
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Efficient Feature Selection with an Enhanced Supervised Term-Weighting Scheme in Multi-Class Text Classification
1 School of Computer Sciences, Universiti Sains Malaysia, George Town, Penang, Malaysia
2 Information Technology Engineering Department, Polytechnic College of Karbala, Al-Furat Al-Awsat Technical University, Karbala, Iraq
* Corresponding Author: Yu-N Cheah. Email:
Computers, Materials & Continua 2026, 87(3), 101 https://doi.org/10.32604/cmc.2026.078927
Received 10 January 2026; Accepted 12 March 2026; Issue published 09 April 2026
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Term weighting scheme and feature selection are two fundamental components in text classification (TC) systems, particularly in high-dimensional, multi-class, and imbalanced settings. Term weighting schemes aim to improve document representation by emphasizing discriminative terms across classes, while feature selection (FS) seeks to reduce dimensionality, eliminate irrelevant and redundant features, and enhance classification efficiency and effectiveness. However, most existing studies focus on FS independently of the term-weighting strategy used during document representation, thereby limiting the potential benefits of their interaction. This study addresses this gap by pursuing two main objectives. First, it employs an enhanced supervised term-weighting scheme, namely MTF-MICF, to construct a more stable and class-discriminative document representation, especially for imbalanced data. Second, it investigates the effectiveness of integrating this scheme with a filter-based FS approach using Information Gain (IG) at various levels of dimensionality reduction to assess the contribution of enhanced term weighting to the FS process. Extensive experiments were conducted across 19 benchmark multi-class text datasets. The performance was evaluated using F1-score and classification accuracy with the three prominent classifiers (MNB, SVM, and LR). The experimental results demonstrate that the proposed approach consistently outperforms conventional methods, achieving significant and stable improvements in both representation quality and classification performance. These findings confirm that enhanced supervised term weighting can serve as an effective supporting mechanism for FS in high-dimensional TC tasks.Keywords
In real-world scenarios, textual data is inherently diverse, inconsistent, and unstructured, which makes its analysis particularly challenging for traditional computational methods. Moreover, most textual datasets are extremely high-dimensional, as each document may generate thousands or even tens of thousands of unique terms [1,2]. This high dimensionality, combined with the presence of irrelevant, redundant, and noisy features, severely affects the efficiency and generalization capability of machine learning algorithms. The abundance of uninformative features not only obscures meaningful patterns in data but also increases the risk of overfitting and degrades classification performance.
High-dimensional feature spaces also impose substantial computational burdens. Irrelevant features distract the learning process from informative patterns, redundant features unnecessarily enlarge the feature space without adding new information, and noisy features introduce random fluctuations that mislead learning algorithms, resulting in unstable models and higher error rates [3–5]. These challenges become even more critical in multi-class TC settings, where documents must be assigned to one of many possible categories under complex and often imbalanced data distributions.
TC has therefore become an essential supervised learning paradigm for organizing and managing the rapidly growing volume of unstructured textual data. Its main objective is to automatically and systematically assign documents to predefined categories or topics [6,7]. A typical TC pipeline consists of several fundamental stages: text preprocessing, feature extraction (document representation), dimensionality reduction through FS, classification, and evaluation [8–11].
Among these stages, feature extraction and FS are widely recognized as two of the most critical components, as they directly determine the quality of the input representation provided to the learning algorithm. Feature extraction in TC is commonly performed using the bag-of-words (BoW) and the Vector Space (VSM) models, where documents are represented as vectors of term frequencies [12]. To enhance this representation, term-weighting schemes are employed to assign importance scores to terms, thereby reflecting their contribution to distinguishing between classes [13–15].
Term-weighting schemes can be broadly categorized into unsupervised and supervised approaches [16–18]. Unsupervised schemes, such as Term Frequency-Inverse Document Frequency (TF-IDF) or their variants, assign weights based solely on term distribution within documents and across the corpus, without exploiting class label information. While computationally simple, these methods often fail to adequately capture the discriminative power of terms in multi-class and imbalanced settings. In contrast, supervised term-weighting schemes explicitly incorporate class information to emphasize terms that are more discriminative across categories, yielding more informative, task-oriented document representations.
Motivated by this observation, this study adopts an enhanced supervised term-weighting scheme, namely Modified Term Frequency-Modified Inverse Class Frequency (MTF-MICF), which extends the traditional Term Frequency-Inverse Class Frequency (TF-ICF) formulation by improving term frequency normalization and class-discriminative weighting. This scheme is specifically designed to mitigate document-length bias, preserve frequency information, and enhance inter-class separability, making it particularly suitable for multi-class imbalanced TC.
Despite the benefits of advanced term-weighting schemes, the resulting feature space often remains extremely large, containing tens or hundreds of thousands of features, many of which are still irrelevant or redundant for the learning task. Such non-informative features introduce noise, increase computational cost, and degrade model performance [19,20]. To address this issue, FS is commonly employed as a dimensionality reduction technique to identify the most informative subset of features.
FS methods are generally classified into filter, wrapper, embedded, and hybrid approaches [8]. Filter methods evaluate features using statistical or information-theoretic criteria independently of the classifier, offering high computational efficiency and scalability to large datasets [10]. Wrapper methods utilize a learning algorithm to evaluate feature subsets, often achieving higher accuracy but at the cost of significantly higher computational complexity [21]. Embedded methods integrate FS into the classifier’s training process, while hybrid methods aim to combine the advantages of filter and wrapper methods [8,22].
In this study, a filter-based approach using IG is adopted due to its simplicity, efficiency, independence from classifiers, and proven effectiveness in high-dimensional TC problems. Moreover, IG provides a stable and interpretable criterion for ranking features based on their discriminative power across classes, making it particularly suitable for large-scale multi-class datasets.
Unlike most existing studies, which treat term weighting and feature selection as independent stages, this work explicitly investigates their interaction by positioning the enhanced supervised term-weighting scheme as a supporting mechanism for FS. Where term-weighting schemes assign importance scores to all terms, while FS methods further rank and filter them to retain only the most discriminative terms for document representation. Specifically, this study aims to demonstrate that improving document representation quality via MTF-MICF can significantly enhance the effectiveness of subsequent filter-based FS across different levels of dimensionality reduction. The proposed framework is extensively evaluated on multiple benchmark multi-class datasets using F1-score and classification accuracy, with results confirming its effectiveness and generalization. The contributions of this study are as follows:
• Introduces a unified framework that explicitly integrates an enhanced supervised term-weighting scheme (i.e., MTF-MICF) with filter-based FS, allowing term weighting to function as a supporting mechanism for improving FS effectiveness rather than treating the two stages independently.
• Employs the MTF-MICF scheme to enhance document representation quality by strengthening class discrimination, mitigating document-length bias, and preserving meaningful term frequency information, particularly in multi-class imbalanced settings.
• Provides a comprehensive experimental investigation of how enhanced supervised term weighting influences the effectiveness of IG-based FS across multiple dimensionality levels, while further validating the results using additional filter-based methods, namely ReliefF and Chi-square.
• Conducts an extensive, large-scale evaluation on 19 widely recognized multi-class benchmark text datasets using three prominent classifiers (MNB, SVM, and LR) to ensure the robustness, consistency, and generalizability of the proposed framework.
The remainder of this paper is organized as follows. Section 2 reviews recent studies on term-weighting schemes and feature selection methods for text classification. Section 3 presents the proposed methodology and provides a comprehensive and systematic investigation of the interdependent effects of term weighting schemes and feature selection. Section 4 reports and discusses the experimental results. Finally, Section 5 concludes the paper and outlines directions for future work.
This section reviews related studies on term-weighting schemes and feature selection methods for text classification and discusses the main limitations of existing approaches in handling unstructured and high-dimensional vector spaces.
2.1 Variants of the Term Weighting Schemes
Term-weighting schemes used in TC are generally divided into unsupervised and supervised approaches, depending on whether class-label information is incorporated into the weighting process [16–18]. Unsupervised schemes estimate term importance solely from term-document and term-corpus statistics and assume that distributional properties such as frequency and dispersion are sufficient for classification [23,24]. While computationally efficient, these methods often fail to capture class-discriminative information, especially in multi-class and imbalanced settings.
Among unsupervised schemes, Term Frequency (TF) and TF-IDF remain the most widely used. TF emphasizes frequently occurring terms but tends to overweight non-informative words, is sensitive to document length, and cannot distinguish between locally frequent but globally uninformative terms [14,25–28]. TF-IDF mitigates some of these issues by penalizing ubiquitous terms, yet it has been shown to favor majority-class terms because global term distributions reflect corpus-level imbalance, which degrades minority-class performance [25,28–30]. Several enhanced unsupervised variants, such as TFmeanIDF, mTF, and mIDF, attempt to improve stability and balance between local and global statistics [16,31], but they remain fundamentally class-agnostic and thus inherit similar structural limitations.
To overcome these drawbacks, supervised term-weighting schemes incorporate class-label information to improve term discrimination [23,32]. Early work replaced the IDF component with FS criteria, such as Chi-squared (CHI), IG, Mutual Information (MI), and Odds Ratio (OR), leading to schemes like TF-CHI and TF-IG [33], followed by other variants such as TF-OR and TF-MI [34,35]. Class-indexing approaches, notably TF-ICF, further extended IDF to the class level by emphasizing terms concentrated in fewer categories [36]. However, TF-ICF and its extensions, such as TF-IDF-ICF and TF-IDF-ICSδF, still rely on relatively coarse class modeling and may penalize representative terms that appear across multiple classes [37–39].
More recent studies explored alternative class-aware criteria, including Term Frequency-Relevance Frequency (TF-RF), Term Frequency-Inverse Gravity Moment (TF-IGM), and their improved variants, as well as entropy-based schemes such as Cumulative Residual Entropy (CRE) and Distorted Cumulative Residual Entropy (DCRE), to better characterize term distribution across categories [15,31,37,39,40]. Another direction integrates FS criteria into term weighting, leading to Modified Distinguishing Feature Selector (MDFS) and MTF-based schemes that alleviate document length bias and improve weighting stability [14,41].
In summary, although unsupervised term-weighting schemes have played a foundational role in vector-space text representation, their inability to exploit class-distribution information fundamentally limits their discriminative capability in modern multi-class and imbalanced TC tasks. This shortcoming has driven the development of supervised and class-aware weighting strategies.
Nevertheless, despite notable advances, existing supervised term-weighting methods still exhibit several inherent limitations, including coarse modeling of class information, sensitivity to class imbalance, and limited ability to capture fine-grained term-class interactions in high-dimensional, sparse feature spaces. These challenges continue to motivate the pursuit of more accurate, adaptive, and highly discriminative supervised term-weighting schemes.
2.2 Feature Selection for Text Document Classification
Following the discussion on term weighting schemes, it is important to emphasize that weighting alone is insufficient to address the high intrinsic dimensionality of BoW text representations. Text documents typically contain tens of thousands of features, many of which are irrelevant, redundant, or only weakly correlated with class labels [42]. Such nondiscriminative features not only increase computational cost and memory consumption but also amplify noise and often degrade classification performance, particularly in large-scale, imbalanced text corpora [11].
FS plays a complementary and indispensable role by identifying a compact subset of the most informative and discriminative features, thereby reducing dimensionality while preserving essential semantic and discriminative content [43]. By eliminating noisy and redundant terms, FS improves learning efficiency, enhances generalization, and stabilizes classifier performance [6,44,45]. Based on the interaction between the selection process and the learning model, FS methods for TC are commonly categorized into three main paradigms: filter, wrapper, and hybrid approaches [8,21,46,47].
Filter methods operate independently of any classifier and rely on statistical, information-theoretic, or correlation-based criteria to estimate feature relevance [11]. Typical measures include distance, consistency, dependency, information, and correlation metrics [46]. These methods are further divided into univariate and multivariate approaches [3,48,49]. Univariate methods evaluate each feature independently and thus ignore redundancy among features, whereas multivariate methods jointly consider both feature relevance and inter-feature dependencies, enabling them to better handle redundant and interacting features [46,50].
Due to their simplicity, scalability, and low computational cost, filter methods have been widely adopted in TC [51,52], and numerous effective techniques have been proposed in the literature [53–57]. However, despite their efficiency, filter methods suffer from a fundamental limitation: they evaluate features in isolation from the classifier and therefore cannot guarantee optimal performance for a specific learning algorithm.
To alleviate the instability and bias of single-criterion filters, recent studies have increasingly explored ensemble-filter-based FS strategies that aggregate multiple ranking criteria to improve robustness, consistency, and selection reliability [58,59]. By leveraging the complementary strengths of diverse selection metrics, ensemble filters have demonstrated improved stability and more reliable performance across different datasets [60,61]. Nevertheless, even ensemble filters remain fundamentally disconnected from the classifier’s actual decision boundaries.
Wrapper methods overcome this limitation by directly integrating a learning algorithm into the FS process. Candidate feature subsets are evaluated using a classifier-driven fitness function, and the search process explicitly accounts for feature interactions and model-specific performance. This tight coupling often yields more compact and highly discriminative feature subsets, leading to superior classification performance compared to filter methods [1,8]. However, this advantage comes at the cost of substantially higher computational complexity, since wrapper methods require repeated model training and validation, especially when cross-validation is employed [19,22]. Consequently, classical exhaustive or greedy wrapper searches become impractical for high-dimensional text spaces, where the FS problem is inherently NP-hard.
To address the combinatorial complexity of wrapper-based FS, metaheuristic optimization algorithms have become the dominant paradigm. These methods are particularly suitable for large, nonlinear, and high-dimensional search spaces due to their stochastic, population-based, and adaptive exploration mechanisms [62]. Recent research has increasingly focused on improved, hybridized, and problem-adapted metaheuristic wrappers to enhance convergence speed, stability, and solution quality in high-dimensional text FS problems [21].
Despite their effectiveness, pure wrapper-metaheuristic approaches remain computationally expensive due to repeated classifier evaluations over large feature spaces. To mitigate this limitation, hybrid filter-wrapper FS frameworks have emerged as a pragmatic and powerful solution. In these approaches, a filter stage (e.g., IG, CHI, or ensemble filters) is first used to aggressively reduce dimensionality, followed by a metaheuristic wrapper stage that refines the reduced feature subset and exploits feature interactions [63].
This strategy achieves a better balance between efficiency and effectiveness. It has gained increasing attention in recent years, as evidenced by a growing body of work, including in [64–67] and the recent comprehensive review by Alyasiri et al. [8,21]. More recently, ensemble filter and hybrid wrapper metaheuristic frameworks have been proposed to simultaneously address (i) the instability of single-filter methods and (ii) the premature convergence of wrapper metaheuristic optimization algorithms [63,68].
Despite these advances, several critical research gaps remain. First, most existing FS frameworks implicitly assume a generic classification setting and rarely consider the specific characteristics of multi-class imbalanced text data. Second, contemporary studies predominantly focus on improving the search strategy or subset evaluation mechanism while overlooking the foundational role of document representation quality. In most frameworks, term weighting is treated as a fixed preprocessing step, and FS is optimized independently of representation-level improvements. Third, limited attention has been given to systematically analyzing how supervised, task-aware term-weighting schemes can influence feature relevance estimation, ranking stability, and dimensionality reduction effectiveness, particularly in high-dimensional, sparse vector spaces.
These gaps are especially critical in multi-class imbalanced TC scenarios, where representation quality directly affects class separability and the statistical reliability of feature evaluation metrics such as Information Gain. Ignoring this interaction may limit the true potential of both term weighting and FS.
Motivated by these limitations, the present study proposes an integrated and task-aware framework that explicitly links enhanced supervised term weighting (i.e., MTF-MICF) with filter-based FS using Information Gain, ReliefF, and Chi-square. Unlike conventional approaches that treat representation and FS as isolated stages, this work positions supervised term weighting as a supporting mechanism that enhances feature relevance estimation prior to dimensionality reduction. Through systematic experimentation across multiple dimensionality reduction levels and extensive evaluation on benchmark multi-class datasets, this study provides a principled and experimentally validated analysis of the interaction between representation quality and feature selection effectiveness.
This section presents a comprehensive and systematic investigation of the interdependent effects of term weighting schemes and FS, both of which play crucial roles in optimizing classification performance in multi-class TC scenarios. In doing so, this section outlines and summarizes the overall experimental methodology adopted to achieve the research objectives.
As illustrated in Fig. 1, the proposed framework follows a structured pipeline that begins with text data preparation and preprocessing. Subsequently, documents are represented using the BoW and VSM models. Within this representation stage, the impact of term weighting schemes, particularly when combined with FS, is systematically examined. The proposed methodology comprises two main components: (i) introducing an enhanced supervised term weighting scheme, namely Modified Term Frequency-Modified Inverse Class Frequency (MTF-MICF), to improve the quality and discriminative power of feature representation; and (ii) applying the IG filter as a FS mechanism to perform dimensionality reduction and to assess the effectiveness of MTF-MICF when integrated with FS in enhancing classification efficiency.
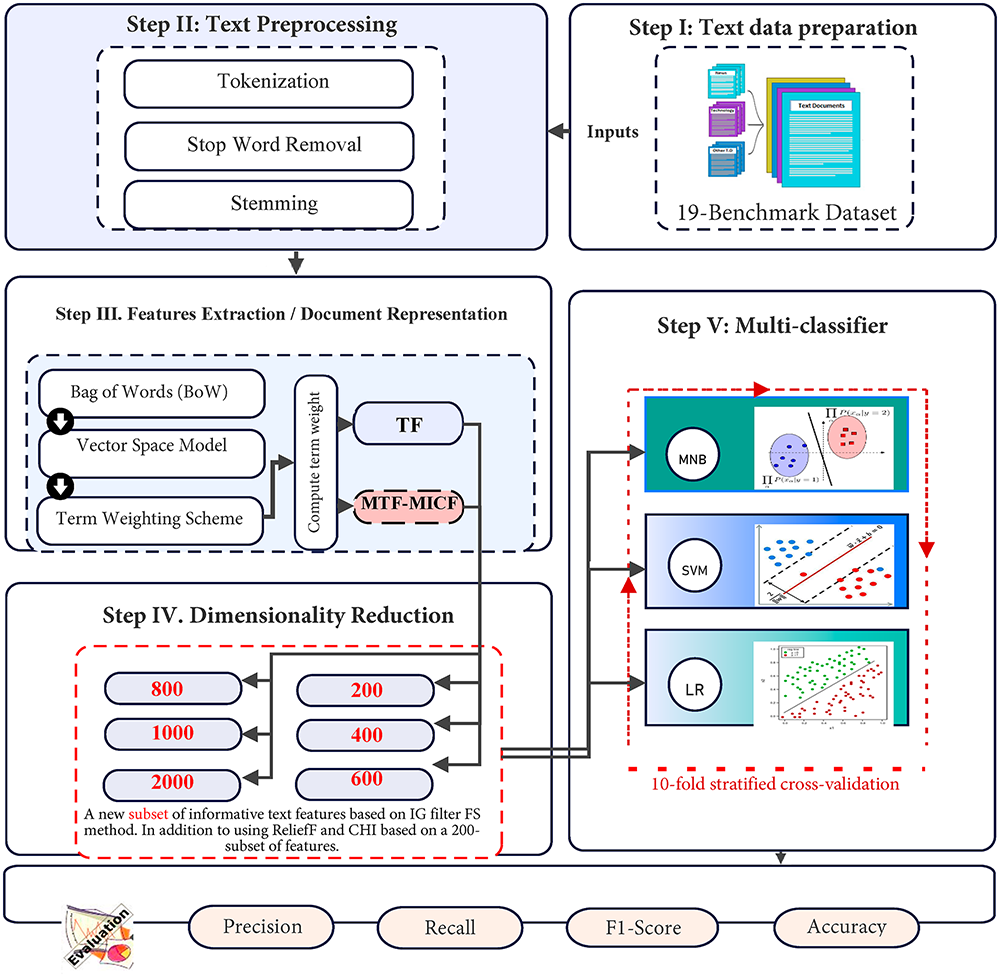
Figure 1: The research methodology phases.
After data preprocessing, feature extraction, and FS, the datasets are partitioned using a holdout strategy, with 80% allocated to training and validation, and the remaining 20% reserved as an independent test set. To address class imbalance and preserve the original class distribution, stratified 10-fold cross-validation is applied to the training portion during model learning and hyperparameter optimization. This validation strategy ensures reliable model selection, reduces performance variance, and guarantees fair representation of minority classes across all folds [69]. Finally, the selected model is evaluated on the unseen test set, which is kept completely isolated from both training and validation processes. This protocol provides an unbiased estimate of the model’s generalization performance and minimizes the risk of overfitting.
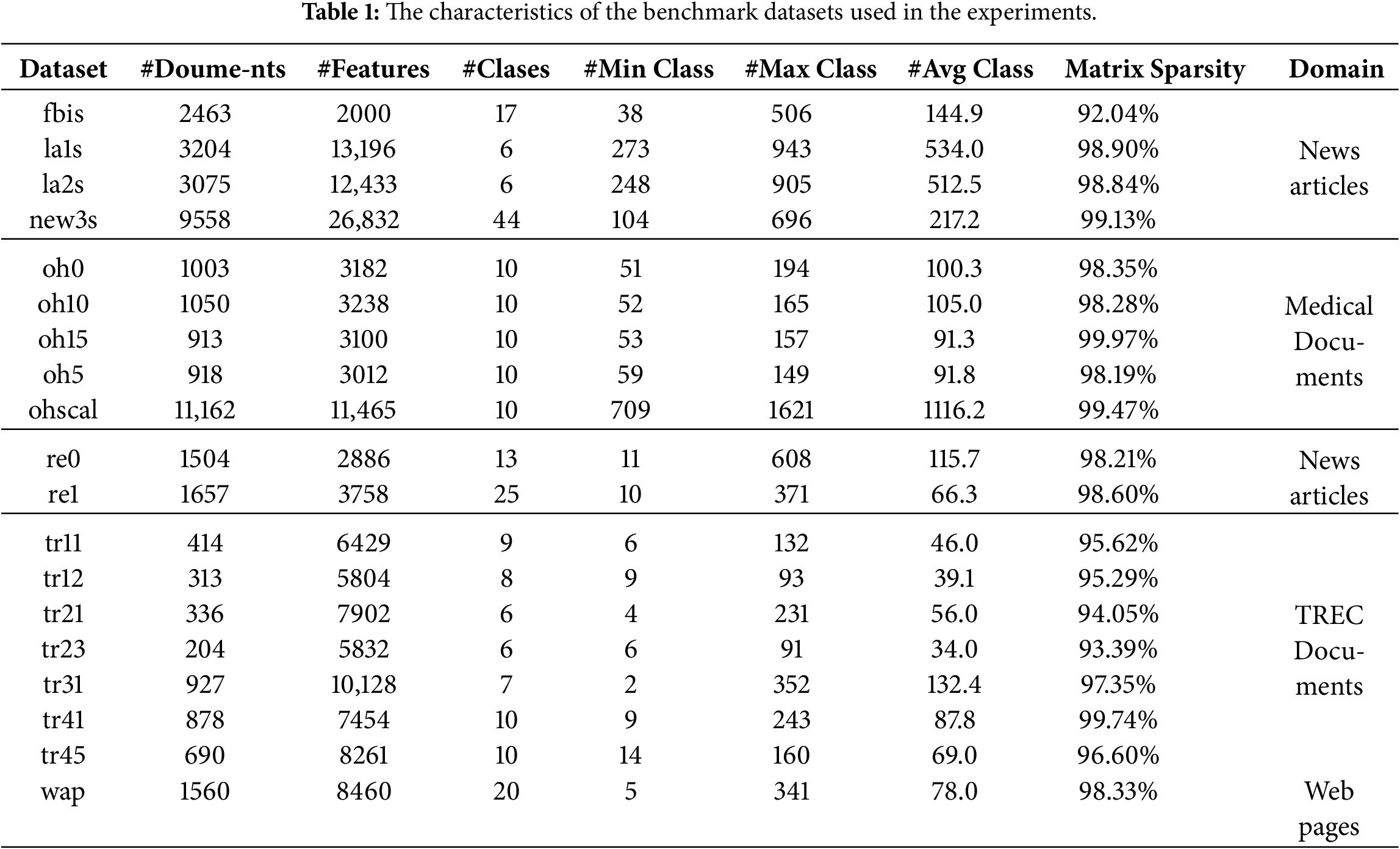
This study employs nineteen text collections extracted from several well-established benchmark corpora, including Reuters-21578, TREC, OHSUMED, and the WebACE project (WAP), as reported in [70]. These datasets cover a wide range of textual domains, including news articles, medical documents, web pages, and TREC collections, thereby enabling a comprehensive evaluation of the proposed approach across diverse application contexts and supporting the development of an accurate, generalizable model.
The selected datasets exhibit substantial variability in size, dimensionality, and class composition, reflecting varying levels of classification difficulty. In many cases, the datasets are characterized by very large vocabularies relative to the number of documents, leading to extremely high feature-to-instance ratios and highly sparse document representations. Such properties are well known to pose significant challenges for learning algorithms, as excessive sparsity can hinder effective pattern learning and degrade classification performance [71,72].
The summary of the characteristics of the nineteen text collections is reported in Table 1.
3.2 Feature Extraction/Documents Representation
Among the most widely adopted document representation models in TC are BoW and VSM. These approaches transform each document into a numerical vector of terms (features), where each dimension corresponds to a distinct term in the vocabulary and is typically associated with its frequency of occurrence within the document. To further refine this representation and enhance its discriminative capability, term weighting schemes assign importance scores to features based on their contribution to distinguishing documents and classes. In this study, an enhanced supervised variant of the Term Frequency-Inverse Class Frequency (TF-ICF) scheme, referred to as MTF-MICF, is adopted from our previous work to improve document representation quality in multi-class imbalanced TC scenarios.
The proposed MTF-MICF scheme is specifically designed to enhance class discrimination and provide more informative input representations for subsequent FS and classification stages. By producing a more discriminative, class-aware term weighting, it facilitates the removal of non-informative features during FS and consequently improves overall classification performance.
The MTF-MICF scheme integrates two complementary components. First, it incorporates a Modified Term Frequency (MTF) factor to preserve informative term frequencies while mitigating bias introduced by variations in document length [14], calculated as:
where fik is the raw term frequency of term ti in dk, and l(dk) is the document length of dk, which is defined as the sum of all term frequencies, and avg_l is the average document length of all training documents.
Second, it introduces a Modified Inverse Class Frequency (MICF) component that jointly considers: (i) the number of categories in which a term appears, and (ii) the average frequency of that term within each category. This dual modeling strategy enables a more balanced, accurate, and class-aware estimation of term importance, particularly in multi-class and imbalanced data settings. The MICF component is computed as follows: (i) The average frequency of each term ti within each category j is calculated as:
where
Next, (ii) the average frequency of each term across all categories is computed as:
where avg_
(iii) to balance the influence of class dispersion and frequency distribution, a weighting parameter 𝛼 is introduced. This parameter controls the trade-off between the number of categories in which a term appears and its average frequency across categories. Accordingly, the proposed Modified Inverse Class Frequency (MICF) is defined as:
where
Finally, the complete MTF-MICF weighting scheme is formulated as:
where
3.3 Dimensionality Reduction Technique
The dimensionality reduction experiment in this study serves a twofold purpose. First, it aims to eliminate irrelevant and weakly informative features, producing compact, discriminative feature subsets that reduce noise, computational complexity, and the risk of overfitting in high-dimensional TC tasks. Given the large variability in vocabulary size and feature dimensionality across benchmark datasets, a fixed set of top-N ranked features is employed to ensure a controlled, dataset-independent evaluation framework.
Since there is no universally standardized range of feature dimensionalities in the literature, many previous studies have explored different dimensionalities to analyze model behavior and performance [61,73–75]. Following this common practice, the number of selected features K is set to range from 200 to 1000 features, with increments of 200 (200, 400, 600, 800, 1000), and an additional setting with 2000 features is included as a reference, corresponding to the maximum dimensionality used in the fbis dataset. This configuration enables a systematic investigation of the impact of feature dimensionality on classification performance and provides a consistent basis for evaluating the effectiveness of the proposed MTF-MICF scheme across datasets with diverse attribute spaces and class distribution.
Second, the experiment is designed to investigate the interaction between FS and the proposed MTF-MICF term weighting scheme under varying reduction ratios using a filter-based approach. By evaluating performance across multiple feature subset sizes, the study assesses its strength and discriminative capacity under both aggressive and moderate feature reduction settings, thereby assessing its ability to preserve informative features as dimensionality decreases.
For this purpose, IG is adopted as the filter-based FS method due to its proven effectiveness in high-dimensional TC. IG measures the reduction in class uncertainty contributed by each feature and ranks them, accordingly, retaining only the most informative terms [66]. This process significantly reduces dimensionality while maintaining strong discriminative power and computational efficiency. Additionally, two widely used filter-based FS techniques, namely Chi-Square (CHI) and ReliefF, were employed to further evaluate the generalizability of the proposed model across different feature ranking strategies.
3.4 Machine Learning Algorithm
To ensure a comprehensive, consistent, and unbiased evaluation, this study adopts the three best-performing classifiers identified as statistically significant in our previous work [76].
3.4.1 Multinomial Naive Bayes (MNB)
MNB is chosen for its simplicity, computational efficiency, and well-established effectiveness in TC tasks, particularly in scenarios where term frequency information plays a dominant role. Despite its strong conditional independence assumption, MNB remains a competitive and reliable baseline for textual data. In this study, MNB is implemented using its standard formulation with default parameter settings.
3.4.2 Support Vector Machine (SVM)
SVMs are particularly well-suited for high-dimensional, sparse feature spaces, which are characteristic of TC problems. By constructing an optimal separating hyperplane, SVM effectively handles large-scale feature spaces while maintaining strong generalization performance. In this study, a linear SVM is employed using the LIBLINEAR library with L2-regularized L2-loss support vector classification (dual formulation) to ensure both scalability and robustness.
3.4.3 Logistic Regression (LR)
LR is a widely used discriminative linear classifier in TC. Unlike linear regression, LR models class membership probabilities through a sigmoid function, thereby providing valid probabilistic outputs. In this study, LR is implemented using LIBLINEAR with L2-regularized logistic regression (dual formulation) to achieve stable, efficient, and scalable optimization.
In TC, particularly in topic classification tasks involving multi-class and imbalanced datasets, selecting appropriate evaluation metrics is crucial for obtaining reliable and meaningful performance estimates. Relying solely on classification accuracy is often inadequate, as it can be biased toward majority classes and may therefore fail to reflect true predictive performance in minority classes [8,76].
For this reason, more informative metrics, such as the F1-score, which combines Precision (P) and Recall (R), are widely recommended [11]. The F1-score provides a balanced trade-off between False Positives (FP) and False Negatives (FN) and thus offers a more robust and reliable assessment of classifier performance under class imbalance conditions. Therefore, in this study, the proposed models are evaluated using both classification accuracy and the weighted-average F1-score, computed from the standard confusion matrix components: True Positives (TP), True Negatives (TN), FP, and FN.
4.1 Experimental Evaluation of MTF-MICF with IG Based on Different Dimension Ratios
Tables 2–4 present a comparative evaluation between the baseline term-weighting scheme (standard Term Frequency—TF) and the enhanced supervised weighting scheme (MTF-MICF), both integrated with IG-based FS across multiple dimensionality levels (200–2000 features). Across the majority of datasets and dimensionality levels, integrating MTF-MICF with IG consistently improves both F1-score and classification accuracy for MNB, SVM, and LR. The improvements are particularly pronounced for MNB and LR, confirming that enhanced supervised weighting strengthens discriminative term representation prior to feature ranking.
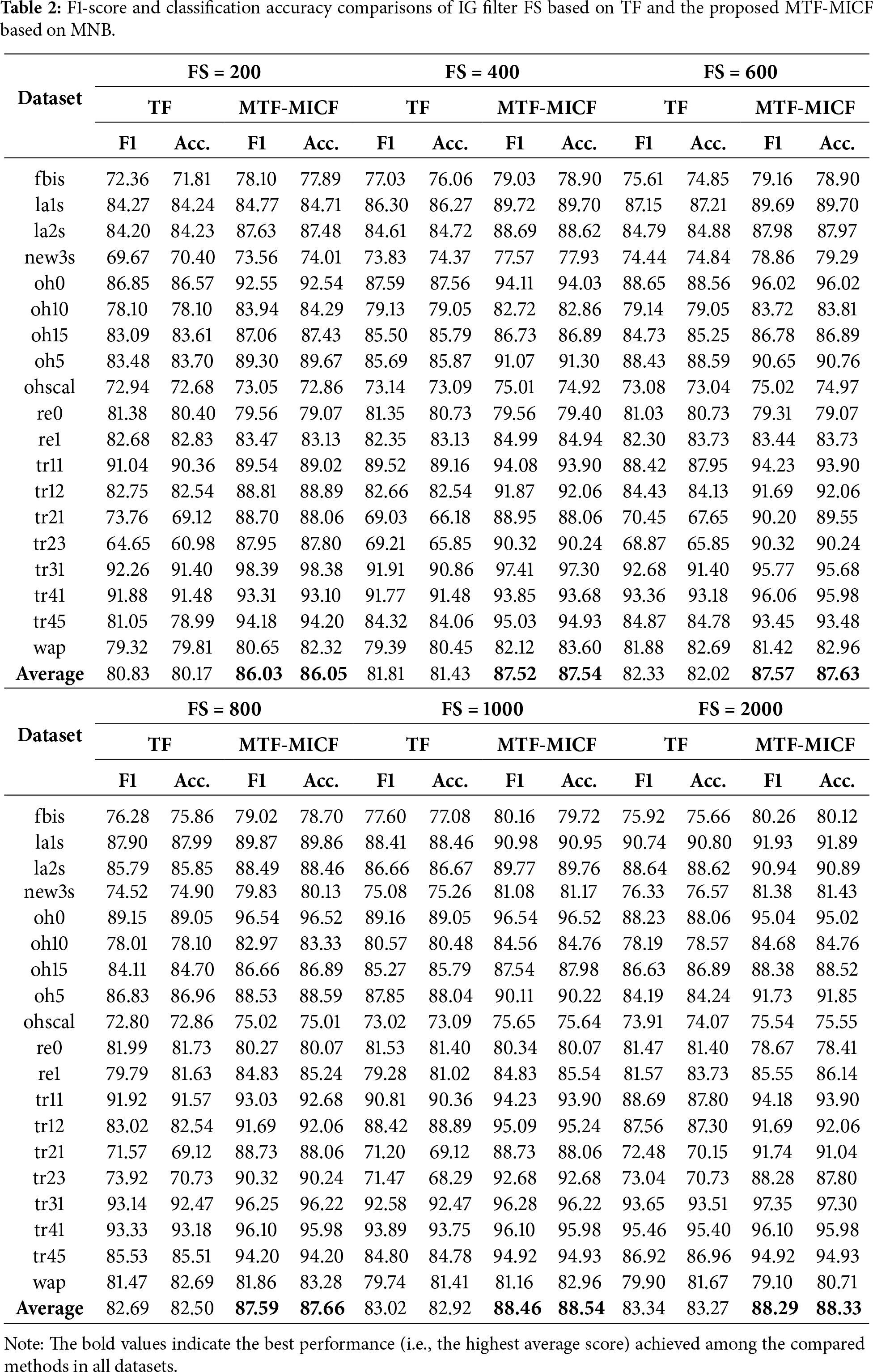
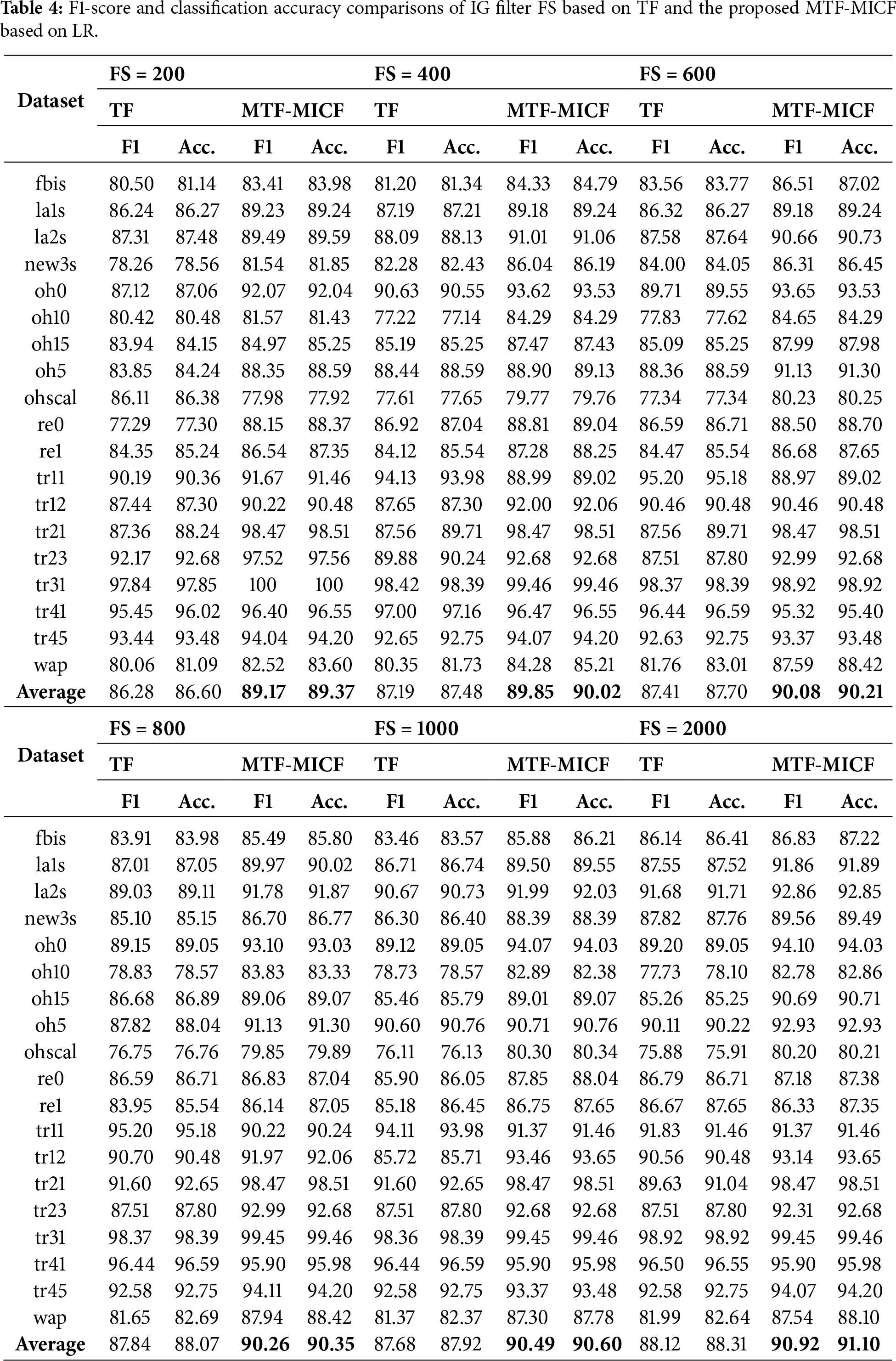
As shown in Table 2, the MNB classifier exhibits consistent and substantial improvements in both average F1-score and classification accuracy across all feature subset sizes when the proposed MTF-MICF scheme is applied. For instance, at FS = 200, the average F1-score increases from 80.83 to 86.03, while classification accuracy improves from 80.17% to 86.05%. Similar performance gains are observed with larger feature subsets, indicating that MNB, which is inherently dependent on accurate term-frequency statistics, benefits strongly from the more stable, class-aware frequency modeling introduced by MTF-MICF. This confirms that enhancing term-frequency representations is particularly crucial for probabilistic classifiers whose decisions are directly driven by word-occurrence statistics.
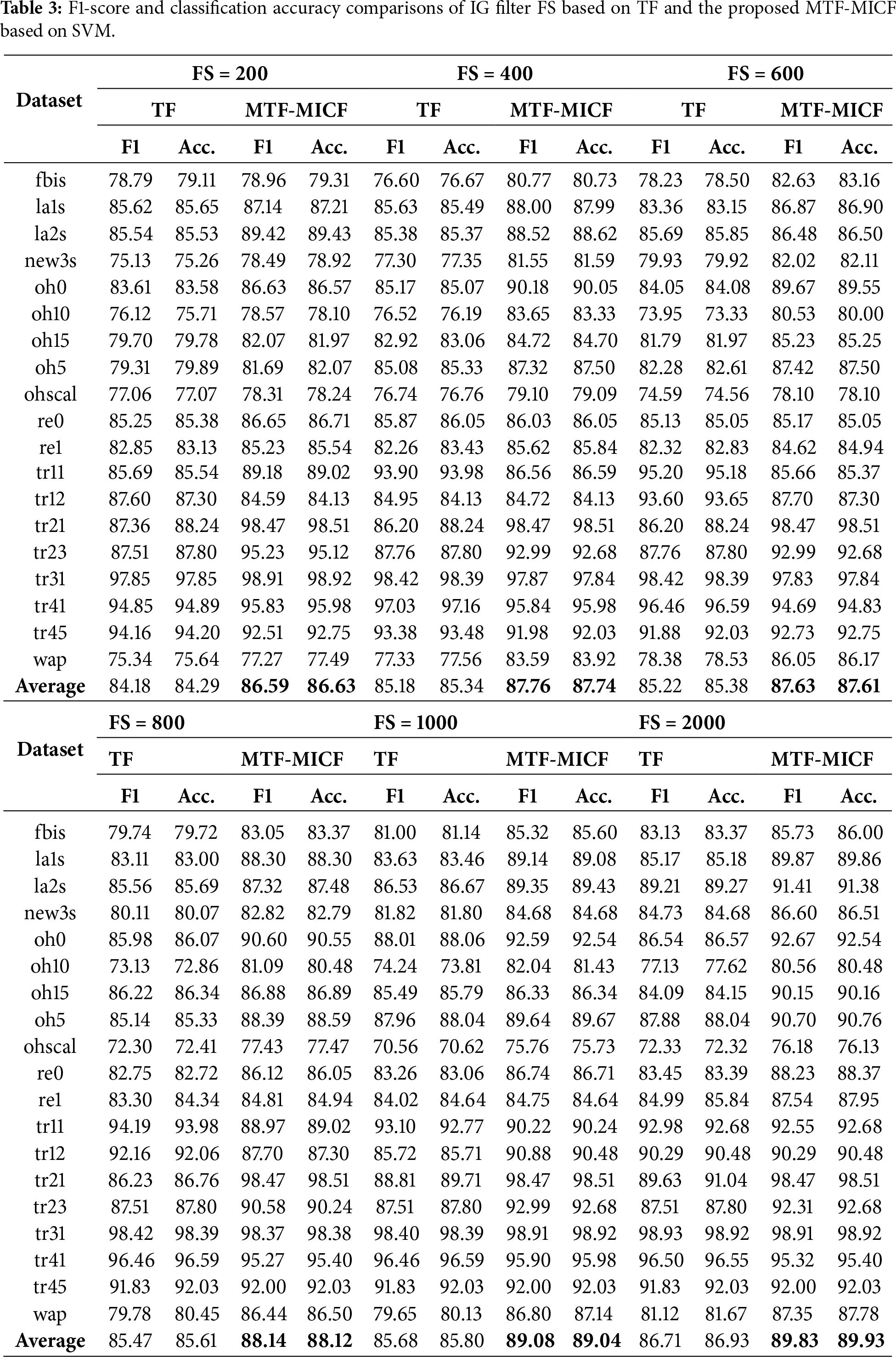
For the SVM classifier, which constructs optimal separating hyperplanes in high-dimensional feature spaces, the integration of the proposed MTF-MICF weighting scheme generally yields consistent and meaningful performance improvements, as shown in Table 3. For instance, at FS = 400, the average F1-score increases from 85.18 to 87.76, while classification accuracy improves from 85.34% to 87.74%. Although these improvements are more moderate compared to those observed with MNB, they remain stable across most feature subset sizes. This behavior indicates that MTF-MICF enhances the discriminative structure of the feature space, thereby improving class separability and enabling SVM to estimate more reliable decision boundaries, even under reduced-dimensional settings.
Nevertheless, despite the overall positive trend, certain configurations exhibit localized performance degradation relative to the TF baseline. For example, the tr11 dataset with SVM at FS = 400 shows a noticeable decrease in both F1-score and accuracy, with minor fluctuations also observed at FS = 800. These isolated cases can be attributed to the interaction between dataset-specific characteristics, feature subset size, and the sensitivity of margin-based classifiers to feature scaling. Specifically, the tr11 dataset exhibits relatively balanced class distributions and moderately discriminative term patterns, where IG-based FS under the TF representation may already preserve highly informative features at intermediate dimensionality levels. In such cases, introducing additional class-sensitive scaling through MICF may slightly alter the geometric distribution of feature vectors, which can affect the margin optimization process of SVM. This effect is particularly evident when the feature space is neither sufficiently reduced to benefit fully from enhanced weighting nor large enough to absorb scaling variations smoothly. Importantly, this degradation is localized rather than systematic, as performance improvements resume at higher dimensionality levels, confirming the overall robustness and effectiveness of the proposed weighting scheme across diverse experimental conditions.
Similarly, for the LR classifier (Table 4), the performance gains introduced by MTF-MICF are particularly pronounced. For instance, at FS = 600, the F1-score increases from 87.41 to 90.08, and classification accuracy improves from 87.70% to 90.21%. Comparable trends are observed across other feature subset sizes, indicating that LR benefits significantly from the improved feature scaling and class-aware weighting provided by MTF-MICF, especially in moderately to highly dimensional settings where representation quality plays a dominant role.
The experimental results clearly demonstrate that the effectiveness of FS is strongly dependent on the quality of the underlying document representation, particularly in high-dimensional TC problems characterized by extreme sparsity and class imbalance, as reported in Table 1. In sparse text matrices, where sparsity often exceeds 99%, most terms occur infrequently and contribute limited statistical evidence for reliable feature evaluation. Under such conditions, conventional TF-based representations tend to assign similar importance to both discriminative and non-discriminative rare terms, thereby weakening the reliability of entropy-based feature ranking methods such as IG. Since IG estimates feature importance based on the reduction of class uncertainty, its effectiveness is fundamentally constrained by the statistical fidelity of the underlying term weights. If term weights do not adequately reflect class-specific distributions, the estimated entropy reduction becomes less reliable, particularly in extremely sparse and imbalanced settings.
By integrating the MICF component into the MTF formulation, the proposed MTF-MICF scheme introduces an explicit class-discriminative scaling factor that adjusts term importance according to its distribution across classes rather than solely its frequency within documents. Mathematically, MICF amplifies terms that are concentrated in a limited number of classes while suppressing terms that are uniformly distributed across many classes. This mechanism effectively increases the signal-to-noise ratio in sparse feature spaces by strengthening the contribution of class-indicative terms and reducing the influence of globally frequent but non-discriminative terms. As sparsity increases, this class-sensitive scaling becomes increasingly important because the discriminative information is concentrated in a small subset of informative features. Consequently, the proposed representation improves the separability between class-conditional feature distributions, which directly enhances the reliability of entropy-based ranking and enables IG to select more informative features even under aggressive dimensionality reduction.
The benefits of MTF-MICF are particularly evident in datasets with severe class imbalance, where conventional TF weighting tends to be biased toward majority-class term distributions. In imbalanced settings, terms associated with minority classes often have lower absolute frequencies and may be undervalued or discarded during FS. The MICF component mitigates this limitation by assigning higher weights to terms that exhibit strong class specificity, regardless of their global frequency. This improves the relative representation of minority-class features and leads to more balanced entropy estimates during IG-based ranking. From a theoretical perspective, this improves the estimation of class-conditional probability distributions, resulting in more accurate posterior probability estimation for probabilistic classifiers (e.g., MNB) and improved margin separability for discriminative classifiers (e.g., SVM and LR).
As sparsity approaches extreme levels, the discriminative power of representation becomes the dominant factor controlling classification performance. In such regimes, FS alone cannot compensate for weak or noisy representations, because entropy-based ranking relies entirely on the statistical structure encoded in the term weights. By improving the alignment between term weights and class-conditional distributions, MTF-MICF enhances the intrinsic quality of the feature space prior to FS. This leads to more stable feature importance estimation, promotes the earlier selection of truly discriminative features, and improves classification performance across different dimensionality levels. Although localized underperformance is observed in a limited number of configurations (e.g., tr11 and tr12), these cases reflect dataset-specific interactions between feature distribution, sparsity structure, and classifier sensitivity, rather than a systematic limitation of the proposed weighting scheme.
Across the comprehensive experimental setting, including 19 benchmark datasets with varying sparsity levels and imbalance ratios, three fundamentally different classifiers, and six dimensionality levels, the proposed MTF-MICF scheme consistently achieves statistically meaningful improvements in both average F1-score and classification accuracy compared to the TF baseline. Notably, the performance gains are more pronounced in datasets exhibiting higher sparsity and stronger imbalance, confirming that the proposed class-sensitive weighting mechanism becomes increasingly beneficial as the statistical estimation problem becomes more challenging. These findings confirm that MTF-MICF plays a central role in improving classification performance by enhancing representation quality prior to FS. By tightly integrating class-aware term weighting with IG-based FS, the proposed framework produces more informative, stable, and discriminative feature subsets while maintaining computational efficiency.
A more comprehensive view of these trends is illustrated in Fig. 2a–f, which depicts the performance of IG filter-based FS with MTF-MICF and without MTF-MICF (using baseline TF) across different dimensionality reduction ratios using MNB, SVM, and LR classifiers. Across all three classifiers, MTF-MICF consistently improves both average F1-score and accuracy for all feature subset sizes (FS = 200, 400, 600, 800, 1000, and 2000). However, the magnitude and dynamics of these improvements vary with the dimensionality level and the learning model. For MNB, the performance gains become more pronounced as the number of retained features increases, indicating that MTF-MICF effectively mitigates information loss induced by aggressive dimensionality reduction while preserving the discriminative power of frequent and class-indicative terms. For SVM, the improvements are more gradual but steady, reflecting the fact that better term weighting primarily refines the geometry of the decision boundary rather than radically altering the feature space structure. For LR, the gains are especially evident in higher-dimensional settings, where MTF-MICF provides better-scaled, more informative inputs, thereby facilitating more accurate probability estimation and improved class separation.
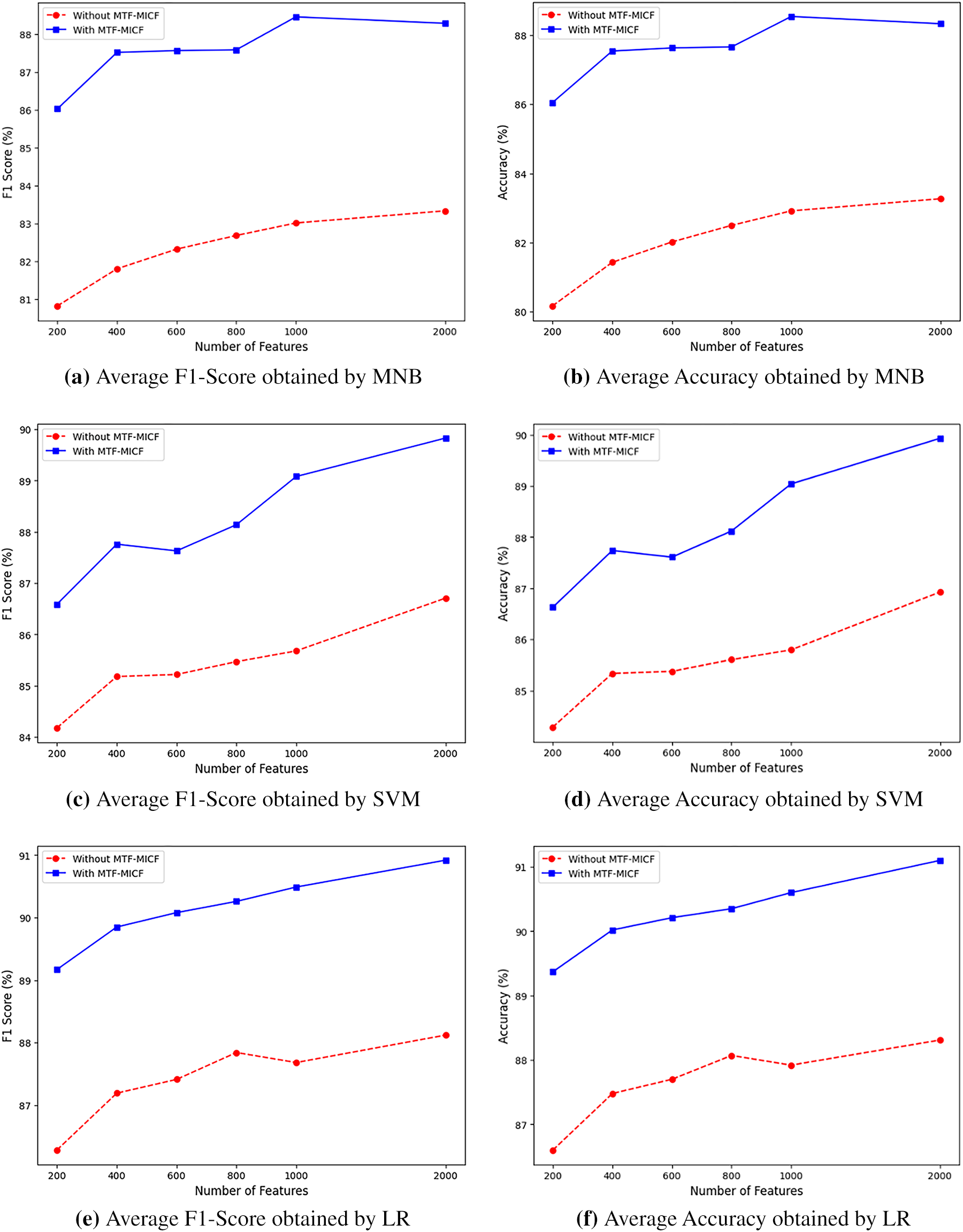
Figure 2: Performance comparison of filter-based FS with and without MTF-MICF across varying feature dimensions.
Overall, these results demonstrate that MTF-MICF not only enhances feature representation quality but also improves learning robustness under varying dimensionality constraints. More importantly, the consistent performance gains across fundamentally different classifiers confirm that the proposed scheme captures intrinsic, classifier-independent properties of term-class relevance. From a broader perspective, these findings indicate that carefully designed, class-aware term weighting is not merely a preprocessing refinement, but a central component in controlling the trade-off between dimensionality reduction and information preservation in high-dimensional, multi-class, and imbalanced TC problems. Consequently, MTF-MICF provides a principled and effective mechanism for managing high-dimensional textual data while maintaining strong and stable classification performance, thereby validating its role as a key building block in the proposed FS and learning framework.
4.2 Experimental Evaluation of MTF-MICF with ReliefF and Chi-Square
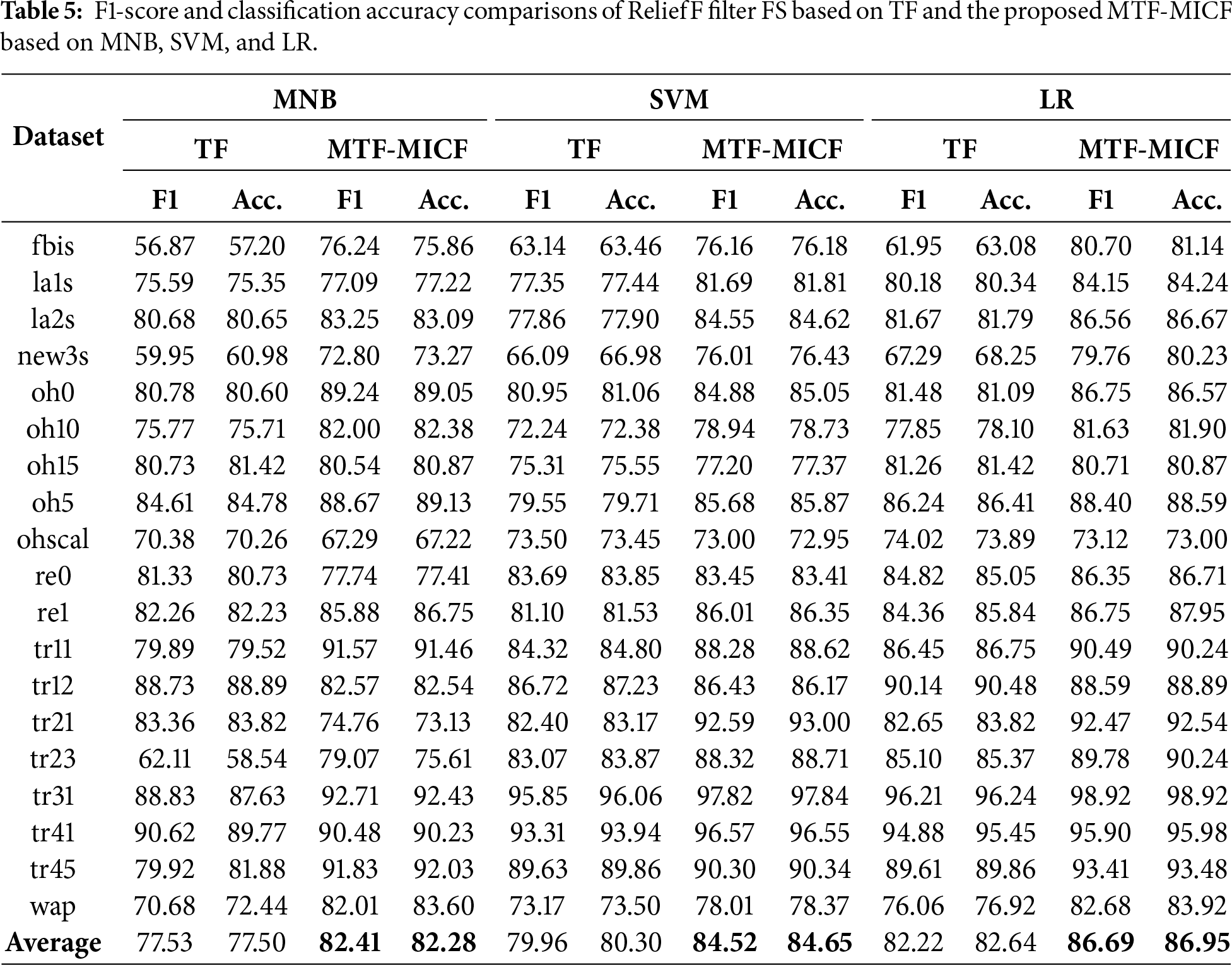
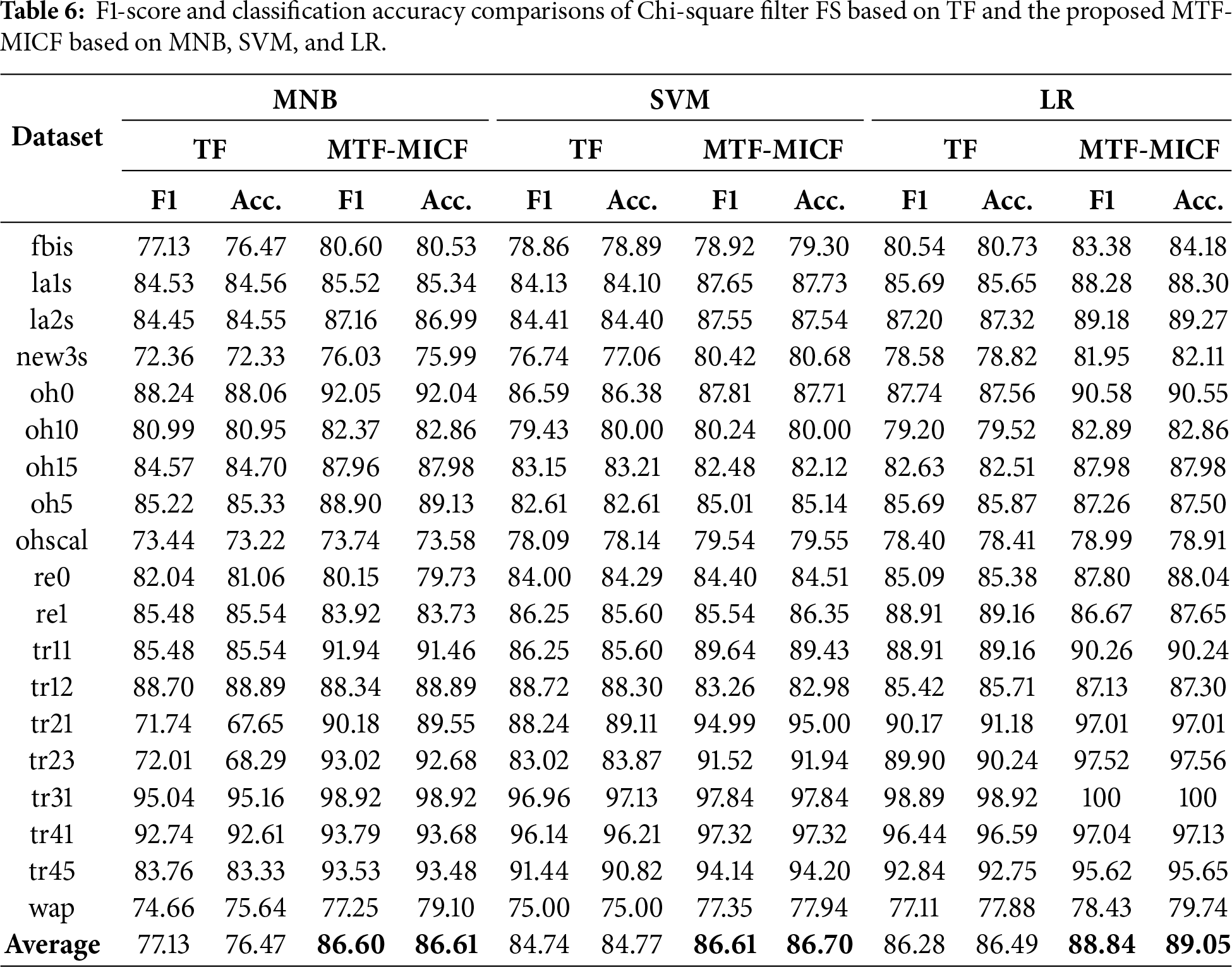
The effectiveness of the proposed MTF-MICF term-weighting scheme was further evaluated using additional filter-based FS methods to examine whether its impact is specific to IG or generalizable across different feature ranking strategies. In particular, two widely used filter techniques, Chi-Square (CHI) and ReliefF, were employed to assess the interaction between the enhanced document representation and alternative FS mechanisms. For computational efficiency and fair comparison, the MTF-MICF weighting scheme was first applied to the full feature space, after which the FS methods were used to extract the top 200 most informative features. This subset size was selected to significantly reduce the computational cost associated with repeated training and evaluation while preserving a representative set of discriminative features for reliable comparison. By fixing the dimensionality level, the experiments focus specifically on analyzing how the enhanced term representation produced by MTF-MICF influences the effectiveness of different FS strategies in ranking and selecting informative terms.
The results reported in Tables 5 and 6 demonstrate that integrating the proposed MTF-MICF weighting scheme consistently improves classification performance compared with the TF baseline when combining with the two widely used filter-based FS methods, namely ReliefF and Chi-Square. Based on the average F1-score and classification accuracy across the 19 benchmark datasets, MTF-MICF achieves noticeable improvements for all three classifiers (MNB, SVM, and LR). For instance, under the ReliefF-based FS (Table 5), the average F1-score increases from 77.53 to 82.41 for MNB, from 79.96 to 84.52 for SVM, and from 82.22 to 86.69 for LR. Similarly, under the Chi-Square-based FS (Table 6), the average results also confirm consistent gains across most datasets and classifiers. Moreover, dataset-level analysis indicates that the proposed representation frequently achieves higher performance on the majority of datasets, further confirming that the enhanced MTF-MICF representation improves the effectiveness of feature ranking and selection. These results indicate that the proposed weighting scheme functions as a robust supporting mechanism for different FS strategies, rather than being limited to a specific FS method.
This study presents a comprehensive investigation into the joint impact of supervised, class-aware term weighting (i.e., MTF-MICF) and filter-based FS (i.e., IG, CHI, and ReliefF) on classification performance for multi-class and imbalanced TC tasks. Rather than treating these two stages as independent preprocessing steps, the proposed framework explicitly integrates them into a unified pipeline, where improved representation quality directly facilitates more effective, stable, and discriminative feature subset selection. Extensive experimental evaluations across nineteen benchmark datasets demonstrate that filter-based FS, combined with MTF-MICF, consistently improves both F1-score and classification accuracy across different classifiers, feature subset sizes, and dimensionality reduction ratios. The results confirm that the proposed approach is not only accurate and scalable, but also highly effective in preserving discriminative information under both aggressive and moderate feature reduction settings. In particular, the analysis across varying feature dimensionalities shows that MTF-MICF maintains stable performance gains, highlighting its generalizability and suitability for small and medium-sized training datasets where feature sparsity and class imbalance are more pronounced. These findings provide strong evidence that class-aware term weighting, when tightly coupled with FS, should be regarded as a core component of modern TC systems rather than merely a preprocessing refinement. Despite the consistent performance of the proposed framwork, several promising research directions remain. Future work will focus on integrating MTF-MICF with ensemble multi-filter and metaheuristic optimization frameworks to further enhance FS constancy and performance, and on extending it to deep learning, cross-domain, and low-resource TC settings. In addition, a systematic sensitivity analysis of the balancing parameter 𝛼 used in the MICF formulation will be conducted to further investigate its influence on classification performance under different data characteristics, such as varying levels of sparsity, class imbalance, and vocabulary size.
Acknowledgement: We would like to express our sincere gratitude to the School of Computer Sciences, Universiti Sains Malaysia (USM), for their encouragement, support, and the conducive academic environment provided throughout this work.
Funding Statement: This work was supported by the Fundamental Research Grant Scheme (FRGS), Ministry of Higher Education Malaysia, under Grant FRGS/1/2023/ICT02/USM/02/4.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Osamah Mohammed Alyasiri; data collection: Osamah Mohammed Alyasiri; analysis and interpretation of results: Osamah Mohammed Alyasiri, Yu-N Cheah; writing—original draft preparation, Osamah Mohammed Alyasiri; writing—review and editing, Osamah Mohammed Alyasiri, Yu-N Cheah; supervision, Yu-N Cheah. All authors reviewed and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in [WEKA platform website] at [https://sourceforge.net/projects/weka/files/datasets/text-datasets/19MclassTextWc.zip/download].
Ethics Approval: This article does not contain any studies with human participants or animals performed by any of the authors.
Conflicts of Interest: The authors declare no conflicts of interest.
References
1. Ayash L, Algarni A, Alqahtani O. Advancements in feature selection and extraction methods for text mining: a review. Discov Appl Sci. 2025;7(8):914. doi:10.1007/s42452-025-07587-w. [Google Scholar] [CrossRef]
2. Allam H, Makubvure L, Gyamfi B, Graham KN, Akinwolere K. Text classification: how machine learning is revolutionizing text categorization. Information. 2025;16(2):130. doi:10.3390/info16020130. [Google Scholar] [CrossRef]
3. Islam MR, Lima AA, Das SC, Mridha MF, Prodeep AR, Watanobe Y. A comprehensive survey on the process, methods, evaluation, and challenges of feature selection. IEEE Access. 2022;10(8):99595–632. doi:10.1109/access.2022.3205618. [Google Scholar] [CrossRef]
4. Dhal P, Azad C. A comprehensive survey on feature selection in the various fields of machine learning. Appl Intell. 2022;52(4):4543–81. doi:10.1007/s10489-021-02550-9. [Google Scholar] [CrossRef]
5. Song X, Zhang Y, Zhang W, He C, Hu Y, Wang J, et al. Evolutionary computation for feature selection in classification: a comprehensive survey of solutions, applications and challenges. Swarm Evol Comput. 2024;90(4):101661. doi:10.1016/j.swevo.2024.101661. [Google Scholar] [CrossRef]
6. Pintas JT, Fernandes LAF, Garcia ACB. Feature selection methods for text classification: a systematic literature review. Artif Intell Rev. 2021;54(8):6149–200. doi:10.1007/s10462-021-09970-6. [Google Scholar] [CrossRef]
7. Dhar A, Mukherjee H, Dash NS, Roy K. Text categorization: past and present. Artif Intell Rev. 2020;54(4):3007–54. doi:10.1007/s10462-020-09919-1. [Google Scholar] [CrossRef]
8. Alyasiri OM, Cheah YN, Zhang H, Al-Janabi OM, Abasi AK. Text classification based on optimization feature selection methods: a review and future directions. Multimed Tools Appl. 2025;84(15):14187–233. doi:10.1007/s11042-024-19769-6. [Google Scholar] [CrossRef]
9. Nafis NSM, Awang S. The impact of pre-processing and feature selection on text classification. In: Advances in electronics engineering. Singapore: Springer; 2019. p. 269–80. doi:10.1007/978-981-15-1289-6_25. [Google Scholar] [CrossRef]
10. Hong M, Wang H. Filter feature selection methods for text classification: a review. Multimed Tools Appl. 2024;83(1):2053–91. doi:10.1007/s11042-023-15675-5. [Google Scholar] [CrossRef]
11. Theng D, Bhoyar KK. Feature selection techniques for machine learning: a survey of more than two decades of research. Knowl Inf Syst. 2024;66(3):1575–637. doi:10.1007/s10115-023-02010-5. [Google Scholar] [CrossRef]
12. HaCohen-Kerner Y, Miller D, Yigal Y. The influence of preprocessing on text classification using a bag-of-words representation. PLoS One. 2020;15(5):e0232525. doi:10.1371/journal.pone.0232525. [Google Scholar] [PubMed] [CrossRef]
13. Samant SS, Bhanu Murthy NL, Malapati A. Improving term weighting schemes for short text classification in vector space model. IEEE Access. 2019;7:166578–92. doi:10.1109/ACCESS.2019.2953918. [Google Scholar] [CrossRef]
14. Chen L, Jiang L, Li C. Using modified term frequency to improve term weighting for text classification. Eng Appl Artif Intell. 2021;101(2–3):104215. doi:10.1016/j.engappai.2021.104215. [Google Scholar] [CrossRef]
15. Okkalioglu M. TF-IGM revisited: imbalance text classification with relative imbalance ratio. Expert Syst Appl. 2023;217(6):119578. doi:10.1016/j.eswa.2023.119578. [Google Scholar] [CrossRef]
16. Alsaeedi A. A survey of term weighting schemes for text classification. Int J Data Min Model Manag. 2020;12(2):237. doi:10.1504/ijdmmm.2020.106741. [Google Scholar] [CrossRef]
17. Mazyad A, Teytaud F, Fonlupt C. A comparative study on term weighting schemes for text classification. In: Machine learning, optimization, and big data. Cham, Switzerland: Springer; 2018. p. 100–8. doi:10.1007/978-3-319-72926-8_9. [Google Scholar] [CrossRef]
18. Rathi RN, Mustafi A. The importance of Term Weighting in semantic understanding of text: a review of techniques. Multimed Tools Appl. 2023;82(7):9761–83. doi:10.1007/s11042-022-12538-3. [Google Scholar] [PubMed] [CrossRef]
19. Thirumoorthy K, Muneeswaran K. Optimal feature subset selection using hybrid binary Jaya optimization algorithm for text classification. Sādhanā. 2020;45(1):201. doi:10.1007/s12046-020-01443-w. [Google Scholar] [CrossRef]
20. Çekik R. Effective text classification through supervised rough set-based term weighting. Symmetry. 2025;17(1):90. doi:10.3390/sym17010090. [Google Scholar] [CrossRef]
21. Alyasiri OM, Cheah YN, Abasi AK, Al-Janabi OM. Wrapper and hybrid feature selection methods using metaheuristic algorithms for English text classification: a systematic review. IEEE Access. 2022;10(1):39833–52. doi:10.1109/ACCESS.2022.3165814. [Google Scholar] [CrossRef]
22. Farek L, Benaidja A. A hybrid feature selection method for text classification using a feature-correlation-based genetic algorithm. Soft Comput. 2024;28(23):13567–93. doi:10.1007/s00500-024-10386-x. [Google Scholar] [CrossRef]
23. Attieh J, Tekli J. Supervised term-category feature weighting for improved text classification. Knowl Based Syst. 2023;261(1):110215. doi:10.1016/j.knosys.2022.110215. [Google Scholar] [CrossRef]
24. Aditya CSK, Sumadi FDS. Combination of term weighting with class distribution and centroid-based approach for document classification. Kinetik. 2023;8(4):781–8. doi:10.22219/kinetik.v8i4. [Google Scholar] [CrossRef]
25. Okkalioglu M. A novel redistribution-based feature selection for text classification. Expert Syst Appl. 2024;246(2):123119. doi:10.1016/j.eswa.2023.123119. [Google Scholar] [CrossRef]
26. Shehzad F, Rehman A, Javed K, Alnowibet KA, Babri HA, Rauf HT. Binned term count: an alternative to term frequency for text categorization. Mathematics. 2022;10(21):4124. doi:10.3390/math10214124. [Google Scholar] [CrossRef]
27. Das M, Kamalanathan S, Alphonse P. A comparative study on TF-IDF feature weighting method and its analysis using unstructured dataset. arXiv:2308.04037. 2023. [Google Scholar]
28. Jiang Z, Gao B, He Y, Han Y, Doyle P, Zhu Q. Text classification using novel term weighting scheme-based improved TF-IDF for internet media reports. Math Probl Eng. 2021;2021(1):6619088. doi:10.1155/2021/6619088. [Google Scholar] [CrossRef]
29. Naderalvojoud B, Akcapinar Sezer E. Term evaluation metrics in imbalanced text categorization. Nat Lang Eng. 2020;26(1):31–47. doi:10.1017/s1351324919000317. [Google Scholar] [CrossRef]
30. Sabbah T, Selamat A, Selamat MH, Al-Anzi FS, Viedma EH, Krejcar O, et al. Modified frequency-based term weighting schemes for text classification. Appl Soft Comput. 2017;58(1):193–206. doi:10.1016/j.asoc.2017.04.069. [Google Scholar] [CrossRef]
31. Tang Z, Li W, Li Y. An improved supervised term weighting scheme for text representation and classification. Expert Syst Appl. 2022;189(24):115985. doi:10.1016/j.eswa.2021.115985. [Google Scholar] [CrossRef]
32. Debole F, Sebastiani F. Supervised term weighting for automated text categorization. In: Text mining and its applications. Berlin/Heidelberg, Germany: Springer; 2004. p. 81–97. doi:10.1007/978-3-540-45219-5_7. [Google Scholar] [CrossRef]
33. Liu Y, Loh HT, Sun A. Imbalanced text classification: a term weighting approach. Expert Syst Appl. 2009;36(1):690–701. doi:10.1016/j.eswa.2007.10.042. [Google Scholar] [CrossRef]
34. Altınçay H, Erenel Z. Analytical evaluation of term weighting schemes for text categorization. Pattern Recognit Lett. 2010;31(11):1310–23. doi:10.1016/j.patrec.2010.03.012. [Google Scholar] [CrossRef]
35. Lertnattee V, Theeramunkong T. Analysis of inverse class frequency in centroid-based text classification. In: Proceedings of the IEEE International Symposium on Communications and Information Technology; 2004 Oct 26–29; Sapporo, Japan. p. 1171–6. doi:10.1109/ISCIT.2004.1413903. [Google Scholar] [CrossRef]
36. Ren F, Sohrab MG. Class-indexing-based term weighting for automatic text classification. Inf Sci. 2013;236(5):109–25. doi:10.1016/j.ins.2013.02.029. [Google Scholar] [CrossRef]
37. Chen K, Zhang Z, Long J, Zhang H. Turning from TF-IDF to TF-IGM for term weighting in text classification. Expert Syst Appl. 2016;66(11):245–60. doi:10.1016/j.eswa.2016.09.009. [Google Scholar] [CrossRef]
38. Quan X, Liu W, Qiu B. Term weighting schemes for question categorization. IEEE Trans Pattern Anal Mach Intell. 2011;33(5):1009–21. doi:10.1109/TPAMI.2010.154. [Google Scholar] [PubMed] [CrossRef]
39. Lan M, Tan CL, Su J, Lu Y. Supervised and traditional term weighting methods for automatic text categorization. IEEE Trans Pattern Anal Mach Intell. 2009;31(4):721–35. doi:10.1109/TPAMI.2008.110. [Google Scholar] [PubMed] [CrossRef]
40. Dogan T, Uysal AK. Improved inverse gravity moment term weighting for text classification. Expert Syst Appl. 2019;130(2):45–59. doi:10.1016/j.eswa.2019.04.015. [Google Scholar] [CrossRef]
41. Chen L, Jiang L, Li C. Modified DFS-based term weighting scheme for text classification. Expert Syst Appl. 2021;168(2–3):114438. doi:10.1016/j.eswa.2020.114438. [Google Scholar] [CrossRef]
42. Wang H, Hong M. Supervised Hebb rule based feature selection for text classification. Inf Process Manag. 2019;56(1):167–91. doi:10.1016/j.ipm.2018.09.004. [Google Scholar] [CrossRef]
43. Palacharla RK, Vatsavayi VK. A novel approach for text classification using feature selection algorithm and term weight measures. In: Accelerating discoveries in data science and artificial intelligence I. Cham, Switzerland: Springer; 2024. p. 287–301. doi:10.1007/978-3-031-51167-7_28. [Google Scholar] [CrossRef]
44. Iqbal M, Abid MM, Khalid MN, Manzoor A. Review of feature selection methods for text classification. Int J Adv Comput Res. 2020;10(49):138–52. doi:10.19101/ijacr.2020.1048037. [Google Scholar] [CrossRef]
45. Dogra V, Singh A, Verma S, Kavita, Jhanjhi NZ, Talib MN. Understanding of data preprocessing for dimensionality reduction using feature selection techniques in text classification. In: Intelligent computing and innovation on data science. Singapore: Springer; 2021. p. 455–64. doi:10.1007/978-981-16-3153-5_48. [Google Scholar] [CrossRef]
46. Ashokkumar P, Siva Shankar G, Srivastava G, Maddikunta PKR, Gadekallu TR. A two-stage text feature selection algorithm for improving text classification. ACM Trans Asian Low-Resour Lang Inf Process. 2021;20(3):1–19. doi:10.1145/3425781. [Google Scholar] [CrossRef]
47. Labani M, Moradi P, Jalili M. A multi-objective genetic algorithm for text feature selection using the relative discriminative criterion. Expert Syst Appl. 2020;149:113276. doi:10.1016/j.eswa.2020.113276. [Google Scholar] [CrossRef]
48. Cekik R. A new filter feature selection method for text classification. IEEE Access. 2024;12(1):139316–35. doi:10.1109/ACCESS.2024.3468001. [Google Scholar] [CrossRef]
49. Al-Shalif SA, Senan N, Saeed F, Ghaban W, Ibrahim N, Aamir M, et al. A systematic literature review on meta-heuristic based feature selection techniques for text classification. PeerJ Comput Sci. 2024;10(3):e2084. doi:10.7717/peerj-cs.2084. [Google Scholar] [PubMed] [CrossRef]
50. Farek L, Benaidja A. An optimal feature selection method for text classification through redundancy and synergy analysis. Multimed Tools Appl. 2025;84(16):16397–423. doi:10.1007/s11042-024-19736-1. [Google Scholar] [CrossRef]
51. Cascaro RJ, Gerardo BD, Medina RP. Filter selection methods for multiclass classification. In: Proceedings of the 2nd International Conference on Computing and Big Data; 2019 Oct 18–20; Taichung, Taiwan. p. 27–31. doi:10.1145/3366650.3366655. [Google Scholar] [CrossRef]
52. Lazhar F, Amira B. Semantic similarity-aware feature selection and redundancy removal for text classification using joint mutual information. Knowl Inf Syst. 2024;66(10):6187–212. doi:10.1007/s10115-024-02143-1. [Google Scholar] [CrossRef]
53. Farek L, Benaidja A. A non-redundant feature selection method for text categorization based on term co-occurrence frequency and mutual information. Multimed Tools Appl. 2024;83(7):20193–214. doi:10.1007/s11042-023-15876-y. [Google Scholar] [CrossRef]
54. Thirumoorthy K, Muneeswaran K. Feature selection for text classification using machine learning approaches. Natl Acad Sci Lett. 2022;45(1):51–6. doi:10.1007/s40009-021-01043-0. [Google Scholar] [CrossRef]
55. Badawi SS, Saeed AM, Ahmed SA, Hassan DA. Enhanced category-feature association measure: a robust approach for text classification through feature selection. Aro Sci J Koya Univ. 2025;13(2):114–23. doi:10.14500/aro.12034. [Google Scholar] [CrossRef]
56. Farghaly HM, Abd El-Hafeez T. A new feature selection method based on frequent and associated itemsets for text classification. Concurr Comput Pract Exp. 2022;34(25):e7258. doi:10.1002/cpe.7258. [Google Scholar] [CrossRef]
57. Singh KN, Devi HM, Mahant AK, Dorendro A. FE-TAC: an effective document classification method combining feature extraction and feature selection. Int J Appl Decis Sci. 2023;16(6):717–40. doi:10.1504/ijads.2023.134204. [Google Scholar] [CrossRef]
58. Bolón-Canedo V, Alonso-Betanzos A. Ensembles for feature selection: a review and future trends. Inf Fusion. 2019;52(2):1–12. doi:10.1016/j.inffus.2018.11.008. [Google Scholar] [CrossRef]
59. Seijo-Pardo B, Porto-Díaz I, Bolón-Canedo V, Alonso-Betanzos A. Ensemble feature selection: homogeneous and heterogeneous approaches. Knowl Based Syst. 2017;118(2):124–39. doi:10.1016/j.knosys.2016.11.017. [Google Scholar] [CrossRef]
60. Fu G, Li B, Yang Y, Li C. Re-ranking and TOPSIS-based ensemble feature selection with multi-stage aggregation for text categorization. Pattern Recognit Lett. 2023;168(3):47–56. doi:10.1016/j.patrec.2023.02.027. [Google Scholar] [CrossRef]
61. Theng D, Bhoyar KK. Stability of feature selection algorithms. In: Artificial intelligence on medical data. Singapore: Springer; 2023. p. 299–316. doi:10.1007/978-981-19-0151-5_26. [Google Scholar] [CrossRef]
62. Kaya C, Kilimci ZH, Uysal M, Kaya M. A review of metaheuristic optimization techniques in text classification. Int J Comput Exp Sci Eng. 2024;10(2):126–33. doi:10.22399/ijcesen.295. [Google Scholar] [CrossRef]
63. Thirumoorthy K, Britto JJ. A two-stage feature selection approach using hybrid elitist self-adaptive cat and mouse based optimization algorithm for document classification. Expert Syst Appl. 2024;254:124396. doi:10.1016/j.eswa.2024.124396. [Google Scholar] [CrossRef]
64. Kaya C, Kilimci ZH, Uysal M, Kaya M. Migrating birds optimization-based feature selection for text classification. PeerJ Comput Sci. 2024;10(4):e2263. doi:10.7717/peerj-cs.2263. [Google Scholar] [PubMed] [CrossRef]
65. Farek L, Benaidja A. An adaptive binary particle swarm optimization algorithm with filtration and local search for feature selection in text classification. Memet Comput. 2025;17(4):45. doi:10.1007/s12293-025-00481-3. [Google Scholar] [CrossRef]
66. Alyasiri OM, Cheah YN, Abasi AK. Hybrid filter-wrapper text feature selection technique for text classification. In: Proceedings of the 2021 International Conference on Communication & Information Technology (ICICT); 2021 Jun 5–6; Basrah, Iraq. p. 80–6. doi:10.1109/ICICT52195.2021.9567898. [Google Scholar] [CrossRef]
67. Thirumoorthy K, Muneeswaran K. Feature selection using hybrid poor and rich optimization algorithm for text classification. Pattern Recognit Lett. 2021;147(10):63–70. doi:10.1016/j.patrec.2021.03.034. [Google Scholar] [CrossRef]
68. Ige OP, Gan KH. Ensemble filter-wrapper text feature selection methods for text classification. Comput Model Eng Sci. 2024;141(2):1847–65. doi:10.32604/cmes.2024.053373. [Google Scholar] [CrossRef]
69. Szeghalmy S, Fazekas A. A comparative study of the use of stratified cross-validation and distribution-balanced stratified cross-validation in imbalanced learning. Sensors. 2023;23(4):2333. doi:10.3390/s23042333. [Google Scholar] [PubMed] [CrossRef]
70. Rossi RG, Marcacini RM, Rezende SO. Benchmarking text collections for classification and clustering tasks [Internet]. 2013 [cited 2026 Jan 1]. Available from: https://repositorio.usp.br/directbitstream/342060e9-eebc-4530-8074-bd60bb8b125e/Relat%C3%B3rios%20T%C3%A9cnicas_395. [Google Scholar]
71. Dönicke T, Damaschk M, Lux F. Multiclass text classification on unbalanced, sparse and noisy data. In: Proceedings of the First NLPL Workshop on Deep Learning for Natural Language Processing; 2019 Sep 30; Turku, Finland. p. 58–65. [Google Scholar]
72. Unnikrishnan P, Govindan VK, Madhu Kumar SD. Enhanced sparse representation classifier for text classification. Expert Syst Appl. 2019;129(3):260–72. doi:10.1016/j.eswa.2019.04.003. [Google Scholar] [CrossRef]
73. Tang Z. A generic multi-level framework for building term-weighting schemes in text classification. Comput J. 2024;67(11):3042–55. doi:10.1093/comjnl/bxae068. [Google Scholar] [CrossRef]
74. Jin L, Zhang L, Zhao L. Feature selection based on absolute deviation factor for text classification. Inf Process Manag. 2023;60(3):103251. doi:10.1016/j.ipm.2022.103251. [Google Scholar] [CrossRef]
75. Li C, Li W, Tang Z, Li S, Xiang H. An improved term weighting method based on relevance frequency for text classification. Soft Comput. 2023;27(7):3563–79. doi:10.1007/s00500-022-07597-5. [Google Scholar] [CrossRef]
76. Alyasiri OM, Cheah YN. Multi-class text classification using machine learning techniques. Eng Technol Appl Sci Res. 2025;15(3):22598–604. doi:10.48084/etasr.9994. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2026 The Author(s). Published by Tech Science Press.
Copyright © 2026 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools