
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Lightweight and Explainable Anomaly Detection in CAN Bus Traffic via Non-Negative Matrix Factorization
Department of Information and Communication Engineering, Yeungnam University, Gyeongsan, Republic of Korea
* Corresponding Author: Seung Yeob Nam. Email:
(This article belongs to the Special Issue: Advances in Machine Learning and Artificial Intelligence for Intrusion Detection Systems)
Computers, Materials & Continua 2026, 87(3), 50 https://doi.org/10.32604/cmc.2026.077582
Received 12 December 2025; Accepted 02 February 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The increasing connectivity of modern vehicles exposes the in-vehicle controller area network (CAN) bus to various cyberattacks, including denial-of-service, fuzzy injection, and spoofing attacks. Existing machine learning and deep learning intrusion detection systems (IDS) often rely on labeled data, struggle with class imbalance, lack interpretability, and fail to generalize well across different datasets. This paper proposes a lightweight and interpretable IDS framework based on non-negative matrix factorization (NMF) to address these limitations. Our contributions include: (i) evaluating NMF as both a standalone unsupervised detector and an interpretable feature extractor (NMF-W) for classical, unsupervised, and deep sequence models; (ii) providing comprehensive benchmarking on the car-hacking dataset (CHD), demonstrating improved robustness in mixed-attack and cross-attack scenarios, with class imbalance addressed through oversampling and class weighting; (iii) offering a component-level interpretability analysis that links NMF factors to meaningful CAN traffic patterns; and (iv) validating cross-dataset transferability on the offset-ratio and time interval-based intrusion detection system (OTIDS) dataset. Additional ablation and efficiency studies confirm the practical feasibility of deploying NMF-based IDS on embedded automotive controllers. Overall, this work presents a balanced IDS solution that combines detection accuracy, computational efficiency, and explainability, thereby advancing the security of in-vehicle networks.Keywords
Supplementary Material
Supplementary Material FileThe rapid integration of connectivity features in modern vehicles, including the vehicle-to-everything (V2X) communication, infotainment systems, and over-the-air (OTA) updates, has significantly expanded the attack surface of in-vehicle networks [1]. The controller area network (CAN) bus, which is the primary communication protocol for electronic control units (ECUs), was originally designed for efficiency and reliability rather than security [2,3]. In particular, CAN lacks fundamental mechanisms such as authentication, encryption, and intrusion tolerance, rendering it highly vulnerable to adversarial manipulation [4]. Attacks such as denial-of-service (DoS), fuzzy injection, Gear spoofing, and RPM spoofing have demonstrated the ability to disrupt critical vehicle functions such as braking, steering, and engine control [5,6].
CAN bus communication relies on the broadcast of short, fixed-length messages called frames. As illustrated in Fig. 1, each CAN frame contains an identifier (CAN ID) that encodes priority, a data length code (DLC) specifying the payload size, and up to eight bytes of data. While this lightweight design ensures real-time performance, it offers no message origin authentication or payload encryption and requires that every node on the bus receive all frames. These properties make CAN efficient for embedded automotive control but simultaneously expose it to spoofing, injection, and DoS attacks when adversaries gain bus access [7].
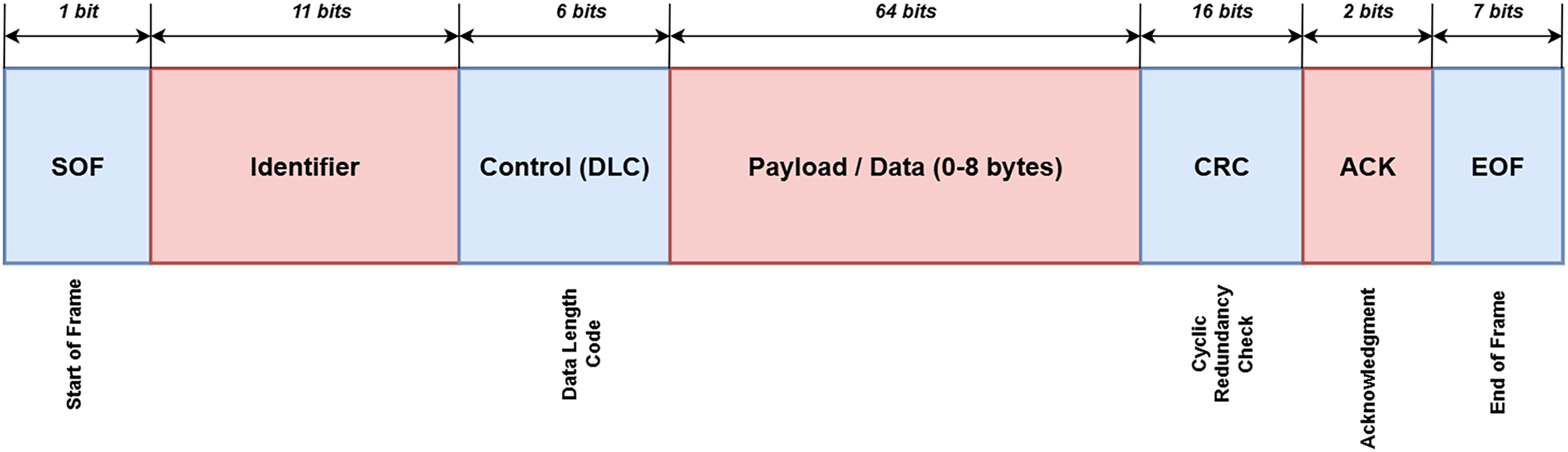
Figure 1: Structure of a standard CAN data frame.
Despite extensive research into intrusion detection systems (IDS) for CAN traffic, several challenges remain unresolved [8–11]. The CAN protocol lacks native authentication or encryption, and the lightweight nature of in-vehicle ECUs limits the deployment of computationally intensive solutions. In real-world settings, attack messages form only a tiny fraction of total traffic, creating a severe class imbalance that degrades the performance of conventional machine learning classifiers [12–14]. Many IDS approaches rely on complex black-box machine learning (ML) and deep learning (DL) models that, while accurate, provide little insight into why anomalies are detected [15,16]. Furthermore, raw feature-based models often exploit artificial signatures in injected datasets, limiting generalization to unseen attack types [12,16]. Finally, IDS solutions must operate within the limited computational and memory resources of ECUs, necessitating lightweight yet practical approaches.
In practical deployments, these limitations directly affect operational reliability and safety. First, because malicious injections are rare compared to normal traffic, even a low false-positive rate can produce frequent alarms, leading to alert fatigue or unnecessary mitigation actions that may disrupt vehicle functionality. Second, models that overfit dataset-specific artifacts (e.g., injected message signatures or logging biases) may show near-perfect accuracy offline but fail under real driving conditions, where traffic distributions vary across vehicle models, software versions, and driving contexts. Third, limited interpretability makes it difficult for security engineers to validate detections, diagnose root causes, and perform post-incident analysis or OTA regression checks. Finally, computationally intensive IDS pipelines may be impractical on resource-constrained ECUs and gateways that must meet strict real-time deadlines. These real-world considerations motivate the need for lightweight, generalizable, and explainable IDS designs for CAN bus monitoring.
This paper addresses these challenges by leveraging non-negative matrix factorization (NMF) for anomaly detection in CAN bus traffic [17,18]. NMF is explored both as a standalone detector and as a feature extractor for supervised, unsupervised, and sequence-based models. We perform a comparative evaluation of NMF-derived feature representations (
Unlike earlier NMF-based intrusion detection studies, which mainly used NMF for feature selection or dimensionality reduction in IT or IoT network data, this study provides a systematic investigation of NMF for automotive CAN intrusion detection. We extend prior efforts by leveraging NMF both as a standalone unsupervised anomaly detector and as a unified, interpretable feature representation for classical, unsupervised, and sequence-based models. Our approach advances the field through comprehensive benchmarking—including attack-wise, cross-attack, and cross-dataset evaluations—detailed component-level interpretability analysis linking latent factors to meaningful CAN traffic structures, and discussion of ECU deployment feasibility. These contributions position NMF as a transparent and lightweight alternative to conventional DL–centric IDS approaches for in-vehicle networks.
The remainder of this paper is organized as follows. Section 2 reviews recent studies on CAN intrusion detection, including transformer-based IDS, interpretable DL models, federated learning frameworks, and NMF-based approaches, as well as sequence modeling and imbalance handling. Section 3 presents the proposed NMF-based framework and methodology, followed by Section 4, which describes the experimental setup and datasets. Section 5 details the experimental analysis, covering standalone NMF detection, baseline and rule-based comparisons, attack-wise evaluation, attack localization, cross-attack and cross-dataset generalization, imbalance handling, interpretability, ablation studies, and efficiency evaluation, together with limitations and threats to validity. Finally, Section 6 concludes the paper and outlines directions for future research.
Intrusion detection in in-vehicle networks has attracted significant research attention due to the lack of built-in authentication and encryption in the CAN protocol. Several surveys provide a comprehensive overview of ML- and DL-based IDS approaches, covering methods from statistical timing analysis to deep neural architectures, and emphasize that intrusion detection remains the primary line of defense against attack injection [19,20]. These works also highlight widely adopted datasets, such as the car-hacking dataset (CHD) and the offset-ratio and time-interval-based intrusion detection system dataset (OTIDS), and emphasize that although DL methods achieve high accuracy, issues of generalization, imbalance, and interpretability remain unresolved [10,21]. Recent advances in interpretable DL for intrusion detection have incorporated explainable artificial intelligence (XAI) techniques such as shapley additive explanations (SHAP), local interpretable model-agnostic explanations (LIME), and RuleFit to provide feature-level explanations for deep neural network (DNN) predictions, enabling greater transparency without sacrificing accuracy [22–24]. However, these methods show that ensuring consistent explanations and deriving operationally actionable insights—especially for ECU-level diagnostics on automotive CAN traffic—remains an open challenge.
Deep models have been a dominant research direction for CAN intrusion detection. Recurrent autoencoder frameworks, such as INDRA, learn the temporal dynamics of normal CAN signals and detect deviations via reconstruction errors, achieving high detection rates but often at a high computational cost [25,26]. LSTM- and gated recurrent unit (GRU)-based autoencoders have been applied and shown to achieve near-perfect performance on benchmark datasets [27], while convolutional and attention-based backbones have also been explored for sequential anomaly detection in CAN traffic [28]. More recently, transformer-based architectures have been deployed for CAN intrusion detection, leveraging self-attention to model long-range dependencies in CAN streams and improve multiclass anomaly classification, though they often incur notable resource demands [29–31]. Recent work has also explored ensemble-based and hybrid intrusion detection models for vehicular and Internet of Vehicular Things (IoVT) environments. For example, ensemble frameworks that combine multiple machine learning classifiers have been proposed to improve robustness against diverse attack patterns and class imbalance, reporting strong detection performance on widely used network intrusion datasets in IoV contexts [32]. While these approaches benefit from model diversity and high accuracy, they typically rely on complex decision fusion and operate as black-box systems, offering limited interpretability at the traffic-pattern level. In contrast, our work emphasizes a single, lightweight factorization-based representation tailored to CAN bus traffic, explicitly exposing latent communication patterns that support both effective detection and component-level interpretability. Beyond accuracy, some studies stress the importance of distributed IDS deployment across ECUs to prevent single points of failure and minimize communication overhead, further motivating lightweight designs. In parallel, federated learning for IDS has attracted attention for its ability to enable privacy-preserving, distributed anomaly detection across vehicles or ECUs. Recent studies demonstrate that federated models deliver robust collaborative intrusion detection while maintaining local data privacy, even across heterogeneous automotive or IoT settings [33–35]. These findings align with our experimental setup, which contrasts raw traffic features with compact latent representations and evaluates both classical and sequence-aware classifiers. In parallel, transfer learning has been explored to improve cross-dataset adaptability of CAN IDS [36], achieving strong generalization across datasets but without addressing the interpretability limitations of deep architectures.
Hardware-efficient IDS has also received growing attention, with field-programmable gate array (FPGA)-based ECUs recently proposed to accelerate inference for onboard intrusion detection. By consolidating lightweight ML models (e.g., quantised multi-layer perceptron) into FPGA architectures, these systems achieve more than twice the power efficiency and significantly lower latency compared to GPU baselines [37]. Such results underscore the necessity of compact representations and efficient algorithms for real-time deployment, an aspect directly addressed in our work by adopting NMF as a low-overhead factorization method.
Classical ML and statistical approaches, including SVMs, RFs, cumulative sum (CUSUM) tests, and entropy-based detectors, have been widely applied to CAN traffic [38]. While effective against simple flooding or replay scenarios, these methods often overfit to dataset-specific artifacts or fail under subtle payload manipulation attacks. Furthermore, their reliance on raw feature distributions makes them sensitive to class imbalance, a fundamental challenge since attack frames typically constitute only a tiny fraction of real traffic [39]. Data augmentation techniques such as SMOTE and ADASYN have been introduced in IDS to alleviate imbalance and improve minority-class recall, though their effectiveness for CAN bus anomaly detection remains underexplored. Our experiments extend this line by systematically benchmarking oversampling on both raw and NMF-transformed feature spaces.
While NMF itself has seen limited application in CAN intrusion detection, it has been successfully leveraged in other intrusion detection contexts. Early works demonstrated its utility for profiling system or user behaviors [40,41], where NMF decomposed audit trails into additive patterns that distinguished normal from anomalous activity. More recent studies extended NMF for feature selection and hybrid detection, applying it to malware identification and IoT intrusion detection [42,43]. NMF has also been adapted into enhanced variants, such as optimal brain surgeon NMF (OBS-NMF) for improved clustering quality in anomaly detection [44], and neighborhood-structure-assisted NMF (NS-NMF) for unsupervised point-wise anomaly detection [45]. Beyond IDS, NMF has been applied in other domains as a tool for interpretable anomaly detection. Physics-enhanced NMF has been shown to improve anomaly identification in mechanical systems by decomposing complex signals into additive, human-understandable components [46]. Similarly, spatio-temporal NMF has been employed in traffic pattern mining, where it captures latent structure and reduces dimensionality without losing interpretability [47]. These successes motivate our use of NMF for CAN traffic, positioning it as both a standalone detector and a feature extractor that enhances the performance of downstream ML/DL models while preserving interpretability.
While prior studies have applied NMF to general network intrusion detection, these efforts differ fundamentally from our work. Early works focused on profiling or fast detection in IT networks, whereas we target the distinctive domain of in-vehicle CAN traffic. Other efforts proposed algorithmic enhancements to NMF (e.g., OBS-NMF, NS-NMF), but we show that even standard NMF, when coupled with supervised and sequential IDS models, achieves high performance while remaining lightweight and explainable. More recent IDS applications have used NMF for feature extraction or hybrid selection, but rarely evaluated its role as both a standalone anomaly detector and as an integrative feature space across multiple backbones. Our work therefore provides a comprehensive benchmark of NMF in CAN intrusion detection, spanning attack-wise, cross-attack, cross-dataset, imbalance, and efficiency evaluations. Compared with previous NMF-based IDS work that primarily focused on feature extraction or hybrid detection in IT or IoT contexts, our study conducts a broader, more integrated evaluation of automotive CAN intrusion detection, emphasizing interpretability, cross-dataset transferability, and deployment feasibility. In summary, prior research underscores three significant gaps: (i) most CAN IDS rely on black-box DL models that achieve accuracy but offer limited transparency, (ii) class imbalance is a persistent obstacle, and (iii) efficiency is rarely considered in realistic ECU-constrained environments. Against this backdrop, our work introduces NMF as a lightweight, interpretable, and transferable representation, benchmarked across both tabular and sequential classifiers, and rigorously evaluated under attack-wise, cross-attack, imbalance-handling, and mixed-attack scenarios.
To investigate the effectiveness of NMF for anomaly detection in CAN bus traffic, we design a comprehensive framework that integrates preprocessing, feature extraction, representation learning, and broad evaluation across multiple models (classical ML, unsupervised, and temporal sequence models) to assess NMF’s utility. Fig. 2 provides an overview of the proposed framework. The process begins with CAN traffic data collected from CHD [10], which contains both normal in-vehicle communication and multiple categories of injected attacks (DoS, Fuzzy, Gear spoofing, RPM spoofing). This dataset serves as the primary benchmark for evaluating the proposed framework’s detection capabilities. The second dataset (OTIDS) [48] is reserved for cross-dataset validation and discussed in Section 5.10.
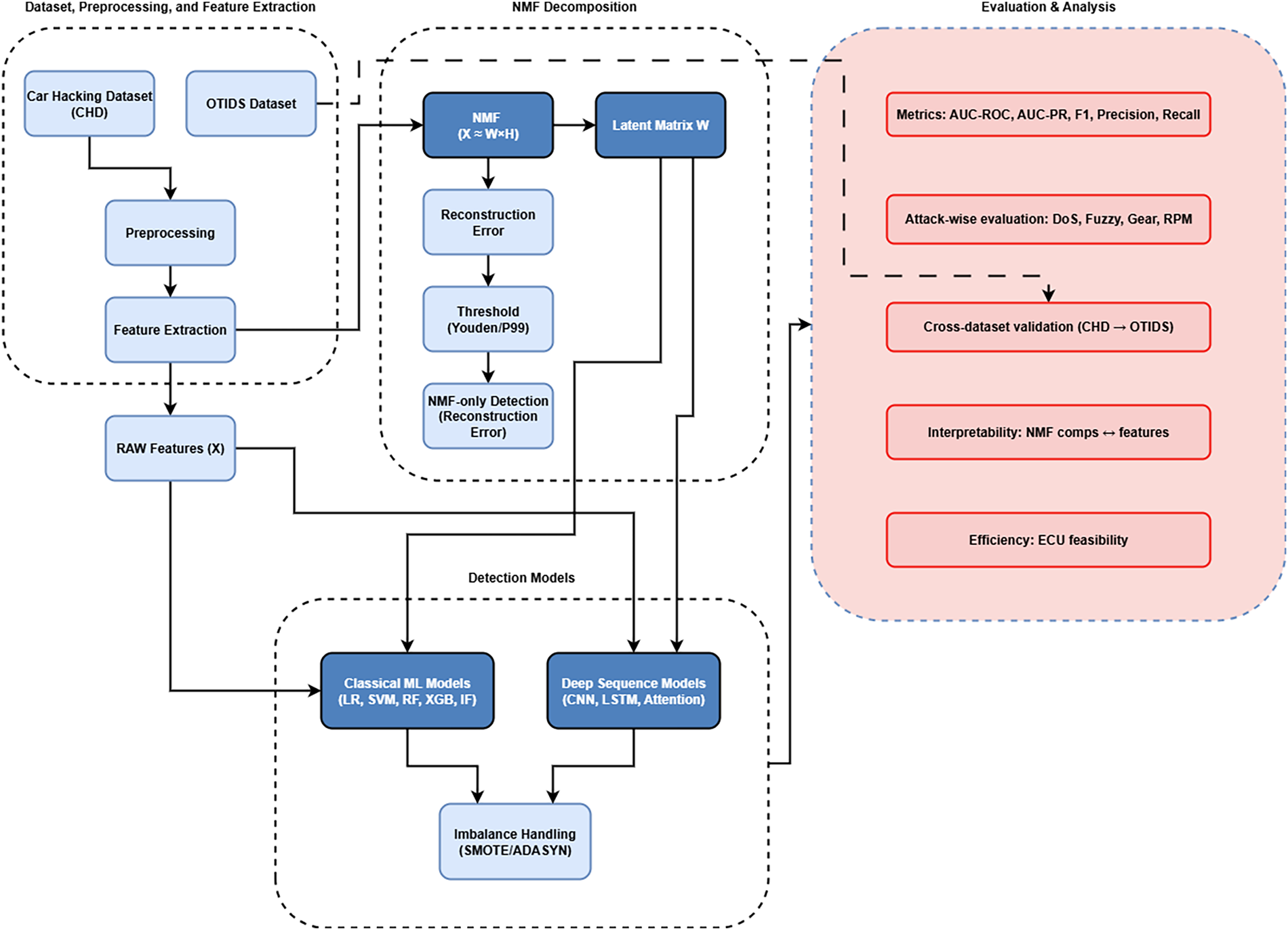
Figure 2: Proposed framework for CAN bus anomaly detection using NMF as both a standalone detector and a feature extractor.
In the preprocessing stage, raw CAN frames are aggregated into fixed-length windows using an overlapping scheme with a 0.1-s overlap and a 0.05-s stride, thereby capturing short-lived attacks in the feature space. From each window, statistical features are extracted to represent message dynamics, including CAN ID frequencies, payload entropy, and mean payload values. In labeled experiments, the attack-flag ratio is additionally included as a diagnostic feature. These features jointly capture both structural (e.g., ID distributions) and content-level (e.g., payload statistics) variations in the traffic. The resulting feature matrix
Downstream detection is performed using multiple approaches to assess NMF’s utility. First, the NMF reconstruction error in Eq. (6) is used directly as an unsupervised anomaly score. Second, the latent representation
3.1 NMF for Feature Representation
NMF is a dimensionality reduction technique that decomposes a nonnegative matrix into additive parts. We employ NMF as both a dimensionality-reduction method and an interpretable representation-learning framework for CAN bus traffic. NMF has been extensively studied in the literature for its algorithms and diverse applications, particularly for uncovering parts-based, interpretable latent representations [18,49]. Fig. 3 provides a schematic illustration.
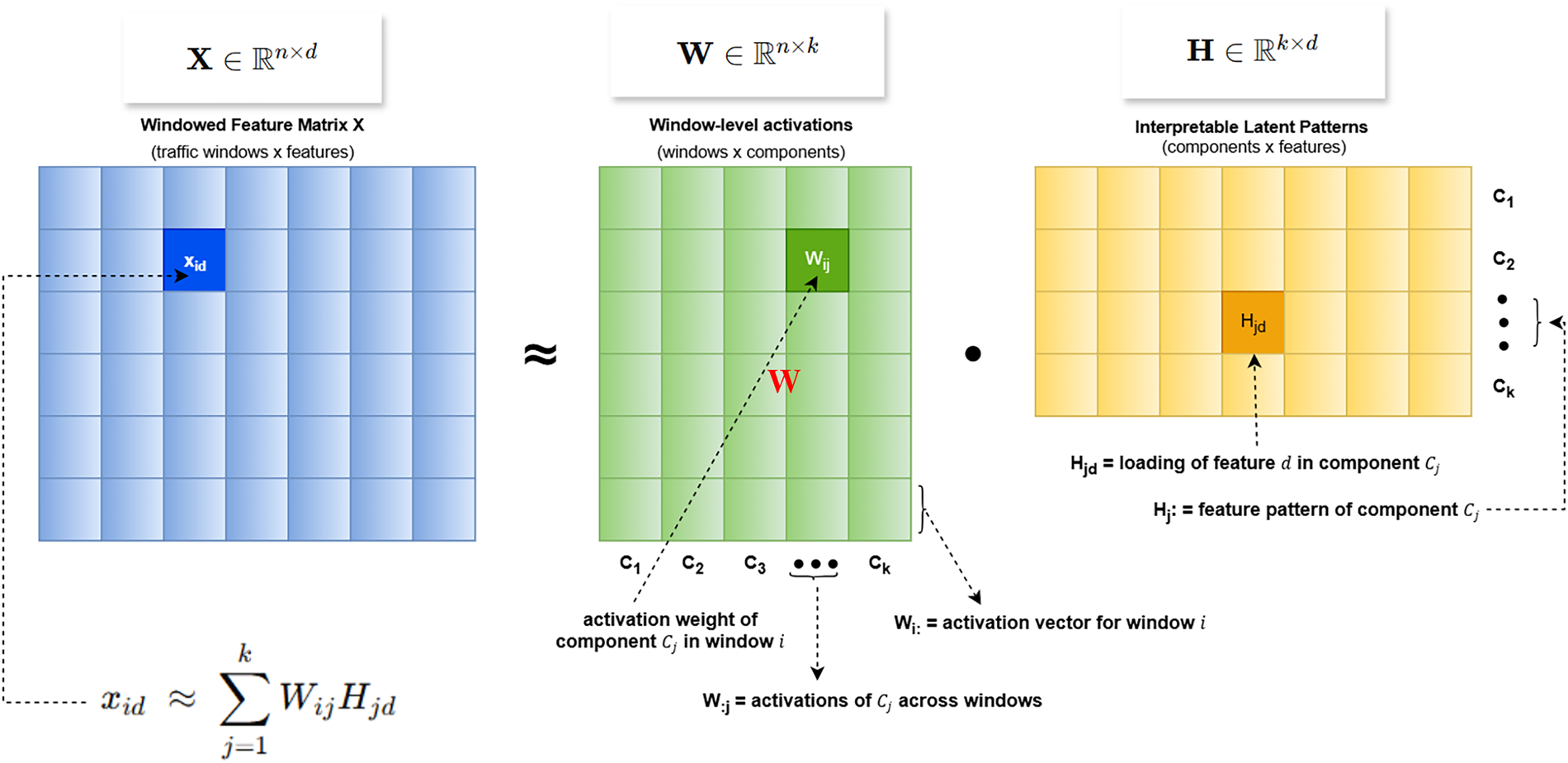
Figure 3: Illustration of NMF decomposition:
Given an input feature matrix
where
Each latent component
where:
Thus, a single window vector
In this way,
which is solved iteratively using coordinate descent [50].
The choice of NMF is motivated by both the structure of CAN traffic and the practical requirements of in-vehicle intrusion detection. First, NMF’s non-negativity constraint naturally aligns with CAN-derived features such as message counts, ID frequencies, entropy values, and payload statistics, allowing the model to operate directly on semantically meaningful inputs without additional transformations. Second, NMF provides a parts-based, additive decomposition that matches the compositional nature of CAN traffic, where each time window is formed by the superposition of messages from multiple ECUs and CAN IDs. In this formulation, traffic windows are expressed as nonnegative combinations of latent components, each capturing a coherent traffic pattern (e.g., dominant IDs, DLC profiles, or payload entropy behavior), enabling transparent interpretation of anomalous activity. Finally, normal CAN traffic exhibits highly regular and repetitive structure, leading to a stable low-rank representation under NMF. Attacks disrupt this structure, resulting in abnormal component activations or increased reconstruction error. This makes NMF particularly suitable for unsupervised anomaly detection under severe class imbalance, while maintaining lightweight computation and interpretability essential for ECU-constrained environments.
In this study, we adopt standard NMF as a stable and interpretable baseline. While variants such as sparse NMF or temporal NMF can impose additional structure, they introduce extra regularization parameters and temporal dependencies that complicate controlled comparison across classifiers and datasets. Our objective is not to optimize NMF variants, but to systematically evaluate whether a simple, lightweight factorization already provides meaningful gains in interpretability, robustness, and efficiency for CAN intrusion detection. A quantitative comparison with other unsupervised detectors is provided in Section 5.11.
3.1.1 Data Splitting and Preprocessing
Since NMF requires nonnegative inputs, we preprocess the features using MinMax scaling on the training set, ensuring that the validation and test data are transformed consistently. Any negative values or NaNs are clipped to zero:
To ensure a fair comparison, the same train-fitted scaler is applied consistently across all baselines: the MinMax scaler is fitted on the training split and reused to transform validation/test data without refitting. Raw-feature baselines are evaluated under the same normalization pipeline, so differences between Raw and NMF–W results reflect representation/model effects rather than inconsistent scaling.
To preserve temporal consistency, we adopt a per-attack time-based split: 70% of each attack subset is allocated to training, 10% to validation, and 20% to testing. The splits are then concatenated across all attack types, ensuring class balance and chronological order.
3.1.2 Anomaly Scoring via Reconstruction Error
For standalone anomaly detection, NMF is first trained on normal traffic. Given a new window
The anomaly score is defined as the residual norm:
where
We evaluate two thresholding strategies to convert continuous scores into binary predictions:
• Youden’s J Statistic: Based on the validation receiver operating characteristic (ROC) curve, we select the threshold
• 99th Percentile (P99): We compute
Youden’s J is derived from validation ROC curves, while
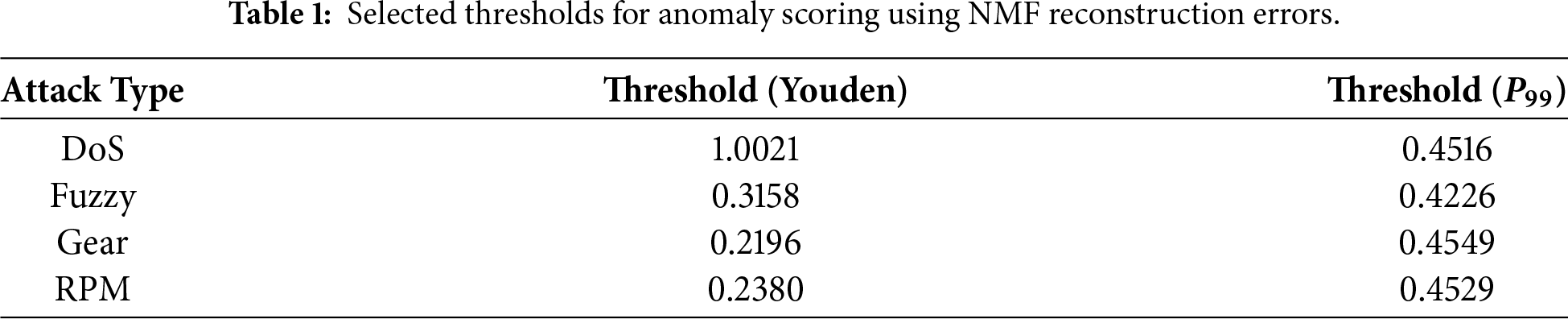
Across all attack scenarios, both Youden-optimized and percentile-based thresholds yield consistent trends in detection performance, with only minor quantitative differences. Youden’s J typically provides slightly higher balanced accuracy when validation labels are available, while the percentile-based threshold offers a stable, label-free alternative suitable for deployment. In practice, percentile thresholds (e.g.,
3.1.4 Interpretability via NMF Components
Beyond anomaly detection, the factorization provides interpretable insights into CAN traffic behavior. The basis matrix
where
Practical interpretation. From an analysis perspective, these component–feature associations allow an analyst to reason about the type of abnormal behavior driving a detected anomaly. For example, components dominated by a small set of CAN IDs with high activation may indicate flooding-like behavior, whereas components weighted toward payload entropy or DLC statistics may reflect spoofing or manipulation patterns. We emphasize that this interpretability is demonstrated through offline analysis in this study; validating its effectiveness in real-world analyst workflows is left for future work.
Dimensionality reduction vs. semantic structure. Although NMF–W reduces the original feature dimension, the observed robustness gains cannot be attributed to dimensionality reduction alone. If reduced dimensionality were the sole factor, similar improvements would be expected from generic compression techniques. Instead, our results show that NMF–W consistently improves cross-attack and cross-dataset generalization while preserving interpretable structure, whereas raw features—even at higher dimensionality—often exhibit brittle transfer. This suggests that the semantic, parts-based organization of NMF components, which align with meaningful CAN traffic patterns (e.g., ID dominance, entropy bursts, timing structure), plays a central role. Dimensionality reduction contributes to noise suppression, but the structured latent representation is the primary driver of robustness and interpretability in hybrid models.
With the NMF formulation and its interpretability clarified, we now present the benchmark datasets that serve as the basis for evaluating our framework.
To evaluate the proposed framework, two publicly available benchmark datasets were utilized. Both datasets provide real CAN traffic traces recorded from production vehicles under normal and attack conditions, enabling reproducible experimentation in vehicular intrusion detection.
In-vehicle networks for modern vehicles are based on the CAN protocol, which lacks robust security measures, making it vulnerable to intrusion. To support cybersecurity research, the hacking and countermeasure research lab (HCRL) released CHD, comprising real CAN traffic captured via an OBD-II port during message-injection attacks on an actual vehicle. It includes four different attack types: DoS, fuzzing, Gear spoofing, and RPM gauge spoofing, as well as normal (attack-free) traffic. These four attack patterns are widely studied in CAN IDS literature [5,7] as they capture three essential categories of adversarial behavior: flooding (DoS), random fuzzing, and spoofing of critical control signals (Gear spoofing and RPM spoofing).
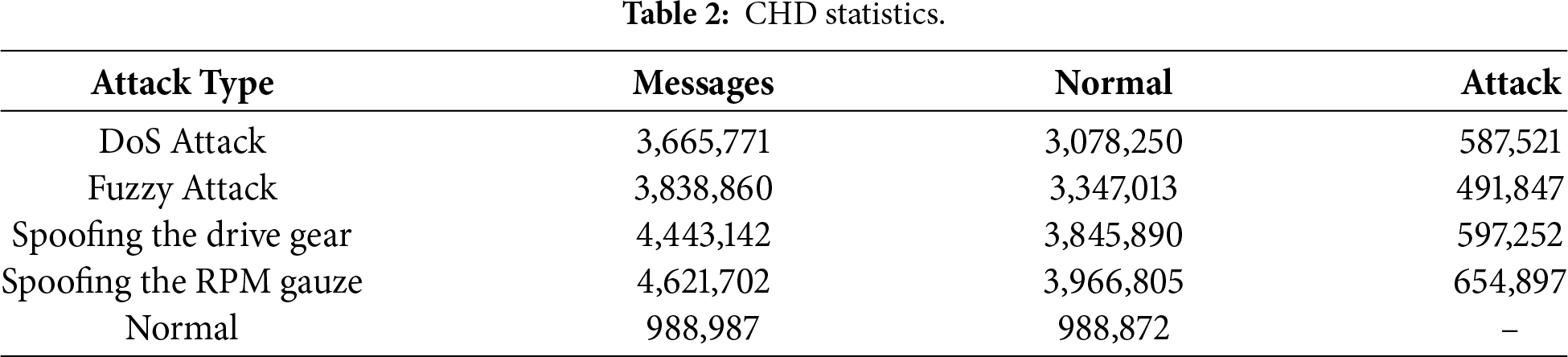
CHD dataset includes 300 intrusion attempts, where each attempt corresponds to a 3–5 s burst of continuous message injection embedded within an otherwise normal driving sequence. Within these bursts, attack frames are transmitted at high frequency (e.g., Fuzzy injects a frame every 0.5 ms and DoS injects every 0.3 ms), resulting in tens of thousands of attack frames per intrusion interval. Thus, “300 intrusion attempts” refers to temporal attack bursts, while the millisecond-scale injection rate describes the per-frame timing inside each burst. Each CHD subset contains approximately 3–4 million CAN messages, including 0.5–0.6 million injected attack frames depending on the attack type. Every record includes a timestamp, CAN ID, DLC, payload bytes, and a flag indicating whether the message is normal or injected. Tables 2 and 3 summarizes the message statistics and describes the characteristic behavior of each attack category in CHD, respectively.

The OTIDS dataset was collected from a Kia Soul vehicle during real-world driving and contains both normal CAN traffic and three attack categories: DoS, Fuzzy, and Impersonation. In contrast to the temporally segmented design of CHD, OTIDS presents a more realistic distribution in which long spans of normal driving are intermittently interspersed with injected frames. The attack patterns occur throughout the driving sequence rather than as isolated bursts, reflecting deployment-like conditions where intrusions may be sparse and embedded within extended periods of routine operation.
OTIDS includes timestamped CAN frames with ID, DLC, and payload fields. Although DoS and Fuzzy attacks share similarities with those in CHD, OTIDS also includes Impersonation attacks, in which an adversary injects forged frames that mimic legitimate IDs with manipulated payload values. A detailed description of all OTIDS attack types is provided in Table 4. Because OTIDS captures genuine driving dynamics and naturally imbalanced traffic, it is particularly suited for testing the cross-dataset generalization of IDS models. In this work, CHD is used as the primary benchmarking dataset, while OTIDS serves to evaluate out-of-distribution performance (Section 5.10). A high-level comparison of CHD and OTIDS is provided in Table 5, highlighting their complementary characteristics for IDS evaluation.


To transform raw CAN bus traffic into a structured representation suitable for anomaly detection, a time-sliding-window feature-extraction pipeline was developed. This process converts sequences of individual CAN frames into fixed-length feature vectors that capture statistical, structural, and entropy-based properties of traffic windows. Raw CAN traffic streams were segmented into overlapping windows of 0.1 s with a stride of 0.05 s. Each window was labeled as an attack if at least one injected (flag “T”) frame was present; otherwise, it was labeled normal. This ensures that even short-lived injections are captured during training and evaluation. Since raw CAN frames consist only of timestamps, IDs, and payload bytes, applying NMF directly is infeasible. Instead, statistical and distributional features are first extracted to provide a meaningful numeric representation that NMF can decompose into interpretable latent factors.
Feature extraction was performed separately for each dataset subset (Normal, DoS, Fuzzy, Gear Spoofing, and RPM Spoofing), and attack-wise feature files were saved for per-attack evaluation. A combined dataset (Normal + all attacks) was also constructed for holistic benchmarking.
The feature extraction pipeline is illustrated in Fig. 4. Raw CAN frames, consisting of a timestamp, CAN ID, DLC, and data bytes, are segmented into overlapping windows. Within each window, multiple groups of features (mentioned in Table 6) are computed. This modular pipeline ensures that each traffic window is transformed into a structured feature vector, enabling subsequent dimensionality reduction via NMF and classification by baseline or sequence-based models.
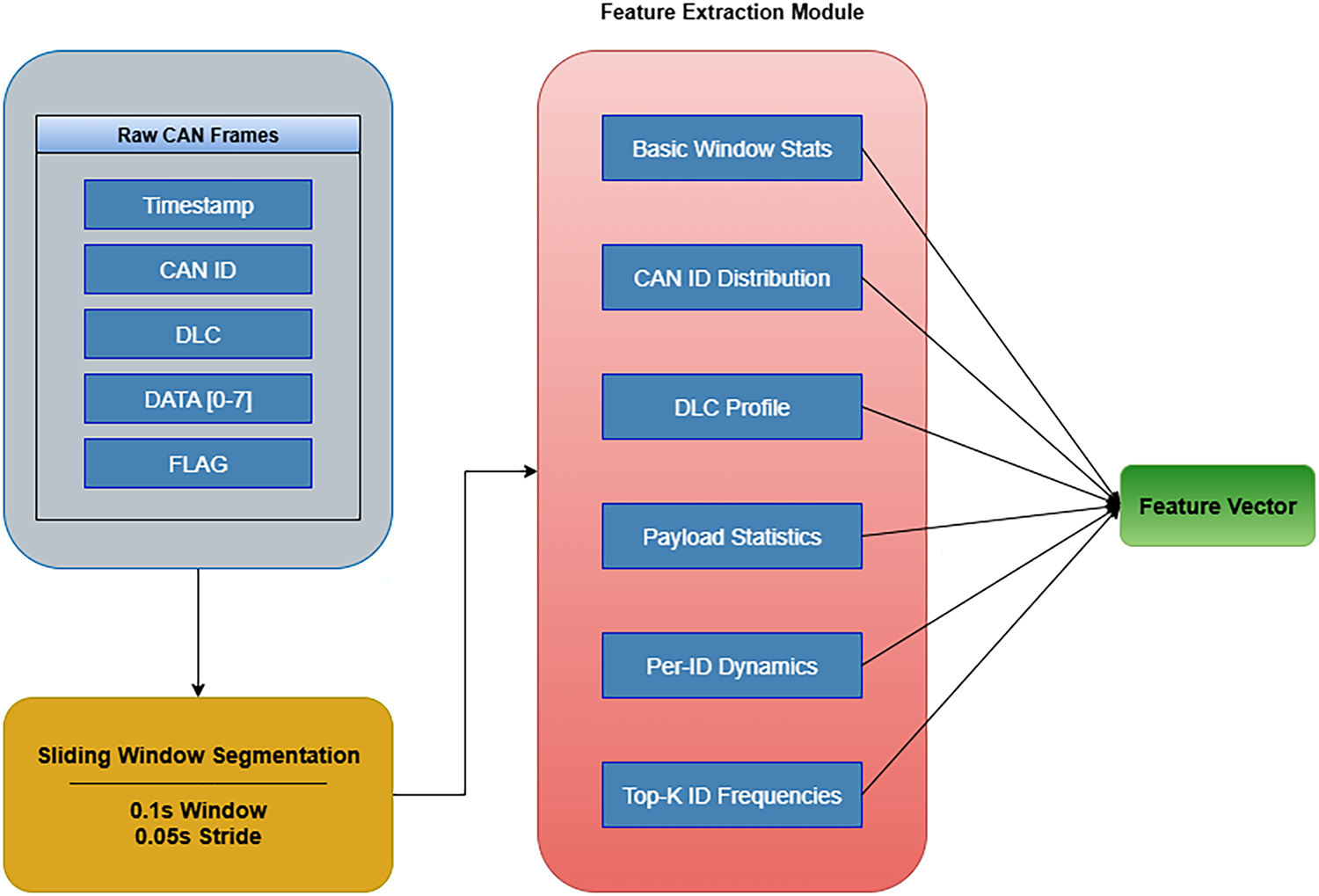
Figure 4: Feature extraction pipeline.
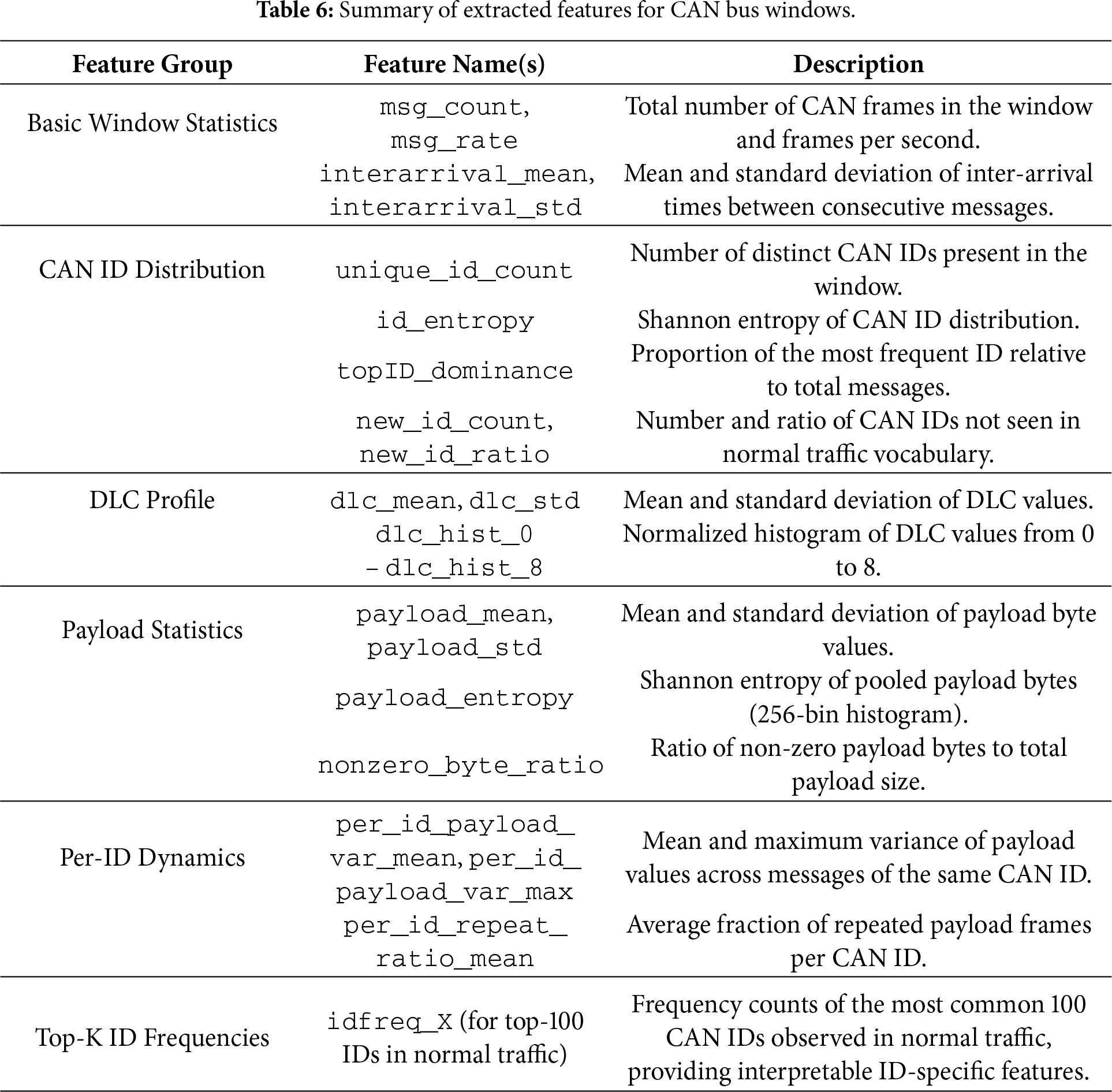
Handcrafted Feature Complexity. Although the feature set contains more than one hundred window-level statistics (ID frequencies, DLC histograms, payload entropy, per-ID dynamics, etc.), these quantities are derived from simple linear-time aggregations (counts, histograms, means, and variances) over raw CAN frames. Importantly, these features are generic and not tuned to any specific attack signature; they describe fundamental structural properties of CAN traffic that remain meaningful across datasets.
Furthermore, the downstream models do not operate directly on the full high-dimensional feature vector (with
We evaluate both classical ML baselines and sequence models, using either the raw statistical features or the NMF coefficient space
LR: A linear decision function with
We further consider temporal models applied to fixed-length sequences of windows. Let
In the hybrid setting, classifiers use the low-dimensional, interpretable activations
We evaluate the proposed framework using the CHD, which contains normal traffic and four attack types (DoS, Fuzzy, Gear spoofing, RPM spoofing). Each subset is sorted chronologically and partitioned into 70% for training, 10% for validation, and 20% for testing, ensuring temporal consistency and preventing leakage. Normal windows from the training set are used to fit the NMF model, while validation and test sets contain both normal and attack windows. Attack-wise feature tables and a merged dataset were prepared using the feature extractor described in Section 3.3. Preprocessing involves MinMax scaling for NMF inputs, with values clipped to enforce nonnegativity; the latent rank
5 Experiment Results and Performance Evaluation
This section provides a comprehensive evaluation of the proposed NMF-based intrusion detection framework. Section 5.1 first introduces the evaluation metrics used throughout the study. Section 5.2 reports the standalone NMF detection performance, followed by Section 5.3, which compares baseline classifiers with their NMF–W counterparts on merged CAN traffic. Rule-based lookup table baselines are presented in Section 5.4 for reference to conventional in-vehicle IDS strategies. Sections 5.5 and 5.6 analyze attack-wise behavior and localization performance, while Section 5.7 examines cross-attack generalization to assess robustness against unseen attack types. Section 5.8 explores imbalance handling and robustness improvements through oversampling and class weighting. Section 5.9 provides a detailed interpretability analysis of NMF components and model decisions. Cross-dataset validation between CHD and OTIDS is presented in Section 5.10, and Section 5.12 situates our approach in comparison with representative state-of-the-art (SOTA) CAN IDS architectures. Section 5.13 presents ablation studies to quantify the contribution of feature groups and design choices. Section 5.14 discusses computational efficiency and ECU deployment feasibility, followed by Section 5.15, which outlines key limitations and threats to validity. Together, these experiments comprehensively evaluate detection performance, generalization capability, interpretability, and deployment readiness of the proposed NMF-based IDS.
Detection performance is evaluated using standard metrics for binary classification and anomaly detection. We report the area under the receiver operating characteristic curve (AUC-ROC), the area under the precision–recall curve (AUC-PR), and the F1-score. AUC-ROC measures overall class separability, while AUC-PR is particularly informative under severe class imbalance, where attack samples are much rarer than normal traffic. The F1-score summarizes the trade-off between Precision and Recall.
Let TP, FP, TN, and FN denote the numbers of true positives, false positives, true negatives, and false negatives, respectively. The metrics are defined as:
The ROC curve plots Recall (TPR) against the false-positive rate (FPR)
and its area is reported as AUC-ROC. Similarly, the precision–recall (PR) curve plots Precision as a function of Recall, and its area is reported as AUC-PR.
Because CAN intrusion detection is highly imbalanced, our analysis focuses primarily on AUC-ROC, AUC-PR, and F1. Accuracy and Precision/Recall are reported for completeness in Sections 5.2 and 5.3, while all comparative evaluations consistently rely on AUC-ROC, AUC-PR, and F1.
5.2 Standalone NMF Detection Results
We first evaluate NMF as a standalone unsupervised anomaly detector following the methodology described in Section 3. The model is trained exclusively on normal windows and evaluated on validation and test sets using reconstruction residuals.
Each attack subset (Normal, DoS, Fuzzy, Gear spoofing, RPM spoofing) is chronologically split into 70% training, 10% validation, and 20% testing. Table 7 summarizes the resulting distribution of normal and attack windows.

The time-based split preserves temporal ordering to prevent leakage between adjacent windows and reflects realistic deployment conditions, where IDS training relies on historical attack traces while future traffic is predominantly normal. The resulting class imbalance is an inherent property of the CHD dataset rather than an artifact of the proposed pipeline. Robustness under imbalance is examined explicitly in later sections, where relative performance trends remain consistent.
To select the number of NMF components
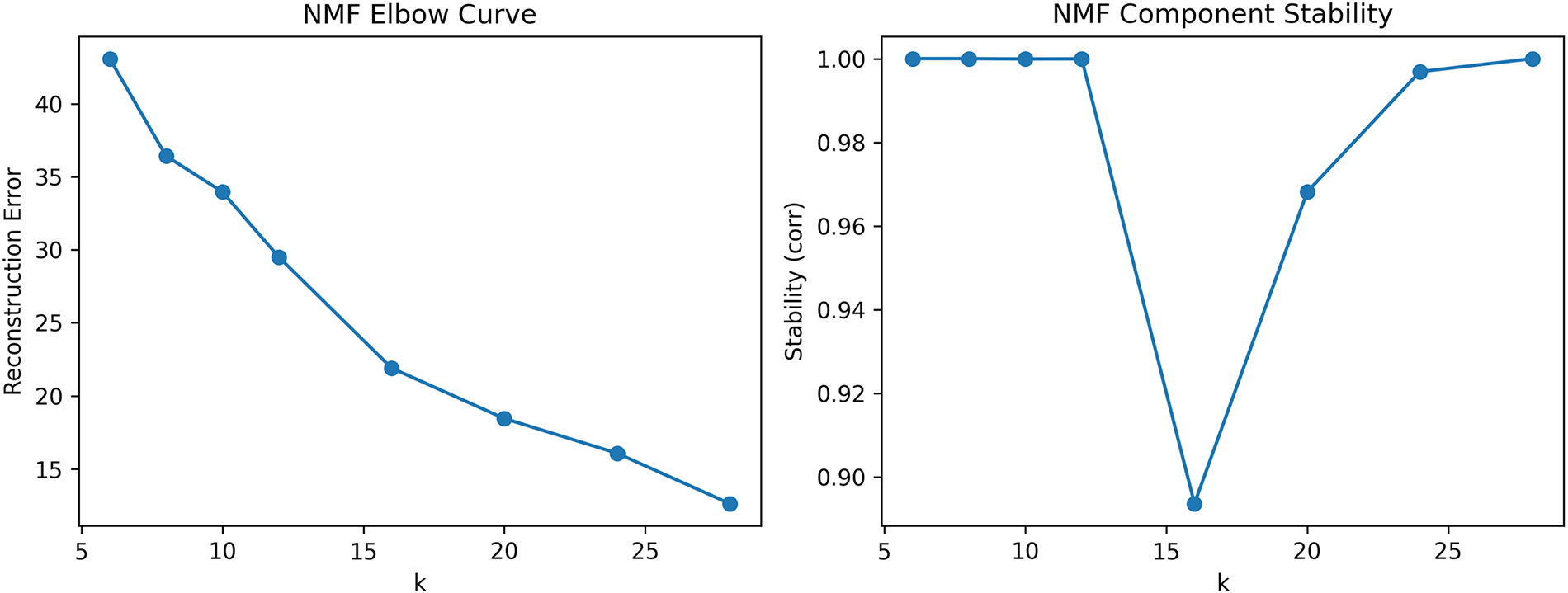
Figure 5: Model selection for NMF. (a) Reconstruction error vs.
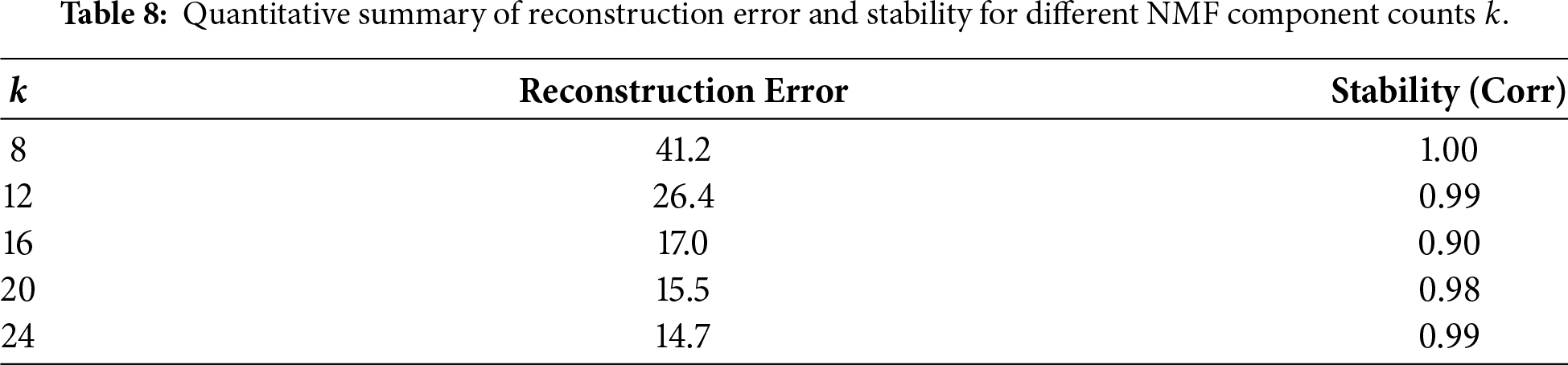
Reconstruction error decreases monotonically with increasing
5.2.3 Interpretability of Components
The learned basis matrix
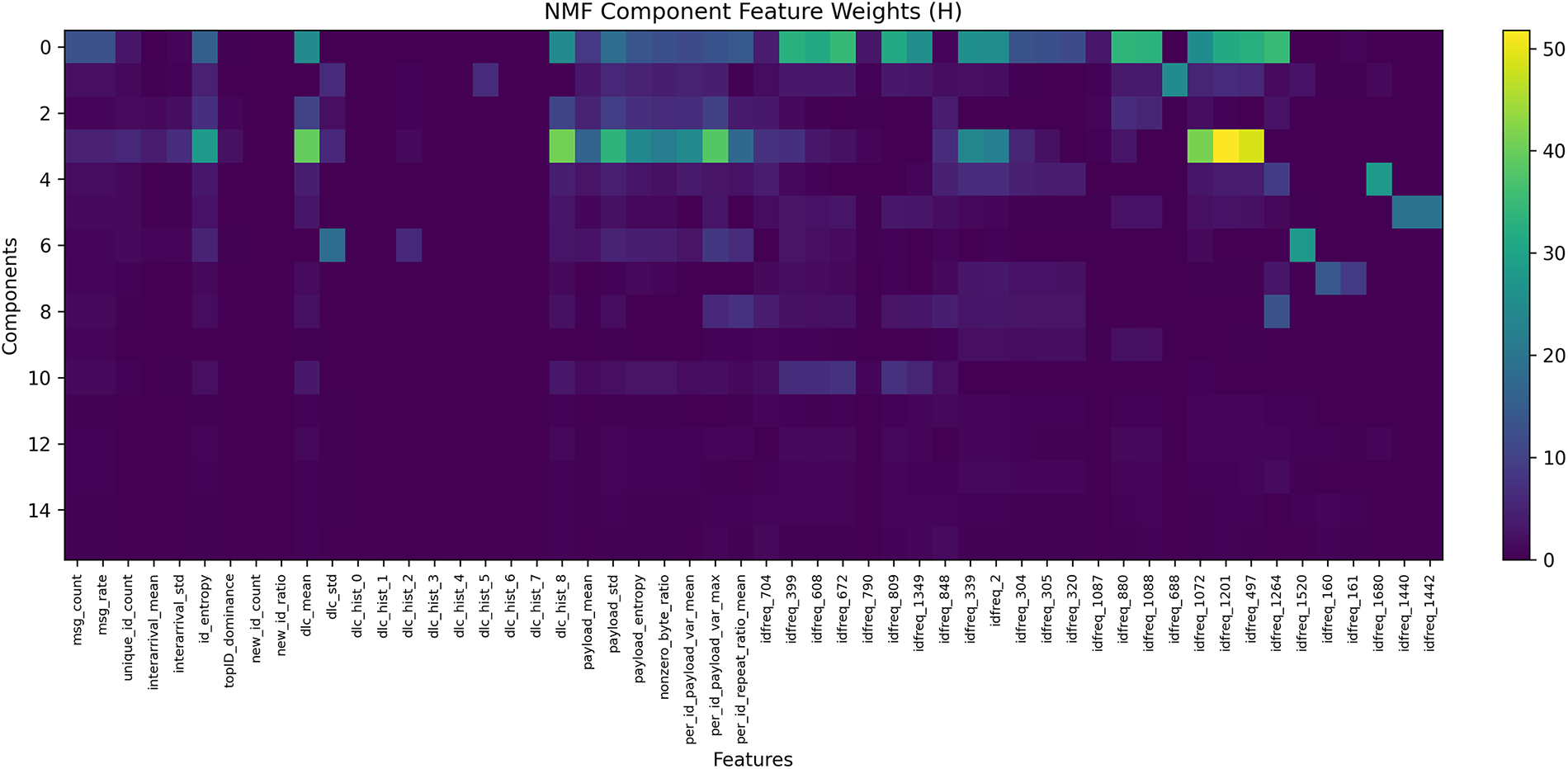
Figure 6: Heatmap of NMF basis matrix
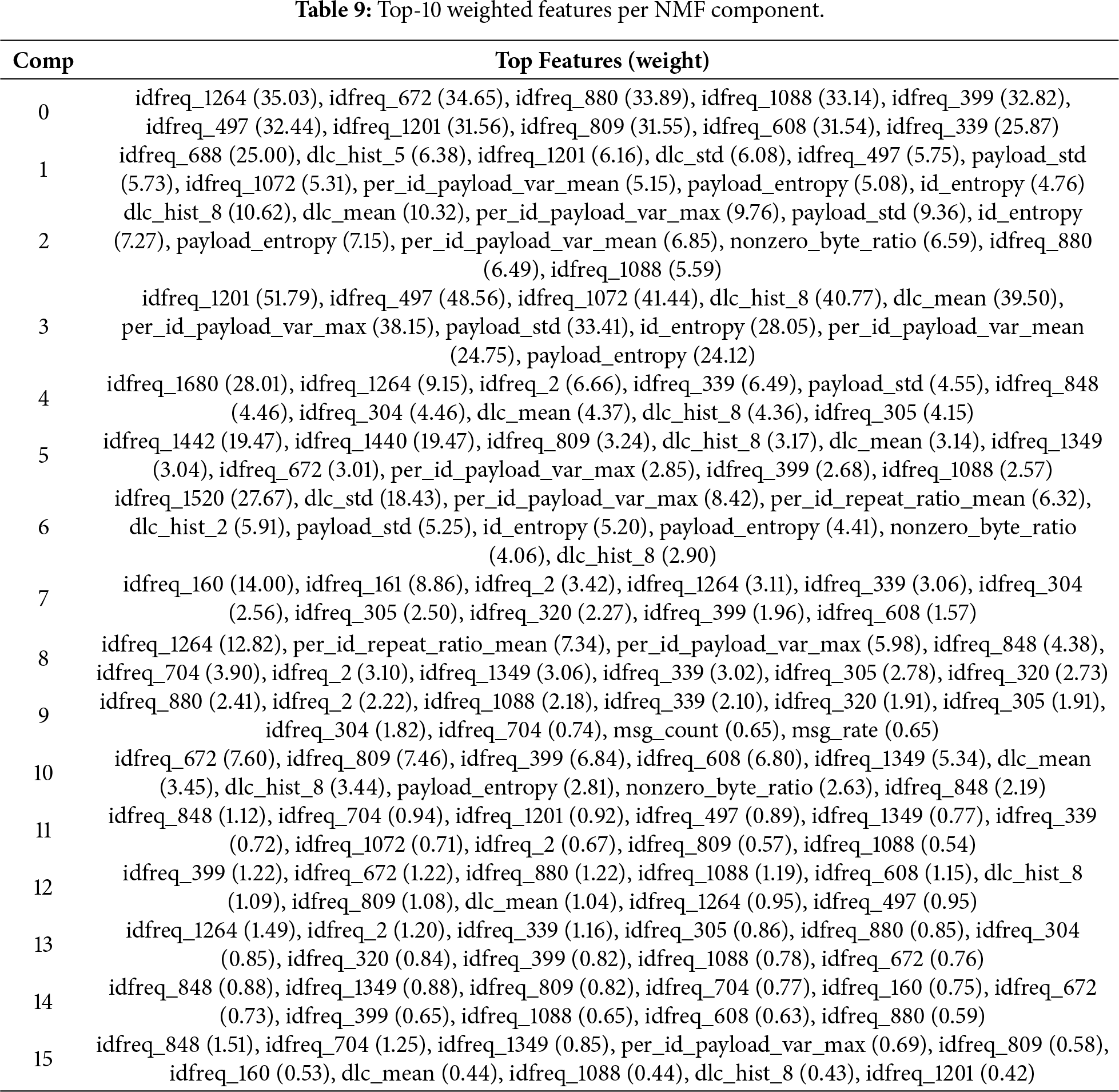
The coefficient matrix
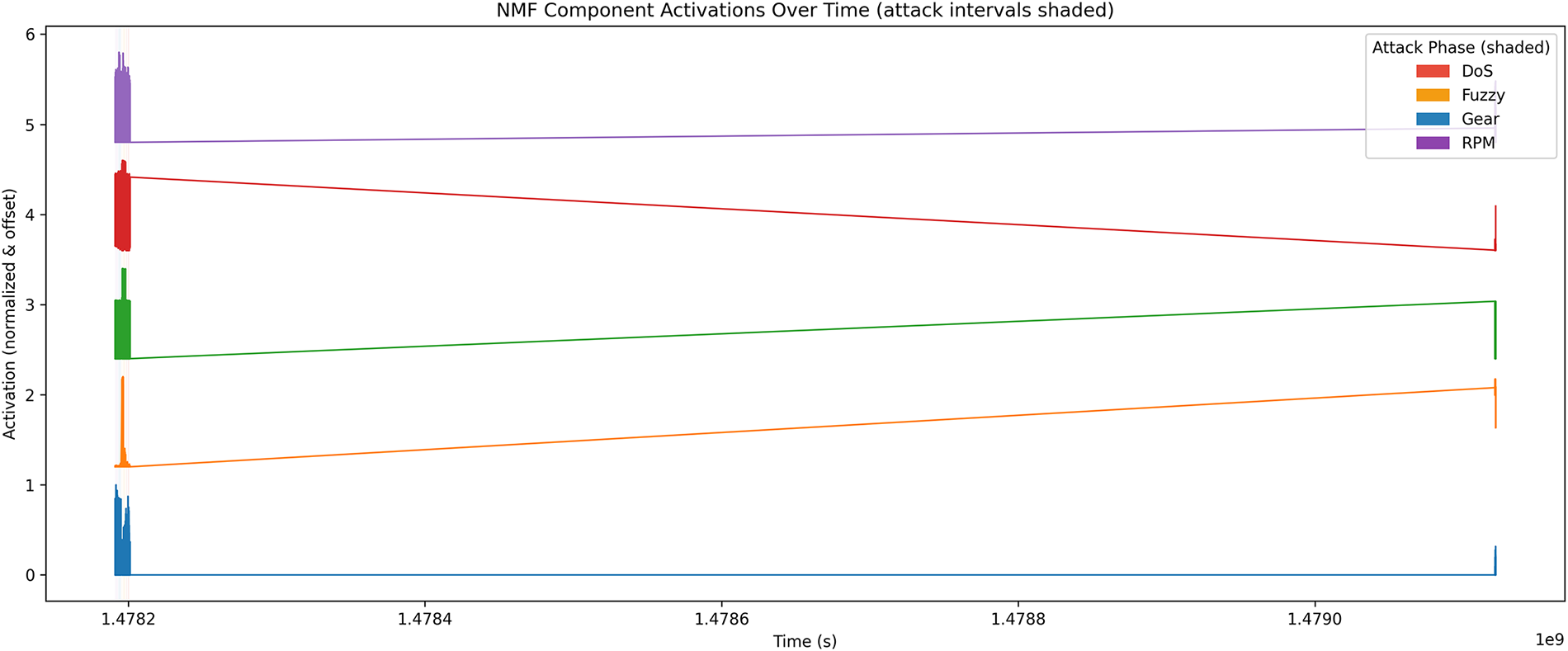
Figure 7: Temporal activations of NMF components (
Component purity analysis (Table 10) shows that several components (e.g., C2, C4, C7, C8, C10, C14) are strongly associated with specific attack types, while others remain dominated by normal traffic. This separation indicates that NMF learns selective latent factors that activate for particular intrusion patterns, supporting interpretable attribution of anomalies.
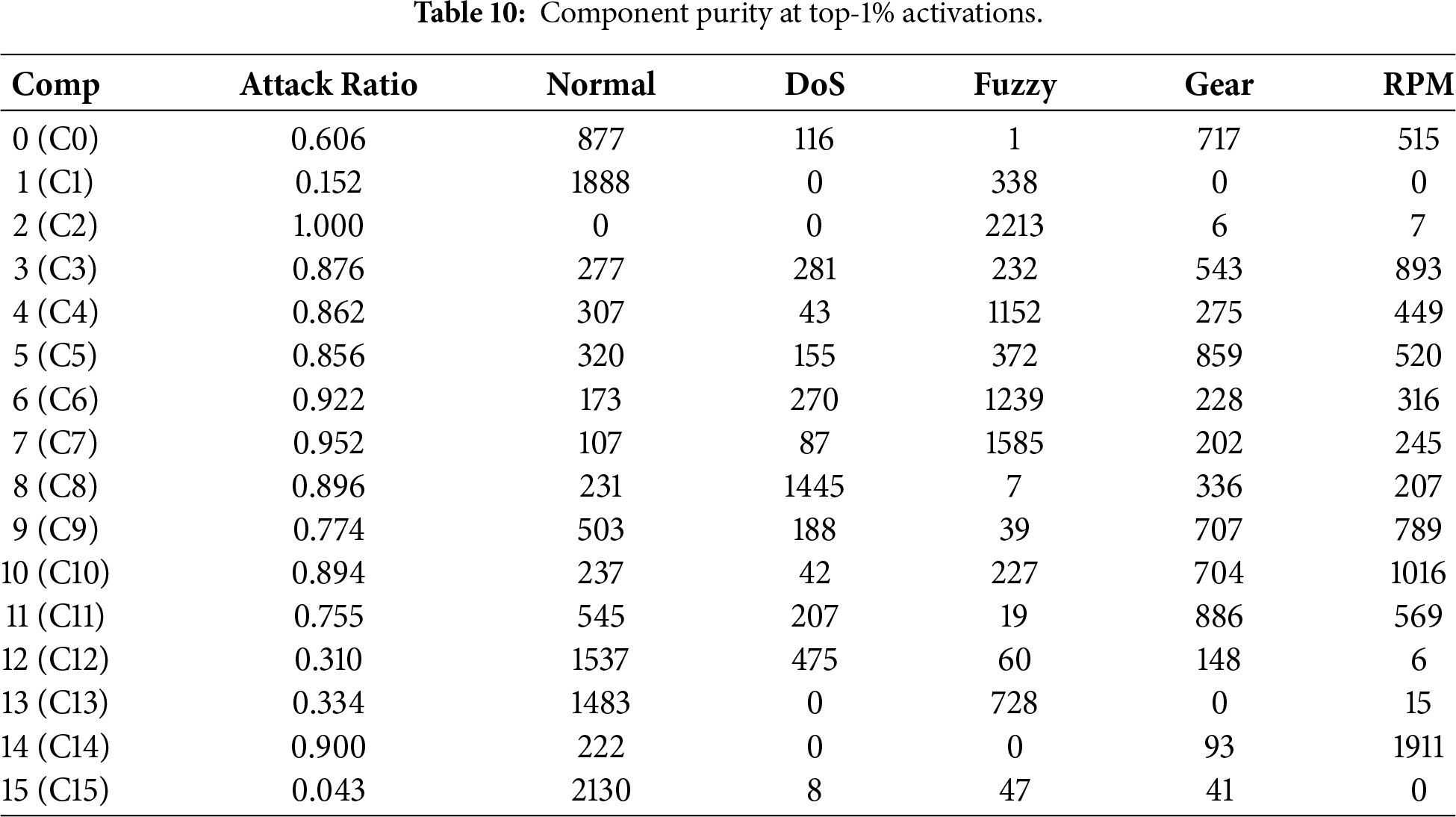
Detection performance is evaluated using two thresholding strategies defined in Section 3: Youden’s J statistic and the 99th percentile (P99) of reconstruction errors on training-normal windows. Table 11 summarizes test-set results. Both strategies achieve near-perfect AUC-ROC (

Overall, standalone NMF demonstrates that reconstruction residuals alone can reliably distinguish normal from anomalous CAN traffic while yielding interpretable latent components aligned with attack phases. The near-saturated scores are partly driven by the strong separability of CHD flooding attacks, motivating the more challenging cross-attack and cross-dataset evaluations presented in later sections.
5.3 Baseline Classifiers vs. NMF-W Features (Merged Data)
While Section 5.2 demonstrated that standalone NMF can detect anomalies using reconstruction errors, it is also important to assess whether the NMF-transformed representation (
All models are trained on the merged dataset spanning normal traffic and all attack types. Performance is reported using AUC-ROC, AUC-PR, Accuracy, Precision, and F1. Experiments are repeated across multiple random seeds and averaged.
Table 12 shows that Raw features provide slightly higher absolute performance across most metrics, consistent with the higher-dimensional representation retaining maximal discriminative information. However, NMF-W remains highly competitive: for example, RF achieves AUC-ROC 0.9972 and AUC-PR 0.9964, and XGB achieves AUC-ROC 0.9981 and AUC-PR 0.9977. Fig. 8 visualizes the Raw vs. NMF-W comparison for AUC-PR, AUC-ROC, and F1. Overall, NMF-W yields a compressed and interpretable feature space while maintaining strong detection performance.
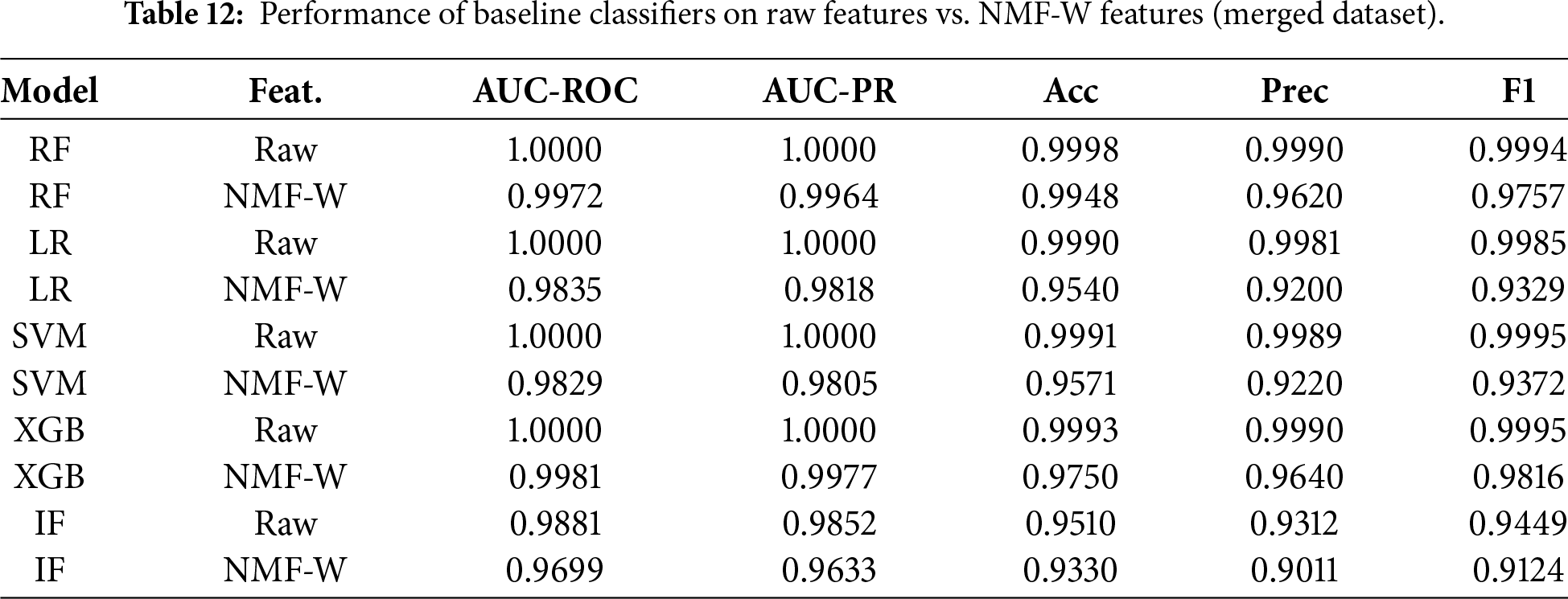
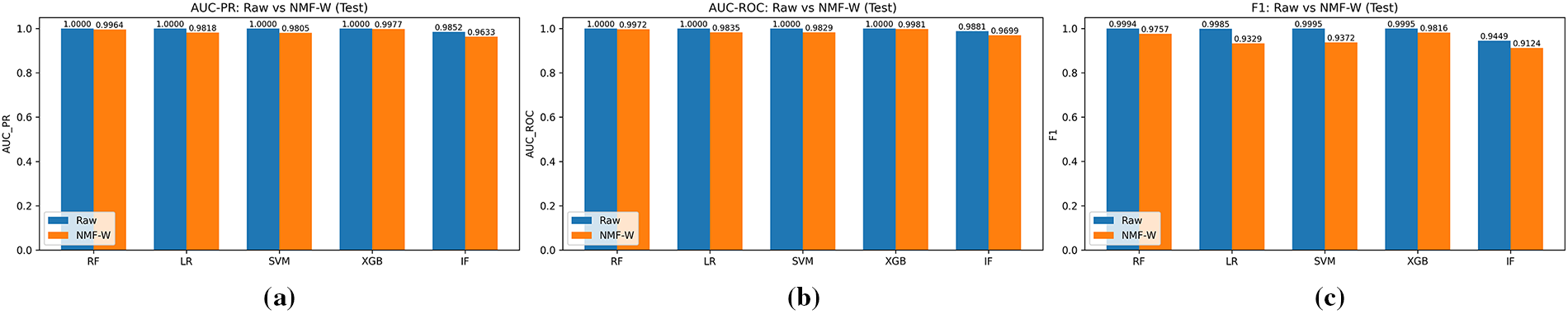
Figure 8: Comparison of classifier performance using raw vs. NMF-W features: (a) AUC-PR; (b) AUC-ROC; (c) F1-score.
Classifier-specific behavior. Performance differences reflect how models exploit the NMF-W representation. XGB performs best on NMF-W because boosting can capture nonlinear interactions among latent components while remaining robust in low dimension. LR and SVM also benefit from the compact, less noisy latent space, which can make separation more linearly accessible. In contrast, RF and IF typically benefit from richer feature heterogeneity in higher-dimensional spaces; compressing the feature space into
IF behavior under NMF transformation. IF occasionally degrades on NMF-W because it isolates anomalies via random partitioning, a mechanism that is often more effective when many heterogeneous features are available. NMF-W compresses the data into a low-rank, semantically structured space, which can reduce the effectiveness of random splits. The magnitude of this effect is dataset dependent and is more visible on CHD, where Raw features already separate flooding attacks strongly. This does not affect the suitability of NMF-W for supervised or hybrid models, where we observe consistent robustness and interpretability gains.
In summary, classifiers trained on Raw features achieve marginally higher in-domain performance, while NMF-W offers a compact, interpretable representation that remains close to Raw (typically within 1%–3%). The near-ceiling results in both spaces are influenced by CHD flooding attacks, whose extreme message rates and ID patterns create large distribution shifts from normal traffic. This trade-off supports NMF as an efficient and explainable preprocessing stage for real-time IDS pipelines in resource-constrained vehicular settings, while later cross-dataset experiments (Section 5.10) provide a more stringent evaluation of generalization.
5.4 Lookup Table and Rule-Based Baselines
Automotive ECUs commonly employ lightweight rule-based checks, such as ID whitelisting and message-rate monitoring, to detect malformed CAN traffic. To assess whether such rules can replace learned detectors, we implement two representative baselines using the same 70/10/20 chronological split and windowed features as the ML models.
ID Whitelist. A window is flagged as an attack if it contains at least one CAN identifier not observed in the normal-training subset (new_id_count
DoS-rate Threshold. A window is flagged as DoS if its message rate exceeds
Table 13 reports AUC-PR, AUC-ROC, and F1-scores for these rule baselines, alongside Random Forest (RF) models trained on Raw and NMF–W features.
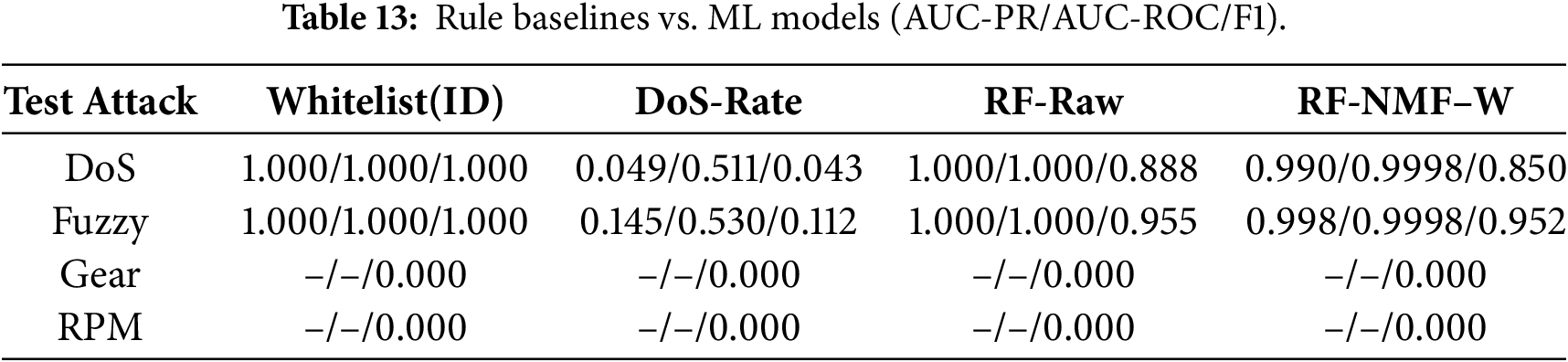
ID whitelisting performs well for DoS and Fuzzy attacks in this dataset, as both introduce identifiers absent during normal operation. In contrast, both rule-based methods fail entirely for Gear and RPM spoofing, which preserve valid CAN IDs and do not induce abnormal message rates. These results highlight the inherent limitations of static rules and motivate the use of statistical and representation-learning approaches, such as NMF–W combined with RF, which capture subtler distributional deviations beyond identifier or rate checks.
We conduct attack-wise evaluations to analyze how NMF-transformed features (
Figs. 9 and 10 report results for DoS and Fuzzy injections. Both Raw and NMF–W representations achieve near-saturated performance, with AUC-ROC and AUC-PR values close to
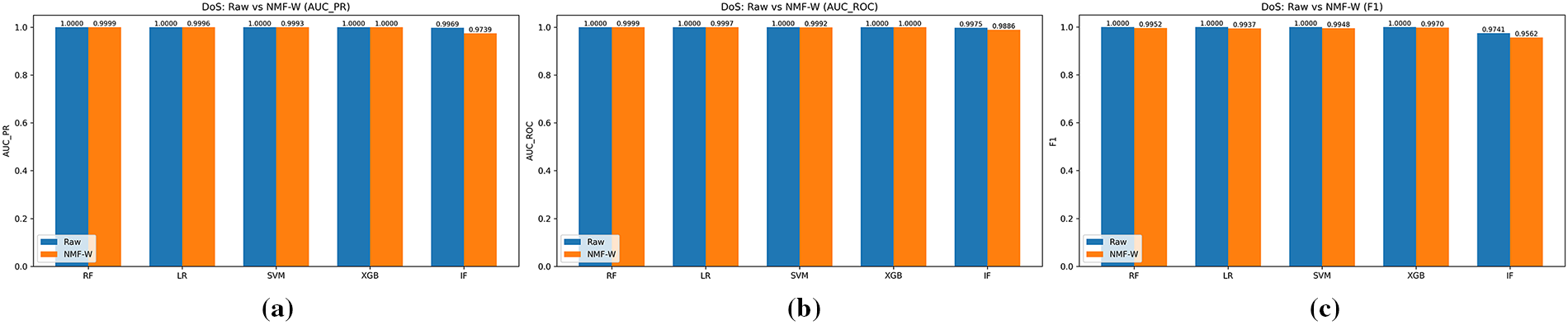
Figure 9: DoS attack: raw vs. NMF–W features across (a) AUC-PR, (b) AUC-ROC, and (c) F1-score.
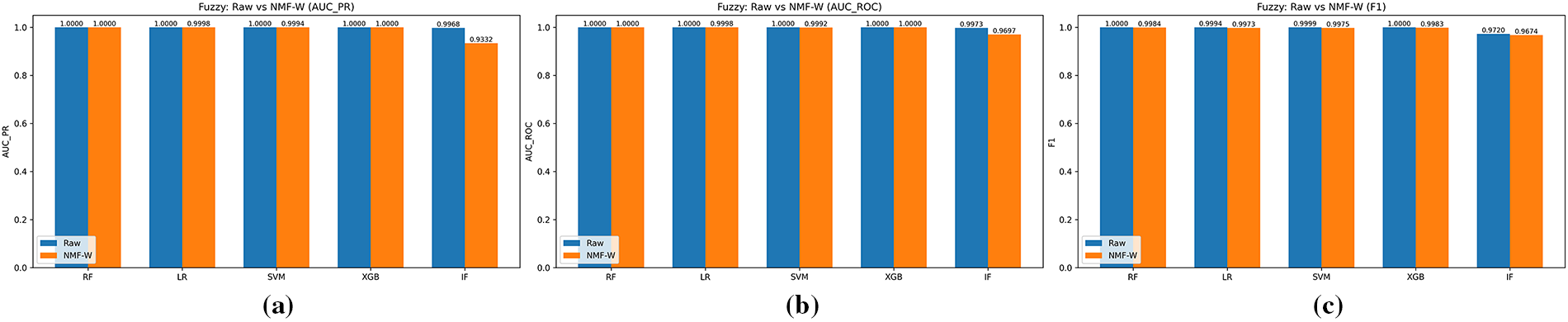
Figure 10: Fuzzy attack: raw vs. NMF–W features across (a) AUC-PR, (b) AUC-ROC, and (c) F1-score.
5.5.2 Gear and RPM Spoofing Attacks
Figs. 11 and 12 summarize results for Gear and RPM spoofing, which represent subtler manipulations that preserve valid CAN identifiers and message rates. While raw features again yield near-perfect metrics for supervised classifiers, NMF–W maintains strong performance for RF, LR, and SVM (
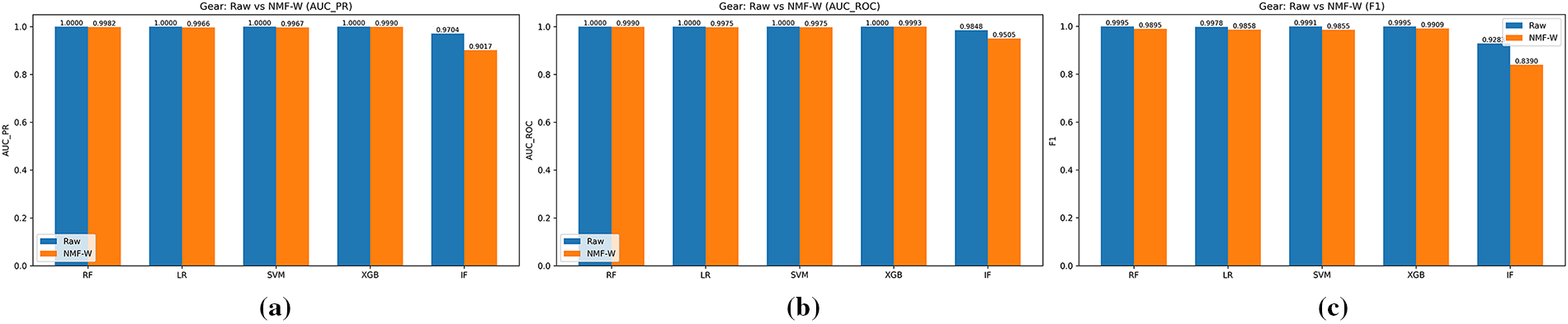
Figure 11: Gear spoofing attack: raw vs. NMF–W features across (a) AUC-PR, (b) AUC-ROC, and (c) F1-score.
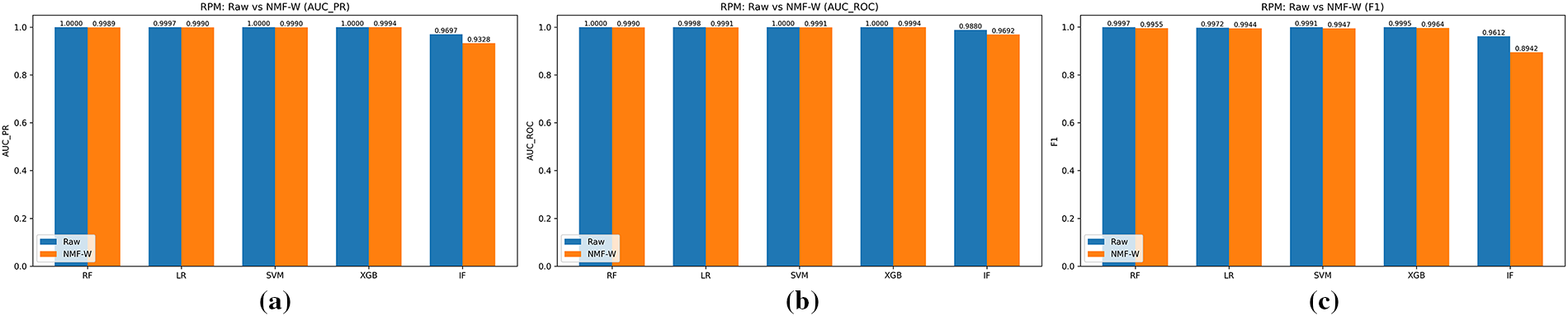
Figure 12: RPM spoofing attack: raw vs. NMF–W features across (a) AUC-PR, (b) AUC-ROC, and (c) F1-score.
Table 14 aggregates the averaged performance across classifiers. While raw features achieve near-perfect scores due to strong dataset separability, these results may overestimate real-world robustness. NMF–W remains competitive across all attack types, particularly for DoS and Fuzzy attacks, while offering reduced dimensionality and improved interpretability. For subtler spoofing attacks, performance degradation is primarily observed in unsupervised models, reinforcing the importance of combining NMF representations with supervised or hybrid detectors for deployment.
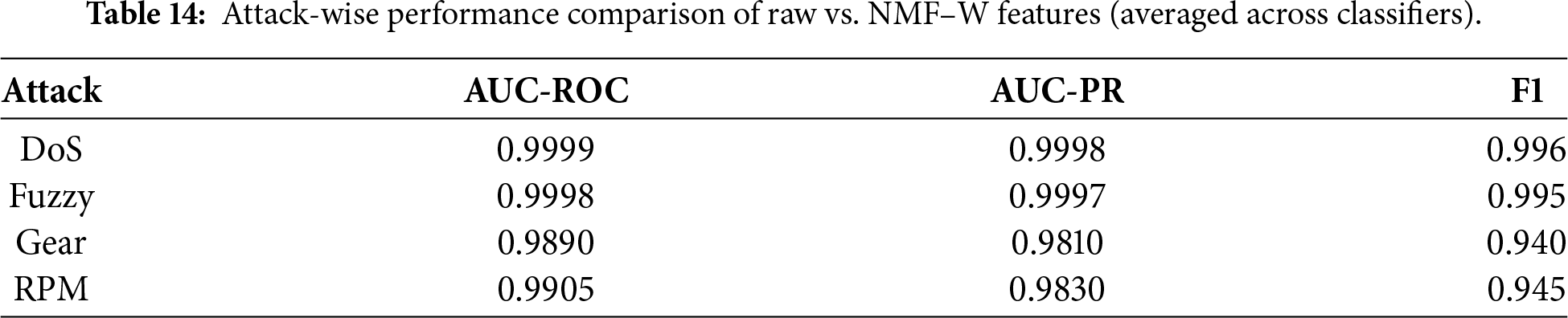
5.6 Attack Localization Analysis
Window-level labeling assigns an attack label to a 0.1 s window whenever it contains at least one injected frame. Although this convention is standard in CAN intrusion detection, it raises a concern: if a window contains only a few injected frames alongside many normal frames, does the entire interval meaningfully reflect anomalous behavior? To examine this, we perform a fine-grained localization analysis to assess whether attack-induced disturbances remain detectable at shorter timescales.
We use the following terminology:
• Attack frame: a CAN frame flagged as injected by the dataset (CHD flag = “T”).
• Normal frame: a frame not labeled as injected.
• Attack window: a 0.1 s window containing at least one attack frame.
• Micro-window: a non-overlapping 10 ms segment obtained by subdividing an attack window.
A statistical baseline is first constructed from normal traffic at the 10 ms resolution. For each normal micro-window, we compute the message rate (msg_rate) and the Shannon entropy of the CAN ID distribution (id_entropy). From these, we estimate the 99th percentile of msg_rate and the 1st–99th percentile range of id_entropy, which define typical normal behavior.
For each attack type (DoS, Fuzzy, Gear spoofing, RPM spoofing), all attack windows are subdivided into 10 ms micro-windows, yielding a total of
1. Has Attack: contains at least one injected frame.
2. Rate Anomaly: msg_rate exceeds the normal 99th percentile.
3. Entropy Anomaly: id_entropy lies outside the normal 1st–99th percentile range.
A micro-window is considered localized if it satisfies at least one indicator.
Table 15 reports localization statistics normalized by
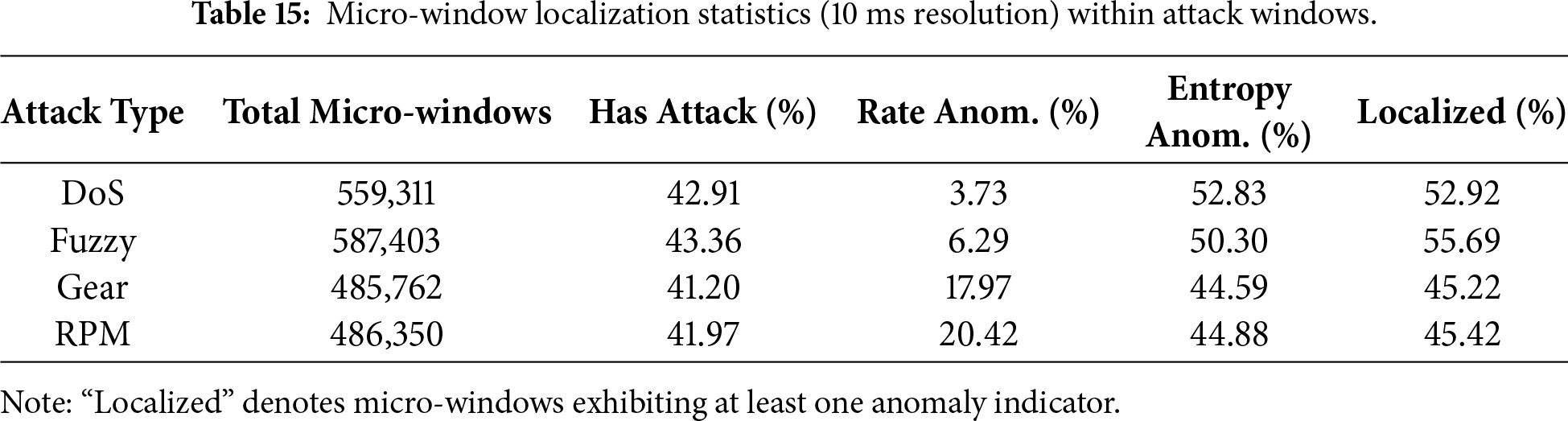
These results demonstrate that window-level labeling does not indiscriminately mark long stretches of normal traffic as anomalous. Instead, injected frames create localized temporal distortions in traffic statistics that remain detectable at the 10 ms scale. Operationally, the proposed system functions as an IDS: a 0.1 s attack window serves as a coarse-grained alert that can trigger lightweight, automated follow-up checks at finer resolution (e.g., micro-window analysis) within the ECU or gateway. The localization results are therefore intended to support operator awareness and hierarchical IDS workflows rather than frame-level intrusion prevention. Limitations of window-based detection for highly stealthy or adaptive attacks are discussed further in Section 5.15.
5.7 Cross-Attack Generalization
To evaluate robustness under unseen attack types, we conducted a cross-attack generalization study using the two attack classes with sufficient temporal coverage in the CHD dataset: DoS and Fuzzy. Both attacks span long durations, yielding adequate attack-labeled windows after the 70/10/20 chronological split. In contrast, Gear and RPM spoofing occur only in short bursts, producing sparse or absent attack windows in some train–test combinations; their cross-attack metrics are therefore statistically unreliable. Accordingly, our controlled analysis focuses on the DoS–Fuzzy pair, while implications for short-duration attacks are discussed in Section 5.15. All reported cross-attack results include 95% bootstrap confidence intervals for AUC-ROC, AUC-PR, and F1.
Tabular models (RF and IF). Fig. 13 summarizes cross-attack F1-scores for RF, IF, CNN, and LSTM using Raw and NMF-W features (full heatmaps and
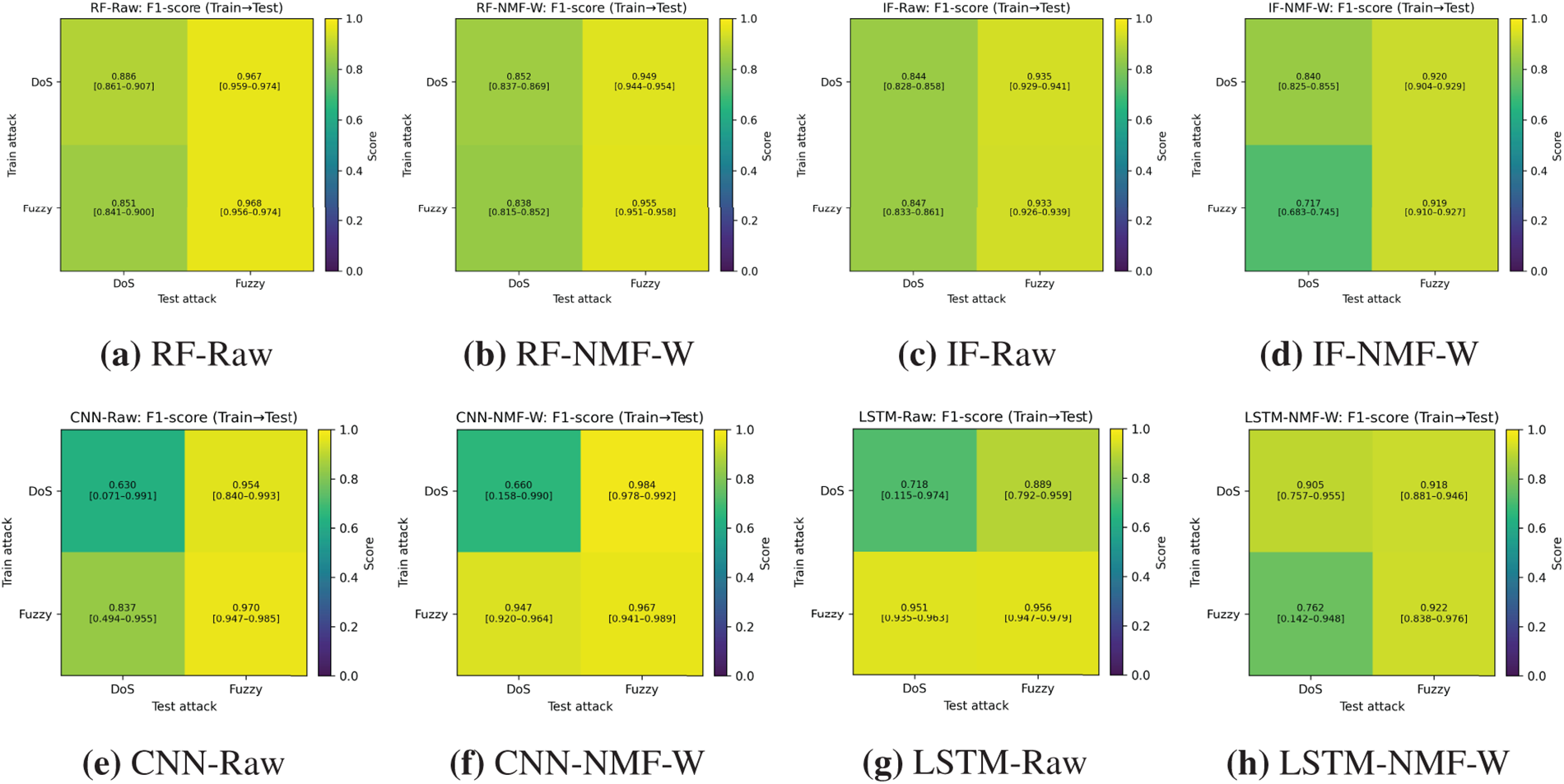
Figure 13: Cross-attack F1-score heatmaps with 95% confidence intervals for RF, IF, CNN, and LSTM using raw and NMF-W features.
Across train–test combinations, two consistent patterns emerge. First, training on Fuzzy generalizes well to DoS, with RF and IF achieving stable AUC-ROC values (0.97–0.99) and F1-scores typically above 0.83 for both Raw and NMF-W representations. Second, the reverse direction (DoS
The effect of NMF-W is attack dependent. For RF, NMF-W slightly reduces F1-scores in some settings while preserving high AUC-ROC values. For IF, NMF-W stabilizes detection when trained on DoS but reduces F1 when trained on Fuzzy. Supplementary
Sequence models (CNN, LSTM, Attention). We further evaluated CNN, LSTM, and Attention-based architectures under the same DoS
Under cross-attack evaluation, the same asymmetry persists. Models trained on Fuzzy generalize more reliably to DoS (AUC-ROC 0.94–0.99; F1 0.83–0.97) than those trained on DoS and tested on Fuzzy, which exhibit greater F1 variability despite high AUC-ROC values. CNN and Attention show moderate degradation under DoS
Overall, the benefit of NMF-W for sequence models is mixed: it improves performance in some cases (e.g., CNN under Fuzzy
5.8 Class Imbalance and Robustness Enhancements
We study three complementary strategies to address skewed labels and improve robustness: (i) tabular resampling with SMOTE/ADASYN, (ii) sequence models with class-weighted training and fixed-recall reporting, and (iii) mixed-attack training (two attacks) evaluated on a held-out third attack. Across all settings, we compare Raw features against NMF representations (
Rationale for imbalance handling. Severe class imbalance is intrinsic to CAN intrusion detection, where attack windows represent a small fraction of overall traffic. We adopt SMOTE and ADASYN as representative data-level techniques because they increase minority-class support without discarding normal samples. SMOTE interpolates between existing minority instances, while ADASYN emphasizes hard-to-learn regions, making both suitable for tabular CAN features and for analyzing how oversampling interacts with Raw vs. NMF-W representations. Alternative strategies such as undersampling or cost-sensitive losses were not emphasized here, as undersampling removes informative normal traffic and loss reweighting is model-specific and not applicable to unsupervised or hybrid settings (e.g., standalone NMF). Our goal is not to propose a new imbalance method, but to systematically assess how standard techniques interact with NMF-based representations under realistic CAN traffic skew.
Tabular resampling (SMOTE/ADASYN). Using the merged tabular dataset, we trained {RF, LR, SVM, XGB} under three settings: pure (no resampling), SMOTE, and ADASYN, for both Raw and NMF-W. Fig. 14 summarizes test AUC-PR, AUC-ROC, and F1. Raw-feature models already operate near ceiling, and resampling yields only marginal changes. In contrast, NMF-W shows small but consistent gains in F1 and AUC-PR under SMOTE/ADASYN (e.g., XGB with ADASYN achieves

Figure 14: Tabular resampling on the merged dataset (SMOTE/ADASYN): (a) Test AUC-PR; (b) Test AUC-ROC; (c) Test F1-score for Raw and NMF-W across {RF, LR, SVM, XGB}.
Sequence models with class-weighting. On the merged sequence dataset, we trained {CNN, LSTM, Attention} using class-weighted loss for both Raw and NMF-W features. Fig. 15 reports test AUC-PR, F1, and precision at a fixed high recall. All architectures achieve strong performance (AUC-PR
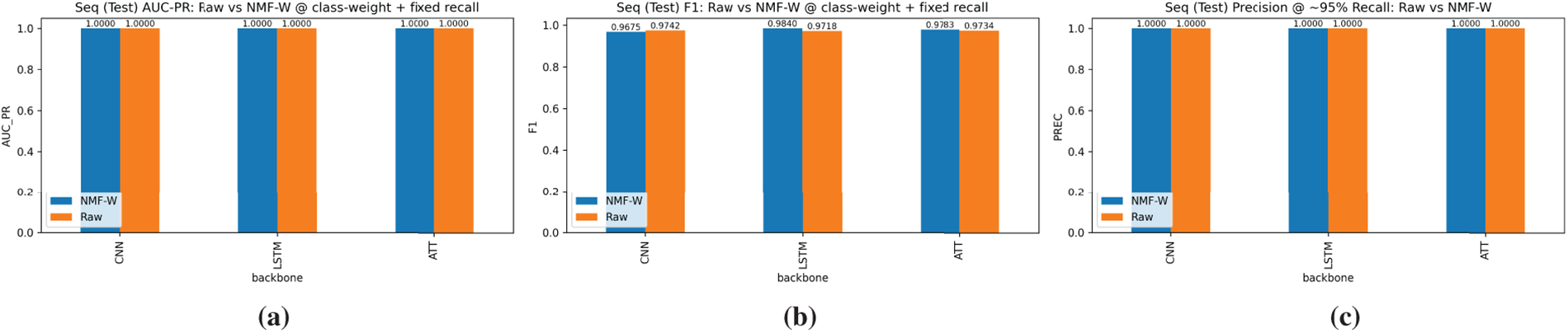
Figure 15: Sequence models with class-weighting on merged data: (a) Test AUC-PR; (b) Test F1; (c) Precision at fixed recall.
Mixed-attack training (2
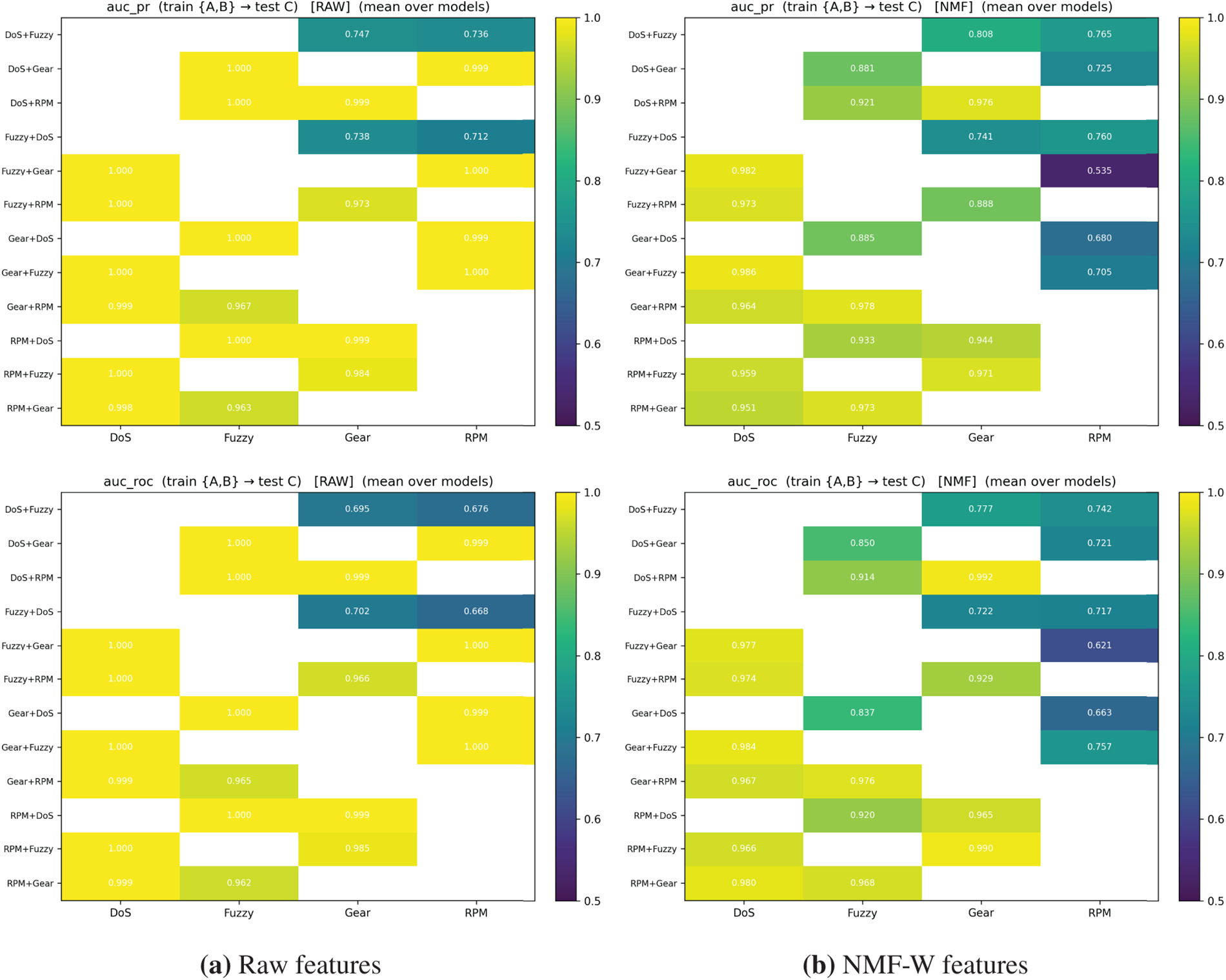
Figure 16: Mixed-attack training (2
Generalization to unseen attacks. Several experiments in this section explicitly assess robustness to previously unseen attack behaviors. The mixed-attack training setup approximates realistic deployment scenarios in which new attack patterns are encountered without explicit labels. Results show that NMF-W representations retain meaningful detection capability for unseen and subtle targets, while raw-feature models may collapse under the same conditions. In addition, standalone NMF operates without attack labels and thus inherently supports anomaly detection beyond known signatures. While no IDS can guarantee detection of all unknown attacks, these findings indicate that the proposed framework exhibits meaningful generalization to novel deviations from learned normal traffic patterns.
A key motivation for adopting NMF is its ability to produce interpretable, parts-based representations of CAN traffic. Here, we focus on internal interpretability: we assess whether NMF components are consistent and semantically meaningful within our datasets and models, without claiming that their usefulness for human operators has been validated in real-world workflows. NMF yields a basis matrix
Phase prototypes. We aggregate mean
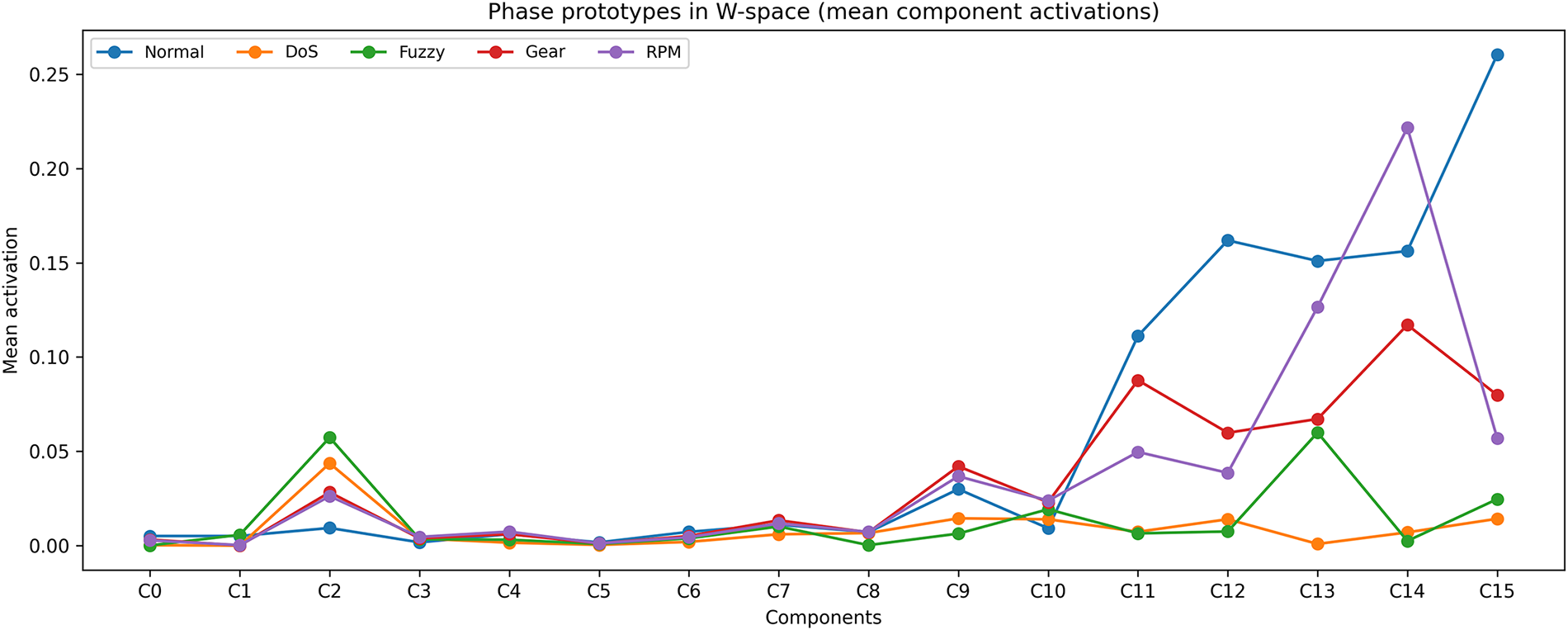
Figure 17: Average NMF component activations per traffic phase. Distinct peaks highlight parts-based structure aligned with DoS, Fuzzy, Gear spoofing, and RPM spoofing attacks.
Distinctive component attribution. We identify the top-
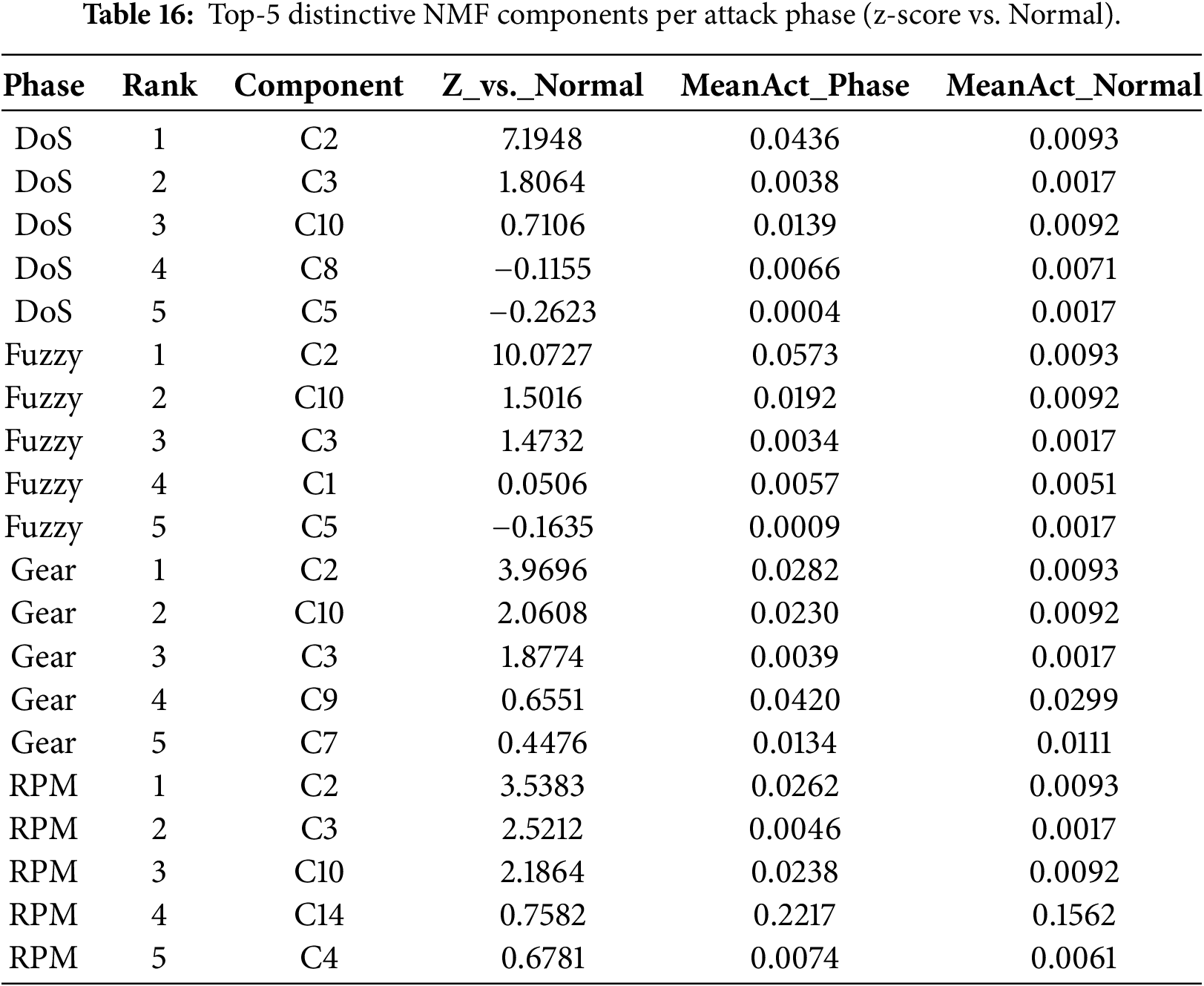
Cross-attack component activation. Several components are consistently activated across multiple attack types (e.g., C2 across all attacks; C3 and C10 across multiple phases), indicating that NMF captures both shared anomaly structure (generic deviations such as entropy distortions or sustained rate changes) and phase-specific behavior. This mixture of shared and specialized components provides an interpretable mechanism for robustness under cross-attack and cross-dataset evaluation.
Component-level summary and phase similarity. Table 17 summarizes each component via purity at top-
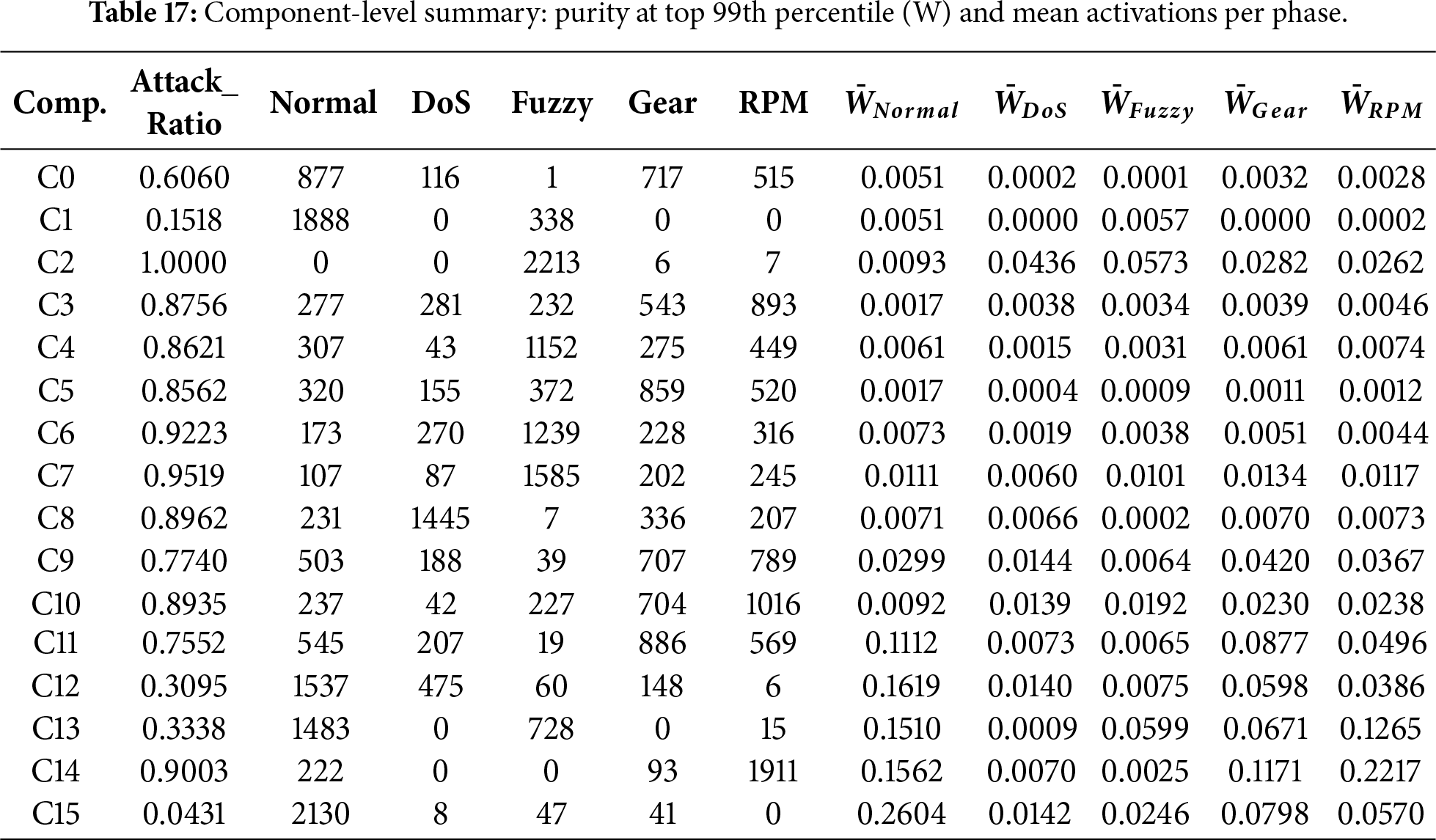
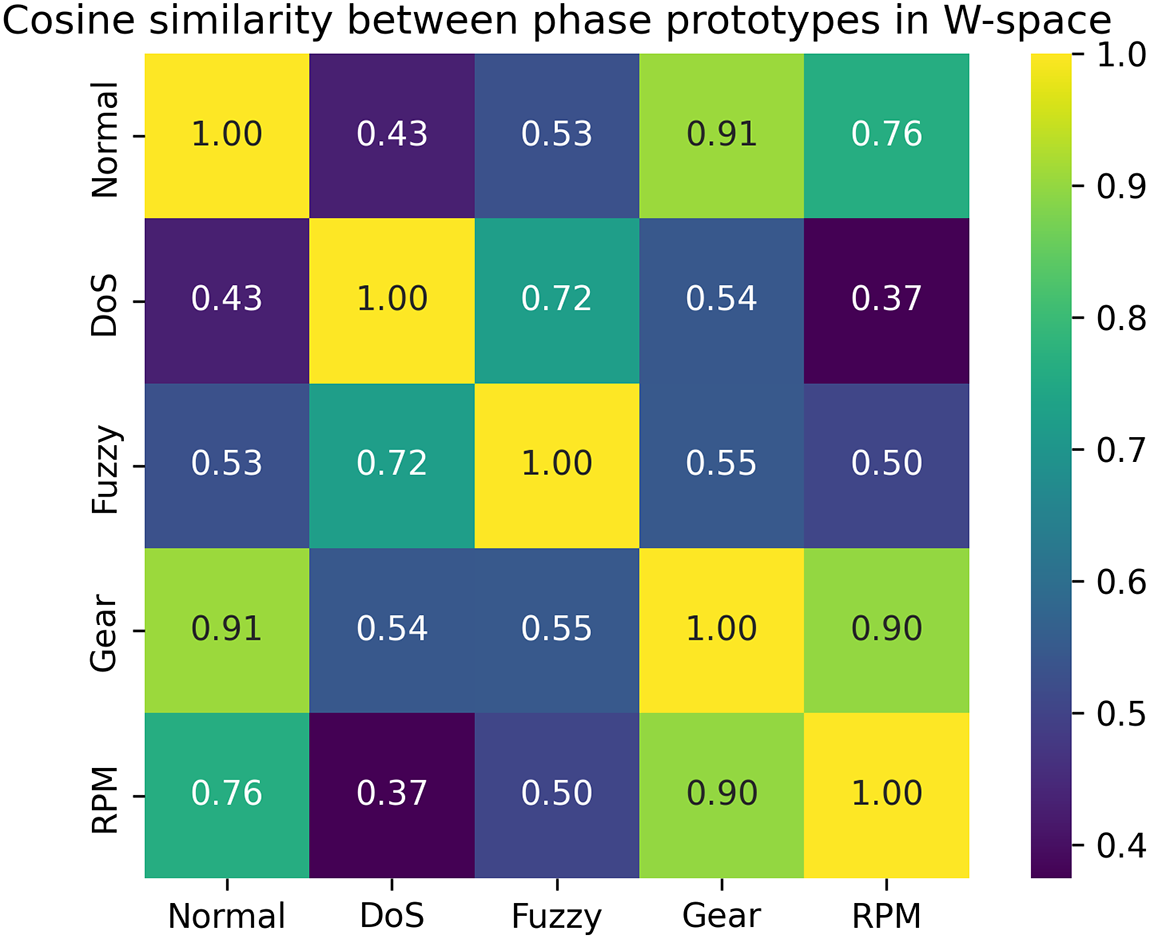
Figure 18: Cosine similarity between phase prototypes in
Overall, these analyses indicate that NMF yields semantically meaningful latent components that are internally consistent across multiple views. Assessing how these interpretations assist security analysts or automotive engineers in real workflows is left for future work. Additional violin plots of per-component activation distributions are provided in the supplementary materials (Figs. S8–S10).
To complement NMF component interpretability, we examine how supervised classifiers prioritize signals when trained on raw handcrafted features vs. NMF-derived latent components. We report feature importances for RF and XGB and absolute coefficients for LR in both spaces.
Raw feature space. Table 18 shows that raw-feature models rely heavily on a small set of identifier-specific features (e.g., idfreq_*) and related count-based indicators. While these features yield near-perfect performance on CHD, they can reflect dataset-specific artifacts (e.g., injected IDs and burst patterns), motivating the use of structured representations for improved robustness.

NMF-W feature space. In the NMF-W space, models distribute attention across multiple latent components (Table 19). Notably, components such as C2 and C3—also highlighted as distinctive in Section 5.9—recur as influential signals across classifiers, providing a consistent bridge between unsupervised component semantics and supervised decision-making. Since each component maps back to a sparse subset of original features via

5.10 Cross-Dataset Validation (CHD
OTIDS represents an independent dataset collected from a different vehicle platform and includes attack realizations not observed during CHD training, providing a stringent test of robustness under dataset shift. To evaluate cross-domain transfer, all models were trained on CHD and evaluated on both the CHD-test split (in-domain) and OTIDS (out-of-domain), which contains CAN traffic from a real KIA Soul vehicle under DoS, Fuzzy, and Impersonation attacks. Table 20 summarizes supervised results, and Table 21 reports standalone NMF reconstruction-error performance.
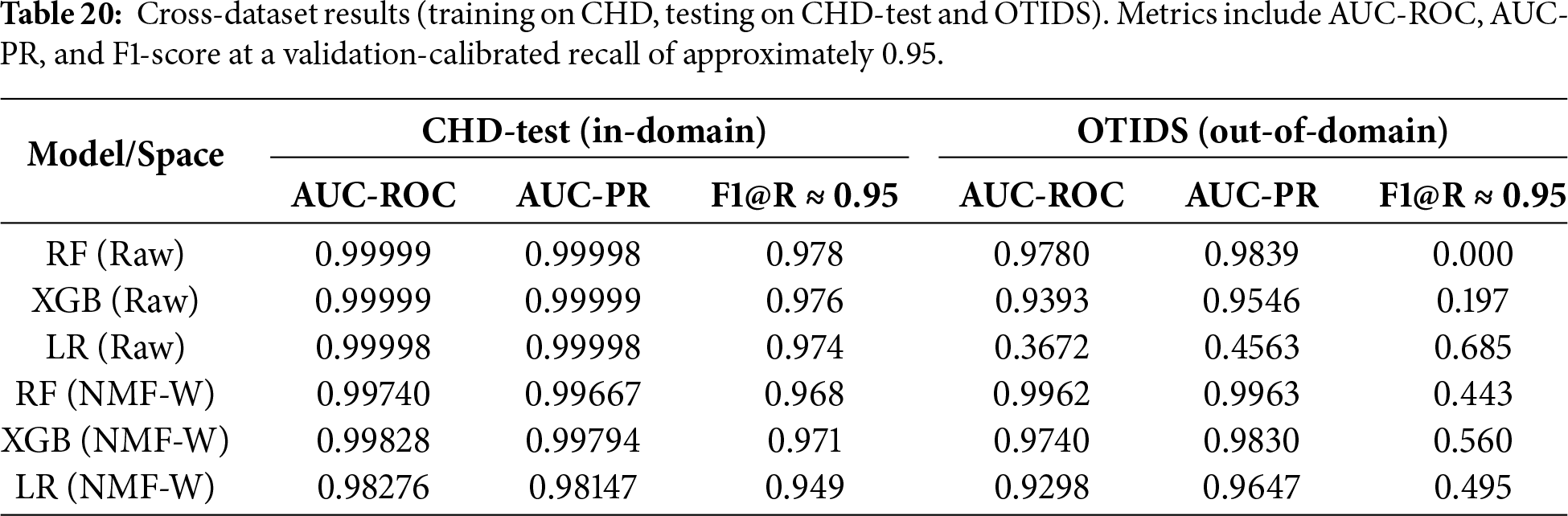

Supervised models. All classifiers achieved near-saturated performance on CHD-test (AUC-ROC/AUC-PR
Standalone NMF. Direct reconstruction-error scoring generalizes poorly across datasets (AUC-ROC
Limitations of cross-dataset transfer. This evaluation reflects transfer between two specific public datasets rather than universal generalization. CHD and OTIDS differ in vehicle platform, CAN ID distributions, logging configurations, and attack execution styles, introducing substantial domain shift. Therefore, the observed performance—especially for standalone reconstruction-error scoring—should be interpreted as evidence of relative robustness of NMF-W rather than a guarantee of deployment-level generalization. Broader validation across additional vehicles, attack types, and data-collection settings is required, as discussed in Section 5.15.
5.11 Comparison with Other Unsupervised Detectors
Table 22 shows that NMF achieves the highest F1-score and precision at a fixed high-recall operating point, substantially outperforming IF and slightly exceeding Autoencoder performance. While Autoencoders provide competitive accuracy, they rely on opaque latent representations, whereas NMF yields additive, parts-based components that are directly interpretable in terms of CAN traffic structure. These results confirm that NMF provides a favorable balance between detection performance, interpretability, and robustness for unsupervised CAN bus intrusion detection.

5.12 Comparison with State-of-the-Art CAN IDS
To contextualize the proposed framework within existing CAN IDS research, we qualitatively compare it with representative learning-based systems: GIDS [10], CANet [12], and INDRA [25]. These methods span GAN-based detection, LSTM autoencoders, and GRU autoencoders. Table 23 summarizes their architectures, datasets, interpretability, and deployment footprint.
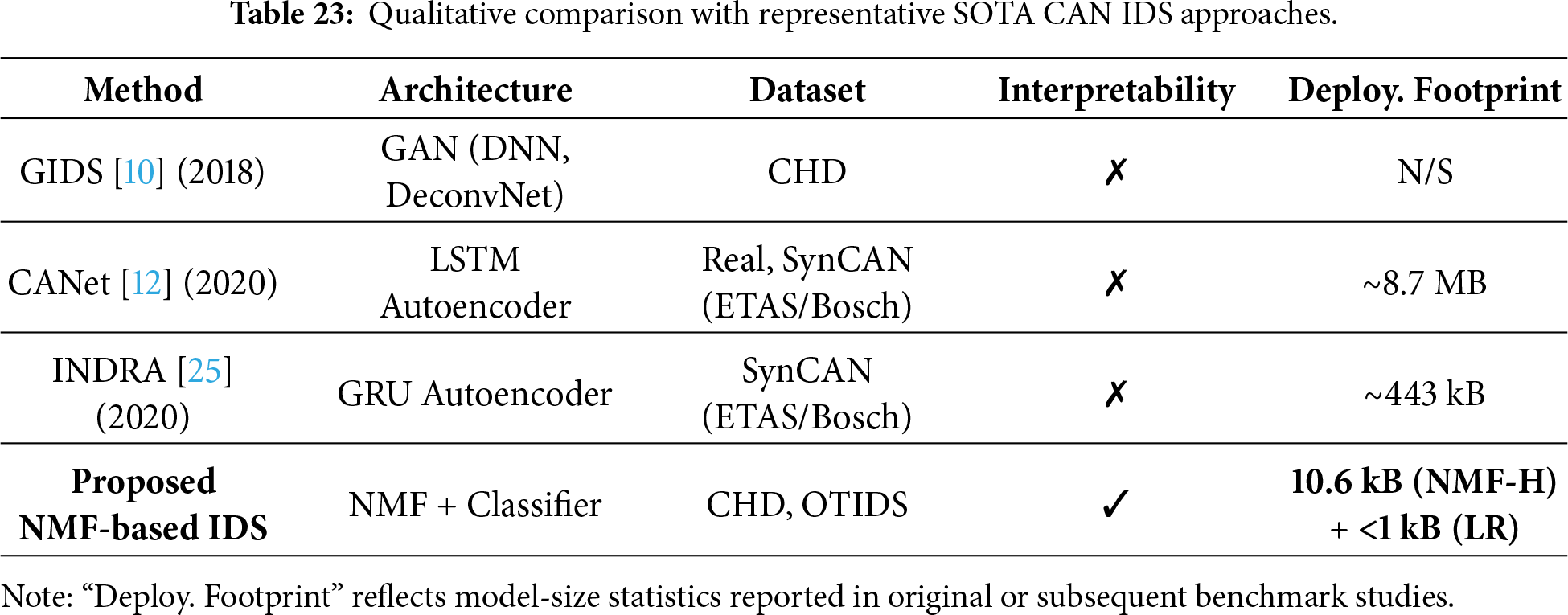
DL baselines. CANet employs an LSTM autoencoder and reports a footprint of approximately 8.7 MB (as benchmarked in [25]), while INDRA reduces this to roughly 443 kB using a GRU autoencoder. GIDS, based on GAN and DNN components, does not report explicit model-size statistics, but GAN-based IDS typically require multi-megabyte models. Although these approaches demonstrate strong detection performance on their respective datasets, they rely on opaque latent representations and incur substantial computational and memory costs, limiting transparency and deployment on resource-constrained ECUs.
Proposed NMF-based IDS. In contrast, the proposed framework yields a compact and interpretable latent representation. Each NMF component corresponds to semantically meaningful traffic patterns, such as CAN ID frequency structure, payload entropy, or DLC behavior. With
Overall, while SOTA DL-based IDS architectures achieve high accuracy, they typically trade interpretability and deployment efficiency for performance. The proposed NMF-based IDS offers a complementary alternative that combines competitive detection capability with explicit interpretability and a markedly smaller deployment footprint, making it well suited for real-time, in-vehicle intrusion detection.
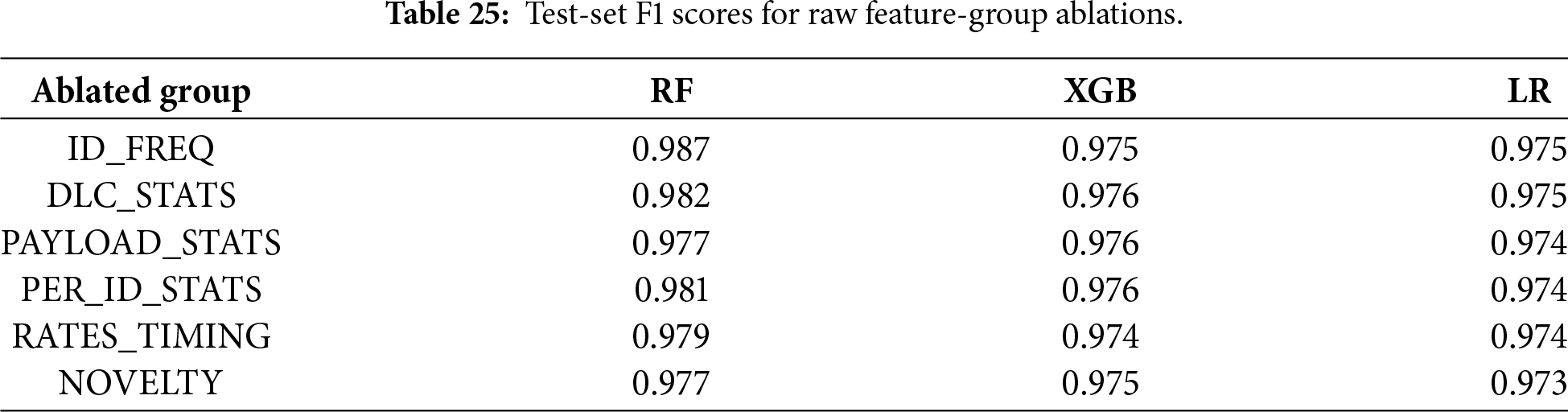
To quantify the contribution of individual design choices, we conduct ablation experiments along three axes: (i) removal of raw feature groups, (ii) variation of the NMF latent rank, and (iii) comparison between raw features and NMF-derived representations. Feature ablations are performed by removing entire semantically coherent groups (Table 24) while keeping all remaining descriptors unchanged. The groups capture complementary aspects of CAN traffic: burstiness and timing (RATES_TIMING), payload length usage (DLC_STATS), byte-level variability (PAYLOAD_STATS), per-ID variability (PER_ID_STATS), ID frequency structure (ID_FREQ), and novelty with respect to normal traffic (NOVELTY).

Raw feature group removal. Table 25 reports test-set F1 scores after removing individual raw feature groups. Across RF, XGB, and LR, performance remains largely stable, with only minor degradation when removing RATES_TIMING or NOVELTY. This indicates substantial redundancy among handcrafted descriptors and suggests that strong performance in the raw space does not depend on any single feature group, reinforcing the motivation for a compact representation.
NMF component sweep. We evaluate the effect of the latent rank by sweeping
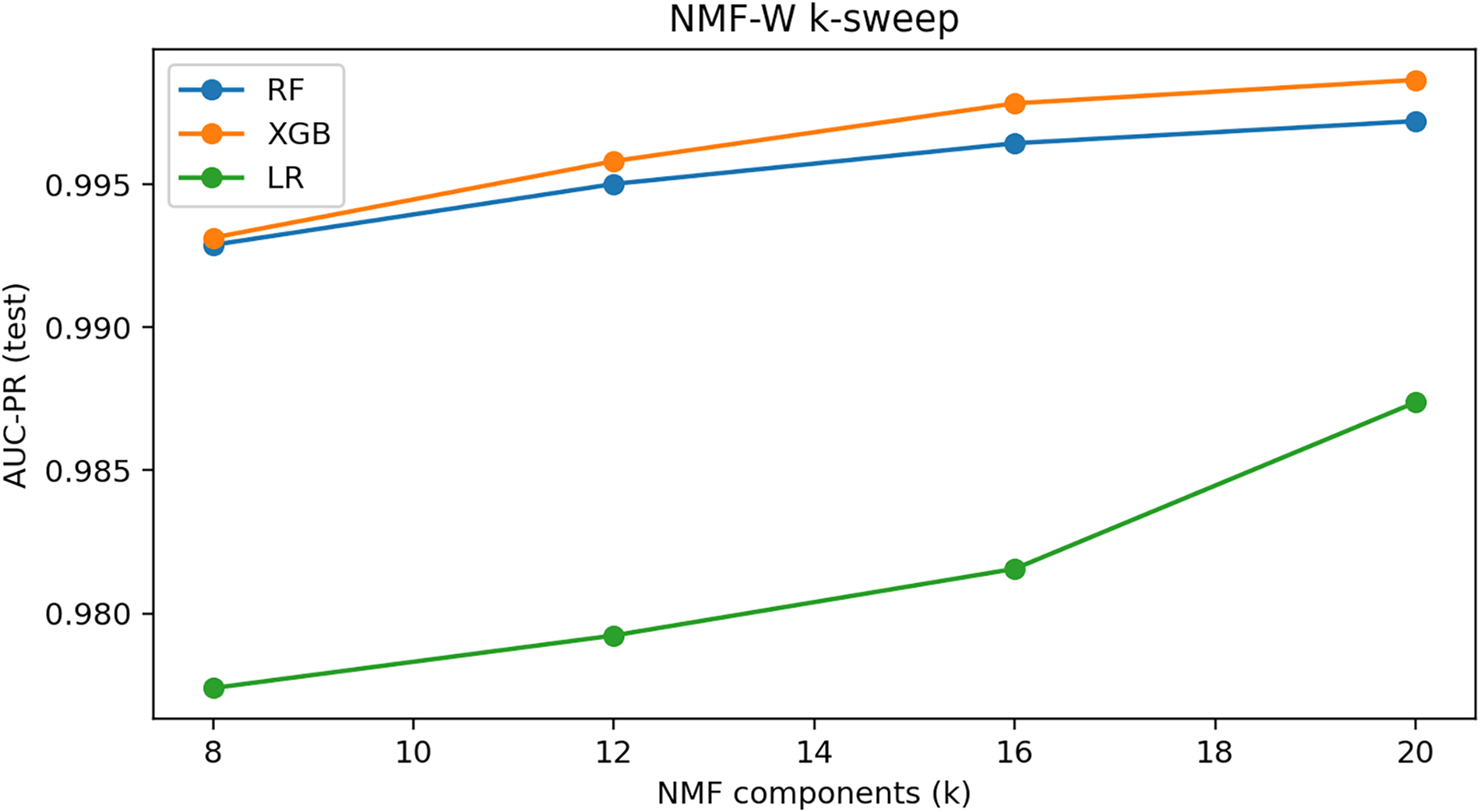
Figure 19: AUC-PR on the test set for NMF-W component sweep (
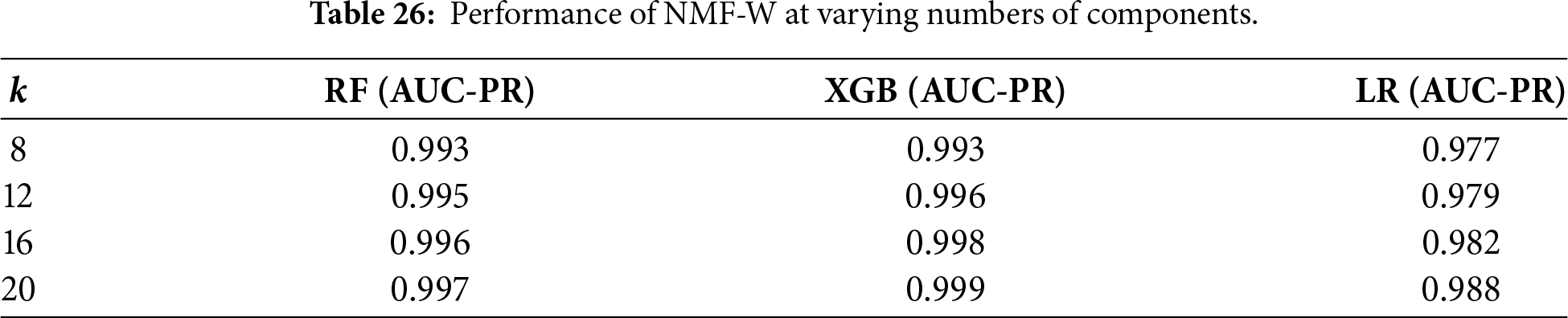
Raw vs. NMF–W comparison. Table 27 directly compares raw features with NMF–W (
Overall, the ablation results show that raw feature performance is driven by redundant descriptors, while NMF–W provides a compact and robust alternative that preserves accuracy and improves downstream generalization and interpretability.
5.14 Efficiency Evaluation and ECU Deployment Feasibility
We evaluate computational efficiency in terms of training time, inference latency, and serialized model size. Table 28 summarizes tabular models (RF, XGB, LR) on Raw and NMF-W representations, while Table 29 reports forward-pass timing for sequence models (CNN, LSTM, Attention).
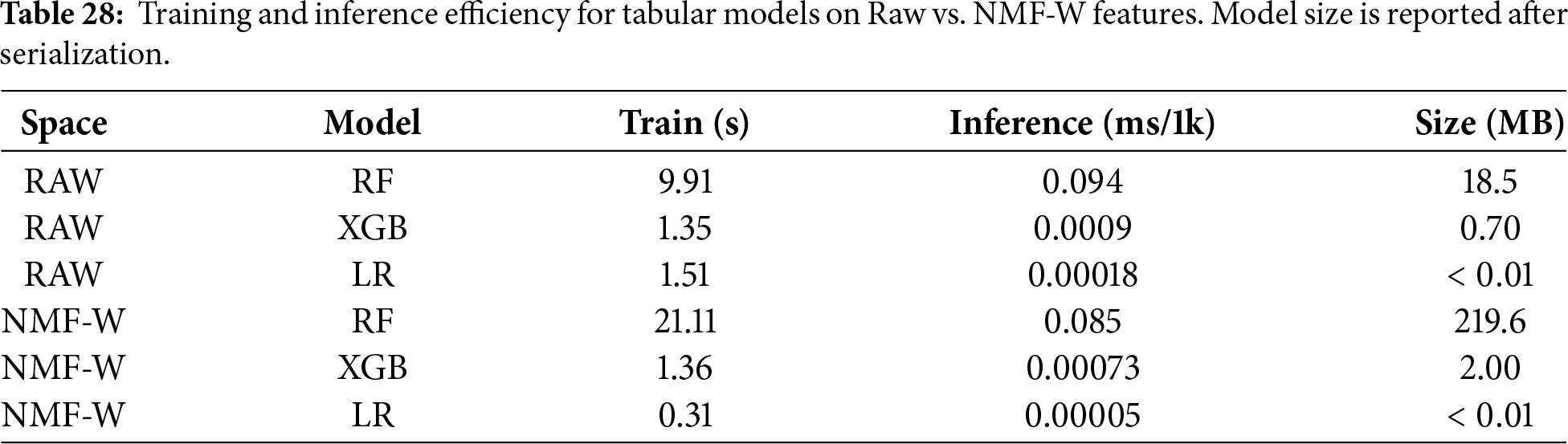

Tabular models. On Raw features, RF trains in 9.9 s and infers in 0.094 ms per 1k windows, while XGB and LR train within
NMF overhead (offline vs. runtime). NMF training is performed offline and yields compact artifacts: for
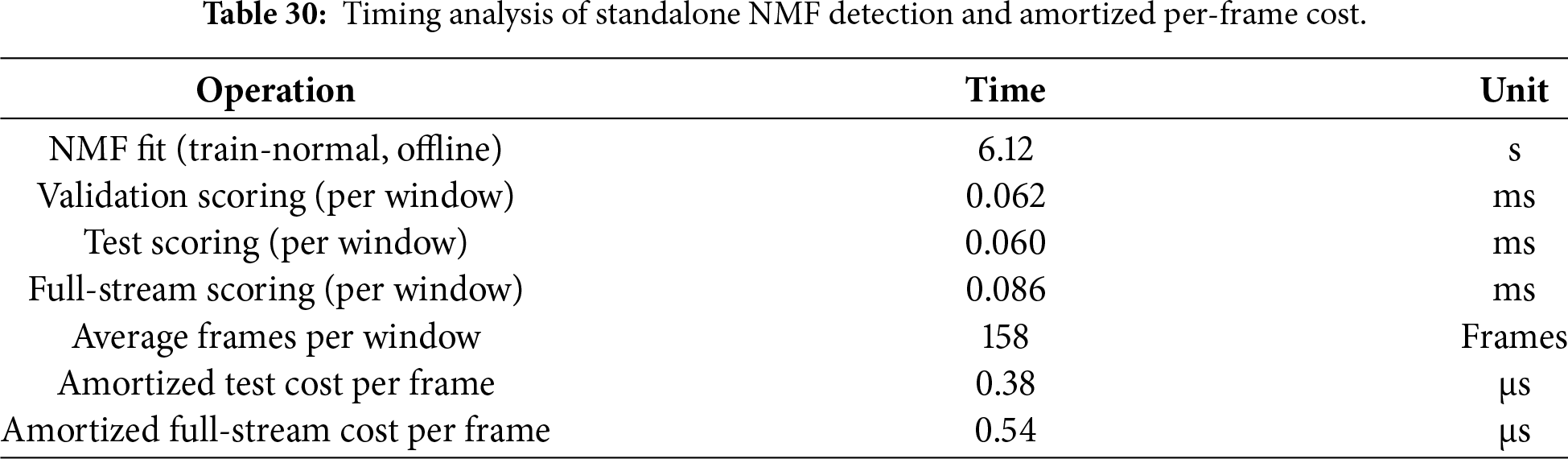
Model size and deployability. Deployability is dominated by the downstream classifier rather than NMF. The RF model on NMF-W is large (219.6 MB) due to the 400-tree ensemble and deep split structures, and thus exceeds typical ECU flash budgets. In contrast, XGB (2.0 MB) and LR (
Sequence models. CNN, LSTM, and Attention contain 14k–45k parameters and require 5–31 ms per 1k windows (Table 29). Although slower than tabular models, their forward-pass latency remains feasible on higher-end automotive processors.
Feasibility for ECU deployment. From an embedded perspective, NMF (10.6 kB for k = 16) paired with lightweight classifiers such as LR or XGB fits within common ECU flash memory ranges (2–16 MB) and supports real-time inference (<1 ms per 1k windows). Therefore, the NMF representation is ECU-friendly, and practical feasibility depends primarily on the downstream classifier.
Runtime efficiency under ECU constraints. Beyond model size, inference latency is a critical factor for embedded deployment. Our timing analysis shows that standalone NMF scoring requires less than
Window-based vs. packet-based IDS. A key design choice in this work is the use of a window-based IDS rather than a purely packet- (frame-) based detector. Packet-based IDS [38,39,51] operate at the granularity of individual CAN frames and prioritize immediate reaction with minimal latency. In practice, such systems commonly rely on lightweight rule-based mechanisms, including CAN ID whitelisting and instantaneous message-rate thresholding, due to their low computational cost and suitability for deployment on resource-constrained ECUs.
In contrast, the proposed window-based NMF IDS aggregates CAN frames over short temporal windows (0.1 s in this study) and analyzes their collective statistical structure. This aggregation enables the detection of more subtle anomalies that preserve valid CAN IDs and per-frame constraints, such as spoofing attacks with realistic timing and payload patterns. While window-based detection introduces a bounded alert delay determined by the window size, it provides richer temporal context and improved robustness without exceeding real-time ECU constraints.
As shown in Table 30, NMF scoring requires approximately 0.06–0.09 ms per window, corresponding to an amortized per-frame cost of 0.38–0.54
Quantitative comparison with packet-based IDS. To contextualize this design choice, we quantitatively compare the proposed window-based NMF IDS against a conventional packet-based IDS implemented using per-frame CAN ID whitelisting and instantaneous rate thresholds [38,39,51]. From Table 31, it is clear that Packet-level detection achieves very low per-frame cost (0.33–0.35

In contrast, the window-based NMF IDS maintains a comparable amortized per-frame cost (0.38–0.54
Overall, packet-based IDS offer immediate response with minimal computation but are inherently limited to detecting simple rule violations only for known attack patterns. The proposed window-based NMF IDS operates as a standalone detector with comparable computational cost and substantially improved robustness to subtle attacks, making it a practical and complementary alternative for in-vehicle intrusion detection.
Practical Deployment and Update Strategy
Vehicle CAN traffic characteristics may evolve over time due to ECU software updates, hardware changes, or driving-pattern shifts. Therefore, practical deployment of an IDS requires not only a small memory footprint, but also the ability to update or retrain models efficiently as vehicle behavior changes.
The proposed NMF-based IDS separates offline training from on-vehicle inference. All computationally expensive steps—feature extraction from raw logs, NMF factorization, and classifier training—are performed on a backend analysis server. The ECU stores only the final artifacts (the NMF basis
Updating models when new attacks emerge. As new attack traces are collected in the field (e.g., via a central gateway ECU or a fleet-level logging infrastructure), they can be aggregated offline and used to retrain or fine-tune the NMF model and downstream classifiers. Because the deployed artifacts are lightweight (Section 5.14), updates can be delivered OTA by replacing only the NMF basis and classifier parameters.
Handling changes in normal CAN traffic over time. Normal CAN traffic may drift due to ECU software updates or hardware changes. Two mechanisms address this: (i) decision thresholds (e.g., the P99 reconstruction-error or classifier score used to define “attack windows”) can be recalibrated using recent normal windows without modifying the model; and (ii) when distribution shifts exceed a safe margin, the NMF and classifier can be retrained offline on updated normal data and redeployed via an OTA patch.
Integration with existing automotive security frameworks. The NMF-based IDS complements rule-based defences such as ID whitelisting and rate limiting. In a typical in-vehicle security architecture, the module resides on a gateway ECU or security processor, receives time-windowed features from a monitoring component, and outputs anomaly scores or alerts. Rule-based checks handle obvious violations (e.g., unknown IDs or extreme DoS rates), while the NMF-based detector identifies subtle or previously unseen patterns. Alerts can be forwarded to a vehicle security manager or backend analysis system for correlation with other logs. This modular design ensures compatibility with existing automotive security workflows while adding a lightweight, interpretable anomaly-detection layer.
5.15 Limitations & Threats to Validity
The findings of this study are influenced by several constraints related to datasets and evaluations. First, the CHD and OTIDS datasets include only a limited set of attack behaviors. Flooding attacks (DoS, Fuzzy) appear as long continuous intervals, whereas Gear spoofing and RPM spoofing occur only in short bursts. Under the chronological 70–10–20 split used to avoid temporal leakage, these short-lived spoofing attacks yield too few attack-labeled windows for stable cross-attack analysis, restricting quantitative generalization to the DoS–Fuzzy pair. Moreover, the flooding attacks in CHD induce extreme message-rate and payload patterns that make them inherently easier to distinguish from normal traffic than more subtle real-world intrusions; thus, the near-saturated AUC values reported on CHD should be interpreted as optimistic upper bounds rather than typical field performance. This limitation reflects constraints of current public datasets rather than shortcomings of the proposed NMF-based framework. Second, the observed asymmetry in cross-attack generalization (Fuzzy
This paper presented NMF as a lightweight and explainable framework for intrusion detection in automotive CAN bus traffic. In contrast to conventional raw feature-based IDS approaches that tend to overfit dataset artifacts and provide limited interpretability, NMF offers a principled decomposition into additive, non-negative latent components that capture meaningful traffic patterns and remain consistent across models and attack scenarios. Our study systematically evaluated NMF in two roles: as a standalone unsupervised detector based on reconstruction error, and as a feature extractor (NMF–W) for classical classifiers, unsupervised detectors, and deep sequence models. Results demonstrated that NMF-based representations provide competitive detection performance while enhancing robustness and interpretability, positioning NMF as a viable alternative to black-box DL approaches.
Future Work. Guided by the limitations identified in Section 5.15, future work will focus on three concrete directions. First, to better capture short-lived and subtle spoofing behaviors, we plan to investigate NMF variants with limited temporal awareness, such as temporally regularized or sequence-aware NMF formulations that preserve interpretability while incorporating short-range dynamics within windows. Second, to enhance robustness under cross-dataset and cross-vehicle distribution shifts, we will explore lightweight domain-alignment strategies, including component-level normalization, adaptive threshold calibration, and incremental updating of the NMF basis using newly observed normal traffic, without retraining complex downstream models. Third, to bridge the gap between algorithmic interpretability and operational usability, we aim to conduct small-scale expert-in-the-loop evaluations, where automotive security analysts assess whether NMF component activations and basis patterns meaningfully support root-cause analysis, attack triage, and ECU-level diagnostics. Together, these directions provide a concrete and feasible roadmap for strengthening the robustness, practicality, and real-world relevance of NMF-based intrusion detection in automotive networks.
Acknowledgement: Not applicable.
Funding Statement: This work was supported in part by the Basic Science Research Program through the NRF funded by the Ministry of Education under Grant 2021R1A6A1A03039493, and in part by the Regional Innovation System & Education (RISE) program through the Gyeongbuk RISE CENTER, funded by the Ministry of Education (MOE) and the Gyeongsangbuk-do, Republic of Korea (2025-RISE-15-115).
Author Contributions: The authors confirm contribution to the paper as follows: conceptualization, Anandkumar Balasubramaniam and Seung Yeob Nam; methodology, Anandkumar Balasubramaniam and Seung Yeob Nam; software, Anandkumar Balasubramaniam; validation, Anandkumar Balasubramaniam and Seung Yeob Nam; formal analysis, Anandkumar Balasubramaniam; investigation, Anandkumar Balasubramaniam and Seung Yeob Nam; resources, Anandkumar Balasubramaniam; data curation, Anandkumar Balasubramaniam; writing—original draft preparation, Anandkumar Balasubramaniam; writing—review and editing, Anandkumar Balasubramaniam and Seung Yeob Nam; visualization, Anandkumar Balasubramaniam; supervision, Seung Yeob Nam; project administration, Seung Yeob Nam; funding acquisition, Seung Yeob Nam. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The datasets used in this study are publicly available and can be accessed from the HCRL website at https://ocslab.hksecurity.net/Datasets/car-hacking-dataset and https://ocslab.hksecurity.net/Dataset/CAN-intrusion-dataset.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
Supplementary Materials: The supplementary material is available online at https://www.techscience.com/doi/10.32604/cmc.2026.077582/s1.
References
1. Petit J, Shladover SE. Potential cyberattacks on automated vehicles. IEEE Trans Intell Transport Syst. 2014;16(2):546–56. doi:10.1109/tits.2014.2342271. [Google Scholar] [CrossRef]
2. Hoppe T, Kiltz S, Dittmann J. Security threats to automotive CAN networks—practical examples and selected short-term countermeasures. Reliab Eng Syst Saf. 2011;96(1):11–25. doi:10.1016/j.ress.2010.06.026. [Google Scholar] [CrossRef]
3. Studnia I, Nicomette V, Alata E, Deswarte Y, Kaâniche M, Laarouchi Y. Survey on security threats and protection mechanisms in embedded automotive networks. In: Proceedings of the 2013 43rd Annual IEEE/IFIP Conference on Dependable Systems and Networks Workshop (DSN-W); 2013 Jun 24–27; Budapest, Hungary. p. 1–12. doi:10.1109/DSNW.2013.6615528. [Google Scholar] [CrossRef]
4. Müter M, Asaj N. Entropy-based anomaly detection for in-vehicle networks. In: Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV); 2011 Jun 5–9; Baden-Baden, Germany. p. 1110–5. doi:10.1109/IVS.2011.5940552. [Google Scholar] [CrossRef]
5. Miller C, Valasek C. A survey of remote automotive attack surfaces. Las Vegas, NV, USA: Black Hat; 2014. p. 1–94. [Google Scholar]
6. Bécsi T, Aradi S, Gáspár P. Security issues and vulnerabilities in connected car systems. In: Proceedings of the 2015 International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS); 2015 Jun 3–5; Budapest, Hungary. p. 477–82. [Google Scholar]
7. Koscher K, Czeskis A, Roesner F, Patel S, Kohno T, Checkoway S, et al. Experimental security analysis of a modern automobile. In: Proceedings of the 2010 IEEE Symposium on Security and Privacy; 2010 May 16–19; Oakland, CA, USA. p. 447–62. doi:10.1109/SP.2010.34. [Google Scholar] [CrossRef]
8. Taylor A, Japkowicz N, Leblanc S. Frequency-based anomaly detection for the automotive CAN bus. In: Proceedings of the 2015 World Congress on Industrial Control Systems Security (WCICSS); 2015 Dec 14–16; London, UK. p. 45–9. [Google Scholar]
9. Song HM, Woo J, Kim HK. In-vehicle network intrusion detection using deep convolutional neural network. Veh Commun. 2020;21(1):100198. doi:10.1016/j.vehcom.2019.100198. [Google Scholar] [CrossRef]
10. Seo E, Song HM, Kim HK. GIDS: GAN based intrusion detection system for in-vehicle network. In: Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST); 2018 Aug 28–30; Belfast, Ireland. p. 1–6. doi:10.1109/PST.2018.8514157. [Google Scholar] [CrossRef]
11. Marchetti M, Stabili D. READ: reverse engineering of automotive data frames. IEEE Trans Inform Forensic Secur. 2019;14(4):1083–97. doi:10.1109/tifs.2018.2870826. [Google Scholar] [CrossRef]
12. Hanselmann M, Strauss T, Dormann K, Ulmer H. CANet: an unsupervised intrusion detection system for high dimensional CAN bus data. IEEE Access. 2020;8:58194–205. doi:10.1109/ACCESS.2020.2982544. [Google Scholar] [CrossRef]
13. Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. Jair. 2002;16:321–57. doi:10.1613/jair.953. [Google Scholar] [CrossRef]
14. He H, Bai Y, Garcia EA, Li S. ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence); 2008 Jun 1–8; Hong Kong, China. p. 1322–28. doi:10.1109/ijcnn.2008.4633969. [Google Scholar] [CrossRef]
15. Neupane S, Ables J, Anderson W, Mittal S, Rahimi S, Banicescu I, et al. Explainable intrusion detection systems (X-IDSa survey of current methods, challenges, and opportunities. IEEE Access. 2022;10(7):112392–415. doi:10.1109/access.2022.3216617. [Google Scholar] [CrossRef]
16. Moustafa N, Koroniotis N, Keshk M, Zomaya AY, Tari Z. Explainable intrusion detection for cyber defences in the Internet of Things: opportunities and solutions. IEEE Commun Surv Tutor. 2023;25(3):1775–807. doi:10.1109/COMST.2023.3280465. [Google Scholar] [CrossRef]
17. Lee DD, Seung HS. Learning the parts of objects by non-negative matrix factorization. Nature. 1999;401(6755):788–91. doi:10.1038/44565. [Google Scholar] [PubMed] [CrossRef]
18. Lee DD, Seung HS. Algorithms for non-negative matrix factorization. Adv Neural Inf Process Syst. 2001;13:556–62 doi: 10.32614/cran.package.nmfn. [Google Scholar] [CrossRef]
19. Marchetti M, Stabili D. Anomaly detection of CAN bus messages through analysis of ID sequences. In: Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV); 2017 Jun 11–14; Los Angeles, CA, USA. p. 1577–83. doi:10.1109/IVS.2017.7995934. [Google Scholar] [CrossRef]
20. Luo F, Wang J, Zhang X, Jiang Y, Li Z, Luo C. In-vehicle network intrusion detection systems: a systematic survey of deep learning-based approaches. PeerJ Comput Sci. 2023;9:e1648. doi:10.7717/peerj-cs.1648. [Google Scholar] [PubMed] [CrossRef]
21. Kang MJ, Kang JW. Intrusion detection system using deep neural network for in-vehicle network security. PLoS One. 2016;11(6):e0155781. doi:10.1371/journal.pone.0155781. [Google Scholar] [PubMed] [CrossRef]
22. Nair R. Unraveling the decision-making process interpretable deep learning IDS for transportation network security. J Cybersecur Inf Manag. 2023;12(2):69–82. doi:10.54216/jcim.120205. [Google Scholar] [CrossRef]
23. Subasi O, Cree J, Manzano J, Peterson E. A critical assessment of interpretable and explainable machine learning for intrusion detection. arXiv:2407.04009. 2024. [Google Scholar]
24. Abou El Houda Z, Brik B, Khoukhi L. “Why should I trust your IDS?”: an explainable deep learning framework for intrusion detection systems in Internet of Things networks. IEEE Open J Commun Soc. 2022;3:1164–76. doi:10.1109/OJCOMS.2022.3188750. [Google Scholar] [CrossRef]
25. Kukkala VK, Thiruloga SV, Pasricha S. INDRA: intrusion detection using recurrent autoencoders in automotive embedded systems. IEEE Trans Comput Aided Des Integr Circuits Syst. 2020;39(11):3698–710. doi:10.1109/TCAD.2020.3012749. [Google Scholar] [CrossRef]
26. Malar Dhas JP, Isravel DP. Anomaly detection in IoV can bus traffic using variational autoencoder-LSTM with attention mechanism. In: Proceedings of the 2024 International Conference on IoT Based Control Networks and Intelligent Systems (ICICNIS); 2024 Dec 17–18; Bengaluru, India. p. 368–73. doi:10.1109/ICICNIS64247.2024.10823311. [Google Scholar] [CrossRef]
27. Kim T, Kim J, You I. An anomaly detection method based on multiple LSTM-autoencoder models for in-vehicle network. Electronics. 2023;12(17):3543. doi:10.3390/electronics12173543. [Google Scholar] [CrossRef]
28. Sun H, Chen M, Weng J, Liu Z, Geng G. Anomaly detection for in-vehicle network using CNN-LSTM with attention mechanism. IEEE Trans Veh Technol. 2021;70(10):10880–93. doi:10.1109/TVT.2021.3106940. [Google Scholar] [CrossRef]
29. Nguyen TP, Nam H, Kim D. Transformer-based attention network for in-vehicle intrusion detection. IEEE Access. 2023;11:55389–403. doi:10.1109/ACCESS.2023.3282110. [Google Scholar] [CrossRef]
30. Chen A, He Z, Zhang D. An anomaly detection model for CAN networks based on CNN and transformer. In: Proceedings of the IECON 2024–50th Annual Conference of the IEEE Industrial Electronics Society; 2024 Nov 3–6; Chicago, IL, USA. p. 1–6. doi:10.1109/IECON55916.2024.10905930. [Google Scholar] [CrossRef]
31. Jo H, Kim DH. Intrusion detection using transformer in controller area network. IEEE Access. 2024;12:121932–46. doi:10.1109/ACCESS.2024.3452634. [Google Scholar] [CrossRef]
32. Ullah I, Khalil I, Bai X, Garg S, Kaddoum G, Shamim Hossain M. An ensemble-based hybrid model for the detection of attacks in the Internet of vehicular things. IEEE Trans Intell Transp Syst. 2025;26(10):17914–27. doi:10.1109/TITS.2025.3547999. [Google Scholar] [CrossRef]
33. Hernandez-Ramos JL, Karopoulos G, Chatzoglou E, Kouliaridis V, Marmol E, Gonzalez-Vidal A, et al. Intrusion detection based on federated learning: a systematic review. ACM Comput Surv. 2025;57(12):1–65. doi:10.1145/3731596. [Google Scholar] [CrossRef]
34. de Oliveira JA, Gonçalves VP, Meneguette RI, de Sousa RT, Guidoni DL, Oliveira JCM, et al. F-NIDS—a network intrusion detection system based on federated learning. Comput Netw. 2023;236(2):110010. doi:10.1016/j.comnet.2023.110010. [Google Scholar] [CrossRef]
35. Idrissi MJ, Alami H, El Mahdaouy A, El Mekki A, Oualil S, Yartaoui Z, et al. Fed-ANIDS: federated learning for anomaly-based network intrusion detection systems. Expert Syst Appl. 2023;234(1):121000. doi:10.1016/j.eswa.2023.121000. [Google Scholar] [CrossRef]
36. Khatri N, Lee S, Nam SY. Transfer learning-based intrusion detection system for a controller area network. IEEE Access. 2023;11:120963–82. doi:10.1109/ACCESS.2023.3328182. [Google Scholar] [CrossRef]
37. Khandelwal S, Shreejith S. A lightweight FPGA-based IDS-ECU architecture for automotive CAN. In: Proceedings of the 2022 International Conference on Field-Programmable Technology (ICFPT); 2022 Dec 5–9; Hong Kong, China. p. 1–9. doi:10.1109/ICFPT56656.2022.9974508. [Google Scholar] [CrossRef]
38. Müter M, Groll A, Freiling FC. A structured approach to anomaly detection for in-vehicle networks. In: Proceedings of the 2010 Sixth International Conference on Information Assurance and Security; 2010 Aug 23–25; Atlanta, GA, USA. p. 92–8. doi:10.1109/ISIAS.2010.5604050. [Google Scholar] [CrossRef]
39. Taylor A, Leblanc S, Japkowicz N. Anomaly detection in automobile control network data with long short-term memory networks. In: Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA); 2016 Oct 17–19; Montreal, QC, Canada. p. 130–9. doi:10.1109/DSAA.2016.20. [Google Scholar] [CrossRef]
40. Wang W, Guan X, Zhang X. Profiling program and user behaviors for anomaly intrusion detection based on non-negative matrix factorization. In: Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC); 2004 Dec 14–17; Nassau, Bahamas. p. 99–104. doi:10.1109/CDC.2004.1428613. [Google Scholar] [CrossRef]
41. Guan X, Wang W, Zhang X. Fast intrusion detection based on a non-negative matrix factorization model. J Netw Comput Appl. 2009;32(1):31–44. doi:10.1016/j.jnca.2008.04.006. [Google Scholar] [CrossRef]
42. Lefoane M, Ghafir I, Kabir S, Awan IU, El Hindi K, Mahendran A. Non-negative matrix factorization and latent semantic analysis for hybrid feature selection: a proposed machine learning system for the detection of malicious executable files. IEEE Access. 2025;13(4):138867–82. doi:10.1109/ACCESS.2025.3596483. [Google Scholar] [CrossRef]
43. Sulistianingsih N, Martono GH. Feature selection versus feature extraction models for IoT intrusion detection system using convolutional neural network. In: Proceedings of the 2024 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT); 2024 Nov 28–30; Mataram, Indonesia. p. 35–42. doi:10.1109/COMNETSAT63286.2024.10862350. [Google Scholar] [CrossRef]
44. Ma W, Wu Y, Wang S, Gong M. Improved OBS-NMF algorithm for intrusion detection. In: Bio-inspired computing: theories and applications. Singapore: Springer; 2017. p. 596–613. doi:10.1007/978-981-10-7179-9_47. [Google Scholar] [CrossRef]
45. Ahmed I, Hu XB, Acharya MP, Ding Y. Neighborhood structure assisted non-negative matrix factorization and its application in unsupervised point-wise anomaly detection. J Mach Learn Res. 2021;22(34):1–32. [Google Scholar]
46. Yan B, Ma X, Sun Q, Shen L. Physics-enhanced NMF toward anomaly detection in rotating mechanical systems. IEEE Trans Rel. 2025;74(3):3911–25. doi:10.1109/tr.2024.3417262. [Google Scholar] [CrossRef]
47. Wang Y, Zhang Y, Wang L, Hu Y, Yin B. Urban traffic pattern analysis and applications based on spatio-temporal non-negative matrix factorization. IEEE Trans Intell Transp Syst. 2022;23(8):12752–65. doi:10.1109/TITS.2021.3117130. [Google Scholar] [CrossRef]
48. Lee H, Jeong SH, Kim HK. OTIDS: a novel intrusion detection system for in-vehicle network by using remote frame. In: Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST); 2017 Aug 28–30; Calgary, AB, Canada. doi:10.1109/PST.2017.00017. [Google Scholar] [CrossRef]
49. Berry MW, Browne M, Langville AN, Pauca VP, Plemmons RJ. Algorithms and applications for approximate nonnegative matrix factorization. Comput Stat Data Anal. 2007;52(1):155–73. doi:10.1016/j.csda.2006.11.006. [Google Scholar] [CrossRef]
50. Hsieh CJ, Dhillon IS. Fast coordinate descent methods with variable selection for non-negative matrix factorization. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, CA, USA: ACM; 2011. p. 1064–72. doi:10.1145/2020408.2020577. [Google Scholar] [CrossRef]
51. Young C, Zambreno J, Olufowobi H, Bloom G. Survey of automotive controller area network intrusion detection systems. IEEE Des Test. 2019;36(6):48–55. doi:10.1109/MDAT.2019.2899062. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools