
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Multi-Agent Large Language Model-Based Decision Tree Analysis for Explainable Electric Vehicle Drive Motor Fault Diagnosis
1 School of Electrical Engineering, Korea University, Seoul, Republic of Korea
2 Department of Data Science, Duksung Women’s University, Seoul, Republic of Korea
* Corresponding Author: Jehyeok Rew. Email:
Computers, Materials & Continua 2026, 87(3), 100 https://doi.org/10.32604/cmc.2026.077691
Received 15 December 2025; Accepted 12 March 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The accelerating transition toward electrified mobility has positioned electric vehicles (EVs) as a primary technology in modern transportation systems. In this context, ensuring the reliability of EV drive motors (EVDMs) becomes increasingly critical, given their central role in propulsion performance and operational safety. Accurate and interpretable fault diagnosis of EVDMs is therefore essential for enabling effective maintenance and supporting the broader sustainability and resilience of EVs. This study presents a novel framework that combines decision tree-based fault classification with a multi-agent large language model (LLM) interpretation architecture to deliver transparent and human-readable diagnostic explanations. The proposed framework integrates domain-specific decision rules derived from sensor measurements and utilizes specialized LLM agents to translate tree-based decision logic into coherent narratives. The multi-agent architecture decomposes complex diagnostic reasoning into modular subtasks, allowing for enhanced interpretability and facilitating practical understanding for vehicle engineers. Experimental results on a publicly available EVDM dataset demonstrate that the proposed framework maintains high classification accuracy while significantly improving explanation quality and trustworthiness relative to conventional rule-based and single-agent approaches. By coupling symbolic decision models with LLM-driven reasoning, this work contributes to the advancement of trustworthy artificial intelligence for energy and mobility systems, particularly in predictive maintenance and explainable fault diagnosis. The findings highlight the value of integrating classical machine learning with multi-agent LLMs to support reliable, transparent, and human-centered EV infrastructures.Keywords
Abbreviations
| API | Application programming interface |
| EV | Electric vehicle |
| EVDM | Electric vehicle drive motor |
| Grad-CAM | Gradient-weighted class activation mapping |
| JSON | Javascript object notation |
| KG | Knowledge graph |
| LIME | Local interpretable model-agnostic explanations |
| LLM | Large language model |
| ML | Machine learning |
| NOM | Normal operation |
| OLF | Overload fault |
| OVF | Overvoltage fault |
| PTGF | Phase-to-ground fault |
| PTPF | Phase-to-phase fault |
| SD | Standarad deviation |
| SHAP | Shapley additive explanations |
| UVF | Undervoltage fault |
| VOBC | Vehicle on-board controller |
| XAI | Explainable artificial intelligence |
In recent years, the global automotive industry has undergone a significant transition driven by environmental sustainability concerns and the depletion of fossil fuels [1]. As a result, electric vehicles (EVs) have emerged as a promising alternative to conventional internal combustion engine vehicles. This transformation is not only reshaping transportation systems but also catalyzing advancements in the design, monitoring, and control of core EV components such as drive motors, batteries, and power electronics [2].
Among the critical components of EVs, the EV drive motors (EVDMs) play a vital role in vehicle propulsion by converting electrical energy into mechanical torque [3]. The performance of EVs is directly governed by the operational health of EVDMs. However, due to their continuous operation under varying thermal, mechanical, and electrical stresses, EVDMs are susceptible to various types of faults, including phase-to-phase short circuits, insulation failures, and overloading [4]. When faults in the EVDMs remain undetected or are identified too late, they can lead to performance degradation and system-level failures. These issues not only compromise vehicle safety but also result in substantial maintenance costs and operational downtime. Therefore, developing intelligent and robust fault diagnosis systems for EVDMs is essential, particularly as the scale and complexity of EV deployment continue to grow [5].
Conventional fault diagnosis approaches for EVDMs have relied heavily on rule-based methods that utilize predefined thresholds, expert knowledge, and deterministic logic [3]. While these methods are simple to implement and interpret, they suffer from limited adaptability under complex operating conditions and unforeseen fault scenarios. Furthermore, they require extensive manual tuning and often fail to generalize across different motor types or operational environments.
To address these limitations, recent studies have increasingly employed machine learning (ML)-based techniques [6,7]. These models have demonstrated high diagnostic accuracy and the capability to detect subtle or incipient faults that are difficult to capture using conventional rule-based systems [8]. Despite their performance advantages, most ML models operate as ‘black box’ models. Their internal decision-making processes are opaque, making it challenging for vehicle engineers to trust or validate the predictions in safety-critical applications. This lack of interpretability poses a significant barrier to the widespread adoption of ML-based diagnostic models in industrial EV settings, where transparency and explainability are crucial for regulatory compliance, model validation, and real-time decision-making [9].
In response to the interpretability challenges of black-box models, various explainable artificial intelligence (XAI) techniques have been proposed [10], including Shapley additive explanations (SHAP) [11] and local interpretable model-agnostic explanations (LIME) [12]. These techniques aim to provide post-hoc explanations by quantifying the contribution of each input feature to a specific prediction [13,14]. Although such model-agnostic approaches have gained attention for their flexibility, they inherently operate as indirect interpretative tools that approximate, rather than reveal, the model’s internal decision logic [15]. As a result, discrepancies may arise between the surrogate interpretation and the true reasoning process of the original model, particularly when nonlinear dependencies or complex feature interactions are involved.
In contrast, decision tree provides inherent interpretability, as their structure naturally encodes a sequence of logical rules that lead to a decision [16]. Unlike post-hoc methods, the decision-making process in a decision tree can be directly traced from root to leaf, allowing vehicle engineers to precisely observe how input features influence the final outcome. Moreover, the hierarchical structure of decision trees facilitates an intuitive understanding of feature importance, decision thresholds, and classification boundaries.
However, interpreting complex decision trees still requires considerable human effort. Vehicle engineers must manually trace decision paths and analyze multiple branching conditions to extract diagnostic insights, which can be both labor-intensive and cognitively demanding, especially when the tree is large or the rules are highly domain-specific. Furthermore, while the structure of decision trees is transparent, their interpretations often lack contextualization in terms of confidence estimation, causal inference, and practical recommendations, factors that are crucial for high-stakes domains such as EVDM fault diagnosis.
Recently, large language models (LLMs) have emerged as powerful tools capable of complex reasoning across diverse domains [17]. Owing to their ability to process structured inputs, capture logical relationships, and generate coherent textual outputs, LLMs are increasingly being explored as autonomous agents within multi-step analytical pipelines. This paradigm, known as the multi-agent LLM approach, enables the decomposition of complex problems into modular subtasks handled by specialized reasoning agents [18]. In the context of XAI, such LLM agent architecture provides strong potential for automating interpretive tasks that would otherwise require considerable human expertise and manual effort.
In this paper, we propose a novel framework that leverages multi-agent LLMs to automate the interpretation of decision tree-based classification models for EVDM fault diagnosis. The proposed framework decomposes the interpretation task into a structured pipeline of specialized LLM agents, each designed to a specific reasoning function. These agents collaboratively interpret decision paths, translate numerical thresholds into domain-relevant expressions, and analyze counterfactual scenarios. They further ensure consistency between local and global reasoning, generate structured diagnostic reports, and verify factual accuracy. This enables a high degree of automation and interpretability across diverse diagnosis contexts.
The main contributions of this paper are summarized as follows:
1. We propose a novel multi-agent LLM-based interpretive framework that explains decision tree-based fault diagnosis models for EVDMs by integrating structural parsing, logic extraction, uncertainty reasoning, and generating domain-level explanations.
2. We design prompt-driven reasoning agents that decompose the model’s decision-making logic into interpretable and verifiable narratives, thereby enhancing transparency and usability for domain practitioners such as vehicle engineers and technicians.
3. We validate the proposed framework on a publicly available EVDM fault classification dataset, demonstrating its ability to generate coherent, faithful, and context-aware explanations.
The remainder of this paper is organized as follows. Section 2 reviews related works on EVDM fault diagnosis, XAI, and LLM-based agents. Section 3 presents the architecture of the proposed framework. Section 4 describes dataset, experimental setup, and evaluation metrics. Section 5 reports the experimental results, and Section 6 provides a detailed discussion of the findings. Finally, Section 7 concludes the paper and outlines directions for future research.
2.1 Electric Vehicle Drive Motor Fault Diagnosis Using Machine Learning
With the increasing adoption of EVs, ensuring the reliability and safety of EVDMs has become a critical concern for both manufacturers and researchers. ML models have shown outstanding performance for enabling automated and accurate fault diagnosis by learning patterns from large-scale sensor datasets [19,20]. Recent studies have explored various ML-based approaches for detecting and classifying a wide range of EVDM faults under diverse operating conditions, outperforming conventional rule-based methods in both flexibility and diagnostic performance.
Thirunavukkarasu et al. [5] proposed an ML-based fault classification method for EVDMs under six operating conditions. Using advanced data transformations including Yeo–Johnson and Hyperbolic Sine, and evaluating multiple classifiers, they found that CatBoost achieved the highest accuracy. Xu et al. [21] proposed a deep learning-based fault diagnosis method for EVDMs using thermographic images and Inception V3 model. By integrating a Squeeze-and-Excitation attention mechanism and applying contrast-limited adaptive histogram equalization for contrast enhancement, their approach achieved high accuracy across 11 fault types. Dettinger et al. [9] presented a digital twin-based fault detection method for EV powertrains, deployed at the edge and connected via 5G. Using a 1-Nearest Neighbor algorithm trained on synthetic simulation data, the method enabled real-time detection and mitigation of faults such as demagnetization and switch failures.
Despite their high diagnostic accuracy, most ML models operate as black-box systems, providing limited insight into their internal reasoning processes. This lack of interpretability poses a significant limitation for safety-critical applications, where understanding the rationale behind a model’s prediction is as important as the prediction itself.
2.2 Fault Diagnosis Using Explainable Artificial Intelligence
With the increasing complexity of ML models used for fault diagnosis, the lack of interpretability has emerged as a critical barrier to adoption in safety-critical domains such as EV systems. XAI techniques have been introduced to address this limitation by providing insights into the internal reasoning processes of predictive models [22]. Recent studies have explored various XAI methods, such as SHAP, LIME, and gradient-weighted class activation mapping (Grad-CAM), integrated into ML and deep learning models to improve fault attribution and interpret model decisions in both time-series and image-based diagnostic applications [14,23].
Haque et al. [3] proposed EnsembleXAI-Motor, a lightweight and interpretable framework for EVDM fault diagnosis. Their approach combined recursive feature elimination, ensemble learning, and LIME to achieve high diagnostic performance with minimal computational overhead. The model demonstrated generalizability across the EVDM dataset, while providing transparent explanations for its predictions. Jang et al. [24] proposed a fault diagnosis framework that integrates an adversarial autoencoder with SHAP values to enhance the interpretability of deep learning-based fault detection in industrial processes. Unlike conventional methods which rely solely on reconstruction error, their approach leverages both latent and reconstruction spaces, enabling more accurate fault attribution and deeper insight into variable contributions. Brito et al. [25] proposed FaultD-XAI, an interpretable fault diagnosis framework for rotating machinery that combines transfer learning from augmented synthetic data with Grad-CAM-based explainability. Their method used a 1-dimensional convolutional neural network to classify vibration signals and leveraged Grad-CAM to visually highlight influential signal regions, thereby increasing trust in model predictions.
While existing XAI techniques have enhanced model transparency through visual explanations such as feature importance plots and activation maps, they rely heavily on manual interpretation. Vehicle engineers need to manually analyze graphical outputs to derive meaningful insights, which can be cognitively demanding and prone to subjective bias. This highlights the need for more autonomous and semantically rich explanation methods that can translate visual information into human-interpretable textual insights.
2.3 Large Language Model-Based Agent
LLMs have rapidly evolved from passive information processors to autonomous agents capable of engaging in reasoning and decision-making [26]. LLM-based agents can dynamically interpret instructions and adapt their behavior using natural language [27]. These agents are increasingly being adopted in multi-step analytical pipelines, where each agent performs a specialized role within a large problem.
Holland and Chaudhari [28] demonstrated the practical application of LLM-based agents in industrial process planning for fiber composite structures. By integrating OpenAI GPT-4 with LangChain, they developed an autonomous agent capable of performing key planning tasks such as cycle time estimation and resource allocation. Peng et al. [29] proposed an adaptive LLM-based fault diagnosis framework for railway vehicle on-board controllers (VOBC) to address the limited suitability of general-purpose LLMs in railway-specific scenarios. Their method, named RFD-LLM, leverages low-rank adaptation and instruction tuning to align the model with VOBC fault patterns, achieving accurate identification of seven fault types. This work demonstrates the potential of domain-adapted LLMs as diagnostic agents in safety-critical railway systems. Lukens et al. [30] investigated the use of LLM-based agents as human-in-the-loop copilots for prognostics and health management tasks. Motivated by labor shortages and the need to preserve domain expertise, their framework integrated LLM-based agents into standard maintenance workflows to assist in data processing, failure-mode identification, and maintenance-recommendation generation.
Building on these developments, our study explores the use of multi-agent LLM systems to enhance the interpretability of safety-critical diagnostic models, in particular decision tree classifiers for EVDM fault diagnosis. In contrast to prior applications that primarily focused on task automation, we design modular agent architectures tailored specifically for explaining model behavior at multiple reasoning levels. To clarify the methodological differences and design motivations, Table 1 provides a qualitative comparison between post-hoc XAI methods, intrinsic tree-based explanations, and the proposed multi-agent LLM-based explanation framework for EVDM fault diagnosis.
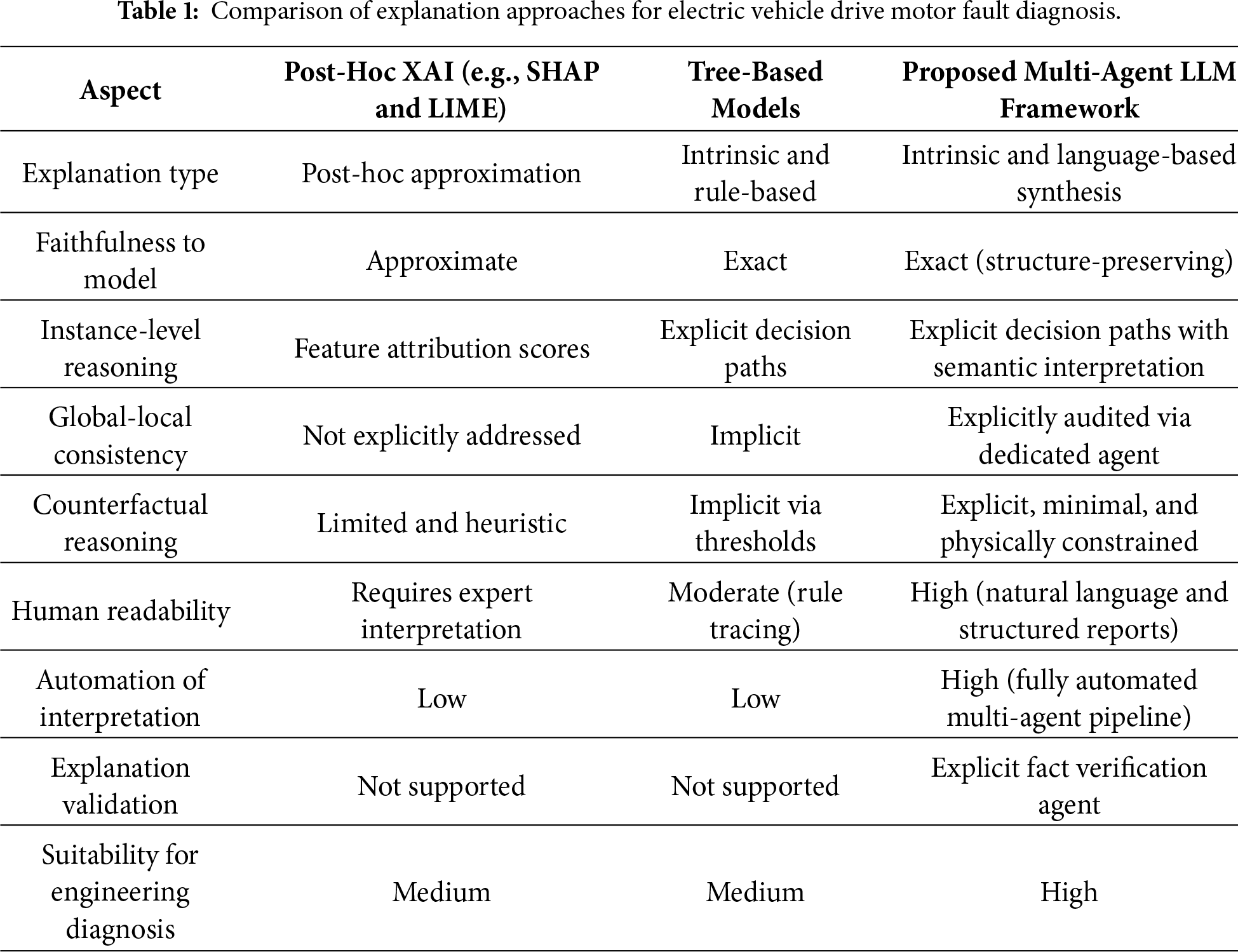
This section describes the overall structure of the proposed framework. Fig. 1 presents overview of the proposed framework.
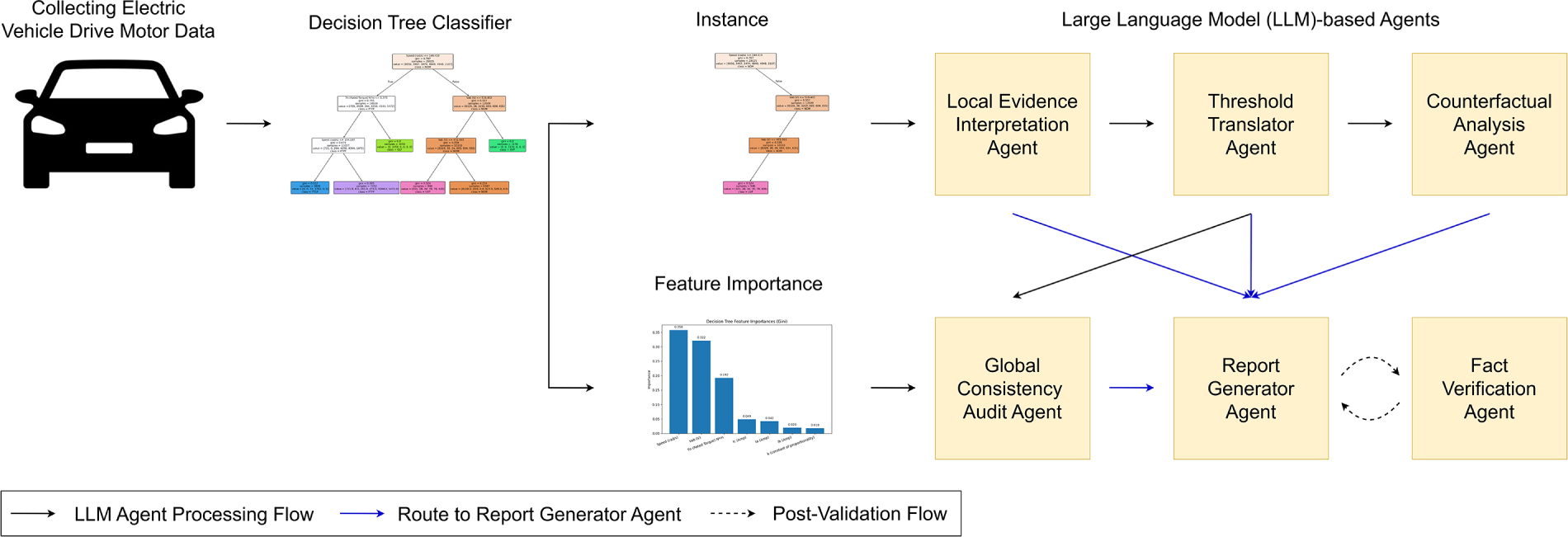
Figure 1: Overview of the proposed framework.
3.1 Electric Vehicle Drive Motor Fault Diagnosis Using Decision Tree
In this study, we employ a decision tree-based classification model to diagnose fault types in EVDMs. Fig. 2 describes the structure of the decision tree. The decision tree algorithm is well-suited for this task due to its hierarchical and rule-based decision-making structure [31]. Each prediction is derived from a sequence of conditional statements that trace a unique path from the root node to leaf node, thereby enabling transparent and interpretable reasoning. This property makes decision trees highly valuable in safety-critical domains, where understanding the decision rationale is as important as the prediction accuracy.
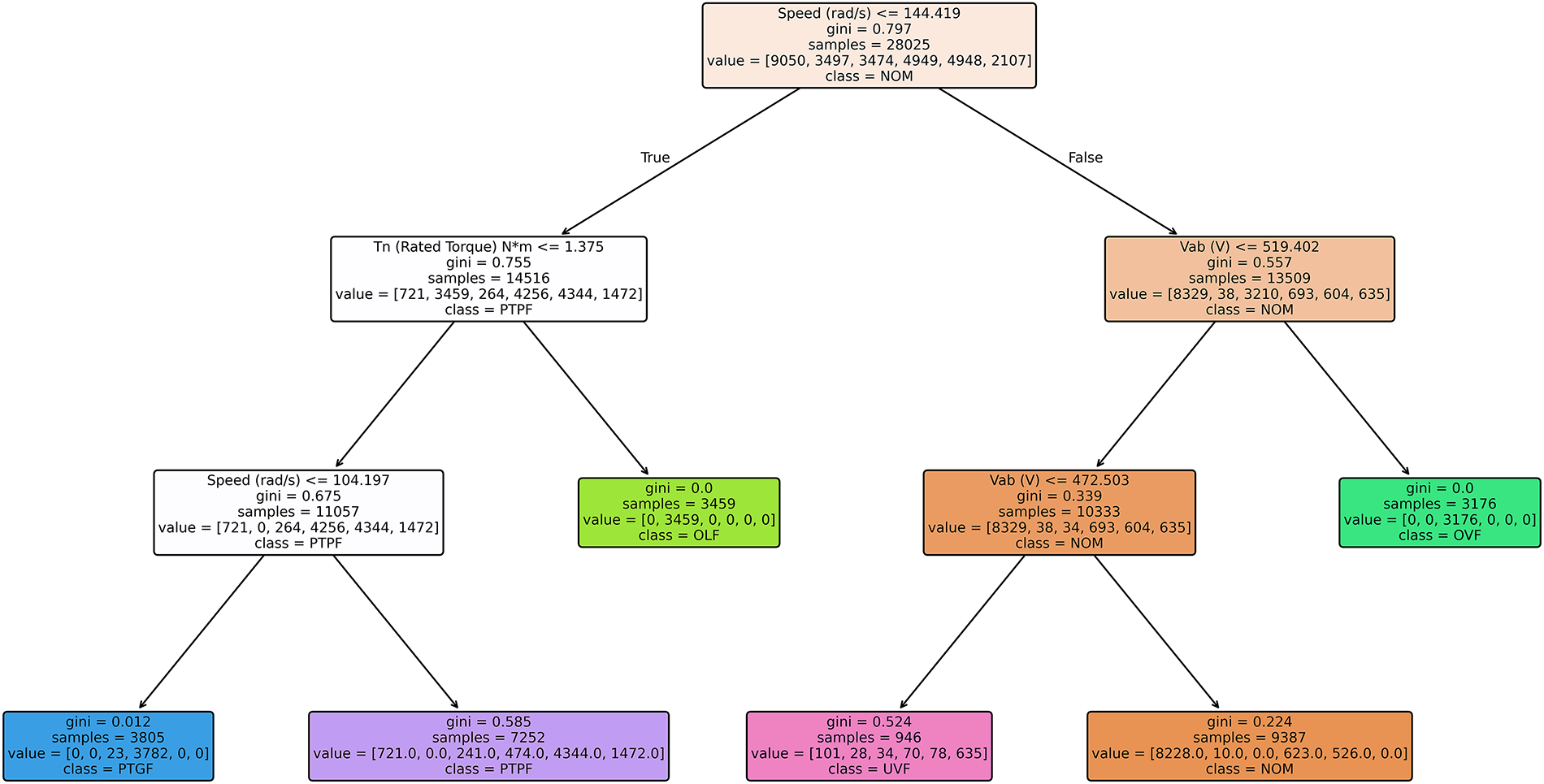
Figure 2: Visualization of the decision tree structure.
To optimize predictive performance while maintaining practical interpretability, hyperparameter tuning was conducted using the training and validation sets derived from the predefined train-validation-test split [32]. Among the tunable parameters, the maximum tree depth plays a central role, as it determines not only the expressive capacity of the classifier but also the structural complexity of the resulting decision paths.
While decision trees are inherently interpretable in a formal sense, increasing tree depth lengthens root-to-leaf decision paths and increases the number of conditional splits involved in each prediction [33]. This growth in structural complexity does not primarily impose a computation burden, given the lightweight nature of decision trees, but instead affects interpretability at the cognitive and explanatory levels. Deep trees yield highly fragmented decision logic with long rule chains, which can hinder human comprehension and reduce the stability and clarity of downstream LLM-based explanation generation.
Conversely, overly shallow trees tend to underfit the data, producing coarse decision boundaries that fail to capture subtle distinctions among fault types, thereby limiting both diagnostic accuracy and explanatory usefulness. The selected tree depth therefore reflects a balance between sufficient model expressiveness for reliable fault discrimination and a constrained decision structure that remains tractable for human interpretation and multi-agent LLM reasoning.
During the tuning process, candidate depths ranging from 3 to 12 are evaluated, and the optimal configuration is selected based on the macro-averaged f1-score on the validation set. The final decision tree achieves a strong balance between classification performance and structural simplicity, maintaining a compact hierarchy of decision rules. This structure serves as the analytical foundation for the subsequent multi-agent LLM-based interpretation framework, where specialized LLM agents systematically analyze, summarize, and contextualize the decision paths to generate human-readable diagnostic explanations.
3.2 Multi-Agent Large Language Model-Based Interpretation Framework
To automate and structure the interpretation of decision tree-based classification models for EVDM fault diagnosis, we propose a multi-agent LLM-based framework composed of six specialized agents. Each agent performs a distinct cognitive function to collectively derive a transparent and human-interpretable understanding of the model’s decision process. Table 2 describes the overall structure of the proposed framework. The following subsections describe the functionality and reasoning flow of each agent in detail. Due to the length, prompt templates used to guide each agent are provided in Appendix A.
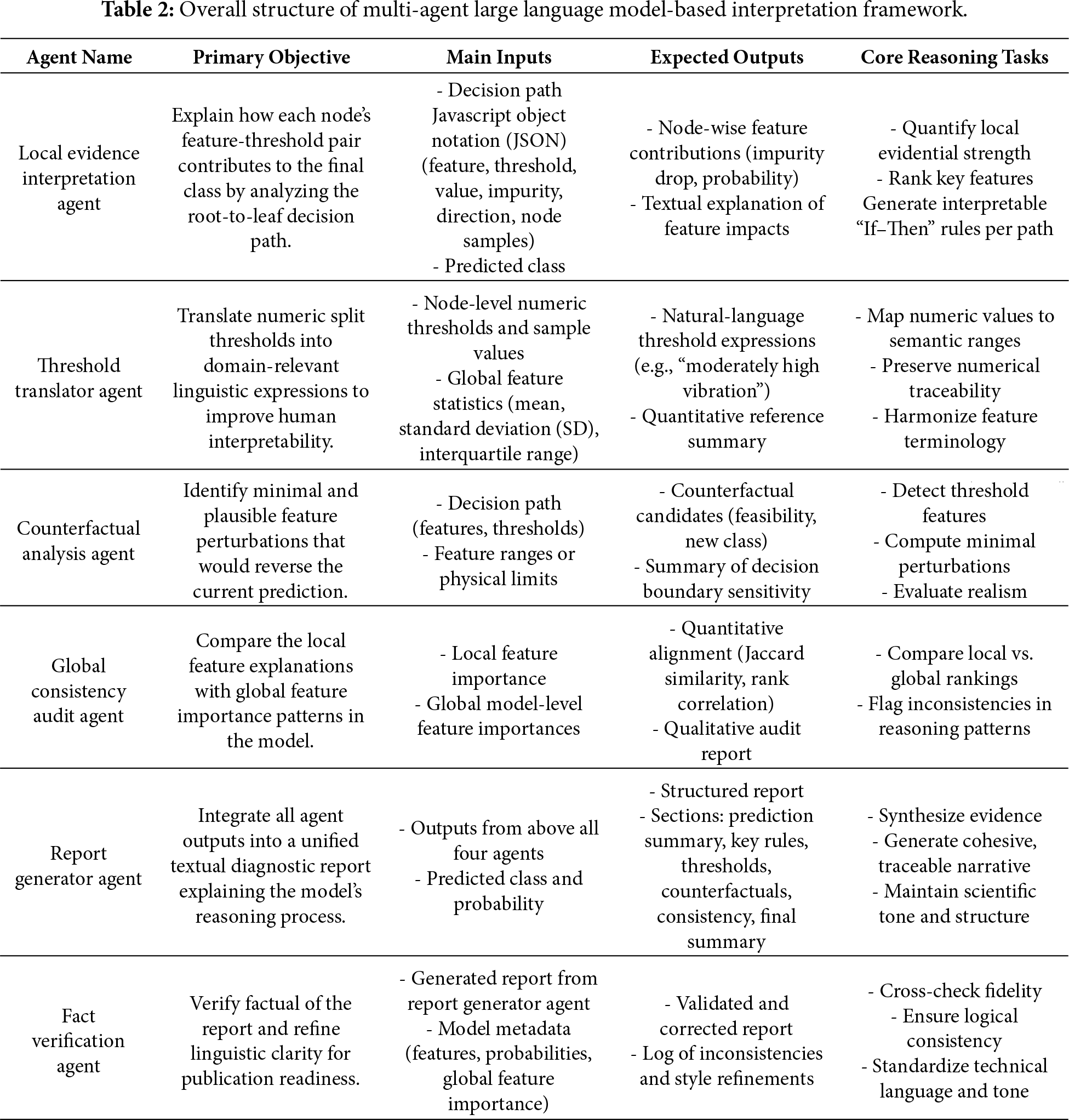
3.2.1 Local Evidence Interpretation Agent
The local evidence interpretation agent is designed to explicitly reconstruct the instance-specific reasoning process embedded in the decision tree, serving as the foundational interpretability layer of the proposed framework. Unlike conventional post-hoc explanation methods that approximate model behavior through feature attribution scores, this agent operates directly on the symbolic structure of the trained decision tree, ensuring faithful and traceable explanations.
Given the root-to-leaf decision path of a specific sample, the agent analyzes each decision node to determine how the observed feature value satisfies or violates the corresponding split condition. For every node along the path, it quantitatively measures both the impurity reduction and the associated shift in class probability. This dual analysis enables the agent to capture not only which features contribute to the prediction, but how and when they influence the decision during the hierarchical reasoning process.
A key motivation for this agent is to decouple model-intrinsic causal evidence from downstream interpretive tasks such as domain contextualization or counterfactual reasoning. The local evidence interpretation agent intentionally focuses on explaining what the model used to reach its decision, without introducing domain semantics or speculative interpretations. This separation ensures that subsequent agents operate on a stable explanation backbone rather than aggregated importance measures.
Each decision node is translated into a human-readable ‘If-Then’ rule, and these rules are ranked according to a composite evidential score combining impurity decrease and probability gain. The resulting ordered rule set provides a transparent and structured account of the decision tree’s internal logic, forming a standardized intermediate representation that is reused by all subsequent agents in the pipeline. In this way, the local evidence interpretation agent contributes not merely as an engineering aid, but as a structural explanation engine that anchors the entire multi-agent interpretability framework.
3.2.2 Threshold Translator Agent
The threshold translator agent transforms numeric split thresholds of the decision tree into distribution-aware and domain-aligned semantic descriptions, thereby addressing a key gap between model-internal decision logic and human diagnostic reasoning. Rather than performing a superficial numeric-to-text conversion, this agent interprets each threshold relative to the empirical distribution of the corresponding feature, enabling consistent and context-sensitive explanations across operating regimes.
The agent takes as input the node-level outputs generated by the local evidence interpretation agent in Section 3.2.1, including feature identities, threshold values, and instance-specific measurements. For each split condition, it evaluates the position of the sample value and threshold within the global feature distribution using summary statistics such as the mean, SD, and interquartile range. Based on this comparison, the agent maps numeric boundaries to percentile-informed semantic categories (e.g., low, medium, and high), ensuring that linguistic descriptions reflect the data-driven context in which the model operates.
To avoid conflating model-internal causality with semantic interpretation, this agent decouples structural causality from semantic contextualization. While the local evidence interpretation agent explains which rules were applied, the threshold translator agent explains what those rules imply in terms of physical or operational conditions. This separation prevents premature domain interpretation from contaminating model-faithful explanations, while still enabling downstream agents to reason in a human-centered manner.
Each semantic description is paired with its original numeric threshold and sample value, preserving traceability to the underlying model logic. By providing standardized and distribution-aware linguistic anchors, the threshold translator agent supports subsequent agents, and ensures that explanations remain interpretable and consistent across different instances and diagnostic contexts. In this way, the agent contributes not merely to readability, but to the semantic robustness and cross-agent coherence of the overall multi-agent interpretation framework.
3.2.3 Counterfactual Analysis Agent
The counterfactual analysis agent analyzes the local decision stability of the trained decision tree by identifying minimal and physically plausible perturbations that would alter the model’s predicted fault class. Rather than generating generic ‘What-If’ explanations, this agent operates directly on the decision tree’s branching structure to reveal how sensitive a specific prediction is to changes in individual features.
The agent receives as input the interpreted decision path and semantically contextualized threshold information generated by the threshold translator agent in Section 3.2.2. For each decision node along the path, it evaluates how close the instance lies to the corresponding split boundary and systematically explores alternative routing scenarios by modifying one feature at a time near its critical threshold. This process identifies the smallest directional change required to redirect the instance to a different leaf node associated with an alternative fault class.
The inclusion of this agent reflects a deliberate architectural decision to separate causal explanation from decision robustness analysis. While preceding agents explain why a prediction was made, the counterfactual analysis agent explains how easily it could change. Each counterfactual scenario is evaluated under physical feasibility constraints derived from EVDM operational limits, ensuring that suggested perturbations correspond to realizable system states rather than abstract mathematical artifacts.
For each valid counterfactual, the agent reports the magnitude and direction of the required feature change, along with the expected class transition. These scenarios are ranked according to minimality and interpretability, prioritizing changes that are both actionable and diagnostically meaningful. By exposing the local decision boundaries of the model, the counterfactual analysis agent provides insights into fault sensitivity and design confidence, thereby extending interpretability beyond static explanations to include dynamic decision behavior.
3.2.4 Global Consistency Audit Agent
The global consistency audit agent assesses the reliability and representativeness of instance-level explanations by examining their alignment with the model’s global decision behavior. While local explanation agents reveal how a specific prediction was produced, they do not indicate whether the resulting reasoning pattern is consistent with the dominant mechanisms learned by the model. This agent addresses the gap by performing a meta-level interpretability audit.
The agent takes as input the locally salient features identified along the decision path, together with global feature importance profiles extracted from the trained decision tree. It quantitatively evaluates consistency using ranking-based metrics, such as overlap ratios and rank correlation, to determine the degree to which features emphasized locally also play a significant role in the model’s overall fault discrimination strategy.
Beyond numerical comparison, the agent performs a qualitative assessment to interpret the nature of any detected discrepancy. Rather than treating all mismatches as errors, it distinguishes between fault-specific local specializations and potentially unreliable explanations driven by low-support branches. When inconsistencies arise, the agent annotates them with interpretive notes, signaling to vehicle engineers that the explanation may reflect localized behavior not representative of the model’s global logic.
By auditing coherence between local fidelity and global interpretability, the global consistency audit agent strengthens trust in the explanatory pipeline and prevents overreliance on locally persuasive but globally unrepresentative reasoning patterns. This step elevates the framework from providing descriptive explanations to delivering validated and confidence-aware interpretability for EVDM fault diagnosis.
The report generator agent performs interpretive synthesis and structural alignment of the heterogeneous outputs generated by the preceding agents in Sections 3.2.1–3.2.4. While earlier agents generate complementary but fragmented explanations, covering local causality, semantic contextualization, decision boundary sensitivity, and global consistency, these outputs should be coherently integrated to support reliable human understanding and decision-making.
The agent organizes the final diagnostic report according to a standardized explanation schema, consisting of: (1) a summary of the predicted fault class and its probability, (2) key decision rules with their respective feature contributions, (3) translated threshold interpretations, (4) counterfactual insights describing boundary conditions, (5) a consistency statement referencing the model’s global importance profile and (6) a final summary of the report. Each section is linked to its underlying numerical evidence, ensuring traceability between the textual explanation and the decision tree’s internal computations.
A key motivation for this agent is to decouple explanation generation from explanation synthesis. Rather than merely concatenating outputs, the report generator agent resolves potential redundancies or emphasis conflicts across agents, prioritizes diagnostically salient evidence, and ensures logical coherence across explanation layers. This process standardizes explanation structure across instances, improving comparability, reproducibility, and interpretive clarity.
By transforming distributed reasoning artifacts into a unified and validated narrative, the report generator agent elevates the framework beyond fragmented explanation delivery. It enables vehicle engineers to systematically understand not only what the model predicted, but how multiple strands of evidence jointly support that conclusion, thereby facilitating informed and trustworthy decision-making in EVDM fault diagnosis.
The fact verification agent is introduced as a model-faithfulness enforcement mechanism that ensures the integrity of the final diagnostic explanation generated by the proposed framework. While preceding agents focus on generating, contextualizing, auditing, and synthesizing explanations, the explicit enforcement of numerical and logical consistency with the underlying decision tree computations is not addressed at earlier stages. This agent is designed to fill the gap.
The agent validates every quantitative statement in the final report by cross-referencing it against the original model artifacts, including impurity reductions, class probabilities, threshold values, and counterfactual perturbations. By checking that all reported figures correspond exactly to the decision tree’s internal statistics, the agent prevents subtle numerical drift and cumulative inconsistencies that can arise from multi-stage LLM-based reasoning.
Beyond numerical verification, the agent performs explanation-level consistency checks to ensure that linguistic claims do not exceed what is supported by the model structure or data distribution. Rather than introducing new interpretations, it constrains the explanation space by removing unsupported assertions, harmonizing technical terminology, and standardizing phrasing across sections. When uncertainty or limited evidential support is detected, the agent annotates the corresponding statements with confidence indicators, signaling potential reliability limitations to human users.
The motivation for this agent lies in separating interpretation generation from interpretation validation. By acting as a final anchoring stage that rebinds natural language explanations to model-grounded evidence, the fact verification agent enhances explanation credibility, reproducibility, and deployment readiness. This final verification step ensures that the proposed framework delivers explanations that are not only interpretable, but also faithful, auditable, and trustworthy for EVDM fault diagnosis.
To evaluate the effectiveness of the proposed framework, we utilize the publicly available EVDM dataset that encompasses various operating and fault conditions of a three-phase induction motor [34]. The dataset comprises time-series measurements of electrical, mechanical, and control variables. It is formatted as a tabular dataset for classification purposes.
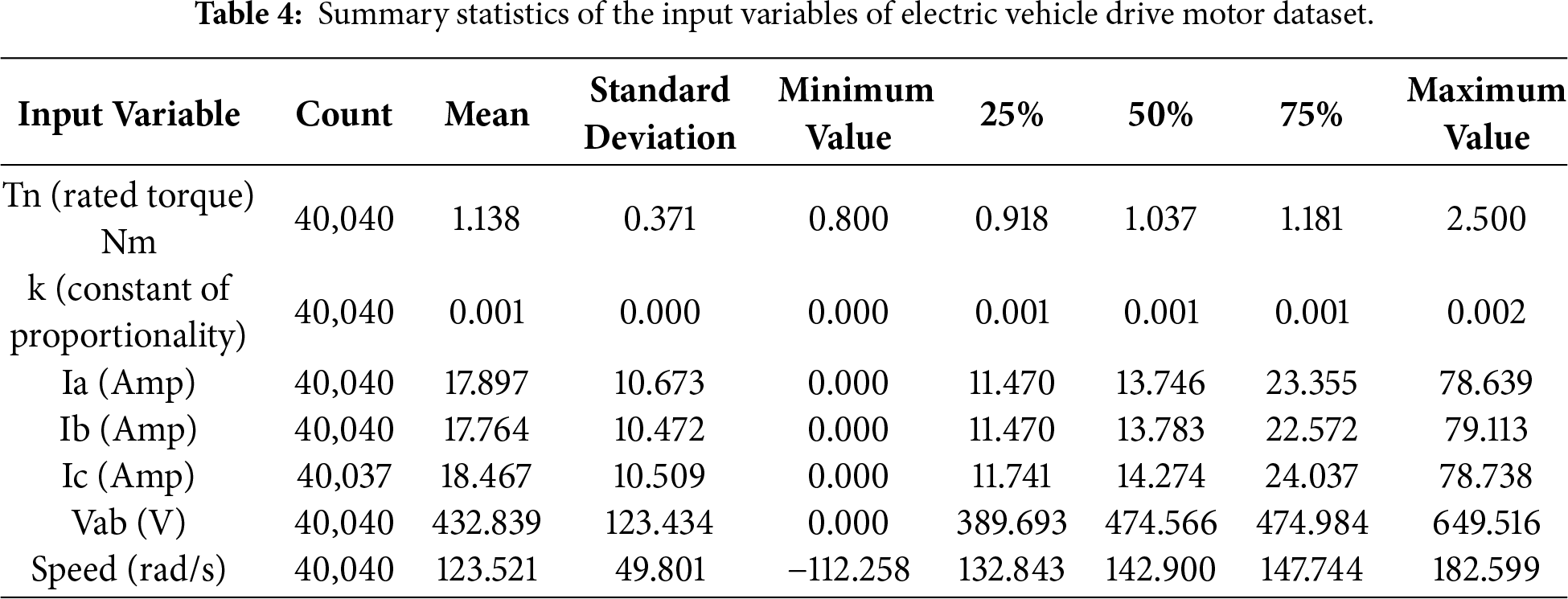
As shown in Table 3, the dataset includes seven input variables, which represent a combination of physical measurements and control parameters. Electrical quantities contain the three-phase currents Ia (Amp), Ib (Amp), Ic (Amp), and the line voltage Vab (V), alongside mechanical feature such as rotational speed. Control parameters, including the Tn (rated torque) Nm and k (constant of proportionality), are also included. All input variables are continuous. Table 4 presents the summary statistics for the input variables of the dataset. It is noted that three missing values were identified in the Ic (Amp). Therefore, the corresponding records were removed, resulting in a total of 40,037 valid samples being used for subsequent analysis.

The output variable is a categorical label that indicates the fault status of the motor. As summarized in Table 5, the dataset contains six classes: one representing normal operation (NOM) and five representing distinct fault types, including phase-to-phase fault (PTPF), phase-to-ground fault (PTGF), overvoltage fault (OVF), overload fault (OLF), and undervoltage fault (UVF).
The performance of the proposed framework was evaluated in two stages: the training and selection of the base classification model, and explanation generation using a multi-agent LLM pipeline.
For the classification model, we employ a decision tree classifier [16] implemented with the scikit-learn library [35]. To balance predictive performance with interpretability, hyperparameter tuning was conducted on the maximum tree depth, which directly controls the complexity of the decision structure and the number of rule branches. The dataset was partitioned into training, validation, and test sets with a 70:10:20 ratio. The training and validation sets were used to perform a grid search over the maximum depth parameter, ranging from 3 to 12 in increments of 1. For each candidate depth, the model was trained on the training set and evaluated on the validation set using the macro-average F1-score. The configuration achieving the best validation performance was selected, and the final model was evaluated on the test set.
For the interpretation phase, all agents in the proposed framework are powered by OpenAI GPT-5, accessed via the official OpenAI application programming interface (API) [36]. Each agent operates with a role-specific system prompt and receives structured inputs derived from the trained decision tree, including decision paths, feature thresholds, impurity values, and class probability distributions. To ensure stable and reproducible outputs, deterministic decoding was employed with the temperature fixed at 0.2 and stochastic sampling disabled. The agent outputs were constrained to structured formats such as JSON and tabular representations, enabling downstream aggregation, verification, and evaluation.
The agents are executed sequentially in a fixed pipeline without shared hidden states, ensuring modularity, traceability, and reproducibility of the interpretation process. This design allows each agent to focus on a clearly defined reasoning task while maintaining transparent links between the generated explanations and the underlying model computations.
To assess both the performance of the decision tree classifier and the effectiveness of the proposed framework, we use a combination of quantitative and qualitative evaluation metrics.
For the classification task, we employ four standard metrics commonly used in multi-class fault diagnosis: precision, recall, F1-score, and accuracy [37]. Precision indicates the ratio of correctly predicted positive samples to all instances predicted as positive by the model. Recall reflects the model’s capability to capture actual positive samples among all true positives. The F1-score, defined as the harmonic mean of precision and recall, serves as a balanced indicator when both measures are of equal importance. Accuracy expresses the proportion of correctly identified samples relative to the total number of observations. The mathematical formulations of these metrics are given in Eqs. (1)–(4).
To comprehensively evaluate the interpretability of the proposed framework, we adopt a hybrid qualitative evaluation approach that integrates both LLM-as-a-Judge [38] and human expert evaluation [39]. In this dual assessment scheme, the LLM and domain experts independently evaluate the quality of generated explanations using the same predefined criteria summarized in Table 6.

The LLM-as-a-Judge leverages GPT-5 as an autonomous evaluator capable of providing consistent judgements on textual explanations. This approach ensures linguistic precision, thereby minimizing subjective bias and enabling the reliable assessment of textual coherence. In parallel, a human evaluation was conducted by domain experts specializing in EVDM systems. The experts evaluated the same set of explanations to provide practical perspectives on their interpretability and diagnostic usefulness. Both the LLM and human evaluators were assigned using a five-point Likert scale [40], where a score of 1 denotes very poor quality and 5 denotes excellent quality.
In addition to numerical ratings, human evaluators provided open-ended feedback regarding both the strengths and areas for improvement in the generated explanations. These responses were analyzed to identify subjective perceptions and contextual insights that might not be captured through quantitative scoring.
5.1 Evaluation of Electric Vehicle Drive Motor Fault Diagnosis
We evaluate the classification performance of the decision tree-based EVDM fault diagnosis model by varying the maximum tree depth from 3 to 12. Table 7 summarizes the results in terms of precision, recall, F1-score, and accuracy. The boldface values indicate the best performance. As the tree depth increases, the model shows improved classification performance across all metrics, with F1-score and accuracy both rising from depth 3 to depth 10.
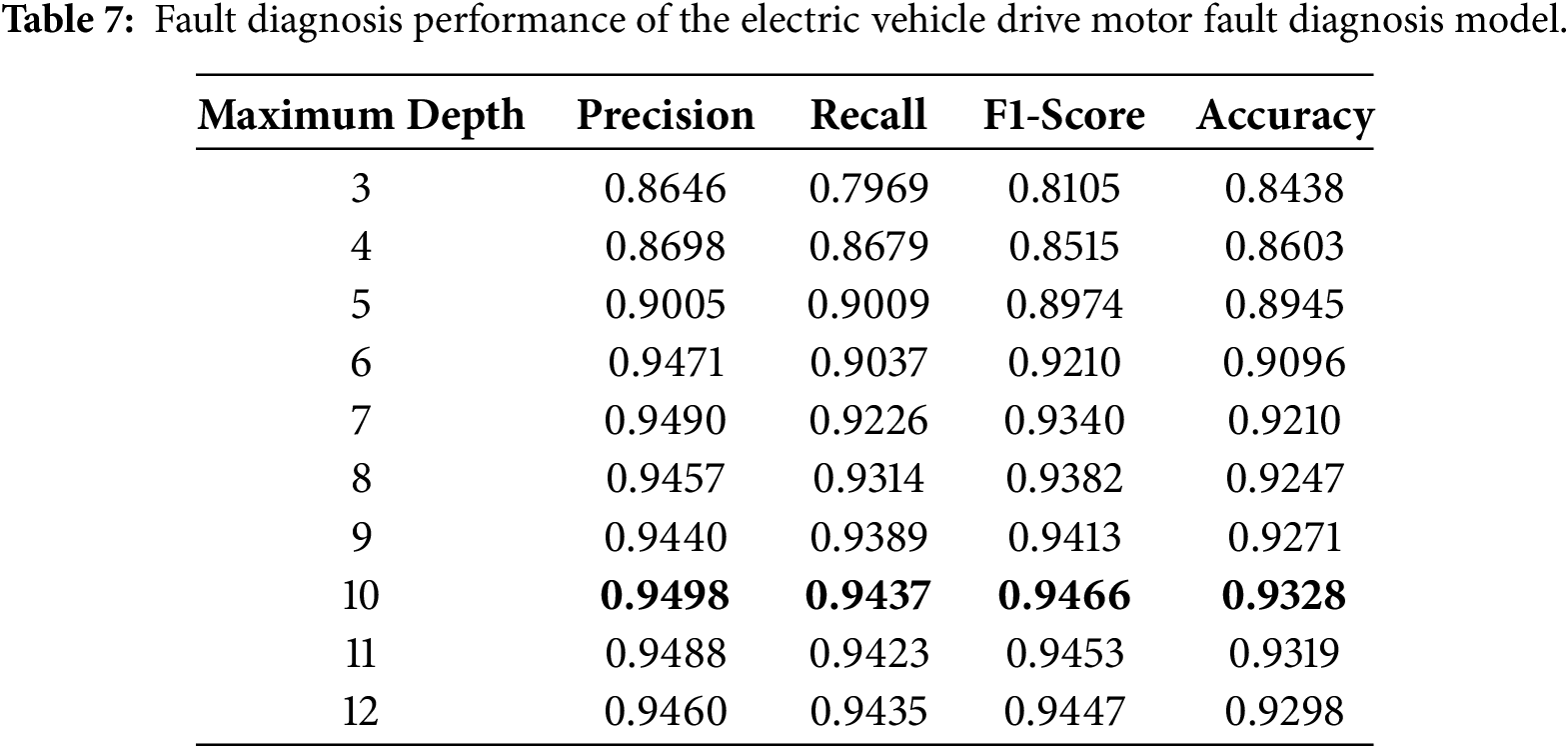
At lower depths, including maximum depths of 3 and 4, the model exhibits modest performance, which can be attributed to underfitting resulting from coarse decision boundaries. As the depth increases to 5 and beyond, the model becomes more expressive and capable of capturing finer-grained decision patterns, leading to consistent improvements across all metrics. However, beyond a certain threshold, the performance gains begin to plateau, suggesting diminishing returns from further increases in model complexity.
The best overall performance is obtained when the maximum depth is set to 10. Beyond this point, further increases in depth do not yield significant improvements and may introduce unnecessary model complexity. Therefore, we select maximum depth of 10 as the final configuration for all subsequent experiments. This configuration provides an effective balance between predictive accuracy and model interpretability, enabling a tractable decision structure that facilitates subsequent analysis.
5.2 Multi-Agent Large Language Model-Based Decision Tree Analysis
This section describes the interpretation outputs produced by each agent in the proposed framework. Fig. 3 presents the visualization of the instance-specific decision path in the decision tree that we analyzed in this section. Due to the length, detailed results are provided in Appendix B.
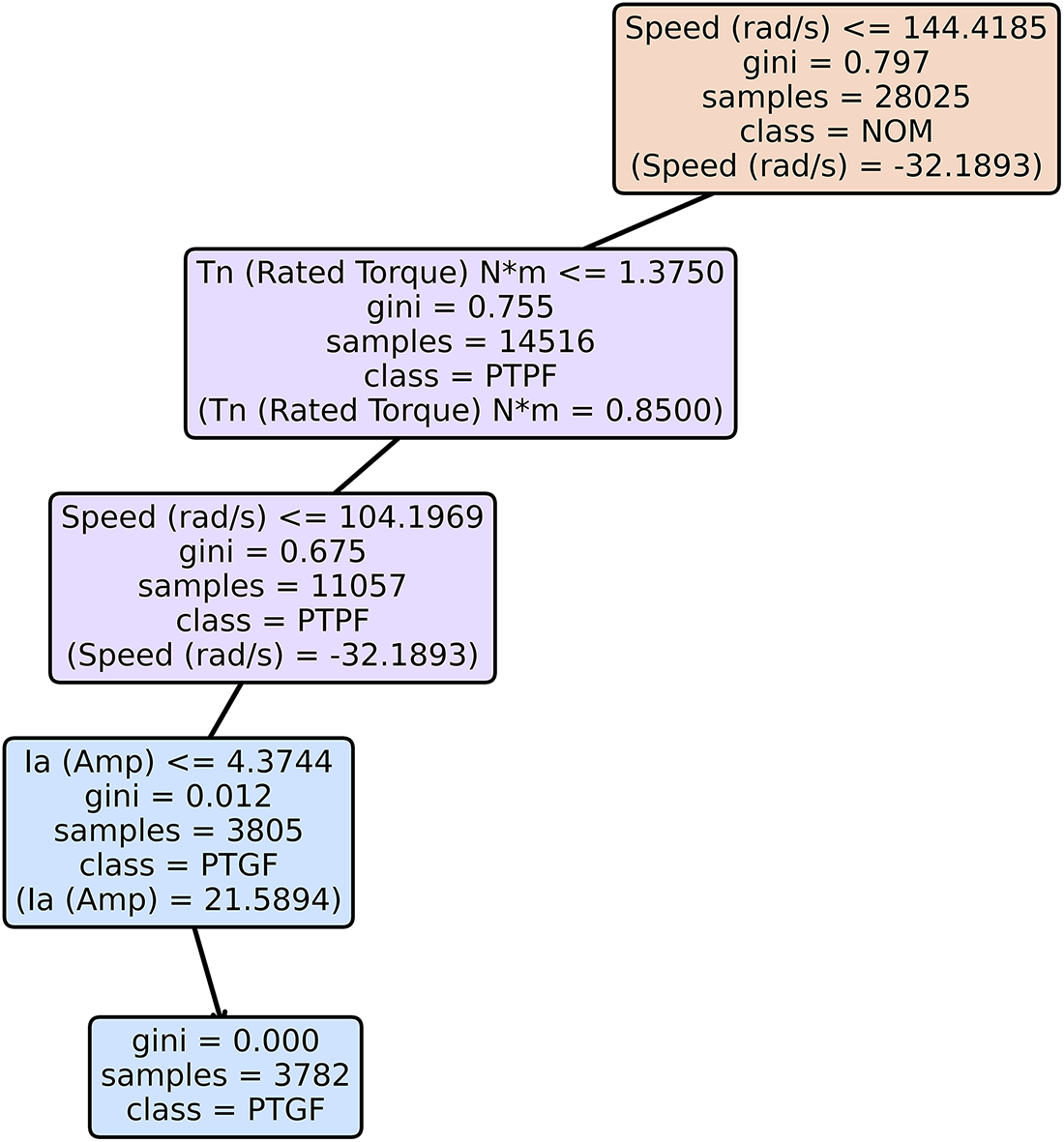
Figure 3: Visualization of the instance-specific decision path in the decision tree.
5.2.1 Local Evidence Interpretation Agent
We evaluated the performance of the local evidence interpretation agent in generating textual explanations for a specific instance. Tables A7–A9 present the complete local interpretation process performed by the local evidence interpretation agent for a representative sample instance that was classified as a PTGF. Table A7 lists the original decision path extracted from the trained decision tree, detailing each node’s feature, threshold, impurity, and class assignment. Table A8 reformats this information into a structured JSON representation, which serves as the standardized input format for the proposed framework. Table A9 presents the output generated by the agent, including node-wise impurity drops, probability shifts, and textual explanations that describe how each decision rule contributes to the final classification outcome.
The agent parsed the decision trajectory from the root to the leaf node and generated interpretable textual explanations for each feature and threshold condition. For sample index 69, the diagnostic path excluded nominal and non-ground fault conditions through sequential threshold evaluations. The initial condition, Speed (rad/s) ≤ 144.4185, indicated abnormally low or negative rotation, directing the instance away from normal operation. The following split on Tn (Road Torque) N∗m ≤ 1.375 reflected a low-torque state associated with potential fault zones. A second speed-based threshold, Speed (rad/s) ≤ 104.1969 reinforced the connection between reduced speed and ground-related faults. The decisive factor emerged at node 3, where Ia (Amp) = 21.5894 exceeded the threshold (4.3744 A), resulting in a complete impurity reduction and a probability shift of 1.0 toward PTGF.
Collectively, these results demonstrate that the interaction between abnormally low rotational speed and elevated Ia (Amp) serves as the dominant diagnostic evidence for the PTGF class. The agent successfully transformed symbolic tree rules into coherent and human-readable reasoning chains, thereby enhancing both the interpretability and diagnostic transparency of the underlying model.
5.2.2 Threshold Translator Agent
The threshold translator agent refines the numerical split conditions produced by the decision tree into domain-relevant linguistic expressions to enhance interpretability for vehicle engineers. This agent serves as an intermediate reasoning layer that connects numerical decision boundaries with domain semantics, enabling the decision tree’s rules to be interpreted in physically meaningful terms.
Table A10 presents the translated outputs generated by the threshold translator agent. The agent interprets the decision path as a sequence of semantically enriched diagnostic conditions. Specifically, the rotational speed of −32.19 rad/s (≤144.4185 rad/s) is described as abnormally low or negative, indicating a non-operational state far below the nominal range. The rated torque of 0.85 N∗m (≤1.375 N∗m) is expressed as below nominal torque, reflecting a light-load or near-idle operation. A subsequent speed threshold (≤104.20 rad/s) is interpreted as persistently very low rotational speed, reinforcing the diagnosis of an off-nominal and quasi-stationary condition. Finally, the Phase-A current of 21.5894 A (>4.3744 A) is translated as abnormally high, signifying a severe overcurrent or grounding anomaly within phase A.
The agent’s final narrative summary consolidates these interpretations, stating that the examined motor operates at near-zero mechanical load and extremely low speed while exhibiting a severe phase, an overcurrent anomaly, conditions collectively aligned with a PTGF diagnosis. Through this translation process, the threshold translator agent bridges quantitative model logic and qualitative engineering reasoning, producing human-understandable diagnostic statements without sacrificing numerical precision.
5.2.3 Counterfactual Analysis Agent
The counterfactual analysis agent identifies the minimal and physically plausible perturbations in input features that would alter the model’s current prediction. By exploring ‘what-if’ scenarios within the learned decision boundaries of the tree, the agent provides actionable insight into the stability of model decisions.
Table A11 presents the outputs of counterfactual analysis agent. The agent determined four feasible perturbations capable of reversing the PTGF decision. The smallest adjustment is a modest increase in rated torque from 0.85 to 1.3751 N∗m, which redirects the decision path toward PTPF. Alternatively, a reduction in phase-A current from 21.5894 to 4.3744 A also eliminates the PTGF signature, rerouting the instance to a non-ground fault region dominated by the PTPF. Larger increases in rotational speed yield more drastic decision changes: surpassing 104.1969 rad/s (node 2) reclassifies the sample as PTPF, while exceeding 144.4185 rad/s (root node) results in NOM.
The summary of the agent indicates that decision reversibility is most sensitive to early-path thresholds and to the decisive current-based split at node 3. Among the identified counterfactuals, small torque adjustments and current reductions are considered both physically feasible and operationally meaningful, whereas large speed increases are less practical under real-world conditions. This analysis enhances interpretability by linking feature-level perturbations to tangible diagnostic actions.
5.2.4 Global Consistency Audit Agent
The global consistency audit agent evaluates the alignment between the local explanation derived from a specific decision path and the global feature importance distribution. The agent assesses whether the locally dominant features for a given instance align with the globally influential variables.
Table A12 presents the consistency evaluation result generated by global consistency audit agent. The local top features identified along the decision path are Ia (Amp), Speed (rad/s), and Tn (Rated Torque) Nm, whereas the global model importances highlight Speed (rad/s), Vab (V), and Tn (Rated Torque) Nm as the most influential. The resulting Jaccard similarity of 0.5 indicates moderate overlap, while the rank correlation of −0.4 reveals divergent ordering, primarily due to the strong local dominance of Ia (Amp) that is globally underrepresented.
Qualitatively, this discrepancy arises because the global importances are averaged across multiple fault types, elevating features such as Speed (rad/s) and Vab (V) that are broadly predictive across classes, whereas Ia (Amp) is highly concentrated in the PTGF decision subspace. The agent interprets this outcome as partial consistency: while the local reasoning path appropriately relies on operational parameters such as Speed (rad/s) and Tn (Rated Torque) Nm that align with global importance features, it also demonstrates an additional dependence on Ia (Amp) that is comparatively underrepresented in the global analysis.
From a diagnostic perspective, this finding underscores the complementary natures of local and global explanations. While global analyses capture general operating regimes of instance-specific paths such as PTGF depend on localized evidence concentrated in single phases or current channels. As a result, integrating path-level interpretive analyses into global summaries can provide a more comprehensive representation of fault-specific mechanisms, reinforcing the transparency of diagnostic reasoning.
The report generator agent integrates the outputs from all preceding agents in Sections 5.2.1–5.2.4 into a unified and human-readable report that explains the model’s reasoning process. This agent combines quantitative evidence, linguistic threshold translations, counterfactual reasoning, and global-local consistency assessments into a coherent narrative suitable for expert interpretation.
Table A13 presents the generated report. The prediction summary describes the sequential rule evaluations on rotational speed, torque, and phase-A current that progressively guided the sample toward the PTGF leaf node, culminating in a zero-impurity decision. The key rules highlight the critical thresholds, abnormally low speed (−32.1893 rad/s ≤ 144.4185 rad/s), low torque (0.85 N∗m <= 1.375 N∗m), and elevated phase-A current (21.5894 A > 4.3744 A) that collectively define the fault condition. Correspondingly, the threshold interpretations provide natural-language descriptions contextualized to the EVDM domain, explaining how these values represent counter-rotating, low-load, and overcurrent states, respectively.
The counterfactual analysis section summarizes minimal feature adjustments capable of reversing the classification outcome. Small increases in torque (+0.5251 N∗m) or moderate reductions in phase-A current (−17.2151 A) redirect the instance toward PTPF, while large speed increases (+176.6079 rad/s) transition it into the NOM branch. These findings highlight the model’s sensitivity to torque-current interactions and its physical interpretability in fault-state transitions. The global consistency audit further indicates partial alignment between local and global explanations (Jaccard = 0.50, p = −0.40), showing that while mechanical variables (speed, torque) are consistently influential, the PTGF pathway depends strongly on localized current evidence, Ia (Amp), that is underrepresented in global profiles.
Overall, the consolidated narrative of the report generator agent provides a transparent and traceable account of the model’s diagnostic logic. By combining evidence across multiple reasoning dimensions, it transforms fragmented analytical outputs into a cohesive and interpretive artifact that enhances explainability, domain trust, and human-machine interpretive alignment in EVDM fault diagnosis.
To address the proposed framework, we conducted an ablation study in which the entire interpretation process was delegated to a single LLM agent, without role-specific decomposition. Table A14 presents the ablation study results, in which the entire interpretation process is performed by a single LLM agent. The table reports the resulting explanation for the same sample instance shown in Table A13, allowing direct comparison with the proposed multi-agent LLM framework.
The ablation study reveals notable qualitative differences between the proposed framework and the single LLM agent. The prediction summary generated by the single LLM agent is more abstract, describing the final decision in broad terms without referencing the specific node-level branching features that informed the classification. In contrast, the proposed framework explicitly incorporates the internal structure of the decision tree, thereby providing a more transparent account of the underlying reasoning process. Second, although the single LLM agent can identify the correct key rules along the decision path, its subsequent threshold interpretations differ markedly from the proposed framework. The proposed framework contextualizes thresholds in relation to the sample’s actual input values, enabling semantically grounded interpretations of why specific splits were triggered. The single LLM agent, however, provides threshold descriptions primarily from the perspective of the tree’s structural logic, without connecting them to the sample’s operational state, resulting in less informative and less user-centered explanations.
The counterfactual analyses produced by the single LLM agent remain reasonably coherent, suggesting that it can still infer plausible decision-boundary inversions when given the full structured input. Nevertheless, the most pronounced limitation emerges in the global consistency section. The single LLM agent fails to articulate how the instance-level reasoning aligns with the tree’s global behavior, providing only a generalized statement rather than connecting fault regions and features observed at the dataset level. This omission contrasts with the multi-agent LLM framework, which provides detailed global-local integration by linking low speed, low torque, and high phase current conditions to the broader fault distribution learned by the model. Finally, the interpretive summary produced by the single LLM agent is considerably less comprehensive. Whereas the multi-agent LLM framework synthesizes threshold logic and domain semantics into a cohesive narrative, the single LLM agent summary provides a comparatively shallow description that does not capture the multi-level reasoning chain underlying the PTGF classification.
Overall, the results demonstrate that the proposed framework derives its interpretive strength from its role-specialized decomposition. This design enables detailed, consistently structured, and domain-grounded explanations, which a single LLM agent fails to replicate.
5.4 Evaluation of Explanatory Quality and User Satisfaction
To assess the explanatory quality of the proposed multi-agent LLM framework, we conducted two complementary evaluation procedures, an LLM-as-a-Judge assessment and a user study involving domain practitioners. In both evaluations, the explanations generated by the proposed multi-agent framework were directly compared with those produced by the single agent configuration used in the ablation study. Table 8 summarizes the results of the LLM-based evaluation in terms of mean score and SD for each criterion, where GPT-5 served as an autonomous evaluator applying the scoring criteria described in Section 4.3. GPT-5 was selected as the evaluation model because the evaluation criteria are inherently language and reasoning-centric, requiring strong semantic and contextual understanding to be evaluated consistently at scale.
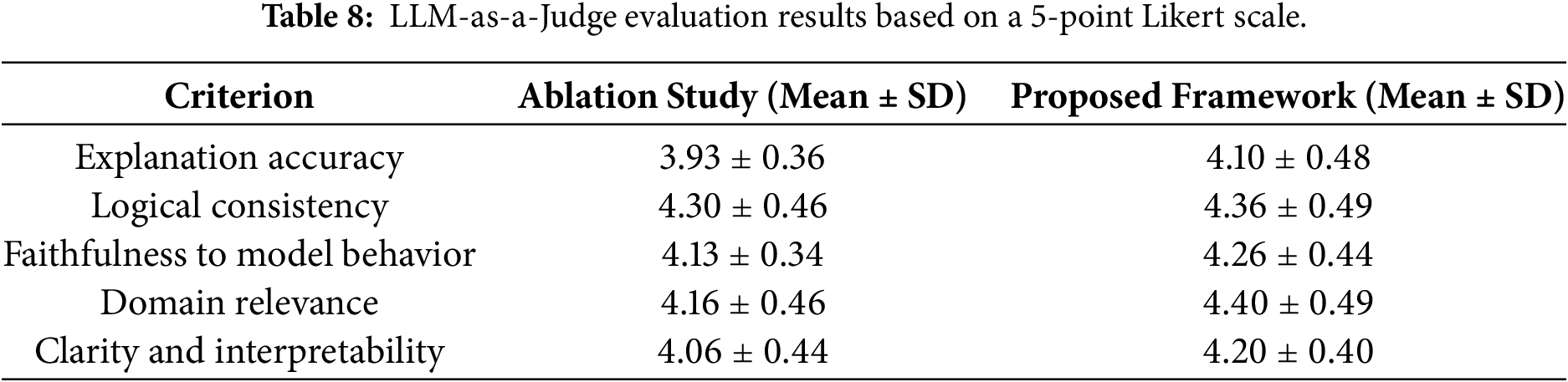
We acknowledge that using the same LLM for both explanation generation and evaluation may arise concerns regarding potential self-evaluation bias. To mitigate this risk, the evaluation process was designed with strict role separation: the evaluator operates under independent prompts and deterministic decoding settings, and assigns scores based solely on predefined criterion-level Likert scales. As a result, the proposed framework outperformed the single-agent ablation study across all five criteria. The performance gains were moderate yet consistent, indicating that the multi-agent architecture enhances the structural quality and contextual appropriateness of generated explanations without introducing instability or verbosity.
As summarized in Table 9, user study results further support the effectiveness of the proposed framework. A total of ten participants took part in the evaluation. Overall, users rated the proposed framework higher than the ablation study, particularly in explanation accuracy and logical consistency. Importantly, the use of human evaluators provides an independent validation of the LLM-as-a-Judge results, alleviating concerns that performance improvements are artifacts of model self-assessment. The magnitude of improvement remained moderate, reflecting realistic user expectations and indicating that interpretability enhancements were perceptible without introducing exaggerated stylistic changes. Furthermore, domain relevance and clarity also showed improvement, although several participants noted that domain-specific phrasing could be further refined to better align with expert diagnostic conventions.
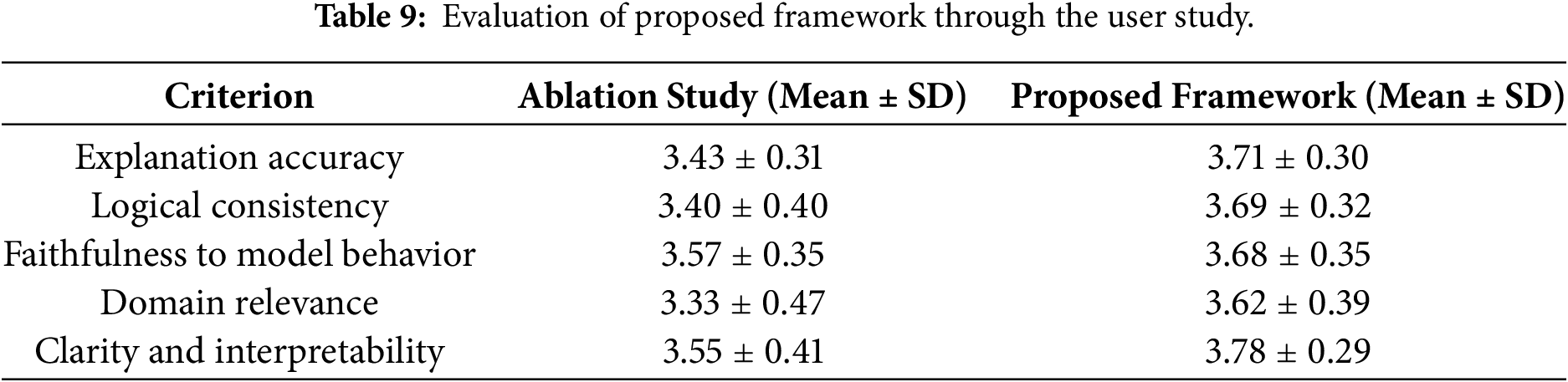
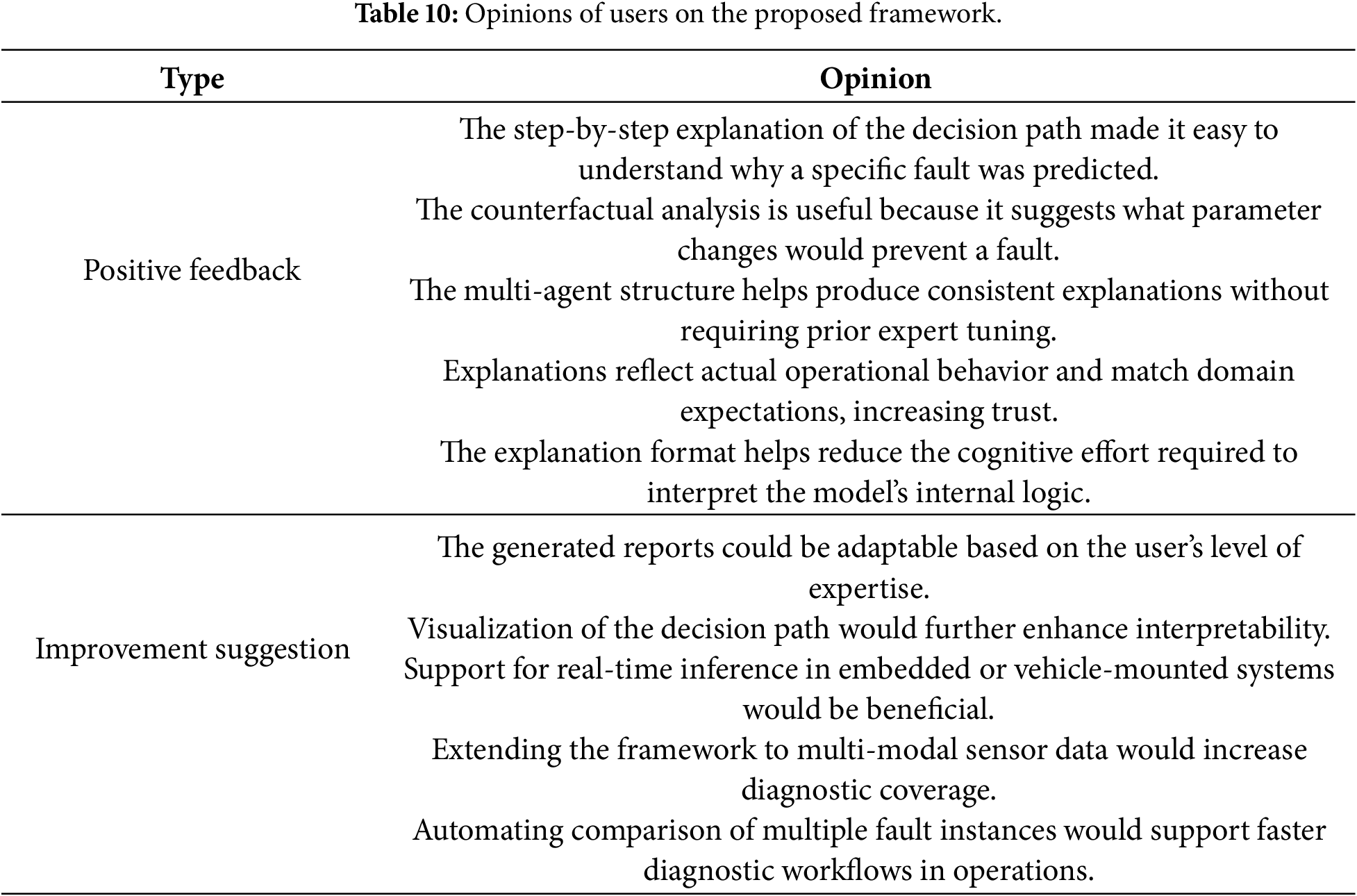
Table 10 provides a qualitative summary of user feedback. Positive comments highlighted the step-by-step traceability of decision paths and the usefulness of counterfactual reasoning in identifying actionable control adjustments. Users reported that these characteristics reduced the cognitive effort required to interpret the model’s internal logic and increased confidence in the diagnostic decision. On the other hand, improvement suggestions emphasized adaptive reporting styles tailored to different expertise levels and the integration of visual aids for decision path interpretation. These findings indicate that the LLM-as-a-Judge evaluation serves as a scalable and reproducible complement to human judgment, rather than a replacement, and that consistent trends across both evaluation modalities strengthen the reliability of the reported results.
5.5 Comparison with Representative Published Studies
To contextualize the contribution of the proposed framework within existing research on EVDM fault diagnosis, Table 11 provides a comparative overview of the proposed framework and representative published studies addressing related diagnostic tasks. The comparison focuses on the target application, core modeling techniques, datasets, and the mechanisms adapted to support interpretability. This analysis aims to clarify how the proposed framework differs from and complements existing methods, especially in terms of explanation fidelity and practical usability for safety-critical maintenance.
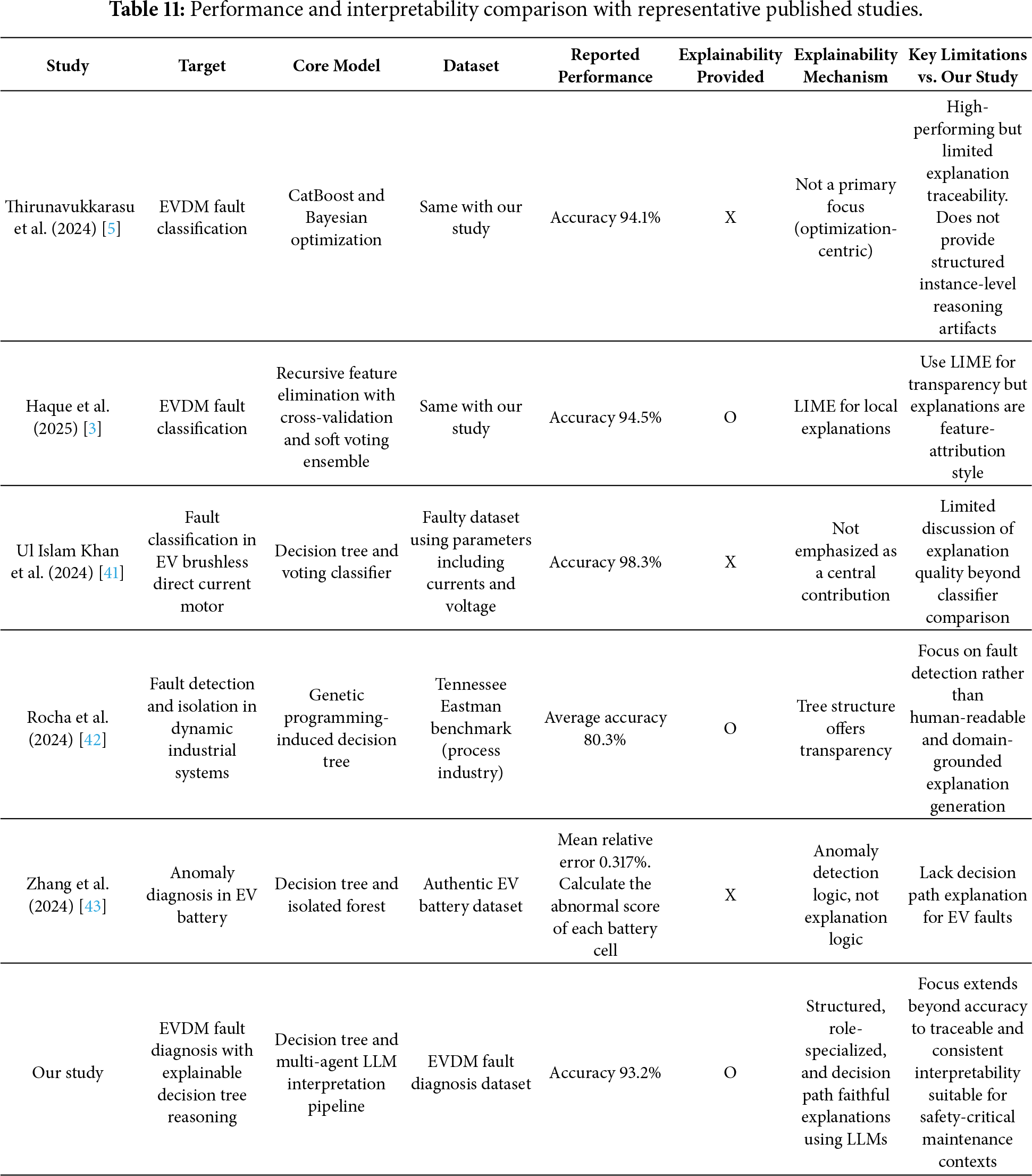
Several prior studies have reported strong diagnostic performance for EVDM fault classification using advanced ML and optimization techniques. Thirunavukkarasu et al. [5] employed ensemble-based models, including CatBoost with Bayesian optimization, and achieved high classification accuracy on the same dataset used in this study. However, interpretability was not treated as primary design objective, and structured instance-level reasoning was not provided. Haque et al. [3] proposed a lightweight ensemble framework with recursive feature elimination and soft voting, supplemented by LIME for local post-hoc explorations. While this improves transparency compared to purely black-box models, the resulting explanations remain feature-attribution oriented and are not explicitly aligned with the classifier’s internal decision logic.
Other representative studies address related EV diagnostic contexts. Ul Islam Khan et al. [41] investigated fault classification in brushless direct current motors using decision trees and voting classifiers, focusing on robustness rather than explanation quality. Rocha et al. [42] applied genetic programming-induced decision trees to fault detection and isolation in an industrial benchmark, emphasizing detection performance over human-readable explanation generation. Zhang et al. [43] targeted anomaly diagnosis in EV battery systems using decision tree-based prediction and isolation forests, addressing a different subsystem and diagnostic objective. Consequently, decision path-level explanations for EVDM faults are not a central focus in these works.
In contrast, the proposed framework explicitly treats interpretability as a first-class objective. By combining a decision tree classifier with a multi-agent LLM interpretation pipeline, the framework generates structured, role-specialized explanations that remain faithful to the underlying decision path. As summarized in Table 11, this design complements competitive diagnostic performance with traceable and consistent interpretability tailored to safety-critical EVDM maintenance.
6.1 Practical Limitations and Deployment Challenges of Large Language Model-Based Agents
Despite the interpretability advances demonstrated in this study, several practical limitations of LLM-based diagnostic frameworks remain to be addressed. First, the proposed framework relies on cloud-hosted LLMs, which introduces dependencies on external service providers [36]. This reliance entails computational costs and inference latency, particularly in a multi-agent configuration where sequential agent invocations can accumulate response delays [26]. Such characteristics pose constraints for resource-constrained environments in on-board diagnostic systems [14].
To mitigate these constraints, the proposed framework adopts modular architecture that enables selective activation of agents according to deployment requirements. For instance, lightweight configurations that exclude counterfactual or global audit agents could be employed when lower latency is required, while full multi-agent reasoning can be reserved for maintenance planning. Future implementations can leverage edge-deployed LLMs or caching strategies to further reduce end-to-end latency and operational cost [44].
In addition, the robustness of LLM-driven reasoning remains a concern. Although role-specific prompting and deterministic decoding were employed to stabilize agent outputs, LLM responses may still exhibit sensitivity to input representations [45]. This sensitivity can be alleviated through prompt standardization, template-based instruction design, and the use of structured intermediate representations such as JSON-based decision paths, which constrain the reasoning space and reduce variability across runs [46]. Furthermore, while the inclusion of a fact verification agent reduces the likelihood of erroneous statements, it does not fully eliminate the risk of domain-level overgeneralization or implicit physical assumptions that are not explicitly supported by the underlying model structure or data distribution. These risks suggest that LLM-generated explanations should be treated as assisted interpretations rather than authoritative physical diagnoses.
Overall, these limitations do not undermine the contribution of the proposed framework but rather delineate its appropriate application domain. By explicitly recognizing deployment constraints and outlining feasible mitigation strategies, this work provides a realistic assessment of how LLM-based diagnostic agents can be effectively integrated into existing engineering workflows. It also identifies promising directions for future optimization toward real-time or embedded diagnostic applications.
6.2 Reproducibility and Model-Agnostic Design of Large Language Model-Based Agents
Another important consideration concerns the reliance of the proposed framework on a specific LLM, namely GPT-5. While this choice was motivated by its strong reasoning capabilities and long-context handling, it inevitably raises concerns regarding reproducibility and long-term sustainability. Variations in model versions or API updates can affect the reproducibility of results if such dependencies are not explicitly managed [47].
To mitigate these concerns, the proposed framework was designed to be model-agnostic at the architectural level. The core contribution of this work lies not in the selection of a particular LLM, but in the decomposition of interpretive reasoning into modular and role-defined agents with standardized input and output interfaces. The agent responsibilities, prompt templates, and structured JSON-based formats are explicitly specified, allowing the entire framework to be re-instantiated using alternative language models with minimal structural modification.
Moreover, several measures were adopted to enhance reproducibility within the current implementation. These include deterministic decoding strategies, fixed prompt versions, and explicit role constraints for each agent [48,49]. Such design choices reduce stochastic variability in generated explanations and facilitate consistent qualitative evaluation across repeated runs. In future work, open-source LLMs such as HyperCLOVA X [50] and LLaMA [51] can be integrated to further improve reproducibility and deployment flexibility.
6.3 Extension to Multimodal Fault Diagnosis
The current implementation of the proposed framework focuses primarily on tabular electrical and mechanical measurements, such as phase currents, voltage, torque, and rotational speed. While these variables are highly informative for EVDM fault scenarios, complex real-world failures often arise from the interaction of multiple physical phenomena that may not be fully captured by a single data modality [52,53]. For example, mechanical imbalances can be reflected in vibration signals, thermal degradation can be observed through temperature sensors or thermal imaging, and acoustic signatures can indicate bearing or insulation faults.
The proposed framework is well suited for extension to multimodal fault diagnosis. Owing to its modular agent design, modality-specific interpretation agents can be introduced to process heterogeneous inputs independently. For example, a vibration interpretation agent can be designed to analyze frequency-domain features. A thermal reasoning agent can focus on spatial or temporal temperature distributions, and an acoustic agent can examine spectral patterns associated with anomalous noise signatures. The outputs for these specialized agents can then be integrated by the report generator agent to form a unified and cross-modal diagnostic narrative. This design enables the framework to scale from single-modality explanations to multi-factor reasoning altering the underlying decision model.
Furthermore, incorporating multimodal evidence has the potential to improve both fault detection coverage and explanation depth, particularly for early-stage faults where electrical indicators alone can be ambiguous. By explicitly representing how different modalities contribute complementary evidence, the framework can better support root-cause analysis and reduce uncertainty in complex diagnostic cases. Although such extensions were beyond the scope of the present study, they represent a promising direction for future work. They will leverage the complementary strengths of symbolic decision models and LLM-based reasoning to address complex EVDM fault scenarios.
6.4 Prompt Engineering and User-Adaptive Explanation Design for Large Language Model-Based Agents
While the proposed framework demonstrates strong capability in generating coherent and faithful diagnostic explanations, the quality and usability of such explanations remain closely tied to prompt engineering strategies and domain alignment [46,54]. In the present implementation, prompts were designed to emphasize clarity and traceability, adopting a model-centric tone. However, this style may not fully align with the terminology and heuristic reasoning patterns commonly used by practicing vehicle engineers in real-world diagnostic settings.
To address this gap, future work will focus on domain-adaptive prompt engineering, incorporating industry-standard diagnostic terminology, fault codes, and maintenance conventions into agent instructions [55,56]. This can be achieved by conditioning prompts on curated domain glossaries and historical maintenance reports, thereby reducing semantic friction and cognitive load for end users. Such alignment is important in safety-critical environments, where subtle differences in phrasing can influence interpretive confidence and decision-making efficiency.
In addition, the framework can be enhanced through adaptive explanation design tailored to diverse stakeholder groups [29]. Different users, including maintenance technicians, system engineers, and managerial decision-makers, require varying levels of technical detail and abstraction. The report generation agent can dynamically adjust explanation granularity, generating simplified summaries for non-experts and detailed context for domain experts. This adaptive reporting capability will improve usability and accessibility without compromising the underlying interpretability of the model.
6.5 Fleet-Level Analysis and Cross-Instance Diagnostic Intelligence with Large Language Model-Based Agents
The analysis presented in this study primarily focuses on instance-level interpretability, demonstrating how the proposed framework can generate faithful and structured explanations for individual EVDM fault cases. While such fine-grained analysis is essential for understanding specific failure events, practical maintenance and operational decision-making in real-world deployments require fleet-level and cross-instance insights [57]. Vehicle engineers are tasked with identifying recurring fault patterns, correlating failures across similar operating conditions, and prioritizing maintenance actions at the system or fleet scale rather than at the level of isolated instances [58,59].
The proposed framework can be extended to support cross-instance diagnostic intelligence by leveraging the structured outputs generated by the multi-agent pipeline. Instance-level explanations, including decision paths, dominant features, counterfactual sensitivities, and consistency metrics, can be aggregated and compared across multiple fault cases. This enables the automatic identification of common diagnostic signatures, recurring decision rules, and shared counterfactual triggers associated with specific fault types. Such aggregation will allow vehicle engineers to move beyond ad hoc inspection toward systematic pattern discovery across flees of vehicles.
At the fleet level, this capability can support a range of maintenance and reliability applications, including early detection of emerging fault trends, prioritization of high-risk components, and validation of maintenance strategies. By transforming individual explanations into a collective knowledge base, the framework can facilitate proactive maintenance planning and reduce diagnostic redundancy. Although fleet-level automation was beyond the scope of the present study, these extensions highlight the potential of LLM-based multi-agent interpretation frameworks to evolve from single-case explanation tools into scalable diagnostic intelligence platforms for large-scale EV operations.
6.6 Knowledge Graph-Augmented Explanation for Mitigating Hallucination in Large Language Model-Based Fault Diagnosis
While the proposed framework emphasizes model-faithful interpretation by operating on decision tree structures, it relies on implicit domain knowledge embedded within LLM. As with other LLM-driven diagnostic systems, this reliance introduces a residual risk of hallucination, including unsupported causal claims or overgeneralized fault semantics that are not grounded in verified engineering knowledge.
Recent studies on knowledge graph (KG)-driven fault diagnosis provide a promising direction for addressing this limitation. Prior work in aviation equipment fault diagnosis has demonstrated that integrating structured KGs with LLMs improves explanation reliability by grounding generation in fault entities, relationships, and causal chains extracted from maintenance manuals and fault logs [60]. In such settings, KGs function as external knowledge anchors that constrain reasoning to validated domain facts, thereby reducing unsupported inferences in safety-critical applications.
Complementary research on KG-enabled heuristic reasoning further shows that KGs can function as active reasoning substrates rather than static knowledge repositories [61]. By formalizing domain rules and semantic relationships, these frameworks support interpretable and reusable reasoning processes while preserving the flexibility of natural language explanations. This highlights the value of structured knowledge grounding for improving explanation faithfulness in complex diagnostic workflows.
In the context of EVDM fault diagnosis, integrating a KG-driven approach into the proposed framework would provide multiple benefits. A fault KG encoding components, failure modes, causal dependencies, maintenance actions, and sensor-fault relationships could serve as a semantic verification layer for explanation agents, enabling cross-checking of generated interpretations against validated fault mechanisms. Moreover, formalized heuristic rules, such as associations between fault types and sensor thresholds, can improve reasoning consistency and efficiency while reducing the cognitive load for vehicle engineers. Although KG integration is beyond the scope of the present study, it represents a promising direction for future work toward more grounded and trustworthy EVDM fault diagnosis.
In this study, we proposed a novel multi-agent LLM-based interpretation framework for explaining decision tree classifiers applied to EVDM fault diagnosis. The proposed framework organizes the interpretation process into a structured sequence of specialized agents, each dedicated to extracting decision rules, assessing reliability, contextualizing domain knowledge, and synthesizing coherent explanations. By leveraging the reasoning capabilities of GPT-5, the framework automates the generation of comprehensive explanations that bridge the gap between model transparency and diagnostic practicality.
Experimental evaluations using a publicly available EVDM dataset demonstrated that the decision tree classifier achieved robust predictive performance, with a maximum depth of 10 providing the optimal balance between accuracy and interpretability. The proposed framework effectively produced coherent, faithful, and domain-relevant explanations, as verified through both quantitative analysis and qualitative assessment involving LLM-as-a-Judge and human expert evaluation. These results confirm the potential of multi-agent LLM frameworks to enhance the interpretability in safety-critical diagnostic applications.
The primary contributions of this work lie in introducing a modular agent architecture for structured model interpretation, integrating domain-specific reasoning with generalizable XAI techniques, and establishing an evaluation protocol combing automated and human assessment for explanation quality. These contributions provide a foundation for future research on scalable and XAI systems in industrial domains.
Future extensions of this study will explore the integration of multi-modal sensor data (e.g., vibration or thermal imaging) and hybrid decision models to further enhance interpretability across heterogeneous diagnostic contexts [62]. In parallel, adapting the proposed framework to real-time monitoring and in-vehicle diagnostic systems will be an important step toward achieving trustworthy and deployable artificial intelligence-driven maintenance in next-generation EVs [2,63]. Furthermore, future work will focus on advancing the multi-agent LLM framework itself through refined prompt engineering strategies and adaptive task orchestration environments [18]. These developments are expected to improve the agents’ reasoning coherence, collaborative efficiency, and contextual adaptability, ultimately enabling a more autonomous and explainable diagnostic intelligence for safety-critical EV systems.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: conceptualization, Jaeseung Lee and Jehyeok Rew; methodology, Jehyeok Rew; software, Jaeseung Lee; validation, Jehyeok Rew; formal analysis, Jehyeok Rew; investigation, Jaeseung Lee; resources, Jehyeok Rew; data curation, Jaeseung Lee; writing—original draft preparation, Jaeseung Lee; writing—review and editing, Jehyeok Rew; visualization, Jaeseung Lee; supervision, Jehyeok Rew; project administration, Jehyeok Rew; funding acquisition, Jehyeok Rew. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support of the findings of this study are openly available in Machine Learning Based Fault Diagnosis of Electric Drives at https://github.com/HassanMahmoodKhan/Machine-Learning-Based-Fault-Diagnosis-of-Electric-Drives.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest.
Appendix A
Appendix A provides the complete prompt templates used for each agent in the proposed framework. These templates define the role instructions, input structure, output formatting requirements, and domain-specific reasoning constraints that guide the behavior of each agent. By presenting these prompts in full, we aim to ensure the reproducibility of the proposed framework and enable researchers and practitioners to adapt the framework to alternative diagnostic domains.
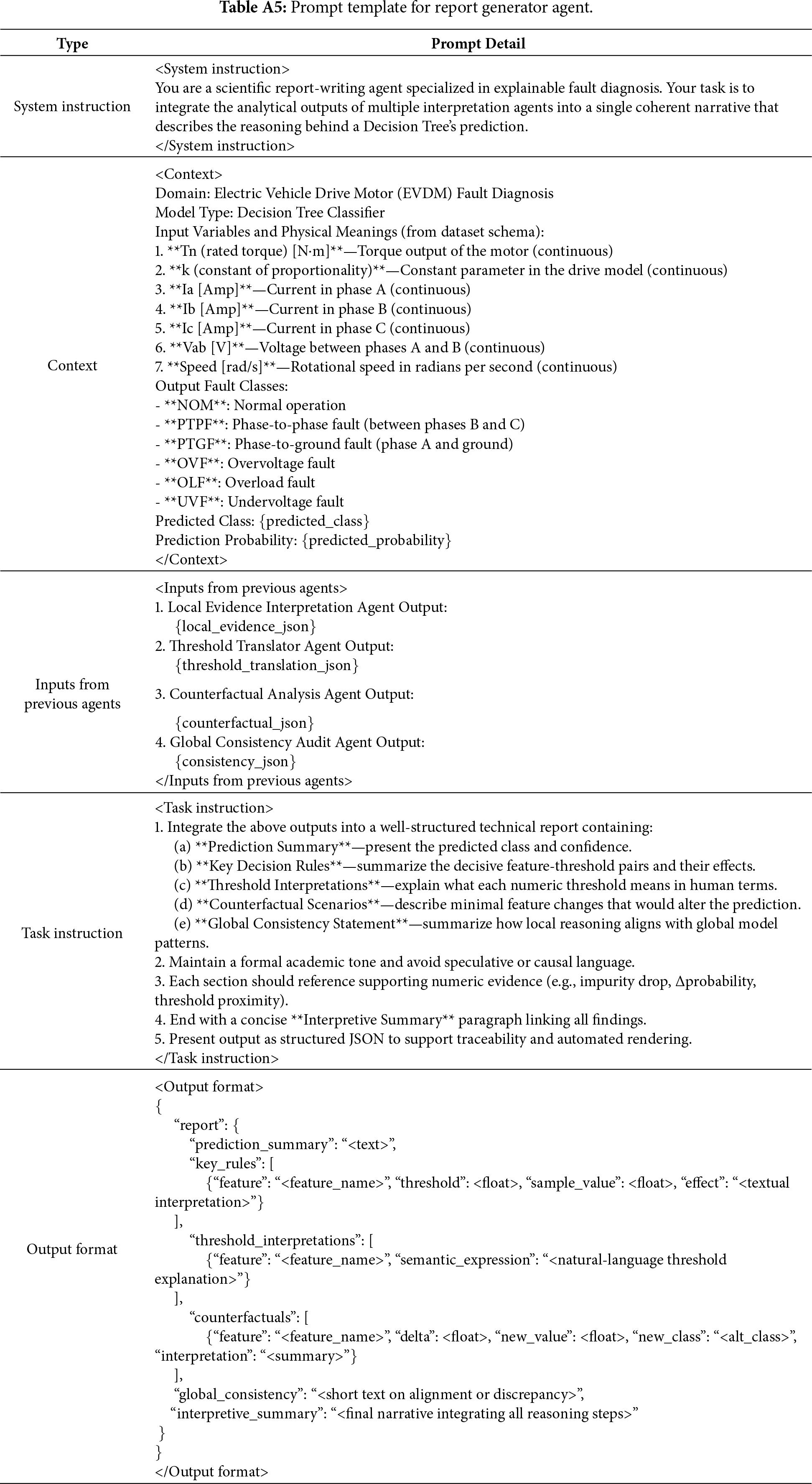
Tables A1–A6 list the prompt templates for each agent in the order in which they operate within the interpretation pipeline: (1) Local Evidence Interpretation Agent, (2) Threshold Translator Agent, (3) Counterfactual Analysis Agent, (4) Global Consistency Audit Agent, (5) Report Generator Agent, and (6) Fact Verification Agent.





Appendix B
Appendix B presents the complete interpretation artifacts generated by the proposed framework for a representative EVDM fault sample. It includes the full reasoning outputs to ensure transparency and reproducibility of the interpretation process. Tables A7–A13 document each stage of the multi-agent pipeline in the exact order of execution: the raw decision path extracted from the trained decision tree, its JSON-formatted representation, and the respective outputs of the local evidence interpretation agent, threshold translator agent, counterfactual analysis agent, global consistency audit agent, and report generator agent. These tables allow readers to trace how input features, split thresholds, and model states are incrementally transformed into a coherent diagnostic explanation.







Furthermore, Table A14 provides the complete ablation study results generated by a single-agent baseline, enabling direct comparison with the proposed multi-agent design. By making full outputs available, Appendix B supports independent verification of interpretive fidelity and provides a practical reference for extending the framework to alternative datasets, diagnostic tasks, or agent configurations.

References
1. Umayal R, Darapaneni N, Aditya V, Paduri AR. Machine learning based remaining useful life prediction of lithium-ion batteries in electric vehicle battery management system. In: Proceedings of the 2023 International Conference on Communication, Security and Artificial Intelligence (ICCSAI); 2024 Nov 23–25; Greater Noida, India. p. 547–51. doi:10.1109/ICCSAI59793.2023.10421014. [Google Scholar] [CrossRef]
2. Gopalakrishnan R, Vidhya DS, Bharath P, Kaviyan P, Sivaselvam P. Battery state estimation and control system for mobile charging station for electric vehicles. In: Proceedings of the 2023 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS); 2023 Mar 23–25; Erode, India. p. 985–9. doi:10.1109/ICSCDS56580.2023.10104624. [Google Scholar] [CrossRef]
3. Haque ME, Zabin M, Uddin J. EnsembleXAI-motor: a lightweight framework for fault classification in electric vehicle drive motors using feature selection, ensemble learning, and explainable AI. Machines. 2025;13(4):314. doi:10.3390/machines13040314. [Google Scholar] [CrossRef]
4. Khaneghah MZ, Alzayed M, Chaoui H. Fault detection and diagnosis of the electric motor drive and battery system of electric vehicles. Machines. 2023;11(7):713. doi:10.3390/machines11070713. [Google Scholar] [CrossRef]
5. Thirunavukkarasu S, Karthick K, Aruna SK, Manikandan R, Safran M. Optimized fault classification in electric vehicle drive motors using advanced machine learning and data transformation techniques. Processes. 2024;12(12):2648. doi:10.3390/pr12122648. [Google Scholar] [CrossRef]
6. Zhu S, Tan MK, Chin RKY, Chua BL, Hao X, Teo KTK. Engine fault diagnosis using probabilistic neural network. In: Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET); 2021 Sep 13–15; Kota Kinabalu, Malaysia. p. 1–6. doi:10.1109/iicaiet51634.2021.9573654. [Google Scholar] [CrossRef]
7. Akbalık F, Yıldız A, Ertuğrul ÖF, Zan H. Engine fault detection by sound analysis and machine learning. Appl Sci. 2024;14(15):6532. doi:10.3390/app14156532. [Google Scholar] [CrossRef]
8. Lee J, Baik N, Rew J. Multi-scale graph neural network for multivariate time-series anomaly detection. J Korea Soc Ind Inf Syst. 2025;30(1):51–65. doi:10.9723/jksiis.2025.30.1.051. [Google Scholar] [CrossRef]
9. Dettinger F, Jazdi N, Weyrich M, Brandl L, Reuss HC, Pecha U, et al. Machine-learning-based fault detection in electric vehicle powertrains using a digital twin. In: SAE technical paper series. Stuttgart, Germany: SAE International; 2023. doi:10.4271/2023-01-1214. [Google Scholar] [CrossRef]
10. Mersha M, Lam K, Wood J, AlShami AK, Kalita J. Explainable artificial intelligence: a survey of needs, techniques, applications, and future direction. Neurocomputing. 2024;599(5):128111. doi:10.1016/j.neucom.2024.128111. [Google Scholar] [CrossRef]
11. Lundberg SM, Lee SI. A unified approach to interpreting model predictions. Adv Neural Inf Process Syst. 2017;30:4766–75. [Google Scholar]
12. Ribeiro M, Singh S, Guestrin C. “Why should I trust you?”: explaining the predictions of any classifier. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. Stroudsburg, PA, USA: ACL; 2016. p. 97–101. doi:10.18653/v1/n16-3020. [Google Scholar] [CrossRef]
13. Lee J, Rew J. Large language model-based SHAP analysis for interpretation of remaining useful life prediction of lithium-ion battery. J Korea Soc Ind Inf Syst. 2024;29(5):51–68. doi:10.2139/ssrn.5537792. [Google Scholar] [CrossRef]
14. Lee J, Rew J. Vision-language model-based local interpretable model-agnostic explanations analysis for explainable in-vehicle controller area network intrusion detection. Sensors. 2025;25(10):3020. doi:10.3390/s25103020. [Google Scholar] [PubMed] [CrossRef]
15. Saranya A, Subhashini R. A systematic review of explainable artificial intelligence models and applications: recent developments and future trends. Decis Anal J. 2023;7(5):100230. doi:10.1016/j.dajour.2023.100230. [Google Scholar] [CrossRef]
16. Izza Y, Ignatiev A, Marques-Silva J. On explaining decision trees. arXiv:2010.11034. 2020. [Google Scholar]
17. Minaee S, Mikolov T, Nikzad N, Chenaghlu M, Socher R, Amatriain X, et al. Large language models: a survey. arXiv:2402.06196. 2024. [Google Scholar]
18. Guo T, Chen X, Wang Y, Chang R, Pei S, Chawla NV, et al. Large language model based multi-agents: a survey of progress and challenges. arXiv:2402.01680. 2024. [Google Scholar]
19. Bari BS, Yelamarthi K, Ghafoor S. Intrusion detection in vehicle controller area network (CAN) bus using machine learning: a comparative performance study. Sensors. 2023;23(7):3610. doi:10.3390/s23073610. [Google Scholar] [PubMed] [CrossRef]
20. Alalwany E, Mahgoub I. Classification of normal and malicious traffic based on an ensemble of machine learning for a vehicle CAN-network. Sensors. 2022;22(23):9195. doi:10.3390/s22239195. [Google Scholar] [PubMed] [CrossRef]
21. Xu L, Teoh SS, Ibrahim H. A deep learning approach for electric motor fault diagnosis based on modified InceptionV3. Sci Rep. 2024;14(1):12344. doi:10.1038/s41598-024-63086-9. [Google Scholar] [PubMed] [CrossRef]
22. Hassija V, Chamola V, Mahapatra A, Singal A, Goel D, Huang K, et al. Interpreting black-box models: a review on explainable artificial intelligence. Cogn Comput. 2024;16(1):45–74. doi:10.1007/s12559-023-10179-8. [Google Scholar] [CrossRef]
23. Zereen AN, Das A, Uddin J. Machine fault diagnosis using audio sensors data and explainable AI techniques-LIME and SHAP. Comput Mater Contin. 2024;80(3):3463–84. doi:10.32604/cmc.2024.054886. [Google Scholar] [CrossRef]
24. Jang K, Pilario KES, Lee N, Moon I, Na J. Explainable artificial intelligence for fault diagnosis of industrial processes. IEEE Trans Ind Inform. 2025;21(1):4–11. doi:10.1109/TII.2023.3240601. [Google Scholar] [CrossRef]
25. Brito LC, Susto GA, Brito JN, Duarte MAV. Fault Diagnosis using eXplainable AI: a transfer learning-based approach for rotating machinery exploiting augmented synthetic data. Expert Syst Appl. 2023;232(4):120860. doi:10.1016/j.eswa.2023.120860. [Google Scholar] [CrossRef]
26. Lee J, Rew J. Memory-augmented large language model for enhanced chatbot services in university learning management systems. Appl Sci. 2025;15(17):9775. doi:10.3390/app15179775. [Google Scholar] [CrossRef]
27. Lee J, Rew J. Automated change history analysis of software bill of materials (SBOM) using large language model-based structural analysis and forgery detection agents. J Korea Soc Ind Inf Syst. 2025;30(4):39–60. doi:10.9723/jksiis.2025.30.4.039. [Google Scholar] [CrossRef]
28. Holland M, Chaudhari K. Large language model based agent for process planning of fiber composite structures. Manuf Lett. 2024;40(2):100–3. doi:10.1016/j.mfglet.2024.03.010. [Google Scholar] [CrossRef]
29. Peng C, Peng J, Wang Z, Wang Z, Chen J, Xuan J, et al. Adaptive fault diagnosis of railway vehicle on-board controller with large language models. Appl Soft Comput. 2025;185(1):113919. doi:10.1016/j.asoc.2025.113919. [Google Scholar] [CrossRef]
30. Lukens S, McCabe LH, Gen J, Ali A. Large language model agents as prognostics and health management copilots. Annu Conf PHM Soc. 2024;16(1):3906. doi:10.36001/phmconf.2024.v16i1.3906. [Google Scholar] [CrossRef]
31. Blockeel H, Devos L, Frénay B, Nanfack G, Nijssen S. Decision trees: from efficient prediction to responsible AI. Front Artif Intell. 2023;6:1124553. doi:10.3389/frai.2023.1124553. [Google Scholar] [PubMed] [CrossRef]
32. Yu T, Zhu H. Hyper-parameter optimization: a review of algorithms and applications. arXiv:2003.05689. 2020. [Google Scholar]
33. Moshkov M. On the depth of decision trees over infinite 1-homogeneous binary information systems. Array. 2021;10(7):100060. doi:10.1016/j.array.2021.100060. [Google Scholar] [CrossRef]
34. H. Mahmood. Khan. Machine learning based fault diagnosis of electric drives. GitHub. [cited 2026 Jan 20]. Available from: https://github.com/HassanMahmoodKhan/Machine-Learning-Based-Fault-Diagnosis-of-Electric-Drives. [Google Scholar]
35. Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30. [Google Scholar]
36. OpenAI. GPT-5 system card. arXiv:2601.03267. 2026. [Google Scholar]
37. Vujovic ŽÐ. Classification model evaluation metrics. Int J Adv Comput Sci Appl. 2021;12(6):0120670. doi:10.14569/ijacsa.2021.0120670. [Google Scholar] [CrossRef]
38. Chiang WL, Gonzalez J, Li D, Li Z, Lin Z, Sheng Y, et al. Judging LLM-as-a-judge with MT-bench and chatbot arena. In: Proceedings of the Advances in Neural Information Processing Systems 36; 2023 Dec 10–16; New Orleans, LA, USA: Neural Information Processing Systems Foundation, Inc. (NeurIPS); 2023. p. 46595–623. doi:10.52202/075280-2020. [Google Scholar] [CrossRef]
39. Rong Y, Leemann T, Nguyen TT, Fiedler L, Qian P, Unhelkar V, et al. Towards human-centered explainable AI: a survey of user studies for model explanations. IEEE Trans Pattern Anal Mach Intell. 2024;46(4):2104–22. doi:10.1109/tpami.2023.3331846. [Google Scholar] [PubMed] [CrossRef]
40. Joshi A, Kale S, Chandel S, Pal D. Likert scale: explored and explained. Br J Appl Sci Technol. 2015;7(4):396–403. doi:10.9734/bjast/2015/14975. [Google Scholar] [CrossRef]
41. Ul Islam Khan M, Pathan MIH, Mominur Rahman M, Islam MM, Arfat Raihan Chowdhury M, Anower MS, et al. Securing electric vehicle performance: machine learning-driven fault detection and classification. IEEE Access. 2024;12(12):71566–84. doi:10.1109/access.2024.3400913. [Google Scholar] [CrossRef]
42. Rocha RCN, Soares RA, Santos LI, Camargos MO, Ekel PY, Libório MP, et al. A new fault classification approach based on decision tree induced by genetic programming. Processes. 2024;12(4):818. doi:10.3390/pr12040818. [Google Scholar] [CrossRef]
43. Zhang Z, Dong S, Li D, Liu P, Wang Z. Prediction and diagnosis of electric vehicle battery fault based on abnormal voltage: using decision tree algorithm theories and isolated forest. Processes. 2024;12(1):136. doi:10.3390/pr12010136. [Google Scholar] [CrossRef]
44. Wang X, Tang Z, Guo J, Meng T, Wang C, Wang T, et al. Empowering edge intelligence: a comprehensive survey on on-device AI models. ACM Comput Surv. 2025;57(9):1–39. doi:10.1145/3724420. [Google Scholar] [CrossRef]
45. Sahoo P, Singh AK, Saha S, Jain V, Mondal S, Chadha A. A systematic survey of prompt engineering in large language models: techniques and applications. arXiv:2402.07927. 2024. [Google Scholar]
46. Vatsal S, Dubey H. A survey of prompt engineering methods in large language models for different NLP tasks. arXiv:2407.12994. 2024. [Google Scholar]
47. Kalyan KS. A survey of GPT-3 family large language models including ChatGPT and GPT-4. Nat Lang Process J. 2024;6(6):100048. doi:10.1016/j.nlp.2023.100048. [Google Scholar] [CrossRef]
48. Singh H, Verma N, Wang Y, Bharadwaj M, Fashandi H, Ferreira K. Personal large language model agents: a case study on tailored travel planners. In: Proceedings of the EMNLP 2024—2024 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Industry Track. Miami, FL, USA: Association for Computational Linguistics; 2024. p. 486–514. [Google Scholar]
49. Jia F, Ye Z, Lai S, Shu K, Gu J, Bibi A, et al. Can large language model agents simulate human trust behaviors? arXiv:2402.04559. 2024. [Google Scholar]
50. Cloud N. HyperCLOVA X THINK technical report. arXiv:2506.22403. 2025. [Google Scholar]
51. Grattafiori A, Dubey A, Jauhri A, Pandey A, Kadian A, Al-Dahle A, et al. The Llama 3 herd of models. arXiv:2407.21783. 2024. [Google Scholar]
52. Hang J, Qiu G, Hao M, Ding S. Improved fault diagnosis method for permanent magnet synchronous machine system based on lightweight multisource information data layer fusion. IEEE Trans Power Electron. 2024;39(10):13808–17. doi:10.1109/TPEL.2024.3432163. [Google Scholar] [CrossRef]
53. He W, Hang J, Ding S, Sun L, Hua W. Robust diagnosis of partial demagnetization fault in PMSMs using radial air-gap flux density under complex working conditions. IEEE Trans Ind Electron. 2024;71(10):12001–10. doi:10.1109/TIE.2024.3349520. [Google Scholar] [CrossRef]
54. Gu J, Han Z, Chen S, Beirami A, He B, Zhang G, et al. A systematic survey of prompt engineering on vision-language foundation models. arXiv:2307.12980. 2023. [Google Scholar]
55. Wu C, Sehab R, Akrad A, Morel C. Fault diagnosis methods and fault tolerant control strategies for the electric vehicle powertrains. Energies. 2022;15(13):4840. doi:10.3390/en15134840. [Google Scholar] [CrossRef]
56. Cui X. Research on common faults and maintenance countermeasures of automobile engines. J Educ Teach Soc Stud. 2023;5(2):p68. doi:10.22158/jetss.v5n2p68. [Google Scholar] [CrossRef]
57. Xu X, Hang J, Cao K, Ding S, Wang W. Unified open-phase fault diagnosis of five-phase PMSM system in normal operation and fault-tolerant operation modes. IEEE Trans Transp Electrif. 2025;11(5):12063–75. doi:10.1109/TTE.2025.3584777. [Google Scholar] [CrossRef]
58. Hossain MN, Rahman MM, Ramasamy D. Artificial intelligence-driven vehicle fault diagnosis to revolutionize automotive maintenance: a review. Comput Model Eng Sci. 2024;141(2):951–96. doi:10.32604/cmes.2024.056022. [Google Scholar] [CrossRef]
59. Hua L, Tang J, Zhu G. A survey of vehicle system and energy models. Actuators. 2025;14(1):10. doi:10.3390/act14010010. [Google Scholar] [CrossRef]
60. Li L, Haruna A, Ying W, Noman K, Li Y. Knowledge graph-driven fault diagnosis for aviation equipment: integrating improved joint extraction with large language model. J Ind Inf Integr. 2026;50:101039. doi:10.1016/j.jii.2025.101039. [Google Scholar] [CrossRef]
61. Haruna A, Noman K, Li Y, Makanda ILD, Zubair A, Hasand MJ, et al. Facilitating heuristic reasoning by utilizing knowledge graph and natural language processing. Knowl Based Syst. 2026;334:115153. doi:10.1016/j.knosys.2025.115153. [Google Scholar] [CrossRef]
62. Hasan MJ, Sohaib M, Kim JM. An explainable AI-based fault diagnosis model for bearings. Sensors. 2021;21(12):4070. doi:10.3390/s21124070. [Google Scholar] [PubMed] [CrossRef]
63. Huang Y, Jafari M, Jin PJ. Driving safety prediction and safe route mapping using in-vehicle and roadside data. SSRN J. 2022;59(12):604. doi:10.2139/ssrn.4135994. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools