
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Personalized Video Synopsis Framework for Spherical Surveillance Video
Department of Computer Science and Engineering, National Institute of Technology Puducherry, India
* Corresponding Author: S. Priyadharshini. Email:
Computer Systems Science and Engineering 2023, 45(3), 2603-2616. https://doi.org/10.32604/csse.2023.032506
Received 20 May 2022; Accepted 13 July 2022; Issue published 21 December 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Video synopsis is an effective way to easily summarize long-recorded surveillance videos. The omnidirectional view allows the observer to select the desired fields of view (FoV) from the different FoV available for spherical surveillance video. By choosing to watch one portion, the observer misses out on the events occurring somewhere else in the spherical scene. This causes the observer to experience fear of missing out (FOMO). Hence, a novel personalized video synopsis approach for the generation of non-spherical videos has been introduced to address this issue. It also includes an action recognition module that makes it easy to display necessary actions by prioritizing them. This work minimizes and maximizes multiple goals such as loss of activity, collision, temporal consistency, length, show, and important action cost respectively. The performance of the proposed framework is evaluated through extensive simulation and compared with the state-of-art video synopsis optimization algorithms. Experimental results suggest that some constraints are better optimized by using the latest metaheuristic optimization algorithms to generate compact personalized synopsis videos from spherical surveillance videos.Keywords
Spherical videos are also known as omnidirectional, 360°, or panoramic videos. They are recorded using a spherical camera that captures the environment on a spherical canvas. Due to the unlimited FoV, the process of identifying key events is challenging. Fig. 1 illustrates an observer viewing three different interested FoVs from the input spherical surveillance video independently. The object-based video synopsis approach is handy to solve this issue. Despite tremendous efforts devoted to the object-based video synopsis on the non-spherical videos [1–6], they cannot be directly applied to the spherical videos. Traditionally, 360-degree video summarization offers fixed FoV-based summarization, the spherical video summarization in a personalized manner is not focused. This motivates to generate an object-based video synopsis for spherical surveillance video in a personalized manner.
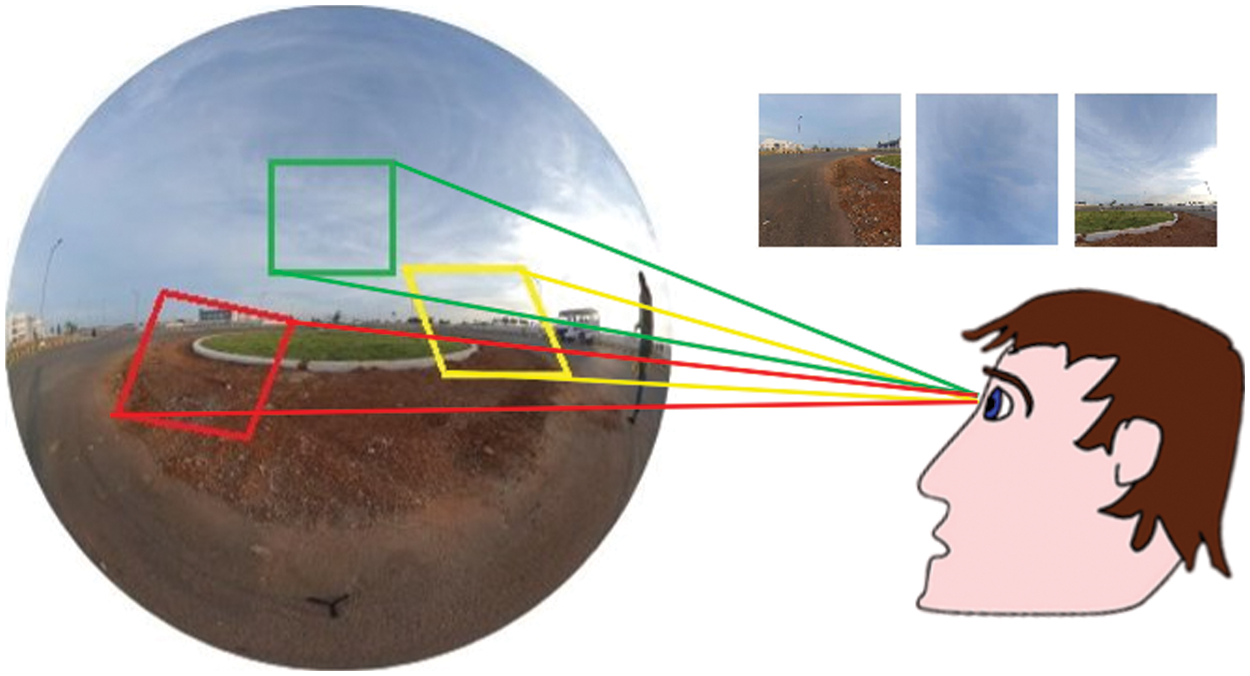
Figure 1: An illustration of an observer viewing the three different interested FoVs in the spherical surveillance video
The novelty of the proffered framework is that it eliminates FOMO and displays the viewer constraint number of objects per frame. FOMO refers to the observer’s concerns about missing the salient part occurring outside the observer’s viewing angle [7]. In this work, our contribution and focus are on the process of grouping objects and rearranging the personalized tubes in the recorded spherical surveillance video. Therefore, we used state-of-the-art methods for preprocessing, action recognition, viewport prediction, and tube stitching.
The key contributions of this work are:
1. A novel personalized video synopsis approach is proposed to generate dynamically non-spherical synopsis video for the spherical surveillance video to eliminate FOMO.
2. An action recognition module is incorporated into the proposed framework to prioritize the actions based on their importance.
3. To precisely understand the scene in the synopsis video the suggested framework provides the observer constraint number of objects for each frame in the non-spherical synopsis video.
4. The comparative performance analysis of the proposed framework using the latest metaheuristic optimization algorithms with the state-of-art video synopsis approach is performed for the generation of personalized non-spherical synopsis videos.
The remainder of this work is organized as follows. In Section 2, related works on 360
This section discusses the literature review for
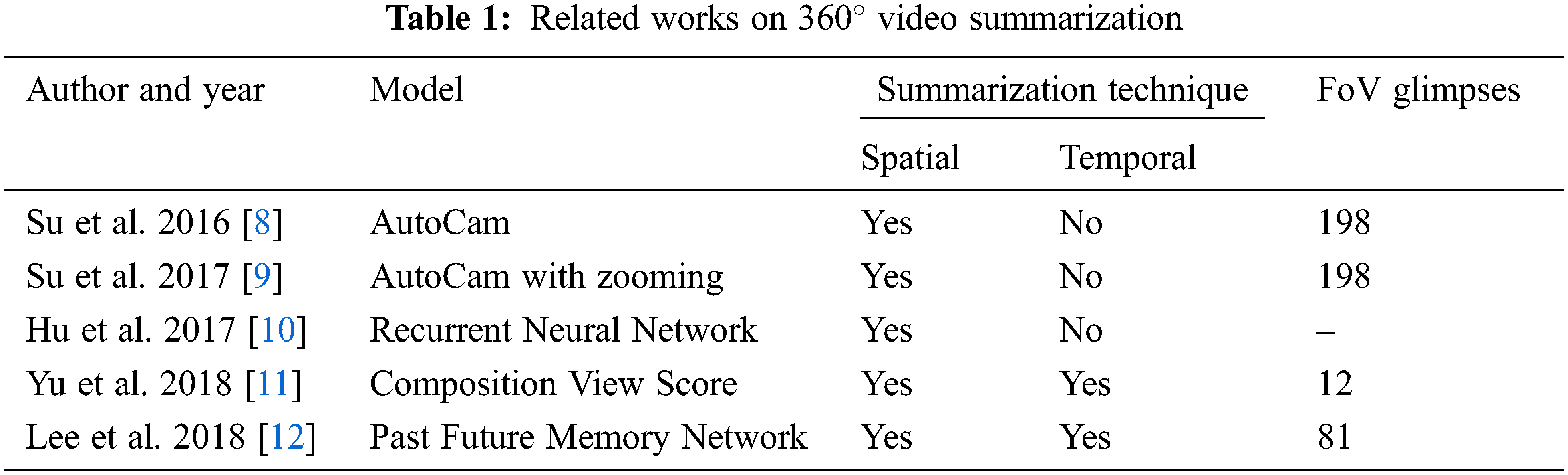
Su et al. [8] proposed autocam, a data-driven methodology to provide automatic cinematography in panoramic videos. Su et al. [9] generalize the introduced Pano2Vid task by allowing it to control the FoV dynamically. It uses a coarse to fine optimization process. Hu et al. [10] proposed a deep learning-based approach, namely, a deep 360 pilot for piloting in 360-degree sports videos. Based on the knowledge of the previous viewing angles, it predicts the current viewing angle. Yu et al. [11] generate a 360-degree score map to identify the suitable view for 360-degree video highlight. This approach outperforms the existing autocam framework. Lee et al. [12] suggested a memory network model to generate summarized non-spherical video. It uses two memories for already selected subshots and future subshots that are likely to be selected, respectively. Tab. 1 gives the summary of related works on
2.2 Non-Spherical Synopsis Video Methods
Pritch et al. [1] proposed two methods for synopsis video generation namely, low-level graph optimization and an object-based approach. Mahapatra et al. [2] proposed a synopsis generation framework for a multi-camera setup. The synopsis generation problem is formulated as a scheduling problem. An action recognition module is incorporated to recognize and prioritize the actions performed by the objects. Ahmed et al. [13] presented a methodology for synopsis generation concerning a user’s query. Ghatak et al. [4] presented a hybridization of Simulated Annealing and Teaching Learning based Optimization algorithms to generate an efficient synopsis video. Ghatak et al. [5] suggested an improved optimization scheme using the hybridization of Simulated Annealing and Jaya algorithms for the generation of video synopsis. Namitha et al. [6] proposed a recursive tube grouping methodology to preserve interacting objects. A spatiotemporal cube voting approach is used to arrange the objects optimally. The length of the synopsis is minimized by introducing the length estimation method. The systematic review of the video synopsis method used in the non-spherical videos is given by [14–16]. Tab. 2 summarizes the video synopsis-related works on non-spherical videos.

3 Generation of Personalized Non-spherical Video Synopsis
The generation of personalized non-spherical synopsis video from the spherical surveillance video is illustrated in Fig. 2. Spherical videos can be generally projected in two ways [17]. This work is based on the equirectangular projection [18] of spherical video. It comprises seven steps. The steps involved in the generation of a personalized spherical synopsis video are explained in detail as follows,
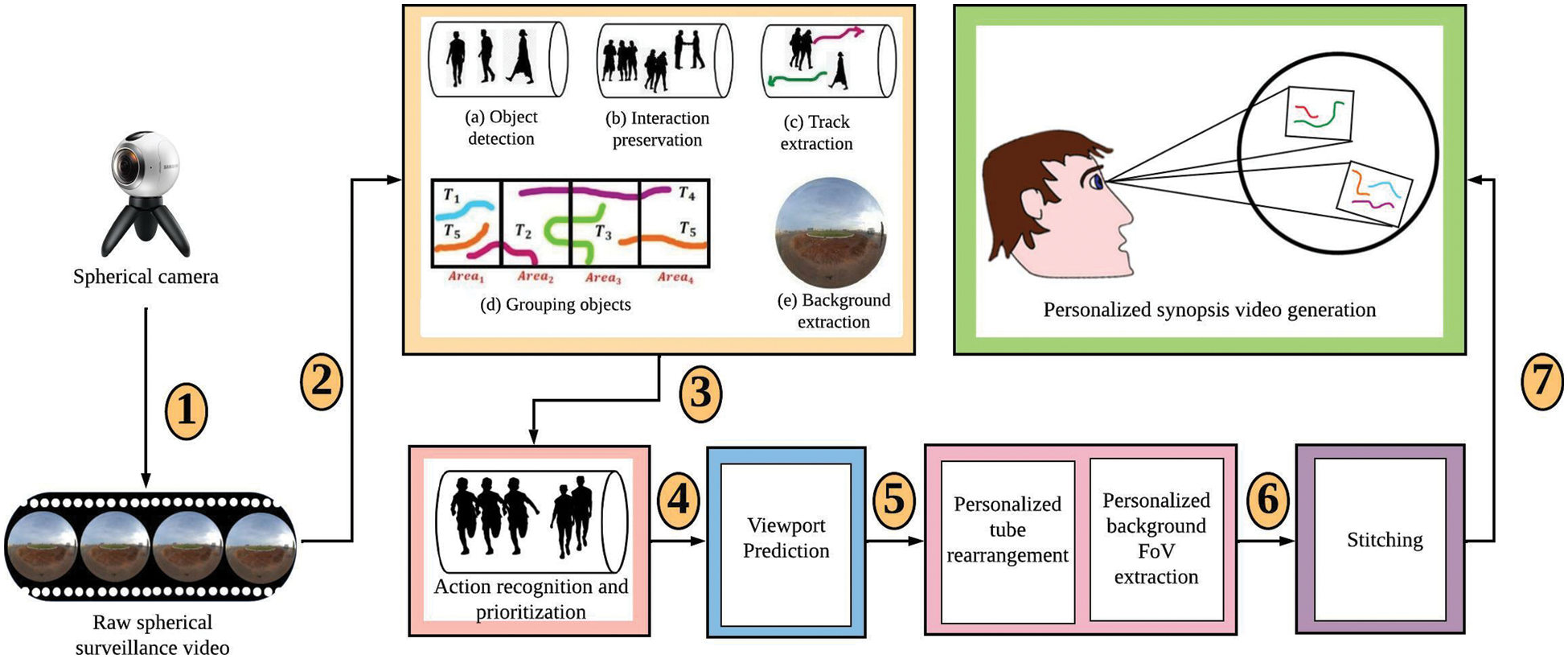
Figure 2: Proposed framework for the generation of personalized non-spherical synopsis video
Step 1: Recording the spherical surveillance video
This step uses a static spherical camera placed in the surveillance area to be monitored in a spherical environment. Due to the capability to record the scene in spherical form, the recorded video allows viewing the video with multiple FoVs.
Step 2: Pre-processing the raw spherical surveillance video
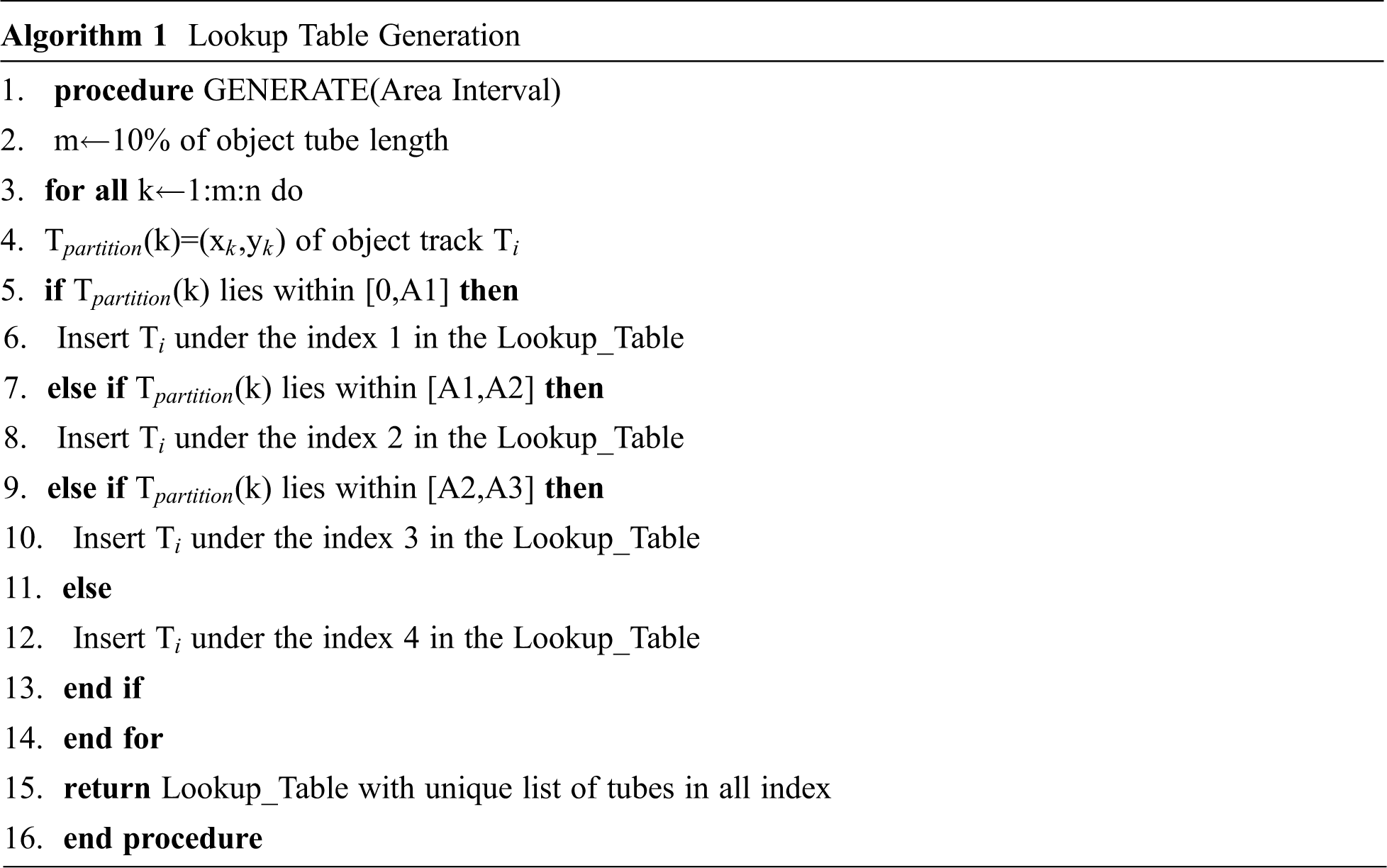
This step detects the moving objects in the raw spherical surveillance video using Faster Region-based Convolutional Neural Network (R-CNN) [19]. Followed by object tube grouping using a recursive tube-grouping algorithm [6]. The movement of the objects is tracked to obtain the track extraction of moving objects by using Deep Simple Online and Real-time Tracking (Deep SORT) [20]. The background of the raw input spherical video is extracted using the timelapse background video generation method [1]. Fig. 3 illustrates the pre-processing step of raw spherical surveillance video. The equirectangular area is partitioned into four areas with equal width of 1440, and then objects are grouped based on their occurrence concerning the area and stored in a lookup table as given in Algorithm 1.

Figure 3: Pre-processing of raw spherical surveillance video
Step 3: Recognizing and prioritizing the actions performed
In this step, the raw spherical video is converted into a normal FoV video by using rectilinear projection [21] and segmented into a sequence of overlapping P-frames of long action segments. The time-series features of these sequence frames are extracted using CNN trained using a pre-trained network, Densenet 201 [22]. KTH dataset [23] is used to train the CNN model. Long Short Term Memory (LSTM) [24] is used to perform the sequence classification. Once the action sequences are classified they are prioritized based on the importance of the action performed [2]. This work involves only two actions namely, running and walking. Running is given higher priority compared to walking.
Step 4: Predicting the future viewports of the viewer
To generate a personalized synopsis video, viewport prediction of the future frames is vital. For training, the dataset given by [25] is used. Using imtool in MATLAB, the cartesian coordinates of the moving objects in the viewport for all frames in the raw spherical surveillance video is simulated on the desktop for testing purpose. Spherical coordinates such as pitch and yaw angles are computed using the simulated cartesian coordinates. The viewport prediction using both the position and content data in the spherical video was introduced by [26]. Densenet 201 [22] is used to extract the features of all the frames in the raw input video, and the upcoming viewports are predicted using LSTM [24]. This step outputs the future viewpoints that the observer will likely view while watching the synopsis video.
Step 5: Personalizing tube rearrangement and FoV background extraction
Once the viewport is predicted, the corresponding FoV background is extracted. The objects within the predicted viewport are selected dynamically from the lookup table created in Step 1. It is performed as per Algorithm 2. The selected objects undergo an optimization process to identify optimal rearrangement of tubes in the synopsis video.

The energy cost function to be minimized is,
Activity loss cost (
where
where
where
where
where
It is the sum of the priority score of each object in the synopsis.
It is solved using various latest optimization algorithms such as Aquila Optimizer (AO) [27], Archimedes Optimization Algorithm (AOA) [28], Dynamic Differential Annealing Optimization (DDAO) [29], Giza Pyramids Construction (GPC) [30], Heap-Based Optimizer (HBO) [31], Hybrid Whale Optimization with Seagull Algorithm (HWSOA) [32] as well as existing works on video synopsis such as Hybrid Simulated Annealing-Jaya (HSAJaya) [5], Hybridization of Simulated Annealing and Teaching Learning based Optimization (HSATLBO) [4], and Simulated Annealing (SA) [1]. The personalized tube rearrangement is given in Algorithm 3.

Step 6: Stitching the object tubes to the FoV background
In this step, the optimal tube shifting results obtained from optimizing the multi-objective function are used. The objects are stitched to the FoV background based on the shifting results using Poisson image editing [33].
Step 7: Generating the personalized synopsis video
After stitching, the personalized synopsis video is generated in this step. Algorithm 4 gives the complete workflow of generating a personalized synopsis video.

Due to the unavailability of real-time spherical surveillance video, in this work Insta360 ONE X is used to record a spherical surveillance video for 01:03:11 (HH:MM:SS) from the National Institute of Technology Puducherry with 24fps. The recorded raw spherical video has a resolution of
a. Non chronology rate
It is the rate of the sum of all objects that are not in chronological order (
b. Collision rate
It is the rate of collision that occurred due to the temporal shifting of two objects.
where
where
c. Inclusion rate
It is the rate of the number of high priority activities retained in the synopsis video compared to the total number of high priority activity in the raw input video.
where
Fig. 4 illustrates the action recognition for prioritizing important actions. Tab. 3 presents the analysis of individual costs used in the process of generating a personalized synopsis video. Fig. 5 illustrates the analysis of optimization algorithms for the proposed work. AO [27] and GPC [30] provide minimum collision and temporal inconsistency while SA [1] and DDAO [29] provide minimum synopsis length and show the observer a specified number of objects per frame respectively. SA [1] provides better results for the preservation of maximum important actions and AO [27] converges faster than other optimization algorithms. Fig. 6 presents the personalized synopsis video generated by using AO [27] with minimum collision.

Figure 4: Action recognition for prioritizing important actions
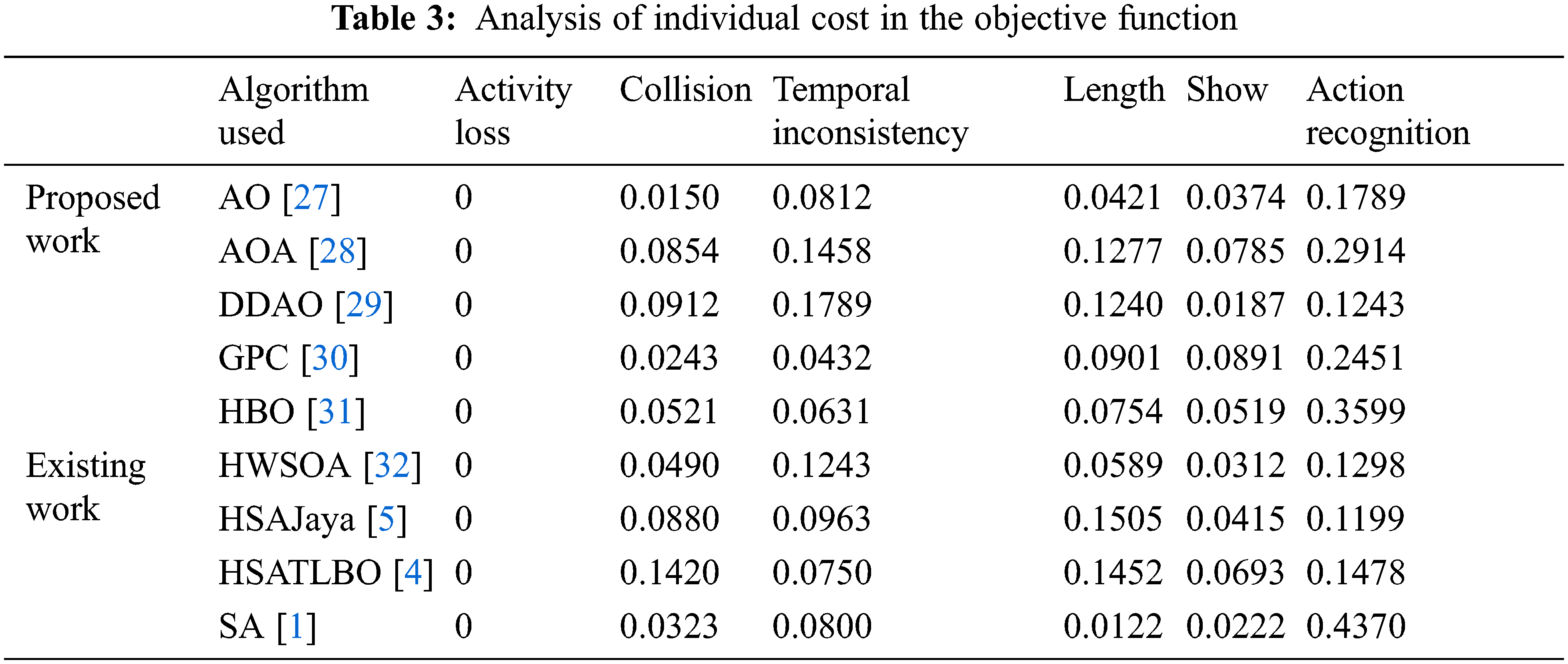
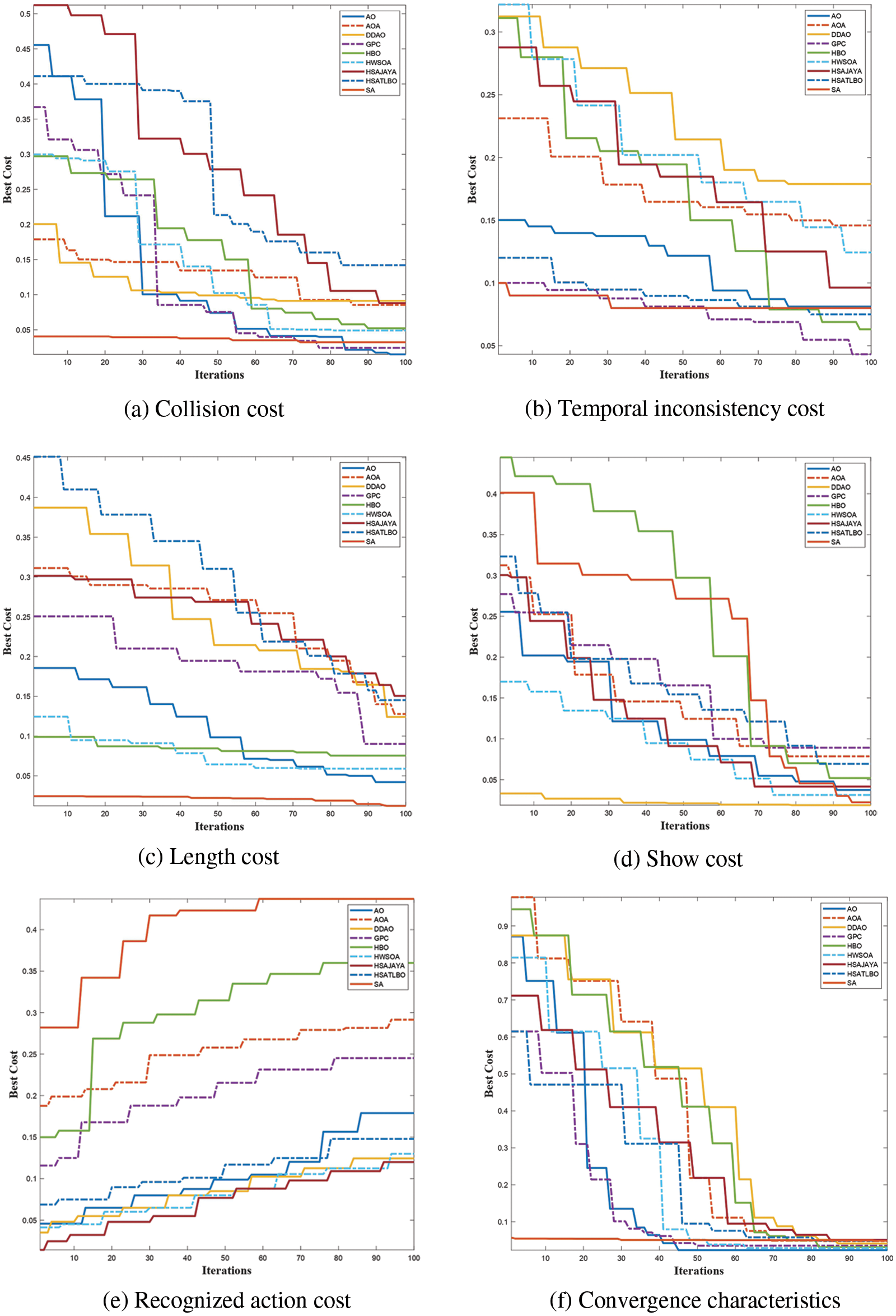
Figure 5: Analysis of optimization algorithms

Figure 6: Personalized synopsis video generated by using AO [27] with minimum collision
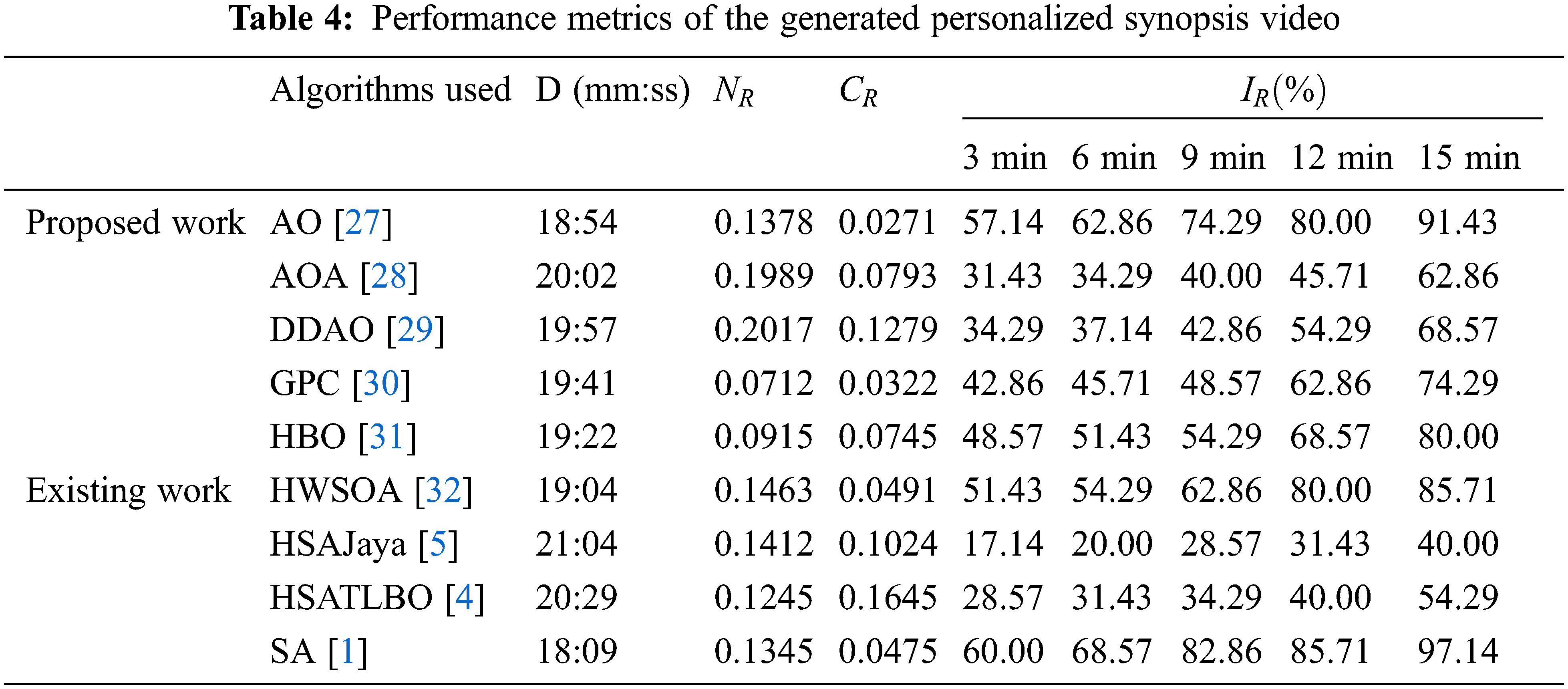
Tab. 4 presents the performance metrics for the generated personalized synopsis video with duration D in minutes. SA [1] generates synopsis length with a shorter duration whereas, GPC [30] and AO [27] provide better results for non chronology rate and collision rate respectively. SA [1] provides better results for inclusion rates as 60.00%, 68.57%, 82.86%, 85.71%, and 97.14% for the synopsis video of duration for the five cases such as 3, 6, 9, 12, and 15 min respectively.
This work introduces a personalized video synopsis framework for generating non-spherical video synopsis from spherical surveillance videos. The advantage of the proposed work is that FOMO is eliminated while watching the spherical videos. Here, an object grouping algorithm is introduced that identifies and groups objects based on the area of occurrence and then divides the objects into four groups. In addition, a personalized tube rearrangement algorithm was proposed. This algorithm aims to perform a tube shift of an object within the viewer's point of view. The action recognition module further reduces the synopsis length by prioritizing important actions. Experimental results and analysis show that the proposed framework offers a potential improvement in collision, temporal consistency, and show cost over the state-of-art video synopsis approach. It is also observed that the convergence rate of the prior art method is slow compared to the proposed framework. Finally, a hybrid optimization framework based on the analysis of the results performed can be considered for future work to condense spherical surveillance video.
Data Availability Statement: The dataset generated and analyzed during this study are available from the corresponding author on reasonable request.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Y. Pritch, A. Rav-Acha and S. Peleg, “Nonchronological video synopsis and indexing,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 30, no. 11, pp. 1971–1984, 2008. [Google Scholar]
2. A. Mahapatra, P. K. Sa, B. Majhi and S. Padhy, “MVS: A multi-view video synopsis framework,” Signal Processing: Image Communication, vol. 42, pp. 31–44, 2016. [Google Scholar]
3. A. Ahmed, S. Kar, D. P. Dogra, R. Patnaik, S. Lee et al., “Video synopsis generation using spatio-temporal groups,” in Proc. ICSIPA, Kuching, Malaysia, pp. 512–517, 2017. [Google Scholar]
4. S. Ghatak, S. Rup, B. Majhi and M. N. Swamy, “An improved surveillance video synopsis framework: A HSATLBO optimization approach,” Multimedia Tools and Applications, vol. 79, no. 7, pp. 4429–4461, 2020. [Google Scholar]
5. S. Ghatak, S. Rup, B. Majhi and M. N. Swamy, “HSAJAYA: An improved optimization scheme for consumer surveillance video synopsis generation,” IEEE Transactions on Consumer Electronics, vol. 66, no. 2, pp. 144–152, 2020. [Google Scholar]
6. K. Namitha and A. Narayanan, “Preserving interactions among moving objects in surveillance video synopsis,” Multimedia Tools and Applications, vol. 79, no. 43, pp. 32331–32360, 2020. [Google Scholar]
7. T. Aitamurto, A. S. Won, S. Sakshuwong, B. Kim, Y. Sadeghi et al., “From fomo to jomo: Examining the fear and joy of missing out and presence in a 360 video viewing experience,” in Proc. CHI Conf. on Human Factors in Computing Systems, Yokohama, Japan, pp. 1–14, 2021. [Google Scholar]
8. Y. C. Su, D. Jayaraman and K. Grauman, “Pano2Vid: Automatic cinematography for watching 360degree videos,” in Proc. Asian Conf. on Computer Vision, Taipei, Taiwan, pp. 154–171, 2016. [Google Scholar]
9. Y. C. Su and K. Grauman, “Making 360 video watchable in 2D: Learning videography for click free viewing,” in Proc. CVPR, Honolulu, HI, USA, pp. 1368–1376, 2017. [Google Scholar]
10. H. N. Hu, Y. C. Lin, M. Y. Liu, H. T. Cheng, Y. J. Chang et al., “Deep 360 pilot: Learning a deep agent for piloting through 360 sports videos,” in Proc. CVPR, Honolulu, HI, USA, pp. 1396–1405, 2017. [Google Scholar]
11. Y. Yu, S. Lee, J. Na, J. Kang and G. Kim, “A deep ranking model for spatio-temporal highlight detection from a 360° video,” in Proc. AAAI, Hilton New Orleans Riverside, New Orleans, Louisiana, USA, 32, 2018. [Google Scholar]
12. S. Lee, J. Sung, Y. Yu and G. Kim, “A memory network approach for story-based temporal summarization of 360 videos,” in Proc. on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 1410–1419, 2018. [Google Scholar]
13. S. A. Ahmed, D. P. Dogra, S. Kar, R. Patnaik, S. C. Lee et al., “Query-based video synopsis for intelligent traffic monitoring applications,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 8, pp. 3457–3468, 2019. [Google Scholar]
14. A. Mahapatra and P. K. Sa, “Video synopsis: A systematic review,” in High Performance Vision Intelligence, Noida, India, pp. 101–115, 2020. [Google Scholar]
15. K. B. Baskurt and R. Samet, “Video synopsis: A survey,” Computer Vision and Image Understanding, vol. 181, pp. 26–38, 2019. [Google Scholar]
16. S. Ghatak and S. Rup, “Single camera surveillance video synopsis: A review and taxonomy,” in Proc. ICIT, Bhubaneswar, India, pp. 483–488, 2019. [Google Scholar]
17. S. Priyadharshini and A. Mahapatra, “360degree user-generated videos: Current research and future trends,” in High Performance Vision Intelligence, Noida, India, pp. 117–135, 2020. [Google Scholar]
18. B. Ray, J. Jung and M. C. Larabi, “A low-complexity video encoder for equirectangular projected 360 video content,” in Proc. ICASSP, Calgary, AB, Canada, pp. 1723–1727, 2018. [Google Scholar]
19. S. Ren, K. He, R. Girshick and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Advances in Neural Information Processing Systems, Montreal, Quebec, Canada, 28, pp. 1–14, 2015. [Google Scholar]
20. N. Wojke, A. Bewley and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in Proc. ICIP, Beijing, China, pp. 3645–3649, 2017. [Google Scholar]
21. W. Fraser and C. C. Gotlieb, “A calculation of the number of lattice points in the circle and sphere,” Mathematics of Computation, vol. 16, no. 79, pp. 282–290, 1962. [Google Scholar]
22. G. Huang, Z. Liu, L. V. D. Maaten and K. Q. Weinberger, “Densely connected convolutional networks,” in Proc. Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 4700–4708, 2017. [Google Scholar]
23. C. Schuldt, I. Laptev and B. Caputo, “Recognizing human actions: A local SVM approach,” in Proc. Pattern Recognition, Cambridge, UK, 3, pp. 32–36, 2004. [Google Scholar]
24. S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. [Google Scholar]
25. W. C. Lo, C. L. Fan, J. Lee, C. Y. Huang, K. T. Chen et al., “360 video viewing dataset in head-mounted virtual reality,” in Proc. Multimedia Systems, Taipei, Taiwan, pp. 211–216, 2017. [Google Scholar]
26. X. Chen, A. T. Z. Kasgari and W. Saad, “Deep learning for content-based personalized viewport prediction of 360-degree VR videos,” IEEE Networking Letters, vol. 2, no. 2, pp. 81–84, 2020. [Google Scholar]
27. L. Abualigah, D. Yousri, M. A. Elaziz, A. A. Ewees, M. AA Al-qaness et al., “Aquila optimizer: A novel meta-heuristic optimization algorithm,” Computers & Industrial Engineering, vol. 157, pp. 1–37, 2021. [Google Scholar]
28. F. A. Hashim, K. Hussain, E. H. Houssein, M. S. Mabrouk and W. Al Atabany, “Archimedes optimization algorithm: A new metaheuristic algorithm for solving optimization problems,” Applied Intelligence, vol. 51, no. 3, pp. 1531–1551, 2021. [Google Scholar]
29. H. N. Ghafil and K. Jarmai, “Dynamic differential annealed optimization: New metaheuristic optimization algorithm for engineering applications,” Applied Soft Computing, vol. 93, no. 4598, pp. 1–33, 2020. [Google Scholar]
30. S. Harifi, J. Mohammadzadeh, M. Khalilian and S. Ebrahimnejad, “Giza pyramids construction: An ancient-inspired metaheuristic algorithm for optimization,” Evolutionary Intelligence, vol. 14, no. 4, pp. 1743–1761, 2021. [Google Scholar]
31. Q. Askari, M. Saeed and I. Younas, “Heap-based optimizer inspired by corporate rank hierarchy for global optimization,” Expert Systems with Applications, vol. 161, no. 3, pp. 1–41, 2020. [Google Scholar]
32. Y. Che and D. He, “A Hybrid whale optimization with seagull algorithm for global optimization problems,” Mathematical Problems in Engineering, vol. 2021, no. 4, pp. 1–31, 2021. [Google Scholar]
33. P. Perez, M. Gangnet and A. Blake, “Poisson image editing,” Proc. SIGGRAPH, vol. 22, no. 3, pp. 313–318, 2003. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools