
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Privacy-Preserving Parallel Non-Negative Matrix Factorization with Edge Computing
1 College of Computer Science and Technology, Qingdao University, Qingdao, China
2 School of Information Science and Engineering, Linyi University, Linyi, China
* Corresponding Authors: Rong Hao. Email: ; Jia Yu. Email:
Computers, Materials & Continua 2026, 87(3), 14 https://doi.org/10.32604/cmc.2026.076731
Received 25 November 2025; Accepted 27 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Non-negative Matrix Factorization (NMF) is a computationally intensive matrix operation that resource-constrained clients struggle to complete locally. Privacy-preserving outsourcing allows clients to offload heavy computing tasks to powerful servers, effectively solving the problem of local computing difficulties. However, the existing privacy-preserving NMF outsourcing schemes only allow one server to perform outsourcing computation, resulting in low efficiency on the server side. In order to improve the efficiency of outsourcing computation, we propose a privacy-preserving parallel NMF outsourcing scheme with multiple edge servers. We adopt the matrix blocking technique to divide the computation task into multiple subtasks, and design the NMF parallel computation algorithm based on the multiplication updating rule. The proposed scheme implements the parallel outsourcing of non-negative matrix factorization based on multiple edge servers. We use random permutation matrices to encrypt original matrix, thereby protecting data privacy. In addition, we utilize the iterative nature of the NMF algorithm for result verification. Theoretical analysis and experimental results prove the advantages of the proposed scheme.Keywords
Today’s society is increasingly driven by big data. With the widespread adoption of the internet, the volume of generated data is growing exponentially, with vast amounts of information being produced every second. The storage, processing, and analysis of this data have become one of the most significant challenges of modern society. Dimensionality reduction techniques play a crucial role in addressing these challenges by converting high-dimensional data into lower-dimensional representations while retaining key information from the original dataset. This is particularly important when dealing with large-scale data. Since most commonly encountered data, such as images and documents, are non-negative, it is essential to address the processing of non-negative data [1]. Non-negative Matrix Factorization (NMF), a widely used dimensionality reduction method, decomposes a non-negative matrix into the product of two non-negative matrices, enabling the efficient extraction of underlying features from the data. NMF has been successfully applied in data mining [2], image processing [3], and text analysis [4,5], offering advantages such as high stability and reduced storage requirements. Compared to other matrix factorization methods, NMF provides interpretable decomposition results and significantly reduces storage space [6]. However, as the scale of data continues to grow, the computational cost of NMF also increases. For clients with limited computing resources, performing NMF on large-scale datasets becomes a challenging task.
Edge computing, as an emerging computational paradigm, effectively addresses the challenges of large-scale data processing and has gained popularity in the Internet of Things (IoT). Unlike the traditional cloud computing that relies on remote data centers, edge computing allows client to offload computational tasks to edge servers located near the data source. This reduces the need for large data transfers to remote servers, saving bandwidth and reducing latency. Client offloading computational tasks to multiple edge servers can significantly reducing the client’s computational overhead and improving efficiency. By enabling multiple edge servers to execute computing tasks in parallel, productivity can be significantly boosted. Despite its significant benefits, edge computing also faces several challenges. When the client outsources the computational task to the edge servers, both the data and computations performed on the server side fall outside the client’s direct control. One of the primary concerns is ensuring data privacy. Data often involves sensitive information, such as personal medical records [7], making privacy protection crucial. Additionally, edge servers may engage in malicious activities, such as falsifying computation results, which requires reliable verification mechanisms to ensure the accuracy of the results [8].
Secure outsourcing computation refers to outsourcing computational tasks to service providers while ensuring data privacy and the correctness of the computation results [9]. In a secure outsourcing computation scheme based on edge servers, both the privacy of the client’s input and output must be adequately protected [10], ensuring that the edge servers cannot gain any valuable information about the client from the outsourced tasks. At the same time, the client should be able to verify the correctness of the computation results returned by the edge servers. This guarantees that the results are accurate and protects against data leakage or result tampering. Furthermore, the client’s local computational overhead in secure outsourcing should be significantly lower than the computational overhead of the original task.
In recent years, several secure outsourcing computation schemes for NMF have been proposed [11,12]. These schemes allow clients to securely outsource NMF tasks to the cloud server. However, none of these schemes support parallel outsourcing across multiple edge servers. Actually, it is common for multiple edge servers to assist in computations. Meanwhile, most existing schemes focus on client side efficiency, they often neglect server-side efficiency. How to enhance server efficiency based on parallel computing is a significant challenge. To address this challenge, we aim to develop a novel privacy-preserving parallel NMF outsourcing scheme.
In recent years, secure outsourcing computation has been widely concerned by people. Research on secure outsourcing of matrix-related computations is quite common. Lei et al. [13] proposed a secure outsourcing scheme for matrix inversion computation (MIC). They utilized the random permutation matrix to transform the original matrix and employed the Monte Carlo algorithm for verification. Later, Lei et al. [14] proposed a scheme to outsource large-scale matrix multiplication calculation. The encryption and verification were similar with the previous scheme [13]. Fu et al. [15] pointed out a security problem in the scheme published by Lei et al. [14]. To protect the number of zero elements in the two original matrices from being leaked to the cloud server, Fu et al. [15] constructed two random matrices and added them to the original matrices. Lei et al. [16] proposed a secure outsourcing scheme for the calculation of determinants of large matrices. They introduced block matrix and permutation technique to protect privacy. Subsequently, they implemented LU decomposition on the cloud server to facilitate the verification process. Liu et al. [17] pointed out that the scheme proposed by Lei et al. [16] cannot achieve the level of security they claim because the encryption matrix can be simplified. This simplification renders the block-matrix technique ineffective. They further prove that the block matrix used in the scheme is redundant. In order to solve these problems, they do not employ the block matrix technique, but instead they introduce mix-row and mix-column operations for privacy protection. For the eigen-decomposition (ED) and singular value decomposition (SVD) of the matrix, Zhou and Li [18] designed two privacy-preserving outsourcing protocols. They used random numbers and identity matrix to protect the information of the original matrix. And then they used orthogonal matrix to rearrange the matrix for privacy protection. But the number of zero elements was revealed. Luo et al. [19] proposed a feasible scheme for secure outsourcing of large-scale QR decomposition and LU decomposition. They designed a series of protection measures for the upper triangle, lower triangle, general, and orthogonal matrices during the decomposition process to ensure privacy protection. The scheme also involves outsourcing matrix inversion operations required for result recovery. Additionally, they implemented security measures for continuous data transmission between the client side and the server side. Li et al. [20] proposed a protocol for IoT devices solving SVD. They used Hestenes method to achieve lightweight transformation of matrices while protecting privacy. Liu et al. [21] proposed a subtly designed invertible matrix and designed an outsourcing scheme based on it. They proposed an optimized matrix chain multiplication that can improve efficiency while also being applied to other outsourced tasks. Gao and Su [22] proposed the first distributed verifiable and traceable utility scheme for matrix multiplication. They proposed a traceable method which minimizes the computational load on the client.
For non-negative matrix factorization, Liu et al. [23] proposed a secure outsourcing scheme by using random permutation matrix for encryption and decryption. They also proposed a method using 1-norm of matrix to verify the results. Duan et al. [12] implemented the encryption of the NMF input matrix through the random arrangement and scaling encryption mechanism. They proposed to run one round of iterative operation on the client for verification. This scheme allows the client to verify the accuracy of the returned results. Then Fu et al. [11] designed a new NMF secure outsourcing scheme based on two non-colluding servers to realize interactive iterative computation of NMF. They used Paillier homomorphic encryption to protect data privacy and utilized two cloud servers to serially execute NMF tasks. Saha and Imtiaz [24] proposed a privacy-preserving NMF algorithm based on differential privacy. They injected Gaussian noise into gradient computation and modelled the outliers in the data to ensure differential privacy. In summary, the above privacy-preserving outsourcing scheme of NMF does not support parallel outsourcing of multiple servers, which motivates our research on parallel outsourcing. In order to improve the efficiency of the server, we devote to the study of privacy-preserving parallel non-negative matrix factorization with multiple edge servers in this paper.
We propose a privacy-preserving parallel outsourcing scheme for non-negative matrix factorization. Our contributions are as follows:
• To enhance efficiency, we design a parallel outsourcing scheme utilizing multiple nearby edge servers. This scheme divides the computation task into several subtasks using matrix block techniques and employs the multiplicative update rule for NMF parallel computation. This approach not only facilitates NMF parallel computation but also significantly boosts computational efficiency.
• To protect data privacy, we employ random permutation matrix to encrypt the input matrix, ensuring the confidentiality of both the input matrix and output results. Concurrently, to guard against incorrect results from the server, we leverage the iterative nature of NMF to verify results, thereby ensuring their verifiability.
• Through theoretical analysis and experimental comparison, our scheme significantly reduces the client’s computation time. Furthermore, parallel computing substantially lightens the computational workload on each edge server.
Organization: The rest of this article is as follows. In Section 2, we present the system model, the threat model and the design goals. In Section 3, we introduce the preliminary content of relevant mathematical knowledge. In Section 4, we construct the scheme of the parallel outsourcing computation of non-negative matrix factorization. Section 5 makes a theoretical analysis of the proposed scheme. Section 6 gives the analysis of the experimental results. Finally we draw the conclusion in Section 7.
As shown in Fig. 1, the system model consists of two types of entities. The first is the client, which wants to complete non-negative matrix factorization tasks but has limited computing power. The second are the edge servers, which have sufficient computing power. In this scenario, the client wants to outsource the NMF task to the edge servers. To protect the privacy of the client, the client first generates a secret key and encrypts the original input matrix. Then the client partitions the encryption matrix and sends the partitioned encrypted matrices to each edge server. The edge servers execute the NMF task in parallel and return the decomposition results
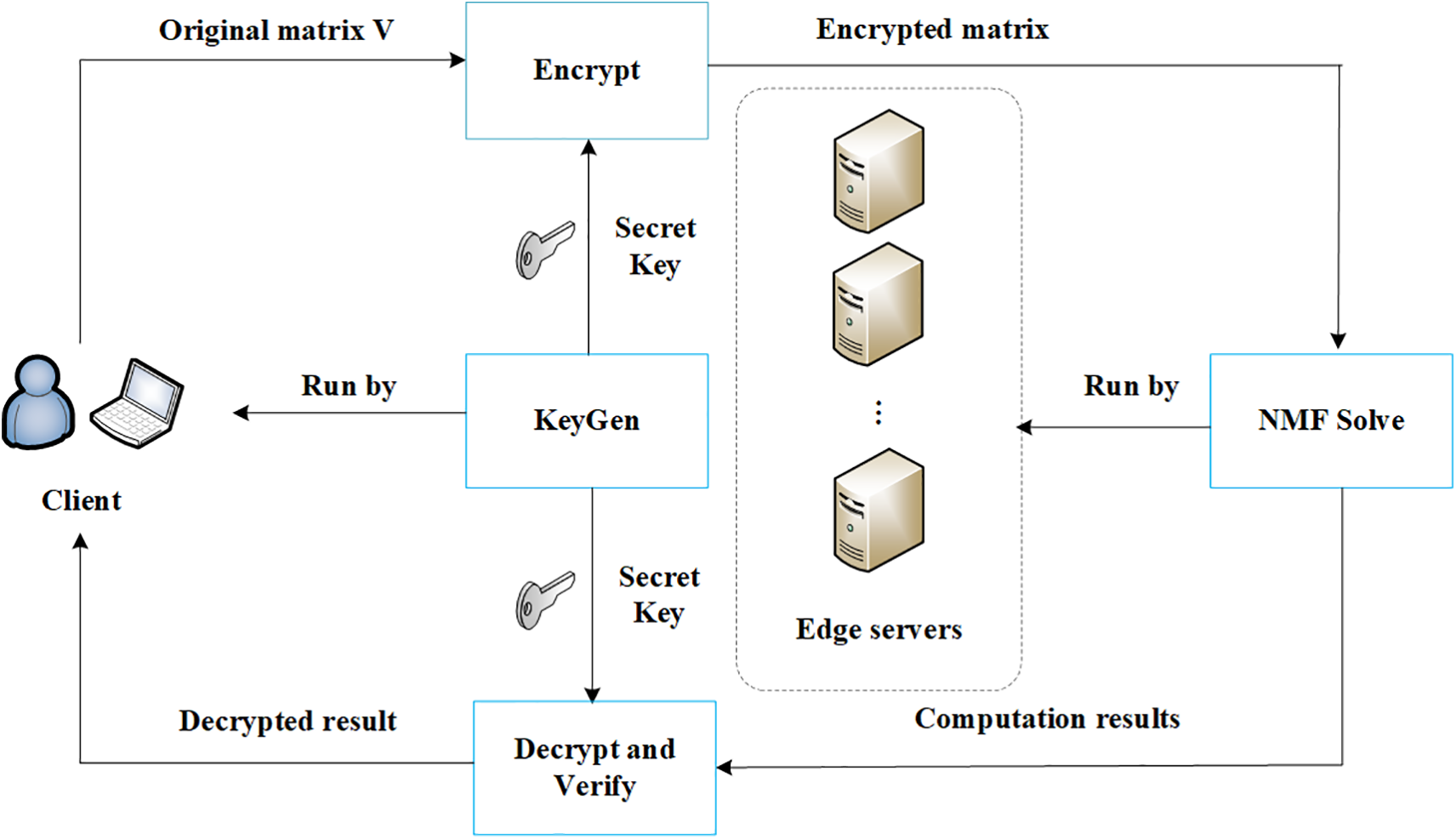
Figure 1: System model.
Generally speaking, there are three main types of threat models in the field of secure outsourcing computation: “lazy-but-honest”, “honest-but-curious” and “fully malicious”. We assume that the edge server is fully malicious, which indicates that the server has the strongest attack capability. That is, the edge servers will try to steal the client’s data and return the wrong result. So the client needs to process the raw plaintext data for privacy protection and verify the returned result. In our threat model, the collusion of multiple edge servers is allowed, which requires our scheme to achieve a high level of security.
The scheme we design should meet the following goals:
• Correctness: If the client and the edge servers follow the scheme honestly, the result the client gets should be the correct solution to the original NMF task.
• Privacy: The proposed scheme ought to protect the privacy of the client, the edge server can not obtain the knowledge related to the client from the encrypted data.
• Efficiency: The client’s local computation should be significantly less than what the original NMF would require by itself. The amount of computation in each edge server decreases with the number of servers involving parallel computing increasing.
• Verifiability: The client possesses the capability to verify the accuracy of the results received. False results generated by a cheating edge server cannot pass the verification with a non-negligible probability.
We give the definition of privacy-preserving parallel computation scheme and provide the security definition in terms of privacy. A privacy-preserving parallel computation scheme PPS is private, if the PPT adversary

In the above experiment, the adversary
Definition 1: A privacy-preserving parallel computation scheme PPS is input-private if for any PPT adversary
3.1 Non-Negative Matrix Factorization
For a given non-negative matrix
where
The cost function
which subjects to
The Kronecker delta function is widely used in engineering and is often employed in matrix construction. The Kronecker delta function is defined as
3.3 Random Permutation Function
Permutation functions have been extensively studied. The permutation function can be expressed as follows:
where

For a non-negative matrix
• Key generation: The client generates the secret key for encryption and decryption.
• Encryption: The client encrypts the original input matrix using the secret key. After that, the client partitions the encrypted matrix by row and column. Then client sends them to edge servers.
• NMF parallel computation: Edge servers that received the outsourced task performs the iterative calculation of the non-negative matrix factorization in parallel.
• Result verification: The client verifies the validity of the result. Accept the result if it passes the verification, reject it otherwise.
• Decryption: The client decrypts the verified matrices and obtains the decomposition result of the original non-negative matrix.
The outline of the proposed scheme is presented in Fig. 2. The detailed descriptions of the algorithms are as follows:
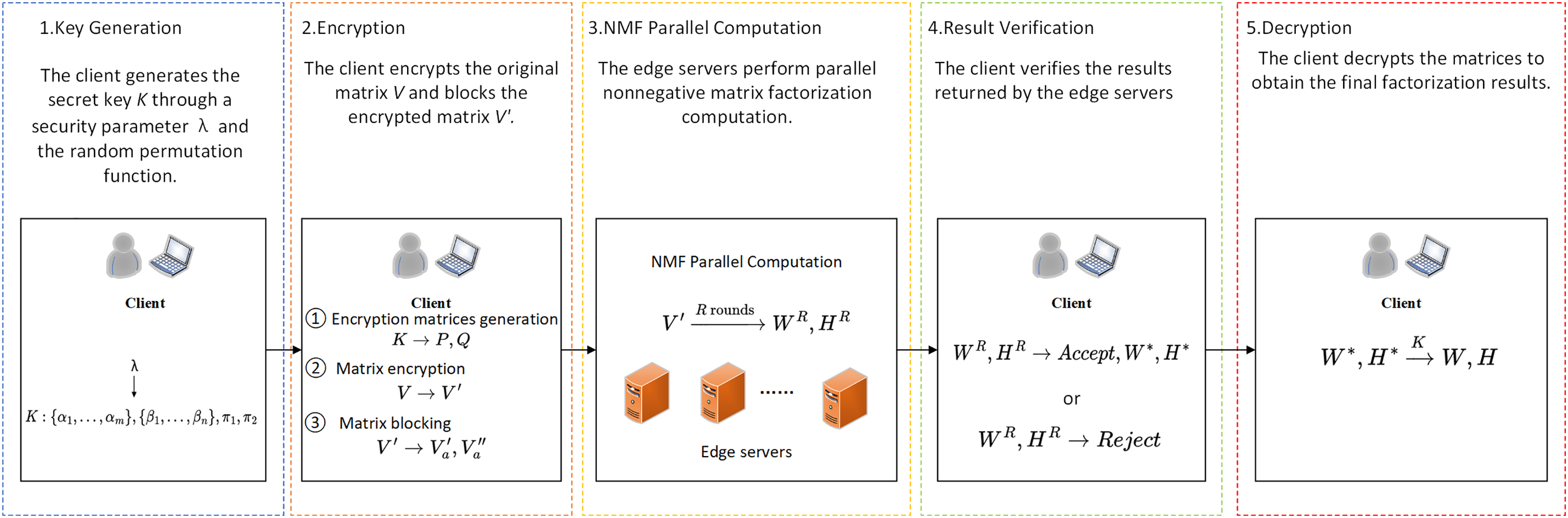
Figure 2: The outline of the proposed scheme.
The client generates secret key K through Algorithm 2. The secret key K consists of two sets of random numbers

The client implements the encryption of the original matrix through Algorithm 3. The client first generates random permutation matrices P and Q using the secret key K. The matrices P and Q are both invertible matrices, which can be supported by Theorem 1. Furthermore, their inverse can be expressed as follows:

The original input matrix is encrypted by calculating
Theorem 1: The matrices P and Q generated in Algorithm 3 are invertible matrices.
Proof of Theorem 1: Since
Theorem 2: During the encryption process, the entry in
Proof of Theorem 2: Let
Since
Due to
Therefore,
By the above calculation, the client can efficiently compute V′ with computational complexity of
For the encrypted matrix V′, edge servers perform NMF parallel computing algorithm as shown in Algorithm 4. The edge server
to update the local matrix. In our scheme, the edge servers update the matrix W through the matrix H and then update the matrix H through the matrix W. Therefore,

After the initialization part over, the iterative update process begin. The turn R of the iteration is entered as a parameter by the client which is usually determined by experience. In the initialization process, each edge server has obtained
to updates the local matrix and sends it to other servers. After the matrix
Remark: The number of iterations R is a parameter specified by the client based on matrix size and accuracy requirements. In practice, larger matrices and higher accuracy demands require more iterations. We know a common criterion set
The client verifies the results
where

If the returned result passes verification, the client runs Algorithm 6 with
By the above calculation, the client can efficiently compute W and H with the complexity computation
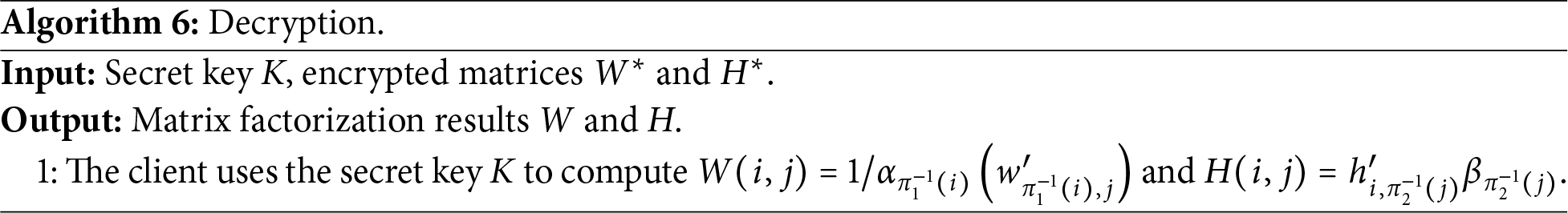
In this section, we provide the analysis of our scheme from the aspects of correctness, privacy, verifiability and efficiency.
Theorem 3: If the client and the edge servers implement the proposed scheme, the client can eventually get the correct non-negative matrix factorization result.
Proof of Theorem 3: Since the solution of NMF is not necessarily unique, there may exist multiple solutions. Our scheme is based on the multiplicative update rules. The results obtained are not exact solutions. Therefore, we consider the results acceptable when the algorithm performs R rounds of iterations. Next we prove that encryption and decryption do not affect the results of NMF for V. According to Algorithm 3, we have
According to Algorithm 6, we can get
Finally, we need to prove that the solution is acceptable. If the results returned by the server satisfy inequality (8), we consider that the servers correctly perform the required number of iteration rounds R. The results are acceptable to the client.
Theorem 4: The proposed scheme can protect the privacy of input and output data according to Definition 1. That is, the original matrix V and the factorization results W and H will not be leaked to the edge servers.
Proof of Theorem 4: First we discuss the privacy of the input matrix V. The elements in the original matrix V are randomly rearranged under two random permutations, denoted as:
Here,
This means that even if the malicious edge servers get the correct matrix
Combining both factors, the total probability that an adversary successfully recovers V from V′ is:
In addition, when an outsourced non-negative matrix factorization is performed on a new input matrix, the secret key is regenerated. Therefore, without the key, the edge servers cannot get the original input from the outsourced task.
Next, we discuss the situation of the collusion among edge servers. Throughout the scheme, each edge server
Besides, the transformation
Theorem 5: A malicious edge server may return incorrect results. In our scheme, the correct results must pass the verification and the incorrect results must not pass the verification.
Proof of Theorem 5: According to the convergence property of the multiplicative update rule,
For properly chosen
Theorem 6: Unless
Proof of Theorem 6: In our scheme, a dishonest edge server that skips the R iterations does not have access to the intermediate states generated during honest execution. As a result, unless the returned
The computational complexity analysis is divided into two parts: Client-side computational complexity and server-side computational complexity. We first analyze the client-side computational complexity. The client-side computational complexity mainly arises from the key generation, encryption, result-verification and decryption algorithms. In the key generation algorithm, the complexity mainly comes from generating random permutations
Next, we analyze the server-side computational complexity. The server-side computational complexity mainly arises from the NMF parallel computation. In each iteration of NMF parallel computation algorithm, matrices W and H are updated by calculating matrix multiplication. The computational complexity of calculating matrix W is
Finally, we compare the time complexity of our proposed scheme with that of representative privacy-preserving NMF outsourcing algorithms in recent years and present the results in Table 1. Here,

The computational complexity analysis is divided into two parts: communication between the client and the edge server, communication among edge servers. We first analyze the communication complexity between the client and the edge server. In the encryption phase, the client encrypts the original matrix and partitions the encrypted matrix V′ by rows and columns. The client sends matrices
Next, we analyze the communication complexity among edge servers in Algorithm 4. In the initialization phase of Algorithm 4, each edge server initializes
It should be noted that our computation is “embarrassingly parallel”. After the initial matrix partitioning, each edge server can independently compute its local matrix blocks
In this section, we conduct the experiment to evaluate the performance of the proposed scheme. We use the Numpy library and Pool library in Python to implement our scheme and test it on a laptop with an Intel Core i5 CPU and 16 GB RAM. The reason for adopting the Pool library is that our computational tasks belong to the “embarrassingly parallel” category, with low communication requirements between tasks. Therefore, we chose the Pool library over MPI-based multiprocessing.
First, we measure the time to resolve the original NMF task locally on the client, expressed as
At the same time, we define
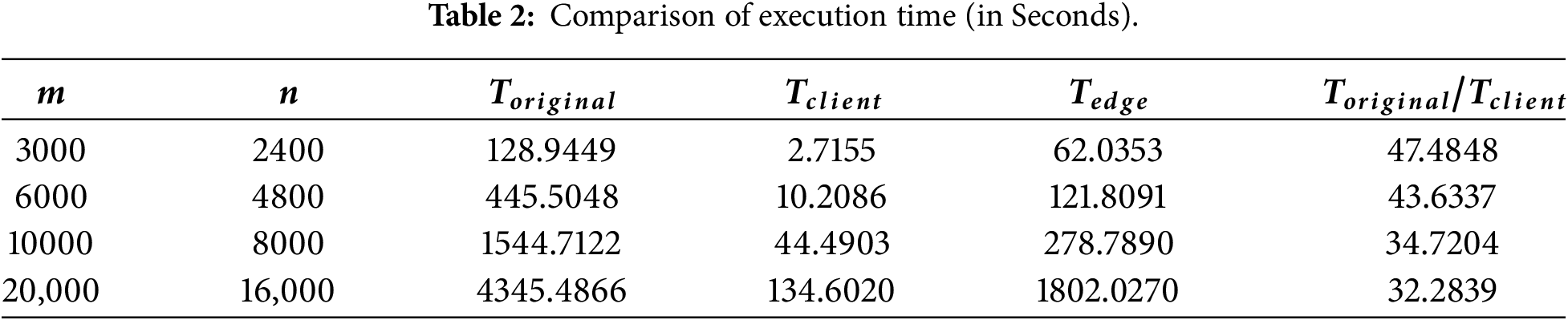
The time overhead is significantly influenced by the size of the original input matrix. We keep the row value
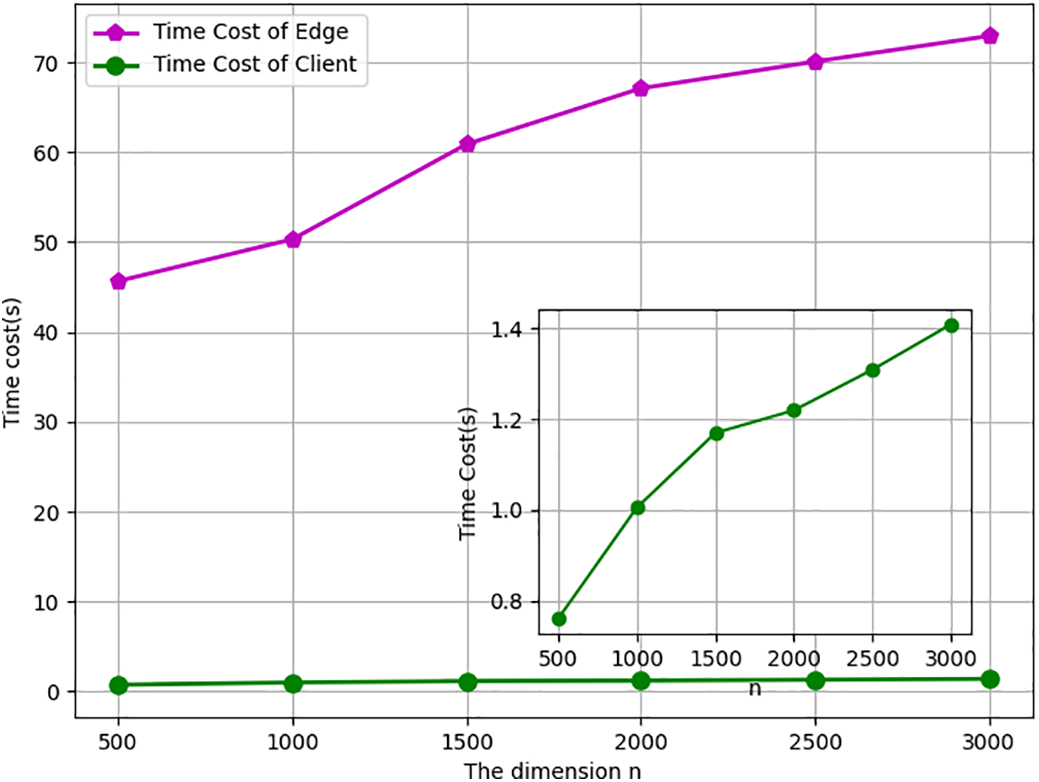
Figure 3: The time cost varying with column size n when m = 3000.
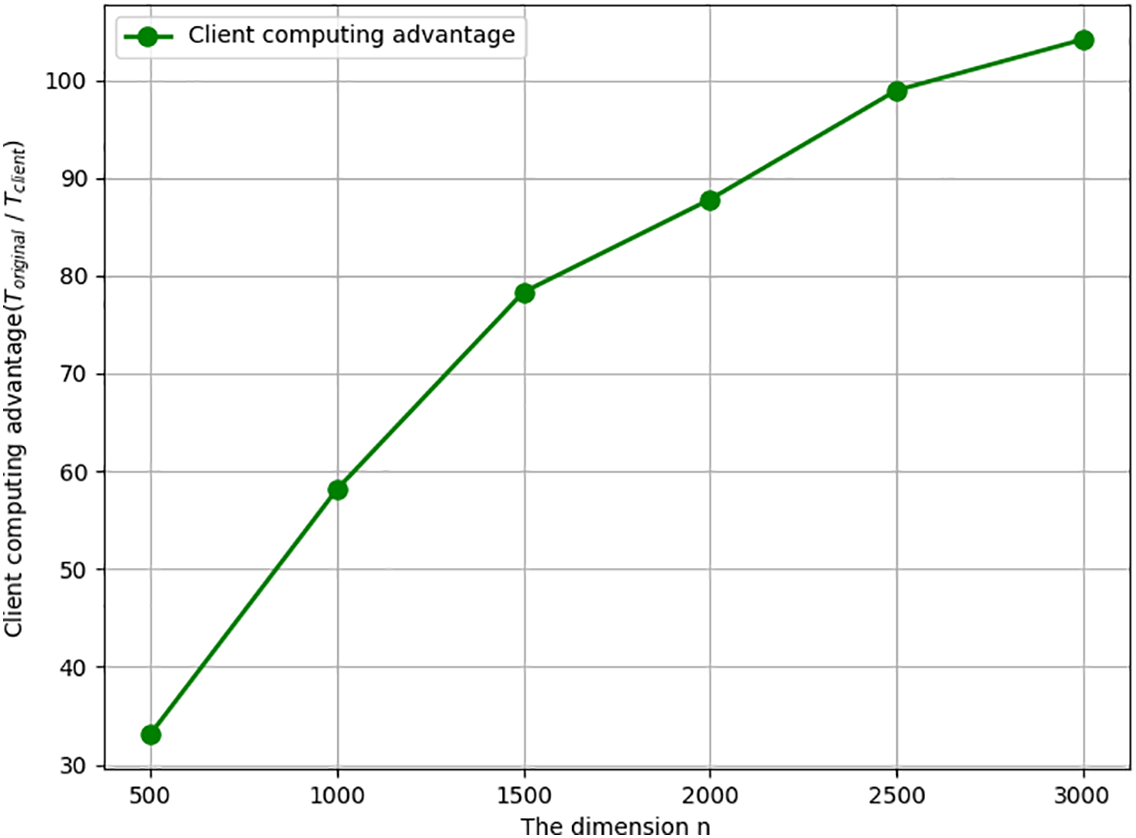
Figure 4: Client computing advantage varying with n when m = 3000.
Meanwhile, we keep the column value
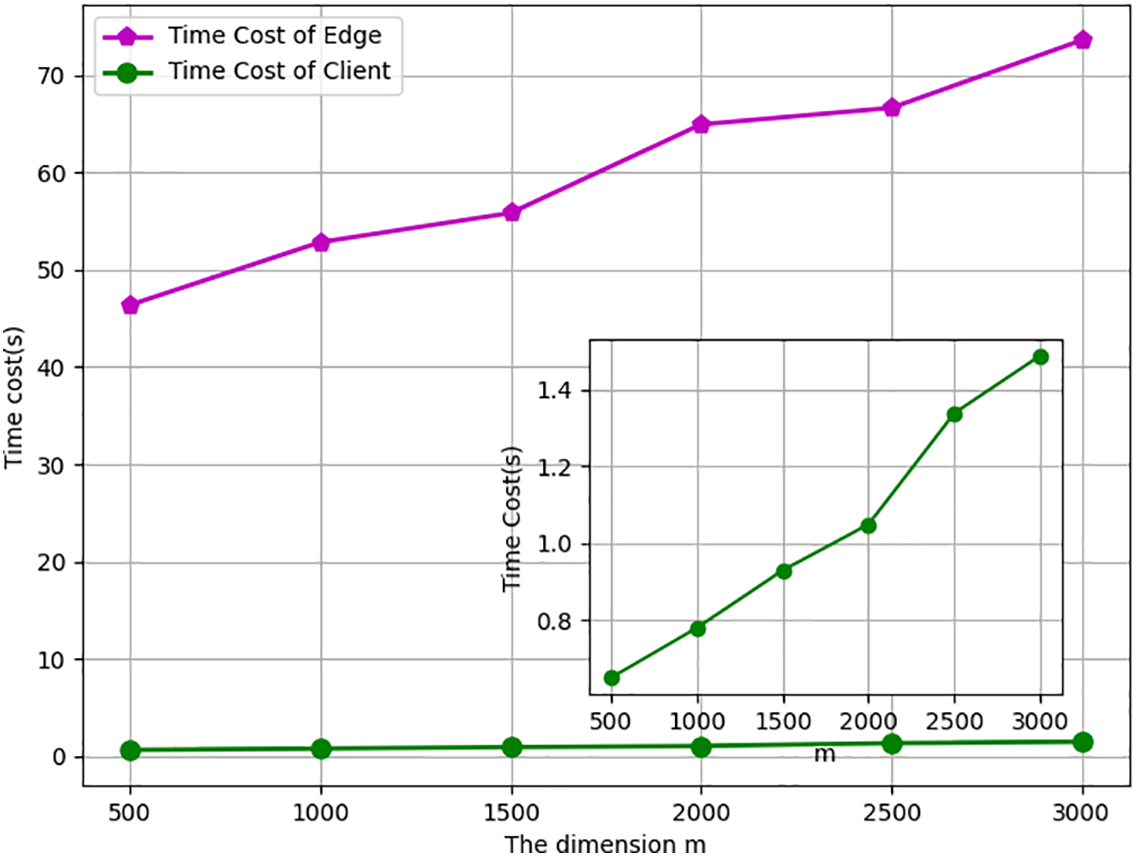
Figure 5: The time cost varying with row size m when n = 3000.
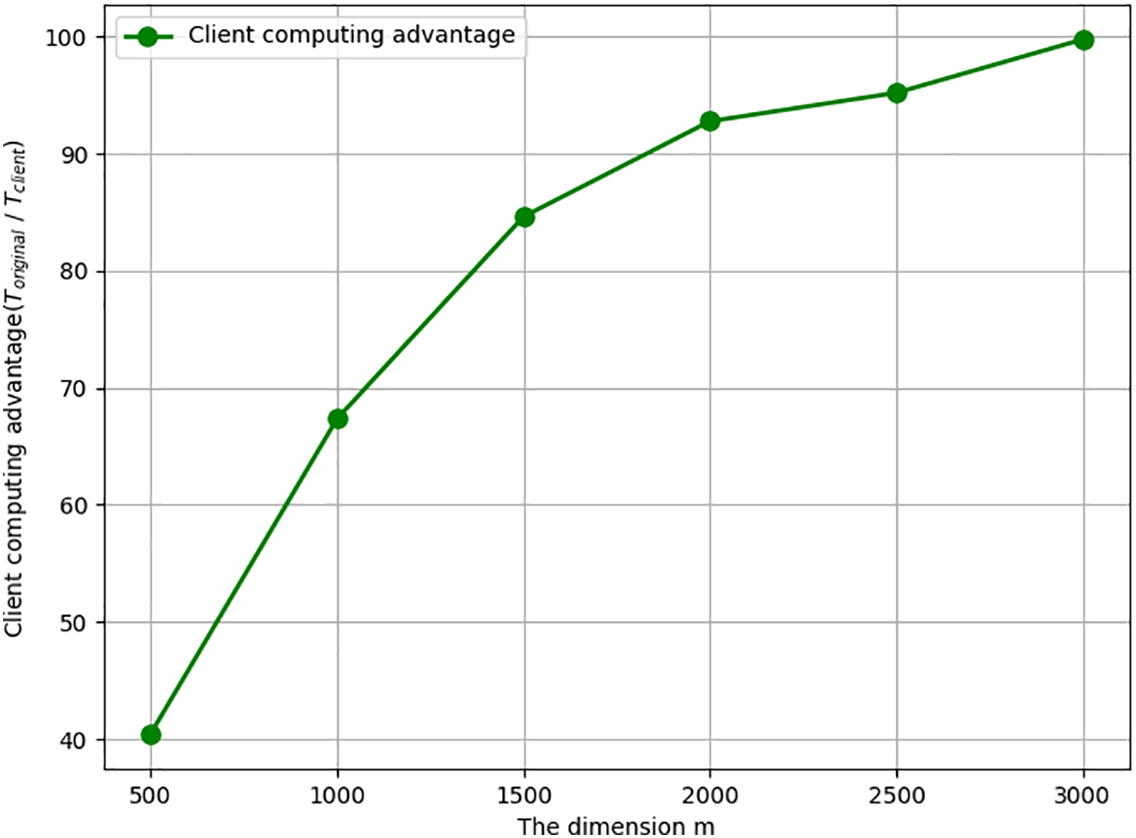
Figure 6: Client computing advantage varying with m when n = 3000.
In NMF tasks, the dimension parameter
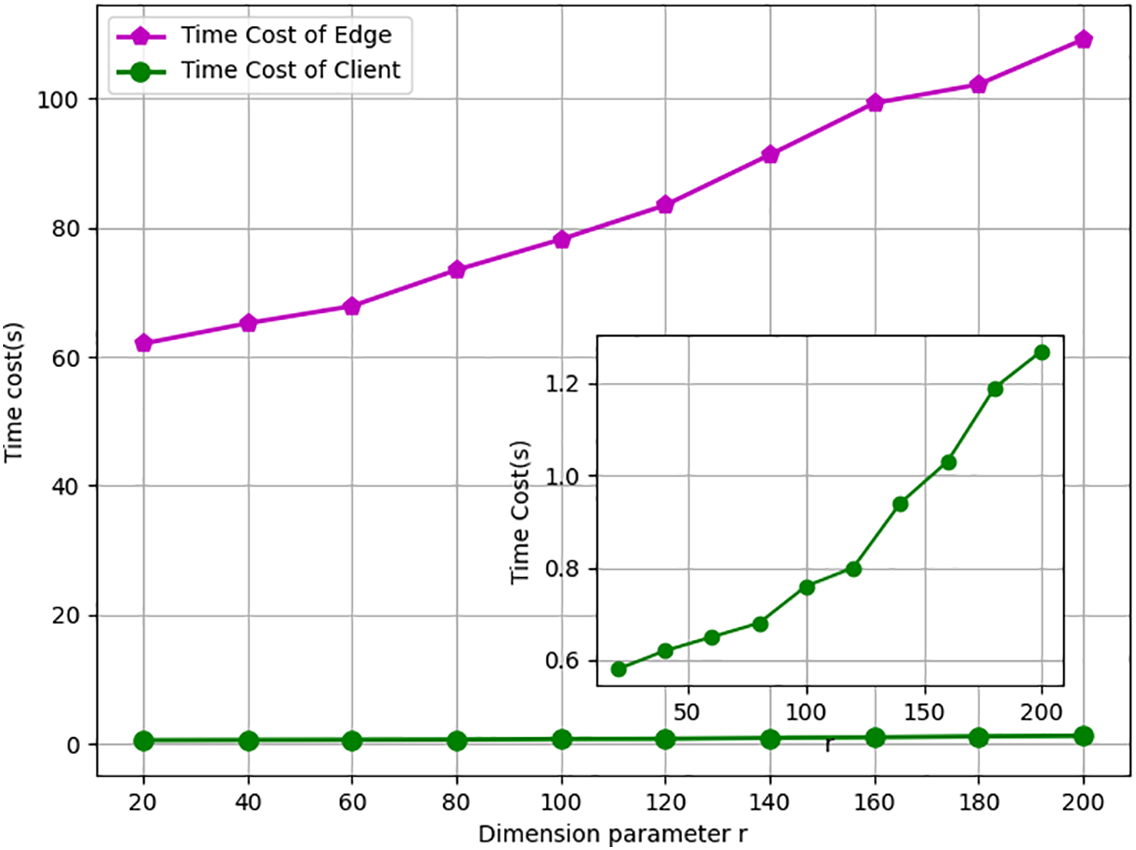
Figure 7: The time cost varying with dimension parameter.
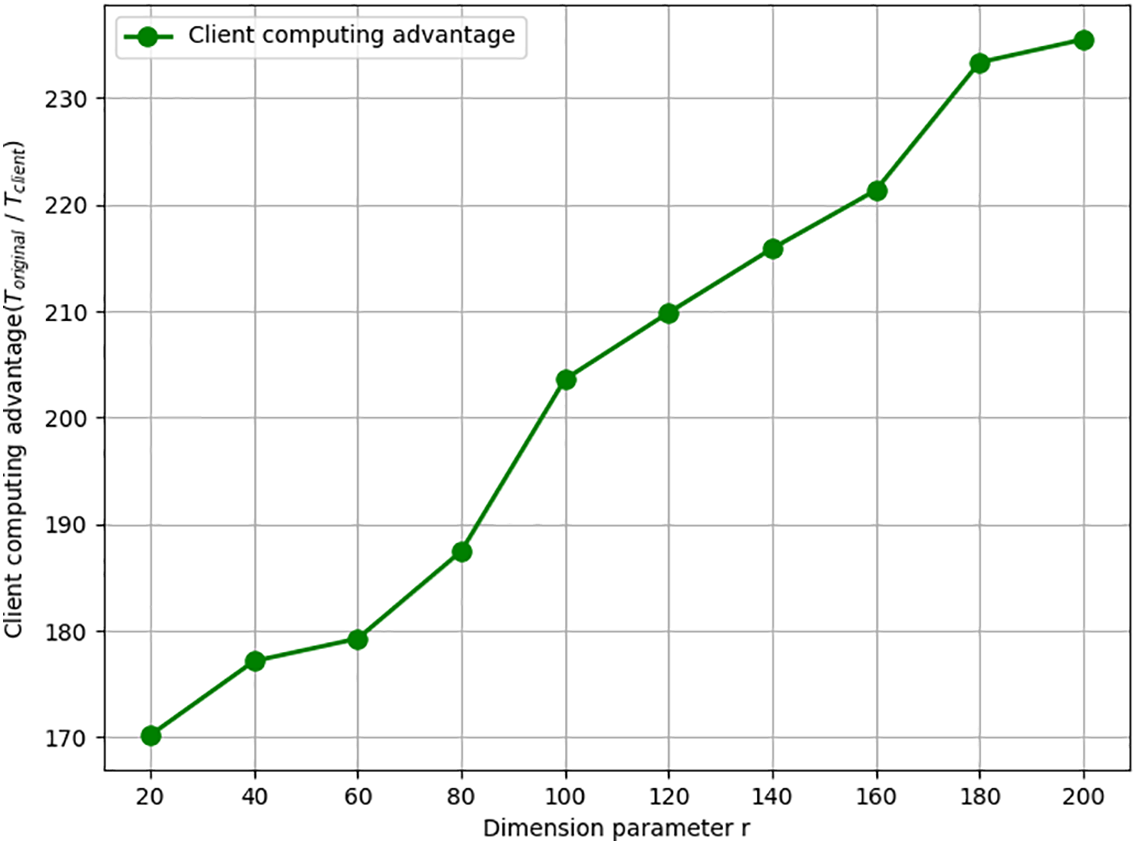
Figure 8: Client computing advantage varying with dimension parameter.
At the same time, we test the trend of average computation time per server as the number of edge servers involved in the computation increased. The results are shown in Fig. 9. The row size
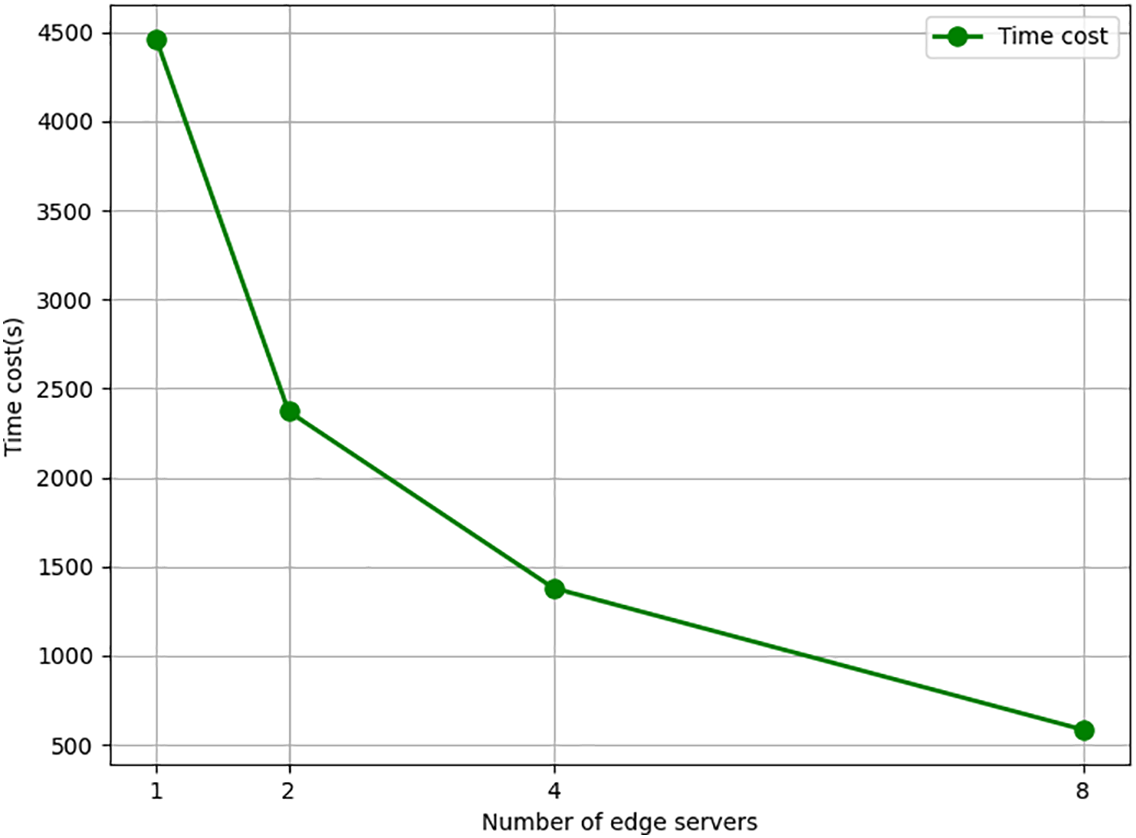
Figure 9: Relationship between the number of servers and the time cost of each server.
Additionally, we report the convergence trajectory of
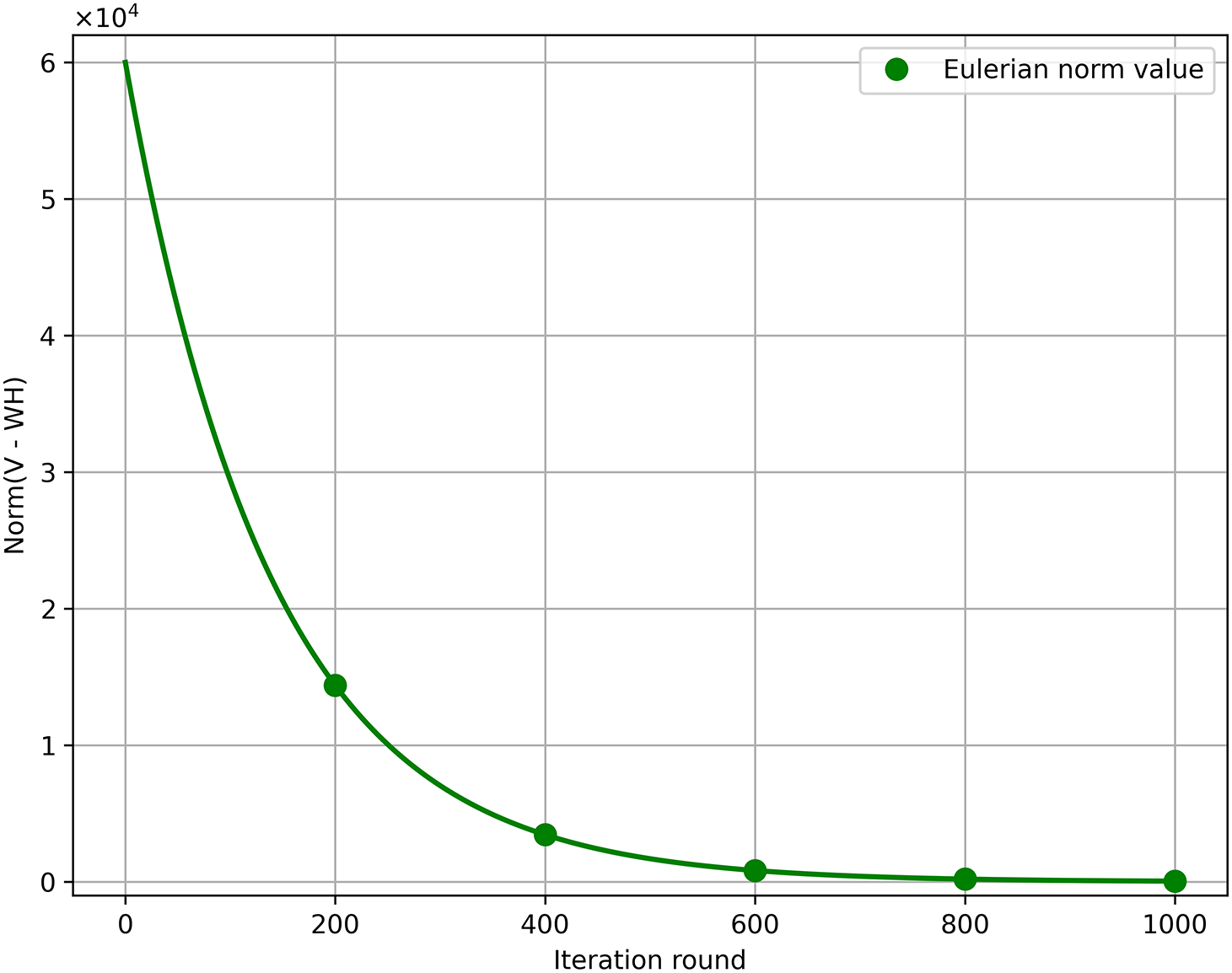
Figure 10: Eulerian norm value of (V − WH) comparison.
In this paper, we propose a privacy-preserving parallel non-negative matrix factorization outsourcing scheme with edge computing. The scheme divides the computational task into multiple sub-tasks using matrix block techniques and designs a parallel NMF computation scheme based on the multiplicative update rule, thereby improving the computational efficiency of edge servers. This means that client’s needs can be quickly satisfied. Additionally, we employ random permutation matrices to protect data privacy and leverage the iterative nature of NMF for result verification. The experimental results and theoretical analysis demonstrate the superiority of the proposed scheme in terms of both computational efficiency and privacy protection.
Acknowledgement: Not applicable.
Funding Statement: This research was supported in part by Shandong Provincial Natural Science Foundation under Grant (ZR2024MF038), and Qingdao Natural Science Foundation (25-1-1-103-zyyd-jchZ).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Wenxuan Yu and Wenjing Gao; methodology, Jiuru Wang, Jia Yu; validation, Wenxuan Yu, Jia Yu and Rong Hao; formal analysis, Wenjing Gao; data curation, Wenxuan Yu; review and editing, Wenjing Gao and Jia Yu; supervision, Rong Hao and Jia Yu. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Langville AN, Meyer CD, Albright R, Cox J, Duling D. Algorithms, initializations, and convergence for the nonnegative matrix factorization. arXiv:1407.7299. 2014. [Google Scholar]
2. Xu W, Liu X, Gong Y. Document clustering based on non-negative matrix factorization. In: Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, NY, USA: ACM; 2003. p. 267–73. [Google Scholar]
3. Liu H, Wu Z, Li X, Cai D, Huang TS. Constrained nonnegative matrix factorization for image representation. IEEE Trans Pattern Anal Mach Intell. 2012;34(7):1299–311. doi:10.1109/tpami.2011.217. [Google Scholar] [PubMed] [CrossRef]
4. Yang CF, Ye M, Zhao J. Document clustering based on nonnegative sparse matrix factorization. In: Advances in Natural Computation (ICNC 2005). Vol. 3611. Berlin/Heidelberg, Germany: Springer; 2005. p. 557–63. [Google Scholar]
5. Shahnaz F, Berry MW, Pauca VP, Plemmons RJ. Document clustering using nonnegative matrix factorization. Inf Process Manag. 2006;42(2):373–86 doi:10.1016/j.ipm.2004.11.005. [Google Scholar] [CrossRef]
6. Guo Y, Li Q, Liang C. The rise of nonnegative matrix factorization: algorithms and applications. Inf Syst. 2024;123:102379. [Google Scholar]
7. Wang H, He D, Fu A, Li Q, Wang Q. Provable data possession with outsourced data transfer. IEEE Trans Serv Comput. 2021;14(6):1929–39 doi:10.1109/tsc.2019.2892095. [Google Scholar] [CrossRef]
8. Shan Z, Ren K, Blanton M, Wang C. Practical secure computation outsourcing: a survey. ACM Comput Surv. 2018;51(2):31:1–31:40. doi:10.1145/3158363. [Google Scholar] [CrossRef]
9. Zhang H, Gao P, Yu J, Lin J, Xiong NN. Machine learning on cloud with blockchain: a secure, verifiable and fair approach to outsource the linear regression. IEEE Trans Netw Sci Eng. 2022;9(6):3956–67. [Google Scholar]
10. Gao W, Yu J, Yang M, Wang H. Enabling privacy-preserving parallel outsourcing matrix inversion in IoT. IEEE Internet Things J. 2022;9(17):15915–27 doi:10.1109/jiot.2022.3150956. [Google Scholar] [CrossRef]
11. Fu A, Chen Z, Mu Y, Susilo W, Sun Y, Wu J. Cloud-based outsourcing for enabling privacy-preserving large-scale non-negative matrix factorization. IEEE Trans Serv Comput. 2022;15(1):266–78 doi:10.1109/tsc.2019.2937484. [Google Scholar] [CrossRef]
12. Duan J, Zhou J, Li Y. Secure and verifiable outsourcing of large-scale nonnegative matrix factorization (NMF). IEEE Trans Serv Comput. 2021;14(6):1940–53 doi:10.1109/tsc.2019.2911282. [Google Scholar] [CrossRef]
13. Lei X, Liao X, Huang T, Li H, Hu C. Outsourcing large matrix inversion computation to a public cloud. IEEE Trans Cloud Comput. 2013;1(1):78–87. doi:10.1109/tcc.2013.7. [Google Scholar] [CrossRef]
14. Lei X, Liao X, Huang T, Heriniaina F. Achieving security, robust cheating resistance, and high-efficiency for outsourcing large matrix multiplication computation to a malicious cloud. Inf Sci. 2014;280:205–17 doi:10.1016/j.ins.2014.05.014. [Google Scholar] [CrossRef]
15. Fu S, Yu Y, Xu M. A secure algorithm for outsourcing matrix multiplication computation in the cloud. In: Proceedings of the Fifth ACM International Workshop on Security in Cloud Computing. New York, NY, USA: ACM; 2017. p. 27–33. [Google Scholar]
16. Lei X, Liao X, Huang T, Li H. Cloud computing service: the case of large matrix determinant computation. IEEE Trans Serv Comput. 2015;8(5):688–700. [Google Scholar]
17. Liu J, Bi J, Li M. Secure outsourcing of large matrix determinant computation. Frontiers Comput Sci. 2020;14(1):146807 doi:10.1007/s11704-019-9189-7. [Google Scholar] [CrossRef]
18. Zhou L, Li C. Outsourcing eigen-decomposition and singular value decomposition of large matrix to a public cloud. IEEE Access. 2016;4:869–79 doi:10.1109/access.2016.2535103. [Google Scholar] [CrossRef]
19. Luo C, Zhang K, Salinas S, Li P. SecFact: secure large-scale QR and LU factorizations. IEEE Trans Big Data. 2021;7(4):796–807. [Google Scholar]
20. Li Y, Zhang H, Lin J, Liang F, Xu H, Liu X, et al. Secure edge-aided singular value decomposition in internet of things. IEEE Internet Things J. 2024;11(13):23207–21 doi:10.1109/jiot.2024.3375394. [Google Scholar] [CrossRef]
21. Liu C, Hu X, Chen X, Wei J, Liu W. SDIM: a subtly designed invertible matrix for enhanced privacy-preserving outsourcing matrix multiplication and related tasks. IEEE Trans Dependable Secur Comput. 2024;21(4):3469–86. [Google Scholar]
22. Gao Z, Su Q. Enabling verifiable and traceable distributed outsourced matrix multiplication in neural networks. Cluster Comput. 2025;28(11):722 doi:10.1007/s10586-025-05472-0. [Google Scholar] [CrossRef]
23. Liu Z, Li B, Han Q. Secure and verifiable outsourcing protocol for non-negative matrix factorisation. Int J High Perform Comput Netw. 2018;11(1):14–23 doi:10.1504/ijhpcn.2018.088875. [Google Scholar] [PubMed] [CrossRef]
24. Saha S, Imtiaz H. Privacy-preserving non-negative matrix factorization with outliers. ACM Trans Knowl Discov Data. 2024;18(3):1–26. doi:10.1145/3632961. [Google Scholar] [CrossRef]
25. Tian C, Yu J, Zhang H, Xue H, Wang C, Ren K. Novel secure outsourcing of modular inversion for arbitrary and variable modulus. IEEE Trans Serv Comput. 2022;15(1):241–53 doi:10.1109/tsc.2019.2937486. [Google Scholar] [CrossRef]
26. Lee DD, Seung HS. Algorithms for non-negative matrix factorization. In: Advances in Neural Information Processing Systems. Vol. 13. Cambridge, MA, USA: MIT Press; 2000. p. 556–62. [Google Scholar]
27. Guo L, Yu J, Yang M, Kong F. Privacy-preserving convolution neural network inference with edge-assistance. Comput Secur. 2022;123:102910 doi:10.1016/j.cose.2022.102910. [Google Scholar] [CrossRef]
28. Shen W, Yin B, Cao X, Cheng Y, Shen XS. A distributed secure outsourcing scheme for solving linear algebraic equations in Ad Hoc clouds. IEEE Trans Cloud Comput. 2019;7(2):16 doi:10.1109/tcc.2016.2647718. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools