
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MDGAN-DIFI: Multi-Object Tracking for USVs Based on Deep Iterative Frame Interpolation and Motion Deblurring Using GAN Model
1 Department of Vehicle and Energy Conversion Engineering, School of Mechanical Engineering, Hanoi University of Science and Technology, Hanoi, Vietnam
2 Department of Mechatronics, School of Mechanical Engineering, Hanoi University of Science and Technology, Hanoi, Vietnam
* Corresponding Authors: Dinh-Quy Vu. Email: ; Thai-Viet Dang. Email:
(This article belongs to the Special Issue: Advances in Video Object Tracking: Methods, Challenges, and Applications)
Computers, Materials & Continua 2026, 87(3), 23 https://doi.org/10.32604/cmc.2026.077237
Received 04 December 2025; Accepted 22 January 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In the realm of unmanned surface vehicle (USV) operations, leveraging environmental factors to enhance situational awareness has garnered significant academic attention. Developing vision systems for USVs presents considerable challenges, mainly due to variable observational conditions and angular vibrations caused by hydrodynamic forces. The paper proposed a novel MDGAN-DIFI network for end-to-end multi-object tracking (MOT), specifically designed for camera systems mounted on USVs. Beyond enhancing traditional MOT models, the proposed MDGAN-DIFI includes preprocessing modules designed to enhance the efficiency of processing input signal quality. Initially, a Deep Iterative Frame Interpolation (DIFI) module is used to stabilize frames in the spatiotemporal domain. Next, an enhanced generative adversarial network (GAN) model is applied to reduce motion blur affecting objects within the field of view. Finally, a YOLO-CSSA architecture combines dual infrared (IR) and RGB data streams to maintain consistent performance across diverse environmental conditions. By synthesizing intermediate frames and restoring blurred details, the framework seeks to stabilize object motion trajectories and recover distinctive appearance features prior to tracking. This approach directly tackles the main causes of tracking failure in maritime environments, such as motion discontinuities and visual degradation. Experimental results demonstrate that the proposed approach outperforms conventional methods in multi-object tracking on USVs, achieving a maximum accuracy (MOTA) of 47.0% and an IDF1 score of 50.1% under challenging operational conditions. Consequently, the proposed multi-object tracking network provides a more robust foundation for subsequent detection and data association processes.Keywords
In the realm of marine resource exploitation and maritime security, Unmanned Surface Vehicles (USVs) have become indispensable for intelligent transportation, autonomous navigation, surveillance, and maritime longistic [1]. A core capability enabling USV autonomy is Multi-Object Tracking (MOT), which aims to accurately localize targets of interest and maintain their identities across video sequences in real time [2]. However, unlike terrestrial computer vision applications, the maritime environment presents significant challenges such as unstable camera viewpoints, poor visibility, occlusions, and substantial variations in target scale. Notably, hydrodynamic interactions between the USV platform and ocean waves cause considerable ego-motion and camera jitter, resulting in nonlinear target trajectories and visual impairments like motion blur [3]. Consequently, developing a robust MOT framework that can mitigate these adverse conditions is crucial for the reliable operation of USVs.
Current MOT methodologies primarily fall into two categories: Joint-Detection-Tracking (JDT) [4] and Tracking-by-Detection (TBD) [5]. The TBD approach, which separates object detection from data association, has traditionally dominated the field. In this framework, neural networks generate detections that are then linked to trajectories using motion models (e.g., Kalman Filters [6]) or appearance-based features (e.g., Re-identification [7]). Established algorithms such as SORT [8] and DeepSORT [9] have proven effective in reducing identity switches. However, TBD approaches incur significant computational overhead due to the need for separate models for detection and feature embedding, leading to increased latency. More importantly, in maritime settings characterized by low resolution and motion blur, TBD methods often struggle to extract reliable appearance features, resulting in fragmented trajectories when detection quality declines. To overcome the efficiency limitations of TBD, the JDT framework known as Joint Detection and Embedding (JDE) [10] has gained considerable attention. Techniques like JDE and FairMOT [11] integrate detection and appearance feature extraction within a single network to enable real-time performance. Despite improvements in speed, JDE methods face intrinsic challenges due to task competition between detection and re-identification within a shared architecture, which can limit tracking accuracy. This issue is especially pronounced in USV applications, where simultaneous training often leads to gradient interference, particularly when tracking small, low-resolution maritime targets. Additionally, motion-centric and geometric strategies, exemplified by OC-SORT [12] and ByteTrack [13], have been developed to address occlusions and low-confidence detections. However, these methods typically rely on standard Kalman filters that assume linear motion dynamics invalidated by the strong wave-induced perturbations experienced by USVs. Recent studies, such as GenTrack [14], highlight that maintaining identity consistency under nonlinear motion requires more sophisticated hybrid approaches. Although some efforts have incorporated long-term spatio-temporal modeling via Transformers [15] or fused multi-modal information, most approaches remain heavily dependent on the quality of the input video data. A critical yet often overlooked limitation in maritime MOT research is the degradation of input frame quality caused by hardware constraints and environmental factors. USVs frequently operate with limited computational resources, necessitating reduced frame rates that exacerbate large inter-frame object displacements. Moreover, pervasive motion blur induced by platform vibrations and rapid target movements significantly impairs the performance of both detectors and appearance feature extractors. While recent contributions such as BoT-SORT [16] and MPMOT [17] have introduced enhancements like camera motion compensation and adaptive cost matrices, these solutions are largely post-processing adjustments that do not fundamentally address the loss of visual information in the input video stream.
To bridge this gap, this paper proposes a novel MDGAN-DIFI network specifically designed for USVs, addressing challenges posed by oceanographic environmental conditions such as motion noise, vibration, and frame blurring caused by wave-induced oscillations. Departing from conventional approaches that focus solely on tracker optimization, the proposed method enhances the temporal and spatial quality of the input data. Firstly, a Deep Iterative Frame Interpolation module stabilizes frames within the spatiotemporal domain. Secondly, an enhanced GAN model was developed to reduce motion blur affecting objects in the observation area. Finally, a YOLO-CSSA architecture that combines dual IR and RGB information streams to maintain performance across diverse environmental conditions. By synthesizing intermediate frames and restoring blurred details, the framework aims to stabilize object motion trajectories and recover discriminative appearance features before tracking. This strategy directly addresses the primary causes of tracking failure in maritime environments, including motion discontinuities and visual degradation. Hence, the proposed multi-object tracking network establishes a more robust foundation for subsequent detection and data association processes.
The main contributions of this work are as follows:
• The development of a multi-object tracking framework optimized for the unique characteristics of oceanographic data based on the improved basic DeepSORT algorithm framework.
• The introduction of a deep iterative frame interpolation network that uses spatiotemporal reference data to mitigate the effects of camera viewpoint instability.
• The application of a GAN model with architectural enhancements and an optimized loss function to effectively deblur and enhance object features within the environment.
• The integration of an object recognition framework that fuses IR and RGB data streams, enabling robust performance under challenging observation conditions such as low light and fog.
The remainder of this paper is organized as follows: Section 2 reviews related work in the field. Section 3 details the architecture of the proposed USV-Track system. Section 4 presents experimental results and comparative analyses. Finally, Section 5 offers concluding remarks and outlines directions for future research.
2.1 Conventional Tracking Methodologies
Before the rise of deep learning (DL), research in visual tracking primarily focused on the single-object tracking. This focused emphasis was largely necessitated by the inherent limitations of traditional object detectors and handcrafted feature descriptors, which rendered large-scale multi-target tracking challenging. In that era, correlation filter-based approaches, notably CSK [18], and KCF [19], showcased remarkable efficiency, often attaining real-time processing speeds through the exploitation of Fourier domain regression and kernel learning techniques. However, their dependence on shallow feature representations and linear models severely constrained their resilience against significant occlusion and abrupt motion changes. Therefore, they lacked effective mechanisms for managing identity persistence.
Conversely, initial MOT strategies employed a tracking-by-detection framework. In this setup, conventional detectors (e.g., HOG-SVM [20]) furnished candidate bounding boxes, and subsequent data association was executed across sequential frames. Established techniques encompassed probabilistic formalisms like Joint Probabilistic Data Association [21] and Multiple Hypothesis Tracking [22]; global graph optimization procedures, including min-cost flow and shortest paths; and filtering mechanisms utilizing particle filters [23]. Despite their foundational importance, these methodologies were ultimately constrained by the modest discriminatory power of handcrafted features, frequently culminating in undesirable identity switches and fragmented trajectories. The subsequent emergence of advanced deep detectors and learned appearance embeddings revolutionized the domain, enabling the synergy of highly accurate localization with robust identity. This technological leap significantly enhanced tracking performance and catalyzed the development of deep learning-based MOT methods, which are generally delineated into motion-centric and hybrid motion-appearance schemes.
2.2 Deep Learning-Based Multi-Object Tracking
Motion-centric deep learning MOT approaches prioritize high computational efficiency by capitalizing on object dynamics and spatial-geometric coherence across frames to facilitate detection association. The SORT algorithm [8] remains a prevalent benchmark, employing Kalman filtering coupled with the Hungarian assignment algorithm to deliver impressive processing throughput [24]. ByteTrack [13] incorporated low-confidence detections with a specialized two-stage matching operation to ensure the augmented robustness. SORT-LFR [25] integrated the low-frame-rate technique (LFT) with SORT to improve the MOT’s tracking in highway surveillance systems. Furthermore, the Kalman filter’s state space had been improved in response to dynamic cameras. OCSORT [26] combined observation center momentum with online smoothing for virtual motion calculation.
To mitigate the inherent limitations of motion trackers, hybrid methodologies integrate both kinetic and visual features for appearance embedding by using deep Convolutional Neural Networks (CNNs). DeepSORT [27] augmented the SORT framework using deep Re-identification (ReID) embeddings to ensure long-term identity. StrongSORT [28] incorporated advanced trajectory linking with Gaussian interpolation. More recent works, such as BoT-SORT-ReID [29] and ImprAssoc, introduced adaptive mechanisms for weighting feature contributions, while DeepOCSORT [30] utilized adaptive cue balancing to dynamically tune the influence of motion and appearance information. To address challenges like target visibility and occlusion, and to facilitate real-time prediction and tracking in dynamic environments, deep learning-based MOT methods effectively capture the dynamic characteristics of targets to varying degrees, thereby enhancing the accuracy and robustness of object tracking [31]. Notwithstanding these considerable gains in reliability, the majority of these trackers operate within a modular, sequentially executed pipeline, a structure that inherently restricts real-time capability and diminishes efficacy under conditions of severe appearance deterioration.
2.3 Specialized Maritime Multi-Object Tracking
In response to these specific difficulties, specialized maritime MOT frameworks have been recently conceptualized. For instance, Sea-IoUTracker [32] introduced a buffered Intersection over Union (IoU) strategy, based on the neighboring-frame recovery mechanism to enhance association stability amidst platform-induced instability. YOLOv7’s detection module integrated Adaptive Spatial Feature Fusion in the Convolutional Block Attention Module for precisely optimized tracking of maritime targets. Similarly, MOMT [33] extended the ByteTrack algorithm by incorporating a composite distance metric to counteract camera motion effects. These innovations markedly boost the robustness of maritime tracking systems while sustaining real-time processing throughput.
Nonetheless, existing maritime MOT solutions largely constitute adaptations of terrestrial MOT frameworks, frequently involving heuristic modifications to ByteTrack-like architectures. Such approaches commonly suffer from a lack of architectural versatility and fail to holistically address the intertwined challenges of scale-aware detection, appearance degradation, and dynamic feature fusion within a unified, coherent system [32,33]. Consequently, there is an escalating need for end-to-end MOT architectures that integrate detection and tracking via parallelizable pipelines, implement adaptive multiscale modeling based on the transformer-based appearance extraction. These highly integrated systems are essential for maintaining peak performance despite the unique visual and kinematic distortions characteristic of authentic maritime operating environments.
This section outlines the architecture for MOT (see Fig. 1). It begins with continuous image frames that are fed into a deep interpolation module designed to improve information reliability by reducing the effects of shaking during environmental image capture. This module comprises a UNet network that synthesizes intermediate frames from adjacent inputs, along with a ResNet18 network that refines these generated frames by preventing the progressive accumulation of blur through iterative processing. The synthesized frames are then processed by a back-end GAN model aimed at minimizing motion blur. This GAN has been pre-trained to reconstruct detailed environmental features from blurred objects within the frames. Next, the frames are passed to the YOLO-CSSA object detection model, which predicts precise bounding boxes. The proposed object recognition framework performs robustly with both IR and RGB images, thanks to the integrated Channel Switching Spatial Attention (CSSA) mechanism that effectively aggregates and selects the most salient features from each processing stream. This results in high efficacy for multi-modal object recognition in environmental contexts, including deployment on USVs. Finally, the frame data and bounding box information are input into an enhanced DeepSort model, which assigns class labels and unique identifiers to tracked objects. This completes the multi-perceptual tracking framework tailored for USV applications.
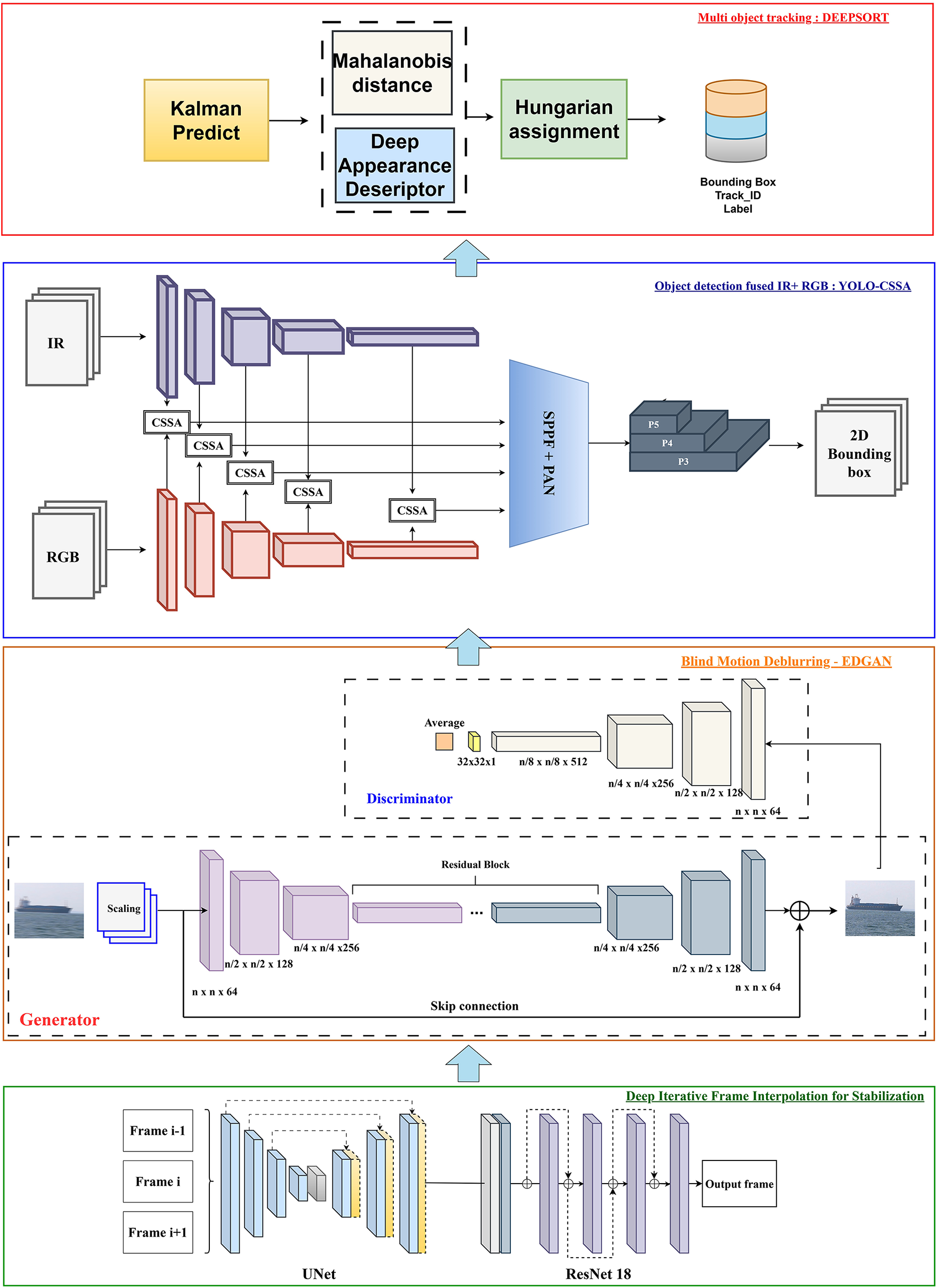
Figure 1: Proposed MDGAN-DIFI architecture for USVs’ MOT.
Regarding the characteristics of the MOT problem on USVs, the fundamental challenges stem from the instability in establishing the viewing angle. The effects of oceanographic factors cause two main problems: unconstrained mobile tracking objects and motion blur. From there, the authors used two separate modules to directly address these issues. Deep Iterative Frame Interpolation is responsible for calculating intermediate frames, which serve to linearize the positions of objects in consecutive frames as a prerequisite for the Kalman filter tracking. The Deblur GAN model reconstructs motion-blurred objects, reducing errors in object recognition.
3.1 Deep Iterative Frame Interpolation
The influence of the oceanographic environment on the acquisition of consecutive frames by the camera system mounted on the USV is notably complex. A significant challenge is the positional displacement of objects between adjacent frames, primarily caused by wave-induced motion. Object tracking algorithms largely depend on this positional information to estimate and predict the locations of reference points, ensuring consistent tracking identification. Therefore, stabilizing and recalibrating object positions is essential for the effective operation of tracking models. To address this, the authors employ an intermediate frame interpolation framework (see Fig. 2) to sequentially synthesize neighboring frames within a video sequence, thereby enhancing observational stability. The core method involves generating two intermediate frames, labeled α and β, interpolated from the (i − 1)th and (i + 1)th frames, respectively. These deformed frames are then processed through a UNet architecture with multi-scale feature fusion to produce an initial spatial frame, fint. Subsequently, a ResNet model refines the frame fi by deforming it based on fint, resulting in the final interpolated frame. Incorporating the original frame helps reduce resampling errors. This approach uses an unsupervised training paradigm, where a pseudo-target frame is created by applying small random translations to the original frame. This strategy directly optimizes the inference process to generate a virtual frame that can replace the actual target frame when its quality is compromised.
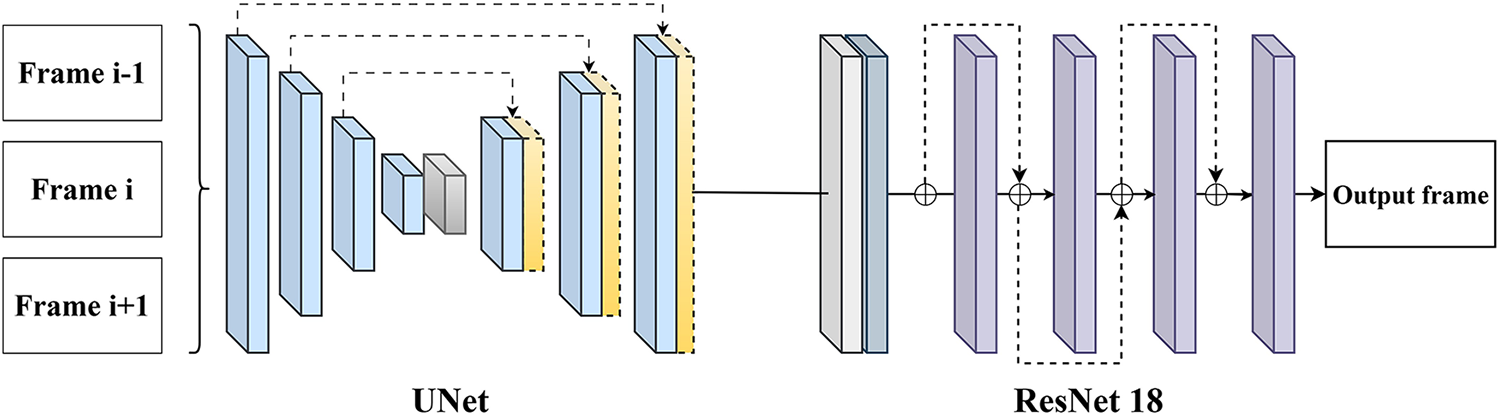
Figure 2: Deep Iterative Frame Interpolation based on Unet and ResNet18.
The UNet architecture is specifically designed for tasks that require high spatial resolution. It consists of two main components: the Encoder and the Decoder, which are connected through upsampling pathways to reconstruct the spatial structure. To preserve gradient information and maintain spatial details, a skip-connection mechanism is employed. The Encoder module includes convolutional blocks that extract features at various scales while progressively reducing data dimensionality across layers. The original spatial input is transformed through successive nonlinear mappings, as described by Eq. (1).
where W represents the weight matrix of layer l, b denotes the bias term, and σ refers to the ReLU activation function. The pooling operation is applied to reduce data dimensionality and improve the feature representation within the processed tensor. The decoder block is responsible for analyzing and reconstructing the data dimensions. Upsampling blocks are used alongside a skip-connection mechanism, where feature maps from the encoder are concatenated with those in the decoder at corresponding scales. This approach helps to preserve spatial information that is often lost during successive convolutional layers. The loss function employed during training is defined as shown in Eq. (2).
where α denotes the scale factor, fint represents the intermediate deformation frame, and ϕ signifies the function that maps the input image to the feature vector within the initial layers. The inclusion of this feature vector component is primarily intended to preserve structural information, capturing shape and boundary characteristics present in layers rich with such details. This design is specifically tailored to improve the assessment of the model’s ability to comprehensively capture these properties.
ResNet18 is enhanced to restore local details and reduce noise in the interpolated frames, in Fig. 2. This process ultimately produces a fully reconstructed intermediate frame. The authors’ architecture consists of four residual blocks, which perform convolution operations and parameter calculations alongside residual function mapping (3) to prevent information loss between consecutive layers.
In which, F(x) is a nonlinear transformation according to Eq. (4):
Finally, Bacth Normalization (BN) is used to stabilize the gradient values and speed up the convergence during training. It ensures that the gradient values are passed straight through the connetion layers which optimizes the computational flow and prevents gradient vanishing.
3.2 Efficient Deblur GAN Model
In the context of USV operations, motion blur poses a significant challenge that must be addressed. This issue stems from the inherent USV’s dynamics as they navigate environments with continuously changing speeds and orientations. Moreover, the persistent influence of oceanographic factors such as waves and wind during real-world deployment further complicates the development of robust perception systems for USVs, as these conditions intensify motion blur effects. Tackling this problem using GAN-based models offers a promising solution. However, many existing models face limitations in adaptability and stability, especially when applied to USV systems. To overcome these challenges, the authors propose the Efficient DeblurGAN model (EDGAN), which incorporates an effective multi-scale strategy for motion deblurring. The key innovation lies in enhancing the traditional DeblurGAN framework to adapt to varying levels of blur across different scales. The overall architecture of the proposed method (see Fig. 3). Fundamentally, the DeblurGAN model is built upon the GAN architecture and employs a perceptual loss function to accurately map blurred images to their sharp counterparts. The supervised spatial training framework consists of Generator and Discriminator modules: the Generator is responsible for producing image pairs that represent the relationship between motion-blurred and sharp images, while the Discriminator evaluates these generated pairs to provide reliable quality assessments. This adversarial process enables the Generator to iteratively improve the quality of the deblurred images.
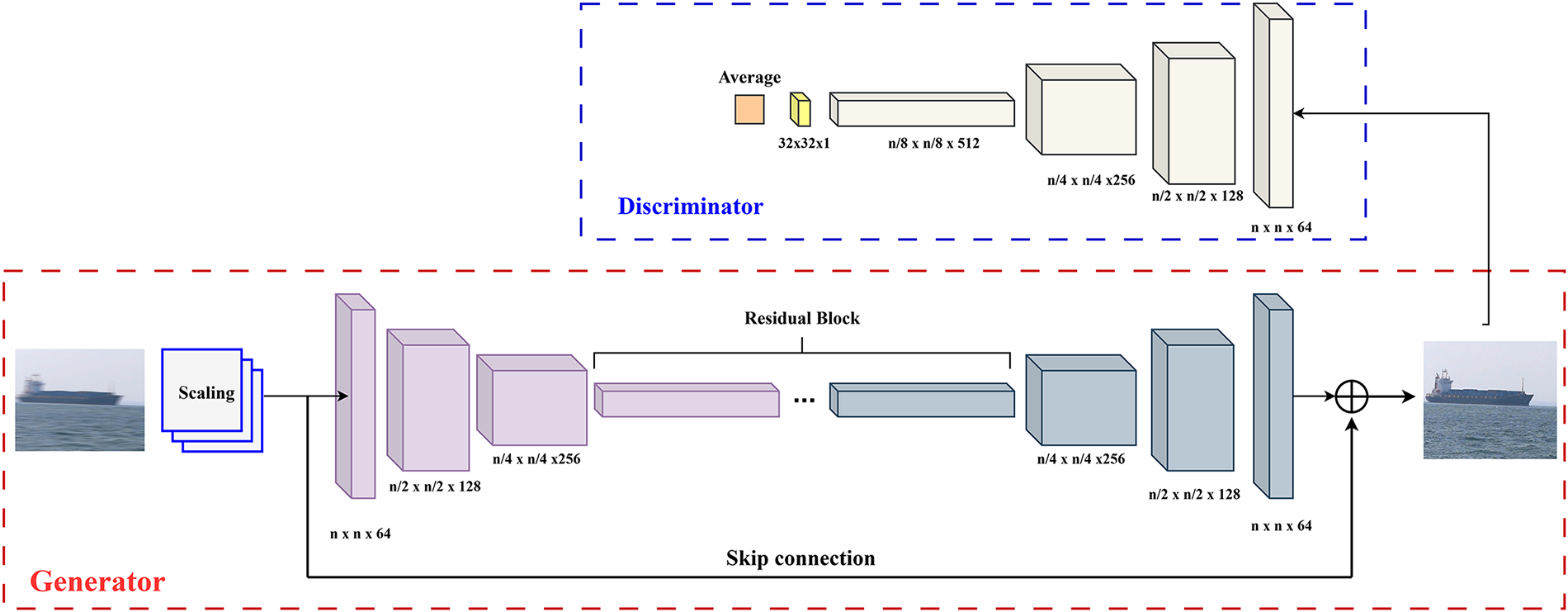
Figure 3: Efficient DeblurGAN architecture.
The authors tackle the challenge of motion blur by developing a model architecture based on the GAN framework. Their approach seeks to improve the traditional model structure through multi-scale adaptation, recognizing that blur occurs simultaneously across different spatial scales. In this study, they propose integrating dual multi-scale generator and discriminator blocks to enhance both the stability and quality of image restoration. Firstly, data pyramids are created by dividing the input frames into multiple scale levels:
where, downsampling is performed using bilinear interpolation to reduce the frame rate by a factor of n. Alternative methods, such as Gaussian filtering, can also be applied. For each integer value of n, a corresponding frame rate layer is generated. In the experimental setup, n is set to 2. For each input data rate, a Generator branch (Gn) of the appropriate size is created. The outputs from these branches are concatenated and then passed to the Discriminator, which evaluates their correspondence with the ground truth. The adjustment coefficient obtained from this evaluation is fed back to Gn to iteratively refine the generation process. The network architecture is built using Residual blocks and includes a skip connection mechanism from the input to the output layers to prevent feature degradation. The Discriminator is combined with conversion blocks that scale the outputs to a uniform size in the final layer. The overall multi-scale loss function, consisting of three components: adversarial, content, and perceptual losses at each reference level (k), is defined by Eq. (6).
Let λadv, λc, λperc represent the balancing coefficient between the adversarial loss, content loss, perceptual loss, respectively. The three loss function components corresponding to the remaining attributes are defined by Eqs. (7)–(10).
where D represents the discriminator operating at scale k.
Eq. (8) represents the loss function of the discriminator:
∇ is the gradient operator, representing the derivative with respect to a vector.
where
The proposed framework improves the conventional YOLOv5 architecture by modifying the feature extraction module to simultaneously process both IR and RGB images [34], as illustrated in Fig. 4. This dual-modality approach allows the model to effectively capture infrared radiation signals alongside the color features of objects in the environment. By integrating data from both IR and RGB channels, the model gains greater versatility, enabling robust performance across diverse data types and varying environmental conditions. This integration significantly enhances the accuracy and reliability of positioning systems by reducing the impact of external factors such as lighting variations, dust, and precipitation. The model’s backbone utilizes Cross Stage Partial (CSP) blocks, where feature maps are split into two branches within the residual block. Unlike traditional linear residual computations, the CSP block introduces a sub-branch that combines gradient information from the previous layer. This architectural design eliminates redundant gradient calculations, thereby improving parameter computation efficiency. Furthermore, the activation function can be adaptively chosen between Leaky ReLU and Mish, depending on the specific task requirements. Although the YOLOv5 version doesn’t provide the highest accuracy in object detection. However, its other properties are prioritized in the choices within this study. The backbone CSPDarkNet53 inherently has a simple architecture and works well with the CSSA channel attention module, which is used as a bridge between the two IR-RGB streams. The model’s lightness and agility are prioritized for integration into resource-constrained systems, with USVs being of particular interest. Fig. 5 shows the use of the CSPDarkNet53 architecture as the foundational backbone for the proposed IR-RGB object detection model.
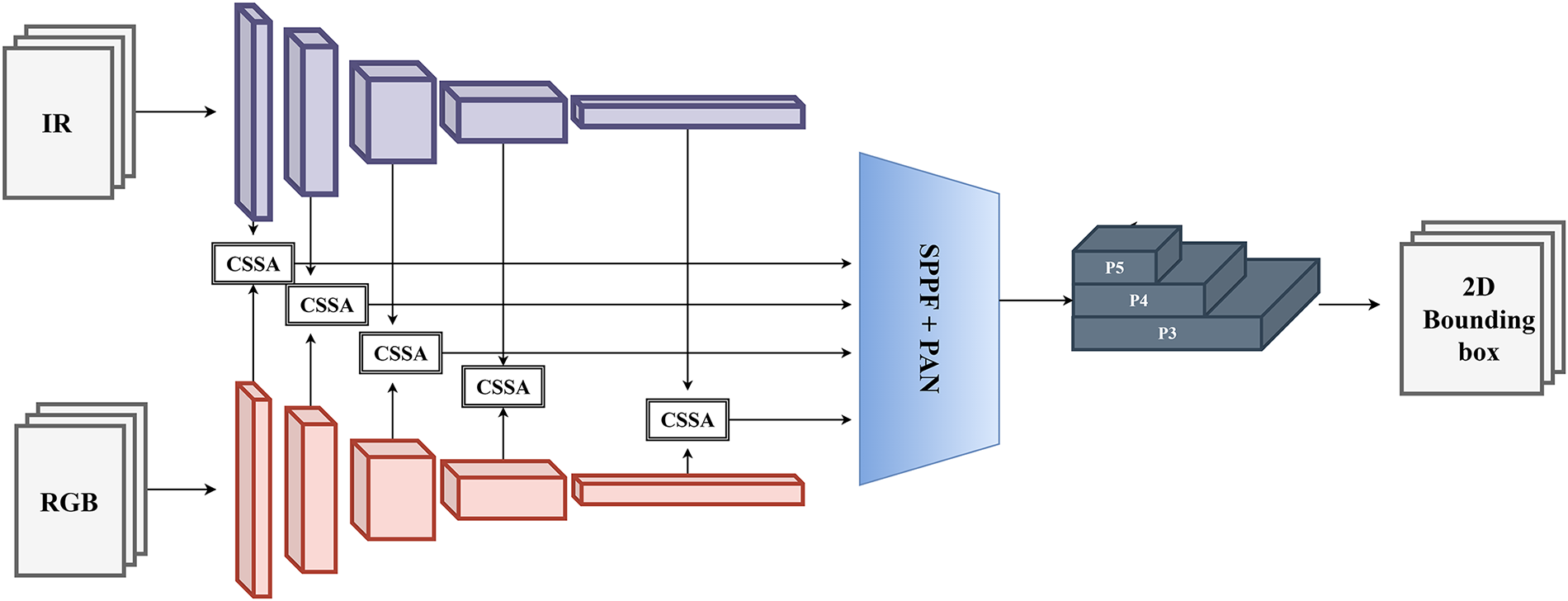
Figure 4: Proposed 2D-OD using CSSA modules.
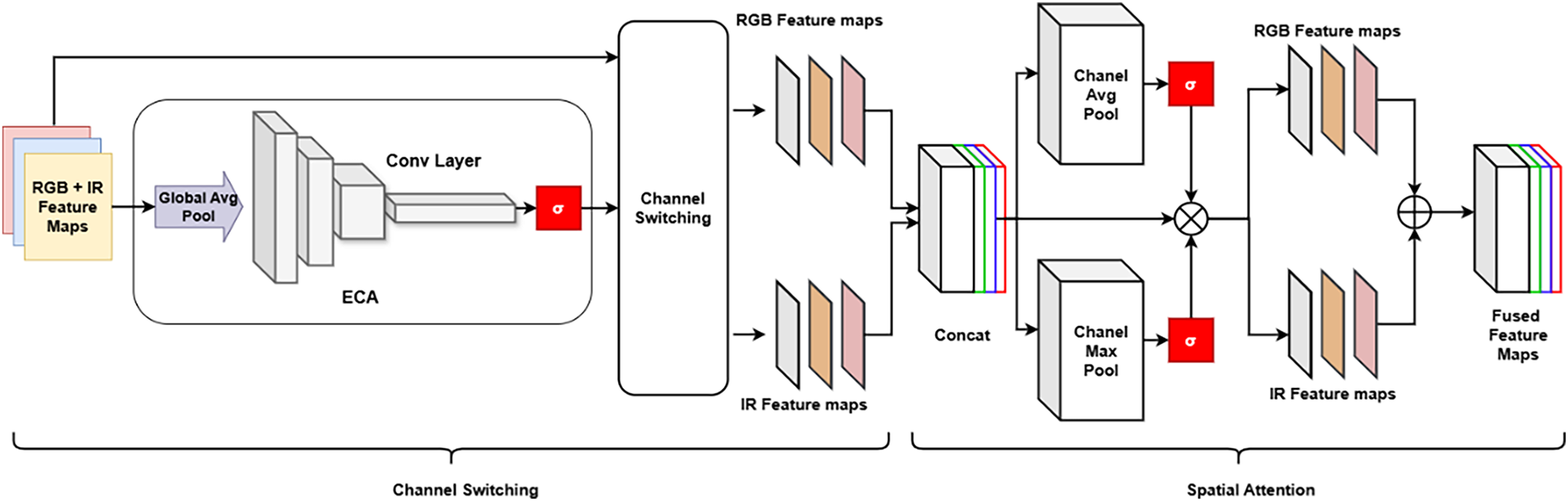
Figure 5: Channel Switching Spatial Attention module (CSSA).
In the context of concurrent training and inference using both IR and RGB images, the backbone architecture is designed with two distinct parallel streams. Corresponding blocks in these streams are connected via Cross-Stream Spatial Attention (CSSA) modules, which enhance the extraction of salient features from both image modalities. These CSSA modules integrate weights from the dual streams and identify critical features across all channels. The CSSA blocks enable the aggregation and fusion of information from both shallow and deep convolutional layers within the backbone network. This architecture is carefully designed and optimized based on the CSPDarkNet53 framework. Empirical evaluations during the design phase show that the CSSA module is highly compatible with the pseudo-monolithic CSP architecture and outperforms alternative YOLO backbone configurations, as illustrated in Fig. 3. The module receives two sets of feature maps processed at each backbone layer. These latent features are then passed to Efficient Channel Attention (ECA) blocks. A Global Average Pooling (GAP) operation captures inter-channel interactions while preserving essential feature information. Subsequently, the input feature space is compressed into a weight vector, which is used to recalibrate and optimize features in later processing stages
Subsequently, the mapping function integrates local neighboring channels to analyze the interrelationships among the channels by employing a convolution with a kernel size that is adaptively scaled. To ensure that
where
The channel exchange process is carried out using a filtering approach based on the weights assigned to each channel, which are determined by the hyperparameter k. Channels with a high presence of two-cascade RGB features are swapped with IR feature channels, and vice versa, according to the aggregate selection feature. The threshold k, expressed as a percentage, ensures that a consistent proportion of the most discriminative channels is retained, regardless of variations in the distribution of attention weights. The dynamic top-k strategy selects a fixed number of the most salient channels for each input, maintaining stability while adapting to individual samples. We propose implementing a non-learnable threshold combined with a continuous update mechanism, allowing the model to flexibly adjust to the dataset’s characteristics as well as to features beyond the two IR and RGB modalities. Finally, the calculation of channel attention weights is formalized by the following Eq. (12):
Then, two feature maps where the channels have been exchanged from their original positions. The output features of ECA are concatenated, followed by a process to obtain attention weights in Eq. (13):
here, CAP (Channel Average Pooling) extracts the channel average, and global component relationship representations are extracted and stored. CMP (Channel Max Pooling) uses small-sized filters to highlight important features of corresponding sizes. ꕕ is the element-wise multiplication. Element-wise multiplication with the original feature map ensures two core elements: preserving the initial contextual information and highlighting valuable features within the computational flow. Next, the performances through the average and maximum values of the channel with the original characteristic map are combined, and the process of analyzing the relationship between important characteristics is carried out. The channels are then separated back out along with internal averaging. A final concatenation layer is added to form the complete feature map. The result after the characteristic shifting process between the streams is the synthesis and selection of the most valuable information to be sent to the subsequent decoding layer. Finally, the decoding blocks designed according to the YOLO model are used to generate class predictions and bounding box location.
The main characteristic in model selection and design is its compactness and efficiency in the training and inference process. CSPBlocks, which are efficient with a limited number of parameters. While the effectiveness has been proven. Instead of extracting features outside of the architecture, CSSA blocks directly use the data and backbone for exploitation, without making the model more cumbersome. The balance between performance and stability in intelligent mechatronic systems is ensured, with the target deployment platform being USVs. In summary, choosing and designing a multimodal object recognition model based on the CSP and CSSA platforms offer numerous advantages, with the primary focus on efficiency and deployability across multi-channel signal acquisition systems. Through this, the premise for the proposed EDGAN was formed.
After objects are detected by the IR-RGB model, tracking is performed using the DeepSORT algorithm, which combines spatial information and appearance features to maintain consistent identification across multiple frames. Each detected object receives a unique identifier, enabling accurate tracking even during temporary occlusions or rapid movements. The state of an object at time t is represented by the vector:
where
where
And the cosine distance between appearance feature vectors
These distances are combined into an overall cost function
The Hungarian algorithm is then applied to optimize the assignment between detections and tracks. Once correspondences are established, track states are updated using the Kalman filter update Eq. (19):
where
The researchers trained and evaluated individual modules using carefully curated datasets. They collected and analyzed both qualitative case studies and quantitative metrics to assess the performance and effectiveness of each component. The training was conducted on a computing system featuring an Intel Core i9 11900K CPU, 64 GB of RAM, and an NVIDIA RTX 3080 GPU. Model components were trained using the Singapore Maritime Dataset (SMD) [35] along with proprietary data gathered from the operational environment of the USV. Images were captured with a Canon 70D camera at a resolution of 1080 × 1920 pixels. The collected videos and images included both IR and RGB formats, obtained from various maritime routes. For the infrared data, the camera was modified by removing the hot mirror and adding a Mid-Opt BP800 infrared bandpass filter. To assess the recovery capabilities of the MDGAN-DIFI module, some samples were artificially degraded using a motion blur filter. The results from both the training and inference phases are presented in the following section. Furthermore, simulation experiments were conducted to examine the effects of frame disturbance phenomena. Measurements from these experiments confirmed the stability and reliability of the intermediate frame estimation module, which is based on interpolation techniques. The self-collected dataset used in this study is provided at the following link: https://github.com/buinghia3101/HUST-USV-Dataset.git. The self-collected dataset includes 20 contextual videos tracking maritime objects. The scenes are divided into 4600 corresponding frames. The images were captured using both infrared and RGB methods. The number of labels is 6, with various types of watercraft and buoys in the observation environment. The corresponding resolution is 1080 × 1080 for the captured images. Objects are annotated according to the YOLO output standard provided by Ultralytics.
The initial evaluation of deep frame interpolation performance was carried out using equipment designed to replicate the operational conditions of an USV in an oceanographically influenced environment. As illustrated in Fig. 6, the experimental setup involved mounting a USV model on a robotic arm fitted with a camera, with a Jetson Nano device integrated to process the captured images. Simulated motion disturbances were generated by continuously oscillating the robotic arm during the experiment.

Figure 6: Experimental validation of deep frame interpolation module for frame tracking stability analysis.
Target objects in the environment were identified using QR codes, as shown in Fig. 7, and the system continuously monitored and recorded their oscillations. Oscillation parameters were measured both before and after implementing the proposed module to evaluate its effectiveness. Simultaneously, various frame stabilization and reconstruction methods were compared. Oscillation indices reflect the temporal instability of the positions of objects continuously tracked within the frame. Sudden changes due to camera shake caused this metric to increase, reducing the ability to predict object movement. This causes a lack of data linkage in the tracking problem. Reducing the oscillation level makes the object’s trajectory smoother and more continuous, increasing the reliability of the motion characteristics used in the tracker. The experimental results, summarized in Table 1, present the oscillation parameters of detected objects relative to a reference optical time. Deviations in object coordinates within frames were calculated based on positional ratios between consecutive frames. Average oscillation levels for each method were computed to demonstrate the improvements achieved by the proposed MDGAN-DIFI compared to existing models (see Fig. 8).

Figure 7: The environment and objects are tracked in frame-by-frame motion. From left to right: original frame and processed frame, coordinates of objects are recorded for continuous motion tracking.

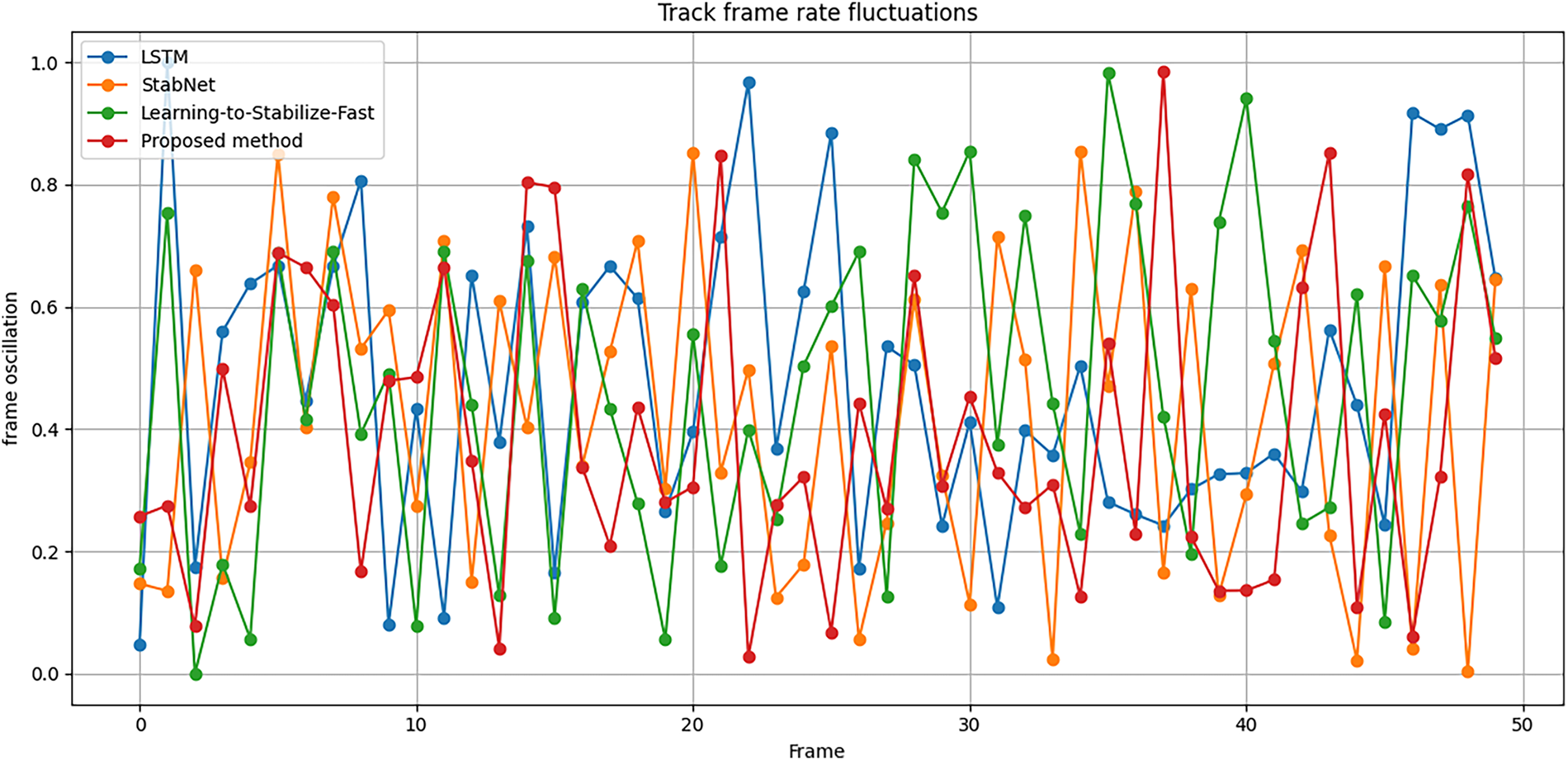
Figure 8: Oscillation parameters of objects in the frame over time compared to the initial oscillation.
The findings indicate that the proposed module exhibits highly competitive adaptability relative to established methods. Comparative analysis included models based on Long Short-Term Memory (LSTM) techniques [36] for frame stabilization, the StabNet model [37], and the Learning-to-Stabilize-Fast (LSF) model [38] (see Fig. 8). The proposed method achieved the highest stability, with an average oscillation level of 0.3907. In contrast, more complex methods with numerous computational parameters did not sufficiently reduce oscillations. Notably, the StabNet method, which performed best among the compared models, still exhibited an oscillation level 0.0342 higher than the proposed approach. These results suggest that deep frame interpolation offers significant advantages, with its superior architecture and performance presenting substantial potential for mitigating viewpoint instability in USVs.
Experiments involving blurred image data were carried out through a systematic process of test data selection and preparation. The authors created a dataset consisting of frames captured from a maritime surface environment. During the pre-processing stage, camera shake was simulated at a high frame rate to induce motion blur in the images. These blurred images were then paired with their corresponding sharp frames to form parallel input pairs for the GAN model. All frames underwent gamma correction with a gamma value of γ = 2.2, followed by the application of the inverse gamma function to generate the final blurred frames. The resulting dataset comprises 2500 image pairs, corresponding to 1250 frames, each containing both blurred and sharp versions. Training is conducted through 150 epochs, until the tracking parameters converge. The adversarial networks are trained with the Adam optimizer and a learning rate of 0.001 and 0.004 or the Generator and Discriminator. The loss weights are fixed to λadv = 1, λc = 10, and λperc = 1. The Generator and Discriminator have a training ratio of 1:1. Convergence is attained when the adversarial losses converge for a set of epochs and there is no further improvement in the validation of PSNR and SSIM. The performance of the proposed MDGAN-DIFI model was thoroughly evaluated, with particular focus on scenarios involving complex contextual information and multiple objects targeted for tracking. Illustrative examples demonstrating the effectiveness of the proposed method were presented throughout most recorded evaluations. The spatial positions and color fidelity of the observed objects within the frames showed high consistency, while the characteristics of the feature map regions were effectively restored. Visual assessments indicated a substantial improvement in the informational content of the generated images compared to those affected by motion blur. Furthermore, the characteristics of the maritime objects need to be restored as they are discovered. Especially with severely blurred pixel clusters that provide little information about objects and landscapes. Restoring details to sharp standards yields the fundamental characteristics captured by the system. The fundamental image properties were inferred as essential prerequisites for effective object detection within the frames. Additionally, the authors conducted an object recognition experiment using the YOLO-CSSA model to quantify the number of detected objects. Two datasets were used: the original dataset containing motion-blurred images and the enhanced dataset produced by the proposed method. The total number of detected objects was compiled and compared across both datasets, with the results summarized in Table 2. The findings revealed a significant increase in object detection efficiency following data augmentation via the proposed MDGAN-DIFI model, demonstrating the feasibility of integrating this approach into the proposed architecture, in Fig. 9.


Figure 9: Proposed MDGAN-DIFI model testing results in generating sharp images from motion blur images. From left to right: original motion blurred image and sharp generated image.
The object detection results on both RGB (top row) and infrared (IR) images (bottom row) demonstrate the proposed MDGAN-DIFI’s effectiveness in identifying objects on the water surface, covering a variety of sizes and distinct visual characteristics (see Fig. 10). The proposed MDGAN-DIFI accurately detects numerous vessels at different distances, including smaller ships at both long and short ranges. The limited data entries indicate that the detected object positions mainly correspond to moored vessels and floating craft, which strongly align with the detection targets. Notably, even objects occupying a small portion of the frame are detected with minimal loss in accuracy. The tested cases showed almost no errors in object classification or localization. In the IR imagery, the YOLO-CSSA model successfully distinguishes object sizes and separates them from the water background despite varying levels of thermal reflection. Small floating objects, such as buoys and small boats, are precisely identified with appropriately scaled bounding boxes, highlighting the model’s ability to differentiate discrete thermal regions. The model’s performance under the observed environmental conditions is particularly impressive. By combining IR and RGB data, this approach provides robust environmental perception in complex scenarios, including low-light and foggy conditions. Overall, these findings suggest that the integrated IR-RGB model holds significant potential for maritime surveillance applications, especially for detecting and tracking multiple objects at sea under challenging environmental conditions or when objects have limited semantic features and are subject to unstable observation circumstances.

Figure 10: Multimodal object detection results using the YOLO-CSSA model through two IR-RGB channels.
The training results indicate that the proposed MDGAN-DIFI converges well and achieves high performance on the dataset (see Fig. 11). The training plots for box loss and objectness loss show a consistent decline over the epochs, demonstrating effective optimization of bounding box localization and objectness confidence. The input resolution is set to 1080 × 1080, the batch size is 16, and the model is optimized using stochastic gradient descent with an initial learning rate of 0.01 and momentum of 0.937. The classification loss remains close to zero throughout training, suggesting that the object classification task is relatively simple or that the dataset contains a limited number of classes. On the validation set, both box loss and objectness loss steadily decrease without signs of overfitting, indicating strong generalization capabilities. Precision and recall metrics increase rapidly during the initial epochs and stabilize near 1.0 after about 10 epochs, showing that the model attains high accuracy while maintaining comprehensive object detection. The mean average precision at an IoU threshold of 0.5 (mAP@0.5) approaches 1.0, reflecting a strong alignment between predicted bounding boxes and ground truth labels. However, the mAP measured across IoU thresholds from 0.5 to 0.95 (mAP@0.5:0.95) fluctuates between approximately 0.65 and 0.7, indicating room for improvement under stricter IoU criteria. In summary, these results confirm that the trained model is stable, converges quickly, and delivers excellent accuracy and detection performance, providing a solid foundation for future implementation of object tracking or integration into the IR-RGB multi-modal detection system.
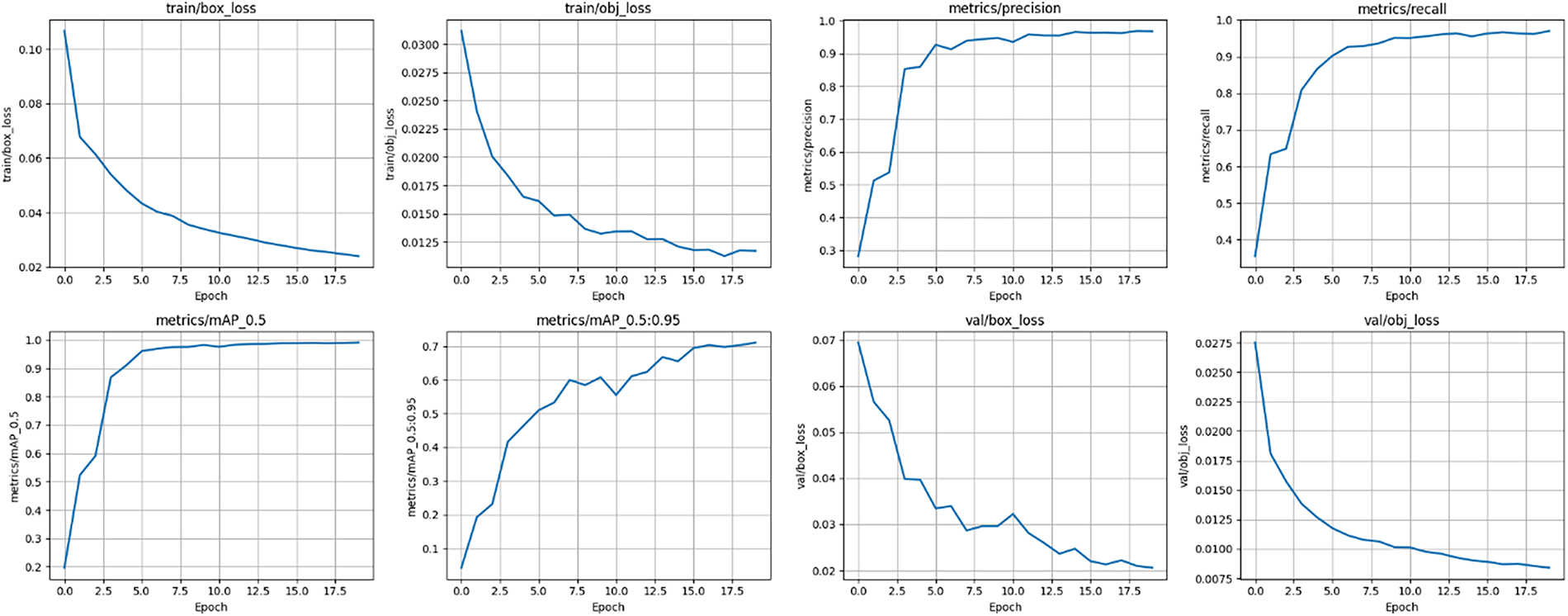
Figure 11: Trained results of proposed MDGAN-DIFI based on box_loss, obj_loss, cls_loss, precision and recall, respectively.
Evaluating the proposed MDGAN-DIFI on test video sequences shows remarkable effectiveness in the USV operating environment, especially when focusing on objects on the water surface. The illustrative examples are collected and presented by the author in Fig. 12. Objects were detected and identified throughout the tracking process. Objects of interest such as boats or floating vessels at any distance are effectively identified and tracked. Combined with preprocessing and frame stabilization modules, this contributes to improved overall tracking performance. Furthermore, the model demonstrates proficiency in continuously tracking objects across subsequent frames by assigning unique identifiers to each vessel, thereby minimizing issues related to object loss or misidentification, especially when vessels are close together. In-depth analysis shows that the impact of environmental factors and the proportion of subjects in the frame have significantly decreased. Overall performance in maintaining overall stability was sustained throughout the evaluation, highlighting its potential usefulness in maritime surveillance and vehicle tracking applications. The results obtained contribute to strengthening the effectiveness and role of the observation range stabilization and turbulence removal modules for the tracked frame sequence.

Figure 12: Experimental results of multi-object tracking based on the proposed model.
Table 3 illustrates the comparison of the proposed MDGAN-DIFI with other MOT methods to confirm substantial advancement in multi-object tracking. It simultaneously achieves the highest overall accuracy (MOTA), the most reliable long-term identity association (IDF1), and the most robust trajectory maintenance (highest MT, lowest ML, IDs, and FM). Furthermore, its competitive FPS rate ensures its practical applicability in real-time scenarios. The exceptional performance, particularly the 40.75% relative improvement in IDF1 and the 28.82% relative reduction in Identity Switches, compared to the next best model (Trades). Achieving the highest MOTA of 47.5%, the model is 1.13 times more accurate than the next best competitor, Trades (42.0), and 1.40 times more accurate than the SORT baseline (33.8%). Crucially, its capability for maintaining identity is vastly superior, scoring an IDF1 of 48.7%, which is approximately 1.41 times greater than Trades (34.6%). This is directly correlated with a massive reduction in identity errors, as the proposed method records the fewest Identity Switches (IDs) at 1805, a figure that is approximately 1.40 times fewer than Trades (2536) and approximately 2.23 times fewer than SORT (4020). Furthermore, the model exhibits exceptional efficiency by achieving the lowest False Negatives (FN) at 43,208, approximately 1.14 times fewer than Trades (49,299) while maintaining a competitive real-time processing speed of 35.5 FPS5. In summary, the proposed MDGAN-DIFI provides a state-of-the-art balance of high accuracy and robust identity preservation without sacrificing real-time performance.
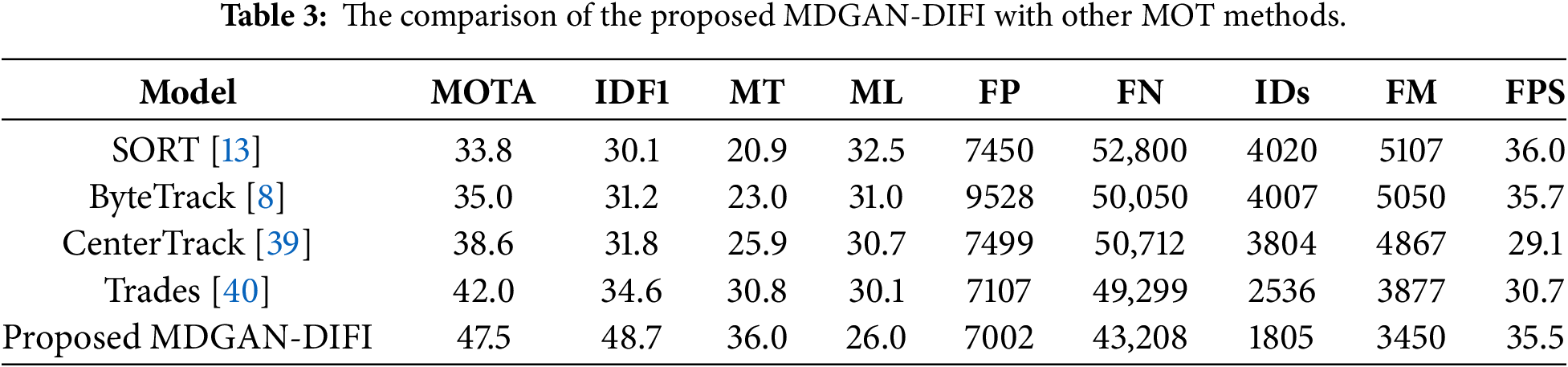
Table 4 presents the metrics used to evaluate the self-collected dataset. The results demonstrate that the proposed method delivers highly competitive performance, especially under complex environmental conditions that affect image data acquisition. Traditional approaches show comparatively lower effectiveness across several indicators, mainly because they do not directly address the challenges of tracking in unstable observation backgrounds. In contrast, the proposed method consistently keeps MOTA, IDF1, FN, FP, IDS, and HS parameters within effective thresholds. Notably, the highest recorded values were 82.3% for MOTA, 80.4 for IDF1, and 66.1 for HOTA, each representing the best performance among all evaluated methods. The IDS metric further highlights the stability of the proposed approach, achieving a top value of 1240 across 20 evaluation videos, significantly outperforming all comparative techniques. Similarly, the optimal HS value reached 0.72, with FN recorded at 79,222. The only exception is the FP metric, which is slightly higher than that of ByteTrack and CenterTrack (22,140). Overall, these comprehensive evaluations emphasize the proposed MDGAN-DIFI’s strong potential for effective adaptation within the USV system, which faces considerable challenges due to unstable observation conditions.
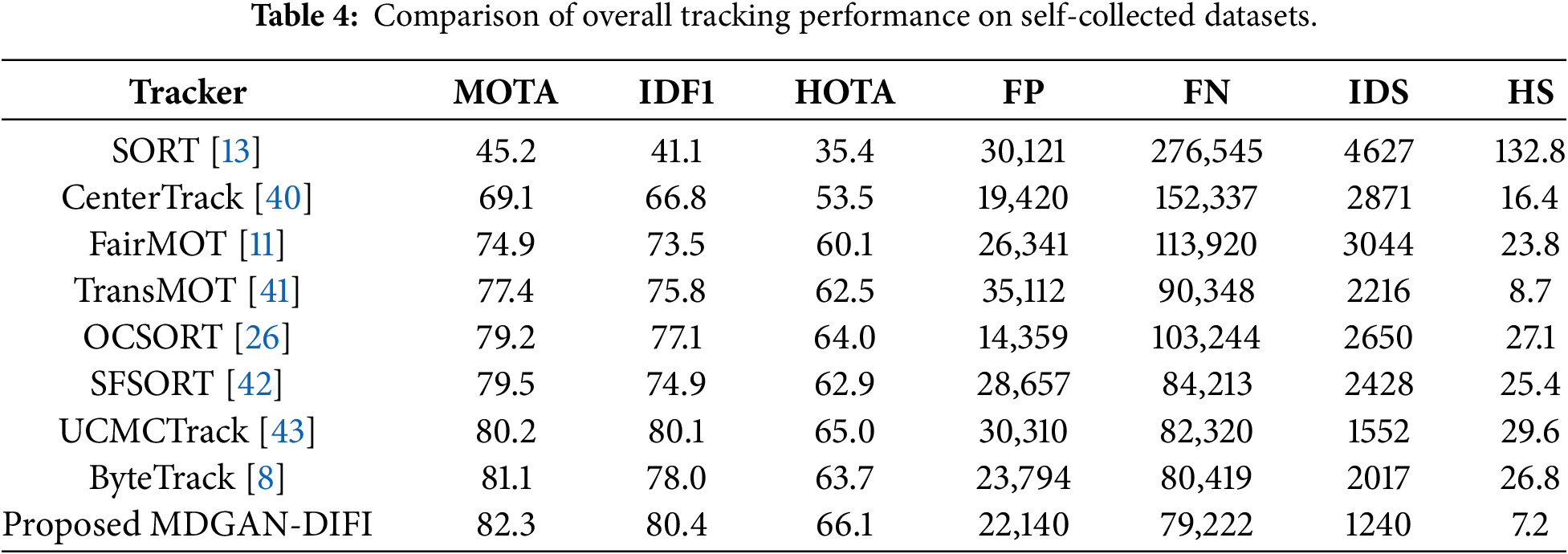
An ablation study is performed to gauge the contribution of each module as illustrated in Table 5. Initially, the baseline DeepSORT model performs with a MOTA score of 50.7 and IDF1 of 42.8. However, with the addition of the proposed DIFI module, the results improve dramatically with the MOTA and IDF1 scores rising to 75.4 and 74.3, respectively. Moreover, the number of identity swaps drops dramatically from 4537 to 2548. This proves the strength of the proposed DIFI module for better data association and temporal consistency. In contrast to this, GAN-DeepSORT offers a modest enhancement to IDF1 (49.0) and HOTA (39.7), whereas a trivial advancement to MOTA (49.6) suggests that GAN alone improves appearance representation but does not adequately tackle fragmentation during tracking. The complete model of MDGAN-DIFI performs best on every evaluation metric, with MOTA, IDF1, and HOTA scores of 82.3, 80.4, and 66.1, respectively, while the number of identity switches is minimized to 1240. The complementary nature of the GAN and DIFI approaches is thus validated by these results.
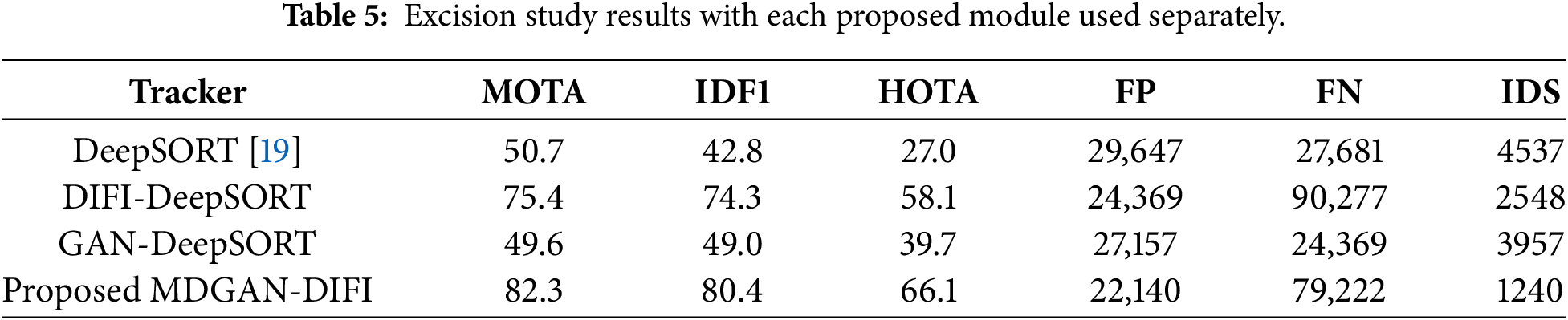
The experimental results validate the high suitability of the proposed MOT method for deployment on embedded controllers, showcasing an effective trade-off between performance and latency across different scales. While the largest W6-1920 model achieves peak accuracy (MOTA 47.0%, IDF1 50.1%), the most practical configuration for real-time embedded systems is the tiny-960 model2. This model delivers high-quality tracking metrics (MOTA 42.7%, IDF1 44.9%) at an impressive total latency of only 6.3 ms (5.0 ms + 1.6 ms). Crucially, the tracking component’s time remains highly stable, ranging minimally from 0.9 to 1.6 ms across all scales, indicating a computationally light and efficient association mechanism. This stability ensures that the MDGAN-DIFI’s bottleneck remains predictable within the detector’s backbone, confirming the proposed architecture’s high efficiency and robustness for resource-constrained, real-time applications. The number of used parameters and the equivalent memory threshold are provided. The core processes utilize a threshold of 12 million parameters and under 700 MB of storage, ensuring the tracker’s functionality on edge devices. As in the study using the NVIDIA Jetson origin. The parameters during performance measurement are illustrated as shown in Table 6.
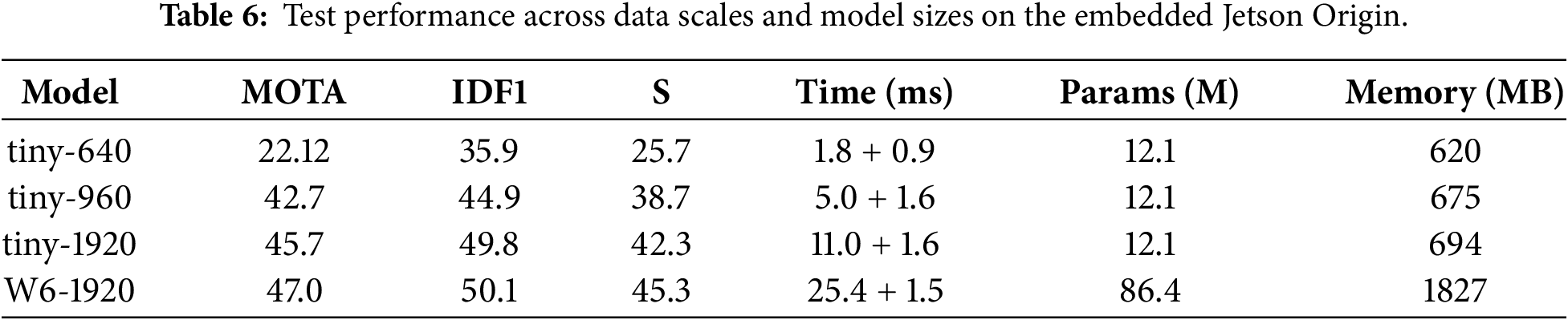
Experiment on USV action navigation in the Webots simulation environment. The authors conducted experiments to integrate the proposed model into the USV’s action planning process within a simulated environment. The platform used is the Webots environment system built on ROS2, with the Ubuntu 22.04 operating system. The navigation framework is built upon the RRT-Star combined with a deep reinforcement learning network [44]. A deep interpolation-based frame stabilization module was added for testing on USV performance. Combined with the MOT network built for USV operation in the created context. The environmental components are set up to include the target and the obstacles that need to be detected. USV operation requires correlating frames in real-time, detecting and tracking obstacles, and finding the optimal path to the destination. Preliminary testing shows initial potential for developing an environmental monitoring mission to support the navigation problem. The test cases did not record collisions with obstacles or reaching the destination. Extract the status history, with actions illustrated as in Fig. 13. The information from the extracted frames is used to write the positions of the obstacle objects that need to be avoided. At the same time, the navigation process quickly brings the USV to the destination.
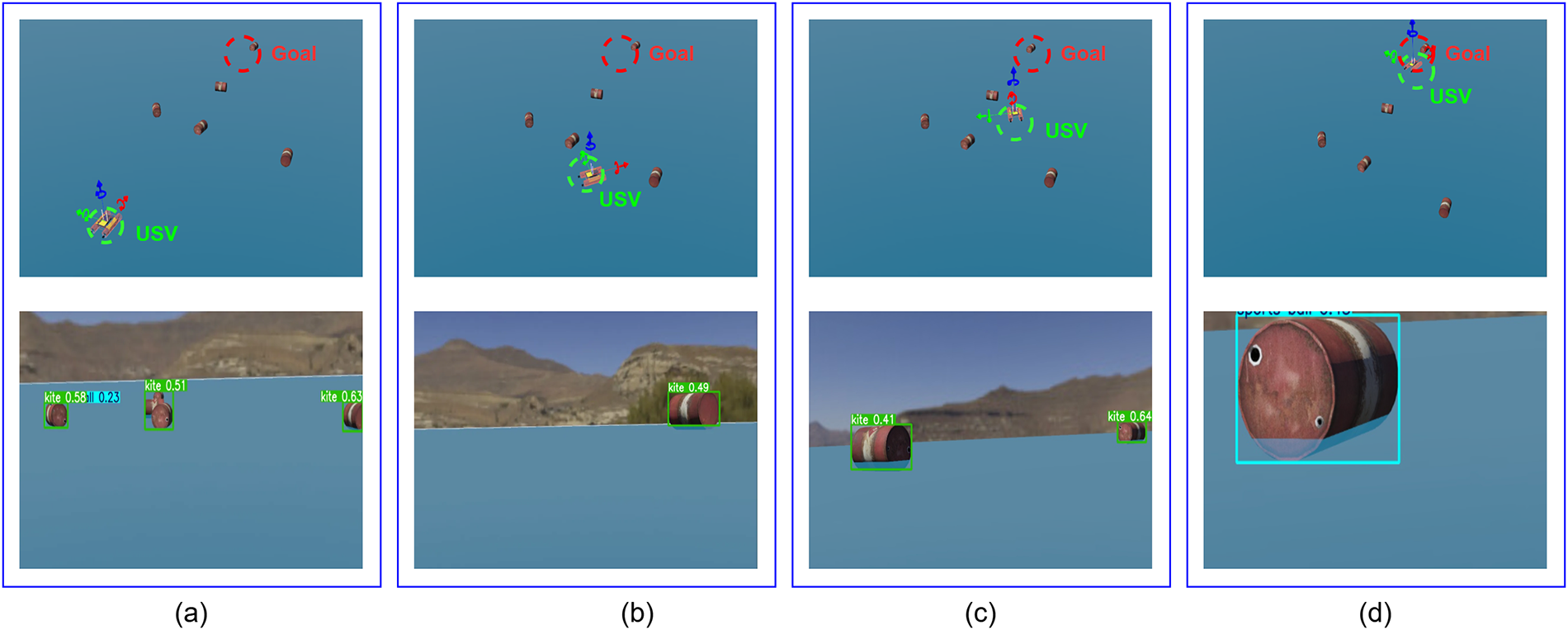
Figure 13: Experiment on USV action navigation in the Webots simulation environment. From top to bottom, the USV position in the wall environment and the viewing angle of the USV are processed at the same time. Cases are recorded in chronological order with (a): the start point, (b): detect and begin entering the obstacle zone, (c): pass through the obstacle, (d): reach the destination with the shortest route, respectively.
The paper proposes an efficient multi-object tracking framework built upon high-performance aggregation modules. The effectiveness of tracking is constituted by frame stability through deep internal features. Combining with this is the EDGAN model, which quickly corrects low-quality frames caused by observation point shaking. The multimodal detection model yields robust object detection performance by combining the IR and RGB attribute branches in the USV’s data acquisition process. The DeepSORT tracking algorithm ensures the efficient combination and operation of the component modules. The experimental results show remarkable effectiveness. Frame rate fluctuations are reduced and are highly competitive with other approaches in the same field. Performance and accuracy metrics for the overall model, such as MOTA and IDF1, yielded promising results. The authors hope this research will demonstrate the potential for an approach to effectively building cognitive systems for intelligent mechatronic systems, including USVs. Future work focuses on continuing to improve the model’s components and architecture and mitigating the effects of ID confusion during multi-object tracking. Simultaneously, establish an effective USV navigation problem in diverse environmental scenarios.
Acknowledgement: Not applicable.
Funding Statement: This research was funded by the Ministry of Education and Training of Vietnam under the research project B2024-BKA-13.
Author Contributions: Conceptualization, Manh-Tuan Ha, Thai-Viet Dang; methodology, Nhu-Nghia Bui, Manh-Tuan Ha, Thai-Viet Dang; software, Nhu-Nghia Bui, Dinh-Quy Vu; formal analysis, Manh-Tuan Ha; investigation, Nhu-Nghia Bui, Dinh-Quy Vu; resources, Nhu-Nghia Bui, Thai-Viet Dang; data curation, Nhu-Nghia Bui; writing—original draft, Dinh-Quy Vu, Thai-Viet Dang; writing—review & editing, Dinh-Quy Vu, Thai-Viet Dang; visualization, Dinh-Quy Vu; funding, Manh-Tuan Ha; supervision, Thai-Viet Dang; project administration, Thai-Viet Dang. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the Corresponding Author, [Thai-Viet Dang], upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Boretti A. Navigating the future: the expanding role of unmanned surface vehicles in maritime security. J Transp Secur. 2025;18(1):24. doi:10.1007/s12198-025-00314-x. [Google Scholar] [CrossRef]
2. Lee J, Shin J, Park E, Kim D. Real-time robust 2.5D stereo multi-object tracking with lightweight stereo matching algorithm. Sensors. 2025;25(21):6773. doi:10.3390/s25216773. [Google Scholar] [PubMed] [CrossRef]
3. Jiang X, Fang X. Formation control and stability analysis of underactuated unmanned surface vehicles based on improved extended state observer: addressing disturbance challenges. J Intell Rob Syst. 2025;111(4):108. doi:10.1007/s10846-025-02316-2. [Google Scholar] [CrossRef]
4. Stanojevic VD, Todorovic BT. BoostTrack: boosting the similarity measure and detection confidence for improved multiple object tracking. Mach Vis Appl. 2024;35(3):53. doi:10.1007/s00138-024-01531-5. [Google Scholar] [CrossRef]
5. Luo W, Xing J, Milan A, Zhang X, Liu W, Kim TK. Multiple object tracking: a literature review. Artif Intell. 2021;293(2):103448. doi:10.1016/j.artint.2020.103448. [Google Scholar] [CrossRef]
6. Weng X, Wang J, Held D, Kitani K. 3D multi-object tracking: a baseline and new evaluation metrics. In: Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); 2020 Oct 24–Jan 24; Las Vegas, NV, USA. p. 10359–66. doi:10.1109/iros45743.2020.9341164. [Google Scholar] [CrossRef]
7. Vo BN, Vo BT, Nguyen TTD, Shim C. An overview of multi-object estimation via labeled random finite set. IEEE Trans Signal Process. 2024;72(5):4888–917. doi:10.1109/TSP.2024.3472068. [Google Scholar] [CrossRef]
8. Liu KC, Shen YT, Chen LG. Simple online and realtime tracking with spherical panoramic camera. In: Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE); 2018 Jan 12–14; Las Vegas, NV, USA. p. 1–6. doi:10.1109/ICCE.2018.8326132. [Google Scholar] [CrossRef]
9. Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric. In: Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP); 2017 Sep 17–20; Beijing, China. p. 3645–9. doi:10.1109/ICIP.2017.8296962. [Google Scholar] [CrossRef]
10. Wang Z, Zheng L, Liu Y, Li Y, Wang S. Towards real-time multi-object tracking. In: Computer vision—ECCV 2020. Cham, Switzerland: Springer; 2020. p. 107–22. doi:10.1007/978-3-030-58621-8_7. [Google Scholar] [CrossRef]
11. Zhang Y, Wang C, Wang X, Zeng W, Liu W. FairMOT: on the fairness of detection and re-identification in multiple object tracking. Int J Comput Vis. 2021;129(11):3069–87. doi:10.1007/s11263-021-01513-4. [Google Scholar] [CrossRef]
12. Cao J, Pang J, Weng X, Khirodkar R, Kitani K. Observation-centric SORT: rethinking SORT for robust multi-object tracking. In: Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17–24; Vancouver, BC, Canada. p. 9686–96. doi:10.1109/CVPR52729.2023.00934. [Google Scholar] [CrossRef]
13. Zhang Y, Sun P, Jiang Y, Yu D, Weng F, Yuan Z, et al. ByteTrack: multi-object tracking by associating every detection box. In: Computer vision—ECCV 2022. Cham, Switzerland: Springer; 2022. p. 1–21. doi:10.1007/978-3-031-20047-2_1. [Google Scholar] [CrossRef]
14. Nguyen VT, Christiansen RGK, Kraft D, Bodenhagen L. GenTrack: a new generation of multi-object tracking. arXiv:2510.24399. 2025. [Google Scholar]
15. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Proceedings of the Neural Information Processing Systems; 2017 Dec 4–9; Long Beach, CA, USA. p. 6000–10. [Google Scholar]
16. Arief M, Afdhal A, SaddamI K, Adriman R, Nasaruddin N. Real-time detection and tracking framework using extended Kalman filter BoT-SORT in uncertainty mixed-traffic. IEEE Open J Veh Technol. 2025;6:2804–27. doi:10.21227/tr7g-xg14. [Google Scholar] [CrossRef]
17. Meng W, Duan S, Ma S, Hu B. Motion-perception multi-object tracking (MPMOTenhancing multi-object tracking performance via motion-aware data association and trajectory connection. J Imaging. 2025;11(5):144. doi:10.3390/jimaging11050144. [Google Scholar] [PubMed] [CrossRef]
18. Hidalgo R, Parron J, Varde AS, Wang W. Robo-CSK-organizer: commonsense knowledge to organize detected objects for multipurpose robots. In: Proceedings of IEMTRONICS 2024; Singapore: Springer; 2025. p. 65–81. doi:10.1007/978-981-97-4784-9_5. [Google Scholar] [CrossRef]
19. Zhao F, Hui K, Wang T, Zhang Z, Chen Y. A KCF-based incremental target tracking method with constant update speed. IEEE Access. 2021;9:73544–60. doi:10.1109/ACCESS.2021.3080308. [Google Scholar] [CrossRef]
20. Zhu X, Zheng Q, Tian X, Elhanashi A, Saponara S, Dini P. Car recognition based on HOG feature and SVM classifier. In: Applications in electronics pervading industry, environment and society. Cham, Switzerland: Springer; 2024. p. 319–26. doi:10.1007/978-3-031-48121-5_45. [Google Scholar] [CrossRef]
21. Zhu Y, Wang H, Liang S, Mallick M, Guo T, Liao J. Particle swarm optimization-based joint integrated probabilistic data association filter for multi-target tracking. Chin J Inf Fusion. 2025;2(2):182–93. doi:10.62762/cjif.2025.506643. [Google Scholar] [CrossRef]
22. Liu Z, Qiu Z, Gao Z, Zhang J. Adaptive multi-hypothesis marginal Bayes filter for tracking multiple targets. Remote Sens. 2024;16(12):2154. doi:10.3390/rs16122154. [Google Scholar] [CrossRef]
23. Chen X, Li Y. Normalizing flow-based differentiable particle filters. IEEE Trans Signal Process. 2025;73:493–507. doi:10.1109/TSP.2024.3521338. [Google Scholar] [CrossRef]
24. Jiang Y, Wang D, Bai T, Yan Z. Multi-UAV objective assignment using Hungarian fusion genetic algorithm. IEEE Access. 2022;10(6):43013–21. doi:10.1109/ACCESS.2022.3168359. [Google Scholar] [CrossRef]
25. Zeng L, Huang Y, Lin Y, Zhu Z, Zhang X, Liu Y, et al. SORT-LFR: revisiting SORT for multi-object tracking in low-frame-rate videos. IEEE Trans Multimed. 2026;1-16:1–16. doi:10.1109/tmm.2026.3651130. [Google Scholar] [CrossRef]
26. He P, Zhao Z, Liu X. Quick-UAV OCSORT: a fast and robust UAV-based tracking-by detection algorithm. Signal Image Video Process. 2025;19(7):577. doi:10.1007/s11760-025-04149-w. [Google Scholar] [CrossRef]
27. Alkandary K, Yildiz AS, Meng H. Enhancing multi object tracking with CLIP: a comparative study on DeepSORT and StrongSORT. Electronics. 2026;15(2):265. doi:10.3390/electronics15020265. [Google Scholar] [CrossRef]
28. Khalil MM, Saleh SN, Tawfik NS, Elagamy MN. EF-StrongSORT: an enhanced feature StrongSORT model for multi-object tracking. IEEE Access. 2025;13(10):53608–20. doi:10.1109/ACCESS.2025.3554706. [Google Scholar] [CrossRef]
29. Chen YH. Strong baseline: multi-UAV tracking via YOLOv12 with BoT-SORT-ReID. In: Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2025 Jun 11–12; Nashville, TN, USA. p. 6575–84. doi:10.1109/CVPRW67362.2025.00654. [Google Scholar] [CrossRef]
30. Singh PR, Gottumukkala R, Maida A. An analysis of Kalman filter based object tracking methods for fast-moving tiny objects. arXiv:2509.18451. 2025. [Google Scholar]
31. Yan B, Wei Y, Liu S, Huang W, Feng R, Chen X. A review of current studies on the unmanned aerial vehicle-based moving target tracking methods. Def Technol. 2025;51(2):201–19. doi:10.1016/j.dt.2025.01.013. [Google Scholar] [CrossRef]
32. Guo Y, Shen Q, Ai D, Wang H, Zhang S, Wang X. Sea-IoUTracker: a more stable and reliable maritime target tracking scheme for unmanned vessel platforms. Ocean Eng. 2024;299(2):117243. doi:10.1016/j.oceaneng.2024.117243. [Google Scholar] [CrossRef]
33. Niu L, Fan Y, Liu T, Han Q. MOMT: a maritime real-time visual multiobject tracking algorithm based on unmanned surface vehicles. IEEE Sens J. 2024;24(21):35429–47. doi:10.1109/JSEN.2024.3455572. [Google Scholar] [CrossRef]
34. Bui TL, Nguyen VT, Bui NN, Dang TV. Four-wheeled omnidirectional mobile robots strategy of navigation using hybrid HPSO-GA-PID controller-based YOLO3D-CSSA network. Intell Serv Robot. 2025;19(1):3. doi:10.1007/s11370-025-00669-z. [Google Scholar] [CrossRef]
35. Moosbauer S, Konig D, Jakel J, Teutsch M. A benchmark for deep learning based object detection in maritime environments. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2019 Jun 16–17; Long Beach, CA, USA. p. 916–25. doi:10.1109/cvprw.2019.00121. [Google Scholar] [CrossRef]
36. Arulalan V, Premanand V, Kumar D. An effective object detection via BS2ResNet and LTK-Bi-LSTM. Multimed Tools Appl. 2025;84(29):35901–20. doi:10.1007/s11042-024-20433-2. [Google Scholar] [CrossRef]
37. Wang M, Yang GY, Lin JK, Zhang SH, Shamir A, Lu SP, et al. Deep online video stabilization with multi-grid warping transformation learning. IEEE Trans Image Process. 2024;28(5):2283–92. doi:10.1109/TIP.2018.2884280. [Google Scholar] [PubMed] [CrossRef]
38. He Q, Li Z, Yang W. Lsf-rdd: a local sensing feature network for road damage detection. Pattern Anal Appl. 2024;27(3):99. doi:10.1007/s10044-024-01314-8. [Google Scholar] [CrossRef]
39. Guan J, Cheng HY, Wu YP, Tian C, Qi JY. Multi-target tracking for star sensor based on CenterTrack deep learning model. Sci Rep. 2025;15(1):37125. doi:10.1038/s41598-025-21077-4. [Google Scholar] [PubMed] [CrossRef]
40. Wu J, Cao J, Song L, Wang Y, Yang M, Yuan J. Track to detect and segment: an online multi-object tracker. In: Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021 Jun 20–25; Nashville, TN, USA. p. 12347–56. doi:10.1109/cvpr46437.2021.01217. [Google Scholar] [CrossRef]
41. Chu P, Wang J, You Q, Ling H, Liu Z. TransMOT: spatial-temporal graph transformer for multiple object tracking. In: Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2023 Jan 2–7; Waikoloa, HI, USA. p. 4859–69. doi:10.1109/WACV56688.2023.00485. [Google Scholar] [CrossRef]
42. Morsali MM, Sharifi Z, Fallah F, Hashembeiki S, Mohammadzade H, Shouraki SB. SFSORT: scene features-based simple online real-time tracker. arXiv:2404.07553. 2024. [Google Scholar]
43. Yi K, Luo K, Luo X, Huang J, Wu H, Hu R, et al. UCMCTrack: multi-object tracking with uniform camera motion compensation. arXiv:2312.08952. 2023. [Google Scholar]
44. Pham HL, Bui NN, Dang TV. Hybrid path planning for wheeled mobile robot based on RRT-star algorithm and reinforcement learning method. J Robot Control. 2025;6(4):2045–51. doi:10.18196/jrc.v6i4.27678. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools