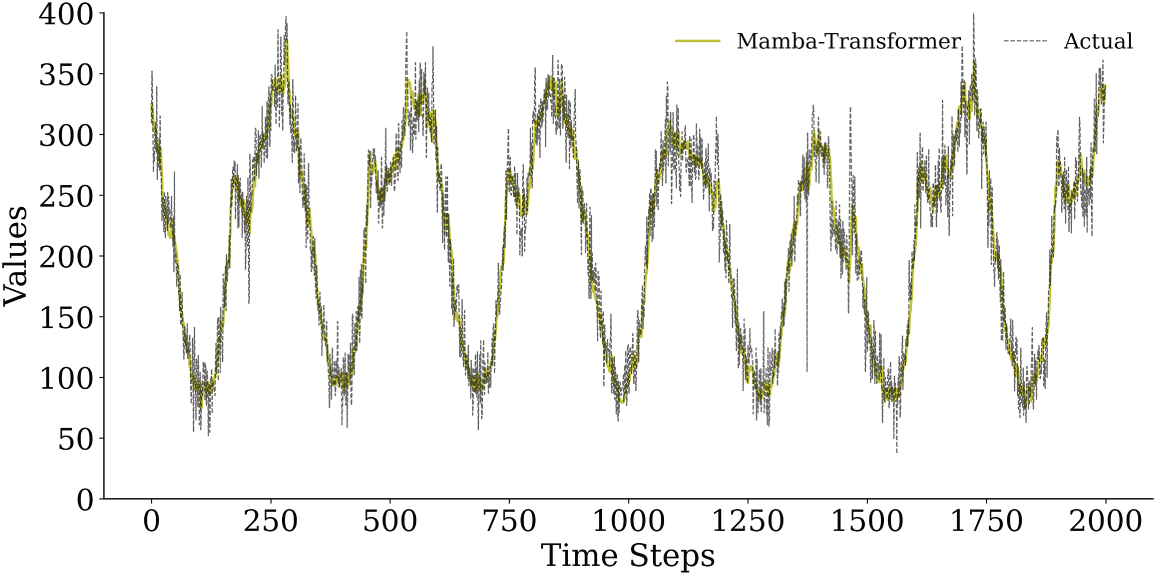
Figure 8: Comparison of the prediction curves of Mamba-Transformer and actual traffic flow in the 5-min prediction task (first 2000 time steps).
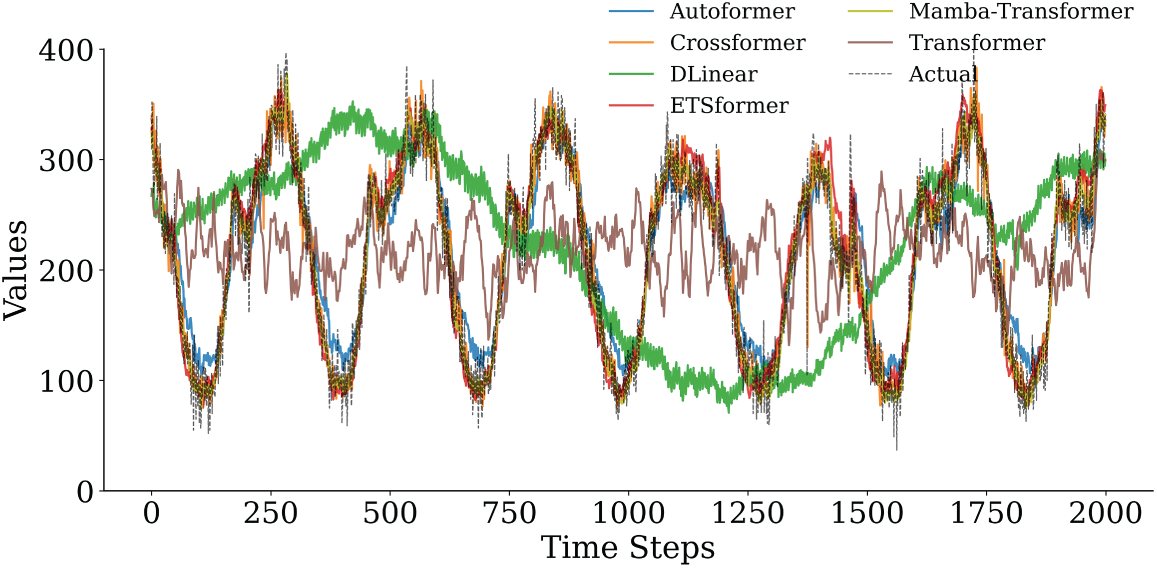
Figure 9: Comparison of the prediction performance of various models in the 5-min prediction task (first 2000 time steps).
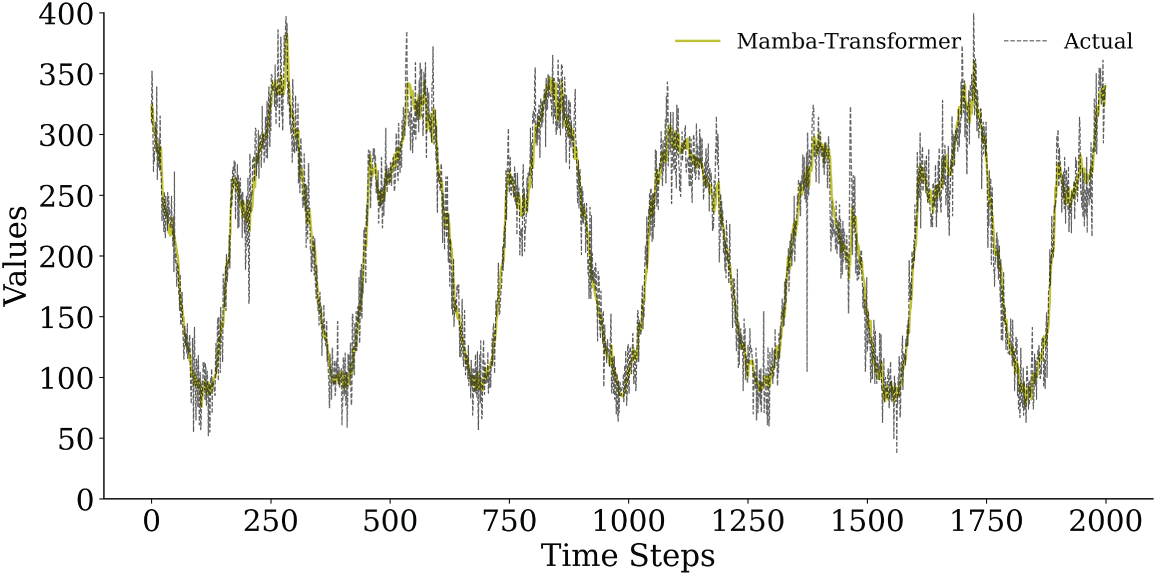
Figure 10: Comparison of the prediction curves of Mamba-Transformer and actual traffic flow in the 60-min prediction task (first 2000 time steps).
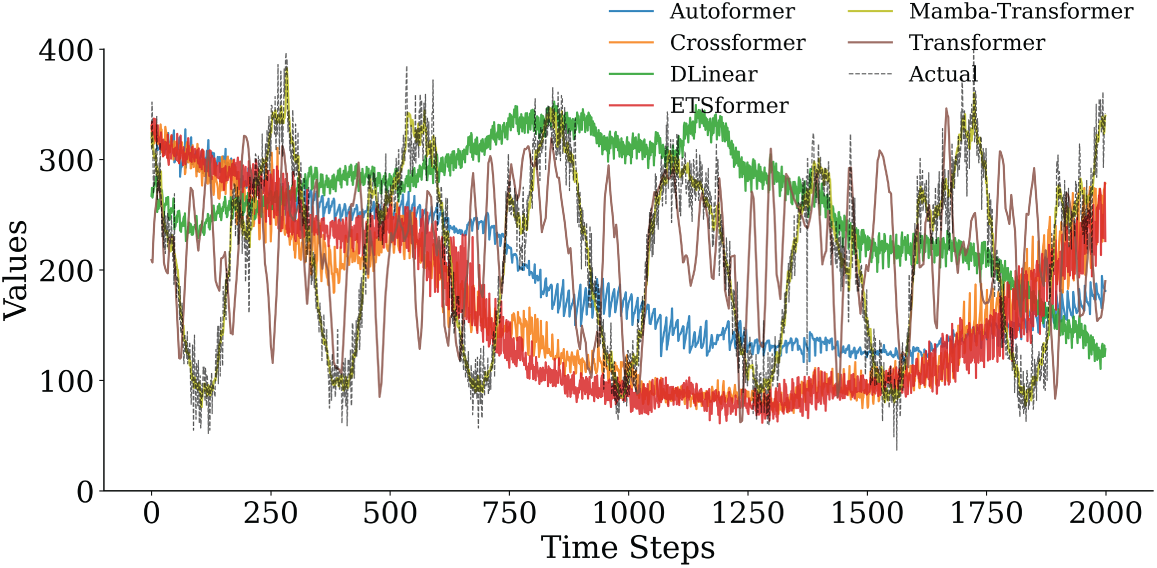
Figure 11: Comparison of prediction performance of various models in a 60-min prediction task (first 2000 time steps).
To assess the contribution of individual components in the proposed Mamba–Transformer framework, three ablation experiments were conducted by sequentially removing the DBSCAN preprocessing module, Mamba, and Transformer modules while keeping other parts unchanged. In the 5-min prediction task (Fig. 12), the complete model achieved an MSE of 414.3574, RMSE of 20.3558, MAE of 15.7857, and MAPE of 9.1176%, consistently outperforming all variants with a removed module.
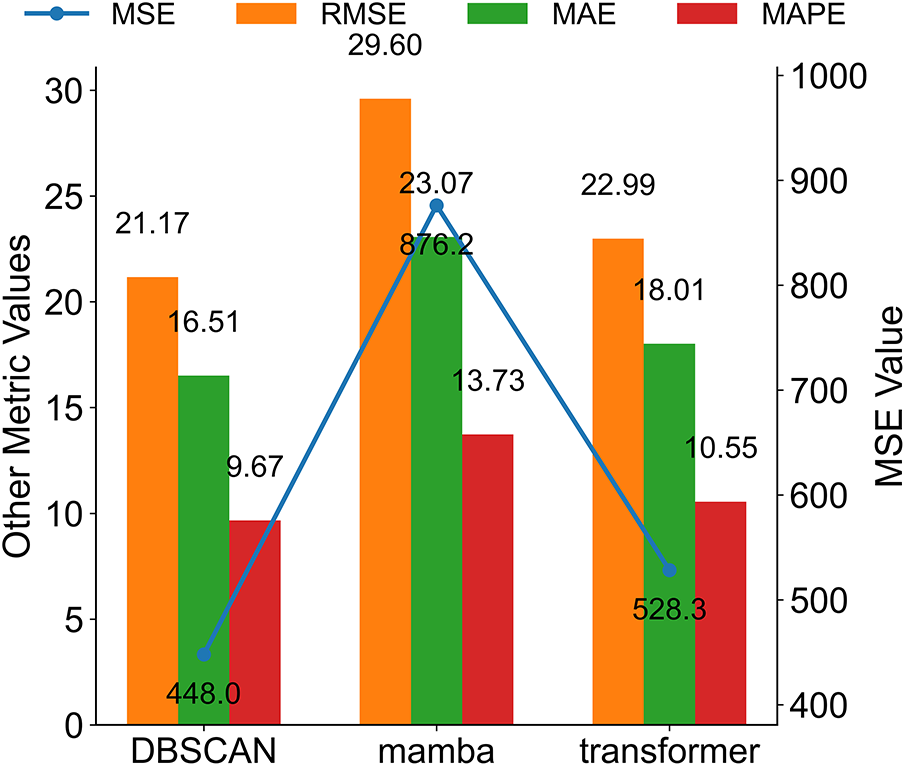
Figure 12: Comparison of various evaluation indicators of the Mamba-Transformer model ablation experiment in 5-min prediction.
Fig. 13 illustrates the performance degradation after removing the DBSCAN clustering module. Without structured preprocessing, the model becomes more sensitive to noise and local fluctuations, resulting in higher prediction errors (MSE = 447.97, MAPE = 9.67%). Compared with the complete model, DBSCAN reduces the MSE by approximately 7.5% and the MAPE by about 5.7%, indicating stable gains from clustering-based denoising and traffic-state aggregation. As DBSCAN mainly operates at the input level, its contribution leads to incremental but consistent improvements rather than drastic accuracy changes. Fig. 14 presents the largest performance drop when the Mamba module is removed. Although the Transformer remains for long-term modeling, the lack of local dynamic modeling markedly reduces the ability to capture fine-grained traffic variations, with MSE rising to 876.2125 and MAPE to 13.7288%. This result highlights the critical role of Mamba in short-term dependency modeling and rapid fluctuation characterization through efficient selective state propagation. Fig. 15 presents the impact of removing the Transformer. While Mamba preserves local temporal modeling, the lack of global attention weakens long-range trend perception and cross-horizon stability, leading to increased errors (MSE = 528.33, MAPE = 10.55%). This suggests that the Transformer primarily contributes to global contextual consistency and long-term trend regulation rather than point-wise accuracy. Overall, the ablation results confirm the complementary roles of the three components: DBSCAN enhances input quality, Mamba captures high-resolution temporal dynamics, and the Transformer maintains global consistency, together ensuring robust predictive performance.
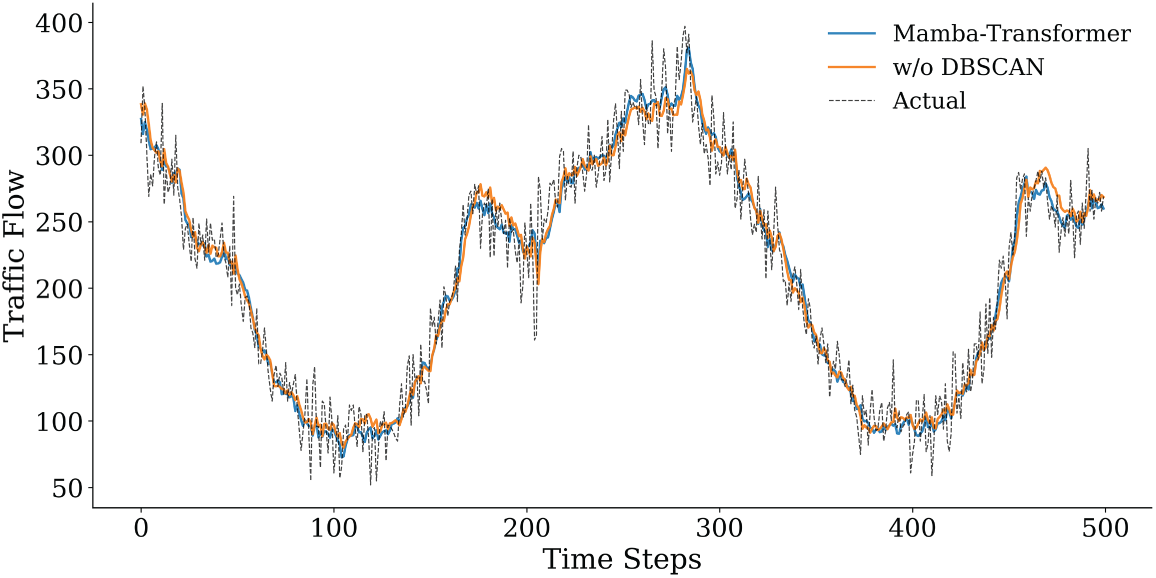
Figure 13: Comparison of prediction results after removing the DBSCAN clustering module and the original model (first 500 time steps).
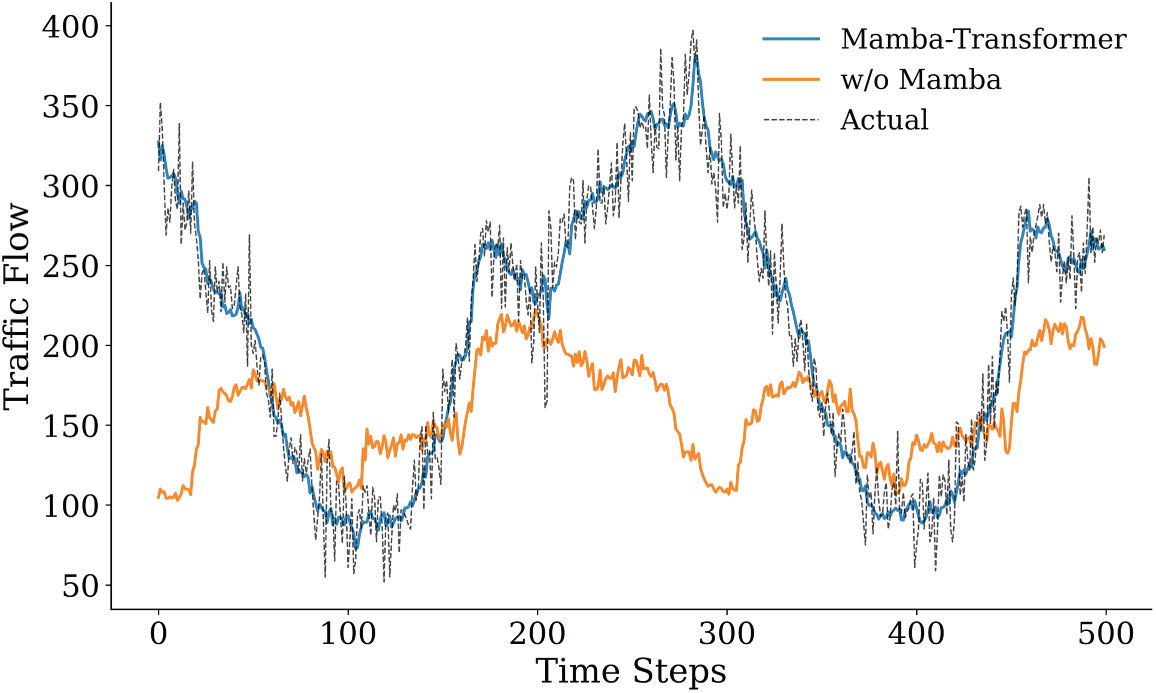
Figure 14: Comparison of prediction results after removing the Mamba module and the original model (first 500 time steps).
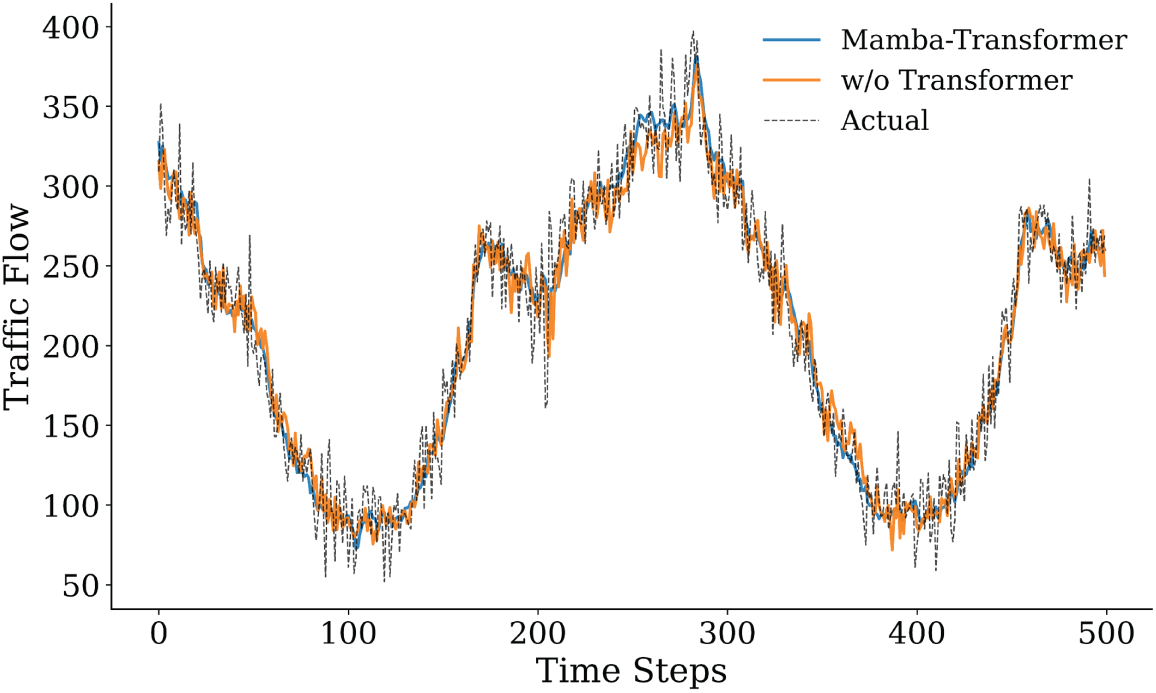
Figure 15: Comparison of prediction results after removing the Transformer module and the original model (first 500 time steps).
The proposed DBSCAN–Mamba–Transformer framework demonstrates stable error control across multiple prediction horizons, which can be attributed to the complementary roles of its three components in modeling different aspects of traffic flow dynamics. DBSCAN-based preprocessing enhances the structural separability of input features by aggregating similar traffic states and filtering noise, thereby stabilizing the input distribution and leading to consistent, though not exaggerated, performance gains. As this module operates at the input level, its primary contribution lies in improving robustness rather than inducing drastic accuracy changes. The Mamba module plays a key role in capturing short-term fluctuations through selective state-space updates, which preserves fine-grained temporal information under high-frequency variations and transient disturbances. In parallel, the Transformer component focuses on modeling long-range temporal dependencies and periodic patterns via attention mechanisms over extended contexts, supporting temporal consistency as the prediction horizon increases. The coordinated interaction between local dynamic modeling and global dependency learning helps mitigate error accumulation in medium- and long-term forecasting scenarios.
Experimental results validate the effectiveness of this hybrid approach. The proposed model consistently achieved lower error metrics than all baseline models across the 5-, 10-, 30-, and 60-min horizons, and it exhibited the smallest performance degradation as the forecast horizon extended. For instance, while certain baseline methods experienced sharp error increases at 30 and 60 min, our DBSCAN–Mamba–Transformer kept the 60-min horizon MSE below 500, and its MAPE remained around 9%–10% across all horizons. In contrast, a baseline model like Autoformer saw its 60-min MAPE rise above 26%. These findings highlight the framework’s superior accuracy and robustness for both short-term and long-term traffic flow prediction tasks. Qualitatively, the predicted traffic trajectories from our model closely tracked the actual observed patterns, capturing peak volumes and abrupt changes with minimal lag. Other models (e.g., DLinear and Crossformer) tended to smooth out these peaks or exhibit noticeable delays, underscoring the advantage of our approach in handling rapid fluctuations without sacrificing overall trend fidelity.
Ablation experiments confirmed the complementary contributions of each component. Removing the Mamba module caused the most significant performance degradation—nearly doubling the 60-min prediction MSE and raising the MAPE from roughly 9% to 13.7%—which emphasizes the critical importance of fine-grained short-term modeling. Excluding the Transformer resulted in a moderate increase in error (for example, the 60-min MAPE rose to about 10.5%), indicating that global attention primarily bolsters long-range consistency. Removing the DBSCAN preprocessing had the smallest effect on accuracy, with MAPE rising only slightly (to approximately 9.7%), reflecting its role in providing incremental yet consistent improvements. Together, these results verify that each component addresses a distinct aspect of the forecasting challenge, and their integration is necessary to achieve the model’s full performance benefits.
This study presents a hybrid traffic flow forecasting framework that integrates DBSCAN-based clustering, Mamba state-space modeling, and Transformer-based attention to address the challenges of noisy inputs, short-term fluctuations, and long-term dependencies. By embedding static traffic-state priors and combining local dynamic modeling with global temporal learning, the framework achieves structurally coordinated and temporally consistent predictions across multiple horizons. Empirical results on 5-, 10-, 30-, and 60-min forecasts demonstrate that the proposed model maintains high accuracy and cross-horizon stability. It consistently achieves mean squared error (MSE) below 500 and mean absolute percentage error (MAPE) under 10%, even at longer horizons, indicating strong robustness to error accumulation and temporal drift. These results confirm the model’s effectiveness in delivering reliable, multi-scale traffic forecasting for intelligent transportation systems.
The current study has several limitations. The use of a single-region dataset may limit generalizability to broader traffic environments. In addition, the DBSCAN module is static and sensitive to feature design, and the model does not currently provide uncertainty estimates. Future work will focus on incorporating adaptive online clustering, integrating external influencing factors such as weather or events, and introducing uncertainty-aware prediction techniques to enhance the model’s adaptability and practical value in real-world applications.
Acknowledgement: None.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, methodology, validation, formal analysis, writing—original draft, supervision: Qinglei Zhang; Conceptualization, validation, writing—review & editing, supervision: Zhenzhen Wang; Formal analysis, data curation, visualization: Jianguo Duan; Software, investigation, resources: Jiyun Qin; Validation, writing—review & editing: Ying Zhou. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data supporting the findings of this study are publicly available at the GitHub repository: https://github.com/suprobe/AT-Conv-LSTM/tree/master/data-urban (Reference No. 401137).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Liu S, Wang X. An improved transformer based traffic flow prediction model. Sci Rep. 2025;15(1):8284. doi:10.1038/s41598-025-92425-7. [Google Scholar] [PubMed] [CrossRef]
2. Boukerche A, Tao Y, Sun P. Artificial intelligence-based vehicular traffic flow prediction methods for supporting intelligent transportation systems. Comput Netw. 2020;182(6):107484. doi:10.1016/j.comnet.2020.107484. [Google Scholar] [CrossRef]
3. Kubek D, Więcek P, Chwastek K. The impact of short term traffic forecasting on the effectiveness of vehicles routes planning in urban areas. Transp Res Procedia. 2016;18(1):172–9. doi:10.1016/j.trpro.2016.12.024. [Google Scholar] [CrossRef]
4. Boukerche A, Wang J. Machine learning-based traffic prediction models for intelligent transportation systems. Comput Netw. 2020;181(3):107530. doi:10.1016/j.comnet.2020.107530. [Google Scholar] [CrossRef]
5. Van Der Voort M, Dougherty M, Watson S. Combining kohonen maps with ARIMA time series models to forecast traffic flow. Transp Res Part C Emerg Technol. 1996;4(5):307–18. doi:10.1016/S0968-090X(97)82903-8. [Google Scholar] [CrossRef]
6. Williams BM, Hoel LA. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: theoretical basis and empirical results. J Transp Eng. 2003;129(6):664–72. doi:10.1061/(asce)0733-947x(2003)129:6(664). [Google Scholar] [CrossRef]
7. Castro-Neto M, Jeong YS, Jeong MK, Han LD. Online-SVR for short-term traffic flow prediction under typical and atypical traffic conditions. Expert Syst Appl. 2009;36(3):6164–73. doi:10.1016/j.eswa.2008.07.069. [Google Scholar] [CrossRef]
8. Ma X, Tao Z, Wang Y, Yu H, Wang Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp Res Part C Emerg Technol. 2015;54(2):187–97. doi:10.1016/j.trc.2015.03.014. [Google Scholar] [CrossRef]
9. Sun P, Boukerche A, Tao Y. SSGRU: a novel hybrid stacked GRU-based traffic volume prediction approach in a road network. Comput Commun. 2020;160(22):502–11. doi:10.1016/j.comcom.2020.06.028. [Google Scholar] [CrossRef]
10. Reza S, Ferreira MC, Machado JJM, Tavares JMRS. A multi-head attention-based transformer model for traffic flow forecasting with a comparative analysis to recurrent neural networks. Expert Syst Appl. 2022;202(18):117275. doi:10.1016/j.eswa.2022.117275. [Google Scholar] [CrossRef]
11. Zong F, Wang SQ, Qin YZ, Zeng M. Analyzing the short- and long-term car-following behavior in multiple factor coupled scenarios. Expert Syst Appl. 2025;272(4):126724. doi:10.1016/j.eswa.2025.126724. [Google Scholar] [CrossRef]
12. Chang A, Ji Y, Bie Y. Transformer-based short-term traffic forecasting model considering traffic spatiotemporal correlation. Front Neurorobot. 2025;19:1527908. doi:10.3389/fnbot.2025.1527908. [Google Scholar] [PubMed] [CrossRef]
13. Li G, Zhong S, Deng X, Xiang L, Gary Chan SH, Li R, et al. A lightweight and accurate spatial-temporal transformer for traffic forecasting. IEEE Trans Knowl Data Eng. 2023;35(11):10967–80. doi:10.1109/TKDE.2022.3233086. [Google Scholar] [CrossRef]
14. Wei S, Yang Y, Liu D, Deng K, Wang C. Transformer-based spatiotemporal graph diffusion convolution network for traffic flow forecasting. Electronics. 2024;13(16):3151. doi:10.3390/electronics13163151. [Google Scholar] [CrossRef]
15. He X, Zhang W, Li X, Zhang X. TEA-GCN: transformer-enhanced adaptive graph convolutional network for traffic flow forecasting. Sensors. 2024;24(21):7086. doi:10.3390/s24217086. [Google Scholar] [PubMed] [CrossRef]
16. Huang J, Yan H, Chen Q, Liu Y. Multi-granularity temporal embedding transformer network for traffic flow forecasting. Sensors. 2024;24(24):8106. doi:10.3390/s24248106. [Google Scholar] [PubMed] [CrossRef]
17. Luo Q, He S, Han X, Wang Y, Li H. LSTTN: a long-short term transformer-based spatiotemporal neural network for traffic flow forecasting. Knowl Based Syst. 2024;293(2):111637. doi:10.1016/j.knosys.2024.111637. [Google Scholar] [CrossRef]
18. Xiao J, Long B. A multi-channel spatial-temporal transformer model for traffic flow forecasting. Inf Sci. 2024;671(4):120648. doi:10.1016/j.ins.2024.120648. [Google Scholar] [CrossRef]
19. Qi J, Fan H. Routeformer: transformer utilizing routing mechanism for traffic flow forecasting. Neurocomputing. 2025;633(2):129753. doi:10.1016/j.neucom.2025.129753. [Google Scholar] [CrossRef]
20. Chen X, Ma F, Wu Y, Han B, Luo L, Biancardo SA. MFMDepth: metaFormer-based monocular metric depth estimation for distance measurement in ports. Comput Ind Eng. 2025;207(4):111325. doi:10.1016/j.cie.2025.111325. [Google Scholar] [CrossRef]
21. Cheng S, Qu S, Zhang J. Transfer-Mamba: selective state space models with spatio-temporal knowledge transfer for few-shot traffic prediction across cities. Simul Model Pract Theory. 2025;140(6):103066. doi:10.1016/j.simpat.2025.103066. [Google Scholar] [CrossRef]
22. Tang Y, Dong P, Tang Z, Chu X, Liang J. VMRNN: integrating vision mamba and LSTM for efficient and accurate spatiotemporal forecasting. In: Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2024 Jun 17–18; Seattle, WA, USA. p. 5663–73. doi:10.1109/CVPRW63382.2024.00575. [Google Scholar] [CrossRef]
23. Zong F, Yue S, Zeng M, He Z, Ngoduy D. Platoon or individual: an adaptive car-following control of connected and automated vehicles. Chaos Solitons Fractals. 2025;191(5):115850. doi:10.1016/j.chaos.2024.115850. [Google Scholar] [CrossRef]
24. Zong F, Yue S, Zeng M, Liu Y, Tang J. Environment reconstruction and trajectory planning for automated vehicles driving through signal intersection. Phys A Stat Mech Appl. 2025;660(8):130323. doi:10.1016/j.physa.2024.130323. [Google Scholar] [CrossRef]
25. Shi Y, Deng M, Gong J, Lu CT, Yang X, Liu H. Detection of clusters in traffic networks based on spatio-temporal flow modeling. Trans GIS. 2019;23(2):312–33. doi:10.1111/tgis.12521. [Google Scholar] [CrossRef]
26. Zhang Y, Han LD, Kim H. Dijkstra’s-DBSCAN: fast, accurate, and routable density based clustering of traffic incidents on large road network. Transp Res Rec J Transp Res Board. 2018;2672(45):265–73. doi:10.1177/0361198118796071. [Google Scholar] [CrossRef]
27. Cesario E, Lindia P, Vinci A. A scalable multi-density clustering approach to detect city hotspots in a smart city. Future Gener Comput Syst. 2024;157(8):226–36. doi:10.1016/j.future.2024.03.042. [Google Scholar] [CrossRef]
28. Tang J, Bi W, Liu F, Zhang W. Exploring urban travel patterns using density-based clustering with multi-attributes from large-scaled vehicle trajectories. Phys A Stat Mech Appl. 2021;561:125301. doi:10.1016/j.physa.2020.125301. [Google Scholar] [CrossRef]
29. Méndez M, Merayo MG, Núñez M. Long-term traffic flow forecasting using a hybrid CNN-BiLSTM model. Eng Appl Artif Intell. 2023;121(2):106041. doi:10.1016/j.engappai.2023.106041. [Google Scholar] [CrossRef]
30. Sattarzadeh AR, Kutadinata RJ, Pathirana PN, Huynh VT. A novel hybrid deep learning model with ARIMA Conv-LSTM networks and shuffle attention layer for short-term traffic flow prediction. Transp A Transp Sci. 2025;21(1):2236724. doi:10.1080/23249935.2023.2236724. [Google Scholar] [CrossRef]
31. Geng Z, Xu J, Wu R, Zhao C, Wang J, Li Y, et al. STGAFormer: spatial-temporal Gated Attention Transformer based graph neural network for traffic flow forecasting. Inf Fusion. 2024;105(6):102228. doi:10.1016/j.inffus.2024.102228. [Google Scholar] [CrossRef]
32. Ren Q, Li Y, Liu Y. Transformer-enhanced periodic temporal convolution network for long short-term traffic flow forecasting. Expert Syst Appl. 2023;227(8):120203. doi:10.1016/j.eswa.2023.120203. [Google Scholar] [CrossRef]
33. Bing Q, Zhao P, Ren C, Wang X, Zhao Y. Short-term traffic flow forecasting method based on secondary decomposition and conventional neural network-transformer. Sustainability. 2024;16(11):4567. doi:10.3390/su16114567. [Google Scholar] [CrossRef]
34. Shao Q, Piao X, Yao X, Kong Y, Hu Y, Yin B, et al. An adaptive composite time series forecasting model for short-term traffic flow. J Big Data. 2024;11(1):102. doi:10.1186/s40537-024-00967-w. [Google Scholar] [CrossRef]
35. Du S, Li T, Gong X, Horng SJ. A hybrid method for traffic flow forecasting using multimodal deep learning. Int J Comput Intell Syst. 2020;13(1):85–97. doi:10.2991/ijcis.d.200120.001. [Google Scholar] [CrossRef]
36. Zheng H, Lin F, Feng X, Chen Y. A hybrid deep learning model with attention-based conv-LSTM networks for short-term traffic flow prediction. IEEE Trans Intell Transp Syst. 2021;22(11):6910–20. doi:10.1109/TITS.2020.2997352. [Google Scholar] [CrossRef]
37. Zeng A, Chen M, Zhang L, Xu Q. Are transformers effective for time series forecasting? Proc AAAI Conf Artif Intell. 2023;37(9):11121–8. doi:10.1609/aaai.v37i9.26317. [Google Scholar] [CrossRef]
38. Wu H, Xu J, Wang J, Long M. Autoformer: decomposition transformers with auto-correlation for long-term series forecasting. Adv Neural Inf Process Syst. 2021;34:22419–30. [Google Scholar]
39. Zhang Y, Yan J. Crossformer: transformer utilizing cross-dimension dependency for multivariate time series forecasting. In: Proceedings of the Eleventh International Conference on Learning Representations; 2023 May 1–5; Kigali, Rwanda. [Google Scholar]
40. Woo G, Liu C, Sahoo D, Kumar A, Hoi S. ETSformer: exponential smoothing transformers for time-series forecasting. arXiv:2202.01381. 2022. [Google Scholar]
41. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017); 2017 Dec 4–9; Long Beach, CA, USA. [Google Scholar]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools