
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Systematic Comparison of Discrete Cosine Transform-Based Approaches for Multi-Focus Image Fusion
1 Department of Computer Science, Iqra National University Swat Campus, Swat, 19200, Pakistan
2 Department of Computer Science, University of Engineering and Technology, Mardan, 23200, Pakistan
3 Department of Computer Science, University of Swat, Swat, 19200, Pakistan
4 Center for Excellence in Information Technology, Institute of Management Sciences, Peshawar, 25000, Pakistan
* Corresponding Author: Sarwar Shah Khan. Email:
Digital Engineering and Digital Twin 2025, 3, 17-34. https://doi.org/10.32604/dedt.2025.066344
Received 06 April 2025; Accepted 18 July 2025; Issue published 19 August 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Image fusion is a technique used to combine essential information from two or more source images into a single, more informative output image. The resulting fused image contains more meaningful details than any individual source image. This study focuses on multi-focus image fusion, a crucial area in image processing. Due to the limited depth of field of optical lenses, it is often challenging to capture an image where all areas are in focus simultaneously. As a result, multi-focus image fusion plays a key role in integrating and extracting the necessary details from different focal regions. This research presents a comparative analysis of various Discrete Cosine Transform (DCT)-based methods for multi-focus image fusion. The primary objective is to provide a clear understanding of how these techniques differ based on mathematical formulations and to compare their visual and statistical performance. The analysed methods include: DCT + Variance and DCT + Variance + Consistency Verification (CV), DCT + Correlation Coefficient (CC) and DCT + CC + CV, DCT + Singular Value Decomposition (SVD) and DCT + SVD + CV, DCT + Sharpening and DCT + Sharpening + CV, DCT + Correlation Energy (Corr_Eng) and DCT + Corr_Eng + CV, Through experimental evaluations, the study finds that DCT + Variance and DCT + Variance + CV consistently deliver superior results across all tested image sets. The performance of these methods is evaluated using six different quantitative metrics, demonstrating their effectiveness in enhancing image quality through fusion.Keywords
In digital image processing, image fusion has emerged as a crucial research field, particularly in applications requiring high-quality visual data. The fundamental objective of image fusion is to integrate complementary information from multiple images into a single, more informative output. Among the various types of image fusion, multi-focus image fusion plays a significant role in scenarios where optical limitations prevent capturing an entirely focused image in a single shot. Due to the limited depth of field of optical lenses, objects at different distances from the camera may not appear sharp simultaneously. This results in some regions of the image being well-focused while others remain blurred. To solve this problem, multi-focus image fusion methods fuse several images captured at various focus levels to produce an image where all the details of interest are focused [1].
Multi-focus image fusion methods can generally be divided into spatial domain and frequency domain methods. Spatial domain methods are based on image pixels directly and encompass methods like the simple averaging method [2], principal component analysis (PCA) [3], and intensity-hue-saturation (IHS) [3] transformations. While these methods are computationally straightforward, they often suffer from spectral distortions and reduced image contrast, which limits their effectiveness [4,5]. On the other hand, frequency domain methods transform images into a frequency representation before fusion, offering advantages such as improved robustness and better feature preservation. Popular techniques in this domain include Discrete Wavelet Transform (DWT) [6], Stationary Wavelet Transform (SWT) [7], and Discrete Cosine Transform (DCT) [8]. Wavelet-based approaches like DWT offer multi-resolution analysis but cause problems like shift variance and ringing effects. To avoid these, SWT was developed as a shift-invariant alternative, with better localization and the capability to retain finer details better. DCT-based fusion approaches, frequently found in image compression standards like JPEG, enable direct fusion within the compressed domain, cutting down on computation overhead and enhancing efficiency [5].
The selection of an appropriate fusion technique relies on the particular application demands, i.e., real-time processing capability, computational efficiency, and noise robustness. Multi-focus image fusion remains a crucial research area, affecting a number of applications ranging from medical imaging [9], remote sensing, surveillance, computer vision [10], and robotics [11]. As research continues, new fusion methods are being investigated to obtain better image clarity, and multi-focus image fusion has become a critical tool in contemporary imaging applications.
This study focuses on methods based on the Discrete Cosine Transform (DCT) domain and explores various DCT-based approaches in detail. By thoroughly analyzing these variations, we aim to gain deeper insights into their functionality and effectiveness. This research also compares different DCT-based methods and presents a better understanding for readers to the point in brief. The techniques considered are DCT with Variance, DCT with Variance and Consistency Verification (CV), DCT with Correlation Coefficient, and DCT with Correlation Coefficient + CV. Next, we consider DCT with Singular Value Decomposition (SVD), DCT with SVD and CV, DCT with Sharpening, and its extended version with CV. Finally, the study also considers DCT with Correlation Energy (Corr_Eng) and DCT with Corr_Eng + CV. Through this comparative analysis, we intend to offer an overall picture of the effectiveness and dependability of various DCT-based fusion methods.
The remaining part of this paper is organized as follows: Section 2 presents an elaboration on Discrete Cosine Transform (DCT)-based Fusion Techniques. Section 3 describes the merit and de-merit of different DCT-based techniques. Section 4 discusses the performance metrics, experimental results, and results and analysis. Lastly, Section 5 presents the key findings and conclusions of the research.
2 Discrete Cosine Transform (DCT)-Based Fusion Approaches
In multi-focus image fusion, a variety of methods have been established in the spatial and frequency domains. However, research indicates that frequency-domain methods generally have more merits than spatial-domain methods, especially in maintaining critical image details and enhancing overall quality [5]. This research mainly investigates Discrete Cosine Transform (DCT)-based fusion schemes and seeks the best method to use by considering their performance using various image data sets. It takes into consideration both qualitative elements, including clarity of vision, and quantitative experimental results to define the best algorithm.
2.1 Discrete Cosine Transforms (DCT)
Discrete Cosine Transform (DCT) is a method that transforms an image from the spatial to the frequency domain. The process is especially suited to capturing fundamental image details like edges and textures by examining pixel frequency data. DCT is generally favored for frequency-based processing because it is efficient since it only depends on cosine functions for transformation and is therefore both computationally light and quick.
To recreate the image in its transformed form, the Inverse Discrete Cosine Transform (IDCT) is used, which returns the frequency components to their pixel values [12]. In short, DCT expresses a limited number of data points as a sum of cosine functions vibrating at different frequencies. Due to its efficiency, DCT is often used with other methods to improve the quality of multi-focus image fusion. The performance of DCT-based approaches is assessed as follows.
Two-dimensional Discrete Cosine Transform (DCT) is performed on an N × N block of an image, in the case of 8 × 8 images, to transform spatial data into frequency components. In the same vein, Inverse Discrete Cosine Transform (IDCT) is performed to revert to the original image from its frequency domain representation [13]. These two operations are mathematically expressed in Eqs. (1) and (3), respectively.
where,
where
In Eq. (1), d(0, 0) is the DC coefficient, which is the component that has zero frequency in both dimensions. The rest of the coefficients in the block are known as AC coefficients, which are the components of non-zero frequencies in either or both dimensions.
To improve the quality of the fused image and minimize errors due to improper block selection, Consistency Verification (CV) is used as a post-processing operation at the last stage of the image fusion process. The method presumes that if a middle block in the merged image is from image B, but most of its adjacent blocks are from image A, then the middle block probably belongs to image A, too. To guarantee consistency, Li et al. suggested employing a majority filter for the CV process [13]. This filter works based on the decision map M(x, y), substituting the central block with the corresponding block of image A when most surrounding blocks are from image A. By incorporating CV as a final step, the overall accuracy of the fused image is improved, reducing inconsistencies in block selection as illustrated in Fig. 1. This CV technique is widely used in DCT-based fusion methods, including those discussed in this study [14].
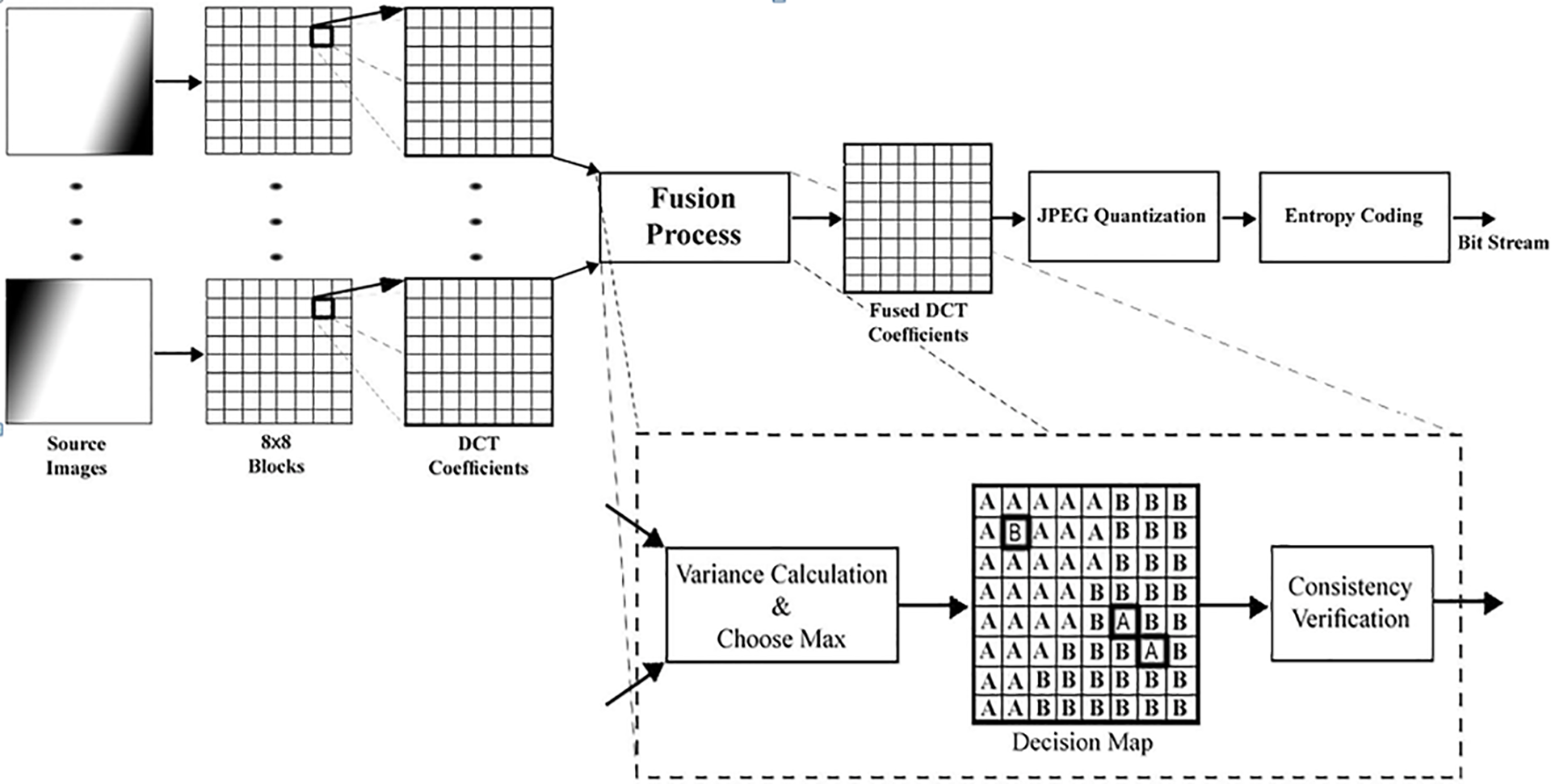
Figure 1: The architecture of a JPEG encoder merging with an image fusion approach
2.3 DCT with Variance and DCT with Variance + CV
In multi-focus images, the regions in focus contain additional information as they preserve finer details. This detailed information is directly related to high variance, which serves as an important indicator of focus. In image processing applications, variance is commonly used as a contrast criterion to differentiate between focused and blurred regions. The computation of variance in the DCT domain is straightforward, as explained in the previous section. Therefore, variance values are utilized to determine the activity level of 8 × 8 blocks within the source images. The fusion process begins by dividing the source images into 8 × 8 blocks and computing the DCT coefficients for each block. As illustrated in Fig. 1, the variance of corresponding blocks from both source images is computed using Eq. (9) as the activity measure. The block with the higher activity measure is selected as the most relevant for the resultant image. Consequently, the DCT representation of the resultant image is constructed using blocks with greater variance, which originate from either source image A or B [15].
The transform coefficients
Compute the values of mean, μ, and variance,
As we already know, the mean value, μ, of the N × N block is given by d(0, 0). For providing the variance of the DCT coefficient for each block, a mathematical evaluation using (3). We have:
By exchanging the places of the sums, we will have:
Then, from (7) and (8), we have:
Finally, the variance of an N × N block of pixels can be correctly computed from its DCT coefficients by the sum of the squared normalized Eq. (4) AC coefficient of the DCT block [15]. Once the variance-based image fusion is completed in the DCT domain, Consistency Verification (CV) is employed as a post-processing step to further refine the fused image, ensuring improved accuracy and visual quality.
2.4 DCT with Correlation Coefficient and DCT with Correlation Coefficient + CV
The correlation coefficient (CC) is the statistical representation that examines the level of linear relationship among two variables. The correlation among the two N × N blocks of images A and B is defined as (10):
whereas
To derive the correlation of the N × N block of image
whereas
Then, the correlation coefficient among two N × N blocks of images
hence, the correlation coefficient of two N × N blocks of images
In multi-focus image fusion, the DCT-based correlation coefficient method follows a structured process. Initially, the input images are filtered using a low-pass filter, producing artificially blurred versions of the original images. These blurred images, along with their corresponding input images, are then divided into 8 × 8 blocks, and the DCT coefficients for each block are computed. Each block from the first input image and its corresponding blurred block, as well as each block from the second input image and its respective blurred block, are analyzed in this process. The difference between a sharp image and its blurred version becomes evident after low-pass filtering. Notably, blocks from the focused regions undergo greater changes when passed through the low-pass filter, whereas blocks from unfocused (blurred) regions remain relatively unchanged.
As a result, the correlation coefficient between a focused image block before and after filtering is lower than that of a blurred region, which remains largely similar. Consequently, blocks exhibiting greater variation after filtering—those with lower correlation coefficient values—are identified as belonging to the focused areas and are selected for the fused image. This correlation coefficient serves as a key decision-making criterion in constructing the decision map for the image fusion process [16].
The block selection for the fused output image (DCT + Corr) is defined as (10):
Once the Correlation coefficient-based image fusion is completed in the DCT domain, Consistency Verification (CV) is employed as a post-processing step to further refine the fused image, ensuring improved accuracy and visual quality.
2.5 DCT with Singular Value Decomposition (SVD) and DCT with SVD + CV
Two-dimensional DCT (using vector processing) transform of N × N blocks of the image
where the orthogonal matrix
The DCT inverse of A is therefore defined as Eq. (18).
The SVD Matrix applies to the spatial domain. But here transforming the discussion into the DCT domain and comparing the SVD matrix, it is concluded that the matrix ∑ has the exact data in both spatial and DCT domains, so
All parameters are different, however, ∑ and ∑′ are identical.
In the equations shown above, it has been proven that
By calculating SVD and eigenvalues of
Accordingly, the block with the most value of
where
Accordingly, for the
2.6 DCT with Sharp and DCT with Sharp + CV
The focused image is highly informative and has high contrast. The image quality and contrast are specified by variance, and the variance of an image is used as a criterion. Thus, the block of the focused area in image h has a higher variance value than the block of the unfocused area. But sometimes the variance criterion finds error in selecting some similar blocks. To avoid selecting the unsuitable block for making the resultant image, and because of the small difference in variance among some corresponding blocks of input multi-focus images, the introduced method increases and enhances the amount of difference among the variances by sharpening the input images [17].
The sharpened input image is obtained using the unsharp mask, as shown in (23).
The DCT-based multi-focus image fusion technique divides the input images and the sharpened input images into 8 × 8 blocks and the DCT coefficients of the sharpened in put images blocks are calculated. So, the variance of the sharpened input image’s blocks is calculated. This algorithm compares the variance value of the corresponding blocks of sharpened input images and gives discrete values defined as (24) to them for making a decision map M (m, n).
Once the sharpness-based image fusion is completed in the DCT domain, Consistency Verification (CV) is employed as a post-processing step to further refine the fused image, ensuring improved accuracy and visual quality.
2.7 DCT with DCT + Corr_eng and DCT with DCT + Corr_eng + CV
The correlation coefficient detailed mathematical explanation is given in the above Section 2.4. However, we will continue to explain the energy-correlation coefficient. So coalescing the image energy of A and B in the correlation coefficient relation could better the focus measurement performance. The input image is represented by symbol A, and the artificially blurred input image is represented by symbol B. The energies of the input images, A and B, are presented as Eqs. (25) and (26), respectively (A comprehensive detail is presented in [18]):
The calculation of (Eng_Corr) is using (27) by combining of correlation coefficients Eq. (13) with Eqs. (25) and (26), accordingly [18]:
Comparison of the advantages and disadvantages of DCT-based multi-focus image fusion methods in Table 1.

This Comparative analysis is based on DCT-based methods in multi-focused image fusion. We are trying to demonstrate the best results in all of them and broaden the knowledge about each technique of DCT based on multi-focused. For demonstrating the best results using six quantitative measures in Table 2.

This study presents a comparative analysis of various DCT-based methods for multi-focus image fusion. The approaches under evaluation include DCT + Variance, DCT + Variance + CV (Consistency Verification), DCT + Correlation Coefficient (CC), DCT + CC + CV, DCT + Singular Value Decomposition (SVD), DCT + SVD + CV, DCT + Sharpening, DCT + Sharpening + CV, DCT + Correlation Energy (Corr_Eng), and DCT + Corr_Eng + CV. The performance of these methods is assessed using three evaluation criteria: Quantitative measures, Qualitative Error Image (QEI) measures, and Qualitative visual assessment. The quantitative evaluation is conducted using six different measures, namely RMSE, PEF, Entropy, SNR, PSNR, and Correlation. For experimentation, well-known standard multi-focus images, including lab, and doll images, are used. Each image in the dataset has a resolution of 520 × 520 pixels. The fusion process involves two images, but the proposed methods can also be extended to handle more than two multi-focus images [18].
Additionally, the Qualitative Error Image (QEI)—also known as the difference image—is generated by subtracting the fused image from the reference image. A less visible QEI indicates a higher similarity between the fused and reference images, signifying better fusion quality [27].
The qualitative results of all the DCT-based approaches are illustrated in Fig. 2. This figure presents the fused image alongside its corresponding error (difference) image for the DCT + Correlation (DCT + Corr) method. Following that, additional images showcase the fused and error images generated by the extended DCT + Corr method incorporating Consistency Verification (CV). From these visual comparisons, it is evident that the difference image of DCT + Corr + CV appears to be more informative than that of DCT + Corr alone. This observation leads us to explore the reasoning behind the improvements brought by the Consistency Verification (CV) process. To illustrate, consider a scene composed of multiple blocks, all of which fall entirely within the depth of focus of image A. Ideally, all blocks in this region should be selected from image A. However, due to the presence of noise or unintended artifacts, some blocks may erroneously be chosen from image B, leading to inconsistencies in the fused image. The CV process effectively corrects such errors by ensuring that the final selection aligns with the majority of correctly chosen blocks, thereby enhancing the overall quality of the fused image [28,29].


Figure 2: The fused images and corresponding error images produced by different DCT-based methods for test Image 1
Burger and Burge [13] introduced a majority filter that plays an important part in the consistency verification (CV) process. Based on this method, if the center block of a region is chosen from source image B, while most of its surrounding blocks are drawn from source image A, the center block is replaced with its corresponding block from image A.
This method ensures that the fused image is constructed with greater accuracy and consistency. By following this straightforward procedure, all DCT-based methods integrate consistency verification (CV) to enhance fusion results. The proposed method, when extended with CV, further refines the output, leading to improved image quality and reduced errors. Based on our observations, a comparison of the error images in Figs. 2 and 3 for all DCT-based methods reveals a clear pattern. Observing these images, it is clear that the DCT + Variance + CV approach consistently yields better qualitative results for all the three datasets. This indicates that the use of Consistency Verification (CV) improves the fusion process and results in a more accurate and refined final image.


Figure 3: The fused images and corresponding error images produced by different DCT-based methods for test Image 2
The quantitative analysis is conducted using six different evaluation metrics, revealing some intriguing insights. The statistical values are notably close to one another, indicating that all DCT-based methods demonstrate strong performance.
From Table 3, the DCT + Variance method appears to yield the best results for the Disk image set. In Table 4, the PEF metric performs well with DCT + SVD, while entropy values are higher for DCT + Sharpen + CV. Meanwhile, the Lab image set results indicate that most metrics favor DCT + Variance.
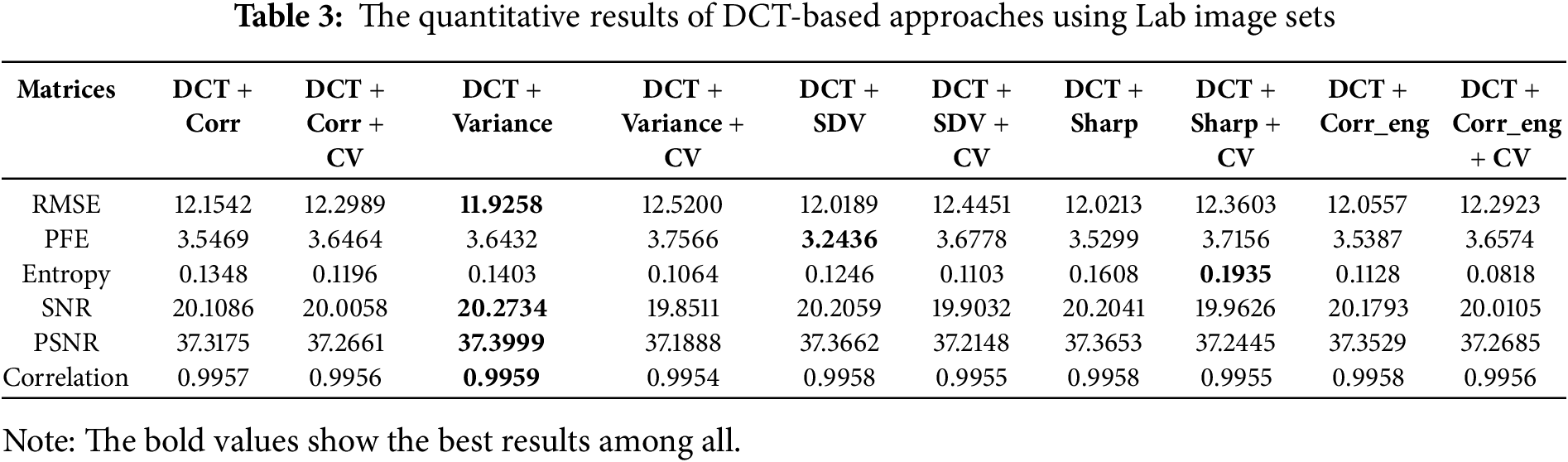

For the Doll image set, DCT + Variance achieves the best scores for RMSE and PEF, while the remaining metrics show higher values for DCT + Variance + CV. Based on both visual and statistical comparisons, our analysis suggests that DCT + Variance and DCT + Variance + CV stand out as the most effective methods among all DCT-based approaches.
The simulations for the DCT-based methods were conducted using MATLAB R2020b on a system equipped with an Intel Core i7-6700K processor (4.00 GHz) and 8 GB of RAM. The simulation codes for all the methods were obtained from an online database, originally provided by Haghighat et al. [15] and further contributed by Naji et al. [16,18,20,21].
In this article, a comparative analysis is conducted to evaluate DCT-based methods. The DCT-based methods of multi-focused image fusion are proven to be more suitable and time-saving in real-time systems for still images or videos. This comparative analysis will broaden the knowledge about a bunch of techniques and explain the technical modifications in these methods for emerging researchers. So, all DCT-based methods are technically (mathematically) elaborated, and the results are compared using six commonly used metrics on two different image sets. According to experiments, we are assuming that based on visual and statistical results, the DCT + Variance and DCT + Variance + CV methods performed well and achieved the most successful results for all of the image sets. The investigation provided a framework for further study in multi-focus image fusion on DCT-based methods. The improvements to the above disadvantages are left as future work.
While the comparative results provide valuable insight into the strengths of DCT-based methods, the study acknowledges that these methods are primarily traditional and may have limitations in handling highly dynamic or complex real-world scenarios. The absence of deep learning-based comparisons, adaptive thresholding techniques, and fusion performance under noisy conditions remains a gap that should be addressed. In future work, we plan to extend this study by:
• Integrating deep learning approaches (e.g., CNNs and Transformers) with DCT-based methods to enhance fusion quality.
• Introducing optimization frameworks for dynamic parameter tuning in DCT variants.
• Conducting large-scale evaluations on diverse and real-time datasets, including noisy, medical, and aerial images.
• Incorporating statistical significance testing (e.g., p-values) to validate differences in performance.
• Exploring hybrid frameworks that combine spatial and frequency domain fusion techniques.
These directions will not only overcome the existing limitations but also offer a more robust, generalizable, and modern approach to multi-focus image fusion.
Acknowledgement: We would like to acknowledge the support of our team members and the Kaggle repository for providing the data. Our sincere gratitude goes team leader for his invaluable guidance and feedback throughout this research.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contribution to the paper as follows: study conception and design: Muhammad Osama and Sarwar Shah Khan; data collection: Sajid Khan and Reshma Khan; analysis and interpretation of results: Muhammad Osama, Sarwar Shah Khan, Sajid Khan, Muzammil Khan and Mian Muhammad Danyal; draft manuscript preparation: Muhammad Osama, Sarwar Shah Khan, Reshma Khan, Muzammil Khan and Mian Muhammad Danyal. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in the Kaggle repository at: https://www.kaggle.com/datasets/masoudnickparvar/brain-tumor-mri-dataset (accessed on 17 July 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Mohamed MA, El-Den BM. Implementation of image fusion techniques for multi-focus images using FPGA. In: Proceedings of the 2011 28th National Radio Science Conference (NRSC); 2011 Apr 26–28; Cairo, Egypt. p. 1–11. doi:10.1109/NRSC.2011.5873618. [Google Scholar] [CrossRef]
2. Siddiqui AB, Jaffar MA, Hussain A, Mirza AM. Block-based feature-level multi-focus image fusion, Busan, Republic of Korea. In: Proceedings of the 2010 5th International Conference on Future Information Technology; 2010 May 21–23; Busan, Republic of Korea. p. 1–7. doi:10.1109/FUTURETECH.2010.5482718. [Google Scholar] [CrossRef]
3. Masood S, Sharif M, Yasmin M, Shahid MA, Rehman A. Image fusion methods: a survey. J Eng Sci Technol Rev. 2017;10(6):186–95. doi:10.25103/jestr.106.24. [Google Scholar] [CrossRef]
4. Jiang S, Yu S. Refined Multi-Focus image fusion on using multi-scale neural network with SpSwin Autoencoder-based matting. Expert Syst Appl. 2025;276:126980. doi:10.1016/j.eswa.2025.126980. [Google Scholar] [CrossRef]
5. Kumari AV. A review of image enhancement techniques. Int J Trend Res Dev. 2017;2(7):232–35. [Google Scholar]
6. Javed U, Riaz MM, Ghafoor A, Ali SS, Cheema TA. MRI and PET image fusion using fuzzy logic and image local features. Sci World J. 2014;2014:708075. doi:10.1155/2014/708075. [Google Scholar] [PubMed] [CrossRef]
7. Bhosekar S, Singh P, Garg D. A recent advancements in multi-modal medical image fusion techniques using SWT, NSST, NSCT, and CNN. In: Proceedings of the 2025 International Conference on Cognitive Computing in Engineering, Communications, Sciences and Biomedical Health Informatics (IC3ECSBHI); 2025 Jan 16–18; Greater Noida, India. Piscataway, NJ, USA: IEEE. p. 928–32. [Google Scholar]
8. Wang M, Shang X. A fast image fusion with discrete cosine transform. IEEE Signal Process Lett. 2020;27:990–4. doi:10.1109/LSP.2020.2999788. [Google Scholar] [CrossRef]
9. Oral M, Turgut SS. A comparative study for image fusion. In: Proceedings of the 2018 Innovations in Intelligent Systems and Applications Conference (ASYU); 2018 Oct 4–6; Adana, Türkiye. p. 1–6. doi:10.1109/asyu.2018.8554000. [Google Scholar] [CrossRef]
10. Zhou Y, Yu L, Zhi C, Huang C, Wang S, Zhu M, et al. A survey of multi-focus image fusion methods. Appl Sci. 2022;12(12):6281. doi:10.3390/app12126281. [Google Scholar] [CrossRef]
11. Zhang H, Xu H, Tian X, Jiang J, Ma J. Image fusion meets deep learning: a survey and perspective. Inf Fusion. 2021;76:323–36. doi:10.1016/j.inffus.2021.06.008. [Google Scholar] [CrossRef]
12. Wang Z, Ziou D, Armenakis C, Li D, Li Q. A comparative analysis of image fusion methods. IEEE Trans Geosci Remote Sens. 2005;43(6):1391–402. doi:10.1109/TGRS.2005.846874. [Google Scholar] [CrossRef]
13. Burger W, Burge MJ. The discrete cosine transform (DCT). In: Digital image processing. Cham, Switzerland: Springer International Publishing; 2022. p. 589–97. doi:10.1007/978-3-031-05744-1_20. [Google Scholar] [CrossRef]
14. Amin-Naji M, Aghagolzadeh A. Multi-focus image fusion using VOL and EOL in DCT domain. arXiv:1710.06511. 2017. [Google Scholar]
15. Haghighat MBA, Aghagolzadeh A, Seyedarabi H. Real-time fusion of multi-focus images for visual sensor networks. In: Proceedings of the 2010 6th Iranian Conference on Machine Vision and Image Processing; 2010 Oct 27–28; Isfahan, Iran. p. 1–6. doi:10.1109/IranianMVIP.2010.5941140. [Google Scholar] [CrossRef]
16. Naji MA, Aghagolzadeh A. Multi-focus image fusion in DCT domain based on correlation coefficient. In: Proceedings of the 2015 2nd International Conference on Knowledge-Based Engineering and Innovation (KBEI); 2015 Nov 5–6; Tehran, Iran. p. 632–9. doi:10.1109/KBEI.2015.7436118. [Google Scholar] [CrossRef]
17. Nie X, Xiao B, Bi X, Li W, Gao X. A focus measure in discrete cosine transform domain for multi-focus image fast fusion. Neurocomputing. 2021;465:93–102. doi:10.1016/j.neucom.2021.08.109. [Google Scholar] [CrossRef]
18. Naji MA, Aghagolzadeh A. Multi-focus image fusion in DCT domain using variance and energy of Laplacian and correlation coefficient for visual sensor networks. J AI Data Min. 2018;6(2):233–50. doi:10.1109/kbei.2015.7436118. [Google Scholar] [CrossRef]
19. Osama M, Khan SS, Khan S. High-quality multi-focus image fusion: a comparative analysis of DCT-based approaches with their variants. ICCK J Image Anal Process. 2025;1(1):27–35. [Google Scholar]
20. Naji MA, Ranjbar-Noiey P, Aghagolzadeh A. Multi-focus image fusion using singular value decomposition in DCT domain. In: Proceedings of the 2017 10th Iranian Conference on Machine Vision and Image Processing (MVIP); 2017 Nov 22–23; Isfahan, Iran. p. 45–51. doi:10.1109/IranianMVIP.2017.8342367. [Google Scholar] [CrossRef]
21. Naji MA, Aghagolzadeh A. A new multi-focus image fusion technique based on variance in DCT domain. In: Proceedings of the 2015 2nd International Conference on Knowledge-Based Engineering and Innovation (KBEI); 2015 Nov 5–6; Tehran, Iran. p. 478–84. doi:10.1109/KBEI.2015.7436092. [Google Scholar] [CrossRef]
22. Danyal MM, Khan S, Khan RS, Jan S, Rahman N. Enhancing multi-modality medical imaging: a novel approach with Laplacian filter + discrete Fourier transform pre-processing and stationary wavelet transform fusion. J Intell Med Healthc. 2024;2:35–53. doi:10.32604/jimh.2024.051340. [Google Scholar] [CrossRef]
23. Khan SS, Khan M, Alharbi Y, Haider U, Ullah K, Haider S. Hybrid sharpening transformation approach for multifocus image fusion using medical and nonmedical images. J Healthc Eng. 2021;2021:7000991. doi:10.1155/2021/7000991. [Google Scholar] [PubMed] [CrossRef]
24. Dogra A, Kumar S. Multi-modality medical image fusion based on guided filter and image statistics in multidirectional shearlet transform domain. J Ambient Intell Humaniz Comput. 2023;14(9):12191–205. doi:10.1007/s12652-022-03764-6. [Google Scholar] [CrossRef]
25. Moushmi S, Sowmya V, Soman KP. Empirical wavelet transform for multifocus image fusion. In: Proceedings of the International Conference on Soft Computing Systems; 2015; New Delhi, India: Springer. p. 257–63. doi:10.1007/978-81-322-2671-0_25. [Google Scholar] [CrossRef]
26. Singh S, Singh H, Bueno G, Deniz O, Singh S, Monga H, et al. A review of image fusion: methods, applications and performance metrics. Digit Signal Process. 2023;137:104020. doi:10.1016/j.dsp.2023.104020. [Google Scholar] [CrossRef]
27. Khan SS, Khan M, Ran Q. Multi-focus color image fusion using Laplacian filter and discrete Fourier transformation with qualitative error image metrics. In: Proceedings of the 2nd International Conference on Control and Computer Vision; 2019; Jeju, Republic of Korea: ACM. p. 41–5. doi:10.1145/3341016.3341019. [Google Scholar] [CrossRef]
28. Haghighat MBA, Aghagolzadeh A, Seyedarabi H. Multi-focus image fusion for visual sensor networks in DCT domain. Comput Electr Eng. 2011;37(5):789–97. doi:10.1016/j.compeleceng.2011.04.016. [Google Scholar] [CrossRef]
29. Shah M, Khan M, Khan SS, Ali S. Multi-focus image fusion using unsharp masking with discrete cosine transform. In: Proceedings of 1st International Conference on Computing Technologies, Tools and Applications (ICTAPP-23); 2023 May 9–11; Peshawar, Pakistan. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools